ИНФОРМАТИКА И ИНФОРМАЦИОННЫЕ
ТЕХНОЛОГИИ
Информатика — наука, изучающая законы и методы накопления, передачи и обработки информации. В качестве источников информатики как теоретической платформы информационных систем обычно называют две науки — документалистику и кибернетику, возникновение которых было тесно связано с бурным развитием сложных производственных систем и технологий. Основным предметом документалистики было изучение рациональных средств и методов повышения эффективности документооборота как информационной основы накопления и поиска информации.
Понятие информации составило также и основу кибернетики, как науки о методах анализа и синтеза систем эффективного управления.
1.1 Информатика — состав и структура
Сфера информатики является в достаточной степени неопределенной по той же причине, по которой неопределенной является область интересов родственной дисциплины — кибернетики, а именно — значительная широта и «размытость» критериев отбора соответствующих знаний для включения в предметную область. Для кибернетики таким критерием является применение математических методов и моделей для описания процессов управления и связи.
Informatique во французском языке трактуется как «вычислительная техника» что, в частности, зафиксировано в названии одной из фирм-производителей ЭВМ — СП («Compagne Internationale pour Informatique», т. е. «Международная компания по информатике», что является почти полным синонимом названия другой фирмы — «International Buisiness Machines» — IBM, гораздо более известным).
В немецком языке Informatik есть совокупность знаний, связанных с документоведением, библиотековедением, архивоведением и т. д. (включая музеи, ландшафты, картографию), т. е. охватывает любые проявления и применения информации.
В англоязычных странах приняты термины computer science (вычислительная техника, программирование и смежные дисциплины), что является аналогом «французской информатики» и information science (информационные науки), что аналогично «немецкой информатике».
Таким образом, здесь мы имеем варианты как наиболее узкого, так и наиболее широкого толкования информатики.
Любая из наук, взаимодействуя с информатикой, может породить свою специальную «отраслевую» информатику, которая будет обслуживать соответствующую науку, содействуя внедрению в нее информационных технологий и способствуя информатизации общества.
Область интересов информатики включает разработку общих подходов к применению информационных технологий в естественно-научных и социально-гуманитарных исследованиях (в том числе — специализированного программного обеспечения); создание баз и банков данных/знаний; применение информационных технологий представления данных и анализа структурированных, текстовых, изобразительных и др. источников; компьютерное моделирование; использование информационных сетей {Internet и др.); развитие и применение мультимедиа и других новых направлений информатизации, а также применение информационных технологий в образовании.
В соответствии со сказанным выше, можно говорить о прикладной информатике (связанной с использованием стандартных и разработкой специфичных информационных технологий) и теоретической информатике.
Развитие информатики сформировало устойчивую структуру профессионального сообщества, состоящего из нескольких групп (слоев), взаимодействующих, но несколько различающихся по своей роли:
• первая группа — это разработчики алгоритмов, программ и
технологий;
• вторая группа — квалифицированные пользователи информационных технологий и программного обеспечения; они осваивают реалии стремительно меняющегося мира информационных технологий, творчески адаптируют его новые достижения (с учетом специфики данных источников и задач их обработки) и внедряют их в свою практику;
• третья (и, возможно, наиболее многочисленная) группа — широкий слой пользователей, пришедших к необходимости применять в своей работе информационные технологии, которые они используют, ориентируясь преимущественно на тот опыт и те образцы, которые продуцируют первые две группы.
Конечно, эта «стратификация» достаточно условна — группы могут пересекаться; специалисты из третьей группы могут переходить во вторую, а из второй группы — в первую и т. д. Важно, однако, другое — эта структура должна не только обеспечивать науку и производство новыми методами и современными технологиями, но и давать убедительные примеры их использования при решении крупных проблем.
Сегодня предмет информатики связывают с совокупность таких понятий, как:
• средства вычислительной техники;
• программное обеспечение средств вычислительной техники;
• методы взаимодействия человека с вычислительной техникой и программными средствами (программным обеспечением);
• информационные ресурсы (ИР), в том числе средства создания, хранения, поиска информации;
• средства и технологии доступа к распределенным информационным ресурсам;
• методы и средства взаимодействия человека с информационными ресурсами на базе вычислительной техники с использованием программного обеспечения;
• инструментальные средства и технологии, обеспечивающие жизненный цикл ИР.
Таким образом, определения понятий «информатика» и «информационные технологии» должны рассматриваться во взаимосвязи с понятиями «информация», «данные», «знания».
Информатика занимается обработкой информации (хотя и представленной преимущественно в числовой и символьной форме), а не собственно вычислениями — обработкой данных, являющимися предметами программирования.
1.2 Соотношение понятий «информация», «данные», «знания»
Понятие «информация» достаточно широко используете? обычной жизни современного человека. Значение информации жизни общества стремительно растет, меняются методы работы с информацией, расширяются сферы применения информационных технологий. Динамизм информатики как науки отражается и в постоянном появлении новых определений и толкован! основного понятия информатики — информации.
Информация
Наиболее часто термин «информация» употребляется в его исходном значении (от латинского слова informatio) — это сведения, сообщения о каком-либо событии, деятельности и т. д. При этом в различных областях знаний могут вводиться разные определения этого понятия.
Информация в кибернетических системах — основа функционирования самоуправляемых систем (технических, биологических, социальных), и она рассматривается как обозначение содержания сигнала, полученного системой из окружающего мира в процессе взаимодействия системы с ним (Н. Винер).
Объединяющим (по крайней мере, с философской точки зрения) определением является следующее: «Информация — это отраженное разнообразие» (А. Д. Урсул). Разнообразие и отражение в развивающемся материальном мире неразрывно связаны и взаимно определяют друг друга: чем выше внутреннее разнообразие системы, тем более адекватно отражение ею внешнего мира. Чем выше возможности отражения (восприятия и понимания взаимодействия с окружающей средой), тем больше у системы возможностей адаптироваться — развиваться и увеличивать свое разнообразие (принцип необходимого разнообразия).
Данные
Остановимся на понятии «данные», которое, например, в [17] вводится следующим образом." «Мы живем в материальном мире. Все, что нас окружает, и с чем мы сталкиваемся, относится либо к физическим телам, либо к физическим полям. Все объекты находятся в состоянии непрерывного движения и изменения, которое сопровождается обменом энергией и ее переходом из одной формы в другую. Все виды энергообмена сопровождаются появлением сигналов. При взаимодействии сигналов с физическими телами в последних возникают определенные изменения свойств — это явление называется регистрацией сигналов. Такие изменения можно наблюдать, измерять или фиксировать теми или иными способами — при этом возникают и регистрируются новые сигналы, т. е. образуются данные».
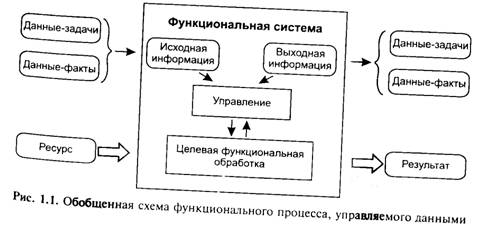
Это определение принимает первичность и объективность существования данных, в том числе — независимость от субъекта их использующего. Но если существование данных не зависит от того, будут ли они когда-либо использованы или нет, эффективность функционирования многих процессов (имеющих контур управления) зависит от данных. Например, данные, используемые для изменения поведения процесса на основе построения прогноза (т. е. факты, характеризующие предшествующие состояния), позволят оптимизировать получение конечного результата, и будут уже выступать в роли управляющей информации. Роль и характер используемых данных в целом отражены на обобщенной схеме управляемого функционального процесса, представленной на рис. 1.1.
Система преобразования ресурса, функциональность которой обусловлена проблемным контекстом (данными, представляющими целевую задачу), фактически преобразует и информацию. Потенциально полезные данные, выделенные из общего множества в соответствии с контекстом задачи (исходная информация) в результате использования порождает выходную информацию — актуализированные данные, подтверждающие или отрицающие действенность выбранных исходных данных для решения задачи.
Знания
Переходя к рассмотрению роли понятия «информация» в человеко-машинных комплексах, используемых в когнитивных, социальных и производственных системах, необходимо более полно определить понятие «знания».
Понятие «знания» может быть определено следующим образом: «Научное знание — вся совокупность сведений, являющаяся результатом отражения материальной и нематериальной действительности в человеческом сознании» (Урсул А. Д.).
С другой стороны, утверждается, что «научно-техническая информация — это задокументированное научное знание, введенное в оборот, участвующее в функционировании и развитии общества» (Муранивский Т. В.). То есть, знание, являющееся достоянием чьего-либо сознания и не получившее «толчка» для циркулирования в обществе, не может рассматриваться как информация.
Основываясь на этом, можно констатировать условность превращения знания в информацию и информации в знание. Информация выступает как форма знания, отчужденная от его носителя (сознания субъекта), и обобществляющая его для всеобщего использования: информация — это динамическая форма существования знания, обеспечивающая его распространение и действенность (применение). Получая информацию, пользователь превращает ее путем интеллектуального усвоения (информационно-когнитивного процесса) в свои новые личностные знания, т. е. происходит воссоздание знаний на основе информации.
Соответственно можно сказать, что на начальном этапе знания — это данные, актуализированные субъектом, особенностью которых является то, что они не могут быть использованы без участия самого субъекта.
Результаты решения задач (обычно, «субъективизированного»), обобщения в виде законов, теорий, совокупностей взглядов и представлений, выступающие как истинная, проверенная информация, отчужденные от субъекта их сформировавших, образуют обобществленные знания. Представленные обычно в форме документов и сообщений, они, в свою очередь, могут рассматриваться как объективно существующие данные.
Функциональное соотношение этих понятий иллюстрируется схемой, приведенной на рис. 1.2, где когнитивный процесс рассматривается как неотъемлемая составляющая любого созидательного, как творческого, так и производственного процесса, предполагающего возможность прогнозирования и управления.
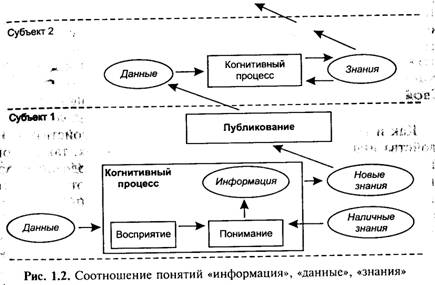
Станут ли данные информацией, зависит от того, известен ли метод преобразования (отражения) данных в новые или уже известные понятия. То есть, чтобы извлечь информацию из Данных, необходимо иметь метод получения информации, адекватный форме представления данных. Причем необходимо учитывать тот факт, что информация не является статичным объектом — она динамична и существует только в момент взаимодействия данных и методов. Можно сказать, что все прочее время она пребывает в «потенциальном» состоянии и представлена как данные.
Кроме того, одни и те же данные могут представлять разную информацию в зависимости от степени адекватности взаимодействующих с ними методов, к которым надо отнести и условия ее извлечения (например, наличного знания субъекта).
Таким образом, в отличие от данных, которые по своей природе являются объективными (так как это результат регистрации объективно существующих сигналов, вызванных изменениями в материальных телах или полях), методы являются субъективными в том смысле, что они создаются или выбираются и далее целенаправленно применяются для решения практически значимых задач конкретного субъекта. В основе создаваемых (искусственных) методов лежат алгоритмы (упорядоченные последовательности команд), составленные и подготовленные субъектами (людьми), а в основе естественных методов лежат биологические свойства субъектов. Соответственно информация возникает и существует в момент взаимодействия объективных данных и субъективных методов.
Свойства информации
Как и всякий объект, информация обладает свойствами. На свойства информации влияют как свойства данных, так и свойства методов, взаимодействующих с данными в ходе информационного процесса. По окончании процесса обработки свойства информации переносятся на свойства новых данных, то есть свойства методов могут переходить в свойства данных.
Спектр свойств информации существенно шире того, которым обладают другие, например, физические объекты. Известно высказывание Б. Шоу: «Если у тебя и меня имеется по одному яблоку, и мы ими обменялись, то у каждого из нас осталось по одному яблоку; если у тебя и меня имеется по одной идее и мы ими обменялись, то у каждого из нас будет по две идеи». Информация специфична и с точки зрения старения (информация не только устаревает со временем, но и при появлении новой, отрицающей или уточняющей информации).
С другой стороны, свойства информации необходимо рассматривать в их органическом единстве: не только в контексте ее использования в сфере информационной деятельности, но и на других этапах работы и в других областях деятельности. С точки зрения исследования и создания эффективных методов и средств обработки информации эти атрибутивные свойства делятся на две группы:
• свойства, определяющие объективные закономерности, связанные с информацией и преимущественно в пределах
отдельной предметной области науки, техники, производства (условно эти свойства можно назвать «внутренними»);
• свойства, определяющие закономерности движения информации в межотраслевом масштабе («внешние» свойства).
Любой процесс (событие, действие) существует не сам по себе, а непременно во взаимосвязи с другими процессами, причем связи эти разнообразны:
• причина — следствие;
• прошлое — настоящее — будущее;
• укрупнение или дробление;
• часть — целое и т. п.
Говоря об информационной технологии как об автоматизированном процессе преобразования объектов (например, представленных в машинной форме описаний реальных объектов), необходимо определить адекватный способ их идентификации. Это необходимо для их поиска — «узнавания» и выделения из множества других объектов окружающей среды.
Виды и коммуникационные свойства информации
Существуют различные деления и классификации информации. Приведем наиболее известные.
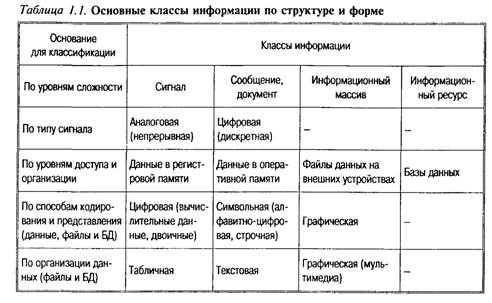
Классификация по структуре и форме. Отметим, что разделение информации на табличную (числовую), текстовую и графическую отражает последовательность, в которой эти виды «осваивались» компьютерами (табл. 1.1). Первоначальные языки программирования (ЯП) были рассчитаны прежде всего на обработку числовой (Fortran, Algol), нежели символьной информации. Раньше появляются и табличные базы данных, также преимущественно рассчитанные на обработку числовых таблиц (файлов). Затем осваиваются текстовые файлы (текстовые редакторы) и текстовые БД автоматизированные информационно-поисковые системы — библиографические и полнотекстовые). Наконец, с существенным повышением быстродействия и емкости памяти компьютеров, на сцену выходят графические и Другие мультимедийные файлы (графические, аудио, видеоредакторы). Говорить о графических (мультимедиа) базах данных и ЛИС пока все же преждевременно.
Эта последовательность прямо противоположна той, в которой данные виды информации осваивает человек. Действительно, сначала он знакомится с графическими образами (птицы, цветы и бабочки на шкафчиках для одежды в детском саду), затем — учится читать и писать, и только потом осваивает таблицу умножения.
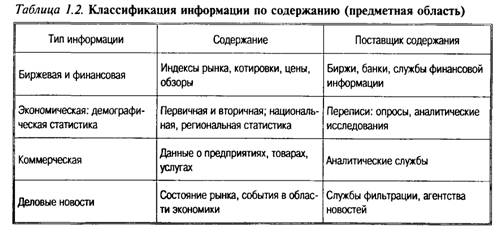
Классификация по содержанию. В то время как классификация по структуре и форме является более характерной и важной с точки зрения информационных систем и технологий, классификация по содержанию более соответствует уровню информационных ресурсов (табл. 1.2).

1.3 Структуризация взаимосвязи информатики с предметной областью применения
Подобная структуризация может быть осуществлена в следующих взаимосвязанных аспектах:
• уровни процессов и объектов информатики, информатизации;
• факторы или компоненты (страты, слои, подслои) информационных технологий;
• фазы или этапы развития автоматизированных информационных технологий (АИТ) и систем (АИС);
• типология пользователей машин, программ, систем
Уровни информационных процессов
Прежде всего, могут быть рассмотрены уровни, различающиеся степенью связи «информатики» с «предметной областью»:
• информационные технологии;
• информационные системы;
• информационные ресурсы.
В принципе, можно утверждать, что информационные технологии являются менее зависимыми от структуры и специфики предметной области, чем информационные системы и/или ресурсы, однако эта связь всегда существует, если, например, определить автоматизированную информационную технологию как целенаправленное и согласованное использование:
• технических средств информатизации (аппаратурный фактор);
• программных средств и систем (программный фактор);
• информационный фактор — собственно информация, т. е. сигналы, сообщения, массивы данных, файлы и базы данных;
• интеллектуальных усилий и человеческого труда (человеческий, гуманитарный фактор), для решения задачи (задач) предметной области — всегда присутствует человек – пользователь, решающий задачи какой-либо предметной области с использованием инструментария информатики.
Аналогично, информационные системы рассматриваются как комплексы информационных технологий, ориентированных на процедуры сбора, обработки, хранения, поиска, передачи и отображения информации предметной области, а информационные ресурсы — комплексы соответствующих информационных систем, рассматриваемые дополнительно также и на социально-экономических уровнях описания и применения.
Этапы развития информатизации
Могут быть выделены следующие этапы развития информатизации, связанные с вышеперечисленными компонентами (факторами).
Технический период («железный век», аппаратная фаза), в течение которого сложились основные представления о структуре универсальных вычислительных машин (ЭВМ), определилась архитектура и типы устройств. За этот период отпали АВМ (аналоговые ВМ), машины для открывания и закрывания дверей, шахматные машины и пр. специализированные контроллеры. Этот период можно ограничить 1947—1970 гг., с момента появления первой ЭВМ и до окончательного утверждения современных представлений о составе, принципах функционирования и структурах ЭВМ. В последующем развитие в основном шло в направлениях повышения экономической, технической, энергетической эффективности путем миниатюризации и повышения
быстродействия электронных и механических устройств ЭВМ. Нет оснований ожидать каких-либо революций с точки зрения появления неожиданных устройств или структур ЭВМ. Исследования в направлении специализированных схем или процессоров постоянно идут: появляются «машины баз данных», «процессоры изображений», «коммуникационные процессоры» и пр., однако вряд ли они смогут в обозримом будущем вытеснить с массовых рынков ЭВМ классической структуры, а разве что будут входить в их состав [14, 24, 25]. Эти машины включают центральное устройство, состоящее из процессора и главной памяти, а также широкий спектр периферийных устройств, используемых для долговременного хранения, ввода-вывода и преобразования информации. Центральный процессор и память при всем многообразии конструкций подчиняются так называемым принципам фон-Неймана [24].
Программный период («бронзовый век», программная фаза) — выработалась современная классификация программных средств, их структур и взаимосвязей, сложились языки программирования, разработаны компиляторы и принципы процедурной обработки, операционные системы, языки управления заданиями. Ограничен 1954 — 1970 гг., а именно — появлением первого языка программирования Fortran и формированием окончательных представлений о функциях операционных систем, систем программирования и прикладных программ (приложений), что наиболее ярко проявилось в появлении операционной системы UNIX и языка программирования С (Си) [9]. Можно сказать, выражаясь экстремистски, что за эти годы «все программы были написаны», осталось их только модернизировать и исправлять (здесь есть элемент преувеличения, однако более чем 2000-летняя история математики, физики, механики к 1970 г. нашла свое полное отражение в библиотеках и фондах программ и алгоритмов).
Информационный период («серебряный век», информационная фаза) — в центре внимания исследователей и разработчиков оказываются структуры данных, языки описания (ЯОД) и манипулирования (ЯМД) данными, непроцедурные подходы к построению систем обработки информации, базы данных, автоматизированные ИПС — с 1970 г. по 1990 г. Придерживаясь выше-использованной терминологии, скажем, что за этот период «все Данные были введены в машины», и их остается только уточнять и исправлять [14].
Гуманитарный период («золотой век») — связан с резким возрастанием круга пользователей АИТ, появлением ПЭВМ, развитием систем коммуникации и повышением роли интерфейсных, коммуникационных и навигационных возможностей соответствующих систем (с 1990 г.).
Конструктивный (процедурный) аспект
Перечисленные компоненты (факторы) — технические, программные средства, информация и человеческий фактор — в значительной степени взаимозаменяемы при решении задач. Это означает, что в широких пределах некоторый эффект может быть получен, а некоторая задача — решена как в рамках электронных схем, так и посредством программ или информационных ресурсов (а также естественно-интеллектуальными усилиями человека).
Предположим, необходимо извлечь квадратный корень из некоторого числа, тогда:
• электронное решение — собрать нелинейный усилитель, в котором диод или транзистор используют начальную часть вольт – амперной характеристики, которая близка к параболе;
• алгоритмический подход — написать программу, реализующую алгоритм Герона извлечения корня;
• информационный подход — построить таблицу величин
X,
Y, в которой Y=![]()
Аналогично могут быть рассмотрены такие примеры, как перемножение двух переменных, построение случайной последовательности чисел и т. п.
Заметим, что чисто аппаратурное решение задач положено в основу так называемых аналоговых вычислительных машин (АВМ), в настоящее время практически забытых. В 1949—1950 гг. были созданы первые АВМ, называемые интеграторами постоянного тока: ИПТ-1—ИПТ-5. Они предназначались для решения линейных дифференциальных уравнений с постоянными и переменными коэффициентами и широко применялись для имитационного моделирования сложных динамических систем (рис. 1.3).
Здесь же надо отметить, что техническое, программное и информационное обеспечение как бы образуют различные слои обработки информации, взаимодействие между которыми должна, быть сбалансировано в том смысле, что не должно быть чрезмерно «толстых» или «тонких» слоев.

Содержательный или информационный аспект
Здесь мы сталкиваемся с трактовкой и связью таких понятий, как адрес, имя, содержание1.
Электронно-аппаратурный уровень (этап) ассоциируется с понятием адреса (номера позиции) данных или устройств (элементов) ЭВМ. Машинные команды оперируют в терминах адресов оперативной памяти, все внешние устройства ЭВМ имеют машинные номера (адреса). На начальном этапе развития систем программирования существовало такое понятие, как программирование в машинных адресах (или машинных кодах), при этом управление как процессами вычислений, так и пересылкой информации между оперативной и внешней памятью осуществляется путем обращения к соответствующим абсолютным адресам памяти.
Программа при этом является просто совокупностью машинных слов и задается своими начальным и конечным адресами в памяти. Например, программист должен был описать процедуру выборки данных с магнитной ленты примерно следующими командами: «на лентопротяжном механизме № 4 перемотать ленту, пропустив 11 блоков, начиная с этого места записать 3 блока информации с магнитной ленты в оперативную память, начиная с адреса 234 561» и т. п. Подобные манипуляции соответствуют программированию в машинных адресах.
Программный этап или уровень приводит к понятию имени данного, устройства, программы и пр. Языки программирования (системы программирования) используют символические обозначения (имена, идентификаторы) для данных (чисел, строк, структур) и элементов программ (блоков, функций, процедур). Операционные системы (ОС) оперируют именами файлов, томов, устройств, реализуя управление данными, избавляют пользователя от работы с адресами, заменяя ее на работу с именами данных. Типичная команда ОС (например, DOS) не содержит каких-либо машинных адресов:
copy c:\games\comic.doc prn.
Информационный этап, или уровень, приводит к определению и использованию содержания (значения) данного. Пользователей информационных систем не волнует машинный адрес хранения информации или имя файла, их интересует содержание. Связи адреса и содержания реализуются на уровне прикладных программ, именуемых СУБД (системы управления базами данных) и АИПС (автоматизированные информационно-поисковые системы).
В свою очередь, установление таких связей может быть осуществлено как программно (вычисление адреса по содержанию, или рандомизация, хэширование) так и информационно, с помощью дополнительных файлов, указательных таблиц (индексов, инверсных списков и пр. — индексирование). Первый тип использовался в ранних СУБД и широкого распространения тогда не получил. Существенное удешевление накопителей информации привело к тому, что в последнее время преимущественно используется второй тип связей «содержание-адрес». Попытки реализовать эти связи аппаратно (ассоциативная память, Data Base Machine и пр. [14]), еще не получили широкого коммерческого распространения. В то же время достигнуты определенные обнадеживающие результаты на пути комбинирования этих двух подходов — индексирования и рандомизации.
Существенно также, что в этот период появились языки программирования информационных систем (в которых основное внимание уделяется описанию данных сложной структуры, а не описанию вычислений и алгоритмов).
Пользователи средств информатизации
Проследим вкратце развитие во времени человеческого фактора информатизации, рассмотрев динамику пользователей (ЭВМ, систем, информационных технологий), а именно:
• программист-алгоритмизатор, оператор ЭВМ (доминируют на первой, аппаратурной, фазе информатизации);
• системный программист, прикладной программист, администратор ОС (системы, машины), оператор ЭВМ (системный оператор, SysOp), вторая фаза;
• администратор базы данных, квалифицированный конечный пользователь (EndUser), информационный посредник
(третья фаза);
• появление в массовом масштабе ПЭВМ (четвертая фаза) прерывает эту дифференциацию и начинает процесс интеграции указанных функций на уровне конечного пользователя, (кроме того, появляются новые профессии — например, WEB-дизайнер и пр.).
В исторической перспективе развития информатики к середине 80-х гг. сложились следующие представления о видах пользователей вычислительных и информационных систем:
• администратор базы данных (АБД) — лицо или группа, отвечающая за сопровождение данных, назначение уровней доступа, включение/исключение пользователей, защиту/восстановление данных. Обычно АБД участвует в проектировании и определении структуры БД;
• системный администратор — лицо (группа), отвечающее за установку и сопровождение операционной системы ЭВМ и приложений общего назначения;
• оператор ЭВМ — отвечает за текущее функционирование вычислительной установки, осуществляет слежение за прохождением задач, готовностью устройств, наличием и использованием машинных ресурсов (оперативной и внешней памяти, времени, расходных материалов и пр.);
• операторы подготовки данных (ОПД) — персонал, осуществляющий ввод данных с рабочих листов или документов, на основе соответствующих инструкций, в среде специальных программных интерфейсов (или аппаратных средств);
• интерактивные пользователи — лица, имеющие доступ на ввод, коррекцию, обновление, уничтожение и чтение данных в рамках, как правило, ограниченной области БД;
• конечные пользователи — лица, использующие БД для получения справок и решения задач.
• Отдельной строкой рассматривались разработчики, среди которых принято выделять две группы:
• системные программисты — персонал, занимающийся разработкой операционных систем, приложений общего назначения, с использованием машинно-ориентированных языков;
• прикладные программисты — персонал, разрабатывающий конкретные прикладные задачи, с использованием систем программирования высокого уровня или готовых других прикладных систем.
Здесь видна достаточно стройная система, в которой выделяются:
• разработчики программных средств (системных и прикладных);
• системные пользователи ЭВМ (администраторы и операторы, ответственные за функционирование ОС и общесистемных приложений);
• системные пользователи ИС и БД (администраторы и операторы, ответственные за функционирование информационной системы);
• конечные пользователи (интерактивные и нет).
С появлением персональных ЭВМ начинается интеграция всех данных ролей. Рядовой пользователь ПЭВМ совмещает в одном лице:
• администратора системы (когда он редактирует файлы config.sys или autoexec.bat или решает, какие файлы ОС или прикладной системы он будет копировать с дистрибутивного диска);
• оператора ЭВМ (запуская и останавливая программы, просматривая содержимое дисков или даже заправляя бумагу в принтер);
• администратора БД (когда он в рамках системы FoxPro создает файлы данных), оператора (когда он заполняет эти файлы);
• конечного пользователя (когда он редактирует или просматривает файлы данных).
Реже пользователь такой становится прикладным программистом и почти никогда — системным.
1.4 Уровни информационных процессов
Рассмотрим подробнее аспект уровней информационных процессов, описанный выше.
Информационные технологии
Для определения содержания и места информационных технологий рассмотрим следующие определения:
• «методология — объединенная единым подходом совокупность методов, применяемых для получения запланированного проектного результата;
• технология — это представленное в инструктивной форме выражение знаний и опыта, позволяющее рационально организовать получение проектного результата путем выполнения некоторого процесса с использованием тех или иных средств, реализующих соответствующий метод;
• технологический процесс — последовательность действий (согласованных, в том числе с условиями выполнения, технологических операций, использующих соответствующие средства), направленных на создание заданного (проектного) объекта;
• технологическая операция представляет собой одно или несколько действий, направленных в рамках технологии на изменение состояния объекта или его взаимосвязи с окружением.
Технологическая операция характеризуется наличием:
• одного или нескольких входных объектов;
• выходного объекта — результата обработки;
• управления (субъекта и средств) обработкой.
Практически любой конкретный технологический процесс можно рассматривать как часть более сложного процесса и совокупность менее сложных (в пределе — элементарных) технологических процессов.
Элементарным технологическим процессом можно назвать такой, дальнейшая декомпозиция которого приводит к потере признаков, характерных для метода, положенного в основу данной технологии. В этом смысле технологическая операция может рассматриваться как элементарный технологический процесс.
В каждом из перечисленных понятий явно или неявно присутствует понятие метод, имеющее общефилософское значение, как путь исследования или преобразования действительности, основанный на знании закономерностей развития этой действительности. Метод предполагает средства — то, с помощью чего осуществляется действие, реализующее метод, и способы — то, каким образом осуществляется действие. Обратим также внимание на то, что методы и средства могут использоваться в разных процессах и, следовательно, технологиях.
В рамках системного анализа сложные системы изучаются посредством разбиения на элементы: предполагается, что сложная система есть целое, состоящее из взаимосвязанных частей, которые не могут быть определены априорно, а строятся или выбираются в процессе декомпозиции (физической или концептуальной) исходной системы. Образующиеся в результате декомпозиции элементы обычно являются центрами некоторой активности (деятельности), и потому называются элементами деятельности. При рассмотрении сложных систем наиболее часто выделяют функциональные элементы/подсистемы (однородные группы решаемых задач или технологических процессов) и организационные (обособленные, автономные и централизованно управляемые как целеустремленные элементы сложной структуры).
Декомпозиция сложной системы на технологические подпроцессы приводит к понятию элемента (объект-процесс) технологии [32] (рис. 1.4):
у = Р(т, и), g = g(y, m, u).
Элементарный процесс состоит из двух контуров:
• рабочего (энергетического, материального), включающего рабочий вход и и рабочий выход у, функция преобразования входа в выход соответствует назначению данного элемента;

• управляющего (информационного), включающего рабочий вход т и выход g.
Первое из вышеприведенных соотношений связывает выход процесса у с управляющим воздействием и рабочим входом, а второе — отражает оценку процесса в тех или иных шкалах g (все переменные в общем случае могут быть векторами разных размерностей).
Комплексные технологические процессы очевидно могут конструироваться по меньшей мере путем соединения элементов последовательно по управляющим (Р1—Р3) или рабочим контурам (Р2—Р3—Р4, рис. 1.5).
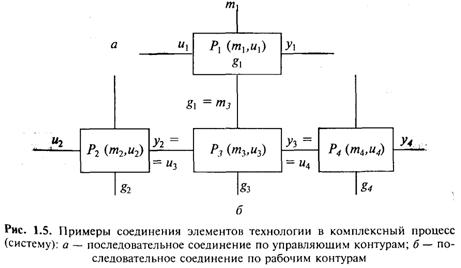
Информационные технологии могут быть определены, как технологии, полностью или частично состоящие из элементарных процессов, в которых рабочий контур образуют информационные потоки (массивы, данные, файлы) (табл. 1.3).
Комплексы информационных технологий представляют собой процессы обработки, поиска, представления данных, результаты шагов которых (элементов технологии) определяются как запланированными типами обработки, выполняемой как на предшествующих/последующих шагах (рабочие контуры т—у и характер операции Р), так и фактически осуществившимися событиями (информация g).
Очевидно, не все из реальных элементов технологий предполагают обязательное наличие всех входов (выходов), указанных на рис. 1.4 (см., например, табл. 1.3).
Автоматизированные информационные технологии (АИТ) могут представлять собой как развитие неавтоматизированных (предметных) [17] технологий (если прототипы известны и существовали достаточно давно), так и новые способы и процессы обработки информации, ранее недоступные. АИТ являются композициями четырех взаимосвязанных и взаимозаменяемых факторов (компонент): интеллектуальных усилий и навыков пользователя; технических средств обработки данных; программного обеспечения; информационных ресурсов.
Схема рис. 1.4 может быть детализирована в схему абстрактного технологического процесса, представленную на рис. 1.6.
Целевая обработка — это функционально-ориентированное преобразование получаемых или хранимых объектов обработки, обеспечивающее получение проектного результата под управлением субъекта (в качестве которого, так или иначе, выступает человек).
Информационные ресурсы — внешние по отношению к функциональному процессу источники информации, использование которых (обычно при управлении процессом) позволяет обеспечить эффективность целевой обработки.
Интерфейсные средства реализуют тот или иной способ (режим) взаимодействия субъекта с компонентами функциональной обработки.

Таким образом, с точки зрения обобщенной схемы, представленной на рис. 1.6, ИТ можно подразделить на три основных класса:
• технологии собственно обработки информации (ввода, обработки, хранения, поиска и передачи данных);
• технологии человеко-машинного взаимодействия, реализуемые в интерфейсах;
• инструментальные и другие вспомогательные технологии, позволяющие эффективно создавать и развивать ИТ предшествующих классов.
Отметим, что такое разделение, отражающее специализированность используемых методов и средств, соответствует и «специализации» пользователей соответствующих технологий, где давно сложилось разделение на «разработчиков», «конечных пользователей» и «администраторов». С точки зрения этой «специализации» представляется целесообразным подразделять технологии на базовые, обеспечивающие и инструментальные.
Базовыми информационными технологиями (т. е. используемыми практически в любом процессе) являются те, которые в значительной степени определяются требованиями «архитектурного» уровня — принципами фон Неймана. Обработка разнородной по форме информации, представляемой разнотипными данными, предопределяет соответствующий ряд средств и технологий, ориентированных на форму представления информации и виды операций, как, например (табл. 1.4):
• системы числовой обработки;
• системы и технологии обработки текстов (текстовые процессоры, системы распознавания текстов);
• средства обработки мультимедийной информации (например, растровой или векторной графики, звука, видео).
Обычно эти технологии реализуются в виде прикладных функционально-ориентированных продуктов, которые ассоциируются с понятием «технологии конечного пользователя».
«Обеспечивающие» информационные технологии — средства, непосредственно позволяющие эффективно достигать целевого, функционально значимого результата, включает:
• технологии и системы управления данными и, в том числе — информационные системы;
• средства и технологии распределенной обработки (сетевые технологии);
• средства удаленного доступа (телекоммуникационные технологии);
• средства и технологии человеко-машинного взаимодействия и интерфейсы конечного пользователя;
• средства и технологии защиты информации.
Отметим, что перечисленные технологии являются, безусловно, важнейшими, но они относятся к «обеспечивающим», поскольку необходимость или необязательность их использования обусловлены характером задач пользователя или средой функционирования.
Эти технологии, имеющие инженерный, «системный» характер, ориентированы на администраторов.
«Инструментальные» технологии, обеспечивающие жизненный цикл самих ИТ, составляют третью группу, как, например:
• технологии проектирования и инструментальные средства разработки программного обеспечения;
• технологии проектирования баз данных;
• технологии реинжиниринга информационных систем.
Такая схема разделения ИТ на «базовые», «обеспечивающие» и «инструментальные» в целом не противоречит и другой классификации ИТ — с точки зрения объектов и методов. Здесь можно выделить следующие «страты»:
• процессов обработки, передачи и управления данными (ввод, хранение, поиск, манипулирование), происходящих в основном без учета семантики и прагматики;
• управления информацией — представление, извлечение, поиск, преобразование данных (ее представляющих) в контексте семантики и прагматики (в том числе для субъекта обработки — это получение, передача и использование знаний);
• управления взаимодействием с человеком (представление информации предметной области и результатов обработки, человеко-машинный диалог). Для случая инструментальных технологий (создания и использования целесообразных средств решения прикладных задач) — это методы и средства связывания технологий обработки данных и технологий обработки информации.
Информационные системы
Обобщенное определение информационной системы может быть построено, например, путем рассмотрения системы информационного обмена с декомпозицией ее на функциональные (основная и информационная деятельность) и организационные (потребители-поставщики информации и информационные системы) элементы [33]. Информационный обмен представляет собой сложный процесс, допускающий рассмотрение в разных аспектах, на различных уровнях иерархии описания, в свете постановки разнообразных исследовательских задач.
Взаимодействие потребителей-поставщиков информации. Элементы систем информационного обмена могут быть выбраны исходя из следующих рассуждений. Решение всякой проблемы в общем случае включает следующие этапы (рис. 1.7).
1. Поиск информации (документов, сообщений). Внешняя среда—с точки зрения потребителя информации — является некоторым генератором потока сообщений, представленных на языке коммуникации, не тождественном «внутреннему языку» потребителя информации, связанному с конкретной решаемой проблемой. На этом этапе используются услуги различных информационных систем и неформальные каналы, доступные конкретному потребителю информации.
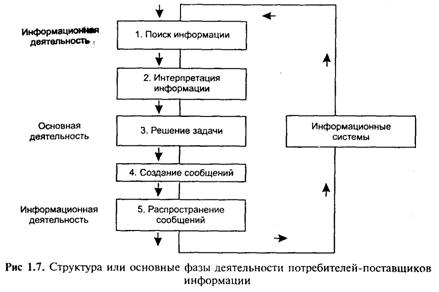
2. Интерпретация сообщений. В связи с конкретным характером решаемой задачи и профилем потребителя, имеет место уже упомянутое различие «языка коммуникаций» и «внутреннего языка». Данный этап заключается в адаптации сообщений — извлечении из сообщений информации, необходимой для решения поставленной задачи. Второй этап заканчивается созданием информационного обеспечения (ИО) решаемой задачи. Информационным обеспечением является результат первого этапа: построение совместными усилиями потребителя и информационной системы некоторой совокупности сообщений, релевантных (потенциально полезных) для задач исследователя.
3. Решение задачи — используя ИО, а также собственные знания и опыт, и прилагая определенные усилия, потребитель (разработчик) создает новую информацию, составляющую решение. Эта информация зафиксирована на языке задачи и без дополнительных затрат труда не представляет ценности за пределами конкретной задачи
4. Создание сообщений — поставщик информации осуществляет интерпретацию полученного результата на «языке коммуникаций», т. е. подготавливает сообщение в стандартной форме, одной из тех, которые приняты на данном этапе развития системы научных, деловых (и др. видов) коммуникаций вообще и информационных систем, в частности. Это может быть письмо, проект договора, статья, выступление на конференции, циркулярное сообщение по электронной почте и т. д.
5. Распространение сообщений. Создатели сообщений вступают в активное взаимодействие с системой коммуникации, затрачивая определенные усилия по вводу новой информации в один (или несколько) из доступных каналов коммуникации (пересылка документа, депонирование рукописи, публикация, аудиторное выступление или сообщение и т. д.). Эффективность данного этапа определяется как степенью усилий, предпринимаемых поставщиком информации, так и теми возможностями, которые ему предоставляет система коммуникации.
Очевидно, что в общем случае данные этапы реализуются сложным последовательно-параллельным образом (рис. 1.7 отображает обобщенную логику рассматриваемого процесса). Кроме того, в конкретных ситуациях процесс принятия и исполнения решения не обязательно включает все указанные этапы или, по крайней мере, не все они предполагают сравнимые затраты труда (времени).
Первый и пятый этапы являются этапами собственно информационной деятельности (ИД), поскольку их эффективность во многом определяется свойствами совокупности коммуникаций и информационных систем.
Третий этап — собственно основная деятельность (ОД).
Этапы второй и четвертый носят пограничный, диффузный характер и могут быть отнесены как к ИД, так и к ОД.
Приведенная линейная микроструктура (последовательность разных типов деятельности) представляет собой некоторый элемент деятельности (центр деятельности); в виде взаимосвязанной совокупности этих элементов может быть представлена любая, весьма сложная и разветвленная система (деятельность), функционирование которой опирается на информационный обмен. Примером может являться система наука — техника — производство.
Пересечение совокупности типов деятельности является организационным элементом системы информационного обмена (ОЭ). Примерами ОЭ, в зависимости от уровня декомпозиции исходной системы, являются отдельные исследователи, малые группы коллективы, НИИ, отрасли, система национальной научной деятельности, другие формально и организационно структурированные элементы и объединения. Характерными признаками организационного элемента являются компактность (территориальная административная, экономическая, физическая и т. д.) и гетерогенность (включение различных типов деятельности).
В противовес организационным могут быть выделены функциональные элементы, соответствующие определенному типу (этапу) деятельности (например, «сбор информации» или «передача информации»). В рассмотренном (рис. 1.7) примере выделяются, по меньшей мере, два функциональных элемента – ИД (по входу и выходу) и ОД. В системах, базирующихся на обмене информацией, целесообразно выделять два типа организационных элементов: включающие и не включающие ОД. Элементы первого типа являются потребителями-поставщиками (конечными) информации и могут взаимодействовать как непосредственно (реализуя информационную деятельность в собственных организационных рамках), так и через посредство элементов второго типа, которые представляют собой промежуточных потребителей-поставщиков информации, или информационные системы.
Наиболее общее представление о взаимодействии потребителей-поставщиков информации проиллюстрировано рис. 1.8. Уровни (каналы) взаимодействия могут быть разделены на три типа:
• непосредственное рабочее взаимодействие (связь 3—3) представляет собой постоянный обмен информацией в группе или коллективе, в процессе совместной деятельности;
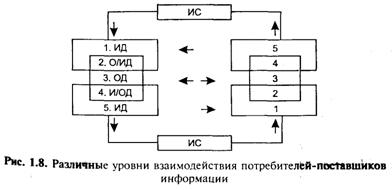
• непосредственное документальное взаимодействие (связь 4—2) заключается в оформлении результата и ограниченном контролируемом распространении (например — передача отчета или документации заказчику);
• опосредованное документальное взаимодействие (связь 5—1) состоит в опубликовании результата и его последующем неограниченном перемещении по каналам ИС.
Управление информационным обменом на макроуровне может быть разделено на три типа задач, соответствующих данным каналам:
• организация работ и взаимодействия соисполнителей при выполнении работ (связи 3—3);
• маркетинг — поиск заказчиков на результат работ, получение заказов, связь с заказчиками, оформление и передача результатов, поиск прочих возможных потребителей результатов (связи 4—2);
• управление документальными потоками — распространение информации в документальной форме по каналам обобщенной ИС, решение задач повышения полноты, точности, оперативности информационного обмена и обслуживания (связи 5—1).
Обобщенными информационными системами в рассматриваемом случае могут являться (в зависимости от уровня рассмотрения):
• специалисты-аналитики или информаторы;
• информационно-аналитические подразделения организаций;
• информационные службы или институты информации;
• мировые информационные системы и сети информационного обмена.
Автоматизированная информационная система (ЛИС) таким образом может быть определена как комплекс автоматизированных информационных технологий, входящий в состав обобщенной ИС и предназначенный для информационного обслуживания — организованного непрерывного технологического процесса подготовки и выдачи научной, управленческой и др. информации потребителям, используемой для принятия решений, в соответствии с их нуждами для поддержания эффективной деятельности.
Компоненты и структуры АИС. Рисунок 1.9 отображает структуру типичного совокупного технологического процесса АИС, или представление АИС как совокупности функциональных под
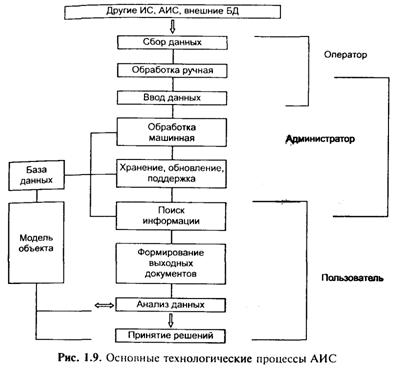
систем — сбор, ввод, обработка, хранение, поиск, распространение информации.
Очевидно (как и в ранее рассмотренных структурах), многие элементы рис. 1.9 являются альтернативными:
• модель объекта может отсутствовать либо отождествляться с базой данных (БД), которая часто интерпретируется как информационная модель предметной области, структурная (для случая табличных, фактографических БД) или содержательная (для случая документальных БД). В экспертных системах (ЭС) в качестве модели объекта (предметной области) фигурирует база знаний (БЗ), представляющая собой процедурное развитие понятия БД (БД, по своей сущности, непроцедурный объект);
• модель объекта и БД могут отсутствовать (а соответственно и процессы хранения и поиска данных), если система осуществляет динамическое преобразование информации и формирование выходных документов, без сохранения исходной,
промежуточной, результирующей информации. Если преобразование данных также отсутствует, то подобный объект информационной системой не является (он не выполняет информационной деятельности), а должен быть отнесен к другим классам систем (например, канал передачи информации и т. п.);
• процессы ввода и сбора данных являются необязательными поскольку вся необходимая и достаточная для функционирования АИС информация может уже находиться в БД у составе модели, и т. д.
Основные типы АИС
К наиболее распространенным и перспективным типам относятся (табл. 1.5):
• фактографические АИС;
• документальные;
• интеллектуальные (экспертные);
• гипертекстовые.
Это определяется следующими факторами [14]:
• системы появлялись и развивались именно в данной исторической последовательности;
• более ранние типы систем (фактографические, документальные) являются, как правило, платформой и средой для реализации более поздних (экспертные, гипертекстовые);
• перечисленные типы характеризуют следующие отличительные черты:
— распространенность (в статистике мировых информационных ресурсов документальные и фактографические БД занимают 1- и 2-е места);
— перспективность (интеллектуальные системы успешно осваивают новые области применения);
— гипертекстовые системы являются основой мировой информационной сети WWW (Word Wide Web) — наиболее популярной составляющей Internet.
При этом хотелось бы отметить, что в традиционном понимании выражение «информационная система» (особенно «автоматизированная информационная система» или «автоматизированная информационно-поисковая система — АИ ПС») обычно ассоциируется с документальными системами (базами данных);
термин же «база данных», как правило, ассоциируется с фактографическими, управленческими системами, задачами типа АСУ. Хотя, конечно же, и те и другие типы систем являются информационными и обычно строятся на основе концепции баз данных, т. е. физически включают базы данных в свой состав.
В этой традиционной интерпретации находит свое отражение то обстоятельство, что в фактографических системах модель предметной области заключена в структуре БД, и потому основное внимание сосредоточивается на проблеме проектирования БД, в документальных же системах моделью является наполнение, содержание БД, в том числе — словарей, тезаурусов и т. д., поэтому основное внимание уделяется языковым, семантическим проблемам. (Эти и другие различия указанных типов систем описываются в табл. 1.5.)
Информационные ресурсы
Кругооборот информационного ресурса, как и всякого иного продукта человеческой деятельности, подчиняется естественному циклу: создание — распространение — потребление. Несмотря на то, что информация физически не разрушается при потреблении и не исчезает (в отличие от материальных товаров и ресурсов), при рассмотрении процессов в длительной перспективе становится очевидным, что информационный ресурс не избегает участи всего сущего и, переходя в новые формы знания, практически бесследно в них растворяется (кому сейчас интересны тексты библиотек программ на Алголе, бывшие бестселлерами всего 40 лет назад !?).
Традиционный цикл информационного обмена, существовавший в течение столетий, представлен на рис 1.10, а и заключается в последовательности процессов концентрации—рассеяния совокупных (составных) информационных потоков (в данном случае образуемых печатными изданиями первичных документов). Основной поток здесь идет по цепочке автор — издательство — библиотека — читатель, однако существуют и обходные пути: автор — читатель; издательство — читатель (подписка), которые также подчиняются принципу концентрации—рассеяния.
Переход в начале 70-х гг. информационных служб на дублирование в машиночитаемой форме сначала вторичных (реферативные журналы, каталоги, справочные издания), а затем и первичных (полнотекстовых) документов, не нарушая в принципе общей структуры (последовательно-параллельное сосуществование процессов концентрации—рассеяния), вносит определенное Разнообразие (рис 1.10, б).

Поставщиками содержания теперь являются любые из участников процесса рис 1.10, а: автор (обычно корпоративный автор — организация или фирма, выполнившая работу), издательство или библиотека. Издание баз данных и онлайновое обслуживание также никому не возбраняется. Например, одна из крупнейших информационных систем по естественным наукам — INSPEC — развилась из библиотечной службы вуза (IEE — Institution of Electrical Engineers, Великобритания). Информационные сети, представляющие собой коммуникационную среду для конечного пользователя, часто входят в состав издательств или распространителей БД, образуя интегральные распределенные информационные службы. Таким образом, электронная инфраструктура образует относительно самостоятельный слой (рис. 1.10, г), не являясь зеркальным подобием традиционных коммуникаций.
Появление в конце 80-х — начале 90-х гг. нового фактора — Internet (рис. 1.10, в) с его информационными ресурсами/сервисами (FTP, Gopher, Usenet, WWW) — дополняет общую картину.
Удешевление и повсеместное распространение коммуникационного оборудования, услуг связи (с повышением их производительности), а также высокая степень стандартизации форматов, протоколов передачи данных и программных средств — все это привело к интеграции информационных сетей разной физической организации и пропускной способности в однородную среду, в которой взаимодействуют все агенты, обозначенные на рис 1.10, а, б и «прозрачность» которой во всех направлениях со временем быстро возрастает.
Таким образом, в настоящее время наблюдается 3-слойная инфраструктура информационных ресурсов (рис 1.10, г), в которой:
• каждый последующий уровень инкапсулирует (поглощает) предшествующий в качестве потребителя-источника информации и добавляет новых участников коммуникации;
• характер коммуникации варьируется от структурированной, но замедленной (уровень 1), до «бурного потока» (уровень 3);
• со временем происходит постепенный переход основной активности от нижних слоев к верхним.
В табл. 1.6 приведены основные классы информационных ресурсов.
В последующих главах настоящего пособия будут рассмотрены:
• технологии конечного пользователя (обработка документов, мультимедиа информации, кросс-технологии), доступ к информационным ресурсам;

• технологии разработчиков и администраторов информационных ресурсов и систем (организация доступа к локальным и распределенным информационным ресурсам, информационный поиск, защита информации).
Контрольные вопросы
1. Охарактеризуйте соотношение понятий «информация», «данные», «знания».
2. Дайте определение понятия «информация».
3. Охарактеризуйте прагматические свойства информации.
4. Перечислите атрибутивные свойства информации.
5. Назовите и охарактеризуйте формы концентрации информации.
6. Что представляют собой факторы информатизации?
7. Какие периоды развития информатизации могут быть выделены?
8. Что такое уровни информационных процессов?
9. Дайте определение технологии и информационной технологии.
10. Что такое элемент технологии? Приведите примеры.
11. Перечислите основные классы информационных технологий.
12. Что такое обобщенная система информационного обмена?
13. Назовите уровни взаимодействия потребителей-поставщиков/Информации.
14. Какова структура технологического процесса АИС?
15. Назовите основные классы АИС.
16. Перечислите основные классы баз данных.
17. Что такое информационные ресурсы? Приведите? примеры.
18. Дайте классификацию информационных ресурсов.
ТЕХНОЛОГИИ ОБРАБОТКИ ДОКУМЕНТОВ
Технологии работы с документами на компьютерах весьма популярны и часто отождествляются пользователями с информационными технологиями вообще. Преподавание информационных технологий в учебных заведениях (средних, да и высших) зачастую исчерпывается обучением навыкам работы с текстовыми редакторами (наподобие MS Word) и табличными процессорами (MS Excel и др.).
Ни в коей мере не умаляя важности и необходимости владения данным инструментарием и уделяя ему соответствующее место в рамках данной главы, авторы попытались основное внимание сосредоточить на вопросах описания и обработки структур документов, охватываемых понятием модель документа. В то время как понятие модели данных (концепции, связанной со структурой предметной области БД, включающей как физический, так и логический уровни, — см. далее, гл. 5 или подробнее [8]) является достаточно распространенным и популярным, модель документа является во многом «вещью в себе».
2.1. Текстовая информация. Модель документа
Известно, что существуют различные типы текстовых файлов (плоские, размеченные, ASCII и пр.). Соответственно, для ввода, работки, представления информации в таких файлах требуются различные программные возможности. Для работы с текстами на компьютере используются программные средства, называемые текстовыми редакторами, или текстовыми
процессорами.
Разновидности текстовых форматов
Существует большое количество разнообразных текстовых редакторов, различающихся по своим возможностям, — от очень простых учебных до мощных, многофункциональных программных средств, называемых издательскими системами, которые используются для подготовки к печати книг, журналов и газет. Эти программы позволяют работать с различными типами и форматами текстовых файлов, по необходимости преобразуя их друг в друга.
Например, в текстовом формате (плоский текст — .ТХТ) работают редактор Notepad, встроенные редакторы оболочек Norton Commander и Far Manager (рис. 2.1), в то время как Word (а также WordPad) позволяют работать с размеченными текстовыми файлами в коммуникативном (тип файла .RTF — rich text format, или «обогащенный формат текста»), внутреннем (.DOC),

И текстовом ( TXT) форматах (рис. 2.2, 2.3). Распространен также редактор документов Adobe Arobat (рис. 2.4), использующий коммуникативный формат .PDF (portable document format). Ниже более подробно рассмотрены форматы разметки текстов HTML (см- рис 2.6, 2.7).

Необходимо отметить, что наиболее развитые редакторы позволяют обрабатывать не просто тексты, а документы (тексты, содержащие встроенные или внедренные объекты или файлы других типов — табличные, графические, мультимедиа и пр.).
Типы файлов для размещения документов
Перечислим наиболее типичные файлы данных:
• текстовые файлы — обобщенное название для простых и размеченных текстов, ASCII-файлов и других наборов данных символьной информации, которые интерпретируются и обрабатываются текстовыми редакторами, процессорами, анализаторами (Lexicon, Word, TEC, анализаторы SGML, HTML);
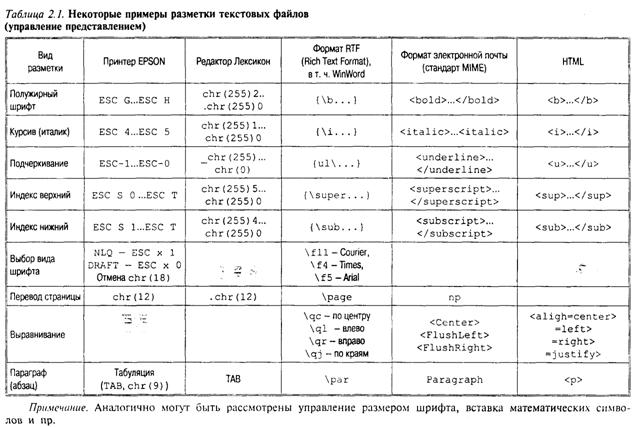
• текст без разметки (планарный) — файл, содержащий только отображаемые (воспроизводимые на всех печатающих устройствах и терминалах) символы кода ASCII, а также простейшие управляющие символы: cr — возврат каретки; lf — перевод строки; tab — символ табуляции, иногда LF — новая страница (табл. 2.1);
• текст с разметкой — планарный файл, содержащий бинарную (см. табл. 2.1, колонки 1, 2) и символьную (остальные колонки) разметку, управляющую отображением информации (программно и/или аппаратно);
• ASCII-файл — содержит только отображаемые коды левой части кодовой таблицы ASCII (латиница и служебные символы), обычно применяется для хранения документов с символьной разметкой (RTF, SGML, HTML).
Форматы полнотекстовых документов. Модель документа
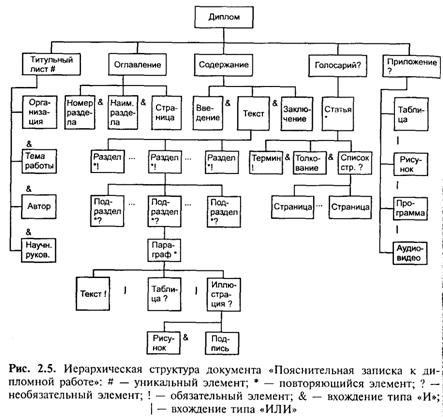
Понятие модель документа охватывает аспекты создания, преобразования, хранения, поиска, передачи и отображения документов. Принято рассматривать структуру документа в двух аспектах: логическом (содержание) и физическом (макет).
Логическая структура определяет составные компоненты и их соотношения в понятиях, отвечающих взгляду на документы как смысловые структуры. Например, к основным смысловым компонентам относятся: авторские данные (имя автора, место работы), аннотация, оглавление, главы, разделы, параграфы, рисунки, сноски. На рис. 2.5 приведен пример документа «Пояснительная записка к дипломному проекту (работе)». Здесь выделены такие базовые понятия структуры документа, как обязательность/необязательность элемента, уникальность или повторяемость, вхождение нижестоящих элементов в вышестоящие по принципу И (оба типа данных должны или могут входить в элемент) либо ИЛИ (только какой-либо один из типов данных может или должен входить в элемент).
Макетная структура содержит описание документа в терминах физических единиц — страниц, полос, колонок, колонтитулов, рамок для рисунков, шрифтов, стилей и пр.
Подходы к моделированию документов опираются на два стандарта — ISO 8613 (ODA — Office Document Architecture — архитектура управленческой документации и ISO 8879 (SCM – Standard Generalized Markup Language — стандартный обобщенный язык разметки).
Документ в ODA представлен в виде профиля и собственно документа, организованных в форме древовидной структуры. Профиль содержит информацию о документе в целом и его прохождении; формальные признаки — дата составления, вид, регистрационный номер и т. д.
Собственно документ содержит текст и сведения о его структуре и стиле, а именно:
• структуру документа — заглавие, параграфы, оглавление и т. п. (логическая структура), а также абзацы, расположение текста, шрифты (физическая структура);
• архитектуру содержания — набор графических элементов, выделение определенных слов, строк и т. п.;
• коммуникативный формат — способы кодирования объектов, признаков и содержания документов.
2 2. Языки разметки документов
В системах обработки текстов в документ включается дополнительная информация, называемая разметкой и выполняющая следующие функции:
• выделение логических элементов данного документа;
• задание функций обработки выделенных элементов.
В обычных текстовых процессорах существуют встроенные команды включения/выключения шрифтов и др., аналогичные командам управления размещением информации на экране или при печати (так называемые Escape-последовательности). Такой подход называется командной или процедурной разметкой (табл. 2.1).
Альтернативный способ разметки заключается в выделении части текста без указания способа обработки выделения. Затем другие команды назначают фрагментам способ обработки. Такая разметка называется описательной (дескриптивной). Она включает метки (tags, таги) начала и окончания элемента текста и указывает, как интерпретировать данный фрагмент.
Изменяя набор процедур, соответствующий описательной разметке, можно изменить внешнее представление одного и того же документа. Развитие идей описательной разметки привело к определению разметки как формального языка. Это позволяет проверить правильность разметки и минимизировать ее объем за счет подстановки умолчаний.
Основным достоинством описательной разметки является ее гибкость, поскольку фрагменты текста отмечены как «чем они являются» (а не «как они должны быть отображены»), причем в будущем может быть написано программное обеспечение для такой обработки этих фрагментов, которая даже не предусматривалась разработчиками языков. Например, гиперссылки HTML, первоначально предназначенные для навигации пользователями по совокупности связей в сети, в дальнейшем стали использоваться также механизмами поиска и индексирования в сети, для оценки популярности ресурсов и т. д.
Описательная разметка также облегчает задачу переформатирования документа при необходимости, поскольку описание формата не связано с содержанием. Например, курсив может использоваться либо для выделения текста, либо отметки иностранных (или жаргонных) слов, либо для других целей.
Однако если слова просто выделены (дескриптивно или процедурно) как курсив в этой двусмысленности нельзя полностью разобраться. Если же эти два случая были по-разному размечены в самом начале, каждый может быть переформатирован независимо от других. Родовидовая (generic markup) разметка — другое наименование для описательной разметки.
Практически элементы различных классов разметок обычно сосуществуют в любой конкретной системе. Например, HTML содержит как элементы разметки, которые являются процедурными ( b для полужирного шрифта), так и другие, которые являются описательными («blockquote», или «href», — признак). HTML также включает элемент pre, который ограничивает область текста, которая будет расположена точно так, как напечатано.
Самые современные системы описательной разметки рассматривают документы как иерархические структуры (деревья), а также обеспечивают некоторые средства для встроенных перекрестных ссылок. Поэтому такие документы могут трактоваться и обрабатываться как базы данных, структура которых достаточно хорошо определена (однако, поскольку они не имеют таких строгих схем, как реляционные базы данных, их обычно называют «слабоструктурированными базами данных»).
С наступлением III тысячелетия возник интерес к документам неиерархических структур. Например, древняя и религиозная литература обычно имеет риторическую структуру или структуру прозы (рассказ, раздел, параграф и т. д.), а также включает справочную информацию (книги, главы, строфы, строки). Так как границы этих модулей часто пересекаются, они не могут быть полностью закодированы с использованием только системы разметки с древовидной структурой. Среди систем моделирования Документов, которые поддерживают такие структуры, — MECS, TEI Guidelines, LMNL, и CLIX.
Термин «разметка» происходит от традиционной практики разметки рукописей перед публикацией (т. е. добавления символических команд на полях и между строк в бумажной рукописи), течение многих столетий это делали работники издательства (редакторы и корректоры) которые отмечали, каким шрифтом, стилем и кеглем должны быть набраны фрагменты текста, а затем передавали рукопись наборщикам, которые вручную осуществляли набор текста с учетом символов разметки.
В настоящее время существует множество языков разметки (табл. 2.2), среди наиболее широко известных — DocBook,
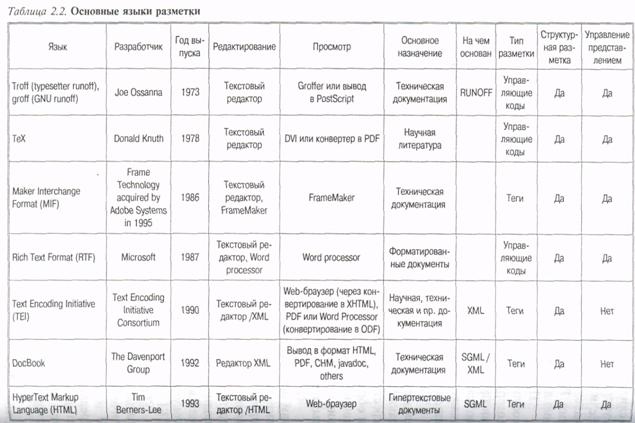
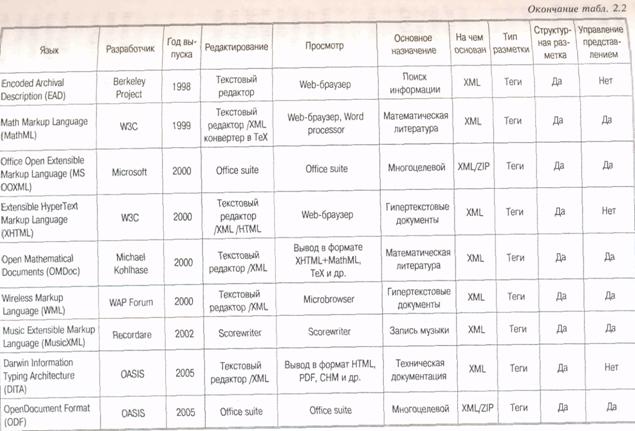
MathML, SVG, Open eBook, XBRL и др. В основном они предназначены для представления различных текстовых документов но специализированные языки могут использоваться во многих других областях. Безусловно, наиболее хорошо известен язык разметки HTML (язык разметки гипертекста), одна из основ WWW (Всемирной паутины).
Рассмотрим некоторые из систем разметки.
RUNOFF
RUNOFF была первой системой форматирования текстов, которая получила значительную известность. Она была разработана в 1964 г. для операционной системы CTSS Джеромом X. Салтзером (Jerome H. Saltzer) с использования ассемблера MAD.
Продукт фактически состоял из пары программ:
• TYPSET, который был в основном редактором документов;
• RUNOFF — процессор вывода.
RUNOFF осуществлял поддержку разбиения на страницы и размещения заголовков, а также выравнивания текста. RUNOFF — прямой предшественник программы форматирования документов в ОС Multics, которая в свою очередь была предком программ форматирования для ОС Unix (roff и nroff), и их потомков. Он был также предком FORMAT для OS/360 IBM, и конечно косвенно для всех последующих программ и систем обработки текстов. Название, как предполагается, исходило из фразы, популярной в то время — I'll run off a copy.
ТеХ
ТеХ — аббревиатура от τεχνη (TEXNH — techne), греческий термин для «искусства, ремесла, умения», источник для слова «технический». По английски произносится «тек» (как в слове technology).
ТеХ — наборная система, созданная Дональдом Нутом (Donald Knuth). Вместе с языком METAFONT для описания шрифта и Computer Modern typeface (Компьютерного Современного шрифта) он был спроектирован для двух основных целей — во-первых, представить каждому пользователю возможность создавать высококачественные книги в пределах разумных трудозатрат во-вторых, чтобы такая система давала идентичные результаты на любых компьютерах как в настоящее время, так и в будущем. ТеХ — бесплатное программное обеспечение, популярное в академическом сообществе, особенно среди математиков, физиков информатиков, экономистов, и в технических сообществах. Оно в значительной степени конкурирует с другим популярным форматизатором ТеХ — Unix troff, и во многих инсталляциях Unix они используются совместно.
Признано, что ТеХ является наилучшим путем создания и распечатки сложных математических формул, но теперь оно также используется для многих других наборных задач, особенно в форме LaTeX и других программных средств форматирования.
Команды ТеХ обычно начинаются с обратной косой черты и группируются в блоки изогнутыми фигурными скобками. Однако почти все синтаксические свойства ТеХ могут быть изменены при исполнении программы, что затрудняет обработку входа ТеХ другими программами. ТеХ — язык на основе макросов и лексем и многие команды, включая наиболее часто определяемые пользователем, расширяются при исполнении, пока не останутся только нерасширяемые лексемы, которые и выполняются.
Базовый вариант ТеХ включает приблизительно 300 команд, названных примитивами. Однако эти команды низкого уровня редко используются непосредственно пользователями, большинство функциональных возможностей обеспечивается файлами формата (копии памяти ТеХ после того, как были загружены большие наборы макрокоманд). Первоначальный формат Нута (по умолчанию), который добавляет приблизительно 600 команд, называется Plain ТеХ. Более широко используемым форматом является LaTeX, первоначально разработанный Лесли Лампортом, который включает стили документа для книг, писем, слайдов и т. д, а также добавляет поддержку ссылок и автоматической нумерации формул и разделов.
Другой широко используемый формат — AMS-TeX, разработан Американским математическим обществом (American Mathematical Society) и предусматривает дополнительно много дружественных команд, которые могут быть изменены издательствами, чтобы обеспечить их фирменный стиль. Большинство особенностей AMS-TeX может применяться в LaTeX при использовании AMS «packages» (что именуется как AMS-LaTeX).
Чтобы написать программу печати строки «Programming» в Plain TeX, необходимо создать файл myfile.tex со следующим содержанием:
Programming
\bye % end of the file; not shown in the final output.
По умолчанию все, что следует за знаком процента на строке, — комментарий, игнорируемый интерпретатором ТеХ. Если выполнить ТеХ на этом файле (например, набирая tex myfile.tex в режиме командной строки), то будет создан выходной файл с именем myfile.dvi, который представляет содержимое страницы в независимом от устройств формате (Device Independent Format — DVI). Результаты могут или быть напечатаны непосредственно из средства просмотра интерактивной цифровой видеосистемы или преобразованы в более общий формат, типа PostScript, используя программу dvips. Такие варианты ТеХ, как PDFTeX, непосредственно производят файлы формата PDF.
Рассмотрим форматирование математической формулы. Например, чтобы написать известное выражение для корня квадратного уравнения, можно ввести:
The quadratic formula is $-b \pm \sqrt{b^2 - 4ac} \over 2a$ \bye
Это приведет к выводу следующего текста:
Несколько систем обработки документов основаны на ТеХ, особенно jadeTeX, который использует ТеХ как внутренний для того, чтобы печатать с выхода James Clark's DSSSL Engine, и Texinfo, обработчик документации системы GNU. ТеХ был официальным наборным пакетом для операционной системы GNU с 1984 г.
Известны многочисленные расширения и сопутствующие программы для ТеХ, среди них BibTeX для библиографий (распространяется совместно с LaTeX), PDFTeX, который обходит формат DVI и осуществляет прямой вывод в Adobe Systems' Portable Document Format (pdf), и Omega, которая позволяет ТеХ использовать набор символов Unicode. Большинство расширений ТеХ может быть получено бесплатно во Всесторонней Сети Архивов ТеХ (Comprehensive ТеХ Archive Network — CTAN). ТеXmacs — редактор научной литературы на основе ТеХ, поддерживает режим полного соответствия (WYSIWYG) и предназначен чтобы быть совместимым с ТеХ и Emacs.
Во многих технических областях, таких как прикладная информатика, математика и физика, ТеХ стал фактическим стандартом. Много тысяч книг были изданы, используя ТеХ, такими издательствами, как Addison-Wesley, Cambridge University Press, Elsevier, Oxford University Press or Springer. Многочисленные журналы в этих областях произведены с использованием ТеХ ил LaTeX, причем авторам разрешено представлять рукописи в формате ТеХ.
Начиная с версии 3 ТеХ использовал специфическую систему нумерации версий, где обновления обозначались с помощью дополнительной цифры к десятичному числу так, чтобы номер версии асимптотически приближался к л. Это — отражение того факта, что ТеХ является очень устойчивым и ожидаются только незначительные обновления. Текущая версия ТеХ — 3.141592; это было последнее обновление в декабре 2002.
PostScript
PostScript (PS) — язык программирования, реализующий функцию описания страниц, использующийся в электронных изданиях и настольных издательских системах.
Концепция языка PostScript была создана в 1976 г., когда Джон Вонок (John Warnock), работая в фирме Evans и Sutherland, известной компании компьютерной графики, разрабатывал интерпретатор для большой трехмерной графической базы данных по нью-йоркской гавани. Вонок задумывал язык систем проектирования для обработки графической информации.
Ранние принтеры были устроены так, чтобы печатать символы текста, обычно поступающего на вход в коде ASCII. Было множество технологий для этой цели, но наиболее распространенным было то, что печатаемые символы были «намертво» проштампованы на клавиши пишущей машинки, отлиты в металле для линотипов или нанесены на негативы фотонаборных устройств и поэтому их было физически трудно изменить.
Это изменилось до некоторой степени с распространением матричных печатающих устройств. Символы на этих системах могли быть «нарисованы» как совокупность точек, соответствующих определенным таблицам шрифтов в принтере. По мере усовершенствования матричные печатающие устройства стали включать несколько встроенных шрифтов, из которых пользователь мог выбирать, а некоторые модели давали пользователям возможность передать (загрузить) их собственные заказные шрифты в принтер.
Матричные печатающие устройства также дали возможность печатать растровую графику. Графические символы интерпретировались компьютером и посылались как ряд точек на принтер, используя «escape-последовательности» (см. табл. 2.1). Эти языки управления менялись от принтера к принтеру, требуя разработки многочисленных драйверов.
Векторный вывод графических символов возлагался на другие устройства — плоттеры (графопостроители). Они также могли использовать общий командный язык — HPGL, но имели ограниченное использование для чего-нибудь другого, кроме вывода векторной графики. Кроме того, они были дорогими и медленными, и таким образом не имели широкого распространения.
PostScript порвал с этой традицией, комбинируя лучшие особенности как принтеров, так и плоттеров. Как и плоттеры, PostScript предложил высококачественную штриховую графику и единый язык управления, который мог использоваться на принтерах любых марок. Как матричные печатающие устройства, PostScript предложил простые способы генерировать страницы текста и растровой графики. Но, в отличие от обоих, PostScript мог располагать все эти данные на единой странице, что предлагало гораздо больше гибкости, чем любой принтер или плоттер. PostScript выходил за пределы типичного языка управления принтером и был полным языком программирования. Многие прикладные программы могут преобразовать документ в программу PostScript, выполнение которой приведет к формированию образа оригинала документа. Эту программу затем можно передать на интерпретатор принтера, который осуществит печать документа, или в другое приложение, которое отобразит документ на экране. Так как документ-программа не требует изменений в зависимости от адресата, он называется независимым от устройства (device-independent).
PostScript примечателен тем, что может осуществлять растеризацию образа в процессе обработки данных («на лету»), поскольку все, даже текст, определено в терминах прямых линий и кубических кривых Безье (cubic Bezier curves, ранее использовавшихся только в САПР — системах автоматизированного проектирования), что позволяет осуществлять произвольное масштабирование, вращение изображения и другие преобразования. В процессе работы интерпретатор программы PostScript преобразует эти команды в точки изображения, формируя вывод. Поэтому интерпретаторы PostScript также иногда называют процессорами растровых изображений (PostScript Raster Image Processors, или RIP).
Почти столь же сложны, как сам Postscript, были его методы обработки шрифтов. Система генерации шрифтов использовала графические примитивы Postscript, чтобы вычерчивать символы в режиме векторной графики, которая затем могла быть передана на устройство с любой разрешающей способностью. При этом возникало множество типографских проблем, которые следовало бы решить.
В 1980-е гг. Adobe получал большую часть своего дохода за счет лицензионных выплат от реализации PostScript для принтеров, известных как процессоры растровых изображений (raster image processor — RIP). Поскольку в середине 1980-х стало доступным множество новых платформ на основе RISC-процессоров, возникло мнение, что поддержка новых машин средствами Adobe явно недостаточна.
Это и проблемы стоимости приводили к реализации PostScript третьими сторонами, что стало обычным, особенно в дешевых принтерах (где лицензионная плата была точкой преткновения), а также в высокопроизводительном типографском наборном оборудовании (где требования скорости вызывали необходимость поддержки новых платформам быстрее, чем Adobe могла бы это обеспечить). В какой-то момент Microsoft и Apple объединились, чтобы попытаться преодолеть монополию лазерных принтеров Adobe. Microsoft лицензировала Apple, приобретенный ею совместимый с Postscript интерпретатор —Truelmage, а Apple лицензировала Microsoft новый формат шрифтов — TrueType. Apple достигла соглашения с Adobe и лицензировала подлинный PostScript для своих принтеров, но TrueType стал стандартной технологией контурного шрифта как для Windows, так и для Macintosh.
Много распространенных и недорогих лазерных принтеров не поддерживают PostScript, а используют драйверы, которые просто растеризуют исходные форматы графических символов вместо того, чтобы сначала преобразовать их в PostScript. Когда поддержка PostScript необходима для такого принтера, может использоваться бесплатный PostScript-совместимый интерпретатор, именуемый Ghostscript. Ghostscript печатает документы PostScript на «нe-PostScriptoвских» принтерах, используя мощности ЦП компьютера для растеризации и передавая на принтер результат как большой точечный рисунок (single large bitmap). Ghostscript может также использоваться для предварительного просмотра документов PostScript на компьютерном мониторе и преобразовать страницы PostScript в растровую графику (файлы типов tiff и рng) и векторные форматы (например, pdf).
PostScript является полным язык программирования (в смысле Тьюринга). Как правило, PostScript-программы создаются не программистами, а другими программами. Конечно, есть возможность создать графические образы или выполнить какие-либо вычисления, кодируя вручную на ЯП PostScript. PostScript — интерпретируемый язык на основе стека (стековый язык), подобный Forth, использующий структуры данных, аналогичные встречающимся в Лиспе (Lisp) и пр. Большинство операторов (в других языках используется термин функция) принимает значения параметров из стека и помещает результат выполнения в стек.
Синтаксис языка опирается на обратную польскую запись (reverse Polish notation — RPN), которая делает круглые скобки ненужными, но при которой чтение программы требует некоторых навыков, поскольку требуется помнить содержание стека. Рассмотрим ряд примеров.
С помощью оператора в RPN
3 4 add 5 1 sub mul
будет вычислен такой результат: (3 + 4) х (5 - 1).
Чтобы производить графические образы, PostScript использует обычную декартову систему координат, например оператор
100 200 moveto 300 400 lineto stroke
перемещает «курсор» в точку с координатами (100, 200), а затем чертит прямую линию к точке (300, 400).
50 70 moveto 100 200 50 80 100 100 curveto stroke
создает кубическую Кривую Безье между точками (50, 70) и (100, 100), проходящую через контрольные точки (100, 200) и (50, 80).
250 250 moveto (Programming Languages) show
поместит начало текста «Programming Languages» в точку с координатами (250, 250). Шрифт, которым будет набран текст, может быть предварительно задан (например, командной строкой
/Courier findfont 12 scalefont setfont).
Portable Document Format (PDF)
Переносимый формат документов — PDF — формат файла, созданный Adobe Systems в 1993 г. для использования в настольных издательских системах. Формат PDF позволяет представлять двумерные документы в форме, независимой от разрешающей способности устройств печати (или дисплеев). Каждый файл формата PDF содержит полное описание двумерного документа (с появлением Acrobat 3D — трехмерных документов), который включает текст, шрифты, изображения и двумерную векторную графику, которые образуют документ.
Когда формат PDF впервые появился в начале 1990-х гг., он не сразу завоевал популярность. В частности, ранние версии формата PDF не имели поддержки механизмов внешних гиперссылок, что ограничивало его применимость в Internet. Кроме того, существовали конкурирующие форматы, например, Envoy, Common Ground Digital Paper и даже собственный формат Adobe — PostScript (.ps). В дальнейшем Adobe начала бесплатно распространять программу чтения Acrobat Reader (сейчас — Adobe Reader) и продолжала поддерживать формат PDF в его медленном многолетнем «пути наверх». PDF в конечном счете стал фактическим стандартом для печатных документов.
Формат файла формата PDF подвергся нескольким изменениям с выпуском новых версий Adobe Acrobat. Известно восемь версий формата PDF - 1.0 (1993 г.), 1.1 (1994 г.), 1.2 (1996 г.), 1.3 (1999 г.), 1.4 (2001 г.), 1.5 (2003 г.), 1.6 (2005 г.) и 1.7 (2006 г. ) которые соответствуют выпускам Adobe Acrobat от 1.0 до 8.0
Формат PDF использует следующие технологии:
• подмножество языка программирования и описания страниц PostScript, чтобы генерировать размещение и графику;
• систему встраивания и замены шрифтов для обеспечения перемести мости документов;
• структурированную систему хранения, позволяющую связывать эти элементы в отдельный файл, с использованием сжатия данных при необходимости.
Язык SGML
SGML разработан на базе программного продукта DCF GML фирмы IBM и представляет собой метод создания структурированных документов, а также языков для их разметки.
В языке SGML каждый документ имеет три части:
• декларации (объявления, определения) языка SGML, привязывающие к определенным значениям параметры обработки, а также имена синтаксиса;
• пролог, состоящий из деклараций о типе документа. Они определяют типы элементов, взаимосвязи между элементами и их атрибуты, а также условные обозначения, которые могут быть задействованы при разметке;
• данные, которые состоят из разметки документа и собственно информации.
Основные типы конструкций языка — описания:
• элементов <!element. . .>;
• объектов <!entity. . .>;
• атрибутов <!attribute list...>,
образующих структуру документа (документов), при этом элемент — основная компонента документа; объект — группа, род элементов; атрибут — характеристика элемента. Все «квадратики», приведенные на рис. 2.5, являются элементами. Запишем одну из возможных конструкций, соответствующую выделенной на рис. 2.5 цепочке элементов (подраздел — параграф — текст...):
<! element subdiv (par*) > — подраздел состоит из параграфов (повторяющихся);
<!Element par (text | table? | pict?)> — параграф — из текста или таблицы/ рисунка (необязательны):
< ! ELEMENT PICT (IMAGE & CAPT) > — рисунок – из изображения и подписи.
Декларации и пролог на языке SGML задают структуру документа и, будучи отделены от размеченного текста, образуют описание типа документа (DTD — Document Type Definition). На сегодня известно более 5000 DTD, соответствующих различным национальным и международным стандартам, из которых наиболее важен HTML.
HTML — язык разметки гипертекста
HTML — Hypertext Markup language формулируется в терминах языка SGML. Например, документ как целое в DTD задается декларацией:
<! ELEMENT HTML ((HEAD | BODY | %oldstyle)*,
PLAINTEXT?)>.
HTML ориентирован на решение нескольких важных задач, в которых участвуют его различные конструкции и элементы:
• описание структуры документа ( head, body, HI—Н6, шрифты, списки и пр.);
• адресация ресурсов (base, link, href и пр.);
• создание гипертекстовых ссылок и управление навигацией в БД локальных и WWW Internet (href и т. п. );
• реализация интерфейсов с пользователем (isindex, menu, FORM и пр.).
Рассмотрим здесь только некоторые функции представления документов (см. также табл. 2.1). Функции навигации и интерфейсов будут детализированы далее (гл. 6).
Базовые элементы HTML-документа:
• head — содержит всю информацию о документе в целом, но не содержит какого-либо текста. Последний является лишь частью документа и должен находиться в элементе body. Декларации SGML:
<! ELEMENT HEAD (%head.content) + (%head.misc)>
<! ENTITY % head.content "TITLE & ISINDEX? & BASE?">
• body — в противоположность элементу HEAD элемент body содержит всю ту информацию, из которой собственно и состоит рассматриваемый документ. Декларация SGML:
<! ELEMENT BODY (%bodyelement | %htext;)*>.
Приведем некоторые элементы HTML, относящиеся к представлению документа. 1.Заголовки разд ел о в документа.
SGML-декларация:
<!ENTITY % heading "HI|Н2|НЗ|Н4|Н5|Н6">.
Возможная интерпретация:
H1 — жирный, очень крупный шрифт, текст центрирован Между заголовком и последующим текстом вставляется одна или две пустые строки. При выводе на принтер заголовок печатается на новой странице;
Н2 — жирный крупный шрифт, до и после заголовка помещаются одна или две пустые строки;
НЗ — наклонный крупный шрифт, до и после заголовка помещаются одна или две пустые строки. Печатается с небольшим отступом;
Н4 — жирный нормальный шрифт, до и после заголовка помещается пустая строка;
Н5 — наклонный шрифт, как и для Н4, пустая строка ставится перед заголовком;
Н6 — жирный шрифт, перед заголовком ставится пустая строка.
2 Физические (макетные) стили.
SGML-декларация:
<!ENTITY % font "TT|I|B|U|STRIKE|BIG|SMALL|SUB|SUP">.
Возможная интерпретация:
тт — (телетайп) шрифт фиксированной ширины;
В — жирный или еще каким-либо образом выделенный шрифт;
I — наклонный шрифт (или видоизмененный еще каким-либо образом);
U — подчеркивание.
3.Логические стили.
SGML-декларация:
<!ENTITY % phrase "EM|STRONG IDFN|CODE|SAMP IKBD|VARI
CITE"> .
Интерпретация:
em — выделение символов (обычно наклон шрифта), смысловое усиление определенного слова или фразы;
strong — более четкое выделение, привлечение внимания (обычно применение более жирного шрифта);
СОDE — пример кода; обычно фиксированный шрифт (формулы, выражения);
samp — последовательность символов (названия команд,
примеры);
VAR — имя переменной (имена переменных в примерах, формулах);
DFN — определение к какому-либо термину — обычно жирный наклонный;
СIТЕ — цитата, обычно наклонный шрифт (названия документов, выдержки из документов, цитируемые фразы и т. д.)
Рассмотрим пример документа с разметкой HTML, содержащий приведенные выше элементы управления стилем символов текста:
<HTML>
<TITLE> Примеры управления шрифтами </TITLE>
<Н1> Заголовок 1 </Н1>
<Н2> Заголовок 2 </Н2>
<Ь> Это текст Bold </b><p>
<i> Это текст Italic</ixp>
<u> Это подчеркнутый текст </и> <р>
<strike> Это перечеркнутый текст </strike>
<р>В обычный текст можно вставить <sub> подстрочный
</sub> текст, что позволяет написать выражение типа
P<sub>max</sub>=max{P<sub>K/sub>,P<sub>2</sub>}
<р>В обычный текст можно вставить <sup>
надстрочный</зир> текст, что позволяет написать
обозначение изотопа в виде Cs<sup>134</sup>
</HTML>
Пример отображения этого текста браузером Mozilla FireFox представлен на рис 2.6.
Некоторые дополнительные возможности. Списки. В HTML
предусмотрены следующие виды списков:
• UL — ненумерованный список (неупорядоченный);
• ol — нумерованный список (упорядоченный);
• DL — список определений. Типичный неупорядоченный список:
<UL>
<LH>Titlе of WWW programmes (NCSA).
<LI> NCSA HTTPD;
<LI> NCSA MOSAIC
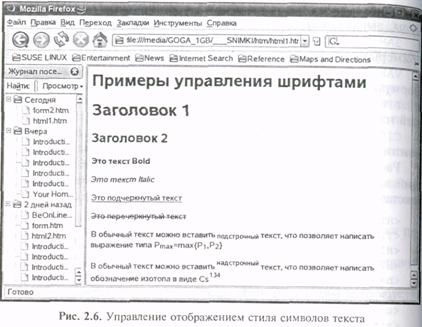
<UL>
<LH>Title of WWW programmes (CERN).
<LI> CERN HTTPD;
<LI> AGORA - email robot;
<LI> HTTPD CERN;
<LI> WWW Line Browser;
<LI> Arena.
</UL>
<UL>
<LH> Title of WWW programmes (Netscape).
<LI> Netsite - server;
<LI> Netscape Navigator.
</UL>
Пример интерпретации данного списка приведен на рис. 2.7-Таблицы. Для описания таблиц служит элемент TABLE, который является контейнером для других элементов описания таблицы. Наиболее часто он употребляется с атрибутом BORDER, определяющим разделительные линии граф таблицы, которые могут быть либо трехмерными (рис. 2,8), либо обычными.

Из элементов формы следует отметить colspec и dp. COLSPEC позволяет заказать параметры отображения каждой колонки таблицы и имеет вид:
COLSPEC="L20 C8 L40"
Здесь определены три колонки шириной 20, 8 и 40 условных единиц которые могут измеряться в пикселях и типографских интервалах или зависеть от размеров самой таблицы. Атрибут dp определяет вид десятичной точки.
Элемент TR (Table Row) дает общее описание строки таблицу Обычно используется для выравнивания содержания граф строки. Способ выравнивания определяют: атрибут align — горизонтальное выравнивание, который принимает значения left,right center, justify, decimal, и атрибут VALIGN — вертикальное выравнивание, который принимает значения top, bottom, middle baseline. По умолчанию графы – заголовки центрируются, а графы – данные выравниваются по левому верхнему углу.
Элементы ТН (Table Header) и TD (Table Data) используются для описания граф таблицы. Кроме выравнивания тн и то позволяют еще и объединять графы, как это показано в примере (третья строка из текстового примера, см. ниже). Это делается с помощью атрибутов rowspan (пропуск строки) и colspan (пропуск столбца). Цифра в этих атрибутах определяет количество последовательно расположенных граф таблицы, объединенных в одну графу.
Приведем пример таблицы (интерпретация отображена на рис. 2.8):
<TABLE BORDER>
<CAPTION>A test table with merged
cells. <CREDIT>(T.Berners
Lee/WWWC, 1995.) </CREDITX></CAPTION>
<TR><TH R0WSPAN=2><TH C0LSPAN=2>Average>
<TH rowspan=2>other<BR>category<TH ROWSPAN=2>Misc</TR>
<TR><TH>height<TH>weight</TR>
<TR><TH ALIGN=left>males<TD>l . 9<TD>0 . 003
<TR><TH ALIGN=left>females<TD>1.7<TD>0.002
</TABLE>
Математика. Для реализации математических выражений в языке определен элемент MATH, внутри которого содержатся следующие компоненты:
• above (запись символа над выражением);
• below (запись символа под выражением);
• sqrt,root (радикалы);
• text (для записи текста);
• в,Т,ВТ (выделение символов);
• OVER (черта) и пр.
Например,
запись <root>3<of>1+x</ROOT> соответствует ![]() .
.
2.3 Технологии XML
С конца 80-х гг. самые существенные языки разметки были основаны на принципах SGML, включая например TEI и DocBook. SGML был провозглашен как международный стандарт ISO8879 в 1986 г.
SGML нашел широкое использование в областях с крупномасштабными документационными требованиями. Однако он оказался слишком громоздким и трудным для обучения (побочный эффект попытки создать универсальный и всеобъемлющий язык). Например, в SGML теги конца (или теги начала, или даже оба) являются необязательными в определенных контекстах (предполагалось, что разметка будет делаться только вручную и это сэкономило бы пользователю время и усилия).
Новый язык разметки, который теперь широко используется, — XML (Extensible Markup Language — расширяемый язык разметки), был разработан Консорциумом WWW и основная задача состояла в том, чтобы упростить SGML, сосредоточиваясь на частной проблеме, — обмен документами в Internet. XML остается метаязыком, как и SGML, разрешая пользователям создавать любые необходимые теги (поэтому он — «расширяемый»), а затем описывая эти теги и их разрешенную интерпретацию.
Принятию XML способствовало то, что каждый документ XML является также и документом SGML, поэтому существующие пользователи SGML и действующее программное обеспечение могли легко адаптироваться к XML. XML устранил также многие из более сложных особенностей SGML, облегчая изучение и выполнение. Другие усовершенствования исправили некоторые проблемы SGML в международных параметрах настройки и позволили анализировать и интерпретировать иерархию документа, даже при отсутствии его схемы в явном виде.
XHTML
С января 2000 г. все рекомендации W3C для HTML основываются на ХML, а не на SGML, при этом используется сокращение XHTML (EХtensible HyperТext Markup Language) — расширяемый язык разметки гипертекста. Языковая спецификация требует, чтобы Web-документы XHTML были «правильно структурированными» документами XML — это позволяет создавать более устойчивые документы, используя теги, знакомые по HTML.
Одно из самых значимых различий между HTML и XHTML — правило, что все теги должны быть закрыты: «пустые» HTML-теги, типа <br> должны быть либо «закрыты» правильным тегом окончания либо заменены специальной формой: <br/> (отметим, что перед «/» на теге конца должен быть «пробел», иначе, тег — недопустимый SGML). Другое — в том, что все «атрибуты» в тегах должны браться в кавычки.
В настоящее время известно множество приложений, основанных на XML, включая Resource Description Framework (RDF), XForms, DocBook, OpenDocument (ODF), SOAP и Web Ontology Language.
Упрощая ситуацию, можно сказать, что разработчики XML взяли лучшие решения SGML и, руководствуюсь опытом HTML, создали язык, не уступающий по мощности SGML, но гораздо более удобный и легкий в использовании. XML предназначен для создания новых языков разметки и используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов.
С его помощью можно описать целый класс агрегатов данных, называемых XML-документами, ориентированными на конкретную предметную область. XML позволяет определить допустимый набор тегов, их атрибуты и внутреннюю структуру документа. Теги (подобно тегам в HTML) представляют специальные инструкции, предназначенные для формирования в документах определенной структуры и четких отношений между различными элементами этой структуры. Для описания данных XML использует DTD (Document Type Definition — Определение типа документа) или схему документа.
Синтаксис XML
Так же, как и в HTML, инструкции, заключенные в угловые скобки, называются тегами и служат для разметки основного текста документа. В XML существуют открывающие, закрывающие и пустые теги (в HTML понятие пустого тега тоже существует, но специального его обозначения не требуется).
Тело документа XML состоит из элементов разметки и непосредственно содержимого документа — данных. XML-теги предназначены определения элементов документа, их атрибутов и других конструкций языка.
Любой XML-документ должен всегда начинаться с инструкции <?xml?>, внутри которой также можно задавать номер версии языка, номер кодовой страницы и другие параметры, необходимые программе-анализатору в процессе разбора документа.
Содержимое XML-документа представляет собой набор элементов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных. Рассмотрим каждый из них подробней.
Элементы данных. Элемент — это структурная единица XML-документа. Например, заключая слово rose в теги, мы определяем непустой элемент, называемый <flower>, содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, т. е. практически любые части XML-документа.
Любой непустой элемент должен состоять из начального, конечного тегов и данных между ними, заключенных: <flower> rose </flower>.
Элемент в DTD определяется с помощью дескриптора ! element, в котором указывается название элемента и структура его содержимого.
Например, для элемента <flower> можно определить следующее правило:
<!ELEMENT flower PCDATA>
Ключевое слово element указывает, что данной инструкцией будет описываться элемент XML. Внутри этой инструкции задается название элемента (flower) и тип его содержимого.
Атрибуты. Если при определении элемента необходимо задать какие-либо параметры, уточняющие его характеристики, то имеется возможность использовать атрибуты элемента. Атрибут – это пара название = значение, которую надо задавать при определении элемента в начальном теге, например,
<cоlor RGB="true">#ff08ff</color>
<cоlor RGB="false">white</color>
Списки атрибутов элемента определяются с помощью ключевого слова !attlist. Внутри него задаются названия атрибутов, типы их значений и дополнительные параметры. Например для элемента <article> могут быть определены следующие атрибуты:
<!ATTLIST article
id ID #REQUIRED
about CDATA #IMPLIED
type (actual | review | teach ) 'actual' ''
>
В данном примере для элемента article определяются три атрибута: id, about и type, которые имеют типы id (идентификатор), cdata и список возможных значений соответственно. Всего существует шесть возможных типов значений атрибута:
• cdata — содержимым документа могут быть любые символьные данные;
• id — определяет уникальный идентификатор элемента в документе;
• idref (idrefs) — указывает, что значением атрибута должно выступать название (или несколько таких названий, разделенных пробелами во втором случае) уникального идентификатора определенного в этом документе элемента;
• entity (entities) — значение атрибута должно быть названием (или списком названий, если используется entities) компонента (макроопределения), определенного в документе;
• nmtoken (nmtokens) — содержимым элемента может быть только одно отдельное слово (т. е. этот параметр является ограниченным вариантом cdata);
• список допустимых значений — определяется список значений, которые может иметь данный атрибут.
Также в определении атрибута можно использовать следующие параметры:
• #required — определяет обязательный атрибут, который должен быть задан во всех элементах данного типа;
• #implied — атрибут не является обязательным;
• #FIXED значение — указывает, что атрибут должен иметь только указанное значение, однако само определение атрибута не является обязательным, но в процессе разбора его значение в любом случае будет передано программе-анализатору. Значение задает значение атрибута по умолчанию
Сущности и специальные символы. Сущности (entity) представляют собой определения, содержимое которых может быть повторна использовано в документе. В языках программирования подобные элементы называются макроопределениями (расширениями). Для того чтобы включить в документ символ, используемый для определения каких-либо конструкции языка (например, символ угловой скобки) и не вызвать при этом ошибок в процессе разбора такого документа, нужно использовать его специальный символьный либо числовой идентификатор.
Например, <, > " или $ (десятичная форма записи), &#xla (шестнадцатеричная) и т. д.
Создаются DTD-сущности с помощью инструкции !entity:
<!ENTITY hello ' Мы рады приветствовать Вас!' >
Программа-анализатор, просматривая в первую очередь содержимое области DTD – определений, обработает эту инструкцию и при дальнейшем разборе документа будет использовать содержимое DTD-сущности в том месте, где будет встречаться его название. То есть теперь в документе мы можем использовать выражение &hello;, которое будет заменено на строчку «Мы рады приветствовать Вас».
В общем случае, внутри DTD можно задать следующие типы сущностей:
• внутренние — предназначены для определения строковой константы, с их помощью можно организовывать ссылки на часто изменяемую информацию, делая документ более читабельным. Внутренние компоненты включаются в документ с помощью амперсанда &;
• внешние — указывают на содержимое внешнего файла, причем этим содержимым могут быть как текстовые, так и двоичные данные. В первом случае в месте использования макроса будут вставлены текстовые строки, во втором — бинарные данные, которые анализатором не рассматриваются и используются внешними программами.
Комментариями является любая область данных, заключенная между последовательностями символов: <!-- -->
Комментарии пропускаются анализатором и поэтому при разборе структуры документа в качестве значащей информации не рассматриваются.
Директивы анализатора. Инструкции, предназначенные для анализаторов языка, описываются в XML-документе с помощью специальных тегов <? и ?>;. Программа клиента использует эти инструкции для управления процессом разбора документа. Наиболее часто инструкции используются при определении типа документа (например, <? Xml version="l. 0"?>) или создании пространства имен.
CDATA. Чтобы задать область документа, которую при разборе анализатор будет рассматривать как простой текст, игнорируя любые инструкции и специальные символы, но, в отличии от комментариев, иметь возможность использовать их в приложении, необходимо использовать теги <![cdata] и ]]>. Внутри этого блока можно помещать любую информацию, которая может понадобиться программе-клиенту для выполнения каких-либо действий (в область cdata можно помещать, например, инструкции JavaScript). Естественно, надо следить за тем, чтобы в области, ограниченной этими тегами, не было последовательности символов]].
Формат DocBook
DocBook — язык разметки технических документов. Он был первоначально предназначен для того, чтобы разрабатывать техническую документацию, связанную с компьютерной аппаратурой и программным обеспечением, однако может использоваться и для любых других видов документации.
Одно из основных преимуществ DocBook — он дает возможность пользователям создавать содержание документа в нейтральной форме, которая описывает только логическую структуру содержания, которое затем может быть отображено в разнообразных форматах, включая HTML, формат PDF, страницы руководства и помощи, не требуя от пользователей каких-либо изменений в исходном тексте.
DocBook появился в 1991 г. как совместная разработка HaL Computer Systems и O'Reilly & Associates и в конечном счете породил свою собственную организацию обслуживания (Davenport Group) перед перемещением в 1998 г. в консорциум SGML Open, который впоследствии был преобразован в OASIS (The Organization for the Advancement of Structured Information Standards — Организация развития стандартов структурированной информации). DocBook в настоящее время поддерживается ПосВоок Technical Committee (подразделение OASIS).
DocBook первоначально начал существование как приложение SGML, однако затем было разработано эквивалентное приложение XML, которое заменило SGML в большинстве применений. Первоначально только ключевая группа компаний-разработчиков программного обеспечения использовала DocBook, поскольку их представители были вовлечены в его начальный дизайн. В конечном счете, однако, DocBook был принят сообществом свободного программного обеспечения, где стал стандартом для того, чтобы создавать документацию для многих проектов, включая FreeBSD, KDE, GNOME, справочную информацию GTK+API, документацию по Linux и работу Linux Documentation
Project.
Рассмотрим пример кода.

Формат DocBook, будучи основанным на XML, легко читается и понимается как людьми, так и компьютерами. Формат состоит из меток (тегов типа <book>), каждой из которых соответствует закрывающая метка (например, </book>), и текстового содержания (например, Hello world!). Полное содержание Документа («книга») структурировано в данном примере в две «главы» (<chapter>), каждая из которых имеет «заголовок» ^:title>) и состоит из одного или более «параграфов» (<рага>). акая структура может образовывать книгу произвольного размера или любой другой документ.
Отметим, что теги указывают структуру и значение содержания, но не его отображение. Нет таких команд, которые требуют «напечатать этот параграф жирным шрифтом» или «центрировать эту строку» и т. д. Один и тот же файл DocBook может быть преобразован во многие различные выходные форматы, каждый с полностью отличным представлением и даже с другим расположением элементов содержания.
ODF
OpenDocument (ODF) — сокращение от «OASIS Open Document Format for Office Applications» (Открытый формат документов для офисных приложений), является форматом файла документа, используемым для того, чтобы описать электронные документы, например письма, сообщения, книги, электронные таблицы, диаграммы, презентации и файлы текстовых процессоров. Стандарт основан на формате XML, был разработан техническим комитетом OASIS (Organization for the Advancement of Structured Information Standards) и первоначально воплощен в офисном комплексе OpenOffice.org. OpenDocument является стандартом OASIS и принят как международный стандарт ISO/ IEC 26300:2006.
Основная цель таких открытых форматов как OpenDocument состоит в том, чтобы гарантировать долгосрочный доступ к данным без юридических или технических барьеров, и некоторые правительства пришли к выводу, что использование открытых форматов следует рассматривать как аспект публичной политики. OpenDocument предназначен, чтобы быть альтернативой закрытым форматам, включая такие, как doc, xls и ppt, обычно используемые Microsoft Office и другими приложениями (эти форматы не описаны в открытой документации, но описание может быть получено путем заключения соответствующего соглашения непосредственно с Microsoft Corporation). Microsoft поддерживает создание дополнений к программам для MS Office, чтобы позволить использовать OpenDocument. В частности, Microsoft создал транслятор Office Open XML — проект «моста» между Office Open ; XML и OpenDocument. Предполагается в течение 2007 г. выпустить версию этого программного обеспечения для Microsoft Word, Excel и PowerPoint. Для имен файлов, содержащих документы OpenDocument, используются следующие расширения:
• . odt — для текстовых документов;
• . ods — для электронных таблиц;
• . odp — для презентаций;
• . odg — для графической информации;
• . odf — для документов, содержащих формулы или математических уравнения.
Файл OpenDocument может быть или XML-файлом, который использует <office:document> как корневой элемент, или сжатым ZIР-архивом, содержащим множество файлов и каталогов. ZIР – формат используется чаще, так как может содержать бинарную информацию и обычно значительно меньше в размере. OpenDocument основан на разделении по четырем отдельным XML-файлам таких составляющих документа, как содержание, стили, метаданные и параметры настройки приложений.
Перевод Excel-таблицы в формат XML
Как уже отмечалось, язык XML позволяет описывать различные типы структурированных данных (листы табличных процессоров, базы данных и пр.). Предположим, имеется простая таблица данных процессора Excel (рис. 2.9, а). Она может быть переведена в формат XML, в котором будет иметь следующий вид (приводится в сокращении):
<?xml version="1. 0"?>
<?mso-application progid="Excel.Sheet"?>
<. . .>
<DocumentProperties
xmlns="urn:schemas-microsoft-com:office: office">
<LastAuthor>Петров</LastAuthor>
<Created>2005-05-04</Created>
<Version>2</Version>
</DocumentProperties>
<ExcelWorkbook
xmlns="urn:schemas-microsoft-com:office:excel">
<WindowHeight>8700</WindowHeight>
<WindowWidth>11355</WindowWidth>
<ProtectStructure>False</ProtectStructure>
<ProtectWlndows>False</ProtectWindows>
</ExcelWorkbook>
<Styles>
<Style ss:ID="Default" ss:Name=Normal">
< Alignment ss : Vertical = "Bottom"/>
<Borders/>
<Font ss:FontName="Arial Cyr" x:CharSet="204"/>
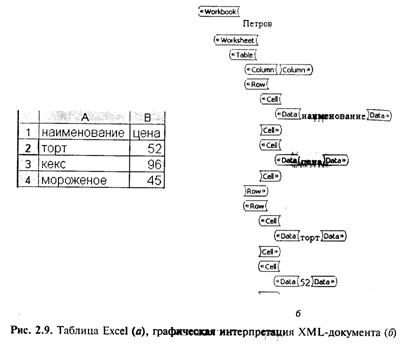
<Interior/>
<NumberFormat/>
<Protection/>
</Style>
</Styles>
<Worksheet ss:Name="Лист1">
<Table ss:ExpandedColumnCount="2"
ss:ExpandedRowCount="5" x:FullColumns="l"
x:FullRows="l">
<Column ss:Width="70.5"/>
<Row ss:Index="2">
<Cell><Data ss:Type="String">наименование</Data></Cell>
<Cell><Data ss:Type="String">цена</Data></Cell>
</Row>
<Row>
<Cell><Data ss:Type="String">торт</Data></Cell>
<Cell><Datа ss:Type="Number">52</Data></Cell>
</Row>
<Row>
<Cell><Datа ss:Type="String">кекс</Data></Cell>
<Cell><Datа ss:Type="Number">96</Data></Cell>
</Row>
<ROW>
<Cell><Data ss:Type="String">мороженое</Data></Cell>
<Cell><Data ss:Type="Number">45</Data></Cell>
</Row>
</Table>
<WorksheetOptions
xmlns="urn:schemas-microsoft-com:office:excel">
............
</WorksheetOptions>
<x:WorksheetOptions></x:WorksheetOptions>
</Worksheet>
</Workbook>
На рис. 2.9, б приводится структурная схема данного XML документа (также в сокращенном виде).
Редакторы, предназначенные для подготовки текстов условно можно разделить на обычные (подготовка писем и других простых документов) и сложные (оформление документов с разными шрифтами, включающие графики, рисунки и др.). Наибольшей популярностью пользуется текстовый процессор MS Word for Windows.
Редактор Word
Основные функции. Текстовый редактор Word реализует следующие функции:
• создание, открытие, закрытие, сохранение текстовых документов (рис. 2.10, а);
• задание параметров страниц (рис. 2.10, б);
• набор текста (режим прописных букв, гарнитура, кегль и Цвет шрифта, страница, работа с выделенным фрагментом "текста, межстрочный интервал, способы выравнивания, буфер обмена);
• форматирование абзаца (задание параметров абзаца, красная строка, межстрочный интервал) — рис. 2.10, в;
• задание шрифтов (рис. 2.10, г);
• установка рамки и заливки абзаца;
• создание нумерованных и маркированных списков, настройка нумерованных списков;
• ссылки, заголовки, оглавления;
• проверка правописания, расстановка переносов;
• создание, заполнение и форматирование статических таблиц; рамки, заливка. Изменение структуры таблицы (добавление и удаление строк и столбцов, объединение ячеек, изменение размеров ячеек). Преобразование текста в таблицу и наоборот (рис. 2.11, а);

• вставка и редактирование объектов — рисунков, клипов, MIDI-файлов, математических формул (рис. 2.11, 6);
• деловая графика (построение диаграмм и графиков). Вставка рисунков, настройка положения, размера и способа обтекания рисунка (в тексте, перед текстом, за текстом и пр.) — рис. 2.12;
• работа с автофигурами (линии, фигуры, стрелки и пр.), использование WordArt;
• печать текста (рис. 2.13).
Добавление символов в текст осуществляется в режиме вставки, при этом текстовый курсор должен находиться в месте

документа, где будет производиться эта процедура. Индикация режима замены или вставки производится в статусной строке служебной области окна программы редактирования. При наборе очередного добавляемого символа часть строки справа (включая курсор) сдвигается на одну позицию вправо, а введенный символ появляется в позиции курсора. Если включен режим замены, то вновь набираемые символы замещают присутствующие в тексте редактируемого документа символы.
Для удаления одного или нескольких символов используются клавиши <Del> или <Backspace>. Нажатие клавиши <Del> приводит к удалению символа, находящегося в позиции курсора, правая часть строки сдвигается влево, сам курсор остается на месте. Нажатие клавиши <Backspace> вызывает удаление символа в позиции слева от курсора, курсор и правая часть строки сдвигаются влево. Эта клавиша используется в основном для удаления одного или нескольких символов. Технология удаления больших фрагментов текста предполагает предварительное выделение фрагмента для редактирования. Как правило, в текстовом окне может быть выделен только один фрагмент.
Удаление может производиться двояко:
• выделенный фрагмент изымается из текста, оставшийся текст смыкается;
• выделенный фрагмент удаляется в буфер памяти временного хранения, откуда может быть извлечен для вставки в другое место редактируемого документа либо использован в текстах других документов.
Поиск в документах, использующих программы обработки текстов, выполняется несколькими способами. Поиск по образцу, например, для последующей замены найденного словосочетания сводится к следующему:
• задается образец (символ, слово или цепочка символов);
• указывается направление поиска (вперед от текущей позиции курсора либо назад); система подготовки текстов начинает поиск заданного фрагмента;
• при обнаружении фрагмента просмотр приостанавливается, курсор позиционируется перед искомым фрагментом, и пользователь имеет возможность произвести нужную коррекцию.
Оформление документа в целом. Важным элементом работы с любым текстовым процессором является установление некоторых начальных параметров, например параметров страницы, формата, языка и др. Такие процедуры называют оформлением структурных элементов текста. Стандартными параметрами оформления страниц документа являются: поля страниц; размер печатного листа и ориентация текста на бумаге; расположение колонтитулов; число колонок текста (газетный стиль).
Текстовый процессор Word для Windows по умолчанию предлагает следующие параметры оформления документа:
• символы в обычном формате типа Times New Roman с размером символа, соответствующим кеглю 10 пунктов;
• абзацы без отступов, выровненные влево, через один интервал;
• табуляция через 0,5 дюйма (или 1,27 см);
• печатная страница документа в формате А4 (210 х 297 мм);
• границы текста на печатной странице: левое и правое поля — 3,17 см, верхнее и нижнее — 1,5 см.
Таким образом, при создании нового документа предлагается некоторый шаблон документа (в данном случае он называется «Normal»).
Текстовые редакторы порой содержат набор шаблонов для создания различных типовых, а порой и стандартизированных, документов. Пример набора шаблонов в WinWord представлен на рис. 2.14, а.
Шаблон содержит разнообразную информацию о стилях форматирования частей документа, вставленных полях и т. д. В шаблонах хранятся выбранные и установленные для них макрокоманды, элементы глоссария, кнопки панели инструментов, нестандартные меню и способы установки клавиш сокращения, облегчающих работу с документами. Один раз созданные и сохраненные в памяти компьютера, шаблоны позволяют быстро готовить аналогичные по форме (но не по содержанию) документы без затрат времени на форматирование.
Одним из основных структурных элементов любого документа является абзац. При наборе текста новый абзац образуется после нажатия <Enter>. При этом курсор ввода переходит на новую строку и устанавливается в позицию левого отступа следующего абзаца. Позиция отступа зависит от параметров настройки конкретной системы текстовой обработки. К наиболее общим параметрам абзацного форматирования можно отнести:
• выравнивание границ строк;
• отступы для строк;
• межстрочные интервалы;
• обрамление и цвета фона текста;
• расположение текста абзаца на смежных страницах документа.
Если система подготовки текста используется для создания и оформления многостраничного документа, то применяется форматирование страниц или разделов. В тексте могут появиться новые структурные элементы: закладки, сноски, перекрестны ссылки, колонтитулы.
Под закладкой (bookmark), или меткой, понимается определенный фрагмент текста документа, которому пользоваться присваивает имя (рис. 2.14, б).
В многостраничном документе закладка может использоваться для:
• быстрого перехода к месту документа, обозначенному закладкой;
• создания перекрестных ссылок в документе.
Иногда документ содержит дополнения к основному тексту подстрочные примечания. Подстрочные примечания оформляют сносками (рис. 2.14, в). В состав подстрочного примечания входят два неразрывно связанных элемента: так сноски и текст собственно примечания. Знак сноски располагают в основном тексте у того места, к которому относится примечание, и в начале самого примечания.
Редактор документов OpenOffice.org Writer
Работая в OpenOffice.org Writer, пользователь может создавать любые текстовые документы, составлять личные и официальные письма, брошюры, факсы и профессиональные учебные пособия. Документы, которые используются часто, можно сохранять как шаблоны, например бланк счета. Имеется проверка орфографии и тезаурус, а при необходимости может быть задействована Автозамена и расстановка переносов во время ввода текста с клавиатуры. В OpenOfTice.org нет ограничений на длину текстового документа (рис. 2.15).
Создание и структурирование документов, OpenOffice.org предлагает большой выбор средств для создания документов. Используя Мастер стилей, можно создавать и редактировать стили абзацев, отдельных символов, рамок и страниц. Навигатор поможет при создании структурированных текстов, а также позволит отредактировать уже созданную структуру текста путем передвижения абзацев из одного места в другое.
Можно создавать разнообразные указатели и таблицы в текстовых документах, а структуру и внешний вид этих указателей и таблиц задавать в соответствии с потребностями. Активные гиперссылки и закладки позволяют переходить к соответствующим местам в тексте.
Подготовка публикации с помощью OpenOffice.org Writer. OpenOffice.org Writer содержит многочисленные возможности для создания профессиональных документов. Текст может быть многостолбцовым и содержать текстовые рамки, рисунки, таблицы и пр., встроенные в него. Текстовые рамки могут создавать газетный формат. Такие возможности, как линии выравнивания, рамки для иллюстраций выборочно и по всему документу и выбор любого цвета для символов, абзацев и таблиц, помогают создавать различные документы на высоком профессиональном уровне.
Вычисления. Текстовые документы в OpеnOffice.org имеют встроенную функцию вычисления, которая позволяет выполнить математические действия или создать логические связи. Чтобы выполнить вычисления, в текстовом документе можно создать таблицу.
Создание чертежей. Удобный и легко доступный инструмент для черчения позволяет создавать чертежи, рисунки, врезки и пр. непосредственно в текстовых документах.
Вставка изображений. Предусмотрена возможность вставки текстовый документ картинок различного формата, включая jpg, gif и пр. Наиболее распространенные форматы могут быть отредактированы непосредственно в текстовом документе с помощью графического редактора. Кроме этого, Галерея предоставляет коллекцию тематически упорядоченных картинок.
Изменяемый интерфейс приложения. Интерфейс программы разработан таким образом, что каждый пользователь может настроить его в соответствии с личными предпочтениями. Различные окна (Мастер стилей, Навигатор и т. п.) могут быть размещены как плавающие окна в любом месте экрана, а некоторые из них могут быть пристыкованы к краю. Значки и меню также могут быть изменены.
Перетаскивание. Возможность перетаскивания позволяет работать с текстовым документом в OpenOffice.org более быстро и эффективно. Например, можно перетаскивать картинки непосредственно из Галереи в активный документ.
Полнообъемная справка. Программа предоставляет Справку, которая служит гидом по элементам программы в OpenOffice.org и включает в себя большой набор инструкций для решения простых и сложных задач.
Стандартный просмотрщик PostScript — ghostview (KGhostView)
GhostView — одна из первых в Unix программа, созданная для просмотра файлов Adobe PostScript. KGhostView (перенесенная на KDE [22] программа Ghostмview отображает и распечатывает файлы PostScript (.ps, .eps) и Portable Document Format (.pdf).
Если документ не соответствует стандарту структуры документа Adobe, функциональность программы ограничена. Например, если отсутствует оглавление, становится невозможным отмечать страницы и перемещаться по документу, пропуская их.
Рассмотрим содержимое основного окна KGhostView, действия с помощью кнопок панели инструментов и методы использования списка страниц.
Могут быть открыты несколько окон KGhostView, чтобы просматривать несколько документов. Заголовок окна отображает название документа, открытого в этом окне (рис. 2.16,
В основной части окна отображается страница текущего документа (рис. 2.16, 2). Если страница слишком велика и не помешается в окне, у его границ автоматически размещаются панели прокрутки. Это свойство может быть отключено с помощью меню Настройка.
Панель инструментов и список страниц могут быть скрыты с помощью опций меню Настройка, чтобы освободить пространство экрана для отображения содержимого.
Предусмотрена возможность прокручивать страницу, используя клавиши <↑> и <↓> или меню Вид\прокрутить вверх (<Shift+Space>) и Вид\Прокрутить вниз (<Ctrl+Space>), чтобы перемещаться по документу.
Кнопки панели инструментов Следующая страница и Предыдущая страница служат для перехода между страницами (также можно щелкнуть левой кнопкой мыши по номеру страницы в списке, чтобы перейти на нее).
Список страниц (если выбран показ в меню Настройка) отображается у левой стороны окна (рис. 2.16, 3). Он включает два столбца: первый может содержать флажок отметки страницы, второй отображает номера страниц. Этот список может использоваться, чтобы перемешаться по документу или отмечать страницы для печати.
Может быть установлен «отмечающий страницу» флажок для отображаемой страницы с помощью комбинации клавиш <Ctrl+M> или щелчком на странице в списке. Вы также можете удалить или изменить пометки, используя меню, выпадающее по щелчку правой кнопки мыши в списке страниц, или с помощью меню Отметки страниц.
2.5. Работа с электронными таблицами
Электронная таблица — интерактивная система обработки информации, упорядоченной в виде таблицы с поименованными строками и столбцами. Прототипом современных электронных таблиц послужила разработанная в 1979 г. специалистами США программа Visual Calc. Ныне наиболее часто используются электронные таблицы Quatro Pro, MS Excel и Lotus 1-2-3.
Основные характеристики программного продукта Excel
Excel представляет собой мощный арсенал средств ввода, обработки и вывода в удобных для пользователя формах фактографической информации. Эти средства позволяют обрабатывать фактографическую информацию, используя большое число типовых функциональных зависимостей: финансовых, математических, статистиченских, логических и т. д., строить объемные и плоские диаграммы, обрабатывать информацию по пользовательским программам, анализировать ошибки, возникающие при обработке информации, выводить на экран или печать результаты обработки информации в наиболее удобной для пользователя форме.
Структура таблицы включает нумерационный и тематический заголовки, головку (шапку), боковик (первая графа таблицы, содержащая заголовки строк) и прографку (собственно данные таблицы). На пересечении столбца и строки устанавливается графическая смысловая связь между понятием, объединяющим материал в строку, и понятием, объединяющим материал в столбец, что позволяет выявить ее без мысленного перевода в словесную форму и существенно облегчить усвоение и анализ организованных в таблицу данных.
Структура таблиц и основные операции:
• в нижней части электронной таблицы расположен алфавитный указатель (регистр), обеспечивающий доступ к рабочим листам. Пользователь может задавать названия листам в папке (вместо алфавитного указателя), что делает наглядным содержимое регистра, облегчает поиск и переход от документа к документу;
• в режиме оформления и модификации экрана можно фиксировать заголовки строк, столбцов, оформлять рабочие листы и т. д.;
• для оформления рабочих листов в табличном процессоре предусмотрены возможности: выравнивания данных внутри клетки, выбора цвета фона клетки и шрифта, изменения высоты строк и ширины колонок, черчения рамок различного вида, определения формата данных внутри клетки (например: числовой, текстовый, финансовый, дата и т. д.), а также обеспечения автоматического форматирования, когда в систему уже встроены различные варианты оформления таблиц, и пользователь может выбрать наиболее подходящий формат;
• для вывода таблиц на печать предусмотрены функции, обеспечивающие выбор размера страницы, разбивку на страницы, установку размера полей страниц, оформление колонтитулов, а также предварительный просмотр получившейся страницы;
• связывание данных — абсолютная и относительная адресации являются характерной чертой всех табличных процессоров. Они дают возможность работать одновременно с несколькими таблицами, которые могут быть тем или иным образом связаны друг с другом;
• вычисления — для удобства вычисления в табличных процессорах имеются встроенные функции: математические, статистические, финансовые, даты и времени, логические и др. Менеджер функций позволяет выбрать нужную и, проставив значения, получить результат;
• деловая графика — возможность построения различного типа двухмерных, трехмерных и смешанных диаграмм (более 20 различных типов и подтипов), которые пользователь может строить самостоятельно. Многообразны и доступны возможности оформления диаграмм, например, вставка и оформление легенд, меток данных; оформление осей — возможность вставки линий сеток и другие;
• выполнение табличными процессорами функций баз данных — обеспечивается заполнением таблиц аналогично заполнению БД, т. е. через экранную форму защитой данных, сортировкой по ключу или по нескольким ключам, обработкой запросов к БД, созданием сводных таблиц. Кроме этого, осуществляется обработка внешних БД, позволяющая работать с файлами, созданными например, в формате dBase, Paradox или других форматах;
• программирование — в табличном процессоре существует возможность использования встроенного языка программирования макрокоманд. Разделяют макрокоманды и макрофункции. При использовании макрокоманд упрощается работа с табличным процессором и расширяется список его собственных команд. С помощью макрофункций определяют собственные формулы и функции, расширив, таким образом, набор функций, предоставляемый системой.
Интерфейс Excel. Интерфейс обеспечивает дружественное выполнение указанных функций и включает иерархическое меню с множеством подменю, директорий и команд и совокупности командных и селекторных кнопок окна Excel.
Окно Excel может содержать множество различных элементов. Все зависит от того, какие инструменты Excel вызваны на экран. Инструменты вызываются командой Панели инструментов меню Вид. В простейшем случае, когда на экран не вызваны никакие инструменты, окно Excel имеет только строку меню, находящуюся в верхней части экрана, расположенную под ней строку формул, вертикальную и горизонтальную полосы прокрутки, линейку прокрутки рабочих листов и рабочую область, занятую рабочим листом.
Рабочий лист отображает электронную таблицу и разбит на ячейки, образующие прямоугольный массив, координаты которых определяются путем задания их позиции по вертикали (в столбцах) и по горизонтали (в строках). Лист может содержать до 256 столбцов (от А до IV) и до 65 536 строк (от 1 до 65 536), в силу чего на экране в каждый данный момент времени расположена только некоторая часть рабочего листа (рис. 2.17).
Столбцы обозначаются буквами латинского алфавита (А,В,С, ..., Z,AA,AB,AC, ..., AZ,BA,BB, ...), а строки — числами натурального ряда (рис. 2.17, а, б). Так, D14 обозначает ячейку, находящуюся на пересечении столбца D и строки 14, a CD99 — ячейку, находящуюся на пересечении столбца CD и строки 99. Имена столбцов всегда отображаются в верхней строке рабочего листа, а номера строк — на его левой границе.
Одна из ячеек таблицы всегда является текущей или активной (рис. 2.17, в). Она отображается указателем в виде утолщенной рамки или прямоугольника с иным цветом фона, а ее адрес указывается в строке ввода и редактирования. Именно в нее вводят информацию. Для перемещения по ячейкам таблицы вправо по строке используется клавиша <Таb>. Если будет достигнут последний столбец созданной пользователем таблицы, произойдет переход на первый столбец следующей строки.
Размеры строк и столбцов можно изменять. Для этого нужно вести курсор мыши на границе между заглавиями столбцов (строк), нажать левую кнопку мыши и переместить появившийся крестик вместе с линией разграничения столбцов (строк) до нужной позиции.
Совокупность одного или нескольких рабочих листов составляет рабочую книгу Excel. Переход от одного рабочего листа к другому той же рабочей книги осуществляется с помощью линейки прокрутки рабочих листов с 1 —8 лепестками их названий, расположенной в нижней левой полосе экрана. Слева от ярлычков листов находятся кнопки, позволяющие перейти к первому рабочему листу, к последующему, к предыдущему.
Полосы прокрутки внизу и справа рабочей области позволяют перемещать рабочий лист горизонтально и вертикально.
Строка формул, расположенная под строкой меню, высвечивает формулу активизированной ячейки (правая часть строки) и ее адрес (левая часть строки).
Справа от строки меню расположена кнопка, позволяющая уменьшить размер рабочего листа, представив его отдельным окном экрана.
Слева от строки меню расположена селекторная кнопка, позволяющая манипулировать окном рабочей книги: перемещать, изменять размер, свертывать в значок, развертывать, восстанавливать, закрывать окно, переходить к другому окну.
В левом верхнем углу экрана есть аналогичная селекторная кнопка, позволяющая манипулировать окном Excel в целом.
В правом верхнем углу экрана расположены две кнопки, одна из которых сворачивает окно, а вторая переводит рабочий лист в режим отдельного окна.
Как правило, при решении большинства задач на экран вызываются следующие панели инструментов: Стандартная, Форматирование, Мастер подсказок. При вызове каждой панели инструментов на экране появляется соответствующая панель командных кнопок, нажатие которых щелчком мыши инициирует выполнение запрограммированных действий. Кнопки Панели инструментов можно убирать, заменять, вводить новые, используя директорию Настроить Панели инструментов меню Вид.
Стандартная панель инструментов (расположена под строкой меню) позволяет вызывать нужную команду, не обращаясь к меню.
Панель Форматирования (расположена ниже стандартной панели) позволяет изменять оформление рабочего листа. Кнопки на панелях инструментов позволяют быстро вызывать многие функции Excel. Те же самые функции можно вызывать посредством меню.
Указатель мыши, направленный на любую кнопку, высвечивает подсказку о назначении кнопки.
Рабочие ячейки Excel, расположенные на пересечении строк и столбцов рабочего листа, определяют основу работы всей системы Excel. Для обеспечения реализации всего многообразия указанных ранее функций Excel рабочая ячейка Excel имеет сложную информационную структуру, включающую пять взаимосвязанных уровней записи, хранения, обработки и вывода информации.
Для объектов электронной таблицы определены следующие операции редактирования, объединенные в одну группу: удаление, очистка, вставка, копирование (рис. 2.18). Операция перемещения фрагмента сводится к последовательному выполнению операций удаления и вставки. Перед выполнением конкретной операции редактирования необходимо определить объект, над которым выполняется действие. По умолчанию таким объектом является текущая ячейка. Остальные объекты должны быть выбраны (выделены) с помощью мыши или клавиатуры.
Обычно при выполнении операций копирования фрагментов фрагменту-копии передаются все свойства соответствующих ячеек фрагмента-оригинала, но возможна передача только содержания, значения или формата.
В качестве содержания ячейки выступают числовые и текстовые константы, а также выражения (формулы).
В качестве значения ячейки рассматриваются выводимые на экран представления числовых и текстовых констант, а также результатов вычисления выражений (формул).
Под выражением понимается совокупность операндов, соединенных знаками операций. В качестве операндов используются числовые и текстовые константы, адреса ячеек и встроенные функции. При этом числовые и текстовые константы используются непосредственно, вместо адресов ячеек используются значения соответствующих клеток таблицы, а вместо встроенных функций — возвращаемые ими значения.
Адреса ячеек в роли операндов и аргументов встроенных функций выступают в двух формах: относительной и абсолютной. Относительный адрес указывает на положение адресуемой ячейки относительно той ячейки, в содержании которой он используется и записывается как обычно (имя столбца и номер строки, например «F7»). Абсолютный адрес указывает на точное положение адресуемой ячейки в таблице и записывается со знаком «$» перед именем столбца и номером строки (например, «$F$7»). Возможна абсолютная адресация только столбца или строки («$F7» или «F$7»). При редактировании объектов таблицы относительные адреса соответствующим образом корректируются, а абсолютные адреса не изменяются.
Шаблоны таблиц. Создав таблицу и выполнив в ней все необходимые процедуры форматирования, можно построить для нее типовые диаграммы, если они будут в дальнейшем использоваться. Для этого из меню Файл вызывают директиву сохранить как. ... В открывшемся диалоговом окне указывают имя типового документа и выбирают директорию, где он будет храниться. Затем щелкают по стрелке в поле Тип файла и в открывшемся списке выбирают элемент Шаблон. Для окончания процедуры закрывают окно щелчком по командной кнопке Сохранить.
Документ получает присваиваемое шаблонам расширение .XLT. В дальнейшем его можно загружать как любой другой файл. В этом случае открывается не сам шаблон, а его копия, что позволяет многократно использовать исходный шаблон при построении других таблиц.
Для модификации шаблона из меню Файл вызывают директиву открыть. После выбора шаблона нажимают клавишу <shift> и «щелкают» по кнопке Открыть. После редактирования шаблон сохраняют обычным образом.
Если необходимо поменять имя листа, то это можно достичь двойным щелчком по корешку листа или в следующей последовательности через меню Формат\Лист\Переименовать. В формулах в открытых книгах, ссылающихся на переименовываемый лист, имя меняется автоматически.
Добавить новый лист можно, щелкнув правой кнопкой мыши по корешку листа и выбрав команду Добавить. При этом появится запрос типа создаваемого листа (лист с таблицей, диаграмма, диалоговое окно, лист макросов или шаблон). Другой вариант — через меню Вставка\Лист, но при этом не появляются запросы, а сразу создается лист с таблицей перед текущим листом.
Табличные вычисления. Важным свойством программы является возможность использования формул и функций. Чтобы процессор мог отличить формулу от текста, ввод формулы в ячейку таблицы начинается со знака равенства (=). После этого знака в ячейку записывается математическое выражение, содержащее аргументы, арифметические операции и функции. В формуле можно использовать числовые и текстовые константы (последние в двойных кавычках), ссылки на ячейки (диапазоны), имена диапазонов и полей, функции и простые арифметические Действия.
В качества аргументов в формуле обычно используют числа и адреса ячеек. Для обозначения арифметических операций можно применять символы: «+» — сложение, «—» — вычитание, «*»— умножение, «/» — деление, «^» — возведение в степень.
Формула может содержать ссылки на ячейки таблицы, расположенные в том числе на другом рабочем листе или в таблице другого файла. Для ссылки на другие листы и книги используются так называемые трехмерные ссылки. Они отличаются от обычных наличием имени книги (в квадратных скобках) и листа, заканчивающегося восклицательным знаком. Например, формула = [otdel. xls]Заказы!Н7 ссылается на ячейку Н7 на листе Заказы в книге Otdel. Для создания такой ссылки можно через меню Окно выбрать исходную (открытую) книгу, затем выбрать лист и щелкнуть по ячейке левой кнопкой мыши.
Однажды введенную формулу можно модифицировать в любое время. Встроенный Менеджер формул помогает найти ошибку или неправильную ссылку в таблице.
Изменения в исходных данных влияют на результат в конечных данных. Табличный процессор автоматически пересчитывает результаты формул, но можно использовать и принудительную команду с помощью клавиши <F9>.
Процессор позволяет работать со сложными формулами, содержащими несколько операций. Для наглядности можно включить текстовый режим, тогда в ячейку будет введен не результат вычисления формулы, а собственно формула.
Мастер функций. Используемые для табличных вычислений формулы и их
комбинации часто повторяются. Процессор предлагает более 200
запрограммированных формул, называемых функциями. Для удобства ориентирования в
них функции разделены по категориям. Встроенный Мастер функций помогает
правильно применять функции на всех этапах работы и позволяет за два шага
строить и вычислять большинство функций. Функции вызываются из списка через
меню Вставка\Функция
или нажатием кнопки ![]() на стандартной панели инструментов. Для выбора
аргументов функции (на втором шаге мастера) используется кнопка, присутствующая
справа от каждого поля ввода. Вернуться в исходное состояние (после выбора
аргументов) можно клавишей <Enter> или кнопкой.
на стандартной панели инструментов. Для выбора
аргументов функции (на втором шаге мастера) используется кнопка, присутствующая
справа от каждого поля ввода. Вернуться в исходное состояние (после выбора
аргументов) можно клавишей <Enter> или кнопкой.
Для конструирования функций предварительно маркируют ячейку, в которой должен появиться результат вычислений. Затем щелчком по пиктограмме Мастера функций со значком «fх» открывают диалоговое окно Мастера. . . (рис. 2.19).
В окне Выберите функцию перечислены предлагаемые Мастером. . . функции, ниже — краткое описание активизированной пользователем функции. Если мышью нажать на кнопку ок, то появится специальное окно Аргументы функции, в которое вводят необходимые значения и нажимают кнопку ок.
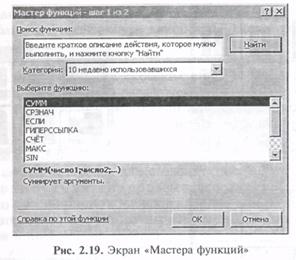
Мастер диаграмм. Табличные процессоры предлагают различные виды иллюстраций деловой графики (диаграмм), причем их построение облегчено за счет использования Мастера диаграмм — встроенных автоматизированных пошаговых процедур, позволяющих выбрать тип диаграммы и для него выполнить все необходимые операции, в том числе оформления различными компонентами.
Гистограмма показывает изменение данных за определенный период времени и иллюстрирует соотношение отдельных их значений. Категории располагаются по горизонтали, а значения — по вертикали. Ориентирована на изменения во времени. Гистограмма с накоплением демонстрирует вклад отдельных элементов в общую сумму (рис. 2.20, а).
Линейчатая диаграмма отражает соотношение отдельных компонентов. Категории расположены по горизонтали, а значения — по вертикали. Ориентирована на сопоставление значений и меньшее — изменения во времени. Линейчатая диаграмма с накоплением показывает вклад отдельных элементов в общую сумму (рис. 2.20, б).
График представляет варианты отображения изменений данных за равные промежутки времени (рис. 2.20, в).
Круговая диаграмма отражает как абсолютную величину каждого элемента ряда данных, так и его вклад в общую сумму. На круговой диаграмме может быть представлен только один ряд данных. Такую диаграмму рекомендуется использовать, когда необходимо подчеркнуть какой-либо значительный элемент (рис. 2.20, г).

Точечная диаграмма показывает взаимосвязь между числовыми значениями в нескольких рядах и представляет две группы чисел в виде одного ряда точек в координатах х и у. Она отображает нечетные интервалы (или кластеры) данных и часто используется для представления данных научного характера. При подготовке данных следует расположить в одной строке или столбце все значения переменной х, а соответствующие значения у — в смежных строках или столбцах (рис. 2.20, д).
Поверхностная диаграмма используется для поиска наилучшего сочетания двух наборов данных. Как на топографической карте, области с одним значением выделяются одинаковым узором и цветом (рис. 2.20, е).
Кроме этого, в инструментарии предусмотрены следующие типы диаграмм.
Диаграмма с областями подчеркивает величину изменения в течение определенного периода времени, показывая сумму введенных значений, а также вклад отдельных значений в общую сумму.
Кольцевая диаграмма, как и круговая диаграмма, показывает вклад каждого элемента в общую сумму, но в отличие от круговой диаграммы может содержать несколько рядов данных. Каждое кольцо в кольцевой диаграмме представляет отдельный ряд данных.
Лепестковая диаграмма. Здесь каждая категория имеет собственную ось координат, исходящую из начала координат. Линиями соединяются все значения из определенной серии. Лепестковая диаграмма позволяет сравнить общие значения из нескольких наборов данных.
Пузырьковая диаграмма является разновидностью точечной диаграммы. Размер маркера данных указывает значение третьей переменной. При подготовке данных в одной строке или столбце располагают все значения переменной х, а соответствующие значения у — в смежных строках или столбцах.
Биржевая диаграмма часто используется для демонстрации цен на акции. Этот тип диаграммы применяют для отображения научных данных, например изменения температуры. Для построения этой и других биржевых диаграмм необходимо правильно организовать данные.
Информационные связи. В табличном процессоре можно ввести ссылки на ячейки, расположенные в другой таблице. После установления ссылки значения, находящиеся в ячейках, будут автоматически обновляться. Для обращения к значению ячейки, расположенной на другом рабочем листе, указывают имя этого листа вместе с адресом соответствующей ячейки. Например, для обращения к ячейке F7 на рабочем листе Akt3 вводится формула =Akt3!A7. Если в названии листа есть пробелы, то название заключается в кавычки. Адреса ячеек указывают латинскими буквами. Информационное связывание двух ячеек можно упростить, если скопировать значение исходной ячейки в буфер (с помощью клавиш <ctrl+C>) и промаркировать ячейку, в которой должен появиться результат. Затем из меню Правка выполняется директива Специальная вставка. В диалоговом окне этой директивы выбирают вариант вставки и щелкают по кнопке ок.
Обмен данными. Функция обмена данными позволяет пользователю процессора импортировать в свои таблицы объекты из других прикладных программ и передавать (экспортировать) собственные таблицы для встраивания их в другие объекты.
Концепция обмена данными является одной из основных в среде Windows. Редактор «Excel» поддерживает стандарт обмена данными OLE 2.0 (Object Linking and Embedding).
Между объектами, обрабатываемыми различными прикладными программами, создаются информационные связи, например между таблицами и текстами (рис. 2.21). Эти информационные связи реализованы динамически, например, копия таблицы, встроенная в текст, будет обновляться (актуализироваться) всякий раз, когда в ее оригинал вносятся изменения.

OpenOffice.org Calc
Редактор электронных таблиц OpenOffice.org Calc позволяет вычислять, анализировать и преобразовывать данные в электронной таблице. Могут быть импортированы и обработаны также таблицы Microsoft Excel (рис. 2.22).
Вычисления. OpenOfficc.org Calc позволяет использовать Функции (включающие статистические, финансовые, банковские операции), которые можно использовать для построения сложных формул обработки данных. Для построения формул предлагается встроенный Мастер функций.
Динамические вычисления. Система предоставляет возможность немедленно увидеть, каким образом меняются результаты вычислений, подверженные влиянию множества факторов, при Условии изменения одного из этих факторов. Предусмотрена возможность построения обширных таблиц, отражающих изменения переменных в различных сценариях.
Функции базы данных. Предусмотрены возможности хранения, фильтрации и сортировки данных в таблицах, а также импорт содержания таблиц из внешних баз данных.
Организация данных. При работе с таблицами можно легко срыть или показать данные, отвечающие определенным критериям, а также форматировать данные и определять итоговые суммы и подсуммы при сортировке строк.
Динамические диаграммы. OpenOffice.org Calc позволяет представлять данные из таблиц в форме разнотипных диаграмм которые автоматически обновляются при изменении данных.
Открытие и сохранение файлов Microsoft. OpenOffice.org Calc позволяет конвертировать файлы Excel (см. рис. 2.21), а также открывать и сохранять их во множестве различных иных форматов.
Список наиболее часто используемых комбинаций клавиш в OpenOffice.org (что относится как к OpenOffice.org Calc, так и к OpenOffice.org Writer) приводится в табл. 2.3.
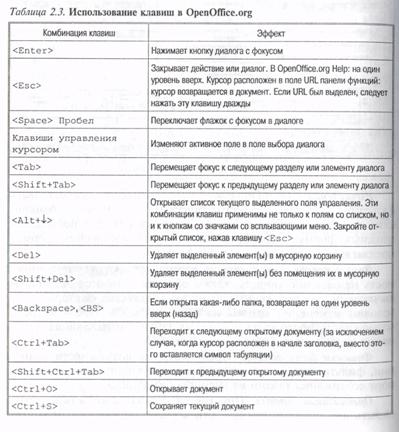
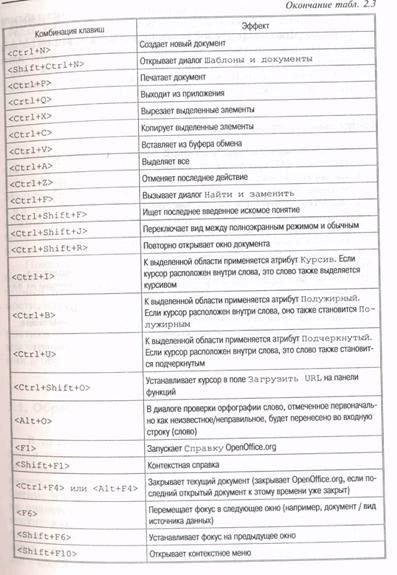
В заключение заметим, что программы электронных таблиц могут успешно использоваться не только для расчетных задач, но и при математическом моделировании и оптимизации, в частности, для решения задач линейного программирования или решения дифференциальных уравнений путем построения динамических имитационных моделей «зацикливанием» функциональных связей между зависимыми переменными.
Контрольные вопросы
1. В чем отличие логической и макетной структур документов?
2. Приведите примеры разметки текстов.
3. Какова структура документа в SGML?
4. Что такое DTD?
5. Что такое логические и физические стили?
6. Охарактеризуйте возможности и назначение языка XML.
7. Перечислите основные синтаксические единицы XML.
8. Назовите основные компоненты семейства XML-технологии.
9. Перечислите функции текстовых редакторов.
10. Охарактеризуйте возможности интерфейса текстового редактора.
11. Перечислите параметры документа в целом и опишите методы их задания.
12. Какова структура рабочего листа табличного процессора?
13. Охарактеризуйте возможности интерфейса табличного процессора.
14. Опишите возможности Мастера функций.
15. Перечислите основные типы диаграмм.