Управление памятью
Функции ОС по управлению памятью
Под памятью (memory) здесь подразумевается оперативная память компьютера. В отличие от памяти жесткого диска, которую называют внешней памятью (storage), оперативной памяти для сохранения информации требуется постоянное электропитание.
Память является важнейшим ресурсом, требующим тщательного управления со стороны мультипрограммной операционной системы. Особая роль памяти объясняется тем, что процессор может выполнять инструкции программы только в том случае, если они находятся в памяти. Память распределяется как между модулями прикладных программ, так и между модулями самой операционной системы.
В ранних ОС управление памятью сводилось просто к загрузке программы и ее данных из некоторого внешнего накопителя (перфоленты, магнитной ленты или магнитного диска) в память. С появлением мультипрограммирования перед ОС были поставлены новые задачи, связанные с распределением имеющейся памяти между несколькими одновременно выполняющимися программами.
Функциями ОС по управлению памятью в мультипрограммной системе являются:
□ отслеживание свободной и занятой памяти;
□ выделение памяти процессам и освобождение памяти по завершении процессов;
□ вытеснение кодов и данных процессов из оперативной памяти на диск (полное или частичное), когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место;
□ настройка адресов программы на конкретную область физической памяти.
Помимо первоначального выделения памяти процессам при их создании ОС должна также заниматься динамическим распределением памяти, то есть выполнять запросы приложений на выделение им дополнительной памяти во время выполнения. После того как приложение перестает нуждаться в дополнительной памяти, оно может возвратить ее системе. Выделение памяти случайной длины в случайные моменты времени из общего пула памяти приводит к фрагментации и, вследствие этого, к неэффективному ее использованию. Дефрагментация памяти тоже является функцией операционной системы.
Во время работы операционной системы ей часто приходится создавать новые служебные информационные структуры, такие как описатели процессов и потоков, различные таблицы распределения ресурсов, буферы, используемые процессами для обмена данными, синхронизирующие объекты и т. п. Все эти системные объекты требуют памяти. В некоторых ОС заранее (во время установки) резервируется некоторый фиксированный объем памяти для системных нужд. В других же ОС используется более гибкий подход, при котором память для системных целей выделяется динамически. В таком случае разные подсистемы ОС при создании своих таблиц, объектов, структур и т. п. обращаются к подсистеме управления памятью с запросами.
Защита памяти — это еще одна важная задача операционной системы, которая состоит в том, чтобы не позволить выполняемому процессу записывать или читать данные из памяти, назначенной другому процессу. Эта функция, как правило, реализуется программными модулями ОС в тесном взаимодействии с аппаратными средствами.
Для идентификации переменных и команд на разных этапах жизненного цикла программы используются символьные имена (метки), виртуальные адреса и физические адреса (рис. 5.1).
□ Символьные имена присваивает пользователь при написании программы на алгоритмическом языке или ассемблере.
□ Виртуальные адреса, называемые иногда математическими, или логическими адресами, вырабатывает транслятор, переводящий программу на машинный язык. Поскольку во время трансляции в общем случае не известно, в какое место оперативной памяти будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что начальным адресом программы будет нулевой адрес.
□ Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды.
Совокупность виртуальных адресов процесса называется виртуальным адресным пространством. Диапазон возможных адресов виртуального пространства у всех процессов является одним и тем же. Например, при использовании 32-разрядных виртуальных адресов этот диапазон задается границами 0000000016 и FFFFFFFF. Тем не менее каждый процесс имеет собственное виртуальное адресное пространство — транслятор присваивает виртуальные адреса переменным и кодам каждой программе независимо (рис. 5.2).
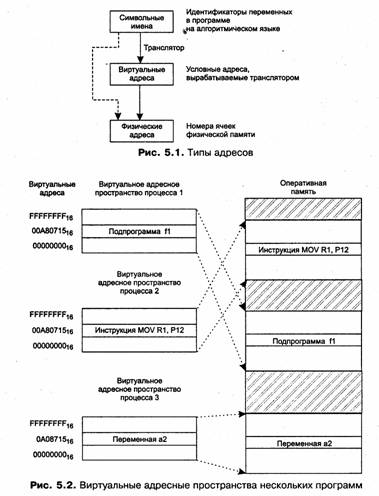
Совпадение виртуальных адресов переменных и команд различных процессов не приводит к конфликтам, так как в том случае, когда эти переменные одновременно присутствуют в памяти, операционная система отображает их на разные физические адреса.
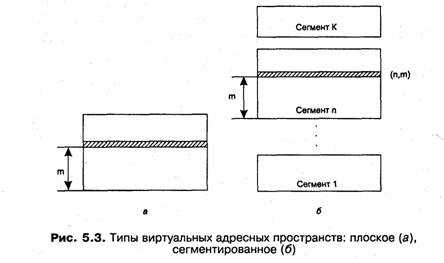
В разных операционных системах используются разные способы структуризации виртуального адресного пространства. В одних ОС виртуальное адресное пространство процесса подобно физической памяти представлено в виде непрерывной линейной последовательности виртуальных адресов. Такую структуру адресного пространства называют также плоской (flat). При этом виртуальным адресом является единственное число, представляющее собой смещение относительно начала (обычно это значение 000...000) виртуального адресного пространства (рис. 5.3, а). Адрес такого типа называют линейным виртуальным адресом.
В других ОС виртуальное адресное пространство делится на части, называемые
сегментами (или секциями, или областями, или другими терминами). В этом
случае помимо линейного адреса может быть использован виртуальный адрес,
представляющий собой пару чисел (и, т), где п определяет сегмент, am — смещение внутри сегмента (рис. 5.3, б).
Существуют и более сложные способы структуризации виртуального адресного пространства, когда виртуальный адрес образуется тремя или даже более числами.
Задачей операционной системы является отображение индивидуальных виртуальных адресных пространств всех одновременно выполняющихся процессов на общую физическую память. При этом ОС отображает либо все виртуальное адресное пространство, либо только определенную его часть. Процедура преобразования виртуальных адресов в физические должна быть максимально прозрачна для пользователя и программиста.
Существуют два принципиально отличающихся подхода к преобразованию виртуальных адресов в физические.
В первом случае замена виртуальных адресов на физические выполняется один раз для каждого процесса во время начальной загрузки программы в память. Специальная системная программа — перемещающий загрузчик — на основании имеющихся у нее исходных данных & начальном адресе физической памяти, в которую предстоит загружать программу, а также информации, предоставленной транслятором об адресно-зависимых элементах программы, выполняет загрузку программы, совмещая ее с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в неизмененном виде в виртуальных адресах, то есть операнды инструкций и адреса переходов имеют те значения, которые выработал транслятор. В наиболее простом случае, когда виртуальная и физическая память процесса представляют собой единые непрерывные области адресов, операционная система выполняет преобразование виртуальных адресов в физические по следующей схеме. При загрузке операционная система фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Схема такого преобразования показана на рис. 5.4. Пусть, например, операционная система использует линейно-структурированное виртуальное адресное пространство и пусть некоторая программа, работающая под управлением этой ОС, загружена в физическую память начиная с физического адреса S. ОС запоминает значение начального смещения S и во время выполнения программы помещает его в специальный регистр процессора. При обращении к памяти виртуальные адреса данной программы преобразуются в физические путем прибавления к ним смещения S. Например, при выполнении инструкции MOV пересылки данных, находящихся по адресу VA, виртуальный адрес VA заменяется физическим адресом VA+S.
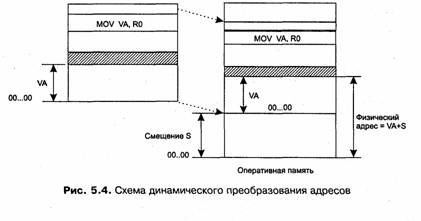
Последний способ является более гибким: в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку памяти, динамическое преобразование виртуальных адресов позволяет перемещать программный код процесса в течение всего периода его выполнения. Но использование перемещающего загрузчика более экономично, так как в этом случае преобразование каждого виртуального адреса происходит только один раз во время загрузки, а при динамическом преобразовании — при каждом обращении подданному адресу.
В некоторых случаях (обычно в специализированных системах), когда заранее точно известно, в какой области оперативной памяти будет выполняться программа, транслятор выдает исполняемый код сразу в физических адресах.
Необходимо различать максимально возможное виртуальное адресное пространство процесса и назначенное (выделенное) процессу виртуальное адресное пространство. В первом случае речь идет о максимальном размере виртуального адресного пространства, определяемом архитектурой компьютера, на котором работает ОС, и, в частности, разрядностью его схем адресации (32-битная, 64-битная и т. п.). Например, при работе на компьютерах с 32-разрядными процессорами Intel Pentium операционная система может предоставить каждому процессу виртуальное адресное пространство до 4 Гбайт (232). Однако это значение представляет собой только потенциально возможный размер виртуального адресного пространства, который редко на практике бывает необходим процессу. Процесс использует только часть доступного ему виртуального адресного пространства.
Назначенное виртуальное адресное пространство представляет собой набор виртуальных адресов, действительно нужных процессу для работы. Эти адреса первоначально назначает программе транслятор на основании текста программы, когда создает кодовый (текстовый) сегмент, а также сегмент или сегменты данных, с которыми программа работает. Затем при создании процесса ОС фиксирует назначенное виртуальное адресное пространство в своих системных таблицах. В ходе своего выполнения процесс может увеличить размер первоначального назначенного ему виртуального адресного пространства, запросив у ОС создания дополнительных сегментов или увеличения размера существующих. В любом случае операционная система обычно следит за корректностью использования процессом виртуальных адресов — процессу не разрешается оперировать с виртуальным адресом, выходящим за пределы назначенных ему сегментов.
Максимальный размер виртуального адресного пространства ограничивается только разрядностью адреса, присущей данной архитектуре компьютера, и, как правило, не совпадает с объемом физической памяти, имеющимся в компьютере.
Сегодня для машин универсального назначения типична ситуация, когда объем виртуального адресного пространства превышает доступный объем оперативной памяти. В таком случае операционная система для хранения данных виртуального адресного пространства процесса, не помещающихся в оперативную память, использует внешнюю память, которая в современных компьютерах представлена жесткими дисками (рис. 5.5, а). Именно на этом принципе основана виртуальная память — наиболее совершенный механизм, используемый в операционных системах для управления памятью.
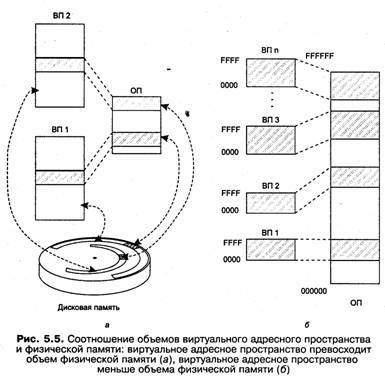
Однако соотношение объемов виртуальной и физической памяти может быть и обратным. Так, в мини-компьютерах 80-х годов разрядности поля адреса нередко , не хватало для того, чтобы охватить всю имеющуюся оперативную память. Несколько процессов могло быть загружено в память одновременно и целиком (рис. 5.5, б).
Необходимо подчеркнуть, что виртуальное адресное пространство и виртуальная память — это различные механизмы и они не обязательно реализуются в операционной системе одновременно. Можно представить себе ОС, в которой поддерживаются виртуальные адресные пространства для процессов, но отсутствует механизм виртуальной памяти. Это возможно только в том случае, если размер виртуального адресного пространства каждого процесса меньше объема физической памяти.
Содержимое назначенного процессу виртуального адресного пространства, то есть коды команд, исходные и промежуточные данные, а также результаты вычислений, представляет собой образ процесса.
Во время работы процесса постоянно выполняются переходы от прикладных кодов к кодам ОС, которые либо явно вызываются из прикладных процессов как системные функции, либо вызываются как реакция на внешние события или на исключительные ситуации, возникающие при некорректном поведении прикладных кодов. Для того чтобы упростить передачу управления от прикладного кода к коду ОС, а также для легкого доступа модулей ОС к прикладным данным (например, для вывода их на внешнее устройство), в большинстве ОС ее сегменты разделяют виртуальное адресное пространство с прикладными сегментами активного процесса. То есть сегменты ОС и сегменты активного процесса образуют единое виртуальное адресное пространство.
Обычно виртуальное адресное пространство процесса делится па две непрерывные части: системную и пользовательскую. В некоторых ОС (например, Windows NT, OS/2) эти части имеют одинаковый размер — по 2 Гбайт, хотя в принципе деление может быть и другим, например 1 Гбайт — для ОС, и 2 Гбайт —для прикладных программ. Часть виртуального адресного пространства каждого процесса, отводимая под сегменты ОС, является идентичной для всех процессов. Поэтому при смене активного процесса заменяется только вторая часть виртуального адресного пространства, содержащая его индивидуальные сегменты как правило, — коды и данные прикладной программы (рис. 5.6). Архитектура современных процессоров отражает эту особенность структуры виртуального адресного пространства, например, в процессорах Intel Pentium существует два типа системных таблиц: одна — для описания сегментов, общих для всех процессов, а другая — для описания индивидуальных сегментов данного процесса. При смене процесса первая таблица остается неизменной, а вторая заменяется новой.
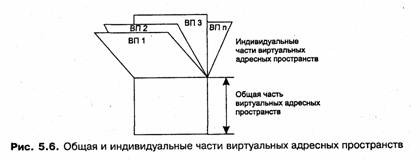
Описанное выше назначение двух частей виртуального адресного пространства — для сегментов ОС и для сегментов прикладной программы — является типичным, но не абсолютным. Имеются и исключения из общего правила. В некоторых ОС существуют системные процессы, порожденные для решения внутренних задач ОС. В этих процессах отсутствуют сегменты прикладной программы, но они могут расположить некоторые свои сегменты (сегменты ОС) в общей части виртуального адресного пространства, а некоторые — в индивидуальной части, обычно предназначенной для прикладных сегментов. И наоборот, в общей, системной части виртуального адресного пространства размещаются сегменты прикладного кода, предназначенные для совместного использования несколькими прикладными процессами.
Механизм страничной памяти в большинстве универсальных операционных систем применяется ко всем сегментам пользовательской части виртуального адресного пространства процесса. Исключения могут составлять специализированные ОС, например ОС реального времени в которых некоторые сегменты жестко фиксируются в оперативной памяти и соответственно никогда не выгружаются на диск — это обеспечивает быструю реакцию определенных приложений на внешние события.
Системная часть виртуальной памяти в ОС любого типа включает область, подвергаемую страничному вытеснению (paged), и область, на которую страничное вытеснение не распространяется {non-paged). В не вытесняемой области размещаются модули ОС, требующие быстрой реакции и/или постоянного присутствия в памяти, например диспетчер потоков или код, который управляет заменой страниц памяти. Остальные модули ОС подвергаются страничному вытеснению, как и пользовательские сегменты.
Обычно аппаратура накладывает свои ограничения на порядок использования виртуального адресного пространства. Некоторые процессоры (например, MIPS) предусматривают для определенной области системной части адресного пространства особые правила отображения на физическую память. При этом виртуальный адрес прямо отображается на физический адрес (последний либо полностью соответствует виртуальному адресу, либо равен его части). Такая особая область памяти не подвергается страничному вытеснению, и поскольку достаточно трудоемкая процедура преобразования адресов исключается, то доступ к располагаемым здесь кодам и данным осуществляется очень быстро.
Алгоритмы распределения памяти
Следует ли назначать каждому процессу одну непрерывную область физической памяти или можно выделять память «кусками»? Должны ли сегменты программы, загруженные в память, находиться на одном месте в течение всего периода выполнения процесса или можно ее время от времени сдвигать? Что делать, если сегменты программы не помещаются в имеющуюся память? Разные ОС по-разному отвечают на эти и другие базовые вопросы управления памятью. Далее будут рассмотрены наиболее общие подходы к распределению памяти, которые были характерны для разных периодов развития операционных систем. Некоторые из них сохранили актуальность и широко используются в современных ОС, другие же представляют в основном только познавательный интерес, хотя их и сегодня можно встретить в специализированных системах.
На рис. 5.7 все алгоритмы распределения памяти разделены на два класса: алгоритмы, в которых используется перемещение сегментов процессов между оперативной памятью и диском, и алгоритмы, в которых внешняя память не привлекается.
Распределение памяти фиксированными разделами
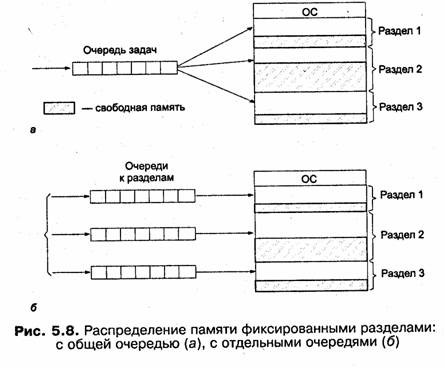
Простейший способ управления оперативной памятью состоит в том, что память разбивается на несколько областей фиксированной величины, называемых разделами. Такое разбиение может быть выполнено вручную оператором во время старта системы или во время ее установки. После этого границы разделов не изменяются.
Очередной новый процесс, поступивший на выполнение, помещается либо в общую очередь (рис. 5.8, а), либо в очередь к некоторому разделу (рис. 5.8, б).
Подсистема управления памятью в этом случае выполняет следующие задачи.
□ Сравнивает объем памяти, требуемый для вновь поступившего процесса, с размерами
□ свободных разделов и выбирает подходящий раздел.
Осуществляет загрузку программы в один из разделов и настройку адресов. Уже на этапе трансляции разработчик программы может задать раздел, в котором ее следует выполнять. Это позволяет сразу, без использования перемещающего загрузчика, получить машинный код, настроенный на конкретную область памяти.
При очевидном преимуществе — простоте реализации, данный метод имеет существенный недостаток — жесткость. Так как в каждом разделе может выполняться только один процесс, то уровень мультипрограммирования заранее ограничен числом разделов. Независимо от размера программы она будет занимать весь раздел. Так, например, в системе с тремя разделами невозможно выполнять одновременно более трех процессов, даже если им требуется совсем мало памяти. С другой стороны, разбиение памяти на разделы не позволяет выполнять процессы, программы которых не помещаются ни в один из разделов, но для которых было бы достаточно памяти нескольких разделов.
Такой способ управления памятью применялся в ранних мультипрограммных ОС. Однако и сейчас метод распределения памяти фиксированными разделами находит применение в системах реального времени, в основном благодаря небольшим затратам на реализацию. Детерминированность вычислительного процесса систем реального времени (заранее известен набор выполняемых задач, их требования к памяти, а иногда и моменты запуска) компенсирует недостаточную гибкость данного способа управления памятью.
Распределение памяти динамическими разделами
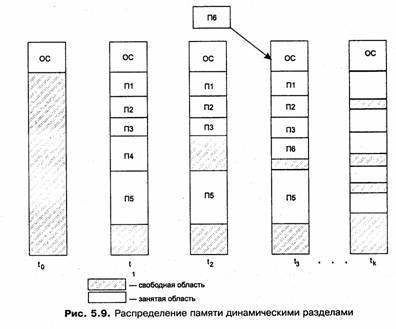
В этом случае память машины не делится заранее на разделы. Сначала вся память, отводимая для приложений, свободна. Каждому вновь поступающему на выполнение приложению на этапе создания процесса выделяется вся необходимая ему память (если достаточный объем памяти отсутствует, то приложение не принимается на выполнение и процесс для него не создается). После завершения процесса память освобождается, и на это место может быть загружен другой процесс. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. На рис. 5.9 показано состояние памяти в различные моменты времени при использовании динамического распределения. Так, в момент t0 в памяти находится только ОС, а к моменту t1 память разделена между 5 процессами, причем процесс П4, завершаясь, покидает память. На освободившееся от процесса П4 место загружается процесс П6, поступивший в момент t3.
Функции операционной системы, предназначенные для реализации данного метода управления памятью, перечислены ниже.
□ Ведение таблиц свободных и занятых областей, в которых указываются начальные адреса и размеры участков памяти.
□ При создании нового процесса — анализ требований к памяти, просмотр таблицы свободных областей и выбор раздела, размер которого достаточен для размещения кодов и данных нового процесса. Выбор раздела может осуществляться по разным правилам, например: «первый попавшийся раздел достаточного размера», «раздел, имеющий наименьший достаточный размер» или «раздел, имеющий наибольший достаточный размер».
□ Загрузка программы в выделенный ей раздел и корректировка таблиц свободных и занятых областей. Данный способ предполагает, что программный код не перемещается во время выполнения, а значит, настройка адресов может быть проведена единовременно во время загрузки.
□ После завершения процесса корректировка таблиц свободных и занятых областей.
По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток — фрагментация памяти. Фрагментация — это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Распределение памяти динамическими разделами лежит в основе подсистем управления памятью многих мультипрограммных операционных системах 60-70-х годов, в частности такой популярной операционной системы, как OS/360.
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших или младших адресов, так, чтобы вся свободная память образовала единую свободную область (рис. 5.10). В дополнение к функциям, которые выполняет ОС при распределении памяти динамическими разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется сжатием. Сжатие может выполняться либо при каждом завершении процесса, либо только тогда, когда для вновь создаваемого процесса нет свободного раздела достаточного размера. В первом случае требуется меньше вычислительной работы при корректировке таблиц свободных и занятых областей, а во втором — реже выполняется процедура сжатия.

Так как программы перемещаются по оперативной памяти в ходе своего выполнения, то в данном случае невозможно выполнить настройку адресов с помощью перемещающего загрузчика. Здесь более подходящим оказывается динамическое преобразование адресов.
Хотя процедура сжатия и приводит к более эффективному использованию памяти, она может потребовать значительного времени, что часто перевешивает преимущества данного метода.
Концепция сжатия применяется и при использовании других методов распределения памяти, когда отдельному процессу выделяется не одна сплошная область памяти, а несколько несмежных участков памяти произвольного размера (сегментов). Такой подход был использован в ранних версиях OS/2, в которых память распределялась сегментами, а возникавшая при этом фрагментация устранялась путем периодического перемещения сегментов.
Необходимым условием для того, чтобы программа могла выполняться, является ее нахождение в оперативной памяти. Только в этом случае процессор может извлекать команды из памяти и интерпретировать их, выполняя заданные действия. Объем оперативной памяти, который имеется в компьютере, существенно сказывается на характере протекания вычислительного процесса. Он ограничивает число одновременно выполняющихся программ и размеры их виртуальных адресных пространств. В некоторых случаях, когда все задачи мультипрограммной смеси являются вычислительными (то есть выполняют относительно мало операций ввода-вывода, разгружающих центральный процессор), для хорошей загрузки процессора может оказаться достаточным всего 3-5 задач. Однако если вычислительная система загружена выполнением интерактивных задач, то для эффективного использования процессора может потребоваться уже несколько десятков, а то и сотен задач. Эти рассуждения хорошо иллюстрирует рис. 5.11, на котором показан график зависимости коэффициента загрузки процессора от числа одновременно выполняемых процессов и доли времени, проводимого этими процессами в состоянии ожидания ввода-вывода.
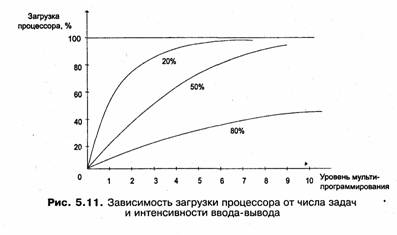
Большое количество задач, необходимое для высокой загрузки процессора, требует большого объема оперативной памяти. В условиях, когда для обеспечения приемлемого уровня мультипрограммирования имеющейся оперативной памяти недостаточно, был предложен метод организации вычислительного процесса, при котором образы некоторых процессов целиком или частично временно выгружаются на диск.
В мультипрограммном режиме помимо активного процесса, то есть процесса, коды которого в настоящий момент. Интерпретируются процессором, имеются приостановленные процессы, находящиеся в ожидании завершения ввода-вывода или освобождения ресурсов, а также процессы в состоянии готовности, стоящие в очереди к процессору. Образы таких неактивных процессов могут быть временно, до следующего цикла активности, выгружены на диск. Несмотря на то что коды и данные процесса отсутствуют в оперативной памяти, ОС «знает» о его существовании и в полной мере учитывает это при распределении процессорного времени и других системных ресурсов. К моменту, когда подходит очередь выполнения выгруженного процесса, его образ возвращается с диска в оперативную память. Если при этом обнаруживается, что свободного места в оперативной памяти не хватает, то на диск выгружается другой процесс.
Такая подмена {виртуализация) оперативной памяти дисковой памятью позволяет повысить уровень мультипрограммирования — объем оперативной памяти компьютера теперь не столь жестко ограничивает количество одновременно выполняемых процессов, поскольку суммарный объем памяти, занимаемой образами этих процессов, может существенно превосходить имеющийся объем оперативной памяти. Виртуальным называется ресурс, который пользователю или пользовательской программе представляется обладающим свойствами, которыми он в действительности не обладает. В данном случае в распоряжение прикладного программиста предоставляется виртуальная оперативная память, размер которой намного превосходит всю имеющуюся в системе реальную оперативную память. Пользователь пишет программу, а транслятор, используя виртуальные адреса, переводит ее в машинные коды так, как будто в распоряжении программы имеется однородная оперативная память большого объема. В действительности же все коды и данные, используемые программой, хранятся на дисках и только при необходимости загружаются в реальную оперативную память. Понятно, однако, что работа такой «оперативной памяти» происходит значительно медленнее.
Виртуализация оперативной памяти осуществляется совокупностью программных модулей ОС и аппаратных схем процессора и включает решение следующих задач:
□ размещение данных в запоминающих устройствах разного типа, например часть кодов программы — в оперативной памяти, а часть — на диске;
□ выбор образов процессов или их частей для перемещения из оперативной памяти на диск и обратно;
□ перемещение по мере необходимости данных между памятью и диском;
□ преобразование виртуальных адресов в физические.
Очень важно то, что все действия по организации совместного использования диска и оперативной памяти — выделение места для перемещаемых фрагментов, настройка адресов, выбор кандидатов на загрузку и выгрузку — осуществляются операционной системой и аппаратурой процессора автоматически, без участия программиста, и никак не сказываются на логике работы приложений.
ПРИМЕЧАНИЕ----------------------------------------------------------------------------------------------
Уже достаточно давно пользователи столкнулись с проблемой размещения в памяти программы, размер которой превышает имеющуюся в наличии свободную память. Одним из первых решений было разбиение программы на части, называемые оверлеями. Когда первый оверлей заканчивал свое выполнение, он вызывал другой оверлей. Все оверлеи хранились на диске и перемещались между памятью и диском средствами операционной системы на основании явных директив программиста, содержащихся в программе. Этот способ, несмотря на внешнее сходство, имеет принципиальное отличие от виртуальной памяти, заключающееся в том, что разбиение программы на части и планирование их загрузки в оперативную память должны были выполняться заранее программистом во время написания программы.
Виртуализация памяти может быть осуществлена на основе двух различных подходов:
□ свопинг (swapping) — образы процессов выгружаются на диск и возвращаются в оперативную память целиком;
□ виртуальная память (virtual memory) — между оперативной памятью и диском перемещаются части (сегменты, страницы и т. п.) образов процессов.
Свопинг представляет собой частный случай виртуальной памяти и, следовательно, более простой в реализации способ совместного использования оперативной памяти и диска. Однако подкачке свойственна избыточность: когда ОС решает активизировать процесс, для его выполнения, как правило, не требуется загружать в оперативную память все его сегменты полностью — достаточно загрузить небольшую часть кодового сегмента с подлежащей выполнению инструкцией и частью сегментов данных, с которыми работает эта инструкция, а также отвести место под сегмент стека. Аналогично при освобождении памяти для загрузки нового процесса очень часто вовсе не требуется выгружать другой процесс на диск целиком, достаточно вытеснить на диск только часть его образа. Перемещение избыточной информации замедляет работу системы, а также приводит к неэффективному использованию памяти. Кроме того, системы, поддерживающие свопинг, имеют еще один очень существенный недостаток: они не способны загрузить для выполнения процесс, виртуальное адресное пространство которого превышает имеющуюся в наличии свободную память.
Именно из-за указанных недостатков свопинг как основной механизм управления памятью почти не используется в современных ОС:. На смену ему пришел более совершенный механизм виртуальной памяти, который, как уже было сказано, заключается в том, что при нехватке места в оперативной памяти на диск выгружаются только части образов процессов.
Ключевой проблемой виртуальной памяти, возникающей в результате многократного изменения местоположения в оперативной памяти образов процессов или их частей, является преобразование виртуальных адресов в физические. Решение этой проблемы, в свою очередь, зависит от того, какой способ структуризации виртуального адресного пространства принят в данной системе управления памятью. В настоящее время jce множество реализаций виртуальной памяти может быть представлено тремя классами.
□ Страничная виртуальная память организует перемещение данных между памятью и диском страницами — частями виртуального адресного пространства, фиксированного и сравнительно небольшого размера.
□ Сегментная виртуальная память предусматривает перемещение данных сегментами — частями виртуального адресного пространства произвольного размера, полученными с учетом смыслового значения данных.
□ Сегментно-страничная виртуальная память использует двухуровневое деление: виртуальное адресное пространство делится на сегменты, а затем сегменты делятся на страницы. Единицей перемещения данных здесь является страница. Этот способ управления памятью объединяет в себе элементы обоих предыдущих подходов.
Для временного хранения сегментов и страниц на диске отводится либо специальная область, либо специальный файл, которые во многих ОС по традиции продолжают называть областью, или файлом свопинга, хотя перемещение информации между оперативной памятью и диском осуществляется уже не в форме полного замещения одного процесса другим, а частями. Другое популярное название этой области — страничный файл (page file, или paging file). Текущий размер страничного файла является важным параметром, оказывающим влияние на возможности операционной системы: чем больше страничный файл, тем больше приложений может одновременно выполнять ОС (при фиксированном размере оперативной памяти). Однако необходимо понимать, что увеличение числа одновременно работающих приложений за счет увеличения размера страничного файла замедляет их работу, так как значительная часть времени при этом тратится на перекачку кодов и данных из оперативной памяти на диск и обратно. Размер страничного файла в современных ОС является настраиваемым параметром, который выбирается администратором системы для достижения компромисса между уровнем мультипрограммирования и быстродействием системы.
На рис. 5.12 показана схема страничного распределения памяти. Виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами {virtual pages). В общем случае размер виртуального адресного пространства процесса не кратен размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками, или кадрами). Размер страницы выбирается равным степени двойки: 512, 1024, 4096 байт и т. д. Это позволяет упростить механизм преобразования адресов.
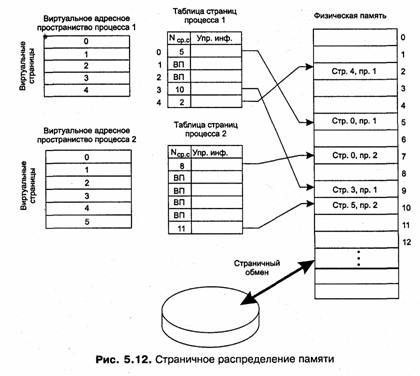
При создании процесса ОС загружает в оперативную память несколько его виртуальных страниц (начальные страницы кодового сегмента и сегмента данных). Копия всего виртуального адресного пространства процесса находится на диске. Смежные виртуальные страницы не обязательно располагаются в смежных физических страницах. Для каждого процесса операционная система создает таблицу страниц — информационную структуру, содержащую записи обо всех виртуальных страницах процесса.
Запись Таблицы, называемая дескриптором страницы, включает следующую информацию:
□ номер физической страницы, в которую загружена данная виртуальная страница;
□ признак присутствия, устанавливаемый в единицу, если виртуальная страница находится в оперативной памяти;
□ признак модификации страницы, который устанавливается в единицу всякий раз, когда производится запись по адресу, относящемуся к данной странице;
□ признак обращения к странице, называемый также битом доступа, который устанавливается в единицу при каждом обращении по адресу, относящемуся к данной странице.
Признаки присутствия, модификации и обращения в большинстве моделей современных процессоров устанавливаются аппаратно, схемами процессора при выполнении операции с памятью. Информация из таблиц страниц используется для решения вопроса о необходимости перемещения той или иной страницы между памятью и диском, а также для преобразования виртуального адреса в физический. Сами таблицы страниц, так же как и описываемые ими страницы, размещаются в оперативной памяти. Адрес таблицы страниц включается в контекст соответствующего процесса. При активизации очередного процесса операционная система загружает адрес его таблицы страниц в специальный регистр процессора.
При каждом обращении к памяти выполняется поиск номера виртуальной страницы, содержащей требуемый адрес, затем по этому номеру определяется нужный элемент таблицы страниц, и из него извлекается описывающая страницу информация1. Далее анализируется признак присутствия, и, если данная виртуальная страница находится в оперативной памяти, то выполняется преобразование виртуального адреса в физический, то есть виртуальный адрес заменяется указанным в записи таблицы физическим адресом. Если же нужная виртуальная страница в данный момент выгружена на диск, то происходит так называемое страничное прерывание. Выполняющийся процесс переводится в состояние ожидания, и активизируется другой процесс из очереди процессов, находящихся в состоянии готовности. Параллельно программа обработки страничного прерывания находит на диске требуемую виртуальную страницу (для этого операционная система должна Помнить положение вытесненной страницы в страничном файле диска) и пытается загрузить ее в оперативную память. Если в памяти имеется свободная физическая страница, то загрузка выполняется немедленно, если же свободных страниц нет, то на основании принятой в данной системе стратегии замещения страниц решается вопрос о том, какую страницу следует выгрузить из оперативной памяти.
После того как выбрана страница, которая должна покинуть оперативную память, обнуляется ее бит присутствия и анализируется ее признак модификации. Если выталкиваемая страница за время последнего пребывания в оперативной памяти была модифицирована, то ее новая версия должна быть переписана на диск. Если нет, то принимается во внимание, что на диске уже имеется предыдущая копия этой виртуальной страницы, и никакой записи на диск не производится. Физическая страница объявляется свободной. Из соображений безопасности в некоторых системах освобождаемая страница обнуляется, с тем чтобы невозможно было использовать содержимое выгруженной страницы.
Для хранения информации о положении вытесненной страницы в страничном файле ОС может использовать поля таблицы страниц или же другую системную структуру данных (например, дескриптор сегмента при сегментно-страничной организации виртуальной памяти).
Виртуальный адрес при страничном распределении может быть представлен в виде пары (р, sv), где р — порядковый номер виртуальной страницы процесса (нумерация страниц начинается с 0), a sv — смещение в пределах виртуальной страни1$ы. Физический адрес также может быть представлен в виде пары (n, sf), где n — номер физической страницы, a sf — смещение в пределах физической страницы. Задача подсистемы виртуальной памяти состоит в отображении (р, sv) в (n, sf).
Прежде чем приступить к рассмотрению схемы преобразования виртуального адреса в физический, остановимся на двух базисных свойствах страничной организации.
Первое из них состоит в том, что объем страницы выбирается равным степени двойки — 2к. Из этого следует, что смещение s может быть получено простым отделением к младших разрядов в двоичной записи адреса, а оставшиеся старшие разряды адреса представляют собой двоичную запись номера страницы (при этом неважно, является страница виртуальной или физической). Например, если размер страницы 1 Кбайт (210), то из двоичной записи адреса 50718 = = 101 000 111 0012 можно определить, что он принадлежит странице, номер которой в двоичном выражении равен 102 и смещен относительно ее начала на 1000 111 0012 байт (рис. 5.13).
 |
Из рисунка хорошо видно, что номер страницы и ее начальный адрес легко могут быть получены один из другого дополнением или отбрасыванием к нулей, соответствующих смещению. Именно по этой причине часто говорят, что таблица страниц содержит начальный физический адрес страницы в памяти (а не номер физической страницы), хотя на самом деле в таблице указаны только старшие разряды адреса. Начальный адрес страницы называется базовым адресом.
Второе свойство заключается в том, что в пределах страницы непрерывная последовательность виртуальных адресов однозначно отображается в непрерывную последовательность физических адресов, а значит, смещения в виртуальном и физическом адресах sv и Sf равны между собой (рис. 5.14).

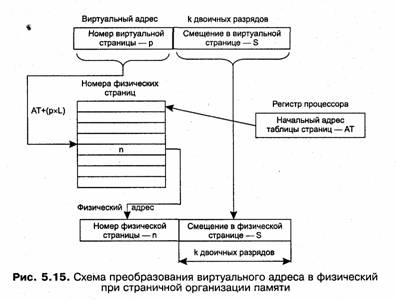
Отсюда следует простая схема преобразования виртуального адреса в физический (рис. 5.15). Младшие разряды физического адреса, соответствующие смещению, получаются переносом такого же количества младших разрядов из виртуального адреса. Старшие разряды физического адреса, соответствующие номеру физической страницы, определяются из таблицы страниц, в которой указывается соответствие виртуальных и физических страниц.
Итак, пусть произошло обращение к памяти по некоторому виртуальному адресу. Аппаратными схемами процессора выполняются следующие действия:
1. Из специального регистра процессора извлекается адрес AT таблицы страниц активного процесса. На основании начального адреса таблицы страниц, номера виртуальной страницы р (старшие разряды виртуального адреса) и длины отдельной записи в таблице страниц L (системная константа) определяется адрес нужного дескриптора в таблице страниц: a=AT+(pxL).
2. Из этого дескриптора извлекается номер соответствующей физической страницы — n.
3. К номеру физической страницы присоединяется смещение s (младшие разряды виртуального адреса).
Типичная машинная инструкция требует 3-4 обращений к памяти (выборка команды, извлечение операндов, запись результата). И при каждом обращении
происходит либо преобразование виртуального адреса в физический, либо обработка страничного прерывания. Время выполнения этих операций в значительной степени влияет на общую производительность вычислительной системы, поэтому столь большое внимание разработчиков уделяется оптимизации виртуальной памяти.
Именно для уменьшения времени преобразования адресов во всех процессорах предусмотрен аппаратный механизм получения физического адреса по виртуальному. С той же целью размер страницы выбирается равным степени двойки, благодаря чему двоичная запись адреса легко разделяется на номер страницы и смещение, и в результате в процедуре преобразования адресов более длительная операция сложения заменяется операцией присоединения (конкатенации). Используются и другие способы ускорения преобразования, такие например, как кэширование таблицы страниц — хранение наиболее активно используемых записей в быстродействующих запоминающих устройствах, в частности в регистрах процессора.
Другим важным фактором, влияющим на производительность системы, является частота страничных прерываний, на которую, в свою очередь, влияют размер страницы и принятые в данной системе правила выбора страниц для выгрузки и загрузки. При неправильно выбранной стратегии замещения страниц могут возникать ситуации, когда система тратит большую часть времени впустую, на подкачку страниц из оперативной памяти на диск и обратно.
При выборе страницы на выгрузку могут быть использованы различные критерии, смысл которых сводится к одному: на диск выталкивается страница, к которой в будущем начиная с данного момента дольше всего не будет обращений. Поскольку точно предсказать ход вычислительного процесса невозможно, то невозможно точно определить страницу, подлежащую выгрузке. В таких условиях решение принимается на основе неких эмпирических критериев, часто основывающихся на предположении об инерционности вычислительного процесса. Так, например, из того, что страница не использовалась долгое время, делается вывод о том, что она, скорее всего, не будет использоваться и в ближайшее время. Однако привлечение критериев |кого рода не исключает ситуаций, когда сразу после выгрузки страницы к ней происходит обращение и она снова должна быть загружена в память. Вероятность таких «напрасных» перемещений настолько велика, что в некоторых реализациях виртуальной памяти вообще отказываются от количественных критериев и предпочитают случайный выбор, при котором на диск выгружается первая попавшаяся страница. Возникающее при этом некоторое увеличение интенсивности страничного обмена компенсируется снижением вычислительных затрат на поддержание и анализ критерия выборки страниц на выгрузку.
Наиболее популярным критерием выбора страницы на выгрузку является число обращений к ней за последний период времени. Вычисление этого критерия происходит следующим образом. Операционная система ведет для каждой страницы программный счетчик. Значения счетчиков определяются значениями признаков доступа. Всякий раз, когда происходит обращение к какой-либо странице, процессор устанавливает в единицу признак доступа в относящейся к данной странице записи таблицы страниц. ОС периодически просматривает признаки доступа всех страниц во всех существующих в данный момент записях таблицы страниц. Если какой-либо признак оказывается равным 1 (было обращение), то система сбрасывает его в 0, увеличивая при этом на единицу значение связанного с этой страницей счетчика обращений. Когда возникает необходимость удалить какую-либо страницу из памяти, ОС находит страницу, счетчик обращений которой имеет наименьшее значение. Для того чтобы критерий учитывал интенсивность обращений за последний период, ОС с соответствующей периодичностью обнуляет все счетчики.
Интенсивность страничного обмена может быть также снижена в результате так называемой упреждающей загрузки, в соответствии с которой при возникновении страничного прерывания в память загружается не одна страница, содержащая адрес обращения, а сразу несколько прилегающих к ней страниц. Здесь используется эмпирическое правило: если обращение произошло по некоторому адресу, то велика вероятность того, что следующие обращения произойдут по соседним адресам.
Другим важным резервом повышения производительности системы является правильный выбор размера страницы. Каким же должен быть оптимальный размер страницы? С одной стороны, чтобы уменьшить частоту страничных прерываний, следовало бы увеличивать размер страницы. С другой стороны, если страница велика, то велика и фиктивная область в последней виртуальной странице каждого процесса. Если учесть, что в среднем в каждом процессе фиктивная область составляет половину страницы, то в сумме при большом объеме страницы потери могут составить существенную величину. Из приведенных соображений еле дует, что выбор размера страницы является сложной оптимизационной задачей, требующей учета многих факторов. На практике же разработчики ОС и процессоров ограничиваются неким рациональным решением, пригодным для широкого класса вычислительных систем. Типичный размер страницы составляет несколько килобайт, например, наиболее распространенные процессоры х86 и
Pentium компании Intel, а также операционные системы, устанавливаемые на этих процессорах, поддерживают страницы размером 4096 байт (4 Кбайт).
Размер Страницы влияет также на количество записей в таблицах страниц. Чем меньше страница, тем более объемными являются таблицы страниц процессов и тем больше места они занимают в памяти. Учитывая, что в современных процессорах максимальный объем виртуального адресного пространства процесса, как правило, не меньше 4 Гбайт (232), то при размере страницы 4 Кбайт (212) и длине записи 4 байта для хранения таблицы страниц может потребоваться 4 Мбайт памяти! Выходом в такой ситуации является хранение в памяти только той части таблицы страниц, которая активно используется в данный период времени — так как сама таблица страниц хранится в таких же страницах физической памяти, что и описываемые ею страницы, то принципиально возможно временно вытеснять часть таблицы страниц из оперативной памяти.
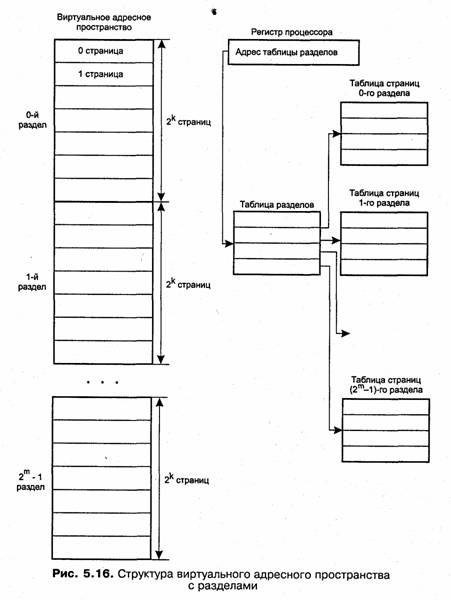
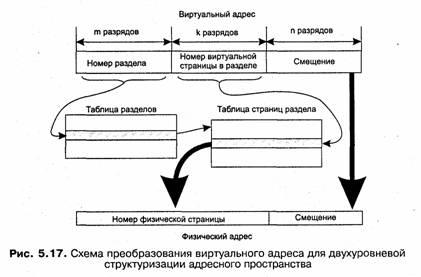
Именно такой результат может быть достигнут путем более сложной структуризации виртуального адресного пространства, при котором все множество виртуальных адресов процесса делится на разделы, а разделы делятся на страницы (рис. 5.16). Все страницы имеют одинаковый размер, а разделы содержат одинаковое количество страниц. Если размер страницы и количество страниц в разделе выбрать равными степени двойки (2к и 2к соответственно), то принадлежность виртуального адреса к разделу и странице, а также смещение внутри страницы можно определить очень просто: младшие к двоичных разрядов дают смещение, следующие разрядов представляют собой номер виртуальной страницы, а оставшиеся старшие разряды (обозначим их количество т) содержат номер раздела.
Для каждого раздела строится собственная таблица страниц. Количество дескрипторов в таблице и их размер подбираются такими, чтобы объем таблицы оказался равным объему страницы. Например, в процессоре Pentium при размере страницы 4 Кбайт длина дескриптора страницы составляет 4 байта и количество записей в таблице страниц, помещающейся на страницу, равняется соответственно 1024. Каждая таблица страниц описывается дескриптором, структура которого полностью совпадает со структурой дескриптора обычной страницы. Эти дескрипторы сведены в таблицу разделов, называемую также каталогом страниц. Физический адрес таблицы разделов активного процесса содержится в специальном регистре процессора и поэтому всегда известен операционной системе. Страница, содержащая таблицу разделов, никогда не выгружается из памяти, в противном случае работа виртуальной памяти была бы невозможна.
Выгрузка страниц с таблицами страниц позволяет сэкономить память, но при этом приводит к дополнительным временным затратам при получении физического адреса. Действительно, может случиться так, что та таблица страниц, которая содержит нужный дескриптор, в данный момент выгружена на диск, тогда процесс преобразования адреса приостанавливается до тех пор, пока требуемая страница не будет снова загружена в память. Для уменьшения вероятности отсутствия страницы в памяти используются различные приемы, основным из которых является кэширование.
Проследим более подробно схему преобразования адресов для случая двухуровневой структуризации виртуального адресного пространства (рис. 5.17).:
1. Путем отбрасывания k+n младших разрядов в виртуальном адресе определяется номер раздела, к которому принадлежит данный виртуальный адрес.
2. По этому номеру из таблицы разделов извлекается дескриптор соответствующей таблицы страниц. Проверяется, находится ли данная таблица страниц в памяти. Если нет, происходит страничное прерывание и система загружает нужную страницу с диска.
3. Далее из этой таблицы страниц извлекается дескриптор виртуальной страницы, номер которой содержится в средних n разрядах преобразуемого виртуального адреса. Снова выполняется проверка наличия данной страницы в памяти и при необходимости ее загрузка.
4. Из дескриптора определяется номер (базовый адрес) физической страницы, в которую загружена данная виртуальная страница. К номеру физической страницы пристыковывается смещение, взятое из к младших разрядов виртуального адреса. В результате получается искомый физический адрес.
Страничное распределение памяти может быть реализовано в
упрощенном варианте, без выгрузки страниц на диск. В этом случае все
виртуальные страницы всех процессов постоянно находятся в оперативной памяти.
Такой вариант страничной организации хотя и не предоставляет пользователю
преимуществ работы с виртуальной памятью большого объема, но сохраняет другое
достоинство страничной организации — позволяет успешно бороться с фрагментацией
физической памяти. Действительно, во-первых, программу можно разбить на части и
загрузить в разрозненные участки свободной памяти, во-вторых, при загрузке
виртуальных страниц
никогда не образуется неиспользуемых остатков, так
как размеры виртуальных и физических страниц совпадают. Такой режим работы системы
управления памятью используется в некоторых специализированных ОС, когда
требуется высокая реактивность системы и способность выполнять переменный
набор приложений (пример — ОС семейства Novell NetWare 3.x и 4.x).
При страничной организации виртуальное адресное пространство процесса делится на равные части механически, без учета смыслового значения данных. В одной странице могут оказаться и коды команд, и инициализируемые переменные, и массив исходных данных программы. Такой подход не позволяет обеспечить дифференцированный доступ к разным частям программы, а это свойство могло бы быть очень полезным во многих случаях. Например, можно было бы запретить обращаться с операциями записи в сегмент программы, содержащий коды команд, разрешив эту операцию для сегментов данных.
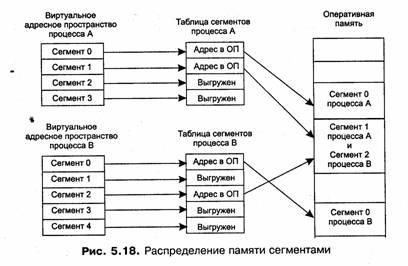
Кроме того, разбиение виртуального адресного пространства на «осмысленные» части делает принципиально возможным совместное использование фрагментов программ разными процессами. Пусть, например, двум процессам требуется одна и та же подпрограмма, которая к тому же обладает свойством реентерабельности. Тогда коды этой подпрограммы могут быть оформлены в виде отдельного сегмента и включены в виртуальные адресные пространства обоих процессов. При отображении в физическую память сегменты, содержащие коды подпрограммы из обоих виртуальных пространств, проецируются на одну и ту же область физической памяти. Таким образом оба процесса получат доступ к одной и той же копии подпрограммы (рис. 5.18).
Итак, виртуальное адресное пространство процесса делится на части — сегменты, размер которых определяется с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т. и. Деление виртуального адресного пространства на сегменты осуществляется компилятором на основе указаний программиста или по умолчанию, в соответствии с принятыми в системе соглашениями. Максимальный размер сегмента определяется разрядностью виртуального адреса, например при 32-разрядной организации процессора он равен 4 Гбайт. При этом максимально возможное виртуальное адресное пространство процесса представляет собой набор из N виртуальных сегментов, каждый размером по 4 Гбайт. В каждом сегменте виртуальные адреса находятся в диапазоне от 00000000 до FFFFFFFF. Сегменты не упорядочиваются друг относительно друга, так что общего для сегментов линейного виртуального адреса не существует, виртуальный адрес задается парой чисел: номером сегмента и линейным виртуальным адресом внутри сегмента.
При загрузке процесса в оперативную память помещается только часть его сегментов, полная копия виртуального адресного пространства находится в дисковой памяти. Для каждого загружаемого сегмента операционная система подыскивает непрерывный участок свободной памяти достаточного размера. Смежные в виртуальной памяти сегменты одного процесса могут занимать в оперативной памяти несмежные участки. Если во время выполнения процесса происходит обращение по виртуальному адресу, относящемуся к сегменту, который в данный момент отсутствует в памяти, то происходит прерывание. ОС приостанавливает активный процесс, запускает на выполнение следующий процесс из очереди, а параллельно организует загрузку нужного сегмента с диска. При отсутствии в памяти места, необходимого для загрузки сегмента, операционная система выбирает сегмент на выгрузку, при этом она использует критерии, аналогичные рассмотренным выше критериям выбора страниц при страничном способе управления памятью.
На этапе создания процесса во время загрузки его образа в оперативную память система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается:
□ базовый физический адрес сегмента в оперативной памяти;
□ размер сегмента;
□ правила доступа к сегменту;
□ признаки модификации, присутствия и обращения к данному сегменту, а также некоторая другая информация.
Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
Как видно, сегментное распределение памяти имеет очень много общего со страничным распределением.
Механизмы преобразования адресов этих двух способов управления памятью тоже весьма схожи, однако в них имеются и существенные отличия, которые являются следствием того, что сегменты в отличие от страниц имеют произвольный размер. Виртуальный адрес при сегментной организации памяти может быть представлен парой (g, s), где g — номер сегмента, as — смещение в сегменте. Физический адрес получается путем сложения базового адреса сегмента, который определяется по номеру сегмента g из таблицы сегментов и смещения s (рис. 5.19).
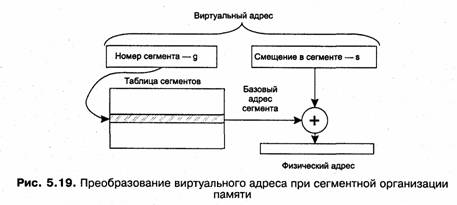
В данном случае нельзя обойтись операцией конкатенации, как это делается при страничной организации памяти. Действительно, поскольку размер страницы равен степени двойки, следовательно, в двоичном виде он выражается числом с несколькими нулями в младших разрядах. Страницы имеют одинаковый размер, а значит, их начальные адреса кратны размеру страниц и выражаются также числами с нулями в младших разрядах. Именно поэтому ОС заносит в таблицы страниц не полные адреса, а номера физических страниц, которые совпадают со старшими разрядами базовых адресов. Сегмент же может в общем случае располагаться в физической памяти начиная с любого адреса, следовательно, для определения местоположения в памяти необходимо задавать его полный начальный физический адрес. Использование операции сложения вместо конкатенации замедляет процедуру преобразования виртуального адреса в физический по сравнению со страничной организацией.
Другим недостатком сегментного распределения является избыточность. При сегментной организации единицей перемещения между памятью и диском является сегмент, имеющий в общем случае объем больший, чем страница. Однако во многих случаях для работы программы вовсе не требуется загружать весь сегмент целиком, достаточно было бы одной или двух страниц. Аналогично при отсутствии свободного места в памяти не стоит выгружать целый сегмент, когда можно обойтись выгрузкой нескольких страниц.
Но главный недостаток сегментного распределения — это фрагментация, которая возникает из-за непредсказуемости размеров сегментов. В процессе работы системы в памяти образуются небольшие участки свободной памяти, в которые не может быть загружен ни один сегмент. Суммарный объем, занимаемый фрагментами, может составить существенную часть общей памяти системы, приводя к ее неэффективному использованию.
Система с сегментной организацией функционирует аналогично системе со страничной организацией: при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический, время от времени происходят прерывания, связанные с отсутствием нужных сегментов в памяти, при необходимости освобождения памяти некоторые сегменты выгружаются.
Одним из существенных отличий сегментной организации памяти от страничной является возможность задания дифференцированных прав доступа процесса к его сегментам. Например, один сегмент данных, содержащий исходную информацию для приложения, может иметь права доступа «только чтение», а сегмент данных, представляющий результаты, — «чтение и запись». Это свойство дает принципиальное преимущество сегментной модели памяти над страничной.
Сегментно-страничное распределение
Данный метод представляет собой комбинацию страничного и сегментного механизмов управления памятью и направлен на реализацию достоинств обоих подходов.
Так же как и при сегментной организации памяти, виртуальное адресное пространство процесса разделено на сегменты. Это позволяет определять разные права доступа к разным частям кодов и данных программы.
Перемещение данных между памятью и диском осуществляется не сегментами, а страницами. Для этого каждый виртуальный сегмент и физическая память делятся на страницы равного размера, что позволяет более эффективно использовать память, сократив до минимума фрагментацию.
В большинстве современных реализаций сегментно-страничной организации памяти в отличие от набора виртуальных диапазонов адресов при сегментной организации памяти (рис. 5.20, а) все виртуальные сегменты образуют одно непрерывное линейное виртуальное адресное пространство (рис. 5.20, б).
Координаты байта в виртуальном адресном пространстве при сегментно-страничной организации можно задать двумя способами. Во-первых, линейным виртуальным адресом, который равен сдвигу данного байта относительно границы общего линейного виртуального пространства, во-вторых, парой чисел, одно из которых является номером сегмента, а другое — смещением относительно начала сегмента. При этом в отличие от сегментной модели, для однозначного задания виртуального адреса вторым способом необходимо каким-то образом указать также начальный виртуальный адрес сегмента с данным номером. Системы виртуальной памяти ОС с сегментно-страничной организацией используют второй способ, так как он позволяет непосредственно определить принадлежность адреса некоторому сегменту и проверить права доступа процесса к нему.
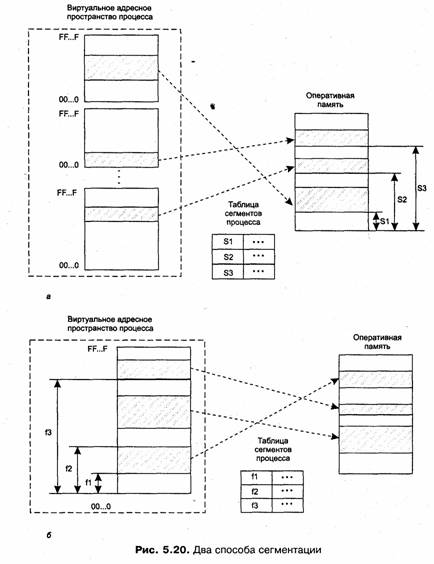
Для каждого процесса операционная система создает отдельную таблицу сегментов, в которой содержатся описатели (дескрипторы) всех сегментов процесса. Описание сегмента включает назначенные ему права доступа и другие характеристики, подобные тем, которые содержатся в дескрипторах сегментов при сегментной организации памяти. Однако имеется и принципиальное отличие. В поле базового адреса указывается не начальный физический адрес сегмента, отведенный ему в результате загрузки в оперативную память, а начальный линейный виртуальный адрес сегмента в пространстве виртуальных адресов (на рис. 5.20 базовые физические адреса обозначены S1, S2, S3, а базовые виртуальные адреса — fl, £2, f3).
Наличие базового виртуального адреса сегмента в дескрипторе позволяет однозначно преобразовать адрес, заданный в виде пары (номер сегмента, смещение в сегменте), в линейный виртуальный адрес байта, который затем преобразуется в физический адрес страничным механизмом.
Деление общего линейного виртуального адресного пространства процесса и физической памяти на страницы осуществляется так же, как это делается при страничной организации памяти. Размер страниц выбирается равным степени двойки, что упрощает механизм преобразования виртуальных адресов в физические. Виртуальные страницы нумеруются в пределах виртуального адресного пространства каждого процесса, а физические страницы — в пределах оперативной памяти. При создании процесса в память загружается только часть страниц, остальные загружаются по мере необходимости. Время от времени система выгружает уже ненужные страницы, освобождая память для новых страниц. ОС ведет для каждого процесса таблицу страниц, в которой указывается соответствие виртуальных страниц физическим.
Базовые адреса таблицы сегментов и таблицы страниц процесса являются частью его контекста. При активизации процесса эти адреса загружаются в специальные регистры процессора и используются механизмом преобразования адресов.
Преобразование виртуального адреса в физический происходит в два этапа (рис. 5.21):
1. На первом этапе работает механизм сегментации. Исходный виртуальный адрес, заданный в виде пары (номер сегмента, смещение), преобразуется в линейный виртуальный адрес. Для этого на основании базового адреса таблицы сегментов и номера сегмента вычисляется адрес дескриптора сегмента. Анализируются поля дескриптора и выполняется проверка возможности выполнения заданной операции. Если доступ к сегменту разрешен, то вычисляется линейный виртуальный адрес путем сложения базового адреса сегмента, извлеченного из дескриптора, и смещения, заданного в исходном виртуальном адресе.
2. На втором этапе работает страничный механизм. Полученный линейный виртуальный адрес преобразуется в искомый физический адрес. В результате преобразования линейный виртуальный адрес представляется в том виде, в котором он используется при страничной организации памяти, а именно в виде пары (номер страницы, смещение в странице). Благодаря тому что размер страницы выбран равным степени двойки, эта задача решается простым отделением некоторого количества младших двоичных разрядов. При этом в старших разрядах содержится номер виртуальной страницы, а в младших — смещение искомого элемента относительно начала страницы. Так, если размер страницы равен 2к, то смещением является содержимое младших к разрядов, а остальные, старшие разряды содержат номер виртуальной страницы, которой принадлежит искомый адрес. Далее преобразование адреса происходит так же, как при страничной организации: старшие разряды линейного виртуального адреса, содержащие номер виртуальной страницы, заменяются номером физической страницы; взятым из таблицы страниц, а младшие разряды виртуального адреса, содержащие смещение, остаются без изменения.
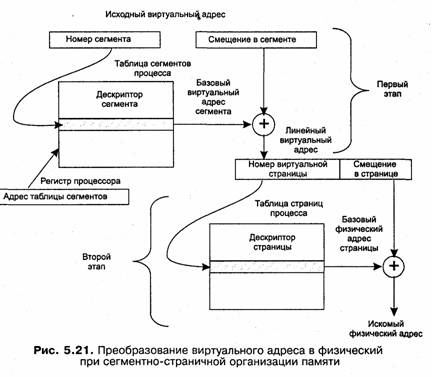
Как видно, механизм сегментации и страничный механизм действуют достаточно независимо друг от друга. Поэтому нетрудно представить себе реализацию сегментно-страничного управления памятью, в которой механизм сегментации работает по вышеописанной схеме, а страничный механизм изменен. Он реализует двухуровневую схему, в которой виртуальное адресное пространство делится сначала на разделы, а уж потом на страницы. В таком случае преобразование виртуального адреса в физический происходит в несколько этапов. Сначала механизм сегментации обычным образом, используя таблицу сегментов, вычисляет линейный виртуальный адрес. Затем из данного виртуального адреса вычленяются номер раздела, номер страницы и смещение. И далее по номеру раздела из таблицы разделов определяется адрес таблицы страниц, а затем по номеру виртуальной страницы из таблицы страниц определяется номер физической страницы, к которому пристыковывается смещение. Именно такой подход реализован компанией Intel в процессорах i386, i486 и Pentium.
Рассмотрим еще одну возможную схему управления памятью, основанную на комбинировании сегментного и страничного механизмов. Так же как и в предыдущих случаях, виртуальное пространство процесса делится на сегменты, а каждый сегмент, в свою очередь, делится на виртуальные страницы. Первое отличие состоит в том, что виртуальные страницы нумеруются не в пределах всего адресного пространства процесса, а в пределах сегмента. Виртуальный адрес в этом случае выражается тройкой (номер сегмента, номер страницы, смещение в странице).
Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть — на диске. Для каждого процесса создается собственная таблица сегментов, а для каждого сегмента — своя таблица страниц. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс.
Таблица страниц содержит дескрипторы страниц, содержимое которых полностью аналогично содержимому ранее описанных дескрипторов страниц. А вот таблица сегментов состоит из дескрипторов сегментов, которые вместо информации о расположении сегментов в виртуальном адресном пространстве содержат описание расположения таблиц страниц в физической памяти. Это является вторым существенным отличием данного подхода от ранее рассмотренной схемы сегментно-страничной организации.
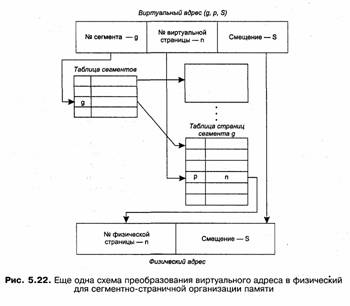
На рис. 5.22 показана схема преобразования виртуального адреса в физический для данного метода.
1. По номеру сегмента, заданному в виртуальном адресе, из таблицы сегментов извлекается физический адрес соответствующей таблицы страниц.
2. По номеру виртуальной страницы, заданному в виртуальном адресе, из таблицы страниц извлекается дескриптор, в котором указан номер физической страницы. 3. К номеру физической страницы пристыковывается младшая часть виртуального адреса — смещение.
Подсистема виртуальной памяти представляет собой удобный механизм для решения задачи совместного доступа нескольких процессов к одному и тому же сегменту памяти, который в этом случае называется разделяемой памятью (shared memory).
Хотя основной задачей операционной системы при управлении памятью является защита областей оперативной памяти, принадлежащей одному из процессов, от доступа к ней остальных процессов, в некоторых случаях оказывается полезным организовать контролируемый совместный доступ нескольких процессов к определенной области памяти. Например, в том случае, когда несколько пользователей одновременно работают с некоторым текстовым редактором, нецелесообразно многократно загружать его код в оперативную память. Гораздо экономичней загрузить всего одну копию кода, которая обслуживала бы всех пользователей, работающих в данное время с этим редактором (для этого код редактора должен быть реентерабельным). Очевидно, что сегмент данных редактора не может присутствовать в памяти в единственном разделяемом экземпляре — для каждого пользователя должна быть создана своя копия этого сегмента, в которой помещается редактируемый текст и значения других переменных редактора, например его конфигурация, индивидуальная для каждого пользователя, и т. п.
Другим примером применения разделяемой области памяти может быть использование ее в качестве буфера при межпроцессном обмене данными. В этом случае один процесс пишет в разделяемую область, а другой — читает.
Для организации разделяемого сегмента при наличии подсистемы виртуальной памяти достаточно поместить его в виртуальное адресное пространство каждого процесса, которому нужен доступ к данному сегменту, а затем настроить параметры отображения этих виртуальных сегментов так, чтобы они соответствовали одной и той же области оперативной памяти. Детали такой настройки зависят от типа используемой в ОС модели виртуальной памяти: сегментной или сегментно-страничной (чисто страничная организация не поддерживает понятие «сегмент», что делает невозможным решение рассматриваемой задачи). Например, при сегментной организации необходимо в дескрипторах виртуального сегмента каждого процесса указать один и тот же базовый физический адрес. При сегментно-страничной организации отображение на одну и ту же область памяти достигается за счет соответствующей настройки таблицы страниц каждого процесса.
В приведенном выше описании подразумевалось, что разделяемый сегмент помещается в индивидуальную часть виртуального адресного пространства каждого процесса (рис. 5.23, а) и описывается в каждом процессе индивидуальным дескриптором сегмента (и индивидуальными дескрипторами страниц, если используется сегментно-страничный механизм). «Попадание» же этих виртуальных сегментов на общую часть оперативной памяти достигается за счет согласованной настройки операционной системой многочисленных дескрипторов для множества процессов.

Возможно и более экономичное для ОС решение этой задачи — помещение единственного разделяемого виртуального сегмента в общую часть виртуального адресного пространства процессов, то есть в ту часть, которая обычно используется для модулей ОС (рис. 5.23, б). В этом случае настройка дескриптора сегмента (и дескрипторов страниц) выполняется только один раз, а все процессы пользуются такой настройкой и совместно используют часть оперативной памяти.
При работе с разделяемыми сегментами памяти ОС должна выполнять некоторые функции, общие для любых разделяемых между процессами ресурсов — файлов, семафоров и т. п. Эти функции состоят в поддержке схемы именования ресурсов, проверке прав доступа определенного процесса к ресурсу, а также в отслеживании количества процессов, пользующихся данным ресурсом (чтобы удалить его в случае ненадобности). Для того чтобы отличать разделяемые сегменты памяти от индивидуальных, дескриптор сегмента должен содержать поле, имеющее два значения: shared (разделяемый) или private (индивидуальный).
Операционная система может создавать разделяемые сегменты как по явному запросу, так и по умолчанию. В первом случае прикладной процесс должен выполнить соответствующий системный вызов, по которому операционная система создает новый сегмент в соответствии с указанными в вызове параметрами: размером сегмента, разрешенными над ним операциями (чтение/запись) и идентификатором. Все процессы, выполнившие подобные вызовы с одним и тем же идентификатором, получают доступ к этому сегменту и используют его по своему усмотрению, например в качестве буфера для обмена данными.
Во втором случае операционная система сама в определенных ситуациях принимает решение о том, что нужно создать разделяемый сегмент. Наиболее типичным примером такого рода является поступление нескольких запросов на выполнение одного и того же приложения. Если кодовый сегмент приложения помечен в исполняемом файле как реентерабельный и разделяемый, то ОС не создает при поступлении нового запроса новую индивидуальную для процесса копию кодового сегмента этого приложения, а отображает уже существующий разделяемый сегмент в виртуальное адресное пространство процесса. При закрытии приложения каким-либо процессом ОС проверяет, существуют ли другие процессы, пользующиеся данным приложением, и если их нет, то удаляет данный разделяемый сегмент.
Разделяемые сегменты выгружаются на диск системой виртуальной памяти по тем же алгоритмам и с помощью тех же механизмов, что и индивидуальные.
Иерархия запоминающих устройств
Память вычислительной машины представляет собой иерархию запоминающих устройств (ЗУ), отличающихся средним временем доступа к данным, объемом и стоимостью хранения одного бита (рис. 5.24). Фундаментом этой пирамиды запоминающих устройств служит внешняя память, как правило, представляемая жестким диском. Она имеет большой объем (десятки и сотни гигабайт), но скорость доступа к данным является невысокой. Время доступа к диску измеряется миллисекундами.
На следующем уровне располагается более быстродействующая (время доступа равно примерно 10-20 наносекундам) и менее объемная (от десятков мегабайт до нескольких гигабайт) оперативная память, реализуемая на относительно медленной динамической памяти DRAM.
Для хранения данных, к которым необходимо обеспечить быстрый доступ, используются компактные быстродействующие запоминающие устройства на основе статической памяти SRAM, объем которых составляет от нескольких десятков до нескольких сотен килобайт, а время доступа к данным обычно не превышает 8 не.
И наконец, верхушку в этой пирамиде составляют внутренние регистры процессора, которые также могут быть использованы для промежуточного хранения данных. Общий объем регистров составляет несколько десятков байт, а время доступа определяется быстродействием процессора и равно в настоящее время примерно 2-3 не.
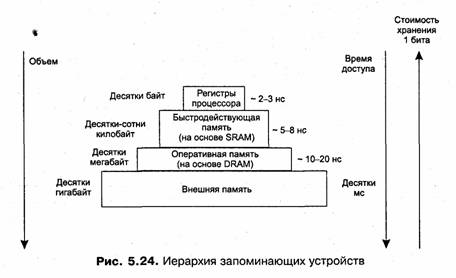
Таким образом, можно констатировать печальную закономерность — чем больше объем устройства, тем менее быстродействующим оно является. Более того, стоимость хранения данных в расчете на один бит также увеличивается с ростом быстродействия устройств. Однако пользователю хотелось бы иметь и недорогую, и быструю память. Кэш-память представляет некоторое компромиссное решение этой проблемы.
Кэш-память
Кэш-память, или просто кэш (cache), — это способ совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который за счет динамического копирования в «быстрое» ЗУ наиболее часто используемой информации из «медленного» ЗУ позволяет, с одной стороны, уменьшить среднее время доступа к данным, а с другой стороны, экономить более дорогую быстродействующую память.
Неотъемлемым свойством кэш-памяти является ее прозрачность для программ и пользователей. Система не требует никакой внешней информации об интенсивности использования данных; ни пользователи, ни программы не принимают никакого участия в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами.
Кэш-памятью, или кэшем, часто называют не только способ организации работы двух типов запоминающих устройств, но и одно из устройств — «быстрое» ЗУ.
Оно стоит дороже и, как правило, имеет сравнительно небольшой объем. «Медленное» ЗУ далее будем называть основной памятью, противопоставляя ее вспомогательной кэш-памяти.
Кэширование — это универсальный метод, пригодный для ускорения доступа к оперативной памяти, к диску и к другим видам запоминающих устройств. Если кэширование применяется для уменьшения среднего времени доступа к оперативной памяти, то в качестве кэша используют быстродействующую статическую память. Если кэширование используя системой ввода-вывода для ускорения доступа к данным, хранящимся на диске, то в этом случае роль кэш-памяти выполняют буферы в оперативной памяти, в которых оседают наиболее активно используемые данные. Виртуальную память также можно считать одним из вариантов реализации принципа кэширования данных, при котором оперативная память выступает в роли кэша по отношению к внешней памяти — жесткому диску. Правда, в этом случае кэширование используется не для того, чтобы уменьшить время доступа к данным, а для того, чтобы заставить диск частично подменить оперативную память за счет перемещения временно неиспользуемого кода и данных на диск с целью освобождения места для активных процессов. В результате наиболее интенсивно используемые данные «оседают» в оперативной памяти, остальная же информация хранится в более объемной и менее дорогостоящей внешней памяти.
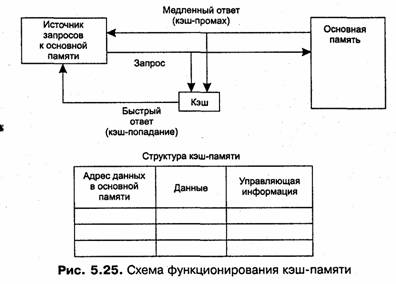
Рассмотрим одну из возможных схем кэширования (рис. 5.25). Содержимое кэш-памяти представляет собой совокупность записей обо всех загруженных в нее элементах данных из основной памяти. Каждая запись об элементе данных включает в себя:
□ значение элемента данных;
□ адрес, который этот элемент данных имеет в основной памяти;
□ дополнительную информацию, которая используется для реализации алгоритма замещения данных в кэше и обычно включает признак модификации и признак действительности данных.
При каждом обращении к основной памяти по физическому адресу просматривается содержимое кэш-памяти с целью определения, не находятся ли там нужные данные. Кэш-память не является адресуемой, поэтому поиск нужных данных осуществляется по содержимому — по взятому из запроса значению поля адреса в оперативной памяти. Далее возможен один из двух вариантов развития событий:
□ если данные обнаруживаются в кэш-памяти, то есть произошло кэш-попадание (cache-hit), они считываются из нее и результат передается источнику запроса;
□ если нужные данные отсутствуют в кэш-памяти, то есть произошел кэш-промах (cache-miss), они считываются из основной памяти, передаются источнику запроса и одновременно с этим копируются в кэш-память.
Интуитивно понятно, что эффективность кэширования зависит от вероятности попадания в кэш. Покажем это путем нахождения зависимости среднего времени доступа к основной памяти от вероятности кэш-попаданий. Пусть имеется основное запоминающее устройство со средним временем доступа к данным tl и кэш-память, имеющая время доступа t2, очевидно, что t2<tl. Пусть t — среднее время доступа к данным в системе с кэш-памятью, ар — вероятность кэш-попадания. По формуле полной вероятности имеем:
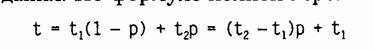
Среднее время доступа к данным в системе с кэш-памятью линейно зависит от вероятности попадания в кэш и изменяется от среднего времени доступа в основное запоминающее устройство tl при р=0 до среднего времени доступа непосредственно в кэш-память t2 при р=1. Отсюда видно, что использование кэш-памяти имеет смысл только при высокой вероятности кэш-попадания.
Вероятность обнаружения данных в кэше зависит от разных факторов, таких, например, как объем кэша, объем кэшируемой памяти, алгоритм замещения данных в кэше, особенности выполняемой программы, время ее работы, уровень мультипрограммирования и других особенностей вычислительного процесса. Тем не менее в большинстве реализаций кэш-памяти процент кэш-попаданий оказывается весьма высоким — свыше 90 %. Такое высокое значение вероятности нахождения данных в кэш-памяти объясняется наличием у данных объективных свойств: пространственной и временной локальности.
□ Временная локальность. Если произошло обращение по некоторому адресу, то следующее обращение по тому же адресу с большой вероятностью произойдет в ближайшее время.
□ Пространственная локальность. Если произошло обращение по некоторому адресу, то с высокой степенью вероятности в ближайшее время произойдет обращение к соседним адресам.
Именно основываясь на свойстве временной локальности, данные, только что считанные из основной памяти, размещают в запоминающем устройстве быстрого доступа, предполагая, что скоро они опять понадобятся. Вначале работы системы, когда кэш-память еще пуста, почти каждый запрос к основной памяти выполняется «по полной программе»:просмотр кэша, констатация промаха, чтение данных из основной памяти, передача результата источнику запроса и копирование данных в кэш. Затем, по мере заполнения кэша, в полном соответствии со свойством временной локальности возрастает вероятность обращения к данным, которые уже были использованы на предыдущем этапе работы системы, то есть к данным, которые содержатся в кэше и могут быть считаны значительно быстрее, чем из основной памяти.
Свойство пространственной локальности также используется для увеличения вероятности кэш-попадания: как правило, в кэш-память считывается не один информационный элемент, к которому произошло обращение, а целый блок данных, расположенных в основной памяти в непосредственной близости с данным элементом. Поскольку при выполнении программы очень высока вероятность, что команды выбираются из памяти последовательно одна за другой из соседних ячеек, то имеет смысл загружать в кэш-память целый фрагмент программы. Аналогично если программа ведет обработку некоторого массива данных, то ее работу можно ускорить, загрузив в кэш часть или даже весь массив данных. При этом учитывается высокая вероятность того, что значительное число обращений к памяти будет выполняться к адресам массива данных.
В процессе работы содержимое кэш-памяти постоянно обновляется, а значит, время от времени данные из нее должны вытесняться. Вытеснение означает либо простое объявление свободной соответствующей области кэш-памяти (сброс бита действительности), если вытесняемые данные за время нахождения в кэше не были изменены, либо в дополнение к этому копирование данных в основную память, если они были модифицированы. Алгоритм замены данных в кэш-памяти существенно влияет на ее эффективность. В идеале такой алгоритм должен, во-первых, быть максимально быстрым, чтобы не замедлять работу кэш-памяти, а во-вторых, обеспечивать максимально возможную вероятность кэш-попаданий. Поскольку из-за непредсказуемости вычислительного процесса ни один алгоритм замещения данных в кэш-памяти не может гарантировать оптимальный результат, разработчики ограничиваются рациональными решениями, которые по крайней мере, не сильно замедляют работу кэша — запоминающего устройства, изначально призванного быть быстрым.
Наличие в компьютере двух копий данных — в основной памяти и в кэше — порождает проблему согласования данных. Если происходит запись в основную память по некоторому адресу, а содержимое этой ячейки находится в кэше, то в результате соответствующая запись в кэше становится недостоверной. Рассмотрим два подхода к решению этой проблемы:
□ Сквозная запись (write through). При каждом запросе к основной памяти, в том числе и при записи, просматривается кэш. Если данные по запрашиваемому адресу отсутствуют, то запись выполняется только в основную память. Если же данные, к которым выполняется обращение, находятся в кэше, то запись выполняется одновременно в кэш и основную память.
□ Обратная запись (write back). Аналогично при возникновении запроса к памяти выполняется просмотр кэша, и если запрашиваемых данных там нет, то запись выполняется только в основную память. В противном же случае запись производится только в кэш-память, при этом в описателе данных делается» специальная отметка (признак модификации), которая указывает на то, что при вытеснении этих данных из кэша необходимо переписать их в основную память, чтобы актуализировать устаревшее содержимое основной памяти.
В некоторых алгоритмах замещения предусматривается первоочередная выгрузка модифицированных, или, как еще говорят, «грязных» данных. Модифицированные данные могут выгружаться не только при освобождении места в кэш-памяти для новых данных, но и в «фоновом режиме», когда система не очень загружена.
Способы отображения основной памяти на кэш
Алгоритм поиска и алгоритм замещения данных в кэше непосредственно зависят от того, каким образом основная память отображается на кэш-память. Принцип прозрачности требует, чтобы правило отображения основной памяти на кэш-память не зависело от работы программ и пользователей. При кэшировании данных из оперативной памяти широко используются две основные схемы отображения: случайное отображение и детерминированное отображение.
При случайном отображении элемент оперативной памяти в общем случае может быть размещен в произвольном месте кэш-памяти. Для того чтобы в дальнейшем можно было найти нужные данные в кэше, они помещаются туда вместе со своим адресом, то есть тем адресом, который данные имеют в оперативной памяти. При каждом запросе к оперативной памяти выполняется поиск в кэше, причем критерием поиска выступает адрес оперативной памяти из запроса. Очевидная схема простого перебора для поиска нужных данных в случае кэша оказывается непригодной из-за недопустимо больших временных затрат.
Для кэшей со случайным отображением используется так называемый ассоциативный поиск, при котором сравнение выполняется не последовательно с каждой записью кэша, а параллельно со всеми его записями (рис. 5.26). Признак, по которому выполняется сравнение, называется тегом (tag). В данном случае тегом является адрес данных в оперативной памяти. Электронная реализация такой схемы приводит к удорожанию памяти, причем стоимость существенно возрастает с увеличением объема запоминающего устройства. Поэтому ассоциативная кэш-память используется в тех случаях, когда для обеспечения высокого процента попадания достаточно небольшого объема памяти.
В кэшах, построенных на основе случайного отображения, вытеснение старых данных происходит только в том случае, когда вся кэш-память заполнена и нет свободного места. Выбор данных на выгрузку осуществляется среди всех записей кэша. Обычно этот выбор основывается на тех же приемах, что и в алгоритмах замещения страниц, например выгрузка данных, к которым дольше всего не было обращений, или данных, к которым было меньше всего обращений.
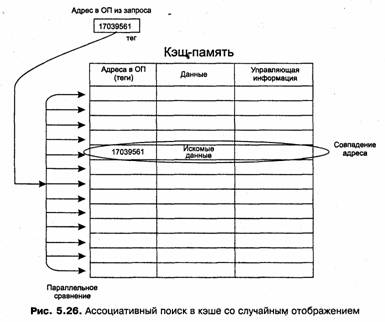
Второй, детерминированный способ отображения предполагает, что любой элемент основной памяти всегда отображается в одно и то же место кэш-памяти. В этом случае кэш-память разделена на строки, каждая из которых предназначена для хранения одной записи об одном элементе данных и имеет свой номер. Между номерами строк кэш-памяти и адресами оперативной памяти устанавливается соответствие «один ко многим»: одному номеру строки соответствует несколько (обычно достаточно много) адресов оперативной памяти.
В качестве отображающей функции может использоваться простое выделение нескольких разрядов из адреса оперативной памяти, которые интерпретируются как номер строки кэш-памяти (такое отображение называется прямым). Например, пусть в кэш-памяти может храниться 1024 записи, то есть кэш имеет 1024 строки, пронумерованные от 0 до 1023. Тогда любой адрес оперативной памяти может быть отображен на адрес кэш-памяти простым отделением 10 двоичных разрядов (рис.5.27)
При поиске данных в кэше используется быстрый прямой доступ к записи по номеру строки, полученному путем обработки адреса оперативной памяти из запроса. Однако поскольку в найденной строке могут находиться данные из любой ячейки оперативной памяти, младшие разряды адреса которой совпадают с номером строки, необходимо выполнить дополнительную проверку. Для этих целей каждая строка кэш-памяти дополняется тегом, содержащим старшую часть адреса данных в оперативной памяти. При совпадении тега с соответствующей частью адреса из запроса констатируется кэш-попадание.
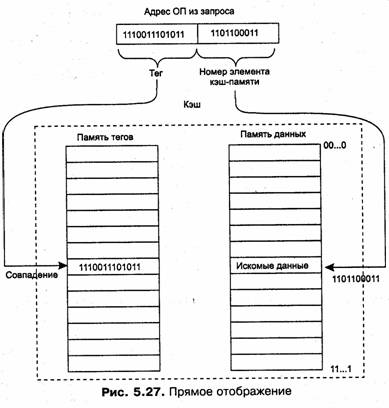
Если же произошел кэш-промах, то данные считываются из оперативной памяти и копируются в кэш. Если строка кэш-памяти, в которую должен быть скопирован элемент данных из оперативной памяти, содержит другие данные, то последние вытесняются из кэша. Заметим, что процесс замещения данных в кэш-памяти на основе прямого отображения существенно отличается от процесса замещения данных в кэш-памяти со случайным отображением. Во-первых, вытеснение данных происходит не только в случае отсутствия свободного места в кэше, во-вторых, никакого выбора данных на замещение не существует. Во многих современных процессорах кэш-память строится на основе
сочетания этих двух подходов, что позволяет найти компромисс между сравнительно низкой стоимостью кэша с прямым отображением и интеллектуальностью алгоритмов замещения в кэше со случайным отображением. При смешанном подходе произвольный адрес оперативной памяти отображается не на один адрес кэш-памяти (как это характерно для прямого отображения) и не на любой адрес кэш памяти (как это делается при случайном отображении), а на некоторую группу адресов. Все группы пронумерованы. Поиск в кэше осуществляется вначале по номеру группы, полученному из адреса оперативной памяти из запроса, а затем в пределах группы путем ассоциативного просмотра всех записей в группе на предмет совпадения старших частей адресов оперативной памяти (рис. 5.28).
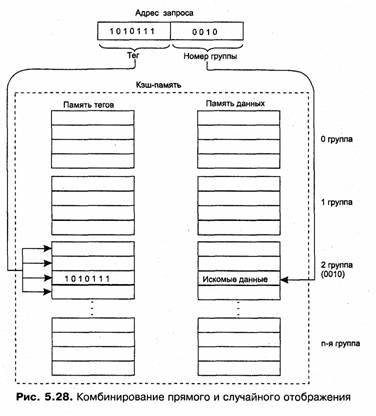
При промахе данные копируются по любому свободному адресу из однозначно заданной группы. Если свободных адресов в группе нет, то выполняется вытеснение данных. Поскольку кандидатов на выгрузку несколько — все записи из данной группы — алгоритм замещения может учесть интенсивность обращений к данным и тем самым повысить вероятность попаданий в будущем. Таким образом в данном способе комбинируется прямое отображение на группу и случайное отображение в пределах группы.
Схемы выполнения запросов в системах с кэш-памятью
На рис. 5.29 приведена обобщенная схема работы кэш-памяти. Большая часть ветвей этой схемы уже была подробно рассмотрена выше, поэтому остановимся здесь только на некоторых особых случаях.
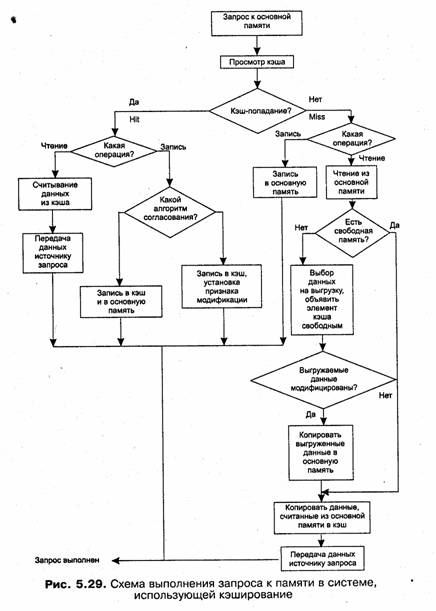
Из схемы видно, что когда выполняется запись, кэш просматривается только с целью согласования содержимого кэша и основной памяти. Если происходит промах, то запросы на запись не вызывают никаких изменений содержимого кэша. В некоторых же реализациях кэш-памяти при отсутствии данных в кэше они копируются туда из основной памяти независимо от того, выполняется запрос на чтение или на запись.
В соответствии с описанной логикой работы кэш-памяти следует, что при возникновении запроса сначала просматривается кэш, а затем, если произошел промах, выполняется обращение к основной памяти. Однако часто реализуется и другая схема работы кэша: поиск в кэше и в основной памяти начинается одновременно, а затем, в зависимости от результата просмотра кэша, операция в основной памяти либо продолжается, либо прерывается.
При выполнении запросов к оперативной памяти во многих вычислительных системах используется двухуровневое кэширование (рис. 5.30). Кэш первого уровня имеет меньший объем и более высокое быстродействие, чем кэш второго уровня. Кэш второго уровня играет роль основной памяти по отношению к кэшу первого уровня.
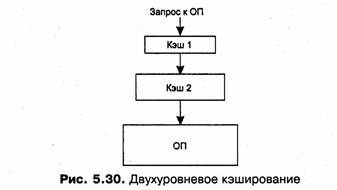
На рис. 5.31 показана схема выполнения запроса на чтение в системе с двухуровневым кэшем. Сначала делается попытка обнаружить данные в кэше первого уровня. Если произошел промах, поиск продолжается в кэше второго уровня. Если же нужные данные отсутствуют и здесь, тогда происходит считывание данных из основной памяти. Понятно, что время доступа к данным оказывается минимальным, когда кэш-попадание происходит уже на первом уровне, несколько большим — при обнаружении данных на втором уровне и обычным временем доступа к оперативной памяти, если нужных данных нет ни в том, ни в другом кэше. При считывании данных из оперативной памяти происходит их копирование в кэш второго уровня, а если данные считываются из кэша второго уровня, то они копируются в кэш первого уровня.
При работе такой иерархической организованной памяти необходимо обеспечить непротиворечивость данных на всех уровнях. Кэши разных уровней могут согласовывать данные разными способами. Пусть, например, кэш первого уровня использует сквозную запись, а кэш второго уровня — обратную запись. (Именно такая комбинация алгоритмов согласования применена в процессоре Pentium при одном из возможных вариантов его работы.)
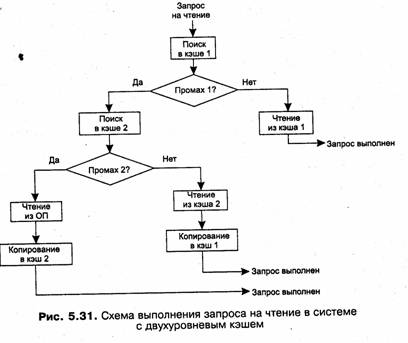
На рис. 5.32 приведена схема выполнения запроса на запись в такой системе. При модификации данных необходимо убедиться, что они отсутствуют в кэшах. В этом случае выполняется запись только в оперативную память. Если данные обнаружены в кэше первого уровня, то вступает в силу алгоритм сквозной записи: выполняется запись в кэш первого уровня и передается запрос на запись в кэш второго уровня, играющий в данном случае роль основной памяти. Запись в кэш второго уровня в соответствии с алгоритмом обратной записи, принятом на данном уровне, сопровождается установкой признака модификации, при этом никакой записи в оперативную память не производится. Если данные найдены в кэше второго уровня, то, так же как и в предыдущем случае, выполняется запись в этот кэш и устанавливается признак модификации. Рассмотренные в данном разделе проблемы кэширования охватывают только такой класс систем организации памяти, в котором на каждом уровне имеется одно кэширующее устройство. Существует и другой класс систем памяти, главной отличительной особенностью которого является наличие нескольких кэшей одного уровня. Этот вариант характерен для распределенных систем обработки информации — мультипроцессорных компьютерах и компьютерных сетях.
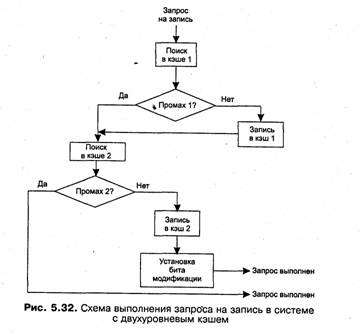
Аппаратная поддержка мультипрограммирования на примере процессора Pentium
Аппаратные средства поддержки мультипрограммирования имеются во всех современных процессорах. Несмотря на различия в реализации, для большинства типов процессоров эти средства имеют общие черты. Это в полной мере относится и к рассматриваемому ниже популярному семейству 32-разрядных процессоров Intel: 80386, 80486, Pentium, Pentium Pro, Pentium II, Celeron и Pentium III. Более того, средства поддержки операционной системы во всех этих процессорах построены почти идентично, поэтому далее в тексте для их обозначения используется обобщенный термин «процессоры Pentium».
Основным режимом работы процессора Pentium является защищенный режим (protected mode). Для совместимости с программным обеспечением, разработанным для предшествующих моделей процессоров Intel (главным образом, модели 8086), в процессорах Pentium предусмотрен так называемый реальный режим (real mode). В реальном режиме процессор Pentium выполняет 16-разрядные инструкции и адресует 1 Мбайт памяти. В этом разделе рассматривается защищенный режим работы процессора, поскольку это основной режим, используемый современными мультипрограммными операционными системами.
В организации вычислительного процесса важную роль играют регистры процессора. В процессорах Pentium эти регистры делятся на несколько групп:
□ регистры общего назначения;
□ регистры сегментов;
□ указатель инструкций;
□ регистр флагов;
□ управляющие регистры;
□ регистры системных адресов;
□ регистры отладки и тестирования, а также регистры математического сопроцессора, выполняющего операции с плавающей точкой.
В процессоре Pentium имеется восемь 32-разрядных регистров общего назначения. Четыре из них, которые можно условно назвать А, В, С и D, используются для временного хранения операндов арифметических, логических и других команд. Программист может обращаться к этим регистрам как к единому целому, используя обозначения ЕАХ, ЕВХ, ЕСХ, EDX, а также к некоторым их частям, как это показано на рис. 6.1. Здесь обозначение AL (L — Low) относится к первому, самому младшему байту регистра ЕАХ, АН (Н — High) — к следующему по старшинству байту, а АХ обозначает оба младших байта регистра. Приставка Е в обозначении этих регистров (а также некоторых других) образована от слова extended (расширенный), что указывает на то, что в прежних моделях процессоров Intel эти регистры были 16-разрядными, а затем их разрядность была увеличена до 32 бит.

Остальные четыре регистра общего назначения — ESI, EDI, ЕВР и ESP — предназначены для задания смещения адреса относительно начала некоторого сегмента данных. Эти регистры используются совместно с регистрами сегментов в системе адресации процессора Pentium для задания виртуального адреса, который затем с помощью таблиц страниц отображается на физический адрес.
Регистры сегментов CS, SS, DS, ES, FS и GS в защищенном режиме ссылаются на дескрипторы сегментов памяти — описатели, в которых содержатся такие параметры сегментов, как базовый адрес, размер сегмента, атрибуты защиты и некоторые другие. Регистры сегментов хранят 16-разрядное число, называемое селектором, в котором 12 старших разрядов представляют собой индекс в таблице дескрипторов сегментов, 1 разряд указывает, в какой из двух таблиц, GDT или LDT, находится дескриптор, а три разряда поля RPL хранят значение уровня привилегий запроса к данному сегменту. Регистр CS (Code Segment) предназначен для хранения индекса дескриптора кодового сегмента, регистр SS (Stack Segment) — дескриптора сегмента стека, а остальные регистры используются для указания на дескрипторы сегментов данных. Все регистры сегментов, кроме CS, программно доступны, то есть в них можно загрузить новое значение селектора соответствующей командой (например, LDS). Значение регистра CS изменяется при выполнении команд межсегментных вызовов CALL и переходов JMP, а также при переключении задач.
Указатель инструкций EIP содержит смещение адреса текущей инструкции, которое используется совместно с регистром CS для получения соответствующего виртуального адреса.
Регистр флагов EFLAGS содержит признаки, характеризующие результат выполнения операции, например флаг знака, флаг нуля, флаг переполнения, флаг паритета, флаг переноса и некоторые другие. Кроме того, здесь хранятся некоторые признаки, устанавливаемые и анализируемые механизмом прерываний, в частности флаг разрешения аппаратных прерываний IF.
В процессоре Pentium имеется пять управляющих регистров — CRO, CR1, CR2, CR3 и CR4, которые хранят признаки и данные, характеризующие общее состояния процессора (рис. 6.2).
Регистр CR0 содержит все основные признаки, существенно влияющие на работу процессора, такие как реальный/защищенный режим работы, включение/ выключение страничного механизма системы виртуальной памяти, а также признаки, влияющие на работу кэша и выполнение команд с плавающей точкой. Младшие два байта регистра CR0 имеют название Mashine State Word, MSW — «слово состояния машины». Это название использовалось в процессоре 80286 для обозначения управляющего регистра, имевшего аналогичное назначение.
Регистр CR1 в настоящее время не используется (зарезервирован).
Регистры CR2 и CR3 предназначены для поддержки работы системы виртуальной памяти. Регистр CR2 содержит линейный виртуальный адрес, который вызвал так называемый страничный отказ (отсутствие страницы в оперативной памяти или отказ из-за нарушения прав доступа). Регистр CR3 содержит физический адрес таблицы разделов, используемой страничным механизмом процессора.
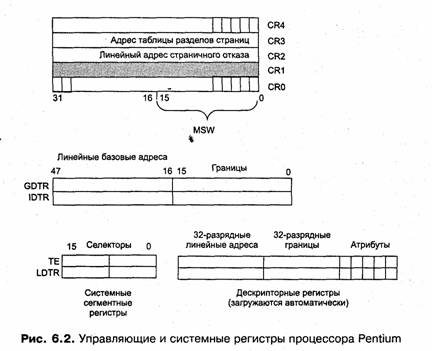
В регистре CR4 хранятся признаки, разрешающие работу так называемых архитектурных расширений, например возможности использования страниц размером 4 Мбайт и т. п.
Регистры системных адресов содержат адреса важных системных таблиц и структур, используемых при управлении процессами и памятью. Регистр GDTR {Global Descriptor Table Register) содержит физический 32-разрядный адрес глобальной таблицы дескрипторов GDT сегментов памяти, образующих общую часть виртуального адресного пространства всех процессов. Регистр IDTR {Interrupt Descriptor Table Register) хранит физический 32-разрядный адрес таблицы дескрипторов прерываний IDT, используемой для вызова процедур обработки прерываний в защищенном режиме работы процессора. Кроме этих адресов в регистрах GDTR и IDTR хранятся 16-битные лимиты, задающие ограничения на размер соответствующих таблиц.
Два 16-битных регистра хранят не физические адреса системных структур, а значения индексов дескрипторов этих структур в таблице GDT, что позволяет косвенно получить соответствующие физические адреса. Регистр TR {Task Register) содержит индекс дескриптора сегмента состояния задачи TSS. Регистр LDTR {Local Descriptor Table Register) содержит индекс дескриптора сегмента локальной таблицы дескрипторов LDT сегментов памяти, образующих индивидуальную часть виртуального адресного пространства процесса.
Регистры отладки хранят значения точек останова, а регистры тестирования позволяют проверить корректность работы внутренних блоков процессора.
Привилегированные команды — это команды, которые могут быть выполнены только при определенном уровне привилегий текущего кода CPL (Current Privilege Level). В процессорах Pentium поддерживается четыре уровня привилегий, от самого привилегированного нулевого, до наименее привилегированного третьего. С помощью привилегированных команд осуществляется защита структур операционной системы от некорректного поведения пользовательских процессов, а также взаимная защита ресурсов этих процессов. (Механизм задания привилегий более детально рассмотрен ниже, в разделах, посвященных средствам управления памятью, так как уровни привилегий используются для определения не только допустимости выполнения той или иной команды, но и возможности доступа исполняемого кода к сегментам данных и кодов, включенным в виртуальное адресное пространство процесса.)
В процессоре Pentium к привилегированным командам относятся:
□команды для работы с управляющими регистрами CR n, а также для загрузки регистров системных адресов GDTR, LDTR, IDTR и TR;
□ команда останова процессора HALT;
□ команды запрета/разрешения маскируемых аппаратных прерываний CLI/SLI;
□ команды ввода-вывода IN, INS, OUT, OUTS.
Первые две группы команд могут выполняться только при самом высшем уровне привилегий кода, то есть при CPL=O. Для двух последних групп команд, иногда называемых чувствительными, условия выполнения не требуют высшего уровня привилегий кода, а связаны с соотношением уровня привилегий ввода-вывода IOPL и уровня привилегий кода CPL — выполнение этих команд разрешено в том случае, если CPL <= IOPL.
Средства поддержки сегментации памяти
Средства поддержки механизмов виртуальной памяти в процессоре Pentium позволяют отображать виртуальное адресное пространство на физическую память размером максимум в 4 Гбайт (этот максимум определяется использованием 32-разрядных адресов при работе с оперативной памятью).
Процессор может поддерживать как сегментную модель распределения памяти, так и сегментно-страничную. Средства сегментации образуют верхний уровень средств управления виртуальной памятью процессора Pentium, а средства страничной организации — нижний уровень. Это означает, что сегментные средства работают всегда, а средства страничной организации могут быть как включены, так и выключены путем установки однобитного признака РЕ (Paging Enable) в регистре CR0 процессора. В зависимости от того, включены ли средства страничной организации, изменяется смысл процедуры преобразования адресов, которая выполняется средствами сегментации. Сначала рассмотрим случай работы средств сегментации при отключенном механизме управления страницами.
Виртуальное адресное пространство
При работе процессора Pentium в сегментном режиме в распоряжении программиста имеется виртуальное адресное пространство, представляемое совокупностью сегментов. Каждый сегмент виртуальной памяти процесса имеет описание, называемое де -скриптором сегмента. Дескриптор сегмента имеет размер 8 байт и содержит все характеристики сегмента, необходимые для проверки правильности доступа к нему и нахождения его в физическом адресном пространстве (рис. 6.3).
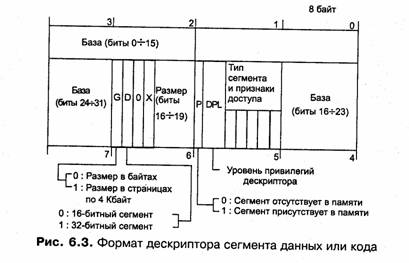
Структура дескриптора, которая поддерживается в процессоре Pentium, сложилась исторически. Многое в ней связано с обеспечением совместимости с предыдущими процессорами семейства х86. Именно этим объясняется то, что базовый адрес сегмента представлен в дескрипторе в виде трех частей, а размер сегмента занимает два поля.
Ниже перечислены основные поля дескриптора.
□ База — базовый адрес сегмента (32 бита).
□ Размер — размер сегмента (24 бита).
□ G (Granularity) — единица измерения размера сегмента, один бит. Если G=0, то размер задан в байтах и тогда сегмент не может быть больше 64 Кбайт, если G=l, то размер сегмента измеряется в страницах по 4 Кбайт.
□ Байт доступа (5-й байт дескриптора) содержит информацию, которая используется для принятия решения о возможности или невозможности обращения к данному сегменту. Бит Р (Present) определяет, находится ли соответствующий сегмент в данный момент в памяти (Р=1) или он выгружен на диск (Р=0). Поле DPL (Descriptor Privilege Level) содержит данные об уровне привилегий, необходимом для доступа к сегменту. Остальные пять битов байта доступа зависят от типа сегмента и определяют способ, которым можно использовать данный сегмент (то есть читать, писать, выполнять). Различаются три основных типа сегментов:
О сегмент данных;
О кодовый сегмент;
О системный сегмент (GDT, TSS и т. п.),
Дескрипторы сегментов объединяются в таблицы. Процессор Pentium для управления памятью поддерживает два типа таблиц дескрипторов сегментов!:
□ глобальная таблица дескрипторов (Global Descriptor Table, GDT), которая предназначена для описания сегментов операционной системы и общих сегментов для всех прикладных процессов, например сегментов межпроцессного взаимодействия;
□ локальная таблица дескрипторов (Local Descriptor Table, LDT), которая содержит дескрипторы сегментов отдельного пользовательского процесса.
Таблица GDT одна, а таблиц LDT столько, сколько в системе выполняется задач (процессов). При этом в каждый момент времени операционной системой и аппаратными средствами процессора используется только одна из таблиц LDT, а именно та, которая соответствует выполняемому в данный момент пользовательскому процессу. Таблица GDT описывает общую часть виртуального адресного пространства процессов, a LDT — индивидуальную часть для каждого процесса. Таблицы GDT и LDT размещены в оперативной, памяти в виде отдельных сегментов. Сегменты LDT и GDT содержат системные данные, поэтому их дескрипторы хранятся в таблице GDT. Таким образом, таблица GDT наряду с записями о других сегментах содержит запись о самой себе, а также обо всех таблицах LDT. В каждый момент времени в специальных регистрах GDTR и LDTR хранится информация о местоположении и размерах глобальной таблицы GDT и активной таблицы LDT соответственно. Регистр GDTR содержит 32-разрядный физический адрес начала сегмента GDT в памяти, а также 16-битный размер этого сегмента (рис. 6.4). Регистр LDTR указывает на расположение сегмента LDT в оперативной памяти косвенно — он содержит индекс дескриптора в таблице GDT, в котором содержится адрес таблицы LDT и ее размер.

Процесс обращается к физической памяти по виртуальному адресу, представляющему собой пару (селектор, смещение). Селектор однозначно определяет виртуальный сегмент, к которому относится искомый адрес, то есть он может интерпретироваться как номер сегмента, а смещение, как это и следует из его названия, фиксирует положение искомого адреса относительно начала сегмента. Смещение задается в машинной инструкции, а селектор помещается в один из сегментных регистров процессора. Под смещение отводится 32 бита, что обеспечивает максимальный размер сегмента 4 Гбайт (232).
Селектор извлекается из одного из шести 16-разрядных сегментных регистров процессора (CS, SS, DS, ES, FS или GS) в зависимости от типа команды и стадии ее выполнения — выборки кода команды или данных. Например, при обращении к памяти во время выборки следующей команды используется селектор из сегментного регистра кода CS, а при записи результатов в сегмент данных процесса селекторы извлекаются из сегментных регистров данных DS или ES, если же данные записываются в стек по команде PUSH, то механизм виртуальной памяти извлекает селектор из сегментного регистра стека SS, и т. п.
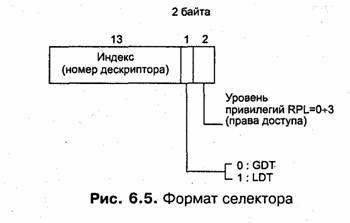
Селектор состоит из трех полей (рис. 6.5):
□ индекса, который задает последовательный номер дескриптора в таблице GDT или LDT (13 бит);
□ указателя типа используемой таблицы дескрипторов: GDT или LDT (1 бит);
□ требуемого уровня привилегий — RPL (2 бита), это поле используется механизмом защиты данных, который будет рассмотрен ниже.
Виртуальное адресное пространство процесса складывается из всех сегментов, описанных в общей для всех процессов таблице GDT, и сегментов, описанных в его собственной таблице LDT. Разрядность поля индекса определяет максимальное число глобальных и локальных сегментов процесса — по 8 Кбайт (213) сегментов каждого типа, всего 16 Кбайт сегментов. С учетом максимального размера сегмента — 4 Гбайт — каждый процесс при чисто сегментной организации виртуальной памяти (без включения страничного механизма) может работать в виртуальном адресном пространстве в 64 Тбайт.
Каждый дескриптор в таблицах GDT и LDT имеет размер 8 байт, поэтому максимальный размер каждой из этих таблиц — 64 Кбайт (8 байт х 8 Кбайт дескрипторов).
Из приведенного описания видно, что процессор Pentium обеспечивает поддержку работы ОС в двух отношениях:
□ поддерживает работу виртуальной памяти за счет быстрого аппаратного способа преобразования виртуального адреса в физический;
□ обеспечивает защиту данных и кодов различных приложений.
Теперь проследим, каким образом виртуальное пространство в 64 Тбайт отображается на физическое пространство размером в 4 Гбайт. Механизм отображения преобразовывает виртуальный адрес, который представлен селектором, находящимся в одном из сегментных регистров, и смещением, извлеченным из соответствующего поля машинной инструкции, в линейный физический адрес.

Рассмотрим сначала случай, когда виртуальный адрес относится к одному из сегментов, дескрипторы которых содержатся в таблице GDT (рис. 6.6).
- Значение селектора указывает механизму преобразования адресов, что виртуальный адрес относится к сегменту, описываемому в таблице, GDT. Местонахождение таблицы GDT система определяет из регистра GDTR, в котором хранится полный 32-битный базовый физический адрес таблицы. Процессор складывает базовый адрес таблицы, взятый из регистра GDTR, со сдвинутым на 3 разряда влево (умножение на 8 в соответствии с числом байтов в одном дескрипторе сегмента) значением поля индекса из селектора. Результатом является физический адрес дескриптора сегмента, к которому относится заданный виртуальный адрес.
2. По вычисленному адресу процессу извлекает из памяти дескриптор нужного сегмента.
3. Выполняется проверка возможности выполнения заданной операции доступа по заданному виртуальному адресу:
О сначала процессор определяет правильность адреса, сравнивая смещение, заданное в виртуальном адресе, с размером сегмента, извлеченным из регистра LDTR (в случае выхода адреса за границы сегмента происходит прерывание);
О затем процессор проверяет права доступа задачи к данному сегменту памяти;
О далее проверяется наличие сегмента в физической памяти (если бит Р дескриптора равен 0, то есть сегмент отсутствует в физической памяти, то происходит прерывание).
4. Если все три условия выполнены, то доступ по заданному виртуальному адресу разрешен. Выполняется преобразование виртуального адреса в физический путем сложения базового адреса сегмента, извлеченного из дескриптора, и смещения, заданного в инструкции. Выполняется заданная операция над элементом физической памяти по этому адресу.
В случае когда селектор в виртуальном адресе указывает не на таблицу GDT, a на таблицу LDT, процедура вычисления физического адреса несколько усложняется. Это связано с тем, что регистр LDTR в отличие от GDTR указывает на размещение таблицы сегментов не прямо, а косвенно. В LDTR содержится индекс дескриптора сегмента LDT. Поэтому в процедуре преобразования адресов появляется дополнительный этап — определение базового адреса таблицы LDT. На основании базового адреса таблицы GDT, взятого из регистра GDTR, и селектора, взятого из регистра LDTR, вычисляется смещение в таблице GDT, которое и является адресом дескриптора сегмента LDT.
Из дескриптора извлекается базовый адрес таблицы LDT, и с этого момента работа механизма отображения полностью аналогична описанному выше преобразованию виртуального адреса с помощью таблицы GDT: на основании базового адреса таблицы LDT и селектора задачи, заданного в одном из сегментных регистров, вычисляется смещение в таблице LDT и определяется базовый адрес дескриптора искомого сегмента. Из этого дескриптора извлекается базовый адрес сегмента, который складывается со смещением из виртуального адреса, что и дает в результате искомый физический адрес.
Таким образом, для использования сегментного механизма процессора Pentium операционной системе необходимо сформировать таблицы GDT и LDT, загрузить их в
память (для начала достаточно загрузить только таблицу GDT), загрузить указатели на эти таблицы в регистры GDTR и LDTR и выключить страничную поддержку.
Операционная система может отказаться от использования средств сегментации процессора Pentium, в таком случае ей достаточно назначить каждому процессу только по одному сегменту и занести в соответствующие таблицы LDT по одному дескриптору. Виртуальное адресное пространство задачи будет состоять из одного сегмента длиной максимум в 4 Гбайт. Поскольку выгрузка процессов на диск будет осуществляться целиком, виртуальная память вырождается в таком частном случае в свопинг.
Защита данных при сегментной организации памяти
Процессор Pentium при работе в сегментном режиме предоставляет операционной системе следующие средства, направленные на обеспечение защиты процессов друг от друга.
□ Процессор Pentium поддерживает для каждого процесса отдельную таблицу дескрипторов сегментов LDT. Эта таблица формируется операционной системой на этапе создания процесса. После активизации процесса в регистр LDTR заносится адрес (селектор) его таблицы LDT. Тем самым система делает недоступным для процесса локальные сегменты других процессов, описанные в их таблицах LDT.
□ Вместе с тем таблица GDT, в которой хранятся дескрипторы сегментов операционной системы, а также сегменты, используемые несколькими процессами совместно, доступна всем процессам, а следовательно, не защищена от их несанкционированного вмешательства. Для решения этой проблемы в процессоре Pentium предусмотрена поддержка системы безопасности на основе привилегий. Каждый сегмент памяти наделяется атрибутами безопасности, которые характеризуют степень защищенности данного сегмента. Процессы также наделяются атрибутами безопасности, которые в этом случае характеризуют степень привилегированности процесса. Уровень привилегий процесса определяется уровнем привилегий его кодового сегмента. Доступ к сегменту регулируется в зависимости от его защищенности и уровня привилегированности запроса. Это позволяет защитить от несанкционированного доступа сегменты GDT, а также обеспечить дифференцированный доступ к локальным сегментам процесса.
□ Само по себе наличие отдельных таблиц дескрипторов для каждого процесса еще не обеспечивает надежной защиты процессов друг от друга. Действительно, что мешает одному пользовательскому процессу изменить содержимое регистра LDTR так, чтобы он указывал на таблицу другого процесса? Аналогично никакие значения атрибутов безопасности не смогут защитить от несанкционированного доступа сегменты, описанные в таблице GDT, если процесс имеет возможность по своей инициативе устанавливать желаемый уровень привилегий для себя. Поэтому необходимым элементом защиты является наличие аппаратных ограничений в наборе инструкций, разрешенных для выполнения процессу. Некоторые инструкции, имеющие критически важное значение
для функционирования системы, такие, например, как останов процессора загрузка регистра GDTR, загрузка регистра LDTR, являются привилегированными как раз по этой причине — процесс может выполнять их, только обладая наивысшим уровнем привилегий.
□ Еще одним механизмом защиты, поддерживаемым в процессоре Pentium, является ограничение на способ использования сегмента. В зависимости от того, к какому типу относится сегмент — сегмент данных, кодовый сегмент или системный сегмент, — некоторое действия по отношению к нему могут быть к запрещены. Например, в кодовый сегмент нельзя записывать какие-либо данные, а сегменту данных нельзя передать управление, даже если загрузить его селектор в регистр CS.
В процессоре Pentium используется мандатный способ определения прав доступа к сегментам памяти (называемый также механизмом колец защиты), при котором имеется несколько уровней привилегий и объекты каждого уровня имеют доступ ко всем объектам равного уровня или более низких уровней, но не имеют доступа к объектам более высоких уровней. В процессоре Pentium существует четыре уровня привилегий — от нулевого, который является самым высоким, до третьего — самого низкого (рис. 6.7). Очевидно, что операционная система может использовать механизм колец защиты по своему усмотрению. Однако предполагается, что нулевой уровень доступен для ядра операционной системы, третий уровень — для прикладных программ, а промежуточные уровни — для утилит и подсистем операционной системы, менее привилегированных, чем ядро.
Система защиты манипулирует несколькими переменными, характеризующими уровень привилегий:
□ DPL {Descriptor Privilege Level) — уровень привилегий дескриптора, задается полем DPL в дескрипторе сегмента;
□ RPL {Requested Privilege Level) — запрашиваемый уровень привилегий, задается полем RPL селектора сегмента;
□ CPL {Current Privilege Level) — текущий уровень привилегий выполняемого кода, задается полем RPL селектора кодового сегмента;
□ EPL {Effective Privilege Level) — эффективный уровень привилегий запроса.
Под запросом здесь понимается любое обращение к памяти независимо от того, произошло ли оно при выполнении кода, оформленного в виде процесса, или вне рамок процесса, как это бывает при выполнении кодов операционной системы.
Поле уровня привилегий является частью двух информационных структур — дескриптора и селектора. В том и другом случае оно задается двумя битами: 00, 01, 10 и 11, характеризуя четыре степени привилегированности, от самой низкой 11 до самой высокой 00.
Уровни привилегий назначаются дескрипторам и селекторам. Во время загрузки операционной системы в память, а также при создании новых процессов операционная система назначает процессу сегменты кода и данных, генерирует дескрипторы этих сегментов и помещает их в таблицы GDT или LDT. Конкретные значения уровней привилегий DPL и RPL задаются операционной системой и транслятором либо по умолчанию, либо на основании указаний программиста. Значения DPL и RPL определяют возможности создаваемого процесса.
Уровень привилегий дескриптора DPL является в некотором смысле первичной характеристикой, которая «переносится» на соответствующие сегменты и запросы. Сегмент обладает тем уровнем привилегий, который записан в поле DPL его дескриптора. DPL определяет степень защищенности сегмента. Уровень привилегий сегмента данных учитывается системой защиты, когда она принимает решения о возможности выполнения для этого сегмента чтения или записи. Уровень привилегий кодового сегмента используется системой защиты при проверке возможности чтения или выполнения кода для данного сегмента.
Уровень привилегий кодового сегмента определяет не только степень защищенности этого сегмента, но и текущий уровень привилегий CPL всех запросов к памяти (на чтение, запись или выполнение), которые возникнут при выполнении этого кодового сегмента. Другими словами, уровень привилегий кодового сегмента DPL характеризует текущий уровень привилегий CPL выполняемого кода. При запуске кода на выполнение значение DPL из дескриптора копируется в поле RPL селектора кодового сегмента, загружаемого в регистр сегмента команд CS. Значение поля RPL кодового сегмента, собственно, и является текущим уровнем привилегий выполняемого кода, то есть уровнем CPL.
От того, какой уровень привилегий имеет выполняемый код, зависят не только возможности его доступа к сегментам и дескрипторам, но и разрешенный ему набор инструкций.
Во время приостановки процесса его текущий уровень привилегий сохраняется в контексте, роль которого в процессоре Pentium играет системный сегмент состояния задачи {Task State Segment, TSS). Если какой-либо процесс имеет несколько кодовых сегментов с разными уровнями привилегий, то поле RPL регистра CS позволяет узнать значение текущего уровня привилегий процесса. Заметим, что пользовательский процесс не может изменить значение поля привилегий в дескрипторе, так как необходимые для этого инструкции ему недоступны. В дальнейшем уровень привилегий процесса может измениться только, в случае передачи управления другому кодовому сегменту путем использования особого дескриптора — шлюза.
Контроль доступа процесса к сегментам данных осуществляется на основе сопоставления эффективного уровня привилегий EPL запроса и уровня привилегий DPL дескриптора сегмента данных. Эффективный уровень привилегий учитывает не только значение CPL, но и значение запрашиваемого уровня привилегий для конкретного сегмента, к которому выполняется обращение. Перед тем как обратиться к сегменту данных, выполняемый код загружает селектор, указывающий на этот сегмент, в один из регистров сегментов данных: DS, ES, FS или GS. Значение поля RPL данного селектора задает уровень запрашиваемых привилегий. Эффективный уровень привилегий выполняемого кода EPL определяется как максимальное (то есть худшее) из значений текущего и запрашиваемого уровней привилегий:
![]()
Выполняемый код может получить доступ к сегменту данных для операций чтения или записи, если его эффективный уровень привилегий не ниже (а в арифметическом смысле «не больше») уровня привилегий дескриптора этого сегмента:
![]()
Уровень привилегий дескриптора DPL определяет степень защищенности сегмента. Значение DPL говорит о том, каким эффективным уровнем привилегий должен обладать запрос, чтобы получить доступ к данному сегменту. Например, если дескриптор имеет DPL=2, то к нему разрешено обращаться всем процессам, имеющим уровень привилегий EPL, равный 0, 1 или 2, а для процессов с EPL, равным 3, доступ запрещен.
ПРИМЕЧАНИЕ-----------------------------------------------------------------------------------------------
Существует принципиальное различие в использовании полей RPL в селекторах, указывающих на кодовые сегменты и сегменты данных. Содержимое поля RPL из селектора, загруженного в регистр CS кодового сегмента, характеризует текущий уровень привилегий CPL выполняемого из этого сегмента кода; значение его никак не связано с сегментами данных, к которым может происходить обращение из этого кодового сегмента. Содержимое поля RPL из селектора, загруженного в один из регистров — DS, ES, FS или GS — сегментов данных, определяет некую «поправку» к текущему уровню привилегий выполняемого кода, вносимую при доступе к сегменту данных, на который указывает этот селектор.
Правило вычисления эффективного уровня привилегий показывает, что он не может быть выше уровня привилегий кодового сегмента. Поэтому загрузка в регистр DS (или любой другой сегментный регистр данных) селектора с высоким уровнем привилегий (например, с RPL = 0) при низком значении уровня CPL (например, 3) ничего нового не даст — если сегмент Данных, на который указывает DS, имеет высокий уровень привилегий (например, 1), то в доступе к нему будет отказано (так как EPL будет равен max {3,0}, то есть 3). По этой причине команды загрузки сегментных регистров не являются привилегированными.
Если запрос обращен к сегменту данных, обладающему более высоким, чем EPL, уровнем привилегий, то происходит прерывание.
Задавая в поле RPL селекторов, ссылающихся на сегменты данных, различные значения, программист может управлять доступом выполняемого кода к этим сегментам. Так, при RPL=0 эффективный уровень привилегий будет всецело определяться только текущим уровнем привилегий CPL. А если поместить в селектор RPL=3, то это означает снижение эффективного уровня привилегий до самого низкого значения, при котором процессу разрешен доступ только к наименее защищенным сегментам с DPL=3.
Контроль доступа процесса к сегменту стека позволяет предотвратить доступ низкоуровневого кода к данным, выработанным высокоуровневым кодом, и помещенным в стек, например к локальным переменным процедуры. Доступ к сегменту стека разрешается только в том случае, когда уровень EPL кода совпадает с уровнем DPL сегмента стека, то есть коду разрешается работать только со стеком своего уровня привилегий. Использование одного и того же стека для процедур разного уровня привилегий может привести к тому, что низкоуровневая процедура, получив управление после возврата из вызванной ею высокоуровневой процедуры (обратная последовательность вызова процедур в процессоре Pentium запрещена, что рассматривается ниже), может прочитать из стекового сегмента записываемые туда во время работы высокоуровневой процедуры данные. Так как в ходе выполнения процесса уровень привилегий его кода может измениться, то для каждого уровня привилегий используется отдельный сегмент стека.
Контроль доступа Процесса к кодовому сегменту производится путем сопоставления уровня привилегий дескриптора этого кодового сегмента DPL с текущим уровнем привилегий выполняемого кода CPL. В зависимости от того, какой способ обращения к кодовому сегменту используется, выполняется внутрисегментная или межсегментная передача управления, вызывается подчиненный или неподчиненный сегмент — по-разному формулируются правила контроля доступа. Эти вопросы будут рассмотрены в разделе «Средства вызова процедур и задач».
Осуществляя контроль доступа к сегменту, аппаратура процессора учитывает не только уровень привилегий, но и «легитимность» способа использования данного сегмента.
Способ, с помощью которого разрешено осуществлять доступ к сегменту того или иного типа, определяется несколькими битами байта доступа дескриптора сегмента. Как уже было сказано, старший, седьмой бит байта доступа является признаком Р присутствия сегмента в памяти, а шестой и пятый биты отведены для хранения уровня привилегий DPL. На рис. 6.8 показаны оставшиеся .пять битов байта доступа, смысл которых зависит от типа сегмента.
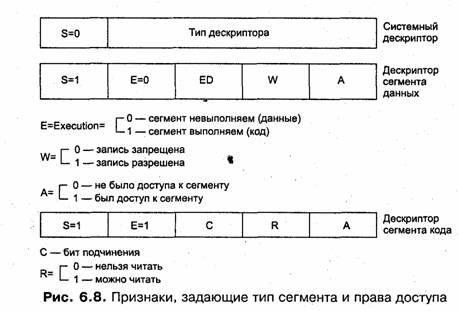
Поле S занимает 1 бит и определяет, является ли сегмент системным (S=0) или сегментом кода или данных (S=l).
Системные сегменты предназначены для хранения служебной информации операционной системы. Примерами системных сегментов являются сегменты, хранящие таблицы LDT, или рассматриваемые ниже сегменты состояния задачи TSS. Конкретный тип системного сегмента указывается в четырех младших битах байта доступа, например, если это поле содержит значение 2, это означает, что данный дескриптор описывает сегмент LDT.
Признак Е позволяет отличить сегмент данных (Е=0) от сегмента кода (Е=1). Для сегмента данных определяются следующие поля:
□ ED (Expand Down) — направления распространения сегмента (ED=O для обычного сегмента данных, распространяющегося в сторону увеличения адресов, ED=1 для стекового сегмента данных, распространяющегося в сторону уменьшения адресов);
□ W (Writeable) — бит разрешения записи в сегмент (при W=l запись разрешена, при W=0 — запрещена);
□ A (Accessed) — признак обращения к сегменту (1 означает, что после очистки этого поля к сегменту было обращение по чтению или записи, это поле может использоваться операционной системой для реализации ее стратегии замены сегментов в оперативной памяти).
Если признак W запрещает запись в сегмент данных, то разрешается только чтение сегмента. Выполнение сегмента данных запрещено всегда, независимо от значения признака W.
Для сегмента кода используются следующие признаки:
□ С (Conforming) — бит подчинения, определяет возможность вызова кода на выполнение из других сегментов; при С=1 (подчиненный сегмент) сегмент может выполняться в том случае, если текущий уровень привилегий вызывающего процесса CPL не выше уровня привилегий DPL данного кодового сегмента, то есть в арифметическом смысле CPL> DPL; после передачи управления новый кодовый сегмент начинает выполняться с уровнем привилегий вызвавшего сегмента, то есть с более низкими или теми же привилегиями; при С=0 (неподчиненный сегмент) код может быть выполнен только при CPL=DPL;
□ R (Readable) — бит разрешения (R=l) или запрета (R=0) чтения из кодового септета;
□ A (Accessed) — признак обращения, имеет смысл, аналогичный полю А сегмента данных.
Если признак R запрещает чтение кодового сегмента, то разрешается только его выполнение. Запись в кодовый сегмент запрещена всегда, независимо от значения признака R.
Выполнение многих операций в процессоре Pentium сопровождается проверкой их допустимости для данного типа сегмента. Первый этап проверки выполняется при загрузке селекторов в сегментные регистры. Так, диагностируется ошибка, если в сегментный регистр CS загружается селектор, ссылающийся на дескриптор сегмента данных, и наоборот, если в регистр сегмента данных DS загружается селектор, указывающий на дескриптор кодового сегмента. Ошибка возникает также, если в регистр стекового сегмента загружается селектор, ссылающийся на дескриптор сегмента данных, который допускает только чтение. Вторым этапом является проверка ссылок операндов во время выполнения команд записи или чтения. Прерывания происходят в следующих случаях:
□ делается попытка прочитать данные из кодового сегмента, который допускает только выполнение;
□ делается попытка записать данные по адресу, принадлежащему кодовому сегменту;
□ делается попытка записать данные в сегмент данных, который допускает только чтение.
Все средства защиты, используемые при работе процессора Pentium в сегментном режиме, полностью применимы и при включении страничного механизма. В этом случае они дополняются возможностями защиты страниц, которые будут рассмотрены ниже.
Включение страничного механизма происходит, если в регистре управления CR0 самый старший бит PG установлен в единицу. При включенной системе управления страницами параллельно продолжает работать и описанный выше сегментный механизм, однако, как будет показано ниже, смысл его работы меняется. Виртуальное адресное пространство процесса при сегментно-страничном режиме работы процессора ограничивается размером 4 Гбайт. В этом пространстве определены виртуальные сегменты процесса (рис. 6.9). Так как теперь все виртуальные сегменты разделяют одно виртуальное адресное пространство, то возможно их наложение, поскольку процессор не контролирует такие ситуации, оставляя эту проблему операционной системе.
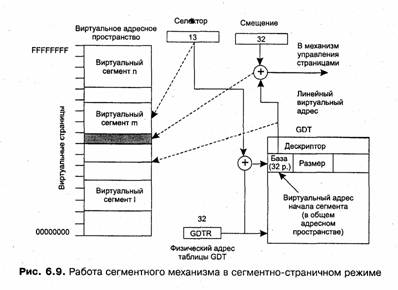
Для реализации механизма управления страницами как физическое, так и виртуальное адресные пространства разбиты на страницы размером 4 Кбайт (начиная с модели Pentium в процессорах Intel существует возможность использования страниц и по 4 Мбайт, но дальнейшее изложение ориентируется на традиционный размер страницы в 4 Кбайт). Всего в виртуальном адресном пространстве в сегментно-страничном режиме насчитывается 1 Мбайт (220) страниц. Несмотря на наличие нескольких виртуальных сегментов, все виртуальное адресное пространство задачи имеет общее разбиение на страницы, так что нумерация виртуальных страниц сквозная.
Виртуальный адрес по-прежнему представляет собой пару: селектор, который определяет номер виртуального сегмента, и смещение внутри этого сегмента. Преобразование виртуального адреса выполняется в два этапа: сначала работает сегментный механизм, а затем результат его работы поступает на вход страничного механизма, который и вычисляет искомый физический адрес.
Работа сегментного механизма в данном случае во многом повторяет его работу при отключенном страничном механизме. На основании значения индекса в селекторе выбирается нужный дескриптор из таблицы GDT или LDT. Из дескриптора извлекается базовый адрес сегмента и складывается со смещением. Дескрипторы и таблицы имеют ту же структуру. Однако имеется и принципиальное отличие, оно состоит в интерпретации содержимого поля базового адреса в дескрипторах сегментов. Если раньше дескриптор сегмента содержал базовый адрес сегмента в физической памяти и при сложении этого адреса со смещением из виртуального адреса получался физический адрес, то теперь дескриптор содержит базовый адрес сегмента в виртуальном адресном пространстве, и в результате его уложения со смещением получается линейный виртуальный адрес.
Результирующий линейный 32-разрядный виртуальный адрес передается страничному механизму для дальнейшего преобразования. Исходя из того что размер страницы равен 4 Кбайт (212), в адресе можно легко выделить номер виртуальной страницы (старшие 20 разрядов) и смещение в странице (младшие 12 разрядов). Как известно, для отображения виртуальной страницы в физическую достаточно построить таблицу страниц, каждый элемент которой — дескриптор виртуальной страницы — содержал бы номер соответствующей ей физической страницы и ее атрибуты. В процессоре Pentium так и сделано, и структура дескриптора страницы показана на рис. 6.10. Двадцать разрядов, в которых находится номер страницы, могут интерпретироваться и как базовый адрес страницы в памяти, который необходимо дополнить 12 нулями, так как младшие 12 разрядов базового адреса страницы всегда равны нулю. Кроме номера страницы дескриптор страницы содержит также следующие поля, близкие по смыслу соответствующим полям дескриптора сегмента:
□ Р — бит присутствия страницы в физической памяти;
□ W — бит разрешения записи в страницу;
□ U — бит пользователь/супервизор;
□ А — признак имевшего место доступа к странице;
□ D — признак модификации содержимого страницы;
□ PWT и PCD — управляют механизмом кэширования страниц (введены начиная с процессора i486);
□ AVL — резерв для нужд операционной системы (AVaiLable for use).

При небольшом размере страницы процессора Pentium относительно размеров адресных пространств таблица страниц должна занимать в памяти весьма значительное место — 4 байт х 1 Мбайт = 4 Мбайт. Это слишком много для нынешних моделей персональных компьютеров, поэтому в процессоре Pentium используется деление всей таблицы страниц на части — разделы по 1024 дескриптора. Размер раздела выбран так, чтобы один раздел занимал одну физическую страницу (1024 х 4 байт = 4 Кбайт). Таким образом таблица страниц делится на 1024 раздела.
Чтобы постоянно не хранить в памяти все разделы, создается таблица разделов {каталог страниц), состоящая из дескрипторов разделов, которые имеют такую же структуру, что и дескрипторы страниц. Максимальный размер таблицы разделов составляет 4 Кбайт, то есть одна страница. Виртуальные страницы, содержащие разделы, как и все остальные страницы, могут выгружаться на диск. Виртуальная страница, хранящая таблицу разделов, всегда находится в физической памяти, и номер ее физической страницы указан в специальном управляющем регистре CR3 процессора.
Преобразование линейного виртуального адреса в физический происходит следующим образом (рис. 6.11).
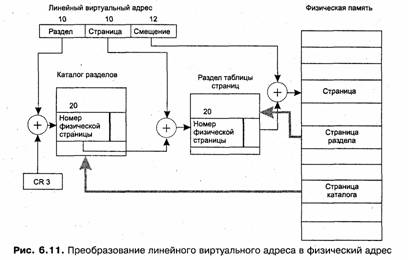
Поле номера виртуальной страницы (старшие 20 разрядов) делится на две равные части по 10 разрядов — поле номера раздела и поле номера страницы в разделе. На основании заданного в регистре CR3 номера физической страницы, хранящей таблицу разделов, и смещения в этой странице, задаваемого полем номера раздела, процессор находит дескриптор виртуальной страницы раздела. В соответствии с атрибутами этого дескриптора определяются права доступа к странице, а также наличие ее в физической памяти. Если страницы нет в оперативной памяти, то происходит прерывание, в результате которого операционная система должна выполнить загрузку требуемой страницы в память. После того как страница (содержащая нужный раздел) загружена, из нее извлекается дескриптор страницы данных, номер которой указан в линейном виртуальном адресе. И наконец, на основании базового адреса страницы, полученного из дескриптора, и смещения, заданного в линейном виртуальном адресе, вычисляется искомый физический адрес.
Таким образом, при доступе к странице в процессоре используется двухуровневая схема адресации страниц, которая хотя и замедляет преобразование, но позволяет использовать страничный механизм для таблицы страниц, что существенно уменьшает объем физической памяти, требуемой для ее хранения. Для ускорения преобразования адресов в блоке управления страницами используется ассоциативная память, в которой кэшируются 32 дескриптора активно используемых страниц, что позволяет по номеру виртуальной страницы быстро извлекать номер физической страницы без обращения к таблицам разделов и страниц.
Средства вызова процедур и задач
Операционная система, как однозадачная, так и многозадачная, должна предоставлять задачам средства вызова процедур операционной системы, библиотечных процедур. Она должна также иметь средства для запуска задач, а при многозадачной работе — средства быстрого переключения с задачи на задачу. Вызов процедуры отличается от запуска задачи тем, что в первом случае виртуальное адресное пространство задачи остается тем же (таблица LDT остается прежней), а при вызове задачи это адресное пространство полностью меняется.
Вызов процедур
Вызов процедуры без смены кодового сегмента в защищенном режиме процессора Pentium производится обычным образом с помощью команд JMP и CALL.
Для вызова процедуры, код которой находится в другом сегменте (этот сегмент может принадлежать другому программному модулю приложения, библиотеке, другой задаче или операционной системе), процессор Pentium предоставляет несколько способов вызова, причем во всех используется защита, основанная на уровнях привилегий.
Прямой вызов процедуры из неподчиненного сегмента. Этот способ состоит в непосредственном указании в поле команды JMP или CALL селектора, который указывает на дескриптор нового кодового сегмента. Этот сегмент содержит код вызываемой процедуры. Базовый адрес сегмента, содержащийся в дескрипторе, и смещение, задаваемое в команде JMP или CALL, определяют начальный адрес вызываемой процедуры.
Схема такого вызова приведена на рис. 6.12. Здесь и далее показан только этап получения линейного адреса в виртуальном пространстве, а следующий этап (подразумевается, что механизм поддержки страниц включен) преобразования этого адреса в номер физической страницы опущен, так как он не содержит ничего нового по сравнению с рассмотренным выше доступом к сегменту данных. Разрешение вызова происходит в зависимости от значения поля С в дескрипторе сегмента вызываемого кода.
При С=0 вызываемый сегмент не считается подчиненным, и вызов разрешается, только если уровень привилегий вызывающего кода совпадает с уровнем привилегий вызываемого сегмента (CPL=DPL). Случаи, когда вызываемый код имеет
более низкий уровень привилегий или более высокий уровень привилегий, являются запрещенными.
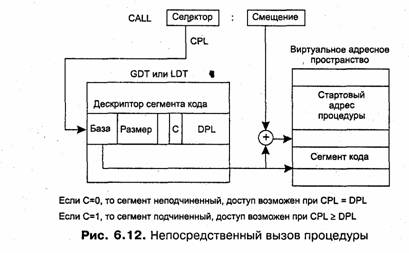
В первом случае запрет является естественным средством защиты ОС от вызова произвольных привилегированных процедур из пользовательских программ. Очевидно, что система защиты ОС не должна быть абсолютной, так как приложения должны иметь возможность обращаться к определенным процедурам ОС, реализующим системные вызовы. Так как с помощью неподчиненных кодовых сегментов этого сделать нельзя, то для решения этой проблемы существуют другие способы — подчиненные сегменты и шлюзы вызовов, рассматриваемые ниже.
Во втором случае запрет звучит так: код не может вызвать другой код, если у последнего привилегии ниже. Это на первый взгляд кажется странным. Действительно, в соответствии с этим правилом операционная система не может вызывать код приложения из неподчиненного сегмента, хотя ее уровень привилегий выше, чем у кода приложения. Однако, по сути, этот запрет является проявлением общего иерархического принципа построения системы защиты процессоров Pentium — привилегированный код не может пользоваться ненадежными в общем случае процедурами с более низким уровнем привилегий, и этот принцип соблюдается для всех способов вызова процедур, а не только для данного.
ПРИМЕЧАНИЕ----------------------------------------------------------------------------------------------
При обсуждении вопросов доступа к сегментам данных с уровнем привилегий сегмента DPL сравнивалось значение эффективного уровня привилегий EPL. При доступе же к кодовому сегменту с его DPL сравнивается значение CPL. Внимательный читатель мог заметить, что здесь нет никакого противоречия или особого случая, потому что при доступе к кодовому сегменту EPL всегда равно CPL: EPL=max (RPL, CPL). А так как CPL — это и есть RPL кодового сегмента, то EPL=max (CPL, CPL)=CPL.
Прямой вызов процедуры из подчиненного сегмента. Процессор должен поддерживать способ безопасного вызова модулей ОС, чтобы пользовательские программы могли получать доступ к службам ОС, например выполнять ввод-вывод с помощью соответствующих системных вызовов. Для реализации этой возможности существует несколько способов, и одним из них является размещение процедур ОС в подчиненном сегменте (С=1). Подчиненный сегмент можно вызывать с помощью указания его селектора в командах CALL или JMP из кода программ с равным или более низким уровнем привилегий (CPL>DPL). Но нужно иметь в виду, что вызываемый код будет в этом случае выполняться с привилегиями вызывающей программы. Например, если код ОС, хранящийся в сегменте с уровнем привилегий 0, будет вызван из пользовательского приложения с уровнем привилегий 3, то процедура ОС будет наследовать привилегии пользовательской программы и возможности этой процедуры по доступу к системным данным будут весьма ограничены. Тем не менее выполнить действия над пользовательскими данными вызванная таким способом процедура ОС сможет.
Косвенный вызов процедуры через шлюз. Очевидно, что оба рассмотренных выше способа вызова процедур не подходят для реализации системных вызовов. Первый способ в принципе не позволяет вызвать из пользовательской программы с третьим уровнем привилегий процедуру операционной системы, находящуюся в неподчиненном сегменте и имеющую более высокий уровень привилегий. С помощью второго способа могут быть вызваны процедуры ОС, находящиеся в подчиненном сегменте, однако они будут выполняться с пользовательским уровнем привилегий и не смогут обрабатывать системные данные, что нужно для большинства системных вызовов. Поэтому процессор Pentium предоставляет еще один способ вызова подпрограмм — через шлюз (вентиль), позволяющий пользовательскому коду вызывать привилегированные процедуры, которые будут работать со своим высоким уровнем привилегий. Шлюзы вызова обладают еще одним преимуществом — появляется возможность контроля точек входа в вызываемые процедуры. В обоих рассмотренных выше способах адрес точки входа в вызываемую процедуру определяется смещением, заданным в команде CALL вызывающей процедуры, то есть существует возможность задания некорректного значения смещения, в результате чего может произойти передача управления не на нужную команду или вообще в середину команды. Шлюзы вызова свободны от данного недостатка.
Набор точек входа в привилегированные кодовые сегменты определяется заранее, и эти точки входа описываются с помощью специальных дескрипторов — дескрипторов шлюзов вызова процедур. Дескрипторы этого типа принадлежат к системным дескрипторам, и хотя их структура отличается от структуры дескрипторов сегментов кода и данных (рис. 6.13), они также включены в таблицы LDT и GDT.

Схема вызова процедуры через шлюз приведена на рис. 6.14. Селектор из поля команды CALL указывает на дескриптор шлюза в таблицах GDT или LDT. Для того чтобы получить доступ к процедуре через шлюз, описываемый данным дескриптором, вызывающий код должен иметь не меньший уровень прав, чем дескриптор шлюза (то есть CPL<DPL). При этом вызываемый код может иметь любой уровень привилегий (в том числе и более высокий, чем у шлюза), который сохраняется при его выполнении. Это позволяет из пользовательской программы вызывать процедуры ОС, работающие с высоким уровнем привилегий. При определении адреса входа в вызываемом сегменте смещение из поля команды CALL не используется, а используется смещение из дескриптора шлюза, что не дает возможности задаче самой определять точку входа в защищенный кодовый сегмент.
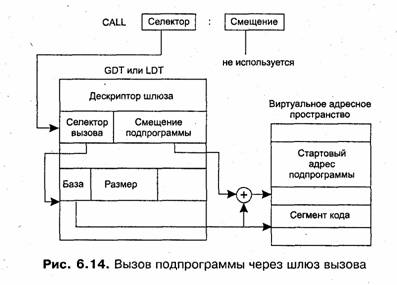
При вызове кодов, обладающих различными уровнями привилегий, возникает проблема передачи параметров между вызывающей и вызываемой процедурами. Для ее решения в процессоре предусмотрено существование стеков разных уровней, по одному стеку на каждый уровень привилегий. Используемый кодовым сегментом стек всегда соответствует текущему уровню привилегий кодового сегмента, то есть значению CPL. В сегменте контекста задачи. TSS (более детально он описан ниже) хранятся значения селекторов стека SS для уровней привилегий 0, 1 и 2. Если вызывается процедура, имеющая уровень привилегий, отличный от текущего, то при выполнении команды CALL создается новый стек. Для этого из сегмента TSS извлекается новое значение селектора стека, соответствующее новому уровню привилегий, которое загружается в регистр SS, из текущего стека в новый стек копируется столько 32-разрядных слов, сколько указано в поле счетчика слов дескриптора шлюза. В новом стеке также запоминается селектор старого стека, который используется при возврате в вызывающую процедуру.
Механизм вызова при переключении между задачами отличается от механизма вызова процедур. В этом случае селектор команды CALL должен указывать на дескриптор системного сегмента TSS. Сегмент TSS хранит контекст задачи, то есть информацию, которая нужна для восстановления выполнения прерванной в произвольный момент времени задачи. Контекст задачи включает значения регистров процессора, указатели на открытые файлы и некоторые другие, зависящие от операционной системы, переменные. Скорость переключения контекста в значительной степени влияет на производительность многозадачной операционной системы.

Процессор Pentium производит аппаратное переключение контекстов задач, используя для этого сегменты специального типа TSS. Структура сегмента TSS задачи приведена на рис. 6.15. Как видно из рисунка, сегмент TSS имеет фиксированные поля, отведенные для содержимого регистров процессора, как универсальных, так и некоторых управляющих (например, LDTR и CR3). Для описания возможностей доступа задачи к портам ввода-вывода процессор использует в защищенном режиме поле IOPL (Input/Output Privilege Level) в своем регистре EFLAGS и карту битовых полей доступа к портам в сегменте TSS. Для получения возможности безусловно выполнять команды ввода-вывода текущий код должен иметь уровень прав CPL не ниже, чем уровень привилегий операций ввода-вывода; задаваемый значением поля IOPL в регистре EFLAGS. Если же это условие не соблюдается, то возможность доступа к порту с конкретным адресом определяется значением соответствующего бита в карте ввода-вывода сегмента TSS (карта состоит из 64 Кбит для описания доступа к 65 536 портам) — значение 0 разрешает операцию ввода-ввода с данным номером порта.
Кроме этого, сегмент TSS может включать дополнительную информацию, необходимую для работы задачи и зависящую от конкретной операционной системы (например, указатели открытых файлов или указатели на именованные конвейеры сетевого обмена).
Информация сегмента TSS автоматически заменяется процессором при выполнении команды CALL, селектор которой указывает на дескриптор сегмента TSS в таблице GDT (дескрипторы этого типа могут быть расположены только в этой таблице). Формат дескриптора сегмента TSS аналогичен формату дескриптора сегмента данных (за исключением, естественно, поля типа сегмента, в котором указывается, что это дескриптор сегмента TSS).
Как и в случае вызова процедуры, имеются два способа вызова задачи — непосредственный вызов путем указания селектора дескриптора сегмента TSS нужной задачи в поле команды CALL и косвенный вызов через шлюз вызова задачи.
Однако условие, разрешающее непосредственный вызов задачи, отличается от условия непосредственного вызова процедуры: вызов возможен только в случае, если вызывающий код обладает уровнем привилегий, не меньшим, чем вызываемая задача (CPL<DPL). Здесь применяется то же правило, что и при доступе к данным. Действительно, операционная система, работающая с высоким уровнем привилегий, должна иметь возможность запускать на выполнение пользовательские задачи, работающие с низким уровнем привилегий. В этом случае ОС не поручает ненадежному низкоуровневому коду выполнять некоторые свои функции, как это происходило бы при вызове низкоуровневых процедур, а просто выполняет переключение между пользовательскими процессами.
При вызове через шлюз (который может располагаться и в таблице LDT) вызывающему коду достаточно иметь права доступа к шлюзу, а шлюз может указывать на дескриптор TSS в таблице GDT с равным или более высоким уровнем привилегий. Поэтому через шлюз вызова задачи можно выполнить переключение на более привилегированную задачу.
Непосредственный вызов задачи показан на рис. 6.16. При переключении задач процессор выполняет следующие действия:
1. Выполняется команда CALL, селектор которой указывает на дескриптор сегмента типа TSS. Происходит проверка прав доступа, успешная при CPL<DPL.
2. В TSS текущей задачи сохраняются значения регистров процессора. На текущий сегмент TSS указывает регистр процессора TR, содержащий селектор сегмента.
3. В TR загружается селектор сегмента TSS задачи, на которую переключается процессор.
4. Из нового TSS в регистр LDTR переносится значение селектора таблицы LDT в таблице GDT задачи.
5. Восстанавливаются значения регистров процессора (из соответствующих полей нового сегмента TSS).
6. В поле селектора возврата нового сегмента TSS заносится селектор сегмента TSS снимаемой с выполнения задачи для организации возврата к ней в будущем.
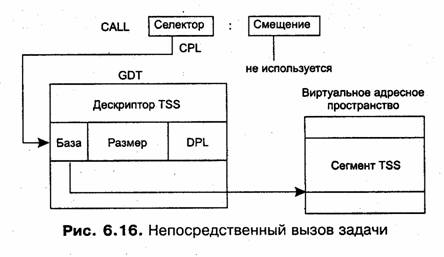
Вызов задачи через шлюз происходит аналогично, добавляется только этап поиска дескриптора сегмента TSS по значению селектора дескриптора шлюза вызова.
Использование всех возможностей, предоставляемых процессорами Intel 80386, 80486 и Pentium, позволяет организовать операционной системе высоконадежную многозадачную среду.
Процессор Pentium поддерживает векторную схему прерываний, с помощью которой может быть вызвано 256 процедур обработки прерываний (вектор имеет длину в один байт). Соответственно таблица процедур обработки прерываний имеет 256 элементов, которые в реальном режиме работы процессора состоят из дальних адресов (CS:IP) этих процедур, а в защищенном режиме — из дескрипторов. Контроллер прерываний в большинстве аппаратных платформ на основе процессоров Pentium реализует механизм опрашиваемых прерываний, поэтому общий механизм компьютера носит смешанный векторно-опрашиваемый характер.
Прерывания, которые обрабатывает Pentium, делятся на следующие классы:
□ аппаратные (внешние) прерывания — источником таких прерываний является сигнал на входе процессора;
□ исключения — внутренние прерывания процессора;
□ программные прерывания, происходящие по команде INT.
Аппаратные прерывания бывают маскируемыми и немаскируемыми. Маскируемые прерывания вызываются сигналом INTR на одном из входов микросхемы процессора. При его возникновении процессор завершает выполнение очередной инструкции, сохраняет в стеке значение регистра признаков программы EFLAGS и адреса возврата, а затем считывает с входов шины данных байт вектора прерываний и в соответствии с его значением передает управление одной из 256 процедур обработки прерываний.
Маскируемость прерываний управляется флагом разрешения прерываний IF (Interrupt Flag), находящимся в регистре EFLAGS процессора. При IF=1 маскируемые прерывания разрешены, a при IF=0 — запрещены. Для явного управления флагом IF в процессоре имеются чувствительные к уровню привилегий инструкции разрешения маскируемых прерываний STI (SeT Interrupt flag) и запрета маскируемых прерываний CLI (CLear Interrupt flag). Эти инструкции разрешается выполнять при CPL<IOPL. Кроме того, состояние флага изменяется неявным образом в некоторых ситуациях, например он сбрасывается процессором при распознавании сигнала INTR, чтобы процессор не входил во вложенные циклы процедуры обработки одного и того же прерывания. Процедура обработки прерывания завершается инструкцией IRET, по которой происходит извлечение из стека признаков EFLAGS, адреса возврата, установка флага разрешения прерываний IF и передача управления по адресу возврата. Для маскируемых прерываний в процессоре отведены процедуры обработки прерываний с номерами 32-255. Соответствие между сигналом запроса прерывания на шине ввода-вывода (например, сигналом IRQn на шине PCI) и значением вектора задается внешним по отношению к процессору блоком компьютера — контроллером прерываний.
Немаскируемое аппаратное прерывание происходит при появлении сигнала NIVtl (Non Maskable Interrupt) на входе процессора. Этот сигнал всегда прерывает работу процессора, вне зависимости от значения флата IF. При обработке немаскируемого прерывания вектор не считывается, а управление всегда передается процедуре с номером 2, описываемой третьим элементом таблицы процедур обработки прерываний (нумерация в этой таблице начинается с нуля). Немаскируемые прерывания предназначаются для реакции на «сверхважные» для компьютерной системы события, например сбой по питанию. В ходе процедуры обслуживания немаскируемого прерывания процессор не реагирует на другие запросы немаскируемых и маскируемых прерываний до тех пор, пока не будет выполнена команда IRET. Если при обработке немаскируемого прерывания возникает новый сигнал NMI, то он фиксируется и обрабатывается после завершения обработки текущего прерывания, то есть после выполнения команды IRET.
Исключения (exeprtions) делятся в процессоре Pentium на отказы (faults), ловушки (traps) и аварийные завершения (aborts).
Отказы соответствуют некорректным ситуациям, которые выявляются до выполнения инструкции, например, при обращении по адресу, находящемуся в отсутствующей в оперативной памяти странице (страничный отказ). После обработки исключения-отказа процессор повторяет выполнения команды, которую он не смог выполнить из-за отказа. Ловушки обрабатываются процессором после выполнения инструкции, например при возникновении переполнения. После обработки процессор выполняет инструкцию, следующую за той, которая вызвала исключение. Аварийные завершения соответствуют ситуациям, когда невозможно точно определить команду, вызвавшую прерывание. Чаще всего это происходит во время серьезных отказов, связанных со сбоями в работе аппаратуры компьютера. Для обработки исключений в таблице прерываний отводятся номера 0-31.
Программные прерывания в процессоре Pentium происходят при выполнении инструкции INT с однобайтовым аргументом, в котором указывается вектор прерывания. Общая длина инструкции INT — два байта, исключение составляет инструкция INT 3, которая целиком помещается в один байт — это удобно при отладке программ, когда инструкция INT заменяет первый байт любой команды, вызывая переход на процедуру отладки. Программные прерывания подобно ловушкам обрабатываются после выполнения соответствующей инструкции INT, а возврат происходит в следующую инструкцию. Программное прерывание может вызвать любую из 256 процедур обработки прерываний, указанных в таблице прерываний.
При одновременном возникновении запросов прерываний различных типов процессор Pentium разрешает коллизию с помощью приоритетов. Немаскируемые прерывания имеют более высокий приоритет, чем маскируемые. Приоритетность внутри маскируемых прерываний устанавливается не процессором, а контроллером прерываний (процессор не может этого сделать, так как для него все маскируемые запросы представлены одним сигналом INTR). Проверка некорректных ситуаций, порождающих исключения (в том числе и при выполнении одной команды), выполняется в процессоре в соответствии с определенной последовательностью.
Таблица прерываний в реальном режиме состоит из 256 элементов, каждый из которых имеет длину в 4 байта и представляет собой дальний адрес (CS:IP) процедуры обработки прерываний. Таблица прерываний реального режима всегда находится в фиксированном месте физической памяти — с начального адреса 00000 по адрес 003FF.
В защищенном режиме таблица прерываний носит название IDT (Interrupt Descriptor Table) и может располагаться в любом месте физической памяти. Ее начало (32-разрядный физический адрес) и размер (16 бит) можно найти в регистре системных адресов IDTR. Каждый из 256 элементов таблицы прерываний представляет собой 8-байтный дескриптор. В таблице прерываний могут находиться .только дескрипторы определенного типа — дескрипторы шлюзов прерываний, шлюзов ловушек и шлюзов задач.
Шлюзы задач уже рассматривались выше, они используются всегда для переключения с задачи на задачу. Шлюзы прерываний и ловушек специально вводятся для вызова процедур обработки прерываний. Если для вызова процедуры обработки прерывания используется шлюз задач, то происходит смена процесса, а по завершении обработки — возврат к прерванному процессу. Обычно обслуживание прерываний со сменой процесса (и запоминанием его контекста) применяется для внешних прерываний, которые не связаны с текущим процессом, например, когда принтер с помощью прерывания требует загрузить в его буфер новую порцию распечатываемых данных приостановленного процесса.
Шлюзы прерываний и ловушек не вызывают смены контекста задачи, следовательно, процедуры обработки прерываний в этом случае вызываются быстрее, чем при использовании шлюза задачи. Формат дескриптора шлюза прерывания и ловушки аналогичен формату дескриптора шлюза вызова, и обработка процессором этих шлюзов во многом аналогична вызову процедуры через шлюз вызова. Отличие состоит в том, что при вызове процедуры через шлюз прерываний сбрасывается флаг IF и тем самым запрещаются вложенные прерывания. При использовании шлюза ловушки сброса флага IF не происходит, но в стек при некоторых видах исключений дополнительно помещается код ошибки, вызвавшей исключение.
Итак, процессор Pentium предоставляет операционной системе широкий диапазон возможностей для организации обработки прерываний различного типа.
Кэширование в процессоре Pentium
В процессоре Pentium кэширование используется в следующих случаях.
□ Кэширование дескрипторов сегментов в скрытых регистрах. Для каждого сегментного регистра в процессоре имеется так называемый скрытый регистр дескриптора. В скрытый регистр при загрузке сегментного регистра помещается информация из дескриптора, на который указывает данный сегментный регистр. Информация из дескриптора сегмента используется для преобразования виртуального адреса в физический при чисто сегментной организации памяти либо для получения линейного виртуального адреса при страничном механизме. Доступ к скрытому регистру выполняется быстрее, чем поиск и извлечение информации из таблицы страниц, находящейся в оперативной памяти. Поэтому если очередное обращение будет относиться к одному из сегментов, дескриптор которого еще хранится в скрытом регистре (а вероятность этого велика), то преобразование адресов будет выполнено быстрее. Тем самым скрытые регистры играют роль кэша таблицы дескрипторов и ускоряют работу процессора.
□ Кэширование пар номеров виртуальных и физических страниц в буфере ассоциативной трансляции TLB (Translation Lookaside Buffer) позволяет ускорять преобразование виртуальных адресов в физические при сегментно-страничной организации памяти. TLB представляет собой ассоциативную память небольшого объема, предназначенную для хранения интенсивно используемых дескрипторов страниц. В процессоре Pentium имеются отдельные TLB для инструкций и данных.
□ Кэширование данных и инструкций в кэш-памяти первого уровня. Эта память, называемая также внутренней кэш-памятью, поскольку она размещена непосредственно на кристалле микропроцессора, имеет объем 16/32 Кбайт. В процессоре Pentium кэш первого уровня разделен на память для хранения данных и память для хранения инструкций. Согласование данных выполняется только методом сквозной записи.
□ Кэширование данных и инструкций в кэш-памяти второго уровня. Эта память называется также внешней кэш-памятью, поскольку она устанавливается в виде отдельной микросхемы на системной плате. Кэш-память второго уровня является общей для данных и инструкций и имеет объем 256/512 Кбайт. Поиск в кэше второго уровня выполняется в случае, когда констатируется промах в кэше первого уровня. Для согласования данных в кэше второго уровня может использоваться как сквозная, так и обратная запись.
Рассмотрим более подробно принципы работы буфера ассоциативной трансляции и кэша первого уровня.
Буфер ассоциативной трансляции
В буфере TLB кэшируются дескрипторы страниц из таблицы страниц (рис. 6.17). Для хранения дескриптора в кэше отводится одна строка. Каждая строка дополнена тегом, в котором содержится номер соответствующей виртуальной страницы. Строки объединены по четыре в группы, называемые наборами. Таблица TLB, используемая для преобразования адресов инструкций, имеет 32 строки и соответственно 8 наборов. Номер набора называют индексом (index). Таким образом, путем кэширования может быть получен физический адрес для доступа к 32 страницам памяти, содержащим инструкции.
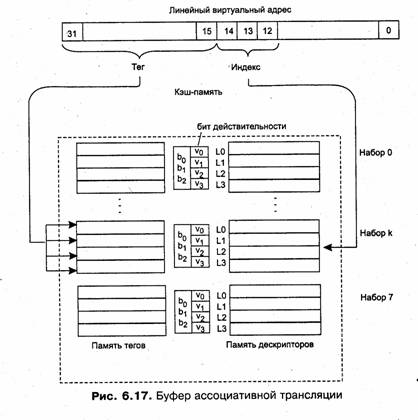
После того как механизмом сегментации получен линейный адрес, он должен быть преобразован в физический адрес. Для этого прежде всего необходимо найти дескриптор страницы, к которой принадлежит данный адрес, и извлечь из него номер физической страницы. Обычная процедура предусматривает обращение к таблице разделов, а затем к таблице страниц. Однако физический адрес может быть получен гораздо быстрее благодаря тому, что в буфере TLB хранятся копии дескрипторов наиболее интенсивно используемых страниц. Поэтому перед тем, как начать сравнительно длительную процедуру преобразования адресов, делается попытка обнаружить нужный дескриптор страницы в быстрой ассоциативной памяти TLB. Затем на основании номера физической страницы, полученного из TLB, вычисляется физический адрес.
При поиске данных в TLB используется линейный виртуальный адрес. Разряды 12-14 используются как индекс набора. Далее проверяются биты действительности v всех строк выбранного набора. В начале работы кэш-памяти биты действительности всех строк сбрасываются в нуль. Бит действительности принимает значение 1, когда в соответствующей строке содержится достоверная информация и сбрасывается в нуль, когда строка объявляется свободной, в результате работы алгоритма замещения. Для всех действительных строк выполняется ассоциативная процедура сравнения тегов со старшими разрядами (15-31 разряд) линейного виртуального адреса. Если произошло кэш-попадание, то номер физической страницы быстро поступает в схему формирования физического адреса.
Если произошел промах и нужного дескриптора в TLB нет, то запускается многоэтапная процедура преобразования адреса, включающая обращения к таблицам разделов и страниц. Когда нужный дескриптор отыскивается в таблице страниц, он копируется в TLB. Номер набора, в который записывается кэшируемый дескриптор, определяется тремя младшими разрядами номера виртуальной страницы (разряды 12-14 линейного виртуального адреса).
Однако поскольку в наборе имеется четыре строки, необходимо определить, в какую именно надо поместить кэшируемые данные. Дескриптор записывается либо в первую попавшуюся свободную строку, либо, если все строки заняты, в строку, к которой дольше всего не обращались. Признаком занятости строки служит бит действительности v, имеющийся у каждой строки. Если v=0, значит, строка свободна для записи в нее нового содержимого. Для определения строки, которая не использовалась дольше всех других, в данном наборе, применяется упрощенный вариант алгоритма PseudoLRU (Pseudo Least Recently Used). Этот алгоритм основан на анализе трех бит: b0, b1 b3, называемых битами обращения. Биты обращения приписываются набору и устанавливаются в соответствии с алгоритмом, приведенном на рис. 6.18. Здесь L0, L1, L2, L3 обозначают последовательные строки набора.
На замену выбирается одна из следующих строк:
□ L0, если b0=0 и b10;
□ L1, если b0=0 и b1=1;
□ L2, если b0=1 и b2=0;
□ L3, если b0=1 и b2=1.

Можно легко показать, что данная процедура не всегда приводит к выбору действительно дольше всех не вызывавшейся строки. Пусть, например, обращения к строкам выполнялись в следующей хронологической последовательности: L0, L2, L3, L1, то есть ближайшее по времени обращение было к строке L1, дольше же всего не было обращений к строке L0. Биты обращения в данном случае примут следующие значения. Поскольку последнее по времени обращение было к строке из пары (L0, L1), значит, b0=1. А в паре (L2, L3) последнее обращение было к L3, следовательно, b2=0. Отсюда, по правилу, приведенному выше, на замену выбирается строка L2, вместо строки L0, к которой на самом деле дольше всего не было обращений.
Однако в большинстве случаев этот алгоритм дает результат, совпадающий с оптимальным. Например, для последовательности L0, L3, LI, L2 биты обращения имеют значения b0=0, b10, отсюда точное решение — L0. Даже в случае ошибки (вероятность которой составляет 33 %) решения, найденные по алгоритму PseudoLRU, близки к оптимальным. Так, в первом примере вместо строки L0, являющейся правильным решением, алгоритм дал ближайшую к ней по времени обращения строку L2.
Несмотря на то что алгоритм PseudoLRU дает в общем случае приближенные решения, он широко применяется при кэшировании, так как является быстрым и экономичным, что чрезвычайно важно для кэш-памяти.
Таким образом, в буфере TLB процессора Pentium используется комбинированный способ отображения кэшируемых данных на кэш-память; прямое отображение дескрипторов на наборы и случайное отображение на строки в пределах набора.
Наличие TLB позволяет в подавляющем числе случаев заменить сравнительно долгую процедуру преобразования адресов, связанную с несколькими обращениями к оперативной памяти, быстрым поиском в ассоциативной памяти.
Кэш первого уровня используется на этапе обработки запроса к основной памяти по физическому адресу.
Работа кэш-памяти первого уровня имеет много общего с работой буфера TLB. В TLB единицей хранения является дескриптор, а в кэше первого уровня — байт данных. Обновление данных в кэше происходит блоками по 16 байт. Таким образом, младшие 4 бита физического адреса байта могут интерпретироваться как смещение в блоке, а старшие разряды — как номер блока.
Для хранения блоков данных в кэше отводятся строки, также имеющие объем 16 байт. Строки объединены в наборы по четыре. При объеме кэша 16 Кбайт в него входят 256 (28) наборов.
При копировании данных в кэш номера блоков основной памяти прямо отображаются на номера наборов. Для этого в адресе основной памяти, относящегося к одному из байтов, входящих в блок, значение 8 битов, находящихся перед битами смещения, интерпретируется как номер набора в кэш-памяти (рис. 6.19). Остальные старшие биты адреса в дальнейшем используются в качестве тега.
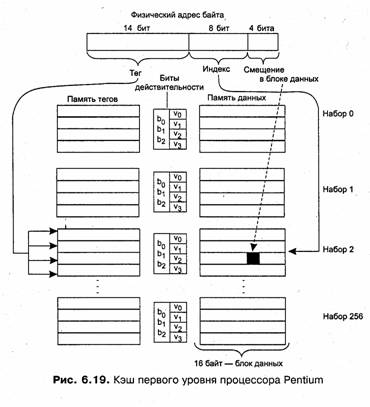
Так же как в TLB, выбор строки в наборе осуществляется на основе анализа битов действительности и битов обращения по алгоритму PseudoLRU. Блок данных заносится в строку кэш-памяти вместе со своим тегом — старшими разрядами адреса основной памяти. Бит действительности строки устанавливается в 1.
При возникновении запроса на чтение из основной памяти вначале делается попытка найти данные в кэше (либо поиск в кэше совмещается с выполнением запроса к основной памяти). По индексу, извлеченному из адреса запроса, определяется набор, в котором могут находиться искомые данные. Затем для строк данного набора, содержимое которых действительно (установлены биты действительности), выполняется ассоциативный поиск: старшие разряды адреса из запроса сравниваются с тегами всех строк набора. Если для какой-нибудь строки фиксируется совпадение, это означает, что произошло кэш-попадание, и из соответствующей строки извлекается байт, смещение которого относительно начала строки определяется четырьмя младшими разрядами из адреса запроса.
Для согласования данных в кэше первого уровня используется метод сквозной записи, то есть при возникновении запроса на запись обновляется не только содержимое соответствующей ячейки основной памяти, но и его копия в кэш-памяти. Заметим также, что запрос на запись при промахе не вызывает обновления кэша.
Совместная работа кэшей разного уровня
Разные виды кэш-памяти вступают «в игру» на разных этапах обработки запроса к основной памяти. В зависимости от того, насколько удачно для запроса сложилась ситуация с попаданиями в кэш-память разного типа, время его выполнения может измениться в десятки раз. На рис. 6.20 показана схема выполнения запроса к памяти с сегментно-страничной организацией.
Рассмотрим операцию считывания операнда из оперативной памяти по его виртуальному адресу — номеру виртуального сегмента и смещения в этом сегменте. Первое обращение к кэш-памяти происходит на этапе работы сегментного механизма, когда необходимо вычислить линейный виртуальный адрес, используя информацию дескриптора сегмента. Все дескрипторы сегментов, входящих в виртуальное адресное пространство процесса, хранятся в оперативной памяти, в таблицах GDT и LDT. Однако реального обращения к оперативной памяти может и не быть, если нужный сегмент является одним из активных сегментов процесса — в этом случае его дескриптор находится в соответствующем скрытом регистре. Кэширование дескрипторов сегментов предоставляет первую возможность сокращения времени доступа к оперативной памяти.
Следующую возможность предоставляет буфер ассоциативной трансляции TLB, в котором кэшируются дескрипторы страниц, что позволяет сэкономить время при вычислении физического адреса. Вероятность кэш-попадания в данном случае очень велика — в среднем она составляет 98 %, и только 2 % обращений требуют действительного чтения таблиц разделов и страниц из оперативной памяти.
При известном физическом адресе и известной степени везения искомый операнд может быть обнаружен в кэше первого уровня. Если же повезет немного меньше, то операнд найдется в кэше второго уровня.
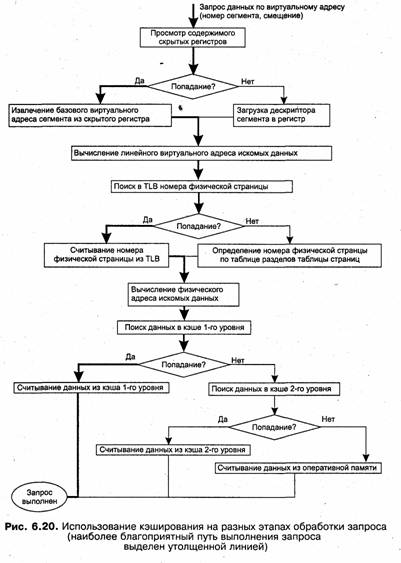
Таким образом, наличие разнообразных кэшей в процессоре Pentium позволяет во многих случаях существенно сократить время обработки запроса к оперативной памяти.