СЕТЕВЫЕ ИНФОРМАЦИОННЫЕ
ТЕХНОЛОГИИ. INTERNET
В исторической перспективе, с появлением в первой половине 1970-х гг. видеотерминалов, первоначально возникли структуры «терминал — хост» (локальный или удаленный).
Чуть раньше и независимо развивались глобальные сети (пакетной коммутации), используемые как для функций связи общего назначения, так и для коммуникаций «хост—хост» с целью (в то время) выравнивания использования вычислительных мощностей по часовым поясам (подобно тому, как это осуществляется в сетях энергопередачи). Это были именно вычислительные сети. Структуры «терминал — хост» вносят сюда дополнительную динамику.
Эта ситуация сохраняется до середины 1980-х гг., когда появление и взрывообразное распространение ПК (как выразился один из тогдашних научных острословов «карлики-млекопитающие на планете вычислительных динозавров») изменило положение. Появляются локальные сети, интегрирующие прежде всего информационные ресурсы (файл-сервер), редкие или дорогостоящие технические средства (принт-сервер) и т. п.
Изучение трафика (потоков данных) в развивающихся сетях показало смещение акцентов с распределенных вычислений на обмен информацией — доступ к удаленным базам данных, о мен сообщениями по электронной почте и пр. Вырисовываются , таким образом, информационные сети.
Наконец, в 1980—1990-е гг. широко распространяется технология TCP/IP, обеспечивая рост и развитие «сети сетей» Internet, которая представляет собой глобальную информационно-вычислительную сеть.
6.1 Некоторые основные понятия
Системы терминал—хост
Первые системы совместной эксплуатации информационных вычислительных ресурсов (системы коллективного пользования) появляются в 1960—1970-е гг. и относятся к вычислительным системам с разделением времени. Первоначально операционные системы ЭВМ (ОС) были рассчитаны на пакетную обработку информации, затем с созданием интерактивных терминальных устройств появляется возможность совместной работы пользователей в реальном масштабе времени. Основные этапы развития систем доступа к информационным ресурсам представлены на рис. 6.1 и включают следующие схемы.
1. Взаимодействие терминала (конечный пользователь, источник запросов и заданий) и хоста (центральная ЭВМ, держатель всех информационных и вычислительных ресурсов) — рис. 6.1 а, б. Может осуществляться как в локальном, так и в удаленном режиме, во втором случае, как правило, некоторая совокупность пользователей (дисплейный класс) размещается в так называемом абонентском пункте — комплексе, снабженном котроллером (устройством управления), принтером, концентратором и обеспечивающим параллельную работу пользователей удаленным хостом. Связь между хостом и абонентским пунктом в этом случае осуществлялась с помощью модемов, по телефонным каналам [26].

2. На следующем этапе (рис. 6.1, в) формируются сети передачи данных (из существующих общих и специальных цифровых каналов), позволяющие как осуществлять более тесное взаимодействие терминал—хост, так и обмен хост—хост для реализации распределенных баз данных и децентрализации процессов обработки информации.
3. Появление и массовое распространение персональных компьютеров выводит на первый план (для массового пользователя) проблему связи ПК— ПК (рис. 6.1, г) для быстрого резервирования и копирования информации (в том числе с использованием модемов) и локальные сети (рис. 6.1, д) — для совместной эксплуатации баз данных (файл—сервер) и дорогостоящего оборудования. В дальнейшем локальные сети потеряли самостоятельное значение вследствие интеграции с глобальными в двухуровневые сети, строящиеся по единому принципу в рамках Internet (рис. 6.1, е).
В последующем перечисленные конфигурации не претерпели существенных изменений, однако понятия хост и терминал из чисто аппаратурных трансформировались в аппаратурно-программные и даже сугубо программные (например, эмуляторы терминала и эмуляторы хоста на однотипных ПК [23, 26]). Кроме того, в 80-е гг. в обиход входит понятие интеллектуального терминала (smart terminal) — сателлитной машины, которая берет на себя часть функций по обработке информации пользователя (например, синтаксический анализ запроса или программы).
Системы клиент—сервер
Таким образом, по мере развития представлений о распределенных вычислительных процессах и процессах обработки данных складывается концепция архитектуры «клиент — сервер» обобщенное представление о взаимодействие двух компонент информационной технологии (технического и/или программного обеспечения) в вычислительных системах и сетях, и которых логически или физически могут быть выделены:
• активная сторона (источник запросов, клиент);
• пассивная сторона (сервер, обслуживание запросов, источник ответов).
Взаимодействие клиент—сервер в сети осуществляется в соответствии с определенным стандартом, или протоколом — совокупностью соглашений об установлении/прекращении связи и обмене информацией.
Обычно клиент и сервер работают в рамках единого протокола – telnet, ftp, gopher, http и пр., однако в связи с недостаточностью такого подхода появляются мультипротокольные клиенты и серверы, например браузер Netscape Navigator.
Основные разновидности функциональных структур клиент—сервер рассмотрены в следующей главе.
Информационно-вычислительные сети
Информационно-вычислительные сети включают вычислительные сети, предназначенные для распределенной обработки данных (совместное использование вычислительных мощностей), и информационные сети, предназначенные для совместного использования информационных ресурсов. Сетевая технология обработки информации весьма эффективна, так как предоставляет пользователю необходимый сервис для коллективного решения различных распределенных прикладных задач, увеличивает степень использования имеющихся в сети ресурсов (информационных, вычислительных, коммуникационных) и обеспечивает удаленный доступ к ним.
Распределение потоков сообщений с целью доставки каждого сообщения по адресу осуществляется на узлах коммутации (УК) с помощью коммутационных устройств. Система распределений потоков сообщений в УК получила название системы коммутации.
Под коммутацией сетях передачи данных имеется в виду совокупность операций, обеспечивающих в узлах коммутации передачу информации между входными и выходными устройствами в соответствии с указанным адресом. При коммутации с накоплением (КН) абонент имеет постоянную прямую связь со своим УК и передает на него информацию. Затем эта информация передается через узлы коммутации другим абонентам, причем в случае занятости исходящих каналов информация запоминается в узлах и передается по мере освобождения каналов нужном направлении.
Коммутация пакетов. В системах ПД широкое распространение получил метод коммутации пакетов (КП), или пакетной коммутации, являющийся разновидностью коммутации с накоплением. При КП сообщения разбиваются на меньшие части, называемые пакетами, каждый из которых имеет установленную максимальную длину. Эти пакеты нумеруются и снабжаются адресами и прокладывают себе путь по сети (методом передачи с промежуточным хранением), которая их коммутирует.
Части одного и того же сообщения могут в одно и то же время находиться в различных каналах связи, более того, когда начало сообщения уже принято, его конец отправитель может еще даже не передавать в канал.
В сети с КП осуществляется следующий процесс передачи (рис. 6.2):
• вводимое в сеть сообщение разбивается на части — пакеты длиной обычно до 1000—2000 единичных интервалов, содержащие адрес ОП получателя. Указанное разбиение осуществляется или в оконечном пункте, если он содержит ЭВМ, или в ближайшем к ОП УК;

• если разбиение сообщения на пакеты происходит в УК, то дальнейшая передача пакетов осуществляется по мере их формирования, не дожидаясь окончания приема в УК целого сообщения;
• в узле КП пакет запоминается в оперативной памяти (ОЗУ) и по адресу определяется канал, по которому он должен быть передан;
• если этот канал к соседнему узлу свободен, то пакет немедленно передается на соседний узел КП, в котором повторяется та же операция;
• если канал к соседнему узлу занят, то пакет может небольшое время храниться в ОЗУ до освобождения канала;
• при хранении пакеты устанавливаются в очереди по направлению передачи, причем длина очереди не превышает 3—4 пакетов. Если длина очереди превышает допустимую, пакеты стираются из ОЗУ и их передача должна быть повторена.
Эталонная модель внутри- и межсетевого взаимодействия (OSI Reference Model). Многослойный (многоуровневый) характер сетевых процессов приводит к необходимости рассмотрения многоуровневых моделей телекоммуникационных сетей. В качестве эталонной модели утверждена семиуровневая модель, в которой все процессы, реализуемые открытой системой, разбиты на взаимно подчиненные уровни. В данной модели обмен информацией может быть представлен в виде стека (табл. 6.1).
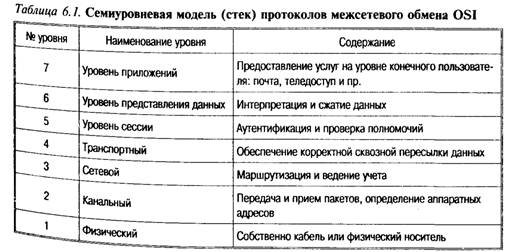
Эти представления были разработаны ISO (International Standard Organization) и получили название «Семиуровневой мо дели сетевого обмена» (Open System Interconnection Reference Model), или ВОС (Взаимодействие Открытых Систем). Основная идея модели заключается в том, что каждому уровню отводится конкретная роль, в том числе и транспортной среде. Благодаря этому общая задача передачи данных расчленяется на отдельные легко обозримые задачи.
Необходимые соглашения для связи одного уровня с выше и нижерасположенными называют протоколом.
Наличие нескольких уровней, используемых в модели, обеспечивает декомпозицию информационно-вычислительного процесса на простые составляющие. В свою очередь, увеличение числа уровней вызывает необходимость включения дополнительных связей в соответствии с дополнительными протоколами и интерфейсами. Интерфейсы (макрокоманды, программы) зависят от возможностей используемой операционной системы.
Рассмотрим вкратце характеристики уровней ВОС.
Уровень 1, физический уровень модели — определяет характеристики физической сети передачи данных, которая используется для межсетевого обмена. Это такие параметры, как напряжение в сети, сила тока, число контактов на разъемах, электрические, механические, функциональные и процедурные параметры для физической связи в системах.
Уровень 2, канальный — представляет собой комплекс процедур и методов управления каналом передачи данных, организованный на основе физического соединения. Канальный уровень формирует из данных, передаваемых 1-м уровнем, так называемые «кадры», последовательности пакетов. Каждый пакет содержит адреса источника и места назначения, а также средства обнаружения ошибок. На этом уровне осуществляются управление доступом к передающей среде, используемой несколькими ЭВМ, синхронизация, обнаружение и исправление ошибок.
К канальному уровню отнесены протоколы, определяющие соединение, — протоколы взаимодействия между драйверами устройств и устройствами, с одной стороны, а с другой — между операционной системой и драйверами устройств.
Уровень 3, сетевой — устанавливает связь в вычислительной сети между двумя абонентами. Соединение происходи благодаря функциям маршрутизации, которые требуют наличия сетевого адреса в пакете. Сетевой уровень должен также обеспечивать обработку ошибок, мультиплексирование, управление потоками данных.
К сетевому уровню относятся протоколы, которые отвечают а отправку и получение данных, где определяется отправитель и получатель и определяется необходимая информация для доставки пакета по сети.
Уровень 4, транспортный — поддерживает непрерывную передачу данных между двумя взаимодействующими друг с другом удаленными пользовательскими процессами. Качество транспортировки, безошибочность передачи, независимость вычислительных сетей, сервис транспортировки из конца в конец, минимизация затрат и адресация связи гарантируют непрерывную и безошибочную передачу данных.
Транспортный протокол связывает нижние уровни (физический, канальный, сетевой) с верхними уровнями, которые реализуются программными средствами. Этот уровень как бы разделяет средства формирования данных в сети от средств их передачи. Сетевой уровень предоставляет услуги транспортному, который требует от пользователей запроса на качество обслуживания сетью.
После получения от пользователя запроса на качество обслуживания транспортный уровень выбирает класс протокола, который обеспечивает требуемое качество обслуживания. При существовании разных типов сетей транспортный уровень позволяет следующие параметры качества обслуживания:
• пропускная способность;
• надежность сети;
• задержка передачи информации через сеть;
• приоритеты;
• защита от ошибок;
• мультиплексирование;
• управление потоком;
• обнаружение ошибок.
Уровень 5, сеансовый (уровень сессии) – на данном уровне осуществляется управление сеансами (сессиями) связи между двумя взаимодействующими прикладными пользовательскими процессами (пользователями). Определяется начало и окончание сеанса связи: нормальное или аварийное; определяется время, длительность и режим сеанса связи, точки синхронизации для промежуточного контроля и восстановления при передаче данных, восстанавливается соединение после ошибок в время сеанса связи без потери данных.
Уровень 6, представления данных (представительский, уровень представления информации, уровень обмена данными с прикладными программами) — управляет представлением данных в необходимой для программы пользователя форме, осуществляет генерацию и интерпретацию взаимодействия процессов, кодирование/декодирование данных, в том числе компрессию и декомпрессию данных (преобразование данных из промежуточного формата сессии в формат данных приложения).
На рабочих станциях могут использоваться различные операционные системы: DOS, UNIX, OS/2. Каждая из них имеет свою файловую систему, свои форматы хранения и обработки данных. Задачей данного уровня является преобразование данных при передаче информации в формат, который используется в информационной системе. При приеме данных уровень представления данных выполняет обратное преобразование.
Уровень 7, прикладной (уровень прикладных программ или приложений) — определяет протоколы обмена данными этих прикладных программ; в его ведении находятся прикладные сетевые программы, обслуживающие файлы, а также выполняются вычислительные, информационно-поисковые работы, логические преобразования информации, передача почтовых сообщений и т. п. Одна из задач этого уровня — обеспечить интерфейс пользователя.
Таким образом, мы видим, что уровень с меньшим номером предоставляет услуги смежному с ним верхнему уровню и пользуется для этого услугами смежного с ним нижнего уровня. Самый верхний (7-й) уровень потребляет услуги, самый нижний (1-й) только предоставляет их.
Кроме того, на разных уровнях обмен происходит в различных единицах информации: биты, кадры, фреймы, пакеты, сеансовые сообщения, пользовательские сообщения. Уровень может «ничего не знать» о содержании сообщения, но он должен «знать», что дальше делать с этим сообщением. Уровень приложений передает сообщение на следующий уровень и т. д. через все уровни, пока физический уровень не передаст его в кабель-Каждый уровень по-своему обрабатывает, например, сообщение электронной почты, но не «знает» о фактическом содержании этого сообщения.
Для правильной и, следовательно, полной и безошибочной передачи данных необходимо придерживаться согласованных и установленных правил, оговоренных в протоколе передачи данных.
Вазовые сетевые топологии
Проиллюстрируем (на примере локальных сетей) основные принципы комплексирования сетевого оборудования (или топологии сетей). При создании сети в зависимости от задач, которые она должна будет выполнять, может быть реализована одна из трех базовых топологий: «звезда», «кольцо» и «общая шина» — рис. 6.3, табл. 6.2.
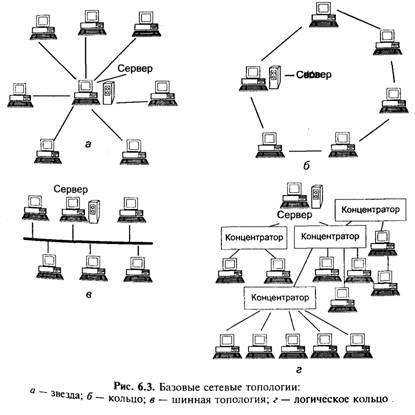

Концепция топологии сети в виде звезды заимствована из области больших ЭВМ, в которой головная (хост-) машина получает и обрабатывает все данные с периферийных устройств (терминалов или рабочих станций пользователя), являясь единственным активным узлом обработки данных.
Информация между любыми двумя пользователями в этом случае проходит через центральный узел вычислительной сети. Пропускная способность сети определяется вычислительной мощностью узла и гарантируется для каждой рабочей станции. Коллизий (столкновений) данных не возникает.
Кабельное соединение достаточно простое, так как каждая рабочая станция связана с узлом. Затраты на прокладку кабелей высокие, особенно когда центральный узел географически расположен не в центре сети. При расширении вычислительных сетей не могут быть использованы ранее выполненные кабельные связи: к новому рабочему месту необходимо прокладывать отдельный кабель из центра сети.
Топология в виде звезды является наиболее быстродействующей из всех топологий вычислительных сетей, поскольку передача данных между рабочими станциями проходит через центральный узел (при его хорошей производительности) по отдельным линиям, используемым только этими рабочими станциями. Кроме того, частота запросов передачи информации от одной станции к другой невысока по сравнению с наблюдаемой при других топологиях.
При кольцевой топологии сети рабочие станции связаны одна с другой по кругу, т. е. рабочая станция 1 с рабочей станцией 2, рабочая станция 3 с рабочей станцией 4 и т. д. Последняя рабочая станция связана с первой. Коммуникационная связь замыкается в кольцо, данные передаются от одного компьютера к другому как бы по эстафете. Если компьютер получит данные, предназначенные для другого компьютера, он передает их следующему по кольцу. Если данные предназначены для получившего их компьютера, они дальше не передаются.
Прокладка кабелей от одной рабочей станции до другой может быть довольно сложной и дорогостоящей, особенно если географически рабочие станции расположены далеко от кольца (например, в линию).
Пересылка сообщений является очень эффективной, так как большинство сообщений можно отправлять по кабельной системе одно за другим. Очень просто можно выполнить циркулярный (кольцевой) запрос на все станции. Продолжительность передачи информации увеличивается пропорционально количеству рабочих станций, входящих в вычислительную сеть.
Основная проблема кольцевой топологии заключается в том, что каждая рабочая станция должна участвовать в пересылке информации, и в случае выхода из строя хотя бы одной из них работа в сети прекращается.
Топология «общая шина» (магистраль) предполагает использование одного кабеля, к которому подключаются все компьютеры сети. В данном случае кабель используется совместно всеми станциями по очереди. Принимаются специальные меры для того, чтобы при работе с общим кабелем компьютеры не мешали друг другу передавать и принимать данные.
Надежность здесь выше, так как выход из строя отдельных компьютеров не нарушает работоспособность сети в целом. Поиск неисправностей в кабеле затруднен. Кроме того, так как и пользуется только один кабель, в случае повреждения нарушается работа всей сети.
Комбинированные топологические решения. Наряду с отмеченными базовыми, на практике применяется ряд комбинированных топологий. К таковым относится, например, логическая кольцевая сеть, которая физически монтируется как соединение звездных топологий (рис. 6.3, г). Отдельные «звезды» включаются с помощью специальных коммутаторов, которые иногда называют «хаб» (от англ. Hub — концентратор).
6.2. Технологии Internet
В [20] приведено следующее определение: «Федеральный сетевой совет признает, что... Internet — это глобальная информационная система, которая:
• логически взаимосвязана пространством глобальных уникальных адресов, основанных на Internet-протоколе (IP) или на последующих расширениях или преемниках IP;
• способна поддерживать коммуникации с использованием семейства Протокола управления передачей/Internet – протокола (TCP/IP) или его последующих расширений/преемников и/или других IP-совместимых протоколов;
• обеспечивает, использует или делает доступной на общественной или частной основе высокоуровневые сервисы, надстроенные над описанной здесь коммуникационной и иной связанной с ней инфраструктурой.
За два десятилетия своего существования Сеть Internet претерпела кардинальные изменения (рис. 6.4). Она зарождалась в эпоху разделения времени, но сумела выжить во времена господства персональных компьютеров, одноранговых сетей, систем клиент/сервер и сетевых компьютеров. Она проектировалась до первых ЛВС, но впитала эту новую сетевую технологию, равно как и появившиеся позднее сервисы коммутации ячеек и кадров. Она задумывалась для поддержки широкого спектра функции, от разделения файлов и удаленного входа до разделения ресурсов сов и совместной работы, породив электронную почту и в более поздний период Всемирную паутину (WWW)».
Рассмотрим некоторые основные Internet-технологии.
Система адресов Internet
Сеть сетей – Internet — базируется на принципах пакетной коммутации и реализует многоуровневую совокупность протоколов, подобную рассмотренной выше модели OSI. Прежде чем перейти описанию данных протоколов, отметим, что на каждом из уровней используются определенные системы адресации, позволяющие осуществлять передачу сообщений и адресацию информационных ресурсов. Основными типами адресов являются следующие:
• адрес Ethernet;
• IP-адрес (основной адрес в Internet);
• доменные адреса;
• почтовые адреса;
• номера портов;
• универсальный локатор (идентификатор) сетевого ресурса (URL/URI).
Адрес Ethernet. Internet поддерживает разные физические среды, из которых наиболее распространенным аппаратурным средством реализации локальных сетей (нижний уровень многоуровневых сетей) является технология Ethernet.
В локальной сети обмен осуществляется кадрами Ethernet каждый из которых содержит адрес назначения, адрес источника, поле типа и данные. Каждый сетевой адаптер (интерфейс, карта Ethernet — физическое устройство, подключающее компьютер к сети) имеет свой сетевой адрес, размер которого составляет 6 байт.
Адаптер «слушает» сеть, принимает адресованные ему кадры и широковещательные кадры с адресом FF:FF:FF:FF:FF:FF и отправляет кадры в сеть, причем в каждый момент времени в сегменте узла сети находится только один кадр.
Собственно Ethernet-адрес соответствует не компьютеру, а его сетевому интерфейсу. Таким образом, если компьютер имеет несколько интерфейсов, то это означает, что каждому интерфейсу будет назначен свой Ethernet-адрес. Каждой карте Ethernet соответствуют Ethernet-адрес и IP-адрес, которые уникальны в рамках Internet.
IP-адрес представляет собой 4-байтовую последовательность, причем каждый байт этой последовательности записывается в виде десятичного числа. Адрес состоит из двух частей: адреса сети и номера хоста. Обычно под хостом понимают компьютер, подключенный к Internet, однако это может быть и принтер с сетевой картой, и терминал или вообще любое устройство, которое имеет свой сетевой интерфейс.
Существует несколько классов адресов, различающихся количеством битов, отведенных на адрес сети и адрес хоста в сет В табл. 6.3 приведены характеристики основных классов сетей-
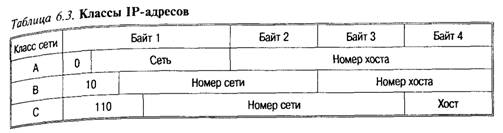
Назначение классов IP-адресов:
А – использование в больших сетях общего доступа;
В — в сетях среднего размера (большие компании, научно-исследовательские институты, университеты);
С — в сетях с небольшим числом компьютеров (небольшие компании и фирмы).
Среди IP-адресов несколько зарезервировано под специальные случаи (табл. 6.4).

Для установления соответствия между IP-адресом и адресом Ethernet в локальных сетях используется протокол отображения адресов — Adress resolution Protocol (ARP). Отображение адресов осуществляется в ARP-таблице (табл. 6.5), которая необходима, так как адреса выбираются произвольно и нет какого-либо алгоритма для их вычисления.
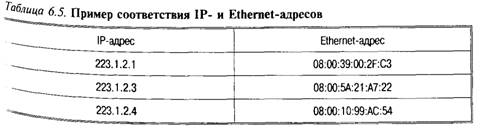
ARP-таблица заполняется автоматически; если нужного адреса в таблице нет, то в сеть посылается широковещательный запрос «чей это IP-адрес?», который получают все сетевые интерфейсы, но отвечает только владелец адреса.
Система доменных имен. Хотя числовая адресация удобна для машинной обработки таблиц маршрутов, она очевидно не приемлема для использования человеком. Для облегчения взаимодействия вначале применялись таблицы соответствия числовых адресов именам машин. Эти таблицы сохранились и используются многими прикладными программами (табл. 6.6).

Пользователь для обращения к машине может использовать как IP-адрес, так и имя.
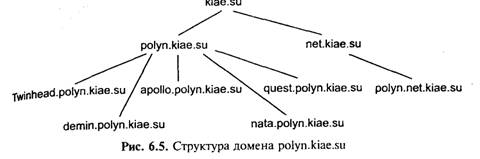
По мере роста сети была разработана система доменных имен — DNS (Domain Name System), которая строится по иерархическому принципу, однако эта иерархия не является строгой. Фактически нет единого корня всех доменов Internet. В 80-е гг. были определены первые домены (национальные, США) верхнего уровня: gov, mil, edu, com, net. Позднее появились национальные домены других стран: uk, jp, аи, ch и т. п. Для СССР был выделен домен su, однако после приобретения республиками союза суверенитета, многие из них получили свои собственные домены: uа, rи, la, li и т. п. Однако домен su был сохранен, и таким образом, например, в Москве существуют организации с доменными именами kiae. su и msk. ru.
Вслед за доменами верхнего уровня следуют домены, определяющие либо регионы (msk), либо организации (kiae); следующие уровни иерархии могут быть закреплены за небольшими организациями, либо за подразделениями больших организации (рис. 6.5).
Наиболее популярной программой поддержки DNS являете BIND, или Berkeley Internet Name Domain, — сервер доменных имен, реализованный в университете Беркли, который широк применяется в Internet. Он обеспечивает поиск доменных имен и IP-адресов для любого узла сети. BIND обеспечивает также рассылку сообщений электронной почты через узлы Internet.
Вообще говоря, сервер имен может быть установлен на любой компьютер локальной сети. При выборе машины для установки сервера имен следует принимать в расчет то обстоятельство, что многие реализации серверов держат базы данных имен в оперативной памяти.
Почтовые адреса. В Internet принята система адресов, которая базируется на доменном адресе машины, подключенной к сети. Почтовый адрес состоит из двух частей: идентификатора пользователя, который записывается перед знаком «коммерческого at — @», и доменного адреса машины, который записывается после знака «@».
Различают следующие типы адресов:
• местный адрес — распознается как адрес на машине, с которой осуществляется отправка почты;
• адреса UUCP — могут имеют вид:

• адреса SMTP — стандартные для Internet:

Если машина, с которой отправляется почта, имеет прямую линию связи по протоколу UUCP со следующей машиной (в адресе), то почта передается на эту машину; если такого соединения нет, то почта не рассылается и выдается сообщение об ошибке. (Программа рассылки почты sendmail сама преобразует адреса формата SMTP в адреса UUCP, если доставка сообщения осуществляется по этому протоколу).
При рассылке может использоваться и смешанная адресация:
• user%hostA@hostB — почта отправляется с машины hostB на машину hostA;
• user!hostA@hostB — почта отправляется с машины hostR на машину hostA;
• hostA!user%hostB — почта отправляется с hostA на hostB
TCP/UDP-nopm — условный номер соединения с хост-машиной по определенному протоколу прикладного уровня (точнее информационный сервис, WKS — Well Known Services, или прикладная программа, которая осуществляет обслуживание по определенном порту TCP или UDP). К сервисам относятся: доступ в режиме удаленного терминала, доступ к файловым архивам FTP, доступ к серверам World Wide Web и т. п.
Система универсальных идентификаторов ресурсов (URI/URL) разработана для использования в системах WWW, и в ее основу заложены следующие принципы.
Расширяемость — новые адресные схемы должны были легко вписываться в существующий синтаксис URI; была достигнута за счет выбора определенного порядка интерпретации адресов, который базируется на понятии «адресная схема». Идентификатор схемы стоит перед остатком адреса, отделен от него двоеточием и определяет порядок интерпретации остатка.
Полнота — по возможности любая из существовавших схем должна была описываться посредством URI.
Читаемость — адрес должен легко пониматься человеком, что вообще характерно для технологии WWW — документы вместе с ссылками могут разрабатываться в обычном текстовом редакторе.
Формат URL включает:
• схему адреса (тип протокола доступа — http, gopher, wais, telnet, ftp и т. п.);
• IP- или доменный адрес машины;
• номер ТСР – порта;
• адрес ресурса на сервере (каталог или путь);
• имя HTML-файла и метку;
• критерий поиска данных.
Для каждого вида протокола приложений выбирается с подмножество полей из представленного выше списка. Прежде чем рассмотреть различные схемы представления адресов, приедем пример простого адреса URI:
![]()
В данном случае путь состоит из доменного адреса машины, которой установлен сервер HTTP, и пути от корня дерева
сервера к файлу index.html.
Схема http — основная для WWW; содержит идентификатор адрес машины, TCP-порт, путь в директории сервера, поисковый критерий и метку. Приведем несколько примеров URI для схемы HTTP:
![]()
Это наиболее распространенный вид URI, применяемый в документах WWW. Вслед за именем схемы (http) следует путь, состоящий из доменного адреса машины и полного адреса HTML-документа в дереве сервера HTTP.
В качестве адреса машины допустимо использование и IP-адреса:
![]()
При указании адреса ресурса возможна ссылка на точку внутри файла HTML. Для этого вслед за именем документа может быть указана метка внутри HTML-документа
![]() :
:
Символ «#» отделяет имя документа от имени метки. Другая возможность схемы HTTP — передача параметров. Первоначально предполагалось, что в качестве параметров будут передаваться ключевые слова, но по мере развития механизма CGI – скриптов в качестве параметров стала передаваться и другая информация:
![]()
В данном примере предполагается, что файл isindex.html — документ с возможностью поиска по ключевым словам.
При использовании HTML Forms параметры передаются как поименованные поля:
![]()
Схема FTP позволяет адресовать файловые архивы FТР из программ-клиентов World Wide Web. При этом возможно указание не только имени схемы, адреса FTP-архива, но и идентификатора пользователя и даже его пароля. Наиболее часто данная схема используется для доступа к публичным архивам FTP:
![]()
В данном случае записана ссылка на архив polyn.net.kiae.su с идентификатором anonymous или ftр (анонимный доступ). Если есть необходимость указать идентификатор пользователя и его пароль, то можно это сделать перед адресом машины:
![]()
В данном случае эти параметры отделены от адреса машины символом @, а друг от друга — двоеточием. В некоторых системах можно указать и тип передаваемой информации, но данная возможность не стандартизована.
Схема Gopher используется для ссылки на ресурсы распределенной информационной системы Gopher; состоит из идентификатора и пути, в котором указывается адрес Gopher-сервера, тип ресурса и команда Gopher:
![]()
В данном примере осуществляется доступ к Gopher-серверу gopher.kiae.su через порт 70 для поиска (тип 7) слова software. Следует заметить, что тип ресурса, в данном случае 7, передается не перед командой, а вслед за ней.
Схема MAILTO предназначена для отправки почты по стандарту RFC-822 (стандарт почтового сообщения). Общий вид схемы выглядит так:
![]()
Схема NEWS — просмотр сообщений системы Usenet.
При этом используется следующая нотация:
![]()
В данном примере пользователь получит идентификаторы ей из группы соmр.infosystems.gopher в режиме уведомления. Можно получить и текст статьи, но тогда необходим ее индентификатор:
![]()
Схема TELNET осуществляет доступ к ресурсу в режиме удаленного терминала. Обычно клиент вызывает дополнительную программу для работы по протоколу telnet. При использовании этой схемы необходимо указывать идентификатор пользователя, допускается использование пароля:
![]()
Схема WAIS (протокол Z39.50). WAIS — распределенная информационно-поисковая система, работающая в режимах поиска и просмотра. При поиске используется форма со знаком «?», отделяющим адресную часть от ключевых слов:
![]()
В данном случае обращаются к базе данных wais на сервере wais.think.com с запросом на поиск документов, содержащих слово guide. Сервер возвращает клиенту список идентификаторов документов, после получения которого можно использовать вторую форму схемы wais-запрос на просмотр документа:
![]()
где 039 — идентификатор документа.
Схема FILE. WWW-технология используется как в сетевом, так и в локальном режимах. Для локального режима используют схему FILE.
![]()
В данном примере приведено обращение к локальному документу на персональном компьютере с MS-DOS или MS -Windows.
Существует несколько схем. Эти схемы реально на практике не используются или находятся в стадии разработки, поэтому останавливаться на них мы не будем.
Совокупность протоколов Internet
Стек, или семейство протоколов TCP/IP, отличается от вышерассмотренной модели OSI и обычно ограничивается схемой, представленной в табл. 6.7. Обе архитектуры включают похожие уровни, однако в TCP/IP несколько «слоев» OSI-модели объединены в один.

Взаимодействие на уровне прикладных протоколов осуществляется путем обмена командами установления/прекращения соединений (типа open/close), приема/передачи (send/receive) и собственно данными. Прикладные протоколы (Telnet, электронная почта, Gopher, Ftp, Http, Wais) будут рассмотрены далее, совместно с информационными сервисами доступа к информационным ресурсам, здесь же мы ограничимся рассмотрением собственно протоколов TCP/IP — канального, сетевого, транспортного уровней. Вот эти протоколы:
TCP — Transmission Control Protocol — базовый транспортный протокол, давший название всему семейству протоколов TCP/IP;
UDP — User Datagram Protocol — второй по распространенности транспортный протокол семейства TCP/IP;
IP — Internet Protocol — межсетевой протокол;
ARP — Address Resolution Protocol — используется для определения соответствия IP-адресов и Ethernet-адресов;
SLIP — Serial Line Internet Protocol — протокол передачи данных по телефонным линиям;
PPP – Point to Point Protocol — протокол обмена данным «точка-точка»;
PРС — Remote Process Control — протокол управления удаленными процессами;
TFTP — Trivial File Transfer Protocol — тривиальный протокол передачи файлов;
DNS — Domain Name System — система доменных имен;
RIP — Routing Information Protocol — протокол маршрутизации.
Некоторые предварительные замечания. На каждом из уровней схемы рис. 6.6 коммуникация осуществляется физически блоками (пакетами), и при переходе с уровня на уровень реализуются следующие преобразования форматов: инкапсуляция/экскапсуляция; фрагментация/дефрагментация.

Инкапсуляция — способ упаковки данных в формате вышестоящего протокола в формат нижестоящего протокола. При этом один или несколько первичных пакетов преобразуются в один вторичный пакет и снабжаются управляющей информацией, характерной для принимающего уровня. Например, помещение пакета IP в качестве данных Ethernet-кадра, помещение TCP-сегмента в качестве данных в IP-пакет (рис. 6.6). При возврате на верхний уровень исходный формат восстанавливается в соответствии с обратной процедурой — экскапсуляцией.
Фрагментация — реализуется, если разрешенная длина пакета нижнего уровня недостаточна для размещения первичного пакета, при этом осуществляется «нарезка» пакетов (например, на пакеты SLIP или фреймы РРР), аналогично при возврате на первичный уровень пакет должен быть дефрагментирован.
При описании основных протоколов стека TCP/IP будем следовать модели, представленной в табл. 6.7. Первыми будут рассмотрены протоколы канального ровня SLIP и РРР единственные протоколы, которые были разработаны в рам Internet и для Internet. Другие протоколы, например NDIS или ODI, мы рассматривать не будем, поскольку они создавались в других сетях, хотя и могут использоваться в сетях TCP/IP также
Протоколы канального уровня SLIP и РРР применяются на телефонных каналах. С помощью этих каналов к сети подключается большинство индивидуальных пользователей, а также не большие локальные сети. Подобные линии связи могут обеспечивать скорость передачи данных до 115 200 бит/с.
Serial Line IP (SLIP). Обычно этот протокол применяют как на выделенных, так и на коммутируемых линиях связи со скоростью передачи от 1200 до 19 200 бит в секунду.
В рамках протокола SLIP осуществляется фрагментация IP-пакетов, при этом SLIP-пакет должен начинаться символом ESC (восьмеричное 333 или десятичное 219) и заканчиваться символом end (восьмеричное 300 или десятичное 192). Стандарт не определяет размер SLIP-пакета, поэтому любой интерфейс имеет специальное поле, в котором пользователь должен указать эту длину.
Соединения типа «точка — точка» — протокол РРР (Point to Point Protocol). Данный протокол обеспечивает стандартный метод взаимодействия двух узлов сети. Предполагается, что обеспечивается двунаправленная одновременная передача данных. Собственно говоря, РРР состоит из трех частей: механизма инкапсуляции (encapsulation), протокола управления соединением (link control protocol) и семейства протоколов управления сетью (network control protocols).
Под датаграммой в РРР понимается информационная единица сетевого уровня (применительно к IP — IP-пакет). Под фреймом понимают информационную единицу канального уровня (согласно модели OSI). Для обеспечения быстрой обработки информации длина фрейма РРР должна быть кратна 32 битам.
Фрейм состоит из заголовка и хвоста, между которыми содержатся данные. Датаграмма может быть инкапсулирована в один или несколько фреймов (рис. 6.7). Пакетом называют информационную единицу обмена между модулями сетевого и канального уровней. Обычно каждому пакету ставится в соответствие один фрейм, за исключением тех случаев, когда канальный уровень требует большей фрагментации данных или, наоборот, объединяет пакеты для более эффективной передачи.

Протокол управления соединением предназначен для установки соглашения между узлами сети о параметрах инкапсуляции (размер фрейма и т. п.), кроме того, он позволяет проводить идентификацию узлов. Первой фазой установки соединения является проверка готовности физического уровня передачи данных. При этом такая проверка может осуществляться периодически, позволяя реализовать механизм автоматического восстановления физического соединения, как это бывает при работе через модем по коммутируемой линии. Если физическое соединение установлено, то узлы начинают обмен пакетами протокола управления соединением, настраивая параметры сессии.
Межсетевые протоколы. К данной группе относятся протоколы IP, ICMP, ARP.
Протокол IP является основным в иерархии протоколов TCP/IP и используется для управления рассылкой TCP/I Р – пакетов по сети Internet. Среди различных функций, возложенных на IP, обычно выделяют следующие:
• определение пакета, который является базовым понятием и единицей передачи данных в сети Internet;
• определение адресной схемы, которая используется в сети Internet;
• передача данных между канальным уровнем (уровнем доступа к сети) и транспортным уровнем (другими словами, преобразование транспортных датаграмм во фреймы канального уровня);
• маршрутизация пакетов по сети, т. е. передач: а пакетов от одного шлюза к другому с целью передачи пакета машине-получателю;
• фрагментация и дефрагментация пакетов транспортного уровня.
Таким образом, вся информация о пути, по которому должен пройти пакет, определяется по состоянию сети в момент прохождения пакета. Эта процедура называется маршрутизацией в отличие от коммутации, используемой для предварительного установления маршрута следования отправляемых данных.
Маршрутизация представляет собой ресурсоемкую процедуру, так как предполагает анализ каждого пакета, который проходит через шлюз или маршрутизатор, в то время как при коммутации анализируется только управляющая информация, устанавливается канал (физический или виртуальный), и все пакеты пересылаются по этому каналу без анализа маршрутной информации. Однако при неустойчивой работе сети пакеты могут пересылаться по различным маршрутам и затем собираться в единое сообщение. При коммутации путь придется устанавливать заново для каждого пакета и при этом потребуется больше накладных затрат, чем при маршрутизации.
Структура пакета IP представлена на рис. 6.8. Фактически в заголовке пакета определены все основные данные, необходимые для перечисленных выше функций протокола IP: адрес отправителя, адрес получателя, общая длина пакета и тип пересылаемой датаграммы.
Используя данные заголовка, машина может определить, на какой сетевой интерфейс отправлять пакет. Если IP-адрес получателя принадлежит одной из ее сетей, то на интерфейс этой сети пакет и будет отправлен, в противном случае пакет отправят на другой шлюз.
Как уже отмечалось, при обычной процедуре инкапсулирования пакет просто помещается в поле данных фрейма, а в случае, когда это не может быть осуществлено, разбивается на более мелкие фрагменты.

Размер максимально возможного фрейма, который передается по сети, определяется величиной MTU (Maximum Transsion Unit), определенной для протокола канального уровня. Для последующего восстановления пакет IP должен содержать информацию о своем разбиении и для этой цели используются поля «flags» и «fragmentation offset». В этих полях определяется, какая часть пакета получена в данном фрейме, если этот пакет был фрагментирован на более мелкие части.
ICMP (Internet Control Message Protocol) — наряду с IP и ARP относится к межсетевому уровню. Протокол используется для рассылки информационных и управляющих сообщений. При этом используются следующие виды сообщений.
Flow control — если принимающая машина (шлюз или реальный получатель информации) не успевает перерабатывать информацию, то данное сообщение приостанавливает отправку пакетов по сети.
Detecting unreachable destination — если пакет не может достичь места назначения, то шлюз, который не может доставить пакет, сообщает об этом отправителю пакета.
Redirect routing — это сообщение посылается в том случае, если шлюз не может доставить пакет, но у него есть на этот счет некоторые соображения, а именно адрес другого шлюза.
Checking remote host — в этом случае используется так называемое ICMP Echo Message. Если необходимо проверить наличие стека TCP/IP на удаленной машине, то на нее посылается сообщение данного типа. Как только система получит это сообщение, она немедленно высылает подтверждение.
ICMP используется также для получения сообщения об истечении срока «жизни» пакета на шлюзе. При этом используется время жизни пакета, которое определяет число шлюзов, через которые пакет может пройти. Программа, которая использует эту информацию (сообщение time execeed протокола ICMP), называется traceroute.
Протоколы управления маршрутизацией. Наиболее распространенный из них – протокол RIP.
Протокол RIP (Routing Information Protocol) — предназначен для автоматического обновления таблицы маршрутов, при этом используется информация о состоянии сети, которая рассылается маршрутизаторами (routers). В соответствии с протоколом RIP любая машина может быть маршрутизатором. При этом все маршрутизаторы делятся на активные и пассивные.
Активные маршрутизаторы сообщают о маршрутах, которые они поддерживают в сети. Пассивные маршрутизаторы читают эти широковещательные сообщения и исправляют свои таблицы маршрутов, но при этом сами информации в сеть не предоставляют. Обычно в качестве активных маршрутизаторов выступают шлюзы, а в качестве пассивных — обычные машины (hosts).
Протоколы транспортного уровня.
User Datagram Protocol (U DР) один из двух протоколов транспортного уровня, используемых в стеке протоколов TCP/IP. UDP позволяет прикладной программе передавать свои сообщения по сети с минимальными издержками, связанными с преобразованием протоколов уровня приложения в протокол 1р Однако при этом прикладная программа сама должна обеспечивать подтверждение того, что сообщение доставлено по месту назначения. Заголовок UDP-датаграммы (сообщения) имеет вид, показанный на рис. 6.9.
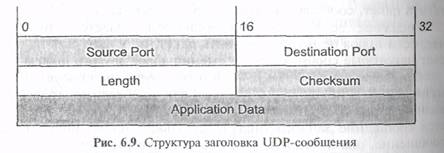
Порты в заголовке определяют протокол UDP как мультиплексор, который позволяет собирать сообщения от приложении и отправлять их на уровень протоколов. При этом приложение использует определенный порт. Взаимодействующие через сеть приложения могут использовать разные порты, что и отражает заголовок пакета. Всего можно определить 216 разных портов. Первые 256 портов закреплены за так называемыми «well known services (WKS)»
Поле Length определяет общую длину сообщения. Поле Checksum служит для контроля целостности данных. Приложение, которое использует протокол UDP, должно поддерживать целостность данных, анализируя поля Checksum и Length. Кроме этого, при обмене данными по UDP прикладная программа сама должна заботиться о контроле получения данных адресатом Обычно это достигается обменом подтверждениями о доставке между прикладными программами.
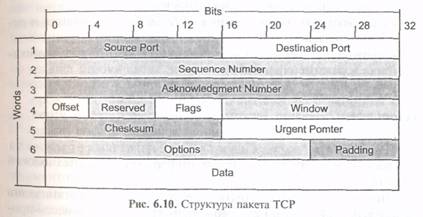
Transfer Control Protocol — TCP. В том случае, когда контроль качества передачи данных по сети имеет особое значение для приложения, используется протокол TCP. Этот протокол также называют надежным, ориентированным на соединение потокоориентированным протоколом. Рассмотрим формат передаваемой по сети датаграммы (рис. 6.10). Согласно этой структуре в TCP, как и в UDP, используются порты. В поле Sequence Number (SYN) определен номер пакета в последовательности пакетов, которая составляет сообщение, затем идет поле подтверждения Asknowledgment Number и другая управляющая информация.
В дальнейшем мы предполагаем рассмотреть основные протоколы прикладного уровня, обеспечивающие доступ к информационным ресурсам Internet (и не только к ним), а также соответствующее программное обеспечение (программы-клиенты и программы-серверы).
Это следующие протоколы:
• эмуляции терминала Telnet;
• электронной почты SMTP, UUCP;
• Распределенных файловых систем — NNTP, Gopher, FTP;
• гипертекстового доступа к WWW — HTTP;
• управления поиском в распределенных базах данных — Z39.50
Каждый из перечисленных протоколов предполагает наличие некоторой совокупности команд (командный язык), которыми обмениваются программы-клиенты и программы-серверы данного протокола. Естественно, целью такого взаимодействия является обмен пользовательскими данными.
Могут быть выделены два основных класса средств доступа и организации информационных ресурсов:
• распределенные файловые системы (Usenet, FTP, Gopher)
• распределенные информационные системы (WWW, WA1S)
6.3. Прикладные протоколы коммуникации Internet
К данной группе протоколов относятся:
• протокол эмуляции терминала Telnet (коммуникация в режиме он-лайн);
• протоколы электронной почты SMTP, UUCP (коммуникация в режиме офф-лайн).
Telnet
Протокол эмуляции удаленного терминала Telnet — одна из самых старых информационных технологий Internet.
Этот протокол может быть использован и для организации взаимодействий «терминал—терминал» (связь) и «процесс—процесс» (распределенные вычисления).
Команды протокола Telnet. Клавиатура должна иметь возможность ввода всех символов US ASCII, а также генерировать специальные стандартные функции управления терминалом (эти функции могут или присутствовать в реальном терминале, и тогда они должны представляться в стандартной форме команды, или отсутствовать и тогда заменяться командой NO (No-Operation)):
IP — Interrupt Process (прервать процесс). Данная команда реализует стандартный для многих систем механизм прерываний процесса выполнения задачи пользователя (<ctrl+C> Unix-системах или <ctrl+Break> в MS-DOS). Следует заметить, что команда IP может быть использована и другим протоколом прикладного уровня, который может использовать Telnet;
AO – Abort Output (прервать процесс выдачи). Многие системы позволяют остановить процесс, выдающий информацию на экран. Здесь следует понять отличие данной команды от IP. При выполнении IP прерывается выполнение текущего процесса пользователя, но не происходит очистка буфера вывода, т. е. процесс может быть остановлен, а буфер вывода будет продолжать передаваться на экран;
AYT – Are You There (вы еще здесь?). Назначение этой командой – дать возможность пользователю убедиться, что в процессе работы по медленным линиям он не потерял связи с удаленной машиной;
EC — Erase Character (удалить символ). Многие системы обеспечивают возможность редактирования командной строки путем введения символов «забой» или удаления последнего напечатанного символа на устройстве отображения;
EL — Erase Line (удалить строку). Команда аналогична ЕС, но удаляет строку ввода целиком. Обычно выполнение этой команды приводит к очистке буфера ввода;
Open host [port] — начать telnet-сессию с машиной host по порту port. Адрес машины можно задавать как в форме IP-адреса, так и в форме доменного адреса (рис. 6.11, а, б);
close — завершить telnet-сессию и вернуться в командный режим. Однако в некоторых системах, если telnet был вызван с аргументом, close приведет к завершению работы telnet;
quit — завершить работу telnet.
На рис. 6.11 приведены примеры экранов Telnet-сессии (связь с библиотекой Колумбийского университета — CLIO).
Электронная почта
Электронная почта является самым массовым средством электронных коммуникаций Internet, через нее можно получить ступ практически ко всем ресурсам Internet, а также к информационным ресурсам других сетей.
При коммуникации в режиме ЭП корреспонденция готовится пользователем посредством программы подготовки почты, которая вызывает текстовой редактор. Затем следует вызвать программу отправки почты (программа подготовки почты вызывает программу отправки автоматически). Для работы электронной почты в Internet используется протокол прикладного уровня SMTP (Simple Mail Transfer Protocol), который использует транспортный протокол TCP. Однако совместно с этим протоколом может использоваться и UUCP.
При работе по протоколу SMTP почта реально отправляется только тогда, когда установлено интерактивное соединение с программой-сервером на машине — получателе почты. При этом происходит обмен командами между клиентом и сервером протокола SMTP в режиме on-line, и почта достигает почтового ящика получателя за считанные минуты.
При использовании UUCP почта передается по принципу «Stop-Go», т. е. почтовое сообщение передается по цепочке почтовых серверов, пока не достигнет машины-получателя, что позволяет доставлять почту по плохим телефонным каналам, поскольку не требуется поддерживать связь все время доставки от отправителя к получателю.
При смешанной адресации доставка почты происходит по смешанному сценарию. О том, как шла доставка и как маршрутизировалось сообщение, можно узнать из заголовка сообщения, которое вы получили.

Согласно схеме почтового обмена (рис. 6.12), взаимодействие между участниками этого обмена строится по схеме «клиент—сервер».
Протоколы обслуживания электронной почты — наиболее распространены — SMTP, РОРЗ, ШАР.
Протокол SMTP (Simple Mail Transfer Protocol) был раз работай для обмена почтовыми сообщениями в сети Internet SMTP не зависит от транспортной среды и может использоваться для доставки почты в сетях с протоколами, отличными от TCP/IP и Х.25.
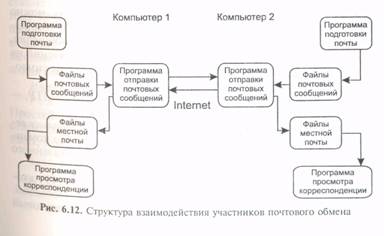
При этом отправитель инициирует соединение и посылает запросы на обслуживание, выступая в роли клиента, а получатель отвечает на эти запросы (выполняя функции сервера).
Обмен сообщениями и инструкциями в SMTP ведется в ASCII-кодах. Для инициализации канала и его закрытия используются команды helo и quit соответственно. Первой командой сеанса должна быть helo.
В протоколе определено несколько видов взаимодействия между отправителем почтового сообщения и его получателем, которые называются дисциплинами.
Наиболее распространенной дисциплиной является отправление почтового сообщения, которое начинается по команде mail, идентифицирующей отправителя:
![]()
Следующей командой определяется адрес получателя:
![]()
После того как определены отправитель и получатель, можно отправлять сообщение командой data, которая вводится без параметров и идентифицирует начало ввода почтового сообщения. Сам протокол SMTP не накладывает каких-либо ограничений на информацию, которая заключена между командой data и символом «.» в первой позиции последней строки.
Следующая дисциплина, определенная в протоколе SMTP, — перенаправление почтового сообщения (forwarding).
Верификация и расширение адресов составляют дисциплину верификации. В ней используются команды vrfy и ехрп. По команде vrfy сервер подтверждает наличие или отсутствие указанного
пользователя.
В список дисциплин, разрешенных протоколом SMTP, входит кроме отправки почты еще и прямая рассылка сообщений. В этом случае сообщение будет отправляться не в почтовый
пик, а непосредственно на терминал пользователя, если пользователь в данный момент находится за своим терминалом. Прямая рассылка осуществляется по команде send, которая имеет такой же синтаксис, как и команда mail. Кроме send прямую расссылку осуществляют soml (Send or Mail) и saml (Send and Mail).
Протокол обмена почтовой информацией РОРЗ (Post Office Protocol, версия 3) предназначен для пересылки почты из почтовых ящиков пользователей (на сервере) на их рабочие места с помощью программ-клиентов. Если по протоколу SMTP пользователи отправляют корреспонденцию через Internet, то по протоколу РОРЗ пользователи получают корреспонденцию из своих почтовых ящиков на почтовом сервере в локальные файлы, однако сообщения можно принимать, но нельзя отправлять. Формально взаимодействие по протоколу РОРЗ можно разделить на две фазы: фазу аутентификации и фазу обмена данными. В фазе аутентификации пользователь должен сообщить свой идентификатор и пароль (команды user и pass).
По команде list система сообщает число сообщений и их размер в байтах. По команде retr можно получить текст сообщения, по команде dele — пометить сообщение к удалению. Удаляются сообщения только в момент окончания сеанса, поэтому по команде rset эти пометки можно снять. Команда quit завершает сеанс работы с сервером.
Протокол IMAP (Interactive Mail Access Protocol) представляет собой более надежную альтернативу протоколу РОРЗ и к тому же обладает более широкими возможностями по управлению процессом обмена с сервером. Главное отличие от POP состоит в возможности поиска нужного сообщения и осуществление разбора заголовков сообщения. Для поиска информации используется команда find с различными аргументами.
Интерфейсные программы (почтовые клиенты).
Режим командной строки — интерфейс mail. Простейшая и самая распространенная программа подготовки и отправки почты — это команда Unix-систем mail или ее аналог mailх, имеющие формат mail пользователь, например,
![]()
В ответ программа выдаст предложение ввести сообщение;.
![]()
После ввода пользователем темы (subject) программа перейдет на следующую строку и будет ждать текста сообщения. Пусть сообщение содержит одну фразу:
![]()
Для завершения ввода сообщения следует нажать <ctrl+D> (конец ввода), после чего сообщение будет отправлено. Чтобы прочитать сообщения, необходимо выполнить команду mail без аргументов.
При этом на экран будет выведена информация, описывающая версию программы, место почтового ящика пользователя и количество сообщений в нем, список новых сообщений и пр. Для просмотра сообщения следует нажать <Enter> и на экране появится текст:

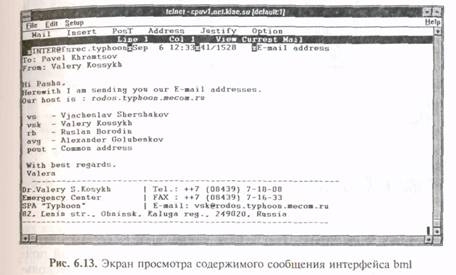
Полноэкранные интерфейсы. Интерфейс bml. Программа bml является стандартной для абонентов сети Relcom, входит в комплект версии для пользователей MS-DOS и имеется на многих Unix-системах Internet.
Основной экран в bml делится на три части:
• верхняя часть экрана занята падающими меню, которые позволяют редактировать, просматривать и отправлять почту;
• в средней части экрана расположено рабочее поле программы, в котором отображается список полученных сообщений и осуществляется редактирование посылаемых сообщений;
• в нижней части экрана расположено вспомогательное меню функциональных клавиш.
При запуске программы в рабочем поле отображаются полученные сообщения, первым из которых выделяется текущее сообщение. При этом рабочее поле разбито на четыре столбца: в первом указывается адрес отправителя, во втором — дата и время получения, в третьем — число строк и символов в сообщении четвертый столбец — тема сообщения. Для просмотра сообщения надо с помощью клавиш-стрелок сделать интересующее пользователя сообщение текущим и нажать <Enter>. В рабочем поле экрана появится текст сообщения (рис. 6.13).
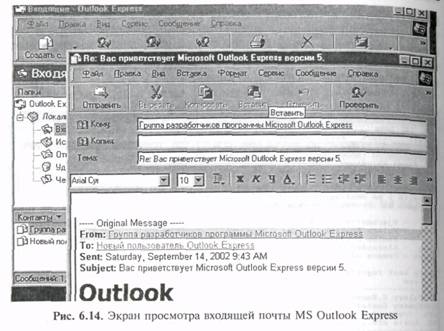
Программа-клиент MS Outlook Express. Начиная с Windows 95 в состав операционных систем включена программ – клиент Outlook Express, которая предназначена для работы с электронной почтой и новостями (рис. 6.14). Для чтения электронной почты из программы Outlook Express необходимо, чтобы используемая система обмена сообщениями поддерживала протоколы SMTP и РОРЗ или IMAP. Программу Outlook Express можно использовать для чтения групп новостей, или групп обсуждений, таких, как Usenet. Работа с группами новостей осуществляется через серверы новостей NNTP.
Outlook Express включает в себя программу адресной книги Windows. Данная программа предоставляет широкие возможности управления контактными данными, включая создание групп контактов и папок для сортировки сообщений и размещения адресов электронной почты. Адресная книга Windows обеспечивает доступ к каталогам Internet, использующим протокол LDAP (протокол облегченного доступа к каталогам). Каталоги Internet облегчают поиск обычных адресов и адресов электронной почты. В программе адресной книги уже настроен доступ к нескольким популярным каталогам.
Можно набрать любой телефонный номер, указанный в адресной книге, используя программу номеронабирателя, установленную в вашем компьютере. Программа Outlook Express может сохранять незаконченные сообщения в папке Черновики, а отправленные сообщения — в папке Отправленные на сервере IМАР. Можно редактировать гипертекстовые (HTML) сообщения и использовать в них теги расширенной версии языка HTML. Имеется более десятка параметров, которые можно использовать при настройке представлений. (Представление — это правило, по которому сообщение отображается либо скрывается).
Программа может определять, произошел ли обрыв телефонного соединения или отключение компьютера от локальной сети. Программа Outlook Express может восстановить разорванное соединение автоматически либо после подтверждения, вводимого пользователем.
Чтобы программа Outlook Express подключалась к сети и производила доставку почты через определенные интервалы, необходимо включить функцию Доставлять почту каждые ... мин поставить продолжением строки Если компьютер не подключен к сети вариант Всегда подключаться либо Подключаться, если не выбран автономный режим.
Если для какой-либо учетной записи почты или новостей требуется подключение через определенного поставщика услуг Internet, включить флажок Подключаться, используя и указать нужную учетную запись. Данный параметр задается во вкладке Подключение в свойствах каждой учетной записи. В основном этот параметр нужен пользователям, имеющим несколько выходов в Internet, например, через локальную сеть и через модем, или через два модемных соединения.
Для проверки новой почты при запуске программы включить функцию Доставлять почту каждые ... мин во вкладке Общие, пункт Параметры, меню Сервис. Необходимо проверить, чтобы для каждой учетной записи, используемой для доставки почты, был включен флажок Использовать данную учетную запись при доставке всей почты во вкладке Общие в свойствах каждой записи. Включение флажка Спрашивать о подключении при запуске только запускает соединение, но не осуществляет проверку почты.
Сообщения, в заголовке которых не указана кодировка, могут быть отображены в правильном виде после выбора нужной кодировки в меню Вид. Однако пересылка таких сообщений или ответ на них с включенной функцией автоматического выбора кодировки приведет к неверному указанию кодировки. Во избежание данной проблемы при отправке таких сообщений следует выбирать кодировку вручную.
Чтобы отправить сообщение кому-либо занесенному в адресную книгу Windows, следует дважды нажать кнопку мыши на соответствующей записи в разделе контактов.
Программа-клиент ВАТ (ThеBat!). Позволяет, кроме всего прочего, отправлять и принимать почтовые сообщения с защитой данных, в формате S/MIME (рис. 6.15). Для использования возможностей S/MIME прежде всего необходимо получить «сертификат», состоящий из двух частей: секретного ключа и публичного ключа. Вы должны защищать свой сертификат от несанкционированного доступа. Имеющийся сертификат необходимо внести в базу данных The Bat!, например, следующим образом:
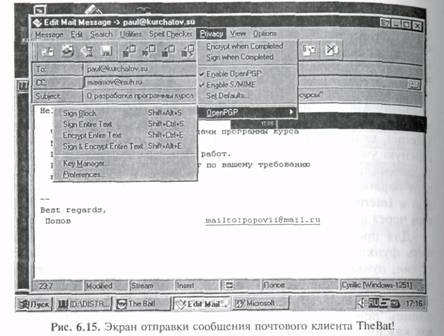
• создать в адресной книге программы «нового адресата» со своим личным именем и адресом и на вкладке Сертификаты нажать кнопку Импортировать;
• найти файл, содержащий сертификат, и нажать кнопку Открыть. Сертификат будет занесен в базу The Bat!
На практике система S/MIME работает следующим образом. Для того чтобы подписать письмо (но не зашифровать), вам нужен ваш собственный сертификат. В меню редактора выберите: PGP-> Использовать S/MIME, РСР->Подписать перед отправкой. В момент отправки письма The Bat!, возможно (в случае, если у вас есть несколько S/MIME сертификатов), запросит вас о том, какой из сертификатов использовать для создания подписи, а затем попросит указать пароль, которым защищен ваш сертификат в базе данных программы. После чего программа автоматически создает электронную подпись для вашего письма и пошлет его по назначению. Обратите внимание, что защищен от несанкционированной модификации оказывается не только текст письма, но и те файлы, что, возможно, вы к нему прикрепили, а также некоторые служебные поля (например, From:, но не Subject:), т.е. если в процессе доставки что-либо из вышеперечисленного окажется изменено, система S/MIME получателя письма отреагирует на это, отказавшись «заверить» электронную подпись отправителя.
6. 4. Распределенные файловые системы Internet
Система архивов FTP
FTP-архивы — это распределенный депозитарий разнообразных данных, накопленных в сети за последние 20—30 лет. Любой пользователь может реализовать анонимный доступ к этому хранилищу и скопировать интересующие его материалы. Только объем программного обеспечения в архивах FTP составляет терабайты информации; кроме того, в FTP-архивах можно найти стандарты Internet (RFC), пресс-релизы, книги по различным отраслям знаний, главным образом по компьютерной проблематике, и многое другое.
Информация в FTP-архивах разделена на три категории (рис. 6.16):
• защищенная информация, режим доступа к которой определяется ее владельцами и разрешается по специальному соглашению с потребителем;
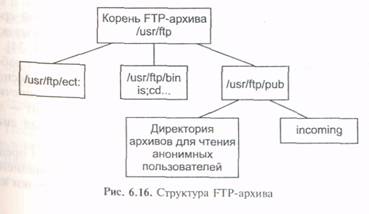
• информационные ресурсы ограниченного использования, к которым относятся, например, ресурсы ограниченного времени использования или ограниченного времени действия т. е. потребитель может использовать текущую версию на свой страх и риск, но никто не будет оказывать ему поддержку;
• свободно распространяемые информационные ресурсы, или freeware, если речь идет о программном обеспечении. К этим ресурсам относится все, что можно свободно получить по сети без специальной регистрации. Это могут быть документация, программы или что-либо еще.
Протокол FTP (File Transfer Protocol) — один из старейших протоколов в Internet; обмен данными в FTP проходит по TCP-каналу и построен по технологии «клиент—сервер».
В FTP соединение инициируется интерпретатором протокола пользователя. Управление обменом осуществляется по каналу управления в стандарте протокола Telnet. Команды FTP генерируются интерпретатором протокола пользователя и передаются на сервер. Ответы сервера отправляются пользователю также по каналу управления.
Команды FTP определяют параметры канала передачи данных и самого процесса передачи. Они также определяют и характер работы с удаленной и локальной файловыми системами.
В протоколе большое внимание уделяется различным способам обмена данными между машинами разных архитектур, которые могут иметь различную длину слова и часто различный порядок битов в слове. Кроме того, различные файловые системы работают с разной организацией данных, которая выражается в понятии метода доступа.
Практически для любой платформы и операционной среды существуют как серверы, так и клиенты. Ниже описываются стандартные сервер и клиент Unix-подобных систем [31, 34].
Программное обеспечение доступа к FTP-архивам. Для работы с FTP-архивами необходимо следующее программное обеспечение: сервер, клиент и поисковая программа. Сервер обеспечивает доступ к ресурсам архива из любой точки сети, клиент — доступ пользователя к любому архиву в сети, а поисковая система — навигацию во всем множестве архивов сети.
Сервер протокола — программа ftpd. Команда ftpd предназначена для обслуживания запросов на обмен информацией по протоколу FTP. Сервер обычно стартует в момент загрузки компьютера. Каждый сервер имеет свое описание команд, которое можно получить по команде help.
Возможен вход в архив по идентификатору пользователя anonimous или ftp. В этом случае сервер принимает меры по ограничению доступа к ресурсам компьютера для данного пользователя. Обычно для таких пользователей создается специальная директория ftp, в которой размещают каталоги bin, etc и pub. В каталоге bin размещаются команды, разрешенные для использования, а в каталоге pub — собственно файлы. Каталог etc закрыт для просмотра пользователем и там размещены файлы идентификации пользователей.
Рассмотрим некоторые команды протокола.
Обычно при передаче групп файлов для каждого файла запрашивается подтверждение. Для того чтобы избежать этого перед приемом/передачей, следует выдать команду prompt. Последняя переключает режим запроса подтверждения и при повторном использовании этой команды состояние запроса подтверждения восстанавливается;
bin — после выдачи этой команды по умолчанию данные будут передаваться в режиме передачи двоичных данных, что весьма существенно, так как в режиме ASCII нельзя передать программы и архивированные данные. Часто бывает полезно включить режим bin для символьных данных с произвольной длиной строки, например файлов postscript (*.ps);
quit — команда выхода из ftp.
Программа обмена файлами ftp — это интерфейс пользователя при обмене файлами по одноименному протоколу. Программа устанавливает канал управления с удаленным сервером и ожидает команд пользователя.
Если команда ftp работает с пользователем и ожидает его команд, то на экране отображается приглашение ftp>.
Вот некоторые команды данного режима:
open — по этой команде открывается сеанс работы с удаленным сервером:
ftp>оpen polyn.net.kiae.su;
После выдачи команды последуют запросы идентификаций пользователя.
user регистрация пользователя:
ftp> user anonymous;
В данном случае пользователь не имеет особых прав доступна удаленном сервере и поэтому регистрируется как аноним. В ответ на запрос идентификации пользователю следует внести свой почтовый адрес;
cd и Ls (dir) — назначение этих команд достаточно очевидно — навигация по дереву файловой системы и просмотр содержания каталогов. Так как в процессе приема-передачи участвуют две машины, то кроме навигации в удаленной файловой системе нужна еще навигация в локальной файловой системе. Для этой цели служит команда lcd (локальная cd).
Кроме того, пользователь может выдать и любую команду локальной оболочки, если предварит ее символом «!»:
![]()
По этой команде будет выдано имя текущей директории на локальной машине.
Команды get, put, mget, mput и bin (прием/передача данных). По командам get и put можно принять или передать один файл:
![]()
Команды mget, mput предназначены для приема/передачи группы файлов:
![]()
Windows Commander. Функции FTP-клиента встроены, например, в программную оболочку Windows Commander. На рис. 6.17 отображен экран настройки на связь с FTP-cepвером. Конфигурации каждой настройки запоминаются в меню Connection и включают в себя:
• адрес FTP-сервера (здесь — ftp.inion.ru);
• имя пользователя и пароль (здесь — anonimous);
• имя удаленного каталога в файловой системе FTP (здесь – w_inion/irb).
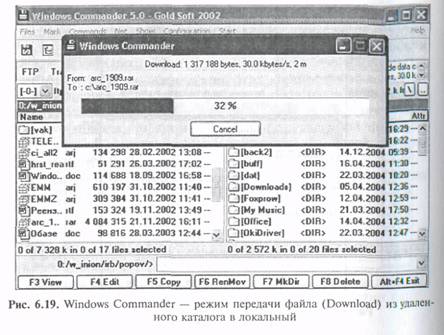
После установления связи на одной из панелей отображается удаленный каталог (рис. 6.18 — слева удаленный каталог, справа — локальный).
Передача файлов в обе стороны (Upload и Download) осуществляется обычным выделением файлов (директорий) и копирования их по команде <F5> (рис. 6.19).
Usenet
Распределенная файловая система Usenet — система телеконференций Internet. (Данный термин не очень удачен — в Internet есть и другие средства, которые также реализуют принцип телеконференций.) Пользователи Usenet предпочитают придерживаться термина newsgroup или group, который можно перевести как группа новостей (группа) — это постоянно изменяющийся набор сообщений, входящих в область интересов участников данной группы. Статья или сообщение отправляется в телеконференцию пользователем и становится доступной для всех подписчиков группы. Данным способом распространяется большинство сообщений Internet, например списки часто задаваемых вопросов (FAQ) или реклама программных продуктов.
Подписка подразумевает процедуру оповещения пользователя о появлении новых статей по интересующей его теме. Сообщение оформляется в соответствии со стандартом почтового сообщения Internet.
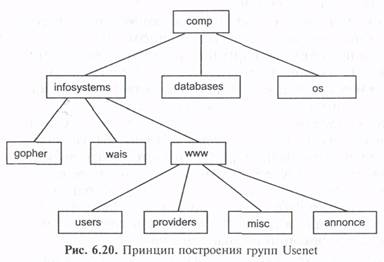
С точки зрения структуры информационного ресурса Usenet организована как иерархический каталог, узлами которого являются группы новостей. Сообщения в группе обычно не задерживаются более нескольких дней (стандартное значение по умолчанию — 5). Проиллюстрировать такую организацию можно на примере группы соmр (компьютеры и компьютерные технологии) на рис. 6.20.
Пользователь осуществляет подписку на одном из серверов Usenet, который террирориально ближе для него (обычно это машина, на которой расположены все информационные ресурсы организации или учебного заведения). По мере поступления новых сообщений от пользователей серверы обмениваются между собой этой информацией.
Первые версии системы появились в 1979 г. в Университете штата Северная Каролина и функционировали на основе межмашинного Unix-протокола UUCP. В 1986 г. система была впервые реализована на основе нового специального протокола обмена новостями Network News Transfer Protocol (NNTP — RFC-977).
Протокол обмена новостями и принципы построения системы. Протокол NNTP пришел на смену UUCP, и его целью было Упорядочить обмен информацией между серверами Usenet.
Протокол NNTP определяет запросно-ответный механизм обмена сообщениями между серверами и сервером и программами-клиентами. Для этой цели в протоколе определен набор команд и ответов на них. Весь диалог осуществляется в текста ASCII, причем каждая команда состоит из идентификатора и параметров.
По команде group выбирается группа новостей. При этом указатель статьи в группе устанавливается на первую запись группе. По команде help можно получить список разрешенных для использования команд.
Команды last и next перемещают указатель текущей строки в группе, команда list выдает список групп с указанием количества новых статей в них и начальным и конечным номерами статей. По командам newgroups и newnews можно получить списки новых групп и новых статей соответственно, а по команде post отправить свою статью на сервер.
По командам article, body, head, stat запрашиваются статьи или их части. Существует два способа запросить статью: либо по ее идентификатору (указывается в заголовке), либо по номеру статьи в группе. Команда article возвращает заголовок и через пустую строку текст статьи, body — только тело статьи, head — только заголовок, а по команде stat устанавливается текущая позиция в группе по идентификатору статьи. При этом никакой информации не возвращается.
Команда slave сообщает о наличии в качестве клиента подчиненного сервера, команда quit позволяет запершить сеанс.
Gopher
Файловая система Gopher была разработана для реализации распределенной базы документов, которые хранятся на машинах сети и предоставляются пользователю в виде единой иерархической файловой системы. Модель файловой системы наилучшим образом подходит для отображения структуры хранения документов по следующим очевидным соображениям:
• иерархическое представление данных привычно большинству пользователей, так как иерархии широко используются во многих компьютерных представлениях (UNIX, MS-DOS, системах BBS);
• Gopher рассчитан на применение недорогих решений как в аппаратной части, так и при программировании, поскольку
первоначально он был ориентирован на разработку информационной системы университета (шт. Миннесота). Система соответствовала реальной структуре университета с его делением на факультеты и кафедры, что также хорошо описывается иерархической моделью данных;
• модель файловой системы может быть легко расширена путем добавления к традиционным файлам и директориям других объектов, которые можно назвать виртуальными файлами. Такие виртуальные объекты могут быть поисковыми запросами или шлюзами в другие информационные ресурсы Internet. Вначале система ориентировалась на два типа виртуальных файлов, добавленных к основным: информационный поиск по ключевым словам и записные/телефонные книжки.
Ресурсы Gopher. Gopher представляет весь Internet (серверы Gopher) в виде единой иерархической системы. Gopher-серверы объединены в единое информационное пространство в Internet. Многие архивы дублируют информацию из других архивов (так называемые «зеркала» — mirrors).
В табл. 6.8 приведены основные типы ресурсов, доступных в системах Gopher, и их коды (для сетевых протоколов).
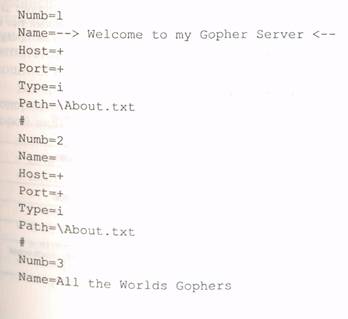
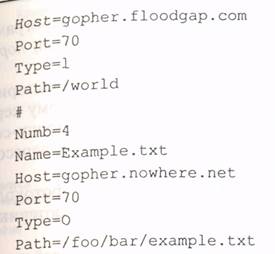
Каждый файл на сервере должен быть описан следующим образом (табл. 6.9).
Пример описания:

На экране пользователя отобразится следующая информация:
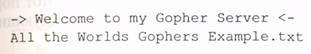
Протокол Gopher. Протокол Gopher предназначен для работы по модели «клиент—сервер», при этом программа-клиент установлена на рабочем месте пользователя. Эта программа посылает запрос-селектор в ТСР – порт 70 (строку текста, которая может быть и пустой), а затем сервер отвечает блоком текста, в конце которого стоит точка. Никакой информации о состоянии соединения сервер клиенту не сообщает и, в свою очередь, не запрашивает. После ответа сервера соединение разрывается, а при новом запросе оно должно быть установлено заново. Простота этого алгоритма позволяет реализовать его даже на маломощных персональных компьютерах.
Возвращаемый сервером текст представляет собой справку о содержании текущей директории (каталога), каждый элемент которой включает:
• тип {объекта в директории);
• имя (используется для отображения и в запросах);
• неотображаемую строку выбора, которая обычно описывает путь, используемый удаленным хостом для доступа к объекту (селектор);
• имя хоста (машины, к которой надо обращаться за информацией);
• номер порта (на котором сервер данного объекта ожидает запрос).
Пользователь реально видит только имя объекта. Программа-клиент может воспользоваться триадой селектор, хост, порт для поиска каждого объекта.
Для использования поискового объекта из директории Gopher клиент посылает запрос специальному поисковому серверу Gopher. В этом случае клиент посылает серверу строку-селектор и ключевые слова, а получает от сервера список адресов документов, удовлетворяющих запросу.
Программы, обслуживающие взаимодействие по протоколу Gopher, существуют практически для всех типов компьютерных платформ.
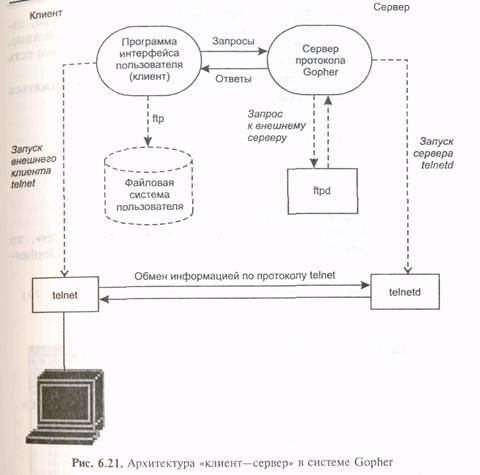
Модель взаимодействия Gopher. Модель взаимодействия Gopher основывается на архитектуре «клиент—сервер» (рис. 6.21). Сервер ожидает запросы пользователя по назначенному порту TCP (по умолчанию это порт 70), а клиент посылает в этот порт запросы. Диалог «клиент—сервер» может выглядеть следующим образом:

Здесь первый символ каждой строки определяет тип ресурса — документ, каталог или поисковый критерий (соответственно цифры 0, 1,7 — см. табл. 6.4). Все остальные символы поел кода типа до первого символа табуляции задают отображаемую в дереве виртуальной файловой системы информацию.
Интерфейсы-клиенты отображают эту информацию в виде идентификатора входа в элемент файловой системы. Тип информации обычно может отображаться в виде изображения (иконки) соответствующего типа в графических интерфейсах или символа, например, V» для каталогов, в алфавитно-цифровых интерфейсах. Таким разом пользователю дается подсказка, с каким типом информации или программ он будет иметь дело, если выберет тот или иной вход в виртуальную файловую систему Gopher. Следующее идентификатором поле — строка-селектор, которую клиент отсылает на сервер, если пользователь выбрал данный вход.
За селектором следует доменный адрес Gopher-сервера за тем номер порта, по которому осуществляется взаимодействие. Обычно это порт 70, но можно указать и другой, на котором ест обслуживание Gopher-клиента.
На экране пользователя в данном случае будет отображаться только следующая информация:

Если пользователь выбрал вход «Microcomputer Prices», то будет инициализировано следующее взаимодействие с Gopher-сервером.

Gopher-клиент WSGopher32. Доступ к системе Gopher может осуществляться путем использования: Gopher-клиента; HTTP-шлюза; навигации по системе с помощью e-mail.
Существует большое количество клиентских программ под различные платформы. Рассмотрим использование Gopher- клиента WSGopher32 (рис. 6.22).
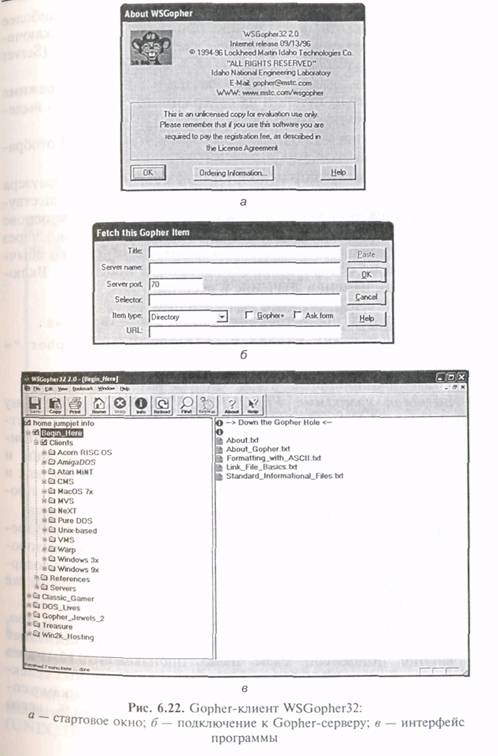
Специализированные Gopher-клиенты позволяют наиб адекватно отображать информацию протокола. Для подключения к gopher-серверу, достаточно указать его адрес (Server name) — см. рис. 6.22, б.
Навигация по серверу осуществляется в привычном режим просмотра структуры папок и их содержимого. Тип файла выделяет соответствующим значком.
На рис. 6.22, в в интерфейсе программы WSGopher32 отображен корневой узел хоста gopher://horae.jumpjet.info.
Кроме того, возможно использование обычного веб-браузепа для просмотра gopher-ресурсов. Поддержка протокола существует изначально в браузерах FireFox и других браузерах на основе Mozilla. Обозреватель Opera поддерживает работу только через шлюз, а в Internet Explorer поддержка существует, однако обычно отключена по соображениям безопасности протокола. Включить ее можно, изменив значение в реестре:

Поисковая программа VERONICA. VERONICA (Very Easy Rodent-Oriented Net-wide Index to Computerized Archives) является инструментом поиска, который позволяет быстро просматривать Gopher-пространство для получения отдельных файлов и каталогов. Она собирает данные точно таким же образом, как и другие АИПС, — посещает Gopher-серверы по всему миру, просматривает меню и запоминает их.
Программа запускается из Gopher-клиента (рис. 6.23, а), результатом поиска является виртуальное меню, пунктами которого будут элементы с Gopher-серверов всего мира, которые содержат поисковые слова. Это временное меню работает таким же образом, как и любое другое Gopher-меню (рис. 6.23, б).
Поданным, представленным на сайте gopher.floodgap.com, указано, что по состоянию на 17 мая 2006 г. последнее обновление поисковой базы было произведено 14 март 2006 г. и содержит 1 246 517 уникальных и проверенных селе торов, содержащихся на 148 серверах. По оценкам сопровождающих систему, поиск охватывает до 40 % всего gopher-пространства.

6.5. Распределенные информационные системы Internet
Файловые системы Internet, рассмотренные выше, во многом аналогичны файловым системам операционных систем ЭВМ (UNIX, DOS и пр. [31]), которые они, собственно и имитируют. Навигация в таких структурах весьма ограничена — «вверх» «вниз» по ветвям каталогов (директорий). Поиск информации почти исключен, поскольку связь между содержанием данных наименованиями файлов или каталогов весьма ограничена. Альтернативным подходом является организация информационных систем, позволяющих проводить содержательный поиск данных в распределенной БД. Применительно к INTERNET такими технологиями являются WWW и WAIS.
Информационные технологии WWW
Основными компонентами данных технологий, состоящих в применении гипертекстовой модели к информационным ресурсам, распределенным в Internet, являются (рис. 6.24):
• HTML — язык гипертекстовой разметки документов;
• URL — универсальный способ адресации ресурсов в сети;
• HTTP (Hypertext Transfer Protocol) — протокол обмена гипертекстовой информацией;
• дополнительные средства (CGI, Java, JavaScript).
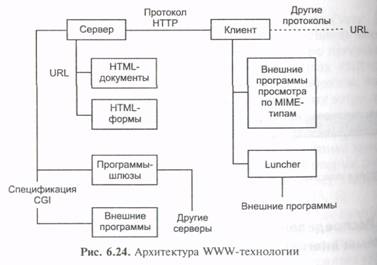
Ранее уже были рассмотрены основные возможности Н как приложения SGML к описанию типов документов. Здесь вкратце остановимся на навигационных компонентах HTML.
Гипертекстовая база данных в концепции WWW — это набор текстовых файлов, написанных на языке HTML, который определяет форму представления информации (разметка) и структуру связей этих файлов (гипертекстовые ссылки) (рис. 6.25).
Такой подход предполагает наличие еще одной компоненты технологии — интерпретатора языка. В World Wide Web функции интерпретатора разделены между сервером гипертекстовой базы Данных и интерфейсом пользователя.
Сервер, кроме обеспечения доступа к документам и реализации гипертекстовых ссылок, осуществляет также препроцессорную обработку документов, в то время как интерфейс пользователя проводит интерпретацию конструкций языка, связанных с представлением информации.
Язык разметки HTML. Описание интерфейсов и навигация. Язык HTML включает две основные компоненты:
• средства отображения документа (рассмотрены выше);
• средства навигации и построения интерфейсов с пользователем.
Гипертекстовые ссылки. Все рассмотренные ранее средства управления отображением текста являются дополнительными к основному элементу документа — гипертекстов ссылкам. Вот некоторые элементы HTML, реализующие данный механизм.
link — элемент заголовка — используется для описания общих для всего документа гипертекстовых ссылок. Элемент имеет три атрибута: rel, rev и href, rel задает тип ссылки, rev обратную ссылку, a href определяет ссылку в форме URL. На данный элемент возложена нагрузка по программированию средств управления интерфейсом пользователя.
При выборе соответствующей позиции в меню интерфейса пользователя или соответствующей этой позиции пиктограммы программа интерфейса должна генерировать запрос к серверу на получение документа, указанного в атрибуте href. Например;
![]()
Данное предложение в заголовке HTML-документа означает, что при выборе режима Help на экране отобразится документ, который хранится по адресу http://polyn.net.kiae.su/ dss/syshelp.html. Таким образом появляется возможность строить системы контекстно-зависимых справок в интерфейсах, построенных по технологии WWW.
Элемент <А. . . >......</А>, который называют «якорь» (anchor), применяется для записи гипертекстовой ссылки из тела документа; имеет несколько атрибутов, главным из которых является HREF (HyperText Reference). Простую ссылку можно записать в виде:
![]()
Здесь значением атрибута href является адрес документа index.html на машине polyn.nct.kiae.su, доступ к которой осуществляется по протоколу HTTP, записанный в формат URL.
Содержание элемента А, заключенное между метками начала и конца элемента, выделяется в тексте цветом, определенным для контекстных гипертекстовых ссылок. На рис. 6.25 привел пример использования в документе меток <А. . . >...<../А>, и его отображение интерфейсом Netscape.
Яругой формой использования элемента а является определение точек внутри текста, на которые можно сослаться:
![]()
Представление multimedia-информации. Система World Wide Web была ориентирована на графические средства представления информации. Первым шагом на этом пути была реализация возможности вставлять в текст графические объекты, затем появилась возможность запуска внешней программы для просмотра файла в форматах, отличных от ASCII (например, GIF). Таким образом, на любой информационный объект можно сослаться из документа HTML, вызвав его через внешнюю программу просмотра. Графические объекты могут использоваться в качестве идентификаторов гипертекстовых ссылок и для перехода по гипертекстовой сети.
Для встраивания в документ графических образов используются элементы IMG и FIG.
IMG — элемент встраивания в текст графического образа, например:

В данном примере атрибут SRC определяет адрес графического объекта, который надо встроить в документ, а атрибут alt предназначен для отображения в интерфейсах, которые не поддерживают встраиваемую графику (типа Lynx). В последнем случае вместо картинки будет отображено содержание атрибута ALT.
IMG можно использовать внутри гипертекстовой ссылки:
![]()
В этом случае весь рисунок целиком используется как идентификатор гипертекстовой ссылки. Кроме того, в данном примере используется атрибут элемента IMG — align, который может принимать значения тор,middle, bottom, left, right и определяет, где относительно других символов текста в строке будет располагаться рисунок.
Элемент FIG (развитие IMG) введен в стандарт языка для улучшения отображения графической информации и использования ее для разработки гипертекстовых баз данных. При использовании img текст разбивается на две части: до рисунка и после при этом реализуется обтекание картинки текстом (рис. 6.26).

Элементы реализации интерфейсов в HTML
ISINDEX — элемент заголовка документа — определяет использование HTML – документа для ввода запроса на поиск по ключевым словам:

В приведенном примере атрибут href определяет адрес про граммы обработки запроса, а атрибут prompt – содержание приглашения.
FORM — средства встраивания элементов интерфейса в тело документа (механизм форм заполнения — fill-out forms) – впервые были подробно описаны в инструкциях по использованию сервера NCSA. Посредством форм осуществляется передача параметров внешним программам, которые вызываются сервером, что сделало WWW универсальным интерфейсом ко всем ресурсам сети.
Вот некоторые вложенные в form элементы HTML:

input — наиболее универсальный из всех элементов формы. Способ его отображения определяется атрибутом type, который может принимать значения text, password, checkbox, radio, range, scribble, file, hidden, submit, reset, image.
Атрибут name определяет идентификатор поля. Данный атрибут не отображается, но его значение передается обрабатывающей программе.
Атрибут value определяет значение поля. Данное значение передастся вслед за именем поля. Если разработчик указал этот атрибут в тексте документа, то это будет значение по умолчанию.
Атрибут disable защищает значение поля формы от изменения пользователем. Часто это бывает полезным при многократных обращениях к внешним базам данных и при коррекции запросов.
Атрибут error определяет текст сообщения об ошибке при неправильном вводе.
Атрибут CHECKED используется в полях типа checkbox и radiobutton. Он определяет состояние данного поля (ВЫБРАНО/НЕ ВЫБРАНО)
Атрибут size определяет размер видимой части поля ввода. Для непропорциональных шрифтов он равен числу символов, для пропорциональных шрифтов — числу типографских интервалов.
Атрибут MAXLENGTH определяет максимальное число символов, которое можно ввести в текстовое поле.
Атрибуты MIN и MAX определяют диапазон разрешенных числовых значений для поля ввода.
Атрибут SRC используется для задания адреса графического объекта, который можно использовать в поле ввода.
Атрибут md задает контрольную сумму для графики.
Атрибут align определяет выравнивание текста.
Приведем фрагмент HTML-документа с элементами группы FORM и их интерпретацию Web-обозревателем Konqueror (рис. 6.27, l):

В первой строке приведено простое текстовое поле с введенным в него значением по умолчанию. Это значение может быть изменено пользователем. В следующей строке отображено поле типа checkbox. Крестик в поле показывает, что оно выбрано (значение по умолчанию установлено атрибутом checked). Ниже приведено поле radiobutton в виде кружка (так как в нем нет черной точки, это поле не выбрано); в поле password введен пароль, который не отображается, а заменяется звездочками; невидимое поле не отображается, а предназначено для реализации диалога с удаленными программами. Кнопка submit активирует передачу параметров серверу, в то время как Reset восстанавливает значения полей формы по умолчанию. Графическая кнопка аналогична кнопке Submit, только она передав также значения координат графического образа.
textarea предназначен для ввода больших многострочных текстовых данных; это связано с ограничениями на длину си вольной строки. Элемент имеет два атрибута: ROWS - число видимых строк и cols — число видимых символов в строке (рис. 6.27, 2):

Элементы select и option предназначены для организации меню, которое может быть падающим, множественным и графическим: в падающем меню можно выбрать только один элемент; в множественном — несколько; графическое меню предназначено Для выбора по графическому образу. Приведем пример организации меню (рис. 6.27, 3):

В данном случае при отображении HTML-документа будет создано падающее меню с тремя элементами. Пользователь может выбрать один из этих элементов в качестве значения поля.
HTTP (Hypertext Transfer Protocol) — протокол прикладного уровня, который разработан для обмена гипертекстовой информацией в сети Internet и используется в Word Wide Web с 1990 г
Реальная информационная система требует гораздо большего количества функций, чем только поиск данных. HTTP позволяет реализовать в рамках обмена информацией широкий набор методов доступа.
Программа-клиент посылает после установления соединения запрос серверу. Этот запрос может быть в двух формах: в форме полного запроса и в форме простого запроса. Простой запрос содержит метод доступа и запрос ресурса. Например:
![]()
В этой записи слово get обозначает метод доступа get, a http: //polyn.net. kiae . su/ — это адрес ресурса.
Методы доступа — в практике World Wide Web реально используются три таких метода: post, get, head.
get — метод, позволяющий получить данные, заданные в форме URI в запросе ресурса. Если ссылаются на программу, то возвращается результат выполнения этой программы, но не ее текст. Дополнительные данные, которые надо передать для обработки, кодируются в запрос ресурса.
head — в отличие от GET не возвращает тела ресурса. Используется для получения информации о ресурсе и для тестирования гипертекстовых ссылок.
post — метод разработан для передачи большого объема информации на сервер. Им пользуются для аннотирования существующих ресурсов, посылки почтовых сообщений, работы с формами интерфейсов к внешним базам данных и внешним исполняемым программам. В отличие от GET и HEAD в POST передается тело ресурса, которое является информацией из поля форм или других источников ввода.
Средства расширения HTML-технологий. Фреймы — тип элементов, обеспечивающих возможность разделить рабочее окно программы просмотра на несколько независимых панелей. В каждый фрейм может быть загружена отдельная страница HTML.
Спецификация CGI (Common Gateway Interface) определяет порядок взаимодействия сервера с прикладной программой, в котором сервер выступает инициирующей стороной, и задает механизм реального обмена данными и управляющими командами в этом взаимодействии, что не определено в HTTP.
Главное назначение — обеспечение единообразного потока иных между сервером и прикладной программой, которая запускается под управлением сервера. CGI устанавливает протокол обмена данными между сервером и программой.
При описании различных программ, которые вызываются сервером HTTP и реализованы в стандарте CGI, используют следующую терминологию.
CGI – скрипт — программа, написанная в соответствии со спецификацией Common Gateway Interface. CGI – скрипты могут быть написаны на любом языке программирования (С, C++, PASCAL, FORTRAN и т. п.) или командном языке (shell, cshell, командный язык MS-DOS, Perl и т. п.).
Шлюз — CGI – скрипт, который используется для обмена данными с другими информационными ресурсами Internet или резидентными приложениями (демонами). Обычная CGI-программа запускается сервером HTTP для выполнения некоторой работы, возвращает результаты серверу и завершает свое выполнение. Шлюз выполняется аналогично, однако он инициирует взаимодействие с третьей программой в качестве клиента. Если эта третья программа является сервисом Internet, например, Gopher-сервером, то шлюз становится клиентом Gopher, который посылает запрос по порту Gopher, а после получения ответа пересылает его серверу HTTP. По аналогии осуществляется взаимодействие с серверами распределенных баз данных (например, Oracle).
JavaScript — язык управления сценарием отображения Документа — является естественным продолжением HTML. По своей природе это объектно-ориентированный язык программирования, который, однако, не поддерживает инкапсуляцию объектов и полиморфизм методов. Объекты, над которыми можно выполнять различные операции в JavaScript — это элементы интерфейса Netscape Navigator и контейнеры HTML. Средствами этого языка могут быть реализованы многие полезные эффекты (мультипликация, контекстная помощь, проверка синтаксиса и многое другое).
JavaScript не единственный язык управления сценария просмотра документов; известна аналогичная разработка – VBScript (на основе Visual Basic, фирмы Microsoft).
Java — объектно-ориентированный язык программирования, который связан с World Wide Web библиотекой классов описывающих элементы интерфейса пользователя (кнопки, поля ввода, меню, метки, графические объекты и пр.), порядок взаимодействия страниц World Wide Web с другими ресурсами сети через транспорт TCP/IP. Язык поддерживает возможность построения многопоточных программ.
Программное обеспечение для World Wide Web
Программное обеспечение World Wide Web можно разделить на группы по направлениям использования. Каждое из этих направлений определяется либо схемой взаимодействия компонентов Web-технологии, либо особенностями применения его субъектами обмена информацией в рамках World Wide Web. Принята следующая классификации программного обеспечения World Wide Web:
• программы-клиенты (в том числе мультипротокольные браузеры);
• программы просмотра документов в форматах, отличных от стандартных форматов Web;
• программы-серверы протокола обмена гипертекстовой информацией (Web-серверы);
• программы подготовки публикаций;
• поисковые машины;
• программы анализа статистики посещений. Рассмотрим некоторые из этих типов программ более подробно.
Программы-клиенты — стандартны для World Wide Web. Первыми распространенными некоммерческими программами этого типа являлись Mosaic (графический интерфейс) и Lynx для алфавитно-цифрового режима доступа.
Mosaic — графический интерфейс доступа в WWW, интерпретирует язык гипертекстовой разметки HTML и позволяет обмениваться данными по протоколу HTTP 1.0 (см. также рис. 2.7, 2.8).
Arena позволяет интерпретировать версии языка, которые в дополнение к возможностям, существующим в Mosaic, также реализуют математические формулы, обтекание графики текстом, прозрачные графические образы и ряд других изобразительных средств.
Lynx __ полноэкранный интерфейс доступа к WWW с алфавитно-цифровых устройств типа терминала VT100. Интерфейс поддерживает все возможности языка HTML 2.0 за исключением графики. Используя Lynx, можно не только просматривать базы данных WWW, но обмениваться данными с CGI – скриптами, размещенными на удаленных серверах.
Line Mode Browser — самый простой интерфейс WWW. Он используется на любых устройствах отображения информации, в том числе и на терминалах типа TTY (телетайп).
Мультипротокольные программы-браузеры. На роль стандартов в этом классе программного обеспечения претендуют две программы: Netscape Communicator (NC) и Microsoft Internet Explorer (IE). По своим возможностям и внешнему оформлению они довольно похожи. Основная задача этих программ — интерпретация разметки на языке HTML, интерпретация встроенных в HTML программ на одном из командных языков Web: JavaScript или VBScript, интерпретация байткодов Java, разбор спецификации ресурсов сети (обработка URI), взаимодействие с серверами по протоколам прикладного уровня стека протоколов TCP/IP.
Netscape. Рассмотрим типовой интерфейс такой программы (рис. 6.28). В верхней части этого интерфейса расположено поле title документа. В нем отображается содержание контейнера title. Ниже расположено текстовое меню настроек и управления просмотром. Под ним расположены пиктограммы графического меню управления просмотром. Затем следует поле закладок пользователя и поле location, которое определяет URL загруженного документа. Ниже расположено меню перехода на встроенные в браузер закладки, которые указывают на наиболее полезные с точки зрения разработчиков программы узлы Web. Далее вниз следует рабочая область программы, в которой отображается содержание документа. Под ним расположены пиктограммы работы в защищенном режиме, поле status, в котором текущего документа или URL-соединения, линейка икон других модулей программы браузера.
Текстовое меню открывает подменю Файл (File). В этом режиме определяется адрес загрузки документа (New, Open page), сохранение текущей страницы (Save, Save as...), режимы редактирования и обмена страницами, печати и выхода из окна или системы просмотра вообще.
За File обычно следует Редактирование (Edit), в котором определяются режимы редактирования и поиска информации на текущей странице, а также режим настроек Preference. Последний чрезвычайно важен для настроек программы.
Для того чтобы просмотреть/изменить настройки NN, необходимо, запустив программу, выбрать команду Edit/Preference в Главном меню. Появится диалоговое окно Preferences (Установки) — рис. 6.29.
Слева расположено меню выбора опций настройки программы, справа — набор параметров, который соответствует выбранной опции. Символ «—» указывает на дополнительные опции. Символ «+» сообщает, что дополнительные опции не отображены. Выбирая ту или иную опцию, можно управлять отображением интерфейса браузера на экране монитора и настройками программы при взаимодействии с серверами Web. Наиболее существенные настройки браузера содержатся в двух группах настроек: Appearance (Появление) и Navigator (браузер NC).
В группе настроек Navigator, показанной на рис. 6.29, в правой части окна имеется три группы параметров. Переключатели в первой группе Navigator Starts With (Браузер стартует с) предназначены для настройки адреса начальной Web страницы. Так же, как и в случае IE, для начинающих рекомендуем первый вариант — Blank Page (чистая страница). Во второй области можно задать адрес домашней страницы. По умолчанию здесь стоит адрес Web-страницы фирмы Netscape nttp://home.netscape.com/. Наконец, в третьей области можно задать срок хранения адресов посещаемых страниц или очистить этот список.
В подгруппе Language (Языки) так же, как и в браузере IE, обязательно должны присутствовать, по крайней мере, два языка: английский и русский. Подгруппа Application (Приложения) дает список всех приложений, которые могут взаимодействовать с браузером NC.
Выбрать правильную кодировку текста можно, выполнив команду VIEW/Encording (Вид/Кодировка) в Главном меню браузера. В открывшемся списке необходимо выбрать кодировку Cyrillic (Windows-125I) и нажать клавишу <Enter>. Для того чтобы эта кодировка оставалась и в дальнейшем, необходимо сразу же еще раз выполнить указанные команды и выбрать последний пункт Set Default Encoding (установка кодировки по умолчанию) и опять нажать клавишу <Enter>.
Вслед за Edit указано меню Вид (view). Данное меню отвечает за отображение информации о странице и позволяет обрабатывать перекодировку текста в тот код, который заказывается через режим Encoding. Практически именно этот режим позволяет читать русский текст, в какой кодировке он не был бы подготовлен.
Меню Перейти (Go) позволяет быстро извлекать из запасников адреса пройденных гипертекстовых ссылок и снова возвращаться к просмотру страниц, на которые они указывают.
Меню Компоненты (Communicator) позволяет запустить на выполнение другие модули системы, например, систему просмотра электронной почты или программу просмотра новостей.
Мультипротокольный браузер Opera. При запуске Opera отображается диалог запуска, который содержит два основных параметра использования Opera (рис. 6.30, а):
• открывать все окна Opera внутри программы (многодокументный интерфейс — MDI);
• открывать отдельное окно приложения для каждого окна Opera (однодокументный интерфейс — SDI).
Рассмотрим элементы пользовательского интерфейса Opera. Главная панель содержит набор кнопок, которые позволяют осуществлять собственно навигацию в Internet:
• создавать новые окна для навигации;
• открывать и сохранять файлы на компьютере;
• распечатывать Web-страницы;
• осуществлять поиск текста на Web-странице;
• отображать список;
• перемещаться назад и вперед по посещенным страницам в одном окне;
• получать самую последнюю версию страницы (обновление);
• осуществлять переход к домашней странице;
• получать доступ к закладкам в активной папке закладок;
• располагать все окна в Opera каскадом, по вертикали и горизонтали.
Пользователь может настроить главную панель, щелкнув по ней правой кнопкой мыши или из раздела вид главного меню.

Личная панель постоянно отображает на экране наиболее посещаемые закладки, поэтому пользователь может получить прямой доступ к ним, минуя список.
На личной панели можно также поместить любимые средства поиска в Internet, тем самым пользователю не нужно будет выбирать их из списка.
Панель адреса. На панели адреса расположены следующие элементы (слева направо):
• значок замка — показывает уровень безопасности узла;
• кнопка рисунка — переключает отображение рисунков на странице;
• кнопка режима отображения— переключает режим автора и режим пользователя;
• кнопка просмотра— включает предварительный просмотр печатной версии страницы;
• поле адреса — поле ввода Web-адресов страниц;
• раскрывающийся список адресов — обеспечивает доступ к ранее введенным адресам;
• кнопка «пуск» — осуществляет переход к введенному адресу;
• поле поиска — осуществляет прямой поиск в Internet;
• раскрывающийся список поиска — обеспечивает выбор средства поиска;
• кнопка поиска — выполняет поиск;
• поле масштаба — изменяет масштаб отображения Web-страниц;
• раскрывающийся список масштаба— выбирает уже существующее значение масштаба.
Панель окон (для MDI). Если запустить Opera с использованием многодокументного интерфейса (MDI), все окна будут отображаться внутри программы (рис. 6.30, а). Панель окон дает возможность управления всеми открытыми окнами и доступа к ним, и заменяет панель страниц, которая отображается при использовании однодокументного интерфейса (SDI).
Панель страниц (для SDI). Если запустить Opera использованием однодокументного интерфейса (SDI), все окна программы будут отображаться как окна отдельных приложений. Но дополнительно в распоряжении пользователя будет возможность открывать несколько страниц внутри каждого окна Орera. Панель страниц обеспечивает доступ к этим страницам с помощью изящных вкладок, и заменяет панель окон, которая используется для многодокументного интерфейса (MDI). Панель загрузки. При загрузке Web-страницы выводится панель загрузки. Она отображает следующую информацию (слева направо):
• объем загруженной страницы, передаваемой на компьютер (в процентах);
• количество загруженных рисунков и их общее количество;
• общий объем загруженных данных;
• среднюю скорость передачи данных во время загрузки страницы;
• время, прошедшее с начала загрузки;
• текущее состояние загрузки страницы.
Браузер Mozilla Firefox. Mozilla Firefox является Internet-браузером, предназначенным для просмотра Web-страниц и поиска в Internet, который реализован в различных ОС — Windows, Linux, Mac OS.
Навигация по Web-страницам. Просмотр начальной страницы. При запуске Firefox открывает начальную страницу (рис. 6.31, /). По умолчанию это будет домашняя страница Firefox.
Чтобы отобразить на экране больше содержимого, можно использовать полноэкранный режим. В полноэкранном режиме
панели Firefox сворачиваются в одну маленькую панель. Чтоб включить полноэкранный режим, следует выбрать пункт вид\ Полноэкранный режим или нажать <F11>. Чтобы быстро перейти к начальной странице, следует нажать <Alt+Home>.
Переход на другую страницу. Чтобы перейти на другую Web-страницу, наберите ее Internet-адрес или URL r панели навигации (рис. 6.31, 3). Адрес страницы обычно начинается с префикса http: //, за которым следует одно или несколько слов определяющих адрес (например, http://www.mozilla.org/).
Возвращение к просмотренным страницам. Существует
несколько путей, чтобы возвратиться к просмотренным страницам, например, чтобы
перейти назад или вперед на одну страницу, следует нажать на кнопки ![]() (Назад) или
(Назад) или ![]() (Вперед).
(Вперед).
Остановка загрузки и обновление страницы. Если
страница загружается слишком медленно или нет необходимости открыть эту
страницу, надо нажать кнопку Стоп ![]()
Просмотр страниц во вкладках. При работе сразу с несколькими Web-страницами в одно и то же время можно открывать их во вкладках для более быстрой и удобной работы в Internet.
Поиск в Internet. Можно легко произвести поиск нужной Web-страницы в Internet, набрав несколько слов в панели поиска Firefox.
Поиск выделенных слов на Web-странице. Firefox позволяет искать в Internet слова, которые выделены мышью на Web-странице. Firefox откроет новое окно и использует поисковую машину по умолчанию для поиска по выделенным словам.
Поиск на странице. Чтобы найти текст на странице, которую вы просматриваете в данный момент в Firefox, следует выбрать пункт меню правка\Найти на этой странице…, после этого в нижней части окна Firefox появится новая панель, в которой следует набрать искомый текст (рис. 6.31, 6).
Копирование части страницы. Чтобы скопировать текст со страницы, следует выделить текст, выбрать пункт меню Правка\Копировать, после этого можно вставить текст в другие программы.
Сохранение изображения со страницы. Необходимо разместить указатель мыши над изображением (рис. 6.32, /), нажать <Ctrl> и щелкнуть клавишей мыши по изображению для отображения контекстного меню. Выбрав пункт Сохранить изображение как. . ., выбрать расположение файла, в котором будет сохранено изображение, набрать имя файла, в который будет сохранено изображение (рис. 6.32, 2), и нажать кнопку Сохранить.

Печать страницы. Чтобы распечатать текущую, страницу следует выбрать пункт меню Файл\Печать .... Как будут выглядеть распечатанные страницы, можно увидеть, используя предварительный просмотр (выбрать пункт Файл\Предварительный просмотр — рис. 6.33).

Управление различными типами файлов. Firefox может работать с многими типами файлов. Тем не менее для работы с некоторыми типами файлов, такими как фильмы или музыка, в Firefox необходимо установить дополнительные модули или вспомогательные приложения, которые позволяют Firefox взаимодействовать с подобными типами файлов. Если в Firefox не имеется необходимого вспомогательного приложения или модуля, он может только сохранять подобные файлы на жесткий диск
Установка Firefox как браузера по умолчанию. Чтобы установить Firefox как браузер по умолчанию, следует перейти в меню Правка\Настройки, а затем в разделе Основное нажать на кнопку Установить как браузер по умолчанию.
Клавиатурные сокращения и приемы работы с мышью. В табл. 6.10 приведен список наиболее часто используемых клавиатурных сокращений, принятых в Mozilla Firefox, и аналогичных сокращений, используемых в Internet Explorer и Opera.

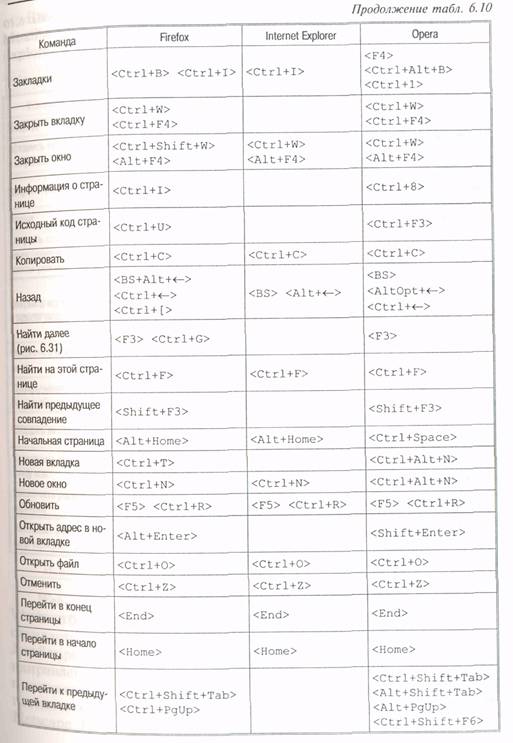

В табл. 6.11 приведены основные приемы работы с мышью в Mozilla Firefox и аналогичные приемы, используемые в Internet Explorer и Opera.
Web-обозревателъ Konqueror (Unix/Linux). В качестве Web-обозревателя Konqueror полностью совместим со стандартом HTML 4.01, имеет встроенную поддержку языка JavaScript (ECMA-262), CSS (каскадные таблицы стилей) и двунаправленного письма (арабский и иврит), позволяет запускать приложения Java, поддерживает SSL (использующийся для безопасного сообщения в Internet), а также дополнительные модули Netscape (в частности, для проигрывания медиафайлов Flash,
RealAudio и RealVideo). Среди особых возможностей — автодополнение вводимого текста и адресов Internet, импорт закладок из других обозревателей, открытие нескольких Web-страниц одном окне, а также выполнение функций клиента FTP.
Во внешнем виде Konqueror практически все может быть на строено по вкусу пользователя — от стиля в целом, размера текста и значков до выбора необходимых панелей инструментов пунктов меню и назначения собственных клавиш быстрого вызова. Различные конфигурации Konqueror можно сохранить для последующего использования. Приводимые ниже иллюстрации относятся к версии LINUX SuSE.
При работе с Konqueror, как и с любым другим приложением KDE, целесообразно использовать трехкнопочную мышь. Однако, если используется двухкнопочная мышь, нажатие средней кнопки можно заменить одновременным нажатием левой и правой (для этого необходимо соответствующим образом настроить систему).
В то время как в системах Windows для открытия документов обычно используется двойной щелчок мышью, следует отметить, что Konqueror, как и другие программы KDE, по умолчанию воспринимает одиночный щелчок.
Работа с Internet и поиск. При нахождении в Internet можно просматривать Web-страницы в Konqueror так же, как в любом другом обозревателе. На рис. 3.34 приведен пример экрана Konqueror.
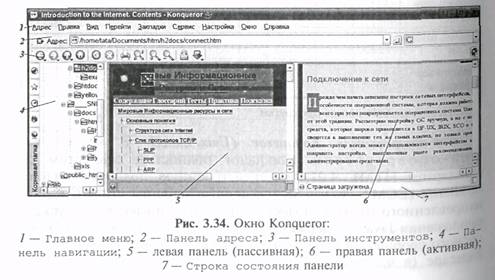
Необходимо ввести адрес страницы в строку адреса, нажать клавишу <Enter> или кнопку Переход справа от строки адреса, и Konqueror загрузит и отобразит указанную страницу. Сообщение узел неизвестен обычно означает, что не установлена связь с Internet (или указан неверный адрес страницы).
Если эта страница ранее посещалась, Konqueror облегчит ввод адреса с помощью функции автозавершения текста. Имеется также возможность выбрать нужный адрес из списка посещенных страниц, для этого следует воспользоваться разделом Журнал на панели навигации. Если необходимо произвести поиск в Internet, специальные Web-сокращения помогут легко указать нужную поисковую машину. В табл. 6.12 приводятся основные действия при навигации по Web-страницам.
Web-сокращения. В Konqueror имеется возможность пользовать Web-сокращения — сокращенные названия поисковых машин, с помощью которых поиск в Internet активизируется вводом искомой фразы в строке адреса (без захода на главную страницу поисковой машины).
Например, если ввести в строке адреса gg: konqueror и нажать <Enter>, обозреватель автоматически передаст поисковой машине Google запрос показать информацию об обозревателе Konqueror, которая есть в Internet.
Чтобы просмотреть список доступных Web-сокращений и добавить новые, следует выбрать пункт меню Настройка \ Настройка Konqueror..., в появившемся окне войти в раздел Настройки и щелкнуть по значку Wеb-сокращения.
Идентификация обозревателя. Когда Konqueror подключается к какому-либо серверу в Internet, он сообщает туда некоторые собственные данные (название, версия, система и т. д. или «User Agent»), исходя из которых сервер пересылает обозревателю такой вариант страницы, который в Konqueror будет выглядеть наилучшим образом. Это связано с тем, что у каждого обозревателя есть свои особенности, и не во всех обозревателях одна и та же страница будет выглядеть одинаково.
Сохранение и печать страниц. Если необходимо сохранить текущую Web-страницу на жестком диске, следует выбрать пункт меню Адрес\Сохранить как. . . . При наличии на странице врезок (frames) каждая из них может быть сохранена отдельно, если щелкнуть по ней левой кнопкой мыши и выбрать пункт меню Адрес\Сохранить врезку как. . . В табл. 6.13 приводятся различные варианты команд сохранения и печати страниц.
Программы-серверы. Сервер WWW — программа, которая принимает запросы от WWW-клиентов и отвечает на них. В качестве ответа может быть возвращен HTML-документ, хранящийся в базе данных сервера, графический образ, аудиозапись, фильм или ответ внешней программы. Сервер обменивается данными не только с клиентами, но и с CGI-скриптами.
В настоящее время серверы WWW существуют для всех типов компьютерных платформ и операционных систем.
Серверы для Unix-систем:
HTTPD (NCSA) — весьма распространен в сети; большое количество клиентов настроены для работы с этим типом сервера,
А р а с h i e — некоммерческое развитие сервера NCSA с учетом спецификаций защиты данных от несанкционированного доступа;
WN-сервер — реализует механизм графического стека ссылок в себе самом, а не через внешний скрипт, что повышает защищенность данных. Кроме того, данный сервер позволяет воспользоваться механизмом обновления информации протокола HTTP для организации видеоклипов.
Сервер Win HTTPD — это сервер для Windows. Он является функционально полным сервером WWW для этого типа операционной системы.
XML-технологии и поиск данных. BizQuery. Просмотр XML-Документов осуществляется специальной программой анализатором. На сегодняшний день разработано около десятка подобных анализаторов. В браузере Internet Explorer 5 предусмотрен анализ XML-документов.
Анализ документа в Internet Explorer 5 осуществляется тремя вариантами: просмотр аналогично HTML-документу, форматирование документа с использованием специальных стилевых таблиц — XSL и анализ с помощью сценариев, написанных на Java Script или VBScript.
Поиск нужного элемента или поддерева осуществляется с помощью XQL-запроса. XQL является частью XML и переводится как язык запросов для XML (XML Query Language). Широко обсуждается вопрос об утверждении языка XQL в качестве стандарта, который может заменить SQL
Синтаксис языка запросов очень гибок и позволяет осуществлять поиск элемента как по названию, значению атрибутов со держанию, так и учитывать вложенность и положение в дереве элементов. С помощью запросов мы можем выделять из общего дерева необходимые нам элементы и применять к ним необходимые инструкции. Запрос возможно применять как к самому XML-документу, так и к ссылкам URL.
Язык запросов напоминает обычный способ определения пути к ресурсу — список узлов дерева, разделенных символом «/». Для указания на текущий элемент используется символ «.» на родительский — «..», для выделения всех дочерних элементов — символ «*», для выделения элемента, расположенного просто «ниже» по дерену (не важно, на каком именно уровне вложенности) — «//». Условие на значение в запросе должно заключаться в символы «f« и «]». Для выбора значения атрибута в условии указывается символ «@».
Примеры простых XQL-шаблонов:

Система виртуальной интеграции BizQuery на основе технологий XML и UML является результатом работы исследовательской группы, которая на протяжении многих лет занимается вопросами исследования и разработки методов управления XML - данными. Основные возможности BizQuery заключаются в следующем:
• интегрированный доступ к нескольким источникам данных, которые могут быть реляционными или содержать XML-данные;
• использование XML как для внутреннего представления данных, так и для представления результата;
• представление глобальной схемы интегрированных данных в терминах XML, так и в терминах UML;
• возможность формулировки запросов к интегрированным данным с использованием декларативных языков запросов;
• развитая обработка запросов, включая оптимизацию запросов; декомпозицию запросов на частичные запросы, адресуемые к индивидуальным источникам данных; формирование окончательного результата с потенциальным выполнением соединений и трансформаций данных.
Приведем пример запроса. Предположим, необходимо обратиться к двум документам одного реляционного источника и выдать данные об отделах, в которых имеются сотрудники моложе 20 лет.

Схемы документов-источников в виде DTD (определение типа документа) имеют следующий вид: (см. также гл. 2, рис. 2.5):

Запрос содержит полусоединение (определяется раздела for и where) двух документов одного источника, которое может быть выполнено на стороне источника, а также трансформаций не поддерживаемую реляционным источником.
Протокол Z39.50
Данный протокол ориентирован на информационный поиск в удаленных базах данных. Это — протокол прикладного уровня в рамках семиуровневой эталонной модели взаимодействия открытых систем, разработанной Международной Организацией Стандартов (ISO), и поэтому может быть реализован в различных типах сетей (например, в сетях TCP/IP, IPX/SPX, OSI) независимо от реализации транспортного уровня. Его назначение — предоставить компьютеру, работающему в режиме «клиент», возможности поиска и извлечения информации из другого компьютера, работающего как информационный сервер.
Особенностями протокола Z39.50 является возможность сохранения состояний системы и присвоение каждому состоянию соответствующего идентификатора. Эта особенность протокола позволяет производить «навигацию во времени» т. е. в любой момент можно вернуться в определенную точку поиска, произведенного ранее. Наличие такой «памяти» позволяет использовать результаты, полученные ранее, в составлении дальнейших запросов.
Первоначально многие Z39.50-пршюжения создавались исключительно для использования с библиографическими данными (например, электронные Online-версии библиотечных каталогов). Однако в настоящее время протокол развит настолько, что позволяет обрабатывать различные данные — финансовую, химическую, техническую информацию, тексты и изображения.
Технология сетевого доступа к базам данных по протоколу Z39.50 существенно отличается от других технологий. Различие обусловлено самой сутью протокола: его ориентацией на работу с базами данных, абстрагированных от конкретных систем.
Состав протокола Z39.50. В основе Z39.50 лежит модель абстрактной базы данных. Каждый элемент этой модели имеет описание с однозначным толкованием и стандартизуется с присвоением уникального идентификатора — OID.
Термин база данных в спецификации Z39.50 означает набор файлов каждый из которых имеет свое уникальное имя. Единицей хранения информации, которая может быть найдена при обращении к базе данных, является запись файла. Все записи одного файла должны иметь одинаковую структуру (т. е. состоять из одного и того же набора элементов и точек доступа). Точка доступа — это уникальный или неуникальный ключ, который может быть указан самостоятельно или в совокупности с другими ключами в поисковом критерии. Ключ может быть элементом данных, состоять из нескольких элементов или быть частью элемента.
Работа с каждой конкретной СУБД согласно Z39.50 должна быть организована только через эту абстрактную модель путем обмена пакетами данных (PDU), содержащими последовательности объектов, идентифицируемых по меткам. В стандарте описаны следующие классы объектов:
• контекст приложения (context);
• протокольные блоки данных — protocol data unit (pdu);
• атрибуты (attributeset);
• диагностика (diagnostic);
• структура записей (recordsyntax);
• синтаксис преобразований (transfersyntax);
• отчет по ресурсам (resourcereport);
• контроль доступа (accesscontrol);
• расширенный сервис (extendedservice);
• пользовательская информация (userinfoformat);
• элементы (elementspec);
• варианты (variantset);
• схема данных (schema);
• схема меток (tagset).
Внутри класса объекты идентифицируются номерами, добавляемыми к номеру класса. Например, в классе recordsyntax {1.2.840.10003.5} объекты имеют OID:
Unimarc {1.2.840.10003.5.1},
USmarc {1.2.840.10003.5.10},
sutrs {1.2.840.10003.5.101} и т. п.
Модель службы 239.50 предусматривает обмен сообщениями типа «запрос—ответ» между соответствующими приложениями – клиентом и сервером. Формат таких сообщений и определяется протоколом Z39.50. После установления ТСР-соединения (или любого другого, зависящего от способа передачи данных) устанавливается 239.50-соединение, посредством обмена протокольными блоками данных — Protocol Data Unit (PDU).
PDU состоят из набора тегов, определяющих тип PDU (запрос или ответ на инициализацию сессии, запрос на поиск зультат поиска, запрос представления, ответ представления, запрос или ответ на закрытие сессии и т. д.), физические параметры сеанса, виды услуг, поддерживаемых клиентом и сервером параметры поиска, содержание запроса, сообщения о проведенном поиске и т. д.
Получив от клиента PDU на инициализацию сессии, сервер формирует ответ — сообщения о параметрах сеанса, видах услуг поддерживаемых клиентом и сервером, после получения которого клиентом 239.50-соединение считается установленным. Далее клиент может либо продолжить работу с такими параметрами, либо закрыть соединение и попытаться затем установить новое — быть может, с другими параметрами. Передавать запрос на поиск информации пользователь может только после установки соединения.
Таким образом, протокол Z39.50 описывает интерактивную сессию между источником запросов и приемником, обслуживающим эти запросы. Полный информационный сервис, как он понимается в стандарте, состоит из инициализации сессии, передачи данных и завершения сессии. Параметры сессии и ее окружение источник и приемник определяют в процессе инициализации.
Согласно Z39.50 существует семь основных видов информационного обмена в рамках распределенной ИПС:
• инициализация сессии;
• поиск информации по запросу;
• представление результатов поиска;
• удаление результатов поиска;
• контроль доступа к информационному ресурсу;
• контроль прав доступа к информационному ресурсу;
• завершение сессии.
Завершение сессии — это закрытие Z-соединения и последующее закрытие ТСР-соединения.
В течение сеанса происходит обмен PDU, инициатором которых, чаще всего, выступает клиент. Основные PDU следующие:


Контрольные вопросы
1 Что такое архитектура «клиент—сервер» и каковы основные видности программно-аппаратных средств на клиентской и се стороне?
2 Дайте определение протокола в информационных сетях.
3. В чем преимущества систем с коммутацией пакетов?
4. Определите 7-уровневую модель протоколов в открытых система.
5. На что ориентированы протоколы 1—3 уровня в 7-уровнево модели OSI?
6. На что ориентированы протоколы 5—7 уровня в 7-уровнево модели OSI?
7. Какой уровень прокладывает путь через сеть?
8. Какой уровень обеспечивает обнаружение и исправление ошибок?
9. Какой уровень определяет процедуру представления перед информации в нужную сетевую форму?
10. Что входит в систему адресов Internet?
11. Какую структуру имеет адрес Ethernet?
12. Какую структуру имеет IP-адрес?
13. Что такое выделенные IP-адреса?
14. Что из себя представляет система доменных имен?
15. Что такое сервер доменных имен?
16. Какие разновидности URL вам известны?
17. Какие протоколы транспортного уровня вы знаете?
18. Что такое инкапсуляция и фрагментация?
19. Что такое TCP/UDP—порт?
20. Что представляют собой протоколы управления маршрутизацией?
21. Какова структура пакета TCP?
22. Что представляет собой ARP?
23. Расставьте на места уровни в архитектуре протокола TCP/IP.
24. Какую функцию описывает протокол TCP?
25. Какую функцию описывает протокол IP?
26. Что такое класс локальной сети, входящей в Internet?
27. Каковы преимущества и недостатки конфигурации «звезда»? В каких локальных сетях она применяется?
28. Каковы преимущества и недостатки конфигурации «общая шина»? В каких локальных сетях она применяется?
29. Каковы преимущества и недостатки конфигурации «кольцо»? В каких локальных сетях она применяется?
30. Какие смешанные топологии вам известны и с помощью какого сетевого оборудования они реализуются?
31. Какие прикладные протоколы Internet вы знаете?
32. Какие информационные ресурсы Internet вы знаете?
33. Какова структура ресурса Usenet?
34. Какова структура распределенной ФС FTP?
35. Перечислите команды Telnet.
36. Какие протоколы электронной почты вам известны?
37. Перечислите программы-клиенты электронной почты.
38. Перечислите команды прикладных протоколов электронной почты.
39. Что такое протокол NNTP? Перечислите команды протокола.
40. Перечислите команды протокола FTP.
41. Назовите программы-клиенты и серверы протокола FTP.
42. Что такое Copher? Какова структура взаимодействия программы-клиента и сервера?
43. Каков состав средств Web-технологий? Что такое CGI?
44. Перечислите команды протокола HTTP.
45. Каков состав программного обеспечения WWW?
46. Перечислите основные программы-клиенты и серверы WWW.
47. Перечислите основные форматы HTML.
48. Каковы основные возможности отображения документов?
49. Расскажите об организации гипертекстовых ссылок.
50. Каковы возможности браузера Netscape Navigator?
51. В чем состоит отличие протокола Z39.50 от других прикладных протоколов?
52. Почему использование протокола HTTP для реализации ИПС вызывает трудности?
53. Из каких фаз состоит взаимодействие по протоколу Z39.50?