Рассмотрим в качестве примера проектирование и создание информационной системы для ввода данных о посещаемости хозрасчетной поликлиники пациентами, выполняемое обычно ординаторами факультета управления здравоохранением московской медицинской Академии им. И.М.Сеченова на занятиях, посвященных проектированию информационных систем. Сразу же отметим, что данный пример носит исключительно учебный характер и ни в коем случае не претендует на роль образцовой информационной системы для данной предметной области - в реальной информационной системе подобного назначения число таблиц и набор полей таблиц должно быть существенно большим, да и автоматизированные рабочие места обычно выглядят несколько по-другому.
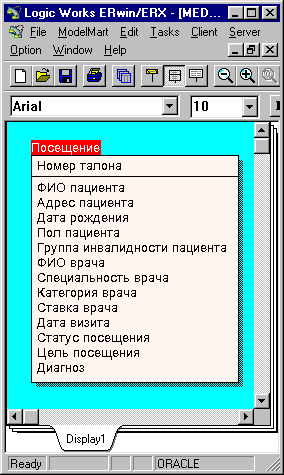
Целью данной информационной системы является хранение данных о посещениях пациентами поликлиники с целью дальнейшей статистической обработки, или, иными словами, регистрация статистических талонов, содержащих набор сведений, сходный с представленным на рис.1
Рис.1. Примерное содержание статистического талона
Итак, центральной сущностью будущей модели данных является посещение врача пациентом. И врач, и пациент участвуют в посещении. В исходной сущности помимо атрибутов, идентифицирующих врача и пациента (которые, следовательно, могут повторяться) присутствуют атрибуты, характеризующие конкретный экземпляр данной сущности - дата посещения, цель посещения, статус (первичное или повторное это посещение), диагноз. При проектировании данных желательно создать также уникальный первичный ключ (номер талона). Это более удобно, чем использование комбинации первичных ключей сущностей "Врач" и "Пациент", так как визитов одного и того же пациента к одному и тому же врачу может быть несколько(рис.2).
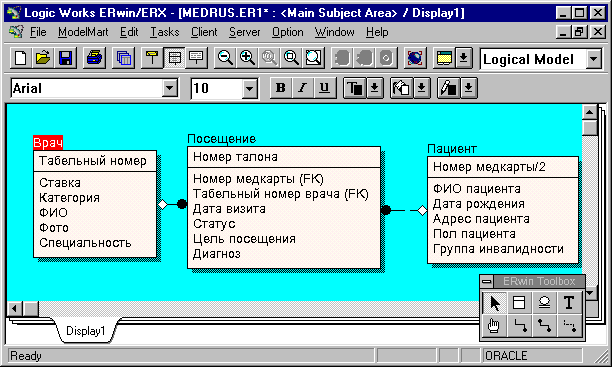
Рис.2. Первый вариант модели данных - выделяем сущности "Врач" и "Пациент"
Учитывая возможную повторяемость значений атрибутов, характеризующих диагноз, цель посещения, статус, создадим соответствующие дополнительные сущности, выполняющие роль справочников (вспомним о том, что модель данных должна удовлетворять первой нормальной форме).
Далее рассмотрим сущность "Врач". Очевидно, в поликлинике может быть несколько врачей, имеющих одну и ту же специальность, поэтому имеет смысл выделить понятие "специальность" в отдельную сущность и связать ее посредством внешнего ключа с сущностью "Врач". В результате получим модель данных, похожую на изображенную на рис.3.
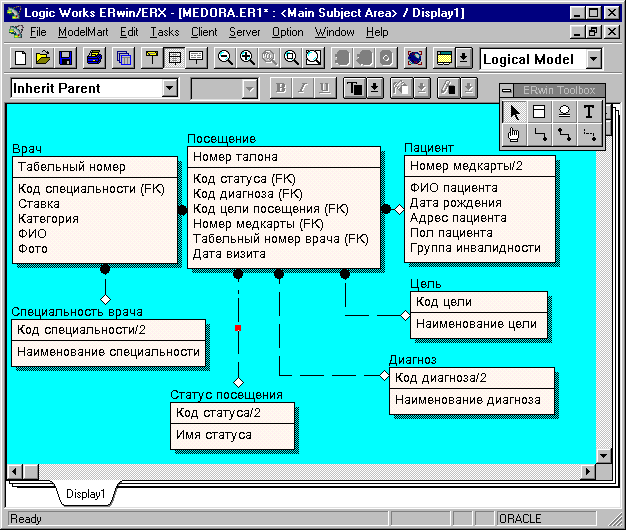
Рис.3. Модель данных после нормализации.
Возникает вопрос: а как быть с остальными атрибутами этой сущности? Ведь очевидно, что атрибуты "Ставка" и "Категория" тоже повторяются. Однако атрибут "Категория" - это обычно целое число, и поэтому нет смысла выносить его в отдельный справочник. Что касается атрибута "Ставка", характеризующего продолжительность рабочего времени, то это обычно дробное число (например, 1.25). В принципе можно было бы вынести его в отдельный справочник, но из соображений разумной достаточности в данном примере мы этого делать не будем (нормализуя модель, можно дойти до такого состояния, когда выполнение запросов к таблицам окажется весьма длительным из-за их большого числа).
Теперь рассмотрим сущность "Пациент". Исходя из требования атомарности атрибутов, следует обдумать, является ли таковым адрес пациента. Отметим, что ответ на этот вопрос неоднозначен. Если, например, речь идет о районной поликлинике с делением на участки, очевидно, что следует как минимум выделить в отдельные атрибут номер квартиры и остальную часть адреса (улица, дом, номер корпуса), так как эта остальная часть адреса указывает на принадлежность к определенному участку, а также, возможно, создать сущности "Участок" и "Часть участка" (со сведениями об улице, доме и номере корпуса), связав их между собой и с сущностью "Пациент". С другой стороны, если речь идет о хозрасчетной или ведомственной поликлинике, где адрес может потребоваться главным образом для отправки по почте счетов за услуги, то вполне возможно, что в этом случае адрес может считаться атомарным атрибутом (если, конечно, в дальнейшем не потребуется какая-либо специфическая статистическая обработка данных, связанная с анализом распределения посещений по районам проживания пациентов). Кроме того, если речь идет о районной поликлинике, возможна повторяемость не только частей адресов, но и самих адресов (в случае, если поликлиника обслуживает нескольких жителей одной квартиры). В любом случае, проектируя данные, следует ставить подобные вопросы перед заказчиками и будущими пользователями информационной системы еще на этапе проектирования данных, так как исправления в модели данных гораздо более удобно делать до разработки автоматизированных рабочих мест, нежели исправлять вместе с моделью готовую базу данных и приложения.
Итак, мы создали логическую модель данных. До этого момента можно было думать о предметной области, не вдаваясь в подробности физической реализации разрабатываемой модели. Теперь же следует подумать о физическом проектировании данных, а именно о выборе СУБД, создании таблиц, соответствующих созданным сущностям, типах полей для хранения атрибутов, а также о создании других объектов базы данных, предназначенных для облегчения поиска в таблицах, контроля ссылочной целостности данных, обработки данных, таких, как индексы, триггеры, хранимые процедуры.
Как уже отмечалось в данном цикле статей, использование серверной СУБД значительно облегчает разработку информационных систем по сравнению с использованием плоских таблиц типа dBase или Paradox, так как в последнем случае реализация правил ссылочной целостности, а также механизмов авторизации пользователя и методов ограничения доступа к данным может быть реализована только в приложении (фактически разработчик вынужден "изобретать велосипед при наличии самолетов", создавая в своих приложениях код, уже реализованный в серверах баз данных). Поэтому для реализации данной информационной системы воспользуемся какой-либо серверной СУБД (например, Oracle Workgroup Server 7.2 for Windows NT).Для создания физической модели выберем соответствующую платформу в используемом CASE-средстве и опишем характеристики таблиц, соответствующих описанным в логической модели сущностям, и содержащихся в них полей, соответствующих их атрибутам (рис.4)
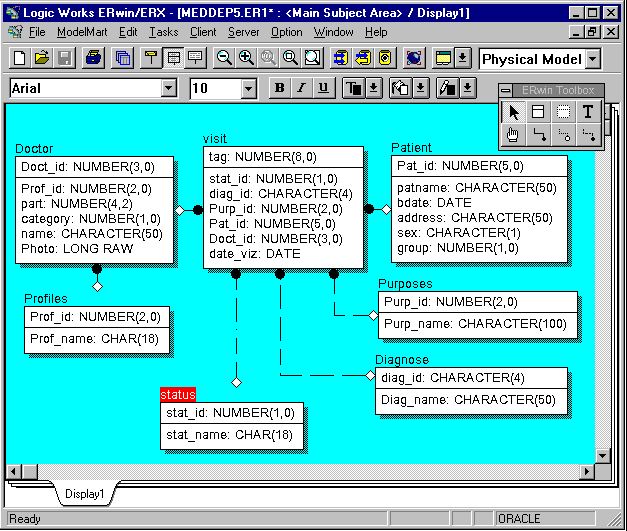
Рис.4. Физическая модель данных
Далее опишем свойства связей между таблицами, в частности, реакцию сервера на попытки нарушения ссылочной целостности со стороны клиентского приложения (рис.5): При желании можно также отредактировать тексты сообщений триггеров сервера, передаваемых клиентскому приложению.
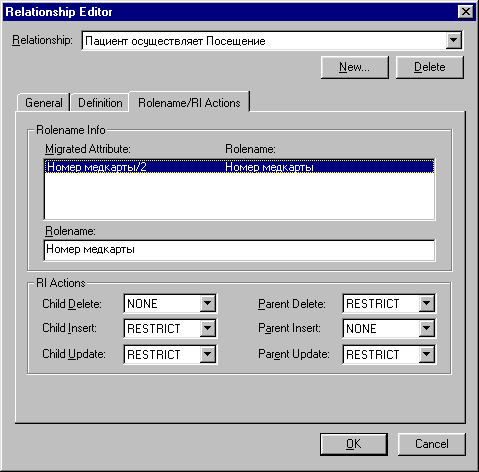
Рис.5. Описание реакции сервера на попытки нарушения ссылочной целостности данных
После этого можно создать на сервере схему базы данных, либо сгенерировать DDL-сценарий создания базы данных, представляющий собой набор предложений на процедурном расширении языка SQL данной серверной СУБД) с целью его последующего выполнения. В результате выполнения DDL-сценария на сервере должны быть созданы пустые таблицы, а также иные объекты базы данных, которые можно просмотреть с помощью утилиты Database Explorer (рис.6)
Рис.6. Созданные на сервере объекты базы данных
Назад | Содержание | Вперед