Итак, база данных создана. Теперь, наконец, можно заняться созданием автоматизированных рабочих мест.
Сколько и каких автоматизированных рабочих мест должно быть создано, обычно решается на этапе проектирования данных. В данном простейшем случае очевидно, что работа по вводу данных в информационную систему подразделяется на три основных дочерних работы: ввод сведений о врачах поликлиники (это обычно делается в отделе кадров, и соответственно следует создать АРМ инспектора отдела кадров), ввод сведений о пациентах (рабочее место медрегистратора), ввод сведений о статистических талонах (рабочее место медстатистика). Помимо этого, кто-то должен осуществлять заполнение справочников "Цель посещения" и "Статус" (можно добавить эти функции в АРМ медстатистика, так как объем этих таблиц невелик). Что касается списка диагнозов, он может быть либо введен в базу данных кем-либо из персонала поликлиники, либо импортирован администратором базы данных из какого-либо другого формата, так как этот список основан на реально существующем и неоднократно опубликованном документе.
В общем случае эти рабочие места могут представлять собой отдельные приложения, обращающиеся к определенным таблицам в базе данных, а различные пользователи информационной системы должны иметь соответствующие их служебным обязанностям права доступа к таблицам. Например, представляется разумным запретить медрегистратору и медстатистику вносить изменения в таблицы со списком врачей, а кадровику вносить изменения в списки пациентов. Если исходить из того, что медстатистиков, медрегистраторов и кадровиков может быть несколько, имеет смысл создать в базе данных соответствующие роли (если, конечно, создание ролей поддерживается выбранным сервером), и назначить каждому пользователю соответствующую роль.
Руководствуясь этими соображениями, создадим три роли в базе данных с соответствующими правами доступа к таблицам и три автоматизированных рабочих места для инспектора отдела кадров, медрегистратора и медстатистика, возложив на последнего также обязанность корректировать список диагнозов.
Первые два АРМ-а создать относительно несложно (одно из них предназначено для ввода данных в одну таблицу, другое - в две таблицы, связанные соотношением "один ко многим"). Для этой цели можно воспользоваться утилитой Database Form Wizard и затем внести небольшие изменения в сгенерированные формы и код, в частности, для обеспечения возможности не использовать мышь при массовом вводе данных, а также для установки фокуса ввода в первое поле формы при создании новой записи (в обработчике события OnNewRecord соответствующего компонента TTable). Кроме того, следует исключить возможность ввода пользователем значения поля PROF_ID в список врачей - в этом случае значение этого поля генерируется автоматически в соответствии со значением в выбранной строке списка специальностей, что исключает попытки создания некорректной записи уже на уровне клиентского приложения (рис. 7,8)
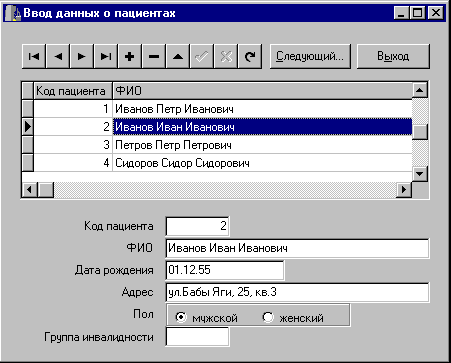
Рис. 7. Автоматизированное рабочее место медрегистратора
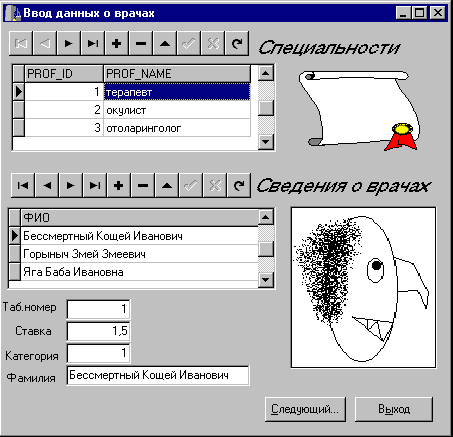
Рис. 8. Автоматизированное рабочее место инспектора отдела кадров.
Автоматизированное рабочее место медстатистика в нашей версии информационной системы используется не только для ввода данных в таблицу статистических талонов, но и для ввода данных в три словарных таблицы - список диагнозов, целей и статусов посещения. Поэтому выполним его в виде многостраничного блокнота. Для ввода словарных таблиц используем компоненты DBGrid (рис.9), а на интерфейсе ввода данных в таблицу статистических талонов остановимся отдельно.
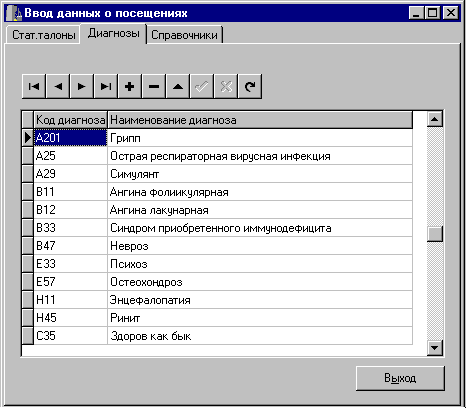
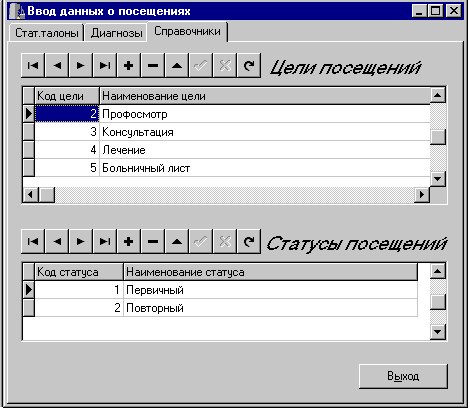
Рис.9. Автоматизированное рабочее место медстатистика - ввод справочных таблиц
Используя серверную СУБД и сгенерировав базу данных с учетом правил ссылочной целостности в соответствии со схемой данных, представленной на рис.4, мы, конечно, можем быть уверены, что ввести в базу данных некорректные значения полей DOCT_ID, DIAG_ID, STAT_ID, PURP_ID, PAT_ID сервер пользователю не даст. Однако это вовсе не означает, что можно поместить на форму набор компонентов TDBEdit для ввода данных в эти поля. Такая реализация интерфейса приведет к совершенно неприемлемым условиям труда пользователя, вводящего данные - он должен помнить наизусть все табельные номера, номера карт и коды во вспомогательных таблицах и в случае ошибок сталкиваться с сообщениями, сгенерированными триггерами сервера. Более разумно использовать выбор нужного значения из списка, поэтому для ввода данных в эти поля поместим на форму компоненты TDBLookupCombBox и выберем в качестве значения ListSource источники данных, связанные с соответствующими словарными таблицами, в качестве значения КеуField - имена их первичных ключей, а в качестве ListField - имена полей, в которых хранятся соответствующие названия статусов, диагнозов, имена врачей и др. Теперь пользователь может выбирать значения полей DOCT_ID, DIAG_ID, STAT_ID, PURP_ID, PAT_ID из выпадающих списков, в которых содержатся не коды, а символьные строки (рис 10). Таким образом, мы избавились от необходимости непосредственного ввода пользователем значений внешних ключей, заменив его выбором из соответствующих списков.
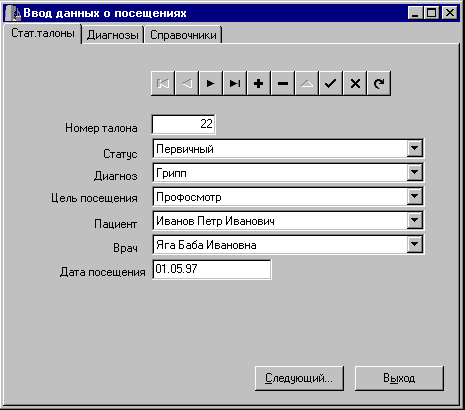
Рис.10. Автоматизированное рабочее место медстатистика - ввод статистических талонов.
Такая реализация автоматизированного рабочего места, разумеется, не является идеальной. Если список статусов и целей посещения обычно действительно невелик, и выпадающий список здесь вполне уместен, то список пациентов, скорее всего, будет составлять не меньше сотни строк. Поэтому вполне уместно либо иметь этот список в отсортированном по алфавиту виде (например, создав соответствующий индекс в базе данных, либо используя в качестве источника данных компонент TQuery с соответствующим предложением Order by). В этом случае при наборе начала фамилии пациента указатель в списке автоматически установится на ближайшую подходящую позицию. Примерно так же можно поступить и со списком диагнозов. Возможен также ввод каких-либо признаков (например, специальности врача или типа заболевания) и дальнейший выбор диагноза или фамилии врача из отфильтрованного списка, причем такая фильтрация записей может быть реализована как с помощью параметризованного запроса, выполняемого на сервере, так и с помощью локального фильтра в клиентском приложении. Какую из реализаций выбрать, зависит от размера справочной таблицы - локальные фильтры могут быть более производительны, чем параметризованный запрос, если таблица целиком кэшируется на рабочей станции, то есть ее объем сравним с емкостью буферов для кэширования данных.
Отметим также, что в списке пациентов могут быть полные тезки. В этом случае следует создать в списке пациентов вычисляемое поле (например, включающее фамилию, имя , отчество и дату рождения пациента) и использовать его для поиска.
Назад | Содержание | Вперед