Это оригинальная разработка научно-производственного центра "Интелтек Плюс". По сравнению с приведенными выше системами управления базами данных эта СУБД находит более широкое применение в России.
При разработке программы ставилось несколько целей: обработка неструктурированной информации, хранение документов сложной структуры, встроенная поддержка полнотекстового поиска, возможность расширения набора типов СУБД.
СУБД ODB-Jupiter оперирует объектами. Особенностью реализации СУБД является тот факт, что непосредственно в базе данных хранятся данные объектов. Они запоминаются в файлах базы данных как блоки двоичной информации. Для представления данных в объектном виде существует отдельный уровень представления данных - объектный уровень. Это расширяемый набор динамических библиотек, в которых содержатся реализации основных типов данных. Среди основных типов строка, целое и вещественное число, текст, дата, время, хранилище объектов OLE. Расширение мощности типов данных возможно путем регистрации динамических библиотек, поддерживающих новые форматы данных.
Клиентом СУБД может быть как любая программа, использующая клиентскую библиотеку, так и браузер Интернет. Существенное отличие в их работе заключается в том, что пользователь браузера не может производить операции изменения над документами базы.
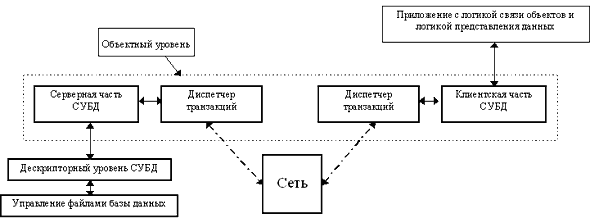
Рисунок 1. Архитектура СУБД ODB-Jupiter
СУБД включает в себя три уровня - Рисунок 1. Первый - уровень управления файлами базы данных. База данных состоит из файла данных и файла индекса. На этом уровне решается задача поддержания целостности данных. Особенно актуально это в связи с мультизадачной средой сервера баз данных. Непосредственно база данных представляет собой хранилище структурированных записей переменной длины и библиотеку, реализующую набор операций над записями: добавление/чтение/замещение/удаление. На этом уровне решается проблема эффективного управления дисковыми файлами, обеспечения отказоустойчивого механизма модификации файлов БД, оптимального кэширования записей. В файле базы данных хранится "проекция" реального объекта - непосредственно данные (атрибуты) и информация для загрузки объекта в оперативную память. Каждой записи при добавлении присваивается уникальный номер - ID. Впоследствии запись доступна по своему идентификатору. Если воспользоваться терминами реляционных СУБД, запись может представлять либо значение, либо массив, либо кортеж.
На дескрипторном уровне известны имена типов записей, хранящихся в БД и присутствуют методы для доступа к компонентам структурированной записи. Таким образом, возможно оперативное извлечение информации без загрузки объекта в оперативную память целиком. Здесь в БД уже просматривается структура в виде списка типов объектов и их расположения. Отметим, что расположение записи однозначно определяется идентификатором.
На объектном уровне присутствуют объекты базы данных, которые взаимодействуют по определенным правилам. Здесь сервер получает сообщения, расшифровывает их, создает объекты и структур, необходимых для интерпретации данных в сообщении. Обратное действие - реакция на команду клиента, после которой извлекается информация из объектов и структур, указанных в команде. Информация укладывается в линейный буфер и в таком виде отправляется на сервер. Таково в общих чертах назначение объектного уровня. С одной стороны, он соприкасается с низкоуровневым интерфейсом сети (в случае сервера - с библиотеками управления записями и индексами), а с другой сам предоставляет интерфейс для реализации более высоких уровней и интерфейса с пользователем.
Объектный уровень, описанный выше, предоставляет обширный программный интерфейс объектно-ориентированной СУБД. Программный интерфейс СУБД собран в одной динамически загружаемой библиотеке. На уровне приложений функционируют библиотеки высокого уровня и прикладные программы, которые связывают данные объектов определенной логикой и осуществляют визуализацию данных из базы, интерактивное или иное взаимодействие с пользователем. Разработчик приложения никак не ограничивается количеством используемых узлов сети и баз данных. Как правило, разработчик-программист создает ряд классов, которые планируется сохраняться в базе данных.
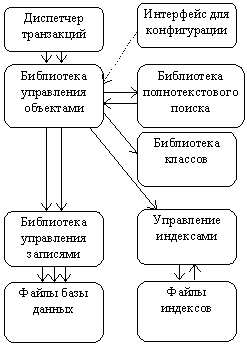
Рисунок 2. Серверная часть СУБД
Ядро СУБД - библиотека управления объектами см. Рисунок 2. Здесь выполняются операции по созданию/индексированию/блокировке объектов. Обратите внимание на то, что в ядро СУБД встроен модуль полнотекстового поиска. Это означает, что ODB-Jupiter эффективно реализует индексацию и поиск текстовых документов.
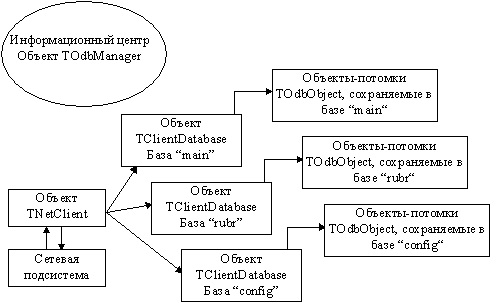
Рисунок 3. Клиентская часть СУБД
Когда клиент устанавливает соединение с сервером, создается один объект класса TNetClient, который обеспечивает поддержание канала связи с клиентской стороны. В одном сеансе связи, как правило, приложение работает с несколькими базами данных. На Рисунке 3 изображен случай когда прикладная программа работает с объектами, находящимися в трех различных базах данных. Имена баз - "main", "rubr", "config". Каждый объект, обладающий свойством обмена с базой данных, знает имя сервера и имя той базы данных, куда он будет отправлен. Каждый объект TClientDatabase поддерживает список объектов-потомков TOdbObject, связанных с данной базой.
СУБД ODB-Jupiter - активно развивающийся проект. В настоящее время планируется встроить в ядро СУБД механизмы репликации, журнализации с целью восстановления от сбоев. Требуется наладить управление транзакциями причем с учетом того, что транзакции могут быть вложенными и длительными. В ближайших планах - обеспечить блокировки объектов чтобы полноценно поддерживать многопользовательскую работу с базами данных.
Назад | Содержание | Вперед