6.9. АЛЬТЕРНАТИВНЫЙ ПРОЕКТ ГРАФИЧЕСКОГО ИНТЕРФЕЙСА
При развитии программ постоянно возникает проблема увеличения функциональных возможностей одного объекта за счет функциональных возможностей другого. Актуальнейшая проблема программирования — написание гибких программ, приспособленных для модификации и развития.
Вначале надо ввести всего одно понятие, предложенное Александром Усовым: контейнер-менеджер, или просто контейнер. Следует отметить, что здесь не идет речь о контейнере С++. Итак, контейнер — это класс, который позволяет объединять (агрегировать) в себе самые разные классы объектов, в том числе и другие контейнеры. Одной из наиболее сложных задач проектирования является агрегация разнородных элементов в новое единое целое. Контейнер — один из механизмов решения проблемы гибкой агрегации.
Простейший контейнер — это список ссылок на объекты. Далее если воспользоваться механизмом сообщений, то... всех этих затруднений можно избежать! Ни строчки нового кода! Сообщения, приходящие контейнеру, проецируются на принадлежащие ему объекты. Но допустима и более сложная логика обработки запросов, перед тем как они попадут к объекту-обработчику.
Сообщения, которые может обрабатывать класс, образуют его интерфейс. При использовании таких контейнеров нет нужды объявлять поля класса private или protected либо еще как-нибудь, поскольку их вообще не должно быть видно (исходные тексты класса больше не надо поставлять вместе с его кодом). Для всех разработчиков, использующих данный класс, достаточно знать его типы и структуры сообщений, т. е. сообщения обеспечивают максимальную защиту полей объектов и при этом не требуют накладных расходов.
Сообщения позволяют увеличить виртуализацию кода, что положительно сказывается на снижении его объема. Сообщения в отличие от вызова процедуры проще перехватить, дабы выполнить над ними предварительную обработку, например фильтрацию или сортировку. Наконец, сообщения позволяют максимально увеличить производительность системы, что недостижимо при вызове процедур.
Контейнеры бывают двух типов: однородные (динамические) и разнородные (статические). Однородный контейнер может включать произвольное множество объектов одного класса либо классов, производных от данного класса. Логика работы такого контейнера предельно проста, например распределять поступающие сообщения по всем включенным в него объектам. Поскольку включенные в него объекты принадлежат одному классу, то, следовательно, они имеют единый интерфейс, но тогда становится совершенно неважно, сколько объектов включено в контейнер в любой момент времени, т. е. это число произвольно. Логика работы такого контейнера с включенными в него объектами одинакова и не зависит от конкретного объекта. Типичный представитель такого контейнера — список (например, строк). При добавлении (удалении) новых объектов (строк) логика работы самого контейнера остается неизменной.
Напротив, контейнер разнородных элементов может состоять из объектов самых разных классов. Его можно представить как схему, где каждый элемент (объект) имеет свою смысловую (функциональную) нагрузку. События, поступающие на такой контейнер, не транслируются примитивно на все объекты, а распределяются между ними по заданной схеме. Для данного типа контейнера применимо понятие «конструирование».
Другим отличием контейнера от множественного наследования является то, что можно произвольно во время работы или проектирования включать новые или исключать старые объекты, например, для того чтобы обеспечить их перенос из одного контейнера в другой. При этом состояние объектов остается тем же самым, мы просто меняем ссылки у контейнеров. Можно динамически подгружать новые логические схемы работы контейнера или изменять старые, что для множественного наследования, наверное, недостижимо в принципе. Следовательно, контейнер может гибко реализовывать полиморфизм в наиболее общем смысле!
Отметим еще раз, что взаимосвязь между объектами осуществляется посредством сообщений. Но здесь сообщения — специальный класс. Именно этот класс несет ответственность за полиморфизм свойств, но никак не классы основной иерархии. В таком случае у нас есть возможность объявить некоторый класс-сообщение и создать набор полиморфных классов-наследников, которые будут обрабатываться объектами основной иерархии классов.
Удобство работы с сообщениями вовсе не означает, что можно менять (добавлять или модифицировать) набор свойств класса основной иерархии. Нет, свойства каждого класса задаются на этапе проектирования иерархии.
При использовании контейнеров ни в одном объекте не используются ни конструкторы, ни деструкторы. Это не случайно. В чем суть конструктора? Реально он должен выполнить два действия: проинициализировать указатель на таблицу виртуальных методов (ЧМТ) и проинициализировать собственные данные.
Рассмотрим пример проекта с использованием контейнеров. Предположим, что перед вами стоит задача разработки графического интерфейса, аналогичного GUI Microsoft Windows. Аналогичный интерфейс создавали разработчики Delphi, и ранее мы ретроспективно выполняли данный проект.
У вас несколько разработчиков (проектировщиков и программистов), и задачу надо решить в максимально короткий срок. Здесь следует отметить следующий важный момент: вы не сразу пишете программу, а скорее создаете инструментарий ее решения.
Прежде всего вы определяете все многообразие элементов GUI: labels, shapes, edit fields, buttons, check & radio buttons, list & combo boxes, bitmap и т. д. Несложно заметить, что большинство элементов представляет собой простые комбинации из двух или более визуальных элементов: например строка и рамка. Интуитивно понятно, что визуальный элемент и элемент интерфейса — это не одно и то же. Главной функцией элемента интерфейса является получение информации от пользователя, в то время как визуальный элемент служит для ее (информации) отображения. Это важно.
Теперь раздробим нашу команду на четыре подкоманды.
Первая команда займется графикой, т. е. визуальными элементами. Им необходимо выстроить иерархию объектов — графических примитивов, начиная от точки и заканчивая фонтами, произвольными многоугольниками и т. п.
Вторая команда должна специфицировать иерархию элементов интерфейса.
Третья команда займется построением дерева сообщений, при помощи которого элементы интерфейса будут взаимодействовать не только между собой, но и с ядром операционной системы.
И наконец, функцией четвертой команды будет создание иерархии объектов ввода-вывода (клавиатура, мышь, дисплей и т.д.).
Задачи каждой из подкоманд в достаточной степени независимы друг от друга и могут выполняться параллельно. Это тоже важно.
Теперь перейдем к контейнерам, для чего вырежем небольшой фрагмент из работы ваших команд. Предположим, что первая группа специфицировала (отметьте, только специфицировала, но еще, возможно, не создала ни одного объекта) дерево визуальных элементов. Пусть где-то в этой иерархии найдется место, скажем, для прямоугольника и строки. Теперь вторая команда может создать свой элемент интерфейса — предположим, что это будет банальная кнопка. Что такое кнопка — прямоугольная рамка и строка. Поскольку мы предполагаем обойтись без множественного наследования, то разумно предположить, что это контейнер. Следовательно, иерархия элементов интерфейса должна включать в себя контейнеры для визуальных элементов. Контейнер распределяет входное воздействие по составляющим его элементам, следовательно, контейнер есть менеджер объектных запросов.
Как представить графы реакций, которые можно условно назвать кодом контейнера? Теперь для нас весьма важно добиться быстрой реакции на каждое событие. Проблема могла бы быть решена множественным наследованием. Но поступим иначе.
У нас была выделена специальная команда, которая должна была разработать механизм объектных сообщений. Дадим им слово. Когда мы им сказали, какого типа объекты будут использоваться в нашей системе, они разработали иерархию сообщений. Да, каждое сообщение является классом, но удивительно не только это, а и то, что сообщения, обрабатываемые каждым классом, компилируются вместе с кодом данного класса. Это в первом приближении можно представить как таблицу виртуальных методов, только раздробленную на кусочки. Таким образом, каждое сообщение несет в себе адрес функции, его обрабатывающей. Когда контейнер получает такое сообщение, он подставляет в него ссылку на принадлежащий экземпляр объекта данного класса и производит вызов. И все...
Что же теперь имеем? Предположим, что надоели прямоугольные кнопки и захотелось круглых, многоугольных или вообще произвольных кнопок. «Ну, уж нет», — сказал бы специалист по множественному наследованию. Но мы спросим: «Вам в runtime или специально настроить?» Действительно, любой наследник от плоской фигуры может быть подставлен в контейнер в любое время, включая время выполнения. И тут вы с удивлением замечаете, что можно считать проект готовым к употреблению, отладив его схемы взаимодействия всего на одном двух реальных объектах и добавляя все остальное по мере необходимости. Предложенная Александром Усовым агрегация есть один из механизмов реализации в рамках ООП, который удачно пересекается и дополняет механизмы наследования, инкапсуляции и полиморфизма.
Вероятно, для обеспечения динамики, будет сделан следующий шаг — использовать теорию ролей. Теория ролей — это просто удобное человеческое название много раз здесь упомянутого разделения объявленного интерфейса и его реализации некоторым объектом (актером), который умеет эту роль исполнять.
Развивая идею использования контейнеров А. Усова, можно получить идею системы генерации все новых программ с используемыми «кубиками» — готовыми объектами, которые при формировании программы автоматически извлекаются объектно-ориентированной СУБД из базы данных объектов.
Создав систему программирования с использованием базы данных объектов и генератором схем свойств контейнеров, А. Усов разработал ядро типовой АСУ предприятия, позволяющее за короткие сроки и при малом количестве программистов генерировать АСУ все новых предприятий.
Информационное пространство любого предприятия состоит из двух частей — зависимой и независимой от профиля предприятия. Независимая часть базируется на общности свойств, которые присущи любому предприятию. Благодаря этому, во-первых, можно построить классификатор предприятий любого профиля так, как это принято в технологии объектно-ориентированного проектирования. Во-вторых, это позволяет объединять предприятия разного профиля в единую корпорацию. В-третьих, можно создавать абстрактные предприятия, требующие минимальной настройки на конкретный профиль. Наконец, благодаря наличию общих свойств у всех предприятий, внешние организации могут контролировать деятельность предприятия.
Каждое предприятие имеет, как правило, иерархическую структуру подразделений. Структурное подразделение (СП) включает в себя три информационных класса: служащие, оборудование и материалы. Здесь под оборудованием будут пониматься основные фонды предприятия или данного СП. Термином «материалы» обозначаются те сущности, которые потребляются в процессе производства. Базовые информационные классы — служащие, оборудование и материалы — могут иметь общий суперкласс (НЕЧТО, УЧАСТВУЮЩЕЕ В ПРОИЗВОДСТВЕ) или нет (дело вкуса).
Таким образом, создав необходимые информационные классы, сложив их в контейнер СП и представив набор этих контейнеров в виде иерархии владения, мы тем самым создаем абстрактное предприятие. Да, это предприятие ничего не производит, ибо производство является специфичным и определяет профиль предприятия. Но такой класс позволяет создавать подклассы предприятий будь то промышленные, муниципальные, транспортные, финансовые или другие. Каждый из этих классов предприятий может образовывать свое поддерево классов.
Есть еще ряд моментов, на которых остановимся. Существующие системы достаточно громоздки и тяжелы в настройке. Перед их установкой, как правило, проводятся исследования по организации бизнес-процессов. По результатам этих обследований выдаются рекомендации, целью которых является оптимизация основных процессов. Однако после внедрения систем переорганизация производства требует значительных усилий по настройке системы на новые условия. Обычно к этой работе привлекаются специальные фирмы, занимающиеся сопровождением АСУ. Но современные условия ведения бизнеса требуют высокой гибкости, которая пока остается недостижимой мечтой.
В предлагаемом решении каждое структурное подразделение выделено в самостоятельную сущность, это позволяет, во-первых, моделировать и просчитывать новые схемы управления производством, а во-вторых, дает возможность внедрять эти схемы «на ходу». Действительно, предприятие, как уже было сказано, представляет собой контейнер с наличием ряда свойств. Разложение этих свойств по СП есть генерация схем. Имея механизм версионности схем, можно строить модели, оптимизируя их по различным критериям и используя строгие математические методы.
Здесь же можно отметить, что современная теория управления предприятиями базируется на BPR (bussiness process re-engine ering) и TQM (total quality managment). Одно из основных положений BPR говорит о необходимости переноса точки принятия тактических решений как можно ближе к исполнителям, т. е. СП должно быть в максимальной степени самостоятельным, само достаточным и компетентным в принятии решений.
Опять же, приобретая возможность рассматривать каждое СП как самостоятельную часть предприятия, нам гораздо легче решить данную задачу. Не составляет труда оценить, во что обходится каждое СП и какую оно дает отдачу, насколько продумана: внутренняя структура СП и его место в общей структуре производства. Так же как и на уровне производства, можно заниматься оптимизацией бизнес-процессов на уровне отдельного подразделения. Наконец, перенос точки принятия тактических решений внутрь СП позволяет если не упразднить совсем, то, по крайней мере, существенно облегчить работу многих отделов, функционирующих на уровне предприятия (отдел кадров, планирование закупок оборудования и проведения ремонтов и т. п.).
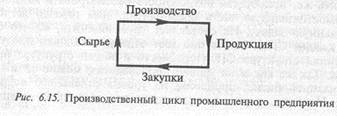
Функциональная часть предприятий различна и зависит от профиля предприятия. Поэтому возьмем за основу рассмотрения типичное (обобщенное) промышленное предприятие, производственный цикл которого можно представить следующей схемой, показанной на рис. 6.15.
Каждая фаза производства дробится на более мелкие, например, стадия «Сырье» состоит в поиске поставщиков, заключении договоров, получении и оплате счетов, получении и складировании сырья и т. п. Деление происходит до получения элементарных операций, реализуемых в виде наборов сервисов.
Когда выполнено разложение исходной задачи на сервисы, можно приступить к комплектованию должностей. Должность определяется набором доступных и необходимых сервисов, т.е. должность представима контейнером сервисов. В свою очередь должности соединяются в структурные подразделения. Таким образом, произошло соединение функциональной и функционально-независимой частей. Мы сохранили возможность динамического изменения как отдельной должности, так и структурного подразделения, следовательно, нам доступно и динамическое перепрофилирование предприятия в целом.
Система поддерживает произвольное количество логических слоев (аналог — многоуровневые системы клиент — сервер). Слой хранения информации представлен средой хранения (СУБД), слой отображения — средой отображения, основанной на GUI (пользовательскими приложениями), слой бизнес правил — схемами и т.д.
Каждый сервис представляет собой группу классов (возможно, иерархий). Классы могут быть объединены в контейнеры, свойства которых реализуются в виде схем. Приложение, взаимодействуя с контейнерами явно или опосредованно, запускает те или иные схемы, реализуя тем самым собственную логику работы.
6.11. ОБЗОР ОСОБЕННОСТЕЙ ПРОЕКТОВ ПРИКЛАДНЫХ СИСТЕМ
Проектируя систему одного из перечисленных далее типов, имеет смысл обратиться к одному из соответствующих решений. Далее рассматриваются следующие типы систем:
— системы пакетной обработки — обработка данных производится один раз для каждого набора входных данных;
— системы непрерывной обработки — обработка данных производится непрерывно над сменяющимися входными данными;
— системы с интерактивным интерфейсом — системы, управляемые внешними воздействиями;
— системы динамического моделирования — системы, моделирующие поведение объектов внешнего мира;
— системы реального времени — системы, в которых преобладают строгие временные ограничения;
— системы управления транзакциями — системы, обеспечивающие сортировку и обновление данных; имеют коллективный доступ (типичной системой управления транзакциями является СУБД).
При разработке системы пакетной обработки необходимо выполнить следующие шаги:
— разбиваем полное преобразование на фазы, каждая из которых выполняет некоторую часть преобразования; система описывается диаграммой потока данных, которая строится при разработке функциональной модели;
— определяем классы промежуточных объектов между каждой парой последовательных фаз, при этом каждая фаза знает об объектах, расположенных на объектной диаграмме до и после нее (эти объекты представляют соответственно входные и выходные данные фазы);
— составляем объектную модель каждой фазы (она имеет такую же структуру, что и модель всей системы в целом: фаза разбивается на подфазы) и далее разрабатываем каждую подфазу.
При разработке системы непрерывной обработки необходимо выполнить следующие шаги:
— строим диаграмму потока данных (активные объекты в ее начале и конце соответствуют структурам данных, значения которых непрерывно изменяются, а хранилища данных, связанные с ее внутренними фазами, отражают параметры, которые влияют на зависимость между входными и выходными данными фазы);
— определяем классы промежуточных объектов между каждой парой последовательных фаз, при этом каждая фаза знает об объектах, расположенных на объектной диаграмме до и после нее (эти объекты представляют соответственно входные и выходные данные фазы);
— представляем каждую фазу как последовательность изменений значений элементов выходной структуры данных в зависимости от значений элементов входной структуры данных и значений, получаемых из хранилища данных (значение выходной структуры данных формируется по частям).
При разработке системы с интерактивным интерфейсом необходимо выполнить следующие шаги:
— выделяем объекты, формирующие интерфейс;
— если есть возможность, используем готовые объекты для организации взаимодействия (например, для организации взаимодействия системы с пользователем через экран дисплея можно использовать библиотеку системы X-Window, обеспечивающую работу с меню, формами, кнопками и т. п.);
— структуру программы определяем по ее динамической модели, а для реализации интерактивного интерфейса используем параллельное управление (многозадачный режим) или механизм событий (прерывания), а не процедурное управление, когда время между выводом очередного сообщения пользователю и его ответом система проводит в режиме ожидания;
— из множества событий выделяем физические (аппаратные, простые) события и стараемся при организации взаимодействия использовать в первую очередь их.
При разработке системы динамического моделирования необходимо выполнить следующие шаги:
— по объектной модели определяем активные объекты; эти объекты имеют атрибуты с периодически обновляемыми значениями;
— определяем дискретные события; такие события соответствуют дискретным взаимодействиям объекта (например, включение питания) и реализуются как операции объекта;
— определяем непрерывные зависимости (например, зависимости атрибутов от времени), при этом значения таких атрибутов должны периодически обновляться в соответствии с зависимостью;
— моделирование управляется объектами, отслеживающими временные циклы последовательностей событий.
Разработка системы реального времени аналогична разработке системы с интерактивным интерфейсом.
При разработке системы управления транзакциями необходимо выполнить следующие шаги:
— отобразить объектную модель на базу данных;
— определить асинхронно работающие устройства и ресурсы с асинхронным доступом; в случае необходимости определить новые классы;
— определить набор ресурсов (в том числе структур данных), к которым необходим доступ во время транзакции (участники транзакции);
— разработать параллельное управление транзакциями; системе может понадобиться несколько раз повторить неудачную транзакцию, прежде чем выдать отказ.
6.12. ГИБРИДНЫЕ ТЕХНОЛОГИИ ПРОЕКТИРОВАНИЯ
Процедурно-ориентированный и объектно-ориентированный подходы к программированию различаются по своей сути и обычно ведут к совершенно разным решениям одной задачи. Этот вывод верен как для стадии реализации, так и для стадии проектирования: вы концентрируете внимание или на предпринимаемых действиях, или на представляемых сущностях, но не на том и другом одновременно.
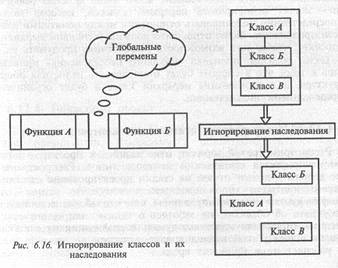
Тогда почему метод объектно-ориентированного проектирования предпочтительнее метода функциональной декомпозиции? Главная причина в том, что функциональная декомпозиция не дает достаточной абстракции данных. А отсюда уже следует, что проект будет менее податливым к изменениям; менее приспособленным для использования различных вспомогательных средств; менее пригодным для параллельного развития; менее пригодным для параллельного выполнения.
Дело в том, что функциональная декомпозиция вынуждает объявлять «важные» данные глобальными, поскольку если система структурирована как дерево функций, всякое данное, доступное двум функциям, должно быть глобальным по отношению к ним. Это приводит к тому, что «важные» данные «всплывают» к вершине дерева по мере того, как все большее число функций требует доступа к ним.
В точности так же происходит в случае иерархии классов с одним корнем, когда «важные» данные всплывают по направлению к базовому классу (рис. 6.16).
6.12.2. Игнорирование наследования
Рассмотрим второй вариант — проект, который игнорирует наследование. Считать наследование всего лишь деталью реализации — значит игнорировать иерархию классов, которая может непосредственно моделировать отношения между понятиями в области приложения. Такие отношения должны быть явно выражены в проекте, чтобы дать возможность разработчику продумать их.
Таким образом, политика «никакого наследования» приведет лишь к тому, что в системе будет отсутствовать целостная общая структура, а использование иерархии классов будет ограничено определенными подсистемами.
6.12.3. Игнорирование статического контроля типов
Рассмотрим третий вариант, относящийся к проекту, в котором игнорируется статический контроль типов. Распространенные доводы в пользу отказа на стадии проектирования от статического контроля типов сводятся к тому, что «типы — это продукт языков программирования» или что «более естественно рассуждать об объектах, не заботясь о типах», или «статический контроль типов вынуждает нас думать о реализации на слишком раннем этапе». Такой подход вполне допустим до тех пор, пока он работает и не приносит вреда.
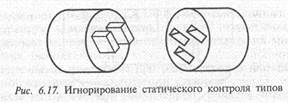
Рассмотрим следующую аналогию: в физическом мире мы постоянно соединяем различные устройства, и существует кажущееся бесконечным число стандартов на соединения. Главная особенность этих соединений — они специально спроектированы таким образом, чтобы сделать невозможным соединение двух устройств, не рассчитанных на него, т. е. соединение должно быть сделано единственным правильным способом. Вы не можете подсоединить радиотрансляционный приемник к розетке с высоким напряжением, Если бы вы смогли сделать это, то сожгли бы приемник или сгорели сами.
Здесь практически прямая аналогия: статический контроль типов эквивалентен совместимости на уровне соединения, а динамические проверки соответствуют защите или адаптации в цепи. Результатом неудачного контроля как в физическом, так и в программном мире будет серьезный ущерб. В больших системах используются оба вида контроля (рис. 6.17).
На раннем этапе проектирования вполне достаточно простого утверждения:
«Эти два устройства необходимо соединить», но скоро становится существенным, как именно следует их соединить: «Какие гарантии дает соединение относительно поведения устройств?» или «Возникновение каких ошибочных ситуаций возможно?», или «Какова приблизительная цена такого соединения?»
Переход на новые методы работы может быть мучителен для любой организации. Поскольку в объектно-ориентированных языках возможны несколько схем программирования, язык допускает постепенный переход на него, используя следующие преимущества такого перехода:
1) изучая объектно-ориентированное проектирование, программисты могут продолжать работать по технологии структурного программирования;
2) в окружении, бедном на программные средства, использование объектно-ориентированных языков может принести значительные выгоды.
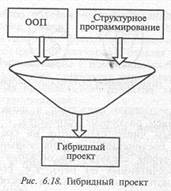
Идея постепенного, пошагового овладения объектно-ориентированными языками и технологий их применения, а также возможность смешения объектно-ориентированного кода с кодом структурного программирования естественно приводит к проекту, имеющему гибридный стиль. Большинство интерфейсов можно пока оставить на процедурном уровне, поскольку что-либо более сложное не принесет немедленного выигрыша (рис. 6.18).
ВЫВОДЫ
• Процедурно-ориентированный и объектно-ориентированный подходы к программированию различаются по своей сути и обычно ведут к совершенно разным решениям одной задачи.
• Объектно-ориентированный подход помогает справиться с такими сложными проблемами, как:
— уменьшение сложности программного обеспечения; — повышение надежности программного обеспечения;
— обеспечение возможности модификации отдельных компонентов программного обеспечения без изменения остальных его компонентов;
— обеспечение возможности повторного использования отдельных компонентов программного обеспечения.
• Методы объектно-ориентированного проектирования используют в качестве строительных блоков объекты.
• Принципы абстрагирования, инкапсуляции и модульности являются взаимодополняющими. Объект логически определяет границы определенной абстракции, а инкапсуляция и модульность делают их физически незыблемыми.
• Наследование выполняет в ООП несколько важных функций:
— моделирует концептуальную структуру предметной области;
— экономит описания, позволяя использовать их многократно для задания разных классов;
— обеспечивает пошаговое программирование больших систем путем многократной конкретизации классов.
• Классы из предметной (прикладной) области непосредственно отражают понятия, которые использует конечный пользователь для описаний своих задач и методов их решения.
• Идеальный класс должен в минимальной степени зависеть от остального мира. Каждый класс имеет набор поведений и характеристик, которые его определяют.
• При перестройке иерархии классов применяются четыре процедуры:
1) расщепление класса на два и более;
2) абстрагирование (обобщение);
3) слияние;
4) анализ возможности использования существующих разработок.
• Разработка проекта начинается с составления функциональной модели.
• Объектная модель представляет статическую структуру проектируемой системы (подсистемы).
• Динамическая модель системы представляется диаграммой последовательности и диаграммой состояний объектов.
Глава 7. ВИЗУАЛЬНОЕ ПРОГРАММИРОВАНИЕ
7.1. ОБЩЕЕ ПОНЯТИЕ ВИЗУАЛЬНОГО ПРОГРАММИРОВАНИЯ
Визуальное программирование является в настоящее время, одной из наиболее популярных парадигм программирования. Визуальное программирование состоит в автоматизированной разработке программ с использованием особой диалоговой оболочки. Рассматривая системы визуального программирования, легко увидеть, что все они базируются на объектно-ориентированном программировании и являются его логическим продолжением. Наиболее часто визуальное программирование используется для создания интерфейса программ и систем управления; базами данных.
С объектно-ориентированными системами ассоциируется программа Browser (рис. 7.1). Это средство вместе с системой экранных подсказок позволяет программисту по желанию просматривать некоторые части программного окружения и видеть весь проект уже созданной программы. Под проектом программы здесь понимается структура программы — состав файлов, объектов и их порождающих классов, которые слагают программу в
целом.
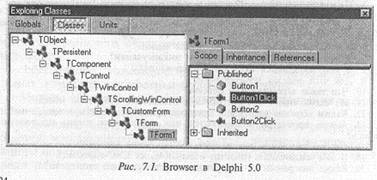
Одну из ключевых возможностей программы Browser предоставляет окно, в котором находится список всех классов системы. При выборе одного из классов в специальных окнах отображаются его локальные функции и переменные. Затем при выборе одного из методов на отдельной панели высвечивается его код. Обычно в системе присутствуют средства для добавления и удаления классов из проекта. Программа Browser — это не просто визуализатор. Это основной, интегрирующий инструмент, который помогает одновременно рассматривать существующую систему и разрабатывать документацию программного проекта.
Структурной единицей визуального программирования в Delphi и C++Buider является компонент. Компонента представляет собой разновидность объекта, который можно перенести (агрегировать) в приложение из специальной Палитры компонент (рис. 7.2). Компонента имеет набор свойств, которые можно изменять, не изменяя исходный код программы.
Компоненты бывают визуальными и не визуальными. Первые предназначены для организации интерфейса с пользователем. Это различные кнопки, списки, статический и редактируемый текст, изображения и многое другое. Эти компоненты отображаются при выполнении разрабатываемого приложения. Не визуальные компоненты отвечают за доступ к системным ресурсам: драйверам баз данных, таймерам и т. д. Во время разработки они отображаются своей пиктограммой, но при выполнении приложения, как правило, невидимы. Компонента может принадлежать либо другой компоненте, либо форме.
Формой называется визуальная компонента, обладающая свойством окна Windows (рис. 7.3). При разработке на форме помещаются необходимые компоненты (например, элементы требуемого
диалога). Форм в приложении может быть несколько — по требуемому числу открываемых при выполнении диалога окон, их можно добавлять и удалять.
Программные средства разработки приложений, относящиеся к предыдущему поколению, предлагают интерактивные средства решения типовых задач (мастера в Borland С++ и Wizards или волшебники в Visual С++), которые позволяют в диалоге с программистом создавать и вставлять в программы готовые фрагменты исходного кода.
Технология создания приложений в среде Delphi вышла на новый уровень развития этих идей. В Delphi разработчик из меню палитры компонент выбирает необходимую компоненту, например кнопку, и буксирует ее при помощи мыши в нужное место окна разрабатываемой формы. При этом кнопке автоматически присваивается название (имя или идентификатор), и она описывается в модуле формы (рис. 7.4).
Щелкнув по изображению компоненты на форме, можно сделать ее активной. Затем, перемещая при помощи мыши границы кнопки и работая в окне Inspector, можно задать надпись (например, ОК) и/или графическую пиктограмму на кнопке, задать цвета и другие настроечные параметры кнопки. Двойной щелчок
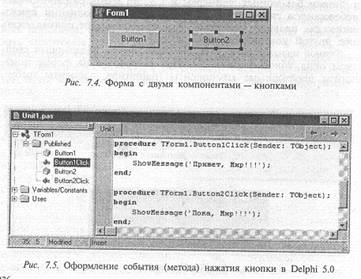
по кнопке — и в исходном тексте формы появится шаблон подпрограммы (метода) нужного типа реакции на щелчок (рис. 7.5). Работая в окне редактора текста, можно оформить тело подпрограммы реакции кнопки на щелчок.
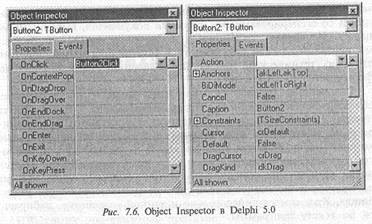
Программа Inspector позволяет входить в исходные тексты методов (подпрограммы обработки событий, названных Events), например, на нажатие Enter, а также задавать начальные значения полям данных, названных Properties (рис. 7.6).
7.2. ТЕХНОЛОГИЯ ВИЗУАЛЬНОГО ПРОГРАММИРОВАНИЯ
Начальные шаги технологии визуального программирования определяются оболочкой самой среды визуального программирования. Сначала создаются экранные формы простейшей буксировкой мыши. В инспекторе объектов производится настройка их свойств путем заполнения отдельных полей. На главную форму помимо визуальных компонент наносятся не визуальные компоненты. Формы объединяются в единый проект. Далее в соответствии со сценарием диалога программируются методы события основной и подчиненных форм. Программы «пустых» методов событий появляются в окне редактора после нажатия соответствующих клавиш или действий мыши. «Пустые» методы дополняются определенными операторами активации и дезактивации форм. По окончании начальных шагов получается работающий «скелет» программы с источниками данных из файловых баз данных и со сгенерированными формами документов, выводимых на печать. Исследователь (Browser) обеспечивает визуализацию схемы иерархии классов полученного «скелета» программы. Другими словами, технический проект реализованной части программы формируется автоматически.
Дальнейшая разработка программы ведется по технологии объектно-ориентированного программирования. Можно часть программы реализовать по технологии структурного программирования. Некоторые недостающие визуальные и не визуальные компоненты получаются модификацией исходных текстов наиболее близких прототипов имеющихся компонент. Рекомендуется новые компоненты помещать в палитру компонент. Это облегчит их повторное использование в данной или последующих разработках. Код, относящийся только к данной разработке, набирается по тексту программы.
ВЫВОДЫ
• Визуальное программирование во многом автоматизирует труд программиста по написанию программ.
• Визуальное программирование — одна из самых популярных парадигм программирования на данный момент. Оно базируется на технологии ООП.
• Среда визуального программирования поддерживает работу браузеров (Browser), при помощи которых можно автоматически получить документацию по структуре программы.
• Основным элементом в средствах визуального программирования является компонент. Компоненты бывают визуальными и не визуальными.
• Технология визуального программирования состоит в следующем: создание экранных форм, нанесение визуальных и не визуальных компонент, программирование событий и методов оконных форм.
Глава 8. САSЕ-СРЕДСТВА И ВИЗУАЛЬНОЕ МОДЕЛИРОВАНИЕ
8.1. ПРЕДПОСЫЛКИ ПОЯВЛЕНИЯ САЯЕ-СРЕДСТВ
Тенденции развития современных информационных технологий приводят к постоянному усложнению автоматизированных систем (АС). Для борьбы со сложностью проектов в настоящее время созданы системы автоматизированного проектирования (САПР) самих программных проектов.
Для успешной реализации проекта объект проектирования (АС) должен быть прежде всего адекватно описан, должны быть построены полные, а также непротиворечивые функциональные
и информационные модели АС. Накопленный к настоящему времени опыт проектирования АС показывает, что это трудоемкая и длительная по времени работа.
Все это способствовало появлению программно-технологических средств особого назначения — CASE-средств, реализующих CASE-технологию создания и сопровождения АС. Термин «САSЕ» (Computer Aided Software Engineering) используется в настоящее время в весьма широком смысле. Первоначальное значение термина CASE, ограниченное вопросами автоматизации разработки только лишь программного обеспечения (ПО), в настоящее время приобрело новый смысл, охватывающий процесс разработки сложных АС в целом.
Теперь под термином «САSЕ-средства» понимаются программные средства поддерживающие процессы создания и сопровождения АС, включая анализ и формулировку требований, проектирование прикладного ПО (приложений) и баз данных, генерацию кода, тестирование, документирование, обеспечение качества, конфигурационное управление и управление проектом, а также другие процессы. САSЕ-средства вместе с системным ПО и техническими средствами образуют среду разработки АС.
CASЕ-технология представляет собой методологию проектирования АС, а также набор инструментальных средств позволяющих в наглядной форме моделировать предметную область, анализировать эту модель на всех этапах разработки и сопровождения АС и разрабатывать приложения в соответствии с информационными потребностями пользователей. Большинство существующих CASE-средств основано на методологиях структурного (в основном) или объектно-ориентированного анализа и проектирования, использующих спецификации в виде диаграмм или текстов для описания внешних требований, связей между моделями системы, динамики поведения системы и архитектуры программных средств.
На основании анкетирования более тысячи американских фирм фирмой «Systems Development Inc.» в 1996 г. был составлен обзор передовых технологий (Survey of Advanced Technology). Согласно этому обзору, CASE-технология в настоящее время попала в разряд наиболее стабильных информационных технологий (ее использовала половина всех опрошенных пользователей более чем в трети своих проектов, из них 85% завершились успешно). Однако несмотря на все потенциальные возможности CASE средств, существует множество примеров их неудачного внедрения. В связи с этим необходимо отметить следующее:
— CASE-средства не обязательно дают немедленный эффект, он может быть получен только спустя какое-то время;
— реальные затраты на внедрение CASE-средств обычно намного превышают затраты на их приобретение;
— CASE-средства обеспечивают возможности для получения существенной выгоды только после успешного завершения процесса их внедрения.
Для успешного внедрения CASE-средств организация должна обладать такими качествами, как:
→ технология — понимание ограниченности существующих возможностей и способность принять новую технологию;
→ культура — готовность к внедрению новых процессов и взаимоотношений между разработчиками и пользователями;
→управление — четкое руководство и организованность по отношению к наиболее важным этапам и процессам внедрения.
На сегодняшний день российский рынок программного обеспечения располагает следующими наиболее развитыми CASE средствами:
→ Vantage Team Builder (Westmount 1-CASE);
→ Designer/2000;
→ Silverrun;
→ ERwin+BPwin;
→ S-Designor;
→ CASE. Аналитик;
→ Rational Rose.
Кроме того, на рынке постоянно появляются как новые для отечественных пользователей системы, так и новые версии и модификации перечисленных систем.
CASE-средство Silverrun американской фирмы «Computer Systems Advisers, Inc.» (CSA) используется для анализа и проектирования АС бизнес-класса и ориентировано в большей степени на спиральную модель жизненного цикла. Оно применимо для поддержки любой методологии, основанной на раздельном построении функциональной и информационной моделей (диаграмм потоков данных и диаграмм «сущность-связь»).
Платой за высокую гибкость и разнообразие изобразительных средств построения моделей является такой недостаток Silverrun, как отсутствие жесткого взаимного контроля между компонентами различных моделей (например, возможности автоматического распространения изменений между ДПД различных уровней декомпозиции).
Для автоматической генерации схем баз данных у Silverrun существуют мосты к наиболее распространенным СУБД: Oracle, Informix, DB2, SQL Server и др. Для передачи данных в средства разработки приложений имеются мосты к языкам 4GL: JAM, PowerBuilder, SQL Windows, Uniface, NewEra, Delphi. Все мосты позволяют загрузить в Silverrun RDM информацию из каталогов соответствующих СУБД или языков 4GL.
Vantage Team Builder представляет собой интегрированный программный продукт, ориентированный на реализацию каскадной модели жизненного цикла (ЖЦ) ПО и поддержку полного жизненного цикла ПО.
Система обеспечивает выполнение следующих функций: — проектирование диаграмм потоков данных, «сущность-связь», структур данных, структурных схем программ и последовательностей экранных форм;
— проектирование диаграмм архитектуры системы SAD (проектирование состава и связи вычислительных средств, распределения задач системы между вычислительными средствами, моделирование отношений типа «клиент-сервер», анализ использования менеджеров транзакций и особенностей функционирования систем в реальном времени);
— генерация кода программ на языке 4GL целевой СУБД с полным обеспечением программной среды и генерация ЯЯ -кода для создания таблиц БД, индексов, ограничений целостности и хранимых процедур;
— программирование на языке С со встроенным сервером
SQL;
— управление версиями и конфигурацией проекта;
— генерация проектной документации по стандартным и индивидуальным шаблонам.
Vantage Team Builder функционирует на всех основных UNIX-платформах (Solaris, SCO UNIX, AIX, HP-UX) и VMS.
CASE-средство Designer/2000 2.0 фирмы «ORACLE» является интегрированным CASE-средством, обеспечивающим в совокупности со средствами разработки приложений Developer/2000 поддержку полного жизненного цикла ПО для систем, использующих СУБД ORACLE.
Базовая методология Designer/2000 (CASE Method) — структурная методология проектирования систем, охватывающая полностью все этапы жизненного цикла АС. Designer/2000 обеспечивает графический интерфейс при разработке различных моделей (диаграмм) предметной области. В процессе построения моделей информация о них заносится в репозитарий.
Среда функционирования Designer/2000 — Windows 3.х, Windows 95, Windows NT.
ERwin — средство концептуального моделирования БД, использующее методологию IDEF1X. ERwin реализует проектирование схемы БД, генерацию ее описания на языке целевой СУБД (ORACLE, Informix, Ingres, Sybase, DB/2, Microsoft SQL Server, Progress и др.) и реинжениринг существующей БД. ERwin выпускается в нескольких различных конфигурациях, ориентированных на наиболее распространенные средства разработки приложений 4GL. Версия ERwin/OPEN полностью совместима со средствами разработки приложений PowerBuilder и SQLWindows и позволяет экспортировать описание спроектированной БД непосредственно в репозитарии данных средств.
Для ряда средств разработки приложений (PowerBuilder, SQLWindows, Delphi, Visual Basic) выполняется генерация форм и прототипов приложений.
Сетевая версия Erwin ModelMart обеспечивает согласованное проектирование БД и приложений в рабочей группе.
BPwin — средство функционального моделирования, реализующее методологию IDEFO.
S-Designor 4.2 представляет собой CASE-средство для проектирования реляционных баз данных. По своим функциональным возможностям и стоимости он близок к CASE-средству Erwin, отличаясь внешне используемой на диаграммах нотацией. S-Designor реализует стандартную методологию моделирования данных и генерирует описание БД для таких СУБД, как ORACLE, Informix, Ingres, Sybase, DB/2, Microsoft SQL Server и др. Для существующих систем выполняется реинжениринг БД.
S-Designor совместим с рядом средств разработки приложений (PowerBuilder, Uniface, TeamWindows и др.) и позволяет экспортировать описание БД в репозитарии данных средств. Для PowerBuilder выполняется прямая генерация шаблонов приложений.
CASE. Аналитик 1.1 является практически единственным в настоящее время конкурентоспособным отечественным CASE-средством функционального моделирования. Его основные функции:
→ анализ диаграмм и проектных спецификаций на полноту и непротиворечивость;
→ получение разнообразных отчетов по проекту;
→генерация макетов документов в соответствии с требованиями ГОСТ 19.ХХХ и 34.XXX.
Среда функционирования: процессор-386 и выше, основная память 4 Мб, дисковая память 5 Мб, MS Windows 3.х или Windows 95.
С помощью отдельного программного продукта (Catherine) выполняется обмен данными с CASE-средством Erwin. При этом из проекта, выполненного в CASE. Аналитик, экспортируется описание структур данных и накопителей данных, которое по определенным правилам формирует описание сущностей и их атрибутов.
И наконец, Rational Rose — САSЕ-средство фирмы «Rational Software Corporation» (США) — предназначено для автоматизации этапов анализа и проектирования ПО, а также для генерации кодов на различных языках и выпуска проектной документации. Rational Козе использует объединенную методологию объектно-ориентированного анализа и проектирования, основанную на подходах трех ведущих специалистов в данной области: Буча, Рамбо и Джекобсона. Разработанная ими универсальная нотация для моделирования объектов (UML — Unified Modeling Language) претендует на роль стандарта в области объектно-ориентированного анализа и проектирования. Конкретный вариант Rational Козе определяется языком, на котором генерируются коды программ (С++, Smalltalk, PowerBuilder, Ada, SQL Windows и Object Pro). Основной вариант — Rational Rose/С++ — позволяет разрабатывать проектную документацию в виде диаграмм и спецификаций, а также генерировать программные коды на С++. Кроме того, Rational Rose содержит средства реинжениринга программ, обеспечивающие повторное использование программных компонент в новых проектах.
Rational Козе функционирует на различных платформах: 1ВМ РС (в среде Windows), Sun SPA RC stations (UNIX, Solaris, SunOS), Hewlett-Packard (НР UX), IBM RS/6000 (AIX).
8.3. ВИЗУАЛЬНОЕ МОДЕЛИРОВАНИЕ В RATIONAL КОБЕ
Изучая требования к системе, вы берете за основу запросы пользователей и далее преобразуете их ® такую форму, которую ваша команда сможет понять и реализовать. На основе этих требований вы генерируете код. Формально преобразуя требования в код, вы гарантируете их соответствие друг другу, а также возможность в любой момент вернуться от кода к породившим его требованиям. Этот процесс называется моделированием. Моделирование позволяет проследить путь от запросов пользователей к требованиям модели и затем к коду и обратно, не теряя при этом своих наработок.
Визуальным моделированием называют процесс графического представления модели с помощью некоторого стандартного набора графических элементов. Наличие стандарта жизненно необходимо для реализации одного из преимуществ визуального моделирования — коммуникации. Общение между пользователями, разработчиками, аналитиками, тестировщиками, менеджерами и всеми остальными участниками проекта является основной целью графического визуального моделирования.
Созданные модели представляются всем заинтересованным сторонам, которые могут извлечь из них ценную информацию. Например, глядя на модель, пользователи визуализируют свое взаимодействие с системой. Аналитики увидят взаимодействие между объектами модели. Разработчики поймут, какие объекты нужно создать и что эти объекты должны делать. Тестировщики визуализируют взаимодействие между объектами, что позволит им построить тесты. Менеджеры увидят как всю систему в целом, так и взаимодействие ее частей. Наконец, руководители информационной службы, глядя на высокоуровневые модели, поймут, как взаимодействуют друг с другом системы в их организации. Таким образом, визуальные модели предоставляют мощный инструмент, позволяющий показать разрабатываемую систему всем заинтересованным сторонам.
8.4.1. Типы визуальных диаграмм UML
UML позволяет создавать несколько типов визуальных диаграмм:
→ диаграммы вариантов использования;
→ диаграммы последовательности;
→ кооперативные диаграммы;
→ диаграммы классов;
→ диаграммы состояний;
→ диаграммы компонентов;
→ диаграммы размещения.
Диаграммы иллюстрируют различные аспекты системы. Например, кооперативная диаграмма показывает, как должны взаимодействовать объекты, чтобы реализовать некоторую функциональность системы. У каждой диаграммы есть своя цель.
8.4.2. Диаграммы вариантов использования
Диаграммы вариантов использования отображают взаимодействие между вариантами использования, представляющими функции системы, и действующими лицами, представляющими людей . или системы, получающие или передающие информацию в данную систему. Пример диаграммы вариантов использования для банковского автомата (АТМ) показан на рис. 8.1.
На диаграмме представлено взаимодействие между вариантами использования и действующими лицами. Она отражает требования к системе с точки зрения пользователя. Таким образом, варианты использования — это функции, выполняемые системой, действующие лица — это заинтересованные лица по отношению к создаваемой системе. Диаграммы показывают, какие
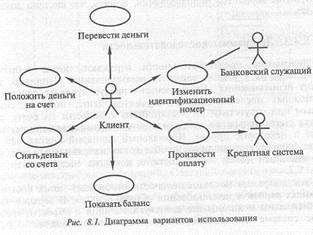
действующие лица инициируют варианты использования. Из них также видно, когда действующее лицо получает информацию от варианта использования. В сущности диаграмма вариантов использования может иллюстрировать требования к системе. В нашем примере клиент банка инициирует различные варианты использования: «Снять деньги со счета», «Перевести деньги», «Положить деньги на счет», «Показать баланс», «Изменить идентификационный номер», «Произвести оплату». Банковский служащий может инициировать вариант использования «Изменить идентификационный номер». От варианта использования «Произвести оплату» идет стрелка к Кредитной системе. Действующими лицами могут быть и внешние системы, в данном случае Кредитная система показана именно как действующее лицо — она является внешней для системы АТМ. Стрелка, направленная от варианта использования к действующему лицу, показывает, что вариант использования предоставляет некоторую информацию действующему лицу. В данном случае вариант использования «Произвести оплату» предоставляет Кредитной системе информацию об оплате по кредитной карточке.
Из диаграмм вариантов использования можно получить довольно много информации о системе. Этот тип диаграмм описывает общую функциональность системы. Пользователи, менеджеры проектов, аналитики, разработчики, специалисты по контролю качества и все, кого интересует система в целом, могут, изучая диаграммы вариантов использования, понять, что система должна делать.
8.4.3. Диаграммы последовательности
Диаграммы последовательности отражают поток событий, происходящих в рамках варианта использования. Например, вариант использования «Снять деньги» предусматривает несколько возможных последовательностей: снятие денег, попытка снять деньги при отсутствии их достаточного количества на счету, попытка снять деньги по неправильному идентификационному номеру и некоторые другие. Нормальный сценарий снятия $20 со счета (при отсутствии таких проблем, как неправильный идентификационный номер или недостаток денег на счету) показан на рис. 8.2.
Эта диаграмма последовательности отображает поток событий в рамках варианта использования «Снять деньги». В верхней части диаграммы показаны все действующие лица и объекты, требуемые системе для выполнения варианта использования «Снять

деньги». Стрелки соответствуют сообщениям, передаваемым между действующим лицом и объектом или между объектами для выполнения требуемых функций. Следует отметить также, что на диаграмме последовательности показаны именно объекты, а не классы. Классы представляют собой типы объектов. Объекты конкретны; вместо класса Клиент на диаграмме последовательности представлен конкретный клиент Джо.
Вариант использования начинается, когда клиент вставляет свою карточку в устройство для чтения — этот объект показан в прямоугольнике в верхней части диаграммы. Он считывает номер карточки, открывает объект «счет Джо» и инициализирует экран АТМ. Экран запрашивает у Джо его регистрационный номер. Клиент вводит число 1234. Экран проверяет номер у объекта «счет Джо» и обнаруживает, что он правильный. Затем экран предоставляет Джо меню для выбора, и тот выбирает пункт «Снять деньги». Экран запрашивает, сколько он хочет снять, и Джо указывает $20. Экран снимает деньги со счета. При этом он инициирует серию процессов, выполняемых объектом «счет Джо». В то же время осуществляется проверка, что на этом счету лежат, по крайней мере, $20 и из счета вычитается требуемая сумма. Затем кассовый аппарат получает инструкцию «выдать чек и $20 наличными». Наконец, все тот же объект «счет Джо» дает устройству для чтения карточек инструкцию вернуть карточку.
Итак, данная диаграмма последовательности иллюстрирует последовательность действий, реализующих вариант использования «Снять деньги со счета» на конкретном примере снятия клиентом Джо $20. Глядя на эту диаграмму, пользователи знакомятся со спецификой своей работы. Аналитики видят последовательность (поток) действий, разработчики — объекты, которые надо создать, и их операции. Специалисты по контролю качества поймут детали процесса и смогут разработать тесты для их проверки. Таким образом, диаграммы последовательности полезны всем участникам проекта.
8.4.4. Кооперативные диаграммы
Кооперативные диаграммы отражают ту же самую информацию, что и диаграммы последовательности. Однако делают они это по-другому и с другими целями. Показанная на рис. 8.2 диаграмма последовательности представлена на рис. 8.3 в виде кооперативной диаграммы.
Как и раньше, объекты изображены в виде прямоугольников, а действующие лица в виде фигур. Если диаграмма последовательности показывает взаимодействие между действующими лицами и объектами во времени, то на кооперативной диаграмме связь со временем отсутствует. Так, можно видеть, что устройство для чтения карточки выдает «счету Джо» инструкцию открыться, а «счет Джо» заставляет это устройство вернуть карточку владельцу. Непосредственно взаимодействующие объекты соединены линиями. Если, например, устройство для чтения карточки общается непосредственно с
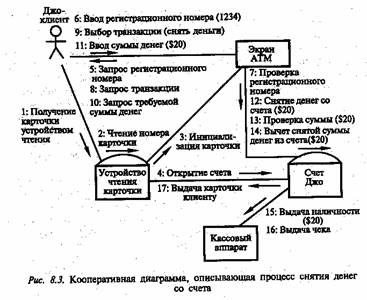
экраном АТМ, между ними следует провести линию. Отсутствие линии означает, что непосредственное сообщение между объектами отсутствует.
Итак, на кооперативной диаграмме отображается та же информация, что и на диаграмме последовательности, но нужна она для других целей. Специалисты по контролю качества и архитекторы системы смогут понять распределение процессов между объектами. Допустим, что какая-то кооперативная диаграмма напоминает звезду, где несколько объектов связаны с одним центральным объектом. Архитектор системы может сделать вывод, что система слишком сильно зависит от центрального объекта, и необходимо перепроектировать ее для более равномерного распределения процессов. На диаграмме последовательности такой тип взаимодействия было бы трудно увидеть.
Диаграммы классов отражают взаимодействие между классами системы. Например, «счет Джо» — это объект. Типом такого объекта можно считать счет вообще, т. е. «Счет» — это класс. Классы содержат данные и поведение (действия), влияющее на эти данные. Так, класс Счет содержит идентификационный номер клиента и проверяющие его действия. На диаграмме классов класс создается для каждого типа объектов из диаграмм последовательности или Кооперативных диаграмм. Диаграмма классов для варианта использования «Снять деньги» показана на рис. 8.4.
На диаграмме показаны связи между классами, реализующими вариант использования «Снять деньги». В этом процессе задействованы четыре класса: Card Reader (устройство для чтения карточек), Account (счет), АТМ (экран АТМ) и Cash Dispenser (кассовый аппарат). Каждый класс на диаграмме классов изображается в виде прямоугольника, разделенного на три части. В первой части указывается имя класса, во второй — его атрибуты. Атрибут — это некоторая информация, характеризующая класс. Например, класс Account (счет) имеет три атрибута: Account Number (номер счета), PIN (идентификационный номер) и Balance (баланс). В последней части содержатся операции класса, отражающие его поведение (действия, выполняемые классом). Связывающие классы линии показывают взаимодействие между классами.
Разработчики используют диаграммы классов для реального создания классов. Такие инструменты, как Козе, генерируют
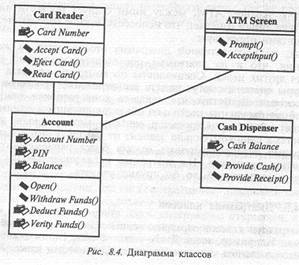
основу кода классов, которую программисты заполняют деталями на выбранном ими языке. С помощью этих диаграмм аналитики могут показать детали системы, а архитекторы — понять ее проект. Если, например, какой-либо класс несет слишком большую функциональную нагрузку, это будет видно на диаграмме классов, и архитектор сможет перераспределить ее между другими классами. С помощью диаграммы можно также выявить случаи, когда между сообщающимися классами не определено никаких связей. Диаграммы классов следует создавать, чтобы показать взаимодействующие классы в каждом варианте использования. Можно строить также более общие диаграммы, охватывающие все системы или подсистемы.
Диаграммы состояний предназначены для моделирования различных состояний, в которых может находиться объект. В то время как диаграмма классов показывает статическую картину классов и их связей, диаграммы состояний применяются при описании динамики поведения системы.
Диаграммы состояний отображают поведение объекта. Так, банковский счет может иметь несколько различных состояний. Он может быть открыт, закрыт или может быть превышен кредит по нему. Поведение счета меняется в зависимости от состояния, в котором он находится. На диаграмме состояний показывают именно эту информацию. На рис. 8.5 приведен пример диаграммы состояний для банковского счета.
На данной диаграмме показаны возможные состояния счета, а также процесс перехода счета из одного состояния в другое. Например, если клиент требует закрыть открытый счет, последний переходит в состояние «Закрыт». Требование клиента называется событием, именно события вызывают переход из одного состояния в другое.
Когда клиент снимает деньги с открытого счета, счет может перейти в состояние «Превышение кредита». Это происходит, только если баланс по счету меньше нуля, что отражено условием отрицательный баланс на нашей диаграмме. Заключенное в квадратные скобки условие определяет, когда может или не может произойти переход из одного состояния в другое.
На диаграмме имеются два специальных состояния — начальное и конечное. Начальное состояние выделяется черной точкой: оно соответствует состоянию объекта в момент его создания. Конечное состояние обозначается черной точкой в белом кружке: оно соответствует состоянию объекта непосредственно перед его уничтожением. На диаграмме состояний может быть одно и только одно начальное состояние. В то же время может быть столько конечных состояний, сколько вам нужно или их может не быть вообще.
Когда объект находится в каком-то конкретном состоянии, могут выполняться те или иные процессы. В нашем примере при превышении кредита клиенту посылается соответствующее сообщение. Процессы, происходящие, когда объект находится в определенном состоянии, называются действиями.
Диаграммы состояний не нужно создавать для каждого класса, они применяются только в очень сложных случаях. Если объект класса может существовать в нескольких состояниях и в каждом из них ведет себя по-разному, для него, вероятно, потребуется такая диаграмма. Однако во многих проектах они вообще не используются. Если же диаграммы состояний все-таки были построены, разработчики могут применять их при создании классов.
Диаграммы состояний необходимы в основном для документирования.
Диаграммы компонент показывают, как выглядит модель на физическом уровне. На ней изображаются компоненты программного обеспечения вашей системы и связи между ними. При этом выделяют два типа компонент: исполняемые компоненты и библиотеки кода.
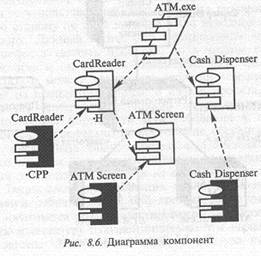
На рис. 8.6 изображена одна из диаграмм компонент для системы АТМ. На этой диаграмме показаны компоненты клиента системы АТМ. В данном случае команда разработчиков решила строить систему с помощью языка С++. У каждого класса имеется свой собственный заголовочный файл и файл с расширением .СРР, так что каждый класс преобразуется в свои собственные компоненты на диаграмме. Выделенная темная компонента называется спецификацией пакета и соответствует файлу тела класса АТМ на языке С++ (файл с расширением .СРР). Не выделена компонента также называется спецификацией пакета, но соответствует заголовочному файлу класса языка С++ (файл с расширением .Н). Компонента АТМ.ехе является спецификацией задачи и представляет поток обработки информации. В данном случае поток обработки — это исполняемая программа.
Компоненты соединены штриховой линией, отображающей зависимости между ними. У системы может быть несколько диаграмм компонент в зависимости от числа подсистем или исполняемых файлов. Каждая подсистема является пакетом компонент.
Диаграммы компонент применяются теми участниками проекта, кто отвечает за компиляцию системы. Диаграмма компонент дает представление о том, в каком порядке надо компилировать компоненты, а также какие исполняемые компоненты будут созданы системой. Диаграмма показывает соответствие классов реализованным компонентам. Итак, она нужна там, где начинается генерация кода.
Диаграммы размещения показывают физическое расположение различных компонент системы в сети. В нашем примере система АТМ состоит из большого количества подсистем, выполняемых на отдельных физических устройствах или узлах. Диаграмма размещения для системы АТМ представлена на рис. 8.7.
Из данной диаграммы можно узнать о физическом размещении системы. Клиентские программы АТМ будут работать в нескольких местах на различных сайтах. Через закрытые сети будет осуществляться сообщение клиентов с региональным сервером АТМ. На нем будет работать программное обеспечение сервера АТМ. В свою очередь, посредством локальной сети региональный сервер будет взаимодействовать с сервером банковской базы данных, работающим под управлением Oracle. Наконец, с региональным сервером АТМ соединен принтер.
Итак, данная диаграмма показывает физическое расположение системы. Например, наша система АТМ соответствует трехуровневой архитектуре, когда на первом уровне размещается база данных, на втором — региональный сервер, а на третьем — клиент.
Диаграмма размещения используется менеджером проекта, пользователями, архитектором системы и эксплуатационным
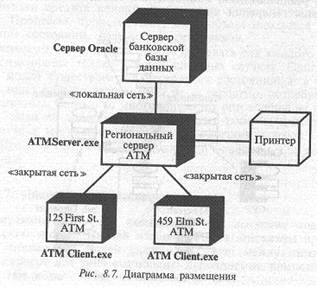
персоналом для выяснения физического размещения системы и расположения ее отдельных подсистем. Менеджер проекта объяснит пользователям, как будет выглядеть готовый продукт. Эксплуатационный персонал сможет планировать работу по установке системы.
8.5. ВИЗУАЛЬНОЕ МОДЕЛИРОВАНИЕ И ПРОЦЕСС РАЗРАБОТКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
8.5.1. Достоинства и недостатки типов процесса разработки
Программное обеспечение может быть создано разными способами. Существует несколько различных типов процесса разработки, которые могут быть использованы в проекте: от «водопада» до объектно-ориентированного подхода. У каждого есть свои преимущества и недостатки. Здесь не указывается, какой именно процесс проектирования необходимо применять разработчикам в своей работе, а представляем лишь краткое описание процесса, связанного с визуальным моделированием.
Долгое время программное обеспечение разрабатывали, следуя так называемой модели «водопада». В соответствии с ней необходимо было сначала проанализировать требования к будущей системе, спроектировать, создать и протестировать систему, а затем установить ее у пользователей. Как видно из названия, движение в обратную сторону по этой цепочке было невозможно — вода не потечет вверх. Данный метод был официальной методологией, применявшейся в тысячах проектов, но в чистом виде, как его принято понимать, он не использовался ни разу. Одним из главных недостатков модели «водопада» является невозможность возврата назад на пройденные этапы. В начале проекта, следующего такой модели, перед разработчиками стоит обескураживающая задача — полностью определить все требования к системе. Для этого необходимо тщательно и всесторонне обсудить с пользователями и исследовать бизнес-процессы. Пользователи должны согласиться со всем тем, что выясняется в ходе такого обследования, хотя они могут до конца и не ознакамливаться с его результатами. Таким способом на стадии анализа при некотором везении удается собрать около 80% требований к системе.
Затем начинается этап проектирования. Необходимо сесть и определить архитектуру будущей системы. Мы выясняем, где будут установлены программы и какая аппаратура нужна для достижения приемлемой производительности. На данном этапе могут обнаружиться новые проблемы, их необходимо опять обсуждать с пользователями, что выразится в появлении новых требований к системе. Итак, приходится возвращаться к анализу.
После нескольких таких кругов, и конец, наступает этап написания программного кода. На этом этапе обнаруживается, что некоторые из принятых ранее решений невозможно осуществить. Приходится возвращаться к проектированию и пересматривать эти решения. После завершения кодирования наступает этап тестирования, на котором выясняется, что требования не были достаточно детализированы и их реализация некорректна. Нужно возвращаться назад, на этап анализа, и пересматривать эти требования.
Наконец, система готова и поставлена пользователям. Поскольку прошло уже много времени и бизнес, вероятно, уже успел измениться, пользователи воспринимают ее без большого энтузиазма, отвечая примерно так: «Да, это то, что я просил, но не то, что я хочу!» Эта магическая фраза, заклинание разом состарит всю команду разработчиков как минимум на 10 лет!
Состоит ли проблема в том, что правила бизнеса изменяются слишком быстро? Может быть, пользователи не могут объяснить, чего они хотят или не понимают команду разработчиков? Или сама команда не придерживается определенного процесса? Ответы на эти вопросы: да, да и нет. Бизнес меняется очень быстро, и профессионалы-программисты должны поспевать за этим. Пользователи не всегда могут сказать, чего они хотят, поскольку их работа стала для них «второй натурой». Спрашивать об этом прослужившего 30 лет банковского клерка — примерно то же самое, что спрашивать, как он дышит. Работа стала для него настолько привычной, что ее уже трудно описать. Еще одна проблема заключается в том, что пользователи не всегда понимают команду разработчиков. Команда показывает им графики, выпускает тома текста, описывающего требования к системе, но пользователи не всегда понимают, что именно им дают. Есть ли способ обойти эту проблему? Да, здесь поможет визуальное моделирование. И наконец, команда разработчиков точно следует процессу — методу «водопада». К сожалению, планирование и реализация метода — две разные вещи.
Итак, одна из проблем заключается в том, что разработчики использовали метод «водопада», заключающийся в аккуратном и последовательном прохождении через все этапы проекта, но им приходилось возвращаться на пройденные этапы. Происходит ли это из-за плохого планирования? Вероятно, нет. Разработка программного обеспечения — сложный процесс, и его поэтапное, аккуратное выполнение не всегда возможно. Если же игнорировать необходимость возврата, то система будет содержать дефекты проектирования, и некоторые требования будут потеряны, возможны и более серьезные последствия. Прошли годы, пока мы не научились заранее планировать возвраты на пройденные этапы.
Таким образом, мы пришли к итеративной разработке. Это название означает лишь, что мы собираемся повторять одни и те же этапы снова и снова. В объектно-ориентированном процессе нужно по многу раз небольшими шагами проходить этапы анализа, проектирования, разработки, тестирования и установки системы.
Невозможно выявить все требования на ранних этапах проектирования. Мы учитываем появление новых требований в процессе разработки, планируя проект в несколько итераций. В рамках такой концепции проект можно рассматривать как последовательность небольших «водопадиков». Каждый из них достаточно велик, чтобы означать завершение какого-либо важного этапа проекта, но мал, чтобы минимизировать необходимость возврата назад. Мы проходим четыре фазы проекта: начальная фаза, уточнение, конструирование и ввод в действие.
Начальная фаза — это начало проекта. Мы собираем информацию и разрабатываем базовые концепции. В конце этой фазы принимается решение продолжать (или не продолжать) проект.
В фазе уточнения детализируются варианты использования и принимаются архитектурные решения. Уточнение включает в себя некоторый анализ, проектирование, кодирование и планирование тестов.
В фазе конструирования разрабатывается основная часть кода.
Ввод в действие — это завершающая компоновка системы и
установка ее у пользователей. Далее рассмотрим, что означает каждая из этих фаз в объектно-ориентированном проекте.
Начальная фаза — это начало работы над проектом, когда кто-нибудь говорит: «А хорошо бы, чтобы система делала...» Затем кто-то еще изучает идею, и менеджер спрашивает, сколько времени потребует ее реализация, сколько это будет стоить и насколько она выполнима. Начальная фаза как раз и заключается в том, чтобы найти ответы на эти вопросы. Мы исследуем свойства системы на высоком уровне и документируем их. Определяем действующих лиц и варианты использования, но не углубляемся в детали вариантов использования, ограничиваясь одним или двумя предложениями. Готовим также оценки для высшего руководства. Итак, применяя Rose для поддержки нашего проекта, создаем действующих лиц и варианты использования, а также строим диаграммы вариантов использования. Начальная фаза завершается, когда данное исследование закончено и для работы над проектом выделены необходимые ресурсы.
Начальная фаза проекта в основном последовательна и не итеративна. В отличие от нее другие фазы повторяются несколько раз в процессе работы над проектом. Так как проект может быть начат только один раз, начальная фаза также выполняется лишь однажды, поэтому в начальной фазе должна быть решена еще одна задача — разработка плана итераций. Это план, описывающий, какие варианты использования, на каких итерациях должны быть реализованы. Если, например, в начальной фазе было выявлено 10 вариантов использования, можно создать следующий план:
Итерация 1 Варианты Использования 1, 5, 6
Итерация 2 Варианты Использования 7, 9
Итерация 3 Варианты Использования 2, 4, 8
Итерация 4 Варианты Использования 3, 10
План определяет, какие варианты использования надо реализовать в первую очередь. Построение плана требует рассмотрения зависимостей между вариантами использования. Если для того, чтобы мог работать Вариант Использования 5, необходима реализация Варианта Использования 3, то описанный выше план неосуществим, поскольку Вариант Использования 3 реализуется на четвертой итерации — значительно позже Варианта Использования 5 из первой итерации. Такой план нужно пересмотреть, чтобы учесть все зависимости.
8.5.3. Использование Козе в начальной фазе
Некоторые задачи начальной фазы включают в себя определение вариантов использования и действующих лиц. Козе можно применять для документирования этих вариантов использования и действующих лиц, а также для создания диаграмм, показывающих связи между ними. Полученные диаграммы вариантов использования можно показать пользователям, чтобы убедиться, что они дают достаточно полное представление о свойствах системы.
В фазе уточнения проекта выполняются некоторое планирование, анализ и проектирование архитектуры. Следуя плану итерации, уточнение проводится для каждого варианта использования в текущей итерации. Уточнение включает в себя такие
аспекты проекта, как кодирование прототипов, разработка тестов и принятие решений по проекту.
Основная задача фазы уточнения — детализация вариантов использования. Предъявляемые к вариантам использования требования низкого уровня предусматривают описание потока обработки данных внутри них, выявление действующих лиц, разработку диаграмм Взаимодействия для графического отображения потока обработки данных, а также определение всех переходов состояний, которые могут иметь место в рамках варианта использования. Из требований, определенных в форме детализированных вариантов использования, составляется документ под названием «Спецификация требований к программному обеспечению».
В фазе уточнения выполняются и такие задачи, как уточнение предварительных оценок, изучение модели вариантов использования с точки зрения качества проектируемой системы, анализ рисков. Можно уточнить модель вариантов использования, а также разработать диаграммы последовательности и кооперативные диаграммы для графического представления потока обработки данных. Кроме того, в этой фазе проектируются диаграммы классов, описывающие объекты, которые необходимо создать.
Фаза уточнения завершается, когда варианты использования полностью детализированы и одобрены пользователями, прототипы завершены настолько, чтобы уменьшить риски, разработаны диаграммы классов. Иными словами, эта фаза пройдена, когда система спроектирована, рассмотрена и готова для передачи разработчикам.
Фаза уточнения предоставляет несколько возможностей для применения Rational Rose. Так как уточнение — это детализация требований к системе, модель вариантов использования может потребовать обновления. Диаграммы последовательности и кооперативные диаграммы помогают проиллюстрировать поток обработки данных при его детализации. С их помощью можно также спроектировать требуемые для системы объекты. Уточнение предполагает подготовку проекта системы для передачи разработчикам, которые начнут ее конструирование. В среде Rose это может быть выполнено путем создания диаграмм классов и диаграмм состояний.
Конструирование — процесс разработки и тестирования программного обеспечения. Как и в случае уточнения, эта фаза выполняется для каждого набора вариантов использования на каждой итерации. Задачи конструирования включают в себя определение всех оставшихся требований, разработку и тестирование программного обеспечения (ПО). Так как ПО полностью проектируется в фазе уточнения, конструирование не предполагает большого количества решений по проекту, что позволяет команде работать параллельно. Это означает, что разные группы программистов могут одновременно работать над различными объектами ПО, зная, что по завершении фазы система «сойдется». В фазе уточнения мы проектируем объекты системы и их взаимодействие. Конструирование только запускает проект в действие, а новых решений по нему, способных изменить это взаимодействие, не принимается.
Еще одним преимуществом такого подхода к моделированию системы является то, что среда Rational Козе способна генерировать «скелетный код» системы. Для использования этой возможности следует разработать компоненты и диаграмму компонентов на раннем этапе конструирования. Генерацию кода можно начать сразу после создания компонентов и нанесения на диаграмму зависимостей между ними. В результате будет автоматически построен код, который можно создать, основываясь на проекте системы. Это не означает, что с помощью Rose можно получить любой код, реализующий бизнес-логику приложений. Результат сильно зависит от используемого языка программирования, но в общем случае предполагает определение классов, атрибутов, областей действия. Это позволяет сэкономить время, так как написание кода вручную — довольно кропотливая и утомительная работа. Получив код, программисты могут сконцентрироваться на специфических аспектах, связанных с бизнес логикой. Еще одна группа разработчиков должна выполнить экспертную оценку кода, чтобы убедиться в его функциональности и соответствии стандартам и соглашениям по проекту. Затем объекты должны быть подвергнуты оценке качества. Если в фазе конструирования были добавлены новые атрибуты или функции или если были изменены взаимодействия между объектами, код следует преобразовать в модель Rose с помощью обратного преобразования.
Конструирование можно считать завершенным, когда программное обеспечение готово и протестировано. Важно убедиться в адекватности модели и программного обеспечения. Модель будет чрезвычайно полезна в процессе сопровождения ПО.
В фазе конструирования пишется большая часть кода проекта. Rose позволяет создать компоненты в соответствии с проектированием объектов. Чтобы показать зависимости между компонентами на этапе компиляции, создаются диаграммы компонентов. После выбора языка программирования можно осуществить генерацию скелетного кода для каждого компонента. По завершении работы над кодом модель можно привести в соответствие с ним с помощью обратного проектирования.
Фаза ввода в действие наступает, когда готовый программный продукт передают пользователям. Задачи в этой фазе предполагают завершение работы над финальной версией продукта, завершение приемочного тестирования, завершение составления документации и подготовку к обучению пользователей. Чтобы отразить последние внесенные изменения, следует обновить спецификацию требований к программному обеспечению, диаграммы вариантов использования, классов, компонентов и размещения. Важно, чтобы ваши модели были синхронизированы с готовым продуктом, поскольку они будут использоваться при его сопровождении. Кроме того, модели будут неоценимы при внесении усовершенствований в созданную систему уже через несколько месяцев после завершения проекта. В фазе ввода в действие Rational Rоsе не настолько полезна, как в других фазах. В этот момент приложение уже создано. Rose предназначена для оказания помощи при моделировании и разработке программного обеспечения и даже при планировании его размещения. Однако Rose не является инструментом тестирования и не способна помочь в планировании тестов или процедур, связанных с размещением ПО. Для этой цели созданы другие продукты. Итак, в фазе ввода в действие Rose применяется, прежде всего, для обновления моделей после завершения работы над программным продуктом.
8.6. РАБОТА НАД ПРОЕКТОМ В СРЕДЕ RATIONAL ROSE
Из всех рассмотренных видов канонических диаграмм в среде Rational Rose 98/98i не поддерживается только диаграмма деятельности.
В ходе работы над диаграммами проекта имеется возможность удаления и добавления соответствующих графических элементов, установления отношений между этими элементами, их спецификации и документирования.
Общая последовательность работы над проектом аналогична последовательности рассмотрения канонических диаграмм в книге.
Одним из наиболее мощных свойств среды Rational Rose является возможность генерации программного кода после построения и проверки моделей. Общая последовательность действий, которые необходимо выполнить для этого, состоит из шести этапов:
— проверки модели независимо от выбора языка генерации кода;
— создания компонентов для реализации классов;
— отображения классов на компоненты;
— установки свойств генерации программного кода;
— выбора класса, компонента или пакета; — генерации программного кода.
ВЫВОДЫ
• CASE-средства позволяют в автоматизированном режиме реализовать проектные модели.
• Реализованные проектные модели должны быть полными, отражать как функциональные, так и информационные аспекты проектируемых автоматизированных систем.
• САSЕ-технология представляет собой методологию проектирования автоматизированных систем, а также набор инструментальных средств, позволяющих в наглядной форме моделировать предметную область, анализировать эту модель на всех этапах разработки и сопровождения программного проекта и разрабатывать приложения в соответствии с информационными потребностями пользователей.
• Большинство существующих CASE-средств основано на методологиях структурного (в основном) или объектно-ориентированного анализа и проектирования, использующих спецификации в виде диаграмм или текстов для описания внешних требований, связей между моделями системы, динамики поведения системы и архитектуры программных средств.
• Передовые CASE-средства способны не только составлять спецификации, но и их проверять, а также генерировать исходный код программ.
• CASE-средства производятся множеством производителей и только наиболее удачные из них проходят проверку практикой.
• CASE-средство Rational Rose фирмы «Software Corporation» (США) предназначено для автоматизации этапов анализа и проектирования ПО, а также для генерации кодов на различных языках и выпуска проектной документации. Rational Rоsе использует объединенную методологию объектно-ориентированного анализа и проектирования, основанную на подходах трех ведущих специалистов в данной области: Буча, Рамбо и Джекобсона.
• Язык UML САSЕ-средства Rational Rose позволяет создавать несколько типов визуальных диаграмм:
→ диаграммы вариантов использования;
→ диаграммы последовательности;
→ кооперативные диаграммы;
→ диаграммы классов;
→ диаграммы состояний;
→ диаграммы компонент;
→ диаграммы размещения.
Глава 9. ТЕСТИРОВАНИЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Любой заказчик хочет получить надежное программное изделие, которое полностью удовлетворяет его потребности. Различные уровни надежности обеспечиваются разными технологиями тестирования. Другими словами, за достаточные средства можно достичь уровня надежности как у такой-то фирмы или даже уровня, необходимого для атомной энергетики или космических исследований.
Итак, уровень надежности программных изделий определяется технологией тестирования. Как достичь высочайшего уровня надежности? Ясно, что тексты программ, написанные в одной организации, можно заново инспектировать, тестировать автономно и в составе ядра в иной организации. В самой программе можно одновременно производить расчеты по разным алгоритмам с использованием разных вычислительных методов и сличать результаты в контрольных точках, использовать подстановки рассчитанных результатов в исходные уравнения и тем самым контролировать результаты решения. Из изложенного видно, что уровень надежности программных изделий напрямую связан с затратами как денежных средств, так и времени проекта.
Как известно, при создании типичного программного проекта около 50% общего времени и более 50 — 60% общей стоимости расходуется на проверку (тестирование) разрабатываемой программы или системы. Кроме того, доля стоимости тестирования в общей стоимости программ имеет тенденцию возрастать при увеличении сложности программных изделий и повышении требований к их качеству.
Учитывая это, при выборе технологии тестирования программ следует четко выделять определенное (по возможности не очень большое) число правил отладки, обеспечивающих высокое качество программного продукта и снижающих затраты на его создание.
Тестирование осуществляется путем исполнения тестов. Смысл теста программ показан на рис. 9.1.
Аксиомы тестирования, выдвинутые ведущими программистами:
— хорош тот тест, для которого высока вероятность обнаружения ошибки;
— главная проблема тестирования — решить, когда закончить (обычно решается просто — кончаются деньги);
— невозможно тестировать свою собственную программу;
— необходимая часть тестов — описание выходных результатов;
— избегайте невоспроизводимых тестов;
— готовьте тесты как для правильных, так и для неправильных данных;
— не тестируйте -«с лету»;
— детально изучайте результаты каждого теста;
— по мере обнаружения все большего числа ошибок в некотором модуле или программе, растет вероятность обнаружения в ней еще большего числа ошибок;
— тестируют программы лучшие умы;
— считают тестируемость главной задачей разработчиков программы;
— не изменяй программу, чтобы облегчить тестирование;
— тестирование должно начинаться с постановки целей.
Если в программе ставят комментарии на месте вызова модуля вместо заглушки, то исключают возможность проверки типов данных, часто забывают снимать комментарии. Для поиска «забытых» комментариев необходима трудоемкая отладка.
Среди приемов тестирования стоит выделить также так называемую отладочную печать. Если отладочные печати изымаются из текста, то утяжеляется сопровождение. Вывод: никогда не изымай отладочные печати даже с использованием препроцессора:
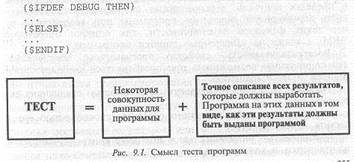
Лучше опишите глобальную переменную DebugLevel и программируйте условные отладочные печати:

9.2. СВОЙСТВА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Следует выделить следующие свойства программного обеспечения.
Корректность программного обеспечения — свойство безошибочной реализации требуемого алгоритма при отсутствии таких мешающих факторов, как ошибки входных данных, ошибки операторов ЭВМ (людей), сбои и отказы ЭВМ.
В интуитивном смысле под корректностью понимают свойства программы, свидетельствующие об отсутствии в ней ошибок, допущенных разработчиком на различных этапах проектирования (спецификации, проектирование алгоритма и структур данных, кодирование). Корректность самой программы понимают по отношению к целям, поставленным перед ее разработкой (т. е. это относительное свойство).
Устойчивость — свойство осуществлять требуемое преобразование информации при сохранении выходных решений программы в пределах допусков, установленных спецификацией. Устойчивость характеризует поведение программы при воздействии на
нее таких факторов неустойчивости, как ошибки операторов ЭВМ, а также не выявленные ошибки программы.
Восстанавливаемость — свойство программного обеспечения, характеризующее возможность приспосабливаться к обнаружению ошибок и их устранению.
Надежность можно представить совокупностью следующих характеристик:
— целостностью программного средства (способностью его к защите от отказов);
— живучестью (способностью к входному контролю данных и их проверки в ходе работы);
— завершенностью (без дефектностью готового программного средства, характеристикой качества его тестирования);
— работоспособностью (способностью программного средства к восстановлению своих возможностей поле сбоев).
Отличие понятия корректности и надежности программ состоит в следующем:
— надежность характеризует как программу, так и ее «окружение» (качество аппаратуры, квалификацию пользователя и т. п.);
— говоря о надежности программы, обычно допускают определенную, хотя и малую долю ошибок в ней и оценивают вероятность их появления.
Вернемся к понятию корректности. Очевидно, что не всякая синтаксически правильная программа является корректной в указанном выше смысле, т. е. корректность характеризует семантические свойства программ.
С учетом специфики появления ошибок в программах можно выделить две стороны понятия корректности:
— корректность как точное соответствие целям разработки программы (которые отражены в спецификации) при условии ее завершения или частичная корректность;
— завершение программы, т. е. достижение программой в процессе ее выполнения своей конечной точки.
В зависимости от выполнения или невыполнения каждого из двух названных свойств программы различают шесть задач анализа корректности:
1) доказательство частичной корректности;
2) доказательство частичной некорректности;
3) доказательство завершения программы;
4) доказательство не завершения программы;
5) доказательство тотальной (полной) корректности (т. е. одновременное решение 1-й и 3-й задач);
6) доказательство некорректности (решение 2-й или 4-й задачи).
Методы доказательства частичной корректности программ, как правило, опираются на аксиоматический подход к формализации семантики языков программирования. Аксиоматическая семантика языка программирования представляет собой совокупность аксиом и правил вывода. С помощью аксиом задается семантика простых операторов языка (присваивания, ввода-вывода, вызова процедур). С помощью правил вывода описывается семантика составных операторов или управляющих структур (последовательности, условного выбора, циклов). Среди этих правил вывода надо отметить правило вывода для операторов цикла, так как оно требует знания инварианта цикла (формулы, истинности которой не изменяются при любом прохождении цикла).
Наиболее известным из методов доказательства частичной корректности программ является метод индуктивных утверждений, предложенный Флойдом и у совершенствованный Хоаром. Один из важных этапов этого метода — получение аннотированной программы. На этом этапе для синтаксически правильной программы должны быть заданы утверждения на языке логики предикатов первого порядка: входной предикат; выходной предикат.
Эти утверждения задаются для входной точки цикла и должны характеризовать семантику вычислений в цикле.
Доказательство неистинности условий корректности свидетельствует о неправильности программы или ее спецификации, или программы и спецификации.
По влиянию на результаты обработки информации к надежности и устойчивости программного обеспечения близка и точность программного обеспечения, определяемая ошибками метода и ошибками представления данных.
Наиболее простыми методами оценки надежности программного обеспечения являются эмпирические модели, основанные на опыте разработки программ: если до начала тестирования на 1000 операторов приходится 10 ошибок, а приемлемым качеством является 1 ошибка, то в ходе тестирования надо найти:
![]()
Более точна модель Холстеда:
N ошибок = N операторов * log2 (N операторов — N операндов),
где N операторов — число операторов в программе; N операндов — число операндов в программе.
Эмпирическая модель фирмы IBM:
![]()
где М(10) — число модулей с 10 и более исправлениями; М(1)— число модулей с менее 10 исправлениями.
Если в модуле обнаружено более 10 ошибок, то его программируют заново.
По методу Милса в разрабатываемую программу вносят заранее известное число ошибок. Далее считают, что темпы выявления ошибок (известных и неизвестных) одинаковы.
9.3. СВЯЗЬ ПРОЦЕССОВ ТЕСТИРОВАНИЯ С ПРОЦЕССОМ ПРОЕКТИРОВАНИЯ
Из рис. 9.2 видно, что ошибки на ранних этапах проекта исчерпывающе могут быть выявлены в самом конце работы.
Тестирование программ охватывает ряд видов деятельности:
постановку задачи;
→проектирование тестов;
→написание тестов;
→тестирование тестов;
→выполнение тестов;
→изучение результатов тестирования.
Здесь наиболее важным является проектирование тестов.
Итак, тестирование — это процесс выполнения программы с целью обнаружения ошибок.
9.4. ПОДХОДЫ К ПРОЕКТИРОВАНИЮ ТЕСТОВ
Рассмотрим два самых противоположных подхода к проектированию тестов.
Сторонник первого подхода ориентируется только на стратегию тестирования, называемую стратегией «черного ящика», тестированием с управлением по данным или тестированием с управлением по входу-выходу. При использовании этой стратегии программа рассматривается как черный ящик. Тестовые данные используются только в соответствии со спецификацией программы (т. е. без учета знаний о ее внутренней структуре). Недостижимый
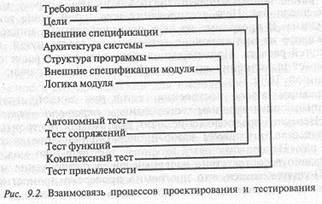
идеал сторонника первого подхода — проверить все возможные комбинации и значения на входе. Обычно их слишком много даже для простейших алгоритмов. Так, для программы расчета среднего арифметического четырех чисел надо готовить 107 тестовых данных.
При первом подходе обнаружение всех ошибок в программе является критерием исчерпывающего входного тестирования. Последнее может быть достигнуто, если в качестве тестовых наборов использовать все возможные наборы входных данных. Следовательно, приходим к выводу, что для исчерпывающего тестирования программы требуется бесконечное число тестов, а значит, построение исчерпывающего входного теста невозможно. Это подтверждается двумя аргументами: во-первых, нельзя создать тест, гарантирующий отсутствие ошибок; во-вторых, разработка таких тестов противоречит экономическим требованиям. Поскольку исчерпывающее тестирование исключается, нашей целью должна стать максимизация результативности вложения капиталовложений в тестирование (максимизация числа ошибок, обнаруживаемых одним тестом). Для этого необходимо рассматривать внутреннюю структуру программы и делать некоторые разумные, но, конечно, не обладающие полной гарантией достоверности предположения.
Сторонник второго подхода использует стратегию «белого ящика», или стратегию тестирования, управляемую логикой программы, которая позволяет исследовать внутреннюю структуру программы. В этом случае тестировщик получает тестовые данные путем анализа только логики программы; стремится, чтобы каждая команда была выполнена хотя бы один раз. При достаточной квалификации добивается, чтобы каждая команда условного перехода выполнялась бы в каждом направлении хотя бы один раз. Цикл должен выполняться один раз, ни разу, максимальное число раз. Цель тестирования всех путей извне также недостижима. В программе из двух последовательных циклов внутри каждого из них включено ветвление на десять путей, имеется 1018 путей расчета. Причем выполнение всех путей расчета не гарантирует выполнения всех спецификаций. Для справки: возраст Вселенной 10 17с.
Сравним способ построения тестов при данной стратегии с исчерпывающим входным тестированием стратегии «черного ящика». Неверно предположение, что достаточно построить такой набор тестов, в котором каждый оператор исполняется хотя бы один раз. Исчерпывающему входному тестированию может быть поставлено в соответствие исчерпывающее тестирование маршрутов. Подразумевается, что программа проверена полностью, если с помощью тестов удается осуществить выполнение этой программы по всем возможным маршрутам ее потока (графа) передач управления.
Последнее утверждение имеет два слабых пункта: во-первых, число не повторяющих друг друга маршрутов — астрономическое; во-вторых, даже если каждый маршрут может быть проверен, сама программа может содержать ошибки (например, некоторые маршруты пропущены).
Свойство пути выполняться правильно для одних данных и неправильно для других — называемое чувствительностью к данным, наиболее часто проявляется за счет численных погрешностей и погрешностей усечения методов. Тестирование каждого из всех маршрутов одним тестом не гарантирует выявление чувствительности к данным.
В результате всех изложенных выше замечаний отметим, что ни исчерпывающее входное тестирование, ни исчерпывающее тестирование маршрутов не могут стать полезными стратегиями, потому что оба они нереализуемы. Поэтому реальным путем, который позволит создать хорошую, но, конечно, не абсолютную стратегию, является сочетание тестирования программы несколькими методами.
Рассмотрим пример тестирования оператора
if А and В then …
при использовании разных критериев полноты тестирования. При критерии покрытия условий требовались бы два теста: А = true, В = false и А = false, В = true. Но в этом случае не выполняется then-предложение оператора if.
Существует еще один критерий, названный покрытием решений/условий. Он требует такого достаточного набора тестов, чтобы все возможные результаты каждого условия в решении выполнялись, по крайней мере, один раз; все результаты каждого решения выполнялись тоже один раз и каждой точке входа передавалось управление, по крайней мере, один раз.
Недостатком критерия покрытия решений/условий является невозможность его применения для выполнения всех результатов всех условий. Часто подобное выполнение имеет место вследствие того, что определенные условия скрыты другими условиями. Например, если условие AND есть ложь, то никакое из последующих условий в выражении не будет выполнено. Аналогично, если условие OR есть истина, то никакое из последующих условий не будет выполнено. Следовательно, критерии покрытия условий и покрытия решений/условий недостаточно чувствительны к ошибкам в логических выражениях.
Критерием, который решает эти и некоторые другие проблемы, является комбинаторное покрытие условий. Он требует создания такого числа тестов, чтобы все возможные комбинации результатов условия в каждом решении и все точки входа выполнялись, по крайней мере, один раз
В случае циклов число тестов для удовлетворения критерию комбинаторного покрытия условий обычно больше, чем число путей.
Легко видеть, что набор тестов, удовлетворяющий критерию комбинаторного покрытия условий, удовлетворяет также и критериям покрытия решений, покрытия условий и покрытия решений/условий.
Таким образом, для программ, содержащих только одно условие на каждое решение, минимальным является критерий, набор тестов которого вызывает выполнение всех результатов каждого решения, по крайней мере, один раз; передает управление каждой точке входа (например, оператор CASE).
Для программ, содержащих решения, каждое из которых имеет более одного условия, минимальный критерий состоит из набора тестов, вызывающих все возможные комбинации результатов условий в каждом решении и передающих управление каждой точке входа программы, по крайней мере, один раз.
Деление алгоритма на типовые стандартные структуры, согласно проектной процедуре кодирования текста модуля (метода) из третьей главы учебника, позволяет минимизировать усилия программиста, затрачиваемые им на тестирование. Запрет на вложенные структуры как раз и объясняется излишними затратами на тестирование. Использование цепочки простых альтернатив с одним действием или структуры ВЫБОР вместо вложенных простых АЛЬТЕРНАТИВ значительно сокращает число тестов!