3.1. Многоуровневые модели предметной области
Обычно отдельная база данных содержит (отражает) информацию о некоторой предметной области — наборе объектов, представляющих интерес для актуальных или предполагаемых пользователей. То есть, реальный мир отображается совокупностью конкретных и абстрактных понятий, между которыми существуют (и соответственно, фиксируются) определенные связи. Выбор для описания предметной области (ПрО) существенных понятий и связей является предпосылкой того, что пользователь будет иметь практически все необходимые ему в рамках задачи знания об объектах предметной области. Однако следует отметить, что пользователь, который хочет работать с базой данных, должен владеть основными понятиями, представляющими предметную область.
И в этом смысле абстрагирование позволяет построить такое описание (модель предметной области), которое другой человек сможет не только воспринять, но и безошибочно использовать для работы с описаниями экземпляров объектов, хранимых в базе данных. Модель предметной области соотносится с реальными объектами и связями так же, как схема маршрутов городского пассажирского транспорта с фактической траекторией движения автобуса. Схема адекватно отражает действительность на уровне основных понятий — маршрутов и остановок: выбрав по схеме маршрут, пассажир достигнет цели (прибудет на нужную остановку) независимо от того, в каком транспортном ряду будет двигаться автобус.
Наиболее простой способ представления предметных областей в БД реализуется поэтапно: 1) фиксацией логической точки зрения на данные (т. е. данные рассматриваются независимо от особенностей их хранения и поиска в конкретной вычислительной среде); 2) определением физического представления данных с учетом выбранных структур хранения данных и архитектуры ЭВМ.
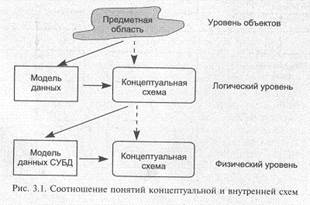
Абстрагированное описание предметной области с фиксированной (логической) точки зрения будем называть концептуальной схемой. Соответственно, систематизация понятий и связей предметной области называется логическим или концептуальным проектированием. Модель (представление логической точки зрения), используемая при абстрагировании — совокупность функциональных характеристик объектов и особенностей представления информации (например, в числовой или текстовой форме), будем называть моделью данных.
Отображение концептуальной схемы на физический уровень будем называть внутренней схемой.
Соотношение этих понятий приведено на рис. 3.1. Отражение взгляда (точки зрения) отдельного пользователя на концептуальную схему (как вариант восприятия предметной области) будем называть внешней схемой. Внешняя схема использует те же абстрактные категории, что и концептуальная, а на практике соответствует логической организации данных в прикладной программе,
Теоретически вопрос о многообразии уровней абстракции был решен еще в 60 — 70-х гг. Основой для его решения является концепция многоуровневой архитектуры системы базы данных. Например, в отчете CODASYL [24] предусматривался архитектурный уровень подсхемы, который позволял для каждого конкретного приложения строить свое собственное «видение» используемого подмножества базы данных путем определения его «персональной» подсхемы базы данных.
В более общем виде этот вопрос решен в архитектурной модели ANSI/ХЗ/SPARC [22]. Здесь на внешнем уровне может поддерживаться совсем иная модель данных (или даже несколько моделей), чем на концептуальном уровне. Поддержка разнообразных возможностей абстрагирования в такой системе достигается благодаря средствам определения и поддержки межуровневого отображения моделей данных.
Помимо этого, для решения указанной проблемы может использоваться внутри модельная структура, например, механизмы
представлений (view). В объектных системах для этих целей может использоваться отношение наследования.
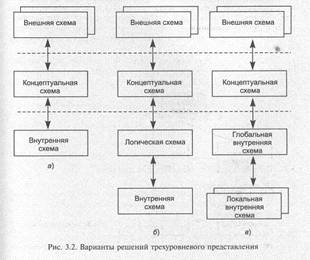
В общем случае концепция трехуровневого представления не требует более трех уровней, однако с практической точки зрения иногда удобно включать схемы дополнительных уровней. На рис. 3.2 приведены некоторые варианты решений.
На рис. 3.2, б выделена логическая схема, учитывающая особенности СУБД.
Пример, приведенный на рис. 3.2, в, характерен для варианта распределенной базы данных, объединяющей информацию, представленную разными внутренними схемами.
Рассмотренная трехуровневая архитектура обеспечивает выполнение основных требований, предъявляемых к системам баз данных:
• адекватность отображения предметной области;
• возможность взаимодействия с БД разных пользователей при решении разных прикладных задач;
• обеспечение независимости программ и данных;
• надежность функционирования БД и защита от несанкционированного доступа.
С точки зрения пользователей различных категорий трехуровневая архитектура имеет следующие достоинства:
• системный аналитик, создающий модель предметной области, не обязательно должен быть специалистом в области программирования и вычислительной техники;
• администратор баз данных, обеспечивающий отражение концептуальной схемы во внутреннюю, не должен беспокоиться о корректности представления предметной области;
• конечные пользователи, используя внешнюю схему, могут не вдаваться полностью в предметную область, обращаясь только к необходимым составляющим. При этом исключается возможность несанкционированного обращения к данным вне объявленных внешней схемой, так как формирование ее находится в сфере деятельности администратора базы данных;
• системный аналитик, как и конечный пользователь, не вмешивается во внутреннее представление данных.
Это отражает распространенную практику специализации и разделения ответственности. Главное же заключается в том, что работу по проектированию и эксплуатации баз данных можно разделить на три достаточно самостоятельных этапа. Хотя надо отметить, что на практике создание концептуальной схемы не всегда предшествует построению внешней. Иногда трудно с самого начала полностью определить предметную область, но с другой стороны, уже известны требования пользователей (именно поэтому создание базы уже имеет смысл). И кроме того, адекватность модели предметной области, в конце концов, должна подтверждаться практикой пользовательских представлений.
3.2. Идентификация объектов и записей
В задачах обработки информации, и в первую очередь в алгоритмизации и программировании, атрибуты именуют (обозначают) и приписывают им значения.
При обработке информации мы, так или иначе, имеем дело с совокупностью объектов, информацию о свойствах каждого из которых надо сохранять (записывать) как данные, чтобы при решении задач их можно было найти и выполнить необходимые преобразования.
Таким образом, любое состояние объекта характеризуется совокупностью актуализированных атрибутов (имеющих некоторое из значений в этот момент времени), которые фиксируются на некотором материальном носителе в виде записи — совокупности (группы) формализованных элементов данных (значений атрибутов, представленных в том или ином формате). Кроме того, в контексте задач хранения и поиска можно говорить, что значение атрибута идентифицирует объект: использование значения в качестве поискового признака позволяет реализовать простой критерий отбора по условию сравнения.
Так же как и в реальном мире, отдельный объект всегда уникален (уже хотя бы потому, что мы именно его выделяем среди других). Соответственно, запись, содержащая данные о нем, также должна быть узнаваема однозначно (по крайней мере, в рамках предметной области), т. е. иметь уникальный идентификатор, причем никакой другой объект не должен иметь такой же идентификатор. Поскольку идентификатор — суть значение элемента данных, в некоторых случаях для обеспечения уникальности требуется использовать более одного элемента. Например, для однозначной идентификации записей о дисциплинах учебного плана необходимо использовать элементы СЕМЕСТР и НАИМЕНОВАНИЕ ДИСЦИПЛИНЫ, тай как возможно преподавание одной дисциплины в разных семестрах.
Предложенная выше схема представляет атрибутивный способ идентификации содержания объекта (рис. 3.3). Она является достаточно естественной для данных, имеющих фактографическую природу и описывающих обычно материальные объекты. Информацию, представляемую такого рода данными, называют хорошо структурированной. Здесь важно отметить, что структурированность относится не только к форме представления данных (формат, способ хранения), но и к способу интерпретации значения пользователем: значение параметра не только представлено в предопределенной форме, но и обычно сопровождается указанием размерности
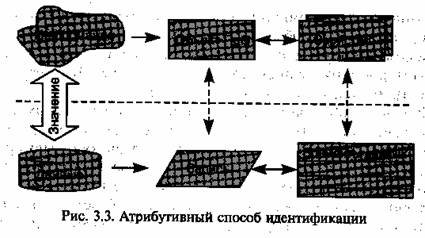
величины, что позволяет пользователю понимать ее смысл без дополнительных комментариев. Таким образом, фактографические данные предполагают возможность их непосредственной интерпретации.
Однако атрибутивный способ практически не подходит для идентификации слабо структурированной информации, связанной с объектами, имеющими обычно идеальную (умозрительную) природу — категориями, понятиями, знаковыми системами. Такие объекты зачастую определяются логически и опосредованно — через другие объекты. Для описания таких объектов используются естественные или искусственные языки (например, язык алгебры). Соответственно, для понимания смысла пользователю необходимо использовать соответствующие правила языка, и, более того, часто необходимо уже располагать некоторой информацией, позволяющей идентифицировать и связать получаемую информацию с наличным знанием. То есть процесс интерпретации такого рода данных имеет опосредованный характер и требует использования дополнительной информации, причем такой, которая не обязательно присутствует в формализованном виде в базе данных.
Такое разделение нашло отражение в традиционном разделении баз данных на фактографические и документальные.
Программисту или пользователю необходимо иметь возможность обращаться к отдельным, нужным ему записям (описаниям объектов) или отдельным элементам данных. В зависимости от уровня, программного обеспечения прикладной программист может использовать следующие способы.
• Задать машинный адрес данных и в соответствии с физическим форматом записи прочитать значение. Это случай, когда программист должен быть «навигатором».
• Сообщить системе имя записи или элемента данных, которые он хочет получить, и возможно, организацию набора данных. В этом случае система сама произведет выборку (по предыдущей схеме), но для этого она должна будет использовать вспомогательную информацию о структуре данных и организации набора. Такая информация по существу будет избыточной по отношению к объекту, однако общение с базой данных не будет требовать от пользователя знаний программиста и позволит переложить заботы о размещении данных на систему.
В качестве ключа, обеспечивающего доступ к записи, можно использовать идентификатор — отдельный элемент данных. Ключ, который идентифицирует запись единственным образом, называется первичным (главным).
В том случае, когда ключ идентифицирует некоторую группу записей, имеющих определенное общее свойство, ключ называется вторичным (альтернативным). Набор данных может иметь несколько вторичных ключей, необходимость введения которых определяется практической необходимостью — оптимизацией процессов нахождения записей по соответствующему ключу.
Иногда в качестве идентификатора используют составной сцепленный ключ — несколько элементов данных, которые в совокупности, например, обеспечат уникальность идентификации каждой записи набора данных.
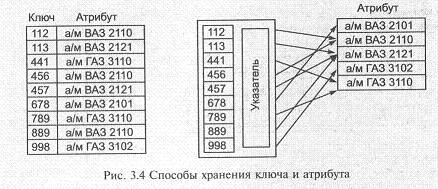
При этом ключ может храниться в составе записи или отдельно. Например, ключ для записей, имеющих неуникальные значения атрибутов, для устранения избыточности целесообразно хранить отдельно. На рис. 3.4 приведены два таких способа хранения ключей и атрибутов для набора простейшей структуры.
Введенное понятие ключа является логическим и его не следует путать с физической реализацией ключа — индексом, обеспечивающим доступ к записям, соответствующим отдельным значениям ключа.
Один из способов использования вторичного ключа в качестве входа — организация инвертированного списка, каждый вход которого содержит значение ключа вместе со списком идентификаторов соответствующих записей. Данные в индексе располагаются в возрастающем или убывающем порядке, поэтому алгоритм нахождения
нужного значения довольно прост и эффективен, а после нахождения значения запись локализуется по указателю физического расположения. Недостатком индекса является то, что он занимает дополнительное пространство и его надо обновлять каждый раз, когда удаляется, обновляется или добавляется запись. На рис. 3.5 приведен инвертированный список для предыдущего примера.

В общем случае инвертированный список может быть построен для любого ключа, в том числе составного.
В контексте задач поиска можно сказать, что существуют два основных способа организации данных. Первый соответствует примеру, приведенному на рис. 3.3, и представляет прямую организацию массива. Второй способ является инверсией первого, он соответствует рис. 3.4. Прямая организация массива удобна для поиска по условию «Каковы свойства указанного объекта?», а инвертированная — для поиска по условию «Какие объекты обладают указанным свойством?».
В [14] приводится следующая типология простых (атомарных) запросов:
1) A(E) = ? Каково значение атрибута А для объекта Е?
2) А(?) = V Какие объекты имеют значение атрибута, равное V?
3) ?(Е) = V Какие атрибуты объекта Е имеют значение, равное V?
4) ?(Е) =? Какие значения атрибутов имеет объект Е?
5) А(?) =? Какие значения имеет атрибут А в наборе?
6) ?(?) = V Какие атрибуты объектов набора имеют значение, равное V?
Здесь в запросах типов 2, 3, 6 вместо оператора равенства может быть использован другой оператор сравнения (больше, меньше, не равно или другие).
Запросы типа 1 выполняются поиском по «прямому» массиву: доступ к записи производится по первичному ключу. Запросы типа 2 выполняются поиском по инвертированному списку: доступ к записи(ям) производится по указателю, выбираемому из списка по значению вторичного ключа. Ответом в этих случаях будет значение атрибута или идентификатора. Запросы типа 3 имеют ответом имя атрибута.
Запросы типа 2, 5, 6 относятся к нескольким атрибутам, и в этом случае могут быть построены несколько индексов, облегчающих поиск по этим ключам.
Составные условия поиска могут использовать несколько простых условий, обычно связанных логическими (булевыми) операторами.
Следует отметить, что в контексте обработки запросов 2-го типа «Какие объекты имеют заданное значение атрибута?» можно выделить три следующих типа архитектур доступа.
1. Системы с вторичными индексами. В этих системах последовательность расположения записей соответствует последовательности значений первичного ключа. Как правило, используется один первичный индекс и несколько вторичных.
2. Системы частично инвертированных файлов. В этих системах записи могут располагаться в произвольной последовательности. В отличие от систем первого типа первичный индекс отсутствует. Вторичные индексы применяются для прямой адресации записей, что существенно облегчает включение в файл новых записей, так как допускается их размещение в любом свободном участке файла.
3. Системы полностью инвертированных файлов. В этих системах предусмотрено наличие файлов, содержащих значения отдельных элементов данных, входящих в состав записей, — допускается раздельное хранение элементов данных записи. Значения элементов данных, составляющих конкретную запись или кортеж, в общем случае могут размещаться в памяти произвольно. Для ускорения процесса поиска в системе используют два набора индексов: индекс экземпляров (значений ключей) и индекс данных (инвертированный список). С помощью индекса экземпляров можно найти в файле элементы данных, имеющих заданное значение. С помощью индекса данных можно найти записи, связанные с заданными значениями элементов. Такая организация характерна для организации данных документальных информационных систем.
3.4. Представление предметной области и модели данных
Если бы назначением базы данных было только хранение и поиск данных в массивах записей, то структура системы и самой базы была бы простой. Причина сложности в том, что практически любой объект характеризуется не только параметрами-величинами, но и взаимосвязями частей или состояний. Есть различия и в характере взаимосвязей между объектами предметной области: одни объекты могут использоваться только как характеристики остальных объектов, другие — независимы и имеют самостоятельное значение (рис. 3.6).
Кроме того, сам по себе отдельный элемент данных (его значение) ничего не представляет. Он приобретает смысл только тогда, когда связан с атрибутом (природой значения, что позволит интерпретировать значение) и другими элементами данных.
Поэтому физическому размещению данных (и, соответственно, определению структуры физической записи) должно предшествовать описание логической структуры предметной области — построение модели соответствующего фрагмента реального мира, выделяющей только те объекты, которые будут интересны будущим пользователям, и представленные только теми параметрами, которые будут значимы при решении прикладных задач, Такая модель
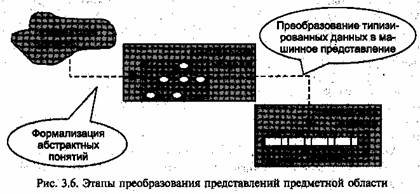
будет иметь очень мало физического сходства с реальностью, но будет полезна как представление пользователя о реальном мире. Причем это представление будет задаваться (описываться) удобными для пользователя средствами в не адекватной человеку жесткой вычислительной среде с двоичной логикой и числовым представлением информации.
Таким образом, прежде чем описывать физическую реализацию объектов и связей между ними, необходимо определить:
1) способ, с помощью которого внешние пользователи представляют (описывают) объекты и связи;
2) форму и методы внутримашинного представления элементов данных и взаимосвязей;
3) средства, обеспечивающие взаимно однозначные преобразования внешнего и внутримашинного представлений.
Такой подход является компромиссом, свойственным языкам программирования: за счет предварительно определяемого множества абстракций, общих для большинства задач обработки данных, обеспечивается возможность построения надежных программ обработки. Пользователь, используя ограниченное множество формальных, но достаточно знакомых понятий, выделяя сущности и связи, описывает объекты и связи предметной области; программист (или система автоматизации проектирования БД), используя такие типовые Абстрактные понятия (как например числа, множества, последовательности, агрегаты), определяет соответствующие информационные структуры. Система управления данными, используя двоичные формы представления типизированных данных, обеспечивает эффективные процедуры хранения и обработки данных.
Именно введение промежуточного уровня абстракции позволяет иметь раздельное описание логического и физического представлений, освобождает конечного пользователя от необходимости беспокоиться о деталях внутримашинного представления и обработки, поскольку он может быть уверен, что программистом выбрана наиболее эффективная форма для данной ситуации. Однако эффективность здесь имеет определенные пределы. Чем ближе система абстракций к особенностям вычислительной среды, тем выше эффективность выполнения программы, но вынужденная «специализациях абстракций увеличивает вероятность того, что они станут неподходящими для некоторых других применений.
Модель данных должна, так или иначе, дать основу для описания данных и манипулирования данными, а также дать средства анализа и синтеза структур данных.
Необходимо отметить, что предметные среды с точки зрения описания целесообразно условно разделить на два полярных случая:
1. Предметная среда характеризуется сравнительно небольшим количеством типов отношений, но каждое отношение само есть большое множество. Эти отношения сравнительно устойчивы, а изменений в пределах каждого множества существенно меньше мощности самого отношения. Например, отношение «вхождения» элементов изделий, содержащееся в конструкторских спецификациях, для среднего предприятия содержит сотни тысяч записей. В этом случае, задав схемы отношений и ориентировочные значения их мощностей, можно достаточно полно представить структуру и масштаб предметной среды.
2. Для предметной среды характерно большое число типов отношений между объектами, но каждое отношение есть множество сравнительно малой мощности. При этом мощность потока изменений для отношений сравнима с мощностью самих отношений.
Первый случай характерен для отображения процессов на уровне автоматизированных систем управления предприятиями. Современные системы управления базами данных наиболее эффективны именно в подобном случае, при отображении статических в указанном смысле предметных сред. Обычно при этом речь идет о целых классах объектов, например, о деталях данного типа и не отображается состояние каждой конкретной детали.
Второй случай характерен для описания производственного технологического процесса, с учетом временных и пространственных факторов нахождения конкретных объектов.
Если в первом случае говорят о реляционной, иерархической или сетевой моделях данных, то во втором — о семантических сетях и фреймах.
Основное отличие этих методов заключается в том, что первые задают четкую схему (так называемую схему базы данных), в рамках которой и отображается предметная область. Подобное построение по сути своей является довольно статичным, требует априорного знания типов отношений, в которых может находиться объект, однако зафиксированная схема базы данных позволяет довольно эффективно организовать поиск необходимой информации. Во втором случае предметная среда отображается (по крайней мере, на уровне модели) в виде однородной сети, любые изменения которой, по вводу как новых классов объектов, так и новых типов отношений, не связаны с какими-либо структурными преобразованиями сети. В силу большого количества типов отношений манипулирование подобной «элементарной» информацией достаточно затруднено, поэтому для данного случая характерно введение большого количества общих понятий (и соответствующих им отношений), что упрощает работу с таким представлением.
В контексте машинного представления модель данных может быть использована следующим образом:
• как средство спецификации типов данных и их организации, разрешенных в конкретной БД;
• как основа разработки общей методологии построения баз данных;
• как основа минимизации влияния эволюции баз данных на уже существующие прикладные программы и работу конечных пользователей;
• как основа разработки семейства языков запросов и языков манипулирования данными;
• как основа архитектуры СУБД;
• как основа изучения динамических свойств различных организаций данных.
Таким образом, модель данных — это базовый инструментарий, обеспечивающий на формальном абстрактном уровне конкретные способы представления объектов и связей.
Модель базы данных охватывает более широкий спектр понятий. Основное назначение модели базы данных состоит в том, чтобы:
• определить ясную границу между логическим и физическим аспектами управления базой данных (независимость данных);
• обеспечить конечным пользователям и программистам, создающим БД, возможность и средства общего понимания смысла данных (коммуникабельность);
• определить языковые понятия высокого уровня, обеспечивающие возможность выполнения однотипных операций над большими совокупностями записей (в общем случае разнотипных данных) как единую операцию (обработка множеств).
При любом методе отображения предметной области в машинных базах данных в основе отображения лежит фиксация (кодирование) понятий и отношений между понятиями. Абстрактное понятие структуры ближе всего к так называемой концептуальной модели предметной среды и часто лежит в основе последней.
Понятие структуры используется на всех уровнях представления предметной области и реализуется как:
• структура информации — схематичная форма представления сложных композиционных объектов и связей реальной предметной области, выделяемых как актуально необходимые для решения прикладных задач;
• структура данных — атрибутивная форма представления свойств и связей предметной области, ориентированная на выражение описания данных средствами формальных языков (т. е. учитывающая возможности и ограничения конкретных средств с целью сведения описаний к стандартным типам и регулярным связям);
• структура записей — целесообразная (учитывающая особенности физической среды) реализация способов хранения данных и организации доступа к ним как на уровне отдельных записей,
так и их элементов (с целью определения основных и вспомогательных функциональных массивов, а также совокупности унифицированных процедур манипулирования данными).
Структура является общепринятым и удобным инструментом, одинаково эффективно используемым как на уровне сознания человека при работе с абстрактными понятиями, так и на уровне логики машинных алгоритмов. Структура позволяет простыми способами свести многомерность содержательного описания к линейной последовательности записей. Именно это позволяет формализовать на общей понятийной основе взаимосвязь представлений информации в разных средах: обеспечить контролируемое сведение бесконечного разнообразия объектов и видов взаимосвязей реального мира к жестко детерминированному описанию — совокупности двоичных данных и машинно-ориентированных алгоритмов их обработки.
Выделение трех видов структур, относящихся к представлению объектов предметной области, имеет, в некотором смысле, принципиальный характер.
Структура информации — это неотъемлемое свойство информации (сведений, сигналов, воспринимаемых субъектом) о некоторой совокупности объектов предметной области в контексте практической задачи (решаемой субъектом), в общем случае без учета того, будут ли для ее решения использованы средства программирования и вычислительные машины. Структурирование информации осуществляется системным аналитиком и сводится к выделению операционных объектов и определению их характеристических свойств и взаимосвязей.
Структура данных — это определение информационных массивов (состава и взаимосвязей данных на логическом уровне, соответствующих характеру информации и видам соответствующих преобразований). При определении структур данных необходимо не только установить состав массива, но и определить оптимальную их взаимосвязь (и, соответственно, определить критерии и методы оценки эффективности), например, выделение групп или агрегатов, имеющих иерархическую идентификацию. Эффективность в этом случае связывается с процессом построения программы («решателя» прикладной задачи) и, в каком-то смысле — с эффективностью работы программиста. Например, при функциональной обработке массива необходимо обращаться к отдельным элементам, в то время как в операциях присваивания или при записи массива в файл поэлементное обращение приведет к увеличению размера текста программы, а в ряде случаев — к увеличению времени выполнения.
Структура записи — это определение структуры физической памяти: выделение, освобождение и защита областей физического носителя, способы адресации и пересылки. Эффективность в этом случае связывается с процессами обмена между устройствами оперативной и внешней памяти, искусственно вводимой для обеспечения функциональной эффективности отдельных операций (например, поиска по ключам) посредством избыточности данных.
Рассмотрим разновидности и типологию «компьютерных» логических структур данных с точки зрения особенности их организации. Структура здесь в первую очередь определяет алгоритм выборки отдельных элементов данных, но в то же время необходимо отметить, что она отражает и особенности «технологии» организации и обработки информации, свойственные человеку в его повседневной деятельности.
Физически понятию структура соответствует запись данных. Запись — это упорядоченная в соответствии с характером взаимосвязей совокупность полей (элементов) данных, размещаемых в памяти в соответствии с их типом". Поле представляет собой минимальную адресуемую (идентифицируемую) часть памяти — единицу данных, на которую можно ссылаться при обращении к данным.
Таким образом, структура данных — это способ отображения значений в памяти: размер области и порядок ее выделения (который и определит характер процедуры адресации/выборки). Зачастую именно успешность структурирования данных определяет сложность процедур их обработки [2].
Классификация структур данных должна проводиться с двух точек зрения.
1. По характеру взаимосвязи элементов структуры (с точки зрения порядка их размещения/выборки) виды структур можно разделить на линейные и нелинейные.
2. По характеру информации, представляемой структурой (с точки зрения однородности и «элементарности» типов данных, отражающих понятийную структуру предметной области) — на однородные структуры, где все элементы находятся на одном понятийном уровне и имеют один тип данных, и неоднородные (композиционные), где элементы относятся к нескольким понятийным уровням или имеют разную природу.
К линейным структурам относятся массивы и последовательности. таблицы.
Порядок следования (и, соответственно, выборки) элементов таких структур имеет линейный характер и соответствует порядку расположения элементов в памяти: один за другим без каких-либо промежутков. Адрес элемента соответствует его положению и определяется индексом — порядковым номером элемента в последовательности размещения. К элементу имеется прямой доступ, если известен его индекс.
Особенностью линейной структуры является то, что при последовательной организации (размещении) она допускает возможность прямого доступа к произвольному элементу, поскольку условие однородности (однотипности) предполагает, что все элементы занимают расположенные строго последовательно области одинакового размера, что и позволяет достаточно просто вычислять значение физического адреса элемента по значению его индекса.
Массив представляет собой совокупность однотипных элементов, причем число элементов массива известно до его размещения, что позволяет строить гибкие многомерные системы адресации. Последовательность, так же, как и массив, представляет собой совокупность однотипных элементов. Однако число элементов до размещения неизвестно. И, хотя каждая конкретная последовательность имеет конечную длину, до начала обработки (и, соответственно, размещения) необходимо считать длину последовательности бесконечной. Принципиальность такого предположения выражается
в том, что необходимо предусматривать специальную процедуру использования памяти (выделения/освобождения) и, возможно, алгоритм обработки последовательности по частям. Важность рассмотрения такого типа данных обусловлена тем, что именно он превалирует в операциях ввода/вывода с устройствами внешней памяти. Именно последовательный доступ позволяет организовать «потоковые» операции: однородность позволяет рассматривать пересылаемые данные как непрерывный поток. Поток не может быть прерван по контекстно определяемому условию, например, при пересылке текста — по значению кода «перевод строки», и это не заставляет программу анализировать значение каждого очередного элемента. И, кроме того, последовательный доступ — это простота управления памятью и устройством ввода-вывода.
Таблица — это последовательности, обычно представляемые строками — совокупностями разнотипных элементов. Или, иначе, таблица — это множество записей, каждая из которых представляет набор поименованных полей.
Однако с точки зрения размещения элементов таблица может быть представлена как одномерный массив (или, в случае ВД — последовательность) с однородными композиционными элементами, каждый из которых представляет собой совокупность разнотипных элементов. Именно это позволяет свести ввод/вывод таких джипов структур к последовательным элементарным операциям.
Кроме того, разнотипность элементов позволяет ввести отличную от перечислительной схему идентификации записей, определив одно из полей как ключ записи. Обычно ключ содержит значение, используемое в процедурах упорядочения и поиска записей.
В качестве примеров нелинейных структур рассмотрим списки, деревья и сети.
Порядок следования (и, соответственно, выборки) элементов таких структур может не соответствовать порядку расположения элементов в памяти. Списки представляют собой пример линейного упорядочения, деревья — двумерного, сети — произвольного. Соответственно различаются методы и средства, обеспечивающие последовательность выборки элементов данных. Обычно для обеспечения возможности прямого доступа к произвольному элементу необходимо использовать вспомогательные структуры типа инвертированных списков.
Списки. Как и массив, список представляет собой совокупность
однотипных элементов. Однако порядок выборки элементов может отличаться от порядка следования в памяти, определенного при размещении. Наиболее очевидный способ установления однонаправленного порядка выборки элементов — это сопоставить каждому элементу списка ссылку, указывающую на следующий элемент. Соответственно, для организации двунаправленного списка, допускающего также выборку в обратном порядке, каждый элемент должен иметь ссылку на предыдущий. Такая организация уже не допускает возможности прямого доступа, например, по номеру элемента.
Кроме того, число элементов списка, как и в случае последовательностей, может быть неизвестно до размещения, и до начала обработки (и, соответственно, размещения) необходимо считать длину списка бесконечной, что ведет к необходимости предусматривать специальную процедуру выделения/освобождения памяти.
Таким образом, с точки зрения физической реализации элемент списка должен быть составным, включающим собственно информативные данные, несущие смысловое значение, и дополнительные данные (ссылки), определяющие порядок доступа к информативным элементам.
Понятие списка достаточно универсально. В общем случае ссылки могут указывать ответвления к другим спискам — подспискам. В зависимости от способа построения списка и предполагаемых путей доступа к элементам различают следующие виды ссылок: перекрестные, боковые, иерархические, множественные, что позволяет изменять «естественный» последовательный порядок прохода по элементам списка.
Деревья. Дерево (рис. 3.7) представляет собой иерархию элементов, называемых узлами. На самом верхнем уровне иерархии имеется только один узел — корень. Каждый узел, кроме корня, связан с одним узлом на более высоком уровне, называемым исходным узлом для данного узла. Каждый элемент имеет только один исходный. Каждый элемент может быть связан с одним или несколькими элементами на более низком уровне, которые называются порожденными. Элементы, расположенные в конце ветви, т. е. не имеющие порожденных, называются листьями.
Существует несколько способов представления структуры дерева. Например, дерево может быть определено как иерархия узлов с попарными связями, в которой:
1. Самый верхний уровень иерархии имеет один узел, называемый корнем.
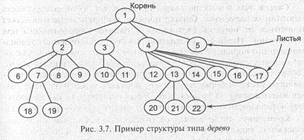
2. Все узлы, кроме корня, связываются с одним и только одним узлом на более высоком уровне по отношению к ним самим.
Такое определение в части организации связей совпадает со списком, и, в частности, список представляет вырожденный случай дерева, в котором каждая вершина имеет не более одного поддерева.
Еще раз отметим, что деревья здесь рассматриваются как средство и для логического, и для физического представления данных. В логическом описании данных они используются для определения связей между элементами структуры, а при определении физической организации данных — для определения набора указателей, реализующих связи между ними.
Использование ссылок для организации доступа к отдельным элементам структуры не позволяет сократить процедуру поиска, в основу которой положен последовательный перебор. Процедура поиска будет эффективнее, если будет предварительно установлен некоторый порядок перехода к следующему элементу дерева. Такой порядок в ряде случаев определяется в отношении метода обхода и регулярности итераций, определяемой длиной пути и кратностью деления вершины.
Выделяют [2] три метода обхода: сверху вниз, слева направо, снизу вверх.
Регулярность обхода дерева может быть связана с упорядоченными деревьями, к которым относятся сбалансированные (рис. 3.8) и двоичные деревья (рис. 3.9).
Сбалансированное дерево в каждом узле имеет одинаковое число ветвей, причем процесс включения новых ветвей в узлы дерева идет сверху вниз, а на каждом уровне дерева — слева направо. Для дерева
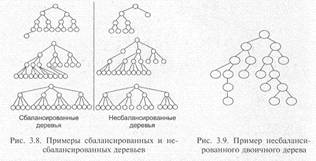
с фиксированным числом ветвей физическая организация данных будет более простой. Однако большая часть логических организаций данных не может быть задана в виде сбалансированной древовидной структуры, и для их представления требуется переменное число ветвей в каждом узле. В то же время индексы могут быть построены в виде сбалансированных древовидных структур.
Двоичные деревья — это особая категория сбалансированных древовидных структур, в которой допускается не более двух ветвей для одного узла. На рис. 3.9 показано несбалансированное двоичное дерево.
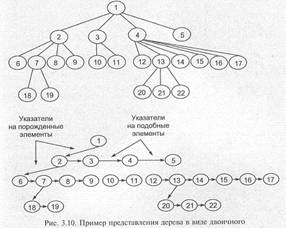
Любые связи в дереве можно представить в виде двоичных древовидных структур. Рис. 3.10 иллюстрирует представление дерева в виде двоичного дерева.
При таком представлении каждый элемент может иметь указатели как на порожденные, так и на подобные элементы.
Различные виды двоичных деревьев, для которых характерно наличие жесткой схемы управления их ростом, достаточно эффективно используются для построения больших поисковых индексов, размещаемых обычно на устройствах внешней памяти. Кроме того, для таких деревьев можно организовать специальное «страничное» хранение поддеревьев, что сократит число физических обращений к устройству.
Заметим, что деревья поисковых индексов являются однородными структурами: каждый узел представлен элементами одного типа. Однако большинство баз должно поддерживать организацию данных, имеющих различную природу. В этом случае при работе с неоднородными
структурами разной глубины, гарантировать регулярность, обеспечивающую эффективность процедур доступа, становится затруднительно.
Иерархические структуры характерны для многих областей, однако во многих случаях отдельная запись требует более одного представления или связана с несколькими другими. В результате получаются обычно более сложные структуры по сравнению с древовидными. Например, генеалогическое дерево может быть представлено в виде древовидной структуры, только если для каждого элемента (личности) будет показан только один исходный элемент (родитель). Если бы были показаны оба родителя, то это была бы более сложная структура.
В сетевой структуре любой элемент может быть связан с любым другим элементом. Примеры сетевых структур приведены на рис. 3.11.
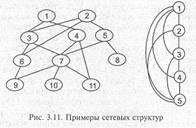
Так же, как и в случае древовидных структур, сетевую структуру можно описать с помощью исходных и порожденных элементов. Удобно представлять ее так, чтобы порожденные элементы располагались ниже исходных. При рассмотрении некоторых сетевых структур естественно говорить об уровнях, так же как и в случае древовидных структур.
Во многих сетевых структурах, задающих связи между элементами, представление отношений между исходными и порожденными элементами аналогично представлению отношений в случае дерева: отношение исходный — порожденный является сложным (указывается сдвоенными стрелками), а отношение порожденный — исходный — простым (указывается одинарными стрелками).
На рис. 3.12 показана неоднородная сетевая структура с пятью типами элементов. Ни одна из их соединяющих линий не имеет сдвоенных стрелок в обоих направлениях. Каждое отношение может рассматриваться как отношение «исходный — порожденный».
Запись ЗАКАЗ-НА-ЗАКУПКУ является порожденной по отношению к записи ИЗДЕЛИЕ и исходной по отношению к записи ПАРТИЯ-ТОВАРА. на закупку
Желательно отличать структуры, в которых представление отношений «порожденный — исходный» является простым или не используется, от структур, в которых представление отношений между какими-то двумя типами данных
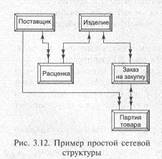
является сложным в обоих направлениях. Для структур второго типа на одной из линий схемы будут сдвоенные стрелки, указывающие в разные стороны. Этот тип схемы назовем сложной сетевой структурой, а схему, в которой ни на одной из линий нет сдвоенных стрелок в обоих направлениях, — простой сетевой структурой. На рис. 3.12 показана простая сетевая структура. Она станет сложной, если ввести отношение ЗАКАЗ-НА-ЗАКУПКУ — ИЗДЕЛИЕ, когда один заказ может быть сделан сразу на несколько изделий. Для образования сложной сетевой структуры достаточно двух типов элементов. Например, ПОСТАВЩИК может иметь несколько порожденных записей, потому что может поставляться более одного вида изделий. С другой стороны, элемент ИЗДЕЛИЕ может иметь более одного исходного элемента, поскольку это изделие может поставляться различными поставщиками.
В некоторых случаях один элемент данных может быть связан с целой совокупностью других элементов данных. Например, одно изделие может поставляться несколькими поставщиками, каждый из которых установил свою цену на это изделие. Элемент данных ЦЕНА не может быть ассоциирован только с элементом ИЗДЕЛИЕ или только с элементом ПОСТАВЩИК, а должен быть связан одновременно с двумя. Информация такого рода, т. е. данные, ассоциированные с совокупностью элементов, называют иногда данными пересечения.
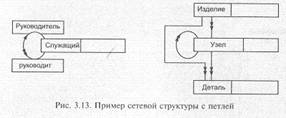
Некоторые структуры содержат циклы. Циклом считается ситуация, в которой предшественник узла является в то же время его последователем. Отношения «исходный — порожденный» образуют при этом замкнутый контур. Например, завод выпускает различную продукцию. Некоторые изделия производятся на других заводах-субподрядчиках. С одним контрактом может быть связано производство нескольких изделий. Представление этих отношений и образует цикл.
Иногда элементы связаны с другими элементами того же типа. Такая ситуация называется петлей. На рис. 3.13 приведены две достаточно распространенные ситуации, где могут использоваться петли. В массиве служащих специфицированы связи, существующие между некоторыми служащими. В базу данных списка материалов введено дополнительное усложнение: некоторые узлы сами состоят из узлов.
Разделение сетевых структур на простые и сложные необходимо потому, что сложные структуры требуют более сложных методов физического представления. Это не всегда является недостатком, поскольку
сложную сетевую структуру можно (а в большинстве случаев и следует) преобразовать к простому виду.
3.6. Реляционная модель данных
3.6.1. Основные понятия реляционной модели данных
Реляционная модель является удобной и наиболее привычной формой представления данных в виде таблицы. В отличие от иерархической и сетевой моделей, такой способ представления: 1) понятен пользователю-непрограммисту; 2) позволяет легко изменять схему— присоединять новые элементы данных и записи без изменения соответствующих подсхем; 3) обеспечивает необходимую гибкость при обработке непредвиденных запросов. К тому же любая сетевая или иерархическая схема может быть представлена двумерными отношениями.
Одним из основных преимуществ реляционной модели является ее однородность. Все данные рассматриваются как хранимые в таблицах, в которых каждая строка имеет один и тот же формат. Каждая строка в таблице представляет некоторый объект реального мира или соотношение между объектами. Пользователь модели сам должен для себя решить вопрос, обладают ли соответствующие сущности реального мира однородностью. Этим самым решается проблема пригодности модели для предполагаемого применения.

Основными понятиями, с помощью которых определяется реляционная модель, являются следующие: домен, отношение, кортеж, кардинальность, атрибуты, степень, первичный ключ. Соотношение этих понятий иллюстрируется рис. 3.14. Эти понятия представляют специальную терминологию, введенную авторами теоретических основ, однако они имеют и более привычные аналоги (но не во всем эквиваленты!), соответствие которых приведено в следующей табл. 3.1.

Домен — это совокупность значений, из которой берутся значения соответствующих атрибутов определенного отношения. С точки зрения программирования, домен — это тип данных, определяемый системой (стандартный) или пользователем.
Первичный ключ — это столбец или некоторое подмножество столбцов, которые уникально, т. е. единственным образом определяют строки. Первичный ключ, который включает. более одного —столбца, называется множественным, или комбинированным, или составным. Правило целостности объектов утверждает, что первичный ключ не может быть полностью или частично пустым, т. е. иметь значение null.
Остальные ключи, которые можно также использовать в качестве первичных, называются потенциальными или альтернативными ключами.
Внешний ключ — это столбец или подмножество одной таблицы, в: который может служить в качестве первичного ключа для другой таблицы. Внешний ключ таблицы является ссылкой на первичный ключ другой таблицы. Правило ссылочной целостности гласит, что, внешний ключ может быть либо пустым, либо соответствовать значению первичного ключа, на который он ссылается. Внешние ключи являются неотъемлемой частью реляционной модели, поскольку реализуют связи между таблицами базы данных.
Внешний ключ, как и первичный ключ, тоже может представлять собой комбинацию столбцов. На практике внешний ключ всегда будет составным (состоящим из нескольких столбцов), если он ссылается на составной первичный ключ в другой таблице. Очевидно, что количество столбцов и их типы данных в первичном и внешнем ключах совпадают.
Если таблица связана с несколькими другими таблицами, она может иметь несколько внешних ключей.
Модель предъявляет к таблицам следующие требования:
1) данные в ячейках таблицы должны быть структурно неделимыми;
2) данные в одном столбце должны быть одного типа;
3) каждый столбец должен быть уникальным (недопустимо дублирование столбцов);
4) столбцы размещаются в произвольном порядке;
5) строки размещаются в таблице также в произвольном порядке;
6) столбцы имеют уникальные наименования.
В целом концепция реляционной модели определяется следующими двенадцатью правилами Кодда (приводится по [3]).
1. Правило информации. Вся информация в базе данных должна быть предоставлена исключительно на логическом уровне и только одним способом — в виде значений, содержащихся в таблицах.
2. Правило гарантированного доступа. Логический доступ ко всем и каждому элементу данных (атомарному значению) в реляционной базе данных должен обеспечиваться путем использования комбинации имени таблицы, первичного ключа и имени столбца.
3. Правило поддержки недействительных значение. В реляционной базе данных должна быть реализована поддержка недействительных значений, которые отличаются от строки символов нулевой длины, строки пробельных символов, от нуля или любого другого числа и используются для представления отсутствующих данных независимо от типа этих данных.
4. Правило динамического каталога, основанного на реляционной модели. Описание базы данных на логическом уровне должно быть представлено в том же виде, что и основные данные, чтобы пользователи, обладающие соответствующими правами, могли работать с ним с помощью того же реляционного языка, который они поменяют для работы с основными данными.
5. Правило исчерпывающего подъязыка данных. Реляционная система может поддерживать различные языки и режимы взаимодействия с пользователем (например режим вопросов и ответов). Однако должен существовать по крайней мере один язык, операторы которого можно представить в виде строк символов в соответствии с некоторым четко определенным синтаксисом и который в полной мере поддерживает следующие элементы:
• определение данных;
• определение представлений;
• обработку данных (интерактивную и программную);
• условия целостности;
• идентификацию прав доступа;
• границы транзакций (начало, завершение и отмена).
6. Правило обновления представлений. Все представления, которые
теоретически можно обновить, должны быть доступны для обновления.
7. Правило добавления, обновления и удаления. Возможность работать с отношением как с одним операндом должна существовать не только при чтении данных, но и при добавлении, обновлении и удалении данных.
8. Правило независимости физических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при любых изменениях способов хранения данных или методов доступа к ним.
9. Правило независимости логических данных. Прикладные программы и утилиты для работы с данными должны на логическом уровне оставаться нетронутыми при внесении в базовые таблицы любых изменений, которые теоретически позволяют сохранить нетронутыми содержащиеся в этих таблицах данные.
10. Правило независимости условий целостности. Должна существовать возможность определять условия целостности, специфические для конкретной реляционной базы данных, на подъязыке реляционной базы данных и хранить их в каталоге, а не в прикладной программе.
11. Правило независимости распространения. Реляционная СУБД не должна зависеть от потребностей конкретного клиента.
12. Правило единственности. Если в реляционной системе есть низкоуровневый язык (обрабатывающий одну запись за один раз), то должна отсутствовать возможность использования его для того, чтобы обойти правила и условия целостности, выраженные на реляционном языке высокого уровня (обрабатывающем несколько записей за один раз).
Правило два указывает на роль первичных ключей при поиске информации в базе данных. Имя таблицы позволяет найти требуемую таблицу, имя столбца позволяет найти требуемый столбец, а первичный ключ позволяет найти строку, содержащую искомый элемент данных.
Правило три требует, чтобы отсутствующие данные можно было представить с помощью недействительных значений (NULL).
Правило четыре гласит, что реляционная база данных должна сама себя описывать. Другими словами, база данных должна содержать набор системных таблиц, описывающих структуру самой базы данных.
Правило пять требует, чтобы СУБД использовала язык реляционной базы данных, например SQL. Такой язык должен поддерживать все основные функции СУБД — создание базы данных, чтение и ввод данных, реализацию защиты базы данных и т. д.
Правило шесть касается представлений, которые являются виртуальными таблицами, позволяющими показывать различным пользователям различные фрагменты структуры базы данных. Это одно из правил, которые сложнее всего реализовать на практике.
Правило семь акцентирует внимание на том, что базы данных по своей природе ориентированы на множества. Оно требует, чтобы операции добавления, удаления и обновления можно было выполнять над множествами строк. Это правило предназначено для того, чтобы запретить реализации, в которых поддерживаются только операции над одной строкой.
Правила восемь и девять означают отделение пользователя и прикладной программы от низкоуровневой реализации базы данных. Они утверждают, что конкретные способы реализации хранения или доступа, используемые в СУБД, и даже изменения структуры таблиц базы данных не должны влиять на возможность пользователя работать с данными.
Правило 10 гласит, что язык базы данных должен поддерживать ограничительные условия, налагаемые на вводимые данные и действия, которые могут быть выполнены над данными.
Правило 11 гласит, что язык базы данных должен обеспечивать возможность работы с распределенными данными, расположенными на других компьютерных системах.
И, наконец, правило 12 предотвращает использование других возможностей для работы с базой данных, помимо языка базы данных, поскольку это может нарушить ее целостность.
3.6.2. Основы реляционной алгебры
С точки зрения внешнего представления (абстрагирования на логическом уровне) объектов реального мира модель данных — это основные понятия и способы, используемые при анализе и описании предметной области.
Среди многих попыток представить обработку данных на формальном абстрактном уровне реляционная модель, предложенная Э. Ф. Коддом, стала по существу первой работоспособной моделью данных, поскольку помимо средств описания объектов имела эффективный инструментарий преобразований этих описаний — операции реляционной алгебры.
Реляционная алгебра в том виде, в котором она была определена Э. Ф. Коддом, состоит из двух групп по четыре оператора.
1. Традиционные операции над множествами (но модифицированные с учетом того, что их операндами являются отношения, а не произвольные множества): объединение, пересечение, разность и декартово произведение.
2. Специальные реляционные операции: выборка, проекция, соединение, деление.
Рассмотрим подробнее операции реляционной алгебры.
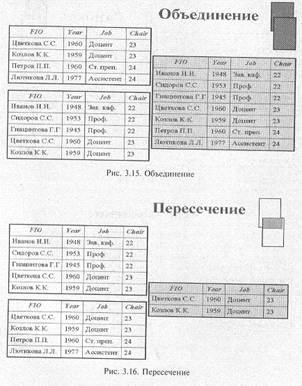
Объединение возвращает отношение, содержащее все кортежи, которые принадлежат либо одному из двух заданных отношений, либо им обоим (рис. 3.15).
Пересечение возвращает отношение, содержащее все кортежи, которые принадлежат одновременно двум заданным отношениям (рис. 3.16).
Разность возвращает отношение, содержащее все кортежи, которые принадлежат первому из двух заданных отношений и не принадлежат второму (рис. 3.17).
Произведение возвращает отношение, содержащее все возможные кортежи, которые являются сочетанием двух кортежей, принадлежащих соответственно двум заданным отношениям (рис. 3.18).

Выборка возвращает отношение, содержащие все кортежи из заданного отношения, которые удовлетворяют указанным условиям (рис. 3.19)
Проекция возвращает отношение, содержащее все кортежи (подкортежи) заданного отношения, которые остались в этом отношении после исключения из него некоторых атрибутов (рис. 3.20).

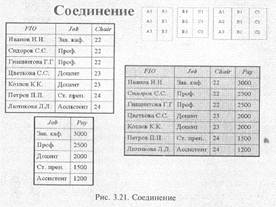
Соединение возвращает отношение, содержащее все возможные кортежи, которые представляют собой комбинацию атрибутов двух кортежей, принадлежащих двум заданным, при условии, что в этих двух комбинированных кортежах присутствуют одинаковые значения в одном или нескольких общих для исходных отношений атрибутах (причем эти общие значения в результирующем кортеже появляются один раз, а не дважды, рис. 3.21).
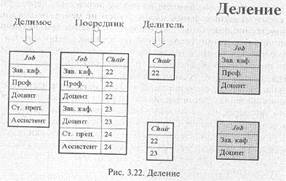
Деление для заданных двух унарных отношений и одного бинарного возвращает отношение, содержащее все кортежи из первого унарного отношения, которые содержатся также в бинарном отношении и соответствуют всем кортежам во втором унарном отношении (рис. 3.22).
Результат выполнения любой операции над отношением также является отношением, поэтому результат одной операции может использоваться в качестве исходных данных для другой. Другими словами, можно записывать вложенные реляционные выражения, т. е. выражения, в которых операторы сами представлены реляционными выражениями, причем произвольной сложности. Эта особенность называется свойством реляционной замкнутости.
Важно, как отмечается в [4], что отношение имеет две части —заголовок и тело. Нестрого говоря, заголовок — это атрибуты, а тело — это кортежи. Заголовок для базового отношения, т. е. значение базовой переменной-отношения, очевидно, вполне конкретен и известен системе, поскольку он задается как часть определения соответствующей базовой переменной-отношения. Результат обязательно должен иметь вполне определенный тип отношения, поэтому, если рассматривать свойство реляционной замкнутости более строго, каждая реляционная операция должна быть определена таким образом, чтобы выдавать результат с надлежащим типом отношения (в частности, с соответствующим набором имен атрибутов или заголовком).
Реляционная алгебра имеет набор правил вывода типов (отношений), позволяющих вывести тип (отношение) на выходе произвольной реляционной операции, зная типы (отношения) на входе этой операции. Задав такие правила для всех операций, можно гарантировать, что для реляционного выражения любой сложности будет вычисляться результат, имеющий вполне определенный тип (отношение) и, в частности, известный набор имен атрибутов.
Рассмотренные восемь операторов Кодда не являются минимальным набором, так как не все они примитивны, т. е. часть из них можно определить через другие операторы. Действительно, операции соединения, пересечения и деления можно определить через остальные пять. Эти пять операций (выборка, проекция, произведение, объединение и разность) можно рассматривать как примитивные в том смысле, что ни одна из них не выражается через другие. Они образуют минимальный набор, но тем не менее, не обязательно единственно возможный. Кроме того, остальные три операции (в особенности операция соединения) на практике используются настолько часто, что, несмотря на то, что они не являются примитивными, имеет смысл обеспечить их непосредственную поддержку.
Предшествующее рассмотрение алгебры представлено в контексте только операций выборки данных. Однако, как отмечается в классических введениях к реляционной алгебре, ее основная цель — обеспечить запись реляционных выражений, позволяющих определять:
• области выборки, т. е. тех данных, которые должны быть доставлены в результате выполнения операции выборки;
• области обновления, т. е. данных, которые должны быть вставлены, изменены или удалены в результате выполнения операции обновления;
• правила поддержки целостности данных, т. е. некоторых особых требований, которым должна удовлетворять база данных;
• производные переменные-отношения, т. е. те данные, которые должны быть включены в представления базы данных;
• требования устойчивости, т. е. данные которые должны быть включены в контролируемую область для некоторых операций управления параллельным доступом к информации;
• ограничения защиты, т. е. данные, для которых осуществляется тот или иной тип контроля доступа.
В целом выражения реляционной алгебры служат для символического высокоуровневого представления намерений пользователя (например, в отношении некоторого определенного запроса). Именно потому, что подобные выражения являются символическими и высокоуровневыми, ими можно манипулировать в соответствии с различными высокоуровневыми правилами преобразования, в том числе и для оптимизации процедур выполнения запросов на данные.
Глава 4. Физические модели баз данных
Физическая модель базы данных определяет способ размещения данных на носителях (устройствах внешней памяти), а также способ и средства организации эффективного доступа к ним. Поскольку СУБД функционирует в составе и под управлением операционной системы, и база данных размещается обычно на устройствах общего доступа (разделяемый ресурс), используемых самой ОС и другими прикладными программами, то организация хранения данных и доступа к ним в значительной степени зависит от принципов и методов управления данными операционной системы. И, естественно, СУБД в той или иной степени использует не только файловую систему и подсистему ввода-вывода ОС, но и специализированные методы доступа, основанные на тех или иных принципах организации данных.
Основное внимание в этой главе будет уделено системам управления данными, построенным на основе однородных файлов, а также рассмотрению основ построения систем управления, использующих «одно файловые» страничные модели организации данных.
4.1. Организация данных на машинных носителях
С общепринятой точки зрения к вопросам организации данных относятся:
• выбор типа записи — единицы обмена в операциях ввода-вывода;
• выбор способа размещения записей в файле и, возможно, метода оптимизации размещения;
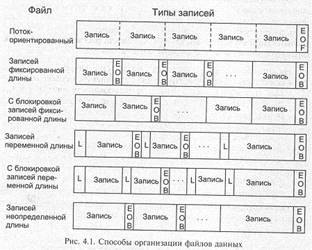
• выбор способа адресации и метода доступа к записям. Целесообразность выделения именно таких аспектов организации была предельно очевидна на начальной стадии развития таких запись ориентированных систем и устройств внешней памяти, как магнитные ленты и диски. Но следует отметить, что широкое использование современных поток ориентированных систем ввода вывода не уменьшило принципиальное, да и практическое значение давно известных методов и решений, построенных на запись ориентированных принципах. Основные понятия и подходы к физической организации и обработке данных, кратко обсуждаемые ниже, иллюстрируются на рис. 4.1.
Логическая запись, с которой работает прикладная программа, — это совокупность элементов или агрегатов данных, воспринимаемая и обычно физически отдельно размещаемая в рабочей области памяти прикладной программой как единое целое. Последовательность записей в логике обработки образует файл.
Физическая запись, с которой работает файловая система, — это совокупность данных, которые размещаются в файле обычно на внешнем носителе, и могут быть считаны или записаны как единое целое одной командой ввода-вывода. Здесь файл — это последовательность физических записей, размещаемых в линейном пространстве носителя, но в общем случае не обязательно в линейном порядке.
Организация данных в случаях логического и физического представления может не совпадать, в частности, одна физическая запись может включать несколько логических (блокирование записей). При этом алгоритмы выделения логических записей из физической в значительной степени зависят от muna записи, рассматриваемого как характер организации последовательности байтов.
На логическом уровне выделяют следующие типы:
• записи фиксированной длины, для размещения каждой из которых выделяется всегда память фиксированной длины, объявляемой заранее. В этом случае данные, образующие запись, имеют устойчивую природу и представляются жесткими структурами, например, ряд числовых полей или символьная последовательность заданной длины;
• записи переменной длины, когда каждый экземпляр записи может иметь длину, отличную от длины другой записи в том же наборе. В этом случае запись содержит либо элементы данных переменной длины (например, текстовую строку), либо переменное число элементов фиксированной длины.
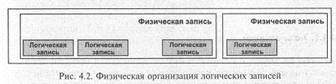
Организация физической записи для достаточно часто встречающегося случая блокирования логических записей фиксированной или переменной длины представлена на рис. 4.2.
При этом структура представления логической записи переменной длины отличается тем, что байтам содержания — собственно данным, образующим логическую запись, предшествуют байты значения длины содержания этой логической записи.
Существует и другая физическая структура представления записей, имеющих переменную длину — запись неопределенной длины, когда данные, образующие логическую запись, завершаются разделителем «конец записи».
Порядок доступа к записи может быть только последовательным, поскольку для определения начала следующей записи надо считать значение длины текущей.
Для файлов записей фиксированной длины доступ будет проще, так как адрес начала любой записи может быть вычислен умножением относительного номера нужной записи на длину записи.
Физические записи на носителе следуют непосредственно друг за другом. При этом выделение отдельной записи может производиться двумя способами, определяемыми технологиями записи данных на носитель.
Первый способ, применяемый в запись ориентированных устройствах внешней памяти мэйнфреймов, основан на том, что каждая запись отделяется от соседней физическим промежутком, не используемым для записи и воспринимаемым устройством чтения как сигнал «конец записи».
Другой способ — это размещение байтов следующей записи непосредственно за последним байтом предыдущей записи без каких-либо разделителей. Для этого способа характерна меньшая зависимость от особенностей устройства: оптимизация процессов ввода-вывода, в том числе блокирование записей, переносится в прикладную программу.
4.1.2. Организация файлов — способ размещения записей
Записи файла обычно располагаются на носителе последовательно в том порядке, как они создаются в прикладной программе. Однако иногда физическая последовательность размещения записей может отличаться от их логической последовательности.
Последовательность размещения физических записей, естественно, может быть только одна (если содержание логической записи сознательно не дублируется в другой форме), и она должна быть выбрана с учетом эффективности использования данных в различных приложениях.
Выбор последовательности связывается с одним из следующих обстоятельств:
1. Ускорение выполнения наиболее частых операций путем размещения записей в той последовательности, которая требуется при последующей обработке.
2. Ускорение или упрощение средств адресации файла (например, средств прямой адресации или хэширования).
3. Уменьшение размера используемого индекса и сокращением таким образом времени поиска в нем.
4. Сокращение среднего времени доступа за счет размещения в наиболее доступных местах записей, к которым происходит наиболее частое обращение.
5. Облегчение операций включения, обновления и удаления записей в интенсивно изменяемых файлах.
Можно выделить две «чистые» стратегии определения места (адреса) для размещения записей: последовательное (sequential) и произвольное (random) размещение. В этом смысле алгоритм размещения определяет mun организации файла.
В первом случае каждая следующая запись будет располагаться физически следом за предыдущей. Во втором — по месту, адрес которого будет определяться в зависимости от некоторых факторов, в том числе упомянутых выше.
Хотя записи на устройствах с прямым доступом могут записываться и читаться в любой последовательности, для каждой структуры данных существует некоторая определенная последовательность, в которой записи можно читать намного быстрее, чем при других способах размещения.
Рассмотрим следующие, наиболее распространенные методы организации файлов, позволяющие оптимизировать доступ к записям (рис. 4.3).
Страничная организация. Данные можно перемещать между внешней и оперативной памятью страницами фиксированной длины. Размер страницы определяется системой, а не длиной записи. Там, где применяется страничная организация памяти, данные логически независимы от размера страницы, но они должны быть физически сгруппированы СУБД так, чтобы эффективно заполнять страницы.
Параллельная секционная организация. Если имеется несколько механизмов доступа, которые могут работать одновременно, то для минимизации времени ожидания данные могут быть расположены
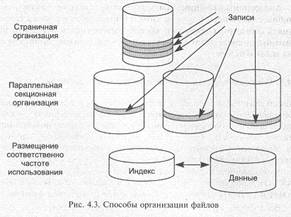
на запоминающих устройствах так, чтобы одновременно было задействовано как можно большее число механизмов доступа.
При параллельной секционной организации существуют два вида ожиданий. Запросы должны ожидать позиционирования механизма доступа (операция установки и задержки на вращение), а затем — ждать выполнения операции чтения-записи. Время, в течение которого запись читается, значительно меньше времени, в течение которого позиционируется механизм доступа. Следовательно, полное время доступа к записи при параллельной организации будет меньше.
В современных СУБД наиболее часто используется страничная организация данных, поскольку гораздо проще иметь весь файл целиком на одном пакете дисков, чем на нескольких, однако принципы секционной организации вновь нашли применение в системах планирования баз данных, а также на уровне аппаратных решений RAID-массивов.
Размещение соответственно частоте использования. Если в системах используется несколько типов запоминающих устройств или в системе предусмотрены специальные методы доступа, то наиболее часто используемые данные можно хранить на более быстрых устройствах или в файлах с «быстрым» методом доступа.
Аналогичный принцип используется при «кэшировании», когда наиболее часто используемые записи помещаются в промежуточную память с быстрым доступом, обеспечивающимся в основном программными средствами за счет упорядочения размещения и введения избыточности.
4.1.3. Способы адресации и методы доступа к записям
Записи логического файла идентифицируются с помощью уникальной последовательности символов или некоторого числа — ключа. Таким ключом обычно является значение поля, расположенное в каждой записи в одной и той же позиции. Иногда бывает необходимо объединить несколько полей, чтобы обеспечить уникальность ключа, который в этом случае называется сцепленным ключом.
В некоторых файлах записи имеют несколько ключей. Запись ЗАКУПКА может иметь различные НОМЕР ПОСТАВЩИКА и НОМЕР ПОКУПАТЕЛЯ, каждый из которых является ключом.
Во многих приложениях требуется идентифицировать записи по ключам, которые не являются уникальными. Однако при этом все равно должен существовать один уникальный ключ, тот, который используется для размещения записи в файле и выборки ее из файла. Такой ключ называется первичным ключом или идентификатором.
Основную проблему при адресации файла можно сформулировать следующим образом: как по первичному ключу определить местоположение записи с данным ключом? Как надо организовать набор записей чтобы поиск потребовал как можно меньше затрат?
При разработке схем адресации файлов и определяемого ими размещения записей в файлах большое значение имеет вопрос о том, как включаются в файл новые записи и удаляются старые.
Существует несколько различных способов адресации и поиска записей, например, на основе упорядочения, различных индексов, преобразования «ключ — адрес». Приведем обзор следующих способов, количественная оценка эффективности которых представлена в [14].
Последовательное сканирование файла. Наиболее простым способом локализации записи является сканирование файла с проверкой ключа каждой записи. Этот способ, однако, требует слишком много времени и может применяться, когда каждая запись все равно должна быть прочитана.
Блочный поиск. Если записи упорядочены по ключу, то при сканировании файла не требуется чтения каждой записи. ЭВМ могла бы, например, просматривать каждую сотую запись в последовательности возрастания ключей. При нахождении записи с ключом большим, чем искомое значение, просматриваются последние 99 записей, которые были пропущены.
Этот способ называется блочным поиском. Записи группируются в блоки и каждый блок проверяется по одному разу до тех пор, пока не будет найден нужный блок. Иногда данный способ называют поиском с пропусками.
Двоичный поиск. При двоичном поиске в файле записей, упорядоченных по ключу, анализируется запись, находящаяся в середине поисковой области файла (изначально всего файла), а ее ключ сравнивается с поисковым ключом. Затем поисковая область делится пополам, и процесс повторяется для соответствующей половины области, пока не будет обнаружено искомое значение или длина области не станет равной 1. Число сравнений в этом случае будет меньше, чем для случая блочного поиска.
Двоичный поиск эффективен для поиска в файлах, организованных в виде двоичного дерева с указателями, когда поиск происходит в направлении, задаваемом указателями. Кроме того, добавление в файл новых записей не приводит к сдвигу других записей, что требует много времени и является достаточно сложной процедурой.
Таким образом, двоичный поиск более пригоден для поиска в индексе файла, чем в самом файле.
Индексно-последовательные файлы. Если файл упорядочен по ключам, то для адресации может использоваться таблица, называемая индексом, связывающая ключ хранимой записи с ее относительным или абсолютным адресом во внешней памяти.
Индекс можно определить как таблицу, с которой связана процедура, воспринимающая на входе информацию о некоторых значениях атрибутов и выдающая на выходе информацию, способствующую быстрой локализации записи или записей, которые имеют заданные значения атрибутов.
Если записи файла упорядочены по ключу, индекс обычно содержит не ссылки на каждую запись, а ссылки на блоки записей, внутри которых можно выполнять поиск или сканирование. Хранение ссылок на блоки записей, а не на отдельные записи в значительной степени уменьшает размер индекса. Причем даже в этом случае индекс часто оказывается слишком большим для поиска, и поэтому используется индекс индекса.
Индексно-произвольные файлы. Произвольный (не упорядоченный по ключу) файл можно индексировать точно так же, как и последовательный файл. Однако при этом индекс должен содержать по одному элементу для каждой записи файла, а не для блока записей. Более того, в нем должны содержаться полные абсолютные (или относительные) адреса, в то время как в индексе последовательного файла адреса могут содержаться в усеченном виде, так как старшие знаки последовательных адресов будут совпадать.
Произвольные файлы в основном используются для обеспечения возможности адресации записей файла с несколькими ключами. Если файл упорядочен по одному ключу, то он не упорядочен по другому ключу. Для каждого типа ключей может существовать свой индекс: для упорядоченных ключей индекс будет иметь по одному элементу на блок записей, для других ключей индексы будут более длинными, так как должны будут содержать по одному элементу для каждой записи. Ключ, который чаще всего используется при адресации файла, обычно служит для его упорядочения.
В индексно-произвольных файлах часто используются символические, а не абсолютные адреса, так как при добавлении новых или удалении старых записей изменяется местоположение записей. Если в записях имеется несколько ключей, то индекс вторичного ключа может содержать в качестве выхода первичный ключ записи. При определении же местоположения записи по ее первичному ключу можно использовать какой-нибудь другой способ адресации. По этому методу поиск осуществляется медленнее, чем поиск, при котором физический адрес записи определяется по индексу. В файлах, в которых положение записей часто изменяется, символическая адресация может оказаться предпочтительнее.
Адресация с помощью ключей, преобразуемых в адрес. Известно много методов преобразования ключа непосредственно в значение адреса в файле. В тех случаях, когда возможно преобразование значения ключа непосредственно в значение адреса в файле, такой способ адресации обеспечивает самый быстрый доступ; при этом нет необходимости организовывать поиск внутри файла или выполнять операции с индексами.
В некоторых приложениях адрес может быть вычислен на основе значений некоторых элементов данных записи.
К недостаткам данного способа относится малое заполнение файла: в файле остаются свободные участки, поскольку ключи преобразуются не в непрерывное множество адресов.
Другим недостатком схем прямой адресации является их малая гибкость. Машинные адреса записей могут измениться при обновлении файла. Для устранения этого недостатка прямую адресацию обычно выполняют в два этапа. Сначала ключ преобразуется в порядковый номер, который затем преобразуется в машинный адрес.
Хэширование. Простым и полезным способом вычисления адреса является хэширование (перемешивание). В данном методе ключ преобразуется в квазислучайное число, которое используется для определения местоположения записи.
Более экономичным является указание на область, в которой размещается группа записей. Эта область называется участком записей (slot, bucket).
При первоначальной загрузке файла адрес, по которому должна быть размещена запись, определяется следующим образом:
1. Ключ записи преобразуется в квазислучайное число, находящееся в диапазоне от 1 до числа участков, используемых для размещения записей.
2. Число преобразуется в адрес участка и, если на участке есть свободное место, то логическая запись размещается на нем.
3. Если участок заполнен, запись должна быть размещена на участке переполнения — следующий по порядку участок либо участок в отдельной области переполнения.
При чтении записей из файла их поиск выполняется аналогично, причем может оказаться, что для поиска записи потребуется чтение нескольких участков переполнения.
Из-за вероятностной природы алгоритма в этом способе не удается достичь 100 % плотности заполнения памяти, однако для большинства файлов может быть достигнута плотность 80 или 90 %; при этом память для индексов не требуется. Большинство записей можно найти за одно обращение, но для некоторых потребуется второе обращение (при переполнении). Для очень небольшой части записей потребуется третье или четвертое обращение к файлу.
Кроме того, в этом случае менее эффективно используется память, чем в индексных методах; записи не упорядочены для последовательной обработки.
Комбинации способов адресации. При адресации записей некоторых файлов используются комбинации перечисленных выше способов. Например, с помощью индекса может определяться ограниченная поисковая область файла, затем эта область просматривается последовательно, либо в ней выполняется двоичный поиск. С помощью алгоритма прямой адресации может определяться нужный раздел индекса, и, таким образом, исчезает необходимость поиска во всем индексе.
4 1.4. Схемы организации данных на внешних носителях
Схема адресации записей в файле является определяющей для способов размещения записей в файлах, т. е. условий и процедур включения в файл новых записей, обновления и удаления старых.
Записи располагаются на внешнем запоминающем устройстве в конкретной физической последовательности. Обработка данных усложняется, если последовательность записей файла не соответствует последовательности их обработки возникает необходимость сортировки записей, что требует значительных временных затрат. Как отмечалось ранее, другой способ организации доступа к записям в нужной последовательности, отличной от порядка физического размещения — это использование различных систем адресации.
Для иллюстрации взаимосвязи схем адресации и организации наборов данных рассмотрим процедуру ведения массива индексно последовательной организации.
При индексно-последовательной организации записи физически размещаются последовательно (или произвольно для индексно произвольной организации) в соответствии с возрастанием исключен, которые чаще всего используются для адресации этих записей.
Для работы с индексно-последовательным файлом можно использовать два режима обработки: 1) последовательную обработку, при которой записи обрабатываются в последовательности их размещения на внешнем запоминающем устройстве, и 2) произвольную обработку, при которой записи обрабатываются в произвольной последовательности, не связанной с физической организацией записей на внешнем устройстве.
На рис. 4.4 приведена схема индексно-последовательного файла, в который добавлены три новые записи.
Новые записи просто включаются в конец файла, и при этом не требуются указатели на область переполнения и выполнение специальных программ поддержки включения записей. Однако в данном случае возникает необходимость перегруппировки элементов индекса.
Существует три способа адресации записей в области переполнения. В первом методе применяются указатели, расположенные в индексах и указывающие на записи, содержащиеся в области переполнения. Кроме этого, в самой области переполнения используются
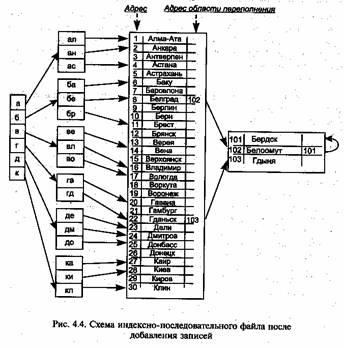
указатели, связывающие записи в цепочки в порядке возрастания ключа.
Второй способ адресации отличается от первого лишь тем, что указатели на область переполнения создаются не для цепочек записей, а для каждой записи переполнения. В этом случае в индексе резервируется место для нескольких указателей. При этом существенно усложняется ведение индексов, а также увеличивается объем памяти для индексов (в связи с увеличением числа указателей).
Третий способ также позволяет избежать поиска записей по цепочкам благодаря созданию специального индекса независимой области переполнения. В этом случае для поиска записи, находящейся в области переполнения, необходимо прочитать индекс независимой области переполнения и считывать соответствующую запись. Данный способ требует больших затрат времени по сравнению с первым способом в том случае, когда записи переполнения не связаны в цепочки; но при многократном включении групп записей опасность возникновения очень больших цепочек здесь отсутствует.
Методы включения записей, основанные на резервировании. Метод, основанный на резервировании участков пространства (например, фиксированной части каждого блока) в файле для ожидаемого включения новых элементов данных, называется методом распределенной свободной памяти. Хотя применяя данный метод, можно избежать записей переполнения, целесообразно периодически выполнять процедуры восстановления заполненных резервных позиций.
Наличие некоторого объема свободной памяти в каждом управляемом интервале приводит к тому, что большая часть вновь поступающих записей умещается в пределах соответствующих интервалов. Тем не менее неизбежны случаи нехватки распределенной свободной памяти в интервалах для включения новых записей. В таких случаях осуществляется «расщепление» интервала. Предположим, что необходимо включить запись с некоторым значением ключевого поля. В соответствии со значением ключевого поля определяется интервал, в который следует включить запись. Однако интервал уже полностью заполнен, поэтому осуществляется его расщепление: половина его записей пересылается в свободный интервал, входящий в состав той же управляемой области.
Резюмируя, перечислим способы включения в файл новых записей.
1. При включении новых записей файл перезаписывается с размещением записей в соответствующих местах.
2. Записи размещаются в области переполнения, которая находится либо в той же области (файле), что и основная область, либо в отдельной независимой области (файле). При этом для обеспечения доступа могут использоваться цепочки, указатели из индекса к каждой записи переполнения, отдельные индексы для каждого блока области переполнения.
3. Записи размещаются в распределенной свободной памяти, которая резервируется при создании базы на уровне физических или логических областей в пространстве файла. При переполнении первоначально зарезервированной области производится ее расщепление.
4.2. Физическое представление иерархических структур
Рассмотрим физическое представление древовидных структур на примере операции обновления дерева с использованием следующих методов.
1. Физически последовательное размещение.
2. Указатели.
3. Цепи и кольца.
На рис. 4.5 и 4.6 представлен пример иерархической структуры до и после обновления.
Записи, относящиеся к разным уровням дерева, обычно рассматриваются как главные и детальные. Поэтому при реализации
такого файла для любой пары уровней дерева есть возможность выбора вариантов включения сегментов нижнего уровня в сегменты верхнего уровня. Хотя, исходя из стремления к однородности массивов, обычно все сегменты нижнего уровня размещаются отдельно от сегментов верхнего уровня.
4.2.1. Физически последовательное размещение
На рис. 4.7 и 4.8 представлен пример реализации иерархической структуры до и после обновления путем физически последовательного размещения данных на носителе.

Последовательность элементов. на рис. 4.7 иногда называется левосписковой структурой (последовательность типа «сверху вниз— слева направо»).
Последовательность строится следующим образом: выбираются узлы, начиная от вершины дерева и вниз по самой левой ветви дерева; когда выбран узел самого нижнего уровня этой ветви, выбираются подобные узлы слева направо; процесс повторяется, причем уже выбранные узлы пропускаются.
При размещении каждой записи последовательности в памяти может указываться, к какому уровню дерева она относится. Это выполняется путем введения в каждую запись специального кода (например, тип записи может быть определен по типу ключа). Возможно также использование некоторой формы разграничения последовательности записей, например, представление записи в таком виде:
A1(132(C5C12C6) В1(С12С9) B3(C14C11C7C18) )
Последовательные левосписковые структуры не позволяют осуществлять быстрый выбор элементов нижних уровней дерева, так как при этом требуется просмотр всего списка.
4.2.2. Левосписковые структуры с переполнениями
Включение и удаление элементов могут быть выполнены с помощью метода переполнения или метода распределенной свободной памяти, рассмотренных ранее на примере метода ведения файлов с индексно-последовательной организацией данных.
На рис. 4.9 и 4.10 представлен пример реализации иерархической структуры до и после обновления путем использования области переполнения.
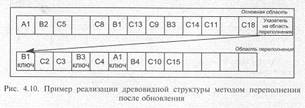
В этом случае для определения местонахождения записей А, В или С можно использовать индексы.
4.2.3. Использование указателей на «подобные» и «порожденные»
Для обеспечения эффективных процедур выборки записей могут использоваться межзаписные ссылки следующих типов:
• указатели на порожденные записи;
• указатели на подобные записи;
• указатели на исходные записи.
При построении древовидных структур, в которых используется какой-либо один тип указателя, всегда исходят из альтернативы между сложностью реализации списка указателей переменной длины на порожденные записи и увеличением времени поиска, связанным с использованием цепочки указателей на подобные записи.
Практически эффективные компромиссы могут быть достигнуты путем использования в каждой записи двух указателей каких-либо двух типов (рис. 4.11), а также использованием кольцевых структур (например, рис. 4.12).
На рис. 4.12 ссылки образуют кольца двух типов: подобных записей и кольца «исходный — порожденный». В записях самого нижнего уровня показаны указатели на исходные записи. Для единообразия здесь каждая запись имеет два указателя. Однако кольца большей частью создаются двусторонними. В этом случае число указателей в каждой записи увеличится до четырех.
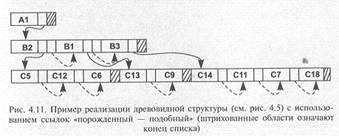
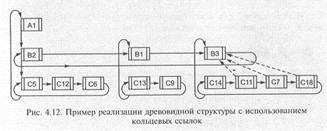
4.3. Физическое представление сетевых структур
Так же, как и в случае древовидных структур, рассмотренных в предыдущей главе, связи в сетевых структурах можно представить, используя физически последовательное размещение, указатели, кольца. Рассмотрим простую сетевую структуру, представленную на рис. 4.13.
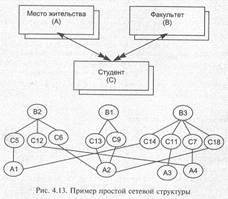
4.3.1. Физически последовательное размещение
Если древовидные структуры можно представить без избыточности с помощью физически последовательного размещения, то для сетевых структур это обычно невозможно. Однако в некоторых случаях может оказаться удобным представить один набор связей типа «исходный — порожденный» путем физически последовательного размещения, а для остальных связей использовать другой метод. Например, можно использовать физически последовательное размещение для представления связей А и С (рис. 4.14).
В этом примере связи между В и С реализуются с помощью множественных указателей на порожденные записи, указателей на исходные записи и указателей на порожденные и подобные записи.
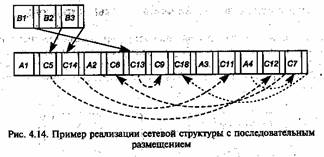
Для множественных указателей на порожденные записи требуются списки указателей переменной длины; для указателей на порожденные и подобные записи необходимы длинные цепочки.
Обычно для представления сетевых структур физически последовательное размещение не применяется.
4.3.2. Использование указателей
Если для реализации сетевых структур используются указатели, то они должны представлять все связи, причем какие-то записи должны называться исходными (например, верхние), а какие-то — порожденными (нижние записи).
На практике могут использоваться много различных вариантов конфигураций указателей. На рис. 4.15 показаны кольцевые структуры, в которых имеются указатели на исходные, порожденные и подобные записи.
Однако, если какая-нибудь связь между записями относится к типу «многие ко многим», то названные три метода физического представления сетевых структур оказываются непригодными. Более того, если в простых сетевых структурах на предыдущих рисунках для хранения указателей на исходные записи требовался один или два указателя в каждой записи, то здесь необходимы списки указателей переменной длины.
Основной проблемой, возникающей при организации встроенных списков указателей переменной длины, является сложность их ведения. При обновлении файла должна существовать возможность сокращения и удлинения списков, что обычно приводит к необходимости периодической реорганизации. Реорганизация является
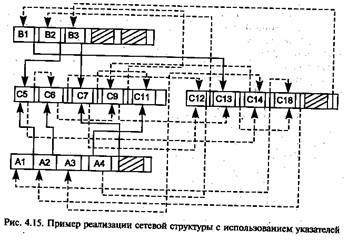
сложной задачей, поскольку при перемещении записей должны быть изменены многие указатели.
Эта проблема частично. решается, если использовать символические указатели, которые не изменяются при перемещении записей. Однако их применение отражается на механизме адресации и при поиске записей в файле: система затрачивает на поиск записей больше времени, чем при использовании прямых указателей.