технологии распределенной обработки информации
Основное назначение БД — многоцелевое параллельное использование данных, уже предопределяет наличие средств, которые должны обеспечить практически одновременный и независимый доступ к одним и тем же данным. При этом данные могут быть размешены как на одном, так и на нескольких компьютерах. Стремление к интеграции и управляемости (обеспечению целостности) естественно порождает стремление к централизации. Однако на практике наблюдается и стремление к децентрализации, в значительно большей степени отражающей организационную структуру предметной области и технологию порождения и использования хранимых данных. Разные фрагменты данных порождаются и используются обычно в разных подразделениях и организациях, зачастую — географически разобщенных. Разработка распределенных баз и технологий распределенной обработки существенно расширяет возможности, как создания, так и использования данных.
7.1. Распределенные базы данных
Следует отметить, что общая тенденция развития технологий обработки данных вполне соответствует этапам развития средств вычислительной техники и информационных технологий, и в первую очередь — сетевых.
Распределенные системы
Классификация. Следует выделить два класса систем распределенной обработки и системы распределенных данных:
• системы распределенной обработки в основном отражают структуру и свойства многопользовательских операционных систем с базой данных, размещенной на центральном компьютере;
• системы распределенных данных обеспечивают обработку распределенных запросов, когда при обработке одного запроса используются информационные ресурсы, размещенные на различных ЭВМ сети. При этом, как и ранее, следует говорить как о распределенных файловых системах, так и о распределенных базах данных.
Для распределенных баз данных свойственны следующие характеристики:
• база данных — это логически связанные, разделяемые на некоторое количество фрагментов данные;
• фрагменты распределяются по разным узлам, которые связаны между собой сетевыми соединениями;
• может быть предусмотрена репликация фрагментов;
• доступ к данным на каждом узле происходит под управлением СУБД, которая на каждом узле должна поддерживать работу как локальных приложений, так и глобальных.
Основные условия и требования к распределенной обработке данных:
• прозрачность относительно расположения данных (СУБД должна представлять все данные так, как если бы они были локальными);
• гетерогенность системы (СУБД должна работать с данными, которые хранятся в системах с различной архитектурой и производительностью);
• прозрачность относительно сети (СУБД должна одинаково работать в условиях разнородных сетей);
• поддержка распределенных запросов (пользователь должен иметь возможность объединять данные из любых баз, даже если они размещены в разных системах);
• поддержка распределенных изменений (пользователь должен иметь возможность изменять данные в любых базах, на доступ к которым у него есть права, даже если эти базы размещены в разных системах);
• поддержка распределенных транзакций (СУБД должна выполнять транзакции, выходящие за рамки одной вычислительной системы, и поддерживать целостность распределенной БД даже при возникновении отказов как в отдельных системах, так и в сети);
• безопасность (СУБД должна обеспечивать защиту всей распределенной БД от несанкционированного доступа);
• универсальность доступа (СУБД должна обеспечивать единую методику доступа ко всем данным).
Поясним некоторые из этих требований:
Прозрачность расположения. Прозрачный (для пользователя) доступ к удаленным данным предполагает использование в прикладных программах такого интерфейса с сервером БД, который позволяет переносить данные в сети с одного узла на другой, не требуя при этом модификации текста программы. Иными словами доступ к информационным ресурсам должен быть полностью прозрачен относительно расположения данных.
Любой пользователь или любая прикладная программа оперирует с одной или несколькими базами данных. В том случае, когда прикладная программа и сервер БД выполняются на одном и том же узле, проблемы расположения не возникает. Для получения доступа к базе данных пользователю или программе достаточно указать имя базы, например: SQL Dbname.
Однако в том случае, когда прикладная программа запускается на локальном узле, а база данных находится на удаленном, возникает проблема идентификации удаленного узла. Для того чтобы получить доступ к базе данных на удаленном узле, необходимо указать имя удаленного узла и имя базы данных. Если использовать жестко фиксированное имя узла в паре «имя_узла, имя_БД», то прикладная программа становится зависимой от расположения БД. Например, обращение к БД «host:stock», где первый компонент — имя узла, будет зависимым от расположения.
Одно из возможных решений этой проблемы состоит в использовании виртуальных имен узлов. Управление ими обеспечивается специальным программным компонентом СУБД — сервером имен (Name Server), который адресует запросы клиентов к серверам.
Прозрачность сети. Клиент и сервер взаимодействуют по сети с конкретной топологией; для поддержки взаимодействия всегда используется определенный протокол. Следовательно, оно должно быть организовано таким образом, чтобы обеспечивать независимость как от используемого сетевого аппаратного обеспечения, так и от протоколов сетевого обмена. Чтобы обеспечить прозрачный доступ пользователей и программ к удаленным данным в сети, объединяющей разнородные компьютеры, коммуникационный сервер должен поддерживать как можно r лее широкий диапазон сетевых протоколов (TCP/IP, DECnet SNA, SPX/IPX, NetBIOS, AppleTalk и др.).
Автоматическое преобразование форматов данных. Как толь ко несколько компьютеров различных моделей под управлением различных операционных систем соединяются в сеть, сразу возникает вопрос о согласовании форматов представления данных Действительно, в сети могут быть компьютеры, отличающиеся разрядностью (16-, 32- и 64-разрядные процессоры), порядком следования байт в слове, представлением чисел с плавающей точкой и т. д. Задача коммуникационного сервера состоит в том чтобы на уровне обмена данными обеспечить согласование форматов между удаленным и локальным узлами с тем, чтобы данные, извлеченные сервером из базы на удаленном узле и переданные по сети, были правильно истолкованы прикладной программой на локальном узле.
Автоматическая трансляция кодов. В неоднородной компьютерной среде при взаимодействии клиента и сервера возникает также задача трансляции кодов. Сервер может работать с одной кодовой таблицей (например, EBCDIC), клиент — с другой (например, ASCII), при этом происходит рассогласование трактовки кодов символов. Поэтому, если на локальном узле используется одна кодовая таблица, а на удаленном — другая, то при передаче запросов по сети и при получении ответов на них необходимо обеспечить трансляцию кодов. Решение этой задачи также ложится на коммуникационный сервер.
Однако ни одна из существующих СУБД не достигает этого идеала вследствие следующих практических проблем:
• низкая и несбалансированная производительность сетей передачи данных, что в распределенных транзакциях сильно снижает общую производительность обработки;
• обеспечение целостности данных в распределенных транзакциях базируется на принципе «все или ничего» и требует специального протокола двухфазного завершения транзакций, что приводит к длительной блокировке изменяемых данных;
• необходимо обеспечить совместимость данных стандартного типа, для хранения которых в разных системах используются разные физические форматы и кодировки;
• трудности выбора схемы размещения системных каталогов. Если каталог будет храниться в одной системе, то удаленный доступ будет замедлен. Если будет размножен, то изменения придется распространять и синхронизировать;
• необходимо обеспечить совместимость СУБД разных типов и поставщиков;
• увеличение потребностей в ресурсах для координации работы приложений с целью обнаружения и устранения тупиковых ситуаций в распределенных транзакциях.
Типы распределенных СУБД
В общем случае режимы работы с БД можно классифицировать по следующим признакам:
• многозадачность — однопользовательский или многопользовательский;
• правило обслуживания запросов — последовательное или параллельное;
• схема размещение данных — централизованная или распределенная БД.
Распределенные СУБД подразделяются на однородные и разнородные.
В однородных системах все узлы используют один и тот же тип СУБД. В разнородных системах на узлах могут функционировать различные типы СУБД, использующие разные модели данных. Однородные системы значительно проще проектировать и сопровождать, добавляя новые узлы к уже существующей распределенной системе и повышая производительность системы за счет параллельной обработки информации.
Разнородные системы обычно возникают в тех случаях, когда узлы, уже эксплуатирующие свои собственные системы с базами данных, со временем интегрируются в распределенную систему. В разнородных системах для организации взаимодействия между различными типами СУБД требуется обеспечить преобразование предаваемых сообщений, для чего каждый из узлов должен иметь возможность формулировать запросы на языке той СУБД, которая используется на их локальном узле или система должна взять на себя выполнение всех необходимых преобразований.
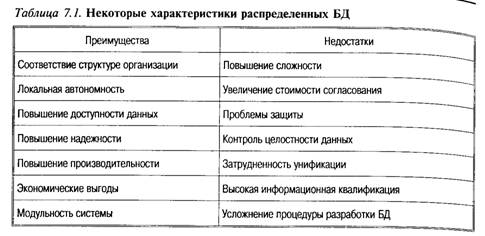
Очевидны следующие преимущества и недостатки распределенных баз данных (табл. 7.1).
Распределенная СУБД должна иметь следующий набор функциональных возможностей:
• расширенные службы установки соединений должны обеспечивать доступ к удаленным узлам и позволять передавать запросы и данные между узлами, входящими в сеть;
• расширенные средства ведения каталога, позволяющие сохранять сведения о распределении данных в сети;
• средства обработки распределенных запросов, включая механизмы оптимизации запросов и организации удаленного доступа к данным;
• расширенные функции управления защитой, позволяющие обеспечить соблюдение правил авторизации и прав доступа к распределенным данным;
• расширенные функции управления параллельным выполнением, позволяющие поддерживать целостность копируемых данных;
• расширенные функции восстановления, учитывающие вероятность отказов в работе отдельных узлов и отказов линий связи.
Соответственно, программные средства, обеспечивающие целевую (функциональную) обработку данных, должны быть организованы таким образом, чтобы обеспечить более эффективное использование совокупных вычислительных ресурсов за счет специализированного разделения функций обработки между центральным процессом СУБД и клиентскими функционально-ориентированными процедурами.
7 2- Клиент-серверные архитектуры распределенной обработки данных
Практически все модели организации взаимодействия пользователя с базой данных, построены на основе модели «клиент – сервер». То есть предполагается, что приложения, реализующие какой-либо тип модели, отличаются способом распределения функций ранее приведенных групп обработки данных между как минимум двумя частями:
• клиентской, которая отвечает за целевую обработку данных и организацию взаимодействия с пользователем;
• серверной, которая обеспечивает хранение данных, обрабатывает запросы и посылает результаты клиенту для специальной обработки.
В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к серверу БД с помощью сети подключены компьютеры пользователей (клиенты).
Сервер — это программа, реализующая функции собственно СУБД: определение данных, запись-чтение данных, поддержка схем внешнего, концептуального и внутреннего уровней, диспетчеризация и оптимизация выполнения запросов, защита данных.
Клиент — это различные программы, написанные как пользователями, так и поставщиками СУБД, внешние или «встроенные» по отношению к СУБД. Программа-клиент организована в виде приложения, работающего «поверх» СУБД и обращающегося для выполнения операций над данными к компонентам СУБД через интерфейс внешнего уровня. Инструментальные средства, в том числе и утилиты, не отнесены к серверной части очень условно. Являясь не менее важной составляющей, чем ядро СУБД, они выполняются самостоятельно, как пользовательское приложение.
Основной принцип технологии «клиент—сервер» заключается разделении функций стандартного интерактивного приложения на четыре группы, имеющие различаю природу:
• функции ввода и отображения данных;
• чисто прикладные функции, характерные для данной предметной области (например, для банковской системы — открытие счета, перевод денег с одного счета другой и т. д.);
• фундаментальные функции хранения и управления информационными ресурсами (базами данных, файловыми системами и т. д.);
• служебные, играющие роль интерфейсов между функциями первых трех групп.
Выделяются четыре основных подхода, реализованные в следующих моделях (или схемах):
• файловый сервер (File Server — FS);
• доступ к удаленным данным (Remote Data Access — RDAV ,
• север базы данных (DataBase Server — DBS);
• сервер приложений (Application Server — AS).
Файловый сервер (FS)
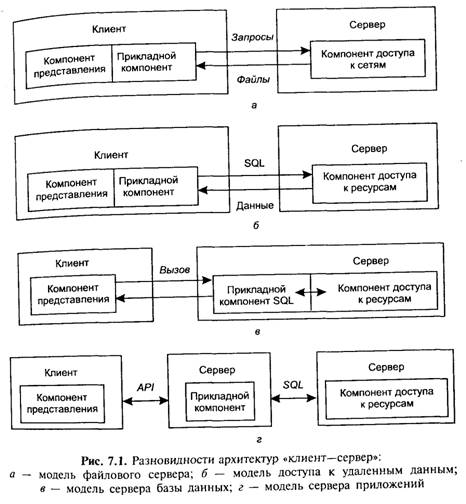
Модель является базовой для локальных сетей персональных компьютеров. В свое время она была исключительно популярной среди отечественных разработчиков, использовавших такие системы, как FoxPRO, Clipper, Clarion, Paradox и т. д. Один из компьютеров в сети считается файловым сервером и предоставляет услуги по обработке файлов другим компьютерам. Здесь мы имеем дело с распределенной файловой системой. Файловый сервер работает под управлением сетевой операционной системы (например, Novell NetWare) и играет роль компонента доступа к информационным ресурсам (т. е. к файлам). На других компьютерах в сети функционируют приложения, в кодах которых совмещены компонент представления и прикладной компонент (рис. 7.1, а). Протокол обмена представляет собой набор низкоуровневых вызовов, обеспечивающих приложению доступ к файловой системе на файл-сервере.
FS-модель послужила фундаментом для расширения возможностей персональных СУБД в направлении поддержки многопользовательского режима. В таких системах на нескольких персональных компьютерах выполняется как прикладная программа, так и копия СУБД, а базы данных содержатся в разделяемых файлах, которые находятся на файловом сервере. Когда прикладная программа обращается к базе данных, СУБД направляет запрос на файловый сервер. В этом запросе указаны файлы, где находятся запрашиваемые данные. В ответ на запрос файловый сервер направляет по сети требуемый блок данных. СУБД, получив его, выполняет над данными действия, которые были декларированы в прикладной программе.
К технологическим недостаткам модели относят высокий сетевой трафик (передача множества файлов, необходимых приложению), узкий спектр операций манипулирования данными («данные — это файлы»), отсутствие адекватных средств безопасности доступа к данным (зашита только на уровне файловой системы) и т. д. Собственно, перечисленное не есть недостатки, но следствие внутренне присущих FS-модели ограничений, определяемых ее характером. Недоразумения возникают в том случае, когда FS-модель используют не по назначению – например, пытаются интерпретировать как модель сервера базы данных.
Удаленный доступ (RDA)
Более технологичная RDA-модель существенно отличается от FS-модели характером компонента доступа к информационным ресурсам. Это, как правило, SQL-сервер. В RDA-модели коды компонента представления и прикладного компонента совмещены и выполняются на компьютере-клиенте. Последний поддерживает как функции ввода и отображения данных, так и чисто прикладные функции. Доступ к информационным ресурсам обеспечивается либо операторами специального языка (языка SQL, например, если речь идет о базах данных) или вызовами функций специальной библиотеки (если имеется соответствующий интерфейс прикладного программирования — API).
Клиент направляет запросы к информационным ресурсам (например, к базам данных) по сети удаленному компьютеру. На нем функционирует ядро СУБД, которое обрабатывает запросы, выполняя предписанные в них действия и возвращает клиенту результат, оформленный как блок данных (рис. 7.1, 6). При этом инициатором манипуляций с данными выступают программы, выполняющиеся на компьютерах-клиентах, в то время как ядру СУБД отводится пассивная роль — обслуживание запросов и обработка данных. Далее будет показано, что такое распределение обязанностей между клиентами и сервером базы данных — не догма: сервер БД может играть более активную роль, чем та, которая предписана ему традиционной парадигмой.
RDA-модель избавляет от недостатков, присущих как системам с централизованной архитектурой, так и системам с файловым сервером.
Основное достоинство RDA-модели заключается в унификации интерфейса «клиент—сервер» в виде языка SQL. Действительно, взаимодействие прикладного компонента с ядром СУБД невозможно без стандартизованного средства общения. Запросы, направляемые программой ядру, должны быть понятны обеим сторонам. Для этого их следует сформулировать на специальном языке. Но в СУБД уже существует язык SQL, о котором речь шла выше. Поэтому было бы целесообразно использовать его не только в качестве средства доступа к данным, но и как стандарта общения клиента и сервера.
К сожалению, RDA-модель не лишена ряда недостатков. Во-первых, взаимодействие клиента и сервера посредством SOL-запросов существенно загружает сеть. Во-вторых, удовлетворительное администрирование приложений в RDA-модели практически невозможно из-за совмещения в одной программе различных по своей природе функций (функции представления и прикладные функции).
Сервер баз данных (DBS)
Наряду с RDA-моделью все большую популярность приобретает DBS-модель (рис. 7.1, в). Последняя реализована в некоторых реляционных СУБД (Informix, Ingres, Sybase, Oracle). Ее основу составляет механизм хранимых процедур — средство программирования SQL-сервера. Процедуры хранятся в словаре базы данных, разделяются между несколькими клиентами и выполняются на том же компьютере, где функционирует SQL-сервер. Язык, на котором разрабатываются хранимые процедуры, представляет собой процедурное расширение языка запросов SQL и уникален для каждой конкретной СУБД.
В DBS-модели компонент представления выполняется на компьютере-клиенте, в то время как прикладной компонент оформлен как набор хранимых процедур и функционирует на компьютере-сервере БД. Там же выполняется компонент доступа к данным, т. е. ядро СУБД. Достоинства DBS-модели очевидны: это и возможность централизованного администрирования прикладных функций, и снижение трафика (вместо SQL-запросов по сети направляются вызовы хранимых процедур), и возможность разделения процедуры между несколькими приложениями, и экономия ресурсов компьютера за счет использования единожды созданного плана выполнения процедуры. К недостаткам можно отнести ограниченность средств, используемых для написания хранимых процедур, которые представляют собой разнообразные процедурные расширения SQL, не выдерживающие сравнения по изобразительным средствам и функциональным возможностям с языками третьего поколения, такими, как Си или Паскаль. Сфера их использования ограничена конкретной СУБД, в большинстве СУБД отсутствуют возможности отладки и тестирования разработанных хранимых процедур.
На практике часто используются смешанные модели, копт поддержка целостности базы данных и некоторые простейшие прикладные функции выполняются хранимыми процедурами (DBS-модель), а более сложные функции реализуются непосредственно в прикладной программе, которая работает на компьютере-клиенте (RDA-модель). Так или иначе, современные многопользовательские СУБД опираются на RDA- и DBS-модели и при создании ИС, предполагающем использование только СУБД, выбирают одну из этих двух моделей либо их разумное сочетание.
Сервер приложений (AS)
В AS -модели (рис. 7.1, г) процесс, выполняющийся на компьютере-клиенте, отвечает обычно за интерфейс с пользователем (т. е. реализует функции первой группы). Обращаясь за выполнением услуг к прикладному компоненту, этот процесс играет роль клиента приложения (Application Client — АС). Прикладной компонент реализован как группа процессов, выполняющих прикладные функции, и называется сервером приложения (Application Server — AS). Все операции над информационными ресурсами выполняются соответствующим компонентом, по отношению к которому AS играет роль клиента. Из прикладных компонентов доступны ресурсы различных типов — базы данных, очереди, почтовые службы и др.
RDA- и DBS-модели опираются на двухзвенную схему разделения функций. В RDA-модели прикладные функции приданы программе-клиенту, в DBS-модели ответственность за их выполнение берет на себя ядро СУБД. В первом случае прикладной компонент сливается с компонентом представления, во втором — интегрируется в компонент доступа к информационным ресурсам. В AS-модели реализована трехзвенная схема разделения функций, где прикладной компонент выделен как важнейший изолированный элемент приложения, для его определения используются универсальные механизмы многозадачной операционной системы, и стандартизованы интерфейсы с двумя другими компонентами. AS-модель является фундаментом для мониторов обработки транзакций (Transaction Processing Monitors — ТРМ) или, проще мониторов транзакций, которые выделяются особый вид программного обеспечения. В заключение отметим, что часто, говоря о сервере базы данных подразумевают как компьютер, так и программное обеспечение – ядро СУБД. При описании архитектуры «клиент—сервер» под сервером базы данных мы имели в виду компьютер. Ниже сервер базы данных будет пониматься как программное обеспечение — ядро СУБД.
7.3. Архитектура сервера баз данных
Эволюция серверов баз данных
В период создания первых СУБД технология «клиент—сервер» только зарождалась. Поэтому изначально в архитектуре систем не было адекватного механизма организации взаимодействия такого типа, в современных же системах он жизненно необходим.
Первое время доминировала модель, в которой управление данными (функция сервера) и взаимодействие с пользователем были совмещены в одной программе (рис. 7.2, а). Затем функции управления данными были выделены в самостоятельную группу — сервер, однако модель взаимодействия пользователя с сервером соответствовала структуре «один к одному» (рис. 7.2, б), т. е. сервер обслуживал запросы ровно одного пользователя (клиента), и для обслуживания нескольких клиентов нужно было запустить эквивалентное число серверов. Выделение сервера в отдельную программу — шаг, позволяющий, в частности, поместить сервер на одну машину, а программный интерфейс с пользователем — на другую, осуществляя взаимодействие между ними по сети (рис. 7.2, в). Однако необходимость запуска большого числа серверов для обслуживания множества пользователей сильно ограничивала возможности такой системы.
Проблемы, возникающие в модели «один к одному», решаются в архитектуре систем с выделенным сервером, способным обрабатывать запросы от многих клиентов. Сервер обладает монополией на управление данными и взаимодействует одновременно со многими клиентами (рис. 7.2, г). Логически каждый клиент связан с сервером отдельной нитью (thread) или потоком, по которому пересылаются запросы.
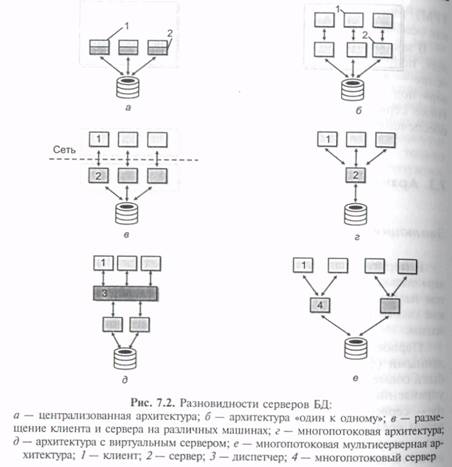
Такая архитектура получила название многопотоковой (multi-threaded). Она позволяет значительно уменьшить нагрузку на операционную систему, возникающую при работе большого числа пользователей. С другой стороны, возможность взаимодействия с одним сервером многих клиентов позволяет в полной степени использовать разделяемые объекты (начиная с открытых файлов и кончая данными из системных каталогов), что сильно уменьшав потребности в памяти и общее число процессов операционную системы, например, системой с архитектурой «один к одному» будет создано 50 копий процессов СУБД для 50 пользователей, тогда как системе с многопотоковой архитектурой для этого понадобится только один сервер.
Однако такое решение привносит новую проблему. Так как сервер может выполняться только на одном процессоре, возникает естественное ограничение на применение СУБД для мультипроцессорных платформ. Если компьютер имеет, например, четыре процессора, то СУБД с одним сервером используют только один из них, не загружая оставшиеся три.
В некоторых системах эта проблема решается заменой выделенного сервера на диспетчер или виртуальны й сервер (virtual server) (рис. 7.2, д), который теряет право монопольно распоряжаться данными, выполняя только функции диспетчеризации запросов к актуальным серверам. Таким образом, в архитектуру системы добавляется новый слой, который размещается между клиентом и сервером, что увеличивает трату ресурсов на поддержку баланса загрузки (load balancing) и ограничивает возможности управления взаимодействием «клиент—сервер». Во-первых, становится невозможным направить запрос от конкретного клиента конкретному серверу, по- вторых, серверы становятся равноправными — невозможно устанавливать приоритеты для обслуживания запросов.
Современное решение проблемы СУБД для мультипроцессорных платформ заключается в возможности запуска нескольких серверов базы данных, в том числе и на различных процессорах. При этом каждый из серверов должен быть многопотоковым. Если два эти условия выполнены, то есть основание говорить о многопотоковой архитектуре с несколькими серверами (multi-threaded, multi-server architecture), представленной на рис. 7.2, е.
Повышение эффективности и оперативности обслуживания большого числа клиентских запросов, помимо простого увеличения ресурсов и вычислительной мощности серверной машины, Может быть достигнуто двумя путями:
• снижением суммарного расхода памяти и вычислительных ресурсов за счет буферизации (кэширования) и совместного использования (разделяемые ресурсы) наиболее часто запрашиваемых данных и процедур;
• распараллеливанием процесса обработки запроса — использованием разных процессоров для параллельной обработки изолированных подзапросов и/или для одновременного обращения к частям базы данных, размещенным отдельных физических носителях.
Таким образом, типология распределенных баз данных определяется схемой распределения данных между узлами и схемой распараллеливания процессов обработки запросов.
Рассмотрим архитектуры, реализующие следующие модели совместной обработки клиентских запросов.
Как уже отмечалось, для однопроцессорных архитектур возможны схемы следующих типов:
• однопотоковые архитектуры — «один к одному», когда для обслуживания каждого запроса запускается отдельный серверный процесс. В этом случае, даже если от клиентов поступят совершенно одинаковые запросы, для обработки каждого из них будет запущен отдельный процесс, каждый из которых будет выполнять одинаковые действия и использовать одни и те же ресурсы;
• многопотоковые архитектуры, когда обработку всех запросов выполняет один серверный процесс (использующий один процессор), взаимодействующий со всеми клиентами и монопольно управляющий ресурсами. Либо в том случае, когда для работы СУБД используются многопроцессорные платформы, обслуживание запросов может быть физически распределено для параллельной обработки между процессорами.
В общем случае для повышения оперативности за счет распараллеливания процесса обработки отдельного клиентского запроса в мультисерверной архитектуре можно использовать следующие подходы:
• размещение хранимых данных БД на нескольких физических носителях (сегментирование базы). Для обработки запроса в этом случае запускаются несколько серверных процессов (использующих обычно отдельные процессоры), каждый из которых независимо от других выполняет одинаковую последовательность действий, определяемую существом запроса, но с данными, принадлежащими разным сегментам базы. Полученные таким образом результаты объединяются и передаются клиенту. Такой тип распараллеливания называют моделью горизонтального параллелизма;
• запрос обрабатывается по конвейерной технологии. Для этого запрос разбивается на взаимосвязанные по результатам подзапросы, каждый из которых может быть обслужен отдельным серверным процессом независимо от обработки других подзапросов. Получаемые результаты объединяются согласно схеме декомпозиции запроса и передаются клиенту. Такой тип распараллеливания называют моделью вертикального параллелизма.
Схема обработки клиентского запроса, построенная с использованием обеих моделей параллелизма (гибридная модель), приведена на рис. 7.3.

Отдельно необходимо упомянуть «интеграционный» подход — использование мультибазовой СУБД, которая размещается над существующими системами баз данных и файловыми системами и позволяет пользователям рассматривать совокупность баз данных (и, возможно, под управлением разнотипных СУБД) как единую базу. Мультибазовая СУБД поддерживает глобальную схему, на основании которой пользователи могут формировать запросы и модифицировать данные. Мультибазовая СУБД работает только с глобальной схемой, тогда как локальные СУБД могут использовать собственные схемы представления и обработки «своих» данных.
Активный сервер
В распределенных БД возникают следующие проблемы:
• база данных в любой момент времени должна правильно отражать состояние предметной области —данные должны быть взаимно непротиворечивыми. Пусть, например, база данных Кадры хранит сведения о рядовых сотрудниках, отделах, в которых они работают, и их руководителях. Нужно учесть следующие правила: каждый сотрудник должен быть подчинен реальному руководителю; если руководитель уволился, то все его сотрудники переходят в подчинение другому, а отдел реорганизуется; во главе каждого отдела должен стоять реальный руководитель; если отдел сокращен, то его руководитель переводится в резерв на выдвижение и т. д.;
• база данных должна отражать некоторые правила предметной области, законы, по которым она функционирует (business rules). Завод может нормально работать только в том случае, если на складе имеется достаточный запас деталей определенной номенклатуры. Следовательно как только количество деталей некоторого типа станет меньше минимально допустимого, завод должен докупить их в нужном количестве;
• необходим постоянный контроль за состоянием базы данных, отслеживание всех изменений и адекватная реакция на них. Например, в автоматизированной системе управления производством датчики контролируют температуру инструмента; она периодически передается в базу данных и там сохраняется; как только температура инструмента превышает максимально допустимое значение, он отключается;
• необходимо, чтобы возникновение некоторой ситуации в базе данных четко и оперативно влияло на ход выполнения прикладной программы. Многие программы требуют оперативного оповещения обо всех происходящих в базе данных изменениях. Так, в системах автоматизированного управления производством необходимо моментально уведомлять программы о любых изменениях параметров технологических процессов, когда последние хранятся в базе данных. Почтовая служба требует оперативного уведомления получателя, как только получено новое сообщение;
• важная функция — контроль типов данных. В базе данных каждый столбец в любой таблице содержит данные некоторых типов. Тип данных определяется при создании таблицы. Каждому столбцу присваивается один из стандартных типов данных, разрешенных в СУБД.
Концепция активного сервера опирается на следующие принципы:
• процедуры базы данных;
• правила (триггеры);
• события в базе данных.
Процедуры базы данных. В различных СУБД они носят название хранимых (stored), присоединенных, разделяемых и т. д. Ниже используется терминология, принятая в СУБД Ingres.
Использование процедур базы данных преследует четыре цели:
• обеспечивается новый независимый уровень централизованного контроля доступа к данным, осуществляемый администратором базы данных;
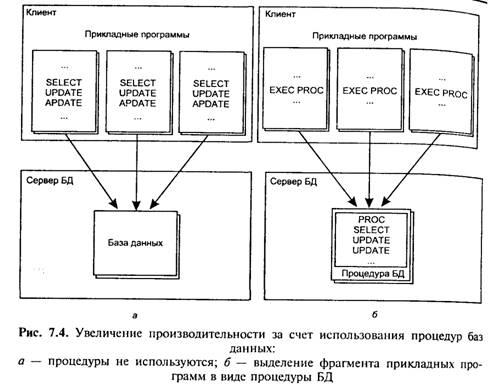
• одна и та же процедура может использоваться несколькими прикладными программами — это позволяет существенно сократить время написания программ за счет оформления их общих частей в виде процедур базы данных. Процедура компилируется и помещается в базу данных, становясь доступной для многократных вызовов. Так как план ее выполнения определяется единожды при компиляции, то при последующих вызовах процедуры фаза оптимизации пропускается, что существенно экономит вычислительные ресурсы системы;
• значительное снижение трафика сети в системах с архитектурой «клиент—сервер». Прикладная программа, вызывающая процедуру, передает серверу лишь ее имя и параметры. В процедуре, как правило, концентрируются повторяющиеся фрагменты из нескольких прикладных программ (рис. 7.4). Если бы эти фрагменты остались частью программы, они загружали бы сеть посылкой полных SQL-запросов;
• процедуры базы данных в сочетании с правилами, о которых речь пойдет ниже, предоставляют администратору мощные средства поддержки целостности базы данных.
Процедура обычно хранится непосредственно в базе данных и контролируется ее администратором. Она имеет параметры и возвращает значение. Процедура базы данных создается оператором CREATE PROCEDURE (СОЗДАТЬ ПРОЦЕДУРУ) И содержит определения переменных, операторы SQL (например, SELECT, INSERT), операторы проверки условий (if/then/else), операторы цикла (for, while), а также некоторые другие.
Пусть, например, необходимо разработать процедуру, которая переводила бы рядового сотрудника в резерв на выдвижение на руководящую должность. Процедура Назначение перемещает строки из таблицы Сотрудник, которая содержит сведения о сотрудниках, в таблицу Резерв для всех сотрудников с указанным номером. Номер сотрудника представляет собой целое число (тип integer), который не может иметь пустое значение, является параметром процедуры и передается ей при вызове из прикладной программы оператором execute procedure (выполнить процедуру):

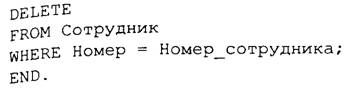
Правила Механизм правил (триггеров) позволяет программировать обработку ситуаций, возникающих при любых изменениях в базе данных.
Правило придается таблице базы данных и применяется при выполнении над таблицей операций включения, удаления или обновления строк.
Одна из целей механизма правил — отражение некоторых внешних правил деятельности организации. Пусть, например, в базе данных Склад содержится таблица Деталь, хранящая сведения о наличии деталей на складе завода. Одно из правил деятельности завода заключается в том, что недопустима ситуация, когда на складе число деталей любого типа становится меньше некоторого числа (например, 1000).
Это требование может быть описано правилом Проверить_деталь. Оно применяется в случае обновления столбца количество таблицы Деталь: если новое значение в столбце меньше 1000, то выполняется процедура Заказать_деталь. В качестве параметров ей передаются номер детали данного типа и остаток (число деталей на складе):

Таким образом, если возникает ситуация, когда на складе количество деталей какого-либо типа становиться меньше требуемого, запускается процедура базы данных, которая заказывает недостающее количество деталей этого типа. Заказ сводится к посылке письма (например, по электронной почте), на завод или в цех, который изготавливает данные детали. Все это происходит автоматически, без вмешательства пользователя.
Важнейшая цель механизма правил — обеспечение целостности базы данных. Один из аспектов целостности — целостность по ссылкам (referential integrity) — относится к связи двух таблиц между собой.
Допустим, таблица Руководитель содержит сведения о начальниках, а таблица Сотрудник — о сотрудниках некоторой организации (см. рис. 5.6). Столбец Номер_руководителя является внешним ключом таблицы Сотрудник и ссылкой на таблицу Руководитель.
Для обеспечения целостности ссылок должны быть учтены два требования. Во-первых, если в таблицу Сотрудник добавляется новая строка, значение столбца номер руководителя должно быть взято из множества значений столбца Номер таблицы Руководитель (сотрудник может быть подчинен только реальному руководителю). Во-вторых, при удалении любой строки из таблицы Руководитель в таблице Сотрудник не должно остаться ни одной строки, в которой в столбце Номер_руководителя было бы значение, тождественное значению столбца Номер в удаляемой строке (все сотрудники, если их руководитель уволился, должны перейти в подчинение другому).
Для того чтобы учесть эти требования, должны быть созданы правила, их реализующие. Первое правило Добавить_сотрудника срабатывает при включении строки в таблицу Сотрудник; его применение заключается в вызове процедуры Проверить_руководителей, устанавливающей, существует ли среди множества значений столбца Номер таблицы Руководитель значение, тождественное значению поля Номер_руководителя добавляемой строки. Если это не так, процедура должна ее отвергнуть. Второе правило применяется при попытке удалить строку из таблицы Руководитель; оно состоит в вызове процедуры, которая сравнивает значения в столбце Номер_руководителя таблицы Сотрудник со значением поля Номер в удаляемой строке. В случае совпадения значение в столбце Номер_руководителя обновляется.

Механизм правил позволяет реализовать и более общие ограничения целостности. Пусть, например, таблица Сотрудник содержит информацию о сотрудниках, в том числе имя и название отдела, в котором они работают. Таблица Отдел хранит для каждого отдела количество работающих в нем сотрудников в столбце Количество_сотрудников. Одно из ограничений целостности заключается в том, что это количество должно совпадать с числом строк для данного отдела в таблице Сотрудник. Чтобы это ограничение, можно использовать правило Добавить_сотрудника, которое применяется при включении строки в таблицу Сотрудник и запускает процедуру Новый_сотрудник. Она, в свою очередь, обновляет значение столбца Количество_сотрудников, увеличивая его на единицу. Параметр процедуры — название отдела.

Разумеется, на практике с помощью механизма правил реализуются более сложные и изощренные ограничения целостности.
Аналогом правил послужили триггеры (triggers), которые впервые появились в СУБД Sybase и впоследствии были реализованы в том или ином виде и под тем или иным названием в большинстве многопользовательских СУБД.
События в базе данных. Механизм событий в базе данных (database events) позволяет прикладным программам и серверу базы данных уведомлять другие программы о наступлении в базе данных определенного события и тем самым синхронизировать их работу. Операторы языка SQL, обеспечивающие уведомление, часто называют сигнализаторами событий в базе данных (database event alerters). Функции управления событиями целиком ложатся на сервер базы данных.
Рисунок 7.5 иллюстрирует один из примеров использования механизма событий: различные прикладные программы и процедуры вызывают события в базе данных, а сервер оповещает монитор прикладных программ об их наступлении. Реакция монитора на события заключается в выполнении действий, которые предусмотрел его разработчик.
Механизм событий используется следующим образом. Вначале в базе данных для каждого события создается флажок, состояние которого будет оповещать прикладные программы о том, что некоторое событие имело место (оператор create dbevent - создать событие). Далее, во все прикладные программы, на ход выполнения которых может повлиять это событие, включается оператор register dbevent (зарегистрировать событие), который оповещает сервер базы данных, что программа заинтересована в получении сообщения о наступлении события.
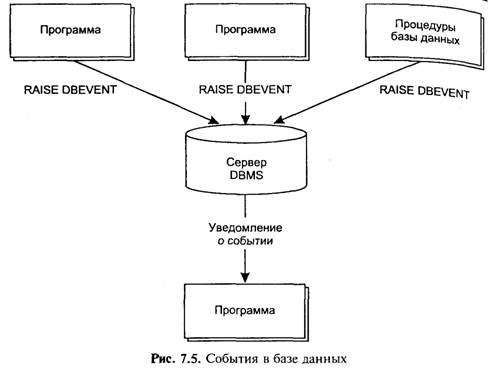
Теперь любая прикладная программа или процедура базы данных может вызвать событие оператором RAISE dbevent (вызвать событие) . Как только событие произошло, каждая зарегистрированная программа может получить его, для чего она должна запросить очередное сообщение из очереди событий (оператор get dbevent — получить событие) и запросить информацию о событии, в частности его имя (оператор SQL INQUIRE_SQL).
Следующий пример иллюстрирует обработку всех событии из очереди:


Рассмотрим пример из производственной системы, иллюстрирующий использование механизма событий в базе данных совместно с правилами и процедурами. События используются для определения ситуации, когда рабочий инструмент нагревается до температуры свыше допустимой и должен быть отключен.
Создается правило, которое применяется всякий раз, когда новое значение температуры инструмента заносится в таблицу Инструмент. Как только оно превосходит 500 градусов, правило вызывает процедуру Отключить__инструмент.

Создается процедура базы данных Отключить_инструмент, которая вызывает событие Перегрев; она будет выполнена в результате применения правила, определенного на шаге 1.

Создается событие Перегрев, которое будет вызвано, когда инструмент перегреется:
![]()
Наконец создается прикладная программа Монитор_Инструментов, которая следит за состоянием инструментов. Она регистрируется сервером в качестве получателя события Перегрев с помощью оператора register dbevent. Если событие произошло, программа посылает сообщение пользователю и сигнал необходимый для отключения инструмента:

Описанные выше конструкции в совокупности определяют логику работы (рис. 7.6).
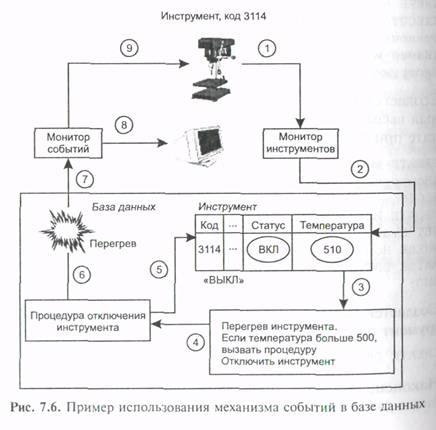
Прикладная программа Монитор_Инструментов периодически регистрирует с помощью датчиков текущие значения параметров множества различных инструментов и заносит в таблицу Инструмент новое значение температуры для данного инструмента.
Всякий раз, когда это происходит, т. е. обновляется значение столбце Температура таблицы Инструмент, применяется правило Перегрев_инструмента.
Применение правила состоит в проверке нового значения температуры. Если оно превышает максимально допустимое, то запускается процедура Отключить_инструмент.
В том случае, когда используются традиционные методы опроса БД, логика работы была бы совершенно иной. Пришлось бы разработать дополнительную программу, которая периодически выполняла бы операцию выборки из таблицы Инструмент по критерию Температура > 500. Это очень сильно сказалось бы на эффективности, поскольку операция select является ресурсоемкой. Разумеется, пример приведен лишь для иллюстрации схемы срабатывания механизма «правило — процедура — событие».
7.4. Схемы размещения и доступа к данным в распределенных БД
Размещение данных в распределенных БД характеризуется следующими понятиями:
• фрагментация. Любая запись (отношение в случае реляционных моделей данных) может быть разделено на некоторое количество частей, называемых фрагментами, которые затем могут распределяться по различным узлам. Как отмечалось ранее, существуют два основных типа фрагментации: горизонтальная и вертикальная. В первом случае фрагменты представляют собой подмножества строк, а во втором — подмножества столбцов (атрибутов);
• размещение. Каждый фрагмент сохраняется на узле, выбранном с учетом оптимальной схемы доступа;
• репликация. Распределенная СУБД может поддерживать актуальную копию некоторого фрагмента на нескольких различных узлах.
Определение и размещение фрагментов должно проводить с учетом особенностей использования базы данных (в частности, на основе анализа транзакций).
Существуют четыре стратегии размещения данных в системе: Централизованное размещение. Данная стратегия предусматривает создание на одном из узлов единственной базы данных под управлением СУБД, доступ к которой будут иметь все пользователи сети.
2. Фрагментированное размещение. В этом случае база данных разбивается на непересекающиеся фрагменты, каждый из которых размещается на одном из узлов системы.
3. Размещение с полной репликацией. Эта стратегия предусматривает размещение полной копии всей базы данных на каждом из узлов системы. Стоимость устройств хранения данных и уровень затрат на передачу информации об обновлениях в этом случае также будут самыми высокими. Для преодоления части этих проблем в некоторых случаях используется технология снимков. Снимок представляет собой копию базы данных в определенный момент времени. Эти копии обновляются через некоторый установленный интервал времени, например 1 раз в час или в сутки.
4. Размещение с избирательной репликацией. Данная стратегия представляет собой комбинацию методов фрагментации, репликации и централизации. Одни массивы данных разделяются на фрагменты, что позволяет добиться для них высокой локализации ссылок, тогда как другие, используемые на многих узлах, но не подверженные частым обновлениям, подвергаются репликации. Все остальные данные хранятся централизованно.
Управление параллельной обработкой в распределенных БД
При параллельной обработке данных (совместной работе нескольких пользователей с общими данными) СУБД должна гарантировать, что пользователи не будут мешать друг другу (сюда относятся, например, проблемы потерянного обновления, зависимости от промежуточных результатов, несогласованности обработки, несогласованности многих копий данных) и их деист вия будут изолированы. Такими единицами изолированности являются транзакции — неделимая (с точки зрения воздействия на состояние целостности БД) последовательность операторов управления данными.
Решения по организации управления параллельным выполнением в распределенной среде основаны на подходах с использованием механизмов блокировок и временных отметок:
• механизм блокировки создает такие условия, что график параллельного выполнения транзакций будет эквивалентен некоторому (но, в общем случае, непредсказуемому) варианту последовательного выполнения этих транзакций;
• механизм обработки временных отметок гарантирует, что график параллельного выполнения транзакций будет эквивалентен конкретному варианту последовательного выполнения этих транзакций в соответствии с их временными отметками.
Механизм блокировки реализуется в виде следующих протоколов двухфазной блокировки (2PL — two-phase lock):
1. При использовании централизованного протокола двухфазной блокировки существует единственный узел, на котором хранится вся информация о блокировке элементов данных в системе. Поэтому во всей распределенной СУБД существует только один диспетчер блокировок, способный устанавливать и снимать блокировку с элементов данных.
2. При двухфазной блокировке с первичными копиями функции диспетчера блокировок распределены по нескольким узлам. Каждый локальный диспетчер отвечает за управление блокировкой некоторого набора элементов данных. В процессе репликации для каждого копируемого элемента данных одна из копий выбирается в качестве первичной копии, а все остальные Рассматриваются как вторичные (зависимые).
3-При использовании распределенного протокола двухфазной блокировки диспетчеры блокировок размещены в каждом узле системы. Каждый отвечает за управление блокировкой данных, находящихся на его узле. Если данные не подвергаются репликации, этот протокол функционирует аналогично протоколу двухфазной блокировки с первичными копиями.
В противном случае распределенный протокол двухфазной блокировки использует особый протокол управления репликацией, получивший название «чтение одной копии и обновление всех копии». В этом случае для операций чтения может использоваться любая копия элемента, но прежде чем можно будет обновит значение элемента, должны быть установлены исключительные блокировки на всех копиях.
4. При использовании протокола блокировки большинства копий диспетчер блокировок также имеется на каждом из узлов системы, но, когда транзакции требуется считать или записать элемент данных, копии которого имеются на узлах системы, она должна отправить запрос на блокировку этого элемента более чем на половину из всех тех узлов, где имеются его копии. Транзакция не имеет права продолжать свое выполнение пока не установит блокировки на большинстве копий элемента данных. Если ей не удастся это сделать за некоторый установленный промежуток времени, она отменяет свои запросы и информирует все узлы об отмене ее выполнения.
Двухфазные протоколы не могут устранить возможность взаимной блокировки, поскольку при их использовании может возникнуть ситуации, когда некоторый узел остается заблокированным. Например, процесс, который обнаружил истечение тайм-аута после отправки своего согласия на фиксацию транзакции, но так и не получил глобального подтверждения от координатора, остается заблокированным, если может взаимодействовать только с узлами, которые также не имеют сведений о принятом глобальном решении. Неблокирующий протокол трехфазной фиксации транзакций не имеет периода ожидания в состоянии неопределенности, в которое переходят участники с момента подтверждения своего согласия на фиксацию транзакции и до момента получения от координатора извещения о глобальной фиксации или глобальном откате. В трехфазном протоколе между этапами голосования и принятия глобального решения вводится третий этап, называемый предфиксацией. После получения результатов голосования всех участников координатор рассылает глобальное сообщение precommit. Таким образом, участник, получивший глобальное извещение о предфиксации, знает, что все остальные участники проголосовали за фиксацию результатов транзакции и что со временем сам этот участник также выполнит фиксацию транзакции, если не произойдет отказ. Далее каждый участник подтверждает получение сообщения о предфиксации, и после чего координатор, получив все подтверждения, рассылает команду глобальной фиксации транзакции.
Многоуровневая модель предметной области для распределенных БД
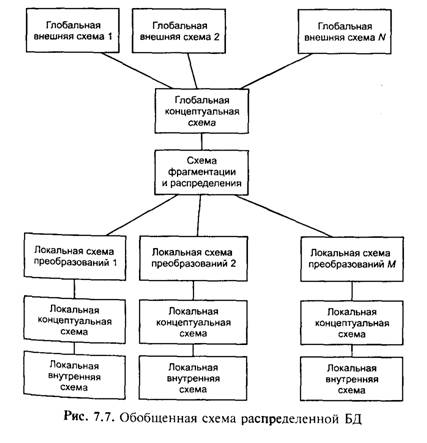
Архитектурная модель ANSI/SPARC, представляющая собой классическое решение для локальных СУБД, может быть расширена на случай распределенных СУБД. На рис. 7.7 приведена обобщенная схема архитектуры распределенной БД, где в верхней части присутствуют схемы глобального уровня, обеспечивающие целостное представление БД, как если бы она была локальной.
Здесь на внешнем уровне может поддерживаться совсем иная модель данных (или даже несколько моделей), чем на концептуальном уровне. Поддержка разнообразных возможностей абстрагирования в такой системе достигается благодаря средствам определения и поддержки межуровневого отображения моделей данных. Схемы фрагментации и распределения определяют размещение логических сегментов данных по физическим разделам (локальным БД), а локальная схема преобразования обеспечивает отображение фрагментов во внешние схемы. При этом локальные концептуальные и внутренние схемы определяют в соответствии с концепцией представление данных с учетом особенностей конкретной СУБД.
Технологии и средства удаленного доступа
Распределенные корпоративные приложения все более усложняются, интегрируя в себя унаследованные приложения, разрабатываемые и вновь приобретаемые готовые программные средства. Кроме того, разные подсистемы решают разные бизнес – задачи, однако одна из главных целей создания корпоративной системы — получить «единый образ» общего состояния системы, что обеспечит пользователям доступ к нужным ресурсам.
Основа такой инфраструктуры — так называемое промежуточное программное обеспечение, позволяющее, не вникая в тонкости сетевых реализаций, создавать и эксплуатировать взаимодействующие между собой приложения с разными требованиями к межмодульным коммуникациям.
Промежуточное ПО эволюционировало вместе с архитектурой «клиент—сервер». Ранние, но достаточно эффективные как с точки зрения разработки, так и эксплуатации, частные решения предназначались для упрощения доступа к базам данных в двухзвенной модели, где «толстый клиент» реализует всю логику обработки информации, предоставляемой сервером базы данных. Такие системы вполне удовлетворяли потребностям небольших корпоративных подразделений с ограниченным числом пользователей и невысокой интенсивностью обмена.
Этот способ реализации клиент-серверной схемы доступа ограничивает возможности масштабирования, поскольку увеличение числа обращений к одной базе данных значительно увеличивает нагрузку на сервер и делает доступ к данным «узким местом» в общей производительности системы. Кроме того, всякая модификация логики приложения требовала внесения изменений во все экземпляры клиентских приложений.
Чтобы избежать таких проблем, для разработки корпоративных приложений используют трехзвенную модель, которая переносит логику приложения на отдельный уровень сервера приложений. В результате клиентская часть приложения становится «тоньше» и в основном отвечает за предоставление удобного пользовательского интерфейса.
Развитие этого среднего звена клиент-серверной модели идет сторону усложнения. Ограничиваясь вначале построением более высокого уровня абстракции для взаимодействия приложения с ресурсами данных, разработчик приложения получал возможность использовать общие API (Application Program Interface), которые скрывали различия специфических интерфейсов коммуникационных протоколов более низкого уровня, например TCP/IP, Sockets или DECNet. Однако теперь этого уже явно недостаточно для построения сложных распределенных приложений. Современные решения не только обеспечивают межпрограммное взаимодействие, но и являются платформой для реализации сервера приложений, обеспечивая обширный набор необходимых служб: управления транзакциями, именования, защиты и т. д.
Вычислительная среда распределенных приложений может включать в себя различные операционные системы, аппаратные платформы, коммуникационные протоколы и разнообразные средства разработки. Соответственно, формат представления данных в различных узлах будет различаться.
Таким образом, в распределенной неоднородной среде программное обеспечение промежуточного уровня играет роль «информационной шины», надстроенной над сетевым уровнем и обеспечивающей доступ приложения к разнородным ресурсам, а также независимую от платформ взаимосвязь различных прикладных компонентов, изолирующую логику приложений от уровня сетевого взаимодействия и ОС.
ПО промежуточного уровня можно разделить на две категории:
• доступа к базам данных (например, ODBC-интерфейсы и SQL-шлюзы);
• межмодульного взаимодействия — системы, реализующие вызов удаленных процедур (RPC — Remote Procedure Call), мониторы обработки транзакций (ТР-мониторы), средства интеграции распределенных объектов.
При этом следует отметить, что различия прикладных задач не позволяют построить универсальное ПО, реализовав в одном продукте все необходимые возможности.
Двухзвенные клиент-серверные архитектуры
В простых двухзвенных моделях клиент—сервер, где сколько баз данных обслуживают ограниченное число пользователей настольных ПК, в роли встроенного ПО доступа к данным могут выступать обычные ODBC-драйверы.
Необходимость в более сложных решениях возникает в больших, разнородных многозвенных системах, где множество приложений в параллельном режиме осуществляет доступ к разнообразным источникам данных, включая разнотипные СУБД и хранилища данных. В таких системах между клиентами и серверами баз данных размещается промежуточное звено — SQL-шлюз, который представляет собой набор общих API, позволяющих разработчику строить унифицированные запросы к разнородным данным (в формате SQL или с помощью ODBC-интерфейса). SQL-шлюз выполняет синтаксический разбор такого запроса, анализирует и оптимизирует его и в конце концов выполняет преобразование в SQL-диалект нужной СУБД. ПО этого типа реализует синхронный механизм связи, когда выполнение приложения, сделавшего запрос, блокируется до момента получения данных.
Каждое приложение, построенное на основе архитектуры «клиент—сервер», включает, как минимум, две части: клиентскую и серверную часть. В общем случае предполагается, что эти части приложения функционируют на отдельных компьютерах, т. е. к выделенному серверу БД с помощью сети подключены узлы-компьютеры пользователей (клиенты). При этом узел-клиент сам может быть СУБД.
Рассмотрим различные способы организации двухуровневого доступа прикладной программы к серверу базы данных в двухзвенной архитектуре.
Открытый интерфейс баз данных ODBC. Спецификация открытого интерфейса баз данных (ODBC — Open Database Connectivity) предназначена для унификации доступа к данным, размещенным на удаленных серверах. ODBC опирается на спецификации CLI.
ODBC представляет собой программный слой, унифицирующий интерфейс взаимодействия приложений с базами данных. За реализацию особенностей доступа к каждой отдельной СУЬД отвечает соответствующий специальный ODBC-драйвер. Пользовательское приложение этих особенностей не видит, так как взаимодействует с универсальным программным слоем более высокого уровня. Таким образом, приложение становится в значительной степени независимым от СУБД. Вместо создания в каждом отдельном случае СУБД-приложения с обращениями через встроенный, но быстро устаревающий интерфейс можно использовать один общий стандартизированный программный интерфейс.
В архитектуре ODBC используется один ODBC Driver Manager и несколько ODBC-драйверов, обеспечивающих доступ к конкретным СУБД. Driver Manager связывает приложение и интерфейсные объекты, которые выполняют обработку SQL-запросов к конкретной СУБД (рис. 7.8).
Такой подход является достаточно универсальным, стандартизируемым, что и позволяет использовать ODBC-механизмы для работы практически с любой системой, однако этот способ также не лишен недостатков:

• увеличивается время обработки запросов (как следствие введения дополнительного программного слоя);
• необходимы предварительная инсталляция и настройка ODBC-драйвера (указание драйвера СУБД, сетевого пути к серверу, базы данных и т. д.) на каждом рабочем месте. Параметры этой настройки являются статическими, т. е. приложение изменить их самостоятельно не может.
Мобильный интерфейс к базам данных на платформе Java — JDBC (Java Data Base Connectivity) — это интерфейс прикладного программирования (API) для выполнения SQL-запросов к базам данных из программ, написанных на платформенно – независимом языке Java, позволяющем создавать как самостоятельные приложения (standalone application), так и аплеты, встраиваемые в Web-страницы.
JDBC во многом подобен ODBC, он также построен на основе спецификации CLI, однако имеет ряд следующих отличий;
• приложение загружает JDBC-драйвер динамически, следовательно, администрирование клиентов упрощается, более того, появляется возможность переключаться на работу с другой СУБД без перенастройки клиентского рабочего места;
• JDBC, как и Java в целом, не привязан к конкретной аппаратной платформе, следовательно проблемы с переносимостью приложений практически снимаются;
• использование Java-приложений и связанной с ними идеологии «тонких клиентов» обещает снизить требования к оборудованию клиентских рабочих мест.
Прикладные интерфейсы OLE DB и ADO. OLE DB (Object Linking and Embedding Data Base), как и ODBC — это прикладные интерфейсы доступа к данным с использованием SQL.
OLE DB специфицирует взаимодействие, обеспечивая единый интерфейс доступа к данным через провайдеров — поставщиков данных не только из реляционных БД. В отличие от ODBC, OLE DB предоставляет общее решение обеспечения СОМ-приложениям доступа к информации независимо от типа источника данных.
OLE DB включает два базовых компонента: провайдер данных и потребитель данных. Потребитель (клиент) — это приложение или СОМ-компонент, обращающийся посредством АР1-вызовов к OLE DB. Провайдер (сервер) — это приложение, отвечающее на вызовы OLE DB и возвращающее запрашиваемый объект — обычно это данные в табличном виде.
ADO (Active Data Object) — это универсальный интерфейс высокого уровня к OLE DB. Модель объекта ADO не содержит таблиц, среды или машины БД. Здесь основными объектами являются следующие: объект Соединение, создающий связь с провайдером данных; объект Набор данных и объект Команда — выполнение процедуры, SQL-строки.
В общем случае ADO можно рассматривать как язык программирования с БД, позволяющий выбирать, модифицировать и удалять записи. Поскольку он опирается на универсальный OLE DB, то может использоваться практически в любых приложениях Microsoft.
Взаимосвязь механизмов доступа к данным
Рассмотренные технологии построения приложения ориентированы на извлечение данных непосредственно из статического источника (хранилища данных) и не могут обращаться за данными к другому прикладному модулю.
Один из способов организации доступа к данным заключается в непосредственном использовании API. Однако это означает полную зависимость создаваемого приложения от используемой СУБД. В этом случае переход к другой системе (например, для перехода от настольной системы к системе типа клиент—сервер) влечет за собой переписывание большей части программного кода клиентского приложения.
Таким образом, следующим этапом в обеспечении доступа клиентского приложения к данным является создание универсального механизма доступа к БД, обеспечивающего для клиентского приложения стандартный набор функций, классов или сервисов (служб), необходимых для работы с различными системами управления базами данных. Эти стандартные функции (классы или сервисы) должны размещаться в библиотеках, именуемых драйверами или провайдерами баз данных (data base drivers (providers)). Каждая такая библиотека реализует набор стандартных функций, классов или сервисов, используя обращения API к конкретной СУБД.
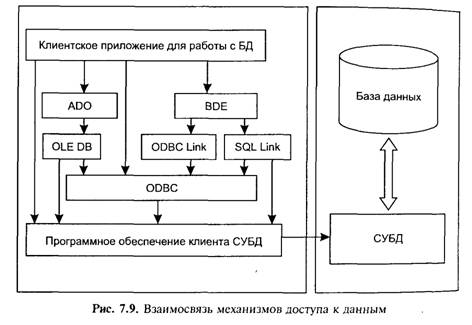
Наиболее популярными механизмами доступа к данным (Universal Data Access — UDA) в настоящий момент являются: ODBC, OLE DB, ADO, BDE.
Первые три являются фактически промышленными стандартами. Последний долгое время был единственным механизм доступа к данным, реализованным в инструментальных средствах разработки компании Borland-Inprise (например Delnhi, C++ Builder).
На рис. 7.9 схематически представлены различные механизмы доступа к данным, включая непосредственные вызовы клиентской частью API системы управления базой данных.
Технологии межмодульного взаимодействия
(трехуровневая архитектура)
Технологии, реализующие трехуровневую архитектуру взаимодействия клиента и сервера, включают ПО промежуточного слоя — сервер приложений, через который один прикладной модуль, используя специальные протоколы, получает данные из другого модуля. Появление серверов приложений как отдельных готовых решений связано и с бурным вторжением Web-технологий в сферу корпоративных высоко критичных систем. Однако возможности протокола HTTP ограничены функциями связи без каких-либо средств сохранения информации о состоянии, поэтому он не подходит для поддержки мощных корпоративных систем.
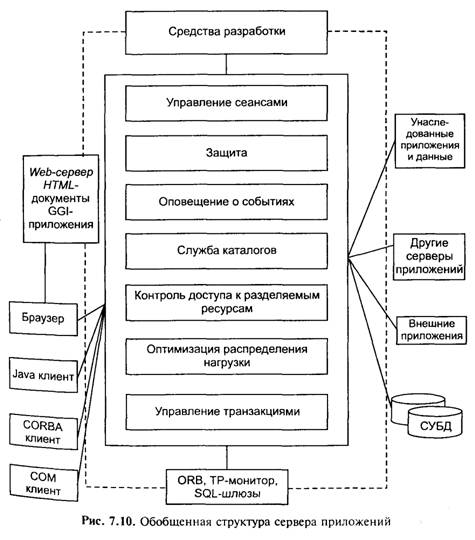
На рис. 7.10 приведен обобщенный состав сервера приложений с набором служб и средств связи с клиентскими системами и информационными ресурсами.
Спецификация вызова удаленных процедур. Протокол вызова удаленных процедур (Remote Procedure Calls — RPC) реализуй асимметричное взаимодействие программных компонентов, когда можно выделить клиента, которому требуется некоторая услуга, и сервер, который такую услугу способен оказать, причем, как правило, клиент не может продолжать свое выполнение, пока сервер не произведет требуемые от него действия. С точки зрения клиентской программы обращение к серверу ничем не отличается от вызова локальной процедуры.
Средства вызова удаленных процедур (RPC) поддерживают синхронный режим коммуникаций между двумя прикладными модулями (клиентом и сервером).
Для установки связи, передачи вызова и возврата результата клиентский и серверный процессы обращаются к специальным процедурам — клиентскому и серверному суррогатам (client stub и server stub). Эти процедуры не реализуют никакой прикладной логики и предназначены только для организации взаимодействия удаленных прикладных модулей.
Каждая функция на сервере, которая может быть вызвана удаленным клиентом, должна иметь такой суррогатный процесс. Если клиент вызывает удаленную процедуру, вызов вместе с параметрами передается клиентскому суррогату. Он упаковывает эти данные в сетевое сообщение и передает его серверному суррогату. Тот, в свою очередь, распаковывает полученные данные и передает их реальной функции сервера и затем проделывает обратную процедуру с результатами. Таким образом изолируются прикладные модули клиента и сервера от уровня сетевых коммуникаций.
Ключевым компонентом RPC является язык описания интерфейсов (interface definition language — IDL), предназначенный для определения интерфейсов, которые задают контрактные отношения между клиентом и сервером. Интерфейс содержит определение имени функции и полное описание передаваемых параметров и результатов выполнения.
Язык IDL обеспечивает независимость механизма RPC от языков программирования — вызывая удаленную процедуру, клиент может использовать свои языковые конструкции, преобразуются в конструкции языка программирования, на котором реализован серверный процесс.
Транзакции в распределенных БД
Если данные хранятся в одной базе данных, то транзакция к ней рассматривается как локальная. В распределенных базах транзакция, выполнение которой заключается в обновлении данных на нескольких узлах сети, называется глобальной или распределен ной транзакцией.
Внешне выполнение распределенной транзакции выглядит как обработка транзакции к локальной базе данных. Тем не менее распределенная транзакция включает в себя несколько локальных транзакций, каждая из которых завершается двумя путями — фиксируется или прерывается. Распределенная транзакция фиксируется только в том случае, когда зафиксированы все локальные транзакции, ее составляющие.
В современных СУБД предусмотрен так называемый протокол двухфазовой (или двухфазной) фиксации транзакций (two-phase commit).
Фаза 1 начинается, когда при обработке транзакции встретился оператор commit. Сервер распределенной БД (или компонент СУБД, отвечающий за обработку распределенных транзакций) направляет уведомление «подготовиться к фиксации» всем серверам локальных БД, выполняющим распределенную транзакцию. Если все серверы приготовились к фиксации (т. е. откликнулись на уведомление и отклик был получен), сервер распределенной БД принимает решение о фиксации. Серверы локальных БД остаются в состоянии готовности и ожидают от него команды «зафиксировать». Если хотя бы один из серверов не откликнулся на уведомление в силу каких-либо причин, будь то аппаратная или программная ошибка, то сервер распределенной БД откатывает локальные транзакции на всех узлах, включая даже те, которые подготовились к фиксации и оповестили его об этом.
Фаза 2 — сервер распределенной БД направляет команду зафиксировать» всем узлам, затронутым транзакцией, и гарантирует, что транзакции на них будут зафиксированы. Если связь с локальной базой данных потеряна в интервал времени между Моментом, когда сервер распределенной БД принимает решение о Фиксации транзакции, и моментом, когда сервер локальной А подчиняется его команде, то сервер распределенной БД продолжает попытки завершить транзакцию, пока связь не будет восстановлена.
Мониторы обработки транзакций. Мониторы обработки транзакций (Transaction Processing Monitor — ТРМ), или мониторы транзакций — это программные системы (которые относят к категории middleware, т. е. к посредническому промежуточному ПО), решающие задачу эффективного управления информационно-вычислительными ресурсами в распределенной системе.
Первоначально основной задачей ТРМ в среде клиент — сервер было сокращение числа соединений клиентских систем с базами данных. При непосредственном обращении клиента к серверу базы данных для каждого клиента устанавливается соединение с СУБД, которое порождает запуск отдельного процесса в рамках операционной системы. ТР-мониторы брали на себя роль концентратора таких соединений, становясь посредником между клиентом и сервером базы данных. Основное назначение ТР-мониторов — автоматизированная поддержка приложений, представленных в виде последовательности транзакций.
Одна из основных функций ТРМ — обеспечение быстрой обработки запросов, поступающих к серверу приложений от множества клиентов (от сотен до тысяч). ТРМ выполняет ее, мультиплексируя запросы на обслуживание, направляя их серверам приложения, число которых контролируется им самим.
Важнейшая характеристика ТРМ — поддержка многомашинных конфигураций с возможностью миграции серверов приложений и их групп на резервный компьютер в случае сбоев в работе основного — является фундаментом, на котором может быть построена система, по надежности близкая к абсолютной. Действительно, применение так называемых безотказных (fault tolerant) компьютеров гарантирует сохранение работоспособности лишь при случайных сбоях, но бессильно перед злоумышленником или в случае механического повреждения.
На современном рынке мониторов транзакций основными являются такие системы, как ACMS (DEC), CICS (IBM), TOP END (NCR), PATHWAY (Tandem), ENCINA (Transarc), TUXEDO Sytem (Novell). Наиболее известной из этой группы является система CICS (Customer Information Control System), работавшая на мэйнфрейме IBM.
Модель обработки транзакций. Понятия транзакции в ТРМ в традиционных СУБД значительно отличаются. Суть остается одной, но в понимании СУБД транзакция — это атомарное действие над базой данных, в то время как в ТРМ транзакция трактуется гораздо шире. Она включает не только операции с данными, но и любые другие действия — передачу сообщений, выдачу отчетов, запись в индексированные файлы, опрос датчиков и т.д. Это позволяет реализовать в ТРМ прикладные транзакции, бизнес-транзакции, которые в СУБД не предусмотрены.
ТРМ опирается на модель обработки распределенных транзакций X/Open DTP, которая описывает взаимодействие трех субъектов обработки транзакций — прикладной программы (в качестве прикладной программы фигурирует как сервер приложения, так и клиент приложения), менеджера транзакций (Transaction Manager — ТМ) и менеджера ресурсов (Resource Manager — RM). Модель представлена на рис. 7.11.

Ha RM возложено управление информационными ресурсами — будь то файлы, базы данных или что-то другое. Приложение взаимодействует с RM либо с помощью набора специальных функций, либо (если в качестве RM выступает реляционная SQL-ориентированная СУБД) посредством операторов языка SQL, инициируя необходимые операции с данными. Последние оформляются как транзакции, обработку которых берет на себя ТМ. Если с помощью монитора транзакций необходимо решать задачи обработки распределенных транзакций, то роль менеджера ресурсов должна играть СУБД, поддерживающая двухфазовый протокол фиксации транзакций и удовлетворяющая стандарту X/Open XA (например, Oracle 7.x, ОрenINGRES, Informix-Online 7.x).
Роль ТМ в модели X/Open DTP — это роль диспетчера, главного координатора транзакций. Он обладает полным набором Функций управления как локальными, так и глобальными распределенными транзакциями. В последнем случае транзакция может обновлять данные на нескольких узлах, причем управление данными на них, вообще говоря, осуществляется различными RM. Обработка распределенных транзакций обеспечивается за счет использования протокола двухфазовой фиксации транзакций, который гарантирует целостность данных в информационной системе, распределенной по нескольким узлам, независимо от того, какой RM управляет обработкой данных на каждом таком узле. Эта уникальная возможность как раз и позволяет рассматривать ТРМ как средство интеграции в гетерогенной информационной среде.
Функции ТМ в модели X/Open DTP не ограничиваются только управлением транзакциями. Он берет на себя также координацию взаимодействия клиента и сервера (поэтому иногда его называют менеджером транзакций и коммуникаций). При этом используется высокоуровневый интерфейс ATMI, представляющий собой набор вызовов функций на языке третьего поколения (например, на языке Си). С его помощью разработчик реализует один из нескольких режимов взаимодействия клиента и сервера в рамках расширенной модели «клиент—сервер». Ни сервер приложения, ни клиент приложения не содержат явных вызовов менеджера транзакций — они включены в библиотечные функции ATMI и «невидимы» извне. Таким образом, детали взаимодействия прикладной программы и монитора транзакций скрыты от разработчика, что и дает основание говорить об ATMI как о высокоуровневом интерфейсе.
Функциональный подход. Фундаментальная характеристика ТРМ — функциональный (function-centric) подход к проектированию бизнес-приложений — сосредоточение всех прикладных функций в серверах приложений по сути означает поставку (или предоставление) функций (functions shipping) для программы-клиента, в отличие от традиционной архитектуры с сервером базы данных, следующей парадигме поставка (или предоставление) данных (data shipping).
Возможность декомпозиции приложений по нескольким уровням с четко очерченными функциями и стандартными интерфейсами позволяет создавать легко модифицируемые системы со стройной и целостной архитектурой. Концентрация чисто прикладных функций в серверах приложений и использование унифицированных интерфейсов с другими логическими компонентами делает прикладную систему практически полностью независимой как от конкретной реализации интерфейса с пользователем, так и от необходимого ей менеджера ресурсов. Первое означает, что для реализации интерфейса с пользователем может быть выбран практически любой удобный и привычный для разработчика инструментарий, будь то Microsoft Visual C++ или Visual Basic; следствием второго является то, что менеджер ре-сов (например, СУБД) может быть заменен на другой, поддерживающий тот же стандарт интерфейса с прикладной программой. Для реляционных СУБД в качестве унифицированного интерфейса используется встроенный (embedded) SQL. Разумеется, в реализации ESQL для каждой конкретной СУБД имеются различия, порой весьма существенные. Поэтому приложение должно быть либо разработано специально с целью работы с конкретной СУБД, либо оно должно быть спроектировано так, чтобы максимально безболезненно перенастраиваться на работу с другой СУБД.
Функциональный подход имеет своим следствием и преимущества администрирования приложения. Отныне оно рассматривается как единое целое; сервер приложения имеет набор параметров, устанавливаемых его администратором; как и сервер БД, сервер приложения запускается и останавливается специальными командами; существуют команды, позволяющие опросить параметры сервера приложения и вывести их на консоль.
Таким образом снимается одно из серьезных ограничений производительности и масштабируемости клиент-серверной среды — необходимость поддержки отдельного соединения с базой данных для каждого клиента.
7.5. Объектно-ориентированные технологии распределенной обработки
Сегодня наибольшее применение для разработок приложений распределенной обработки находят две компонентные модели — DCOM и CORBA. Эти технологии реализуют трехуровневую архитектуру модели «клиент—сервер». Введение специального промежуточного слоя — сервера приложений, которому «делегированы полномочия» организации взаимодействия клиента и сервера, обеспечивает возможность интеграции объектов, размещенных на машинах разных платформ и под управление разнотипных операционных систем.
Обе модели распространяют принципы вызова удаленных процедур на объектные распределенные приложения и обеспечивают прозрачность реализации и физического размещения серверного объекта для клиентской части приложения; поддерживают возможность взаимодействия объектов, созданных различных объектно-ориентированных языках и скрывают от приложения детали сетевого взаимодействия.
Основу этого подхода составляет «минимальная» объектная модель, обладающая ограниченными возможностями, но имеющая обязательные аналоги в наиболее распространенных объектных системах. В архитектуре CORBA используется модель Core Object Model с соответствующим языком спецификации интерфейсов объектов (Interface Definition Language — IDL). Чтобы обеспечить возможность взаимодействия объекта, существующего в одной системе программирования, с некоторым объектом из другой системы программирования, в исходный текст первого объекта (объявления его класса) должна быть помещена IDL-спецификация интерфейса (имя метода, список имен и типов данных входных и выходных параметров) того объекта, метод которого должен быть вызван. Аналогичная спецификация должна быть помещена на стороне вызываемого объекта. Далее, спецификации, транслированные IDL-процессором в выражения языка программирования, включаются в исходный текст программы на языках Си, Java.
DCOM
В DCOM-технологии, представленной на рис. 7.12, взаимодействие между клиентом и сервером осуществляется через двух посредников. Клиент помещает параметры вызова в стек и обращается к методу интерфейса объекта. Это обращение перехватывает посредник Proxy, упаковывает параметры вызова в СОМ-пакет и адресует его в Stub, который в свою очередь распаковывает параметры в стек и инициирует выполнение метода объекта в пространстве сервера.
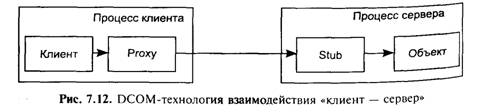
При этом объект должен быть предварительно зарегистрирован на локальной машине, чтобы клиент с помощью распределенной службы имен (в качестве которой Microsoft предлагает Active Directory) мог его отыскать по глобальному уникальному идентификатору (GUId).
CORBA
CORBA-технология также использует интерфейс объекта, но в этом случае схема взаимодействия объектов (рис. 7.13) включает промежуточное звено (Smart agent), реализующее доступ к удаленным объектам. Smart agent, установленный на машинах сетевого окружения (сервере локальной сети или Internet-узле), моделирует сетевой каталог известных ему серверов объектов. Регистрация объектов сервера в каталоге одного или нескольких Smart agent'oB происходит автоматически при создании сервера.

Связи между брокерами осуществляются в соответствии с требованиями специального протокола General Inter ORB Protocol, определяющего низкоуровневое представление данных и множество форматов сообщений.
На машине клиента создаются два объекта-посредника: Stab (заглушка) и ORB (Object Required Broker — брокер вызываемого объекта). Так же как и в DCOM-технологии, Stub передает перекаченный вызов брокеру, который посылает широковещательное сообщение в сеть. Smart agent, получив сообщение, отыскивает сетевой адрес сервера и передает запрос брокеру, размещенному на машине сервера. Вызов требуемого объекта производится через специальный базовый объектный адаптер (BOA). При этом данные в стек пространства вызываемого объекта помещает особый объект сервера (Skeleton — каркас), который вызывается адаптером.
CORBA имеет два механизма реализации запросов к объектам:
• статический, предполагающий использование заглушек каркасов, интерфейсы которых были сгенерированы при создании объекта;
• динамический вызов с помощью интерфейса динамического вызова (DII).
Интерфейс динамического вызова позволяет определять объекты и их интерфейсы во время выполнения, а затем формировать заглушки. Аналогично, на стороне сервера может использоваться динамический интерфейс каркасов (DSI), что позволяет обращаться к реализации объекта, для которого на этапе создания не был сформирован каркас.
Ключевым компонентом архитектуры CORBA является язык описания интерфейсов IDL, на уровне которого поддерживаются «контрактные» отношения между клиентом и сервером и обеспечивается независимость от конкретного объектно-ориентированного языка. CORBA IDL поддерживает основные понятия объектно-ориентированной парадигмы (инкапсуляцию, полиморфизм и наследование). При этом CORBA-объекты могут быть преобразованы в объекты языков программирования (например, Java, С, C++), т. е. будут сформированы файлы:
• исходного клиентского кода, содержащего интерфейсные заглушки;
• исходного серверного кода, содержащего каркасы;
• заголовков, которые включаются в клиентскую и серверную программы.
В модели DCOM также может использоваться разработанный Microsoft язык IDL, который, однако, играет вспомогательную роль и используется в основном для удобства описания объектов. Реальная интеграция объектов в DCOM происходит не на уровне абстрактных интерфейсов, а на уровне бинарных кодов, и это одно из основных различий этих двух объектных моделей.
Как DCOM, так и CORBA, в отличие от процедурного RPС., дают возможность динамического связывания удаленных объектов: клиент может обратиться к серверу-объекту во время выполнения, не имея информации об этом объекте на этапе компиляции. В CORBA для этого существует специальный интерфейс динамического вызова DII, a COM использует механизм OLE-Automation. Информацию о доступных объектах сервера на этапе выполнения клиентская часть программы получает из специального хранилища метаданных об объектах — репозитария интерфейсов Interface Repositary в случае CORBA, или библиотеки типов (Type Library) в модели DCOM. Эта возможность очень важно для больших распределенных приложений, поскольку позволяет менять и расширять функциональность серверов, не внося существенных изменений в код клиентских компонентов программы. Например, банковское приложение, основная бизнес-логика которого поддерживается сервером в центральном офисе, а клиентские системы — в филиалах, размещенных в разных городах.
Контрольные вопросы
1. Какие разновидности систем «клиент—сервер» вы знаете?
2. Что такое файловый сервер?
3. Что такое сервер баз данных?
4. Что такое сервер приложений?
5. Сформулируйте основные требования к системам управления распределенными базами данных.
6. Перечислите основные условия и предпосылки появления систем управления распределенными базами данных.
7. Перечислите основные различия системы распределенной обработки данных и системы распределенных баз данных.
8. Обоснуйте целесообразность разделения «клиентских» и «серверных» функций.
9. Проведите сравнительный анализ распределения функций для различных базовых архитектур.
10. Определите основные принципы и примерные структурные схемы
сервера распределенной обработки.
11 Перечислите основные решения распределенной обработки на основе
межмодульного взаимодействия.