
Размещение собственных материалов в Интернете включает два этапа: подготовку материалов и их публикацию. Подготовка материалов состоит в создании документов, имеющих формат, принятый в Интернете, то есть Web-страниц, написанных на языке HTML. Публикация материалов, то есть открытие к ним доступа, осуществляется после решения организационных вопросов, связанных с получением дискового пространства на Web-сервере для их размещения.
19.1. Создание Web-документов
Автономные Web-документы используют язык HTML (HyperText Markup Language — язык разметки гипертекста). Гипертекст, то есть расширенный текст, включает дополнительные элементы: иллюстрации, ссылки, вставные объекты. Под разметкой понимается использование специальных кодов, легко отделяемых от смыслового содержания документа и используемых для реализации гипертекста. Применение этих кодов подчиняется строгим правилам, определяемым спецификацией языка HTML.
Особенность описания документа средствами языка HTML связана с принципиальной невозможностью достижения абсолютной точности воспроизведения исходного документа. Предполагается, что документ будет широко доступен в Интернете, и поэтому неизвестно, как будет организовано его воспроизведение. Документ может быть представлен на графическом экране, выведен в чисто текстовом виде или просто «прочитан» программой синтеза речи. Разметка HTML во всех этих случаях должна быть принята во внимание. Поэтому язык HTML предназначен не для форматирования документа, а для его функциональной разметки. Например, документы обычно начинаются с заголовков. Свойство части документа «быть заголовком» — это не особенность форматирования документа, а характеристика его содержания. Конкретное средство отображения документа (браузер) выбирает свой способ представления части документа, описанной как заголовок.
Современная версия HTML 4.0 может в настоящий момент рассматриваться как «окончательная» редакция языка HTML, содержащая все необходимое для функциональной разметки документа. Недостаток оформительских средств и средств
обеспечения интерактивности восполняется внешними по отношению к HTML средствами, такими как списки стиля и динамические сценарии. Многие Web-узлы выполняют автоматическую генерацию Wei-страниц на основе содержания некоторой базы данных и запроса пользователя. Подобные элементы стали стандартными компонентами современных Web-страниц, но лежат за пределами данного пособия.
Управляющие конструкции языка HTML называются тегами и вставляются непосредственно в текст документа. Все теги заключаются в угловые скобки <...>. Сразу после открывающей скобки помещается ключевое слово, определяющее тег, например <DIV>. Теги HTML бывают парными и непарными. Непарные теги оказывают воздействие на весь документ или определяют разовый эффект в месте своего появления. При использовании парных тегов в документ добавляются открывающий и закрывающий теги, которые воздействуют на часть документа, заключенную между ними. Закрывающий тег отличается от открывающего наличием символа «/» (косая черта) перед ключевым словом (</DIV>). Закрытие парных тегов выполняется так, чтобы соблюдались правила вложения.
<В><1>На этот текст воздействуют два тега</1х/В>
Эффект применения тега может видоизменяться путем добавления атрибутов. В парных тегах атрибуты добавляются только к открывающему тегу. Атрибуты представляют собой дополнительные ключевые слова, отделяемые от ключевого слова, определяющего тег, и от других атрибутов пробелами и размещаемые до завершающего тег символа «>». Способ применения некоторых атрибутов требует указания значения атрибута. Значение атрибута отделяется от ключевого слова атрибута символом «=» (знак равенства) и заключается в кавычки.
<Н1 ALIGN="LEFT">
Определение HTML как языка разметки основывается на том, что при удалении из документа всех тегов получается текстовый документ, совершенно эквивалентный по содержанию исходному гипертекстовому документу. Таким образом, при отображении документа HTML сами теги не отображаются, но влияют на способ отображения остальной части документа.
Если говорить о создании документов HTML, то можно представить себе два способа их формирования. Первый состоит в разметке существующего (или создаваемого) документа вручную. При этом автор или редактор добавляет в документ теги разметки. Эту работу можно выполнять в текстовом редакторе или редакторе HTML, имеющем специальные элементы управления для упрощения ввода тегов. В обоих этих случаях работа ведется средствами языка HTML, и человек, выполняющий эту работу, должен знать и уметь применять этот язык.
Принципы иного подхода можно понять на основе изучения работы текстовых процессоров. Информацию о форматировании документа можно рассматривать как «разметку», добавляемую в форматируемый документ. Однако для использования текстового процессора не требуется знаний о формате документа и «языке разметки»: изменения, отображаемые на экране, вносятся в документ автоматически. Такой принцип соответствия экранного изображения реальному получил название WYSIWYG (от английского What You See Is What You Get — Что видите, то и получаете).
В качестве редактора WYSIWYG для языка HTML можно использовать текстовый процессор Word или входящую в состав пакета Microsoft Office программу FrontPage. Существуют и другие программы того же самого назначения.
Работа вручную позволяет создавать более универсальные, более качественные и более разнообразные документы. Второй способ проще освоить, так как он не требует знания языка HTML. Однако в этом случае используются средства форматирования вместо средств описания, что может иногда приводить к нежелательным последствиям. При подготовке крупных Web-узлов, содержащих десятки, а то и сотни Web-страниц, та или иная автоматизация работы необходима. Как правило, в таких случаях используют комбинированный подход: «рядовые» страницы готовят с помощью автоматизированных средств, а в особо сложных или в особо важных случаях задают оформление вручную.
Процесс создания Web-документов сродни программированию и так же подвержен ошибкам. Независимо от того, каким способом создается документ, следует регулярно проверять его соответствие замыслу, просматривая его в различных браузерах. Для художественной оценки получающейся страницы следует обратиться к независимому мнению.
19.2. Применение языка HTML
Структура документа HTML
Все документы HTML имеют одну и ту же структуру, определяемую фиксированным набором тегов структуры. Документ HTML всегда должен начинаться с тега <HTML> и заканчиваться соответствующим закрывающим тегом (</HTML>). Внутри документа выделяются два основных раздела: раздел заголовков и тело документа, — идущих именно в таком порядке. Раздел заголовков содержит информацию, описывающую документ в целом, и ограничивается тегами <HEAD> и </HEAD>. В частности, раздел заголовков должен содержать общий заголовок документа, ограниченный парным тегом <TITLE>.
Основное содержание размещается в теле документа, которое ограничивается парным тегом <BODY>. Строго говоря, положение структурных тегов в документе нетрудно определить, даже если они опущены. Поэтому стандарт языка HTML требует только наличия тега <TITLE> (и, соответственно, </TITLE>). Тем не менее, при создании документа HTML опускать структурные теги не рекомендуется.
Простейший правильный документ HTML, содержащий все теги, определяющие структуру, может выглядеть следующим образом:
<HTML>
<НЕАО><ТГП-Е>3аголовок документа<Я1Т1.Е></НЕАО>
<BODY>
Текст документа
</BODY>
</HTML>
Элементы HTML
Для парных тегов область влияния определяется частью документа между открывающим и закрывающим тегом. Такую часть документа рассматривают как элемент языка HTML. Так, можно говорить об «элементе BODY», включающем тег <BODY>, основное содержание документа и закрывающий тег </BODY>. Весь документ HTML можно рассматривать как «элемент HTML». Для непарных тегов элемент совпадает с тегом, который его определяет.
Большинство элементов языка HTML описывает части содержания документа и помещается между тегами <BODY> и </BODY>, то есть внутрь структурного элемента BODY. Такие элементы делят на блочные и текстовые. Блочные элементы относятся к частям текста уровня абзаца. Текстовые элементы описывают свойства отдельных фраз и еще более мелких частей текста.
Теперь можно сформулировать правила вложения элементов.
• Элементы не должны пересекаться. Другими словами, если открывающий тег располагается внутри элемента, то и соответствующий закрывающий тег должен располагаться внутри этого же элемента.
• Блочные элементы могут содержать вложенные блочные и текстовые элементы.
• Текстовые элементы могут содержать вложенные текстовые элементы.
• Текстовые элементы не могут содержать вложенные блочные элементы.
Строго говоря, все правила языка HTML можно рассматривать исключительно как «пожелания». Средство, используемое для отображения Web-документа, сделает все возможное, чтобы истолковать разметку наиболее разумным образом. Тем не менее, гарантию правильного воспроизведения документа дает только неукоснительное следование требованиям спецификации языка.
Функциональные блочные элементы
В большинстве документов основными функциональными элементами являются заголовки и абзацы (рис. 19.1). Язык HTML поддерживает шесть уровней заголовков. Они задаются при помощи парных тегов от <Н1> до <Н6>. При отображении Web-документа на экране компьютера эти элементы показываются при помощи шрифтов разного размера.
Обычные абзацы задаются с помощью парного тега <Р>. Язык HTML не содержит средств для создания абзацного отступа («красной строки»), поэтому при отображении на экране компьютера абзацы разделяются пустой строкой. Закрывающий тег </Р> рассматривается как необязательный. Подразумевается, что он стоит перед тегом, который задает начало очередного абзаца документа. Например:
<Н1 >Заголовок</Н1>
<Р>Первый абзац<Р>Второй абзац
<Н2>Заголовок второго уровня</Н2>
Следствием наличия специального тега, определяющего абзац, является тот факт, что обычного символа конца строки, вводимого по нажатию клавиши ENTER, для

Рис. 19.1. Форматирование заголовков и абзацев при отображении Web-страницы
в окне браузера
создания абзацного отступа недостаточно. Язык HTML рассматривает символы конца строки и пробелы особым образом. Любая последовательность, состоящая только из пробелов и символов конца строки, при отображении документа рассматривается как одиночный пробел. Это, в частности, означает, что символ конца строки даже не осуществляет перехода на новую строку (для этой цели используется текстовый элемент, задаваемый непарным тегом <BR>).
В качестве ограничителя абзацев может также использоваться горизонтальная линейка. Этот элемент задается непарным тегом <HR>. При отображении документа на экране линейка разделяет части текста друг от друга. Ее длина и толщина задается атрибутами тега <HR>.
<HR ALIGN="RIGHT" SIZE="10" WIDTH="50%">
Этот тег создает горизонтальную линейку шириной в 10 пикселов, занимающую половину ширины окна и расположенную справа.
Гипертекстовые ссылки
Гипертекстовая ссылка (рис. 19.2) является фрагментом текста документа и потому задается текстовым элементом, определяемым при помощи парного тега <А>. Этот элемент содержит обязательный атрибут, который не может быть опущен. В данном случае обязательным является атрибут HREF= (знак равенства показывает, что необходимо задать значение этого атрибута).
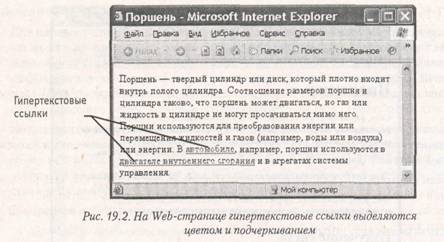
В качестве значения атрибута используется адрес URL документа, на который указывает ссылка. Она может указывать на произвольный документ, располагающийся на любом общедоступном узле сети (Web-узел, архив FTP и прочие). Например, открывающий тег ссылки может иметь вид <AHREF="http://www.site.com/index.htm">.
Адрес URL может быть задан в абсолютной форме, то есть начинаться с указания протокола и адреса Web-узла.. Такая запись адреса используется, когда необходимо направить посетителя на другой Web-узел, и рассматривается как внешняя ссылка. При использовании относительного адреса в ссылке задается только относительный путь поиска для документа. В этом случае предполагается использование того же протокола и того же Web-узла, а ссылка рассматривается как внутренняя. Внутренняя ссылка сохраняет свою работоспособность в случае изменения адреса Web-узла как целого (например, в результате его переноса на другой сервер), поэтому при потенциальной возможности такого события следует отказываться от полного задания адресов в гиперссылках.
Гиперссылки можно использовать для ссылки на мультимедийные файлы. Это удобно, так как в этом случае не приходится ждать загрузки мультимедийных файлов при работе с данной страницей. Если же требуется интегрирование объектов мультимедиа в Web-страницу, используют парный тег <OBJECT> или нестандартный непарный тег <EMBED>, который тоже поддерживается наиболее распространенными браузерами.
Полный формат гиперссылки включает возможность ссылки на определенное место внутри страницы. Но это можно сделать для страниц собственной разработки, пометив соответствующее место при помощи якоря. Якорь задается также при помощи парного тега <А>, но в роли обязательного выступает атрибут NAME=. Значение этого атрибута — произвольная последовательность латинских букв и цифр (пробелы недопустимы), рассматриваемая как имя якоря. Для ссылки на якорь его имя указывается в конце адреса URL после символа «#».
<AHREF="http://www.site. com/index. htm#address">
Web-графика
Графические иллюстрации в большинстве случаев являются неотъемлемой частью Web-документов. Сегодня графические элементы Web-страншх используют два основных формата — GIFhJPEG (допустим также формат PNG, который, однако, так и не получил широкого распространения). Все графические браузеры, предназначенные для отображения Web-страниц на экране компьютера, способны распознавать и отображать файлы этих форматов.
Для подготовки изображений можно использовать любой графический редактор, например стандартное приложение Paint (в Windows XP), которое позволяет сохранять файлы в этих форматах.
Файлы формата GIF (Graphic Interchange Format) имеют расширение .GIF. Изображения в этом формате содержат 256 цветов, заданных индексной палитрой. Файл упакован и может занимать значительно меньше места, чем неупакованный растровый рисунок (например, в формате .BMP).
Спецификация формата GIF89a позволяет создавать файлы .GIF, обладающие специальными возможностями.
• Один из цветов изображения может быть объявлен прозрачным. Это означает, что в соответствующих местах сквозь него будет проглядывать фон Web-страницы, что позволяет задать не только прямоугольную форму рисунка и делает его более естественным.
• Чересстрочные изображения при их приеме из Интернета прорисовываются постепенно, вначале грубо, а затем все более и более четко. Это «скрадывает» время, необходимое на их загрузку из Интернета, особенно при приеме информации по медленным линиям.
• GIF-анимация превращает обычный рисунок в небольшой видеоролик. В стандартном файле с расширением .GIF хранится набор кадров, а также сценарий их отображения.
Для создания файлов .GIF, использующих эти расширенные возможности, необходим графический редактор, более мощный, чем программа Paint. Для создания GIF-анимации используют специальные средства.
Файлы формата/PfG (Joint Photographic Expert Group — по названию группы исследователей, предложившей этот формат, читается «джей-пег») могут иметь расширение JPEG или JPG. Формат предназначен для хранения фотографических изображений, использующих 24-разрядный цвет. При конвертировании в формат,/Р£С происходит потеря части информации, приводящая к некоторому ухудшению качества изображения, обычно незаметному на глаз.
При выборе формата изображения в первую очередь принимают во внимание объем получающегося файла и во вторую — качество изображения. При загрузке Web-документа львиную долю времени занимает именно загрузка иллюстраций, так что любая экономия приветствуется. При выборе формата рекомендуется создать два файла: в формате GIF w в формате JPEG с минимально приемлемым качеством, после чего выбрать вариант, имеющий меньший объем.
Рисунки хранятся на Web-узлах в отдельных файлах, но отображаются как элементы Wei-страниц. Для вставки рисунка используется текстовый элемент, задаваемый непарным тегом <IMG>. Тег <IMG> должен содержать обязательный атрибут SRC=, задающий адрес URL файла с изображением в относительной или абсолютной форме.
<IMG SRC="picture1.gif">
При отображении рисунка браузер по умолчанию использует его реальные размеры. Если рисунок необходимо отмасштабировать, применяют атрибуты WIDTH= и HEIGHT=, задающие ширину и высоту рисунка (в пикселах), соответственно. Если эти параметры заданы, то браузер может определить, какое место надо выделить для отображения рисунка, еще до того, как рисунок загружен. Это несколько ускоряет отображение загружаемой страницы, так что удобно задавать эти атрибуты всегда.
<IMG SRC="picture2.jpg" WIDTH="100" HEIGHT="40">
Внешний вид Web-страницы зависит от того, как именно рисунок располагается на ней. Так как рисунок задается как текстовый элемент, находящийся внутри какого-то абзаца, по умолчанию он рассматривается как встроенное изображение, включаемое в строку текста. Чтобы изображение отображалось автономно, его включают в отдельный абзац.
Для изображения, которое действительно включено в строку, можно задать режим взаимодействия с текстом с помощью атрибута ALIGN=.
<IMG SRC="picture3.gif" ALIGN="BOTTOM">
Этот атрибут может принимать три значения:
• если задано ALIGN="BOTTOM", то нижняя граница изображения совмещается с основанием текстовой строки;
• если задано ALIGN="MIDDLE", то середина изображения совмещается с серединой текстовой строки;
• если задано ALIGN="TOP", то верхняя граница изображения выравнивается по верхнему обрезу текстовой строки.
Однако более предпочтительно использование «плавающего» изображения, обтекаемого текстом, что также достигается использованием атрибута ALIGN=:
• если задано ALIGN="LEFT", то изображение размещается у левого края страницы, а последующий текст размещается справа от него;
• если задано ALIGN="RIGHT", то изображение размещается у правого края страницы, а последующий текст размещается слева от него.
В этом случае рекомендуется помещать тег <IMG> в самое начало соответствующего абзаца.
Однако нормальный режим обтекания требует, чтобы между текстом и изображением оставался некоторый промежуток (рис. 19.3). Задать величину этого промежутка можно при помощи атрибутов HSPACE= (по горизонтали) и VSPACE= (по вертикали). Размеры задаются в пикселах.

Рис. 19.3. Изображение в тексте, выровненное по левому полю
Создавая иллюстрированные страницы, не следует забывать, что не все смогут увидеть эти иллюстрации. Читателей, не имеющих адекватного средства просмотра, можно ознакомить с содержанием иллюстраций при помощи альтернативного текста. Альтернативный текст задается как значение атрибута ALT= и отображается вместо картинки, если она по каким-то причинам не может быть выведена.
Так как изображение задается как текстовый элемент, оно может быть помещено внутрь другого текстового элемента, например задающего гиперссылку (тег <А>). В этом случае изображение становится изображением-ссылкой. При отображении документа на экране компьютера такое изображение отличается синей рамкой и изменением формы указателя при наведении.
Еще один способ применения изображений па Web-страницах состоит в использовании их в качестве фонового рисунка. При отображении документа, содержащего фоновый рисунок, на компьютере рабочая область окна заполняется этим рисунком последовательно (как паркетом), считая от верхнего левого угла документа или окна (рис. 19.4). Фоновый рисунок задается с помощью атрибута BACKGROUND= в теге <BODY>. Значением этого атрибута должен быть абсолютный или относительный адрес URL для файла с изображением.
<BODYBACKGROUND="waves.girTEXr="YELLOW">
Форматирование текста
Управление форматированием текста не является основной задачей языка HTML, и поэтому текстовые элементы, выполняющие эту задачу, начиная с версии 4.0 рассматриваются как устаревшие, и их использование не рекомендуется. Однако они все еще предоставляют удобный способ управления видом документа на экране компьютера.

Рис. 19.4. К выбору фонового рисунка следует подходить с особой осторожностью, так как неудачный фон может сильно затруднить чтение документа
Парный тег <FONT> позволяет управлять параметрами шрифта. Он должен обязательно содержать хотя бы один из трех атрибутов: COLOR=, FACE= или SIZE=.
<FONTSIZE="6">
Атрибут COLOR= задает цвет текста, который может быть задан текстовым значением (например, COLOR="GREEN") или шестнадцатеричным кодом, в котором последовательные байты задают значения красной, зеленой и синей составляющих цвета (COLOR="#OOFFOO" дает тот же результат, что и COLOR="GREEN"). Атрибут FACE= задает гарнитуру шрифта. Значение этого атрибута сравнивается с именами шрифтов, которые установлены на компьютере. Атрибут SIZE= определяет размер шрифта в относительных единицах (от 1 до 7). Для этого атрибута можно определять значение со знаком (плюс или минус), которое определяет увеличение или уменьшение шрифта относительно текущего размера.
Параметры шрифта, используемые в документе по умолчанию, задают с помощью непарного тега <BASEFONT>, который помещают один раз внутри элемента BODY. Он может использовать те же атрибуты, что и тег <FONT>.
Начертание символов задается при помощи парных тегов <В> (полужирный шрифт), <1> (курсив), <U> (подчеркнутый текст) <S> (вычеркнутый текст). Их использование не рекомендуется. Вместо них следует применять элементы фразы, описывающие функциональные особенности текста; например, вместо
<В>Обратите внимание!</В>
лучше написать
<STRONG>06paTMTe8HHMaHHe!</STRONG>
Так, парный тег <С1ТЕ> предназначен для отображения цитат (выводятся курсивом). Парные теги <ЕМ> (выделение) и <STRONG> (сильное выделение) являются функциональными аналогами курсивного и полужирного начертаний. Кроме того, язык HTML содержит набор элементов для описания работы компьютерных программ. Для этой цели используют парные теги <CODE> (исходный текст программы), <KBD> (текст, вводимый с клавиатуры), <SAMP> (пример вывода программы) и <VAR> (программные переменные). Для вывода соответствующих элементов используется моноширинный шрифт. Кроме того, переменные выводятся курсивом, а клавиатурный ввод (в некоторых браузерах) — полужирным шрифтом.
Списки
Язык HTML поддерживает пять видов списков, из которых два (спискименю и списки каталогов) считаются устаревшими и не рекомендуются к применению. Оставшиеся три типа — это упорядоченные списки, неупорядоченные списки и списки определений. Все списки представляют собой блочные элементы.
Упорядоченные (нумерованные) и неупорядоченные (маркированные) списки, примеры которых приведены на рис. 19.5, оформляются одинаково. Они создаются при помощи парных тегов: <OL> для упорядоченного списка и <UL> для неупорядоченного. Эти списки могут содержать только элементы списка, определяемые парным тегом <LI>. Закрывающий тег </LI> можно опускать, так как его местонахождение легко восстановить. Открывающие теги могут содержать атрибуты, определяющие вид маркера (для неупорядоченного списка), способ и последовательность нумерации (для упорядоченного). Разрешается вложение списков друг в друга.

Рис. 19.5. Создание маркированных и нумерованных списков
Список определений задается парным тегом <DL>. Он содержит элементы двух типов: определяемые термины (парный тег <DT>) и определения (парный тег <DD>). Закрывающие теги </DT> и </DD> можно опускать. Обычно определяемые термины и определения чередуют, хотя это нигде не оговорено. Определения отображаются на экране с отступом от левого края. Такой список может быть сформирован следующим образом:
<DL>
<DТ>Поршень
<DD>Сплошной цилиндр или диск, который плотно входит внутрь полого цилиндра
</DL>
Таблицы
Таблицы удобны для представления больших объемов данных, а многие Web-дизайнеры используют их также для точного размещения элементов Web-страниц (рис. 19.6). Таблица в языке HTML задается при помощи парного тега <TABLE>. Она может содержать заголовок таблицы, определяемый парным тегом <CAPTION>, и строки таблицы, задаваемые при помощи парных тегов <TR>. Закрывающие теги </TR> можно опускать.
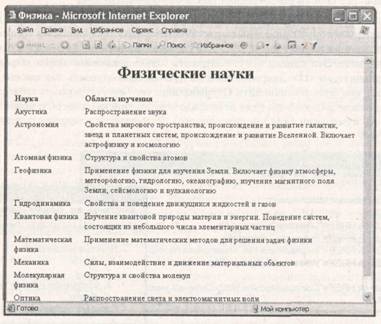
Рис. 19.6. Для размещения текста в двух колонках использована «невидимая» таблица
Каждая строка таблицы содержит ячейки таблицы, которые могут относиться к двум разным типам. Ячейки в заголовках столбцов и строк задают парным тегом <ТН>, а обычные ячейки — парным тегом <TD>. Закрывающие теги </ТН> и <Д0> можно опускать. Например, «пустая» таблица с двумя строками и двумя столбцами может быть задана следующим образом:
<TABLE>
<САРТЮЫ>Пустая таблица</САРТЮМ>
<TR><TDXTD>
<TRXTDXTD>
</TABLE>
Каждая ячейка может содержать произвольный текст, а также любые теги HTML, допустимые в «теле» документа. В частности, ячейка таблицы может содержать вложенную таблицу или изображение.
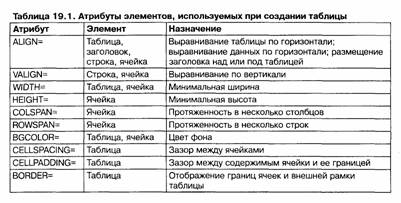
При отображении таблицы на экране компьютера происходит ее автоматическое форматирование с подбором размеров ячеек в соответствии с объемом размещаемой информации и заданными атрибутами. Атрибуты элементов позволяют сколь угодно причудливо оформить таблицу по своему вкусу. В таблице 19.1 приведена краткая сводка допустимых атрибутов.
Отображение нескольких документов
Язык HTML позволяет в рамках одной Web-страницы отобразить несколько документов. Для этого страница должна быть разбита на несколько областей — фреймов. Разбиение страницы описывается документом HTML особого рода, структура которого отличается от обычной. Тело документа заменяется описанием фреймов, задаваемым парным тегом <FRAMESET>. Элемент BODY в таком документе отсутствует, а при наличии — игнорируется браузером.
Открывающий тег <FRAMESET> должен содержать обязательный атрибут COLS= или ROWS=, определяющий способ разбиения окна. В первом случае окно разбивается вертикальными линиями, во втором — горизонтальными. Если заданы оба атрибута, создается сетка фреймов. Значение любого из этих атрибутов — это перечисленные через запятую размеры отдельных фреймов.
<FRAMESET COLS="60%, 40%">
Значения могут быть заданы в пикселах или в процентах от ширины окна. Последняя область может быть определена с помощью символа «*», что означает, что ей выделяется все оставшееся пространство.
<FRAMESET ROWS="40%, 40%,*">
Между тегами <FRAMESET> и </FRAMESET> должно располагаться ровно столько элементов, сколько областей создано с помощью атрибутов COLS= и ROWS=. При этом могут использоваться дополнительные элементы FRAMESET, описывающие дальнейшее разбиение на подобласти еще меньшего размера, или непарные теги <FRAME>, определяющие способ использования области.
Тег <FRAME> должен содержать обязательный атрибут SRC=, с помощью которого указывается, какой документ первоначально загружается в соответствующую область. Значение этого атрибута — абсолютный или относительный адрес URL нужного документа.
Среди прочих атрибутов выделяется атрибут NAME=, позволяющий задать «имя» созданной области в виде последовательности латинских букв и цифр, использованной как значение этого атрибута.
<FRAME SRC="text.htm" NAME="left">
Это имя можно использовать, чтобы загружать новые документы в ранее созданную область. Для этого в тег <А>, определяющий гиперссылку, необходимо добавить атрибут TARGET=, значение которого совпадает с ранее определенным именем области. При переходе по данной гиперссылке новый документ загрузится в указанный фрейм.
Например, предположим, что начальная страница Web-узла состоит из двух фреймов: слева располагается навигационная панель, а справа — текущая страница. Если правой области присвоено имя, используемое во всех ссылках, имеющихся в левой области, то щелчок на любой ссылке навигационной панели приведет к обновлению информации в соседней области, оставляя навигационную панель без изменений.
Интерактивные Web-страницы
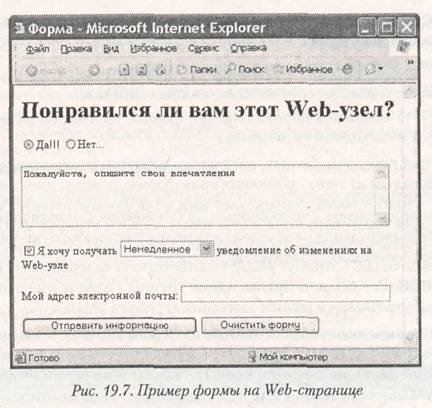
Web-страницы являются интерактивными по самой своей природе, связанной с использованием гиперссылок. Но это пассивная интерактивность, жестко заданная в рамках структуры Web-узла. Подлинная интерактивность, позволяющая получать от посетителей Web-страницы произвольные данные, достигается путем использования форм.
Форма на Web-странице представляет собой лишь набор полей, которые можно также рассматривать как элементы управления (рис. 19.7). Посетитель в процессе работы с Web-страницей заполняет форму, после чего отправляет ее. Далее поступившие данные обычно передают специальной программе, предназначенной для ее обработки (программе или сценарию CGI).
Форма — это блочный элемент, описываемый парным тегом <FORM>. Теги, задающие поля формы, можно использовать только внутри этого элемента. Открывающий тег <FORM> определяет способ обработки формы при помощи нескольких атрибутов. Атрибут METHOD= определяет способ передачи представленных пользователем данных. Он может иметь два значения. Значение «GET» указывает, что данные будут переданы программе (или сценарию) CGI. В этом случае атрибут ACTION= содержит адрес URL этой программы. Если указано METHOD="POST", то данные,
введенные пользователем, отправляются по электронной почте. Атрибут ACTION= в этом случае должен содержать нужный адрес электронной почты с указанием протокола mailto:. Кроме этих, можно также указать атрибут ENCTYPE=, значение которого определяет тип MIME для отправки информации по электронной почте. По умолчанию используется значение application/x-www-form-urlencoded, но, если форма предназначена для обработки вручную, лучше использовать тип MIME text/plain.
Внутри элемента формы располагаются поля формы. Они задаются при. помощи различных тегов. Вот те, которые используются чаще всего.
• Непарный тег <INPUT> позволяет создавать различные элементы управления, в том числе текстовые поля и командные кнопки.
• Парный тег <TEXTAREA> определяет текстовые области.
• Парный тег <SELECT> позволяет создавать обычные и раскрывающиеся списки. Отдельные пункты задаются при помощи парного тега <OPTION>, который допустим только внутри данного элемента (закрывающий тег </OPTION> можно опускать).
Тег <INPUT> должен содержать обязательный атрибут TYPE=, определяющий конкретный тип элемента управления. Вот основные возможные значения этого атрибута;
• "TEXT" — создается текстовое поле;
• "PASSWD" — создается текстовое поле, но вводимая информация не отображается на экране («текстовое поле для ввода пароля»);
• "CHECKBOX" — создается флажок, который может быть установлен или сброшен;
• "RADIO" — создается переключатель (из группы переключателей может быть включен только один);
• "SUBMIT" — создается кнопка отправки формы;
• "IMAGE" — создается графическая кнопка отправки;
• "RESET" — создается кнопка очистки формы, щелчок на которой возвращает форму к ее исходному состоянию;
Организация передачи данных, введенных в форму, осуществляется следующим образом. Каждый из тегов, задающих поля формы, должен иметь атрибуты NAME= и VALUE=. Атрибут NAME= определяет имя поля формы, атрибут VALUE= — значение поля. Для текстового поля и текстовой области атрибут VALUE= приобретает значение, соответствующее содержимому этого поля, заданному пользователем. Для элемента SELECT атрибут VALUE= соответствует содержимому выбранного элемента OPTION. Все переключатели одной группы должны иметь одинаковые значения атрибута NAME= и разные значения атрибута VALUE=.
По щелчку на кнопке отправки данные из формы передаются в виде пар текущих значений атрибутов NAME= и VALUE=, соединенных знаком равенства. Информация о флажке передается только в том случае, если он установлен. Если атрибуты NAME= и VALUE= определены для использованной кнопки отправки, соответствующие данные также передаются (это позволяет включать в форму несколько кнопок отправки). Данные, поступающие в таком виде, удобны как для ручной, так и для автоматической обработки.
Создавая формы, следует иметь в виду, что информацию, передаваемую по электронной почте, нельзя считать конфиденциальной. Большинство браузеров может предупредить пользователя о возможности постороннего доступа к передаваемой информации. Эту особенность надо учитывать как при создании Web-страниц, содержащих формы, так и при заполнении форм на Web-страницах, встретившихся в Интернете.
19.3. Работа в редакторе FrontPage
Программа FrontPage, входящая в состав пакета Microsoft Office, рассчитана, в первую очередь, не на создание отдельных We/j-страниц, а на сопровождение полноценного Web-узла. Она содержит средства контроля структуры узла, единства оформления, правильности внутренних и внешних гиперссылок. Средства создания страниц, рассматриваемые в этом пособии, — это всего лишь небольшая и не основная часть возможностей этой программы.
Начиная работу в редакторе FrontPage, следует отдавать себе отчет, что в результате его применения получается документ HTML, построенный по тем же правилам, что и создаваемый вручную. Этот факт сразу же определяет возможности и ограничения в работе этого редактора.
• Все функции редактора FrontPage однозначно реализуются тегами HTML.
• Редактор FrontPage не имеет средств, которые нельзя было бы представить в виде тегов HTML.
• Пользователь обычно не знает, какие именно средства HTML используются для достижения заданного эффекта и насколько корректно они применяются.
Редактор FrontPage «ориентирован» на применение браузера Internet Explorer, так что создаваемый им код HTML наиболее адекватно отображается именно в этом браузере. В частности, FrontPage позволяет использовать «бегущую строку», средство, которое не входит в стандарт HTML, но поддерживается Internet Explorer.
Создание и редактирование документа
Окно программы FrontPage (рис. 19.8) представляет собой комбинацию окна редактора и окна браузера. Документ HTML отображается редактором, как специфическим браузером, отображающим даже обычно невидимые элементы (такие, как якоря). В то же время, этот текст можно редактировать средствами, аналогичными имеющимся в текстовом процессоре.

В качестве основного средства форматирования используется панель инструментов Форматирование, почти идентичная подобной панели текстового процессора Word. Она содержит:
• раскрывающийся список Стиль, позволяющий выбрать стиль оформления абзаца (соответствующий стандартным функциональным элементам HTML);
• раскрывающийся список Шрифт, позволяющий выбрать гарнитуру шрифта (наличие такого же шрифта в ходе просмотра документа через Интернет не гарантируется);
• раскрывающийся список Размер, позволяющий управлять размером текста (в относительных единицах HTML);
• кнопки выбора начертания;
• кнопки выбора выравнивания текста (с помощью атрибута ALIGN= в теге абзаца
• кнопки создания маркированных (неупорядоченных) и нумерованных (упорядоченных) списков;
• кнопки задания отступа текста (на основе некорректного использования элементов HTML);
• кнопки задания рамок и цвета шрифта и фона. Эти функции реализуются с помощью списков стилей, которые рассматриваются как расширение HTML.
Дополнительные элементы форматирования, не вынесенные на панель инструментов, задаются в отдельных диалоговых окнах. Их можно открыть, например, с помощью команд Формат > Шрифт и Формат ► Список.
Для создания гиперссылки надо выделить фрагмент текста, который будет использоваться как ссылка, и дать команду Вставка ► Гиперссылка. В открывшемся диалоговом окне Добавление гиперссылки тип гиперссылки выбирают на панели Связать с. Можно выбрать для ссылки другой файл (Связать с файлом, Web-страницей), место в этом же документе (Связать с местом в документе), новую страницу своего Web-узла (Связать с новым документом; документ, на который указывает ссылка, создается немедленно) или адрес электронной почты (Связать с электронной почтой).
Кнопки Выбор рамки и Закладка позволяют указать, соответственно, имя фрейма, в котором будет открываться страница, и якорь, который необходимо использовать.
Созданная гиперссылка отображается в окне программы FrontPage так же, как и в окне браузера: синим цветом и с подчеркиванием. Чтобы проверить работоспособность ссылки, следует щелкнуть на ней правой кнопкой мыши и выбрать в контекстном меню команду По ссылке.
Таблицы и формы невозможно создать только с помощью команд форматирования. Чтобы создать таблицу, используют команду Таблица ► Вставить ► Таблица. В открывшемся диалоговом окне указывают размер таблицы (в ячейках), а также дополнительные параметры, реализуемые как атрибуты соответствующих тегов. Чтобы занести информацию в таблицу, следует установить курсор в нужную ячейку и начать ввод. При работе с ячейками таблицы можно применять любые команды форматирования.
Для вставки формы и ее элементов служит меню Вставка ► Форма. При вставке любого элемента управления формы, программа FrontPage автоматически встраивает в страницу новую форму, выделяя ее пунктирной рамкой и добавляя кнопки отправки и сброса. При добавлении последующих полей следует следить за тем, чтобы они включались в ту же самую форму.
В языке HTML свойства элемента задаются атрибутами тега. Редактор FrontPage обеспечивает их задание с помощью специальных диалоговых окон. Чтобы открыть такое диалоговое окно, следует щелкнуть на редактируемом элементе правой кнопкой мыши. В нижней части контекстного меню располагаются команды, относящиеся к элементам документа, рассматриваемым редактором как открытые. Порядок следования команд соответствует порядку вложения элементов. Выбор одной из этих команд приводит к открытию диалогового окна свойств соответствующего элемента. Элементы управления в этом диалоговом окне соответствуют атрибутам открывающего тега для выбранного элемента.
Дополнительные объекты вставляются в редактируемый документ при помощи меню Вставка. Например, для вставки изображения используется команда Вставка ► Рисунок ► Из файла. В диалоговом окне свойств изображения можно выбрать предпочтительный формат (GIF или JPEG), если исходный формат рисунка иной. При сохранении документа программа автоматически выполнит преобразование изображения и его сохранение.
Другие элементы, которые можно разместить на странице, — это:
• горизонтальная линейка (Вставка ► Горизонтальная линия);
• видеозапись (Вставка ► Рисунок ► Видеозапись);
• фоновое звуковое сопровождение (Файл ► Свойства > Общие ► Фоновый звук);
• встроенный фрейм (Вставка ► Встроенная рамка);
• нестандартные компоненты (Вставка ► Веб- компонент). Эти компоненты используют нестандартную разметку и способны работать не на всех серверах.
Иногда требуется вмешаться в процесс автоматического формирования Web-страницы и внести изменения непосредственно в генерируемый код HTML. Для этого надо щелкнуть на кнопке HTML-код в нижней части окна. При этом отображается не примерный вид документа, а сгенерированный программой FrontPage код HTML (рис. 19.9). Цветная маркировка позволяет немедленно увидеть ключевые слова тегов и названия атрибутов. Этот код можно редактировать вручную, однако в этом случае ответственность за правильность кода переносится с программы FrontPage на создателя страницы. Возможно, например, некорректное взаимодействие кода, введенного вручную, и элементов HTML, сгенерированных автоматически. Некоторые «ошибки» могут быть даже исправлены автоматически, причем не всегда с ожидаемым результатом.

Редактор FrontPage также позволяет просмотреть Web-страницу в таком виде, в каком ее представит браузер (в режиме редактирования в тексте страницы имеется дополнительная маркировка, облегчающая работу). Для этого надо щелкнуть на кнопке Просмотр. Отображение страницы осуществляется исходя из возможностей браузера Internet Eplorer.
Применение мастеров и шаблонов
Для упрощения и автоматизации создания Web-страниц редактор FrontPage позволяет использовать мастера и шаблоны. Для этого надо создать новый документ командой Файл ► Создать ► Страница или Web-узел — на экране появится Область задач в режиме Создание веб – страницы или узла. Щелкните на ссылке Шаблоны страниц в разделе Создание с помощью шаблона — откроется диалоговое окно Шаблоны страниц.
На вкладке Общие располагаются мастера и шаблоны для обычных Web-страниц.
При использовании мастера (Мастер страницы формы) программа задает ряд вопросов и на основании ответов формирует заготовку документа. Результат представляет собой скорее план страницы, чем законченный продукт, и от пользователя требуется наполнение созданных разделов конкретным содержимым.
Шаблоны представляют собой готовый документ «общего характера». В тех местах, где должен располагаться текст, соответствующий нуждам конкретного пользователя, вместо этого помещен текст, описывающий принципы заполнения соответствующего раздела. Этот текст заменяется в ходе редактирования документа. В начале документа-шаблона может располагаться комментарий (не отображаемый в обычном браузере), описывающий общие правила заполнения данного шаблона. Сохранение документа, сформированного на основе шаблона, не изменяет сам шаблон, который может использоваться многократно.
Создать страницу, состоящую из фреймов, можно только на основе шаблона. Соответствующие шаблоны отображаются на вкладке Страница рамок. Выбрав любой из этих шаблонов, можно вносить дополнительные изменения в структуру фреймов, используя пункт Рамки в строке меню.
19.4. Публикация Web-документов
Публикация Web-узла (Шей-страниц) состоит в размещении документов HTML и всех сопроводительных файлов (изображений, мультимедиа и прочего) на Web-сервере. Если оставить в стороне организационные вопросы (получение места на Web-сервере, оплата и другие), то остаются две основные проблемы.
• Как подготовить документы Web -узла таким образом, чтобы перенос их на Web-сервер не привел к нарушению целостности структуры узла?
• Как произвести копирование файлов на Web -сервер?
Первый вопрос возникает в том случае, если файлы на Web -сервере предполагается разместить в группе тематических каталогов. Он решается с помощью организационных мер в ходе работы над Web-узлом. При формировании будущего узла на своем компьютере необходимо разработать структуру папок и сразу же размещать документы в соответствующих папках. Во внутренних ссылках следует использовать только относительные адреса документов. Перенос файлов и папок на Web-сервер с сохранением структуры сохраняет работоспособность ссылок и корректность подключения вставных объектов (иллюстраций и мультимедиа). При таком подходе облегчается также обновление Web-узла в целом или его отдельных файлов.
Для копирования нужных документов на Web-сервер можно применять как передачу данных на съемном носителе, так и прямое копирование данных через Интернет. Последний способ более надежен. Чтобы воспользоваться им, следует узнать адреса, используемые при отправке файлов (обычно для публикации Web-страниц применяют протокол FTP),
При использовании специализированных программных средств (например, редактора FrontPage) инструменты публикации обычно предоставляет сама программа. Например, в FrontPage для этой цели служит команда Файл ► Опубликовать Web-узел. Во многих случаях организация, предоставляющая место для размещения Web-узла, сама определяет порядок публикации и предоставляет средства для ее выполнения.
Если доступ осуществляется по протоколу FTP, необходимо узнать адрес каталога, а также имя пользователя и пароль для доступа к нему (доступ на запись по протоколу FTP всегда защищается паролем). Для выполнения переноса файлов можно использовать программу Internet Explorer. Введите адрес нужного каталога на панели Адрес и щелкните на кнопке Переход.
Программа Internet Explorer отобразит содержимое узла в виде, подобном папке локального компьютера. Для выполнения файловых операций можно использовать те же команды, что и на локальном компьютере: копирование, перемещение, переименование и удаление файлов (после подтверждения прав доступа).
Следует понимать, что при этих операциях используются довольно медленные линии связи, так что продолжительность передачи файлов может быть довольно велика. По завершении этих операций обновленный Web-узел может быть сразу доступен любым посетителям в Интернете.
Практическое занятие
Упражнение 19.1. Создание простейшей Web-страницы
1. Запустите текстовый редактор Блокнот (Пуск ► Программы ► Стандартные ► Блокнот).
2. Введите следующий документ:

- Сохраните этот документ под именем first.htm!
ü Перед сохранением убедитесь, что сброшен флажок Скрывать расширения для зарегистрированных типов файлов (Пуск ► Настройка ► Панель управления ► Свойства папки ► Вид). В противном случае редактор Блокнот может автоматически добавить в конец имени расширение .ТХТ.
4. Запустите программу Internet Explorer (Пуск ► Программы ► Internet Explorer).
5. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл first.htm.
6. Посмотрите, как отображается этот файл — простейший корректный документ HTML. Где отображается содержимое элемента TITLE? Где отображается содержимое элемента BODY?
7. Как отображаются слова «Содержание» и «документа», введенные в двух отдельных строчках? Почему? Проверьте, что происходит при уменьшении ширины окна!
ü В этом упражнении мы создали простейший документ HTML. Мы познакомились с особенностями форматирования документов HTML и их отображения при помощи браузера Internet Explorer.
Упражнение 19.2. Изучение приемов форматирования абзацев
1. Если это упражнение выполняется не сразу после предыдущего, откройте документ first.htm в программе Блокнот.
2. Удалите весь текст, находящийся между тегами <BODY> и </BODY>. Текст, который будет вводиться в последующих пунктах этого упражнения, необходимо поместить после тега <BODY>, а его конкретное содержание может быть любым.
3. Введите заголовок первого уровня, заключив его между тегами <Н1 > и </Н1 >.
4. Введите заголовок второго уровня, заключив его между тегами <Н2> и </Н2>.
5. Введите отдельный абзац текста, начав его с тега <Р>. Пробелы и символы перевода строки можно использовать внутри абзаца произвольно.
6. Введите тег горизонтальной линейки <HR>.
7. Введите еще один абзац текста, начав его с тега <Р>.
8. Сохраните этот документ под именем paragraph.htm.
9. Запустите программу Internet Explorer (Пуск ► Программы ► Internet Explorer).
10. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл paragraph.htm.
11. Посмотрите, как отображается этот файл. Установите соответствие между элементами кода HTML и фрагментами документа, отображаемыми на экране.
[►]. В этом упражнении мы создали документ HTML с разметкой абзацев. Мы определили, как влияют теги HTML на отображение соответствующих частей документа.
Упражнение 19.3. Создание гиперссылок
1. Если это упражнение выполняется не сразу после предыдущего, откройте документ first.htm в программе Блокнот.
2. Удалите весь текст, находящийся между тегами <BODY> и </BODY>. Текст, который будет вводиться в последующих пунктах этого упражнения, необходимо поместить после тега <BODY>.
3. Введите фразу: Текст до ссылки.
4. Введите тег: <А HREF=»first.htm»>.
5. Введите фразу: Ссылка.
6. Введите закрывающий тег </А>.
7. Введите фразу: Текст после ссылки.
8. Сохраните документ под именем link.htm.
9. Запустите программу Internet Explorer (Пуск ► Программы ► Internet Explorer).
10. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл link.htm.
11. Убедитесь в том, что текст между тегами <А> и </А> выделен как ссылка (цветом и подчеркиванием).
12. Щелкните на ссылке и убедитесь, что при этом загружается документ, на который указывает ссылка.
13. Щелкните на кнопке Назад на панели инструментов, чтобы вернуться к предыдущей странице. Убедитесь, что ссылка теперь считается «просмотренной» и отображается другим цветом.
[►].В этом упражнении мы создали документ HTML, содержащий гиперссылки. Мы увидели, как гиперссылки отображаются в документе, и научились пользоваться ими.
Упражнение 19.4. Создание изображения и использование его на Web-странице
1. Откройте программу Paint (Пуск ► Программы ► Стандартные ► Paint). Задайте размеры нового рисунка, например 50x50 точек (Рисунок ► Атрибуты).
2. Выберите красный цвет переднего плана и зеленый цвет фона. Залейте рисунок фоновым цветом.
3. Инструментом Кисть нанесите произвольный красный рисунок на зеленый фон.
4. Сохраните рисунок под именем pid .gif (в формате GIF).
[►]В некоторых версиях Windows программа Paint позволяет создавать рисунки GIF с прозрачным фоном. В этом случае диалоговое окно Атрибуты (Рисунок ► Атрибуты) содержит флажок Использовать прозрачный цвет фона.
5. Если это упражнение выполняется не сразу после предыдущего, откройте документ first.htm в программе Блокнот.
6. Удалите весь текст, находящийся между тегами <BODY> и </BODY>. Текст, который будет вводиться в последующих пунктах этого упражнения, необходимо поместить после тега <BODY>.
7. Введите произвольный текст (протяженностью 4-5 строк) и установите текстовый курсор в его начало.
8. Введите тег <IMGSRC="pic1.gif" ALIGN="BOTTOM">.
9. Сохраните документ под именем picture.htm.
10. Запустите программу Internet Explorer (пуск ► Программы ► Internet Explorer).
11. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл picture.htm. Посмотрите на получившийся документ, обращая особое внимание на изображение.
12. Вернитесь в программу Блокнот и измените значение атрибута: ALIGN="TOP". Сохраните файл под тем же именем.
13. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить на панели инструментов. Посмотрите, как изменился вид страницы при изменении атрибутов.
14. Вернитесь в программу Блокнот и измените значение атрибута: ALIGN="LEFT". Сохраните файл под тем же именем.
15. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить на панели инструментов. Посмотрите, как изменился вид страницы при изменении атрибутов.
16. Вернитесь в программу Блокнот и добавьте в тег <IMG> атрибуты: HSPACE=40 VSPACE=20. Сохраните файл под тем же именем.
17. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить на панели инструментов. Посмотрите, как изменился вид страницы при изменении атрибутов.
[►].В этом упражнении мы научились вставлять изображения в документ. Мы выяснили, как влияют атрибуты тега <IMG> на способ отображения изображения.
Упражнение 19.5. Приемы форматирования текста
1. Если это упражнение выполняется не сразу после предыдущего, откройте документ first.htm в программе Блокнот.
2. Удалите весь текст, находящийся между тегами <BODY> и </BODY>. Текст, который будет вводиться в последующих пунктах этого упражнения, необходимо поместить после тега <BODY>, а его конкретное содержание может быть любым.
3. Введите тег <BASEFONT SIZE="5" COLOR="BROWN">. Он задает вывод текста по умолчанию увеличенным шрифтом и коричневым цветом.
4. Введите произвольный абзац текста, который будет выводиться шрифтом, заданным по умолчанию. Начните этот абзац с тега <Р>.
5. Введите теги: <PXFONT SIZE="-2" FACE="ARIAL" COLOR="GREEN">.
6. Введите очередной абзац текста, закончив его тегом </FONT>.
7. В следующем абзаце используйте по своему усмотрению парные теги: <В> (полужирный шрифт), <1> (курсив), <U> (подчеркивание), <S> (вычеркивание), <SUB> (нижний индекс), <SUP> (верхний индекс).
8. В следующем абзаце используйте по своему усмотрению парные теги: <ЕМ> (выделение), <STRONG> (сильное выделение), <CODE> (текст программы), <KBD> (клавиатурный ввод), <SAMP> (пример вывода), <VAR> (компьютерная переменная).
9. Сохраните полученный документ под именем format.htm.
10. Запустите программу Internet Explorer (Пуск ► Программы ► Internet Explorer).
11. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл format.htm.
12. Изучите, как использованные элементы HTML влияют на способ отображения текста.
13. Вернитесь в программу Блокнот и измените документ так, чтобы элементы, задающие форматирование, были вложены друг в друга. Сохраните документ под тем же именем.
14. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить на панели инструментов. Посмотрите, как изменился вид страницы.
[►]Мы познакомились с некоторыми элементами языка HTML, которые могут использоваться для форматирования текста документа. Мы выяснили, как эти элементы воздействуют на отображение документа, и узнали, что такие элементы можно вкладывать друг в друга.
Упражнение 19.6. Приемы создания списков
1. Если это упражнение выполняется не сразу после предыдущего, откройте документ first, htm в программе Блокнот.
2. Удалите весь текст, находящийся между тегами <BODY> и </BODY>. Текст, который будет вводиться в последующих пунктах этого упражнения, необходимо поместить после тега <BODY>, а его конкретное содержание может быть любым.
3. Вставьте в документ тег <OL TYPE="I">, который начинает упорядоченный (нумерованный) список.
4. Вставьте в документ элементы списка, предваряя каждый из них тегом <LI>.
5. Завершите список при помощи тега </OL>.
6. Сохраните полученный документ под именем list.htm.
7. Запустите программу Internet Explorer { Пуск ► Программы ► Internet Explorer).
8. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл list.htm.
9. Изучите, как упорядоченный список отображается в программе Internet Explorer, обращая особое внимание на способ нумерации, заданный при помощи атрибута TYPE=.
10. Вернитесь в программу Блокнот и установите текстовый курсор после окончания введенного списка.
11. Вставьте в документ тег <ULTYPE="SQUARE">, который начинает неупорядоченный (маркированный) список.
12. Вставьте в документ элементы списка, предваряя каждый из них тегом <LI>.
13. Завершите список при помощи тега </UL>. Сохраните документ под тем же именем.
14. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить на панели инструментов. Посмотрите, как изменился вид страницы, обратив внимание на способ маркировки, заданный при помощи атрибута TYPE=.
15. Вернитесь в программу Блокнот и установите текстовый курсор после окончания введенного списка.
16. Вставьте в документ тег <DL>, который начинает список определений.
17. Вставьте в список определяемые слова, предваряя соответствующие абзацы тегом <DT>.
18. Вставьте в список соответствующие определения, предваряя их тегом <DD>.
19. Завершите список при помощи тега </DL>. Сохраните документ под тем же именем.
20. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить на панели инструментов. Посмотрите, как выглядит при отображении Web-страницы список определений.
[►]Мы научились создавать списки средствами языка HTML и определять способ их нумерации (маркировки). Мы установили, как выглядят списки при их отображении в браузере Internet Explorer. Мы также научились создавать список определений.
Упражнение 19.7. Создание таблиц
1. Если это упражнение выполняется не сразу после предыдущего, откройте документ first.htm в программе Блокнот.
2. Удалите весь текст, находящийся между тегами <BODY> и </BODY>. Текст, который будет вводиться в последующих пунктах этого, упражнения, необходимо поместить после тега <BODY>. В данном упражнении используется список номеров телефонов.
3. Введите тег <TABLEBORDER="10"WIDTH="100%">.
4. Введите строку: <CAPTION АибЫ="ТОР">Списоктелефонов</САРТЮг\1>.
5. Первая строка таблицы должна содержать заголовки столбцов. Определите ее следующим образом:
<TR BGCOLOR="YELLOW" ALIGN="CENTER"> <ТН>Фамилия<ТН>Номер телефона
6. Определите последующие строки таблицы, предваряя каждую из их тегом <TR> и помещая содержимое каждой ячейки после тега <TD>.
7. Последнюю строку таблицы задайте следующим образом:
<TR><TD ALIGN="CENTER" COLSPAN="2">Ha первом этаже здания имеется бесплатный телефон-автомат.
8. Завершите таблицу тегом </TABLE>.
9. Сохраните документ под именем table.htm.
10. Запустите программу Internet Explorer (Пуск ► Программы ► Internet Explorer).
11. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл table.htm.
12. Изучите, как созданная таблица отображается в программе Internet Explorer, обращая особое внимание на влияние заданных атрибутов.
13. Измените ширину окна браузера и установите, как при этом изменяется внешний вид таблицы.
[►]Мы познакомились с приемами создания таблиц средствами языка HTML для представления данных. Мы научились создавать таблицы и изменять их вид при помощи атрибутов тегов HTML.
Упражнение 19.8. Создание описания фреймов
1. Запустите текстовый редактор Блокнот (Пуск ► Программы ► Стандартные ► Блокнот).
2. Введите следующий документ:

3. Сохраните этот документ под именем frames.htm.
4. Запустите программу Internet Explorer ( Пуск ► Программы ► Internet Explorer).
5. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл frames.htm.
6. Изучите представление нескольких созданных ранее документов в отдельных фреймах.
7. Посмотрите, что происходит при изменении ширины окна браузера.
8. Проверьте, можно ли изменить положение границ фреймов методом перетаскивания при помощи мыши.
9. Щелкните на ссылке, имеющейся в одном из фреймов, и посмотрите, как будет отображен новый документ.
10. Щелкните на кнопке Назад на панели инструментов и убедитесь, что возврат к предыдущему документу не нарушает структуру фреймов.
11. Вернитесь в программу Блокнот и измените структуру и параметры фреймов по своему усмотрению. Сохраните документ под тем же именем.
12. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить на панели инструментов. Убедитесь, что измененный вид Web-страницы соответствует замыслу. Если это не так, вернитесь в программу Блокнот, найдите и исправьте ошибки.
ü Мы научились отображать в рамках одной Web-страницы несколько документов при помощи фреймов. Мы узнали, как фреймы отображаются в программе Internet Explorer. Мы исследовали особенности навигации с помощью гиперссылок по Web-странице, содержащей фреймы.
Упражнение 19.9. Создание Web-документа с помощью редактора FrontPage
1. Запустите программу FrontPage (Пуск ► Программы > Microsoft FrontPage).
2. Введите в автоматически созданную Web-страницу произвольный текст документа.
3. С помощью панели инструментов Форматирование отформатируйте текст по собственному усмотрению.
4. Для создания таблицы щелкните на кнопке Добавить таблицу на панели инструментов Стандартная.
5. Для добавления иллюстраций используйте кнопку Добавить рисунок из файла на панели инструментов Стандартная. Иллюстрации возьмите из папки \Windows.
6. Дайте команду Файл ► Сохранить и задайте имя файла wysiwyg.htm. Подтвердите сохранение изображений, требующих преобразования формата.
7. Запустите программу Internet Explorer (Пуск ► Программы ► Internet Explorer).
8. Дайте команду Файл ► Открыть. Щелкните на кнопке Обзор и откройте файл wysiwyg.htm.
9. Убедитесь, что созданный документ правильно отображается браузером. Обратите внимание на наличие отличий вида документа при отображении в браузере и в программе FrontPage.
10. Измените ширину окна браузера и посмотрите, как при этом меняется вид документа.
11. Вернитесь в программу FrontPage и щелкните на кнопке HTML-код.
12. Изучите автоматически сгенерированный код HTML, определите, как с помощью тегов HTML реализованы использованные команды форматирования.
13. Оцените качество получившегося кода HTML.
ü Мы научились использовать редактор FrontPage для создания Web-документов. Мы узнали, как с его помощью форматируют текст документа, создают таблицы и вставляют изображения. Мы исследовали полученный при этом код HTML
Исследовательская работа
Задание 19.1. Исследование методов создания
абзацного отступа в документах HTML
Язык HTML не содержит «официальных» средств для создания абзацных отступов. Все браузеры, предназначенные для вывода текста на экран компьютера, выводят текст без отступа, вставляя пустую строку между отдельными абзацами. Создание абзацного отступа, таким образом, требует использования специальных приемов.
1. Запустите текстовый редактор (например, Блокнот) и начните создание документа HTML. Введите теги структурных элементов и дайте документу заголовок, например Имитация абзацных отступов.
2. Введите небольшой абзац текста, который будет использоваться как эталон. Сохраните документ.
3. Запустите браузер Internet Explorer и откройте в нем созданный документ. Отрегулируйте ширину окна программы так, чтобы исследуемый абзац занимал несколько строк. Убедитесь, что он выводится без отступа.
4. Добавление пробелов. Вернитесь к редактированию документа. Разместите после эталонного абзаца горизонтальную линейку (тег <HR>). Скопируйте эталонный абзац через буфер обмена, поместив копию ниже линейки. Добавьте в начало скопированного абзаца несколько пробелов. Сохраните документ.
5. Вернитесь в программу Internet Explorer-и щелкните на кнопке Обновить. Посмотрите на добавленный абзац. Объясните, почему создать абзацный отступ таким образом не удается.
6. Метод элемента списка. Вернитесь к редактированию документа. Разместите после последнего абзаца горизонтальную линейку. Скопируйте эталонный абзац через буфер обмена, поместив копию ниже линейки. Добавьте в начало скопированного абзаца тег <DD>. Сохраните документ.
7. Вернитесь в программу Internet Explorers щелкните на кнопке Обновить. Посмотрите на добавленный абзац. Убедитесь, что появился абзацный отступ. Правильно ли используется код HTML в полученном документе? Можно ли рекомендовать такой метод создания абзацного отступа? Почему?
8. Метод неразрывных пробелов. Вернитесь к редактированию документа. Разместите после последнего абзаца горизонтальную линейку. Скопируйте эталонный абзац через буфер обмена, поместив копию ниже линейки. Добавьте в начало скопированного абзаца повторенную несколько раз комбинацию символов . Сохраните документ.
ü Комбинации символов, начинающиеся со знака «&» (амперсанд) и заканчивающиеся точкой с запятой, служат в языке HTML для задания символов, которые отсутствуют на клавиатуре или не могут включаться в текст документа согласно спецификации языка HTML (например, «<»). Комбинация задает неразрывный пробел.
9. Вернитесь в программу Internet Explorer и щелкните на кнопке Обновить. Посмотрите на добавленный абзац. Убедитесь, что появился абзацный отступ. Можно ли рекомендовать такой метод создания абзацного отступа? Почему?
10. Метод предварительно отформатированного текста. Вернитесь к редактированию документа. Разместите после последнего абзаца горизонтальную линейку. Скопируйте эталонный абзац через буфер обмена, поместив копию ниже линейки. Добавьте в начало скопированного абзаца тег <PRE>, задающий предварительно отформатированный текст, и несколько пробелов. В конце абзаца добавьте тег </PRE>. Сохраните документ.
11. Вернитесь в программу Internet Explorer w щелкните на кнопке Обновить. Посмотрите на добавленный абзац. Убедитесь, что появился абзацный отступ. Обратите внимание на способ обработки пробелов и символов конца строки в предварительно отформатированном тексте. В чем особенность используемого шрифта? Выскажите свое мнение об использовании этого метода создания абзацного отступа.
12. Метод невидимого изображения. Вернитесь к редактированию документа. Разместите после последнего абзаца горизонтальную линейку. Скопируйте эталонный абзац через буфер обмена, поместив копию ниже линейки. Добавьте в начало скопированного абзаца тег <IMG>, укажите используемый файл изображения и задайте отступ по горизонтали в 10 пикселов (HSPACE="10"). Файл изображения должен представлять собой картинку в формате GIF, состоящую из одного пиксела (1x1), заданного прозрачным цветом. Сохраните документ.
13. Вернитесь в программу Internet Explorerи щелкните на кнопке Обновить. Посмотрите на добавленный абзац. Убедитесь, что появился абзацный отступ.
14. Проанализируйте все использованные методы и выскажите свое мнение о принципиальной целесообразности их использования и о том, какой из них наиболее удобен.
ü Мы познакомились с ограничениями, имеющимися в языке HTML, и некоторыми приемами для их преодоления. Мы выяснили, что некоторые эффекты можно обеспечить путем некорректного или нестандартного применения элементов HTML. Мы также познакомились с возможностью ввода символов, отсутствующих на клавиатуре, с помощью специальных последовательностей кодов.

Компьютерные программы создают программисты — люди, обученные процессу их составления (программированию). Мы знаем, что программа — это логически упорядоченная последовательность команд, необходимых для управления компьютером (выполнения им конкретных операций), поэтому программирование сводится к созданию последовательности команд, необходимой для решения определенной задачи.
20.1. Языки программирования
Машинный код процессора
Процессор компьютера — это большая интегральная микросхема. Все команды и данные он получает в виде электрических сигналов. Фактически процессор можно рассматривать как огромную совокупность достаточно простых электронных элементов — транзисторов. Транзистор имеет три вывода. На два крайних подается напряжение, необходимое для создания в транзисторе электрического тока, а на средний вывод — напряжение, с помощью которого можно управлять внутренним сопротивлением транзистора, а значит, управлять и током, и напряжением на его выводах.
В электронике транзисторы имеют три применения: для создания усилителей, в электронных схемах, обладающих автоколебательными свойствами, и в электронных переключателях. Последний способ и применяется в цифровой вычислительной технике. В процессоре компьютера транзисторы сгруппированы в микроэлементы, называемые триггерами и вентилями. Триггеры имеют два устойчивых состояния {открыт — закрыт) и переключаются из одного состояния в другое электрическими сигналами. Этим устойчивым состояниям соответствуют математические понятия 0 или 1. Вентили немного сложнее — они могут иметь несколько входов (напряжение на выходе зависит от комбинаций напряжений на входах) и служат для простейших арифметических и логических операций.
Команды, поступающие в процессор по его шинам, на самом деле являются электрическими сигналами, но и их тоже можно представить как совокупности нулей и единиц, то есть числами. Разным командам соответствуют разные числа. Поэтому реально программа, с которой работает процессор, представляет собой последовательность чисел, называемую машинным кодом.
Алгоритм и программа
Управлять компьютером нужно по определенному алгоритму. Алгоритм — это точно определенное описание способа решения задачи в виде конечной (по времени) последовательности действий. Такое описание еще называется формальным. Для представления алгоритма в виде, понятном компьютеру, служат языки программирования. Сначала всегда разрабатывается алгоритм действий, а потом он записывается на одном из таких языков. В итоге получается текст программы — полное, законченное и детальное описание алгоритма на языке программирования. Затем этот текст программы специальными служебными приложениями, которые называются трансляторами, либо переводится в машинный код, либо исполняется.
Что такое язык программирования
Самому написать программу в машинном коде весьма сложно, причем эта сложность резко возрастает с увеличением размера программы и трудоемкости решения нужной задачи. Условно можно считать, что машинный код приемлем, если размер программы не превышает нескольких десятков байтов и нет потребности в операциях ручного ввода/вывода данных.
Поэтому сегодня практически все программы создаются с помощью языков программирования. Теоретически программу можно написать и средствами обычного человеческого (естественного) языка — это называется программированием на метаязыке (подобный подход обычно используется на этапе составления алгоритма), но автоматически перевести такую программу в машинный код пока невозможно из-за высокой неоднозначности естественного языка.
Языки программирования — искусственные языки. От естественных они отличаются ограниченным числом «слов», значение которых понятно транслятору, и очень строгими правилами записи команд {операторов). Совокупность подобных требований образует синтаксис языка программирования, а смысл каждой команды и других конструкций языка — его семантику. Нарушение формы записи программы приводит к тому, что транслятор не может понять назначение оператора и выдает сообщение о синтаксической ошибке, а правильно написанное, но не отвечающее алгоритму использование команд языка приводит к семантическим ошибкам (называемым еще логическими ошибками или ошибками времени выполнения).
Процесс поиска ошибок в программе называется тестированием, процесс устранения ошибок — отладкой.
Компиляторы и интерпретаторы
С помощью языка программирования создается не готовая программа, а только ее текст, описывающий ранее разработанный алгоритм. Чтобы получить работающую программу, надо этот текст либо автоматически перевести в машинный код (для этого служат программы-компиляторы) и затем использовать отдельно от исходного текста, либо сразу выполнять команды языка, указанные в тексте программы (этим занимаются программы-интерпретаторы).
Интерпретатор берет очередной оператор языка из текста программы, анализирует его структуру и затем сразу исполняет (обычно после анализа оператор транслируется в некоторое промежуточное представление или даже машинный код для более эффективного дальнейшего исполнения). Только после того, как текущий оператор успешно выполнен, интерпретатор перейдет к следующему. При этом, если один и тот же оператор должен выполняться в программе многократно, интерпретатор всякий раз будет выполнять его так, как будто встретил впервые. Вследствие этого, программы, в которых требуется осуществить большой объем повторяющихся вычислений, могут работать медленно. Кроме того, для выполнения такой программы на другом компьютере там также должен быть установлен интерпретатор — ведь без него текст программы является просто набором символов.
По-другому можно сказать, что интерпретатор моделирует некую виртуальную вычислительную машину, для которой базовыми инструкциями служат не элементарные команды процессора, а операторы языка программирования.
Компиляторы полностью обрабатывают весь текст программы (он иногда называется исходный код). Они просматривают его в поисках синтаксических ошибок (иногда несколько раз), выполняют определенный смысловой анализ и затем автоматически переводят (транслируют) на машинный язык — генерируют машинный код. Нередко при этом выполняется оптимизация с помощью набора методов, позволяющих повысить быстродействие программы (например, с помощью инструкций, ориентированных на конкретный процессор, путем исключения ненужных команд, промежуточных вычислений и т. д.). В результате законченная программа пол'уча-ется компактной и эффективной, работает в сотни раз быстрее программы, выполняемой с помощью интерпретатора, и может быть перенесена на другие компьютеры с процессором, поддерживающим соответствующий машинный код.
Основной недостаток компиляторов — трудоемкость трансляции языков программирования, ориентированных на обработку данных сложной структуры, часто заранее неизвестной или динамически меняющейся во время работы программы. Тогда в машинный код приходится вставлять множество дополнительных проверок, анализировать наличие ресурсов операционной системы, динамически их захватывать и освобождать, формировать и обрабатывать в памяти компьютера сложные объекты, что на уровне жестко заданных машинных инструкций осуществить довольно трудно, а для ряда задач практически невозможно.
С помощью интерпретатора, наоборот, допустимо в любой момент остановить работу программы, исследовать содержимое памяти, организовать диалог с пользователем, выполнить сколь угодно сложные преобразования данных и при этом постоянно контролировать состояние окружающей программно-аппаратной среды, благодаря чему достигается высокая надежность работы. Интерпретатор при выполнении каждого оператора проверяет множество характеристик операционной системы и при необходимости максимально подробно информирует разработчика о возникающих проблемах. Кроме того, интерпретатор очень удобен для использования в качестве инструмента изучения программирования, так как позволяет понять принципы работы любого отдельного оператора языка.
В реальных системах программирования перемешаны технологии и компиляции, и интерпретации. В процессе отладки программа может выполняться по шагам, а результирующий код не обязательно будет машинным — он даже может быть исходным кодом, написанным на другом языке программирования (это существенно упрощает процесс трансляции, но требует компилятора для конечного языка), или промежуточным машинно-независимым кодом абстрактного процессора, который в различных компьютерных архитектурах станет выполняться с помощью интерпретатора или компилироваться в соответствующий машинный код.
Уровни языков программирования
Разные типы процессоров имеют разные наборы команд. Если язык программирования ориентирован на конкретный тип процессора и учитывает его особенности, то он называется языком программирования низкого уровня. В данном случае «низкий уровень» не значит «плохой». Имеется в виду, что операторы языка близки к машинному коду и ориентированы на конкретные команды процессора.
Языком самого низкого уровня является язык ассемблера, который просто представляет каждую команду машинного кода, но не в виде чисел, а с помощью символьных условных обозначений, называемых мнемониками. Однозначное преобразование одной машинной инструкции в одну команду ассемблера называется транслитерацией. Так как наборы инструкций для каждого модели процессора отличаются, конкретной компьютерной архитектуре соответствует свой язык ассемблера, и написанная на нем программа может быть использована только в этой среде.
С помощью языков низкого уровня создаются очень эффективные и компактные программы, так как разработчик получает доступ ко всем возможностям процессора. С другой стороны, при этом требуется очень хорошо понимать устройство компьютера, затрудняется отладка больших приложений, а результирующая программа не может быть перенесена на компьютер с другим типом процессора. Подобные языки обычно применяют для написания небольших системных приложений, драйверов устройств, модулей стыковки с нестандартным оборудованием, когда важнейшими требованиями становятся компактность, быстродействие и возможность прямого доступа к аппаратным ресурсам. В некоторых областях, например в машинной графике, на языке ассемблера пишутся библиотеки, эффективно реализующие требующие интенсивных вычислений алгоритмы обработки изображений.
Языки программирования высокого уровня значительно ближе и понятнее человеку, нежели компьютеру. Особенности конкретных компьютерных архитектур в них не учитываются, поэтому создаваемые программы на уровне исходных текстов легко переносимы на другие платформы, для которых создан транслятор этого языка. Разрабатывать программы на языках высокого уровня с помощью понятных и мощных команд значительно проще, а ошибок при создании программ допускается гораздо меньше.
Поколения языков программирования
Языки программирования принято делить на пять поколений. В первое поколение входят языки, созданные в начале 50-х годов, когда первые компьютеры только появились на свет. Это был первый язык ассемблера, созданный по принципу «одна инструкция — одна строка».
Расцвет второго поколения языков программирования пришелся на конец 50-х — начало 60-х годов. Тогда был разработан символический ассемблер, в котором появилось понятие переменной. Он стал первым полноценным языком программирования. Благодаря его возникновению заметно возросли скорость разработки и надежность программ.
Появление третьего поколения языков программирования принято относить к 60-м годам. В это время родились универсальные языки высокого уровня, с их помощью удается решать задачи из любых областей. Такие качества новых языков, как относительная простота, независимость от конкретного компьютера и возможность использования мощных синтаксических конструкций, позволили резко повысить производительность труда программистов. Понятная большинству пользователей структура этих языков привлекла к написанию небольших программ (как правило, инженерного или экономического характера) значительное число специалистов из некомпьютерных областей. Подавляющее большинство языков этого поколения успешно применяется и сегодня.
С начала 70-х годов по настоящее время продолжается период языков четвертого поколения. Эти языки предназначены для реализации крупных проектов, повышения их надежности и скорости создания. Они обычно ориентированы на специализированные области применения, где хороших результатов можно добиться, используя не универсальные, а проблемно-ориентированные языки, оперирующие конкретными понятиями узкой предметной области. Как правило, в эти языки встраиваются мощные операторы, позволяющие одной строкой описать такую функциональность, для реализации которой на языках младших поколений потребовались бы тысячи строк исходного кода.
Рождение языков пятого поколения произошло в середине 90-х годов. К ним относятся также системы автоматического создания прикладных программ с помощью визуальных средств разработки, без знания программирования. Главная идея, которая закладывается в эти языки, — возможность автоматического формирования результирующего текста на универсальных языках программирования (который потом требуется откомпилировать). Инструкции же вводятся в компьютер в максимально наглядном виде с помощью методов, наиболее удобных для человека, не знакомого с программированием.
Обзор языков программирования высокого уровня
FORTRAN (Фортран). Это первый компилируемый язык, созданный Джимом Бэкусом в 50-е годы. Программисты, разрабатывавшие программы исключительно на ассемблере, выражали серьезное сомнение в возможности появления высокопроизводительного языка высокого уровня, поэтому основным критерием при разработке компиляторов Фортрана являлась эффективность исполняемого кода. Хотя в Фортране впервые был реализован ряд важнейших понятий программирования, удобство создания программ было принесено в жертву возможности получения эффективного машинного кода. Однако для этого языка было создано огромное количество библиотек, начиная от статистических комплексов и кончая пакетами управления спутниками, поэтому Фортран продолжает активно использоваться во многих организациях, а сейчас ведутся работы над очередным стандартом Фортрана F2k, который появится в 2000 году. Имеется стандартная версия Фортрана HPF(High Performance Fortran) для параллельных суперкомпьютеров со множеством процессоров.
COBOL (Кобол). Это компилируемый язык для применения в экономической области и решения бизнес-задач, разработанный в начале 60-х годов. Он отличается большой «многословностью» — его операторы иногда выглядят как обычные английские фразы. В Коболе были реализованы очень мощные средства работы с большими объемами данных, хранящимися на различных внешних носителях. На этом языке создано очень много приложений, которые активно эксплуатируются и сегодня. Достаточно сказать, что наибольшую зарплату в США получают программисты на Коболе.
Algol (Алгол). Компилируемый язык, созданный в 1960 году. Он был призван заменить Фортран, но из-за более сложной структуры не получил широкого распространения. В 1968 году была создана версия Алгол 68, по своим возможностям и сегодня опережающая многие языки программирования, однако из-за отсутствия достаточно эффективных компьютеров для нее не удалось своевременно создать хорошие компиляторы.
Pascal (Паскаль). Язык Паскаль, созданный в конце 70-х годов основоположником множества идей современного программирования Никлаусом Виртом, во многом напоминает Алгол, но в нем ужесточен ряд требований к структуре программы и имеются возможности, позволяющие успешно применять его при создании крупных проектов.
Basic (Бейсик). Для этого языка имеются и компиляторы, и интерпретаторы, а по популярности он занимает первое место в мире. Он создавался в 60-х годах в качестве учебного языка и очень прост в изучении.
С (Си). Данный язык был создан в лаборатории Bell и первоначально не рассматривался как массовый. Он планировался для замены ассемблера, чтобы иметь возможность создавать столь же эффективные и компактные программы и в то же время не зависеть от конкретного типа процессора.
Си во многом похож на Паскаль и имеет дополнительные средства для прямой работы с памятью (указатели). На этом языке в 70-е годы написано множество прикладных и системных программ и ряд известных операционных систем (Unix).
C++ (Си++). Си++ — это объектно-ориентированное расширение языка Си, созданное Бьярном Страуструпом в 1980 году. Множество новых мощных возможностей, позволивших резко повысить производительность программистов, наложилось на унаследованную от языка Си определенную низкоуровневость, в результате чего создание сложных и надежных программ потребовало от разработчиков высокого уровня профессиональной подготовки.
Java (Джава, Ява). Этот язык был создан компанией Sun в начале 90-х годов на основе Си++. Он призван упростить разработку приложений на основе Си++ путем исключения из него всех низкоуровневых возможностей. Но главная особенность этого языка — компиляция не в машинный код, а в платформно-независимый байт-код (каждая команда занимает один байт). Этот байт-код может выполняться с помощью интерпретатора — виртуальной Java-машины JVM(Java Virtual Machine), версии Которой созданы сегодня для любых платформ. Благодаря наличию множества Java-машин программы па Java можно переносить не только на уровне исходных текстов, но и на уровне двоичного байт-кода, поэтому по популярности язык Ява сегодня занимает второе место в мире после Бейсика.
Особое внимание в развитии этого языка уделяется двум направлениям: поддержке всевозможных мобильных устройств и микрокомпьютеров, встраиваемых в бытовую технику (технология Jini) и созданию платформно -независимых программных модулей, способных работать на серверах в глобальных и локальных сетях с различными операционными системами (технология Java Beans). Пока основной недостаток этого языка — невысокое быстродействие, так как язык Ява интерпретируемый.
С# (Си Шарп). В конце 90-х годов в компании Microsoft под, руководством Андерса Хейльсберга был разработан язык С#. В нем воплотились лучшие идеи Си и Си++, а также достоинства Java. Правда, С#, как и другие технологии Microsoft, ориентирован на платформу Windows. Однако формально он не отличается от прочих универсальных языков, а корпорация даже планирует его стандартизацию. Язык С# предназначен для быстрой разработки .МЕТ-приложений, и его реализация в системе Microsoft Visual Studio .NET содержит множество особенностей, привязывающих С# к внутренней архитектуре Windows и платформы .NET.
Языки программирования баз данных
Эта группа языков отличается от алгоритмических языков прежде всего решаемыми задачами. База данных — это файл (или группа файлов), представляющий собой упорядоченный набор записей, имеющих единообразную структуру и организованных по единому шаблону (как правило, в табличном виде). База данных может состоять из нескольких таблиц. Удобно хранить в базах данных различные сведения из справочников, картотек, журналов бухгалтерского учета и т. д.
При работе с базами данных чаще всего требуется выполнять следующие операции:
• создание/модификация свойств/удаление таблиц в базе данных;
• поиск, отбор, сортировка информации по запросам пользователей;
• добавление новых записей;
• модификация существующих записей;
• удаление существующих записей.
Первые базы данных появились очень давно, как только появилась потребность в обработке больших массивов информации и выборки групп записей по определенным признакам. Для этого был создан структурированный язык запросов SQL {Structured Query Language). Он основан на мощной математической теории и позволяет выполнять эффективную обработку баз данных, манипулируя не отдельными записями, а группами записей.
Для управления большими базами данных и их эффективной обработки разработаны СУБД (Системы Управления Базами Данных). Практически в каждой СУБД помимо поддержки языка SQL имеется также свой уникальный язык, ориентированный на особенности этой СУБД и не переносимый на другие системы. Сегодня в мире насчитывается три ведущих производителя СУБД: Microsoft (SQL Server), IBM (DB2) и Oracle. Их продукты нацелены на поддержку одновременной работы тысяч пользователей в сети, а базы данных могут храниться в распределенном виде на нескольких серверах. В каждой из этих СУБД реализован собственный диалект SQL, ориентированный на особенности конкретного сервера, поэтому SQL-программы, подготовленные для разных СУБД, друг с другом, как правило, несовместимы.
С появлением персональных компьютеров были созданы так называемые настольные СУБД. Родоначальником современных языков программирования баз данных для ПК принято считать СУБД dBase II, язык которой был интерпретируемым. Затем для него были созданы компиляторы, появились СУБД FoxPro и Clipper, поддерживающие диалекты этого языка. Сегодня самой распространенной настольной СУБД стала система Microsoft Access.
Языки программирования для Интернета
С активным развитием глобальной сети было создано немало реализаций популярных языков программирования, адаптированных специально для Интернета. Все они отличаются характерными особенностями: языки являются интерпретируемыми, интерпретаторы для них распространяются бесплатно, а сами программы — в исходных текстах. Такие языки называют скрипт-языками.
HTML. Общеизвестный язык для оформления документов. Он очень прост и содержит элементарные команды форматирования текста, добавления рисунков, задания шрифтов и цветов, организации ссылок и таблиц. Все Web-страницы написаны на языке HTML или используют его расширения.
Perl. В 80-х годах Ларри Уолл разработал язык Perl. Он задумывался как средство эффективной обработки больших текстовых файлов, генерации текстовых отчетов и управления задачами. По мощности Perl значительно превосходит языки типа Си. В него введено много часто используемых функций работы со строками, массивами, всевозможные средства преобразования данных, управления процессами, работы с системной информацией и др.
РНР. Расмус Лердорф, активно использовавший Регl-скрипты, в 1995 году решил улучшить этот язык, упростив его и дополнив встроенными средствами доступа к базам данных. В результате появилась разработка Personal Contents Page/Forms Interpreter (PHP/FI). Уже через пару лет программы на ее основе использовались на 50 тыс. сайтов. В 1997 году ее значительно усовершенствовали Энди Гутмане и Зив Сураски, и под названием РНР 3.0 этот язык быстро завоевал популярность у создателей динамических сайтов во всем мире.
Tcl/Tk. В конце 80-х годов Джон Аустираут придумал популярный скрипт-язык Tel и библиотеку Tk. В Tel он попытался воплотить видение идеального скрипт-языка. Язык Tel ориентирован на автоматизацию рутинных процессов и состоит из мощных команд, предназначенных для работы с абстрактными нетипизированными объектами. Он независим от типа системы и при этом позволяет создавать программы с графическим интерфейсом.
VRML. В 1994 году был создан язык VRML для организации виртуальных трехмерных интерфейсов в Интернете. Он позволяет описывать в текстовом виде различные трехмерные сцены, освещение и тени, текстуры (покрытия объектов), создавать свои миры, путешествовать по ним, «облетать» со всех сторон, вращать в любых направлениях, масштабировать, регулировать освещенность и т. д.
XML. В августе 1996 года WWW-консорциум, ответственный за стандарты на Интернет - технологии, приступил к подготовке универсального языка разметки структуры документов, базировавшегося на достаточно давно созданной в IBM технологии SGML. Новый язык получил название XML. Сегодня он служит основой множества системных, сетевых и прикладных приложений, позволяя представлять в прозрачном для пользователей и программ текстовом виде различные аспекты внутренней структуры иерархически организованных документов. В недалеком будущем он может стать заменой HTML.
Языки моделирования
При создании программ и формировании структур баз данных нередко применяются формальные способы их представления — формальные нотации, с помощью которых можно визуально представить (изобразить с помощью мыши) таблицы баз данных, поля, объекты программы и взаимосвязи между ними в системе, имеющей специализированный редактор и генератор исходных текстов программ на основе созданной модели. Такие системы называются CASE-системами. В них активно применяются нотации IDEF, а в последнее время все большую популярность завоевывает язык графического моделирования UML.
Прочие языки программирования
PL/I (ПЛ/1). В середине 60-х годов компания IBM решила взять все лучшее из языков Фортран, Кобол и Алгол. В результате в 1964 году на свет появился новый компилируемый язык программирования, который получил название Programming Language One. В этом языке было реализовано множество уникальных решений, полезность которых удается оценить только спустя 33 года, в эпоху крупных программных систем. По своим возможностям ПЛ/1 значительно мощнее многих других языков (Си, Паскаля). Например, в ПЛ/1 присутствует уникальная возможность указания точности вычислений — ее нет даже у Си++ и Явы. Этот язык и сегодня продолжает поддерживаться компанией IBM.
Smalltalk (Смолток). Работа над этим языком началась в 1970 году в исследовательской лаборатории корпорации XEROX, а закончились спустя 10 лет, воплотившись в окончательном варианте интерпретатора SMALLTALK-80. Данный язык оригинален тем, что его синтаксис очень компактен и базируется исключительно на понятии объекта. В этом языке отсутствуют операторы или данные. Все, что входит в Смолток, является объектами, а сами объекты общаются друг с другом исключительно с помощью сообщений (например, появление выражения 1 + 1 вызывает посылку объекту I сообщения «+», то есть «прибавить», с параметром 1, который считается не числом-константой, а тоже объектом). Больше никаких управляющих структур, за исключением «оператора» ветвления (на самом деле функции, принадлежащей стандартному объекту), в языке нет, хотя их можно очень просто смоделировать. Сегодня версия Visual Age for Smalltalk активно развивается компанией IBM.
LISP (Лисп). Интерпретируемый язык программирования, созданный в 1960 году Джоном Маккарти. Ориентирован на структуру данных в форме списка и позволяет организовывать эффективную обработку больших объемов текстовой информации.
Prolog (Пролог). Создан в начале 70-х годов Аланом Колмероэ. Программа на этом языке, в основу которого положена математическая модель теории исчисления предикатов, строится из последовательности фактов и правил, а затем формулируется утверждение, которое Пролог будет пытаться доказать с помощью введенных правил. Человек только описывает структуру задачи, а внутренний «мотор» Пролога сам ищет решение с помощью методов поиска и сопоставления.
Ada (Ада). Назван по имени леди Огасты Ады Байрон, дочери английского поэта Байрона и его отдаленной родственницы Анабеллы Милбэнк. В 1980 году сотни экспертов Министерства обороны США отобрали из 17 вариантов именно этот язык, разработанный небольшой группой под руководством Жана Ишбиа. Он удовлетворил на то время все требования Пентагона, а к сегодняшнему дню в его развитие вложены десятки миллиардов долларов. Структура самого языка похожа на Паскаль. В нем имеются средства строгого разграничения доступа к различным уровням спецификаций, доведена до предела мощность управляющих конструкций.
Forth (Форт). Результат попытки Чарльза Мура в 70-х годах создать язык, обладающий мощными средствами программирования, который можно эффективно реализованным на компьютерах с небольшими объемами памяти, а компилятор мог бы выдавать очень быстрый и компактный код, то есть служил заменой ассемблеру. Однако сложности восприятия программного текста, записанного в непривычной форме, сильно затрудняли поиск ошибок, и с появлением Си язык Форт оказался забытым.
Вопросы для самоконтроля
1. Что такое язык программирования?
2. В чем различие компиляторов и интерпретаторов?
3. Объясните термины «язык низкого уровня» и «язык высокого уровня».
4. Расскажите о поколениях языков программирования.
5. Какие языки программирования активно используются сегодня?
20.2. Системы программирования
Средства создания программ
В самом общем случае для создания программы на выбранном языке программирования нужно иметь следующие компоненты.
1. Текстовый редактор. Так как текст программы записывается с помощью ключевых слов, обычно происходящих от слов английского языка, и набора стандартных символов для записи всевозможных операций, то формировать этот текст можно в любом редакторе, получая в итоге текстовый файл с исходным текстом программы. Лучше использовать специализированные редакторы, которые ориентированы на конкретный язык программирования и позволяют в процессе ввода текста выделять ключевые слова и идентификаторы разными цветами и шрифтами. Подобные редакторы созданы для всех популярных языков и дополнительно могут автоматически проверять правильность синтаксиса программы непосредственно во время ее ввода.
2. Исходный текст с помощью программы-компилятора переводится в машинный код. Если обнаружены синтаксические ошибки, то результирующий код создан не будет.
На этом этапе уже возможно получение готовой программы, но чаще всего в ней не хватает некоторых компонентов, поэтому компилятор обычно выдает промежуточный объектный код (двоичный файл, стандартное расширение .OBJ).
3. Исходный текст большой программы состоит, как правило, из нескольких модулей (файлов с исходными текстами), потому что хранить все тексты в одном файле неудобно — в них сложно ориентироваться. Каждый модуль компилируется в отдельный файл с объектным кодом, которые затем надо объединить в одно целое.
Кроме того, к ним надо добавить машинный код подпрограмм, реализующих различные стандартные функции (например, вычисляющих математические функции sin или In). Такие функции содержатся в библиотеках (файлах со стандартным расширением .LIB), которые поставляются вместе с компилятором. Сгенерированный код модулей и подключенные к нему стандартные функции надо не просто объединить в одно целое, а выполнить такое объединение с учетом требований операционной системы, то есть получить на выходе программу, отвечающую определенному формату.
Объектный код обрабатывается специальной программой —редактором связей или сборщиком, который выполняет связывание объектных модулей и машинного кода стандартных функций, находя их в библиотеках, и формирует на выходе работоспособное приложение — исполнимый код для конкретной платформы.
Если по каким-то причинам один из объектных модулей или нужная библиотека не обнаружены (например, неправильно указан каталог с библиотекой), то сборщик сообщает об ошибке и готовой программы не получается.
- Исполнимый код — это законченная программа, которую можно запустить на любом компьютере, где установлена операционная система, для которой эта программа создавалась. Как правило, итоговый файл имеет расширение .ЕХЕ.
Интегрированные системы программирования
Итак, для создания программы нужны:
• текстовый редактор;
• компилятор;
• редактор связей;
• библиотеки функций.
Как правило, в стандартную поставку входят как минимум три последних компонента, но хорошая интегрированная система включает в себя и специализированный текстовый редактор, причем почти все этапы создания программы в ней автоматизированы: после того как исходный текст введен, его компиляция и сборка выполняются одним нажатием клавиши. Это очень удобно, так как не требует ручной настройки множества параметров запуска компилятора и редактора связей, указывания им нужных файлов вручную и т. д. Процесс компиляции обычно демонстрируется на экране: показывается, сколько строк исходного текста откомпилировано, или выдаются сообщения о найденных ошибках.
В современных интегрированных системах имеется еще один компонент — отладчик, который позволяет анализировать работу программы во время ее выполнения. С его помощью можно последовательно выполнять отдельные операторы исходного текста по шагам, наблюдая при этом, как меняются значения различных переменных. Без отладчика разработать крупное приложение очень сложно.
Среды быстрого проектирования
В последние несколько лет в программировании (особенно в программировании для операционной системы Windows) наметился так называемый визуальный подход. До этого серьезным препятствием для разработки графических приложений была сложность создания различных элементов управления и контроля их работы. Достаточно взглянуть на окно любой Windows- про граммы. В нем имеется множество стандартных элементов управления (кнопки, пункты меню, списки, переключатели и т. д.). Очень трудоемко вручную описывать процесс создания этих элементов в соответствии с требованиями Windows, на глазок определять координаты, отслеживать их состояние с помощью специальных команд. Например, для простой программы, складывающей два числа, потребуется один оператор (одна строка исходного текста) для выполнения нужного вычисления и сотни строк кода для подготовки приложения к работе в Windows, создания кнопки и пары полей ввода.
Этот процесс автоматизирован в средах быстрого проектирования (Rapid Application Development, RAD-среды). Все необходимые элементы оформления и управления создаются и обслуживаются не путем ручного программирования, а с помощью готовых визуальных компонентов, которые с помощью мыши «перетаскиваются» в проектируемое окно. Их свойства и поведение затем настраиваются с помощью простых редакторов, визуально показывающих характеристики соответствующих элементов. При этом вспомогательный исходный текст программы, ответственный за создание и работу этих элементов, генерируется RAD-средой автоматически, что позволяет сосредоточиться только на логике решаемой задачи. В результате программирование во многом заменяется на проектирование — подобный подход называется еще визуальным программированием.
Компоненты достаточно легко создавать самостоятельно, поэтому в мире сегодня распространяются тысячи бесплатных и платных компонентов для наиболее известных RAD-сред, из них формируются библиотеки компонентов — объектные репозитории. Компоненты выступают в роли «строительных кирпичиков», позволяющих собирать готовое приложение с богатыми возможностями, написав всего десяток строк исходного кода, и такой компонентный подход к созданию программ считается очень перспективным, потому что без лишних усилий и на законных основаниях допускает повторное использование чужого труда.
Архитектура программных систем
В то время как большинство автономных приложений: офисные программы, среды разработки, системы подготовки текстов и изображений — выполняются на одном компьютере, крупные информационные комплексы (например, система автоматизации предприятия) состоят из десятков и сотен отдельных программ, которые взаимодействуют друг с другом по сети, выполняясь на разных компьютерах. В таких случаях говорят, что они работают в различной программной архитектуре. Она делится на следующие группы.
Автономные приложения. Работают на одном компьютере.
Приложения в файл-серверной архитектуре. Компьютеры пользователей системы объединены в сеть, при этом на каждом из них (на клиентском месте) запущены копии одной и той же программы, которые обращаются за данными к серверу — специальному компьютеру, который хранит файлы, одновременно доступные всем пользователям (как правило, это базы данных). Сервер обладает повышенной надежностью, высоким быстродействием, большим объемом памяти, на нем установлена специальная серверная версия операционной системы.
При одновременном обращении нескольких программ к одному файлу, например, с целью его обновления, могут возникнуть проблемы, связанные с неоднозначностью определения его содержимого. Поэтому каждое изменение общедоступного файла выделяется в транзакцию — элементарную операцию по обработке данных, имеющую фиксированные начало, конец (успешное или неуспешное завершение) и ряд других характеристик.
Особенность этой архитектуры в том, что все вычисления выполняются на клиентских местах, что требует наличия на них достаточно производительных ПК (это так называемые системы с толстым клиентом — программой, которая выполняет всю обработку получаемой от сервера информации).
Приложения в клиент-серверной архитектуре. Эта архитектура похожа на предыдущую, только сервер помимо простого обеспечения одновременного доступа к данным способен еще выполнять программы (обычно выполняются СУБД — тогда сервер называется сервером баз данных), которые берут на себя определенный объем вычислений (в файл-серверной архитектуре он реализуется полностью на клиентских местах). Благодаря этому удается повысить общую надежность системы, так как сервер работает значительно более устойчиво, чем ПК, и снять лишнюю нагрузку с клиентских мест, на которых удается использовать дешевые компьютеры. Запускаемые на них приложения реально осуществляют небольшие объемы вычислений, а иногда занимаются только отображением получаемой от сервера информации, поэтому они называются тонкими клиентами.
Приложения в многозвенной архитектуре. Недостаток предыдущей архитектуры в том, что резко возрастает нагрузка на сервер, а если он выходит из строя, то работа всей системы останавливается. Поэтому в некоторых случаях в систему добавляется так называемый сервер приложений, на котором выполняется вся вычислительная работа. Другой сервер баз данных обрабатывает запросы пользователей, на третьем может быть установлена специальная программа—монитор транзакций, которая оптимизирует обработку транзакций и балансирует нагрузку на серверы. В большинстве практических случаев все серверы соединены последовательно — позвенно, и выход из строя одного звена если и не останавливает всю работу, то, по крайней мере, резко снижает производительность системы.
Приложения в распределенной архитектуре. Чтобы избежать недостатков рассмотренных архитектур, были придуманы специальные технологии, позволяющие создавать программу в виде набора компонентов, которые можно запускать на любых серверах, связанных в сеть (компоненты как бы распределены по сети). Основное преимущество подобного подхода в том, что при выходе из строя любого компьютера специальные программы-мониторы, которые следят за корректностью работы компонентов и позволяют им «переговариваться» между собой, сразу перезапуская временно пропавший компонент на другом компьютере. При этом общая надежность всей системы становится очень высокой, а вычислительная загрузка распределяется между серверами оптимальным образом.
Доступ к возможностям любого компонента, предназначенного для общения с пользователем, осуществляется с произвольного клиентского места. При этом, так как все вычисления происходят на серверах, появляется возможность создавать сверхтонкие клиенты — программы, только отображающие получаемую из сети информацию и требующие минимальных компьютерных ресурсов. Благодаря этому доступ к компонентной системе возможен не только с ПК, но и с небольших мобильных устройств.
Частный случай компонентного подхода — доступ к серверным приложениям из браузеров через Интернет.
Сегодня наиболее популярны три компонентные технологии — CORBA консорциума OMGJava Beans компании Sun и COM+/.NET корпорации Microsoft. Эти технологии будут определять развитие информационной индустрии в ближайшие десятилетия.
Основные системы программирования
Из универсальных языков программирования сегодня наиболее популярны следующие:
• Бейсик (Basic) — для освоения требует начальной подготовки (общеобразовательная школа);
• Паскаль (Pascal) — требует специальной подготовки (школы с углубленным изучением предмета и общетехнические вузы);
• Си++ (C++), Ява (Java), Си Шарп (С#) — требуют профессиональной подготовки (специализированные средние и высшие учебные заведения).
Для каждого из этих языков программирования сегодня имеется немало систем программирования, выпускаемых различными фирмами и ориентированных на различные модели ПК и операционные системы. Наиболее популярны следующие визуальные среды быстрого проектирования программ для Windows:
• Basic: Microsoft Visual Basic;
• Pascal: Borland Delphi;
• C++: Microsoft Visual C++;
• Java: BorlandJBuilder,
• С#: Microsoft Visual Studio .NET, Borland С#Builder.
Для разработки серверных и распределенных приложений можно использовать систему программирования Microsoft Visual C++, продукты фирмы Borland, практически любые средства программирования на Java.
В дальнейшем будут рассматриваться возможности, характерные для Бейсика, Паскаля и Си++.
Вопросы для самоконтроля
1. Что нужно для создания программы?
2. Что такое среды быстрого проектирования?
3. Объясните понятие «архитектура программной системы».
4. Опишите основные типы программных архитектур.
5. Какая программная архитектура обеспечивает работу Интернета?
20.3. Алгоритмическое (модульное) программирование
Алгоритм — это формальное описание способа решения задачи путем разбиения ее на конечную по времени последовательность действий (элементарных операций). Под словом «формальное» подразумевается, что описание должно быть абсолютно полным и учитывать все возможные ситуации, которые могут встретиться по ходу решения. Под элементарной операцией понимается действие, которое по заранее определенным критериям (например, очевидности) не имеет смысла детализировать.
Основная идея алгоритмического программирования — разбиение программы на последовательность модулей, каждый из которых выполняет одно или несколько действий. Единственное требование к модулю — чтобы его выполнение всегда начиналось с первой команды и всегда заканчивалось на самой последней (то есть, чтобы нельзя было попасть на команды модуля извне и передать управление из модуля на другие команды в обход заключительной).
Алгоритм на выбранном языке программирования записывается с помощью команд описания данных, вычисления значений и управления последовательностью выполнения программы.
Переменные и константы
Реальные данные, с которыми работает программа, — это числа, строки и логические величины (аналоги 1 и 0, «да» и «нет», «истина» и «ложь»). Эти типы данных называют базовыми.
Каждая единица информации хранится в ячейках памяти компьютера, имеющих свои адреса. На практике заранее неизвестно, в каких конкретно ячейках памяти во время работы программы будут записаны ее данные, поэтому в языках программирования введено понятие переменной, позволяющее отвлечься от конкретных адресов и обращаться к содержимому памяти с помощью идентификатора или имени — как правило, последовательности, содержащей английские буквы, цифры, символы подчеркивания и начинающейся не с цифры. Например:
Hello
_SumOfReal
X1
H8_G7_F6
Это имя будет указывать на значение, о реальном адресе и способе хранения которого можно забыть. В процессе работы программы содержимое соответствующих ячеек можно менять, обращаясь к переменной по имени. Лучше выбирать такие названия, которые отражают назначение данной переменной.
Кроме имени и значения, переменная обычно имеет тип, определяющий, какая информация хранится в данной переменной (число, строка и т. д.). В зависимости от объема памяти, отведенного для хранения значения переменной, оно должно укладываться в допустимый диапазон. Например, значение типа «байт» имеет диапазон от 0 до 255.
Переменные с указанием их типа можно вводить в программу с помощью специальных команд описания (объявления, декларации). Это позволяет компилятору организовать эффективное хранение и обработку данных и повышает ясность исходных тестов. Каждый тип описывается своим ключевым словом. Значения переменных разных типов допускается преобразовывать друг в друга в соответствии с соглашениями языка программирования. Такой процесс называется приведением типов.
Переменные могут существовать на всем протяжении работы программы — тогда они называются статическими, а могут создаваться и уничтожаться на разных этапах ее функционирования — такие переменные называются динамическими. Все остальные данные в программе, значение которых не меняется на протяжении ее работы, называются константами или постоянными. Константы, как и переменные, обычно имеют тип. Данные можно указывать явно:
123
2.87
"это строка"
или для удобства обозначать их идентификаторами. Например, число π, равное 3,1416, можно обозначить как pi и везде вместо числа применять идентификатор. Только изменять значение pi нельзя, так как это не переменная, а константа.
Числовые данные
Числа обычно бывают двух видов: целые и дробные. Если число отрицательное, перед ним ставится знак <<-»; если положительное, то знак «+» можно ставить, а можно и опускать. Вычисления над целыми числами выполняются точно, вычисления над дробными числами — приближенно. При записи дробных чисел в качестве десятичного разделителя используется точка:
1.28
3.333321
Очень большие или очень маленькие числа записываются специальным образом. Для них дополнительно указывается мантисса — число со знаком, являющееся степенью числа 10. Мантисса записывается справа от числа через букву е (или Е). Пробелы в такой записи не допускаются.
Например, число 100 (единица, умноженная на 10 во второй степени) запишется так:
1е+2
число 0,003 (тройка, умноженная на 10 в минус третьей степени) так:
3е-3
число со 120 нулями — так:
1Е+120
Допускается дробная запись числа с мантиссой:
31.4е-1
|
Тип числа |
Бейсик |
Паскаль |
Си++ |
|
целое |
INTEGER |
integer |
int |
|
дробное |
DOUBLE |
real |
float |
Арифметические операции
Для записи арифметических действий используются арифметические операторы. В некоторых языках программирования они считаются не операторами, а операциями, предназначенными для вычисления значения выражения, но не влияющими на другие значения и не сказывающимися на ходе выполнения программы.
К основным арифметическим операциям относятся:
+ (сложение)
- (вычитание)
* (умножение)
/ (деление)
Такая форма записи отвечает общепринятым соглашениям и принята в большинстве языков программирования.
Каждая арифметическая операция имеет свой приоритет. Операции с более высоким приоритетом (умножение и деление) будут выполняться раньше, чем операции с более низким приоритетом (сложение и вычитание). Изменить порядок вычисления выражения можно с помощью круглых скобок.
b*2 + с/3
b*(2 + с) - 3
Скобки допускается вкладывать друг в друга произвольное число раз. При этом использование квадратных или фигурных скобок, как правило, не допускается.
((у+2)*3 + 1) / 2
Арифметические выражения
С помощью арифметических операций формируются арифметические выражения, которые состоят из операций и операндов (переменных и констант).
Выражение
il + 2
состоит из одной операции «+» и двух операндов — переменной И и числовой константы 2.
Каждое выражение имеет значение, которое определяется в момент выполнения оператора, содержащего это выражение. Если на момент вычисления выражения И +2 в переменной И хранится число 3, то значение этого выражения будет равно 5 (3+2).
Логические выражения
При создании программ не обойтись без логических выражений. Они отличаются тем, что результат их вычислений может принимать только одно из двух допустимых значений — true (истина, да, включено) и false (ложь, нет, выключено). Чаще всего значение false ассоциируется с нулем, а значение true — с числом 1 или просто ненулевым значением.
При записи логических выражений используются операции сравнения и логические операции. Операции сравнения сличают значения правого и левого операндов. Результатом сравнения является true, если оно удачно, и false в противном случае.
В таблице даны примеры записи операций сравнения для разных языков.
|
Операция |
Варианты написания |
|
|
Бейсик, Паскаль |
Си++ |
|
|
Равно |
= |
== |
|
Не равно |
о |
\= |
|
Меньше |
< |
< |
|
Меньше или равно |
<= |
<= |
|
Больше |
> |
> |
|
Больше или равно |
>= |
>= |
Pi == 3.14
х > О
al о b 1
В одном выражении может потребоваться проверка нескольких подобных условий. Например, надо определить, больше ли значение переменной X, чем 0 и меньше ли, чем 10. Условия могут быть связаны с помощью логических операций, наиболее активно используемые из которых — это И и ИЛИ. В компьютерной графике также часто применяется так называемое исключающее ИЛИ и операция отрицания НЕ. Для нее требуется только один операнд, указывающийся справа от знака операции. Эта операция просто меняет значение своего операнда на противоположное.
|
1операнд |
2oперанд |
И |
ИЛИ |
исключающее ИЛИ |
HE (только первый операнд) |
|
true |
true |
true |
true |
false |
false |
|
true |
false |
false |
true |
true |
false |
|
false |
true |
false |
true |
true |
true |
|
false |
false |
false |
false |
false |
true |
В следующей таблице приведен синтаксис записи логических операций.
|
Логическая операция |
Бейсик |
Паскаль |
Си++ |
|
И |
AND |
and |
&& |
|
ИЛИ |
OR |
or |
II |
|
НЕ |
NOT |
not |
i |
Приоритеты всех логических операций ниже, чем приоритеты операций сравнения, поэтому сравнения всегда выполняются первыми. А логические операции вычисляются в следующем порядке: сначала НЕ, потом И, потом ИЛИ. При необходимости этот порядок может быть изменен с помощью скобок.
Примеры логических выражений:
xl >= 1 && xl <= 10
(R > 3.14) and (R < 3.149)
(Value < Oldvalue) OR (Value <> 0)
Логический тип
|
Бейсик |
Паскаль |
Си++ |
|
Базового типа нет. Используется числовой тип INTEGER |
boolean |
bool |
Строчные выражения
Строки в языках программирования всегда заключаются в кавычки. В Си++ и Бейсике для этого используются двойные кавычки, в Паскале — одинарные.
"это строка Бейсика или Си++"
'это строка Паскаля'
Строка может быть пустой — не содержать ни одного символа.
Например:
Как правило, строки можно сравнивать друг с другом на эквивалентность (равно и не равно). В некоторых языках программирования допускаются также сравнения типа «больше» или «меньше» — при этом происходит последовательное сравнение значений символов (каждый символ представляется в компьютере конкретным числом).
Кроме того, часто допускается также операция сцепления строк, записываемая с помощью символа «+». Например:
"123" + "4567" - получится "1234567" "абв " + "abc " + " эюя" - получится "абв abc эюя"
Тип «строка»
|
Бейсик |
Паскаль |
Си++ |
|
STRING |
string |
Базового типа «строка» нет |
Указатели
Некоторые языки программирования допускают в явном виде работу с указателями — адресами физической памяти. При этом в них имеется специальная операция получения адреса конкретной переменной, что позволяет работать с памятью напрямую, примерно так, как это происходит в языках ассемблера. Такая возможность позволяет добиваться высокой эффективности работы программы, но часто приводит к ошибкам, если указатель вдруг получает неверное значение и при его использовании начинает портиться область памяти, предназначенная совсем для других целей.
Сложные данные
Структуры. До сих пор рассматривались базовые типы данных: числа, строки, логические величины — и операции над базовыми данными. Однако для повышения производительности труда программистов и повышения качества их работы необходимо, чтобы язык программирования имел средства, позволяющие описывать данные в виде, максимально приближенном к их реальным аналогам. Например, чтобы организовать обработку данных по студентам, в программе удобно не просто описать десяток различных переменных, а объединить их в структуру (или запись) «студент», состоящую из полей разного типа «имя», «пол», «год рождения», «группа» и т. д.
Современные языки программирования позволяют применять такие сложные типы данных, составляющиеся из базовых и определенных ранее сложных типов. В результате удается организовывать структуры данных произвольной сложности: списки, деревья и т. п. При этом структура объединяет группу разных данных под одним названием.
Получить доступ к отдельным составляющим (полям) этой структуры можно по их именам. В рассматриваемых языках программирования такой доступ осуществляется указанием имени структуры и имени поля через точку. Если подобным способом происходит обращение к полю, которое само является структурой, то выделение нужного поля продолжается приписыванием справа имени вложенного поля через точку.
Синтаксис описания структуры
|
Бейсик |
Паскаль |
Си++ |
|
TYPE имя-структуры поле AS тип ... END TYPE |
record поле: тип; ... end; |
struct имя { тип поле; ... }; |
Вот примеры описания структур.
Бейсик:
TYPE Student
Name AS STRING
Sex AS INTEGER
BirthYear AS INTEGER
END TYPE
Паскаль:
Record
Name: string;
Sex: boolean;
BirthYear: integer;
end;
Си++:
struct Student
{
bool Sex;
int BirthYear;
};
Доступ к содержимому структуры:
Student.BirthYear = 1980;
Массивы. Доступ к элементам структуры осуществляется по имени ее составляющих. В одних случаях это значительно повышает наглядность исходных текстов и упрощает процесс программирования, но имеется немало ситуаций, когда надо организовать обработку больших объемов данных одного типа, при этом создавать структуры с сотнями и тысячами полей неразумно. Поэтому в дополнение к структурам в языки программирования введено понятие массива, сложного типа данных, доступ к элементам которого происходит по их положению, по номеру или индексу. Например, можно описать массив, состоящий из тысячи элементов численного типа, и затем обратиться к десятому или сотому элементу по его номеру.
При описании массива обычно указывается его размер (число элементов) или верхняя и нижняя границы — диапазон, в рамках которого можно обращаться к элементам массива.
Синтаксис описания массива
|
Бейсик |
DIM имя (число элементов) AS тип |
|
Паскаль |
аггау[ нижняя_граница .. верхняя_граница ] of тип; |
|
Си++ |
тип имя[ число-элементов ]; |
В Бейсике нижней границей считается 1, в Си++ — 0, в Паскале она указывается явно.
Вот примеры описания массивов. Бейсик:
DIM IntArray(lOOO) AS INTEGER
Паскаль:
array[1..1000] of integer
Си++:
int IntArray[1000];
Доступ к элементу массива осуществляется по его номеру. Этот номер указывается в круглых (Бейсик) или квадратных (Паскаль, Си++) скобках сразу за именем массива (такое действие называется индексированием):
IntArray( 12 )
IntArray[ i+1 ]
Массивы, границы которых явно заданы в команде описания, называются статическими. Их размер известен заранее и не меняется на всем протяжении работы программы.
В последних версиях компилируемых языков программирования реализуются так называемые динамические массивы, размер которых может меняться во время выполнения программы. В ряде случаев это весьма удобно, так как позволяет экономно расходовать память, захватывая ее по мере необходимости. Недостаток динамических массивов в том, что организовать эффективную работу с ними, используя компиляторы, сложно. Приходится выполнять множество проверок, связанных с расходованием памяти компьютера, что понижает общую эффективность приложения. Динамические массивы в Паскале начали поддерживаться совсем недавно, с активным распространением новых мощных ПК, а в интерпретируемых языках типа Бейсика это было сделано довольно давно.
Во многих языках программирования строки рассматриваются как массивы символов. Их допускается индексировать как обычные массивы.
Правила работы со сложными типами
Отличие базовых типов от сложных в том, что в базовых типах нельзя выделить составные части. При этом поле структуры или элемент массива считаются обычными переменными, и их использование в любых операторах ничем не отличается от использования переменных базовых типов.
В развитых языках программирования допускаются массивы, состоящие из структур, и структуры, состоящие из массивов. При этом возможны достаточно сложные формы записи, например:
а[0].Items.Strings[4].value
Массив а состоит из структур, в описании которых есть поле Items, являющееся тоже структурой, имеющей поле Strings, которое, в свою очередь, представляет собой массив структур, имеющих поле value.
Описание переменных
Чтобы переменную можно было использовать в программе, ее надо предварительно описать, указав ее тип. Пока переменная не описана, обращаться к ней нельзя (хотя в некоторых языках, например в Бейсике и Фортране, считается, что все переменные, не объявленные явно, имеют числовой тип). После того как переменная описана, к ней можно обращаться, но она обычно исходно имеет неопределенное значение, поэтому ее надо предварительно инициализировать — присвоить ей начальное значение.
Синтаксис команд описания данных
|
Бейсик |
Паскаль |
Си++ |
|
DIM имя AS тип |
var имя: тип; |
тип имя; |
Вот примеры описания переменных.
Бейсик:
DIM X AS DOUBLE
Паскаль:
var x: real;
var Str: record
P1: integer;
S: string;
end;
Си++:
float x;
int a[20];
При описании переменных одного типа в Паскале и Си++ их можно указывать через запятую.
Паскаль:
var хх, z2: integer;
Си++:
int xx, yy[10], z2;
Новые типы данных
При определении нескольких переменных со сложной структурой удобно описывать каждую переменную, многократно используя одну и ту же запись структуры. Если, например, в нее потребуется внести изменение (добавить новое поле, изменить тип существующего и т. д.), то придется делать это несколько раз, рискуя ошибиться и пропустить одно из описаний, особенно если они сделаны в разных местах программы.
Чтобы избежать этой проблемы и позволить программистам активно применять нужные структуры данных, в современных языках программирования разрешено определять собственные типы данных, которые допускается использовать в командах описания наравне с базовыми типами.

Название нового типа можно использовать во всех последующих командах описания переменных.
Паскаль:
type TMyArray = array[0..99] of integer;
type TMyRecord = record
Iteml: integer;
Item2: string;
end;
var MyArray: TMyArray;
var R: TMyRecord;
Си++:
typedef struct namel
{
int i;
float x;
} TNewStruct;
TNewStruct NewStruct;
Разделение операторов
Если записать подряд несколько операторов и не указать, где кончается один и начинается другой, то в процессе компиляции возникнет множество проблем с выделением отдельных операторов. Поэтому операторы в Паскале и Си++ отделяются друг от друга точкой с запятой «;» (каждый оператор в этих языках должен заканчиваться таким символом), а в Бейсике — двоеточием «:» или переходом на новую строку.
Блок операторов
Часто в программе возникает необходимость выполнить группу операторов (например, в зависимости от какого-либо условия). Такая группа объединяется в блок с помощью специальных скобок начала и конца блока, называемых логическими скобками.
В Бейсике явного понятия «блок операторов» нет, в Паскале для этого используются ключевые слова begin и end, а в Си++ — фигурные скобки «{» и «}».
Область действия переменных
Команды описания переменных могут встречаться в разных местах программы. При этом считается, что объявленные в них переменные являются локальными и их область действия — текущий блок, в котором они описаны. Как только встречается логическая скобка, закрывающая блок (например,«}»), соответствующая переменная перестает существовать, а выделенная для нее память освобождается.
Некоторые переменные описываются вне блоков и доступны из любого места программы.
Оператор присваивания
Оператор присваивания позволяет изменять текущее значение переменной. Синтаксис его очень простой. В левой части оператора присваивания указывается имя переменной, значение которой изменяется, а справа — выражение, значение которого будет записано в переменную. При этом старое значение, хранившееся в ней, безвозвратно пропадет.
Сам оператор присваивания записывается знаком «=» в Бейсике и Си++ и комбинацией двух знаков «:=» в Паскале (пробел между ними не допускается).
Например:
Result = 5
В переменную Result запишется число 5. Знак «=» означает именно присваивание, а не сравнение, которое может использоваться только в логических выражениях.
Другой пример:
X = X + 1
Сначала вычисляется значение выражения Х+1, и затем оно заносится в переменную X.
Допустима и такая запись:
X = X = X
Прежде всего выполняется сравнение в правой части (X = X), его значение всегда будет true, и значением переменной X, соответственно, тоже станет true. Для повышения наглядности оператора присваивания в Паскале принята специальная форма его записи:
Примеры.
Бейсик:
а23 = а22(12) + 1: Ы = Ы - 1
Паскаль:
а := Ь*2 + с; d := (е[8] - f)*2.2;
Си++:
х[5] = у/3.33; у = z[0] - 0.001;
Комментарии
При составлении программы очень полезно комментировать различные участки . кода, чтобы потом, обратившись к ним, сразу понять, что конкретно выполняется в том или ином месте программы. Забыть смысл того, что было сделано совсем недавно, можно очень быстро — за несколько недель, а в больших проектах и за несколько дней.
Эта проблема становится особенно актуальной, когда группой специалистов разрабатывается объемное приложение, и разобраться в сотнях тысяч строк своего и чужого исходного текста очень сложно.
Языки программирования допускают использование комментариев — частей исходных текстов, выделяемых с помощью специальных обозначений и пропускаемых компилятором при анализе текста программы.
Комментарии могут начинаться и заканчиваться особыми символами и охватывать несколько строк кода, а могут записываться только в конце строки — при этом считается, что весь остаток строки является комментарием.
Для обозначения комментариев в одном и том же языке программирования могут использоваться разные символы, поэтому возможно возникновение вложенных комментариев. Допустимость такого вложения задается, как правило, в настройках компилятора.
Синтаксис комментария
|
|
Бейсик |
Паскаль |
Си++ |
|
Однострочный комментарий |
REM или' |
// |
// |
|
Многострочный комментарий |
нет |
{} или (**) |
/*7 |
X = 5 "комментарий до конца строки
X := 5; // комментарий до конца строки
/*
это комментарий
языка Си++
*/
{
это комментарий
языка Паскаль
(* а это вложенный комментарий *)
Условный оператор (условные вычисления)
С помощью одного оператора присваивания можно создавать достаточно сложные расчетные программы, однако реализовать абсолютное большинство алгоритмов, просто последовательно выполняя операторы присваивания, невозможно. Постоянно приходится изменять порядок выполнения последовательности вычислений в зависимости от определенных условий. Эти условия записываются в виде логических выражений и всегда принимают одно из двух значений — true или false (истинно или ложно). При этом происходит разветвление программы — выполнение в дальнейшем может продолжиться с разных операторов.
Синтаксис условного оператора примерно одинаков во всех языках программирования — он представляет собой конструкцию:
если условие истинно то выполнить оператор-1 иначе выполнить оператор-2
После ключевого слова IF {если) следует условие, и если оно истинно, то выполняется оператор или блок операторов, следующих за ключевым словом THEN (то); если же оно ложно, то выполняется оператор или блок операторов, следующих за ключевым словом ELSE (иначе).
Синтаксис условного оператора
|
Бейсик |
Паскаль |
Си++ |
|
IF условие THEN |
if условие then |
if( условие ) |
|
оператор-1 |
оператор-1 |
оператор-1 |
|
ELSE |
else |
else |
|
оператор-2 |
оператор-2; |
оператор-2; |
|
END IF |
|
|
Примеры.
Бейсик:
IF А <> О THEN
А = О
ELSE
А = -1
END IF
Паскаль:
if а о 0 then a := О
else a := -1;
Си++:
if ( а о 0 ) а = О
else a = -1;
Вторую часть условного оператора, выполняющуюся в случае, если условие ложно, всегда можно опускать.
Бейсик:
IF х < О THEN
у = х / 2
х = 1
END IF
Паскаль:
if х < 0 then
begin
у := х / 2;
х := 1;
end
Си++:
if( x < 0 )
{
у = x / 2;
х = 1;
};
Повторяющиеся вычисления (операторы цикла)
С помощью условных операторов и операторов присваивания теоретически можно реализовать сколь угодно сложный алгоритм. Однако на практике при необходимости организовать обработку тысяч элементов массива (например, присвоить каждому элементу начальное значение) вручную набирать тысячу операторов присваивания крайне тяжело.
Поэтому в языках программирования имеются средства для организации повторных вычислений, называемые операторами цикла. Они бывают двух видов: с фиксированным числом повторений и условные операторы цикла.
Каждый оператор цикла состоит из заголовка цикла, определяющего число повторений, и тела цикла — повторяемого оператора или блока операторов.
Первый вид оператора цикла
При решении задачи примерно в половине случаев заранее известно, сколько раз понадобится выполнить тело цикла. Так бывает, как правило, при обработке массивов, размер которых всегда или известен заранее, или легко определяется.
Заголовок такого оператора состоит из трех частей — инициализации переменной-счетчика или параметра цикла (присваивания ей начального значения), определения конечного значения счетчика, по достижении которого тело цикла надо выполнить в последний раз, и приращения счетчика, определяющего, на сколько будет меняться значение счетчика после каждого выполнения тела цикла.
Синтаксис оператора цикла

Примеры инициализации тысячи элементов массива а.
Бейсик:
FOR I = 1 ТО 1000
А(1) =0
NEXT
Паскаль:
for i := 1 to 1000 do
a[i] := 0;
Си++:
for( i = 0; i < 1000; i = i + 1 )
a[i] = 0;
В последнем примере счетчик будет принимать значения от 0 до 999, потому что нумерация элементов массива в Си++ начинается с нуля.
Второй вид оператора цикла
Не менее часто встречаются ситуации, когда число повторений заранее неизвестно — надо выполнять цикл, пока не произойдет некоторое событие (пользователь нажмет на кнопку, точность вычислений уложится в заданный порог и т. д.). В таких ситуациях заголовок цикла упрощается. В нем указывается только условие (логическое выражение) — пока его значение равно true, цикл будет выполняться.
Синтаксис оператора цикла
|
Бейсик |
Паскаль |
Си++ |
|
DO WHILE условие группа операторов LOOP |
while условие do оператор или группа операторов; |
while( условие ) оператор или группа операторов; |
Бейсик:
DO WHILE A > В
А = А - 0.01
LOOP
Паскаль:
while a > b do
а := а - 0.01;
Си++:
while( а > b )
а = а - 0.01;
Зацикливание
При использовании условных операторов цикла программиста подстерегает одна опасность. Как показывает практика, достаточно легко сделать ошибку и неверно задать условие окончания цикла, которое всегда будет истинным, — при этом тело цикла станет выполняться бесконечно. Подобная ситуация называется зацикливанием.
Например:
а = 0; b = 1;
while ( а < b )
а = а - 0.01;
Так как исходное значение переменной а меньше, чем значение переменной Ь, и это значение будет только уменьшаться, то подобный цикл никогда не закончится.
В некоторых случаях программисты специально применяют подобный трюк, чтобы организовать бесконечный цикл, в котором будут приниматься и обрабатываться внешние сообщения (события). Тогда использование условного оператора цикла может выглядеть так:
while true do
begin
// тело цикла
end;
Контроль над выходом из цикла при наступлении определенного события при этом полностью возлагается на программиста.
В Бейсике есть специальная форма оператора цикла, позволяющая явно описывать такие бесконечные циклы:
DO
, тело цикла
LOOP
Исключения
Управление порядком выполнения программы может происходить не только с помощью условных операторов и операторов цикла, но и при возникновении исключений — ситуаций в программе или операционной системе, требующих немедленного реагирования. Например, при выполнении оператора присваивания и вычислении выражения произошло деление на ноль. Программа остановилась, так как не знает, что ей делать дальше, — ведь получено ошибочное значение. Чаще всего выполнение программы просто прекращается по ошибке, но современные системы разработки позволяют программисту явно контролировать возникновение самых разных исключений (они еще называются исключительными ситуациями, требующими немедленного вмешательства) и указывать, какие операторы следует выполнять при их возникновении.
Параллельные вычисления
Еще одна область программирования, в которой возможно изменение явно указанного порядка выполнения операторов, — это область параллельных вычислений. С появлением недорогих ПК с несколькими процессорами возникла возможность распараллеливания программы — одновременного выполнения ее независимых частей на разных процессорах, что теоретически позволяет получить выигрыш в быстродействии, линейно зависящий от числа процессоров. Однако на практике это очень сложная задача, которая требует правильного выделения независимых модулей кода (так называемых процессов), выполнение которых не скажется на результатах работы других процессов. Так как момент окончания работы того или иного процесса заранее неизвестен, то в программе надо предусмотреть действия, связанные с синхронизацией обработки получаемых результатов. Их выполнение может потребоваться в самые неожиданные моменты, поэтому изменение линейной последовательности работы операторов неизбежно.
Ввод и вывод
Чтобы получать от человека информацию для обработки и показывать результаты своей работы, программа должна иметь средства для организации интерактивного общения с пользователем (общения в реальном масштабе времени — человек щелкнул мышкой на кнопке и сразу получил ответ) и средства для ввода данных из файлов и сохранения данных в файлах. Интерактивное общение реализуется с помощью iMD-систем, позволяющих быстро спроектировать пользовательский интерфейс. Ввод и вывод информации осуществляется в разных языках по-разному. В Паскале и Бейсике есть операторы для такой работы, в Си++ они выделены в специальные библиотеки. Введен также специальный тип данных «файл» (FILE).
Работа с файлами всегда происходит в три этапа.
1. Файл открывается в одном из выбранных режимов (он рассматривается как последовательность строк или двоичных чисел, разрешается только считывать из него данные или только записывать и т. д.). Файл может состоять из последовательности одинаковых блоков, каждый из которых будет представлять собой копию структуры данных определенного типа, описанного в программе. Каждый такой блок называется записью.
2. Выполняется считывание, обновление или удаление записей в файле.
3. Файл закрывается. Если этого не сделать, то он останется открытым и в дальнейшем к нему нельзя будет обратиться из других программ.
Каждый из этих пунктов реализуется в каждом из языков программирования по-своему. Некоторые пункты требуют для своей реализации нескольких операторов.
Вопросы для самоконтроля
1. Какие типы данных считаются базовыми?
2. Приведите примеры арифметических и логических выражений.
3. Напишите формулу для вычисления среднего арифметического и среднего геометрического значений двух переменных.
4. В чем различие структуры и массива?
5. Зачем нужны комментарии?
6. С помощью условных операторов выполните проверку неравенства х < у < z.
7. Из каких частей состоит оператор цикла?
8. Назовите достоинства и недостатки параллельных вычислений.
9. Как организуется работа с файлами?
20.4. Структурное программирование
Подпрограммы
В предыдущем разделе рассматривались основные операторы и типы данных, необходимые для составления программ. При этом предполагалось, что текст программы представляет собой линейную последовательность операторов присваивания, цикла и условных операторов. Таким способом можно решать не очень сложные задачи и составлять программы, содержащие несколько сот строк кода. После этого понятность исходного текста резко падает из-за того, что общая структура алгоритма теряется за конкретными операторами языка, выполняющими слишком детальные, элементарные действия. Возникают многочисленные вложенные условные операторы и операторы циклов, логика становится совсем запутанной, при попытке исправить один ошибочный оператор вносится несколько новых ошибок, связанных с особенностями работы этого оператора, результаты выполнения которого нередко учитываются в самых разных местах программы. Поэтому набрать и отладить длинную линейную последовательность операторов практически невозможно.
При создании средних по размеру приложений (несколько тысяч строк исходного кода) используется структурное программирование, идея которого заключается в том, что структура программы должна отражать структуру решаемой задачи, чтобы алгоритм решения был ясно виден из исходного текста. Для этого надо иметь средства для создания программы не только с помощью трех простых операторов, но и с помощью средств, более точно отражающих конкретную структуру алгоритма. С этой целью в программирование введено понятие подпрограммы — набора операторов, выполняющих нужное действие и не зависящих от других частей исходного кода. Программа разбивается на множество мелких подпрограмм (занимающих до 50 операторов — критический порог для быстрого понимания цели подпрограммы), каждая из которых выполняет одно из действий, предусмотренных исходным заданием. Комбинируя эти подпрограммы, удается формировать итоговый алгоритм уже не из простых операторов, а из законченных блоков кода, имеющих определенную смысловую нагрузку, причем обращаться к таким блокам можно по названиям. Получается, что подпрограммы — это новые операторы или операции языка, определяемые программистом.
Возможность применения подпрограмм относит язык программирования к классу процедурных языков.
Нисходящее проектирование
Наличие подпрограмм позволяет вести проектирование и разработку приложения сверху вниз — такой подход называется нисходящим проектированием. Сначала выделяется несколько подпрограмм, решающих самые глобальные задачи (например, инициализация данных, главная часть и завершение), потом каждый из этих модулей детализируется на более низком уровне, разбиваясь в свою очередь на небольшое число других подпрограмм, и так происходит до тех пор, пока вся задача не окажется реализованной.
Такой подход удобен тем, что позволяет человеку постоянно мыслить на предметном уровне, не опускаясь до конкретных операторов и переменных. Кроме того, появляется возможность некоторые подпрограммы не реализовывать сразу, а временно откладывать, пока не будут закончены другие части. Например, если имеется необходимость вычисления сложной математической функции, то выделяется отдельная подпрограмма такого вычисления, но реализуется она временно одним оператором, который просто присваивает заранее выбранное значение (например, 5). Когда все приложение будет написано и отлажено, тогда можно приступить к реализации этой функции.
Немаловажно, что небольшие подпрограммы значительно проще отлаживать, что существенно повышает общую надежность всей программы.
Очень важная характеристика подпрограмм — это возможность их повторного использования. С интегрированными системами программирования поставляются большие библиотеки стандартных подпрограмм, которые позволяют значительно повысить производительность труда за счет использования чужой работы по созданию часто применяемых подпрограмм.
Рассмотрим пример, демонстрирующий методику нисходящего проектирования. Имеется массив Ocenki, состоящий из N (N> 2) судейских оценок (каждая оценка положительна). В некоторых видах спорта принято отбрасывать самую большую и самую маленькую оценки, чтобы избежать влияния необъективного судейства, а в зачет спортсмену идет среднее арифметическое из оставшихся оценок. Решим эту задачу, постепенно детализируя алгоритм (без привязки к конкретному языку программирования).
1. Процесс решения наиболее просто описывается подпрограммами:
Ввести_оценки_в_массив;
Удалить_самую большую оценку;
Удалить_самую маленькую оценку;
Рассчитать_среднее_арифметическое_оставшихся_оценок;
Вывести_результаты;
Теперь можно приступить к детализации каждой их этих подпрограмм.
2. Удалить_самую_большую_оценку;
Как удалить самую большую оценку из статического массива? Вместо нее можно просто записать значение 0, а при подсчете среднего арифметического нулевые значения не учитывать.
I = Номер_самого_большого_элемента_в_массиве;
Ocenki[ I ] = 0;
3. Удалить_самую_маленькую_оценку;
I = Номер_самого маленького элемента в массиве;
Ocenki( I ) = 0;
При реализации подпрограммы Номер_самого_маленького_элемента_в_массиве надо учесть, что искать придется самое маленькое из положительных значений (больших нуля).
- Рассчитать_среднее_арифметическое_оставшихся_оценок;
Здесь потребуется оператор цикла, вычисляющий сумму всех элементов массива Ocenki.
SUM = О
FOR I = 1 ТО N
SUM = SUM + Ocenki( I )
NEXT
SUM = SUM / (N - 2)
В последнем операторе происходит вычисление среднего арифметического всех оценок. Сумма элементов массива делится на число элементов, уменьшенное на 2, потому что две оценки, самую большую и самую маленькую, учитывать не надо.
Если бы эта задача решалась последовательно, то уже на этапе удаления оценок могли возникнуть определенные проблемы.
Реализацию подпрограмм Номер_самого_большого_элемента_в_массиве и Номер_ самого_маленького_элемента_в_массиве выполните самостоятельно.
Процедуры и функции
Подпрограммы бывают двух видов — процедуры и функции. Отличаются они тем, что процедура просто выполняет группу операторов, а функция вдобавок вычисляет некоторое значение и передает его обратно в главную программу (возвращает значение). Это значение имеет определенный тип (говорят, что функция имеет такой-то тип).
В Си++ понятия «процедура» нет — там имеются только функции, а если никакого значения функция не вычисляет, то считается, что она возвращает значение типа «никакое» (void).
Параметры подпрограмм
Чтобы работа подпрограммы имела смысл, ей надо получить данные из внешней программы, которая эту подпрограмму вызывает. Данные передаются подпрограмме в виде параметров или аргументов, которые обычно описываются в ее заголовке так же, как переменные.
Управление последовательностью вызова подпрограмм
Подпрограммы вызываются, как правило, путем простой записи их названия с нужными параметрами. В Бейсике есть оператор CALL для явного указания того, что происходит вызов подпрограммы.
Подпрограммы активизируются только в момент их вызова. Операторы, находящиеся внутри подпрограммы, выполняются, только если эта подпрограмма явно вызвана. Пока выполнение подпрограммы полностью не закончится, оператор главной программы, следующий за командой вызова подпрограммы, выполняться не будет.
Подпрограммы могут быть вложенными — допускается вызов подпрограммы не только из главной программы, но и из любых других подпрограмм.
В некоторых языках программирования допускается вызов подпрограммы из себя самой. Такой прием называется рекурсией и потенциально опасен тем, что может привести к зацикливанию — бесконечному самовызову.
Структура подпрограммы
Подпрограмма состоит из нескольких частей: заголовка с параметрами, тела подпрограммы (операторов, которые будут выполняться при ее вызове) и завершения подпрограммы.
Локальные переменные, объявленные внутри подпрограммы, имеют областью действия только ее тело.
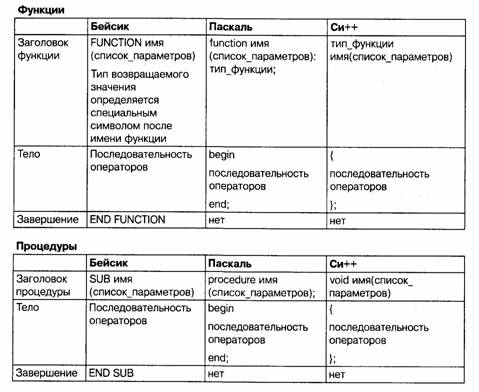
Как функция возвращает значение
После того как функция рассчитала нужное значение, ей требуется явно вернуть его в вызывающую программу. Для этого может использоваться специальный оператор (return в Си++) или особая форма оператора присваивания, когда в левой части указывается имя функции, а справа — возвращаемое значение.
Далее приведены примеры функции, вычисляющей значение квадрата аргумента.
Бейсик:
FUNCTION SQR% (X AS INTEGER)
SQR% = X*X
END FUNCTION
Паскаль:
function SQR(X: integer): integer;
begin
SQR := X*X
end;
Си++:
int SQR(int x)
{
return x*x;
{;
Формальные и фактические параметры
Во время создания подпрограммы заранее не известно, какие конкретно параметры она может и будет получать. Поэтому в качестве переменных, выступающих в роли ее аргументов в заголовке, могут использоваться произвольные допустимые названия, даже совпадающие с уже имеющимися. Компилятор все равно поймет, что это не одно и то же.
Параметры, которые указываются в заголовке подпрограммы, называются формальными. Они нужны только для описания тела подпрограммы. А параметры (конкретные значения), которые указываются в момент вызова подпрограммы, называются фактическими параметрами. При выполнении операторов подпрограммы формальные параметры как бы временно заменятся на фактические.
Пример.
int а, у;
а = 5;
у = SQR(a);
Программа вызывает функцию SQR() с одним фактическим параметром а. Внутри подпрограммы формальный параметр х получает значение переменной а и возводится в квадрат. Результат возвращается обратно в программу и присваивается переменной у.
Событийно-ориентированное программирование
С активным распространением системы Windows и появлением визуальных RAD-сред широкую популярность приобрел событийный подход к созданию программ — событийно-ориентированное программирование.
Идеология системы Windows основана на событиях. Щелкнул человек на кнопке, выбрал пункт меню, нажал на клавишу или кнопку мыши — в Windows генерируется подходящее сообщение, которое отсылается окну соответствующей программы.
Структура программы, созданной с помощью событийного программирования, следующая. Главная часть представляет собой один бесконечный цикл, который опрашивает Windows, следя за тем, не появилось ли новое сообщение. При его обнаружении вызывается подпрограмма, ответственная за обработку соответствующего события (обрабатываются не все события, их сотни, а только нужные), и подобный цикл опроса продолжается, пока не будет получено сообщение «Завершить работу».
События могут быть пользовательскими, возникшими в результате действий пользователя, системными, возникающими в операционной системе (например, сообщения от таймера), и программными, генерируемыми самой программой (например, обнаружена ошибка и ее надо обработать).
Событийное программирование является развитием идей нисходящего проектирования, когда постепенно определяются и детализируются реакции программы на различные события.
Вопросы для самоконтроля
1. С какой целью применяют подпрограммы?
2. Чем характеризуются процедурные языки программирования?
3. В чем состоит идея нисходящего проектирования?
4. Что общего и в чем отличия процедуры и функции?
5. Определите значение выражения F(1,2) + F( 10,0.1), если функция F(a,b) рассчитывается как а*а + b*b.
6. В чем различие между событийным и структурным программированием?
7. Как организуется обработка программных событий?
20.5. Объектно-ориентированное программирование
Понятие объекта
Развитие идей структурного и событийного программирования существенно подняло производительность труда программистов и позволило в разумные сроки (несколько месяцев) создавать приложения объемом в сотни тысяч строк. Однако такой объем уже приблизился к пределу возможностей человека, и потребовались новые технологии разработки программ.
В начале 80-х годов в программировании возникло новое направление, основанное на понятии объекта. До того времени основные ограничения на возможность создания больших систем накладывала разобщенность в программе данных и методов их обработки.
Реальные объекты окружающего мира обладают тремя базовыми характеристиками: они имеют набор свойств, способны разными методами изменять эти свойства и реагировать на события, возникающие как в окружающем мире, так и внутри самого объекта. Именно в таком виде в языках программирования и реализовано понятие объекта как совокупности свойств (структур данных, характерных для этого объекта), методов их обработки (подпрограмм изменения свойств) и событий, на которые данный объект может реагировать и которые приводят, как правило, к изменению свойств объекта.
Появление возможности создания объектов в программах качественно повлияло на производительность труда программистов. Максимальный объем приложений, которые стали доступны для создания группой программистов из 10 человек, за несколько лет увеличился до миллионов строк кода, при этом одновременно удалось добиться высокой надежности программ и, что немаловажно, повторно использовать ранее созданные объекты в других задачах.
Класс
Объекты могут иметь идентичную структуру и отличаться только значениями свойств. В таких случаях в программе создается новый тип, основанный на единой структуре объекта (по аналогии с тем, как создаются новые типы для структур данных). Он называется классом, а каждый конкретный объект, имеющий структуру этого класса, называется экземпляром класса.
Описание нового класса
Описание нового класса похоже на описание новой структуры данных, только к полям (свойствам) добавляются методы — подпрограммы.
В Си++ и Паскале для описания класса используется ключевое слово class.
Паскаль:
class TMyClass
Iteml: integer;
Item2: string;
function GetSum(n: integer): integer;
procedure Initialize;
end;
Си++:
class TMyClass
{
int Iteml;
int Item2;
int GetSum(int n);
void Initialize ( );
} ;
При определении подпрограмм, принадлежащих конкретному классу, его методов, в заголовке подпрограммы перед ее названием явно указывается, к какому классу она принадлежит. Название класса от названия метода отделяют специальные символы (точка в Паскале или два двоеточия в Си++).
Паскаль:
procedure TMyClass.Initialize;
begin
Iteml := 1;
Item2 := «»;
end;
Си++: ..... .
void TMyClass::Initialize( )
{
Iteml = 1;
Item2 = 0;
}
Класс — это тип данных, такой же, как любой другой базовый или сложный тип. На его основе можно описывать конкретные объекты (экземпляры классов).
Паскаль:
var Cl, C2: TMyClass;
Си++:
TMyClass Cl, C2;
Доступ к свойствам объектов и к их методам осуществляется так же, как к полям записей, через точку:
Cl.Iteml := 5;
С2.Initialize;
х := Cl.GetSum(21);
Объектно-ориентированное программирование базируется на трех ключевых концепциях — инкапсуляции, наследовании и полиморфизме. Объединение данных с методами в одном типе (классе) называется инкапсуляцией. Помимо объединения, инкапсуляция позволяет ограничивать доступ к данным объектов и реализации методов классов. В результате у программистов появляется возможность использования готовых классов в своих приложениях на основе только описаний этих классов.
Наследование
Важнейшая характеристика класса — возможность создания на его основе новых классов с наследованием всех его свойств и методов и добавлением собственных. Класс, не имеющий предшественника, называется базовым. Например, класс «животное» имеет свойства «название», «размер», методы «идти» и «размножаться». Созданный на его основе класс «кошка» наследует все эти свойства и методы, к которым дополнительно добавляется свойство «окраска» и метод «пить».
Наследование позволяет создавать новые классы, повторно используя уже готовый исходный код и не тратя времени на его переписывание.
Полиморфизм
В большинстве случаев методы базового класса у классов-наследников приходится переопределять — объект класса «кошка» выполняет метод «идти» совсем не так, как объект класса «амеба». Все переопределяемые методы по написанию (названию) будут совпадать с методами базового объекта, однако компилятор по типу объекта (его классу) распознает, какой конкретно метод надо использовать, и не вызовет для объекта класса «кошка» метод «идти» класса «животное». Такое свойство объектов переопределять методы наследуемого класса и корректно их использовать называется полиморфизмом.
Визуальное программирование
Технологии объектного, событийного и структурного программирования сегодня объединены в RAD-системах, которые содержат множество готовых классов, представленных в виде визуальных компонентов, которые добавляются в программу одним щелчком мыши. Программисту надо только спроектировать внешний вид окон своего приложения и определить обработку основных событий — какие операторы будут выполняться при нажатии на кнопки, при выборе пунктов меню или щелчках мышкой. Весь вспомогательный исходный код среда сгенерирует сама, позволяя программисту полностью сосредоточиться только на реализации алгоритма.
Вопросы для самоконтроля
1. Для чего в языки программирования было введено понятие класса?
2. В чем различие между классом и объектом?
3. Поясните понятие инкапсуляции на бытовых примерах.
4. Для чего применяется механизм наследования?
5. Как полиморфизм модифицирует принцип наследования?
6. Опишите использование принципов объектно-ориентированного программирования в средах быстрого проектирования.
20.6. Проектирование программ Программирование как вид деятельности
Появление первых компьютеров породило программирование как науку. Разрабатывались первые математические теории обработки информации, средства доказательства правильности программ, оптимизации кода, создания эффективных компиляторов, формального тестирования и т. д. Затем, с появлением универсальных языков программирования третьего поколения, эти аспекты стали менее актуальными — исследования шли и идут в основном в области автоматической генерации исходных текстов и повышения эффективности компиляторов. Программирование превратилось в искусство — миллионы людей, не имевших специального образования, получили возможности применять компьютеры для решения собственных прикладных задач, что потребовало от них мастерства создавать правильно работающие программы. Искусством программирование остается и сегодня для профессиональных разработчиков и любителей, создающих программы в одиночку или в небольших компаниях, где все решает индивидуальное мастерство. Вместе с тем, при росте спроса со стороны государственных и частных организаций на все более и более сложные системы автоматизации предприятий, надежные операционные среды, комплексы глобального телекоммуникационного управления, возникла необходимость в постановке процесса разработки программного обеспечения (ПО) на поток, превращения программирования времесло. Было разработано несколько методологий и стандартов, позволивших эффективно организовывать труд сотен программистов средней квалификации, точно укладываться в отпущенные сроки и средства и не зависеть от настроения нескольких талантливых ведущих специалистов. Отрицательная сторона подобных методологий — отсутствие творческого элемента в работе и своеобразная конвейерная «потогонная» система промышленного производства программ, которая, будучи внедренной в организации, в условиях жесточайшего дефицита программистов во всем мире может только отпугнуть сотрудников.
Потенциальные возможности человека
|
Объем проекта, строк исходного кода |
Тип программы |
Время создания |
Вероятность успешного завершения |
Число программистов |
|
100 |
Утилиты для временных нужд |
1 день |
100% |
1 |
|
1000 |
Небольшие приложения и дополнения, вносимые в готовые системы |
до 1 месяца |
100% |
1 |
|
10 000 |
Типичная средняя программа, разрабатываемая на заказ |
до 6 месяцев |
85% |
1 (предел возможностей среднего программиста) |
|
100 000 |
Большинство современных коммерческих автономных и небольших клиент-серверных приложений |
1 год |
85% для групп, 35% для одиночки |
10 |
|
1 млн |
Крупные системы автоматизации |
1,5-5 лет |
50% для группы, 0% для одиночки |
100 |
|
10 млн |
Операционные системы (Microsoft Windows, IBM VMS), большие военные комплексы. Предел сегодняшних возможностей. Стоимость подобной разработки может равняться стоимости большого стадиона или крупного корабля |
5-8 лет |
35% |
до тысячи |
Экономические аспекты программирования
Когда на свет появились первые компьютеры, одна минута их работы стоила очень дорого, а задачи решались достаточно простые, поэтому в расходах на подготовку программ труд разработчиков составлял небольшую часть. С появлением ПК и ростом спроса на большие программные системы практически всю расходную часть проекта стала составлять зарплата программистов. Как видно из таблицы, большой процент таких проектов заканчивается неудачно, а расходы на них очень велики, поэтому проблемы создания качественного программного обеспечения точно в срок и в рамках бюджета сегодня самые важные и над созданием эффективных методологий производства ПО трудятся специалисты во всех развитых странах.
Этапы разработки программ
Программы небольшого и среднего размера (несколько тысяч строк) создаются, как правило, в два этапа. Сначала необходимо точно установить, что надо сделать, продумать соответствующий алгоритм, определить структуры данных, объекты и взаимодействие между ними (это этап системного анализа), а затем выразить этот алгоритм в виде, понятном машине (этап кодирования). Если же разрабатывается крупный проект объемом от десятков тысяч до миллионов строк кода, тогда приходится применять специальные методологии проектирования, охватывающие период разработки ПО.
Период разработки ПО
Рассмотрим классический период разработки ПО.
1. Формируются и анализируются требования к проекту. Этот этап самый важный, так как неправильное формулирование требований приводит к выполнению ненужной работы, а недооценка сложности вызывает перерасход средств и времени. Сегодня около 60% крупных проектов завершаются неудачей именно из-за ошибок на стадии подготовки требований.
На основе требований по различным методикам определяется примерный объем проекта и его трудоемкость, рассчитываются будущие трудозатраты и определяется его стоимость. Так как требования к проекту во время работы над ним могут уточняться и меняться, а выполнение требований надо отслеживать, применяются специальные программы для управления требованиями.
Часто заказчик не в состоянии точно выразить, чего он хочет, и задача специалистов по системному анализу — помочь ему выразить свои требования в виде, пригодном для формализации. После согласования требований подписывается контракт на разработку ПО. В дальнейшем любые отклонения от сформулированных требований к продукту (как со стороны заказчика, так и со стороны исполнителя) рассматриваются как нарушение контракта.
Каждый этап требует от заказчика вложения собственных трудозатрат и привлечения высокопрофессиональных специалистов, поэтому он обязательно должен оплачиваться — бесплатно выполнять сложную работу никто не будет. Однако, хотя первый этап самый важный, заказчик редко понимает эту важность и не готов платить достаточно большие суммы. Примерный объем работ на этом этапе — 5% от объема всего проекта.
2. Начинается предпроектное обследование объекта автоматизации. С помощью СЛ5£"-средств составляется формальная модель его работы, модель базы данных, объектов и потоков информации. На этом этапе привлекаются специалисты заказчика и эксперты, хорошо знакомые с предметной областью, для которой составляется задача.
Примерный объем работ второго этапа — 10% от общего.
3. На основе формальной модели составляется подробное техническое задание для программистов, спецификации отдельных модулей, таблицы баз данных, другая сопроводительная документация. Готовится подробный календарный план работ, где указываются все сроки, конкретные исполнители и выполняемые объемы работ (понедельно, помесячно). Для составления планов работ имеется немало хороших программ, ориентированных как на небольшие группы программистов, так и на коллективы из сотен сотрудников, выполняющих тысячи различных работ в рамках общего плана.
Примерный объем работ третьего этапа — 10% от общего.
4. Выбирается методология разработки ПО и начинается разработка (кодирование). Крупные компании имеют собственные методологии, ориентированные на конкретные задачи (как правило, это задачи автоматизации предприятий), однако все методологии имеют общие черты и более-менее серьезно различающихся известно около двух десятков.
Мы коснулись, в частности, методологий структурного (нисходящего) и объектного проектирования. Хотя объектный подход, безусловно, один из самых передовых, он подразумевает высокую квалификацию всех исполнителей без исключения и поэтому распространен не очень широко.
Достаточно популярна методология итерационного проектирования, ориентированная на использование RAD-средств и систем автоматической генерации исходных текстов на основе созданной формальной модели. Такой подход хорош тем, что позволяет быстро создать первый работающий прототип программы, когда еще требования к ней окончательно не определены, а в дальнейшем, на следующих итерациях (их обычно требуется от двух до пяти), постепенно детализировать и реализовывать конкретные возможности, пропущенные по каким-то причинам на предыдущей итерации. Эта методология немного отличается от нисходящего проектирования тем, что применяется, когда окончательные требования неизвестны и могут меняться, а основные работающие функции нужны заказчику как можно быстрее (заказчик чаще хочет получить приложение, законченное на 80%, сегодня, чем законченное на 100% завтра). При нисходящем проектировании основная структура задачи должна быть определена заранее.
Принятие решения о выборе подходящей методологии — очень ответственный процесс. Человек, принимающий такое решение, должен обладать богатым опытом и знаниями в области создания ПО. Многое зависит от инфраструктуры заказчика — какие у него компьютеры, операционные системы, каковы их ресурсы. В соответствии с этим выбираются и средства разработки. Иногда бывает, что лучше всего подходит, например, итерационная методология, но для операционной системы заказчика нет хорошей /MD-среды и приходится остановиться на менее эффективной методологии.
В процессе разработки необходимо:
• непрерывно поддерживать обратную связь с заказчиком, чтобы следить за правильностью реализации требований;
• непрерывно контролировать ход работ в соответствии с планом и при отклонениях от него принимать экстренные меры.
Примерный объем этих работ — 10% от общего объема проекта.
5. Когда программа закончена (готова работоспособная альфа-версия), она поступает к тестерам компании-исполнителя, которые начинают проверять ее на наличие ошибок и сообщать о найденных ошибках программистам. Анализируется, в частности, устойчивость работы программы при вводе недопустимых или критических значений, при отсутствии информации, при неверных действиях, при сбоях аппаратуры, в стрессовых режимах и т. п. Когда число ошибок, выявляемых за определенный срок (неделя, месяц), снижается ниже экспериментально подобранного уровня (на основе аналогичных проектов), начинается бета-тестирование программы у заказчика. К такому тестированию привлекается максимально возможное число сотрудников, и программа уже начинает частично функционировать в рабочем режиме.
Примерный объем этих работ — 10% от общего объема проекта.
6. После того как заказчик удовлетворен качеством продукта, начинается его внедрение — подготовка к окончательному запуску в эксплуатацию. Если приложение многопользовательское, нередко требуется сформировать и настроить локальную сеть, установить серверы, инсталлировать вспомогательные программы. Очень много проблем возникает при переходе со старых программ (например, бухгалтерского учета, расчета зарплаты, работы с персоналом), которые создавались разными сотрудниками и покупались в разных фирмах (так называемая лоскутная автоматизация), к новой интегрированной системе. Необходимо выверить, ввести или перенести множество жизненно важной информации: всю бухгалтерскую и финансовую отчетность, данные о хранимом оборудовании и множество других сведений. Этот этап самый трудоемкий и «нудный» и занимает порой до 90% времени всего проекта. Для систем автоматизации больших предприятий он растягивается на годы.
7. После того как новая система готова к работе, сотрудников организации заказчика нужно обучить работе с этой системой, потому что книг о ней не написано, да и содержится в такой системе, внедренной на конкретном предприятии, множество нюансов, связанных со спецификой работы.
Примерный объем трудозатрат на обучение — 5% от общего объема проекта.
8. После того как заказчик подписывает акт приемки, проект считается завершенным, но связь с исполнителем не теряется. Особенно в первое время у пользователей системы постоянно будет возникать множество вопросов по работе с ней. Неизбежно и возникновение ошибок, которые требуется устранять. Кроме того, исполнитель может выпускать новые версии системы, и старая система потребует обновления. Сотрудничество с заказчиком по обслуживанию системы называется сопровождением. Оно бесплатно на определенный гарантийный срок (например, год).
Реально объем непосредственного программирования и отладки (тестирования) в цикле разработки невелик. Он составляет 10-20% от общего объема работ.
Контроль качества
Чем крупнее проект, тем больше в нем ошибок. При этом слишком затягивать этап тестирования нельзя — нарушаются сроки, растет недовольство потребителей, и на рынок выпускается «сырая» система с множеством ошибок, которые устраняются уже в процессе эксплуатации выпуском многочисленных «заплаток».
Современные технологии создания надежного ПО предусматривают непрерывный сквозной контроль качества разрабатываемого продукта на всех этапах жизненного цикла — от анализа требований до внедрения и сопровождения, а не только на этапе тестирования. Качество каждой работы в плане формализуется числовой величиной с помощью специальных методик, но его можно контролировать, только оптимальным образом организовав работу большой группы аналитиков и программистов. Для этого надо иметь возможность отслеживать вносимые в проект изменения — изменения требований, формальных моделей, сопроводительной документации, версий исходных текстов, хода выполнения календарного плана по разработке, тестированию, внедрению, сопровождению, а также контролировать и управлять всеми этапами периода создания программы — процессом разработки ПО. Для этого предназначены системы конфигурационного управления — сложные и дорогие (десятки и сотни тысяч долларов) продукты, однако без них крупный проект, скорее всего, обречен на неудачу.
Системы не очень сложного конфигурационного управления, охватывающие контроль версий исходных текстов и ряд других аспектов работы группы программистов, встроены, в частности, в такие системы, как Delphi 7 и Visual Studio .NET.
Стандарты качества ПО
Компания может организовать у себя очень эффективный процесс разработки ПО, однако заказчик вполне обоснованно может ей не поверить. Существует международная система сертификации компаний по стандарту качества ISO 9000, которая гарантирует, что данная компания выполняет программные проекты в срок и с высоким качеством. Процесс сертификации сложен и требует подготовительной работы в течение нескольких лет.
В университете Карнеги-Меллона в США несколько лет назад была разработана специальная методология СММ (Capability Maturity Model for Software), позволяющая сертифицировать компании по одному из 5 уровней «зрелости» процесса разработки ПО. Согласно результатам 20-летних исследований Министерства обороны США оказалось, что главная причина слишком частых неудач при разработке крупных информационных проектов заключается прежде всего в неумении менеджеров управлять процессом создания качественного ПО.
В отличие от стандарта /50 9000, который просто подтверждает качественную работу компании на основании достаточно общих критериев, методология СММ ориентирована именно на качество управления процессом разработки и имеет множество конкретных рекомендаций и указаний по способам организации всех этапов создания ПО. Сегодня в США невозможно получить крупный государственный или военный заказ на создание программного продукта стоимостью более 2 млн. долларов, если компания не сертифицирована как минимум по третьему уровню СММ. Сегодня на смену этой модели приходит новая интеграционная концепция CMMI, дополняющая процессы разработки не менее важными вопросами организации деятельности персонала, общения с подрядчиками, выбора программного обеспечения и т. д.
Повышение индивидуального мастерства
На основе методологии СММ была создана методология PSP (Personal Software Process), ориентированная на индивидуальных разработчиков. Она позволяет в несколько раз повысить качество создания программ, значительно поднять собственную производительность и научиться предсказывать сроки выполнения работ.
Методология PSP состоит из 7 этапов самосовершенствования, и, чтобы хорошо ее освоить, надо закончить специальные курсы. Однако даже простое знакомство с ее идеологией позволит любому программисту значительно улучшить свою работу.
Перед началом проекта составляется подробный календарный план работ и производится попытка оценить его объем в строках кода и рабочих днях. Весь процесс работы детально хронометрируется, а найденные ошибки подробно описываются — накапливается статистика. По окончании проекта весь процесс тщательно анализируется и делаются выводы о том, что можно улучшить в своей работе, каких ошибок надо стараться избегать, какова реальная производительность труда и т. п. Сегодня лучшая характеристика программиста — это не просто знание Си++ или Delphi, a способность планировать свой труд, разрабатывать программу точно в срок и без ошибок.
Гибкие методики
В последние годы наряду с ростом интереса к «тяжелым» сертификационным методологиям значительно увеличилась роль и популярность так называемых гибких, проворных (agile) методик. Они не требуют значительных усилий по реорганизации компании-разработчика и могут быть внедрены не за годы, а за недели. Наиболее известные среди них — экстремальное программирование, MDA (архитектура системы, управляемая моделью), Scrum и другие.
Гибкие методики не навязывают исполнителю множество формализованных действий по разработке ПО. Они предоставляют участникам проекта большую свободу (но и требуют от них большей ответственности) и акцентируют их внимание на важнейших задачах соблюдения требований заказчика, сроков и качества работы.
Методы маркетинга программного обеспечения
Коммерческое ПО. При создании программного продукта издатель, выполнив анализ рынка, заказывает у исполнителя разработку такого ПО, которое должно пользоваться на рынке спросом, и выделяет на его создание деньги. По окончании работ издатель получает все имущественные права на созданный продукт (право на тиражирование, продажу под собственной торговой маркой, право на получение дохода от программы любым способом). При этом может быть оговорено получение исполнителем некоторого процента (роялти) с каждой проданной копии (как правило, для программ, издающихся сотнями тысяч или миллионами копий, роялти составляет 1-3%) — тогда он получает меньшую сумму на разработку или вообще создает программу за свой счет. Если же отчисления не предусмотрены, то все расходы по подготовке программы издатель берет на себя. Он также вкладывает средства в упаковку, рекламную кампанию, организацию сетей сбыта и т. д. Издатель обеспечивает расходы, связанные с сопровождением продукта и технической поддержкой пользователей.
За исполнителем навечно остаются авторские права на программу — право указывать свое имя или логотип своей фирмы на начальной заставке, в документации, на упаковочной коробке.
Крупные компании имеют и подразделения разработки ПО, и отделы, занимающиеся его распространением, что помогает эффективно организовать весь процесс от производства программ до доставки их потребителю.
Условно-бесплатное ПО (shareware). В связи с активным развитием Интернета огромное число индивидуальных разработчиков получили возможность распространения своих программ по всему миру. Не имея средств на рекламные кампании, они предоставляют возможность получения ознакомительных версий их программ (демонстрационных или имеющих искусственные ограничения) через Интернет. Если человеку эта программа нравится, он оплачивает небольшую сумму и получает полную работоспособную версию.
В Интернете есть немало узлов, которые предлагают бесплатные услуги по размещению таких программ. Отечественным shareware-разработчикам можно порекомендовать сайт www.swrus.com , на котором можно найти множество материалов и форумов по всем вопросам организации shareware.
Бесплатное ПО (freeware, public domain). Такие программы не имеют никаких ограничений, однако автор может попросить заплатить ему некоторую сумму, не настаивая, впрочем, на этом (это метод freeware). Некоторые программы авторы называют «общественным достоянием» (public domain), ничего взамен не требуют и нередко распространяют такое ПО в исходных текстах.
Как правило, стимулом к созданию бесплатных программ служит стремление повысить собственную квалификацию, установить контакты с коллегами, а в случае удачно созданной программы получить известность.
Вопросы для самоконтроля
1. В чем трудности разработки крупных программных проектов?
2. Опишите организацию работы над сложной программной системой.
3. Какой этап разработки проекта является наиболее ответственным?
4. Какова роль собственно программирования в ходе работы над проектом?
5. Опишите известные вам методы контроля качества программного обеспечения.
6. Каковы основные методы распространения программного обеспечения?
20.7. Пример на Бейсике. Разведение кроликов
В данном и последующих разделах рассматриваются три примера, реализованные с помощью разных систем программирования: QBasic корпорации Microsoft (интерпретирующая версия Бейсика для операционной системы MS-DOS), Borland Delphi 7 (система визуального программирования на Паскале) и Microsoft Visual Studio .NET (система программирования на Си++). Эти примеры включают в себя описание основных приемов работы с данными системами.
Постановка задачи
Итальянский математик Леонардо Фибоначчи придумал оригинальную числовую последовательность, названную в его честь, которая описывает рост численности поколений кроликов. Считается, что каждый год каждая пара животных приносит приплод — новую пару (самца и самку), которые в свою очередь начинают давать приплод через два года (смертность не учитывается). То есть каждый следующий член последовательности равен сумме двух предыдущих, а классическая последовательность Фибоначчи выглядит так:
1,1,2,3,5,8,13,21,...
Надо определить, через сколько лет будет достигнута популяция в N особей.
Запуск QBasic
Интерпретатор QBasic входит в стандартную поставку MS-DOS и расположен обычно в каталоге \DOS. Программа-интерпретатор называется qbasic.exe. После ее запуска на экране появится приветствие, которое пропускается нажатием на клавишу ENTER, после чего QBasic вызывает встроенную справочную систему на английском языке. Она закрывается нажатием клавиши ESC.
Рабочая область экрана (рис. 20.1) поделена на две части. В нижней части, в окне Immediate (Немедленное выполнение) можно вводить операторы Бейсика и тут же их выполнять.
Вывод на экран
Каждый язык программирования имеет оригинальные средства вывода информации, сильно зависящие от операционной системы. В Бейсике реализован оператор PRINT, который выводит значение следующего за ним выражения на экран, в новую строку.
Для перехода в окно Immediate (Немедленное выполнение) надо нажать клавишу F6. Чтобы сразу получить ответную реакцию от QBasic, достаточно набрать оператор
PRINT 2+2
и нажать клавишу ENTER, чтобы этот оператор выполнился.
На экране вывода появится число 4 (результат вычисления выражения 2+2), а в нижней строке — сообщение Press any key to continue (Нажмите любую клавишу для продолжения). Чтобы вернуться в QBasic, надо это сделать.
В операторе вывода можно указывать несколько значений через запятую, тогда они будут выведены в одной строке. Ранее введенный оператор можно изменить, добавив к нему текстовую подсказку:
PRINT "Сумма = "; 2+3
Если теперь нажать клавишу ENTER, то на экране вывода в новой строке (под ранее напечатанной четверкой) появится фраза
Сумма =5
Редактор программы
Таким образом можно познакомиться с работой разных операторов Бейсика, однако выполнять их удастся только поодиночке. Чтобы выполнить группу операторов, их надо объединить в программу.
Набор и редактирование исходного текста программы осуществляется в верхнем окне интерпретатора. Для перехода в него используется клавиша F6.
Решать данную задачу удобнее всего с помощью нисходящего метода. В программе будет бесконечный главный цикл, в котором осуществляется ввод очередного значения количества особей, происходит расчет числа лет, необходимых для размножения, полученный результат печатается, и цикл повторяется снова. Если человек вводит ноль, это будет означать, что программу надо завершить.
Ввод информации от пользователя
В Бейсике ввести в переменную значение с экрана можно с помощью оператора INPUT. Сначала указывается необязательная текстовая подсказка, а потом — имя переменной. Например, оператор
INPUT "Введите число: ", х при выполнении напечатает в новой строке подсказку
Введите число:
и будет ожидать, когда пользователь введет число и нажмет клавишу ENTER. В результате в переменную х запишется новое, введенное с клавиатуры значение.
Главная часть программы
Ввод и редактирование текста программы осуществляется во встроенном редакторе QBasic, правила работы с которым аналогичны правилам работы с большинством известных текстовых редакторов.

Главная часть программы набирается в этом редакторе и должна выглядеть так (комментарии вводить не обязательно):
' описание переменной N — числа особей
DIM N AS INTEGER
' начало бесконечного цикла
DO
' ввод числа особей в переменную N
INPUT "Введите количество особей: ", N
' если введен 0, то
IF N = 0 THEN
' закончить программу
END
END IF
' напечатать результат:
PRINT "Требуемое число лет: ", Years%(N)
' продолжить цикл с начала
LOOP
В тексте используется оператор END, который предназначен для немедленного завершения работы программы. Операторы, вложенные в цикл и в условные операторы, выделяются отступами, чтобы структура текста была более понятной и наглядной.
Основная, глобальная часть алгоритма реализована. Осталось «спуститься вниз» и запрограммировать функцию Years%(), которая в качестве аргумента получает количество особей и возвращает число лет, требуемое для их разведения.
Типы данных в Бейсике
В конце названия функции Years% указан символ %. Таким образом в Бейсике описывается тип возвращаемого функцией значения. Допустимые символы приведены в таблице.
|
Тип переменной |
Символ в конце имени переменной |
|
INTEGER |
% |
|
STRING |
$ |
|
DOUBLE |
# |
Добавление новой функции
В QBasic имеется удобная возможность добавить в программу новую функцию, избежав при этом дополнительного ручного кодирования. Это делает команда Edit ► New Function (Правка ► Создать функцию). В появившемся диалоговом окне надо ввести название функции Years% и нажать клавишу ENTER. Основной текст программы временно пропадет, и появится автоматически сгенерированное описание новой функции:
FUNCTION Years% \
END FUNCTION
Для того чтобы вернуться обратно к главному тексту, а из него — к любой введенной подпрограмме, необходимо использовать клавишу F2. При ее нажатии на экран выводится список всех созданных подпрограмм, а в первой строке — имя главного модуля.
Функции Years% надо указать список аргументов. В данном случае он будет состоять из одного параметра:
FUNCTION Years%(X AS INTEGER)
Расчет популяции
Так как для определения нового члена последовательности Фибоначчи требуется знать значения двух предыдущих членов, прежде всего надо описать три локальные переменные F1, F2 и F3, хранящие три очередных значения последовательности. Исходно первые три значения 1,1 и 2 запишутся в переменные F1, F2 и F3 явно, а в дальнейшем новые значения будут вычисляться программно.
Сам расчет представляет собой условный цикл, который выполняется до тех пор, пока очередное значение не превысит заданное количество особей. Число таких циклов — число лет — будет подсчитываться в локальной переменной-счетчике. YearsNum, первоначально имеющей значение 3.
FUNCTION Years%(X AS INTEGER)
описание переменных
DIM Fl AS INTEGER, F2 AS INTEGER, F3 AS INTEGER
DIM YearsNum AS INTEGER
' задание начальных значений
Fl = 1: F2 = 1: F3 = 2: YearsNum = 3
' цикл, пока число кроликов меньше заданного
DO WHILE F3 < X
' определяем новый член последовательности
Fl = F2: F2 = F3
F3 = Fl + F2
' увеличиваем число лет на 1:
YearsNum = YearsNum + 1
' повторяем цикл
LOOP
' в качестве возвращаемого значения используется значение переменной YearsNum
Years% = YearsNum
END FUNCTION
Сохранение текста программы в файле
После того как текст программы набран, его желательно сохранить в файле, чтобы потом снова обращаться к нему, улучшать, изменять или просто повторно запускать готовую программу.
Сохранение текста программы в файле осуществляется командой File ► Save (Файл ► Сохранить), в результате чего на экране показывается диалоговое окно выбора каталога и имени файла. В качестве такого имени можно указать kroliki, выбрать нужный каталог и нажать клавишу ENTER. По умолчанию к названию kroliki припишется расширение .BAS. В дальнейшем эту программу можно снова загрузить в QBasic командой File ► Open (Файл ► Открыть).
Запуск программы
Для запуска программы надо перейти к ее главной части (с помощью клавиши F2) — при этом в самом ее начале автоматически добавится строка с объявлением только что определенной функции:
DECLARE FUNCTION Years% (X AS INTEGER)
Теперь надо нажать клавишу F5 (Запуск). Программа начинает работать. Возможный вариант диалога:
Введите количество особей: 10
Требуемое число лет: 7
Введите количество особей: 100
Требуемое число лет:12
Введите количество особей: 1000
Требуемое число лет: 17
Введите количество особей: 10000
Требуемое число лет: 21
Введите количество особей: 0
Первую сотню кроликов надо разводить довольно долго, зато потом их приплод будет увеличиваться стремительными темпами.
20.8. Пример на Паскале. Раскрашивание круга
Постановка задачи
В рабочем окне программы должны находиться: изображение круга, поле ввода с подписью, кнопки Закрасить и Закрыть. В поле ввода шестью символами (шестнадцатеричными цифрами от 0 до F) задается новый цвет круга. Первые два символа определяют интенсивность синего цвета, третий и четвертый — интенсивность зеленого, пятый и шестой — интенсивность красного. Чистый синий опишется строкой ffOOOO, чистый зеленый — строкой OOffOO, чистый красный — строкой OOOOff, черный — строкой 000000, белый — строкой ffffff и т. д.
В самой программе надо дополнительно проверить, правильно ли введена эта строка. При нажатии на кнопку Закрасить цвет круга должен измениться.
Знакомство с Delphi
Для работы со средой Delphi необходимо, чтобы она была предварительно установлена на компьютере.
После ее запуска (например, Пуск ► Программы ► Borland Delphi 7 ► Delphi 7) на экране появятся следующие окна (рис. 20.2).
Главное окно Delphi 7. Здесь расположено основное меню, командные кнопки, а в правой части — палитра компонентов. Она состоит из набора панелей, на которых компоненты сгруппированы по решаемым задачам: панель Standard (Стандартная) — стандартные элементы управления, панель Win32 — элементы управления для версии Windows 9x, панель Internet (Интернет) — компоненты для организации работы в Интернете и т. д.
Визуальный проектировщик. С его помощью проектируется будущее окно программы. Оно представлено в виде формы, у которой можно менять свойства и размеры. На ней будут располагаться нужные элементы управления.
Редактор исходных тестов. Предназначен для набора и редактирования текстов программы. Ключевые слова и различные идентификаторы выделяются в этом редакторе особыми цветами и разным шрифтом. Принцип его работы аналогичен принципам работы большинства редакторов Windows.

Инспектор объектов. Используется для визуальной (без программирования) настройки свойств различных объектов на этапе проектирования.
Заголовок окна
Понять, как работает Инспектор объектов, лучше всего на примере. Пока что автоматически создана только одна пустая форма (называющаяся ForrrM), но она обладает множеством различных свойств. Заголовок формы (будущего окна программы) задается в свойстве Caption (Заголовок). Чтобы его изменить, надо в Инспекторе объектов найти строку, в левой части которой написано Caption, и в правой части этой строки, небольшом поле ввода, указать новое название, например Раскрашивание. Тут же изменится и заголовок формы в визуальном проектировщике.
Аналогично меняются и любые другие свойства. Сначала в выпадающем списке в верхней части Инспектора выбирается нужный объект (или он выделяется на форме щелчком мыши), затем находится название свойства и в правой части его значение меняется на новое, Изменение может происходить как путем простого ввода нового значения с клавиатуры, так и выбором одного из предопределенных значе-ний из списка. В некоторых случаях для редактирования свойства вызывается специальный редактор.
Свойства могут быть многосоставными, например, свойство Font (Шрифт) — слева от названия такого свойства ставится символ «+». Двойным щелчком мыши на его названии оно раскрывается и показывает все свои вложенные подсвойства.
Размещение компонентов на форме
Прежде всего разместим на форме поле ввода. Для этого на палитре компонентов с помощью закладки выбирается панель Standard (Стандартная) и нажимается кнопка с всплывающей подсказкой Edit (выбран компонент «поле ввода»). Затем надо щелкнуть мышкой на форме, и в месте щелчка появится элемент управления Edit1. Его можно перетаскивать по форме и менять размеры.
В свойстве Text (Содержимое) этого объекта исходно надо задать пустую строку, чтобы при запуске программы в данном поле ничего не показывалось.
Рядом с полем ввода надо разместить свободное поле с комментарием. Для этого на панели компонентов выбирается компонент, называющийся Label (Подпись), и помещается на форме так, как это было сделано с полем ввода. Новый объект автоматически получит название Label1. Чтобы указать в нем текст «Цвет:», его надо ввести в свойство Caption.
Изменить название любого объекта на форме можно, изменив его свойство Name в Инспекторе объектов.
В нижней части формы надо разместить кнопку — компонент Button (Кнопка) на панели Standard (Стандартная). Название этой кнопки (Закрасить) задается в свойстве Caption.
На панели Additional (Дополнительно) имеется компонент Shape (Фигура). Этот компонент помещается в центр формы. Он получит название Shape 1 и исходно примет форму квадрата, закрашенного белым цветом. Чтобы превратить его в круг, надо значение свойства Shape изменить на stCircle.
Теперь осталось только добавить кнопку, закрывающую форму. Это действие стандартное, поэтому в Delphi 7 имеется специальный компонент BitBtn (Кнопка с картинкой) на панели Additional (Дополнительно), позволяющий автоматизировать такие действия, не прибегая к программированию.
После размещения такой кнопки на форме (она получит название BitBtn 1) значение ее свойства Kind (Вид выполняемого действия) надо установить в bkClose (Закрыть окно). При этом на кнопке появится изображение стандартной картинки, символизирующей действие закрытия.
В завершение надо изменить заголовок этой кнопки (свойство Caption) с английского слова Close на русское Закрыть, и на этом процесс проектирования приложения можно считать законченным.
Сохранение проекта
Перед тем как приступить к программированию, проект надо сохранить. Это действие выполняется командой File ► Save All (Файл ► Сохранить все), после чего сначала выбирается каталог и указывается имя файла, в котором хранится программное описание (на Паскале) структуры и работы спроектированной формы. Имя файла будет иметь расширение .PAS по умолчанию. Далее система Delphi 7 спросит, куда и под каким именем сохранить файл проекта, содержащий всю информацию об используемых формах и модулях (их может быть в одном проекте сколько угодно, но одна форма всегда будет главной) и всевозможные настройки. Название файла проекта не должно совпадать с названием файла с исходным текстом программы.
Обработка нажатия кнопки
В создаваемой программе вручную придется запрограммировать фактически только одно событие — нажатие на кнопку Закрасить. Чтобы создать первоначально пустую подпрограмму, вызываемую при нажатии на эту кнопку, надо просто дважды щелкнуть на ней мышкой. При этом система Delphi 7 вызовет редактор, автоматически сгенерирует нужный текст и разместит курсор именно в том месте, где можно начать описание нужного алгоритма.
procedure TForml.ButtonlClick(Sender: TObject);
begin
end;
Обработчик события Нажатие на кнопку Button 1 — это обычная подпрограмма, метод класса TForm 1 (этот класс описывает главную форму Form 1). Единственный параметр Sender характеризует источник сообщения о случившемся событии. Его практически всегда можно игнорировать.
Алгоритм работы данного метода будет следующим. Первоначально надо убедиться, что длина введенной в поле Editi строки равна 6 символам и каждый из этих символов — шестнадцатеричная цифра. Если это не так, то выполнение обработчика надо сразу завершить (для этого предназначена стандартная процедура Паскаля Exit, мгновенно завершающая работу текущей подпрограммы).
Если же введенные данные корректны, их надо:
1. Преобразовать в промежуточную строку в формате $00хххххх, где хххххх — шесть введенных цифр.
2. Эту строку преобразовать в число, которое будет рассматриваться как цвет.
3. Установить новый цвет круга на основании полученного значения.
Содержимое поля ввода Edit1 хранится в виде строки в его свойстве Text. Доступ к этому свойству осуществляется с помощью конструкции Edit1. Text.
Длина строки определяется стандартной функцией length() со строкой в качестве параметра.
Стандартная функция Pos(), получая две строки как аргументы, проверяет, не содержится ли первая строка во второй, и если содержится, то возвращает номер начальной позиции. В противном случае Pos() возвращает ноль. Эта функция потребуется для определения, все ли символы во введенной строке допустимы.
Стандартная функция UpperCase() преобразует строку к верхнему регистру. Такое преобразование требуется, чтобы разрешить ввод значений цветов на любых регистрах.
Преобразование строки в число выполняет стандартная функция StrTolnt().
Объект Shapei имеет свойство Brush (Кисть для фона), которое, в свою очередь, имеет вложенное свойство Color (Цвет заливки). Его и надо в конечном счете изменить. Как только это произойдет, цвет круга в окне автоматически изменится на новый.


Запуск программы

Программа запускается нажатием на клавишу F9. Так как Delphi 7 — это компилирующая система, сначала автоматически выполнится компиляция и только потом программа запустится. Задавая различные строки (FFOFFF, abcdef, 987654 и т. п.), можно наглядно увидеть соответствующие им цвета.
20.9. Пример на Си++. Рисование графиков
Система Microsoft Visual Studio .NETbo многом схожа с рассмотренной средой Delphi, но визуальные возможности построения пользовательского интерфейса реализованы в ней только для Бейсика и С#. Поддержка Си++ в этой системе унаследована от старых версий и не предоставляет разработчику столь удобного проектирования. Тем не менее мы рассмотрим простой пример ее использования для создания программы, рисующей график функции.
Постановка задачи
Некоторая подпрограмма задает зависимость значения функции от аргумента. Надо нарисовать в окне график, показывающий эту зависимость.
Принципы рисования в Visual Studio
Перерисовывать экран в Windows приходится по самым разным причинам. Например, окно было закрыто другими приложениями, свернуто или оказалось временно заслоненным своими вспомогательными окнами. При этом перерисовывать приходится или все содержимое, или только часть. Программа, созданная с помощью Visual Studio, сама определяет, что и когда ей надо перерисовать, и все элементы управления тоже это «понимают». Особое требование к организации перерисовки возникает, только когда программист напрямую использует функции рисования. Все эти функции в таком случае надо размещать в обработчике события OnDraw, которое вызывается автоматически.
Технология рисования
Система Microsoft Visual Studio .NET не содержит визуальных средств создания программ на Си++, аналогичных возможностям Delphi. Она предлагает дизайнеры форм только для Бейсика и С#. Поэтому мы изучим несложный вариант использования графических примитивов Windows для демонстрации техники рисования графиков в пределах клиентского окна шаблонного приложения. Любое окно Windows характеризуется так называемым контекстом устройства, своеобразным объектом, содержащим различные методы графического вывода в пределах этого окна. Доступ к контексту нужного нам окна будет автоматически предоставлен Microsoft Visual Studio .NETпри формировании обработчика OnDraw.
Для создания графика потребуются два метода этого объекта: метод MoveTo(x.y), устанавливающий новое начальное положение — точку (х, у) для следующих операций рисования, и метод LineTo(x,y), проводящий линию из предыдущей точки в новую.
Метод отрисовки
Так как система Microsoft Visual Studio .NETне дает возможности работать с формой напрямую, подготовка «пустого» приложения будет немного сложнее, чем в предыдущих примерах. После запуска системы надо дать команду File ► New ► Project (Файл ► Создать ► Проект), на панели Project Types (Типы проектов) выбрать раздел Visual C++ Projects (Проекты Visual C++), а на панели Templates (Шаблоны) — значок MFC Application (Оконное приложение).
Название проекта (например, Grafiki) и его местонахождение задается в полях Name (Имя) и Location (Расположение). После нажатия на кнопку ОК запускается Мастер настройки вида будущего приложения. Изменять в нем ничего не надо, достаточно нажать кнопку Finish (Готово). Система сгенерирует заготовку пустого, но работоспособного проекта. Посмотреть его структуру можно с помощью средства Просмотра решения (Solution Explorer), вызываемого командой View ► Solution Explorer (Вид ► Просмотр решения).
В этом множестве автоматически сгенерированных файлов нас интересует файл GrafikiView.cpp, непосредственно ответственный за отображение содержимого клиентских окон на экране. Чтобы открыть его в редакторе, надо дважды щелкнуть мышкой на соответствующей строке.
Алгоритм отображения графика несложен. Он умещается в нескольких операторах.
Координату по оси Y нельзя взять непосредственно из переменной у, а надо вычислять по формуле Height-y, потому что в системе Windows считается, что точка с координатами (0,0) расположена в верхнем левом углу окна, а ось Y направлена вниз. Для удобства восприятия эту ось надо перевернуть.

Необходимо сформировать обработчик события OnDraw. Для этого перейдем в раскрывающийся список в верхнем правом углу окна редактора исходных текстов, и найдем в нем строку OnDraw. После ее выбора в редакторе появится следующий новый текст:

Параметр pDC — это нужный нам указатель на контекст устройства. Его мы и будем использовать для вывода графиков. Обратите внимание, что по умолчанию он взят в скобки-комментарии и недоступен внутри функции. Поэтому его надо раскомментировать.

Чуть выше метода OnDraw надо определить функцию f(), не привязанную ни к какому классу. В ней происходит вычисление значения анализируемой математической функции по заданному аргументу. Для примера, она может выглядеть так:

Стандартная функция log() вычисляет значение логарифма. Коэффициент 50 нужен, чтобы кривая пропорционально размещалась в окне. Хотя функция log() рассчитывает действительное значение, компилятор автоматически настроит программный код так, чтобы оно было преобразовано в целый тип, соответствующий типу переменной у.
Исходно функция log() и ряд других не подключены к текущему проекту. Чтобы они стали доступными, библиотеку, в которой они хранятся, необходимо явно указать компилятору. Делается это с помощью командной строки
![]()
которую можно поместить в самое начало текущего файла.
Далее проект надо сохранить, выполнить компиляцию и запустить, нажав клавишу F5. В дальнейшем, изменив один оператор присваивания в функции f() и подобрав подходящие коэффициенты, с помощью этой программы можно строить самые разные графики.
Практические задания по программированию
Задание 1
Дано натуральное число. Составить программу, которая представляет данное число в виде суммы квадратов натуральных чисел, содержащей минимальное число слагаемых. Например:
9=32
12=22+22+22
23=32+32+22+12
Задание 2
Дан массив, содержащий N элементов.
Написать подпрограммы, выполняющие следующие действия:
• перестановку элементов массива в обратном порядке;
• вычисление суммы А[1] +А[2]*А[2] + А[3]*А[3]*А[3]...;
• определение элементов массива, разность модулей которых имеет наибольшее значение;
• определение значения, которое встречается среди элементов массива максимальное число раз, и вычисление количества таких вхождений;
• упорядочение элементов массива по возрастанию.
Задание 3
Дан двумерный массив, содержащий N x N элементов. Написать подпрограммы, выполняющие следующие действия:
• вычисление среднего арифметического для элементов каждой строки массива;
• замену нулями всех элементов, расположенных на главной диагонали матрицы;
• определение наибольшего элемента и его положения в массиве.
Задание 4
Дана текстовая строка.
Написать подпрограммы, выполняющие следующие действия:
• подсчет количества слов в строке (в качестве границ слов рассматриваются пробелы);
• подсчет количества цифр в строке;
• определение десятичного числа, которому соответствует строка, если она представляет запись этого числа в шестнадцатеричной системе;
• проверку соответствия содержимого строки правилам записи идентификаторов языков программирования.