Использование концепции файлов и файловых групп для физического размещения хранимых данных упрощает управление базами данных и дисковой памятью, а также обеспечивает гибкость при размещении конкретных объектов на устройстве или устройствах. Причем в этом случае обеспечивается реальное распределение данных между всеми входящими в группу файлами (отдельными дисковыми устройствами или RAID-массивами): дисковые устройства действительно одновременно, а не поочередно будут заполняться поступающими данными, поскольку данные будут пропорционально «чередоваться» по файлам группы (рис. 10.1).

Для повышения производительности системы в ряде случаев может использоваться индекс — отдельная физическая структура в базе данных, создаваемая на основе таблицы и предназначенная для ускорения выборки данных, поиск которых осуществляется по значению из проиндексированного столбца. Кроме того, индексы используются для обеспечения уникальности строк и столбцов таблиц, упорядочения данных таблицы в отдельном файле или группе файлов для повышения скорости доступа.
Однако наличие индекса замедляет такие операции с таблицей, как вставка, обновление и удаление данных: индексы являются динамически поддерживаемыми структурами, т. е. при вставке, удалении или обновлении данных информация в индексах также должна быть изменена для отражения выполненных в таблице изменений. Для такой обработки требуются дополнительные операции ввода-вывода.
Кластеризованный индекс представляет собой двоичное дерево, в котором на нулевом уровне (уровне листьев) содержатся страницы актуальных данных таблицы, а физическое расположение информации в данном индексе логически упорядочено. Такое размещение данных позволяет сократить время доступа к данным, но только при отборе по этому индексу. В других случаях это приводит к задержкам, так как доступ к данным осуществляется только через индекс и начинается всегда с корня.
Для отдельной таблицы можно построить только один кластеризованный индекс.
В случае не кластеризованный индексов страницы уровня листа содержат не текущие данные таблицы (как в случае кластеризованного индекса), а указатель на строку данных, включающий номер страницы данных и порядковый номер записи на станице.
Не кластеризованный индекс позволяет быстро получить доступ к данным и не требует физического переупорядочения строк данных таблицы. Для каждой таблицы можно создавать до 249 не кластерйзованных индексов.
Система безопасности SQL Server имеет несколько уровней безопасности:
• операционная система;
• SQL Server;
• база данных;
• объект базы данных.
С другой стороны механизм безопасности предполагает существование четырех типов пользователей:
• системный администратор, имеющий неограниченный доступ;
• владелец БД, имеющий полный доступ ко всем объектам БД;
• владелец объектов БД;
• другие пользователи, которые должны получать разрешение на доступ к объектам БД.
Модель безопасности SQL Server включает следующие компоненты:
• тип подключения к SQL Server;
• пользователь базы данных;
• пользователь (guest);
• роли (roles).
10.2.1. Тип подключения к SQL Server
При подключении (и в зависимости от типа подключения) SQL Server поддерживает два режима безопасности:
• режим аутентификации Windows NT;
• смешанный режим аутентификации.
В режиме аутентификации Windows NT используется система безопасности Windows NT и ее механизм учетных записей. Этот режим позволяет SQL Server использовать имя пользователя и пароль, которые определены в Windows, и тем самым обходить процесс подключения к SQL Server. Таким образом, пользователи, имеющие действующую учетную запись Windows, могут подключиться к SQL Server, не сообщая своего имени и пароля. Когда пользователь обращается к СУБД, последняя получает информацию об имени пользователя и пароле из атрибутов системы сетевой безопасности пользователей Windows (которые устанавливаются, когда пользователь подключается к Windows).
В смешанном режиме аутентификации задействованы обе системы аутентификации: Windows и SQL Server. При использовании системы аутентификации SQL Server отдельный пользователь, подключающийся к SQL Server, должен сообщить имя пользователя и пароль, которые будут сравниваться с хранимыми в системной таблице сервера. При использовании системы аутентификации Windows пользователи могут подключиться к SQL Server, не сообщая имя и пароль.
10.2.2. Пользователи базы данных
Понятие пользователь базы данных относится к базе (или базам) данных, к которым может получить доступ отдельный пользователь. После успешного подключения сервер определяет, имеет ли этот пользователь разрешение на работу с базой данных, к которой обращается.
Единственным исключением из этого правила является пользователь guest (гость). Особое имя пользователя guest разрешает любому подключившемуся к SQL Server пользователю получить доступ к этой базе данных. Пользователю с именем guest назначена роль public.
Права доступа
Для управления правами доступа в SQL Server используются следующие команды:
• GRANT. Позволяет выполнять действия с объектом или, для команды — выполнять ее;
• REVOKE. Аннулирует права доступа для объекта или, для команды — не позволяет выполнить ее;
• DENY. Не разрешает выполнять действия с объектом (в то время, как команда REVOKE просто удаляет эти права доступа).
Объектные права доступа позволяют контролировать доступ к объектам в SQL Server, предоставляя и аннулируя права доступа для таблиц, столбцов, представлений и хранимых процедур. Чтобы выполнить по отношению к некоторому объекту некоторое действие, пользователь должен иметь соответствующее право доступа. Например, если пользователь хочет выполнить оператор SELECT * FROM table, то он должен иметь права выполнения оператора SELECT для таблицы table.
Командные нрава доступа определяют тех пользователей, которые могут выполнять административные действия, например, создавать или копировать базу данных. Ниже приведены командные права доступа:
CREATE DATABASE — право создания базы данных;
CREATE DEFAULT — право создания стандартного значения для столбца таблицы;
CREATE PROCEDURE — право создания хранимой процедуры.
CREATE ROLE — право создания правила для столбца таблицы;
CREATE TABLE — право создания таблицы;
CREATE VIEW — право создания представления;
BACKUP DATABASE — право создания резервной копии;
BACKUP TRANSACTION — право создания резервной копии журнала транзакций.
Назначение пользователю некоторой роли позволяет ему выполнять все функции, разрешенные этой ролью. По сути роли логически группируют пользователей, имеющих одинаковые права доступа. В SQL Server есть следующие типы ролей:
• роли уровня сервера;
• роли уровня базы данных.
Роли уровня сервера
С помощью этих ролей предоставляются различные степени доступа к операциям и задачам сервера. Роли уровня сервера заранее определены и действуют в пределах сервера. Они не зависят от конкретных баз данных, и их нельзя модифицировать.
В SQL Server существуют следующие типы ролей уровня сервера:
Sysadmin — дает право выполнить любое действие в SQL Server;
Serveradmin — дает право изменить параметры SQL Server и завершить его работу;
Setupadmin — дает право инсталлировать систему репликации и управлять выполнением расширенных хранимых процедур;
Securityadmin — дает право контролировать параметры учетных записей для подключения к серверу и предоставлять права доступа к базам данных;
Processadmin — дает право управлять ходом выполнения процессов в SQL Server;
Dbcreator — дает право создавать и модифицировать базы данных;
Diskadmin — дает право управлять файлами баз данных на диске.
Роли уровня базы данных
Роли уровня базы данных позволяют назначить права для работы с конкретной базой данных отдельному пользователю или группе. Роли уровня базы данных можно назначать учетным записям пользователей в режиме аутентификации Windows или SQL Server. Роли могут быть и вложенными, так что учетным записям можно назначить иерархическую группу прав доступа.
В SQL Берег существует три типа ролей:
• заранее определенные роли;
• определяемые пользователем роли;
• неявные роли.
Заранее определенными являются стандартные роли уровня БД. Эти роли имеет каждая база данных SQL Server. Они позволяют легко и просто передавать обязанности.
Заранее определенные роли зависят от конкретной базы данных
и не могут быть изменены. Ниже перечислены стандартные роли уровня базы данных.
Db_ owner — определяет полный доступ ко всем объектам базы данных, может удалять и воссоздавать объекты, а также присваивать объектные права другим пользователям. Охватывает все функции, перечисленные ниже для других стандартных ролей уровня базы данных;
Db_ accessadmin — осуществляет контроль за доступом к базе данных путем добавления или удаления пользователей в режимах аутентификации;
Db_ datareader — определяет полный доступ к выборке данных (с помощью оператора SELECT) из любой Таблицы базы данных. Запрещает выполнение операторов INSERT, DELETE и UPDATE для;: любой таблицы БД;
Db_ datawriter — разрешает выполнять операторы INSERT, DELETE и UPDATE для любой таблицы базы данных. Запрещает выполнение оператора SELECT для любой таблицы базы данных;
Db_ ddladmin — дает возможность создавать, модифицировать и удалять объекты базы данных;
Db_ securityadmin — управляет системой безопасности базы данных, а также назначением объектных и командных разрешений и ролей для базы данных;
Db_ backupoperator — позволяет создавать резервные копии базы данных;
Db_ denydatareader — отказ в разрешении на выполнение оператора SELECT для всех таблиц базы данных. Позволяет пользователям изменять существующие структуры таблиц, но не позволяет создавать или удалять существующие таблицы;
Db_ denydatawriter — отказ в разрешении на выполнение операторов модификации данных (INSERT, DELETE и UPDATE) для любых таблиц базы данных;
public — автоматически назначаемая роль сразу после предоставления права доступа пользователя к БД.
Роли, определяемые пользователем, позволяют группировать пользователей и назначать каждой группе конкретную функцию безопасности.
Существуют два типа ролей уровня базы данных, определяемых пользователем:
• стандартная роль;
• роль уровня приложения.
Стандартная роль предоставляет зависящий от базы данных метод создания определяемых пользователем ролей. Самое распространенное назначение стандартной роли — логически сгруппировать пользователей в соответствии с их правами доступа. Например, в приложениях выделяют несколько типов уровней безопасности, ассоциируемых с тремя категориями пользователей. Опытный пользователь может выполнять в базе данных любые операции; обычный пользователь может модифицировать некоторые типы данных и обновлять данные; неквалифицированному пользователю обычно запрещается модифицировать любые типы данных.
Роль уровня приложения позволяет пользователю выполнять права некоторой роли. Когда пользователь принимает роль уровня приложения, он берет на себя выполнение новой роли и временно отказывается от всех других назначенных ему прав доступа к конкретной базе данных. Роль уровня приложения имеет смысл применять в среде, где пользователи делают запросы и модифицируют данные с помощью клиентского приложения.
10.3. Управление обработкой. Представления, хранимые процедуры, триггеры
Для решения типовых (часто повторяющихся) задач выборки или обновления данных, а также в значительной части для управления доступом к данным (как альтернатива механизму разрешения — запрета) и обеспечения целостности данных целесообразно использовать процедуры. Кроме того, другое преимущество, уже в части администрирования, состоит в том, что не надо специально определять пользователю права доступа к таблицам и представлениям, используемым в процедуре: достаточно определить только разрешение на выполнение процедуры.
Существуют два способа взаимодействия приложения с SQL Server. Можно создать приложение, отправляющее клиентские операторы Т-SQL на сервер, либо создать хранимые процедуры непосредственно на сервере. В первом случае операторы каждый раз рекомпилируются сервером. Второй способ активизирует хранимые процедуры, вызывая их из приложения одним оператором. При первом вызове хранимой процедуры она компилируется и создается план ее выполнения, который сохраняется в памяти. При последующих вызовах SQL Server будет использовать этот план и процедуру повторно не компилирует. Таким образом, когда для решения определенных задач требуется многократно выполнить одну и ту же последовательность операторов SQL, применение хранимой процедуры обеспечивает более высокую производительность.
Для управления обработкой в процедурах можно использовать локальные переменные, которые создаются с помощью оператора DECLARE. Переменная доступна с момента ее объявления и до выхода из процедуры. После выхода из процедуры на переменную ссылаться нельзя. Локальные переменные можно объявлять в пакете, в сценарии, внешней программе, а также в хранимой процедуре. В операторе DECLARE необходимо указать имя переменной и ее тип.
Представления (View) существуют независимо от информации в базе данных, но тесно с ней связаны. Представления используются для фильтрования и предварительной обработки данных.
Представление — это по существу некая виртуальная таблица, содержащая результаты выполнения запроса (оператора SELECT) к одной или нескольким таблицам. Для конечного пользователя представление выглядит как обычная таблица в базе данных, над которой можно выполнять операторы SELECT, INSERT, UPDATE и DELETE. В действительности представление хранится в виде предопределенного оператора SQL.
Типы представлений. Различные типы представлений имеют свои преимущества и недостатки. Выбор того или иного типа представлений полностью зависит от задач приложения. Выделяют следующие типы представлений:
• подмножество полей таблицы — состоит из одного или более полей таблицы и считается самым простым типом представления. Обычно используется для упрощения представления данных и обеспечения безопасности;
• подмножество записей таблицы — включает определенное количество записей таблицы и также применяется для обеспечения безопасности;
• соединение двух и более таблиц — создается соединением нескольких таблиц и используется для упрощения сложных операций соединения;
• агрегирование информации — создается группированием данных и также применяется для упрощения сложных операций.
Представления также позволяют логически объединять данные. Например, если данные хранятся в нескольких таблицах, их затем посредством представления можно объединить в более крупную виртуальную таблицу.
Еще одно преимущество представлений заключается в том, что они могут иметь более низкий уровень безопасности, чем их исходные таблицы. Запрос для представления выполняется согласно уровню безопасности вызывающего его пользователя. Таким образом, представление можно применять для сокрытия данных от определенной группы пользователей.
Представления, как и индексы, можно создавать различными способами: использовать для этого «мастер» или команду Т-SQL, имеющую в общем случае следующий формат.
CREATE VIEW имя_ представления [столбец[…]]
AS SELECT-оператор
Следует отметить, что использование в операторе SELECT предложения WHERE позволяет локализовать доступ пользователя к данным даже на уровне отдельных строк и столбцов.
Хранимая процедура (stored procedure) — это набор операторов Т-SQL, которые SQL SERVER компилирует в единый план выполнения. Этот план сохраняется в кэше процедур при первом выполнении хранимой процедуры, и затем план можно повторно использовать уже без рекомпиляции при каждом вызове. Хранимая процедура аналогична процедурам в языках программирования: она может принимать входные параметры, возвращать данные и коды завершения.
Применение хранимых процедур улучшает производительность, например, при использовании в хранимой процедуре условных операторов (таких как И. и WHILE), поскольку условие будет проверяться непосредственно на сервере и серверу не потребуется возвращать промежуточные результаты проверки условия программам клиентам.
Хранимые процедуры также позволяют централизованно контролировать выполнение задачи, что гарантирует соблюдение бизнес-правил,
Хранимые процедуры, как и представления, можно создавать различными способами: использовать для этого «мастер» или команду Т-SQL, имеющую в общем случае следующий формат
CREATE PROCEDURE имя_ процедуры [(%параметр1 mun_данных] …]]
AS SQL-операторы
Существует два типа хранимых процедур: системные и пользовательские. Первые поддерживается SQL Server и применяются для управления сервером и отображения информации о базах данных и пользователях. Вторые создаются пользователями для выполнения прикладных задач.
Триггер (trigger) — это особый тип хранимой процедуры, которая автоматически выполняется при изменении таблицы с помощью операторов UPDATE, INSERT или DELETE. Как и хранимые процедуры, триггеры содержат операторы Т-SQL, но в отличие от процедур запускаются не индивидуально, а автоматически при выполнении операций изменения данных. Триггеры наряду с ограничениями обеспечивают целостность данных и соблюдение бизнес правил, однако их следует использовать разумно. Например, не, нужно создавать триггер, проверяющий наличие значения первичного ключа в одной таблице, чтобы определить, можно ли вставить значение в соответствующее поле другой таблицы. Однако трудно обойтись без триггеров при выполнении каскадных изменений в дочерних таблицах.
Триггер создается на одной таблице в текущей базе данных, хотя может использовать данные других таблиц и объекты других баз данных. Триггеры нельзя создавать на представлениях, временных и системных таблицах. Таблица, для которой определен Тригrep, называется таблицей триггера.
Существуют три типа триггеров: UPDATE, INSERT и DELETE, каждый из которых инициируется при выполнении одноименной команды. Операции UPDATE, INSERT и DELETE иногда называют событиями изменения данных. Можно создать триггер, который будет срабатывать при возникновении более чем одного события, например, запускаться в ответ на операторы UPDATE или INSERT. Такие комбинированные триггеры называются UPDATE/INSERT. Возможно создание триггеров, срабатывающих при выполнении любого из трех операторов обновления данных (триггер UPDATE/ INSERТ/DELETE).
Триггеры, как и представления, можно создавать различными способами: использовать для этого «мастер» или команду Т-SQL, имеющую в общем случае следующий формат:
CREATE TRIGGER имя_ триггера
ON имя_ таблицы
FOR [INSERT] [,] [UPDATE] [,] [DELETE]
AS SQL-операторы
В программе-триггере нельзя использовать операторы создания, реструктуризации, удаления объектов, реконфигурации и восстановления.
Работа триггеров подчиняется следующим правилам:
• триггеры запускаются только после завершения выполнения вызывающего их оператора. Например, триггер UPDATE не начинает работать, пока не завершится выполнение оператора UPDATE;
• триггер не начинает работать, если при выполнении оператора происходит нарушение какого-либо ограничения таблицы или возникает другая ошибка;
• триггер и вызывающий его оператор образуют транзакцию. В результате вызова из триггера оператора ROLLBACK отменяются изменения, выполненные триггером и оператором. При возникновении серьезной ошибки, например, при отключении пользователя, SQL -Server автоматически выполнит откат всей транзакции;
• триггер запускается один раз для каждого оператора, не зависимо от количества изменяемых оператором записей.
Триггеры возвращают результаты своей работы в приложение, подобно хранимым процедурам. Как правило, пользователь не ожидает вывода после выполнения операторов UPDATE, INSERT и DELETE, вызывающих срабатывание триггеров. Если триггер возвращает данные, приложение должно содержать код, правильно интерпретирующий результаты модификации таблицы и вывод триггера.
Для каждого триггера SQL Server создает две временные таблицы, на которые можно ссылаться в описании триггера. Эти таблицы хранятся в памяти и локальны по отношению к триггеру, то есть триггер имеет доступ только к своей собственной версии таблиц. Временные таблицы применяются для сравнения состояния таблицы до и после внесения изменений.
В MS SQL Server возможно создание нескольких триггеров на таблице для каждого события изменения данных (UPDATE, INSERT или DELETE) и рекурсивный вызов триггера. Например, если для таблицы уже определен триггер UPDATE, то можно определить еще один триггер UPDATE для той же самой таблицы. В этом случае после выполнения соответствующего оператора сработают оба триггера. Кроме того, допускаются вложенные триггеры, которые срабатывают в результате выполнения других триггеров. Они отличаются от рекурсивных тем, что не запускают сами себя.
Репликация базы данных заключается в копировании, или тиражировании, данных из одной таблицы или базы данных в другую.
Офис с сетью региональных отделений — показательный случай для использования системы с репликацией транзакций. Каждый филиал ведет работу со своими счетами, информация о которых содержится в его базе данных. Главный офис является подписчиком на базы данных всех филиалов, что позволяет собирать в нем информацию по всей организации.
Репликация основана на метафоре «издатель — подписчик». издатель (публикующий сервер) предоставляет данные; распространитель содержит тиражируемую базу или служебную информацию для управления репликацией; подписчик — получает и обрабатывает реплицированные данные. Данные передаются от публикующего или рассылающего сервера в направлении каждого из подписчиков. Данные не могут пересылаться подписчику непосредственно от другого подписчика. Если один из подписчиков перестает функционировать, это не должно оказывать никакого влияния на издателя или других подписчиков.
В схеме репликации транзакций для доставки данных от публикующего сервера на каждый из серверов-подписчиков используются три следующих компонента:
• агент синхронизации (Snapshot Agent). Создает файлы данных и структуры, используемые для согласования новых подписчиков с текущим состоянием публикации;
• агент чтения журнала (Log Reader Agent). Считывает из журнала транзакций публикующего сервера подлежащие репликации транзакции и помещает их в базу данных рассылки;
• агент рассылки (Distributation Agent). Пересылает подлежащие репликации транзакции из базы данных рассылки всем подписчикам на публикацию.
Каждая публикация (набор реплицируемых данных — статей, которыми могут быть таблицы, записи, поля или хранимые процедуры) создается для выделения данных, подлежащих репликации в базе данных подписчиков. Агент синхронизации создает файл схемы, предназначенный для создания в базе данных табличных структур реплицируемых данных. Этот агент также создает файлы, содержащие данные из публикуемых статей, и обновляет содержимое базы данных рассылки для фиксации нового задания на согласованною
В журнале транзакций публикующего сервера все транзакции, подлежащие репликации в адрес одного или более подписчиков, помечаются специальным флажком. Агент чтения журнала считывает из журнала все помеченные этим флажком команды INSERT, UPDATE и DELETE. Агент следит за появлением подлежащих репликации транзакций для каждой публикации, существующей в базе данных публикующего сервера. Любая обнаруженная транзакция копируется им в базу данных рассылки. Затем агент чтения журналов адресует рассылаемые данные каждому подписчику на публикацию.
После исходного согласования состояний подписчика и публикующего сервера весь объем данных никогда не пересылается в адрес подписчика. Поддержание актуального состояния базы данных подписчика обеспечивается агентом рассылки. Он пересылает подписчику все команды INSERT, UPDATE и DELETE, введенные пользователями на стороне публикующего сервера. Очень важно четко представлять всю последовательность действий, которые выполняются при передаче подписчику сведений об изменениях, проведенных на стороне публикующего сервера.
При создании публикации разработчик может разрешить подписчику выполнять обновление собственной локальной копии данных. В этом случае все выполненные на стороне такого подписчика изменения будут переданы в обратном направлении на публикующий сервер, а последний разошлет их в адрес всех остальных серверов-подписчиков. Отсутствие конфликтов и гарантия внесения изменений на публикующий сервер обеспечиваются благодаря использованию на сервере-подписчике протокола двухступенчатой фиксации изменений. Если публикующий сервер по какой-либо причине не сможет получить сведения о внесенных изменениях, выполненная на стороне подписчика транзакция будет отменена и восстановится исходное состояние базы данных. В такой схеме непосредственно обновляемых подписчиков используются триггеры, хранимые процедуры, координатор распределенных транзакций, а также средства обнаружения конфликтов и рекурсии.
Триггеры размещаются на стороне подписчика. Это гарантирует, что любая начатая на сервере-подписчике транзакция будет обязательно зафиксирована на публикующем сервере, прежде чем появится возможность зафиксировать ее на сервере-подписчике. Здесь используется протокол с двухступенчатой фиксацией изменений (Two Phase Commit — 2PC). Если транзакцию не удастся зафиксировать на публикующем сервере, она будет отменена и на сервере подписчике, поэтому состояние обеих баз данных останется согласованным.
Хранимые процедуры размещаются на стороне публикующего сервера. Это гарантирует, что любые реплицируемые транзакции будут выполнены только в том случае, если это не приведет к конфликту. Если в результате выполнения транзакции возникает конфликт, на серверах обоих узлов для данной транзакции будет выполнен откат.
Координацию выполнения двухступенчатой фиксации изменений между публикующим сервером и сервером-подписчиком осуществляет Координатор распределенных транзакций (Microsoft Distributed Transaction Coordinator — MS DTC), который вызывает выполнение удаленных хранимых процедур.
10.5. Резервное копирование и восстановление
Архивирование и восстановление базы данных с корректировкой целостности основаны на механизме регистрации изменений, использующем журнал транзакций и контрольные точки.
В журнале транзакций регистрируются все транзакции и все изменения базы данных, произведенные в их рамках. Транзакция не считается завершенной, пока соответствующая запись не будет внесена в журнал.
Журнал может размещаться в нескольких файлах, допускающих автоматический рост. Журнал рассматривается не как таблица, а как отдельный файл в базе данных; запись в журнал ведется блоками любого размера, не зависящего от размера страниц сервера. При обновлении журнала или его архивировании происходит усечение журнала.
Контрольная точка — это операция согласования состояния базы данных в физических файлах с текущим состоянием кэша системного буфера. С целью улучшения производительности сохраняемые в БД данные сначала помещаются в кэш, а потом система перезапишет модифицированные страницы на диск (отложенная запись), причем пользователь не может знать, когда эта запись про изводится.
Контрольная точка выполняется командой CHECKPOINT при завершении работы сервера, а также в соответствии с установленным интервалом контрольных точек и включает выполнение следующих операций:
• запись на диск всех страниц, измененных к началу контроль ной точки;
• запись в журнал транзакций списка незавершенных транзакций;
• запись в журнал транзакций всех измененных страниц;
• регистрация завершения контрольной точки в базе данных (а не в журнале транзакций).
Резервное копирование выполняется для каждой базы индивидуально и может производиться несколькими способами.
Полное резервное копирование обеспечивает архивирование всех данных базы, размещенных как в группах файлов, так и в отдельных файлах. Этот способ наиболее часто используется для архивирования баз данных не очень большого размера. В противном случае надо использовать выборочное копирование или копирование групп файлов.
Выборочное (дифференциальное) резервное копирование обеспечивает архивирование только тех данных базы, которые были изменены с момента последнего архивирования.
Резервное копирование журнала транзакций обеспечивает архивирование и усечение журнала.
В случае резервного копирования файлов и групп файлов их можно копировать вместе или по отдельности. Полностью восстановить базу данных с помощью резервной копии файлов и группы файлов несколько сложнее, чем с помощью обычной резервной копии. Для восстановления таблиц и индексов, которые охватывают несколько групп файлов, нужно, чтобы эти файлы и группы файлов были скопированы вместе с охватывающими их объектами.
Для правильного восстановления базы данных на основе файлов или группы файлов, необходимо использовать резервную копию журнала транзакций.
Резервное копирование и восстановление можно выполнить с помощью Enterprise Manager, «мастера» или Т-SQL. Для размещения архивных копий должно быть создано логическое устройство (которое может быть и отдельным физическим устройством).
Информация о выполнении резервного копирования сохраняется как запись в системной таблице backupfile базы msdb, что позволяет определить, когда и на какое устройство сделана копия.
Процесс восстановления базы данных зависит от типа архива. При восстановлении из дифференциального архива или из архива журнала транзакций необходимо предварительно восстановить БД из последнего полного архива.
Глава 11. Направления развития концепций и систем обработки данных
11.1. Еще раз о проектировании и реализации систем баз данных
Приведем из [7) обзор проблем, связанных с реальностью проектирования и использования систем баз данных.
Прежде всего, необходимо отметить, что многое из классических подходов и методов на практике не используется или используется плохо. В первую очередь это относится к использованию формализованных методов и моделей, если только они не входят в используемую модель данных непосредственно, а должны применяться проектировщиками для получения и верификации высокого качества проектных решений. Например, полная процедура нормализации высоких степеней и минимизации набора отношений не проводится или проводится редко ввиду ее громоздкости и высоких требований к квалификации проектировщика оптимизация размещения БД на устройствах внешней памяти и по сети проводится «на глазок». В последнее время значительно меньше внимания уделяется и инструментальным средствам автоматизации физического проектирования БД, включая математическое и натурное моделирование характеристик, в том числе, распределенных БД.
Это объясняется несколькими, отчасти субъективными, при» чинами:
• громоздкостью методов, используемых в рамках «каскадной» схемы, в условиях практической невозможности обеспечить устойчивость больших интегрированных решений в мире с, постоянно меняющимися требованиями к информационным системам;
• высокими требования к квалификации проектировщиков в области теоретических основ классического проектирования БД;
• относительной легкостью выполнения реорганизации логической и физической структуры БД в современных СУБД, что зачастую становится одной из ловушек для проектировщика.
Существенны и ограничения, свойственные классическим методам. Классические модели и методы ориентировались на организацию хранения и обработки хорошо структурированных данных, чему отвечало понятие «атрибута» как свойства объекта, представляемого атомарным элементом данных. Именно вследствие этого, как отмечалось ранее, документальные БД выделились в особый тип баз данных.
Спустя годы и десятилетия после объявления своих классических моделей и концепций классики в явном виде указали на их oграниченность. Так, в [25] было признано, что «при обсуждении моделирования семантики данных акцент делается на структурные аспекты в ущерб аспектам обработки. Структура без соответствующих операций или подразумеваемых методов подобна анатомии в отсутствие физиологии». А в [26] отмечается, что «...обладание большой корпоративной БД имеет маленькое значение, если конечные пользователи не имеют возможностей легко синтезировать необходимую информацию из этих запасов данных». Проектирование БД (и ИС в целом) по классическим правилам полноты и целостности часто стало признаваться практически бессмысленным. «К 1990 году почти все аспекты стандартной процедуры работы с информационными технологиями быть оспорены, и вычислительные архитектуры вырвались из-под контроля.... Стандарты программирования размывались, а понятие не избыточных, непротиворечивых, высококачественных данных годилось разве что для груды хлама» [16].
Вместе с тем становились значимыми новые причины появления новых требований. Глобальность компьютерных коммуникаций и падение удельной стоимости средств вычислительной техники привели ко многим новым возможностям. Список типов хранимых и обрабатываемых данных расширился до пределов, определяемых самым общим нормативным значением понятия «данное». В базы данных включаются не только неформатированные элементы и полнотекстовые фрагменты: успешно создаются и широко используются мультимедийные, Геоинформационным и другие БД. Более того, новые возможности ИТ привели к увеличению рыночных возможностей и требований потребителей, как следствие — к резкому усилению конкуренции в различных отраслях промышленности и услуг.
Это в свою очередь стимулировало появление технологии бизнес реинжиниринга [27] и строительство киберкорпораций [15]. Эти подходы ориентированы, в первую очередь, на осуществление радикальных изменений в организации основной деятельности предприятий и, в частности, на резкое снижение затрат времени, числа работников и других ресурсов; глобализацию работы с клиентами и партнерами в любой точке мира, в том числе в режиме 24*365; увеличение мобильности персонала — снабжение работника всеми возможностями для самостоятельного получения конечного результата и ориентацией на будущие потребности клиента.
Новые требования к архитектуре корпоративных ИС и, как следствие, новые требования к корпоративным БД должны рассматриваться как интеграция трех составных частей требований бизнес реинжиниринга, человеческого фактора и методов новых ИТ. Реальное объединение этих трех составных частей, каждая из которых приобрела в 90-е гг. качественно новое наполнение, включает следующие требования:
• обеспечение максимальных возможностей для каждого работника, т. е. поддержка выполнения всех бизнес-функций тем самым работником, который и получает конечный результат;
• использование архитектуры и программных средств хранилища данных, средств Оперативной Аналитической Обработки Данных (OLAP), применение средств быстрой разработки приложений (RAD), средств поддержки принятия решений (DSS) на основе хранилища данных, ОЕАР и RAD/Е1S~применение средств DSS на основе анализа БД прецедентов, а также методов логического вывода, нейронных сетей и др.;
• предложение единого интерфейса пользователя для работы с разными компонентами данных и приложений;
• разработка концепции и структуры корпоративной базы данных для новой ИС, реализация структуры БД, предполагающая снятие (существенное уменьшение) ограничений на ее развитие, в том числе при смене функций или функциональных компонентов обработки информации; применение методов компонентного проектирования БД;
• постоянная актуализация понятийной модели деятельности предприятия для учета новых понятий, возникающих при изменении прикладных компонент на функционально сходные и при изменении видов деятельности предприятия, и построение на этой основе новых интерфейсов между компонентами ИС;
• динамическое администрирование фрагментами распределенной корпоративной БД при изменении частоты их использования, при модификации их структуры и при изменении их размещения.
Объединение требований к динамике и разнообразию типов информационных потоков, обрабатываемых в ИС, с учетом роста их объемов и требований к разнообразию методов обработки позволяет дать следующую обобщенную характеристику технологий, определяющих архитектуру БД:
• компонентная технология проектирования и представления предметно-ориентированных баз данных, допускающих работу пользователей через общие интерфейсы;
• расширенная технология Хранилища данных, интегрирующая наследованные форматированные данные, архивные текстовые документы, звуковые и видеоархивы, и включающая средства оперативной аналитической обработки данных, необходимые виды «дружественных» интерфейсов;
• открытость БД для включения в нее и получения из нее информации с использованием принципов и средств глобальной сети Internet;
• использование архитектуры Открытых Систем, расширенной методами и средствами, обеспечивающими открытость компонентного проектирования БД, переносимость, интероперабельности, масштабируемость и др.
Еще раз напомним, что требование интеграции ресурсов появилось в связи с необходимостью комплексирования ресурсов, и в первую очередь систем БД, основанных на разных моделях данных и управляемых разными СУБД. Основной задачей такой интеграции является предоставление пользователям интегрированной системы некоторой глобальной схемы БД, обеспечение метода доступа к данным, в том числе автоматическое преобразование операторов манипулирования данными в операторы, понятные соответствующим локальным СУБД, организация доступа к данным на сетевом уровне.
Среди направлений исследований и разработок последних лет, в той или иной степени ориентированных на решение этих задач, и получивших не только развитие, но также нашедших практическое воплощение и применение, можно выделить следующие:
• объектно-ориентированные базы данных, как развитие парадигмы построения баз данных на основе хорошо формализованных моделей, ориентированные на расширение возможностей использования атрибутивных представлений объектов и процессов предметной области, а также учет поведенческого аспекта;
• ориентированная на интеграцию данных технология Хранилища данных — построение федеративных систем неоднородных БД, объединяющая на логическом или физическом уровне на следованные форматированные данные, архивные текстовые документы, звуковые и видеоархивы, и включающая средства оперативной аналитической обработки данных, необходимые виды «дружественных» интерфейсов;
• интеграция с Internet-технологиями — не только включение в состав СУБД средств и интерфейсов поддержки Internet-доступа, но и создание Internet-протоколов и технологий, ориентированных на задачи информационного (документального) поиска.
11.2. Объектно-ориентированные базы данных
В объектно-ориентированной парадигме модель предметной области — это класс взаимодействующих объектов, каждый из которых представляется набором свойств (статическими характеристиками) и набором методов работы с этим объектом (что и позволяет отразить «поведение» объекта), и обладающих следующими свойствами.
1. Инкапсуляция — объекты наделяются некоторой структурой и обладают определенным набором операций (методов). Внутренняя структура объекта скрыта от пользователя; манипуляция объектом, изменение его состояния возможны лишь посредством его методов. Таким образом, объекты можно рассматривать как самостоятельные сущности.
2. Наследование — возможность создавать из объектов новые объекты, которые унаследуют структуру и поведение своих предшественников, добавляя к ним черты, отражающие их собственную индивидуальность.
3. Полиморфизм — различные объекты могут получать одинаковые сообщения, но реагировать на них по-разному, в соответствии с тем, как реализованы у них методы, реагирующие на сообщения.
В [1] определены следующие свойства, положенные в основу создания объектно-ориентированных баз данных.
1. Сложные объекты строятся из более простых при помощи конструкторов. Простейшими объектами являются такие объекты, как целые числа, символы, и др. Минимальный набор конструкторов, который должна иметь система, — это конструкторы множеств, списков и кортежей.
2. Идентифицируемость объектов. В модели с идентифицируемостью объектов объект существует независимо от его значения. Таким образом, имеется два понятия эквивалентности объектов: два объекта могут быть идентичны (они представляют собой один и тот же объект) или они могут быть равны (имеют одно и тоже значение). Это влечет два следствия: первое — существование совместно используемых (разделяемых) объектов, а второе — изменения объектов.
3. Инкапсуляция. Идея инкапсуляции связана с одной стороны, с потребностью четко различать состояния (время) спецификации и реализации операций, а с другой, для обеспечения модульности, являющейся основой для структурирования сложных приложений, разрабатываемых группой программистов. Интерпретация этого принципа для баз данных состоит в том, что объект инкапсулирует и программу, и данные.
Таким образом, имеется единая модель для данных и операций, причем информация может быть скрыта, т. е. никакие операции, кроме указанных в интерфейсе, не могут выполняться. Инкапсуляция обеспечивает логическую независимость данных»: можно изменить реализацию типа, не меняя каких-либо программ, использующих этот тип.
4. Типы и классы. В объектно-ориентированной системе тип обобщает общие черты множества объектов с одинаковыми характеристиками. Понятие класса отличается от понятия типа. Его спецификация совпадает со спецификацией типа, но является более динамическим понятием. Классы используются не для проверки правильности программы, а скорее для создания и манипулирования объектами. В большинстве систем классами можно манипулировать во время выполнения, т. е. изменять их и передавать как параметры.
5. Иерархии классов или типов. Наследование обладает двумя положительными достоинствами. Во-первых, оно является мощным средством моделирования, поскольку обеспечивает возможность краткого и точного описания предметной области. Во-вторых, эта возможность помогает факторизовать спецификации и реализации, совместно используемые в приложениях.
6. Перекрытие, перегрузка и позднее связывание. Чтобы исключить переписывание программ при введении нового типа и добавлении нового экземпляра существующего типа, система не должна связывать имена операций с программами во время компиляции. Поэтому имена операций должны разрешаться во время выполнения. Эта отложенная трансляция называется поздним связыванием. Отметим, что хотя позднее связывание затрудняет проверку типов (а в некоторых случаях делает ее невозможной), оно не отменяет ее полностью.
7. Вычислительная полнота. С точки зрения языка программирования это свойство является очевидным: оно просто означает, что любую вычислимую функцию можно выразить с помощью языка манипулирования данными системы баз данных. С точки зрения базы данных это является новшеством, так как SQL, например, не является полным языком.
8. Расширяемость. Система базы данных поставляется с набором предопределенных типов, но этот набор должен быть расширяемым: нужны средства для определения новых типов и должны отсутствовать различия в использовании системных и определенных пользователем типов. Способы поддержания системой системных и пользовательских типов могут значительно различаться, но эти различия должны быть невидимыми для приложения и прикладного программиста.
9. Стабильность. Стабильность (persistence) означает возможность обеспечить сохранность данных после завершения выполнения одного процесса для последующего использования в другом процессе.
10. Управление вторичной памятью. Управление вторичной памятью является классической чертой систем управления базами данных. Эта возможность обычно поддерживается с помощью набора механизмов, таких как управление индексами, кластеризация данных, буферизация данных, выбор метода доступа и оптимизация запросов.
11. Параллелизм. Система должна обеспечивать пользователям возможность одновременно работать с базой данных. Следовательно, система должна поддерживать стандартное понятие атомарности последовательности операций и управляемого совместного доступа.
12. Восстановление. В случае аппаратных или программных сбоев система должна восстанавливаться, т. е. возвращаться к некоторому согласованному состоянию данных.
13. Средства обеспечения незапланированных запросов. Система должна позволять обрабатывать запросы, не предусмотренные при проектировании базы данных.
С точки зрения вышеуказанных требований можно отметить следующие ограничения реляционной технологии:
1. Неестественное представление данных со сложной структурой. Реляционная модель данных не допускает «естественного» моделирования данных со сложной структурой, поскольку в ее рамках возможно моделирование лишь с помощью плоских отношений (таблиц). Так как все отношения принадлежат одному уровню, многие значимые связи между данными либо теряются, либо их поддержку приходится осуществлять в рамках конкретной прикладной программы.
2. Затруднительно должным образом смоделировать свойства данных. Чтобы смоделировать структуру сложных данных, пользователь должен иметь возможность определять свои типы данных, не ограничиваясь типами данных, предоставляемыми определенной СУБД.
3. Реляционная модель данных не позволяет определить набор операций, связанных с данными определенного типа, что часто является естественным требованием при моделировании данных со сложной структурой. Операции приходится задавать в конкретном приложении.
4. Реляционная модель не позволяет рассматривать данные послойно, на
различных уровнях абстракции, при необходимости отвлекаясь от ненужных деталей.
5. Усложненный доступ к базе данных. Интерфейс между языком программирования и языком баз данных обычно усложнен, поскольку каждый язык имеет свой набор типов и свою модель вычислений. Организуя обращение к базе данных из прикладной программы, написанной, например, на С++, приходится подвергать данные структурной трансформации при передаче их из/в базу данных.
Модель данных, созданная на этапе концептуального конструирования, не находит непосредственного выражения в структуре базы данных, поскольку модель реализации не предоставляет для этого необходимых средств.
Однако также необходимо привести ряд в той или иной степени важных недостатков, отмеченных, например, в [10].
Большинство современных ООБД не делают существенного шага вперед к полным возможностям обработки запросов по сравнению с реляционными БД; они обладают простыми средствами извлечения постоянных объектов.
Так или иначе, объектное ориентированные БД (ООБД) накладывают некоторые ограничения в части определения постоянных данных. В частности, большинство систем по-разному трактуют постоянные и непостоянные данные поэтому пользователи должны явно объявлять, постоянный объект или нет.
Второй, гораздо более серьезный, показатель незрелости большей части современных ООБД — недостаток средств, к которым привыкли и появления которых ожидают пользователи баз данных, в том числе полный непроцедурный язык запросов, автоматическая оптимизация и обработка запросов, одновременный доступ, авторизация, динамическое изменение схем, обработка вложенных подзапросов, операции над множествами (объединение, пересечение, разность), функции агрегирования.
Большинство современных ООБД предоставляют возможность только добавлять новые классы к базе данных, но не позволяют добавить к классу новый атрибут или метод.
Ведутся жаркие споры о степени однородности таких систем. Являются ли тип и метод объектами? На уровне реализации необходимо решить, будет ли информация о типе храниться как объект, или будет реализована некоторая специализированная система. Это тот же самый вопрос, с которым сталкиваются проектировщики систем реляционных баз данных при принятии решения о том, как следует хранить схему: в виде таблицы или некоторым специальным образом.
Наконец, на уровне интерфейса требуется принять еще одно решение. Типы, объекты и методы могут быть представлены для пользователя как однородные, если даже в семантике языка программирования они предстают как различные по своей природе понятия. И наоборот, они могут быть представлены для пользователя как различные сущности, хотя язык программирования не делает между ними различия. Это решение следует принимать с учетом человеческого фактора.
11.3. Интеграция БД и хранилища данных
Направление появилось в связи с необходимостью комплексирования систем БД, основанных на разных моделях данных и управляемых разными СУБД'~.
При строгой интеграции неоднородных БД локальные системы утрачивают свою автономность. После включения локальной БД в федеративную систему все дальнейшие действия с ней, включая администрирование, должны вестись на глобальном уровне. Однако на практике возможны два следующих способа интеграции.
В первом случае — создание мульти баз, ресурсы объединяются локально (например, в составе конкретной организационной структуры, для решения некоторого класса задач, организации доступа определенного круга пользователей и т. д.), при этом пользователи не теряют автономность и имеют возможность работать со всеми локальными СУБД на одном языке, адресуя запросы одновременно в разные локальные БД. В системах мульти-БД не поддерживается глобальная схема интегрированной БД и применяются специальные способы идентификации объектов и методов для доступа к локальным БД. Чаще всего в таких системах на глобальном уровне допускается только выборка данных, что позволяет достаточно просто сохранить автономность локальных БД. В последнее время для внешнего представления интегрированных и мульти-БД все чаще предлагается использовать объектно-ориентированные модели, но на практике пока чаще встречаются частные решения, ориентированные на конкретные СУБД.
Во втором случае, как правило, интегрировать приходится неоднородные БД, распределенные в вычислительной сети. Это в значительной степени усложняет реализацию. Дополнительно к собственным проблемам интеграции приходится решать все проблемы, присущие распределенным СУБД: управление глобальными транзакциями, сетевую оптимизацию запросов и т. д. В этом случае добиться эффективности решений очень трудно.
11.3.1. Основы технологии интеграции распределенных данных
Одна из главных задач, которую призваны решать системы управления — это интеграция данных из различных источников, в том числе со слабоструктурированными данными. Системы интеграции данных должны обрабатывать запросы, для ответа на которые может потребоваться извлечение и обобщение данных из различных источников. При этом возможны следующие варианты:
• регулярные источники, где представление и организация данных в той или иной степени формализованы, хотя при этом могут использоваться различные модели данных и интерфейсы доступа к ним, или данные источника могут быть неструктурированными (HTML-файлы, текстовые файлы и т. д.);
• источники уникальные, т. е. взаимодействовать с источником можно только через предоставляемый им интерфейс и нет никакой возможности повлиять на его внутренние процессы. Теоретически и практически возможны два подхода к решению задачи интеграции данных — создание хранилищ данных и виртуальных хранилищ (или «витрин данных»). При использовании первого подхода хранилище физически или логически объединяет данные из различных источников, и затем все запросы обрабатываются с использованием этих данных. В этом случае актуальность данных не гарантируется, поскольку никакой синхронизации с источником не происходит, но преимущество заключается в том, что объединение централизованно и, следовательно, время выполнения запроса невелико.
При использовании второго подхода данные хранятся в источниках, а запросы к системе интеграции транслируются в запросы или операции, понятные источнику. Данные, полученные в ответ на эти запросы к источникам, объединяются и предоставляются пользователю. Преимущество виртуальных хранилищ заключается в гарантии того, что пользователь получает только актуальные данные. Но поскольку источники могут значительно отличаться, возникают трудности, связанные с оптимизацией запросов, и необходимы дополнительные расходы на конвертирование данных, что существенно снижает общую производительность системы.
Для построения систем, объединяющих большое количество источников, содержание которых часто изменяется (например, Web-серверы), наиболее предпочтительным является виртуальный подход.
Рассматривая типичную организацию виртуального хранилища, выделим два уровня — логический и физический.
Логический уровень определяется выбором модели данных и языка запросов для этой модели. Выбранная модель используется для представления данных, извлекаемых из всех источников. Таким образом, пользователь системы интеграции получает возможность унифицированного доступа ко всем данным. Важным требованием к модели данных является обеспечение прозрачности доступа к внешним источникам, т. е. пользователь видит внешние данные как локальные и в выбранной им модели, не заботясь об управлении доступом к источнику.
Физический уровень. Ключевым понятием организации виртуального хранилища являются средства преобразования данных. На рис,. 11.1 приведена типичная архитектура, основанная на распространенной концепции посредников.
Основными компонентами, обеспечивающими возможность интегральной обработки распределенных данных, являются «оболочка» и «посредник».
Оболочка используется для хранения информации о внешнем источнике и организации доступа к нему. При получении запроса оболочка обращается к источнику через предоставляемый им интерфейс. Полученные от источника данные конвертируются во внутренний формат данных хранилища (т. е. в модель данных хранилища).
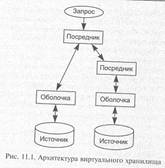
Очевидно, что для каждого источника необходима своя оболочка.
Посредник осуществляет интеграцию данных из различных источников, используя различные оболочки. Посредник может взаимодействовать как с оболочками, так и с другими посредниками. Таким образом, предоставляется возможность построения сложной сети взаимодействующих между собой посредников, что позволит обобщать данные различными способами для удовлетворения нужд различных приложений. Важно отметить, что посредник не содержит данных — интеграция происходит, как правило, за счет использования технологии представлений.
Поскольку при использовании предложенной архитектуры задача построения виртуального хранилища сводится к созданию оболочек и посредников, необходимо иметь средства, позволяющие легко их генерировать. С этой целью разрабатываются специальные декларативные языки, с помощью которых описываются оболочки и посредники. По этим описаниям и происходит их генерация.
11.3.2. Аналитическая обработка данных
Хранилища данных становятся реальной информационной основой для принятия решений и интеллектуального анализа информации в науке и задачах управления. Особенно широко методы аналитической обработки применяются в бизнесе аналитиками и руководителями организационных структур. Инструментальные средства, основанные на использовании хранилищ данных, позволяют пользователям, не имеющим достаточной математической подготовки, решать достаточно сложные задачи обработки данных.
Системы аналитической обработки типа OLTP (Online Analytical Processing) используют многомерное представление (но не хранение!) агрегируемых данных. В этом случае многомерный анализ представляется как одновременный анализ по нескольким «измерениям», каждое из которых — некоторый способ объединения элементов данных БД. Причем каждое измерение может иметь несколько уровней обобщения. Соответственно, система предоставляет средства выбора уровня детализации информации и перемещения по каждому измерению.
Это также заставляет на новой основе ставить вопрос о разработке интегрированной совокупности интерфейсов пользователя: они должны создавать естественные условия для работы с информацией и функциями, причем вне зависимости от того, к какому классу хранимых данных разработчик должен был бы отнести сегодня его (пользователя) информацию.
Задача системы интеграции информации, поддерживаемой средствами Internet, состоит в том, чтобы отвечать на запросы, которые могут потребовать извлечения данных из множества Internet-источников. Многие из проблем, с которыми связаны эти задачи, аналогичны проблемам создания систем неоднородных баз данных, но при этом мы имеем дело с большим и непостоянным множеством Internet-источников, каждый из которых имеет большую степень автономности и характеризуется разными метаданными.
Так же, как и в ранее рассмотренном случае, интеграция может строиться на подходе, основанном на хранилищах данных или на виртуальном подходе. В первом случае данные из множества Internet-источников загружаются в хранилище, и далее все запросы будут обращены к этому хранилищу данных. При этом необходимо, чтобы данные, изменяемые в источниках, обновлялось и в хранилище. Однако преимущество состоит в том, что может быть гарантирована адекватная эффективность на стадии обработки запроса.
При виртуальном подходе, когда данные остаются в Internet-источниках, запросы к системе интеграции на стадии исполнения разделяются на запросы к отдельным источникам, а результаты, соответственно, интегрируются. При таком подходе данные не тиражируются, и тем самым гарантируется их актуальность на стадии обработки запросов. С другой стороны, поскольку Internet-источники автономны, для обеспечения адекватной эффективности необходима более сложная технология обработки запросов. Виртуальный подход более уместен при построении таких систем, где число источников велико, данные изменяются часто, и имеется слабый контроль над Internet-источниками. Нужно, однако, подчеркнуть, что многие проблемы, которые возникают при виртуальном подходе, возникают также и при использовании хранилищ данных (хотя зачастую и в несколько иной форме).
Создание систем для решения любой из указанных выше задач требует, как и в случае классических баз данных, выбора для моделирования предметной области. Однако кроме модели самих информационных объектов, нам необходимо также моделировать сам Internet (как среду доступа), структуру Web-сайтов, внутреннюю структуру Web-страниц или другого типа ресурса.
Важной особенностью моделирования Internet-ресурса является и то, что во многих случаях данные слабо структурированы: нет какой-либо фиксированной схемы, которая была бы задана заранее, а представления данных, поступающих из разных источников, могут различаться уже на уровне набора атрибутов или иметь различные типы.
Другая особенность Internet-ресурса — это связи между объектами. Моделирование множества Web-страниц, а также связи между ними основано на модели помеченных графов. В этой модели узлы представляют Web-страницы (или внутренние компоненты страниц), а дуги — связи между страницами. Метки на дугах могут рассматриваться как имена атрибутов.
Важный аспект языков запросов данных в Web-приложениях это необходимость генерировать сложные структуры в результате обработки запроса. Например, результат некоторого запроса в системе управления Web-сайтом может представлять собой граф, моделирующий этот Web-сайт.
11.5. Еще раз о проблемах и решениях
В заключение считаем целесообразным привести требования и рекомендации [7] к «новым» методам и инструментам проектирования БД, практически подтверждающие, что все новое есть в той или иной степени забытое старое.
Об исключении избыточности в Ванных. Требование однократного ввода данных в БД сохраняется как разумное и прежде всего для защиты от возникновения противоречий (нарушении логической целостности) при актуализации хранимых данных. Однако в условиях глобального информационного пространства и компонентного проектирования контекст этих требований должен быть пересмотрен. Несомненно, в операционных БД рационально планировать «острова» нормализованных и, в классическом смысле, безызбыточных кластеров отношений или объектов. Эти «острова» чаще всего и будут являться давно известными предметными БД.
Кроме того, заранее не регламентированный поток информации из Internet в корпоративную БД потребует разработки или увеличения возможностей «процедур отождествления» экземпляров информационных структур, т. е. выяснения того, что эти экземпляры описывают один и тот же предмет реального мира.
Проблема консервации проблем проектирования. Сам характер дисциплины проектирования, предусмотренный каскадной схемой, методами структурного проектирования, подталкивает проектировщиков фиксировать достаточно жестко определенные модели предметной области. Технология проектирования БД должна быть изменена таким образом, чтобы исключить консервацию существующих проблем предприятий в жестких, «цельных» структурах БД. Для того может потребоваться изменение не только технологии, но и инструментов проектирования.
Компонентная открытость и смысловая интероперабельности. Замена некоторой функциональной компоненты ИС на подобную, но спроектированную другим разработчиком, потребует структурной замены некоторой части корпоративной БД. Такая замена должна поддерживаться как постоянный процесс перепроектирование БД. При замене компоненты БД интерфейсы с ней имеющихся приложений и их пользователей должны получать точно ту же в смысловом отношении информацию, что и ранее.
Реальное компонентное проектирование БД может основываться на формировании и использовании общей для комплексируемых компонент понятийной модели и поддержании соответствий между моделями компонент БД (и связанных с ними приложений) и общей понятийной моделью.
Необходимость использования общих понятийных моделей заставляет заново рассматривать и использование нормативно-справочной информации и систем кодирования. До сих пор часто встречается мнение, что системы классификации и кодирования.
(СКК) — это средство сокращенного представления информации в БД. На самом деле отсутствие СКК или использование некорректно построенных СКК приводит к смысловой несовместимости информации, хранимой в различных БД или даже в одной БД. Таким образом, целесообразно использовать работы по проектированию БД с НСИ и проектирование СКК как начало и основу для создания понятийного пространства предметной области.
Примеры организации данных фактографических и документальных БД
П1. Физическая структура данных в dBase
Dbase-подобная база данных физически может состоять из специализированных файлов следующего назначения:
• основного файла базы данных;
• memo-файла для хранения длинных полей;
• индексного файла.
Структура основного файла базы данных (тип .DBF)
Файл базы данных состоит из записи заголовка и записей с данными. В записи заголовка, начинающейся с нулевой позиции, определяется структура базы данных.
Количество полей определяет число подзаписей полей. В фазе данных для каждого поля существует одна подзапись поля.
Структура заголовка файла данных

Записи с данными следуют за заголовком и включают в себя фактическое содержимое полей. Длина записи (в байтах) определяется суммированием длин полей, указанных в заголовке.
Записи данных (значений полей) в файле начинаются с позиции, указываемой в записи заголовка в байтах 08 — 09. Записи начинаются с байта, содержащего признак удаления. Если в этот байт занесен пробел, то запись не удалялась; если же в первом байте звездочка, то запись удалена. За признаком удаления следуют данные из полей, названия которых находятся в подзаписях полей.
Структура memo-файла (тип .FPT)
Файл типа memo содержит одну запись заголовка файла и произвольное число блоков данных.
В записи заголовка располагается указатель на следующий свободный блок и размер блока в байтах, который устанавливается командой SET BLOCKSIZE (или фиксированная длина 512 байтов для файлов типа .DBT) при создании файла. Запись заголовка начинается с нулевой позиции файла и занимает 512 байтов.
За записью заголовка следуют блоки, в которых содержатся заголовок блока и текст memo. В файл базы данных включены номера блоков, которые используются для ссылки на блоки memo. Расположение блока в niemo-файле определяется умножением номера блока на размер блока (находящийся в записи заголовка). Все memo-блоки начинаются с четных адресов границ блоков.


Структура индексного файла (тип .IDХ)
В индексных файлах располагается одна запись заголовка и одна или больше записей вершин. В записи заголовка находится информация о корневой вершине, текущем размере файла, длине ключа, особенностях индекса и сигнатура, а также представление ключа в коде ASCII, которое можно вывести на печать, и выражения FOR. Запись заголовка начинается с нулевой позиции файла.
Во всех других записях вершин содержатся атрибут, количество существующих ключей и указатели на вершины, располагающиеся слева и справа (на том же уровне) от данной вершины. Помимо этого в них находится группа символов, представляющая значение ключа, и либо указатель на вершину нижнего уровня, либо подлинный номер записи в базе данных. Размер каждой записи равен 512 байтам.



Структура компактного индексного файла (тип .IDX)




П2. Физическая структура данных в MS SQL Server
Файлы операционной системы в MS SQL Server представляются как нумерованные устройства для хранения БД. Каждое устройство разбивается на виртуальные страницы по 8 Кбайт.
MS SQL Server используется следующая иерархия понятий: База данных — некоторый объем файлового физического пространства для размещения данных, принадлежащих одной логической базе.
Файлы БД. Каждая база данных состоит не менее чем из двух файлов. Один из них отводится под журнал транзакций. Отдельный файл данных может принадлежать только одной базе данных.
Экстент. Пространство для хранения объектов выделяется блоками (экстентами) по 8 следующих друг за другом страниц размером 8К. Экстент является единицей выделения пространства. Поэтому при создании БД нужно указывать размер файла с точностью до 64Кбайт.
Страница. Файлы делятся на страницы размером по 8 Кбайт каждая. Логический номер страницы складывается из внутреннего номера базы данных, номера файла и номера страницы в файле. В рамках БД файлы нумеруются, начиная с 1, и так же нумеруются страницы в рамках файла.
Используется два типа экстентов: однородные и смешанные. Однородные экстенты всегда принадлежат только одному объекту. Смешанный экстент может использоваться несколькими объектами;
В SQL Server существуют несколько типов страниц.
Следующие типы страниц относятся к хранению и поиску информации:
• страниц данных;
• индексных страниц;
• текстовых страниц;
• страницы журнала транзакций;
Кроме этого используются также страницы размещения:
• карты распределения блоков (основная и вторичная);
• карты свободного пространства;
• индексные карты размещения.
На странице всегда (в отличие от экстента) хранится однородная информация. Все страницы имеют заголовок, в котором хранится общая информация, используемая ядром СУБД для работы со страницам и:
• номер страницы в формате <номер файла, номер страницы>;
• идентификатор объекта, которому принадлежит страница;
• индекс и уровень внутри индексного дерева, которому принадлежит страница;
• количество строк на странице;
• общий объем свободного пространства на странице;
• указатель на свободное пространство после последней строки на странице;
• минимальная длина строки на странице;
• объем зарезервированного пространства.
После заголовка следует информация о статусе страницы в картах распределения блоков и карте свободного пространства.
SQL Server использует три типа страниц размещения: карты распределения экстентов, карты свободного пространства, индексные карты размещения.
Карты распределения экстентов
Карта распределения экстентов состоит из стандартного заголовка и битового массива в 64 000 битов. Каждый бит характеризует один экстент. Поэтому одна страница карты распределения описывает пространство в 64 000 экстентов или 4 Мбайт данных.
При отведении пространства используются два типа карт распределения экстентов:
• глобальная карта распределения (Global Allocation Map— GAM) хранит информацию об использовании экстентов. Если бит установлен в 0, то экстент занят данными, если в 1 — то экстент свободен;
• вторичная глобальная карта распределения (Secondary Global Allocation Мар — SGAM) хранит информацию о типе экстентов. Если бит установлен в 1, то соответствующий экстент смешанный и минимум одна страница в нем свободна, в остальных случаях бит равен 0.
Карты свободного пространства
Карта свободного пространства (Page Free Space Page — PFS) отражает степень заполнения страниц. Каждая PFS-страница хранит информацию о 8000 страницах — по одному байту на страницу. Каждый байт представляет собой битовую карту, которая сообщает о степени занятости страницы и о том, принадлежит ли она объекту.
Карта распределения размещается с первой страницы файла БД. Страницы повторяются через каждые 8000 страниц.
Первая страница PFS после стандартного заголовка страницы содержит заголовок файла (его описание), затем размещается сам блок PFS. Вторая страница — это GAM, третья — SGAM. Карты распределения экстентов повторяются через каждые 512000 страниц.
Карты размещения
Для организации связи между экстентами и расположенными на них объектами используются индексные карты размещения (Index Allocation Мар — IAM). Каждая таблица или индекс имеют одну или более страниц IAM. В каждом файле, в котором размещаются таблица или индекс, существует минимум одна карта размещения для этой таблицы или индекса. Страницы IAM размещаются произвольно внутри файла и отводятся по мере необходимости. IAM объединены друг с другом в цепочку двунаправленными ссылками. Указатель на первую карту размещения содержится в поле FirstIAM системной таблицы Sysindex.
Каждая IAM описывает некоторый диапазон экстентов и представляет собой битовую карту: если бит установлен в 1, то в данном экстенте есть страницы, принадлежащие данному объекту, если в 0 — то нет.
Все страницы размещения не связаны напрямую с некоторым объектом БД, они соответствуют некоторой системной информации, поэтому параметр «идентификатор объекта» для всех этих страниц одинаков и равен 99.
Страницы данных
Страницы данных используются для хранения собственно данных. Структурно страницу данных можно подразделить на три зоны: заголовок, строки данных и таблицу размещения строк (слоты). Связь между страницами и объектами реализует специальная структура — карты размещения.
Строка данных должна полностью умещаться на странице, поэтому существуют ограничения на длину строки. Размер страницы 8 Кбайт, 96 байт занимает заголовок. Кроме того, в таблице размещения каждому слоту отводится по 4 байта для каждой строки, размещенной на странице.
Строки данных на странице не обязательно хранятся непрерывно. При удалении строки пустое пространство помечается как свободное, и потом его может занять новая строка, перемещения строк не происходит. Адрес (смещение) на странице и длина строки фиксируются в слове (Slot).
Если таблица не имеет кластеризованного индекса, то номер слота является идентификатором строки, пока не будет удалена соответствующая строка. Если же таблица имеет кластеризованный индекс, то слоты располагаются в порядке, задаваемом индексом.
Первые страницы данных таблиц БД расположены не подряд: сразу за первой страницей данных таблицы следует ее индексная карта размещения.
Для более эффективного управления дисковым пространством SQL Server не выделяет создаваемым таблицам сразу целый экстент. Для новой таблицы или индекса, как правило, выделяется место на смешанном экстенте. Когда объем таблицы или индекса увеличивается до восьми страниц, все последующие выделяемые экстенты будут однородными. Соответственно, если на смешанных экстентах места нет, а объем таблицы не достиг еще восьми страниц, то выделяемый новый экстент будет объявлен смешанным. Например, если таблица занимает две страницы на смешанном экстенте и в нее еще добавляется сразу шесть записей, то при отсутствий свободных страниц на смешанных экстентах будет выделен новый смешанный экстент, и на нем разместятся шесть записей. Потом, если добавляется еще одна запись, будет выделен полный новый однородный экстент, и на нем размещена эта новая запись.
Строки данных
Данные хранятся на страницах в виде строк. Каждая строка кроме собственно данных хранит дополнительную форматирующую информацию. Длина строки зависит от типов полей таблицы. Независимо от объявления каждая строка имеет поле с количеством полей переменной длины (к ним относятся также поля фиксированной длины, допускающие неопределенные значения NULL, которые при этом резервируют пространство, указанное в определении поля).
Фиксированные поля вместе с описателями хранятся до полей переменной длины. Поля фиксированной длины всегда занимают свою полную длину, значение NULL задается специальным флагом.
В каждой строке хранится общая длина строки и текущие длины полей переменной длины. Данные считываются последовательно с начального адреса.
Вторая часть — это необязательная область, она существует только тогда, когда в записи имеются поля переменной длины, и включает:
• указатель на местоположение полей переменной длины;
• собственно значения полей переменной длины.
Текстовая страница может содержать несколько текстовых полей. Строка данных содержит указатель на корневую структуру. Собственно данные хранятся в виде сбалансированного В-дерева. Данные длиной менее 64 байт хранятся в корневой структуре. Для данных до 32 Кбайт корневая структура может адресовать 4
блока данных (это не экстенты страниц) до 8 Кбайт каждый. Блоки наращиваются до 8 Кбайт (реально на одной текстовой странице может быть размещено до 8080 байт).
Если же длина текстового поля более 32 Кбайт, то строятся промежуточные узлы.
Кластеризованный индекс представляет собой двоичное дерево, в котором на нулевом уровне (уровне листьев) содержатся страницы актуальных данных таблицы, а физическое расположение информации в данном индексе логически упорядочено.
В случае не кластеризованный индексов страницы уровня листа содержат не актуальные данные таблицы (как в случае кластеризованного индекса), а указатель на строку данных, включающий номер страницы данных и порядковый номер записи на станице. Не кластеризованный индекс не требует физического переупорядочения строк данных таблицы.
Двоичные деревья являются динамически поддерживаемыми структурами, т.е при вставке, удалении или обновлении строк данных информация в индексах также должна быть изменена для отражения выполненных в таблице изменений. Для обработки страниц индексов требуются дополнительные операции ввода-вывода.
Но при разбивке страницы кластеризованного индекса не требуется вносить изменения в информацию не кластерйзованных индексов, так как в SQL Server 7 эти дополнительные операции ввода вывода полностью исключены за счет использования в не кластерйзованных индексах значений ключей кластеризованного индекса вместо номеров физических страниц, в случае когда таблица имеет оба типа индексов.
Индексы таблиц хранятся в виде страниц. Каждая страница размером 8192 байт включает заголовок, имеющий длину 96 байт. Еще один фрагмент страницы используется для размещения других структур данных, например, информации о переполнении строк. Вся оставшаяся часть страницы (8060 байт) предназначена для размещения данных. Каждая строка включает элемент индекса (значение индексируемого поля таблицы) и идентификатор RowID (включающий идентификатор файла, номер страницы, номер строки), указывающий на соответствующую запись в таблице.
Организация и оптимизация доступа к данным
Вследствие объективно существующей разницы в скорости работы процессоров и оперативной памяти с одной стороны, и устройств внешней памяти, с другой — буферизация страниц базы данных в оперативной памяти — единственно реальный способ достижения удовлетворительной эффективности СУБД. Кроме этого используется механизм распределенного хранения информации — расщепления данных между файлами и файловыми группами, физически размещаемыми на разных устройствах или RAID-массивах. Логически такое устройство представляется как единое целое, но на самом деле состоит из нескольких физических дисков. Данные на дисках размещаются блоками одной длины и, таким образом, легко могут быть распределены по всем дискам.
Стратегия буферизации, применяемая в операционных средах, не соответствует целям и задачам СУБД, поэтому для оптимизации обработки данных одной из главных задач СУБД является создание эффективной системы управления процессом буферизации.
Память, управляемая СУБД, состоит из нескольких типов буферов:
• буфера страниц данных, с которыми работает СУБД;
• буфера страниц журнала транзакций, которые отражают процесс выполнения транзакции — последовательности операций над БД, переводящей БД из одного непротиворечивого состояния в другое непротиворечивое состояние;
• системные буферы, которые содержат общую информацию о БД, о пользователях, о физической структуре БД, о базе метаданных.
Если бы запись об изменении базы данных реально немедленно записывалась во внешнюю память, это привело бы к существенному замедлению работы системы. Поэтому записи в журнал тоже буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном наполнении записями.
Но поскольку имеются два вида буферов, содержащих взаимосвязанную информацию, — буфер журнала и буфер страниц оперативной памяти, которые могут выталкиваться во внешнюю память, буферы выделяются не для каждого пользовательского процесса, а для всех процессов сервера. Это позволяет увеличить степень параллелизма при исполнении клиентских процессов.
П3. Документальная информационно-поисковая система
Организация данных и механизмы поиска в базах данных документальных информационных систем построены на тех же принципах, что и фактографические системы. Однако в физической реализации есть и существенные отличия, которые обусловлены в первую очередь информационной природой элементов данных:
1. Запись базы данных — документ, который задается как набор в общем случае необязательных полей, для каждого из которых определены имя и тип. Допустимы большинство стандартных типов (так называемые «форматные» поля, задающие числовые, символьные и другие величины), а также текстовые. Текстовые поля имеют переменную длину и композиционную структуру, не имеющую прямых аналогов среди стандартных типов языков программирования: текстовое поле состоит из параграфов; параграф — из предложений; предложение — из слов. При этом идентифицируемым (адресуемым атомарным) элементом данных с точки зрения хранения будет поле, а с точки зрения поиска (атомарным семантически значимым)— слово. Вследствие этого поисковые структуры строятся в виде инвертированных файлов.
2. Семантическая природа текстовых полей, представляющих смысл в основном на естественном языке, определяет необходимость учитывать важнейшие свойства используемых терминов: синонимию, полисемию, омонимию, контекстную обусловленность смысла отдельного слова и возможность выразить один смысл многими способами. Вследствие этого поисковые индексы могут быть отличны от соответствующих словоформ поля.
На рис. п.1 приведена принципиальная схема организации данных для представления и поиска информации диалоговой системы поиска документов STAIRS (Storage and Information Retrieval System), разработанной фирмой IBM в 70-х гг. Данная структура характерна и для большинства современных ГИПС.
Физическая структура БД рассматриваемой системы включает в себя четыре файла операционной системы:
• файл частотного словаря, устанавливающий соответствие между словом, встречающимся в БД, его кодом и частотой, используется при текстовом поиске;
• инверсный (инвертированный, обратный) список, содержащий для каждого слова БД список документов, его содержащих, используется при текстовом поиске;
• текстовый файл, содержащий собственно документы, используется при выдаче (просмотре) документов;
• прямой, последовательный файл, содержащий «собранные» в одну строку фиксированной длины форматные поля и список двухбайтовых кодов слов, находящихся в тексте данного документа. При необходимости в соответствующих местах находятся разделители сегментов и/или предложений. Файл используется при форматном поиске и при наличии в запросах конструкций SENT, SEGN, СТХ
На рис. п.2 детально представлен словарь слов, в котором содержится перечень слов, встречающихся в документах. Ввиду значительных размеров словаря его организация должна предусматривать наличие специального индекса, представленного матрицей пар знаков. Каждой паре знаков поставлен в соответствие указатель на блок словаря, содержащий группу слов, начинающихся с этих знаков. Знаками могут быть буквы, цифры, а также специальные символы. Второй знак может быть пробелом. Группы слов в словаре имеют переменную длину. Первые два знака слов, содержащихся в словаре, отсутствуют, но они показаны на рисунке, чтобы облегчить понимание структуры файла. Некоторые слова в словаре могут иметь одинаковый смысл; такие слова связаны с помощью специального указателя «синоним» (на рисунке связи данного типа показаны штриховыми стрелками).
Каждому слову поставлен в соответствие указатель на списки экземпляров, являющихся перечнем документов, в которых встречается данное слово. Каждый список экземпляров содержит заголовок, из которого можно узнать число экземпляров слова во всем файле документов, а также число документов, в которых это слово встречается.
Система присваивает каждому документу уникальный номер. Этот номер является внутрисистемным и не связан с номерами, по которым пользователь может получить данный документ где-нибудь вне системы, В списке экземпляров, соответствующем какому-либо слову, содержатся внутрисистемные номера всех документов, в которых оно
встречается. Поисковый критерий может включать

требование поиска всех документов, содержащих одновременно два специфических слова. Например, можно осуществлять поиск документа, в котором содержится как слово ORANGUTANG, так и слово OSTRICH. В этом случае система находит множество документов, содержащих первое слово, а затем множество документов, содержащих второе слово, и путем их пересечения определяет множество документов, содержащих как первое, так и второе слово.
На рис. п.3 показан файл документов, каждому из которых система сама. присваивает внутренний порядковый номер. Документы состоят из параграфов и текстов, причем тексты также пронумерованы. Каждому параграфу присвоен специальный код, определяющий его тип (например, заголовок, автор, аннотация и т. д.).
Внутрисистемный номер документа является ключом к индексу документов. Этот индекс содержит адреса соответствующих документов в памяти. В принципе можно хранить эти адресные указатели непосредственно в списке экземпляров, но это нецелесообразно, так как объем памяти, необходимый для хранения адреса, больше объема памяти, необходимого для хранения номера документа. Индекс документов содержит не только адреса, но также некоторые вспомогательные сведения о документах. К этим сведениям относятся внешний номер документа, признак удаления документа, указывающий, какие параграфы документа (или документ в целом) исключены из файла, а также уровень секретности.
В состав документов могут входить параграфы различных типов, поэтому пользователь может потребовать, чтобы заданное слово содержалось в названии документа, аннотации, введении или каком либо конкретном параграфе. В критерии отбора можно указывать автора, место издания документа и дату издания. Независимо от содержания критерия отбора поиск документа осуществляется на уровне списка экземпляров без необходимости входа в файл документов.
П4. Интегральный банк юридической информации ЮРИУС
С логической точки зрения банк имеет «стандартную» структуру и включает две компоненты: регистрационные карты (PK) и полные тексты.
РК представляют собой форматированные записи, содержащие относительно стандартный набор библиографических данных, а также ссылку на соответствующий полный текст (рис. п.4).
Полные тексты документов состоят из страниц двух типов:
• логических, т. е. структурных единиц текста — пункт, параграф, статья;
• физических — принудительное разбиение длинного неструктурированного текста на фрагменты одинаковой длины.
Кроме этого имеется возможность отнесения документа к тому или иному тому Свода законов (с номерами 1 — 10). Это связано с традицией выпуска Свода законов в форме десятитомного печатного издания.
Физическая структура БД ЮРИУС (рис. п.5.) является примером реализации документальной системы в среде реляционной СУБД.
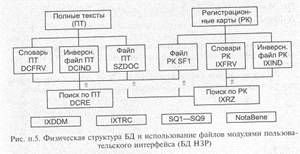
Файл текстовой части БД (SZDOC) — один или несколько файлов, в которых содержатся полные тексты актов. На логическом уровне образует представленную на рис. иерархическую структуру: БД (том), документ, страница.
Словарный файл текстовой части (DCFRV) — представляет собой список слов и стандартных словосочетаний (например, «статья 256», «п. 13», «N 1400-РП»), извлеченных из текста, сопровождаемых частотами появления в данной БД. Практика выделения словосочетаний при индексировании с целью включения их в словарь и инверсный список является достаточно известной.
Инверсный файл текстовой части (DCIND) — список кодов слов и словосочетаний, сопровождаемых номерами страниц. Словарный и инверсный файлы используются для сквозного полнотекстового поиска.
Справочно-поисковые файлы (СПФ) (до девяти различных файлов SF1 — SF9). Стандартным является файл регистрационных карт нормативных актов (РК), запись которого содержит наименование, дату, номер, вид, ссылки на страницы БД и другие поля, перечень которых может изменяться для конкретной БД.
Словарь справочно-поисковых файлов (IXFRV) содержит значения и коды полей (например, РК) совместно с частотой появления и ссылкой на номер файла СПФ.
Инверсный файл СПФ (IXIND) содержит коды слов и словосочетаний. Словарный и инверсный файлы используются для поиска записей СПФ (PK, рубрики указателя и т. д.) с доступом к странице БД.
Файл синонимов (IXTRC) служит для расшифровки кодов или для обеспечения двуязычного поиска в словарных файлах.
Файл описания СПФ (словарь данных IXDDM) — содержит данные о полных, сокращенных и внутренних именах полей каждого СПФ, типах данных, разделителях слов, методах обработки числовых кодов и т. д. Используется при поиске через СПФ и при построении словарных и инверсных файлов.
Файлы хранимых запросов (SQ1 — SQ9) содержат запросы к СПФ БД, отлаженные и сохраненные пользователем.
Файл заметок (NotaBene) позволяет пользователю дополнить СПФ собственными именованными прямыми ссылками на страницы БД.
П5. Технологии индексирования текстовой информации
В рассмотренной выше документальной ГИПС STAIRS используется стратегия свободного индексирования. Каждое (за исключением так называемых стоп-слов, т. е. информационно незначимых слов, перечисленных в специальном словнике) слово загружаемого в базу данных документа может использоваться в качестве индекса — ключа поиска этого документа.
Индексирование по ключевым словам (или атрибутное индексирование) является наиболее простой и экономичной в отношении дискового пространства технологией. Суть ее заключается в том, что для каждого вводимого или сохраняемого документа заполняются соответствующие поля в индексном файле. Заполнение осуществляется как вручную, так и с помощью программы, выделяющей в документе по какому-либо признаку значения ключей/атрибутов. Эта технология позволяет индексировать как текстовые документы (в ручном и автоматическом режимах), так и изображения (в ручном режиме). В простейшем случае ключевыми словами служат название и/или имя автора документа. В более сложных ситуациях необходимо использовать независимого эксперта для чтения документа и выделения ключевых слов.
Серьезные ограничения при использовании этих систем связаны со следующими обстоятельствами:
• определение ключевых слов — достаточно субъективный процесс; даже при участии самого независимого эксперта трудно избежать односторонности при выборе ключевых слов;
• определение ключевых слов — достаточно дорогостоящая процедура (по оценкам AIIM, наиболее авторитетной организации на рынке систем, связанных с управлением документами, это от 5 до 20 долларов за документ) из-за невозможности автоматической индексации и низкой производительности при определении ключевых слов вручную;
• предполагается, что пользователи будут осуществлять поиск информации предсказуемым способом, используя предопределенные ключевые слова;
• поиск по ключевым словам — это четкий поиск, когда пользователь должен точно знать, что он ищет. Если сделана ошибка при написании ключевого слова в запросе для поиска, система; никогда не найдет нужную информацию;
• ключевые слова могут со временем меняться (понятия, которые были ключевыми вчера, вовсе не обязательно будут столь 3 же важны через год).
Поиск информации в таких системах происходит с использованием механизмов полнотекстового поиска, который реализуется с помощью технологии индексирования на основе инвертированных структур: при создании индексного файла в него вносятся все значимые слова (без союзов, предлогов и т. п.) из всех документов в алфавитном порядке. Эти слова затем объединяются в пары с указателями на документы, содержащие эти слова.
Цель индексирования документов — возможность их быстрого поиска. Индекс — это набор слов документа или о документе, по которым этот поиск производится. Основными критериями качества индексирующее поисковых подсистем являются качество поиска (процент нерелевантных документов в списке найденных), размер индекса по отношению к размеру документа и скорость поиска по нему.
Развитие индексирования в документальных системах происходило от ручного заполнения списка ключевых слов в системах первого поколения до автоматического полнотекстового индексирования сегодня, подразумевающего сохранение всех слов текста. Несмотря на большой пройденный путь говорить о полном решении проблемы, наверное, пока рано.
Индексирование документа обычно организуется через автоматическую обработку его текста и заполнение метаданных. Автоматическая обработка — полнотекстовое индексирование — заключается в преобразовании текста документа в набор слов. Причем обычно для слов сохраняется их позиция в документе, что обеспечивает возможность поиска по словосочетаниям. Существуют два принципиально различных метода такого индексирования с учетом применяемых в дальнейшем методов поиска:
• бинарное индексирование — не зависит от языка документа по причине бинарной или словарной индексации;
• морфологическое индексирование — производится с учетом морфологии и семантики языка.
При бинарном индексировании поиск ведется на основе алгоритмов «нечеткого поиска», т. е. поиска с ошибками. В этом случае допускается неполное (с заданным количеством ошибок в начале, середине и конце слова) совпадение слов с шаблоном. При втором методе индексации слова преобразуются в словоформы с отсечением суффиксов и окончаний, что позволяет искать склонения и спряжения шаблонов.
Заметим, что несмотря на несомненные плюсы, полнотекстовое индексирование в любом своем виде имеет и существенный минус: большое количество «мусора» в индексе, т. е. слов, никак не характеризующих документ, а связывающих «ключевые» слова.
Эти недостатки обусловлены самой концепцией такого индексирования — сохранением всего текста за исключением «стоп слов», под которыми подразумеваются предлоги, союзы, местоимения и т. п. Действительно, с одной стороны наличие в индексе всех слов текста гарантирует его нахождение по любому из них, но с другой стороны встает вопрос: «А насколько это корректно?». Предположим, мы имеем текст о компьютерных технологиях, в котором приведена пословица: «За двумя зайцами погонишься, ни одного не поймаешь». При проведении поиска по слову «заяц» система выдаст этот документ, хотя он не будет иметь ни малейшего отношения к фауне. Безусловно, можно найти и сотни менее экзотичных примеров.
Среди других «узких мест» можно назвать следующие.
1. Индекс, создаваемый такими системами, обычно составляет от 200 до 400 % от объема исходного текста, что означает увеличение времени поиска и ресурсов компьютера.
2. Из-за необходимости «очистки» текста стоимость обработки документов достаточно велика.
3. Механизм четкого поиска через инвертированный файл не позволит найти информацию, если были допущены ошибки при загрузке текста или при написании запроса.
В начале 90-х гг. появились технологические разработки, связанные с индексацией и поиском документов и использующие результаты, полученные в области нейронных сетей и искусственного интеллекта. Они позволили сформулировать принципиально новые концепции построения систем управления неструктурированной информацией в электронном виде.
Компания Excalibur Technologies разработала и представила на рынке технологию адаптивного распознавания образов APRP (Adaptive Pattern Recognition Processing), которая была положена в основу программного продукта — систему управления документами Excalibur EFS [81. Технология APRP основана на нейронных сетях, что позволяет не только обойти проблемы ошибок распознавания текстов, но и предоставляет возможности автоматического индексирования и поиска различных типов неструктурированной информации.
Ядро технологии APRP «выросло» из работ основателя компании Excalibur Technologies Джеймса Дау 111, посвященных изучению и разработке моделей нейронных сетей, способных идентифицировать, или, более точно, распознавать присутствие тех или иных образов в составе данных специального вида. Это позволило построить систему индексации общего назначения, которую можно применять к основным видам данных, включая устную речь (голос), сигналы, тексты и изображения. Был также создан комплекс алгоритмов, самостоятельно адаптирующихся к особенностям обрабатываемой информации и позволяющих осуществлять нечеткий поиск — поиск образов, составленных из двоичных символов.
В технологии APRP под нечетким поиском понимается возможность найти достаточно близкое соответствие к запрошенному термину или фразе. Нечеткий поиск устраняет для пользователя необходимость знать правильное написание каждого термина, с которым он работает. Поскольку APRP работает не с ключевыми словами, а с образами, две-три ошибочные буквы в слове или фразе не могут существенно изменить базовую картину текста. Таким образом, автоматически становится исправимой ошибка как во входных данных, так и в терминах запроса. APRP всегда в состоянии найти ближайшее приближение к терминам и фразам, заданным в качестве объектов поиска. Поясним это на примере.
Даже если мы напишем в запросе:
ЦЦЦТЕРМАРГИАСАРИТАЭЭЭЭЭЭ,
имея в виду название романа Михаила Булгакова, мы получим правильный ответ: «Мастер и Маргарита».
Поиск происходит следующим образом:
• запрос конвертируется в бинарную форму;
• игнорируется шум, т. е. отбрасываются ЦЦЦ и ЭЭЭЭЭЭ;
• проводится нечеткий поиск.
Как реально происходит нечеткий поиск? Ранее упоминалось, что технология APRP оперирует информацией на уровне двоичных кодов, т. е. каждое слово для нее — это образ, состоящий из нулей и единиц. Например, слово «пень» для нее представляется двоичным образом 10101111 10100101 10101101 11101100; а слово «печь» имеет двоичный образ 10101111 10100101 11100111 11101100 (каждая буква в слове представляется одним байтом). Сравним двоичные образы обоих слов
ПЕН –
10101111 10100101 10101101 11101100
ПЕЧЬ –
10101111 10100101 11100111 11101100
Из 32 позиций каждого двоичного образа не совпадают только комбинации из шести элементов, что составляет лишь около 20 % от длины двоичного образа. С точки зрения технологии APRP образы этих слов очень близки друг другу, и в качестве результата поиска вам могут быть предложены документы, содержащие оба слова, а вы укажете, которые из них вы имели в виду при поиске. Приведенный пример, однако, не означает, что вам будет предложен бесконечный список вариантов, в той или иной степени похожих на ваш запрос.
Автоматизированная информационно-поисковая система (АИПС) — совокупное название как для программных оболочек, ориентированных на ввод, хранение, поиск и выходное представление документов (структур данных сложного или неопределенного формата), так и для конкретных систем определенного наполнения и предметной ориентации, реализованных на основе таких оболочек (или иными программными методами). Примерами программных оболочек ГИПС являются STAIRS, DPS, ISIS, IRBIS.
Агрегат данных — именованная совокупность элементов данных, представленных простой (векторной) или иерархической (группы или повторяющиеся группы) структурой. Примеры — массивы, записи, комплексные числа и пр.
Администратор базы данных (АБД) — лицо или группа лиц, уполномоченных на ведение БД (модификация структуры и содержания БД, активизация доступа пользователей, выполнение других административных функций, которые затрагивают всех пользователей).®
Адрес данных — идентификация места расположения данных.
Адресация — способ размещения и выборки данных в памяти.
Атрибут — поле данных, содержащее информацию об объекте.
База данных (БД) — именованная совокупность взаимосвязанных данных, отображающая состояние объектов и их отношений в некоторой предметной области, используемых несколькими пользователями и хранящимися с минимальной избыточностью.
Банк данных (БнД) — система специально организованных данных,
программных, языковых, организационных и технических средств, предназначенных для централизованного накопления и коллективного многоцелевого использования данных.
Внешняя схема — представление данных с точки зрения пользователя или прикладной программы.
Внутренняя схема — физическая структура данных.
Документ — агрегат данных в документальных системах (ГИПС), имеющий иерархическую структуру и, кроме форматных полей (элементы или агрегаты данных фиксированной длины), обычно содержащий текстовые поля или символьные последовательности неопределенной длины, логически подразделяющиеся на параграфы (PAR, SEGM), предложения (SENT), слова (WORD).
Запись логическая — идентифицируемая (именованная) совокупность элементов или агрегатов данных, воспринимаемая прикладной программой как единое целое при обмене информацией с внешней памятью. Запись — это упорядоченная в соответствии с характером: взаимосвязей совокупность полей (элементов) данных, размещаемых в памяти в соответствии с их типом.
Запись физическая — совокупность данных, которая может быть считана или записана как единое целое одной командой ввода-вывода.
Иерархическая модель данных — использует представление предметной области БД в форме иерархического дерева, узлы которого связаны по вертикали отношением «предок — потомок». Навигация в БД представляет собой перемещение по вертикали и горизонтали в данной структуре. Одной из наиболее популярных иерархических СУБД была Information Management System (IMS) компании IВМ, появившаяся в 1968 г. Преимущества IMS и реализованной в ней иерархической модели: (1) Простота модели. Принцип построения IMS легок для понимания. Иерархия базы данных напоминает структуру компании или генеалогическое дерево; (2) Использование отношений «предок — потомок». СУБД IMS позволяла легко представлять отношения «предок— потомок», например: «А является частью В» или «А владеет В»; (3) Быстродействие. В СУБД IMS отношения «предок — потомок» были реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных происходило быстро. Поскольку структура данных в этой СУБД отличалась простотой, IMS могла размещать записи предков и потомков на диске друг рядом с другом, что позволяло свести к минимуму количество операций записи-чтения.
Импорт (загрузка, download) — утилита (функция, команда) СУБД, служащая для чтения файлов операционной системы, которые содержат данные.из базы данных, представленные в некотором коммуникативном формате.
Инвертированный файл (список) — файл, предназначенный для быстрого произвольного поиска записей по значениям ключей, организованный в виде независимых упорядоченных списков (индексов) ключей — значений определенных
полей записей основного файла.
Индекс — таблица, используемая для определения адреса записи.
Информационная база — данные, отражающие состояние определенной предметной области и используемые информационной системой. Информационная база состоит из двух компонент: 1) коллекций записей собственно данных и 2) описаний этих данных — метаданных. Данные отделены от описаний, но в то же время данные не могут использоваться без обращения к соответствующим описаниям.
Клиент — программа, написанная как пользователем, так и поставщиком СУБД, внешняя или «встроенная» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД и обращающегося для выполнения операций с данными к компонентам СУБД через интерфейс внешнего уровня.
Ключ — значение (элемент данных), используемое для идентификации или определения адреса записи.
Ключ первичный (главный) — ключ, значение которого идентифицирует запись единственным образом.
Ключ вторичный (альтернативный) — ключ, который идентифицирует некоторую группу записей, имеющих определенное общее свойство. Набор данных может иметь несколько вторичных ключей, необходимость введения которых определяется практической необходимостью — оптимизацией процессов нахождения записей по соответствующему ключу.
Ключ сцепленный (составной) — несколько элементов данных, которые в совокупности обеспечивают уникальность идентификации каждой записи набора данных.
Кольцевая структура — списковая структура данных, в которой последний элемент указывает на первый, образуя тем самым кольцо.
Контрольная точка — операция согласования состояния базы данных в физических файлах с текущим состоянием кэша — системного буфера в операциях обновления БД.
Концепция баз данных — информационная технология интегрированного хранения и обработки данных, в основе которой лежит механизм выделения обрабатывающей программе из всех хранимых данных только тех, которые ей необходимы, и в форме, требуемой именно этой программе.
Коммуникативный формат — способ представления данных в файле операционной системы, обеспечивающий безошибочное распознавание единиц информации (записей, агрегатов, полей) при импорте (загрузке) информации файла ОС в базу данных (обычно в одну из таблиц БД). Файлы в коммуникативных форматах (КФ) предназначены для архивного хранения и транспортировки содержимого БД.
Примерами КФ могут служить основные методы, используемые в, системах семейства FoxPro: (1) SDF (системный формат данных), когда каждая строка таблицы БД выводится в виде записи текстового файла, где каждый элемент данных (поле) имеет длину и тип, соответствующие описанию в БД; (2) Метод с разделителями, где каждый элемент данных отделяется от соседнего символом-разделителем (терминатором»). В системах, ориентированных на обработку документов (ГИПС), используются более сложные форматы, например, представленные в стандарте ISO 2709, использующем рекурсивное описание агрегатов и элементов данных.
Логическая структура БД — определение БД на физически независимом уровне.
Логический файл — файл в представлении прикладной задачи, состоящий из логических записей, структура которых может отличаться от структуры физических записей, представляющих информацию в памяти.
Метод доступа— метод (способ) организации обмена данными, обычно между оперативной и внешней памятью; поддерживаемый ОС, например, прямой, последовательный, индексный методы доступа.
Модель базы данных — комплекс средств, позволяющих определить границу между логическим и физическим аспектами управления базой данных (независимость данных); обеспечить конечным пользователям и программистам возможность и средства общего понимания смысла данных (коммуникабельность); определить языковые понятия высокого уровня, обеспечивающие возможность выполнения однотипных операций над большими совокупностями записей (в общем случае разнотипных данных) как единую операцию (обработка множеств).
Модель данных — базовый инструментарий, обеспечивающий на формальном абстрактном уровне конкретные способы представления объектов и связей.
Модель даталогическая — описание, создаваемое по инфологической модели данных и представленное на языке описания данных конкретной СУБД.
Модель инфологическая (концептуальная) — описание предметной области, выполненное с использованием естественного языка, математических выражений, таблиц, графов и других средств, понятных всем людям, работающим над проектированием базы данных.
Модель физическая — определяющая размещение и способы поиска данных на внешних запоминающих устройствах СУБД.
Моделирования парадигма — условности, определяющие способ представления взаимосвязи объектов на уровне структур данных. С этой точки зрения различаются реляционные, сетевые, иерархические, объектные, объектно-реляционные, документальные и другие виды моделей.
Независимость данных логическая (физическая) — свойство системы,
обеспечивающее возможность изменять логическую (физическую) структуры данных без изменения физической (логической).
Нормализация — представление сложных структур данных (документов) в виде двухмерных таблиц (отношений).
Отношение (relation) — агрегат данных, хранящийся в одной из таблиц (в строке таблицы) табличной, реляционной БД, или создаваемый виртуально в процессе выполнения операции над базой данных при выполнении запросов к данным.
Пользователь БД — программа или человек, обращающийся к базе данных с помощью средств управления данными СУБД.
Предметная область (ПрО) — набор объектов, представляющих интерес для актуальных или предполагаемых пользователей, когда реальный мир отображается совокупностью конкретных и абстрактных понятий, между которыми фиксируются определенные связи.
Представление (View) — это средство создания виртуальной таблицы, содержащей результаты выполнения запроса (оператора SELECT) к одной или нескольким таблицам. Для конечного пользователя представление выглядит как обычная таблица в базе данных, над которой можно выполнять операторы SELECT, INSERT, UPDATE и DELETE. Представления используются для фильтрования и предварительной обработки данных.
Проектирование базы данных — упорядоченный формализованный процесс создания системы взаимосвязанных описаний — таких моделей предметной области, которые связывают (фиксируют) хранимые в базе данные с объектами предметной области, описываемые этими данными.
Распределенная база данных — совокупность баз данных, которые обрабатываются и управляются по отдельности, а также могут разделять информацию.
Реляционная алгебра — алгебра (язык), включающая набор операций для, манипулирования отношениями.
Реляционная база данных — база данных, состоящая из отношений. Здесь вся информация, доступная пользователю, организована в виде таблиц, обычно имеющих уникальные имена, состоящих из строк и столбцов, на пересечении которых содержатся значения, данных, а операции над данными сводятся к операциям над этими таблицами. Сервер — программа, реализующая функции СУБД: определение данных, запись — чтение — удаление данных, поддержку схем внешнего — концептуального — внутреннего уровней, диспетчирования и оптимизацию выполнения запросов, защиту данных.
Сетевая модель данных (модель C0DASFL) — предложенная CODASYL. модификация иерархической модели, в которой одна запись могла участвовать в нескольких отношениях «предок — потомок». В сетевой модели такие отношения называются множествами. В 70-е гг. независимые производители программного обеспечения реализовали сетевую модель в таких продуктах, как IDMS компании Cullinet, Total компании Cincom, которые приобрели большую популярность. Сетевые базы данных обладали рядом преимуществ: (1) Гибкость. Множественные отношения «предок — потомок» позволяют сетевой базе данных хранить данные, структура которых сложнее обычной иерархии; (2) Стандартизация. Появление стандарта CODASYL; (3) Быстродействие. Вопреки своей сложности, сетевые базы данных достигали быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных, и в некоторых системах администратор мог задать кластеризацию данных на основе множества отношений. Недостатки — жесткость БД, наборы отношений и структуру записей приходилось задавать наперед. Изменение структуры данных означало перестройку всей базы данных.
Система управления базами данных (СУБД) — совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Словарь данных — исчерпывающий набор таблиц или файлов, представляющий собой каталог всех описаний данных (имен, типов). Может содержать также информацию о пользователях, привилегиях и т. д., доступную только администратору базы данных. Является центральным источником информации для СУБД, АБД и всех пользователей.
Структура данных — атрибутивная форма представления свойств и связей предметной области, ориентированная' на выражение описания данных средствами формальных языков и таким образом учитывающая возможности и ограничения конкретных средств, с целью сведения описаний к стандартным типам и регулярным связям. Структура данных с точки зрения программирования — это способ отображения значений в памяти — размер области и порядок ее выделения (который и определит характер процедуры адресации— выборки).
Структура данных линейная — порядок следования элементов данных, который имеет линейный характер и соответствует порядку расположения элементов в памяти.
Структура записей данных — целесообразная (учитывающая особенности физической среды) реализация способов хранения данных и организации доступа к ним как на уровне отдельных записей, так и их элементов.
Структура информации — схематичная форма представления сложных
композиционных объектов и связей реальной предметной области, выделяемых как актуально необходимые для решения прикладных задач.
Таблица — основная единица информации в системе управления реляционной базой данных. Состоит из одной или более единиц информации (строк), каждая из которых содержит значения некоторого вида (столбцы).
Тип данных — характер данных, определяющий способ представления значения в памяти, и соответственно множество стандартных операций (примитивов) преобразования этого значения.
Топология БД — схема распределения компонент базы данных по физическим носителям, в том числе различным узлам вычислительной.
Точка сохранения — момент времени, когда в БД записывается вся работа в транзакции. В транзакции могут применяться ряд точек сохранения, выступающих в роли промежуточных точек для работы.
Транзакция — последовательность операций над данными базы, переводящая БД из одного непротиворечивого состояния в другое, которое может быть представлено как одно «событие».
Триггер (trigger) — Особый тип хранимой процедуры, которая автоматически выполняется при изменении таблицы с помощью операторов UPDATE, INSERT или DELETE.
Уровни представления данных — концептуальный, внутренний и внешний. Внутренний уровень — глобальное представление БД, определяет необходимые условия в первую очередь для организации хранения данных на внешних запоминающих устройствах. Представление на концептуальном уровне представляет собой обобщенный взгляд на данные с позиций предметной области. Внешний уровень представляет потребности пользователей и прикладных программ.
Утилиты СУБД — программа, которая запускается в работу командой операционной системы главного компьютера и выполняет какую-то функцию над базой данных (обычно на физическом уровне: данных), либо команда (функция ядра СУБД, доступная только АБД), реализующая аналогичную операцию.
Файл — именуемая единица информации, поддерживаемая операционной системой. Доступ к данным реализуется либо в рамках ОС, либо пользовательскими программами, либо в рамках СУБД, либо комбинированно. Обычно ОС может предоставить пользовательским программам не более двух типов файлов: (1) запись ориентированные, когда при обращении к файлу из пользовательской программы считывается или выводится в файл запись (агрегат или элемент данных — логическая единица информации), и (2) поток ориентированные, когда пользовательской программе предоставляется для записи или чтения физический элемент файла (очередной бит или байт данных).
Файл ASCII (ASCII-File) — файл, содержащий символьную информацию, представленную только ASCII-кодами «левой части» (первые 128 символов кодовой таблицы, или код Latin-1) и символьную разметку.
Файл базы данных — физический файл ОС, используемый для размещения БД. Управление данными в таком файле производится совместно ОС и СУБД. Крайние варианты размещения БД по файлам:
(1) все данные БД — в одном файле (файл РАТА, СУБД ADABAS);
(2) каждая таблица БД — в отдельном файле ОС (DBF-файлы, системы FoxPro). Промежуточный вариант размещения, например— ORACLE — база данных состоит из одного или более табличных пространств, которые в свою очередь состоят из одного или более файлов базы данных.
Файл бинарный (Binary File) — файл, содержащий произвольную двоичную информацию (текст с бинарной разметкой, программа, графика, архивный файл).
Файл графический (Image file) — бинарный файл, содержащий данные, обычно полученные с помощью растрового сканера и соответствующие двухмерному изображению объекта.
Файл текстовый (Text file) — файл, содержащий символьную информацию в одном из соответствующих кодов и коды, управляющие режимом отображения символов на печать и экранные устройства.
Хранимая процедура (stored procedure) — набор операторов SQL, которые сервер компилирует в единый план выполнения. Этот план сохраняется в кэше процедур при первом выполнении хранимой процедуры и затем может быть повторно использован уже без рекомпиляции при каждом вызове.
Цепочка данных — организация данных, в которой записи связываются друг с другом посредством указателей.
Экспорт (выгрузка, upload) — утилита (функция, команда) СУБД, служащая для вывода информации из БД (обычно одной из таблиц) в файл(ы) операционной системы, организованные в некотором, обычно коммуникативном формате.
Элемент данных (элементарное данное) — неделимое именованное данное, характеризующееся типом (например, символьный, числовой, логический и пр.), длиной (в байтах) и обычно рассчитанное на размещение в одном машинном слове соответствующей разрядности. Это минимальная адресуемая (идентифицируемая) часть памяти — единица данных, на которую можно ссылаться при обращении к данным. Ранние языки программирования (Алгол, Фортран) были рассчитаны на обработку элементарных данных или их простейших агрегатов — массивов (матрицы, векторы). С появлением ЯП Кобол появляется возможность представления и обработки агрегатов разнотипных данных (записей). В реляционных БД элементарное данное есть элемент таблицы. Иногда используется термин поле записи в качестве синонима.
Язык манипулирования данными (ЯМД). ЯМД обычно включает в себя средства запросов к базе данных и поддержания базы данных (добавление, удаление, обновление данных, создание и уничтожение БД, изменение определений БД, обеспечение запросов к сп1щвочнику БД).
Язык описания данных (ЯОД) — средство внутрисистемного определения данных, представляющего обобщение внешних взглядов. Описание представляет собой модель данных и их отношений, т. е. структур, из которых образуется БД.
Язык структурированных запросов (ЯЩ) — основной интерфейс пользователя и АБД для сохранения, обновления и поиска информации в базе данных для ряда СУБД. Включает в себя в качестве подмножеств следующие группы операторов: (1) Язык описания данных (ЯОД). Эти операторы определяют или удаляют объекты базы данных; (2) Язык управления данными (ЯУД). Эти операторы управляют доступом к данным и к базе данных; (3) Язык манипулирования данными (ЯМД). Эти операторы позволяют искать и обновлять данные.