ИНФОРМАЦИОННЫЕ КРОСС-ТЕХНОЛОГИИ
К данному классу отнесены технологии пользователя, ориентированные на следующие (или аналогичные) виды преобразования информации:
• распознавания символов;
• звук—текст;
• текст—звук;
• автоматический перевод.
4.1. Оптическое распознавание символов (OCR)
Когда страница текста отсканирована в ПК, она представлена в виде состоящего из пикселей растрового изображения. Такой формат не воспринимается компьютером как текст, а как изображение текста и текстовые редакторы не способны к обработке подобных изображений. Чтобы превратить группы пикселей в доступные для редактирования символы и слова, изображение должно пройти сложный процесс, известный как оптическое распознавание символов (optical character recognition — OCR).
В то время как переход от символьной информации к графической (растровой) достаточно элементарен и без труда осуществляется, например при выводе текста на экран или печать, обратный переход (от печатного текста к текстовому файлу в машинном коде) весьма затруднителен. Именно в связи с этим для ввода информации в ЭВМ исстари использовались перфоленты, перфокарты и др. промежуточные носители, а не исходные «бумажные» документы, что было бы гораздо удобнее. «В защиту» перфокарт скажем здесь, что наиболее «продвинутые» устройства перфорации делали надпечатку на карте для проверки ее содержания.
Первые шаги в области оптического распознавания символов были предприняты в конце 50-х гг. XX в. Принципы распознавания, заложенные в то время, используются в большинстве систем OCR: сравнить изображение с имеющимися эталонами и выбрать наиболее подходящий.
В середине 70-х гг. была предложена технология для ввода информации в ЭВМ, заключающаяся в следующем:
• исходный документ печатается на бланке с помощью пишущей машинки, оборудованной стилизованным шрифтом (каждый символ комбинируется из ограниченного числа вертикальных, горизонтальных, наклонных черточек, подобно тому, как это делаем мы и сейчас, нанося на почтовый конверт цифры индекса);
• полученный «машинный документ» считывается оптоэлектрическим устройством (собственно OCR), которое кодирует каждый символ и определяет его позицию на листе;
• информация переносится в память ЭВМ, образуя электронный образ документа или документ во внутреннем представлении.
Очевидно, что по сравнению с перфолентами (перфокартами) OCR-документ лучше хотя бы тем, что он без особого труда может быть прочитан и проверен человеком и, вообще, представляет собой «твердую копию» соответствующего введенного документа. Было разработано несколько модификаций подобных шрифтов, разной степени «удобочитаемости» (OCR A, OCR В и пр., рис. 4.1).

Очевидно также, что считывающее устройство представляет собой сканер, хотя и специализированный (считывание стилизованных символов), но интеллектуальный (распознавание их).
OCR-технология в данном виде просуществовала недолго и в настоящее время приобрела следующий вид:
• считывание исходного документа осуществляется универсальным сканером, осуществляющим создание растрового образа и запись его в оперативную память и/или в файл;
• функции распознавания полностью возлагаются на программные продукты, которые, естественно, получили название OCR-software.
Исследования в этом направлении начались в конце 1950-х гг., и с тех пор технологии непрерывно совершенствовались. В 1970-х гг. и в начале 1980-х гг. программное обеспечение оптического распознавания символов все еще обладало очень ограниченными возможностями и могло работать только с некоторыми типами и размерами шрифтов. В настоящее время программное обеспечение оптического распознавания символов намного более интеллектуально и может распознать фактически все шрифты, даже при невысоком качестве изображения документа.
Основные методы оптического распознавания
Один из самых ранних методов оптического распознавания символов базировался на сопоставлении матриц или сравнении с образцом букв. Большинство шрифтов имеют формат Times, Courier или Helvetica и размер от 10 до 14 пунктов (точек). Программы оптического распознавания символов, которые используют метод сопоставления с образцом, имеют точечные рисунки для каждого символа каждого размера и шрифта (рис. 4.2, а). Сравнивая базу данных точечных рисунков с рисунками отсканированных символов, программа пытается их распознавать. Эта ранняя система успешно работала только с непропорциональными шрифтами (подобно Courier), где символы в тексте хорошо отделены друг от друга. Сложные документы с различными шрифтами оказываются уже вне возможностей таких программ.

Выделение признаков было следующим шагом в развитии оптического распознавания символов. При этом распознавание символов основывается на идентификации их универсальных особенностей, чтобы сделать распознавание символов независимым от шрифтов. Если бы все символы могли быть идентифицированы, используя правила, по которым элементы букв (например, окружности и линии) присоединяются друг к другу, то индивидуальные символы могли быть описаны независимо от их шрифта. Например: символ «а» может быть представлен как состоящий из окружности в центре снизу, прямой линии справа и дуги окружности сверху в центре (рис. 4.2, б). Если отсканированный символ имеет эти особенности, он может быть правильно идентифицирован как символ «а» программой оптического распознавания.
Выделение признаков было шагом вперед сравнительно с соответствием матриц, но практические результаты оказались весьма чувствительными к качеству печати. Дополнительные пометки на странице или пятна на бумаге существенно снижали точность обработки. Устранение такого «шума» само по себе стало целой областью исследований, пытающейся определить, какие биты печати не являются частью индивидуальных символов. Если шум идентифицирован, достоверные символьные фрагменты могут тогда быть объединены в наиболее вероятные формы символа.
Некоторые программы сначала используют сопоставление с образцом и/или метод выделения признаков для того, чтобы распознать столько символов, сколько возможно, а затем уточняют результат, используя грамматическую проверку правильности написания для восстановления нераспознанных символов. Например, если программа оптического распознавания символов неспособна распознать символ «е» в слове «th~ir», программа проверки грамматики может решить, что отсутствующий символ — «е».
Современные технологии оптического распознавания намного совершеннее, чем более ранние методы. Вместо того чтобы только идентифицировать индивидуальные символы, современные методы способны идентифицировать целые слова. Эту технологию, предложенную Caere, называют прогнозирующим оптическим распознаванием слов (Predictive Optical Word Recognition — POWR).
Используя более высокие уровни контекстного анализа, метод POWR способен устранить проблемы, вызванные шумом. Компьютер анализирует тысячи или миллионы различных способов, которыми точки изображения могут быть собраны в символы слова. Каждой возможной интерпретации приписывается некоторая вероятность, после чего используются нейронные сети и прогнозирующие методы моделирования, заимствованные от исследований в области искусственного интеллекта. Они предполагают использование «экспертов» — алгоритмов, разработанных специалистами в различных областях распознавания символов. Один «эксперт» может знать многое о начертаниях шрифта, другой — о словарной информации, третий — об ухудшении качества от «зашумленности» и пр. На каждой стадии исследования привлекается новый набор «экспертов» с учетом близости их «областей знаний» к специфической ситуации и статистики успеха в подобных ситуациях.
Окончательный итог — то, что система POWR способна идентифицировать слова способом, который близко напоминает человеческое визуальное распознавание. Практически, методика значительно улучшает точность распознавания слов во всех типах документа. Все возможные интерпретации слова оцениваются, комбинируя все источники доказательства, от информации пикселя нижнего уровня до контекстных особенностей высокого уровня, в результате чего выбирается самая вероятная интерпретация.
Технологии Finereader
Хотя системы оптического распознавания символов существовали в течение долгого времени, их выгоды только сейчас начали по достоинству оценивать. Первые разработки были чрезвычайно дорогостоящими (в терминах программного обеспечения и оборудования), неточны и трудны для использования. За несколько последних лет системы оптического распознавания полностью преобразились. Современное программное обеспечение распознавания символов очень удобно в использовании, обладает высокой точностью и находится на пути к распространению на все виды рабочих сред в массовом масштабе.
Типичным представителем данного семейства программ является ABBYY FineReader, технологический процесс которого включает следующие шаги (рис. 4.3):
• сканирование исходного документа (страницы);
• разметку областей (ручную или автоматическую), требующих различные виды обработки (страницы разворота книги, таблицы, рисунки, колонки текста и пр.);
• распознавание — создание и вывод на экран текстового файла (с вставленными рисунками и таблицами, если это необходимо);
• контроль правильности (ручной, автоматический, полуавтоматический);
• вывод информации в выходной файл в заданном формате (.DOC или .RTF для Word, .XSL для Excel и пр.).
Данные, полученные на каждом этапе (изображение, текстовый файл), сохраняются под «общей вывеской» пакета (страницы с номером), что позволяет в любой момент вернуться и повторить разметку, распознавание и пр.

Если нет необходимости сохранять цветовую информацию оригинала документа (например, для последующей обработки системами оптического распознавания символов), изображение лучше всего сканировать в режиме grayscale (полутоновое изображение). При этом файл будет занимать одну треть объема сравнительно со сканированием в цвете RGB. Можно использовать также режим штриховой графики (line art), однако при этом часто теряются подробности, существенные для точности последующего процесса распознавания символов.
Рассмотрим основные принципы функционирования программного продукта.
Принципы IPA (целостности, целенаправленности, адаптивности). Пользователь помещает документ в сканер, нажимает кнопку, и через небольшое время в компьютер поступает электронное изображение, «фотография» страницы. На ней присутствуют все особенности оригинала, вплоть до мельчайших подробностей. Это изображение содержит всю необходимую для OCR-системы информацию об исходном документе.
Принцип целостности (integrity), согласно которому объект рассматривается как целое, состоящее из связанных частей. Связь частей выражается в пространственных отношениях между ними, и сами части получают толкование только в составе предполагаемого целого, т. е. в рамках гипотезы об объекте.
Принцип целенаправленности (purposefulness): любая интерпретация данных преследует определенную цель. Согласно этому принципу, распознавание представляет собой процесс выдвижения гипотез о целом объекте и целенаправленной их проверки.
Принцип адаптивности (adaptability) подразумевает способность системы к самообучению. Полученная при распознавании информация упорядочивается, сохраняется и используется впоследствии при решении аналогичных задач. Преимущество самообучающихся систем заключается в способности «спрямлять» путь логических рассуждений, опираясь на ранее накопленные знания.
Вместо полных названий этих принципов часто употребляют аббревиатуру IPA, составленную из первых букв соответствующих английских слов. Преимущества системы распознавания, работающей в соответствии с принципами IРА, очевидны — именно они способны обеспечить максимально гибкое и осмысленное поведение системы.
Например, на этапе распознавания символов изображение, согласно принципу целостности, будет интерпретировано как некий объект, только если на нем присутствуют все структурные части этого объекта, и эти части находятся в соответствующих отношениях. Иначе говоря, FineReader не пытается принимать решение, перебирая тысячи эталонов в поисках наиболее подходящего. Вместо этого выдвигается ряд гипотез относительно того, на что похоже обнаруженное изображение, затем каждая гипотеза целенаправленно проверяется. Допуская, что найденный объект может быть буквой «A», FineReader будет искать именно те особенности, которые должны быть у изображения этой буквы. Как и следует поступать, исходя из принципа целенаправленности. Причем проверять, верна ли выдвинутая гипотеза, система будет, опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
Многоуровневый анализ документа (MDA)
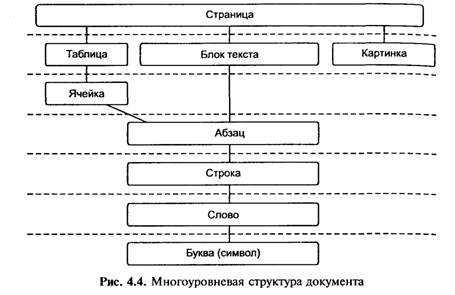
Подлежащий распознаванию документ часто выглядит заметно сложнее, чем белая страница с черным текстом. Иллюстрации, таблицы, колонтитулы, фоновые изображения — эти элементы, все чаще применяемые для оформления, усложняют структуру страницы. Для того чтобы корректно воспроизводить в электронном виде такие документы, все современные OCR-программы начинают распознавание именно с анализа структуры. Как правило, при этом выделяют несколько иерархически организованных логических уровней. Объект наивысшего Уровня только один — собственно страница, на следующей ступени иерархии располагаются таблица и текстовый блок, и так далее (рис. 4.4).
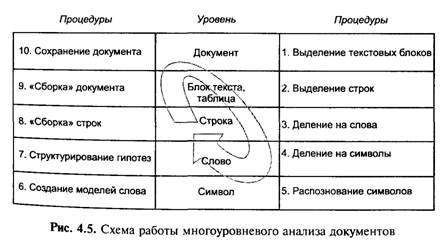
Любой высокоуровневый объект может быть представлен как объектов более низкого уровня: буквы образуют слово, слова — строки и т. д. Поэтому анализ всегда начинается в направлении сверху вниз. Программа делит страницу на объекты, их, в свою очередь, — на объекты низших уровней, и так далее, вплоть до символов. Когда символы выделены и распознаны, начинается обратный процесс — «сборка» объектов высших уровней, который завершается формированием целой страницы. Такая процедура называется многоуровневым анализом документа, или MDA (multilevel document analysis).
Очевидно, что программа, допустившая ошибку при распознавании объекта высокого уровня (например, перепутавшая абзац текста с иллюстрацией), почти не имеет шансов корректно завершить процедуру — итоговый электронный документ будет искажен. Риск столкнуться с подобной ситуацией существовал бы и для FineReader, однако он ведет анализ документа несколько иначе.
Во-первых, объекты любого уровня FineReader распознает в соответствии с принципами IPА. В первую очередь выдвигаются гипотезы относительно типов обнаруженных объектов, затем они целенаправленно проверяются. При этом система учитывает найденные ранее особенности данного документа, а также сохраняет вновь поступающую информацию (обучается).
Допустим, все объекты текущего уровня распознаны. FineReader переходит к детальному анализу одного из них, определенного, к примеру, как текстовый блок. Предположим, вдруг оказывается, что результаты анализа этого блока крайне неубедительны; не удается выделить ни абзацы, ни строки. Повторный анализ позволяет внести коррективы: да, это текст, но наложенный на фоновое изображение. После дополнительной обработки распознавание будет продолжено — и уже без ошибок.
Описанная ситуация наглядно иллюстрирует вторую важную особенность используемого в системе FineReader алгоритма MDA: на всех этапах многоуровневого анализа существует возможность обратной связи — результаты анализа на одном из нижних уровней всегда могут повлиять на действия с объектами более высоких уровней. Наличие обратной связи в процедуре MDA дает возможность резко понизить вероятность грубых ошибок, связанных с неверным распознаванием объектов более высоких уровней.
Распознавание любого документа производится поэтапно, с помощью процедуры многоуровневого анализа документа (MDA). Деление страницы на объекты низших уровней, вплоть до отдельных символов, распознавание этих символов и «сборку» электронного документа FineReader проводит, опираясь на принципы целостности, целенаправленности и адаптивности (IPA) (рис. 4.5).
Распознавание от уровня «страница» до уровня «слово»
На первом этапе распознавания система структурирует страницу, выделяет на ней текстовые блоки. Как мы знаем, современные документы часто содержат всевозможные элементы дизайна: иллюстрации, колонтитулы, цветной фон или фоновые изображения, и т. д. Основная задача на данном этапе состоит в том, чтобы отделить текст от иллюстраций и «подложенных» текстур.
Все современные системы распознавания начинают процесс «знакомства» с создания черно-белого изображения документа. При этом подлежащее анализу изображение чаше всего цветное или полутоновое (т. е. состоящее из разных оттенков серого цвета, подобно картинке на экране черно-белого телевизора). Любая OCR-система прежде всего преобразует такое изображение в монохромное, состоящее только из черных и белых точек. Процесс преобразования называется бинаризацией, он всегда предшествует детальной обработке распознаваемой страницы.
Блок текста, состоящий из строк, должен иметь характерную линейчатую структуру. Разделив этот блок на строки, можем приступать к выделению слов. Однако на практике столь простые варианты встречаются нечасто. Возьмите любой документ, где строки текста наложены на цветной фон, и представьте, как будет выглядеть эта страница в черно-белом варианте. Вокруг каждого символа обнаружатся десятки и сотни «лишних» точек, оставшихся от фона. Работая с таким «загрязненным» текстом, большинство OCR-программ не сможет уверенно распознавать символы, поскольку лишние точки будут искажать очертания букв и даже границы строк, приводя к ошибкам.
FineReader не пытается решать задачу бинаризации «в лоб». Принцип целенаправленности диктует иной подход к обнаружению строк в текстовом блоке или слов в строке: они должны быть где-то здесь, надо только суметь их узнать. Для повышения качества поиска FineReader использует процедуры интеллектуальной фильтрации фоновых текстур (рис. 4.6, о) и адаптивной бинаризации (рис. 4.6, б). Первая позволяет уверенно отделять строки текста от сколь угодно сложного фона, вторая — гибко выбирать оптимальные для данного участка параметры бинаризации. Естественно, к этим процедурам система прибегает не всегда, а лишь в тех случаях, когда предварительный анализ указывает на подобную необходимость. В каждом конкретном случае FineReader выбирает подходящий «инструмент», опираясь на информацию, накопленную в процессе анализа документа.
Например, идет анализ строки. Система занята поиском объектов уровня «слово». На первый взгляд, проще всего разделить строку на слова по найденным пробелам. Однако первичный анализ показывает, что в конце строки пробелы попадаются заметно чаще, чем в начале.

Процедура адаптивной бинаризации исследует яркость фона и насыщенность черного цвета на протяжении всей строки и подбирает оптимальные параметры бинаризации для каждого фрагмента по отдельности. В результате оказывается, что часть символов в конце строки получилась слишком светлой и могла бы быть «потеряна» при обработке обычной OCR-программой, но в результате применения адаптивной бинаризации все слова будут выделены точно. При неправильном выборе параметров бинаризации слово окажется «нечитаемым».
Уровни «слово» и «символ». Распознаватели символов (классификаторы)
Разделив строку на отдельные слова, FineReader приступает к обработке символов. Разделение слов на символы и собственно распознавание букв, как и все остальные механизмы многоуровневого анализа документа, реализованы в виде составных частей единой процедуры. Это позволяет в полной мере использовать преимущества принципов IPA. Выделенные изображения символов поступают на рассмотрение механизмов распознавания букв, называемых классификаторами.
В системе ABBYY FineReader применяются следующие типы классификаторов: растровый, контурный, признаковый, структурный, признаково – дифференциальный и структурно-дифференциальный.
Растровый классификатор. Классификатор сравнивает символ с набором эталонов, поочередно накладывая изображения друг на друга. Эталонами в данном случае выступают специально подготовленные изображения; каждое из них объединяет в себе очертания множества вариантов написания того или иного символа. Гипотезы выдвигаются в зависимости от того, с какими эталонами точнее совпало изображение буквы. Сами эталоны строятся методом наложения друг на друга большого количества одних и тех же букв в разных вариантах начертания (рис. 4.7, а).
Контурный классификатор. Представляет собой разновидность признакового классификатора. От вышеописанного отличается тем, что признаки вычисляются не по полному изображению символа, а по его контуру (рис. 4.7, б). Этот быстродействующий классификатор предназначен для распознавания текста, набранного декоративными шрифтами (например, стилизованного под готический, старорусский стиль и т. п.).
Признаковый классификатор. Аналогичен растровому (выдвигает гипотезы, исходя из степени совпадения параметров символа с эталонными значениями). Оперирует определенными числовыми признаками, такими, например, как длина периметра, количество черных точек в разных областях или вдоль различных направлений и т. п. (рис. 4.7, в). Весьма популярен у разработчиков OCR-систем. В определенных условиях способен работать почти так же быстро, как растровый. Точность работы признакового классификатора во многом зависит от качества признаков, выбранных для каждого символа. Под качеством признаков в данном случае понимается их способность максимально точно, но без избыточной информации охарактеризовать начертание буквы.
Структурный классификатор. Первоначально был создан и использовался для распознавания рукописного текста, однако в последнее время применяется и для обработки печатных документов. Этот классификатор проводит структурный анализ символа, раскладывая последний на элементарные составляющие (отрезки, дуги, окружности, точки) и формируя точную схему анализируемого знака (рис. 4.7, г).
Затем полученная схема (структурное описание буквы) сравнивается с эталоном. Этот классификатор работает медленнее растрового и признакового, но отличается высокой точностью Более того, он способен «мысленно» восстанавливать не пропечатанные или залитые символы.

Признаково-дифференциальный классификатор. Предназначен для различения похожих друг на друга объектов, таких, например, как буква «m» и сочетание «rn». Принципиальное отличие этого классификатора от описанных выше заключается в том что он не анализирует все изображение. Дифференциальный классификатор обращается только к тем частям объекта, где может находиться ключ к правильному ответу. В случае с «m» и «rn» ключом служит наличие и ширина разрыва в месте касания предполагаемых букв. Признаково-дифференциальный классификатор используется во многих системах распознавания символов (рис. 4.7, д).
Структурно-дифференциальный классификатор. Аналогичен структурному; был разработан и первоначально применялся для обработки рукописных текстов. Как и признаково-дифференциальный, этот классификатор решает задачи различения похожих объектов, но работает на порядок точнее (за счет анализа структуры) и способен «узнавать» искаженные знаки (рис. 4.7, е).
В самых общих чертах процесс обработки символа выглядит так: растровый и признаковый классификаторы анализируют изображение и выдвигают несколько гипотез относительно того, какая буква им представлена. Следует заметить, что при выдвижении каждой гипотезе присваивается определенная оценка (так называемый вес гипотезы). В результате работы растрового и признакового классификаторов система получает список гипотез, отсортированный по весу (т. е. по степени уверенности).
Затем, в соответствии с принципами IРА, FineReader приступает к целенаправленной проверке имеющихся гипотез с помощью дифференциального признакового классификатора. В тех случаях, когда требуется различить дна похожих символа (например, «I» и «l»), к анализу подключается дифференциальный структурный классификатор. В самых трудных ситуациях задействуют структурный классификатор. Построив полную схему распознаваемого знака и проанализировав ее на предмет наличия ключевых элементов структуры, этот классификатор изменяет веса гипотез в соответствии с результатами своей работы.
C уровня «символ» до уровня «слово». Структурирование гипотез
На каждом логическом уровне документа выдвигается ряд гипотез. Каждая из них на следующем уровне порождает еще несколько предположений. Поэтому при распознавании букв FineReader оперирует множеством гипотез, учитывающих возможные варианты деления строки на слова, слова на буквы, и т. д. Для быстрого и точного принятия решений система объединяет гипотезы в многоуровневые структуры — модели. Существуют следующие типы моделей слова: словарное слово, несловарное слово (для каждого из поддерживаемых языков распознавания построены соответствующие разновидности), e-mail или URL, цифры с префиксом или суффиксом, регулярное выражение и т. д. В результате структурирования количество подлежащих проверке гипотез сильно сокращается, так что последующая проверка происходит максимально быстро и эффективно.
Рассмотрим процесс структурирования на примере слова «turn» (рис. 4.8). Предположим, при разделении слова на символы было выдвинуто две гипотезы: первая соответствует прочтению «turn», вторая — «turn». Классификаторы, обработав символы, в свою очередь предложили для каждой буквы обоих слов некоторый ряд гипотез. Последние, как мы помним, обычно сортируются по весу. Следующий шаг кажется очевидным — теперь надо выбрать гипотезы с максимальным весом. Однако далеко не всегда наиболее вероятная гипотеза в итоге оказывается истинной. Лучший способ принять правильное решение — перейти на уровень «слово» и путем нескольких проверочных one раций выяснить, какой из вариантов больше остальных похож на правильный.
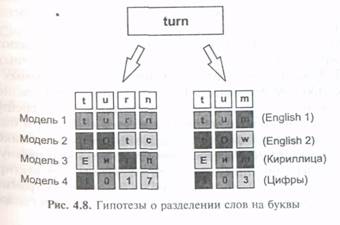
В рассматриваемом примере произойдет следующее: контекстная проверка покажет, что весь текст состоит из английских слов, и вес моделей «слово — английский язык» значительно увеличится, а моделей «слово — кириллица» соответственно уменьшится. Модель «цифры» также останется позади в силу крайне малого суммарного веса составляющих гипотез. Затем словарная проверка подтвердит, что в словаре английского языка слова «turn» нет, a «turn» — есть. Следовательно, гипотеза относительно слова «turn» приобретет еще больший вес, что позволит ей в дальнейшем оказаться «победителем». Заметим, что «авторитет» словаря значительно выше, нежели у любого классификатора, поэтому в данном примере даже при полностью слившихся буквах г и п итоговое решение будет принято правильно.
С уровня «строка» до уровня «страница». Формирование электронного документа
Итак, все слова текстового блока распознаны. Пользуясь информацией, полученной при анализе структуры документа, ABBYY FineReader расставляет слова по местам. Из образующихся при этом строк формируются текстовые блоки, размещаемые на странице в точном соответствии с оригиналом. Когда формирование документа завершено, система обращается к пользователю за подтверждением — правильно ли распознана страница (рис. 4.9)?
Никакое программное обеспечение оптического распознавания символов никогда не распознает 100 % сканированных символов. В большинстве случаев количество допускаемых FineReader ошибок не превышает 1—3 на страницу при среднем качестве оригинального документа. Исправить пару специально подсвеченных ошибок, конечно, существенно проще и быстрее, чем перепечатывать и форматировать весь документ целиком.
В результате пользователь получает точную электронную копию страницы; при необходимости ее можно отредактировать либо сохранить «как есть». Специальный модуль программы может экспортировать результат практически в любой из современных форматов электронных документов. Для сохранения текста удобен формат Microsoft Word, а если исходный документ представлял собой таблицу, то вполне резонно сохранить электронную копию в формате Microsoft Excel. Если же статью предполагается опубликовать в сети Интернет, можно использовать формат HTML или PDF.

4.2. Системы распознавания речи
Теоретически машинное распознавание речи, т. е. ее автоматическое представление в виде текста, является крайней степенью сжатия речевого сигнала,
Процесс распознавания речи (STT — speech-to-text) в последние годы сделал гигантский скачок вперед. В наибольшей мере его стимулирует отнюдь не желание разработчиков создать
пользовательские суперудобства, а существование специфических областей компьютеризации, где голосовые команды являются более приемлемым или даже единственно возможным решением. К ним относятся телефонный доступ к автоматическим справочным системам, управление удаленным компьютером или мобильным портативным устройством, осуществляемое во время движения.
Принципы распознавания речи
Системы распознавания речи обычно состоят из двух компонент, которые могут быть выделены в блоки или в подпрограммы — акустической и лингвистической. Лингвистическая часть может включать в себя фонетическую, фонологическую, морфологическую, синтаксическую и семантическую модели языка. Акустическая модель отвечает за представление речевого сигнала. Лингвистическая модель интерпретирует информацию, получаемую от акустической модели, и отвечает за представление результата распознавания потребителю.
Акустическая модель. Существуют два подхода к построению акустической модели: изобретательский и бионический. Оба подхода имеют свои достоинства и недостатки. Первый базируется на результатах поиска механизма функционирования акустической модели. При втором подходе разработчик пытается понять и смоделировать работу естественных систем.
Лингвистическая модель. Лингвистический блок подразделяется на следующие слои (уровни); фонетический, фонологический, морфологический, лексический, синтаксический, семантический. Все уровни содержат априорную информацию о структуре естественного языка, а, как известно, любая априорная информация об интересующем предмете увеличивает шансы принятия верного решения. Поскольку естественный язык несет весьма сильно структурированную информацию, для каждого естественного языка может потребоваться своя уникальная лингвистическая модель (отсюда трудности русификации сложных систем распознавания речи зарубежной разработки).
В соответствии с данной моделью на первом (фонетическом) уровне производится преобразование входного (для лингвистического блока) представления речи в последовательность фонем, как наименьших единиц языка. Считается, что в реальном речевом сигнале можно обнаружить лишь аллофоны — варианты фонем, зависящие от звукового окружения.
На следующем (фонологическом) уровне накладываются ограничения на комбинаторику фонем (аллофонов) — не все сочетания фонем (аллофонов) встречаются, а те, что встречаются, имеют различную вероятность появления, зависящую еще и от окружения. Для описания этой ситуации используется математический аппарат цепей Маркова.
Далее, на морфологическом уровне оперируют со слогопо-добными единицами речи более высокого уровня, чем фонема. Иногда они называются морфемами. Они накладывают ограничение уже на структуру слова, подчиняясь закономерностям моделируемого естественного языка.
Лексический уровень охватывает слова и словоформы того или иного естественного языка, т. е. словарь языка, также внося важную априорную информацию о том, какие слова возможны для данного естественного языка. Семантика устанавливает соотношения между объектами действительности и словами, их обозначающими. Она является высшим уровнем языка. При помощи семантических отношений интеллект человека производит как бы сжатие речевого сообщения в систему образов, понятий, представляющих суть речевого сообщения.
Российская компания «ИстраСофт» известна пакетом для обучения английскому языку с визуальным контролем произношения «Профессор Хиггинс». Развивая «Хиггинса», сотрудники «ИстраСофт» совершили технологический прорыв, значение которого трудно переоценить: они научились членить слова на элементарные сегменты, соответствующие звукам речи, независимо от диктора и от языка (Существующие системы распознавания Речи не производят сегментации, наименьшей единицей для них является слово.) Демонстрация новой технологии выглядит пока не очень эффектно: это всего-навсего упаковка и распаковка звуковых файлов с записью речи — правда, с высокими коэффициентами сжатия. Если файл был сжат сильно, то после распаковки в нем появляются отчетливо слышные границы между сегментами; использованию программы по прямому назначению они, конечно, мешают, но специалисту позволяют убедиться в правильности членения.
В соответствии с этим решение задачи речевых технологий можно представить в виде схемы рис. 4.10.
В основе алгоритма лежит выделение фонем из потока слитной речи в режиме реального времени, их кодирование и последующее восстановление, однако у разработчиков нет единого мнения о том, что считать фонемой при машинной обработке речи. Способ, предложенный фирмой «ИстраСофт», допускает сжатие речи в 200 раз, причем при сжатии менее чем в 40 раз качество сигнала практически не падает.
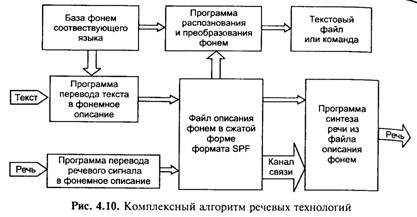
Чтобы создать основанную на новой технологии систему распознавания, необходимо «привязать» сегментацию к конкретному языку с помощью двух словарей — «звукового», сопоставляющего реальным звукам речи определенные фонемы, т. е. смыслоразличительные единицы (на слух мы, как правило, воспринимаем именно фонемы родного языка, не замечая различий между их вариантами, обусловленными, например, позицией), и «фонетико-орфографического», который будет переводить фонемную запись в письменную. Принципиально ничего сложного здесь нет: это вполне рутинная, умеренно трудоемкая техническая задача.
Интеллектуальная обработка речи на уровне фонем перспективна не только как способ сжатия, но и как шаг на пути к созданию нового поколения систем распознавания речи.
Практическая реализация. Многие научные центры, в том числе и в нашей стране, брались за решение этой проблемы (фундаментальные исследования теории языка, которые велись в 1970-х гг. в СССР, легли в основу многих современных продуктов), но первый серьезный прорыв в области речевых технологий удалось сделать только в 1986 г. в Defense Advanced Research Project Agency (DARPA) — Агентстве перспективных исследований Министерства обороны США.
Успех связан с тем, что ученые решили уменьшить число фонетических структур, предлагаемых распознающему устройству. Для реализации этой задачи они применили так называемую крытую марковскую модель» (Hidden Markov Model — НММ), основанную на свойстве марковской цепи генерировать последовательность определенных детерминированных символов при переходах между некоторыми состояниями вероятностного характера (в марковском процессе параметры системы зависят только от предыдущего состояния и «не помнят» более глубокой предыстории) Имея последовательность символов, сгенерированную марковской моделью, можно однозначно восстановить породившую ее последовательность состояний, но лишь только при том условии что каждый символ соответствует одному состоянию.
В процессе цифровой обработки речевой сигнал подвергается сначала логарифмическому, а затем обратному преобразованию Фурье, в результате чего отыскивается с десяток первых коэффициентов, несущих наиболее существенную информацию об огибающей спектральной характеристики сигнала. Собственно, современные развитые коммерческие программы распознавания речи и отличаются именно способом реализации механизма выбора из встроенной (или созданной пользователем) базы данных наиболее вероятного набора фонем (минимально значимых элементов, из которых состоит слово).
На первом этапе компьютер записывает звук речи в виде цифровой аудиопоследовательности и делит ее на фрагменты длительностью несколько миллисекунд. Программа сравнивает эти аудиофрагменты с записанными в память речевыми образцами. Качество базы данных образцов является наиболее важным условием для безошибочного распознавания речи. Она содержит фрагменты речи различных людей с разными особенностями произношения, такими, как снижение звука, диалект, выделение слогов и произношение. Эта часть системы распознавания речи называется системой, не зависящей от говорящего.
Систему, не зависящую от говорящего, дополняет систем распознавания говорящего. В основе последней лежит понятие фонемы — наименьшей акустической единицы языка. В процессе тренировки программное обеспечение распознает наиболее важные признаки произношения пользователем фонем и записывает полученные данные в виде профиля говорящего. Очень важно, чтобы в дальнейшем во время диктовки пользователь по возможности точно выдерживал мелодию реи и произношение.
В системе распознавания говорящего при определении «сомнительных слов» используется тот факт, что после определенного слова могут следовать (и имеют при этом смысл) лишь не многие конкретные слова. Владельцам мобильных телефонов этот способ знаком по SMS-сообщениям, при наборе которых нужное слово предлагается автоматически.
Классификация систем распознавания речи.
Классификация по назначению:
• командные системы;
• системы диктовки текста.
По потребительским качествам:
• диктороориентированные (тренируемые на конкретного диктора);
• дикторонезависимые;
• распознающие отдельные слова;
• распознающие слитную речь.
По механизмам функционирования:
• простейшие (корреляционные) детекторы;
• экспертные системы с различным способом формирования и обработки базы знаний;
• вероятностно-сетевые модели принятия решения, в том числе нейронные сети.
Разумеется, относительно проще реализовать программу, способную распознавать только ограниченный, совсем небольшой набор управляющих команд и символов. Это, например, могут быть цифры от 0 до 9, слова «да», «нет», односложные команды типа «открыть», «закрыть», «выйти» и т. п. Такие программы появились первыми и уже давно применяются в компьютерной телефонии для голосового набора телефонного номера или выбора пункта меню. Если в словарь добавить названия букв алфавита, то, в принципе, по буквам можно продиктовать и любое слово или название — например, при заказе билета таким путем можно ввести станцию назначения.
Подобные системы могут похвастаться тем, что распознавание происходит без предварительной настройки под конкретного пользователя, т. е. они независимы от диктора (speaker-independent). Применение их для получения автоматической справки и генерации запросов к базам данных позволяет компаниям высвободить большое количество сотрудников, обеспечить круглосуточный доступ к информации, причем зачастую появляется возможность дополнительно расширить сферу предоставляемых услуг.
Помимо этого, системы с распознаванием ограниченного набора слов могут применяться и для голосового управления компьютером, а через него и другой техникой. Можно предусмотреть и добавление в базу данных индивидуальных макросов пользователя. При ограниченном словаре также легче реализовать систему распознавания слитной речи, характеризующейся отсутствием специальных пауз между словами.
Точность распознавания, как правило, повышается при предварительной настройке на голос конкретного пользователя, причем этим способом можно добиться распознавания даже тогда когда говорящий имеет дефект речи или акцент. Все бы хорошо, но длительное только в том случае, если предполагается индивидуальное применение ПО одним пользователем, в крайнем случае — небольшой группой пользователей, для каждого из которых создается свой индивидуальный «профиль».
Программы для диктовки текстов (еще одно очевидное применение функции распознавания речи) первоначально могли понимать только так называемую «раздельную» речь, в которой после каждого произнесенного слова требовалось сделать небольшую паузу. Такая манера говорить неестественна — в процессе обычного человеческого разговора интенсивность звука практически никогда не падает до нуля (в этом можно убедиться, разглядывая спектрограммы).
Распознавать диктовку текстов общей тематики, выполняемую в манере слитной речи, коммерческие программы научились только в 1997 г. Разумеется, что словарь подобных пакетов обслуживает так называемую общую тематику и охватывает лишь небольшую часть всей лексики. Значительная часть пользователей этим словарем не ограничивается и подключает еще специализированные (технические, медицинские, юридические и другие) словари.
Впрочем, на качество распознавания влияет даже манера ведения разговора — непринужденную беседу с относительно небольшим количеством используемых лексических единиц запротоколировать гораздо сложнее, чем размеренный диктант. Проблема заключается, в основном, в вариативности и наличии большого количества различных смысловых оттенков у самых простых конструкций. Тяжелее всего распознаются короткие слова, в результате по сравнению с многосложными частот ошибок при их обработке несравненно больше.
Серьезнейшая проблема — одно – двухбуквенные слова. Заставить компьютер различать английские «а» и «an» можно только обращаясь к контексту всей фразы. Расшифровка диктофонных записей, компьютерное стенографирование конференций и обсуждений — задача, к решению которой создатели ПО для распознавания речи только приблизились. По заявлениям разработчиков компаний Dragon Systems, IBM и Lernout&Hauspie, компьютер (при непрерывной диктовке) способен правильно распознавать до 95 % текста, а меж тем известно, что для комфортной работы точность распознавания требуется довести до 99 %.
Требования к оборудованию. Вначале системы для распознавания речи реализовывались, как правило, на специализированном оборудовании и соответствующих платформах. В силу того, что требования, предъявляемые к обработке речи в реальном времени, высоки, слабые центральные процессоры были не в силах взять на себя подобную задачу. Основой компьютерного распознавания речи являлось применение предварительной цифровой обработки сигналов на внешних платах. Производители ПО для распознавания речи, даже перейдя на однопроцессорные компьютеры, некоторое время продолжали применять специальные звуковые карты и микрофоны. Например, популярная программа KurzWeil Voice недавно требовала в обязательном порядке «свою» звуковую карту.
Модульные системы компьютерно-телефонных средств распознавания голоса, выполненные в виде плат расширения для компьютера, включают специализированные процессоры цифровой обработки звуковых сигналов (Digital Signal Processor или DSP), берущие на себя ряд операций нижнего уровня и позволяющие снизить требования к быстродействию основного процессора. Например, плата распознавания речи VR/160, поставляемая фирмой Dialogic, поддерживает до 16 каналов одновременно, причем она прекрасно работает совместно с процессором DX-486. Dialogic выпускает и более мощные четырехпроцессорные платы Antares с большим объемом оперативной памяти.
Работа в зашумленных помещениях также, разумеется, оказывает самое негативное влияние на качество распознавания. Каждый микрофон имеет свой особый «профиль», поэтому программу требуется «обучить» не только работе с конкретным пользователем, но и с конкретным оборудованием. Подключенному к компьютеру диктофону тоже потребуется свой «профиль». Специальные микротелефонные гарнитуры поставляются вместе с известными программами распознавания речи — Via Voice Gold корпорации IBM Research, Naturally Speaking Preferred фирмы Dragon Systems и Voice Xpress (Lernout&Hauspie Speech Products).
На работу с диктовочными программами накладываются и дополнительные ограничения. В большинстве случаев трудно обойтись без гарнитуры с микрофоном. Правда, радиомикрофоны допускают больший радиус действия, однако для контроля результатов пользователь должен видеть экран ПК.
Программное обеспечение, применяемое за рубежом
Функцию распознавания речи IBM не только встроила в свою операционную систему OS/2 Warp 4, известную под кодовым названием Merlin (конец 1996 г.), но и выпускает в качестве отдельного продукта. Пакет IBM для распознавания слитной речи Via Voice (www.ibm.com/viavoice) отличается своей способностью с самого начала, без обучения, распознавать до 80 % слов. При обучении вероятность правильного распознавания повышается до 95 %, причем параллельно с настройкой программы на конкретного пользователя происходит освоение будущим оператором навыков работы с системой. Небезынтересно, что, рекламируя этот пакет, IBM утверждает, будто средняя машинистка набивает примерно 80 слов в минуту, a Via Voice достигает скорости 150 слов в минуту.
Dragon Dictate Naturally Speaking (Ньютон, шт. Массачусетс, www.drag-onsys.com) — первый коммерческий продукт для Распознавания слитной речи, вышедший в начале 1997 г. Позволяет непосредственно диктовать в программы Word, WordPerfect, Netscape Navigator, Internet Explorer и приложения, причем ему Доступен богатый набор управляющих команд. Пользуясь только голосом, можно исправлять и переставлять слова, выделять текст даже менять размер шрифта и позиционировать курсор с абсолютной точностью. Первоначальная настройка на конкретный голос пользователя является обязательной, но программа способна обучаться и в процессе дальнейшего диктанта; рабочее качество распознавания может быть достигнуто спустя примерно пару недель пользования системой.
L&H Speech Products (Берлингтон, шт. Массачусетс www.lhs.com) в 1997 г. приобрела KurzWeil Applied Intelligence основатель которой (Рей Курцвайль) стал в L&H главным техническим руководителем. После этого фирма получила инвестиции от Microsoft, а затем выпустила Voice Commands — программу для голосового управления с развитыми возможностями. Несколько позже эта компания создала и свою систему распознавания речи Voice Xpress Plus, которая по качеству распознавания незначительно уступает Dragon Dictate Naturally Speaking, Ho зато при работе с офисными программами (например, с Word) реализует более «естественный» интерфейс (можно подавать команды вроде «изменить шрифт последнего предложения на Arial» или «сложить эту колонку цифр»).
Программное обеспечение для распознавания речи фирмы Nuance Communications использует крупнейшая в Канаде дисконтная брокерская контора Toronto Dominion, запустив в эксплуатацию службу Green Line Investors, позволяющую абонентам получать по телефону информацию о биржевых котировках. Вводятся особые пользовательские «профили», на основе которых система определяет, например, следует ли зачитывать данному абоненту краткую или подробную информацию.
Программу распознавания речи Natural Dialogue System фирмы Philips Speech Processing (Вена, Австрия, www.speech.be. philips.com) использует первая канадская система автоматических «желтых страниц» (Торонто), предоставляющая информацию о местных ресторанах и способная по желанию абонента соединить его с выбранным заведением.
Она же используется швейцарской железнодорожной компанией Swiss Railways. Предусмотрена возможность самообучения системы во время эксплуатации. Из запросов, требующих сложного «восприятия речи» (вроде «Я бы хотел попасть из Женевы в Цюрих через Берн»), выделяются ключевые слова — названия станций, предлоги «из», «в», «через» — и на основании наиболее правдоподобного варианта строится обращение к базе данных.
Авиакомпания Lufthansa своим потенциальным пассажирам предлагает автоматическое расписание своих рейсов, а радиостанция Radio Luxembourg — прогноз погоды по туристическим маршрутам всего мира.
Немецкая служба сотовой телефонной GSM-связи Dutch РТТ внедрила систему обработки речи Voice Dialing, разработанную американской компанией Glenayre, что обеспечивает не только голосовой набор телефонного номера, но и выполнение необходимых команд и возможность программирования до 40 наиболее часто набираемых телефонных номеров. В результате на возможным звонить прямо во время движения автомобиля не отвлекаясь от управления.
Программы от IBM и Dragon Dictate используются в надеваемых компьютерах (wearable PC) компании Xybernaut (www.xybernaut.com). Эти устройства весом всего 795 г используются, например, американскими таможенниками, несущими службу на границе с Мексикой. Стражи порядка проверяют номера проезжающих автомобилей, сверяясь с удаленными центральными правоохранительными базами. Правда, служащие таможни жалуются на проблемы с распознаванием, возникающие при сильном ветре.
IBM уже давно использует технологию распознавания речи для своих внутренних задач, а сейчас выпускает средства создания автоматизированных речевых агентов, способных распознавать называемые телефонными абонентами имена людей и названия организаций и соединять их с соответствующими номерами. Объем каталога имен может достигать 200 тыс. записей.
Фирма Language Force (www.lan-guageforce.com) на основе технологии распознавания речи Via Voice разработала автоматический переводчик Universal Translator Deluxe, позволяющий устную английскую речь переводить на 33 различных языка, в число которых входят арабский, китайский, японский, корейский, испанский, немецкий и иврит.
Достижения компьютерной обработки речевых сигналов могут применяться не только для того, чтобы вести беседы по мобильному телефону, — ряд парламентариев стран Западной Европы добиваются контроля над центром прослушивания Менвич-Хилл Агентства национальной безопасности (АНБ) США, Расположенным в Англии, недалеко от Йоркшира. Первоначально центр, созданный при поддержке британской разведки MI 5, предназначался для анализа информационного трафика из СССР, но ныне, как следует из отчета технической службы Европарламента, осуществляет перехват всех европейских телефонных разговоров, факсов и электронной почты. Система распознавания речи используется для выделения ключевых слов, при наличии которых автоматически включается запись разговора с последующим ее перенаправлением для проверки в американское отделение АНБ.
На текущий момент ПО для распознавания речи работает только с английским языком, качественная поддержка русского пока что не достигнута. Однако командовать компьютером можно хоть сейчас, а для того, кто имеет дело с англоязычными текстами каждый день, подобное ПО окажется полезным.


В дополнение к программам диктования Dragon Systems и IBM предлагают инструменты для разработчиков, желающих усилить мощность своих программ. Dragon предлагает DragonDictate, дискретный механизм распознавания языка, а IBM — набор инструментов Via Voice Developer Tools.
Dragon предлагает ряд опций для разработчиков, желающих использовать DragonDictate. Во-первых, вы можете добавить к DragonDictate специальный словарь, используя любое приложение, включая Microsoft Excel или Word. Семейство программ, именуемое DragonPro, содержит DragonBusiness, DragonExtra (журналистика), DragonLaw (юриспруденция), DragonMed (медицина) и DragonTech. Если вам нужно что-то еще более специфическое, вы можете использовать Dragon SpeechTool, чтобы разработать специальный словарь и эталоны произношения.
Вы можете использовать таблицу фонем и средства редактирования для создания, добавления, изменения слов и их произношения, а также их удаления.
DragonXTools поддерживает режимы 16-bit VBX и 32-bit OCX для добавления голосовых параметров к существующим приложениям. DragonXTools также поддерживает режим текст-речь DgnTTS, что позволит придать голос вашим программам. Руководство DragonXTools начинается с простого примера на языке VB и показывает, как создавать программы на С, C++, Delphi Visual Basic и т. п. Руководство содержит большой объем документации по событиям, свойствам и процедурам, необходимым, чтобы разговаривать с DragonDictate.
Вместе с DragonXTools пользователь получает также документацию по DragonDictate Macro Language Guide & Reference, зыку, основанному на BASIC, который разработчики могут использовать, чтобы добавлять команды к DragonDictate, DDE и DLL для контроля за работой мыши, звуковых эффектов и т. п.
Отечественные разработки
К сожалению, распространенные зарубежные системы распознавания речи русский язык не поддерживают. Правда, уже упоминавшиеся платы Dialogic в число используемых европейских и некоторых азиатских языков включают и русский, но их возможностей хватает только на речевой ввод телефонных номеров и построение простейших голосовых меню. Намерение включить поддержку русского языка в свои продукты неоднократно выражали многие производители, в том числе и Dragon Systems, но дальше этих заявлений дело так и не пошло.
В этих условиях своеобразной сенсацией стал выход в 1997 г. на коммерческий рынок знаменитого «Горыныча» — адаптации Dragon Dictate Naturally Speaking, проведенной силами малоизвестной до того российской компании White Group — официального дистрибьютора Dragon Systems. Программа оказалась вполне работоспособной, а ее стоимость — весьма умеренной.
К сожалению, основой послужила уже устаревшая вторая версия Dragon Dictate, не поддерживающая распознавание слитной речи. Кроме того, программа требует длительной «тренировки» и настройки на конкретного пользователя, очень капризна к оборудованию, более чем чувствительна к интонации и скорости произнесения фраз, возможности ее «обучения» весьма разнятся для различных голосов. Созданная для распознавания английской речи, программа не может учитывать всей специфики русского произношения.
По всей видимости, положение на отечественном рынке ПО для распознавания речи (если вообще можно говорить о таком) напоминает недавнюю ситуацию с оптическим распознаваем текста. Только специализированные отечественные продукты, изначально ориентированные именно на русский язык, смогут по-настоящему решить ту задачу, что не по силам ни «Горынычу», ни «Комбату» (еще один продукт той же фирмы White Group).
Не случайно лидеры отечественного рынка программ OCR которыми являются ABBYY (BIT Software) и Cognitive Technologies, заявили о ведущихся ими в области распознавания русской речи разработках. ABBYY работает над проектом NLC связанным с естественно-языковой обработкой распознаваемых текстов. Пока же технология распознавания речи российскими разработчиками применяется в основном в интерактивных обучающих системах и играх вроде «Мой говорящий словарь», «Talk to Me» или «Профессор Хиггинс», а целью их использования являются контроль произношения у изучающих английский язык и аутентификация пользователя. Еще одно остроумное применение технологии — распознавания речи — позволяет весьма ощутимо сжимать файлы с диктофонными записями или посланиями звуковой почты.
Перспективы систем распознавания речи
Важная задача, которая стоит перед создателями речевых технологий, — выработка единого стандарта на API-интерфейс (Applications Programming Interface), который должен связывать приложения и обеспечивать своевременную передачу управляющих функций. Такой стандарт должен не только позволять строить приложения на базе какой-либо распространенной операционной системы, имеющей соответствующие встроенные функции (первой такой ОС стала OS/2 Warp), но и обеспечивать переносимость систем распознавания речи на другие ОС.
ПО для распознавания слитной речи, как правило, не только снабжается собственными текстовыми редакторами, но и способно встраиваться в популярные программы, среди которых MS Word, Excel, Lotus Smart Suite Millennium Edition (Lotus Development) и Word Perfect Suite (Corel).
С другой стороны, производители офисных программ стали включать в состав своего ПО системы распознавания речи, как правило, от IBM (Smart Suite), Dragon Dictate (Word Perfect Suite) или Lernout&Hauspie.
Современные программы распознавания речи для ПК позволяют диктовать в обычной разговорной манере. Так называемая дискретная надиктовка с частыми остановками и паузами между словами осталась в прошлом. Однако непрерывный процесс расставания речи, дающий точность до 95 % в оптимальных условиях все-таки дает пять неправильных букв на 100 знаков. Около 200 ошибок на странице формата А4 — слишком много для профессиональной работы.
Несмотря на все достижения последних лет, средства для распознавания слитной речи все же допускают большое количество ошибок, нуждаются в длительной настройке, требовательны к аппаратной части и к квалификации пользователя и отказываются работать в зашумленных помещениях (а это важно как для шумных офисов, так и для мобильных систем и эксплуатации в условиях телефонной связи).
Известно, что спонтанная речь произносится со средней скоростью 2,5 слов в секунду, профессиональная машинопись — 2 слова в секунду, непрофессиональная — 0,4.
Таким образом, на первый взгляд, речевой ввод имеет значительное превосходство по производительности. Однако оценка средней скорости диктовки в реальных условиях снижается до 0,5 слова в секунду в связи с необходимостью четкого произнесения слов при речевом вводе и достаточно высоким процентом ошибок распознавания, нуждающихся в корректировке.
Речевой интерфейс естественен для человека и обеспечивает дополнительное удобство при наборе текстов. Однако даже профессионального диктора может не обрадовать перспектива в течение нескольких часов диктовать малопонятливому и немому компьютеру. Кроме того, имеющийся опыт эксплуатации подобных систем свидетельствует о высокой вероятности заболевания голосовых связок операторов, что связано с неизбежной при диктовке компьютеру монотонностью речи.
Часто к достоинствам речевого ввода текста относят отсутствие необходимости в предварительном обучении. Однако одно из самых слабых мест современных систем распознавания речи, — чувствительность к четкости произношения, — приводит к потере этого, казалось бы, очевидного преимущества. Печатать на клавиатуре оператор учится в среднем 1—2 месяца. Постановка правильного произношения может занять несколько лет. Кроме того, дополнительное напряжение, следствие сознательных и подсознательных усилий по достижению более высокой распознаваемости, совсем не способствует сохранению нормального режима работы речевого аппарата оператора и значительно увеличивает риск появления специфических заболеваний.
Существует и еще одно неприятное ограничение применимости — оператор, взаимодействующий с компьютером через речевой интерфейс, вынужден работать в звукоизолированном отдельном помещении либо пользоваться звукоизолирующим шлемом. Иначе он будет мешать работе своих соседей по офису, которые, в свою очередь, создавая дополнительный шумовой фон, будут значительно затруднять работу речевого распознавателя.
Таким образом, речевой интерфейс вступает в явное противоречие с современной организационной структурой предприятий, ориентированных на коллективный труд. Ситуация несколько смягчается с развитием удаленных форм трудовой деятельности, однако еще достаточно долго самая естественная для человека производительная и потенциально массовая форма пользовательского интерфейса обречена на узкий круг применения. Ограничения применимости систем распознавания речи в рамках наиболее популярных традиционных приложений заставляют сделать вывод о необходимости поиска потенциально перспективных для внедрения речевого интерфейса приложений за пределами традиционной офисной сферы, что подтверждается коммерческими успехами узкоспециализированных речевых систем.
Парадоксально, но самый успешный на сегодня проект коммерческого применения распознавания речи — телефонная сеть фирмы АТТ. Клиент может запросить одну из пяти категорий услуг, используя любые слова. Он говорит до тех пор, пока в его высказывании встретится одно из пяти ключевых слов. Эта система в настоящее время обслуживает около миллиарда звонков в год.
Говоря о речевом интерфейсе, часто делают упор на распознавание речи, забывая о другой его стороне — речевом синтезе. Заглавную роль в этом перекосе сыграло быстрое развитие систем, ориентированных на события в значительной степени подавляющих отношение к компьютеру как активной стороне диалога. Еще относительно недавно подсистемы распознавания и синтеза речи рассматривались как части единого комплекса речевого интерфейса.
Обратная распознаванию задача — синтез речи, или Text-to-Speech (TTS), — столь же проста в первом приближении и по-своему не менее сложна по мере достижения вершин. Известно, что синтезированная речь воспринимается человеком хуже, чем живая, причем это особенно заметно при передаче по каналу телефонной связи, т. е. как раз в тех условиях, в которых было бы наиболее заманчиво ее использовать. Тем не менее эксперты отмечают улучшение звучания синтезированной английской речи. В интеллектуальных телефонных системах, таких, как IVR (interactive voice responce) и центры телефонного обслуживания, технологии TTS начинают теснить традиционные наборы записываемых заранее слов и реплик — прежде всего благодаря своей гибкости, простоте переналадки и сокращению требований к объему памяти.
Качество речи прямо пропорционально размеру синтезатора и объему потребляемых им ресурсов системы (загрузка процессора, выделение памяти и т. п.) Для характеристики качества речи обычно используют такие понятия, как естественность звучания, фонетическая разборчивость, комфортность восприятия и время привыкания.
Естественность звучания характеризует то, насколько близок синтезированный звук к человеческой речи. Пока еще не существует синтезатора, прослушав который, человек не мог бы указать, что это неестественный звук. Однако уровень синтезаторов растет год от года, и неестественность их звучания уже не является сильной помехой восприятию информации. Первые же синтезаторы отличались такими нежелательными эффектами, как металлический призвук, отсутствие интонационного деления Фрагмента речи, резкость звучания или наоборот — слишком затянутые гласные звуки.
Фонетическая разборчивость характеризует, насколько слушателю легко или трудно разобрать фонемы, произносимые синтезатором. Здесь надо понимать, что неестественная с металлическим призвуком «речь робота», может обладать высокой фонической разборчивостью, т. е. слушатель с легкостью может фонемы (слоги) произносимых слов. В то же время в с естественной речи разборчивость может быть невысокой (представьте себе бубнящего человека — речь на сто процентов естественная, а ничего не понять). Так происходит потому, что для придания естественности звучания синтезируемая речь проходит дополнительную фильтрацию, в результате чего получает дополнительные обертона (их богатство во многом и определяет близость синтезированной речи к человеческой). Степень фильтрации не всегда адекватно подбирается синтезатором и это ухудшает фонетическую разборчивость.
Комфортность восприятия и время привыкания показывают субъективную оценку слушателем качества синтезируемой речи Несмотря на свою субъективность, с точки зрения пользователя это самые главные критерии, по которым оценивается работа синтезатора. Долгое прослушивание синтезированной речи не должно вызывать чрезмерного утомления, а время привыкания должно быть достаточно коротким, чтобы обеспечить легкий переход от одного синтезатора к другому.
История проблемы
В 1779 г. русский профессор Кристиан Краценштейн (иногда упоминается в источниках как Кристиан Готтлиб) построил акустическую модель, позволяющую создавать гласные звуки, используя различные геометрические формы резонаторов, как это показано на рис. 4.11.

При этом использовался аддитивный синтез (см. гл. 3), как в обычных органах (напомним, что один из регистров органа так и называется — vox humanum — голос человеческий) -В 1791 г. Вольфганг фон Кемпелен (Volfgang von Kempelen) представил акустико-механическую говорящую машину, которая воспроизводила определенные звуки и их комбинации. Шипящие и свистящие выдувались с помощью специального меха с ручным правлением. Затем это изобретение было улучшено ученым Чарльзом Уитстоуном (Charles Wheatstone), и уже могло воспроизводить гласные и большинство согласных звуков. В 1846 г. Джезеф Фабер представил свой говорящий орган, в котором была реализована попытка синтезирования не только речи, но и пения. В конце XVIII в. знаменитый ученый Александр Белл (Alexander Graham Bell) создал собственную «говорящую» механическую модель, очень схожую с конструкцией Уитстоуна. Начиная с 1920 г. наступила эра электрических инструментов, при этом основным видом синтеза оставался аддитивный.
Ключевой датой в развитии вокодеров является 1939 г. Именно в этом году ученый-изобретатель Хомер Дадли (Homer. W. Dudley) из Bell Laboratories представил устройство Parallel Bandpass Vocoder, над разработкой которого он трудился три года (рис. 4.12, 4.13).

Voder, представленный в 1939 г., управлялся человеком-оператором. Вот как описывает свои впечатления Ванневар Буш Vannevar Bush) в работе «As We May Think», 1945 г. (см. также [14], с. 171): «На мировой выставке 1939 г. было показано устройство, называемое Voder.

Девушка-оператор нажимала на его клавиши, и Voder воспроизводил звук, похожий на речь. Это происходило без использования человеческих голосов, нажатие на клавиши просто вызывало комбинации нескольких вибраций, созданных электронным способом, которые воспроизводились с помощью громкоговорителя».
В 1940 г. Хомер Дадли представил свою новую модель голосового синтезатора, именуемую The Vocoder (аббревиатура от Voice Operated reCorDER). В 1948 г. на выставке «Electronische Musik» (Германия) VODER был представлен как электронный инструмент будущего.
Алгоритмические модели синтезаторов речи с того времени практически не изменились. При этом эти системы развивались параллельно с аналоговыми синтезаторами.
Методы озвучивания речи
Рассмотрим какой-нибудь хотя бы минимально осмысленный текст. Текст состоит из слов, разделенных пробелами и знаками препинания. Произнесение слов зависит от их расположения в предложении, а интонация фразы — от знаков препинания и довольно часто от типа применяемой грамматической конструкции — в ряде случаев при произнесении текста слышится явная пауза, хотя какие-либо знаки препинания отсутствуют. Произнесение зависит и от смысла слова — сравните, например, выбор одного из вариантов «замок» или «замок» для одного и того же слова «замок».
Основная классификация стратегий, применяемых при озвучивании речи — это разделение на две группы подходов:
• построение действующей модели речепроизводящей системы человека;
• моделирование акустического сигнала как таковой.
Первый подход известен под названием артикуляторного синтеза. Второй подход представляется на сегодняшний день более простым, поэтому он гораздо лучше изучен и практически более успешен. Внутри него выделяется два основных направления — формантный синтез по правилам и компилятивный синтез.
Формантные синтезаторы используют возбуждающий сигнал, который проходит через цифровой фильтр, построенный на нескольких резонаторах, похожих на резонансы голосового тракта. Разделение возбуждающего сигнала и передаточной функции голосового тракта составляет основу классической акустической теории речеобразования. Компилятивный синтез осуществляется путем склейки нужных единиц компиляции из имеющегося инвентаря.
На этом принципе построен ряд систем, использующих разные типы единиц и различные методы составления инвентаря. В таких системах необходимо применять обработку сигнала для приведения частоты основного тона, энергии и длительности единиц к тем, которыми должна характеризоваться синтезируемая речь. Кроме того, требуется, чтобы алгоритм обработки сигнала сглаживал разрывы в формантной (и спектральной в целом) структуре на границах сегментов.
И системах компилятивного синтеза применяются два разные типа алгоритмов обработки сигнала: LP (Linear Prediction — линейноe предсказание) и PSOLA (Pitch Synchronous Overlap
and Add ). LP-синтез основан в значительной степени на акустической теории речеобразования, в отличие от PSOLA-синтеза, который действует путем простого разбиения звуковой волны,
составляющей единицу компиляции, на временные окна и их преобразования. Алгоритмы PSOLA позволяют добиваться хорошего сохранения естественности звучания при модификации исходной звуковой волны.
Обобщенная функциональная структура синтезатора
Структура идеализированной системы автоматического синтеза речи состоит из нескольких блоков:
• определение языка текста;
• нормализация текста;
• лингвистический анализ (синтаксический, морфемный и т. д.);
• формирование просодических характеристик;
• фонемный транскриптор;
• формирование управляющей информации;
• получение звукового сигнала.
Такая схема содержит компоненты, которые можно обнаружить во многих системах. Разработчики конкретных систем уделяют различное внимание отдельным блокам и реализуют их очень по-разному, в соответствии с практическими требованиями.
Модуль лингвистической обработки. Прежде всего, текст, подлежащий прочтению, поступает в модуль лингвистической обработки. В нем производится определение языка (в многоязычной системе синтеза), а также отфильтровываются не подлежащие произнесению символы. В некоторых случаях используются спелчекеры (модули исправления орфографических и пунктуационных ошибок). Затем происходит нормализация текста, т. е. осуществляется разделение введенного текста на слова и остальные последовательности символов. К символам относятся, в частности, знаки препинания и символы начала абзаца. Все знаки пунктуации очень информативны. Для озвучивания цифр разрабатываются специальные подблоки.
Преобразование цифр в последовательности слов является относительно легкой задачей (если читать цифры как цифры, а не как числа, которые должны быть правильно оформлены грамматически), но цифры, имеющие разное значение и функцию, произносятся по-разному. Для многих языков можно говорить, например, о существовании отдельной произносительной подсистемы телефонных номеров. Пристальное внимание уделяется правильной идентификации и озвучиванию цифр, обозначающих числа месяца, годы, время, телефонные
номера, денежные суммы и т. д. (список для различных языков может быть разным).
Лингвистический анализ. После процедуры нормализации каждому слову текста (каждой словоформе) необходимо приписать сведения о его произношении, т. е. превратить в цепочку фонем или, иначе говоря, создать его фонемную транскрипцию. Во многих языках, в том числе и в русском, существуют достаточно регулярные правила чтения — правила соответствия между буквами и фонемами (звуками), которые, однако, могут требовать предварительной расстановки словесных ударений. В английском языке правила чтения очень нерегулярны, и задача данного блока для английского синтеза тем самым усложняется. В любом случае при определении произношения имен собственных, заимствований, новых слов, сокращений и аббревиатур возникают серьезные проблемы. Просто хранить транскрипцию для всех слов языка не представляется возможным из-за большого объема словаря и контекстных изменений произношения одного и того же слова во фразе.
Кроме того, следует корректно рассматривать случаи графической омонимии: одна и та же последовательность буквенных символов в различных контекстах порой представляет два различных слова/словоформы и читается по-разному (например, ранее приведенный пример слова «замок»).
Для языков с достаточно регулярными правилами чтения одним из продуктивных подходов к переводу слов в фонемы является система контекстных правил, переводящих каждую букву/буквосочетание в ту или иную фонему, т. е. автоматический фонемный транскриптор. Однако чем больше в языке исключений из правил чтения, тем хуже работает этот метод. Стандартный способ улучшения произношения системы состоит в занесении нескольких тысяч наиболее употребительных исключений в словарь. Альтернативное подходу «слово—буква—фонема» решение предполагает морфемный анализ слова и перевод в фонемы морфов (т. е. значимых частей слова: приставок, корней, суффиксов и окончаний). Однако в связи с разными пограничными явлениями на стыках морфов разложение на эти элементы представляет собой значительные трудности. В то же время для языков с богатой морфологией, например, для русского, словарь морфов был бы компактнее. Морфемный анализ удобен еще и потому, что с его помощью можно определять принадлежность слов к частям речи, что очень важно для грамматического анализа текста и задания его просодических характеристик. В английских системах синтеза морфемный анализ был реализован в системе МIТа1к, для которой процент ошибок транскриптора составляет 5 %. Особую проблему для данного этапа обработки текста образуют имена собственные.
Формирование просодических характеристик. К просодическим характеристикам высказывания относятся его тональные, акцентные и ритмические характеристики. Их физическими аналогами являются частота основного тона, энергия и длительность. В речи просодические характеристики высказывания определяются не только составляющими его словами, но также тем, какое значение оно несет и для какого слушателя предназначено, эмоциональным и физическим состоянием говорящего и многими другими факторами. Многие из этих факторов сохраняют свою значимость и при чтении вслух, поскольку человек обычно интерпретирует и воспринимает текст в процессе чтения. Таким образом, от системы синтеза следует ожидать примерно того же, т. е. она сможет понимать имеющийся у нее на входе текст, используя методы искусственного интеллекта. Однако этот уровень развития компьютерной технологии еще не достигнут, и большинство современных систем автоматического синтеза стараются корректно синтезировать речь с эмоционально нейтральной интонацией. Между тем, даже эта задача на сегодняшний день представляется очень сложной.
Формирование просодических характеристик, необходимых для озвучивания текста, осуществляется тремя основными блоками, а именно:
• расстановки синтагматических границ (паузы);
• приписывания ритмических и акцентных характеристик (длительности и энергия);
• приписывания тональных характеристик (частота основного тона).
При расстановке синтагматических границ определяются части высказывания (синтагмы), внутри которых энергетические и тональные характеристики ведут себя единообразно и которые человек может произнести на одном дыхании. Если система не делает пауз на границах таких единиц, то возникает отрицательный эффект: слушающему кажется, что говорящий (в ном случае — система) задыхается. Помимо этого, расстановка синтагматических границ существенна и для фонемной транскрипции текста. Самое простое решение состоит в том, чтобы ставить границы там, где их диктует пунктуация. Для наиболее простых случаев, когда пунктуационные знаки отсутствуют можно применить метод, основанный на использовании служебных слов. Именно эти методы используются в системах синтеза Pro-Se-2000, Infovox-5A-101 и DECTalk, причем в последней просодически ориентированный словарь, помимо служебных слов, включает еще и глагольные формы.
Задача приписывания тональных характеристик обычно ставится достаточно узко. В системах синтеза речи предложению, как правило, приписывается нейтральная интонация. Не предпринималось попыток моделировать эффекты более высокого уровня, такие, как эмоциональная окраска речи, поскольку эту информацию извлечь из текста трудно, а часто и просто невозможно.
Некоторые другие реализации
Наиболее распространенными системами синтеза речи на сегодня являются те, которые поставляются в комплекте со звуковыми платами. Если компьютер пользователя оснащен какой-либо из них, существует значительная вероятность того, что на нем установлена система синтеза речи (не русской, а английской речи, точнее, ее американского варианта). К большинству оригинальных звуковых плат Sound Blaster прилагается система Сreative Text-Assist, а вместе со звуковыми картами других производителей часто поставляется программа Monologue компании First Byte.
TextAssist представляет собой реализацию формантного синтезатора по правилам и базируется на системе DECTalk, разработанной корпорацией Digital Eguipment, который до сих пор остается своего рода стандартом качества для синтеза речи американского варианта английского. Компания Creative Technologies предлагает разработчикам использовать TextAssist в своих программах с помощью специального TextAssistApi (AAPI). Поддерживаемые операционные системы - MS Windows и Windows 95; для Windоws NT также существует версия системы DECTalk, изначально создававшейся для Digital Units. Новая версия TextAssist объявленная фирмой Assotiative Computing Inc, разработанная ё использованием технологий DECTalk и Creative, является в то же время многоязычной системой синтеза, поддерживая английский, немецкий, испанский и французский языки. Это обеспечивается прежде всего использованием соответствующих лингвистических модулей, разработчик которых — фирма Lernout& Hauspie Speech Products, признанный лидер в поддержке многоязычных речевых технологий.
Monologue — программа, предназначенная для озвучивания текста, находящегося в буфере обмена MS Windows, использует систему ProVoice. ProVoice — компилятивный синтезатор с использованием оптимального выбора режима компрессии речи и сохранения пограничных участков между звуками, разновидность TD-PSOLA. Рассчитан на американский и британский английский, немецкий, французский, латино-американскую разновидность испанского и итальянский языки. Инвентарь сегментов компиляции — смешанной размерности: сегменты — фонемы или аллофоны. Компания First Byte позиционирует систему ProVoice и программные продукты, основанные на ней, как приложения с низким потреблением процессорного времени. FirstByte также предлагает рассчитанную на мощные компьютеры систему артикуляторного синтеза PrimoVox для использования в приложениях телефонии. Для разработчиков: Monologue Win32 поддерживает спецификацию Microsoft SAPI.
MBROLA — так называется система многоязычного синтеза, реализующая особый гибридный алгоритм компилятивного синтеза и работающая как под Windows, так и на платформах Sun4. Впрочем, система принимает на входе цепочку фонем, а не текст, и потому не является, строго говоря, системой синтеза речи по тексту. Формантный синтезатор Tru-Voice фирмы Centigram Communication Corporation(CUIA) близок к описанным выше системам по архитектуре и предоставляемым возможностям, однако он поддерживает больше языков: американский английский, латино-американский, испанский, немецкий, французский, итальянский. Кроме того, в этот синтезатор включен специальный препроцессор, который обеспечивает быструю подготовку для чтения сообщений, получаемых по электронной почте, факсов и баз данных.
Engine – «машины» синтеза и распознавания речи
«Машина» (в просторечии — «движок») — это пакет программных средств, выполняющих строго определенную задачу и поставляющий интерфейс для использования его возможностей В настоящее время существует целый ряд машин синтеза и Опознавания речи, которые разработаны для использования совместно с MS Speech API.
smARTspeak CS — настраиваемая независимая от языка «машина» распознавания речи для набора цифр, указания имен и речевой навигации, т. е. для приложений, используемых в сотовых телефонах и беспроводных устройствах. Созданный для использования в указанных устройствах, smARTspeak CS удовлетворяет потребностям как пользователей, так и разработчиков: иммунитет к фоновому шуму, малые требования к процессору и памяти, совместимость с MS SAPI 5.0, оптимизация для средств быстрой разработки приложений и для интеграции в сертифицированные устройства.
Conversay предоставляет решение для речевого взаимодействия с информацией, поставляемой через сеть, включая Internet в случае, когда другие интерфейсы слишком сложны или отсутствуют. Conversay разрабатывает речевую технологию, которая позволяет пользователям взаимодействовать через мобильные устройства привычным для себя способом.
Lernout&Hauspie. Система компании L&H позволяет настраивать чтение аббревиатур и слов (ударения). Продукт, активно продвигаемый Microsoft.
Digalo. Голосовой «движок» для русского языка Digalo — продукт французской фирмы Elan Informatique. Digalo различает буквы «Е» и «Ё» и виртуозно владеет русской ненормативной лексикой. В основном ошибки в ударениях приходятся на некоторые фамилии и имена, малоупотребительные слова и термины, замечено не всегда корректное озвучивание чисел и очень акцентированное произнесение слов «нет» и «не». Разработчики обещают в дальнейшем сделать возможной корректировку произнесения отдельных слов и слогов.
Аctor 5. Новый «движок» фирмы Loquendo «Actor 5» предназначен для использования в областях голосовых технологий и сервиса. Синтезирует речь на итальянском, испанском, английском, немецком, мексиканском, бразильском и американском иском диалекте (русского, к сожалению, нет).
PC Voice Club. Движок синтеза речи Клуба голосовых технологий при Научном Парке МГУ. При его создании использована базовая технология синтеза речи, разработанная на филологическом факультете МГУ. Синтезатор характеризуется высоким качеством синтеза речи, что позволяет прослушивать тексты без их специальной подготовки. Позволяет синтезировать речь на английском и русском языках. Кроме того, имеет около десятка голосовых типажей (робот, эльф, мышь и пр.) Имеются возможности редактирования голосов. Помимо стандартных функций синтеза речи имеется дополнительная функция встраивания в текст управляющих символов, которые позволяют устанавливать паузы, изменять тембр, тон и длительность звучания. К примеру, можно, отредактировав текст, заставить синтезатор петь.
Творческий коллектив радиофизиков и программистов разработал серию программных продуктов под общим названием «Говорящая мышь»
Синтезатор русской речи
Рассмотрим разработку «Говорящая мышь» упоминавшегося Клуба голосовых технологий. В основе речевого синтеза лежит идея совмещения методов конкатенации и синтеза по правилам. Метод конкатенации при адекватном наборе базовых элементов компиляции обеспечивает качественное воспроизведение спектральных характеристик речевого сигнала, а набор правил — возможность формирования естественного интонационно-просодического оформления высказываний. Существуют и другие методы синтеза, может быть, в перспективе более гибкие, но дающие пока менее естественное озвучивание текста. Это, прежде всего, параметрический (формантный) синтез речи по правилам или на основе компиляции, развиваемый для ряда языков зарубежными исследователями. Однако для реализации этого метода необходимы статистически представительные акустико-фонетические базы данных и соответствующая компьютерная технология, которые пока доступны не всем.
Язык формальной записи правил синтеза. Для создания удобного и быстрого режима изменения и верификации правил, включенных в разные блоки синтезирующей системы, был разработан формализованный и в то же время содержательно прозрачный и понятный язык записи правил, который легко компилируется в исходные тексты программ. В настоящее время блок автоматического транскриптора насчитывает около 1000 строк, записанных на формализованном языке представления правил.
Интонационное обеспечение. Функция разработанных правил состоит в том, чтобы определить временные и тональные характеристики базовых элементов компиляции, которые при обработке синтагмы выбираются из библиотеки в нужной последовательности специальным процессором (блоком кодировки). Необходимые для этого предварительные операции над синтезируемым текстом: выделение синтагм, выбор типа интонации, определение степени выделенности (ударности-безударности) гласных и символьного звукового наполнения слоговых комплексов осуществляются блоком автоматического транскриптора.
Во временной процессор входят также правила, задающие длительность паузы после окончания синтагмы (конечной/неконечной), которые необходимы для синтеза связного текста. Предусмотрена также модификация общего темпа произнесения синтагмы и текста в целом, причем в двух вариантах: в стандартном — при равномерном изменении всех единиц компиляции — ив специальном, дающем возможность изменения длительности только гласных или только согласных.
Тональный процессор содержит правила формирования для одиннадцати интонационных моделей: нейтральная повествовательная интонация (точка), точковая интонация, типичная для фокусируемых ответов на вопросы; интонация предложений с контрастивным выделением отдельных слов; интонация специального и общего вопроса; интонация особых противопоставительных или сопоставительных вопросов; интонация обращений, некоторых типов восклицаний и команд; два вида незавершенности, перечислительная интонация; интонация вставочных конструкций.
Аллофонная база данных. Необходимый речевой материал записан в режиме оцифровки с частотой дискретизации 22 кГц с разрядностью 16 бит. В качестве базовых элементов компиляции выбраны аллофоны, оптимальный набор которых и представляет собой акустико-фонетическую базу синтеза. Инвентарь базовых единиц компиляции включает в себя 1200 элементов, который занимает около 7 Мбайт памяти. В большинстве случаев элементы компиляции представляют собой сегменты речевой волны фонемной размерности. Для получения необходимой исходной базы единиц компиляции был составлен специальный словарь, который содержит слова и словосочетания с аллофонами во всех учитываемых контекстах. В нем содержится 1130 словоупотреблений.
Лингвистический анализ. На основе данных, полученных от остальных модулей синтеза речи и от аллофонной базы, программа формирования акустического сигнала позволяет осуществлять модификацию длительности согласных и гласных. Она дает возможность модифицировать длительность отдельных периодов на вокальных звуках, используя две или три точки тонирования на аллофонном сегменте, осуществляет модификацию энергетических характеристик сегмента и соединяет модифицированные аллофоны в единую слитную речь.
На этапе синтеза акустического сигнала программа позволяет получать разнообразные акустические эффекты — такие, как реверберация, эхо, изменение частотной окраски.
Готовый акустический сигнал преобразуется в формат данных, принятый для вывода звуковой информации. Используются два формата: WAV (Waveform Audio File Format), являющийся одним из основных, или VOX (Voice File Format), широко используемый в компьютерной телефонии. Вывод также может осуществляться непосредственно на звуковую карту.
Инструментарий синтеза русской речи. Упоминавшийся выше инструментарий синтеза русской речи по тексту позволяет читать вслух смешанные русско-английские тексты. Инструментарий представляет собой набор динамических библиотек (DLL), в который входят модули русского и английского синтеза, словарь ударений русского языка, модуль правил произнесения английских слов. На вход инструментария подается слово или предложение, подлежащее произнесению, с выхода поступает звуковой файл в формате WAV или VOX, записываемый в память или на жесткий диск.
В табл. 4.2 приводятся характеристики ряда систем синтеза речи.

SSML
Speech Synthesis Markup Language (Язык разметки для синтеза речи) представляет собой основанный на XML язык разметки для приложений, связанных с синтезом речи. Он рекомендован рабочей группой Консорциума WWW по голосовым браузерам (W3C's voice browser working group). SSML часто встраивается в сценарии VoiceXML, чтобы управлять интерактивными системами телефонной связи. Однако он также может использоваться самостоятельно, например, для того, чтобы создавать звучащие документы. Известны также и другие аналогичные изделия включая встроенные речевые команды Apple, или SAPI TTS (разработка Microsoft также на базе языка XML).
SSML разработан на базе языка JSML (Sun Microsystems), хотя основные рекомендация были сделаны главным образом производителями синтезаторов речи. SSML охватывает фактически все аспекты синтеза, хотя некоторые области оставлены неопределенными, и таким образом каждый синтезатор может здесь давать собственную интерпретацию текста (SSML не является таким строгим стандартом как С или хотя бы HTML).
Пример документа SSML:

4.4 Системы автоматизированного и автоматического перевода текстов
Перевод с одного языка на другой человеком происходит путем восприятия и понимания исходного текста и последующей передачи его смысла средствами выходного языка. При этом переводятся не слова и словосочетания, а понятийные образы, порождаемые в сознании переводчика под их воздействием. Однако если в настоящее время пока еще нет возможности моделировать работу человека-переводчика, то, по крайней мере, нужно стремиться оперировать теми единицами языка и речи, которые позволяют наиболее точно передавать содержание текста, написанного на одном языке, средствами другого языка. Такими единицами являются, прежде всего, фразеологические обороты и терминологические словосочетания и, во вторую очередь, отдельные слова. Если в настоящее время полностью автоматический высококачественный научно-технический перевод практически невозможен, то автоматизированный человеко-машинный перевод вполне реален.
Обобщенная технология работы системы машинного перевода
Процесс машинного перевода текстов с одного естественного языка на другой может быть в крупном плане разделен на три этапа (рис. 4.14).
Текст на входном языке поступает в систему перевода, на этапе семантико-синтаксического анализа выявляется его грамматическая структура, распознаются наименования понятий и устанавливаются отношения между понятиями.
На этапе трансфера производится переход от наименований понятий и структуры текста на входном языке к наименованиям и структуре текста на выходном языке. В результате семантико-синтаксического синтеза на основании полученных эквивалентов получается текст на выходном языке (его грамматическое оформление), который выдается в качестве
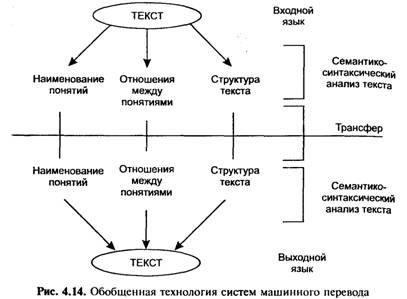
Действующие системы машинного перевода ориентированы на конкретные пары языков (например, французский и русский или японский и английский) и используют, как правило, переводные соответствия либо на поверхностном уровне, либо на некотором промежуточном уровне между входным и выходным языком. Качество машинного перевода зависит от объема словаря, объема информации, приписываемой лексическим единицам, от тщательности составления и проверки работы алгоритмов анализа и синтеза, от эффективности программного обеспечения. Информация может быть представлена как в декларативной (описательной), так и в процедурной (учитывающей потребности алгоритма) форме.
Машинный перевод следует отличать от использования компьютеров в помощь человеку-переводчику. В последнем случае имеется в виду автоматический словарь, помогающий человеку быстрее подбирать нужный переводной эквивалент. Хотя и в том, и в другом случае компьютер работает вместе с человеком (переводчиком или редактором), в содержание термина «машинный перевод» входит представление о том, что главную, большую часть работы по переводу и отысканию переводных эквивалентов и переводных соответствий машина берет на себя, оставляя человеку лишь контроль и исправление ошибок, в то время как компьютерный словарь в помощь человеку — это чисто вспомогательное средство.
Основные проблемы машинного перевода
Для создания систем, работающих со всем естественным языком без потери глубины анализа, в настоящий момент не хватает либо технических возможностей (быстродействия, памяти), либо теоретической базы. Однако в коммерческих системах, ввиду того, что предназначаются они для большого количества пользователей, разных предметных областей, принята концепция поверхностного анализа, к тому же и производится такой анализ значительно быстрее.
Исторически машинный перевод является первой попыткой использования компьютеров для решения невычислительных задач (Джорджтаунский эксперимент в США в 1954 г.; работы по машинному переводу в СССР, начавшиеся в 1954 г.). Развитие электронной техники, рост объема памяти и производительности компьютеров создавали иллюзию быстрого решения этой задачи. Практическая цель была простой: загрузить в память компьютера максимально возможный словарь и с его помощью из иноязычных текстов получать текст на родном языке в удобочитаемом виде. Однако первоначальная эйфория по поводу того, что столь трудоемкую работу можно поручить ЭВМ, сменилась разочарованием в связи с абсолютной непригодностью получаемых текстов.
Конечно, системы, настроенные на определенную предметную область, дают гораздо более приемлемые результаты. Однако в этом случае системы перевода получаются очень узко ориентированными, и попытка использовать их даже в смежных предметных областях дает совершенно непредсказуемые результаты.
Возникают эти проблемы из-за принципиально разных подходов к переводу человека и машины. Квалифицированный переводчик понимает смысл текста и пересказывает его на другом зыке словами и стилем, максимально близкими к оригиналу.
компьютера этот путь выливается в решение двух задач:
• перевод текста в некоторое внутреннее семантическое представление;
• генерация по этому представлению текста на другом языке.
Поскольку не только не решена сама по себе ни одна из этих задач, и даже нет общепринятой концепции семантического представления текстов, при автоматическом переводе приходится фактически делать «подстрочник», заменяя по отдельности слова одного языка на слова другого и пытаясь после этого придать получившемуся предложению некоторую синтаксическую согласованность. Смысл при этом может быть искажен или безвозвратно утерян.
Фразеологический машинный перевод
Концепция фразеологического перевода базируется на понимании того факта, что в естественных языках смысл лексических единиц более высокого уровня (например, фразеологических единиц, являющихся наименованиями понятий или ситуаций), как правило, не сводим к смыслу составляющих их лексических единиц более низкого уровня (например, слов).
При решении проблемы перевода ранее делалась ставка прежде всего на грамматически правильный пословный перевод, а полисемия слов разрешалась в основном процедурными средствами на основе учета их синтаксических и семантических признаков. Поэтому системы МП первых трех десятилетий их развития можно охарактеризовать как системы семантико-синтаксического преимущественно пословного перевода. Словосочетания здесь также использовались, но в меньшей степени.
Семантико-синтаксический пословный машинный перевод текстов не имеет особой перспективы, так как в естественных языках смысл словосочетаний, как правило, не сводим или не полностью сводим к смыслу составляющих их слов, и при переводе он не обязательно может быть «вычислен» на основе синтаксических и семантических признаков этих слов.
Принципы построения систем фразеологического машинного перевода текстов были впервые сформулированы Г. Г. Белоноговым в 1975 г. и изложены в 1983 г. в книге Г. Г. Белоногова и Б. А. Кузнецова «Языковые средства автоматизированных информационных систем». В 1984 г. аналогичная идея была высказана японским ученым профессором Нагао из университета Киото. Он предложил в качестве альтернативы подход, основанный на использовании ранее переведенных текстов, представленных одновременно на двух языках (билингв).
Важнейшими среди этих принципов являются следующие:
• основными единицами языка и речи, которые прежде всего следует включать в машинный словарь, должны быть фразеологические единицы (словосочетания, фразы). Отдельные слова также могут включаться в словарь, но они должны использоваться только в тех случаях, когда не удается осуществить перевод, опираясь только на фразеологические единицы;
• наряду с фразеологическими единицами, состоящими из непрерывных последовательностей слов, в системах машинного перевода следует использовать и так называемые речевые модели — фразеологические единицы-шаблоны с «пустыми местами», которые могут заполняться различными словами и словосочетаниями, порождая осмысленные отрезки речи;
• реальные тексты, независимо от их принадлежности к той или иной тематической области, обычно бывают политематическими, если они имеют достаточно большой объем. И отличаются они друг от друга не столько словарным составом, сколько распределениями вероятностей появления в них различных слов из общенационального словарного фонда. Поэтому машинный словарь, предназначенный для перевода текстов даже только из одной тематической области, должен быть политематическим, а для перевода текстов из различных предметных областей — тем более;
• для систем фразеологического перевода необходимы машинные словари большого объема. Такие словари могут создаваться на основе автоматизированной обработки двуязычных текстов, являющихся переводами друг друга, и в процессе функционирования систем перевода;
• наряду с основным (политематическим) словарем большого объема в системах фразеологического машинного перевода целесообразно использовать также набор небольших по объему дополнительных тематических словарей. Дополнительные словари должны содержать только ту информацию, которая отсутствует в основном словаре (например, информацию о приоритетных переводных эквивалентах словосочетаний и слов для различных предметных областей, если эти эквиваленты не совпадают с приоритетными переводными эквивалентами основного словаря);
• основным средством разрешения полисемии (многозначности) слов в системах фразеологического перевода является их использование в составе фразеологических словосочетаний. Дополнительным — аппарат дополнительных тематических словарей, где для каждого многозначного слова или словосочетания указывается его приоритетный переводной эквивалент, специфичный для рассматриваемой предметной области;
• большую роль в системах фразеологического машинного перевода текстов могут играть процедуры морфологического и синтаксического анализа и синтеза русских и английских текстов, построенные на основе принципа аналогии. Эти процедуры позволяют отказаться от хранения в словарях большого объема грамматической информации и порождать ее по мере необходимости автоматически, в процессе перевода. Они делают систему перевода открытой — способной обрабатывать тексты с «новой» лексикой;
• наряду с переводом текстов в автоматическом режиме в системах фразеологического машинного перевода целесообразно предусмотреть интерактивный режим работы. В этом режиме пользователь должен иметь возможность вмешиваться в процесс перевода и настраивать дополнительные машинные словари на тематику переводимых текстов.
В соответствии с главным тезисом концепции фразеологического перевода, система фразеологического машинного перевода должна включать в свой состав базу знаний, содержащую переводные эквиваленты для наиболее часто встречающихся фраз, фразеологических сочетаний и отдельных слов (рис. 4.15) и программные средства для морфологического и синтаксического анализа и синтеза текстов и для их редактирования человеком.
В процессе перевода текстов система должна использовать хранящиеся в ее базе знаний переводные эквиваленты в следующем порядке: сначала для очередного предложения исходного текста делается попытка перевести его как целостную фразеологическую единицу; затем, в случае
неудачи, — входящие в его состав словосочетания; и, наконец, осуществляется пословный перевод тех фрагментов текста, которые не удалось перевести первыми двумя способами. Фрагменты выходного текста, полученные всеми тремя способами, должны грамматически согласовываться друг с другом (с помощью процедур морфологического и синтаксического синтеза).

Словари систем фразеологического перевода
Словари являются наиболее важной компонентой систем Фразеологического машинного перевода. Они должны быть достаточно большого объема, чтобы хорошо покрывать тексты, и должны содержать преимущественно словосочетания. Опыт создания больших русско-английских и англо-русских машинных словарей показал, что наиболее надежным источником для их составления могут служить русские и английские тексты, являющиеся переводами друг друга, в частности двуязычные заголовки Документов.
Составление машинных словарей по двуязычным текстам проводится как вручную, так и с помощью ЭВМ. Ручное составление словарей связано с большими трудозатратами. Поэтому
была разработана процедура автоматизированного составления словарей. Эта процедура основана на использовании того факта, что во множестве двуязычных пар предложений, являющихся
переводами друг друга и содержащих одно и то же слово или словосочетание одного из языков, максимальную частоту встречаемости имеет слово или словосочетание другого языка, являющееся переводом этого слова или словосочетания.
Машинные словари системы могут корректироваться и пополняться в процессе перевода текстов в интерактивном режиме В этом режиме есть возможность обнаруживать слова и словосочетания, для которых в словаре не указаны переводные эквиваленты или эти эквиваленты не соответствуют контексту, или указано несколько эквивалентов, но на первом месте стоит эквивалент, не соответствующий контексту. В случае отсутствия переводных эквивалентов у некоторых слов они могут быть указаны человеком; если эквиваленты не соответствуют контексту они могут быть заменены; если их несколько, то есть возможность выбрать только те из них, которые соответствовали контексту.
В системе фразеологического перевода используются следующие типы словарей:
• тематический;
• политематический;
• словарь пользователя.
Технология использования различных типов словарей в процессе перевода следующая: после семантико-синтаксического анализа входного текста на этапе трансфера идет обращение к двуязычным словарям. Если подключены все три типа словарей, то порядок обращения будет следующим: наивысший приоритет у словаря пользователя, проводится поиск всех фразеологических единиц переводимого текста, для найденных дается перевод; затем идет обращение к тематическому словарю (тематика словаря выбирается пользователем в системе перед началом перевода), в нем проводится поиск для всех еще непереведенных единиц; если после работы двух словарей еще остались непереведенные фрагменты, то система обращается к политематическому словарю, который содержит переводные эквиваленты для самых различных понятий, принадлежащих разным тематикам.
Все словари имеют линейную структуру:
[понятие на входном языке] [переводной эквивалент 1] /
[перев. эквив. 2] /......../ [перев. эквив. п]
Словарная статья состоит из двух частей: из исходного наименования понятия и его переводного эквивалента. Разделителем между этими частями служит косая черта. Записи в словаре пользователя располагаются в порядке их ввода. Исходное наименование понятия и его перевод хранятся в словаре в том виде, в котором они были в него первоначально введены, но в процессе его подключения к системе перевода производится пословная нормализация исходных наименований понятий, что позволяет отождествлять их различные формы.
При этом если перевод осуществляется в автоматическом режиме (без участия пользователя), берется первый слева переводной эквивалент. Фрагмент словаря пользователя представлен в табл. 4.3.

По структуре словарных статей словарь пользователя аналогичен основному политематическому и дополнительным тематическим словарям, но он отличается от них количеством возможных вариантов перевода, указываемых для входных наименований понятий. Здесь для каждого входного наименования понятия может указываться только один вариант перевода. Отличается пользователя также и способом его хранения в файле. Это связано с необходимостью оперативного изменения содержимого словаря и тем, что его объем значительно меньше, чем объем словарей других типов.
В системе фразеологического перевода используются также словари словообразовательных эквивалентов и словарей синонимов, гипонимов (термины, находящиеся в видовых отношениях с исходным) и гиперонимов (термины, находящиеся в родовых отношениях с исходным). Эти словари являются вспомогательными, они позволяют дополнять словарные статьи основного словаря: имеющемуся понятию на английском языке ставится в соответствие не единственный эквивалент русского языка, а несколько вариантов переводных эквивалентов этого понятия.
Системы автоматического перевода
Рассмотрим вкратце характеристики некоторых из таких систем, предназначенных для достижения максимальной скорости обработки больших потоков информации.
Скорость перевода страницы текста у разных систем составляет от 0,5 до 2 с в автоматическом режиме. Полученный в результате текст в большинстве случаев понятен сразу. Поэтому, потратив какие-то минуты на осознание информации, пользователь может сразу сохранить документ для более тщательного изучения.
Основными поставщиками подобных систем в настоящий момент являются московская компания «Арсеналъ» и санкт-петербурская «ПРОМТ».
Одним из продуктов «Арсеналъ» является переводчик «СОКРАТ». Данная система поставляется в комплекте с общелексическим, коммерческим и компьютерным словарями. Данная база составляет 95 % требуемого словарного запаса для текстов, которые существуют в электронном виде. Отдельно существует 9 дополнительных подключаемых к системе «СОКРАТ» словарей специализированного назначения, среди которых словари по медицине, машиностроению, юриспруденции и др.
Интерфейс представляет собой два окна, одно из которых содержит текст оригинала, а в другом появляется перевод. Известны версии «СОКРАТа», понимающие соответственно английский, немецкий и французский языки. Перевод в любом случае является двухсторонним, т. е. можно переводить не только с иностранного языка на русский, но и наоборот.
Компания «ПРОМТ» давно специализируется на производстве языковых систем. Системы перевода STYLUS 2.xx и 3.хх известны пользователям Windows. «PROMT» также комплектуется общелексическим и компьютерным словарями. Однако основной особенностью данной программы является наличие гораздо большего количества подключаемых словарей. Их число составляет на данный момент несколько десятков. Существуют четыре коллекции или подборки словарей — наука, коммерция, техника и промышленность. Каждая из коллекций содержит от 5 до 10 словарей определенной направленности. Например, коллекция «Коммерция» содержит словари «Коммерческий», «Информатика» и «Юридический», причем для всех возможных языковых пар.
Системы автоматического перевода Promt и XT-Diamond. Данные системы являются довольно типичными для рынка программных продуктов РФ и обеспечивают следующие возможности:
• ручной выбор и настройку словарей предметной области;
• пополнение словарей пользователем;
• автоматическое определение предметной области, при необходимости;
• выборочный или полный перевод текстового файла;
• редактирование оригинала и результата перевода.
На рис. 4.16—4.19 приведены примеры некоторых экранов данных систем, иллюстрирующие их возможности.
В табл. 4.4 приведен пример исходного и результирующего технического текста при автоматизированном переводе различными системами, из которого видно, что несмотря на несомненные успехи в данной области, технология все еще имеет определенные резервы для своего совершенствования.
Еще одна тенденция последних лет — слияние речевых технологий с лингвистическими. Показателен пример L&H, ставший действующим лицом в области машинного перевода с момента приобретения фирмы Mendez в 1996 г. После этого к L&H присоединились AILogic Corp. и NeocorTech (специализировавшиеся на машинном переводе с английского на японский и с японского на китайский и обратно), германская фирма Heitmann Group и, наконец Globalink. Новая версия известной программы-переводчика Power Translator Pro фирмы Globalink вышла уже под маркой L&H.

Продукция L&H поддерживает в общей сложности 25 языков. Однако еще эффектнее выглядит программа Universal Translator фирмы LanguageForce (США). Серия Universal Translator включает четыре системы машинного перевода, работающие с MS Office, имеющие функции распознавания/синтеза речи и проверки орфографии; при этом Universal Translator 2000 Professional переводит с 40 языков: арабский, китайский (упрошенный и традиционный варианты), чешский, датский, нидерландский, английский британский и американский, эсперанто, фарси, финский, французский (канадский и европейский варианты), немецкий, греческий, иврит, венгерский, итальянский, индонезийский, латинский, японский, корейский, норвежский, польский, португальский (бразильский и европейский варианты) румынский, русский, словацкий, испанский (латиноамериканский и европейский варианты), суахили, шведский, тагальский, тайский, турецкий, украинский, вьетнамский, зулусский. Для Universal Translator 2000 Professional объявлена возможность перевода в любом направлении для любой языковой пары. Нетрудно подсчитать, что число таких пар составляет 1560. Кроме того, программа записывает текст под диктовку, читает вслух и проверяет грамотность написанного. Вместе с переводчиком поставляются две обучающие игры Space Attack и WortTris, которые должны, по-видимому, окончательно сразить потребителя и конкурентов.
Лингвистический анализ текста — обязательная стадия процесса автоматического ввода текста под диктовку. Без этой стадии современное качество распознавания не могло бы быть достигнуто, и многие эксперты связывают перспективы речевых систем именно с дальнейшим развитием содержащихся в них лингвистических механизмов. Как следствие, речевые технологии делаются все более зависимыми от языка, с которым работают. В сфере распознавания слитной речи зависимость стала абсолютной, что подтверждается, в частности, отрицательным опытом локализации программного пакета фирмы Dragon Systems для русского языка (имеется в виду система «Горыныч», показавшая объявленного качества распознавания). Однако и других областях работы с речью, включая TTS и даже механизмы редактирования и сжатия, специфика языка все более дает себя знать. Следовательно распознавание, синтез и обработка русской речи являются той нишей, занять которую должны именно российские разработчики.
Контрольные вопросы
1. Перечислите основные принципы распознавания символов (OCR)
2. Что такое OCR А и OCR В?
3. В чем заключается содержание метода сопоставления с образцом?
4. Перечислите основные особенности метода POWR.
5. Каковы возможности программного продукта Finereader?
6. Что такое принципы IPA?
7. В чем заключается MDA?
8. Что такое бинаризация изображения?
9. Какие типы классификаторов-распознавателей вам известны?
10. Перечислите основные принципы систем распознавания речи (STT).
11. Охарактеризуйте программные продукты STT.
12. Перечислите основные принципы систем генерации речи (TTS).
13. Охарактеризуйте программные продукты TTS.
14. Назовите основные принципы систем автоматизированного перевода.
15. Что такое фразеологический машинный перевод?
16. Какова структура машинного словаря?
17. Назовите возможности системы машинного перевода Promt.
18. В чем заключается интеграция систем перевода и обработки речи?