Организация памяти в ЭВМ
ЭВМ, реализованная по классической фон-неймановской архитектуре, включает в себя:
• процессор, содержащий арифметико-логическое устройство (АЛУ) и центральное устройство управления (ЦУУ);
• память, которая в современных ЭВМ подразделяется на оперативную (ОП или ОЗУ) и сверхоперативную (СОЗУ);
• внешние устройства, к которым относят внешнюю память (ВЗУ) и устройства ввода/вывода (УВВ).
В этой главе рассмотрим организацию устройств памяти. Принципы взаимодействия других устройств ЭВМ с процессором рассмотрены в разд. 6.3.
5.1. Концепция многоуровневой памяти
Известно, что память ЭВМ предназначена для хранения программ и данных, причем эффективность работы ЭВМ во многом определяется характеристиками ее памяти. Во все времена к памяти предъявлялись три основных требования: большой объем, высокое быстродействие и низкая (умеренная) стоимость.
Все перечисленные выше требования к памяти являются взаимно-противоречивыми, поэтому пока невозможно реализовать один тип ЗУ, отвечающий всем названным требованиям. В современных ЭВМ организуют комплекс разнотипных ЗУ, взаимодействующих между собой и обеспечивающих приемлемые характеристики памяти ЭВМ для каждого конкретного применения. В основе большинства ЭВМ лежит трехуровневая организация памяти: сверхоперативная (СОЗУ) — оперативная (ОЗУ) — внешняя (ВЗУ). СОЗУ и ОЗУ могут непосредственно взаимодействовать с процессором, ВЗУ взаимодействует только с ОЗУ.
СОЗУ обладает максимальным быстродействием (равным процессорному), небольшим объемом (105 — 107 байтов) и располагается, как правило, на кристалле процессорной БИС. Для обращения к СОЗУ не требуются магистральные (машинные) циклы. В СОЗУ размещаются наиболее часто используемые на данном участке программы данные, а иногда — и фрагменты программы.
Быстродействие ОЗУ может быть ниже процессорного (не более чем на порядок), а объем составляет 105 — 107 байтов. В ОЗУ располагаются подлежащие выполнению программы и обрабатываемые данные. Связь между процессором и ОЗУ осуществляется по системному или специализированному интерфейсу и требует для своего осуществления машинных циклов.
Информация, находящаяся в ВЗУ, не может быть непосредственно использована процессором. Для использования программ и данных, расположенных в ВЗУ, их необходимо предварительно переписать в ОЗУ. Процесс обмена информацией между ВЗУ и ОЗУ осуществляется средствами специального канала или (реже) — непосредственно под управлением процессора. Объем ВЗУ практически неограничен, а быстродействие на 3 — 6 порядков ниже процессорного.
Схематически взаимодействие между процессором и уровнями памяти представлено на рис. 5.1.
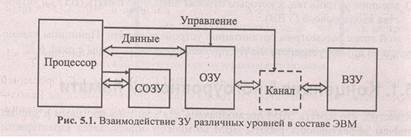
Следует помнить, что положение ЗУ в иерархии памяти ЭВМ определяется не элементной базой запоминающих ячеек (известны случаи реализации ВЗУ на БИС — "электронный диск" и, наоборот, организация оперативной памяти на электромеханических ЗУ — магнитных барабанах), а возможностью доступа процессора к данным, расположенным в этом ЗУ.
При организации памяти современных ЭВМ (МПС) особое внимание уделяется сверхоперативной памяти и принципам обмена информацией между ОЗУ и ВЗУ.
Применение СОЗУ в иерархической памяти ЭВМ может обеспечить повышение производительности ЭВМ за счет снижения среднего времени обращения к памяти Т при условии, что время цикла СОЗУ Тс будет (значительно) меньше времени цикла ОЗУ Т~. Очевидно:
где рc — вероятности обращения к СОЗУ. Обозначим так же: рo — вероятности обращения к ОЗУ.
Из (5.1) следует, что повышение производительности ЭВМ может осуществляться двумя путями:
уменьшением
отношения — ![]()
увеличением вероятности рc обращения в СОЗУ.
Первый путь связан, прежде всего, с технологическими особенностями производства БИС и здесь не рассматривается.
Если считать, что информация размещается в СОЗУ и ОЗУ случайным образом, то вероятности рc и рo пропорциональны объемам соответствующих ЗУ. В этом случае рc < рo и наличие в ЭВМ СОЗУ практически не влияет на ее производительность.
То
же можно было бы сказать и о ситуации, когда отношение ![]() =1; но не
следует забывать, что наличие в ЭВМ СОЗУ с прямой адресацией (POH)
позволяет включать в систему команд короткие команды, использовать
косвенно-регистровую адресацию и, в конечном итоге, увеличивать
производительность ЭВМ даже при Тс = Тo.
=1; но не
следует забывать, что наличие в ЭВМ СОЗУ с прямой адресацией (POH)
позволяет включать в систему команд короткие команды, использовать
косвенно-регистровую адресацию и, в конечном итоге, увеличивать
производительность ЭВМ даже при Тс = Тo.
Итак, для эффективного применения СОЗУ следует таким образом распределять информацию по уровням памяти ЭВМ, чтобы в СОЗУ всегда располагались наиболее часто используемые в данный момент коды.
Принято различать СОЗУ по способу доступа к хранимой в нем информации. Известны два основных класса СОЗУ по этому признаку:
• с прямым доступом;
• с ассоциативным доступом.
СОЗУ с прямым доступом (POH — регистры общего назначения) получило широкое распространение в большинстве современных ЭВМ. Фактически РОН — это небольшая регистровая намять, доступ к которой осуществляется специальными командами. Стратегия размещения данных в РОН целиком определяется программистом (компилятором). Обычно в РОН размещают многократно используемые адреса (базы, индексы), счетчики циклов, данные активного фрагмента задачи, что повышает вероятность обращения в ячейки РОН по сравнению с ячейками ОЗУ.
5.2.2. СОЗУ с ассоциативным доступом
Применение СОЗУ с ассоциативным доступом позволяет автоматизировать процесс размещения данных в СОЗУ, обеспечивая "подмену" активных в данный момент ячеек ОЗУ ячейками СОЗУ. Эффективность такого подхода существенно зависит от выбранной стратегии замены информации в СОЗУ, причем использование ассоциативного СОЗУ имеет смысл только при условии Тc <<T0.
Принцип ассоциативного доступа состоит в следующем. Накопитель ассоциативного запоминающего устройства (АЗУ) разбит на два поля — информационное и признаков. Структура информационного поля накопителя соответствует структуре обычного ОЗУ, а запоминающий элемент поля признаков, помимо функции записи, чтения и хранения бита, обеспечивает сравнение хранимой информации с поступающей и выдачу признака равенства.
Признаки равенства всех элементов одной ячейки поля признаков объединяются по "И" и устанавливают в 1 индикатор совпадения ИС, если информация, хранимая в поле признака ячейки, совпадает с информацией, подаваемой в качестве признака на вход Р накопителя.
Во второй фазе обращения (при чтении) на выход данных D последовательно поступает содержимое информационных полей тех ячеек, индикаторы совпадения которых установлены в 1 (если таковые найдутся).
Способ использования АЗУ в качестве сверхоперативного иллюстрирует рис. 5.2. В информационном поле ячеек АСОЗУ — копия информации некоторых ячеек ОЗУ, а в поле признаков — адреса этих ячеек ОЗУ. Когда процессор генерирует обращение к ОЗУ, он одновременно (или прежде) инициирует процедуру опроса АСОЗУ, выдавая в качестве признака адрес ОЗУ.
Если имеет место совпадение признака ячейки с запрашиваемым адресом (не более одного раза, алгоритм загрузки АСОЗУ не предусматривает возможности появления одинаковых признаков), то процессор обращается (по чтению или по записи) в информационное поле этой ячейки АСОЗУ, при этом блокируется обращение к ОЗУ. Если требуемый адрес не найден в АСОЗУ, инициируется (или продолжается) обращение к ОЗУ, причем в АСОЗУ создается копия ячейки ОЗУ, к которой обратился процессор. Повторное обращение процессора по этому адресу будет реализовано в АСОЗУ (на порядок быстрее, чем в ОЗУ).
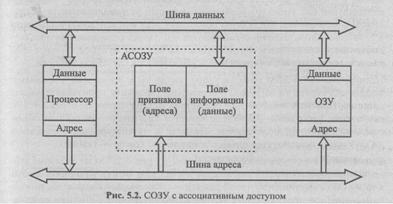
Таким образом, в АСОЗУ создаются копии тех ячеек ОЗУ, к которым в данный момент обращается процессор в надежде, что "в ближайшее время" произойдет новое обращение по этому адресу. (Существуют и другие стратегии загрузки АСОЗУ, например, если процессор обращается в ОЗУ по определенному адресу, то в АСОЗУ перемещается содержимое целого блока соседних ячеек.)
При необходимости записи в АСОЗУ новой информации требуется отыскать свободную ячейку, а при ее отсутствии (что чаще всего и бывает) — отыскать ячейку, содержимое которой можно удалить из АСОЗУ. При этом следует помнить, что если во время пребывания ячейки в АСОЗУ в нее производилась запись, то требуется не просто очистить содержимое ячейки, а записать его в ОЗУ по адресу, хранящемуся в поле признаков, т. к. процессор, отыскав адрес в АСОЗУ, производит запись только туда, оставляя в ОЗУ старое значение (т. н. "АСОЗУ с обратной записью"). Возможен и другой режим работы СОЗУ — со сквозной записью, при котором всякая запись осуществляется и СОЗУ, и в ОЗУ.
При поиске очищаемой ячейки чаще всего используют метод случайного выбора. Иногда отмечают ячейки, в которые не проводилась запись, и поиск "кандидата на удаление" проводят из них.
Более сложная процедура замещения предполагает учет длительности пребывания ячеек в АСОЗУ, или частоты обращения по этому адресу, или времени с момента последнего обращения. Однако все эти методы требуют дополнительных аппаратных и временных затрат.
Одним из наиболее дешевых способов, позволяющих учитывать поток обращений к ячейкам, является следующий. Каждой ячейке АСОЗУ ставится в соответствие бит (триггер) обращения, который устанавливается при обращении к этой ячейке. Когда биты обращения всех ячеек АСОЗУ установятся в 1, все они одновременно сбрасываются в О. Поиск очищаемой ячейки осуществляется среди ячеек, биты обращения которых нулевые, причем если таких ячеек несколько, то среди них осуществляется случайная выборка.
Наличие АСОЗУ в ЭВМ позволяет (при достаточном его объеме и правильно выбранной стратегии загрузки) значительно увеличить производительность системы. При этом наличие или отсутствие АСОЗУ никак не отражается на построении программы. АСОЗУ не является программно-доступным объектом, оно скрыто от пользователя. Недаром в литературе для обозначения АСОЗУ часто используется термин "кэш-память" (cache — тайник).
Кэш-память, структура которой приведена на рис. 5.2, носит название полностью ассоциативной. Здесь каждая ячейка кэш может подменять любую ячейку ОЗУ. Достоинство такой памяти — максимальная вероятность кэш- попадания (при прочих равных условиях), по сравнению с другими способами организации кэш. К недостаткам можно отнести сложность ее структуры (а следовательно, и высокую стоимость). Действительно, в каждом разряде поля признаков необходимо реализовать, наряду с возможностями записи и хранения, функцию сравнения хранимого бита с соответствующим битом признака, а потом конъюнкцию результатов сравнения разрядов в каждой ячейке.
Кэш-память с прямым отображением требует минимальных затрат оборудования (по сравнению с другими вариантами организации кэш), но имеет минимальную вероятность кэш-попаданий. Суть организации (рис. 5.3) состоит в следующем. Физическая оперативная намять разбивается на блоки (множества) одинакового размера, количество которых (блоков) соответствует числу ячеек кэш, причем каждой строке ставится в соответствие определенное множество ячеек памяти, не пересекающееся с другими. Все ячейки множества претендуют на одну строку кэш.
Такая организация кэш исключает собственно ассоциативный поиск, а следовательно, значительно упрощается схема ячейки поля признаков. Действительно, здесь копия требуемой ячейки оперативной памяти может располагаться в единственной строке кэш. Часть физического адреса (на рис. 5.3— старшая) определяет номер множества и, следовательно, строку кэш. Содержимое этой строки выбирается по обычному адресному принципу, и поле тега сравнивается с младшей частью физического адреса. Таким образом, для всей кэш-памяти (любого размера) достаточно единственной схемы сравнения.
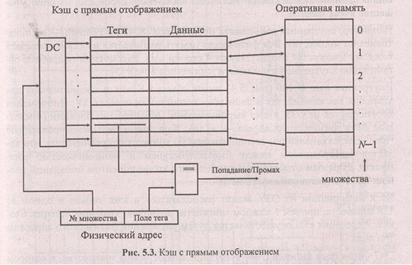
Однако предложенная выше структура имеет существенный недостаток. Если проводить разбиение памяти на множества, как показано на рис. 5.3, то в большинстве случаев кэш будет использоваться крайне неэффективно.
Во-первых, хотя адресное пространство физической памяти 32-разрядных
микропроцессоров составляет 232 байтов, в современных ПЭВМ обычно используют намять объемом 225 — 229 байтов. Следовательно, строки кэш, отображаемые на старшие (физически отсутствующие) множества памяти, никогда не будут использованы.
Во-вторых, если в множества включать следующие подряд ячейки ОЗУ, то копии никаких двух последовательных ячеек ОЗУ нельзя одновременно иметь в кэш (кроме случая последней и первой ячеек двух соседних множеств), что противоречит одной из основополагающих стратегий загрузки кэш — целесообразности копирования в кэш группы последовательных ячеек ОЗУ.
Для исключения отмеченных недостатков разбиение ячеек памяти на множества осуществляется таким образом, чтобы соседние ячейки относились к разным множествам, что достигается размещением поля номера множества не в старших, а в младших разрядах физического адреса.
Для дальнейшего увеличения вероятности кэш-попаданий можно реализовать вариант кэш-памяти, ассоциативной по множеству, которая отличается от кэш с прямым отображением наличием нескольких строк кэш на одно множество ячеек памяти.
Например, внутренняя кэш-память процессоров i80486 и Pentium — ассоциативная по множеству. Вся физическая память разбивается на 128 множеств, а каждому множеству соответствуют 4 строки кэш. Рассмотрим подробнее организацию внутренней кэш-памяти процессора 80486 [3].
Внутренняя кэш 80486 (рис. 5.4) имеет объем 8 Кбайт и предназначена для хранения как команд, так и данных — копий информации ОЗУ. Информация перемещается из ОЗУ в кэш выровненными 16-байтовыми блоками (4 младшие бита физического адреса — нули). Кэш имеет четырех направленную (или четырехканальную) ассоциативную по множеству организацию, что является компромиссом между быстродействием и экономичностью кэш- памяти с прямым отображением и большим коэффициентом попаданий полностью ассоциативной кэш-памяти.
Блок информации из ОЗУ может располагаться в кэш только в одном из 128 множеств, причем в каждом множестве возможно хранение четырех блоков. Адресация кэш осуществляется путем разделения физического адреса на три поля:
• 7 битов поля индекса (А4 — А10) определяют номер множества, в котором проводится поиск;
• старшие 21 бит адреса являются полем тега (признака), по которому осуществляется ассоциативный поиск (внутри множества из четырех блоков);
• четыре младшие бита адреса определяют позицию байта в блоке.
Когда при чтении возникает промах, в кэш копируется из ОЗУ 16-байтовый
блок (строка), содержащий запрошенную информацию.
4-битовое поле достоверности показывает, являются ли в данный момент кэшированные данные достоверными (для каждого блока (строки) множества — свой бит). При очистке кэш-памяти или сбросе процессора все биты достоверности сбрасываются в О. Когда производится заполнение строки кэш, место для заполнения выбирается просто нахождением любой недостоверной строки (из четырех строк "своего" множества).
Если недостоверных строк нет, то реализуется алгоритм замещения строк "nceвдo LRU" ("наиболее давно используемый"). Для каждого множества в блоке отведено три бита LRU, которые обновляются при каждом кэш-

попадании или заполнении строки. Они используются для реализации алгоритма замещения строки следующим образом.
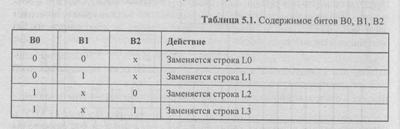
Обозначим строки в множестве как L0, L1, L2, L3. Каждому множеству в блоке LRU соответствуют три бита В0, Вl, В2, которые модифицируются при каждом кэш-попадании или заполнении строки множества следующим образом:
• если последнее обращение было к строке L0 или Ll, то бит В0 устанавливается в 1, иначе — сбрасывается в 0;
• если последнее обращение в паре L0 —L1 было к строке L0, то бит B l устанавливается в 1, иначе — сбрасывается в 0;
• если последнее обращение в паре L2 — LЗ было к строке L2, то бит В2 устанавливается в 1, иначе — сбрасывается в О.
Выбор заменяемой строки (когда все строки множества достоверны) определяет содержимое битов ВО, B l, В2 (табл. 5.1).
Цикл записи при наличии кэш-памяти может реализоваться по-разному. Различают кэш со сквозной записью и кэш с обратной записью.
В первом случае в цикле записи всегда осуществляется запись как в кэш, так и в ОЗУ. Этот способ записи не приводит к сокращению цикла записи даже при кэш-попадании, но гарантирует идентичность данных по адресам ОЗУ и кэш.
При обратной записи в случае кэш-попадания запись осуществляется только в кэш, при этом в соответствующей ячейке ОЗУ сохраняется прежнее (уже неверное) значение. Запись в ОЗУ происходит при очистке (замещении) строки кэш, если ее содержимое изменялось в процессе пребывания в кэш. Ситуация временного несоответствия содержимого ячеек кэш и ОЗУ может быть допустима в одних случаях и недопустима в других (например, когда несколько процессоров со своими кэш общаются через общее поле ОЗУ), По этому в большинстве случаев пользователю предоставляется возможность выбора способа записи в кэш — за счет модификации некоторых программно-доступных флагов в регистре управления.
В 80486 строки кэш-памяти можно по отдельности объявить недостоверными, задавая операцию недостоверности кэш-памяти на шине процессора. При инициализации такой операции кэш сравнивает объявленный недостоверным адрес с тегом строк, находящихся в кэш, и сбрасывает бит достоверности при обнаружении соответствия тегов. Предусмотрена также операция очистки, которая превращает в недостоверное все содержимое кэш.
Конфигурацией кэш-памяти управляют два бита регистра CRO состояния машинам
D CD (Cache Disable) — запрещение кэш-памяти;
NW (Not Write-through) — несквозная (обратная) запись.
При CD = 1 и NW = 1 запрещено заполнение строк, сквозная запись и объявление кэш-памяти недостоверной. Такая конфигурация позволяет использовать внутреннюю кэш-память как быстродействующее ЗУПВ.
При CD = 1 и NW = 0 заполнение строк запрещено, а сквозная запись и объявление кэш-памяти недостоверной разрешено. Эта конфигурация позволяет программе запрещать кэш-память на короткое время, а затем разрешать без очистки содержимого.
При С0 = 0 и NW = 0 заполнение строк, сквозная запись и объявление кэш- памяти недостоверной разрешены. Такая конфигурация является обычной рабочей для кэш-памяти.
При С0 = 0 и NW = 1 осуществляется работа кэш в режиме обратной записи. Когда кэширование разрешено, кэшируются считывания данных из ОЗУ и предвыборка команд, если внешняя схема подает входной сигнал разрешения кэш-памяти в данном цикле шины или текущий элемент таблицы страниц разрешает кэширование. В тех циклах, где кэширование запрещено при промахе, заполнение строки кэш-памяти не производится. Однако кэш-память продолжает действовать, несмотря на то, что она запрещена для заполнения. Уже находящиеся в кэш-памяти данные используются, если, конечно, они являются достоверными. (Фактически реализуется режим быстродействующего ОЗУ.) Только когда все данные в кэш-памяти отмечены как недостоверные, что происходит при ее очистке, все внутренние запросы считывания приводят к формированию внешних циклов шины.
Когда разрешена сквозная запись, все записи, в том числе и при кэш- попадании, инициируют запись в память. Когда сквозная запись запрещена, внутренний запрос записи, вызвавший попадание, не приводит к производству записи в ОЗУ, а операции недостоверности запрещены.
Когда запрещены кэширование и сквозная запись, кэш-память можно использовать как быстродействующее статическое ОЗУ. В такой конфигурации на шину процессора передаются только записи, вызвавшие промах, а операции недостоверности игнорируются. Если предполагается использовать этот режим (CD = 1 и NW = 1), следует предварительно загрузить достоверные строки, используя операции чтения из памяти или регистров.
Выше были рассмотрены способы организации сверхоперативной памяти и ее взаимодействия с оперативной. Не менее, а порой и более важной проблемой является организация взаимодействия в паре ОЗУ — ВЗУ.
Известно, что в современных ЭВМ (кроме простейших) реализовано динамическое распределение памяти между несколькими задачами, существующими в ЭВМ в процессе решения. Даже для однозадачных конфигураций проблема динамического распределения памяти не теряет актуальности, т. к. в памяти, помимо задачи пользователя, всегда присутствует операционная система или ее фрагмент.
Наличие динамического распределения памяти предполагает, что программа . компилируется в т. н. "логических" адресах, а в процессе работы происходит автоматическое преобразование логических адресов в физические. Наибольшее распространение в ЭВМ получил метод динамического распределения памяти, называемый страничной организацией виртуальной памяти.
При использовании этого метода вся память ЭВМ (ОЗУ и ВЗУ) рассматривается как единая виртуальная память. Адрес в этой памяти называется виртуальным или логическим. Вся виртуальная память делится на фрагменты одинакового размера, называемые виртуальными страницами. Размер страницы обычно составляет 0,5 — 4 Кбайт. Виртуальный адрес представляется состоящим из двух частей — номера страницы и номера слова на странице (смещения).
Физическая память ЭВМ (ОЗУ и ВЗУ) так же делится на страницы, причем размер физической страницы выбирается равным размеру виртуальной. Таким образом, одна физическая страница может хранить одну виртуальную, причем порядок следования виртуальных страниц в программе совсем не обязательно сохранять на физических страницах. Достаточно лишь установить однозначное соответствие между номерами виртуальных и физических страниц.
Соответствие между номерами виртуальных и физических страниц устанавливается с помощью специальной страничной таблицы (СТ), которую поддерживает операционная система. Размер физической страницы равен размеру виртуальной, поэтому преобразования смещений на странице не производятся.
Поскольку размер СТ достаточно велик, она хранится целиком в ОЗУ и модифицируется операционной системой всякий раз, когда в распределении памяти происходят изменения.
Для увеличения скорости обращения к памяти активная часть СТ обычно хранится в специальной быстродействующей памяти, организованной, как правило, по ассоциативному принципу. При этом в поле признаков АЗУ СТ хранятся виртуальные адреса страниц (иногда вместе с номером программы.— в мультипрограммных системах), а в информационной части — соответствующие им номера физических страниц.
Если в результате преобразования виртуального адреса в физический оказывается, что требуемая физическая страница располагается в ВЗУ, то выполнение программы становится невозможным, пока не произойдет "подкачка" требуемой страницы в ОЗУ. Такая ситуация называется страничным сбоем и должна формировать внутреннее прерывание, по которому запускается подпрограмма чтения страницы из ВЗУ в ОЗУ.
При этом возникает серьезная проблема поиска той страницы, которую можно удалить из ОЗУ, чтобы на освободившееся место записать требуемую страницу. Серьезность проблемы обусловлена тем, что неудачный выбор удаляемой страницы (в ближайшее время она вновь понадобится) связан со значительной потерей времени на передачу страниц между ОЗУ и ВЗУ.
Правило, по которому при возникновении страничного сбоя выбирается страница для удаления из ОЗУ, называется алгоритмом замещения.
Для данной программы, порождающей некоторый поток обращений к памяти, существует, по крайней мере, одна такая последовательность замещений страниц, которая дает для этой программы минимальное количество страничных сбоев.
Теоретически доказано, что минимальное число страничных сбоев будет получено, если в алгоритме замещения использовать информацию о потоке обращений к страницам в будущем (алгоритм Михновского — Шopa) или, по крайней мере, о вероятности обращений к страницам в будущем.
Алгоритмы замещения, использующие "информацию о будущем", называются физически нереализуемыми, их обычно применяют для оценки качества эвристических алгоритмов замещения.
Эвристические алгоритмы замещения используют информацию о потоке обращений к страницам в прошлом (историю процесса) для экстраполяции характеристик потока обращений в будущем. Как правило, используют три типа информации о прошлом: время пребывания страницы в ОЗУ (или, что то же — очередность поступления страниц), число обращений к страницам за определенный промежуток времени или отрезки времени с момента последнего обращения к страницам.
Эффективность эвристического алгоритма можно характеризовать отношением:
![]()
где N0 — число страничных сбоев при решении данной задачи с применением физически нереализуемого алгоритма; Ne, — то же с применением исследуемого эвристического алгоритма.
Эвристический алгоритм можно считать выбранным удачно (для данного
класса задач), если коэффициент k близок к 1. Значение N0 может быть получено путем моделирования решения задачи (повторное) с предварительно зафиксированным потоком обращений к страницам.
При выборе подходящего алгоритма замещения следует учитывать не только его эффективность k, но и аппаратные затраты и затраты времени на его реализацию.
Например, для реализации т. н. НДИ-алгоритма (наиболее давно используемая) каждой странице, находящейся в ОЗУ, ставится в соответствие таймер, который сбрасывается при обращении к странице. При страничном сбое необходимо осуществить поиск максимального элемента массива таймеров страниц. Для некоторых задач выигрыш времени за счет увеличения k при применении НДИ-алгоритма, по сравнению с алгоритмом случайного замещения, может быть сравним с потерей времени на поиск максимальных значений таймеров.
Некоторые алгоритмы замещения учитывают одновременно несколько параметров прошлого потока обращений.
Алгоритм "Карабкающаяся страница" (KC-алгоритм) поддерживает последовательность номеров страниц, находящихся в ОЗУ. При любом обращении к странице ее номер в последовательности перемещается на одну позицию в направлении начала, меняясь местами с предыдущим в последовательности номером (исключение — обращение к странице, номер которой стоит в начале последовательности). При возникновении страничного сбоя из ОЗУ удаляется страница, номер которой расположен в конце последовательности, а номер вновь поступившей страницы помещается в конец последовательности. КС-алгоритм учитывает как время пребывания страницы в ОЗУ, так и интенсивность обращения к странице, причем не требует значительных аппаратных затрат, а при страничном сбое — времени на поиск.
Алгоритм "Рабочий комплект" (PK-алгоритм) более сложен в реализации, но позволяет адаптировать свои параметры под конкретный класс задач. Все страницы ОЗУ, к которым было обращение в течение отрезка времени Т, образуют т. и. рабочий комплект и не подлежат удалению из ОЗУ. Остальные страницы (не вошедшие в рабочий комплект) образуют две очереди кандидатов на замещение, причем в первую очередь попадают страницы, на которые не было записи во время пребывания их в ОЗУ. При страничном сбое удаляется страница из первой очереди (FIFO — первый пришел из рабочего комплекта — первый ушел из ОЗУ), а если первая очередь пуста, то — из второй. Из очереди страница может опять попасть в рабочий комплект, если к ней будет обращение. Для реализации РК-алгоритма каждой странице ставится в соответствие таймер на Т, причем каждое обращение к странице сбрасывает таймер (и переводит страницу в рабочий комплект, если она там отсутствовала), а переполнение таймера выводит страницу из рабочего комплекта. Под- бором величины Т можно оптимизировать РК-алгоритм под конкретный класс задач.
5.3.2. Сегментная организация памяти
До сих пор предполагалось, что виртуальная память, которой располагает программист, представляет собой непрерывный массив с единой нумерацией слов. Однако при написании программы удобно располагать несколькими независимыми сегментами (кода, данных, подпрограмм, стека и др.), причем размеры сегментов, как правило, заранее не известны. В каждом сегменте слова нумеруются с нуля независимо от других сегментов. В этом случае виртуальный адрес представляется состоящим из трех частей: <номер ceгмента> <номер страницы> <номер слова>. В машине к виртуальному адресу может добавиться слева еще <номер задачи>. Таким образом, возникает определенная иерархия полей виртуального адреса, которой соответствует иерархия таблиц, с помощью которых виртуальный адрес переводится в физический. В конкретных системах может отсутствовать тот или иной элемент иерархии.
Виртуальная память была первоначально реализована на "больших" ЭВМ, однако по мере развития микропроцессоров в них так же использовались идеи страничной, и сегментной организации памяти.
Архитектура микропроцессорных систем
Глава 6. Базовая архитектура микропроцессорной системы
Глава 7. Эволюция архитектур микропроцессоров и микро ЭВМ
Интегральная технология (ИТ) за первые 20 — 30 лет своего развития достигла таких относительных темпов роста характеристик качества, которых не знала ни одна область человеческой деятельности (включая и такие бурно растущие, как авиация и космонавтика). Действительно, рассмотрим динамику изменений основных параметров ИТ за первые 20 лет ее развития (1960— 1980 гг.):
• степень интеграции N увеличилась на 5 — 6 порядков;
• площадь транзистора S уменьшилась на 3 порядка;
• рабочая частота f увеличилась на 1 — 3 порядка;
• факторы добротности:
• f x N увеличился на 5 — 7 порядков;
• Pxt уменьшился на 4 порядка, где t — задержка на элементе, P— мощность, рассеиваемая элементом;
• надежность (при сопоставлении элементо-часов) увеличилась на 4 -8 порядков;
• производительность технологии (в транзисторах) увеличилась на 4-6 порядков;
• цена на транзистор в составе ИС уменьшилась на 2 — 4 порядка.
Американцы подсчитали, что если бы авиапромышленность в те же годы имела аналогичные темпы роста соответствующих показателей качества (стоимость — скорость — расход топлива = стоимость — быстродействие— рассеиваемая мощность), то "Боинг 767" стоил бы $500, облетал земной шар за 20 мин и расходовал на этот полет 10 л горючего.
Успехи ИТ в области элементной базы позволяли "поглощать" кристаллом все более высокие уровни ЭВМ: сначала — логические элементы, потом— операционные элементы (регистры, счетчики, дешифраторы и т. д.), далее— операционные устройства. Степень функциональной сложности, достигнутой в ИС, определяется особенностью технологии, разрешающей способностью инструмента, а также структурными особенностями схемы: регулярностью, связностью.
Под регулярностью схемы здесь будем понимать степень повторяемости элементов и связей по одной или двум координатам (при размещении структуры на плоскости). Связность — число внешних выводов схемы.
Кроме того, следует иметь в виду, что выпуск ИС был экономически оправдан лишь для функционально универсальных схем, обеспечивающих их достаточно большой тираж.
С этой точки зрения интересно взглянуть на соотношение ИС логики и памяти в процессе эволюции ИС — СИС — БИС — СБИС. Первые ИС (степень интеграции N-10 ) были исключительно логическими элементами. При 1 достижении N примерно 10 стали появляться, наряду с операционными элементами, первые элементы памяти объемом в 16 — 64 — 128 битов.
По мере дальнейшего роста степени интеграции память стала быстро опережать "логику", т. к. по всем трем параметрам (регулярность, связность, тираж) имела перед логическими схемами преимущество. Действительно, структура накопителя ЗУ существенно регулярна (повторяемость элементов и связей по двум координатам), связность ее растет пропорционально логарифму объема (при увеличении объема памяти вдвое и сохранении без изменения способа доступа в БИС достаточно добавить лишь один вывод). Наконец, память "нужна всем" и "чем больше, тем лучше", особенно если "больше, но за ту же (почти) цену".
Что касается ИС логики, то на уровне N -10 на кристалле можно уже размещать устройство ЦВМ (например, АЛУ, ЦУУ), но схемы логики (особенно управление) существенно нерегулярны, их связность (сильно зависящая от конкретной схемы) растет примерно пропорционально N, причем такие схемы, как правило, не являлись универсальными и не могли выпускаться большими тиражами (исключения в то время — БИС часов и калькуляторов).
Разработка первого микропроцессора (МП) — попытка создать универсальную логическую БИС, которая настраивается на выполнение конкретной функции после изготовления средствами программирования. На подобную БИС — МП первоначально предполагалось возложить лишь достаточно произвольные управляющие функции, однако позже МП стал использоваться как элементная база ЦВМ четвертого и последующих поколений. Появление МП вызвало необходимость разработки целого спектра универсальных логических БИС, обслуживающих МП: контроллеры прерываний и прямого доступа в память (ПДП), шинные формирователи, порты ввода/вывода и др.
Первый МП был разработан фирмой Intel и выпущен в 1971 г. на основе р-МОП-технологии (i4004). В 1972 и 1973 годах этой же фирмой были выпущены модели i4040, i8008. Эти микропроцессоры относились к т. н. первому поколению, обладали весьма ограниченными функциональными возможностями и очень быстро были вытеснены вторым поколением, которое было реализовано на основе п-МОП-технологии, что позволило, прежде всего, поднять тактовую частоту примерно на порядок относительно микропроцессоров первого поколения. Кроме того, прогресс интегральной технологии позволил повысить степень интеграции транзисторов на кристалле, а следовательно, увеличить сложность схемы.
Микропроцессоры второго поколения, самым распространенным из которого
был выпущенный в 1974 г. i8080 (отечественный аналог — К580ВМЗО), отличались достаточно развитой системой команд, наличием подсистем прерывания, прямого доступа в память, снабжался достаточным числом вспомогательных БИС, обеспечивающих управление памятью, параллельный и последовательный обмен с внешними устройствами, реализацию векторных прерываний, ПДП и др.
Многие идеи, заложенные в архитектуру систем на базе 8-разрядного микро процессора i8080, неизменными используются и в современных мощных микропроцессорах.
Постоянное стремление к увеличению быстродействия ЭВМ привело разработчиков микропроцессоров "на поле" биполярной интегральной технологии, прежде всего — ТТЛ, где были выпущены микропроцессоры, отнесенные к третьему поколению, причем архитектура этих микропроцессоров существенно отличалась от их предшественников.
Известно, что для любого электронного прибора справедливо соотношение:
![]()
где ΔP— энергия переключения, Δt — время переключения.
ТТЛ-транзисторы в составе ИС обладали (в то время) на порядок большим (по сравнению с n-МОП) быстродействием и соответственно на порядок большим потреблением мощности. Технологические трудности в то время не позволяли широко использовать активные способы отвода тепла от кристалла, поэтому единственный способ сохранения работоспособности кристалла в этих условиях — снижение степени интеграции.
Первый из выпущенных микропроцессоров третьего поколения — i3000 был двухразрядным! Очевидно, сохранение в этом случае традиционной архитектуры, характерной для микропроцессоров второго поколения, не привело бы к увеличению производительности системы, несмотря на то, что тактовая частота кристалла увеличивалась значительно (на порядок).
Решение этой проблемы повлекло значительные структурные изменения в микропроцессорах третьего поколения по сравнению со вторым:
• микропроцессоры выпускались в виде секций со средствами меж разрядных связей, позволяющими объединять в одну систему произвольное число секций для достижения заданной разрядности. В состав секций включалось АЛУ, РОН и некоторые элементы устройства управления;
• устройство управления выносилось на отдельный кристалл (группу кристаллов), общий для всех процессорных секций;
• за счет резерва внешних выводов (малая разрядность) предусматривались отдельные шины адреса, ввода и вывода данных, причем данные от разных источников вводились по различным шинам;
• кристаллы управления представляли собой управляющий автомат с программируемой логикой, что позволяет достаточно легко реализовать практически любую систему команд на фиксированной структуре операционного устройства.
Таким образом, разработчики систем на базе микропроцессоров третьего поколения получали две "дополнительные степени свободы" — возможность выбрать произвольную разрядность процессора (кратную разрядности секции) Ю самостоятельно реализовать практически произвольную систему команд, оптимизированную для решения задач конкретного класса.
Поскольку микропроцессор в такой архитектуре размещался на нескольких кристаллах БИС: арифметико-логические секции, схемы управления вместе с БИС памяти микрокоманд, вспомогательные БИС (например, схемы ускоренного распространения переноса для АЛС) и др., то подобные микропроцессоры стали называть много кристальными, в отличие от однокристальных микропроцессоров второго поколения.
Очевидно и то, что разработка систем на многокристальных микропроцессорах требовала значительно больших усилий, времени и квалификации разработчиков, по сравнению с разработкой системы на "готовых" микропроцессорах второго поколения с фиксированной структурой и системой команд.
В конце 70-х и начале 80-х годов прошлого века значительное число отечественных и зарубежных фирм разрабатывали и выпускали серии БИС много кристальных микропроцессоров, причем разрядность секций постепенно увеличивалась до 4, 8 и даже 16 битов.
К тому времени технология уже не являлась решающим фактором классификации МП, ибо появились разновидности технологий одного типа, обеспечивающие очень широкий спектр характеристик МП, широкое распространение, получили комбинированные технологии (например, И2 Л + ТТЛШ). По этому многокристальные МП выпускались как по биполярной, так и по МДП технологиям.
Одной из наиболее удачных разработок этого направления можно считать комплект БИС серии Am2900 фирмы AMD и близкую ему по архитектур отечественную серию К1804 [13].
Параллельно интенсивно развивалась архитектура однокристальных микро- процессоров, наиболее характерным представителем которой можно считать семейство х86 фирмы Intel. Развитие этого направления отличал безудержный рост производительности процессоров, обусловленный увеличением разрядности процессоров, тактовой частоты, реализацией параллелизма на всех уровнях работы процессора и применением других архитектурных решений, характерных ранее для "больших" ЭВМ.
Быстро возрастающие возможности микропроцессоров позволяли "захватывать" в область цифровой обработки информации все новые сферы человеческой деятельности (достаточно вспомнить появление и распространение персональных ЭВМ).
Однако в сфере применения микропроцессоров всегда существовали задачи, для решения которых не требовалась высокая производительность процессов (например, управление не сложным инерционным технологическим оборудованием, бытовыми приборами). В этих случаях на первый план выступали акте параметры, как надежность, простота реализации (стоимость). Для решения таких задач использование мощных однокристальных микропроцессов становилось существенно избыточным.
Возрастающие возможности технологии в этом случае использовались не для величания производительности процессора, а для размещения на кристалле, наряду с относительно простым процессором, тех устройств, которые в традиционной архитектуре располагались на плате рядом с микропроцессором в идея отдельных БИС (СИС): тактовый генератор, ПЗУ, ОЗУ, порты параллельного и последовательного обмена, контроллер прерываний, таймеры и др.
Таким образом, были получены полностью "самодостаточные" однокристальные микро ЭВМ (ОМЭВМ). Это направление стало интенсивно развиваться, вначале на базе 8-разрядной архитектуры. Наиболее популярными из их можно считать ОМЭВМ семейств MCS-51 фирмы Intel, МС68НС11 фирмы Motorola, PIC16 и PIC18 фирмы Microchip.
По мере развития на кристаллах ОМЭВМ стали, помимо перечисленных выше устройств, размещать аналого-цифровые и цифроаналоговые преобразователи, блоки энергонезависимой памяти (EEPROM), сложные таймерные системы, схемы управления специализированными ВУ (например, семи сегментной индикацией) и др.
Дальнейшее развитие технологии привело к появлению 16- и даже 32-разядных однокристальных микро ЭВМ (наиболее известные — от фирмы motorola), включающих, наряду с мощным центральным процессором, специализированные процессоры — таймерный и ввода/вывода, работающие независимо от центрального, широкий набор блоков памяти и внешних устройств. Модульность архитектуры кристалла ОМЭВМ позволяет в рамках одного семейства варьировать в широких пределах набор параметров кристалла: состав и объем блоков памяти, набор внешних устройств и даже тип дометаемого на кристалл центрального процессора.
Таким образом, пользователю предоставляется возможность выбора в очень широких пределах архитектуры и параметров ОМЭВМ. При этом он получать "готовую" ЭВМ, не требующую схемотехнических и архитектурных доработок. В итоге современные ОМЭВМ практически полностью заняли ту нишу, в которой долгое время существовали многокристальные микропроцессоры.
Базовая архитектура микропроцессорной системы
Пожалуй, наиболее популярными в мире (и в нашей стране) являлись и являются однокристальные микропроцессоры семейства х86 фирмы Intel. Семейство берет свое начало от первого 8-разрядного микропроцессора i8080 (отечественный аналог — К580ВМ80) и включает 16- и 32-разрядные микропроцессоры i8086, i80286, i80386, i80486, Pentium, ..., Pentium 4.
Схемотехнические решения систем на 18080 можно было бы считать базовыми, но его система команд значительно отличается от языка старших моделей микропроцессоров семейства. Поэтому "родоначальником" семейства принято считать первый 16-разрядный микропроцессор — i8086 (отечественный аналог — К1810ВМ86), на котором, кстати, были реализованы персональные ЭВМ IBM РС ХТ.
Анализ архитектуры микропроцессорных систем (МПС) целесообразно начинать с рассмотрения простейшей (базовой) модели, отражающей основные принципы организации процессора, его системы команд, функционирование основных подсистем. Большинство принципиальных решений, реализованных в МПС на базе младших моделей семейства, сохранились и в старших: моделях.
Рассмотрим кратко организацию МПС на базе микропроцессора i8086. При этом выделим для рассмотрения следующие подсистемы:
• процессорный модуль;
• память;
• ввод/вывод;
• прерывания;
• прямой доступ в память со стороны ВУ.
Процессорный модуль — основная часть любой МПС. Помимо собственно микропроцессора, он включает ряд вспомогательных схем, без которых МПС не может функционировать (тактовый генератор, интерфейсные схемы и др.).
6.1.1. Внутренняя структура микропроцессора
Структурная схема микропроцессора i8086 представлена на рис. 6.1. Микро- процессор включает в себя три основных устройства:
УОД — устройство обработки данных;
УСМ — устройство связи с магистралью;
УУС — устройство управления и синхронизации.
УОД предназначено для выполнения команд и включает в себя 16-разрядное АЛУ, системные регистры и другие вспомогательные схемы; блок регистров (POH, базовые и индексные) и блок микропрограммного управления.
УСМ обеспечивает формирование 20-разрядного физического адреса памяти и 16-разрядного адреса ВУ, выбор команд из памяти, обмен данными с ЗУ, ВУ, другими процессорами по магистрали. УСМ включает в себя сумматор адреса, блок регистров очереди команд и блок сегментных регистров.
УУС обеспечивает синхронизацию работы устройств МП, выработку управляющих сигналов и сигналов состояния для обмена с другими устройствами, анализ и соответствующую реакцию на сигналы других устройств МПС.
Микропроцессор i8086 может работать в одном из двух режимов — минимальном и максимальном. Минимальный режим предназначен для реализации однопроцессорной конфигурации МПС с организацией, подобной МПС на базе i8080, но с увеличенным адресным пространством, более высоким быстродействием и значительно расширенной системой команд. Максимальный режим предполагает наличие в системе нескольких микропроцессор, работающих на общую системную шину. МПС на базе i8086 с использованием максимального режима не получили широкого распространения. Более того, в последующих моделях своих микропроцессоров (80286, 80386, 80486) фирма Intel отказалась от поддержки мультипроцессорной архитектуры. Поэтому мы здесь не будем рассматривать особенности организации максимального режима.
На внешних выводах МП i8086 широко используется принцип мультиплексирования сигналов — передача разных сигналов по общим линиям с разделением во времени. Кроме того, одни и те же выводы могут использоваться для передачи разных сигналов в зависимости от режима (min — max).

В табл. 6.1 приведено описание внешних выводов МП i8086. При описании выводов косой чертой (/) разделены сигналы, появляющиеся на выводе в разные моменты машинного цикла. В круглых скобках указаны сигналы, характерные только для максимального режима. Символ * после имени сигнала— знак его инверсии.
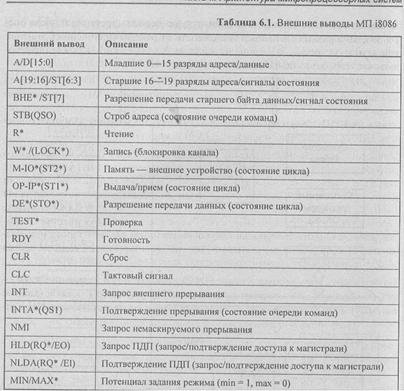
6.1.2. Командный и машинный циклы микропроцессора
Микропроцессор i8086 работает в составе МПС, обмениваясь с памятью и ВУ словами длиной 2 байта, т. к. разрядность шины данных составляет 16 битов. В основе работы микропроцессора лежит командный цикл — действия по выбору из памяти и выполнению одной команды.
Любой командный цикл (КЦ) начинается с извлечения из памяти первого слова команды по адресу, хранящемуся в счетчике команд (РС). Команды i8086 могут иметь длину от 1 до 6 байтов, причем в первом слове содержится информация о длине команды. Таким образом, для извлечения из памяти одной команды может потребоваться одно или несколько обращений к ОЗУ.
В зависимости от типа и формата команды, способов адресации и числа операндов командный цикл может включать в себя различное число обращений к памяти и ВУ, поскольку кроме чтения самой команды в КЦ может потребоваться чтение операндов и размещение результата.
Хотя обращения к ЗУ/ВУ располагаются в разных частях КЦ, выполняются они по единым правилам, соответствующим интерфейсу МПС, и реализованы на общем оборудовании управляющего автомата. Действия МПС по передаче в (из) МП одного слова команды (данных) называются машинным циклом. КЦ состоит из одного или нескольких машинных циклов (МЦ). Машинный цикл включает выдачу процессором адреса памяти или внешнего устройства, по которому производится обращение, выдачу управляющих сигналов, характеризующих тип машинного цикла и направление передачи данных (М-IO, OP-IP), выдачу синхронизирующих (стробирующих) сигналов (STB, R, W) и собственно передачу данных. В i8086 реализована мультиплексированная шина адреса/данных. Это объясняется дефицитом внешних выводов кристалла и требует дополнительного такта для выдачи адреса и дополнительного управляющего сигнала STB, идентифицирующего наличие адреса на общей шине А//D.
По большому счету разнообразие МЦ сводится к двум разновидностям—
чтению (данные или команды принимаются в процессор) и записи (данные выдаются из процессора). Временные диаграммы соответствующих МЦ приведены на рис. 6.2.

Цикл начинается с формирования в такте Tl сигнала М-IO, определяющего тип устройства — память или ВУ, с которым осуществляется обмен данными. Длительность сигнала М-IO равна длительности машинного цикла, и он используется для селекции адреса устройств. В Tl и в начале Т2 МП выдает адреса А[19:16] и A[15:0] и сигнал ВНЕ, который вместе с АО определяет выбор передачи либо всего слова, либо одного из его байтов. По спаду строба АЬЕ адрес фиксируется во внешних регистрах-защелках. В такте Т2 происходит переключение шин: на выводы А[19:16]/ST[6:3] поступают сигналы состояния; а выводы А/D[15:0] используются для приема/передачи данных.
Описанные выше машинные циклы являются синхронными. их длительность определяется только процессором. Однако такой обмен возможен лишь с устройствами, быстродействие которых не уступает процессорному. В противном случае микропроцессор должен реализовать асинхронный способ обмена, включающий анализ сигнала от устройства о готовности к обмену или о завершении процедуры обмена.
Роль такого сигнала в i8086 (и всех процессорах старших моделей семейства х86) играет вход RDY (от англ. ready — готовность), который всегда должен быть активным при синхронном обмене (с "быстрыми" устройствами). При обмене с "медленными" устройствами значение RDY должно оставаться неактивным (в разных процессорах активным для RDY может быть уровень логической 1 или логического 0) до тех пор, пока устройство, с которым связывается процессор, не завершит процедуру обмена, сообразуясь со своим быстродействием.
Время ожидания процессором готовности устройства может быть сколь угодно большим. Для этого в такте ТЗ процессор проверяет значение сигнала RDY, и если он неактивен, после такта Т3 в машинный цикл вставляется произвольное количество тактов ожидания Tw, в каждом из которых анализируется значение RDY. При появлении активного значения RDY микропроцессор переходит к такту Т4 и завершает МЦ. Таким образом, удается согласовывать работу микропроцессора с устройствами различного быстродействия.
6.1.3. Реализация процессорных модулей и состав линий системного интерфейса
Большинство микропроцессоров не могут работать в составе МПС без некоторых дополнительных схем, составляющих вместе с микропроцессором т. н. процессорный модуль. Прежде всего, на вход СLК микропроцессора необходимо подать прямоугольные импульсы тактовой частоты от специального внешнего тактового генератора.
Для микропроцессора i8086 частота тактовых импульсов может лежать в диапазоне 2 — 6 МГц.
На рис. 6.3 приведен один из вариантов упрощенной функциональной схемы процессорного модуля на базе i8086. На схеме не показаны некоторые элементы и связи (например, схема начального сброса и др.).

Микропроцессор i8086 реализован по n-МДП-технологии, и его выходные каскады не обеспечивают достаточной нагрузочной способности для линий системного интерфейса. Поэтому к выходным линиям микропроцессора обычно подключают буферные схемы BD, реализованные по технологии ТТЛ. Кроме того, шины адреса и данных в i8086 мультиплексированы. Адрес удерживается на выводах микропроцессора только в течение одного такта машинного цикла, а использоваться должен весь МЦ. Поэтому адрес необходимо запомнить в специальных внешних регистрах-защелках RG (которые, кстати, играют и роль буферной схемы шины адреса).
Наконец, часто требуется преобразовать управляющие сигналы, выдаваемые микропроцессором, в стандартные сигналы системного интерфейса. Так, i8086 формирует выходные сигналы, идентифицирующие тип машинного цикла, и сигналы стробирования: М-IO, OP-IP, R, W. Системная шина использует сигналы записи и чтения памяти — RDM, WRM и записи и чтения внешнего устройства — RDIO, WRIO. Преобразования процессорных сигналов в шинные осуществляет простая логическая схема L.
6.2. Машина пользователя и система команд
Программная модель микропроцессора (рис. 6.4) включает в себя программно доступные объекты МПС, т. е. те объекты, состояние которых можно про анализировать и/или изменить при помощи команд микропроцессора. К таким объектам относятся внутренние регистры микропроцессора, ячейки памяти и порты ввода/вывода.

Рассмотрим машину пользователя i8086. Кроме показанных на рис. 6.4 регистров процессора, в машину пользователя i8086 включатся адресное пространство памяти объемом 1 Мбайт и два пространства портов ввода и вывода по 64 Кбайт каждое.
Помимо операций с 16-разрядными регистрами общего назначения (РОН) АХ — DX, допускается обращение к каждому байту этих регистров: AL- DL, АН — DH. В процессорах семейства х86 система команд построена таким образом, что в некоторых командах POH выполняют определенные по умолчанию функции счетчиков, индексных регистров, источников адреса и др.

16-разрядные регистры BP, SI, И используются для образования исполнительных адресов памяти, SP — указатель стека, IP — программный счетчик (СчК), Flags — регистр флагов, формат которого приведен на рис. 6.5, где:
CF — перенос/заем из старшего разряда;
PF — паритет (четность числа единиц в результате);
AF — дополнительный перенос (из 3-гo разряда); D ZF — нулевой результат;
SF — отрицательный результат (знак);
OF — признак арифметического переполнения;
DF — направление, определяет направление модификации адресов массивов в командах цепочек (увеличение или уменьшение адреса);
IF — маскирует внешнее прерывание по входу INT (при IF = 1 прерывание
разрешено);
TF — управляет пошаговым режимом работы микропроцессора.
При TF = 1 после выполнения каждой команды автоматически формируется
прерывание с вектором 1.
6.2.1. Распределение адресного пространства
Адресное пространство МП определяется в i8086 разрядностью шины адреса данных и адреса и составляет 220 байтов = 1 Мбайт. В этом адресном пространстве микропроцессору одновременно доступны лишь четыре сегмента, два из которых (DS и ES) предназначены для размещения данных, CS — сегмент кода (для размещения программы) и SS — сегмент стека.
Размеры сегментов определяются разрядностью логических адресов команд, данных и стека. Логические адреса команд и стека (верхушки) хранятся в 16-разрядных регистрах IP и SS соответственно, а логический адрес данных вычисляется в команде одним из многочисленных, предусмотренных системой команд, способов и также составляет 16 битов.
Таким образом, размер каждого сегмента в i8086 составляет 216 байтов = 64 Кбайт. Положение сегмента в адресном пространстве (его начальный адрес) определяется содержимым одноименного сегментного регистра. Формирование физического адреса иллюстрируется на рис. 6.6, из которого видно, что граница сегмента в адресном пространстве может быть установлена не произвольно, а таким образом, чтобы начальный адрес сегмента был кратен 16.

По умолчанию сегментные регистры выбираются для образования физического адреса следующим образом: при считывании команды по адресу IP используется CS, при обращении к данным — DS или ES, при обращении к стеку — SS. С помощью специальных приставок к команде (префиксов) можно назначить для использования произвольный сегментный регистр (кроме пары CS:IP, которая не подлежит модификации). Границы сегментов могут быть выбраны таким образом, что сегменты будут изолированы друг от друга, пересекаться или даже полностью совпадать. Например, если загрузить CS = SS = DS = ES = 0, то все сегменты будут совпадать друг с другом и начинаться с нулевого адреса — вариант организации адресного пространства i8080.
Система команд i8086 и, вообще, всего семейства х86 подробно описана в многочисленных справочниках и руководствах, например [11, 12, 13], поэтому далее мы кратко остановимся только на особенностях системы команд |8086, не вдаваясь в излишние подробности.
i8086 отличается разнообразием форматов команд и способов адресации. Длина команды может составлять от 1 до 6 байтов, причем в первых двух байтах (иногда — в первом) определяется код операций, количество и длина операндов и способ их адресации. В остальных байтах команды могут размещаться непосредственный операнд, прямой адрес или смещение.
Большинство команд i8086 являются двухадресными, причем один адрес определяет регистр процессора, а другой — ячейку памяти или регистр.
Операнд в памяти может адресоваться прямо или косвенно посредством содержимого базовых (ВР, ВХ) или индексных (SI, DI) регистров, а также их суммы. Предусмотрены многочисленные варианты относительной адресации, при которых логический адрес образуется как сумма двух или трех слагаемых — одного или двух регистров процессора и 8- или 16-разрядного смещения, размещаемого в команде.
Режимы адресации спроектированы с учетом эффективной реализации языков высокого уровня. Например, к простой переменной можно обратиться в режиме прямой адресации, а к элементу массива — в режиме косвенной адресации посредством ВХ, Sl. Режим адресации через ВР предназначен для доступа к данным из сегмента стека, что удобно при реализации рекурсивных процедур и компиляторов языков высокого уровня.
Система команд насчитывает 113 базовых команд, объединенных в следующие группы:
• команды передачи данных:
• между регистрами и памятью (включая стек), обмен содержимым источника и приемника;
• ввод, вывод, табличное преобразование;
• загрузка исполнительного адреса в РОН, загрузка 4-байтового адресного объекта в регистры-указатели (начальный адрес сегмента и смещение в сегменте);
• передача содержимого регистра F флагов в память, в стек и из стека;
• арифметические команды:
• сложение, вычитание, умножение и деление двоичных чисел со знаком
и без знака (произведение и делимое представляются числами двойной длины);
• десятичная коррекция сложения и вычитания упакованных двоично-десятичных чисел;
• десятичная коррекция сложения, вычитания, умножения и деления распакованных двоично-десятичных чисел;
• логические команды и сдвиги:
• инверсия, конъюнкция, дизъюнкция, неравнозначность;
• TEST — поразрядная конъюнкция операндов с установкой флагов, но
без занесения результатов;
• сдвиги на 1 или заданное число разрядов (константа сдвига располагается в СЬ);
О команды передачи управления: переходы, вызовы, возвраты имеют две разновидности — внутрисегментные ("близкие" ) и межсегментные ("дальние"). При близких передачах загружается только IP, при дальних— IP и CS. Передачи управления могут быть прямыми (целевой адрес в команде) или косвенными (целевой адрес вычисляется с использованием стандартных режимов адресации). В 16 командах условных переходов проверяются отношения знаковых и без знаковых чисел. Имеются 4 команды управления циклами, которые рассчитаны на размещение числа повторений цикла в регистре СХ;
команды обработки цепочек данных манипулируют последовательностями байтов или слов в памяти. Время обработки цепочек этими командами гораздо меньше, чем соответствующей программной реализацией.
6.3. Функционирование основных подсистем MПC
Теперь можно рассмотреть функционирование основных подсистем базовой МПС с интерфейсом типа "общая шина". Этот термин используется в двух смыслах: во-первых, как обозначение принципа организации связи процессора с другими устройствами в составе ЭВМ, во-вторых, как обозначение (в русском переводе) конкретного интерфейса Unibus мини-ЭВМ семейства PDP-11 фирмы DEC.
Unibus явился, пожалуй, первым интерфейсом, в котором были полностью реализованы принципы "общей шины":
• все линии интерфейса делятся на три группы: адрес, данные, управление;
• все устройства, в т. ч. процессор, подключаются к линиям интерфейса одинаковым образом;
• идентификация объектов на шине (ячеек памяти, регистров внешних устройств) осуществляется с помощью уникального для каждого объекта адреса;
• в каждый момент времени по шине могут взаимодействовать только два устройства, одно из которых является активным, а другое — пассивным. Активное устройство формирует адрес обмена, управляющие сигналы и может выдавать (в цикле записи) или принимать (в цикле чтения) данные, которые принимает или выдает пассивное устройство;
• обмен между устройствами может осуществляться в синхронном или асинхронном режиме. При синхронном обмене все временные характеристики обмена определяются только активным устройством, которое не анализирует ни готовность пассивного к обмену, ни факт завершения обмена. Синхронный обмен допустим лишь с быстродействующими пассивными устройствами (их быстродействие должно быть не ниже быстродействия активного устройства), которые всегда готовы к обмену (например, регистр двоичной индикации). При асинхронном обмене пассивное устройство формирует сигнал готовности к обмену и/или сигнал завершения обмена, которые анализирует активное устройство.
Интерфейсы, реализующие принципы "общей шины", широко распространились в мини и микро ЭВМ, МПС различного назначения. Многие из них, правда, нарушали некоторые принципы "канонической общей шины", например, за счет появления отдельных адресных пространств регистров процессора и портов ввода и вывода. Однако основные принципы, изложенные выше, сохраняются в многочисленных разновидностях таких интерфейсов.
К достоинствам интерфейсов типа "общая шина" можно отнести его относительную простоту, гибкость системы и возможность ее модификации в широких пределах.
К недостаткам — невозможность распараллеливания процессов обмена (одновременно осуществляется связь только пары устройств). Кроме того, наличие на общей шине устройств с существенно различным быстродействием затрудняет достижение оптимальных характеристик системы.
В разд. б.1.3 мы подробно рассмотрели организацию процессорного модуля на базе процессора i8086. Состав внешних выводов процессорного модуля (см. рис. 6.3) позволяет подключить его к интерфейсу, реализованному по принципу общей шины:
• линии адреса АВ[19:0];
• линии данных DB[15:0];
• линии управления RDM, WRM, RDIO,WRIO.
Другие линии управления, входящие в состав интерфейса, будт добавлены при рассмотрении соответствующих подсистем.
Объем адресного пространства МПС с интерфейсом "общая шина" определяется главным образом разрядностью шины адреса и, кроме того, номенклатурой управляющих сигналов интерфейса. Управляющие сигналы могут определять тип объекта, к которому производится обращение (ОЗУ, ВУ, стек, специализированные ПЗУ и др.). В случае, если МП не выдает сигналов, идентифицирующих тип пассивного устройства (или они не используются в МПС) — для селекции берутся только адресные линии. Число адресуемых объектов составляет в этом случае 2, где k — разрядность шины адреса.. Будем называть такое адресное пространство единым. Иногда говорят, что ВУ в едином адресном пространстве "отображены на память", т. е. адреса ВУ занимают адреса ячеек памяти.
При использовании информации о типе устройства, к которому идет обращение, одни и те же адреса можно назначать для устройств разных типов, осуществляя селекцию с помощью управляющих сигналов.
Так, большинство МП выдают в той или иной форме информацию о типе
обращения. В результате в большинстве интерфейсов присутствуют отдельные управляющие линии для обращения к памяти и вводу/выводу, реже — к стеку или специализированному ПЗУ. В результате суммарный объем адресного пространства МПС может превышать величину 2 .
Например, системная шина МПС на базе микропроцессора i8086 включает 20-разрядную шину адреса и управляющие сигналы, идентифицирующие обращение к памяти (RDM, WRM) и вводу/выводу (RDIO, WRIO). Поэтому в системе доступны 1 Мбайт ячеек памяти (адреса 00000 — FFFFF) + 64 Кбайт адресов ввода + 64 Кбайт адресов вывода (0000 — FFFF). Последняя величина определяется тем, что в командах ввода/вывода процессоров семейства x86 адрес внешнего устройства имеет разрядность 16 битов.
При необходимости расширить объем памяти за пределы адресного пространства можно воспользоваться т. н. диспетчером памяти. В простейшем случае он представляет собой программно-доступный регистр, который должен располагаться в пространстве ввода/вывода. В него заносится номер активного в данный момент банка памяти, причем объем банка может равняться объему адресного пространства МП.
Очевидно, в каждый момент времени процессору доступен только один банк. При необходимости перехода в другой банк памяти МП должен предварительно выполнить программную процедуру (часто всего одну команду)
перезагрузки содержимого регистра номера банка.
К развитию этой идеи можно отнести механизм сегментации памяти в 16- и 32-разрядных МП фирмы Intel.