7.4.1.8. Раздел INTO. Использование команды SELECT...INTO
При указании этой конструкции результат выполнения запроса будет сохранен в новой таблице. Синтаксис раздела INTO следующий:
INTO <имя_ новой_ таблицы>
Аргумент <имя_ новой_ таблицы> определяет имя таблицы, в которую будут вставлены результаты.
При выполнении запроса SELECT...INTO автоматически создается новая таблица с нужной структурой и в нее заносится полученный набор строк. При этом в базе данных не должно существовать таблицы, имя которой совпадает с именем таблицы, указанной в команде SELECT...INTO, Если необходимо быстро создать таблицу со структурой, позволяющей сохранить результат выполнения запроса, то лучшим выходом будет использование команды SELECT...INTO.
Синтаксис команды SELECT...INTO следующий:
SELECT {<имя_ столбца> [[AS] <псевдоним_ столбца>] [, ..., n] }
INTO <имя_ новой_ таблицы> FROM {<имя исходной таблицы> [,...; n]}
Приведенный вариант синтаксиса далеко не исчерпывает все возможности вставки данных с помощью команды SELECT... INTO. Допускаются практически все варианты синтаксиса запроса SELECT, то есть можно выполнять группировку, сортировку, объединение и т. д.
Рассмотрим назначение аргументов команды.
<имя_ столбца> [[AS] <псевдоним_ столбца>]. Аргумент <имя_ столбца> задает имя столбца таблицы, который будет включен в результат. Указанный столбец должен принадлежать одной из таблиц, перечисленных в списке FROM {<имя_ исходной_ таблицы> [,..., n]]. Если столбцы, принадлежащие разным таблицам, имеют одинаковые имена, то для столбцов необходимо использовать псевдонимы. В противном случае произойдет попытка создать таблицу со столбцами, имеющими одинаковые имена, что приведет к ошибке, и выполнение запроса будет прервано. Указание псевдонимов также обязательно для столбцов, значения в которых формируются на основе вычисления выражений (по умолчанию такие столбцы не имеют никакого имени, что недопустимо для таблицы) и когда пользователь хочет задать столбцам в создаваемой таблице новые имена (отличные от исходных). Имя псевдонима задается с помощью параметра <псевдоним_ колонки>.
INTO <имя_ новой_ таблицы>. Аргумент <имя_ новой_ таблицы> содержит имя создаваемой таблицы. Это имя должно быть уникальным в пределах базы данных.
FROM {<имя_ исходной_ таблицы> [,..., n]}. В простейшем случае конструкция FROM содержит список исходных таблиц. В более сложных запросах с помощью этой конструкции определяются условия связывания двух и более таблиц.
С помощью команды SELECT...INTO, например, можно разделить таблицу «Студенты» на две, выделив в отдельную таблицу «Контакты» адреса и телефоны, а затем удалив эти столбцы из таблицы «Студенты»:
SELECT ID_ Студент, Адрес, Телефон
INTO Контакты
FROM Студенты
Будет создана новая таблица, показанная на рис. 7.32.

Запрос для таблицы «Контакты»:
SELECT *
FROM Контакты
WHERE Телефон LIKE 120%
выдает результат, показанный на рис. 7.33.
Построим внешний ключ для таблицы «Контакты», обеспечив связь с таблицей «Студенты»:
ALTER TABLE Контакты
ADD CONSTRAINT FK_ Контакт
FOREIGN KEY (ID_ Студент)
REFERENCES Студенты
Модифицируем запрос для таблицы «Контакты» (результат ® на рис. 7.34):
SELECT *
FROM Студенты INNER JOIN
Контакты. ON
Студенты. ID_ Студент = контакты. ID_Студент
WHERE Телефон LIKE.'120%'


7.4.2. Добавление данных — команда INSERT.
Рассмотрим некоторые возможности заполнения таблиц. Данные в таблицу могут быть внесены различными способами:
• с помощью команды INSERT. Используя команду INSERT, можно добавить как одну строку, так и, множество строк;
• с помощью команды SELECT INTO. В; этом случае на основе результата выборки, возвращаемого запросом, автоматически создается новая таблица (аппарат использования команды рассмотрен выше).
Рассмотрим процесс внесения данных в таблицу с помощью команды INSERT. Как уже было сказано, эта команда может быть использована для вставки как одной, так и множества строк.
Вставка одной строки
В простейшем случае вставка данных с помощью команды INSERT предполагает использование конструкции INSERT VALUES:
INSERT [INTO] <имя_ таблицы> [(<список_ колонок>)]
VALUES (<список_ значений>)
С помощью этой команды можно добавить только одну строку. Аргумент <имя_ таблицы> идентифицирует имя таблицы, в которую необходимо вставить строку данных. Необязательный параметр <список_ столбцов> задает имена столбцов, в которые будет производиться добавление данных.
Рассмотрим процесс добавления данных в таблицу «Сводная_ ведомость». Каждая строка этой таблицы содержит результат сдачи экзамена (зачета) по отдельной дисциплине отдельным студентом. Если студент, ID_ Студент которого равен 10, сдал экзамен по дисциплине со значением 3 в столбце ID_ Дисциплина. на оценку «пять», то команда добавления этих данных в таблицу «Сводная_ ведомостью выглядит следующим образом:
INSERT Сводная_ ведомость
VALUES (10, 3, 5)
Для назначения произвольного порядка и состава столбцов в этом случае можно использовать следующую, команду:
INSERT INTO Сводная_ ведомость
(ID_ дисциплина, ID_ Студент)
VALUES (3, 10)
Если для столбца Оценка определено значение по умолчанию или разрешено хранение значений NULL, то значение для этого столбца можно вообще не указывать.
Мы рассматривали вставку строк в таблицу, значения для которых были заданы с помощью констант. Однако вставляемые значения можно идентифицировать и с помощью переменных, функций, а также любых сложных выражений. Единственным требованием является совпадение типов данных столбца и значения, возвращаемого выражением.
Вставка результата запроса
Приведем упрощенный синтаксис команды INSERT:
INSERT [ INTO]
<имя_ таблицы>
{ [ (<список_ колонок>) ]
{VALUES
( { DEFAULT /NULL / <выражение> } [, ..., n] )
<результирующая_ таблица>
}
}
DEFAULT VALUES
Рассмотрим назначение каждого из аргументов.
INTO — дополнительное ключевое слово, которое может быть использовано между словом INSERT и именем таблицы для обозначения того, что следующий параметр является именем таблицы, в которую будут вставлены данные;
<имя_ таблицы> — имя таблицы, в которую необходимо вставить данные;
<список_ столбцов> — содержит список столбцов, в которые будет производиться вставка данных. Если он опущен, то данные будут вставляться последовательно во все столбцы, начиная с первого. Значения для столбцов указываются после ключевого слова VALUES. Для каждого столбца должно быть задано выражение, имеющее соответствующий тип данных. Если список столбцов не указан, то количество значений VALUES должно соответствовать количеству столбцов таблицы. Если же список столбцов явно задан, то это определяет порядок значений VALUES (и, соответственно, их типы). Можно не указывать явно значения для столбцов, если для них определено значение по умолчанию или разрешено хранение значений NULL.
VALUES ( ( DEFAULT / NULL / <выражение> ) [,..., п]) — определяет набор данных, которые будут вставлены в таблицу. Количество аргументов VALUES определяется количеством столбцов в таблице или количеством столбцов в списке (если таковой имеется). Для каждого столбца таблицы можно указать один из трех возможных вариантов:
DEFAULT — будет вставлено значение по умолчанию, определенное для столбца. Если для столбца разрешено хранение значений NULL, а значение по умолчанию не определено, то в столбец будет вставлено значение NULL .
NULL — в столбец будет вставлено значение NULL. Естественно, вставка таких значений будет успешной, если для столбца была разрешена возможность хранения значений NULL. Следует помнить, что для столбцов, входящих в первичный ключ, возможность хранения значений NULL не предусмотрена.
<выражение> — задает значение, которое будет вставлено в столбец таблицы. Этот параметр должен иметь тот же тип данных, что и столбец, а также удовлетворять ограничениям целостности, определенным для соответствующего столбца.
<результирующая_ таблица> — этот параметр подразумевает указание запроса SELECT, с помощью которого будет формироваться набор данных, вставляемых в таблицу. Количество столбцов, порядок их перечисления и их типы данных должны соответствовать столбцам, указанным в списке <список_ столбцов>. Если последний отсутствует, то запрос должен возвращать значения для всех столбцов таблицы.
DEFAULT VALUES — при указании этого параметра строка будет содержать только значения по умолчанию. Если для столбца не установлено значение по умолчанию, но разрешено хранение значений NULL, то в столбец будет вставлено значение NULL. Если же для столбца не разрешено хранение значений NULL, нет значения по умолчанию и в команде INSERT не указано значение для вставки, то будет выдано сообщение об ошибке и выполнение команды прервется.
Более сложный случай вставки данных предполагает использование конструкции INSERT INTO...SELECT:
INSERT INTO <имя_ таблицы> SELECT' <выражение_ запроса>
Аргумент <имя таблицы> содержит имя таблицы, в которую будут вставляться выбранные данные. Таблица должна иметь соответствующую структуру и быть предварительно создана.
<Выражение_ запроса> определяет тело запроса SELECT, с помощью которого производится выборка данных из одной или нескольких таблиц. Например, для выборки данных из таблицы «Студенты» обо всех студентах, поступивших в ВУЗ в 2000 г., и сохранения их в таблице «Студент 2000» можно использовать такую последовательность инструкций:
CREATE TABLE Студент_ 2000
(ID _Студент_ 2000 INTEGER NOT NULL,
Фамилия CHAR (30) NOT NUL
Имя СНАR (15) NOT NULL,
Отчество CHAR (20) NOT NULL
Адрес CHAR (30)
Телефон CHAR (8),
PRIMARY KEY (ID_ Студент_ 2000))
INSERT INTO Студент_ 2000
SELECT ID_ Студент Фамилия, Имя, отчество, Адрес, Телефон
FROM Студенты
WHERE Год_ поступления = 2000
После выполнения этой последовательности команд инициируем запрос на отбор строк из новой таблицы:
SELECT TOP 5 Фамилия, Имя, Отчество
FROM Студент_ 2000
Будет выдан результат, показанный на рис. 7.35.

Приведенный пример иллюстрирует вставку строк данных в таблицу на основе результата выполнения запроса, обращающегося к одной таблице. Более сложные запросы могут обращаться к множеству таблиц одной или нескольких баз данных.
В качестве еще одного примера рассмотрим помещение в новую таблицу «Преподаватель-дисциплина» информации о том, какой преподаватель какую дисциплину ведет.
Для этого мы будем работать с тремя таблицами: «Кадровый_ состав», «Учебный_ план» и «Дисциплины». В первой таблице содержится список преподавателей, тогда как в третьей — список дисциплин. С помощью таблицы «Учебный план» устанавливается связь «многие ко многим» между таблицами «Кадровый_ состав» и «Дисциплины».
Прежде чем приступать к вставке данных, необходимо создать таблицу, которая будет содержать интересующие нас данные. Помимо столбцов для хранения информации об имени и фамилии преподавателя и названии дисциплины, предусмотрим столбцы для хранения идентификационных номеров преподавателей и дисциплин:
CREATE TABLE Преподаватель_ дисциплина
(ID_ Дисциплина INTEGER НОТ NULL
ID_ Преподаватель INTEGER NOT NULL
Наименование CHAR (20) NОТ NULL,
Фамилия СНАR (30) NOT NULL,
Имя CHAR (15) NOT NULL
Отчество CHAR (20) NOT NULL,
Должность. CHAR (20) NOT NULL
Теперь вставим в созданную таблицу нужные нам данные, выполнив для этого следующий запрос:
INSERT INTO Преподаватель_ дисциплина
SELECT ПХЗТТИСТ Дисциплины. ID_ Дисциплина,
Кадровый_ состав. ID_ Преподаватель, Наименование,
Фамилия, Имя,. Отчество, Должность
FROM Кадровый_ состав, Учебный_ план, Дисциплины
WHERE Кадровый_ состав. ID_ Преподаватель =
Учебный_ план. ID_ Преподаватель
АND Дисциплины ID_ Дисциплина. Учебный_ план. ID_дисциплина
В результате в таблицу будет вставлено 54 строки.
SELEST TOP 4 *
FROM Преподаватель_ дисциплина
Результат запроса по новой таблице показан на рис. 7.36.

7.4.3. Изменение данных — команда UPDATE
Для внесения изменений в данные таблиц служит команда UPDATE, позволяющая выполнять как простое обновление данных в столбце, так и сложные операции модификации данных во множестве строк таблицы. Рассмотрим упрощенный синтаксис этой команды:
UPDATE <имя_ таблицы>
SET { <имя_ колонки> = { <выражение> / DEFAULT / NULL }}[,...,n]
{ [ FROM { <имя_ исходной_ таблицы> } [,...,п] ]
[WHERE <условие_ отбора> ) }
Рассмотрим назначение каждого из аргументов. <имя_ таблицы> — имя_ таблицы, в которой необходимо произвести изменение данных.
SET — с этого ключевого слова начинается блок, в котором определяется список изменяемых столбцов. За один вызов UPDATE можно изменить данные в нескольких столбцах множества строк одной таблицы.
<имя_ столбца> = {<выражение> / DEFAULT / NULL — для каждого изменяемого столбца нужно задать значение, которое он примет после выполнения изменения. С помощью ключевого слова DEFAULT можно присвоить столбцу значение, определенное для него по умолчанию. Можно также установить для столбца значение NULL. Изменению подвергнутся все строки, удовлетворяющие критериям ограничения области действия запроса UPDATE, которые задаются с помощью раздела WHERE. При составлении выражения можно ссылаться на любые столбцы таблицы, включая изменяемые. При этом следует учитывать, что изменения в данные вносятся только после выполнения команды. Таким образом, при ссылке на изменяемые столбцы будут использоваться старые значения.
FROM (<имя_ исходной_ таблицы>} — если при изменении данных в таблице необходимо учесть состояние данных в других таблицах, то эти источники данных необходимо указать в разделе FROM. Собственно источник данных описывается с помощью конструкции <имя_ исходной_ таблицы>.
WHERE <условие_ отбора> — назначение раздела WHERE, используемого в запросе UPDATE, полностью соответствует назначению, которое раздел имеет в запросе SELECT, т. е. с помощью раздела WHERE можно сузить диапазон строк, в которых будет выполняться изменение данных. Необходимо указать логическое условие, на основе которого будет приниматься решение об изменении данных конкретной строки. Если в контексте значений строки указанное логическое условие выполняется (т. е. возвращает значение TRUE), то данные этой строки будут изменены. В противном случае изменение не выполняется. Предполагается, что логическое условие включает имена столбцов изменяемой таблицы, однако это необязательно.
Приведем простейший пример изменения данных. Добавим в таблицу «Учебный_ план» по два часа в столбец Количество_ часов для дисциплин 1-го семестра с формой отчетности «экзамен».
Выведем сначала исходное состояние данных (рис. 7.37):
SELEST *
FROM Учебный_ план
WHERE (Отчетность = 'э') AND (Семестр = 1)

Затем выполним изменения и снова посмотрим данные (рис. 7.38).
UPDATE Учебный_ план
SET Количество_ часов = Количество_ часов + 2
WHERE (Отчетность = 'э') AND (Семестр = 1) '
SELETS *
FROM Учебный _ план
WHERE (Отчетностью э ) АИ1) (Семестр = 1)

7.4.4. Удаление данных – команда DELETE
Удаление данных из таблицы выполняется построчно. За одну операцию можно выполнить удаление как одной строки, так и нескольких тысяч строк. Если необходимо удалить из таблицы все данные, то можно удалить саму таблицу. Естественно, при этом будут удалены и все хранящиеся в ней данные. Однако этот способ следует использовать лишь в самых крайних случаях, так как помимо данных будет удалена и структура таблицы.
Чаще всего удаление данных выполняется с помощью команды DELETE, удаляющей строки таблицы.
Синтаксис команды, чаще всего использующийся на практике, следующий:
DELETE <Имя_ таблицы>
[WHERE <Условие_ отбора> ]
Таким образом, в большинстве случаев требуется указание лишь имени таблицы, из которой необходимо удалить данные, и логического условия, ограничивающего диапазон удаляемых строк. Причем последнее вовсе не обязательно, и при отсутствии условия из таблицы будут удалены все имеющиеся строки. Как и при выборке и изменении строк, диапазон удаляемых строк формируется с помощью раздела WHERE, использование которого было подробно рассмотрено ранее.
Пусть из таблицы «Учебный план» необходимо удалить дисциплины первого семестра с формой отчетности «зачет», т. е. строки, у которых значение в столбце Отчетность равно 'з'. Команда, которая позволит выполнить эту функцию, имеет следующий вид:
DELETE Учебный_ план
WHERE (отчетность = `з` ) AND (Семестр = 1)
Глава 8. Распределенная обработка данных
8.1. Основные условия и требования к распределенной обработке данных
Такая отличительная особенность БД, как многоцелевое параллельное использование данных, предопределяет наличие средств, обеспечивающих практически одновременный и независимый доступ к одним и тем же данным. Причем сама база может быть размещена на одном или нескольких компьютерах.
В [3] приводятся следующие, сформулированные ведущими поставщиками СУБД, свойства «идеальной» системы управления распределенными базами данных:
• прозрачность относительно расположения данных. СУБД должна представлять все данные так, как если бы они были локальными;
• гетерогенность системы: СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью (независимость от СУБД);
• прозрачность относительно сети: СУБД должна одинаково работать в условиях разнородных сетей;
• поддержка распределенных запросов: пользователь должен иметь возможность объединять данные из любых баз, даже если они размещены в разных системах;
• поддержка распределенных изменений: пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в разных системах;
• поддержка распределенных транзакций: СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов как в отдельных системах, так и в сети;
• безопасность: СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа;
• универсальность доступа: СУБД должна обеспечивать единую методику доступа ко всем данным.
Однако ни одна из существующих СУБД не достигает этого идеала вследствие следующих практических проблем:
• низкая и несбалансированная производительность сетей передачи данных, что в распределенных транзакциях сильно снижает общую производительность обработки;
• обеспечение целостности данных в распределенных транзакциях базируется на принципе «все или ничего» и требует специального протокола двухфазного завершения транзакций, что приводит к длительной блокировке изменяемых данных;
• необходимо обеспечить совместимость данных стандартного типа, для хранения которых в разных системах используются разные физические форматы и кодировки;
• выбор схемы размещения системных каталогов. Если каталог будет храниться в одной системе, то удаленный доступ будет замедлен. Если будет размножен — изменения придется распространять и синхронизировать;
• необходимо обеспечить совместимость СУБД разных типов и поставщиков;
• увеличение потребностей в ресурсах для координации работы приложений с целью обнаружения и устранения тупиковых ситуаций в распределенных транзакциях.
Именно указанные причины определили на практике частичность и «этапность» введения в СУБД тех или иных возможностей распределенной обработки данных. В простейшем случае пользователь имеет возможность обращаться по сети к записям в БД, размещенным на других компьютерах. В других случаях СУБД сама производит аутентификацию удаленного клиента и устанавливает сетевые соединения.
В общем случае режимы работы с БД можно классифицировать по следующим признакам:
• многозадачность — однопользовательский или многопользовательский;
• правило обслуживания запросов — последовательное или параллельное;
• схема размещение данных — централизованная или распределенная БД.
Следует отметить, что общая тенденция развития технологий обработки данных вполне соответствует этапам развития средств вычислительной техники и информационных технологий, и в первую очередь, — сетевых. В этом смысле следует выделить два класса: системы распределенной обработки данных и системы распределенных баз данных.
Системы распределенной обработки данных в основном отражают структуру и свойства многопользовательских операционных систем с базой данных, размещенной на большом центральном компьютере (мэйнфрейме). Еще до недавнего времени это был единственно возможный вариант вычислительной среды для реализации больших баз данных. Клиентские места в этом случае реализовались в виде терминалов или мини-ЭВМ, обеспечивающих в основном ввод-вывод данных и не имеющих собственных вычислительных ресурсов для функционально-ориентированной обработки получаемых данных.
Развитие сетевых технологий в сочетании с широким распространением персональных ЭВМ и внедрением стандартов открытых систем привело к появлению систем баз данных, размещенных в сети разнотипных компьютеров. Такие системы распределенных баз данных обеспечивают обработку распределенных запросов, когда при обработке одного запроса используются ресурсы базы, размещенные на различных ЭВМ сети. Система распределенных баз данных состоит из узлов, каждый из которых является СУБД, а узлы взаимодействуют между собой так, что база данных любого узла будет доступна пользователю, как если бы она была локальной.
Соответственно, программы, обеспечивающие целевую (функциональную) обработку данных, могут быть организованы таким образом, чтобы обеспечить более эффективное использование совокупных вычислительных ресурсов за счет специализированного разделения функций обработки между центральным процессом СУБД и клиентскими функционально-ориентированными процедурами.
Для «типового» приложения обработки данных можно выделить следующие группы (уровни) функций:
• ввод и отображение данных: внешний (пользовательский) уровень реализации целевой функциональной обработки и представления (Presentation logic);
• функциональная обработка, реализующая алгоритм решения задач пользователя. Соответствующие «бизнес-правила» реализуются обычно средствами высокоуровневого языка программирования или расширенного языка манипулирования данными типа ADABAS Natural или 4-GL (Business logic);
• манипулирование данными БД в рамках приложения, которое обычно реализуется средствами SQL (Database logic);
• управление данными и другими ресурсами БД, реализуемое специализированными (внутренними) средствами конкретной СУБД обычно в рамках файловой системы ОС;
• управление процессами обработки: связывание и синхронизация процессов обработки данных разного уровня.
8.2. Архитектура распределенной обработки данных
Почти все модели организации взаимодействия пользователя с базой данных построены на основе модели «клиент — сервер». То есть предполагается, что каждое такое приложение отличается способом распределения функций ранее приведенных групп обработки данных между, как минимум, двумя частями:
• клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем;
• серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к серверу БД с помощью сети подключены компьютеры пользователей (клиенты).
Сервер — это программа, реализующая функции собственно СУБД: определение данных, запись — чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных.
Клиент — это различные программы, написанные как пользователями, так и поставщиками СУБД, внешние или «встроенные» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД, и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня.
Разделение процесса выполнения запроса на «клиентскую» и «серверную» компоненту позволяет:
• различным прикладным (клиентским) программам одновременно использовать общую базу данных;
• централизовать функции управления, такие, как защита информации, обеспечение целостности данных, управление совместным использованием ресурсов;
• обеспечивать параллельную обработку запроса в случае распределенных БД;
• высвобождать ресурсы рабочих станций и сети;
• повышать эффективность управления данными за счет использования ЭВМ, специально разработанных для работы СУБД (серверы баз данных и машины баз данных).
8.2.1. Базовые архитектуры распределенной обработки
Учитывая, что одним из основных показателей эффективности сетевой обработки данных является время обслуживания запроса, рассмотрим различные модели архитектуры распределенной обработки на примере, когда прикладная программа работы с базой данных, расположенной на сервере, загружена на рабочую станцию, и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям.
8.2.1.1. Архитектура файл-сервере
В архитектуре «файл — сервер», схема которой представлена на рис. 8.1, средства организации и управления базой данных (в том числе и СУБД) целиком располагаются на машине клиента, а база данных, представляющая собой обычно набор специализированных структурированных файлов, на машине-сервере. В этом случае серверная компонента представлена даже не средствами СУБД, а сетевыми
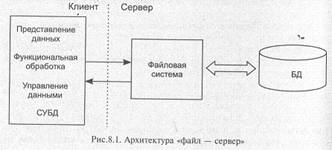
составляющими операционной системы, обеспечивающими удаленный разделяемый доступ к файлам. Таким образом, «файл сервер» представляет собой вырожденный случай клиент-серверной архитектуры.
Взаимодействие между клиентом и сервером происходит на уровне команд ввода-вывода файловой системы, которая возвращает запись или блок данных. Запрос к базе, сформулированный на языке манипулирования данными, преобразуется самой СУБД в последовательность команд ввода-вывода, которые обрабатываются операционной системой машины-сервера.
Достоинство — возможность обслуживания запросов нескольких клиентов.
Недостатки:
• высокая загрузка сети и машин-клиентов, так как обмен идет на уровне единиц информации файловой системы — физических записей, блоков или даже файлов, из которых на машине клиента будут выбраны и представлены необходимые для приложения элементы данных;
• низкий уровень защиты данных, так как доступ к файлам БД управляется общими средствами ОС-сервера;
• низкий уровень управления целостностью и непротиворечивостью информации, так как бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми и не синхронизированными.
В среде файлового сервера программа управления данными, которая выполняется на машине-клиенте, должна осуществить запрос каждой записи базы, после чего она может определить, удовлетворяет ли запись поисковым условиям, лишь после этого передать запись для функциональной обработки. Очевидно, что для этой схемы характерно наибольшее суммарное время обработки информации.
8.2.1.2. Архитектура «выделенный сервер базы данных»
В архитектуре сервера базы данных, схема которой представлена на рис. 8.2, средства управления базой данных и база данных размещены на машине-сервере.
Взаимодействие между клиентом и сервером происходит на уровне команд языка манипулирования данными СУБД (обычно SQL), которые обрабатываются СУБД на машине-сервере. Сервер базы данных осуществляет поиск записей и анализирует их. Записи, удовлетворяющие условиям, могут накапливаться на сервере и после того, как запрос будет целиком обработан, пользователю на
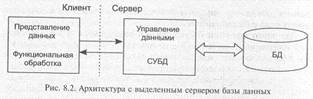
клиентскую машину передаются все логические записи (запрашиваемые элементы данных), удовлетворяющие поисковым условиям.
Достоинства:
• возможность обслуживания запросов нескольких клиентов;
• снижение нагрузки на сеть и машины сервера и клиентов;
• защита данных осуществляется средствами СУБД, что позволяет блокировать не разрешенные пользователю действия;
• сервер реализует управление транзакциями и может блокировать попытки одновременного изменения одних и тех же записей.
Недостатки:
• бизнес-логика функциональной обработки и представление данных могут быть одинаковыми для нескольких клиентских приложений и это увеличит совокупные потребности в ресурсах при исполнении вследствие повторения части кода программ и запросов;
• низкий уровень управления непротиворечивостью информации, так как бизнес-правила функциональной обработки, сосредоточенные на клиентской части, могут быть противоречивыми.
Данная технология позволяет снизить сетевой трафик и повысить общую эффективность обработки за счет оптимизации и буферизации ввода-вывода. Таким образом, сервер может осуществлять поиск и обрабатывать запросы даже быстрее, чем если бы они обрабатывались на рабочей станции.
8.2.1.3. Архитектура активный сервер баз данных
Для того, чтобы устранить недостатки, свойственные архитектуре сервера базы данных, необходимо, чтобы непротиворечивость бизнес-логики и изменения базы данных контролировались на стороне сервера. Причем некоторые заранее специфицированные состояния могли бы изменять последовательность взаимодействия приложения с базой данных.
Для этого функции бизнес-логики разделяются между клиентской и серверной частями. Общие или критически значимые функции оформляются в виде хранимых процедур, включаемых в состав базы данных. Кроме этого вводится механизм отслеживания событий БД — триггеров, также включаемых в состав базы. При возникновении соответствующего события (обычно изменения данных), СУБД вызывает для выполнения хранимую процедуру, связанную с триггером, что позволяет эффективно контролировать изменение базы данных.
Хранимые процедуры и триггеры могут быть использованы любыми клиентскими приложениями, работающими с базой данных. Это снижает дублирование программных кодов и исключает необходимость компиляции каждого запроса (рис. 8.3).
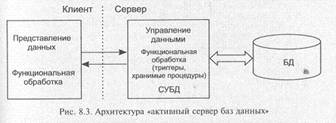
Недостатком такой архитектуры становится существенно возрастающая загрузка сервера за счет необходимости отслеживания событий и выполнения части бизнес-правил.
Такую архитектуру организации взаимодействия (а также рассматриваемый далее сервер приложений) иногда называют моделью с «тонким клиентом», в отличие от предыдущих архитектур, называемых моделью с «толстым клиентом», где на стороне клиента выполняется большинство функций.
8.2.1.4. Архитектура «cepвep приложений»
Рассмотренные выше архитектуры являются двухзвенными: здесь все функции доступа и обработки распределены между программой клиента и сервером БД.
Дальнейшее снижение уровня требований к ресурсам клиента достигается за счет введения промежуточного звена — сервера приложений, на который переносится значительная часть программных компонентов управления данными и большая часть бизнес-логики. При этом серверы баз данных обеспечивают исключительно функции СУБД по ведению и обслуживанию базы данных. Схема трехзвенной архитектуры сервера приложений приведена на рис. 8.4.
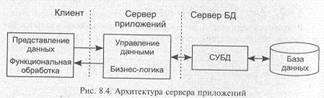
К другим (организационно-технологическим) достоинствам трехзвенной архитектуры можно отнести:
• централизованное ведение бизнес-логики, и в случае внесения изменения отсутствие необходимости их тиражирования в клиентских приложениях;
• отсутствие необходимости устанавливать на клиентских машинах компоненту программного обеспечения управления доступом к данным;
• возможность отложенного обновления БД в случае изменения данных, запрошенных с сервера, в автономном режиме. Данные будут обновлены в базе после следующего соединения клиентской программы с сервером приложений.
8.2.2. Архитектура сервера баз данных
Повышение эффективности и оперативности обслуживания большого числа клиентских запросов, помимо простого увеличения ресурсов и вычислительной мощности серверной машины, может быть достигнуто двумя путями:
• снижением суммарного расхода памяти и вычислительных ресурсов за счет буферизации (кэширования) и совместного использования (разделяемые ресурсы) наиболее часто запрашиваемых данных и процедур;
• распараллеливанием процесса обработки запроса — использованием разных процессоров для параллельной обработки изолированных подзапросов и/или для одновременного обращения к частям базы данных, размещенным на отдельных физических носителях.
Рассмотрим архитектуры, реализующие следующие модели совместной обработки клиентских запросов.
8.2.2.1. Архитектура «один к одному»
В этом случае (рис. 8.5) для обслуживания каждого запроса запускается отдельный серверный процесс.
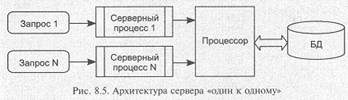
Таким образом, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будут запущены отдельные процессы, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы.
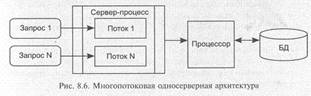
8.2.2.2. Многопотоковая односерверная архитектура
Обработку всех клиентских запросов выполняет один серверный процесс (использующий один процессор), взаимодействующий со всеми клиентами и монопольно управляющий ресурсами (рис. 8.6). При этом для отдельного клиентского процесса создается поток (thread), в рамках которого локализуется обработка запроса.
8.2.2.3. Мультисерверная архитектура
В том случае, когда для работы СУБД используются многопроцессорные платформы, обслуживание запросов может быть физически распределено для параллельной обработки между процессорами (рис. 8.7). Такое решение требует введения дополнительного звена, в задачи которого входит диспетчеризация запросов для обеспечения сбалансированной загрузки процессоров.
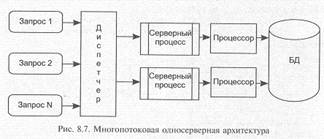
В том случае, когда серверный процесс реализуется как многопоточное приложение, говорят, что СУБД имеет мультисерверную много потоковую архитектуру.
Следует отметить, что характер распределения запросов в значительной степени зависит от того, поддерживает ли операционная система потоковую обработку, а также от возможностей средств управления приоритетами задач.
8.2.2.4. Серверные архитектуры с параллельной обработкой запроса
Для повышения оперативности за счет распараллеливания процесса обработки отдельного клиентского запроса в мульти серверной архитектуре можно использовать следующие подходы.
1. Размещение хранимых данных БД на нескольких физических носителях (сегментирование базы). Для обработки запроса в этом случае запускаются несколько серверных процессов (использующих обычно отдельные процессоры), каждый из которых независимо от других выполняет одинаковую последовательность действий, определяемую существом запроса, но с данными, принадлежащими разным сегментам базы. Полученные таким образом результаты объединяются и передаются клиенту. Такой тип распараллеливания называют моделью горизонтального параллелизма.
2. Запрос обрабатывается по конвейерной технологии. Для этого запрос разбивается на взаимосвязанные по результатам подзапросы, каждый из которых может быть обслужен отдельным серверным процессом независимо от обработки других подзапросов. Получаемые результаты объединяются согласно схеме декомпозиции запроса и передаются клиенту. Такой тип распараллеливания называют моделью вертикального параллелизма.
Примерная схема обработки клиентского запроса, построенная с использованием обеих моделей параллелизма (гибридная модель) приведена на рис. 8.8.
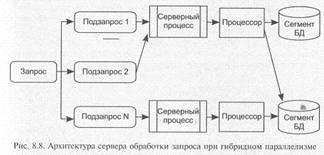
Использование моделей параллельной обработки позволяет существенно сократить общее время обслуживания запроса, что особенно важно в случае работы с большими базами данных и аналитической обработки (OLAP-приложений).
8.3. Технологии и средства доступа к удаленным БД
8.3.1. Программное обеспечение распределенных приложений
Распределенные корпоративные приложения все более усложняются, интегрируя унаследованные приложения, разрабатываемые и вновь приобретаемые готовые программные средства. Кроме того, разные подсистемы решают разные бизнес-задачи, однако одна из главных целей создания корпоративной системы — получить «единый образ» общего состояния системы, что обеспечит пользователям доступ к нужным операциям и ресурсам.
Основа такой инфраструктуры — так называемое промежуточное программное обеспечение, позволяющее, не вникая в тонкости сетевых реализаций, создавать и эксплуатировать взаимодействующие приложения с разными требованиями к межмодульным коммуникациям.
Промежуточное ПО эволюционировало вместе с архитектурой «клиент — сервер». Ранние, но достаточно эффективные как с точки зрения разработки, так и эксплуатации, частные решения предназначались для упрощения доступа к базам данных в двухзвенной модели, где «толстый» клиент реализует всю логику обработки информации, предоставляемой сервером базы данных. Такие системы вполне удовлетворяли потребностям небольших корпоративных подразделений с ограниченным числом пользователей и невысокой интенсивностью обмена.
Однако по мере того, как клиент-серверная архитектура стала проникать в сферу высоко критичных корпоративных приложений, обслуживающих уже не десятки, а сотни пользователей, и работающих со значительными массивами данных, стали очевидны недостатки двухзвенного подхода. Этот способ реализации клиент-серверной схемы доступа ограничивал возможности масштабирования, поскольку увеличение числа обращений к одной базе данных непомерно увеличивало нагрузку на сервер и делало доступ к данным «узким местом» в общей производительности системы. Кроме того, всякая модификация логики приложения требовала внесения изменений во все экземпляры клиентских приложений.
Чтобы избежать таких проблем, для разработки корпоративных приложений используют трехзвенную модель, которая переносит логику приложения на отдельный уровень сервера приложений. В результате клиентская часть приложения становится «тоньше» и в основном отвечает за предоставление удобного пользовательского интерфейса. Как правило, сервер баз данных также освобождается от необходимости поддерживать бизнес-логику, которая в двухзвенной модели реализуется с помощью специальных расширений СУБД, например, хранимых процедур. Перенос основных операций приложения на отдельный уровень позволяет с максимальной эффективностью распределить нагрузку на аппаратные средства (трехзвенная модель на самом деле может быть многозвенной с разделением нагрузки на несколько серверов приложений и обеспечивает безболезненное наращивание как функциональности приложения, так и числа обслуживаемых пользователей.
Развитие этого среднего звена клиент-серверной модели идет в сторону усложнения. Ограничиваясь вначале построением более высокого уровня абстракции для взаимодействия приложения с ресурсами данных, разработчик приложения получал возможность использовать общие API (Application Program Interface), которые скрывали различия специфических интерфейсов коммуникационных протоколов более низкого уровня, например, ТСР/IP, Sockets или DECNet. Однако теперь этого уже явно недостаточно для построения сложных распределенных приложений. Современные решения не только обеспечивают межпрограммное взаимодействие, но и являются платформой для реализации сервера приложений, обеспечивая обширный набор необходимых служб: управления транзакциями, именования, защиты и т. д.
Вычислительная среда распределенных приложений может включать в себя различные операционные системы, аппаратные платформы, коммуникационные протоколы и разнообразные средства разработки. Соответственно, формат представления данных в различных узлах будет различаться.
Таким образом, в распределенной неоднородной среде программное обеспечение промежуточного уровня играет роль «информационной шины», надстроенной над сетевым уровнем и обеспечивающей доступ приложения к разнородным ресурсам, а также независимую от платформ взаимосвязь различных прикладных компонентов, изолирующую логику приложений от уровня сетевого взаимодействия и ОС (рис. 8.9).
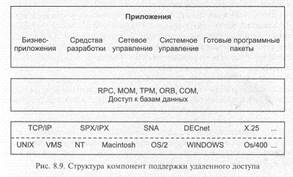
ПО промежуточного уровня можно разделить на две категории.
1. ПО доступа к базам данных (например, ODBC-интерфейсы и SQL-шлюзы).
2. ПО межмодульного взаимодействия — системы, реализующие вызов удаленных процедур (RPC — Remote Procedure Call); мониторы обработки транзакций (TP-мониторы); средства интеграции распределенных объектов.
При этом следует отметить, что различия прикладных задач не позволяют построить универсальное ПО, реализовав в одном продукте все необходимые возможности.
8.3.2. Доступ к базам данных в двухзвенных моделях «клиент — сервер»
В простых двухзвенных моделях «клиент — сервер», где несколько баз данных обслуживают ограниченное число пользователей настольных ПК, в роли встроенного ПО доступа к данным могут выступать обычные ODBC-драйверы.
Необходимость в более сложных решениях возникает в больших, разнородных многозвенных системах, где множество приложений в параллельном режиме осуществляют доступ к разнообразным источникам данных, включая разнотипные СУБД и хранилища данных. В таких системах между клиентами и серверами баз данных размещается промежуточное звено — SQL-шлюз, который представляет собой набор общих АРI, позволяющих разработчику строить унифицированные запросы к разнородным данным (в формате SQL или с помощью ODBC-интерфейса). SQL-шлюз выполняет синтаксический разбор такого запроса, анализирует и оптимизирует его и в конце концов выполняет преобразование в SQL-диалект нужной СУБД. ПО этого типа реализует синхронный механизм связи, когда выполнение приложения, сделавшего запрос, блокируется до момента получения данных.
Примером такого приложения может быть система анализа статистических данных о деятельности компаний, которая отбирает соответствующую информацию из расположенных в различных регионах баз данных с разными СУБД. Подобные решения достаточно просты, не требуют сложных механизмов управления транзакциями и способны обеспечить постепенную миграцию важных приложений с унаследованных платформ в архитектуру «клиент сервер».
Каждое приложение, построенное на основе архитектуры «клиент — сервер», включает, как минимум, две части:
• клиентскую часть, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем;
• серверную часть, которая собственно хранит данные, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к выделенному серверу БД с помощью сети подключены узлы — компьютеры пользователей (клиенты). При этом узел-клиент сам может быть СУБД.
Создается такое приложение обычно с использованием средств языков высокого уровня (например, С++, Pascal, Visual Basic), позволяющих реализовать эффективную целевую обработку данных и дружественный пользовательский интерфейс. В исходный текст программы включаются SQL-выражения, специфицирующие условия выборки или изменения данных в базе. Во время исполнения приложения эти выражения передаются серверу, который, собственно, и манипулирует данными. Данные, полученные в результате выполнения сервером SQL-запросов, возвращаются прикладной программе и размещаются в заранее определенных структурах для дальнейшей обработки, в том числе корректировки записей.
Рассмотрим различные способы организации доступа прикладной программы к серверу базы данных в двухзвенной архитектуре.
8.3.2. 1. Использование библиотек доступа и встраиваемого SQL
Каждая СУБД помимо интерактивной SQL-утилиты обязательно имеет библиотеку процедур доступа и набор драйверов СУБД для различных операционных систем. Схема взаимодействия клиентского приложения с сервером базы данных в этом случае представлена на рис. 8.10.
Библиотека доступа содержит набор функций, позволяющих клиентскому приложению соединяться с базой данных, передавать запросы серверу, и получать данные — результаты обработки запроса. Типичный набор функций такой библиотеки включает:
• соединение с базой данных;
• запрос к базе данных на выполнение SQL-выражения;
• запрос на извлечение данных;
• запрос на изменение данных;
• закрытие соединения с базой данных.
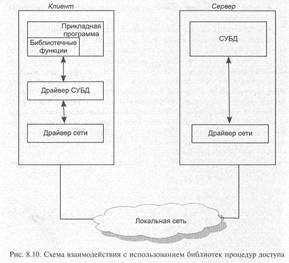
Обычно в библиотеке присутствуют также функции, позволяющие определить характеристики структуры набора результата (число, порядок и имена столбцов, число строк, номер текущей строки), передвигаться по этой структуре не только вперед, но и назад и т. д.
Библиотечные вызовы преобразуются драйвером базы данных в сетевые вызовы и передаются сетевым программным обеспечением на сервер. На сервере происходит обратный процесс преобразования сетевых пакетов в SQL-запросы, которые обрабатываются СУБД. Результаты обработки передаются клиенту.
Такой способ создания приложений достаточно гибок и позволяет реализовать практически любое приложение, однако имеет и недостатки:
• разработка клиентской программы возможна только для той операционной системы и на том языке программирования, в которых поддерживается библиотека;
• драйвер базы данных определяет допустимые типы сетевых интерфейсов;
• библиотечные функции обычно не унифицированы. Некоторой модификацией данного способа является использование «встроенного» языка SQL. В этом случае текст программы на языке третьего поколения вместо вызовов функций библиотеки включает непосредственно предложения SQL, которые предваряются выражением «ЕХЕС SQL». Перед компиляцией в машинный код такая программа обрабатывается препроцессором, который транслирует смесь операторов «собственного» языка СУБД и ЯЯ -предложений в промежуточный «чистый» исходный код, а затем коды SQL замещаются вызовами соответствующих процедур из библиотек, поддерживающих конкретную СУБД. Такой подход позволяет несколько снизить степень привязанности к СУБД, например, при переключении прикладной программы на работу с другим сервером базы данных — достаточно указать новый сервер и заново перекомпилировать программу.
8.3.2.2. Программный интерфейс уровня вызовов
Стандарт SQL2 определил интерфейс уровня вызова (CLI — Call 1.еуе1 Interface), в котором стандартизирован общий набор рабочих процедур, обеспечивающий совместимость со всеми основными типами серверов баз данных.
Технологическая основа CLI — размещаемая на компьютере клиента специальная библиотека, в которой хранятся вызовы процедур и сетевых компонентов для организации связи с сервером. Это программное обеспечение поставляется обычно в составе среды разработки и поддерживает разнообразные сетевые протоколы.
Использование программных вызовов позволяет свести к минимуму операции на компьютере-клиенте. В общем случае клиент формирует оператор языка SQL в виде строки и пересылает ее на сервер посредством процедуры исполнения (execute). Когда же сервер в качестве ответа возвращает несколько строк данных, клиент считывает результат последовательным вызовом процедуры выборки данных. Далее данные из столбцов полученной таблицы могут быть связаны с соответствующими переменными приложения. Вызов специальной процедуры позволяет клиенту определить число полученных строк, столбцов и типы данных в каждом столбце.
8.3.2.3. Открытый интерфейс доступа к базам данных
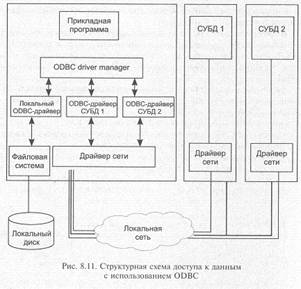
Спецификация открытого интерфейса баз данных (ODBC Open Database Connectivity), предназначена для унификации доступа к данным, размещенным на удаленных серверах. ODBC опирается на спецификации СЫ.
ODBC представляет собой программный слой, унифицирующий интерфейс взаимодействия приложений с базами данных. За реализацию особенностей доступа к каждой отдельной СУБД отвечает соответствующий специальный ODBC-драйвер. Пользовательское приложение этих особенностей не видит, так как взаимодействует с универсальным программным слоем более высокого уровня. Таким образом, приложение становится в значительной степени независимым от СУБД. Вместо создания в каждом отдельном случае СУБД приложения с обращениями через «родной», но быстро устаревающий интерфейс, можно использовать один общий стандартизированный программный интерфейс.
В архитектуре ODBC используется один ODBC Driver Manager и несколько ODBC-драйверов, обеспечивающих доступ к конкретным СУБД. Driver Manager связывает приложение и интерфейсные объекты, которые выполняют обработку SQL-запросов к конкретной СУБД.
Такой подход является достаточно универсальным, стандартизируемым, что и позволяет использовать ODBC-механизмы для работы практически с любой системой.
Однако этот способ также не лишен недостатков:
• увеличивается время обработки запросов (как следствие введения дополнительного программного слоя);
• необходимы предварительная инсталляция и настройка ODBC-драйвера (указание драйвера СУБД, сетевого пути к серверу, базы данных и т. д.) на каждом рабочем месте. Параметры этой настройки являются статическими, т. е. приложение их изменить самостоятельно не может.
8.3.2.4. Мобильный интерфейс к базам данных на платформе Java
JDBC (Java Data Base Connectivity) — это интерфейс прикла34о го программирования (АР1) для выполнения SQL-запросов к базам данных из программ, написанных на платформенное независимом языке Java, позволяющем создавать как самостоятельные приложения (standalone application), так и апплеты, встраиваемые в web страницы.
JDBC во многом подобен ODBC, он также построен на основе спецификации CL1, однако имеет ряд следующих отличий:
• приложение загружает JDBC-драйвер динамически, следовательно, администрирование клиентов упрощается, более того, появляется возможность переключаться на работу с другой СУБД без перенастройки клиентского рабочего места;
• JDBC, как и Java в целом, не привязан к конкретной аппаратной платформе, следовательно проблемы с переносимостью приложений практически снимаются;
• использование Java-приложений и связанной с ними идеологии «тонких клиентов» обещает снизить требования к оборудованию клиентских рабочих мест.
Обобщенная структурная схема доступа к данным с использованием JDBC приведена на рис. 8.12.

8.3.2.5. Прикладные интерфейсы OLE DB и ADO
Встраивание и связывание объектов в базах данных — OLE DB (Object Linking and Embedding Data Base), как и ODBC — прикладные интерфейсы доступа к данным с использованием SQL.
OLE DB специфицирует взаимодействие, обеспечивая единый интерфейс доступа к данным через провайдеров — поставщиков данных не только из реляционных БД. В отличие от ODBC, OLE DB предоставляет общее решение обеспечения СОМ-приложениям доступа к информации независимо от типа источника данных.
OLE DB включает два базовых компонента: провайдер данных и потребитель данных. Потребитель (клиент) — это приложение или СОМ-компонент, обращающийся посредством API-вызовов к OLE DB. Провайдер (сервер) — это приложение отвечающее на вызовы OLE DB и возвращающее запрашиваемый объект — обычно это данные в табличном виде.
ADO (Active Data Object) — это универсальный интерфейс высокого уровня к OLE DB. Модель объекта ADO не содержит таблиц, среды или машины БД. Здесь основными объектами являются следующие: объект Соединение, создающий связь с провайдером данных; объект Набор данных и объект Команда — выполнение процедуры, SQL-строки
В общем случае ADO можно рассматривать как язык программирования с БД, позволяющий выбирать, модифицировать и удалять записи. И поскольку он опирается на универсальный OLE DB,, то может использоваться практически в любых приложения Microsoft.
Рассмотренные технологии построения приложения ориентированы на извлечение данных непосредственно из статического источника (хранилища данных) и не могут обращаться за данными к другому прикладному модулю.
8.4. Технологии межмодульного взаимодействия
Следующий тип промежуточного ПО ориентирован на архитектуру приложения, в которой один прикладной модуль, используя специальные протоколы, получает данные из другого модуля.
8.4.1. Спецификация вызова удаленных процедур
Средства вызова удаленных процедур (RPC) поддерживает синхронный режим коммуникаций между двумя прикладными модулями (клиентом и сервером).
Для установки связи, передачи вызова и возврата результата клиентский и серверный процессы обращаются к специальным процедурам — клиентскому и серверному суррогатам (client stub и server stub). Эти процедуры не реализуют никакой прикладной логики и предназначены только для организации взаимодействия удаленных прикладных модулей,
Каждая функция на сервере, которая может быть вызвана удаленным клиентом, должна иметь такой суррогатный процесс, Если клиент вызывает удаленную процедуру, вызов вместе с параметрами передается клиентскому суррогату. Он упаковывает эти данные в сетевое сообщение и передает его серверному суррогату. Тот, в свою очередь, распаковывает полученные данные и передает их реальной функции сервера и затем проделывает обратную процедуру с результатами. Таким образом прикладные модули клиента и сервера изолируются от уровня сетевых коммуникаций.
По существу, RPC реализует в распределенной среде принципы традиционного структурного программирования. Клиент обращается к процессу-суррогату так, как будто он и есть реальный серверный процесс, и этот вызов ничем не отличается от вызова локальной функции. Как и в случае нераспределенной программы, вызов процедуры на удаленном компьютере влечет за собой передачу управления этой процедуре, то есть блокирует выполнение клиентской программы на время обработки вызова.
В общем случае механизм RPC создает статические отношения между компонентами распределенного приложения — привязка клиентского процесса к конкретным серверным суррогатам происходит на этапе компиляции и не может быть изменена во время выполнения. Этим RPC отличается от таких более выгодных решений, как TP-мониторы, которые поддерживают возможности оптимального распределения нагрузки на серверы и средства восстановления при сбоях.
Ключевым компонентом RPC является язык описания интерфейсов (Interface Defmition Language — IDL.), предназначенный для определения интерфейсов, которые задают контрактные отношения между клиентом и сервером. Интерфейс содержит определение имени функции и полное описание передаваемых параметров и результатов выполнения.
Язык IDL обеспечивает независимость механизма RPC от языков программирования — вызывая удаленную процедуру, клиент может использовать свои языковые конструкции, которые IDL компилятор преобразует в свои описания. На сервере IDL-описания обратно преобразуются в конструкции языка программирования, на котором реализован серверный процесс.
8.4.2. Мониторы обработки транзакций
Первоначально основной задачей мониторов обработки транзакций (TP-мониторов) в среде «клиент — сервер» было сокращение числа соединений клиентских систем с базами данных. При непосредственном обращении клиента к серверу базы данных для каждого клиента устанавливается соединение с СУБД, которое порождает запуск отдельного процесса в рамках операционной системы. TP мониторы брали на себя роль концентратора таких соединений, становясь посредниками между клиентом и сервером базы данных.
Постепенно, с развитием трехзвенной архитектуры «клиент сервер» функции ТР-мониторов расширились, и они превратились в платформу для транзакционных приложений в распределенной среде с множеством баз данных под различными СУБД.
ТР-мониторы представляют собой одну из самых сложных и многофункциональных технологий в мире промежуточного ПО. Основное их назначение — автоматизированная поддержка приложений, оформленных в виде последовательности транзакций. Каждая транзакция — это законченный блок обращений к ресурсу (как правило, базе данных) и некоторых действий над ним, для которого гарантируется выполнение четырех условий:
• атомарность — операции транзакции образуют неразделимый, атомарный блок с определенным началом и концом. Этот блок либо выполняется от начала до конца, либо не выполняется вообще. Если в процессе выполнения транзакции произошел сбой, происходит откат (возврат) к исходному состоянию;
• согласованность — по завершении транзакции все задействованные ресурсы находятся в согласованном состоянии;
• изолированность — одновременный доступ транзакций различных приложений к разделяемым ресурсам координируется таким образом, чтобы эти транзакции не влияли друг на друга;
• долговременность — все изменения данных (ресурсов), осуществленные в процессе выполнения транзакции, не могут быть потеряны.
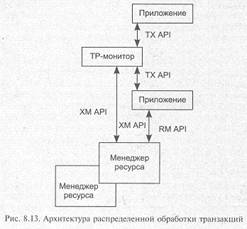
В системе без ТР-монитора обеспечение этих свойств берут на себя серверы распределенной базы данных, использующие двухфазный протокол (2PC-two-phase commit). Протокол 2РС описывает двухфазный процесс, в котором перед началом распределенной транзакции все системы опрашиваются о готовности выполнить необходимые действия. Если каждый из серверов баз данных дает утвердительный ответ, транзакция выполняется на всех задействованных источниках данных. Если хотя бы в одном месте происходит какой-либо сбой, будет выполнен откат для всех частей транзакции.
Однако в системе с распределенными базами данных выполнение протокола 2РС можно гарантировать только в том случае, если все источники данных принадлежат одному поставщику. Поэтому для сложной распределенной среды, которая обслуживает тысячи клиентских мест и работает с десятками разнородных источников данных, без монитора транзакций не обойтись. ТР-мониторы способны координировать и управлять транзакциями, которые обращаются к серверам баз данных от различных поставщиков благодаря тому, что большинство этих продуктов помимо протокола 2PC поддерживают транзакционную архитектуру (XA), которая определяет интерфейс для взаимодействия TP-монитора с менеджером ресурсов, например, СУБД Oracle или Sybase. Спецификация ХА является частью общего стандарта распределенной обработки транзакций (distributed transaction processing — DTP), разработанного Х/Open (рис. 8.13).
Функции современных TP-мониторов не ограничиваются поддержкой целостности прикладных транзакций. Большинство продуктов этой категории способны распределять, планировать и выделять приоритеты запросам нескольких приложений одновременно, тем самым сокращая процессорную нагрузку и время отклика системы. Обработка запросов организуется в виде «нитей» ОС, а не полновесных процессов, тем самым значительно снижая загруженность системы.
Таким образом, снимается одно из серьезных ограничений производительности и масштабируемости клиент-серверной среды— необходимость поддержки отдельного соединения с базой данных для каждого клиента.
8.4.3. Корпоративные серверы приложений
Появление серверов приложений как отдельных готовых решений связано и с бурным вторжением Web-технологий в сферу корпоративных высоко критичных систем. Однако возможности протокола НТТР ограничены функциями связи без каких-либо средств сохранения информации о состоянии, поэтому он не подходит для поддержки мощных корпоративных систем
На рис. 8.14 приведен «идеальный» состав сервера приложений с максимальным набором необходимых служб и средств связи с клиентскими системами и информационными ресурсами.
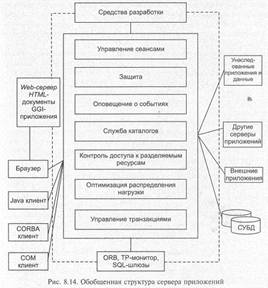
Сегодня прикладные разработки базируются на одной из двух компонентных моделей — MTS/DCOM и CORBA, способных интегрировать объекты на удаленных платформах.
Обе модели распространяют принципы вызова удаленных процедур на объектные распределенные приложения и обеспечивают прозрачность реализации и физического размещения серверного объекта для клиентской части приложения; поддерживают возможность взаимодействия объектов, созданных на различных объект но ориентированных языках, и скрывают от приложения детали сетевого взаимодействия.
В DCOM взаимодействие удаленных объектов, представленное на рис. 8.15, базируется на спецификации DCE RPC, а CORBA использует брокер объектных запросов (ORB), синхронный механизм которого во многом схож с RPC.
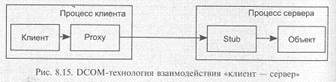
В DCOM-технологии взаимодействие между клиентом и сервером осуществляется через двух посредников. Клиент помещает параметры вызова в стек и обращается к методу интерфейса объекта. Это обращение перехватывает посредник Proxy, упаковывает параметры вызова в СОМ-пакет и адресует его в Stub, который в свою очередь распаковывает параметры в стек и инициирует выполнение метода объекта в пространстве сервера.
CORBA-технология также использует интерфейс объекта, но в: этом случае схема взаимодействия объектов (рис. 8.16) включает промежуточное звено (Smart agent), реализующее доступ к удаленным объектам. Smart agent, установленный на машинах сетевого окружения (сервере локальной сети или Internet-узле), моделирует сетевой каталог известных ему серверов объектов. При создании сервера происходит автоматическая регистрация его объектов в каталоге одного или нескольких Smart Agent.
Связи между брокерами осуществляются в соответствии с требованиями специального протокола General Inter ORB Protocol, определяющего низкоуровневое представление данных и множество форматов сообщений.
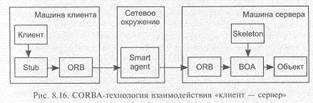
На машине клиента создаются два объекта-посредника: Stab и ORB (Object Required Broker — брокер вызываемого объекта). Также как и в DCOM-технологии, Stub передает перехваченный вызов брокеру, который посылает широковещательное сообщение в сеть. Smart agent, получив сообщение, отыскивает сетевой адрес сервера и передает запрос брокеру, размещенному на машине сервера. Вызов требуемого объекта производится через специальный базовый объектный адаптер (ВОА). При этом данные в стек пространства вызываемого объекта помещает особый объект сервера (Skeleton), который вызывается адаптером.
Кроме того, CORBA, помимо механизма взаимодействия с помощью ORB, включает в себя ряд общих служб CORBA Services (службы каталогов, защиты, оповещения о событиях, поддержки транзакций и ряд других), а также реализаций объектов для разных прикладных областей.
Ключевым компонентом архитектуры CORBA является язык описания интерфейсов IDL, на уровне которого поддерживаются «контрактные» отношения между клиентом и сервером и обеспечивается независимость от конкретного объектно-ориентированного языка. CORBA IDL поддерживает основные понятия объектно-ориентированной парадигмы (инкапсуляцию, полиморфизм и наследование).
В модели DCOM также может использоваться разработанный Microsoft язык IDL, который, однако, играет вспомогательную роль и используется в основном для удобства описания объектов. Реальная интеграция объектов в DCOM происходит не на уровне абстрактных интерфейсов, а на уровне бинарных кодов, и это одно из основных различий этих двух объектных моделей.
И DCOM, и CORBA, в отличие от процедурного RPC, дают возможность динамического связывания удаленных объектов: клиент может обратиться к серверу-объекту во время выполнения, не имея информации об этом объекте на этапе компиляции. В CORBA для этого существует специальный интерфейс динамического вызова DII, а СОМ использует механизм OLE-Automation. Информацию о доступных объектах сервера на этапе выполнения клиентская часть программы получает из специального хранилища метаданных об объектах — репозитария интерфейсов Interface Repositary в случае CORBA, или библиотеки типов (Туре Library) в модели DCOM. Эта возможность очень важна для больших распределенных приложений, поскольку позволяет менять и расширять функциональность серверов, не внося существенных изменений в код клиентских компонент программы. Пример — банковское приложение, основная бизнес логика которого поддерживается сервером в центральном офисе, а клиентские системы разбросаны по филиалам в разных городах.
8.4.4. Доступ к данным с помощью ADO.NET
АDO. NЕТ является преемником Microsoft ActiveX Data Objects (ADO). Это W3C-стандартизированная модель программирования для создания распределенных прикладных программ, нацеленных на совместное использование данных.
ADO.NET является программным интерфейсом (API) для прикладного программного обеспечения, позволяющим обращаться к данным и другой информации. ADO.NET поддерживает такие современные требования, как создание клиентского интерфейса к базам данных на фронтальном уровне и на уровне промежуточного слоя объектов клиентских приложений, инструментальных средств, языков программирования или Internet-браузера.
ADO. NЕT, подобно ADO, обеспечивает интерфейс доступа к OLE DB-совместимым источникам данных, таким, как Microsoft SQL Server 2000. Прикладные программы, позволяющие пользователям совместно использовать данные, могут использовать ADO.NET для подключения к источникам данных, а также для поиска и модификации этих данных. Прикладные программы также могут использовать OLE DB для управления данными, хранящимися в неструктурированных форматах, таких как Microsoft Excel.
В решениях, требующих автономного или удаленного доступа к данным, ADO.NЕТ использует XML для обмена данными между программами или с Web-страницами. Любая компонента, которая обслуживает XML, также может использовать и компоненты АРОЛЕТ. Если передача пакетов компонентой ADO.NET подразумевает поставку набора данных в файле XML, то компонентой, способной обеспечить его получение, может быть только компонента АDО. NЕТ. Передача данных в XML-формате дает возможность легко отделить обработку данных от компонент пользовательского интерфейса.
Для распределенных приложений использование наборов данных ХМL в АDО. NЕТ обеспечивает большую эффективность, чем использование СОМ для офлайнового обслуживания данных в ADO. Поскольку передача наборов данных происходит через файлы XML, описанные в достаточно простом стандартном языке и являющиеся обычными текстовыми файлами, компоненты АРОЛЕТ не имеют архитектурных ограничений, свойственных СОМ. Фактически любые два компонента могут совместно использовать наборы ХМL-данных при условии, что они оба используют ту же самую XML-схему форматирования.
АРОЛЕТ обладает хорошей масштабируемостью, что удобно для совместно использующих данные Web-приложений. Кроме того, ADO.NET не использует длительные блокировки баз данных и активные подключения, которые на долгое время монополизируют ресурсы сервера, являющиеся, как правило, весьма ограниченными. Это позволяет увеличивать число пользователей без значительного увеличения загрузки ресурсов системы.
Глава 9. Транзакции и целостность БД
Применение СУБД для работы с интегрированными БД выявило особую важность проблемы целостности БД. Под целостностью БД понимают правильность и непротиворечивость ее содержимого. Нарушение целостности может быть вызвано, например, ошибками и сбоями, так как в этом случае система не в состоянии обеспечить нормальную обработку или выдачу правильных данных.
Рассмотрим два аспекта целостности — на уровне отдельных объектов и операций и на уровне базы данных в целом.
Первый аспект целостности обеспечивается на уровне структур данных и отдельных операторов языковых средств СУБД (вспомним ограничения целостности для столбцов и таблиц в языке SQL). При нарушениях такой целостности (например, ввод значения больше 10 в столбец Семестр таблицы «Учебный_ план» БД «Сессия») соответствующий оператор отвергается.
Некоторые ограничения целостности не нужно выражать в явном виде, поскольку они встроены в структуры данных. Например, в СУБД, поддерживающей структуры, составленные из записей, каждый экземпляр записи в БД должен отображать спецификацию типа записи. Это означает, что все поля, специфицированные в описании типа, должны быть представлены в каждом экземпляре записи, а значение, заносимое в отдельное поле, должно иметь соответствующий описанию тип данных.
Часто же база данных может иметь такие ограничения целостности, которые требуют обязательного выполнения не одной, а нескольких операций. Для иллюстрации примеров этой главы расширим функциональные возможности учебной БД «Сессия», добавив в таблицу «Кадровый_ состав» столбец Нагрузка для решения дополнительной задачи — расчета общей годовой нагрузки преподавателей (в часах учебной работы). Тогда любая операция по внесению изменений или по добавлению данных в столбец ID_ Преподаватель таблицы «Учебный_ план» должна сопровождаться соответствующими изменениями данных в столбце Нагрузка. Если после внесения изменений в столбец ID_ Преподаватель произойдет сбой, то БД окажется в нецелостном состоянии.
Для обеспечения целостности в случае ограничений на базу данных, а не на какие-либо отдельные операции, служит аппарат транзакций.
Транзакция — неделимая с точки зрения воздействия на БД последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации), такая, что:
1) либо результаты всех операторов, входящих в транзакцию, отображаются в БД;
2) либо воздействие всех этих операторов полностью отсутствует. При этом для поддержания ограничений целостности на уровне
БД допускается их нарушение внутри транзакции так, чтобы к моменту завершения транзакции условия целостности были соблюдены.
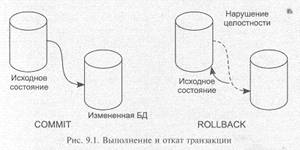
Для обеспечения контроля целостности каждая транзакция должна начинаться при целостном состоянии БД и должна сохранить это состояние целостным после своего завершения. Если операторы, объединенные в транзакцию, выполняются, то происходит нормальное завершение транзакции, и БД переходит в обновленное (целостное) состояние (ситуация СОММ1Т на рис. 9.1). Если же происходит сбой при выполнении транзакции, то происходит так называемый откат к исходному состоянию БД (ситуация ROLLВАСК на рис. 9.1).
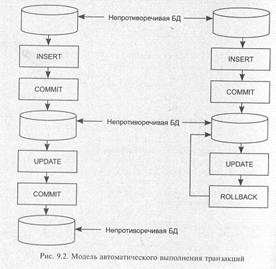
Рассмотрим две модели транзакций, используемые в большинстве коммерческих СУБД: модель автоматического выполнения транзакций и модель управляемого выполнения транзакций, обе основанные на инструкциях языка SQL — СОММIТ и ROLLBACK.
Автоматическое выполнение транзакций
В стандарте ANSI/ISO зафиксировано, что транзакция автоматически начинается с выполнения пользователем или программой первой инструкции SQL. Далее происходит последовательное выполнение инструкций до тех пор, пока транзакция не завершается одним из двух способов (рис. 9.2):
• инструкцией COMMIT, которая выполняет завершение транзакции: изменения, внесенные в БД, становятся постоянными, а новая транзакция начинается сразу после инструкции COMMIT;
• инструкцией ROLLBACK, которая отменяет выполнение текущей транзакции и возвращает БД к состоянию начала транзакции, новая транзакция начинается сразу после инструкции ROLLBACK.
Такая модель создана на основе модели, принятой в СУБД DB2.
Управляемое выполнение транзакций
Отличная от модели ANSI/ISO модель транзакций используется в СУБД Sybase; где применяется диалект Transact-SQL, в котором для обработки транзакций служат четыре инструкции (см. рис. 9.3):
• инструкция BEGIN TRANSACTION сообщает о начале транзакции, т. е. начало транзакции задается явно;
• инструкция COMMIT TRANSACTION сообщает об успешном выполнении транзакции, но при этом новая транзакция не начинается автоматически;
• инструкция SAVE TRANSACTION позволяет создать внутри транзакции точку сохранения и присвоить сохраненному состоянию имя точки сохранения, указанное в инструкции;
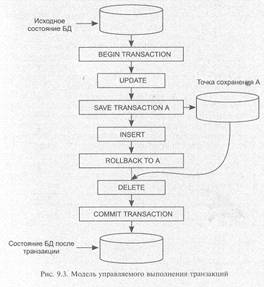
• инструкция ROLLВАСК отменяет выполнение текущей транзакции и возвращает БД к состоянию, где была выполнена инструкция SAVE TRANSACTION (если в инструкции указана точка сохранения — ROLLВАСК ТО имя _точки_ сохранения), или к состоянию начала транзакции.
Возможность восстановления состояния базы данных после сбоев обеспечивается с помощью журнала транзакций. Журнализация изменений, т. е. сохранение во внешней памяти информации обо всех модификациях БД, тесно связана с управлением транзакциями.
Основным принципом согласованной политики записи изменений в журнал и непосредственно в базу данных является то, что запись об изменении объекта базы данных должна попадать во внешнюю память журнала раньше, чем измененный объект оказывается во внешней памяти базы данных. Соответствующий протокол журнализации (и управления буферизацией) называется Write Ahead Log (WAL) — «пиши сначала в журнал», и состоит в том, что если требуется сохранить во внешней памяти измененный объект базы данных, то перед этим нужно гарантировать сохранение во внешней памяти журнала записи о его изменении.
Другими словами, если во внешней памяти базы данных находится некоторый объект базы данных, по отношению к которому выполнена операция модификации, то во внешней памяти журнала обязательно находится запись, соответствующая этой операции. Каждая успешно завершившаяся транзакция должна быть реально зафиксирована во внешней памяти. Какой бы сбой ни произошел, система должна иметь все данные для восстановления состояния базы данных, содержащие результаты всех зафиксированных к моменту сбоя транзакций. Минимальным требованием, гарантирующим возможность восстановления последнего согласованного состояния базы данных, является сохранение во внешней памяти журнала всех записей об изменении базы данных этой транзакцией. При этом последней записью в журнал, производимой от имени данной транзакции, является специальная запись о конце транзакции.
Иногда для восстановления последнего согласованного состояния базы данных после сбоя журнала изменений базы данных явно не достаточно. Основой восстановления в этом случае являются журнал и архивная копия базы данных.
Восстановление начинается с обратного копирования базы данных из архивной копии. Затем для всех закончившихся транзакций в прямом смысле повторно выполняются все операции. Более точно, происходит следующее: по журналу в прямом направлении выполняются все операции; для транзакций, которые не закончились к моменту сбоя, выполняется откат (англ. back up).
Хотя к ведению журнала предъявляются особые требования по части надежности, реально возможна и его утрата. Тогда единственным способом восстановления базы данных является возврат к архивной копии. Конечно, в этом случае не удастся получить последнее согласованное состояние базы данных.
Рассмотрим способы производства архивных копий базы данных. Самый простой способ — архивировать базу данных при переполнении журнала. В этом случае образование новых транзакций временно блокируется. Когда все транзакции закончатся, и, следовательно, база данных придет в согласованное состояние, можно выполнять ее архивацию, после чего начинать заполнять журнал заново.
Можно выполнять архивацию базы данных реже, чем переполняется журнал. При переполнении журнала и окончании всех начатых транзакций можно архивировать сам журнал. Поскольку такой архивированный журнал, по сути дела, требуется только для воссоздания архивной копии базы данных, журнальная информация при архивации может быть существенно сжата.
В заключение сформулируем общие требования к системе восстановления данных в составе СУБД.
1. Пользователь не должен осуществлять рестарт транзакций или повторный ввод данных. Восстановление должно проходить на базе транзакции с помощью отмены или изменения отдельных транзакций.
2. Быстрое восстановление данных обеспечивается генерацией данных, используемых для восстановления.
3. При выполнении процедур автоматизированного восстановления пользователь не должен анализировать состав данных и выбирать сами процедуры.
Для восстановления базы данных СУБД имеют в своем составе сервисные программные средства:
Программы ведения системного журнала регистрируют операции над БД: описание соответствующей транзакции, код пользователя, текст входного сообщения, тип изменения БД, адреса изменяемых данных вместе с их значениями до и после изменения.
Программы архивации используются для регулярного получения копий БД для последующего ее восстановления.
Программы восстановления применяются для возврата БД или некоторых ее частей в состояние, предшествующее возникновению отказа. При этом используют архивную копию БД и системный журнал.
Программы отката ликвидируют последствия выполнения определенной транзакции в БД.
Программы записи контрольных точек и повторного исполнения позволяют ускорить восстановление.
9.3. Параллельное выполнение транзакций
При параллельной обработке данных (т. е. при совместной работе с БД нескольких пользователей) СУБД должна гарантировать, что пользователи не будут мешать друг другу. Средства обработки транзакций позволяют изолировать пользователей друг от друга таким образом, чтобы у каждого из них было ощущение монопольной работы с БД.
Транзакции являются подходящими единицами изолированности пользователей благодаря свойству сохранения целостности БД. Действительно, если с каждым сеансом работы с базой данных ассоциируется транзакция, то каждый пользователь начинает работу с согласованным состоянием базы данных, т. е. с таким состоянием, в котором база данных могла бы находиться, даже если бы пользователь работал с ней в одиночку.
Чтобы понять, как должны выполняться параллельные транзакции, рассмотрим проблемы, возникающие при параллельной работе с данными.
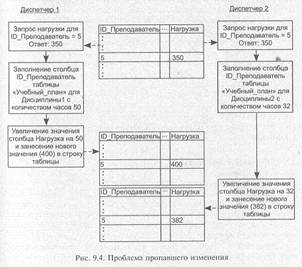
Рассмотрим пример работы двух диспетчеров с модифицированной БД «Сессия». Пусть Диспетчер 1 вносит в текущий учебный план для каждой дисциплины, читаемой на третьем курсе, сведения о преподавателях, параллельно изменяя при этом значение столбца Нагрузка в таблице «Кадровый_ состав», а Диспетчер 2 выполняет такую же операцию для дисциплин второго курса.
Диспетчер 1 начинает работу по изменению таблицы «Учебный_ план» для Дисциплины 1 с количеством часов, равным 50.
В столбец ID_ Преподаватель для этой дисциплины предполагается внести значение 5. Запрос текущей нагрузки преподавателя возвращает значение 350, и Диспетчер 1 подтверждает изменение таблицы «Учебный_ план». При этом выполняются дополнительные действия по изменению столбца Нагрузка в таблице «Кадровый_ состав» для строки с ID_ Преподаватель = 5 (в столбец заносится значение 400).
До завершения операции Диспетчер 2 начинает те же действия для Дисциплины 2 с количеством часов 32, которую должен читать тот же преподаватель (ID_Преподаватель = 5). Запрос текущей нагрузки преподавателя также возвращает значение 350, с которым и работает дальше Диспетчер 2. Выполнив те же операции, что и Диспетчер 1 (но после него), Диспетчер 2 помещает в столбец Нагрузка значение 382, отменив тем самым предыдущие изменения (рис. 9.4).
Для избежание подобных ситуаций к СУБД по части синхронизации параллельно выполняемых транзакций предъявляется минимальное требование — отсутствие потерянных изменений.
9.3.2. Чтение «грязных» данных
Другой пример коллизий при несогласованной работе двух параллельных транзакций представлен на рис. 9.5.
Как показано на рисунке, Диспетчер 1 и Диспетчер 2 опять выполняют действия, описанные в предыдущем примере, но Диспетчер 2 начинает запрашивать данные о нагрузке преподавателя в тот момент, когда изменения, сделанные Диспетчером 1, уже зафиксированы в столбце Нагрузка, а транзакция еще не закончилась. Запрос Диспетчера 2 возвращает значение 400, и Диспетчер 2 вынужден отменить свои действия потому, что 400 часов — это максимальное разрешенное значение нагрузки. Между тем транзакция Диспетчера 1 закончилась возвратом к исходному состоянию, т. е. на самом деле Диспетчер 2 мог бы успешно завершить операцию.
Это тоже не соответствует требованию изолированности пользователей (каждый пользователь начинает свою транзакцию при

согласованном состоянии базы данных и вправе ожидать увидеть согласованные данные). Чтобы избежать ситуации чтения «грязных» данных, необходимо требовать, чтобы до завершения одной транзакции, изменившей некоторый объект, никакая другая транзакция не могла читать изменяемый объект.
9.3.3. Чтение несогласованных данных
Рассмотрим ситуацию, которая приводит к получению несогласованных данных при выполнении операций над БД (рис. 9.6).
По-прежнему Диспетчер 1 выполняет операцию по заполнению строки учебного плана, а Диспетчер 2 при выполнении своей операции должен сделать выбор между двумя преподавателями в соответствии с их текущей нагрузкой.
Начиная работу практически одновременно с Диспетчером 1, Диспетчер 2 получает следующие сведения: нагрузка первого преподавателя (ID_ Преподаватель = 5) составляет 350 часов, а нагрузка второго преподавателя (ID_ Преподаватель = 7) составляет 370 часов. Далее Диспетчер 2 принимает решение в пользу первого преподавателя, но повторный запрос нагрузки возвращает значение 400, так как Диспетчер 1 уже сохранил новые данные в таблице «Кадровый_ состав».
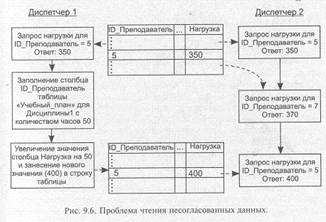
В большинстве систем обеспечение изолированности пользователей в подобных ситуациях является максимальным требованием к синхронизации транзакций.
К более тонким проблемам изолированности транзакций относится так называемая проблема строк-призраков, вызывающая ситуации, которые также противоречат изолированности пользователей. Рассмотрим следующий сценарий.
Диспетчер 1 инициирует Транзакцию 1, которая выполняет оператор выборки строк таблицы в соответствии с некоторым условием (например, формирование списка студентов, сдавших дисциплину с ID_ Дисциплина = N, по таблице «Сводная_ ведомость»). До завершения Транзакции 1 Транзакция 2, вызванная Диспетчером 2, вставляет в таблицу «Сводная_ ведомость» новую строку, удовлетворяющую условию отбора Транзакции 1 (данные о результате сдачи дисциплины N еще одним студентом), и успешно завершается. Транзакция 1 повторно выполняет оператор выборки, и в результате появляется строка, которая отсутствовала при первом выполнении оператора. Конечно, такая ситуация противоречит идее изолированности транзакций.
Чтобы добиться изолированности транзакций, СУБД должна использовать специальные методы регулирования совместного выполнения транзакций.
Метод сериализаций транзакций — это механизм их выполнения по такому плану, когда результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций. Обеспечение такого механизма является основной функцией управления транзакциями. Система, в которой поддерживается метод сериализаций транзакций, реально обеспечивает изолированность пользователей при работе с БД.
Основная реализационная проблема метода состоит в обеспечении такого выполнения транзакций, при котором не слишком ограничивалась бы их параллельность. Простейшим решением является действительно их последовательное выполнение, но существуют ситуации, когда можно выполнять операторы разных транзакций в любом порядке, и это не приведет к проблемным ситуациям. Примерами могут служить транзакции, выполняющие только операции чтения, или транзакции, работающие с разными объектами базы данных.
На самом деле между транзакциями могут существовать следующие виды конфликтов:
• Транзакция 2 пытается изменять объект, измененный не закончившейся Транзакцией 1 (W-W — конфликт);
• Транзакция 2 пытается изменять объект, прочитанный не закончившейся Транзакцией 1 (R-W — конфликт);
• Транзакция 2 пытается читать объект, измененный не закончившейся Транзакцией 1 (W-R — конфликт).
Практические методы сериализаций транзакций основываются на учете этих конфликтов.
9.5. Захват и освобождение объекта
Для обеспечения сериализаций транзакций применяются методы «захвата» и «освобождения» объектов, производимого по инициативе транзакции: транзакция «захватывает» объект, что приводит к его блокировке для других транзакций, и освобождает его только„при своем завершении. При этом захваты объектов несколькими транзакциями на чтение совместимы (т. е. нескольким транзакциям разрешается читать один и тот же объект), захват объекта одной транзакцией на чтение не совместим с захватом другой транзакцией того же объекта на запись, и захваты одного объекта разными транзакциями на запись не совместимы. Тем самым, выделяются два основных режима захватов:
• совместный режим — S (Shared), означающий разделяемый захват объекта и необходимый для выполнения операции чтения объекта;
• монопольный режим — Х (eXclusive), означающий монопольный захват объекта и необходимый для выполнения операций записи, удаления и модификации.
Наиболее распространенным в СУБД, основанных на архитектуре «клиент — сервер», является подход, реализующий соблюдение двухфазного протокола захватов объектов БД. В общих чертах протокол состоит в том, что перед выполнением любой операции над объектом базы данных от имени транзакции запрашивается захват объекта в соответствующем режиме (в зависимости от вида операции — совместном или монопольном). В соответствии с этим протоколом выполнение транзакции разбивается на две фазы: первая фаза транзакции — накопление захватов; вторая фаза (фиксация или откат) — освобождение захватов.
При соблюдении двухфазного протокола основная проблема состоит в том, что следует считать объектом для захвата?
В контексте реляционных баз данных возможны следующие варианты:
• файл — физический (с точки зрения базы данных) объект, область хранения нескольких отношений и, возможно, индексов;
• таблица — логический объект, соответствующий множеству записей данного отношения;
• страница данных — физический объект, хранящий записи одного или нескольких отношений, индексную или служебную информацию;
• запись — элементарный физический объект базы данных. Очевидно, что чем крупнее объект захвата, тем меньше захватов будет поддерживаться в системе, и на это, соответственно, будут тратиться меньшие накладные расходы. Более того, если выбрать в качестве уровня объектов для захватов файл или отношение, то будет решена даже проблема строк-призраков. Однако при использовании для захватов крупных объектов возрастает вероятность конфликтов транзакций и тем самым уменьшается допускаемая степень их параллельного выполнения. Фактически, при укрупнении объекта синхронизационного захвата мы умышленно огрубляем ситуацию и видим конфликты в тех ситуациях, когда на самом деле конфликтов нет.
Таким образом, можно резюмировать, что транзакция — это законченный блок обращений к базе данных и некоторых действий над ней, для которого гарантируется выполнение четырех условий, так называемых свойств ACID (Atomicity, Consistency, Isolation, Durability):
• атомарность — операции транзакции образуют неразделимый атомарный блок с определенным началом и концом. Этот блок либо выполняется от начала до конца, либо не выполняется вообще. Если в процессе выполнения транзакции произошел сбой, происходит откат к исходному состоянию;
• согласованность — по завершении транзакции все за действо ванные объекты находятся в согласованном состоянии;
• изолированность — одновременный доступ транзакций различных приложений к разделяемым объектам координируется таким образом, чтобы эти транзакции не влияли друг на друга;
• долговременность — все изменения данных, осуществленные в процессе выполнения транзакции, не могут быть потеряны.
Глава 10. Управление базами данных в СУБД
Для обеспечения эффективного контролируемого управления доступом к данным, целостности и сокращения избыточности хранимых данных большинство СУБД должны быть тесно связаны с операционной системой: многопользовательские приложения, обработка распределенных запросов, защита данных, использование многопроцессорных систем и мульти поточных технологий требуют использовать ресурсы, управление которыми обычно является функцией ОС. Соответственно, средства управления доступом и обеспечения защиты также обычно интегрируются с соответствующими средствами операционной системы.
Напомним, что с точки зрения операционной системы база данных — это один или несколько обычных файлов ОС, доступ к данным которых осуществляется не напрямую, а через СУБД. При этом данные обычно располагаются на машине-сервере, а СУБД обеспечивает корректную и эффективную их обработку из приложений, выполняющихся на машинах-клиентах.
С другой стороны, в рамках СУБД, база данных — это логически структурированный набор объектов, связанных не только с хранением и обработкой прикладных данных, но и обеспечивающих целостность БД, управление доступом, представление данных и т. д. Например, в MS SQL Server база данных включает следующие объекты:
• таблицы;
• хранимые процедуры;
• триггеры;
• представления;
• правила;
• пользовательские типы данных;
• индексы;
• пользователи;
• роли;
• публикации;
• диаграммы.
Кроме того, при создании базы данных для нее всегда определяется журнал транзакций, который используется для восстановления состояния базы данных в случае сбоев или потери данных. Журнал размещается в одном или нескольких файлах. В журнале регистрируются все транзакции и все изменения, произведенные в их рамках. Транзакция не считается завершенной, пока соответствующая запись не будет внесена в журнал.
Управление системой баз данных производится обычно с помощью нескольких сервисных программ — отдельных приложений, выполняемых в среде операционной системы. Рассмотрим основные функции и компоненты управления на примере сервера реляционных баз данных MS SQL Server.
Большая часть функций администрирования работы пользователей, серверов и баз данных сосредоточена в приложении SQL Server Enterprise Manager, которое позволяет осуществлять, в том числе, следующие функции:
• запускать и конфигурировать SQL Server;
• управлять доступом пользователей к объектам БД;
• создавать и модифицировать базы данных и их объекты, такие, как таблицы, индексы, представления и т. д.;
• управлять выполнением заданий «по расписанию»;
• управлять репликациями;
• создавать резервные копии баз данных и журналов транзакций.