ЛИТЕРАТУРА КАК ИСТОЧНИК ИНФОРМАЦИИ
Основные понятия, эволюция и типология
Строго говоря, источником любой информации является человек или группа людей. Ответственность за достоверность тех или иных сведений могут брать на себя учреждения или организации, которые в этом случае также служат как бы источниками информации. Но в профессиональной информационной деятельности информация циркулирует в виде документов, и именно они считаются источниками информации.
Под документом понимается совокупность логически завершенных сведений и материального носителя, на котором они записаны, с непременным указанием кем, где и когда документ был создан. Понятие документа является альтернативным и обобщающим по отношению к понятию произведения письменности и печати, часто употребляемому в гуманитарных науках.
Произведением письменности считается результат целенаправленной познавательной деятельности (факты, идеи, образы), имеющий определенную логическую взаимосвязь частей, завершенность в целом и изложенный в письменном виде. Произведение печати, кроме того, получает обязательную редакционную апробацию и имеет точный библиографический адрес, состоящий из стандартного набора выходные сведений (автор, заглавие, город, издательство и год публикации или название публикующего органа).
Поскольку способы хранения и передачи информации играют большую роль в развитии коммуникации, да и цивилизации в целом, интересно проследить эволюцию этих способов.
С развитием каждой цивилизации по мере усовершенствования ее языка и письменности вырабатывались и определенные типы документов, как по форме, так и по содержанию. Самые древние из дошедших до нас документов — клинописные плитки Месопотамии — датируются четвертым тысячелетием до н.э.
От шумерской культуры того времени и вавилоно-ассирийской, расцвет которой приходится на второе тысячелетие до н.э., сохранились сочинения в области астрономии географии истории, права, торговли, Наряду с небольшими глиняными плитками высотой в 2,5 см изготовлялись плитки высотой др,40 см, содержащие до 400 строк в 4 колонки с двух сторон. Основным недостатком этих глиняных книг, в течение тысячелетий обслуживавших культурные и научные потребности человека, была их громоздкость и недостаточная емкость. Отдельные произведения занимали до .10 плиток. Собрания, насчитывавшие десятки тысяч плиток (а до нас дошли остатки подобных библиотек), требовали огромных помещений.
Папирусный свиток — более компактная форма документа, позволявшая накапливать большие собрания произведений письменности. Начиная с третьего тысячелетия до н.э. в Египте изготовлялись именно такие книги. Текст на папирусном свитке располагался перпендикулярно его длине колонками от 25 до 45 строк. Хрупкость и недолговечность папируса обусловила незначительное число дошедших до нас образцов древнеегипетских документов (древнейший из них восходит к ХИН в. до н.э.). Это, главным образом, ритуальные «книги мертвых», извлекаемые археологами из, пирамид и других захоронений.
У греков и римлян на протяжении долгого времени сведения (особенно научного характера) распространялись устным путем. Известно, что лишь после Аристотеля для этих целей стали широко применяться рукописи. До середины прошлого века мы не располагали ни одним оригиналом времен античных классиков, часто столетия отделяют последнюю сохранившуюся копают возможной даты написания текста. Исключение составляют лишь найденные во время второй мировой войны кумранские рукописи («рукописи Мертвого моря»), датируемые первым веком н.э. Сведения о греческих и римских папирусах почерпнуты из малоазиатских и позднеегипетских образцов. Средняя длина свитка не превышала 10 м, ширина — 30 см.
Пергамент, изготовлявшийся из телячьих шкур, известен как материал для письма с III в. до н.э. Он позволял писать с двух сторон, был более долговечен, чем папирус, и обусловил переход к современной блочной форме книги — кодексу. Кодексы из папируса изготовлялись еще в первые века н.э., но к V в. были вытеснены пергаментным кодексом.
Кодекс — более емкая форма книги, чем свиток, он удобнее для записи больших текстов и для наведения справок, Пергаментные кодексы вплоть до ХИ в. были единственной формой книги в Европе. Основным их недостатком, препятствовавшим широкому распространению письменных документов, была дороговизна. Для одного экземпляра пергаментной книги требовались шкуры целого стада. На смену пергаменту пришла бумага, изобретенная в 105 г. в Китае. На Ближнем Востоке ее начали изготовлять с 751 г., а в ХП в. через арабских завоевателей Испании она проникла в Европу.
Бумажная книга, значительно более дешевая, чем пергаментная, стала широко использоваться в научных и образовательных целях. Опыт нескольких тысячелетий развития письменных документов показывает; что их форма менялась главным образом под влиянием потребностей общества: документы становились все более емкими, удобными для использования и дешевыми; Именно эта тенденция развития средств, служивших для закрепления информации, привела к появлению бумажного книжного блока, который до нашего времени оставался основной материальной формой документа.
В XV в. стала повсеместно ощущаться потребность в новом способе изготовления документов: Рукописная книга перестала удовлетворять культурные и научные запросы общества по двум причинам. Во-первых, она изготовлялась слишком долго и требовала значительных затрат труда. Во-вторых, переписка текстов от руки не давала возможности получить большое число экземпляров идентичного содержания, так как копии одного и того же текста отличались друг от друга из-за искажений, вносимых переписчиками.
Именно к этому времени относится историческое изобретение в 1448 г. немецким ремесленником И. Гуттенбергом книгопечатания подвижными литерами. Технические средства, которые легли в основу книгопечатания, — граверная и литейная техника и винодельческий пресс, преобразованный Гуттенбергом в печатный станок,— были известны еще в античные времена. Однако лишь настоятельная потребность общества в быстром и точном механическом воспроизведении текстов вызвала к жизни это изобретение, совершенству которого мы не перестаем удивляться и основными принципами которого продолжаем пользоваться для размножения документов.
Мы знаем, что теперь появились технические средства, значительно повысившие наши возможности хранения больших массивов информации с быстрым доступом к любой единице этой информации. Речь идет о компактных оптических дисках, используемых в качестве внешней памяти компьютера (CD- ROM — Compact Disc Read Only Memory). В этой области прогресс происходит так быстро, что рискованно приводить какие- либо точные данные. Но объем одного диска измеряется тысячами мегабайт, т.е. миллионами страниц текста, время записи и считывания одной страницы не превышает 1-2 сек., а в «библиотеке» из 64 дисков поиск и выдача информации по запросу занимает 10-15 сек. Выведенные на экран тексты и изображения можно изменять по мере необходимости. Эти новые средства начинают широко использоваться, и мы еще будем о них говорить.
В широком смысле документами иногда считают не только надписи, рукописи и печатные издания, но и произведения искусства, нумизматические памятники, музейные экспонаты минерального, ботанического, зоологического или антропологического характера. П. Отле считал документом любой материальный объект, который фиксирует или подтверждает какие-либо знания и может быть включен в определенное собрание.
Различные виды научных документов возникали в разное время и на протяжении последних столетий и даже десятилетий претерпевают значительную эволюцию. Книга существует уже несколько тысячелетий, описание изобретений — 500 лет, научный журнал — немногим менее 350 лет, а журнальная статья в ее настоящем виде — 100-150 лет. Типология документов также существенно меняется. До последнего времени наиболее важным считалось деление научных документов на опубликованные и непубликуемые. Еще несколько десятилетий назад идеи и факты признавались введенными в оборот только после их опубликования, означавшего широкое распространение и официальную регистрацию документов, в которых они содержались.
Для информационной деятельности это разграничение менее существенно: во-первых, в неопубликованных документах содержится много ценной информации„опережающей сведения, появляющиеся в публикациях: во-вторых, новые средства репродуцирования делают это разграничение очень условным. Такие научные документы, считающиеся обычно непубликуемыми, как отчеты, диссертации, переводы, часто распространяются в сотнях и даже тысячах экземпляров.
Информатика выдвинула на первый план деление документов на первичные и вторичные. Деление это также очень условно и приблизительно, поскольку оно главным образом относится к самой информации, а не к документам, в которых она содержится. Считается, что в первичных документах отражаются непосредственные результаты познания, а во вторичных — результаты аналитико-синтетической переработки информации, содержащейся в первичных документах. Однако исторически сложившаяся система научных документов такова, что многие из них содержат одновременно и результаты научных исследований и переработку прежних сведений, содержавшихся в ранее опубликованных документах. Примером могут служить и статьи в научных журналах, и монографии, и учебники, и особенно— справочная литература.
Тем не менее, деление это удобно, так как позволяет характеризовать различные потоки документов в информационной деятельности. Мы придерживаемся его в информатике, считая первичными те документы и издания, в которых преимущественно содержатся новые сведения или новое осмысление известных идей и фактов, а вторичными те документы и издания, в которых содержатся сведения о первичных документах. С учетом сделанных оговорок к первичным документам и изданиям можно отнести большинство книг (за исключением справочников), журналы, газеты и сериальные издания, описания изобретений, стандарты, отчеты, диссертации, переводы, а ко вторичным— справочники и энциклопедии, обзоры, реферативные журналы, библиотечные каталоги, библиографические. указатели и картотеки.
Основные виды первичных документов изданий охарактеризованы в книговедческих курсах, а вторичных будет посвящена в данном курсе лекция об информационных изданиях и услугах. Здесь хотелось бы высказать некоторые соображения лишь о журналах, так как на их примере дальше будут анализироваться закономерности роста, старения и распределения научных публикаций. Журналом мы будем называть: периодическое (сериальное) издание, регулярно публикуемое в. течение одного года, выпусками, одинаково оформленными и содержащими статьи иные материалы научно-технического или общественно; политического содержания, а также произведения художественной литературы. В журналах содержится новейшая информация, освещаются последние достижения науки и техники. Журналы появились почти триста пятьдесят лет назад: точной датой этого события считается 5 января 1665 г., когда опубликован первый номер французского еженедельника «Журнал„ученых», который дал название этому виду периодических изданий.
Основным назначением этого журнала, предопределившим характер научных журналов на 150 лет вперед, стадо оповещение о новых книгах по всем отраслям науки, литературы и искусства однако с особым вниманием к естественным наукам и технике. Для раскрытия содержания книг, в то время широко пользовались прямыми, заимствованиями и цитатами из, текста. Вначале научная хроника играла в журнале второстепенную роль, постепенно все больше места в нем стали занимать сообщения об экспериментах в области естественных наук и, вновь открытых явлениях природой. Оригинальные статьи в, течение всего XVIII в. публиковались в журналах редко. Обычно они принадлежали крупным ученым и имели традиционно-условную форму писем одного ученого к другому так было принято сообщать о научных открытиях в предшествующие эпохи.
Начиная с Х1Хв. журнал становится основным источником научной информации. В Х1Х в. столетии установилась исключительно важная практика поминания в каждой журнальной статье всех научных работ, которые использовались при ее написании. Статьи: в научных журналах являются в настоящее время основным источником научн6й информации. Они прочно занимают первое место среди всех других документов. Обследование библиографических запросов нескольких тысяч ученых и инженеров показало, что до 70% всех используемых ими источников составляют журнальные статьи.
Однако рост числа журналов, их недостаточная профилированность, быстрое старение опубликованных в них материалов привели к тому, что уже с 30-х годов журнал как источник информации стал подвергаться критике ученых. Они выдвинули множество проектов замены научных журналов другими средствами распространения знаний. В их основе лежит предложение вместо издания Журналов депонировать разрозненные статьи в специальных отраслевых центрах и отражать их в реферативный журналах.
Один из первых проектов такого рода выдвинут отечественными учеными, делегатами Международного геол6гическ6го конгресса в 1933 г. В этом же году англичанин У. Дэвис сделал аналогичное предложение, которое легло в основу известного «плана Бернала», опубликованного в 1939 г. в книге Дж. Бернала «Социальная функция науки». Этот план был предметом обсуждения: в 1048 г; на Конференции научной информации; созванной английским Королевским обществом, а в 1958 г. на Международной конференции научной информации в Вашингтоне. Дж. Бернал предложил отказаться и от самой статьей как формы сообщения результатов научного исследования, поскольку она не обеспечивает их быстрого и адекватного отражения. Рациональные моменты в этих идеях были воплощены при создании системы депонирования неопубликованных научно- технических документов однако полностью план Бернала вряд ли когда-либо будет реализован, так как он не учитывает многих закономерностей системы научных публикаций.
Закономерности роста и старения
С развитием информатики наступил новый этап в изучении научных публикаций, поскольку основное внимание стали уделять закономерностям, характеризующим внутреннюю связь изданий с развитием науки, количественные зависимости между числом публикаций и показателями роста науки. Закономерности эти связаны со структурой и свойствами научной информации, но проявляются несколько иначе и могут быть достаточно точно измерены.
Выяснилось, что для числа авторов, публикующих определенное количество работ в течение своей жизни, числа журналов, ежегодно публикующих определенное количество статей, числа публикаций, содержащих определенное количество ссылок на другие публикации, существует общая закономерность распределения. «Они следуют тому же типу распределения, который характеризует соотношение миллионеров и бедняков в условиях высокоразвитой капиталистической экономики: огромная доля богатств находится в руках узкого круга сверхбогачей, а небольшой остаток — в руках несметного множества мелких производителей. Является ли точная форма распределения логарифмической, экспоненциальной, описывается ли она законом Ципфа или обратной квадратной функцией это предмет особого рассмотрения в каждом отдельном случае».
Это означает, что большинство авторов за всю жизнь публикует лишь одну или две статьи, тогда как небольшая группа авторов отличается плодовитостью, публикуя по несколько десятков или даже сотен работ. По большей части прекращают выходить в свет периодические издания, успевшие выпустить несколько годовых комплектов, тогда как небольшое число давно выходящих изданий публикует львиную долю всех статей. Примерно половина опубликованной литературы обязана такому числу авторов или журналов, которое составляет квадратный корень общего их количества. «Короче, если, например, в мире выходит 30 тыс. журналов или в какой-либо стране имеется 1 млн. научных работников, то лишь небольшое ядро в 175 журналов и 1 тыс. ученых ответственно за половину всей литературы по количеству и, вероятно, за 70-80% по важности содержания».
Эти положения Д. Прайс иллюстрирует схемой, которую он назвал «подходом страхового агента» к проблеме авторства научных статей. На рис. 7 круг обозначает 100 % авторов в какой- либо области или стране, опубликовавших статьи в определенном году. Левая сторона схемы показывает распределение авторов этих статей по их публикуемости в предыдущие годы (год назад, два-три года назад и ранее не публиковавшихся). Правая сторона показывает то же распределение в последующие годы. Под кругом изображено движение «постоянных» авторов, т.е. публикующихся на протяжении ряда лет (и не учитывавшихся в приведенном выше распределении). Обобщенный смысл этой схемы заключается в том, что для увеличения числа постоянных авторов на одну единицу необходим6 появление примерно четырех новых авторов. Один из них заменяет постоянного автора, переставшего публиковать свои труды, два других выбывают по причине «детской смертности». Это те, кто приходят в систему научных публикаций и уходят из нее в течение одного года. И только четвертый остается на более или менее длительный срок печатающимся автором.
Рост литературы выражается в непрерывном увеличении числа вновь появляющихся изданий и публикаций. Широко распространенное представление об экспоненциальном росте основных видов литературы справедливо лишь для ее суммарного количества, причем без учета старения; Реальной моделью такого представления могут служить крупные научные библиотеки, комплектующие литературу по широкому профилю и выполняющие функции архивного хранения литературы. Но если нас интересует ежегодный прирост новой литературы, то приходится быть более осторожными в оценках.
Статистика мирового книжного рынка за последние полстолетия показывает, что число ежегодно выпускаемых на рынок книг увеличивается в арифметической прогрессии, а именно, на l5-20тыс. названий. В 1955 г. по сданным ЮНЕСКО опубликовано 269 тыс. названий книг, в 1960 г. — 332 тыс. в 1970 г. —521 тыс., в 1980 г. — 715 тыс., в 1990 г. — 842 тыс. в 2000 г.— 1,25 млн. Справедливость требует заметить, что это далеко не все выходящие книги, а только те, которые поступают в продажу. Если бы было возможно учесть заказные, бесплатные, ведомственные, учебно-методические и другие издания ограниченного распространения, то приведенные цифры можно было бы удвоить. Следует также иметь в виду, что научны книги (т.е. содержащие научную информацию в нашем понимании) составляют 20-25 % от общего их числа.
Подсчет числа журналов значительно сложнее, так как они в отличие от книг все время находятся в процессе изменений. Журналы возникают, прекращаются, сливаются, дробятся, меняют название, издателей, периодичность и т.д. По мнению специалистов только по естественным, точным и прикладным наукам ежедневно три новых журнала возникает, а один перестает выходить.
Наиболее достоверные сведения о числе выходящих журналов можно получить из «Международной библиографии периодических изданий», выходящей под именем Констанции Ульрик. В последнем издании этого справочника зарегистрировано 164400 названий журналов, из. которых около 50% падает на издания по общественным и гуманитарным наукам, 40% составляют журналы по точным, естественным и прикладным наукам и лишь 10 % — литературно-художественные и, общественно- политические журналы. Некоторое представление о темпах роста числа журналов можно получить, сравнивая объемы различных изданий библиографии. К. Ульрик: 13-е изд. (1969 — 70) — 40.тыс названий, 15-е изд., (1971 —,72) — 55тыс., 17-е изд. (1973 — 74) — 60 тыс., 19 е изд., (1980) — 62 тыс., 21-е изд. (1982) —63 тыс., 24-е изд. (1988) =100 тыс., 30-е, изд. (1995) — 120 тыс., 39;e. изд. (2001) — 164 тыс.
Старение публикаций заключается в том, что они с увеличением своего «возраста», теряют ценность как источники информации и все меньше используются специалистами. Степень этого использования, можно устанавливать при помощи учета цитирования. В, данном случае стареет, не сама информация, а содержащие ее, публикации, поскольку (как мы выяснили) в свежих, работах эта информация может быть «упакована» более плотно вместе с новой.
Для измерения скорости, старения публикаций американские ученые Р. Бартон и Р. Кеблер предложили в 1960, г. меру, названную, «периодом полужизни», публикаций по аналогии с показателем скорости: распада радиоактивных веществ. Период полужизни публикации — это время, в течение которого была опубликовано половина всей используемой в настоящее время литературы, по какой-либо отрасли или предмету. Например, если этот период ранен 5, то это значит, что 50% всех процитированных в текущем году по данному предмету работ не старше пяти лет. Ниже приводятся данные разных авторов о периодах полужизни публикаций в различных отраслях науки:
Биомедицина 3,0
Химия 8,1
Ботаника 10„0
Биомедицина 3,0
Металлургия 4,6
Хим. технология 4,8
Социология 5,0
Математика 10,5
Геология 11,8
География 16,0
Машиностроение 5,2
Физиология 7,2
Достоверность приведенных цифр зависит от величины выборки цитирования, от типа и характера публикаций, поэтому даже в пределах одной науки данные разных авторов могут существенно расходиться. Но дело не только в этом. В 70-е и 80-е годы проблема старения литературы подверглась интенсивным исследованиям, в результате которых ее понимание стало сильно отличаться от концепции «периода полужизни». Начало этому пересмотру положил М. Лайн, который ввел в расчет характеристики старения литературы темпы ее экспоненциального роста. Сущность того, что произошло в трактов- кестарения, как всегда ярко выразил Д. Прайс: «В течение нескольких лет после публикации спрашиваемость статьи или ее относительная цитируемость уменьшается крайне медленно (по параболе, если считать по логарифмам прошедших лет). Даже через столетие возможность цитирования уменьшается только на порядок. Большинство ссылок падает на работы последних лет потому, что этих работ большинство, и очень сомнительно, чтобы это вызывалось эффектом немедленности, связанным с быстрым старением..».
Этой проблеме до сих пор и у нас и в ряде зарубежных стран посвящается много серьезных работ, которые убеждают в том, что частота использования определенной совокупности литературы одного года издания меняется очень медленно. Использование публикаций, определяемое по их цитированию или на основе запросов читателей, отражает не только старение литературы, но и ее рост. Для теоретиков информатики и историков науки важно учитывать старение литературы в чистом виде, для информаторов и библиотекарей период полужизни служит важным практическим показателем и продолжает широко использоваться. Следует также иметь в виду, что цитируются далеко не все научные публикации. Половина статей в определенной области в текущем году, как правило, не упоминается, а еще 40% цитируется лишь один раз (обычно самим автором). Таким образом, активный исследовательский фронт, те число работ, цитируемых более одного раза в году, на порядок меньше корпуса опубликованной литературы.
Еще одним важным свойством научных публикаций является их рассеяние. Закон рассеяния научных статей в журналах открыт в 1934 г. С. Бредфордом, который в 1948 г. дал ему следующую формулировку. «Если научные журналы расположить в порядке убывания числа помещенных в них статей по какому-либо заданному предмету, то в полученном списке можно выделить ядро журналов, посвященных непосредственно этому предмету, и несколько групп или зон, каждая из которых содержит столько же статей. что и ядро. Тогда числа журналов в ядре и в последующих зонах будут относиться как
1:a:а». 2
В соответствии с этим законом журналы по продуктивности можно сгруппировать так„чтобы они как бы образовали три зоны. Включенные в каждую такую зону журналы содержали бы одну треть публикаций по данному предмету, помещенных во всех этих журналах. Первая, ядерная зона содержит публикации из небольшого числа самых продуктивных журналов — Tl. Вторая зона содержит публикации из большего числа журналов средней продуктивности Т2, а третья зона — из еще большего числа журналов с низкой продуктивностью — T3. Тогда в соответствии рассматриваемым законом,
Tl: Т2: T3=1: а: а2
где а является коэффициентом рассеяния, т.е. величиной для данного предмета и времени постоянной.
Для 248 журналов по электрохимии, проанализированных
С. Бредфордом, численное значение а составляло примерно 5. В ядерной зоне содержалось 8 самых продуктивных журналов, во второй зоне 8х5=40 журналов средней продуктивности и в третьей зоне 8 х 25 = 200 журналов. В каждый из этих трех зон содержалось по 220 релевантных публикаций, общее число которых составляло 660. Кривая рассеяния публикаций в соответствии с законом Бредфорда представлена на рис. 8. Другими словами, если совокупность всех публикаций по какому-либо вопросу принять за целое, то в специальных журналах данного профиля (число которых невелико) помещается лишь одна треть этих публикаций.
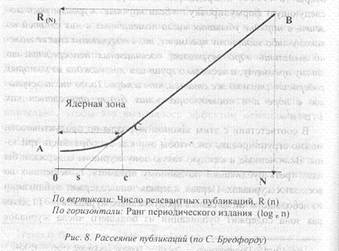
Вторая треть статей по данному вопросу оказывается опубликованной в значительно большем числе тематически родственных (смежных): журналов. Последняя треть этих публикаций рассеяна в огромном числе периодических изданий, в которых появление статей данной тематики труды предвидеть, так как эти издания имеют широкий профиль или: общенаучный характер.
За годы, прошедшие со времен открытия этого закона, проведены сотни исследований с целью проверить его истинность и найти для него строгой математическое выражение. Они показали, что закон этот выполняется только при определенных условиях, когда предмет или тема четко сформулированы, учитываются все релевантные документы в полном перечне изданий и строго ограничено время выхода этих изданий.
Последнее условие имеет особый смысл, так как закон этот характеризует рассеяние в определенный момент. Он является частным случаем более общего распределения, описываемого законом Ципфа. Дж. Ципф установил, что если к Достаточно большому тексту составить список всех встретившихся a нем слон расположить их в порядке убывания частоты встречаемости в данном тексте, то для любого слова произведение его порядкового номера (ранга) на эту частоту есть постоянная величина, имеющая одинаковое численное значение в данном тексте. Этому закону подчиняется распределение не только слов во всех языках Мира, но и других явлений социального характера ученых по числу опубликованных ими работ, городов по численности населения, людей по размерам дохода и даже биологических родов по числу входящих в них видов.
Следует: отметить, что многие, попытки объяснить механизм осуществления закона Бредфорда оказались неубедительными из-за того, что их авторы распространяли этот закон на процессы, происходящие во времени (т. p. e диахронии), тогда как он справедлив только для определенного временного среза (т.е. в синхронии) Закон Бредфорда отражает одно из свойств открытой социальной системы, каковой и является научная литературе по предмету, а именно стабильность ее иерархической структуры.
Некоторое отличие этого закона от ципфовского распределения объясняется спецификой периодических изданий как формы квантования научной литературы. Эти издания обладают большой инерционностью: изменения в их профилях и номенклатуре происходят значительно медленнее, чем в содержании статей, которые непосредственно отражают все процессы в науке и технике.
Закон рассеяния публикаций имеет большое практическое значение. Из него следует, что охват всех публикаций по какой- либо отрасли или предмету не может быть обеспечен, если ограничиться просмотром лишь профильных журналов и журналов по родственной тематике — для этого приходится просматривать значительную часть научно-технических журналов. Этот закон учитывается при организации национальных информационных систем. Он позволяет решить ряд практических задач информационной деятельности:
определять число журналов, которые обеспечивают тот или иной процент всех публикаций по какой-либо отрасли или предмету, составлять списки журнальных публикаций по определенной теме с гарантированной степенью полноты, оценивать полноту библиографических списков журнальных публикаций, комплектовать журнальные фонды при фиксированных ассигнованиях на подписку, вычислять длину полок, необходимых для хранения оптимального фонда журналов.
Рассмотренные нами закономерности далеко не исчерпывают всех достижений информатики в изучении средств информационной коммуникации. К ним следует также добавить и результаты исследований последних десятилетий в области социологии массовой коммуникации и информации: распределение типов и видов передач на радио и телевидении, организацию газетных банков данных и информационно-поисковых систем и т.п.
В последнее время наблюдается много признаков того, что система периодических изданий утрачивает значение основного средства распространения научной информации. Об этом свидетельствует быстрый рост удельного веса непубликуемой научной литературы — отчетов, докладов, обзоров, справок и т.п., а также все увеличивающаяся роль неформальных коммуникаций — всевозможных конференций и совещаний, выставок, посещений учеными лабораторий своих коллег, обмена препринтами и другими непубликуемыми материалами. Если на научно- информационную деятельность в США расходуется до 10% правительственных ассигнований на науку, то более 10% из них тратится на научно-технические совещания. Каждый день там происходит несколько конференций или симпозиумов. Совершенно ясно, что это значительно ускоряет распространение информации и стало возможным в результате достижений в области транспорта и связи.
Но это вовсе не означает, что журнальные публикации вообще утрачивают свое значение. По мнению Д. Прайса, «80% ценности и функционального назначения статьи лежат вне Области коммуникации. Статья и коммуникация перекрывают друг другая лиги на 20%». Статья, а тем более монография становятся для ученого средством кристаллизации и формулирования своих идей, самовыражения и утверждения своей личности в науке, закрепления своего приоритета на результаты исследования. Недаром суммарное число опубликованных работ служит общепринятым показателем продуктивности труда ученого. Кроме того, если рассматривать каждый документ как составную часть литературы, то его опубликование означает индивидуальный вклад в общечеловеческое знание и возможность его сохранения для последующих поколений, т.е. передачу не только в пространстве, но и во времени.
Мы уже говорили„раньше о том, что наряду с источниками информации в традиционной литературной форме новая информационная технология выдвигает на передний план документы в электронной машиночитаемой форме. Именно это дало основание французскому социологу Ж. Андерса утверждать, что темпы роста информации, будут возрастать, несмотря на ограничение выпуска журналов и книг. По его мнению, в 1955 г. ежегодный прирост не дублируемых единиц научной информаций составил 0 5 млн., в 1970 г. он вырос до 2 млн., а к 1985.г. — до 12 млн.
Увеличение темпов роста первичной и вторичной информации он оценивал в 12-13%, в год. При этом он считал, что от 1/4 до 1/3 всей, информации сосредоточено в автоматизированных системах и циркулирует в их сетях, а прирост этих электронных источников информации является наиболее интенсивным и достигает 40% в год. Хотя этот прогноз был встречен скептически большинством специалистов, в действительности темп этого роста оказался еще более динамичным.
Электронные источники информации отличаются от традиционных двумя существенными чертами: во-первых, более широким составом авторов и во-вторых, большими изобразительными возможностями. В отношении первого обстоятельства выдвигается следующая гипотеза: «В настоящее время установлено, что в распространении новой информации важную роль играют такие категории авторов, которые не являются собственно научными работниками. На первом месте здесь, должны быть названы экономисты, демографы, юристы, социологи, психологи, географы, педагоги и другие представители общественных, наук, которых обычно не учитывают в статистических исследованиях численности научных работников. Вполне вероятно также, что значительная и без сомнения все возрастающая часть общего объема информации производится инженерами, техниками и другими специалистами-практиками, работающими в различных областях и на разных уровнях».
Второе обстоятельство обсуждается в связи с электронной книгой. Эта книга интерактивна, с ней можно взаимодействовать как с диалоговой информационной системой, вносить в нее собственные изменения и комментарии, компоновать фрагменты текста в соответствии с заданной читателем логикой. Кроме того, она не ограничивается текстом и статичными иллюстрациями, в ней возможны видеосюжеты в цвете и со звуком в цифровой записи. К примеру; вы обращаетесь к электронной книге с записью энциклопедии на компакт-диске. Под. заголовком «Бетховен» вы можете вывести на экран компьютера не только обычную статью о жизни и творчестве композитора, но и все его прижизненные портреты, фрагменты посвященных ему кинофильмов, партитуры и звукозаписи его произведений и другую необходимую информацию. Разумеется, реализация этих возможностей потребовала решения многих проблем. Некоторых из них мы коснемся в связи с информационной технологией в отдельной лекции, посвященной этой теме.
ИНФОРМАЦИОННЫЕ ИЗДАНИЯ И УСЛУГИ
Основными видами информационных изданий являются: библиографические указатели (БУ), бюллетени сигнальной информации (СИ), в которых приводятся в систематизированном виде библиографические данные о новейших журнальных и других публикациях по определенной отрасли, проблеме или предмету;
реферативные журналы (РЖ), в которых приводятся в систематизированном виде рефераты и аннотации журнальных и других публикаций и непубликуемых документов по определенной отрасли, проблеме или предмету;
продолжающиеся обзорно-аналитические издания по избранным отраслям, предметам и проблемам (типа «Advances in...», «Progress in...», «Итоги науки и техники» ВИНИТИ), в которых дается обобщение важнейших достижений по публикациям и непубликуемым документам за год или за несколько лет.
Бюллетени СИ обычно издаются еженедельно, дважды в месяц или ежемесячно и снабжаются, по крайней мере, полномерными авторскими указателями. Наилучшие бюллетени СИ отражают материалы за четыре недели со времени их опубликования. РЖ обычно издаются раз в две недели или ежемесячно и снабжаются, по крайней мере, полномерными авторским и предметным указателями, а также соответствующими годовыми указателями. Наилучшие РЖ отражают 50% материалов за срок, не превышающий 60 календарных дней со времени их выхода в свет.
Все виды информационных изданий могут выпускаться как в традиционной печатной форме, так и на машиночитаемых носителях информации (магнитных лентах, дискетах, оптических компакт-дисках) и на микрофильмах. Особенно большой популярностью среди ученых пользуются бюллетени СИ, в которых приводятся оглавления важнейших журналов по соответствующим отраслям (типа «Current Contents»). Обычно такого рода бюллетени издаются по важнейшим отраслям естественных, технических и общественных наук, сельскому хозяйству и медицине и снабжаются авторскими и предметными указателями.
Реферирование и библиографирование
Основой информационных изданий служат библиографические описания и рефераты. Методику их составления трудно излагать на лекциях, поэтому она изучается на практических занятиях. Здесь хотелось бы обсудить некоторые проблемы, связанные с этими важными видами информационной деятельности. Они свидетельствуют о том, что это не просто рутинная техника, а сложные интеллектуальные процессы.
Даже самый беглый взгляд на историю реферирования, которая уходит корнями в глубокую древность, показывает, что этот вид информационной деятельности возник из потребности кратко изложить существо, основное смысловое содержание того, что мы теперь называем первичным документом. Его развитие шло от простого извлечения наиболее содержательных фрагментов текста к концентрированному изложению его определенных аспектов. К настоящему времени мы располагаем арсеналом специализированных методов как самого реферирования, включая использование, формализованных схем (анкетное и избирательное реферирование), содержательного изложения текста (экстрагирование, перефразирование, интерпретацию), так и оценки рефератов. Продолжают совершенствоваться статистические, логические и лингвистические методы автоматизации реферирования.
Однако грандиозный и все возрастающий объем реферирования, исчисляемый миллионами документов в год, заставляет задуматься о целях реферирования и их возможной модификации в будущем. В соответствии с известным принципом оценивать перспективы развития как разрешение существующих противоречий, нужно эти противоречия выявить. Одним из них является многофункциональность реферата, в которой основные его функции — служить средством текущего оповещения о новых достижениях и одновременно средством ретроспективного поиска — выдвигают противоречивые требования.
При использовании реферата как средства текущего оповещения он составляется в расчете на узкий круг специалистов, занятых разработкой проблемы, которой посвящено; основное содержание реферируемого документа. Состав извлекаемых из документов фактических сведений и логика изложения нацелены на решение конкретных текущих задач исследования, известных и понятных референту, который чаще всего сам принадлежит к числу активных исследователей данной проблемы.
При этом реферат не просто индикатор необходимости обратиться к первичному документу. Он становится как бы консолидированной информацией, облегчающей принятие того или иного научного, технического или иного решения. Внимательный анализ деятельности специалиста меняет традиционный взгляд на реферат. Он выступает не как промежуточный этап на пути к первоисточнику, а наоборот, как документ, который ближе к конечному продукту информационного обеспечения, чем первоисточник.
Как средство ретроспективного поиска информации, реферат, напротив, не имеет определенного адреса и должен быть рассчитан на длительное использование и непредвиденно широкий круг специалистов, по преимуществу исследующих: смежные проблемы. В этом случае для реферата важен охват всех, в том числе и побочных линий содержания реферируемого документа, а его ценность тем выше, чем более общее представление он дает не только о методах и результатах исследования или разработки, но и о позиции автора первичного документа, ходе его рассуждений и т.п.
Возникает явное противоречие связанное с тем; что первая функция тяготеет к аспектному, анкетному, специализированному, формализованному реферированию, а вторая — к реферированию общенаучному, системному, понятийному, интерпретационному, Для первого нужен в качестве референта узкий специалист а для второго специалист более широкого профиля и высокого уровня.
Другое важное противоречие связано с тем, что издание реферативных журналов становится частью интегральных автоматизированных систем НТИ, их побочным продуктом при генерировании машиночитаемых баз данных. Как мы убедились, прогресс в, информационной технологии в последние десятилетия намного опережает совершенствование интеллектуальных процессов. Методы реферирования не являются исключением. В течение долгого времени они развивались в расчете на логику человеческого восприятия, и до сих пор продукция реферативных служб целиком состоит из рефератов, предназначенных для традиционных реферативных журналов, т.е. исключительно для чтения их человеком (с их рубрикацией, расположением материала, дублированием рефератов в разных разделах и рубриках и т.п.).
Реферативный журнал и другие информационные издания на машиночитаемых носителях (не вполне правомерно называемые базами данных) должны быть рассчитаны, в первую очередь, как показывает и их название, на переработку электронными машинами, для которых не только не имеет смысла порядок расположения рефератов и их дублирование; но требуются и определенные правила составления. В настоящее время остро встал вопрос о необходимости автоматического извлечения из рефератов сведений для пополнения специализированных баз данных и автоматизированных интеллектуальных информационных систем (экспертных, диагностических и т.п.). Эту: предполагает разработку особых методов реферирования и представления данных в реферате, которые могут существенно отличаться от традиционных.
Вместе с тем реферативные журналы и в машиночитаемой форме сохраняют многие функции, которые пока не может взять на себя никакое другое издание и никакой другой вид информационного обслуживания. Они делают для исследователя обозримой не только ту область, которой он непосредственно занимается, но и смежные области, компенсируют рассеивание информации, способствуя интеграции и сохранению единства науки, служат средством косвенной оценки научного качества публикаций. Выполнение этих функций предполагает совершенствование традиционных методов реферирования и издания реферативных журналов.
Дальнейшее развитие реферирования и реферативных служб будет происходить в преодолении этих противоречий. Можно констатировать, что общенаучные функции реферативных журналов все больше превалируют над их оперативными и специальными функциями. Это может повести к разделению этих изданий на специализированные (машиночитаемые) и общенаучные (человекочитаемые), подготавливаемые в рамках единых реферативных центров по разной методике. Следует подчеркнуть, что изучение этого вопроса должно стать одной из «горячих» точек современной информатики.
Аналогичное положение наблюдается и в области библиографирования, где теория библиографического описания, в течение многих лет развивавшаяся под влиянием библиотечной каталогизации, пришла в противоречие с новой информационной технологией. Основные принципы книгоописания, сложившиеся к настоящему времени, нацелены на выбор сведений, которые содержат самые важные для идентификации данного документа признаки и определяют место его библиографического описания в алфавитном ряду других описаний.
Библиографическое описание в научно-информационной деятельности выполняет ряд важных функций, из которых две считались до сих пор основными — адресная и сигнальная. Функция адресности выполняется благодаря тому, что описание содержит необходимые и достаточные сведения для отыскания и отождествления определенных документов по их основным библиографическим признакам: фамилиям авторов и других лиц, принимавших участие в создании документа, наименованиям учреждений, ответственных за содержание и издание документа, первым словам заглавия.
При использовании традиционных библиографических средств информационного поиска — каталогов, картотек и указателей — обычно приходится ограничивать число авторов, имена которых служат характеристиками для поиска документов. Необходимость в таком ограничении отпадает, когда информационный поиск ведется при помощи компьютера. Это дает возможность отразить в описании и использовать в качестве признаков для поиска не только имена всех авторов, но и имена других лиц, участвовавших в создании документа — составителей, авторов отдельных глав или статей, редакторов, переводчиков и т.п.
Сигнальная функция описания заключается в том, что оно может использоваться в качестве средства оповещения о появлении документа, имеющего определенное научное содержание. Из всех элементов описания этой цели в наибольшей степени служат заглавия и подзаголовочные данные, хотя они и не всегда в достаточной мере раскрывают содержание документа. Новая информационная технология позволяет использовать значимые слова заглавия в качестве поисковых признаков, а также снимает жесткость требований к строгой последовательности элементов описания. Однако все эти соображения, давно предвиденные в связи с использованием компьютеров, далеко не исчерпывают круга проблем, встающих перед информационными работника- ми в связи с необходимостью перехода на новую информационную технологию.
Новейшие исследования показывают, что сформулированные нами десятилетия назад основные функции описания сохраняются и поныне, независимо от предложений называть их по-другому: поисковую функцию — идентификационной, а сигнальную — информационной. Долгое время казалось, что книгоописания развивалось под влиянием только интеллектуальных потребностей социальной коммуникации. Лишь теперь пришло понимание того, как много для него значила ориентированность на определенные технические средства — карточные каталоги и указатели в форме списков. Именно под влиянием широкого внедрения компьютеров стали по-новому подходить к обоснованию функций библиографического описания, определению факторов, влияющих на его структуру.
Прежде всего, функция идентификации до настоящего времени выполнявшаяся всеми элементами описания, теперь во многих процессах удовлетворяется международным стандартным номером для книг и периодических изданий (ISBN и 'ISSN). Это в значительной мере снимает идентификационную нагрузку с других элементов описания. Новшество состоит и в том, что заголовок описания, в течение целого столетия составлявший главную заботу профессиональных каталогизаторов, исключается из состава библиографического описания и переносится во вспомогательные элементы библиографической записи, т.е. попадает в один разряд с классификационными индексами, предметными заголовками, дескрипторами и ключевыми словами.
Однако в практическом применении этого положения остается некоторая неясность. Все хорошо, пока мы не выходим за пределы применения описания в каталогах, указателях и других поисковых системах. Но ведь мы забываем обширную область литературного, так сказать, использования описания: упоминание произведений печати в тексте и подстрочных примечаниях других произведений. Здесь роль заголовка как привычного элемента в начале описания и как связующего элемента «бытового» описания с «профессиональным» (т.е. для связи ссылок в тексте и описаний в каталоге) настолько велика, что полное исчезновение заголовка из описания в будущем представляется сомнительным, Есть еще один, на первый взгляд мелкий, но на самом деле важный аспект библиографического описания, связанный с автоматизацией библиографирования. Это пунктуация библиографического описания, выраженная ныне сложной системой так называемых разделительных знаков. Традиционно роль этих знаков, отделяющих один элемент библиографического описания от другого, исполняли обычные знаки препинания: точка, запятая, тире, скобки. На первых этапах автоматизации появилась необходимость обозначать каждое поле различающимися метками, которые заменили обычные разделительные знаки. Эти метки (разделительные знаки) были взяты из англо- американских правил каталогизации, которые восходят к первым печатным каталогам библиотеки Британского музея. В наборных кассах середины прошлого века не было достаточного числа обычных знаков препинания, и тогдашний директор Британского музея А. Паницци решил употребить для этой цели неиспользуемые литеры наборных касс: «косую черту», «знак равенства», «плюс» и т.п. По традиции они перешли в Британскую национальную библиографию, а оттуда в международные правила книгоописания. 3.ч ..
В нашей стране эта система разделительных: знаков, которая имеет тенденцию усложняться, была введена государственным стандартом. В аналитическом описании, например, сведения о статье отделяются от названия источника знаком «двойная косая черта» (что можно видеть и в сносках этой книги). Мотивы, которыми оправдывают необходимость этих нелепых знаков, малоубедительны. Из требования автоматизации иметь при каждом элементе описания метку при вводе его в машину вовсе не вытекает необходимость выводить аналог этой метки в человекочитаемую форму описания.
Что же касается стремления сделать описание на малопонятных языках доступным для различения элементов, то это может иметь значение лишь для каталогизаторов, да и то в редких случаях. И ради этого мы. заставляем миллионы людей составлять и читать тексты, в которых «неграмотно» употребляются знаки препинания. Нам эти мотивы не представляются достаточными для превращения описания в искусственную и неудобочитаемую запись. По всей вероятности, профессиональные каталогизаторы руководствуются в своей нормативной деятельности принципами, которые не в полной мере учитывают общекультурное значение библиографического описания и его фактическую роль в научной и деловой прозе. Следует заметить, что в условиях новой информационной технологии, когда масштаб библиографирования измеряются десятками и сотнями миллионов записей в год, эти мелочи оборачиваются серьезными экономическими потерями.
Этот частный пример свидетельствует о том, что и в нашей сфере развитие не всегда происходит по прямой линии целесообразности, что в нем возможны такие несообразности, как стандартизация практики, восходящей к историческим анекдотам, дань консерватизму, фетишизация узких технических требований, ослепление международной всеобщностью и т.п.
Говоря о перспективах развития этого наиболее древнего вида информационной деятельности, долгое. время развивавшегося в рамках библиотеко- и библиографоведения, необходимо остановиться на тенденции, наметившейся в последние годы, рас- сматривать библиографическое описание как особый информационно-поисковый язык. Такого рода предложения неоднократно высказывались как в советской, так и в зарубежной литературе.
Изучение библиографического описания как особого информационного языка (библиографического языка) сделалось по- настоящему актуальным после того как библиографическая информация стала служить материалом для создания поисковых систем нетрадиционного типа, в которых элементы описания позволяют искать информацию по содержанию документов, воссоздавать структуру научных коммуникаций, строить кластеры научных сообществ и дисциплин.
Методы семиотики позволяют исследовать подобные знаковые системы в разных аспектах. С точки зрения синтактики (отношения знаков и их систем между собой) выявляются правила построения библиографического языка. В новых стандартах описания, в отличие от прежних каталогизационных правил, знаки препинания имеют не разделительный, а рыличительный смысл, т.е. не отделяют один элемент описания от другого, а маркируют следующий за знаком элемент. Однако эта осуществляется весьма непоследовательно и с нарушением законов семиотики.
В аспекте семантики (отношения знаков к их смыслу) используют семиотические понятия денотата (обозначаемого знаком конкретного объекта) и концепта (смысла этого знака). Сравнение в этом плане библиографического языка с дескрипторным и классификационным выявляет то преимущество первого, что только библиографическое описание однозначно соответствует своему денотату, тогда как дескриптор и классификационная рубрика находятся со своими денотатами в размытых отношениях.
В плане прагматики (отношения, знаковой системы к обозначенной ею реальной действительности) библиографический язык позволяет моделировать структуру научных публикаций, коллективов и коммуникаций, примеры чего были неоднократно представлены в этой лекции.
В мире выходит свыше полутора тысяч реферативных журналов, которые продолжают служить специалистам основным средством доступа к мировой научной литературе. В нашей стране таким средством служит Реферативный журнал ВИНИТИ, выпускаемый с 1953 г. Первые выпуски этого журнала охватывали астрономию, математику, механику и химию.
Потребовалось почти десять лет, чтобы этот журнал сложился как ведущий многоотраслевой реферативный журнал мира. В настоящее время он отражает около 1 млн. статей из 10тыс. журналов 50 стран. Для удобства читателей РЖ ВИНИТИ выходит в 22 сводных томах, 250 входящих в них выпусках и 100 отдельных выпусках, не входящих в сводные тома.
Все опубликованные материалы обязательно проходят научную экспертизу (путем их рецензирования и рассмотрения ред. коллегиями или научными редакторами) и потому удовлетворяют требованиям, которые предъявляются современной наукой к материалам, пропускаемым в формальные каналы научной коммуникации. Из этого следует, что мнение о «не научности» опубликованной статьи или книги, как правило, не может быть достаточным основанием для отказа от отражения ее в виде реферата, аннотации или библиографического описания в информационных изданиях.
При этом следует помнить, что если какая-либо публикация не будет отражена в РЖ или другом информационном издании, то при нынешних потоках научных публикаций она будет практически безвозвратно потеряна для будущих поколений читателей.
Любая публикация может иметь своих читателей. Поэтому при подготовке информационных изданий недопустимо отбраковывать опубликованные документы на том основании, что они «не представляют интереса», т.е. мало полезны. К числу важных недостатков многих информационных изданий, в том числе и изданий ВИНИТИ, следует отнести то, что в них не отражаются рекламные материалы, заметки технико-экономического и хроникального характера, реферируются не все 100% описаний изобретений приоритетную заявки и не помают ся рисунки. Если информационные издания действительно призваны служить главным источником сведений о, мировых достижениях в науке, то в них в той или иной форме должны отражаться все без исключения материалы мировой литературы по этой тематике. Реферативные журналы служат своего рода путеводителями по мировой научно-технической литературе. Прочтение ученым или специалистом реферата какой-либо публикации позволяет лишь определить, может ли эта публикация содержать интересующие его сведения и следует ли ее читать, но не заменяет чтения такой публикации. Поэтому нецелесообразно стремиться к помещению в РЖ чрезмерно расширенных рефератов, если это не вызвано достаточно важными причинами (например трудно- доступностью языка исходного документа).
В РЖ и других информационных изданиях, которые не являются узкоспециализированными, а рассчитаны на широкие круги пользователей, имеющих разные задачи и разные уровни профессиональной подготовки, должна отражаться JIHIU центральная тема или предмет каждой публикации и непосредственно относящиеся к нему сведения, а не сопутствующие темы, предметы, сведения. Это означает, что в информационных изданиях общего назначения исходная публикация может быть вполне адекватно, отражена одним рефератом или аннотацией несмотря на то, что данная публикация относится одновременно к двум и более отраслям науки, техники или производства.
Авторские рефераты или резюме, помещаемые и в отечественных, и в зарубежных журналах, становятся все более информативными и пригодными для публикации в PK без существенных изменений (но, разумеется, под редакторским контролем). Сам факт использования какого-либо элемента публикации в информационных изданиях способствует его совершенствованию.
При современных возможностях электронного сканирования текста и его перевода в. машиночитаемую форму авторские резюме позволяют существенно сократить, затраты труда и времени на подготовку РЖ. В печатных изданиях в связи с ростом стоимости бумаги сокращение затрат на 10-15% возможно за счет более компактной верстки, совершенствования структурной схемы реферата и библиографического описания (например, отказа от заглавий на языке оригинала).
Зарубежные реферативные журналы
Для характеристики этого важнейшего вида информационных изданий выбраны 10 реферативных журналов, отражающих мировую литературу по естественным и техническим наукам.
Applied Afechaniqp Reviews (AMR) — ежемесячный РЖ по техническим наукам, издается Американским обществом инженеров-механиков с 1948 г., публикует около 15 тыс. рефератов в год. С середины 80-х годов перешел на частичную публикацию авторских резюме. Рефераты упорядочиваются по трехуровневой классификационной схеме, содержащей по,90-,рубрик на двух первых уровнях и 1,2 тыс. — на нижнем. Основные элементы и форма представления реферата номер реферата (сквозной по всем выпускам в. пределах года, имя первого автора (не латинские алфавиты транслитерируются), адрес первого автора, имена остальных авторов, заглавие статьи, (только на английском языке), название и выходные данные журнала первоисточника, текст реферата, имя референта с указанием страны. Имеет полномерные авторские указатели и годовой по отдельным выпускам авторский с ключевыми словами— AKWAS (Authors and Key Words in Alphabetical Sequence). Том годового указателя включает руководство для пользователя, перечни индексационных терминов, классификационных. рубрик первого уровня, отражаемых первоисточников (свыше 1 тыс.), референтов и таблицу транслитерации. В этом РЖ отражаются статьи из журналов, научно-технические отчеты, книги, труды конференций, ежегодники.
Astronomy and Astrophysics Abstracts (AAA) — РЖ по астрономии, астрофизике и смежным областям, выходит 2 раза в год в виде двух полугодовых томов (в переплете с суперобложкой), издается с 1969 г. Астрономическим вычислительным институтом (Astronomisches Recheninstitute, Гейдельберг, Германия) под эгидой Международного астрономического союза. В этом РЖ отражаются около 20 тыс. публикаций в год по их авторским резюме; реферируются только статьи без резюме. Статьи популярного характера отражаются только в виде библиографического описания. Сроки прохождения материалов — не более 8 месяцев. Рефераты располагаются по перечню предметных рубрик (108) и получают порядковые номера внутри раздела. Основные элементы и форма представления: номер реферата (шесть цифр: код рубрики и порядковый номер в разделе), заглавие статьи на английском языке, имя автора (нелатинский алфавит транслитерируется), название первоисточника на языке оригинала (или в транслитерации) и выходные данные, язык публикации, текст реферата (без подписи референта и указания количества ссылок). Выпускаются годовые авторский и предметный указатели с двухтомной пятилетней кумуляцией. В каждом томе дается перечень свыше 750 первоисточников, из которых 150 реферируются полностью. Перепечатываются рефераты из других РЖ, в том числе из отдельных выпусков РЖ ВИНИТИ.
Biological Abstracts (ВА) — РЖ по биологическим наукам, издается информационной службой BIOSIS (BioSciences Information Service, США) с 1926 г., выходит 2 раза в месяц (2 тома в год по 12 выпусков), публикует около 600 тыс. рефератов в год. Рефераты упорядочиваются по собственному рубрикатору. В начале каждого выпуска приводится перечень предметных рубрик с синонимами из смежных областей. Основные элементы и форма представления реферата: номер реферата (сквозной по всем выпускам каждого тома), имена авторов на языке оригинала (транслитерируются для нелатинских алфавитов), адрес автора, отмеченного , на языке оригинала, название первоисточника и выходные данные, язык публикации, заглавие статьи на английском языке, текст реферата. Каждый номер имеет указатели: авторский, биосистематический, биологических родов, понятий, пермутационный и сокращений, Издаются также полугодовые кумулятивные указатели в трех отдельно издаваемых частях. Периодические и продолжающиеся издания, отражаемые в ВА (около 7 тыс.), приводятся в ежегодно издаваемом указателе источников Serial Sources for BIOSIS Data BASE, в котором указывается полное название издания (в алфавитном порядке сокращенных названий, выделенных в полном полужирным шрифтом), перевод названия на английский язык, примечания об изменениях, прекращении издания или его отражения в ВА, шифр CODEN, периодичность, издатель (два последних в закодированном виде).
Chemical Abstracts (СА) — издается службой Chemical Abstracts Service (CAS) Американского химического общества с 1907 г. и отражает выпускаемую в мире литературу по химии и химической технологии. Публикует около 1 млн. рефератов в год в виде еженедельных выпусков (2 тома по 26 номеров). Каждый еженедельный выпуск состоит из двух частей — собственно рефератов и указателей. Рефераты распределяются по 80 тематическим разделам и внутри каждого раздела по 7 видам первоисточников: журнальные статьи, труды конференций и сборники, научно-технические отчеты, депонированные рукописи, диссертации, сообщения о новых книгах, патентные описания. Структура библиографического описания (БО) определяется видом реферируемого документа. БО журнальной статьи включает:
номер реферата (сквозной во всех выпусках полугодового тома, начинается с номера тома, заканчивается /с 1967 г./ контрольной буквой для автоматической проверки правильности написания номера);
заглавие реферата (заглавие реферируемого документа на английском языке воспроизводится полужирным шрифтом, на других языках дается в переводе на английский, для книг приводится также заглавие на языке оригинала);
полные имена авторов в инвертированной форме, приводятся до 10 имен, при большем числе — 9 с сокращением et al. (и др.), нелатинский алфавит транслитерируется);
место проведения исследования или адрес для переписки; сокращенное название первоисточника: (курсивом в соответствии с international List of Periodtcal Title Word Abbreviation);
год издания (полужирным шрифтом);
номер тома и (в скобках) Номер выпуска;
начальная и последняя страницы публикации;
язык публикации.
Библиографические описания других видов документов отличаются от приведенного дополнительными элементами (такими, например, как дата проведения конференции, номер научно-технического отчета, место депонирования рукописи и т.п.). Каждый еженедельный выпуск включает указатель ключевых слов, авторский и патентный указатели. Указатель ключевых слов, выбранных или составленных по заглавиям и/или текстам рефератов, представляет собой их алфавитный перечень с пояснительными записями:. В патентном указателе перечисляются по странам и номерам описания всех впервые реферируемых патентных документов, даются перекрестные ссылки на первый документ, если их несколько, и при первом документе — перечень всех других, относящихся к этому изобретению. Патентные документы систематизируются также по кодам видов документов, принятым всеми странами. К каждому тому CA издаются кумулятивные годовые указатели: авторский, ключевых слов, патентный и предметный из двух частей: общий и химических соединений.
Отражаемые периодические и другие издания и документы включены в Указатель источников (The Cheini cal Abstracts Service Source index — CASSI), кумулятивный выпуск с 1907 г. и квартальные (с кумуляцией за год) дополнения: Сведения о новых журналах и об изменении названий публикуются в CASSI и в каждом еженедельном выпуске CA непосредственно за авторским указателем. В начале кумулятивного выпуска CA551 за 1907-1979 гг. приведен перечень 1 тыс. наиболее продуктивных журналов, алфавитный и ранжированный по продуктивности, Всего в CASSI описано 50 тыс. источников информации.
Computer and Control Abstracts (CCA) — ежемесячный РЖ по вычислительной технике и управлению, издается с 1966 г., публикует более 50тыс. рефератов в год. Полугодовые кумулятивные указатели издаются в виде одного тома, включающего указатели: авторский, библиографий, книг, трудов конференций, коллективных авторов, предметный, отражаемых журналов и (отдельно) других периодических и продолжающихся изданий. Авторские и предметные указатели кумулируются каждые три года.
Electrical and Electronics Abstracts (EEA) — ежемесячный РЖ по электротехнике и электронике, издается с 1903 г., отражает свыше 80 тыс. публикаций в год. Полугодовые кумулятивные указатели издаются: двумя отдельными томами: предметный составляется на основе тезауруса INSPEC, в авторском имена авторов сопровождаются заглавиями статей, а также приведены «малые» указатели — библиографий, книг, трудов конференций, коллективных авторов и источников. Авторские и предметные указатели кумулируются каждые четыре года.
Physics Abstracts (PA) — реферативный журнал по физике издается с 1903 г. по два выпуска в месяц, ежегодно отражает свыше 150 тыс. публикаций. Полугодовые кумулятивные указатели издаются тремя отдельными томами: два тома предметного (А-L, М-Z) и один авторский. В остальном указатели аналогичны предыдущему, включая четырехлетнюю кумуляцию. В конце 1994 г. в РЖ Physics Abstracts влился другой РЖ по физике— Physics Briefs /Physikalische Berichie, который выходил в Германии под разными названиями с 1848 г. С января 1995 г. этот объединенный и расширенный журнал выходит под названием Physics Abstracts в виде двухнедельных выпусков.
Все три РЖ — CCA, ЕЕ4, РА — издаются Институтом инженеров-электриков (Institute of Electrical Engineers — IEE) Великобритании и в настоящее время подготавливаются при помощи автоматизированной информационной системы INSPEC (Information Services in Physics, Electrotechnology Computers and Control), функционирующей с 1969 г. Они имеют одинаковую структуру, формы представления реферируемых материалов и систему указателей. С 1898 г. IEE совместно с Лондонским физическим обществом издавал РЖ по физике и электротехнике Science Abstracts, который в 1903 г. разделился на две серии — PA и ЕЕА, а с 1966 г. к ним прибавилась третья — ССА. Рефераты в каждом выпуске этих РЖ упорядочиваются по четырехуровневой рубрикации соответствующих отраслевых рубрикаторов.
Вначале каждого выпуска перечень предметных рубрикрик с подрубриками и классификационными кодами, а за ним предметный указатель. Обязательные элементы реферата журнальной статьи: номер реферата (сквозной по всем выпускам за год), заглавие статьи (на английском языке в оригинале или переводе, для статей на другом языке он указывается), имя и адрес автора (нелатинские алфавиты транслитерируются), название и выходные данные первоисточника, текст реферата, количество ссылок. Полномерные указатели: авторский, библиографий (перечень статей с обширными пристатейными библиографиями), книг, трудов конференций, коллективных авторов (организаций, ответственных за содержание документа), новых журналов (дополнительный перечень). В указателе источников INSPEC при- ведено свыше 3 тыс. журналов, из которых около 600 реферируются полностью, а также свыше 400 не журнальных периодических и продолжающихся изданий. Все содержание этих РЖ доступно в машиночитаемом виде.
Engineering Index Monthly (Ei Monthly) — ежемесячный РЖ, издается с 1884 г. (до 1962 г. — под заглавием Engineering Index) фирмой Engineering Information, Inc. (до 19&1 г. — Engineering Index, Inc., США) и охватывает литературу, публикуемую в мире по всем техническим отраслям (около 15 тыс. рефератов в каждом выпуске). Рефераты упорядочиваются по основным предметным рубрикам, выбираемым из отдельно изданного перечня индексационных терминов Subject Headings for Engineering (SHE), из которого используется около 12 тыс. рубрик, подрубрик и их сочетаний.
Рефераты, опубликованные в 12 выпусках Ei Monthly за каждый календарный год, кумулируются в алфавите предметных рубрик и подрубрик и издаются с 1959 г. в нескольких переплетенных томах издания Engineering index Аппиа1 (Е1Annual) — массив с 1884 г. доступен на микрофильмах. Номера рефератов в Ei Monthly и Е Аппиа! не совпадают, основные элементы и форма представления реферата — общие: номер реферата (сквозной по всем выпускам за год), заглавие статьи на английском языке (или в транслитерации с переводом на английский в скобках), текст реферата, количество ссылок, имена авторов и адрес первого, сокращенное название первоисточника, том, выпуск, дата и страницы, предметная рубрика, под рубрика, перекрестная ссылка.
Каждый выпуск Ei Annual включает перечень сокращений, а Ei Monthly — авторский указатель с заглавиями статей при именах авторов. Для помощи читателям в определении предметных рубрик и подрубрик отдельно издается Subject Headings Guide to Engineering Categories. Реферативный журнал Ei Annual помимо рефератов включает указатели: источников, отраженных в текущем году (Publication Index for Engineering — PIE), кумулятивный авторский, адресов авторов, соответствия номеров Ei Monthly и Ei Annual.
Указатель PIE включает перечень источников по сокращенным в соответствии с американским стандартом названиям (с шифрами CODEN, новыми и измененными шифрами), источники без шифров, труды конференций, перекрестные ссылки от названия организации к сокращенному названию, от транслитерированных названий на неанглийском языке, от переводов на английский язык названий на японском и китайском языках, от названий, начинающихся с сокращений. Всего в PIE описано свыше 2,5 тыс. первоисточников.
Выпускаются также специализированные ежемесячные РЖ Energy Abstracts (с 1974 г.) — по традиционным и новым источникам энергии, Bioengineering Abstracts (с 1975 г.) — по биотехнике; библиографическая серия Technical Bulletins — по актуальным вопросам техники; пятилетние кумулятивные указатели к Ei Annual. На машиночитаемых носителях доступны БД COMPENDEX (аналог Е Monthly) и Ei Engineering Meeting, включающая рефераты материалов около 2 тыс. конференций (С 1984 г. издается и в печатном виде).
Майетапси Revtews (МК) — ежемесячный РЖ, издается Американским математическим обществом с 1940 г. Охватывает все разделы теоретической и прикладной математики, публикует ежегодно около 50 тыс. рефератов, отражает полностью 8 журналов Американского математического общества, 7 российских (в переводе на английский язык), а всего около 1,5 тыс. периодических и продолжающихся изданий. Перепечатывает также (с указанием источника) рефераты других РЖ: Applied Mechanics Reviews, Computing Reviews (CIIIA)Д Physics Abstracts (Великобритания) (Россия). Время опубликования рефератов с момента издания первоисточника — 7 месяцев, средн11й объем реферата — 200 слов.
Рефераты систематизируются по трехуровневой рубрикации; под названием рубрики, которая может быть и пустой, указываются номера рефератов, частично относящихся к данному разделу, но помещенных в других, разделах. Выпуски могут охватывать от одного до четырех разделов. Нумерация рефератов производится по разделам: год выхода (2 цифры), буквенный код выпуска (1), «двоеточие, шифр раздела (2), «пробел», порядковый номер реферата а разделe (3).
БО журнальных статей. имеет следующую структуру: имя автора, заглавие статьи (на английском, немецком и французском языках, заглавия на других языках — в английском переводе), язык оригинала, резюме на других языках, сокращенное. название источника, том, год, выпуск, страницы, Дается указание о наличии перевода статьи на английский язык., В конце текста реферата указывается количество рисунков, таблиц и библиографических ссылок, а также имя и шифр референта. В описании книги или периодического издания как, целого ставится астериск (*), а имя автора и заглавие приводятся в оригинале и переводе на английский язык.
В каждом выпуске РЖ два указателя: авторский (все авторы) и ключевой (предметные заголовки, названия конференций и семинаров, географические названия и виды изданий — словарь, биография, некролог и т.п.; ключевые фразы до 8 слов). В последнем номере приводятся годовые кумулятивные указатели: полный авторский (с заглавиями публикаций) и систематический (по рубрикатору). Авторские указатели кумулируются за не сколько (5-20) лет. Создана БД MATHFILE; охватывающая все рефераты с 1973 г.
Meteorological and Geoastrophysical Abstracts (AfGA) — ежемесячный РЖ по метеорологии и геоастрофизике; издается Американским метеорологическим обществом с 19бО г. (до этого назывался Meteorological: Abstracts and Bibliography); ежегодно отражает свыше 7 тыс. публикаций из 150 журналов и нескольких десятков ежегодников и продолжающихся изданий, названия которых приводятся в начале каждого выпуска РЖ. Рефераты упорядочиваются в соответствии с рубрикацией (с перекрестными ссылками). Обязательные элементы реферата номер (в пределах одного выпуска), имя автора, его адрес, заглавие статьи на языке оригинала (нелатинские алфавиты транслитерируются а заглавие переводится на английский язык), полное название и выходные данные первоисточника (географические названия: — только по-английски), количество ссылок, иллюстраций, таблиц, код библиотеки (где хранится источник), текст реферата, предметные рубрики, имя референта код рубрикации. Каждый выпуск содержит авторский, предметный и географический указатели.
Электронная информация и базы данных
Все более важным видом источников первичной и вторичной информации становятся базы данных (БД), представляющие собой в большинстве случаев электронные версии печатных изданий — газет, научных, научно-технических и общественно-политических журналов и бюллетеней, энциклопедий, справочников и т.п. В настоящее время принята следующая типология БД: 1) первичные (source) БД, которые подразделяются на цифровые, тексто-цифровые, полнотекстовые и по физика химическим свойствам веществ; 2) вторичные (reference) БД; которые подразделяются на библиографические (в том числе
реферативные) и адресно-справочные. Эти БД распространяются на машиночитаемых носителях (магнитных лентах, дискетах, оптических компакт-дисках) и после загрузки в ЭВМ используются для автоматизированного поиска информации. В мире насчитывается около 20 тыс. общедоступных БД, и их число ежегодно возрастает.
Составной частью системы информационных изданий является служба быстрого изготовления и доставки читателям (потребителям информации) копий первоисточников, отраженных в этих изданиях. Сроки изготовления и доставки копий первоисточников соразмерны времени, затрачиваемому на проведение поиска информации о них в банках данных.
Большое значение в научно-информационной практике имеют указатели цитирования литературы, которые являются не только эффективным инструментом библиографического информационного поиска, но и уникальным средством для наука метрических исследований. Они позволяют оценивать вклад отдельных ученых и стран в мировую науку, выявлять наиболее активные точки роста в науке, определять взаимосвязи между конкретными исследованиями (публикациями) и научными дисциплинами, решать другие важные задачи. Печатные и машиночитаемые версии таких указателей, выпускаются в США фирмой Institute for Scientific Information с 1961 г.
Внедрение средств вычислительной техники в сферу подготовки печатных изданий привело к появлению электронных аналогов этих изданий — журналов, справочников, энциклопедий и т.п. В таких электронных изданиях текст и иллюстрации представлены в цифровой форме, что позволяет производить их автоматизированную обработку и передавать по каналам электросвязи.
В электронных изданиях с помощью компьютеров можно проводить также быстрый поиск нужной информации по сочетаниям разных признаков — ключевых слов, имен и т.д. В настоящее время все крупнейшие газеты и журналы США, а также других развитых стран издаются как в печатной, так и в электронной форме. Электронные версии печатных изданий называются также «полнотекстовыми базами данных».
В последнее время начали выходить научные журналы, уже не имеющие печатных версий. В связи с появлением все большего числа электронных журналов и книг некоторые специалисты предсказывают, что электронные издания будут вытеснять печатные журналы и книги и что поэтому библиотеки в их традиционном понимании не имеют будущего. Однако такие предсказания противоречат историческому опыту, который свидетельствует, что новые носители и средства распространения информации обычно дополняют, а не заменяют уже существующие.
Базы данных как средства поиска и распространения научной и иной информации появились 40 лет назад. База данных (БД) представляет собой упорядоченную совокупность информационных сообщений — библиографических описаний статей, рефератов, записей фактов или иных текстов, относящихся к какой-либо теме и представленных на машиночитаемом носителе (магнитной ленте, дискете, компакт-диске). Поиск информации в БД можно производить как на своем компьютере, так и в режиме теледоступа по каналам электросвязи к центральному компьютеру, в котором она имеется.
В России крупнейшим производителем БД по естественным и техническим наукам является Всероссийский институт научной и технической информации (ВИНИТИ), а по общественным наукам — Институт научной информации по общественным наукам (ИНИОН).
Для сбора и хранения БД, а также для обеспечения поиска в них информации созданы специальные службы или «банки данных», число которых в мире составляет около 800, причем наблюдается устойчивая тенденция к их укрупнению. Крупнейшими зарубежными службами автоматизированного поиска информации в БД являются американские Dialog и Mead Data Central, французская Telesystemes-Questel и международная STN International.
Служба Dialog (1972 — ) находится в г. Пало-Альто (шт. Калифорния), предоставляет доступ более чем к 400 БД и имеет 155 тыс. абонентов в 100 странах мира. Служба Mead Data Central (1968 — ) находится в г. Дейтон (шт. Огайо) и предоставляет доступ к 450 БД. Она располагает наиболее полным собранием полнотекстовых БД и большим опытом поиска информации в них. Только в двух БД этой службы — NEXIS (наука, техника, экономика) и LEXIS (судебно-юридическая информация) — ежедневно проводится примерно 200 тыс. поисков.
Служба Telesystemes-Questel (1979 — ) находится в Париже и предоставляет доступ более чем к 1S0 БД. В начале 1994 г. она приобрела американскую службу ORBIT (1970 —, свыше 70 БД), которая включена в ее североамериканский филиал (r. Александрия, шт. Виргиния).
Служба STN International (1987 — ) представляет собой сеть из трех банков данных — Chemical Abstracts Service (г. Колумбус, шт. Огайо, США), Информационного центра по энергетике физике и математике (г. Карлсруэ, Германия) и Японского информационного центра по науке и технике (г. Токио); Эта служба предоставляет доступ более чем к 170 БД. С 1992 г. центры теледоступа к STN International Открыты в Москве и Новосибирске.
Сети передачи и средства хранения и обработки данных
Для теледоступа к БД, находящимся в специальных службах поиска информации, кроме персонального компьютера необходимы соответствующие каналы и сети связи. И такие сети созданы. В настоящее время крупнейшей сетью, позволяющей компьютерам взаимодействовать с другом в масштабе реального времени, является Internet, началом которой послужила сеть ARPANET, созданная в 1969г. Министерством обороны США. Сегодня Internet представляет собой фактически объединение примерно из 9 тыс. других сетей: Если в 1981 г. сеть Internet связывала всего 213 компьютеров, а в 1989 г. — 80 тыс., то в январе 1993 г. число подключенных к ней компьютеров превысило 13 млн., в январе 1995 г. — 35 млн., а в настоящее время их число перевалило за 1 млрд причем они находятся в 160 странах мира Сеть Internet все больше используется учеными й специалистами для получения научной информации, тем более Что для многих из них пользование этой сетью является бесплатным. В настоящее: время через сеть Internet открыт доступ к электронным каталогам более 200 библиотек, в том числе g каталогу Библиотеки Конгресса США (свыше 30 млн. каталожных карточек), а также к службам поиска информации в БД. В настоящее время к internet подключено более четверти всех публичных библиотек, обслуживающих население численностью не менее 250 тыс. человек каждая.
В США завершается создание еще более мощной Национальной сети для исследований и образования (Майкопа! Research and Education Network — NREN): Сначала эта сеть позволяла передавать данные со скоростью 1,5 млн. бит/с, что эквивалент-
но примерно 50 страницам текста. К 1996 г. быстродействие NRCN было доведено до 3 млрд. бит/с. Это позволило за одну секунду передавать 100 тыс. страниц текста, т.е. все 32 тома Британской энциклопедии. Аналогичные быстродействующие сети цифровой связи созданы и развиваются в Великобритании, Германии, Франции, Японии и других передовых странах мира.
Создание быстродействующих цифровых сетей передачи данных позволило разработать и внедрить видеографические системы типа «видеотекс». Особенно большие успехи в этой области достигнуты во Франции: созданная там видеографическая система Teletel основана на использовании телефонных линий связи. Видеотерминалы этой системы, получившие название Minitel, устанавливаются в учреждениях, гостиницах и частных домах. Эти видеотерминалы, число которых превысило 5 млн., позволяют запрашивать и получать самую разнообразную информацию — сводки погоды, сведения о репертуарах театров„ котировки акций, расписания самолетов и поездов, номера телефонов и т.п., а также осуществлять поиск информации в БД службы Telesystemes-Questel Кроме того. такая система позволяет абонентам вести переписку друг с другом.
Информационные услуги
Современные информационные услуги можно разделить на три взаимодействующих области:
специальная информация,
электронные сделки,
электронная коммуникация.
В области специальной информации выделяются следующие основные сектора:
1. Сектор деловой информации (биржевой, финансовой, коммерческой, экономической, статистической), охватывающий:
биржевую и финансовую информацию — информацию о котировках ценных бумаг, валютных курсах, учетных ставках, рынке товаров и капиталов, инвестициях, ценах, предоставляемую биржами, специальными службами биржевой и финансовой информации, брокерскими компаниями, банками;
экономическую и статистическую информацию — числовую экономическую, демографическую, социальную информацию в виде рядов динамики, прогнозных моделей и оценок, предоставляемую государственными службами, а также компаниями, занятыми исследованиями, разработками и консалтингом; коммерческую информацию — информацию по компаниям, фирмам, корпорациям, ценам, о финансовом состоянии, связях, сделках, руководителях, о направлениях их работы и продукции и т.п.;
деловые новости в области экономики и бизнеса, предоставляемые специальными информационными службами.
2. Сектор научно-профессиональной информации: научно- технической, медицинской, юридической и другой информации, охватывающий документальную, библиографическую, реферативную, справочную информацию и данные в области фундаментальных и прикладных, естественных, технических и общественных наук, отраслей производства и сфер человеческой деятельности. В этом секторе предусмотрена организация доступа к первоисточникам информации через библиотеки и специализированные службы, возможность приобретения первоисточников, их получения по межбиблиотечному абонементу в виде полноразмерных и микроскопий.
3. Сектор массовой, потребительской информации, охватывающий новости и литературу, справочники, энциклопедии, потребительскую и развлекательную информацию, ориентированную на домашнее, а не служебное использование, в том числе сведения о погоде, расписании транспорта, игры, программное обеспечение, предложения по обмену, покупкам и продажам, справочники отелей и ресторанов, информацию по курсам валют, аренде, турах, а также услуги телетекста и видеотекса и т.п.
4. Сектор социально-политической информации, обслуживающий органы государственной власти и управления статистической, социальной, архивной и другой специальной информацией.
В России понятие информационной деятельности в течение долгого времени связывалось в основном с научно-технической, а также некоторыми видами социальной информации, в то время как на них приходится около 15-25% мирового рынка информационных услуг.
В бывшем СССР созданы достаточно развитые, но замкнутые автоматизированные информационные системы, направленные в основном на реализацию внутренних задач тех ведомств, в рамках которых и на средства которых они существовали. Задачи обеспечения научной и технической информацией решались в рамках Государственной системы научной и технической информации (ГСНТИ), где ведущая роль генератора информации принадлежала ВИНИТИ, статистическая информация по состоянию экономики была сосредоточена исключительно в ведомствах Государственного комитета по статистике ит.д. Открытая информация, сосредоточенная в основном в рамках системы научной и технической информации, была изолирована от системы информации в оборонных отраслях и системы массовой информации.
Что касается экономической, коммерческой (конъюнктурной), массовой и прочей информации, то командно административная система удовлетворялась ею в том виде и количестве, которое было необходимо для целей директивного управления. Такие важнейшие для нужд рыночной экономики информационные составляющие, как биржевая и финансовая информация, демографическая и потребительская информация, еще предстоит создавать. В условиях централизованно планируемой экономики основная часть информации, необходимой предприятиям и организациям в их хозяйственной деятельности, поступала в виде. директив административной системы и носила служебный характер. С разрушением административной системы предприятия столкнулись с острой нехваткой практически любой информации делового характера, необходимой для работы в условиях формирующегося рынка. Отсутствие такой деловой информации не способствовало восстановлению внутриотраслевых и межотраслевых экономических связей и возникновению негосударственных экономических партнеров (кооперативов, малых предприятий, банков, бирж).
Мировая практика последних десятилетий показала, что информация в электронной форме превратилась в важнейший компонент современной: рыночной инфраструктуры; Доступность информации тесно связывается западными экономистами со свободой конкуренции и рассматривается как одно их базисных условий эффективного функционирования рыночной Экономики, Независимый, самостоятельный производитель товаров или услуг (а именно эта фигура наилучшим образом характеризует рыночную экономику и ее основного субъектам; а также все те, кто обеспечивает непрерывность цикла «наука-техник производство-сбыт — потребление» не могут успешно действовать на рынке, не имея информации. Это информация о других производителях, о возможных потребителях продукций; о поставщиках сырья; комплектующих и технологиях, о положении на Товарных рынках и рынках капитала, наконец об общей экономической и политической ситуации не только в собственной стране, но и во всем мире, тенденциях развития экономики, перспективах развития науки и техники, о правовых условиях хозяйственной деятельности и т.п.
Информация лежит в основе современной маркетинговой концепции управления производственной и сбытовой деятельностью и используется как для формирования и уточнения производственной программы, так и для проверки ее обоснованности: рынком в процессе реализации - произведенных товаров. Современный этап развития экономики требует наличия специального механизма, обеспечивающего связь между предложением и спросом, ориентирующегося на конкретные потребности рынка и подчинение этим потребностям различных сторон производства и сбыта. Важной частью такого механизма выступает информационная деятельность.
Электронные сделки (операции) включают системы резервирования билетов и мест в гостиницах, заказа товаров и услуг, банковских и расчетных операций. Они формируются:
системами заказа билетов на железнодорожном и авиационном транспорте (системы резервирования авиабилетов «Сирена и железнодорожных билетов «Экспресс»); системами электронных банковских операций; так называемыми, электронными биржами.
Электронные коммуникации реализуются современными средствами связи и человеческого общения. Это сети передачи данных, системы электронной почты, компьютерные сети, телеконференции, электронные сетевые доски объявлений и бюллетени, центры общедоступного программного обеспечения и т.п.
Информационные структуры и инфраструктура
Информационными структурами принято считать учреждения и организации, профессионально производящие, обрабатывающие и «переупаковывающие» информацию разного рода, обеспечивающие ее хранение и доступ к ней пользователям. Это информационные агентства, службы, центры и институты информации, библиотеки и другие подобного рода учреждения и организации.
Наиболее упорядоченными информационными структурами являются системы научно-технической информации, существующие фактически в любой стране. Особенности построения каждой такой системы зависят от многих причин: географического положения: страны, размеров ее территории, численности населения, используемых в ней языков, ее истории, уровня экономического развития, политического строя и др. Такие системы могут быть централизованными, децентрализованными и смешанного типа.
В настоящее время, когда информация все больше становится экономическим фактором, правительства всех стран принимают доступные им меры для укрепления и развития таких систем в своих странах. Эти меры составляют содержание информационной политики, которая разрабатывается и осуществляется в каждой стране.
В странах, ставших политически независимыми после второй мировой войны и/или не имевших исторически сложившихся научно-информационных систем, они стали создаваться по централизованной схеме, Она была рекомендована ЮНЕСКО и предусматривала создание национальных центров и находящихся под их методическим руководством сетей специальных центров и научно-технических библиотек. Такие национальные центры были созданы в Аргентине, Бразилии, Египте, Израиле, Индии, Индонезии, Иране, Испании, Китае, Пакистане, Португалии, Турции, ЮАР, Южной Корее, Японии, в странах СЭВ и многих других странах.
Для общего руководства работой национальной информационной системы и главных направлений ее развития в большинстве стран созданы межведомственные комиссии или комитеты, которые функционируют при соответствующем органе государственной власти (парламенте, премьер-министре, министерстве или госкомитете). Такие межведомственные комиссии (комитеты) выполняют следующие основные функции:
организуют разработку прогнозов развития информационных систем и проводят их экспертную оценку;
определяют цели и разрабатывают основные направления государственной информационной политики;
разрабатывают среднесрочные (до. 5 лет) и долгосрочные (10 и более лет) программы развития национальной информационной системы;
осуществляют научную экспертизу проектов, направленных на развитие национальной системы;
организуют разработку законодательных актов и других нормативных документов, относящихся к деятельности национальной системы.
Основными средствами, которые применяются для решения задач, одобренных
межведомственными комиссиями или комитетами, являются:
законодательные акты;
прямые распоряжения органов государственного управления административно подчиненным организациям и учреждениям;
прямые государственные заказы на выполнение конкретных заданий;
государственное субсидирование проектов, способствующих достижению поставленных комиссией (комитетом) целей.
Научно-методическое руководство национальной информационной системой (сетью) той или иной страны осуществляется либо специально созданным для этой цели национальным институтом (центром) научной и технической информации, либо национальной библиотекой.
В странах, которые имеют давно сложившиеся механизмы и традиции децентрализованного управления научными исследованиями и их информационного обеспечения, они основаны на принципах координации и кооперации. Эти страны раньше других осознали большое значение научных исследований и разработок для развития экономики и культуры. Поэтому в таких странах были созданы эффективно действующие сети научно- технических библиотек, которые преимущественно и осуществляли научно-информационное обслуживание исследователей (т.е. выполняли функции информационных центров) вплоть до начала второй мировой войны. К числу таких стран относятся США, Великобритания, Германия, Франция, Италия и скандинавские страны.
Важным средством повышения эффективности национальной системы (сети) информационных органов, особенно при наличии в стране частного и государственного секторов экономики, является развитие и укрепление научных обществ, научно-исследовательских ассоциаций в отраслях промышленности и профессиональных ассоциаций. Эти общества и ассоциации обеспечивают неформальное взаимодействие между частным и государственным секторами экономики, в том числе и в области информационного ее сектора. Они решают следующие основные задачи:
выпускают научно-техническую литературу, особенно периодические издания, по своим отраслям;
организуют научные совещания ученых и специалистов; создают центры и системы информационного обеспечения своих членов;
организуют и/или проводят исследования в интересах всех своих членов;
разрабатывают общие методические и нормативные материалы, необходимые для взаимодействия между государственными и частными организациями и учреждениями; разрабатывают общие профессиональные требования к специалистам собственной сферы, организуют и контролируют их подготовку и повышение квалификации;
развивают координацию и кооперацию между однотипными организациями и учреждениями;
информируют общественность о целях, задачах и достижениях своих членов.
В области научно-технической информации такими обществами и профессиональными ассоциациями в США являются: Американская библиотечная ассоциация (1876 — 47 тыс. чл.), Ассоциация специальных библиотек (1909 — 4 тыс. чл.), Ассоциация научных библиотек (1932 — ок. 120 чл.), Ассоциация медицинских библиотек (1898 — 5 тыс. чл.), Ассоциация по образованию в области библиотековедения и информатики (1915 — ок. 700 чл.) и еще не менее 30 других библиотечных ассоциаций; Библиографическое общество Америки (1904 — ок. 1,4 тыс. чл.), Американское общество по информационной науке и технологии (1937 — ок. 4,3тыс. чл.), Ассоциация информационной промышленности (1968 — ок. 600 чл.), Американское общество индексаторов (1968- св. 750 чл.), Ассоциация американских издателей (1970 — св., 250 чл.), Общество научного книгоиздания (1979 — ок. 600 чл.), Американская ассоциация книготорговцев (1900 — 7,3 тыс. чл.) и многие другие.
В Великобритании важнейшими обществами и профессиональными ассоциациями в области библиотечного дела и информатики являются: Библиотечная ассоциация (1877 — ), Ассоциация по информационному менеджменту (прежде Ассоциация специальных библиотек и информационных бюро, 1926 — ок. 2 тыс. чл.), Институт информационных специалистов (1958 — св. 2 тыс. чл.), Общество индексаторов (1957).
Во Франции такими организациями являются: Ассоциация французских библиотекарей, Французская ассоциация документалистов и работников специальных библиотек, Французский союз органов документации (1932 — ). В Германии насчитывается несколько десятков обществ и профессиональных ассоциаций в области библиотечного дела и информатики, из которых крупнейшими являются: Объединение немецких библиотекарей (1900 — 1350 чл.), Немецкий библиотечный союз (1949 — 2,3 тыс. чл.), Объединение дипломированных библиотекарей научных библиотек (1948 — ок. 3 тыс. чл.), Объединение немецких документалистов.
В настоящее время стал модным термин инфраструктура, который неправильно употребляют в значении внутренней структуры. Понятие инфраструктуры на самом деле определяется как совокупность отраслей хозяйства, которые организационно не входят в данную отрасли но без участия и развития которых невозможно эффективное функционирование последней. Для информационной отрасли инфраструктурными отраслями можно считать издательское дело и полиграфическую промышленность, книжную торговлю, библиотечное дело, почтовую и телеграфную связь, телевидение и некоторые другие отрасли.
В информатике это понятие связано с понятиями национальной и глобальной инфраструктуры и впервые возникло в США. В речах о политике в области науки и технике 17 и 22 февраля 1993 г. президент США Б. Клинтон объявил о намерении своей администрации создать в стране Национальную информационную инфраструктуру и супермагистраль (National Information Infrastructure — NII).
Идея создания инфраструктуры и ее станового хребта — информационной супермагистрали (information superhighway) или инфобана (Intobahn) была выдвинута в 1989 г. А. Гором, тогда еще сенатором, а затем вице-президентом США. Им же введен в обращение в 1978 г. и сам термин «информационная супермагистраль». Осуществление этой идеи — по замыслу ее авторов— должно было стать национальной задачей США, вдохновляющей и сплачивающей исследователей, инженеров, бизнесменов и других граждан этой страны, т.е. примерно такой, какой была в 60-е годы программа «Аполлон» по выполнению полетов американских астронавтов на Луну.
За всю 225-летнюю историю США по этой стране прокатились лишь две обновляющие экономические волны, которые радикально изменили образ жизни ее населения. Первую волну породило строительство железных дорог в середине XIX века, а вторую — строительство скоростных автострад, особенно между штатами, в 50-х годах ХХ века. Третью волну должно было породить строительство информационной супермагистрали, что могло бы оказать на жизнь американцев и людей всего мира не меньшее воздействие, чем в XV веке оказало на жизнь народов Европы изобретение книгопечатания Гуттенбергом.
В документе «План действий по созданию Национальной информационной инфраструктуры», который был обнародован Белым Домом 15 сентября 1993 г., эта инфраструктура видится как «бесшовное сплетение коммуникационных сетей, компьютеров, баз данных и устройств бытовой электроники, которое будет доставлять непосредственным потребителям огромные объемы информации. Создание национальной информационной инфраструктуры может способствовать развязыванию информационной революции, которая навсегда изменит образ жизни людей, то, как они работают и взаимодействуют друг с другом».
В другом документе Национальная информационная инфраструктура трактуется как программа, направленная «на повышение эффективности работы правительства», на «сохранение Соединенными Штатами мирового лидерства в науке, технике и технологии», на то, чтобы «все американцы получали нужную им информацию тогда, когда она нужна им, когда они хотят ее получить — и за приемлемую плату».
Как следует из названия этой программы, в ней предусматривалось создание информационной инфраструктуры. Это означало разработку средств, позволяющих быстро передавать и получать информацию, организационно не входящих в существующие информационные структуры (например, как почта, которая лишь обеспечивает быструю доставку корреспонденции адресатам, но не создает и не использует ее сама). Поэтому, чтобы собственно информационные структуры — центры информации, библиотеки и т.п. — могли эффективно пользоваться этой инфраструктурой (т.е. сверхбыстродействующей сетью передачи данных), они должны быть переоснащены новейшим информационным оборудованием, создавать новые виды информационной продукции, внедрять новые методы информационного обслуживания.
Основой для создания информационной супермагистрали должна служить сначала сеть Internet, а затем — сеть NREN, которая создается с 1989 г. тоже по инициативе А. Гора. С созданием инфраструктуры тесно связывают программы оцифровки рукописных и печатных фондов библиотек и появление так называемых «виртуальных библиотек».
«Знание бывает двух видов. Мы знаем предмет по существу, или же мы знаем, где можно найти информацию о нем». В этой простой мысли давно известного высказывания английского писателя XVIII в. Сэмюеля Джонсона содержится главный признак, по которому деятельность информационная отделяется от научно-исследовательской. В ходе научного исследования возникает новое знание, а в сфере информации происходит отчуждение этого знания от его творцов и превращение в общее достояние. Однако простота этого разграничения мнимая, потому что в науке грань, отделяющая информационную деятельность от исследовательской, непостоянна. Развитие информационной технологии все время сдвигает эту грань, поскольку информационной деятельности становятся подвластны все более сложные процессы переработки знаний. То что вчера еще делали сами исследователи, сегодня оказывается целесообразным передать информационным работникам.
Эти соображения, уже высказанные в лекции об информационной деятельности, уместно повторить, начиная разговор об информационном поиске, поскольку он является основным процессом этой деятельности и на протяжении нескольких десятилетий — центральной проблемой информатики. Новая информационная технология меняет подход к этой извечной проблеме и во многом определяет сегодня развитие информационных систем. Но информационный поиск как процесс и проблема известен с давних пор (наиболее ранние из дошедших до нас информационно-поисковых систем насчитывают тысячелетия) и продолжает волновать ученых и специалистов-практиков.
Само понятие информационного поиска появилось только в середине ХХ века. Оно объединили такие, казалось бы, разные виды деятельности, как составление библиотечных каталогов и библиографических указателей, организация библиотек и справочно-информационного обслуживания, архивное дело, создание словарей, справочников, энциклопедий, вспомогательных указателей к монографиям и сборникам.
В основе этого понятия лежит представление о том, что поиск необходимой информации в любом собрании документов практически невозможен путем прочтения или даже беглого просмотра текстов всех документов данного собрания. Поэтому уже с незапамятных времен для поиска информации применяют ряд логических процедур, которые в совокупности и составляют процесс информационного поиска. Прочтение полного текста документа заменили просмотром заглавий, аннотаций, рефератов. Однако и эта процедура в многотысячных собраниях документов оказалась слишком трудоемкой. Документы пришлось систематизировать по содержанию, которое условно стали обозначать индексами, т.е. буквами и/или цифрами. Систематизация по разделам наук (классам) — один из самых первых способов раскрытия содержания научно-технических документов, моделирующий работу человеческого сознания и восходящий к глубокой древности.
По мере увеличения количества письменных и печатных документов и объема наших знаний о мире их классификация усложнялась. Эти классификации получили название иерархических. Многотомные схемы классификации конца XIX — начала XX века насчитывали десятки тысяч классов, подклассов, отдельных рубрик. Специалистам смежных областей знания и особенно массовому читателю библиотек стало трудно ориентироваться в схемах классификации и определять в их иерархии место той рубрики, по которой необходимо получать информацию.
Да и сами рубрики, строго ориентированные на узкие разделы наук, подвергающихся непрерывному процессу дифференциации, перестали удовлетворять специалистов-практиков, которым нужна была все более комплексная, предметная информация. Это привело к созданию в 70-х годах XIX в. предметной или точнее алфавитно-предметной классификации. На долгие годы она стала господствующей при составлении энциклопедий, вспомогательных указателей к трудам, систематически излагающим проблему или раздел науки, а в США, где она была создана, при организации каталогов.
Стремительный рост объемов литературы значительно усложнил также задачу идентификации каждого произведения печати. Библиотеки первыми столкнулись с необходимостью создать инструмент, при помощи которого можно было бы быстро и надежно устанавливать наличие определенного произведения в их фондах. Таким инструментом стал в XIX в. авторский, именной указатель (алфавитный каталог, по библиотечной терминологии), который однозначно идентифицировал произведение по именам лиц, принимавших участие в его создании или же связанных с его содержанием. Таким образом, до середины ХХ в. возможности содержательного поиска информации по справочникам или документов, содержащих нужную информацию, в библиотеках ограничивались тремя способами: систематическим, предметным и алфавитным.
Традиционной технологией реализации этих способов были списки, перечни книг и статей, содержавших необходимую информацию. С 70-х годов XIX в. эти сведения стали записываться на дискретных носителях — библиотечных карточках из плотного картона формата 75 х 125 мм (размер сложенной пополам американской почтовой карточки). Следует отдать должное этой традиционной технологии. Она успешно обеспечивала культурный прогресс на протяжении целого столетия вплоть до нынешнего этапа: научно-технической революции, позволила накапливать и использовать многомиллионные собрания документов, обслуживать тематические потребности ученых и специалистов в необходимой им информации. На ней и сегодня еще в значительной степени зиждется деятельность всей мировой библиотечной системы — этого краеугольного камня человеческой культуры, важными составными частями которой является наука и техника.
Однако недостаточность, ограниченность этой технологии стала все более остро ощущаться уже в первой четверти ХХ в. В науке первыми почувствовали это химики из-за быстрого роста числа синтезируемых ими веществ. В, настоящее время каждые три
года появляется свыше миллиона таких веществ. Обычные методы оповещения — библиографические указатели, библиотечные каталоги, справочники типа «Гмелина» для неорганической химии и «Бельштейна» для органической — начали значительно отставать по времени от успехов исследователей и перестали охватывать их результаты в полном объеме. Революции в физике и электронике, характеризующие середину прошлого столетия, усугубили трудности информационной коммуникации.
Процедуры и понятия
Научное сообщество осознало необходимость организационного оформления информационной деятельности, которая в течение нескольких десятилетий подспудно созревала в недрах науки и техники. Большая: наука индустриального типа, пришедшая на смену «малой» науке университетского типа, выдвинула задачу создания систем научно технической информации. Именно в это время, в конце 40-х — начале 50-х годов были сформулированы понятия информационного поиска, информационно-поисковой системы, информационно-поискового языка, была выдвинута задача механизации, а затем и автоматизации информационного поиска, Не случайно именно в это время В. Буш писал о необходимости новых, форм справочных материалов, которые учитывали бы ассоциативные связи и были пригодны для механизации.
К этому времени стало ясно, что информационный поиск- это совокупность логических процедур, в результате которых в ответ на информационный запрос выдается либо необходимая информация, либо документы, в которых она может содержаться, либо библиографические адреса этих документов. В первом случае поиск получил название фактографического, во — втором документального, в третьем — библиографического. Эти процедуры сводятся к следующему.
Каждый вновь появляющийся документ подвергается анализу, в результате которого определяется его смысловое содержание. Этот анализ осуществляется интеллектом человека, возможность его формализации остается пока неясной. У автора документа и различных его читателей может быть разное представление о содержании документа. Затем это абстрактное представление о содержании (считается, что оно должно совпадать с авторским) выражается на некотором информационно-поисковом языке, т.е. синтезируется в виде библиографического описания и индекса.
Индекс образуется путем мысленного сопоставления основного смыслового содержания с потенциальными запросами потребителей информации. Эти запросы как бы зафиксированы в схемах классификации и обозначены индексами. Сама процедура выражения основного смыслового содержания документов и информационных запросов на информационно-поисковом языке получила название индексирования и составляет существенную часть аналитико-синтетической обработки документов. Информационный поиск, таким образом, заключается в замене содержательного прочтения полного текста документов формальным сличением (сравнением на соответствие) их поисковых образов с запросами на языке индексов.
Понятно, что такая замена значительно упрощает и убыстряет нахождение нужной информации, делает возможной автоматизацию процедуры сравнения. Но за это приходится платить не- полнотой и неточностью поиска. Описанные выше логические процедуры допускают субъективизм осуществляющих их лиц, а используемые информационно-поисковые языки несовершенны и неспособны адекватно передавать содержание документов и смысл запросов. Следовательно, информационные потери й шум — неизбежные условия информационного поиска. Когда говорят, что поиск осуществлен со 100 %-ной полнотой, имеют в виду, что информационного поиска не производилось, а был осуществлен полный перебор всех текстов (современная технология в некоторых случаях предоставляет такую возможность).
Информационный поиск реализуется при помощи информационно-поисковой системы, которая в абстрактном виде должна состоять из информационно-поискового языка, правил перевода на этот язык и критерия смыслового соответствия, определяющего объем выдачи документов или информации (критерий выдачи). Конкретная система включает также средства реализации (перечень, картотека, механический селектор, компьютер), информационный массив и обслуживающий персонал.
Функционирование простейшей документальной информационно-поисковой системы можно проследить по ее блок-схеме на рис. 9. В системе имеется два входа (для документов и запросов) и один выход (для выдачи документов по запросам). На входах имеются преобразователи для индексирования документов и запросов. Поисковые образы документов вместе с адресами их хранения (номерами) направляются в активное запоминающее устройство (ЗУакт), а сами документы — в пассивное (ЗУпас). Индексы каждого запроса сравниваются с индексами всех документов в решающем устройстве (РУ), которое в случае их соответствия (полного или предусмотренного критерием выдачи) дает в хранилище (ЗУпас) команду на выдачу документа. Это хранилище составляет как бы второй контур системы (сами документы), которого нет у библиографических (одноконтурных) систем.
Даже названия элементов на блок-схеме говорят о возможности автоматизации информационно-поисковой системы. Однако блок-схема верно обрисовывает работу любой системы, включая и наиболее традиционные. Это легко видеть на примере библиотеки. Преобразователи на входах соответствуют отделам обработки и справочно-библиографическому, ЗУакт — каталогам, ЗУпас — фондам. Нет в библиотеке только РУ — оно моделируется интеллектом читателя, который (хотя часто он и не осознает этого) вырабатывает собственный критерий выдачи, и собственную стратегию поиска.
Не случайно именно эта интеллектуальная часть функционирования информационно-поисковой системы представила наибольшие трудности для автоматизации, именно она больше всего сдерживала развитие этих систем. Камнем преткновения явились, прежде всего, традиционные информационно- поисковые языки, ограничивающие возможности содержательного поиска информации. Расхожее мнение о том, что эти языки трудно поддаются автоматизации, неверно. Но они рассчитаны на ручную реализацию, и поэтому использование их в компьютерах удорожает поиск, ограничивает число пользователей и не дает никаких выигрышей т.е., не снимает ограничений присущих этим языкам.
А ограничения эти стали особенно ощутимыми на нынешнем этапе научно-технической революции. Прежде всего, традиционная технология поиска рассчитана на стабильный, медленно меняющийся состав запросов. В схемах классификации и перечнях предметных рубрик уже заранее как бы скоординированы все понятия, по которым можно извлекать информацию из документов и затем производить по ним поиск (такие языки поэтому и получили название предкоординатных). Это приводит к тому, что при возникновении новой проблемы или направления исследований, по которым имеется полученная прежде информация, система не обеспечивает ее поиска. Ведь эта тематика раньше не была сформулирована и не нашла места в схемах классификации и списках предметных рубрик, а значит и индексирование по ней не производилось.
Другими словами, традиционная технология поиска. Не позволяет искать информацию по любому, заранее не предвиденному сочетанию признаков. При этом, как уже говорилось, субъективизм индексатора при извлечении основного содержания документа увеличивает информационный шум и потери, предопределенные характером традиционных поисковых языков. Нельзя не отметить также, что основанные на них системы ручного поиска, даже фактографические, не предназначены для манипулирования полученными из них данными. Они не имеют логического аппарата для содержательной переработки этих данных. Подобная задача всегда решалась самими потребителями без помощи информационных систем.
Новая технология пришла в информационный поиск в виде метода координатного индексирования, разработанного а США в 50-е годы математическим логиком М. Таубе и работником службы химической информации К. Муэрсом. Этот метод основан на предположении, что основное смысловое содержание любого документа и информационного запроса можно выразить при помощи набора терминов, по большей части содержащихся в самом индексируемом документе. Эти термины получили название ключевых слов. Если, к примеру, нужно заиндексировать документ, в котором говорится о защите от коррозии лопаток газовых турбин, то совокупность терминов «турбина», «газ», «лопатки», «коррозия», «защита» и будет служить поисковым образом документа. Эти ключевые слова образуют для данного документа как бы координатную сетку, по которой в дальнейшем ведется информационный поиск по соответствующему запросу.
Преимущества данного метода очевидны. Прежде всего, информационные работники и потребители информации освобождаются от жестких рамок классификационных схем и перечней предметных рубрик. Индексирование новых документов ведется без оглядки на отраженные в них потенциальные и часто уже устаревшие запросы специалистов. С другой стороны, индексирование освобождается от субъективизма — ключевые слова выбираются формально. Эту работу, в принципе, можно поручить автомату. Во многих современных информационно-поисковых системах оператор вводит в машину библиографические данные документа, его реферат (аннотацию, резюме), а иногда и наиболее информативные части текста (например, первый и последний абзацы статьи, содержащие наибольшее число терминов, относящихся к ее содержанию). При помощи «запретительного» списка служебных и общезначимых слов, введенных в компьютер, осуществляется автоматический отбор ключевых слов, которые программно приводятся к нормальному виду (единственное число именительного падежа существительных и прилагательных, инфинитив глаголов). Это существенный шаг к автоматизации ввода информации в информационно-поисковую систему.
При поиске необходимой информации специалист Может формулировать свой запрос в виде цепочки терминов, на пересечении которых и окажется большинство документов; содержащих необходимую информацию. При этом потребитель может произвольно менять стратегию поиска в зависимости от оценки его промежуточных результатов. Если документов по запросу мало или нет в системе, можно снять из запроса какие- либо ключевые слова (в приведенном выше примере «газ» и «защита»). Тогда система выдаст документы более широкого содержания о коррозии лопаток турбин, в которых все же может содержаться нужная информация. В случае, если документов по запросу слишком много, можно добавить ключевые слова, ограничивающие поиск, например, определенным классом турбин или же конкретными методами защиты их лопаток от коррозии. В этом уже заключен важный элемент возможности диалога с системой при помощи слов естественного языка.
Основные достоинства этого принципиально нового подхода к раскрытию содержания документов и поиску информации заключаются в том, что он позволяет находить информацию по любому, заранее не предвиденному сочетанию признаков. Кроме того, при появлении совершенно новых направлений исследований можно вести поиск во всем массиве документов, ранее за индексированных по этому методу. Традиционные методы таких возможностей не предоставляли...
Было бы несправедливо умолчать о том, что достоинства нового метода приходится оплачивать преодолением дополнительных трудностей, Прежде всего, поиск с использованием, естественного языка ограничивает его рамками знакомых пользователю языков. Чтобы расширить этот круг, приходится прибегать к словарям. Затем, каждый естественный язык отличается богатством своего словарного состава — слова, одинаковые по написанию, могут иметь разный смысл (многозначность, омонимия), а одно и то же понятие может выражаться разными терминами (синонимия). Запросив информацию о косах, вы получите сведения не только о сельскохозяйственных орудиях, но и о географических объектах, а может быть и о прическах. Желая получить документы о транзисторах, следует помнить, что они могут также называться полупроводниками.
Термины находятся в сложных взаимоотношениях между собой, выражают более узкие или более широкие понятия, могут быть связанными по сходству по контрасту или по другим ассоциациям. Чтобы иметь возможность учитывать это при поиске, приходится составлять на каждом языке специальные понятийные справочники (тезаурусы). В них для каждого понятия (класса условной эквивалентности) выбирается один термин,— дескриптор, а для остальных слов указывается их связь с дескриптором. Тезаурусы иногда называют дескрипторными словарями, а сам поиск с их использованием дескрипторным. Кроме словарей для поиска по ключевым словам и дескрипторам часто создают специальную грамматику, Необходимость в ней вызывается возникновением ложной координации терминов, ошибочным их сочетанием. В ответ на запрос «трубы» х «медь» х «свинец» х «покрытие» можно получить не только необходимую информацию о покрытии медных труб свинцом; но и о покрытии свинцовых труб медью.
Курьеза ради, следует упомянуть, что метод координатного индексирования для поиска информации, явившийся принципиальным шагом к новой информационной технологии, на самом деле новшеством не был. В 1915 г. он был реализован на перфокартах американским орнитологом Т. Тейлором при составлении определителя птиц, а у Б. Виккери возникло предположение, что шумерские врачи еще в III тысячелетии до н.э. пользовались диагностическими устройствами, работавшими по этому принципу. На глиняных клинописных плитках записывались симптомы болезней, а под каждым из них — названия болезней, при которых эти симптомы встречаются. Совокупность симптомов составляла координатную сетку, а совпадающие для всех симптомов названия болезней — наиболее вероятные недуги больного.
Из этого понятно, что информационно-поисковые системы, основанные на принципе координатного индексирования, могут быть реализованы простейшими средствами ручного обращения. Система «унитерм-карт» самого М. Таубе представляла собой особым образом организованную картотеку, позволявшую легко сличать номера документов, чтобы выявить совпадающие номера для заданных терминов («унитермов»). Первые информационно-поисковые системы такого типа часто создавались на просветных перфокартах. Однако подлинный размах создание координатных, по большей части дескрипторных систем получило, когда они стали использовать компьютеры второго поколения. В 60-е — 70-е годы на базе крупнейших в мире реферативных служб были созданы мощные автоматизированные информационные системы, которые предназначались для ускорения выпуска информационных изданий и расширения спектра информационных услуг, а затем стали основными генераторами документальных баз данных на магнитных лентах.
Цитирование, библиографическое
сочетание, социтирование
Принцип цитирования использован Институтом, научной информации США, основанным в 1958 г. Ю. Гарфилдом, для создания принципиально нового вида информационного обслуживания. При поиске информации он взял в качестве индексов библиографические ссылки в документах. В выпускаемых им указателях цитированной литературы, называемых также «индексами цитирования», эти ссылки располагаются по алфавиту фамилий авторов цитированных работ с указанием сведений о документах, в которых они упоминаются, Произведения, использованные при написании статьи, составляют как бы координатную сетку для ее поиска. Если статья написана по совсем новой проблеме, не нашедшей рубрики в классификации наук, с еще не устоявшейся и малоизвестной терминологией, найти ее в потоке мировой литературы другими методами 'очень трудно. Указатель цитированной литературы можно представить себе как многоуровневую систему библиографических описаний документов, находящихся в обратной связи друг с другом.
Указатели цитированной литературы позволяют искать информацию по, совершенно новым межотраслевым или, комплексным проблемам под фамилиями пионеров и наиболее известных специалистов каждой из таких проблем. Например для поиска литературы по цитированию достаточно знать фамилию Ю. Гарфилда, так, как дочти каждой рвоте, по этой проблеме есть упоминание о нем и его статьях. Фамилии авторов найденных работ могут в свою очередь служить входами в указатель, и за 1-5 таких итераций (последовательных поисков) всё сведения об отраженной в указателе литературе по проблеме оказываются найденными. Индексы цитирования предоставляют уникальную возможность проследить за всеми случаями применения какой-либо идеи или метода, за их критикой и обсуждением оценить информационный вклад того или иного ученого или научной школы, степень и динамику популярности их работ. Известны случаи, когда по этим указателям предсказывали нобелевских лауреатов. Институт научной информации США выпускает указатели цитированной литературы по точным, естественным и прикладным наукам (c 1964 г.); по общественным наукам (с 1969 г.), по искусству и гуманитарным наукам (с 1976 г.), для чего просматривается около 8,5 тыс. научных журналов и ежегодно до 1,5 тыс. названий книг. Большинство указателей распространяется не только в обычном (бумажном), но и в машиночитаемом виде (на магнитной ленте, дискетах, оптических дисках). Нужно ли говорить о том, что осуществление принципа, положенного в основу этих изданий, стало возможным лишь благо- даря компьютерам. Ведь речь идет о ежегодном библиографировании почти 10 млн. ссылок.
В двух статьях Е и F, например, (см. рис. 10) имеются библиографические ссылки, которые устанавливают прямую библиографическую связь между ними (цитирующими документами) и статьями А, В, С и О, которые в них упоминаются (цитируемыми документами), В указателе цитированной литературы эти ссылки, по алфавиту которых упорядочивается его массив («цитации» по терминологии Г.Я. Узилевского, которому принадлежит данный пример), обозначают цитируемые документы, а под ними располагаются «библиограммы, т.е. описания цитирующих документов.
Понимание потенциальных возможностей комплексирования документов по признаку общих ссылок и стремление максимально использовать накопленный массив в машиночитаемой форме повели к поискам новых путей применения метода цитирования. Еще в 1963 г. М. Кесслер в Массачусетском технологическом институте предложил считать связанными по смыслу документы, авторы которых ссылаются на одни и те же работы, а числом совпадающих ссылок измерять степень такой связанности. Этот метод, который он назвал библиографическим сочетанием документов, долгое время не имел широкого практического применения, но в 1968 г. Ю. Гарфилд использовал его для создания ретроспективной поисковой системы на компакт-дисках.
По-другому подошли к этой проблеме сотрудник Института научной информации США Г. Смолл и тогдашняя аспирантка ВИНИТИ И.В. Маршакова, Они одновременно и независимо друг от друга в 1972 г. предложили считать связанными по смыслу и тематике работы, на которые совместно ссылаются авторы нескольких документов. Этот метод, чаще всего называемый социтированием, имеет другую коммуникационную основу. В каждой исследовательской области имеется некоторый набор важных работ, отражающих познавательную основу этой области. Данные работы цитируются многими исследователями и по- этому принадлежат к числу высоко цитируемых. Больше того, они часто цитируются вместе, образуя таким образом социтирование. Другими словами, социтированием принято называть одновременное упоминание любых двух или большего числа публикаций в какой-либо последующей.
Для лучшего представления разницы в этих методах выше приведена схема, на которой Е и F являются цитирующими документами текущего года, а А, В, С и D — цитируемыми документами более ранних годов. Сплошными стрелками показаны связи по цитированию, т.е. Е цитирует А, В и С, а F цитирует В, С и D . Тогда между цитирующими работами F и. F образуется библиографическое сочетание, а между цитируемыми работами В и С — социтирование (обозначено пунктиром). Для простоты и наглядности степень связанности на схеме минимальная, хотя на практике она значительно больше (т.е. для признания библиографического. сочетания между двумя работами или кластера со- цитирования в каждом отдельном случае устанавливается определенный минимальный порог, который тем выше, чем интенсивнее цитирование).
Между характером этих методов установления связи и областью их применения имеется существенная разница, Библиографическое сочетание — это однократно произошедший факт, поскольку Е и F были однажды опубликованы со своими ссылками, и с ними в дальнейшем ничего уже произойти не может. Именно поэтому данный метод применяется для ретроспективного поиска документов, связанных между собой единством тематики, исследовавшейся их авторами.
Совсем по-другому обстоит дело с социтированием так как связь между цитируемыми В и С может сохраняться (увеличиваться или уменьшаться) в последующие годы в зависимости от того, насколько часто они будут попарно цитироваться в новых работах. Частое социтирование указывает на их концептуальную близость, поскольку они используются как единый комплекс Между этими работами как бы возникают невидимые связи, которые после наглядного их выражения образуют смысловые сгустки (кластеры). Совокупность таких кластеров ключевых работ, отражающих исследовательские области, представляют собой как бы карту определенной научной области, а совокупность карт — атлас науки на данный момент.
При регулярном выпуске подобных атласов (выходили атласы по биологии, биохимии, геологии, математике, вычислительной технике) появляется возможность регулярно следить за динамикой развития научных. дисциплин, школ, направлений, коллективов, а, следовательно и целенаправленно, воздействовать на это развитие, т.е. управлять им. Методы библиографического сочетания и кластеризации социтирования моделируют содержательные отношения между документами, используя практику цитирования, сложившуюся при публикации научных работ. Но это не единственный возможный подход к установлению таких связей между документами, заложенных в их библиографических элементах и фрагментах текстов. В следующей лекции об информационных системах вы познакомитесь с методом логико-смыслового моделирования, а теперь мы перейдем к более традиционным видам информационно-поисковых языков.
Иерархические и фасетные классификации
Было бы неверно думать, что будущее только за цитированием, за информационно-поисковыми языками координатного индексирования, которые вытеснят традиционные языки. В этом случае, как и во всей системе коммуникации, действует закон развития, по которому новые средства не заменяют полностью прежних, а лишь перераспределяют функции между ними. Это в полной мере относится и к такому древнему средству информационной технологии, как иерархические классификации, наиболее распространенной представительницей которых выступает Универсальная десятичная классификация (УДК). Создание УДК явилось переломным моментом в развитии ИПЯ: она завершила тысячелетнюю историю линейных классификаций перечислительного типа и открыла пути к построению фацетных классификаций.
Библиотечные классификации — самый ранний из известных нам типов ИПЯ. Если проследить за их развитием от классификации вавилонских библиотек вплоть до библиотечных классификаций второй половины XIX в., становится ясно, что принципы их построения почти не изменялись. Следуя за наиболее известными системами классификации наук, библиотечные классификации строились на основе иерархического «древа знаний» с выделением специальных разделов и подразделов для систематизации особых видов книг. До нас дошло очень немного сведений о классификациях, применявшихся в древних библиотеках. Вероятно в античные времена такие классификации были разработаны достаточно детально. Об этом можно судить по обширности библиотек, высокому уровню классификации наук того времени, а также по некоторым косвенным свидетельствам, содержащимся в литературных памятниках.
На классификации средневековья известное влияние оказала распространенная в то время система «семи свободных искусств». Она состояла из двух комплексов наук, изучавшихся в тогдашней школе: «тривиума» (грамматики, диалектики и риторики) и «квадривиума» (арифметики, геометрии, музыки и астрономии). К концу XV в. в университетских библиотеках начали применять группировку книг по содержанию в соответствии с существовавшими в большинстве университетов четырьмя факультетами: философским, медицинским, юридическим и богословским. Это послужило толчком к возникновению так называемых факультетских систем классификации, пользовавшихся популярностью на протяжении столетий вплоть до Х1Х в. Они оказали влияние на выдающиеся для своего времени классификации швейцарского ученого и библиографа К. Геснера (1548),и немецкого, философа Г. Лейбница (1700).
Дальнейшее развитие библиотечно-библиографических классификаций проходило под воздействием идей английского философа Ф. Бэкона (1561-1626). Созданная им в начале ХЧ11 в, классификация наук группировала знания в соответствии с идеалистической традицией по «способностям человеческого духа». «Память» определяла возникновение истории, «воображение»- поэзии, «разум»-философии, или собственно науки. При всей условности такого деления классификация Ф. Бэкона включала новые отрасли знания и представляла собой значительное событие для науки того времени.
В Х1Х в. библиотечно-библиографические классификации стали широко разрабатываться в России. Большой интерес представляет схема ученого-натуралиста П.Г. Демидова, составленная им для каталога личной библиотеки. В этой схеме наиболее детализированными были разделы естественных наук и технологии. Заслуживает внимания схема, опубликованная в 1809 г. А.Н. Олениным и предназначенная для императорской СПб Публичной библиотеки, а также оригинальная схема К.Ф. Рейса, предложенная им для библиотеки Московского университета в 1826 г. и основанная на дихотомическом принципе деления. Самостоятельную схему классификации, в основу которой было положено условное деление наук «по потребностям человека», создал для библиотеки Казанского университета К.К.Фойгт в 1843.г.
Одной из лучших в первой половине Х1Х в. заслуженно считается классификация выдающегося русского натуралиста К.Э. Бэра, которую он разработал для иностранного отделения библиотеки Академии: наук в Санкт-Петербурге в 1841 г. В этой классификации была предпринята одна из первых попыток расположить науки в последовательности, отражающей историю развития мира: науки о неорганической природе, науки об органической природе, науки о человеке и обществе.
В библиотеках Западной Европы в этот период особенно широко применялись схемы классификации Ж.Ш. Брюне (1810} и А.Э.Шлейермахера (1847). Первая из них представляла собой одну из поздних разновидностей так называемой французской системы, которая в течение почти двух столетий использовалась в библиографии и книготорговле Франции. Вторая, особенно популярная в библиотеках немецких университетов, была создана на основе старой «факультетской системы». Эти классификации создавались для расположения книг на полках и для систематизации их описаний в каталогах и указателях. Такое их назначение обусловило необходимость линейной последовательности их рубрик и строгого подчинения между классами и подклассами, всегда связанными в этих классификациях родовидовыми отношениями. Одна из наиболее сильных сторон этих языков заключается в том, что классификация по родовидовым признакам всегда служила важным инструментом познания и привычным методом определения понятий.
Иерархические классификации обеспечивают высокую эффективность информационного поиска по широким тематическим запросам, сформулированным в определенном аспекте, который был предусмотрен заранее, при составлении схемы и при индексировании по ней документов. Для реализации подобного поиска наиболее оптимальным техническим средством служит просто перечень (каталог). Эти особенности объясняют прочное положение иерархических классификаций как единственного на протяжении тысячелетий средства поиска документов по их содержанию. Лишь во второй половине XIX в. появилась необходимость в другом типе языка, который упрощал бы для массового читателя разыскание нужных ему рубрик и облегчал бы введение в систему новых понятий без коренной ее перестройки. Таким языком стала алфавитно-предметная классификация, теорию которой в 70-80-х годах прошлого века разработал Ч.Э. Кеттер.
Крупнейшим достижением в области систематизации явилось создание в 1876 г. видным американским библиотечным деятелем М. Дьюи «десятичной классификации». Сам он видел свою основную заслугу в том, что применил в своей схеме децимальную индексацию: «Дело шло о достижении абсолютной простоты путем использования самых простых и известных символов- арабских цифр в виде десятичных дробей в качестве индексов классификации всех человеческих знаний в печатных произведениях». Однако теперь, по прошествии столетия, значение созданного М. Дьюи нам представляется в другом. Он теоретически обосновал и практически внедрил стандартизацию тыновых делений (литературной формы, вида издания и т.п.) в различных разделах схемы и частично лингвистических, этнических и гeoграфических делений, использовав прием факультативного превращения в постоянные подразделения окончаний индексов разделов «Филологии» и «Истории».
Другой его важной заслугой было введение в систему алфавитно-предметного указателя, который позволил разыскивать книги по любому предмету независимо от его места в схеме.. Идея такого вспомогательного указателя, правда, не была новостью, такие указатели уже применялись в энциклопедиях Х111 в., в изданиях эпохи Возрождения, у К. Геснера, в таблицах А.Э. Шлейермахера. Однако только теперь подобные указатели стали неотъемлемой частью классификационных таблиц и систематических каталогов библиотек. Таким образом, впервые была предпринята попытка избавиться от жесткости линейной схемы иерархической классификации и расширить число входов в ее схему. Однако этот шаг был еще очень робким, и принцип проводился не очень последовательно.
Эта непоследовательность была преодолена в «брюссельском варианте» десятичной классификации, которая получила широкое распространение после 1905-1907 гг. как «Универсальная десятичная классификация». Ее создатели выдающиеся бельгийские документалисты П. Отле и А. Лафонтен использовали преимущества десятичной системы, индексация которой понятна людям, говорящим на разных языках, и развили заложенные в невозможности более гибкого использования иерархической классификации. Идею стандартизации делений схемы они довели до логического конца, создав вспомогательные таблицы типовых делений — общих и специальных (аналитических) определителей. Общие определители (языка, формы документа, места, времени, народности, точки зрения) используются во всех отделах схемы с одним и тем же значением. Специальные определители предназначены для использования только в нескольких отделах одной отрасли знания для их деления по одним и тем же признакам.
Важным достижением УДК явилось также введение принципа комбинации индексов, разработка приемов их присоединения, распространения, отношения и объединения (синтеза), кроме того, было предусмотрено использование индексов подразделений одного раздела в других и введение параллельных (альтернативных) делений для отражения классифицируемых объектов в разных аспектах: Таким образом, на смену прежним «перечислительным» схемам с заранее установленными рубриками и готовыми индексами пришла подвижная схема, в которой нужные рубрики могут создаваться в процессе классификации путем сочетания индексов с определителями или соединения их друг с другом.
К основным достоинствам УДК как иерархической классификации относятся следующие ее характерные черты:
универсальность, заключающаяся в охвате всех отраслей знания,
логическая ступенчатая индексация, позволяющая неограниченно делить подклассы без нарушения основной структуры классификации,
международная применимость благодаря использованию только цифровых десятичных индексов, всем понятных и легко запоминаемых,
развитая система определителей и комбинационного построения индексов, обеспечивающих относительную гибкость при отражении достаточно узких и сложных понятий,
устойчивый и четко организованный международный механизм поддержания классификации на уровне новых достижений науки.
В качестве недостатков УДК часто называют ее естественные ограничения, присущие всем иерархическим классификациям. Они не могут удовлетворительно отражать процессы интеграции и взаимопроникновения наук, и в них трудно находить место для направлений и понятий, возникающих на стыке наук. Далеко не все явления в природе и понятия в науке можно связать родовидовыми отношениями. Это особенно ярко проявляется в технике, медицине, в других прикладных, а также в комплексных дисциплинах, таких, например, как кибернетика, информатика, семиотика. Эта ограниченность УДК, в которой отдельные науки жестко разделены в соответствии с формальными логическими правилами, противоречит тенденции синтетического развития науки. Нельзя сказать, чтобы это были недостатки, скорее это внутренние свойства иерархических классификаций, обеспечивающие их эффективность в условиях широкого тематического поиска.
Следующий шаг в развитии комбинационного принципа в классификации был сделан выдающимся индийским библиотековедом Ш.Р. Ранганатаном в созданной им в 1933 г. «Классификации с двоеточием», которая явилась родоначальницей фасетных классификаций. Об их функциях. английский информатик Б. Виккери писал: «Потребители хотят иметь возможность отыскать документ, посвященный сложной специальной теме, не только тогда, когда именно она является непосредственным объектом поиска, но также тогда, когда поиск ведется по любому термину или группе терминов, входящих в сложное понятие. Для удовлетворения этих требований необходимо, чтобы не только понятия могли входить в неограниченное количество сочетаний, но также, чтобы в структуре системы были отражены родовые связи понятий и связи между разделами».
Фасетная классификация вместо единого ряда делений в каждом основном классе имеет несколько «фасетов», соответствующих аспектам классифицируемого понятия или предмета. Все существенные термины данного класса распределяются по фасетам и образуют их «фокусы». При индексировании документов их содержание, выражается цепочкой фокусов, последовательность которых определяется специальной «фасетной формулой». Примером построения индексов по системе Ш. Ранганатана могут служить следующие фасеты и фокусы из области медицины:

В этой схеме индекс документа по диагностике инфекционных заболеваний кишечника — 25:42:3, по лечению туберкулеза легких — 45:421:4.
Преимущества этого вида классификаций в том, что они облегчают многоаспектное индексирование документов, позволяя собирать в одном месте все аспекты рассмотрения какого-либо предмета или темы, они легче поддаются изменениям при введении новых понятий, допускают большую глубину индексирования при более коротких индексах. Их применение особенно эффективно при поиске в небольших по объему узкоспециализированных собраниях документов. Видный английский информатик Д. Фоскетт так обосновал достоинства фасетных классификаций: «От схемы не требуется более, чтобы она указывала «место» для каждого документа, включая любой термин или набор терминов в явном виде в классификационные таблицы по каждой предметной области. Эти схемы могут задать набор правил, или рабочих процедур, с помощью которых такие контексты можно, по мере надобности, формулировать на основе тех же самых схем».
Рубрикаторы информационных изданий
На большинстве европейских языков рубрикатором называли переписчика рукописей, который в скрипториях средневековья и Возрождения размечал красной краской первые буквы смысловых фрагментов текста, получивших название рубрик. Это название сохранилось и до наших дней, хотя в нынешних произведениях печати рубрики отмечаются абзацными отступами или отделяются друг от друга пробелами. В журналистике рубриками принято также называть постоянные разделы в журналах и газетах, а в библиотековедении — структурные подразделения систематического и предметного каталогов.
В 50-е годы в информатике рубрикаторами стали называть перечни рубрик реферативных журналов и других информационных изданий. В данном случае рубрика выступает как содержательный фрагмент такого издания и состоит из индекса и заголовка раздела, а также библиографических записей (с аннотациями или рефератами) произведений печати, которые по своему содержанию относятся к данной рубрике. По мере роста числа и увеличения объемов реферативных журналов их рубрикация стала усложняться. Появилась необходимость в создании такого перечня рубрик, который отвечал бы определенным требованиям и мог бы служить средством систематизации библиографических записей вместе с рефератами. Поскольку библиотечно-библиографические классификации оказались непригодными для этого, реферативные службы стали создавать собственные рубрикаторы.
Рубрикатор — это особым образом организованный перечень рубрик иерархической классификации, предназначенный для отражения сведений о текущих публикациях в информационных изданиях или системах информационного обслуживания. К его характерным особенностям относятся сравнительно небольшая глубина индексации, ориентированность на межотраслевые, междисциплинарные, комплексные проблемы, простота и линейность структуры, достаточная гибкость, частая и безболезненная изменяемость формулировки рубрик. Любой рубрикатор создается под влиянием двух противоречивых факторов, отражает два взаимосвязанных, но разных информационных потока: документального и запросов потребителей. Первый оказывает преимущественное влияние на структуру рубрикатора, второй на формулировку заголовков рубрик, причем изменение структуры документального потока несколько отстает от быстро меняющегося характера информационных запросов.
Возникает вопрос, почему же все-таки для создания рубрикаторов не использовались существующие классификации? Можно указать на несколько обстоятельств, которые ведут к серьезным различиям в схемах иерархических классификаций, используемых для библиотечных каталогов и для построения рубрикаторов. Первые, рассчитанные, в первую очередь, на систематические каталоги и картотеки библиотек, отражают структуру универсального потока документов: книг, брошюр, периодических и продолжающихся изданий. Рубрикаторы реферативных журналов ориентированы преимущественно на
журнальные статьи и другие публикации из научной периодики, которые имеют другую содержательную структуру, более дробную и гибкую. В реферативных журналах подчас приходится открывать рубрики для таких вопросов, которые в библиотечном каталоге могут стать необходимыми лишь через десять лет.
Систематические каталоги библиотек ориентированы на дисциплинарную структуру, т.е. на выделение основных классов в соответствии с научной классификацией. В рубрикаторе наряду с дисциплинарными характеристиками необходимо учитывать комплексные междисциплинарные проблемы и отрасли народного хозяйства. Это нарушает строгую логику иерархической классификации, но придает рубрикатору особую гибкость. Библиотечная классификация предназначена для ретроспективного поиска, для накопления записей за много лет, это требует сложной структуры, ее стабильности, устойчивости, медлительности в изменениях. Для рубрикатора частые изменения являются правилом, формулировка заголовков рубрик, публикуемых в каждом номере издания играет сравнительно большую роль, а форма индексов, выполняющих служебную роль, менее значима. Рубрикатор легко обозрим, имеет небольшую глубину и простой служебный аппарат (систему ссылок и вспомогательных делений, способы сочетания рубрик).
По рубрикаторам классифицируются самые мощные потоки научных публикаций — во всем мире ежегодно не менее 5 млн. несовпадающих документов (из них только в ВИНИТИ около 1 млн.). Если ориентировочное число публикуемых ежегодно научных документов принять близким к 10 млн., то половина из них систематизируется по различным рубрикаторам. Это на порядок больше, чем приходится на долю классификаций, применяемых ежегодно для описания входных потоков всеми библиотеками мира. Поэтому рубрикаторы приобрели большое значение в научно-информационной деятельности. Во многих информационных центрах избирательное распространение информации, сигнальная информация и даже справочно-библиографическое обслуживание осуществляются при помощи рубрикаторов. Чтобы они могли справиться с такими несвойственными им функциями, приходится
оснащать их различными вспомогательными средствами, которые приближают их к библиотечным классификациям, но затрудняют их использование по прямому назначению. Как и во всех подобных случаях, здесь приходится прибегать к разного рода компромиссам, но это неизбежно там, где мы не пользуемся новой информационной технологией.
Разные типы информационно-поисковых языков
Информатика, заявившая.о себе в середине нашего века, принесла с собой не только новую и получившую распространение терминологию («дескрипторы», «тезаурусы», «индексирование») и не только удовлетворила нашу обычную потребность в противопоставлении нового традиционному. Новым, действительно новым, оказался более широкий подход к явлениям и принципам. Понятие, например, информационно-поискового языка (ИПЯ) позволило рассматривать предметизацию, систематизацию, книгоописания, координатное индексирование как процессы, использующие искусственные языки, семантическую силу которых можно измерять по сравнению с возможностями естественного языка. Понятие информационно-поисковой системы (ИПС), как уже говорилось, объединило многие предметы, которые прежде рассматривались изолированно, например, библиотечные фонды и каталоги, различного вида самостоятельные и вспомогательные указатели, справочники, энциклопедии, автоматизированные поисковые системы. Это дало возможность выявить общие принципы их построения, найти общие критерии их эффективности и другие общие параметры.
Мы установили, что дескрипторные информационно- поисковые системы открыли принципиально новую возможность поиска необходимых документов и содержащейся в них информации по любому сочетанию заранее не предвиденных признаков. Однако за реализацию этой возможности приходится платить не только интеллектуальными потерями, но и материальными ресурсами. Эти системы приходится ориентировать на дорогостоящие компьютеры и программы, что предполагает более трудоемкий ввод информации и более. строгие ограничения на число одновременных пользователей. Вполне естественно в такой ситуации попытаться сочетать уже имеющиеся, поисковые средства со вновь создаваемыми. Отсюда вытекает и желание найти общие черты в этих разных системах и лежащих в их основе ИПЯ: языке предметных рубрик, и дескрипторном языке, что обычно сочетается с поисками путей их совместимости.
Всегда можно найти такую удаленную позицию, такое основание деления, при которых эти языки попадут в один общий класс. В ряду искусственных языков они принадлежат к классу информационных, в ряду информационных — к подклассу информационно-поисковых. В них используются в качестве индексов слова естественного языка. При построении этих языков применяются внешне схожие приемы: перечень предметных заголовков и словарная часть тезауруса упорядочиваются в алфавите слов. Тем не менее, учитывая эти общие и сходные черты, нельзя забывать и о принципиальных различиях данных языков. Основной словарный состав языка предметных рубрик это имена сложных классов, построенных до индексирования документов, поскольку этот язык принадлежит к типу предкоординиремых. Дескрипторный же язык является посткоординируемым, т.е. строится из имен простых классов, которые образуют необходимые понятия при их пересечении (логическом умножении) в момент индексирования и/или поиска документов.
Для того, например, чтобы индексировать статью о производстве и экспорте вычислительных и пишущих машин в (США, Японии и Великобритании достаточно дескрипторов ПРОИЗВОДСТВО, ЭКСПОРТ, КОМПЬЮТЕР, ПИШУЩАЯ MAШИHA и названий трех этих стран. Тогда при любой комбинации признаков при запросе (а таких комбинаций может быть 1 х 2 х 3 х 4 х 5 х х 6 х 7 = 5040, т.е. число перестановок из семи признаков) этот документ будет найден. Если же пользоваться языком предметных заголовков, то в зависимости от их заранее составленного перечня потребуется значительное число готовых рубрик. Оно, конечно, меньше указанного выше, но ровно настолько будет больше потерь при поиске.
Координатное индексирование в том и состоит, что для характеристики содержания документа или запроса перечисляются такие ключевые слова или дескрипторы, пересечение (логическое умножение) которых выражает основное смысловое содержание (главную тему, предмет) этого документа или запроса, тогда как в предметизацию для данной цели используются заранее сформулированные заголовки и подзаголовки.
При индексировании, т.е. выражении основного смыслового содержания документа в терминах ИПЯ, процессы информационного анализа и синтеза совершаются в два этапа. Первый этап является общим для всех языков. Содержание документа анализируется как с позиций того, какие идеи и факты заложены в него автором, так и с позиций научных и практических интересов большинства его потенциальных читателей. (Если не иметь в виду узкоспециальных интересов, то обе точки зрения чаще всего совпадают). Результаты этого анализа синтезируются в виде субъективного представления индексатора об основном содержании документа.
Второй этап зависит от языка индексирования. Если, это предкоординированный алфавитно-предметный язык, то свое представление о содержании документа индексатор сверяет с потенциальными запросами читателей, отраженными в перечне предметных заголовков. Для посткоординируемого дескрипторного языка аналогичному анализу подвергается тезаурус (не связанный непосредственно с потенциальными запросами потребителей) и сам текст индексируемого документа. Синтез в данном случае выражается в выборе соответствующих предметных заголовков или дескрипторов (ключевых слов).
Другими словами, при всей внешней схожести процедур индексирования посредством этих разных типов ИПЯ, характер их использования различен. В одном случае мы пользуемся готовыми продуктами в виде заголовков и подзаголовков, обозначающих класс документов определенного содержания. В другом случае это лишь исходный материал, дескрипторы и ключевые слова, при перемножении которых образуется класс, соответствующий данному содержанию. Вот почему перечень предметных заголовков и словарная часть тезауруса, при всей их внешней схожести, при том, что определенная часть слов в них может совпадать, на самом деле являются совершенно отличными друг от друга списками, слова для которых отбираются на основе разных критериев и играют различную роль.
Разные типы ИПЯ имеют свои достоинства и ограничения, которые делают их особо пригодными для решения разных поисковых задач. Возможности дескрипторного языка эффективно реализуются при узко тематическом поиске по произвольной комбинации признаков. Широкий тематический поиск по традиционным отраслям знаний и поиск по конкретным предметам, дисциплинам и их разделам в фондах документов за многие годы и в условиях одновременного обращения к ним большого числа читателей по-прежнему хорошо обеспечиваются библиотечными каталогами, основанными на иерархических и алфавитно-предметных классификациях. Выпуск информационных изданий требует разработки специальных рубрикаторов с не большим числом уровней иерархии и подвижной быстро меняющейся рубрикацией.
С самого начала в теории информационного поиска предполагалась возможность построения не только информационно- поисковых, но и информационно-логических систем, которые осуществляли бы автоматическую переработку информации, а также извлечение из научных текстов неявно, содержавшейся в ней информации. Эту идею много лет назад высказал один из пионеров этой теории в нашей стране В.А. Успенский. В то время такая возможность связывалась с дальнейшим совершенствованием электронной вычислительной техники, главным образом, с увеличением емкости оперативной памяти компьютеров и их быстродействием, что было вполне понятно. Но подобный ход мысли характерен и в наше время для специалистов в области вычислительной техники. Недаром девизом пятого поколения вычислительных машин служил переход от, переработки данных и информации к переработке знаний.
Информатики же давно поняли, что переработка знаний связана не только и даже не столько с совершенствованием компьютеров, сколько с организацией самих этих знаний. В этой сфере до последнего времени господствовали представления, связанные с традиционной структурой научного знания, которое фиксируется в статьях и монографиях и отражается в библиографических бюллетенях и реферативных журналах. Но задача заключается в том, чтобы понять внутреннюю структуру знаний, взаимосвязь данных, фактов, гипотез и теорий.
За последние десятилетия значительное развитие получили исследования в области неклассических логик, баз данных и баз знаний, формализованного представления содержания текстов, Они опираются на достижения математической логики, логической семантики, структурной лингвистики и ряда других фундаментальных и прикладных дисциплин, Результаты этих теоретических исследований находят, все большее применение в автоматизации информационных процессов и построении информационных систем различных типов, которые рассматриваются как средство переработки данных и знаний.
В среде информационных работников стало привычным проверить о базах и банках данных (БД и БНД). Само по себе это свидетельствует о, том, что профессионалы эффективно используют компьютеры в информационной деятельности. Хуже, то, что смысл и значение этих терминов, пришедших из области программирования, понимаются недостаточно глубоко. Это напоминает библиотекарей, которые с появлением теории информационного поиска стали называть каталоги информационно-поисковыми системами, что, в общем-то, верно, но ничем го не изменило в традиционной организации каталогов. Так и теперь информационные издания (бюллетени сигнальной информации, реферативные журналы) 'на магнитной ленте или дискете любят называть базами данных, что тоже не совсем
неправильно, но не отражает принципиального смысла этого понятия.
Понятие базы (или банка) данных возникло в конце 60-х гг. в связи с необходимостью освободить программы от данных, которыми они оперируют, сделать их независимыми. До этих пор данные организовывались под нужды каждой конкретной программы, что создавало массу неудобств и затруднений, особенно при изменении данных или самих программ. «База данных это реализованная средствами вычислительной техники специальная система для хранения данных о некотором фрагменте действительности. Главные идеи, лежащие в основе такой системы,— это объединение в одном месте данных, нужных для решения многих задач (может быть, даже тех, которые еще не начинали программироваться) и обеспечение независимости данных от их обработки». В процессе развития этого понятия базой данных стала называться и сама совокупность данных, организованных по определенным правилам их описания, хранения и манипулирования ими независимо от прикладных программ.
Появление баз и банков данных оказалось существенным шагом, приблизившим возможность автоматического решения многих интеллектуальных задач. Некоторые специалисты даже сравнивают это достижение с изобретением книгопечатания. Информационные работники со временем стали различать термины «база» и «банк» данных, которые первоначально употреблялись как синонимы. Теперь они понимают под банком данных систему программных, языковых, организационных и технических средств, предназначенных для централизованно накопления и коллективного использования данных, а также сами данные, хранимые в виде баз данных. Сущёствует и более ограниченное понимание БНД как одних только программных средств: — баз данных, их справочника, системы управления ими (СУБД) и библиотеки запросов и прикладных программ.
Для автоматизированных информационных систем создание банков и баз данных открывает возможность осуществлять информационный поиск не только документов, но и заключенных в них фрагментов — идей и фактов, а также манипулировать ими. Появляется реальная перспектива обогащать собственные наблюдения и результаты исследований ученых всем мировым опытом науки, содержащимся в научно-технической литературе. Значительная часть трудоемкой работы по извлечению и упорядочиванию имеющихся в документах данных, производимая прежде каждым исследователем, в принципе может быть переложена на информационную систему. В концепции банка данных реализуется давняя мечта информационных работников о создании не только автоматизированной информационно-поисковой системы, но и информационно-логической системы, позволяющей осуществлять анализ и синтез научной информации.
Ученый-исследователь и экспериментатор, инженер- разработчик и проектировщик получают возможность оперировать большим, чем до сих пор количеством данных, быстро меняя их организацию. Это можно проиллюстрировать на примере научной работы врачей. Целенаправленное наблюдение и лечение больных, страдающих определенным недугом, получает отражение в историях их болезни. Обычно несколько десятков историй болезни, сопоставленных с данными нескольких десятков литературных источников, служат материалом для написания статьи, и, в конечном счете, кандидатской диссертации. На эту работу уходят годы труда. Несколько сотен историй болезни и литературных источников могут привести к созданию монографии и докторской диссертации, на что приходилось затрачивать значительную часть жизни. Непосредственный доступ к банку данных позволяет выполнить существенную часть этой работы значительно быстрее. Банк данных облегчает перестройку всевозможных сведений, приведение их к необходимому единообразию, получение статистической информации, поиск зависимостей между параллельными рядами данных. Другими словами, работа с базами данных на компьютере в оперативном режиме устраняет противопоставление поиска информации ее творческой переработке, стирает грань между ними. Происходит как бы диалектический возврат к слиянию этих процессов в деятельности ученого на новом витке развития по спирали.
Было бы неверно думать, что информационные системы уже сегодня готовы к повсеместному переходу на описанный режим работы, хотя и в нашей стране и особенно за рубежом создаются и функционируют автоматизированные системы такого рода. Прежде всего, теория и практика баз и банков данных еще очень молоды и быстро развиваются. Даже наиболее распространенная реляционная ее модель, имеющая ряд преимуществ перед иерархической и сетевой организацией банков данных, как математическая структура реальной действительности далека от совершенства. Именно поэтому разрабатываемые в математической логике модели информационных систем пользуются в информатике таким вниманием. Многообразные задачи, поставленные перед новыми типами информационных систем, называемых теперь интеллектуальными, требуют адекватных средств реализации.
Информационно-поисковые системы
За последние десятилетия в области информационного поиска произошли важные изменения, которые требуют принципиально новых подходов и решений. В крупных банках данных накоплено огромное количество источников информации.
Насчитываются десятки тысяч общедоступных базы данных, в которых содержатся миллиарды записей. В них ежегодно проводятся десятки миллионов информационных поисков. Почти на каждый из них информационно-поисковые системы теперь быстро выдают сотни и, тысячи источников, т.е. слишком много, чтобы потребитель был в состоянии все прочитать или хотя бы просмотреть. Поэтому потребитель вынужден ужесточать свои требования к выдаваемым источникам. Возникла возрастающая потребность в значительном, усилении критериев выдачи релевантных документов, более строгом их отборе, для чего необходима разработка и применение других, принципов, переход на моделирование — пусть вначале даже самое грубое — процессов информационного поиска в памяти человека. Ясно, что поиск информации в памяти человека осуществляется совершенно иначе, чем посредством современных информационно-поисковых систем.
Другой важный фактор, все сильнее воздействующий на сферу информационного поиска, заключается в появлении и росте численности полнотекстовых БД, представляющих собой электронные аналоги печатных изданий и документов — энциклопедий, словарей, справочников, книг, журналов и т.п. Это обусловлено расширяющимся внедрением современных средств вычислительной техники в издательское дело и полиграфию.
Опыт информационного поиска в полнотекстовых БД, когда поиск проводится не по поисковым образам документов, а по их полным текстам, показывает, что использование ключевых слов, встречающихся в полных текстах, не дает тех результатов, которые получаются в первом случае. Хотя использование полных текстов документов создает новые, дополнительные возможности для повышения эффективности поиска (например, благодаря использованию библиографических ссылок как поисковых признаков), стало ясно, что необходима разработка существенно новых принципов информационного поиска по полным текстам документов, основанных на результатах исследования механизмов человеческого мышления и на использовании баз знаний и опыта, накопленного при разработке и эксплуатации экспертных систем, систем машинного перевода и других интеллектуальных информационных систем.
Проблема информационного поиска весьма существенно усложнилась еще в одном отношении. Если раньше объектом поиска были источники информации, то теперь возрастает потребность в поиске самой информации, которая при этом не всегда имеется в поисковом массиве в явном виде. Для получения такой информации необходимо выполнять над текстами источников или записями фактов те или иные логические операции, требующие привлечения определенных знаний о мире, которые непосредственно не содержатся в этих текстах и записях. Такого рода знания отображаются в базах знаний, простейшими примерами которых могут служить информационно- поисковые тезаурусы и таблицы классификации. Кроме того, необходимо учить компьютеры «понимать» тексты и факты, оценивать их, рассуждать, делать логические выводы, формулировать гипотезы, т.е. выполнять многие интеллектуальные операции, присущие человеческому мозгу. А это становится все более возможным по мере того, как мы узнаем все больше о механизмах человеческого мышления и учимся их моделировать. Таким образом, возрастает потребность в глубоком изучении процессов языкового и логического мышления, в создании и использовании информационно-логических, или интеллектуальная систем, которые сами становятся мощнейшим инструментом исследования этих процессов.
Интеллектуальные информационные системы
В настоящее время зрелость информатики как науки. характеризуется тем, что в ней взаимодействуют теория вычислений, алгоритмических языков и архитектуры компьютеров, а также искусственный интеллект, понимаемый как дисциплина об имитации и. усилении рассуждений, и о восприятии и переработке информации посредством компьютера.
В, результате развития этих разделов информатики стало возможно создание нового информационного продукта — интеллектуальных систем. Интеллектуальные системы, реализуют взаимодействие «человек — компьютерная система» таким образом, что они., являясь человеко-машинными системами, образуют симбиоз (человек, компьютерная система). Компьютер в диалоговом режиме усиливает комбинаторное мышление и логические возможности человека. С этим фактом связано возникновение новой информационной технологии, реализующей функционирование интеллектуальных систем по следующей схеме:
Интеллектуальная система=
= рассуждающая система +поисковая система+
+интеллектуальный интерфейс.
Интеллектуальная система — открытая система, принимающая решение с использованием новой поступающей информации, если она релевантна цели рассуждения. Таким образом, поисковая система оказывается средством принятия решения в интеллектуальной системе. Очевидно, что поисковая система может использоваться в двух режимах: в автоматическом — для подбора информации, близкой решаемой задаче, в диалоговом — для отбора информации, релевантной цели рассуждения, которая задана пользователем на некотором этапе работы системы.
Информационно-поисковая, система как подсистема интеллектуальной системы должна обладать как механизмом поиска фактов, так и механизмом поиска документов. Высокоразвитая информационно-поисковая система (ее можно назвать интеллектуальной информационно-поисковой системой) должна обладать процедурами извлечения фактов, пополняющих базы данных из текстов на естественных языках. Это делает возможным полуавтоматическое (с использованием диалога пользователя и системы) расширение базы знаний, которая пополняется индуктивными обобщениями. Интеллектуальные системы являются средством компьютерной обработки и анализа данных и знаний высокого уровня: они не только имитируют рассуждения квалифицированного эксперта, но и усиливают их.
Из сказанного следует, что охарактеризованные нами интеллектуальные системы являются системами поддержки и усиления интеллектуальной активности человека в том смысле, который декларировался авторами известного японского проекта компьютерных систем: пятого поколения. Для отечественных условий, в которых создаются интеллектуальные системы, разумеется, специфичны трудности реализации конструктивных идей, воплощенных в современных по замыслам, логическим и программным средствам системах, так как для задач большой комбинаторной сложности требуется применение суперкомпьютеров и рабочих станций. В настоящее же время многие отечественные интеллектуальные системе созданы для персональных компьютеров. В связи с этим актуальной является задача создания сетей с использованием больших ЭВМ.
Интеллектуальные системы как инструмент новой информационной технологии обладают некоторыми новыми (по сравнению с информационными системами предшествующих поколений) возможностями. Например, при прогнозировании биологических активностей химических соединений интеллектуальные системы могут содержать как информацию о химических соединениях (физико-химические и стереохимические данные), так и информацию о путях их воздействия на организм (биохимические данные) и о противопоказаниях лекарственных соединений (медицинские и экологические данные).
В ВИНИТИ разрабатываются интеллектуальные системы типа ДСМ, названные так по имени английского философа Джона Стюарта Миля. Эти системы применяются для прогнозирования свойств структурированных объектов в базах данных с неполной информацией для задач фармакологии, медицины и технической диагностики. Они могут быть применены и в других областях науки (например, в социологии), где знания слабо формализованы, данные хорошо структурированы, а в базах данных содержатся как положительные, так и отрицательные примеры некоторых эффектов.
Возникновение и развитие идеи гипертекста Гипертекст — это форма организации текстового материала, при которой его смысловые единицы (фразы, абзацы, разделы) представлены не в линейной последовательности, а как система явно указанных возможных переходов, связей между ними. Следуя этим связям, можно читать материал в любом порядке, образуя разные линейные тексты. Если речь идет о достаточно обширном материале с большим количеством связей; то возникает весьма сложное гипертекстовое пространство (сеть). Формирование и просмотр такой сети текстовых единиц возможны только при помощи компьютера.
Компьютерная гипертекстовая технология в самой общей форме понимается как «поддержка связей», т.е. обеспечение максимальной комфортности для пользователя при формировании и обработке сети связей. Имеется в виду, прежде всего, предоставление пользователю возможности легко добавлять в базу данных новые текстовые единицы, указывая их связи с уже имеющимися (было бы оптимально, если бы эти связи устанавливались автоматически на основе учета значения служебных слов). Не менее важна для пользователя и простота перемещения по образованной сети, т.е. возможность «читать» гипертекст в любом задуманном порядке.
Широкое внимание научной общественности к этой идее было привлечено несколько лет назад, когда на рынке компьютерных программ стали появляться системы, предназначенные для необычной интеллектуальной деятельности составления текста, имеющего нетрадиционную, «нелинейную» форму. Смысловые элементы этого текста могут читаться в разной последовательности, в соответствии с «разрешенными» смысловыми переходами, которые так или иначе указаны автором.
Теперь становится ясно, что успехи в развитии вычислительной техники и программирования позволили реализовать идеи, давно разрабатывавшиеся в недрах информатики. Возможности и тенденции развития информационной технологии в данном направлении были угаданы и верно предсказаны пионерами информатики. П. Отле, имя которого большинству, специалистов известно лишь в связи с созданной им в 1905.г. Универсальной десятичной классификацией (УДК), уже в начале нашего века понимал необходимость упорядочения всемирной системы научной коммуникации.
В его докладе на Международном конгрессе по библиографии и документации (Брюссель, 1908) была высказана мысль, содержавшая зерно гипертекстовой технологии: «Средствами организации научной работы является книга и особенно ее нынешняя форма — журнал. Развитие науки шагнуло так далеко, что единственно правильным, соответствующим действительности подходом будет рассматривать все книги, все журнальные статьи, все официальные отчеты как тома, главы, параграфы одной великой книги, универсальной
книги, исполинской энциклопедии, составленной из всего того, что было напечатано...».
Следует, конечно, учитывать, что эта мысль была высказана в начале прошлого века и ориентирована на технические возможности того времени. И хотя по теперешним понятиям они были весьма ограниченными, П. Отле предвидел современные достижения вплоть до систем теледоступа к банкам данных. В 934 г. в «Трактате о документации» он писал: «Любой человек сможет прочесть издалека спроецированный на его персональный экран отрывок, расширенный или суженный до объема необходимого предмета. Тем самым, сидя в своем кресле, каждый сможет созерцать весь мир или отдельные его части.»
Статья другого видного предтечи информатики В. Буша (1890-1974) «Возможный способ нашего мышления», опубликованная в 1945 г., получила всемирную известность в свое время и до сих пор считается наиболее значимым прогнозом развития информатики. На нее ссылаются и почти все пишущие о гипертексте, так как в ней впервые было ясно показано, что неизбежная специализация научных интересов и ассоциативный характер мышления ученых приходят во все большее противоречие с традиционной информационной технологией. Человеческий мозг, по мнению В. Буша, работает совсем не так, как традиционные информационно-поисковые системы, — он мыслит ассоциативно. Получив информацию, ученый моментально испытывает потребность в другой информации, причем эта потребность возникает по ассоциации мысли, в соответствии с сетью связей между клетками мозга. Желая имитировать этот мыслительный процесс техническими средствами, В. Буш предложил создать «расширитель памяти» — Метех, который хотя и не был построен, послужил прототипом микрофильмовых селекторов и других поисковых устройств. В начале 60-х годов эти идеи были использованы Д. Энгельбартом и Т. Нельсоном, которые независимо друг от друга работали над созданием автоматизированных систем информационного поиска.
Как известно Т. Нельсон является создателем термина «гипертекст», впервые приведенного им в докладе на конференции, а затем в статье 1967 г. он привел этот термин в следующем контексте: «Современные информационно-поисковые системы как документального, так и фактографического типа не всегда могут удовлетворить запросы специалистов. Применение совершенных методов хранения и отображения текста в цифровой форме обеспечивает потенциальную возможность построения массива информации по крайней мере одного нового мощного вида: гипертекста или нелинейного текста. Ему будут, свойственны отличительные черты книги и фильма. Гипертекст может, отличаться от обычного текста порядком следования материала (его элементы могут размещаться в виде иерархического дерева или сети, он может иметь несколько уровней краткости изложения и детализации материала), способом его представления (воспроизведение движущихся и преобразуемых иллюстраций) и т. д».
В то время и доклад и основанная на нем статья Т. Нельсона прошли незамеченными иди в лучшем случае были восприняты как очередная компьютерная фантазия. И лишь спустя десятилетия идея гипертекста получила практическое воплощение, а сфера ее применения быстро расширяется. Со времени этих первых работ 60-х годов и до середины 80-х годов идея гипертекста переживала «инкубационный» период, когда многочисленные разработки, развивающие отдельные стороны этой идеи, велись разрозненно в рамках разных научных направлений
Логико-смысловой граф и логика связности
Гипертекст всегда представляет собой некоторую сеть, или граф, отображающие систему связей между смысловыми единицами текста. Свойства гипертекста, его функциональные возможности в значительной степени зависят от структурных характеристик гипертекстовой сети. Она может иметь разную степень сложности, быть иерархической или циклической, члениться на обособленные части, быть «стройной» или «хаотичной». Чем более сложной, запутанной, насыщенной циклами является структура гипертекста, тем труднее его освоение как в функции чтения, так и в функции подготовки текста. Почти все авторы отмечают, что в гипертексте можно «заблудиться», потерять ориентацию, не найти удобных путей чтения и письма.
Можно трактовать семантические графы не как отображения текстов, а как представление знаний о предметных областях. Это явилось промежуточным этапом на пути к смысловым сетям, которые стали служить самостоятельным авторским средством изложения своих знаний представлений о соответствующей предметной области. При формировании смысловых графов автор должен пользоваться определенными критериями и процедурами, чтобы отличать прямую смысловую связь от косвенной.
Смежными по смыслу считались лишь те понятия и утверждения, которые можно объединить при помощи логических связок (типа «есть», «является причиной», «поэтому», «в этих целях» и т.п.). Послё того как был принят этот своеобразный критерий связи, направление стало называться «логико-смысловым моделированием», а логико-смысловые графы вплотную приблизились к гипертекстам. Их можно было читать, вставляя при переходе к смежному узлу соответствующую логическую связку.
Логико-смысловые графы, действительно, можно рассматривать как одну из версий гипертекста. Но введение критерия связи повело и к другим важным следствиям. Стал применяться принцип полноты связей, т.е. связь стала фиксироваться для всех пар высказываний, которые могли быть соединены связкой. Для каждого нового высказывания, вводимого в логико-смысловой граф, нужно было указать все его связи с высказываниями, уже имеющимися в этом графе. Это, конечно, создавало технологические трудности подбора «кандидатов на связь». Но именно принцип полноты связей открыл путь к исследованию структурных характеристик смысловой сети.
Стали значимыми такие характеристики, как число связей высказывания (степень соответствующей вершины графа), показатель центральности (сумма расстояний от данной вершины до всех других), наличие и число путей между какими-либо вершинами. При этом структурные характеристики получают содержательное толкование. Например, число связей высказывания можно рассматривать как признак его относительной значимости в рамках данной системы суждений. Появилась возможность представления предметной области с разной степенью детализации путем построения укрупненных графов, включающих лишь те смысловые единицы, у которых число связей превышает определенный порог. Но и для самого гипертекста здесь таятся интересные возможности: ведь таким способом в его смысловой сети можно автоматически отыскивать предпочтительные пути.
Логико-смысловой граф оказывается адекватным средством для анализа связности, для исследования систем, у которых ценится высокая связность. Так могут интерпретироваться социальные позиции, системы взглядов, научные концепции, новые идеи, которые должны обладать единством, целостностью. Все элементы такого смыслового образования — принципы, утверждения, аргументы — должны быть хорошо связаны между собой, а не являться набором разрозненных высказываний. Взаимосвязанность положений концепции обычно ощущается непосредственно, интуитивно. Однако довольно часто возникает необходимость представить эти связи эксплицитно, особенно если концепция претендует на практическое воплощение и затрагивает интересы многих людей. Описываемый метод позволяет установить, насколько тесно конечные выводы связаны с тем материалом, на который они опираются.
Гипертекст как развитие функций чтения и письма
Известны, гипертекстовые системы, в которых на первый план выступает функция чтения. Таковы например, учебные и справочные системы, в которых читатель сам выбирает, как ему двигаться при освоении, материала в сети связанных по смыслу, текстовых фрагментов, причем система подсказывает ему возможные варианты такого движения. В других случаях в качестве основной выступает функция, письма, авторской работы по составлению текста. Здесь многовариантное представление фрагментов текста в виде. сети возможных переходов используется дня нахождения хорошей последовательности изложения. В соответствии с этим в применении гипертекстовых систем сложилось, несколько основных направлений. Одно из них «электронная книга» — обеспечивает освоение материала с большим количеством ссылок и смысловых пересечений. В качестве объектов могут выступать справочные и учебные материалы, проектная и программная документация. Каждый предъявляемый пользователю текстовой фрагмент снабжается указанием всех его ссылок и возможных смысловых; переходов к другим фрагментам. Другое направление применения гипертекстовых систем — компоновка крупных текстовых материалов из фрагментов, которые первоначально представлены в форме сети с указанием их взаимных смысловых связей. Третье направление — представление в форме единого гипертекста идей, аргументов и предложений, вносимых участниками коллективной работы, рассмотрение и анализ взаимосвязи этих идей и аргументов.
Коммерческие гипертекстовые системы выпускаются с 1987 г. Наибольшую известность получили американские системы Guide, Hypercard и французская — Hyperdoc. Первая из них принадлежит американо-шотландской фирме Owl Technologies и привлекает своей простотой. Фактически Guide является развитой системой обработки текста с оригинальной концепцией «кнопки». Любое слово или словосочетание в тексте может быть определено как «кнопка». В этом случае постановка над ним курсора активизирует определенное действие: замену слова другим, вызов комментариев, установление связей слова с другими текстами, формирование на экране окон.
Система Hypercard фирмы Apple для персональных компьютеров Macintosh представляет собой своеобразную электронную картотеку. Карточки могут содержать не только текст, но и изображения. Определенные места карточки являются «кнопками», нажатие на которые вызывает новые карточки, которые тоже имеют «кнопки». Это позволяет охватывать любое число карточек, связанных между собой иерархически, тематически, ассоциативно. Массивы могут обрабатываться независимыми программами, написанными на специальном языке Hypertalk. Это позволяет сделать изображения движущимися, проводить сложные виды поиска, генерировать музыкальное сопровождение, создать систему обработки текста и изображений. Можно считать, что эта система явилась полной реализацией Мелелса, предложенного В. Бушем.
Еще одной коммерческой системой является Hyperdoc, созданная французской фирмой GECl. Основное ее достоинство — независимость от характера данных и от аппаратных средств. Hyperdoc оперирует с текстами, чертежами, диаграммами, логическими схемами, реализуется на компьютерах IBM РС, Macintosh, Atari, Чах. Информационные массивы хранятся на оптических дисках. Любая зона экрана может быть ассоциирована с любой группой данных при помощи устройства «мышь». Наряду с межуровневыми связями каждый уровень может иметь свои связи. Hyperdoc легко сопрягается с системами обработки текста, электронной графики, издательскими пакетами, СУБД dBASE-З.
Интересным применением гипертекстовой технологии является представление в форме гипертекста Оксфордского словаря английского языка (322 тыс. статей, 56,3 млн. слов, 2,4 млн. ссылок). Это позволяет просматривать все связи между словами и их толкования с помощью программ, повышает эффективность справочного аппарата. Словарь служит основой установления гипертекстовых связей для других документов. Их тексты смогут связываться отношениями социтирования и тематической близости. Гипертекст будет использоваться и как средство совершенствования и редактирования словаря в рамках систем компьютерной лексикографии.
Отечественные гипертекстовые системы ГИПЕРЛОГ и СЕМПРО
Системы разработаны на основе многолетних исследований М.М. Субботина, о которых говорилось выше. Они реализуют функции и процедуры, позволяющие:
формировать из элементов гипертекстовой базы данных связные, упорядоченные тексты на задаваемые пользователем темы;
контролировать качество формируемого текста, выявлять в нем логические и смысловые разрывы структурировать гипертекстовую базу данных, выявлять в ней комплексы тесно взаимосвязанных идей, понятий, проблем.
Эти функции и процедуры реализуются на основе оригинальных идей так называемой логизированной версии гипертекста. Системы предоставляют пользователю возможность при вводе фрагментов текста в базу данных устанавливать между ними связи (ссылочные, смысловые, логические, ассоциативные и другие), обеспечивают компьютерную поддержку этих связей и перемещение по ним. Таким образом, гипертекст формируется как совокупность взаимосвязанных фрагментов текста. Эти фрагменты могут представлять собой как целые документы, так и отдельные высказывания, формулировки идей, проблем, предложений, мероприятий, фактов. Система обеспечивает максимальную открытость гипертекста, возможность его пополнения, изменения структуры и содержания на любом этапе работы. Она не навязывает пользователю готовые схемы и ограничения на структуру представления информации.
Данные системы предназначены для использования в таких областях деятельности, как анализ проблем, изучение прецедентов, прогнозирование социальных явлений, обоснование управленческих решений, подготовка различных документов: обзоров,
аналитических материалов, пояснительных записок, докладов и т.п. В ряду гипертекстовых систем общего назначения, они выделяются тем, что позволяют посредством анализа структурных характеристик гипертекста увидеть в обозримой форме укрупненные комплексы проблем, узловые вопросы и аспекты. При формировании текстовых документов рассматриваемые системы позволяют увидеть в текстах логические пробелы, для устранения которых требуется дополнительная информация. Первая система реализована на основе СУБД Revelation, вторая — на специально разработанной СУБД, которая имеет более дружественный интерфейс и предоставляет большие возможности пользователю. Обе они могут функционировать на IBM- совместимых компьютерах в среде MS-DOS.
Системы гипермедиа как развитие гипертекста
Новые подходы к манипулированию. информацией, хранящейся в ретроспективном фонде, открывают перспективы качественно иного, более эффективного использования постоянно возрастающего объема документальных источников информации. Принципиальной особенностью гипермедиа (их, называют еще «гиперсредствами» или «системами гиперзаписи») является распространение идеи гипертекста, т.е. ассоциативно связанной текстовой информации, на изобразительную и звуковую информацию, хранящуюся в цифровой форме.
Информационные системы, обеспечивающие функционирование гипермедиа, должны иметь особые технические, программные и телекоммуникационные средства. Разумеется, эти средства создают лишь необходимые предпосылки для реализации систем гипермедиа, основу же их функционирования составляют алгоритмы и программы. Можно указать на некоторые из них:
указатель к гиперБД, содержащий аннотированный перечень характеристик всего массива;
карта связей гипер БД, отражающая в графической форме ее структуру и методы доступа к информации;
средства передвижения пользователя в гиперБД, и возможности создания им своих способов манипулирования данными;
средства аудио- и видеоконтроля, обеспечивающие доступ к изобразительной и звуковой информации.
Поскольку гипермедиа не имеют пока точного определения, есть тенденция понимать их слишком широко. В одном из ранних определений говорилось: «Системы гипермедиа относятся к типу систем, базирующихся на использовании наиболее передовых технологий и технических средств и предназначенных для повышения эффективности и интенсификации процессов взаимодействия человека и всей среды, относящейся к знаниям». Данное определение подчеркивает основное функциональное назначение гипермедиа — обеспечивать эффективную коммуникацию между человеком и источниками знания, а также их связь с новыми для нашего времени технологиями, но оно, разумеется, носит слишком общий характер.
Не претендуя на свое определение гипермедиа, хотел бы сказать, что из всех возможных трактовок, предпочтительной является та, которая связывает эти системы с интеллектуальными информационными системами. Верно, что гипермедиа интегрирует цифровую запись текстовой, изобразительной и звуковой информации, но это чисто прикладная особенность данных систем, как и то, что они используют все существущие виды носителей оцифрованной информации. Все же основные функциональные характеристики этих систем связаны с решением принципиального вопроса о формализации представления и структурирования информации и алгоритмизации процессов ее обработки.
Системы гипермедиа, как и гипертекстовые, могут рассматриваться в разных аспектах. Один из подходов, близкий программистам, заключается в том, чтобы сравнить методы доступа к информации в гипертексте с соответствующими методами в СУБД. Эти методы различны: в гипертексте они опираются на ассоциативные связи между понятиями, а в СУБД — на структурные свойства данных. В соответствии с этим гипертекст можно рассматривать как систему ассоциативной организации и поиска информации. Между системами гипертекста и гипермедиа нет четкой границы. Следует иметь в виду, что в последнее время термин «гипермедиа» используется все реже, так как заменяется термином «мультимедиа», который первоначально означал систему совместного использования цифровой и аналоговой записи информации (например, компьютерного текста и видеоизображений). Эти системы представляют собой этапное достижение в развитии информационной технологии, ориентированной в первую очерёдь на обработку знаний. Новые возможности интерактивного доступа человека к неограниченным объемам накопленных знаний, обусловленные широким использованием вычислительной техники и интеграцией различных носителей информации, создают предпосылки для повышения творческой активности человека.
Многие специалисты высоко оценивают перспективы технологий гипертекста и гипермедиа, считая, что эти технологии вышли на уровень стратегических ресурсов компьютерных корпораций.
Системы машинного перевода
В современную эпоху научно-технической революции информатизации общества возросла интенсивность обществе народами и странами. Однако этот процесс в значительной мере тормозится языковыми барьерами. Обучение иностранным языкам и переводческая деятельность в какой-то мере смягчают остроту проблемы, но полностью ее не решают. Более радикальным решением является создание систем автоматического перевода текстов с одних естественных языков на другие. Такие системы создаются во многих развитых странах мира, однако качество автоматического перевода оставляет желать лучшего.
Многие выдающиеся лингвисты вообще ставили под сомнение — и не без основания — возможность адекватного перевода текстов с одного естественного языка на другой, как это ни парадоксально звучит в эпоху интенсивной переводческой деятельности. Для получения на практике адекватного перевода не обходимо использование экстралингвистической информации:4а т.е. такой, которая не содержится в переводимом тексте, но существует в виде накопленного общественного знания. Это и служит основным препятствием для полностью автоматическою (т.е. осуществляемого без участия человека). перевода с одном языка на другой. Поэтому, говоря о машинном переводе, мы подразумеваем лишь частично автоматизируемую деятельность в которой на разных ее этапах участвует человек. Поскольку перевод специальных текстов при помощи компьютера может быть значительно облегчен и ускорен, системы машинного перевода стали полезным инструментом в работе переводчика и важным снижения затрат в этой области.
Человеческий перевод текстов с одних естественных языков на другие — это сложный мыслительный процесс. Он осуществляется на основе восприятия исходного текста и последующей передачи его смысла средствами выходного языка. При этом переводятся не слова и их последовательности, а понятия и мыслительные, образы, порождаемые в сознании переводчика под их воздействием. Системы машинного перевода текстов предназначены для моделирования работы человека-переводчика. Но если моделировать эту работу в полном объеме пока не представляется возможным то нужно, по крайней мере, стремиться при машинном переводе оперировать теми единицами языка и речи, которые позволяют наиболее точно передавать содержание текста, написанного на одном языке, средствами другого языка. Такими единицами являются, прежде всего, фразеологические обороты и терминологические словосочетания и, во вторую очередь, отдельные слова. Поэтому перспективные системы машинного перевода должны опираться на фразеологическое богатство естественных языков. Они должны быть системами фразеологического перевода.
Концепция фразеологического машинного перевода была впервые четко сформулирована профессором Г.Г.Белоноговым в 1975 г. Далее она была развита и в настоящее время реализована в ВИНИТИ в виде двух систем: системы русско-английского перевода (RETRANS) и системы англо-русского перевода (ERTRANS). Если в других системах перевода в качестве основной минимальной единицы смысла, представляемой в машинных словарях, рассматривается слово и их можно охарактеризовать как системы преимущественно пословного семантико-синтаксического перевода, то в системах фразеологического перевода в качестве основной единицы смысла считаются фразеологические словосочетания, выражающие понятия отношения между понятиями и ситуации. Это позволяет точнее передавать смысл переводимых текстов.
Как уже было указано, система RETRANS предназначена для перевода текстов с русского языка на английский. Тематика переводимых текстов включает широкий спектр предметных областей: экономику, коммерческую деятельность, машиностроение, электротехнику, энергетику, транспорт, аэронавтику, космонавтику, биологию, медицину, экологию, сельское хозяйство, математику, физику, химию, автоматику и радиоэлектронику, вычислительную технику, информатику, астрономию, геофизику, геологию, горное дело, металлургию, политику, законодательство и другие дисциплины. Словарь системы содержит около миллиона словарных статей и обеспечивает покрытие политематических текстов на 97-99%..Это самый большой в мире русско- английский машинный словарь. Доля словосочетаний и фразеологических оборотов в словаре — около 80 %.
Система реализована на персональных компьютерах типа IBM РС/АТ. Скорость перевода текстов в автоматическом режиме не менее 10-30 слов/сек. и зависит от быстродействия машины. Предусмотрена возможность работы в интерактивном режиме (с целью повышения качества перевода). Есть также возможность дополнительной настройки системы на конкретного пользователя. Для функционирования системы необходим объем оперативной памяти не менее 600 Кбайт и объем дисковой памяти не менее 20 Мбайт. Система работала под управлением операционной системы MS-DOS 6.0 и выше. Теперь она работает под Windows 2000, встраивается в Word и доступна в Интернете на сайте ВИНИТИ. Система англо-русского перевода (ERTRANS) имеет характеристики, аналогичные системе RETRANS.
Одной из важнейших проблем, стоящих перед переводом, является частое и не всегда сразу заметное изменение значений слов. Словари не всегда успевают отразить эти изменения в научно-технической терминологии. В одном из докладов на международной конференции переводчиков приводились интересные примеры из вычислительной техники. Слово «компьютер» во времена Шекспира обозначало человека, выполняющего арифметические вычисления. В наше время подобное изменение претерпело слово «редактор», которым все больше обозначали. программу обработки текста. Английские же слова и word processor, первоначально употреблявшиеся в значении компьютера для обработки текста, а затем — и соответствующей программы претерпело обратное изменение: теперь они часто применяются к людям и указывают на специалистов, поддерживающих работу этих программ.
С точки зрения пользователя системы машинного перевода могут подразделяться на три основных типа.
Информативные, предназначенные для помощи тем, кому нужен доступ к информации на иностранном языке и кто готов пользоваться «грубым», но достаточно понятным переводом. Такие системы, как правило, имеют словари большого объема, но не опираются на новейшие достижения в лингвистике и программировании.
Профессиональные, которые дают лишь черновые наброски перевода для профессиональных переводчиков и тем освобождают их от черновой работы. Такие системы теперь используются все реже, — как правило, при большом объеме текущей переводческой работы, выполняемой одновременно многими специалистами в одной предметной области. Чаще в этих ситуациях переводчиков снабжают автоматическими словарями; тезаурусами с интерактивным доступом или системами, получившими название «памяти переводчика».
Персональные — для авторов, желающих перевести свой статьи на иностранный, язык, которым они не вполне владеют. Такие системы обычно работают в диалоге с пользователем и могут давать удовлетворительный перевод (качество которого все же зависит от того, насколько автор владеет выходным языком).
По применяемым лингвистическим методам системы машинного перевода можно разделить также на три типа:
Системы прямого перевода — наиболее многочисленные, поскольку начали создаваться еще в 50-60-е годы для фиксированных пар языков. В этих системах словарь и синтаксис входного языка анализируются лишь в той мере, в какой это необходимо для идентификации правильных выражений, выходного языка и порядка слов. В начале своего развития эти системы выдавали пословные переводы и лишь позднее — переводы, основанные на анализе предложений входного языка.
Системы перевода с использованием языка-посредника, служащего для отображения «смысла» входного текста, который преобразуется в семантические и синтаксические представления, общие для нескольких выходных языков. Этот метод применяется обычно при необходимости перевода исходного текста на несколько языков (в переводческих центрах Европейского сообщества, например).
Системы перевода с трансфертом более сложны, нежели предыдущие типы, поскольку языки-посредники применяются дважды — первый раз при переводе с входного языка, второй при переводе на выходной язык. В этом случае становится необходимым дополнительный этап перевода — с языка-посредника входного языка на язык-посредник выходного языка. За этот счет достигается более глубокий лингвистический анализ и синтез.
В последние годы все большее применение в машинном переводе находят методы искусственного интеллекта, которые при переводе учитывают семантику текста, Это означает, что они опираются не столько на грамматические, сколько на семантико-синтаксические категории. Обычные, для лингвистических методов многочисленные неоднозначности и неясности устраняются за счет внеязыковой базы данных. Это означает, что система пытается «понять» текст на входном языке до его перевода. Однако и методы искусственного интеллекта пока не дают всей информации, необходимой для полноценного машинного перевода. В частности, проблемы возникают при переводе с английского языка на японский. «Понимание» английского текста не дает достаточной информации о состоянии пишущего и читающего, необходимой для адекватного перевода на японский язык-
Несмотря на все оговорки, связанные с несовершенством систем машинного перевода, существуют уже сотни достаточно широко используемых систем такого рода.
О понятии информационной технологии
Слово «технология» имеет в русском языке два значения. В соответствии с толковым словарем оно означает совокупность процессов обработки или переработки материалов в определен ной отрасли, а также научное описание способов производства. В каком-то смысле оно противопоставляется слову «техника», которое означает совокупность средств труда и приемов, служащих для создания материальных ценностей а также употребляется собирательно вместо слов «машины», «орудия», «устройства». В английском языке слово и technology означает технические науки и часто употребляется в значении, которое на русский язык должно переводиться словом «техника», хотя обычно калькируется как «технология».
Вот почему термин «информационная технология», пришедший к нам из английского языка, часто трактуется расширитель, но и охватывает не только процессы и методы обработки информации, но и технические средства их осуществления. Это обстоятельство наложило некоторый отпечаток на содержание данной лекции, так как трудно говорить о собственно технологии без учета быстрого развития технических средств. Однако сведения об основной технике — вычислительных машинах и их программировании вынесены в отдельные лекции, чтобы здесь акцентировать внимание на электронных информационных технологиях, их применении и социальных последствиях их внедрения.
Информационные технологии не являются самоцелью: их разработка и внедрение служат основой информатизации общества как один из главных факторов научно-технической революции. Новые и перспективные информационные технологии, в свою очередь, создаются на основе новейших технических средств, высокопроизводительных вычислительных машин, внешних запоминающих устройств сверхбольшой емкости, информационно-вычислительных сетей, электронных средств коммуникации и печати.
Информационная технология нередко включается в более широкое понятие информационной сферы, которая представляет собой совокупность общенациональных отраслевых и региональных информационных структур, в составе которых находятся и библиотеки. Информационные технологии удовлетворяют их потребности не только при помощи технических средств, но и социальных институтов и действующих норм. Хотя термин «технология» и трактуется нами расширительно и охватывает не только и не столько процессы и методы обработки информации, сколько технические средства их осуществления, однако нельзя сводить информационную технологию к технике, только к вычислительным машинам и их периферийным устройствам. Она определяется, в первую очередь, видом перерабатываемой информации, производимым продуктом или предоставляемой услугой, а также информационной структурой, которая использует данную технологию.
Примерами информационных технологий могут служить:
автоматизированное проектирование и производство,
телеобработка данных,
автоматическая обработка текстов и изображений,
поиск информации в базах данных,
системы мониторинга окружающей среды,
системы технической диагностики и контроля,
экспертные, обучающие и роботизированные системы,
гибкие автоматизированные производства,
видеотеке и телетекст, электронная полиграфия,
моделирование сложных научно-технических процессов в реальном масштабе времени и многое другое.
Обо всем этом следовало сказать, чтобы не создалось обманчивое представление о том, что в сфере науки используется весь современный арсенал электронной технологии, вся совокупность ее методов и средств. Пока мы освоили лишь незначительную ее часть, связанную, главным образом, с обработкой информации и ее поиском.
Западные специалисты считают, что можно выделить три стадии усвоения обществом той или иной технологии: улучшение и ускорение привычно выполняемой работы, появление под влиянием технологических изменений новых проблем, задач и целей, ранее не возникавших, изменения в самом обществе, его институтах и образе жизни его членов в связи с технологическими достижениями.
В развитых странах уже не первое десятилетие решается вопрос информатизации общества, что соответствует третьей стадии усвоения электронной информационной технологии.
Традиционная информационная технология тесно связана с процессами письма и чтения, редактирования и издания, которые осуществляются «естественным» интеллектом человека и на протяжении прошлого тысячелетия предполагали использование бумаги. Поэтому процессы автоматического представления и сканирования текста, автоматизированной перёработки информации, осуществляемые при помощи «искусственного» интеллекта в процессоре ЭВМ, часто называют «безбумажными».
Сначала специалисты по обработке данных писали о безбумажных информационных системах, о безбумажной информатике, а затем социологи начали говорить о безбумажном обществе. Концепция безбумажного общества есть не что иное, как представление о воздействии новой информационной технологии на те сферы жизни людей, которые ближе всего соприкасаются с научной или, шире, с семантической информацией.
В нашу специальную литературу термин «безбумажная информатика» вошел как синоним новой информационной технологии вместе с книгой В.М. Глушкова (1923-1981) «Основы безбумажной информатики», вышедшей в 1982 г. Во введении к ней значение электронной технологии обработки информации обосновывалось следующим образом: «Задача накопления, обработки и распространения (обменах информации стояла перед человечеством на всех этапах его развития. В течение долгого времени основными инструментами для ее решения были мозг, язык и слух человека. Поскольку в эпоху книгопечатания основным носителем накапливаемой информации стала бумага, технологию накопления и распространения информации естественно называть бумажной информатикой. Следует подчеркнуть, что революция в информатике, связанная со становлением письменности и книгопечатания, практически не затронула область переработки информации. Положение в корне изменилось с появлением электронных вычислительных машин (ЭВМ). Подобно тому, как изобретение механического двигателя открыло эру комплексной механизации и автоматизации физического труда, изобретение ЭВМ сделало то же самое в отношении труда умственного».