7.3. Прерывания и особые случаи
Прерывания текущей программы могут возникать по следующим трем причинам:
• внешний сигнал по входам INTR или NMI;
• аномальная ситуация, сложившаяся при выполнении конкретной команды и зафиксированная аппаратурой контроля;
• находящаяся в программе команда прерывания INT и.
Первая из указанных выше причин относится к аппаратным прерываниям, а две другие — к программным.
Программные прерывания, вызываемые причинами 2 и 3, называют обычно особыми случаями (иногда используют термин исключения). Особые случаи возникают, например, при нарушении защиты по привилегиям, превышении предела сегмента, делении на ноль и т. д.
Все особые случаи классифицируются как нарушения, ловушки или аварии. Нарушение (fault) — этот особый случай процессор может обнаружить до возникновения фактической ошибки (например, нарушение правил привилегий или отсутствие сегмента в оперативной памяти). Очевидно, после обработки нарушения можно продолжить программу, осуществив рестарт виновной команды.
Ловушка (trap) — обнаруживается после окончания выполнения виновной команды. После ее обработки процессор возобновляет действия с той команды, которая следует за "захваченной" (например, прерывание при переполнении или команда INT n). Большинство отладочных контрольных точек также интерпретируются как ловушки.
Авария (abort) — приводит к потере контекста программы, ее продолжение невозможно. Причину аварии установить нельзя, поэтому осуществить рестарт программы не удается, ее необходимо прекратить. К авариям ("выходам из процесса") относятся аппаратные ошибки, а также несовместимые или недопустимые значения в системных таблицах.
Общая реакция процессора на прерывания или особые случаи состоит в сохранении минимального контекста прерываемой программы (в стеке — адрес возврата и, может быть, некоторую дополнительную информацию), идентификации источника прерывания или особого случая и передаче управления соответствующему обработчику (программе, подпрограмме, задаче). Однако имеются принципиальные различия по формированию сохраняемого контекста.
При возникновении нарушений в стек обработчика особого случая в качестве адреса возврата включается CS: EIP команды, вызвавшей нарушение.
При распознавании ловушки (к ним относятся и большинство внешних прерываний) процессор включает в стек адрес возврата, относящийся к следующей за ловушкой команде.
Наконец, при авариях содержательный адрес возврата отсутствует, поэтому рестарт задачи при авариях невозможен.
Принцип реализации прерываний (внешних) и особых случаев (внутренних) в микропроцессорах фирмы Intel сохранился практически неизменным с МП 8086.
В 8086 сигналы запросов на обработку прерываний формировались либо аппаратурой контроля процессора (внутренние прерывания), либо поступали из внешней среды на входы процессора INTR или NMI. При обнаружении (разрешенного) запроса в стек помещались текущие значения FLAGS, CS и IP.
В процессе идентификации источника запроса ему ставился в соответствие восьмиразрядный двоичный код n — вектор прерывания, причем за каждым внутренним прерыванием и за внешним NMI жестко закреплялся свой вектор, а для запросов, поступивших по входу INTR, реализовывалась процедура ввода вектора с внешней шины. 11алее, определенный вектор прерывания рассматривался как номер строки таблицы, располагающейся с нулевого физического адреса памяти. Четырехбайтовыми элементами этой таблицы были адреса CS: IP точек входа в подпрограммы — обработчики прерываний. Таким образом, в системе поддерживалось до 256 различных обработчиков прерываний, причем векторы 0 — 31 резервировались за внутренними прерываниями (и NMI), а остальные — для внешних прерываний.
При идентификации источника запроса INTR выполняются следующие действия (при условии, что флаг IF = 1, иначе запрос INTR игнорируется):
1. Генерируется два цикла шины для ввода вектора внешнего прерывания.
2. Помещается в стек содержимое регистра FLAGS.
3. Помещается в стек содержимое регистра CS. Д
4. Помещается в стек содержимое регистра IP.
5. Сбрасывается в 0 флаг разрешения внешних прерываний IF, запрещая восприятие новых запросов по входу INTR до явной установки флага IF в 1 командой STI.
6. По значению вектора n обращаются к n-му элементу таблицы векторов прерываний и из нее загружаются новые значения регистров CS: IP.
7. Начинается выполнения обработчика прерывания с точки входа, определяемой CS: IP.
Сохраненное в стеке старое содержимое регистров CS: IP образует адрес возврата. Когда обработчик прерываний заканчивает свои действия, он должен выполнить команду возврата IRET, которая, извлекая из стека содержимое FLAGS, CS, IP, возвращает управление прерванной программе.
Механизм реализации внешних и внутренних прерываний МП 80486 и Pentium в R-режиме аналогичен описанному выше, однако в P-режиме он значительно усовершенствован:
таблица векторов прерываний трансформирована в дескрипторную таблицу прерываний IDT (рис. 7.13);
более сложен процесс перехода к обработчику прерывания или особого случая;
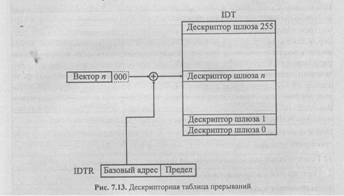
Механизм передачи управления обработчику особого случая (прерывания) соответствует обычному способу передачи управления через шлюз вызова. При этом процессор аппаратно включает в стек значения EFLAGS, CS: EIP (адрес возврата) прерываемой программы и, кроме того, в некоторых случаях — код ошибки и текущие значения SS, ESP (последние — при смене привилегий).
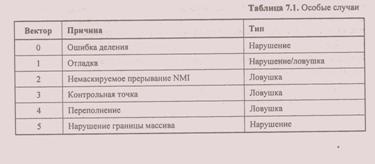
Точное значение адреса возврата зависит от того, является ли особый случай нарушением, ловушкой или аварией. Первые 32 вектора зарезервированы за особыми случаями P-режима (табл. 7.1).
7.3.1. Дескрипторная таблица прерываний
Дескрипторная таблица прерываний IDT является прямой заменой таблицы векторов прерываний процессора 8086. Она должна определять 256 обработчиков прерываний и особых случаев, поэтому ее максимальный размер составляет 256 х 8 = 2048 байтов. Таблица IDT может находиться в любой области памяти, процессор локализует ее с помощью 48-битного регистра IDTR, который содержит базовый адрес и предел таблицы. Таблицу не рекомендуется объявлять короче максимального размера, т. к. любое обращение за пределы таблицы вызывает нарушение общей защиты, а вектор внешнего прерывания, вообще говоря, может иметь любое значение в диапазоне 00 — FFh.
В таблице IDT разрешается применять только три вида дескрипторов: шлюз ловушки, шлюз прерывания и шлюз задачи (но не дескриптор TSS). Шлюзы прерывания и ловушки имеют большое сходство со шлюзом вызова (см. рис. 7.9). Единственное отличие состоит в отсутствии в этих шлюзах 5-битового поля счетчика WC, которое в шлюзе вызова определяет число параметров, передаваемых в вызываемую подпрограмму через стек. Соответствующее поле в шлюзах прерывания и ловушки зарезервировано.

Напомним, что шлюз вызова (а также ловушки и прерывания) содержит селектор сегмента кода и смещение внутри него, которые однозначно определяют точку передачи управления. Шлюз задачи содержит лишь селектор ceгмента состояния задачи TSS (разумеется, каждый дескриптор содержит и байт доступа).
После локализации сегмента кода обработчика особого случая и включения информации в стек, выполнение начинается с той команды, которая определяется смещением в шлюзе ловушки. Обработчик действует до тех пор, пока не достигнет команды такт. По этой команде процессор извлекает из стека адрес возврата и содержимое регистра флажков (а также 48-битный указатель внешнего стека, если при обработке особого случая происходила смена уровней привилегий).
Если особый случай вызывается через шлюз прерывания, процессор сбрасывает флаг разрешения прерывания IF после включения в стек адреса возврата и содержимое регистра флажков, но до выполнения первой команды обработчика. При переходе через шлюз ловушки никакие флаги не изменяются. Обработка особого случая через шлюз задачи аналогична действию команды где FAR CALL приводящей к переключению задачи. Однако здесь невозможен прямой переход через дескриптор TSS, а требуется промежуточный шлюз задачи. С дескриптором шлюза задачи ассоциируется уровень привилегий, который не должен быть выше уровня привилегий прерываемой задачи. По существу, прерываемая задача как бы выполняет команду FAR CALL вызова другой задачи через шлюз задачи, и здесь действуют стандартные правила защиты по привилегиям.
Обработка особого случая через шлюз задачи, т. е. в другой задаче, имеет определенные преимущества:
• автоматически сохраняется весь контекст прерванной задачи;
• обработчик особого случая не может исказить прерванную задачу, т. к. он полностью изолирован от нее;
• обработчик прерывания может работать на любом уровне привилегий и в
заведомо правильной среде; он может иметь свое локальное адресное пространство благодаря наличию отдельной локальной дескрипторной таблицы (при необходимости).
К недостаткам применения шлюза задачи для вызова обработчика можно отнести:
• замедленную реакцию процессора на особый случай;
• в шлюзе задачи невозможно определить начальную точку выполнения задачи;
• сложность получения информации о прерванной задаче.
Переключение задачи, инициируемое особым случаем, производит вложение задачи обработчика в прерванную задачу. Старая задача остается занятой, а новая — обработчик особого случая — отмечается как занятая, причем в ней будет установлен флажок NT и загружено поле обратной связи. Состояние флага IF в новой задаче не меняется и определяется тем значением бита регистра EFLAGS, которое хранилось в TSS. Поэтому, если обработчик особого случая через шлюз задачи предназначен для обработки внешних прерываний, следует в TSS установить IF = 0, "аппаратно" запретив внешние прерывания на время работы обработчика, или пока он явно не установит IF = 1.
Все особые случаи должны обрабатываться через шлюзы. В дескрипторах шлюзов всех трех типов, содержащихся в IDT, имеется поле уровня привилегий дескриптора DPL, определяющее минимальный уровень привилегий, необходимый для использования шлюза. Для обработчиков прерываний рекомендуется устанавливать DPL = 3, чтобы обработка особого случая не зависела от уровня привилегий текущей задачи.
Шлюзы ловушек или прерываний должны передавать управление сегменту кода с более высоким или равным уровнем привилегий. Обработчику не разрешается работать на уровне привилегий, который ниже уровня прерываемой задачи (если, конечно, он не является отдельной задачей). Из-за непредсказуемости возникновения прерываний и особых случаев требуется гарантировать невозможность нарушения правил защиты по привилегиям при обработке особого случая. Этого можно достичь двумя способами:
• определить все обработчики особых случаев, не вызывающие переключения задачи, в сегментах кода с уровнем привилегий 0;
• такие обработчики будут действовать всегда, независимо от значения CPL программы;
• определить все обработчики особых случаев, не вызывающие переключения задачи, в подчиненные сегменты кода.
В некоторых особых случаях процессор включает в стек 4 байта кода ошибки (error code), причем действительными являются только 2 младших байта, остальные включаются лишь для выравнивания стека. Когда процессор обнаруживает недействительный сегмент TSS:
• нарушение не присутствия;
• нарушение стека;
• нарушение общей защиты,
• он включает в стек обработчика особого случая информацию, идентифицирующую "виновный" дескриптор.
Формат кода ошибки напоминает селектор, т. к. большинство особых случаев связано с ошибками дескрипторов и содержит следующие поля:
• биты [15:3] — индекс (номер строки дескрипторной таблицы);
• бит [2] — TI, как и в других селекторах, определяет принадлежность дескриптора к локальной (TI = 1) или глобальной (TI = 0) дескрипторной таблице;
• бит [1] — 1. Если 1 = 1, то индекс в старших битах [15:3] кода ошибки от носится к дескрипторной таблице прерываний IDT;
• бит [0] — ЕХТ = 1 означает, что особый случай был вызван аппаратным прерыванием (внешним) или возник, когда процессор обрабатывал другой особый случай.
Если процессор не может сформировать содержательный код ошибки, он включает в стек код, равный 0.
Помимо кода ошибки в некоторых особых случаях дополнительная диагностическая информация находится в других регистрах процессора. Например, при страничном нарушении в регистре CR2 содержится линейный адрес, преобразование которого привело к ошибке. Обработчик этого особого случая может обратиться к соответствующим элементам PDE и PTE. Для особого случая отладки полезная информация содержится в регистре состояния отладки DR6.
7.3.4. Описание особых случаев
Далее приводится краткое описание действий процессора х86 при возникновении особых случаев [3].
Ошибка деления (0) — автоматически формируется, когда в команде DIV или IDIV делитель равен нулю или частное слишком велико для получателя (АL/АХ/ЕАХ).
Отладка (1) — формируется в следующих случаях (может быть нарушение или ловушкой):
• нарушение контрольной точки по адресу команд;
• ловушка контрольной точки по адресу данных;
• нарушение общей защиты;
• ловушка покомандной работы (флаг TF =1);
• ловушка контрольной точки по переключению задачи (в сегменте TSS бит Т = 1).
Немаскируемое прерывание NMI$2) — единственное внешнее радиальное прерывание.
Контрольная точка (3) — формируется при выполнении команды INT3 (код операции — CCh), Передача управления обработчику особого случая является частью команды INT3 адрес возврата в стеке относится к началу следующей команды. Тот же обработчик вызывается при выполнении внешнего прерывания с вектором 03 или двухбайтовой команды INT 03.
Переполнение (4) — возникает при выполнении команды INTO при условии установки в 1 флага переполнения OF. Как и для INT 3, передача управления обработчику особого случая является частью команды INTO, адрес возврата в стеке относится к началу следующей команды. Обычно команда INTO применяется в компиляторах для выявления переполнения в арифметике знаковых чисел. Тот же обработчик вызывается при выполнении внешнего прерывания с вектором 04 или команды INTO 04
Нарушение границы массива (5) — возникает при выполнении команды если контрольная проверка дает отрицательный результат, т. е. проверяемый (первый) операнд не попадает в диапазон значений, определенных вторым (нижняя граница) и третьим (верхняя граница) операндами команды.
Недействительный код операции (6) — генерируется, когда операционное устройство процессора обнаруживает неверный код операции, виде типа операндов коду операции, попытку выполнения привилегированных команд в R-режиме, неверные байты mod r/m или sib, использование префикса блокировки LOCK с командами, которые нельзя блокировать. Характерно, что существует несколько одно и двухбайтовых кодов, зарезервированных фирмой Intel для развития системы команд, и хотя им в 80486 не соответствуют никакие команды, зарезервированные коды не вызывают особого случая.
Устройство недоступно (7) — возникает в двух ситуациях:
• процессор выполняет команду Esc и бит ЕМ (эмуляция сопроцессора) в
регистре CRO установлен в 1;
• процессор выполняет команду WAIT или ESC и бит TS (переключение задачи) в регистре CRO установлен в 1.
В первом случае программист намерен выполнить операции плавающей арифметики программно.
Второй случай может возникнуть после переключения задачи. Бит ТБ аппаратно устанавливается в 1 при переключении задачи, а первая же встретившаяся в новой задаче команда сопроцессора вызывает особый случай 7, ибо контекст устройства с плавающей точкой старой задачи не сохранен. Обработчик особого случая 7 сохраняет старое состояние устройства с плавающей точкой в сегменте TSS старой задачи и загружает новое состояние устройства из сегмента TSS новой задачи. (В случае работы цепочки вложенных задач обработчик должен программно отследить ту старую задачу, которая последней использовала FPU.) После этого привилегированной командой сын сбрасывается флажок TS и осуществляется возврат на команду устройства с плавающей точкой. Так как теперь флаг TS сброшен, команда сопроцессора будет выполнена.
Двойное нарушение (8) — обычно, когда процессор обнаруживает особый случай при попытке вызвать обработчик предыдущего особого случая, два особых случая обрабатываются последовательно. Если процессор не может обрабатывать их последовательно, он сигнализирует о двойном нарушении. Для определения того, когда о двух нарушениях следует сообщать как о двойном нарушении, процессор подразделяет все особые случаи на три класса:
• легкие особые случаи — векторы 1, 2, 3, 4, 5, 6, 7,16;
• тяжелые особые случаи — векторы 0, 10, 11, 12, 13;
• страничные нарушения — вектор 14.
Когда возникают два легких особых случая или один легкий и один тяжелый, эти два события допускают последовательную обработку. При появлении двух тяжелых событий их обработать нельзя, поэтому процессор формирует особый случай двойного нарушения. Аналогичное состояние наступает, если после страничного нарушения возникает тяжелый особый случай или второе страничное нарушение, хотя если, наоборот, после тяжелого особого случая возникает страничное нарушение, эти события могут быть обработаны.
Если при попытке вызвать обработчик двойного нарушения возникает любое другое нарушение, процессор переходит в режим отключения. Этот режим аналогичен состоянию процессора после выполнения команды . До восприятия сигналов NMI или RESET никакие команды не выполняются, причем если отключение возникло при выполнении обработчика немаскируемого прерывания, запустить процессор может только сигнал RESET.
Недействительный сегмент TSS (10) — возникает при попытке переключения на задачу с неверным сегментом TSS. Поскольку сегмент TSS может определять LDT, сегменты кода, стека, данных, к особому случаю 10 относятся ситуации с нарушением границ этих сегментов, нарушением прав доступа, запретом записи в сегмент стека и др. Нарушения могут возникать как в контексте старой, так и новой задачи, поэтому обработчик особого случая 10 должен сам быть задачей и вызываться через шлюз задачи (десятая строка IDT должна содержать шлюз задачи).
Heпpucymcmвue сегмента,(11) — формируется, когда бит присутствия сегмента в дескрипторе Р = 0. Это нарушение допускает рестарт, если обработчик особого случая 11 реализует механизм виртуальной памяти на уровне сегментов.
Нарушение стека (12) — возникает в двух ситуациях:
• в результате нарушения предела любой операции, которая обращается к
регистру SS (POP, PUSH, Enter, неявное использование стека при обращении к памяти, например, MOV AX [BR+6]);
• при попытке загрузить в регистр SS дескриптор, который отмечен не присутствующим.
Нарушение обидней защитныее (13) — все нарушения защиты, которые не служат
причиной конкретного особого случая, вызывают особый случай общей защиты:
• превышение предела сегмента (кроме стека);
• передача управления сегменту, который не является выполняемым;
• запись в защищенный от записи сегмент;
• считывание из выполняемого сегмента;
• загрузка в SS селектора сегмента, защищенного от записи;
• загрузка в регистры SS, DS, ES, FS, GS селектора системного сегмента;
• загрузка в регистры SS, DS, ES, FS, GS селектора выполняемого сегмента;
• обращение к памяти через DS, ES, FS, GS, когда в них пустой селектор;
• переключение на занятую задачу;
• нарушение правила привилегий и др.
Страничное нарушение (14) — возникает, когда разрешено страничное преобразование и имеет место одна из следующих ситуаций:
• в элементе каталога разделов или таблицы страниц, используемом для
преобразования линейного адреса в физический, сброшен бит присутствия;
• процедура не имеет достаточного уровня привилегий для доступа к адресуемой странице.
Ошибка операции с плавающей точкой (16) — сигнализирует об ошибке, возникшей в команде устройства с плавающей точкой.
Контроль выравнивания (17) — возникает при нарушении выравнивания операндов. Операнды считаются выровненными, если адрес двухбайтового слова является четным (младший разряд равен 0), адрес четырехбайтового двойного слова кратен 4, а адрес восьми байтовой структуры данных кратен 8. Для разрешения контроля выравнивания должны выполняться три условия:
∙ бит АМ в регистре СКЗ установлен;
∙ флаг АС установлен;
∙ выполняется программа на уровне привилегий 3.
Традиционно средства отладки микропроцессоров ограничивались наличием: О короткой команды программного прерывания, которую можно было устанавливать вместо первого байта любой команды; О аппаратной реализации пошагового (покомандного) режима, который инициировался установкой специального бита Т в регистре флагов.
По мере усложнения МПС возможности внешних аппаратных средств по наблюдению операций, происходящих внутри процессора, уменьшаются. Поэтому в схемах мощных процессоров стали предусматривать разнообразные средства отладки.
Основу средств отладки в процессорах х86 старших моделей составляют специализированные регистры отладки — программируемые регистры задания контрольных точек, регистры управления и состояния отладки. Они заменяют собой средства аппаратных внутрисхемных эмуляторов. Процессоры х86 старших моделей обеспечивают не только покомандную работу, но и регистрацию переключения на конкретную задачу, установку контрольных точек по адресам команд и фиксацию модификации значений переменных в памяти.
Регистры отладки поддерживают контрольные точки по командам и данным. В общем, под контрольной точкой понимается адрес, при использовании которого программой возникает особый случай отладки. Установка контрольной точки по команде обеспечивает регистрацию команды по любому линейному адресу. Задание контрольной точки по данным позволяет узнать, когда производится обращение к конкретной переменной.
Отладочные средства х86 включают в себя: CI однобайтовую команду контрольной точки INT 3, которую можно вставлять в программу по любому адресу; при выполнении этой команды генерируется особый случай отладки;
∙ флаг пошагового режима TF в регистре EFLAGS, позволяющий выполнить программу по командам;
∙ четыре регистра отладки DRO — DR3, которые определяют четыре независимые контрольные точки по командам или данным; регистр управления отладкой DR7 и регистр состояния отладки DR6;
∙ флаг ловушки Т в TSS, который вызывает особый случай отладки при переключении на задачу с установленным в 1 битом Т;
∙ флаг возобновления RF в регистре EFLAGS, с помощью которого подавляются многократные особые случаи в одной и той же команде.
Все эти средства действуют как ловушки, следя за возникновением условий, представляющих интерес для программиста. Когда возникает такое условие, формируется особый случай отладки (с вектором 1); только команда INT 3 генерирует прерывание с вектором 3. Зарезервированный вектор отладки 1 упрощает процедуру вызова отладчика.
Итак, отладчик по вектору 1 вызывается в следующих случаях: D INT 3 TF = 1 после каждой команды;
∙ при TTSS = 1 в момент переключения на задачу;
∙ ловушка контрольной точки по данным;
∙ нарушение контрольной точки по команде.
Команда INT 3 предоставляет альтернативный способ задания контрольной
точки и особенно удобна, если контрольные точки размещаются в исходном коде или требуется установить более четырех контрольных точек.
Программные контрольные точки задаются путем замены обычных команд на команды INT 3 — при этом требуется осуществлять запись в сегмент кода (создавать альтернативный сегмент данных), а после отладки — восстанавливать исходный код. Использование аппаратных контрольных точек исключает необходимость модификации кода (можно отлаживать программу, размещенную в ПЗУ), а так же допускает контроль обращения к данным.
Рассмотренные средства позволяют вызывать отладчик как процедуру в контексте текущей задачи или как отдельную задачу при выполнении одного из следующих условий:
∙ выполнение команды контрольной точки INT 3;
∙ выполнение любой команды (при TF = 1);
∙ выполнение команды по указанному адресу;
∙ считывание или запись байта, слова или двойного слова по указанному адресу;
∙ запись байта, слова или двойного слова по указанному адресу;
∙ переключение на конкретную задачу;
∙ попытка изменить содержимое регистра отладки.
Регистры отладки, форматы которых приведены на рис. 7.14, включают в себя:
• четыре регистра DRO — DR3, предназначенные для хранения линейных адресов четырех контрольных точек, каждая из которых независимо может быть определена как контрольная точка по команде или по данным;
• регистр DR7 управления отладкой, включающий поля, которые определяют свойства контрольных точек и некоторые параметры процесса отладки;
• регистр DR6 состояния отладки, предназначенный для идентификации
причины прерывания отладки;
• наконец, зарезервированные регистры DR5, DR4.
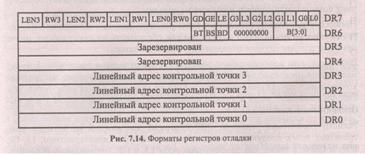
Рассмотрим форматы регистров состояния и управления.
Выше отмечалось, что все события отладки, кроме INT 3, вызывают прерывание с вектором 1. Следовательно, при возникновении особого случая отладки встает вопрос о причине прерывания. Именно для идентификации причин прерывания 1 предусмотрен регистр состояния отладки DR6.
Младшие четыре бита ВО — ВЗ относятся к четырем контрольным точкам и единичное состояние В означает достижение контрольной точки, линейный адрес которой находится в регистре DR i.
Флаг BS (Step) устанавливается в 1, когда процессор начинает отрабатывать
особый случай, вызванный ловушкой покомандной работы, т. е. при BS = 1 причиной особого случая является состояние TF = 1 регистра EFLAGS. Этот случай имеет высший приоритет среди всех случаев отладки, когда BS = 1, могут быть установлены и другие биты состояния отладки.
Флаг ВТ (Task) устанавливается в 1, когда особый случай отладки вызван переключением на задачу, в TSS которой установлен бит ловушки Т =1.
Регистры отладки доступны (по записи или чтению) только в реальном режиме или в защищенном режиме по привилегированной (т. е. разрешенной к выполнению только на нулевом уровне) команде Mov:
mov еах, dr6
mov drl, еах
В регистре DR7 предусмотрен флаг GD, который, будучи установленным, обеспечивает "сверх защиту" всех обращений к регистрам отладки, вызывая при любой попытке обращения к этим регистрам прерывание 1. Для идентификации этой ситуации в DR6 предусмотрен бит BD. Он устанавливается в 1, если следующая команда будет считывать или записывать в один из восьми регистров отладки. Характерно, что при вызове процедуры обработчика с вектором 1 бит GD автоматически сбрасывается, что обеспечивает обработчику возможность доступа к регистрам отладки.
Процессор никогда не сбрасывает биты регистра состояния отладки DR6, по этому обработчик особого случая должен сбрасывать их программно, иначе причины особых случаев отладки будут накапливаться.
Возможно, при возникновении особого случая отладки в состоянии 1 будут находиться несколько битов DR6 (что возможно при разрешении аппаратных контрольных точек) или, наоборот, в DR6 не окажется единичных битов. Последнее возможно, если возникло внешнее прерывание с вектором 1 или выполняется команда INT 1
Регистр управления отладкой DR7 содержит для каждой из четырех контрольных точек следующие поля, определяющие ее характеристики: Li, Gi, RWi и LENi, а также два однобитовых поля LE и GE, определяющие свойства, общие для всех контрольных точек. Назначение этих полей приведены в табл. 7.2. Кроме того, в регистре DR7 бит 13 — GD — предназначен для включения режима защиты регистров отладки от любого обращения со стороны программ пользователя.


Контрольная точка может быть локальной (в пределах одной задачи) или глобальной — в зависимости от значений битов Li и Gi.
Допускается одновременное значение Li = Gi = 1 или Li;= Gi = 0. В первом случае это эквивалентно; Gi = 1, а во втором — контрольная точка запрещена и соответствие линейного адреса из регистра DRi адресу команды не вызывает особого случая (но Bi в регистре DR6 устанавливается в 1).
Аппаратные контрольные точки по командам устанавливаются путем загрузки в один из регистров DRi линейного адреса требуемой команды, установки в 00 соответствующих полей RWi и LENi, установки в 1 бита Li и/или Gi. После этого процессор начинает контролировать устройство предвыборки команд. Когда фиксируется равенство адреса команды и содержимого одного из "разрешенных" регистров DRi, хранящих контрольную точку по командам, формируется особый случай отладки, причем в DR6 устанавливается в 1 бит Bi.
Адреса команд в регистрах DRO — DR3 должны быть 32-разрядными линейными, а не логическими (селектор: смещение) или физическими. Линейный адрес не зависит от страничного преобразования, поэтому контрольная точка действует даже тогда, когда целевая команда участвует в свопинге и отображается на различные адреса физической памяти.
Если контрольная точка установлена как локальная, она сбрасывается при переключении задачи, причем значение DR7 не сохраняется в TSS, поэтому при восстановлении задачи контрольные точки не возобновляются. При необходимости следует предусмотреть программное возобновление контрольных точек. Для этого можно расширении сегмента TSS той задачи, в которой определены локальные контрольные точки, записать значения DRO — DR3 и DR7, а так же установить в TSS бит Т = 1. При переходе к такой задаче вызывается обработчик особого случая, который и восстановит значения регистров DR из сегмента TSS.
Аппаратные контрольные точки по командам являются нарушениями, т.е. процессор включает в стек адрес команды, вызвавшей нарушение, и обработчик особого случая возвращает управление на ту же команду. Поскольку аппаратные контрольные точки по команде проверяются до выполнения самой команды, процессор должен вновь сформировать особый случай. Необходимо обойти данную команду, для этого используется флаг возобновления RF в регистре EFLAGS. Процессор автоматически устанавливает RF = 1 при возникновении любого нарушения, включая и аппаратные контрольные точки по командам. Аппаратные прерывания по входам INTR и NMI, а так же программные ловушки и аварии не воздействуют на флаг RF. Когда RF = 1, процессор игнорирует особый случай аппаратной контрольной точки по командам, а после первой же команды, которая выполнена без особых случаев, процессор сбрасывает RF.
Аппаратные контрольные точки по данным устанавливаются с помощью тех же регистров отладки DR. Процессор формирует особый случай отладки как ловушку, когда происходит обращение к данным по установленным в DR адресам. Разрешается совместное применение контрольных точек по командам и по данным, причем возможно произвольное назначение типа контрольной точки (поле RWi в регистре DR7).
Процессор контролирует выравнивание данных, если их длина, указанная в поле LENi, равна слову или двойному слову. В этом случае при сравнении текущего адреса сегмента данных с адресом контрольной точки игнорируются один или два младших бита регистра DRi.
Конвейерная архитектура старших моделей х86 обеспечивает одновременную обработку нескольких команд. Случается, что контрольная точка по данным фиксируется только после выполнения нескольких следующих команд. В регистре управления отладкой DR6 предусмотрены биты, задающие локальную LE и глобальную GE "точность" определения контрольной точки по данным. Будучи установленными в 1, эти биты замедляют внутренние операции процессора таким образом, что сообщают об обращении по контролируемому адресу данных точно в тот момент, когда происходит обращение к памяти.
Биты LЕ, GE действуют только на контрольные точки по данным, являются общими для всех таких точек, причем LЕ автоматически сбрасывается при переключении задачи, а GE может быть сброшен лишь программно.
Регистрация нескольких особых случаев
Если команда, на которую настроена контрольная точка, вызывает данные по контролируемому адресу, процессор правильно сформирует два особых случая отладки. Первый — по команде — является нарушением, и обработчик этого особого случая возвращает управление той же команде. При выполнении команды второй особый случай не возникает (см. выше назначение бита RF), зато фиксируется ловушка по данным. Причина текущего особого случая фиксируется в DR6.
7.5. Увеличение быстродействия процессора
Одним из самых распространенных способов определения производительности процессора является оценка времени Т решения некоторой (тестовой) задачи. Очевидно,
![]()
где N — количество выполненных при решении задачи машинных команд; S — среднее количество тактов, приходящихся на выполнение одной команды; f — тактовая частота процессора.
Если длительности различных команд (в тактах) существенно отличаются друг от друга, то более точно можно оценить значение Т по выражению
![]()
где S; — число тактовoй команды.
Используются и более точные (и, соответственно, более сложные) методы оценки производительности [7, 11, 12], однако и из выражений (7.1), (7.2) видны пути увеличения производительности процессора:
∙ увеличение тактовой частоты (решения лежат в области технологии СВИС);
∙ сокращение длины программы (совершенствование технологии программирования, разработка оптимизирующих компиляторов);
∙ сокращение числа тактов, приходящихся на выполнение одной команды.
Последнее возможно за счет усложнения схемы процессора, при этом значительное усложнение может привести к сокращению числа тактов команды при увеличении "глубины схемы", что повлечет за собой увеличение длительности такта, так что выигрыш может обернуться проигрышем.
Магистральным путем увеличения производительности ЭВМ можно считать параллелизм на различных уровнях.
Существуют две основные формы параллелизма [11]:
∙ параллелизм на уровне процессов;
∙ параллелизм на уровне команд.
В первом случае над одной задачей могут одновременно работать несколько
процессоров или других устройств ЭВМ.
Во втором случае параллелизм реализуется в пределах отдельных команд. Обычно стремятся совмещать во времени процедуры обращения к памяти и обработки информации, параллельно выполнять арифметические операции сразу над несколькими (или даже всеми) разрядами операндов, одновременно выполнять несколько последовательных команд программы (разумеется, на разных стадиях) и т. п.
Уже в младшей модели семейства х86 — микропроцессоре 8086 предусматривалась одновременная работа двух основных устройств — обработки данных и связи с магистралью. Подобный механизм (с модификациями) сохранился и в старших моделях семейства.
Особенно эффективным способом организации параллельных операций в компьютерной системе является конвейерная обработка команд.
Далее мы кратко рассмотрим некоторые из перечисленных методов увеличения производительности процессора. Более подробную информацию по этим вопросам можно найти, например, в [11, 12].
При отсутствии конвейера процессор выполняет программу, по очереди выбирая из памяти и активизируя ее команды.
Процесс обработки команды может быть разбит, например, на следующие шаги (стадии):
F — выборка (от англ. fetch) — чтение команды из памяти;
D — декодирование (от англ. decode) — декодирование команды;
А — формирование адресов (от англ. address generate) и выборка операндов;
Е — выполнение (от англ. execute) — выполнение заданной в команде операции;
W — запись (от англ. write) — сохранение результата по целевому адресу. Приведенное разбиение не является единственно возможным — в некоторых случаях рассматривают четырех стадийный командный цикл, иногда (например, для процессоров, реализующих команды над числами с плавающей запятой) — восьми стадийный и др.
Для реализации каждой из стадий командного цикла в процессоре предусмотрено соответствующее оборудование (регистры, дешифраторы, сумматоры, управляющие автоматы или их фрагменты), причем операционные элементы разных стадий обычно слабо пересекаются между собой. Поэтому когда очередная команда завершает действия на одной стадии, например F, и переходит на следующую — D, то оборудование стадии F "простаивает" и может быть использовано для чтения следующей команды. Таким образом, очередная команда может начинать выполнение, не дожидаясь окончания командного цикла предыдущей команды.
При рассмотрении пяти стадийного командного цикла одновременно на разных стадиях может выполняться до пяти команд. Организация пяти стадийного конвейера потребует дублирования некоторых операционных элементов на разных стадиях (например, регистра команд PC) и усложнение схемы управления, однако игра стоит свеч.
Очевидно, очередная команда может перейти с одной стадии командного цикла на другую при выполнении двух условий:
∙ действия команды на текущей стадии завершены;
∙ предыдущая команда освободила оборудование следующей стадии.
При условии, что каждая стадия выполняется в любой команде одинаковое количество тактов (например, один), конвейер работает идеально, и одновременно всегда выполняются пять команд (для пяти стадийного конвейера).
Для большинства процессоров т. н. CISC-архитектуры (к ним относятся, в частности, процессоры семейства х86) такая идеальная ситуация складывается далеко не всегда.
Действительно, команда, извлекаемая из памяти на стадии F, может иметь разную длину и, следовательно, извлекаться из памяти за разное число машинных циклов.
В зависимости от заданного в команде способа адресации операндов время выполнения стадии А может быть существенно различным (сравните непосредственную адресацию и косвенно-автоинкрементную). Расположение адресуемых операндов (и размещение результата) в памяти разного уровня так же существенно влияет на время реализации стадии А (и стадии W).
Наконец, на стадии Е время выполнения операции зависит не только от типа операции (короткие — сложение, конъюнкция, ..., длинные — умножение, деление), но даже иногда и от значений операндов.
Учитывая отмеченные выше обстоятельства, можно сказать, что конвейеры процессоров с классической CISC-архитектурой редко работают "на полную мощность", находясь значительную часть времени в ожидании завершения "длинных" операций.
Желание увеличить производительность конвейеров привело к появлению процессоров т. н. RISC-архитектуры, из систем команд которых были исключены все факторы, тормозящие реализацию командного цикла — длинные команды, сложные способы адресации, размещение операндов в ОЗУ. К особенностям RISC-архитектуры можно отнести:
∙ форматы всех команд имеют одинаковую длину, в крайнем случае, разнообразие длин форматов ограничивается двумя вариантами;
∙ все операции выполняются за одинаковый промежуток времени (обычно 1 или 2 такта);
∙ операнды всех арифметических и логических операций располагаются только в регистрах, к оперативной памяти обращаются только команды загрузки и сохранения;
∙ сверхоперативная память представлена большим числом регистров (32 — 256).
Реализация этих особенностей, с одной стороны, позволяет приблизить работу конвейера к идеальной, с другой стороны — существенно ограничивает возможности системы команд процессора. Действительно, из системы операций исключаются "длинные" операции — умножение, деление, операции над числами с плавающей запятой и др. Исключаются сложные (и эффективные) способы адресации, например, авто индексные. Это приводит к значительному увеличению длины программ, увеличению времени на выборку команд из памяти, при этом среднее число команд, выполняемых в единицу времени, в RISC-процессорах значительно больше, чем в CISC-процессорах.
По мере совершенствования интегральной технологии появилась возможность ценой значительных аппаратных затрат теперь разработчики уже могли их себе позволить) резко сократить время выполнения "длинных" операций, например, за счет реализации матричного умножителя, табличной арифметики и др. В этом случае длинные операции можно включать в систему команд RISC-процессоров, не нарушая принципов их организации, но увеличивая эффективность системы команд.
В настоящее время понятия "RISC- и "CISC-архитектура" скорее являются обозначением некоторых принципов проектирования, но не характеристиками конкретных процессоров. Современные процессоры, как правило, реализованы "гибридному" принципу: содержат ядро RISC, которое выполняет простые и самые распространенные команды за один такт на стадию конвейера, а сложные команды интерпретируются как некая последовательность простых (на уровне микрокоманд). Пользователь же в этом случае имеет дело с системой команд привычной CISC-архитектуры, а внутренние вопросы реализации командного цикла его, как правило, не интересуют.
При реализации конвейеров возникает еще одна проблема, связанная с его оптимальной загрузкой — команды условной передачи управления (в среднем каждая 5 — 6-я команда программы). Действительно, когда такая команда передается со стадии F на стадию D, на стадию F надо ставить следующую команду, но какую? Условие перехода будет проверено лишь на стадии Е, тогда же определится адрес следующей команды. Здесь возможны два пути решения:
• приостановить загрузку конвейера до завершения командой перехода стадии Е;
• загрузить конвейер "наугад" командой по одному из двух возможных адресов, а на стадии Е проверить правильность выбора и, если он оказался неверным — очистить весь конвейер и начать загрузку заново по правильному адресу.
Второй путь представляется предпочтительным, т. к. конвейер не останавливается, и (в среднем) в половине случаев мы избежим потери времени на перезагрузку. Результаты работы конвейера будут еще лучше, если мы научимся правильно предсказывать адрес перехода, чтобы вероятность угадывания адреса приближалась к 1.
В современных процессорах часто предусматривают специальные аппаратные блоки предсказания переходов. В разных процессорах реализуются различные алгоритмы предсказания, основанные на анализе результатов выполнения предыдущих команд переходов [12].
7.5.2. Динамический параллелизм
Один конвейер хорошо, а два лучше? Почему бы, если позволяют ресурсы интегральной технологии, не построить два конвейера и ставить на них одновременно пару команд программы. В процессоре Pentium именно так и сделали — предусмотрели два 5-уровневых конвейера, которые могли работать одновременно и выполнять две целочисленные команды за машинный такт.
Однако возможность одновременной постановки на два разных конвейера пары последовательных команд программы ограничивается рядом условий. Очевидно, что нельзя ставить на разные конвейеры две последовательные команды, если вторая использует в качестве операнда результат работы первой или, во всяком случае, необходимо гарантировать, что к началу стадии выборки операндов второй команды первая (на другом конвейере) уже завершит стадию размещения результата. Существуют и другие ограничения, которые определяют т. н. условия "спаривания" последовательных команд (pairing), позволяющие размещать их одновременно на разных конвейерах.
В процессоре Pentium два конвейера не являются равноправными. Один из них (U) может принять любую команду, а другой (Ч) — только удовлетворяющую условиям "спаривания" (довольно сложным) с командой, поставленной на U. Если эти условия не соблюдаются, следующая команда так же помещается на конвейер, а Ч-конвейер пропускает такт. Некоторые команды могут появляться только на U-конвейере.
Разумеется, производительность двухконвейерного процессора, при прочих равных условиях, превышает производительность одноконвейерного, но далеко не в два раза. Эффективность во многом определяется, насколько часто будут встречаться в программе пары последовательных команд, допускающих "спаривание".
Очевидно, движение в направлении увеличения в процессоре числа конвейеров, работающих по описанным выше принципам, бесперспективно. Условия "страивания" (если можно так сказать) и т. д. будут настолько сложны, что редко будут выполняться.
Следующим шагом на пути увеличения производительности было решение, которое принято называть динамическим параллелизмом, а процессоры, реализующие этот принцип, называют суперскалярными.
Рассмотрим фрагмент программы, написанный на некотором условном языке:
MOV R1, R4
ADD R1,
M0V R5, R6
SUB R5, R7
CLR R6
Вторая команда этого фрагмента использует в качестве операнда содержимое ячейки памяти (косвенно-регистровая адресация) и, следовательно, попав на конвейер, будет "тормозить" его на стадии А. В то же время следующие три команды этого фрагмента никак не связаны с результатами работы второй команды, выполняют действия только над регистрами и могли бы выполняться еще до завершения предыдущей команды, однако в этом случае пришлось бы изменить порядок выполнения команд, определенный программой, чего конвейер не предусматривает.
Суперскалярная архитектура процессора предполагает, что команды (на не котором ограниченном участке программы) могут выполняться не только в порядке их размещения в программе, но и по мере возможности их выполнения независимо от порядка следования. Возможность выполнения определяется, во-первых, отсутствием зависимостей от ранее расположенных, но еще не завершенных команд, во-вторых, наличием свободных ресурсов процессора, необходимых для выполнения команды.
Одним из первых микропроцессоров, реализующих механизм динамического параллелизма, был процессор Pentium Pro (Pentium II) фирмы Intel (рис. 7.15).
На кристалле процессора размещаются два блока кэш-памяти первого уровня, в одном из которых (кэш-С) размещается программа, а в другом (кэш-D) — данные.
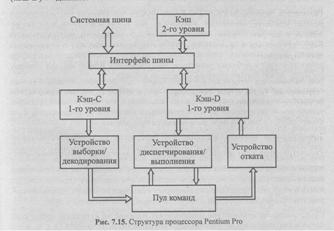
Устройство выборки декодирования выбирает очередную команду из кэш-С (в порядке их размещения в программе), при необходимости заменяет сложные команды на последовательность микрокоманд, снабжает каждую команду полем признаков (тегом) и помещает в специальным образом организованную память — пул команд.
Устройство диспетчирования постоянно анализирует, с одной стороны, содержимое пула команд и выявляет команды, готовые к выполнению на какой-нибудь стадии, с другой стороны - свободные в данный момент операционные устройства. При совпадении "желания" (команда завершила предыдущую стадию и готова к выполнению следующей) и "возможностей" (свободны соответствующие ресурсы) устройство диспетчирования отправляет команду на выполнение независимо от порядка поступления команд в пул. После завершения обработки на очередной стадии команда возвращается в пул с соответствующей пометкой в поле тега.
Устройство отката размещает результаты выполнения команд по адресам назначения. Оно просматривает содержимое пула команд, отыскивает команды, завершившие работу, и извлекает их из пула с размещением результата в строгом соответствии с порядком расположения команд в программе.
Небольшое количество регистров в архитектуре процессоров Intel приводит к интенсивному использованию каждого из них и, как следствие, к возникновению множества мнимых зависимостей между командами, использующими один и тот же регистр. Поэтому, чтобы исключить задержку в выполнении команд из-за мнимых зависимостей, устройство диспетчирования/выполнения работает с дублями регистров, находящимися в пуле команд (одному регистру может соответствовать несколько дублей).
Реальный набор регистров контролируется устройством отката, и результаты выполнения команд отражаются на состоянии вычислительной системы только после того, как выполненная команда удаляется из пула команд в соответствии с истинным порядком команд в программе.
Таким образом, принятая в Pentium Pro технология динамического выполнения может быть описана как оптимальное выполнение программы, основанное на предсказании будущих переходов, анализе графа потоков данных с целью выбора наилучшего порядка исполнения команд и на опережающем выполнении команд в выбранном оптимальном порядке. Однако следует иметь в виду, что процессор оптимизирует выполнение только ограниченного участка программы, который в текущий момент располагается в пуле.
Суперскалярная архитектура предполагает наличие на кристалле процессора нескольких параллельно работающих операционных устройств (в т. ч. и нескольких одинаковых). Так, например, RISC-процессор Power PC содержит шесть параллельно работающих исполнительных устройств: блок предсказания ветвлений, два устройства для выполнения простых целочисленных операций (сложение, вычитание, сравнение, сдвиги, логические операции), одно устройство для выполнения сложных целочисленных операций (умножение, деление), устройство обработки чисел с плавающей запятой и блок обращения к внешней памяти. При этом обеспечивается одновременное выполнение четырех команд.
Все операции обработки данных выполняются с регистровой адресацией. При для хранения целочисленных операндов используется блок, включающий тридцать два 32-разрядных регистра, а для хранения операндов с плавающей запятой — блок из тридцати двух 64-разрядных регистров.
Выборка данных из памяти производится только командами пересылки, которые выполняются блоком обращения к памяти и осуществляют загрузку данных в регистры или запись их содержимого в память.
При параллельной работе исполнительных устройств возможно их одновременное обращение к одним регистрам. Чтобы избежать ошибок, возникающих при этом в случае записи нового содержимого до того, как другим устройством будет считано предыдущее, введены буферные регистры — 12 для целочисленных регистров и 8 — для регистров с плавающей запятой. Эти регистры служат для промежуточного хранения операндов, дублируя основные регистры блоков, используемые при выполнении текущих операций. После завершения операций производится перезапись полученных результатов в основные регистры (обратная запись).
Для реализации динамического параллелизма в процессорах с традиционной системой команд и способами компиляции программного кода требуются весьма сложные схемы организации пула, планировщики, схемы "отката" и др. Процессоры такой архитектуры имеют несколько операционных блоков различного, а иногда и одинакового назначения, которые могут работать параллельно, например, 1 — 2 блока вычисления адресов, 2 — 3 блока АЛУ для чисел с фиксированной запятой, блок обработки чисел с плавающей запятой, блок размещения результата, блок предсказания переходов и др.
Поскольку процессор может планировать и формировать последовательность выполнения команд на ограниченном (размером пула) участке программы, то для эффективной загрузки операционных блоков требуются не только сложные и эффективные процедуры планирования, но и некоторое "везение"— хорошо, если в пул загружены команды, для выполнения которых нужны различные операционные блоки, а если нет?
Один из путей дальнейшего повышения эффективности подобных систем лежит в области разработки специальных компиляторов, которые упаковывают несколько простых команд в "очень длинное командное слово" (VLIW — аббревиатура от Very Long Instruction Word) таким образом, чтобы в одной "очень длинной команде" можно было использовать все существующие в процессоре операционные блоки. В этом случае командное слово соответствует набору функциональных устройств.
VLIW-архитектуру можно рассматривать как статическую суперскалярную,
поскольку распараллеливание кода производится на этапе компиляции, а не динамически во время исполнения, Ф. е. в машинном коде VLIW присутствует явный параллелизм.
Одним из примеров воплощения идей VLIW может служить предложенная Intel в содружестве с HP концепция 64-разрядной архитектуры микропроцессора IA-64 (Intel 64-bit Architecture, 64-разрядная архитектура Intel). Для ее обозначения использована аббревиатура EPIC (Explicitly Parallel Instruction Computing, вычисления с явным параллелизмом команд).
Процессор, разработанный на базе этой концепции, отличающийся следующими особенностями:
• большое количество регистров: 128 64-разрядных регистров общего назначения (целочисленных), плюс 128 80-разрядных регистров арифметики плавающей запятой, плюс 64 1-разрядных предикатных регистра;
• масштабируемость архитектуры до большого количества функциональных
устройств. Это свойство представители фирм Intel и HP называют "наследственно масштабируемым набором команд" (inherently scaleable instruction set);
• явный параллелизм в машинном коде: поиск зависимостей между командами производит не процессор, а компилятор;
• предикация (predication): команды из разных ветвей условного ветвления снабжаются предикатными полями (полями условий) и запускаются на выполнение параллельно;
• загрузка по предположению (speculative loading): данные из медленной основной памяти загружаются заранее.
Формат команды IA-64 включает код операции, три 7-разрядных поля операндов — 1 приемник и 2 источника (операндами могут быть только регистры), особые поля для вещественной и целой арифметики, 6-разрядное предикатное поле.
Команды IA-64 упаковываются (группируются) компилятором в "связку" длиною в 128 разрядов. Связка содержит 3 команды и шаблон, в котором указаны зависимости между командами в связке (можно ли с командой k запустить параллельно kg, или же kg должна выполниться только после k)), а также между другими связками (можно ли с командой k3 из связки с1 запустить параллельно команду k4 из связки с2).
Одна такая связка, состоящая из трех команд, соответствует набору из трех
функциональных устройств процессора. Процессоры IA-64 могут содержать разное количество таких блоков, оставаясь при этом совместимыми по коду. Ведь благодаря тому, что в шаблоне указана зависимость и между связками, процессору с N одинаковыми блоками из трех функциональных устройств будет соответствовать командное слово из N x3 команд (N связок). Таким образом, обеспечивается масштабируемость IA-64.
Предикация — способ обработки условных ветвлений. Суть этого способа— компилятор указывает, что обе ветви выполняются на процессоре параллельно. Если в исходной программе встречается условное ветвление, то команды из разных ветвей помечаются различными предикатными регистрами (команды имеют для этого предикатные поля), далее они выполняются совместно, но их результаты не записываются, пока значения предикатных регистров не определены. Когда, наконец, вычисляется значение условия ветвления, предикатный регистр, соответствующий "правильной" ветви, устанавливается в 1, а другой — в 0. Перед записью результатов процессор будет проверять предикатное поле и записывать результаты только тех команд, предикатное поле которых содержит предикатный регистр, установленный в 1.
Загрузка по предположению — это механизм, который предназначен снизить простои процессора, связанные с ожиданием выполнения команд загрузки из относительно медленной основной памяти. Компилятор перемещает команды загрузки данных из памяти так, чтобы они выполнились как можно раньше. Следовательно, когда данные из памяти понадобятся какой-либо команде, процессор не будет простаивать. Перемещенные таким образом команды называются командами загрузки по предположению и помечаются особым образом. Непосредственно перед командой, использующей загружаемые по предположению данные, компилятор вставляет команду проверки предположения.
Основная особенность EPIC — распараллеливанием потока команд занимается компилятор, а не процессор.
Достоинства данного подхода:
∙ упрощается архитектура процессора; вместо распараллеливающей логики на EPIC-процессоре можно разместить больше регистров, функциональных устройств;
∙ процессор не тратит время на анализ потока команд на предмет возможности их параллельного выполнения — эту работу уже выполнил компилятор;
∙ возможности процессора по анализу программы во время выполнения ограничены сравнительно небольшим участком программы, тогда как компилятор способен произвести анализ по всей программе;
∙ если некоторая программа должна запускаться многократно, выгоднее
распараллелить ее один раз (при компиляции), а не каждый раз, когда она исполняется на процессоре.
Недостатки:
∙ компилятор производит статический анализ программы, раз и навсегда
планируя вычисления. Однако даже при небольшом изменении начальных данных путь выполнения программы может сколь угодно сильно измениться;
·серьезно увеличивается сложность компиляторов. Значит, увеличится число ошибок в них, время компиляции;
∙ еще более увеличивается сложность отладки, т. к. отлаживать придется оптимизированный параллельный код;
∙ производительность EPIC будет всецело зависеть от качества компилятора;
∙ проблематичным пока видится преемственность программного обеспечения при переходе на новые поколения микропроцессоров (скомпилированный код очень сильно "привязан" к конкретной архитектуре процессора).
Тем не менее, представители Intel и НР называют EPIC концепцией следующего поколения и противопоставляют ее CISC и RISC. По мнению Intel, традиционные архитектуры имеют фундаментальные свойства, ограничивающие производительность.
Производители RISC-процессоров не разделяют подобного пессимизма. Кстати, в 1980-х годах, когда возникла концепция RISC, прозвучало много заявлений, что концепция CISC устарела, имеет фундаментальные свойства, ограничивающие производительность. Но процессоры, причисляемые к CISC (например, семейство х86), широко используются до сих пор, их производительность растет.
В действительности же, все эти аббревиатуры — CISC, RISC, VLIW, EPIC— обозначают только идеализированные концепции. Реальные современные микропроцессоры трудно подвести исключительно под какой-либо из перечисленных выше классов. Просто в наиболее совершенных современных процессорах заложено большое число удачных идей, использующих многие рассмотренные здесь концепции.
7.6. Однокристальные микро ЭВМ
При рассмотрении процессов эволюции современных процессоров и ЭВМ, прежде всего, обращают внимание на увеличение производительности системы (быстродействие процессора). Некоторые из путей повышения быстро действия были обсуждены в предыдущих разделах, другие, реализующие параллелизм на уровне процессов (мультипроцессоры, векторные, массивно- параллельные, компьютерные сети [11, 12], нейро матричные процессоры, и др.), выходят за рамки настоящей книги.
Однако всегда существовали и существуют задачи, для решения которых вовсе не требуется высокое быстродействие процессора и мощная система команд. На первый план здесь выступают другие характеристики: стоимость, надежность, малые габариты, способность работать в экстремальных климатических условиях, при значительных перепадах питающего напряжения и на фоне высокого уровня электромагнитных помех, с автономным питанием.
Для получения таких характеристик растущие возможности интегральной технологии можно использовать не для увеличения разрядности и вычислительной мощности процессора, а размещая на кристалле, наряду с простым (на первых порах — восьмиразрядным) процессором, все другие устройства, входящие в состав ЭВМ: регистры, различные типы памяти (на первых порах — небольшого объема), тактовый генератор, порты параллельного и последовательного обмена, различные внешние устройства (таймеры, АЦП и др.).
При этом получается полностью "само достаточный" кристалл БИС (СВИС) однокристальной микро ЭВМ (некоторые авторы используют термин микроконтроллер, учитывая, что основная сфера применения подобных изделий— управляющие системы, работающие в реальном времени).
В настоящее время многие фирмы (Motorola, Intel, Micro Chip, Zilog и др.) выпускают широкую номенклатуру подобных однокристальных микро ЭВМ (ОМЭВМ), отличающихся разрядностью, системой команд, типами и объемом памяти, составом и характеристиками внешних устройств. Большинство ОМЭВМ выпускается с 8-разрядным процессором, но на рынке присутствуют и 16- и даже 32-разрядные ОМЭВМ.
Базовые принципы архитектуры ОМЭВМ можно проиллюстрировать на примере 8-разрядных ОМЭВМ. Далее кратко отметим некоторые особенности этих контроллеров. Подробнее архитектура ряда ОМЭВМ и примеры их применения описаны в [4].
Контроллеры разных фирм, несмотря на кажущиеся различия, имеют много общих черт, определяющих тенденции развития современных ОМЭВМ малой и средней производительности. Попробуем отметить некоторые из них.
• Все без исключения контроллеры имеют встроенные тактовые генераторы; для запуска большинства из них используют одну из четырех возможных внешних цепей: источник внешних тактовых импульсов, кварцевый резонатор, LС-цепь, RC-цепь. Последние две можно использовать лишь в системах, где точностью временных привязок можно пренебречь. Большинство контроллеров имеют в своем составе динамические элементы памяти, что ограничивает допустимую тактовую частоту не только сверху, но и снизу (обычно — до 1 МГц). ОМЭВМ Motorola используют на кристалле только статические элементы памяти, что позволяет работать на произвольно низких системных тактовых частотах. Снижение тактовой частоты контроллера целесообразно при управлении инерционными объектами, если необходимо отслеживать достаточно длительные временные, задержки (от долей секунды до десятков секунд). Процессоры большинства ОМЭВМ реализуют классическую ("интеловскую") систему команд, включающую одно и двухадресные команды с операциями над ячейками памяти и регистрами, с использованием разнообразных способов адресации (прямая, регистровая, косвенно-регистровая, индексная, непосредственная). Предусмотрен широкий выбор команд передачи управления, в т. ч. вызовы подпрограмм. Во многих контроллерах реализовано умножение и деление.
Процессоры семейств MCS-51 и МС68НС11 имеют развитую систему операций с битами.
• Память большинства ОМЭВМ организована по гарвардской архитектуре, предполагающей различные адресные пространства для памяти программ и памяти данных (исключение составляют лишь контроллеры фирмы Motorola, традиционно поддерживающие единое адресное пространство). Такое решение снижает риск потери управления при выполнении программы, но ограничивает возможности по распределению ресурсов памяти системы.
• На кристалле могут располагаться различные типы памяти: масочное или однократно программируемое ПЗУ, ППЗУ со стиранием ультрафиолетовым излучением, электрически стираемое ППЗУ (флэш-память), ОЗУ (регистры).
• Многие параллельные порты контроллеров допускают двунаправленный обмен, часто возможно независимое программирование линий порта на ввод или вывод. Допускается выбор типа выхода — обычный ТТЛ-вывод или вывод с открытым коллектором (стоком). Большинство линий портов имеют одну или несколько альтернативных функций, выбор которых осуществляется программно.
• Важным элементом ОМЭВМ являются системы контроля времени, представленные различными счетчиками с управляемыми коэффициентами пересчета и возможностью выбора источника счетных импульсов: тактовый генератор — в режиме таймера и внешний вывод — в режиме счетчика внешних событий. Более мощные контроллеры имеют в своем составе таймерные системы, включающие несколько модулей сравнения, авто захвата, ШИМ (широтно-импульсная модуляция) и др.
• Последовательные каналы включаются обычно в старшие модели семейств. Предусматриваются либо универсальные синхронно-асинхронные приемопередатчики, программируемые на работу в определенном режиме, либо отдельные блоки SCI (UART) — асинхронный приемопередатчик и SPI — синхронный периферийный интерфейс, работающие независимо друг от друга.
• Средства работы с аналоговыми сигналами включают в себя компараторы,
многоканальные 8-разрядные аналого-цифровые и реже — цифроаналоговые преобразователи.
• Подсистема прерываний включает несколько внешних радиальных входов
и большое число внутренних прерываний, которые генерируются в системе контроля времени, АЦП, последовательных и параллельных каналах.
В современных микроконтроллерах предусматривается широкий набор специальных средств, повышающих надежность и эффективность функционирования систем управления. Прежде всего, это т. н. сторожевой таймер WDT (Watch-Dog Timer), который предотвращает аварийное зацикливание программы. В некоторых контроллерах предусматриваются специальные схемы, следящие за правильной работой тактового генератора. В системах с автономным питанием большое значение имеют средства энергосбережения. Большинство контроллеров программно можно переводить в специальные режимы пониженного энергопотребления (в состоянии ожидания) с остановкой основных подсистем (в т. ч. иногда и тактового генератора), но с сохранением контекста задачи. Выход из таких режимов возможен по разрешенному прерыванию или по сбросу (часто системный сброс реализуется как одно из прерываний).
16- и 32-разрядные ОМЭВМ построены обычно по модульному принципу. На внутри кристальный системный интерфейс могут подключаться процессоры различной вычислительной мощности, различные модули памяти, контроллеры параллельного и последовательного обмена, модули АЦП и ЦАП, таймерные сопроцессоры и сопроцессоры ввода/вывода. В зависимости от требований решаемой задачи пользователь может выбрать подходящую конфигурацию кристалла ОМЭВМ. В качестве примера коротко рассмотрим семейство 32-разрядных микроконтроллеров фирмы Motorola.
Отличительной особенностью ОМЭВМ фирмы Motorola является модульная технология построения много функциональных устройств на одном кристалле. Определен стандарт внутри кристальной межмодульной шины IMB и множество наборов системных модулей, из которых собирается ОМЭВМ:
∙ процессорные ядра (CPU), включающие 16- и 32-разрядные микропроцессоры различной вычислительной мощности, но относящиеся к одному семейству;
∙ системные интеграционные модули (SIM), контролирующие внешнюю шину, запуск, инициализацию и конфигурацию микроконтроллера. Они включают в себя тактовый генератор, блок системной конфигурации и защиты, блок тестирования и интерфейс с внешней шиной. Модули отличаются друг от друга, главным образом, разрядностью шин адреса и данных;
∙ модули памяти, отличающиеся типом и объемом запоминающих устройств: ОЗУ, ПЗУ(включая однократно программируемое пользователем), ЭСППЗУ;
∙ модули последовательных портов включают различные варианты синхронных и асинхронных программируемых контроллеров последовательного обмена. Предусмотрены модули, содержащие несколько различных интерфейсов;
∙ таймерные системы представлены различными вариантами таймерных сопроцессоров (TPU). TPU способен независимо от процессора выполнять как простые, так и сложные таймерные функции, его можно считать отдельным специализированным микропроцессором, который осуществляет две основные операции — проверку на совпадение (от англ. match— сравнение) и сохранение значения счетчика-таймера в момент изменения состояния какого-либо входа (от англ. capture — захват) над одним операндом — временем. Выполнение любой из них называется событием. Обслуживание событий сопроцессором замещает обработку прерываний центральным процессором. С помощью двух основных операций TPU может реализовать значительный набор функций: счет внешних событий, захват по внешнему входу, сравнение временных интервалов, широтно-импульсную модуляцию, измерение периода входного сигнала, программируемую генерацию импульсов и многие другие, программируемые пользователем. TPU, естественно, имеет собственную систему команд, его программы хранятся на общей памяти системы или в специализированной памяти программ TPU;
системы аналогового ввода реализованы на различных вариантах АЦП (ADC), отличающихся разрядностью получаемого кода и способом (а следовательно, и временем) аналого-цифрового преобразования.
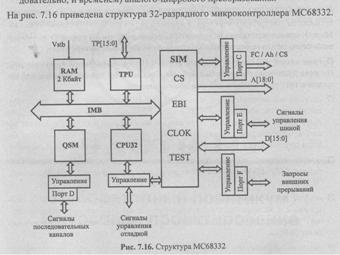
Кристалл микроконтроллера содержит следующие модули:
CPU32 — 32-разрядный центральный процессор семейства МС68000;
RAM — 2 Кбайт ОЗУ с независимым питанием для размещения программ и данных (напомним, что большинство изделий Motorola поддерживают архитектуру фон Неймана с единым адресным пространством программ и данных);
QSM — подсистемы последовательного ввода/вывода, включающие универсальный асинхронный приемопередатчик (UART) и дуплексный синхронный последовательный интерфейс (SPI);
TPU — шестнадцати канальный таймерный сопроцессор;
SIM — системный интеграционный модуль.
Внешняя память может при необходимости подключаться к контроллеру к шинам адреса A[18:0], данных D[15:0], управления шиной.
Линии порта С могут использоваться для выдачи функционального кода, идентифицирующего состояние процессора и адресное пространство текущего цикла шины (FC[2:0)), старших разрядов адреса (Ah) в режиме расширенного адресного пространства и сигналов выбора кристалла (CS), разрешающих работу периферийных устройств по запрограммированным адресам.
Порт F принимает запросы внешних прерываний, линии порта D могут использоваться для передачи сигналов последовательных интерфейсов.
Группа линий ТР[15:0] — входы/выходы каналов таймерного сопроцессора. На вход Vstb может подаваться независимое питание для сохранения информации в ОЗУ при отключении основного питания.
ЧАСТ III. ЛАБОРАТОРНЫЙ ПРАКТИКУМ И КУРСОВОЕ ПРОЕКТИРОВАНИЕ
Описание архитектуры учебной ЭВМ
Современные процессоры и операционные системы — не слишком благоприятная среда для начального этапа изучения архитектуры ЭВМ.
Одним из решений этой проблемы может быть создание программных моделей учебных ЭВМ, которые, с одной стороны, достаточно просты, чтобы обучаемый мог освоить базовые понятия архитектуры (система команд, командный цикл, способы адресации, уровни памяти, способы взаимодействия процессора с памятью и внешними устройствами), с другой стороны — архитектурные особенности модели должны соответствовать тенденциям развития современных ЭВМ.
Программная модель позволяет реализовать доступ к различным элементам ЭВМ, обеспечивая удобство и наглядность. С другой стороны, модель позволяет игнорировать те особенности работы реальной ЭВМ, которые на данном уровне рассмотрения не являются существенными.
Далее приводится описание программной модели учебной ЭВМ, предназначенной для начальных этапов изучения архитектуры (в т. ч. на младших курсах вуза и даже в школе). Именно этим объясняется использование в модели десятичной системы счисления для кодирования команд и представления данных.
Моделируемая ЭВМ включает процессор, оперативную (ОЗУ) и сверхоперативную память, устройство ввода (УВв) и устройство вывода (УВыв). Процессор, в свою очередь, состоит из центрального устройства управления (УУ), арифметического устройства (АУ) и системных регистров (CR, РС, SP и др.). Структурная схема ЭВМ показана на рис. 8.1.
В ячейках ОЗУ хранятся команды и данные. Емкость ОЗУ составляет 1000 ячеек. По сигналу MWr выполняется запись содержимого регистра данных (MDR) в ячейку памяти с адресом, указанным в регистре адреса (MAR). По сигналу MRd происходит считывание — содержимое ячейки памяти с адресом, содержащимся в MAR, передается в MDR.
Сверхоперативная память с прямой адресацией содержит десять регистров общего назначения RO — R9. Доступ к ним осуществляется (аналогично доступу к ОЗУ) через регистры RАR и RDR.
АУ осуществляет выполнение одной из арифметических операций, определяемой кодом операции (СОР), над содержимым аккумулятора (Асс) и регистра операнда (DR). Результат операции всегда помещается в Асс. При завершении выполнения операции АУ вырабатывает сигналы признаков результата: Z (равен 1, если результат равен нулю); S (равен 1, если результат отрицателен); ОV (равен 1, если при выполнении операции произошло переполнение разрядной сетки). В случаях, когда эти условия не выполняются, соответствующие сигналы имеют нулевое значение.
В модели ЭВМ предусмотрены внешние устройства двух типов. Во-первых, это регистры IR и OR, которые могут обмениваться с аккумулятором с помощью безадресных команд IN (Асс:= IR) и OUT (OR:= Асс). Во-вторых, это набор моделей внешних устройств, которые могут подключаться к системе и взаимодействовать с ней в соответствии с заложенными в моделях алгоритмами. Каждое внешнее устройство имеет ряд программно-доступных регистров, может иметь собственный обозреватель (окно видимых элементов). Подробнее эти внешние устройства описаны в разд. 8.6.
УУ осуществляет выборку команд из ОЗУ в последовательности, определяемой естественным порядком выполнения команд (т. е. в порядке возрастания адресов команд в ОЗУ) или командами передачи управления; выборку из ОЗУ операндов, задаваемых адресами команды; инициирование выполнения операции, предписанной командой; останов или переход к выполнению следующей команды.
В качестве сверхоперативной памяти в модель включены регистры общего назначения (РОН), и может подключаться модель кэш-памяти. В состав УУ ЭВМ входят:
РС — счетчик адреса команды, содержащий адрес текущей команды;
CR — регистр команды, содержащий код команды;
RB — регистр базового адреса, содержащий базовый адрес;
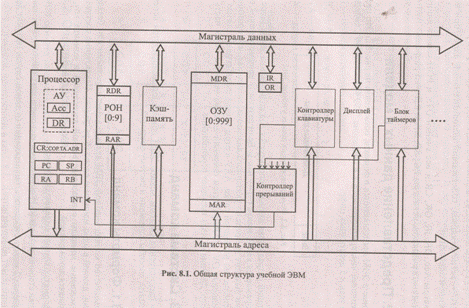
SP — указатель стека, содержащий адрес верхушки стека;
RA — регистр адреса, содержащий исполнительный адрес при косвенной адресации.
Регистры Асс, DR, IR, OR, CR и все ячейки ОЗУ и РОН имеют длину 6 десятичных разрядов, регистры РС, SP, RA и RB — 3 разряда.
8.2. Представление данных в модели
Данные в ЭВМ представляются в формате, показанном на рис. 8.2. Это целые десятичные числа, изменяющиеся в диапазоне "— 99 999...+99 999", содержащие знак и 5 десятичных цифр.

Старший разряд слова данных используется для кодирования знака: плюс (+) изображается как 0, минус (-) — как 1. Если результат арифметической операции выходит за пределы указанного диапазона, то говорят, что произошло переполнение разрядной сетки. АЛУ в этом случае вырабатывает сигнал переполнения ОV = 1. Результатом операции деления является целая часть частного. Деление на ноль вызывает переполнение.
При рассмотрении системы команд ЭВМ обычно анализируют три аспекта: форматы, способы адресации и систему операций.