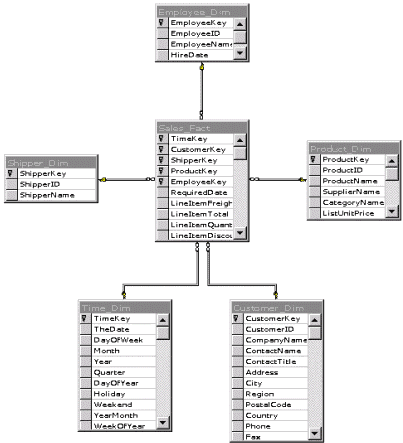
С точки зрения бизнес-анализа каждый анализируемый факт удобно рассматривать как функцию от его характеристик. Например, продажа есть функция от товара, покупателя, продавца, места и времени совершения сделки, возможно, еще каких-то существенных для нас параметров. Эти параметры носят название измерений. Возьмем n-мерную систему координат, где n - число измерений. По каждой оси отложим члены измерения. Например, по измерению "Продавец" это будут засечки, соответствующие всем торговым представителям нашего предприятия. В узлах координатной сетки будем откладывать факты продаж. Каждый факт есть совокупность одной или нескольких мер. Например, отдельный факт продажи заключает в себе совокупность трех величин - суммы сделки, объема сделки и скидки. Могут быть вычисляемые меры, например, чистая продажа = сумма сделки - скидка. Таким образом, естественная структура базы данных для подобного представления - это многомерный куб, ребра которого соответствуют измерениям, а внутренний объем - мерам. Многомерное хранилище (MOLAP) обеспечивает максимальную производительность, так как его структура и интерфейсы наилучшим образом соответствуют структуре аналитических запросов. Этот способ более родственен ментальной модели человека, так как аналитик привык оперировать плоскими таблицами. Производя сечение куба двумерной плоскостью в том или ином направлении, легко получить взаимозависимость любой пары величин относительно выбранной меры. Например, как изменялись продажи (мера) во времени (измерение) в разрезе по регионам (другое измерение). Альтернативой MOLAP служит ROLAP - реляционный OLAP, когда многомерность эмулируется с помощью реляционной СУБД. Посмотрим на рис.4. Представим себе, что наш кубик - это картонная коробка, которую мы раскладываем на плоскость. Центральная таблица (начинка куба) - есть таблица фактов (меры). С ней отношениями "один ко многим" связаны таблицы измерений (стенки многомерной коробки). Такая схема получила название "звездной". Иногда измерение может состоять не из одной, а нескольких таблиц. Например, таблица Product_Dim в этом примере может быть разбита на две: собственно продукты и категории продуктов. Однако это все равно будет одно продуктовое измерение. Разновидность звездной схемы, когда измерение состоит из нескольких таблиц, получило название "снежинки", видимо, из-за того, что лучи "звезды" тоже в этом случае ветвятся.
Рис. 4
Сравним аналитический запрос к новой структуре базы:
SELECT Product_Dim.ProductName, Product_Dim.CategoryName,
Product_Dim.SupplierName,
SUM(Sales_Fact.LineItemQuantity) AS [Total Units Sold]
FROM Sales_Fact INNER JOIN
Product_Dim ON
Sales_Fact.ProductKey = Product_Dim.ProductKey INNER JOIN
Shipper_Dim ON
Sales_Fact.ShipperKey = Shipper_Dim.ShipperKey INNER JOIN
Employee_Dim ON
Sales_Fact.EmployeeKey = Employee_Dim.EmployeeKey
GROUP BY Product_Dim.ProductName,
Product_Dim.CategoryName, Product_Dim.SupplierName,
Sales_Fact.RequiredDate, Shipper_Dim.ShipperName,
Employee_Dim.EmployeeName
HAVING (Sales_Fact.RequiredDate < GETDATE()) AND
(Employee_Dim.EmployeeName = N'Шуленин') AND
(Shipper_Dim.ShipperName = N'Speedy Express') OR
(Shipper_Dim.ShipperName = N'Federal Shipping')
c тем, что был построен в п.1. Во-первых, он короче (меньше join'ов), во-вторых, его проще составлять, так как по схеме (рис.4) мы сразу видим, что относительно чего требуется получить, в третьих, он в 1.7 раз приятнее оптимизатору (это можно увидеть, сравнивая их планы так же, как мы сравнивали планы OLAP и OLTP запросов в п.1).
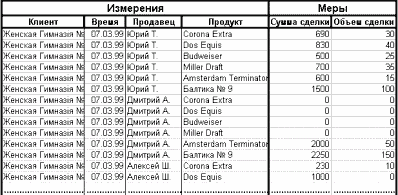
Рис. 5
Таким образом, даже элементарный переход от OLTP к звездной схеме позволяет получить выигрыш в аналитических запросах, несмотря на то, что с точки зрения реляционной модели OLAP есть сплошное надругательство надо всеми правилами нормализации поочередно, ибо здесь имеется масса избыточности, вычисляемых полей и т.д. В частности, повышая степень денормализации, любую "снежинку" можно привести к канонической "звезде". Далее, куб вообще можно представить в виде одной плоской таблицы, выписывая построчно все комбинации членов всех измерений с соответствующими им величинами мер. Пример такого вложенного цикла глубины n, где n - число измерений, показан на рис.5. Примерно так, с точностью до пустот хранятся данные в истинно многомерном (MOLAP) кубе. Куб не хранит пустоты с целью экономии места. Ключи (координаты по измерениям) кодируются и сжимаются до 4 - 8 байт. Для быстрого доступа к значениям в кубах используются битовые индексы. Все сказанное означает, что MOLAP намного эффективнее проявляет себя в хранении, чем ROLAP, и при одинаковых объемах данных потребляет меньше места на диске, чем ROLAP-хранилище. Меньше места - меньше операций ввода/вывода. Кроме того, MOLAP не нуждается в отработке многочисленных join'ов, не заботится о блокировках, так как все операции происходят на чтение, и работает только с численными данными (мерами не могут быть строки, BLOBы и т.п.). Следовательно, MOLAP намного быстрее, чем ROLAP. Аналитические запросы к многомерным кубам имеют простую и компактную форму. Например, приблизительный аналог нашего аналитического запроса, показывающий динамику объемов продаж во времени по продуктам и компаниям, занимающимися доставкой, в MDX-выражении выглядит так:
select
non empty {[Время].members} on rows,
crossjoin ({[Продукт].[Категория товара].members}, {[Доставка].[Speedy Express],
[Доставка].[Federal Shipping]}) on columns
from [Продажи]
where ([measures].[Продажи в ед], [Сотрудник].[Алексей Шуленин])
Тогда возникает вопрос: с какой стати, вообще, о ROLAP еще может идти речь? Дело, по-видимому, в том, что: 1) берет верх психологический фактор (знакомая испытанная схема хранения); 2) возникает стремление сохранить существующие инвестиции в реляционные СУБД, получившие широчайшее распространение; 3) при выборе ROLAP-подхода не требуется перекачивать детальные данные в многомерное хранилище, что требует дополнительного пространства, пусть даже меньшего, чем их исходный размер, и времени.
На каждом измерении определяются совокупности детализаций данных - иерархии, например, для измерения "География" типичной иерархией может быть "Мир -> континенты -> страны -> регионы -> города". В иерархии выделяются уровни. В нашем примере это "Мир", "Континенты", "Страны", "Регионы", "Города". Каждый уровень состоит из членов. Например, "Города" = {Москва, Ярославль, Владимир, Новгород, Псков}, "Регионы" = {Центр, Северо-Запад}, "Страны" = {Россия, США} и т.д. Члены измерений связаны друг с другом отношениями родитель-потомок, например, "Северо-Запад" является родителем членов "Новгород" и "Псков", но сам, в свою очередь, выступает потомком по отношению к "Россия". По одному и тому же измерению допускается иметь одновременно несколько иерархий, например, для измерения "Время" такими иерархиями могут быть "Год -> неделя -> день" и "Год -> квартал -> месяц -> день". Основными операциями над измерениями являются погружение (drilldown - переход вглубь по иерархии на более детальные уровни) и свертка (rollup - наоборот, движение вверх по иерархии для получения более крупномасштабной картины. Например, продажи по Центральному региону складываются из продаж по Москве, Ярославлю и Владимиру. Соответственно, в качестве мер допускаются величины таких типов, над которыми возможны агрегирующие операции (sum, count и т.д.), с помощью которых складываются значения мер для членов более высоких уровней иерархии. Типичными примерами примерами мер являются количественные и денежные значения. Как известно, в аббревиатуре OLAP скрывается обман - на самом деле это не есть он-лайновая обработка. Наоборот, еще на стадии наполнения хранилища OLAP стремится посчитать агрегаты для членов более высоких уровней иерархий (например, "Регионы") на основе значений, содержащихся в реляционной базе учета, где обыкновенно хранятся данные только детального уровня (например, по городам). Получив запрос на продажи по Центральному региону, процессор OLAP возьмет уже готовую предвычисленную величину, добившись тем самым минимального времени обработки запроса.
Назад | Содержание | Вперед