Глава 1 Введение в базы и банки данных
1.1. Понятие базы и банка данных
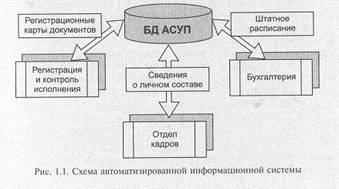
Развитие вычислительной техники и появление емких внешних запоминающих устройств прямого доступа предопределило интенсивное развитие автоматических и автоматизированных систем разного назначения и масштаба, в первую очередь заметное в области бизнес приложений. Такие системы работают с большими объемами информации, которая обычно имеет достаточно сложную структуру, требует оперативности в обработке, часто обновляется и в то же время требует длительного хранения. Примерами таких систем являются автоматизированные системы управления предприятием, банковские системы, системы резервирования и продажи билетов и т. д. (рис. 1.1)
Другими направлениями, стимулировавшими развитие, стали, с одной стороны, системы управления физическими экспериментами, обеспечивающими сверхоперативную обработку в реальном масштабе времени огромных потоков данных от датчиков, а с другой — автоматизированные библиотечные информационно поисковые системы.
Это привело к появлению новой информационной технологии интегрированного хранения и обработки данных — концепции баз данных, в основе которой лежит механизм предоставления обрабатывающей программе из всех хранимых данных только тех, которые ей необходимы, и в форме, требуемой именно этой программе. При этом сама форма (структура данных и форматы полей, входящих в эту структуру) описывается на логическом, т. е. «видимом» из программы, уровне. Более того, поскольку различные программы могут по-разному «видеть» (а следовательно, и использовать) одни и те же данные, то система должна сделать «прозрачными» для программы все данные, кроме тех, которые для нее являются «своими».
Банк данных (БнД) — это система специально организованных данных, программных, языковых, организационных и технических средств, предназначенных для централизованного накопления и коллективного многоцелевого использования данных.
Под базой данных (БД) обычно понимается именованная совокупность данных, отображающая состояние объектов и их отношений в рассматриваемой предметной области. Характерной чертой баз данных является постоянство: данные постоянно накапливаются и используются; состав и структура данных, необходимых для решения тех или иных прикладных задач, обычно постоянны и стабильны во времени; отдельные или даже все элементы данных могут меняться — но и это есть проявление постоянства — постоянная актуальность.
Система управления базами данных (СУБД) — это совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями.
Иногда в составе банка данных выделяют архивы. Основанием для этого является особый режим использования данных, когда только часть данных находится под оперативным управлением СУБД. Все остальные данные (собственно архивы) обычно располагаются на носителях, оперативно не управляемых СУБД. Одни и те же данные в разные моменты времени могут входить как в базы данных, так и в архивы. Банки данных могут не иметь архивов, но если они есть, то в состав банка данных может входить и система управления архивами.
Проблемы совместного использования данных и периферийных устройств компьютеров и рабочих станций быстро породили модель вычислений, основанную на концепции файлового сервера — сеть создает основу для коллективной обработки, сохраняя простоту работы с персональным компьютером, позволяет совместно использовать данные и периферию.
В этом смысле главной отличительной чертой баз данных является использование централизованной системы управления данными, причем как на уровне файлов, так и на уровне элементов данных. Централизованное хранение совместно используемых данных приводит не только к сокращению затрат на создание и поддержание данных в актуальном состоянии, но и к сокращению избыточности информации, упрощению процедур поддержания непротиворечивости и целостности данных.
Эффективное управление внешней памятью является основной функцией СУБД. Эти обычно специализированные средства настолько важны с точки зрения эффективности, что при их отсутствии система просто не сможет выполнять некоторые задачи уже потому, что их выполнение будет занимать слишком много времени. При этом ни одна из таких специализированных функций, как построение индексов, буферизация данных, организация доступа и оптимизация запросов, не является видимой для пользователя и обеспечивает независимость между логическим и физическим. уровнями системы: прикладной программист не должен писать программы индексирования, распределять память на диске и т. д.
Развитие теории и практики создания информационных систем, основанных на концепции баз данных, создание унифицированных методов и средств организации и поиска данных позволяют хранить и обрабатывать информацию о все более сложных объектах и их взаимосвязях, обеспечивая много аспектные информационные потребности различных пользователей. Основные требования, предъявляемые к банкам данных, можно сформулировать следующим образом [14].
Многократное использование данных: пользователи должны иметь возможность использовать данные различным образом.
Простота: пользователи должны иметь возможность легко узнать и понять, какие данные имеются в их распоряжении.
Легкость использования: пользователи должны иметь возможность осуществлять (процедурно) простой доступ к данным, при этом все сложности доступа к данным должны быть скрыты в самой системе управления базами данных.
Гибкость использования: обращение к данным или их поиск должны осуществляться с помощью различных методов доступа.
Быстрая обработка запросов на данные: запросы на данные, в том числе незапланированные, должны обрабатываться с помощью высокоуровневого языка запросов, а не только прикладными программами, написанными с целью обработки конкретных запросов (разработка таких программ в каждом конкретном случае связана с большими затратами времени). Пользователь должен иметь возможность кратко выразить нетривиальные запросы (в нескольких словах или несколькими нажатиями клавиш мыши). Это означает, что средство формулирования должно быть достаточно «декларативным», т. е. упор должен быть сделан на «что», а не на «как». Кроме того, средство обработки запросов не должно зависеть от приложения, т. е. оно должно работать с любой возможной базой данных.
Язык взаимодействия конечных пользователей с системой должен обеспечивать конечным пользователям возможность получения данных без использования прикладных программ.
База данных — это основа для будущего наращивания прикладных программ: базы данных должны обеспечивать возможность быстрой и дешевой разработки новых приложений.
Сохранение затрат умственного труда: существующие программы и логические структуры данных (на создание которых обычно затрачивается много человек лет) не должны переделываться при внесении изменений в базу данных.
Наличие интерфейса прикладного программирования: прикладные программы должны иметь возможность просто и эффективно выполнять запросы на данные; программы должны быть изолированы от расположения файлов и способов адресации данных.
Распределенная обработка данных: система должна функционировать в условиях вычислительных сетей и обеспечивать эффективный доступ пользователей к любым данным распределенной БД, размещенным в любой точке сети.
Адаптивность и расширяемость: база данных должна быть настраиваемой, причем настройка не должна вызывать перезаписи прикладных программ. Кроме того, поставляемый с СУБД набор предопределенных типов данных должен быть расширяемым — в системе должны иметься средства для определения новых типов и не должно быть различий в использовании системных и определенных пользователем типов.
Контроль за целостностью данных: система должна осуществлять контроль ошибок в данных и выполнять проверку взаимного логического соответствия данных.
Восстановление данных после сбоев: автоматическое восстановление без потери данных транзакции. В случае аппаратных или программных сбоев система должна возвращаться к некоторому согласованному состоянию данных.
Вспомогательные средства должны позволять разработчику или администратору базы данных предсказать и оптимизировать производительность системы.
Автоматическая реорганизация и перемещение: система должна обеспечивать возможность перемещения данных или автоматическую реорганизацию физической структуры.
Определение банка данных предполагает, что с функционально-организационной точки зрения банк данных является сложной человеко-машинной системой, включающей в себя все подсистемы, необходимые для надежного, эффективного и продолжительного во времени функционирования.
В структуре банка данных выделяют следующие компоненты (подсистемы):
• информационная база;
• лингвистические средства;
• программные средства;
• технические средства;
• организационно-административные подсистемы и нормативно-методическое обеспечение.
Данные, отражающие состояние определенной предметной области и используемые информационной системой, принято называть информационной базой. Информационная база состоит из двух компонент: 1) коллекции записей собственно данных; 2) описания этих данных — метаданных.
Данные отделены от описаний, но в то же время данные не могут использоваться без обращения к соответствующим описаниям.
Уже из определения базы данных и приведенных ранее основных требований следует, что данные могут использоваться (т. е. представляться) по-разному. С одной стороны, разные прикладные задачи требуют разных наборов данных, в совокупности обеспечивающих функциональную полноту информации, а с другой — они должны быть различны для различных категорий субъектов (разработчиков или пользователей). Также должны быть различными и, способы описания самих данных, их природы, формы хранения, условий взаимной непротиворечивости.
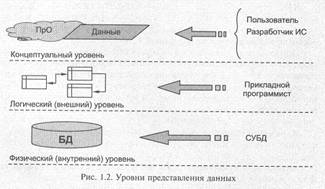
В литературе по базам данных упоминаются три уровня представления данных — концептуальный, внутренний и внешний (рис. 1.2).
Эти уровни представлений введены исходя из различного рассмотрения БД. Например, прикладному программисту требуются не все данные БД, а только некоторая их часть, используемая в его программе. Внешний уровень представления обеспечивает именно эту форму обмена данными.
Внутренний уровень — глобальное представление БД, определяет необходимые условия для организации хранения данных на внешних запоминающих устройствах.
Описание БД на концептуальном уровне представляет собой обобщенный взгляд на данные с позиций предметной области (разработчика приложений, пользователя или внешней информационной системы).
Внешний уровень представления данных не затрагивает физической организации (размещения) данных во внешней памяти, поэтому его называют иногда логическим уровнем. Соответственно внутренний уровень называют физическим уровнем.
1.2.2. Лингвистические средства
Многоуровневое представление БД предполагает соответствующие описания данных на каждом уровне и согласование одних и тех же данных на разных уровнях. С этой целью в состав СУБД включаются специальные языки для описания представлений внутреннего и внешнего уровней. Кроме того, СУБД должна включать в себя язык манипулирования данными (ЯМД). Желательно также наличие тех или иных дополнительных сервисных средств, например средств генерации отчетов.
Работа с базами данных предполагает несколько этапов:
• описание БД;
• описание частей БД, необходимых для конкретных приложений (задач, групп задач);
• программирование задач или описание запросов в соответствии с правилами конкретного языка и использованием языковых конструкций для обращения к БД;
• загрузка БД и т. д.
Для выражения обобщенного взгляда на данные применяют язык описания данных (ЯОД) внутреннего уровня, включаемый в состав СУБД. Описание представляет собой модель данных и их отношений, т. е. структур, из которых образуется БД.
ЯОД позволяет определять схемы базы данных, характеристики хранимых и виртуальных данных и параметры организации их хранения в памяти и может включать в себя средства поддержки целостности базы данных, ограничения доступа, секретности.
ЯМД обычно включает в себя средства запросов к базе данных и поддержания базы данных (добавление, удаление, обновление данных, создание и уничтожение БД, изменение определений БД, обеспечение запросов к справочнику БД).
Исторически первым типом структур данных, который был включен в языки программирования, была иерархическая структура. Некоторые ранние СУБД также предполагали использование в качестве основной модели иерархические структуры типа дерева. Основанием для такого выбора было удобство представления (моделирования) естественных иерархических структур данных, существующих, например, в организациях.
В ряде предметных областей структура данных имеет более сложный вид, в котором поддерживаются связи типа «многие к одному», и которые могут быть представлены ориентированным графом. Такие структуры называют сетевыми. Для управления БД сетевой структуры международной ассоциацией Кодасил была предложена обобщенная архитектура системы с ЯОД схемы (модели БД) и подсхемы (модели части БД для конкретного приложения), а также ЯМД для оперирования данными БД в прикладных программах.
В настоящее время разработаны десятки языков, основанных на реляционном исчислении, различие которых обусловлено особенностями математических теорий, положенных в основу их построения. Среди этих языков можно выделить базирующиеся на С-исчислении, предложенном Коддом, и Р-исчислении, предложенном Пиротти.
С-исчисление базируется на классическом прикладном исчислении предикатов. Р-исчисление представляет собой разновидность прикладного многотипного исчисления предикатов. Существенное различие между этими исчислениями, а следовательно и языками заключается в том, что в С-исчислении в качестве области изменения значений предметной переменной используется множество выборок (кортежей) отношения, а в Р-исчислении каждому типу переменных или констант соответствует определенный домен базы данных.
Функциональные характеристики языков отражают возможности описания данных, средств представления запроса, обновления, поддержки целостности и секретности, включения в языки программирования, управления форматом ответов, средств запроса к словарю данных БД и т. д.
Качественные характеристики языков запросов могут определяться такими свойствами, как полнота, селективная мощность, простота изучения и использования, степень процедурности и модульности, унифицированность, производительность и эффективность. Рассмотрим некоторые из этих понятий.
Селективная мощность языков запросов характеризует возможность выбора данных по разным критериям. Данное понятие плохо поддается формализации; можно сказать, что язык с большей селективной мощностью позволяет сформулировать большинство запросов так, что ответ на них содержит меньше ненужных данных. Языки, обладающие малой селективной мощностью, в общем случае уже требуют привлечения дополнительных средств для анализа ответов на запросы (например, оценки пользователя).
Простота изучения является во многом субъективной оценкой и может быть в некоторой мере охарактеризована степенью это близости к естественному языку, требуемым для его освоения временем и необходимым уровнем подготовки пользователя.
Высокий уровень процедурности, свойственный реляционным языкам, определяется присущими реляционной модели свойствами, в частности, полным отделением логической структуры данных от структур хранения и стратегий доступа. Снижение уровня процедурности увеличивает свободу в выборе способов реализации языка, что позволяет осуществить его реализацию более оптимальным способом. Однако необходимо отметить, что меньшая степень процедурности еще не означает автоматически меньшую сложность написания запросов. Некоторые сложные запросы можно более просто сформулировать в виде алгоритма поиска ответа, в то время как его формулировка в декларативном виде может оказаться достаточно трудной.
Модульность построения языка характеризует возможность существования нескольких уровней языка и зависит от специфических свойств математической теории, лежащей в его основе. Минимальный уровень языка, обычно легко понимаемый пользователем, бывает достаточным для формулирования большинства запросов, и лишь формулировка сложных запросов может потребовать использования всех выразительных средств языка, о существовании которых пользователи начального уровня могут и не знать. Языки, не обладающие модульностью, требуют от пользователя знания почти всего объема средств языка, что усложняет процесс их изучения.
Наиболее распространенным языком для работы с базами данных является SQL (Structured Query Language), в своих последних реализациях предоставляющий не только средства для спецификации и обработки запросов на выборку данных, но также и функции по созданию, обновлению, управлению доступом и т. д.
По существу SQL уже соединяет в себе язык описания данных и язык манипулирования данными. Он не является полноценным языком программирования, и в случае его использования для организации доступа к БД из прикладных программ, ЯП -выражения встраиваются в конструкции базового языка.
Являясь внутренним языком баз данных, SQL естественно отражает особенности конкретной СУБД. Сегодня это единственный стандартизованный язык фактографических баз данных, достаточно мощный и в то же время простой для понимания и использования. Сочетание этих факторов вместе с поддержкой ведущих производителей, таких как IBM и Microsoft, привели не только к широкому его распространению, но и совершенствованию. Сегодня, благодаря независимости от конкретных СУБД и межплатформенной переносимости, SQL стал языком распределенных баз данных и языком шлюзов, позволяющим совместно использовать СУБД разного типа.
Обработка данных и управление этой обработкой в вычислительной среде, а также взаимодействие с операционной системой и прикладными программами осуществляется комплексом программных средств, взаимосвязь которых иллюстрируется рис. 1.3. В составе комплекса обычно выделяют следующие компоненты:
• ядро, обеспечивающее управление данными во внешней и оперативной памяти, а также протоколирование изменений;
• процессор языка базы данных, обеспечивающий обработку (трансляцию или компиляцию) и оптимизацию запросов на выборку и изменение данных;
• подсистему (библиотеку) поддержки программных вызовов, которая обслуживает прикладные программы управления данными, взаимодействующие с СУБД через средства пользовательского интерфейса;
• сервисные программы (системные и внешние утилиты), обеспечивающие настройку СУБД, восстановление после сбоев и ряд дополнительных возможностей обслуживания.
Большинство СУБД работают в среде операционной системы и тесно с ней связаны. Многопользовательские приложения, обработка распределенных запросов, защита данных требуют эффективно использовать ресурсы, управление которыми обычно является функцией ОС. Использование многопроцессорных систем и мульти поточных технологий обработки данных позволяет эффективно обслуживать параллельно выполняемые запросы, но требует координации

использования ресурсов между ОС и СУБД. Соответственно, управление доступом и обеспечение защиты также обычно интегрируются с соответствующими средствами операционной системы.
Именно централизованное управление данными обеспечивает:
• сокращение избыточности в хранимых данных;
• совместное использование хранимых данных;
• стандартизацию представления данных, упрощающую эксплуатацию БД;
• разграничение доступа к данным;
• целостность данных, обеспечиваемую процедурами, предотвращающими включение в БД неверных данных, и ее восстановление после отказов системы.
Сегодня большинство банков данных создается и функционирует на основе универсальных вычислительных машин". Однако для больших баз данных, функционирующих в промышленном режиме, обеспечение эффективной и бесперебойной работы должно основываться на использовании адекватных аппаратных средств.
Устройства ввода-вывода и накопители внешней памяти — традиционно «узкое место» любой базы данных. Объем и быстро действие накопителей являются, очевидно, важными параметрами. Однако столь же значима и отказоустойчивость. Здесь следует отметить необходимость согласованных решений при распределении ролей между аппаратными и программными компонентами управления операциями ввода-вывода. Например, наличие буферной памяти в накопителе, ускоряющей ввод-вывод (аппаратное кэширование) при сбоях системы во время выполнения операции записи в БД может привести к потере данных: переданные для записи данные еще будут находиться в буфере, а так как СУБД отметит операцию записи как уже завершившуюся, откат для восстановления данных станет невозможен.
Для повышения надежности хранения часто используют специализированные дисковые подсистемы — RAID (Redundant Array of Inexpensive Disk). Один логический RAID-диск — это несколько физических дисков, объединенных в одно устройство, управляемое специализированным контроллером, что позволяет распределять основные и системные данные между несколькими носителями (дисками), в том числе дублировать данные. Таким образом, в случае повреждения одного из дисков, можно оперативно восстановить потерянные данные.
Не менее значима роль центрального процессора. Многие промышленные СУБД поддерживают многопроцессорную обработку запросов. Теоретически использование еще одного процессора позволит ускорить обработку. Однако на практике многопроцессорные системы требуют повышенного внимания при приобретении оборудования: надежно работают только сертифицированные системы, использующие соответствующие периферийные устройства.
Для распределенных и удаленно используемых баз данных также важно сетевое окружение: связное оборудование и сетевые протоколы. Здесь важны не только показатели быстродействия, но и поддерживаемые ими возможности обеспечения безопасности.
1.2.5. Организационно-административные подсистемы
Организационно-методические средства не являются технической компонентой системы, однако трудно рассчитывать на устойчивое и долговременное функционирование банка данных, если будут отсутствовать необходимые методические и инструктивные материалы, регламентирующие работу пользователей, различных по своему статусу и уровню подготовленности.
В информационных системах, создаваемых на основе СУБД, способы организации данных и методы доступа к ним перестали играть решающую роль, поскольку оказались скрытыми внутри СУБД. Массовый, так называемый конечный пользователь, как правило, имеет дело только с внешним интерфейсом, поддерживаемым СУБД.
Эти преимущества, как уже понятно, не могут быть реализованы путем механического объединения данных в БД. Предполагается, что в системе обязательно существует специальное должностное лицо (группа лиц) — администратор базы данных (АБД), который несет ответственность за проектирование и общее управление базой данных. АБД определяет информационное содержание БД. С этой целью он идентифицирует объекты БД и моделирует базу, используя язык описания данных. Получаемая модель служит в дальнейшем справочным документом для администраторов приложений и пользователей. Администратор решает также все вопросы, связанные с размещением БД в памяти, выбором стратегии и ограничений доступа к данным. В функции АБД входят также организация загрузки, ведения и восстановления БД и многие другие действия, которые не могут быть полностью формализованы и автоматизированы.
Администратор приложений (или, если таковой специально не выделяется — администратор БД) определяет для приложений подмодели данных. Тем самым разные приложения обеспечиваются собственным «взглядом», но не на всю БД, а только на требуемую для конкретного приложения («видимую») ее часть. Вся остальная часть БД для данного приложения будет «прозрачна».
Прикладные программисты имеют, как правило, в своем распоряжении один или несколько языков программирования, с помощью которых генерируются прикладные программы.
Классификация баз и банков данных может быть произведена по разным признакам (относящимся к разным компонентам и сторонам функционирования банков данных (БнД), среди которых выделяют, например, в [5] следующие.
По форме представляемой информации можно выделить фактографические, документальные, мультимедийные, в той или иной степени соответствующие цифровой, символьной и другим (нецифровой и не символьной) формам представления информации в вычислительной среде. К последним можно отнести картографические, видео-, аудио-, графические и другие БД.
По типу хранимой (не мультимедийной) информации можно выделить фактографические, документальные, лексикографические БД. Лексикографические базы — это классификаторы, кодификаторы, словари основ слов, тезаурусы, рубрикаторы и т. д., которые обычно используются в качестве справочных совместно с документальными или фактографическими БД. Документальные базы подразделяются по уровню представления информации на полнотекстовые (так называемые «первичные» документы) и библиографическо-реферативные («вторичные» документы, отражающие на адресном и содержательном уровнях первичный документ).
По типу используемой модели данных выделяют три классических класса БД: иерархические, сетевые, реляционные. Развитие технологий обработки данных привело к появлению постреляционных, объектно-ориентированных, многомерных БД, которые в той или иной степени соответствуют трем упомянутым классическим моделям.
По топологии хранения данных различают локальные и распрей деленные БД.
По типологии доступа и характеру использования хранимой информации БД могут быть разделены на специализированные и интегрированные.
По функциональному назначению (характеру решаемых с помощью БД задач и, соответственно, характеру использования данных) можно выделить операционные и справочно-информационные. К последним можно отнести ретроспективные БД (электронные каталоги библиотек, БД статистической информации и т. д.), которые используются для информационной поддержки основной деятельности и не предполагают внесения изменений в уже существующие записи, например, по результатам этой деятельности. Операционные БД предназначены для управления различными технологическими процессами. В этом случае данные не только извлекаются из БД, но и изменяются (добавляются) в том числе в результате этого использования.
По сфере возможного применения можно различать универсальные и специализированные (или проблемно-ориентированные) системы.
По степени доступности можно выделить общедоступные и БД с ограниченным доступом пользователей. В последнем случае говорят об управляемом доступе, индивидуально определяющем не только набор доступных данных, но и характер операций, которые доступны пользователю.
Следует отметить, что представленная классификация не является полной и исчерпывающей. Она в большей степени отражает исторически сложившееся состояние дел в сфере деятельности, связанной с разработкой и применением баз данных.
1.4.1. Типология баз данных с точки зрения информационных процессов
С другой стороны, БД могут соотноситься с различными уровнями информационных процессов: уровень информационных технологий (ИТ), уровень системы (ИС), уровень информационных ресурсов (ИР).
На уровне информационных технологий БД определяется как взаимосвязанная совокупность файлов ОС, содержащих данные о предметной области решаемой задачи. При этом основное внимание уделяется физической структуре БД
На уровне информационных систем БД рассматривается как компонента, представляющая собой информационную модель предметной области. Здесь наиболее важной является проблема логической структуры БД.
При рассмотрении на уровне информационных ресурсов БД трактуется как элемент мировых ИР. Основной характеристикой здесь является содержание БД, хотя и структуры данных также немаловажны.
Основное внимание в данном пособии будет уделяться рассмотрению БД на уровне технологии и систем, уровень информационных ресурсов будет вкратце рассмотрен только в настоящей главе.
Программные средства баз данных. Оболочки информационных систем (системы программирования ИС) представляют собой гибкие программные комплексы, настраиваемые на задачи пользователя. Наиболее распространенными классами данных программных средств являются системы управления базами данных (СУБД) и оболочки автоматизированных информационно-поисковых систем (АИПС).
Информационно-поисковые системы. В узком смысле под АИПС принято понимать открытый (обычно) или замкнутый (реже) программный продукт, предназначенный для реализации практически большинства функций (процессов) — ввод, обработка, хранение, поиск, представление данных (организованных в записи или документы, находящиеся в БД). В этом смысле часто отождествляют АИПС с АИС, и это трудно оспаривать.
Среди АИПС в узком смысле принято выделять:
• фактографические системы (отличающиеся фиксированной структурой данных или записей), для разработки которых как правило используются СУБД, поддерживающие табличные (реляционные) БД;
• документальные системы (отличающиеся неопределенной или переменной структурой данных или документов), для разработки которых часто (но не обязательно) применяют оболочки АИПС.
В более широком смысле под АИПС подразумеваются также программные оболочки, ориентированные на разработку продуктов muna ГИПС (в узком смысле). Это связанно с тем фактом, что первые системы типа СУБД и оболочек АИПС были предложены в 60-е — 70-е гг. фирмой IBM (и сотрудничавшими с ней организациями) и включали в себя:
• IMS/360 (Information Management System) — по-видимому, первую реальную СУБД, поддерживавшую так называемую иерархическую модель данных (понятие появилось позже, в связи с необходимостью систематизации СУБД), нашедшую достаточно широкое применение (в частности, для информационного обеспечения проекта Apollo, завершившегося, как известно, высадкой граждан США на Луну в 1969 г.);
• DPS/360 (Document Processing System) — первый промышленный пакет прикладных программ (ППП), предназначенный для реализации документальных АИПС. В дальнейшем на основе развития принципов DPS, фирмой в 1972 г. был выпущен пакет STAIRS (STorage And Information Retrieval System), предназначенный для диалогового, обслуживания множества (удаленных) пользователей;
• IRMS (Information Retrieval and Management System), ТЕХТPAC и другие аналогичные пакеты.
Как это следует из наименований продуктов, разработчики понимали под АИПС именно ППП-оболочки.
Системы управления базами данных и программирования АНС. Среди различных программных средств данного класса следует различать три типа;
• СУБД в «чистом виде» (IMS, CETOP и пр.);
• СУБД с элементами систем программирования АИС (ADA-BAS/NATURAL, ORACLE);
• системы программирования АИС с элементами СУБД (FoxBase / FoxPro, Clipper).
Первый тип фактически относится к начальному этапу развития систем второго (реже — третьего) типов. В этом случае СУБД состоит только из системы интерпретации вызовов (обращений) из пользовательской программы (call-interface) на выборку (корректировку, занесение) информации из/в БД, причем программа написана на одном из универсальных языков программирования (ЯП), таких как Кобол, Фортран, Паскаль и пр., получивших название включающие языки СУБД. Данная система в последующих СУБД (второй тип) получила наименование ядра. Соглашения о форматах и структурах такого взаимодействия обычно пытаются оформить в виде некоторого формального языка (языка ядра). В частности, вдохновленная успехами в разработке и распространении универсального ЯП PL/1 (Programming Language #1), фирма IВМ разработала описание форматов интерфейса пользовательских программ с БД IMS в форме языка DL/1 (Data Language #1), который, однако, значительного успеха не имел.
Второй тип представляет собой расширение первого в направлении создания универсальной системы разработчика АИС, включающей также специализированные языковые средства. В этом случае СУБД представляет собой совокупность специализированных программных средств, вспомогательных файлов и управляющих таблиц (иногда находящихся в составе БД, реже это файлы ОС), которая обеспечивает доступ пользователей к БД при соблюдении следующих существенных критериев:
• целостность и непротиворечивость данных, описывающих различные аспекты объектов реального мира, защита информации от несанкционированного доступа к чтению/обновлению содержимого БД;
• установление и поддержание связей между зависимыми данными;
• удобство использования данных. Третий тип представляют собой (разработанные обычно для ПК) системы, содержащие элементы как непроцедурного (язык запросов), так и процедурного (язык программирования) типов во входном языке, предназначенном для управления данными и обработки информации. Элементы СУБД здесь также заключаются в наличии простейшего словаря данных, возможности создания модели предметной области в форме совокупности таблиц, связанных между собой простейшим образом, а также в наличии средств генерации отчетов и управления доступом пользователей.
Как уже отмечалось, база данных не может рассматриваться в отрыве от назначения и особенностей ее использования для решения практических задач, причем обязательно в составе более крупных информационных или технологических автоматизированных систем. Задачи таких систем — не только планирование и управление предприятием, но и интеграция разработки и сопровождения основных и технологических объектов и процессов, диагностика, мониторинг, моделирование. Соответственно, задачи и назначение БД как системы, хранящей информацию обо всех этих составляющих, — обеспечить информационную поддержку этих процессов.
База данных — это отражение реальной предметной области, «действующая» информационная модель, которая, обеспечивая субъект информацией для принятия решения, позволяет в том числе и управлять объектами и процессами в отражаемой предметной области (ПрО). Такая функциональная направленность (естественно, предполагающая достижение эффективности в первую очередь за счет использования именно БД) обусловливает и обратную зависимость: объекты, процессы и события ПрО выделяются таким образом, чтобы было возможно их представление в виде системы взаимосвязанных данных и процессов, удобных для их последующей (человеко-машинной) обработки.
В каком-то смысле базу данных можно сравнить с сообщением о состоянии предметной области, воспринимаемым некоторым субъектом, задачей которого и является преобразование объектов этой ПрО, причем в своей деятельности субъект руководствуется информацией, извлекаемой именно из этого «сообщения». Схема этого соотношения, приведенная на рис. 1.4, иллюстрирует еще и то, что система, преобразующая объект, принципиально является комплексной (состоящей, по крайней мере, из двух компонент, работающих с объектами разной природы: субъект преобразования
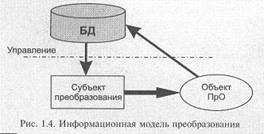
взаимодействует преимущественно с материальными объектами, а БД — с информационными).
Для многокомпонентных систем с многоуровневым представлением семантики эффективность обработки достигается через специализированность представления объектов или процессов (а для вычислительных систем — как среды хранения информации — с единственно возможной двоичной формой представления) и, в первую очередь, путем сведения представления множества обрабатываемых (локально) объектов к однородности природы и формы их представления. Поэтому, в общем случае для реализации эффективного межуровневого взаимодействия (на каждом из уровней объекты представлены в виде, наиболее адекватном функциональным средствам этого уровня) любая величина должна быть преобразована в соответствии с «контекстом» этого уровня для получения такого ее представления, которое будет значимо для воспринимающего уровня, т. е. может быть обработано средствами этого уровня.
Здесь «контекст» — это декларативное или иногда процедурное определение способа использования элементарных составляющих величины для получения значения. Например, порядок использования байтов при преобразовании вещественного числа, представленного в двоичной форме, в символьный формат.
Соотношение понятий «величина», «контекст» и «значением, приведено на рис. 1.5. Здесь значение, получаемое на уровне 1, на следующем рассматривается в свою очередь как величина, которая будет интерпретироваться в соответствии с контекстом своего уровня.
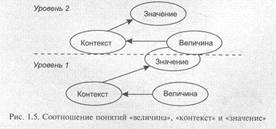
Таким образом, можно сказать, что значение в общем случае определяется парой <контекст, величина>. Причем, поскольку контекст и величина имеют разную природу, они должны быть представлены в вычислительной среде самостоятельными, скорее всего, разнотипными объектами.
Такое, хотя и упрощенное представление о БД как о средстве информационных коммуникаций позволяет тем не менее увидеть взаимосвязь вида информации (способа реализации смысла) с формой ее представления и особенностью ее использования.
В этом смысле (с точки зрения способа представления и, соответственно, восприятия) в отдельный класс можно выделить фактографическую информацию: такое представление реально существующих событий и явлений, когда они могут быть описаны как факты, задаваемые парой <имя, значение>, где имя — знак, уникально определяющий (идентифицирующий) факт в заданной предметной области, и обычно не нуждающийся в явном определении или до определении его существа; а значение — характеристика, задающая одно из множества возможных состояний.
Таким образом, здесь факт (его значение) задается величиной, например, числовой для параметров, измеримых физически, в том числе и логическими величинами «истина»/«ложь» для указания, свершилось событие или нет.
Можно сказать, что особенностью фактографической информации является практическая очевидность (минимальная неопределенность, не требующая использования сложных или нечетких процедур) идентификации и интерпретации «факта», как его имени, так и состояния. Таким образом, контекст в этом случае в достаточной степени определяется однозначно понимаемым объявлением о назначении базы данных и таким именованием полей данных, когда в качестве имени используется общепринятое, не зависящее от прикладных задач, имя свойства (и таким образом определяются характеристические признаки). Такая ситуация предопределяет для пользователя возможность адекватного восприятия содержания: способ интерпретации данных в этом случае практически не может быть неоднозначным, причем для пользователя определение способа происходит неявно (не требует от него явных действий для определения и использования контекста). Это, с одной стороны, позволяет свести представление предметной области к точной теоретико-множественной модели, а с другой — обусловливает возможность непосредственного использования данных в задачах обработки (на уровне прикладных программ) для генерации новой информации без участия субъекта (человека), внешнего по отношению к машинной среде, обеспечивающего определение и использование контекста. Например, ОЕАР-технологии баз данных, позволяющие строить на основе множества данных, количественно характеризующих состояние объектов предметной области и представленных обычно регулярными таблицами, новые значения, отражающие это состояние на ином качественном уровне, например, интегральные показатели, диаграммы, графики и т. д.
Однако большинство задач, решаемых человеком, не могут быть сведены к «фактографическому» представлению и описываются (и, соответственно, представляются в машинной среде) средствами естественного или специализированного языков, оперирующих лингвистическими переменными, значение которых может зависеть не только от контекста предметной области, но также и от контекста ближайшего окружения — значения соседних переменных. Причем, появление нового смысла (факта) не обязательно приводит к появлению новой переменной: новый факт представляется с помощью уже существующих переменных. Например, словесные определения философских или географических понятий.
В отличие от ранее рассмотренного фактографического представления, для вербальной формы представления факта (выражениями языка с использованием лингвистических переменных) характерно то, что для задания имени, значения и контекста может использоваться единый способ и средства — лингвистические переменные одного и того же языка. Например, описание весовых свойств может быть представлено несколькими, но имеющими один смысл, вариантами предложений: «Чугунная заготовка весом 29 килограммов» или «Чугунная заготовка имеет свойство т = 29, где т — вес в килограммах».
Автоматическое приведение такого рода представлений к очевидно наилучшей для этого случая табличной форме, потребовало бы применения трудно реализуемых процедур морфологического и семантического анализов. Однако с другой стороны, выделение смысла (и генерация новой информации) обычно производится человеком, сознание которого (как среда преобразования) ориентировано именно на обработку лингвистических переменных.
Рассматривая процесс автоматизированной генерации новой информации (рис. 1.6), где в качестве источника исходных данных используются БД,
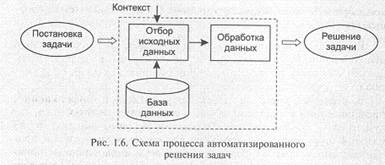
нужно сказать, что отбор и обработка должны быть выделены в отдельные процессы, так как с точки зрения общей (суммарной) эффективности один из них (обычно поиск) должен быть опосредованным — оценка полезности найденной информации производится обычно человеком, так как сознание человека— внешняя по отношению к машине среда, работает со слабоструктурированной информацией эффективнее машин.
Случаи, когда информация представляется в форме, не адекватной архитектуре фон-неймановских машин, могут быть обусловлены разными факторами. Рассмотрим следующие случаи.
1. Хорошо структурированная информация, представляемая в графическом или специальном формате. Например, структурные химические формулы, конструкторская документация и т. д. В этом случае для автоматической обработки требуются узкоспециализированные средства, что приводит к общей неунифицированности представления семантических элементов (например, графических примитивов) на уровне данных.
2. Информация, точная по содержанию, но вариантно представляемая по форме. Например, описание в текстовом виде численно задаваемых параметров изделия. Лингвистические переменные в этом случае имеют точное значение, однако построение универсальной процедуры автоматического выделения факта из текста трудоемко и потому нецелесообразно.
3. Слабоструктурированная информация, обычно представляемая в текстовой форме. Например, учебная или научная публикация, где новые понятия строятся на основании ранее определенных. В этом случае лингвистические переменные могут принимать новые, ранее не определенные значения, которые определяются контекстом — ближним (словосочетания) или общим (темой сообщения).
Возвращаясь к процедуре поиска как важнейшей составляющей использования баз данных, еще раз отметим, что критерий отбора должен содержать не только величину (например, слово), но и контекст.
В реальных системах поиск документальной информации, представленной в текстовой форме, производится по вторичным документам — специально создаваемым поисковым образам, точно идентифицирующим сам документ как единицу хранения, и приблизительно, в краткой форме, путем перечисления основных понятий, отражающий смысловое содержание. Такой подход позволяет построить процедуры поиска на основе теоретико-множественной модели с точной логикой отбора по критерию наличия заданного сочетания терминов запроса в списке терминов поискового образа. Однако контекст использования терминов должен быть доопределен отдельно — либо во время поиска, например, указанием тематической области, либо после отбора из базы — во время ознакомления человека с содержанием найденного.
Определение контекста предметной области в целом осуществляется с помощью тезаурусов терминологических систем, фиксирующих с помощью родо-видовых и других отношений роль и семантику дескрипторов — выделенных терминов, которые используются для формирования поисковых образов документов.
Для доопределения смысла термина в составе поискового образа документа в первых поколениях автоматизированных информационных систем применялись специальные указатели роли, однако их использование было трудоемко и требовало специальной подготовки пользователя, поэтому в современных системах не применяется.
Другой важный фактор, влияющий на эффективность работы человека с информацией — это форма хранения и представления— структура и оформление документа. Это особенно заметно при работе с объемными полнотекстовыми документами, причем иногда определяется на уровне машинного формата (например, DOC, PDF, HTML и т. д.), от выбора которого зависит возможность дальнейшей обработки.
В том случае когда для хранения информации используются базы данных, структура документов может быть определена двумя путями.
• так же как и для фактографических БД, заданием схемы — последовательности именованных типизированных полей данных;
• контекстным определением — использованием специализированных языков разметки (например, НТМL или ХМL), задающим индивидуальные особенности представления материала каждого документа.
Использование встраиваемых определений структуры позволяет ввести «само определяемые» форматы представления документов. Это обеспечивает практически неограниченную гибкость при организации хранения коллекций разнородных документов, однако создает семантические проблемы согласованного использования материала (из-за возможности различной интерпретации определений), что в свою очередь требует создания доступного всем пользователям репозитария метаинформации — описаний природы и способов представления информации.
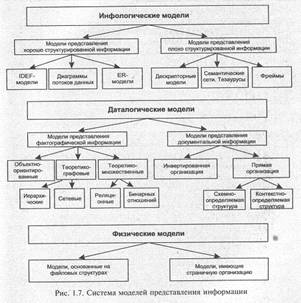
Основные отличия любых методов представления информации заключаются в том, каким способом фиксируется семантика предметной области. Однако следует особо отметить, что для всех уровней и для любого метода представления предметной области (нам важен контекст создания и использования машинных баз данных) в основе отображения (т. е. собственно формирования представления) лежит кодирование понятий и отношений между понятиями. Многоуровневая система моделей представления информации иллюстрируется рис. 1.7. Рассмотрим далее основные из них.
Ключевым этапом при разработке любой информационной системы является проведение системного анализа: формализация предметной области и представление системы как совокупности компонент. Системный анализ позволяет, с одной стороны, лучше понять «что надо делать» и «кому надо делать» (аналитику, разработчику,
руководителю, пользователю), а с другой — отслеживать во времени изменения рассматриваемой модели и обновлять проект.
Декомпозиция как основа системного анализа может быть функциональной (построение иерархий функций) или объектной.
Однако в большинстве систем, если говорить, например, о базах данных, типы данных являются более статичным элементом, чем способы их обработки. Поэтому получили интенсивное развитие такие методы системного анализа, как диаграммы потоков данных (Data Flow Diagram). Развитие реляционных баз данных в свою очередь стимулировало развитие методик построения моделей данных, и в частности, ER-диаграмм (Entity Relationship Diagram). Однако и функциональная декомпозиция и диаграммы потоков данных дают только некоторый срез исследуемой предметной области, но не позволяют получить представление системы в целом.
Различаются и методы отображения, используемые на этапе построения даталогических моделей, отражающих способ идентификации элементов и связей, но, что особенно важно — в контексте их будущего представления в одномерном пространстве памяти вычислительной машины. Модели подразделяются на фактографические — ориентированные на представление хорошо структурированной информации, и документальные — представляющие наиболее распространенный способ отражения слабоструктурированной информации. Если в первом случае говорят о реляционной, иерархической или сетевой моделях данных, то во втором — о семантических сетях и документальных моделях.
При проектировании информационных систем свойства объектов (их характеристики) называются атрибутами. Именно значения атрибутов позволяют выделить как в предметной области различные объекты (типы объектов), так и среди объектов одного типа — их различные экземпляры. Представление атрибутов удобнее всего моделируется теоретико-множественными отношениями. Отношение наглядно представляется как таблица, где каждая строка — кортеж отношения, а каждый столбец (домен) представляет множество значений атрибута. Список имен атрибутов отношения образует схему отношения, а совокупность схем отношений, используемых для представления БД, в свою очередь образует схему базы данных.
Представление схем БД в виде схем отношений упрощает процедуру проектирования БД. Этим объясняется создание систем, в которых проектирование БД ведется в терминах реляционной модели данных, а работа с БД поддерживается СУБД одного из упомянутых ранее типов.
Основное отличие методов представления информации заключается в том, каким способом фиксируется семантика предметной области. Первые, фактографические БД, задают четкую схему соответствия, в рамках которой и отображается предметная область. Подобное построение по сути своей является довольно статичным, требует априорного знания типов отношений. В нем достаточно сложно вводить информацию о новых типах отношений между объектами, но с другой стороны, зафиксированная схема базы данных позволяет довольно эффективно организовать поиск информации.
Во втором случае предметная среда отображается (по крайней мере, на уровне модели) в виде однородной сети, любые изменения которой, как по вводу новых классов объектов, так и новых типов отношений, не связаны с какими-либо структурными преобразованиями сети. В силу большого количества типов отношений манипулирование подобной «элементарной» информацией достаточно затруднено, поэтому для данного случая характерно введение большого количества более общих понятий (и соответствующих им отношений), что упрощает работу с сетью.
Модель данных должна, так или иначе, дать основу для описания данных и манипулирования ими, а также дать средства анализа и синтеза структур данных. Любая модель, построенная более или менее аккуратно с точки зрения математики, сама создает объекты для исследования и начинает жить как бы параллельно с практикой.
Реляционная модель данных в качестве основы отображения непосредственно использует понятие отношения. Она ближе всего находится к так называемой концептуальной модели предметной среды и часто лежит в основе последней.
В отличие от теоретико-графовых моделей в реляционной модели связи между отношениями реализуются неявным образом, для чего используются ключи отношений. Например, отношения иерархического типа реализуется механизмом первичных / внешних ключей, когда в подчиненном отношении должен присутствовать набор атрибутов, связывающих это отношение с основным. Такой набор атрибутов в основном отношении будет называться первичным ключом, а в подчиненном — вторичным.
Прогресс в области разработки языков программирования, связанный в первую очередь с типизацией данных и появлением объектно-ориентированных языков, позволил подойти к анализу сложных систем с точки зрения иерархических представлений — с помощью классов объектов со свойствами инкапсуляции, наследования и полиморфизма, схемы которых отображают не только данные и их взаимосвязи, но и методы обработки данных.
В этом смысле объектно-ориентированный подход является гибридным методом и позволяет получить более естественную формализацию системы в целом. В итоге это позволяет снизить существующий барьер между аналитиками и разработчиками (проектировщиками и программистами), повысить надежность системы и упростить сопровождение, в частности, интеграцию с другими системами. Модель будет структурно объектно-ориентированной, если она поддерживает сложные объекты; модель будет поведенчески объектно-ориентированной, если она обеспечивает процедурную расширяемость; для того чтобы модель была полностью объектно-ориентированной, она должна обладать обоими свойствами.
Разделение на фактографические и документальные в этой группе моделей является достаточно условным. Документ как последовательность полей может быть представлен в том числе и реляционной моделью. И в этом случае выбор специализированного решения чаще всего обуславливается требованием общей эффективности.
В заключение отметим, что представленная здесь типология моделей не претендует на полноту, и она не является классификацией в точном смысле этого слова. Она скорее иллюстрирует эклектичность преобладающих в разное время взглядов, методов и решений, используемых при проектировании и реализации баз данных.
Глава 2. Базовые технологии и основные этапы развития машинной
обработки данных
2.1. Введение в технологии машинной обработки данных и основные определения
Реальные базы данных промышленного масштаба содержат миллионы записей, данные которых описывают состояния и взаимосвязи многих и многих объектов реального мира. Требования, предъявляемые пользователями к автоматизированным или автоматическим системам, обрабатывающим эти данные, обусловливают и требования к параметрам подсистем внешней памяти, в первую очередь, предполагают высокую оперативность доступа.
Важной особенностью здесь является то, что архитектура систем и технологий управления данными непосредственно связана с двумя следующими значительными, хотя и противоположными обстоятельствами:
• непредсказуемой вариантностью представления данных в прикладной программе, зависящей от разнообразных особенностей пользовательских задач;
• жесткостью технических решений устройств внешней памяти, выражающейся в функциональной простоте операций и ограниченности форм представления данных.
Высокая эффективность решений в области обработки данных достигается введением промежуточных слоев специализированных технических и программных средств. Характер проблем и архитектурно-технологические решения такого рода достаточно полно иллюстрируются приведенной на рис. 2.1 примерной схемой реализации операций ввода-вывода — взаимодействия прикладной программы с компонентами операционной системы и устройствами внешней памяти. Здесь специализация компонент выражается в том, что по существу каждый из них реализует различные способы работы с потоком данных (и в частности, его фрагментацию на блоки), что и обеспечивает, с одной стороны, необходимый уровень декомпозиции и идентификации логических/физических записей, а с другой — независимость физического и логического уровней представления данных.
Здесь термины логический и физический отражают различия аспектов представления данных. Логическое представление указывает на то, как данные используются в прикладной программе, т. е. отражают логику обработки. Физическое представление — это то, как данное хранятся на физическом носителе.
Будем считать логической записью идентифицируемую (именованную) совокупность элементов или агрегатов данных, воспринимаемую прикладной программой как единое целое при обмене информацией с внешней памятью (по крайней мере, для операций ввода-вывода).
Физической записью будем считать совокупность данных, которая может быть считана или записана как единое целое одной командой ввода-вывода. Важно, что для компонент различного уровня в технологической цепи ввода-вывода состав и структура физической записи может быть разной.
Структура данных и их взаимосвязь в случаях логического и физического представления могут не совпадать. Например, а) одна физическая запись может включать несколько логических; б) порядок следования элементов данных в физической записи может быть изменен для оптимизации использования пространства памяти. То есть, если логическая структура может варьироваться в широком диапазоне и даже представляться, например, вариантными записями, то физическая — практически всегда, представлена жесткой структурой, причем в значительной степени определяемой типом носителя.

2.2. Примерная схема организации файлового ввода-вывода
Рассмотрим для представленной, на рис. 2,1, схемы ввода-вывода способы адресации и последовательность операций выборки данных, обеспечивающих чтение прикладной программой с тома внешней памяти (например, магнитного диска ПЭВМ) некоторой произвольной (l-ой) записи. Отметим еще раз, что «специализация» компонент, участвующих в операциях ввода-вывода, выражается прежде всего в используемом способе адресации.
Прикладная программа использует одномерную (или сводимую к одномерной) сквозную адресацию данных на уровне логических записей: запись определяется номером, например, соответствующим порядку их размещения.
Система управления физическим вводом-выводом (в рассматриваемом примере — BIOS ПЭВМ) использует трехмерную систему координат: адрес записи составляется из номера дорожки, номера головки чтения-записи (номер поверхности) и номера сектора. Операционная система же использует одномерную сквозную систему координат: сектора нумеруются от края диска к центру последовательно, причем сначала в рамках одного сегмента цилиндра (кластера), далее сектора следующего сегмента дорожки, после чего происходит переход к следующей дорожке.
Этот способ адресации и, соответственно, порядок использования пространства отчасти отражает специфику аппаратных решений, ориентированных на временную оптимизацию операций ввода-вывода: большее количество данных будет считано при одном обращении к диску за счет одновременного обращения через головки чтения-записи к данным, размещенным на параллельных дорожках в одном секторе одного цилиндра. Фиксированное количество битов, равное размеру сектора, определенного при разметке, умноженному на число головок, будет прямо (без дополнительной обработки, например, проверки логических условий конца файла или записи) передано в буфер оперативной памяти устройства или операционной системы.
Таким образом, если система адресации в прикладной программе является относительной и отражает логику взаимосвязи записей (например,, порядок создания файла), то для подсистем ввода-вывода она является абсолютной и определяется физическим форматом носителя размером сектора, количеством секторов на дорожке, количеством поверхностей и дорожек и т. д. При этом независимость от особенностей физического размещения и механизма адресации обеспечивается на уровне логической структуры носителя.
Например, логически последовательная выборка записей файла обеспечивается таблицей размещения файлов, определяющей используемое файлом пространство как цепочку кластеров; физически находящихся в любой доступной части диска. Доступ к файлу производится по идентификатору (составному имени) через систему каталогов, связывающих идентификатор файла с началом цепочки указателей на кластеры данных в таблице размещения файлов. Кроме того, логическая структура содержит (в составе загрузочной записи) информацию, идентифицирующую пространство в целом, а также данные, определяющие физическую структуру (физический формат носителя, рассмотренный ранее).
В общем случае операция чтения физической записи включает следующие действия.
1. Определение адреса записи в координатах устройства (например, для файлов с записями фиксированной длины — пересчет номера нужной записи в относительный адрес сектора и далее определение абсолютного номера сектора на диске).
2. Перемещение головки чтения в соответствующую координату: позиционирование к дорожке и сектору на дорожке, складывающееся из двух действий — собственно радиального перемещения головки на расстояние от текущего положения до нужной дорожки и ожидания подхода указанного сектора вращающегося диска к позиции, где находится головка. Следует также отметить, что высокая плотность записи данных означает, что промежуток между секторами и дорожками сравнительно мал (сопоставим с погрешностями механизма перемещения и тепловым расширением), и поэтому правильность позиционирования определяется по служебным данным заголовка" сектора, считываемым до начала передачи прикладных данных.
3. Пересылка данных, расположенных в области кластера, в буфер, который физически может быть как частью устройства, так и областью оперативной памяти.
4. Завершение операции (проверка корректности чтения, например по контрольной сумме) и возврат управления ОС для обработки считанных данных.
5. Выделение системой данных, относящихся к затребованным записям. Причем во многих случаях в системный буфер считываются не только данные логической записи, нужные прикладной программе, но и соседние. Это позволяет сократить суммарные затраты времени при чтении нескольких записей, исключив наиболее долгую операцию позиционирования. Указание на такое блокирование может выдаваться явно прикладной программой при открытии файла или операционной системой, использующей собственные механизмы кэширования для оптимизации" ввода-вывода.
6. Передача в рабочую область прикладной программы данных запрошенной ею логической записи или указателя на соответствующую область памяти в системном буфере.
В этой последовательности наиболее медленными операциями являются механическое позиционирование головок и чтение данных с поверхности носителя (выполняемые на порядки медленнее, чем операции пересылки). Поэтому выигрыш во времени может быть получен только в случае выполнения ряда запросов на доступ к данным, причем экономия может достигаться следующими путями.
1. Суммарным сокращением перемещения головок за счет организации такой последовательности обращения к записям (или такого порядка их физического размещения), когда перемещение от текущего положения к следующему будет минимальным.
2. Формированием логических записей таким образом, чтобы их формат (длина данных) соответствовал физическому формату хранения. В случае кратности длин, т. е. если длина логической записи будет кратной длине кластера или в кластере будет размещаться целое число записей, будет исключена передача данных, не запрошенных текущей операцией.
Непосредственное применение приведенных методов повышения эффективности тем не менее достаточно ограниченно по целому ряду причин. По мере добавления новых типов данных или при появлении новых приложений структура записей должна будет меняться. Требования к обработке изменяются случайным образом. Если возникает необходимость модификации выбранных структур данных, то приходится соответственно переписывать и отлаживать прикладные программы. Чем большее количество прикладных программ имеется в наличии, тем более дорогой становится эта процедура. Кроме того, логическая структура записей стала бы зависимой от параметров физической структуры носителя, и планирование эффективной физической организации для конкретной структуры данных потребовало бы уже знаний системного аналитика.
Практическое решение состоит во введении контролируемой функциональной и информационной избыточности, обеспечивающей сокращение времени доступа за счет: 1) специализации компонент, т. е. упрощения процедур преобразований; 2) построения вспомогательных структур (в той или иной степени дублирующих основную информацию). Основой этого подхода является принцип выделения и представления описательных составляющих в виде самостоятельных операционных объектов, хранимых отдельно от определяемых ими данных.
2.3. Эволюция концепций обработки данных
Характер возможных представлений данных и архитектурные решения, отражающие степень специализации компонент управления, хорошо иллюстрируются представленной в [14] эволюцией концепций обработки данных.
С появлением в конце 60-х гг. понятия база данных взаимосвязь файлов (логических) и наборов данных (физических файлов) рассматривается в контексте неизбыточности и независимости данных, их защитой, и возможностью доступа в реальном времени.
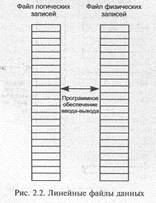
2.3.1. Простые (линейные) файлы данных (начало 60-х гг.)
Для линейных «простых» файлов организация хранения и доступа характеризуется следующими особенностями (рис. 2.2):
• записи в файлах размещаются и обрабатываются последовательно. Физическая структура хранения данных точно такая, же, как логическая;
• программное обеспечение ввода-вывода выполняет только операции физического чтения-записи. При обновлении отдельной записи файл всегда перезаписывается на другой носитель, а предыдущие поколения данных сразу не уничтожаются;
• прикладной программист определяет физическое расположение данных и включает формирование физической структуры в прикладные программы. Если структура данных или запоминающее устройство изменяется, прикладную программу необходимо переписать;
• наборы данных обычно создаются и оптимизируются для одного приложения. Одни и те же данные редко используются для нескольких приложений.
2.3.2. Методы доступа к записям (конец 60-х гг.)
Этот этап характеризуется изменением природы файлов и устройств. Появляются дисковые устройства с прямым доступом и возможностью обновления «по месту изменений», а программное обеспечение позволяет без перекомпиляции программы изменять расположение набора данных, но без изменения структуры записей и типа организации набора (рис. 2.3).
Организация хранения и доступа в этом случае характеризуется следующими особенностями:
• логическая и физическая структуры файла различаются между собой, но взаимосвязь между ними достаточно простая. Запоминающее устройство можно менять без изменения прикладной программы;
• файл создается в прикладной программе как набор данных с последовательным, индексно-последовательным или с прямым доступом (по физическому адресу). Возможен последовательный или произвольный доступ к записям (но не к полям). Поиск по многим ключам, как правило, не используется. Если используются иерархические файлы, то взаимосвязь «исходный — порожденный» программируется в прикладной программе;

• типовое программное обеспечение системы обработки данных представляет собой методы доступа, но не «управление данными». Данные в основном разрабатываются и оптимизируются для одного приложения;
• средства обеспечения защиты данных недостаточно надежны.
2.3.3. Первые системы управления базами данных (начало 70-х гг.)
Для этого этапа характерно изменение представления о назначении и возможностях систем управления данными. По мере развития средств обработки данных становилось ясно, что прикладные программы желательно сделать независимыми не только от изменений в аппаратных средствах хранения, но также и от добавления к хранимым данным новых полей и новых взаимосвязей. Система должна быть способна обрабатывать новые типы запросов пользователей (рис. 2.4).
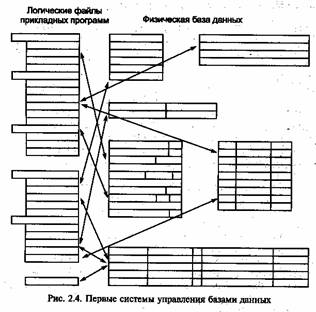
Организация хранения и доступа в случае систем управления данными характеризуется следующими особенностями:
• различные логические файлы могут быть получены из одних и тех же физических данных. Доступ к одним и тем же данным может осуществляться различными приложениями по различным путям, отвечающим требованиям этих приложений;
• данные адресуются на уровне полей и групп. Можно использовать поиск по многим ключам;
• физическая структура данных независима от прикладных программ. Ее можно изменять с целью повышения эффективности базы данных, не модифицируя при этом прикладные программы. Использование сложных форм организации данных не требует усложнения прикладных программ;
• элементы данных являются общими для различных приложений. Отсутствие избыточности способствует целостности данных.
2.3.4. Системы управления базами данных
Требования к системе основываются на том, что структура базы данных является менее статичной, чем файловая структура. Элементы хранимых данных и способы их представления непрерывно изменяются.
Из одних и тех же данных могут быть получены различные логические файлы, а доступ к одним и тем же данным со стороны различных приложений может осуществляться различными путями, отвечающими требованиям этих приложений. Это часто приводит к созданию сложных структур данных. Независимо от того, каким образом данные организованы на самом деле, прикладной программист должен представлять себе файл в виде сравнительно простой структуры, которая спланирована в соответствии с требованиями его приложения.
Программное обеспечение баз данных должно располагать средствами отображения файлов структуры прикладного уровня в такую физическую структуру данных, которая эффективно запоминается на реальном носителе, и наоборот.
Для этого вводятся два уровня независимости данных (рис. 2.5). Логическая независимость данных означает, что общая логическая структура данных может быть изменена без изменения прикладных программ (изменение, конечно, не должно заключаться в удалении из базы данных таких элементов, которые используются прикладными программами).

Физическая независимость данных означает, что физическое расположение и организация данных могут изменяться, не вызывая при этом изменения ни общей логической структуры данных, ни прикладных программ.
Система обеспечивает привязку данных — связывание физического представления данных с программой, которая эти данные использует, путем преобразования обращения прикладной программы к логической записи или к элементам логической записи в машинные обращения к физической записи и ее элементам.
Физическая и логическая независимость данных обеспечивается программными средствами. Допускается существование глобального логического представления данных. Предусматривается использование языка описания банных для администратора базы данных, языка команд для прикладного программиста и языка запросов для пользователя.
Для систем управления базами данных также характерны следующие особенности:
• так как базы данных конструируются для выдачи ответов на не запланированные заранее запросы, то используются дополнительные функционально-ориентированные структуры, например, инвертированные файлы, позволяющие осуществлять быстрый поиск в базе данных по некоторым не основным ключам;
• вводятся средства администрирования, которое позволяют управлять системой (в том числе управление защитой, секретностью, целостностью и безопасностью данных), проектировать структуры, оптимальные для пользователей, обеспечивать импорт-экспорт и перемещение данных.
2.4. Схема управления данными в СУБД
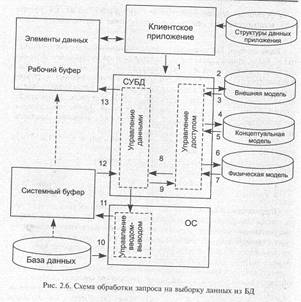
Рассмотрим примерную последовательность операций, обеспечивающих чтение прикладной программой из базы данных, представленную на рис. 2.6:
(1) — прикладная программа (клиентское приложение) формирует и вещает системе управления базами данных запрос на чтение необходимых данных, содержащихся в базе;
(2 — 3) — СУБД отыскивает описание затребованных данных в структуре описания данных прикладного уровня (внешняя модель);
(4 — 5) — СУБД по глобальному описанию БД (концептуальная схема) определяет необходимые данные на логическом уровне;
(6 — 7) — СУБД по описанию физической структуры БД (физическая модель) определяет физическую запись (или совокупность записей), которую необходимо считать для выборки данных, затребованных прикладной программой;
(8 — 9) — СУБД через подсистему управления потоками данных выдает операционной системе запрос на чтение хранимой записи;
(10 — 11) — подсистема управления вводом-выводом операционной системы осуществляет физическое чтение записи в системный буфер ОС;
(13) — СУБД выделяет необходимую логическую запись, осуществляет форматные преобразования, обусловленные различиями описаний на глобальном и прикладном уровнях, и передает для функциональной обработки приложением данные в рабочий буфер, выделяемый прикладной программой или самой СУБД.
2.5. Данные и управление их обработкой
2.5.1. Типы, форматы, структуры данных
Структура информационных единиц, обрабатываемых на ЭВМ, определяется следующими понятиями:
• тип данных, или совокупность соглашений о программно-аппаратурной форме представления и обработки, а также ввода, контроля и вывода элементарных данных;
• структуры данных — способы композиции простых данных в агрегаты и операции над ними;
• форматы файлов — представление информации на уровне взаимодействия операционной системы с прикладными программами.
Типы данных. Ранние языки программирования — Фортран, Алгол — были ориентированы исключительно на вычисления и не содержали систем типов и структур данных. Типы числовых данных Алгола: INTEGER (целое число), REAL (действительное) — различаются диапазонами изменения, внутренними представлениями и применяемыми командами процессора ЭВМ (соответственно арифметика с фиксированной и плавающей точкой). Нечисловые данные представлены типом BOOLEAN — логические, имеющие диапазон значений {TRUE, FALSE).
Появившиеся позже языки программирования COBOL, PL/1, Pascal уже предусматривают новые типы данных:
• символьные (цифры, буквы, знаки препинания и пр.);
• числовые символьные для вывода;
• числовые двоичные для вычислений;
• числовые десятичные (цифры 0 — 9) для вывода и вычислений.
Структуры данных. В языке программирования Алгол были определены два типа структур: элементарные данные и массивы (векторы, матрицы, тензоры, состоящие из арифметических или логических переменных). Основным нововведением, появившимся первоначально в Коболе, (затем в PL/1, Паскале и пр.) являются агрегаты данных (структуры, записи), представляющие собой именованные комплексы переменных разного типа, описывающих некоторый объект или образующих некоторый достаточно сложный документ.
Термин запись подразумевает наличие множества аналогичных по структуре агрегатов, образующих файл (картотеку), содержащих данные по совокупности однородных объектов. Элементы данных образуют поля, среди которых выделяются элементарные и групповые (агрегатные).
Появление СУБД и АИПС приводит к появлению новых разновидностей структур:
• множественные поля данных;
• периодические групповые поля;
• текстовые объекты (документы), имеющие иерархическую структуру (документ, сегмент, предложение, слово).
Форматы файлов. В зависимости от типа и назначения файлов и возможностей ОС (методов доступа) файл может передаваться в прикладную программу как целое или блоками (физическими записями) либо логическими записями (строками, словами, символами).
Например, в системе OS/360 основную роль играли два типа файлов:
• символьные (исходные программы или данные);
• двоичные (программы в машинных кодах).
В современных системах активно используется значительно большее разнообразие файлов, например, текстовые файлы — обобщенное название для простых и размеченных текстов, ASCII-файлов и других наборов данных символьной информации, которые интерпретируются и обрабатываются текстовыми редакторами, процессорами, анализаторами.
2.5.2. Описание и обработка файлов
По мере развития средств вычислительной техники и расширения спектра задач, связанных с обработкой на ЭВМ, разработчики и пользователи стали уделять больше внимания информационной (нежели алгоритмической) стороне вопроса.
По-видимому достаточно подробное описание структур данных и установление их связи с файлами было впервые сделано в языке программирования Cobol (Common Business Oriented Language). Эта проблема была решена следующим образом — файл (набор данных на внешнем носителе) рассматривается как совокупность записей одинаковой структуры, каждая из которых представляет собой набор (агрегат) разнородных данных (в более поздних языках программирования — РL/1, Pascal, С, за подобными объектами так и закрепилось название «структура — structure»).
Проблема локализации описания данных. Приемы распознавания программой элементов данных или записей относятся к такому типу взаимодействия программ и данных, когда описание данных размещено в программе, а файл данных организован в соответствии с этим описанием (рис. 2.7, а). Однако этот способ может привести к нарушению функционирования или разрушению данных, если из-за ошибок программиста или оператора к программе будет подсоединен «неправильный файл».
Для установления независимости программ от данных в некоторых системах описание данных размещают совместно с файлом данных (рис. 2.7, б). По такому принципу организован весьма распространенный формат файла данных (с1Ы-формат), происходящий от систем dBase — Clipper — Foxbase — FoxPro, а затем принятый и рядом
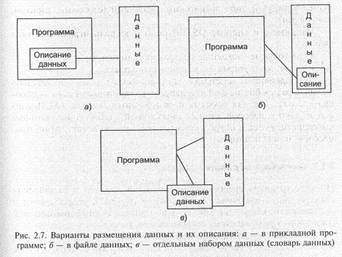
других систем. В этом случае в начале файла создается заголовок, содержащий описание полей записи файла (имя, тип, длина данного, код информации и пр.), и таким образом, описание данных файла в программе не нужно.
Недостатком такого подхода является, например, необходимость использования программистами тех же имен данных, что содержатся в описании файла.
Следующим шагом явилось полное отделение описаний от данных и программ и сосредоточение их в специальных файлах (таблицах) — словарях данных (рис. 2.7, в), которые относятся к базам данных и системам управления базами данных.
2.6. Особенности и компромиссы реализаций баз данных
В заключение приведем основные отличительные особенности обработки данных, характерные для файловых систем и систем управления базами данных.
Файлы обладают следующими свойствами:
• файл, как правило, представляет собой совокупность записей одного типа, доступ к которым определяется типом организации файла и осуществляется только средствами операционной системы;
• файл описывают и используют в прикладной программе, работающей с данными.
Базы данных имеют следующие особенности:
• база данных представляет собой совокупность данных разного типа, причем часто по одним данным получают другие;
• база данных существует независимо от конкретной прикладной программы — база создается с целью интеграции данных, объединяющей данные многих приложений (но определенного назначения). База данных предназначена для совместного, многофункционального использования многими пользователями один раз введенных данных.
Надо отметить, что с точки зрения управления данными СУБД оперируют данными на содержательном уровне, хотя физические структуры, используемые для этих целей, могут и совпадать с аналогичными структурами, создаваемые ОС.
Коренное же отличие СУБД от файловых систем ОС состоит в том, что СУБД устанавливает связь между содержанием и адресом, а ОС — между именем и адресом данных.
В то же время эта граница постоянно подвергается «атакам» с обеих сторон. Например, ОС-360 с «индексным доступом к данным», IN-PICK, включающая язык поиска записей файлов по содержанию, UNIX, включающая команды сортировки, коррекции или объединения содержимого текстовых файлов, наподобие того, как это осуществляется с таблицами данных в СУБД. Тем не менее, следует признать это скорее исключением, чем правилом и в компетенцию ОС надо относить только связь «имя — адрес», оставляя другие зависимости на ответственность прикладных программ и оболочек СУБД и ГИПС (автоматизированные информационно-поисковые системы).
В общем случае можно сказать, что основные задачи обработки данных, решаемые на основе концепций баз данных, сводятся к следующим вопросам.
1. Каким образом сложные нелинейные структуры данных представить в виде линейных — наиболее соответствующих принципу последовательного представления (хранения) в машинной памяти?
2. Каким образом организовать данные, чтобы была возможность эффективного внесения, удаления и редактирования данных?
3. Как организовать данные, чтобы использование пространства памяти (плотность данных) было достаточно рациональным, а скорость доступа к записям данных высокой?
4. Каким образом организовать данные, чтобы поиск был эффективным и позволял отыскивать записи по нескольким ключам?
При этом, с точки зрения прагматики, создание базы данных это, по существу, попытка найти компромисс сразу по нескольким направлениям и сочетаниям нескольких взаимообратных факторов (с точки зрения их влияния на показатель общей эффективности системы), в том числе следующих:
1) эффективность — простота;
2) скорость выборки — стоимость (сложность) аппаратных средств;
3) скорость выборки — сложность процедур доступа;
4) плотность данных — время доступа и сложность процедур;
5) независимость данных — производительность;
6) гибкость средств поиска — избыточность данных;
7) гибкость поиска — скорость поиска;
8) сложность процедур доступа — простота обслуживания.
Глава 3. Модели и структуры данных
Рассматриваемые в контексте понятия «информационная система» элементы реального мира, информацию о которых мы сохраняем и обрабатываем, будем называть объектами. Объект может быть материальным (например, служащий, изделие или населенный пункт) и нематериальным (например, имя, понятие, абстрактная идея). Будем называть набором объектов совокупность объектов, однородных с не которой точки зрения (например, объектов нашего внимания, пусть даже и разнородных по своей внутренней природе).
Объект имеет различные свойства (например, цвет, вес, имя), которые важны для нас в то время, когда мы обращаемся к объекту (например, выбираем среди множества других) с какой-либо целью его использования. Причем свойства могут быть заданы как отдельными однозначно интерпретируемыми количественными показателями, так и словесными нечеткими описаниями, допускающими разную трактовку, иногда зависящую от точки зрения и наличных знаний воспринимающего субъекта.
Однако во всех случаях человек, работая с информацией, имеет дело с абстракцией, представляющей интересующий его фрагмент реального мира — той совокупностью характеристических свойств (атрибутов), которые важны для решения его прикладной задачи. Абстрагирование — это способ упрощения совокупности фактов, относящихся к реальному объекту (по своей сути бесконечно сложному и разнообразному при изучении его человеком). При этом некоторые свойства объекта игнорируются, поскольку считается, что для решения данной прикладной задачи (или совокупности задач) они не являются определяющими и не влияют на конечный результат действий при решении.
Цель такого абстрагирования — построение конструктивного операбельного описания (рабочей модели), удобного в обработке как для человека, так и для машины, позволяющего организовать эффективную обработку больших объемов информации, причем высокопроизводительной должна быть работа не только вычислительной системы, но и взаимодействующего с ней человека.