Сетевые службы
Практически все современные операционные системы являются сетевыми, то есть позволяют своим пользователям получать доступ не только к локальным ресурсам их собственных компьютеров, но и к ресурсам других компьютеров, подключенных к сети (конечно, только в том случае, если удаленные ресурсы объявлены разделяемыми и у пользователя есть соответствующие права на доступ к ним). При работе в сети операционные системы опираются на функции ОС по управлению локальными ресурсами, рассмотренные в предыдущих главах, но в них также имеются специальные сетевые службы, которые реализуют специфические функции по организации совместной работы пользователей сети.
Ключевым компонентом любой распределенной системы является файловая система, которая также является в этом случае распределенной. Как и в централизованных системах, в распределенной системе функцией файловой системы является хранение программ и данных и предоставление доступа к ним по мере необходимости. Распределенная файловая система поддерживается одним или более компьютерами, хранящими файлы. Эти компьютеры, которые позволяют пользователям сети получать доступ к своим файлам, обычно называют файловыми серверами. Файловые серверы отрабатывают запросы на чтение или запись файлов, поступающие от других компьютеров сети, которые в этом случае являются клиентами файловой службы. Каждый посланный запрос проверяется и выполняется, а ответ отсылается обратно. Файловые серверы обычно содержат иерархические файловые системы, каждая из которых имеет корневой каталог и каталоги более низких уровней. Во многих сетевых файловых системах клиентский компьютер может подсоединять и монтировать эти файловые системы к своим локальным файловым системам, обеспечивая пользователю удобный доступ к удаленным каталогам и файлам. При этом данные монтируемых файловых систем физически никуда не перемещаются, оставаясь на серверах.
С программной точки зрения распределенная файловая система — это сетевая служба, имеющая типичную структуру, рассмотренную в главе 2 «Назначение .
и функции операционной системы». Файловая служба включает программы-серверы и программы-клиенты, взаимодействующие с помощью определенного протокола по сети между собой. Таким образом, файловым сервером называют не только компьютер, на котором хранятся предоставляемые в совместный доступ файлы, но и программу (или процесс, в рамках которого выполняется данная программа), которая работает на этом компьютере и обеспечивает совокупность услуг по доступу к файлам и каталогам на удаленном компьютере. Соответственно программу, работающую на клиентском компьютере и обращающуюся к файловому серверу с запросами, называют клиентом файловой системы, как и компьютер, на котором она работает. Такая неоднозначность терминов «файловый сервер» и «клиент» обычно не вызывает затруднений, так как из контекста, как правило, понятно, о каком программном или аппаратном компоненте сети идет речь. В сети может одновременно работать несколько программных файловых серверов, каждый из которых предлагает различные файловые услуги. Например, в распределенной системе может быть два сервера, которые предоставляют файловые услуги систем UNIX и Windows соответственно, и пользовательские процессы могут обращаться к подходящему серверу. Кроме того, один компьютер может в одно и то же время предоставлять пользователям сети услуги различных файловых служб, для этого нужно, чтобы на этом компьютере работало несколько процессов, каждый из которых реализовывал бы файловую службу определенного типа.
Файловая служба в распределенных файловых системах (впрочем, как и в централизованных) имеет две функционально различные части: собственно файловую службу и службу каталогов файловой системы. Первая имеет дело с операциями над отдельными файлами, такими как чтение, запись или добавление, а вторая — с созданием каталогов и управлением ими, добавлением и удалением файлов из каталогов и т. п.
В хорошо организованной распределенной системе пользователи не знают, как реализована файловая система. В частности, они не знают количество файловых серверов, их месторасположение и функции. Они только знают, что если процедура определена в файловой службе, то требуемая работа каким-то образом выполняется, возвращая им результаты. Более того, пользователи даже не должны знать, что файловая система является распределенной. В идеале для пользователя она должна выглядеть так же, как и централизованная файловая система. Современные сетевые файловые системы пока еще не полностью соответствуют идеалу. В большинстве коммерческих ОС (таких, как ОС семейств UNIX, Windows NT/2000, NetWare) пользователь должен явно указать имя файлового сервера при доступе к его ресурсам. Большую степень прозрачности демонстрируют сетевые файловые системы экспериментальных операционных систем — Amoeba, Mach и Chorus. Тем не менее работы в этом направлении продолжаются и сетевые файловые системы постепенно приближаются к истинно распределенным.
Модель сетевой файловой системы
Сетевая файловая система (ФС) в общем случае включает следующие элементы (рис. 10.1):
□ локальная файловая система;
□ интерфейс локальной файловой системы;
□ сервер сетевой файловой системы;
□ клиент сетевой файловой системы;
□ интерфейс сетевой файловой системы;
□ протокол клиент-сервер сетевой файловой системы.
Клиенты сетевой ФС — это программы, которые работают на многочисленных компьютерах, подключенных к сети. Эти программы обслуживают запросы приложений на доступ к файлам, хранящимся на удаленном компьютере. В качестве таких приложений часто выступают графические или символьные оболочки ОС, такие как Windows Explorer или UNIX shell, а также любые другие пользовательские программы.
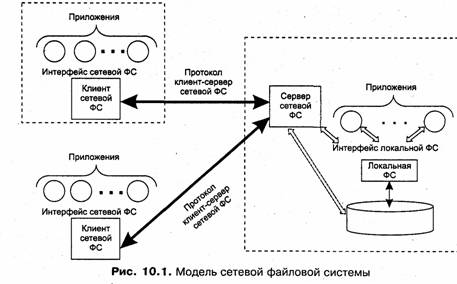
Клиент сетевой ФС передает по сети запросы другому программному компоненту — серверу сетевой ФС, работающему на удаленном компьютере. Сервер, получив запрос, может выполнить его либо самостоятельно, либо, что является более распространенным вариантом, передать запрос локальной файловой системе для отработки. После получения ответа от локальной файловой системы сервер передает его по сети клиенту, а тот, в свою очередь, — приложению, обратившемуся с запросом.
Приложения обращаются к клиенту сетевой ФС, используя определенный программный интерфейс, который в данном случае является интерфейсом сетевой файловой системы. Этот интерфейс стараются сделать как можно более похожим на интерфейс локальной файловой системы, чтобы соблюсти принцип прозрачности. При полном совпадении интерфейсов приложение может обращаться к локальным и удаленным файлам и каталогам с помощью одних и тех же системных вызовов, совершенно не принимая во внимание места хранения данных. Например, если на серверах сети используются локальные файловые системы FAT, то интерфейс сетевой файловой системы повторяет системные вызовы FAT.
Клиент и сервер сетевой файловой системы взаимодействуют друг с другом по сети по определенному протоколу. В случае совпадения интерфейсов локальной и сетевой файловых систем этот протокол может быть достаточно простым — в его функции будет входить ретрансляция серверу запросов, принятых клиентом от приложений, с которыми тот затем будет обращаться к локальной файловой системе. Одним из механизмов, используемых для этой цели, может быть механизм RPC,
Рассмотрим сетевую файловую систему, построенную на базе локальной файловой системы FAT и использующую в качестве протокола клиент-сервер протокол SMB (Server Message Block), который был совместно разработан компаниями Microsoft, Intel и IBM и до сих пор является основой сетевой файловой службы в операционных системах семейства Windows (его последние расширенные версии получили название Common Internet File System, CIFS).
Как и все протоколы файловых служб, этот протокол работает на прикладном уровне модели OSI. Для передачи по сети своих сообщений протокол SMB использует различные транспортные протоколы. Исторически основным протоколом передачи сообщений SMB был протокол NetBIOS (и его более поздняя реализация NetBEUI), но сейчас сообщения SMB могут передаваться и с помощью других протоколов, например TCP/UDP и IPX.
SMB относится к классу протоколов, ориентированных на соединение. Работа протокола начинается с того, что клиент отправляет серверу специальное сообщение с запросом на установление соединения. В процессе установления соединения клиент и сервер обмениваются информацией о себе: они сообщают друг другу, какой диалект протокола SMB они будут использовать в этом соединении (диалект здесь — определенное подмножество функций протокола, так как кроме файловых функций SMB поддерживает также доступ к принтерам, управление внешними устройствами и некоторые другие). Если сервер готов к установлению соединения, он отвечает сообщением-подтверждением.
После установления соединения клиент может обращаться к серверу, передавая ему в сообщениях SMB команды манипулирования файлами и каталогами. Клиент может попросить сервер создать и удалить каталог, предоставить содержимое каталога, создать и удалить файл, прочитать и записать содержимое файла, установить атрибуты файла и т. п.
Протокол сетевой файловой системы кроме простой ретрансляции системных файловых вызовов от клиента серверу может выполнять и более сложные функции, учитывающие природу сетевого взаимодействия, например то, что клиент и сервер работают на разных компьютерах, которые могут отказывать, или что сообщения передаются по ненадежной и вносящей порой большие задержки сетевой среде.
Рассмотрим несколько ситуаций, в которых протокол взаимодействия клиента и сервера файловой системы может повлиять на эффективность удаленного доступа к файлам.
□ Отказ компьютера, на котором выполняется сервер сетевой файловой системы, вовремя сеанса связи с клиентом. Локальная файловая система запоминает состояние последовательных операций, которые приложение выполняет с одним и тем же файлом, за счет ведения внутренней системной таблицы открытых файлов (системные вызовы pen, read, write изменяют состояние этой таблицы). Если таблица открытых файлов хранится на серверном компьютере, то после его перезагрузки, вызванной крахом системы, содержимое этой таблицы теряется, так что приложение, работающее на клиентском компьютере, не может продолжить нормальную работу с открытыми до краха файлами. Протокол должен позволять приложениям выйти из такой ситуации с наименьшими потерями. Одно из решений этой проблемы основано на передаче функции ведения и хранения таблицы открытых файлов от сервера клиенту. Файловый сервер в этом варианте получил название «stateless», то есть «не запоминающий состояния». Протокол клиент-сервер при такой организации упрощается, так как перезагрузка сервера приводит только к паузе в обслуживании, но работа с файлами может быть после этого продолжена безболезненно для клиента.
□ Большие задержки обслуживания из-за заторов в сети и перегрузки файлового сервера при подключении большого числа клиентов. Протокол может для решения этой проблемы организовывать кэширование файлов целиком или частично на стороне клиента. При этом протокол должен учитывать то обстоятельство, что в сети при этом может образоваться одновременно большое количество копий одного и того же файла, которые независимо могут модифицироваться разными пользователями. То есть протокол должен каким-то образом обеспечивать согласованность копий файлов, имеющихся на разных компьютерах.
□ Потери данных и разрушение целостности файловой системы при сбоях и отказах компьютеров, играющих роль файловых серверов. Для повышения отказоустойчивости файловой системы в сети можно хранить несколько копий каждого файла (или целиком локальной файловой системы), причем каждую копию — на отдельном компьютере. Такие копии файлов называются репликами (replica). Протокол сетевого доступа к файлам должен учитывать такую организацию файловой службы, например, обращаясь в случае отказа одного файлового сервера к другому, работоспособному и поддерживающему реплику требуемого файла. Репликация файлов не только повышает отказоустойчивость, но решает также и проблему перегрузки файловых серверов, так как запросы к файлам распределяются между несколькими серверами и повышают производительность сетевой файловой системы. Репликация в некоторых аспектах похожа на кэширование — в том и другом случаях в сети создается несколько копий одного и того же файла, при этом повышается скорость доступа к данным. Основным отличием репликации от кэширования является то, что реплики хранятся на файловых серверах, а кэшированные файлы — на клиентах.
□ Аутентификация выполняется на одном компьютере, например на клиентском, а авторизация, то есть проверка прав доступа к каталогам и файлам, — на другом, выполняющем роль файлового сервера. Эта общая проблема всех сетевых служб должна каким-то образом учитываться и протоколом взаимодействия клиентов и серверов файловой службы1.
Перечисленные проблемы решаются обычно комплексно, в том числе за счет соответствующей организации файловых серверов и клиентов, а также создания специальных служб, таких как служба централизованной аутентификации или репликации. Все эти дополнительные функции файловой службы обязательно находят свое отражение в протоколе взаимодействия клиентов и серверов, в результате чего создаются различные протоколы этого типа, поддерживающие тот или иной набор дополнительных функций и в общем случае по-своему решающие проблемы эффективного взаимодействия (иногда эту роль возлагают на отдельные протоколы, которые работают наряду с основным).
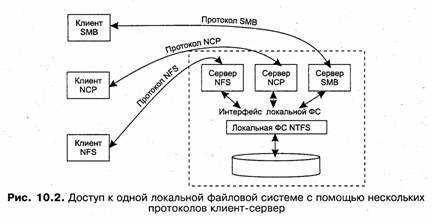
Поэтому для одной и той же локальной файловой системы могут существовать различные протоколы сетевой файловой системы. Так, к файловой системе NTFS сегодня можно получить доступ с помощью различных протоколов (рис. 10.2), в том числе таких распространенных, как SMB, NCP (NetWare Control Protocol — основной протокол доступа к файлам и принтерам сетевой ОС NetWare компании Novell) и NFS (Network File System — протокол сетевой файловой системы компании Sun Microsystems, чрезвычайно популярный в различных вариантах ОС семейства UNIX).
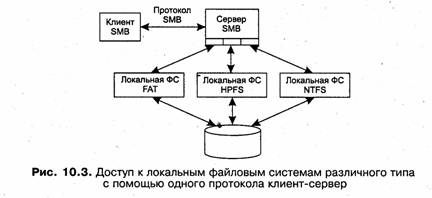
С другой стороны, помощью одного и того же протокола может реализовываться удаленный доступ к локальным файловым системам разного типа. Например, протокол SMB используется для доступа не только к файловой системе FAT, но и к файловым системам NTFS и HPFS (рис. 10.3). Эти файловые системы могут располагаться как на разных, так и на одном компьютере.
За достаточно долгий срок развития сетей в них утвердилось несколько сетевых файловых систем. В локальных сетях на протяжении многих лет доминировала сетевая операционная система NetWare, которая использовала на файловых серверах оригинальную локальную файловую систему, также носящую имя NetWare, и уже упомянутый протокол NCP. Клиенты этой сетевой файловой системы обеспечивали приложениям расширенный интерфейс файловой системы FAT — расширения включали в основном поддержку разграничения прав доступа к файлам и каталогам. Интерфейс FAT был выбран как наиболее распространенный локальный интерфейс для приложений и пользователей персональных компьютеров, работающих под управлением MS-DOS или Windows 3.x и поддерживающих только FAT в качестве локальной файловой системы. Сетевая файловая система NetWare является хорошим примером зависимости между свойствами интерфейса, предоставляемого приложениям на клиентских машинах, и свойствами локальной файловой системы сервера. Требования к поддержке прав доступа пользователей сети к удаленным файлам (помимо других существенных соображений) привели к разработке новой локальной файловой системы NetWare, так как FAT не хранит в своих служебных структурах данных о правах пользователей.
Другим популярным типом сетевых файловых систем стали системы компаний Microsoft и IBM, которые также были первоначально разработаны для локальных сетей на основе персональных компьютеров под управлением MS-DOS и Windows 3.x. Общим для этих сетевых файловых систем стало использование FAT в качестве локальной файловой системы, протокола SMB и интерфейса FAT с расширениями для клиентов. Для разграничения прав доступа здесь был применен другой прием — файловая система FAT была оставлена в качестве локальной системы серверов, но сами серверы стали хранить в ней дополнительные служебные файлы с указанием прав пользователей на доступ к разделяемым каталогам. Эти права проверялись сервером при поступлении запроса из сети, локальные же запросы обслуживались в FAT по-прежнему без проверки прав доступа. Естественно, средства защиты каталогов нашли отражение в командах и ответах протокола SMB, а также в расширениях интерфейса FAT на стороне клиентов. Позже протокол SMB был применен и для доступа к локальным файловым системам HPFS и NTFS.
В среде операционной системы UNIX наибольшее распространение получили две сетевые файловые системы — FTP (File Transfer Protocol) и NFS (Network File System). Они первоначально разрабатывались для доступа к локальной файловой системе s5/ufs, являющейся основной для большинства ОС семейства UNFX. Эти сетевые файловые системы используют собственные протоколы клиент-сервер FTP и NFS, предоставляя интерфейс s5/ufs своим клиентам.
Со временем в крупных сетях стали одновременно применяться несколько сетевых файловых систем разных типов, например NetWare и SMB или NetWare и NFS. Это часто происходило при объединении нескольких сетей в одну. Для пользователей каждой из сетей, привыкших к определенному интерфейсу и работающих с приложениями, рассчитанными на интерфейс FAT или s5/ufs, требовалось сохранить удобную среду. В. результате в сети появились различные файловые серверы, поддерживающие различные локальные файловые системы и протоколы клиент-сервер, а также клиенты, обеспечивающие приложениям и пользователям различные интерфейсы. Возникла проблема — как обеспечить доступ клиента любого типа к файловому серверу любого типа? Рассмотренные выше принципы организации сетевой файловой системы и ее основных компонентов подсказывают, что существует несколько вариантов решения этой проблемы, основанных на комбинировании локальных файловых систем, протоколов клиент-сервер и интерфейсов, поддерживаемых клиентами файловой системы.
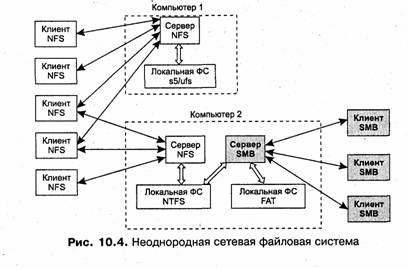
На рис. 10.4 показан вариант организации неоднородной сетевой файловой системы, в которой на компьютере с локальной файловой системой NTFS работает несколько файловых серверов, поддерживающих различные протоколы клиент-сервер. Каждый файловый сервер обеспечивает доступ к одним и тем же данным всем клиентам, работающим по протоколу данного сервера, например протоколу NFS. Клиенты, в свою очередь, поддерживают для приложений и пользователей интерфейс s5/ufs, для которого разрабатывался протокол NFS.
Возможны и другие варианты решения проблемы, которые с общих для любых сетевых служб позиций мы и рассмотрим в этой главе.
Интерфейс сетевой файловой службы
Для пользователей сети и сетевых приложений в основном интересен интерфейс, который предоставляет сетевая файловая служба, а не ее внутреннее устройство. Существует несколько типов интерфейсов сетевой файловой службы, которые отличаются несколькими ключевыми аспектами, рассматриваемыми в данном разделе.
Структура файла
Для любой файловой службы, независимо от того, централизована она или распределена, самым главным является вопрос, что такое файл? Во многих системах, таких как UNIX и Windows, файл — это не интерпретируемая последовательность байтов. Значение и структура информации в файле является заботой прикладных программ, операционную систему это не интересует. В ОС мэйнфреймов поддерживаются разные типы логической организации файлов, каждый с различными свойствами. Файл может быть организован как последовательность записей, и у операционной системы имеются вызовы, которые позволяют работать на уровне этих записей.
Большинство современных сетевых файловых систем поддерживают определение файла как последовательности байтов, а не последовательности записей, следуя примеру локальных файловых систем. Структура файла естественным образом отражается на типе сетевого файлового интерфейса, поддерживающего для неструктурированных файлов чтение любой области в файле, а для структурированных — только записей определенного формата.
Модифицируемость файлов
Важным аспектом файловой модели является возможность модификации файла после его создания. В большинстве сетевых файловых систем файлы могут модифицироваться, но в некоторых распределенных системах единственными операциями с файлами являются create (создать) и read (прочитать). Такие файлы называются неизменяемыми. Для неизменяемых файлов намного легче осуществить кэширование файла и его репликацию (тиражирование), так как исключаются все проблемы, связанные с обновлением всех копий файла при его изменении. В файловых системах, работающих с немодифицируемыми файлами, проблемы поддержки многочисленных версий файла, возникающих при его модификации, перекладываются на плечи пользователей, которые должны давать им имена, отражающие тот факт, что все множество файлов имеет близкое содержание, и в то же время позволяющие различать версии файлов.
Семантика разделения файлов
Когда два или более пользователей разделяют один файл, необходимо точно определить семантику чтения и записи, чтобы избежать проблем с интерпретацией результирующих данных файла.
□ Семантика UNIX. В централизованных многопользовательских операционных системах, разрешающих разделение файлов, таких как UNIX (имеется в виду локальная версия этой ОС), обычно определяется, что когда операция чтения следует за операцией записи, то читается только что обновленный файл. Аналогично, когда операция чтения следует за двумя операциями записи, то читается файл, измененный последней операцией записи. Тем самым система придерживается абсолютного временного упорядочивания всех операций и всегда возвращает самое последнее значение данных. Если запись осуществляется в открытый многими пользователями файл, то все эти пользователи немедленно видят результат изменения данных файла. Обычно такая модель называется семантикой UNIX. В централизованной системе, где файлы хранятся в единственном экземпляре, ее легко и понять, и реализовать.
Семантика UNIX может быть обеспечена и в распределенных системах, но только если в ней имеется лишь один файловый сервер и клиенты не кэшируют файлы. Для этого все операции чтения и записи направляются на файловый сервер, который обрабатывает их строго последовательно. На практике, однако, производительность распределенной системы, в которой все запросы к файлам идут на один сервер, часто становится неудовлетворительной. Эта проблема иногда решается за счет разрешения клиентам обрабатывать локальные копии часто используемых файлов в своих личных кэшах. Если клиент сделает локальную копию файла в своем локальном кэше и начнет ее модифицировать, а вскоре после этого другой клиент прочитает этот файл с сервера, то он получит неверную копию файла. Одним из способов устранения этого недостатка является немедленный возврат всех изменений в кэшированном файле на сервер. Такой подход хотя и концептуально прост, но не эффективен. Распределенные файловые системы обычно используют более свободную семантику разделения файлов.
□ Сеансовая семантика. В соответствии с этой моделью изменения в открытом файле сначала видны только процессу, который модифицирует файл, и только после закрытия файла эти изменения могут видеть другие процессы. При использовании сеансовой семантики возникает проблема одновременного использования одного и того же файла двумя или более клиентами. Одним из решений этой проблемы является принятие правила, в соответствии с которым окончательным является тот вариант, который был закрыт последним. Однако из-за задержек в сети часто оказывается трудно определить, какая из копий файла была закрыта последней. Менее эффективным, но гораздо более простым в реализации является вариант, при котором окончательным результирующим файлом на сервере считается любой из этих файлов, то есть результат операций над файлом не является детерминированным.
□ Семантика неизменяемых файлов. Следующий подход к разделению файлов заключается в том, чтобы сделать все файлы неизменяемыми. Тогда файл нельзя открыть для записи, а можно выполнять только операции create (создать) и read (читать). Тогда для изменения файла остается только возможность создать полностью новый файл и поместить его в каталог под новым именем. Следовательно, хотя файл и нельзя модифицировать, его можно заменить (автоматически) новым файлом. Таким образом, проблема, связанная с одно-
временным использованием файла, для файловой системы просто исчезнет, но с ней столкнутся пользователи, которые будут вынуждены вести учет имен своих копий модифицированного файла.
□ Трапзакционная семантика. Четвертый способ работы с разделяемыми файлами в распределенных системах — это использование механизма неделимых транзакций, достаточно подробно описанного в главе 8 «Дополнительные возможности файловых систем».
Контроль доступа
С каждым разделяемым файлом обычно связан список управления доступом (Access Control List, ACL), обеспечивающий защиту данных от несанкционированного доступа. В том случае, когда локальная файловая система поддерживает механизм ACL для файлов и каталогов при локальном доступе, сетевая файловая система использует этот механизм и при доступе по сети. Если же механизм защиты в локальной файловой системе отсутствует, то сетевой файловой системе приходится поддерживать его самостоятельно, иногда — упрощенным способом, защищая разделяемый каталог и входящие в него файлы и подкаталоги как единое целое. В Windows NT/2000 существуют два механизма защиты — на уровне разделяемых каталогов и на уровне локальных каталогов и файлов. Последний работает только в том случае, когда в качестве локальной файловой системы используется система NTFS, поддерживающая механизм ACL. Механизм защиты разделяемых каталогов нужен для того, чтобы защищать данные, хранящиеся в локальной файловой системе FAT, не имеющей механизмов защиты. В том случае, когда работают оба уровня защиты, у пользователей и администраторов могут иногда возникать некоторые логические сложности, связанные с определением реальных прав доступа как комбинации нескольких правил.
Единица доступа
Файловый интерфейс может быть отнесен к однму из двух типов в зависимости от того, поддерживает ли он модель загрузки-выгрузки или модель удаленного доступа. В модели загрузки-выгрузки пользователю предлагаются средства чтения или записи файла целиком. Эта модель предполагает следующую схему обработки файла: чтение файла с сервера на машину клиента, обработка файла на машине клиента и запись обновленного файла на сервер. Типичным представителем этого вида файлового интерфейса является служба FTP, пользователь которой должен применить команду get file_name для перемещения файла с сервера на клиентский компьютер и команду put file_name для возвращения файла на сервер.
Преимуществом этой модели является ее концептуальная простота. Кроме того, передача файла целиком очень эффективна в отношении объема создаваемого трафика. Главным недостатком этой модели являются высокие требования к объему диска клиента, который должен вместить любой файл, хранящийся на сервере. Кроме того, неэффективно перемещать весь файл, если нужна его небольшая часть. Недостатком многих реализаций такого интерфейса является отсутствие прозрачности операций с удаленными файлами, когда пользователь должен самостоятельно набирать команды перемещения файлов (как в службе FTP), хотя существуют реализации, выполняющие такую работу полностью самостоятельно при первом обращении к удаленному файлу (при этом, правда, необходимо решить вопрос, каким образом пользователь может задать обращение к удаленному файлу).
Другой тип файлового интерфейса соответствует модели удаленного доступа, которая предполагает поддержку большого количества операций над файлами: открытие закрытие файлов, чтение и запись частей файла, позиционирование в файле, проверка и изменение атрибутов файла и т. д. В то время как в модели загрузки-выгрузки файловый сервер обеспечивал только хранение и перемещение файлов, в данном случае все файловые операции выполняются на серверах, а клиенты только генерируют запросы на их отработку. Преимуществом такого подхода являются низкие требования к дисковому пространству на клиентских машинах, а также исключение необходимости передачи целого файла, когда нужна только его часть. Модель удаленного доступа часто используется в прозрачных реализациях файлового интерфейса, когда удаленные файловые системы монтируются в общее с локальной системой дерево (или его часть, что происходит при отображении удаленной системы на букву логического диска).
Модели удаленного доступа могут использовать различные наименьшие единицы перемещения части файла. Наиболее популярны такие единицы, как байт, блок или запись. Последний вид единицы может применяться только в том случае, когда локальная файловая система поддерживает структурированные файлы.
Вопросы реализации сетевой файловой системы
Интерфейс определяет способ общения пользователей и приложений с файловой системой, скрывая от них особенности ее реализации. В то же время эти особенности во многом определяют ее эффективность в таких аспектах, как производительность, отказоустойчивость и масштабируемость.
Размещение клиентов и серверов
по компьютерам и в операционной системе
Рассмотрим прежде всего вопрос о распределении серверной и клиентской частей между компьютерами. В некоторых файловых системах (например, NFS или файловых системах Windows 95/98/NT/2000) на всех компьютерах сети работает одно и то же базовое программное обеспечение, включающее как клиентскую, так и серверную части, так что любой компьютер, который захочет предложить услуги файловой службы, может это сделать. Для этого администратору ОС достаточно объявить имена выбранных каталогов разделяемыми (экспортируемыми в терминах NFS), чтобы другие машины могли иметь к ним доступ. В некоторых случаях выпускается так называемая серверная версия ОС (например, Windows
NT Server), которая использует то же программное обеспечение файловой службы, но только позволяющее за счет выделения файловому серверу большего количества ресурсов (в основном оперативной памяти) обслуживать одновременно большее число пользователей, чем версии файлового сервера для клиентских компьютеров. В других системах файловый сервер — это специализированный компонент серверной ОС, отсутствующий в клиентских компьютерах. По такому пути пошли разработчики сетевой ОС NetWare, созвав операционную систему, оптимизированную для работы в качестве файлового сервера, но не поддерживающую работу в качестве клиентской ОС.
Для повышения эффективности работы файловый сервер и клиент обычно являются модулями ядра ОС, работающими в привилегированном режиме. В современных ОС эти компоненты чаще всего оформляются как высокоуровневые драйверы, работающие в составе подсистемы ввода-вывода. Эффективность работы при этом повышается за счет прямого доступа ко всем внутренним модулям ОС, в том числе и к дисковому кэшу, без выполнения дополнительных операций и смены пользовательского режима на привилегированный. Прямой доступ к содержимому дискового кэша существенно повышает скорость доступа к данным файлов по сети, поэтому для повышения производительности файлового сервера ОС должна быть сконфигурирована для поддержки дискового кэша большого объема.
Файловый сервер и клиенты могут в некоторых случаях оформляться и как модули, работающие в пользовательском режиме. Такое построение было характерно для ранних сетевых файловых систем сетей персональных компьютеров (например, IBM LAN Program), от которых не требовалась высокая скорость доступа, а объемы хранимых данных были весьма невелики. Используется такой режим работы и в файловых серверах ОС, основанных на микроядерной архитектуре, например ОС, построенных на основе микроядра Mach. Такие файловые серверы предназначены для выполнения самой ответственной работы (в отличие от серверов ранних систем для персональных компьютеров), и перенесение сервера в пользовательский режим обусловлено общим подходом к архитектуре ОС, преследующим, как это уже было отмечено в главе 3 «Архитектура операционной системы» такие цели, как повышение устойчивости и модифицируемости ОС. Однако работа файлового сервера в пользовательском режиме снижает его производительность, из-за чего на практике такая архитектура применяется пока редко.
Файловые серверы типа stateful и stateless
Файловый сервер может быть реализован по одной из двух схем: с запоминанием данных о последовательности файловых операций клиента, то есть по схеме stateful, и без запоминания таких данных, то есть по схеме stateless.
Первая состоит в том, что сервер не должен хранить такую информацию (сервер stateless). Другими словами, когда клиент посылает запрос на сервер, сервер его выполняет, отсылает ответ, а затем удаляет из своих внутренних таблиц всю информацию о запросе. Между запросами на сервере не хранится никакой текущей информации о состоянии клиента. Другая точка зрения состоит в том, что сервер должен хранить такую информацию (сервер stateful).
Серверы stateful работают по схеме, обычной для любой локальной файловой службы. Такой сервер поддерживает тот же набор вызовов, что и локальная система, то есть вызовы open, read, write, seek и close, рассмотренные в главе 7 «Ввод-вывод и файловая система». Открывая файлы по вызову open, переданному по сети клиентом, сервер stateful должен запоминать, какие файлы открыл каждый пользователь в своей внутренней системной таблице (рис. 10.5). Обычно при открытии файла клиентскому приложению возвращается по сети дескриптор файла fd или другое число, которое используется при последующих вызовах для идентификации файла. При поступлении вызова read, write или seek сервер использует дескриптор файла для определения, какой файл нужен. В этой таблице хранится также значение указателя на текущую позицию в файле, относительно которой выполняется операция чтения или записи. Таблица, отображающая дескрипторы файлов на сами файлы, является хранилищем информации о состоянии клиентов.
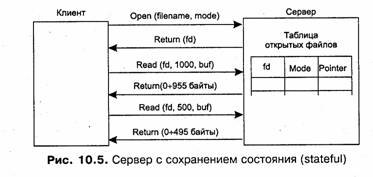
Для сервера stateless каждый запрос должен содержать исчерпывающую информацию (полное имя файла, смещение в файле и т. п.), необходимую серверу для выполнения требуемой операции. Очевидно, что эта информация увеличивает длину сообщения и время, которое тратит сервер на локальное открытие файла каждый раз, когда над ним производится очередная операция чтения или записи. Серверы, работающее по схеме stateless, не поддерживают в протоколе обмена с клиентами таких операций, как открытие (open) и закрытие (close) файлов. Принципиально набор команд, предоставляемый клиенту сервером stateless, может состоять только из двух команд: read и write (рис. 10.6). Эти команды должны передавать в своих аргументах всю необходимую для сервера информацию — имя файла, смещение от начала файла и количество читаемых или записываемых байт данных.
Для того чтобы обеспечить приложениям, работающим на клиентских машинах, привычный файловый интерфейс, включающий вызовы открытия и закрытия файлов, клиент файловой службы должен самостоятельно поддерживать таблицы открытых его приложениями файлов.
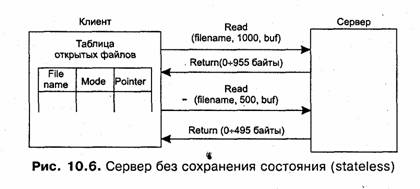
Основным последствием переноса таблиц открытых файлов на клиентов при применении серверов stateless является реакция файловой службы на отказ сервера. При отказе сервера stateful теряются все его таблицы, и после перезагрузки неизвестно, какие файлы открыл каждый пользователь. Последовательные попытки провести операции чтения или записи с открытыми файлами будут безуспешными. Серверы stateless в этом плане являются более отказоустойчивыми, позволяя клиентам продолжать операции с открытыми файлами, и это является основным аргументом в пользу их применения. Платой за отказоустойчивость может быть скорость работы сервера, так как ему приходится выполнять больше операций с файлами. Кроме того, применение серверов stateless затрудняет реализацию блокировок файлов, так как информацию о блокировке файла одним из пользователей необходимо запоминать на всех клиентах файлового сервера.
Преимущества каждого из подходов можно обобщить следующим образом.
□ Серверы stateless:
О отказоустойчивы;
О не нужны вызовы open/close;
О меньше памяти сервера расходуется на таблицы;
О нет ограничений на число открытых файлов;
О отказ клиента не создает проблем для сервера.
□ Серверы stateful:
О более короткие сообщения при запросах;
О лучше производительность;
О возможно опережающее чтение;
О возможна блокировка файлов.
Кэширование данных в оперативной памяти, как было показано в главе 8 «Дополнительные возможности файловых систем», может существенно повысить скорость доступа к файлам, хранящимся на дисках. Кэширование также широко используется в сетевых файловых системах, где оно позволяет не только повысить скорость доступа к удаленным данным (это по-прежнему является основной целью кэширования), но и улучшить масштабируемость и надежность файловой системы.
Схемы кэширования, применяемые в сетевых файловых системах, отличаются решениями по трем ключевым вопросам:
□ месту расположения кэша;
□ способу распространения модификаций;
□ проверке достоверности кэша.
Кроме того, на схему кэширования влияет выбранная в файловой системе модель переноса файлов между сервером и клиентами: модель загрузки-выгрузки, переносящая файл целиком, или модель удаленного доступа, позволяющая переносить файл по частям. Соответственно в первом случае файл кэшируется целиком, а во втором кэшируются только те части файла, к которым выполняется обращение.
Место расположения кэша
В системах, состоящих из клиентов и серверов, потенциально имеются три различных места для хранения кэшируемых файлов и их частей: память сервера, диск клиента (если имеется) и память клиента.
Память сервера практически всегда используется для кэширования файлов, к которым обращаются по сети пользователи и приложения. Кэширование в памяти сервера уменьшает время доступа по сети за счет исключения времени обмена с диском сервера. При этом файловый сервер может использовать для кэширования своих файлов существующий механизм локального кэша операционной системы, не применяя никакого дополнительного программного кода. Однако кэширование только в памяти сервера не решает всех проблем — скорость доступа по-прежнему снижают задержки, вносимые сетью, и перегруженность процессора сервера при одновременном обслуживании большого потока сетевых запросов от многочисленных клиентов.
Кэширование па стороне клиента. Это способ кэширования файлов, который подразделяется на кэширование на диске клиента и в памяти клиента, исключает обмен по сети и освобождает сервер от работы после переноса файла на клиентский компьютер. Использование диска как места временного хранения данных на стороне клиента позволяет кэшировать большие файлы, что особенно важно при применении модели загрузки-выгрузки, переносящей файлы целиком. Диск также является более надежным устройством хранения информации по сравнению с оперативной памятью. Однако такой способ кэширования вносит дополнительные задержки доступа, связанные с чтением данных с клиентского диска, а также неприменим на бездисковых компьютерах.
Кэширование в оперативной памяти клиента позволяет ускорить доступ к данным, но ограничивает размер кэшируемых данных объемом памяти, выделяемой под кэш, что может стать существенным ограничением при применении модели загрузки-выгрузки.
Способы распространения модификаций
Существование в одно и то же время в сети нескольких копий одного и того же файла, хранящихся в кэшах клиентов, порождает проблему согласования копий.
Для решения этой проблемы необходимо, чтобы модификации данных, выполненные над одной из копий, были своевременно распространены на все остальные копии. Существует несколько вариантов распространения модификаций. От выбранного варианта в значительной степени зависит семантика разделения файлов.
Одним из путей решения проблемы согласования является использование алгоритма сквозной записи. Когда кэшируемый элемент (файл или блок) модифицируется, новое значение записывается » кэш и одновременно посылается на сервер для обновления главной копии файла. Теперь другой процесс, читающий этот файл, получает самую последнюю версию данных. Данный вариант распространения модификаций обеспечивает семантику разделения файлов в стиле UNIX.
Один из недостатков алгоритма сквозной записи состоит в том, что он уменьшает интенсивность сетевого обмена только при чтении, при записи интенсивность сетевого обмена та же самая, что и без кэширования. Многие разработчики систем находят это неприемлемым и предлагают следующий алгоритм отложенной записи: вместо того чтобы выполнять запись на сервер, клиент просто. помечает, что файл изменен. Примерно каждые 30 секунд все изменения в файлах собираются вместе и отсылаются на сервер за один прием. Одна большая запись для сетевого обмена обычно более эффективна, чем множество коротких.
Следующим шагом в этом направлении является принятие сеансовой семантики, в соответствии с которой запись файла на сервер производится только после закрытия файла. Этот алгоритм называется «запись по закрытию» и приводит к тому, что если две копии одного файла кэшируются на разных машинах и последовательно записываются на сервер, то второй записывается поверх первого. Данная схема не может снизить сетевой трафик, если объем изменений за сеанс редактирования файла невелик.
Для всех схем, связанных с задержкой записи, характерна низкая надежность, так как модификации, не отправленные на сервер на момент краха системы, теряются. Кроме того, задержка делает семантику совместного использования файлов не очень ясной, поскольку данные, которые считывает процесс из файла, зависят от соотношения момента чтения с моментом очередной записи модификаций.
Проверка достоверности кэша
Распространение модификаций решает только проблему согласования главной копии файла, хранящейся на сервере, с клиентскими копиями. В то же время этот прием не дает никакой информации о том, когда должны обновляться данные, находящиеся в кэшах клиентов. Очевидно, что данные в кэше одного клиента становятся недостоверными, когда данные, модифицированные другим клиентом, переносятся в главную копию файла. Следовательно, необходимо каким-то образом проверять, являются ли данные в кэше клиента достоверными. В противном случае данные кэша должны быть повторно считаны с сервера. Существуют два подхода к решению этой проблемы — инициирование проверки клиентом и инициирование проверки сервером.
В первом случае клиент связывается с сервером и проверяет, соответствуют ли данные в его кэше данным главной копии файла на сервере. Клиент может выполнять такую проверку одним из трех способов:
□ Перед каждым доступом к файлу. Этот способ дискредитирует саму идею кэширования, так как каждое обращение к файлу вызывает обмен по сети с сервером. Но зато это обеспечивает семантику разделения файлов UNIX.
□ Периодические проверки. Улучшают производительность, но делают семантику разделения неясной, зависящей от временных соотношений.
□ Проверка при открытии файла. Этот способ подходит для сеансовой семантики.
Необходимо отметить, что сеансовая семантика требует одновременного применения модели доступа загрузки-выгрузки, метода распространения модификаций «запись по закрытию» и проверки достоверности кэша при открытии файла.
Совершенно другой подход к проблеме проверки достоверности кэша реализуется при инициировании проверки сервером, который также можно назвать методом централизованного управления. Когда файл открывается, то клиент, выполняющий это действие, посылает соответствующее сообщение файловому серверу, в котором указывает режим открытия файла — чтение или запись. Файловый сервер сохраняет информацию о том, кто и какой файл открыл, а также о том, открыт файл для чтения, для записи или для того и другого. Если файл открыт для чтения, то нет никаких препятствий для разрешения другим процессам открыть его для чтения, но открытие его для записи должно быть запрещено. Аналогично, если некоторый процесс открыл файл для записи, то все другие виды доступа должны быть запрещены. При закрытии файла также необходимо оповестить файловый сервер для того, чтобы он обновил свои таблицы, содержащие данные об открытых файлах. Модифицированный файл также может быть выгружен на сервер в такой момент.
Когда новый клиент делает запрос на открытие уже открытого файла и сервер обнаруживает, что режим нового открытия входит в противоречие с режимом текущего открытия, то сервер может ответить на такой запрос следующими способами:
□ отвергнуть запрос;
□ поместить запрос в очередь;
□ запретить кэширование для данного конкретного файла, потребовав от всех
клиентов, открывших этот файл, удалить его из кэша.
Подход, основанный на централизованном управлении, весьма эффективен, обеспечивает семантику разделения UNIX, но обладает следующими недостатками:
□ Он отклоняется от традиционной модели взаимодействия клиента и сервера, при которой сервер только отвечает на запросы, инициированные клиентами. Это делает код сервера нестандартным и достаточно сложным.
□ Сервер обязательно должен хранить информацию о состоянии сеансов клиентов, то есть иметь тип stateful.
□ По-прежнему должен использоваться механизм инициирования проверки достоверности клиентами при открытии файлов.
Сетевая файловая система может поддерживать репликацию (тиражирование) файлов в качестве одной из услуг, предоставляемых клиентам. Иногда репликацией занимается отдельная служба ОС. Репликация (replication) подразумевает существование нескольких копий одного и того же файла, каждая из которых хранится на отдельном файловом сервере, при этом обеспечивается автоматическое согласование данных в копиях файла.
Имеется несколько причин для применения репликации, главными из которых являются две:
□ Увеличение надежности за счет наличия независимых копий каждого файла, хранящихся на разных файловых серверах. При отказе одного из них файл остается доступным.
□ Распределение нагрузки между несколькими серверами. Клиенты могут обращаться к данным реплицированного файла на ближайший файловый сервер, хранящий копию этого файла. Ближайшим может считаться сервер, находящийся в той же подсети, что и клиент, или же первый откликнувшийся, или же выбранный некоторым сетевым устройством, балансирующим нагрузки серверов, например коммутатором 4-го уровня.
Репликация похожа на кэширование файлов на стороне клиентов тем, что в системе создается несколько копий одного файла. Однако существуют и принципиальные отличия репликации от кэширования, прежде всего в преследуемых целях. Если кэширование предназначено для обеспечения локального доступа к файлу одному клиенту и повышения за счет этого скорости работы этого клиента, то репликация нужна для повышения надежности хранения файлов и снижения нагрузки на файловые серверы. Реплики файла доступны всем клиентам, так как хранятся на файловых серверах, а не на клиентских компьютерах, и о существовании реплик известно всем компьютерам сети. Файловая система обеспечивает достоверность данных реплики и защиту ее данных.
Прозрачность репликации
Как обычно, ключевым вопросом, связанным с репликацией, является прозрачность. До какой степени пользователи должны быть в курсе того, что некоторые файлы реплицируются? Должны они играть какую-либо роль в процессе репликации или репликация должна выполняться полностью автоматически? В одних системах пользователи полностью вовлечены в этот процесс, в других система все делает без их ведома. В последнем случае говорят, что система репликационно прозрачна.
Прозрачность репликации зависит от двух факторов используемой схемы именования реплик и степени вовлеченности пользователя в управление репликацией.
Именование реплик. Прозрачность доступа к файлу, существующему в виде нескольких реплик, может поддерживаться системой именования, которая отображает имя файла на его сетевой идентификатор, однозначно определяющий место хранения файла. Если в сети используется централизованная справочная служба, которая позволяет хранить отображения имен объектов на их сетевые идентификаторы (например, IP-адреса серверов), то для реплицированных файлов допустима прозрачная схема именования. В этом случае файлу присваивается имя, не содержащее старшей части, соответствующей имени компьютера. В справочной службе этому имени соответствует несколько идентификаторов, указывающих на серверы, хранящие реплики файла. При обращении к такому файлу приложение использует имя, а справочная система возвращает ему один из идентификаторов, указывающий на сервер, хранящий реплику. Наиболее просто такую схему реализовать для неизменяемых файлов, все реплики которых всегда (или почти всегда, если файлы редко, но все же изменяются) идентичны. В случае когда реплицируются изменяемые файлы, полностью прозрачный доступ требует ведения некоторой базы, хранящей сведения о том, какие из реплик содержат последнюю версию данных, а какие еще не обновлены. Для поддержки полностью прозрачной системы репликации необходимо также постоянное использование в файловом интерфейсе имен, не зависящих от местоположения, то есть не содержащих старшей части с указанием имени сервера. В более распространенной на сегодня схеме именования требуется явное указание имени сервера при обращении к файлу, что приводит к не полностью прозрачной системе репликации.
Управление репликацией. Этот процесс подразумевает определение количества реплик и выбор серверов для хранения каждой реплики. В прозрачной системе репликации такие решения принимаются автоматически при создании файла на основе правил стратегии репликации, определенных заранее администратором системы. В непрозрачной системе репликации решения о количестве реплик и их размещении принимаются с участием пользователя, который создает файлы, или разработчика приложения, если файлы создаются в автоматическом режиме. В результате существуют два режима управления репликацией:
□ При явной репликации (explicit replication) пользователю (или прикладному программисту) предоставляется возможность управления процессом репликации. При создании файла сначала создается первая реплика с явным указанием сервера, на котором размещается файл, а затем создается несколько реплик, причем для каждой реплики сервер также указывается явно. Пользователь при желании может впоследствии удалить одну или несколько реплик. Явная репликация не исключает автоматического режима поддержания, согласованности реплик, которые создал и разместил на серверах пользователь.
□ При неявной репликации (implicit replication) выбор количества и места размещения реплик производится в автоматическом режиме, без участия пользователя. Приложение не должно указывать место размещения файла при запросе на его создание. Файловая система самостоятельно выбирает сервер, на который помещает первую реплику файла. Затем в фоновом режиме система создает несколько реплик этого файла, выбирая их количество и серверы для их
размещения. Если надобность в некоторых репликах исчезает (это также определяется автоматически), то система их удаляет.
Согласование реплик
Согласование реплик, обеспечивающее хранение в каждой реплике последней версии данных файла, является одним из наиболее важных вопросов при разработке системы репликации. Так как изменяемые файлы являются наиболее распространенным типом файлов, то в какой-то момент времени данные в одной из реплик модифицируются и требуется предпринять усилия для распространения модификаций по всем остальным репликам. Существует несколько способов обеспечения согласованности реплик.
Чтение любой — запись во все (Read-Any — Write-All). При необходимости записи в файл все реплики файла блокируются, затем выполняется запись в каждую копию, после чего блокировка снимается и файл становится доступным для чтения. Чтение может выполняться из любой копии. Этот способ обеспечивает семантику разделения файлов в стиле UNIX. Недостатком является то, что запись не всегда можно осуществить, так как некоторые серверы, хранящие реплики файла, могут в момент записи быть неработоспособными.
Запись в доступные (Available-Copies). Этот метод снимает ограничение предыдущего, так как запись выполняется только в те копии, серверы которых доступны на момент записи. Чтение осуществляется из любой реплики файла, как и в предыдущем методе. Любой сервер, хранящий реплику файла, после перезагрузки должен соединиться с другим сервером и получить от него обновленную копию файла и только потом начать обслуживать запросы на чтение из файла. Для обнаружения отказавших серверов в системе должен работать специальный процесс, постоянно опрашивающий состояние серверов. Недостатком метода является возможность появления несогласованных копий файла из-за коммуникационных проблем в сети, когда невозможно выявить отказавший сервер.
Первичная реплика (Primary-Copy). В этом методе запись разрешается только в одну реплику файла, называемую первичной (primary). Все остальные реплики файла являются вторичными (secondary), и из них можно только читать данные. После модификации первичной реплики все серверы, хранящие вторичные реплики, должны связаться с сервером, поддерживающим первичную реплику, и получить от него обновления. Этот процесс может инициироваться как первичным сервером, так и вторичными (периодически проверяющими состоянии первичной реплики). Это метод является одной из реализаций метода «чтение любой — запись во все», в которой процесс записи реализован иерархическим способом. Для аккумулирования нескольких модификаций и сокращения сетевого трафика распространение модификаций может быть выполнено с запаздыванием, но в этом случае ухудшается согласованность копий. Недостатком метода является его низкая надежность — при отказе первичного сервера модификации файла невозможны (для решения этой проблемы необходимо повысить статус некоторого вторичного сервера до первичного).
Кворум (Quorum). Этот метод обобщает подходы, реализованные в предыдущих методах. Пусть в сети существует п реплик некоторого файла. Алгоритм основан
на том, что при модификации файла изменения записываются в w реплик, а при чтении файла клиент обязательно производит обращение к г репликам. Значения да и г выбираются так, что w+f>n. При чтении клиент должен иметь возможность сначала проверить версию каждой реплики, а затем выбрать старшую и читать, данные уже из нее. Очевидно, что при модификации файла номер версии должен наращиваться, а если при записи в да реплик они имеют разные версии, то выбирается максимальное значение версии для наращивания и присваивания всем репликам.
При выполнении условия w+r > n среди любых выбранных произвольным образом г реплик всегда найдется хотя бы одна из w реплик, в которую были записаны последние обновления. Так, если реплик восемь (и = 8), можно выбрать в качестве г значение 4, а в качестве w — значение 5 (рис. 10.7). Условие w+r > n при этом удовлетворяется.
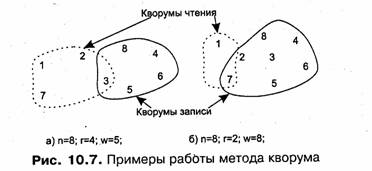 |
Предположим, что запись последних изменений была выполнена в реплики с номерами 3, 4, 5, 6, 8. Если при чтении выбраны реплики 1, 2, 3, 7, то реплика 3 окажется общей для операций записи и чтения, поэтому прочитаны будут корректные данные. В другом примере, который тоже иллюстрирует рисунок, г выбрано равным 2, a w — 7. Результат также получен корректный.
У метода кворума имеются частные случаи. Так, если г = 1, a w = n, то получаем метод «чтение любой — запись во все».
Примеры сетевых файловых служб: FTP и NFS
Протокол передачи файлов FTP
Сетевая файловая служба на основе протокола FTP (File Transfer Protocol) представляет собой одну из наиболее ранних служб, используемых для доступа к удаленным файлам. До появления службы WWW это была самая популярная служба доступа к удаленным данным в Интернете и корпоративных IP-сетях. Первые спецификации FTP относятся к 1971 году. Серверы и клиенты FTP имеются практически в каждой ОС семейства UNIX, а также во многих других сетевых ОС. Клиенты FTP встроены сегодня в программы просмотра (браузеры) Интернета, так как архивы файлов на основе протокола FTP по-прежнему популярны и для доступа к таким архивам браузером используется протокол FTP.
Протокол FTP позволяет целиком переместить файл с удаленного компьютера на локальный и наоборот, то есть работает по схеме загрузки-выгрузки. Кроме того, он поддерживает несколько команд просмотра удаленного каталога и перемещения по каталогам удаленной файловой системы. Поэтому FTP особенно удобно использовать для доступа к тем файлам, данные которых нет смысла просматривать удаленно, а гораздо эффективней целиком переместить на клиентский компьютер (например, файлы исполняемых модулей приложений). В протокол FTP встроены примитивные средства аутентификации удаленных пользователей на основе передачи по сети пароля в открытом виде. Кроме того, поддерживается анонимный доступ, не требующий указания имени пользователя и пароля, который является более безопасным, так как не подвергает пароли пользователей угрозе перехвата.
Протокол FTP выполнен по схеме клиент-сервер. Клиент FTP состоит из нескольких функциональных модулей:
□ User Interface — пользовательский интерфейс, принимающий от пользователя символьные команды и отображающий состояние сеанса FTP на символьном экране.
□ User-PI — интерпретатор команд пользователя. Этот модуль взаимодействует с соответствующим модулем сервера FTP.
□ User-DTP — модуль, осуществляющий передачу данных файла по командам, получаемым от модуля User-PI по протоколу клиент-сервер. Этот модуль взаимодействует с локальной файловой системой клиента.
FTP-сервер включает следующие модули:
□ Server-PI — модуль, который принимает и интерпретирует команды, передаваемые по сети модулем User-PL
□ Server-DTP — модуль, управляющий передачей данных файла по командам от модуля Server-PI. Взаимодействует с локальной файловой системой сервера.
Клиент и сервер FTP поддерживают параллельно два сеанса — управляющий сеанс и сеанс передачи данных. Управляющий сеанс открывается при установлении первоначального FTP-соединения клиента с сервером, причем в течение одного управляющего сеанса может последовательно выполняться несколько сеансов передачи данных, в рамках которых передаются или принимаются несколько файлов.
Общая схема взаимодействия клиента и сервера выглядит следующим образом:
1. Сервер FTP всегда открывает управляющий порт TCP 21, для прослушивания, ожидая приход запроса на установление управляющего сеанса FTP от удаленного клиента.
2. После установления управляющего соединения клиент отправляет на сервер команды, которые уточняют параметры соединения:
О имя и пароль клиента;
О роль участников соединения (активная или пассивная);
О порт передачи данных;
О тип передачи;
О тип передаваемых данных (двоичные данные или ASCII-код);
О директивы на выполнение действий (читать файл, писать файл, удалить файл и т. п.).
3. После согласования параметров пассивный участник соединения переходит в режим ожидания открытия соединения на порт передачи данных. Активный участник инициирует это соединение и начинает передачу данных.
4. После окончания передачи данных соединение по портам данных закрывается, а управляющее соединение остается открытым. Пользователь может по управляющему соединению активизировать новый сеанс передачи данных.
Порты передачи данных выбирает клиент FTP (по умолчанию клиент может использовать для передачи данных порт управляющего сеанса), а сервер должен использовать порт, на единицу меньший порта клиента.
Протокол FTP использует при взаимодействии клиента с сервером несколько команд (не следует их путать с командами пользовательского интерфейса клиента, которые использует человек).
Эти команды делятся на три группы:
□ команды управления доступом к системе;
□ команды управления потоком данных;
□ команды службы FTP.
В набор команд управления доступом входят следующие команды:
□ USER — доставляет серверу имя клиента. Эта команда открывает управляющий сеанс и может также передаваться при открытом управляющем сеансе для смены имени пользователя.
□ PASS — передает в открытом виде пароль пользователя.
□ CWD — изменяет текущий каталог на сервере.
□ REIN — повторно инициализирует управляющий сеанс.
□ QUIT — завершает управляющий сеанс.
Команды управления потоком устанавливают параметры передачи данных:
□ PORT — определяет адрес и порт хоста, который будет активным участником соединения при передаче данных. Например, команда PORT 194,85,135,126,7,205 назначает активным участником хост 194.85.135.126 и порт 1997 (вычисление номера порта не тривиально, но вполне однозначно).
□ PASV — назначает хост пассивным участником соединения по передаче данных. В ответ на эту команду должна быть передана команда PORT с указанием адреса и порта, находящегося в режиме ожидания.
□ TYPE — задает тип передаваемых данных (ASCII-код или двоичные данные).
□ STRU — определяет структуру передаваемых данных (файл, запись, страница).
□ MODE — задает режим передачи (потоком, блоками и т. п.).
Как видно из описания, служба FTP может применяться для работы как со структурированными файлами, разделенными на записи или страницы, так и с неструктурированными.
Команды службы FTP инициируют действия по передаче файлов или просмотру удаленного каталога:
□ RETR — запрашивает передачу файла от сервера на клиентский хост. Параметрами команды является имя файла. Может быть задано также смещение от начала файла — это позволяет начать передачу файла с определенного места при непредвиденном разрыве соединения (этот параметр используется в команде reget пользовательского интерфейса).
□ STOR — инициирует передачу файла от клиента на сервер. Параметры аналогичны команде RETR.
□ RNFR и RNTO — команды переименования удаленного файла. Первая в качестве аргумента получает старое имя файла, а вторая — новое.
□ DELE, MKD, RMD, LIST — эти команды соответственно удаляют файл, создают каталог, удаляют каталог и передают список файлов текущего каталога.
Каждая команда протокола FTP передается в текстовом виде по одной команде в строке. Строка заканчивается символами CR и LF ASCII-кода. Пользовательский интерфейс клиента FTP зависит от его программной реализации. Наряду с традиционными клиентами, работающими в символьном режиме, имеются и графические оболочки, не требующие от пользователя знания символьных команд.
Символьные клиенты обычно поддерживают следующий основной набор команд:
□ open имя_хоста — открытие сеанса с удаленным сервером.
□ bye — завершение сеанса с удаленным хостом и завершение работы утилиты ftp.
□ close — завершение сеанса с удаленным хостом, утилита ftp продолжает работать.
□ ls (dir) — печать содержимого текущего удаленного каталога.
□ get имя_файла — копирование удаленного файла на локальный хост.
□ put имя_файла — копирование удаленного файла на удаленный сервер.
Файловая система NFS
Файловая система NFS {Network File System) создана компанией Sun Microsystems. В настоящее время это стандартная сетевая файловая система для ОС семейства UNIX, кроме того, клиенты и серверы NFS реализованы для многих других ОС. Принципы ее организации на сегодня стандартизованы сообществом Интернета, последняя версия NFS v.4 описывается спецификацией RFC 3010, выпущенной в декабре 2000 года.
NFS представляет собой систему, поддерживающую схему удаленного доступа к файлам. Работа пользователя с удаленными файлами после выполнения операции монтирования становится полностью прозрачной — поддерево файловой системы сервера NFS становится поддеревом локальной файловой системы.
Одной из целей разработчиков NFS была поддержка неоднородных систем с клиентами и серверами, работающими под управлением различных ОС на различной аппаратной платформе. Этой цели способствует реализация NFS на основе механизма Sun RPC, поддерживающего по умолчанию средства XDR для унифицированного представления аргументов удаленных процедур.
Для обеспечения устойчивости клиентов к отказам серверов в NFS принят подход stateless, то есть серверы при работе с файлами не хранят данных об открытых клиентами файлах.
Основная идея NFS — позволить произвольной группе пользователей разделять общую файловую систему. Чаще всего все пользователи принадлежат одной локальной сети, но не обязательно. Можно выполнять NFS и на глобальной сети. Каждый NFS-сервер предоставляет один или более своих каталогов для доступа удаленным клиентам. Каталог объявляется доступным со всеми своими подкаталогами. Список каталогов, которые сервер передает, содержится в файле /etc/exports, так что эти каталоги экспортируются сразу автоматически при загрузке сервера. Клиенты получают доступ к экспортируемым каталогам путем монтирования. Многие рабочие станции Sun бездисковые, но и в этом случае можно монтировать удаленную файловую систему к корневому каталогу, при этом вся файловая система целиком располагается на сервере. Выполнение программ почти не зависит от того, где расположен файл: локально или на удаленном диске. Если два или более клиента одновременно смонтировали один и тот же каталог, то они могут связываться путем разделения файла.
В своей работе файловая система NFS использует два протокола.
Первый NFS-протокол управляет монтированием. Клиент посылает серверу полное имя каталога и запрашивает разрешение на монтирование этого каталога в какую-либо точку собственного дерева каталогов. При этом серверу не указывается, в какое место будет монтироваться каталог сервера. Получив имя, сервер проверяет законность этого запроса и возвращает клиенту дескриптор файла, являющегося удаленной точкой монтирования. Дескриптор включает описатель типа файловой системы, номер диска, номер индексного дескриптора (inode) каталога, который является удаленной точкой монтирования, информацию безопасности. Операции чтения и записи файлов из монтируемых файловых систем используют дескрипторы файлов вместо символьного имени.
Монтирование может выполняться автоматически, с помощью командных файлов при загрузке. Существует другой вариант автоматического монтирования: при загрузке ОС на рабочей станции удаленная файловая система не монтируется, но при первом открытии удаленного файла ОС посылает запросы каждому серверу и после обнаружения этого файла монтирует каталог того сервера, на котором расположен найденный файл.
Второй NFS-протокол используется для доступа к удаленным файлам и каталогам. Клиенты могут послать запрос серверу для выполнения какого-либо действия над каталогом или операции чтения или записи файла. Кроме того, они могут запросить атрибуты файла, такие как тип, размер, время создания и модификации. NFS поддерживается большая часть системных вызовов UNIX, за исключением open и close. Исключение open и сlose не случайно. Вместо операции открытия удаленного файла клиент посылает серверу сообщение, содержащее имя файла, с запросом отыскать его (lookup) и вернуть дескриптор файла. В отличие от вызова open вызов lookup не копирует никакой информации во внутренние системные таблицы. Вызов read содержит дескриптор того файла, который нужно читать, смещение в уже читаемом файле и количество байт, которые нужно прочитать. Преимуществом такой схемы является то, что сервер не запоминает ничего об открытых файлах. Таким образом, если сервер откажет, а затем будет восстановлен, информация об открытых файлах не потеряется, потому что она не поддерживается.
При отказе сервера клиент просто, продолжает посылать на него команды чтения или записи в файлы, однако не получив ответа и исчерпав тайм-аут, клиент повторяет свои запросы. После перезагрузки сервер получает очередной повторный запрос клиента и отвечает на него. Таки образом, крах сервера вызывает только некоторую паузу в обслуживании клиентов, но никаких дополнительных действий по восстановлению соединений и повторному открытию файлов от клиентов не требуется.
К сожалению, NFS затрудняет блокировку файлов. Во многих ОС файл может быть открыт и заблокирован так, чтобы другие процессы не имели к нему доступа. Когда файл закрывается, блокировка снимается. В системах stateless, подобных NFS, блокирование не может быть связано с открытием файла, так как сервер не знает, какой файл открыт. Следовательно, NFS требует специальных дополнительных средств управления блокированием.
В NFS используется кэширование на стороне клиента, данные в кэш переносятся поблочно и применяется упреждающее чтение, при котором чтение блока в кэш по требованию приложения всегда сопровождается чтением следующего блока по инициативе системы. Метод кэширования NFS не сохраняет семантику UNIX для разделения файлов. Вместо этого используется не раз подвергавшаяся критике семантика, при которой изменения данных в кэшируемом клиентом файле видны другому клиенту, в зависимости от временных соотношений. Клиент при очередном открытии файла, имеющегося в его кэше, проверяет у сервера, когда файл был в последний раз модифицирован. Если это произошло после того, как файл был помещен в кэш, файл удаляется из кэша и от сервера получается новая копия файла. Клиенты распространяют модификации, сделанные в кэше, с периодом в 30 секунд, так что сервер может получить обновления с большой задержкой. В результате работы механизмов удаления данных из кэша и распространения модификаций данные, получаемые каким-либо клиентом, не всегда являются самыми свежими.
Репликация в NFS не поддерживается.
Служба каталогов
Назначение и принципы организации
Подобно большой организации, большая компьютерная сеть нуждается в централизованном хранении как можно более полной справочной информации о самой
себе. Решение многих задач в сети опирается на информацию о пользователях сети — их именах, используемых для логического входа в систему, паролях, правах доступа к ресурсам сети, а также о ресурсах и компонентах сети: серверах, клиентских компьютерах, маршрутизаторах, шлюзах, томах файловых систем, принтерах и т. п.
Приведем примеры наиболее важных задач, требующих наличия в сети централизованной базы справочной информации:
□ Одной из наиболее часто выполняемых в системе задач, опирающихся на справочную информацию о пользователях, является их аутентификация, на основе которой затем выполняется авторизация доступа. В сети должны каким-то образом централизованно храниться учетные записи пользователей, содержащие имена и пароли.
□ Наличия некоторой централизованной базы данных требует поддержка прозрачности доступа ко многим сетевым ресурсам. В такой базе должны храниться имена этих ресурсов и отображения имен на числовые идентификаторы (например, IP-адреса), позволяющие найти этот ресурс в сети. Прозрачность может обеспечиваться при доступе к серверам, томам файловой системы, интерфейсам процедур RPC, программным объектам распределенных приложений и многим другим сетевым ресурсам.
□ Электронная почта является еще одним популярным примером службы, для которой желательна единая для сети справочная служба, хранящая данные о почтовых именах пользователей.
□ В последнее время в сетях все чаще стали применяться средства управления качеством обслуживания трафика (Quality of Service, QoS), которые также требуют наличия сведений обо всех пользователях и приложениях системы, их требованиях к параметрам качества обслуживания трафика, а также обо всех сетевых устройствах, с помощью которых можно управлять трафиком (маршрутизаторах, коммутаторах, шлюзах и т. п.).
□ Организация распределенных приложений может существенно упроститься, если в сети имеется база, хранящая информацию об имеющихся программных модулях-объектах и их расположении на серверах сети. Приложение, которому необходимо выполнить некоторое стандартное действие, обращается с запросом к такой базе и получает адрес программного объекта, имеющего возможность выполнить требуемое действие.
□ Система управления сетью должна располагать базой для хранения информации о топологии сети и характеристиках всех сетевых элементов, таких как маршрутизаторы, коммутаторы, серверы и клиентские компьютеры. Наличие полной информации о составе сети и ее связях позволяет системе автоматизированного управления сетью правильно идентифицировать сообщения об аварийных событиях и находить их первопричину. Упорядоченная по подразделениям предприятия информация об имеющемся сетевом оборудовании и установленном программном обеспечении полезна сама по себе, так как помогает администраторам составить достоверную картину состояния сети и разработать планы по ее развитию.
Такие примеры можно продолжать, но нетрудно привести и контраргумент, заставляющий усомниться в необходимости использования в сети централизованной базы справочной информации — долгое время сети работали без единой справочной базы, а многие сети и сейчас работают без нее. Действительно, существует много частных решений, позволяющих достаточно эффективно организовать работу сети на основе частных баз справочной информации, которые могут быть представлены обычными текстовыми файлами или таблицами, хранящимися в теле приложения. Например, в ОС UNIX традиционно используется для хранения данных об именах и паролях пользователей файл passwd, который охватывает пользователей только одного компьютера. Имена адресатов электронной почты также можно хранить в локальном файле клиентского компьютера. И такие частные справочные системы неплохо работают — практика это подтверждает.
Однако это возражение справедливо только для сетей небольших и средних размеров, в крупных сетях отдельные локальные базы справочной информации теряют свою эффективность. Хорошим примером, подтверждающим неприменимость локальных решений для крупных сетей, является служба имен DNS, работающая в Интернете. Как только размеры Интернета превысили определенный предел, хранить информацию о соответствии имен и IP-адресов компьютеров сети в локальных текстовых файлах стало неэффективно. Потребовалось создать распределенную базу данных, поддерживаемую иерархически связанными серверами имен, и централизованную службу над этой базой, чтобы процедуры разрешения символьных имен в Интернете стали работать быстро и эффективно.
Для крупной сети неэффективным является также применение большого числа справочных служб узкого назначения: одной для аутентификации, другой — для управления сетью, третей — для разрешения имен компьютеров и т. д. Даже если каждая из таких служб хорошо организована и сочетает централизованный интерфейс с распределенной базой данных, большое число справочных служб приводит к дублированию больших объемов информации и усложняет администрирование и управление сетью. Например, в Windows NT имеется по крайней мере пять различных типов справочных баз данных. Главный справочник домена (NT Domain Directory Service) хранит информацию о пользователях, которая требуется при организации их логического входа в сеть. Данные о тех же пользователях могут содержаться и в другом справочнике, используемом электронной почтой Microsoft Mail. Еще три базы данных поддерживают разрешение адресов: WINS устанавливает соответствие Netbios-имен IP-адресам, справочник DNS (сервер имен домена) оказывается полезным при подключении NT-сети к Интернету, и наконец, справочник протокола DHCP используется для автоматического назначения IP-адресов компьютерам сети. Очевидно, что такое разнообразие справочных служб усложняет жизнь администратора и приводит к дополнительным ошибкам, когда учетные данные одного и того же пользователя нужно ввести в несколько баз данных. Поэтому в новой версии Windows 2000 большая часть справочной информации о системе может храниться службой Active Directory — единой централизованной справочной службой, использующей распределенную базу данных и интегрированной со службой имен DNS.
Результатом развития систем хранения справочной информации стало появление в сетевых операционных системах специальной службы — так называемой службы каталогов {Directory Services), называемой также справочной службой (directory — справочник, каталог). Служба каталогов хранит информацию обо всех пользователях и ресурсах сети в виде унифицированных объектов с определенными атрибутами, а также позволяет отражать взаимосвязи между хранимыми объектами, такие как принадлежность пользователей к определенной группе, права доступа пользователей к компьютерам, вхождение нескольких узлов в одну подсеть, коммуникационные связи между подсетями, производственную принадлежность серверов и т. д. Служба каталогов позволяет выполнять над хранимыми объектами набор некоторых базовых операций, таких как добавление и удаление объекта, включение объекта в другой объект, изменение значений атрибута объекта, чтение атрибутов и некоторые другие. Обычно над службой каталогов строятся различные специфические сетевые приложения, которые используют информацию службы для решения конкретных задач: управления сетью, аутентификации пользователей, обеспечения прозрачности служб и других, перечисленных выше. Служба каталогов обычно строится на основе модели клиент-сервер: серверы хранят базу справочной информации, которой пользуются клиенты, передавая серверам по сети соответствующие запросы. Для клиента службы каталогов она представляется единой централизованной системой, хотя большинство хороших служб каталогов имеют распределенную структуру, включающую большое количество серверов, но эта структура для клиентов прозрачна.
Важным вопросом является организация базы справочных данных. Единая база данных, хранящая справочную информацию большого объема, порождает все то же множество проблем, что и любая другая крупная база данных. Реализация справочной службы как локальной базы данных, хранящейся в виде одной копии на одном из серверов сети, не подходит для большой системы по нескольким причинам, и в первую очередь вследствие низкой производительности и низкой надежности такого решения. Производительность будет низкой из-за того, что запросы к базе от всех пользователей и приложений сети будут поступать на единственный сервер, который при большом количестве запросов обязательно перестанет справляться с их обработкой. То есть такое решение плохо масштабируется в отношении количества обслуживаемых пользователей и разделяемых ресурсов. Надежность также не может быть высокой в системе с единственной копией данных. Кроме снятия ограничений по производительности и надежности желательно, чтобы структура базы данных позволяла производить логическое группирование ресурсов и пользователей по структурным подразделениям предприятия и назначать для каждой такой группы своего администратора.
Проблемы сохранения производительности и надежности при увеличении масштаба сети обычно решаются за счет распределенных баз данных справочной информации. Разделение данных между несколькими серверами снижает нагрузку на каждый сервер, а надежность при этом достигается за счет наличия нескольких реплик каждой части базы данных. Для каждой части базы данных можно назначить своего администратора, который обладает правами доступа только к объектам своей порции информации обо всей системе. Для пользователя же (и для сетевых приложений) такая распределенная база данных представляется единой базой данных, которая обеспечивает доступ ко всем ресурсам сети вне зависимости от того, с какой рабочей станции поступил запрос.
Существуют два популярных стандарта для служб каталогов. Во-первых, это стандарт Х.500, разработанный ITU-T (во время разработки стандарта эта организация носила имя CCITT). Этот стандарт определяет функции, организацию справочной службы и протокол доступа к ней. Разработанный в первую очередь для использования вместе с почтовой службой Х.400 стандарт Х.500 позволяет эффективно организовать хранение любой справочной информации и служит хорошей основой для универсальной службы каталогов сети.
Другим стандартом является стандарт LDAP (Light-weight Directory Access Protocol), разработанный сообществом Интернета. Этот стандарт определяет упрощенный протокол доступа к службе каталогов, так как службы, построенные на основе стандарта Х.500, оказались чересчур громоздкими. Протокол LDAP получил широкое распространение и стал стандартом де-факто в качестве протокола доступа клиентов к ресурсам справочной службы.
Существует также несколько практических реализаций служб каталогов для сетевых ОС. Наибольшее распространение получила служба NDS компании Novell, разработанная в 1993 году для сетевой ОС NetWare 4.0, а сегодня реализованная также и для Windows NT/2000. Большой интерес вызывает служба каталогов Active Directory, разработанная компанией Microsoft для Windows 2000. Обе эти службы поддерживают протокол доступа LDAP и могут работать в очень крупных сетях благодаря своей распределенности.
Служба каталогов NDS
Служба NDS (NetWare Directory Services) — это глобальная справочная служба, опирающаяся на распределенную объектно-ориентированную базу данных сетевых ресурсов. База данных NDS содержит информацию обо всех сетевых ресурсах, включая информацию о пользователях, группах пользователей, принтерах, томах и компьютерах. ОС NetWare (а также другие клиенты NDS, работающие на других платформах) использует информацию NDS для обеспечения доступа к этим ресурсам.
База данных NDS заменила в свое время справочник bindery предыдущих версий NetWare. Справочник bindery — это «плоская», или одноуровневая база данных, разработанная для поддержки одного сервера. В ней также использовалось понятие «объект» для сетевого ресурса, но трактовка этого термина отличалась от общепринятой. Объекты bindery идентифицировались простыми числовыми значениями и имели определенные атрибуты. Однако для этих объектов не определялись явные взаимоотношения наследования классов объектов, поэтому взаимоотношения между объектами bindery устанавливались администратором произвольно, что часто приводило к нарушению целостности данных.
База данных службы NDS представляет собой многоуровневую базу данных, поддерживающую информацию о ресурсах всех серверов сети. Для совместимости с предыдущими версиями NetWare в службе NDS предусмотрен механизм эмуляции базы bindery.
Служба NDS — это значительный шаг вперед по сравнению с предыдущими версиями за счет:
□ распределенности;
□ реплицируемости;
□ прозрачности;
□ глобальности.
Распредленность заключается в том, что информация не хранится на одном сервере, а разделена на части, называемые разделами (partitions). NetWare хранит эти разделы на нескольких серверах сети (рис. 10.8). Это свойство значительно упрощает администрирование и управление большой сетью, так как она представляется администратору единой системой. Кроме того, обеспечивается более быстрый доступ к базе данных сетевых ресурсов за счет обращения к ближайшему серверу.
Реплика — это копия информации раздела NDS. Можно создать неограниченное количество реплик каждого раздела и хранить их на разных серверах. Если один сервер останавливается, то копии этой информации могут быть получены с другого сервера. Это увеличивает отказоустойчивость системы, так как ни один из серверов не отвечает за всю информацию базы данных NDS. Прозрачность заключается в том, что NDS автоматически создает связи между программными и аппаратными компонентами, которые обеспечивают пользователю доступ к сетевым ресурсам. NDS при этом не требует от пользователя знаний физического расположения этих ресурсов. Задавая сетевой ресурс по имени, вы получите к нему корректный доступ даже в случае изменения его сетевого адреса или места, расположения.
Глобальность NDS заключается в том, что после входа вы получаете доступ к ресурсам всей сети, а не только одного сервера, как было в предыдущих версиях. Это достигается за счет процедуры глобального логического входа (global login). ' Вместо входа в отдельный сервер пользователь NDS входит в сеть, после чего он получает доступ к разрешенным для него ресурсам сети. Информация, предоставляемая во время логического входа, используется для идентификации пользователя. Позже, при попытке пользователя получить доступ к ресурсам, таким как серверы, тома или принтеры, фоновый процесс идентификации проверяет, имеет ли пользователь право на данный ресурс.
Объектно-ориентированный подход
В NDS информация о сетевых ресурсах организована с помощью объектов. Каждый объект представляет собой ресурс, такой как принтер, том, пользователь или сервер.
Объекты организованы в иерархическую структуру, соответствующую структуре организации, отражающую реальные информационные потоки и потребности разделения ресурсов. Одни объекты представляют физические сущности, например объект-пользователь представляет пользователя, а объект-принтер представляет принтер. Другие объекты представляют логические понятия, такие как группы или очереди к принтерам.
Еще одна категория объектов, в которую входят, например, объекты типа отдела предприятия, помогают организовывать и упорядочивать другие объекты.
Объекты имеют атрибуты, в которых хранится индивидуальная для данного объекта информация, например имя и телефон пользователя или место расположения факса и т. п.
Дерево каталогов
NDS использует для хранения информации логическую структуру, называемую деревом каталогов (Directory Tree, DT). Эта иерархическая структура имеет корневой элемент (root) и ветви (рис. 10.9). Администратору сети NetWare 4.x предоставляется удобная графическая утилита NetWare Administrator, работающая в среде Windows, наглядно представляющая каждый объект дерева каталогов NDS в виде значка и отражающая связи между объектами. Пользователи также получают удобства прозрачного доступа к ресурсам всей сети, если они пользуются оболочкой NetWare для Windows, которая поддерживает диалог с NDS и представляет доступные пользователю ресурсы в виде вложенных значков. Дерево каталогов содержит объекты двух типов:
□ объекты-контейнеры,
□ объекты-листья.
Объекты-контейнеры содержат или включают другие объекты. Они используются для логического упорядочивания и организации других объектов дерева.
NDS содержит объекты-контейнеры трех типов, которые можно использовать для организации дерева объектов.
□ страна {Country) — необязательный объект, который можно использовать в сетях, охватывающих несколько стран;
□ организация {Organization) — располагается уровнем ниже, чем объекты-страны (если они используются);
□ отдел или подразделение организации (Organizational Unit) — располагается уровнем ниже, чем объекты-организации, помогает в дальнейшем упорядочивании остальных объектов.
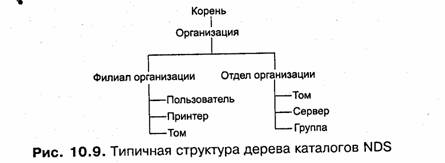
Объекты-листья не содержат других объектов, они используются для представления конечных сетевых ресурсов, таких как компьютеры, тома, принтеры, пользователи и группы пользователей. В NDS определены еще и такие типы объектов-листьев, как:
□ организатор — идентифицирует руководящих лиц фирмы (руководитель группы или вице-президент);
□ сервер;
□ сервер печати;
□ очередь печати;
□ карта каталогов на томе;
□ псевдоним — идентифицирует оригинальное местонахождение объекта в дереве (любой объект можно расположить в нескольких местах дерева посредством назначения ему псевдонимов, что делает использование NDS более гибким и удобным).
Служба NDS и файловая система
Служба NDS предназначена для управления такими сетевыми ресурсами, как серверы и тома NetWare, но она не обеспечивает управление файловой системой. Файлы и каталоги не являются объектами службы NDS. Одним из атрибутов объекта-тома является месторасположение физического тома, который содержит файлы и каталоги. Таким образом, объект-том представляет собой связь между NDS и файловой системой.
Служба NDS предоставляет средства для поиска объектов в ее базе данных сетевых ресурсов. Можно делать запросы, типичные для баз данных, например поиск пользователей, живущих на одной улице, и т. п. Можно также сделать запрос о значениях всех атрибутов какого-либо конкретного объекта. NDS также поддерживает синхронизацию часов между всеми серверами сети для обеспечения правильного порядка событий в сети.
Имена и контексты
Именование объектов службы ND"S организовано по тем же принципам, что и в файловых системах с иерархической организацией каталогов. Эти же принципы построения составных имен используются в стандартах Х.500, LDAP, а также в службе DNS.
Объект-лист имеет краткое имя, называемое Common Name (CN). Оно может состоять максимум из 64 символов, включая пробелы. Поэтому имя принтера «Быстрый, но часто ломающийся Epson» является законным. Аналогом полного имени файловой системы является так называемое «различимое имя» — Distinguished Name. Различимое имя представляет собой конкатенацию всех имен объектов, расположенных на пути этого объекта к корню дерева. Составляющие различимого имени отделяются друг от друга точкой. В отличие от полных имен файлов крайней левой составляющей различимого имени является краткое имя объекта, а крайней правой составляющей — имя корневого объекта. Например, следующая запись представляет собой различимое имя объекта-пользователя с сетевым именем Vova S, работающего в сетевом отделе фирмы BestFirm, расположенной в России:
Vova S.NetProgrammers.BestFirm.RU
Возможен и другой вариант записи различимого имени с указанием типов объектов:
CN=Vova s.Оu=NetProgrammers.O=BestFirm.C=RU Такой вид записи более содержателен.
Средства защиты объектов в NDS
Служба NDS определяет права доступа одних сетевых объектов к другим. Различаются права доступа к объекту в целом и права доступа к его атрибутам.
По отношению к объектам существует следующий набор прав:
□ Browse — просмотр;
□ Add — добавление;
□ Delete — удаление;
□ Rename — переименование;
□ Supervisor — обеспечивает все перечисленные выше права. По отношению к атрибутам объектов используются такие права:
□ Compare — сравнение значения атрибута;
□ Read — чтение значения атрибута;
□ Write — запись нового значения атрибута;
□ Self — присвоение себя в качестве значения атрибута другого объекта, например, если объект-группа разрешает право Self для объекта User, то последний может сделать себя членом этой группы;
□ Supervisor — все права по доступу к атрибутам.
С каждым объектом связан список управления доступом (ACL), в котором определяются права доступа к данному объекту со стороны других объектов.
Права доступа наследуются в дереве объектов сверху вниз, поэтому права объекта-контейнера наследуются входящими в него объектами. Для достижения необходимой гибкости в наделении объекта правами используется маска наследования (Inheritance Mask), с помощью которой можно заблокировать некоторые наследуемые права. С помощью механизма наследования прав доступа главный администратор дерева, имеющий доступ ко всем его объектам, может назначить администратора поддерева, который получит права доступа ко всем объектам данного поддерева. Если поддерево соответствует какой-либо структурной единице предприятия (что и подразумевается), например отделу, то это будет администратор отдела, управляющий пользователями и ресурсами данного отдела.
После подробного рассмотрения свойств дерева каталогов NDS можно уточнить понятия раздела (partition) и реплики (replica). Раздел представляет собой поддерево общего дерева сети. Для определения раздела необходимо выбрать объект-контейнер в общем дереве, который будет корневым объектом данного раздела. Создание раздела уменьшает объем хранимой на сервере информации базы данных NDS за счет исключения редко используемой информации и делает доступ к локальным объектам более быстрым, хотя объекты, находящиеся в других разделах, также доступны всем клиентам сети.
Реплика — это точная копия определенного раздела, хранящаяся на различных серверах. Наличие нескольких реплик обеспечивает отказоустойчивость службы NDS, а также ускоряет доступ к информации при перенесении реплики с подключенного через глобальную сеть сервера на локальный сервер.
Существуют три типа реплик: главная реплика (master replica), вторичная реплика (read/write replica) и реплика только для чтения (read-only replica).
Главная реплика позволяет проводить над ней такие операции, как создание нового раздела, слияние разделов и удаление раздела. Вторичная реплика разрешает обновлять информацию об объектах, добавлять новые объекты, но не разрешает создавать новые разделы. Реплика только для чтения позволяет только читать информацию из ее базы и проводить операции поиска. В сети может существовать произвольное количество реплик. При изменении информации в какой-либо реплике автоматически запускается процесс обновления всех остальных реплик. Этот процесс называется процессом синхронизации службы каталогов.
Только небольшое количество сетей обладает однородностью (гомогенностью) программного и аппаратного обеспечения. Однородными чаще всего являются
сети, которые состоят из небольшого количества компонентов от одного производителя.
Нормой сегодняшнего дня являются неоднородные (гетерогенные) сети, состоящие из разнотипных рабочих станций, операционных систем и приложений, в которых для реализации взаимодействия между компьютерами используются различные концентраторы, коммутаторы и маршрутизаторы.
Одной из причин неоднородности служит эволюционный характер развития любой большой сети. Сеть, как правило не строится с нуля и не появляется в одно мгновение. Поскольку жизнь не стоит на месте, за время существования сети появляются привлекательные технологические новшества, и создатели сети вынуждены вносить в нее изменения, которые, возможно, потребуют решения задачи согласования новых технологий с уже имеющимися старыми. Неоднородность — это также естественное следствие того, что люди, ответственные за функционирования сети, стремятся выбрать программные и аппаратные средства, которые наилучшим образом отвечают поставленным целям. Часто оказывается, что средство, которое хорошо подходит для решения одной задачи, совсем необязательно также хорошо работает при решении другой задачи. Поэтому и появляются в сети коммуникационное оборудование разных технологий и разных производителей, сегменты Ethernet соседствуют с сегментами ATM, а серверы работают под управлением Windows 2000, Solaris или NetWare. Отсюда следует важное требование, предъявляемое к современных сетевым ОС, — способность к интеграции с другими ОС.
Основные подходы к организации межсетевого взаимодействия
На первый взгляд выражение «организация межсетевого взаимодействия» может показаться парадоксальным. Действительно, если сети взаимодействуют, значит, их компьютеры связаны между собой и, следовательно, они все вместе образуют сеть. Тогда что же понимается под сетями, взаимодействие которых надо организовать? Понимается ли под этим совокупность компьютеров, которые работают под управлением одной сетевой операционной системы, например Windows NT или NetWare? Или это те компьютеры, которые связаны между собой средствами одной и той же базовой сетевой технологии, такой как, например, Ethernet или Token Ring? И наконец, может быть, здесь имеются в виду сети в терминах протокола сетевого уровня, то есть части большой сети, разделенные между собой маршрутизаторами?
Ни то, ни другое, ни третье. В контексте межсетевого взаимодействия под термином «сеть» понимается совокупность компьютеров, общающихся друг с другом с помощью единого стека протоколов. Средства взаимодействия компьютеров в сети организованы в виде многоуровневой структуры — стека протоколов. В однородной сети все компьютеры используют один и тот же стек. Проблема возникает тогда, когда требуется организовать взаимодействие компьютеров, принадлежащих разным сетям в указанном выше смысле, то есть организовать взаимодействие компьютеров, на которых поддерживаются отличающиеся стеки коммуникационных протоколов.
Проблема межсетевого взаимодействия может иметь разные внешние проявления, но суть ее одна — несовпадение используемых коммуникационных протоколов. Например, эта проблема возникает в сети, в которой имеется только одна сетевая ОС, однако транспортная подсистема неоднородна из-за того, что сеть включает в себя фрагменты Ethernet, объединенные кольцом FDDI. Здесь в качестве взаимодействующих сетей выступают группы компьютеров, работающие по различным протоколам канального и физического уровня, например сеть Ethernet, сеть FDDI.
Равным образом проблема межсетевого взаимодействия может возникнуть в сети, построенной исключительно на основе технологии Ethernet, но в которой установлено несколько разных сетевых ОС. В этом случае все компьютеры и все приложения используют для транспортировки сообщений один и тот же набор протоколов, но взаимодействие клиентских и серверных частей сетевых служб осуществляется по разным протоколам прикладного уровня. В этом случае компьютеры могут быть отнесены к разным сетям, если у них различаются протоколы прикладного уровня, например компьютеры, использующие для доступа к файлам протокол SMB, образуют сеть Windows NT, а компьютеры, использующие для доступа к файлам протокол NCP, — сеть NetWare. Конечно, эти сети могут сосуществовать независимо, передавая данные через общие транспортные средства, но не предоставляя пользователям возможности совместно использовать ресурсы. Однако если потребуется обеспечить доступ к данным файлового сервера Windows NT для клиентов NetWare, администратор сети столкнется с необходимостью согласования сетевых служб. Задачи устранения неоднородности имеют некоторую специфику и даже разные названия в зависимости от того, к какому уровню модели OSI они относятся. Задача объединения транспортных подсистем, отвечающих только за передачу сообщений, обычно называется internetworking — образование интерсетей. Классическим подходом для ее решения является использование единого сетевого протокола, такого, например, как IP или IPX. Однако существуют ситуации, когда этот подход неприменим или нежелателен, и они будут рассмотрены ниже. Другая задача, называемая interoperability, возникает при объединении сетей, использующих разные протоколы более высоких уровней — в основном прикладного и представительного. Будем называть это задачей согласования сетевых служб операционных систем, так как протоколы прикладного и представительного уровней реализуются именно этими сетевыми компонентами. Кардинальным решением проблемы межсетевого взаимодействия могло бы стать повсеместное использование единого стека протоколов. И такая попытка введения единого стека коммуникационных протоколов была сделана в 1990 году правительством США, которое обнародовало программу GOSIP — Government OSI Profile, в соответствии с которой стек протоколов OSI предполагалось сделать общим для всех сетей, устанавливаемых в правительственных организациях США. Однако массового перехода на стек OSI не произошло. Тем временем в связи с быстрым ростом популярности Интернета стандартом де-факто становится стек протоколов TCP/IP. Но это пока не означает, что другие стеки протоколов полностью вытесняются протоколами TCP/IP. По-прежнему очень много сетевых узлов поддерживает протоколы IPX/SPX, DECnet, IBM SNA, NetBEUI, так что до единого стека протоколов еще далеко.
Самыми общими подходами к согласованию протоколов являются:
□ трансляция;
□ мультиплексирование;
□ инкапсуляция (туннелирование).
Трансляция обеспечивает согласование стеков протоколов путем преобразования сообщений, поступающих от одной сети в формат сообщений другой сети. Транслирующий элемент, в качестве которого могут выступать, например, программный или аппаратный шлюз, мост, коммутатор или маршрутизатор, размещается между взаимодействующими сетями и служит посредником в их «диалоге». Термин «шлюз» обычно подразумевает средство, выполняющее трансляцию протоколов верхних уровней, хотя в традиционной терминологии Интернета шлюзом (gateway) называется маршрутизатор.
В зависимости от типа транслируемых протоколов процедура трансляции может иметь разную степень сложности. Так, преобразование протокола Ethernet в протокол Token Ring сводится к нескольким несложным действиям, главным образом благодаря тому, что оба протокола ориентированы на единую адресацию узлов. А вот трансляция протоколов сетевого уровня IP и IPX представляет собой гораздо более сложный, интеллектуальный процесс, включающий не только преобразование форматов сообщений, но и отображение адресов сетей и узлов, различным образом трактуемых в этих протоколах.
Трансляция протоколов прикладного уровня включает отображение инструкций одного протокола в инструкции другого, что представляет собой сложную логически неоднозначную интеллектуальную процедуру, которую можно сравнить с работой переводчика с одного языка на другой. Например, в файловой службе операционной системы NetWare (протокол NCP) определены следующие права доступа к файлу: read, write, erase, create, file scan, modify, access control, supervisory, а файловая служба UNIX (протокол NFS) оперирует совсем другим перечнем прав доступа: read, write, execute. Для некоторых из этих прав доступа существует прямое соответствие, для других же оно полностью отсутствует. Так, если клиент NCP назначает право доступа к файлу supervisory или access control, то трансляция этих операций на язык протокола NFS не является очевидной. С другой стороны, в протоколе NCP отсутствует обычное для протокола NFS понятие монтирования файловой системы.
На рис. 10.10 показан шлюз, размещенный на компьютере 2, который согласовывает протоколы клиентского компьютера 1 в сети А с протоколами компьютера 3 в сети В. Допустим, что стеки протоколов в сетях А и В отличаются на всех уровнях. В шлюзе установлены оба стека протоколов.
Запрос от прикладного процесса клиентского компьютера сети А поступает на прикладной уровень его стека протоколов. В соответствии с этим протоколом на прикладном уровне формируется пакет (или несколько пакетов), в котором передается запрос на выполнение услуг некоторому серверу сети В. Пакет прикладного уровня перемещается вниз по стеку компьютера сети А, обрастая заголовками нижележащих протоколов, а затем передается по линиям связи в компьютер 2, то есть в шлюз.
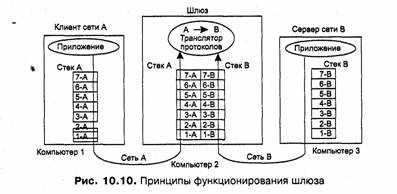
На шлюзе обработка поступивших данных идет в обратном порядке, от протокола самого нижнего к протоколу самого верхнего уровня стека А. Затем пакет прикладного уровня стека сети А преобразуется (транслируется) в пакет прикладного уровня серверного стека сети В. Алгоритм преобразования пакетов зависит от конкретных протоколов и, как уже было сказано, может быть достаточно сложным. В качестве общей информации, позволяющей корректно провести трансляцию, может использоваться, например, информация о символьном имени сервера и символьном имени запрашиваемого ресурса сервера (в частности, это может быть имя каталога файловой системы). Преобразованный пакет от верхнего уровня стека сети В передается к нижним уровням в соответствии с правилами этого стека, а затем по физическим линиям связи в соответствии с протоколами физического и канального уровней сети В поступает в другую сеть к нужному серверу. Ответ сервера преобразуется шлюзом аналогично.
Примером шлюза, транслирующего протоколы прикладного уровня, является компонент Windows NT Gateway Services for NetWare (GSNW), который обеспечивает клиентам Windows NT прозрачный доступ к томам и каталогам серверов NetWare 3.x и 4.x. Шлюз устанавливается на том же компьютере, на котором установлен сервер Windows NT. Между шлюзом и сервером NetWare устанавливается связь по протоколу NCP.
Для доступа к файлам NetWare клиенты Windows NT, используя свой «родной» протокол SMB, обращаются к серверу Windows NT, на котором работает шлюз GSNW. Шлюз виртуализирует разделяемые каталоги серверов NetWare: они выглядят для клиентов SMB точно так же, как и разделяемые каталоги сервера Windows NT (рис. 10.11). Если запрос, поступивший на сервер Windows NT, относится к ресурсам серверов NetWare, то он переадресуется шлюзу, который транслирует его в понятный для сервера NetWare вид и передает по протоколу NCP соответствующему серверу. При этом шлюз выступает по отношению к серверам NetWare как клиент-пользователь.
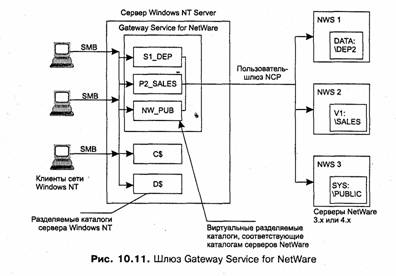
Таким образом, шлюз реализует взаимодействие «многие ко многим».
Достоинство шлюзов состоит в том, что они сохраняют в неизменном виде программное обеспечение на клиентских компьютерах. Пользователи работают в привычной среде и могут даже не заметить, что они получают доступ к ресурсам другой сети. Однако, как и всякий централизованный ресурс, шлюз снижает надежность сети. Кроме того, при обработке запросов в шлюзе возможны относительно большие временные задержки, во-первых, из-за затрат времени на собственно процедуру трансляции, а во-вторых, из-за задержек запросов в очереди к разделяемому всеми клиентами шлюзу, особенно если запросы поступают с большой интенсивностью. Это делает шлюз плохо масштабируемым решением. Правда, ничто не мешает установить в сети несколько параллельно работающих шлюзов.
Мультиплексирование стеков протоколов
Другой подход к согласованию протоколов получил название мультиплексирования стеков протоколов. Он заключается в том, что в сетевое оборудование или в операционные системы серверов и рабочих станций встраиваются несколько стеков протоколов. Это позволяет клиентам и серверам выбирать для взаимодействия тот протокол, который является для них общим.
Сравнивая мультиплексирование с уже рассмотренной выше трансляцией протоколов, можно заметить, что взаимодействие компьютеров, принадлежащих разным сетям, напоминает общение людей, говорящих на разных языках (рис. 10.12). Для достижения взаимопонимания они также могут использовать два подхода: пригласить переводчика (аналог транслирующего устройства) или перейти на язык собеседника, если они им владеют (аналог мультиплексирования стеков протоколов).
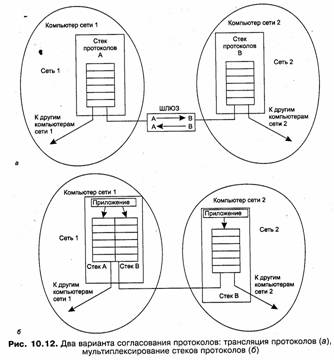
При мультиплексировании стеков протоколов на один из двух взаимодействующих компьютеров с различными стеками протоколов помещается коммуникационный стек другого компьютера. На рис. 10.13 приведен пример взаимодействия клиентского компьютера сети В с сервером в своей сети и сервером сети А, работающей со стеком протоколов, полностью отличающимся от стека сети В. В клиентском компьютере реализованы оба стека. Для того чтобы запрос от прикладного процесса был правильно обработан и направлен через соответствующий стек, необходимо наличие специального программного элемента — мультиплексора протоколов, называемого также менеджером протоколов. Менеджер должен уметь определять, к какой сети направляется запрос клиента. Для этого может использоваться служба имен сети, в которой отмечается принадлежность того или иного ресурса определенной сети с соответствующим стеком протоколов.
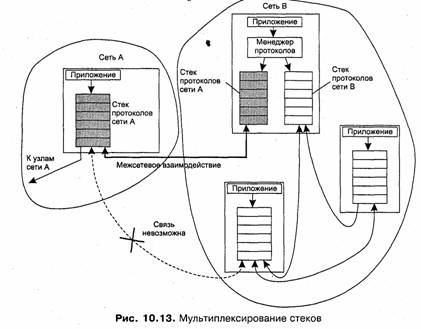
При использовании технологии мультиплексирования структура коммуникационных средств операционной, системы может быть и более сложной. В общем случае на каждом уровне вместо одного протокола появляется целый набор протоколов и может существовать несколько мультиплексоров, выполняющих коммутацию между протоколами разных уровней. Например, рабочая станция, стек протоколов которой показан на рис. 10.14, может через один сетевой адаптер получить доступ к сетям, работающим по протоколам NetBIOS, IP, IPX. Данная рабочая станция может быть клиентом сразу нескольких файловых серверов: NetWare (NCP), Windows NT (SMB) и Sun (NFS).
Предпосылкой для развития технологии мультиплексирования стеков протоколов стало появление строгих открытых описаний протоколов различных уровней и межуровневых интерфейсов, так что фирма-производитель при реализации «чужого» протокола может быть уверена, что ее продукт будет корректно взаимодействовать с продуктами других фирм по данному протоколу, этот протокол корректно впишется в стек и с ним будут нормально взаимодействовать протоколы соседних уровней.
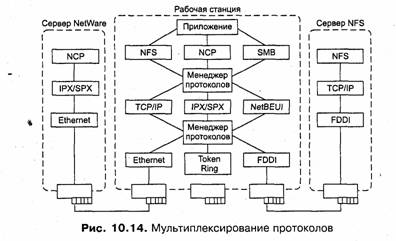
Производителями операционных систем предпринимаются попытки стандартизации не только межуровневых интерфейсов, но и менеджеров протоколов. Наиболее известными стандартами являются менеджеры Network Driver Interface Specification — NDIS (первоначально — совместная разработка 3Com и Microsoft, версии NDIS 3.0 и 4.0 — реализации Microsoft), а также стандарт Open Data-Link Interface — ODI, представляющий совместную разработку компаний Novell и Apple. Эти менеджеры реализуют мультиплексирование протоколов канального уровня, реализованных в драйверах сетевых адаптеров. С помощью мультиплексора NDIS или ODI можно связать один драйвер сетевого адаптера с несколькими протоколами сетевого уровня, а также с несколькими однотипными сетевыми адаптерами.
Мультиплексирование протоколов реализует отношение «один ко многим», то есть один клиент с дополнительным стеком может обращаться ко всем серверам, поддерживающим этот стек, или один сервер с дополнительным стеком может предоставлять услуги многим клиентам.
При использовании мультиплексоров протоколов существуют два варианта размещения дополнительного стека протоколов — на одном или на другом взаимодействующем компьютере. Если дополнительный стек устанавливается на сервере, то этот сервер становится доступным для всех клиентов с этим стеком. При этом нужно тщательно оценивать влияние установки дополнительного продукта на производительность сервера.
Аналогично дополнительный стек на клиенте дает ему возможность устанавливать связи с другими серверами, использующими этот стек протоколов. При размещении дополнительного стека на клиентах вопросы производительности не так важны. Здесь более важными являются ограничения таких ресурсов, как память и дисковое пространство клиентских машин, а также затраты труда администратора на установку и поддержание дополнительных стеков в работоспособном состоянии на большом числе компьютеров.
Заметим, что при организации взаимодействия двух разнородных сетей в общем случае нужно решать две задачи согласования служб (рис. 10.15):
□ обеспечение доступа клиентам сети А к ресурсам сети В;
□ обеспечение доступа клиентам сети В к ресурсам сети А.
Эти задачи независимы, и их можно решать отдельно. В некоторых случаях требуется полное решение, например, чтобы пользователи UNIX-машин имели доступ к ресурсам серверов сети NetWare, а пользователи персональных машин имели доступ к ресурсам UNIX-хостов, в других же случаях достаточно обеспечить доступ клиентам из сети NetWare к ресурсам сети UNIX. Большинство имеющихся на рынке продуктов обеспечивает только однонаправленное согласование прикладных служб.
Рассмотрим возможные варианты размещения программных средств, реализующих взаимодействие двух сетей, которые основаны на мультиплексировании протоколов. Введем обозначения: С — сервер, К — клиент, ∆ — дополнительный протокол (или протоколы), предоставляющий возможности межсетевого взаимодействия.
На рис. 10.16 показаны оба возможных варианта однонаправленного взаимодействия А→В: путем добавления нового стека к клиентам сети А (рис. 10.16, а) либо путем присоединения «добавки» к серверам сети В (рис. 10.16, б).
В первом случае, когда средства мультиплексирования протоколов располагаются на клиентских частях, только клиенты, снабженные такими средствами, могут обращаться к серверам сети В. При этом они могут обращаться к любому серверу сети В. Во втором случае, когда набор дополнительных стеков расположен на каком-либо сервере сети В, данный сервер может обслуживать всех клиентов сети А. Очевидно, что серверы сети В без средств мультиплексирования не могут быть использованы клиентами сети А.
Примером «добавки», модифицирующей клиентскую часть, может служить популярное программное средство компании Microsoft Client Services for NetWare (CSNW), которое превращает клиента Windows NT в клиента серверов NetWare за счет установки клиентской части протокола NCP.
Примером расширения возможностей сетевого взаимодействия сервера является установка на сервер Windows NT продукта Microsoft File and Print Services for NetWare, который реализует серверную часть протокола NCP. Это позволяет клиентам NetWare обращаться к файлам и принтерам сервера Windows NT.
При мультиплексировании протоколов дополнительное программное обеспечение — соответствующие стеки протоколов — должно быть установлено на каждый компьютер, которому может потребоваться доступ к нескольким различным сетям. В некоторых операционных системах имеются средства борьбы с избыточностью, свойственной этому подходу. Операционная система может быть сконфигурирована для работы с несколькими стеками протоколов, но динамически загружаются только нужные.
С другой стороны, избыточность повышает надежность системы в целом, отказ компьютера с установленным дополнительным стеком не ведет к потере возможности межсетевого взаимодействия для других пользователей сети.
Важным преимуществом мультиплексирования является меньшее время выполнения запроса, чем при использовании шлюза. Это связано, во-первых, с отсутствием временных затрат на процедуру трансляции, а во-вторых, с тем, что при мультиплексировании на каждый запрос требуется только одна сетевая передача, в то время как при трансляции — две: запрос сначала передается на шлюз, а затем из шлюза на ресурсный сервер.
В принципе, при работе с несколькими стеками протоколов у пользователя может возникнуть проблема работы в незнакомой среде, с незнакомыми командами, правилами и методами адресации. Чаще всего разработчики операционных систем стремятся в какой-то степени облегчить жизнь пользователю в этой ситуации. Независимо от используемого протокола прикладного уровня (например, SMB или NCP) ему предоставляется один и тот же интуитивно понятный графический интерфейс, с помощью которого он просматривает и выбирает нужные удаленные ресурсы.
В табл. 10.1 приведены сравнительные характеристики двух подходов к реализации межсетевого взаимодействия.

Инкапсуляция (encapsulation), или туннелирование (tunneling), — это еще один метод решения задачи согласования сетей, который, однако, применим только для согласования транспортных протоколов и только при определенных ограничениях. Инкапсуляция может быть использована, когда две сети с одной транспортной технологией необходимо соединить через транзитную сеть с другой транспортной технологией.
В процессе инкапсуляции принимают участие три типа протоколов:
□ протокол-«пассажир»;
□ несущий протокол;
□ протокол инкапсуляции.
Транспортный протокол объединяемых сетей является протоколом-пассажиром, а протокол транзитной сети — несущим протоколом. Пакеты протокола-пассажира помещаются в поле данных пакетов несущего протокола с помощью протокола инкапсуляции. Пакеты протокола-пассажира никаким образом не обрабатываются при транспортировке их по транзитной сети. Инкапсуляцию выполняет пограничное устройство (обычно маршрутизатор или шлюз), которое располагается на границе между исходной и транзитной сетями. Извлечение пакетов-пассажиров из несущих пакетов выполняет второе пограничное устройство, которое находится на границе между транзитной сетью и сетью назначения. Пограничные устройства указывают в несущих пакетах свои адреса, а не адреса узлов назначения.
В связи с большой популярностью Интернета и стека TCP/IP несущим протоколом транзитной сети все чаще выступает протокол IP, а в качестве протоколов-пассажиров — все остальные протоколы локальных сетей (как маршрутизируемые, так и не маршрутизируемые).
В приведенном на рис. 10.17 примере две сети, использующие протокол IPX, нужно соединить через транзитную сеть TCP/IP. Необходимо обеспечить только взаимодействие узлов двух сетей IPX, а взаимодействие между узлами IPX и узлами cfra TCP/IP не предусматривается. Поэтому для соединения сетей IPX можно применить метод инкапсуляции.
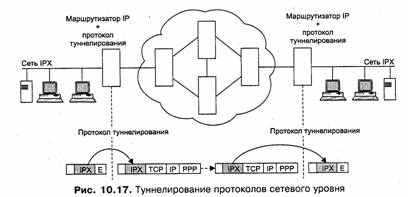
В пограничных маршрутизаторах, соединяющих сети IPX с транзитной сетью IP, работают протоколы IPX, IP и дополнительный протокол — протокол инкапсуляции IPX в IP. Этот протокол извлекает пакеты IPX из кадров Ethernet и помещает их в дейтаграммы UDP или TCP (на рисунке выбран вариант с TCP). Затем несущие IP-пакеты направляются другому пограничному маршрутизатору. Протокол инкапсуляции должен иметь информацию о соответствии IPX-адреса удаленной сети IP-адресу пограничного маршрутизатора, обслуживающего эту сеть. Если через IP-сеть объединяется несколько IPX-сетей, то должна быть таблица соответствия всех IPX-адресов IP-адресам пограничных маршрутизаторов.
Инкапсуляция может быть использована для транспортных протоколов разного уровня. Например, протокол сетевого уровня Х.25 может быть инкапсулирован в протокол транспортного уровня TCP или же протокол сетевого уровня IP может быть инкапсулирован в протокол сетевого уровня Х.25. Существуют протоколы инкапсуляции трафика РРР через сети IP.
Обычно инкапсуляция приводит к более простым и быстрым решениям по сравнению с трансляцией, так как решает более частную задачу, не обеспечивая взаимодействия с узлами транзитной сети. Помимо согласования транспортных технологий инкапсуляция используется для обеспечения секретности передаваемых данных. При этом исходные пакеты-пассажиры шифруются и передаются по транзитной сети с помощью пакетов несущего протокола.
Сетевая безопасность
При рассмотрении безопасности информационных систем обычно выделяют две группы проблем: безопасность компьютера и сетевая безопасность. К безопасности компьютера относят все проблемы защиты данных, хранящихся и обрабатывающихся компьютером, который рассматривается как автономная система. Эти проблемы решаются средствами операционных систем и приложений, таких как базы данных, а также встроенными аппаратными средствами компьютера. Под сетевой безопасностью понимают все вопросы, связанные с взаимодействием устройств в сети, это прежде всего защита данных в момент их передачи по линиям связи и защита от несанкционированного удаленного доступа в сеть. И хотя подчас проблемы компьютерной и сетевой безопасности трудно отделить друг от друга, настолько тесно они связаны, совершенно очевидно, что сетевая безопасность имеет свою специфику.
Автономно работающий компьютер можно эффективно защитить от внешних покушений разнообразными способами, например просто запереть на замок клавиатуру или снять жесткий накопитель и поместить его в сейф. Компьютер, работающий в сети, по определению не может полностью отгородиться от мира, он должен общаться с другими компьютерами, возможно, даже удаленными от него на большое расстояние, поэтому обеспечение безопасности в сети является задачей значительно более сложной. Логический вход чужого пользователя в ваш компьютер является штатной ситуацией, если вы работаете в сети. Обеспечение безопасности в такой ситуации сводится к тому, чтобы сделать это проникновение контролируемым — каждому пользователю сети должны быть четко определены его права по доступу к информации, внешним устройствам и выполнению системных действий на каждом из компьютеров сети.
Помимо проблем, порождаемых возможностью удаленного входа в сетевые компьютеры, сети по своей природе подвержены еще одному виду опасности — перехвату и анализу сообщений, передаваемых по сети, а также созданию «ложного» трафика. Большая часть средств обеспечения сетевой безопасности направлена на предотвращение именно этого типа нарушений.
Вопросы сетевой безопасности приобретают особое значение сейчас, когда при построении корпоративных сетей наблюдается переход от использования выделенных каналов к публичным сетям (Интернет, frame relay). Поставщики услуг публичных сетей пока редко обеспечивают защиту пользовательских данных при их транспортировке по своим магистралям, возлагая на пользователей заботы по их конфиденциальности, целостности и доступности.
Конфиденциальность, целостность и доступность данных
Безопасная информационная система — это система, которая, во-первых, защищает данные от несанкционированного доступа, во-вторых, всегда готова предоставить их своим пользователям, а в-третьих, надежно хранит информацию и гарантирует неизменность данных. Таким образом, безопасная система по определению обладает свойствами конфиденциальности, доступности и целостности.
□ Конфиденциальность (confidentiality) — гарантия того, что секретные данные будут доступны только тем пользователям, которым этот доступ разрешен (такие пользователи называются авторизованными).
□ Доступность (availability) — гарантия того, что авторизованные пользователи всегда получат доступ к данным.
□ Целостность (integrity) — гарантия сохранности данными правильных значений, которая обеспечивается запретом для неавторизованных пользователей каким-либо образом изменять, модифицировать, разрушать или создавать данные.
Требования безопасности могут меняться в зависимости от назначения системы, характера используемых данных и типа возможных угроз. Трудно представить систему, для которой были бы не важны свойства целостности и доступности, но свойство конфиденциальности не всегда является обязательным. Например, если вы публикуете информацию в Интернете на Web-сервере и вашей целью является сделать ее доступной для самого широкого круга людей, то конфиденциальность в данном случае не требуется. Однако требования целостности и доступности остаются актуальными.
Действительно, если вы не предпримете специальных мер по обеспечению целостности данных, злоумышленник может изменить данные на вашем сервере и нанести этим ущерб вашему предприятию. Преступник может, например, Внести такие изменения в помещенный на Web-сервере прайс-лист, которые снизят конкурентоспособность вашего предприятия, или испортить коды свободно распространяемого вашей фирмой программного продукта, что безусловно скажется на ее деловом имидже.
Не менее важным в данном примере является и обеспечение доступности данных. Затратив немалые средства на создание и поддержание сервера в Интернете, предприятие вправе рассчитывать на отдачу: увеличение числа клиентов, количества продаж и т. д. Однако существует вероятность того, что злоумышленник предпримет атаку, в результате которой помещенные на сервер данные станут недоступными для тех, кому они предназначались. Примером таких злонамеренных действий может служить «бомбардировка» сервера IP-пакетами с неправильным обратным адресом, которые в соответствии с логикой работы этого протокола могут вызывать тайм-ауты, а в конечном счете сделать сервер недоступным для всех остальных запросов.
Понятия конфиденциальности, доступности и целостности могут быть определены не только по отношению к информации, но и к другим ресурсам вычислительной сети, например внешним устройствам или приложениям. Существует множество системных ресурсов, возможность «незаконного» использования которых может привести к нарушению безопасности системы. Например, неограниченный доступ к устройству печати позволяет злоумышленнику получать копии распечатываемых документов, изменять параметры настройки, что может привести к изменению очередности работ и даже к выводу устройства из строя. Свойство конфиденциальности, примененное к устройству печати, можно интерпретировать так, что доступ к устройству имеют те и только те пользователи, которым этот доступ разрешен, причем они могут выполнять только те операции с устройством, которые для них определены. Свойство доступности устройства означает его готовность к использованию всякий раз, когда в этом возникает необходимость. А свойство целостности может быть определено как свойство неизменности параметров настройки данного устройства. Легальность использования сетевых устройств важна не только постольку, поскольку она влияет на безопасность данных. Устройства могут предоставлять различные услуги: распечатку текстов, отправку факсов, доступ в Интернет, электронную почту и т. п., незаконное потребление которых, наносящее материальный ущерб предприятию, также является нарушением безопасности системы.
Любое действие, которое направлено на нарушение конфиденциальности, целостности и/или доступности информации, а также на нелегальное использование других ресурсов сети, называется угрозой. Реализованная угроза называется атакой. Риск — это вероятностная оценка величины возможного ущерба, который может понести владелец информационного ресурса в результате успешно проведенной атаки. Значение риска тем выше, чем более уязвимой является существующая система безопасности и чем выше вероятность реализации атаки.
Универсальной классификации угроз не существует, возможно, и потому, что нет предела творческим способностям человека, и каждый день применяются новые способы незаконного проникновения в сеть, разрабатываются новые средства мониторинга сетевого трафика, появляются новые вирусы, находятся новые изъяны в существующих программных и аппаратных сетевых продуктах. В ответ на это разрабатываются все более изощренные средства защиты, которые ставят преграду на пути многих типов угроз, но затем сами становятся новыми объектами атак. Тем не менее попытаемся сделать некоторые обобщения. Так, прежде всего угрозы могут быть разделены на умышленные и неумышленные.
Неумышленные угрозы вызываются ошибочными действиями лояльных сотрудников, становятся следствием их низкой квалификации или безответственности. Кроме того, к такому роду угроз относятся последствия ненадежной работы программных и аппаратных средств системы. Так, например, из-за отказа диска, контроллера диска или всего файлового сервера могут оказаться недоступными данные, критически важные для работы предприятия. Поэтому вопросы безопасности так тесно переплетаются с вопросами надежности, отказоустойчивости технических средств. Угрозы безопасности, которые вытекают из ненадежности работы программно-аппаратных средств, предотвращаются путем их совершенствования, использования резервирования на уровне аппаратуры (RAID-массивы, многопроцессорные компьютеры, источники бесперебойного питания, кластерные архитектуры) или на уровне массивов данных (тиражирование файлов, резервное копирование).
Умышленные угрозы могут ограничиваться либо пассивным чтением данных или мониторингом системы, либо включать в себя активные действия, например нарушение целостности и доступности информации, приведение в нерабочее состояние приложений и устройств. Так, умышленные угрозы возникают в результате деятельности хакеров и явно направлены на нанесение ущерба предприятию.
В вычислительных сетях можно выделить следующие типы умышленных угроз:
□ незаконное проникновение в один из компьютеров сети под видом легального пользователя;
□ разрушение системы с помощью программ-вирусов;
□ нелегальные действия легального пользователя;
□ «подслушивание» внутрисетевого трафика.
Незаконное проникновение может быть реализовано через уязвимые места в системе безопасности с использованием недокументированных возможностей операционной системы. Эти возможности могут позволить злоумышленнику «обойти» стандартную процедуру, контролирующую вход в сеть.
Другим способом незаконного проникновения в сеть является использование «чужих» паролей, полученных путем подглядывания, расшифровки файла паролей, подбора паролей или получения пароля путем анализа сетевого трафика. Особенно опасно проникновение злоумышленника под именем пользователя, наделенного большими полномочиями, например администратора сети. Для того чтобы завладеть паролем администратора, злоумышленник может попытаться войти в сеть под именем простого пользователя. Поэтому очень важно, чтобы все пользователи сети сохраняли свои пароли в тайне, а также выбирали их так, чтобы максимально затруднить угадывание.
Подбор паролей злоумышленник выполняет с использованием специальных программ, которые работают путем перебора слов из некоторого файла, содержащего большое количество слов. Содержимое файла-словаря формируется с учетом психологических особенностей человека, которые выражаются в том, что человек выбирает в качестве пароля легко запоминаемые слова или буквенные сочетания.
Еще один способ получения пароля — это внедрение в чужой компьютер «троянского коня». Так называют резидентную программу, работающую без ведома хозяина данного компьютера и выполняющую действия, заданные злоумышленником. В частности, такого рода программа может считывать коды пароля, вводимого пользователем во время логического входа в систему.
Программа «троянский конь» всегда маскируется под какую-нибудь полезную утилиту или игру, а производит действия, разрушающие систему. По такому принципу действуют и программы-вирусы, отличительной особенностью которых является способность «заражать» другие файлы, внедряя в них свои собственные копии. Чаще всего вирусы поражают исполняемые файлы. Когда такой исполняемый код загружается в оперативную память для выполнения, вместе с ним получает возможность исполнить свои вредительские действия вирус. Вирусы могут привести к повреждению или даже полной утрате информации.
Нелегальные действия легального пользователя — этот тип угроз исходит от легальных пользователей сети, которые, используя свои полномочия, пытаются выполнять действия, выходящие за рамки их должностных обязанностей. Например, администратор сети имеет практически неограниченные права на доступ ко всем сетевым ресурсам. Однако на предприятии может быть информация, доступ к которой администратору сети запрещен. Для реализации этих ограничений могут быть предприняты специальные меры, такие, например, как шифрование данных, но и в этом случае администратор может попытаться получить доступ к ключу. Нелегальные действия может попытаться предпринять и обычный пользователь сети. Существующая статистика говорит о том, что едва ли не половина всех попыток нарушения безопасности системы исходит от сотрудников предприятия, которые как, раз и являются легальными пользователями сети.
«Подслушиванием внутрисетевого трафика — это незаконный мониторинг сети, захват и анализ сетевых сообщений. Существует много доступных программных и аппаратных анализаторов трафика, которые делают эту задачу достаточно тривиальной. Еще более усложняется защита от этого типа угроз в сетях с глобальными связями. Глобальные связи, простирающиеся на десятки и тысячи километров, по своей природе являются менее защищенными, чем локальные связи (больше возможностей для прослушивания трафика, более удобная для злоумышленника позиция при проведении процедур аутентификации). Такая опасность одинаково присуща всем видам территориальных каналов связи и никак не зависит от того, используются собственные, арендуемые каналы или услуги общедоступных территориальных сетей, подобных Интернету.
Однако использование общественных сетей (речь в основном идет об Интернете) еще более усугубляет ситуацию. Действительно, использование Интернета добавляет к опасности перехвата данных, передаваемых по линиям связи, опасность несанкционированного входа в узлы сети, поскольку наличие огромного числа хакеров в Интернете увеличивает вероятность попыток незаконного проникновения в компьютер. Это представляет постоянную угрозу для сетей, подсоединенных к Интернету.
Интернет сам является целью для разного рода злоумышленников. Поскольку Интернет создавался как открытая система, предназначенная для свободного обмена информацией, совсем не удивительно, что практически все протоколы стека TCP/IP имеют «врожденные» недостатки защиты. Используя эти недостатки, злоумышленники все чаще предпринимают попытки несанкционированного доступа к информации, хранящейся на узлах Интернета.
Системный подход к обеспечению безопасности
Построение и поддержка безопасной системы требует системного подхода. В соответствии с этим подходом прежде всего необходимо осознать весь спектр возможных угроз для конкретной сети и для каждой из этих угроз продумать тактику ее отражения. В этой борьбе можно и нужно использовать самые разноплановые средства и приемы — морально-этические и законодательные, административные и психологические, защитные возможности программных и аппаратных средств сети.
К морально-этическим средствам защиты можно отнести всевозможные нормы, которые сложились по мере распространения вычислительных средств в той или иной стране. Например, подобно тому как в борьбе против пиратского копирования программ в настоящее время в основном используются меры воспитательного плана, необходимо внедрять в сознание людей аморальность всяческих покушений на нарушение конфиденциальности, целостности и доступности чужих информационных ресурсов.
Законодательные средства защиты — это законы, постановления правительства и указы президента, нормативные акты и стандарты, которыми регламентируются правила использования и обработки информации ограниченного доступа, а также вводятся меры ответственности за нарушения этих правил. Правовая регламентация деятельности в области защиты информации имеет целью защиту информации, составляющей государственную тайну, обеспечение прав потребителей на получение качественных продуктов, защиту конституционных прав граждан на сохранение личной тайны, борьбу с организованной преступностью. Административные меры — это действия, предпринимаемые руководством предприятия или организации для обеспечения информационной безопасности. К таким мерам относятся конкретные правила работы сотрудников предприятия, например режим работы сотрудников, их должностные инструкции, строго определяющие порядок работы с конфиденциальной информацией на компьютере. К административным мерам также относятся правила приобретения предприятием средств безопасности. Представители администрации, которые несут ответственность за защиту информации, должны выяснить, насколько безопасным является использование продуктов, приобретенных у зарубежных поставщиков. Особенно это касается продуктов, связанных с шифрованием. В таких случаях желательно проверить наличие у продукта сертификата, выданного российскими тестирующими организациями.
Психологические меры безопасности могут играть значительную роль в укреплении безопасности системы. Пренебрежение учетом психологических моментов в неформальных процедурах, связанных с безопасностью, может привести к нарушениям защиты. Рассмотрим, например, сеть предприятия, в которой работает много удаленных пользователей. Время от времени пользователи должны менять пароли (обычная практика для предотвращения их подбора). В данной системе выбор паролей осуществляет администратор. В таких условиях злоумышленник может позвонить администратору по телефону и от имени легального пользователя попробовать получить пароль. При большом количестве удаленных пользователей не исключено, что такой простой психологический прием может сработать.
К физическим средствам защиты относятся экранирование помещений для защиты от излучения, проверка поставляемой аппаратуры на соответствие ее спецификациям и отсутствие аппаратных «жучков», средства наружного наблюдения, устройства, блокирующие физический доступ к отдельным блокам компьютера, различные замки и другое оборудование, защищающие помещения, где находятся носители информации, от незаконного проникновения и т. д. и т. п.
Технические средства информационной безопасности реализуются программным и аппаратным обеспечением вычислительных сетей. Такие средства, называемые также службами сетевой безопасности, решают самые разнообразные задачи по защите системы, например контроль доступа, включающий процедуры аутентификации и авторизации, аудит, шифрование информации, антивирусную защиту, контроль сетевого трафика и много других задач. Технические средства безопасности могут быть либо встроены в программное (операционные системы и приложения) и аппаратное (компьютеры и коммуникационное оборудование) обеспечение сети, либо реализованы в виде отдельных продуктов, созданных специально для решения проблем безопасности.
Важность и сложность проблемы обеспечения безопасности требует выработки политики информационной безопасности, которая подразумевает ответы на следующие вопросы:
□ Какую информацию защищать?
□ Какой ущерб понесет предприятие при потере или при раскрытии тех или иных данных?
□ Кто или что является возможным источником угрозы, какого рода атаки на безопасность системы могут быть предприняты?
□ Какие средства использовать для защиты каждого вида информации?
Специалисты, ответственные за безопасность системы, формируя политику безопасности, должны учитывать несколько базовых принципов. Одним из таких принципов является предоставление каждому сотруднику предприятия того минимально уровня привилегий на доступ к данным, который необходим ему для выполнения его должностных обязанностей. Учитывая, что большая часть нарушений в области безопасности предприятий исходит именно от собственных сотрудников, важно ввести четкие ограничения для всех пользователей сети, не наделяя их излишними возможностями.
Следующий принцип — использование комплексного подхода к обеспечению безопасности. Чтобы затруднить злоумышленнику доступ к данным, необходимо предусмотреть самые разные средства безопасности, начиная с организационно-
административных запретов и кончая встроенными средствами сетевой аппаратуры. Административный запрет на работу в воскресные дни ставит потенциального нарушителя под визуальный контроль администратора и других пользователей, физические средства защиты (закрытые помещения, блокировочные ключи) ограничивают непосредственный контакт пользователя только приписанным ему компьютером, встроенные средства сетевой ОС (система аутентификации и авторизации) предотвращают вход в сеть нелегальных пользователей, а для легального пользователя ограничивают возможности только разрешенными для него операциями (подсистема аудита фиксирует его действия). Такая система защиты с многократным резервированием средств безопасности увеличивает вероятность сохранности данных.
Используя многоуровневую систему защиты, важно обеспечивать баланс надежности защиты всех уровней. Если в сети все сообщения шифруются, но ключи легкодоступны, то эффект от шифрования нулевой. Или если на компьютерах установлена файловая система, поддерживающая избирательный доступ на уровне отдельных файлов, но имеется возможность получить жесткий диск и установить его на другой машине, то все достоинства средств защиты файловой системы сводятся на нет. Если внешний трафик сети, подключенной к Интернету, проходит через мощный брандмауэр, но пользователи имеют возможность связываться с узлами Интернета по коммутируемым линиям, используя локально установленные модемы, то деньги (как правило, немалые), потраченные на брандмауэр, можно считать выброшенными на ветер.
Следующим универсальным принципом является использование средств, которые при отказе переходят в состояние максимальной защиты. Это касается самых различных средств безопасности. Если, например, автоматический пропускной пункт в какое-либо помещение ломается, то он должен фиксироваться в таком положении, чтобы ни один человек не мог пройти на защищаемую территорию. А если в сети имеется устройство, которое анализирует весь входной трафик и отбрасывает кадры с определенным, заранее заданным обратным адресом, то при отказе оно должно полностью блокировать вход в сеть. Неприемлемым следовало бы признать устройство, которое бы при отказе пропускало в сеть весь внешний трафик.
Принцип единого контрольно-пропускного пункта — весь входящий во внутреннюю сеть и выходящий во внешнюю сеть трафик должен проходить через единственный узел сети, например через межсетевой экран (firewall). Только это позволяет в достаточной степени контролировать трафик. В противном случае, когда в сети имеется множество пользовательских станций, имеющих независимый выход во внешнюю сеть, очень трудно скоординировать правила, ограничивающие права пользователей внутренней сети по доступу к серверам внешней сети и обратно — права внешних клиентов по доступу к ресурсам внутренней сети.
Принцип баланса возможного ущерба от реализации угрозы и затрат на ее предотвращение. Ни одна система безопасности не гарантирует защиту данных на уровне 100%, поскольку является результатом компромисса между возможными рисками и возможными затратами. Определяя политику безопасности, администратор должен взвесить величину ущерба, которую может понести предприятие в результате нарушения защиты данных, и соотнести ее с величиной затрат, требуемых на обеспечение безопасности этих данных. Так, в некоторых случаях можно отказаться от дорогостоящего межсетевого экрана в пользу стандартных средств фильтрации обычного маршрутизатора, в других же можно пойти на беспрецедентные затраты. Главное, чтобы принятое решение было обосновано экономически.
При определении политики безопасности для сети, имеющей выход в Интернет, специалисты рекомендуют разделить задачу на две части: выработать политику доступа к сетевым службам Интернета и выработать политику доступа к ресурсам внутренней сети компании.
Политика доступа к сетевым службам Интернета включает следующие пункты:
□ Определение списка служб Интернета, к которым пользователи внутренней сети должны иметь ограниченный доступ.
□ Определение ограничений на методы доступа, например на использование протоколов SLIP (Serial Line Internet Protocol) и РРР (Point-to-Point Protocol). Ограничения методов доступа необходимы для того, чтобы пользователи не могли обращаться к «запрещенным» службам Интернета обходными путями. Например, если для ограничения доступа к Интернету в сети устанавливается специальный шлюз, который не дает возможности пользователям работать в системе WWW, они могут устанавливать с Web-серверами РРР-соединения по коммутируемой линии. Во избежание этого надо просто запретить использование протокола РРР.
□ Принятие решения о том, разрешен ли доступ внешних пользователей из Интернета во внутреннюю сеть. Если да, то кому. Часто доступ разрешают только для некоторых, абсолютно необходимых для работы предприятия служб, например электронной почты.
Политика доступа к ресурсам внутренней сети компании может быть выражена в одном из двух принципов:
□ запрещать все, что не разрешено в явной форме;
□ разрешать все, что не запрещено в явной форме.
В соответствии с выбранным принципом определяются правила обработки внешнего трафика межсетевыми экранами или маршрутизаторами. Реализация защиты на основе первого принципа дает более высокую степень безопасности, однако при этом могут возникать большие неудобства у пользователей, а кроме того, такой способ защиты обойдется значительно дороже. При реализации второго принципа сеть окажется менее защищенной, однако пользоваться ею будет удобнее и потребуется меньше затрат.
Базовые технологии безопасности
В разных программных и аппаратных продуктах, предназначенных для защиты данных, часто используются одинаковые подходы, приемы и технические решения. К таким базовым технологиям безопасности относятся аутентификация, авторизация, аудит и технология защищенного канала.
Шифрование — это краеугольный камень всех служб информационной безопасности, будь то система аутентификации или авторизации, средства создания защищенного канала или способ безопасного хранения данных.
Любая процедура шифрования, превращающая информацию из обычного «понятного» вида в «нечитабельный» зашифрованный вид, естественно, должна быть дополнена процедурой дешифрирования, которая, будучи примененной к зашифрованному тексту, снова приводит его в понятный вид. Пара процедур — шифрование и дешифрирование — называется криптосистемой.
Информацию, над которой выполняются функции шифрования и дешифрирования, будем условно называть «текст», учитывая, что это может быть также числовой массив или графические данные.
В современных алгоритмах шифрования предусматривается наличие параметра — секретного ключа. В криптографии принято правило Керкхоффа: «Стойкость шифра должна определяться только секретностью ключа». Так, все стандартные алгоритмы шифрования (например, DES, PGP) широко известны, их детальное описание содержится в легко доступных документах, но от этого их эффективность не снижается. Злоумышленнику может быть все известно об алгоритме шифрования, кроме секретного ключа (следует отметить, однако, что существует немало фирменных алгоритмов, описание которых не публикуется).
Алгоритм шифрования считается раскрытым, если найдена процедура, позволяющая подобрать ключ за реальное время. Сложность алгоритма раскрытия является одной из важных характеристик криптосистемы и называется криптостойкостью.
Существуют два класса криптосистем — симметричные и асимметричные. В симметричных схемах шифрования (классическая криптография) секретный ключ зашифровки совпадает с секретным ключом расшифровки. В асимметричных схемах шифрования (криптография с открытым ключом) открытый ключ зашифровки не совпадает с секретным ключом расшифровки.
Симметричные алгоритмы шифрования
На рис. 11.1 приведена классическая модель симметричной криптосистемы, теоретические основы которой впервые были изложены в 1949 году в работе Клода Шеннона. В данной модели три участника: отправитель, получатель, злоумышленник. Задача отправителя заключается в том, чтобы по открытому каналу передать некоторое сообщение в защищенном виде. Для этого он на ключе к зашифровывает открытый текст X и передает шифрованный текст Y. Задача получателя заключается в том, чтобы расшифровать Y и прочитать сообщение X. Предполагается, что отправитель имеет свой источник ключа. Сгенерированный ключ заранее по надежному каналу передается получателю. Задача злоумышленника заключается в перехвате и чтении передаваемых сообщений, а также в имитации ложных сообщений.
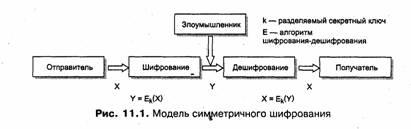
Модель является универсальной — если зашифрованные данные хранятся в компьютере и никуда не передаются, отправитель и получатель совмещаются в одном лице, а в роли злоумышленника выступает некто, имеющий доступ к компьютеру в ваше отсутствие.
Наиболее популярным стандартным симметричным алгоритмом шифрования данных является DES (Data Encryption Standard). Алгоритм разработан фирмой IBM и в 1976 году был рекомендован Национальным бюро стандартов к использованию в открытых секторах экономики. Суть этого алгоритма заключается в следующем (рис. 11.2).
Данные шифруются поблочно. Перед шифрованием любая форма представления данных преобразуется в числовую. Эти числа получают путем любой открытой процедуры преобразования блока текста в число. Например, ими могли бы быть значения двоичных чисел, полученных слиянием ASCII-кодов последовательных символов соответствующего блока текста. На вход шифрующей функции поступает блок данных размером 64 бита, он делится пополам на левую (L) и правую (R) части. На первом этапе на место левой части результирующего блока помещается правая часть исходного блока. Правая часть результирующего блока вычисляется как сумма по модулю 2 (операция XOR) левой и правой частей исходного блока. Затем на основе случайной двоичной последовательности по определенной схеме в полученном результате выполняются побитные замены и перестановки. Используемая двоичная последовательность, представляющая собой ключ данного алгоритма, имеет длину 64 бита, из которых 56 действительно случайны, а 8 предназначены для контроля ключа.
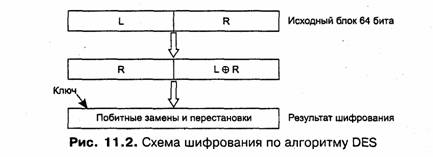
Вот уже в течение двух десятков лет алгоритм DES испытывается на стойкость. И хотя существуют примеры успешных попыток «взлома» данного алгоритма, в целом можно считать, что он выдержал испытания. Алгоритм DES широко используется в различных технологиях и продуктах безопасности информационных систем. Для того чтобы повысить криптостойкость алгоритма DES, иногда применяют его усиленный вариант, называемый «тройным DES», который включает троекратное шифрование с использованием двух разных ключей. При этом можно считать, что длина ключа увеличивается с 56 бит до 112 бит, а значит, криптостойкость алгоритма существенно повышается. Но за это приходится платить производительностью — «тройной DES» требует в три раза больше времени, чем «обычный» DES.
В симметричных алгоритмах главную проблему представляют ключи. Во-первых, криптостойкость многих симметричных алгоритмов зависит от качества ключа, это предъявляет повышенные требования к службе генерации ключей. Во-вторых, принципиальной является надежность канала передачи ключа второму участнику секретных переговоров. Проблема с ключами возникает даже в системе с двумя абонентами, а в системе с n абонентами, желающими обмениваться секретными данными по принципу «каждый с каждым», потребуется n х(n-1)/2 ключей, которые должны быть сгенерированы и распределены надежным образом. То есть количество ключей пропорционально квадрату количества абонентов, что при большом числе абонентов делает задачу чрезвычайно сложной. Несимметричные алгоритмы, основанные на использовании открытых ключей, снимают эту проблему.
Несимметричные алгоритмы шифрования
В середине 70-х двое ученых — Винфилд Диффи и Мартин Хеллман — описали принципы шифрования с открытыми ключами.
Особенность шифрования на основе открытых ключей состоит в том, что одновременно генерируется уникальная пара ключей, таких, что текст, зашифрованный одним ключом, может быть расшифрован только с использованием второго ключа и наоборот.
В модели криптосхемы с открытым ключом также три участника: отправитель, получатель, злоумышленник (рис. 11.3). Задача отправителя заключается в том, чтобы по открытому каналу связи передать некоторое сообщение в защищенном виде. Получатель генерирует на своей стороне два ключа: открытый Е и закрытый D. Закрытый ключ D (часто называемый также личным ключом) абонент должен сохранять в защищенном месте, а открытый ключ Е он может передать всем, с кем он хочет поддерживать защищенные отношения. Открытый ключ используется для шифрования текста, но расшифровать текст можно только с помощью закрытого ключа. Поэтому открытый ключ передается отправителю в незащищенном виде. Отправитель, используя открытый ключ получателя, шифрует сообщение X и передает его получателю. Получатель расшифровывает сообщение своим закрытым ключом D.
Очевидно, что числа, одно из которых используется для шифрования текста, а другое — для дешифрирования, не могут быть независимыми друг от друга, а значит, есть теоретическая возможность вычисления закрытого ключа по открытому, но это связано с огромным количеством вычислений, которые требуют соответственно огромного времени. Поясним принципиальную связь между закрытым и открытым ключами следующей аналогией.
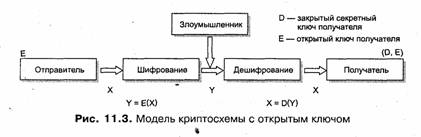
Пусть абонент 1 (рис. 11.4, а) решает вести секретную переписку со своими сотрудниками на малоизвестном языке, например санскрите. Для этого он обзаводится санскритско-русским словарем, а всем своим абонентам посылает русско-санскритские словари. Каждый из них, пользуясь словарем, пишет сообщения на санскрите и посылает их абоненту 1, который переводит их на русский язык, пользуясь доступным только ему санскритско-русским словарем. Очевидно, что здесь роль открытого ключа Е играет русско-санскритский словарь, а роль закрытого ключа D — санскритско-русский словарь. Могут ли абоненты 2, 3 и 4 прочитать чужие сообщения S2, S3, S4, которые посылает каждый из них абоненту 1 ? Вообще-то нет, так как, для этого им нужен санскритско-русский словарь, обладателем которого является только абонент 1. Но теоретическая возможность этого имеется, так как затратив массу времени, можно прямым перебором составить санскритско-русский словарь по русско-санскритскому словарю. Такая процедура, требующая больших временных затрат, является отдаленной аналогией восстановления закрытого ключа по открытому.
На рис. 11.4, б показана другая схема использования открытого и закрытого ключей, целью которой является подтверждение авторства (аутентификация или электронная подпись) посылаемого сообщения. В этом случае поток сообщений имеет обратное направление — от абонента 1, обладателя закрытого ключа D, к его корреспондентам, обладателям открытого ключа Е. Если абонент 1 хочет аутентифицировать себя (поставить электронную подпись), то он шифрует известный текст своим закрытым ключом D и передает шифровку своим корреспондентам. Если им удается расшифровать текст открытым ключом абонента 1, то это доказывает, что текст был зашифрован его же закрытым ключом, а значит, именно он является автором этого сообщения. Заметим, что в этом случае сообщения S2, S3, S4, адресованные разным абонентам, не являются секретными, так как все они — обладатели одного и того же открытого ключа, с помощью которого они могут расшифровывать все сообщения, поступающие от абонента 1.
Если же нужна взаимная аутентификация и двунаправленный секретный обмен сообщениями, то каждая из общающихся сторон генерирует собственную пару ключей и посылает открытый ключ своему корреспонденту.
Для того чтобы в сети все п абонентов имели возможность не только принимать зашифрованные сообщения, но и сами посылать таковые, каждый абонент должен обладать своей собственной парой ключей Е и D. Всего в сети будет 2п ключей: п открытых ключей для шифрования и п секретных ключей для дешифрирования. Таким образом решается проблема масштабируемости — квадратичная зависимость количества ключей от числа абонентов в симметричных алгоритмах заменяется линейной зависимостью в несимметричных алгоритмах. Исчезает и задача секретной доставки ключа. Злоумышленнику нет смысла стремиться завладеть открытым ключом, поскольку это не дает возможности расшифровывать текст или вычислить закрытый ключ.
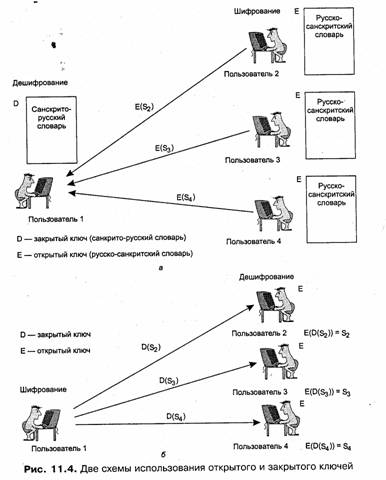
Хотя информация об открытом ключе не является секретной, ее нужно защищать от подлогов, чтобы злоумышленник под именем легального пользователя не навязал свой открытый ключ, после чего с помощью своего закрытого ключа он может расшифровывать все сообщения, посылаемые легальному пользователю и отправлять свои сообщения от его имени. Проще всего было бы распространять списки, связывающие имена пользователей с их открытыми ключами широковещательно, путем публикаций в средствах массовой информации (бюллетени, специализированные журналы и т. п.). Однако при таком подходе мы снова, как и в случае с паролями, сталкиваемся с плохой масштабируемостью. Решением этой проблемы является технология цифровых сертификатов. Сертификат — это электронный документ, который связывает конкретного пользователя с конкретным ключом.
В настоящее время одним из наиболее популярных криптоалгоритмов с открытым ключом является криптоалгоритм RSA.
Криптоалгоритм RSA
В 1978 году трое ученых (Ривест, Шамир и Адлеман) разработали систему шифрования с открытыми ключами RSA (Rivest, Shamir, Adleman), полностью отвечающую всем принципам Диффи-Хеллмана. Этот метод состоит в следующем:
1. Случайно выбираются два очень больших простых числа р и q.
2. Вычисляются два произведения n=pxq и m=(p-l)x(q-l).
3. Выбирается случайное целое число Е, не имеющее общих сомножителей с т.
4. Находится D, такое, что DE=1 по модулю m.
5. Исходный текст, X, разбивается на блоки таким образом, чтобы 0<Х<п.
6. Для шифрования сообщения необходимо вычислить С=ХЕ по модулю п.
7. Для дешифрирования вычисляется X=CD no модулю п.
Таким образом, чтобы зашифровать сообщение, необходимо знать пару чисел (Е, n), а чтобы дешифрировать — пару чисел (D, n). Первая пара — это открытый ключ, а вторая — закрытый.
Зная открытый ключ (Е, n), можно вычислить значение закрытого ключа D. Необходимым промежуточным действием в этом преобразовании является нахождение чисел р и q, для чего нужно разложить на простые множители очень большое число n, а на это требуется очень много времени. Именно с огромной вычислительной сложностью разложения большого числа на простые множители связана высокая криптостойкость алгоритма RSA. В некоторых публикациях приводятся следующие оценки: для того чтобы найти разложение 200-значно-го числа, понадобится 4 миллиарда лет работы компьютера с быстродействием миллион операций в секунду. Однако следует учесть, что в настоящее время активно ведутся работы по совершенствованию методов разложения больших чисел, поэтому в алгоритме RSA стараются применять числа длиной более 200 десятичных разрядов.
Программная реализация криптоалгоритмов типа RSA значительно сложнее и менее производительна, чем реализация классических криптоалгоритмов типа DES. Вследствие сложности реализации операций модульной арифметики криптоалгоритм RSA часто используют только для шифрования небольших объемов информации, например для рассылки классических секретных ключей или в алгоритмах цифровой подписи, а основную часть пересылаемой информации шифруют с помощью симметричных алгоритмов.
В табл. 11.1 приведены некоторые сравнительные характеристики классического криптоалгоритма DES и криптоалгоритма RSA.

Односторонние функции шифрования
Во многих базовых технологиях безопасности используется еще один прием шифрования — шифрование с помощью односторонней функции (one-way function), называемой также хэш-функцией (hash function), или дайджест-функцией (digest function).
Эта функция, примененная к шифруемым данным, дает в результате значение (дайджест), состоящее из фиксированного небольшого числа байт (рис. 11.5, а). Дайджест передается вместе с исходным сообщением. Получатель сообщения, зная, какая односторонняя функция шифрования (ОФШ) была применена для получения дайджеста, заново вычисляет его, используя незашифрованную часть сообщения. Если значения полученного и вычисленного дайджестов совпадают, то значит, содержимое сообщения не было подвергнуто никаким изменениям. Знание дайджеста не дает возможности восстановить исходное сообщение, но зато позволяет проверить целостность данных.
Дайджест является своего рода контрольной суммой для исходного сообщения. Однако имеется и существенное отличие. Использование контрольной суммы является средством проверки целостности передаваемых сообщений по ненадежным линиям связи. Это средство не направлено на борьбу со злоумышленниками, которым в такой ситуации ничто не мешает подменить сообщение, добавив к нему новое значение контрольной суммы. Получатель в таком случае не заметит никакой подмены.
В отличие от контрольной суммы при вычислении дайджеста требуются секретные ключи. В случае если для получения дайджеста использовалась односторонняя функция с параметром, который известен только отправителю и получателю, любая модификация исходного сообщения будет немедленно обнаружена.
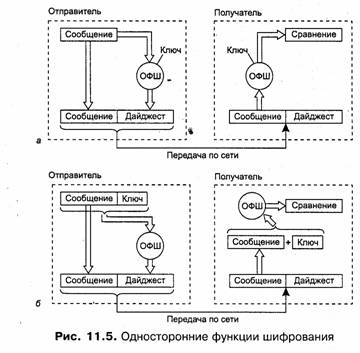
На рис. 11.5, б показан другой вариант использования односторонней функции шифрования для обеспечения целостности данных. В данном случае односторонняя функция не имеет параметра-ключа, но зато применяется не просто к сообщению, а к сообщению, дополненному секретным ключом. Получатель, извлекая исходное сообщение, также дополняет его тем же известным ему секретным ключом, после чего применяет к полученным данным одностороннюю функцию. Результат вычислений сравнивается с полученным по сети дайджестом.
Помимо обеспечения целостности сообщений дайджест может быть использован в качестве электронной подписи для аутентификации передаваемого документа.
Построение односторонних функций является трудной задачей. Такого рода функции должны удовлетворять двум условиям:
□ по дайджесту, вычисленному с помощью данной функции, невозможно каким-либо образом вычислить исходное сообщение;
□ должна отсутствовать возможность вычисления двух разных сообщений, для которых с помощью данной функции могли быть вычислены одинаковые дайджесты.
Наиболее популярной в системах безопасности в настоящее время является серия хэш-функций MD2, MD4, MD5. Все они генерируют дайджесты фиксированной длины 16 байт. Адаптированным вариантом MD4 является американский стандарт SHA, длина дайджеста в котором составляет 20 байт. Компания IBM поддерживает односторонние функции MDC2 и MDC4, основанные на алгоритме шифрования DES,
Аутентификация, авторизация, аудит
Аутентификация
Аутентификация (authentication) предотвращает доступ к сети нежелательных лиц и разрешает вход для легальных пользователей. Термин «аутентификация» в переводе с латинского означает «установление подлинности». Аутентификацию следует отличать от идентификации. Идентификаторы пользователей используется в системе с теми же целями, что и идентификаторы любых других объектов, файлов, процессов, структур данных, но они не связаны непосредственно с обеспечением безопасности. Идентификация заключается в сообщении пользователем системе своего идентификатора, в то время как аутентификация — это процедура доказательства пользователем того, что он есть тот, за кого себя выдает, в частности, доказательство того, что именно ему принадлежит введенный им идентификатор.
В процедуре аутентификации участвуют две стороны: одна сторона доказывает свою аутентичность, предъявляя некоторые доказательства, а другая сторона — аутентификатор — проверяет эти доказательства и принимает решение. В качестве доказательства аутентичности используются самые разнообразные приемы:
□ аутентифицируемый может продемонстрировать знание некоего общего для обеих сторон секрета: слова (пароля) или факта (даты и места события, прозвища человека и т. п.);
□ аутентифицируемый может продемонстрировать, что он владеет неким уникальным предметом (физическим ключом), в качестве которого может выступать, например, электронная магнитная карта;
□ аутентифицируемый может доказать свою идентичность, используя собственные биохарактеристики рисунок радужной оболочки глаза или отпечатки пальцев, которые предварительно были занесены в базу данных аутентификатора.
Сетевые службы аутентификации строятся на основе всех этих приемов, но чаще всего для доказательства идентичности пользователя используются пароли. Простота и логическая ясность механизмов аутентификации на основе паролей в какой-то степени компенсирует известные слабости паролей. Это, во-первых, возможность раскрытия и разгадывания паролей, а во-вторых, возможность «подслушивания» пароля путем анализа сетевого трафика. Для снижения уровня угрозы от раскрытия паролей администраторы сети, как правило, применяют встроенные программные средства для формирования политики назначения и использования паролей задание максимального и минимального сроков действия пароля, хранение списка уже использованных паролей, управление поведением системы после нескольких неудачных попыток логического входа и т. п. Перехват паролей по сети можно предупредить путем их шифрования перед передачей в сеть.
Легальность пользователя может устанавливаться по отношению к различным системам. Так, работая в сети, пользователь может проходить процедуру аутентификации и как локальный пользователь, который претендует на использование ресурсов только данного компьютера, и как пользователь сети, который хочет получить доступ ко всем сетевым ресурсам. При локальной аутентификации пользователь вводит свои идентификатор и пароль, которые автономно обрабатываются операционной системой, установленной на данном компьютере. При логическом входе в сеть данные о пользователе (идентификатор и пароль) передаются на сервер, который хранит учетные записи обо всех пользователях сети. Многие приложения имеют свои средства определения, является ли пользователь законным. И тогда пользователю приходится проходить дополнительные этапы проверки.
В качестве объектов, требующих аутентификации, могут выступать не только пользователи, но и различные устройства, приложения, текстовая и другая информация. Так, например, пользователь, обращающийся с запросом к корпоративному серверу, должен доказать ему свою легальность, но он также должен убедиться сам, что ведет диалог действительно с сервером своего предприятия. Другими словами; сервер и клиент должны пройти процедуру взаимной аутентификации. Здесь мы имеем дело с аутентификацией на уровне приложений. При установлении сеанса связи между двумя устройствами также часто предусматриваются процедуры взаимной аутентификации на более низком, канальном уровне. Примером такой процедуры является аутентификация по протоколам РАР и CHAP, входящим в семейство протоколов РРР. Аутентификация данных означает доказательство целостности этих данных, а также того, что они поступили именно от того человека, который объявил об этом. Для этого используется механизм электронной подписи.
В вычислительных сетях процедуры аутентификации часто реализуются теми же программными средствами, что и процедуры авторизации. В отличие от аутентификации, которая распознает легальных и нелегальных пользователей, система авторизации имеет дело только с легальными пользователями, которые уже успешно прошли процедуру аутентификации. Цель подсистем авторизации состоит в том, чтобы предоставить каждому легальному пользователю именно те виды доступа и к тем ресурсам, которые были для него определены администратором системы.
Авторизация доступа
Средства авторизации {authorization) контролируют доступ легальных пользователей к ресурсам системы, предоставляя каждому из них именно те права, которые ему были определены администратором. Кроме предоставления прав доступа пользователям к каталогам, файлам и принтерам система авторизации может контролировать возможность выполнения пользователями различных системных функций, таких как локальный доступ к серверу, установка системного времени, создание резервных копий данных, выключение сервера и т. п.
Система авторизации наделяет пользователя сети правами выполнять определенные действия над определенными ресурсами. Для этого могут быть использованы различные формы предоставления правил доступа, которые часто делят на два класса:
□ избирательный доступ;
□ мандатный доступ.
Избирательные права доступа реализуются в операционных системах универсального назначения. В наиболее распространенном варианте такого подхода определенные операции над определенным ресурсом разрешаются или запрещаются пользователям или группам пользователей, явно указанным своими идентификаторами. Например, пользователю, имеющему идентификатор User_T, может быть разрешено выполнять операции чтения и записи по отношению к файлу File1. Модификацией этого способа является использование для идентификации пользователей их должностей, или факта их принадлежности к персоналу того или иного производственного подразделения, или еще каких-либо других позиционирующих характеристик. Примером такого правила может служить следующее: файл бухгалтерской отчетности BUCH могут читать работники бухгалтерии и руководитель предприятия.
Мандатный подход к определению прав доступа заключается в том, что вся информация делится на уровни в зависимости от степени секретности, а все пользователи сети также делятся на группы, образующие иерархию в соответствии с уровнем допуска к этой информации. Такой подход используется в известном делении информации на информацию для служебного пользования, «секретно», «совершенно секретно». При этом пользователи этой информации в зависимости от определенного для них статуса получают различные формы допуска: первую, вторую или третью. В отличие от систем с избирательными правами доступа в системах с мандатным подходом пользователи в принципе не имеют возможности изменить уровень доступности информации. Например, пользователь более высокого уровня не может разрешить читать данные из своего файла пользователю, относящемуся к более низкому уровню. Отсюда видно, что мандатный подход является более строгим, он в корне пресекает всякий волюнтаризм со стороны пользователя. Именно поэтому он часто используется в системах военного назначения.
Процедуры авторизации реализуются программными средствами, которые могут быть встроены в операционную систему или в приложение, а также могут поставляться в виде отдельных программных продуктов. При этом программные системы авторизации могут строиться на базе двух схем:
□ централизованная схема авторизации, базирующаяся на сервере;
□ децентрализованная схема, базирующаяся на рабочих станциях.
В первой схеме сервер управляет процессом предоставления ресурсов пользователю. Главная цель таких систем — реализовать «принцип единого входа». В соответствии с централизованной схемой пользователь один раз логически входит в сеть и получает на все время работы некоторый набор разрешений по доступу к ресурсам сети. Система Kerberos с ее сервером безопасности и архитектурой клиент-сервер является наиболее известной системой этого типа. Системы TACACS и RADIUS, часто применяемые совместно с системами удаленного доступа, также реализуют этот подход.
При втором подходе рабочая станция сама является защищенной — средства защиты работают на каждой машине, и сервер не требуется. Рассмотрим работу системы, в которой не предусмотрена процедура однократного логического входа. Теоретически доступ к каждому приложению должен контролироваться средствами безопасности самого приложения или же средствами, существующими в той операционной среде, в которой оно работает. В корпоративной сети администратору придется отслеживать работу механизмов безопасности, используемых всеми типами приложений — электронной почтой, службой каталогов локальной сети, базами данных хостов и т. п. Когда администратору приходится добавлять или удалять пользователей, то часто требуется вручную конфигурировать доступ к каждой программе или системе.
В крупных сетях часто применяется комбинированный подход предоставления пользователю прав доступа к ресурсам сети: сервер удаленного доступа ограничивает доступ пользователя к подсетям или серверам корпоративной сети, то есть к укрупненным элементам сети, а каждый отдельный сервер сети сам по себе ограничивает доступ пользователя к своим внутренним ресурсам: разделяемым каталогам, принтерам или приложениям. Сервер удаленного доступа предоставляет доступ на основании имеющегося у него списка прав доступа пользователя (Access Control List, ACL), а каждый отдельный сервер сети предоставляет доступ к своим ресурсам на основании хранящегося у него списка прав доступа, например ACL файловой системы.
Подчеркнем, что системы аутентификации и авторизации совместно выполняют одну задачу, поэтому необходимо предъявлять одинаковый уровень требований к системам авторизации и аутентификации. Ненадежность одного звена здесь не может быть компенсирована высоким качеством другого звена. Если при аутентификации используются пароли, то требуются чрезвычайные меры по их защите. Однажды украденный пароль открывает двери ко всем приложениям и данным, к которым пользователь с этим паролем имел легальный доступ.
Аудит
Аудит (auditing) — фиксация в системном журнале событий, связанных с доступом к защищаемым системным ресурсам. Подсистема аудита современных ОС позволяет дифференцированно задавать перечень интересующих администратора событий с помощью удобного графического интерфейса. Средства учета и наблюдения обеспечивают возможность обнаружить и зафиксировать важные события, связанные с безопасностью, или любые попытки создать, получить доступ или удалить системные ресурсы. Аудит используется для того, чтобы засекать даже неудачные попытки «взлома» системы.
Учет и наблюдение означает способность системы безопасности «шпионить» за выбранными объектами и их пользователями и выдавать сообщения тревоги, когда кто-нибудь пытается читать или модифицировать системный файл. Если кто-то пытается выполнить действия, определенные системой безопасности для отслеживания, то система аудита пишет сообщение в журнал регистрации, идентифицируя пользователя. Системный менеджер может создавать отчеты о безопасности, которые содержат информацию из журнала регистрации. Для «сверхбезопасных» систем предусматриваются аудио- и видеосигналы тревоги, устанавливаемые на машинах администраторов, отвечающих за безопасность.
Поскольку никакая система безопасности не гарантирует защиту на уровне 100 %, то последним рубежом в борьбе с нарушениями оказывается система аудита.
Действительно, после того как злоумышленнику удалось провести успешную атаку, пострадавшей стороне не остается ничего другого, как обратиться к службе аудита. Если при настройке службы аудита были правильно заданы события, которые требуется отслеживать, то подробный анализ записей в журнале может дать много полезной информации. Эта информация, возможно, позволит найти злоумышленника или по крайней мере предотвратить повторение подобных атак путем устранения уязвимых мест в системе защиты.
Как уже было сказано, задачу защиты данных можно разделить на две подзадачи: защиту данных внутри компьютера и защиту данных в процессе их передачи из одного компьютера в другой. Для обеспечения безопасности данных при их передаче по публичным сетям используются различные технологии защищенного канала.
Технология защищенного канала призвана обеспечивать безопасность передачи данных по открытой транспортной сети, например по Интернету. Защищенный канал подразумевает выполнение трех основных функций:
□ взаимную аутентификацию абонентов при установлении соединения, которая может быть выполнена, например, путем обмена паролями;
□ защиту передаваемых по каналу сообщений от несанкционированного доступа, например, путем шифрования;
□ подтверждение целостности поступающих по каналу сообщений, например, путем передачи одновременно с сообщением его дайджеста.
Совокупность защищенных каналов, созданных предприятием в публичной сети для объединения своих филиалов, часто называют виртуальной частной сетью (Virtual Private Network, VPN).
Существуют разные реализации технологии защищенного канала, которые, в частности, могут работать на разных уровнях модели OSI. Так, функции популярного протокола SSL соответствуют представительному уровню модели OSI. Новая версия сетевого протокола IP предусматривает все функции — взаимную аутентификацию, шифрование и обеспечение целостности, — которые по определению свойственны защищенному каналу, а протокол туннелирования РРТР защищает данные на канальном уровне.
В зависимости от места расположения программного обеспечения защищенного канала различают две схемы его образования:
□ схему с конечными узлами, взаимодействующими через публичную сеть (рис. 11.6, а);
□ схему с оборудованием поставщика услуг публичной сети, расположенным на границе между частной и публичной сетями (рис. 11.6, б).
В первом случае защищенный канал образуется программными средствами, установленными на двух удаленных компьютерах, принадлежащих двум разным локальным сетям одного предприятия и связанных между собой через публичную сеть. Преимуществом этого подхода является полная защищенность канала вдоль всего пути следования, а также возможность использования любых протоколов создания защищенных каналов, лишь бы на конечных точках канала поддерживался один и тот же протокол. Недостатки заключаются в избыточности и децентрализованности решения. Избыточность состоит в том, что вряд ли стоит создавать защищенный канал на всем пути прохождения данных: уязвимыми для злоумышленников обычно являются сети с коммутацией пакетов, а не каналы телефонной сети или выделенные каналы, через которые локальные сети подключены к территориальной сети. Поэтому защиту каналов доступа к публичной сети можно считать избыточной. Децентрализация заключается в том, что для каждого компьютера, которому требуется предоставить услуги защищенного канала, необходимо отдельно устанавливать, конфигурировать и администрировать программные средства защиты данных. Подключение каждого нового компьютера к защищенному каналу требует выполнения этих трудоемких работ заново.
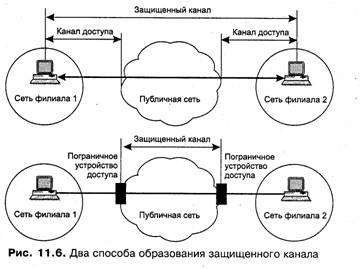
Во втором случае клиенты и серверы не участвуют в создании защищенного канала — он прокладывается только внутри публичной сети с коммутацией пакетов, например внутри Интернета. Канал может быть проложен, например, между сервером удаленного доступа поставщика услуг публичной сети и пограничным маршрутизатором корпоративной сети. Это хорошо масштабируемое решение, управляемое централизованно как администратором корпоративной сети, так и администратором сети поставщика услуг. Для компьютеров корпоративной сети канал прозрачен — программное обеспечение этих конечных узлов остается без изменений. Такой гибкий подход позволяет легко образовывать новые каналы защищенного взаимодействия между компьютерами независимо от их места расположения. Реализация этого подхода сложнее — нужен стандартный протокол образования защищенного канала, требуется установка у всех поставщиков услуг программного обеспечения, поддерживающего такой протокол, необходима поддержка протокола производителями пограничного коммуникационного оборудования. Однако вариант, когда все заботы по поддержанию защищенного канала берет на себя поставщик услуг публичной сети, оставляет сомнения в надежности защиты: во-первых, незащищенными оказываются каналы доступа к публичной сети, во-вторых, потребитель услуг чувствует себя в полной зависимости от надежности поставщика услуг. И тем не менее, специалисты прогнозируют, что именно вторая схема в ближайшем будущем станет основной в построении защищенных каналов.
Сетевая аутентификация на основе
многоразового пароля
В соответствии с базовым принципом «единого входа», когда пользователю достаточно один раз пройти процедуру аутентификации, чтобы получить доступ ко всем сетевым ресурсам, в современных операционных системах предусматриваются централизованные службы аутентификации. Такая служба поддерживается одним из серверов сети и использует для своей работы базу данных, в которой хранятся учетные данные (иногда называемые бюджетами) о пользователях сети. Учетные данные содержат наряду с другой информацией идентификаторы и пароли пользователей. Упрощенно схема аутентификации в сети выглядит следующим образом. Когда пользователь осуществляет логический вход в сеть, он набирает на клавиатуре своего компьютера свои идентификатор и пароль. Эти данные используются службой аутентификации — в централизованной базе данных, хранящейся на сервере, по идентификатору пользователя находится соответствующая запись, из нее извлекается пароль и сравнивается с тем, который ввел пользователь. Если они совпадают, то аутентификация считается успешной, пользователь получает легальный статус и те права, которые определены для него системой авторизации.
Однако такая упрощенная схема имеет большой изъян. А именно при передаче пароля с клиентского компьютера на сервер, выполняющий процедуру аутентификации, этот пароль может быть перехвачен злоумышленником. Поэтому в разных операционных системах применяются разные приемы, чтобы избежать передачи пароля по сети в незащищенном виде. Рассмотрим, как решается эта проблема в популярной сетевой ОС Windows NT.
В основе концепции сетевой безопасности Windows NT лежит понятие домена. Домен — это совокупность пользователей, серверов и рабочих станций, учетная информация о которых централизованно хранится в общей базе данных, называемой базой SAM (Security Accounts Manager database). Над этой базой данных реализована служба Directory Services, которая, как и любая централизованная справочная служба, устраняет дублирование учетных данных в нескольких компьютерах и сокращает число рутинных операций по администрированию. Одной из функций службы Directory Services является аутентификация пользователей. Служба Directory Services построена в архитектуре клиент-сервер. Каждый пользователь при логическом входе в сеть вызывает клиентскую часть службы, которая передает запрос на аутентификацию и поддерживает диалог с серверной частью.
Аутентификация пользователей домена выполняется на основе их паролей, хранящихся в зашифрованном, виде в базе SAM (рис. 11.7). Пароли зашифровываются с помощью односторонней функции при занесении их в базу данных во время процедуры создания учетной записи для нового пользователя. Введем обозначение для этой односторонней функции — 0ФШ1. Таким образом, пароль Р хранится в базе данных SAM в виде дайджеста d(P). (Напомним, что знание дайджеста не позволяет восстановить исходное сообщение.)
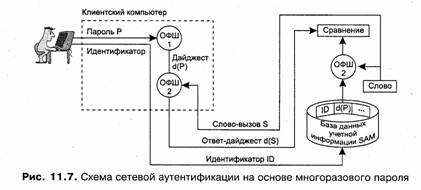
При логическом входе пользователь локально вводит в свой компьютер имя-идентификатор (ID) и пароль Р. Клиентская часть подсистемы аутентификации, получив эти данные, передает запрос по сети на сервер, хранящий базу SAM. В этом запросе в открытом виде содержится идентификатор пользователя ID, но пароль не передается в сеть ни в каком виде.
К паролю на клиентской станции применяется та же односторонняя функция 0ФШ1, которая была использована при записи пароля в базу данных SAM, то есть динамически вычисляется дайджест пароля d(P).
В ответ на поступивший запрос серверная часть службы аутентификации генерирует случайное число S случайной длины, называемое словом-вызовом (challenge). Это слово передается по сети с сервера на клиентскую станцию пользователя. К слову-вызову на клиентской стороне применяется односторонняя функция шифрования 0ФШ2. В отличие от функции 0ФШ1 функция 0ФШ2 является параметрической и получает в качестве параметра дайджест пароля d(P). Полученный в результате ответ d(S) передается по сети, на сервер SAM.
Параллельно этому на сервере слово-вызов S аналогично шифруется с помощью той же односторонней функции 0ФШ2 и дайджеста пароля пользователя d(P), извлеченного из базы SAM, а затем сравнивается с ответом, переданным клиентской станцией. При совпадении результатов считается, что аутентификация прошла успешно. Таким образом, при логическом входе пользователя пароли в сети Windows NT никогда не передаются по каналам связи.
Заметим также, что при каждом запросе на аутентификацию генерируется новое слово-вызов, так что перехват ответа d(S) клиентского компьютера не может быть использован в ходе другой процедуры аутентификации.
Аутентификация с использованием одноразового пароля
Алгоритмы аутентификации, основанные на многоразовых паролях, не очень надежны. Пароли можно подсмотреть или просто украсть. Более надежными оказываются схемы, использующие одноразовые пароли. С другой стороны, одноразовые пароли намного дешевле и проще биометрических систем аутентификации, таких как сканеры сетчатки глаза или отпечатков пальцев. Все это делает системы, основанные на одноразовых паролях, очень перспективными. Следует иметь в виду, что, как правило, системы аутентификации на основе одноразовых паролей рассчитаны на проверку только удаленных, а не локальных пользователей.
Генерация одноразовых паролей может выполняться либо программно, либо аппаратно. Некоторые реализации аппаратных устройств доступа на основе одноразовых паролей представляют собой миниатюрные устройства со встроенным микропроцессором, похожие на обычные пластиковые карточки, используемые для доступа к банкоматам. Такие карточки, часто называемые аппаратными ключами, могут иметь клавиатуру и маленькое дисплейное окно. Аппаратные ключи могут быть также реализованы в виде присоединяемого к разъему устройства, которое располагается между компьютером и модемом, или в виде карты (гибкого диска), вставляемой в дисковод компьютера.
Существуют и программные реализации средств аутентификации на основе одноразовых паролей (программные ключи). Программные ключи размещаются на сменном магнитном диске в виде обычной программы, важной частью которой является генератор одноразовых паролей. Применение программных ключей и присоединяемых к компьютеру карточек связано с некоторым риском, так как пользователи часто забывают гибкие диски в машине или не отсоединяют карточки от ноутбуков.
Независимо от того, какую реализацию системы аутентификации на основе одноразовых паролей выбирает пользователь, он, как и в системах аутентификации с использованием многоразовых паролей, сообщает системе свой идентификатор, однако вместо того, чтобы вводить каждый раз один и тот же пароль, он указывает последовательность цифр, сообщаемую ему аппаратным или программным ключом. Через определенный небольшой период времени генерируется другая последовательность — новый пароль. Аутентификационный сервер проверяет введенную последовательность и разрешает пользователю осуществить логический вход. Аутентификационный сервер может представлять собой отдельное устройство, выделенный компьютер или же программу, выполняемую на обычном сервере.
Рассмотрим подробнее две схемы, основанные на использовании аппаратных ключей.
Синхронизация по времени
Механизм аутентификации в значительной степени зависит от производителя. Одним из наиболее популярных механизмов является схема, разработанная компанией Security Dynamics (рис. 11.8). Схема синхронизации основана на алгоритме, который через определенный интервал времени (изменяемый при желании администратором сети) генерирует случайное число. Алгоритм использует два параметра:
□ секретный ключ, представляющий собой 64-битное число, уникально назначаемое каждому пользователю и хранящееся одновременно в аппаратном ключе и в базе данных аутентификационного сервера;
□ значение текущего времени.
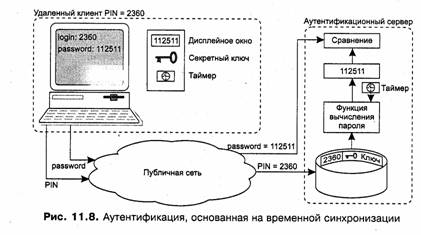
Когда удаленный пользователь пытается совершить логический вход в сеть, то ему предлагается ввести его личный персональный номер (PIN), состоящий из 4 десятичных цифр, а также 6 цифр случайного числа, отображаемого в тот момент на дисплее аппаратного ключа. На основе PIN-кода сервер извлекает из базы данных информацию о пользователе, а именно его секретный ключ. Затем сервер выполняет алгоритм генерации случайного числа, используя в качестве параметров найденный секретный ключ и значение текущего времени, и проверяет, совпадает ли сгенерированное число с числом, которое ввел пользователь. Если они совпадают, то пользователю разрешается логический вход.
Потенциальной проблемой этой схемы является временная синхронизация сервера и аппаратного ключа (ясно, что вопрос согласования часовых поясов решается просто). Гораздо сложнее обстоит дело с постепенным рассогласованием внутренних часов сервера и аппаратного ключа, тем более что потенциально аппаратный ключ может работать несколько лет. Компания Security Dynamics решает эту проблему двумя способами. Во-первых, при производстве аппаратного ключа измеряется отклонение частоты его таймера от номинала. Далее эта величина учитывается в виде параметра алгоритма сервера. Во-вторых, сервер отслеживает коды, генерируемые конкретным аппаратным ключом, и если таймер данного ключа постоянно спешит или отстает, то сервер динамически подстраивается под него.
Существует еще одна проблема, связанная со схемой временной синхронизации. Случайное число, генерируемое аппаратным ключом, является достоверным паролем в течение определенного интервала времени. Теоретически возможно, что очень проворный хакер может перехватить PIN-код и случайное число и использовать их для доступа к какому-либо серверу сети.
Схема с использованием слова-вызова
Другая схема применения аппаратных ключей основана на идее, очень сходной с рассмотренной выше идеей сетевой аутентификации. В том и другом случаях используется слово-вызов. Такая схема получила название «запрос-ответ». Когда пользователь пытается осуществить логический вход, то аутентификационный сервер передает ему запрос в виде случайного числа (рис. 11.9). Аппаратный ключ пользователя зашифровывает это случайное число, используя алгоритм DES и секретный ключ пользователя. Секретный ключ пользователя хранится в базе данных сервера и в памяти аппаратного ключа. В зашифрованном виде слово-вызов возвращается на сервер. Сервер, в свою очередь, также зашифровывает сгенерированное им самим случайное число с помощью алгоритма DES и того же секретного ключа пользователя, а затем сравнивает результат с числом, полученным от аппаратного ключа. Как и в методе временной синхронизации, в случае совпадения этих двух чисел пользователю разрешается вход в сеть.
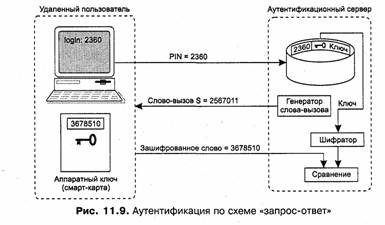
Механизм слова-вызова имеет свои ограничения — он обычно требует наличия компьютера на каждом конце соединения, так как аппаратный ключ должен иметь возможность как получать, так и отправлять информацию. А схема временной синхронизации позволяет ограничиться простым терминалом или факсом. В этом случае пользователи могут даже вводить свой пароль с телефонной клавиатуры, когда звонят в сеть для получения голосовой почты.
Схема «запрос-ответ» уступает схеме временной синхронизации по простоте использования. Для логического входа по схеме временной синхронизации пользователю достаточно набрать 10 цифр. Схемы же «запрос-ответ» могут потребовать от пользователя выполнения большего числа ручных действий. В некоторых схемах «запрос-ответ» пользователь должен сам вводить секретный ключ, а затем набирать на клавиатуре компьютера полученное с помощью аппаратного ключа зашифрованное слово-вызов. В некоторых случаях пользователь должен вторично совершить логический вход в коммуникационный сервер уже после аутентификации.
Аутентификация на основе сертификатов
Аутентификация с применением цифровых сертификатов является альтернативой использованию паролей и представляется естественным решением в условиях, когда число пользователей сети (пусть и потенциальных) измеряется миллионами. В таких обстоятельствах процедура предварительной регистрации пользователей, связанная с назначением и хранением их паролей, становится крайне обременительной, опасной, а иногда и просто нереализуемой. При использовании сертификатов сеть, которая дает пользователю доступ к своим ресурсам, не хранит никакой информации о своих пользователях — они ее предоставляют сами в своих запросах в виде сертификатов, удостоверяющих личность пользователей. Сертификаты выдаются специальными уполномоченными организациями — центрами сертификации (Cettificate Authority, CA). Поэтому задача хранения секретной информации (закрытых ключей) возлагается на самих пользователей, что делает это решение гораздо более масштабируемым, чем вариант с использованием централизованной базы паролей.
Схема использования сертификатов
Аутентификация личности на основе сертификатов происходит примерно так же, как на проходной большого предприятия. Вахтер пропускает людей на территорию на основании пропуска, который содержит фотографию и подпись сотрудника, удостоверенных печатью предприятия и подписью лица, выдавшего пропуск. Сертификат является аналогом пропуска и выдается по запросам специальными сертифицирующими центрами при выполнении определенных условий.
Сертификат представляет собой электронную форму, в которой содержится следующая информация:
□ открытый ключ владельца данного сертификата;
□ сведения о владельце сертификата, такие, например, как имя, адрес электронной почты, наименование организации, в которой он работает, и т. п.;
□ наименование сертифицирующей организации, выдавшей данный сертификат.
Кроме того, сертификат содержит электронную подпись сертифицирующей организации — зашифрованные закрытым ключом этой организации данные, содержащиеся в сертификате.
Использование сертификатов основано на предположении, что сертифицирующих организаций немного и их открытые ключи могут быть всем известны каким-либо способом, например, из публикаций в журналах. Когда пользователь хочет подтвердить свою личность, он предъявляет свой сертификат в двух формах — открытой (то есть такой, в которой он получил его в сертифицирующей организации) и зашифрованной с применением своего закрытого ключа (рис. 11.10). Сторона, проводящая аутентификацию, берет из открытого сертификата открытый ключ пользователя и расшифровывает с помощью него зашифрованный сертификат. Совпадение результата с открытым сертификатом подтверждает факт, что предъявитель действительно является владельцем закрытого ключа, парного с указанным открытым.
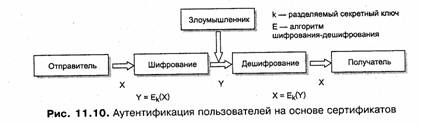
Затем с помощью известного открытого ключа указанной в сертификате организации проводится расшифровка подписи этой организации в сертификате. Если в результате получается тот же сертификат с тем же именем пользователя и его открытым ключом — значит, он действительно прошел регистрацию в сертификационном центре, является тем, за кого себя выдает, и указанный в сертификате открытый ключ действительно принадлежит ему.
Сертификаты можно использовать не только для аутентификации, но и для предоставления избирательных прав доступа. Для этого в сертификат могут вводиться дополнительные поля, в которых указывается принадлежность его владельцев той или иной категории пользователей. Эта категория назначается сертифицирующей организацией в зависимости от условий, на которых выдается сертификат. Например, организация, поставляющая через Интернет на коммерческой основе информацию, может выдавать сертификаты определенной категории пользователям, оплатившим годовую подписку на некоторый бюллетень, а Web-сервер будет предоставлять доступ к страницам бюллетеня только пользователям, предъявившим сертификат данной категории.
Подчеркнем тесную связь открытых ключей с сертификатами. Сертификат является не только удостоверением личности, но и удостоверением принадлежности открытого ключа. Цифровой сертификат устанавливает и гарантирует соответствие между открытым ключом и его владельцем. Это предотвращает угрозу подмены открытого ключа. Если некоторому абоненту поступает открытый ключ в составе сертификата, то он может быть уверен, что этот открытый ключ гарантированно принадлежит отправителю, адрес и другие сведения о котором содержатся в этом сертификате.
При использовании сертификатов отпадает необходимость хранить на серверах корпораций списки пользователей с их паролями, вместо этого достаточно иметь на сервере список имен и открытых ключей сертифицирующих организаций. Может также понадобиться некоторый механизм отображений категорий владельцев сертификатов на традиционные группы пользователей для того, чтобы можно было использовать в неизменном виде механизмы управления избирательным доступом большинства операционных систем или приложений.
Сертифицирующие центры
Сертификат является средством аутентификации пользователя при его обращении к сетевым ресурсам, роль аутентифицирующей стороны играют при этом информационные серверы корпоративной сети или Интернета. В то же время и сама процедура получения сертификата включает этап аутентификации, здесь аутентификатором выступает сертифицирующая организация. Для получения сертификата клиент должен сообщить сертифицирующей организации свой открытый ключ и те или иные сведения, удостоверяющие его личность. Все эти данные клиент может отправить по электронной почте или принести на гибком диске лично. Перечень необходимых данных зависит от типа получаемого сертификата. Сертифицирующая организация проверяет доказательства подлинности, помещает спою цифровую подпись в файл, содержащий открытый ключ, и посылает сертификат обратно, подтверждая факт принадлежности данного конкретного ключа конкретному лицу. После этого сертификат может быть встроен в любой запрос на использование информационных ресурсов сети.
Практически важным вопросом является вопрос о том, кто может выполнять функции сертифицирующей организации. Во-первых, задачу обеспечения своих сотрудников сертификатами может взять на себя само предприятие. В этом случае упрощается процедура первичной аутентификации при выдаче сертификата. Предприятия уже достаточно осведомлены о своих сотрудниках, чтобы брать на себя задачу подтверждения их личности. Для автоматизации процесса генерации, выдачи и обслуживания сертификатов предприятия могут использовать готовые программные продукты, например компания Netscape Communications выпустила сервер сертификатов, который организации могут у себя устанавливать для выпуска своих собственных сертификатов.
Во-вторых, эти функции могут выполнять независимые центры по выдаче сертификатов, работающие на коммерческой основе, например сертифицирующий центр компании Verisign. Сертификаты компании Verisign выполнены в соответствии с международным стандартом Х.509 и используются во многих продуктах защиты данных, в том числе в популярном протоколе защищенного канала SSL. Любой желающий может обратиться с запросом на получение сертификата на Web-сервер этой компании. Сервер Verisign предлагает несколько типов сертификатов, отличающихся уровнем возможностей, которые получает владелец сертификата.
□ Сертификаты класса 1 предоставляют пользователю самый низкий уровень полномочий. Они могут быть использованы для отправки и получения шифрованной электронной почты через Интернет. Чтобы получить сертификат этого класса, пользователь должен сообщить серверу Verisign свой адрес электронной почты или свое уникальное имя.
□ Сертификаты класса 2 дают возможность их владельцу пользоваться внутрикорпоративной электронной почтой и принимать участие в подписных интерактивных службах. Чтобы получить сертификат этого более высокого уровня, пользователь должен организовать подтверждение своей личности сторонним лицом, например своим работодателем. Такой сертификат с информацией от работодателя может быть эффективно использован для деловой корреспонденции.
□ Сертификаты класса 3 предоставляют владельцу все те возможности, которые имеет обладатель сертификата класса 2, плюс возможность участия в электронных банковских операциях, электронных сделках по покупке товаров и некоторые другие возможности. Для доказательства своей аутентичности соискатель сертификата должен явиться лично и предоставить подтверждающие документы.
□ Сертификаты, класса 4 используются при выполнении крупных финансовых операций. Поскольку такой сертификат наделяет владельца самым высоким уровнем доверия, сертифицирующий центр Verisign проводит тщательное изучение частного лица или организации, запрашивающей сертификат.
Механизм получения пользователем сертификата хорошо автоматизируется в сети в модели клиент-сервер, когда браузер выполняет роль клиента, а в сертифицирующей организации установлен специальный сервер выдачи сертификатов. Браузер вырабатывает для пользователя пару ключей, оставляет закрытый ключ у себя и передает частично заполненную форму сертификата серверу. Для того чтобы неподписанный еще сертификат нельзя было подменить при передаче по сети, браузер ставит свою электронную подпись, зашифровывая сертификат выработанным закрытым ключом. Сервер сертификатов подписывает полученный сертификат, фиксирует его в своей базе данных и возвращает его каким-либо способом владельцу. Очевидно, что при этом может выполняться еще и неформальная процедура подтверждения пользователем своей личности и права на получение сертификата, требующая участия оператора сервера сертификатов. Это могут быть доказательства оплаты услуги, доказательства принадлежности к той или иной организации — все случаи жизни предусмотреть и автоматизировать нельзя. После получения сертификата браузер сохраняет его вместе с закрытым ключом и использует при аутентификации на тех серверах, которые поддерживают такой процесс.
В настоящее время существует уже большое количество протоколов и продуктов, использующих сертификаты. Например, компания Netscape Communications поддерживает сертификаты стандарта Х.509 в браузерах Netscape Navigator и своих информационных серверах. В технологиях Microsoft сертификаты также представлены очень широко. Microsoft реализовала поддержку сертификатов в своих браузерах Internet Explorer и в сервере Internet Information Server, разработала собственный сервер сертификатов, а также продукты, которые позволяют хранить сертификаты пользователя, его закрытые ключи и пароли защищенным образом.
Инфраструктура с открытыми ключами
Несмотря на активное использование технологии цифровых сертификатов во многих системах безопасности, эта технология еще не решила целый ряд серьезных проблем. Это прежде всего поддержание базы данных о выпущенных сертификатах. Сертификат выдается не навсегда, а на некоторый вполне определенный срок. По истечении срока годности сертификат должен либо обновляться, либо аннулироваться. Кроме того, необходимо предусмотреть возможность досрочного прекращения полномочий сертификата. Все заинтересованные участники информационного процесса должны быть вовремя оповещены о том, что некоторый сертификат уже не действителен. Для этого сертифицирующая организация должна оперативно поддерживать список аннулированных сертификатов.
Имеется также ряд проблем, связанных с тем, что сертифицирующие организации существуют не в единственном числе. Все они выпускают сертификаты, но даже если эти сертификаты соответствуют единому стандарту (сейчас это, как правило, стандарт Х.509), все равно остаются нерешенными многие вопросы. Все ли сертифицирующие центры заслуживают доверия? Каким образом можно проверить полномочия того или иного сертифицирующего центра? Можно ли создать иерархию сертифицирующих центров, когда сертифицирующий центр, стоящий выше, мог бы сертифицировать центры, расположенные ниже по иерархии? Как организовать совместное использование сертификатов, выпущенных разными сертифицирующими организациями?
Для решения упомянутых выше и многих других проблем, возникающих в системах, использующих технологии шифрования с открытыми ключами, оказывается необходимым комплекс программных средств и методик, называемый инфраструктурой с открытыми ключами (Public Key Infrastructure, РКГ). Информационные системы больших предприятий нуждаются в специальных средствах администрирования и управления цифровыми сертификатами, парами открытых/закрытых ключей, а также приложениями, функционирующими в среде с открытыми ключами.
В настоящее время любой пользователь имеет возможность, загрузив широко доступное программное обеспечение, абсолютно бесконтрольно сгенерировать себе пару открытый/закрытый ключ. Затем он может также совершенно независимо от администрации вести шифрованную переписку со своими внешними абонентами. Такая «свобода» пользователя часто не соответствует принятой на предприятии политике безопасности. Для обеспечения более надежной защиты корпоративной информации желательно реализовать централизованную службу генерации и распределения ключей. Для администрации предприятия важно иметь возможность получить копии закрытых ключей каждого пользователя сети, чтобы в случае увольнения пользователя или потери пользователем его закрытого ключа сохранить доступ к зашифрованным данным этого пользователя. В противном случае резко ухудшается одна из трех характеристик безопасной системы — доступность данных.
Процедура, позволяющая получать копии закрытых ключей, называется восстановлением ключей. Вопрос, включать ли в продукты безопасности средства восстановления ключей, в последние годы приобрел политический оттенок. В Соединенных Штатах Америки прошли бурные дебаты, тему которых можно примерно сформулировать так: обладает ли правительство правом иметь доступ к любой частной информации при условии, что на это есть постановление суда? И хотя в такой широкой постановке проблема восстановления ключей все еще не решена, необходимость наличия средств восстановления в корпоративных продуктах ни у кого не вызывает никаких сомнений. Принцип доступности данных не должен нарушаться из-за волюнтаризма сотрудников, монопольно владеющих своими закрытыми ключами. Ключ может быть восстановлен при выполнении некоторых условий, которые должны быть четко определены в политике безопасности предприятия.
Как только принимается решение о включении в систему безопасности средств восстановления, возникает вопрос, как же быть с надежностью защиты данных, как обеспечить пользователю уверенность в том, что его закрытый ключ не используется с какими-либо другими целями, отличными от резервирования? Некоторую уверенность в секретности хранения закрытых ключей может дать технология депонирования ключей. Депонирование ключей — это предоставление закрытых ключей на хранение третьей стороне, надежность которой не вызывает сомнений. Этой третьей стороной может быть правительственная организация или группа уполномоченных на это сотрудников предприятия, которым оказывается полное доверие.
Под аутентификацией информации в компьютерных системах понимают установление подлинности данных, полученных по сети, исключительно на основе информации, содержащейся в полученном сообщении.
Если конечной целью шифрования информации является обеспечение защиты от несанкционированного ознакомления с этой информацией, то конечной целью аутентификации информации является обеспечение защиты участников информационного обмена от навязывания ложной информации. Концепция аутентификации в широком смысле предусматривает установление подлинности информации как при условии наличия взаимного доверия между участниками обмена, так и при его отсутствии. В компьютерных системах выделяют два вида аутентификации информации:
□ аутентификация хранящихся массивов данных и программ — установление того факта, что данные не подвергались модификации;
□ аутентификация сообщений — установление подлинности полученного сообщения, в том числе решение вопроса об авторстве этого сообщения и установление факта приема.
Цифровая подпись
Для решения задачи аутентификации информации используется концепция цифровой (или электронной) подписи. Согласно терминологии, утвержденной Международной организацией по стандартизации (ISO), под термином «цифровая подпись» понимаются методы, позволяющие устанавливать подлинность автора сообщения (документа) при возникновении спора относительно авторства этого сообщения. Основная область применения цифровой подписи — это финансовые документы, сопровождающие электронные сделки, документы, фиксирующие международные договоренности и т. п.
До настоящего времени наиболее часто для построения схемы цифровой подписи использовался алгоритм RSA. В основе этого алгоритма лежит концепция Диффи-Хеллмана. Она заключается в том, что каждый пользователь сети имеет свой закрытый ключ, необходимый для формирования подписи; соответствующий этому секретному ключу открытый ключ, предназначенный для проверки подписи, известен всем другим пользователям сети.
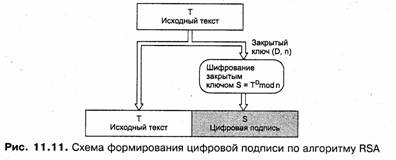
На рис. 11.11 показана схема формирования цифровой подписи по алгоритму RSA. Подписанное сообщение состоит из двух частей: незашифрованной части, в которой содержится исходный текст Т, и зашифрованной части, представляющей собой цифровую подпись. Цифровая подпись S вычисляется с использованием закрытого ключа (D, n) по формуле S =Td mod n.
Сообщение посылается в виде пары (Т, S). Каждый пользователь, имеющий соответствующий открытый ключ (Е, n), получив сообщение, отделяет открытую часть Т, расшифровывает цифровую подпись S и проверяет равенство Т = SE mod n.
Если результат расшифровки цифровой подписи совпадает с открытой частью сообщения, то считается, что документ подлинный, не претерпел никаких изменений в процессе передачи, а автором его является именно тот человек, который передал свой открытый ключ получателю. Если сообщение снабжено цифровой подписью, то получатель может быть уверен, что оно не было изменено или подделано по пути. Такие схемы аутентификации называются асимметричными. К недостаткам данного алгоритма можно отнести то, что длина подписи в этом случае равна длине сообщения, что не всегда удобно.
Цифровые подписи применяются к тексту до того, как он шифруется. Если помимо снабжения текста электронного документа цифровой подписью надо обеспечить его конфиденциальность, то вначале к тексту применяют цифровую подпись, а затем шифруют все вместе: и текст, и цифровую подпись (рис. 11.12).
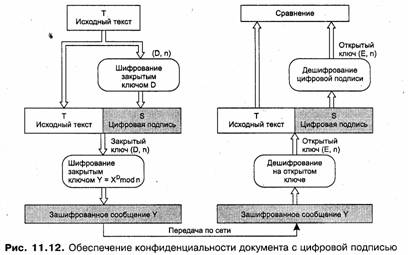
Другие методы цифровой подписи основаны на формировании соответствующей сообщению контрольной комбинации с помощью классических алгоритмов типа DES. Учитывая более высокую производительность алгоритма DES по сравнению с алгоритмом RSA, он более эффективен для подтверждения аутентичности больших объемов информации. А для коротких сообщений типа платежных поручений или квитанций подтверждения приема, наверное, лучше подходит алгоритм RSA.
Аутентификация программных кодов
Компания Microsoft разработала средства для доказательства аутентичности программных кодов, распространяемых через Интернет. Пользователю важно иметь доказательства, что программа, которую он загрузил с какого-либо сервера, действительно содержит коды, разработанные определенной компанией. Протоколы защищенного канала типа SSL помочь здесь не могут, так как позволяют удостоверить только аутентичность сервера. Microsoft разработала технологию аутентикода (Authenticode), суть которой состоит в следующем.
Организация, желающая подтвердить свое авторство на программу, должна встроить в распространяемый код так называемый подписывающий блок (рис. 11.13). Этот блок состоит из двух частей. Первая часть — сертификат этой организации, полученный обычным образом от какого-либо сертифицирующего центра. Вторую часть образует зашифрованный дайджест, полученный в результате применения односторонней функции к распространяемому коду. Шифрование дайджеста выполняется с помощью закрытого ключа организации.
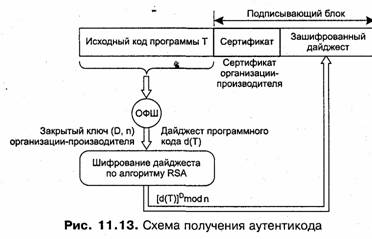
Система Kerberos
Kerberos — это сетевая служба, предназначенная для централизованного решения задач аутентификации и авторизации в крупных сетях. Она может работать в среде многих популярных ОС, например в последней версии Windows 2000 система Kerberos встроена как основной компонент безопасности.
В основе этой достаточно громоздкой системы лежит несколько простых принципов.
□ В сетях, использующих систему безопасности Kerberos, все процедуры аутентификации между клиентами и серверами сети выполняются через посредника, которому доверяют обе стороны аутентификационного процесса, причем таким авторитетным арбитром является сама система Kerberos.
□ В системе Kerberos клиент должен доказывать свою аутентичность для доступа к каждой службе, услуги которой он вызывает.
□ Все обмены данными в сети выполняются в защищенном виде с использованием алгоритма шифрования DES.
Сетевая служба Kerberos построена по архитектуре клиент-сервер, что позволяет ей работать в самых сложных сетях. Kerberos-клиент устанавливается на всех компьютерах сети, которые могут обратиться к какой-либо сетевой службе. В таких случаях Kerberos-клиент от лица пользователя передает запрос на Kerberos-сервер и поддерживает с ним диалог, необходимый для выполнения функций системы Kerberos.
Итак, в системе Kerberos имеются следующие участники: Kerberos-сервер, Кеrberos-клиенты, ресурсные серверы (рис. 11.14). Kerberos-клиенты пытаются получить доступ к сетевым ресурсам — файлам, приложениям, принтеру и т. д. Этот доступ может быть предоставлен, во-первых, только легальным пользователям, а во-вторых, при наличии у пользователя достаточных полномочий, определяемых службами авторизации соответствующих ресурсных серверов — файловым сервером, сервером приложений, сервером печати. Однако в системе Kerberos ресурсным серверам запрещается «напрямую» принимать запросы от клиентов, им разрешается начинать рассмотрение запроса клиента только тогда, когда на это поступает разрешение от Kerberos-сервера. Таким образом, путь клиента к ресурсу в системе Kerberos состоит из трех этапов:
1. Определение легальности клиента, логический вход в сеть, получение разрешения на продолжение процесса получения доступа к ресурсу.
2. Получение разрешения на обращение к ресурсному серверу.
3. Получение разрешения на доступ к ресурсу.
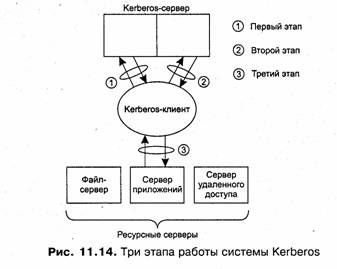
Для решения первой и второй задач клиент обращается к Kerberos-серверу. Каждая из этих двух задач решается отдельным сервером, входящим в состав Kerberos-сервера. Выполнение первичной аутентификации и выдача разрешения на продолжение процесса получения доступа к ресурсу осуществляется так называемым аутентификационным сервером (Authentication Server, AS). Этот сервер хранит в своей базе данных информацию об идентификаторах и паролях пользователей.
Вторую задачу, связанную с получением разрешения на обращение к ресурсному серверу, решает другая часть Kerberos-сервера — сервер квитанций (Ticket-Granting Server, TGS). Сервер квитанций для легальных клиентов выполняет дополнительную проверку и дает клиенту разрешение на доступ к нужному ему ресурсному серверу, для чего наделяет его электронной формой-квитанцией. Для выполнения своих функций сервер квитанций использует копии секретных
ключей всех ресурсных серверов, которые хранятся у него в базе данных. Кроме этих ключей сервер TGS имеет еще один секретный DES-ключ, который разделяет с сервером AS.
Третья задача — получение разрешения на доступ непосредственно к ресурсу — решается на уровне ресурсного сервера.
ПРИМЕЧАНИЕ ----------------------------------------------------------------------------------------------При описании протоколов взаимодействие Kerberos-клиента и Kerberos-сервера, а также Kerberos-клиента и ресурсного сервера использован термин «квитанция» (ticket), означающий в данном случае электронную форму, выдаваемую Kerberos-сервером клиенту, которая играет роль некоего удостоверения личности и разрешения на доступ к ресурсу.
Процесс доступа пользователя к ресурсам включает две процедуры: во-первых, пользователь должен доказать свою легальность (аутентификация), а во-вторых, он должен получить разрешение на выполнение определенных операций с определенным ресурсом (авторизация). В системе Kerberos пользователь один раз аутентифицируется во время логического входа в сеть, а затем проходит процедуры аутентификации и авторизации всякий раз, когда ему требуется доступ к новому ресурсному серверу.
Выполняя логический вход в сеть, пользователь, а точнее клиент Kerberos, установленный на его компьютере, посылает аутентификационному серверу AS идентификатор пользователя ID (рис. 11.15).
Вначале аутентификационный сервер проверяет в базе данных, есть ли запись о пользователе с таким идентификатором, затем, если такая запись существует, извлекает из нее пароль пользователя р. Данный пароль потребуется для шифрования всей информации, которую направит аутентификационный сервер Kerberos-клиенту в качестве ответа. А ответ состоит из квитанции TTGS на доступ к серверу квитанций Kerberos и ключа сеанса Ks. Под сеансом здесь понимается все время работы пользователя, от момента, логического входа в сеть до момента логического выхода. Ключ сеанса потребуется для шифрования в процедурах аутентификации в течение всего пользовательского сеанса. Квитанция шифруется с помощью секретного DES-ключа К, который разделяют аутентификационный сервер и сервер квитанций. Все вместе — зашифрованная квитанция и ключ сеанса — еще раз шифруются с помощью пользовательского пароля р. Таким образом, квитанция шифруется дважды ключом К и паролем р. В приведенных выше обозначениях сообщение-ответ, которое аутентификационный сервер посылает клиенту, выглядит так: {{TTGS}K, Ks}p.
После того как такое ответное сообщение поступает на клиентскую машину, клиентская программа Kerberos просит пользователя ввести свой пароль. Когда пользователь вводит пароль, то Kerberos-клиент пробует с помощью пароля расшифровать поступившее сообщение. Если пароль верен, то из сообщения извлекается квитанция на доступ к серверу квитанций {TTGS}K (в зашифрованном виде) и ключ сеанса Ks (в открытом виде). Успешная расшифровка сообщения означает успешную аутентификацию. Заметим, что аутентификационный сервер AS аутентифицирует пользователя без передачи пароля по сети.
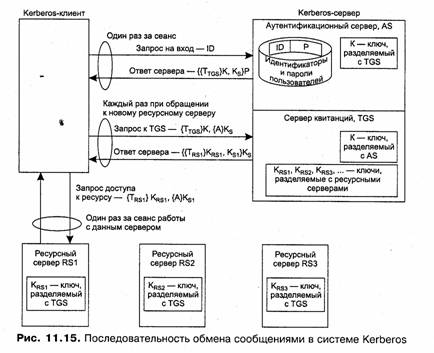
Квитанция TTGS на доступ к серверу квитанций TGS является удостоверением легальности пользователя и разрешением ему продолжать процесс получения доступа к ресурсу. Эта квитанция содержит:
□ идентификатор пользователя;
□ идентификатор сервера квитанций, на доступ к которому получена квитанция;
□ отметку о текущем времени;
□ период времени, в течение которого может продолжаться сеанс;
□ копию ключа сессии Ks.
Как уже было сказано, клиент обладает квитанцией в зашифрованном виде. Шифрование повышает уверенность в том, что никто, даже сам клиент — обладатель данной квитанции, — не сможет квитанцию подделать, подменить или изменить. Только сервер TGS, получив от клиента квитанцию, сможет ее расшифровать, так как в его распоряжении имеется ключ шифрования К.
Время действия квитанции ограничено длительностью сеанса. Разрешенная длительность сеанса пользователя, содержащаяся в квитанции на доступ к серверу квитанций, задается администратором и может изменяться в зависимости от требований к защищенности сети. В сетях с жесткими требованиями к безопасности время сеанса может быть ограничено 30 минутами, в других условиях это, время может составить 8 часов. Информация, содержащаяся в квитанции, определяет ее срок годности. Предоставление квитанции на вполне определенное время защищает ее от неавторизованного пользователя, который мог бы ее перехватить и использовать в будущем.
Получение разрешения на доступ к ресурсному серверу
Итак, следующим этапом для пользователя является получение разрешения на доступ к ресурсному серверу (например, к файловому серверу или серверу приложений). Но для этого надо обратиться к серверу TGS, который выдает такие разрешения (квитанции). Чтобы получить доступ к серверу квитанций, пользователь уже обзавелся квитанцией {TTGS}K, выданной ему сервером AS. Несмотря на защиту паролем и шифрование, пользователю, для того чтобы доказать серверу квитанций, что он имеет право на доступ к ресурсам сети, нужно кое-что еще, кроме квитанции.
Как уже упоминалось, первое сообщение от аутентификационного сервера содержало не только квитанцию, но и секретный ключ сеанса Ks, который разделяется с сервером квитанций TGS. Клиент использует этот ключ для шифрования еще одной электронной формы, называемой аутентификатором {A}KS. Аутентификатор А содержит идентификатор и сетевой адрес пользователя, а также собственную временную отметку. В отличие от квитанции {TTGS}K, которая в течение сеанса используется многократно, аутентификатор предназначен для одноразового использования и имеет очень короткое время жизни — обычно несколько минут. Kerberos-клиент посылает серверу квитанций TGS сообщение-запрос, содержащее квитанцию и аутентификатор: {TTGS}K, {A}KS.
Сервер квитанций расшифровывает квитанцию имеющимся у него ключом К, проверяет, не истек ли срок действия квитанции, и извлекает из нее идентификатор пользователя.
Затем сервер TGS расшифровывает аутентификатор, используя ключ сеанса пользователя Ks, который он извлек из квитанции. Сервер квитанций сравнивает идентификатор пользователя и его сетевой адрес с аналогичными параметрами в квитанции и сообщении. Если они совпадают, то сервер квитанций получает уверенность, что данная квитанция действительно представлена ее законным владельцем.
Заметим, что простое обладание квитанцией на получение доступа к серверу квитанций не доказывает идентичность пользователя. Так как аутентификатор действителен только в течение короткого промежутка времени, то маловероятно украсть одновременно и квитанцию, и аутентификатор и использовать их в течение этого времени. Каждый раз, когда пользователь обращается к серверу квитанций для получения новой квитанции на доступ к ресурсу, он посылает многократно используемую квитанцию и новый аутентификатор.
Клиент обращается к серверу квитанций за разрешением на доступ к ресурсному серверу, который здесь обозначен как RS1. Сервер квитанций, удостоверившись в легальности запроса и личности пользователя, отсылает ему ответ, содержащий две электронных формы: многократно используемую квитанцию на получение доступа к запрашиваемому ресурсному серверу TRS1 и новый ключ сеанса KS1.
Квитанция на получение доступа шифруется секретным ключом KRS1, разделяемым только сервером квитанций и тем сервером, к которому предоставляется доступ, в данном случае — RS1. Сервер квитанций разделяет уникальные секретные ключи с каждым сервером сети. Эти ключи распределяются между серверами сети физическим способом или каким-либо иным секретным способом при установке системы Kerberos. Когда сервер квитанций передает квитанцию на доступ к какому-либо ресурсному серверу, то он шифрует ее, так что только этот сервер сможет расшифровать ее с помощью своего уникального ключа.
Новый ключ сеанса KS1 содержится не только в самом сообщении, посылаемом клиенту, но и внутри квитанции TRS]. Все сообщение шифруется старым ключом сеанса клиента Ks, так что его может прочитать только этот клиент. Используя введенные обозначения, ответ сервера TGS клиенту можно представить в следующем виде: {{TRSi}KRS1, KS1}KS.
Когда клиент расшифровывает поступившее сообщение, то он отсылает серверу, к которому он хочет получить доступ, запрос, содержащий квитанцию на получение доступа и аутентификатор, зашифрованный новым ключом сеанса: {TRS1}KRS1, {A}KS1.
Это сообщение обрабатывается аналогично тому, как обрабатывался запрос клиента сервером TGS. Сначала расшифровывается квитанция ключом KRS1, затем извлекается ключ сеанса KS) и расшифровывается аутентификатор. Далее сравниваются данные о пользователе, содержащиеся в квитанции и аутентификаторе. Если проверка проходит успешно, то доступ к сетевому ресурсу разрешен.
На этом этапе клиент также может захотеть проверить аутентичность сервера перед тем, как начать с ним работать. Взаимная процедура аутентификации предотвращает любую возможность попытки получения неавторизованным пользователем доступа к секретной информации от клиента путем подмены сервера.
Аутентификация ресурсного сервера в системе Kerberos выполняется в соответствии со следующей процедурой. Клиент обращается к серверу с предложением, чтобы тот прислал ему сообщение, в котором повторил временную отметку из аутентификатора клиента, увеличенную на 1. Кроме того, требуется, чтобы данное сообщение было зашифровано ключом сеанса KS1. Чтобы выполнить такой запрос клиента, сервер извлекает копию ключа сеанса из квитанции на доступ, использует этот ключ для расшифровки аутентификатора, наращивает значение временной отметки на 1, заново зашифровывает сообщение, используя ключ сеанса, и возвращает сообщение клиенту. Клиент расшифровывает это сообщение, чтобы получить увеличенную на единицу отметку времени.
При успешном завершении описанного процесса клиент и сервер удостоверяются в секретности своих транзакций. Кроме этого, они получают ключ сеанса, который могут использовать для шифрования будущих сообщений.
Изучая довольно сложный механизм системы Kerberos, нельзя не задаться вопросом: какое влияние оказывают все эти многочисленные процедуры шифрования и обмена ключами на производительность сети, какую часть ресурсов сети они потребляют и как это сказывается на ее пропускной способности?
Ответ весьма оптимистичный — если система Kerberos реализована и сконфигурирована правильно, она незначительно уменьшает производительность сети. Так как квитанции используются многократно, сетевые ресурсы, затрачиваемые на запросы предоставления квитанций, невелики. Хотя передача квитанции при аутентификации логического входа несколько снижает пропускную способность, такой обмен должен осуществляться и при использовании любых других систем и методов аутентификации. Дополнительные же издержки незначительны. Опыт внедрения системы Kerberos показал, что время отклика при установленной системе Kerberos существенно не отличается от времени отклика без нее — даже в очень больших сетях с десятками тысяч узлов. Такая эффективность делает систему Kerberos весьма перспективной.
Среди уязвимых мест системы Kerberos можно назвать централизованное хранение всех секретных ключей системы. Успешная атака на Kerberos-сервер, в котором сосредоточена вся информация, критическая для системы безопасности, приводит к крушению информационной защиты всей сети. Альтернативным решением могла бы быть система, построенная на использовании алгоритмов шифрования с парными ключами, для которых характерно распределенное хранение секретных ключей. Однако в настоящий момент еще не появились коммерческие продукты, построенные на базе несимметричных методов шифрования, которые бы обеспечивали комплексную защиту больших сетей.
Еще одной слабостью системы Kerberos является то, что исходные коды тех приложений, доступ к которым осуществляется через Kerberos, должны быть соответствующим образом модифицированы. Такая модификация называется «керберизацией» приложения. Некоторые поставщики продают «керберизованные» версии своих приложений. Но если такой версии нет и нет исходного текста, то Kerberos не может обеспечить доступ к такому приложению.
Модель ISO/OSI
Организация взаимодействия между устройствами в сети является сложной проблемой, она включает много аспектов, начиная с согласования уровней электрических сигналов, формирования кадров, проверки контрольных сумм и кончая вопросами аутентификации приложений. Для ее решения используется универсальный прием — разбиение одной сложной задачи на несколько частных, более простых задач. Средства решения отдельных задач упорядочены в виде иерархии уровней. Для решения задачи некоторого уровня могут быть использованы средства непосредственно примыкающего нижележащего уровня. С другой стороны, результаты работы средств некоторого уровня могут быть переданы только средствам соседнего вышележащего уровня.
Многоуровневое представление средств сетевого взаимодействия имеет свою специфику, связанную с тем, что в процессе обмена сообщениями участвуют две машины, то есть в данном случае необходимо организовать согласованную работу двух «иерархий». При передаче сообщений оба участника сетевого обмена должны принять множество соглашений. Например, они должны согласовать способ кодирования электрических сигналов, правило определения длины сообщений, договориться о методах контроля достоверности и т. п. Другими словами, соглашения должны быть приняты для всех уровней, начиная от самого низкого уровня передачи битов до самого высокого уровня, предоставляющего услуги пользователям сети.
Формализованные правила, определяющие последовательность и формат сообщений, которыми обмениваются сетевые компоненты, лежащие на одном уровне, но в разных узлах, называются протоколом.
Модули, реализующие протоколы соседних уровней и находящиеся в одном узле, также взаимодействуют друг с другом в соответствии с четко определенными правилами и с помощью стандартизованных форматов сообщений. Эти правила принято называть интерфейсом. Интерфейс определяет услуги, предоставляемые данным уровнем соседнему уровню.
В сущности, протокол и интерфейс выражают одно и то же понятие, но традиционно в сетях за ними закрепили разные области действия: протоколы определяют правила взаимодействия модулей одного уровня в разных узлах, а интерфейсы — модулей соседних уровней в одном узле.
Средства каждого уровня должны отрабатывать, во-первых, свой собственный протокол, а во-вторых, интерфейсы с соседними уровнями. Иерархически организованный набор протоколов, достаточный для организации взаимодействия узлов в сети, называется стеком коммуникационных протоколов. Коммуникационные протоколы могут быть реализованы как программно, так и аппаратно. Протоколы нижних уровней часто реализуются комбинацией программных и аппаратных средств, а протоколы верхних уровней, как правило, чисто программными средствами.
В начале 80-х годов ряд международных организаций по стандартизации — ISO, ITU-T и некоторые другие — разработали модель, которая сыграла значительную роль в развитии сетей. Эта модель называется моделью взаимодействия открытых систем (Open System Interconnection, OSI), или моделью OSI. Модель OSI определяет различные уровни взаимодействия систем, дает им стандартные имена и указывает, какие функции должен выполнять каждый уровень.
В модели OSI (рис. П.1) средства взаимодействия делятся на семь уровней: прикладной, представительный, сеансовый, транспортный, сетевой, канальный w физический. Каждый уровень имеет дело с одним определенным аспектом взаимодействия сетевых устройств.
Физический уровень (Physical layer) имеет дело с передачей битов по физическим каналам связи, таким, например, как коаксиальный кабель, витая пара, оптоволоконный кабель или цифровой территориальный канал. К этому уровню имеют отношение характеристики физических сред передачи данных, такие как полоса пропускания, помехозащищенность, волновое сопротивление и другие. На этом же уровне определяются характеристики электрических сигналов, передающих дискретную информацию, например крутизна фронтов импульсов, уровни напряжения или тока передаваемого сигнала, тип кодирования, скорость передачи сигналов. Кроме этого, здесь стандартизуются типы разъемов и назначение каждого контакта.
Функции физического уровня реализуются во всех устройствах, подключенных к сети. Со стороны компьютера функции физического уровня выполняются сетевым адаптером или последовательным портом.
Примером протокола физического уровня может служить спецификация 10Base-T технологии Ethernet, которая определяет в качестве используемого кабеля неэкранированную витую пару категории 3 с волновым сопротивлением 100 Ом, разъем RJ-45, максимальную длину физического сегмента 100 метров, манчестерский код для представления данных в кабеле, а также некоторые другие характеристики среды и электрических сигналов.
На физическом уровне просто пересылаются биты. При этом не учитывается, что в некоторых сетях, в которых линии связи используются (разделяются) попеременно несколькими парами взаимодействующих компьютеров, физическая среда передачи может быть занята. Поэтому одной из задач канального уровня (Data Link layer) является проверка доступности среды передачи. Другой задачей канального уровня является реализация механизмов обнаружения и коррекции ошибок. Для этого на канальном уровне биты группируются в наборы, называемые кадрами (frames). Канальный уровень обеспечивает корректность передачи кадров, помещая для выделения каждого кадра специальную последовательность бит в его начало и конец, а также вычисляет контрольную сумму, обрабатывая все байты кадра определенным способом и добавляя контрольную сумму к кадру.
В локальных сетях протоколы канального уровня используются компьютерами, мостами, коммутаторами и маршрутизаторами. В компьютерах функции канального уровня реализуются совместными усилиями сетевых адаптеров и их драйверов.
В глобальных сетях, которые в отличие от локальных сетей редко обладают регулярной топологией, канальный уровень обеспечивает обмен сообщениями только между двумя соседними компьютерами, соединенными индивидуальной линией связи. Примерами протоколов «точка-точка» (как часто называют такие протоколы) могут служить широко распространенные протоколы РРР и LAP-B.
Сетевой уровень (Network layer) служит для образования единой транспортной системы, объединяющей несколько сетей, причем эти сети могут использовать
совершенно различные принципы передачи сообщений между конечными узлами и обладать произвольной структурой связей.
Сети соединяются между собой специальными устройствами, называемыми маршрутизаторами. Маршрутизатор — это устройство, которое собирает информацию о топологии межсетевых соединений и на ее основании пересылает пакеты сетевого уровня в сеть назначения. Для того чтобы передать сообщения сетевого уровня, или, как их принято называть, пакеты (packets), от отправителя, находящегося в одной сети, получателю, находящемуся в другой сети, нужно совершить некоторое количество транзитных передач между сетями. Таким образом, маршрут представляет собой последовательность маршрутизаторов, через которые проходит пакет. Проблема выбора наилучшего пути называется маршрутизацией, и ее решение является одной из главных задач сетевого уровня. Сетевой уровень решает также задачи согласования разных технологий, упрощения адресации в крупных сетях и создания надежных и гибких барьеров на пути нежелательного трафика между сетями.
Примерами протоколов сетевого уровня являются протокол межсетевого взаимодействия IP стека TCP/IP и протокол межсетевого обмена пакетами IPX стека Novell.
На пути от отправителя к получателю пакеты могут быть искажены или утеряны. Хотя некоторые приложения имеют собственные средства обработки ошибок, существуют и такие, которые предпочитают сразу иметь дело с надежным соединением. Работа транспортного уровня (Transport layer) заключается в том, чтобы обеспечить приложениям или верхним уровням стека — прикладному и сеансовому — передачу данных с той степенью надежности, которая им требуется. Модель OSI определяет пять классов услуг, предоставляемых транспортным уровнем. Эти виды услуг отличаются качеством: срочностью, возможностью восстановления прерванной связи, наличием средств мультиплексирования нескольких соединений между различными прикладными протоколами через общий транспортный протокол, а главное — способностью к обнаружению и исправлению ошибок передачи, таких как искажение, потеря и дублирование пакетов. Как правило, все протоколы, начиная с транспортного уровня и выше, реализуются программными средствами конечных узлов сети — компонентами их сетевых операционных систем. В качестве примера транспортных протоколов можно привести протоколы TCP и UDP стека TCP/IP и протокол SPX стека Novell.
Сеансовый уровень (Session layer) обеспечивает управление диалогом для того, чтобы фиксировать, какая из сторон является активной в настоящий момент, а также предоставляет средства синхронизации. Последние позволяют вставлять контрольные точки в длинные передачи, чтобы в случае отказа можно было вернуться назад к последней контрольной точке вместо того, чтобы начинать все с начала. На практике немногие приложения используют сеансовый уровень, и он редко реализуется в виде отдельных протоколов, хотя функции этого уровня часто объединяют с функциями прикладного уровня и реализуют в одном протоколе.
Уровень представления (Presentation layer) имеет дело с формой представления передаваемой по сети информации, не меняя при этом ее содержания. За счет уровня представления информация, передаваемая прикладным уровнем одной системы, всегда будет понятна прикладному уровню в другой системе. С помощью средств данного уровня протоколы прикладных уровней могут преодолеть синтаксические различия в представлении данных или же различия кодов символов, например кодов ASCII и EBCDIC. На этом уровне может выполняться шифрование и дешифрирование данных, благодаря которому секретность обмена данными обеспечивается сразу для всех прикладных служб. Примером такого протокола является протокол Secure Socket Layer (SSL), который обеспечивает секретный обмен сообщениями для протоколов прикладного уровня стека TCP/IP.
Прикладной уровень (Application layer) — это в действительности просто набор разнообразных протоколов, с помощью которых пользователи сети получают доступ к разделяемым ресурсам, таким как файлы, принтеры или гипертекстовые Web-страницы, а также организуют свою совместную работу, например с помощью протокола электронной почты. Единица данных, которой оперирует прикладной уровень, обычно называется сообщением (message).
Существует очень большое разнообразие служб прикладного уровня. Приведем в качестве примеров протоколов прикладного уровня хотя бы несколько наиболее распространенных реализаций файловых служб: NCP в операционной системе Novell NetWare, SMB в Microsoft Windows NT, NFS, FTP и TFTP, входящие в стек TCP/IP.