ГЛАВА 4. СЖАТИЕ ЗВУКОВОЙ ИНФОРМАЦИИ [9,16-26]
При первичном кодировании в студийном тракте используется об равномерное квантование отсчетов звукового сигнала (ЗС) с разрешением ∆А=16...24 бит/отсчет при частоте дискретизации f = 44,1...96 кГц. В каналах студийного качества обычно
∆А =16 бит/отсчет, f = 48 кГц, полоса частот кодируемого звукового сигнала
∆F = 20...20000 Гц. Динамический диапазон так цифрового канала составляет около 54 дБ. Если f = 48 кГц и ∆А =16 бит/отсчет, то скорость цифрового потока при передаче одного такого сигнала равна V= 48x16 = 768 кбит/с. Это требует суммарной пропускной способности канал связи при передаче звукового сигнала форматов 5.1 (Dolby Digital) или 3/2 плюс канал сверхнизких частот (Dolby Surround, Dolby-Pro-Logic, Dolby THX) более 3,840 Мбит/с. Но человек способен своими органами чувств сознательно обрабатывать лишь около 100 бит/с информации. Поэтому можно говорить о присущей сущей первичным цифровым звуковым сигналам значительной избыточности
Различают статистическую и психоакустическую избыточность первичных цифровых сигналов. Сокращение статистической избыточности базируется на учете свойств самих звуковых сигналов, а психоакустичсской - на учете свойств слухового восприятия.
Статистическая избыточность обусловлена наличием корреляционной связи между соседними отсчетами временной функции звукового сигнала при его дискретизации. Для ее уменьшения применяют достаточно сложные алгоритмы обработки. При их использовании потери информации нет, однако исходный сигнал оказывается представленным в более компактной форме, что требует меньшего количества бит при его кодировании. Важно, чтобы все эта алгоритмы позволяли бы при обратном преобразовании восстанавливать исходные сигналы без искажений. Наиболее часто для этой цели используют ортогональные преобразования. Оптимальным с этой точки зрения является преобразование Карунена -Лоэва. Но его реализация требует существенных вычислительных затрат. Незначительно по эффективности ему уступает модифицированное дискретное косинусное преобразование (МДКП). Важно также, что для реализации МДКП разработаны быстрые вычислительные алгоритмы. Кроме того, между коэффициентами преобразования Фурье (к которому мы все привыкли) и коэффициентами МДКП существует простая связь, что позволяет представлять результаты вычислений в форме, достаточно хорошо согласующейся с работой механизмов слуха. Дополнительно уменьшить скорость цифрового потока позволяют также методы кодирования, учитывающие стати звуковых сигналов (например, вероятности появления уровней звукового нала разной величины). Примером такого учета являются коды Хаффмана где наиболее вероятным значениям сигнала приписываются более короткие кодовые слова, а значения отсчетов, вероятность появления которых мала кодируются кодовыми словами большей длины. Именно в силу этих двух причин в наиболее эффективных алгоритмах компрессии цифровых аудиоданных кодирование подвергаются не сами отсчеты ЗС, а коэффициенты МДКП, и для их кодирования используются кодовые таблицы Хаффмана. Заметим, что число таких таблиц достаточно велико и каждая из них адаптирована к звуковому сигналу определенного жанра.
Однако даже при использовании достаточно сложных процедур обработки устранение статистической избыточности звуковых сигналов позволяет в конечном итоге уменьшить требуемую пропускную способность канала связи лишь 15...25% по сравнению с ее исходной величиной, что никак нельзя считать революционным достижением.
После устранения статистической избыточности скорость цифрового пока при передаче высококачественных ЗС и возможности человека по их обработке отличаются, по крайней мере, на несколько порядков. Это свидетельствует также о существенной психоакустической избыточности первичных цифровых ЗС и, следовательно, о возможности ее уменьшения. Наиболее перспективными с этой точки зрения оказались методы, учитывающие такие свойства слуха, как маскировка, предмаскировка и послемаскировка. Если известно, какие доли (части) звукового сигнала ухо воспринимает, а какие нет вследствие маскировки, то можно вычленить и затем передать по каналу связи лишь те части сигнала, которые ухо способно воспринять, а неслышимые доли (составляющие исходного сигнала) можно отбросить (не передавать по каналу связи). Кроме того, сигналы можно квантовать с возможно меньшим разрешением по уровню , так, чтобы искажения квантования, изменясь по величине с изменением уровня самого сигнала, еще оставались бы неслышимыми, т.е. маскировались бы исходным сигналом. Однако, после устранения психоакустической избыточности точное восстановление формы временной функции ЗС при декодировании оказывается уже невозможным.
В этой связи следует обратить внимание на две очень важные для практики особенности. Если компрессия цифровых аудиоданных уже использовалась ранее в канале связи при доставке программы, то ее повторное применение часто ведет к появлению существенных искажений, хотя исходный сигнал кажется нам на слух вполне качественным перед повторным кодированием. Поэтому очень важно знать «историю» цифрового сигнала, и какие методы кодирования при его передаче уже использовались ранее. Если измерять традиционными методами параметры качества таких кодеков на тональных сигналах (как это часто и делается), то мы будем для них получать при разных, даже самых малых установленных значениях скорости цифрового потока, практически идеальные величины измеряемых параметров. Результаты же тестовых прослушиваний для них, выполненные на реальных звуковых сигналах, будут принципиально отличаться Иными словами, традиционные методы оценки качества для кодеков с компрессией цифровых аудиоданных не пригодны.
Работы по анализу качества и оценке эффективности алгоритмов компрессии цифровых аудиоданных с целью их последующей стандартизации начались в 1988 году, когда была образована международная экспертная группа MPEG ( Moving Pictures Experts Group). Итогом работы этой группы на первом этапе явилось принятие в ноябре 1992 года международного, стандарта MPEG 1 ISO/IEC 11172-3 (здесь и далее цифра 3 после номера стандарта относится к той его части, где речь идет о кодировании звуковых сигналов).
К настоящему времени достаточное распространение в радиовещании получили также еще нескольких стандартов MPEG, таких, как MPEG-2 ISO/IEC 13818-3, 13818-7 и MPEG-4 ISO/IEC 14496-3.
В отличие от этого в США был разработан стандарт Dolby АС-3 (ад/52) качестве альтернативны стандартам MPEG. Несколько позже четко сформировались две разные платформы цифровых технологий для радиовещания и телевидения - это DAB (Digital Audio Broadcasting), DRM (Digital Radio Mondiale), DVB (с наземной DVB-T, кабельной DVB-C, спутниковой DVB-S разновидностями) и ATSC (Dolby АС-3). Первая из них (DAB, DRM) продвигается Европой, ATSC - США. Отличаются эти платформы, прежде всего, выбранным алгоритмом компрессии цифровых аудиоданных, видом цифровой модуляции и процедурой помехоустойчивого кодирования ЗС.
Несмотря на значительное разнообразие алгоритмов компрессии цифровых аудиоданных, структура кодера, реализующего такой алгоритм обработки сигналов, может быть представлена в виде обобщенной схемы, показанной на рис. 4.1. В блоке временной и частотной сегментации исходный звуковой сигнал разделяется на субполосные составляющие и сегментируется по времени, Длина кодируемой выборки зависит от формы временной функции звукового сигнала. При отсутствии резких выбросов по амплитуде используется так называемая длинная выборка, обеспечивающая высокое разрешение по частоте. В случае же резких изменений амплитуды сигнала длина кодируемой выборки резко уменьшается, что дает более высокое разрешение по времени. Решение об изменении длины кодируемой выборки принимает блок психоакустического анализа, вычисляя значение психоакустической энтропии сигнала. После сегментации субполосные сигналы нормируются, квантуются и кодируются. В наиболее эффективных алгоритмах компрессии кодированию подвергаются не сами отсчеты выборки ЗС, а соответствующие им коэффициенты МДКП.
Обычно при компрессии цифровых аудиоданных используется энтропийное кодирование, при котором одновременно учитываются как свойства слуха человека, так и статистические характеристики звукового сигнала. Однако основную роль при этом играют процедуры устранения психоакустической избыточности. Учет закономерностей слухового восприятия звукового сигнала выполняется в блоке психоакустического анализа. Здесь по специальной процедуре для каждого субполосного сигнала рассчитывается максимально допустимый уровень искажений (шумов) квантования, при котором они еще маскируются полезным сигналом данной субполосы. Блок динамического распределения бит в соответствии с требованиями психоакустической модели для каждой субполосы кодирования выделяет такое минимально возможное их количество при котором уровень искажений, вызванных квантованием, не превышал порога их слышимости, рассчитанного психоакустической моделью. В современных алгоритмах компрессии используются также специальные процедуры форме итерационных циклов, позволяющие управлять величиной энергии искажений квантования в субполосах при недостаточном числе доступных для кодирования бит.
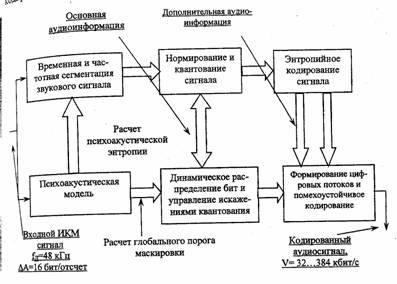
Рис. 4.1. Обобщенная структурная схема кодера с компрессией цифровых аудиоданных
Алгоритмы сжатия звука MPEG основаны на описанных в первой главе свойствах восприятия звуковых сигналов слуховым аппаратом человека. Использование эффекта маскировки позволяет существенно сократить объем звуковых данных, сохраняя приемлемое качество звучания. Принцип здесь достаточно простой: «Если какая-то составляющая не слышна, то и передавать ее не следу». На практике это означает, что в области маскирования можно снизить число битов на отсчет до такой степени, чтобы шум квантования все еще оставался ниже порога маскирования. Таким образом, для работы звукового кодера необходимо знать пороги маскирования при различных комбинациях воздействующих сигналов. Вычислением этих порогов занимается важный узел в кодере психоакустическая модель слуха (ПАМ). Она анализирует входной сигнал в последовательные отрезки времени и определяет для каждого блока отсчетов спектральные компоненты и соответствующие им области маскирования. Входной сигнал анализируется в частотной области, для этого блок отсчетов, взятых во времени, с помощью дискретного преобразования Фурье преобразуется в набор коэффициентов при компонентах частотного спектра сигнала. Разработчики кодеров компрессии имеют значительную свободу в построении модели, точность ее функционирования зависит от требуемой степени сжатия
Полосное кодирование и блок фильтров. Наилучшим методом к кодирования звука, учитывающим эффект маскирования, оказывается полосное кодирование. Сущность его заключается в следующем. Группа отсчетов входного звукового сигнала, называемая кадром, поступает на блок фильтров (БФ) который содержит, как правило, 32 полосовых фильтра. Учитывая сказанное pan критических полосах и маскировании, хорошо бы иметь в блоке фильтров полосы пропускания, по возможности совпадающие с критическими. Однако практическая реализация цифрового блока фильтров с неравными полосами достаточно сложна и оправдана только в устройствах самого высокого класса Обычно используется блок фильтров на основе квадратурно-зеркальных (W. ров с равными полосами пропускания, охватывающих с небольшим взаимным, перекрытием всю полосу слышимых частот (рис. 4.2). В этом случае полоса пропускания фильтра равна π/32T, а центральные частоты полос равны (2к + 1) π /64Т, где Т - период дискретизации;
к = 0,1,..., 31. При частоте дискретизации 48 кГц полоса пропускания секции фильтра составляет 750 Гц.
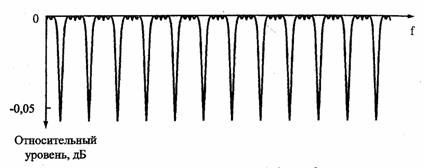
Рис. 4.2. Нормированная АЧХ блока фильтров
На выходе каждого фильтра оказывается та часть входного сигнала, которая попадает в полосу пропускания данного фильтра. Далее, в каждой полосе с помощью ПАМ, анализируется спектральный состав сигнала и оценивается, какую часть сигнала следует передавать без сокращений, а какая лежит ниже порога маскирования и может быть переквантована на меньшее число бит. Поскольку, в реальных звуковых сигналах максимальная энергия обычно сосредоточена точена в нескольких частотных полосах, может оказаться, что сигналы в других полосах не содержат различимых звуков и могут вообще не передаваться, личие, например, сильного сигнала в одной полосе означает, что несколько вышележащих полос будут маскироваться и могут кодироваться меньшим лом бит.
Для сокращения максимального динамического диапазона определяется максимальный отсчет в кадре и вычисляется масштабирующий множитель, который приводит этот отсчет к верхнему уровню квантования. Эта операция аналогична компандированию в аналоговом вещании. На этот же множитель умножаются и все остальные отсчеты. Масштабирующий множитель передается к декодеру вместе с кодированными данными для коррекции коэффициента передачи последнего. После масштабирования производится оценка порога маскирования и осуществляется перераспределение общего числа битов между всеми полосами.
Квантование и распределение битов. Все вышеописанные операции не
сокращали заметно объем данных, они были как бы подготовительным этапом к собственно сжатию звука. Как и при компрессии цифровых видеосигналов, основное сжатие происходит в квантователе. Исходя из принятых ПАМ решений о переквантовании отсчетов в отдельных частотных полосах, квантователь
меняет шаг квантования таким образом, чтобы приблизить шум квантования
данной полосе к вычисленному порогу маскирования. При этом на отсчет
может понадобиться вместо 16 ... 20 всего 4 или 5 битов.
Принятие решения о передаваемых компонентах сигнала в каждой частотной полосе происходит независимо от других, и требуется некий «диспетчер», который выделил бы каждому из 32 полосных сигналов часть из общего ресурса битов, соответствующую значимости этого сигнала в общем ансамбле. Роль такого диспетчера выполняет устройство динамического распределения
битов.
Возможны три стратегии распределения битов.
В системе с прямой адаптацией кодер производит все расчеты и посылает результаты декодеру. Преимущество данного способа в том, что алгоритм распределения битов может обновляться и изменяться, не затрагивая работы декодера. Однако для пересылки дополнительных данных декодеру расходуется заметная часть общего запаса битов.
Система с обратной адаптацией осуществляет одинаковые расчеты и в кодере, и в декодере, поэтому нет необходимости пересылать декодеру дополнительные данные. Однако сложность и стоимость декодера значительно выше, чем в предыдущем варианте, и любое изменение алгоритма требует обновления
или переделки декодера.
Компромиссная система с прямой и обратной адаптацией разделяет функции расчета распределения битов между кодером и декодером таким образом, что кодер производит наиболее сложные вычисления и посылает декодеру только ключевые параметры, затрачивая на это относительно немного битов, Декодер проводит лишь несложные вычисления. В такой системе кодер не может быть существенно изменен, но настройка некоторых параметров допустим.
Обобщенная схема звукового кодера и декодера, выполняющих цифровое сжатие согласно описанному алгоритму с прямой адаптацией, приведена на рисунки 4.3,а. Сигналы на выходе частотных полос объединяются в единый цифровой поток с помощью
мультиплексора.
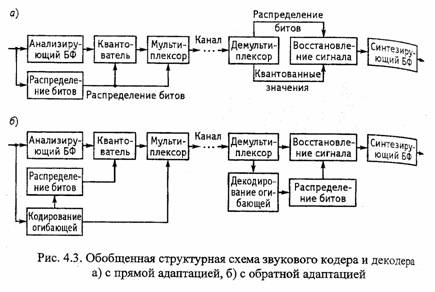
В декодере процессы происходят в обратном порядке. Сигнал демультиплексируется, делением на масштабирующий множитель восстанавливаются исходные значения цифровых отсчетов в частотных полосах и поступают на объединяющий блок фильтров, который формирует на выходе поток звуковых данных, адекватный входному с точки зрения психофизиологического восприятия звукового сигнала человеческим ухом.
Вариант схемы с обратной адаптацией показан на рисунке 4.3, б.
MPEG расшифровывается как «Moving Picture Coding Experts Group», дословно - группа экспертов по кодированию подвижных изображений. MPEG ведет свою историю с января 1988 года. Начиная с первого собрания в мае 1988 года, группа начала расти, и выросла до очень большого коллектива специалистов. Обычно, в собрании MPEG принимают участие около 350 специалистов из более чем 200 компаний. Большая часть участников MPEG — это специалисты, занятые в тех или иных научных и академических учреждениях.
4.2.1.Стандарт MPEG-1
Стандарт MPEG-1 (ISO/IEC 11172-3) включает в себя три алгоритма различных уровней сложности: Layer (уровень) I, Layer II и Layer III. Общая структура процесса кодирования одинакова для всех уровней. Однако, несмотря схожесть уровней в общем подходе к кодированию, уровни различаются п левому использованию и внутренним механизмам. Для каждого уровня определен цифровой поток (общая ширина потока) и свой алгоритм декодирования
MPEG-1 предназначен для кодирования сигналов, оцифрованных с частотой дискретизации 32, 44.1 и 48 КГц. Как было указано выше, MPEG-1 имеет три уровня (Layer I, II и Ш). Эти уровни имеют различия в обеспечиваемом коэффициенте сжатия и качестве звучания получаемых потоков.
MPEG-1 нормирует для всех трех уровней следующие номиналы скоростей цифрового потока: 32, 48, 56, 64, 96, 112, 192, 256, 384 и 448 кбит/с, число уровней квантования входного сигнала - от 16 до 24. Стандартным входным ^гналом для кодера MPEG-1 принят цифровой сигнал AES/EBU (двухканальный цифровой звуковой сигнал с разрядностью квантования 20 ... 24 бита на отчет) Предусматриваются следующие режимы работы звукового кодера:
■ одиночный канал (моно);
■ двойной канал (стерео или два моноканала);
■ joint stereo (сигнал с частичным разделением правого и левого каналов). Важнейшим свойством MPEG-1 является полная обратная совместимость
всех трех уровней. Это означает, что каждый декодер может декодировать сигналы не только своего, но и нижележащих уровней.
В основу алгоритма Уровня I положен, разработанный компанией Philips для записи на компакт-кассеты, формат DCC (Digital Compact Cassette). Кодирование первого уровня применяется там, где не очень важна степень компрессии и решающими факторами являются сложность и стоимость кодера и декодера. Кодер Уровня I обеспечивает высококачественный звук при скорости цифрового потока 384 кбит/с на стереопрограмму.
Уровень II требует более сложного кодера и несколько более сложного декодера, но обеспечивает лучшее сжатие — «прозрачность» канала достигается уже при скорости 256 кбит/с. Он допускает до 8 кодирований/декодирований без заметного ухудшения качества звука. В основу алгоритма Уровня П положен популярный в Европе формат MUSICAM.
Самый сложный Уровень III включает все основные инструменты сжатия: полосное кодирование, дополнительное ДКП, энтропийное кодирование, усовершенствованную ПАМ. За счет усложнения кодера и декодера он обеспечивает высокую степень компрессии - считается, что «прозрачный» канал формируется на скорости 128 кбит/с, хотя высококачественная передача возможна и на более низких скоростях,
В стандарте рекомендованы две психоакустические модели: более простая Модель 1 и более сложная, но и более высококачественная Модель 2. Они
отличаются алгоритмом обработки отсчетов. Обе модели могут использоваться
всех трех уровней, но Модель 2 имеет специальную модификацию для Уровня III.
MPEG -1 оказался первым международным стандартом цифрового сжатия звуковых сигналов и это обусловило его широкое применение во многих областях: вещании, звукозаписи, связи и мультимедийных приложениях. Наиболее широко используется Уровень II, он вошел составной частью в европейские спутникового, кабельного и наземного цифрового ТВ вещания, в стандарты звукового вещания, записи на DVD, Рекомендации МСЭ BS.1115 и J.52. Уровень III (его еще называют МР-3) нашел широкое применение в цифровых сетях с интегральным обслуживанием (ISDN) и в сети Интернет Подавляющее большинство музыкальных файлов в сети записаны именно в этом стандарте.
Кодер первого уровня. Рассмотрим более подробно работу кодера первого уровня (рис 4.4). Блок фильтров (БФ) обрабатывает одновременно 384 о счета звуковых данных и распределяет их с соответствующей субдискретизацией в 32 полосы, по 12 отсчетов в каждой полосе с частотой дискретизации 48/32 =1,5 кГц. Длительность кадра при частоте дискретизации 48 кГц составляет 8 мс. Упрощенная психоакустическая модель оценивает только частотное маскирование по наличию и «мгновенному» уровню компонентов сигнала в каждой полосе. По результатам оценки для каждой полосы назначается как можно более грубое квантование, но так, чтобы шум квантования не превышал порога маскирования. Масштабирующие множители имеют разрядность 6 бит и перекрывают динамический диапазон 120 дБ с шагом 2 дБ. В цифровом потоке передаются также 32 кода распределения битов. Они имеют разрядность 4 бита и указывают на длину кодового слова отсчета в данной полосе после переквантования .
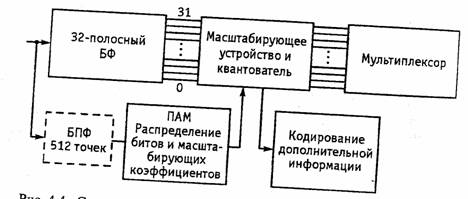
Рис. 4.4. Структурная схема звукового кодера MPEG-1 первого и второго уровней (пунктиром показан модуль быстрого преобразования Фурье (БПФ), добавляемый на втором уровне)
В декодере (рис. 4.5) отсчеты каждой частотной полосы выделяются демультиплексором и поступают на перемножитель, который восстанавливает их первоначальный динамический диапазон. Перед этим восстанавливается исходная разрядность отсчетов — отброшенные в квантователе младшие разряды заменяются нулями. Коды распределения битов помогают демультиплексору разделить в последовательном потоке кодовые слова, принадлежащие разным отсчетам и передаваемые кодом с переменной длиной слова. Затем отсчеты всех 32 каналов подаются на синтезирующий БФ, который проводит повышающую дискретизацию и расставляет отсчеты должным образом во времени, восстанавливая исходную форму сигнала.
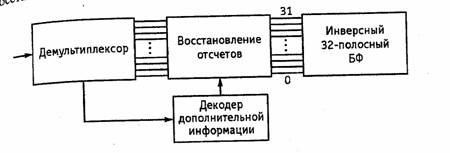
Рис. 4.5. Структурная схема звукового декодера MPEG-1 первого и второго уровней
Кодер второго уровня. В кодере второго уровня устранены основные недостатки базовой модели полосного кодирования, связанные с несоответствием критических полос слуха и реальных полос БФ, из-за чего в низкочастотных участках диапазона эффект маскирования практически не использовался. Величина кадра увеличена втрое, до 24 мс при дискретизации 48 кГц, одновременно обрабатываются уже 1152 отсчета (3 субкадра по 384 отсчета). В качестве входного сигнала для ПАМ используются не полосные сигналы с выхода БФ, а спектральные коэффициенты, полученные в результате 512-точечного преобразования Фурье входного сигнала кодера. Благодаря увеличению и временной длительности кадра и точности спектрального анализа эффективность
работы ПАМ возрастает.
На втором уровне применен более сложный алгоритм распределения битов. Полосы с номерами от 0 до 10 обрабатываются с четырехразрядным кодом распределения (выбор любой из 15 шкал квантования), для полос с номерами от 11 до 22 выбор сокращается до 3 разрядов (выбор одной из 7 шкал), полосы с номерами от 23 до 26 предоставляют выбор одной из 3 шкал (двухбитовый код), а полосы с номерами от 27 до 31 (выше 20 кГц) не передаются. Если шкалы квантования, выбранные для всех блоков кадра, оказываются одинаковыми, то номер шкалы передается только один раз.
Еще одно существенное отличие алгоритма второго уровня в том, что не все масштабирующие множители передаются по каналу связи. Если различие множителей трех последовательных субкадров превышает 2 дБ не более чем в течение 10% времени, передается только один набор множителей и это дает экономию расходуемых битов. Если в данной полосе происходят быстрые изменения уровня звука, передаются два или все три набора масштабирующих множителей. Соответственно декодер должен запоминать номера выбранных писал квантования и масштабирующие множители и применять их при необходимости к последующему субкадру.
Кодер третьего уровня. Кодер Уровня III использует усовершенствованный алгоритм кодирования с дополнительным ДКП. Структурная схема кодера
показана на рис. 4.6.
Основной недостаток кодеров второго уровня - неэффективная обработка быстро изменяющихся переходов и скачков уровня звука – устраняется благодаря введению двух видов блоков ДКП - «длинного» с 18 отсчетами и «короткого» с 6 отсчетами. Выбор режима осуществляется адаптивно путем переключения оконных функций в каждой из 32 частотных полос. Длинные блоки обеспечивают лучшее частотное разрешение сигнала со стандартными характеристиками, в то время как короткие блоки улучшают обработку быстрых переходов. В одном кадре могут быть как длинные, так и короткие блоки, однако общее число коэффициентов ДКП не изменяется, так как вместо одного длинною передаются три коротких блока. Для улучшения кодирования применяются также следующие усовершенствования.
■ Неравномерное квантование (квантователь возводит отсчеты в степень 3/4 перед квантованием для улучшения отношения сигнал-шум; соответственно, декодер возводит их в степень 4/3 для обратной линеаризации).
■ В отличие от кодеров первого и второго уровней, на третьем уровне масштабирующие множители присваиваются не каждой из 32 частотных полос БФ, а полосам масштабирования - участкам спектра, не связанным с этими полосами и примерно соответствующим критическим полосам.
■ Энтропийное кодирование квантованных коэффициентов кодом Хаффмана.
■ Наличие «резервуара битов» - запаса, который кодер создает в периоды стационарного входного сигнала.
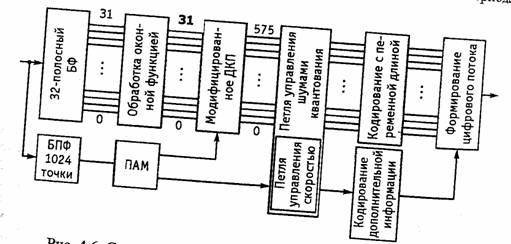
Рис. 4.6. Структурная схема звукового кодера третьего уровня
Кодер третьего уровня более полно обрабатывает стереосигнал в формате joint stereo (MS Stereo). Если кодеры нижележащих уровней работают только в режиме кодирования по интенсивности, когда левый и правый каналы в полосах выше 2 кГц кодируются как один сигнал (но с независимыми масштабирующими множителями), кодер третьего уровня может работать и в режиме «сумма-разность», обеспечивая более высокую степень сжатия разностного канала. Стереосигнал раскладывается на средний между каналами и разностный. При этом второй кодируется с меньшей скоростью. Это позволяет несколько увеличить качество кодирования в обычной ситуации, когда каналы по фазе совпадают. Но это приводит и к резкому его ухудшению, если кодируются сигналы, по фазе не совпадающие, в частности, фазовый сдвиг практически всегда
присутствует в записях, оцифрованных с аудиокассет, но встречается и на CD,
особенно если сам CD был записан в свое время с аудиоленты.
В рамках третьего уровня кодирование стереосигнала допустимо еще тремя различными методами.
■ Joint Stereo (MS/IS Stereo) вводит еще один метод упрощения стереосигнала, повышающий качество кодирования на особо низких скоростях. Состоит в том, что для некоторых частотных диапазонов оставляется уже даже не разностный сигнал, а только отношение мощностей сигнала в разных каналах. Понятно, что для кодирования этой информации употребляется еще меньшая скорость. В отличие от всех остальных, этот метод приводит к потере фазовой информации, но выгоды от экономии места в пользу среднего сигнала оказываются выше, если речь идет об очень низких скоростях. Этот режим по умолчанию используется для высоких частот на скоростях от 96 кбит/с и ниже (другими качественными кодерами этот режим практически не используется). Но, как уже говорилось, при применении данного режима происходит потеря фазовой информации. Кроме того, теряется также любой противофазный сигнал.
■ Dual Channel - каждый канал получает ровно половину потока и кодируется отдельно как монофонический сигнал. Метод рекомендуется главным образом в случаях, когда разные каналы содержат принципиально разные сигналы, например, текст на разных языках. Данный режим устанавливается в некоторых кодерах по требованию.
■ Stereo - каждый канал кодируется отдельно, но кодер может принять решение отдать одному каналу больше места, чем другому. Это может быть полезно в том случае, когда после отброса части сигнала, лежащей ниже порога слышимости или полностью маскируемой код не полностью заполняет выделенный для данного канала объем, и кодер имеет возможность использовать это место для кодирования другого канала. Этим, например, избегается кодирование «тишины» в одном канале, когда в другом есть сигнал. Данный режим используется на скоростях выше 192 кбит/с. Он применим и на более низких скоростях порядка 128 ... 160 кбит/с.
Основные используемые кодеры III Уровня - кодеры от фирмы XingTech, кодеры от фирмы FhG IIS, и кодеры, основанные на исходном коде ISO.
Кодеры от XingTech не отличаются высоким качеством кодирования, но вполне подойдут для кодирования электронной музыки. Благодаря своей скорости они остаются идеальными кодерами для музыки, не требующей высокого качества кодирования.
Кодеры от FhG IIS известны наивысшим качеством кодирования на низких и средних скоростях, благодаря наиболее подходящей для таких скоростей психоакустичекой модели. Из консольных кодеров данной группы наиболее предпочтителен 13епс 2.61. Пока также используется кодер mр3епс 3.1, но последний никто всерьез не тестировал. Другие кодеры, такие, как Audio Active или МРЗ Producer, обладают значительными недостатками в основном из-за ограничения возможностей настройки и неразвитости интерфейса.
Остальные кодеры ведут свое происхождение от исходных кодов ISO. Существует два основных направления развития — оптимизация кода по скорости и оптимизация алгоритма по качеству. Первое направление наилучшим образом представлял кодер BladeEnc, в котором используется первоначальная модель ISO, но проведено много оптимизаций кода, а вторую модель представляет mpegEnc.
Кодер МР3Рго анонсирован в июле 2001 года компанией Coding Technologies вместе с Tomson Multimedia и институтом Fraunhofer. Формат МР3Рго является развитием III уровня (МРЗ). МР3Рго является совместимым с МРЗ назад (полностью) и вперед (частично), т.е. файлы, закодированные с помощью МР3Рго, можно воспроизводить в обычных проигрывателях. Однако качество звучания при этом заметно хуже, чем при воспроизведении в специальном проигрывателе. Это связано с тем, что файлы МР3Рго имеют два потока аудио, в то время как обычные проигрыватели распознают в них только один поток, т.е. обычный MPEG-1 Layer 3.
В МР3Рго использована новая технология — SBR (Spectral Band Replication). Она предназначена для передачи верхнего частотного диапазона. Дело в том, что предыдущие технологии использования психоакустических моделей имеют один общий недостаток: все они работают качественно, начиная со скорости 128 кбит/с. На более низких скоростях начинаются различные проблемы: либо для передачи звука необходимо обрезать частотный диапазон, либо кодирование приводит к появлению различных артефактов. Новая технология SBR дополняет использование психоакустических моделей. Передается (кодируется) чуть более узкий диапазон частот чем обычно (т.е. с обрезанными «верхами»), а верхние частоты воссоздаются (восстанавливаются) уже самим декодером на основе информации о более низких частотных составляющих. Таким образом, технология SBR применяется фактически не столько на стадии сжатия, сколько на стадии декодирования. Второй поток данных, о котором говорилось выше, как раз и есть та минимальная необходимая информация, которая используется при воспроизведении для восстановления верхних частот. Пока достоверно не известно, какую точно информацию несет этот поток, однако проведенные исследования показывают, что эта информация о средней мощности в нескольких полосах частот верхнего диапазона.
Качество звучания МР3Рго можно назвать субъективно очень хорошим даже при скорости потока 64 кбит/с, при этом субъективно несложные композиции при такой скорости воспринимаются не хуже, чем МР3128 кбит/с. Однако, необходимо учитывать тот факт, что такое звучание достигается искусственным путем, и, что слышимый сигнал представляет собой уже не столько оригинал, сколько синтезированную копию оригинала.
4.2.2. Стандарт MPEG-2
MPEG -2 это расширение MPEG-1 в сторону многоканального звука. Следствием совместимости MPEG-2 с MPEG-1 в части кодирования звука стало полное пользование трехуровневой системы, разработанной в MPEG-1 для обработки звуковых данных кодерами стандарта MPEG-2. Различия между стандартами начинаются при переходе от двухканального звука, принятого за основу в MPEG-1, к многоканальному звуку, поддерживаемому в MPEG-2.
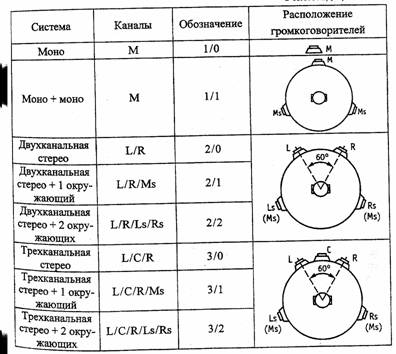
MPEG-2 специфицирует различия режима передачи многоканального звука, в том числе пятиканальный формат, семиканальный звук с двумя дополнительными громкоговорителями, применяемыми в кинотеатрах с очень широким экраном, расширения этих форматов с низкочастотным каналом. Соответствующее расположение громкоговорителей показано в таблице 4.1. В данном случае в числителе дроби указывается число фронтальных каналов, в знаменателе – число каналов, излучаемых сзади.
Таблица 4.1- Иерархия многоканальных звуковых систем согласно
Рекомендации BS.775
Одной из разновидностей многоканального звука является многоязычное звуковое сопровождение. Оно может осуществляться либо передачей отдельного цифрового потока для каждого языка, либо добавлением нескольких (до 7) языковых каналов со скоростью 64 кбит/с к многоканальному потоку кбит/с. Возможна передача дополнительных звуковых каналов для людей с ухудшением зрения и слуха (с описанием сцены в первом случае и отдельным каналом диалогов во втором).
Как же обеспечивается совместимость этих сложных многокомпонентных, сигналов с относительно простым декодером MPEG-1? В кодере MPEG-2 сначала с помощью матрицы формируются комбинированный двухканальный сигнал, совместимый со стереосигналом MPEG-1, и набор вспомогательных сигналов, не совместимых с ним и служащих для восстановления многоканального сигнала в декодере MPEG-2 (рис. 4.7, а). При кодировании двухканальный сигнал укладывается в структуру пакетированного элементарного потока звука совместимого с MPEG-1, и может прочитываться соответствующим декодером. Остальные компоненты после кодирования размещаются в других структурных единицах цифрового потока и доступны только декодеру MPEG-2.
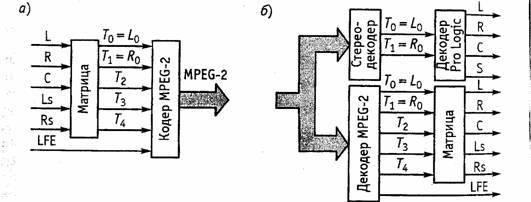
Рис.4.7. Обработка многоканального звукового сигнала в кодере и декодере MPEG-2: а) кодер б) декодер
Учитывая широкое распространение в мире системы Dolby Pro Logic и совместимость ее с обычным стереоканалом, разработчики звукового стандарта MPEG-2 заложили в алгоритм формирование стереосигнала в таком виде, как его формирует указанная система. Владельцы декодера Dolby Pro Logic могут теперь получить многоканальный сигнал двумя способами: либо непосредственно с выхода декодера MPEG-2, либо подав комбинированный стереосигнал (stereo downmix) с выхода более простого декодера MPEG-1 на вход декодера Pro Logic, который выделит из него многоканальный сигнал (рис.4.7, б). Соответствующий интерфейс определен в стандарте IEC61937, он основан на линейной передаче звуковых данных с ИКМ и скоростью до 1536 кбит/с.
Система улучшенного кодирования звука ААС. Одной из лучших современных систем сжатия звука признана система ААС (Advanced Audio Coding) усовершенствованная система кодирования звука), специфицированная в седьмой части стандарта ISO/EEC 13818. В отличие от других методов сжатия звуко данных, принятых в MPEG-2, она не обладает свойством обратной совместимости - декодеры MPEG-1 не могут декодировать сигнал ААС. По своей эффективности ААС вдвое превосходит Уровень II и в 1,4 раза Уровень III стандарта MPEG-1. Высококачественное воспроизведение звука достигается при скорости цифрового потока 96 кбит/с. В стандарте поддерживается широкий набор параметров и возможностей: частоты дискретизации от 8 до 96 кГц моно- и стереосигналы, три профиля - Основной (Main), Упрощенный (LC - Low complexity), Масштабируемый (SSR - Scalable Sampling Rate). Одновременно может быть описано до 16 звуковых программ, состоящих из большого числа сигналов звука и данных (до 48 основных, 15 низкочастотных, 15 многоязычных каналов, 15 потоков данных).
Как и самый сложный из предшествующих, Уровень III из MPEG-1/2 ААС использует все средства цифрового сжатия - полосное кодирование, неравномерное квантование, кодирование кодом Хаффмана, итерационные алгоритмы распределения битов. Однако он улучшает алгоритм Уровня Ш во многих деталях и использует новые эффективные средства кодирования для улучшения качества звучания при очень низких скоростях.
Основные улучшения можно свести к следующим моментам.
■ Улучшено разрешение по частоте благодаря использованию 1024 частотных полос по сравнению с 576 в алгоритме Уровня Ш. При этом короткие блоки имеют длину всего 256 отсчетов, что обеспечивает эффективную обработку быстрых изменений звукового сигнала. Переключение производится по результатам анализа поведения входного сигнала во времени.
■ В Основном профиле применена оптимальная схема предсказания назад, обеспечивающая более высокую эффективность отработки изменений основного тона.
■ Применен более гибкий алгоритм кодирования в режиме joint stereo, как в
режиме кодирования по интенсивности, так и в режиме «сумма-разность».
■ Применен улучшенный код Хаффмана, кодирование четверками частотных линий применяется очень часто, что дополнительно сокращает расход битов.
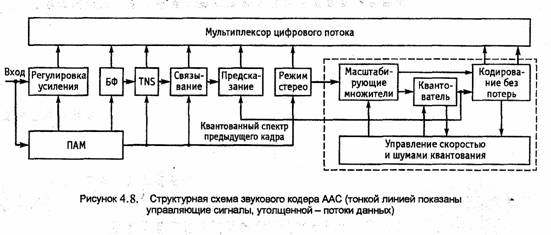
Структурная схема звукового кодера формата ААС Основного профиля приведена на рис. 4.8. Новым элементом по сравнению с Уровнем III можно считать функцию управления шумами во временной области (TNS - Temporal Noise Shaping), позволяющую формировать огибающую шума во временной области по предсказанию в частотной области. Устройство осуществляет фильтрацию сигнала с выхода ДКП набором из нескольких переключаемых Фильтров и квантование полученных групп отсчетов. Коэффициенты квантования передаются в общем цифровом потоке декодеру, который перераспределяет огибающую шума в реконструируемом сигнале с учетом спектрального распределения энергии сигнала. Это полезно при быстрых изменениях
уровня звукового сигнала, когда кодер не успевает переключить блок фильтров на обработку коротких блоков и возникают искажения в виде пред-эхо
На данный момент существуют пять разновидностей формата ААС:
1. Homeboy AAC;
2. AT&T а2Ь ААС;
3. 3.LiquifierPROAAC;
4. Astrid/Quartex ААС;
5. AACPlus.
Все эти модификации несовместимы между собой, имеют собственные
кодеры/ декодеры и неодинаковы по качеству. В целях ознакомления и сравнения этих модификаций между собой рассмотрим все представленные форматы этого семейства.
■ Homeboy ААС. Это самый первый общедоступный кодер, использующий алгоритмы ААС. К сожалению, в процессе модификации авторами были допущены ряд ошибок, что привело к выпадению частот и искажениям, легко слышимыми даже неопытным ухом. Однако и он имел ряд преимуществ. Так, в комплекте с кодеком поставлялся самый первый проигрыватель ААС файлов BitAAC, отличающийся высокой скоростью и приятным интерфейсом, но главное — впервые при использовании алгоритмов ААС было достигнуто качество MP3 128 кбит/с на гораздо более низких скоростях.
Сейчас этот формат уже практически не развивается, последняя версия кодека вышла довольно давно. Но до сих пор появляются бесплатные, так называемые freeware кодеры ААС, которые на самом деле являются разнообразными интерфейсами к кодеку Homeboy ААС.
■ AT&T а2Ь ААС. Компания AT&T являлась одним из крупнейших инвесторов, вложивших свои деньги в разработку алгоритмов MPEG-2 ААС. Вначале алгоритмы сжатия звука интересовали компанию AT&T только как средство для компрессии записанной голосовой информации, передаваемой затем по цифровым телефонным сетям. Но, оценив затем все те выгоды, которые сулил быстрый выход на рынок новейших средств компрессии аудиоданных, особенно в области коммерческого распространения музыки по сети Internet, компания AT&T забрала причитающиеся ей, как инвестору исходные коды формата MPEG-2 ААС и пустилась в самостоятельные разработки.
С этой целью было создано отдельное подразделение компании, которое занималось разработкой собственного формата компрессии аудиоданных, базирующегося на алгоритмах MPEG-2 ААС, и его дальнейшим продвижением. Этот формат получил название а2Ь.
В формат ААС был внесен целый ряд изменений. Так, основной упор был сделан на улучшение качества, но как следствие, при этом уменьшилась степень компрессии аудиоданных. Можно сказать, что а2Ь - это формат с самой низкой степенью сжатия из всего семейства ААС. Так, по степени сжатия а2Ь ААС превосходит МРЗ, но на 15...20% уступает другим форматам семейства ААС. Не удалось добиться и какого-то исключительного качества. Качество звучания а2Ь со скоростью 96 кбит/с существенно лучше, чем качество МРЗ со скоростью 128 кбит/с, но однозначно хуже, чем у форматов Liquid Pro ААС.
Помимо изменения соотношения размер/качество, в формат а2Ь были внесены такие новшества, как возможность включения текста песни и изображений (например, обложка альбома, фотография исполнителя и т.д.) внутрь аудиофайла. Впервые также появилась возможность создавать самовоспроизводящиеся аудиокомпозиции, т.е. аудиофайл преобразуется в запускаемый ехефайл, в который включается необходимый для воспроизведения декодер, при этом размер файла возрастает примерно на 170... 180 кбайт. Не все эти нововведения являются уникальными. Так возможность вставлять текст и картинки в аудиофайл присутствует так же в формате Liquid Pro AAC.
Но отсутствие общедоступного кодека и ничтожно малое количество аудиокомпозиций в формате а2Ь, по сравнению с МРЗ, делают этот формат совершенно не перспективным, особенно на фоне многочисленных конкурентов, продукты которых обладают гораздо более высокими показателями.
■ Liquid Pro AAC. Молодая малоизвестная фирма Liquid Audio в тесной кооперации с институтом Fraunchofer сумела создать формат аудиокомпрессии, который во всех тонкостях следовал алгоритмам MPEG-2 ААС и, помимо этого, содержал ряд нововведений. В результате этого сотрудничества появился формат аудиосжатия Liquid Pro AAC, файлы которого имеют расширение .LQT. Этот формат обладает самым высоким качеством из всех кодеков, базирующихся на алгоритмах MPEG-2 ААС, а также самым лучшим соотношением размер/качество. Данный формат непрерывно развивается. На текущий момент вышли уже пятые версии кодера и плеера, что является своеобразным рекордом для кодеков семейства ААС. Все дефекты звучания и ошибки программ, обнаруженные пользователями немедленно исправляются в новых версиях. Помимо этого компания Liquid Audio непрерывно работает над улучшением кодека и уменьшением размера файлов LQT.
В тестировании, организованном MPEG, было предложено отличить на слух оригинальную CD-композицию и ту же композицию сжатую Liquid Pro ААС со скоростью 256 кбит/с и 80% экспертов не смогли найти разницы. Liquid Pro AAC со скоростью 96 кбит/с, звучит качественнее других ААС кодеков с той же скоростью и однозначно лучше чем МРЗ со скоростью 128 кбит/с.
■ Astrid/Quartex AAC. Этот стандарт, в отличие от всех остальных, создан не большими компаниями, а одним единственным программистом. Никому не известный программист сумел сделать кодек, превосходящий по качеству практически все коммерческие ААС кодеки, за исключением разве что Liquid Pro ААС. 12 сентября 1998 года на некоторых форумах появилось приглашение протестировать новый кодек, находящийся в сети. Уже тогда добровольных тестеров удивила очень высокая степень сжатия при отличном качестве звука, которую предоставлял новоявленный формат. Этот формат содержит все слагаемые успеха: бесплатный общедоступный кодер; такой же бесплатный общедоступный плеер; высокая степень сжатия и отличное качество звука. И действительно, хотя Astrid/Quartex AAC самый молодой из всех ААС кодеков, однако уже добился популярности несравнимой со всеми остальными. Конечно, и у этого кодека есть недостатки. Так, последняя, на текущий момент, версия Astrid/Quartex AAC 0.2 поддерживает только три скорости 64, 96 и 128 кбит/с.
■ AACPlus. 9 октября 2002 года компания Coding Tech анонсировала выход нового кодека AACPlus. AACPlus основан на совершенно аналогичной МР3 Proидее использования технологии SBR. Разница заключается лишь в том, что в МР3Рго основной поток кодируется в МРЗ (MPEG-1 Layer III), а в AACPlus - в AAC (MPEG-2/4 ААС).
4.2.3. Стандарт MPEG-4
В качестве средств компрессии звука в MPEG-4 (ISO/IEC 14496-3) используется комплекс нескольких стандартов кодирования звука: улучшенный алгоритм MPEG-2 ААС, алгоритм TwinVQ, а также алгоритмы кодирования речи HVXC и CELP. Кроме того, MPEG-4 предусматривает множество механизмов обеспечения масштабируемости и предсказания. Однако в целом, стандарт MPEG-4 ААС, предусматривающий правила и алгоритмы кодирования звука, является, в общем, продолжением MPEG-2 AAC. MPEG-4 ААС стандартизует следующие типы объектов (именно так называются профили в MPEG-4 ААС): MPEG-4 AAC LC (Low Complexity), MPEG-4 AAC Main, MPEG-4 AAC SSR (Scalable Sampling Rate), MPEG-4 AAC LTP (Long Term Prediction). Как видно, первые три позаимствованы у MPEG-2 ААС, четвертый же является новшеством. LTP основан на методах предсказания сигнала и является более сложным алгоритмом, нежели остальные.
MPEG-4 - аудио предлагает широкий перечень приложений, которые покрывают область от простой речи до высококачественного многоканального звука, и от естественных до синтетических звуков.
В частности, он поддерживает высокоэффективную презентацию следующих звуковых объектов.
Речь. Кодирование речи может производиться при скоростях обмена от 2 до 24 кбит/с. Низкие скорости передачи, такие как 1,2 кбит/с, также возможны, когда разрешена переменная скорость кодирования. Для коммуникационных приложений возможны малые задержки. Когда используются средства HVXC (Harmonic Vector eXcitation Coding - кодирование с гармоническим возбуждением вектора), скорость и высота тона могут модифицироваться пользователем при воспроизведении. Если используются средства CELP (Code Excited Linear Predictive - линейное предсказание, стимулируемое кодом), изменение скорости воспроизведения может быть реализовано с помощью дополнительного средства.
■ Синтезированная речь. TTS-кодировщики (Text-to-speech — текст в голос) с масштабируемой скоростью в диапазоне от 200 бит/с до 1,2 кбит/с, которые позволяют использовать текст или текст с интонационными параметрами (вариация тона, длительность фонемы, и т.д.), в качестве исходных данных для генерации синтетической речи. При этом выполняются следующие функции:
■ синтез речи с использованием интонации оригинальной речи, управление синхронизацией губ и фонемной информации;
■ трюковые возможности: пауза, возобновление, переход вперед/назад;
■ международный язык и поддержка диалектов для текста (т.е. можно сигнализировать в двоичном потоке, какой язык и диалект следует использовать);
■ поддержка интернациональных символов для фонем;
■ поддержка спецификации возраста, пола, темпа речи говорящего;
■ поддержка передачи меток анимационных параметров лица FAP (facial animation parameter — параметры анимации лица).
Общие аудиосигналы. Поддержка общей кодировки аудиопотоков от низких скоростей до высококачественных. Рабочий диапазон начинается от 6 кбит/с при полосе ниже 4 кГц и распространяется до широковещательного качества передачи звукового сигнала для моно- и многоканальных приложений.
Синтезированный звук. Поддержка синтезированного звука осуществляется декодером структурированного звука (Structured Audio Decoder), который позволяет использовать управление музыкальными инструментами с привлечением специального языка описания.
Синтетический звук с ограниченной сложностью. Реализуется структурируемым аудиодекодером, который позволяет работать со стандартными волновыми форматами.
Примерами дополнительной функциональности является возможность управления скоростью обмена и масштабируемость в отношении потоков данных, полосы пропускания, вероятности ошибок, сложности, и т.д. как это определено ниже.
Возможность работы при изменении скорости передачи допускает изменение временного масштаба без изменения шага при выполнении процесса декодирования. Это может быть, например, использовано для реализации функции «быстро вперед» (поиск в базе данных) или для адаптации длины аудио-последовательности до заданного значения и т.д.
Функция изменения шага позволяет варьировать шаг без изменения временного масштаба в процессе кодирования или декодирования. Это может быть использовано, например, для изменения голоса или для приложений типа караоке. Эта техника используется в методиках параметрического и структурированного кодирования звука.
Изменение скорости передачи допускает анализ потока данных с разбивкой на субпотоки меньшей скорости, которые могут быть декодированы в осмысленный сигнал. Анализ потока данных может осуществляться при передаче или в декодере.
Масштабируемость полосы пропускания является частным случаем масштабируемости скорости передачи данных, когда часть потока данных, представляющая часть частотного спектра, может быть отброшена при передаче или декодировании.
Масштабируемость сложности кодировщика позволяет кодировщикам различной сложности генерировать корректные и осмысленные потоки данных.
Масштабируемость сложности декодера позволяет заданную скорость потока данных дешифровать посредством декодеров с различным уровнем сложности. Качество звука, вообще говоря, связано со сложностью используемого кодировщика и декодера.
Звуковые эффекты предоставляют возможность обрабатывать декодированные аудиосигналы с полной временной точностью с целью достижения эффектов смешения, реверберации, создания объемного звучания и т.д.
Натуральный звук. MPEG-4 стандартизирует кодирование естественного звука при скоростях передачи от 2 до 64 кбит/с. Когда допускается переменная скорость кодирования, допускается работа и при низких скоростях вплоть до 1,2 кбит/с. Использование стандарта MPEG-2 ААС в рамках набора средств MPEG-4 гарантирует сжатие аудиоданных при любых скоростях вплоть до самых высоких. Для того чтобы достичь высокого качества звука во всем диапазоне скоростей передачи и в то же время обеспечить дополнительную функциональность, техники кодирования голоса и общего звука интегрированы в одну систему:
■ кодирование голоса при скоростях между 2 и 24 кбит/с поддерживается системой кодирования HVXC, для рекомендуемых скоростей 2...4 кбит/с; CELP для рабочих скоростей 4...24 кбит/с. Кроме того, HVXC может работать при скоростях вплоть до 1,2 кбит/с в режиме с переменной скоростью. При кодировании CELP используются две частоты дискретизации — 8 и 16 кГц, чтобы поддержать узкополосную и широкополосную передачу голоса, соответственно. Подвергнуты верификации следующие рабочие режимы: HVXC при 2 и 4 кбит/с, узкополосный CELP при 6, 8,3 , и 12 кбит/с, и широкополосный CELP при 18 кбит/с;
■ . для обычного аудиокодирования при скоростях порядка 6 кбит/с и выше, применены методики преобразующего кодирования, в частности TwinVQ и ААС. Аудиосигналы в этой области обычно дискретизируется с частотой 8 кГц.
Метод кодирования MPEG-4 CELP. Метод кодирования MPEG-4 CELP предназначен для обработки речевых сигналов. На практике применяются в основном три основных класса кодеров: кодеры формы, вокодеры и гибридные кодеры.
Кодеры формы характеризуются способностью сохранять основную форму речевого сигнала. К кодерам формы относятся кодеры с импульсно кодовой модуляцией (ИКМ), кодеры с дифференциальной ИКМ (ДИКМ), адаптивной дифференциальной ИКМ (АДИКМ) и др. Системы передачи с подобным типом кодеров обеспечивают хорошее качество воспроизведения речевых сигналов (стандартная полоса частот которых составляет 300...3400 Гц) и более широкополосных звуковых сигналов. Однако, эти кодеры малоэффективны с точки зрения снижения скоростей передачи цифровых сигналов.
Вокодеры (от английских слов «voice» - голос и «coder» - кодирующее устройство) обеспечивают значительно большее снижение скоростей передачи речевых сигналов. Сжатие на передающей стороне производится в анализаторе, выделяющем из речевого сигнала медленно меняющиеся составляющие, которые передаются по каналу связи в виде кодовых комбинаций. На приемной стороне с помощью местных источников сигналов, управляемых с использованием принятой информации, синтезируется речевой сигнал.
Работа вокодеров основана на моделировании человеческой речи с учетом ее характерных особенностей. Вокодер преобразует входной сигнал в некий другой, похожий на исходный. При этом измеряемые характеристики используются для подстройки параметров вокодера в соответствии с принятой моделью речевого сигнала. Именно эти параметры и передаются на декодер
приемника, который по ним восстанавливает (синтезирует) речевой сигнал. При этом оценка качества воспроизведения речи (разборчивость, естественность, узнаваемость и др.) производится с применением субъективно-статистических экспертиз.
Наибольшее распространение получили параметрические вокодеры, в которых из речевого сигнала выделяют два типа параметров:
■ параметры, характеризующие огибающую спектра речевого сигнала (фильтровую функцию);
■ параметры, характеризующие источник речевых колебаний (генераторную функцию): частоту основного тона, ее изменения во времени, моменты появления и исчезновения основного тона, шумового сигнала и др.
В вокодерах с линейным предсказанием (LPC — Linear Predictive Coding) при анализе речевого сигнала в передающем устройстве определяются коэффициенты предсказания, а в приемном устройстве на основе этих коэффициентов с помощью рекурсивного цифрового фильтра синтезируется эквивалент голосового тракта.
При кодировании с линейным предсказанием моделируются различные параметры человеческой речи, которые передаются вместо отсчетов речевого сигнала или их разностей. Это позволяет существенно снизить скорость передачи речевого сигнала по сравнению с методами ИКМ, ДИКМ, АДИКМ.
При кодировании речевых сигналов по методу LPC обычно применяют метод анализа через синтез (Analysis - by - Synthesis (AbS)).
Метод кодирования MPEG-4 HVXC. MPEG-4 HVXC обеспечивает различные категории устойчивости к ошибкам и может применяться в каналах передачи, подверженных влиянию ошибок. Объект HVXC, устойчивый к ошибкам (ER) поддерживается средствами параметрического кодирования голоса (ER HVXC), которые предоставляют режимы с фиксированными скоростями обмена (2...4 кбит/с) и режим с переменной скоростью передачи (более 2 кбит/с, более 4 кбит/с), в рамках масштабируемой и не масштабируемой схем. В версии 1 HVXC, режим с переменной скоростью передачи поддерживается максимум 2 кбит/с, а режим с переменной скоростью передачи в версии ER HVXC 2 дополнительно поддерживается максимум 4 кбит/с. ER HVXC обеспечивает качество передачи голоса международных линий (100...3800Гц) при частоте дискретизации 8 кГц. Когда разрешен режим с переменной скоростью передачи, возможна работа при низкой средней скорости передачи. Речь, кодированная в режиме с переменной скоростью передачи при среднем потоке 1,5 кбит/с, и типовом среднем значении 3 кбит/с имеет то же качество, что и для 2 кбит/с при фиксированной скорости и 4 кбит/с, соответственно. Функциональность изменения тона и скорости при декодировании поддерживается для всех режимов. Кодировщик речи ER HVXC ориентирован на приложения от мобильной и спутниковой связи до IP-телефонии и голосовых баз данных.
Аудиокодирование с малыми задержками. В то время как универсальный аудиокодировщик MPEG-4 очень эффективен при кодировании аудиосигналов при низких скоростях передачи, он имеет алгоритмическую задержку кодирования/декодирования, достигающую нескольких сот миллисекунд и является таким образом, неподходящим для приложений, требующих малых задержек кодирования, таких как двунаправленные коммуникации реального времени Для обычного кодировщика звука, работающего при частоте дискретизации 24 кГц и скорости передачи 24 кбит/с, алгоритмическая задержка кодирования составляет 110 мс плюс до 210 мс дополнительно, в случае использования буфера. Чтобы кодировать обычные аудиосигналы с алгоритмической задержкой, не превышающей 20 мс, MPEG-4 специфицирует кодировщик, который использует модификацию алгоритма MPEG-2/4 ААС.
По сравнению со схемами кодирования речи, этот кодировщик позволяет сжимать обычные типы аудиосигналов, включая музыку, при достаточно низких задержках. Он работает вплоть до частот дискретизации 48 кГц и использует длину кадров 512 или 480 отсчетов, по сравнению с 1024 или 960 отсчетами, используемых в стандарте MPEG-2/4 ААС. Размер окна, используемого при анализе и синтезе блока фильтров, уменьшен в два раза. Чтобы уменьшить искажения в случае переходных сигналов используется переключение размера окна. Для непереходных частей сигнала используется окно синусоидальной формы, в то время как в случае переходных сигналов используется, так называемое, окно с низким перекрытием. Использование буфера битов минимизируется, чтобы сократить задержку. В крайнем случае, такой буфер вообще не используется.
Масштабируемость скорости передачи. Масштабируемость скорости передачи, известная как встроенное кодирование, является крайне желательной функцией. Обычный аудиокодировщик поддерживает масштабируемость с большими шагами, где базовый уровень потока данных может комбинироваться с одним или более улучшенных уровней потока данных, чтобы можно было работать с высокими скоростями и, таким образом, получить лучшее качество звука. В типовой конфигурации может использоваться базовый уровень 24 кбит/с и два по 16 кбит/с, позволяя декодирование с полной скоростью 24 кбит/с (моно), 40 кбит/с (стерео), и 56 кбит/с (стерео). Из-за побочной информации, передаваемой на каждом уровне, малые уровни-добавки поддерживаются не очень эффективно. Чтобы получить эффективную масштабируемость с малыми шагами для стандартного аудиокодировщика, имеется средство побитового арифметического кодирования BSAC (Bit-Sliced Arithmetic Coding). Это средство используется в комбинации с ААС-кодированием и замещает бесшумное кодирование спектральных данных и масштабных коэффициентов.
BSAC предоставляет масштабируемость шагами в 1 кбит/с на аудиоканал, т.е. шагами по 2 кбит/с для стереосигнала. Используется один базовый поток (уровень) данных и много небольших потоков улучшения. Базовый уровень содержит общую информацию вида, специфическую информацию первого уровня и аудиоданные первого уровня. Потоки улучшения содержат только специфические данные вида и аудиоданные соответствующего слоя. Чтобы получить масштабируемость с небольшими шагами, используется побитовая схема квантования спектральных данных. Сначала преобразуемые спектральные величины группируются в частотные диапазоны. Каждая из этих групп содержит оцифрованные спектральные величины в их двоичном представлении. Затем биты группы обрабатываются порциями согласно их значимости. Таким образом, сначала обрабатываются все наиболее значимые биты (MSB) оцифрованных величин в группе и т.д. Эти группы битов затем кодируются с привлечением арифметической схемы кодирования, чтобы получить энтропийные коды с минимальной избыточностью. Представлены различные модели арифметического кодирования, чтобы перекрыть различные статистические особенности группировок бит.
Параметрическое кодирование звука. Средства параметрического аудиокодирования сочетают в себе низкую скорость кодирования обычных аудиосигналов с возможностью модификации скорости воспроизведения или шага при декодировании без блока обработки эффектов. Ожидается улучшенная эффективность кодирования для использования объектов, базирующихся на кодировании, которое допускает выбор и/или переключение между разными техниками кодирования.
Параметрическое аудиокодирование использует для кодирования общих аудиосигналов технику HDLN (Harmonic and Individual Lines plus Noise) при скоростях 4 кбит/с, а выше применяется параметрическое представление аудиосигналов. Основной идеей этой методики является разложение входного сигнала на аудиообъекты, которые описываются соответствующими моделями источника и представляются модельными параметрами. В кодировщике HELN используются модели объектов для синусоид, гармонических тонов и шума.
Из-за очень низкой скорости передачи могут быть переданы только параметры для ограниченного числа объектов. Следовательно, модель восприятия устроена так, чтобы отбирать те объекты, которые наиболее важны для качества приема сигнала.
В HILN параметры частоты и амплитуды оцифровываются согласно с «заметной разницей», известной из психоакустики. Спектральный конверт шума и гармонический тон описан с использованием моделирования LPC. Корреляция между параметрами одного кадра и между последовательными кадрами анализируется методом предсказания параметров. Оцифрованные параметры подвергаются энтропийному кодированию, после чего эти данные вводятся в общий информационный поток.
Очень интересное свойство этой схемы параметрического кодирования происходит из того факта, что сигнал описан через параметры частоты и амплитуды. Эта презентация сигнала позволяет изменять скорость и высоту звука простой вариацией параметров декодера. Параметрический аудиокодировщик HTLN может быть объединен с параметрическим кодировщиком речи MPEG-4 HVXC, что позволит получить интегрированный параметрический кодировщик, покрывающий широкий диапазон сигналов и скоростей передачи. Этот интегрированный кодировщик поддерживает регулировку скорости и тона. Используя в кодировщике средство классификации речи/музыки, можно автоматически выбрать HVXC для сигналов речи и HELN для музыкальных сигналов.
Синтетический звук. MPEG-4 определяет декодеры для генерирования звука на основе нескольких видов структурированного ввода. Текстовый ввод преобразуется в декодере TTS (Text-To-Speech), в то время как прочие звуки,
включая музыку, могут синтезироваться стандартным путем. Синтетическая музыка может транспортироваться при крайне низких потоках данных.
Декодеры TTS (Text To Speech) работают при скоростях передачи от 200 бит/с до 1,2 кбит/с, что позволяет использовать их при синтезе речи в качестве входных данных текст или текст с периодическими параметрами (тональная конструкция, длительность фонемы, и т.д.). Такие декодеры поддерживают генерацию параметров, которые могут быть использованы для синхронизации с анимацией лица, при осуществлении перевода с другого языка и для работы с международными символами фонем. Дополнительная разметка используется для передачи в тексте управляющей информации, которая переадресуется другим компонентам для обеспечения синхронизации с текстом.
Синтез с множественным управлением (Score Driven Synthesis). Средства структурированного звука декодируют входные данные и формируют выходной звуковой сигнал. Это декодирование управляется специальным языком синтеза, называемым SAOL (Structured Audio Orchestra Language), который является частью стандарта MPEG-4. Этот язык используется для определения «оркестра», созданного из «инструментов» (загруженных в терминал потоком данных), которые формируют и обрабатывают управляющую информацию. Инструмент представляет собой маленькую сеть примитивов обработки сигналов, которые могут эмулировать некоторые специфические звуки, которые могут производить настоящие акустические инструменты. Сеть обработки сигналов может быть реализована аппаратно или программно и включать как генерацию, так и обработку звуков, а также манипуляцию записанными ранее звуками.
MPEG-4 не стандартизует «единственный метод» синтеза, а скорее описывает путь описания методов синтеза. Любой сегодняшний или будущий метод синтеза звука может быть описан в SAOL, включая таблицу длин волн, FM, физическое моделирование и гранулярный синтез, а также непараметрические гибриды этих методов.
Управление синтезом выполняется путем включения «примитивов» (score) или «скриптов») в поток данных. Примитив представляет собой набор последовательных команд, которые включают различные инструменты в определенное время и добавляют их сигнал в общий музыкальный поток или формируют заданные звуковые эффекты. Описание примитива, записанное на языке SASL (Structured Audio Score Language), может использоваться для генерации новых звуков, а также включать дополнительную управляющую информацию для модификации существующих звуков. Это позволяет композитору осуществлять тонкое управление синтезированными звуками. Для процессов синтеза, которые не требуют такого тонкого контроля, для управления оркестром может также использоваться протокол МIDI (цифровой интерфейс музыкальных инструментов).
Тщательный контроль в сочетании с описанием специализированных инструментов позволяет генерировать звуки, начиная с простых аудиоэффектов, таких как звуки шагов или закрытия двери, и заканчивая естественными звуками, такими как шум дождя или музыка, исполняемая на определенном инструменте или синтетическая музыка с полным набором разнообразных эффектов.
Для терминалов с меньшей функциональностью, и для приложений, которые не требуют такого сложного синтеза, стандартизован также «формат волновой таблицы» («wavetable bank format»). Используя этот формат, можно загрузить звуковые образцы для использования при синтезе, а также выполнить простую обработку, такую как фильтрация, реверберация, и ввод эффекта хора. В этом случае вычислительная сложность необходимого процесса декодирования может быть точно определена из наблюдения потока данных, что невозможно при использовании SAOL.
4.2.4. Стандарт MPEG-7
Аудио MPEG-7 FCD имеет пять технологий: структура описания звука, которая включает в себя масштабируемые последовательности, дескрипторы нижнего уровня и униформные сегменты тишины; средства описания тембра музыкального инструмента; средства распознавания звука; средства описания голосового материала и средства описания мелодии.
Описание системы аудио MPEG-7. Аудиоструктура содержит средства нижнего уровня, которые обеспечивают основы для формирования звуковых приложений высокого уровня. Предоставляя общую платформу структуры описаний, MPEG-7 Audio устанавливает базис для совместимости всех приложений, которые могут быть созданы в рамках данной системы.
Существует два способа описания звуковых характеристик нижнего уровня. Один предполагает дискретизацию сигнала на регулярной основе, другой . может использовать сегменты для пометки сходных и отличных областей для заданного звукового отрывка. Обе эти возможности реализованы в двух типах дескрипторов нижнего уровня (один - для скалярных величин, таких как мощность или частота, другой — для векторов, таких как спектры), которые создают совместимый интерфейс. Любой дескриптор, воспринимающий эти типы может быть проиллюстрирован примерами, описывающими сегмент одной результирующей величиной или последовательностью результатов стробирования, как этого требует приложение.
Величины, полученные в результате стробирования, сами могут подвергаться последующей обработке с привлечением другого унифицированного интерфейса: они могут образовать масштабируемые ряды (Scalable Series). Дерево шкал может также хранить различные сводные значения, такие как минимальное, максимальное значение дескриптора и его дисперсию.
Звуковые дескрипторы. Звуковые дескрипторы нижнего уровня имеют особую важность при описании звука. Существует семнадцать временных и пространственных дескрипторов, которые могут использоваться в самых разных приложениях. Они могут быть грубо поделены на следующие группы:
■ базовая — мгновенные значения уровня волнового сигнала и мощности;
■ базовая спектральная - частотный спектр мощностей, спектральные характеристики, включая среднее значение, спектральная полоса и спектральная однородность;
■ параметры сигнала - фундаментальная частота квазипериодических
сигналов гармоничность сигналов;
■ временная группа по тембру - временной центроид;
■ спектральная группа по тембру - специфические спектральные актеристики в линейном пространстве частот (включая спектральный центроид и спектральные свойства), специфические для гармонических частей сигналов (включая спектральное смещение и спектральную ширину);
■ представления спектрального базиса - характеристики, используемые для распознавания звука.
Каждый из них может использоваться для описания сегмента с результирующим значением, которое применяется для всего сегмента или для последовательности результатов дискретизации. Временная группа по тембру (Timbral Temporal) является исключением, так как ее значения применимы только к сегменту, как целому.
В то время как звуковые дескрипторы нижнего уровня вообще могут служить для многих возможных приложений, дескриптор однородности спектра поддерживает аппроксимацию сложных звуковых сигналов. Приложения включают в себя голосовую идентификацию.
Кроме того, очень простым, но полезным средством является дескриптор тишины. Он использует простую семантику «тишины» (т.е. отсутствие значимого звука) для аудиосегмента. Такой дескриптор может служить для целей дальнейшей сегментации звукового потока.
Средства описания звука верхнего уровня (D и DS). Четыре набора средств описания звука, которые приблизительно представляют области приложения, интегрированы в FCD: распознавание звука, тембр музыкального инструмента, разговорный материал и мелодическая линия.
Средства описания тембра музыкальных инструментов. Дескрипторы тембра служат для описания характеристик восприятия звуков. Тембр в настоящее время определен в литературе как характеристика восприятия, которая заставляет два звука, имеющих одну высоту и громкость, восприниматься по-разному. Целью средства описания тембра является представление этих характеристик восприятия сокращенным набором дескрипторов. Дескрипторы относятся к таким понятиям как «атака», «яркость» или «богатство» звука.
В рамках четырех возможных классов звуков музыкальных инструментов, два класса хорошо детализированы, и являются центральным объектом экспериментального исследования. В FCD представляются гармонические, когерентные непрерывные звуки и прерывистые, ударные звуки. Дескриптор тембра для непрерывных гармонических звуков объединяет спектральные дескрипторы тембра с временным дескриптором (log attack). Дескриптор ударных инструментов комбинирует временные дескрипторы тембра с дескриптором спектрального центроида. Сравнение описаний, использующих один из наборов Дескрипторов, выполняется с привлечением метрики масштабируемого расстояния.
Средства распознавания звука. Схемы дескрипторов и описаний распознавания звука, представляют собой наборы средств для индексирования и категорирования звуков, с немедленным использованием для звуковых эффектов. Добавлена также поддержка автоматической идентификации звука и индексация. Это сделано для систематики звуковых классов и средств для спецификации онтологии устройств распознавания звука. Такие устройства могут использоваться для автоматической индексации сегментов звуковых треков.
Средства распознавания используют в качестве основы спектральные базисные дескрипторы низкого уровня. Эти базисные функции далее сегментируются и преобразуются в последовательность состояний, которые заключают в себя статистическую модель, такую как смешанная модель Маркова или Гаусса. Эта модель может зависеть от своего собственного представления, иметь метку, ассоциированную с семантикой исходного звука, и/или с другими моделями для того, чтобы разбить на категории новые входные звуковые сигналы для системы распознавания.
Средства описания содержимого сказанного (Spoken Content). Средства описания Spoken Content позволяют детальное описание произнесенных слов в пределах аудиопотока. Учитывая тот факт, что сегодняшнее автоматическое распознавание речи ASR-технологий (Automatic Speech Recognition) имеет свои ограничения, и что всегда можно столкнуться с высказыванием, которого нет в словаре, средства описания Spoken Content жертвует некоторой компактностью ради надежности поиска. Чтобы этого добиться, средства отображают выходной поток и то, что в норме может быть видно в качестве текущего результата автоматического распознавания речи ASR. Средства могут использоваться для двух широких классов сценария поиска: индексирование и выделение аудиопотока, а также индексирование мультимедийных объектов аннотированных голосом
Средства описания Spoken Content поделены на два широких функциональных блока: сетка, которая представляет декодирование, выполненное сиcтемой ASR, и заголовок, который содержит информацию об узнанных собеседниках и о самой системе распознавания. Сетка состоит из комбинаций слов голосовых записей для каждого собеседника в аудио потоке. Комбинируя эти сетки, можно облегчить проблему со словами, отсутствующими в словаре, и поиск может быть успешным, даже когда распознавание исходного слова невозможно.
Средства описания мелодии. DS (схема описания) мелодического очертания (Melody Contour) является компактным представлением информации о мелодии, которая позволяет эффективно и надежно контролировать мелодическую идентичность. Например, в запросах с помощью наигрывания. DS мелодического очертания используется пятиступенчатый контур (представляющий интервал между смежными нотами), в котором интервалы дискретизированы. DS мелодического очертания (Melody Contour DS) предоставляет также базовую информацию ритмики путем запоминания частот, ближайших к каждой из нот. Это может существенно увеличить точность проверки соответствия запросу.
Для приложений, требующих большей описательной точности или реконструкции заданной мелодии, DS-мелодии поддерживает расширенный набор дескрипторов и высокую точность кодирования интервалов. Вместо привязки к одному из пяти уровней, в точных измерителях используется существенно больше уровней между нотами (100 и более). Точная информация о ритмике получается путем кодирования логарифмического отношения разностей между началами нот. При этом способ аналогичен способу, используемому для кодирования уровней сигнала.
Для обеспечения правильного декодирования компрессированных сигналов кроме кодовых слов отсчетов звуковых сигналов или соответствующих им коэффициентов МДКП (основная аудиоинформация), к декодеру передается также и определенная дополнительная информация. После кодирования цифровые потоки основной и дополнительной информации форматируются. При этом наиболее важная часть цифровых данных подвергается помехоустойчивому кодированию.
4.3. Метод сжатия звука Ogg Vorbis
Сразу после своего появления формат МРЗ приобрел бешеную популярность у пользователей персонального компьютера. Подумать только, теперь на аудиодиск размером 650 Мб можно поместить в 10 раз больше звуковой информации, при этом сохранив приемлемое качество. Созданные таким образом файлы можно без проблем пересылать через Интернет, использовать в переносных устройствах, собирать музыкальные коллекции. Но не все было так безоблачно. Появившись, он практически сразу стал причиной многочисленных скандалов, споров, преследований.
Все началось с того, что компании Fraunhofer Institute и Thomson Multimedia, имеющие патент на данный формат, объявили, что он, увы, совсем не бесплатный, и потребовали некоторых отчислений за каждый кодек. Но и этого мало: постоянно в Сети появляются сообщения о том, что условия лицензирования данного продукта могут в корне измениться, и теперь придется платить и за каждый распространенный экземпляр декодера (проигрывателя). Вдоволь наслушавшись споров и возмущений общественности, остановились (пока) на отчислениях только с коммерческих программ и бытовых устройств, но кто знает, что нас ждет впереди. С другой стороны, в странах, особо тщательно следящих за соблюдением патентов, могут возникнуть проблемы при его использовании, именно поэтому компания Red Hat, находящаяся в США, отказалась от включения в последних версиях своего дистрибутива средств работы с Данным форматом, опасаясь возможных проблем.
Следующая проблема заключается в том, что в самом формате не была заложена возможность препятствовать нарушению авторских прав. Даже всемогущая Microsoft не удержалась и на всякий случай изобрела быстренько свой собственный алгоритм сжатия звуковых файлов (он нем мы поговорим позже). Не остался в стороне и мир
OpenSource - в июле 2002 года миру был официально представлен оригинальный формат сжатия звука, именуемый Ogg Vorbis. Спонсором проекта на первом этапе была компания iCast, транслировавшая и Распространявшая музыку через Интернет. В случае успеха и перехода на новый формат она могла бы сэкономить на отчислениях, но к сожалению, до выхода своего детища компания разорилась.
Итак, что же представляет собой новый формат? OggVorbis — это самый молодой формат из всех конкурентов МРЗ разработан группой Xiphophorus и является всего лишь небольшой частью из мультимедиа проекта OggSquish, в котором будет помимо форматов аудиосжатия еще и кодеки видеокомпрессии. Впрочем, это все в будущем, а пока OggVorbis - единственный реально существующий формат из этого семейства, да и то в виде бета-версии кодека.
OggVorbis принадлежит к тому же типу форматов аудиосжатия, что и МРЗ, AAC, VQF, РАС, QDesign AEFF и WMA, т.е. к форматам сжатия с потерями. Психоакустическая модель, используемая в OggVorbis по принципам действия близка к МРЗ и иже с ними, но и только — математическая обработка и практическая реализация этой модели в корне отличается, что позволяет авторам объявить свой формат совершенно независимым от всех предшественников.
Главное неоспоримое преимущество формата OggVorbis — это его полная открытость и бесплатность. Казалось бы, что тут удивительного? WMA тоже бесплатен и Astrid/Quartex... Да это так, но авторам этих форматов и в голову не пришло опубликовать исходные коды своих разработок, a Xiphophorus именно это и сделала. OggVorbis создается в рамках проекта GNU и полностью подчиняется GNU GPL (генеральная публичная лицензия). А это означает, что формат совершенно открыт для коммерческого и некоммерческого использования, его коды можно модифицировать безо всяких ограничений, группа разработчиков оставляет за собой лишь право утверждать новые спецификации формата. Некоторые ограничения, конечно, все же есть, они определены в GNU GPL. Согласно правилам GNU GPL можно делать любые изменения в коде программы, но при этом получившийся программный продукт так же должен подчиняться уложениям GNU GPL.
Правда, Xiphophorus все еще имеет возможность закрыть этот открытый формат и сделать его полностью коммерческим, ведь GNU — это полностью добровольная концепция. Но по заявлениям разработчиков, они этого делать не собираются. Выгоды от доступного, свободного от лицензий формата перевешивают выгоды получения денег за лицензии на его использование - именно так считают создатели OggVorbis и в качестве примера указывают на МРЗ. Разве достигла бы такого размаха индустрия МРЗ, если бы сам формат не стал бы бесплатен для конечных пользователей? Xiphophorus собирается пойти еще дальше и сделать формат бесплатным не только для пользователей, но и разработчиков программного обеспечения и аппаратуры. Создатели формата не требуют никаких лицензионных плат за любое использование спецификации OggVorbis. Сторонние разработчики вполне свободны создавать и продавать (или отдавать) свои собственные кодеры и декодеры использующие спецификацию OggVorbis. Но если используются программные продукты созданные именно Xiphophorus, например, кодек в виде DLL библиотеки или SDK-комплекты OggVorbis, в составе коммерческих разработок, необходимо будет j за них заплатить. Бесплатно только для некоммерческих проектов, подчиняющихся GNU GPL, т.е. распространяющихся свободно и вместе с исходными копами. Подобный подход заранее определяет мультиплатформенность OggVorbis.
Помимо бесплатности, OggVorbis, как спецификация, обладает также еще целым рядом неоспоримых достоинств. Так, верхняя планка частоты выборки составляет не 44 кГц, как у всех форматов, а 48 кГц, что, безусловно, более близко к живой музыке по сравнению с CD. Кроме того, число каналов не ограничено двумя как обычно — моно и стерео, а достигает 255! Представьте себе акустическую систему из 255 акустических систем! Поистине формат сделан с запасом. А ведь наступит когда-нибудь время, когда 48 кГц и 255 каналов станут нормой для компьютерного музыкального центра, а не экзотикой как сейчас.
OggVorbis использует математическую психоакустическую модель отличную от МРЗ, и это сказывается на звучании. МРЗ и OggVorbis трудно сравнивать, но в целом звучание OggVorbis гораздо лучше.
При кодировании кодеки OggVorbis используют VBR (variable bitrate), подобно некоторым МРЗ кодекам, что позволяет существенно уменьшить размер композиции, при незначительной потере качества.
Вышедшая бета версия кодека OggVorbis содержит всего одну довольно странную скорость — 136 кбит/с, но в самой спецификации заложен гораздо более широкий диапазон от 8 до 512 кбит/с. Последняя цифра выглядит чрезмерной, но не стоит забывать, что OggVorbis поддерживает до 255 каналов одновременно и, возможно, что если такие аудиокомпозиции появятся, то даже полумегабитной ширины потока может оказаться недостаточно.
Спецификация OggVorbis содержит очень гибкий и развитый механизм включения комментариев и иллюстраций в тело аудиокомпозиции. Заголовок комментария легко расширяется и позволяет включать тексты любой длины и сложности, перемежающиеся изображениями. Можно разместить хоть целую книгу о любимом актере. К сожалению, в бета-версии кодека эта возможность не реализована, но в будущем все исправится.
Что же касается скорости кодирования, то тут пока нет никаких выдающихся результатов. Скорость кодека OggVorbis не быстрее кодека МРЗ. Разработчики признают, что код кодека совершенно не оптимизирован, так как эта программа была выпущена как можно быстрее для демонстрации спецификации, чтобы не быть голословными. Т.е., в будущем можно ожидать существенного улучшения скоростных характеристик, особенно, когда подключатся сторонние производители.
OggVorbis, как и МРЗ, изначально разрабатывался как сетевой потоковый формат. Это свойство является очень важным, особенно учитывая мультиплатформенную направленность формата OggVorbis. Интернет-радиостанция использующая низкоскоростные версии OggVorbis сможет вещать сразу на всех платформах, тогда как такая же радиостанция, использующая для передачи WMA (в виде ASF) будет ограничена только пользователями Windows.
Формат OggVorbis прочился разработчиками в преемники МРЗ. И для этого есть все основания. OggVorbis содержит не только все те компоненты, которые обеспечили популярность МРЗ: отличное качество, малый размер, бесплатность для конечного пользователя, потоковость, но и ряд преимуществ, которых у МРЗ нет: бесплатность для разработчиков, отсутствие лицензионных платежей, более высокая частота дискретизации и значительно большее число поддерживаемых каналов.
Именно благодаря открытости формата об OggVorbis удалось узнать то, что не удавалось для всех других форматов (разве что, кроме МрЗ) — как он работает. Все остальные конкуренты МРЗ тщательно скрывают внутренние алгоритмы компрессии, и лишь OggVorbis выставляет их на показ. Разумеется, мы не будем рассматривать исходные коды формата, ограничившись простым описанием того, что происходит внутри кодека при кодировании/декодировании аудиокомпозиций.
На первом этапе кодирования, композиция временно разбивается на блоки таким образом, чтобы их было целое число. Размер блоков варьируется. Далее в ход вступают алгоритмы анализа. Кодер анализирует содержимое аудиокомпозиции с целью добиться ее максимально компактного представления. При анализе происходит разделение блоков входящего аудиопотока на индивидуальные и повторяющиеся. Это разделение необходимо при кодировании с использованием переменной скорости потока. Соответственно индивидуальные и повторяющиеся блоки будут кодироваться с разными скоростями.
Далее идет анализ содержимого блоков на предмет выявления нужных и ненужных частот и тонов, т.е. вступает в ход психоакустическая модель. Так как OggVorbis, как и МРЗ, это формат с потерями, то качество формата во многом зависит от того, насколько эти потери серьезны, и насколько удачно их можно замаскировать. Насколько можно судить по бета-версии кодека психоакустическая модель работает вполне корректно, качество довольно высокое, по крайней мере выше, чем у МРЗ. Насколько можно понять, психоакустическая модель OggVorbis практически не сокращает диапазон верхних звуковых частот, вернее, сокращает, но верхняя планка поднята достаточно высоко, чтобы удовлетворить даже самый изысканный слух. Итак, верхние частоты не трогают, но уменьшать композицию надо. За счет чего?
В OggVorbis главный акцент сделан на анализе маскирующего влияния сигналов звучащих одновременно. Эта часть сделана гораздо более изощренно и эффективно чем у МРЗ. В ходе анализа находятся сильные сигналы и сигналы, которые маскируются этими сигналами, т.е. находятся в своеобразной звуковой «тени». Затем рассчитывается среднее время маскировки для каждого из маскируемых сигналов. Все сигналы, лежащие в области звуковой «тени» и попадающие в расчетное время маскировки помечаются на удаление. Конечно, всегда найдутся люди, не вписывающиеся в среднестатистическое большинство. У них эффект маскировки может проходить быстрее, чем за рассчитанное кодеком время и может ощущаться отсутствие определенных частот и сигналов. Но обычные слушатели ничего не заметят.
На следующей стадии происходит удаление информации, которую алгоритмы анализа признали излишней.
Оставшуюся информацию сжимают алгоритмами Хаффмана и подвергают векторному квантованию в соответствии с установленной скоростью.
При декодировании или синтезе звука, происходит обратный процесс. В целом декодирование проще, так как отсутствует стадия анализа, но оно осложнено технологиями, назначение которых состоит в том, чтобы улучшить качество звучания. В процессе воспроизведения качество звука повышается путем использования интерполяции билинейной или бикубической, в зависимости от реализации декодера. Интерполяция позволяет смягчить потери при использовании низких скоростей. Качество композиции повышается, но при этом теряется четкость, особенно слоговая разборчивость человеческого голоса. Подобный поход оправдывает себя на мелодиях без голоса, но для песен и арий из опер он малопригоден. На высокой скорости интерполяция минимальна, заглаживаются лишь те «дыры», которые образовались на месте звуков оказавшихся в «тени» сильных тонов. Кроме интерполяции используются разнообразные шумовые фильтры, позволяющие смягчить или совсем убрать шумы квантования, которые появляются при потере информации в результате процедуры векторного квантования. Чем ниже скорость, тем выше шум квантования.
Но вернемся к кодированию аудиофайла. После стадий анализа, удаления избыточной информации и собственно кодирования происходит преобразование уже конечной информации в потоковый формат bitstream OggSqish. Подобно тому, как ASF является форматом пересылки данных для всего семейства Windows Media, так и bitstream OggSquish является единым форматом пересылки потока данных для всего мультимедиа семейства OggSquish.
Полученная информация разбивается на кадры (фреймы). Каждый кадр имеет упорядоченную структуру и заголовок, содержащий номер кадра, его контрольную сумму и прочую инженерную информацию. Контрольная сумма нужна для коррекции ошибок. В том случае если кадр испорчен, декодер его воспроизводить не будет, т.е. кадр пропускается, и воспроизведение начинается со следующего целого кадра.
После формирования заголовка композиции и первого кадра, далее процесс идет по циклу, эта стадия называется «конкатенация» или формирование цепочки. Начало и конец каждого кадра отмечается специальными сигналами-маркерами. И так до образования последнего кадра и концовки содержащей код окончания файла.
И напоследок несколько слов о перспективах формата OggVorbis.
Формат очень новый и трудно что-либо сказать до выхода первого официального кодека, в котором будут реализованы все особенности спецификации OggVorbis. Но даже сейчас видно, что у формата большие возможности, главное его надо «раскрутить» и привлечь сторонних разработчиков.
4.4. Метод сжатия звука MusePack
Естественно, Ogg Vorbis является не единственной некоммерческой разработкой такого рода. Энтузиасты продолжали и продолжают делать попытки создания альтернативных качественных аудиокодеков. Кодек MPEGplus (MPEG+) был позже переименован в MusePack (MPC) из-за проблем, которые появились у автора кодека в связи с тем, что название последнего содержало в себе аббревиатуру «MPEG».
MusePack — это еще одна разновидность сжатия звука с потерями сродни МРЗ. Точнее, MusePack не является продолжением MPEG-1 Layer III, а лишь, как и МРЗ, берет свое начало в MPEG-1 Layer П. MusePack создан «в домашних условиях» и разрабатывался(ется) в основном двумя людьми: Andre Buschmann и Frank Klemm. Кодек, как уже было сказано, базируется на MPEG-1 Layer П, отсюда его направленность на кодирование преимущественно на более высоких скоростях, нежели МРЗ. В то же время, кодек является совершенно самостоятельной разработкой.
Кодеком предусмотрено кодирование только в режиме переменной скорости потока. Скорость компрессии и декомпрессии в/из МРС заметно выше скорости выполнения этих операций применительно к МРЗ.
В среднем, качество кодирования МРС на высоких скоростях (160 Кбит/с и выше) заметно (если не сказать «значительно») выше качества, обеспечиваемого МРЗ. Это связано с различиями в механизмах кодирования. Ранее мы отмечали, что МРЗ при кодировании разбивает сигнал на частотные подполосы, затем производит разложение сигнала в ряд косинусов (MDCT — частный случай преобразования Фурье) и записывает округленные (квантованные) значения полученных после преобразования коэффициентов. МРС же после разбиения сигнала на частотные подполосы просто производит переквантование (опираясь на психоакустическую модель) сигнала в каждой подполосе и полученные округленные (квантованные) значения записывает в выходной поток. Этим же фактом объясняется и большая скорость компрессии и декомпрессии МРС.
В отличие от Ogg Vorbis , кодек MusePak переживает сегодня не самые лучшие времена — в то время, как Ogg Vorbis получает все более и более широкое распространение (как среди пользователей, так и среди производителей), MusePak остается малоизвестным, хотя и незаслуженно.
4.5. Формат Windows Media Audio (WMA)
Перед тем, как приступить к рассмотрению этого формата хотелось бы разрешить некоторую путаницу, которая возникла вокруг его названия. Некоторые авторы в своих статьях называют этот формат форматом аудиосжатия WMA (Windows Media Audio), а некоторые - форматом аудио- (видео-) сжатия ASF (Advansed Streaming Format). Так вот, ASF ни коим образом не является форматом сжатия аудио- или видеоинформации, а те, кто так пишет либо заблуждаются, либо просто не удосужились вникнуть в некоторые тонкости перевода технической документации. Как следует из названия, ASF - это продвинутый формат передачи информационного потока и вполне годится для пересылки как аудио- и видеоданных, так и вообще любой информации. При этом ASF не сжимает данные, этим занимаются отдельные кодеки, например, WMT
для аудиофайлов и Windows Media MPEG-4 (а теперь и Windows Media Video) для видео.
ASF обеспечивает непрерывность получения потока данных, столь необходимую любому сетевому формату мультимедиа. Для достижения этой цели формат использует наряду с уже известными и проверенными решениями, такими как разбивку передаваемой информации на кадры, буферизацию для обеспечения одновременного получения и обработки данных, проверку контрольной суммы кадров для коррекции ошибок, и некоторые технологические новинки являющиеся секретом фирмы Microsoft .
На практике сочетание ASF + мультимедиа-кодек является примерным аналогом широко распространенной в Unix - системах парой tar + gzip. Gzip -это архиватор,
a tar - это менеджер - «сборщик», собирающий все сжатые файлы и каталоги в один файл архива. Здесь ситуация весьма схожа. Кодек — это своего мультимедиа-архиватор, а формат ASF - менеджер пересылки, отвечающий за передачу данных.
Нас интересует, собственно, только звуковая часть кодеков, которые используются вместе с ASF. Именно та часть, которую Microsoft (устав от неразберихи, связанной с ASF) наконец-то, решив стандартизировать свои мультимедиа-форматы, требует называть WMA (существует еще и WMV — Windows Media Video - стандарт, который все еще продолжают называть ASF, тем более, что Media Player прекрасно его понимает и с таким расширением).
Несмотря на то, что WMA как стандарт появился сравнительно недавно, чуть ли не последним из всех конкурентов МРЗ, история этого формата, вернее его кодека, началась гораздо раньше.
Компания Voxware известная своими разработками в области мультимедиа, непоседливостью и большим интересом ко всему новому и передовому в мае 1998 года примкнула к проекту TwinVQ, разработанному творческой группой Human Interface Laboratory, являющейся подразделением компании NTT, с целью развития и усовершенствования этого формата, который на тот момент был еще очень сырым и не оптимизированным. Содружество это увенчалось успехом - стандарт VQF был доработан и приобрел тот вид, в котором мы его видим и сейчас.
Ну, а компания Voxware, убедившись, что и без нее дела идут неплохо, решительно пустилась в самостоятельное плавание. Используя собственные новаторские идеи, а также некоторые фрагменты технологии TwinVQ, приобретя на эту разработку определенные права, Voxware создала собственный формат, который реально воплотился в кодеке под названием Voxware Audio CODEC v4.0. Когда были выпущены первые три версии - это науке не известно, ну а этот кодек прославился сразу по нескольким номинациям.
Во-первых, в этом кодеке было впервые достигнуто качество МРЗ 128 при скорости всего 64 кбит/с!
Во-вторых, на этот формат обратили внимание сразу несколько крупных телефонных компаний, так как сжатая этим кодеком голосовая информация обладала, даже при скорости всего 64 кбит/с очень высокой разборчивостью. Экспертами было установлено, что при скорости 64 кбит/с слоговая разборчивость голоса достигала 90%, в то время, как у других форматов аудиосжатия подобный показатель наблюдается при скорости в 2...2,5 раза больше, т.е. при скорости 128 и 160 кбит/с соответственно. Новый формат Voxware, как оказалось идеально адаптирован именно для сжатия оцифрованного человеческого голоса.
На некоторых высокоскоростных цифровых телефонных сетях США и Канады была апробирована система сжатия голосовой информации имеющая в своей основе аппаратную реализацию разработок Voxware. Данная система позволяла вести по одной линии четыре отдельных разговора одновременно без каких-либо искажений.
И, наконец, поддержка этого кодека была включена компанией Microsoft в бесплатный Media Player. Чтобы убедиться в этом, достаточно посмотреть список поддерживаемых форматов - там есть строчка «Voxware Audio CODEC». Если учесть тот факт, что Microsoft до сих пор так и не удосужилась поддержать VQF и все разновидности ААС, то такая поддержка дорогого стоит. Но помимо этих неоспоримых достоинств кодек обладает также массой недостатков, представляя собой недоделанный, сырой продукт. Собственно после выпуска работающей версии кодека пыл Voxware несколько поугас, ведь эта область уже более или менее отработана, а на свете столько всего нового, не открытого. В общем, выпуска следующей версии кодека пользователи ждали бы долго, если бы не произошло одно событие...
А это событие заключается в том, что в один прекрасный день руководство фирмы Microsoft вдруг осознало, что множество компаний в мире производит программные кодеки для сжатия звуковой информации. При этом компания Microsoft, которая бьется за звание крупнейшего мирового монополиста, еще ничего не сделала в этой области, продолжая использовать в качестве основного звукового формата своих операционных систем несжатую аудиоинформацию в виде WAV-файлов. Правда, регулярно выходят новые версии Media Player, в котором постоянно увеличивается список поддерживаемых форматов, но нет ни одного кодека, на котором было бы написано «Сделано компанией Microsoft». Надо что-то срочно делать, но что, если своих разработок нет?
И Microsoft поступила, как она поступала уже не раз, в точности в соответствии своему главному принципу «Зачем изобретать велосипед, если его уже изобрел кто-то другой? Его надо купить!». Да, своей популярностью операционная система Windows во многом обязана именно тем компонентам, которые были в свое время удачно куплены и впоследствии доработаны и разрекламированы.
Достаточно привести всего несколько примеров. В феврале 1995 года компания Microsoft, что называется буквально «на корню» закупила маленькую британскую компанию RenderMorphics и на основе ее революционных разработок в области трехмерной графики под общим названием RealityLabs создала один из своих главнейших программных продуктов, на долгие годы определивший популярность операционной среды Windows. Речь идет о DirectX комплекте программ и библиотек, который является ни много, ни мало, как одним из китов, на котором покоится популярность Windows.
Другой опорный кит был куплен Microsoft у творческой группы National Сenter for Supercomputing Applications (NCSA). Речь идет о некогда знаменном Интернет-браузере Mosaic или вернее NCSA Mosaic. Уже немногие помнят те далекие времена, когда на рынке веббраузеров были всего два представителя Netscape и Mosaic. В ходе маркетинговых баталий Mosaic проиграл битву, но уникальные разработки не пропали, а были куплены Microsoft и после тщательной переработки превращены в продукт, который теперь знают все - Microsoft Internet Explorer. Начиная с 1996 года этот браузер не только бесплатен, но и весьма навязчиво предлагается всем пользователям Windows, являясь неотьемлемой частью этой операционной системы Этот факт послужил причиной вполне законной обиды компании Netscape. Понятно, что конкурировать с бесплатным продуктом невероятно сложно, но дело уже было сделано и никакими судами и дроблениями Microsoft на отдельные компании случившегося уже не поправишь. Стоит отметить, что MSIE честно пишет, что он основан на технологиях NCSA Mosaic.
Итак, есть два кита, две опоры, но, как известно, такая конструкция неустойчива. И Microsoft решила прикупить третью опору в образе перспективного кодека Voxware Audio CODEC v4.0. Разработка была полностью скуплена и программисты компании приступили к дальнейшей доработке и сопряжению ее с другими частями операционной системы Windows.
К чести Microsoft, стоит отметить, что эта компания не сразу кинулась в погоню за конкурентами заполучив новинку, а предварительно хорошо поработала над этим в общем-то сыроватым кодеком доведя его до ума и лишь потом выпустила в широкие массы. Этот кодек хоть и вышел позднее других, зато обладал гораздо более высокими характеристиками и главное он бесплатен! Похоже Microsoft изобрела наиболее эффективный способ уничтожения конкурентов - делать собственные продукты бесплатными, но с поддержкой только Windows и MSIE.
Новорожденный формат без потуг на оригинальность был назван WMA -Windows Media Audio. Этот формат позиционируется своими создателями как преемник целой плеяде устаревающих аудиоформатов, начиная с Real Audio и заканчивая MPEG Layer Ш.
Но, похоже, что WMA может сменить не только устаревающие форматы, но и относительно новые. Вот несколько фактов.
Низкоскоростная версия WMA по качеству ощутимо превосходит Real Audio. Соотношение размер/качество для WMA в 2...3 раза выше, чем аналогичный параметр у Real Audio. Более того, WMA превосходит по качеству относительно новый формат QDesign AIFF. Так, при максимальной для QDesignAIFF скорости 48 кбит/с, аудиофайлы WMA имеют гораздо меньше искажении потерь. Кроме того, формат WMA бесплатен, a QDesign AIFF стоит порядка 20 долларов. Так что, думаю, судьба сетевого радио на ближайшие несколько лет предопределена.
WMA со скоростью 64 кбит/с лучше МРЗ 128 кбит/с или по крайне мере обладает тем же качеством. Кодек позволяет легко перекодировать из МРЗ в WMA с любой скоростью.
И напоследок несколько слов о перспективах WMA. Аналитики довольно известной компании International Data Corp., которая занимается в основном прогнозами состояния рынка компьютерных технологий, позволили себе высказать мнение о том, что WMA на данный момент является единственной серьезной альтернативой сверхпопулярному МРЗ. Кроме того, зная феноменальную способность Microsoft к навязыванию собственных стандартов окружающему миру, думаю, за судьбу этого формата можно не беспокоиться. Кстати о навязывании стандартов, появились уже первые жертвы — компания Liquid Audio, известная своей разработкой Liquid Pro AAC, заключила сделку с Microsoft. Теперь во все программные продукты Liquid будет включаться поддержка WMA, а огромная аудиотека в формате LQT будет продублирована в WMA. «Это позволит исполнителям донести свою музыку до миллионов пользователей плееров Microsoft, база распространения которых огромна» - считает шеф Liquid Audio Джери Кирби (Gerry Kearby). Нельзя не порадоваться оптимизму шефа компании, но на практике подобное соглашение означает смерть формата LQT, так как WMA, не хуже и при этом кодеки от Microsoft бесплатны, a Liquid Pro AAC стоит денег.
В общем WMA вскоре придет на смену МРЗ, тем более что уже появились первые аппаратные плееры с поддержкой этого формата. Правда подобный переход светит только пользователям операционной системы Windows, поклонникам других платформ, например Linux, пока придется искать альтернативы WMA.
4.6. Формат сжатия звука QDesign AIF
Этот формат аудиосжатия был разработан компанией QDesign и впоследствии был замечен и активно поддержан концерном Apple/Macintosh. QDesign AIF является доработкой семейства стандартов AIFF, которое представляет собой разновидность мультимедийных стандартов используемых на платформе Apple/Macintosh. Пара QDesign AIF-AIFF является полным аналогом пары WAV-MP3 используемой на платформе Wintel, за исключением степени сжатия. Впрочем, об этом речь впереди.
Рождение формата сопровождалось многочисленными рекламно-сенсационными заявлениями компании-разработчика о том, что ими достигнуто CD-качество при небывало низкой скорости потока 48 кбит/с, т.е. этот формат должен был обеспечивать степень сжатия исходной композиции примерно в 100 раз без потери качества!
Первая реакция - недоверие. Конечно, научно-технический прогресс творит чудеса, но не так же быстро и не до такой же степени! Правда, с другой сны, хочется иногда и в чудо поверить, тем более, что некоторые новостные интерне-сайты вроде бы подтвердили рекламные заявления QDesign. Haпример довольно таки солидный сайт http://freecenter.digiweb.com опубликовал несколько графиков АЧХ, согласно которым аудиокомпозиции сжатые QDesignAIF со скоростью 48 кбит/с отличаются от исходной CD-композиции не более, чем на 3 дБ. Кроме того, еще свежи в памяти воспоминания о лихом взлете формата МРЗ, а ведь в свое время коэффициент сжатия аудиоинформации 1:12 тоже казался чем-то невероятным.
Так, со странной смесью недоверия и надежды многие пользователи-меломаны ожидали выхода кодека QDesign AIF.
И вот он вышел QDesign Audio Codec vl.l. Вышел, правда, не как самостоятельный кодек, а как составная часть зарегистрированной полной версии QuickTime 3.0 (и в дальнейшем во всех более высоких версиях) от компании Apple. Поддержка кодирования аудиокомпозиций из WAV-файлов в формат QDesign AIF была включена в MoviePlayer, входящий в состав QuickTime.
Однако при прослушивании файла QDesign AIF понимаешь, что никакого чуда не произошло. Какое там CD-качество?! Чтобы получить такое плохое качество на нормальном CD-проигрывателе, его надо засунуть в гулкую металлическую бочку, бочку засмолить и в воде утопить...
Ну а если серьезно, то малый размер файла полностью соответствует его низкому качеству. Так из аудиокомпозиции были удалены многие частоты, как из верхнего, так и из нижнего диапазона звукового спектра, в результате звучание стало не только очень глухим, но при этом утратило и характерные басы. Очень высок шум квантования. Речь звучит неразборчиво. Кроме того, был замечен один очень неприятный дефект - для уменьшения размера композиции некоторые места преобразовывались из стерео в моно. Идея в целом верна, в любой стереофонической аудиокомпозиции встречаются места, где оба канала звучат одинаково, и вместо двух стереоканалов можно пустить удвоенный моноканал, но вот реализация подкачала.
Компания QDesign AIF в ответ на вполне понятное возмущение обманутых пользователей, пообещала в следующей версии формата улучшить качество звучания и увеличить максимальную скорость потока. Среди этих обещаний также фигурировало обещание увеличить скорость кодирования в три раза. Новая версия кодека получила название QDesign Audio Codec Pro Edition 2.0 и была включена в QuickTime 4.0.
Однако, вместо обещанного ускорения в три раза пользователи получили… замедление, правда, не в три раза (это было бы верхом цинизма), но вполне ощутимое. Качество сжатых композиций практически не изменилось, исчезло только преобразование стереофонического звучания в монофоническое, повидимому, разработчики убрали этот модуль, не сумев довести его до ума v следствие, несколько возрос размер файлов. Ни одно из обещаний не было сдержано. Один раз вступив на скользкую дорожку обмана, QDesign продолжает по ней катиться, а между тем, напомню, что регистрация QuickTime легальными средствами, которыми пользуются подавляющее большинство западных пользователей стоит порядка 20 долларов. Можно представить, сколько денег принесла компании Apple фирма QDesign, сколько обманутых рекламой пользователей отдали свои доллары, поверив в несуществующее чудо.
Справедливости ради стоит отметить, что QDesign AIF с максимально возможной скоростью 48 кбит/с все же лучше, чем МРЗ, ААС, РАС и VQF с этой же шириной потока и безусловно лучше Real audio. Да, этот формат годится только для сетевого радио или для ознакомления с композицией чтобы впоследствии закачать ее в виде более громоздких, но зато и более качественных файлов в форматах МРЗ, AAC, VQF...
Зато на один CD-диск можно разместить около 100 часов музыки в этом формате, если только кто-то захочет ее слушать.
Название формата РАС расшифровывается как perceptual audio coding, что на русский язык переводится плохо, так слово perceptual означает восприятие. Поэтому вариантов перевода много, но наиболее благозвучным является «аудиокодирование, основанное на восприятии».
Данный формат был разработан фирмой Lucent Technologies при мощной инвестиционной поддержке компании Bell Labs, которую, так же, как и AT&T интересовали системы сжатия голосовой аудиоинформации передаваемой по цифровым телефонным сетям. К чести инвесторов можно сказать, что в отличие от AT&T, компания Bell Labs не стала претендовать на слишком большой кусок пирога и предоставила доводку и развитие стандарта создателям, ограничившись только той частью, которая непосредственно касалась телефонных сетей. И довела эту часть до ума, опять таки в отличие от AT&T, у которой до сих пор все в стадии разработки. Некоторые высокоскоростные многоканальные цифровые телефонные сети США и Канады используют для сжатия аудиоинформации алгоритмы, основанные на разработках РАС. Сама же Lucent Technologies, закончив черновую разработку формата и трезво оценив свои слабые маркетинговые возможности, решила пойти тем же путем, что и разработчики VQF. Напомню, VQF, как стандарт был разработан творческой группой Human Interface Laboratories, которая является подразделением компании NTT, но доработкой, развитием и продвижением формата на рынке занималась и занимается фирма Yamaha.
Lucent Technologies поступила схожим образом, решившись доверить новорожденный формат компании Celestial Technologies, которая и занялась дальнейшей судьбой РАС.
Была выпущена первая общедоступная версия кодека РАС под несколько
банальным названием Audio Library 1.0. Первая выпущенная версия этого программного продукта была демонстрационной и работала в течение 15 дней.
При этом самим своим существованием данный кодек РАС опровергал все
сложившиеся со времен МРЗ представления о том, как должны выглядеть сжатые аудиокомпозиции. Любому поклоннику МРЗ, VQF, AAC должен был показаться несколько диким тот способ хранения аудиокомпозиций, который был
реализован в Audio Library 1.0.
Во-первых, разработчиками было наложено нелепое условие о том, что в
дном каталоге могут храниться не более пяти сжатых композиций. Правда
этот запрет легко обходится возможностью быстрой смены каталогов, причем
сам процесс чем-то напоминает монтаж устройств в UNIX-системах. Но при большом количестве кодируемой информации это не выход. Второе, еще более нелепое нововведение заключается в том, что аудиокомпозиций в формате РАС в привычном виде (т.е. один файл - одна аудиокомпозиция) просто не существует. При кодировании исходной аудиокомпозиции кодер Audio Library 1.0 в качестве выходного продукта создает не один файл, а целых восемь, с расширениями .TPS, причем при сжатии сразу нескольких композиций и сохранении их в один и тот же каталог, количество файлов не увеличивается, но зато растет объем файла songdata.tps.
Несмотря на эти нелепости, формат получился в общем неплохой. Звучание в целом примерно такого же качества, как и у лучших кодеков из семейства ААС - Liquid Pro AAC и Astrid/Quartex AAC. Конечно, есть нюансы в вечном споре, какие частоты объявить лишними и выкинуть, чтобы уменьшить размер композиции, а какие необходимо оставить, чтобы не ухудшилось качество. Но в целом можно констатировать факт, что РАС со скоростью потока 96 кбит/с лучше МРЗ 128 кбит/с, а РАС со скоростью 128 кбит/с приближается к CD-Звучанию, но не достигает его.
При этом поражает невероятно высокая скорость кодирования при использовании Audio Library 1.0. Четырехминутная аудиокомпозиция (песня средней длины) кодируется чуть больше 100 секунд (сравните, на кодирование четырех минут музыки в формат VQF уходит более 20 минут).
Кодек Audio Library 1.0 не
содержит каких либо возможностей по кодированию аудиокомпозиций
непосредственно с Audio CD, т.е. не содержит в своем составе так называемый CD-extractor, так
же нет возможности непосредственного перекодирования из одного формата в
другой (например, РАС![]() МРЗ
или РАС
МРЗ
или РАС![]() ААС). В
качестве исходного материала принимаются только файлы формата WAV 44 кГц 16
бит РСМ, что не всегда удобно, так эти файлы зачастую имеют гигантские размеры.
ААС). В
качестве исходного материала принимаются только файлы формата WAV 44 кГц 16
бит РСМ, что не всегда удобно, так эти файлы зачастую имеют гигантские размеры.
К числу недостатков этого кодека можно отнести и неприменимость сжатых композиций в качестве сетевого формата. Формат не поддерживает потоковую пересылку данных, т.е. одновременное воспроизведение и получение аудиокомпозиции. Это формат только для домашней аудиотеки и для продаж на CD-дисках.
Кроме того, аудиокомпозиции в данном формате имеют мощную защиту от нелегального копирования и очень плохо работают с CD-R при воспроизведении не на «родной» машине, на которой производилось кодирование и запись на CD-заготовку, а скажем, на машине вашего друга.
Впрочем, если вас пугает та странная организация сжатых композиций которую обеспечивает кодек Audio Library 1.0 и не нравится ограничение «5 композиций на каталог», но при этом хочется быстрого кодека с хорошим соотношением размер/качество который был бы основан на тех же алгоритмах РАС то не надо отчаиваться! Компания Celestial Technologies совместно с Lucent Technologies, идя навстречу пожеланиям пользователей, выпустили вторую версию кодека, использующую технологии РАС, переименовав свой продукт в Audio Veda 2.O. Этот кодек гораздо более удобен в работе и не пугает непривычных пользователей странными нововведениями.
Кодер, входящий в этот комплекс, позволяет сжать аудиокомпозицию и сохранить ее не в виде базы данных из восьми файлов, а, как и полагается, в виде одного файла с расширением .ЕРС. В отличие от предыдущей версии кодер поддерживает кодирование с переменной скоростью потока. Аналог VBR присутствует в МРЗ кодеке Lame. Подобная технология позволяет существенно уменьшить размер аудиофайла при незначительной потере качества.
В комплект Audio Veda 2.0 входит плеер-декодер, позволяющий проигрывать файлы в формате .ЕСР. Файлы, закодированные Audio Library 1.0 этим проигрывателем воспроизводить нельзя, поэтому можно сказать, что Audio Library 1.0 и
Audio Veda 2.0 - это два разных формата, хотя оба основаны на одной и той же технологии РАС и разработаны одной и той же фирмой.
Помимо кодера и декодера в состав полной версии AudioVeda 2.0 входят так же
CD-экстактор и
преобразователь МРЗ![]() РАС, которых так не
хватало в предыдущей версии
РАС, которых так не
хватало в предыдущей версии
Следует упомянуть, что файлы сжатые AudioVeda 2.0 в отличие от предыдущего кодека поддерживают потоковую пересылку данных, т.е. этот формат является уже гораздо более сетевым и менее домашним, по сравнению с предыдущим.
Итак, подведем итоги. Кодеки, использующие алгоритмы РАС - быстрые, качественные, с хорошим соотношением размер/качество. Идеально подходят для создания домашних аудиотек. Однако, реально могут пригодиться только заядлым индивидуалистам, не испытывающим желания делиться нажитыми ayдиокомпозициями с другими.
ГЛАВА 5. МНОГОКАНАЛЬНЫЕ ЗВУКОВЫЕ СИСТЕМЫ [13,14,26-37]
Окружающий звук (он же объемный, он же surround) в настоящее время стремительно распространяется по планете. Он используется в кино, на видео и DVD на презентациях, в музыкальных записях, и даже на телевидении. Слушателям он сулит новые ощущения, музыкантам — новые способы выразить себя, а звукозаписывающим студиям - переоборудование и приток клиентов. В общем, окружающий звук нужен и выгоден многим. Однако с его производством (особенно при ограниченном бюджете) все еще связано немало проблем, ряд сложностей также возникает на пути доставки многоканального звука слушателям. Форматы DVD-Audio и Super Audio CD, которые позволяют записать шестиканальный (или более) звук в несжатом виде, пока еще не завоевали широкой популярности, так что сейчас неизбежным является использование одного из способов сжатия звуковых данных, адаптированных для surround-фонограмм. Все эти способы сжатия пришли к нам из кино, так что, рассматривая современные способы создания многоканального звука, нам никак не обойти истории развития окружающего звука.
А начиналось все в 1941 году, когда на экраны вышел фильм студии Диснея «Fantasia». От монофонического звука создатели картины перешли сразу к трем каналам звука: левому, правому и центральному. Формат записи был назван «Fantasound», и по тем временам это было нечто невиданное - ведь и монозвук в кино появился совсем недавно, а тут сразу три независимых канала, которые записывались на кинопленку оптическим способом. Но трудности производства подобного рода фонограмм (тогда в Америке еще не было магнитофонов, да и другая звукозаписывающая техника была в зачаточном состоянии), сложная и дорогая система воспроизведения и начавшаяся Вторая Мировая война остановили проникновение многоканального звука в киноиндустрию более чем на десять лет.
5.1. Технологии Cinemascope и Todd-AO
Появление коммерчески успешных форматов стереозвука в кинопроизводстве было обусловлено развитием в США магнитной звукозаписи. Первые ленточные магнитофоны были привезены в качестве трофеев из побежденной Германии (в русском языке слово «магнитофон» также обязано своим появлением названию одной из немецких моделей этого устройства - Magnetofon), и вскоре фирма Ampex выпустила американский аппарат для записи на ленту Аmрех Model 200, являвшийся копией немецкого AEG Model K-4 Magnetofon. Магнитная запись стремительно развивалась, вскоре появился многодорожечный магнитофон, изобретенный легендарным гитаристом Лесом Полом. Немного ранее этот разносторонний музыкант придумал электрогитару, да и использовать монофонические магнитофоны для записи музыки в США начал именно он. Первые форматы окружающего звука были основаны именно на магнитной записи (вместо старой оптической монодорожки) - непосредственно на кинопленку наносился магнитный слой, на который записывалось звуковое сопровождение к фильмам. Кинопроекторы оснащались магнитными головками для считывания этого звука. В те годы киноиндустрия США процветала, и публике был представлен новый широкоэкранный кинематограф (использовавший пленку, шириной 70 мм, вместо обычных 35), а в дополнение к громадным широкий экранам требовалась соответствующая звуковая картина. Тогда существовали два основных формата: Cinemascope, разработанный компанией 20th Century Fox для 35-мм пленки (четыре канала —левый, центральный, правый и surround канал, который воспроизводился с боков и позади зрителя, первый фильм – The Robe, 1953 год) и Todd-AO для широкоформатной 70-мм кинопленки (шесть каналов — левый, дополнительный левый, центральный, дополнительный правый, правый и surround-канал, первый фильм - Oklahoma!, 1955 год).
Необходимость центрального канала была обусловлена большими размерами киноэкрана и тем, что зрители сидят не только по центру зала. Если использовать только два громкоговорителя (левый и правый), то диалоги актеров для зрителя, сидящего в боковой части зала, будут звучать не посередине экрана, где обычно и происходит основное действие, а сбоку, так как ближайший громкоговоритель будет слышен лучше всего. Поэтому всю речь героев фильма обычно располагали в центральном канале, иногда его так и называют - канал диалогов.
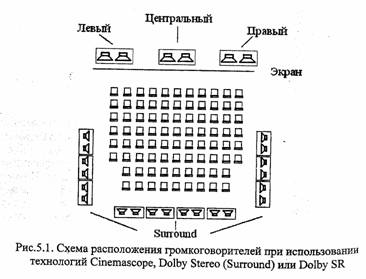
А для огромных широкоформатных (70 мм) кинотеатров потребовалось установить за экраном пять независимых громкоговорителей, чтобы обеспечить равномерное распределение звука для всех зрителей в зале.
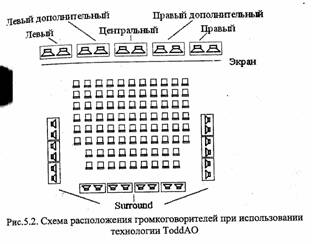
Параллельно возникали и другие форматы, не нашедшие широкого распространения. Например, VistaVision, в котором на монофоническую оптическую дорожку записывались специальные управляющие сигналы (30, 35 и 40 Гц), под воздействием которых декодер переключал монозвук на центральный, левый или правый громкоговорители. Это было, конечно, не стерео, но обеспечить, например, выстрел или взрыв справа или слева от зрителя с помощью VistaVision было возможно.
Справедливости ради необходимо отметить, что звуковая картина и в системе Cinemascope, и в системе Todd-AO существенно отличалась от того, что мы слышим в современных фильмах (хотя количество звуковых каналов практически такое же). Дело в том, что звукозаписывающая техника тогда была на начальной стадии своего развития, многодорожечных магнитофонов и сложных микшерных пультов еще не было, да и магнитные дорожки на кинопленке ощутимо шумели, что сокращало доступный звукоинженерам динамический Диапазон. Поэтому создание сложных спецэффектов было просто технически невозможным, к тому же «идеология» кинозвука была отличной от нынешней -головокружительные звуковые трюки не были тогда важной частью фильма, и их влияние на аудиторию еще не было оценено. Распространение этих форматов тоже не было повсеместным - оснащение кинотеатров нужным оборудованием стоило недешево, и его могли позволить себе только крупные, успешные кинозалы.
Форматы с магнитной записью звука на пленку просуществовали до середины 70-х годов, когда на сцену вышла фирма Dolby. Dolby приобрела известность своими системами шумоподавления, появившимся в 1970 году: Dolby В, которая использовалась в бытовых магнитофонах, и Dolby A - более сложная и эффективная система, применяющаяся и по сей день в профессиональной звукозаписи. Не удовлетворившись успехом в области обычной звукозаписи, основатель фирмы Рей Долби устремил свои взоры на звук для кинофильмов. Уже в 1971 году появился первый фильм (A Clockwork Orange — Заводной апельсин), звук для которого был записан с применением шумоподавления Dolby А, заметно расширившего динамический диапазон. А в 1974 году была представлена технология Dolby Stereo*, использующаяся в большинстве фильмов и поныне. Взамен магнитных звуковых дорожек, которые довольно сильно шумели и быстро изнашивались, фирма Dolby предложила использовать старую добрую оптическую дорожку, но уже с двумя каналами звука. Эти две дорожки располагались там же, где и старая моно дорожка (которую продолжали использовать для совместимости со старыми кинопроекторами), и поэтому фонограмма могла быть считана любым киноаппаратом если не в стерео, то хотя бы в моно варианте. Для уменьшения шумов на оптических дорожках использовалась система шумоподавления Dolby A.
Однако экраны кинозалов к 80-м годам стали очень большими, поэтому кроме традиционных правой и левой акустических систем потребовалась третья, центральная, чтобы обеспечить пространственное восприятие для зрителей, сидящих не в центральной части зала. Кроме того, для кинозала, анонсирующего стереозвук, обязательно требовался четвертый канал — Surround. Так сформировалась традиционная схема объемного звука в кино: четыре канала - левый (Left, L), правый (Right, R), центральный (Center, С) и пространственный (Surround, S).
Однако в распоряжении разработчиков было только два физических канала, по которым необходимо было передать четыре сигнала. Приемлемым решением оказалась матричная технология, первоначально разработанная для домашних систем квадрафонического звука. Было внесено два принципиальных
изменения. Первое — расположение акустических систем и, следовательно, назначение каналов соответствовали теперь уже традиционной схеме для кинематографа - L,C,R,S. Второе — была серьезно усовершенствована схема аналогового декодера, в котором были реализованы более интеллектуальные алгоритмы. Так появилась технология Dolby Surround.
5.2. Технология Dolby Surround
Dolby Surround, называемый также Dolby Stereo Optical, является в настоящее время стандартом пространственного звука для полноэкранного кино. Он используется повсеместно — процессорами Dolby оборудованы десятки тысяч кинотеатров во всем мире. Даже теперь, с появлением цифрового формата Dolby Digital, на кинопленках остаются две аналоговых оптических дорожки Dolby Surround - для обеспечения совместимости со всеми существующими проекторами.
Первыми на рынке появились простые декодеры Dolby Surround, которые позволяли на домашней аппаратуре выделить и прослушать третий, пространственный канал — канал Surround. Впоследствии был разработан декодер Dolby Surround Pro Logic, который выделял и центральный канал. Получился «домашний кинотеатр» — комплекс аппаратуры для высококачественного воспроизведения звука и видео с декодером Dolby Pro Logic Surround Sound.
Кодер Dolby Surround. Сразу отметим, что система не предназначена для передачи четырех независимых сигналов звука, каждый из которых надо прослушивать раздельно (например, звука одной ТВ программы на разных языках). В этом случае развязка между двумя любыми каналами должна была бы быть максимальной, а амплитуды и фазы сигналов могли бы быть совершенно не связаны между собой. Напротив, задача Dolby Surround — передать четыре канала звука, которые будут прослушиваться одновременно, и при этом воссоздавать в сознании слушателя пространственную звуковую картину. Эта картина составляется из нескольких звуковых образов — звуков, которые слушатель воспринимает связанными со зрительными образами на экране.
На входе кодера Dolby Surround присутствуют сигналы четырех каналов -L, С, R и S, а на выходах - два канала Lt (левый общий) и Rt (правый общий). Общий означает, что каналы содержат не только «свой» сигнал (левый и правый), но и кодированные сигналы других каналов - С и S. Функциональная схема кодера показана на рис.5.3.
Сигналы каналов L и R передаются на выходы Lt и Rt без каких-либо изменений. Сигнал канала С делится поровну и складывается с сигналами каналов Lt и Rt. Предварительно сигнал С ослабляется на 3 дБ (чтобы сохранить неизменной акустическую мощность сигнала после сложения его «половинок» в Матрице декодера). Сигнал канала S также ослабляется на 3 дБ, но, кроме того, перед сложением с сигналами Lt и Rt он подвергается следующим преобразованиям:
■ полоса частот ограничивается полосовым фильтром от Ю0 Гц до 7 кГц;
■ сигнал обрабатывается шумоподавителем - процессором Dolby В;
■ сигнал сдвигается по фазе на +90 и -90 градусов, таким образом, составляющие сигнала S, предназначенные для сложения с Lt и Rt, оказываются в противофазе друг с другом.
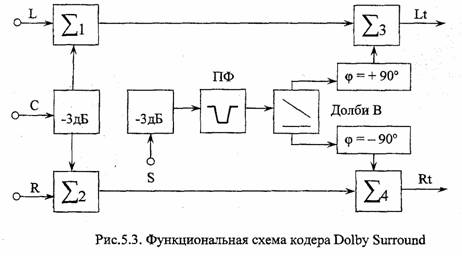
Из описания этого кодера понятно, что кодирование реализуется аналоговыми методами. Сигнал, кодированный в Dolby Surround, не содержит каких -либо управляющих сигналов или инструкций для декодера. По своим электрическим характеристикам он ничем не отличается от обычного двухканального стереосигнала, и опознать кодированный сигнал простыми «аппаратными» методами невозможно.
Предположим, что сигнал, кодированный в Dolby Surround, прослушивается на обычной стереофонической аппаратуре без декодера Surround. Сигнал Lt поступает на акустическую систему левого канала, сигнал Rt — на систему правого. При записи двухканального звука сигнал от источника, расположенного у левого микрофона, поступает преимущественно в левый канал, от источника, расположенного у правого микрофона — преимущественно в правый канал. Если источник равноудален от левого и правого микрофонов, его сигнал делится поровну между правым и левым каналами. В кодере сигнал С делится между каналами Lt и Rt именно таким образом, но не на акустическом, а на электрическом уровне. Поэтому при прослушивании на две акустические системы L и R звук канала С воспринимается, как сигнал виртуальной акустической системы, расположенной между реальными системами L и R. Кроме сигнала С, в каналах Lt и Rt присутствуют компоненты сигнала S, но они находятся в противофазе, и акустические сигналы, соответствующие этим компонентам, компенсируются в пространстве между акустическими системами. Поэтому звук канала Surround воспринимается как едва заметный, «призрачный» звук, витающий где-то между акустическими системами L и R. Таким образом,
сигнал Dolby Surround совместим с любой стерео аппаратурой, как с декодером Surround, так и без него.
Пассивный декодер Dolby Surround. Простейший декодер Dolby Surround выделяет только один дополнительный канал — канал S. Функциональная схема такого декодера показана на рисунке 5.4. Сигнал Lt без каких-либо изменений поступает на выход L декодера. Сигнал Rt таким же образом поступает на выход декодера R. Сигналы Lt и Rt содержат «половинки» сигнала центрального канала С, которые создают виртуальную акустическую систему между реальными акустическими системами L и R. Узел вычитания L-R выделяет сигнал surround, который поступает на отдельную акустическую систему. Компоненты сигнала S воспроизводятся также акустическими системами R и L, но, так как они в противофазе, слушателем не воспринимаются. Так как основу декодера составляет простой дифференциальный усилитель, выполняющий операцию вычитания L-R, такой декодер получил название «пассивного декодера».
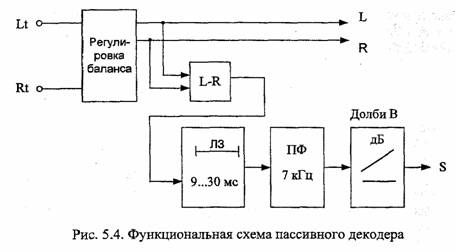
На рис. 5.5 показаны взаимные развязки между каналами простейшего декодера. Диаметральное расположение каналов на схеме относится только к электрическим сигналам. Реальное расположение акустических систем иное - системы трех каналов расположены в одной фронтальной плоскости, а системы четвертого канала — по бокам сзади слушателя. Напомним, что акустическая система С — виртуальная, ее сигнал формируется пространственно-акустическими системами правого и левого каналов. Поэтому для такого декодера очень важно положение слушателя относительно акустических систем L и R, и, в идеальном случае, он должен быть равноудален от них. Понятно, что развязка между соседними каналами (L и С; С и R; R и S; S и L) не может быть более 3 дБ. Однако субъективно она воспринимается иначе.
Если на входе кодера присутствует только сигнал левого канала, он воспроизводится одновременно громкоговорителями левого канала и каналаSurround - в правом канале звука нет. То же самое происходит, если на входе присутствует только сигнал правого канала. Если на входе только сигнал центрального канала, он воспроизводится громкоговорителями левого и правого каналов, при этом пространственно формируется виртуальный канал С.
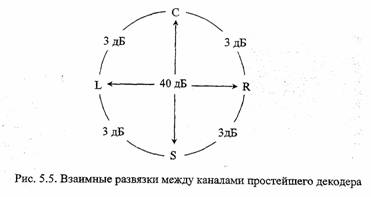
Таким образом, даже простейший пассивный декодер обеспечивает восприятие сигналов трех фронтальных каналов - L, R и С с идеальной развязкой между ними. Это не удивительно - этот же психоакустический эффект лежит в основе двухканального стереозвука. Именно поэтому слушатель стереосистемы старается разместить громкоговорители двух каналов как можно более точно - на равном расстоянии прямо перед собой. Для четвертого канала достаточная развязка не обеспечивается.
В том, что часть сигнала Surround проникает в левый и правый каналы, нет большой беды. Во-первых, слушатель ожидает, что все звуки исходят, прежде всего, спереди, так как вызваны действиями, происходящими на экране. Во-вторых, звук, передаваемый в канале Surround, обычно не связывается с каким-то конкретным источником. Например, мы видим на экране вспышку молнии, а гром, шум дождя и ветра мы слышим отовсюду - со всех направлений сразу.
Гораздо хуже обратное явление - проникновение сигналов L и R в канал S. Разумеется, технологией Surround предполагается, что акустические системы всех каналов установлены в помещении конечного объема и пространственное сложение всех сигналов неизбежно. Это вовсе не значит, что можно пренебречь слабой развязкой между фронтальными каналами и каналом Surround. Действительно, если источник звука расположен на разных расстояниях от микрофонов L и R, уровень сигналов в этих каналах будет различным. В результате на выходе дифференциального усилителя кроме сигнала Surround неизбежно будет присутствовать разностный сигнал (L-R). Эксперименты показали, что прослушивание сигналов фронтальных каналов в громкоговорителях Surround, особенно речи, портит впечатление. Дело вот в чем, несмотря на то, что мощность
звука на фронтальном направлении больше, из-за временного опережения звуковой образ в сознании слушателя связывается с направлением тыла.
Для того чтобы обеспечить развязку центральных каналов и канала Surround, в пассивном декодере в канале S используются дополнительные преобразования:
■ вводится временная задержка (около 10 мс), которая позволяет исключить эффект Хааса. Напомним, что сущность эффекта заключается в том, что если слушатель располагается ближе к акустическим системам Surround, чем к системам фронтальных каналов, он вначале слышит компоненты сигналов L и R, проникшие в канал Surround, и только затем эти же сигналы, излученные громкоговорителями фронтальных систем. Задержка гарантирует, что звук фронтальных каналов достигнет слушателя раньше, чем тот же звук, попавший в канал S;
■ используется фильтр нижних частот с частотой среза 7 кГц, который выполняет следующие функции. Основная из них: если источник звука смещен вправо или влево от центра, то чем выше частота звука, тем выше амплитуда сигнала, проникающего в канал Surround. Это естественно, так как при одинаковой геометрической разности хода разность фаз зависит от частоты, а при одинаковой амплитуде L и R амплитуда разностного сигнала L-R (т.е. сигнала, проникающего в канал S) определяется только разностью фаз. Поэтому на высоких частотах труднее добиться эффективного разделения каналов. Вторая функция: чем выше частота звука, тем более точно слушателем определяется направление на его источник (тем острее «диаграмма направленности» ушей). Исключение высокочастотной составляющей «размазывает» звуковые образы в
канале Surround, благодаря этому слушатели, сидящие рядом с акустическими системами Surround, не связывают звуки в этом канале с направлением на громкоговорители;
■ для подавления проникающих сигналов каналов L и R, если их уровни значительно ниже уровня сигнала S, используется система шумоподавления Dolby В.
Как видно из вышесказанного, технологии Dolby Surround используют особенности восприятия звуков человеком – психоакустические эффекты.
Активный декодер Dolby Surround Pro Logic. Пассивный декодер обеспечивает высокую степень воспринимаемой развязки между фронтальными каналами, но только для слушателей, равноудаленных от акустических систем. Кроме того, несмотря на специальную обработку сигнала Surround, в пассивном декодере невозможно добиться полного разделения сигналов Surround и R/L. Использование пассивных декодеров ограничено, поскольку они не способны обеспечить корректное восприятие для любого положения слушателя в зале.
Активные декодеры предполагают как бы пространственную фокусировку звуковых образов. Этим термином обозначается любая технология, используемая для устранения проникновения сигналов одного канала в другой и основанная на изменении выходных сигналов декодера. Активный декодер представляет собой комбинацию пассивного декодера и регулирующей цепи. Чтобы понять сам принцип, рассмотрим простейшую технику активного декодирования - регулировку усиления каналов. На рис. 5.6 показана функциональная схема активного декодера. На каждом выходе декодера установлен регулируемый усилитель (РУ), управляемый напряжением, вырабатываемым управляющей цепью (УЦ).
Для примера возьмем случай, когда источник звука — единственный, и он расположен непосредственно у микрофона центрального канала С. Из рис. 5.5 видно, что пассивный декодер передаст сигнал центрального канала в выходной канал С, а также и в каналы R и L с ослаблением всего на 3 дБ. Управляющая цепь активного декодера определяет, в каких каналах необходимо уменьшить усиление, чтобы подавить проникающие сигналы соседних каналов до необходимого уровня. В данном примере декодеру необходимо уменьшить усиление в каналах L и R, оставив слышимым сигнал канала С. Таким же образом можно развязать выход левого канала, уменьшив усиление в каналах С и S, когда на входе декодера присутствует только сигнал Lt. Так как сигнал может приходить с любого направления в пределах всех 360 градусов, то, изменяя усиление каналов в определенной пропорции, можно достичь достаточной степени развязки.
Таким «прямым» методом проблема решается только для единственного звукового образа. Реальная звуковая панорама содержит звуки нескольких независимых источников. Рассмотрим случай, когда речь звучит на фоне музыки. Музыка должна воспроизводиться акустическими системами левого и правого каналов, а речь — только системой центрального канала. Пассивный декодер с такой задачей не справится вообще. Речь будет воспроизводиться как системой центрального канала, так и системами левого и правого каналов. Стереофоническая музыка будет воспроизводиться системами L и R, кроме того, суммарный сигнал L+R будет прослушиваться через систему С, а разностный L-R - через систему S.
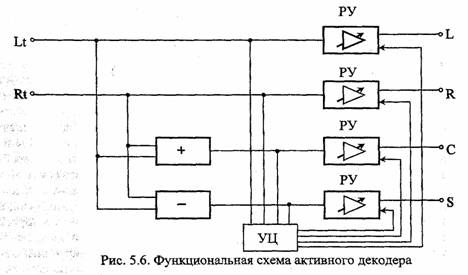
Полагаем, что активный декодер считает речь доминирующим звуковым образом, и уменьшает усиление каналов L и R, чтобы сфокусировать этот образ в направлении С. Но при этом теряется стереофоническая музыка, остается только монофонический звук суммы (L+R) в канале С и «фантомный» звук разности (L-R) в канале S. Если говорящие герои замолкают, декодер восстанавливает усиление каналов L и R, и музыка становится слышимой и, наоборот, при возобновлении речи музыка пропадает. Такое явление «качания» мощности не доминирующих звуковых образов в зависимости от мощности доминирующего образа хорошо ощутимо
Другой способ избавиться от проникновения речевого сигнала в левый и правый каналы показан на рис. 5.7. Если взять сигнал правого канала, инвертировать его полярность и сложить с выходным сигналом левого канала - компоненты сигнала С в левом и правом каналах окажутся противофазными и взаимно компенсируются, таким образом, в канал L компоненты сигнала С не попадут.
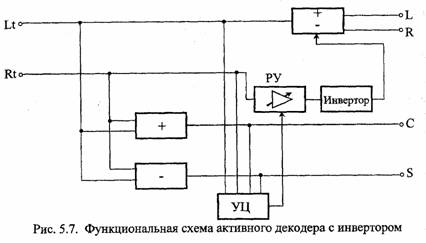
Принцип взаимной компенсации — основной принцип активного декодирования и он в том или ином виде используется во всех активных декодерах. После исключения сигнала центрального канала мощность звука в левом канале не уменьшается, часть сигнала левого канала заменяется инвертированным сигналом правого канала. Кроме того, в центральном канале по-прежнему прослушивается суммарный сигнал L+R. В результате доминирующий звуковой образ (речь в канале С) фокусируется в направлении акустической системы С, а образы, соответствующие направлениям R и L, наоборот, «размазываются» в пространстве. Декодером используется один из принципов психоакустики, принцип маскирования: воздействие доминирующего звукового образа временно снижает способность слушателя определять направления на другие звуковые образы. Так как мощность звуков, соответствующих этим образам, остается неизменной, «качания» (модуляции) этих звуков не наблюдается. В этом заключается другой принцип психоакустики — принцип постоянства мощности. Выполняя принцип постоянства мощности в сочетании с активной взаимной компенсацией только в те моменты, когда требуется передача точного направления на звуковой образ, можно эффективно скрыть факт перераспределения мощности не доминирующих звуков.
В рассмотренном примере мы предполагали, что громкость речи выше громкости музыки, поэтому сигнал речи используется как управляющий, сигнал музыки — как управляемый. В реальности разница уровней подобных сигналов может быть менее значительной. Если два разных звука близки по уровню, один из них становится маскирующим для компонентов другого, попавших не в «свои» каналы, и наоборот. При этом требования к степени развязки снижаются. В таком случае требуется меньшая степень активной компенсации и, соответственно, меньшая степень перераспределения по направлению не доминирующих сигналов.
Иногда желательно вообще исключить регулировку усиления, сделав декодер «пассивным». Например, звуки дождя или ветра воспринимаются слушателем на подсознательном уровне. Они не связываются с конкретным источником и могут воспроизводиться всеми громкоговорителями одновременно. В этом случае не требуется пространственной фокусировки звука, следовательно, и активного декодирования.
Крайнее проявление доминирования: все присутствующие в звуковой панораме звуки в данный момент связаны с одним направлением. Если сигнал обрабатывается пассивным декодером, из-за перетекания части мощности сигнала в соседние каналы возникает ошибка направления. Так как звуковой образ один, то в сигнале нет других звуков, способных маскировать эту ошибку. Таким образом, если доминирующий звуковой образ — единственный звуковой образ, перераспределение мощности по направлению становится особенно заметным. Но именно при этом условии легче всего компенсировать проникновение сигнала в другие каналы, используя технику компенсации. Так как сигналов с других направлений нет, нет и эффекта модуляции их мощности.
Другой крайний случай: два или более звуковых образа присутствуют одновременно на разных направлениях и имеют примерно одинаковую мощность. В этом случае способность слушателя к определению направления на образы притупляется, поэтому технику компенсации можно не использовать или использовать не в полной мере.
Чтобы обеспечить эффективное декодирование для обоих случаев, декодер Pro Logic автоматически выбирает один из режимов декодирования, «быстрый» или «медленный». «Быстрый» режим используется, если доминирующий звуковой образ намного мощнее других образов. Если такие образы возникают на разных направлениях последовательно во времени, декодер должен воспроизвести их на соответствующих направлениях. В любой момент времени декодер регулирует усиление выходов, исходя из наличия одного источника доминирующего звука, но в течение некоторого времени все источники последовательно воспринимаются раздельно. Для этого необходимо, чтобы время реакции управляющей цепи декодера на изменение входных сигналов было минимальным. Второй режим, «медленный», включается декодером, если мощности разных образов отличаются незначительно. В «медленном» режиме декодер отслеживает изменения входных сигналов с большей задержкой. В таких условиях маскирование проявляется слабо, поэтому, если декодер продолжит работу в «быстром» режиме, модуляция мощности не доминирующих образов станет заметной.
По определению, в каждый момент времени может существовать только один доминирующий образ, и ему соответствует единственное направление. Декодеру необходимо в любой момент времени иметь информацию о точном направлении на доминирующий образ, независимо от того, как быстро меняется пространственная звуковая картинка. Анализируя две пары электрических сигналов, соответствующих ортогональным осям декодера (левый-правый каналы, центральный канал-Surround), можно однозначно идентифицировать любое направление в пространстве.
На рис. 5.8 изображена система координат. Оси «левый-правый канал» соответствует ось X, оси «центр-Surround» — ось Y. Если на осях отложить значения отношений амплитуд одного и того же сигнала в соответствующих каналах, по двум проекциям можно построить вектор, полностью определяющий доминирующий звуковой образ в данный момент времени.

Угол вектора относительно оси X определяет направление на источник звука, длина вектора — мощность звука.
Декодер Dolby Surround Pro Logic-П. Pro Logic П - активный декодер Dolby Surround следующего поколения. Он также использует пространственную
фокусировку, но реализован принципиально другими методами. Новый декодер получился намного проще и при этом эффективнее.
Как и раньше, задача декодера — предотвратить проникновение сигналов L и R в канал S, независимо от того, где находится источник сигнала — точно между микрофонами L и R, смещен от центра в ту или иную сторону или вообще находится непосредственно рядом с микрофоном одного из каналов. Например, если источник звука находится между микрофонами каналов R и С (справа от центра), то уровень сигнала в каналах С и R будет одинаковым. В этом случае часть сигнала неизбежно проникнет на выход S пассивного декодера, так как уровень в канале L ниже, чем в канале R, и при вычитании одного сигнала из другого результат не будет нулевым.
Чтобы полностью компенсировать сигналы L и R на входах декодера Surround, необходимо перед подачей на сумматор выровнять их уровни. Для этого между входами Lt и Rt и входами сумматора устанавливаются два регулируемых усилителя (РУ). Усиление РУ двух каналов изменяется одним и тем же управляющим сигналом, но в разной полярности. Если усиление одного РУ . увеличивается, усиление второго уменьшается. Если такую регулировку осуществлять достаточно точно и достаточно синхронно с изменениями самого сигнала, можно полностью подавить разностный сигнал каналов Lt и Rt в канале Surround (рис. 5.9).
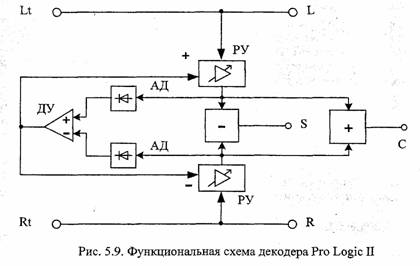
Чтобы автоматически отследить изменения входных сигналов, используется специальная цепь отрицательной обратной связи. Выходные сигналы обоих РУ поступают на амплитудные детекторы (АД), которые выделяют огибающую звуковых сигналов. Сигналы постоянного тока, пропорциональные амплитудам сигналов L и R, сравниваются ДУ. Сигнал с выхода усилителя, пропорциональный разности амплитуд, используется для управления РУ. На I рис.5.9 показана только одна ось декодера (ось «левый-правый»). Вторая пара РУ с такой же-управляющей цепью выравнивает уровни сигналов суммы L+R (фронтальный) и разности L-R (тыловой) для подавления сигналов С и S в каналах R и L (ось «центр-Surround»). Сигнал центрального канала С получается сложением (вместо вычитания) двух сигналов Lt и Rt, выровненных по уровню усилителями (РУ).
Благодаря использованию управляющих цепей с обратными связями, декодер Pro Logic II приобрел следующие преимущества:
■ простыми и дешевыми аппаратными средствами достигается более эффективная компенсация противофазных сигналов в выходной матрице, и, как Я результат, высокая степень развязки между каналами разных осей;
■ в декодере Pro Logic обей оси контролируются единой переключающей
цепью «быстро/медленно». Если хотя бы по одной оси существует значительное доминирование, переключающая цепь переводит обе оси в «быстрый» режим, принудительно изменяя постоянную времени управляющих цепей РУ. Только при условии, что в обеих осях амплитуды сигналов примерно одинаковы, обе они переходят в «медленный» режим. В декодере Pro Logic II две оси функционируют независимо друг от друга, поэтому их управляющие цепи сами «решают», насколько быстро необходимо изменять усиление РУ, анализируя только собственные сигналы. Кроме того, постоянная времени управляющей цепи в декодерах Pro Logic II изменяется непрерывно.
Декодер Pro Logic II может быть использован как универсальный декодер не только для фильмов, но и для других звуковых записей в Dolby Surround. Он идеально подходит для простой и недорогой бытовой аппаратуры. Именно поэтому в декодер Pro Logic II, кроме «штатного» режима Movie, был добавлен «пользовательский» режимы работы - Music.
Известно, что характеристики звука на дорожках записи фильмов и на музыкальных записях отличаются. Главное отличие в том, что в первом случае дорожки пишутся на калиброванной аппаратуре Dolby, поэтому при прослушивании через калиброванный декодер точность воспроизведения гарантируется. При записи музыки, как правило, не используется аппаратура Dolby, поэтому невозможно предугадать, как конкретная запись будет воспроизводиться декодером. Поэтому режим Movie декодера Pro Logic-II имеет фиксированные параметры, а режим Music, напротив, предполагает несколько настроек пользователя. Эти настройки могут быть использованы в любой аппаратуре с декодером Pro Logic.
В декодере Pro Logic П предусмотрены следующие регулировки пользователя:
■ регулировка глубины. Позволяет виртуально перемещать положение слушателя в направлении фронт-тыл. С помощью этой настройки можно добиться оптимального баланса между фронтальными каналами и surround для каждой музыкальной записи;
■ регулировка положения центра и ширины стереобазы. С помощью этой настройки пользователь может сконфигурировать декодер таким образом, что звук, соответствующий центральному положению звукового образа, будет прослушиваться только в акустической системе центрального канала, только в системах левого и правого каналов (виртуальный центральный канал) или во всех трех системах с любой комбинацией уровней. Таким образом можно изменять баланс трех фронтальных каналов для оптимального прослушивания. например, водителем и пассажиром автомобиля. В домашней системе можно таким образом изменять ширину стереобазы - расстояния между акустическими системами фронтальных каналов, не перемещая сами системы;
■ режим панорамы. В этом режиме создается впечатление «звучания со всех сторон сразу». Такой эффект достигается использованием естественного отражения акустической энергии систем surround от боковых стен помещения.
В режиме Music предусмотрен ступенчатый фильтр высоких частот в канале Surround. Он обеспечивает более верное, реалистичное восприятие звука. Благодаря фильтру устраняются искажения на высоких частотах, связанные с многократными отражениями от стен и поглощением звука в элементах интерьера. Временная задержка канала surround в режиме Music не нужна, так как звуковые образы не обязательно должны восприниматься слушателем преимущественно на фронтальных направлениях.
После выхода в 1976 году фильма Джорджа Лукаса «Звездные войны», продемонстрировавшего потрясающие звуковые и визуальные эффекты, формат Dolby Stereo довольно быстро распространился, что было обусловлено, среди прочего, неважным состоянием киноиндустрии в то время. Телевидение уже пришло в каждый американский дом, и зрители не особенно ходили в кинотеатры, ведь все те же фильмы можно было увидеть через некоторое время у себя в гостиной. Соответственно, поток денег в кино постоянно снижался, при том, что производство прокатных копий фильмов по технологиям, использующим магнитную запись на кинопленке, было очень сложным и дорогим. Производство прокатных копий по старой технологии состояло из трех этапов: сначала пленку проявляли, затем на нее наносились магнитные дорожки, а уже потом на ленту записывался звук (в реальном времени). Все это стоило очень дорого - в 5...8 раз дороже простой печати фильма с монозвуком. Оптическая же дорожка Dolby Stereo упростила производство до предела — звук печатается вместе с изображением, и все.
Еще одна причина успеха - применение звукового кинопроцессора. Для переоборудования кинотеатра под Dolby Stereo, при условии наличия нужного количества громкоговорителей, требовалось лишь обеспечить считывание стереофонической оптической дорожки с кинопленки и подключить к выходу с этой дорожки процессор, а он уже выполнял все функции декодирования и управления звуком в кинотеатре. До появления таких кинопроцессоров для переоборудования кинотеатра под какой-либо новый звуковой формат требовалось приобретать множество разных приборов, дорогих, да к тому же сложных в установке и эксплуатации. Один из первых кинопроцессоров, Dolby CP 100, кроме звука Dolby Stereo мог еще работать и со старыми магнитными аудио-форматами, чем облегчал кинотеатрам переход на новый стандарт.
Чтобы обеспечить высокий уровень качества кинопродукции, выпускаемой с логотипом Dolby, фирма ввела строгую сертификацию кинотеатров, звукозаписывающих студий и собственно фильмов. Ведь даже двухканальная фонограмма, воспроизведенная в разных помещениях и с разных громкоговорителей, звучит по-разному (изменяется общий частотный баланс, а также положение кажущихся источников звука), что уж тут говорить о четырехканальном окружающем звуке, закодированном матричным способом. Поэтому сертификация, для получения которой кинотеатр должен был обеспечить достаточно высокое качество звуковоспроизводящей аппаратуры, нужное звуковое давление во всех точках зала и хорошую акустику помещения, помогла сделать звучание фильма примерно одинаковым во всех сертифицированных кинотеатрах.
Сертификация студий звукозаписи необходима для того, чтобы звук, сделанный в этой студии и слышимый режиссером, был таким же, как и в кинотеатрах. Для студий требования примерно такие же, как и для кинотеатров — наличие микшерного пульта с surround-панорамированием, правильная акустика аппаратной, наличие кинопроектора и большого экрана (что автоматически требовало помещения соответствующих размеров), линейность звуковоспроизводящего тракта и обеспечение заданного уровня звукового давления в точке прослушивания. Такая сертификация и рекламная кампания сделали логотип Dolby приманкой для зрителя, который знал, что, придя в кинотеатр, носящий такой логотип, он услышит высокое качество окружающего звука и получит зрелище, недостижимое в домашних условиях. Именно с широким распространением Dolby Stereo связывают расцвет киноиндустрии, произошедший в начале восьмидесятых.
5.3. Технология Dolby Stereo 70 mm
Наряду с внедрением Dolby Stereo компания усовершенствовала звук и для широкоэкранного кино. Способ записи был тот же, на магнитную полосу на 70-мм кинопленке, но теперь уже с шумопонижением Dolby А. Кроме того, шестиканальный формат Todd-AO был модифицирован: две из пяти фронтальных дорожек (а именно левая и правая дополнительные) были убраны, так как время гигантских киноэкранов уже прошло, и вполне хватало одного центрального канала, а место удаленных занимали теперь два канала низкочастотных эффектов. Применение низкочастотных каналов для специальных «громоподобных» эффектов было продемонстрировано впервые, такая инновация была хорошо воспринята индустрией и используется по сей день. С тех пор в обозначении формата канал LFE (Low Frequency Effects) из-за ограниченного частотного диапазона (не выше 300 Гц, обычно до 125 Гц) принято писать через точку, например, 5.1.
В 1978 году формат был еще раз модифицирован: теперь surround-каналов стало два, левый и правый, и, таким образом, этот формат звука на 70-мм кинопленке стал предвестником современного окружающего звука, построенного по схеме 5.1. Первой картиной, выпущенной в этом обновленном звуковом формате (он был назван Dolby Stereo 70mm), стала Apocalypse Now (Апокалипсис сегодня) Френсиса Копполы, но, в связи с закатом популярности широкоэкранного кино, фильмов с новым типом фонограммы вышло немного.
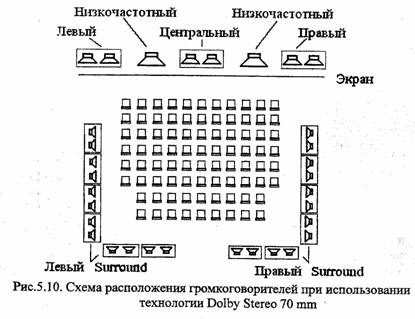
В 1986 году фирма Dolby представила новый аналоговый формат записи звука на кинопленку — Dolby SR (Spectral Recording). От обычного Dolby Stereo он отличался только применением новой системы шумоподавления (SR), в два раза более эффективной, чем Dolby А. Благодаря этому динамический диапазон звуковой дорожки к фильмам увеличился, но все еще применялся матричный способ кодирования. В настоящее время большая часть фильмов выходит со звуком в Dolby SR (наряду с одним или несколькими цифровыми форматами), кроме того, эта система шумоподавления до сих пор используется в профессиональной аналоговой звукозаписи и послужила основой для Dolby S, которая применяется в кассетных магнитофонах.
5.4. Цифровые технологии Dolby Digital, Dolby Digital EX, Dolby-E и ТНХ
В конце 1980-х, на волне возобновившегося интереса к кино, Dolby Laboratories разработала цифровую технологию записи и воспроизведения многоканального звука для 35мм целлулоидной пленки.
Dolby Digital. В системе Dolby Digital несколько аналоговых сигналов звука преобразовываются в цифровой поток, который затем подвергается информационному сжатию по алгоритму Dolby АС-3. Dolby АС-3 — не что иное, как описанный нами в главе 3 стандарт МРЗ. Так как к этому времени большое
число существующих проекторов использовали двухканальный стереозвук или аналоговую систему Dolby Pro Logic, то две аналоговые оптические дорожки на ленте необходимо было сохранить. Цифровая информация была размещена на «нерабочей» части пленки — между окошками перфорации. Система использовала шесть каналов звука и получила наименование «Dolby Digital 5.1».
Эта система предполагает пять полноценных (с точки зрения частотного диапазона) каналов звука: левый, правый, центральный, пространственный правый (Right Surround, RS), пространственный левый (Left Surround, LS), плюс шестой канал с ограниченной полосой частот. Этот канал получил название канала низкочастотных звуковых эффектов (Low Frequency Effects, LFE). Акустическая система канала LFE (для нее также распространено название — Subwoofer) располагается перед экраном кинозала, между системами каналов L и С. Для канала LFE требовалась полоса частот примерно в 10 раз меньшая, чем для пяти основных каналов. Отсюда обозначение, соответствующее шестому каналу « .1» (одна десятая). Первое коммерческое использование систем Dolby Digital состоялось в кинотеатрах в 1992 году, и на сегодняшний день этот формат звука используется не только в кино, но и в цифровом вещательном телевидении (спутниковом и кабельном), в DVD и множестве мультимедийных приложений.
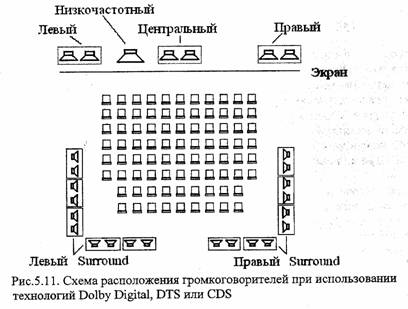
Появление Dolby Digital практически уравняло возможности кинозала и (домашнего кинотеатра». Как и в настоящем кинотеатре, в домашнем кинотетре с Dolby Digital реализуются шесть каналов - L, С, R, LS, RS и LFE. Если в аналоговой системе Dolby Surround использовался только один канал Surround с ограниченной полосой частот (как правило, для его воспроизведения используются две акустические системы, синфазно излучающие один и тот же сигнал), то Dolby Digital предоставляет пользователю два раздельных канала Surround с такой же полосой частот, как у трех фронтальных каналов. Благодаря такому набору, системы с Dolby Digital создают наиболее реалистичные ощущения и позволяют использовать сложные пространственные эффекты.
В декодерах высшего уровня возможности Dolby Digital реализованы полностью — на выходе декодера шесть звуковых каналов по схеме «5» или «5.1» - L, С, R, LS, RS,
(LFE - если имеется Subwoofer). Декодеры уровнем ниже формируют из цифрового потока Dolby AC-3 два аналоговых канала в Dolby Pro Logic — Lt и Rt, из которых декодер Pro Logic затем выделяет четыре каната Dolby Surround — L, С, R, S. Более простые декодеры имеют на выходе традиционный двухканальный стерео — R и L. Наконец, самый простой декодер предназначен для монофонической аппаратуры — на выходе единственный канал звука. Разумеется, декодеры высших уровней могут работать в режимах, соответствующих более простым декодерам. С одной стороны, это позволяет потребителю выбрать оптимальную по стоимости аппаратуру, соответствующую его возможностям и потребностям. С другой стороны, пользователь, купив аппаратуру со сложным декодером, может постепенно наращивать возможности своего
аудио - видеокомплекса — от монофонического звука до «домашнего кинотеатра», т.е. до 5.1.
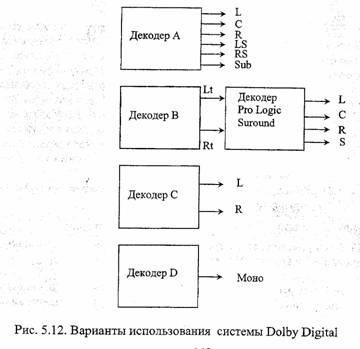
Другое важное достоинство технологии Dolby Digital - масштабируемость аппаратуры. В рамках одной технологии производится целый ряд аппаратно и программно совместимых декодеров (рис.5.12).
Возможности Dolby Digital на этом не исчерпываются. Например, декодер предусматривает управляемую компрессию (сжатие динамического диапазона). Использование компрессии удобно, если слушателю по какой—либо причине необходимо ограничить общую громкость звука. Компрессор повышает уровень слабых звуков, чтобы они были отчетливо слышимы, и наоборот, ослабляет слишком сильные звуки. При этом можно сконфигурировать цифровой декодер таким образом, чтобы низкочастотные составляющие присутствовали только в тех каналах, для которых предусмотрены сабвуферы или широкополосные акустические системы с отдельными низкочастотными громкоговорителями.
Dolby Digital EX. Dolby Surround EX. Этот новый формат кинозвука был разработан Dolby в сотрудничестве с ТНХ и Skywalker Sound Studios. Он был представлен публике в 1999 году с фильмом «Star Wars: Episode I - The Phantom Menace» Джорджа Лукаса. В Dolby Surround EX звук записан по схеме 6.1, дополнительная шестая дорожка используется как центральный канал эффектов (он располагается сзади, между левым и правым surround-громкоговорителями). Однако закодирован шестой канал не дискретно, а старым добрым матричным способом — он записывается в противофазе в левый и правый surround-каналы. С одной стороны, дополнительная звуковая дорожка добавляет в палитру звукоинженера новый инструмент, но возврат к матричному кодированию (и присущим ему ограничениями) понравился не всем. Для Dolby такой способ добавки звукового канала, несомненно, выгоден - не требуется полного переоборудования кинотеатра, а только покупка небольшого «довеска» к декодеру; соответственно, распространился новый формат довольно быстро. К тому же полностью сохранилась совместимость с кинотеатрами, оборудованными Dolby Digital 5.1. В настоящее время уже доступны и бытовые декодеры Dolby Surround EX, поэтому новый формат все чаще находит себе место и на DVD.
Dolby-E. Цифровой поток Dolby-E может содержать до восьми каналов звука с полной полосой частот. Кроме собственно сжатых данных звука, в поток вводятся метаданные - инструкции для декодера Dolby-E, которые носят необязательный рекомендательный характер. Например, специальная инструкция может автоматически установить в декодере то или иное ограничение динамического диапазона выходных сигналов. В зависимости от оборудования, используемого для приема и обработки сигнала Dolby-E, метаданные могут использоваться полностью, частично или не использоваться вообще. Поток Dolby-E делится на два потока, которые могут быть переданы по двум физическим линиям стандарта AES-3 или записаны на цифровой магнитофон вместо двух каналов несжатого звука. Структура потока соответствует кадровой структуре видеосигнала, поэтому материал со звуком Dolby-E можно легко монтировать и редактировать, не нарушая синхронность аудио и видео. Формат допускает до десяти последовательных циклов кодирования-декодирования.
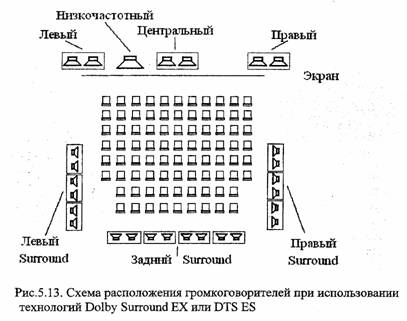
Dolby Surround и Dolby Digital в спутниковом телевидении. В аналоговом спутниковом телевидении с самого начала были предусмотрены два канала звука, поэтому звук Dolby Surround — привычный атрибут спутниковых программ.
Несколько сложнее с цифровым спутниковым телевидением. Разумеется, любой цифровой спутниковый ресивер предполагает стереофонический звук с качеством CD, следовательно, может быть использован для приема программ со звуком, кодированным в аналоговой системе Dolby Surround. Один из первых стандартов информационного сжатия звука, используемый и по сей день в DVB, КОЛЕС 11172-3 предполагает передачу в цифровом потоке звука двух каналов, кодированных в Dolby Surround. Спецификация DVB ETSI TR-101-154 предусматривает в служебных таблицах DVB специальный признак Dolby Surround. Согласно рекомендации, цифровой ресивер DVB должен анализировать этот признак и, если звук кодирован, выводить на экран соответствующую информацию. Для воспроизведения всех четырех каналов требуется внешний аналоговый декодер. Таким образом, пользователь может прослушивать звук в Surround и на цифровых спутниковых программах, используя дополнительно к ресиверу MPEG-2/DVB, например, ресивер с процессором Dolby Pro Logic.Однако, это не совсем удобно для пользователя. Кроме того, в этом нет принципиальной необходимости: пропускная способность цифровых спутниковых каналов DVB не ограничивает количество каналов звука, их может быть сколько угодно. Действительно, не логично аналоговыми методами уплотнять четыре звуковых канала в два, чтобы затем передавать их в цифровом потоке, если можно сразу мультиплексировать по времени все четыре или более каналов. Единого стандарта для звука Surround в цифровом телевидении на сегодня
не существует.
Системы спутникового телевидения DigiCipher-II и эфирного цифрового телевидения ATSC изначально предполагают декодирование Dolby Digital (цифровой поток Dolby АС-3), т.е. позволяют передавать звук Surround «5.1», если приемник оборудован декодером соответствующего уровня. Однако Dolby Digital является официальным стандартом звука в цифровом телевидении только в странах Северной Америки (США и Канада), Южной Корее и Австралии. В Европе и Азии повсеместно принят универсальный стандарт DVB, использующий другую технологию цифрового информационного сжатия звука -MPEG. Только совсем недавно в дополнение к старому документу ISO/EEC 11172-3 был принят документ ISO/IEC 13818-3, описывающий алгоритм сжатия для звука Surround в системах цифрового телевидения DVB-MPEG-2-5.1. Эта технология по своим возможностям аналогична Dolby Digital — пять полноценных каналов звука плюс один канал с ограниченной полосой частот. К сожалению, ресиверов с декодером Surround MPEG-2-5.1 на российском рынке пока нет. А вот носителей видео, аудио и мультимедийных приложений в Dolby Digital, несовместимом с MPEG, уже достаточно как в нашей стране, так и в Европе вообще. Соответственно, есть парк декодеров Dolby Digital, и желательно обеспечить их совместимость с цифровыми ресиверами.
Решение такой задачи нашлось в рамках DVB. Это мультимедийный стандарт, который позволяет одновременно с видео и аудио в одном цифровом потоке передавать с гарантированной скоростью любые данные. Поэтому оказалось возможным передавать звуковое сопровождение цифровых программ DVB параллельно - как собственно звук в MPEG и как дополнительные данные в виде потока Dolby Digital АС-4. Поток АС-3 выделяется демультиплексором ресивера и направляется через соответствующий оптический порт на внешний декодер.
Система ТНХ. Компания ТНХ в области многоканального звука занимает несколько обособленное положение. ТНХ не устанавливает собственных стандартов; вы также не увидите фильма, звук к которому записан в формате ТНХ. Свое название подразделение получило в честь первого фильма Джорджа Лукаса, «ТНХ 1138».
Зато ТНХ занимается другим очень важным делом. Эта компания была организована Лукасом, после того как он посетил несколько кинотеатров и был
совершенно неудовлетворен качеством звука, — его фильмы в различных залах звучали совершенно по-разному, иногда совеем не так, как того хотел их создатель. Таким образом, Лукас решил разработать и воплотить в жизнь программу контроля качества звучания для театральных звуковых систем.
Голливуд оказался благодатной почвой для этой идеи, и компания ТНХ вполне успешно создает и воплощает новые стандарты качества и программы сертификации в мире большого кино. А с появлением систем домашних кинотеатров ТНХ прочно обосновалась и в этой области, но несколько в ином ключе.
По мнению ТНХ, основная проблема, которую необходимо решать производителям аппаратуры для домашних кинотеатров, состоит в следующем. Звуковое сопровождение в фильмах создается из расчета на большие кинозалы, заполненные людьми, и мощные акустические системы, расположение которых в зале стандартизировано. Поэтому, когда такая звуковая дорожка воспроизводится на домашней аппаратуре, звук доходит до слушателя совсем не так, как задумывалось. Естественно, это можно и нужно исправлять с помощью различных электронных ухищрений, чем и занимаются бытовые ресиверы и декодеры, получившие сертификацию ТНХ.
Программы сертификации бытовой аппаратуры от ТНХ носят названия ТНХ Select и ТНХ Ultra (а также ее более новая версия ТНХ Ultra 2). Кроме того, современные
7.1-канальные ресиверы и декодеры, соответствующие спецификациям ТНХ, часто маркируются «ТНХ Surround EX». В области мультимедиа ТНХ с недавних пор также взялась за сертификацию многоканальных мультимедийных акустических систем, и теперь вы сможете увидеть этот логотип даже на комплектах акустики.
Первой ТНХ-кинокартиной стала Return of the Jedi (Возвращение Джедая) из цикла «Звездные войны». В программу входили (и входят) жесткие правила по акустике помещения, расположению, мощности, качеству и настройке громкоговорителей и усилителей.
В 1999 г. фирмы Dolby Laboratories и Lucasfilm ТНХ объединили свои усилия с целью создания улучшенной системы звука формата 5.1. Система ТНХ в отличие от традиционного формата 5.1, имела еще один дополнительный тыловой канал. При этом третий тыловой громкоговоритель располагался непосредственно за спиной слушателя с целью усиления звука левого и правого каналов окружения.
Использование третьего тылового громкоговорителя, расположенного позади слушателя, позволяет точнее позиционировать источники звука и создавать более реалистичную звуковую панораму (за счет кажущегося перемещения источников звука). Например, при использовании двух тыловых громкоговорителей зрителю кажется, что шум от пролетающего над его головой космического корабля перемещается вдоль боковых стен помещения; при использовании же третьего окружающего громкоговорителя у слушателя создается впечатление, что корабль пролетает прямо над ним.
5.5. Технология Cinema Digital Sound
Не только Долби и Лукас занимались в 90-ые годы развитием цифровых технологий в кино. В первую очередь следует упомянуть формат Cinema Digital Sound (CDS), разработанный компанией Optical Radiation Corporation совместно с Eastman Kodak. Дорожка цифрового звука в этом формате помещалась вместо аналоговой, а роль бит выполняли мельчайшие точки (пиксели) на кинопленке. Размер этих точек был очень мал, так как формат разрабатывался при поддержке фирмы Kodak, которая создала для CDS специальную кинопленку. Благодаря малому размеру пикселей и тому, что они были расположены по всей длине кинопленки, на цифровую дорожку удалось «втиснуть» шесть (а, точнее, 5.1) каналов звука с разрешением 12 бит. Правда, эти биты были не линейные, как на компакт-диске, а логарифмические, т.е. квантование звука было более адаптировано к особенностям человеческого слуха, что делало динамический диапазон записи в таком формате практически равным «обычным», линейным 16-ти битам. В CDS, в отличие от всех современных цифровых форматов, применялось сжатие данных без потерь, т.е. звуковые данные на выходе декодера были идентичны данным на входе кодера. Но, несмотря на то, что этот формат был достаточно «продвинутым» для своего времени (например, там применялась схема обнаружения и коррекции ошибок), особого успеха он не снискал, и в нем успело выйти всего несколько фильмов. Причина этому — полный отказ от аналоговой оптической дорожки. Из-за того, что она была вытеснена цифровой, CDS остался без подстраховки, и когда цифровая дорожка давала сбой (что случалось, в том числе, из-за малого размера пикселей), то, в лучшем случае, в зале воцарялась тишина. Отсутствие аналоговой дорожки также требовало изготовления специальных прокатных копий для цифровых кинотеатров, что было достаточно дорого.
5.6. Технология Digital Theatre Systems
Формат DTS (от одноименной компании Digital Theatre Systems) был впервые представлен публике в 1993 году вместе с фильмом Jurassic Park (Парк Юрского периода) Стивена Спилберга. В разработке и тестировании нового формата активно участвовали как сам Спилберг, так и компания Universal, являющиеся совладельцами DTS. Следует иметь в виду, что DTS-кодирование для показа в кинотеатрах и для записи звука на бытовые носители (CD, LD и DVD) сильно между собой различаются. Сама компания DTS этот факт не слишком афиширует, называются обе разновидности совершенно одинаково, хотя способы кодирования, степени сжатия и качество звука у них довольно ощутимо разнятся. Делается это, видимо, из каких-то маркетинговых соображений, но зачастую вносит немалую путаницу в представления широкой публики (да и многих профессионалов) о возможностях DTS в его разных ипостасях.
DTS в кино. Разработчики формата посчитали, что выкраивать на кинопленке (где уже разместились аналоговая дорожка и Dolby Digital) дополнительное место для записи многоканального цифрового звука не имеет смысла, поэтому было принято решение записать звук на CD-ROM, и с него воспроизводить фонограмму в кинотеатрах. Для точной синхронизации с изображением на кинопленку печатается временной код (он расположен рядом с аналоговой звуковой дорожкой). Таймкод содержит не только стандартную синхронизационную информацию (часы, минуты, секунды, кадры), но и кодовый номер фильма и рулона кинопленки. Кинопроцессор сверяет эту информацию из кода на кинопленке с информацией, которая содержится на диске, и допускает воспроизведение только в том случае, если диск соответствует демонстрируемому фильму. Для считывания временного кода с кинопленки требуется относительно простая (и недорогая) насадка на проектор, которая подключается к DTS-кинопроцессору со встроенными дисководами CD-ROM. Сам таймкод из-за больших размеров сигнальных точек очень устойчив к износу и может быть считан даже при повреждениях пленки. Если же временной код в силу каких-то причин перестает поступать на процессор, он воспроизводит звук с CD-ROM еще четыре секунды, после чего (если не восстановился временной код) переключается на резервную аналоговую дорожку с Dolby Stereo. Интересно, что своим успехом формат DTS во многом обязан разработанному контейнеру для дисков. Этот контейнер содержит два диска и удобно помещается в коробку для кинопленки. Такое решение успокоило прокатные компании, опасавшиеся, что диски могут быть утеряны при перевозке или доставлены в кинотеатр не вовремя.
Как и во всех современных системах многоканального цифрового звука в кинотеатры, в DTS используется деструктивное сжатие данных. В DTS для кинопоказа применяется схема компрессии apt-ХЮО, разработанная компанией Advanced Processing Technology. Эта компания, в настоящее время принадлежащая небезызвестной Solid State Logic, занимается передачей высококачественного звука по телефонным сетям ISDN. Собственно, apt-ХЮО изначально был разработан именно для этой цели, DTS лишь адаптировала кодек для передачи многоканального звука. В стандартном варианте DTS кодируются пять независимых каналов цифрового звука с разрядностью 16 бит и частотой дискретизации 44,1 кГц. Шестой (сабвуферный) канал просто подмешивается в левый и правый surround-каналы, частота раздела - 80 Гц. Таким образом, в «киношном» DTS сабвуферный канал не является полностью независимым, однако это обстоятельство не сильно сказывается на результате - в большинстве кинотеатров surroud-громкоговорители и не рассчитаны на передачу частот выше 80 Гц.
Apt-ХЮО является довольно простой схемой сжатия звука. В ее основе лежит адаптивная дифференциальная импульсно-кодовая модуляция (АДИКМ). Этот способ не предусматривает использования каких-либо психоакустических моделей, основанных на особенностях человеческого слуха, и является довольно простым как при кодировании, так и декодировании, что позволяет использовать недорогие кодеры-декодеры, а также снижает задержку между поступлением сигнала и его кодированием/декодированием (это обстоятельство и обусловило успех алгоритмов АДИКМ при передаче звука по
ISDN-сетям).
Принцип кодирования, вкратце, таков. Входящий сигнал кроссовером разбивается на четыре равные частотные полосы, затем для каждого поступающего семпла (отсчета) в полосе кодер предсказывает его значение, основываясь на предыдущих 122 семплах. Затем из предсказанного значения семпла вычитается его реальное (поступившее) значение, после чего эта разница передается по ISDN или, как в случае с DTS, записывается на диск. Естественно, для записи разницы между предсказанным и реальным значением семпла тратится намного меньше бит, чем на запись исходного значения семпла, что и позволяет уменьшать поток передаваемых данных. Единственная «психоакустичность» в кодеке apt-ХЮО — это то, что для высоких и низких частот применяются несколько отличающиеся механизмы предсказания, и этим частотным полосам выделяется меньшее количество бит по сравнению со средними частотами
(в соответствии с известным фактом, что человеческий слух менее чувствителен к высоким и низким частотам).
Основным недостатком apt-ХЮО является то, что алгоритм кодирования невозможно улучшать без смены всего парка декодеров - если применить более совершенный метод предсказания, то его необходимо использовать одновременно и в кодере, и в декодере. Не предусмотрено использование метаданных, что усложняет использование этого кодека в вещании и бытовой технике. Эффективность и качество звучания данного алгоритма сильно зависят от исходного сигнала — почти идеальный результат достигается при кодировании чистых синусоидальных сигналов (где легко с приемлемой точностью предсказать, какое значение будет иметь следующий семпл), а при кодировании случайного шума эффективность падает почти до нуля. В реальных фонограммах соотношение этих двух типов сигналов может существенно отличаться в зависимости от ситуации на экране (например, если кодируется шум дождя, возрастает случайная компонента), соответственно и меняется качество звука. Однако в ситуациях, когда случайного шума в сигнале много, точность передачи (как в том же шуме дождя) не играет большой роли.
С помощью apt-ХЮО при кодировании в DTS удается добиться степени сжатия данных 4:1 и потока данных 882 кбит/с без заметной потери качества звучания. Таким образом, на один CD-ROM (а используется именно CD-ROM, a не аудио-CD, из-за большей избыточности и, следовательно, надежности первого) помещается до 100 минут многоканального звука. Если фильм длится дольше 100 минут, то звуковое сопровождение размещается на двух или более дисках (современные кинопроцессоры DTS имеют два или три встроенных дисковода CD-ROM).
DTS в бытовой технике. Система кодирования DTS нашла довольно широкое применение и на бытовых носителях. Изначально DTS дебютировала на видеодисках формата LD (LaserDisc). Впоследствии довольно широко распространились чисто музыкальные программы с многоканальным (5.1) звуком записанным с применением DTS на обычные аудио-CD. С приходом DVD система DTS заняла свое место и на этом носителе, хотя так и не стала для него обязательным звуковым форматом.
Однако для размещения многоканального звука на бытовых носителях DTS применила другой способ кодирования звука — Coherent Acoustics (разработан фирмой AlgoRhythmic Technology). В его основе лежит все та же АДИКМ, но при кодировании учитываются особенности человеческого слуха (психоакустическая модель). Кроме того, алгоритм Coherent Acoustics очень гибок в применении — с его помощью можно закодировать от одного до восьми независимых звуковых каналов с разрядностью от 16 до 24 бит и частотой дискретизации от 8 до 192 кГц. Диапазон возможных скоростей — от 32 до 4096 кбит/с. Естественно, в DTS используются не все эти возможности — в классическом варианте этой системы кодируется звук в формате 5.1 (на этот раз сабву ферный канал — независимый) с частотой дискретизации 44,1 кГц (для LD и CD) или 48 кГц (для DVD). Разрядность кодируемого источника может быть различной, от 16 до 24 бит, при этом кодер использует преимущества 20/24-битного звука. Сама фирма DTS утверждает, что звук, закодированный с помощью Coherent Acoustics, примерно соответствует по качеству 20-битному несжатому РСМ (т.е. лучше, чем у классического CD), однако это все-таки «небольшое маркетинговое преувеличение».
В процессе кодирования в Coherent Acoustics, входящий ИКМ-звук так же, как и в АС-3, разбивается на блоки. Размер блоков может быть разным: 256, 512, 1024, 2048 или 4096 семплов. Конкретное значение длительности блока определяется кодером в зависимости от нужной скорости потока и сложности материала - чем больше блок, тем эффективнее сжатие, но хуже качество звука. На больших скоростях (с которыми в основном и приходится иметь дело в нашем случае) размер блока, как правило, не превышает 1024 семплов. Затем в каждом блоке происходит разбиение на 32 равные частотные полосы, причем для этой задачи могут применяться два типа фильтров. Первый тип — non-perfect reconstructing (NPR) — использует фильтры с более крутой характеристикой (соответственно, обеспечивается лучшее разделение между соседними частотными полосами), и сжатие информации в данном случае происходит более эффективно. Однако при декодировании такой тип фильтров не позволяет точно восстановить исходный материал, что, естественно, сказывается на качестве звучания. Во втором типе - perfect reconstructing (PR) - фильтры более пологие, и информация в двух соседних частотных полосах перекрывается сильнее. В этом случае сжатие менее эффективно, зато при декодировании использование такого типа фильтров позволяет точно восстановить исходный материал. Какой из этих двух типов будет применен в каждом конкретном блоке, кодер решает
«по обстоятельствам» и включает информацию о типе фильтров в поток данных DTS, чтобы декодер впоследствии мог правильно раскодировать материал. На высоких скоростях, как правило, используется второй тип фильтров.
Затем в каждой частотной полосе происходит АДИКМ-сжатие, построенное по такому же принципу, что и в apt-ХЮО. Однако в Coherent Acoustics сжимаются не все частотные полосы подряд и с одинаковой степенью, как в случае с apt-ХЮО. Перед стадией АДИКМ-кодирования звук анализируется кодером и, в соответствии с заданной психоакустической моделью, определяются необходимость и степень (количество выделенных битов) ADPCM-сжатия. При этом в поток данных включается информация для декодера о том, было ли использовано сжатие или нет. Такая техника позволяет совершенствовать психоакустическую модель (и, соответственно, качество кодирования) без смены парка декодеров.
Для улучшения передачи транзиентных (быстроменяющихся) сигналов в Coherent Acoustics применяется детектор быстрой смены громкости звука (детектирование применяется для каждой частотной полосы отдельно). Если кодер замечает транзиентный сигнал, то он вычисляет коэффициент громкости и расположение такого сигнала в блоке, и эти данные передаются в потоке DTS-декодеру. Используя эту информацию, декодер может восстановить исходный транзиентный сигнал более качественно.
В Coherent Acoustics используются также алгоритмы распределения доступной пропускной способности между каналами (тот канал, который считается кодером, вносящим больше значимой звуковой информации в общую картину, получает больший «кусок», а для малозначительного, с точки зрения кодера, канала отводится меньший), однако эти алгоритмы не такие изощренные, как в Dolby Digital, и используются в гораздо меньшей степени. На низких скоростях допускается объединение высоких частот (так же, как и в Dolby Digital), но к DTS на CD, LD и DVD это не относится. В Coherent Acoustics предусмотрено использование метаданных, управляющих автоматическим микшированием и динамическим диапазоном фонограммы, однако, из-за недостатка инструментария для работы с метаданными они в настоящее время практически не используются.
DTS-звук записывается на CD и LD со скоростью 1235 кбит/с, степень
сжатия при этом варьируется от 2,9:1 (если использовался 16-битный исходный материал) до 4,3:1 (при 24-битных исходных). На DVD, из-за использования рабочей частоты дискретизации 48 кГц, скорость возрастает до 1509 кбит/с. В DTS предусмотрена также уменьшенная скорость для DVD (он может использоваться, например, для дополнительной звуковой дорожки) - 754 кбит/с. Естественно что, качество звука при такой скорости ухудшается.
Для мониторинга и кодирования DTS-звука (не для кино) компания выпускает два прибора: САЕ 4 (кодер) и CAD 4 (декодер). Кодирование в DTS может осуществляться также рядом программных средств, например, программой SurCode компании Minnetoka Audio или специальным подключаемым модулем для Pro Tools.
DTS-ES. Естественно, компания DTS не смогла не ответить на выход системы Dolby Surround EX и создала систему DTS-ES. В исполнении для кинотеатров (а это лишь небольшая насадка на существующие кинопроцессоры), способ получения дополнительного шестого канала такой же, как и в Surround EX - матричное кодирование в левый и правый surround-каналы. Кстати, аббревиатуры ЕХ и ES означают одно и то
же - Extended Surround. Однако для декодеров, применяющихся в домашних кинотеатрах, DTS предусмотрела еще один режим — с независимым шестым каналом. Эти два режима называются, соответственно, DTS ES 6.1 Matrix и DTS ES 6.1 Discrete. Еще раз повторюсь, что в кинотеатрах (из-за особенностей примененного алгоритма сжатия) возможен только матричный способ.
Одновременно DTS представила систему NEO 6 (в пику Pro Logic II), которая предназначена для «разворачивания» полноценного (насколько это возможно)
5-6-канального окружающего звука из старых стереофонограмм (в том числе чисто музыкальных) и фонограмм Dolby Stereo. Естественно, NEO 6 применяется только в домашних кинотеатрах.
DTS 96/24. Весной 2001 года компания DTS представила новое поколение своей системы сжатия звука, названной DTS 96/24 (она также основана на Coherent Acoustics и, соответственно, предназначена для бытовых носителей, в основном для DVD). Как следует из названия, эта система позволяет кодировать многоканальный звук с частотой дискретизации 96 кГц и разрядностью 24 бита (последнее, впрочем, было возможно и в более ранних версиях DTS). Предполагается, что новая система найдет свое место на дисках DVD-Audio в качестве дополнительной фонограммы. Звук, закодированный в DTS 96/24, предполагается размещать в видеозону DVD и, таким образом, он может быть прослушан практически на любом DVD-проигрывателе (при наличии DTS-декодера). А несжатый ИКМ-звук располагается в аудиозоне диска, она «видна» только специальным проигрывателям для DVD-Audio, которые пока еще не слишком распространены. Особенностью системы DTS 96/24 является то, что она полностью обратно совместима со старыми версиями DTS. Т.е. фонограмма, закодированная в DTS 96/24, может быть раскодирована и предыдущими поколениями DTS-декодеров (правда, только с частотой дискретизации 48 кГц, при этом вся «ультразвуковая» составляющая сигнала теряется). Это стало возможным благодаря самой природе алгоритма Coherent Acoustics — первые 32 частотные полосы передаются в DTS-потоке как обычно, а дополнительная информация о частотах от 24 до 48 кГц кодируется в дополнительные частотные полосы, которые не «видят» декодеры предыдущих поколений, но зато могут использовать новые модели. Пока декодеры (равно как и диски) DTS 96/24 еще не появились на рынке, однако новый формат в силу своей совместимости с имеющимся парком оборудования (а это и проигрыватели DVD-Video, и декодеры) имеет все шансы в ближайшем будущем стать довольно популярным.
5.7. Технология Sony Dynamic Digital Sound (SDDS)
Система SDDS (Sony Dynamic Digital Sound) была представлена в 1993 году с фильмом Last Action Него (Последний киногерой). SDDS доступна только для кинопленки, и это принципиальная позиция Sony — адаптации системы для DVD и прочих бытовых носителей не предвидится, поэтому мы рассмотрим ее лишь вкратце. Физически SDDS размещается на кинопленке между ее краем и перфорацией. Информация записывается посредством пикселей, причем эти пиксели имеют меньший размер по сравнению с Dolby Digital. По этой причине, а также из-за того, что SDDS записывается по всей длине пленки (а не только между перфорациями), достигается довольно большой поток данных — до 1235 кбит/с (степень сжатия около 5:1).
Как видно из рис 5.14, Dolby Digital, DTS и SDDS вполне могут сосуществовать на одной прокатной копии фильма.
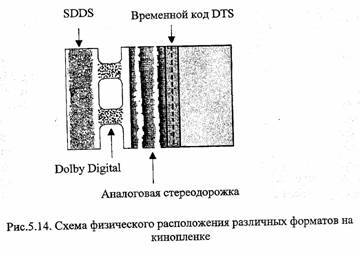
В SDDS можно закодировать до восьми независимых звуковых каналов (семь полнодиапазонных и один низкочастотный), два дополнительных громкоговорителя при этом располагаются за киноэкраном между центральным и левым-правым (так же, как и в системе Todd-AO). По этой причине SDDS нашла широкое применение в больших широкоэкранных кинотеатрах, которые в последнее время опять начали набирать популярность. Естественно, в этой системе тоже теоретически возможно закодировать матричным способом дополнительный (девятый по счету) центральный канал эффектов (так же, как в Dolby Surround EX или DTS ES). Как утверждает Sony, работы в этом плане ведутся, однако готовый стандарт пока еще не вышел в свет (соответственно, нет и необходимого оборудования).
В SDDS используется система сжатия ATRAC (Adaptive TRansform Acoustic Coding), хорошо известная нам по минидискам той же Sony. Основная рабочая частота дискретизации ATRAC (как для кино, так и для мини-диска) — 44,1 кГц. Кодирование в ATRAC построено примерно по тем же принципам, что и в АС-3 или Coherent Acoustics, т.е. звуковой поток разбивается на блоки по времени, а затем по частоте, после чего с применением психоакустической модели «отсекаются» лишние для нашего слуха, по мнению кодера, данные. Временные блоки в ATRAC не имеют фиксированного значения, а варьируются кодером в пределах от 1,45 до 11,6 мс, что позволяет качественно кодировать транзиентные сигналы. Количество частотных полос - 52. ATRAC со времени своего представления широкой публике постоянно совершенствовался, и последние версии этого кодека звучат довольно хорошо (в том числе и на чисто музыкальном материале).
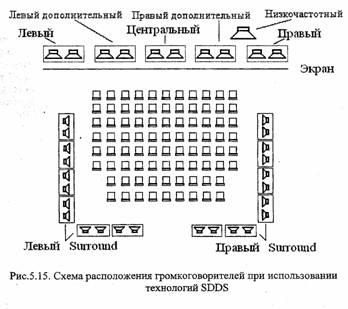
Для обеспечения надежности воспроизведения в SDDS предусмотрены три уровня «защиты»: все-таки самый край пленки за перфорациями не лучшее место на кинопленке для записи звука. Во-первых, это мощная система коррекции ошибок, способная исправить небольшие выпадения в считываемом цифровом потоке. Во-вторых — дублирование звуковой дорожки (SDDS записывается по обоим краям пленки, так что если возникают проблемы со считыванием звука с одной стороны, декодер начинает считывать информацию с другой). Ну и, в-третьих — если ничто не помогает, и цифровой звук не может быть считан с кинопленки, декодер переходит на аналоговую звуковую дорожку. Таким образом, SDDS в настоящее время является одним из самых «продвинутых» форматов, сочетающим в себе высокое качество звука, большое количество доступных каналов, «пуленепробиваемую» надежность воспроизведения и простоту производства прокатных копий. Однако все это доступно только в кинотеатрах, да и то за пределами нашей страны.
5.8. Качество звучания различных форматов
По поводу качества звучания различных форматов единого мнения в настоящее время не существует. В области бытовых носителей идет речь, в основном, о сравнении Dolby Digital и DTS. К сожалению, сравнить качество звука напрямую (прослушивая одну и ту же фонограмму, закодированную в разных форматах) практически невозможно.
Во-первых, потому что для одного и того же фильма (даже на одном DVD) исходные материалы для изготовления фонограмм DTS и Dolby Digital чаще всего разные. Обычно многоканальную фонограмму немного «подстраивают» под конкретный кодек, чтобы максимально использовать его преимущества и скрыть недостатки. Если же «подстройки» не происходит, то возможна ситуация, когда одна фонограмма при прочих равных звучит лучше в DTS, а другая - в Dolby Digital. Кроме того, многое зависит от мастерства человека, закодировавшего звук. Если в кодерах DTS практически нет управляемых оператором параметров (кроме скорости цифрового потока и количества каналов), то кодирование в Dolby Digital довольно тонкий процесс, позволяющий оператору динамически управлять, например, громкостью центрального канала (с помощью метаданных). И в этом случае слушатель может предпочесть один кодек другому только из соображений громкости (или разборчивости), а не общего качества звучания.
Делать выводы, исходя только из скорости потока, тоже некорректно - мы ведь имеем дело с разными алгоритмами. Исходя из документации обеих фирм, складывается впечатление, что DTS берет «числом», - высокие скорости, довольно простые алгоритмы, a Dolby - «умением», все-таки, если при в три раза меньшей скорости, по сравнению с конкурентами, нет единого мнения о превосходстве одного из форматов, это кое о чем говорит.
В общем, однозначного выбора не существует, хотя для чисто музыкальных фонограмм предпочтение, в большинстве случаев, отдается DTS (правда, это может быть вызвано и активным продвижением DTS своего кодека на музыкальный рынок, в то время как Dolby в своей маркетинговой политике больше ориентируется на кино).
В связи с обсуждением сравнительного качества звучания разных форматов интересна история о «ссоре» Dolby и DTS. Правда, все происходит довольно корректно — компании просто периодически выкладывают на свои сайты PDF-файлы с контраргументами (кстати, спор этот не закончен до сих пор). Началось все с того, что фирма Dolby, недовольная сложившейся ситуацией, когда для кодирования «чистой» музыки ее кодек обычно даже и не рассматривается (кстати, это действительно несколько несправедливо и является следствием маркетинговой политики обоих участников), решила провести собственное тестирование. Dolby приобрела кодер и декодер от DTS и провела сравнение субъективного качества звука на одном и том же оборудовании и на одном материале со своими кодером и декодером («при участии квалифицированных экспертов»). Как и следовало ожидать, большая часть экспертов предпочла Dolby Digital. DTS такие результаты, естественно, не удовлетворили, и она представила свои аргументы, почему результатам этих тестов доверять нельзя (досталось и «квалифицированным экспертам»). Dolby не замедлила объяснить, почему аргументы DTS некорректны. И так далее. В общем, пока не будет квалифицированного независимого тестирования, этот спор, похоже, продолжится до бесконечности. К сожалению, пока ни одна из
фирм-конкурентов по каким-то своим причинам не идет на проведение независимого теста.