Сети
документальной электросвязи
Лекция 21
Эволюция сетей передачи данных
Прогресс - это лучшее, а не только новое.
Лопеде Вега
21.1. Принципы коммутации пакетов
Прогресс вычислительной техники породил новый вид электросвязи - передачу данных. В начале развития передачи данных (конец 60-х годов прошлого столетия) и примерно в течение 25 лет объем трафика данных составлял не более одного - двух процентов трафика телефонных сетей. Однако в середине 90-х годов ситуация начала изменяться, мировой трафик данных стал расти достаточно быстро, и в последние годы объем трафика данных удваивается каждые два года.
Говоря о росте трафика данных, мы подразумеваем всю совокупность трафика, первоначально обслуживавшегося специализированными сетями передачи данных, которые называются более строго в образовательном стандарте (и, следовательно, - в этой книге) сетями документальной электросвязи (СДЭ), а в переводной литературе - компьютерными сетями. Не вдаваясь в детали, все три приведенных термина мы будем считать синонимами.
Широкое разнообразие услуг передачи данных в сетях документальной электросвязи, в отличие от рассмотренного в предыдущих лекциях речевого обмена, требует применения принципиально другого механизма доставки информации, в отличие от принятого в телефонных сетях метода коммутации каналов.
Этот механизм должен быть адаптирован не только к разнообразию типов данных и услуг, но и к пачечной структуре трафика, что является характерной чертой СДЭ. Названные фундаментальные различия определили два принципиально разных вида сетей:
• сети с коммутацией каналов, по которым передаются непрерывные потоки информации с постоянной скоростью, как правило, равной 64 кбит/с;
• сети с коммутацией пакетов с пачечной структурой трафика, передаваемые в широком диапазоне скоростей, начиная от сотен бит/с вплоть до десятков Мбит/с.
В первых десяти лекциях этой книги (и, частично, в следующих десяти лекциях) рассматривались процессы транспортировки речевых сигналов между станциями в телефонных сетях. Основным свойством таких сетей является использование принципа коммутации каналов, в основе которого лежит закрепление канальных ресурсов за общающимися терминалами на все время сеанса связи, независимо от его длительности. Такое закрепление ресурсов может приводить при определенных условиях к перегрузкам и, как следствие, к отказам или к ощутимым задержкам в обслуживании. К счастью для абонентов, фиксированные телефонные сети проектируются так, что практически никогда не используется их пропускная способность, рассчитанная на периоды наибольшей нагрузки. Но, с другой стороны, такие сети не эффективны при передаче данных. Альтернативный подход к построению сети базируется на принципе коммутации пакетов. Техника коммутации пакетов, развитая в 70-х годах прошлого столетия, основана на разделении полезной нагрузки (сообщений, подлежащих передаче) на множество пакетов или ячеек. Перед передачей к пункту назначения каждый пакет дополняется заголовком (служебная часть содержимого пакета). В заголовке пакета указываются его порядковый номер и адрес пункта назначения, а также другая сигнальная информация. Хотя заголовок не переносит полезную нагрузку и рассматривается при передаче данных как разновидность накладных расходов, но без служебной информации пакет не может передаваться по сети. Последовательность пакетов, принадлежащих одному сообщению, определяется как логический канал. Базируясь на понятии логических каналов, можно говорить о том, что коммутация пакетов делает возможной организацию определенного количества логических каналов в одной линии передачи. Если N пакетов, соответствующих разным пунктам назначения, передаются по одной линии, это означает, что в такой линии существует одновременно N логических каналов. При достижении очередного узла сети пакеты вначале накапливаются, а затем поступают в коммутатор пакетов.
Коммутатор считывает адрес пункта назначения из заголовка пакета и направляет пакет к следующему узлу в соответствии с выбранным маршрутом и правилами приоритетного обслуживания трафика.
Оптимальный маршрут соответствует определенному критерию, например, минимуму числа коммутационных узлов, минимальной сетевой задержке, максимально возможной пропускной способности выбранного маршрута и так далее. Если, например, соседний узел, выбранный по определенному критерию, в данный момент занят, маршрут может быть изменен путем выбора более длинного пути. Такой процесс коммутации определяется как процесс накопления и передачи. Функция накопления пакетов, или буферизация, является весьма полезной для решения проблем, возникающих при одновременном поступлении пакетов в коммутатор пакетов. В общем случае поступающие пакеты обслуживаются в соответствии с правилом FIFO (первым пришел, первым обслужен), если в буфере отсутствуют пакеты, поступившие по логическим каналам с разными предварительно назначенными уровнями приоритета.
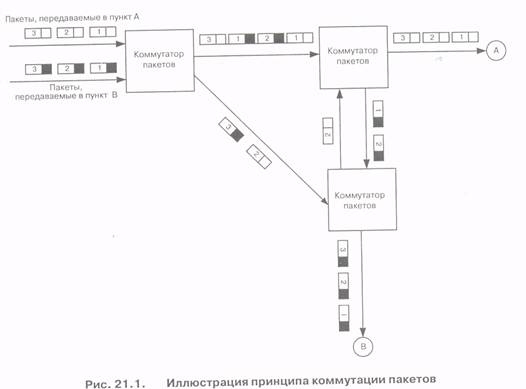
Рис. 21.1 иллюстрирует принципы сети с коммутацией пакетов. Одним из наиболее важных свойств такой сети, как следует из рисунка, является то, что пакеты одного сообщения могут прибывать в пункт назначения в случайном порядке из-за разных маршрутов их доставки и задержек в накопителях узлов. Для восстановления требуемого порядка пакетов в соответствии с их номерами, полученными в пункте отправления, в пункте назначения предусмотрена возможность буферизации.
Сеть, в которой пакеты одного логического канала на пути к пункту назначения проходят через разные пути, называется сетью, не ориентированной на соединения. В такой сети реализуется маршрутизация, известная как маршрутизация датаграмм, и соответствующий режим транспортировки пакетов получил название датаграммного режима. В сетях такого типа возможны потери пакетов в процессе транспортировки по ряду причин (например, из-за перегрузки коммутаторов или из-за ошибок маршрутизации). В этом случае в пункте назначения имеется возможность послать запрос повторить передачу потерянных пакетов. Альтернативный подход к построению сетей с коммутацией пакетов состоит в выделении одного и того же пути для последовательности пакетов, связанной с одним и тем же логическим каналом. Тогда пакеты достигают пункта назначения в правильном порядке, в соответствии с их номерами. Такие сети называются сетями, ориентированными на соединения; в сети реализуется путь-ориентированная маршрутизация, а путь передачи пакетов одного сообщения называется виртуальным каналом. Важно отметить, что метод виртуальных каналов не должен рассматриваться как полный аналог коммутации каналов, поскольку путь для последовательности пакетов формируется на базе выделения памяти в узлах коммутации, а не за счет резервирования всех ресурсов между источником и получателем.
Достоинством сетей, ориентированных на соединения, является возможность управления потоком пакетов, что обеспечивает более высокие показатели качества обслуживания. Среди недостатков путь-ориентированной маршрутизации необходимо отметить менее полное, по сравнению с маршрутизацией датаграмм, использование сетевого ресурса.
Сети с коммутацией пакетов могут быть использованы для передачи данных и речи в сетях всех типов, начиная с локальных сетей (Local Area Network, LAN) и кончая крупномасштабными городскими (Metropolitan Area Network, MAN) и территориально распределенными сетями (Wide Area Networks, WAN).
Для реализации процессов транспортировки в таких сетях должны быть определены специальные протоколы, в которых описываются правила инициирования вызовов, установления логических соединений и обмена данными между элементами сетей.
Известны четыре наиболее широко используемых протокола для передачи информации в сетях с коммутацией пакетов - протокол Х.25, протокол Frame Relay, протокол ATM и протокол IP. Эти протоколы будут описаны в следующих лекциях.
21.2. История создания компьютерных сетей
История компьютерных сетей начиналась в Агентстве перспективных исследовательских проектов, созданном в 1958 году в Вашингтоне под эгидой Министерства обороны США. Это Агентство известно в компьютерном и телекоммуникационном сообществе, независимо от используемого языка, под названием ARPA {Advanced Research Projects Agency). В середине 60-х годов прошлого столетия проблемами связи между удаленными компьютерами активно занимались и специалисты из Национальной физической лаборатории (NPL) в Англии. Коллективы изARPAи NPL пришли к примерно одинаковым результатам в отношении формы представления сообщений при передаче их между компьютерами: сообщения должны быть разделены на стандартные блоки определенного формата, включающего в себя заголовок и признак конца блока.
Разработка принципа связи, позже названного коммутацией пакетов, связана с именами П. Бэрена(АРРА) и Д. Дэвиса (NPL). Вместе с тем, работы американских специалистов из ARPA и английских исследователей из NPL привели к развитию двух методов коммутации пакетов - метода датаграмм (Бэрен) и метода виртуальных соединений (Дэвис). Режим виртуальных соединений предполагает резервирование ресурса (пусть даже виртуального) на время сеанса связи и, в какой-то степени, напоминает метод коммутации каналов, применяемый в классических телефонных сетях. Наличие резервированного ресурса позволяет гарантировать определенный уровень качества обслуживания и, естественно, подходит для применения в сетях общего пользования. Метод коммутации пакетов, предложенный Дэвисом, был стандартизован Международным союзом электросвязи (ITU) в 1976 году в виде Рекомендации Х.25 и рекомендован ITU для сетей передачи данных общего пользования. На базе протокола Х.25 во многих странах, где связь была монополией государства, построили значительное число сетей передачи данных (ПД), как общего пользования, так и корпоративных.
В методе датаграмм Бэрена, тоже основанном на коммутации пакетов, отсутствовал принцип резервирования ресурсов, то есть он не обеспечивал гарантированное качество обслуживания и не мог быть применен в сетях ПД общего пользования. Главным его достоинством была простота механизма передачи пакетов. Метод передачи датаграмм был положен в основу протокола IP (Internet Protocol) и успешно использован при построении сети ARPANET и ряда других корпоративных сетей, в основном, в университетских и исследовательских структурах.
Днем рождения компьютерных сетей можно считать 2 сентября 1969 года, когда был осуществлен обмен сообщениями между двумя компьютерами ARPA; один из компьютеров был установлен в Калифорнийском университете Лос-Анджелеса, а второй - в Стенфордском исследовательском институте. К концу 1969 года уже четыре компьютера были объединены каналами со скоростью передачи 56 кбит/с.
В 1974 году в статье В. Серфа и Р. Кана, посвященной протоколу транспортного уровня (Transmission Control Protocol, TCP), впервые был использован термин «Internet». В следующем году группа В. Серфа и Р. Кана разработала спецификации стека протоколов TCP/IP. Впоследствии термин «Интернет» широко использовался для определения сетей, базировавшихся на стеке протоколов TCP/IP; при этом сеть ARPANET всегда рассматривалась как родоначальница всех последующих сетей Интернет.
Стартовавшая как ARPANET, сеть Интернет на протяжении 70-х и начала 80-х годов использовалась преимущественно американским правительством, а также академическими и исследовательскими организациями. Технология Интернет применялась для строительства академических сетей и в ряде европейских стран. Однако сети на базе технологии Интернет как часть телекоммуникационной инфраструктуры все еще оставались в относительно узкой нише приложений, не будучи востребованными в среде Операторов общего пользования и уступая по масштабам сетям Х.25. Эта ситуация сохранялась до середины 90-х годов, когда появились первые удобные пользователю приложения в среде Интернет, в том числе, такие как системы поиска информации Mosaic, World Wide Web (WWW), гипертекстовый язык HTML. Были разработаны недорогие модемы для подключения абонентов квартирного сектора к компьютерным сетям и созданы высокоскоростные магистрали, способные пропускать трафик со скоростями несколько сот М бит/с.
В середине 1995 года на рынке появилась операционная система Windows 95 с интегрированным стеком TCP/IP, и услуги Интернет стали доступны многим миллионам пользователей. Сегодня сеть Интернет представляет собой всемирную систему добровольно объединенных компьютерных сетей, построенных на стеке протоколов TCP/IP. Начиная с середины 90-х годов прошлого столетия, развитие сетей Интернет напоминает взрывоподобный процесс.
К середине 2008 года число пользователей Интернет в мире достигло 1,2 миллиарда, что очень близко к числу абонентов фиксированных телефонных сетей, история развития которых насчитывает более 120 лет. Пропускная способность глобальной сети Интернет, измеренная в битах за секунду, превышает суммарную пропускную способность глобальной телефонной сети в десятки раз.
Сегодня через сеть Интернет доставляются не только данные, ради передачи которых и были построены первые компьютерные сети, но также речевая информация и видео.
21.3. Модель взаимосвязи открытых систем
Прежде чем перейти к характеристике протоколов, на базе которых построены сети передачи данных, рассмотрим модель взаимосвязи открытых систем, содержащую набор стандартных уровней, определяющих процессы транспортировки и обработки информации в современных телекоммуникационных сетях. В начале 80-х годов прошлого столетия Международная организация по стандартизации ISO {International Standardization Organization) в сотрудничестве с ITU начала разработку нового стандарта в области технологий для компьютерных сетей, получившего в русском языке название Взаимосвязи Открытых Систем (ВОС), а в английском языке - Open Systems Interconnection (OSI).
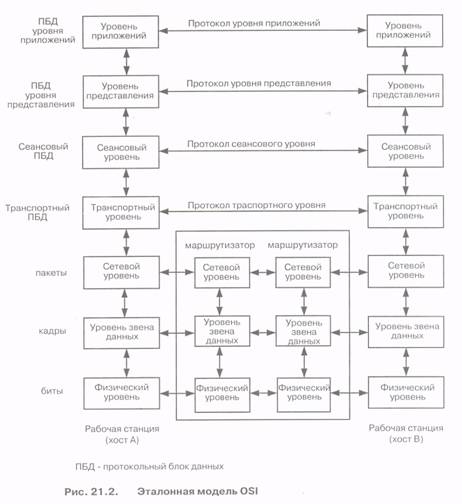
В основе стандарта OSI, в результате разработки которого была создана эталонная модель OSI, лежала идея построения общей модели расположенных на разных уровнях протоколов, которые соответствуют основным процессам в компьютерных сетях и определяют взаимодействие между этими уровнями в различных системах. Стандарт OSI был принят в 1982 году и, по существу, принятие такого стандарта означало создание сетевых стандартов для обеспечения совместимости оборудования разных производителей. Следует отметить, что после принятия стандарта OSI все работы по стандартизации протоколов взял на себя ITU. Эталонная модель OSI определяет процессы в компьютерных сетях через стандартный набор уровней, число которых в документах ISO было выбранным равным семи. Эти семь уровней представлены на рис. 21.2. Они формируют модель, в соответствии с которой разные сетевые функции могут быть реализованы в иерархической форме и в нужной последовательности.
На верхнем уровне модели расположен уровень приложений. Этот уровень является первым между оборудованием пользователя (например, компьютером) и оборудованием сети, поскольку этот уровень оперирует с содержанием информации, которая должна быть передана от пункта отправления к пункту назначения.
Нижний, физический уровень, где данные генерируются в электрической или оптической форме, наиболее удален от пользователя. Каждый уровень реализует свой набор функций с тем, чтобы представить данные на следующий уровень. При передаче терминал реализует процессы сверху вниз, начиная от уровня приложений (формирование содержания сообщения, например, подготовка электронной почты) и заканчивая генерацией «единиц» и «нулей». Приемный терминал реализует процессы снизу вверх, начиная с детектирования «единиц» и «нулей», заканчивая выводом информации на уровне приложений (вывод на экран компьютера, вывод на печать и так далее).
Рассмотрим более детально функции разных уровней модели OSI.
Физический уровень (уровень 1) преобразует электрические (оптические) сигналы в стандартную форму с определенными значениями напряжения, частот и длин волн. Для обмена информацией на уровне 1 имеется ряд стандартов ITU-T, используемых для передачи речи и данных: Е1, Т1, SDH, а также относительно новые протоколы, такие, как xDSL и WDM.
Уровень звена данных (уровень 2) поддерживает управление потоками данных, обнаружение и исправление ошибок и мультиплексирование логических каналов. На втором уровне пакеты преобразуются в кадры, размер которых существенно меньше размера пакетов. В то время как пакеты содержат адрес пункта назначения, кадр на уровне 2 включает в свой состав маршрутный адрес соседнего коммутатора, к которому должен быть послан этот кадр. Кадры фланкируются на обоих концах флагами, используемыми как разделители кадров. Структура байтов флагов выбирается таким образом, чтобы она не повторялась в оставшейся части кадра. На уровне 2 используются, в частности, такие протоколы, как Frame Relay, Ethernet, маркерные протоколы (Token bus, Token ring) и протокол ATM (Asynchronous Transfer Mode).
Сетевой уровень (уровень 3) связан с функциями маршрутизации (выбор наиболее быстрого пути) и борьбы с перегрузками (минимизация задержек в очередях коммутаторов). Маршрутизация может быть статической или динамической. Статическая маршрутизация базируется на принципе минимального числа узлов на маршруте (минимальное число скачков), в то время как динамическая маршрутизация выбирает наилучший путь в соответствии с реальными данными о нагрузке в сети. Этот принцип может быть реализован путем анализа маршрутных таблиц, которыми коммутаторы обмениваются друг с другом. Такие таблицы обеспечивают узлы информацией о нагрузке на каждом коммутационном узле, доступности портов коммутатора и возможных перегрузках. Примерами протоколов для уровня 3 являются протоколы Х.25 и IP. Следующие четыре уровня реализуют функции взаимодействия сетей. При рассмотрении этой группы логически целесообразно рассматривать характеристики уровней, начиная с уровня 7 по направлению к уровню 4.
Уровень приложений (уровень 7) оперирует со смысловым содержанием данных, передаваемых или получаемых компьютерным терминалом. Примерами таких «смысловых» приложений являются подключение к Web-сайтам и электронная почта. Использование протокола пересылки гипертекстовых файлов HTTP (Hypertext File Transfer Protocol) и простого протокола пересылки почты SMTP (Simple Mail Transfer Protocol) обеспечивает возможность передачи сообщений через мировую компьютерную сеть, независимо оттого, как сконфигурирован компьютер и к каким интерфейсам он подключен. Другие широко используемые приложения уровня 7 включают в свой состав корпоративные сети Интранет, удаленный доступ к базам данных (например, по протоколу Х.500 ITU-T), а также управление сетями, необходимое для системных администраторов.
Уровень представления (уровень 6) определяет формат кода, который используется для кодировки информации, поступающей с уровня 7 (режим передачи), или для детектирования информации, поступающей с уровня 5 (режим приема). Наиболее популярным кодом на уровне 6 является код ASCII (American Standard Code for Information Exchange). На этом же уровне может быть реализована процедура защиты данных. Кроме того, возможна реализация алгоритмов сжатия информации, что особенно важно при передаче изображений и видеоинформации. Наиболее популярными для этих целей являются, соответственно, стандарты JPEG (Joint Photographic Expert Group) и MPEG (Moving Pictures Expert Group).
Уровень сеанса (уровень 5) управляет открытием, поддержкой и закрытием сессий. Понятие сессии наиболее хорошо знакомо пользователям персональных компьютеров, поскольку оно связано со всем тем, что может произойти между вызовом и закрытием определенной программы. Примером сессии является подключение к сети Интернет, во время которого могут быть удовлетворены запросы всех видов (Web-поиск, загрузка файлов, отправка почтовой корреспонденции).
Транспортный уровень (уровень 4) обеспечивает коррекцию ошибок и управление потоками, в целом отвечая за качество передачи. Уровень 4 поддерживает также возможности выбора между разными сетевыми конфигурациями (WAN, IAN, ТфОП...), используя сетевую адресацию. Транспортный уровень принимает от уровня 5 запросы обслуживания нескольких одновременных сессий или поддерживает одиночную сессию, обрабатываемую одновременно сетями разных типов.
21.4. Стандартизация в сетях Интернет
Параллельно стандартизации сетей общего пользования с коммутацией пакетов, реализуемой под эгидой ITU, проводились работы по стандартизации сетей Интернет. Основной массив спецификаций для сетей, построенных на базе стека TCP/IP, был разработан организацией IETF (Internet Engineering Task Force),
Организация IETF была создана в 1986 году и финансировалась Правительством США. В начале 90-х годов XX века IETF изменила свой статус, перейдя от государственного финансирования к формату независимой организации, работающей под эгидой Internet Society (ISOC) - Общества Интернет, представляющего собой неправительственную некоммерческую организацию. В состав ISOC входят более 100 организаций (производителей оборудования, поставщиков услуг, организаций, занимающихся стандартизацией) и более 20 тысяч индивидуальных членов в 180 странах.
Спецификации, выпускаемые IETF, издаются под общим названием RFC (Request for Comments - Запрос комментариев) и признаны сегодня в качестве международных стандартов. Первый документ RFC, написанный студентом Калифорнийского университета, появился в 1969 году при обсуждении проекта ARPANET. Вначале RFC распространялись в виде обычных писем, но уже с декабря 1969 года RFC начали рассылаться в электронном виде.
Общее число RFC в настоящее время насчитывает более 6 тысяч документов. Доступ к документам RFC открыт для любого желающего на сайте www.ietf.org. Среди большого количества документов RFC самыми популярными являются RFC, относящиеся к сетевому протоколу IP (RFC 791), транспортным протоколам TCP (RFC 793) и UDP (RFC 791), протоколу транспортировки электронной почты (RFC 822), архитектуре MPLS (RFC 3031). Как известно, физики всегда были остроумнее, чем лирики. Это справедливо и для Интернет-сообщества, в котором очень популярны юмористические документы RFC. Так, существует традиция выпуска первоапрельских шуточных RFC, например, RFC 1149 повествует о передаче пакетов IP с помощью почтовых голубей.
Сети на базе виртуальных соединений
Компромисс всегда обходится дороже, чем любая из альтернатив.
Закон Джухени
22.1. Сети на базе протокола Х.25
В этой лекции рассматриваются сетевые технологии на базе виртуальных каналов, являющиеся, в той или иной степени, компромиссом между сетями с коммутацией каналов и с коммутацией пакетов. Прежде всего это относится к сетям ATM, но рассмотрение мы начнем со старейшей технологии Х.25.
Сети с коммутацией пакетов (КП) на базе протокола Х.25 были разработаны в середине - конце 1970-х годов с целью обеспечить передачу данных между двумя удаленными пунктами через аналоговую передающуюсреду. Основной сферой ихиспользования была связь между терминалами и рабочими компьютерами (хостами). Протокол Х.25, разработанный в ITU-T, обеспечивает передачу пакетов через сеть, являясь протоколом третьего (сетевого) уровня модели ВОС. Фрагмент сети Х.25, включающий в себя различные сетевые элементы сети КП, представлен на рис. 22.1.
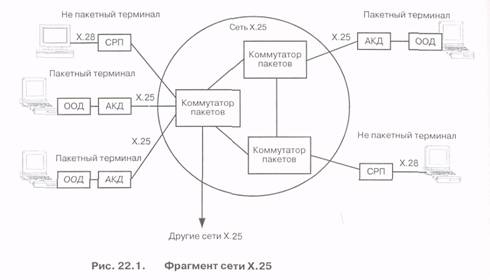
В сети на базе протокола Х.25 устанавливаются виртуальные соединения между оконечным оборудованием данных {ООД) разных пользователей, то есть технология Х.25 является технологией, ориентированной на соединения.
Режим виртуальных соединений характеризуется тем, что между терминалами абонентов сети не создается физическое соединение, а организуется виртуальный канал путем резервирования памяти во всех узлах сети, расположенных на пути от одного терминала к другому. При этом виртуальные каналы могут быть коммутируемыми (Switched Virtual Circuit, SVC), как в ТфОП, или постоянными (Permanent Virtual Circuit, PVC), аналогично выделенным или арендованным каналам.
В протоколе Х.25 задача сохранения целостности сообщений возлагалась на сеть, что достигалось путем применения помехоустойчивых кодов, запросов и повторений пакетов между узлами сети.
Соединение между ООД и аппаратурой канала данных (АКД), выполняющей функции шлюза сети КП, обеспечивают три нижних уровня модели ВОС, а именно, уровни; физический (1), звена данных (2} и сетевой (3).
Протокол, определяющий процедуру доступа на уровнях (1) и (2), называется процедурой доступа к звену (link access procedure, LAP}. На уровне звена данных обмен между ООД и АКД происходит на основе протокола HDLC (High-level Data Link Protocol) с помощью протокольных блоков, называемых кадрами.
Длина кадров может варьироваться, однако рекомендованная длина выбирается в пределах 128 - 256 байтов. Отметим, что функции ООД реализуются в терминале абонента, а функции АКД обычно выполняются модемом. На рис. 22.2 показана структура кадра одного из типов - информационного, предназначенного для транспортировки полезной нагрузки.
В состав информационного кадра входят служебные поля и поле полезной нагрузки. Служебные поля располагаются в начале и в конце кадра. Отношение длин служебных полей к общей длине кадра определяет в процентах избыточность протокольного блока.

Каждый кадр отделяется от другого кадра с помощью флага. Затем идет двухбайтовый заголовок, содержащий байт адреса и байт управления. Адресный байт определяет, является ли кадр командой (между ООД и АКД) или откликом.
Эта информация позволяет интерпретировать байт управления. Имеются три типа байтов управления: информационные (только команды) - для кадров, переносящих полезную информацию; супертзизорные (только команды), содержащие инструкции управления звеном данных; ненумерованные (команды/отклики), используемые для дополнительных функций управления. Проверочная последовательность (2 байта) формируется в соответствии с правилами кодирования циклических кодов.
Поле полезной нагрузки имеется только в информационных кадрах. В этом поле располагаются данные, поступающие с третьего сетевого уровня.
Задача сетевого уровня состоит в передаче протокольных блоков, получивших название пакетов. Рекомендация Х.25 определяет более 20 типов пакетов, выполняющих как служебные функции, так и функции переноса полезной информации. Из общего числа возможных форматов пакетов только три используются для переноса полезной нагрузки. На рис. 22.3 приведен пример пакета для транспортировки данных.
При установлении в сети ПД виртуального соединения или постоянного виртуального канала на стыке ООД - АКД создается логический канал, которому присваивается групповой номер (ГНЛК), меньший или равный 15, и номер самого канала (НЛК), меньший или равный 255. Таким образом, теоретически в одном физическом канале можно организовать до 4095 логических каналов.
Номера ГНЛК и НЛК присваиваются виртуальному соединению в фазе его установления и сохраняются за ним в течение фаз обмена данными и завершения обмена.
Номера ГНЛК и НЛК служат идентификаторами логического канала. Поле данных (полезной нагрузки) пакета содержит информационные данные, максимальный объем которых не превышает 1 кбайт.

Оборудование ООД представляет собой устройство, работающее в пакетном режиме, то есть на выходе ООД формируются пакеты для передачи и поступают пакеты в режиме приема. Вместе с тем, имеется возможность подключения низкоскоростных не пакетных устройств для асинхронного соединения с сетью X. 25. В этом случае необходимо использовать концентратор, называемый сборщиком/ разборщиком пакетов, СРП (Packet Assembler/Disassembler, PAD). Как следует из названия, СРП подготавливает и распаковывает кадры Х.25 от/к асинхронным терминалам (смотри рис. 22.1).
Протокол Х.28 определяет процедуры обмена между асинхронными терминалами и устройством СРП. Протокол, обеспечивающий взаимодействие СРП и удаленного ООД, известен как протокол Х.29.
Коммутатор одной сети Х.25 может быть соединен с коммутатором другой сети Х.25 через интерфейс Х.75.
Одним из главных достоинств протокола Х.25 является возможность подключения относительно большого числа терминалов к коммутатору путем разделения сетевых ресурсов на скоростях до десятков кбит/с.
Количество подключаемых терминалов определяется производительностью коммутатора или СРП. При этом могут использоваться линии невысокого качества, поскольку протокол предполагает коррекцию ошибок.
Основным недостатком протокола Х.25 является его относительно невысокое быстродействие.
Во-первых, реализация протокола Х,25 связана с необходимостью передачи большого числа команд, откликов, запросов и подтверждений, то есть велик объем "накладных расходов", не связанных с передачей полезной информации.
Во-вторых, пачечная природа трафика, характерная для компьютерных сетей, может приводить к перегрузкам и, как следствие, к росту сетевых задержек.
Наконец, в телефонных сетях, для которых и был разработан протокол Х.25, имеет место высокая {для передачи данных) вероятность ошибки ( 10-3 – 10-4 ), что ведет к потере пакетов и необходимости их повторной передачи. Решение перечисленных выше проблем обеспечивается технологией Frame Relay, представляющей собой упрощенную версию протокола Х.25.
22.2. Сети на базе протокола Frame Relay
Протокол Х.25 разрабатывался в конце 70-х годов и был рассчитан для применения в аналоговых телефонных каналах, то есть в каналах весьма невысокого качества, что определило высокую избыточность этого протокола.
В конце 1980-х годов появились сети с цифровыми каналами и цифровыми узлами коммутации. Передача стала более надежной, сочетая более высокую скорость с меньшей частотой появления ошибок.
Протокол Frame Relay {коммутация/ретрансляция кадров), который был стандартизован в начале 90-х годов XX века, разрабатывался уже во время широкого использования цифровых каналов со значительно меньшей вероятностью ошибки в канале (порядка 10-6).
Технология Frame Relay явилась первой технологией, получившей широкое распространение в компьютерных сетях благодаря тому, что в этой технологии использовались преимущества более надежной цифровой передачи.
Как и технология Х.25, протокол Frame Relay также ориентирован на установление соединений. Протокол Frame Relay реализуется не на трех уровнях эталонной модели ВОС, а только на первых двух уровнях. В качестве протокольных блоков в технологии Frame Relay используются кадры, в которых длина поля полезной нагрузки увеличена до 4096 байтов по сравнению с 256 байтами кадров в протоколе Х.25.
Более высокая помехоустойчивость цифровых каналов по сравнению с аналоговым и позволила при использовании технологи и Frame Relay освободиться от ряда процедур, в частности, от необходимости проверки целостности кадров в промежуточных узлах коммутации и, как следствие, от большого числа команд, запросов и откликов, которыми обмениваются между собой узлы коммутации Х.25.
В сетях Frame Relay задача обеспечения целостности данных была возложена не на сеть (как в случае Х.25), а на аппаратуру, установленную в помещении пользователя. При обнаружении кадра, содержащего ошибки, этот кадр отбрасывался в приемном оконечном устройстве.
Технология Frame Relay позволяет построить более высокоскоростные сети передачи данных (от 56 кбит/с до 34 Мбит/с). В сетях Frame Relay предлагается дополнительная услуга гарантированной минимальной битовой скорости (в отличие от сети Х.25), определяемой как гарантированная скорость передачи {Committed Information Rate, CIR).
При отсутствии перегрузки для пользователя может быть доступной повышенная скорость передачи информации (Excess Information Rate, EIR), и в результате средняя скорость передачи будет определяться значениями между CIR и EIR.
В целом, с учетом функций оконечных устройств, протокол Frame Relay позволяет удовлетворить требования пользователей к времени доставки и к достоверности информации при достаточно высокой скорости передачи.
Эти свойства отличают протокол Frame Relay от протокола Х.25, разработанного для сетей общего пользования, что и обеспечило широкое применение протокола Frame Relay при организации высокоэффективных частных сетей передачи данных с высокой пропускной способностью.
22.3. Сети ATM
22.3.1. Введение
Технология ATM является результатом эволюции всех рассмотренных выше технологий (коммутации каналов, протоколов Х.25, Frame Relay). Технология ATM позволяет передавать речь, видеоинформацию и данные и поддерживает механизмы обеспечения гарантированного QoS для приложений с высоким приоритетом, обеспечивая обслуживание видео и речевого трафика и передачу больших массивов данных в реальном времени. Как и протокол Frame Relay, ATM является протоколом уровня 2. Но в отличие от Frame Relay в ATM передача данных происходитячейками фиксированной длины, а не кадрами переменной длины.
Технология ATM была разработана как основная технология для широкополосных цифровых сетей интегрального обслуживания (сетей B-ISDN), стандартизированных ITU в конце 80-х годов прошлого столетия.
В русскоязычной литературе технологию ATM иногда переводят как Асинхронный режим доставки. Под асинхронным режимом подразумевается способ выделения ресурсов в сети ATM, отличный от используемого в сетях на базе синхронного мультиплексирования с временным разделением (TDM), где полоса пропускания распределяется при планировании или конфигурировании сети. В технологии ATM используется принцип статистического мультиплексирования (как в протоколах Х.25 и Frame Relay).
Протокол ATM является протоколом, ориентированным на соединения. В сетях ATM существуют два основных типа виртуальных соединений:
• Постоянное виртуальное соединение (Permanent Virtual Connection, PVC); PVC устанавливается вручную администратором сети и сохраняется до его удаления тем же лицом (или лицом, его замещающим).
• Коммутируемое виртуальное соединение (Switched Virtual Connection, SVC); SVC динамически создается, когда конечный пункт запрашивает создание соединения с определенным адресатом, и этот канал разрушается после завершения связи.
22.3.2. Структура ячейки ATM
Определим ячейку ATM как пакет фиксированной определенной длины, в противоположность пакетам и кадрам Х.25 и Frame Relay, имеющим переменную длину. Ячейка ATM состоит из заголовка и поля полезной нагрузки.
Стандартная структура ячейки представлена на рис. 22.4. В соответствии со стандартами ATM, принятыми ITU, длина ячейки составляет 53 байта. Заголовок и поле полезной нагрузки ячейки составляют, соответственно, 5 байтов и 48 байтов. Кроме того, в поле полезной нагрузки также может быть небольшой заголовок длиной от одного до двух байтов. В терминах ATM разделение пользовательских данных на блоки полезной нагрузки носит название сегментации; добавление заголовка к тому или иному блоку полезной нагрузки определено как процесс инкапсуляции.

Определим функции полей, расположенных в заголовке в следующем порядке:
• Общее управление потоком (General Flow Control, GFC), длина 4 бита; этот идентификатор функционирует только в интерфейсе пользователь-сеть. Основная функция этого поля состоит в регулировании трафика на уровне мультиплексирования, где ячейки, приходящие от разного терминального оборудования, объединяются в единый поток данных.
• Идентификатор виртуального пути (маршрута) (Virtual Path Identifier, VPI), длина 8 битов; виртуальный путь, ВП, (Virtual Path, VP) представляет собой мультиплексированную группу виртуальных каналов (Virtual Channel, VC). Адресная часть идентификатора VP может быть расширена до 12 битов за счет поля GFC. Это расширение позволяет сформировать до 212 -1=4095 идентификаторов виртуальных путей.
• Идентификатор виртуального канала (Virtual Channel Identifier, VCI), длина 16 битов; виртуальный путь соответствует пользовательскому адресу назначения, к которому должна быть направлена ячейка.
• Идентификатор типа данных (Payload Type Identifier, PTI), длина 3 бита; это поле выполняет несколько функций. Имеются 8 возможных значений (от 000 до 111) для кодирования различной специфической информации. Например, значения от 000 до 011 указывают отсутствие или наличие перегрузки в сети от источника к получателю (или в обратном направлении); значения 100 и 101 показывают, генерируется ли ячейка, соответственно, конечным пользователем или сетевым сегментом и так далее. Следующий по порядку бит резервируется (поле RES).
• Приоритет при потере ячейки {Cell Loss Priority, CLP), длина 1 бит; значениебитаС1_Руказываетнато, должна либытьотброшена данная ячейка (CLP - 1) или ячейка должна быть сохранена (CLP= 0) в случае перегрузки коммутатора или сети.
• Контроль ошибок заголовка (Header Error Control, НЕС), длина 8 битов; это поле выполняет функцию коррекции ошибок с использованием избыточного циклического кода, обеспечивающего исправление одиночных ошибок в заголовке и обнаружение многократных ошибок. При обнаружении многократных ошибок ячейка отбрасывается.
22.3.3. Эталонная модель протоколов ATM
Протокол ATM действует на двух первых уровнях модели ВОС - на физическом (уровень 1) и на уровне звена данных (уровень 2). Эталонная модель протоколов ATM требует более детального описания процессов в связи с разделением функций на уровне звена. Модель включает в себя следующие четыре уровня:
• Служба верхнего уровня (выше уровня 2) определяет информацию, которая должна быть передана через сеть ATM. Эта информация может быть связана с типом источника/получателя (речь, данные, видео), видом управления (установление или разрушение соединений ВК) и видом сетевого менеджмента (мониторинг, конфигурирование сетевых элементов и сигнализация).
• Уровень адаптации ATM (уровень 2) содержит два подуровня:
- подуровень сегментации и повторной сборки (Segmentation And Reassembly, SAR); этот подуровень отвечает за генерацию (при передаче) 48-байтовых сегментов (без заголовков) из входных данных, поступающих с верхнего уровня, а также за обратный процесс (восстановление исходных данных при приеме полезной части ячеек после удаления заголовков);
- подуровень конвергенции (Convergence Sublayer, CS); этот подуровень различает четыре класса обслуживания, соответственно, от класса А до класса D; более детальная характеристика классов дана ниже.
Уровень ATM (уровень 2) поддерживает следующие 5 функций:
- статистическое мультиплексирование ячеек на передаче и демультиплексирование ячеек на приеме;
- формирование заголовков ячеек и инкапсуляцию;
- управлениетранспортом ячеек (коммутация ВП и ВК, назначение идентификаторов ВП и ВК);
- идентификацию типа полезной нагрузки (ячейка пользователя или сетевая ячейка);
- контроль потока ячеек с использованием поля общего управления GFC.
• Физический уровень (уровень 1) обеспечивает разделение ячеек, синхронизацию, контроль битовых ошибок (в поле заголовка), модуляцию и детектирование сигналов, скремблирование/ дескремблирование, преобразование сигналов для/от оптических линий и транспорт сигналов.
Процесс генерации ячеек, транспортировки их через сеть и приема может быть просто представлен как проход через стек протокольных уровней сначала сверху вниз, а затем снизу вверх. Служба верхнего уровня передает пользовательские данные на уровень AAL; уровень AAL сегментирует эти данные в 48-байтовые сегменты и передает их на уровень ATM; уровень ATM формирует заголовок и упаковывает сегменты полезной нагрузки в ячейки ATM; затем ячейки передаются на физический уровень. После того как ячейки будут переданы через сеть ATM, на приемном конце реализуется обратный процесс, в результате которого происходит восстановление пользовательских данных в службе верхнего уровня.
22.3.4. Классы обслуживания на уровне AAL
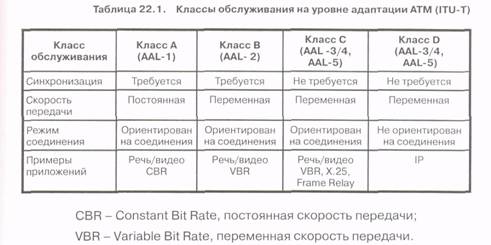
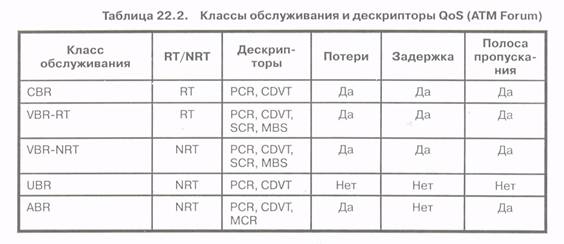
Выше было отмечено, что уровень AAL, расположенный непосредственно над уровнем ATM, обеспечивает четыре класса обслуживания, определенных как классы А, В, Си D в рекомендациях ITU-T. Эти классы отличаются друг от друга в соответствии со следующими тремя критериями (смотри табл. 22.1):
• требования к синхронизации между источником и получателем;
• скорость передачи;
• режим соединения.
Класс обслуживания определяет процессы сегментации и инкапсуляции полезной нагрузки. Формируемые ячейки названы по имени классов (соответственно, AAL1, AAL2, AAL3/4 и AAL5), имеющих следующие характеристики:
• AAL1: класс обслуживания А предназначен для поддержки транспортировки речи/видео с постоянной скоростью (Constant Bit Rate, CBR). Другое принятое название для класса AAL1 - эмуляция каналов, что соответствует соединению в сети с коммутацией каналов.
• AAL2: класс обслуживания В предназначен для поддержки транспортировки речи/ видео с переменной скоростью (Variable Bit Rate, VBR). Примерами видео в этом классе обслуживания могут служить неподвижные изображения и компрессированное видео.
• AAL3/4: класс обслуживания С (ориентированный на соединения) или класс D (не ориентированный на соединения) предназначены для поддержки транспортировки пакетов переменной длины с длиной до 65,5 кбайтов.
• AAL5: класс D предназначен для поддержки транспортировки пакетов переменной длины без установления соединения. В классе D в отличие от формата AAL3/4 нет защиты от нарушения порядка следования ячеек в последовательности и меньше служебной информации, что приводит к большей эффективности этого класса обслуживания. Поэтому класс AAL5 рассматривается как наиболее простой уровень адаптации.
В табл. 22.1 представлены примеры различных приложений в соответствии с классами обслуживания, в том числе, приложения Х.25 и Frame Relay для класса С и IP для класса D.
22.3.5. Классы обслуживания в сети ATM и показатели качества обслуживания
В предыдущем пункте были описаны классы обслуживания на уровне адаптации AAL в соответствии с рекомендациями ITU-T. Эти классы отличаются друг от друга требованиями к синхронизации, скоростями передачи и связностью (ориентированы или не ориентированы на соединения}.
Другой подход для определения сетевых услуг ATM, разработанный Форумом ATM, основан на концепции использования сети в реальном времени (Real Time, RT) и не в реальном времени (Non-Real Time, NRT).
В табл. 22.2 представлены пять возможных классов обслуживания в соответствии не только с приложениями RT и NRT, но и с набором показателей качества обслуживания (QoS). Приведем более детальное описание этих классов обслуживания:
Класс 1. Постоянная скорость передачи (CBR) в реальном времени: обеспечивает гарантированную пиковую скорость передачи ячеек (Peak Cell Rate, PCR) и устойчивость к вариации задержки ячеек (Cell-Delay Variation Tolerance, CDVT)\ наиболее подходит к приложениям, связанным с речью и видео.
Класс 2. Переменная скорость передачи в реальном времени (VBR-RT):KaKnCBR, обеспечивает PCR и CDVT, но скорость передачи адаптируется в соответствии с требованиями реального времени при гарантированной поддерживаемой скорости передачи ячеек (Sustained Cell Rate, SCH) и максимальном размере пачки ячеек (Maximum Bursts Size, MBS); используется для компрессированных сигналов речи и видео.
Класс 3. Переменная скорость передачи не в реальном времени {VBR-NRT}: без ограничений, связанных с задержками; рекомендована для трафика с ярко выраженной пачечной структурой, характерного для локальных сетей и сетей Интернет.
Класс 4. Не специфицированная скорость передачи (Unspecified Bit Rate, UBR): без ограничений по времени, потерям, задержкам и полосе пропускания; рекомендована для электронной почты, передачи файлов и других случаев неприоритетного обслуживания трафика.
Класс 5. Доступная скорость передачи (Available Bit Rate, ABR) ABR): так же, как и класс 4, но с гарантированной минимальной скоростью передачи ячеек (Minimum Cell Rate, MCR}; в этом классе предполагается возможность резервирования сетевых ресурсов для обеспечения минимальных потерь ячеек и полосы пропускания; полоса пропускания распределяется по принципу наилучшей попытки (best effort); рекомендована для передачи файлов, электронной почты, круглосуточного мониторинга сети и других случаев не приоритетного обслуживания трафика.
Кроме указанных параметров для характеристики классов обслуживания используется еще ряд параметров, таких как вариация задержки ячеек (Cell Delay Variation, CDV), максимальная и средняя задержка ячеек (Maximum and Mean Cell Transfer Delay, max-CTD, mean-CTD) и вероятность потери ячеек (Cell Loss Ratio, CLR).
В табл. 22.2 показано, насколько разные классы чувствительны к потерям, задержкам и полосе пропускания.
Сети на базе протоколов TCP/IP
Как сеть состоит из множества узлов, так и все на этом свете связано
узлами. Если кто-то полагает, что ячейка сети является чем-то независимым,
изолированным, то он ошибается. Сеть и называется сетью, поскольку состоит
из множества взаимосвязанных ячеек, и у каждой ячейки свое место
и свои обязательства по отношению к другим ячейкам.
Будда
23.1. Сети Интернет
Как было отмечено в лекции 21, в сентябре 1969 года в США стартовал проект по созданию сети передачи данных ARPANET.
В сети ARPANET транспортировка данных между компьютерами осуществлялась методом коммутации пакетов, получившим название метода датаграмм.
Процедуры транспортировки пакетов между узами сети ARPANET определялись протоколом IP (Internet Protocol) - протоколом сетевого уровня - и протоколом TCP [Transmission Control Protocol) - протоколом транспортного уровня. Широкое распространение IP-технологии в последние годы определяется рядом ключевых свойств, среди которых мы отметим наиболее существенные.
• Универсальность. Протоколы семейства IP сегодня используются во всех сетевых сегментах, начиная от локальных и кампусных сетей и кончая магистральными сетями. Технология IP используется для передачи данных, речи и видеоинформации. На базе IP-ориентированных протоколов строятся как фиксированные, так и беспроводные сети. Используемый вначале в корпоративных сетях, стек TCP/IP нашел широкое применение в сетях связи общего пользования.
• Масштабируемость. Крупномасштабные сети должны иметь возможность легко развиваться, Масштабируемость сетей на базе IP была одним из основных свойств, заложенных при разработке сети ARPANET поскольку с самого начала ставилась задача создать протокол, позволяющий объединять большое число сетей. Количественные оценки, характеризующие современные масштабы Интернет, являются предпосылкой к созданию глобальной сети.
• Открытость. Сеть Интернет базируется на принципе открытых систем. Это означает, что при выполнении очень небольшого числа правил, определяющих структуру протоколов и интерфейсов, в сети могут взаимодействовать разнотипные аппаратные и программные средства. Правила присоединения сетей с любыми протоколами к сетям IP относительно просты и реализуются на базе шлюзов, обеспечивающих согласование протоколов. Развитие мировой сети Интернет в 90-х годах прошлого столетия является прямым результатом прогресса программного обеспечения, микроэлектроники и высокопроизводительных систем связи, и изменений в телекоммуникационном законодательстве и регулировании. Рост масштабов сети Интернет настолько впечатляет, что среди сетевых Операторов, разработчиков оборудования, поставщиков услуг (провайдеров) и даже пользователей постепенно формируется мнение о возможности преобразования сети Интернет в некую универсальную сеть, обеспечивающую предоставление услуг всех видов.
23.2. Эталонная модель протоколов сети Интернет
Сеть Интернет предоставляет услуги коммутации пакетов без установления соединений, что является фундаментальным свойством этой сети. Как было отмечено выше, Интернет базируется на двух основных протоколах - протоколе IP и протоколе TCP. Совокупность TCP и IP, а также ряда сопровождающих протоколов, определяется как стек протоколов Интернет TCP/IP.
Разные сети на базе TCP/IP соединяются друг с другом с помощью маршрутизаторов IP, формируя пространство Интернет.
Определим сеть Интернет как набор связанных между собой сетей,
которые используют для коммуникаций стек TCP/IP, уникальное адресное пространство Интернет и принципы маршрутизации при транспортировке пакетов. В этой лекции мы дадим обзор свойств сетей Интернет, начиная со стека TCP/IP и заканчивая услугами и приложениями Интернет.
На рис. 23.1 представлена модель протоколов стека TCP/IP, разработанная Комитетом IETF. Прежде всего, отметим, что модель IETF состоит из пяти уровней {а не из семи, как модель OSI). Первые два уровня соответствуют физическому уровню и уровню звена данных модели OSI.
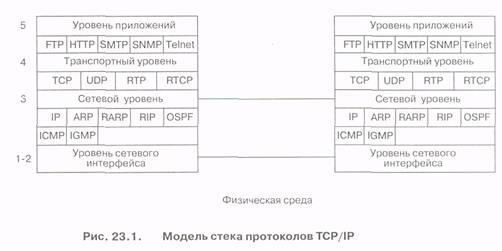
Протокол IP расположен на третьем уровне модели IETF, и функции этого протокола соответствуют функциям сетевого уровня модели OSI.
Протокольные блоки (пакеты) IP, называемые датаграммами, имеют существенно больший размер, чем пакеты X.25 (но не свыше 65,5 кбайтов), характеризуются переменной длиной и передаются по сети независимо друг от друга. В отличие от технологии коммутации пакетов (технология Х.25) и коммутации ячеек (технология ATM}, доставка датаграмм на сетевом уровне сетей Интернет производится методом маршрутизации (см. ниже).
Протокол TCP расположен на четвертом уровне модели IETF, и его функции во многом подобны функциям транспортного протокола модели OSI. Протокол TCP обеспечивает сквозной контроль передачи пакетов. На пятом уровне расположены подсистемы, называемые приложениями. Этот уровень соответствует уровню приложений (седьмому уровню) модели OSI.
Далее рассматриваются особенности протоколов сети Интернет на разных уровнях модели IETF.
23.3. Протоколы стека TCP/IP
Модель IETF содержит ряд подуровней с соответствующими протоколами и функциями. В результате развития Интернет общее число IP-ориентированных протоколов включает в свой состав более сотни спецификаций. Эти спецификации, как было отмечено в лекции 21, выпускаются организацией IETF под общим названием RFC (Request for Comments) и свободно доступны в сети Интернет, в отличие от стандартов других организаций (ITU, ETS! и др.).
На рис. 23.1 представлены основные протоколы, которые можно разделить на три группы: первая группа соответствует сетевому уровню, вторая - транспортному уровню и третья - уровню приложений. В этой лекции мы рассмотрим функции протоколов IP, TCP и UDP. Остальные протоколы будут описаны в следующих лекциях.
На третьем (сетевом) уровне протокол IP (Internet Protocol) обеспечивает:
• маршрутизацию пакетов через сеть по принципу «наилучшей попытки» (см. ниже);
• соединения между сетями с различными базовыми протоколами (например, Х.25, ATM, Frame Relay, Ethernet);
• контроль перегрузок.
На четвертом (транспортном) уровне протокол TCP (Transmission Control Protocol - протокол управления транспортировкой) обеспечивает:
• установление надежных соединений между конечными пользователями (инициирование, подтверждение, передача/прием, разрушение соединений);
• целостность сообщений и контроль ошибок;
• восстановление работоспособности сети после сетевых отказов.
Протокол UDP (User Datagram Protocol - пользовательский протокол передачи датаграмм) является более простой, но и менее надежной альтернативой протоколу TCP. Функции TCP и UDP описаны далее в разделе «Структура заголовков TCP и UDP».
23.4.Принципы организации сети Интернет
Как уже было отмечено, два первых уровня IETF, обозначенных на рис. 23.1 как уровень сетевого интерфейса, совпадают с двумя первыми уровнями модели OSI. На втором уровне реализуются представление информации в виде кадров и помехоустойчивое кодирование данных. На первом уровне обеспечивается соединение с физическим каналом передачи.
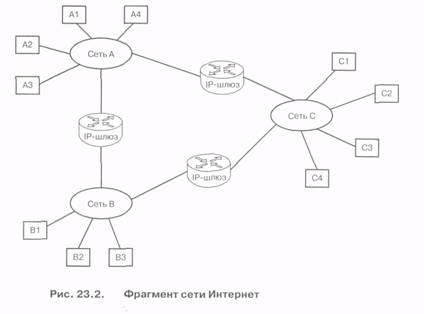
На третьем уровне ключевым элементом является iP-маршрутизатор, называемый также IP-шлюзом. Через такой интерфейс могут быть соединены сети самых разных типов - локальные сети (LAN), городские сети (MAN), крупномасштабные сети (WAN). Рабочие станции, подключаемые к сети, называются хостами. В сети Интернет хосты действуют или как клиенты, или как поставщики (провайдеры) услуг. Клиент представляет собой объект, запрашивающий набор услуг. Провайдер, выступающий как сервер, обрабатывает запросы и обеспечивает реализацию запрашиваемых услуг. Таким образом, в сети устанавливается набор отношений между множеством хостов. На рис. 23.2 представлен фрагмент сети Интернет, объединяющей три сети.
23.5.Структура заголовков IPv4 и IPv6
Структура заголовка датаграммы IPv4. Каждая датаграмма IP, переносящая полезную нагрузку, включает в свой состав заголовок и данные. На рис. 23.3 показан заголовок датаграммы IP, соответствующий версии 4. Первые реализации версии 4 относятся к началу 1980-х годов, и эта версия наиболее распространена сегодня.
Заголовок состоит, как минимум, из 20 байтов с возможностью расширения путем добавления до 4 байтов, обеспечивающих разные дополнительные опции. Для удобства заголовок представлен в виде набора строк, каждая из которых содержит по 4 байта. Общее число таких полей равно 5 или 6.
Дадим краткое описание этих полей.
Поле «Версия», 4 бита, идентифицирует заголовок IP, в данном случае, версию IPv4. Поле «Длина заголовка» определяет размер заголовка (20 или 24 байта). Поле «Тип обслуживания» {Type of Service, ToS) состоит из 8 битов. Первые 3 бита определяют приоритет датаграммы (000 - без приоритета, 111 - уровень управления сетью). Следующие три бита определяют минимальную задержку, высокую пропускную способность и высокую надежность (каждый бит равен единице). Последние два бита не применяются. Отметим, что в сетях Интернет 1990-х годов поле ToS не использовалось.
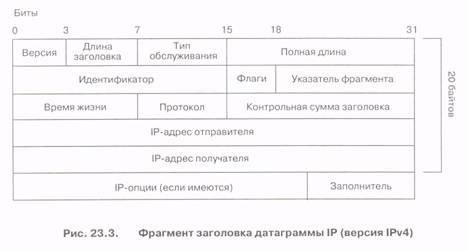
Поле «Полная длина», 16 битов, определяет полную длину датаграммы в байтах, включая заголовок и данные, передаваемые в пакете. Поскольку длина поля равна 16 битам, максимальная длина датаграммы равна 216-1-65535 байтов. В зависимости от ее длины, датаграмм может быть разделена на блоки (фрагменты) в тех случаях, когда маршрутизаторы не могут обрабатывать датаграммы полного размера.
Поля «Идентификатор», «Флаги» и «Указатель фрагмента» используются при восстановлении датаграммы из фрагментов на приемном конце.
Поле «Идентификатор», 16 битов, позволяет восстановить датаграмму из фрагментов в пункте назначения.
Поле «Флаг», 3 бита, также используется для восстановления датаграммы на приемном конце. Первый бит указывает, допустима ли фрагментация (0 соответствует отсутствию фрагментации), второй бит определяет, является ли фрагмент последним в последовательности фрагментов, принадлежащих одной датаграмме (1 означает последний фрагмент, 0 - наличие дополнительных фрагментов).
Третий бит не используется. Поле "Указатель фрагмента», 13 битов, определяет смещение фрагмента относительно начала исходной датаграммы. Полностью нулевое поле указывает, что датаграмма не фрагментирована.
Поле «Время жизни», 8 битов, определяет предельное время, в течение которого датаграмма может находиться в сети. Время жизни, как правило, задается числом маршрутизаторов (числом шагов), и при каждом прохождении через маршрутизатор этот показатель уменьшается на единицу. Когда значение поля достигает нуля, датаграмма выбрасывается из сети.
Восьмибитовое поле «Протокол» определяет протокол, использующийся на транспортном уровне. Значения в этом поле задают протоколы TCP и UDP для транспортировки информационных да-таграмм, a ICMP - для сетевого контроля.
Поле «Контрольная сумма заголовка», 16 битов, предназначено для контроля ошибок в заголовке (только в заголовке, а не во всей датаграмме!) с помощью циклического кода. Эта проверка осуществляется при прохождении датаграммы или ее фрагмента через каждый маршрутизатор.
Следующие два поля предназначены для адресов отправителя и получателя. Обычно принято записывать IP-адреса в десятичной форме с разделением в виде точек, т.е. в форме А.В.CD. Однако в полях IP-адреса отправителя и получателя представлены IP-адреса в двоичной форме.
Во время прохождения датаграмм одного сообщения через сетевые узлы эти адреса не изменяются. Узел-отправитель, исходя из таблицы маршрутизации, знает, к какому соседнему узлу необходимо передать датаграмму. В свою очередь, IP-маршрутизатор знает к какому следующему узлу, исходя из адреса узла-получателя, следует переслать датаграмму.
Поле «Опции», максимум - 4 байта, делает возможным введение различных функций тестирования и контроля.
Поле «Заполнитель» используется для дополнения строки «Опции» до полной длины 32 бита. Необходимо отметить, что наиболее важное свойство протокола IP в его исходном виде (четвертая версия, без применения поля ToS для контроля качества обслуживания) состоит в том, что датаграммы передаются от источника к получателю без установления любого соединения, практически при отсутствии управления процессом передачи.
Очевидно, что при передаче фрагменты датаграмм и датаграммы могут быть потеряны или сброшены в узлах сети, или, из-за больших задержек отдельных фрагментов, датаграммы могут быть потеряны при сборке в месте получения. Таким образом, режим IP при использовании четвертой версии в ее первоначальной редакции обеспечивает минимальный уровень качества обслуживания, получивший название принципа «наилучшей попытки».
Принцип «наилучшей попытки» заключается в том, что сеть берет на себя только попытки доставить поступившие пакеты без гарантии выполнения любых норм, определяемых показателями качества обслуживания. Такой режим доставки был приемлем, когда в сетях Интернет передавался трафик, не предъявляющий высоких требований к доступным сетевым ресурсам (например, пересылка файлов или электронная почта).
Однако в настоящее время в сетях IP передается трафик разных видов, втом числе интерактивный трафик реального времени, чувствительный к задержкам (речь поверх IR видеоконференции, интерактивные игры и т.д.), а также к надежности, к защите информации от несанкционированного доступа и др. Эти требования привели к разработке для сетей Интернет новых протоколов, в число которых входит и протокол IPv6.
Структура заголовка датаграммы IPv6 (рис. 23.4). Протокол IPv4 был реализован в сетях Интернет в 1980 году. Двадцать лет спустя, в 2000 году, половина всех адресов Интернет была использована, причем 75% из них были закреплены за пользователями в Северной Америке. Начиная с конца 90-х годов, начался взрывной процесс развития Интернет, продвижение Интернет в страны Азии с миллиардным населением. В этих условиях стало очевидным, что адресное пространство, которое используют как абоненты, так и разные устройства, ограничивает повсеместное распространение Интернет. Чтобы сеть Интернет могла развиваться, необходимо было увеличить доступное адресное пространство, что и привело к разработке новой версии протокола IP, известной как IPv6. Однако, кроме проблемы адресов, при разработке новой версии был учтен еще ряд недостатков четвертой версии.

Основными свойствами усовершенствованного протокола IPv6, полученными на основе структуры заголовка, являются;
• введение нового размера адресного поля, обеспечивающего увеличение числа доступных IP-адресов и упрощение процесса их конфигурации;
• разработка механизмов, поддерживающих гарантированное качество обслуживания;
• возможность применения средств аутентификации и защиты информации.
Как видно из рис. 23.4, длина заголовка IPv6 равна 40 байтам, что в два раза больше, чем в версии v4. Первые две строки (8 байтов} обеспечивают функции контроля, и структура этих двух строк существенно отличается от структуры строк, расположенных над адресной частью заголовка IPv4.
Поле «Версия», 4 бита, указывает, что пакет имеет заголовок IPv6.
Поля "Класс трафика», 8 битов, и «Метка потока», 20 битов, определяют предварительно назначенный уровень качества обслуживания для определенной пары адресов источника и пункта назначения.
Качество обслуживания в Интернет определяется пропускной способностью сети, задержкой и джиттером пакетов, а также потерями пакетов. Уровни качества обслуживания определяются двумя классами услуг, известных как Integrated Services (интегрированные услуги) и Differentiated Services (дифференцированные услуги). Детальное описание этих услуг дано ниже, в лекции 28.
Поле «Длина поля полезной нагрузки», 2 байта, определяет длину пакета в байтах, исключая длину заголовка. Так же, как и в четвертой версии, длина поля равна 16 битам и максимальная длина пакета равна 216-1=65535 байтам.
Поле «Следующий заголовок», 8 битов, определяет типы дополнительных заголовков, которые должны следовать за основным заголовком IPv6.
Поля, в которых располагаются дополнительные заголовки, размещаются между заголовком IP и заголовками TCP или UDR Дополнительные заголовки включают в себя большой набор функций, таких как маршрутизация, фрагментация, защита информации, аутентификация.
Поле «Ограничение числа шагов», 8 битов, выполняет те же функции, что и поле «Время жизни» в четвертой версии.
Адреса отправителя и получателя имеют каждый по 16 байтов (128 битов), то есть превышают аналогичные поля четвертой версии в четыре раза.
Число возможных адресов в протоколе IPv6 равно 2128-1≈3,4х1038. При таком количестве адресов очевидно, что в будущем каждое устройство на микропроцессорах может получить собственный адрес. Отметим, что в протоколе IPv6 датаграммы называются пакетами IPv6; сетевые элементы (маршрутизаторы и хосты) называются узлами (nodes).
Несмотря на то что работы, связанные с внедрением протокола IPv6, ведутся уже более 10 лет, необходимо иметь в виду, что основную часть аппаратно-программных модулей в сетях IP реализует протокол IP четвертой версии. В связи с этим возникает проблема перехода на новое семейство протоколов, ориентированных на версию IPv6.
По инициативе IETF была создана экспериментальная сеть бВопе, охватывавшая страны Северной Америки, Европы (в том числе и Россию), Японию и включавшая в себя несколько сотен сетей IP
В сети бВопе часть маршрутизаторов поддерживали обе версии протокола IP, образуя виртуальную сеть, функционирующую поверх сети IPv4 и обеспечивающую передачу пакетов по протоколу IPv6 между рабочими станциями и между маршрутизаторами.
В 2004 году сеть бВопе закрыта и в настоящее время в США активно разрабатывается некоммерческий проект Internet2, как прообраз перспективных сетей Интернет общего пользования, которые будут строиться на базе протокола IPv6 (см. лекцию 30).
Благодаря большому набору новых функциональных возможностей, протокол IPv6, безусловно, получит широкое распространение. Однако переход к новому протоколу связан с существенной модификацией сетевых устройств, что потребует значительных затрат
23.6.Структура заголовков TCP и UDP
Протокол TCP (Transmission Control Protocol). Для повышения надежности транспортировки в сетях IP в 1974 году был разработан протокол транспортного уровня TCP, который обеспечивает гарантированную доставку датаграмм. Протокол TCP является ориентированным на соединений. Пакет TCP называется также сегментом.
На рис. 23.5 показана структура заголовка протокола TCP, содержащая пять строк, каждая по 4 байта. К заголовку может быть прибавлена еще одна строка для опций. Если протокол IP работает с адресами отправителя и получателя, то протокол TCP устанавливает соединение с портами, идентифицирующими, какой тип приложения в оконечных хостах используется в этом соединении.
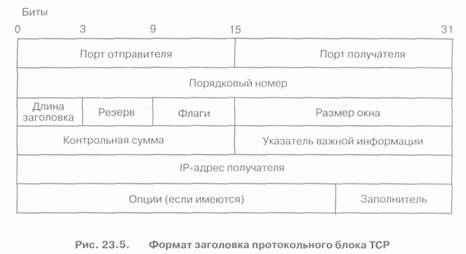
Заголовок протокола TCP начинается с полей номеров портов отправителя и получателя (2 байта в каждом поле). Адрес IP вместе с номером порта TCP называется оконечной точкой хоста. Комбинация порта отправителя TCP, адреса отправителя IP, порта назначения TCP и адреса получателя IP определяет уникальное соединение TCP, называемое сокетом.
Поле «Порядковый номер», 4 байта, определяет смещение пакета от начального порядкового номера, используемого в передаваемом сегменте TCP для нумерации байтов. Порядковый номер используется приемным хостом для упорядочения прибывающих сегментов. При этом потерянные сегменты повторяются источником по требованию со стороны получателя.
Поле «Длина заголовка», 4 бита, определяет полную длину заголовка TCP
Поле «Резерв» в настоящее время не используется и должно обнуляться.
Поле «Флаги», 6 битов, определяет 6 индивидуальных флагов. Каждый флаг, имеющий значение «1», указывает на определенную процедуру (важность информации, подтверждение того, что номер следующего пакета является правильным, быстрая передача информации приемнику, прерывание связи, запрос синхронизации при установлении нового соединения, отсутствие на передающей стороне данных для передачи).
Поле «Размер окна», 2 байта, задает количество байтов, которые могут быть приняты и накоплены в буфере приемника перед отправкой подтверждения.
Поле «Контрольная сумма», 2 байта, выполняет функции, аналогичные функциям поля «Контрольная сумма заголовка» в протоколе IPv4.
Поле «Указатель важной информации», 2 байта, указывает номер последнего байта сегмента, который содержит высокоприоритетные данные.
Поле «Опции» делает возможным введение функций контроля и мониторинга сети.
Поле «Заполнитель» используется для дополнения строки «Опции» до полной длины 32 бита.
Как было отмечено выше, протокол TCP устанавливает соединение между двумя оконечными точками сети или хостами. Основными функциями протокола TCP являются инициирование соединения, соглашение о том, какой порт (или программа) будет использоваться (например, для пересылки файлов или для электронной почты), управление передачей сегментов и завершение сеанса связи между любыми двумя оконечными точками. Сегменты TCP могут переносить сообщения различных типов - полезную нагрузку, запросы установления/закрытия соединения TCP, подтверждения и др.
Протокол UDP (User Datagram Protocol) представляет собой другой пример транспортного протокола в сетях Интернет. Так же, как протокол TCP, UDP обеспечивает доставку датаграмм, однако функционируете режиме без установления соединений между оконечными точками.
Пакет протокола UDP, содержащий заголовок и поле данных, называется датаграммой UDP. Протокол UDP не поддерживает надежную доставку датаграмм, поскольку в его функции не входят управление передачей данных и подтверждение приема. Заголовок датаграммы включает в себя порты отправителя и получателя, поле длины датаграммы UDP и поле контрольной суммы. Необходимо отметить, что перечисленные выше свойства протокола UDP не позволяют применять этот протокол для передачи данных, предъявляющих высокие требования к надежной доставке. С другой стороны, небольшой объем заголовка и, как следствие, небольшие накладные расходы (например, по сравнению с TCP) определили возможности его применения в надежных локальных сетях.
В последние несколько лет протокол UDP нашел широкое применение при передаче речи в сетях Интернет. Характеристика услуги «Речь поверх IP» (Voice over IP, VoIP) дана в лекции 26.
Системы сигнализации VoIP
Архитектура - это застывшая музыка.
Ф. Шеллинг
24.1. Создание архитектуры SIP
Работы в области создания протоколов сигнализации для системы VoIP начались в IETF с выпуска спецификации draft-ietf-mmusic-sip-ОО, где был описан протокол Session Invitation Protocol, получивший впоследствии название SIP/1.0.
Этот документ специфицировал только запрос установления сеанса связи, однако в перспективе эта спецификация ориентировалась на интеграцию в создававшуюся в то время мультимедийную архитектуру конференций, о чем свидетельствовала аббревиатура MMUSIC в названии этого документа, которая не была непосредственно связана с музыкой, а расшифровывалась как Multiparty Multimedia Session Control.
Любопытно отметить, что до создания первой спецификации протокола инициирования сеансов, известного сейчас как SIP (Session Initiation Protocol), в 1996 году в IETF соперничали два протокола установления сеансов связи: уже упомянутый выше и протокол Simple Conference Invitation Protocol(SCIP).
Первый протокол поддерживал установление сеанса, был рассчитан на работу только поверх рассмотренного в лекции 23 протокола UDP, а для описания сеанса использовал протокол SDP, о котором мы поговорим чуть позже в этой лекции.
Второй протокол, SCIP, позволял обслуживать сеанс уже после его установления, базировался на протоколе TCP (см. лекцию 23) и использовал протоколы Hypertext Transport Protocol(HTTP) и Simple Mail Transport Protocol (SMTP), но не применял протокол SDP для описания своих сеансов.
Именно эти два протокола были объединены в протокол Session Initiation Protocol, который позаимствовал позитивные идеи у каждого из своих «родителей».
От протокола Session Invitation Protocol новый протокол воспринял взаимодействие с UDP и использование SDP, от протокола SCIP- поддержку TCP и применение протоколов SMTP и HTTP. Вначале новый протокол получил название SIP/2.0, чтобы отличить его otSIP/1.0.
Первая спецификация протокола SIP/2.0 была опубликована в RFC 2543, и впоследствии именно этот протокол стал известен как SIP.
С момента публикации спецификация RFC 2543 претерпевала многочисленные модификации; работа по дальнейшему улучшению протокола SIP продолжается и сейчас. В настоящее время действующим стандартом SIP является RFC 3261. В основу протокола SIP положены следующие основные свойства:
• персональная мобильность пользователей, основанная на присвоении пользователю уникального идентификатора, который позволяет ему перемещаться в пределах сети и получать связь вне зависимости от места, где он находится, сообщаемого серверу определения местонахождения при помощи специального сообщения;
• масштабируемость сети, построенной на базе этого протокола;
• открытость протокола, характеризуемая возможностью дополнять его функциями поддержки новых услуг и его адаптации к работе с различными приложениями.
Более подробно с протоколом SIP можно познакомиться в [14].
24.2. Протокол SDP
Протокол SIP используется для установления сеансов связи между пользователями. Но кроме этого, пользователи должны согласовать тип и правила кодирования информации, которой они собираются обмениваться, то есть совместно использовать описание сеанса между ними. Такое описание сеанса составляется в соответствии с уже упомянутым протоколом SDP (Session Description Protocol).
Протокол SDP представляет собой язык для описания сеансов связи. Он содержит информацию об участвующих в сеансе сторонах, дате и времени, когда должен состояться сеанс, о типах совместно используемых медиапотоков, а также об используемых адресах и номерах портов. Вполне возможно, что описание сеанса может относиться к нескольким медиапотокам, как в видеоконференции, где один медиапоток относится к кодированной речи, а другой - к кодированному видео. Поэтому протокол SDP структурирован так, что он может представлять информацию, относящуюся к сеансу в целом (например, имя сеанса), плюс информацию, связанную с каждым отдельным потоком (например, формат медиапотока и применяемый номер порта).
Объединенное использование протоколов SIP и SDP иллюстрирует пример на рис. 24.1. Это возможный вариант сценария установления соединения между User1@niits.ru, который зарегистрирован в area1.niits.ru, и User2@niits.ru, который зарегистрирован Barea2.niits.ru.
Запрос сеанса SIP начинается приглашением INVITE, которое указывается в первой строке запроса. Эта строка указывает также адрес объекта, которому передается сообщение, называемый URI (uniform resource indicator) запроса. В данном случае сообщение передается непосредственно к абоненту User2
Поле заголовка Via вводится каждым объектом в цепочке от источника сообщения до пункта назначения. Поля заголовков From и То указывают инициатора и получателя запроса. Дальнейшее описание сценария на рис. 24.1 мы оставим читателю в качестве упражнения.
24.3. Управление медиашлюзами
Принцип декомпозиции шлюзов предусматривает разбиение шлюза IP-телефонии на структурные элементы.
Первым протоколом, базирующимся на этом принципе и получившим широкое распространение, стал разработанный IETF протокол управления шлюзами Media Gateway Control Protocol (MGCP).
Этот протокол представляет собой объединение двух протоколов - простого протокола управления шлюзами SGCP (Simple Gateway Control Protocol), и протокола управления IP-оборудованием IDCP (IP Device Control Protocol).
Рабочая группа MEGACO в составе IETF усовершенствовала протокол управления шлюзами и предложила протокол MEGACO.
Разработкой протокола управления медиашлюзами занималась и Исследовательская Комиссия 16 (ITU-T), которая раньше ввела принцип декомпозиции шлюзов в рекомендацию Н.323.

Эта Исследовательская Комиссия предложила модифицировать MEGACO в направлении большей совместимости с Н.323, и опубликовала рекомендацию Н.248.1. В результате был принят новый, совместно разработанный IETF и ITU протокол, получивший название MEGACO/H. 248.
Для переноса сигнальных сообщений протокол MEGACO/H.248 может использовать протоколы UDP и TCP, а также протокол SCTP, речь о котором пойдет ниже в этой лекции.
Важной особенностью протокола MEGACO/H.248 является то, что его сообщения могут кодироваться двумя способами. IETF использует текстовый способ кодирования сигнальной информации, а для описания сеанса связи - вышеупомянутый протокол SDP. В свою очередь, ITU-T предусматривает двоичный способ представления сигнальной информации - ASN.1, а для описания сеансов связи рекомендует используемый во многих других протоколах ТфОП и СПС механизм TLV (Tag-length-value). Более подробно с протоколом MEGACO/H.248 можно познакомиться в [3].
24.4. Протокол Н.323
Первой рекомендацией для построения сетей IP-телефонии стала рекомендация Н.323. Так как ITU исторически занимался проблемами ТфОП, то и предложенная рекомендация фактически определяла сеть ISDN, наложенную на IP-сеть. В частности, процедура установления соединения в сети IP-телефонии по Н.323 базируется на рекомендации Q.931 и практически идентична той же процедуре в сетях ISDN.
Основными устройствами сети Н.323 являются терминал, шлюз, привратник и устройство управления конференциями. В связи с неоднократно упоминавшейся в предыдущих лекциях проблемой мобильности абонентов отметим, что в отличие от телефонов ТфОП, терминалы Н.323 не имеют жестко закрепленного места в сети и подключаются к любой точке IP-сети. При этом сеть Н.323 разбивается на зоны, а каждой зоной управляет привратник.
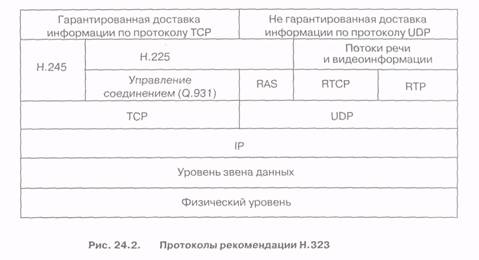
В рекомендацию Н.323 входят три основных протокола: протокол RAS(Registration, Admission and Status) взаимодействия оконечного оборудования с привратником, протокол управления соединениями Н. 225 и протокол управления логическими каналами Н. 245.
Эти протоколы, вместе с протоколами Интернет IP, TCP, UDP, RTP и RTCP, а также с протоколом Q.931, представлены на рис. 24.2.
Как видно на рисунке, протокол TCP используется для переноса сигнальных сообщений Н.225 и управляющих сообщений Н.245, сигнальные сообщения RAS переносятся с помощью протокола UDP, а доставка речевой и видеоинформации производится с использованием протоколов RTP/RTCP, входящих в стек TCP/IP.
24.5. Сигнализация ОКС7 поверх IP
Универсальность и повсеместное развертывание системы общеканальной сигнализации ОКС7, о чем подробно говорилось в лекции 4, а затем и в лекции 14, стимулируют работы, направленные на ее использование совместно с протоколами TCP/IP. Задачами организации переноса сообщений ОКС7 через сеть IP занимается рабочая группа Sigtran, входящая в IETF. Основой стека протоколов Sigtran для надежной транспортировки сообщений ОКС7 по сетям IP (рис. 24.3) является протокол управления потоками SCTP(Stream Control Transmission Protocol), который поддерживает перенос сигнальных сообщений между конечными пунктами сигнализации в сети IP.

24.5.1. Протокол управления потоками SCTP
Для организации сигнальной связи один конечный пункт предоставляет другому перечень своих транспортных адресов {IP-адреса в сочетании с номером порта SCTP). Протокол SCTP позволяет независимо упорядочивать сигнальные сообщения в разных потоках и обеспечивает перенос сигнальной информации с подтверждением приема, доставку сообщений каждого потока с сохранением очередности их следования, возможность объединения нескольких сообщений в один пакет SCTP, фрагментацию данных по мере необходимости, устойчивость к перегрузкам и т.п.
24.5.2. Протоколы адаптации M2UA, М2РА и M3UA
Для реализации функциональных возможностей рассмотренного в лекции 4 протокола МТР в сетях IP рабочая группа Sigtran рекомендовала три новых протокола - M2UA, М2РА и M3UA. Каждый из них кратко рассматривается ниже, но прежде приведем основные требования ITU-T к переносу сообщений МТР как по цифровым телефонным сетям, так и по IP-сетям:
• для одноранговых процедур уровня 3 МТР требуемое время отклика должно находиться в пределах от 500 мс до 1200 мс;
• вероятность потери сообщения из-за отказов на транспортном уровне должна быть не более 10'7;
• вероятность несвоевременной доставки сообщения из-за отказов на транспортном уровне должна быть не более 10'9.
Протокол M2UA уровня адаптации для пользователей уровня 2 МТР (МТР Level-2 User Adaptation Layer) предусматривает набор услуг, эквивалентный тому, который предоставляет уровень 2 МТР уровню 3 МТР в обычной сети ОКС7.
Протокол используется между шлюзом сигнализации и контроллером транспортного шлюза в сетях VoIP. Шлюз сигнализации принимает сообщения ОКС7 через интерфейс уровня 1 и уровня 2 МТР от конечного или транзитного пункта сигнализации. Шлюз является окончанием для звена ОКС7 на уровне 2 МТР и транспортирует информацию уровня 3 МТР и верхних уровней к контроллеру транспортного шлюза или к другому конечному пункту сети IP, используя протокол M2UA поверх SCTP/IP
Протокол М2РА уровня адаптации для одноранговых пользователей МТР2 (МТР2 User Peer-to-Peer Adaptation Layer), в отличие от протокола M2UA, используется для полномасштабной обработки сообщений уровня 3 МТР, которыми обмениваются два любых узла сети ОКС7, взаимодействующих через сеть IR
Пункты сигнализации сети IP функционируют как обычные узлы ОКС7, используя протоколы стека TCP/IP.
Каждый пункт сигнализации сети с коммутацией каналов или сети IP имеет код пункта сигнализации ОКС7. Протокол М2РА предусматривает тот же набор услуг, который предоставляет уровень 2 МТР уровню ЗМТР.
Протокол может использоваться между шлюзом сигнализации и контроллером транспортного шлюза, между шлюзом сигнализации и пунктом сигнализации сети IR а также между двумя пунктами сигнализации сети IP. Пункты сигнализации могут использовать протокол М2РАдля передачи и приема сообщений уровня 3 МТР по сети IP или уровень 2 МТР для обмена этими сообщениями по стандартным звеньям ОКС7.
Протокол М2РА облегчает интеграцию сетей ОКС7 и IP благодаря тому, что позволяет узлам сети с коммутацией каналов иметь доступ к базам данных IP-телефонии и к другим узлам сетей IP, используя сигнализацию ОКС7. И, наоборот, протокол М2РА позволяет приложениям IP-телефонии получать доступ к базам данных сети ОКС7.
Протоколы М2РА и M2UA имеют следующие различия:
• при использовании протокола М2РА шлюз сигнализации является узлом ОКС7 с кодом пункта сигнализации, а при использовании протокола M2UA шлюз сигнализации не является узлом ОКС7 и не имеет кода пункта сигнализации;
• в случае применения протокола М2РА соединение между шлюзом сигнализации и пунктами сигнализации сети IP представляет собой звено ОКС7, а в случае применения протокола M2UA соединение между шлюзом сигнализации и контроллером транспортного шлюза не является звеном ОКС7;
• при использовании М2РА шлюз сигнализации может выполнять функции верхних уровней ОКС7, например, функции SCCP, а при использовании M2UA шлюз сигнализации не выполняет функции верхних уровней ОКС7, поскольку он не содержит функций уровня 3 МТР;
• в случае применения протокола М2РА выполнение функций эксплуатационного управления базируется на соответствующих процедурах уровня 3 МТР, а в протоколе M2UA используются собственные процедуры эксплуатационного управления;
• при использовании М2РА пункты сигнализации сети IP обрабатывают примитивы уровня 3 МТР и уровня 2 МТР, а в случае M2UA контроллер транспортного шлюза переносит примитивы уровня 3 МТР и уровня 2 МТР на уровень 2 МТР шлюза сигнализации для их последующей обработки.
Протокол M3UA уровня адаптации для пользователей уровня 3 МТР (МТР Level-3 User-Adaptation Layer) связан с переносом по сети IP средствами протокола SCTP сигнальных сообщений подсистем-пользователей уровня 3 МТР (например, ISUP, SCCP). Подсистема SCCP может переносить сообщения своих пользователей (ТСАРили INAP) с помощью либо протокола M3UA, либо другого продукта группы Sigtran - протокола SUA, который рассматривается ниже.
Протокол M3UA используется между шлюзом сигнализации и контроллером транспортного шлюза или базой данных IP-телефонии. Он расширяет доступ к услугам уровня 3 МТР шлюза сигнализации, охватывая удаленные конечные пункты IP-сети.
24.5.3. Протоколы SUA и IUA
Протокол SUA уровня адаптации для пользователей SCCP поддерживает перенос по IP-сети (средствами протокола SCTP} сигнальных сообщений пользователей SCCP, например, ТСАРили INAR представленных в четвертой лекции на рис. 4.4 и в четырнадцатой лекции на рис. 14.2. По аналогии с этими двумя рисунками покажем пример применения SUA на рис. 24.4, где протокол SUA используется между шлюзом сигнализации и конечным пунктом сигнализации IP-сети. Протокол SUA поддерживает как услуги SCCP без соединения с неупорядоченной и упорядоченной доставкой, так и услуги, ориентированные на соединение, с управлением или без управления потоком данных и с обнаружением потерь сообщений и ошибок вследствие несвоевременной доставки сообщений (то есть классы услуг SCCP с 0 по 3). В случае услуг без соединения протоколы SCCP и SUA взаимодействуют в шлюзе сигнализации.
С точки зрения пункта сигнализации ОКС7 пользователь SCCP находится в шлюзе сигнализации. Сообщения ОКС7 направляются к этому шлюзу на основании анализа кода пункта сигнализации и номера подсистемы SCCP, а тот направляет сообщения SCCP к удаленному конечному пункту IP-сети.
Протокол уровня адаптации для ISDN-пользователя (IUA) поддерживает перенос через сеть IP сообщений Q.931. Протокол IUA исключает использование в системе сигнализации части протокола МТР и позволяет приложениям верхнего уровня непосредственно взаимодействовать с транспортным протоколом SCTP.
В заключение этой лекции отметим, что Sigtran является не единственной рабочей группой IETF, участвующей в определении новых протоколов для обеспечения конвергенции сетей ТфОП и IP Следует еще упомянуть группу PINT (PSTN and Internet Interworking) взаимодействия ТфОП и Интернет и группу услуг SPIRITS (Service in the PSTN/IN Requesting Internet Service).

Согласно PINT услуги ТфОП активизируются путем запросов из сети IP, когда клиент SIP создает запросы инициирования телефонных вызовов в ТфОП. Целью этого является обеспечение телефонной и факсимильной связи из Интернет.
В работах SPIRITS услуги сети IP активизируются путем запросов из ТфОП. SPIRITS обеспечивает такие услуги, как уведомление о поступлении нового вызова в сети Интернет, предоставление идентификатора вызывающего абонента из сети Интернет и переадресация IP-вызовов.
Рабочая группа IPTEL разрабатывает протокол TRIP (Telephony Routing over IP) маршрутизации телефонных вызовов по сети IP Этот протокол информирует серверы адресов о доступности телефонных адресатов и обеспечивает атрибуты маршрутов к этим адресатам. Протокол TRIP позволяет обмениваться информацией маршрутизации, используя стандартные протоколы IP.
Результаты рабочей группы ENUM в составе IETF, разрабатывающей схему преобразования телефонных номеров Е.164в IP-адреса, мы рассмотрим в следующей лекции.
Системы адресации и маршрутизации в СПД
Черная королева покачала головой:
«Вы, конечно, можете назвать это чушью,
но я-то встречала чушь такую, что в сравнении с ней
эта кажется толковым словарем».
Л. Кэрролл
25.1. Нумерация и адресация
Недостатки адресации в IP-сетях, например, ограничения использованием только латинского алфавита, не столь существенны по сравнению с ограничениями телефонной нумерации, описанной в лекциях 5 и 15. Действительно, вряд ли телефонный номер, при всей его привычности, можно считать удобным средством определения абонента. И как только вместо тастатуры телефона у пользователя оказалась компьютерная клавиатура, начали появляться более комфортные и эффективные средства идентификации. Разработка планов нумерации в сетях фиксированной и мобильной телефонной связи производилась с учетом ряда ограничений, среди которых следует выделить два аспекта.
Во-первых, на форму нового плана нумерации и на его функциональные возможности существенно влияют решения, принятые ранее. Во-вторых, устройства набора номера в терминалах телефонной связи (особенно на начальном этапе создания ТфОП) и, главным образом, возможности оборудования коммутации не позволяли ввести удобный - с точки зрения абонентов - план нумерации.
Сеть Интернет с самого начала была свободна от этих ограничений, что стимулировало разработку принципов нумерации фактически с «чистого листа».
В сети Интернет вместо термина «нумерация» введено понятие «адресация». Формально, цели нумерации и адресации сходны. С другой стороны, различия функций, реализуемых в системах нумерации и адресации, весьма существенны. Правда, процессы конвергенции сблизили операции, выполняемые абонентами при работе в сетях телефонной связи (преимущественно, в СПС) и в Интернет.
Например, выбор в записной книжке телефонного аппарата имени вызываемого абонента очень похож на аналогичную процедуру заполнения поля «Кому» для последующего составления письма, отправляемого по "Электронной почте». Однако действия сетевого оборудования в этих двух случаях будут заметно отличаться друг от Друга.
25.2. Принципы назначения адресов в сетях IP
В лекции 23 приведено описание заголовка протокола IP версии 4 (IPv4), включающего в себя IP-адрес Для записи адресов отправителя и получателя в заголовке выделены два поля одинаковой длины - одно поле для записи адреса отправителя, второе - для записи адреса получателя; длина каждого поля равна 4 байтам или 32 битам.
Полный IP-адрес включает в себя адрес сети (идентификатор сети, netid) и адрес хоста (идентификатор хоста, hostid). IP-адрес может быть представлен как в двоичном, так и в десятичном формате с разделением точками. В примере, рассматриваемом ниже, IP-адрес записан в десятичном формате: первая часть адреса (два байта) представляет собой сетевой адрес, вторая часть (следующие два байта) - адрес хоста. Например, адрес
136.104.53.11
соответствует сети, идентифицируемой сетевым адресом 136.104.0.0 (netid) и адресом хоста 0,0.53.11 (hostid) внутри этой сети.
Для данного примера IP-адрес в двоичном формате будет иметь следующий вид (байты разделяются пробелом):
10001000 01101000 00110101 00001011
Кроме того, предполагается возможность представления адреса в шестнадцатеричной системе.
Адресное пространство Интернет разделяется по Классам адресов А, В, С, D и Е с разным числом битов, выделяемых на сетевые адреса и адреса хостов в каждом классе. Разделение сетей по классам определяется первыми несколькими битами сетевого адреса в двоичной системе.
Класс А идентифицируется первым битом сетевого адреса, равным «О». Класс А имеет только 7 битов для своих сетей, что означает возможность получения адресов для 27 - 2 = 126 «больших» сетей; идентификатор хоста задается 24 битами, что определяет [214 - 2] адресов хостов. Вычитание «2» в этих вычислениях определяется тем, что адреса, в которых все биты - единицы и в которых все биты - нули, резервируются. В качестве примера адресов класса А можно привести адреса, полученные такими организациями, как IBM (9.0.0.0), ARPANET {10.0.0.0) и AT&T (12.0.0.0.).
Класс В идентифицируется двумя первыми битами, равными «10». Класс В имеет 14 битов для адресов, принадлежащих этому классу «средних» сетей ([216- 2] адресов). Для адресов хостов используются 16 битов ([216- 2] адресов).
Класс С идентифицируется первыми тремя битами, равными «110». Адреса сетей Класса С задаются 21 битом и только 8 битов определяют адреса хостов, то есть только 254 хоста могут быть определены в сети Класса С.
Класс D идентифицируется четырьмя битами первого байта адреса, равными «1110». Оставшаяся часть сетевого адреса (4 бита) соответствует 14 сетевым адресам, разделяемым большим числом хостов ([216 - 2] адресов). Класс D используется для передачи датаграмм к оконечным устройствам в режиме селективного вещания (multicasting, мультикастинг). В отличие от обычного вещательного режима, когда один источник передает информацию всем достижимым получателям, селективное вещание (или мультикастинг) предполагает вещание только определенным получателям.
В последние годы был добавлен еще один класс - Класс Е, идентифицируемый пятью первыми битами сетевого адреса, равными «11110». Этот класс резервируется для будущего использования.
Систематизация адресного пространства в первых трех Классах А - С позволяет формировать сети разного размера и конфигурации, начиная от небольшого числа сетей (126) и практически неограниченного числа хостов (16,8 миллиона) в Классе А (предполагается, что Классу А принадлежат большие территориально разнесенные сети) до большого числа сетей в Классе С (более 2 миллионов), каждая из которых имеет до 254 хостов, что соответствует размерам локальных сетей.
Общее число адресов, доступных в первых трех Классах А - С,
составляет величину порядка 4 миллиардов. Это число адресов в настоящее время перекрывает количество пользователей: в 2000 году число пользователей составляло 110 миллионов, в 2001 году - 200 миллионов, в 2008 году число пользователей достигло 1,2 миллиарда. На заре Интернет, когда число сетей и пользователей было относительно невелико, адреса Классов А и В раздавались свободно организациям, которые не могли целиком заполнить адресное пространство и, таким образом, часть адресов, выделенных для хостов, оказалась неиспользованной. В то же время быстрый рост числа хостов приводит к необходимости более эффективного и экономного использования адресного пространства.
На начальном этапе развития сетей IP использовался принцип фиксированной границы между частями адреса, соответствующими адресу сети и адресу хоста. В этом случае каждая из сетей, независимо от ее класса (А, В, С, D), получает максимальное число адресов хостов. При таком жестком подходе задача удовлетворения требований к адресному пространству со стороны больших и малых организаций не может быть успешно решена. Например, очевидно, что не все организации, получившие на начальном этапе развития сетей Интернет адреса Класса А, имеют достаточное число хостов, чтобы заполнить пространство, включающее в себя около 17 миллионов хостов. В то же время, в сетях Класса С часто возникают ситуации, когда число хостов (не более 254 пользователей) становится явно недостаточным.
Со второй половины 90-х годов XX века подход, основанный на фиксированной границе между адресом сети и адресом хоста, был постепенно заменен подходом, использующим концепцию так называемой маски сети (подсети). Маска представляется в десятичной или в двоичной форме, В случае двоичного представления маска содержит группы единиц в тех разрядах, которые в IP-адресе соответствуют номеру сети (netid). Чтобы получить адрес сети, зная IP-адрес и маску подсети, необходимо применить к ним операцию поразрядной конъюнкции (логическое И). Рассмотрим пример получения адреса сети, когда IP-адрес и маска представлены в двоичной форме:
IP-адрес: 11000000 10101000 00000001 00000010(192.168.1.2)
«И»
Маска сети: 111111111111111111111111 00000000 (255.255.225.0)
Адрес сети: 1100000010101000 00000001 00000000(192.168.1.0)
Для стандартных классов сетей маски имеют следующие значения:
• Класс А - 11111111 00000000 00000000 00000000 (255.0.0.0);
• Класс В - 11111111 11111111 00000000 00000000 (255.255.0.0);
• Класс С - 11111111 11111111 11111111 00000000 (255.255.255.0). Подход к назначению адресов с использованием масок позволяет отказаться от разделения на классы и делает систему распределения адресов достаточно гибкой. При использовании маски сетевой администратор может разбить адресное пространство сети, выделенное ему провайдером, на несколько подсетей, не требуя от провайдера дополнительных адресов.
Концепция масок легла в основу метода междоменной бесклассовой маршрутизации (Classless Inter-Domain Routing, CIDR). Более подробно о методе CIDR можно прочесть в дополнительной литературе к этой лекции.
Для удобства пользователей в сетях Интернет широко используются имена хостов, понятные пользователю, например, info@mail.ru. И имена, и адреса должны быть уникальными, при этом сетевые адреса являются глобально уникальными, тогда как адрес хоста является уникальным внутри сети, за которой закреплен этот хост.
Почему же в сети Интернет используются и имена, и адреса (скажем, в отличие от ТфОП, где используются только телефонные номера) Имеется несколько причин таких решений.
Во-первых, необходимо, чтобы адреса могли быть прочитаны компьютерами, а для этого адреса должны быть представлены в цифровой форме. С другой стороны, имена в буквенной форме удобны для их чтения пользователями.
Во-вторых, имена хостов могут иметь переменную длину и быть довольно длинными. Если в сети использовать имена хостов в заголовках пакетов, поля отправления и назначения должны иметь переменную и, возможно, большую длину. Это приводит к неэффективному использованию сетевых ресурсов, а также к росту сложности маршрутизаторов, которые должны дешифрировать имена, размещать их в таблицах маршрутизации и так далее. Использование адресов фиксированной длины в заголовках пакетов является более эффективным.
Остановимся на порядке назначения IP-адресов. Так же, как и телефонные номера в ТфОП и в мобильных сетях, адреса в больших сетях Интернет должны быть уникальными. Уникальность сетевых адресов определяется путем их централизованного распределения.
Центральным органом регистрации глобальных адресов в сетях Интернет является организация IANA (Internet Assigned Numbers Authority), действующая на некоммерческой основе.
Распределением сетевых адресов в крупных территориальных регионах занимаются некоммерческие организации, называемые Regional Internet Registries, RIR.
К 2008 году имелось 5 RIR для следующих регионов: Северная Америка; Европа, Ближний Восток и Центральная Азия; Азия и Тихоокеанский регион; Латинская Америка и Карибский регион; Африка. Здесь полезно упомянуть о частных адресах, рекомендуемых для автономного использования. Сети частных адресов назначаются в трех основных классах - А, В и С:
• Класс А-сеть 10.0.0.0 (вспомним, что это пространство адресов было выделено сети ARPANET);
• Класс В- 16 сетей в диапазоне 172.16.0.0- 172.31.0.0
• Класс С - 256 сетей в диапазоне 192.168.0.0- 192.168.255.0.
Эти частные номера выделены для использования в автономных системах, представляющих собой объединение нескольких сетей под управлением одной административной системы (как правило, принадлежащей поставщику услуг). Общее адресное пространство, охватываемое указанными адресами, достаточно велико. При этом, хотя адреса хостов в частных адресах могут совпадать с адресами сетей, назначаемых централизованно, специальные технологии обеспечивают бесконфликтное подключение хостов автономных систем к сети Интернет общего пользования. Примером такой технологи является технология трансляции сетевых адресов (Network Address Translation, NAT"). Несмотря на кажущийся запас доступных адресов, число хостов (терминалов), претендующих на получение IP-адреса, постоянно растет за счет «умных» домашних устройств, обеспечивающих безопасность, контроль здоровья, бытовые услуги, работу домашних телевизоров и радиоприемников и так далее. Все это ведет к тому, что оставшееся пространство IP-адресов довольно быстро уменьшается.
По этой причине Комитет IETF, наряду с другими проблемами, начиная с 1998 года, занимается вопросами модернизации системы адресации, что привело к разработке новой, шестой версии протокола IP, известной как IPv6.
В протоколе IPv6 длина адреса составляет 128 битов. Общее количество адресов достигает огромного, трудно представимого числа порядка 1038.
Среди основных требований к новому протоколу отметим следующие: возможность сосуществования двух протоколов (IPv4 и IPv6), уменьшение числа сетевых классов для упрощения таблиц маршрутизации и ряд дополнительных функций (защита информации, поддержка качества обслуживания и обеспечение мобильности пользователей).
25.3. Протоколы поддержки системы адресации
Протокол ARP (Address Resolution Protocol - протокол преобразования адресов, RFC 826) используется для однозначного отображения IP-адресов (А.В.CD) в физические (аппаратные) адреса, по которым могут быть найдены хосты, расположенные в локальных сетях. Физический адрес хоста называется адресом MAC (Media Access Control).
Первоначально ARP применялся для перевода адресов IP в адреса Ethernet. Необходимость такого преобразования определяется тем, что IP-адреса назначаются независимо от физических адресов хостов.
В протоколе IPv4 длина адресного поля равна 32 битам, тогда как в технологии Ethernet длина адресов подключенных устройств равна 48 битам. Впоследствии ARP использовался для получения адресов практически всех типов проводных локальных сетей и для определения адресов в сетях «IP поверх ATM». В настоящее время протокол ARP применяется для определения адресов сетей стандарта IEEE 802.11.
Преобразование адресов производится в соответствии с таблицей, известной как кэш-таблица ARP. Кэш-таблица ARP устанавливает однозначное соответствие между адресом MAC и IP-адресом и обеспечивает преобразование адресов в обоих направлениях.
Протокол ARP работает следующим образом. Когда входящий IP-пакет, направляемый к определенному хосту в локальной сети, прибывает в маршрутизатор (шлюз), шлюз просит программу ARP отыскать физический хост или адрес MAC, соответствующий IP-адресу в пришедшем пакете. Протокол ARP просматривает кэш-таблицу ARP и, если находит искомый адрес, обеспечивает преобразование пакета в требуемый формат и передает его нужному хосту. Если для IP-адреса не найден соответствующий адрес MAC, протокол ARP передает в вещательном режиме специальный пакет запроса ко всем хостам локальной сети. В этом пакете заполнены все поля, кроме искомого физического адреса. Устройство, опознавшее свой IP-адрес, заполняет соответствующее поле и посылает заполненный пакет обратно к шлюзу. Поскольку протоколы разных локальных сетей (Ethernet, FDDI, маркерное кольцо и др.) отличаются друг от друга, протокол ARP может иметь различные форматы пакетов запроса.
Протокол RARP (Reverse Address Resolution Protocol, RFC 903) -обратный протокол преобразования адресов, обеспечивает зеркальную по отношению к протоколу ARP операцию, соответствующую случаю, когда известен физический (аппаратный) адрес хоста, а IP-адрес неизвестен. Такая ситуация может возникнуть, например, если хост не имеет своей памяти и хранит данные на удаленном сервере. Запросы и ответы RARP обрабатываются аналогично пакетам ARR
25.4. Принципы маршрутизации датаграмм в сетях IP
Маршрутизацией называется процесс выбора пути через сеть, по которому будет передаваться сетевой трафик. Процесс маршрутизации обеспечивается в сетях многих типов, в том числе в телефонных и транспортных сетях. В этой лекции мы рассматриваем процесс маршрутизации применительно к сетям Интернет.
В сети Интернет датаграммы передаются от источника к пункту назначения, используя адрес пункта назначения в адресном поле заголовка пакета. Как было отмечено выше, ключевым элементом сети Интернет является маршрутизатор, задачей которого является определение пути (маршрута), по которому будут передаваться датаграммы от источника к получателю. Маршруты делятся на две группы:
• статические маршруты (например, изменяющиеся по расписанию);
• динамические маршруты, вычисляемые с помощью алгоритмов маршрутизации на основе информации о топологии и состоянии сети, полученной с помощью протоколов маршрутизации,
Каждый маршрутизатор вдоль пути передачи пакетов формирует собственную таблицу маршрутизации, в которой задаются все возможные пути к другим маршрутизаторам и хостам в сети. Оптимальные маршруты определяются по числу маршрутизаторов на пути между источником и получателем (статическая маршрутизация) или по сетевым параметрам, таким как задержки, надежность, пропускная способность (динамическая маршрутизация).
Маршрутизатор считывает адрес назначения из заголовка поступившего пакета (который может быть как фрагментом, так и полной датаграммой) и использует таблицу маршрутизации для пересылки пакета к соответствующему выходному интерфейсу.
Размер фрагмента определяется размером кадра на уровне звена данных. Так, для протокола двухточечных соединений уровня РРР (одного из самых распространенных в сетях Интернет) и для Ethernet максимальный размер кадра (максимальный размер информационного блока на уровне звена данных) не должен превышать 1500 байтов (по сравнению с 256 байтами для протокола Х.25).
На рис. 25.1 показан принцип фрагментации датаграмм.
Хост А сети А посылает датаграмму D к хосту 6 сети В. В том случае, если размер датаграммы превышает размер поля полезной нагрузки кадра, допустимого в маршрутизаторах, датаграмма фрагментируется (в нашем примере - на два фрагмента, D1 и D2). Фрагменты одной датаграммы передаются от маршрутизатора к маршрутизатору по независимым путям и затем собираются в маршрутизаторе, который относится к сети назначения В. Заголовок каждого фрагмента является копией заголовка исходной датаграммы, показанного черным цветом.
25.5. Протоколы маршрутизации
Протокол RIP (Routing information Protocol) - протокол информации о маршрутизации, относится к динамическим протоколам маршрутизации. Протокол RIP обеспечивает обмен информацией между маршрутизаторами о маршрутах (путях передачи) и корректирует таблицы маршрутизации каждые 30 секунд.
Маршрутизатор, используя протокол RIP, передает маршрутную таблицу (в которой отмечены все известные маршрутизатору узлы) к ближайшему соседнему узлу. Соседний узел, в свою очередь, передает информацию к следующему соседнему узлу, пока все узлы внутри сети не получат одинаковую информацию о маршрутах.
Передача информации о маршрутах производится в форме пакетов, которые содержат набор дистанционно-векторных пар. Каждая пара (а, I) включает в себя адрес IP-сети (а - А.В.CD) и число узлов I, которые необходимо пройти, чтобы достичь данную сеть. Выбор оптимальных путей производится по критерию числа маршрутизаторов, лежащих между источником и получателем (по числу переприемов).
Отметим, что RIP рассматривается как эффективный протокол только для небольших сетей, в частности, для сетей, в которых имеется не более 16 переприемов. Для сетей большего размера передача маршрутных таблиц каждые 30 секунд может привести к перегрузке сети, вызывающей большие задержки доставки датаграмм.
С учетом быстро растущих масштабов сетей Интернет даже при рассмотрении 16 переприемов объемы маршрутной информации, передаваемой по сети, становятся огромными. Как альтернатива дистанционно-векторного подхода был предложен протокол OSPF (Open Shortest-Path First) - протокол маршрутизации по принципу «кратчайший путь выбирается первым», эффективно решающий проблему перегрузки сетей служебной информацией.
Используя динамический протокол OSPF, маршрутизатор, который изменил таблицу маршрутизации или обнаружил изменения в сети, немедленно передает в вещательном режиме информацию ко всем соседним маршрутизаторам сети с тем, чтобы все они имели одну и ту же маршрутную таблицу.
В отличие от RIP, в соответствии с которым передается вся маршрутная таблица, в протоколе OSPF передается только та часть таблицы, в которой появились изменения. При этом информация передается не через 30 секунд, а только когда имеют место изменения в сети. Кроме того, в отличие от протокола RIP, в котором выбор путей основан на подсчете числа переприемов, в протоколе OSPF используется понятие «состояние звена»', которое учитывает такие параметры, как задержки, пропускная способность, надежность и другие.
«Состояние звена» с минимальной задержкой или максимальной пропускной способностью и определяет путь, выбираемый первым.
В протоколе OSPF маршрутизаторы группируются в независимые подсети, называемые зонами. В зонах информация о маршрутах и периодическая их коррекция поддерживаются на локальном и автономном уровнях. Это позволяет определить виртуальные сетевые топологии, не принимающие во внимание незначительные и краткосрочные локальные детали, связанные с процессом маршрутизации.
Для передачи пакетов от одного источника по нескольким адресам в сетях Интернет используется протокол IGMP (Internet Group Management Protocol, RFC 3376) - протокол групповой адресации. Этот протокол обеспечивает многоадресную доставку информации по схеме «точка-группа точек» (мультикастинг). Как видно из раздела 25.2 этой лекции, IP multicasting (или IP-вещание) использует адреса Класса D.
Режим многоадресной передачи позволяет одному хосту передавать информацию набору других хостов, которые идентифицируют себя как члены такой группы. Когда новый хост желает войти в группу многоадресной рассылки, он посылает соответствующее сообщение 1GMP, которое приходит на все маршрутизаторы, входящие в многоадресную группу.
Вещательные маршрутизаторы поддерживают информацию об участии хостов в вещательной сети, используя периодический опрос. Эта процедура выполняется очень короткими сообщениями с небольшим периодом (например, 60 секунд). Такое же простое подтверждение от хоста-участника достаточно, чтобы поддерживать режим вещания; при отсутствии подтверждения после определенного числа запросов вещание к данному хосту прекращается. Таким образом, протокол 1GMP обеспечивает динамическое управление IP-вещанием с предотвращением перегрузок маршрутизаторов.
Многоадресный режим может применяться для таких приложений, как рассылка новостей в соответствии со списком, коррекция адресных книг удаленных пользователей и вещание программ потокового видео для пользователей, присоединившихся к многоадресной группе.
Протокол ICMP (Internet Control Message Protocol, RFC 792) -протокол межсетевых управляющих сообщений, используется для того, чтобы информировать передающую сторону о потере пакетов из-за отказов в системе маршрутизации.
Сообщения ICMP инкапсулируются в датаграммы IP. Данные, передаваемые в соответствии с протоколом ICMP, информируют источник о типах отказов, например, таких как недостижимость пункта назначения (хост не подключен к сети или попытка доступа была отменена из-за действия экрана защиты), перегрузка промежуточного маршрутизатора, превышение «срока жизни» датаграммы, некорректность установленных параметров IP-заголовка.
Протокол 1СМР может также использоваться, чтобы информировать хост-источник о достижимости хоста-получателя.Такая процедура основана на принципе локации путем посылки эхо-запроса и получении эхо-ответа и реализуется с помощью программы, известной и в русскоязычной литературе как ping.
25.6. Концепция ENUM
Концепция ENUM (tElephone NUmber Mapping) предполагает, что можно обеспечить преобразование телефонного номера одной сети в номер или адрес, используемый в другой сети и обратное преобразование. Речь идет о правилах установления соответствия между номерам ив ТфОП и номерами (адресами) в этих других сетях. Авторами концепции упоминаются, например, номера мобильных телефонов, факсимильных аппаратов, терминалов персонального радиовызова (paging), а также адреса Интернети электронной почты.
Попытка унификации различных номеров (и адресов), используемых одним абонентом, предпринимается не впервые. В концепции Универсальная персональная связь», разработанной ITU-T, также предполагается использование единого номера для разных видов связи. Правда, эта концепция создавалась до активной экспансии сетей Интернет. По этой причине в ней не изложены современные варианты отображения номеров, назначаемых абонентам ТфОП согласно рекомендации ITU-T E.164, в доменные имена сети Интернет.
С другой стороны, адрес IP состоит из целого числа байтов и определяется совокупностью цифр, то есть формально похож на номер абонента ТфОП. Задачей системы доменных имен и является преобразование таких имен в адреса IP. По запросу, содержащему доменное имя хоста (компьютера или другого сетевого устройства), система DNS сообщает маршрутизатору адрес IP.
Концепция ENUM обеспечивает пользователям возможность, набрав в окне Web-браузера (средство просмотра информации в сети Internet) номер телефона, найти соответствующий идентификатор URL (единообразный идентификатор ресурса), адреса IP или электронной почты. Способ входящей связи абонент может выбирать, указывая вид терминала, который будет участвовать в соединении. Концепция ENUM в настоящее время дорабатывается совместными усилиями IETF и ITU-T.
Процедуры преобразования телефонных номеров сравнительно просты.
Например, международному номеру +7 (812) 315-4873 (Центральный музей связи имени А.С. Полова в Санкт-Петербурге) будет соответствовать такой IP-адрес: 3.7.8.4.5.1.3.2.1.8.7.е164.аrpа.
Цифры международного номера записываются в противоположном порядке - начиная с последней. Это отражает принцип формирования доменных имен.
В отличие от кода страны в ТфОП (первая цифра номера) в IP-адресе аналогичные данные приводятся в самом конце. В частности, международные номера абонентов российской ТфОП начинаются с цифры «7», а домен «ru»T также свидетельствующий о регистрации URL в нашей стране, помещается в самом конце IP-адреса. Домен «е164.агра» выделен для номеров всемирной телефонной сети. Обозначение «е164» указывает на рекомендацию ITU-T, которая посвящена плану нумерации в ТфОП.
Слово «аrpа» - название исторически первой сети с коммутацией пакетов, в которой передавались датаграммы (см. лекцию 23). Концепция ENUM может считаться характерным примером процессов конвергенции в сетях связи. Она обеспечивает возможность совместной работы сетей телефонной связи и Интернет, повышая их эффективность.
Технологии поддержки новых услуг в сетях Интернет
На словах только в любви объясняются, а о делах следует писать.
Петр Капица
26.1. Услуги IP-коммуникаций
Передаче речи по сетям связи немногим более 100 лет. Передаче данных по сетям связи, включая голубиную почту, фельдъегерей их императорских величеств, телеграф, сеть Х.25 и Интернет, гораздо больше. Совместно же применять оба названных в эпиграфе способов обмена информацией - объясняться на словах и писать о делах - стало возможно только 15 лет назад в единой универсальной IP-среде, когда к электронной почте добавилась технология Voice over IP (VoIP) или IP-телефония. Технологии, компоненты сетевой архитектуры и протоколы поддержки этой услуги рассматриваются в первой, большей части этой лекции {разделы с 26.2 по 26.8).
Наряду с услугой передачи речи поверх IP, в сетях Интернет развиваются услуги передачи мультимедийного трафика, включающего в свой состав видео, аудио, текст, графику и данные. Именно совокупность этих технологий привела к замещению уже ставшего привычным термина IP-телефония новым термином.
IP-коммуникации. Ни об IP-телефонии, ни, тем более, об IP-коммуникациях еще полтора десятка лет назад практически ничего не было известно. Сегодня одна из технологий - VoIP, сумела отобрать у фиксированных телефонных сетей примерно 20% трафика и рассматривается как серьезный конкурент классической телефонии.
Другая технология - IPTV, находящаяся еще в начале развития, позволяет Операторам предоставлять перспективные мультисервисные услуги, связанные, в первую очередь, с возможностями доступа по требованию к разнообразному цифровому контенту. Поддержке услуги IPTV посвящается вторая часть лекции (разделы 26.9 и 26.10). Но начнем с технологий IP-телефонии.
26.2. Технология VoIP
Технология передачи речевой информации по IP-сетям существует уже более 10 лет, но только в последние годы она стала рассматриваться как альтернатива традиционной телефонной связи. Термин IP-телефония является общим термином, определяющим набор технологий на базе протокола Интернет для обмена речевыми и факсимильными сообщениями, которые до появления IP-телефонии передавались через телефонные сети.
За последние годы объем речевого трафика увеличился незначительно, в то время как трафик данных растет с очень высокой скоростью. Трафик и масштабы применения сетей IP все последние годы постоянно растут (число пользователей, объемы трафика, применимость для большого числа приложений), а в 90-х годах прошлого века к этому росту добавилась возможность передачи речевого трафика через Интернет.
Интерес к этой технологии на начальном этапе внедрения определялся более низкой стоимостью телефонных переговоров (особенно, междугородных и международных) при использовании сети IP для передачи речи благодаря эффективному разделению сетевых ресурсов. Однако стоимость не является главным фактором для того, чтобы новую технологию полностью приняли как пользователи, так и поставщики услуг.
Основным требованием здесь является уровень качества услуг, обеспечиваемый новой технологией, поскольку пользователи не согласятся на худшее качество передачи речи по сравнению с тем, которое они привыкли получать в ТфОП. В дополнение к уменьшению стоимости телефонных услуг есть все основания ожидать, что VoIP значительно ускорит продвижение на рынок новых мультимедийных услуг.
26.3. Основные функции, реализуемые в сети VoIP
Перед тем как перейти к описанию архитектуры системы передачи речи через сеть IP, обсудим основные процессы, реализуемые в технологии VoIP. Очевидно, что система VoIP должна выполнять по отношению к речевому сигналу те же функции, что и обычные телефонные сети. В число этих основных функций входят:
• на передающей стороне - преобразование аналоговой речи в цифровой сигнал и представление цифрового сигнала в формате, необходимом для передачи через сеть (в данном случае через сеть IP); последнее означает, что речевой сигнал инкапсулируется в пакеты протокола IP;
• в сети /Р - управление обслуживанием телефонного вызова (создание соединения, поддержание речевого обмена, разъединение) и транспортировка пакетов;
• на приемной стороне - восстановление аналоговой речи из принятых пакетов и дискретного сигнала.
На рис. 26.1 иллюстрируется процесс обработки речевого сигнала при его прохождении через сеть IP. Здесь в виде блоков представлены перечисленные выше функции - кодирование, представление в форме пакетов IP, передача пакетов через сеть, разборка пакетов и восстановление аналогового речевого сигнала.

Прежде всего, рассмотрим преобразование речи на передающей и приемной сторонах. Оба эти процесса реализуются кодеками (сокращенная форма сочетания кодер-декодер).
Отметим, что большинство методов такого кодирования основано на технологии ИКМ и характеризуется требуемой скоростью передачи, и, как следствие, занимаемой полосой пропускания. Типы кодеков различаются по названию соответствующего стандарта ITU-T содержащего спецификацию того или иного кодека.
Исторически первый тип кодека, известный как G.711, преобразует аналоговый сигнал в цифровой с очень высоким качеством. Однако при этом требуется более высокая пропускная способность по сравнению с кодеками более поздних поколений, в которых обеспечивается эффективное сжатие информации. При создании первых кодеков (70-е годы XX столетия) технология современных цифровых сигнальных процессоров DSP была недоступна. Сегодня на базе DSP можно строить весьма эффективные кодеки со значительно меньшими требованиями к пропускной способности тракта передачи, Формирование пакетов IP из цифрового сигнала на передающей стороне и обратное преобразование на приемной стороне не отличается от аналогичных процессов в обычных сетях IP. Выходной сигнал кодека на передающей стороне представляет собой поток данных. Этот поток упаковывается в датаграммы IP (на что затрачивается определенное время), и затем датаграммы VoIP передаются к терминалу-приемнику, используя протоколы стека IP.
В табл. 26.1 приведен список некоторых наиболее распространенных типов кодеков, разработанных ITU-T. Здесь следует обратить внимание на компромисс между эффективностью кодирования, выражаемой через требуемую скорость передачи (и, соответственно, полосу пропускания), и задержками, возникающими при преобразовании. Влияние кодеков на качество обслуживания речевых сообщений в сетях IP будет обсуждаться в лекции 28.
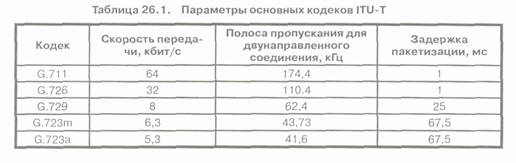
Теперь перейдем к управлению обслуживанием вызова (соединение, поддержание речевого обмена и разъединение). По аналогии с телефонной связью в технологии VoIP необходимо установить соединение между абонентами. Это реализуется системой сигнализации, с помощью которой терминальные устройства общаются в сети, активизируя и координируя работу сетевых элементов, необходимых для обслуживания вызовов. В сети VoIP сигнализацию обеспечивает обмен датаграммами IP между сетевыми компонентами. Основные протоколы сигнализации для систем VoIP рассматрены в лекции 24. Соединение устанавливается между двумя оконечными пунктами, открывающими сеанс между собой. Идентификация этих пунктов производится через специальную базу данных. Как сеть ТфОП использует телефонные номера, чтобы идентифицировать оконечные пункты, так и сеть VoIP использует для этого IP-адреса, хранящиеся в базе данных, что подробно обсуждалось в предыдущей лекции. Транспортировка датаграмм VoIP выполняется путем последовательных переприемов пакетов речи в маршрутизаторах IP.
26.4. Архитектура сети VoIP
Основные компоненты сети VoIP реализуют функции, подобные функциям сети ТфОП, и позволяют сетям VoIP решать те же самые задачи, что и телефонная сеть. Вместе с тем, имеется ряд существенных различий между этими сетями, накладывающих определенные особенности на архитектуру сетей IP.
Отличие тракта передачи речи в системе VoIP от телефонного тракта состоит в том, что для реализации телефонных разговоров сеть IP должна включать в состав оборудования два специализированных устройства. Первоеустройство, взависимости от стандарта, на базе которого построена сеть VoIP, имеет несколько названий: привратник, контроллер шлюзов, шлюз сигнализации, Softswitch. Вместо всех этих названий может использоваться термин сервер обработки вызовов. Задача этого устройства состоит в передаче сигнальных сообщений из телефонной сети в сеть VoIP и наоборот. Второе устройство называется медиашлюзом. Основная функция медиашлюзов состоит в создании пакетов IP из речевого сигнала и в обратном преобразовании пакетов в речевой сигнал. В качестве терминальных устройств в системах VoIP, кроме стандартных телефонов, могут применяться IP-телефоны или устройства на базе персональных компьютеров.
26.5. Сервер обработки вызовов
Основным компонентом системы VoIP является сервер обработки вызовов, в котором терминируются все сигнальные сообщения. Установление/разрушение соединений и передача полезной речевой нагрузки реализуются с помощью сигнального механизма. За исключением речевого трафика, направляемого к другому серверу обработки вызовов, это устройство не обрабатывает полезную нагрузку пакетов VoIP. Полезная информация, которой обмениваются между собой терминальные устройства, переносится между терминалами в соответствии с протоколами UDP/RTP (протокол UDP был описан в лекции 23, протокол RTP будет рассмотрен ниже в этой лекции).
Сервер обработки вызовов обеспечивает также преобразование между системой адресации, используемой в сетях IP, и телефонной нумерацией, определенной в рекомендации Е.164 ITU-T что обсуждалось в предыдущей лекции. Серверы обработки вызовов обычно реализуются в виде программного продукта на платформе маршрутизатора IP, но могут быть выполнены в виде автономного устройства. На рис. 26.2 показан сервер обработки вызовов с соответствующими сигнальными протоколами.
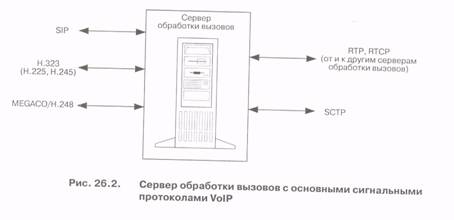
26.6. Шлюз
Как было отмечено выше, основной функцией шлюза VoIP является преобразование речевого сигнала в форму пакетов VoIP и передача пакетов через сеть IR Каждый телефонный разговор является сеансом IP, в котором полезная информация переносится с помощью протоколов UDP/RTP. В том случае, когда вместо терминального устройства используется обычный телефонный аппарат, шлюз выполняет функции кодека; обеспечивает аналого-цифровое преобразование, компрессию речи, подавление эхо и пауз в речевом сигнале. Шлюзы могут быть выполнены в виде специализированного оборудования или быть реализованы программно на базе персонального компьютера. На рис. 26.3 показан шлюз с соответствующими сигнальными протоколами.

Шлюзы, в зависимости от выполняемых ими функций, делятся на две большие группы:
• магистральные (транкинговые) шлюзы, обеспечивающие интерфейс между телефонной сетью и сетью VoIP; магистральные шлюзы, как правило, обрабатывают информацию в большом числе цифровых каналов;
• шлюзы доступа, поддерживающие интерфейс аналоговой части сети с сетью VoIP.
26.7. Особенности использования сети IP для передачи речи
Особенности использования сети IP для передачи речи связаны с тем, что инфраструктура IP должна гарантировать доставку речевых и сигнальных пакетов к элементам системы VoIP. Сеть должна обрабатывать трафик речи и трафик данных разными способами. Если в сети IP передается трафик обоих видов, необходимо обеспечить приоритетное обслуживание трафика речи. Существует определенное соответствие между компонентами сети VoIP и телефонной сети, однако имеется гораздо больше различий. В сетях ТфОП используется принцип коммутации каналов, что означает выделение каналов с гарантированной полосой пропускания для каждого сеанса связи. Сети IP используют коммутацию пакетов, в основе которой лежит возможность статистического уплотнения. Введение понятия класс обслуживания предполагает, что пакеты, принадлежащие определенным приложениям, имеют заданный приоритет. Введение приоритетной системы требуется для прило жений реального времени (VoIP), чтобы гарантировать, что на речевой трафик не будет влиять трафик другого типа.
26.8. Протокол RTP
Транспортный протокол реального времени RTP (Real-time Transport Protocol), описанный в RFC 1889 и RFC 1890, поддерживает услугу сквозной доставки данных, передаваемых в реальном времени, таких как интерактивный трафик аудио и видео. Протокол RTP обеспечивает идентификацию типа полезной нагрузки, нумерацию последовательности пакетов, присвоение меток времени и контроль доставки. В протоколе предусмотрены следующие функции:
• обнаружение ошибок;
• защита информации;
• контроль времени пребывания пакета в сети;
• идентификация схемы кодирования;
• контроль доставки.
Для доставки речевого трафика шлюзы VoIP используют протокол RTP. В системах VoIP протокол RTP используется поверх протокола UDP и относится к протоколам, не ориентированным на соединения. Несмотря на это свойство, протокол поддерживает систему упорядочения пакетов, что позволяет обнаруживать потерянные пакеты. Протокол RTP может использоваться поверх любого другого транспортного протокола, в том числе, ориентированного на установление соединений (например, протокола TCP).
Протокол RTP работает вместе с протоколом управления RTCP (RTP Control Protocol), периодически предоставляющим управляющую информацию для протокола RTP. Протокол RTCP обеспечивает передачу пакетов управления к участникам сеанса VoIP. Основная функция протокола состоит в том, чтобы информировать участников об уровне качества обслуживания, поддерживаемом протоколом RTP. Протокол RTCP собирает информацию о числе переданных и потерянных пакетов, о значениях задержки и джиттера. Например, получив информацию о снижении показателей качества обслуживания, механизмы контроля QoS могут ограничить поток сообщений VoIP. После восстановления требуемых значений показателей QoS интенсивность потока может восстановиться.
На рис. 26.4 показана общая схема организации сеанса VoIP. Пользователь вызывающего ТА набирает номер вызываемого ТА, и шлюз на передающей стороне с помощью сигнальных сообщений информирует сервер обработки вызовов (ОВ) о входящем вызове. Сервер ОВ анализирует принятый номер и, используя сигнальные сообщения, информирует шлюз на приемной стороне о поступле нии вызова. Затем сервер ОВ дает команду шлюзам установить прямое соединение RTP через сеть IP. Шлюзы открывают сеанс RTP, когда пользователь ТА пункта назначения поднимает трубку. В зависимости от выбранной системы сигнализации в качестве сервера ОВ могут использоваться привратник (Н.323, ITU-T), контроллер шлюза (MEGACO/H.248, IETF, ITU-T) или прокси-сервер {SIR IETF RFC 3261).

26.9. Определение и основные свойства 1PTV
Технология IPTV (IP Television) представляет собой технологию доставки мультимедийных услуг (ТВ, аудио/видео, текст, данные, графика) на базе сетей IP в интерактивном режиме и в режиме вещания. Технология IPTV характеризуется следующими основными свойствами.
• Поддержка интерактивного ТВ. Возможности IPTV поддерживать двунаправленную передачу позволяют Оператору/Провайдеру обслуживать широкий спектр интерактивных приложений: стандартное телевидение, телевидение высокой четкости, интерактивные игры, высокоскоростной доступ к Интернет.
• Персонализация. Система IPTV поддерживает двухстороннюю связь и позволяет пользователям самостоятельно решать, что и когда они хотят смотреть (например, услуга видео по требованию VoD (Video on Demand) - трансляция фильмов из видеосервера Оператора по заказу абонента).
• Отложенный просмотр (Time Shifting). Комбинация IPTV с видеомагнитофоном обеспечивает механизм для записи контента IPTV для последующего просмотра.
• Доступность услуг IPTV при использовании терминалов разных типов. Просмотр контента IPTV не ограничивается только телевизионными приемниками. Для доступа к услугам IPTV потребители могут использовать свои персональные компьютеры и мобильные устройства.
26.10. Архитектура IPTV
Архитектура системы IPTV в общем виде представлена на рис. 26.5. Архитектура включает в свой состав следующие функциональные блоки:
• Источники контента. Источник контента определяется как центр данных IPTV, принимающий видеоконтент от производителей (вещательные программы, фильмы, игры и т.д.). Затем контент кодируется и передается пользователям или накапливается в базе данных для услуг VoD.
• Узлы услуг IPTV. Узел услуг представляет собой компонент, принимающий видеопотоки в различных форматах. Эти видеопотоки затем инкапсулируются в пакеты для передачи в сеть IP.
• Широкополосные сети. Широкополосные сети, включающие в себя магистральные сети и сети доступа, характеризуются высокой пропускной способностью, высокими показателями качества обслуживания и распределительными возможностями. Важным свойством таких сетей является многоадресная рассылка (мультикастинг), которая необходима для надежного распределения потоков данных IPTV от узлов услуг к оборудованию пользователей. Магистральные сети IPTV реализуются на волоконно-оптических линиях, а в сетях доступа могут быть использованы разные широкополосные технологии - проводные и беспроводные.
• Оборудование пользователя. В состав оборудования пользователя IPTV входят средства, формирующие интерфейс с широкополосным сетевым окончанием. Здесь могут быть применены шлюзы, образующие домашние сети. Функциональный блок, терминирующий трафик IPTV в оборудовании пользователя, называется клиентом IPTV. Этот блок обычно реализуется в виде ТВ-приставки {set-top box). Основные функции ТВ-приставки включают в свой состав установление соединения с узлом услуг, декодирование видеопотоков, отображение управления со стороны пользователя и подключение к монитору.
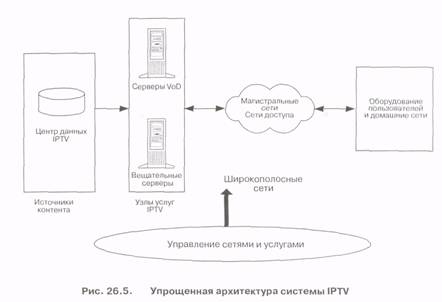
В сетях IPTV используется большой набор стандартов, разработанных разными международными организациями, в том числе ITU-T, ETSI, IETF, MPEG (Moving Picture Experts Group) и др. Стандарты сжатия ТВ-сигнала (семейство MPEG) позволяют уменьшить требуемую полосу пропускания в десятки и сотни раз. Наиболее распространенными стандартами цифрового вещания являются европейский стандарт DVB, американский стандарт ATSC и японский стандарт 1SDB. Среди большого числа сетевых протоколов, поддерживающих предоставление услуг IPTV, назовем только некоторые из них: транспортные протоколы UDP, RTP и RTCP, протоколы сигнализации SIR H.323, протоколы маршрутизации RIP, OSPF, протокол многоадресной рассылки IGMR
В транспортных сетях используется, как правило, технология MPLS] технологии, применяемые в сетях доступа, определяются типом физической среды - витая пара, коаксиальный кабель, волоконно-оптический кабель или беспроводная среда.
В заключение этого краткого описания IPTV отметим, что услуги IPTV относятся к услугам Triple Play, в которых предусматривается доставка трафика всех трех видов - аудио, данных и видео в фиксированных сетях. В сочетании IPTV с мобильными сетями эта услуга превращается в Quadruple Play.
Традиционные услуги в сетях Интернет
Тот, кто знает, не говорит;
Тот, кто говорит, не знает.
Лао-Цзы
27.1 Введение
Услуги для тех, кто говорит, мы подробно обсудили в лекциях 7 и 17 для фиксированных телефонных сетей и сетей подвижной связи, соответственно. Более того, в лекции 26 были рассмотрены услуги для тех, кто говорит и кто смотрит через Интернет - соответственно, услуги VoIP и IPTV. Здесь же сосредоточимся на услугах Интернет, которые можно рассматривать как традиционные.
Огромное число людей, а не только специалисты и студенты телекоммуникационных и информационных специальностей знают сегодня приложения, реализуемые в сети Интернет. В число этих приложений входят World Wide Web, WWW (Всемирная Паутина}, электронная почта, обмен сообщениями через Интернет в реальном времени {так называемые chat rooms), потоковое видео, доступ к музыкальным сайтам. В случае использования WWW пользователь видит на экране компьютера страницы текста и графических объектов, нажимает кнопку мыши на выбранном объекте, о котором он хочет узнать больше, и соответствующая страница появляется на экране.
Другим приложением, пока еще не так популярным, как WWW, является услуга потокового видео. Потоковое видео предполагает, что источник и получатель имеют соответствующие устройства для воспроизведения видеозаписей. Видеопоток пересылается от источника к получателю с использованием средств и протоколов Интернет. Эта услуга может рассматриваться как одно из приложений видео по требованию (Video on Demand).
Хотя здесь мы упомянули только два примера - загрузку страниц из Всемирной Паутины и потоковое видео, - эти примеры демонстрируют разнообразие приложений, которые могут быть созданы на базе протоколов TCP/IP, и говорят о сложности проектирования и эксплуатации сети Интернет. В этой лекции мы рассмотрим услуги, реализуемые в Интернет и ставшие сегодня уже классическими.
27.2. Протокол пересылки файлов FTP
Одним из методов доступа к удаленным файлам данных, расположенных на удаленном сервере, является передача копии файла по запросу клиента. В сетях Интернет для этой цели используется стандартный протокол FTP (File Transfer Protocol) - протокол пересылки файлов. Протокол FTP, являющийся одним из старейших протоколов (он был разработан в начале 70-х годов прошлого века), относится к протоколам уровня приложений и использует для передачи данных транспортный протокол TCP.
Протокол FTP используется для обмена файлами данных между клиентом (группой клиентов) и сервером, хранящим данные (сервером FTP), причем каждая оконечная точка имеет возможности передачи и запроса/получения файлов. Такими файлами могут быть тексты, графические изображения, звуки, видео и мультимедийная информация. Протокол FTP используется также для загрузки программного обеспечения в компьютер клиента (пользователя). С помощью FTP пользователь может корректировать получаемые файлы (удалять, переименовывать, копировать их и т.д.). На многих FTP-серверах существует каталог (под названием incoming, upload и т. п.}, открытый для записи и обеспечивающий получение сервером файлов. Это позволяет пользователям пополнять сервер свежими данными.
Сеанс FTP инициируется клиентом, который должен выполнить определенную последовательность команд. Первая команда соединяет клиента с удаленным хостом. Вторая команда обеспечивает идентификацию пользователя путем передачи к хосту имени пользователя и его пароля. Затем клиент через каталог выбирает доступные файлы и определяет вид кода, в котором должна быть произведена передача файлов. После того как файлы скопированы, клиент отсоединяется от удаленного хоста.
До начала 90-х годов XX века на долю протокола FTP приходилось около половины трафика в сети Интернет. Протокол и сегодня используется для распространения ПО и доступа к удаленным серверам и хостам, однако ему на смену быстро приходят методы доступа, основанные на технологии Всемирной Паутины (см. следующий раздел).
27.3. Протокол пересылки гипертекстовых сообщений HTTP и Всемирная Паутина
В 1989 году физик Томас Бернерс-Ли, работая в Европейском совете по ядерным исследованиям (CERN) в Женеве, предложил проект, теперь известный как Всемирная паутина (World Wide Web). Проект предполагал публикацию гипертекстовых документов, связанных между собой гиперссылками, что облегчило бы поиск информации для ученых CERN. Для реализации проекта Т. Бернерс-Ли разработал три основных инструмента, без которых нельзя представить себе современный Интернет - идентификаторы UR1, протокол HTTP и язык HTML. В рамках проекта Т. Бернерс-Ли написал первую в мире программу Web-сервера и первый в мире гипертекстовый Web-браузер, названный World Wide Web. В 1991-1993 годах Бернерс-Ли усовершенствовал их технические спецификации, и IETF принял соответствующие стандарты. Официальным годом рождения Всемирной Паутины считается 1989 год.
Для идентификации ресурсов (зачастую - файлов или их частей) во Всемирной Паутине используются единообразные идентификаторы ресурсов URI (Uniform Resource Identifier). Для определения местонахождения ресурсов в сети используются единообразные локаторы ресурсов URL [Uniform Resource Locator). Адрес URL представляет собой стандартизованную строку символов, указывающую местонахождение документа или его части в Интернет. Строка начинается с указания типа протокола, за которым следует идентификатор конкретной информации - имя домена, которому принадлежит сервер, название организации и URL-путь (информация о месте размещения ресурса). Сегодня URL применяется для обозначения адресов почти всех ресурсов сети Интернет.
Всемирная Паутина обеспечила доступность ресурсов Интернет столь большому числу людей, что иногда выступает как синоним сети Интернет. С технической точки зрения полезно рассматривать WWW как множество клиентов и серверов, которые общаются с помощью единого протокола, известного как HTTP (Hypertext Transfer Protocol). Для облегчения создания, хранения и отображения гипертекста во Всемирной паутине используется язык разметки гипертекста HTML [Hypertext Markup Language). Комбинация протоколов HTTP и HTML обеспечивает доставку текстов, графики, звука, видео и других мультимедийных файлов через глобальную сеть Интернет.
Всемирную Паутину образуют миллионы Web-серверов Интернет, расположенных по всему миру. Web-сервер представляет собой сервер, принимающий по протоколу HTTP запрос определенного информационного ресурса от клиента. Сервер находит соответствующий файл на локальном жестком диске и отправляет его по сети запросившему компьютеру, используя тот же протокол HTTP.
Для просмотра информации, полученной от Web-сервера, на клиентском компьютере применяется специальная программа просмотра документов в Интернет, называемая Web-браузером. Основная функция Web-браузера состоит в отображении гипертекста. С момента начала работ по созданию Всемирной Паутины было создано несколько видов Web-браузеров. Сегодня наиболее популярными Web-браузерами являются Internet Explorer, поставляемый вместе с Microsoft Windows, а также бесплатные браузеры Mozilla Firefox и Safari.
Для определения местонахождения ресурсов в сети используются, как было отмечено выше, адреса URL, через которые клиент получает доступ к Web-серверу. Адреса URL обеспечивают информацию о расположении объектов во Всемирной Паутине; эта информация выглядит подобно следующей записи: http://www.seti.sut.ru
После того, как обычный документ преобразуется с помощью HTML-разметки в гипертекст, документ помещается в файл и становится доступным Web-серверу. Эти файлы называются Web-страницами. Набор Web-страниц образует Web-сайт.
В гипертекст Web-страниц добавляются гипертекстовые ссылки (или гиперссылки). Основное отличие доступа к файлам на базе HTTP от описанного выше доступа на базе FTP заключается в том, что файлы, представленные в формате HTML, могут содержать ссылки на другие файлы, которые могут быть извлечены из сети в рамках одного сеанса. Когда пользователь вводит запрос какого-либо файла, открыв определенный Web-сайт, он может перейти к другому файлу, не закрывая сеанс, а «щелкая» курсором по ссылке, расположенной в полученном файле. Гиперссылки помогают пользователям Всемирной Паутины легко перемещаться между ресурсами (файлами) вне зависимости от того, где находятся ресурсы -на локальном компьютере или на удаленном сервере.
Web-браузер реализует сеанс HTTP на базе протокола TCP Браузер осуществляет четыре основных этапа сеанса HTTP: открытие соединения TCP, передача запроса к серверу, получение ответа от сервера и закрытие соединения. Первая версия HTTP (1.0) предполагала закрытие соединения после передачи ответа на один запрос. Очевидно, что с точки зрения использования сетевых и серверных ресурсов это был неэффективный механизм. В последней версии HTTP (1.1) используется механизм долговременного соединения (persistent connection), когда клиент и сервер могут обмениваться множеством запросов/ответов в течение одного соединения TCP. Механизм долговременного соединения имеет ряд преимуществ, среди которых нужно отметить уменьшение количества управляющих сообщений, благодаря чему уменьшается нагрузка на сервер, и отсутствие фазы многократного открытия соединения TCP.
27.4. Протокол электронной почты SMTP
Электронная почта является одним из самых старых приложений в сетях IP. Сегодня обмен сообщениями через электронную почту используется миллионами людей ежедневно. Этот обмен, являющийся еще одной формой обмена данными между клиентом и сервером, реализуется с помощью протокола SMTP (Simple Mail Transfer Protocol - простой протокол доставки почтовых сообщений). Спецификация RFC 822 определяет две части сообщения - заголовок и тело. Обе части кодируются 7-разрядным кодом ASCII. Индивидуальные почтовые адреса имеют формат вида <username@domain> (имя пользователя@подсеть). Эти адреса почтовых ящиков распознаются на уровне SMTP.
Почтовое сообщение обычно передается от клиента (пользователя электронной почтой) к локальному серверу SMTP, который отвечает за доставку почты по запросам клиентов. Процесс обработки почты в сервере заключается в накоплении приходящих сообщений, каждое из которых содержит адреса отправителя, получателя, а также время отправления. Локальный сервер, получив исходящее сообщение, идентифицирует IP-адрес удаленного сервера SMTP в пункте назначения и производит попытку установить сеанс TCP с этим удаленным сервером. После того как соединение установлено, почтовое сообщение копируется в сервере назначения. Как только сервер-отправитель получает подтверждение успешной передачи, сообщение удаляется из памяти локального сервера. Затем удаленный пользователь может получить доступ к своему серверу и принять доставленное сообщение.
Нужно отметить следующее. При разработке протокола SMTP предполагалось, что электронная почта будет использоваться только для передачи простого текста. В 1993 г. спецификация RFC 822 была расширена для того, чтобы обеспечить передачу данных различных типов - аудио, видео, документов Word и других. Для этих целей используется протокол MIME (Multipurpose Internet Mail Extension - многоцелевое почтовое расширение Интернет). MIME определяет механизмы передачи различных типов информации с помощью электронной почты, включая текст на языках, для которых используется кодирование, отличное от кода ASCII, а также музыку, графику и фильмы. Преобразование формата MIME обычно производится почтовыми серверами или клиентской почтовой программой при передаче и получении электронных сообщений.
В заключение отметим, что популярность электронной почты сегодня настолько высока, что она практически заменила протокол FTP для передачи данных всех типов в форме присоединенных файлов. Вместе с тем, следует иметь в виду, что для предотвращения перегрузок некоторые почтовые серверы ограничивают передачу файлов больших объемов (например, могут быть запрещены файлы объемом больше, чем несколько Мбайт).
Качество обслуживания в СПД
Нетрудно свести лошадь к воде. Но если вы заставите ее
плавать на спине - это значит, что вы чего-то добились!
(Законы Мерфи: первый закон Хартли)
28.1. Основные проблемы качества обслуживания в сетях IP
Б лекциях 8 и 18, посвященных ТфОП и СПС, уже отмечалось, что качество обслуживания QoS (Quality of Service) остается предметом активных исследований и стандартизации с момента создания сетей связи. За более чем столетний период своей работы Международный союз электросвязи внес существенный вклад в развитие различных аспектов концепции QoS, включая разработку норм и стандартизацию механизмов, обеспечивающих их поддержку. Применение IP-технологии стимулировало существенный пересмотр всей системы показателей QoS, а также механизмов поддержки высокого качества обслуживания в сетях NGN.
В отличие от технологий, рассмотренных в лекции 22 для СПД на базе виртуальных каналов и в лекциях частей 1 и 2, посвященных ТфОП и СПС, в классических сетях IP применяется метод доставки информации, не ориентированный на соединения - как на физические, так и на виртуальные. Этот метод основан на рассылке датаграмм. Качество доставки в традиционных сетях IP базируется на принципе best effort. Концепция best effort предполагает, что пользователи справедливо разделяют доступные сетевые ресурсы, трафик передается со скоростью, максимально возможной при имеющейся нагрузке ресурсов сети, но при этом не гарантируется обеспечение любого предварительно заданного уровня качества обслуживания. Это означает, что нет гарантии в том, что пакет будет доставлен в требуемое время или что он вообще будет доставлен, причем - вне зависимости от вида трафика.
Концепция best effort была достаточно эффективной для приложений, где можно передавать данные не в реальном времени (например, электронная почта и передача файлов). Кроме того, известны примеры применения сетей IP для мультимедийных приложений, (потоковые данные (аудио/видео) и Web-трафик).
Однако как только возникает недостаток ресурсов, ведущий к увеличению вероятности потерь пакетов и росту их задержек, для приложений реального времени необходимые показатели качества обслуживания не могут быть обеспечены. Прежде всего, это объясняется основным принципом функционирования IP-сетей - передачей данных в датаграммном режиме. С появлением новых приложений, особенно приложений реального времени (интерактивная передача речи, видеотелефония и видеоконференции), вопрос о гарантированном качестве обслуживания в сетях IP становится одним из основных. Это объясняет, почему качество обслуживания в сетях IР является предметом постоянного внимания ITU, ETSI, IETF и других организаций стандартизации в электросвязи.
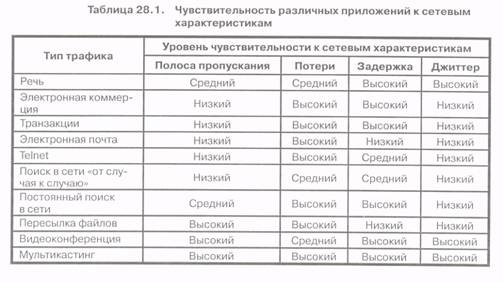
Главным стимулом являются уже не раз упоминавшиеся в предыдущих лекциях (начиная с рис. 02 во вводной лекции) процессы конвергенции, в связи с чем необходимо в будущих IP-ориентированных сетях NGN разработать новые принципы распределения ресурсов сетей и управления трафиком, которые будут гарантировать разные уровни качества обслуживания для большого числа разнообразных приложений, реализуемых конечными пользователями. При большом количестве приложений с существенно различающимися требованиями к рабочим характеристикам сети (смотри табл. 28.1 и 28.2) разделение ресурсов и процессы управления трафиком должны быть координированы.
28.2. Работы ITU-T по стандартизации QoS в IP-сетях
В 2002 году 13-я Исследовательская комиссия ITU-T опубликовала две рекомендации, касающиеся общего набора рабочих характеристик сетей IP и норм для этого набора. Рекомендация ITU-T Y1540 описывает стандартные сетевые характеристики передачи пакетов в сетях IP. Рекомендация ITU-TY1541 задает нормы для характеристик и параметров, определенных в Рекомендации Y1540.
28.2.1. Рекомендация ITU-T Y.1540
Следующие пять сетевых характеристик рассматриваются в Рекомендации ITU-TY1540 как наиболее важные с точки зрения степени их влияния на сквозное качество обслуживания (от источника до получателя):
• пропускная способность сети;
• надежность сети/сетевых элементов;
• задержка;
• вариация задержки (джиттер);
• потери пакетов.
Пропускная способность сети (или скорость передачи данных) определяется как эффективная скорость передачи, измеряемая в битах в секунду. В рекомендации ITU-TY1540 не приведены значения пропускной способности для разных приложений; но вместе с тем, отмечено, что параметры, связанные с пропускной способностью, могут быть определены с помощью рекомендации ITU-T Y1221.
Надежность сети/сетевых элементов может определяться рядом параметров, из которых чаще всего используется коэффициент готовности, представляющий собой отношение времени работоспособности объекта к времени наблюдения. В идеальном случае коэффициент готовности должен быть равен 1, что означает 100%-ю готовность сети. На практике коэффициент готовности оценивается числом «девяток» в соответствии с уже приводившейся в лекции 18 табл. 18.1.
Параметры доставки пакетов IP. В общем, сеанс связи состоит из трех фаз – установлениия соединения, передачи информации и разъединения. В Рекомендации ITU-TY1540 из этих фаз рассматривается только вторая - фаза доставки пакетов IP. Такой подход отражает природу сетей IP, не ориентированных на установление соединений. Рекомендация ITU-T Y1540 определяет следующие параметры доставки IP-пакетов.
Задержка доставки пакета IPTD [IP packet transfer delay) определяется как время t2-t1 между двумя событиями - вводом пакета во входную точку сети в момент t1 и выводом пакета из выходной точки сети в момент t1, где t2 > t1 и t2 - t1 ≤ Tmax
В общем, IPTD определяется как время доставки пакета от источника к получателю для всех пакетов. Средняя задержка доставки пакета IP определяется как среднее арифметическое задержек пакетов в выбранном наборе переданных и принятых пакетов. Рост нагрузки и уменьшение доступных сетевых ресурсов ведут к росту очередей в узлах сети и, как следствие, к увеличению средней задержки доставки.
Речевая информация и, отчасти, видеоинформация являются примерами трафика, чувствительного к задержкам, тогда как приложения данных, в основном, к задержкам менее чувствительны. Когда задержка доставки пакета превышает определенное значение Tmax пакет отбрасывается. В приложениях реального времени (например, в IP-телефонии, в системах видеоконференций) это ведет к ухудшению качества речи.
Параметр vk - вариация задержки IP-пакета IPDV (IP packet delay variation) между входной и выходной точками сети определяется как разность между величиной задержки хк при доставке пакета с индексом к, и с/1 2 - минимальной величиной задержки доставки пакета IP для тех же сетевых точек: vk = xk-d1,2 Вариация задержки пакета IP, называемая также джиттером, проявляется в том, что регулярно передаваемые пакеты прибывают к получателю в нерегулярные моменты времени. В системах IP-телефонии это, к примеру, ведет к искажениям звука и, в результате, к тому, что речь становится неразборчивой.
Коэффициент потерь IP-пакетов IPLR {IP packet loss ratio) определяется как отношение суммарного числа потерянных пакетов к общему числу переданных пакетов в выбранном наборе переданных и принятых пакетов. Если пакеты теряются, то при передаче данных возможна их повторная передача по запросу принимающей стороны. В системах VoIP пакеты, пришедшие к получателю с задержкой, превышающей Tmax отбрасываются, что ведет к провалам в принимаемой речи.
Коэффициент искажений IP-пакетов IPER (IP packet error ratio) определяется как отношение суммарного числа пакетов, принятых с искажениями, к сумме успешно принятых пакетов и пакетов, принятых с искажениями.
28.2.2. Рекомендация ITU-T Y.1541
Рекомендация 1TU-TY1540 определяет для параметров численные значения норм, которые должны выполняться в сетях IP при международных соединениях. Эти нормы разделены по классам QoS, которые определены в зависимости от приложений и сетевых механизмов, применяемых для обеспечения гарантированного качества обслуживания. В табл. 28.2 представлены нормы для определенных выше сетевых характеристик.
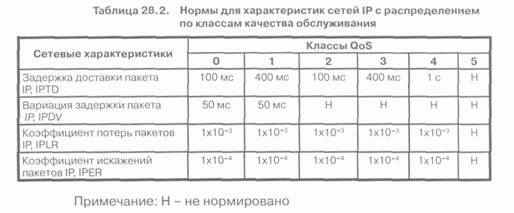
Значения параметров, приведенные в табл. 28.2, представляют собой, соответственно, верхние границы для средних задержек, джиттера, потерь и искажений пакетов. Рекомендация Y1541 устанавливает соответствие между классами качества обслуживания и приложениями:
• Класс 0 - Приложения реального времени, чувствительные к джиггеру и характеризуемые высоким уровнем интерактивности (VoIP, видеоконференции);
• Класс 1 - Приложения реального времени, чувствительные к джиттеру, интерактивные (VoIP, видеоконференции);
• Класс 2 - Транзакции данных, характеризуемые высоким уровнем интерактивности (например, сигнализация);
• Класс 3 - Транзакции данных, интерактивные;
• Класс 4 - Приложения, допускающие низкий уровень потерь (короткие транзакции, массивы данных, потоковое видео);
• Класс 5 - Традиционные виды приложений в сетях IP.
28.3. Механизмы обеспечения QoS в IP-сетях
Помимо определения сетевых параметров и спецификации норм для них, ITU-T проводит в настоящее время работы по стандартизации архитектуры сетевых механизмов для поддержки качества обслуживания в IP-ориентированных сетях. При разработке архитектуры сетевых механизмов должен быть учтен тот факт, что различные услуги будут предъявлять разные требования к характеристикам сети. Например, для телемедицины точность доставки играет более существенную роль, чем суммарная средняя задержка или джиттер, тогда как для IP-телефонии джиггер и задержка являются ключевыми характеристиками и должны быть минимизированы.
В настоящее время определен начальный набор механизмов, структурированных в соответствии с тремя логическими плоскостями - плоскостью управления, плоскостью данных (информационной плоскостью) и плоскостью менеджмента.
28.3.1. Механизмы QoS в плоскости управления
Механизмы QoS контрольной плоскости оперируют с путями, по которым передается трафик пользователей.
Управление доступом при соединении (Call Admission Control, САС). Этот механизм контролирует новые заявки на пропуск трафика через сеть, определяя, может ли вновь поступающий трафик привести к перегрузке сети или к ухудшению уровня качества обслуживания уже имеющегося в сети трафика.
QoS-маршрутизация (QoS routing). Маршрутизация обеспечивает выбор пути, который удовлетворяет требованиям к качеству обслуживания конкретного потока данных. Как правило, при вычислениях оптимального пути в QoS-маршрутизации учитывается или одна сетевая характеристика, или, максимум, две (производительность и задержка, стоимость и производительность, стоимость и задержка и т.д.).
Резервирование ресурсов [Resource reservation). В IP-ориентированных сетях наиболее типичным механизмом резервирования является механизм, базирующийся на протоколе RSVP, который рассматривается ниже в этой лекции.
28.3.2. Механизмы QoS в плоскости данных
Эта группа механизмов оперирует непосредственно с пользовательским трафиком.
Управление буферами узлов [Buffer management). Управление буферами (или очередями) состоит в управлении пакетами, стоящими в очереди на передачу. Основные задачи управления очередями - минимизация средней длины очереди при одновременном обеспечении высокого использования канала, а также справедливое распределение буферного пространства между разными потоками данных. Сегодня распространены механизмы активного управления очередями; типичным примером является алгоритм вероятностного заблаговременного обнаружения перегрузки RED (Random Early Detection). При использовании алгоритма RED поступающие в буфер пакеты отбрасываются на основании оценки средней длины очереди. Вероятность сброса пакетов растет с ростом средней длины очереди.
Предотвращение перегрузок {Congestion avoidance). Механизмы предотвращения перегрузок поддерживают уровень нагрузки в сети ниже пропускной способности сети. Обычный путь предотвращения перегрузок состоит в уменьшении трафика, поступающего в сеть. Как правило, команда уменьшить трафик влияет в первую очередь на низкоприоритетные источники. Одним из примеров механизма предотвращения перегрузок является механизм окна в протоколе TCP.
Маркировка пакетов (Packet marking). Пакеты могут быть маркированы в соответствии с определенным классом обслуживания. Маркировка обычно производится во входном узле, где в специальное поле заголовка (Type of Service в заголовке IP или DS-байт в заголовке DiffServ, см. ниже) вводится определенное значение.
Организация и планирование очередей (Queuing and scheduling). Цель механизмов этой группы - выбор пакетов для передачи из буфера в канал. Большинство дисциплин обслуживания (или планировщиков) основано на схеме «первый пришел - первый обслуживается». Для обеспечения более гибких процедур вывода пакетов из очереди был предложен ряд схем, основанных на формировании нескольких очередей. Среди них, в первую очередь, необходимо назвать схемы приоритетного обслуживания. Другой пример гибкой организации очереди - механизм взвешенной справедливой буферизации WFQ (Weighted Fair Queuing), когда ограниченная пропускная способность на выходе узла распределяется между несколькими потоками (очередями) в зависимости от требований к пропускной способности со стороны каждого потока. Еще одна схема организации очереди основана на классификации потоков по классу обслуживания CBQ (Class-Based Queuing). Потоки классифицируются в соответствии с классами обслуживания и затем размещаются в буфере в разных очередях. Каждой очереди выделяется определенная доля пропускной способности в зависимости от класса, и очереди обслуживаются по циклической схеме.
Классификация трафика (Traffic classification). На входе в сеть в узле доступа (пограничном маршрутизаторе) пакеты классифицируются для того, чтобы выделить пакеты одного потока, характеризуемого общими требованиями к качеству обслуживания. Затем трафик подвергается процедуре нормирования (механизм Traffic Conditioning), Нормирование трафика предполагает измерение параметров трафика и сравнение результатов измерений с параметрами, оговоренными в контракте о трафике, известном как соглашение об уровне обслуживания (Service Level Agreement, SLA), которое рассматривается ниже. Если условия соглашения нарушаются, то часть пакетов может быть отброшена.
Управление характеристиками трафика (Traffic shaping). Управление характеристиками трафика предполагает контроль скорости и объема потоков, поступающих на вход сети. При прохождении через специальные формирующие буферы уменьшается пачечность исходного трафика, и его характеристики становятся более предсказуемыми. Известны два механизма обработки трафика - Leaky Bucket («дырявое ведро») и Token Bucket («ведро с жетонами»). Алгоритм Leaky Bucket регулирует скорость пакетов, покидающих узел. Независимо от скорости входного потока, скорость на выходе узла является постоянной. Когда «ведро» (буфер) переполняется, лишние пакеты сбрасываются.
В противоположность этому, алгоритм Token Bucket не регулирует скорость на выходе узла и не отбрасывает пакеты. Скорость пакетов на выходе узла может быть такой же, как и на входе, если только в соответствующем буфере («ведре») есть жетоны. Жетоны генерируются с определенной скоростью и накапливаются в «ведре». Алгоритм характеризуется двумя параметрами - скоростью генерации жетонов и размером «ведра» для них. Пакеты не могут покинуть узел, если в ведре нет жетонов. И наоборот, сразу пачка пакетов может покинуть узел, израсходовав соответственное число жетонов.
28.3.3. Механизмы QoS в плоскости менеджмента
Эта плоскость включает в себя механизмы QoS, имеющие отношение к эксплуатации, администрированию и управлению сетью применительно к доставке пользовательского трафика.
Измерения (Metering), Измерения обеспечивают контроль показателей обслуживания трафика - например, реальная скорость потока данных сравнивается с согласованной в SLA скоростью. По результатам измерений могут быть реализованы определенные процедуры, такие, как сброс пакетов и применение механизмов Leaky Bucket и Token Bucket.
Соглашение об уровне обслуживания SLA (Service Level Agreement). Соглашение SLA, называемое в ряде источников контрактом по трафику, представляет собой договор между пользователем и провайдером услуг. В соглашении SLA описываются основные характеристики (профиль) трафика, формируемого в оборудовании пользователя, и параметры QoS, предоставляемые провайдером.
28.4. Основные модели обеспечения качества обслуживания в сетях IP
28.4.1. Модель предоставления интегрированных услуг
Процесс превращения сети Интернет в середине 90-х гг. из академической в коммерческую инфраструктуру, рост числа узлов и количества пользователей, применение сети Интернет для разнообразных приложений с разными требованиями к качеству обслуживания - все эти факторы определили быстрое развитие механизмов поддержки QoS. Комитет IETF разработал большой набор моделей и механизмов для обеспечения качества обслуживания в сетях Интернет.
Рабочая группа интегрированные услуги (Integrated Services Working Group) разрабатывала модель предоставления интегрированных услуг {IntServ), основанную на принципе интегрированного резервирования ресурсов. Модель IntServ была разработана для поддержки приложений реального времени, чувствительных к задержкам. Механизмы группы IntServ относятся к группе методов, гарантирующих «жесткое»' качество обслуживания. Наиболее детально среди механизмов группы IntServ проработан протокол RSVP (Resource ReSerVation Protocol), спецификация которого была принята Комитетом IETF в 1997 г.
Протокол RSVP. Протокол RSVP является наиболее известным представителем группы механизмов интегрированного обслуживания. По существу, RSVP представляет собой протокол сигнализации, в соответствии с которым осуществляется резервирование и управление ресурсами с целью гарантии «жесткого» качества обслуживания.
Резервирование производится для определенного потока IP-пакетов перед началом передачи этого потока. Идентификация потока (определение пакетов, принадлежащих одному потоку) производится по специальной метке, размещаемой в основном заголовке каждого пакета IP. После резервирования пути начинается передача пакетов этого потока, обслуживаемых во всем сквозном (от передающего до принимающего пользователя) соединении с заданным качеством.
Протокол RSVP является только протоколом сигнализации. Для обеспечения требуемого качества обслуживания на фазе переноса пакетов трафика он должен быть дополнен одним из существующих протоколов маршрутизации, а также набором механизмов управле ния трафиком, включающих в себя управление доступом, классификацию трафика, управление и планирование очередей и другие.
Несмотря на возможности протоколов группы IntServ, недостатки, заложенные в самом принципе модели IntServ (жесткие гарантии качества обслуживания, низкий уровень масштабирования}, привели к необходимости создания более гибких механизмов обеспечения QoS. Поэтому во второй половине 90-х гг. прошлого века в IETF начались работы по созданию моделей и механизмов дифференцированного обслуживания.
28.4.2. Модель предоставления дифференцированных услуг
Модель дифференцированных услуг (Differentiated Services, DiffServ) разработана группой Differentiated Services Working Group Комитета IETF. Детальная спецификация модели DiffServ была опубликована в середине 1999 г. Основная идея механизмов DiffServ состоит в дифференцированном предоставлении услуг для набора классов трафика, различающихся требованиями к показателям качества обслуживания. Другими словами, методы DiffServ, в отличие от методов IntServ, обеспечивают относительное или «мягкое» качество обслуживания.
Как и в случае механизмов IntServ, для дифференцированного предоставления услуг широко применяются механизмы, входящие в состав рассмотренной выше архитектуры поддержки QoS в сетях IP. Одним из центральных понятий модели DiffServ является соглашение об уровне обслуживания, SLA, входящее в состав механизмов QoS на плоскости менеджмента. В модели DiffServ архитектура сети представляется в виде двух сегментов - пограничных участков и ядра. На входе в сеть в узле доступа (пограничном маршрутизаторе} пакеты классифицируются (механизм Traffic classification), и трафик нормируется (механизм Traffic conditioning).
При необходимости поток пакетов проходит через устройство профилирования (механизм Traffic shaping). Магистральные маршрутизаторы, составляющие ядро сети, обеспечивают пересылку пакетов в соответствии с требуемым уровнем QoS.
Требования к необходимому набору характеристик качества обслуживания задаются в специальном однобайтовом поле каждого пакета - в октете Type of Service (ToS) протокола IPv4 или в октете Traffic Class (ТС) протокола IPv6. Отметим, что в модели DiffServ это поле называется DS-байтом. Содержание DS-байта определяет вид предоставляемых услуг.
Первые два бита определяют приоритет пакета, следующие четыре - требуемый класс обслуживания пакета в узле и два бита остаются неиспользуемыми. Класс обслуживания здесь означает механизм обработки и продвижения пакета из данного узла к следующему узлу (Per-Hop Behavior, PHB) в соответствии с необходимым качеством обслуживания. Таким образом, с помощью поля DS можно определить до 32 разных уровней качества обслуживания.
В 1999 г. были определены два класса услуг для модели DiffServ. В документе RFC 2598 описан класс «срочной доставки» (Expedited Forwarding, EF), обеспечивающий наивысший из возможных уровней качества обслуживания (Premium Service) и применяемый для приложений, требующих доставки с минимальными задержкой и джиггером.
Второй класс обслуживания, получивший название «гарантированной доставки» (Assured Forwarding, AF), представлен в документе RFC 2597. Класс гарантированной доставки поддерживает уровень качества обслуживания более низкий, чем класс срочной доставки, но более высокий, чем обслуживание по принципу «best effort». Внутри этого диапазона QoS класс AF определяет четыре типа трафика и три уровня отбрасывания пакетов. Таким образом, класс AF обеспечивает возможность обслуживания до 12 разновидностей трафика в зависимости от набора требуемых показателей качества обслуживания.
Обработка пакетов в соответствии с определенными уровнем приоритета и типом трафика осуществляется специальными схемами обслуживания очередей, обеспечивающими контроль задержек и джиттера пакетов и исключение возможных потерь. Среди основных механизмов управления очередями отметим приоритетное обслуживание (Priority Queuing), взвешенное справедливое обслуживание (Weighted Fair Queuing) и обслуживание в соответствии с механизмом РНВ (Class-Based Queuing).
Следует отметить, что механизмы DiffServ все же не могут гарантировать такой же уровень QoS, какой можно получить в цифровых телефонных сетях, базирующихся на коммутации каналов (например, в ISDN). Вместе с тем, можно ожидать, что в будущих сетях вес служб, требующих «телефонное качество», будет относительно небольшим, тогда как для приложений с менее критическими требованиями к QoS модели и механизмы дифференцированных услуг будут способны обеспечить необходимый уровень качества обслуживания.
28.4.3. Механизм многопротокольной коммутации по меткам (MPLS)
Еще одним механизмом обеспечения требуемых показателей качества обслуживания является многопротокольная коммутация по меткам (Multi-Protocol Label Switching, MPLS). Технология MPLS представляет собой развитие технологии Tag Switching (коммутация по тегам или по меткам), разработанной компанией Cisco в середине 90-х годов прошлого столетия. Существо механизма Tag Switching состоит в следующем. Вначале каждый маршрутизатор сети IP формирует маршрутные таблицы, используя стандартные протоколы маршрутизации (например, протокол OSPF). Затем каждому маршруту ставится в соответствие (генерируется) метка (label), которая может определять один маршрут или набор маршрутов. Набор меток формирует определенный аналог виртуального соединения, называемый «трактом, коммутируемым по меткам» {Label Switched Path, LSP}. Таким образом, метки могут рассматриваться как определенный аналог идентификаторов виртуальных соединений в технологии ATM или идентификаторов логических каналов в технологиях Frame Relay или Х.25. Сформированный набор меток соответствует определенному набору маршрутных таблиц.
В течение 1996-97 годов компании-производители маршрутизаторов для сетей IP предложили большое число вариантов схем коммутации по меткам, что привело к необходимости стандартизации механизмов этой группы. С этой целью в IETF в 1997 году была создана специальная рабочая группа MPLS. Первая спецификация MPLS была опубликована в 1999 году. Главная особенность технологии MPLS состоит в существенном упрощении процесса маршрутизации пакета за счет отказа от необходимости анализа IP-адресов в его заголовке. Это приводит к существенному уменьшению времени пребывания пакетов в маршрутизаторе и, как следствие, к возможности поддержки показателей QoS для различных видов трафика.
Принцип коммутации MPLS основан на обмене метками. Любой передаваемый пакет ассоциируется с определенным «классом эквивалентной пересылки" {Forwarding Equivalence Class, FEC). В узле, через который проходит LSP, каждый класс идентифицируется определенной меткой. Значение метки, размер которой составляет 32 бита, уникально для участка LSP между соседними узлами сети MPLS, через которые этот LSP проходит. Узлы MPLS называются маршрутизаторами LSR (Label Switching Router, LSR), коммутирующими по меткам. Маршрутизаторы LSR анализируют вместо заголовка пакета IP (160 битов) метку (32 бита), что приводит к существенному уменьшению времени пребывания пакетов в маршрутизаторе.
28.5. Оценка качества обслуживания в системах VoIP
28.5.1. Субъективные и объективные оценки качества обслуживания
При оценке качества услуг в сетях IP необходимо учитывать, что требования к сетевым характеристикам со стороны приложений данных и приложений, связанных с передачей речи, существенно различаются. Например, при передаче больших массивов данных необходима большая полоса частот, при этом данные могут не быть критичными к задержкам. В противоположность этому, для приложений VoIP требуются относительно небольшие сетевые ресурсы, но эти приложения критичны и к задержкам, и к вариации задержек. Следует учитывать, что речевой трафик и трафик данных, передаваемые через сеть IP, не могут обрабатываться одинаково в силу ряда причин, в том числе таких:
• пакеты речи и данных различны по длине;
• пакеты речи и данных передаются с разными скоростями;
• пакеты речи и данных обрабатываются в узлах и доставляются получателю с использованием разных механизмов и протоколов;
• сообщения электронной почты или массивы данных могут быть задержаны на десятки минут без влияния на оценку качества обслуживания, тогда как задержки, равные нескольким сотням миллисекунд, могут привести к значительным искажениям речевого сигнала, доставленного с помощью технологии VoIP.
В течение многих лет объективные количественные оценки, которые определяли бы качество обслуживания с учетом того, как оно воспринимается пользователем, отсутствовали. Оценки качества обслуживания были субъективными (лекция 8, модель MOS). В 1998 году ITU стандартизовал Е-модель, в которой были предложены объективные оценки качества, базирующиеся на измерении физических характеристик сетей и терминальных устройств. Эти оценки основаны на вычислении так называемого R-фактора, определяемого с использованием большого числа показателей, характеризующих как сеть, так и терминалы (задержки, потери, типы кодеков и т.д.).
Мы рассмотрим, как применяются R-фактор и модель MOS при оценке качества обслуживания в технологии VoIP.
28.5.2. Анализ искажающих факторов, влияющих на качество передачи речи в пакетных сетях
А. Влияние кодеков на качество пакетизированной речи При обработке аудио (и видео) информации используются специальные устройства - кодеки. На передающей стороне кодек преобразует аналоговый сигнал в цифровой, и на приемной стороне кодек выполняет обратное преобразование. Сегодня имеется большой набор эффективных кодеков с различными характеристиками (смотри табл. 28.3).
Типы кодеков различаются по названию соответствующего стандарта ITU-T, содержащего спецификацию того или иного кодека. Первый из специфицированных тип кодека, известный как G.711, преобразует аналоговый сигнал в цифровой с очень высоким качеством и без применения операции сжатия. Однако скорость передачи на выходе источника оказывается существенно выше скорости на выходе кодека, в котором осуществляется сжатие информации.
При создании первых кодеков (70-е годы прошлого века) технология современных цифровых сигнальных процессоров была недоступна. Сегодня на базе DSP можно построить весьма эффективные кодеки со значительно меньшими требованиями к пропускной способности тракта передачи. Меньшая скорость передачи информации означает, что можно организовать большее число телефонных соединений по одному и тому же тракту. Однако при этом уменьшается разборчивость речи, возрастают задержки, и качество речи становится более чувствительно к потере пакетов. В табл. 28.3 представлены характеристики кодеков, а в табл. 28.4 -оценки качества речи на базе R-фактора и модели MOS для некоторых типов кодеков ITU-T.
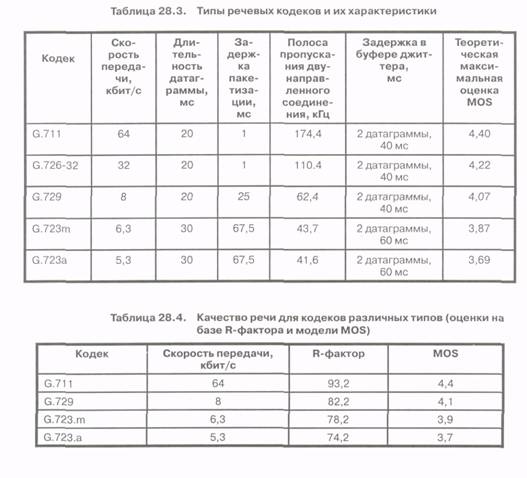
Б. Задержки иджиттер в сетях IP
Задержка доставки пакета речи. Речь представляет собой трафик, чувствительный к задержке, тогда как большинство приложений данных относительно устойчиво к задержке. Если задержка доставки пакета речи превышает определенное значение (нормированное в Рекомендациях 1TU-T), пакет отбрасывается. В результате, при большом числе отброшенных пакетов качество речи ухудшается.
Какая же задержка допустима при пакетной передаче речи? В результате исследований качества речевого сигнала еще в 60-х годах XX века было установлено, что человек начинает чувствовать задержки речевого сигнала, превышающие 150 мс, и ощущает заметный дискомфорт, если задержка превышает 250 мс. Позднее, при поддержке ITU были проведены масштабные исследования влияния сетевой задержки на качество телефонного разговора. Эти результаты нашли отражение в Рекомендации ITU-T G.114, в соответствии с которой рекомендуемый порог задержки при передаче речи составляет 150 мс. Задержки выше 150 мс осложняют телефонный разговор, в частности, при этом значении задержки оба участника начинают говорить одновременно. При задержке 300 мс разговор распадается на фрагменты, которые невозможно связать в слитную речь.
Рассмотрим, какие факторы определяют суммарную величину задержки доставки пакета. Сквозная задержка доставки пакета Од определяется как сумма четырех составляющих:
![]()
Dp - задержка распространения: время прохождения электрического сигнала либо в кабеле с медными проводниками или оптическими волокнами, либо в беспроводной среде. В вакууме время распространения сигнала составляет примерно 3,3 мкс/км, в случае кабелей с медными проводниками - примерно 4 мкс/км, в кабелях с оптическими волокнами - примерно 5 мкс/км.
Таким образом, в случае организации сеанса связи через спутник, находящийся на высоте 40тыс. км, задержка прохождения сигнала между двумя земными станциями может составить порядка 270 мс; задержка распространения на трассе Москва - Владивосток по кабелю с медными проводниками равна примерно 40 мс, по волоконно-оптическому кабелю - 50 мс;
DnK – задержка пакетизации: время, которое необходимо затратить в кодеке для преобразования аналогового сигнала в цифровой и на формирование пакета. Чем ниже скорость сигнала на выходе кодека, тем выше задержка пакетизации (смотри табл. 28.3);
Dnp - задержка переноса пакета: время прохождения пакета через все устройства сети, расположенные вдоль пути передачи пакета, включая маршрутизаторы, шлюзы, сетевые экраны, сегменты сети с относительно малой пропускной способностью в условиях перегрузки и т.д.;
DБД - задержка на приемной стороне в буфере джиттера. Буфер джиттера используется для уменьшения вариации между моментами поступления пакетов на вход приемного устройства. Буфер может накапливать от одной до нескольких датаграмм. В соответствии с данными табл. 28.3 типичный буфер джиттера накапливает две датаграммы, и задержка DБД составляет от 20 до 30 мс в зависимости от типа кодека.
Очевидно, что задержка распространения, задержки в кодеке и в буфере джиттера являются постоянными величинами для выбранного пути передачи пакета, тогда как задержка переноса является случайной величиной, зависящей от условий в сети в той или иной момент времени.
Рассматривая возможные количественные оценки всех составляющих задержки доставки пакета, можно видеть, что в сети Интернет общего пользования задержка речевого сигнала может легко превысить 150 мс из-за перегрузок, пакетизации, наличия буфера джиттера и использования спутниковых каналов.
На рис. 28.1 показано, как задержки влияют на R-фактор и показатели мое.
В заключение заметим следующее.
Решение задачи обеспечения требуемого качества обслуживания в сетях следующего поколения, безусловно, может быть достигнуто прямым путем - на основе предоставления гарантированной полосы пропускания, повышения производительности сетевых устройств - маршрутизаторов и шлюзов, использовании магистралей с высокой пропускной способностью.
Однако более эффективным представляется применение гибких методов управления ресурсами, которые обеспечивают требуемые показатели качества обслуживания при эффективном использовании ресурсов сети для большого набора различных приложений, включая и наиболее критичные аудио- и видеоприложения реального времени.

Задачи расчета СПД
Подобно тому, как все искусства тятотеют к музыке,
все науки стремятся к математике.
Д. Сантаяна
29.1. Особенности расчета сетей передачи данных
Задачи расчета сетей передачи данных по существу не отличаются от аналогичных задач расчета телефонных сетей и, как отмечено в лекции 9, могут быть разделены на три больших направления. Первое направление связано с определением структурных характеристик сети, второе - с оптимизацией использования ресурсов сети, третье - с оценкой параметров качества обслуживания, то есть с анализом вероятностно-временных характеристик работы сети, таких как задержки и потери. Первые два направления и в телефонных сетях, и в сетях передачи данных базируются на общих принципах, связанных с решением топологических задач, расчетом пропускной способности каналов и производительности узлов. В то же время подходы к оценке характеристик качества обслуживания в сетях обоих типов, хотя и базируются на теории массового обслуживания, однако, в качестве аналитических моделей для расчета характеристик сетей ПД используются, в основном, системы с очередями, тогда как в телефонных сетях применяются, как правило, системы с потерями вызовов.
В качестве основных параметров качества обслуживания (QoS) в сетях ПД на базе коммутации пакетов рассчитываются задержки и потери (и в узлах сети, и сквозные). В этой лекции мы рассмотрим несколько задач, иллюстрирующих подходы к расчету задержек и потерь пакетов как в классических сетях Интернет, так и в сетях IP, обслуживающих мультимедийный трафик.
29.2. Расчет длительности задержек в узле коммутации пакетов
Рассматривается задача расчета средней длительности задержек в узле коммутации пакетов. Термин «узел коммутации пакетов» означает здесь и концентратор (статистический мультиплексор), и узел виртуальной коммутации пакетов {сети Х*25, Frame Relay, сети ATM), и маршрутизатор (сети IP). Узел коммутации пакетов может быть представлен в виде элемента с множеством входных каналов и одним выходным каналом (концентратор) или элемента с множеством входных и выходных каналов (коммутатор/ маршрутизатор). С использованием символики Кендалла такие сетевые элементы могут быть представлены системами массового обслуживания вида G/G/1 или G/G/n {произвольные вероятностные распределения, описывающие и входящий поток заявок {в нашем случае - пакетов или протокольных блоков), и время их обслуживания. (Отметим, что при анализе узлов коммутации пакетов часто используются модели с одним обслуживающим прибором, то есть системы G/G/1).
Средняя длина очереди в системе M/G/1 (пуассоновский поток пакетов на входе, произвольное распределение времени обслуживания) при бесконечном размере буфера рассчитывается по классической формулеХинчина-Полячека:


Для расчета средней длины очереди и средней длительности задержки необходимо знать значения дисперсии и математического ожидания (или коэффициента вариации) распределения времени обслуживания протокольного блока (время обслуживания пропорционально длине протокольного блока). В табл. 29.1 приведены выражения для расчета квадратичных коэффициентов вариации некоторых распределений, применяемых при оценке средней длительности задержки в сетях Интернет.
Гиперэкспоненциальное распределение формируется путем суммирования нескольких экспоненциальных распределений; каждое входящее в сумму распределение при этом взвешивается, и сумма весов равна единице. В табл. 29.1 гиперэкспоненциальное распределение представлено для случая, когда результирующее распределение содержит две составляющие. Вес одной составляющей равен S, вес второй составляющей равен (1-S).
Геометрическое распределение, представляющее в таблице единственное дискретное распределение вероятностей, используется применительно к некоторым приложениям для описания распределения времени пребывания системы в определенном состоянии. Геометрическое распределение характеризуется вероятностью р пребывания системы в этом состоянии и вероятностью 1-р. нахождения системы в другом состоянии.

Параметры систем вида G/G/1 с бесконечной памятью не могут быть рассчитаны точно при распределениях параметров входящих потоков, отличных от пуассоновского. Однако существует набор приближенных формул, позволяющих рассчитать очереди и задержки. Ниже приведены формулы для расчета средней длины очереди в системе G/G/1, откуда легко может быть получена средняя длительность задержки:

входящего потока протокольных блоков и времен и их обслуживания, соответственно.
Из формул для оценки средних длин очередей (задержек) видно, что в знаменателе каждой формулы присутствует множитель (1-р), который является полюсом уравнения.
При приближении р к единице полюс стремится к нулю и кривые для очередей (задержек) стремятся к бесконечности {см. рис. 29.2 в конце лекции). Это явление должно учитываться при выборе нагрузки, чтобы обеспечить границы длительности задержек в соответствии с нормами качества обслуживания.
Приближение (29.3) сводится к формуле Хинчина-Полячека, то есть является точным для системы M/G/1. Использование той или иной приближенной формулы для расчета очереди определяется тем, насколько распределение входящего потока отличается от пуассоновского, а также от нагрузки обслуживающего устройства p [24].
29.3. Расчет вероятности потерь в узле коммутации пакетов
Еще одним важным параметром QoS в сетях передачи данных является вероятность потерь пакетов. Имеется ряд факторов, благодаря которым пакеты не доставляются в пункт назначения.
Среди основных причин отметим искажение пакетов в процессе передачи через сеть, превышение «времени жизни» пакетов, а также отброс пакетов в узлах при отсутствии свободного места в буферном накопителе узла.
Последнее явление встречается в том случае, если накопитель имеет конечную емкость памяти. Вероятность потерь определяется как вероятность переполнения буферного накопителя.
В данном разделе рассматривается задача расчета вероятности переполнения памяти в узле, который в общем виде описывается системой массового обслуживания вида G/G/1/N. Начнем с модели простейшей системы с пуассоновским входящим потоком и экспоненциальным распределением времени обслуживания, а затем рассмотрим более общие модели системы массового обслуживания.
Система M/M/1/N. Вероятность переполнения памяти определяется на основе процессов гибели и размножения и равна:

На рис. 29.1 представлены зависимости вероятности переполнения памяти P/oss от размера памяти накопителя N, измеряемого в числе протокольных блоков (пакетов, кадров, ячеек), при разных значениях нагрузки р . Эти зависимости рассчитаны по формуле (29.7). Заметим, что для фиксированного размера буфера вероятность переполнения возрастает по мере увеличения нагрузки Р .
При заданной вероятности переполнения памяти существует максимальное значение нагрузки узла, при которой система с очередями удовлетворяет требованиям к вероятности потерь, определяемых нормами для этой вероятности (см. лекцию 28).
Из уравнения (29.7) можно также получить необходимый размер буфера в узле, исходя из вероятности потерь. Решение уравнения относительно емкости буфера N выражается следующей формулой:

Система G/G/1/N. Получение точных решений в замкнутой форме для систем такого типа при известных распределениях входящего потока и времени обслуживания, особенно при конечной емкости накопителя, сопряжено со значительными трудностями. Более эффективным является использование приближенных, но простых в применении оценок, базирующихся на квадратичных коэффициентах вариации входящего потока и времени обслуживания. Приближенная формула для оценки вероятности потерь в системе, если эти параметры распределений входящего потока и времени обслуживания известны, была предложена в середине 70-х годов прошлого столетия В.В. Липаевым и С.Ф. Яшковым и имеет следующий вид:
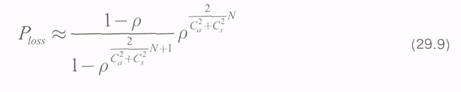
Зная распределения входящего потока и времени обслуживания и, таким образом, получив значения квадратичных коэффициентов вариации, можно рассчитать вероятность потерь в довольно сложной системе. Конечно, следует учитывать, что эти оценки будут приближенными, но можно всегда оценить погрешность вычислений, проведя имитационное моделирование выбранной системы, например, с использованием системы ns2.
Рассмотренные примеры вычислений длительности задержек и вероятности потерь позволяют провести оценки для изолированных сетевыхузлов. Представляет интерес также и оценка так называемых сквозных задержек и потерь. Что касается длительности задержки, определяемой узлами, то она считается простым суммированием задержек на всех узлах, включая и мультиплексоры. Вычисление сквозной вероятности потерь, учитывающей только потери в узлах из-за переполнения памяти, является более сложной задачей. Однако приняв гипотезу Л. Клейнрока о независимости узлов сети Интернет, можно свести расчет потерь в сети, содержащей К узлов, к простой формуле:

29.4. Особенности анализа мультимедийного трафика в сетях IP
Сегодня весь сетевой трафик Интернет практически можно разделить на два класса - трафик, передаваемый под управлением протокола TCP, и трафик, передаваемый под управлением протокола UDP.
Пропорции трафика TCP и UDP изменялись очень мало в течение последних 5-7 лет. Примерно 90% трафика передается через соединения TCP. Приложения, влияющие на рост трафика TCP, развиваются очень быстро, в первую очередь, благодаря разнообразным Web-приложениям и одноранговым (peer-to-per) межсетевым соединениям. В то же время наблюдается рост обьемов трафика UDP в связи нарастающей популярностью новых приложений, таких как VoIP, 1PTV и др. Примерные объемы трафика UDP сегодня составляют около 9%, однако следует ожидать существенный рост этого класса трафика в ближайшие годы.
В сетях IP присутствует также трафик управления, который формируется различными протоколами сигнализации и управления сетью. Хотя обработка трафика управления необходима для нормального функционирования сети, его объем относительно мал (1 - 1,5%) и не влияет на характеристики работы сети.
Кроме разделения на классы в зависимости от вида транспортного протокола, в сетях Интернет принято различать трафик трех основных типов: эластичный, потоковый и реального времени. Термин «эластичный» применяется к трафику, создаваемому при передаче данных под управлением протокола TCP, и его название связано с тем, что скорость передачи может изменяться в широких пределах в ответ на изменения нагрузки сети. Трафик этого вида чувствителен к потерям и не критичен относительно задержек.
Потоковый трафик порождается приложениями, связанными с передачей аудио- и видеоинформации. Эти приложения генерируют потоки пакетов, имеющие определенную скорость передачи, которая должна быть сохранена во время сеанса связи путем ограничения задержек, но при этом допустимы более длительные, по сравнению с трафиком реального времени, задержки, и этот тип трафика относительно малочувствителен к потерям.
Трафик реального времени допускает относительно небольшие длительности задержек и малочувствителен к потерям. Трафик этого типа создается в системах IP-телефонии и видеоконференц-связи. И потоковый трафик, и трафик реального времени передаются под управлением протокола UDR
В кпассических сетях IP присутствовал только эластичный трафик, который обслуживался по принципу best effort. Для современных сетей IP, где имеется трафик всех трех типов, требуется широкий набор показателей параметров качества обслуживания, начиная от параметров уровня best effort и заканчивая параметрами, соответствующими трафику реального времени.
29.5. Распределения для различных приложений в сетях IP
Процесс поступления потоков в ядро сети обычно представляет собой суперпозицию большого числа независимых сеансов (сессий). Статистические данные о характере потоков в сетях IP свидетельствуют о том, что во многих случаях распределение, описывающее входящий поток и время обслуживания, можно считать экспоненциальным.
Вместе с тем, статистические исследования эластичного трафика показывают, что наряду с простейшими распределениями, процессы поступления и обслуживания могут описываться и медленно затухающими распределениями.
Структуры потокового трафика и трафика реального времени во многих приложениях также описываются медленно затухающими распределениями. Отметим, что у таких распределений дисперсия может быть довольно большой, так что квадратичные коэффициенты вариации будут превышать единицу (т.е. значение коэффициента вариации для экспоненциального распределения).
Случайные процессы, описывающиеся медленно затухающими распределениями, относятся к классу самоподобных процессов. Наиболее распространенными распределениями указанного типа являются распределения Парето, Вейбулла и логнормальное распределение.
В табл. 29.2 приведены обобщенные результаты статистических исследований в сетях IP для различных приложений; здесь через А обозначается распределение входящего потока, а через В - распределение длины протокольных блоков.
Из табл. 29.2 видно, что почтовый трафик (протокол SMTP) описывается экспоненциальным распределением, тогда как большому числу популярных IP-приложений соответствуют медленно затухающие распределения.
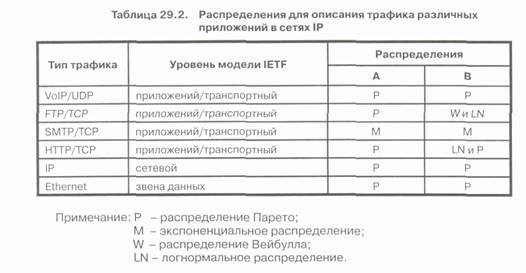
29.6. Задержки и потери в системах массового обслуживания, описываемых медленно затухающими распределениями
Расчет средних очередей (задержек) и вероятности потерь в системе массового обслуживания с медленно затухающими распределениями входящего потока и времени обслуживания можно произвести по приближенным формулам, приведенным выше.
Результаты расчетов длительности задержек и вероятности потерь для узла коммутации, моделируемого системой вида G/G/1, по формулам (29.3) и (29.9) соответственно, представлены на рис. 29.2 и 29.3.
При вычислениях длительности задержек и вероятности потерь необходимо знать квадратичные коэффициенты вариации каждого распределения. Формулы для расчета этих коэффициентов сложны и здесь не приводятся. Вместе с тем, представленные результаты расчетов позволяют сделать ряд полезных выводов. На графиках для задержек видно влияние знаменателя (1-р) на ход кривых. Длительность задержек и вероятность потерь существенно зависят от распределений входящего потока и времени обслуживания. Важно отметить, что задержки и потери в системе М/М/1 оказываются существенно меньше соответствующих параметров в системах с медленно затухающими процессами из-за разницы в значениях квадратичных коэффициентов вариации.
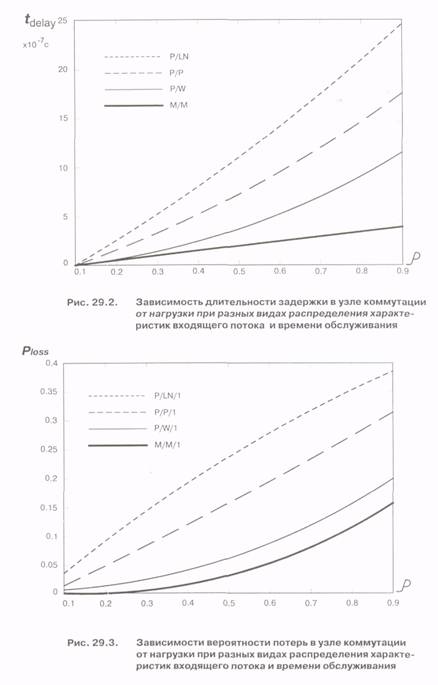
Перспективы развития СПД
Мечты слабых - бегство от действительности,
мечты сильных формируют действительность.
Юзеф Бестер
30.1. Проблемы роста сетей передачи данных
При работе над последней лекцией части 3, посвященной сетям передачи данных (а на самом деле - сетям Интернет), авторы оказались в довольно затруднительном положении.
В лекциях 10 и 20 уже был определен вектор развития фиксированных и мобильных телефонных сетей, и этот вектор однозначно был направлен в сторону построения сетей следующего поколения, использующих в качестве базовых протоколы TCP/IP. В лекции 10 транспортный сегмент сети следующего поколения строится как сеть с коммутацией пакетов, в лекции 20 в качестве ядра применяется IP Multimedia Subsystem (IMS) - мультимедийная подсистема на базе семейства IP.
В этой ситуации естественно возникает вопрос - если перспективы телефонных сетей однозначно связаны с построением сетей IP, в каком направлении в этом случае должна развиваться сама сеть Интернет? Определим круг задач, стоящих на пути эволюции сетей СПД на базе семейства протоколов IP.
Современная сеть Интернет, как уже отмечалось выше, имеет сорокалетнюю историю. Созданная в конце 60-х годов прошлого столетия на заре развития цифровых технологий и первых успехов систем передачи на базе волоконно-оптических технологий, инфраструктура Интернет, наряду с огромными достижениями, унаследовала большое число проблем, в первую очередь, обусловленных резким ростом числа пользователей, количества и разнообразия приложений, предоставляемых Операторами и Провайдерами.
Первая проблема определяется небывалым ростом количества пользователей. Только за последние 10 лет (с 1998 по 2008 год) число пользователей, подключенных к Интернет через фиксированные сети, выросло с 50 миллионов примерно до 1,2 миллиарда. Из 3 миллиардов мобильных пользователей примерно 20% имеют доступ к Интернет, увеличивая общее число ее пользователей до величины 1,8 миллиарда. Появилось множество устройств (кроме телефонов и компьютеров), подключенных к Интернет и «требующих» собственные адреса {см., например, табл. 20.1 в лекции 20). Рост числа пользователей приводит к истощению доступного адресного пространства протокола IPv4 и необходимости перехода к протоколу IPv6.
Вторая проблема в сегодняшних сетях Интернет определяется огромным ростом объемов трафика, обусловленным как ростом числа потребителей, так и увеличением количества и разнообразия приложений.
Потребители информации все большее внимание уделяют приложениям, связанным с мгновенной передачей сообщений, социальными и игровыми Web-сайтами, загрузкой видео и музыкальных файлов.
По оценкам компании Cisco видеоприложения в Интернет занимают примерно от 20 до 30% общего объема трафика. Например, в США в 2000 году общий объем ежемесячного суммарного магистрального трафика Интернет (генерируемого всеми приложениями) составлял 25 Пбайт, тогда как в 2007 году только ежемесячные объемы видеотрафика оценивались величиной порядка 29 Пбайт.
Большинство новых приложений, требующих большого объема сетевых ресурсов, получило название «пожирателей полосы». Ответом на эту проблему явилось внедрение технологий на базе волоконно-оптических сетей, существенный рост пропускной способности во всех сегментах сети Интернет - в магистральных и городских сетях, а также в сетях доступа.
Пропускная способность магистральных сегментов Интернет выросла за прошедшие 10 лет от сотен Мбит/с до десятков и сотен Гбит/с, и в сотни раз возросли скорости доступа в Интернет. Возможности, связанные с более высокими скоростями, привели к созданию аудио- и видеоархивов (например, YouTube), так же, как и к развитию одноранговых сетей для разделения цифрового контента.
Протокол VoIP, еще 10 лет назад рассматривавшийся как экзотическая новинка, сегодня отвоевал у традиционной телефонии примерно 20% речевого трафика. В сети Интернет получили широкое распространение видеоконференции, услуги определения местонахождения, анализ карт, научных данных, результатов измерений датчиков и т.д.
Рассмотрим более подробно вопросы, связанные с истощением адресного пространства и ростом трафика.
30.2. Переход к протоколу IPv6
В лекции 23 рассматривались свойства протоколов IPv4 и IPv6. Было отмечено, что одним из основных минусов протокола IPv4 на современном этапе развития глобальной сети Интернет является недостаточный объем числа адресов, обусловленный взрывным ростом количества пользователей с середины 90-х годов прошлого столетия и появлением большого числа устройств, подключенных к сети Интернет.
По оценкам IETF, сделанным в 2006 году, ожидается, что основное адресное пространство, которым распоряжается IANA (Internet Assigned Numbers Authority ), будет исчерпано к 2011 году, а адреса, принадлежащие региональным регистраторам (RIR), закончатся в 2012 году. Поэтому первой задачей перехода от версии IPv4 к новой версии протокола IPv6 было расширение адресного пространства. Расширение полей адреса от 32 битов в версии 4 до 128 битов в версии 6 позволило увеличить число адресов с 4x10э до 3,4x1038.
Кроме расширения адресного поля, в версии 6 значительно увеличена полная длина заголовка пакета - со 192 (IPv4) до 320 битов с учетом опций. Это расширение обеспечивает разделение служебной части пакета на основной и дополнительный заголовки и позволяет вынести ряд опциональных параметров в дополнительные поля.
В версии 4 опциональные параметры размещались в основном заголовке, и маршрутизаторы должны были обрабатывать значительный объем ненужной информации. В протоколе IPv6 предусматривается ряд процедур, снижающих нагрузку на маршрутизаторы, что позволяет уменьшить время обработки пакетов. В число этих процедур входят:
• агрегация адресов, ведущая к уменьшению размера адресных таблиц и, как следствие, к уменьшению времени анализа и обновления таблиц;
• перенос функций фрагментации пакетов (в случае их слишком большой длины) в узлы доступа (пограничные узлы);
• использование механизма маршрутизации от источника (Source Routing), когда узел-источник определяет сквозной маршрут прохождения пакета через сеть, а маршрутизаторы внутри сети освобождаются от процедуры определения следующего маршрутизатора для этого пакета.
Шестая версия протокола IP предусматриваеттакже применение встроенных механизмов защиты информации, объединяемых общим названием IPSec (IP Security), для чего в заголовок вводится дополнительное поле Encryption. Спецификации IPSec обеспечивают механизмы аутентификации источников/получателей информации, а также шифрование, аутентификацию и целостность передаваемых данных.
Еще одна проблема, решаемая с помощью протокола IPv6, -обеспечение гарантированных показателей качества обслуживания с помощью двух полей: «класс трафика» и «метка потока», реализуемых с помощью механизмов дифференцированного обслуживания. Вместе с тем, сегодня можно констатировать, что такие приложения, как Skype и iChat, демонстрируют возможности надежных аудио- и видеоконференций в реальном времени в сети Интернет общего пользования, где все еще используется принцип наилучшей попытки (best effort).
30.3. Взрыв трафика IP, рост пропускной способности магистральных сетей и скоростей доступа в Интернет
На рубеже 80 - 90-х годов прошлого столетия, еще до появления сетей Интернет общего пользования, прогнозы объемов трафика на 2000 год определяли соотношение трафика телефонии (естественно, фиксированной) и трафика данных как 10:1.
С появлением коммерческих сетей Интернет трафик данных начал расти, и в 2000 году объемы трафика речи, передаваемые в фиксированных телефонных сетях, и объемы трафика в сетях IP сравнялись. С этого момента трафик IP начал существенно опережать трафик традиционной телефонии. Исследования трафика в сетях Интернет, проводимые университетами и исследовательскими центрами, показывают, что сегодня объемы мирового трафика Интернет растут приблизительно на 50 - 60% в год. Анализ трафика, проведенный в Университете Миннесота, США, являющемся признанной международной организацией по мониторингу трафика IP, свидетельствует, что ежемесячный объем трафика Интернет в конце 2008 года составлял около 8 экзабайтов или порядка 100 экзабайтов в год. Эти наблюдения подтверждаются компанией Cisco', по данным которой трафик Интернет будет удваиваться каждые два года. В соответствии с данными Cisco в 2012 году сети IP в мире будут транспортировать 44 экзабайта в месяц или 528 экзабайтов в год, что несколько больше, чем половина одного дзеттабайта (для получения представления об объемах трафика см. материалы вводной лекции). Этот рост вызван как ростом числа пользователей, так и появлением новых приложений, предъявляющих высокие требования к пропускной способности сетей Интернет. Объемы трафика в Интернет определяются следующими основными приложениями;
• Web, электронная почта, пересылка файлов (без учета одноранговых приложений);
• одноранговые приложения (Peer-to-Peer, P2P) распределения файлов (Freenet, Gnutella, Morpheus, Kazaa и др.)
• видеоприложения, включая видеотелефонию, YouTube, IPTV, видео по требованию;
• приложения обработки данных, в которых программное обеспечение предоставляется пользователю как Интернет-сервис («Cloud Computing»');
• игры, распространяемые через Интернет;
• приложения, связанные с телеучастием (telepresence) -телеобучение, телемедицина.
Ожидается, что к 2015 году объемы мирового трафика Интернет возрастут примерно в 20 - 50 раз по сравнению с 2007 годом. Эти тенденции заставляют Поставщиков услуг и Операторов заново продумать свои подходы к архитектуре сети. При таком росте трафика возникают проблемы масштабируемости сетей IP с тем, чтобы поддержать требования к громадной полосе пропускания в ближайшие годы.
Кроме того, эти тенденции потребуют новых решений в области систем управления трафиком, обеспечивающих динамическое сквозное качество обслуживания для любой услуги, в любом месте, в любое время во всех элементах Интернет - в ядре сети, в городских сегментах и в сетях доступа.
Решение названных задач возможно при использовании архитектуры IPo DWDM, сочетающей свойства технологии IP и технологии разделения сетевых ресурсов на базе мультиплексирования по длине волны (Dense Wave Division Multiplexing, DWDM) с учетом новых интеллектуальных свойств обеих технологий.
Системы DWDM увеличивают пропускную способность оптических волокон путем распределения входящих оптических потоков, отвечающих стандартам SDH (например, несколько потоков STM-16/64), по определенным длинам волн и последующего мультиплексирования этих сигналов в виде единого цифрового потока в одном волокне. Объединение технологии DWDM и реконфигурируемых оптических мультиплексоров в совокупности с новыми свойствами технологии IP позволяет построить сети Интернет следующего поколения, отвечающие новым требованиям.
В 2008 году пропускная способность магистральных сетей IR используемая для пропуска всего международного трафика, составила примерно 20 Тбит/с, тогда как в 2000 году она равнялась 1 Тбиту в секунду.
Современные системы DWDM, используемые в магистральных сетях, позволяют пропустить только по одной паре волокон до одного Тбита в секунду. Существенно выросли и скорости доступа в Интернет. 10 лет назад практически все пользователи получали доступ путем предварительного набора номера модемного пула (а это означало 28 кбит/с или, в лучшем случае, 56 кбит/с).
Сегодня значительная часть пользователей имеет возможность осуществить широкополосный доступ к Интернет, начиная от скоростей 1 - 4 Мбит/с (с помощью модемов семейства xDSL через стандартные абонентские линии} до скоростей десятки-сотни Мбит/с (доступ через коаксиальные и волоконно-оптические системы, сети Ethernet, системы беспроводного доступа). По данным международной организации DSL Forum (см. www.broadband-forum.org) в конце 2008 года доступ через устройства xDSL получали 400 миллионов потребителей, то есть около 20% всех пользователей Интернет, без учета абонентов широкополосного доступа через другие системы.
В качестве примера эффективности широкополосного доступа рассмотрим передачу через Интернет всемирно известной Британской Энциклопедии (БЭ), изданной в 2000 году на DVD.
В этом формате БЭ содержит 4,5 Гбайта данных. Если для соединения с Интернет использовать мобильный телефон стандарта GSM (со скоростью передач данных 9,6 кбит/с), то пришлось бы ожидать около 43 суток, чтобы получить БЭ через сеть. При использовании фиксированной телефонной сети и модема 34 кбит/с необходимо было бы потратить на загрузку БЭ около 12 суток. В случае применения доступа через модем ADSL со скоростью 4 Мбит/с потребовалось бы 2,5 часа для загрузки БЭ, а при наличии доступа через коаксиальный кабель с модемом 30 Мбит/с мы смогли бы передать (и, соответственно, принять} весь файл за 20 минут.
30.4. Проект Internet2 (сеть Интернет следующего поколения)
В середине 90-х годов прошлого века в IETF начались активные работы по созданию спецификаций для сетей Интернет следующего поколения. Одним из результатов этих исследований была разработка протокола IPv6, вначале известного как протокол следующего поколения IPng (next generation). Примерно в то же время американские университеты создавали сети на базе IP, способные преодолеть ограничения, связанные с доступной пропускной способностью.
Необходимость в сетях с высокой пропускной способностью привела к созданию в 1995 году сети vBNS (very-high-performance Backbone Network Service). В создании сети приняли участие американский Национальный научный фонд (НСФ) и компания MCI - один из крупнейших американских Операторов. Концепция «Интернет следующего поколения» была рождена.
Следует отметить, что имеется определенная разница в трактовке терминов «Сеть Интернет следующего поколения» и «Сеть следующего поколения». Первый термин определяет сеть, задачей которой является улучшение характеристик традиционных сетей Интернет, тогда как второй термин относится к сети на базе протоколов семейства IP, которая должна объединять (конвергировать) все известные сети передачи информации.
В это же время (1996 год) был начат другой исследовательский проект, куда перешли практически все участники проекта vBNS в связи с его окончанием (1999 год). Ряд ведущих американских университетов (более 200 вузов), поддержанных правительством США, образовал некоммерческий консорциум Internet2, целью которого была разработка перспективных технологий и приложений с тем, чтобы приблизить появление «сети Интернет будущего».
Консорциум активно сотрудничает с ведущими производителями телекоммуникационного оборудования и программного обеспечения (Cisco, Nortel, Juniper, IBM, Microsoft) и Операторами (Level 3 и Quest).
Основным результатом деятельности консорциума сегодня является создание в 1999 году экспериментальной высокоскоростной сети Abilene, охватывающей всю страну и имеющей выход на европейские сети.
Отличительными особенностями новой сети являются применение протокола IPv6 и технологии вещательной передачи данных (multicast), реализация механизмов QoS при передаче видео и речевой информации. Пропускная способность магистральной сети равна 10 Гбит/с, а в отдельных сегментах достигает 100 Гбит/сек. Минимальная скорость доступа к сети составляет 100 Мбит/с и осуществляется через gigapops - высокоскоростные шлюзы (Point of Presence, PoP).
Сеть IP поддерживает протоколы IPv4 и IPv6, а также другие усовершенствованные сетевые протоколы, позволяющие гибко увеличивать пропускную способность и обеспечивать требуемое качество обслуживания. На базе сети Internet2 предоставляется набор услуг, в число которых входят:
• услуги IP (на базе маршрутизаторов компании Juniper);
• услуги динамической коммутации оптических трактов (на базе коммутаторов компании Ciena);
• услуги долговременной коммутации оптических трактов (на базе оборудования компании Infinera).
30.5. Заключительные замечания о будущем сети Интернет
Проект Internet2 позволяет видеть свет в конце туннеля, хотя время от времени появляются пессимистические прогнозы, предвещающие близкий конец сетей Интернет (например, анализ компании Nemertes Research, опубликованный в 2008 году). Вместе с тем, на пути развития сетей Интернет имеется достаточно большой список нерешенных задач, среди которых отметим следующие.
Адресная проблема, как было отмечено и в этой лекции, и в предыдущих лекциях, состоит в том, что истощается доступное адресное пространство протокола IPv4 и необходимо пополнять это пространство за счет протокола IPv6.
Отметим, что начиная с 2003 года, большинство ведущих производителей телекоммуникационного оборудования начали массовый выпуск сетевых устройств с поддержкой протокола IPv6. Очевидно, что в ближайшем будущем в сети Интернет будут использоваться два параллельных адресных пространства, определяемых протоколами IPv4 и IPv6.
По-видимому, основным требованием к сетям является совместимость обоих протоколов с точки зрения адресов, с тем чтобы каждый пользователь был уверен в доступности всех адресов при использовании обоих адресных пространств. В отсутствии этой согласованности часть адресов IPv6 может быть недоступна другим адресам, что поставит под сомнение идею создания сети с полной достижимостью пользователей.
Вместе с тем, чтобы ограничить эффект истощения адресного пространства IPv4 необходимо ускорить внедрение протокола IPv6.
Сеть Интернет превратилась в глобальную инфраструктуру, используемую огромным числом людей, для которых языки, основанные на латинице, не являются родными. Это - китайцы, русские, арабы и другие народы.
В связи с этим возникает проблема создания и регистрации огромного диапазона нелатинских доменных имен, причем ожидается, что многие нелатинские имена будут предложены для главного уровня, не говоря о вторых или более низких уровнях в иерархии доменных имен.
В легализации назначения доменных имен и адресов Интернет цифровые подписи будут играть все более и более важную роль. Чтобы реализовать принципы защиты доменных имен, необходимо будет разработать процедуры управления цифровыми сертификатами или другими механизмами аутентификации.
Число мобильных устройств с доступом в Интернет будет возрастать очень быстро. Скорости доступа увеличатся, что обеспечит введение большого числа новых приложений и расширит возможности уже существующих услуг. Будет развиваться электронная торговля при условии устойчивого, безопасного и надежного функционирования сети Интернет.
Сеть Интернет может служить как полезная глобальная инфраструктура и в общественной жизни, включая общественную безопасность, свободу слова, защиту частной жизни и цифровой собственности.
Сегодня почти 1,9 миллиарда человек в мире используют Интернет. В течение следующего десятилетия это число может приблизиться к 6 миллиардам.
Сеть Интернет должна служить платформой, создающей равные возможности, чтобы увеличить богатство наций.
Заключительная
Если высыпать содержимое кошелька себе
в голову, его уже никто у вас не отнимет.
Бенджамин Франклин
31.1. Краткие итоги
Первый раз Вы последовали предложению, приведенному в эпиграфе, когда купили эту книгу. Второй раз - когда дочитали ее до этой заключительной лекции. Разумеется, авторы при написании книги постарались коснуться всех основных аспектов современных сетей связи, но жизнь не стоит на месте. Ради удовлетворения желания людей получать информацию всюду и всегда, общаться в разных аудио-, видео- и мультимедиа форматах продолжают непрерывно создаваться и развиваться сети связи.
Собственно говоря, это непосредственно следует из предыдущих лекций, где были изложены основные аспекты создания и развития сетей электросвязи, предназначенных для предоставления интерактивных и вещательных услуг. В трех частях книги рассматривались:
• ТфОП (телефонная сеть общего пользования);
• СПС (сеть подвижной связи);
• СДЭ (сеть документальной электросвязи).
Телекоммуникационная система любого назначения может быть представлена моделью, состоящей из четырех компонентов. Эту модель, предложенную ITU, мы рассматривали во вводной лекции. Воспроизведем ее еще раз, выделив тот компонент, который стал в этой книге основным.
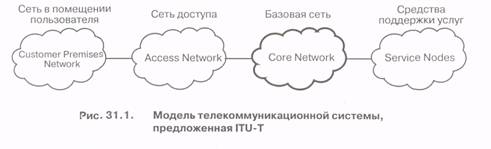
Выбор компонента «Базовая сеть» в качестве основного объекта для изучения был сделан по ряду причин.
Во-первых, авторам показалось логичным начать курс лекций с той части телекоммуникационной системы, которая входит в сферу ответственности Оператора связи. Во-вторых, следует вспомнить, что сеть доступа часто называют «последней милей». Из этого следует, что базовая сеть занимает - с точки зрения ее масштаба - существенно большее пространство. В-третьих, с базовой сети начиналось практическое применение новых технологий передачи и коммутации. В-четвертых, после изучения принципов построения и развития базовой сети методологически проще анализировать процессы модернизации всех остальных компонентов телекоммуникационной системы.
Четыре названные причины не умаляют значения остальных компонентов модели ITU. По всей видимости, появятся и другие курсы лекций, посвященные сетям в помещении пользователя, сетям доступа и средствам поддержки услуг.
В этой лекции основное внимание уделяется ряду направлений развития сетей связи, обусловленных важнейшей тенденцией развития телекоммуникационной системы - постепенному переходу к NGN.
31.2. Эволюция сетей доступа
Изложить суть эволюционных процессов, характерных для сетей доступа, в одном разделе невозможно. Тем не менее, следует отметить некоторые важные моменты. На рис. 31.2 выделены основные этапы развития сетей доступа и систем коммутации.

Начнем с нижнего графика. Ручные коммутаторы стали основой ТфОП. Позже они были вытеснены автоматическими телефонными станциями. На рисунке показаны три типа АТС: декадно-шаговые, координатные и цифровые. В разное время они занимали лидирующее положение на рынке оборудования коммутации. Кроме того, в телефонных сетях применялись также машинные АТС.
Между координатными и цифровыми АТС на телекоммуникационном рынке - в небольших объемах - появилось квазиэлектронное коммутационное оборудование. Цифровые системы коммутации, по-видимому, - последнее поколение АТС. Им на смену придут системы распределения информации, отвечающие требованиям NGN.
За более чем столетний период в системах коммутации периодически происходили заметные изменения. Развитию сетей доступа свойственны иные законы. После появления двухпроводных абонентских линий начался период, который можно считать стагнацией. Двухпроводные физические цепи надолго стали практически единственным средством построения сетей доступа. Было известно, что такой способ построения сети доступа экономически неэффективен, но приемлемого решения никто не нашел. В конце XX века начал формироваться платежеспособный спрос на услуги, поддержка которых потребовала существенного расширения полосы пропускания сети доступа. Эти услуги, в конечном счете, можно отнести к функциональным возможностям Triple-play services. которые подразумевают способность к обмену информацией трех видов: речь, данные и видео. Успехи телекоммуникационных технологий позволили разработать ряд новых вариантов модернизации сетей доступа. В некоторых случаях полностью или частично использовались эксплуатируемые многопарные кабели. Другие решения опирались на иные среды распространения сигналов.
Период стагнации сменился почти одновременным появлением множества решений, среди которых на верхнем графике выделены только три крупных направления:
xDSL - совокупность технологий, позволяющих организовать цифровой тракт по физическим цепям;
FTTx - ряд решений, подразумевающих доведение кабеля с оптическими волокнами до некоторой точки «х», после которой информация передается с использованием другой среды распространения сигналов;
BWA - широкополосные беспроводные средства доступа, ориентированные на подключение терминалов без использования кабелей связи.
Выбор оптимального решения для модернизации сети доступа зависит от многих факторов. В первую очередь, следует уяснить те требования телекоммуникационной системы, которые предъявляются к перспективным сетям доступа. Из всей совокупности таких требований целесообразно выделить следующие тенденции:
• рост скорости передачи информации;
• ужесточение требований некоторых групп пользователей к показателям качества обслуживания;
• поддержка функций мобильности терминала для ряда приложений, включая функциональные возможности triple-play services;
• снижение затрат, необходимых для создания и дальнейшего развития всех элементов инфокоммуникационной системы. Проиллюстрируем первую из упомянутых тенденций при помощи графика, который был построен на основании прогноза компании Technology Future Inc. для пользователей квартирного сектора в США. Кривые, приведенные на рис. 31.3, отражают вероятный тренд изменения требований потенциальных абонентов к скорости обмена данными через сеть доступа. Прогноз был сделан в начале XXI века.
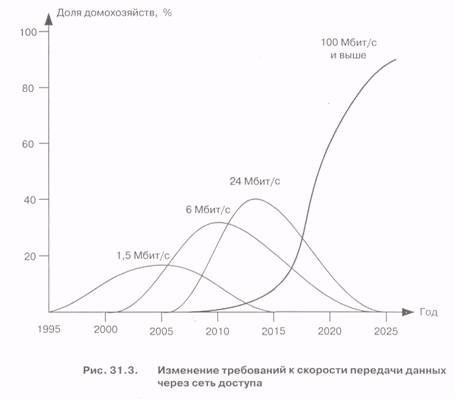
Столь существенный рост скорости обмена информацией обусловлен, в основном, двумя тенденциями:
• развитие системы телевидения высокой четкости, для которого необходимы широкополосные каналы;
• повышение скорости передачи данных в Интернет для поддержки информационных услуг и игровых приложений новых видов.
Следует отметить, что скорость 100 Мбит/с (верхний предел для последней кривой) совпадает с максимальной скоростью передачи информации в перспективных сетях мобильной связи. Хотя такая скорость даже в отдаленной перспективе представляется более чем достаточной, некоторые специалисты считают, что определенной группе пользователей потребуются ресурсы доступа порядка 1 Гбит/с.
31.3. Система эксплуатационно-технического управления
Система эксплуатационно-технического управления - еще один важный компонент телекоммуникационного мира, который не рассматривается в этой книге.
В технической литературе на английском языке система эксплуатационно-технического управления известна по термину management system. Она, как и сеть доступа, - тема для отдельной книги.
Для каждого элемента технической системы можно определить «жизненный цикл» - время с момента зарождения идеи до вывода из эксплуатации оборудования, в котором она была воплощена. Большинство элементов телекоммуникационных сетей относятся к так называемым консервативным сложным системам. Подобным системам присущи две особенности:
• эволюция в процессе эксплуатации происходит сравнительно медленно и не связана с радикальными изменениями;
• каждый элемент системы представляет собой сложное устройство, анализ которого нельзя свести к простой задаче.
Система эксплуатационно-технического управления предусматривает решение ряда важных задач. Одна из таких задач - техническое обслуживание. Оно включает в себя комплекс технических и организационных мероприятий, выполняемых в процессе эксплуатации технических объектов с целью обеспечить требуемую эффективность выполняемых функций. В документах ITU конкретизируется это определение, разработанное для сложных систем универсального назначения. В частности, в рекомендациях ITU серии М техническое обслуживание рассматривается как совокупность технических и административных действий, обеспечивающих поддержание (включая восстановление) объекта в состоянии, в котором он может выполнять требуемые функции.
На рис. 31.4 приведена простейшая модель, в которой выделен элемент сети связи, представляющий собой - с точки зрения рассматриваемых в этом разделе вопросов - объект управления.
Для этого объекта, согласно рекомендациям ITU-T серии М, определены интерфейсы электросвязи (для обмена информацией между терминалами пользователей) и технического обслуживания.

Через интерфейс технического обслуживания происходит обмен информацией, которая необходима для работы системы эксплуатационно-технического управления. В рассматриваемой модели предполагается формирование сигналов запроса и передачи информации технического обслуживания.
Реализацию эксплуатационных процессов часто рассматривают как совокупность задач, решение которых производится двумя системами, известными по аббревиатуре OSS/BSS {Operation Support System/Business Support System). Речь идет о системах поддержки эксплуатационных и бизнес-процессов. Системы OSS/BSS ориентированы на полную или частичную автоматизацию этих процессов.
Многие специалисты связывают дальнейшее развитие систем OSS/BSS с концепцией NGOSS (New Generation Operation System and Software). С некоторыми допущениями NGOSS можно считать следующей генерацией систем OSS/BSS, ориентированной на сети NGN.
Идеология NGOSS разработана международной независимой организацией TMF (TeleManagement Forum). Одна из основных задач NGOSS заключается в том, чтобы предоставить основным участникам телекоммуникационного рынка средства для создания и модернизации современных эксплуатационных и бизнес-процессов.
31.4. Глобальная информационная инфраструктура
Мы живем в мире, в котором информация имеет большое значение. Ежедневно человек получает информацию и узнает для себя что-то новое. Не так давно общая сумма человеческих знаний удваивалась каждые пятьдесят лет. В наши дни обьем информации удваивается каждые два года.
В 1994 году вице-президент США Альберт Гор обратился к странам-членам Международного союза электросвязи с предложением объединить национальные информационные инфраструктуры. В результате проведенной работы родилась идея ГИИ, упоминавшаяся во вводной лекции. В настоящее время разработан ряд соответствующих рекомендаций ITU-T (серия Y). Из определений ГИИ следует выделить такую трактовку: «Совокупность информационных и вычислительных ресурсов, предоставляемых для организаций и/или населения, и средств доступа {в том числе - дистанционного) к этим ресурсам». Модель ГИИ, которая предложена ITU-T в рекомендациях серии Y приведена на рис. 31.5.
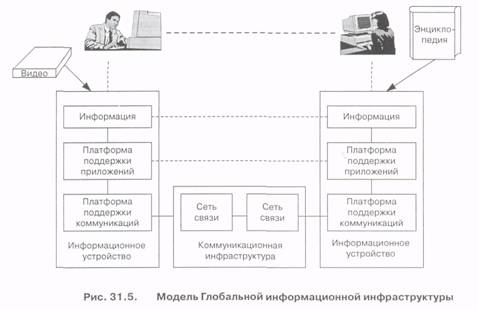
В этой модели между двумя информационными устройствами расположена коммуникационная инфраструктура, состоящая из нескольких сетей связи, которые используются в процессе передачи информации. Обмен информацией может происходить между людьми, между человеком и каким-либо техническим устройством, а также без участия людей. Концепция NGN обычно рассматривается как одно из самых перспективных направлений практической реализации идеологии ГИИ.
31.5. Вместо послесловия
Футурологи уже сошлись во мнении, что нынешнее столетие можно считать веком инфокоммуникаций. Этот введенный ITU но-выйтермин подразумевает информатику и ряд смежных дисциплин, среди которых важнейшая роль отводится телекоммуникациям.
Отсюда следует, что электросвязь станет одним из локомотивов экономики XXI века. Перед специалистами в области электросвязи открываются заманчивые перспективы профессиональной деятельности. Можно не сомневаться в появлении новых идей, в разработке оригинальных технологий, в качественном обновлении всех используемых технических средств.
Если решению возникающих задач будет хоть как-то способствовать эта книга, авторы смогут считать, что трудились не зря.
Завершая книгу, мы с благодарностью вспоминаем своих учителей. И надеемся, что нам, в свою очередь, удастся выполнить вечную задачу: «Учитель, воспитай ученика, чтоб было у кого потом учиться!»2.