Существует множество сетевых устройств, которые возможно использовать для создания, сегментирования и усовершенствования сети. Основными из них являются сетевые адаптеры, повторители, усилители, концентраторы, мосты, маршрутизаторы и шлюзы.
Сетевые адаптеры (карты), или NIC (Network Interface Card), являются теми устройствами, которые физически соединяют компьютер с сетью. Прежде чем выполнить такое соединение, надо правильно установить и настроить сетевой адаптер. Простота или сложность этой установки и настройки зависит от типа сетевого адаптера, который предполагается использовать. Для некоторых конфигураций достаточно просто вставить адаптер в подходящий слот материнской платы компьютера. Автоматически конфигурирующиеся адаптеры, а также адаптеры, отвечающие стандарту «plug and play» («вставь и работай»), автоматически производят свою настройку. Если сетевой адаптер не отвечает стандарту «plug and play», требуется настроить его запрос на прерывание IRQ (Interrupt ReQuest) и адрес ввода — вывода (input — output address). IRQ представляет собой логическую коммуникационную линию, которую устройство использует для связи с процессором. Адрес ввода— вывода — это трехзначное шестнадцатеричное число, которое идентифицирует коммуникационный канал между аппаратными устройствами и центральным процессором. Чтобы сетевой адаптер функционировал правильно, должны быть правильно настроены как IRQ, так и адрес ввода — вывода.
Сигнал при перемещении по сети ослабевает. Чтобы противодействовать этому ослаблению, можно использовать повторители и/или усилители, которые усиливают сигналы, проходящие через них по сети.
Обычно плата адаптера использует адреса портов ввода — вывода, которые выбираются перемычками или переключателями на плате. Прежде чем выбрать значения адресов адаптера, необходимо убедиться, что в данном компьютере эти адреса свободны, иначе возможны конфликты. Кроме того, адаптер, -как правило, применяет одно из аппаратных прерываний компьютера. Номер канала прерывания, используемого адаптером, чаще всего выбирается перемычками или переключателями. Прежде чем выбрать номер прерывания необходимо убедиться, что оно не использовалось другими устройствами. Иногда адаптер работает в режиме прямого доступа к памяти (ПДП, или DMA — Direct Memory Access). Номер канала ПДП выбирается перемычками или переключателями таким образом, чтобы не было конфликтов с другими устройствами компьютера. Информацию о свободных адресах, номерах каналов прерывания и ПДП можно получить из тестовых программ.
В последнее время появились адаптеры, в которых выбор адресов и каналов прерываний и ПДП производится не переключателями, а с помощью специальной программы установки (jumperless адаптеры), что гораздо удобнее. При запуске программы пользователю предлагается установить конфигурацию аппаратуры с помощью простого меню: выбрать адреса ввода — вывода, номер канала прерывания, ПДП, адреса, загрузочного ППЗУ и тип используемого внешнего разъема (тип среды передачи). Эта же программа позволяет произвести самотестирование адаптера.
Повторители (repeater) используются в сетях с цифровым сигналом для борьбы с его ослаблением. Они обеспечивают надежную передачу данных на большие расстояния, нежели обычно позволяет тип носителя. Когда повторитель получает ослабленный входящий сигнал, он очищает его, увеличивает мощность сигнала и посылает его следующему сегменту.
Усилители (amplifier), хоть и имеют сходное назначение, применяются для увеличения дальности передачи в сетях, использующих аналоговый сигнал. Аналоговые сигналы могут переносить одновременно и голос, и данные — носитель делится на несколько каналов, так что разные частоты могут передаваться параллельно.
Концентратор (hub) представляет собой сетевое устройство, служащее в качестве центральной точки соединения в сетевой конфигурации звезда (star). Он также может быть использован для соединения сетевых сегментов. Существуют три основных типа концентраторов: пассивные (passive), активные (active) и интеллектуальные (intelligent). Пассивные концентраторы, не требующие электроэнергии, действуют просто как физическая точка соединения, ничего не добавляя к проходящему сигналу. Активные концентраторы требуют энергии, которую они используют для восстановления и усиления сигнала, проходящего через них. Интеллектуальные концентраторы могут предоставлять такие сервисы, как переключение пакетов (packet switching) и перенаправление трафика (traffic routing).
Напомним, что переключение пакетов позволяет не поддерживать постоянный физический канал между двумя устройствами. Информация при этом способе коммутации делится на части, называющиеся пакетами, и каждый пакет передается отдельно по свободным в данный момент каналам связи. При этом каждый пакет может проходить по своему маршруту. Перенаправление трафика осуществляется при перегрузках и отказах оборудования.
Мост (bridge) представляет собой устройство, используемое для соединения сетевых сегментов. Он функционирует в первую очередь как повторитель, может получать данные из любого сегмента, однако более разборчив в передаче этих сигналов, чем повторитель. Если получатель пакета находится в том же физическом сегменте, что и мост, то мост знает, что этот пакет достиг цели и, таким образом, больше не нужен. Если же получатель находится в другом физическом сегменте, мост знает, что пакет надо переслать. Эта обработка помогает уменьшить загрузку сети. Например, сегмент не получает сообщений, не относящихся к нему.
Мосты могут соединять сегменты, которые используют разные типы носителей (кабелей), а также сети с разными схемами доступа к носителю, например сеть Ethernet и сеть Token Ring. Примером таких устройств являются мосты трансляторы (translating bridge), которые осуществляют преобразование различных форм информации в единый вид, позволяя связывать сети разных типов. Другой специальный тип моста — прозрачный (transparent bridge), или интеллектуальный, мост (learning bridge) — периодически «изучает», куда направлять получаемые им пакеты. Он делает это посредством непрерывного построения специальных таблиц, добавляя в них по мере необходимости новые элементы.
Недостатком мостов является то, что они передают данные дольше, чем повторители, так как проверяют адрес сетевой карты получателя для каждого пакета. Они также сложнее в управлении и дороже, нежели повторители.
Маршрутизатор (router) представляет собой сетевое коммуникационное устройство, которое может связывать два и более сетевых сегментов (или подсетей). Маршрутизатор функционирует подобно мосту, но для фильтрации трафика он использует не адрес сетевой карты компьютера, а информацию о сетевом адресе, передаваемую в относящейся к сетевому уровню части пакета. После получения этой информации об адресе маршрутизатор использует таблицу маршрутизации (routing table), содержащую сетевые адреса, чтобы определить, куда направить пакет. Он делает это посредством сравнения сетевого адреса в пакете с элементами в таблице маршрутизации. Если совпадение найдено, пакет направляется по указанному маршруту, если же совпадение не найдено, пакет обычно отбрасывается.
Маршрут по умолчанию (default route) используется в том случае, если не подходит ни один из других маршрутов. Требуемый маршрут сначала ищется в таблицах. Если он не находится, пакет посылается в узел, специально выбранный для данного случая. Маршруты по умолчанию, используются обычно тогда, когда маршрутизатор имеет ограниченный объем памяти или по какой-то иной причине не имеет полной таблицы маршрутизации. Маршрут по умолчанию может помочь реализовать связь даже при ошибках в маршрутной таблице, однако для региональных сетей с ограниченной пропускной способностью такое решение может иметь серьезные последствия. Например, из-за такого рода ошибки пакеты внутри локальной сети могут пересылаться через сеть другой страны.
Существуют два типа маршрутизирующих устройств: статические и динамические. Статические маршрутизаторы (static router) используют таблицы маршрутизации, которые должен создавать и вручную обновлять сетевой администратор. Динамические маршрутизаторы (dynamic router) создают и обновляют свои собственные таблицы маршрутизации. Они используют информацию, найденную на своих собственных сегментах, а также полученную от других динамических маршрутизаторов. Динамические маршрутизаторы всегда содержат свежую информацию о возможных маршрутах по сети, а также информацию об узких местах и задержках в прохождении пакетов. Эта информация позволяет им определить наиболее эффективный путь, доступный в данный момент для перенаправления пакетов данных к их получателям.
Поскольку маршрутизаторы могут осуществлять интеллектуальный выбор пути и отфильтровывать пакеты, которые им не нужно получать, они помогают уменьшить загрузку сети, сохранить ресурсы и увеличить пропускную способность. Кроме того, они повышают надежность доставки данных, так как могут выбрать для пакетов альтернативный путь, если маршрут по умолчанию недоступен.
Термин «маршрутизатор» (router) может обозначать устройство электронной аппаратуры, сконструированное специально для маршрутизации. Он также может означать компьютер (обеспеченный таблицей маршрутизации), подключенный к другим сегментам сети с помощью нескольких сетевых карт и, следовательно, способный выполнять функции маршрутизации между связанными сегментами.
Маршрутизаторы превосходят мосты в способности фильтровать и направлять пакеты данных по сети и в отличие от мостов могут отключить пересылку широковещательных сообщений, что уменьшает сетевой широковещательный трафик.
Другое важное преимущество маршрутизатора как соединительного устройства заключается в том, что, поскольку он работает на сетевом уровне, он может соединять сети, использующие различную сетевую архитектуру, методы доступа к устройствам или протоколы. Например, маршрутизатор может соединять подсеть Ethernet и сегмент Token Ring.
Он может связывать несколько небольших сетей, использующих различные протоколы, если эти протоколы поддерживают маршрутизацию.
Маршрутизаторы по сравнению с повторителями дороже и сложнее в управлении. У них меньшая пропускная способность, чем у мостов, так как они должны производить дополнительную обработку пакетов данных. Кроме того, динамические маршрутизаторы могут добавлять излишний трафик в сети, поскольку для обновления таблиц маршрутизации постоянно обмениваются сообщениями.
Английский термин «brouter» (мост маршрутизатор) представляет собой комбинацию слов «bridge» (мост) и «router» (маршрутизатор). Из этого можно сделать вывод, что мост маршрутизатор сочетает функции моста и маршрутизатора. Когда мост маршрутизатор получает пакет данных, он проверяет, послан пакет с использованием маршрутизируемого протокола или нет. Если это пакет маршрутизируемого протокола, мост маршрутизатор выполняет функции маршрутизатора, посылая при необходимости пакет получателю вне локального сегмента. Если же пакет содержит не маршрутизируемый протокол, мост маршрутизатор выполняет функции моста, используя адрес сетевой карты для поиска получателя на локальном сегменте. Для выполнения этих двух функций мост маршрутизатор может поддерживать как таблицы маршрутизации, так и таблицы мостов.
Шлюз (gateway) представляет собой устройство для осуществления связи между двумя или несколькими сетевыми сегментами. В качестве шлюза обычно выступает выделенный компьютер, на котором запущено программное обеспечение шлюза и производятся преобразования, позволяющие взаимодействовать несходным системам в сети. Например, при использовании шлюза персональные компьютеры на базе Intel-совместимых процессоров на одном сегменте могут связываться и разделять ресурсы с компьютерами Macintosh.
Другой функцией шлюзов является преобразование протоколов. Шлюз может получить сообщение IPX/SPX, направленное клиенту, использующему другой протокол, например ТСР/IP, на удаленном сетевом сегменте. После того как шлюз определяет, что получателем сообщения является станция ТСР/IP, он преобразует данные-сообщения в протокол ТСР/IP. В этом состоит его отличие от моста, который просто пересылает сообщение, используя один протокол внутри формата данных другого протокола; преобразование при необходимости происходит у получателя. Почтовые шлюзы производят сходные операции по преобразованию почтовых сообщений и других почтовых передач из родного формата приложения электронной почты в более универсальный почтовый протокол, например SMTP, который может быть затем использован для направления сообщения в Интернет.
Хотя шлюзы имеют много преимуществ, нужно учитывать несколько факторов при принятии решения об использовании шлюзов в сети. Шлюзы сложны в установке и настройке. Они также дороже других коммуникационных устройств. Вследствие лишнего этапа обработки, связанного с процессом преобразования, шлюзы работают медленнее, чем маршрутизаторы и подобные устройства.
Глава2.ОСНОВНЫЕ ТЕХНИЧЕСКИЕ ХАРАКТЕРИСТИКИ И КАЧЕСТВО СЕТЕЙ ЭВМ И ТЕЛЕКОММУНИКАЦИОННЫХ КАНАЛОВ
Согласно Серии Международных Стандартов ISO 9000 качество — это совокупность свойств системы, позволяющих отвечать потребностям и ожиданиям потребителя.
Основные показатели качества информационно-вычислительных сетей:
полнота выполняемых функций — сеть должна обеспечивать выполнение всех предусмотренных для нее функций по доступу ко всем ресурсам, по совместной работе узлов и по реализации всех протоколов и стандартов работы;
производительность — среднее количество запросов пользователей сети, исполняемых за единицу времени;
пропускная способность — важная характеристика производительности сети, определяемая объемом данных, передаваемых через сеть (или ее звено — сегмент) за единицу времени. Часто используется другое название — скорость передачи данных;
надежность — важная техническая характеристика сети, чаще всего определяемая средним временем наработки на отказ;
достоверность результатной информации — важная потребительская характеристика сети;
безопасность — важнейшая характеристика, поскольку современные сети имеют дело с конфиденциальной информацией. Способность сети защитить информацию от несанкционированного доступа и определяет степень ее безопасности;
прозрачность — еще одна потребительская характеристика сети, означающая невидимость особенностей ее внутренней архитектуры для пользователя. Он должен иметь возможность обращаться к ресурсам сети как к локальным ресурсам своего собственного компьютера;
масштабируемость — возможность расширения сети без заметного снижения ее производительности;
универсальность — возможность подключения к сети разнообразного технического оборудования программного обеспечения от разных производителей;
эффективность — возможность выполнения сетью возложенных на нее функций с меньшими затратами оборудования, времени или средств по сравнению с прототипами либо с другими типами сетей.
Рассмотрим часть этих показателей подробнее.
2.2. Производительность ЭВМ, вычислительных систем и сетей
2.2.1. Производительность ЭВМ и ее оценка
Производительность ИВС зависит от времени выполнения запроса пользователя tвып.3П , затрачиваемого на обработку информации и определяемого производительностью ЭВМ и ВС как элементов сети.
Определение производительности ЭВМ, измеряемой в МИПС (MIPS) — миллионах операций в секунду над числами с фиксированной запятой (точкой) и в МФлоПС (MFloPS) для операций над числами, представленными в форме с плавающей точкой, было дано в под разд. 1.2. С 1946 г., когда появилась первая супер ЭВМ ENIAC, и до сего времени производительность наиболее мощных машин увеличивалась в десять раз за каждое пятилетие. В приложениях 1 и 2 указана производительность некоторых типов современных ЭВМ. На рис. 2.1 в координатах производительность — емкость памяти приведены требования к ЭВМ для решения различных задач. Производительность рассчитана исходя из требования 15-минутного решения задачи, указаны типы современных ЭВМ, включая суперЭВМ.
Таким образом, производительность — это показатель эффективности ЭВМ или ВС, для оценки которого используются некоторые характеристики скорости работы системы. Она измеряется иногда числом наиболее повторяющихся либо средних по длительности операций в секунду (опер./с). Значения производительности изменяются от сотен операций в секунду у персональных компьютеров, микро ЭВМ и микропроцессоров до 1013 операций в секунду и более у суперЭВМ.
Производительность зависит не только от самой ЭВМ, но и от особенностей обрабатываемой информации, таких как разрядность слов, форма представления чисел (с плавающей или фиксированной точкой), частоты повторения различных операций в общем потоке выполняемых программ и др. Поэтому производительность ЭВМ оценивается с помощью тестовых наборов задач, предварительно выявляя процентное содержание команд различного типа. В 70-х гг. ХХ в. были разработаны усредненные наборы операций — смеси Гибсона для разных типов задач (экономических, технических, математических и т.д.), в которые разные команды входили в определенном процентном отношении. По смесям Гибсона

можно определять среднее быстродействие компьютера для этих типов задач.
Фирмы-изготовители для определения быстродействия своих изделий разработали более новые тестовые наборы: в 1992 г. для микропроцессоров фирмы Intel — показатель iCOMP (Intel Comparative Microprocessor Performance), в 1ф96 г. — показатель 1СОМР2.0, ориентированный на 32-битные OC и мультимедийные технологии. Разработаны специализированные тесты для конкретных областей применения ЭВМ: Winstone 97-Business для офисной группы задач; варианты тестов WinBench 97 для других видов задач.
Значения производительности могут использоваться для ориентировочной оценки реальной производительности при решении конкретных задач. Иногда производительность удобно оценивать числом выполняемых команд в минуту, числом выполняемых заданий в день и т.д.
Оценки производительности для ЭВМ, выполняющих самые разные задания, будут весьма неточными. Поэтому для характеристики ПК вместо производительности обычно указывают тактовую частоту, более объективно определяющую быстродействие машины, так как каждая операция требует для своего выполнения определенного числа тактов.
Пример 2.1. Частота тактового генератора микропроцессора равна 100 МГц. Чему равна производительность ПК (при отсутствии конвейерного выполнения команд и увеличения внутренней частоты)?
Решение. У микропроцессоров короткие машинные операции (простые сложение и вычитание, пересылки информации и др.) выполняются обычно за 5 машинных тактов. В нашем случае один такт равен 1/100 МГц = 1/100∙106 Гц = 10-8 с; время выполнения одной операции составит 5∙ 10-8 с. За одну секунду могут выполняться 1/(5∙10-8) = 20 ∙106 операций, т.е. 20 млн. операций. Следовательно, производительность ПК на базе данного микропроцессора равна 20 млн. опер./с.
Производительность ЭВМ на базе микропроцессора с тактовой частотой 1000 МГц будет равна 200 млн. коротких операций в секунду.
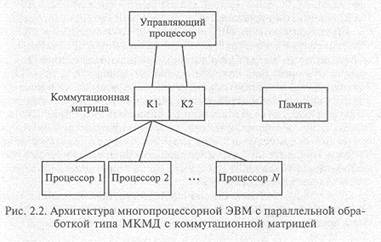
Рассмотрим метод оценки производительности и загрузки многопроцессорной потоковой машины с параллельной обработкой данных. В таких машинах любой алгоритм вычислительного процесса разбивается на группы независимых операций, последовательно обрабатываемых машиной. Число операций, находящихся в одной такой группе, определяет величину параллелизма вычислительного процесса n на данном этапе или шаге вычисления. Условием полной загрузки многопроцессорных машин должно быть выполнение на каждом шаге вычисления неравенства N < n, где N — число процессоров.
Это только нижняя оценка требуемого неравенства, которое должно быть уточнено: N необходимо умножить на С — максимально возможное число операций в каждом процессоре, которые должны в них одновременно выполняться для обеспечения полной загрузки ЭВМ. Фактически должна быть учтена глубина конвейеризации по каждому параллельно работающему процессору. В этом случае неравенство принимает вид: NC < n. Поэтому предельные возможности по загрузке разрабатываемой ЭВМ можно оценить следующим образом: если NC < n, то загрузка полная; если NC > n, то загрузка пропорциональна отношению N/nC.
Для архитектуры ЭВМ типа МКМД с коммутационной матрицей, представленной на рис. 2.2, условие полной загрузки будет выражаться так:
![]()
где Nпр NK1, NK2, Nап — число параллельно работающих процессоров, коммутаторов и модулей ассоциативной памяти в одном канале; Cпр C K1, C K2, Сап— соответствующие им значения глубины конвейеризации.
Для простоты будем считать, что пропускные способности коммутаторов, процессоров и ассоциативной памяти согласованы, равны и все устройства работают с одним и тем же темпом П. Тогда максимальная производительность системы будет равна ПКК где NK — число параллельно работающих коммутаторов. Произведение NC определяет число операций, над которыми вычислительная система потока данных должна работать одновременно, чтобы была обеспечена ее 100%-ная загрузка.
Из приведенных соотношений видно, что чем меньше значение NC, тем более эффективно будет работать многопроцессорная ЭВМ или многомашинный комплекс при малом параллелизме задачи. В ЭВМ традиционной архитектуры ОКОД с увеличением значений N и n возможности человека как программиста резко
снижаются (начиная с N 3). Именно поэтому пользователи машин с коммутационной матрицей (connection mashine), имеющей в своем составе более 64 тыс.элементарных процессоров, сообщают об их только 10%-ной средней загрузке при решении ориентированных на эту машину задач. Кроме того, в традиционных машинах параллелизм выявляется человеком или процессором на небольшом участке программы, в лучшем случае в десяток команд. Поэтому средний параллелизм выполнения скалярных операций для машин архитектуры ОКОД, таких, например, как суперЭВМ «Эльбрус-2», не превышает 2 — 3, а для векторных конвейерных машин типа Cray он не более 10.
Основным звеном, сдерживающим производительность машины потока данных, является ассоциативная память (АП). АП выполняет несколько команд в зависимости от кода операции. Ключом поиска — дескриптором — является код, состоящий из номера команды, индекса, итераций и активации. При реализации памяти на интегральных схемах БИК-МОП-структуры с разрешающей способностью технологического процесса 0,7 мкм период темпа работы не превышает 10 нс. Модуль такого порядка можно реализовать объемом в 32 тыс. ключей. Из ста модулей такой памяти можно получить достаточный объем ассоциативной памяти— более 310 слов. С таким темпом могут справиться два — четыре транспьютера, в каждом из которых могут обрабатываться два пакета одновременно в конвейерном режиме. Четыре коммутатора обеспечат необходимый темп работы.
2.2.2. Производительность вычислительных систем и ее оценка
Для повышения производительности многопроцессорной вычислительной системы (ВС) с массовым параллелизмом необходимо иметь возможность программировать в структуре универсальной многопроцессорной ВС архитектуру виртуальной проблемно ориентированной ВС, соответствующей решаемой задаче. Причем программирование архитектуры виртуального компьютера должно выполняться с таким расчетом, чтобы степень адекватности его архитектуры А структуре решаемой задачи была близка к единице (А = 1), коэффициент согласованности параллельно работающих процессоров L был близок к единице (L = 1) и коэффициент обменов D был минимальным, что достигается за счет максимального сближения структур графов решаемой задачи G* и ее компьютерной модели G.
На рис. 2.3 приведена фрейм-архитектура параллельной много процессорной ВС (суперкомпьютера с массовым параллелизмом), основанная на аппаратно-программных подсистемах, которые дают
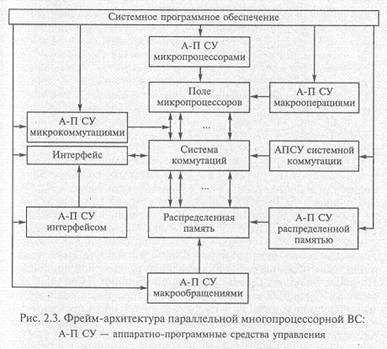
пользователю возможность как до начала решения задачи, так и в процессе ее решения быстро программировать и настраивать архитектуру ВС с целью получения виртуальной архитектуры, адекватной структуре решаемой задачи.
Параллельная многопроцессорная ВС с программируемой архитектурой отличается следующим: обеспечивает производительность, близкую к пиковой, на любом классе решаемых задач;
дает возможность программировать архитектуру, включая прямые каналы коммуникаций, наборы макро операций, внутренний язык высокого уровня и структуру распределенной памяти;
обеспечивает практически линейный рост производительности пропорционально числу параллельно функционирующих супер транспьютеров;
может работать как в режиме решения одной сложной задачи с использованием всех вычислительных ресурсов, так и в режиме разделения аппаратных ресурсов между несколькими пользователями;
обеспечивает за счет модульной конструкции масштабируемость суперкомпьютера.
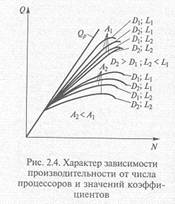
Реальная производительность Q многопроцессорной ВС существенно зависит от коэффициентов А, D, L, общего числа процессоров N и числа процессоров n, используемых в ВС для моделирования системы, а также от производительности каждого процессора q:
![]()
Реальная производительность ВС растет с увеличением и, А, L и с уменьшением D. Наибольшая производительность ВС до производительности от числа достигается в случае, когда для решения задачи используются все процессоры (n = N), степень адекватности максимальна (А = 1), согласованность процессоров максимальна (L = 1) и операции обмена между процессорами ВС отсутствуют (D = 0). При этом достигается пиковая производительность ВС Qp = qN, которая растет линейно в зависимости от числа процессоров N. Если коэффициент адекватности А < 1 и коэффициент L < 1, а коэффициент обменов между процессорами достаточно высок (D > 0), реальная производительность Q является нелинейной функцией числа процессоров N.
На рис. 2.4 представлены зависимости пиковой производительности о и реальной производительности Q от числа процессоров N в ВС и значений коэффициентов А, L и D при n = 1. Если степень адекватности А близка к единице, реальная производительность Q растет достаточно быстро с увеличением числа процессоров N, но замедляет свой рост и даже уменьшается с увеличением объема операций обменов D и с уменьшением коэффициента согласованности L. В том же случае, когда степень адекватности существенно меньше единицы (А «1), реальная производительность Q при росте числа процессоров N быстро достигает максимума, а затем начинает уменьшаться. При больших значениях D и малых значениях L максимум производительности Q достигается при малом числе процессоров N, а при дальнейшем росте N реальная производительность многопроцессорной ВС быстро уменьшается.
2.2.3. Производительность и пропускная способность ИВС
Одним из основных свойств сетей ЭВМ является потенциально высокая производительность, обеспечиваемая возможностью распараллеливания вычислительного процесса между несколькими компьютерами ВС сети. Эту возможность не всегда удается реализовать, и загрузка вычислительных мощностей получается далеко не всегда полной.
Производительность ИВС, иначе называемая вычислительной мощностью, определяется тремя характеристиками:
временем реакции сети на запрос пользователя;
пропускной способностью сети; задержкой передачи.
Время реакции сети tреак.ЗП определяется как интервал времени между возникновением запроса пользователя (ЗП) к какой-либо сетевой службе и получением ответа на этот запрос. Оно складывается из следующих составляющих:
времени подготовки запроса на компьютере пользователя tподг. ЗП;
времени передачи запроса через сегменты сети и промежуточное телекоммуникационное оборудование от пользователя к узлу сети, ответственному за его исполнение tперед.ЗП;
времени выполнения (обработки) запроса в этом узле tвып.ЗП;
времени передачи пользователю ответа на запрос tперед.отв;
времени обработки полученного от сервера ответа на компьютере пользователя tобраб.отв.
Таким образом,
![]()
Время реакции зависит от типа службы, к которой обращается пользователь, от того, какой пользователь и к какому узлу обращается, а также от состояния элементов сети на данный момент, а именно: от загруженности сервера и сегментов, коммутаторов и маршрутизаторов, через которые проходит запрос, и др. Поэтому на практике используется оценка времени реакции сети, усредненная по пользователям, серверам, времени суток, от которого зависит загрузка сети. Эти сетевые составляющие времени реакции дают возможность оценить производительность отдельных элементов сети и выявить «узкие» места с целью модернизации сети для повышения общей производительности.
Значительную часть времени реакции составляет время передачи информации по телекоммуникациям сети, от длительности которого и зависит пропускная способность. Пропускная способность определяет скорость выполнения внутренних операций сети по передаче пакетов данных между узлами сети через коммутационные устройства и характеризует качество выполнения одной из основных функций сети — транспортировки сообщений. По этой причине при анализе производительности сети эта характеристика чаще используется, чем время реакции.
Пропускная способность, называемая в некоторых литературных источниках скоростью передачи данных, измеряется в бодах либо в пакетах в секунду и характеризует эффективность передачи данных. Например, скорость передачи данных по кабельным линиям связи ЛВС — от 10 Мбит/с, по телефонным каналам связи глобальных сетей — всего 1200 бит/с.
Используются три понятия пропускной способности — средняя, мгновенная и максимальная. Средняя пропускная способность вычисляется делением объема переданных данных на время их передачи за длительный интервал времени (час, день, неделя). Мгновенная пропускная способность — средняя пропускная способность за очень маленький интервал (10 мс или 1 с). Максимальная пропускная способность — это наибольшая мгновенная пропускная способность, зафиксированная за время наблюдения.
Средняя пропускная способность отдельного элемента или всей сети позволяет оценить работу сети за большой промежуток времени, в течение которого пики и спады интенсивности трафика компенсируют друг друга. С целью повышения пропускной способности сети ЭВМ применяется метод конвейерной обработки информации, при котором команды и/или данные, заранее выбранные из общей памяти («опережающая выборка»), размещаются в промежуточном запоминающем устройстве (ЗУ) — кэш-памяти (от cach — карман). Кэш-память (или просто кэш) — быстродействующее ЗУ в одном кристалле с микропроцессором либо внешнее по отношению к нему, представляет собой высокоскоростной буфер между процессором и низкоскоростной внешней памятью (ВЗУ). Емкость кэш-памяти, например, у процессора типа Ridge System 32 равна 4 Кбайт, или сокращенно 4К, а время доступа к ней tдост = 120 нс.
В кэше помимо команд и данных размещают и командные циклы с водящими в них командами переходов. Это позволяет избегать большого числа циклов ожидания при работе с памятью через системную шину, что характерно для сетей ЭВМ.
Обращение к памяти считается удачным, если необходимая информация уже находится в кэше. При емкости кэша 4К и длине строки 4 байта вероятность удачного обращения Рудач= 80%, при удвоении строки Рудач= 85%, при следующем удвоении длины строки кэша Рудач повышается лишь до 87%.
Полная производительность памяти зависит от среднего времени доступа к памяти tдост.cр, которое определяется временем доступа к кэшу tдост.кэш, вероятностью удачных обращений Рудач и временем обращения к основной памяти, происходящего при неудачном обращении к кэшу:
![]()
Пример 2.2. Рассчитать среднее время доступа процессора с кэш-памятью при вероятности удачных обращений 80%, времени доступа к кэш-памяти 120 нс, вероятности обращения к основной памяти 20 % и времени доступа к ней 600 нс.
![]()
Применение кэш-памяти высвобождает часть пропускной способности, что будет показано в примере 2.3.
Пропускная способность сети обозначается W (иногда С) и измеряется в мегабайтах в секунду (Мбайт/с) либо в бодах:
![]()
где K — коэффициент использования шины; Сn— объем пересылаемой информации, байт; Тц — длительность цикла, с; n — число циклов на одну пересылку.
Пример 2.3. При каждом обращении к памяти пересыпаются 4 байта, на что затрачивается 3 синхроцикла длительностью 60 нс. У микропроцессора без кэша К = 82%, а у микропроцессора МС68020 фирмы Моторола, содержащего кэш, К= 65 % за счет того, что Рудач= 100%. Рассчитать необходимую пропускную способность системной шины в том и другом случае.
Решение. Wбез кэш = 0,82 4/(60∙10-9∙ 3) = 18,22∙ 106 байт/с = = 18,22 Мбайт/с;
Wс кэш = 0,65∙4/(60∙10-9∙ 3) = 14,44∙ 106 байт/с = 14,44 Мбайт/с.
Высвобожденная благодаря наличию кэш-памяти часть пропускной
способности шины может быть использована процессором или другим устройством системы.
По значению максимальной пропускной способности можно оценить возможность сети справляться с пиковыми нагрузками, например, утром, когда производятся регистрация пользователей сети и обращение к разделяемым файлам и базам данных. Связь между максимально возможной пропускной способностью и полосой пропускания линии вне зависимости от принятого способа физического кодирования установил Клод Шеннон:
![]()
где С — максимально возможная пропускная способность линии, бит/с; F — ширина полосы пропускания линии, Гц; Pс — мощность сигнала; Pш — мощность шума.
Подробно о ширине полосы пропускания линии связи говорится в гл. 4 и 5.
Максимально возможную пропускную способность линии связи без учета шума можно определить и по формуле, полученной Найквистом:
![]()
где М — число различимых состояний информационного параметра. Отсюда следует, что если сигнал может иметь два состояния (О и 1), то пропускная способность равна удвоенному значению ширины полосы пропускания линии связи.
Пример 2.4. Соотношение между мощностями сигнала и шума равно 100, что типично для линий связи. Мощность передатчика увеличили вдвое. На сколько увеличится максимально возможная полоса пропускания?
Решение. Применим формулу Шеннона (2.1). Будем считать, что первоначально множитель log2(1 + 100) соответствует 100 %. После увеличения Рc вдвое log2(1 + 200) соответствует 115%. Это означает, что из-за логарифмической зависимости от отношения сигнал/шум пропускная способность увеличится всего на 15%.
Пропускная способность может измеряться между двумя узлами или точками сети, например между компьютером пользователя и сервером, между входным и выходным портами маршрутизатора. Общая пропускная способность любого составного пути сети будет равна минимальной из пропускных способностей составляющих элементов маршрута, поскольку пакеты передаются различными элементами сети последовательно. Поэтому для повышения пропускной способности составного пути необходимо выявить самые медленные элементы. Обычно это маршрутизатор, так как если средняя интенсивность передаваемого по составному пути трафика будет превосходить среднюю пропускную способность самого медленного элемента пути, очередь пакетов к этому элементу будет нарастать, пока не заполнится буферная память элемента, после чего пакеты будут отбрасываться и теряться. Общая пропускная способность сети характеризует качество сети в целом и определяется как среднее количество информации, переданной между всеми узлами сети в единицу времени.
Задержка передачи — это задержка между моментом поступления пакета на вход какого-нибудь сетевого устройства или части сети и моментом появления его на выходе данного устройства. Эта характеристика производительности отличается от времени реакции сети тем, что включает в себя только время этапов сетевой обработки данных без учета задержек обработки данных компьютерами сети. Практически задержка не превышает сотен миллисекунд, реже — нескольких секунд, и не влияет на качество файловой службы, служб электронной почты и печати с точки зрения пользователя. Однако такие задержки пакетов, переносящих изображение или речь, приводят к снижению качества предоставляемой пользователю информации из-за возникновения дрожания изображения, эффекта эха, неразборчивости слов и т.п.
Задержка передачи и пропускная способность являются независимыми характеристиками, поэтому несмотря на высокую пропускную способность сеть может вносить значительные задержки при передаче каждого пакета.
Пример 2.5. Канал связи образован геостационарным спутником на высоте h = 36 000 км. Определить задержку передачи tзад.
Решение. Скорость распространения сигнала равна скорости распространения радиоволн v = 300 000 км/с. Расстояние, которое проходит сигнал, равно удвоенной высоте спутника, т.е. 2 h. Отсюда tзад = 2h/v = = 72000 км/300000 км/с = 0,24 с.
Отметим, что пропускная способность рассматриваемого канала может быть весьма высокой, например 2 Мбит/с.
Пример 2.6. Оценить и сравнить задержки в передаче данных в сетях с коммутацией пакетов и с коммутацией каналов. Объем тестового сообщения С = 200 Кбайт, расстояние между отправителем и получателем l = 5000 км. Пропускная способность линии связи W= 2 Мбит/с. Скорость распространения сигнала v = 200 000 км/с. Путь от отправителя до получателя пролегает через 10 коммутаторов, каждый из которых вносит задержку коммутации tзад.ком= 20 мс (рис. 2.5). (Эта задержка у реальных коммутаторов может иметь большой разброс — от долей до тысяч миллисекунд.) Исходное сообщение разбивается на пакеты объемом Спак = 1 Кбайт (всего 200 пакетов). Доля служебной информации, расположенной в заголовках пакетов, по отношению к общему объему сообщения составляет 10%. Интервал между отправкой пакетов tм.пак= 1 мс.
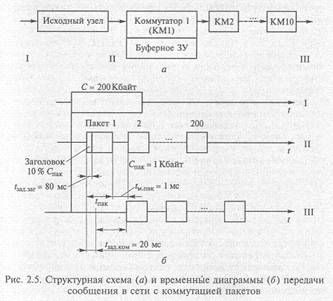
Решение. В сети с коммутацией каналов время задержки передачи данных tзад.к.к складывается из времени распространения сигнала tраспр и времени передачи сообщения по сети tперед:
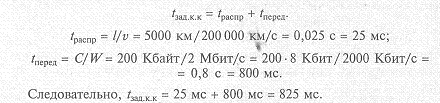
В такой же сети, но с коммутацией пакетов, при передаче этого же сообщения возникает задержка в исходном узле сети, связанная с передачей заголовков пакетов:
![]()
Потери времени в исходном узле за счет интервалов между пакетами
![]()
Всего в исходном узле из-за пакетирования сообщения возникает задержка
![]()
Помимо того, возникает задержка, вносимая десятью коммутаторами:
![]()
Задержка буферизации пакета при прохождении информации через коммутатор:
![]()
Таким образом, задержка, вносимая десятью коммутаторами на буферизацию tбуф, составит 40 мс.
Общая задержка на коммутаторах
tком= t10ком+tбуф = 200 мс + 40 мс = 240 мс.
В результате дополнительная задержка в сети, созданная коммутацией пакетов:
tзад.к.п = tисх.уз + tком = 280 мс + 240 мс = 520 мс.
Эта дополнительная задержка соизмерима с временем задержки передачи данных в сети с коммутацией каналов tзад.к.к= 825 мс и может считаться существенной.
2.2.4. Методы повышения производительности ИВС
Путь повышения производительности компьютеров увеличением быстродействия элементной базы — интегральных микросхем — практически исчерпал свои возможности, натолкнувшись на теоретический предел 109...1010 опер./с. Дальнейшее продвижение в этом направлении требует открытия новых физических принципов обработки информации. Второй путь, в основе которого лежит распараллеливание процесса обработки информации на всех уровнях решения задачи, широко использовался на всех этапах развития вычислительных средств.
К методам распараллеливания относятся:
переход от последовательного счета к параллельному;
параллельная работа основных устройств ЭВМ;
введение пакетного режима работы и режима разделения времени;
мультиплексный режим обработки данных;
конвейерный режим;
многопроцессорные (см. рис. 2.2) и многомашинные комплексы;
режим управления потоками данных и др.
Второй путь не исчерпал себя и должен получить дальнейшее успешное развитие в перспективных ЭВМ и особенно в суперЭВМ.
Производительность компьютера как элемента ИВС может быть повышена за счет освобождения его от функций управления сложной сетью (на что, согласно статистике, затрачивается до 75 % его времени), путем введения в сеть связных процессоров. Целесообразность применения связного процессора совместно с высокопроизводительной основной ЭВМ очевидна, поскольку управление сложной системой телеобработки данных, а тем более сетью, требует обработки большого числа обращений в режиме реального времени, что связано с прерыванием вычислений и обработкой этих прерываний. Связной процессор выполняет почти все функции управления сетью, высвобождая дорогостоящее время основной ЭВМ.
В настоящее время используются следующие способы повышения производительности при создании ЛВС:
применение высокоскоростных технологий передачи данных;
сегментация структуры сети;
применение технологии коммутации кадров.
Технология передачи данных Ethernet 10Base обеспечивает скорость передачи данных 10 Мбит/с. Современные высокоскоростные технологии, например, Fast Ethernet 100Base и Gigabit Ethernet 1000Base позволяют при применении хороших каналов связи повысить скорость передачи соответственно в 100 и 1000 раз.
Удаление из трафика ненужных составляющих понижает его интенсивность и благоприятствует передаче действительно важной информации, чем повышает производительность сети. В сети выделяются группы пользователей, более интенсивно обменивающихся данными, решающих однородные задачи. Разместив разные рабочие группы в отдельных сегментах сети, можно увеличить производительность сети. Сегментация может быть осуществлена путем установки мостов, коммутаторов и маршрутизаторов, тогда интенсивный обмен будет проходить внутри одного сегмента, интенсивность межсегментного трафика уменьшится и количество коллизий в сети снизится.
Совместное применение в сегментированной ЛВС коммутаторов, маршрутизаторов технологии коммутации кадров (пакетов) снижает интенсивность внутрисегментного трафика. Интеллектуальные коммутаторы и маршрутизаторы определяют порт назначения кадра на основании адреса, включенного в кадр, и посылают его, не дублируя по всем направлениям, а лишь в нужный сегмент.
Повышение производительности корпоративных и территориальных сетей достигается применением технологии Frame Relay (FR). В сетях FR протокол обмена канального уровня LAP-F, описывающий взаимодействие соседних узлов, имеет два режима: основной и управляющий. В основном режиме кадры передаются без преобразования и контроля, как в обычных коммутаторах, чем достигается высокая производительность, тем более, что не требуется подтверждения передачи.
Существенный вклад в повышение производительности корпоративных сетевых технологий вносит сетевая операционная система. Лидирующее место занимает высокопроизводительная, защищенная и надежная ОС Windows Server 2000, применяемая в качестве интегрированной платформы для корпоративных информационных сетей любого масштаба. В качестве сервера ОС использует сервер баз данных Microsoft SQL Server (Structured Query Language — язык структурированных запросов), обеспечивающий более высокую производительность по сравнению с другими типами серверов системы — сервером электронной почты Microsoft Exchenge Server и сервером удаленного доступа Remote Access Server.
2.3. Эффективность сети ЭВМ и системы телекоммуникаций
2.3.1. Эффективность неоднородной сети ЭВМ
Для решения больших задач, характеризующихся многообразием форм и уровней параллелизма, высокопроизводительные вычислительные системы класса суперЭВМ объединяют в единый комплекс путем построения локальных сетей с помощью различных стандартных каналов. При этом основными факторами, ограничивающими производительность комплекса, являются потери на неэффективный обмен между подсистемами и простои части оборудования из-за неоптимального распределения работ. Эта не оптимальность возникает в результате несоответствия форм параллелизма программных и аппаратных средств и неадекватного динамического планирования.
Решением указанных проблем может быть построение вычислительной сети из сильно связанных вычислительных модулей и устройств, каждое из которых имеет свою форму параллелизма, при одновременном согласовании форм параллелизма прикладных задач и аппаратных средств и улучшении статического и динамического планирования суперсистемы в целом. Для обеспечения этих условий в сеть следует включить аппаратно-программную подсистему, выполняющую анализ, подготовку и распределение работ между вычислительными подсистемами.
ИВС может включать от одной до восьми основных ЭВМ, каждая из которых содержит уни процессор и мультипроцессор из 8 ... 512 микропроцессоров. Считая, что длительность такта уни процессора равна 4 нс, производительность уни процессора можно оценить в 16 ... 128 ГФлоПС. При производительности микропроцессора 300 МФлоПС производительность мультипроцессора составит 2,4... 153,6 ГФлоПС.
На перспективной элементной базе производительность одного мультипроцессора может составить 8 ТФлоПС, одного унипроцессора — 4 ТФлоПС, одной ЭВМ — 12 ТФлоПС, а всей вычислительной сети — до 100 ТФлоПС.
2.3.2. Критерий эффективности Т-системы
Оценка эффективности телекоммуникационных систем (Т-систем) должна охватывать все стороны деятельности компонентов системы на всех этапах ее создания и развития и иметь конкретное выражение в единицах системных величин. Разнородный контингент пользователей, составляющий социально-финансовую базу Т-системы (государственные структуры и ведомства, банковские и биржевые структуры), должен оплатить как ее создание, так и услуги. Это реально только в том случае, если полезность Т-системы для пользователей будет адекватной и достаточной. Учитывая разнообразие состава, требований и возможностей потенциальных пользователей, это достижимо только при условии, что Т-система будет обладать соответствующими свойствами и ресурсами.
Критерий эффективности Э основан на главном понятии экономики и социологии «капитал». Современные определения капитала ограничиваются констатацией факта: капитал — это стоимость, приносящая дополнительную стоимость (деньги). Это определение выбрано как рабочий инструмент для оценки эффективности Т-системы. Критерий эффективности учитывает ряд особенностей, присущих системам телекоммуникаций России.
1. Т-система накладывается на действующие сети связи — общегражданские и ведомственные.
2. Действующая общая сеть связи изначально дотационная, ее технический уровень и возможности низки, а повышение тарифов с целью замены оборудования и развития (масштабирования) вызовет ответную реакцию —отказ от услуг и перегрузку ведомственных сетей. В то же время путь ведомственной дифференциации и автономизации телекоммуникаций (отдельно для силовых структур, транспорта, топливно-энергетического комплекса, госструктур) потребует больших ресурсов при низкой отдаче, т.е. приведет к снижению эффективности. Единственный реальный путь — привлечение коммерческих кредитов и инвестиций. Это возможно только при условии, что Т-система будет приносить доход и даст вкладчикам оправдывающий выигрыш, а вклады вместе с процентами будут возвращены в приемлемые сроки.
3. Т-система России должна быть интегрирована в мировую;
систему, для этого она не должна уступать ей в техническом совершенстве и социальных возможностях.
4. Расходная часть включает: расходы на техническую эксплуатацию, зарплату персоналу, налоги и нормативные отчисления, уплату процентов за инвестиции и кредиты; расходы на расширение Т-системы, возвращение вкладов инвесторам и кредиторам.
5. Начиная с некоторого этапа Т-система становится прибыльной, часть прибыли направляется на дальнейшее развитие системы. Кредиты должны поступать и после создания стартового капитала

до тех пор, пока прибыль не станет достаточной, чтобы прекратить кредитование и возвратить долги.
Обосновать критерий эффективности и способ ее оценки, удовлетворяющие перечисленным свойствам системы, весьма непросто, поскольку приходится преодолевать ряд различных препятствий в каждом конкретном случае. Процесс создания и действия Т-системы можно представить в виде цепочки, приведенной на рис. 2.6. Этот процесс циклически повторяется до замены системы. Цепочку можно упростить, как показано на рис. 2.7. Эта замкнутая цепочка отражает обратную связь в процессе создания и эксплуатации системы. Позиции 1, 2 — социальные, 3 — экономическая, 4, 5 — технические. Для оценки эффективности в принципе может быть использована каждая из пяти позиций. Рассмотрим подробнее позицию 4, так как она отражает все остальные, причем знания о содержании остальных позиций и оценки их эффективности не требуются.
Развивающаяся Т-система состоит из материальных и интеллектуальных средств: зданий, сооружений, технического оснащения, программ. В совокупности все это и создает соответствующий . комплекс услуг. В любой момент времени можно установить состав системы и определить состав и качество реализуемых ею услуг. Система имеет цену, иначе говоря, капитал, размер которого К отражает технический уровень системы и ее экономику. От капитала зависят уровень и рост потребностей П, спрос и его увеличение С, финансирование Ф. Рост капитала выражается скалярной функцией времени:
К=К(П, С, Ф).
Обычно К измеряется и вычисляется непосредственно, знания П, С, Ф не потребуется, нужно только знать состав действующей или проектируемой системы.
Возможность развития системы определяется ростом капитала, что и приводит к увеличению услуг, затрат, стимулированию потребностей и росту спроса. Увеличение К в n раз отражает развитие системы. При n = 1 имеем критерий самоокупаемости: капитал определяется вложенными ресурсами (после оплаты долгов); это критерий для плановой экономики.
При n = 2 (темп удвоения капитала) получаем критерий для рыночной экономики. Критерий «темп удвоения капитала» может быть как прогнозным (тогда он вычисляется путем математического моделирования), так и оперативным (тогда капитал непосредственно измеряется).
Для Т-систем как одинарного, так и двойного применения, в качестве критерия оценки эффективности системы для владельца можно выбрать любое значение n, но n = 2 (темп удвоения капитала) наиболее удобен. Критерий применим к каждому подциклу жизненного цикла, подциклы создают свой «капитал» — материальный и интеллектуальный. Входные данные модели соответствуют компоненту «потребность» структурной цепочки, выходные данные — эффекту G; с учетом затрат на подцикл определяется его «капитал». Основой модели здесь является структурно-функциональная схема жизненного цикла.
2.3.3. Оценка эффективности Т-системы
Критерий «темп удвоения капитала» позволяет от начала разработки и творческого замысла до конца завершения жизненного цикла системы, используя оценку эффективности, целенаправленно направлять усилия на создание и развитие системы, поддержание ее работоспособности. Жизненный цикл завершается, когда система перестает приносить прибыль: темп удвоения равен нулю, период удвоения уходит в бесконечность. Тогда систему нужно заменять другой, более совершенной в смысле удовлетворения потребностей и, следовательно, приносящей прибыль.
На основании этого критерия можно оценивать не только стратегические, но и любые оперативные решения: стоит ли разрабатывать свою технику или лучше закупить наилучшую зарубежную; готовить ли кадры самим или заказывать программы подготовки в учебных заведениях, инвестируя их; как устанавливать приоритеты; как формировать тарифы; какие и на какой период вводить льготы; в каком направлении развивать состав услуг; как определить, справляется ли руководство корпорации со своими функциями; целесообразно ли интегрироваться с ведомственными системами телекоммуникации; принимать ли инвестиции или брать кредиты и т.д. Оценка эффективности по критерию «темп удвоения капитала» действует как стимул, на ее основании можно принимать решения как на один день, даже на один час (например, допустима ли часовая профилактика с выключением системы?), так и на десятилетия (строить новую трассу телекоммуникации световодной или ограничиться кабельной?).
Одним из важнейших свойств рассматриваемого критерия эффективности является его универсальность, единство критерия для всех изделий, подсистем и системы в целом, для каждого рабочего, инженера, должностного лица и всего персонала. Сотрудник должен приносить прибыль, в системотехнике это называется «доброжелательной эксплуатацией». Коммерческая оценка полезности по критерию эффективности соответствует реальности и выражается через прибыль П, иными словами эффективность Э и полезность в коммерческом смысле тождественны, хотя по содержанию они отличаются: полезность — тактическая оценка, строго ситуационная, эффективность — оперативно-стратегическая оценка. В дифференциальной форме Э(t) — это оперативная оценка, в интегральной форме Э(0, Т) — стратегическая (Т — время передачи информации, время создания системы и др.). Необходимы обе формы, так как приходится принимать как оперативные управленческие, так и стратегические решения; иначе может оказаться, например, что в погоне за текущей прибылью будет утеряна перспектива развития системы. Поэтому серьезные решения должны опираться на распределение эффективности во времени, прогнозируемое на определенный обозримый период.
Прибыль есть разность между доходной и расходной частью бюджета системы, обе части монотонны и зависят от соотношения между качеством обслуживания и темпом развития. Эти факторы альтернативны. Действительно, на коротком интервале и при ограниченном капитале максимальную. прибыль дает вклад капитала в сферу обслуживания, на достаточно длинном же интервале выгоднее (эффективнее) отвлечь часть капитала на развитие. Весь вопрос стратегической эффективности в оптимальном определении этой части и в направлении ее использования. Это не означает характерную для коммерческих систем погоню за максимумом прогнозной стратегической эффективности, выражаемой формулой
![]()
Необходимо одновременно обеспечить выполнение ограничения
![]()
иначе коммерческая система может разрушиться (обанкротиться). Здесь Э* — эффективность системы без отвлечения части капитала на вклад в совершенствование Т-системы.
Теория эффективности предлагает два пути оценки значения критерия, удовлетворяющего рассмотренным требованиям и свойствам. При первом пути вводятся показатели качества Q — совокупность положительных (с позиции подсистемы, пользователей, владельца) свойств системы. Отрицательное свойство может быть заменено на обратное ему положительное. Показатели качества являются системными инвариантами, функционально независимыми и имеющими различные размерности. Это неупорядоченное дискретное множество:
![]()
где i — множество всех переменных, от которых зависит эффективность. Qi определены на различных измеримых множествах, каждый из показателей качества — упорядоченное множество (непрерывное, дискретное, булево):
![]()
Качество системы есть частично упорядоченное множество показателей качества компонентов сети Qk:
![]()
где fi — отображение прямого (декартова) произведения U ×Q, а U — упорядочивающее множество, т.е. множество, вносящее в заданное неупорядоченное множество отношение порядка.
Эффект G есть упорядоченное множество:
![]()
где ψ — отображение; Т — множество моментов времени (вполне упорядоченное множество).
Эффективность есть вполне упорядоченное множество
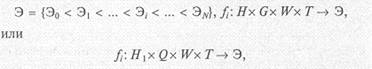
где fi — отображения; Н, Н1 — упорядочивающие множества; W ресурс, израсходованный на интервале Т.
Единицы измерения введенных величин определяют исходя из назначения и свойств системы, на что и ориентирован первый путь, в сущности ситуационный.
Второй путь ориентирован на целенаправленность и перспективу: критерий эффективности вводится как положительное упорядоченное множество — на основе целевой функции системы и к сферы ее применения. Затем вводятся одно или несколько промежуточных множеств, взаимно отображаемых и вполне упорядоченных. В эти множества осуществляется сжатое отображение свойств и параметров системы. Для свойств, не имеющих принятых единиц измерения, вводятся условные топологические шкалы. В результате последовательного отображения свойства характеризуются (совместно) эффективностью по установленному критерию. Достоинством этого варианта является то, что применение упорядочивающих множеств исключается.
Наиболее рационально совместно использовать оба пути, ситуационно их комбинируя на основании отечественного и мирового опыта создания, развития и эксплуатации Т-систем. Промежуточные множества вводят поэтапно в соответствии с развитием системы (следуя второму пути), показатели качества и упорядочивающие множества вводят с учетом принятого критерия и тоже поэтапно (следуя первому пути). Такое сочетание позволяет сохранить критерий эффективности в течение всего жизненного цикла системы и учесть все неизбежно изменяющиеся свойства системы и социума.
Пример 2.7. Рассмотрим результаты оценки эффективности телекоммуникационных систем «Росуником». В полном объеме оценить Э Т-систем (включая базовый комплекс) невозможно ввиду нестабильности экономической обстановки. Отдельные объекты с учетом проектной загрузки имеют следующую прогнозную эффективность (разбросы региональные и зависят от последовательности ввода объектов):
спутниковые линии — 0,33...0,2 год-1 (период удвоения капитала 3...5 лет);
волоконно-оптические линии — 0,2 ...0,1 год-1 (период удвоения капитала 5...10 лет);
сотовая радиосвязь — 0,5...0,33 год-1 (период удвоения капитала 2...3 года);
коммутационные узлы — 0,25 ... 0,17 год-1 (период удвоения капитала 4...6 лет);
телепорты — 0,17 ...0,1 год-1 (период удвоения капитала 6... 10 лет);
абонентские комплекты пользователей — 1... 0,5 год-1 (период удвоения капитала 1... 2 года).
Эти оценки коммерческие и не учитывают положительных социальных последствий, связанных с повышением производительности общественного труда.
2.4. Надежность информационно-вычислительных систем и сетей
Надежность — свойство программной организации структуры системы и функционального взаимодействия между ее ресурсами, при которых обеспечивается безотказное функционирование системы в течение заданного времени при сохранении заданных параметров аппаратуры передачи данных и собственно ЭВМ (ГОСТ 27.003 — 83).
Отказ — это такое нарушение работоспособности, когда для ее восстановления требуются определенные действия обслуживающего персонала по ремонту, замене и регулировке неисправного элемента, узла, устройства, ЭВМ. С надежностью взаимосвязано понятие живучесть — способность программной настройки . структуры и организации функционального взаимодействия между ее компонентами, при которых отказы или восстановления любых элементарных машин не нарушают процесса выполнения параллельных программ сложных задач, а увеличивают или уменьшают время их реализации. Под элементарной машиной понимается ЭВМ, дополненная системным устройством.
Для характеристики качества функционирования ВС в теории надежности разработаны набор интервальных, интегральных и точечных показателей надежности, а также методы их расчета. Показатели надежности имеют вероятностный характер и основываются на значениях л-характеристик — интенсивностей отказов составляющих систему элементов.
Невосстанавливаемые системы (например, бортовые ЭВМ ракет), поведение которых существенно лишь до первого отказа, характеризуются следующими количественными показателями надежности: интенсивность отказов λ(t); частота отказов f(t); вероятность безотказной работы Р(t); вероятность отказа Q(t); наработка до отказа Тο.
Интенсивность отказов λ (t) — один из наиболее удобных количественных показателей надежности изделий электроники, к которым относятся аппаратные средства ЭВМ и систем. Изменение λ (t) во времени у большинства изделий электронной техники имеет существенно нелинейный характер (рис. 2.8), тем не менее на большом по времени участке работы интенсивность отказов изделия обычно мало изменяется и принимается в практических расчетах постоянной. Значения λ -характеристик для элементов ЭВМ берут из их технической документации и стандартов либо получают путем сбора статистики отказов при проведении испытаний или во время эксплуатации.
λ -характеристика, оставаясь постоянной во времени на основном участке работы, существенно зависит от условий эксплуатации
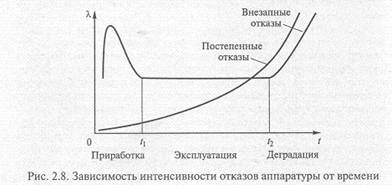
— климатических, механических и радиационных воздействий, нестабильности источников питания и электрической нагрузки и т.п. Таким образом,
![]()
где λ0 — интенсивность отказов изделия при нормальных (лабораторных) условиях эксплуатации; аi — поправочный коэффициент i-го эксплуатационного фактора.
Вероятность безотказной работы за время гарантированного срока службы персональной ЭВМ равна 0,999. Увеличение числа взаимодействующих компьютеров снижает показатели надежности, и система на десяти однотипных компьютерах может обеспечить вероятность безотказной работы, равную лишь 0,99.
На практике часто используется интегральная характеристика надежности наработка до отказа Тo (иначе — наработка на отказ, время до возникновения первого отказа, mean time between failure— среднее время между отказами). Она представляет собой математическое ожидание случайного момента времени τ, в который происходит отказ (ГОСТ 27.410 — 83), т.е.
![]()
Иногда время наработки обозначается ТН и под ним подразумевается среднее значение длительности непрерывной работы :, аппаратуры между двумя отказами:
![]()
где Тi — время безотказной (исправной) работы между i-м и (i+ 1)-м отказами; n — общее число отказов за время сбора статистики отказов. На практике для аппаратуры передачи данных массового применения необходимо, чтобы время наработки на отказ составляло не менее 5000 ч.
Восстанавливаемые системы, эксплуатация которых допускает многократный ремонт для устранения возникающих отказов, характеризуются следующими количественными показателями надежности: параметры потока отказов составляющих элементов ω(t) и потока восстановлений элементов μ(t); функция готовности Kr(t) коэффициент готовности Kr; среднее время работы между двумя отказами tср; среднее время восстановления tв.
Если в процессе функционирования невосстанавливаемого изделия возможен ремонт отдельных его элементов при сохранении работоспособности изделия в целом за счет резерва или если ожидаемая (потенциальная) надежность функционирования восстанавливаемого изделия оценивается в интервале времени до первого отказа восстанавливаемого изделия в целом, то такие изделия характеризуются следующими количественными показателями надежности: вероятность безотказной работы P(t); вероятность отказа Q(t); наработка до отказа Тο; параметры потока отказов составляющих элементов ω(t) и потока восстановлений элементов μ(t).
Для восстанавливаемых систем точечный (локальный) показатель надежности параметр потока отказов составляющих элементов ω(t) — это удельная вероятность появления хотя бы одного отказа в единицу времени:
![]()
где Пο(t) — поток отказов, т.е. последовательность отказов, наступающих в случайные моменты времени.
Точечный (локальный) показатель надежности параметр потока восстановлений μ(t) — это удельная вероятность хотя бы одного восстановления в единицу времени:
![]()
где ПВ(t) — поток восстановлений, т.е. последовательность восстановлений, наступающих в случайные моменты времени.
В теории надежности наиболее важные для практики результаты получены для простейших потоков отказов (восстановлений). Простейший поток — это поток, при котором события потока удовлетворяют одновременно условиям стационарности, ординарности и отсутствия последействия.
Для практических расчетов важна связь между параметром ω(t) восстанавливаемого изделия и λ(t) того же изделия, рассматриваемого как невосстанавливаемое, т.е. функционирующее до первого отказа. Известно, что
![]()
где f(t) = λ(t)Р(t) — частота отказов восстанавливаемого изделия. Решение этого дифференциального уравнения для простейшего потока отказов восстанавливаемого изделия дает ω(t) =λ(τ). Если на практике в большинстве случаев предполагается, что λ(t) = = λ = const, то ω(t) = λ, т.е. численно параметр потока отказов восстанавливаемого изделия равен интенсивности отказов соответствующего невосстанавливаемого изделия.
На практике параметр потока восстановлений изделия находят так:
![]()
где ТВ — эмпирическое (опытное) значение среднего времени восстановления (ремонта) изделия бригадой обслуживания системы.
Среднее время восстановления — это среднее время простоя, вызванного отысканием и устранением отказа.
2.4.2. Коэффициент готовности восстанавливаемой системы
Точечный (локальный) показатель восстанавливаемого изделия функция готовности Кr(t) определяется как вероятность того, что в произвольный момент времени t изделие оказывается в работоспособном (исправном) состоянии:
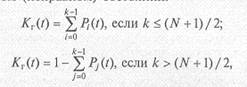
где Рi(t) и Рj(t) — вероятности нахождения системы в момент времени t соответственно в i-м исправном и j-м отказовом состояниях; N+ 1 — общее число состояний изделия; k — число исправных состояний изделия.
Предел функции готовности при t →∞ называется коэффициентом готовности Kr (ГОСТ 27.002 — 83). Он служит интегральным (комплексным) показателем надежности восстанавливаемого изделия:

Для учета простоев, обусловленных техническим обслуживанием, а также времени, затраченного на ремонт за определенный период эксплуатации, применяется комплексный коэффициент технического использования
![]()
где ТП— время простоя системы, обусловленное выполнением планового технического обслуживания и ремонта (время профилактики), пересчитанное на один отказ.
Для пользователей коэффициент готовности в наибольшей степени выражает понятие надежности сложных информационных
систем.
Для аппаратуры передачи данных массового применения необходимо, чтобы коэффициент готовности каналов передачи данных без резервирования находился в пределах 0,9 ... 0,98. Для аппаратуры передачи данных (АПД), применяемой в АСУ, Kr должен быть не менее 0,99, что означает примерно 3,5 сут простоя в год,

для некоторых специализированных ВС — не менее 0,9999 («четыре девятки»). Классификация систем по уровню надежности приведена в табл. 2.1.
Названия типов систем, употребляемые в зарубежной литературе, происходят от английских слов conventional — обычный; high — высокий, availability — пригодность; fault — неисправность, resilient — эластичный; tolerant — терпимый.
Что касается надежности сети, то она чаще всего характеризуется средним временем наработки на отказ.
2.4.3. Обеспечение отказоустойчивости аппаратуры ИВС
Сетевые операционные системы (ОС) обладают свойствами обеспечения отказоустойчивости благодаря применению аппаратных и программных средств. Наиболее развиты в этом отношении распространенные ОС локальных вычислительных сетей Microsoft LAN Manager 2.2 OS/2; IBM OS/2 LAN Server 3.0; версии Novell NetWare 2.2, 3.11, 4.0, SFT Ш 3.11 (System Fault Tolerance — система, устойчивая к ошибкам); LANtastic; UNIX; Banyan VINES 5.50 (VIrtual NEtworking Systems — глобальная сетевая ОС и сеть); Ваnуаn VINES for UNIX. Охарактеризуем кратко средства защиты данных от последствий отказов аппаратуры, применяемые в этих системах в разных сочетаниях.
Дублирование файловой системы FAT (File Allocation Table— таблица размещения файлов). FAT является одним из самых чувствительных файлов на жестком диске, поэтому сетевая ОС хранит резервную копию FAT и в случае выхода из строя одной из копий использует уцелевшую копию, помечая поврежденные секторы испорченного файла и создавая новую копию в другом месте.
Копирование при сбоях носителя. Жесткие диски обычно используются круглосуточно в течение всей недели, что приводит к возникновению на их поверхности дефектов, которые обнаруживаются системой. Размещение файлов на дефектных дорожках не допускается; файлы записываются в другой доступный сектор.
Зеркальное отображение дисков (disk mirroring; от mirror — зеркало). Это дублирование информации на двух накопителях. Если один диск отказывает, выполняется автоматическое переключение на другой без потери данных и прерывания работы.
В сети Интернет все происходящее в процессе передачи и обработки данных на одном компьютере дублируется на другом мощном компьютере. Таких машин-дублеров может быть несколько, так как в каждой стране свои требования. Если информация будет повреждена на одном из сайтов, теоретически ее можно будет восстановить, что потребует определенных временных и финансовых затрат.
Дуплексированне дисков. Это дублирование аппаратуры контроллеров, блоков питания, кабелей и жестких дисков. Если какой-то из этих компонентов или даже половина указанной системы откажет, другая часть системы будет продолжать функционировать и работа сети не прервется.
Дублирование файлов (file replication). Это режим дублирования на сервере выбранных администратором сети важных файлов через определенные промежутки времени.
Отслеживание транзакций (transaction tracking). При вводе новой записи в базу данных в момент выхода из строя системы база может быть повреждена, что зачастую остается незамеченным. При применении отслеживания транзакций каждая совокупность операций по изменению базы данных рассматривается как одна транзакция, в результате чего сетевая ОС не обновляет базу данных до тех пор, пока транзакция не завершится.
Наблюдение за работой UPS (Uninterruptible Power Supply— бесперебойный источник питания). Это процесс, при котором UPS посылает, обычно через порт RS-232С, сигналы серверу о переключении питания сервера на UPS.
Сервер в свою очередь рассылает всем пользователям сообщение о том, что он закончит работу через N минут. По истечении этого времени, когда аккумуляторные батареи UPS достигают уровня истощения, сервер закрывает все файлы, записывает все, данные из оперативной памяти на диск и самостоятельно отключается.
Автоматическое подключение (auto-reconnection). Это свойство автоматического восстановления связи с рабочими станциями после временной потери питания сервером.
Восстановление и очистка удаленных файлов. Сетевые ОС предоставляют возможность восстановить удаленные с сервера файлы, а также очистить сервер (Purge) так, чтобы нельзя было, если это необходимо, файлы восстановить.
Отказоустойчивость является важной, но не единственной частью обеспечения такого показателя качества, как безопасность сети, которая будет рассмотрена в под разд. 2.6.
2.5. Достоверность функционирования информационно-вычислительной системы
Так как сеть представляет собой информационную систему, то с точки зрения потребителя более важной, чем надежность, характеристикой является достоверность ее результантной информации. Существуют технологии, обеспечивающие высокую достоверность функционирования системы даже при низкой надежности составляющих ее элементов, например введение избыточности путем резервирования аппаратуры и применения корректирующих (исправляющих) кодов, а также применение средств автоматического контроля передачи данных, средств автоматического контроля и диагностики и др. Поэтому можно сказать, что надежность ИВС — это не самоцель, а средство обеспечения достоверной информации на ее выходе.
Достоверность функционирования информационно-вычислительной системы — свойство системы, обусловливающее безошибочность производимых ею передачи и преобразований данных и характеризуемое закономерностями появления ошибок из-за сбоев.
Сбоем называют кратковременное самоустраняющееся нарушение нормального функционирования ЭВМ или ВС вследствие кратковременного воздействия на некоторый элемент (или элементы) внешних помех, из-за кратковременного нарушения контактов и т.п. После сбоя машина или система длительное время может работать нормально.
Сбой сопровождается искажением данных, поэтому, если не устранить последствий сбоя, задача может оказаться неправильно решенной из-за искажений в данных, промежуточных результатах или в самой программе. Под достоверностью данных понимается их безошибочность, измеряемая вероятностью появления ошибок в данных. Недостоверность данных может не повлиять на объем данных, а может даже увеличить его в отличие от недостоверности информации, всегда уменьшающей ее количество.
Достоверность функционирования ИВС полностью определяется и измеряется достоверностью ее результатной информации.
Один из основных показателей достоверности информации— показатель корректируемости информационной системы Ти т.е. среднее время исправления (коррекции) информации. Оно представляет собой математическое ожидание времени, затрачиваемого на идентификацию и исправление ошибки.
Комплексными показателями достоверности информации являются коэффициенты информационной готовности и информационного технического использования. Коэффициент информационной готовности КИГ — это вероятность того, что информационная система окажется способной к преобразованию информации в произвольный момент времени периода Траб, который планировался для этого преобразования, т.е. того, что в данный момент времени система не будет находиться в состоянии внепланового обслуживания, вызванного устранением отказа или идентификацией и коррекцией ошибки:
![]()
Коэффициент информационного технического использования Кти кроме параметров, от которых зависит КиГ (Tраб, Тв и Ти), учитывает еще время контроля Тк и время профилактического обслуживания Тпф.
![]()
Достоверность (верность) передачи данных количественно оценивается вероятностью ошибочного приема единичных элементов и вероятностью кодовой комбинации
![]()
и вероятностью кодовой комбинации
![]()
где nош и Nош — число ошибочно принятых соответственно единичных элементов и кодовых комбинаций; n и Nп — число переданных соответственно единичных элементов и кодовых комбинаций.
На практике в связи с ограниченным числом n и Nп вместо вероятностей Pо и PКК используют коэффициент ошибки по элементам Ко =nош /n коэффициент ошибки по кодовым комбинациям Kкк = Nош/Nп.
Коэффициент Ко нормируется для телефонных каналов рекомендацией V53 международного консультативного комитета по телефонии и телеграфии (МККТТ). Его значения зависят от типа канала и скорости модуляции (табл. 2.2).
Некоммутируемый канал, или выделенная линия, представляет собой отдельное постоянное соединение между двумя пунктами, которое осуществляется посредством телефонной разводки. Линия называется выделенной, поскольку соединение активно в
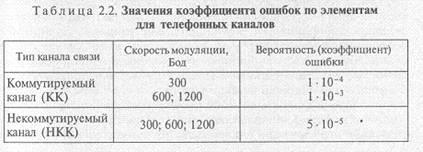
течение всех 24 ч в сутки и вычислительные процессы не соревнуются за полосу пропускания этой линии.
Коэффициент ошибки по кодовым комбинациям КKK независимо от типа канала и скорости передачи должен быть не более 1∙10-6.
С целью оценки совокупного влияния на работу системы рассмотренных выше отдельных показателей надежности и достоверности введен комплексный коэффициент эксплуатационной надежности (комплексный коэффициент использования)
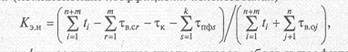
где n, т, k — соответственно число отказов, сбоев и профилактических обслуживаний за рассматриваемый период; ti — интервал времени работы системы между (i — 1)-м и i-м нарушениями функционирования системы из-за отказов или сбоев; τв.сr— время восстановления достоверности информации после r-го сбоя (время, потраченное на повторный пуск программы, части программы, команды и т.д.); τк— суммарное машинное время, затраченное в рассматриваемый период пользователями на контроль достоверности (из-за двойного просчета, контрольных вариантов и т.д.); τпфs — время, затраченное на s-е профилактическое обслуживание; τв.оj — время восстановления j-го отказа.
Из приведенного выражения видно, что для сокращения потерь от сбоев и отказов, порождающих ошибки в передаваемых и обрабатываемых данных, надо предотвращать распространение ошибки в информационно-вычислительном процессе, так как в противном случае существенно усложнятся и удлинятся процедуры проверки правильности работы программы, определения и устранения искажений в программе, данных и промежуточных результатах. Для этого необходимо обнаруживать появление ошибки в выполняемых преобразованиях информации возможно ближе к моменту ее возникновения.
Для указанной цели в ВС существует система автоматического контроля и диагностики, сочетающая программные и аппаратные средства. При появлении ошибки она немедленно приостанавливает работу ВС, производит диагностику характера ошибки с тем, чтобы в случае сбоя автоматически восстанавливались достоверность информации и выполнение программы и при этом был минимален повторяемый участок программы, а в случае отказа обслуживающий персонал извещался о необходимости ремонта. Наличие системы автоматического контроля и диагностики освобождает пользователя от забот о контроле достоверности и снижает связанные с этим временные потери (τк).
Обнаружение ошибок должно вестись непрерывно и не должно заметно снижать быстродействие, поэтому эта функция возлагается на быстродействующие аппаратные средства контроля, позволяющие совместить во времени выполнение основных и контрольных операций. Для выполнения же коррекции ошибок и диагностики используются программные средства в виде корректирующих и диагностических программ.
В приложении 8 приведены требования к специализированным компьютерам сети ЭВМ системы ПРО США с элементами космического базирования. Одно из основных требований предъявляется к показателю надежности — среднему времени наработки на отказ.
Одним из способов проверки достоверности информации в информационных сетях является ее контроль. При контроле выявляется наличие или отсутствие ошибок в информации. При обнаружении ошибки принимаются меры для определения ее места (локализации) и идентификации (определения типа ошибки— одиночная или пакетная), а также для ее устранения (исправления, коррекции). Реализация помехоустойчивых кодов подробно освещена в гл. 6.
Существуют разнообразные по назначению, способу реализации и степени выявления ошибок методы контроля достоверности информации, классификация которых и достигаемые ими цели подробно описаны в приложении 9.
2.6.1. Методы управления безопасностью сетей
Информационная безопасность сетей ЭВМ — одна из основных проблем XXI в., так как хищение, сознательное искажение и уничтожение информации могут привести к катастрофическим последствиям вплоть до человеческих жертв. Так, террористы, атаковавшие Всемирный торговый центр в Нью-Йорке и Пентагон в Вашингтоне в 2002 г. предварительно вывели из строя компьютерную систему управления безопасностью, тем самым разрушив систему информационного обеспечения безопасности США. Компьютерные коммерческие преступления приводят к потерям сотен миллионов долларов. Только в США за 1996 — 1999 гг. эти потери достигли 626 млн. долларов. Мировой годовой ущерб от несанкционированного доступа к информации составил в 1999 г. около 0,5 млрд. долларов. Ежегодно эта цифра увеличивается в полтора раза. Свыше 10 млрд. долларов составил ущерб, нанесенный вирусом «I love you», распространенным по электронной почте в 1999 г. К серьезным моральным потерям приводит хищение конфиденциальной информации.
Безопасность (security) информационно-вычислительной системы — это ее способность защитить данные от не санкционированного доступа с целью ее раскрытия, изменения или разрушения, т.е. обеспечить конфиденциальность и целостность информации.
Архитектура сети, включающая аппаратное обеспечение, является одним из факторов, влияющих на ее безопасность, т.е. некоторые виды сетей безопаснее других. Методы защиты сетей разного типа приведены в табл. 2.3.