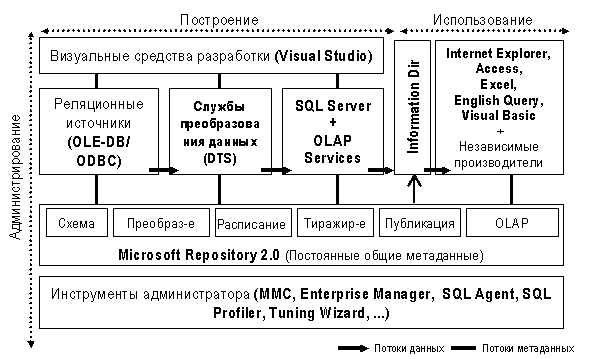
Аббревиатура OLAP (On-Line Analytical Processing) была впервые введена Коддом (E.F.Kodd), известным ученым в области баз данных, создателем широко распространенной реляционной модели, в его работе "Providing OLAP to User Analysis: An IT Mandate" в 1993 г., где он сформулировал 12 основных правил, которым должны удовлетворять OLAP-системы. Позднее Пендс (Nigel Pendse) и Крит (Richard Creeth) переработали эти требования, сделав акцент на скорость обработки, многопользовательский доступ, релевантность информации, наличие средств статистического анализа и многомерность, т.е. представление анализируемых фактов как функций от большого числа их характеризующих параметров. Подход Microsoft к построению хранилищ опирается на эти и другие фундаментальные работы в области анализа данных. Графически его можно представить в виде диаграммы, показанной на рис.1
Рис. 1
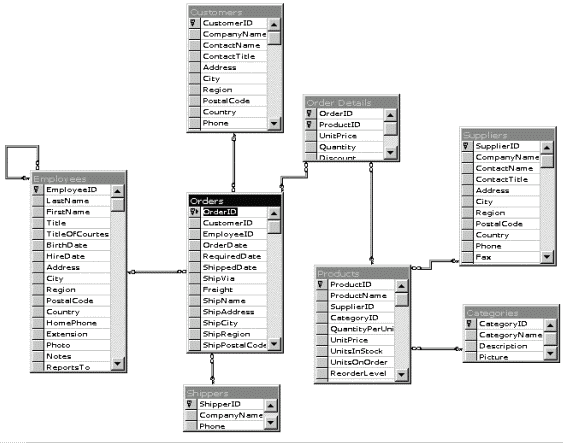
Первоначально данные находятся в реляционной базе данных, куда они попадают благодаря приложению, занимающемуся учетом данных. Это может быть система складского учета, регистрации заявок клиентов, составления ордеров и т.п., о чем мы говорили во Введении. Эта база данных в большинстве случае имеет OLTP (On-line Transactional Processing) структуру, которая назвается так потому, что она оптимизирована для обслуживания коротких обновляющих транзакций, каждая из которых затрагивает сравнительно небольшое число таблиц базы данных. Максимально нормализованная структура базы отвечает именно задаче учета и регистрации. В состав SQL Server 7.0 входит модельное приложение, занимающееся ведением заказов некоего предприятия, торгующего продуктами питания. Обратим внимание на диаграмму его базы данных (рис.2). Это типичный пример OLTP-структуры. Например, операция "Поступление товара от поставщика" есть, очевидно, INSERT в таблицу Products (и, возможно, в Categories), всего задействовано 3 таблицы: Suppliers, Products, Categories. Операция "Заказ товара потребителем" - INSERT в Orders и Order Details, задействовано 4 таблицы: Customers, Orders, Order Details, Products. Операция "Обслуживание заказа сотрудником" задействует 2 таблицы: Orders и Employees и т.д.
Представим себе теперь, что нам необходимо узнать общее количество единиц товара каждого вида, заказанных потребителями по сегодняшний день, заказы на которые оформил интересующий нас сотрудник и в доставке которых были задействованы фирмы Speedy Express или Federal Shipping. Соответствующий запрос приведен ниже:
SELECT Products.ProductName, Categories.CategoryName,
Suppliers.CompanyName AS SupplierName,
SUM([Order Details].Quantity) AS [Total Units Sold]
FROM Orders INNER JOIN
[Order Details] ON
Orders.OrderID = [Order Details].OrderID INNER JOIN
Products ON
[Order Details].ProductID = Products.ProductID INNER JOIN
Categories ON
Products.CategoryID = Categories.CategoryID INNER JOIN
Suppliers ON
Products.SupplierID = Suppliers.SupplierID INNER JOIN
Employees ON
Orders.EmployeeID = Employees.EmployeeID INNER JOIN
Shippers ON Orders.ShipVia = Shippers.ShipperID
GROUP BY Products.ProductName, Suppliers.CompanyName,
Categories.CategoryName, Orders.RequiredDate,
Employees.LastName, Shippers.CompanyName
HAVING (Orders.RequiredDate < GETDATE()) AND
(Employees.LastName = N'Шуленин') AND
(Shippers.CompanyName = N'Speedy Express') OR
(Shippers.CompanyName = N'Federal Shipping')
Сравним стоимость этого запроса с типичным OLTP-запросом, например, с уже упоминавшейся нами операцией "Обслуживание заказа сотрудником" (см. рис.3).
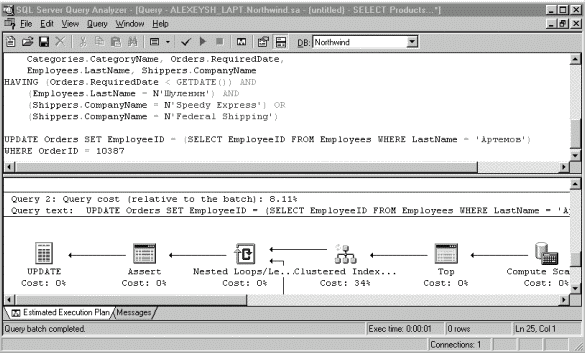
Рис. 3
Принимая стоимость батча за 100%, оптимизатор оценивает первый запрос в 91.89%, а второй, соответственно, - в 8.11%. Из этого следует, что этот запрос будет выполняться примерно в 92/8=11.5 раза дольше, чем OLTP-запрос. Кроме того, обратим внимание, что в нем задействовано 7 таблиц из 8 показанных на диаграмме. Все эти таблицы будут блокированы на чтение все время выполнения аналитического запроса. Вывод, который можно сделать из этого простого эксперимента, состоит в следующем: аналитические запросы - это запросы на массированное чтение. (В каком регионе был достигнут максимальный уровень сбыта данной продукции в прошлом году? В какой именно торговой точке? У какой категории покупателей она пользовалась наивысшим спросом? Кто из сотрудников был при этом наиболее результативен? Какова была динамика продаж по этому региону в более детальном временнОм масштабе? Были ли сезонные всплески? Хватало ли запаса товара на складах? Какой прогноз спроса дает тренд на 2-й квартал этого года? А что, если уровень инфляции составит 2.5% в месяц, а конкуренты поднимут цены на 10%? и т.д.) Структура транзакционной базы не оптимизирована для таких запросов, так как они задействуют все или почти все таблицы в базе (а отработка многочисленных связей между ними есть время- и ресурсоемкая операция) и подолгу блокируя данные на чтение, препятствуют оперативному прохождению OLTP-транзакций в системе учета. Следовательно, для обработки OLAP-запросов необходим отдельный формат хранения данных.
Назад | Содержание | Вперед