Подсистема ввода вывода (ПВВ) обеспечивает связь МП с внешними устройствами, к которым будем относить:
• устройства ввода/вывода (УВВ): клавиатура, дисплей, принтер, датчики и исполнительные механизмы, АЦП, ЦАП, таймеры и т. п.;
• внешние запоминающие устройства (ВЗУ): накопители на магнитных дисках, "электронные диски", CD и др.
В рамках рассмотрения ПВВ будем полагать термины "УВВ" и "ВУ" синонимами, т. к. обращение к ним со стороны процессора осуществляется по одним законам.
ПВВ в общем случае должна обеспечивать выполнение следующих функций:
• согласование форматов данных, поскольку процессор всегда выдает/принимает данные в параллельной форме, а некоторые ВУ — в последовательной. С этой точки зрения различают устройства параллельного и последовательного обмена. В рамках параллельного обмена не производится преобразование форматов передаваемых слов, в то время как при последовательном обмене осуществляется преобразование параллельного кода в последовательный и наоборот. Все варианты, при которых длина слова ВУ (больше 1 бита) не совпадает с длиной слова МП, сводятся к разновидностям параллельного обмена;
• организация режима обмена — формирование и прием управляющих сигналов, идентифицирующих наличие информации на различных шинах, ее тип, состояние ВУ (Готово, Занято, Авария), регламентирующих временные параметры обмена. По способу связи процессора и ВУ (активного и пассивного) различают синхронный и асинхронный обмены, различия между которыми мы обсудили в начале настоящей главы.
Простейшая подсистема параллельного обмена должна обеспечить лишь де- шифрацию адреса ВУ и электрическое подключение данных ВУ к системной шине данных DB по соответствующим управляющим сигналам. На рис. 6.7 показаны устройства параллельного ввода и вывода информации в составе МПС на базе буферных регистров К580ИР82.
Очевидно, при обращении процессора (он в подобных циклах играет роль активного устройства) к устройству ввода, адрес соответствующего регистра помещается процессором на шину адреса и формируется управляющий сигнал RDIO. Дешифратор адреса, включающий и линию RDIO, при совпадении адреса и управляющего сигнала активизирует выходные линии регистра и его 1 содержимое поступает по шине данных в процессор.
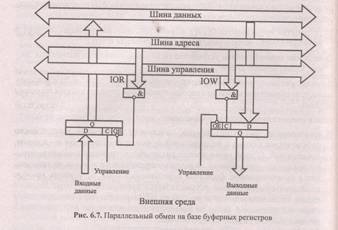
Аналогично идет обращение к устройству вывода. Совпадение адреса устройства на шине адреса с активным уровнем сигнала WRIO обеспечивает "защелкивание" состояния шины данных в регистре вывода.
Характерно, что при таком способе обмена процессор не анализирует готовность ВУ к обмену, а длительность существования адреса, данных и управляющего сигнала целиком определяется тактовой системой процессора и принятым алгоритмом командного цикла.
Напомним, что такой способ обмена называется синхронным. Синхронный обмен реализуется наиболее просто, но он возможен только с устройствами, всегда готовыми к обмену, либо процессор должен перед выполнением команды ввода/вывода программными средствами убедиться в готовности ВУ к обмену (обычно в этом случае предварительно анализируется состояние флага готовности, формируемого ВУ). Кроме того, быстродействие ВУ, взаимодействующее с процессором в синхронном режиме, должно гарантировать прием/выдачу данных за фиксированное время, выделенное процессором на цикл обмена.
Во многих микропроцессорных комплектах выпускают специальные интерфейсные БИС, существенно расширяющие (по сравнению с использованием регистров) возможности разработчиков при организации параллельного обмена в МПС. Такие БИС обычно имеют несколько каналов передачи информации, позволяют программировать направление передачи (ввод или вывод) по каждому каналу и выбирать способ обмена — синхронный или асинхронный.
Типичным примером такой БИС может служить программируемый контроллер параллельного обмена (далее "контроллер") 8255A (отечественный аналог — К580ВВ55).
Контроллер параллельного обмена K580BB55 [13] представляет собой трех канальный байтовый интерфейс и позволяет организовать обмен байтами с периферийным оборудованием в различных режимах. Он включает в себя три 8-разрядные канала ввода/вывода А, В и С, буфер шины данных, 8-разрядный регистр управления Y и блок управления.
Подключение контроллера к системной шине показано на рис. 6.8. Каналы адресуются двумя линиями адреса А1, АО. В МПС контроллер размещают, как правило, в пространстве адресов ввода/вывода. Поэтому в качестве стробов чтения и записи используются сигналы RDIO, WRIO, для селекции контроллера по CS дешифрируются старшие разряды адреса, а для выбора адресуемого объекта внутри контроллера — два младших.
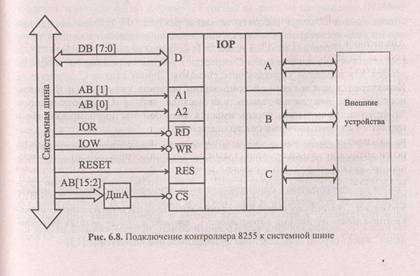
Каналы контроллера программируются для работы в одном из трех режимов:
• режим "0" — синхронный однонаправленный ввод/вывод;
• режим "1" — асинхронный однонаправленный ввод/вывод;
• режим "2" — асинхронный двунаправленный ввод/вывод.
Режим работы контроллера устанавливается кодом управляющего слова, которое предварительно записывается в регистр управления Y. В режиме "0" контроллер может работать как четыре порта ввода/вывода: А[7:О]. В[7:О], С[7:4], С[3:О], причем каждый порт может быть независимо запрограммирован на ввод или на вывод. При этом к порту, определенному как выходной, нельзя обращаться по чтению, а на входной порт нельзя выводить информацию.
В асинхронном однонаправленном режиме "1" могут работать только каналы А и В, причем соответствующие линии канала С придаются каналам А и В для передачи управляющих сигналов. Как и в режиме "0", каналы А и В программируются на ввод или вывод (независимо).
В режиме "2" может работать только канал А, к которому в этом случае можно обращаться как по записи, так и по чтению (двунаправленный асинхронный обмен). При этом канал В может быть запрограммирован как на работу в режиме "1", так и в режиме "0".
Выбор режимов каналов и направления передачи данных в них осуществляется загрузкой во внутренний управляющий регистр Y соответствующего кода.
Линии канала С могут работать только в режиме "0", причем независимо можно запрограммировать направление передачи старшей и младшей тетради канала С. Если для каналов А и/или В выбраны режимы "2" и/или "1", то соответствующие линии канала С перестают работать в режиме "0" и используются для передачи управляющих сигналов. Линии канала С, которые не используются при выбранной комбинации режимов каналов А и В, можно использовать как линии ввода или вывода канала С, работающего в "0"-режиме. Кроме того, всегда имеется возможность программного сброса/установки произвольного разряда канала С.
Режим "0" является синхронным и во многом напоминает рассмотренный выше механизм обмена с использованием регистров. Рассмотрим подробнее процесс асинхронного обмена в режиме "1".
Режим "1" обеспечивает однонаправленную асинхронную передачу информации между процессором и ВУ. При этом каналы А и В используются как регистры данных, а канал С — для приема и формирования управляющих сигналов, сопровождающих асинхронный обмен, причем каждый разряд канала С имеет строго определенное функциональное назначение [13].
Например, если канал запрограммирован на ввод в режиме "1", то процессор может вводить данные этого канала только "будучи уверенным" в их готовности. Об этой готовности ему должен сообщить контроллер путем установки специального признака — флага в определенном разряде регистра С и, может быть, формированием запроса на прерывание с соответствующим век- тором (о прерываниях подробнее см. в разд. 6.3.3). С другой стороны, внешнее устройство, подключенное к каналу, не должно выдавать новую порцию информации, пока прежняя не будет прочитана процессором.
Для обеспечения синхронизации ввода в режиме "1" каналу придаются три линии канала С для передачи управляющих сигналов:
STB (строб записи) — сигнал, формируемый ВУ для записи очередного байта данных в регистр канала:
IBF (подтверждение приема) — сигнал, формируемый контроллером для ВУ в тот момент, когда процессор прочитал содержимое регистра канала. Пока сигнал IBF неактивен, ВУ запрещается вырабатывать новый строб записи;
INT (запрос прерывания) — вырабатывается контроллером для процессора после того, как очередной байт данных запишется в регистр канала. Это же событие устанавливает флаг готовности канала в разряде регистра С.
Обмен начинается с подачи ВУ сигнала STB, по которому данные помещаются в регистр канала. Контроллер, во-первых, сбрасывает сигнал IBF, запрещая ВУ выработку нового строба, и, во-вторых, устанавливает флаг готовности и (может быть) формирует сигнал запроса на прерывание INT процессору. Процессор может достаточно долго не реагировать на сообщение о готовности канала, занятый более приоритетными процедурами. Все это время установлены готовность и INT и сброшен IBF, новая порция информации не может поступить в канал.
Когда процессор обратится по адресу канала и введет хранящуюся в регистре информацию, контроллер сбрасывает флаг готовности и запрос на прерывание INT и устанавливает сигнал IBF, разрешая ВУ записывать следующий байт в регистр канала. Однако ВУ может быть достаточно инерционным и довольно долго подготавливает следующую порцию информации, но пока ВУ не сформирует новый сигнал STB, контроллер не выработает сигнал готовности и, следовательно, процессор не будет обращаться по адресу канала. Подобный режим обмена позволяет исключить как потерю информации в контроллере, так и повторный ввод в процессор прежней информации.
Аналогично реализуется и асинхронный режим вывода. Каналу, запрограммированному на вывод в режиме "1", придаются три линии управления канала С:
OBF (выходной буфер заполнен) — сигнал формируется контроллером для ВУ после того, как процессор записал в регистр канала новую порцию информации;
АСК (подтверждение записи) — сигнал от ВУ контроллеру, подтверждающий прием очередного байта;
INT (запрос прерывания) — запрос прерывания от контроллера процессору для выдачи процессором в канал следующего байта информации.
Процедуры ввода и вывода в режиме "2" осуществляются аналогично соответствующим процедурам в режиме "1".
При организации последовательного обмена ключевыми могут считаться две проблемы:
синхронизация битов передатчика и приемника;
фиксация начала сеанса передачи.
Различают два способа передачи последовательного кода: синхронный и асинхронный.
При синхронном методе передатчик генерирует две последовательности— информационную T x D и синхроимпульсы СЬК, которые передаются на приемник по разным линиям. Синхроимпульсы обеспечивают синхронизацию передаваемых битов, а начало передачи отмечается по-разному. При организации внешней синхронизации (рис. 6.9) сигнал начала передачи BD генерируется передатчиком и передается на приемник по специальной линии.
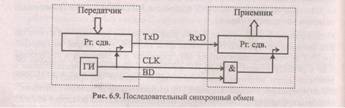
Системы с внутренней синхронизацией генерируют на линию данных специальные коды длиной 1 — 2 байта — символы синхронизации. Для каждого приемника предварительно определяются конкретные синхросимволы, таким образом можно осуществлять адресацию конкретного абонента из нескольких, работающих на одной линии. Каждый приемник постоянно принимает биты с линии RxD, формирует символы и сравнивает с собственными синхросимволами. При совпадении принятых символов с заданными для этого приемника синхросимволами последующие биты поступают в канал данных приемника. В случае реализации внутренней синхронизации между приемником передатчиком "прокладывают" только две линии — данных и синхроимпульсов.
Наконец, при асинхронном способе обмена можно ограничиться одной линией — данных. Для надежной синхронизации обмена в асинхронном режиме:
• передатчик и приемник настраивают на работу с одинаковой частотой;
• передатчик формирует стартовый и стоповый биты, отмечающие начало и конец посылки;
• передача ведется короткими посылками (5 — 9 битов), а частоты передачи выбираются сравнительно низкими.
Принцип последовательного асинхронного обмена по единственной линии показан на рис. 6.10. Пока передачи нет, на линии передатчик удерживает высокий уровень (Н). Передача начинается с выдачи в линию стартового бита низкого уровня (длительности всех битов т одинаковы и определяются частотой передатчика fT= 1/τ
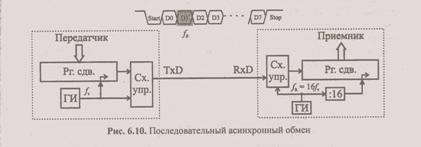
Частота приемника fR устанавливается равной 16 ×fT . Когда приемник обнаруживает на линии перепад Н → L, он включает счетчик тактов до 16, причем еще дважды за период т проверяет состояние линии. Если низкий уровень (L подтверждается, приемник считает, что принял старт-бит, и включает счетчик принимаемых битов. Если во второй и третьей проверке на линии определяется Н-уровень, то перепад считается помехой и старт-бит не фиксируется.
Каждый последующий (информационный) бит принимается таким образом, что за период т трижды проверяется состояние линии (например, в 3, 8 и 11 тактах приемника) и значение принимаемого бита определяется по мажоритарному принципу. Принятый бит помещается слева в сдвиговый регистр приемника. После принятия последнего информационного бита (количество битов в посылке определяется протоколом обмена и составляет обычно от 5 до 9) обязательно должен последовать стоповый бит Н-уровня. Во время поступления стоп-бита содержимое сдвигового регистра приемника передается в память, а в регистр передатчика может загружаться новая порция информации для передачи. Отсутствие стопового бита воспринимается приемником как ошибка передачи посылки.
После стопового бита можно формировать стартовый бит новой посылки или "держать паузу" произвольной длительности, при которой на линии присутствует Н-уровень.
Наличие стартового бита позволяет в начале каждой посылки синхронизировать фазы приемника и передатчика, компенсировав неизбежный уход фаз передатчика и приемника. Короткие посылки и относительно низкая частота передачи позволяют надеяться, что неизбежное рассогласование частот передатчика и приемника не приведет к ошибкам при передаче посылки.
Подсистема прерываний — совокупность аппаратных и программных средств, обеспечивающих реакцию программы на события, происходящие вне программы. Такие события возникают, как правило, случайно и асинхронно по отношению к программе и требуют прекращения (чаще временного) выполнения текущей программы и переход на выполнение другой программы (подпрограммы), соответствующей возникшему событию.
Различают внутренние и внешние (по отношению к процессору) события, требующие реакции подсистемы прерываний. К внутренним событиям относятся переполнение разрядной сетки при выполнении арифметических операций, попытка деления на О, извлечение корня четной степени из отрицательного числа, появление несуществующего кода команды, обращение программы в область памяти, для нее не предназначенную, сбой при выполнении передачи данных или операции в АЛУ и многое другое. Внутренние прерывания должны обеспечиваться развитой системой аппаратного контроля процессора, поэтому они не получили широкого распространения в простых 8- и 16-разрядных МП.
Внешние прерывания могут возникать во внешней по отношению к процессору среде и отмечать как аварийные ситуации (кончилась бумага на принтере, температура в реакторе превысила допустимый уровень, исполнительный орган робота дошел до предельного положения и т. п.), так и нормальные рабочие события, которые происходят в случайные моменты времени (нажата клавиша, исчерпан буфер принтера или ВЗУ и т. п.). Во всех этих случаях требуется прервать выполнение текущей программы и перейти на выполнение другой программы (подпрограммы), обслуживающей данное событие.
С точки зрения реализации внутренние и внешние прерывания функционируют одинаковым образом, хотя при работе подсистемы с внешними прерываниями возникают дополнительные проблемы идентификации источника прерывания. Поэтому ниже остановимся на рассмотрении внешних прерываний.
Анализ состояния внешней среды можно осуществлять путем программного сканирования — считывания через определенные промежутки времени слов состояния всех возможных источников прерываний, выделения признаков отслеживаемых событий. и переход (при необходимости) на прерывающую подпрограмму (часто ее называют обработчиком прерывания).
Однако такой способ не обеспечивает для большинства применений приемлемого времени реакции системы на события, особенно при необходимости отслеживания большого числа событий. К тому же при коротком цикле сканирования большой процент процессорного времени тратится на проверку (чаще безрезультатную) состояния внешней среды.
Гораздо эффективней организовать взаимодействие с внешней средой таким образом, чтобы всякое изменение состояния среды, требующее реакции МПС, вызывало появление на специальном входе МП сигнала прерывания текущей программы. Организация прерываний должна быть обеспечена определенными аппаратными и программными средствами, которые мы и называем подсистемой прерываний.
Подсистема прерываний должна обеспечивать выполнение следующих функций:
•обнаружение изменения состояния внешней среды (запрос на прерывание);
• идентификация источника прерывания;
• разрешение конфликтной ситуации в случае одновременного возникновения нескольких запросов (приоритет запросов);
• определение возможности прерывания текущей программы (приоритет программ);
• фиксация состояния прерываемой (текущей) программы;
• переход к программе, соответствующей обслуживаемому прерыванию;
• возврат к прерванной программе после окончания работы прерывающей программы.
Рассмотрим варианты реализации в МПС перечисленных выше функций.
Обнаружение изменения состояния внешней среды
Фиксация изменения состояния внешней среды может осуществляться различными схемами: двоичными датчиками, компараторами, схемами формирования состояний и др. Будем полагать, что все эти схемы формируют в конечном итоге логические сигналы запроса на прерывание z, причем для определенности будем считать, что активное состояние этого сигнала передается уровнем логической единицы (Н-уровень).
Количество источников запросов в МПС может быть различно, в т. ч. и довольно велико. Дефицит внешних выводов МП в общем случае исключает возможность передачи каждого запроса от ВУ по "собственной" линии интерфейса. Обычно на одну линию запроса подключается несколько источников прерываний (по функции ИЛИ), а иногда и все источники запросов — на единственный вход.
Управляющий автомат процессора должен периодически анализировать состояние линии (линий) запросов на прерывания. Каким образом выбирается период проверки? С одной стороны, этот период должен быть коротким, что бы обеспечить быструю реакцию системы на события. С другой стороны, при переходе на обслуживание прерывания требуется сохранить текущее состояние процессора на момент прерывания, с тем, чтобы, завершив программу обработчик, продолжить выполнение прерванной программы "с того же места", на котором произошло прерывание.
Напомним, что в основе работы процессора лежит командный цикл (см. разд. 2.1), состоящий, в свою очередь, из машинных циклов, каждый из которых длится несколько тактов. Осуществлять прерывание в произвольном такте невозможно, т. к. при этом пришлось бы сохранять в качестве контекста прерванной программы состояние всех элементов памяти процессора.
Прерывание по завершению текущего машинного цикла требует сохранение текущего состояния незавершенной команды. Например, при возникновении прерывания в том месте командного цикла, когда из памяти выбраны код команды и первый операнд, а для второго операнда только сформирован исполнительный адрес, следует сохранить: содержимое программного счетчика РС, код команды, первый операнд и адрес второго операнда. Сохранение этой информации требует как дополнительных аппаратных, так и временных затрат. Очевидно, при возврате к прерванной программе проще начать выполнение текущей команды заново. В этом случае сохранять при прерывании достаточно лишь значение РС. Поэтому в большинстве случаев процессоры анализируют состояние линий запросов в конце каждого командного цикла.
Идентификация источника прерывания
Различают два типа входов запросов на прерывания — радиальные и векторные. Получив запрос на прерывание, процессор должен идентифицировать его источник, т. е. в конечном счете определить начальный адрес обслуживающей это прерывание программы. Способ идентификации зависит от типа входа, на который поступил запрос.
Каждый радиальный вход связан с определенным адресом памяти, по которому размещается указатель на обслуживающую программу или сама программа. Если радиальный вход связан с несколькими источниками запросов, то необходимо осуществить программную идентификацию путем последовательного (в порядке убывания приоритетов) опроса всех связанных с этим входом источников прерывания. Этот способ не требует дополнительных аппаратных затрат и одновременно решает проблему приоритета запросов, однако время реакции системы на запрос может оказаться недопустимо большим, особенно при большом числе источников прерываний.
Гораздо чаще в современных МПС используется т. н. векторная подсистема прерываний. В такой системе микропроцессор, получив запрос на векторном входе INT, выдает на свою выходную линию сигнал подтверждения прерывания INTA, поступающий на все возможные источники прерывания. Источник, не выставивший запроса, никак не реагирует на сигнал INTA. Источник, выставивший запрос, получая сигнал INTA, выдает на системную шину данных "вектор прерывания" — свой номер или адрес обслуживающей программы или, чаще, адрес памяти, по которому расположен указатель на обслуживающую программу. Время реакции МПС на запрос векторного прерывания минимально (1 — 3 машинных цикла) и не зависит от числа источников.
Для исключения конфликтов при одновременном возникновении нескольких запросов на векторном входе ответный сигнал INTA подается на источники запросов не параллельно, а последовательно — в порядке убывания приоритетов запросов. Источник, не выставлявший запроса, транслирует сигнал INTA со своего входа на выход, а источник, выставивший запрос, блокирует дальнейшее распространение сигнала INTA. Таким образом, только один источник, выставивший запрос, получит от процессора сигнал INTA и выдаст по нему свой вектор на шину данных.
Более гибко решается проблема организации приоритетов запросов при использовании в МПС специальных контроллеров прерываний.
Конфликты на радиальном входе исключаются самим порядком программно- го опроса источников.
Прерывание в общем случае может возникать не только при решении "фоновой" задачи, но и в момент работы другой прерывающей программы, причем не всякую прерывающую программу допустимо прерывать любым запросом. В фоновой задаче также могут встречаться участки, при работе которых прерывания (все или некоторые) недопустимы. В общем случае в каждый момент времени работы процессора должно быть выделено подмножество запросов, которым разрешено прерывать текущую программу.
В МПС эта задача решается на нескольких уровнях. В процессоре обычно предусматривается программно-доступный флаг разрешения/запрещения прерывания, значение которого определяет возможность или невозможность всех прерываний. Для создания более гибкой системы приоритетов программ на каждом источнике прерываний может быть предусмотрен специальный программно-доступный триггер разрешения формирования запроса. В таком случае возможно формирование произвольного подмножества разрешенных в данный момент источников прерываний.
При использовании контроллера внешних прерываний, в нем обычно предусматривают специальный программно-доступный регистр, разряды которого маскируют соответствующие линии запросов на прерывание, запрещая контроллеру вырабатывать сигнал прерывания процессору, если запросы от ВУ поступают по замаскированным линиям. Однако замаскированные запросы сохраняются в контроллере и в дальнейшем, при изменении состояния регистра маски, могут быть переданы на обслуживание.
К обработке прерывания отнесем фиксацию состояния прерываемой программы, переход к программе, соответствующей обслуживаемому прерыванию, и возврат к прерванной программе после окончания работы прерывающей программы.
Выше мы определили, что большинство процессоров может прервать выполнение текущей программы и переключиться на реализацию обработчика прерывания только после завершения очередной команды. При этом в качестве контекста прерванной программы необходимо сохранить текущее состояние счетчика команд РС, а в РС загрузить новое значение — адрес программы обработчика прерывания. Очевидно, адрес возврата в прерванную программу (содержимое РС на момент прерывания) следует размещать в стеке, что позволит при необходимости осуществлять вложенные прерывания (когда в процессе обслуживания одного прерывания получен запрос на обслуживание другого).
Можно вспомнить, что подобный механизм реализован в системах команд многих процессоров для выполнения команд вызовов подпрограммы (сил., JSR). В этих командах адрес вызываемой подпрограммы содержится в коде команды.
В случае вызова обработчика прерывания его адрес необходимо связать либо со входом, на который поступил запрос (радиальные прерывания), либо с номером источника прерываний, сформировавшего запрос (векторные прерывания). В первом случае не требуется никаких внешних процедур для идентификации источника, сразу можно запускать связанный со входом обработчик. Понятно, здесь идет речь об отсутствии необходимости в аппаратных процедурах идентификации источника запроса. Если на радиальный вход "работают" несколько источников, то выбор осуществляется программными способами.
В случае векторных прерываний адрес перехода связывают с информацией, поступающей от источника запроса по шине данных в машинном цикле обслуживания прерывания — вектором прерывания.
Напомним, что любой командный цикл процессора начинается с чтения команды из памяти. В первом машинном цикле командного цикла процессор выдает на шину адреса содержимое РС, формирует управляющий сигнал RDM и помещенное памятью на шину данных слово интерпретирует как команду (или ее начальную часть, если длина команды превышает длину машинного слова).
Если в конце очередного командного цикла процессор обнаруживает (не замаскированный) запрос на векторном входе, он начинает следующий командный цикл с небольшими изменениями: содержимое РС по-прежнему выдается на шину адреса (чтобы не нарушать общности цикла), но вместо сигнала RDM формирует сигнал INTA. Источник запроса (чаще — контроллер прерываний) в ответ на сигнал INTA формирует на шину данных код команды вызова подпрограммы, в адресной части которой размещается адрес обработчика соответствующего прерывания.
Такой простой способ реализации векторных прерываний, с использованием уже существующего механизма вызова подпрограмм, был реализован, например, в микропроцессоре i8080 с контроллером прерываний i8259. Однако этот механизм, как, впрочем, и все остальное, допускает дальнейшее совершенствование.
Прежде всего, желание иметь возможность располагать подпрограммы в произвольной области памяти приводит к необходимости размещать в поле адреса команды вызова полно разрядный адрес (16 — 20 — 32 бита). В этом случае длина команды превышает длину машинного слова и ее ввод требует нескольких машинных циклов (например, в i8080 — трех), что увеличивает время реакции системы на запрос прерывания.
Для преодоления этого недостатка в систему команд процессора включают дополнительно "укороченные" команды вызова длиной в одно машинное слово. Эти команды в процессорах 8080 и х86 имеют мнемокод INT. В микропроцессоре i8080 имеется 8 таких команд длиной в 1 байт, адресующих под программы по фиксированным адресам памяти: 0000h, 0008h, 0010h, ..., 003811.
В процессорах х86 имеется 256 вариантов двухбайтовых команд INT INT 00h,…INT FFh, байт поля адреса которых (называемый вектором) после умножения на 4 указывает на четырехбайтовую структуру, определяющую произвольный адрес в адресном пространстве памяти.
Напомним, что доступ в память процессоров х86 (в реальном режиме) осуществляется только в рамках сегментов размером в 64 Кбайт. Положение начала сегмента в адресном пространстве памяти определяется содержимым 16-разрядного сегментного регистра, а положение адресуемого байта внутри сегмента — 16-разрядным смещением. Среди команд передачи управления различают короткие и длинные переходы (вызовы). При коротком вызове подпрограмма должна располагаться в текущем сегменте кода, и ее вызов сопровождается только изменением счетчика команд (в х86 он обозначается, как IP). При длинном вызове новое значение загружается как в IP, так и в сегментный регистр кода CS. Таким образом, для осуществления длинного вызова (перехода) в адресном поле команды необходимо разместить 4 байта.
Механизм векторных прерываний в процессорах х86 в реальном режиме реализован следующим образом. В начальных адресах 00000h, ..., 003FFh пространства памяти размещается таблица векторов прерываний объемом 1 Кбайт, включающая 256 строк таблицы — четырехбайтовых структур CS:IP, которые определяют адреса соответствующих обработчиков прерываний. В цикле обработки векторного прерывания (запрос по входу INT), процессор получает от источника байт — номер строки таблицы векторов прерываний, из которой и загружаются новые значения CS и IP. Старые значения CS:IP (адрес возврата) размещаются в стеке.
Запросу по радиальному входу NMI соответствует вектор 2, поэтому появление активного значения не вызывает машинного цикла обслуживания прерывания, а сразу вызывается обработчик по адресу из ячеек памяти 00008h, ..., 0000Bh. Кстати, любой обработчик прерывания (независимо от значения маскирующих флагов) можно вызвать программно с помощью команды INTnn , где nn — номер строки таблицы векторов прерываний.
Таким образом, команда ют отличается от команды CALL, во-первых, способом адресации вызываемой подпрограммы (прямой адрес — в команде CALL, косвенный — в INT), во-вторых, при реализации INT в стек, помимо CS и IP) помещается содержимое регистра признаков процессора — FLAGS. Соответственно, завершаться подпрограмма, вызываемая командой IRET, должна командой INT ("возврат из прерывания"). Действие IRET отличается от действия от извлечением из стека дополнительного слова в регистр FLAGS.
В процессе работы МПС с интерфейсом типа "общая шина" часто возникает необходимость передачи достаточно больших массивов данных между памятью и ВУ (например, копирование сектора диска, загрузка видеопамяти и т. п.). При наличии в системе единственного активного устройства — процессора возможен единственный путь решения этой задачи — программно- управляемый обмен "Память → Процессор →ВУ" (или "ВУ → Процессор →Память").
Рассмотрим вариант программно-управляемого обмена между памятью и внешним устройством в МПС на базе МП i8080 [13]. Пусть необходимо передать массив данных длиной L, начиная с адреса ADR на ВУ с адресом AIO. Положим, что начальный адрес массива загружен в регистровую пару НЬ, а длина массива — в регистр С. Тогда фрагмент программы обмена может иметь вид, представленный в табл. 6.2.

Таким образом, для того чтобы в рамках процедуры копирования массива данных переслать из памяти в ВУ один байт данных, потребуется десять машинных циклов. Процессоры с более совершенной системой команд (например, х86) могут использовать для этой цели меньшее число МЦ, но все равно их будет более одного.
Управляя обменом, микропроцессор "ведет" два счетчика — адресов массива и количества переданных байтов и формирует на магистраль сигналы управления. Если снабдить ВУ аппаратными счетчиками и схемой формирования управляющих сигналов (т. н. "канал прямого доступа в память" — ПДП), то передачу одного байта (слова) можно осуществить за один МЦ без участия процессора. Необходимо лишь на время передачи данных под управлением канала ПДП блокировать работу процессора, отключив его от системной шины. Для этого служит вход захвата шины HLD. Если подать на него активный уровень, то МП по окончании текущего МЦ, безусловно, перейдет в режим ожидания, переведя все свои выходные линии, кроме НLDА, в высокоимпедансное состояние, а выход HLDA — в состояние логической 1. Выходной сигнал HLDA используется для отключения процессорного модуля от системной шины — перевода шинных формирователей, включенных между локальной и системной шиной, в
высокоимпедансное состояние.
Если в МПС используется несколько ВУ, снабженных каналом ПДП, то целесообразно использовать специальный контроллер ПДП, который обеспечивает программирование каналов ПДП, подключение их к системной шине и дисциплину обслуживания.
ГЛАВА 7
Эволюция архитектур микропроцессоров и микро ЭВМ
В главе 6 была рассмотрена архитектура 16-разрядного микропроцессора i8086 и систем на его основе. Эту архитектуру мы (условно) будем считать базовой. Уже в ней по сравнению с первыми 8-разрядными системами (на базе i8080) реализован ряд новых архитектурных решений:
• расширена система команд (по набору операций и способам адресации);
• архитектура микропроцессора ориентирована на мультипроцессорную работу. Разработана группа вспомогательных БИС (контроллеров и специализированных процессоров) для организации мульти микропроцессорных систем различной конфигурации;
• начато движение в сторону совмещения во времени выполнения различных операций. Микропроцессор включает два параллельно работающих устройства: обработки данных и связи с магистралью, что позволяет совместить во времени процессы обработки информации и передачи ее по магистрали;
• введена новая (по сравнению с i8080) организация памяти, которая далее использовалась во всех старших моделях семейства Intel — сегментация памяти.
Можно сказать, что основная цель совершенствования микропроцессоров - это увеличение их производительности. Достигается эта цель различными путями: повышением тактовой частоты работы кристалла, совершенствованием операционных устройств (например, применение параллельного умножителя), организацией параллельной во времени работы нескольких устройств, совершенствованием системы команд (с ориентацией под конкретный класс задач), эффективной организацией иерархии памяти, опережающим выполнением ряда процедур командных циклов, организацией мульти задачных и мультипроцессорных систем и другими способами.
На примере микропроцессоров Intel линии 8080 → 8086→ 80286→80386→ 80486→ Pentium →... →Pentium 4 (это семейство принято обозначать как x86) можно проследить реализацию многих из перечисленных выше путей. Рассмотрим некоторые из них, не придерживаясь хронологической последовательности нововведений. Более подробные сведения о рассматриваемых в этой главе вопросах можно найти в [3, 11, 12, 14].
7.1. Защищенный режим и организация памяти
Первый шаг для увеличения производительности систем на базе процессоров х86 был сделан в направлении мультипроцессорной конфигурации. В 8086 предусмотрены два режима работы — минимальный и максимальный (см. разд. 6.1.1), причем последний ориентирован на организацию мультипроцессорных систем. Часть выводов микропроцессора в максимальном режиме вместо сигналов управления шиной передает коды внутренних состояний управляющего автомата; кроме того, в составе серии выпускались специализированные модули, которые обеспечивали доступ микропроцессора к системной шине — арбитраж шины.
Однако широкого распространения подобная архитектура не получила, поскольку при отсутствии на кристалле микропроцессора достаточно "вместительной" внутренней памяти процессоры постоянно ожидают в очереди на доступ к шине. Характерно, что в последующих моделях семейства — 80286, 80386, 80486 поддерживалась только однопроцессорная конфигурация, и лишь в Pentium вновь вернулись к возможности организации многопроцессорных систем.
7.1.1. Сегментная организация памяти
Как вы, очевидно, помните, в микропроцессоре 8086 в рамках адресного пространства объемом 1 Мбайт одновременно было доступно четыре сегмента по 64 Кбайт каждый.
В следующих моделях микропроцессоров семейства х86' в рамках т. н. защищенного режима (protect mode, Р-режим) организовано линейное адресное пространство объемом 232 байтов, в котором допускается создание практически любого числа сегментов.
Если в 8086 единственным атрибутом сегмента был его начальный адрес, то в
Р-режиме старших моделей семейства х86 для описания многочисленных атрибутов предусмотрена специальная структура — дескриптор.
Дескриптор — это 8-байтовый блок, содержащий атрибуты области линейных адресов — сегмента. Дескриптор включает в себя информацию о положении сегмента в линейном адресном пространстве, размере сегмента, типе информации, хранящемся в сегменте и правах доступа к ней, а также другие атрибуты сегмента. Формат дескриптора представлен на рис. 7.1.
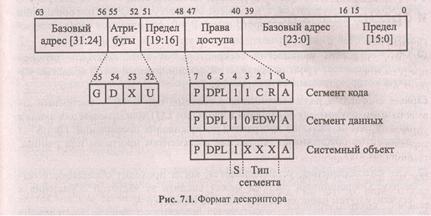
Назначение полей дескриптора:
• базовый адрес1 [31:0] определяет место сегмента (начальный адрес) внутри 4-гигабайтного адресного пространства;
• предел [19:0] определяет размер сегмента с учетом бита гранулярности (см. далее).
Поле атрибутов включает следующие признаки:
G — бит гранулярности. При значении G = 0 размер сегмента задается в байтах, а при G = 1 — в страницах по 4 Кбайт. В первом случае максимальный размер сегмента может достигать 1 Мбайт, во втором — 4 Мбайт;
D — бит размера по умолчанию (от англ. defaults size) обеспечивает совместимость с процессором 80286. При D=O находящиеся в сегменте операнды считаются имеющими размер 16 битов, иначе — 32 бита;
Х — зарезервирован Intel и не должен использоваться программистом (содержит 0);
U — бит пользователя (от англ. user) предназначен для использования системным программистом. Процессор игнорирует этот бит.
Байт права доступа (AR) имеет несколько отличающуюся структуру для дескрипторов сегментов разных типов, но некоторые поля этого байта являются общими для всех дескрипторов: ) Р — бит присутствия (от англ. present) сегмента, если Р = 0, то дескриптор не может использоваться, т. к. сегмент отсутствует в ОЗУ. При обращении к сегменту, дескриптор которого имеет Р = 0, формируется соответствующее прерывание;
DRL уровень привилегий дескриптора (от англ. descriptor privilege level) определяет уровень привилегий, ассоциируемый с той областью памяти, которую описывает дескриптор;
S — определяет роль дескриптора в системе: при S = 0 — системный дескриптор, служит для обращения к таблицам LDT или шлюзам для входа в другие задачи, включая программы обслуживания прерываний. При S = 1 дескриптор обеспечивает обращение к сегментам программ или данных, включая стек;
А — бит обращения, устанавливается, когда проходит обращение к сегменту. Операционная система может следить за частотой обращения к сегменту путем периодического анализа и очистки А.
Трех битное поле mun сегмента определяет целевое использование сегмента, давая допустимые в сегменте операции. Значение этого поля для системных дескрипторов (S = 0) безразлично. Для несистемных сегментов биты поля тип сегмента имеют следующие значения:
бит 3 различает сегменты кода (1) и данных (О); ) для сегмента кода бит 2 (Conforming) отмечает при С = 1 т. н. "подчиненные сегменты" (см. далее), а бит 1 (Read) при R = 1 допускает чтение кода как данных с помощью префикса замены сегмента;
для сегмента данных бит 2 (Expand Down) определяет т. н. "расширение вниз" — для сегментов стека ED = 1, а для сегментов собственно данных ED=0;
бит 1 (Write) показывает возможность записи в сегмент при W = 1.
Дескрипторы хранятся в памяти и группируются в дескрипторные таблицы: )
GDT — глобальная дескрипторная таблица; )
IDT — дескрипторная таблица прерываний; )
LDT — локальная дескрипторная таблица.
Причем, если GDT и IDT — общесистемные, присутствуют в системе в единственном экземпляре и являются общими для всех задач, то LDT может создаваться для каждой задачи.
Максимальный размер дескрипторной таблицы может составлять 2' = 8192 дескриптора (213× 8 = 65 536 байтов).
Дескрипторная таблица локализуется в памяти с помощью соответствующего
регистра. 48-битовые регистры GDTR и IDTR содержат 32-битовое поле базового адреса таблицы и 16-битный предел (размер) таблицы с байтовой гpaнулярностью.
Для локализации LDT используется 16-разрядный регистр LDTR, содержащий только селектор сегмента, в котором размещена таблица. Таблицы LDT хранятся как сегменты, а дескрипторы этих сегментов размещаются в GDT. Селектор регистра LDTR выбирает из GDT нужный дескриптор, и атрибуты LDT становятся доступны процессору. С LDTR, как и с сегментными регистрами, ассоциируется соответствующий "теневой регистр", в который помещается выбранный из GDT дескриптор LDT текущей задачи. При переключении задачи достаточно заменить 16-разрядное содержимое LDTR, а процессор автоматически загрузит теневой регистр.
Доступ к памяти в любом режиме х86 возможен лишь в область, определенную как сегмент. Количество доступных в данный момент сегментов определяется числом сегментных регистров (CS, SS, DS, ES, FS, GS). Однако в защищенном режиме содержимое сегментного регистра не является базой сегмента, а рассматривается как селектор сегмента и имеет формат, приведенный на рис. 7.2.

Индекс определяет смещение внутри дескрипторной таблицы, которая соответственно разрядности индекса может содержать 2 8-байтовых дескрипторов. Бит TI определяет тип дескрипторной таблицы: 0 — глобальная, 1— локальная. Поле RPL определяет запрашиваемый уровень привилегий.
Итак, селектор адресует дескриптор сегмента в одной из дескрипторных таблиц. Всякий раз, когда производится перезагрузка сегментного регистра (замена селектора), адресуемый им дескриптор извлекается из соответствующей дескрипторной таблицы и помещается в "теневой регистр" дескриптора. Все последующие обращения к этому сегменту не требуют чтения из дескрипторной таблицы.
Логический адрес в защищенном режиме, как и в реальном, описывается парой RS:ЕА, где RS — содержимое выбранного сегментного регистра, ЕА— эффективный адрес, генерируемый программой (смещение в сегменте).
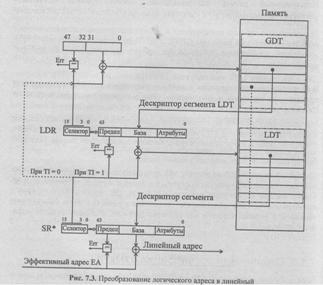
Процесс загрузки дескрипторных регистров и преобразования эффективного . (логического) адреса в линейный протекает следующим образом (рис. 7.3):
1. При переходе в защищенный режим в памяти создается глобальная дескрипторная таблица, базовый адрес которой размещается в регистре GDTR
2. Несколько сегментов определяется в памяти, и их дескрипторы помещаются в GDT.
3. При запуске очередной задачи можно определить дополнительно несколько сегментов и для хранения их дескрипторов создать локальную дескрипторную таблицу, как системный сегмент, дескриптор которого хранится в GDT, а его положение в GDT определяется селектором в регистре LDTR. В теневой регистр LDTR автоматически помещается дескриптор сегмента LDT.
4. При загрузке в любой сегментный регистр нового содержимого в соответствующий теневой регистр автоматически помещается новый дескриптор из GDTR или LDTR.
5. При генерации программой очередного адреса ЕА из соответствующего теневого сегментного регистра выбирается базовый адрес сегмента и складывается со значением ЕА. Полученная сумма представляет собой линейный адрес.
В приведенной выше процедуре не отражены особые случаи, которые могут
возникать при различных нарушениях (ошибках) в процессе формирования линейного адреса.
Механизм сегментации можно искусственно подавить, назначив все базовые адреса сегментов равными нулю и определив длину всех сегментов в 4 Мбайт. Таким образом, в адресном пространстве определится единственный сегмент размером 2 байтов.
Сегмент в защищенном режиме — область памяти, снабженная рядом атрибутов: типом, размером, положением в памяти, уровнем привилегий ид р. Сегмент может начинаться и кончаться, где угодно, и его размер — произвольный. Другой элемент памяти — страница — имеет строго фиксированный размер (4 Кбайт) и положение в линейном адресном пространстве: страница всегда выровнена по границе 4-килобайтовых фрагментов, т. е. 12 младших разрядов адреса страницы — всегда нули.
7.1.2. Страничная организация памяти
Наряду с сегментной организацией в микропроцессорах х86 возможна дополнительно страничная организация памяти. Механизм страничной организации памяти может включаться (выключаться) программно путем установки (сброса) флага PG регистра CRO.
Все линейное адресное пространство делится на разделы, число которых может достигать 1024. Каждый раздел, в свою очередь, может содержать до 1024 страниц (рис. 7.4), размер которых фиксирован — 4 Кбайт, причем начальные адреса страниц жестко фиксированы в физическом адресном пространстве: границы страниц совпадают с границами 4-килобайтовых блоков.
32-разрядный логический адрес, полученный на предыдущем этапе преобразования адреса, рассматривается состоящим из трех полей:
[31:22] — номер раздела (ТАВДЕ);
[21:12) — номер страницы в разделе (PAGE);
[11:0] — номер слова на странице (смещение).

Начальные адреса страниц данного раздела (вместе с атрибутами страницы) хранятся в памяти в страничной таблице, размер которой 1024 стр. х 4 байта = 4096 байтов.
Поскольку в задаче может быть несколько разделов и, следовательно, столько же страничных таблиц, то начальные адреса всех страничных таблиц одного сегмента хранятся в специальной таблице — каталоге раздела.
Линейный 32-разрядный адрес является исходной информацией для формирования 32-разрядного физического адреса (рис. 7.5) с помощью каталога раздела и страничной таблицы (СТ). Старшие 10 разрядов линейного адреса определяют номер строки каталога разделов, который локализуется содержимым системного регистра CR3.
Поскольку каталог разделов имеет размер 1 Кбайт х 4байта, он занимает точно одну страницу (CR3[11:0] =0) и содержит 4-байтовые поля, формат которых показан на рис. 7.6. Помимо базового адреса страничной таблицы, это поле хранит атрибуты страницы. Извлеченный из каталога базовый адрес страничной таблицы складывается (конкатенируется) с разрядами [21:12] линейного адреса для получения адреса строки страничной таблицы, из которой, в свою очередь, извлекается базовый адрес страницы. Конкатенацией базового адреса страницы с разрядами [11:0] линейного адреса получается физический адрес.
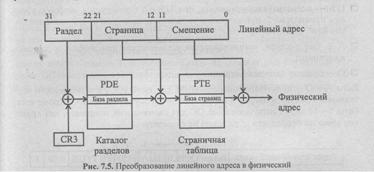
Такая двухуровневая организация страничной таблицы позволяет значительно экономить память для хранения страничных таблиц. Действительно, если рассматривать разряды [31:20] линейного адреса как номер строки страничной таблицы, то ее (таблицы) размер должен составлять 2 х 4 байтов, т. е. 4 Мбайт. Абсолютное большинство задач никогда не использует такого количества страниц, однако, во избежание возникновения особого случая (внутреннего прерывания) необходимо поддерживать всю такую таблицу целиком.
При двухуровневой организации страничного преобразования (см. рис. 7.5) в памяти достаточно хранить каталог разделов и страничные таблицы только реально существующих разделов. Максимальное число разделов может достигать 1024, однако во многих случаях достаточно бывает двух-трех разделов, а то и единственного.
Каждая четырехбайтовая строка каталога разделов и страничной таблицы содержит, помимо 20-разрядного базового адреса, атрибуты страницы, определяющие ее назначение, положение в физической памяти, а также информацию, позволяющую аппаратно поддерживать некоторые алгоритмы замещения страниц при страничных сбоях. Формат строки этих таблиц представлен на рис. 7.6.
Атрибуты страницы (СТ):
Р — бит присутствия, при Р = 0 страница отсутствует в оперативной памяти, попытка обращения к ней вызывает прерывание 14 — "страничный сбой";
В/W — чтение/запись, если работает программа с уровнем привилегий 3 (низший), то при R/W =0 разрешается только чтение, но не запись на страницу;
ИБ — пользователь/супервизор, при U S = 0 блокируется запрос с уровнем привилегий 3; при запросе с уровнями привилегий 0, 1, 2 значения битов R/W, U/$ игнорируются;
А — бит доступа, устанавливается процессором при любом обращении к странице;
D — признак записи на страницу.
Биты А и D используются операционной системой (ОС) для поддержки виртуальной памяти, проверку и сброс этих битов осуществляет ОС. Кроме того, биты 9 — 11 могут использоваться ОС для своих целей, например, для хранения времени последнего обращения на страницу.

В х86 предусмотрена ассоциативная память страничных таблиц, которая называется буфером ассоциативной трансляции — ТLВ.
ТLВ представляет собой 32 ячейки АЗУ 1-гo рода, поле признаков которого (теги) включают старшие 20 разрядов линейного адреса. Информационное поле ячейки включает 20 старших битов физического адреса страницы и ряд ее атрибутов. Биты D, U S, R/W имеют тот же смысл, что в слове СТ, а бит достоверности V сбрасывается при записи в CR3 нового слова (смена каталога). После преобразования очередного линейного адреса в физический бит V в этой ячейке устанавливается.
Наличие TLВ позволяет при кэш-попадании избежать обращения к ОЗУ при преобразовании линейного адреса. При кэш-промахе микропроцессор выполняет процедуру формирования физического адреса по каталогу раздела и СТ. Полученный из СТ 20-разрядный базовый адрес вместе с 20-разрядным тегом заносятся в свободную ячейку TLB или занимают ячейку, в которой хранится адрес, введенный в ТLВ ранее других.
Так как ТLВ хранит адреса 32 страниц по 4 Кбайт, то непосредственно доступными становятся физические адреса 128 Кбайт памяти.
В х86 предусмотрены два вида защиты памяти: на уровне сегментов и на уровне страниц.
Защита памяти на уровне сегментов
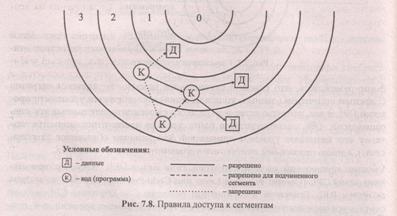
В х86 определено понятие привилегии для сегмента и установлены 4 уровня привилегий PL (рис. 7.7), которые задаются номерами от 0 (наиболее защищенный) до 3 (низший).
В ядро входит часть ОС, обеспечивающая инициализацию работы, управление доступом к памяти, защиту и ряд других жизненно важных функций, нарушение которых полностью выводит из строя МПС. Основная часть ОС должна иметь уровень 1. К уровню 2 обычно относят ряд служебных программ ОС, например, драйверы внешних устройств, системы управления базами данных, специализированные подсистемы программирования и др..

Выше отмечалось, что основой организации памяти х86 является сегмент. С каждым сегментом (данных, кода или стека) ассоциируется уровень привилегий DPL и все, что находится внутри этого сегмента, имеет данный уровень привилегий. DPL располагается в байте доступа дескриптора сегмента, по этому его называют уровнем привилегий дескриптора (Descriptor Privilege Level), однако правильнее считать его уровнем привилегий сегмента.
Уровень привилегий выполняющегося кода называется текущим уровнем привилегий CPL (Current Privilege Level или Code Privilege Level) и он задается полем RPL селектора в сегментном регистре CS. Значение CPL можно считать уровнем привилегий процессора в текущий момент времени, т. к. при передаче управления сегменту кода с другим уровнем привилегий процессор . будет работать на новом уровне привилегий.
Каждый селектор выбирает точно один дескриптор и, соответственно, один сегмент, но конкретный сегмент могут идентифицировать несколько селекторов ("альтернативное именование"). Младшие два бита селектора содержат поле запрашиваемого уровня привилегий RPL (Requested Privilege Level). Это поле не влияет на выбор дескриптора, но учитывается при контроле привилегий.
Таким образом, текущее состояние системы защиты характеризуется следующими признаками:
• CPL — уровень привилегий выполняемого кода, размещается в поле RPL сегментного регистра кода CS;
• DPL — уровни привилегий для каждого из восьми открытых сегментов, располагаются в байте доступа дескрипторов, помещенных в "теневые регистры";
• RPL — определяют уровни привилегий источника селектора, размещаются в полях RPL сегментных регистров.
Процессор постоянно контролирует, обладает ли текущая программа достаточным уровнем привилегий, чтобы:
• выполнять некоторые команды;
• обращаться к данным других программ;
• передавать управление внешнему (по отношению к программе) коду
командами передачи управления типа FAR.
В системе команд существуют специальные привилегированные команды, которые могут выполняться процессором, работающим только на уровне привилегий О. При попытке выполнить их на другом уровне привилегий генерируется прерывание 13 — нарушение общей защиты. К привилегированным относятся команды:
• останов процессора;
• сброс флага переключенной задачи;
• загрузка регистров дескрипторных таблиц;
• загрузка регистра задачи;
• загрузка слова состояния машины;
• модификация флага прерываний IF*;
• команды ввода/выводам.
Последние две группы команд (отмеченные *) не обязательно выполняются на нулевом уровне, достаточно, чтобы уровень привилегий программы был выше уровня привилегий ввода/вывода, определяемого полем IOPL в регистре EFLAGS.
Данные из сегмента могут выбираться только программой, имеющей такой же или более высокий, чем сегмент, уровень привилегий. Программам не разрешается обращение к данным, которые имеют более высокий уровень привилегий, чем выполняемая программа. Программы могут использовать данные на своем и более низких уровнях привилегий. Ограничения на возможность доступа к данным иллюстрирует рис. 7.8.
Контроль реализуется двумя способами. Во-первых, проверка привилегий осуществляется при загрузке селектора в один из сегментных регистров данных — DS, ES, FS или GS. Если значение DPL того сегмента, который выбирает селектор, численно меньше CPL, процессор не загружает селектор и формирует нарушение общей защиты. Во-вторых, после успешной загрузки селектора при использовании его для фактического обращения к памяти процессор контролирует, разрешена ли для этого сегмента запрашиваемая операция (чтение или запись). Кроме того, при обращении контролируется значение запрашиваемого уровня привилегий RPL, причем обращение разрешается, если DPL > max(RPL, CPL), иначе формируется прерывание 13.
Обращение к сегменту стека возможно, если RPL = DPL = CPL, причем сегмент стека должен иметь разрешение на запись — бит W в байте доступа должен быть установлен.
Межсегментная передача управления происходит по командамJMP, CALL, RET, INT, IRET. Для передачи управления существуют жесткие ограничения: передавать управление в общем случае можно только в пределах своего уровня привилегий, т. е. DPL целевого дескриптора должен быть точно равен CPL (см. рис. 7.8).
Однако часто бывает необходимо обойти установленные ограничения (например, фрагменты операционной системы могут использоваться программами пользователя). В х86 предусмотрены два механизма передачи управления между уровнями привилегий: подчиненные сегменты и шлюзы вызова.
Если сегмент кода определен как подчиненный (установлен в 1 бит подчиненности С в байте доступа дескриптора), то для него вводятся другие правила защиты. С подчиненными сегментами не ассоциируется конкретный уровень привилегий, он устанавливается равным уровню привилегий вызывающей программы. Поэтому код подчиненных сегментов не должен содержать привилегированных команд.
Когда управление передается подчиненному сегменту, биты поля RPL регистра CS не изменяются на значение поля DPL дескриптора нового сегмента кода, а сохраняют прежнее значение. Только в этой единственной ситуации биты поля RPL регистра CS не соответствуют битам поля DPL дескриптора текущего выполняемого сегмента кода.
При использовании подчиненных сегментов сохраняется одно ограничение — значение DPL дескриптора подчиненного сегмента всегда должно быть меньше или равно текущему значению CPL. Другими словами, передача управления подчиненному сегменту разрешается только во внутренние, более защищенные сегменты. Если бы это ограничение нарушалось, то возврат в вызывающую программу был бы вызовом неподчиненного более защищенного сегмента, что никогда не разрешено.
Наличие подчиненных сегментов кода обеспечивает некоторую свободу передачи управления между уровнями привилегий. Для реализации фактического изменения уровня привилегий привлекаются особые системные объекты, называемые шлюзами вызова (рис. 7.9).

Хотя шлюзы вызова и располагаются в дескрипторной таблице, они, по существу, дескрипторами не являются, т. к. не определяют никакого сегмента. Поэтому в дескрипторе шлюза отсутствует база и граница сегмента, а содержится лишь селектор вызываемого сегмента программы и относительный адрес шлюза — задается фактически адрес селектор: смещение точки входа той процедуры (назначения), которой шлюз передает управление. Байт доступа имеет тот же смысл, что и в обычных дескрипторах, а пяти битовое поле WC указывает количество параметров, переносимых из стека текущей программы в стек новой программы.
При этом, если вызываемая программа имеет более высокий уровень привилегий, чем текущая, то для нее по команде CALL создается новый стек, позиция которого определяется из сегмента состояния задачи TSS. В этот стек последовательно записываются: старые значения SS и ESP, параметры, переносимые из старого стека, старые CS и EIP. По команде происходит возврат к старому стеку.
Дескриптор шлюза вызова действует как своеобразный интерфейс между сегментами кода на разных уровнях привилегий. Шлюзы вызова идентифицируют разрешенные точки входа в более привилегированные программы, которым может быть передано управление.
Селектор, определяющий шлюз вызова, можно загружать только в сегментный регистр CS для передачи управления сегменту кода на другом уровне привилегий.
Защита памяти на уровне страниц
В отличие от 80386, процессоры 80486 и Pentium имеют дополнительные поля в элементе страничной таблицы [3]. Формат строки СТ i80486 представлен на рис. 7.10, сравните его с форматом на рис. 7.6.

Кроме используемых в i80386 полей:
Р — бит присутствия;
R/W — чтение/запись;
U/S — пользователь/супервизор;
А — бит доступа;
D — признак записи на страницу;
резерв ОС
введены биты управления кэшированием:
PCD — запрет кэширования страницы
PWT — сквозная запись.
На уровне страниц в 80486 предусмотрены две разновидности контроля:
• ограничение адресуемой области;
• контроль типа.
Ограничение адресуемой области. Для страниц и сегментов привилегии интерпретируются по-разному: для сегментов — 4 уровня, для страниц— только 2, определяемые битом U/S. При U/S = 0 страница имеет уровень супервизора, иначе — уровень пользователя. На уровне супервизора работают обычно операционные системы, драйверы ВУ, а также располагаются защищенные данные (например, страничные таблицы). Уровни привилегий сегментов отображаются на уровень привилегий страниц: если значение CPL равно 0, 1 или 2, то процессор, работает на уровне супервизора, при CPL=3 — на уровне пользователя. На уровне супервизора доступны все страницы, а на уровне пользователя — только страницы уровня пользователя.
Контроль типа. Механизм защиты распознает только два типа страниц: с доступом только по считыванию (R/W= 0) и с доступом по считыванию/записи (R/W = 1), причем в 80386 ограничение по записи действительно только для уровня пользователя. Программа уровня супервизора игнорирует значение бита R/W и может записывать на любые страницы. В отличие от 80386, процессор 80486 разрешает защитить от записи страницы уровня пользователя в режиме супервизора: установка в регистре CRO бита WR = 1 обеспечивает чувствительность режима супервизора к защищенным от записи страницам режима пользователя.
Для любой страницы атрибуты защиты ее элемента каталога разделов могут отличаться от атрибутов защиты ее элемента страничной таблицы. Процессор контролирует атрибуты защиты в таблицах обоих уровней и принимает решение таким образом, что всякое разночтение в уровне привилегий раздела и страницы всегда разрешается в сторону большей защиты (предоставления меньших прав пользователю).
Под мультизадачностью понимают способность процессора выполнять несколько задач "одновременно". Конечно, процессор традиционной архитектуры не может выполнять строго одновременно более одного потока команд, однако он может некоторое время выполнять один поток команд, потом быстро переключиться на выполнение другого потока команд, потом третьего, потом — снова первого и т. д. Такая организация вычислительных процессов при высоком быстродействии процессора создает иллюзию одновременности (параллельности) выполнения нескольких задач.
Для реализации мультизадачности необходимо:
• располагать быстродействующим процессором;
• процессор должен аппаратно поддерживать механизм быстрого переключения задач;
• процессор должен аппаратно поддерживать механизм защиты памяти;
• использовать специальную мультипрограммную операционную систему. Под задачей в мульти задачной системе понимается программа, которая выполняется или ожидает выполнения, пока выполняется другая задача, причем в определение задачи обычно включают ресурсы, требуемые для ее решения (объем памяти, процессорное время, дисковое пространство и др.).
Рассмотрим, как реализуется механизм переключения задач в процессорах 86.
7.2.1. Сегмент состояния задачи
Переключение задач в мульти задачной системе предполагает сохранение состояния приостанавливаемой задачи на момент ее останова. Информация о задаче, сохраняемая для последующего восстановления прерванного процесса, называется ее контекстом. В системе выделяется область оперативной памяти, доступная только ОС, в которой хранятся контексты задач. Для минимизации времени переключения контекста следует сохранять и восстанавливать минимальную информацию о каждой задаче.
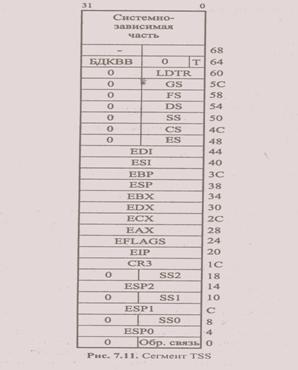
В какой-то степени процесс переключения задачи напоминает вызов процедуры. Отличие состоит в том, что при вызове процедуры информация о точке возврата (автоматически) и содержимое некоторых РОН (программно) помещается в стек, что определяет свойство реентерабельности процедур (возможность вызова самой себя). Задачи не являются реентерабельными, т. к. контексты сохраняются не в стеке, а в фиксированной (для каждой задачи) области памяти в специальной структуре данных, называемой сегментом состояния задачи (Task State Segment, TSS), причем каждой задаче соответствует один TSS.
Сегмент TSS определяется дескриптором, который может находиться только в GDT. Формат дескриптора TSS похож на дескриптор сегмента кода и содержит обычные для дескриптора сегмента поля: базового адреса, предела, DPL, биты гранулярности (G = 0) и присутствия Р, бит S = 0 — признака системного сегмента. В поле типа бит занятости В показывает, занята задача или нет. Занятая задача выполняется сейчас или ожидает выполнения. Процессор использует бит занятости для обнаружения попытки вызова задачи, выполнение которой прервано. Поле предела должно содержать значение, не меньшее 67h, что на один байт меньше минимального размера TSS. Формат 32-разрядного TSS представлен на рис. 7.11.
Процедура, которая обращается к дескриптору TSS, может вызвать переключения задачи. В большинстве случаев поле DPL дескрипторов сегментов TSS должно содержать 00, поэтому переключение задач могут проводить только привилегированные программы (на нулевом уровне).
Сегмент TSS не является ни сегментом кода, ни сегментом данных. Доступ к нему имеет только процессор, но не задача, даже на нулевом уровне! Если предполагается программно использовать сегмент TSS, то следует применить альтернативное именование.
Обращение к дескриптору TSS не предоставляет возможность процедуре считать или модифицировать сегмент TSS. Загрузка селектора дескриптора TSS в сегментный регистр вызывает особый случай. Доступ к сегменту TSS возможен только с помощью альтернативного именования, когда сегмент данных отображен на ту же область памяти.
Сегмент состояния задачи TSS (рис. 7.11) включает в себя содержимое всех пользовательских регистров процессора, причем 8 регистров общего назначения хранятся в сегменте в том же порядке, в каком они помещаются в стек командой RUSHAD. Кроме того, в TSS сохраняются значения трех указателей стека SSi: ESPi для трех уровней привилегий —iε{0,12} . Сохранение в TSS регистров CS и EIP позволяет осуществлять рестарт задачи, при этом гарантируется правильное действие команд условных переходов, т. к. в TSS сохраняется и EFLAGS. Сохранение в TSS содержимого регистров CR3 и LDTR позволяет для каждой задачи образовывать свой каталог разделов и локальную дескрипторную таблицу.
В сегменте TSS имеется также несколько дополнительных полей. Поле обратной связи содержит селектор TSS той задачи, которая выполнялась перед данной; с его помощью можно организовать цепь вложенных задач. Поле базы двоичной карты разрешения ввода/вывода (БДКВВ) содержит 16-битовое смещение в данном сегменте TSS, с которого начинается сама двоичная карта ввода/вывода. Эта карта позволяет определить произвольное подмножество адресов в пространстве ввода/вывода, по которым данной задаче разрешено обращаться независимо от уровня привилегий. Если в этом поле — 00h, то карта отсутствует. Бит ловушки Т применяется для отладки: когда в TSS Т = 1, при переключении на данную задачу генерируется особый случай отладки (прерывание 1).
При переключении задач между ними не передается никакой информации, т. е. они максимально изолированы друг от друга. Этим исключается искажения задач и обеспечивается возможность прекращения и запуска любой задачи в любой момент времени и в любом порядке.
С целью экономии времени на процедуру переключения задач все поля TSS разделяются на "статические" и "динамические". К статическим относятся поля указателей стека трех уровней и содержимое регистра LDTR — они остаются неизменными в течение всего времени существования задачи. Содержимое статических полей TSS определяется ОС при создании задачи. Статические поля процессор только считывает при переключении задачи. Поля регистров и поле обратной связи модифицируются при каждом переключении задачи.
До перехода в мультипрограммный режим необходимо определить дескрипторы TSS, разместить сами сегменты TSS в адресном пространстве и правильно инициировать их. Напомним, что селекторы TSS нельзя загружать в сегментные регистры, поэтому для работы с TSS следует пользоваться альтернативным именованием, т. е. псевдонимами этих сегментов. При загрузке начальных значений полей TSS в CS: EIP указывают точку старта программы (задачи), а в регистр SS — селектор сегмента стека с правильным уровнем привилегий. Если предполагается работа задачи на разных уровнях привилегий, следует инициализировать поля SSI: ESPI, а если задача рассчитана на использование локальной дескрипторной таблицы и страничного преобразования, в сегменте TSS потребуется инициировать поля LDTR и CR3.
В сегменте TSS отсутствуют поля для" регистров CRO и CR2, следовательно, их значение не изменяется при переключениях задач. Поэтому страничное преобразование и условия работы с устройством "плавающей арифметики" (определяются полями CRO и CR2) являются глобальными для всех задач. Для каждой задачи может быть свой каталог разделов, но страничное преобразование может быть разрешено или запрещено только для всей системы. Переключение задач не затрагивает регистры GDTR и IDTR, а также регистры отладки и проверки.
Минимальный размер сегмента TSS должен быть 104 байта (6811). Однако пользователь может увеличить размер сегмента TSS для размещения дополнительной информации, например, состояние устройства регистров сопроцессора "плавающей арифметики" FPU, списка открытых файлов, двоичной карты ввода/вывода и др. Однако когда процессор привлекает TSS для переключения задач, он игнорирует все данные сверх аппаратно поддерживаемых 104 байтами, и эту дополнительную информацию из TSS считывают программно.
Переключение задачи в х86 могут вызвать следующие четыре события:
• старая задача выполняет команду FAR CALL или FAR JMP, и селектор выбирает шлюз задачи;
• старая задача выполняет команду FAR CALL или FAR JMP, и селектор выбирает дескриптор TSS;
• старая задача выполняет команду IRET для возврата в предыдущую задачу; эта команда приводит к переключению задачи, если в регистре EFLAGS бит вложенной задачи NT = 1;
• возникло аппаратное или программное прерывание и соответствующий элемент дескрипторной таблицы прерываний IDT содержит шлюз задачи.
Под термином "старая задача" ("выходящая задача") будем понимать ту задачу, выполнение которой прекращается; под термином "новая задача" ("входящая задача") будем понимать ту задачу, которую начинает выполнять процессор.
Таким образом, селекторами в командах переходов и вызовов могут быть как селекторы TSS (прямое переключение задачи), так и селекторы шлюзов задачи (косвенное переключение задачи). В последнем случае дескриптор шлюза задачи обязательно содержит селектор TSS.
Формат дескриптора шлюза задачи приведен на рис. 7.12.

Старая задача должна быть достаточно привилегированна для доступа к шлюзу задачи или к сегменту TSS. Правила привилегий обычные:
max(CPL, RPL) > DPL шлюза задачи:
max(CPL, RPL) > DPL сегмента TSS. Процедура возврата из прерываний IRET всегда возвращает управление прерванной программе. Если флаг NT сброшен в 0, производится обычный возврат, а если он установлен в 1 — происходит переключение задачи. При этом процессор сохраняет свое состояние в сегменте TSS старой задачи, загружает в регистр TR содержимое поля обратной связи — селектор новой задачи ("задачи-предка", т. к. осуществляется возврат) и восстанавливает из сегмента TSS контекст новой задачи. Благодаря наличию в каждом сегменте TSS поля обратной связи можно поддерживать многократные вложения задач. Характерно, что команда возврата из подпрограммы RET не чувствительна к значению флага NT и не может осуществить переключение задачи.
После модификации TR и загрузки нового контекста из сегмента TSS процессор отмечает этот сегмент как занятый (устанавливает бит 41 занятости Busy в его дескрипторе). Занятый TSS может относиться либо к выполняющейся, либо ко вложенной задаче. Переключение на задачу, отмеченную как занятая, не производится! В частности, это исключает возможность реализации реентерабельных задач. Исключение представляет только команда такт, которая возвращает управление задаче-предку (очевидно, будучи вложенной, она отмечена как запятая).
При переключении задачи процессор устанавливает также флаг переключения задачи TS в регистре CRO. Сброс этого флага может осуществиться только привилегированной командой CLTS. TS применяется для правильного использования некоторых системных ресурсов, в частности — устройства плавающей арифметики (Float Point Unit, FPU). Если при каждом переключении задачи сохранять состояние FPU, то на это уйдет много времени, причем новая задача может вообще не использовать ресурсы FPU, и тогда такое сохранение окажется напрасным. В процессоре 80486 команды FPU анализируют состояние флага TS и если TS = 1, формируется особый случай 7 и вызывается системная процедура сохранения состояния FPU. После этого флаг TS сбрасывается.
При переключении задачи процессор не фиксирует факт использования новой задачей FPU. Очевидно, это забота обработчика прерывания 7 — сам обработчик или ОС может поддерживать в TSS флаг использования сопроцессора. Кроме того, обработчик прерывания 7 может запоминать селектор TSS последней программы, использующей FPU.
Итак, процесс переключения задачи можно представить следующим образом. Имеется TR с теневым регистром дескриптора TSS, определяющий TSS старой задачи. Если селектор в командах FAR JMP, FAR CALL, IRET (NT = 1), INT указывает прямо (дескриптор TSS) или косвенно (шлюз задачи) в GDT на системный объект переключения задачи, то производится переключение задачи:
• процессор сохраняет контекст старой задачи в сегменте TSS старой задачи;
• процессор загружает в TR селектор сегмента новой задачи;
• процессор загружает в сегмент TSS новой задачи селектор TSS старой задачи (в поле обратной связи);
• получив доступ к сегменту TSS новой задачи, процессор загружает контекст новой задачи в регистры (в том числе CS: EIP — точка старта);
• процессор устанавливает флаги NT (в регистре EFLAGS) и TS (в CRO для анализа командами FPU), устанавливает бит занятости задачи в дескрипторе TSS новой задачи.