УЗБЕКСКОЕ АГЕНТСТВО СВЯЗИ И ИНФОРМАТИЗАЦИИ
ТАШКЕНТСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Конспект лекций
По предмету
Системное программное
обеспечение
Ташкент 2008.
1. Введение.
Предмет "Системное программное обеспечение", основные понятия.
Операционные системы и среды
В англоязычной
технической литературе термин System Software (системное
программное обеспечение) означает программы и комплексы программ, являющиеся
общими для всех, кто совместно использует технические средства компьютера и
применяемые как для автоматизации разработки (создания) новых программ так и
для организации выполнения программ существующих. С этих позицию системное
программное обеспечение может быть разделено на следующие пять групп:
1.
Операционные системы.
2.
Системы управления файлами.
3.
Интерфейсные оболочки для взаимодействия
пользователя с ОС и программ ные среды.
4.
Системы программирования.
5.
Утилиты.
Рассмотрим вкратце эти группы системных программ.
1. Под операционной системой (ОС) обычно понимают комплекс управляющих и обрабатывающих программ, который, с одной стороны, выступает как интерфейс между аппаратурой компьютера и пользователем его задачам! а с другой — предназначен для наиболее эффективного использования ресурсов вычислительной системы и организации надежных вычислений. Любо: из компонентов прикладного программного обеспечения обязательно рабе тает под управлением ОС. На рис. 1 изображена обобщенная структура прс граммного обеспечения вычислительной системы. Видно, что ни один и компонентов программного обеспечения, за исключением самой ОС, не имеет непосредственного доступа к аппаратуре компьютера. Даже пользовател аимодействуют со своими программами через интерфейс ОС. Любые их шанды, прежде чем попасть в прикладную программу, сначала проходят!
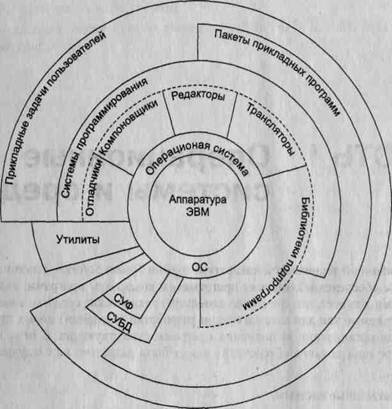 Рис.1. Обобщенная структура программного
обеспечения вычислительной системы
Рис.1. Обобщенная структура программного
обеспечения вычислительной системы
Основными функциями, которые выполняет ОС, являются следующие:
- прием от пользователя (или от оператора системы) заданий или команд, сформулированных на соответствующем языке — в виде директив (команд) оператора или в виде указаний (своеобразных команд) с помощью соответствующего манипулятора (например, с помощью мыши), — и их обработка;
- прием и исполнение программных запросов на запуск, приостановку, остановку других программ;
- загрузка в оперативную память подлежащих исполнению программ; Э инициация программы (передача ей управления, в результате чего процессор исполняет программу); идентификация всех программ и данных;
- обеспечение работы систем управлений файлами (СУФ) и/или систем управления базами данных (СУБД), что позволяет резко увеличить эффективность всего программного обеспечения;
- обеспечение режима мультипрограммирования, то есть выполнение двух или более программ на одном процессоре, создающее видимость их одновременного исполнения;
- обеспечение функций по организации и управлению всеми операциями ввода/вывода;
- удовлетворение жестким ограничениям на время ответа в режиме реального времени (характерно для соответствующих ОС);
- распределение памяти, а в большинстве современных систем и организация виртуальной памяти;
О планирование и диспетчеризация задач в соответствии с заданными стратегией и дисциплинами обслуживания;
- организация механизмов обмена сообщениями и данными между выполняющимися программами;
- защита одной программы от влияния другой; обеспечение сохранности данных;
- предоставление услуг на случай частичного сбоя системы;
- обеспечение работы систем программирования, с помощью которых пользователи готовят свои программы.
2. Назначение системы управления файлами — организация более удобного доступа к данным, организованным как файлы. Именно благодаря системе управления файлами вместо низкоуровневого доступа к данным с указанием конкретных физических адресов нужной нам записи используется логический доступ с указанием имени файла и записи в нем. Как правило, все современные ОС имеют соответствующие системы управления файлами. Однако выделение этого вида системного программного обеспечения в отдельную категорию представляется целесообразным, поскольку ряд ОС позволяет работать с несколькими файловыми системами (либо с одной из нескольких, либо сразу с несколькими одновременно). В этом случае говорят о монтируемых файловых системах (дополнительную систему управления файлами можно установить), и в этом смысле они самостоятельны. Более того, можно назвать примеры простейших ОС, которые могут работать и без файловых систем, а значит, им необязательно иметь систему управления файлами, либо они могут работать с одной из выбранных файловых систем. Надо понимать, что любая система управления с файлами не существует сама по себе — она разработана для работы в конкретной ОС и с конкретной файловой системой. Можно сказать, что всем известная файловая система FAT (file allocation table)1 имеет множество реализаций как система управления файлами, например FAT-16 для самой MS-DOS, super-FAT для OS/2, FAT для Windows NT
Здесь и далее без указания на источник заимствования приводятся английские эквиваленты слов и словосочетаний.
т. д. Другими словами, для работы с файлами, организованными в соответ-вии с некоторой файловой системой, для каждой ОС должна быть разра-1тана соответствующая система управления файлами; и эта система управ-ния файлами будет работать только в той ОС, для которой она и создана.
гя удобства взаимодействия с ОС могут использоваться дополнительные гтерфейсные оболочки. Их основное назначение — либо расширить возможности по управлению ОС, либо изменить встроенные в систему возможности, в качестве классических примеров интерфейсных оболочек и соответствующих операционных сред выполнения программ можно назвать различные варианты графического интерфейса X Window в системах семейства UNIX апример, К Desktop Environment в Linux), PM Shell или Object Desktop OS/2 с графическим интерфейсом Presentation Manager; наконец, можно :азать разнообразные варианты интерфейсов для семейства ОС Windows Алании Microsoft, которые заменяют Explorer и могут напоминать либо NTX с его графическим интерфейсом, либо OS/2, либо MAC OS. Следует метить, что о семействе ОС компании Microsoft с общим интерфейсом, реа-[зуемым программными модулями с названием Explorer (в файле system.ini, •торый находится в каталоге Windows, имеется строка SHELL=EXPLORER.EXE), е же можно сказать, что заменяемой в этих системах является только ин-рфейсная оболочка, в то время как сама операционная среда остается неиз-;нной; она интегрирована в ОС. Другими словами, операционная среда феделяется программными интерфейсами, то есть API (application program terface). Интерфейс прикладного программирования (API) включает в себя управление процессами, памятью и вводом/выводом.
ад операционных систем могут организовывать выполнение программ, соз-нных для других ОС. Например, в OS/2 можно выполнять как программы, зданные для самой OS/2, так и программы, предназначенные для выполнения в среде MS-DOS и Windows 3.x. Соответствующая операционная среда танизуется в операционной системе в рамках отдельной виртуальной ма-ины. Аналогично, в системе Linux можно создать условия для выполнения некоторых программ, написанных для Windows 95/98. Определенными воз-шностями исполнения программ, созданных для иной операционной среды, ■ладает и Windows NT. Эта система позволяет выполнять некоторые про-аммы, созданные для MS-DOS, OS/2 1.x, Windows 3.x. Правда, в своем по-еднем семействе ОС Windows XP разработчики решили отказаться от 'Ддержки возможности выполнения DOS-программ.
аконец, к этому классу системного программного обеспечения следует отне-и и эмуляторы, позволяющие смоделировать в одной операционной сис-ме какую-либо другую машину или операционную систему. Так, известна схема эмуляции WMWARE, которая позволяет запустить в среде Linux любую другую ОС, например Windows. Можно, наоборот, создать эмулятор, .ботающий в среде Windows, который позволит смоделировать компьютер, ботающий под управлением любой ОС, в том числе и под Linux.
жим образом, термин операционная среда означает соответствующий ин-Рфейс, необходимый программам для обращения к ОС с целью получить определенный сервис1 — выполнить операцию ввода/вывода, получить или освободить участок памяти и т. д. 3. Система программирования на рис. 1 представлена прежде всего такими компонентами, как транслятор с соответствующего языка, библиотеки подпрограмм, редакторы, компоновщики и отладчики. Не бывает самостоятельных (оторванных от ОС) систем программирования. Любая система программирования может работать только в соответствующей ОС, под которую она создана, однако при этом она может позволять разрабатывать программное обеспечение и под другие ОС. Например, одна из популярных систем программирования на языке C/C++ от фирмы Watcom для OS/2 позволяет получать программы и для самой OS/2, и для DOS, и для Windows. В том случае, когда создаваемые программы должны работать совсем на другой аппаратной базе, говорят о кросс-системах. Так, для ПК на базе микропроцессоров семейства i80x86 имеется большое количество кросс-систем, позволяю,-щих создавать программное обеспечение для различных микропроцессоров и микроконтроллеров. 4. Наконец, под утилитами понимают специальные системные программы, с помощью которых можно как обслуживать саму операционную систему, так и подготавливать для работы носители данных, выполнять перекодирование данных, осуществлять оптимизацию размещения данных на носителе и производить некоторые другие работы, связанные с обслуживанием вычислительной системы. К утилитам следует отнести и программу разбиения накопителя на магнитных дисках на разделы, и программу форматирования, и программу переноса основных системных файлов самой ОС. Также к утилитам относятся и небезызвестные комплексы программ от фирмы Symantec, носящие имя Питера Нортона (создателя этой фирмы и соавтора популярного набора утилит для первых IBM PC). Естественно, что утилиты могут работать только в соответствующей операционной среде.
Сервис (service) - обслуживание, выполнение соответствующего запроса.
имеет почти то же значение. Разница между ними объясняется в той главе, в которой даются точные определения этим понятиям; здесь же можно только сказать, что «транслятор» — понятие более широкое, а «компилятор» — более узкое (любой компилятор является транслятором, но не наоборот).
Традиционная архитектура компьютера (архитектура фон Неймана) остается неизменной и преобладает в современных вычислительных системах. Столь же неизменными остаются и базовые принципы, на основе которых строятся средства разработки программного обеспечения для компьютеров — трансляторы, компиляторы и интерпретаторы. Видимо, этим объясняется практически полное отсутствие современных публикаций в этой области, а те, что известны, являются не достаточно широко доступными (автор может выделить книги и публикации [4, 13, 18, 26, 27, 35, 40, 45, 47]). Тем не менее современные средства разработки, оставаясь на тех же базовых принципах, что и компьютеры традиционной архитектуры, прошли долгий путь совершенствования и развития от командных систем до интегрированных сред и систем программирования. И это обстоятельство нашло отражение в предлагаемом учебном пособии.
Ныне существует огромное количество разнообразных языков программирования. Все они имеют свою историю, свою область применения, и перечислять даже наиболее известные из них здесь не имеет смысла. Но все эти языки построены на основе одних и тех же принципов, основы которых определяет теория формальных языков и грамматик. Именно теоретическим основам посвящены четыре первые главы пособия, поскольку для построения транслятора необходимо знать все те принципы, на основе которых он работает. Первая глава посвящена общим принципам и определениям, на которых построена теория формальных языков и грамматик; вторая глава посвящена регулярным языкам, а третья и четвертая — контекстно-свободным языкам и грамматикам.
В пятой и шестой главах рассматривается работа компилятора как генератора кода результирующей программы. Она рассматривается с точки зрения существующих примеров и методов реализации, поскольку семантика языков программирования и генерация кода, к сожалению, не основаны на столь же «красивом», математически обоснованном аппарате, как анализ текста исходной программы в компиляторе.
Наконец, все современные компиляторы являются составной частью системного программного обеспечения. Они составляют основу всех современных средств разработки как прикладных, так и системных программ. Принципы организации и структура современных систем программирования рассматриваются в последней (седьмой) главе. Там же приводятся примеры некоторых современных систем программирования с разъяснением принципов, положенных в их основу.
2.
Формальные языки и грамматики. Способы задания языков. символов. Операции над
цепочками символов. Понятие языка. Способы задания языков. Синтаксис и
семантика языка. Особенности языков программирования.
Цепочки символов. Операции над цепочками символов
Цепочкой символов (или строкой ) называют произвольную последовательность символов, записанных один за другим. Понятие символа (или буквы) является базовым в теории формальных языков и не нуждается в определении.
Далее цепочки символов будем обозначать греческими буквами: а, р\ у.
Итак, цепочка — это последовательность, в которую могут входить любые допустимые символы. Строка, которую вы сейчас читаете, является примером цепочки, допустимые символы в которой — строчные и заглавные русские буквы, знаки препинания и символ пробела. Но цепочка — это необязательно некоторая осмысленная последовательность символов. Последовательность «аввв.лагрьъ ,.лл» — тоже пример цепочки символов.
Для цепочки символов важен состав и количество символов в ней, а также порядок символов в цепочке. Один и тот же символ может произвольное число раз входить в цепочку. Поэтому цепочки «а» и «аа», а также «аб» и «ба» — это различные цепочки символов. Цепочки символов аир равны (совпадают), а = р, если они имеют один и тот же состав символов, одно и то же их количество и одинаковый порядок следования символов в цепочке.
Количество символов в цепочке называют длиной цепочки. Длина цепочки символов а обозначается как |а|. Очевидно, что если а = р, то и |А| = |В|.
Основной операцией над цепочками символов является операция конкатенации (объединения или сложения) цепочек.
Конкатенация (сложение, объединение) двух цепочек символов — это дописывание второй цепочки в конец первой. Конкатенация цепочек аир обозначается как ар. Выполнить конкатенацию цепочек просто: например, если а = «аб», а р = «вг», то ар = «абвг».
Так как в цепочке важен порядок символов, то очевидно, что операция конкатенации не обладает свойством коммутативности, то есть в общем случае Заир такие, что ар*ра. Также очевидно, что конкатенация обладает свойством ассоциативности, то есть (аР)у = а(Ру). Можно выделить еще две операции над цепочками.
Обращение цепочки — это запись символов цепочки в обратном порядке. Обращение цепочки а обозначается как aR. Если a = «абвг», то aR = «гвба». Для операции обращения справедливо следующее равенство V a,p: (aP)R = pRaR.
Итерация (повторение) цепочки п раз, где neN, n > 0 — это конкатенация цепочки самой с собой п раз. Итерация цепочки a n раз обозначается как an. Для операции повторения справедливы следующие равенства V а: а1 = а, а2 = аа, а3 = ааа, ... и т. д.
Среди всех цепочек символов выделяется одна особенная — пустая цепочка. Пустая цепочка символов — это цепочка, не содержащая ни одного символа. Пустую цепочку здесь везде будем обозначать греческой буквой А, (в литературе ее иногда обозначают латинской буквой е или греческой г).
Для пустой цепочки справедливы следующие равенства:
1. N = 0;
2.
Va: Ха = аХ = а;
3.
XR = X;
4.
\/п>0:Хп = Х;
5.
Va:a°=l.
Понятие языка. Формальное определение языка
В общем случае язык — это заданный набор символов и правил, устанавливающих способы комбинации этих символов между собой для записи осмысленных текстов. Основой любого естественного или искусственного языка является алфавит, определяющий набор допустимых символов языка.
Алфавит — это счетное множество допустимых символов языка. Будем обозначать это множество символом V. Интересно, что согласно формальному определению, алфавит не обязательно должен быть конечным (перечислимым) множеством, но реально все существующие языки строятся на основе конечных алфавитов.
Цепочка символов а является цепочкой над алфавитом V: a(V), если в нее входят только символы, принадлежащие множеству символов V. Для любого алфавита V пустая цепочка X может как являться, так и не являться цепочкой Х(У). Это условие оговаривается дополнительно
Если V — некоторый алфавит, то:
□
V+ — множество всех цепочек над
алфавитом V без X;
□
V* — множество всех цепочек над алфавитом V, включая А,.
Справедливо равенство: V* = V+ u {X}.
Языком L над алфавитом V:L(V) называется некоторое счетное подмножес цепочек конечной длины из множества всех цепочек над алфавитом V. Из эп определения следуют два вывода: во-первых, множество цепочек языка не обя но быть конечным; во-вторых, хотя каждая цепочка символов, входящая в яз: обязана иметь конечную длину, эта длина может быть сколь угодно больше формально ничем не ограничена.
Все существующие языки подпадают под это определение. Большинство реа ных естественных и искусственных языков содержат бесконечное множество почек. Также в большинстве языков длина цепочки ничем не ограничена (нап мер, этот длинный текст — пример цепочки символов русского языка). Цепо1 символов, принадлежащую заданному языку, часто называют предложением язь а множество цепочек символов некоторого языка L(V) — множеством предло: ний этого языка.
Для любого языка L(V) справедливо: L(V) с V*.
Язык L(V) включает в себя язык L'(V): L'(V)cL(V), если V aeL(V): aeL'( Множество цепочек языка L'(V) является подмножеством множества цепо языка L(V) (или эти множества совпадают). Очевидно, что оба языка доля строится на основе одного и того же алфавита.
Два языка L(V) и L'(V) совпадают (эквивалентны): L'(V) = L(V), если L'(V)cL и L(V)cL'(V); или, что то же самое: V aeL'(V): aeL(V) и V aeL'(V): aeL( Множества допустимых цепочек символов для эквивалентных языков доля быть равны.
Два языка L(V) и L'(V) почти эквивалентны: L'(V) = L(V), если L'(V)u{/ = L(V)u{A.}. Множества допустимых цепочек
символов почти эквивалент языки могут различаться только на пустую цепочку символов.
Способы задания языков
Итак, каждый язык — это множество цепочек символов над некоторым алфавитом. Но кроме алфавита язык предусматривает и задание правил построения пустимых цепочек, поскольку обычно далеко не все цепочки над заданным алфавитом принадлежат языку. Символы могут объединяться в слова или лексем элементарные конструкции языка, на их основе строятся предложения — сложные конструкции. И те и другие в общем виде являются цепочками сил лов, но предусматривают некоторые правила построения. Таким образом, необходимо указать эти правила, или, строго говоря, задать язык.
Язык задать можно тремя способами:
1.
Перечислением всех допустимых цепочек языка.
2.
Указанием способа порождения цепочек языка (заданием грамматики языка)
3.
Определением метода распознавания цепочек языка.
Первый из методов является чисто формальным и на практике не применяется, так как большинство языков содержат бесконечное число допустимых цепочек и перечислить их просто невозможно. Трудно себе представить, чтобы появилась возможность перечислить, например, множество всех правильных текстов на русском языке или всех правильных программ на языке Pascal. Иногда, для чисто формальных языков, можно перечислить множество входящих в них цепочек, прибегнув к математическим определениям множеств. Однако этот метод уже стоит ближе ко второму способу.
Например, запись Ц{0,1}) = {0nln, n > 0} задает язык над алфавитом V п {0,1}, содержащий все последовательности с чередующимися символами 0 и 1, начинающиеся с 0 и заканчивающиеся 1. Видно, что пустая цепочка символов в этот язык не входит. Если изменить условие в этом определении с п > 0 на п>0, то получим почти эквивалентный язык L'({0,1}), содержащий пустую цепочку.
Второй способ предусматривает некоторое описание правил, с помощью которых строятся цепочки языка. Тогда любая цепочка, построенная с помощью этих правил из символов алфавита языка, будет принадлежать заданному языку. Например, с правилами построения цепочек символов русского языка вы долго и упорно знакомились в средней школе.
Третий способ предусматривает построение некоторого логического устройства (распознавателя) — автомата, который на входе получает цепочку символов, а на выходе выдает ответ: принадлежит или нет эта цепочка заданному языку. Например, читая этот текст, вы сейчас в некотором роде выступаете в роли распознавателя (надеюсь, что ответ о принадлежности текста русскому языку будет положительным).
Синтаксис и семантика языка
Говоря о любом языке, можно выделить его синтаксис и семантику. Кроме того, трансляторы имеют дело также с лексическими конструкциями (лексемами), которые задаются лексикой языка. Ниже даны определения для всех этих понятий.
Синтаксис языка — это набор правил, определяющий допустимые конструкции языка. Синтаксис определяет «форму языка» — задает набор цепочек символов, которые принадлежат языку. Чаще всего синтаксис языка можно задать в виде строгого набора правил, но полностью это утверждение справедливо только для чисто формальных языков. Даже для большинства языков программирования набор заданных синтаксических конструкций нуждается в дополнительных пояснениях, а синтаксис языков естественного общения вполне соответствует общепринятому мнению о том, что «исключения только подтверждают правило».
Например, любой окончивший среднюю школу может сказать, что строка «3+2» является арифметическим выражением, а «3 2 +» — не является. Правда, не каждый задумается при этом, что он оперирует синтаксисом алгебры.
Семантика языка — это раздел языка, определяющий значение предложений языка. Семантика определяет «содержание языка» — задает значение для всех допустимых цепочек языка. Семантика для большинства языков определяется неформальными методами (отношения между знаками и тем, что они обозначают, изучаются семиотикой). Чисто формальные языки лишены какого-либо смыс/ Возвращаясь к примеру, приведенному выше, и используя семантику алгебр мы можем сказать, что строка «3 + 2» есть сумма чисел 3 и 2, а также то, ч «3 + 2 - 5» — это истинное выражение. Однако изложить любому ученику си таксис алгебры гораздо проще, чем ее семантику, хотя в данном случае семант ку как раз можно определить формально.
Лексика — это совокупность слов (словарный запас) языка. Слово или лексическая единица (лексема) языка — это конструкция, которая состоит из элементов алфавита языка и не содержит в себе других конструкций. Иначе говоря, лексическая единица может содержать только элементарные символы и не может с держать других лексических единиц.
Лексическими единицами (лексемами) русского языка
являются слова русского языка, а знаки препинания и пробелы представляют собой
разделители, не образующие
лексем. Лексическими единицами алгебры являются числа, знаки математических операций, обозначения
функций и неизвестных величин. В язьи программирования лексическими единицами являются ключевые
слова, идет фикаторы, константы, метки, знаки операций; в них также существуют
и раз, лители (запятые, скобки, точки с
запятой и т. д.).
Особенности языков программирования
Языки программирования занимают некоторое промежуточное положение между формальными и естественными языками. С формальными языками их of единяют строгие синтаксические правила, на основе которых строятся пред. жения языка. От языков естественного общения в языки программирования решли лексические единицы, представляющие основные ключевые слова (чаще всего это слова английского языка, но существуют языки программирования чьи ключевые слова заимствованы из русского и других языков). Кроме того, алгебры языки программирования переняли основные обозначения математи ских операций, что также делает их более понятными человеку. Для задания языка программирования необходимо решить три вопроса:
□
определить множество допустимых символов языка;
□
определить множество правильных программ языка;
□
задать смысл для каждой правильной программы.
Только первые два вопроса полностью или частично удается решить с помоп
теории формальных языков.
Первый вопрос решается легко. Определяя алфавит языка, мы автоматиче
определяем множество допустимых символов. Для языков программирова:
алфавит — это чаще всего тот набор символов, которые можно ввести с юш
туры. Основу его составляет младшая половина таблицы международной кс
ровки символов (таблицы ASCII), к которой добавляются символы национ;
ных алфавитов.
Второй вопрос решается в теории формальных языков только частично. ,
всех языков программирования существуют правила, определяющие синтаь
языка, но как уже было сказано, их недостаточно для того, чтобы строго определить все возможные синтаксические конструкции. Дополнительные ограничения накладываются семантикой языка. Эти ограничения оговариваются в неформальной форме для каждого отдельного языка программирования. К таким ограничениям можно отнести необходимость предварительного описания переменных и функций, необходимость соответствия типов переменных и констант в выражениях, формальных и фактических параметров в вызовах функций и др.
Отсюда следует, что практически все языки программирования, строго говоря, не являются формальными языками. И именно поэтому во всех трансляторах, кроме синтаксического разбора и анализа предложений языка, дополнительно предусмотрен семантический анализ.
Третий вопрос в принципе не относится к теории формальных языков, поскольку, как уже было сказано, такие языки лишены какого-либо смысла. Для ответа на него нужно использовать другие подходы. В качестве таких подходов можно указать следующие:
□
изложить смысл программы, написанной на языке программирования, на другом языке, более понятном тому,
кому адресована программа;
□
использовать для проверки смысла некоторую «идеальную машину», которая предназначена для выполнения
программ, написанных на данном языке.
Все, кто писал программы, так или иначе обязательно использовали первый подход. Комментарии в хорошей программе — это и есть изложение ее смысла. Построение блок-схемы, а равно любое другое описание алгоритма программы — это тоже способ изложить смысл программы на другом языке (например, языке графических символов блок-схем алгоритмов, смысл которого в свою очередь, изложен в соответствующем ГОСТе). Да и документация к программе — тоже способ изложения ее смысла. Но все эти способы ориентированы на человека, которому они, конечно же, более понятны. Однако не существует пока универсального способа проверить, насколько описание соответствует программе.
Машина же понимает только один язык — язык машинных команд. Но изложить программу на языке машинных команд — задача слишком трудоемкая для человека, как раз для ее решения и создаются трансляторы.
Второй подход используется при отладке программы. Оценку же результатов выполнения программы при отладке выполняет человек. Любые попытки поручить это дело машине лишены смысла вне контекста решаемой задачи.
Например, предложение в программе на языке Pascal вида: i:=0; while i=0 do i:=0; может быть легко оценено любой машиной как бессмысленное. Но если в задачу входит обеспечить взаимодействие с другой параллельно выполняемой программой или, например, просто проверить надежность и долговечность процессора или какой-то ячейки памяти, то это же предложение покажется уже не лишенным смысла.
Некоторые успехи в процессе проверки осмысленности программ достигнуты в рамках систем автоматизации разработки программного обеспечения (CASE-системы). Их подход основан на проектировании сверху вниз — от описания задачи на языке, понятном человеку, до перевода ее в операторы языка программирования. Но такой подход выходит за рамки возможностей трансляторов, поэтому здесь рассматриваться не будет.
Однако разработчикам компиляторов так или иначе приходится решать вопрос о смысле программ. Во-первых, компилятор должен все-таки преобразовать исходную программу в последовательность машинных команд, а для этого ему необходимо иметь представление о том, какая последовательность команд соответствует той или иной части исходной программы. Обычно такие последовательности сопоставляются базовым конструкциям входного языка (далее будет рассмотрено, как это можно сделать). Здесь используется первый подход к изложению смысла программы. Во-вторых, многие современные компиляторы позволяют выявить сомнительные с точки зрения смысла места в исходной программе — такие, как недостижимые операторы, неиспользуемые переменные, неопределенные результаты функций и т. п. Обычно компилятор указывает такие места в виде дополнительных предупреждений, которые разработчик может принимать или не принимать во внимание. Для достижения этой цели компилятор должен иметь представление о том, как программа будет выполняться — используется второй подход. Но в обоих случаях осмысление исходной программы закладывает в компилятор его создатель (или коллектив создателей) — то есть человек, который руководствуется неформальными методами (чаще всего, описанием входного языка). В теории формальных языков вопрос о смысле программ не решается.
Итак, на основании изложенных положений можно сказать, что возможности трансляторов по проверке осмысленности предложений входного языка сильно ограничены, практически даже равны нулю. Именно поэтому большинство из них в лучшем случае ограничиваются рекомендациями разработчикам по тем местам исходного текста программ, которые вызывают сомнения с точки зрения смысла. Поэтому большинство трансляторов обнаруживает только незначительный процент от общего числа смысловых («семантических») ошибок, а следовательно, подавляющее число такого рода ошибок всегда, к большому сожалению, остается на совести автора программы.
3. Определение грамматики. Форма Бэкуса-Наура. Принцип
рекурсии в правилах грамматики. Другие способы задания грамматик.
Определение грамматики. Форма Бэкуса—Наура
Понятие о грамматике языка
Грамматика — это описание способа построения предложений некоторого языка. Иными словами, грамматика — это математическая система, определяющая язык.
Фактически, определив грамматику языка, мы
указываем правила порождения цепочек символов, принадлежащих этому языку. Таким образом, грамматика —
это генератор цепочек языка. Она относится ко второму способу определения языков — порождению цепочек символов. ![]() Грамматику языка можно описать
различными способами; например, грамма-гика русского языка описывается довольно сложным набором
правил, которые изучают в начальной школе. Но для многих языков (и для
синтаксической части гзыков
программирования в том числе) допустимо использовать формальное шисание грамматики, построенное
на основе системы правил (или продукций).
Грамматику языка можно описать
различными способами; например, грамма-гика русского языка описывается довольно сложным набором
правил, которые изучают в начальной школе. Но для многих языков (и для
синтаксической части гзыков
программирования в том числе) допустимо использовать формальное шисание грамматики, построенное
на основе системы правил (или продукций).
Правило (или продукция) — это упорядоченная пара цепочек символов (а,(3). В правилах очень важен порядок цепочек, поэтому их чаще записывают в виде х->(3 (или а::=Р). Такая запись читается как «а порождает р» или «(3 по определению есть а».
Грамматика языка программирования содержит правила двух типов: первые ^определяющие синтаксические конструкции языка) довольно легко поддают-;я формальному описанию; вторые (определяющие семантические ограничения ?зыка) обычно излагаются в неформальной форме. Поэтому любое описание ^или общепринятый стандарт) языка программирования обычно состоит из двух частей: вначале формально излагаются правила построения синтаксических кон-:трукций, а потом на естественном языке дается описание семантических правил. Естественный язык понятен человеку, пользователю, который будет писать программы на языке программирования; для компилятора же семантические эграничения необходимо излагать в виде алгоритмов проверки правильности программы (речь, как уже было сказано выше, не идет о смысле программ, а только лишь о семантических ограничениях на исходный текст). Такой проверкой в компиляторе занимается семантический анализатор — специально для этого разработанная часть компилятора.
Далее, говоря о грамматиках языков программирования, будем иметь в виду только правила построения синтаксических конструкций языка. Однако следует помнить, что грамматика любого языка программирования в общем случае не ограничивается только этими правилами.
Язык, заданный грамматикой G, обозначается как L(G).
Две грамматики G и G' называются эквивалентными, если они определяют один и тот же язык: L(G) = L(G'). Две грамматики G и G' называются почти эквивалентными, если заданные ими языки различаются не более чем на пустую цепочку символов: L(G) u {A,} = L(G') и {Ц.
Формальное определение грамматики. Форма Бэкуса—Наура
Для полного формального определения грамматики кроме правил порождения цепочек языка необходимо задать также алфавит языка.
Формально грамматика G определяется как четверка G(VT,VN,P,S), где:
□
VT — множество терминальных
символов;
□
VN — множество нетерминальных символов: VNnVT = 0;
Р — множество правил (продукций) грамматики вида а-»р, где aeV+, PeV*; Q S- целевой (начальный) символ грамматики SeVN. Множество V = VNuVT называют полным алфавитом грамматики G.
Рассмотрим множества VN и VT. Множество терминальных символов VT содержит символы, которые входят в алфавит языка, порождаемого грамматикой. Как правило, символы из множества VT встречаются только в цепочках правых частей правил, если же они встречаются в цепочке левой части правила, то обязаны быть и в цепочке правой его части. Множество нетерминальных символов VN содержит символы, которые определяют слова, понятия, конструкции языка. Каждый символ этого множества может встречаться в цепочках как левой, так и правой частей правил грамматики, но он обязан хотя бы один раз быть в левой части хотя бы одного правила. Правила грамматики строятся так, чтобы в левой части каждого правила был хотя бы один нетерминальный символ.
Эти два множества не пересекаются: каждый символ может быть либо терминальным, либо нетерминальным. Ни один символ в алфавите грамматики не может быть нетерминальным и терминальным одновременно. Целевой символ грамматики — это всегда нетерминальный символ.
Во множестве правил грамматики может быть несколько правил, имеющих одинаковые правые части, вида: а->р(, ач>р2, ... а->рп. Тогда эти правила объединяют вместе и записывают в виде: a—>p1|p2|—lPn • Одной строке в такой записи соответствует сразу правил.
Такую форму записи правил грамматики называют формой Бэкуса—Наура. Форма Бэкуса—Наура предусматривает, как правило, также, что нетерминальные символы берутся в угловые скобки: < >. Иногда знак «->» в правилах грамматики заменяют на знак «::=» (что характерно для старых монографий), но это всего лишь незначительные модификации формы записи, не влияющие на ее суть.
Ниже приведен пример грамматики для целых десятичных чисел со знаком:
G({0,1.2.3.4.5.6.7.8.9.-.+}.{<число>.<чс>,<цифра>},Р.<число>) Р:
<число> -» <чс> | +<чс> | -<чс>
<чс> -> <цифра> | <чс><цифра>
<цифра> ->0|1|2|3|4|5|6|7|8|9
Рассмотрим составляющие элементы грамматики G:
□
множество терминальных символов VT содержит двенадцать элементов: десять десятичных цифр и два знака;
□
множество нетерминальных символов VN содержит три элемента: символы <число>, <чс> и <цифра>;
□
множество правил содержит 15 правил, которые записаны в три строки (то есть имеются только три
различных правых части правил);
□
целевым символом грамматики является символ <число>.
Следует отметить, что символ <чс> — это бессмысленное сочетание букв русского языка, но это обычный нетерминальный символ грамматики, такой же, как и два других. Названия нетерминальных символов не обязаны быть осмысленными, это сделано просто для удобства понимания правил грамматики человеком. В принципе в любой грамматике можно полностью изменить имена всех нетер-минальных символов, не меняя при этом языка, заданного грамматикой, — точно также, например, в программе на языке Pascal можно изменить имена идентификаторов, и при этом не изменится смысл программы.
Для терминальных символов это неверно. Набор терминальных символов всегда строго соответствует алфавиту языка, определяемого грамматикой.
Бот, например, та же самая грамматика для целых десятичных чисел со знаком, в которой нетерминальные символы обозначены большими латинскими буквами (далее это будет часто применяться в примерах):
G'({0.1.2.3.4.5.6.7.8.9,-.+}.{S,T.F}.P,S)
Р:
S -» Т | +Т | -Т
Т -> F | TF
F-»0|l|2|3|4|5|6|7|8|9
Здесь изменилось только множество нетерминальных символов. Теперь VN = = {S,T,F}. Язык, заданный грамматикой, не изменился — грамматики G и G' эквивалентны.
Принцип рекурсии в правилах грамматики
Особенность формальных грамматик в том, что они позволяют определить бесконечное множество цепочек языка с помощью конечного набора правил (конечно, множество цепочек языка тоже может быть конечным, но даже для простых реальных языков это условие обычно не выполняется). Приведенная выше в примере грамматика для целых десятичных чисел со знаком определяет бесконечное множество целых чисел с помощью 15 правил.
Возможность пользоваться конечным набором правил достигается в такой форме записи грамматики за счет рекурсивных правил. Рекурсия в правилах грамматики выражается в том, что один из нетерминальных символов определяется сам через себя. Рекурсия может быть непосредственной (явной) — тогда символ определяется сам через себя в одном правиле, либо косвенной (неявной) — тогда то же самое происходит через цепочку правил.
В рассмотренной выше грамматике G непосредственная рекурсия присутствует в правиле: <чс>-»<чс><цифра>, а в эквивалентной ей грамматике G' — в правиле: T-»TF.
Чтобы рекурсия не была бесконечной, для участвующего в ней нетерминального символа грамматики должны существовать также и другие правила, которые определяют его, минуя самого себя, и позволяют избежать бесконечного рекурсивного определения (в противном случае этот символ в грамматике был бы просто не нужен). Такими правилами являются <чс>-»<цифра> — в грамматике G и T-»F — в грамматике G'.
□
В теории формальных языков более ничего сказать о рекурсии нельзя. Но,
чтобы полнее понять
смысл рекурсии, можно прибегнуть к семантике языка — в рассмотренном выше примере это язык
целых десятичных чисел со знаком. Рассмотрим
его смысл.
Если попытаться дать определение тому, что же является числом, то начать можно с того, что любая цифра сама по себе есть число. Далее можно заметить, что любые две цифры — это тоже число, затем — три цифры и т. д. Если строить определение числа таким методом, то оно никогда не будет закончено (в математике разрядность числа ничем не ограничена). Однако можно заметить, что каждый раз, порождая новое число, мы просто дописываем цифру справа (поскольку привыкли писать слева направо) к уже написанному ряду цифр. А этот ряд цифр, начиная от одной цифры, тоже в свою очередь является числом. Тогда определение для понятия «число» можно построить таким образом: «число — это любая цифра, либо другое число, к которому справа дописана любая цифра». Именно это и составляет основу правил грамматик G и G' и отражено во второй строке правил в правилах <чс>—><цифра> j <чс><цифра> и T-»F|TF. Другие правила в этих грамматиках позволяют добавить к числу знак (первая строка правил) и дают определение понятию «цифра» (третья строка правил). Они элементарны и не требуют пояснений.
Принцип рекурсии (иногда его называют «принцип итерации», что не меняет сути) — важное понятие в представлении о формальных грамматиках. Так или иначе, явно или неявно рекурсия всегда присутствует в грамматиках любых реальных языков программирования. Именно она позволяет строить бесконечное множество цепочек языка, и говорить об их порождении невозможно без понимания принципа рекурсии. Как правило, в грамматике реального языка программирования содержится не одно, а целое множество правил, построенных с помощью рекурсии.
Другие способы задания грамматик
Форма Бэкуса—Наура — удобный с формальной точки зрения, но не всегда доступный для понимания способ записи формальных грамматик. Рекурсивные определения хороши для формального анализа цепочек языка, но не удобны с точки зрения человека. Например, то, что правила <чс>—><цифра> | <чс><цифра> отражают возможность для построения числа дописывать справа любое число цифр, начиная от одной, неочевидно и требует дополнительного пояснения.
Но при создании языка программирования важно, чтобы его грамматику понимали не только те, кому предстоит создавать компиляторы для этого языка, но и пользователи языка — будущие разработчики программ. Поэтому существуют другие способы описания правил формальных грамматик, которые ориентированы на большую понятность человеку.
Далее рассмотрим два наиболее распространенных из этих способов: запись правил грамматик с использованием метасимволов и запись правил грамматик в графическом виде.
Запись правил грамматик
с использованием метасимволов
Запись правил грамматик с использованием метасимволов предполагает, что в строке правила грамматики могут встречаться специальные символы — мега-символы, — которые имеют особый смысл и трактуются специальным образом. В качестве таких метасимволов чаще всего используются следующие символы: (круглые скобки), (квадратные скобки), (фигурные скобки), (запятая) и "" (кавычки).
Эти метасимволы имеют следующий смысл:
□
круглые скобки означают, что из всех перечисленных внутри них цепочек символов в данном месте правила
грамматики может стоять только одна цепочка;
□
квадратные скобки означают, что указанная в них цепочка может встречаться, а может и не встречаться в данном
месте правила грамматики (то есть может
быть в нем один раз или ни одного раза);
□
фигурные скобки означают, что указанная внутри них цепочка может не
встречаться в
данном месте правила грамматики ни одного раза, встречаться один раз или сколь угодно много раз;
□
запятая служит для того, чтобы разделять цепочки символов внутри круглых
скобок;
О кавычки используются в тех случаях, когда один из метасимволов нужно включить в цепочку обычным образом — то есть когда одна из скобок или запятая должны присутствовать в цепочке символов языка (если саму кавычку нужно включить в цепочку символов, то ее надо повторить дважды — этот принцип знаком разработчикам программ).
Вот как должны выглядеть правила рассмотренной выше грамматики G, если их записать с использованием метасимволов:
<число> -» [(+.-)]<цифра>{<цифра>}
<цифра> ->0|1|2|3|4|5|6|7|8|9
Вторая строка правил не нуждается в комментариях, а первое правило читается так: «число есть цепочка символов, которая может начинаться с символов + или - должна содержать дальше одну цифру, за которой может следовать последовательность из любого количества цифр». В отличие от формы Бэкуса—Наура, в форме записи с помощью метасимволов, как видно, во-первых, убран из грамматики малопонятный нетерминальный символ <чс>, а во-вторых — удалось полностью исключить рекурсию. Грамматика в итоге стала более понятной.
Форма записи правил с использованием метасимволов — это удобный и понятный способ представления правил грамматик. Она во многих случаях позволяет полностью избавиться от рекурсии, заменив ее символом итерации (фигурные скобки). Как будет понятно из дальнейшего материала, эта форма наиболее употребительна для одного из типов грамматик — регулярных грамматик.
Запись правил грамматик в графическом виде
При записи правил в графическом виде вся грамматика представляется в форме набора специальным образом построенных диаграмм. Эта форма была предложена при описании грамматики языка Pascal, а затем она получила широкое распространение в литературе. Она доступна не для всех типов грамматик, а толькодля контекстно-свободных и регулярных типов, но этого достаточно, чтобы ее можно было использовать для описания грамматик известных языков программирования.
В такой форме записи каждому нетерминальному символу грамматики соответствует диаграмма, построенная в виде направленного графа. Граф имеет следующие типы вершин:
□
точка входа (на диаграмме никак не обозначена, из нее просто начинается входная дуга графа);
□
нетерминальный символ (на диаграмме обозначается прямоугольником, в который вписано обозначение символа);
□
цепочка терминальных символов (на диаграмме обозначается овалом, кругом
или прямоугольником с закругленными краями, внутрь которого вписана цепочка);
□
узловая точка (на диаграмме обозначается жирной точкой или закрашенным кружком);
□
точка выхода (никак не обозначена, в нее просто входит выходная дуга
графа).
Каждая диаграмма имеет только одну точку входа и одну точку выхода, но сколько угодно вершин других трех типов. Вершины соединяются между собой направленными дугами графа (линиями со стрелками). Из входной точки дуги могут только выходить, а во входную точку — только входить. В остальные вершины дуги могут как входить, так и выходить (в правильно построенной грамматике каждая вершина должна иметь как минимум один вход и как минимум один выход).
Чтобы построить цепочку символов, соответствующую какому-либо нетерминальному символу грамматики, надо рассмотреть диаграмму для этого символа. Тогда, начав движение от точки входа, надо двигаться по дугам графа диаграммы через любые вершины вплоть до точки выхода. При этом, проходя через вершину, обозначенную нетерминальным символом, этот символ следует поместить в результирующую цепочку. При прохождении через вершину, обозначенную цепочкой терминальных символов, эти символы также следует поместить в результирующую цепочку. При прохождении через узловые точки диаграммы над результирующей цепочкой никаких действий выполнять не надо. Через любую вершину графа диаграммы, в зависимости от возможного пути движения, можно пройти один раз, ни разу или сколь угодно много раз. Как только мы попадем в точку выхода диаграммы, построение результирующей цепочки закончено.
Результирующая цепочка, в свою очередь, может содержать нетерминальные символы. Чтобы заменить их на цепочки терминальных символов, нужно, опять же, рассматривать соответствующие им диаграммы. И так до тех пор, пока в цепочке не останутся только терминальные символы. Очевидно, что для того, чтобы построить цепочку символов заданного языка, надо начать рассмотрение с диаграммы целевого символа грамматики.
Это удобный способ описания правил грамматик,
оперирующий образами, а потому ориентированный исключительно на людей. Даже простое изложение его
основных принципов здесь оказалось довольно громоздким, в то время как суть
ztjz^^=-=^~l~
|
■©• |
|
Цифра |
|
t^m |
|
-о |
Число:
Рис. 9.1. Графическое представление грамматики целых десятичных чисел со знаком: вверху — для понятия «число»; внизу — для понятия «цифра»
Как уже было сказано выше, данный способ в основном применяется в литературе при изложении грамматик языков программирования. Для пользователей — разработчиков программ — он удобен, но практического применения в компиляторах пока не имеет.
Классификация языков и грамматик
Выше уже упоминались различные типы грамматик, но не было указано, как и по какому принципу они подразделяются на типы. Для человека языки бывают простые и сложные, но это сугубо субъективное мнение, которое зачастую зависит от личности человека.
Для компиляторов языки также можно разделить на простые и сложные, но в данном случае существуют жесткие критерии для этого разделения. Как будет показано далее, от того, к какому типу относится тот или иной язык програмирования, зависит сложность распознавателя для этого языка. Чем сложнее язык, тем выше вычислительные затраты компилятора на анализ цепочек исходной программы, написанной на этом языке, а следовательно, сложнее сам компилятор и его структура. Для некоторых типов языков в принципе невозможно построить компилятор, который бы анализировал исходные тексты на этих языках за приемлемое время на основе ограниченных вычислительных ресурсов (именно поэтому до сих пор невозможно создавать программы на естественных языках/например на русском или английском).
Классификация грамматик.
Четыре типа грамматик по Хомскому
Формальные грамматики классифицируются по структуре их правил. Если все без исключения правила грамматики удовлетворяют некоторой заданной структуре, то ее относят к определенному типу. Достаточно иметь в грамматике одно правило, не удовлетворяющее требованиям структуры правил, и она уже не попадает в заданный тип. По классификации Хомского выделяют четыре типа грамматик.
Тип 0: грамматики с фразовой структурой
На структуру их правил не накладывается никаких ограничений: для грамматики вида G(VT,VN,P,S), V » VNuVT правила имеют вид: а-»р, где aeV\ (3eV*. Это самый общий тип грамматик. В него подпадают все без исключения формальные грамматики, но часть из них, к общей радости, может быть также отнесена и к другим классификационным типам. Дело в том, что грамматики, которые относятся только к типу 0 и не могут быть отнесены к другим типам, являются самыми сложными по структуре. Практического применения грамматики, относящиеся только к типу 0, не имеют.
Тип 1: контекстно-зависимые (КЗ) и неукорачивающие грамматики
В этот тип входят два основных класса грамматик.
Контекстно-зависимые грамматики G(VT,VN,P,S), V = VNuVT имеют правила вида: сцАаг-юцрсхг, где а^еУ, AeVN, PeV+.
Неукорачивающие грамматики G(VT,VN,P,S), V = VNu VT имеют правила вида: а->Р, где a,PeV+, ]p|>|a|.
Структура правил КЗ-грамматик такова, что при построении предложений заданного ими языка один и тот же нетерминальный символ может быть заменен на ту или иную цепочку символов в зависимости от того контекста, в котором он встречается. Именно поэтому эти грамматики называют «контекстно-зависимыми». Цепочки а) и а2 в правилах грамматики обозначают контекст (щ — левый контекст, а а2 — правый контекст), в общем случае любая из них (или даже обе) Может быть пустой. Говоря иными словами, значение одного и того же символа может быть различным в зависимости от того, в каком контексте он встречаетсяНеукорачиваювдие грамматики имеют такую структуру правил, что при построении предложений языка, заданного грамматикой, любая цепочка символов может быть заменена на цепочку символов не меньшей длины. Отсюда и название «неукорачивающие».
Доказано, что эти два класса грамматик эквивалентны. Это значит, что для любого языка, заданного контекстно-зависимой грамматикой, можно построить неукорачивающую грамматику, которая будет задавать эквивалентный язык, и наоборот: для любого языка, заданного неукорачивающей грамматикой, можно построить контекстно-зависимую грамматику, которая будет задавать эквивалентный язык.
При построении компиляторов такие грамматики не применяются, поскольку языки программирования, рассматриваемые компиляторами, имеют более простую структуру и могут быть построены с помощью грамматик других типов.
Тип 2: контекстно-свободные (КС) грамматики
Контекстно-свободные (КС) грамматики G(VT,VN,P,S), V = VNuVT имеют правила вида: А-»р\ где AeVN, |3eV+. Такие грамматики также иногда называют неукорачивающими контекстно-свободными (НКС) грамматиками (видно, что в правой части правила у них должен всегда стоять как минимум один символ).
Существует также почти эквивалентный им класс грамматик — укорачивающие контекстно-свободные (УКС) грамматики G(VT,VN,P,S), V = VNuVT, правила которых могут иметь вид: А->р\ где AeVN, PeV*.
Разница между этими двумя классами грамматик заключается лишь в том, что в УКС-грамматиках в правой части правил может присутствовать пустая цепочка (X), а в НКС-грамматиках — нет. Отсюда ясно, что язык, заданный НКС-грамматикой, не может содержать пустой цепочки. Доказано, что эти два класса грамматик почти эквивалентны. В дальнейшем, когда речь будет идти о КС-грамматиках, уже не будет уточняться, какой класс грамматики (УКС или НКС) имеется в виду, если возможность наличия в языке пустой цепочки не имеет принципиального значения.
КС-грамматики широко используются при описании синтаксических конструкций языков программирования. Синтаксис большинства известных языков программирования основан именно на КС-грамматиках, поэтому в данном курсе им уделяется большое внимание.
Внутри типа КС-грамматик кроме классов НКС и УКС выделяют еще целое множество различных классов грамматик, и все они относятся к типу 2. Далее, когда КС-грамматики и КС-языки будут рассматриваться более подробно, на некоторые из этих классов грамматик и их характерные особенности будет обращено особое внимание.
Тип 3: регулярные грамматики
К типу регулярных относятся два эквивалентных класса грамматик: леволинейные и праволинейные.
Леволинейные грамматики G(VT,VN,P,S), V = VNuVT могут иметь правила двух видов: А-»Ву или А->у, где A,BeVN, yeVT.
В свою очередь, праволинейные грамматики G(VT,VN,P,S), V = VNuVT могут иметь правила тоже двух видов: А~-»уВ или А-»у, где A.BeVN, yeVT*.
Эти два класса грамматик эквивалентны и относятся к типу регулярных грамматик.
Регулярные грамматики используются при описании простейших конструкций языков программирования: идентификаторов, констант, строк, комментариев и т. д. Эти грамматики исключительно просты и удобны в использовании, поэтому в компиляторах на их основе строятся функции лексического анализа входного языка (принципы их построения будут рассмотрены далее).
Типы грамматик соотносятся между собой особым образом. Из определения типов 2 и 3 видно, что любая регулярная грамматика является КС-грамматикой, но не наоборот. Также очевидно, что любая грамматика может быть отнесена и к типу 0, поскольку он не накладывает никаких ограничений на правила. В то же время существуют укорачивающие КС-грамматики (тип 2), которые не являются ни контекстно-зависимыми, ни неукорачивающими (тип 1), поскольку могут содержать правила вида «А-»Ъ>, недопустимые в типе 1. В целом можно сказать, что сложность грамматики обратно пропорциональна тому максимально возможному номеру типа, к которому может быть отнесена грамматика. Грамматики, которые относятся только к типу 0, являются самыми сложными, а грамматики, которые можно отнести к типу 3 — самыми простыми.
Классификация языков
Языки классифицируются в соответствии с типами грамматик, с помощью которых они заданы. Причем, поскольку один и тот же язык в общем случае может быть задан сколь угодно большим количеством грамматик, которые могут относиться к различным классификационным типам, то для классификации самого языка среди всех его грамматик всегда выбирается грамматика с максимально возможным классификационным типом. Например, если язык L может быть задан грамматиками Gt и G2, относящимися к типу (контекстно - зависимые), грамматикой G3, относящейся к типу 2 (контекстно-свободные), и грамматикой G4, относящейся к типу 3 (регулярные), то сам язык должен быть отнесен к типу 3 и является регулярным языком.
От классификационного типа языка зависит не только то, с помощью какой грамматики можно построить предложения этого языка, но также и то, насколько сложно распознать эти предложения. Распознать предложения — значит построить распознаватель для языка (третий способ задания языка). Сами распознаватели, их структура и классификация будут рассмотрены далее, здесь же можно указать, что сложность распознавателя языка напрямую зависит от классификационного типа, к которому относится язык.
Сложность языка убывает с возрастанием номера классификационного типа языка. Самыми сложными являются языки типа 0, самыми простыми — языки типа 3.
Согласно классификации грамматик, существуют также четыре типа языков.
Тип О: языки с фразовой структурой
Это самые сложные языки, которые могут быть заданы только грамматикой, относящейся к типу 0. Для распознавания цепочек таких языков требуются вычислители, равномощные машине Тьюринга. Поэтому можно сказать, что если язык относится к типу 0, то для него невозможно построить компилятор, который гарантированно выполнял бы разбор предложений языка за ограниченное время на основе ограниченных вычислительных ресурсов.
К сожалению, практически все естественные языки общения между людьми, строго говоря, относятся именно к этому типу языков. Дело в том, что структура и значение фразы естественного языка может зависеть не только от контекста данной фразы, но и от содержания того текста, где эта фраза встречается. Одно и то же слово в естественном языке может не только иметь разный смысл в зависимости от контекста, но и играть различную роль в предложении. Именно поэтому столь велики сложности в автоматизации перевода текстов, написанных на естественных языках, а также отсутствуют (и видимо, никогда не появятся) компиляторы, которые бы воспринимали программы на основе таких языков.
Далее языки с фразовой структурой рассматриваться не будут.
Тип 1: контекстно-зависимые (КЗ) языки
Тип 1 — второй по сложности тип языков. В общем случае время на распознавание предложений языка, относящегося к типу 1, экспоненциально зависит от длины исходной цепочки символов.
Языки и грамматики, относящиеся к типу 1, применяются в анализе и переводе текстов на естественных языках. Распознаватели, построенные на их основе, позволяют анализировать тексты с учетом контекстной зависимости в предложениях входного языка (но они не учитывают содержание текста, поэтому в общем случае для точного перевода с естественного языка все же требуется вмешательство человека). На основе таких грамматик может выполняться автоматизированный перевод с одного естественного языка на другой, ими могут пользоваться сервисные функции проверки орфографии и правописания в языковых процессорах.
В компиляторах КЗ-языки не используются, поскольку языки программирования имеют более простую структуру, поэтому здесь они подробно не рассматриваются.
Тип 2: контекстно-свободные (КС) языки
КС-языки лежат в основе синтаксических конструкций большинства современных языков программирования, на их основе функционируют некоторые довольно сложные командные процессоры, допускающие управляющие команды цикла и условия. Эти обстоятельства определяют распространенность данного класса языков.
В общем случае время на распознавание предложений языка, относящегося к типу 1, полиномиально зависит от длины исходной цепочки символов (в зависимости от класса языка это либо кубическая, либо квадратичная зависимость).
Однако среди КС-языков существует много классов языков, для которых эта зависимость линейна. Многие языки программирования можно отнести к одному из таких классов.
КС-языки подробно рассматриваются в главе «Контекстно-свободные языки» данного учебного пособия.
Тип 3: регулярные языки
Регулярные языки — самый простой тип языков. Наверное, поэтому они являются самым распространенным и широко используемым типом языков в области вычислительных систем. Время на распознавание предложений регулярного языка линейно зависит от длины исходной цепочки символов.
Как уже было сказано выше, регулярные языки лежат в основе простейших конструкций языков программирования (идентификаторов, констант и т. п.), кроме того, на их основе строятся многие мнемокоды машинных команд (языки ассемблеров), а также командные процессоры, символьные управляющие команды и другие подобные структуры.
Регулярные языки — очень удобное средство. Для работы с ними можно использовать регулярные множества и выражения, конечные автоматы. Регулярные языки подробно рассматриваются в следующей главе учебного пособия.
Примеры классификации языков и грамматик
Классификация языков идет от простого к сложному. Если мы имеем дело с регулярным языком, то можно утверждать, что он также является и контекстно-свободным, и контекстно-зависимым, и даже языком с фразовой структурой. В то же время известно, что существуют КС-языки, которые не являются регулярными, и существуют КЗ-языки, которые не являются ни регулярными, ни контекстно-свободными.
Далее приводятся примеры некоторых языков указанных типов.
Рассмотрим в качестве первого примера ту же грамматику для целых десятичных чисел со знаком G({0,1,2,3,4>5,6,7,8,9,-I+},{S,T,F},P.S):
Р:
S -> Т | +Т | -Т
Т -> F | TF
F->0|1|2|3|4|5|6|7|8|9
По структуре своих правил данная грамматика G относится к контекстно-свободным грамматикам (тип 2). Конечно, ее можно отнести и к типу 0, и к типу 1, но максимально возможным является именно тип 2, поскольку к типу 3 эту грамматику отнести никак нельзя: строка Т—»F | TF содержит правило Т—»TF, которое недопустимо для типа 3, и, хотя все остальные правила этому типу соответствует, одного несоответствия достаточно.
Для того же самого языка (целых десятичных чисел со знаком) можно построить и другую грамматику G'({0,1,2.3,4,5,б,7,8,9,-,+}.{S,T},P.S):
Р:
S -> Т | +Т | -Т
Т -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ОТ | IT | 2Т | ЗТ | 4Т | 5Т | 6Т | 7Т | 8Т | 9Т
По структуре своих правил грамматика G' является праволинейной и может быть отнесена к регулярным грамматикам (тип 3).
Для этого же языка можно построить эквивалентную леволинейную грамматику (тип 3) G"({0,l>2,3,4,5.6,7.8,9>-,+},{SJ},P,S):
Р:
Т^+ | - | X
S -> ТО | Т1 | Т2 | ТЗ | Т4 | Т5 | Т6 | Т7 | Т8 | Т9 | SO | S1 | S2 | S3 | S4 | S5 | S6 | S7 | S8 | S9
Следовательно, язык целых десятичных чисел со знаком, заданный грамматиками G, G' и G", относится к регулярным языкам (тип 3).
В качестве второго примера возьмем грамматику G2({0,1},{A,S},P>S) с правилами Р:
S -> 0А1 ОА -» 00А1 А -> X
Эта грамматика относится к типу 0. Она определяет язык, множество предложений которого можно было бы записать так: L(G2) = {0nln |'n > 0}.
Для этого же языка можно построить также контекстно-зависимую грамматику G2'({0.1},{A,S},P',S) с правилами Р":
S -t 0A1 | 01 ОА -> 00А1 | 001
Однако для того же самого языка можно использовать и контекстно-свободную грамматику G2"({0,1},{S},P",S) с правилами Р":
S —> 0S1 | 01
Следовательно, язык L = {0nln | n > 0} является контекстно-свободным (тип 2).
В третьем примере рассмотрим грамматику G3({a,b,c},{B,C,D,S},P,S) с правилами Р:
S -» BD
В -> аВЬС | ab СЬ -> ЬС CD -> Dc bDc -> bcc abD -» abc
Эта грамматика относится к типу 1. Очевидно, что она является неукорачиваю-щей. Она определяет язык, множество предложений которого можно было бы записать так: L(G3) = {anbncn | n > 0}. Известно, что этот язык не является КС-языком, поэтому для него нельзя построить грамматики типов 2 или 3. Язык L - {anbncn | п > 0} является контекстно-зависимым (тип 1). Конечно, для произвольного языка, заданного некоторой грамматикой, в общем случае довольно сложно так легко определить его тип. Не всегда можно так просто построить грамматику максимально возможного типа для произвольного языка. К тому же при строгом определении типа требуется еще доказать, что две грамматики (первоначально имеющаяся и вновь построенная) эквивалентны, а также то, что не существует для того же языка грамматики с большим по номеру типом. Это нетривиальная задача, которую не так легко решить.
Для многих языков, и в частности для КС-языков и регулярных языков, существуют специальным образом сформулированные утверждения, которые позволяют проверить принадлежность языка к указанному типу. Такие утверждения (леммы) будут рассмотрены далее в соответствующих главах этого учебника. Тогда для произвольного языка достаточно лишь доказать нужное утверждение, и после этого можно точно утверждать, что данный язык относится к тому или иному типу. Преобразование грамматик в этом случае не требуется.
Тем не менее иногда возникает задача построения для имеющегося языка грамматики более простого типа, чем данная. И даже в том случае, когда тип языка уже известен, эта задача остается нетривиальной и в общем случае не имеет формального решения (проблема преобразования грамматик рассматривается далее).
Цепочки вывода. Сентенциальная форма
Вывод. Цепочки вывода
Выводом называется процесс порождения предложения языка на основе правил определяющей язык грамматики. Чтобы дать формальное определение процессу вывода, необходимо ввести еще несколько дополнительных понятий. Цепочка Р = 5ty52 называется непосредственно выводимой из цепочки а = 5!(о52 в грамматике G(VT,VN,P,S), V = VTuVN, 8Ь у, 52 е V", со е V+, если в грамматике G существует правило: ш-»у е Р. Непосредственная выводимость цепочки Р из цепочки а обозначается так: а=>р. Иными словами, цепочка р выводима из цепочки а в том случае, если можно взять несколько символов в цепочке а, заменить их на другие символы согласно некоторому правилу грамматики и получить цепочку р. В формальном определении непосредственной выводимости любая из цепочек 5t или 52 (а равно и обе эти цепочки) может быть пустой. В предельном случае вся цепочка а может быть заменена на цепочку р, тогда в грамматике G должно существовать правило: а-»Р е Р.
Цепочка Р называется выводимой из цепочки а (обозначается а=>*Р) в том случае, если выполняется одно из двух условий:
□
р непосредственно выводима из а (а=>Р);
□
3 у, такая, что: у выводима из а и р непосредственно выводима из у
(а=>*у и у=>Р).
Это рекурсивное определение выводимости цепочки. Суть его заключается в том, что цепочка р выводима из цепочки а, если а=>р или же если можно построить последовательность непосредственно выводимых цепочек от а к р следующеговида: a^Yi^-^Yi^-^Yn^P, п>1. В этой последовательности каждая последующая цепочка у{ непосредственно выводима из предыдущей цепочки ум-Такая последовательность непосредственно выводимых цепочек называется выводом или цепочкой вывода. Каждый переход от одной непосредственно выводимой цепочки к следующей в цепочке вывода называется шагом вывода. Очевидно, что шагов вывода в цепочке вывода всегда на один больше, чем промежуточных цепочек. Если цепочка р непосредственно выводима из цепочки а: а=>р, то имеется всего один шаг вывода.
Если цепочка вывода из а к р содержит одну или более промежуточных цепочек (два или более шагов вывода), то она имеет специальное обозначение а=>+Р (говорят, что цепочка р нетривиально выводима из цепочки а). Если количество шагов вывода известно, то его можно указать непосредственно у знака выводимости цепочек. Например, запись а=>4Р означает, что цепочка Р выводится из цепочки а за 4 шага вывода1.
Возьмем в качестве примера ту же грамматику для целых десятичных чисел со знаком G({0.1.2>3,4,5.6,7,8.9.-.+}.{S.T.F},P,S):
Р:
S -> Т | +Т | -Т Т -> F | TF
F -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 Построим в ней несколько произвольных цепочек вывода:
1. S =>
-Т => -TF => -TFF => -FFF => -4FF
=>
2. S ==> Т => TF => Т8 => F8 => 18
3.Т => TF => ТО => TF0 => Т50 => F50 =>
350
4.TFT => TFFT => TFFF => FFFF => 1FFF => 1FF4 => 10F4 => 1004
5.
F=>5
Получили следующие выводы:
1. S => *
-479 или S => + -479 или S => 7 -479
2.
S => * 18 или S => + 18 или S
=> 5 18
3.
Т => * 350 или Т => + 350 или Т => 6 350
4.
TFT => * 1004 или TFT => + 1004 или TFT => 7 1004
5.
F => * 5 или F =>' 5 (утверждение F
=> + 5 неверно!)
Все эти выводы построены на основе грамматики G. В принципе в этой грамматике (как, практически, и в любой другой грамматике реального языка) можно построить сколь угодно много цепочек вывода.
Возьмем в качестве второго примера грамматику G3 ({a,b,c},{B,C,D,S}.P,S) с правилами Р, которая уже рассматривалась выше:
1 В литературе встречается также обозначение а=>°(3, которое означает, что цепочка а выводима из цепочки р за 0 шагов — иными словами, в таком случае эти цепочки равны: а = р. Подразумевается, что обозначение вывода а=>*р допускает и такое толкование — включает в себя вариант а=> р. S -» BD
В -> аВЬС | ab СЬ -> ЬС CD -» Dc bDc -* bcc abD -» abc
Как было сказано ранее, она задает язык L(G3) = {0nln | п > 0}. Рассмотрим npi мер вывода предложения «aaaabbbbcccc » языка L(G3) на основе грамматики G
S => BD => aBbCD => aaBbCbCD => aaaBbCbCbCD => aaaabbCbCbCD => aaaabbbCCbCD = aaaabbbCbCCD => aaaabbbbCCCD => aaaabbbbCCDc => aaaabbbbCDcc => aaaabbbbDccc s aaaabbbbcccc. Тогда для грамматики G3 получаем вывод: S => * aaaabbbbcccc.
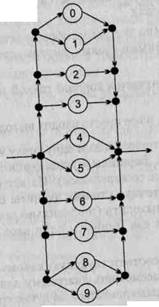
Иногда, чтобы пояснить ход вывода, над стрелкой, обозначающей каждый ш; вывода, пишут обозначение того правила грамматики, на основе которого сдела этот шаг (для этой цели правила грамматики проще всего просто пронумеровать! в порядке их следования). Грамматика, рассмотренная в приведенных здесь npi мерах, содержит всего 15 правил, и на каждом шаге в цепочках вывода можг понять, на основании какого правила сделан этот шаг (читатели могут легко сделать это самостоятельно), но в более сложных случаях пояснения к шагам вывода с указанием номеров правил грамматики могут быть весьма полезными.
Сентенциальная форма грамматики. Язык, заданный грамматикой
Вывод называется законченным, если на основе цепочки р\ полученной в резул: тате вывода, нельзя больше сделать ни одного шага вывода. Иначе говоря, вывс называется законченным, если цепочка р, полученная в результате вывода, пу тая или содержит только терминальные символы грамматики G(VT,VN,P,S PeVT*. Цепочка р, полученная в результате законченного вывода, называете конечной цепочкой вывода.
В рассмотренном выше примере все построенные выводы являются закончеными, а, например, вывод S =>* -4FF (из первой цепочки в примере) будет незако] ченным.
Цепочка символов asV* называется сентенциальной формой грамматики G(V VN,P,S), V = VTuVN, если она выводима из целевого символа грамматики S =>* а. Если цепочка ae VT* получена в результате законченного вывода, то oi называется конечной сентенциальной формой.
Из рассмотренного выше примера можно заключить, что цепочки в символе «—479>> и «18» являются конечными сентенциальными формами грамматики цель Десятичных чисел со знаком, так как существуют выводы S =>* -479 и S =>* 1 (примеры 1 и 2). Цепочка F8 из вывода 2, например, тоже является сентенциальнс формой, поскольку справедливо S =>* F8, но она не является конечной цепочке вывода. В то же время в выводах примеров 3—5 явно не присутствуют сентенц: эльные формы. На самом деле цепочки «350», «1004» и «5» являются конечнг Ми сентенциальными формами. Чтобы доказать это, необходимо просто построить другие цепочки вывода (например, для цепочки «5» строим: S => Т => F => и получаем S => * 5). А вот цепочка «TFT» (пример 4) не выводима из целевого символа грамматики S, а потому сентенциальной формой не является. Язык L, заданный грамматикой G(VT,VN,P,S), — это множество всех конечных сентенциальных форм грамматики G. Язык L, заданный грамматикой G, обозначается как L(G). Очевидно, что алфавитом такого языка L(G ) будет множество терминальных символов грамматики VT, поскольку все конечные сентенциальные формы грамматики — это цепочки над алфавитом VT. Следует помнить, что две грамматики G(VT,VN,P,S) и G'(VT',VN',P',S') называются эквивалентными, если эквивалентны заданные ими языки: L(G) = L(G'). Очевидно, что эквивалентные грамматики должны иметь, по крайней мере, пересекающиеся множества терминальных символов VTnVT * 0 (как правило, эти множества даже совпадают VT = VI"), а вот множества нетерминальных символов, правила грамматики и целевой символ у них могут кардинально отличаться.
Левосторонний и правосторонний выводы
Вывод называется левосторонним, если в нем на каждом шаге вывода правило грамматики применяется всегда к крайнему левому нетерминальному символу в цепочке. Другими словами, вывод называется левосторонним, если на каждом шаге вывода происходит подстановка цепочки символов на основании правила грамматики вместо крайнего левого нетерминального символа в исходной цепочке.
Аналогично, вывод называется правосторонним, если в нем на каждом шаге вывода правило грамматики применяется всегда к крайнему правому нетерминальному символу в цепочке.
Если рассмотреть цепочки вывода из того же примера, то в нем выводы 1 и 5 являются левосторонними, выводы 2, 3 и 5 — правосторонними (вывод 5 одновременно является и лево- и правосторонним), а вот вывод 4 не является ни левосторонним, ни правосторонним.
Для грамматик типов 2 и 3 (КС-грамматик и регулярных грамматик) для любой сентенциальной формы всегда можно построить левосторонний или правосторонний выводы. Для грамматик других типов это не всегда возможно, так как по структуре их правил не всегда можно выполнить замену крайнего левого или крайнего правого нетерминального символа в цепочке.
Рассмотренный выше вывод S => * aaaabbbbcccc для грамматики G3, задающей язык L(G3) = {Onln|n > 0}, не является ни левосторонним, ни правосторонним. Грамматика относится к типу 1, и в данном случае для нее нельзя построить такой вывод, на каждом шаге которого только один нетерминальный символ заменялся бы на цепочку символов.
Дерево вывода. Методы построения дерева вывода
Деревом вывода грамматики G(VT,VN,P,S) называется дерево (граф),
которое соответствует
некоторой цепочке вывода и удовлетворяет следующим условиям:
□
каждая вершина дерева обозначается символом грамматики Ae(VT uVN);
□
корнем дерева является вершина, обозначенная целевым символом грамматики — S;
□
листьями дерева (концевыми вершинами) являются вершины, обозначенные
терминальными символами грамматики или символом пустой цепочки X;
□ если некоторый узел дерева
обозначен символом AeVN, а связанные с ним узлы — символами Ь^.-.^! п > 0, Vn > i
> 0: bje(VTuVNu{A.}), то в
грамматике G(VT,VN,P,S) существует
правило А-^Ь^Ьг bn e Р.
Из определения видно, что по структуре правил дерево вывода в указанном виде всегда можно построить только для грамматик типов 2 и 3 (контекстно-свободных и регулярных). Для грамматик других типов дерево вывода в таком виде можно построить не всегда (либо же оно будет иметь несколько иной вид).
На основе рассмотренного выше примера построим деревья вывода для цепочек вывода 1 и 2. Эти деревья приведены на рис. 9.2.
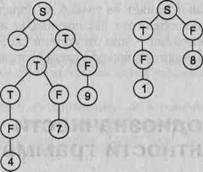
Рис. 9.2. Примеры деревьев вывода для грамматики целых десятичных чисел со знаком
Для того чтобы построить дерево вывода, достаточно иметь только цепочку вывода. Дерево вывода можно построить двумя способами: сверху вниз и снизу вверх. Для строго формализованного построения дерева вывода всегда удобнее пользоваться строго определенным выводом: либо левосторонним, либо правосторонним.
При построении дерева вывода сверху вниз построение начинается с целевого символа грамматики, который помещается в корень дерева. Затем в грамматике выбирается необходимое правило, и на первом шаге вывода корневой символ раскрывается на несколько символов первого уровня. На втором шаге среди всех концевых вершин дерева выбирается крайняя (крайняя левая — для левостороннего вывода, крайняя правая — для правостороннего) вершина, обозначенная нетерминальным символом, для этой вершины выбирается нужное правило грамматики, и она раскрывается на несколько вершин следующего уровня. Построение дерева заканчивается, когда все концевые вершины обозначены терминальными символами, в противном случае надо вернуться ко второму шагу и продолжить построение.
Построение дерева вывода снизу вверх начинается с листьев дерева. В качестве листьев выбираются терминальные символы конечной цепочки вывода, которые на первом шаге построения образуют последний уровень (слой) дерева. Построение дерева идет по слоям. На втором шаге построения в грамматике выбирается правило, правая часть которого соответствует крайним символам в слое дерева (крайним правым символам при правостороннем выводе и крайним левым — при левостороннем). Выбранные вершины слоя соединяются с новой вершиной, которая выбирается из левой части правила. Новая вершина попадает в слой дерева вместо выбранных вершин. Построение дерева закончено, если достигнута корневая вершина (обозначенная целевым символом), а иначе надо вернуться ко второму шагу и повторить его над полученным слоем дерева. Поскольку все известные языки программирования имеют нотацию записи «слева — направо», компилятор также всегда читает входную программу слева направо (и сверху вниз, если программа разбита на несколько строк). Поэтому для построения дерева вывода методом «сверху вниз», как правило, используется левосторонний вывод, а для построения «снизу вверх» — правосторонний вывод. На эту особенность компиляторов стоит обратить внимание. Нотация чтения программ «слева направо» влияет не только на порядок разбора программы компилятором (для пользователя это, как правило, не имеет значения), но и на порядок выполнения операций — при отсутствии скобок большинство равноправных операций выполняются в порядке слева направо, а это уже имеет существенное значение.
Проблемы однозначности
и эквивалентности грамматик
Однозначные и неоднозначные грамматики
Рассмотрим некоторую грамматику G ({+,-.*,/,(,). а, b}, {S}, Р, S):
Р: S -> S+S | S-S | S*S | S/S | (S) | а | b Видно, что представленная грамматика определяет язык арифметических выражений с четырьмя основными операциями (сложение, вычитание, умножение и деление) и скобками над операндами а и Ь. Примерами предложений этого языка могут служить: a*b+a, a*(a+b), а*Ь+а*а и т. д.
Возьмем цепочку а*Ь+а и построим для нее левосторонний вывод. Получится два варианта:
S => S+S => S*S+S о a*S+S => a*b+S => a*b+a S => S*S => a*S => a*S+S => a*b+S => a*b+a Каждому из этих вариантов будет соответствовать свое дерево вывода. Два варианта дерева вывода для цепочки «а*Ь+а» приведены на рис. 9.3. С точки зрения формального языка, заданного грамматикой, не имеет значения, какая цепочка вывода и какое дерево вывода из возможных вариантов будут построены. Однако для языков программирования, которые не являются чисто
формальными языками и несут некоторую смысловую нагрузку, это имеет значение. Например, если принять во внимание, что рассмотренная здесь грамматика определяет язык неких арифметических выражений, то с точки зрения арифметики порядок построения дерева вывода соответствует порядку выполнения арифметических действий. В арифметике, как известно, при отсутствии скобок умножение всегда выполняется раньше сложения (умножение имеет более высокий приоритет), но в рассмотренной выше грамматике это ниоткуда не следует—в ней все операции равноправны. Поэтому с точки зрения арифметических операций приведенная грамматика имеет неверную семантику — в ней нет приоритета операций, а, кроме того, для равноправных операций не определен порядок выполнения («слева направо»), хотя синтаксическая структура построенных с ее помощью выражений будет правильной.
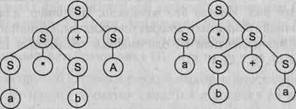
Рис. 9.3. Два варианта дерева цепочки «а*Ь+а» вывода для неоднозначной грамматики арифметических выражений
Такая ситуация называется неоднозначностью в грамматике. Естественно, для построения компиляторов и языков программирования нельзя использовать грамматики, допускающие неоднозначности. Дадим более точное определение неоднозначной грамматики.
Грамматика называется однозначной, если для каждой цепочки символов языка, заданного этой грамматикой, можно построить единственный левосторонний (и единственный правосторонний) вывод. Или, что то же самое: грамматика называется однозначной, если для каждой цепочки символов языка, заданного этой грамматикой, существует единственное дерево вывода. В противном случае грамматика называется неоднозначной.
Рассмотренная в примере грамматика арифметических выражений, очевидно, является неоднозначной.
Эквивалентность и преобразование грамматик
Поскольку грамматика языка программирования, по сути, всегда должна быть однозначной, то возникают два вопроса, которые необходимо в любом случае решить:
Q как проверить, является ли данная грамматика однозначной? □ если заданная грамматика является неоднозначной, то как преобразовать ее к однозначному виду?
Однозначность — это свойство грамматики, а не языка. Для некоторых языков, заданных неоднозначными грамматиками, иногда удается построить эквивалентную однозначную грамматику (однозначную грамматику, задающую тот же язык).
Чтобы убедиться в том, что некоторая грамматика не является однозначной (является неоднозначной), согласно определению достаточно найти в заданном ею языке хотя бы одну цепочку, которая бы допускала более чем один левосторонний или правосторонний вывод (как это было в рассмотренном примере). Однако не всегда удается легко обнаружить такую цепочку символов. Кроме того, если такая цепочка не найдена, мы не можем утверждать, что данная грамматика является однозначной, поскольку перебрать все цепочки языка невозможно -как правило, их бесконечное количество. Следовательно, нужны другие способы проверки однозначности грамматики.
Если грамматика все же является неоднозначной, то необходимо преобразовать ее в однозначный вид. Иногда это возможно. Например, для рассмотренной выше неоднозначной грамматики арифметических выражений над операциями а и b существует эквивалентная ей однозначная грамматика следующего вида G'({+,-.*,/,(.),a,b}.{S,T,E},P\S):
Р':
S _> S+T |
S-T | Т
Т -> Т*Е | Т/Е | Е
Е -> (S) | а | b В этой грамматике для рассмотренной выше цепочки символов языка а*Ь+а возможен только один левосторонний вывод:
S => S+T => Т+Т => Т*Е+Т Ь Е*Е+Т =* а*Е+Т => а*Ь+Т => a*b+E => a*b+a Этому выводу соответствует единственно возможное дерево вывода. Оно приведено на рис. 9.4. Видно, что хотя цепочка вывода несколько удлинилась, но приоритет операций в данном случае единственно возможный и соответствует их порядку в арифметике.
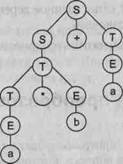
Рис. 9.4. Дерево вывода для однозначной грамматики арифметических выражений
В таком случае необходимо решить две проблемы: во-первых, доказать, что две имеющиеся грамматики эквивалентны (задают один и тот же язык); во-вторых, иметь возможность проверить, что вновь построенная грамматика является однозначной.
Проблема эквивалентности грамматик в общем виде формулируется следующим образом: имеются две грамматики G и G', необходимо построить алгоритм, который бы позволял проверить, являются ли эти две грамматики эквивалентными.
К сожалению, доказано, что проблема эквивалентности грамматик в общем случае алгоритмически неразрешима. Это значит, что не только до сих пор не существует алгоритма, который бы позволял проверить, являются ли две заданные грамматики эквивалентными, но и доказано, что такой алгоритм в принципе не существует, а значит, он никогда не будет создан.
Точно так же неразрешима в общем виде и проблема однозначности грамматик. Это значит, что не существует (и никогда не будет существовать) алгоритм, который бы позволял для произвольной заданной грамматики G проверить, является ли она однозначной или нет. Аналогично, не существует алгоритма, который бы позволял преобразовать заведомо неоднозначную грамматику G в эквивалентную ей однозначную грамматику G'.
В общем случае вопрос об
алгоритмической неразрешимости проблем однознач
ности и
эквивалентности грамматик сводится к вопросу об алгоритмической
неразрешимости
проблемы, известной как «проблема соответствий Поста». Про
блема соответствий
Поста формулируется следующим образом: имеется задан
ное множество пар
непустых цепочек над алфавитом V: {(ctj,Pi)> (а2,р2)............. (ап>Рп)}>
п > 0, Vn > i > 0: oippieV*; необходимо проверить, существует ли среди них такая последовательность пар цепочек: (cq.Pi), (a2,P2),..., (am,pm), m > 0 (необязательно различных), что a^.-.a,,, = p1p2...prn- Доказано, что не существует алгоритма, который бы за конечное число шагов мог дать ответ на этот вопрос, хотя на первый взгляд постановка задачи кажется совсем несложной.
То, что проблема не решается в общем виде, совсем не значит, что ее нельзя решить в каждом конкретном случае. Например, для алфавита V - {а,Ь} можно построить множество пар цепочек {(abbb.b). (a.aab), (ba.b)} и найти одно из решений: (a,aab),(a,aab),(ba,b),(abbb,b) - видно, что (a)(a)(ba)(abbb) = (aabKaab) (b)(b). А для множества пар цепочек {(ab,aba),(aba,baa),(baa,aa)} очевидно, что решения не существует.
Точно так же неразрешимость проблем эквивалентности и однозначности грамматик в общем случае совсем не означает, что они не разрешимы вообще. Для некоторых частных случаев — например, для определенных типов и классов грамматик (в частности, для регулярных грамматик) — эти проблемы решены. Также их иногда удается решить полностью или частично в каждом конкретном случае, и для конкретной заданной грамматики доказать, является ли она однозначной или нет. Например, приведенная выше грамматика G' для арифметических выражений над операндами а и b относится к классу грамматик операторного предшествования из типа КС-грамматик. На основе этой грамматики возможно построить распознаватель в виде детерминированного расширенного МП-автомата, а потому можно утверждать, что она является однозначной (см. раздел «Восходящие распознаватели КС-языков без возвратов», глава 12).
Правила, задающие неоднозначность в грамматиках
В общем виде невозможно проверить, является ли заданная грамматика однозначной или нет. Однако для КС-грамматик существуют определенного вида правила, по наличию которых в множестве правил грамматики G(VT,VN,P,S) можно утверждать, что она является неоднозначной. Эти правила имеют следующий вид:
1.
А -» АА | а,
2.
А -» АаА | (3,
3.
А -> аА | Ар | у,
4.
А -> аА | аАрА | у,
здесь AeVN; a,p,ye(VNuVT)*. Если в заданной грамматике встречается хотя бы одно правило подобного вида (любого из приведенных вариантов), то доказано, что такая грамматика точно будет неоднозначной. Однако если подобных правил во всем множестве правил грамматики нет, это совсем не означает, что грамматика является однозначной. Такая грамматика может быть однозначной, а может и не быть. То есть отсутствие правил указанного вида (всех вариантов) — это необходимое, но не достаточное условие однозначности грамматики.
С другой стороны, установлены условия, при удовлетворении которым грамматика заведомо является однозначной. Они справедливы для всех регулярных и многих классов контекстно-свободных грамматик. Однако известно, что эти условия, напротив, являются достаточными, но не необходимыми для однозначности грамматик.
В рассмотренном выше примере грамматики арифметических выражений с операндами а и b — G({+,-,*,/,(.),а,b},{S},P,S) — во множестве правил Р: S -> S+S | S-S | S*S | S/S | (S) | а | b встречаются правила 2 типа. Поэтому данная грамматика является неоднозначной, что и было показано выше.
Распознаватели. Задача разбора
Общая схема распознавателя
Для каждого языка программирования (как, наверное, и для многих других языков) важно не только уметь построить текст програмы на этом языке, но и определить принадлежность имеющегося текста к данному языку. Именно эту задачу решают компиляторы в числе прочих задач (компилятор должен не только распознать исходную программу, но и построить эквивалентную ей результирующую программу). В отношении исходной программы компилятор выступает как распознаватель, а человек, создавший программу на некотором языке, выступает в роли генератора цепочек этого языка.
Распознаватель (или разборщик) — это специальный алгоритм, который позволяет определить принадлежность цепочки символов некоторому языку. Задача распознавателя заключается в том, чтобы на основании исходной цепочки дать ответ, принадлежит ли она заданному языку или нет. Распознаватели, как было сказано выше, представляют собой один из способов определения языка.
В общем виде распознаватель можно отобразить в виде условной схемы, представленной на рис. 9.5.
дом шаге работы распознавателя считывающая головка может либо переместиться по ленте символов на некоторое число позиций в заданном направлении, либо остаться на месте. Поскольку все языки программирования подразумевают нотацию чтения исходной программы «слева направо», то так же работают и все распознаватели. Поэтому, когда говорят об односторонних распознавателях, то прежде всего имеют в виду левосторонние, которые читают исходную цепочку слева направо и не возвращаются назад к уже прочитанной части цепочки.
Двусторонние распознаватели допускают, что считывающая головка может перемещаться относительно ленты входных символов в обоих направлениях: как вперед, от начала ленты к концу, так и назад, возвращаясь к уже прочитанным символам.
По видам устройства управления распознаватели бывают детерминированные и недетерминированные.
Распознаватель называется детерминированным в том случае, если для каждой допустимой конфигурации распознавателя, которая возникла на некотором шаге его работы, существует единственно возможная конфигурация, в которую распознаватель перейдет на следующем шаге работы.
В противном случае распознаватель называется недетерминированным. Недетерминированный распознаватель может иметь такую допустимую конфигурацию, для которой существует некоторое конечное множество конфигураций, возможных на следующем шаге работы. Достаточно иметь хотя бы одну такую конфигурацию, чтобы распознаватель был недетерминированным.
По видам внешней памяти распознаватели бывают следующих типов:
□
распознаватели без внешней памяти;
□
распознаватели с ограниченной внешней памятью;
□
распознаватели с неограниченной внешней памятью.
У распознавателей без внешней памяти эта память полностью отсутствует. В процессе их работы используется только конечная память устройства управления, доступ к внешней памяти не выполняется.
Для распознавателей с ограниченной внешней памятью размер внешней памяти ограничен в зависимости от длины исходной цепочки символов. Эти ограничения могут налагаться некоторой зависимостью объема памяти от длины цепочки — линейной, полиномиальной, экспоненциальной и т. д. Кроме того, для таких распознавателей может быть указан способ организации внешней памяти — стек, очередь, список и т. п.
Распознаватели с неограниченной внешней памятью предполагают, что для их работы может потребоваться внешняя память неограниченного объема (как правило, вне зависимости от длины входной цепочки). У таких распознавателей предполагается память с произвольным методом доступа.
Вместе эти три составляющих позволяют организовать общую классификацию распознавателей. Например, в этой классификации возможен такой тип: «двусторонний недетерминированный распознаватель с линейно ограниченной стековой памятью».
Тип распознавателя в классификации определяет сложность создания такого распознавателя, а следовательно, сложность разработки соответствующего программного обеспечения для компилятора. Чем выше в классификации стоит распознаватель, тем сложнее создавать алгоритм, обеспечивающий его работу. Разрабатывать двусторонние распознаватели сложнее, чем односторонние. Можно заметить, что недетерминированные распознаватели по сложности выше детерминированных. Зависимость затрат на создание алгоритма от типа внешней памяти также очевидна.
Классификация распознавателей по типам языков
Как было показано в предыдущей главе, классификация распознавателей (вид входящих в состав распознавателя компонентов) определяет сложность алгоритма работы распознавателя. Но сложность распознавателя также напрямую связана с типом языка, входные цепочки которого может принимать (допускать) распознаватель.
Выше было определено четыре основных типа языков. Доказано, что для каждого из этих типов языков существует свой тип распознавателя с определенным составом компонентов и, следовательно, с заданной сложностью алгоритма работы. Для языков с фразовой структурой (тип 0) Необходим распознаватель, равномощной машине Тьюринга — недетерминированный двусторонний автомат, имеющий неограниченную внешнюю память. Поэтому для языков данного типа нельзя гарантировать, что за ограниченное время на ограниченных вычислительных ресурсах распознаватель завершит работу и примет решение о том, принадлежит или не принадлежит входная цепочка заданному языку. Отсюда можно заключить, что практического применения языки с фразовой структурой не имеют (и не будут иметь), а потому далее они не рассматриваются. Для контекстно-зависимых языков (тип 1) распознавателями являются двусторонние недетерминированные автоматы с линейно ограниченной внешней памятью. Алгоритм работы такого автомата в общем случае имеет экспоненциальную сложность — количество шагов (тактов), необходимых автомату для распознавания входной цепочки, экспоненциально зависит от длины этой цепочки. Следовательно, и время, необходимое на разбор входной цепочки по заданному алгоритму, экспоненциально зависит от длины входной цепочки символов. Такой алгоритм распознавателя уже может быть реализован в программном обеспечении компьютера — зная длину входной цепочки, всегда можно сказать, за какое максимально возможное время будет принято решение о принадлежности цепочки данному языку и какие вычислительные ресурсы для этого потребуются. Однако экспоненциальная зависимость времени разбора от длины цепочки существенно ограничивает применение распознавателей для контекстно-зависимых языков. Как правило, такие распознаватели применяются для автоматизированного перевода и анализа текстов на естественных языках, когда временные ограничения на разбор текста несущественны (следует также напомнить, что, поскольку естественные языки более сложны, чем контекстно-зависимый тип, то после такой обработки часто требуется вмешательство человека). В компилято-
Входная цепочка символов
|ai|a2| |an|
+ Считывающая головка
|
УУ К- |
Рабочая
(внешняя)
память
Рис. 9.5. Условная схема распознавателя
Следует подчеркнуть, что представленный рисунок — всего лишь условная схема, отображающая работу алгоритма распознавателя. Ни в коем случае не стоит искать подобного устройства в составе компьютера. Распознаватель, являющийся частью компилятора, представляет собой часть программного обеспечения компьютера.
Как видно из рисунка, распознаватель состоит из следующих основных компонентов:
□
ленты, содержащей исходную цепочку входных символов, и считывающей головки, обозревающей очередной символ в этой цепочке;
□
устройства управления (УУ), которое координирует работу распознавателя,
имеет некоторый набор состояний и конечную память (для хранения своего состояния и некоторой промежуточной информации);
□
внешней (рабочей) памяти, которая может хранить некоторую информацию в
процессе работы распознавателя и в отличие от памяти УУ может иметь неограниченный объем.
Распознаватель работает с символами своего алфавита — алфавита распознавателя. Алфавит распознавателя конечен. Он включает в себя все допустимые символы входных цепочек, а также некоторый дополнительный алфавит символов, которые могут обрабатываться УУ и храниться в рабочей памяти распознавателя.
В процессе своей работы распознаватель может выполнять некоторые элементарные операции, такие как чтение очередного символа из входной цепочки, сдвиг входной цепочки на заданное количество символов (вправо или влево), доступ к рабочей памяти для чтения или записи информации, преобразование информации в памяти, изменение состояния УУ. То, какие конкретно операции должны выполняться в процессе работы распознавателя, определяется в УУ.
Распознаватель работает по шагам или тактам. В начале такта, как правило, счи-тывается очередной символ из входной цепочки, и в зависимости от этого символа УУ определяет, какие действия необходимо выполнить. Вся работа распознавателя состоит из последовательности тактов. В начале каждого такта состояние распознавателя определяется его конфигурацией. В процессе работы конфигурация распознавателя меняется. Конфигурация распознавателя определяется следующими параметрами:
□
содержимое входной цепочки символов и положение считывающей головки в ней;
□
состояние УУ;
□
содержимое внешней памяти.
Для распознавателя всегда задается определенная конфигурация, которая считается начальной конфигурацией. В начальной конфигурации считывающая головка обозревает первый символ входной цепочки, УУ находится в заданном начальном состоянии, а внешняя память либо пуста, либо содержит строго определенную информацию.
Кроме начального состояния для распознавателя задается одна или несколько конечных конфигураций. В конечной конфигурации считывающая головка, как правило, находится за концом исходной цепочки (часто для распознавателей вводят специальный символ, обозначающий конец входной цепочки). Распознаватель допускает входную цепочку символов а, если, находясь в начальной конфигурации и получив на вход эту цепочку, он может проделать последовательность шагов, заканчивающуюся одной из его конечных конфигураций. Формулировка «может проделать последовательность шагов» более точна, чем прямое указание «проделает последовательность шагов», так как для многих распознавателей при одной и той же входной цепочке символов из начальной конфигурации могут быть допустимы различные последовательности шагов, не все из которых ведут к конечной конфигурации.
Язык, определяемый распознавателем, — это множество всех цепочек, которые допускает распознаватель.
Далее в главах этого пособия рассмотрены конкретные типы распознавателей для различных типов языков. Но все, что было сказано здесь, относится ко всем без исключения типам распознавателей для всех типов языков.
Виды распознавателей
Распознаватели можно классифицировать в зависимости от вида составляющих их компонентов: считывающего устройства, устройства управления (УУ) и внешней памяти.
По видам считывающего устройства распознаватели могут быть двусторонние и односторонние.
Односторонние распознаватели допускают перемещение считывающей головки по ленте входных символов только в одном направлении. Это значит, что на каж-
рах для анализа текстов на различных языках программирования контекстно-зависимые распознаватели не применяются, поскольку скорость работы компилятора имеет существенное значение, а синтаксический разбор текста программы можно выполнять в рамках более простого, контекстно-свободного типа языков.
Поэтому в рамках этого учебного пособия контекстно-зависимые языки также не рассматриваются.
Для контекстно-свободных языков (тип 2) распознавателями являются односторонние недетерминированные автоматы с магазинной (стековой) внешней памятью — МП-автоматы. При простейшей реализации алгоритма работы такого автомата он имеет экспоненциальную сложность, однако путем некоторых усовершенствований алгоритма можно добиться полиномиальной (кубической) зависимости времени, необходимого на разбор входной цепочки, от длины этой цепочки. Следовательно, можно говорить о полиномиальной сложности распознавателя для КС-языков.
Среди всех КС-языков можно выделить класс детерминированных КС-языков, распознавателями для которых являются детерминированные автоматы с магазинной (стековой) внешней памятью — ДМП-автоматы. Эти языки обладают свойством однозначности — доказано, что для любого детерминированного КС-языка всегда можно построить однозначную грамматику. Кроме того, для таких языков существует алгоритм работы распознавателя с квадратичной сложностью. Поскольку эти языки являются однозначными, именно они представляют наибольший интерес для построения компиляторов.
Более того, среди всех детерминированных КС-языков существуют такие классы языков, для которых возможно построить линейный распознаватель — распознаватель, у которого время принятия решения о принадлежности цепочки языку имеет линейную зависимость от длины цепочки. Синтаксические конструкции практически всех существующих языков программирования могут быть отнесены к одному из таких классов языков. Это обстоятельство очень важно для разработки современных быстродействующих компиляторов. Поэтому в главе, посвященной КС-языкам, в первую очередь будет уделено внимание именно таким классам этих языков.
Тем не менее следует помнить, что только синтаксические конструкции языков программирования допускают разбор с помощью распознавателей КС-языков. Сами языки программирования, как уже было сказано, не могут быть полностью отнесены к типу КС-языков, поскольку предполагают некоторую контекстную зависимость в тексте исходной программы (например, такую, как необходимость предварительного описания переменных). Поэтому кроме синтаксического разбора практически все компиляторы предполагают дополнительный семантический анализ текста исходной программы. Этого можно было бы избежать, если построить компилятор на основе контекстно-зависимого распознавателя, но скорость работы такого компилятора была бы недопустима низка, поскольку время разбора в таком варианте будет экспоненциально зависеть от длины исходной программы. Комбинация из распознавателя КС-языка и дополнительного семантического анализатора является более эффективной с точки зрения скорости разбора исходной программы. Для регулярных языков (тип 3) распознавателями являются односторонние недетерминированные автоматы без внешней памяти — конечные автоматы (KA'i Это очень простой тип распознавателя, который всегда предполагает линейную зависимость времени на разбор входной цепочки от ее длины. Кроме того, конечные автоматы имеют важную особенность: любой недетерминированный КА всегда может быть преобразован в детерминированный. Это обстоятельство существенно упрощает разработку программного обеспечения, обеспечивающего функционирование распознавателя.
Простота и высокая скорость работы распознавателей определяют широкую область применения регулярных языков.
В компиляторах распознаватели на основе регулярных языков используются для лексического анализа текста исходной программы — выделения в нем простейших конструкций языка, таких как идентификаторы, строки, константы и т. п. Это позволяет существенно сократить объем исходной информации и упрощает синтаксический разбор программы. Более подробно взаимодействие лексического и синтаксического анализаторов текста программы рассмотрено дальше, в главе, посвященной структуре компилятора. На основе распознавателей регулярных языков функционируют ассемблеры — компиляторы с языков ассемблера (мнемокода) в язык машинных команд.
Кроме компиляторов регулярные языки находят применение еще во многих областях, связанных с разработкой программного обеспечения вычислительных систем. На их основе функционируют многие командные процесоры как в системном, так и в прикладном программном обеспечении. Для регулярных языков существуют развитые, математически обоснованные механизмы, которые позволяют облегчить создание распознавателей. Они положены в основу существующих разнообразных программных средств, которые позволяют автоматизировать этот процесс.
Регулярные языки и связанные с ними математические методы рассматриваются в отдельной главе данного учебного пособия.
Задача разбора (постановка задачи)
Грамматики и распознаватели — два независимых метода, которые реально могут быть использованы для определения какого-либо языка. Однако при разработке компилятора для некоторого языка программирования возникает задача, которая требует связать между собой эти методы задания языков. Разработчики компилятора всегда имеют дело с уже определенным языком программирования. Грамматика для синтаксических конструкций этого языка известна. Она, как правило, четко описана в стандарте языка, и хотя форма описания может быть произвольной, ее всегда можно преобразовать к требуемому виду (например, к форме Бэкуса—Наура или к форме описания с использованием метасимволов). Задача разработчиков заключается в том, чтобы построить распознаватель для заданного языка, который затем будет основой синтаксического анализатора в компиляторе.
Таким образом, задача разбора в общем виде заключается в следующем: на основе имеющейся грамматики некоторого языка построить распознаватель для этого языка. Заданная грамматика и распознаватель должны быть эквивалентны, то есть определять один и тот же язык (часто допускается, чтобы они были почти эквивалентны, поскольку пустая цепочка во внимание обычно не принимается).
Задача разбора в общем виде может быть решена не для всех типов языков. Но как было сказано выше, разработчиков компиляторов интересуют, прежде всего, контекстно-свободные и регулярные языки. Для данных типов языков доказано, что задача разбора для них разрешима. Более того, для них найдены формальные методы ее решения. Описанию и обоснованию именно методов решения задачи разбора и будет посвящена большая часть материала последующих глав.
Поскольку языки программирования не являются чисто формальными языками и несут в себе некоторый смысл (семантику), то задача разбора для создания реальных компиляторов понимается несколько шире, чем она формулируется для чисто формальных языков. Компилятор должен не просто дать ответ, принадлежит или нет входная цепочка символов заданному языку, но и определить ее смысловую нагрузку. Для этого необходимо выявить те правила грамматики, на основании которых цепочка была построена. Фактически работа распознавателей в составе компиляторов сводится к построению в том или ином виде дерева разбора входной цепочки. Затем уже это дерево разбора используется компилятором для синтеза результирующего кода.
Кроме того, если входная цепочка
символов не принадлежит заданному языку — исходная программа содержит ошибку, —
разработчику программы не интересно просто узнать сам факт наличия ошибки. В данном случае
задача разбора также расширяется:
распознаватель в составе компилятора должен не только установить факт присутствия ошибки во
входной программе, но и по возможности определить тип ошибки и то место в цепочке
символов, где она встречается.
Регулярные языки и грамматики
Леволинейные и праволинейные грамматики. Автоматные грамматики
К регулярным, как уже было сказано, относятся два типа грамматик: леволинейные и праволинейные.
Леволинейные грамматики G(VT,VN,P,S), V = VNuVT могут иметь правила дву видов: А-»Ву или А-»у, где A,BeVN, yeVT*.
В свою очередь, праволинейные грамматики G(VT,VN,P,S), V - VNuVT могу иметь правила также двух видов: А-»уВ или А-»у, где A.BeVN, yeVT*.
Доказано, что эти два класса грамматик эквивалентны. Для любого регулярног языка, заданного праволинейной грамматикой, может быть построена левол* нейная грамматика, определяющая эквивалентный язык; и наоборот — для лк бого регулярного языка, заданного леволинейной грамматикой, может быть ш строена праволинейная грамматика, задающая эквивалентный язык.
Разница между леволинейными и праволинейными грамматиками заключаете в основном в том, в каком порядке строятся предложения языка: слева направления для леволинейных либо справа налево для праволинейных. Поскольку предл< жения языков программирования строятся, как правило, в порядке слева направления; то в дальнейшем в разделе регулярных грамматик будет идти речь в перву очередь о леволинейных грамматиках.
Среди всех регулярных грамматик можно выделить отдельный класс — автома ные грамматики. Они также могут быть леволинейными и праволинейными.
Леволинейные автоматные грамматики G(VT,VN,P,S), V - VNuVT могут имс правила двух видов: A-»Bt или A-»t, где A.BeVN, teVT.
Праволинейные автоматные грамматики G(VT,VN,P,S), V - VNuVT могут име правила двух видов: A-»tB или A-»t, где A.BeVN, teVT.
Разница между автоматными грамматиками и обычными
регулярными rpai матиками заключается в следующем: там, где в правилах обычных регулярнь![]() грамматик
может присутствовать цепочка терминальных символов, в автоматных грамматиках
может присутствовать только один терминальный символ. Любая автоматная
грамматика является регулярной, но не наоборот — не всякая регулярная
грамматика является автоматной.
грамматик
может присутствовать цепочка терминальных символов, в автоматных грамматиках
может присутствовать только один терминальный символ. Любая автоматная
грамматика является регулярной, но не наоборот — не всякая регулярная
грамматика является автоматной.
Доказано, что классы обычных регулярных грамматик и автоматных грамматик почти эквивалентны. Это значит, что для любого языка, который задан регулярной грамматикой, можно построить автоматную грамматику, определяющую почти эквивалентный язык (обратное утверждение очевидно).
Чтобы классы автоматных и регулярных грамматик были полностью эквивалентны, в автоматных грамматиках разрешается дополнительное правило вида S->^., где S — целевой символ грамматики. При этом символ S не должен встречаться в правых частях других правил грамматики. Тогда язык, заданный автоматной грамматикой G может включать в себя пустую цепочку: >.eL(G). В таком случае автоматные леволинейные и праволинейные грамматики, так же как обычные леволинейные и праволинейные грамматики, задают регулярные языки. Поскольку реально используемые языки, как правило не содержат пустую цепочку символов, разница на пустую цепочку между этими двумя типами грамматик значения не имеет и правила вида S->X далее рассматриваться не будут.
Существует алгоритм, который позволяет преобразовать произвольную регулярную грамматику к автоматному виду — то есть построить эквивалентную ей автоматную грамматику. Этот алгоритм рассмотрен ниже. Он является исключительно полезным, поскольку позволяет существенно облегчить построение распознавателей для регулярных грамматик.
Алгоритм преобразования регулярной грамматики к автоматному виду
Имеется регулярная грамматика G(VT,VN,P,S), необходимо преобразовать ее в почти эквивалентную автоматную грамматику G'(VT,VN',P',S'). Для определенности будем рассматривать леволинейные грамматики, как уже было сказано выше (для праволинейных грамматик можно легко построить аналогичный алгоритм).
Алгоритм преобразования прост и заключается он в следующей последовательности действий:
Шаг 1. Все нетерминальные символы из множества VN грамматики G переносятся во множество VN' грамматики G'.
Шаг 2. Необходимо просматривать все множество правил Р грамматики G.
Если встречаются правила вида А->Ва!, A.BeVN, ateVT или вида А-^, AeVN, aieVT, то они переносятся во множество Р' правил грамматики G' без изменений.
Если встречаются правила вида A->Baia2...a„, n>
символы Ai,A2. Ап_ь а во множество правил Р' грамматики G' добавляются
правила:
A—> An_!an An-i->
An_2an_i
A2—> Aja2 A^Ba!
Если встречаются правила вида A-^a^.-.a,,, n > 1, AeVN, Vn > i > 0: а;еVT, то во множество нетерминальных символов VN' грамматики G' добавляются символы AtA^-A,,-!, а во множество правил Р' грамматики G' добавляются правила:
А—> Ап_!ап An-i-* An.^n-j
А2-> А,а2
Если встречаются правила вида А-»В или вида А->Х., то они переносятся во множество правил Р' грамматики G' без изменений.
Шаг 3. Просматривается множество правил Р' грамматики G'. В нем ищутся правила вида А->В или вида А-»А,.
Если находится правило вида А->В, то просматривается множество правил Р' грамматики G'. Если в нем присутствует правила вида В-»С, В->Са, В-»а или В-»Х,, то в него добавляются правила вида А-»С, А->Са, А->а и А->Х соответственно, VA,B,CeVN\ VaeVT' (при этом следует учитывать, что в грамматике не должно быть совпадающих правил, и если какое-то правило уже присутствует в грамматике G', то повторно его туда добавлять не следует). Правило А->В удаляется из множества правил Р'.
Если находится правило вида А->\, то просматривается множество правил Р' грамматики G'. Если в нем присутствует правило вида В->А или В->Аа, то в него добавляются правила вида В-»А, и В-»а соответственно, VA.BeVN', VaeVT' (при этом следует учитывать, что в грамматике не должно быть совпадающих правил, и если какое-то правило уже присутствует в грамматике G', то повторно его туда добавлять не следует). Правило А-»Х, удаляется из множества правил Р'. Шаг 4. Если на шаге 3 было найдено хотя бы одно правило вида А->В или А-»Х во множестве правил Р' грамматики G', то надо повторить шаг 3, иначе перейти к шагу 5.
Шаг 5. Целевым символом S' грамматики G' становится символ S. Шаги 3 и 4 алгоритма в принципе можно не выполнять, если грамматика не содержит правил вида А-»В (такие правила называются цепными) или вида А-»> (такие правила называются ^-правилами). Реальные регулярные грамматики обычно не содержат правил такого вида. Тогда алгоритм преобразования грамматик* к автоматному виду существенно упрощается. Кроме того, эти правила можн( было бы устранить предварительно с помощью специальных алгоритмов преоб разования (они рассмотрены дальше, в главе, посвященной КС-грамматикам, не также применимы и к регулярным грамматикам).
Пример преобразования регулярной грамматики к автоматному виду
Рассмотрим в качестве примера следующую простейшую регулярную грамматику: G({"a". "(","*",")","{"."}"}. {S.CK}, Р, 5)(символыа. (, *, ), {, } из множества терминальных символов грамматики взяты в кавычки, чтобы выделить их среди фигурных скобок, обозначающих само множество):
Р:
S -> С*) | К}
С -* (* | Са | С{ | С} | С( | С* | С)
К -► { | Ка | К( | К* | К) | К{
Если предположить, что а здесь — это любой алфавитно-цифровой символ, кроме символов (, *. ), {, }, то эта грамматика описывает два типа комментариев, допустимых в языке программирования Borland Pascal. Преобразуем ее в автоматный вид.
Шаг 1. Построим множество VN' = {S,C,K}.
Шаг 2. Начинаем просматривать множество правил Р грамматики G.
Для правила S ->• С*) во множество VN' включаем символ Si, а само правило разбиваем на два: S -> St) и Si -» С*; включаем эти правила во множество правил Р'.
Правило S -» К} переносим во множество правил Р' без изменений.
Для правила С -> (* во множество VN' включаем символ Сь а само правило разбиваем на два: С -> Ct* и С! -> (; включаем эти два правила во множество правил Р'.
Правила С -» Са | С{ | С} | С( | С* | С) переносим во множество правил Р' без изменений.
Правила К -» { | Ка | К( | К* | К) | К{ переносим во множество правил Р' без изменений.
Шаг 3. Правил вида А->В или А-»Х, во множестве правил Р' не содержится.
Шаг 4. Переходим к шагу 5.
Шаг 5. Целевым символом грамматики G' становится символ S.
В итоге получаем автоматную грамматику:
G'({"a"."("."*".")"."{"."}"}■ {S
S[ c Ci|K^ р._ S).
Р':
$% ЭД | К}
S, -+ с*
С -> d* | Са | С{ | С} | С( | С* | С)
t, -> (
К -» { | Ка | К( | К* | К) | К{
Эта грамматика, так же как и рассмотренная выше, описывает два типа комментариев, допустимых в языке программирования Borland Pascal.
Конечные автоматы
Определение конечного автомата
Конечным автоматом (КА) называют пятерку следующего вида: M(Q,V,8,qo,F),
где
□
Q, — конечное множество состояний автомата;
□
V — конечное множество допустимых входных символов
(алфавит автомата);
□
5 — функция переходов, отображающая VxQ (декартово произведение множеств) в множество подмножеств Q: R(Q), то есть 8(a,q) = R, ае V, qeQ, RcOj
□
q0 — начальное состояние автомата Q, q0eOj
□
F — непустое множество конечных состояний автомата, FcQ, F*0.
КА называют полностью определенным, если в каждом его состоянии существует функция перехода для всех возможных входных символов, то есть VaeV, VqeQ38(a,q) = R, RcQ.
Работа конечного автомата представляет собой последовательность шагов (или тактов). На каждом шаге работы автомат находится в одном из своих состояний Q (в текущем состоянии), на следующем шаге он может перейти в другое состояние или остаться в текущем состоянии. То, в какое состояние автомат перейдет на следующем шаге работы, определяет функция переходов 8. Она зависит не только от текущего состояния, но и от символа из алфавита V, поданного на вход автомата. Когда функция перехода допускает несколько следующих состояний автомата, то КА может перейти в любое из этих состояний. В начале работы автомат всегда находится в начальном состоянии q0. Работа КА продолжается до тех пор, пока на его вход поступают символы из входной цепочки coeV+.
Видно, что конфигурацию КА на каждом шаге работы можно определить в виде (q,co,n), где q — текущее состояние автомата, qeQj со — цепочка входных символов, соеV+; n — положение указателя в цепочке символов, neNu{0}, п < |co| (N — множество натуральных чисел). Конфигурация автомата на следующем шаге — это (q',co,n+l), если q'e8(a,q) и символ aeV находится в позиции п+1 цепочки со. Начальная конфигурация автомата: (q0,co,0); заключительная конфигурация автомата: (f,co,n), feQ,, n = |со|, она является конечной конфигурацией, если feF.
КА M(Q,V,S,qo,F) принимает цепочку символов coeV4, если, получив на вход эту цепочку, он из начального состояния q0 может перейти в одно из конечных состояний feF. В противном случае КА не принимает цепочку символов.
Язык ЦМ), заданный КА М(О,У,8^0,Р), — это множество всех цепочек символов, которые принимаются этим автоматом. Два КА эквивалентны, если они задают один и тот же язык.
Таким образом, КА является распознавателем для формальных языков. Далее будет показано, что КА — это распознаватели для регулярных языков.
КА часто представляют в виде диаграммы или графа
переходов автомата.
![]() Граф
переходов КА — это направленный помеченный граф, с символами состояний КА в
вершинах, в котором есть дуга (p,q) p,qeQ, помеченная символом aeV, если в КА определена 5(а,р) и qe8(a,p). Начальное
и конечные состояния автомата на графе состояний помечаются специальным
образом (в данном пособии начальное состояние — дополнительной пунктирной
линией, конечное состояние — дополнительной сплошной линией).
Граф
переходов КА — это направленный помеченный граф, с символами состояний КА в
вершинах, в котором есть дуга (p,q) p,qeQ, помеченная символом aeV, если в КА определена 5(а,р) и qe8(a,p). Начальное
и конечные состояния автомата на графе состояний помечаются специальным
образом (в данном пособии начальное состояние — дополнительной пунктирной
линией, конечное состояние — дополнительной сплошной линией).
Рассмотрим конечный автомат: M({H,A,B,S}.{a,b},8,H,{S}); 8: 8(H,b) = В, 8(В,а) = А, 8(A,b) = {B,S}. Ниже на рис. 10.1 приведен пример графа состояний для этого КА.
" b а ь^=^
р
Рис. 10.1. Граф переходов недетерминированного конечного автомата
Для моделирования работы КА его удобно привести к полностью определенному виду, чтобы исключить ситуации, из которых нет переходов по входным символам. Для этого в КА добавляют еще одно состояние, которое можно условно назвать «ошибка». На это состояние замыкают все неопределенные переходы, а все переходы из самого состояния «ошибка» замыкают на него же.
Если преобразовать подобным образом рассмотренный выше автомат М, то получим полностью определенный автомат: M({H,A,B,E,S},{a,b},8,H,{S}); 8: 8(Н,а) = Е, 8(H,b) = B, 8(B,a) = A, 8(B,b) = E, 8(A,a) = {E}, 8(A,b) = {B,S}, 8(E,a) = {Е}, 8(E,b) = {E}, 8(S,a) = {E}, 8(S,b) = {Е}. Состояние Е как раз соответствует состоянию «ошибка». Граф переходов этого КА представлен на рис. 10.2.
|
|
,_.. Ь а Ь
|
а__ |
а,Ь
*а-
Рис. 10.2. Граф переходов полностью определенного недетерминированного конечного автомата
Детерминированные и недетерминированные конечные автоматы
Конечный автомат M(Q,V,8,q0,F) называют детерминированным конечным автоматом (ДКА), если в каждом из его состояний для любого входного символа функция перехода содержит не более одного состояния: VaeV, VqeQ; либо S(a,q) = {г}, reQ либо 8(a,q) = 0.
В противном случае конечный автомат называют недетерминированным. ДКА может быть задан в виде пятерки:
M(Q,V,5,q0,F),
где Q — конечное множество состояний автомата; V — конечное множество допустимых входных символов; 8 — функция переходов, отображающая VxQ e множество Q: S(a,q) = г, aeV, q,reQ; q0 — начальное состояние автомата Q q0eQ; F — непустое множество конечных состояний автомата, FcQ F*0.
Если функция переходов ДКА определена для каждого состояния автомата, тс автомат называется полностью определенным ДКА: VaeV, VqeQ: либо 38(a,q) = r reQ.
Моделировать работу ДКА существенно проще, чем работу произвольного ДКА.
Доказано, что для любого ДКА можно построить эквивалентный ему ДКА. Поэтому используемый произвольный ДКА А стремятся преобразовать в ДКА. При построении компиляторов чаще всего используют полностью определеный ДКА.
Преобразование конечного автомата к детерминированному виду
Алгоритм преобразования
произвольного ДКА M(Q)V,8,q0,F) в эквивалентный ему ДКА M'(Q',V,S',q'
1. Множество состояний Q' автомата М' строится из комбинаций
всех состоя
ний множества Q автомата М. Если qi,q2 qn, n > 0 — состояния автомата М
V0<i<n qjeQ, то всего будет 2п-1 состояний автомата М'. Обозначим ю так: [q,,q2,...,qm], 0<m<n.
2.
Функция переходов 8' автомата М' строится так: 8'(a,[q1,q2,...,qm]) = [г^г^л-Л] где V0 < i < m Э0 < j < k так, что 8(а^)
= г,;
3.
Обозначим q'0 = [q0];
4.
Пусть f^.-jfi, 1
> 0 — конечные состояния автомата М, V0 < i < 1 f^eF, тогдг множество конечных
состояний F' автомата
М' строится из всех состояний имеющих вид [...,1,,...], fjeF.
Доказано, что описанный выше алгоритм строит ДКА, эквивалентный заданному произвольному КА.
После построения из нового ДКА необходимо удалить все недостижимые состояния.
Состояние qeQ в КА M(QV,S,q0,F) называется недостижимым, если ни при какой входной цепочке юе V+ невозможен переход автомата из начального состояния q0 в состояние q. Иначе состояние называется достижимым.
Для работы алгоритма удаления недостижимых состояний используются двг множества: множество достижимых состояний R и множество текущих активных состояний на каждом шаге алгоритма Рг Результатом работы алгоритма является полное множество достижимых состояний R. Рассмотрим работу алгоритма по шагам:
1.
R:={q0}; i:=0; P0:={q0};
2.
Pi+1:=0;
3.
VaeV, VqePj: Pi+1:-Pi+1u8(a,q);
4.
Если Pi+i-R = 0, то выполнение алгоритма закончено, иначе R:=RuPi+1, i:=i+l и перейти к шагу 3.
После выполнения данного алгоритма из КА можно исключить все состояния, не входящие в построенное множество R.
Рассмотрим работу алгоритма преобразования произвольного КА в ДКА на примере автомата M({H,A,B,S},{a.b},8,H,{S}); 5: 8(H,b) «- В, 8(В,а) = А, 5(А,Ь) = {B.S}. Видно, что это недетерминированный КА (из состояния А возможны два различных перехода по символу Ь). Граф переходов для этого автомата был изображен выше на рис. 10.1.
Построим множество состояний эквивалентного ДКА:
Q'={[H].[A],[B].[S].[HA],[HB].[HS].[AB],[AS],[BS].[HAB].[HAS].[HBS]. [ABS].[HABS]}.
Построим функцию переходов эквивалентного ДКА:
|
8'([Н],Ь) |
= [B] |
|
8'([А],Ь) |
H [BS] |
|
8'([В],а) |
- [A] |
|
8Х[НА],Ь) |
= [BS] |
|
8'([НВ],а) |
= [A] |
|
8'([НВ],Ь) |
= [B] |
|
5'([HS],b) |
= [B] |
|
8'([АВ],а) |
= [A] |
|
8Х[АВ],Ь) |
= [BS] |
|
8'([AS],b) |
= [BS] |
|
S'([BS],a) |
- [A] |
|
8'([НАВ],а) |
= [A] |
|
8X[HAB],b) |
- [BS] |
|
8X[HAS],b) |
= [BS] |
|
8X[HBS],b) |
- [B] |
|
8X[HBS],a) |
= [A] |
|
8X[ABS],b) |
= [BS] |
|
8X[ABS],a) |
= [A] |
|
SX[HABS],a) |
= [A] |
|
SX[HABS],b) |
- [BS] |
Начальное состояние эквивалентного ДКА:
Qo' = [Н] Множество конечных состояний эквивалентного ДКА:
F' - {[S].[HS].[AS].[BS].[HAS].[HBS].[ABS].[HABS]}
После построения ДКА исключим недостижимые состояния. Множество достижимых состояний ДКА будет следующим R = {[H],[B],[A],[BS]}. В итоге, исключив все недостижимые состояния, получим ДКА:
M4{[H].[B].[A].[BS]}.{a.b}.[H].{[BS]}).
S([H].b)=[B]. 5([B].a)-[A]. 8([A],b)=[BS]. 5([BS].a)=[A].
Ничего не изменяя, переобозначим состояния ДКА. Получим:
M'({H.B.A.S}.{a.b}.H.{S}).
5(H.b)=B. 6(B.a)=A.
8(A.b)=S. 5(S,a)-A.
Граф переходов полученного ДКА изображен на рис. 10.3.
Рис. 10.3. Граф переходов детерминированного конечного автомата
Этот автомат можно преобразовать к полностью определенному виду. Получим граф состояний, изображенный на рис. 10.4 (состояние Е — это состояние «ошибка»).
Рис. 10.4. Граф переходов полностью определенного детерминированного конечного автомата
При построении распознавателей к вопросу о необходимости преобразования К/ в ДКА надо подходить, основываясь на принципе разумной достаточности. Мо делировать работу ДКА существенно проще, чем произвольного КА, но при вы полнении преобразования число состояний автомата может существенно возрас ти и, в худшем случае, составит 2п-1, где п — количество состояний исходноп КА. В этом случае затраты на моделирование ДКА окажутся больше, чем на моделирование исходного КА. Поэтому не всегда выполнение преобразования ав томата к детерминированному виду является обязательным.
Минимизация конечных автоматов
Многие КА можно минимизировать. Минимизация КА заключается в построе нии эквивалентного КА с меньшим числом состояний. В процессе минимизаци необходимо построить автомат с минимально возможным числом состояний, эквивалентный данному КА.
Для минимизации автомата используется алгоритм построения эквивалентны состояний КА. Два различных состояния в конечном автомате M(Q,V,5,q0,F
qeQ,и q'eQ. называются п-эквивалентными (n-неразличимыми), п > О neNu{0}, если, находясь в одном из этих состояний и получив на вход любую цепочку символов со: <oeV* |co| < п, автомат может перейти в одно и то же множество конечных состояний. Очевидно, что эквивалентными состояниями автомата M(Q,V, 5,q0,F) являются два множества его состояний: F и Q-F. Множества эквивалентных состояний автомата называют классами эквивалентности, а всю их совокупность — множеством классов эквивалентности R(n) причем R(0)={F,Q,-F}.
Рассмотрим работу алгоритма построения эквивалентных состояний по шагам:
1.
На первом шаге п:=0 строим R(0).
2.
На втором шаге п:=п+1 строим R(n) на основе R(n-l): R(n) = {Г((п): {qjjeQj VaeV 8(a,qjj)cij(n-l)} VijeN}. To есть в классы эквивалентности на шаге п входят те состояния, которые по одинаковым
символам переходят в п-1 эквивалентные состояния.
3.
Если R(n) = R(n-l), то работа алгоритма
закончена, иначе необходимо вернуться к
шагу 2.
Доказано, что алгоритм построения множества классов эквивалентности завершится максимум для n = m-2, где т — общее количество состояний автомата.
Алгоритм минимизации КА заключается в следующем:
1.
Из автомата исключаются все недостижимые состояния.
2.
Строятся классы эквивалентности автомата.
3.
Классы эквивалентности состояний исходного КА становятся состояниями результирующего минимизированного КА.
4.
Функция переходов результирующего КА очевидным образом строится на основе функции переходов исходного КА.
Для этого алгоритма доказано, во-первых, что он строит минимизированный КА, эквивалентный заданному; во-вторых, что он строит КА с минимально возможным числом состояний (минимальный КА).
Рассмотрим пример: задан автомат M({A,B,C,D,E,F,G},{0,1},5,A,{D,E}), 5(A,0) = {В}, 5(А,1) = {С}, 8(В,1) = {D}, 5(С,1) = {Е}. 5CD.0) = {С}, 5(0,1) = {Е}, 5(Е,0) = {В}, 5(E.l) = {D}, 5(F,0) = {D}, 5(F.l) = {G}, 5(G,0) = {F}, 5(G,1) = {F}; необходимо построить эквивалентный ему минимальный КА.
|
|
Рис. 10.5. Граф переходов конечного автомата до его минимизации
Состояния F и G являются недостижимыми, они будут исключены на первом шаге алгоритма. Построим классы эквивалентности автомата:
R(0)={{A,B,C},{D,E}}, n=0;
R(1)={{A},{B.C},{D,E}}, n=l;
R(2)={{A},{B,C},{D,E}}, n=2.
Обозначим соответствующим образом состояния полученного минимального КА и построим автомат: M({A.BC,DE},{0,1},5',A,{DE}), 5'(А,0) = {ВС}, 5'(А,1) = {ВС} 5ЧВС.1) = {DE}, 54DE.0) = {ВС}, 54DE.1) = {DE}.
Граф переходов минимального КА приведен на рис. 10.6.
Рис. 10.6. Граф переходов конечного автомата после его минимизации
Минимизация конечных автоматов позволяет при построении распознавателей получить автомат с минимально возможным числом состояний и тем самым г дальнейшим упростить функционирование распознавателя.
Регулярные множества и регулярные выражения
Определение регулярного множества
Определим над множествами цепочек символов из алфавита V операции конкатенации и итерации следующим образом:
PQ - конкатенация PeV* и QeV*: PQ = {pq VpeP, VqeQJ; P* - итерация PeV*: P* = {pn VpeP, VneN}.
Тогда для алфавита V регулярные множества определяются рекурсивно:
1. 0 — регулярное множество.
2.
{к} —
регулярное множество.
3.
{а} — регулярное множество VaeV.
4.
Если Р и Q. — произвольные регулярные множества, то множества PuQ, PC
и Р* также являются регулярными
множествами.
5.
Ничто другое не является регулярным множеством.
Фактически регулярные множества — это множества цепочек символов над заданным алфавитом, построенные определенным образом (с использованием операций объединения, конкатенации и итерации).
Все регулярные языки представляют собой
регулярные множества.
Регулярные выражения. Свойства регулярных выражений
Регулярные множества можно обозначать с помощью регулярных выражений. Эти обозначения вводятся следующим образом:
1. 0 — регулярное выражение,
обозначающее 0.
2.
X — регулярное выражение,
обозначающее {X}.
3.
а — регулярное выражение, обозначающее {a} VaeV.
4.
Если р и q — регулярные выражения, обозначающие регулярные множества Р и Q, то p+q, pq, p* — регулярные выражения,
обозначающие регулярные множества PuQ, PQ и Р* соответственно.
Два регулярных выражения а и (3 равны, а = Р, если они обозначают одно и то же множество.
Каждое регулярное выражение обозначает одно и только одно регулярное множество, но для одного регулярного множества может существовать сколь угодно много регулярных выражений, обозначающих это множество.
При записи регулярных выражений будут использоваться круглые скобки, как и для обычных арифметических выражений. При отсутствии скобок операции выполняются слева на право с учетом приоритета. Приоритет для операций принят следующий: первой выполняется итерация (высший приоритет), затем конкатенация, потом — объединение множеств (низший приоритет).
Если а, р и у — регулярные выражения, то свойства регулярных выражений можно записать в виде следующих формул:
|
1. |
^+а<х* г А.+а*а = а* |
|
2. |
а+Р = р+аЗ. |
|
3. |
а+(Р+у) = (а+р)+у |
|
4. |
а(Р+У) ? оф+ау |
|
5. |
(Р+у)а = Ра+уа |
|
6. |
а(Ру) = (ар)у |
|
7. |
а+а = а |
|
8. |
а+а* *■ а* |
|
9. |
Х+а' = а*+Х - а* |
|
10. |
0' = Х |
|
П. |
0а=а0~0 |
|
12. |
0+а = а+0"а |
|
13. |
tax = аХ = а |
|
14. |
(а*)* - а* |
Все эти свойства можно легко доказать, основываясь на теории множеств, так как регулярные выражения — это только обозначения для соответствующих множеств. Следует также обратить внимание на то, что среди прочих свойств отсутствует равенство оф = ра, то есть операция конкатенации не обладает свойством коммутативности. Это и не удивительно, поскольку для этой операции важен порядок следования символов.
Уравнения с регулярными коэффициентами
На основе регулярных выражений можно построить уравнения с регулярными коэффициентами [32]. Простейшие уравнения с регулярными коэффициентами будут выглядеть следующим образом:
X = аХ + р,
Х= Ха + р,
где a,PeV* — регулярные выражения над алфавитом V, а переменная XgV.
Решениями таких уравнений будут регулярные множества. Это значит, что если взять регулярное множество, являющееся решением уравнения, обозначить его в виде соответствующего регулярного выражения и подставить в уравнение, то получим тождественное равенство. Два вида записи уравнений (правосторонняя и левосторонняя запись) связаны с тем, что для регулярных выражений операция конкатенации не обладает свойством коммутативности, поэтому коэффициент можно записать как справа, так и слева от переменной и при этом получатся различные уравнения. Обе записи равноправны.
Решением первого уравнения является множество, обозначенное регулярным выражением а*р. Проверим это решение, подставив его в уравнение вместо переменной X:
aX+p =
a(a*p)+P =6 (aa*)P+P =13 (aa*)p+ty3 =5
(aa*+?,)p -i a*p = X
Над знаками равенства указаны номера свойств регулярных выражений, которые были использованы для выполнения преобразований.
Решением второго уравнения является множество, обозначенное регулярным выражением pa*.
Xa+p = (pa*)a+p =6 p(a*a)+p =13 P(a*a)+pb =4 |3(a'a+X.) ** Pa* = X
Указанные решения уравнений не всегда являются единственными. Например, если регулярное выражение а в первом уравнении обозначает множество, которое содержит пустую цепочку, то решением уравнения может быть любое множество, обозначенное выражением X = а*(Р+у), где у — выражение, обозначающее произвольное множество над алфавитом V (причем это множество даже может не быть регулярным). Однако доказано, что X = а'Р и X = Ра* — это наименьшие из возможных решений для данных двух уравнений. Эти решения называются наименьшей подвижной точкой.
Из уравнений с регулярными коэффициентами можно формировать систему уравнений с регулярными коэффициентами. Система уравнений с регулярными коэффициентами имеет вид (правосторонняя запись):
Xt = а10 + a.nXi + а12Х2 +
... + а1пХп Х2 = а20 + a21Xt + а22Х2
+ ... + а2пХп
Xj = ai0 + auXi + ai2X2 +
... + ainXn
Xn = an0 + anlXj + a12X2 + ... + annXn или (левосторонняя запись):
X, = a10 + Xjan + X2a12 + ... + Xnaln
X2 = a20 + Хха21 + X2a22
+ ... + Xna2n
Xj = ai0 + XjOit + X2ai2 + ... + Xnain
Xn = an0 + Xtanl + X2a12 + ... + Xnann
В системе уравнений с регулярными коэффициентами все коэффициенты а^ являются регулярными выражениями над алфавитом V, а переменные не входят в алфавит V: Vi Xjg V. Оба варианта записи равноправны, но в общем случае могут иметь различные решения при одинаковых коэффициентах при переменных. Чтобы решить систему уравнений с регулярными коэффициентами, надо найти такие регулярные множества Xj, при подстановке которых в систему все уравнения превращаются в тождества множеств. Иными словами, решением системы является некоторое отображение f(X) множества переменных уравнения Л={Х|: n > i > 0} на множество языков над алфавитом V*.
Системы уравнений с регулярными коэффициентами решаются методом последовательных подстановок. Рассмотрим метод решения для правосторонней записи. Алгоритм решения работает с переменной номера шага i и состоит из следующих шагов.
Шаг 1. Положить i := 1.
Шаг 2. Если i = п, то перейти к шагу 4, иначе записать i-e уравнение в виде: Xj = ajXi+Pi, где a; = aii7 Pi = рю + РИ-цХ1+1 + ... + pinXn. Решить уравнение и получить Xj = ocj'pj. Затем для всех уравнений с переменными Xi+1,...,Xn подставить в них найденное решение вместо Xj.
Шаг 3. Увеличить i на 1 (i := i+1) и вернуться к шагу 2.
Шаг 4. После всех подстановок уравнение для Хп будет иметь вид Xn = anXn+p, где an = ann. Причем р будет регулярным выражением над алфавитом V* (не содержит в своем составе переменных системы уравнений Xj). Тогда можно найти окончательное решение для Xn: Xn r an*p. Перейти к шагу 5. Шаг 5. Уменьшить i на 1 (i := i-1). Если i = 0, то алгоритм завершен, иначе перейти к шагу 6.
Шаг 6. Берем найденное решение для Xj = cxjXj+Pj, где оц = aii; р( = pi0 + Pii+iXi+i +
+ ... + pinXn> и подставляем в него окончательные решения для
переменных
Xj+i... Хп.
Получаем окончательное решение для Х;. Перейти к шагу 5.
Для левосторонней записи системы уравнений алгоритм решения будет аналогичным, с разницей только в порядке записи коэффициентов (справа от переменных).
Система уравнений с регулярными коэффициентами всегда имеет решение, но это решение не всегда единственное. Для рассмотренного алгоритма решения системы уравнений с регулярными коэффициентами доказано, что он всегда находит решение f(X) (отображение f: Vi Xj->V"), которое является наименьшей неподвижной точкой системы уравнений. То есть если существует любое другое решение g(X), то всегда f(X)cg(X).
В качестве примера рассмотрим систему уравнений с регулярными коэффициентами над алфавитом V = {"-", "+", ".", О, 1, 2, 3, 4, 5, 6, 7, 8, 9} (для ясности записи символы -, + и . взяты в кавычки, чтобы не путать их со знаками операций):
Xj = ("-" + "+" + X)
Х2 = Х1"."(0+1+2+3+4+5+6+7+8+9) + Х3"." + Х2(0+1+2+3+4+5+6+7+8+9)
Х3 - Х1(0+1+2+3+4+5+6+7+8+9) + Х3(0+1+2+3+4+5+6+7+8+9)
х4 = х2 + х3
Обозначим регулярное выражение (0+1+2+3+4+5+6+7+8+9) через а для краткости записи: a = (0+1+2+3+4+5+6+7+8+9). Получим:
Xl = ("-" + "+;; + х)
Х2 - X,"."a + Х3"." + Х2а
Х3 = XjCt + Х3а
х4 = х2 + х3
Решим эту систему уравнений. Шаг 1. i := 1.
Шаг 2. Имеем i = 1 < 4. Берем уравнение для i = 1. Имеем Х1 = ("-" + "+" + X). Это уже и есть решение для Xj. Подставляем его в другие уравнения. Получаем:
Х2 = ("-" + "+" + ху."а + Х3"." + Х2а Х3 = ("-" + "+" + А.)а + Х3а
х4 = х2 + х3
Шаг 3. i:- i + 1 - 2.
Возвращаемся к шагу 2.
Шаг 2. Имеем i = 2 < 4. Берем уравнение для i = 2. Имеем
Х2 = ("-" + "+" + Х)"."а + Х3"." + Х2а. Преобразуем уравнение к виду:
Х2 = Х2а + (("-" + "+" + Х)"."а + Х3"."). Тогда а2 = а, р2 = ("-" + "+" + Х)""а + Х3".". Решением для Х2 будет:
Х2 = р2а2* - (("-" + "+" + Х)"."а + Х3".")а* = ("-" + "+" + Х)"."аа' + Х3"."а*.
Подставим его в другие уравнения. Получаем:
Х3 = ("-" + "+" + ^)а + Х3а
Х4 - ("-" + "+" + ^)"."аа* + Х3"."а* + Х3
Шаг 3. i:- i + 1 = 3.
Возвращаемся к шагу 2.
Шаг 2. Имеем i = 3 < 4. Берем уравнение для i = 3. Имеем
Х3 - ("-" + "+" + Х)а + Х3а. Преобразуем уравнение к виду
Х3 = Х3а + ("-" + "+" + Х)а. Тогда а3 = а, р3 = ("-" + "+" + Х)а. Решением для Х3 будет: Х3 = (33а3* = ("-" + "+" + ^)аа*. Подставим его в другие уравнения. Получаем:
Х4 - ("-" + "+" + b)"."aa* + ("-" + "+" + A,)aa*"."a* + ("-" + "+" + X,)aa*.
Шаг 3. i:- i + 1 = 4.
Возвращаемся к шагу 2.
Шаг 2. Имеем i = 4 = 4. Переходим к шагу 4.
Шаг 4. Уравнение для Х4 теперь имеет вид
Х4 = ("-" + "+" + ^)"."aa* + ("-" + "+" + ^)aa*"."a* + ("-" + "+" + я,)аа*. Оно не нуждается в преобразованиях и содержит окончательное решение для Х4. Переходим к шагу 5. Шаг 5. i := i - 1 - 3 > 0. Переходим к шагу 6.
Шаг 6. Уравнение для Х3 имеет вид Х3 = ("-" + "+" + X,)aa*. Оно уже содержит окончательное решение для Х3. Переходим к шагу 5.
Шаг 5. i:- i - 1 = 2 > 0. Переходим к шагу 6.
Шаг 6. Уравнение для Х2 имеет вид Х2 = ("-" + "+" + X,)"."aa* + X3"."a*. Подставим в него окончательное решение для Х3. Получим окончательное решение для Х2: Х2 = ("-" + "+" + X.)"."aa* + ("-" + "+" + Я.)аа*"."а*. Переходим к шагу 5.
Шаг 5. i:- i - 1 = 1 > 0. Переходим к шагу 6.
Шаг 6. Уравнение для Xt имеет вид Xt = ("-" + "+" + X). Оно уже содержит окончательное решение для Х\. Переходим к шагу 5. Шаг 5. i :=. i - 1 - 0'- 0. Алгоритм завершен. В итоге получили решение:
Xj = ("-" + "+" + X)
Х2 - ("-" + "+" + Х)"."аа + ("-" + "+" + >.)aa*"."a* Х3 = ("-" + "+" + ^)аа
Х4 = ("-" + "+" + %)".Ш' + ("-" + "+" + ^)aa*".V + ("-" + "+" + A.)aa*
Выполнив несложные преобразования, это же решение можно представить в более простом виде:
Х1 = ("-" + "+" + X)
Х2 = ("_" + "+" + Х)("."а + aa*".")a*
Х3 - ("-" + "+" + ^)aa*
Х4 = ("-" + "+" + Х)("."а + aa*"." + a)a*
Если подставить вместо обозначения а соответствующее ему регулярное выражение a = (0+1+2+3+4+5+6+7+8+9), то можно заметит, что регулярное выражение для Х4 описывает язык десятичных чисел с плавающей точкой.
Способы задания регулярных языков
Три способа задания регулярных языков
Регулярные (праволинейные и леволинейные) грамматики, конечные автоматы (КА) и регулярные множества (равно как и обозначающие их регулярные выражения) — это три различных способа, с помощью которых можно задавать регулярные языки. Регулярные языки в принципе можно определять и другими способами, но именно три указанных способа представляют наибольший интерес.
Доказано, что все три способа в равной степени могут быть использованы для определения регулярных языков. Для них можно записать следующие утверждения:
Утверждение 2.1. Язык является регулярным множеством тогда и только тогда, когда он задан леволинейной (праволинейной) грамматикой.
Утверждение 2.2. Язык может быть задан леволинейной (праволинейной) грамматикой тогда и только тогда, когда он является регулярным множеством.
Утверждение 2.3. Язык является регулярным множеством тогда и только тогда, когда он задан с помощью конечного автомата.
Утверждение 2.4. Язык распознается с помощью конечного автомата тогда и только тогда, когда он является регулярным множеством.
Все три способа определения
регулярных языков эквивалентны. Существуют алгоритмы, которые позволяют для регулярного языка,
заданного одним из указанных способов, построить другой способ, определяющий
тот же самый язык. Это не всегда справедливо для других способов, которыми
можно определить регулярные
языки. Ниже рассмотрены некоторые из таких алгоритмов.
Связь регулярных выражений и регулярных грамматик
Регулярные выражения и регулярные грамматики связаны между собой следующим образом:
□
для любого регулярного языка, заданного регулярным выражением, можно построить регулярную грамматику,
определяющую тот же язык;
□
для любого регулярного языка, заданного регулярной грамматикой, можно получить регулярное выражение,
определяющее тот же язык.
Ниже будут рассмотрены два алгоритма, реализующие эти преобразования. В алгоритмах будут использоваться леволинейные грамматики и леволинейная запись уравнений с регулярными коэффициентами, но очевидно, что все то же самое справедливо также для праволинейных грамматик и праволинейной записи уравнений.
Построение леволинейной грамматики для языка, заданного регулярным выражением
Регулярные множества (и обозначающие их регулярные выражения) заданы с помощью рекурсивного определения. Будем строить леволинеиную грамматику для регулярного выражения над алфавитом V, следуя шагам этого определения.
1.
Для регулярного выражения 0 построим леволинеиную грамматику G(V, {S},0,S), которая будет определять язык,
заданный этим выражением (грамматика, в
которой нет ни одного правила).
2.
Для регулярного выражения X построим леволинеиную грамматику G(V,{S}, {S—>A.},S), которая будет определять язык,
заданный этим выражением.
3.
Для регулярного выражения aeV построим леволинеиную грамматику G(V, (S},{S-»a},S), которая будет определять язык, заданный этим
выражением.
4. Имеем регулярные выражения аир,
заданные ими языки Ц и L2, а также со
ответствующие им
леволинейные грамматики G^V.VNt.Pj.S!) и G2(V,VN2,
P2,S2): Ц = L(G4) и L2 = L(G2). Необходимо на основе этих
данных построить
леволинейные грамматики для языков,
заданных выражениями а+р (L3 =
= Lj и L2), ар (L4 = L,L2) и а* (L5 = Ц*):
О для языка, заданного выражением а+р,
строим грамматику G3(V,VN3,P3,S3):
VN3 = VNi u VN2 u {S3} (алфавит нетерминальных символов G3 строится на основе алфавитов нетерминальных символов Gj и G2 с добавлением но-' вого символа S3), P3 = Pt u Р2 и {S3-»S2|Si} (множество правил G3 строится на основе множеств правил G] и G2 с добавлением двух новых правил S3—>S2lSt), целевым символом грамматики G3 становится символ S3; О для языка, заданного выражением ар, строим грамматику G4(V,VN4,P4,S2): VN3 r VNj u VN2 (алфавит нетерминальных символов G3 строится на основе алфавитов нетерминальных символов Gt и G2), множество правил Р4 строится на основе множеств правил Pt и Р2 следующим образом: все правила из множества Р4 переносятся в Р4,
если правило из множества Р2 имеет вид А-»Ву, A,BeVN2, yeV, то оно г реносится в Р4 без изменений,
если правило из множества Р2 имеет вид А->у, Ае VN2, ye V", то в Р4 доба ляется правило A-^S1y,
целевым символом грамматики G4 становится целевой символ граммат ки G2 - S2;
- для языка, заданного выражением а*, строим грамматику G5(V,VN5,P5,S VN3 = VNj U {S5} (алфавит нетерминальных символов G3 строится на с нове алфавита нетерминальных символов Gj с добавлением нового симв ла S5), множество правил Р5 строится на основе множеств правил ', следующим образом:
если правило из множества Pt имеет вид А-»Ву, А,ВеVN1; yeV*, то оно б реносится в Р5 без изменений,
если правило из множества Pi имеет вид А-»у, АеVN2, yeV*, то в Р5 доба ляются два правила A—>S1y|y,
дополнительно в Р5 добавляются два новых правила S5—>S1|A., целевым си волом грамматики G3 становится символ S5.
Используя указанные построения в качестве базиса индукции, на основе матем тической индукции можно доказать, что для любого регулярного языка, заданн го регулярным выражением, можно построить определяющую этот язык левол нейную грамматику.
Для любого произвольного регулярного выражения, напрямую применяя ра смотренные выше выкладки, можно построить леволинеиную грамматику, опр деляющую заданный этим выражением язык. Начинать построение надо от эл ментарных операндов выражения: символов, пустых цепочек и пустых множеств Построение необходимо вести в порядке выполнения операций выражения.
Построение регулярного выражения для языка, заданного леволинейной грамматикой
Имеем леволинеиную грамматику G(VT,VN,P,S), необходимо найти регуляр» выражение над алфавитом VT, определяющее язык L(G), заданный этой грамм тикой.
В данном случае преобразование не столь элементарно. Выполняется оно следующим образом:
1.
Обозначим символы алфавита нетерминальных символов VN
следующим о разом: VN
= {Xt,
X2, ...,
Х„}. Тогда все правила грамматики будут иметь ви X,—»Х/у или X,—>у X;,X;eVN, yeVT*; целевому
символу грамматики S буд соответствовать некоторое
обозначение X*.
2.
Построим систему уравнений с регулярными коэффициентами на основе п ременных Х1;Х2,...,Х„:
Xi = a0i + Xjttj, + Х2а21 + ... + Х„а„!
Х2 = а02 + Х1ОЧ2 + Х2а22 + ... + Хпап2
Хп = а0п + Хдац, + Х2а2п + ... + Xnann;
коэффициенты a0i, a02,..., а0п выбираются следующим образом: a0i = (Yi + Y2 + + - + Ут)> если во множестве правил Р грамматики G существуют правила Х4—>Y1ly2l...JYm' и aoi= 0> если правил такого вида не существует; коэффициенты а^, сы, ..., ajn для некоторого j выбираются следующим образом: otji = (yt + у2 + ... + Ym)>если в0 множестве правил Р грамматики G существуют правила Xj—>XjYi|XjY2|...lXjym, и о^ = 0, если правил такого вида не существует.
3. Находим решение построенной системы уравнений.
Доказано, что решение для Хк (которое обозначает целевой символ S грамматики G) будет представлять собой искомое регулярное выражение, обозначающее язык, заданный грамматикой G. Остальные решения системы будут представлять собой регулярные выражения, обозначающие понятия грамматики, соответствующие ее нетерминальным символам. В принципе для поиска регулярного выражения, обозначающего весь язык, не нужно искать все решения — достаточно найти решение для Хк, если выражения для понятий грамматики не представляют отдельного интереса.
Например, рассмотрим леволинейную грамматику, определяющую язык десятичных чисел с плавающей точкой G({".", "-". "+", "О", "1", "2". "3", "4", "5", "6", "7", "8", "9"}, {<знак>, <дробное>, <целое>, <число>},Р,<число>):
Р:
<знак> -> -' | +\'%
<дробное> -> <знак>.0 | <знак>.1 | <знак>.2 | <знак>.3 | <знак>.4 | <знак>,5 | <знак>.6 | <знак>.7 | <знак>.8 | <знак>.9 | <целое>. | <дробное>0 | <дробное>1 | <дробное>2 | <дробное>3 | <дробное>4 | <дробное>5 | <дробное>6 | <дробное>7 | <дробное>8 | <дробное>9 <целое> -> <знак>0 | <знак>1 | <знак>2 | <знак>3 | <знак>4 | <знак>5 | <знак>6 | <знак>7 | <знак>8 | <знак>9 | <целое>0 | <целое>1 | <целое>2 | <целое>3 | <целое>4 | <целое>5 | <целое>6 | <целое>7 | <целое>8 | <целое>9 <число> -» <дробное> | <целое> Обозначим символы множества VN = {<знак>, <дробное>, <целое>, <число>} соответствующими переменными Хр получим: VN = {Xl Х2, Х3, Х4}. Построим систему уравнений на основе правил грамматики G:
Xj = ("-•• + "+" + X)
Х2 = Xj"."(0+1+2+3+4+5+6+7+8+9) + Х3"." + Х2(0+1+2+3+4+5+6+7+8+9)
Х3 « X t(0+1+2+3+4+5+6+7+8+9) + Х3(0+1+2+3+4+5+6+7+8+9)
Х4 = Х2 + Х3 Эта система уравнений уже была решена выше. В данном случае нас интересует только решение для Х4, которое соответствует целевому символу грамматики G <число>. Решение для Х4 может быть записано в виде: Х4 = ("-" + "+" + X) ("."(0+1+2+3+4+5+6+7+8+9) + (0+1+2+3+4+5+6+7+8+9) (O+l+2+3-t +4+5+6+7+8+9)*"." + (0+1+2+3+4+5+6+7+8+9)) (0+1+2+3+4+5+6+7+8+9)*
Это и есть регулярное выражение, определяющее язык, заданный грамматикой G.
Связь регулярных выражений и конечных автоматов
Регулярные выражения и конечные автоматы связаны между собой следующим образом:
□ для любого регулярного языка, заданного регулярным выражением, можнс построить конечный автомат, определяющий тот же язык;
□ для любого регулярного языка, заданного конечным автоматом, можно получить регулярное выражение, определяющее тот же язык.
Ниже будет рассмотрен алгоритм, реализующий построение конечного автомате по регулярному выражению. Алгоритм построения регулярного выражения пс конечному автомату здесь не рассматривается — он не представляет интереса поскольку, как будет показано ниже, проще построить грамматику, эквивалентную заданному конечному автомату, а потом уже найти регулярное выражение для заданного грамматикой языка (по алгоритму, который уже был выше рассмотрен) [5, 6, т. 1, 12, 26].
Построение конечного автомата для языка, заданного регулярным выражением
Регулярные множества (и обозначающие их регулярные выражения) заданы ( помощью рекурсивного определения. Будем строить КА для регулярного выражения над алфавитом V, следуя шагам этого определения.
1.
Для регулярного выражения 0 построим КА M(Q,= {H,F},V,5,H,{F}), у кото рого функция переходов VqeQ, VaeV имеет вид 5(q,a) = 0.
2.
Для регулярного выражения X построим
КА M(Q= {F},V,5,F,{F}), у которой функция переходов VaeV имеет
вид 8(F,a) = 0, а множество конечных
состояний содержит только начальное состояние.
3.
Для регулярного выражения asV построим КА M(Q= {H,F},V,8,H,{F}), с функ цией переходов 8(Н,а) = {F}.
4. Имеем регулярные выражения аир, заданные ими языки Lt и L2, а также со ответствующие им КА M^Qj.V.SLq^F,) и M2(Q2,V,52,q2,F2): L{ = L(Mi) 1 L2 = L(M2). Необходимо на основе этих данных построить КА для языков, за данных выражениями а+р (L3 = Lj u L2), ар (L4 = L(L2) и а* (L5 - L/).
О для языка, заданного выражением а+р, строим КА M3(Q3,V,53,q3,F3): Оз г Qi u Q2 Ч {Яз} (множество состояний М3 строится из множеств со стояний М( и М2 с добавлением нового состояния q3),
§з(Яз>а) = S^qj.a) u 52(q2,a) VaeV, 53(q,a) = 5,(q,a)
VaeV VqeQ,,
83(q,a)
= 52(q,a) VaeV VqeQa,
F3 = Ft О F2 О {q3}, если a+p содержит X, или F3 = Ft и F2, если a+p не содержит X, начальным состоянием КА М3 становится состояние q3;
- для языка, заданного выражением ар, строим КА M4(Q4,V,84,qi,F4):
Q4 = Qi V Q2 (множество состояний М4 строится из множеств состояний
Mj и М2),
54(q,a) = ЩЩк) VaeV ЧЩ%/*д\
54(q,a) = 8!(q,a) и 82(q2,a)
VaeV VqeFt,
84(q,a)
= 82(q,a) VaeV VqeQ,,
F4 = F2, если q2gF2 или F4 = Щ и F2, если q2eF2,
начальным состоянием К А М3 становится начальное состояние К A Mt — q(; О для языка, заданного выражением а*, строим КА M5(Q5,V,85,q5,F5):
Q5 = Q.! u {qs} (множество состояний М5 строится из множества состояний
Mt с добавлением нового состояния q5),
55(q,a) - 8,(q,a) VaeV Vqe(Q1/F1),
85(q,a) = 8i(q,a) u S^q^a) VaeV VqeFt,
85(q5.a)
Г 8i(q!,a)
VaeV,
F5 = Fi О {q5}, >m
начальным состоянием КА М5 становится состояние q5. Используя указанные построения в качестве базиса индукции, на основе математической индукции можно доказать, что для любого регулярного языка, заданного регулярным выражением, можно построить определяющий этот язык КА. Построение КА на основе регулярного выражения выполняется аналогично построению леволинейной грамматики.
Связь регулярных грамматик и конечных автоматов
На основе имеющейся регулярной грамматики можно построить эквивалентный ей конечный автомат и, наоборот, для заданного конечного автомата можно построить эквивалентную ему регулярную грамматику.
Это очень важное утверждение, поскольку регулярные грамматики используются для определения лексических конструкций языков программирования. Создав автомат на основе известной грамматики, мы получаем распознаватель для лексических конструкций данного языка. Таким образом, удается решить задачу разбора для лексических конструкций языка, заданных произвольной регулярной грамматикой. Обратное утверждение также полезно, поскольку позволяет узнать грамматику, цепочки языка которой допускает заданный автомат. Для построения конечного автомата на основании известной грамматики и для построения грамматики на основании данного конечного автомата используются достаточно простые алгоритмы. Все языки программирования определяют нотацию записи «слева направо». В той же нотации работают и компиляторы. Поэтому далее рассмотрены алгоритмы для леволинейных грамматик.
Построение конечного автомата на основе леволинейной грамматики
Имеется леволинейная грамматика G(VT,VN,P,S), необходимо построить эквивалентный ей конечный автомат M(Q,V,5,q0,F).
Прежде всего для построения автомата исходную грамматику G необходимо привести к автоматному виду. Известно, что такое преобразование можно выполнить для любой регулярной грамматики. Алгоритм преобразования к автоматному виду был рассмотрен выше, поэтому здесь на данном вопросе останавливаться нет смысла. Можно считать, что исходная грамматика G уже является леволинейной автоматной грамматикой.
Тогда построение конечного автомата M(Q,V,8,q0,F) на основе грамматики G(VT, VN,P,S) выполняется по следующему алгоритму.
Шаг 1. Строим множество состояний автомата 0\ Состояния автомата строятся таким образом, чтобы каждому нетерминальному символу из множества VN грамматики G соответствовало одно состояние из множества Q автомата М. Кроме того, во множество состояний автомата добавляется еще одно дополнительное состояние, которое будем обозначать Н. Сохраняя обозначения нетерминальных символов грамматики G, для множества состояний автомата М можно записать: Q = VNu{H}.
Шаг 2. Входным алфавитом автомата М является множество терминальных символов грамматики G: V = VT.
Шаг 3. Просматриваем все множество правил исходной грамматики. Если встречается правило вида A->teP, где AeVN, teVT, то в функцию переходов 8(H,t) автомата М добавляем состояние A: AeS(H,t).
Если встречается правило вида A-»BteP, где A.BeVN, teVT, то в функцию переходов 8(B,t) автомата М добавляем состояние A: Ae8(B,t).
Шаг 4. Начальным состоянием автомата М является состояние Н: q0 = Н.
Шаг 5- Множество конечных состояний автомата М состоит из одного состояния. Этим состоянием является состояние, соответствующее целевому символу грамматики G: F = {S}.
На этом построение автомата заканчивается.
Построение леволинейной грамматики на основе конечного автомата
Имеется конечный автомат M(Q,V,8,q0,F), необходимо построить эквивалентную ему леволинейную грамматику G(VT,VN,P,S). Построение выполняется по следующему алгоритму. Шаг 1. Множество терминальных символов грамматики G строится из алфавита входных символов автомата М: VT = V.
Шаг 2. Множество нетерминальных символов грамматики G строится на основании множества состояний автомата М таким образом, чтобы каждому состоянию автомата, за исключением начального состояния, соответствовал один нетерминальный символ грамматики: VN = Q\{qo}.
Шаг 3. Просматриваем функцию переходов автомата М для всех возможных состояний из множества Одля всех возможных входных символов из множества V. Если имеем 8(A,t) = 0, то ничего не выполняем.
Если имеем 8(A,t) = {В^Вг^.Д,}, п >0, где AeQ, Vn>i>0: B;eQ, teV, тогда для всех состояний Bj выполняем следующее:
□
добавляем правило Bs—>t во множество Р правил грамматики G, если А = q0;
□
добавляем правило B^At во множество Р правил грамматики G, если A*q0. Шаг 4. Если множество конечных
состояний F автомата М содержит только одно состояние F = {F0}, то целевым символом S грамматики G становится символ множества VN, соответствующий этому
состоянию: S = F0; иначе,
если множество конечных
состояний F автомата М содержит более одного состояния F = {¥и F2,...,Fn}, п>1, тогда во множество
нетерминальных символов VN грамматики G добавляется новый нетерминальный
символ S: VN = VNu{S}, а во множество правил Р
грамматики G добавляются правила: S—»Fi|F2|...|Fn.
На этом построение грамматики заканчивается.
Пример построения конечного автомата на основе заданной грамматики
Рассмотрим грамматику 6({"а","(","*".")"."{"'"}"}• {S.C.K}, P. S) (символы а, (, *, ), {, } из множества терминальных символов грамматики взяты в кавычки, чтобы выделить их среди фигурных скобок, обозначающих само множество):
Р:
S -> С*) | К}
С -» (* | Са | С{ | С} | С( | С* | С)
К -» { | Ка | К( | К* | К) | К{ Это леволинейная регулярная грамматика. Как было показано выше, ее можно преобразовать к автоматному виду.
Получим леволинейную автоматную грамматику следующего вида: G'({"a","(", "*".")","{"."}"}. {S.SlCCl^.P'.S):
Р':
S -> S,) | К}
S! -» С*
С -> С,* | Са | С{ | С} | С( | С* | С)
С, -» С
К -> { | Ка | К( | К* | К) | К{
Для удобства переобозначим нетерминальные символы Q и S4 символами D и Е. Получим грамматику G'({"a","С."*",")","{",'■}"}. {S.E.C.D.K}, P\ S):
Р':
S -> Е) | К}
Е -> С*
С -> D* | Са | С{ | С} | С( | С* | С)
О -> (
К -» { | Ка | К( | К* | К) | К{
Построим конечный автомат M(Q,V,8,q0,F), эквивалентный указанной грамматике.
Шаг 1. Строим множество состояний автомата. Получаем: Q=VNu{H} = = {S,E,C,D,K,H}.
Шаг 2. В качестве алфавита входных символов автомата берем множество терминальных символов грамматики. Получаем: V = {"а","(","*",")","{ ">"}"}•
Шаг 3. Рассматриваем множество правил грамматики.
Для правил S -> Е) | К} имеем 5(Е,")") = {S}: 5(К,"}") = {S}.
Для правила Е ->• С* имеем 8(С,"*") = {Е}.
Для правил С -» D* | Са | С{ | С} | С( | С* | С) имеем 5(D,"*") = {С}: 5(С."а") = {С}; 5(С,"{") = {С}: 5(С,"}") = {С}; 5(С."(") = {С}: 8(С,"*") = {Е.С}; 8(С,"Г) = {С}.
Для правила D -> ( имеем 5(Н,"(") = {D}.
Для правил К -+ { | Ка | К( | К* | К) | К{ имеем 5(Н,"{") = {К}: 5(К,"а") = {К}: 5(К,"(") = {К}; 8(К,"*") = {К}; 5(К,")") = {К}: 8(К."{") = {К}.
Шаг 4. Начальным состоянием автомата является состояние q0 = Н.
Шаг 5. Множеством конечных состояний автомата является множество F = {S}.
Выполнение алгоритма закончено.
В итоге получаем автомат M({S.E.CD,К,Н}, {"а","(","*",")","{"."}"}. 8, Н, {S}) с функцией переходов:
|
8(Н.' |
{ |
') " {<} |
|
5(Н.' |
( |
') = {0} |
|
5(К,' |
а |
') = {<} |
|
6(К.' |
( |
') = {К} |
|
5(К,' |
* |
') - {к} |
|
5(К.' |
) |
') = (к} |
|
5СК.' |
{ |
') - {к} |
|
5(К.' |
} |
') - {S} |
|
5(D.' |
* |
') ■ (С} |
|
8(С |
а |
') - {С} |
|
6(С |
{ |
') ■ {С} |
|
8(С.' |
} |
') - {С} |
|
8(С |
( |
') - {С} |
|
8(С.' |
* |
') = {Е.С} |
|
5(С.")") 5(1,"О") |
|
{С} {S} |
|
Граф переходов этого автомата изображен на рис. 10.7. |
а, (,*,)ДЛ
Рис. 10.7. Недетерминированный КА для языка комментариев в Borland Pascal
Это недетерминированный конечный автомат, поскольку существует состояние, в котором множество, получаемое с помощью функции переходов по одному и тому же символу, имеет более одного следующего состояния. Это состояние С и функция 8(0,"*") - {Е,С}.
Моделировать поведение недетерминированного КА — непростая задача, поэтому можно построить эквивалентный ему детерминированный КА. Полученный таким путем КА можно затем минимизировать.
В результате всех преобразований получаем детерминированный конечный автомат M'({S.E, CD. К, Н},{"а", ■•(»,•'*",")","{". "}"}.5',H.{S}) с функцией переходов:
Граф переходов этого автомата
изображен на рис. 10.8.
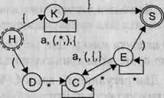
а,(,Ш Рис. 10.8. Детерминированный КАдля языка комментариев в Borland Pascal
На основании этого автомата можно легко построить распознаватель. В данном случае мы можем получить распознаватель для двух типов комментариев языка программирования Borland Pascal, если учесть, что а может означать любой алфавитно-цифровой символ, кроме символов (, *, ), {, }.
Свойства регулярных языков
Свойства регулярных языков
Множество называется замкнутым относительно некоторой операции, если в результате выполнения этой операции над любыми элементами, принадлежащими данному множеству, получается новый элемент, принадлежащий тому же множеству.
Например, множество целых чисел замкнуто относительно операций сложения, умножения и вычитания, но оно не замкнуто относительно операции деления — при делении двух целых чисел не всегда получается целое число.
Регулярные множества (и однозначно связанные с ними регулярные языки) замкнуты относительно многих операций, которые применимы к цепочкам символов.
Например, регулярные языки замкнуты относительно следующих операций:
□
пересечения;
□
объединения;
□
дополнения;
□
итерации;
□
конкатенации;
□
гомоморфизма (изменения имен символов и подстановки цепочек вместо символов).
Поскольку регулярные множества замкнуты относительно операций пересечения, объединения и дополнения, то они представляют булеву алгебру множеств. Существуют и другие операции, относительно которых замкнуты регулярные множества. Вообще говоря, таких операций достаточно много.
Регулярные языки представляют собой очень удобный тип языков. Для них разрешимы многие проблемы, неразрешимые для других типов языков. Например, доказано, что разрешимыми являются следующие проблемы.
Проблема эквивалентности. Даны два регулярных языка Lt(V) и L2(V). Необходимо проверить, являются ли эти два языка эквивалентными. Проблема принадлежности цепочки языку. Дан регулярный язык L(V) и цепочка символов cteV*. Необходимо проверить, принадлежит ли цепочка данному языку. Проблема пустоты языка. Дан регулярный язык L(V). Необходимо проверить, является ли этот язык пустым, то есть найти хотя бы одну цепочку а^Х, такую что aeL(V).
Эти проблемы разрешимы вне зависимости от того, каким из трех способов задан регулярный язык. Следовательно, эти проблемы разрешимы для всех способов представления регулярных языков: регулярных множеств, регулярных грамматик и конечных автоматов. На самом деле достаточно доказать разрешимость любой из этих проблем хотя бы для одного из способов представления языка, тогда для остальных способов можно воспользоваться алгоритмами преобразования, рассмотренными выше1.
Для регулярных грамматик также разрешима проблема однозначности — доказано, что для любой регулярной грамматики можно построить эквивалентную ей однозначную регулярную грамматику. Это очевидно, поскольку для любой регулярной грамматики можно однозначно построить регулярное выражение, определяющее заданный этой грамматикой язык.
Лемма о разрастании для регулярных языков
Иногда бывает необходимо доказать, является или нет некоторый язык регулярным. Конечно, можно пойти путем поиска определения для цепочек заданного языка через один из рассмотренных выше способов (регулярные грамматики, конечные автоматы и регулярные выражения). Если для этого языка хотя бы один из способов будет определен, следовательно, язык является регулярным (и на основании одного найденного способа определения языка можно найти остальные). Но если не удается построить определение языка ни одним из этих способов, то остается неизвестным: то ли язык не является регулярным, то ли просто не удалось найти определение для него.
Однако существует простой метод проверки, является или нет заданный язык регулярным. Этот метод основан на проверке так называемой леммы о разрастании языка. Доказано, что если для некоторого заданного языка выполняется лемма о разрастании регулярного языка, то этот язык является регулярным; если же лемма не выполняется, то и язык регулярным не является [6, т. 1]. Лемма о разрастании для регулярных языков формулируется следующим образом: если дан регулярный язык и достаточно длинная цепочка символов, принадлежащая этому языку, то в этой цепочке можно найти непустую подцепочку, которую можно повторить сколь угодно много раз, и все полученные таким способом новые цепочки будут принадлежать тому же регулярному языку2.
1 Возможны и другие способы представления регулярных множеств, а для них разрешимость указанных проблем будет уже не очевидна.
2Если найденную подцепочку повторять несколько раз, то
исходная цепочка как бы «раз
растается» - отсюда
и название «лемма о разрастании языков». Формально эту лемму можно записать так: если дан язык L, то 3 константа р > О, такая, что если asL и |а|>р, то
цепочку а можно записать в виде а = 8ре, где О < |р| < р, и тогда а' = 8р!е,
a'eL Vi > 0.
Используя
лемму о разрастании регулярных языков, докажем, что язык L
= {апЬл
| п > 0} не является регулярным.
Предположим, что этот язык регулярный, тогда для него должна выполняться лемма о разрастании. Возьмем некоторую цепочку этого языка a = anbn и запишем ее в виде a = 5рБ. Если Реа+ или Peb+, то тогда для i = 0 цепочка 5р°е = 8е не принадлежит языку L, что противоречит условиям леммы; если же Реа+Ь+, тогда для i = 2 цепочка 5p2s = 5рре не принадлежит языку L. Таким образом, язык L не может быть регулярным языком.
Контекстно-свободные языки
Распознаватели КС-языков. Автоматы с магазинной памятью
Определение МП-автомата
Контекстно-свободными (КС) называются языки, определяемые грамматиками типа G(VT,VN,P,S), в которых правила Р имеют вид: А-»р, где AeVN и peV, V=VTuVN.
Распознавателями КС-языков служат автоматы с магазинной памятью (МП-автоматы). В общем виде МП-автомат можно определить следующим образом:
RtaV.ZAqo.Zo.F), где Q, — множество состояний автомата; V — алфавит входных символов автомата; Z — специальный конечный алфавит магазинных символов автомата (обычно он включает в себя алфавиты терминальных и нетерминальных символов грамматики), VcZ; 8 — функция переходов автомата, которая отображает множество Qx(Vu{?i})xZ на конечное множество подмножеств P(QxZ'); qoeQ. — начальное состояние автомата; z0eZ — начальный символ магазина; FcQ, — множество конечных состояний.
МП-автомат в отличие от обычного КА имеет стек (магазин), в который можно помещать специальные «магазинные» символы (обычно это терминальные и нетерминальные символы грамматики языка). Переход из одного состояния в другое зависит не только от входного символа, но и от одного или нескольких верхних символов стека. Таким образом, конфигурация автомата определяется тремя

Конфигурация МП-автомата описывается в виде тройки (q,a,eo)eQxV*xZ*, кот< рая определяет текущее состояние автомата q, цепочку еще непрочитанных сил волов а на входе автомата и содержимое магазина (стека) со. Вместо а в конф! гурации можно указать пару (Р,п), где PeV* — вся цепочка входных символо а neNu{0}, п > 0 — положение считывающего указателя в цепочке.
Тогда один такт работы автомата можно описать в виде (q,aa,zco) -s- (q',a,yco), есл (q',y)e8(q,a,z), где q.q'eQ, aeVu{^}, aeV, zeZu{A.}, y,coeZ*. При выполнени такта (перехода) из стека удаляется верхний символ, соответствующий услови перехода, и добавляется цепочка, соответствующая правилу перехода. Первы символ цепочки становится верхушкой стека. Допускаются переходы, при коп рых входной символ игнорируется (и тем самым он будет входным символо при следующем переходе). Эти переходы (такты) называются ^-переходами (^-та тами). Аналогично, автомат не обязательно должен извлекать символ из стека когда z=X,, этого не происходит.
МП-автомат называется недетерминированным, если из одной и той же его ко] фигурации возможен более чем один переход.
Начальная конфигурация МП-автомата, очевидно, определяется как (q0,a,z0), ae\ Множество конечных конфигураций автомата — (q,?t,co), qeF, coeZ*.
МП-автомат допускает (принимает) цепочку символов, если, получив эту цепо ку на вход, он может перейти в одну из конечных конфигураций, — когда щ окончании цепочки автомат находится в одном из конечных состояний, а cti содержит некоторую определенную цепочку. Тогда входная цепочка принимаеся (после окончания цепочки автомат может сделать произвольное количесп А.-переходов). Иначе цепочка символов не принимается.
Язык, определяемый МП-автоматом, — это множество всех цепочек символе которые допускает данный автомат. Язык, определяемый МП-автоматом R, об значается как L(R). Два МП-автомата называются эквивалентными, если oi определяют один и тот же язык. Если два МП-автомата Rj и R2 определяют 0Д1 и тот же язык, это записывается как L(Rj) = L(R2)-
МП-автомат допускает цепочку символов с опустошением магазина, если п] окончании разбора цепочки автомат находится в одном из конечных состояни
а стек пуст — конфигурация (q,X,\), qeF. Если язык задан МП-автоматом R, который допускает цепочки с опустошением стека, это обозначается так: L^(R). Для любого МП-автомата всегда можно построить эквивалентный ему МП-автомат, допускающий цепочки заданного языка с опустошением стека. То есть V МП-автомата R: 3 МП-автомат R', такой что L(R) = L^(R').
Кроме обычного МП-автомата существует также понятие расширенного МП-автомата.
Расширенный МП-автомат может заменять цепочку символов конечной длины в верхней части стека на другую цепочку символов конечной длины. В отличие от обычного МП-автомата, который на каждом такте работы может изымать из стека только один символ, расширенный МП-автомат может изымать за один такт сразу некоторую цепочку символов, находящуюся на вершине стека. Функция переходов 5 для расширенного МП-автомата отображает множество Qx(Vu{A,})xZ* на конечное множество подмножеств P(QxZ').
Доказано, что для любого расширенного МП-автомата всегда можно построить эквивалентный ему обычный МП-автомат (обратное утверждение очевидно, так как любой обычный МП-автомат является и расширенным МП-автоматом). Таким образом, классы МП-автоматов и расширенных МП-автоматов эквивалентны и задают один и тот же тип языков.
Эквивалентность языков МП-автоматов и КС-грамматик
Пусть задана КС-грамматика G(VT,VN,P,S). Построим на ее основе МП-автомат R({q},VT,VTuVN,5,q,S,{q}). Этот автомат имеет только одно состояние. Определим функцию переходов автомата следующим образом:
(q,a)e5(q,X.,A), VA-»a ё Р; (яЛ)е5(я,а,а), Va e VT.
Начальная конфигурация автомата: (q,a,S); конечная конфигурация автомата: (q,U).
Докажем, что данная грамматика и построенный на ее основе автомат определяют один и тот же язык. Для этого надо доказать два следующих утверждения:
□
если в грамматике G существует вывод А=>*ос, то автомат R
может сделать последовательность шагов (q,a,A)-s-*(q,^), где AeVN
— некоторый произвольный нетерминальный символ
грамматики, а aeVT*;
□
если автомат R может сделать последовательность шагов (q,a,A)+*(q,X,X), то в грамматике G существует вывод А=>*а.
Докажем первое утверждение. Доказательство будем вести на основе математической индукции. Положим, что в грамматике G существует вывод A=>ma для некоторого m > 0.
Для m = 1 имеем А=>а, а = а^-з.^, к>0.
Тогда если к = 0, то a = X, и должно существовать правило
грамматики А—>Х, а по определению автомата R имеем:
(q,a,A) + (q,A.,A.). Если к > 0, то должно существовать правило грамматики А-»а, и по определению автомата R получаем:
(q,a1a2...ak,A)
j (q,a1a2...ak,a1a2...ak)
4- (q,a2...ak,a2...ak) * ...
4- (q,ak,ak) + (q,X,X),
следовательно,
(q,a1a2...ak,A)
+ (q,a1a2...ak,a1a2...ak)
+k (q,X,X) и (q,a1a2...ak,A) ** (q,X,X).
Таким образом, утверждение для m = 1 доказано.
Предположим, что для некоторого т>1 это утверждение справедливо. Значит, если существует вывод А=>тгх в грамматике G, то существует и последовательность шагов автомата R: (q,a,A) +* (q,X,X).
Следуя принципу математической индукции, докажем теперь, что это утверждение справедливо и для некоторого т+1. То есть докажем, что если существует вывод A=>m+1a в грамматике G, то существует и последовательность шагов автомата R: (q,a,A)+*(q,A,,X,).
Рассмотрим первый шаг вывода A=>m+1a: A=>X!X2...Xk, где V k>i>0: Xje(VTuVN). Если X;eVN, то существует вывод Xj =>mi xi; причем XjeVT* и m^m; если же XjeVT, to Xi=Xj. Саму исходную цепочку а можно записать как конкатенацию цепочек терминальных символов х^ a = xtx2...xk.
Если первый шаг вывода А=>Х1Х2...Хк, тогда в грамматике G существует правило А->Х!Х2...Хк, и, по определению автомата R, первым шагом его работы может быть шаг: (q,a,A) * (q,a)X1X2..'Xk).
Но для всех XjeVN, так как V k > i > 0: Xj =>mi ,xj и т{ < пт, то по утверждению индукции имеем (q^i.Xj) +* (q,X,X).
А для всех X;eVT по определению автомата R имеем (q.x'^Xj) * (q,X,X).
Объединяя шаги работы автомата R для всех Xj из конфигурации (q,a,X!X2...Xk), получаем (q,a,X1X2...Xk) -гЛ (q,^.,A,), следовательно, (q,a,A) + (q,a,X1X2...Xk) +* (q,X,X), и отсюда можно утверждать, что (q,a,A) +* (q,A.,A.).
На основании положений математической индукции утверждение доказано.
Докажем второе утверждение. Доказательство будем вести на основе математической индукции. Положим, что автомат R может выполнить последовательность шагов (q,a,A) 4Г (q,X,X) для некоторого п > 0.
Если п = 1, тогда имеем один шаг работы автомата: (q,a,A) -f (q,X,X) и, следовательно, a = X. Отсюда, согласно определению автомата R, в грамматике G должно существовать правило вида А->А,. Тогда в грамматике G существует и вывод А=>А, или, что то же самое, А=>*а. Для п = 1 утверждение доказано.
Предположим, что для некоторого п>1 это утверждение справедливо. Значит, если существует последовательность шагов работы автомата R: (q,a,A) -ьп (q,X,X), то в грамматике G существует вывод А=>*а.
Теперь докажем, что это утверждение справедливо и для некоторого п +1. Рассмотрим последовательность шагов работы автомата R: (q,a,A) -ьп+1 (q,X,X). Первым шагом этой последовательности будет шаг (q,a,A) + (q,a,X1X2...Xk), V k S i > 0: Xje(VTuVN). Причем, по определению автомата R, в грамматике G должно существовать правило вида A-»XiX2...Xk.
Можно утверждать, что V Xje(VTuVN), (q^.Xj) *ni (q,^), X;eVT*, причем a = Х$£.щ, и в грамматике G существует вывод Х;=>*х;.
Действительно, если X^VN и (q,Xj,Xi) +ni (q,X,X), X;eVT, то по сделанному предположению индукции справедливо утверждение, что существует вывод Х,=>*Х; в грамматике G, так как Vi: nj<n.
Если же Х.еУТ, то по определению автомата R: (q.Xj.Xj) * (q,A-,A,), fcjssXi, что соответствует выводу Х|=>°Х;, и тогда также справедливо Х,=>*Х|. 1
Тогда можно построить левосторонний вывод в грамматике G: А => Х^.-.Хк =>* Х!Х2...Хк =>* Х!Х2...Хк =>* ... =>* х^.-.Хк = а. Следовательно, в грамматике G существует вывод А =>* а.
На основании положений математической индукции утверждение доказано.
Поскольку из двух доказанных утверждений однозначно следует, что в КС-грамматике G существует вывод S =>* а (где S — целевой символ грамматики) тогда и только тогда, когда в МП-автомате R существует последовательность шагов работы автомата (q,a,S) ■*•* (q,X,X), то можно утверждать, что построенный МП-автомат R распознает язык, заданный КС-грамматикой G: L(R) = L(G). Поскольку построенный МП-автомат допускает входные цепочки языка с опустошением стека, то доказано также утверждение L^(R) = L(G).
При доказательстве на структуру правил грамматики G не накладывалось никаких дополнительных ограничений, поэтому все доказанные утверждения справедливы для произвольной КС-грамматики.
После того как доказано, что для произвольной КС-грамматики всегда можно построить МП-автомат, распознающий заданный этой грамматикой язык, можно говорить, что МП-автоматы распознают КС-языки. На самом деле существует также и доказательство того, что для произвольного МП-автомата всегда можно построить КС-грамматику, которая задает язык, распознаваемый этим автоматом. Таким образом, КС-грамматики и МП-автоматы задают один и тот же тип языков — КС-языки.
Поскольку класс расширенных МП-автоматов эквивалентен классу обычных МП-автоматов и задает тот же самый тип языков, то можно утверждать, что и расширенные МП-автоматы распознают языки из типа КС-языков. Следовательно, язык, который может распознавать расширенный МП-автомат, также может быть задан с помощью КС-грамматики.
1 Здесь используется представление о том, что обозначение «=>*» включает в себя также понятие «вывод с нулевым количеством шагов», которое обозначается «=> » и на самом деле означает, что две цепочки символов совпадают (равны). Если каждая цепочка состоит из одного символа, то символы двух цепочек эквивалентны между собой. Эта особенность упоминалась, когда вводилось понятие — «а =>* Р» — «цепочка Р выводима из цепочки а», но до настоящего момента явно нигде не использовалась. В данном случае это не влияет на структуру доказательства, но очень удобно, поскольку не требует ввода дополнительного обозначения для понятия «цепочка р выводима из цепочки а или совпадает с нею».
Детерминированные МП-автоматы
МП-автомат называется детерминированным, если из одной и той же его конф гурации возможно не более одного перехода в следующую конфигурацию.
формально для детерминированного МП-автомата R(Q,V,Z,8,q0,z0,F) функщ переходов 8 может VqeQ, VaeV, VzeZ иметь один из следующих трех видов:
1. 5(q,a,z) содержит один элемент: 5(q,a,z) = {(q',y)}, yeZ* и 5(q,^.,z) = 0.
2.
5(q,a,z) = 0 и 5(q,X.,z) содержит один элемент: 8(q,A,,z) = {(q',y)}, yeZ*.
3.
5(q,a,z) = 0 и 5(q,X,z)
* 0.
Класс ДМП-автоматов и соответствующих им языков значительно уже, чем ве класс МП-автоматов и КС-языков. В отличие от обычного конечного автома: не для каждого МП-автомата можно построить эквивалентный ему ДМП-авт мат. Иными словами, в общем случае невозможно преобразовать недетермин рованный МП-автомат в детерминированный.
Детерминированные МП-автоматы (ДМП-автоматы) определяют очень важнь класс среди всех КС-языков, называемый детерминированными КС-языкам Доказано, что все языки, принадлежащие к классу детерминированных КС-яз ков, могут быть построены с помощью однозначных КС-грамматик. Посколь однозначность — это важное и обязательное требование в грамматике любого яз ка программирования, ДМП-автоматы представляют особый интерес для созг ния компиляторов. Синтаксический распознаватель цепочек любого языка пр граммирования может быть построен на основе ДМП-автомата.
Кроме того, доказано, что для любого ДМП-автомата всегда можно построй эквивалентный ему ДМП-автомат, который будет учитывать входную цепочку до конца — не допускать бесконечной последовательности ^.-переходов по завершении цепочки [6, т. 1]. Это значительно облегчает моделирование работы ДМ автоматов.
Все без исключения синтаксические конструкции языков программирования : даются с помощью однозначных КС-грамматик (неоднозначность, конечно >: ни в одном компиляторе недопустима). Синтаксические структуры этих язык относятся к классу детерминированных КС-языков и могут распознаваться с г мощью ДМП-автоматов. Поэтому большинство распознавателей, которые бул рассмотрены далее, относятся к классу детерминированных КС-языков.
Свойства КС-языков
Свойства произвольных КС-языков
Класс КС-языков замкнут относительно операции подстановки. Это означа что если в каждую цепочку символов КС-языка вместо некоторого символа ш ставить цепочку символов из другого КС-языка, то получившаяся новая цепоч также будет принадлежать КС-языку. Это основное свойство КС-языков. Формально оно может быть записано так. Если L,Lai,La2,...,Lan — это произвольные КС-языки и {a^.-.a,,} — алфавит языка L, п>0, то тогда язык L' = {х!Х2...хк| а^.д-ёЬ, xieL x2eL^,..., хкеЦк, к > 0: V к > i > 0: п > j S > 0} также является КС-языком [6, т. 1].
Например:
L = {0П1П | п > 0}, Lo = {a}, Lt = {bmcm | m > 0} — это исходные КС-языки, тогда после подстановки получаем новый КС-язык: L' = {anbmicmibm2cm2...bmncmn | n > 0, Vi:mi>0}.
На основе замкнутости относительно операции подстановки можно доказать другие свойства КС-языков. В частности, класс КС-языков замкнут относительно следующих четырех операций:
□
объединения;
□
конкатенации;
□
итерации;
□
гомоморфизма (изменения имен символов).
Интересно, что класс КС-языков не замкнут относительно операции пересечения, а поэтому не является классом булевой алгебры. Как следствие, этот класс не замкнут и относительно операции дополнения [6, т. 1].
Например:
L{ = {anbncj | п > 0, i > 0} и L2 = {ajbncn | n > 0, i > 0} - КС-языки, но L = I^nL, = = {anbncn | n > 0} не является КС-языком (это можно проверить с помощью леммы о разрастании КС-языков, которая рассмотрена ниже).
Для КС-языков разрешимы проблема пустоты языка и проблема принадлежности заданной цепочки языку — для их решения достаточно построить МП-автомат, распознающий данный язык. Но для КС-языков является неразрешимой проблема эквивалентности двух произвольных КС-грамматик, а, как следствие, также и проблема однозначности заданной КС-грамматики. Не разрешима даже более узкая проблема — проблема эквивалентности заданной произвольной КС-грамматики и произвольной регулярной грамматики.
Тем не менее, хотя в общем случае проблема однозначности для КС-языков не разрешима, для некоторых КС-грамматик можно построить эквивалентную им однозначную грамматику.
Свойства детерминированных КС-языков
Детерминированные КС-языки — это класс тех КС-языков, цепочки которых можно распознавать с помощью ДМП-автоматов. Класс детерминированных КС-языков, естественно, является собственным подмножеством всего класса КС-языков [6, т. 1].
Как уже было сказано ранее, детерминированные КС-языки — это значительно более узкий класс, чем все КС-языки. Класс детерминированных КС-языков не замкнут даже относительно операции объединения, равно как и операции пересечения (хотя и замкнут относительно операции дополнения, в отличие от всех КС-языков в целом).
Класс детерминированных КС-языков интересен тем, что для него разрешима проблема однозначности. Доказано, что если язык может быть распознан с помощью ДМП-автомата (и потому является детерминированным КС-языком), то он может быть описан на основе однозначной КС-грамматики. Именно поэтому данный класс как раз и используется для построения синтаксических конструкций языков программирования.
Дополнительно следует заметить, что в общем случае подавляющее большинство языков программирования (таких, как Pascal, С, FORTRAN и т. п.) формально не являются КС-языками. Причина в том, что в языках программирования всегда присутствует контекстная зависимость, которая выражается, например, в необходимости предварительного описания переменных, в соответствии количества и типов формальных и фактических параметров процедур и функций и т. п. Но с целью упрощения работы компиляторов подобного рода зависимости на этапе синтаксического анализа не учитывают, рассматривая только сами конструкции языков программирования, которые формально могут быть описаны с помощью КС-грамматик. Соблюдение контекстных условий (зависимостей) в компиляторах проверяется уже на этапе семантического анализа при подготовке к генерации кода.
Лемма о разрастании КС-языков
Лемма о разрастании КС-языков звучит так: если взять достаточно длинную цепочку символов, принадлежащую произвольному КС-языку* то в ней всегда можно выделить две подцепочки, длина которых в сумме больше нуля, таких, что, повторив их сколь угодно большое число раз, можно получить новую цепочку символов, принадлежащую данному языку [6, т. 1].
Формально ее можно определить следующим образом: если L — это КС-язык, то 3 keN, k > 0, что если |а| > к и aeL, то а = еР5ую, где Ру^А., |рбу| < к и ep'Sy'oeL Vi > 0 (где N — это множество целых чисел)1.
Как и для регулярных языков, лемма о разрастании для КС-языков служит для проверки принадлежности заданного языка классу КС-языков. Доказано, что всякий язык является КС-языком тогда и только тогда, когда для него выполняется лемма о разрастании КС-языков.
Например, докажем, что язык L = {anbncn | n > 0} не является КС-языком.
Предположим, что этот язык все же является КС-языком. Тогда для него должна выполняться лемма о разрастании, и существует константа к, заданная в этой лемме. Возьмем цепочку a = akbkc\ |a| > к, принадлежащую этому языку. Если ее записать в виде а = spSyco, то по условиям леммы |р5у| < к, следовательно, цепочка рбу не может содержать вхождений всех трех символов a, b и с — каких-то
Для КС-языков, как и для регулярных языков, с помощью леммы о разрастании можно повторять подцепочки сколько угодно раз и получать новые цепочки языка — исходная цепочка как бы «разрастается» (отсюда название леммы). На самом деле лемма о разрастании для КС-языков является частным случаем более общей леммы, известной как «лемма Огдена» [6, т. 1]. символов в ней нет. Рассмотрим цепочку ер°5у°со = ебсо. По условиям леммы она должна принадлежать языку, но в то же время она содержит либо к символов а, либо к символов с и при этом не может содержать к вхождений каждого из символов a, b и с, так как |eSco| < 3k. Значит, какой-то символ в ней встречается меньше, чем другие — такая цепочка не может принадлежать языку L. Следовательно, язык L не удовлетворяет требованиям леммы о разрастании КС-языков и поэтому не является КС-языком.
Преобразование КС-грамматик. Приведенные грамматики
Преобразование грамматик. Цель преобразования
Как было сказано выше, для КС-грамматик невозможно в общем случае проверить их однозначность и эквивалентность. Но очень часто правила КС-грамматик можно и нужно преобразовать к некоторому заранее заданному виду таким образом, чтобы получить новую грамматику, эквивалентную исходной. Заранее определенный вид правил грамматики позволяет упростить работу с языком, заданным этой грамматикой, и облегчает создание распознавателей для него.
Таким образом, можно выделить две основные цели преобразований КС-грамматик: упрощение правил грамматики и облегчение создания распознавателя языка. Не всегда эти две цели можно совместить. В случае с языками программирования, когда итогом работы с грамматикой является создание компилятора языка, именно вторая цель преобразования является основной. Поэтому упрощениями правил пренебрегают, если при этом удается упростить построение распознавателя языка [12, 15, 32].
Все преобразования условно можно разбить на две группы:
□
первая группа — это преобразования, связанные с исключением из грамматики тех правил и символов, без
которых она может существовать (именно эти преобразования позволяют выполнить основные упрощения
правил);
□
вторая группа — это преобразования, в результате которых изменяется вид
и состав правил грамматики, при этом грамматика может дополняться новыми
правилами, а ее словарь нетерминальных символов — новыми символами (то есть преобразования второй
группы не связаны с упрощениями).
Следует еще раз подчеркнуть, что всегда в результате преобразований мы получаем новую КС-грамматику, эквивалентную исходной, то есть определяющую тот же самый язык.
Тогда формально преобразование можно определить следующим образом: G(VT,VN,P,S) -» G'(VT,,Vhf,,P',S'): L(G) - L(G')
Приведенные грамматики
Приведенные грамматики — это КС-грамматики, которые не содержат недостижимых и бесплодных символов, циклов и ^.-правил («пустых» правил). Приведенные грамматики называют также КС-грамматиками в каноническом виде.
Для того чтобы преобразовать произвольную КС-грамматику к приведенному виду, необходимо выполнить следующие действия:
□
удалить все бесплодные символы;
□
удалить все недостижимые символы;
□
удалить ^.-правила;
□
удалить цепные правила.
Следует подчеркнуть, что шаги преобразования должны выполняться именно в указанном порядке, и никак иначе.
Удаление недостижимых символов
Символ xe(VTuVN) называется недостижимым, если он не встречается ни в одной сентенциальной форме грамматики G(VT,VN,P,S).
Конечно, чтобы исключить из грамматики все недостижимые символы, не надо рассматривать все ее сентенциальные формы (это просто невозможно), достаточно воспользоваться специальным алгоритмом удаления недостижимых символов.
Алгоритм удаления недостижимых символов строит множество достижимых символов грамматики G(VT,VN,P,S) — Vj. Первоначально в это множество входит только целевой символ грамматики S, затем оно пополняется на основе правил грамматики. Все символы, которые не войдут в данное множество, являются недостижимыми и могут быть исключены в новой грамматике G' из словаря и из правил.
Алгоритм удаления недостижимых символов по шагам
1. V0
= {S},i:=l.
2.
V; - {х | xe(VTuVN) и (А-хххр)еР, AeV|_„ <x,pe(VTuVN)*} u
Vj_01.
3.
Если Vj ф Vj.t, то i := i+1 и перейти к шагу 2, иначе
перейти к шагу 4.
4.
VN' = VN п Vj, VT = VT n
Vj, в Р' входят те правила из Р, которые содержат только символы из множества Vj, S' = S.
Удаление бесплодных символов
В грамматике G(VT,VN,P,S) символ AeVN называется бесплодным, если для него выполняется: {а | А=>*а, oieVT} = 0, то есть нетерминальный символ является бесплодным тогда, когда из него нельзя вывести ни одной цепочки терминальных символов.
В простейшем случае символ является бесплодным, если во всех правилах, где этот символ стоит в левой части, он также встречается и в правой части. Более сложные варианты предполагают зависимости между цепочками бесплодных символов, когда они в любой последовательности вывода порождают друг друга.
Для удаления бесплодных символов используется специальный алгоритм удаления бесплодных символов. Он работает со специальным множеством нетерминальных символов Yj. Первоначально в это множество попадают только те символы, из которых непосредственно можно вывести терминальные цепочки, затем оно пополняется на основе правил грамматики G.
Алгоритм удаления бесплодных символов по шагам
1.
Yo = 0, i:-l.
2.
Yj = {А | (А-ж)еР, ae(YMuVT)*}
u YM.
3.
Если Yj ф Yi_1, то i := i+1 и перейти к шагу 2, иначе
перейти к шагу 4.
4.
VN' =
Пример удаления недостижимых и бесплодных символов
Рассмотрим работу алгоритмов удаления недостижимых и бесплодных символов на примере грамматики:
G({a.b,c}.{A,B,C.D.E.F.G.S},P,S)
Р:
S -» аАВ | Е
А -> аА | ЬВ
В -*■ АСЬ | Ь
С -> А | ЬА | сС | аЕ
Е —> сЕ | аЕ J ЕЬ | ED | FG
D -> а | с | Fb
F -> ВС |. ЕС | АС
G -> Ga | Gb
Следует обратить внимание, что для правильного выполнения преобразований необходимо сначала удалить бесплодные символы, а потом — недостижимые символы, но не наоборот. То есть порядок, в каком будут выполняться алгоритмы, имеет существенное значение.
Удалим бесплодные символы:
1.
Yo = 0, i:-l.
2.
Y, = {B,D}, Y^Y0: i:=2.
3.
Y2 = {B,D,A},
Y2*Yi: i:=3.
4.
Y3 = {B,D,A,S,C},
Y3*Y2: i:=4.
5.
Y4 = {B,D,A,S,C,F}, Y4*Y3:
i:-5.
6.
Y5 = {B,D,A,S,C,F},
Y5 = Y4.
Строим множества VN' = {A,B,C,D,F,S}, VT' - {a,b,c} и Р'.
Получили грамматику:
G'({a.b.c}.{A.B.C.D.F,S}.P',S) P':
S -> aAB A -> aA | bB В -> ACb | b С -> A | bA | cC D -> a | С | Fb F -> ВС | AC
Удалим недостижимые символы:
1.
V0 = {S},i~l.
2.
V, = {S,A,B}, V^V0: i:=2.
3.
V2 = {S,A,B,C},
y>Vj: i:=2.
4.
V3 = {S,A,B,C},V3
= V2.
5.
Строим множества VN" - {A,B,C,S}, VT" = {a,b,c} и Р'.
В итоге получили грамматику:
G"({a,b.c},{A.B,C.S}.P".S)
Р":
S i* aAB
A -> aA | bB
В -> ACb | b
С -» A | bA | cC Алгоритмы удаления бесплодных и недостижимых символов относятся к первой группе преобразований КС-грамматик. Они всегда ведут к упрощению грамматики, сокращению количества символов алфавита и правил грамматики.
Устранение л-правил
^-правилами (или правилами с пустой цепочкой) называются все правила грамматики вида А->Х, где AeVN.
Грамматика G(VT,VN,P,S) называется грамматикой без ^-правил, если в ней не существует правил (А-»^)еР, A*S и существует только одно правило (S-»^.)eP, в том случае, когда ^eL(G), и при этом S не встречается в правой части ни одного правила грамматики.
Для того чтобы упростить построение распознавателей цепочек языка L(G), любую грамматику G целесообразно преобразовать к виду без ^.-правил. Существует алгоритм преобразования произвольной КС-грамматики к виду без ^-правил. Он работает с некоторым множеством нетерминальных символов W;.
Алгоритм устранения - правил по шагам
1.
W0
= {A:(A-^)eP}, i:-l.
2.
Wi - WH u {A: (А-кх)еР, aeW,.,').
3.
Если W, ф Wi-ii то i := i+1 и перейти к шагу 2, иначе
перейти к шагу 4.
4.
VN' =
5.
Если (А-»а)е Р и в цепочку а входят символы из множества Wj, тогда на
основе цепочки а
строится множество цепочек {а'} путем исключения из а всех возможных комбинаций символов из
Wj, и все правила вида А-»а' добавляются
в Р'.
6.
Если SeWj, то значит XeL(G), и тогда в VN' добавляется новый символ S', который становится целевым символом грамматики G, а в Р'
добавляются два новых правила: S'-»X,|S; иначе S' = S.
Данный алгоритм часто ведет к увеличению количества правил грамматики, но позволяет упростить построение распознавателя для заданного языка.
Пример устранения - правил
Рассмотрим грамматику:
G({a.b.c}.{A,B.C.S}.P.S)
Р:
S -> АаВ | аВ | сС
А -> АВ | а | b | В
В -> Ва | X
С -> АВ | с
Удалим Х-правила:
1. W0
= {B},i:=l.
2.
W, = {В,А}, W^W0, i:-2.
3.
W2 = {В,А,С}, W2*Wi,
i:=3.
4.
W3 - {B,A,Q,
W3 = W2.
5.
Построим множества VN' = {A,B,C,S}, VT' я {a,b,c} и множество правил Р'.
6.
Рассмотрим все правила из множества Р':
О Из правил S-»AaB | аВ | сС исключим все комбинации А, В и С и получим новые правила S—>Аа | аВ j a | a | с, добавим их в Р', исключая дубликаты, получим: S->AaB | аВ | сС | Аа | аВ | а | с.
О Из правил А->АВ | а | b | В исключим все комбинации А и В и получим новые правила A-W\|B, в Р' их добавлять не надо, поскольку правило А-»В там уже есть, а правило А->А бессмысленно.
О Из правила В—>Ва исключим В и получим новое правило В->а, добавим его в Р', получим В->Ва|а.
О Из правил С->АВ | с исключим все комбинации А и В и получим новые правила С—>А| В, добавим их в Р', получим С—>АВ | А | В | с.
7. SeW3, поэтому в грамматику С не надо
добавлять новый целевой символ S',
S' = S.
Получим грамматику:
G'({a.b,c}.{A,B.C.S}.P'.S)
Р':
S -> АаВ | аВ | сС | Аа | а | с
А -> АВ | а | b | В
В —> Ва | а
С -> АВ | А | В | с
Устранение цепных правил
Циклом (циклическим выводом) в грамматике G(VT,VN,P,S) называется вывод вида А=>*А, AeVN. Очевидно, что такой вывод абсолютно бесполезен. Поэтому в распознавателях КС-языков целесообразно избегать возможности появления циклов.
Циклы возможны только в том случае, если в КС-грамматике присутствуют цепные правила вида А-»В, А,Ве VN. Чтобы исключить возможность появления циклов в цепочках вывода, достаточно устранить цепные правила из набора правил грамматики.
Чтобы устранить цепные правила в КС-грамматике G(VT,VN,P,S), для каждого нетерминального символа XeVN строится специальное множество цепных символов Nx, а затем на основании построенных множеств выполняются преобразования правил Р. Поэтому алгоритм устранения цепных правил надо выполнить для всех нетерминальных символов грамматики из множества VN.
Алгоритм устранения цепных правил по шагам
1.
Для всех символов X из множества VN повторять шаги 1-4, затем
перейти к шагу 5.
2.
NV{X},i:=l.
3.
N* = Щл
и {В: (А->В)еР, Ве№У.
4.
Если Nx ф N\i, то i:=i+l и перейти к шагу 2, иначе Nx'=
N^-{X} и перейти к шагу 1.
5.
VN' =
6.
Для всех правил
(А-»а)еР', если BeNA, B*A, то в Р'
добавляются правила вида В->а.
Данный алгоритм, так же как и алгоритм устранения А,-правил, ведет к увеличению числа правил грамматики, но упрощает построение распознавателей.
Пример устранения цепных правил
Рассмотрим работу алгоритмов удаления недостижимых и бесплодных символов на примере грамматики:
G({a.b.c}.{A.B.C,S}.P,S)
Р:
S -> АаВ | аВ | сС | Аа | а | с
А —> АВ | а | b | В
В -> Ва | а С —> АВ | А | с
Устраним цепные правила:
1. Ns0
= {S},i:=l.
2.
Ns! = {S}, Nsj= Ns0, Ns = 0.
3.
РП = {А},1:=1.
4.
NA! - {A,B},
NVNV i:-2.
5.
NA2 = {A,B}, Щ = NA,,
NA = {B}.
6.
NB0 =
{B},i:=l.
7.
NB! = {B}, NB,-
NB0, NB = 0.
8.
Nc0 =
{C},i:=l.
9.
Nc, = {C,A}, NC^NC0:
i:-2.
10.
Nc2 = {C,A,B},
NC2^NS: i:=3.
11.
Nc3 - {C,A,B},
Nc3 = Nc2, Nc = {A,B}.
12.
Получили: Ns = 0, NA = {B}, NB
- 0, Nc = {A,B}, S' = S, построим множества VN' = {A,B,C,S}, VT = {a,b,c} и множество правил Р'.
13.
Рассмотрим все
правила из множества Р' — интерес для нас представляют только правила для символов А и В, так как NA = {В } и Nc = {А,В}.
О Для правил А-»АВ | а | b имеем новые правила С-»АВ | а | Ь, поскольку Ае№ (правило А-»В цепное и поэтому не входит в Р'), из них правило С-»АВ уже существует в Р'.
О Для правил В-»Ва|а имеем новые правила А-»Ва|а и С—>Ва | а, поскольку BeNA и BeNc, из них правила Ан>а и С-»а (последнее добавлено на предыдущем шаге) уже существуют в Р'.
Получим новую грамматику:
G'({a.b.c}.{A.B.C.S}.P'.S)
Р':
S -> АаВ | аВ | сС | Аа | а | с
А -> АВ | а | b | Ва
В -» Ва | а
С -» АВ | с | а | b | Ва
Рассмотрим дополнительно в качестве примера грамматику для арифметических выражений над символами «а» и «Ь», которая уже рассматривалась ранее в этом пособии в разделе «Проблемы однозначности и эквивалентности грамматик», глава 9 - G({+.-,/.*.a,b}, {S.T.E}, P. S):
Р:
S -> S+T | S-T |
Т
Т
-> Т*Е | Т/Е | Е
Е -> (S) | а | Ь
Устраним цепные правила:
1. Ns0
= {S},i:=l.
2.
Ns! - {S,T};
NVNso, i:-2.
3.
Ns2 = {S,T,E}, ЩфЩ, i:-3.
4.
NS3 = {S)T,E},NS3 = NS2lNs = {T1E}.
5.
NT0 =
{T},i:=l.
6.
NT! = {T,E},
NVNT0: i:=2.
7.
NT2 = {T,E})NT2=NT1,NT = {E}.
8.
NE0 =
{E},i:=l.
9.
NE! = {E}, NEj=
NE0, NE = 0.
10.
Получили: Ns = {T,E}, NT = {E}, NE
= 0, S' - S, построим множества VN' = {S,T,E}, VT' = {+,-,/,*,a,b } и множество правил Р'.
11.
Рассмотрим все правила из множества Р' — интерес представляют только правила для символов Т и Е, так как Ns =
{Т,Е} и NT =
{Е}:
О Для правил Т->Т*Е|Т/Е имеем новые правила S->T*E|T/E, поскольку TeNs.
О Для правил E->(S)|a|b имеем новые правила S-»(S)|a|b и T->(S)|a|b, поскольку EeNs и EeNT.
Получим новую грамматику:
G'({+.-./.*.a.b}, {S.T.E}. Р'. S) Р';
S -> S+T | S-T | Т*Е | Т/Е | (S) | а | b Т -> Т*Е | Т/Е | (S) | а | b Е -у (S) | а | b
Эту грамматику мы дальше будем использовать для построения распознавателей КС-языков.
КС-грамматики в нормальной форме
Грамматики в нормальной форме Хомского
Нормальная форма Хомского или бинарная нормальная форма (БНФ) — это одна из предопределенных форм для правил КС-грамматики. В нормальную форму Хомского можно преобразовать любую произвольную КС-грамматику. Для преобразования в нормальную форму Хомского предварительно грамматику надо преобразовать в приведенный вид.
Определение нормальной формы Хомского
КС-грамматика G(VT,VN,P,S) называется грамматикой в
нормальной форме Хомского,
если в ее множестве правил Р присутствуют только правила следующего вида:
1.
А -> ВС, где A,B,CeVN.
2.
А -» а, где AeVN и aeVT.
3.
S -» X, если XeL(G), причем S не должно встречаться в правых
частях других правил.
Никакие другие формы правил не должны встречаться среди правил грамматики в нормальной форме Хомского [6, т. 1, 26].
КС-грамматика в нормальной форме Хомского называется также грамматикой в бинарной нормальной форме (БНФ). Название «бинарная» происходит от того, что на каждом шаге вывода в такой грамматике один нетерминальный символ может быть заменен только на два других нетерминальных символа. Поэтому в дереве вывода грамматики в нормальной форме Хомского каждая вершина либо распадается на две другие вершины (в соответствии с первым видом правил), либо содержит один последующий лист с терминальным символом (в соответствии со вторым видом правил). Третий вид правил введен для того, чтобы к нормальной форме Хомского можно было преобразовывать грамматики КС-языков, содержащих пустые цепочки символов.
Алгоритм преобразования грамматики в нормальную форму Хомского
Алгоритм позволяет преобразовать произвольную исходную КС-грамматику в эквивалентную грамматику в нормальной форме Хомского.
Условие: дана КС-грамматика G(VT,VN,P,S), необходимо построить эквивалентную ей грамматику G'(VT,VN',P',S') в нормальной форме Хомского: L(G) = = L(G').
На первом шаге исходную грамматику надо преобразовать к приведенному виду. Поскольку алгоритм преобразования КС-грамматик к приведенному виду был рассмотрен выше, можно считать, что исходная грамматика уже является приведенной (не содержит бесполезных и недостижимых символов, цепных правил и ^.-правил).
В начале работы алгоритма преобразования приведенной КС-грамматики в нормальную форму Хомского множество нетерминальных символов VN' результирующей грамматики G' строится на основе множества нетерминальных символов VN исходной грамматики G: VN' = VN.
Затем алгоритм преобразования работает с множеством правил Р исходной грамматики G. Он просматривает все правила из множества Р и в зависимости от вида каждого правила строит множество правил Р' результирующей грамматики G' и дополняет множество нетерминальных символов этой грамматики VN'.
1. Если встречается правило вида А—>а,
где AeVN и aeVT, то оно переносится во множество
Р' без изменений.
2.
Если встречается правило вида А-»ВС, где A,B,CeVN, то оно переносится во множество Р' без изменений.
3.
Если встречается правило вида S-^>X, где S — целевой символ грамматики G, тп оно переносится во множество Р' без изменений. Если встречается правило вида А-»аВ, где A.BeVN и aeVT, то во множество правил Р'
включаются правила А-»<АаВ>В и <АаВ>-»а и новый символ <АаВ > добавляется во
множество нетерминальных символов VN' грамматики G'.
4.
Если встречается правило вида А-»Ва, где A,BeVN и aeVT, то во множество правил Р' включаются правила
А-»В<АВа> и <АВа>-»а, и новый символ <АВа> добавляется во множество
нетерминальных символов VN' грамматики
G'.
5.
Если встречается правило вида A->ab, где A eVN и a,beVT, то во множество правил Р' включаются правила
А-»<Аа><АЬ>, <Аа>-»а и <Ab>->b, новые символы <Аа> и <АЬ>
добавляются во множество нетерминальных символов VN' грамматики G'.
6.
Если встречается
правило вида А-^...Xk, к>2, где AeVN и Vi: X^VTuVN, то во множество правил Р' включается цепочка правил:
А 4 <Х1'><Х2...Хк>
<Х2...Хк> -* <Х2'><Х3...Хк>
<ХыХк> -> <Хы'><Хк'>
новые нетерминальные символы <Х2...Хк>, <Х2...Хк>,..., <Хк. Хк> включаются во множество нетерминальных символов VN' грамматики G', кроме того, Vi: если XeVN, то <Xi'>sXi, иначе (если XjeVT) <Xi'> — это новый нетерминальный символ, он добавляется во множество VN', а во множество правил Р' грамматики G' добавляется правило <Xj'> -> X,.
Целевым символом результирующей грамматики G' является целевой символ исходной грамматики G.
Пример преобразования грамматики в нормальную форму Хомского
Рассмотрим в качестве примера грамматику G({a,b,c},{A,B,C,S},P,S)
Р:
S -* АаВ | Аа | be А —> АВ | а | аС В -> Ва | b ,
С -> АВ | с
Эта грамматика уже находится в приведенной форме. Построим эквивалентную ей грамматику G'(VT,VN',P',S ) в нормальной форме Хомского. Начнем построение с множества нетерминальных символов новой грамматики: VN' = {A,B,C,S}. Множество еще будет дополняться в процессе работы алгоритма.
Начнем разбирать правила этой грамматики.
Первое правило исходной
грамматики S-»AaB подпадает под 7-й вариант работы алгоритма. В соответствии с требованиями алгоритма
заменяем его на последовательность:
S -> <A'><aB> <aB> -j> <a'><B'>
Поскольку А и В — нетерминальные символы, а «а» — терминальный символ, то получаем, что <А'>г=А и <В'>=В, а новое правило <а'>-»а должно быть добавлено во множество правил Р' новой грамматики. Получаем последовательность правил:
S -> А<аВ> <аВ> -> <а'>В <а' >->а
Во множество нетерминальных символов VN' новой грамматики необходимо добавить новые символы <аВ> и <а'>. Получаем VN' = {A,B,C,S,<aB>,<a'>}.
Второе правило исходной грамматики S-»Aa подпадает под 5-й вариант работы алгоритма. Заменяем его на два правила:
S -» A<SAa> <SAa> -> a
Новый символ <SAa> добавляется во множество нетерминальных символов новой грамматики. Получаем VN' = {A,B,C,S,<aB>,<a'>,<SAa>}.
Третье правило исходной грамматики S—>Ьс подпадает под 6-й вариант работы алгоритма. Заменяем его на три правила:
S -» <Sb><Sc>
<Sb> -* b <Sc> -> с
Новые символы <Sb> и <Sc> добавляются во множество нетерминальных символов новой грамматики. Получаем VN' = {A,B,C,S,<aB>,<a'>,<SAa>,<Sb>,<Sc>}. Четвертое правило исходной грамматики А->АВ подпадает под 2-й вариант работы алгоритма. Переносим его во множество правил новой грамматики без изменений.
Пятое правило исходной грамматики А-»а подпадает под 1-й вариант работы алгоритма. Переносим его во множество правил новой грамматики без изменений.
Шестое правило исходной грамматики А-»аС подпадает под 4-й вариант работы алгоритма. Заменяем его на два правила:
А -> <АаОС <АаС> -> а
Новый символ <АаС> добавляется во множество нетерминальных символов новой грамматики. Получаем VN' = {A,B,C,S,<aB>,<a'>,<SAa>,<Sb>,<Sc>,<AaC>}.
Седьмое правило исходной грамматики В-»Ва подпадает под 5-й вариант работы алгоритма. Заменяем его на два правила:
В -» В<ВВа> <ВВа> -> а
Новый символ <ВВа> добавляется во множество
нетерминальных символов новой грамматики. Получаем VN' = {A,B,C,S,<aB>,<a'>,<SAa>,<Sb>,<Sc>,<AaC>, <ВВа>}.
Восьмое правило исходной грамматики В->Ь подпадает под 1-й вариант работы алгоритма. Переносим его во множество правил новой грамматики без изменений.
Девятое правило исходной грамматики С-»АВ подпадает под 2-й вариант работы алгоритма. Переносим его во множество правил новой грамматики без изменений.
Десятое правило исходной грамматики С-»с подпадает под 1-й вариант работы алгоритма. Переносим его во множество правил новой грамматики без изменений.
Рассмотрение множества правил исходной грамматики закончено. Множестве правил Р' новой грамматики G' и множество нетерминальных символов VN этой грамматики окончательно построены. Целевым символом новой грамматики является символ S.
Получаем новую грамматику в нормальной форме Хомского, эквивалентную исходной: G4{a,b,с} ,{А,В,С,S,<aB>,<a4<SAa>,<Sb>,<Sc>,<AaC>,<BBa>},P\S)^
Р':
S -> А<аВ> |
A<SAa> | <Sb><Sc>
<аВ> -4 <а'>В
<а'>-»а
<SAa> -* a
<Sb> --» b
<Sc> -> с
А —> АВ | а | <АаОС
<АаС> -> а
В -» В<ВВа> | b
<ВВа> -> а
С —> АВ | с Видно, что при приведении грамматики к нормальной форме Хомского количе ство правил и нетерминальных символов в грамматике увеличивается. При этом растет объем грамматики и несколько затрудняется ее восприятие человеком. Од нако цель преобразования — не упрощение грамматики, а упрощение построе ния распознавателя языка на ее основе. Именно этой цели и служит нормальна форма Хомского. Далее будут рассмотрены методы построения распознавателей в основе которых лежит именно эта форма представления грамматики КС языка.
Устранение левой рекурсии. Грамматики в нормальной форме Грейбах
Определение левой рекурсии
Символ AeVN в КС-грамматике G(VT,VN,P,S) называется рекурсивным, есл для него существует цепочка вывода вида А=>+аА(3, где a,pe(VTuVN)*.
Если а = X и $*\, то рекурсия называется левой, а грамматика G — леворекурсивной; если а*Х и (3 = X, то рекурсия называется правой, а грамматика G — прг ворекурсивной. Если a = X и р = X, то рекурсия представляет собой цикл. Котр грамматика G — приведенная, в ней нет цепных правил и не может встречатьс циклов, поэтому далее циклы рассматриваться не будут.
Любая КС-грамматика может быть как леворекурсивной, так и праворекурсивной, а также леворекурсивной и праворекурсивной одновременно (по различным символам из множества нетерминальных символов).
КС-грамматика называется нелеворекурсивной, если она не является леворекурсивной. Аналогично, КС-грамматика является неправорекурсивной, если не является праворекурсивной.
Некоторые алгоритмы левостороннего разбора для КС-языков не работают с леворекурсивными грамматиками, поэтому возникает необходимость исключить левую рекурсию из выводов грамматики. Далее будет рассмотрен алгоритм, который позволяет преобразовать правила произвольной КС-грамматики таким образом, чтобы в выводах не встречалась левая рекурсия.
Следует отметить, что поскольку рекурсия лежит в основе построения языков на основе правил грамматики в форме Бэкуса—Наура, полностью исключить рекурсию из выводов грамматики невозможно. Можно избавиться только от одного вида рекурсии — левого или правого, то есть преобразовать исходную грамматику G к одному из видов: нелеворекурсивному (избавиться от левой рекурсии) или неправорекурсивному (избавиться от правой рекурсии). Для левосторонних распознавателей интерес представляет избавление от левой рекурсии — то есть преобразование грамматики к нелеворекурсивному виду.
Доказано, что любую КС-грамматику можно преобразовать к нелеворекурсивному или неправорекурсивному виду.
Алгоритм устранения левой рекурсии
Условие: дана КС-грамматика G(VT,VN,P,S), необходимо построить эквивалентную ей нелеворекурсивную грамматику G'(VN',VT,P',S'): L(G) = L(G').
Алгоритм преобразования работает с множеством правил исходной граммати-1 ки Р, множеством нетерминальных символов VN и двумя переменными счетчиками: i и j.
Шаг 1. Обозначим нетерминальные символы грамматики так: VN = {А!,А2,...,АП}. i:= 1.
Шаг 2. Рассмотрим правила для символа А;. Если эти правила не содержат левой рекурсии, то перенесем их во множество правил Р' без изменений, а символ Aj добавим во множество нетерминальных символов VN'.
Иначе запишем правила для Aj в виде А, -» Aiai|Aia2|...|AiaJpi|P2l-|Pp. где Vj 1 < j < Р ни одна из цепочек Pj не начинается с символов Ак, таких, что k < i.
Вместо этого правила во множество Р' запишем два правила вида:
А^ —»a1|a2|...|aJa1Ai'|a2Ai'|...|amAi'
Символы Aj и А;' включаем во множество VN'.
Теперь все правила для А; начинаются либо с терминального символа, либо с нетерминального символа Ак, такого, что k > i. Шаг 3. Если i = п, то грамматика G' построена, иначе i := i+1, j := 1 и перейти к шагу 4.
Шаг 4. Для символа Aj во множестве правил Р' заменить все правила вида А;-»Аа, где ae(VTuVN)*, на правила вида А^р^Рзоф.^Рща, причем Aj—>Pi|p2l---lPm — все правила для символа Aj.
Так как правая часть правил Aj-»p1|p2|...|pm уже начинается с терминального символа или нетерминального символа Ак, к > j, то и правая часть правил для символа Aj будет удовлетворять этому условию.
Шаг 5. Если j = i-1, то перейти к шагу 2, иначе j := j+1 и перейти к шагу 4.
Шаг 6. Целевым символом грамматики G' становится символ Ак, соответствующий символу S исходной грамматики G.
Рассмотрим в качестве примера грамматику для арифметических выражений над символами «а» и «b» G({+,-,/,*,a,b}, {S,T,E}, P, S):
Р:
S -> S+T | S-T
| Т
Т
-> Т*Е | Т/Е
| Е
Е -4 (S) | а | b
Эта грамматика является леворекурсивной. Построим эквивалентную ей нелеворекурсивную грамматику G'.
Шаг
1. Обозначим VN - {Ah A2, A3}. i .:= 1,
Тогда правила грамматики G будут иметь вид:
Aj -> At+A2 | АГА2 | А2
А2 -> А2*А3 | А2/А3 | А3
А3 -> (Aj) | а | Ь
Шаг 2. Для А! имеем правила А1->А1+А2|А1-А2|А2. Их можно записать в виде At-> —>А1сх11 A(a21 р1( где Щ = + А2, a2 = -A2, Pt = A2.
Запишем новые правила для множества Р':
Aj -» А2|А2А1;'
A,i' -> +А2| -A2|+A2Ai'
j-AvjAi'
Добавив эти правила в Р', а символы Aj и А{ во множество нетерминальных
символов, получим: VN' = {А1(АГ}-
Шаг 3. i = 1 < 3. Построение не закончено: i := i+1 = 2, j := 1.
Шаг 4. Для символа А2 во множестве правил Р' нет правила вида А2->А1а, поэтому на этом шаге никаких действий не выполняем.
Шаг 5. j = 1 = i-1, переходим опять к шагу 2.
Шаг 2. Для А2 имеем правила А2->А2*А31A2/A31А3. Их можно записать в виде А2-» -^А2а, | А2а21 р1; где сц = *А3, а2 = /A3. Pi = А3. Запишем новые правила для множества Р':
А2 -> А31А3А2"
А2: -> *А31 /А31 *А3А2 ■ [ /А3А2'
Добавим эти правила в Р', а символы А2 и А2' во множество нетерминальных символов, получим: VN' = {А^А/.А^А^}.
Шаг j?. i = 2 < 3. Построение не закончено: i := i+1 = 3, j := 1.
Шаг 4. Для символа А3 во множестве правил Р' нет правила вида Аз-^а, поэтому на этом шаге никаких действий не выполняем.
Шаг 5. j = 1 < i-1, j := j+1 = 2, переходим к шагу 4.
Шаг 4. Для символа А3 во множестве правил Р' нет правила вида А3-»А2а, поэтому на этом шаге никаких действий не выполняем.
Шаг 5. j = 2 = i-1, переходим опять к шагу 2.
Шаг 2. Для А3 имеем правила
А3 -> (А,) | а | Ь. Эти правила не содержат левой рекурсии. Переносим их в Р', а символ А3
добавляем в VN'. Получим: VN' = =s {A^Aj ,A2,A2
,A3}.
Шаг 3. i = 3 = 3. Построение грамматики G' закончено.
В результате выполнения алгоритма преобразования получили нелеворекурсивную грамматику G({+,-./.*,a,b}, {At.Aj' ,А2,А2' ,А3}, Р', At) с правилами:
Р':
А, -» А2 | A2At'
Aj' -> +А2 | -А2 | +А2А,' | -А2А('
А2 -> А3 | А3А2'
V -> *А3 | /Аз | *А3А2' | /А3А2'
А3 -> (Aj) | а | b
Грамматики в нормальной форме Грейбах
На основании грамматики, в которой исключена левая рекурсия, можно построить грамматику в нормальной форме Грейбах.
КС-грамматика G(VT,VN,P,S) называется грамматикой в нормальной форме Грейбах, если она не является леворекурсивной и в ее множестве правил Р присутствуют только правила следующего вида:
1.
А -> аа, где aeVT и aeVN*.
2.
S -» X, если ^eL(G), причем S не должно встречаться в правых
частях других правил.
Никакие другие формы правил не должны встречаться среди правил грамматики в нормальной форме Грейбах.
Нормальная форма Грейбах является удобной формой представления грамматик для построения нисходящих левосторонних распознавателей (в тех случаях, когда присутствие левой рекурсии в правилах грамматики недопустимо). В данном пособии эта нормальная форма отдельно не рассматривается. Подробнее с нею можно ознакомиться в [6, т. 1, 26].
Распознаватели КС-языков с возвратом
Принципы работы распознавателей с возвратом
Распознаватели с возвратом — это самый примитивный тип распознавателей для КС-языков. Логика их работы основана на моделировании недетерминированного МП-автомата.
Поскольку моделируется недетерминированный МП-автомат (который в общем виде не преобразуется в детерминированный), то на некотором шаге работы моделирующего алгоритма возможно возникновение нескольких допустимых следующих состояний автомата. В таком случае существуют два варианта реализации алгоритма [6, т. 1, 40].
В первом варианте на каждом шаге работы алгоритм должен запоминать все возможные следующие состояния МП-автомата, выбирать одно из них, переходить в это состояние и действовать так до тех пор, пока либо не будет достигнуто конечное состояние автомата, либо автомат не перейдет в такую конфигурацию, когда следующее состояние будет не определено. Если достигнуто одно из конечных состояний — входная цепочка принята, работа алгоритма завершается. В противном случае алгоритм должен вернуть автомат на несколько шагов назад, когда еще был возможен выбор одного из набора следующих состояний, выбрать другой вариант и промоделировать поведение автомата с этим условием. Алгоритм завершается с ошибкой, когда все возможные варианты работы автомата будут перебраны и ни одно из возможных конечных состояний не было достигнуто.
Во втором варианте алгоритм моделирования МП-автомата должен на каждом шаге работы при возникновении неоднозначности с несколькими возможными следующими состояниями автомата запускать новую свою копию для обработки каждого из этих состояний. Алгоритм завершается, если хотя бы одна из выполняющихся его копий достигнет одно из конечных состояний. При этом работа всех остальных копий алгоритма прекращается. Если ни одна из копий алгоритма не достигла конечного состояния МП-автомата, то алгоритм завершается с ошибкой.
Второй вариант реализации алгоритма связан с управлением параллельными процессами в вычислительных системах, поэтому сложен в реализации. Кроме того, на каждом шаге работы МП-автомата альтернатив следующих состояний может быть много, а количество возможных параллельно выполняющихся процессов в операционных системах ограничено, поэтому применение второго варианта алгоритма осложнено. По этим причинам большее распространение получил первый вариант алгоритма, который предусматривает возврат к ранее запомненным состояниям МП-автомата — отсюда и название «разбор с возвратами». Следует отметить, что, хотя МП-автомат является односторонним распознавателем, алгоритм моделирования его работы предусматривает возврат назад, к уже прочитанной части цепочки символов, чтобы исключить недетерминизм в поведении автомата (который невозможно промоделировать).
Есть еще одна особенность в моделировании МП-автомата: любой практически ценный алгоритм должен завершаться за конечное число шагов (успешно или неуспешно). Алгоритм моделирования работы произвольного МП-автомата в общем случае не удовлетворяет этому условию. Например, даже после считывания всей входной цепочки символов МП-автомат может совершить произвольное (в том числе и бесконечное) число переходов. В том случае, если цепочка не принята, это может привести к бесконечному количеству шагов моделирующего алгоритма, который по этой причине никогда не будет закончен.
Чтобы избежать таких ситуаций, алгоритмы разбора с возвратами строят не для произвольных МП-автоматов, а для МП-автоматов, удовлетворяющим некоторым заданным условиям. Как правило, эти условия связаны с тем, что МП-автомат должен строиться на основе грамматики заданного языка только после того, как она подвергнется некоторым преобразованиям. Поскольку преобразования грамматик сами по себе не накладывают каких-либо ограничений на входной класс КС-языков (в результате преобразования мы всегда получаем эквивалентную грамматику), то они и не ограничивают применимости алгоритмов разбора с возвратами — эти алгоритмы применимы для любого КС-языка, заданного произвольной КС-грамматикой или МП-автоматом.
Алгоритмы разбора с возвратами обладают экспоненциальными характеристиками. Это значит, что вычислительные затраты алгоритмов экспоненциально зависят от длины входной цепочки символов: a, aeVT, n = |а|. Конкретная зависимость определяется вариантом реализации алгоритма.
Доказано, что в общем случае при первом варианте реализации для произвольной КС-грамматики G(VT,VN,P,S) время выполнения данного алгоритма Тэ будет иметь экспоненциальную зависимость от длины входной цепочки, а необходимый объем памяти Мэ — линейную зависимость от длины входной цепочки: Тэ = 0(еп) и Мэ = О(п). При втором варианте реализации, наоборот, время выполнения данного алгоритма Тэ будет иметь линейную зависимость от длины входной цепочки, а необходимый объем памяти Мэ — экспоненциальную зависимость от длины входной цепочки: Тэ = О(п) и Мэ = 0(еп).
Экспоненциальная зависимость вычислительных затрат от длины входной цепочки существенно ограничивает применимость алгоритмов разбора с возвратами. Они тривиальны в реализации, но имеют неудовлетворительные характеристики, поэтому могут использоваться только для простых КС-языков с малой длиной входных предложений языка1. Для многих классов КС-языков существу-
Возможность использовать эти алгоритмы в реальных компиляторах весьма сомнительна, поскольку длина входной цепочки может достигать нескольких тысяч и даже десятков тысяч символов. Очевидно, что время работы алгоритма при экспоненциальной зависимости требуемых вычислительных ресурсов от длины входной цепочки символов будет в таком варианте явно неприемлемым даже на самых современных компьютерах. ют более эффективные алгоритмы распознавания, поэтому алгоритмы разбор; с возвратами применяются редко.
Далее рассмотрены два основных варианта таких алгоритмов.
Нисходящий распознаватель с возвратом
Принцип работы нисходящего распознавателя с подбором альтернатив
Этот распознаватель моделирует работу МП-автомата с одним состояние\ q: R({q}, V,Z,5,q,S,{q}). Автомат распознает цепочки КС-языка, заданного КС грамматикой G(VT,VN,P,S). Входной алфавит автомата содержит терминальны! символы грамматики: V = VT, а алфавит магазинных символов строится из тер минальных и нетерминальных символов грамматики: Z = VTuVN.
Начальная конфигурация автомата определяется так: (q,a,S) — автомат пребы вает в своем единственном состоянии q, считывающая головка находится в нача ле входной цепочки символов aeVT*, в стеке лежит символ, соответствующие целевому символу грамматики S.
Конечная конфигурация автомата определяется так: (q,X,X) — автомат пребывае-в своем единственном состоянии q, считывающая головка находится за концов входной цепочки символов, стек пуст.
Функция переходов МП-автомата строится на основе правил грамматики:
1. (q,a)e8(q,A.,A), AeVN, ae(VTuVN)*, если правило A->a содержится во мно жестве правил Р грамматики G: A-»a e
Р.
2.
(q,X,)eS(q,a,a) VaeVT.
Этот МП-автомат уже был рассмотрен выше.
Работу данного МП-автомата можно неформально описать следующим образом если на верхушке стека автомата находится нетерминальный символ А, то еп можно заменить на цепочку символов а, если в грамматике языка есть правил! А—>а, не сдвигая при этом считывающую головку автомата (этот шаг работы на зывается «подбор альтернативы»); если же на верхушке стека находится терми нальный символ а, который совпадает с текущим символом входной цепочки, п этот символ можно выбросить из стека и передвинуть считывающую головку н; одну позицию вправо (этот шаг работы называется «выброс»). Данный МП-ав томат может быть недетерминированным, поскольку при подборе альтернатив! в грамматике языка может оказаться более одного правила вида А-»сс, следо вательно, тогда функция 8(q,A.,A) будет содержать более одного следующего со стояния — у автомата будет несколько альтернатив.
Данный МП-автомат строит левосторонние выводы для грамматики G(VT,Vr> P,S). Для моделирования такого автомата необходимо, чтобы грамматика G(VT VN,P,S) не была леворекурсивной (в противном случае, очевидно, автомат мо жет войти в бесконечный цикл). Поскольку, как было доказано выше, произволь ную КС-грамматику всегда можно преобразовать к нелеворекурсивному виду, т этот алгоритм применим для любой КС-грамматики, следовательно, им мож» распознавать цепочки любого КС-языка. Рассмотренный МП-автомат строит левосторонние выводы и читает цепочку входных символов слева направо. Поэтому для него естественным является построение дерева вывода сверху вниз. Такой распознаватель называется нисходящим.
Решение о том, выполнять ли на каждом шаге работы МП-автомата выброс или подбор альтернативы, принимается однозначно. Моделирующий алгоритм должен обеспечивать выбор одной из возможных альтернатив и хранение информации о том, какие альтернативы на каком шаге уже были выбраны, чтобы иметь возможность вернуться к этому шагу и подобрать другие альтернативы. Такой алгоритм разбора называется алгоритмом с подбором альтернатив.
Реализация алгоритма распознавателя с подбором альтернатив
Существует масса способов реализации алгоритма, моделирующего работу этого МП-автомата. Рассмотрим один из примеров реализации алгоритма нисходящего распознавателя с возвратом.
Для работы алгоритма используется МП-автомат, построенный на основе исходной грамматики G(VT,VN,P,S). Для удобства работы все правила из множества Р в грамматике G представим в виде A-»ai|a2|.:.|etnj то есть пронумеруем все возможные альтернативы для каждого нетерминального символа AeVN. Входная цепочка символов имеет вид a = а1а2...ап, |а| = п. В алгоритме используется также еще дополнительное состояние автомата b (от «back» — «назад»), которое сигнализирует о выполнении возврата к уже прочитанной части входной цепочки1. Для хранения уже выбранных альтернатив используется дополнительный стек L2, который может содержать следующую информацию:
□
символы aeVT входного языка автомата;
□
символы вида Aj, где AeVN — это означает, что среди всех
возможных правил для символа А была
выбрана альтернатива с номером j.
В итоге алгоритм работает с двумя стеками: Lt — стек МП-автомата и L2 — стек возвратов. Оба они представлены в виде цепочек символов. Символы в цепочку стека Lt помещаются слева, а в цепочку стека L2 — справа. В целом состояние алгоритма на каждом шаге определяется четырьмя параметрами: (Q, i, Lb L2), где Q — текущее состояние автомата (q или b); i — положение считывающей головки во входной цепочке символов а (1 < i < n+1); Lt — содержимое стека МП-автомата; L2 — содержимое дополнительного стека.
Начальным состоянием алгоритма является состояние (q, 1, S, X), где S — целевой символ грамматики. Алгоритм начинает свою работу с начального состояния и циклически выполняет шесть шагов до тех пор, пока не перейдет в конечное состояние или не обнаружит ошибку. На каждом шаге алгоритма проверяется,
Сам автомат имеет только одно состояние q, которого
достаточно для его функционирования, однако нет возможности моделировать на компьютере работу
недетерминированного
автомата, поэтому приходится выполнять возврат к уже прочитанной части цепочки и вводить для этой цели дополнительное состояние.
соответствует ли текущее состояние алгоритма заданному для данного шага и< ходному состоянию, и выполняются ли заданные дополнительные условия. Есл это требование выполняется, алгоритм переходит в следующее состояние, уст; новленное для этого шага, если нет — шаг пропускается, алгоритм переходит следующему шагу.
Алгоритм предусматривает циклическое выполнение следующих шагов.
Шаг 1 (Разрастание), (q, i, Ар, а) ->■ (q, i, уф, аА^, если A-»Yi — это первая i всех возможных альтернатив для символа А.
Шаг 2 (Успешное сравнение), (q, i, ар, а) -> (q, i+1, Р, аа), если а = ai? aeVT.
ШагЗ (Завершение). Если состояние соответствует (q, п+1Д, а), то разбор заве' шен, алгоритм заканчивает работу, иначе (q, i, X, а) -» (b, i, X, а), когда i*n+l.
Шаг 4 (Неуспешное сравнение), (q, i, ар, а) -> (b, i, ap, а), если а Ф a;, aeVT.
Шаг 5 (Возврат по входу), (b, i, Р, аа) -> (q, i-1, ар, а), V aeVT.
Шаг 6 (Другая альтернатива). Исходное состояние (b, i, Yjp, aAj), действия:
О перейти в состояние (q, i, Yj+tP> otAj+1), если еще существует альтерната: A—>Yj+1 для символа AeVN;
О сигнализировать об ошибке и прекратить выполнение алгоритма, если А= и не существует больше альтернатив для символа S;
О иначе перейти в состояние (q, i, Ap, a).
В случае успешного завершения алгоритма цепочку вывода можно построить основе содержимого стека L2, полученного в результате выполнения алгорит\ Цепочка вывода строится следующим образом: поместить в цепочку номер пр вила т, соответствующий альтернативе А—»у|, если в стеке содержится симв> Aj-, все символы aeVT, содержащиеся в стеке L2, игнорируются.
Этот алгоритм может быть напрямую использован для построения распознаг телей. Следует помнить, что для применения этого алгоритма исходная гра матика не должна быть леворекурсивной. Если это условие не удовлетворяв ся, то грамматику предварительно надо преобразовать к нелеворекурсивному виду.
Рассмотрим в качестве примера грамматику G({+,-,/,*,а,b}, {S,R,T,F,E}, P,
с правилами:
Р:
S -» Т | TR
R _> +т | -Т | +TR | -TR
Т -> Е | EF
F -> *Е | /Е | *EF | /EF
Е -» (S) |
a | b
Это
нелеворекурсивная грамматика для арифметических выражений (pai в
разделе «Устранение левой рекурсии. Грамматики в нормальной фор Грейбах» она
была построена с помощью алгоритма устранения левой ] курсии).
На основании полученной цепочки номеров альтернатив
SjTtEsRjTiEjSiTaEiFtEa
построим последовательность номеров примененных правил: 2, 7, 14, 3, 7, 13, 1, 8, 14, 9, 15. Получаем левосторонний вывод: S => TR => ER => aR => а+Т => а+Е ^> a+(S) => а+(Т) Щ a+(EF) => a+(a'F) => a+(a*E) => a+(a*b). Соответствующее ему дерево вывода приведено на рис. 11.2.
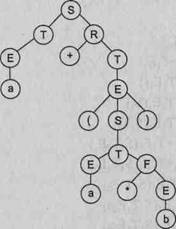
Рис. 11.2. Дерево вывода для грамматики без левых рекурсий
Из приведенного примера очевиден недостаток алгоритма нисходящего разбора с возвратами — значительная временная емкость: для разбора достаточно короткой входной цепочки (всего 7 символов) потребовалось 68 шагов работы алгоритма. Такого результата и следовало ожидать, исходя из экспоненциальной зависимости необходимых для работы алгоритма вычислительных ресурсов от длины входной цепочки. Это существенный недостаток данного алгоритма. Преимуществом данного алгоритма можно считать простоту его реализации. Практически этот алгоритм разбора можно использовать только тогда, когда известно, что длина исходной цепочки символов заведомо не будет большой (не больше нескольких десятков символов). Для реальных компиляторов такое условие невыполнимо, но для некоторых небольших распознавателей вполне допустимо, и здесь данный алгоритм разбора может найти применение именно благодаря своей простоте.
Еще одно преимущество алгоритма — его универсальность. На его основе можно распознавать входные цепочки языка, заданного любой КС-грамматикой, достаточно лишь привести ее к нелеворекурсивному виду (а это можно сделать с любой грамматикой, см. раздел «Преобразование КС-грамматик. Приведенные грамматики»). Интересно, что грамматика даже не обязательно должна быть однознач-
ной — для неоднозначной грамматики алгоритм найдет один из возможных левосторонних выводов.
Сам по себе алгоритм разбора с подбором альтернатив, использующий возвраты, не находит применения в реальных компиляторах. Однако его основные принципы лежат в основе многих нисходящих распознавателей, строящих левосторонние выводы и работающих без использования возвратов. Методы, позволяющие строить такие распознаватели для некоторых классов КС-языков, рассмотрены далее. Эти распознаватели будут более эффективны в смысле необходимых вычислительных ресурсов, но алгоритмы их работы уже более сложны, кроме того, они не являются универсальными.
Распознаватель на основе алгоритма «сдвиг-свертка»
Принцип работы восходящего распознавателя по алгоритму «сдвиг-свертка»
Этот распознаватель строится на основе расширенного МП-автомата с одним состоянием q: R({q},V,Z,5,q,S,{q}). Автомат распознает цепочки КС-языка, заданного КС-грамматикой G(VT,VN,P,S). Входной алфавит автомата содержит терминальные символы грамматики: V = VT; а алфавит магазинных символов строится из терминальных и нетерминальных символов грамматики: Z = VTuVN.
Начальная конфигурация автомата определяется так: (q,a,X) — автомат пребывает в своем единственном состоянии q, считывающая головка находится в начале входной цепочки символов aeVT", стек пуст.
Конечная конфигурация автомата определяется так: (q,X,S) — автомат пребывает в своем единственном состоянии q, считывающая головка находится за концом входной цепочки символов, в стеке лежит символ, соответствующий целевому символу грамматики S.
Функция переходов МП-автомата строится на основе правил грамматики:
1. (q,A)e8(q,^,y), AeVN, ye(VTuVN)*, если правило А-»у содержится
во множестве правил Р грамматики G: А->у е Р.
2.
(q,a)e5(q,a,A.) VaeVT.
Неформально работу этого расширенного автомата можно описать так: если на верхушке стека находится цепочка символов у, то ее можно заменить на нетерминальный символ А, если в грамматике языка существует правило вида А-»у, не сдвигая при этом считывающую головку автомата (этот шаг работы называется «свертка»); с другой стороны, если считывающая головка автомата обозревает некоторый символ входной цепочки а, то его можно поместить в стек, сдвинув при этом головку на одну позицию вправо (этот шаг работы называется «сдвиг» или «перенос»). Сам алгоритм, моделирующий работу такого расширенного автомата, называется алгоритмом «сдвиг-свертка» или «перенос-свертка» (по названиям основных действий алгоритма).
Данный расширенный МП-автомат строит правосторонние выводы для грамматики G(VT,VN,P,S). Для моделирования такого автомата необходимо, чтобы грамматика G(VT,VN,P,S) не содержала ^.-правил и цепных правил (в противном случае, очевидно, автомат может войти в бесконечный цикл из сверток). Поскольку, как было доказано выше, произвольную КС-грамматику всегда можно преобразовать к виду без ^.-правил и цепных правил, то этот алгоритм применим для любой КС-грамматики, следовательно, им можно распознавать цепочки любого КС-языка.
Этот расширенный МП-автомат строит правосторонние выводы и читает цепочку входных символов слева направо. Поэтому для него естественным является построение дерева вывода снизу вверх. Такой распознаватель называется восходящим.
Данный расширенный МП-автомат потенциально имеет больше неоднозначностей, чем рассмотренный ваше МП-автомат, основанный на алгоритме подбора альтернатив. На каждом шаге работы автомата надо решать следующие вопросы:
□
что необходимо выполнять: сдвиг или свертку;
□
если выполнять свертку, то какую цепочку у выбрать для поиска правил (цепочка у должна встречаться в
правой части правил грамматики);
□
какое правило выбрать для свертки, если окажется, что существует
несколько правил
вида А-»у (несколько правил с одинаковой правой частью).
Чтобы промоделировать работу этого расширенного МП-автомата, надо на каждом шаге запоминать все предпринятые действия, чтобы иметь возможность вернуться к уже сделанному шагу и выполнить эти же действия по-другому. Этот процесс должен повторяться до тех пор, пока не будут перебраны все возможные варианты.
Реализация распознавателя с возвратами на основе алгоритма «сдвиг-свертка»
Существует несколько реализаций для алгоритма моделирования работы такого расширенного МП-автомата [6, т. 1, 40]. Один из вариантов рассмотрен ниже.
Для работы алгоритма всем правилам грамматики G(VT,VN,P,S ), на основе которой построен автомат, необходимо дать порядковые номера. Будем нумеровать правила грамматики в направлении слева направо и сверху вниз в порядке их записи в форме Бэкуса—Наура. Входная цепочка символов имеет вид а = aia2...an,
|а| = п.
Алгоритм моделирования расширенного МП-автомата, аналогично алгоритму нисходящего распознавателя, использует дополнительное состояние b и дополнительный стек возвратов L2. В стек помещаются номера правил грамматики, использованных для свертки, если на очередном шаге алгоритма была выполнена свертка, или 0, если на очередном шаге алгоритма был выполнен сдвиг.
В итоге алгоритм работает с двумя стеками: L] — стек МП-автомата и L2 — стек возвратов. Первый представлен в виде цепочки символов, второй — цепочки целых чисел от 0 до т, где т — количество правил грамматики G. Символы в це- почку стека Li помещаются справа, числа в стек L2 — слева. В целом состояние алгоритма на каждом шаге определяется четырьмя параметрами: (Q, i, L,, L2), где Q. — текущее состояние автомата (q или b); i — положение считывающей головки во входной цепочке символов а (К i < n+1); Lj - содержимое стека МП-автомата; L2 — содержимое дополнительного стека возвратов.
Начальным состоянием алгоритма является состояние (q, 1, X, X). Алгоритм
начинает свою работу с начального состояния и циклически выполняет пят!
шагов до тех пор, пока не перейдет в конечное состояние или не обнаружш
ошибку.
Алгоритм предусматривает циклическое выполнение следующих шагов.
Шаг 1 (Попытка свертки), (q, i, ар, у) ->• (q, i, аА, jy), если А-»Р - это первое и:
всех возможных правил из множества правил Р с номером j для подцепочки р
причем оно есть первое подходящее правило для цепочки ар, для которой пра
вило вида А-»р существует. Если удалось выполнить свертку — возвращаемся i
шагу 1, иначе — переходим к шагу 2.
Шаг 2 (Перенос - сдвиг). Если i<n+l, то (q, i, а, у) -> (q, i+1, агь Оу), a, eVT
Если i = n+1, то перейти к шагу 3, иначе перейти к шагу 1.
Шаг 3 (Завершение). Если состояние соответствует (q, n+1, S, у), то разбор завер
шен, алгоритм заканчивает работу, иначе перейти к шагу 4.
Шаг 4 (Переход к возврату), (q, n+1, а, у) -» (Ь, п+1, а, у). Шаг 5 (Возврат). Если исходное состояние (b, i, аА, jy), то:
О перейти в состояние (q, i, а'В, ky), если j > 0, и А-»Р - это правило с номе ром j и существует правило В->Р' с номером к, к > j, такое, что ар = а'Р после чего надо вернуться к шагу 1;
О перейти в состояние (Ь, п+1, ар, у), если i = n+1, j > 0, А->Р - это правил с номером j и не существует других правил из множества Р с номеро: k > j, таких, что их правая часть является правой подцепочкой из цепочк ар; после этого вернуться к шагу 5;
О перейти в состояние (q, i+1, ар^, Оу), aj eVT, если i * n+1, j > 0, A->P - эт правило с номером j и не существует других правил из множества Р с^нс мером k>j, таких, что их правая часть является правой подцепочкой у цепочки аР; после этого перейти к шагу 1;
О иначе сигнализировать об ошибке и прекратить выполнение алгоритма.
Если исходное состояние (b, i, аа, Оу), a eVT, то если i > 1, тогда перейти в cm
дующее состояние (b, i-1, а, у) и вернуться к шагу 5; иначе сигнализировать с
ошибке и прекратить выполнение алгоритма.
В случае успешного завершения алгоритма цепочку вывода можно построить i
основе содержимого стека L2, полученного в результате выполнения алгоритм
Для этого достаточно удалить из стека L2 все цифры 0 — и получим последов
тельность номеров правил.
Этот алгоритм может быть напрямую использован для построения распознав
телей. Следует помнить, что для применения этого алгоритма исходная грамм
тика не должна допускать циклов и не должна содержать ^-правил. Если это условие не удовлетворяется, то грамматику надо предварительно преобразовать к приведенной форме.
Возьмем в качестве примера грамматику G({+,-,/,*,а,b}, {S.T.E}, P, S):
Р:
S -> S+T | S-T | Т*Е | Т/Е | (S) | а |
b
Т -» Т*Е | Т/Е | (S) | а | b
Е 4
(S) | а | b
Это грамматика для арифметических выражений, в которой устранены цепные правила (ее уже рассматривали в разделе «Преобразование КС-грамматик. Приведенные грамматики»). Следовательно, в ней не может быть циклов1. Кроме того, видно, что в ней нет ^.-правил. Таким образом, цепочки языка, заданного этой грамматикой, можно распознавать с помощью алгоритма восходящего распознавателя с возвратами.
Проследим разбор цепочки а+(а*Ь) из языка этой грамматики. Работу алгоритма будем представлять в виде последовательности его состояний, взятых в скобки {} (фигурные скобки используются, чтобы не путать их с круглыми скобками, предусмотренными в правилах грамматики). Правила будем нумеровать слева направо и сверху вниз (всего в грамматике получается 15 правил). Для пояснения каждый шаг работы сопровождается номером шага алгоритма, который был применен для перехода в очередное состояние (записывается перед состоянием через символ : — двоеточие).
Алгоритм работы восходящего распознавателя с возвратами при разборе цепочки а+(а*Ь) будет выполнять следующие шаги:
{q, 1, К Ц
{q, 2, а, [0]}
{q. 2, S, [6,0]}
{q, 3, S+, [0,6,0]}
{q, 4, S+(, [0,0,6,0]}
{q, 5,
S+(a, [0,0,0,6,0]}
{q, 5,
S+(S, [6,0,0,0,6,0]}
{q, 6,
S+(S*, [0,6,0,0,0,6,0]}
{q, 7,
S+(S*b, [0,0,6,0,0,0,6,0]}
{q, 7, S+(S*S, [7,0,0,6,0,0,0,6,0]}
На самом деле исходная грамматика для арифметических выражений, которая была рассмотрена в разделе «Проблемы однозначности и эквивалентности грамматик», тоже не содержит циклов (это легко заметить из вида ее правил), однако для чистоты утверждения цепные правила были исключены. Кроме того, следует отметить, что рассмотренные грамматики эквивалентны (задают один и тот же язык) — это можно утверждать, поскольку обе они были получены из одной и той же фамматики путем строгих преобразований, не меняющих заданный грамматикой язык.
11.
2: {q, 8, S+(S*S), [0,7,0,0,6,0,0,0,6,0]}
12.
4: {b, 8, S+(S*S), [0,7,0,0,6,0,0,0,6,0]}
13.
5: {b, 7, S+(S*S, [7,0,0,6,0,0,0,6,0]}
14.
5: {q, 7, S+(S*T, [12,0,0,6,0,0,0,6,0]}
15.
2: {q, 8, S+(S*T), [0,12,0,0,6,0,0,0,6,0]}
16.
4: (b, 8, S+(S*T), [0,12,0,0,6,0,0,0,6,0]}
17.
5: (b, 7, S+(S*T, [12,0,0,6,0,0,0,6,0]}
18.
5: {q, 7, S+(S*E, [15,0,0,6,0,0,0,6,0]}
19.
2: {q, 8, S+(S*E), [0,15,0,0,6,0,0,0,6,0]}
20. 4:
{b, 8, S+(S*E), [0,15,0,0,6,0,0,0,6,0]}
21. 5:
{b, 7, S+(S*E, [15,0,0,6,0,0,0,6,0]}
22. 5:
{q, 8, S+(S*a), [0,0,0,6,0,0,0,6,0]}
23. 4:
{b, 8, S+(S*a), [0,0,0,6,0,0,0,6,0]}
24. 5:
(b, 7, S+(S*a, [0,0,6,0,0,0,6,0]}
25. 5:
{b, 6, S+(S*, [0,6,0,0,0,6,0]}
26.
5: {b, 5, S+(S, [6,0,0,0,6,0]}
27.
5:{q,5,S+(T,
[11,0,0,0,6,0]}
28.
2:{q,
6, S+(T*, [0,11,0,0,0,6,0]}
29.
2: {q, 7, S+(T*b, [0,0,11,0,0,0,6,0]}
30.
1: {q, 7, S+(T*S, [7,0,0,11,0,0,0,6,0]}
31.
2: {q, 8, S+(T*S), [0,7,0,0,11,0,0,0,6,0]}
32.
4: {b, 8, S+(T*S), [0,7,0,0,11,0,0,0,6,0]}
33.
5: {b, 7, S+(T*S, [7,0,0,11,0,0,0,6,0]}
34.
5: {q, 7, S+(T*T, [12,0,0,11,0,0,0,6,0]}
35.
2: {q, 8, S+(T*T), [0,12,0,0,11,0,0,0,6,0]}
36.
4: {b, 8, S+(T*T), [0,12,0,0,11,0,0,0,6,0]}
37.
5: {b, 7, S+(T*T, [12,0,0,11,0,0,0,6,0]}
38.
5: {q, 7, S+(T*E, [15,0,0,11,0,0,0,6,0]}
39.
1: (q, 7, S+(S, [3,15,0,0,11,0,0,0,6,0]}
40.
2: {q, 8, S+(S), [0,3,15,0,0,11,0,0,0,6,0]}
41.
1: {q, 8, S+S, [5,0,3,15,0,0,11,0,0,0,6,0]}
42.
4: {b, 8, S+S, [5,0,3,15,0,0,11,0,0,0,6,0]}
43.
5: {q, 8, S+T, [10,0,3,15,0,0,11,0,0,0,6,0]}
44.
1: {q, 8, S, [1,10,0,3,15,0,0,11,0,0,0,6,0]}
3: Разбор закончен, алгоритм
завершен.
|
На основании полученной цепочки номеров правил: 1, 10, 3, 15, 11, 6 получаем правосторонний вывод: S => S+T => S+(S) => S+(T*E) => S+(T*b) => S+(a*b) => a+(a*b). Соответствующее ему дерево вывода приведено на рис. 11.3. |
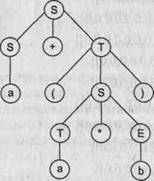
Рис. 11.3. Дерево вывода для грамматики без цепных правил
В приведенном примере очевиден тот же недостаток алгоритма восходящего разбора с возвратами, что и у алгоритма нисходящего разбора с возвратами — значительная временная емкость: для разбора достаточно короткой входной цепочки (всего 7 символов) потребовалось 45 шагов работы алгоритма. Такого результата и следовало ожидать, исходя из экспоненциальной зависимости необходимых для работы алгоритма вычислительных ресурсов от длины входной цепочки. Это существенный недостаток данного алгоритма.
Преимущество у данного алгоритма то же, что и у алгоритма нисходящего разбора с возвратами — простота реализации. Поэтому и использовать его можно практически в тех же случаях — когда известно, что длина исходной цепочки символов заведомо не будет большой (не больше нескольких десятков символов).
Этот алгоритм также универсален. На его основе можно распознавать входные цепочки языка, заданного любой КС-грамматикой, достаточно лишь преобразовать ее к приведенному виду (а это можно сделать с любой грамматикой, см. раздел «Преобразование КС-грамматик. Приведенные грамматики»), чтобы она не содержала цепных правил и ^-правил.
Сам по себе алгоритм «сдвиг-свертка» с возвратами не находит применения в реальных компиляторах. Однако его базовые принципы лежат в основе многих восходящих распознавателей, строящих правосторонние выводы и работающих без использования возвратов. Методы, позволяющие строить такие распознаватели для некоторых классов КС-языков, рассмотрены далее. Эти распознаватели будут более эффективны в смысле потребных вычислительных ресурсов, но алгоритмы их работы уже сложнее, кроме того, они не являются универсальными. В тех случаях, когда удается дать однозначные ответы на поставленные выше три вопроса о выполнении сдвига (переноса) или свертки при моделировании данного алгоритма, он оказывается очень удобным и полезным.
В принципе два рассмотренных алгоритма — нисходящего и восходящего разбо ра с возвратами — имеют схожие характеристики по потребным вычислитель ным ресурсам и одинаково просты в реализации. То, какой из них лучше взят для реализации простейшего распознавателя в том или ином случае, зависи прежде всего от грамматики языка. В рассмотренном примере восходящий алгс ритм смог построить вывод за меньшее число шагов, чем нисходящий — но эт еще не значит, что он во всех случаях будет эффективнее для рассмотренног языка арифметических выражений. Вопрос о выборе типа распознавателя — нис ходящий либо восходящий — достаточно сложен. В компиляторах на него кром структуры правил грамматики языка влияют и другие факторы, например, нео£ ходимость локализации ошибок в программе, а также то, что предложения все языков программирования строятся в нотации «слева направо». Этот вопро будет затронут далее, при рассмотрении других вариантов распознавателей дл КС-языков; пока же эти два типа распознавателей можно считать сопоставимь ми по эффективности (отметим — низкой эффективности) своей работы и прс стоте реализации.
Табличные распознаватели для КС-языков
Общие принципы работы табличных распознавателей
Табличные распознаватели используют для построения цепочки вывода К( грамматики другие принципы, нежели МП-автоматы. Как и МП-автоматы, ог получают на вход цепочку входных символов а = aia2...an, aeVT*, |a| = n,an строение вывода основывают на правилах заданной КС-грамматики G(VT,VN,P,S Принцип их работы заключается в том, что искомая цепочка вывода строится ) сразу — сначала на основе входной цепочки порождается некоторое промеж точное хранилище информации объема п*п (промежуточная таблица)1, а поте уже на его основе строится вывод.
Табличные алгоритмы обладают полиномиальными характеристиками требу мых вычислительных ресурсов в зависимости от длины входной цепочки. Д. произвольной КС-грамматики G(VT,VN,P,S) время выполнения алгоритма ' имеет кубическую зависимость от длины входной цепочки, а необходимый об ем памяти Мэ — квадратичную зависимость от длины входной цепочки: а, ае V п = |а|: Тэ = 0(п3) и Мэ = 0(п2), Квадратичная зависимость объема необходим! памяти от длины входной цепочки напрямую связана с использованием пром жуточного хранилища данных.
1 В алгоритме Кока—Янгера—Касами промежуточная таблица используется в явном ви, а в алгоритме Эрли она завуалирована под хранилище, именуемое «список ситуацш которое организовано несколько сложнее, чем простая таблица.
Табличные распознаватели универсальны — они могут быть использованы для распознавания цепочек, порожденных с помощью произвольной КС-грамматики (возможно, саму грамматику первоначально потребуется привести к заданному виду, но это не ограничивает универсальности алгоритмов). Кроме того, табличные распознаватели — это самые эффективные с точки зрения требуемых вычислительных ресурсов универсальные алгоритмы для распознавания цепочек КС-языков1,
Алгоритм Кока—Янгера—Касами
Алгоритм Кока—Янгера—Касами для заданной грамматики G(VT,VN,P,S) и цепочки входных символов а = aia2...an, aeVT*, |a| = п строит таблицу Тп.п, такую, что VAeVN: AeT[i,j], тогда и только тогда, если A=>+ai...ai+j.1. Таким образом, элементами таблицы Тп»п являются множества нетерминальных символов из алфавита VN.
Тогда существованию вывода S=>*a соответствует условие SeT[l,n].
При условии существования вывода по таблице Тп.п можно найти всю полную цепочку вывода S=s>*a.
Для построения вывода по алгоритму Кока—Янгера—Касами грамматика G(VT, VN,P,S) должна быть в нормальной форме Хомского. Поскольку, как было показано выше, любую произвольную КС-грамматику можно преобразовать в нормальную форму Хомского, это не накладывает дополнительных ограничений на применимость данного алгоритма.
Алгоритм Кока—Янгера—Касами фактически состоит из трех вложенных циклов. Поэтому ясно, что время выполнения алгоритма имеет кубическую зависимость от длины входной цепочки символов. Таблица Тп»п, используемая для хранения промежуточных данных в процессе работы алгоритма, является таблицей множеств. Очевидно, что требуемый для ее хранения объем памяти имеет квадратичную зависимость от длины входной цепочки символов.
Сам алгоритм Кока—Янгера—Касами можно описать следующим образом:
Шаг 1.
Цикл для j от 1 до п
T[l.j] := {А | 3 АтМ, eP}-i T[l,j] включаются все нетерминальные символы,
для которых в грамматике G существует правило А->а.,.
Конец цикла для j.
Хотя табличные распознаватели и являются самыми эффективными среди универсальных распознавателей, тем не менее они не находят широкого применения. Дело в том, что полиномиальная зависимость требуемых вычислительных ресурсов от длины входной цепочки символов является неудовлетворительной для компиляторов (длины входных цепочек — тысячи и десятки тысяч символов). Поэтому практически всегда используются не универсальные, а более узкие, специализированные алгоритмы распознавателей, которые имеют обычно линейную зависимость требуемых вычислительных ресурсов от длины входной цепочки символов. К универсальным алгоритмам прибегают только тогда, когда специализированный распознаватель построить не удается. Шаг 2.
Цикл для i от 2 до п
Цикл для j от 1 до n-1+l T[i.j] := 0; Цикл для к от 1 до п-1
Tti.j] : = T[i.j] и {А | .3 А^ВС € P. BeT[k.j]. CeT[i-k.j+k]} Конец цикла для к. Конец цикла для j. Конец цикла для i. Результатом работы алгоритма будет искомая таблица Тп.п. Для проверки супц ствования вывода исходной цепочки в заданной грамматике остается только прс верить условие SeT[l,n].
Если вывод существует, то необходимо получить цепочку вывода. Для этот, существует специальная рекурсивная процедура R. Она выдает последовательность номеров правил, которые нужно применить, чтобы получить цепочку вь вода. Ее можно описать следующим образом: R(i,j,A), где AeVN.
1.
Если j = 1 и существует правило A-»aj, то выдать номер этого правила.
2.
Иначе (если j > 1) возьмем к как наименьшее из
чисел, для которых 3 А--»ВХ е Р, BeT[k,j], CeT[i-k,j+k] (таких правил может быть несколько,
д; определенности берем наименьшее к). Пусть правило А-»ВС имеет номер i Тогда
нужно выдать этот номер ш, потом вызвать сначала R(i,k,B), а затем R(i-k,j+k,C).
Для получения всей последовательности номеров правил нужно вызвать R(l,n,S Рекурсивная процедура R не требует дополнительной памяти для своего выпо нения, кроме стека, необходимого для организации рекурсии. Время ее выполн ния имеет квадратичную зависимость от длины входной цепочки. На основании последовательности номеров правил, полученной с помощью алг ритма Кока—Янгера—Касами и рекурсивной процедуры R, можно построить лев сторонний вывод для заданной грамматики G(VT,VN,P,S) и цепочки входных си волов а. Таким образом, с помощью данного алгоритма решается задача разбора.
Алгоритм Эрли (основные принципы)
Алгоритм Эрли основан на том, что для заданной КС-грамматики G(VT,VN,P, и входной цепочки со = а^.-.а,,, goeVT, |со| = п строится последовательность era ков ситуаций 10,11?..., 1п. Каждая ситуация, входящая в список Ij для входной i почки со, представляет собой структуру вида [A->X1X2...Xk»Xk+1...Xm,i], N Xke(VNuVT), причем правило A-^Х^..Х,,, принадлежит множеству правил грамматики G, и 0<i<n, 0<k<m. Символ • («точка») — это метасимвол особе вида, который не входит ни во множество терминальных (VN), ни во множе! во нетерминальных (VT) символов грамматики. В ситуации этот символ мои стоять в любой позиции, в том числе в начале (•Щ.:.Хт) или в конце (Х)...Х, всей цепочки символов правила А->Х)...Хт. Если цепочка символов правг пустая (А—>Х), то ситуация будет выглядеть так: [A—>«,i]. Список ситуаций строится таким образом, что Vj, 0<j<n: [A->a»p,i]eIj тогда и только тогда, если 3 S=>*yAS, у=>*а1...а, и a=>*ai+1...aj. Иначе говоря, между вторым компонентом ситуации и номером списка, в котором он появляется, заключена часть входной цепочки, выводимая из А. Условия ситуации L гарантируют возможность применения правила А-»сф в выводе некоторой входной цепочки, совпадающей с заданной цепочкой со до позиции j.
Условием существования вывода заданной входной цепочки со в грамматике G(VN,VT,P,S) после завершения алгоритма Эрли служит [S-Ko»,0]sln. На основании полученного в результате выполнения алгоритма списка ситуаций можно затем с помощью специальной процедуры построить всю цепочку вывода и получить номера применяемых правил. Причем проще построить правосторонний вывод.
Алгоритм Эрли подробно здесь не рассматривается. Его описание можно найти, например, в книге [6, т. 1].
Как и все табличные алгоритмы, алгоритм Эрли обладает полиномиальными характеристиками в зависимости от длины входной цепочки. Доказано, что для произвольной КС-грамматики G(VN,VT,P,S) время выполнения данного алгоритма Тэ будет иметь кубическую зависимость от длины входной цепочки, а необходимый объем памяти Мэ — квадратичную зависимость от длины входной цепочки: а, ае VT*, п т |а|: Тэ = 0(п3) и Мэ = 0(п2). Но для однозначных КС-грамматик алгоритм Эрли имеет лучшие характеристики — его время выполнения в этом случае квадратично зависит от длины входной цепочки: Тэ = 0(п2). Кроме того, для некоторых классов КС-грамматик время выполнения этого алгоритма линейно зависит от длины входной цепочки (правда, для этих классов, как правило, существуют более простые алгоритмы распознавания). В целом алгоритм Эрли имеет лучшие характеристики среди всех универсальных алгоритмов распознавания входных цепочек для произвольных КС-грамматик. Он превосходит алгоритм Кока—Янгера—Касами для однозначных грамматик (которые представляют интерес в первую очередь), хотя и является более сложным в реализации.
Принципы построения распознавателей КС-языков без возвратов
Выше были рассмотрены различные универсальные распознаватели для КС-языков — то есть распознаватели, позволяющие выполнить разбор цепочек для любого КС-языка (заданного произвольной КС-грамматикой). Они универсальны, но имеют неудовлетворительные характеристики. Распознаватели с возвратами имеют экспоненциальную зависимость требуемых для выполнения алгоритма разбора вычислительных ресурсов от длины входной цепочки символов, а табличные распознаватели — полиномиальную. Для практического применения в реальных компиляторах такие характеристики являются неудовлетворительными. К сожалению, универсальных распознавателей с лучшими характеристиками для КС-языков построить не удается. Среди универсальных распознавателей лучшими по эффективности являются табличные.
С другой стороны, универсальные распознаватели для КС-языков на практике и не требуются. В каждом конкретном случае компилятор имеет дело с синтаксическими структурами, заданными вполне определенной грамматикой. Чаще всего эта грамматика является не просто КС-грамматикой, а еще и относится к какому-нибудь из известных классов КС-грамматик (нередко сразу к нескольким классам). Как минимум грамматика синтаксических конструкций языка программирования должна быть однозначной, а это уже значит, что она относится к классу детерминированных КС-языков.
Для многих классов КС-грамматик (и соответствующих им классов КС-языков) можно построить распознаватели, имеющие лучшие характеристики, чем рассмотренные выше распознаватели с возвратами и табличные. Эти распознаватели уже не будут универсальными — они будут применимы только к заданному классу КС-языков с соответствующими ограничениями, зато они будут иметь лучшие характеристики.
Далее будут рассмотрены некоторые из таких распознавателей. Все они имеют линейные характеристики — линейную зависимость необходимых для выполнения алгоритма разбора вычислительных ресурсов от длины входной цепочки. Для каждого распознавателя рассматривается класс КС-грамматик, с которым он связан. Это значит, что он может принимать только входные цепочки из КС-языков, заданных такими грамматиками. Всегда описываются ограничения, налагаемые на правила грамматики, или дается алгоритм проверки принадлежности произвольной КС-грамматики к заданному классу.
Однако следует всегда помнить, что проблема преобразования КС-грамматик алгоритмически неразрешима. Если какая-то грамматика не принадлежит к требуемому классу КС-грамматик, это еще не значит, что заданный ею язык не может быть описан грамматикой такого класса. Иногда удается выполнить преобразования и привести исходную грамматику к требуемому виду. Но, к сожалению, этот процесс не формализован, не поддается алгоритмизации и требует участия человека. Чаще всего такую работу вынужден выполнять разработчик компилятора (правда, выполняется она только один раз для синтаксических конструкций каждого языка программирования).
Существуют два принципиально разных класса распознавателей. Первый — нисходящие распознаватели, которые порождают цепочки левостороннего вывода и строят дерево вывода сверху вниз. Второй — восходящие распознаватели, которые порождают цепочки правостороннего вывода и строят дерево вывода снизу вверх. Названия «нисходящие» и «восходящие» связаны с порядком построения дерева вывода. Как правило, все распознаватели читают входную цепочку символов слева направо, поскольку предполагается именно такая нотация в написании исходного текста программ.
Нисходящие распознаватели используют модификации алгоритма с подбором альтернатив. При их создании применяются методы, которые позволяют однозначно выбрать одну и только одну альтернативу на каждом шаге работы МП-
автомата (шаг «выброс» в этом автомате всегда выполняется однозначно). Алгоритм подбора альтернатив без модификаций был рассмотрен выше.
Восходящие распознаватели используют модификации алгоритма «сдвиг-свертка» (или «перенос-свертка», что то же самое). При их создании применяются методы, которые позволяют однозначно выбрать между выполнением «сдвига» («переноса») или «свертки» на каждом шаге работы расширенного МП-автомата, а при выполнении свертки однозначно выбрать правило, по которому будет производиться свертка. Алгоритм «сдвиг-свертка» без модификаций был рассмотрен выше.
Далеко не все известные распознаватели с линейными характеристиками рассматриваются в данном пособии. Более полный набор распознавателей, а также описание связанных с ними классов КС-грамматик и КС-языков вы можете найти в [5, 6, 23, 42, 65]. Далее будут рассмотрены только самые часто встречающиеся и употребительные классы.
Классы кс-языков и грамматик.
Нисходящие распознаватели КС-языков без возвратов
Левосторонний разбор по методу рекурсивного спуска
Стремление улучшить алгоритм нисходящего разбора заключается в первую очередь в определении метода, по которому на каждом шаге алгоритма можно был бы однозначно выбрать одну из всего множества возможных альтернатив. В тг ком случае алгоритм моделирования работы МП-автомата не требовал бы возврг та на предыдущие шаги и за счет этого обладал бы линейными характеристике ми от длины входной цепочки. В случае неуспеха выполнения такого алгоритм входная цепочка однозначно не принимается, повторные итерации разбора н выполняются.
Наиболее очевидным методом выбора одной из множества альтернатив являете выбор ее на основании символа ае VT, обозреваемого считывающей головкой ai томата на каждом шаге его работы (находящегося справа от положения текуще головки во входной цепочке символов). Поскольку в процессе нисходящего ра: бора именно этот символ должен появиться на верхушке магазина для продв! жения считывающей головки автомата на один шаг (условие 5(q,a,a) = {(q,^-) VaeVT в функции переходов МП-автомата), то разумно искать альтернатив где он присутствует в начале цепочки, стоящей в правой части правила грамм; тики. По такому принципу действует алгоритм разбора по методу рекурсивного спуска
Алгоритм разбора по методу рекурсивного спуска
В реализации этого алгоритма для каждого нетерминального символа AeV грамматики G(VN,VT,P,S) строится процедура разбора, которая получает i вход цепочку символов а и положение считывающей головки в цепочке i. Ecj для символа А в грамматике G определено более одного правила, то процедура разбора ищет среди них правило вида А-»ау, aeVT, ye(VNuVT)*, первый символ правой части которого совпадал бы с текущим символом входной цепочки а = оц. Если такого правила не найдено, то цепочка не принимается. Иначе (если найдено правило А-»ау или для символа А в грамматике G существует только одно правило А-»у), то запоминается номер правила, и когда а = ocj, то считывающая головка передвигается (увеличивается i), а для каждого нетерминального символа в цепочке у рекурсивно вызывается процедура разбора этого символа. Название метода происходит из реализации алгоритма, которая заключается в последовательности рекурсивных вызовов процедур разбора. Для начала разбора входной цепочки нужно вызвать процедуру для символа S с параметром i = 1.
Условия применимости метода можно получить из описания самого алгоритма—в грамматике G(VN,VT,P,S) VAeVN возможны только два варианта правил:
А->у, ye(VNuVT)* и это единственное правило для А;
A->a,pi|a2p2|...|anpn, Vi: aieVT, pi6(VNuVT)* и если щ, то аЦ.
Этим условиям удовлетворяет незначительное количество реальных грамматик. Это достаточные, но не необходимые условия. Если грамматика не удовлетворяет этим условиям, еще не значит, что заданный ею язык не может распознаваться с помощью метода рекурсивного спуска. Возможно, над грамматикой просто необходимо выполнить ряд дополнительных преобразований.
К сожалению, не существует алгоритма, который бы позволил преобразовать произвольную КС-грамматику к указанному выше виду, равно как не существует и алгоритма, который бы позволял проверить, возможны ли такого рода преобразования. То есть для произвольной КС-грамматики нельзя сказать, анализируема ли она методом рекурсивного спуска или нет.
Можно рекомендовать ряд преобразований, которые способствуют приведению грамматики к требуемому виду, но не гарантируют его достижения.
1.
Исключение ^-правил.
2.
Исключение левой рекурсии.
3.
Добавление новых нетерминальных символов. Например:
если правило: A->aa1|aa2|...|aan|b1p1|b2p2|...|bmpm,
то заменяем его на два: А-»аА'| b1p1|b2p2l—|bmpm и A'—>cc1jot2|---|a.n.
4. Замена нетерминальных символов в правилах на цепочки их выводов.
Например:
если имеются правила:
A->B1|B2|...|Bn|b1p,|b2p2|...|bmpmi
Bj-KXnIa^Ulcq,,,
Bn->anl|an2|...|a
заменяем первое правило на A^an|a12|...|alk|...|anl|an2|...|anp|b1p1|b2p2|...|bmpm.
В целом алгоритм рекурсивного спуска эффективен и прост в реализации, но имеет очень ограниченную применимость.
Пример реализации метода рекурсивного спуска
Дана грамматика G({a,b,c},{A,B,C,S},P,S):
Р:
S -> аА | ЬВ
А -> а | ЬА | сС
В -> b | аВ | сС
С.-> АаВЬ Необходимо построить распознаватель, работающий по методу рекурсивного спуска.
Видно, что грамматика удовлетворяет условиям, необходимым для построения такого распознавателя.
Напишем процедуры на языке программирования С, которые будут обеспечивать разбор входных цепочек языка, заданного данной грамматикой. Согласно алгоритму, необходимо построить процедуру разбора для каждого нетерминального символа грамматики, поэтому дадим процедурам соответствующие наименования. Входные данные для процедур разбора будут следующие:
□
цепочка входных символов;
□
положение указателя (считывающей головки МП-автомата) во входной цепочке;
□
массив для записи номеров примененных правил;
□
порядковый номер очередного правила в массиве.
Результатом работы каждой процедуры может быть число, отличное от нуля («истина»), или 0 («ложь»). В первом случае входная цепочка символов принимается распознавателем, во втором случае — не принимается. Для удобства реализации в том случае, если цепочка принимается распознавателем, будем возвращать текущее положение указателя в цепочке. Кроме того, потребуется еще одна дополнительная процедура для ведения записей в массиве последовательности правил (назовем ее WriteRules).
void
WriteRulesdnt* piRul. int* iP, int iRule)
{
piRul[*iP] = iRule;
*iP - *iP +
1; }
int
proc_S (char* szS, int IN, int* piRul, int* iP)
{
switch CszSCiN])
case а :
WriteRules(piRul.iP.l);
return proc_A(szS.iN+l.piRul .iP); case 'b':
WriteRules(piRul.iP,2):
return proc_B(szS.iN+l,piRul,iP);
return 0:
int proc_A (char* szS. int iN. int* piRul. int*
iP) {
switch CszS[iN])
{
case 'a':
writeRu1es(piRul,iP.3);
return iN+1:
case 'b':
WriteRules(piRul,iP.4):
return proc_A(szS.1N+l,piRul,i P); case 'c':
WnteRules(piRul.iP,5);
return
proc_C(szS.iN+l.piRul,iP);
} return
0;
}
int proc_B (char*
szS. int iN. int* piRul. int* iP) {
switch (szS[iN])
{
case 'b':
WriteRules(piRul,iP,6):
return iN+1; case 'a':
WriteRules(piRul.iP.7); return proc_B(szS,iN+l,piRul.iP); case 'c':
WriteRules(piRul.iP,8); return proc_B(szS.i N+l,pi Rul.i P); } return
0;
}
int proc_C (char* szS, int iN, int* piRul. int* iP) { i nt i;
WriteRules(piRu1.iP,9): i =
proc_A(szS.iN,piRul .iP); if (i «— 0) return 0; if (szS[i]
!= 'a') return 0; i++;
i - proc_B(szS,i.piRul.iP); if (i == 0) return 0; if (szS[i] != 'b') return 0: return i+1: }
Теперь для распознавания входной цепочки необходимо иметь целочисленный массив Rules достаточного объема для хранения номеров правил. Тогда работа распознавателя заключается в вызове процедуры proc_S(Str,0,Rules,&N), где Str -это входная цепочка символов, N — переменная для запоминания количества примененных правил (первоначально N = 0). Затем требуется обработка полученного результата: если результат на 1 превышает длину цепочки — цепочка принята, иначе — цепочка не принята. В первом случае в массиве Rules будем иметь последовательность номеров правил грамматики, необходимых для вывода цепочки, а в переменной N — количество этих правил. На основе этой цепочки можнс легко построить дерево вывода.
Объем массива Rul es заранее не известен, так как заранее не известно количестве шагов вывода. Чтобы избежать проблем с недостаточным объемом статическогс массива, приведенные выше процедуры распознавателя можно модифицировал так, чтобы они работали с динамическим распределением памяти (изменив процедуру WriteRules и тип параметра pi Rul в вызовах остальных процедур). На логику работы распознавателя это никак не повлияет. Следует помнить также, чте метод рекурсивного спуска основан на рекурсивном вызове множества процедур, что при значительной длине входной цепочки символов может потребовал соответствующего объема стека вызовов для хранения адресов процедур, их параметров и локальных переменных (более подробно об этом можно посмотрел в данном пособии в разделе «Семантический анализ и подготовка к генерации кода», глава 14).
Из приведенного примера видно, что алгоритм рекурсивного спуска удобен и прост в реализации. Главным препятствием в его применении является то, что класс грамматик, допускающих разбор на основе этого алгоритма, сильно ограничен.
Расширенное применение распознавателей на основе метода рекурсивного спуска
Метод рекурсивного спуска позволяет выбрать альтернативу, ориентируясь нг текущий символ входной цепочки, обозреваемый считывающей головкой МП автомата. Если имеется возможность просматривать не один, а несколько симво лов вперед от текущего положения считывающей головки, то можно расширит! область применимости метода рекурсивного спуска. В этом случае уже можнс искать правила на основе некоторого терминального символа, входящего в пра вую часть правила. Естественно, и в таком варианте выбор должен быть однознач
ным — для каждого нетерминального символа в левой части правила необходимо, чтобы в правой части правила не встречалось двух одинаковых терминальных символов.
Этот метод требует также анализа типа присутствующей в правилах рекурсии, поскольку один и тот же терминальный символ может встречаться во входной строке несколько раз, и в зависимости от типа рекурсии следует искать его крайнее левое или крайнее правое вхождение в строке.
Рассмотрим грамматику арифметических выражений без скобок для символов aHbG({+, -./.*. a, b}. {S.T.E}, Р, S):
Р:
S -> S+T | S-T | Т
Т -> Т*Е | Т/Е | Е
Е -» (S) | a | b Это грамматика для арифметических выражений, которая уже была рассмотрена в разделе «Проблемы однозначности и эквивалентности грамматик», глава 9 и служила основой для построения распознавателей в разделе «Распознаватели КС-языков с возвратом», глава 11.
Запишем правила этой грамматики в форме с применением метасимволов. Получим:
Р:
S ^ Т{(+Т,-Т)}
Т -» Е{(*Е,/Е)}
Е -> (S) | а | b При такой форме записи процедура разбора для каждого нетерминального символа становится тривиальной.
Для символа S распознаваемая строка должна всегда начинаться со строки, допустимой для символа Т, за которой может следовать любое количество символов + или -, и если они найдены, то за ними опять должна быть строка, допустимая для символа Т. Аналогично, для символа Т распознаваемая строка должна всегда начинаться со строки, допустимой для символа Е, за которой может следовать любое количество символов * или /, и если они найдены, то за ними опять должна быть строка, допустимая для символа Е. С другой стороны, для символа Е строка должна начинаться строго с символов (, а или Ь, причем в первом случае за ( должна следовать строка, допустимая для символа S, а за ней — обязательно символ ).
Исходя из этого, построены процедуры разбора
входной строки на языке Pascal (используется Borland Pascal или Borland Delphi, которые допускают тип string — строка). Входными данными для них являются:
□
исходная строка символов;
□
текущее положение указателя в исходной строке;
□
длина исходной строки (в принципе, этот параметр можно опустить, но он введен для удобства);
□
результирующая строка правил.
Процедуры построены так, что в результирующую строку правил помещаются номера примененных правил в строковом формате, перечисленные через запятую (.). Правила номеруются в грамматике, записанной в форме Бэкуса—Наура, в порядке слева направо и сверху вниз (всего в исходной грамматике 9 правил). Распознаватель строит левосторонний вывод, поэтому на основе строки номеров правил всегда можно получить цепочку вывода или дерево вывода. Для начала разбора нужно вызвать процедуру proc_S(S,l,N,Pr), где S — входная строка символов; N — длина входной строки (в языке Borland Pascal вместо N можно взять Length(S)); Pr — строка, куда будет помещена последовательность примененных правил.
Результатом proc_S(S,l,N,Pr) выполнения будет N+1, если строка S принимается, и некоторое число, меньшее N+1, если строка не принимается. Если строка S принимается, то строка Рг будет содержать последовательность номеров правил, которые необходимо применить для того, чтобы вывести S1.
procedure
proc_S (S; string: i.n: integer; var pr: string): integer:
var
si : string:
begin
i :* proc_T(S.i,n,sl);
if 1 > 0 then begin
pr := '3.' + si: while (i <* n) and (i <>
0) do case S[i] of '+': begin
if i = n then i :» 0
else
begin
i := proc_T(S.i+l,n,sl): pr := '1.' + pr +'.'+ si;
end: end: '-': begin
if i = n then i
:= 0
else
begin
i := proc_T(S,i+l.n,sl): pr := '2,' + pr +'.'+ si:
1 Использование языка программирования Borland Pascal накладывает определенные технические
ограничения на данный распознаватель - длина строки в этом языке не может
превышать 255 символов. Однако данные ограничения можно снять если реализовать
свои тип данных «строка», или используя тот же алгоритм в другом языке
программиоо-вания. При использовании Borland Delphi эти
ограничения отпадают Конечно такого рода ограничения не имеют принципиального
значения при теоретическом исслеловя нии работы распознавателя, тем не менее
автор считает необходимым упомянуть о них
|
end: |
|
|
|
|
end: |
|
|
|
|
else break; |
|
|
|
|
end;{case} |
|
|
|
|
end;{if} |
|
|
|
|
proc_S :- i: |
|
|
|
|
end; |
|
|
|
|
procedure
proc_S (S; string; |
i,n:
integer; var pr: |
string): integer |
|
|
var si : string; |
|
|
|
|
begin |
|
|
|
|
i
:= proc_E(S.i.n.sl): |
|
|
|
|
if i > 0 then |
|
|
|
|
begin |
|
|
|
|
pr ;= '6.' + si; |
|
|
|
|
while
(i <= n) and (i |
<> 0) do |
|
|
|
case S[i] of |
|
|
|
|
.'*': begin |
|
|
|
|
if i - n then |
i :- 0 |
|
|
|
else |
|
|
|
|
begin |
|
|
|
|
i := proc_ |
E(S.i+l.n |
si); |
|
|
pr : = '4,' |
+ pr +', |
+ si: |
|
|
end; |
|
|
|
|
end; |
|
|
|
|
7'; begin |
|
|
|
|
if i = n then |
i := 0 |
|
|
|
else |
|
|
|
|
begin |
|
|
|
|
i := proc |
_E(S.i+l.r |
.si); |
|
|
pr ;= '5. |
' + pr +' |
' + si: |
|
|
end; |
|
|
|
|
end; |
|
|
|
|
else break; |
|
|
|
|
end;{case} |
|
|
|
|
end;{if} |
|
|
|
|
proc_S ;= i; |
|
|
|
|
end; |
|
|
|
procedure
procJ (S: string: i.n: integer; var pr: string): integer:
var si : string:
begin
case S[i] of
'a': begin pr := '8': proc_E := i+1: end;
'to': begin рг
:= '9'; ргос_Е
:= i+1; end:
'С: begin '
ргос_Е
:- 0; if i < n then begin
i := proc_S(S.i+l.n.sl); if (i > 0) and (i <
n) then begin
pr := '7,' + si;
if S[i] = ')'
then proc_E := i+1; end; end; end;
else proc_E :-
0; end;{case} end;
Конечно, и в данном случае алгоритм рекурсивного спуска позволил построить достаточно простой распознаватель, однако, прежде чем удалось его применить, потребовался неформальный анализ правил грамматики. Далеко не всегда такого рода неформальный анализ является возможным, особенно если грамматика содержит десятки и даже сотни различных правил — человек не всегда в состоянии уловить их смысл и взаимосвязь. Поэтому расширения алгоритма рекурсивного спуска, хотя просты и удобны, но не всегда применимы. Даже понять сам факт того, можно или нет в заданной грамматике построить такого рода распознаватель, бывает очень непросто [15, 26, 74].
Далее будут рассмотрены распознаватели и алгоритмы, которые основаны на строго формальном подходе. Они предваряют построение распознавателя рядом обоснованных действий и преобразований, с помощью которых подготавливаются необходимые исходные данные. Все такого рода действия построены на основе операций над множествами и символами, а исходными данными для них служат множества символов и правил исходной грамматики. В этом случае подготовку всех исходных данных для распознавателя можно формализовать и автоматизировать вне зависимости от объема грамматики (количества правил и символов в ней). Эти предварительные действия можно выполнить на компьютере, в то время как расширенная трактовка рекурсивного спуска предполагает неформальный анализ грамматики человеком, и в этом серьезный недостаток метода.
Определение 1_Цк)-грамматики
Логическим продолжением идеи, положенной в основу метода рекурсивного спуска, является предложение использовать для выбора одной из множества альтернатив не один, а несколько символов входной цепочки. Однако напрямую пере- дожить алгоритм выбора альтернативы для одного символа на такой же алгоритм для цепочки символов не удастся — два соседних символа в цепочке на самом деле могут быть выведены с использованием различных правил грамматики, поэтому неверным будет напрямую искать их в одном правиле. Тем не менее существует класс грамматик, основанный именно на этом принципе — выборе одной альтернативы из множества возможных на основе нескольких очередных символов в цепочке. Это так называемые LL(k)-грамматики. Правда, алгоритм работы распознавателя для них не так очевидно прост, как рассмотренный выше алгоритм рекурсивного спуска.
Грамматика обладает свойством LL(k), k > 0, если на каждом шаге вывода для однозначного выбора очередной альтернативы МП-автомату достаточно знать символ на верхушке стека и рассмотреть первые к символов от текущего положения считывающей головки во входной цепочке символов. Грамматика называется LL(k)-грамматикой, если она обладает свойством LL(k) для некоторого к > О1.
Название «LL(k)>> несет определенный смысл. Первая литера «L» происходит от слова «left» и означает, что входная цепочка символов читается в направлении слева направо. Вторая литера «L» также происходит от слова «left» и означает, что при работе распознавателя используется левосторонний вывод. Вместо «к» в названии класса грамматики стоит некоторое число, которое показывает, сколько символов надо рассмотреть, чтобы однозначно выбрать одну из множества альтернатив. Так, существуют LL(1)-грамматики, 1Х(2)-грамматики и другие классы.
В совокупности все П_(к)-грамматики для всех к>0 образуют класс LL-грам-матик.
На рис. 12.1 схематично показано частичное дерево вывода для некоторой LL(k)-грамматики. В нем ю обозначает уже разобранную часть входной цепочки а, которая построена на основе левой части дерева у. Правая часть дерева х — это еще не разобранная часть, а А — текущий нетерминальный символ на верхушке стека МП-автомата. Цепочка х представляет собой незавершенную часть цепочки вывода, содержащую как терминальные, так и нетерминальные символы. После завершения вывода символ А раскрывается в часть входной цепочки о, а правая часть дерева х преобразуется в часть входной цепочки т. Свойство LL(k) предполагает, что однозначный выбор альтернативы для символа А может быть сделан на основе к первых символов цепочки от, являющейся частью входной цепочки а.
Алгоритм разбора входных цепочек для 1Х(к)-грамматики носит название «к-предсказывающего алгоритма». Принципы его выполнения во многом соответствуют функционированию МП-автомата с той разницей, что на каждом шаге ра-
Требование к > 0, безусловно, является разумным — для принятия решения о выборе той или иной альтернативы МП-автомату надо рассмотреть хотя бы один символ входной цепочки. Если представить себе LL-грамматику с к = 0, то в такой грамматике вывод совсем не будет зависеть от входной цепочки. В принципе такая грамматика возможна, но в ней будет всего одна-единственная цепочка вывода. Поэтому практическое применение языка, заданного такого рода грамматикой, представляется весьма сомнительным. боты этот алгоритм может просматривать к символов вперед от текущего положения считывающей головки автомата.
|
V |
ш |
л |
|
1 |
и - \\ |
\ |
|
со |
и |
1х |
|
к |
||
|
а |
||
Рис. 12.1. Схема построения дерева вывода для Щк)-грамматики
Для LL(k)-грамматик известны следующие полезные свойства:
□
всякая 1_Цк)-грамматика для любого к>0 является однозначной;
□
существует алгоритм, позволяющий проверить, является ли заданная грамматика ЬЦк)-грамматикой для строго
определенного числа к.
Кроме того, известно, что все грамматики, допускающие разбор по методу рекурсивного спуска, являются подклассом ЬЦ1)-грамматик. То есть любая грамматика, допускающая разбор по методу рекурсивного спуска, является LL( 1 ^грамматикой (но не наоборот!).
Есть, однако, неразрешимые проблемы для произвольных КС-грамматик:
□
не существует алгоритма, который бы мог проверить, является ли заданная КС-грамматика 1Х(к)-грамматикой
для некоторого произвольного числа к;
□
не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику к виду
ЬЦк)-грамматики для некоторого к (или доказать, что преобразование невозможно).
Это несколько ограничивает применимость ГЦк)-грамматик, поскольку не всегда для произвольной КС-грамматики можно очевидно найти число к, для которого она является LL(k)-грамматикой, или узнать, существует ли вообще для нее такое число к.
Для ЬЦк)-грамматики при к>1 совсем не обязательно, чтобы все правые части правил грамматики для каждого нетерминального символа начинались с к различных терминальных символов. Принципы распознавания предложений входного языка такой грамматики накладывают менее жесткие ограничения на правила грамматики, поскольку к соседних символов, по которым однозначно выбирается очередная альтернатива, могут встречаться и в нескольких правилах грамматики (эти условия рассмотрены ниже). Грамматики, у которых все правые части правил для всех нетерминальных символов начинаются с к различных терминальных символов, носят название «сильно ЬЦк)-грамматик». Метод построения распознавателей для них достаточно прост, алгоритм разбора очевиден, но, к сожалению, такие грамматики встречаются крайне редко.
Для LL(l)-rpaMMaTHKH, очевидно, для каждого нетерминального символа не может быть двух правил, начинающихся с одного и того же терминального символа. Однако это менее жесткое условие, чем то, которое накладывает распознаватель по методу рекурсивного спуска, поскольку в принципе LL(l)-rpaMMaTHKa допускает в правой части правил цепочки, начинающиеся с нетерминальных символов, а также ^.-правила. LL(l)-rpaMMaTHKH позволяют построить достаточно простой и эффективный распознаватель, поэтому они рассматриваются далее отдельно в соответствующем разделе.
Поскольку все LL(k)-rpaMMaTHKH используют левосторонний нисходящий распознаватель, основанный на алгоритме с подбором альтернатив, очевидно, что они не могут допускать левую рекурсию. Поэтому никакая леворекурсивная грамматика не может быть LL-грамматикой. Следовательно, первым делом при попытке преобразовать грамматику к виду LL-грамматики необходимо устранить в ней левую рекурсию (соответствующий алгоритм был рассмотрен выше). Класс LL-грамматик широк, но все же он недостаточен для того, чтобы покрыть все возможные синтаксические конструкции в языках программирования (к ним относим все детерминированные КС-языки). Известно, что существуют детерминированные КС-языки, которые не могут быть заданы LL(k)-грамматикой ни для каких к. Однако LL-грамматики удобны для использования, поскольку позволяют построить распознаватели с линейными характеристиками (линейной зависимостью требуемых для работы алгоритма распознавания вычислительных ресурсов от длины входной цепочки символов).
Принципы построения распознавателей для LL(k)-грамматик
Для построения распознавателей LL(k)-rpaMMaraK используются два важных множества, определяемые следующим образом:
□
FIRST(k,a) — множество терминальных
цепочек, выводимых из ae(VTuVN)*, укороченных до к символов;
□
FOLLOW(k.A) — множество укороченных до к
символов терминальных цепочек, которые могут следовать непосредственно за AeVN в цепочках вывода.
Формально эти два множества могут быть определены
следующим образом: FIRST(k,a) = {coeVT* | либо |со|<к и а=>*со,
либо |ео|>к и а=>*сох, xe(VTuVN)*}, ae(VTuVN)*, k>0. FOLLOW(k,A) = {coeVT* |
S=>*aAy и coeFIRST(y,k), aeVT*}, AeVN, k>0.
Очевидно, что если имеется цепочка терминальных символов aeVT*, то FIRST(k,a) — это первые к символов цепочки а.
Доказано, что грамматика G(VT,VN,P,S) является LL(k
)-грамматикой тогда
и только тогда, когда выполняется
следующее условие: V А—»р е Р и V
А-> ->g
е P (pVy): FIRST(k,(3co) n
FIRST(k,yco) = 0 для всех цепочек со таких, что S =>* схАсо.
Иначе говоря, если существуют две цепочки вывода: S =>* aAy => azy =>* асо S =>* aAy => aty =>* аи
то из условия FIRST(k,co) = FIRST(k,u) следует, что z = t.
На основе этих двух множеств строится алгоритм работы распознавателя для LL(k)-rpaMMaTHK, который представляет собой k-предсказывающий алгоритм для МП-автомата, заданного так: R({q},VT,Z,5,q,S,{q}), где Z = VTuVN, a S — целевой символ грамматики G. Функция переходов автомата строится на основе управляющей таблицы М, которая отображает множество (Zu{^}) x VT*k на множество, состоящее из следующих элементов:
□
пар вида (РД), где (3 — цепочка символов, помещаемая автоматом на
верхушку стека, a i — номер правила вида А-»р, AeVN, peZ*;
□
«выброс»;
□
«допуск»;
□
«ошибка».
Конфигурацию распознавателя можно отобразить в виде конфигурации МП-автомата с дополнением цепочки п, в которую помещаются номера примененных правил. Поскольку автомат имеет только одно состояние, его в конфигурации можно не указывать. Если считать, что X — это символ на верхушке стека автомата, а — непрочитанная автоматом часть входной цепочки символов, а и = FIRST(k,a), то работу алгоритма распознавателя можно представить следующим образом:
□
(а, Ху, п) н- (а, Ру, rci), yeZ*, если М(Х,и) = (P,i);
□
(а, Ху, я) * (а',
у, л), если X = aeVT и а = аа', М(а,и) = «выброс»;
□
(X, X, л) — завершение работы, при этом
М(^Д) = «допуск»;
□
иначе — «ошибка».
Цепочка и = FIRST(k,a) носит в работе автомата название «аванцепочка».
Таким образом, для создания алгоритма распознавателя языка, заданного произвольной LL(k)-rpaMMaTHKoft, достаточно уметь построить управляющую таблицу М. Управляющую таблицу М, а также множества FIRST и FOLLOW можно получить на основе правил исходной грамматики. Методы построения этой таблицы для к>1 в данном пособии не рассматриваются, с ними можно ознакомиться в работах [5, 6, т. 1, 65].
При к= 1 все существенно проще. Методы построения для LL(1)-грамматик, а также проверки принадлежности грамматики к классу LL(l)-rpaMMaTHK рассмотрены ниже.
Алгоритм разбора для Щ1)-грамматик
Для LL(l)-rpaMMaTHK алгоритм работы распознавателя предельно прост. Он заключается всего в двух условиях, проверяемых на шаге выбора альтернативы. Исходными данными для этих условий являются символ aeVT, обозревав-мый считывающей головкой МП-автомата (текущий символ входной цепочки), и символ AeVN, находящийся на верхушке стека автомата1. Эти условия можно сформулировать так:
□ необходимо выбрать в качестве альтернативы правило А->х, если
aeFIRST(l,x);
□ необходимо выбрать в качестве альтернативы
правило А-+Х, если
aeFOLLOW(l,A).
Если ни одно из этих условий не выполняется (нет соответствующих правил), то цепочка не принадлежит заданному языку и МП-автомат не принимает ее (алгоритм должен сигнализировать об ошибке). Работа автомата на шаге «выброса» остается без изменений. Кроме того, чтобы убедиться, является ли заданная грамматика G(VT,VN,P,S) ЬЦ1)-грамматикой, необходимо и достаточно проверить следующее условие: для каждого символа AeVN, для которого в грамматике существует более одного правила вида А -> а^агЩйп, должно выполняться требование
FIRST(l,OiFOLLOW(l,A))
n FIRST(l,<XjFOLLOW(l,A)) = 0
Vi*j,n>i>0, n>j>0. Очевидно, что если для символа AeVN отсутствует правило вида А-»Х., то согласно этому требованию все множества FIRST(l,a1), FIRST(l,a2), ..., FIRST(l,an) должны попарно не пересекаться, если же присутствует правило А-Л, то они не должны также пересекаться со множеством FOLLOW(l,A). Отсюда видно, что ЬЦ1)-грамматика не может содержать для одного и того же нетерминального символа AeVN двух правил, начинающихся с одного и того же терминального символа.
Условие, накладываемое на правила ЬЦ1)-грамматики, является довольно жестким. Очень немногие реальные грамматики могут быть отнесены к классу LL(1)-грамматик. Например, даже довольно простая грамматика G({a},{S}, {S-»a|aS}, S) не удовлетворяет этому условию (хотя она является ЬЦ2)-грамматикой и даже регулярной праволинейной грамматикой).
Иногда удается преобразовать правила грамматики так, чтобы они удовлетворяли требованию LL(1)-грамматик. Например, приведенная выше грамматика мо-
Может показаться, что класс ЬЦ1)-грамматик соответствует классу грамматик, анализируемых методом рекурсивного спуска, где выбор альтернативы также основан на текущем символе входной цепочки. На самом деле это не так — класс LL(1)-грамматик является более широким, чем класс грамматик, анализируемым методом рекурсивного спуска. Любая грамматика, анализируемая методом рекурсивного спуска, является ЬЦ1)-грамматикой, но не наоборот: существуют ЬЦ1)-грамматики, которые напрямую методом рекурсивного спуска не анализируются. Дело в том, что распознаватель на базе ЬЦ1)-грамматики (который основан на множествах FIRST и FOLLOW) при выборе альтернативы фактически анализирует не одно, а сразу несколько правил, связанных с текущим символом на верхушке стека, в то время как рекурсивный спуск основан на анализе только одного правила, непосредственно относящегося к этому символу. жет быть преобразована к виду G'({a},{S,A}, {S-»aA, A—>X,|S}, S)1. В такой форме она уже является LL(1)-грамматикой (это можно проверить). Но формальной метода преобразовать произвольную КС-грамматику к виду LL(1)-грамматик! или убедиться в том, что такое преобразование невозможно, не существует. Пер вое преобразование правил грамматики, которое можно рекомендовать, — устра нение левой рекурсии2. Второе преобразование носит название «левая фактори зация», оно уже было упомянуто выше при знакомстве с методом рекурсивной спуска. Это преобразование заключается в следующем: если для символа AeV> существует ряд правил
A->ap1|ap2|...|apn|YilY2l-L- Vi: pie(VTuVN)*, Vj: 7je(VTuVN)*, aeVT
и ни одна цепочка символов 7j не начинается с символа а, тогда во множество нетерминальных символов грамматики VN добавляется новый символ А', а правила для А и А' записываются следующим образом: А—>аА.' jy t |у2|- - -1 Ym и A'->Pi|p2|...|pn Левую факторизацию можно применять к правилам грамматики несколько раз с целью исключить для каждого нетерминального символа правила, начинающиеся с одних и тех же терминальных символов. Однако применение этих двух преобразований отнюдь не гарантирует, что произвольную КС-грамматику удастся привести к виду ЬЬ(1)-грамматики.
Для того чтобы запрограммировать работу МП-автомата, выполняющего разбор входных цепочек символов языка, заданного ЬЦ1)-грамматикой, надо научиться строить множества символов FIRST(l,x) и FOLLOW(l,A). Для множества FIRST(l,x) все очевидно, если цепочка х начинается с терминального символа, если же она начинается с нетерминального символа В (х = By, xe(VTuVN)+ ye(VTuVN)*), то FIRST(l,x) = FIRST(1,B). Следовательно, для Ы(1)-грамматив остается только найти алгоритм построения множеств FIRST(1,B) и FOLLOW(l,A^ для всех нетерминальных символов A.BeVN.
Исходными данными для этих алгоритмов служат правила грамматики.
Алгоритм построения множества FIRST(1,A)
Алгоритм строит множества FIRST(1,A) сразу для всех нетерминальных символов грамматики G(VT,VN,P,S), AeVN. Для выполнения алгоритма надо предварительно преобразовать исходную грамматику G(VT,VN,P,S) в грамматику G'(VT,VN',P',S'), не содержащую А,-правил (см. алгоритм преобразования в разделе «Преобразование КС-грамматик. Приведенные грамматики», глава 11). На основании полученной грамматики G' и выполняется построение множеств FIRST(l.A) для всех AeVN (если AeVN, то согласно алгоритму преобразова-
Можно убедиться, что две приведенные грамматики задают один и тот же язык: L(G) = = L(G'). Это легко сделать, поскольку обе они являются не только КС-грамматиками, но и регулярными праволинейными грамматиками. Кроме того, формальное преобразование G' в G существует — достаточно устранить в грамматике G' Pt-правила и цепные правила, и будет получена исходная грамматика G. А вот формального преобразования G в G' нет. В общем случае все может быть гораздо сложнее.
1 Устранение левой рекурсии — это, конечно, необходимое, но не достаточное условие для преобразования грамматики к виду LL-грамматики. Это будет видно далее из примера.
ния также справедливо AeVN'). Множества строятся методом последовательного приближения. Если в результате преобразования грамматики G в грамматику G' множество VN' содержит новый символ S', то при построении множества FIRST(1,A) он не учитывается. Алгоритм состоит из нескольких шагов.
Шаг 1. Для всех AeVN: FIRST0(1,A) = {X | А->Ха е Р, Xe(VTuVN), ae(VTuVN)*} (первоначально вносим во множество первых символов для каждого нетерминального символа А все символы, стоящие в начале правых частей правил для этого символа A); i:=0.
Шаг 2. Для всех AeVN: FIRSTi+1(l,A) = FIRSTj(l,A) и FIRST^LB), для всех нетерминальных символов Be(FIRSTi(l,A) n VN).
Шаг 3. Если 3 AeVN: FIRSTi+1(l,A) * FIRSTj(l,A), то 1:4+1 и вернуться к шагу 2, иначе перейти к шагу 4.
Шаг 4. Для всех AeVN: FIRST(1,A) = FIRSTi(l,A) \ VN (исключаем из построенных множеств все нетерминальные символы).
Алгоритм построения множества FOLLOW(1,A)
Алгоритм строит множества FOLLOW(l,A) сразу для всех нетерминальных символов грамматики G(VT,VN,P,S), AeVN. Для выполнения алгоритма предварительно надо построить все множества FIRST(1,A), V AeVN. Множества строятся методом последовательного приближения. Алгоритм состоит из нескольких шагов.
Шаг 1. Для всех AeVN: FOLLOW0(1,A) - {X | 3 В-ххАХр е Р, BeVN, Xe(VTuVN), a,pe(VTuVN)*} (первоначально вносим во множество последующих символов для каждого нетерминального символа А все символы, которые в правых частях правил встречаются непосредственно за символом A); i:=0. Шаг 2. FOLLOW0(1,S) = FOLLOW0(1,S) u {1} (вносим пустую цепочку во множество последующих символов для целевого символа S — это означает, что в конце разбора за целевым символом цепочка кончается, иногда для этой цели используется специальный символ конца цепочки: 1к).
Шаг 3. Для всех AeVN: FOLLOW; (1,A) = FOLLOWj(l,A) u FIRST(1,B), для всех нетерминальных символов Be(FOLLOWj(l,A) n VN). Шаг 4. Для всех AeVN: FOLLOW", (1,A) = FOLLOW'i(l,A) u FOLLOW^l.B). для всех нетерминальных символов Be(FOLLOW'j(l,A) n VN) и существует правило В-»А..
Шаг 5. Для всех AeVN: FOLLOWi+1(l,A) = FOLLOW"j(l,A) U FOLLOW"j(l,B). для всех нетерминальных символов BeVN, если существует правило В-»аА, ae(VTuVN)*.
Шаг 6. Если 3 AeVN: FOLLOWi+1(l,A) ф FOLLOW^l.A), то i:=i+l и вернуться к шагу 3, иначе перейти к шагу 7.
Шаг 7. Для всех AeVN: FOLLOW(l,A) = FOLLOWj(l,A) \ VN (исключаем из построенных множеств все нетерминальные символы).
Пример построения распознавателя для Щ1)-грамматики
Рассмотрим в качестве примера грамматику G({+,-,/,*,а,b}, {S,R,T,F,E}, P, S) с правилами:
Р:
S -> Т | TR
R -> +Т | -Т | +TR | -TR
Т ~> Е | EF
F -> *Е | /Е | *EF | /EF
Е -> (S) | а | b
Это нелеворекурсивная грамматика для арифметических выражений (ранее она была построена в разделе «Распознаватели КС-языков с возвратом», глава 11). Эта грамматика не является ЕЕ(1)-грамматикой. Чтобы убедиться в этом, достаточно обратить внимание на правила для символов R и F — для них имеется по два правила, начинающихся с одного и того же терминального символа. Преобразуем ее в другой вид, добавив ^-правила. В результате получим новую грамматику G'({+.-,/,*,а,b}, {S,R,T,F,E}, P', S) с правилами:
Р':
S -> TR
R -» X | +TR | -TR
Т -> EF
F 1> X | *EF | /EF
Е -> (S) | а | Ь
Построенная грамматика G' эквивалентна исходной грамматике G. В этом можно убедиться, если воспользоваться алгоритмом устранения ^.-правил из раздела «Преобразование КС-грамматик. Приведенные грамматики», глава 11. Применив его к грамматике G', получим грамматику G, а по условиям данного алгоритма L(G') = L(G). Таким образом, мы получили эквивалентную грамматику, хотя она и построена неформальным методом (следует помнить, что не существует формального алгоритма, преобразующего произвольную КС-грамматику в LL(k)-грамматику для заданного к).
Эта грамматика является ЕЕ(1)-грамматикой. Чтобы убедиться в этом, построим множества FIRST и FOLLOW для нетерминальных символов этой грамматики (поскольку речь заведомо идет об LL(1)-грамматике, цифру «1» в обозначении множеств опустим для сокращения записи).
Для построения множества FIRST будем использовать исходную грамматику G, так как именно она получается из G' при устранении Я,-правил. Построение множеств FIRST.
Шаг 1. FIRSTo(S) = {Т}; FIRSTo(R) = {+,-}; FIRSTo(T) = {E}; FIRSTo(F) = {*,/};
FIRSTo(E) = {(,a,b};
i = 0. Шаг
2. FIRSTj(S)
- {Т,Е};
FIRSTAR) = {+,-};
FIRSTt(T) = {E,(,a,b};
FIRST^F) = {*,/};
FIRST^E) = {(,a,b}. Шаг 3. i = 1, возвращаемся к шагу 2. Шаг
2. FIRST2(S)
- {T,E,(,a,b};
FIRST2(R) = {+,-};
FIRST2(T) = {E,(,a,b};
FIRST2(F) = {*,/};
FIRST2(E) = {(,a,b}.
Шаг 3- i = 2, возвращаемся к шагу 2. Шаг
2. FIRST3(S)
- {T,E,(,a,b};
FIRST3(R) = {+,-};
FIRST3(T) = {E,(,a,b};
FIRST3(F) = {*,/};
FIRST3(E)
= {(,a,b}. Шаг
3. i = 2, переходим к шагу 4. Шаг 4. FIRST(S) = {(,a,b};
FIRST(R) = {+,-};
FIRST(T) = {(,a,b};
FIRST(F) = {*,/};
FIRST(E) - {(,a,b}.
Построение закончено. Построение множества FOLLOW.
|
FOLLOW0(S) - |
mi |
|
FOLLOWq(R) ■ |
-0; |
|
FOLLOWq(T) ■ |
- {R}; |
|
FOLLOWq(F) ■ |
= 0; |
|
FOLLOW0(E)
■ i-0. FOLLOW0(S) • |
= {F}; |
|
• Ш |
|
|
FOLLOW0(R) ■ |
= 0; |
|
FOLLOWq(T) ■ |
= {R}; |
|
FOLLOWq(F) = |
= 0; |
|
FOLLOW0(E) - |
= {F}. |
ШагЗ. FOLLOW'0(S) = {)Д};
FOLLOW'o(R) = 0;
FOLLOW'0(T) = {R,+,-};
FOLLOW'0(F) = 0;
FOLLOW'0(E)
= {FA/}. Шаг
4. FOLLOW'o(S)
= {)Д};
FOLLOWER) = 0;
FOLLOW"0(T) = {R,+,-};
FOLLOW"0(F) = 0;
FOLLOW'o(E)
= {FA/}. Шаг 5. FOLLOW^S) = {)Д};
FOLLOWER) = {)Л};
FOLLOW^T) = {R,+,-};
FOLLOW^F) = {R,+,-};
FOLLOW^E) = {F,*,/}. Шаг 6. i = 1, возвращаемся к шагу 3. Шаг 3. FOLLOW'^S) - {Щ
FOLLOWER) = {)Л};
F0LL0W'1(T) = {R,+,-};
FOLLOW',^) * {R,+ -};
FOLLOW'^E)
= {F ,*,/}. Шаг 4. FOLLOW'^S) = {)Д};
FOLLOWER) = {)Л};
FOLLOW",(T) = {R,+,-,),M;
FOLLOW",(F) - {R,+ -,)Л};
FOLLOW"i(E) = {F,RV,+,-)Л}-Шаг 5. FOLLOW2(S) = {)Д};
FOLLOW2(R) = {)Л|;
FOLLOW2(T) = {R.+ -, )Л};
FOLLOW2(F) = {R,+,-,U};
FOLLOW2(E)
= {F,R,*,/,+ -,),M. Шаг 6. i = 2, возвращаемся к шагу 3. Шаг 3. FOLLOW'2(S)
- {)Л};
FOLLOW'2(R) = {)Д};
FOLLOW'2(T) = {R,+ ,-,),*.};
FOLLOW'2(F) = {R,+,-,),M;
FOLLOW'2(E) = {F,R,*,/,+,-,),A.}.
![]() Шаг 4. FOLLOW"2(S)
- {)Д};
Шаг 4. FOLLOW"2(S)
- {)Д};
FOLLOWER) - {)Д};
FOLLOW"2(T) - {R,+,-)M
FOLLOW"2(F)
= {R,+,-,)Д};
FOLLOW"2(E)
= {F,RA/>+-,)ЛЬ Шаг 5. FOLLOW3(S) = {)Д};
FOLLOW3(R) - {),%};
FOLLOW3(T)
= \R,+-,)Д};
FOLLOW3(F) = {ЕЯ-)Д};
FOLLOW3(E)
= {F,R, *,/,+~,)Д}-Шаг
6. i = 2, переходим к шагу 7. Шаг 7. FOLLOW(S)
- {)Д};
FOLLOW(R) = ОД};
FOLLOW(T) f {+,-,)Д};
FOLLOW(F) - {+,-,)Д};
FOLLOW(E)
= {*,/,+,-,)Д}.
Построение закончено.
В результате выполненных построений можно видеть, что необходимое и достаточное условие принадлежности КС-грамматики к классу ЪЦ1)-грамматик выполняется.
Построенные множества FIRST и FOLLOW можно представить в виде
таблицы. Результат выполненных построений
отражает табл. 12.1.
|
Таблица 12.1. |
Множества FIRST и FOLLOW для грамматики G' |
||
|
Символ AeVN |
FIRST(1 ,A) |
FOLLOW(1 ,A) |
|
|
S |
(ab |
)i |
|
|
R |
+ - |
ух |
|
|
Т |
(ab |
+ -)Х |
|
|
F |
V |
+ -)Х |
|
|
Е |
|
(ab |
* / + - ) X |
Рассмотрим работу распознавателя. Ход разбора будем отражать по шагам работы автомата в виде конфигурации МП-автомата, к которой добавлена цепочка, содержащая последовательность примененных правил грамматики. Состояние автомата q, указанное в его конфигурации, можно опустить, так как оно единственное: (a, Z, у), где а — непрочитанная часть входной цепочки символов; Z — содержимое стека (верхушка стека находится слева); у — последовательность номеров примененных правил (последовательность дополняется слева, так как автомат порождает левосторонний вывод). Примем, что правила в грамматике номеруются в порядке слева направо и сверху вниз. На основе номеров примененных правил при успешном завершении разбо ра можно построить цепочку вывода и дерево вывода.
В качестве примера возьмем две правильные цепочки символов а+а*Ь и (a+a)*b i две ошибочные цепочки символов а+а* и (+а)*Ь. Разбор цепочки а+а*Ь.
1. (а+а*Ь, БД)
2.
(a+a*b, TR, 1), так как aeFIRST(l,TR)
3.
(a+a*b, EFR, 1,5), так как aeFIRST(l,EF)
4.
(a+a*b, aFR, 1,5,10), так как aeFIRST(l,a)
5.
(+a*b, FR, 1,5,10)
6.
(+a*b, R, 1,5,10,6), так как +eFOLLOW(l,F)
7.
(+a*b, +TR, 1,5,10,6,3), так как +eFIRST(l,+TR)
8.
(a*b, TR, 1,5,10,6,3)
9. (a*b, EFR, 1,5,10,6,3,5), так как aeFIRST(l,EF)
10. (a*b,aFR,
1,5,10,6,3,5,10), так как a6FIRST(l,a)
И. (*b, FR, 1,5,10,6,3,5,10)
12.
(*b, *EFR, 1,5,10,6,3,5,10,7), так как *eFIRST(l,*EF)
13.
(b, EFR, 1,5,10,6,3,5,10,7)
14.
(b, bFR, 1,5,10,6,3,5,10,7,11), так как beFIRST(l,b)
15.
(X, FR, 1,5,10,6,3,5,10,7,11)
16.
(X, R, 1,5,10,6,3,5,10,7,11,6), так как ?i6F0LL0W(l,F)
17.
(X, X, 1,5,10,6,3,5,10,7,11,6,2), так
как keFOLLOW(l,R), разбор закончен. Це почка принимается.
Получили цепочку вывода:
S => TR => EFR => aFR => aFR =>
aR => a+TR => a+EFR => a+aFR => a+a*EFR => a+a*bFR
=> a+a*bR => a+a*b
Соответствующее ей дерево вывода приведено на рис. 12.2. Разбор цепочки (а+а)*Ь.
1.
((a+a)*b, S, Я.)
2.
((a+a)*b, TR, 1), так как (eFIRST(l.TR)
3.
((a+a)*b, EFR, 1,5), так как (eFIRST(l,EF)
4.
((a+a)*b, (S)FR, 1,5,9), так как (eFIRST(l,(S))
5.
(a+a)*b, S)FR, 1,5,9)
6.
(a+a)*b, TR)FR, 1,5,9,1), так как aeFIRST(i.TR)
7.
(a+a)*b, EFR)FR, 1,5,9,1,5), так как aeFIRST(l,EF)
8.
(a+a)*b, aFR)FR, 1,5,9,1,5,10), так как aeFIRST(i,a)
(+a)*b,
FR)FR, 1,5,9,1,5,10)
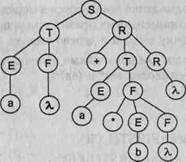
Рис. 12.2. Дерево вывода в Щ1)-грамматике для цепочки «а+а*Ь»
10. (+a)*b, R)FR, 1,5,9,1,5,10,6), так как
+<=FOLLOW(l,F)
11. (+a)*b, +TR)FR, 1,5,9,1,5,10,6,3), так как
+eFIRST(l,+TR)
12.
(a)*b,
TR)FR, 1,5,9,1,5,10,6,3)
13. (a)*b, EFR)FR, 1,5,9,1,5,10,6,3,5), так как
aeFIRST(l,EF)
14. (a)*b, aFR)FR, 1,5,9,1,5,10,6,3,5,10),
так как aeFIRST(l,a)
15.
(q,)*b,
FR)FR, 1,5,9,1,5,10,6,3,5,10)
16. ()*b, R)FR, 1,5,9,1,5,10,6,3,5,10,6),
так как )eFOLLOW(l,F)
17.
()*b,
)FR, 1,5,9,1,5,10,6,3,5,10,6,2), так как )eFOLLOW(l,R)
18.
(*b,
FR, 1,5,9,1,5,10,6,3,5,10,6,2)
19.
(*b,
*EFR, 1,5,9,1,5,10,6,3,5,10,6,2,7), так как *eFOLLOW(l,*EF)
20. (b, EFR, 1,5,9,1,5,10,6,3,5,10,6,2,7)
21. (b, bFR, 1,5,9,1,5,10,6,3,5,10,6,2,7,11),
так как beFIRST(l,b)
22. (X, FR, 1,5,9,1,5,10,6,3,5,10,6,2,7,11)
23. (X, R, 1,5,9,1,5Д0,6,3,5Д0Д2,7,11,6), так
как Хе FOLLOW(l.F)
24. (X, X, 1,5,9,1,5,10,6,3,5,10,6,2,7,11,6,2),
так как ?ieFOLLOW(l,R), разбор закончен. Цепочка принимается.
Получили цепочку вывода:
S => TR => EFR => (S)FR =}
(TR)FR => (EFR)FR => (aFR)FR => (aR)FR => (a+TR)FR => (a+EFR)FR =»
(a+aFR)FR s» (a+aR)FR => (a+a)FR => (a+a)*EFR => (a+a)*bFR => (a+a)*bR
=> (a+a)*b
Соответствующее ей дерево вывода приведено на рис. 12.3. Разбор цепочки а+а*.
1.
(а+а*, S, X)
2.
(а+а*, TR, 1), так как aeFIRST(l.TR)
3.
(а+а*, EFR, 1,5), так как aeFIRST(l.EF)
4.
(а+а*, aFR, 1,5,10), так как aeFIRST(l.a)
(+а*, FR, 1,540)
s
© sx © © © лЗ
(© ©>■>. (ь) (х)
© © © Jj) (я)
© © © © ©
Рис. 12.3. Дерево вывода в Щ1)-грамматике для цепочки <<(а+а)*Ь»
6.
(+а*, R, 1,5,10,6), так как +eFOLLOW(l,F)
7.
(+а*, +TR, 1,5,10,6,3), так как +eFIRST(l,+TR)
8.
(a*,
TR, 1,5,10,6,3)
9.
(a*,
EFR, 1,5,10,6,3,5), так как aeFIRST(l,EF) 10. (a*,
aFR, 1,5,10,6,3,5,10), так как aeFIRST(l,a) И. (*, FR, 1,5,10,6,3,5,10)
12.
(*, *EFR, 1,5,10,6,3,5,10,7), так как *eFIRST(l,*EF)
13.
(X, EFR, 1,5,10,6,3,5,10,7)
14.
Ошибка, так как A,eFOLLOW(l,E), но нет правила вида Е->Х.
Цепочка i принимается.
Разбор цепочки (+а)*Ь.
1.
((+a)*b,S,V)
2.
((+a)*b,
TR, 1), так как (eFIRST(l,TR)
3.
((+a)*b,
EFR, 1,5), так как (eFIRST(l,EF)
4.
((+a)*b,
(S)FR, 1,5,9), так как (eFIRST(l,(S))
5.
(+a)*b,
S)FR, 1,5,9)
6.
Ошибка, так как нет правил для S вида S-»a таких, чтобы +eFIRST(l,c и +gFOLLOW(l,S). Цепочка не принимается.
Из рассмотренных примеров видно, что алгоритму разбора цепочек, построе] ному на основе распознавателя для LL(1)-грамматик, требуется гораздо меньн шагов на принятие решения о принадлежности цепочке языку, чем рассмотре] ному выше алгоритму разбора с возвратами. Надо отметить, что оба алгоритл распознают цепочки одного и того же языка. Данный алгоритм имеет большу эффективность, поскольку при росте длины цепочки количество шагов его ра
тет линейно, а не экспоненциально. Кроме того, ошибка обнаруживается этим алгоритмом сразу, в то время как разбор с возвратами будет просматривать для неверной входной цепочки возможные варианты до конца, пока не переберет их все.
Очевидно, что этот алгоритм является более эффективным, но жесткие ограничения на правила для ЬЦ1)-грамматик сужают возможности его применения.
Восходящие распознаватели КС-языков без возвратов
Определение 1.Щк)-грамматики
Восходящие распознаватели выполняют построение дерева вывода снизу вверх. Результатом их работы является правосторонний вывод. Функционирование таких распознавателей основано на модификациях алгоритма «сдвиг-свертка» (или «перенос-свертка»), который был рассмотрен в разделе «Распознаватели КС-языков с возвратом», глава 11.
Идея состоит в том, чтобы модифицировать этот алгоритм таким образом, чтобы на каждом шаге его работы можно было однозначно дать ответ на следующие вопросы:
□
что следует выполнять: сдвиг (перенос) или свертку;
□
какую цепочку символов а выбрать из стека для выполнения свертки;
□
какое правило выбрать для выполнения свертки (в том случае, если существует несколько правил вида At-»a, A2->a, ... Ап-ж).
Тогда восходящий алгоритм распознавания цепочек КС-языка не требовал бы выполнения возвратов, поскольку сам язык мог бы быть задан детерминированным расширенным МП-автоматом. Конечно, как уже было сказано, это нельзя сделать в общем случае, для всех КС-языков (поскольку даже сам класс детерминированных КС-языков более узкий, чем весь класс КС-языков). Но, вероятно, среди всех КС-языков можно выделить такой класс (или классы), для которых подобная реализация распознающего алгоритма станет возможной.
В первую очередь можно использовать тот же самый подход, который был положен в основу определения LL(k)-грамматик. Тогда мы получим другой класс КС-грамматик, который носит название LR(k)-грамматик.
КС-грамматика обладает свойством LR(k), k>0, если на каждом шаге вывода для однозначного решения вопроса о выполняемом действии в алгоритме «сдвиг-свертка» («перенос-свертка») расширенному МП-автомату достаточно знать содержимое верхней части стека и рассмотреть первые к символов от текущего положения считывающей головки автомата во входной цепочке символов.
Грамматика называется LR(k)-грамматикой, если она обладает свойством LR(k^ для некоторого к^О1.
Название «LR(k)>>, как и рассмотренное выше «LL(k)», также несет определенный смысл. Первая литера «L» также обозначает порядок чтения входной цепочки символов: слева— направо. Вторая литера «R» происходит от слова «right» и по аналогии с LL(k), означает, что в результате работы распознавателя получа ется правосторонний вывод. Вместо «к» в названии грамматики стоит число, ко торое показывает, сколько символов входной цепочки надо рассмотреть, чтобь принять решение о действии на каждом шаге алгоритма «сдвиг-свертка». Так существуют ]Л(0)-грамматики, 1^(1)-грамматики и другие классы.
В совокупности все 1Л(к)-грамматики для всех к>0 образуют класс LR-грамма тик.
На рис. 12.4 схематично показано частичное дерево вывода для некоторой LR(k) грамматики. В нем со обозначает уже разобранную часть входной цепочки а, н: основе которой построена левая часть дерева у. Правая часть дерева х — это ещ> не разобранная часть, а А — это нетерминальный символ, к которому на очеред ном шаге будет свернута цепочка символов z, находящаяся на верхушке стек; МП-автомата. В эту цепочку уже входит прочитанная, но еще не разобранна; часть входной цепочки и. Правая часть дерева х будет построена на основе част] входной цепочки х. Свойство LR(k) предполагает, что однозначный выбор дей ствия, выполняемого на каждом шаге алгоритма «сдвиг-свертка», может быт: сделан на основе цепочки и и к первых символов цепочки т., являющихся часть» входной цепочки а. Этим очередным действием может быть свертка цепочки z к сим волу А или перенос первого символа из цепочки т. и добавление его к цепочке г.
со и | т
к a Рис. 12.4. Схема построения дерева вывода для 1Я(к)-грамматики
Рассмотрев схему построения дерева вывода для 1^(к)-грамматики на рис. 12. и сравнив ее с приведенной выше на рис. 12.1 схемой для ЬЦк)-грамматию
Существование Ы1(0)-грамматик уже не является бессмыслицей в отличие от LL(0 грамматик. В данном случае используется расширенный МП-автомат, который анализ! рует не один, а сразу несколько символов, находящихся на верхушке стека. Причем сред этих символов могут быть и терминальные символы из входной цепочки, попавшие стек при выполнении сдвигов (переносов). Поэтому даже если автомат при к = 0 и не б; дет смотреть на текущий символ входной цепочки, построенный им вывод все равно б; дет зависеть от содержимого стека, а значит, и от содержимого входной цепочки.
можно предположить, что класс LR-грамматик является более широким, чем класс LL-грамматик. Основанием для такого предположения служит тот факт, что на каждом шаге работы распознавателя Ы1(к)-грамматики обрабатывается больше информации, чем на шаге работы распознавателя ЬЦк)-грамматики. Действительно, для принятия решения на каждом шаге алгоритма распознавания LL(k)-грамматики используются первые к символов из цепочки от, а для принятия решения на шаге распознавания ЬЫ(к)-грамматики — вся цепочка и и еще первые к символов из цепочки т. Очевидно, что во втором случае можно проанализировать больший объем информации и, таким образом, построить вывод для более широкого класса КС-языков.
Приведенное выше довольно нестрогое утверждение имеет строго обоснованное доказательство. Доказано, что класс LR-грамматик является более широким, чем класс LL-грамматик [6, т. 2]. То есть для каждого КС-языка, заданного LL-грам-матикой, может быть построена LR-грамматика, задающая тот же язык, но не наоборот. Существуют также языки, заданные LR-грамматиками, для которых невозможно построить LL-грамматику, задающую тот же язык. Иначе говоря, для всякой LL-грамматики существует эквивалентная ей LR-грамматика, но не для всякой LR-грамматики существует эквивалентная ей LL-грамматика1. Для LR(k)-rpaMMaTHK известны следующие полезные свойства:
□
всякая LR(k)-rpaMMaTHKa для любого к > О является
однозначной;
□
существует алгоритм, позволяющий проверить, является ли заданная грамматика LR(k)-rpaMMaTHKoft для строго определенного числа
к.
Есть, однако, неразрешимые проблемы для произвольных КС-грамматик (они аналогичны таким же проблемам для других классов КС-грамматик):
□
не существует алгоритма, который бы мог проверить, является ли заданная КС-грамматика LR(k)-rpaMMaraKoft для
некоторого произвольного числа к;
□
не существует алгоритма, который бы мог преобразовать (или доказать, что
преобразование
невозможно) произвольную КС-грамматику к виду LR(k)-грамматики для некоторого к.
Кроме того, для LR-грамматик доказано еще одно очень интересное свойство — класс LR-грамматик полностью совпадает с классом детерминированных КС-языков. То есть, во-первых, любая LR(k)-rpaMMaraKa задает детерминированный КС-язык (это очевидно следует из однозначности всех LR-грамматик), а во-вторых, для любого детерминированного КС-языка можно построить LR-граммати-ку, задающую этот язык. Второе утверждение уже не столь очевидно, но доказано в теории формальных языков [6, т. 1, 65]2.
1 Говоря о
соотношении классов LL-грамматик и LR-грамматик, мы не затрагиваем вопрос
о значениях к для этих грамматик. Если для некоторой LL(k)-rpaMMaraKH всегда
сущест
вует эквивалентная ей LR-грамматика, то
это вовсе не значит, что она будет LR(k)-rpaM-
матикой с тем же значением к, и наоборот. Но если говорится, что существуют LR-
грамматики, для которых нет эквивалентных им LL-грамматик, то это означает, что нет
эквивалентных им LL(k)-rpaMMaraK для
всех возможных значений к>0.
2 Более
того, доказано даже, что любой детерминированный КС-язык может быть задан
LR( 1 )-грамматикой. В принципе класс LR-грамматик очень удобен для
построения распознавате; детерминированных КС-языков (а все языки программирования, безуслов относятся к этому классу). Но
тот факт, что для каждого детерминирован» КС-языка существует задающая его LR-грамматика, еще ни о чем не
говорит, ] скольку
из-за неразрешимости проблемы преобразования отсутствует алгори который позволил бы эту
грамматику построить всегда. Данный детермини ванный КС-язык может быть
изначально задан грамматикой, которая не on сится к классу LR-грамматик.
В таком случае совсем не очевидно, что для эт( языка удастся построить распознаватель на основе LR-грамматики,
потому > в общем
случае нет алгоритма, который бы позволил эту грамматику получк хотя и известно, что она
существует. То, что проблема не разрешима в оби случае, совсем не означает, что ее не удастся решить в конкретной
ситуац И здесь факт существования LR-грамматики
для каждого детерминирован» КС-языка играет важную роль — всегда есть смысл в каждом конкретном слу
пытаться построить такую грамматику.
Принципы построения распознавателей для LR(k)-rpaMMaTHK
Для того чтобы формально определить LR(k) свойство для КС-грамматик, в дем понятие пополненной КС-грамматики. Грамматика G' является пополн ной грамматикой, построенной на основании исходной грамматики G(VT,VN,P если выполняются следующие условия:
□
грамматика G' совпадает с грамматикой G, если целевой символ S
не ветре ется нигде в правых частях правил грамматики G;
□
грамматика G' строится как грамматика G'(VT,VNu{S'},Pu{S'-»S},S'), если левой символ S встречается в правой части хотя
бы одного правила из мно: ства Р в
исходной грамматике G.
Фактически пополненная КС-грамматика строится таким образом, чтобы ее левой символ не встречался в правой части ни одного правила. Если нужно, в исходную грамматику G для этого добавляется новый терминальный сим! S', который становится целевым символом, и новое правило S'-»S. Очевид что пополненная грамматика G' эквивалентна исходной грамматике G, то е L(G') = L(G).
Теперь рассмотрим формальное определение LR(k) свойства.
Если для произвольной КС-грамматики G в ее пополненной грамматике G'; двух произвольных цепочек вывода из условий:
1. S' =>* aAw => aPw
2.
S' =>* уВх У
ару
3.
FIRST(k,w) - FIRST(k,y)
следует, что aAw = уВх (то есть а = у, А = В и х =
у), то доказано, что грамма ка G обладает LR(k) свойством. Очевидно, что тогда и пополненная
грамма ка G' также обладает LR(k) свойством.
Понятие «пополненной грамматики» введено исключительно с той целью, чтобы в процессе работы алгоритма «сдвиг-свертка» выполнение свертки к целевому символу пополненной грамматики S' служило сигналом к завершению алгоритма (поскольку в пополненной грамматике символ S' в правых частях правил нигде не встречается). Если условие отсутствия целевого символа в правых частях правил грамматики не будет соблюдаться, то на алгоритм распознавателя потребуется наложить дополнительные ограничения, так как появление целевого символа на вершине стека уже не будет означать завершение работы алгоритма. Поскольку построение пополненных грамматик выполняется элементарно и не накладывает никаких дополнительных ограничений на исходную КС-грамматику, то дальше будем считать, что все распознаватели для Ь11(к)-грамматик работают с пополненными грамматиками.
Распознаватель для Ы1(к)-грамматик функционирует на основе управляющей таблицы Т. Эта таблица состоит из двух частей, называемых «действия» и «переходы». По строкам таблицы распределены все цепочки символов на верхушке стека, которые могут приниматься во внимание в процессе работы распознавателя. По столбцам в части «действия» распределены все части входной цепочки символов длиной не более к (аванцепочки), которые могут следовать за считывающей головкой автомата в процессе выполнения разбора; а в части «переходы» — все терминальные и нетерминальные символы грамматики, которые могут появляться на верхушке стека автомата при выполнении действий (сдвигов или сверток).
Клетки управляющей таблицы Т в части «действия» содержат следующие данные:
□
«сдвиг» — если
в данной ситуации требуется выполнение сдвига (переноса текущего символа из входной цепочки в стек);
□
«успех» — если
возможна свертка к целевому символу грамматики S и разбор входной цепочки завершен;
□
целое число («свертка») — если возможно выполнение свертки (число
обозначает номер
правила грамматики, по которому должна выполняться свертка);
□
«ошибка» —
во всех других ситуациях.
Действия, выполняемые распознавателем, можно вычислять всякий раз на основе состояния стека и текущей аванцепочки. Однако этого вычисления можно избежать, если после выполнения действия сразу же определять, какая строка таблицы Т будет использована для выбора следующего действия. Тогда эту строку можно поместить в стек вместе с очередным символом и выбирать затем в момент, когда она понадобится. Таким образом, автомат будет хранить в стеке не только символы алфавита, но и связанные с ними строки управляющей таблицы Т.
Клетки управляющей таблицы Т в части «переходы»
как раз и служат для выяснения номера строки таблицы, которая будет использована для определения
выполняемого действия на очередном шаге. Эти клетки содержат следующие данные:
□
целое число — номер строки таблицы Т;
□
«ошибка» — во всех других ситуациях.
Для удобства работы распознаватель Ы1(к)-грамматики использует также два cni циальных символа -LH и J_K. Считается, что входная цепочка символов всегда н; чинается символом _1_я и завершается символом 1к. Тогда в начальном состояни работы распознавателя символ 1н находится на верхушке стека, а считывающг головка обозревает первый символ входной цепочки. В конечном состоянии стеке должны находиться символы S (целевой символ) и 1„, а считывающая п ловка автомата должна обозревать символ -LK.
Алгоритм функционирования распознавателя Ы1(к)-грамматики можно описа! следующим образом:
Шаг 1. Поместить в стек символ ±н и начальную (нулевую) строку управляюще таблицы Т. В конец входной цепочки поместить символ 1к. Перейти к шагу 2.
Шаг 2. Прочитать с вершины стека строку управляющей таблицы Т. Выбрать i этой строки часть «действие» в соответствии с аванцепочкой, обозреваемой сч] тывающей головкой автомата. Перейти к шагу 3.
Шаг 3. В соответствии с типом действия выполнить выбор из четырех вариантов
□
«сдвиг» —
если входная цепочка не прочитана до конца, прочитать и запо1 нить как «новый символ»
очередной символ из входной цепочки, сдвину считывающую головку на одну позицию вправо, иначе
прервать выполнен] алгоритма и сообщить
об ошибке;
□
целое число («свертка») — выбрать правило в соответствии с
номером, уд лить из
стека цепочку символов, составляющую правую часть выбранно правила, взять символ из левой
части правила и запомнить его как «новь символ»;
□
«ошибка» —
прервать выполнение алгоритма, сообщить об ошибке;
□
«успех» —
выполнить свертку к целевому символу S, прервать выполнен: алгоритма, сообщить об успешном
разборе входной цепочки символов, ее. входная цепочка прочитана до конца, иначе сообщить об
ошибке.
Конец выбора. Перейти к шагу 4.
Шаг 4. Прочитать с вершины стека строку управляющей таблицы Т. Выбрать этой строки часть «переход» в соответствии с символом, который был запомн как «новый символ» на предыдущем шаге. Перейти к шагу 5.
Шаг 5. Если часть «переход» содержит вариант «ошибка», тогда прервать выпе нение алгоритма и сообщить об ошибке, иначе (если там содержится номер стр ки управляющей таблицы Т) положить в стек «новый символ» и строку табл цы Т с выбранным номером. Вернуться к шагу 2.
Для работы алгоритма кроме управляющей таблицы Т используется также нев торая временная переменная («новый символ»), хранящая значение термина; ного или нетерминального символа, полученного в результате сдвига или све{ ки. В программной реализации алгоритма вовсе не обязательно помещать в ст сами строки управляющей таблицы — поскольку сама таблица неизменна в щ цессе выполнения алгоритма, то достаточно запоминать соответствующие ссылв
Доказано, что данный алгоритм имеет линейную зависимость необходимых для его выполнения вычислительных ресурсов от длины входной цепочки символов. Следовательно, распознаватель для ЬЩк)-грамматики имеет линейную зависимость сложности от длины входной цепочки, а потому является линейным распознавателем.
Для построения распознавателя осталось научиться строить управляющую таблицу Т. Исходными данными для ее построения служат правила исходной грамматики. Вопросы построения этой таблицы в данном пособии не рассматриваются, они достаточно подробно освещены в [6, т. 1]. Далее будут рассмотрены только примеры управляющих таблиц для некоторых достаточно простых грамматик.
Распознаватель для 1.Р.(0)-грамматики
Простейшим случаем ЬИ(к)-грамматик являются Ы1(0)-грамматики. При к - О распознающий расширенный МП-автомат совсем не принимает во внимание текущий символ, обозреваемый его считывающей головкой. Решение о выполняемом действии принимается только на основании содержимого стека автомата. При этом не должно возникать конфликтов между выполняемым действием (сдвиг или свертка), а также между различными вариантами при выполнении свертки. Управляющая таблица для Ь11(0)-грамматики строится на основании понятия «левых контекстов» для нетерминальных символов: очевидно, что после выполнения свертки для нетерминального символа А в стеке МП-автомата ниже этого символа будут располагаться только те символы, которые могут встречаться в цепочке вывода слева от А. Эти символы и составляют «левый контекст» для А. Поскольку выбор между сдвигом или сверткой, а также между типом свертки в Ь11(0)-грамматиках выполняется только на основании содержимого стека, то Ы1(0)-грамматика должна допускать однозначный выбор на основе левого контекста для каждого символа [5, 65, т. 1, 15, 65].
Рассмотрим простую КС-грамматику G({a,b}, {S}, {S-»aSS|b}, S). Пополненная грамматика для нее будет иметь вид G({a,b}, {S, S'}, {S'-»S, S ->aSS|b), $'). Эта грамматика является Ы1(0)-грамматикой. Управляющая таблица для нее приведена в табл. 12.2.
Таблица 12.2. Пример управляющей таблицы для 1_В(0)-грамматики
|
Стек |
Действие |
Переход |
||
|
S |
а |
b |
||
|
1« |
сдвиг |
1 |
2 |
3 |
|
S |
успех, 1 |
|
|
|
|
а |
сдвиг |
4 |
2 |
3 |
|
b |
свертка, 3 |
|
|
|
|
aS |
сдвиг |
5 |
2 |
3 |
|
aSS |
свертка, 2 |
|
|
|
Колонка «Стек», присутствующая в таблице, в принципе не нужна для распозь вателя. Она введена исключительно для пояснения каждого состояния сте автомата. Пустые клетки в таблице соответствуют состоянию «ошибка». Праг ла в грамматике пронумерованы от 1 до 3 (при этом будем считать, что состс нию «успех» — свертке к нулевому символу — в пополненной грамматике Bcei соответствует первое правило). Распознаватель работает, невзирая на текущ символ, обозреваемый считывающей головкой расширенного МП-автомата, i этому колонка «Действие» в таблице имеет только один столбец, не помеченш никаким символом, — указанное в ней данное действие выполняется всегда д каждой строки таблицы.
Рассмотрим примеры распознавания цепочек этой грамматики. Работу распоз) вателя будем отображать по шагам. Конфигурацию расширенного МП-автом; будем отображать в виде трех компонентов: не прочитанная еще часть входн цепочки символов, содержимое стека МП-автомата, последовательность номер примененных правил грамматики (поскольку автомат имеет только одно состс ние, его можно не учитывать). В стеке МП-автомата вместе с помещенными tj символами показаны и номера строк управляющей таблицы, соответствуют этим символам в формате {символ, номер строки).
Разбор цепочки abababb.
1.
(abababblK, {_LH,0},
X)
2.
(bababblK,
{±„,0}{a,2}, X)
3.
(ababblK, {±H,0}{a,2}{b,3}, X)
4.
(ababblK, {±H,0}{a,2}{S,4},
3)
5.
(babblK, {±H,0}{a,2}{S,4}{a,2}, 3)
6.
(abblK,
{±,„0}{a,2}{S,4}{a,2}{b>3}, 3)
7.
(abblK,
{±„,0}{a,2}{S,4}{a,2}{S,4}, 3,3)
8.
(bblK,
{±„,0}{a,2}{S,4}{a,2}{S,4}{a,2}, 3,3)
9.
(blK,
{±,„0}{a,2}{S,4}{a,2}{S,4}{a,2}{b,3}, 3,3)
10.
(blK, {±H,0}{a,2}{S,4}{a,2}{S,4}{a,2}{S,4}, 3,3,3)
11.
(1K, {±H,0}{a,2}{S,4}{a,2}{S,4}{a,2}{S,4}{b,3},
3,3,3)
12.
(1K, {±H,0}{a,2}{S,4}{a,2}{S,4}{a,2}{S,4}{S,5},
3,3,3,3)
13.
(1K,
{±„,0}{a,2}{S,4}{a,2}{S,4}{S,5}, 3,3,3,3,2)
14.
(J_KI
{l„,0}{a,2}{S,4}{S,5}, 3,3,3,3,2,2)
15.
(1K, {±H,0}{S,1},
3,3,3,3,2,2,2)
16.
(_LK, {-LH,0}{S',*}, 3,3,3,3,2,2,2,1) — разбор
завершен.
Соответствующая цепочка вывода будет иметь вид (используется правостор* ний вывод): S' => S => aSS => aSaSS => aSaSaSS => aSaSaSb => aSaSabb => aSababb abababb.
Разбор цепочки aabbb.
1. (aabbb-LK, {±,,,0}, X)
(abbb-LK, {±,„0}{a,2}, X)
3.
(bbblK, {1,„0}{а,2}{а,2}, X)
4.
(bb±K, {±H,0}{a,2}{a,2}{b,3},
X)
5.
(bb±K, {lH,0}{a,2}{a,2}{S,4},
3)
6.
(blK, {lH,0}{a,2}{a,2}{S,4}{b,3},
3)
7.
(blK, {±H,0}{a,2}{a,2}{S,4}{S,5},
3,3)
8.
(blK, {lH,0}{a,2}{S,4},
3,3,2)
9.
(1K, {lH,0}{a,2}{S,4}{b,3},
3,3,2)
10.
(1K, {lH,0}{a,2}{S,4}{S,5},
3,3,2,3)
11.
(1K, {1H,0}{S,1},
3,3,2,3,2)
12.
(1K, {1H,0}{S',*}, 3,3,2,3,2,1) - разбор
завершен.
Соответствующая цепочка вывода будет иметь вид (используется правосторонний вывод): S' => S => aSS => aSb => aaSSb => aaSbb => aabbb. Разбор цепочки a abb.
1.
(aabb±K, {±„,0}Д)
2.
(abblK, {lH,0}{a,2},
X)
3.
(bblK, {lH,0}{a,2}{a,2},
X)
4.
(blK, {lw0}{a,2}{a,2}{b,3},
X)
5.
(blK, {±H,0}{a,2}{a,2}{S,4},
3)
6.
(1K, {lH,0}{a,2}{a,2}{S,4}{b,3},
3)
7.
(1K) {lH,0}{a,2}{a,2}{S,4}{S,5},
3,3)
8.
(1K, {lH,0}{a,2}{S,4},
3,3,2)
9. Ошибка, невозможно выполнить сдвиг.
Распознаватель для Ы1(0)-грамматики достаточно прост. Приведенный выше пример можно сравнить с методом рекурсивного спуска или с распознавателем для LL(1)-грамматики — оба эти метода применимы к описанной выше грамматике. По количеству шагов работы распознавателя эти методы сопоставимы, но по реализации нисходящие распознаватели в данном случае немного проще.
Распознаватель для 1Е(1)-грамматики
Другим употребительным классом LR(k)-грамматик являются LR( ^-грамматики. В этих грамматиках основанием для принятия расширенным МП-автоматом решения о выполнении сдвига или свертки служит информация о содержимом стека автомата и текущий символ, обозреваемый считывающей головкой. Рассмотрим простую КС-грамматику G({a,b}, {S}, {S-»SaSb|X}. S). Пополненная грамматика для нее будет иметь вид G({a,b}, {S, S'}. {S'->S, S-»SaSb|X}, S'). Эта грамматика является 1Л(1)-грамматикой [5, 15, 65]. Управляющая таблица для нее приведена в табл. 12.3.
Колонка «Стек», присутствующая в таблице, в принципе не нужна для распознавателя. Она введена исключительно для пояснения каждого состояния стека автомата. Пустые клетки в таблице соответствуют состоянию «ошибка». Прави-
ла в грамматике пронумерованы от 1 до 3 (при этом будем считать, что состс нию «успех» — свертке к нулевому символу — в пополненной грамматике всег соответствует первое правило). Колонка «Действие» в таблице содержит пег чень действий, соответствующих текущему входному символу, обозреваемо] считывающей головкой расширенного МП-автомата.
Таблица 12.3. Пример управляющей таблицы для 1.Р(1)-грамматики
|
Стек |
Действие |
Переход |
||||
|
a |
Ь |
J» |
а |
b |
S |
|
|
1„ |
свертка, 3 |
|
свертка, 3 |
|
|
1 |
|
S |
сдвиг |
|
успех, 1 |
2 |
|
|
|
Sa |
свертка, 3 |
свертка, 3 |
|
|
|
3 |
|
SaS |
сдвиг |
сдвиг |
|
4 |
5 |
|
|
SaSa |
свертка, 3 |
свертка, 3 |
|
|
|
6 |
|
SaSb |
свертка, 2 |
|
свертка, 2 |
|
|
|
|
SaSaS |
сдвиг |
сдвиг |
|
4 |
7 |
|
|
SaSaSb |
свертка, 2 |
свертка, 2 |
|
|
|
|
Рассмотрим примеры распознавания цепочек этой грамматики по шагам, ког рые совершает распознаватель. Конфигурацию расширенного МП-автомата ( дем отображать в виде трех компонентов: не прочитанная еще часть входной ] почки символов, содержимое стека МП-автомата, последовательность номер примененных правил грамматики (поскольку автомат имеет только одно сост< ние, его можно не учитывать). В стеке МП-автомата вместе с помещенными тз символами показаны и номера строк управляющей таблицы, соответствует этим символам в формате {символ, номер строки}.
Разбор цепочки abababb.
1. (abababb±K, {±„,0}Д)
2. (abababblK> {±„,0}{S,1}, 3)
3. (bababblK, {lH,0}{S,l}{a,2},
3)
4. (bababblK, {±H,0}{S,l}{a,2}{S,3},
3,3)
5. (ababblK, {±„,0}{S,l}{a,2}{S,3}{b,5},
3,3)
6. (ababblK, {±„,0}{S,1}, 3,3,2)
7. (babblK, {±H,0}{S,l}{a,2}, 3,3,2)
8. (babbJLK, {±H,0}{S,l}{a,2}{S,3},
3,3,2,3)
9. (abblK, {±H,0}{S,l}{a,2}{S,3}{b,5},
3,3,2,3)
10. (abbJ_K, {±„,0}{S,1}, 3,3,2,3,2)
U. (bb±K, {±H,0}{S,l}{a,2}, 3,3,2,3,2)
12. (bb±K, {_L„,0}{S,l}{a,2}{S,3},
3,3,2,3,2,3)
13.
![]() (b±K,
{±H,0}{S,l}{a,2}{S,3}{b,5}, 3,3,2,3,2,3)
(b±K,
{±H,0}{S,l}{a,2}{S,3}{b,5}, 3,3,2,3,2,3)
14.
Ошибка, нет данных для «Ь» в строке 5.
Разбор цепочки aababb.
1.
(aababblK,
{±и,0}, к)
2.
(aababblK, {±„,0}{S,1}, 3)
3.
(ababblK,
{:Ц0}{ЗДаД 3)
4.
(ababb±K,
{lH,0}{S,l}{a,2}{S,3}, 3,3)
5.
(babblK)
{±11,0}{S,l}{a,2}{S,3}{a,4}, 3,3)
6.
(babb±K,
{±„,0}{S,l}{a,2}{S,3}{a,4}{S,6}, 3,3,3)
7.
(abblK, {lH,0}{S,l}{a,2}{S,3}{a,4}{S,6}{b,7}, 3,3,3)
8.
(abblK, {lH,0}{S,l}{a,2}{S,3}, 3,3,3,2)
9.
(bblK>
{±H,0}{S,l}{a,2}{S,3}{a,4}, 3,3,3,2)
10.
(bb±K,
{lH,0}{S,l}{a,2}{S,3}{a,4}{S,6}) 3,3,3,2,3)
11.
(blK, {lH,0}{S,l}{a,2}{S,3}{a,4}{S,6}{b,7}, 3,3,3,2,3)
12.
(blK, {±H,0}{S,l}{a,2}{S,3}, 3,3,3,2,3,2)
13.
(1K, {±1I,0}{S,l}{a>2}{S,3}{b,5},
3,3,3,2,3,2)
14.
(1K, {1H,0}{S,1}, 3,3,3,2,3,2,2)
15.
(1K, {1H,0}{S',*},
3,3,3,2,3,2,2,1) — разбор завершен.
Соответствующая цепочка вывода будет иметь вид (используется правосторонний вывод): S' => S => SaSb => SaSaSbb => SaSabb => SaSaSbabb => SaSababb => Saababb => aababb.
Невозможно непосредственно сравнить работу двух рассмотренных вариантов распознавателей: восходящего (LR) и нисходящего (LL). Это очевидно, поскольку приведенная в примере грамматика не является ЬЦ1)-грамматикой. Соответственно, она не может быть разобрана и методом рекурсивного спуска (можно убедиться в этом, построив множества FIRST и FOLLOW для символов грамматики: FIRST(1,S) = {a}, FOLLOW(l,S) = {а,ЬЛ}; FIRST(1,S) n FOLLOW(l.S) * 0). На основании этой грамматики вообще невозможно построить нисходящий распознаватель, поскольку она явно содержит левую рекурсию. Устранив левую рекурсию (см. алгоритм в разделе «Преобразование КС-грамматик. Приведенные грамматики», глава 11) и выполнив ряд несложных преобразований, можно получить эквивалентную ей грамматику G"({a,b},{S},{S->A|aSbS},S), которая будет относиться к классу LL(l)-rpaMMaraK (действительно, для нее FIRST(1,S) = {a}, FOLLOW(l,S) = = {ЬД};. FIRST(1,S) n FOLLOW(l,S) = 0)1. Теперь уже возможно сравнить работу двух вариантов распознавателей — нисходящего и восходящего.
Чтобы доказать, что две рассмотренные грамматики эквивалентны (определяют один и тот же язык: L(G) = L(G")), предлагаем читателям выполнить преобразования G в G" самостоятельно. Это несложно: первым шагом будет устранение левой рекурсии, затем необходимо несколько раз выполнить левую факторизацию (см. раздел «Нисходящие распознаватели КС-языков без возвратов» этой главы), после чего дальнейшее преобразование становится очевидным.
Несмотря на то что распознаватель на основе LL(l)-rpaMMaTHKH и в данном случае имеет более простой алгоритм функционирования, нельзя сказать, что им легче воспользоваться, поскольку его создание требует дополнительных преобразований исходной грамматики. Для более сложных LR(l)-rpaMMaTHK такие преобразования могут быть в принципе невозможны, поскольку класс языков, заданных LR(l)-rpaMMaTHKaMH, шире, чем класс языков, заданных LL(l)-rpaM-матиками. Поэтому для конкретной заданной грамматики чаще бывает проще построить восходящий распознаватель, чем нисходящий.
На практике LR(k)-rpaMMaTHKH при к > 1 не применяются. На это имеются две причины. Во-первых, управляющая таблица для LR(k)-rpaMMaraKH при к > 1 будет содержать очень большое число состояний, и распознаватель будет достаточно сложным и не столь эффективным1. Во-вторых, для любого языка, определяемого LR(k)-грамматикой, существует LR(l)-rpaMMaraKa, определяющая тот же язык. То есть для любой LR(k)-rpaMMaraKH с к > 1 всегда существует эквивалентная ей LR(l)-rpaMMaTHKa. Более того, для любого детерминированного КС-языка существует LR(l)-rpaMMaraKa (другое дело, что далеко не всегда такую грамматику можно легко построить)2.
Грамматики предшествования (основные принципы)
Еще одним распространенным классом КС-грамматик, для которых возможно построить восходящий распознаватель без возвратов, являются грамматики предшествования. Так же как и распознаватель рассмотренных выше LR-грам-матик, распознаватель для грамматик предшествования строится на основе алгоритма «сдвиг-свертка» («перенос-свертка»), который в общем виде был рассмотрен в разделе «Распознаватели КС-языков с возвратом», глава 11. Принцип организации распознавателя входных цепочек языка, заданного грамматикой предшествования, основывается на том, что для каждой упорядоченной пары символов в грамматике устанавливается некоторое отношение, называемое отношением предшествования. В процессе разбора входной цепочки расширенный МП-автомат сравнивает текущий символ входной цепочки с одним из символов, находящихся на верхушке стека автомата. В процессе сравнения проверяется, какое из возможных отношений предшествования существует между этими двумя символами. В зависимости от найденного отношения выполняется либо
1 Безусловно, при любых значениях к распознаватель
для LR(k)-грамматик
остается ли
нейным распознавателем — необходимые
вычислительные ресурсы для него линейно за
висят от длины входной цепочки
символов. Но с ростом к будет расти и коэффициент
зависимости. Из алгоритма функционирования распознавателя видно, что этот
коэффи
циент напрямую связан с объемом
управляющей таблицы, причем ее объем возрастает
в квадратичной зависимости от величины к.
2 Число состояний управляющей таблицы для
практически интересных LR(l)-rpaMMaTHK
также весьма велико. А к классу
1Л(0)-грамматик такие грамматики почти никогда не
относятся. На практике чаще всего используются промежуточные между LR(0) и LR(l)
методы, известные под названиями SLR(l) — Simple («Простые») LR(1) — и LALR(l) —
Look Ahead («С заглядыванием вперед») LR(1) [6, 12, 23].
сдвиг (перенос), либо свертка. При отсутствии отношения предшествования между символами алгоритм сигнализирует об ошибке.
Задача заключается в том, чтобы иметь возможность непротиворечивым образом определить отношения предшествования между символами грамматики. Если это возможно, то грамматика может быть отнесена к одному из классов грамматик предшествования.
Существует несколько видов грамматик предшествования. Они различаются по тому, какие отношения предшествования в них определены и между какими типами символов (терминальными или нетерминальными) могут быть установлены эти отношения. Кроме того, возможны незначительные модификации функционирования самого алгоритма «сдвиг-свертка» в распознавателях для таких грамматик (в основном на этапе выбора правила для выполнения свертки, когда возможны неоднозначности) [5, 6, 23, 65].
Выделяют следующие виды грамматик предшествования:
□
простого предшествования;
□
расширенного предшествования;
□
слабого предшествования;
□
смешанной стратегии предшествования;
□
операторного предшествования.
Далее будут рассмотрены два наиболее простых и распространенных типа — грамматики простого и операторного предшествования.
Грамматики простого предшествования
Грамматикой простого предшествования называют такую приведенную КС-грамматику1 G(VN,VT,P,S), V = VTuVN, в которой:
1. Для каждой упорядоченной пары терминальных и
нетерминальных символов
выполняется не более чем одно из
трех отношений предшествования:
О Bj =• Bj (V Bj,BjeV), если и только если 3 правило А->хВ(В;у еР, где AeVN,
О Bj <• Bj (V Bj,BjeV), если и только если 3 правило A-»xBjDy еР и вывод D=>*SjZ, где A,DeVN, x,y,zeV*;
О Bj'•> Bj (V Bj,BjeV) , если и только если 3 правило A-»xCBjy еР и вывод C=>*zB; или 3 правило A->xCDy еР и выводы C=>*zBj и D=>*Bj\v, где A,C,DeVN, x,y,z,weV*.
2. Различные правила в грамматике имеют разные
правые части (то есть в грам
матике не должно быть двух различных
правил с одной и той же правой ча
стью).
Напоминаем, что КС-грамматика называется приведенной, если она не содержит циклов, бесплодных и недостижимых символов и А.-правил (см. раздел «Преобразование КС-грамматик. Приведенные грамматики», глава 11).
Отношения =•, <• и •> называют отношениями предшествования для символов. Отношение предшествования единственно для каждой упорядоченной пары символов. При этом между какими-либо двумя символами может и не быть отношения предшествования — это значит, что они не могут находиться рядом ни в одном элементе разбора синтаксически правильной цепочки. Отношения предшествования зависят от порядка, в котором стоят символы, и в этом смысле их нельзя путать со знаками математических операций — они не обладают ни свойством коммутативности, ни свойством ассоциативности. Например, если известно, что В( •> Bj, то не обязательно выполняется Bj <• В; (поэтому знаки предшествования иногда помечают специальной точкой: =•, <•, •>). Для грамматик простого предшествования известны следующие полезные свойства:
□
всякая грамматика простого предшествования является однозначной;
□
легко проверить, является или нет произвольная КС-грамматика грамматикой простого предшествования
(для этого достаточно проверить рассмотренные выше свойства грамматик простого предшествования или
воспользоваться
алгоритмом построения матрицы предшествования, который рассмотрен далее).
Как и для многих других классов грамматик, для грамматик простого предшествования не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику в грамматику простого предшествования (или доказать, что преобразование невозможно).
Метод предшествования основан на том факте, что отношения предшествования между двумя соседними символами распознаваемой строки соответствуют трем следующим вариантам:
□
Bj <■ Bi+1, если символ Bi+1 — крайний левый символ некоторой
основы (это отношение
между символами можно назвать «предшествует основе» или просто «предшествует»);
□
Bj •> Bi+1, если символ Bj — крайний правый символ некоторой
основы (это отношение между символами можно назвать «следует за основой» или
просто «следует»);
□
Bj =• Bi+1, если символы В; и Bi+i принадлежат одной основе (это отношение между символами можно назвать «составляют
основу»).
Исходя из этих соотношений, выполняется разбор строки для грамматики предшествования.
Суть принципа такого разбора можно пояснить на рис. 12.5. На нем изображена входная цепочка символов ау(38 в тот момент, когда выполняется свертка цепочки у. Символ а является последним символом подцепочки а, а символ Ъ — первым символом подцепочки р\ Тогда, если в грамматике удастся установить непротиворечивые отношения предшествования, то в процессе выполнения разбора по алгоритму «сдвиг-свертка» можно всегда выполнять сдвиг до тех пор, пока между символом на верхушке стека и текущим символом входной цепочки существует отношение <■ или =•. А как только между этими символами будет обнару-
жено отношение •>, так сразу надо выполнять свертку. Причем для выполнения свертки из стека надо выбирать все символы, связанные отношением =•. То, что все различные правила в грамматике предшествования имеют различные правые части, гарантирует непротиворечивость выбора правила при выполнении свертки.
Таким образом, установление непротиворечивых отношений предшествования между символами грамматики в комплексе с несовпадающими правыми частями различных правил дает ответы на все вопросы, которые надо решить для организации работы алгоритма «сдвиг-свертка» без возвратов.
|
а |
a |
Y |
Ь |
Р |
6 |
<. =. .>
Рис. 12.5. Отношения между символами входной цепочки в грамматике предшествования
На основании отношений предшествования строят матрицу предшествования грамматики. Строки матрицы предшествования помечаются первыми (левыми) символами, столбцы — вторыми (правыми) символами отношений предшествования. В клетки матрицы на пересечении соответствующих столбца и строки помещаются знаки отношений. При этом пустые клетки матрицы говорят о том, что между данными символами нет ни одного отношения предшествования. Матрицу предшествования грамматики сложно построить, опираясь непосредственно на определения отношений предшествования. Удобнее воспользоваться двумя дополнительными множествами — множеством крайних левых и множеством крайних правых символов относительно нетерминальных символов грамматики G(VN,VT,P,S), V = VTuVN. Эти множества определяются следующим образом:
□
L(A) = {X | 3 A=>*Xz}, AeVN, XeV, zeV — множество крайних левых символов
относительно нетерминального символа А (цепочка z может быть и пустой цепочкой);
□
R(A) = {X | 3 A=>*zX}, AeVN, XeV, zeV* — множество крайних правых символов относительно нетерминального символа А.
Иными словами, множество крайних левых символов относительно нетерминального символа А — это множество всех крайних левых символов в цепочках, которые могут быть выведены из символа А. Аналогично, множество крайних правых символов относительно нетерминального символа А — это множество всех крайних правых символов в цепочках, которые могут быть выведены из символа А.
Тогда отношения предшествования можно определить так:
□
Bj =• Bj (V Bi,BjeV), если 3
правило А-^хВ^у е Р, где AeVN, x,yeV;
□
Bj <• Bj (V Bi7BjeV), если 3 правило A-McBiDy e P и BjeL(D), где A,DeVN,
x,yeV*;
□ B, •> B, (V Bj.BjsV), если
Э правило A-»xCBjy e P и BisR(C) или З правило
A^xCDye
P и B:eR(C), BjsL(D), где A,C,DeVN, x,yeV*.
Такое определение отношений удобнее на практике, так как не требует построения выводов, а множества L(A) и R(A) могут быть построены для каждого нетерминального символа AeVN грамматики G(VN,VT,P,S), V = VTuVN по очень простому алгоритму.
Шаг 1. V AeVN:
Ro(A) = {X | А^уХ, XeV, yeV*}, L0(A) = {X | A-+Xy, XeV, yeV*}, i := 1. Для каждого нетерминального символа А ищем все правила, содержащие А в левой части. Во множество L(A) включаем самый левый символ из правой части правил, а во множество R(A) — самый крайний правый символ из правой части. Переходим к шагу 2. Шаг 2. V AeVN:
Ri (A) = R,!(A) ц RM(B), V В е (ЛИ(А) n VN), Ц (А) = Lh(A) и Li4(B), V В е (LM(A) n VN). Для каждого нетерминального символа А: если множество L(A) содержит нетерминальные символы грамматики А', А", ..., то его надо дополнить символами, входящими в соответствующие множества L(A'), L(A"), ... и не входящими в L(A). Ту же операцию надо выполнить для R(A).
Шаг 3. Если 3 AeVN: Ri(A) * Ri_i(A) или Lj(A) * ЬИ(А), то i:=i+l и вернуться к шагу 2, иначе построение закончено: R(A) = Rj(A) и L(A) = Lj(A). Если на предыдущем шаге хотя бы одно множество L(A) или R(A) для некоторого символа грамматики изменилось, то надо вернуться к шагу 2, иначе построение закончено.
После построения множеств L(A) и R(A) по правилам грамматики создается матрица предшествования. Матрицу предшествования дополняют символами 1и и ±к (начало и конец цепочки). Для них определены следующие отношения предшествования:
±н <■ X, V aeV, если 3 S=>*Xy, где SeVN, yeV или (с другой стороны) если
XeL(S);
1К •> X, V aeV, если 3 S=>*yX, где SeVN, yeV* или (с другой стороны) если
XeR(S). Здесь S — целевой символ грамматики.
Матрица предшествования служит основой для работы распознавателя языка, заданного грамматикой простого предшествования.
Алгоритм «сдвиг-свертка» для грамматики простого предшествования
Данный алгоритм выполняется расширенным МП-автоматом с одним состоянием. Отношения предшествования служат для того, чтобы определить в процессе выполнения алгоритма, какое действие — сдвиг или свертка — должно выполняться на каждом шаге алгоритма, и однозначно выбрать цепочку для свертки. Однозначный выбор правила при свертке обеспечивается за счет различия правых частей всех правил грамматики. В начальном состоянии автомата считываю-
щая головка обозревает первый символ входной цепочки, в стеке МП-автомата находится символ ±н (начало цепочки), в конец цепочки помещен символ _LK (конец цепочки). Символы _1_н и J_K введены для удобства работы алгоритма, в язык, заданный исходной грамматикой, они не входят.
Разбор считается законченным (алгоритм завершается), если считывающая головка автомата обозревает символ _LK и при этом больше не может быть выполнена свертка. Решение о принятии цепочки зависит от содержимого стека. Автомат принимает цепочку, если в результате завершения алгоритма в стеке находятся начальный символ грамматики S и символ 1н. Выполнение алгоритма может быть прервано, если на одном из его шагов возникнет ошибка. Тогда входная цепочка не принимается.
Алгоритм состоит из следующих шагов.
Шаг 1. Поместить в верхушку стека символ 1,„ считывающую головку — в начало входной цепочки символов.
Шаг 2. Сравнить с помощью отношения предшествования символ, находящийся на вершине стека (левый символ отношения), с текущим символом входной цепочки, обозреваемым считывающей головкой (правый символ отношения).
Шаг 3. Если имеет место отношение <• или =•, то произвести сдвиг (перенос текущего символа из входной цепочки в стек и сдвиг считывающей головки на один шаг вправо) и вернуться к шагу 2. Иначе перейти к шагу 4.
Шаг 4. Если имеет место отношение •>, то произвести свертку. Для этого надо найти на вершине стека все символы, связанные отношением =• («основу»), удалить эти символы из стека. Затем выбрать из грамматики правило, имеющее правую часть, совпадающую с основой, и поместить в стек левую часть выбранного правила (если символов, связанных отношением =-<$]command>, на верхушке стека нет, то в качестве основы используется один, самый верхний символ стека). Если правило, совпадающее с основой, найти не удалось, то необходимо прервать выполнение алгоритма и сообщить об ошибке, иначе, если разбор не закончен, то вернуться к шагу 2.
Шаг 5. Если не установлено ни одно отношение предшествования между текущим символом входной цепочки и символом на верхушке стека, то надо прервать выполнение алгоритма и сообщить об ошибке.
Ошибка в процессе выполнения алгоритма возникает, когда невозможно выполнить очередной шаг — например, если не установлено отношение предшествования между двумя сравниваемыми символами (на шагах 2 и 4) или если не удается найти нужное правило в грамматике (на шаге 4). Тогда выполнение алгоритма немедленно прерывается.
Пример распознавателя для грамматики простого предшествования
Рассмотрим в качестве примера грамматику G({+,-,/,*,a,b}, {S,R,T,F,E}, P, S) с правилами:
Р:
S -> TR | Т
R _> +т | -Т | +TR | -TR
Т -> EF | Е
F -> *Е | /Е | *EF | /EF
Е -+ (S) | а | b Эта нелеворекурсивная грамматика для арифметических выражений над символами а и b уже несколько раз использовалась в качестве примера для построения распознавателей (см. раздел «Распознаватели КС-языков с возвратом», глава И). Хотя эта грамматика и содержит цепные правила, легко увидеть, что она не содержит циклов, совпадающих правых частей правил и ^-правил, следовательно, по формальным признакам ее можно отнести к грамматикам простого предшествования. Осталось определить отношения предшествования. Построим множества крайних левых и крайних правых символов относительно нетерминальных символов грамматики.
1. Шаг 1.
L0(S) = {Т} Ro(S) - {R, Т}
L0(R) = {+, -} R0(R)
" {R Т}
Lo(T) - {Е} Ro(T)
- {Е,
F}
L0(F) -{*,/} R0(F) = {E,F}
' Lo(E) - {(, a, b} R0(E) = {), a, b}
2. Шаг 2.
Li(S)-{T;E) R,(S) - {R, T E, F}
L,(R) = {+, -} Ri(R) = {R T, E, F}
L,(T) = {E, (, a, b} Ri(I) r {E, F, ), a,
b}
L,(F) = {*, /} Rj(F)
= {E, F, ), a, b }
Lt(E) = {(, a, b} R,(E) =
{), a, b}
3.
Шаг 3. Имеется
L0(S) * L,(S), возвращаемся к шагу 2.
4.
Шаг 2.
L2(S)
= {Т, Е, (, a, b} R2(S) =
{R, T, E, F, ), а, Ь}
L2(R)
= {+, -} R2(R)
= {R t E> F>)- a' b>
L2(T) = {E, (, a,
b} R2(T.) = {E, F, ), a,
b}
L2(F) = {*, /} R2(F)
= (E, F, ), a, b }
L2(E) = {(, a, b} R2(E) - {), a, b}
5.
Шаг З. Имеется
Lt(S) Ф L2(S), возвращаемся к шагу 2.
6.
Шаг 2.
L3(S) = {Т, Е, (, a, b} R3(S)
- {R, T E, F, ), а, Ь}
L3(R)
- {+, -} R3(R)
" {R. T, E, F, ), а, Ь}
L3(T) - {Е, (, a,
b} R3(T)
- {Е,
F, ), а,
Ь}
L3(F) - {*, /} R3(F)
- {Е,
F, ), a, b }
L3(E) = {(, a, b} R3(E) = {), a, b}
7. Шаг 3. Ни одно множество
не изменилось, построение закончено. Результат:
L(S) - {Т, Е, (, a, b} R(S) - {R, T, E, F, ), а, Ь}
L(R) - {+, -} R(R) - {R, T, E, F, ), а, Ь}
R(T) = {Е, F, ), а, Ь}
R(F) т {E, F, ), а, Ь }
R(E) = {), а, Ь}
На основании построенных множеств крайних левых и крайних правых символов и правил грамматики построим матрицу предшествования. Результат приведен в табл. 12.4.
Таблица 12.4. Таблица предшествования для грамматики простого предшествования
|
|
+ |
- |
* |
/ |
( |
) |
а |
b |
S |
R |
Т |
F |
Е |
К |
|
+ |
|
|
|
|
<■ |
|
<• |
<• |
|
|
=■ |
|
<• |
|
|
- |
|
|
|
|
<• |
|
<• |
<• |
|
|
=■ |
|
<■ |
|
|
* |
|
|
|
|
<• |
|
<• |
<• |
|
|
|
|
=■ |
|
|
/ |
|
|
|
|
<• |
|
<• |
<• |
|
|
|
|
-• |
|
|
( |
|
|
|
|
<■ |
|
<• |
<• |
=• |
|
<• |
|
<■ |
|
|
) |
•> |
> |
•> |
•> |
|
•> |
|
|
|
> |
|
■ > |
|
■> |
|
а |
•> |
•> |
•> |
■> |
|
■> |
|
|
|
•> |
|
•> |
|
■> |
|
b |
> |
•> |
•> |
•> |
|
'> |
|
|
|
• > |
|
> |
|
■> |
|
S |
|
|
|
|
|
«• |
|
|
|
|
|
|
|
|
|
R |
|
|
|
|
|
•> |
|
|
|
|
|
|
|
■> |
|
Т |
<• |
<■ |
|
|
|
•> |
|
|
|
=. |
|
|
|
■> |
|
F |
•> |
•> |
|
|
|
•> |
|
|
|
•> |
|
|
|
■> |
|
Е |
•> |
■> |
<• |
<• |
|
•> |
|
|
|
•> |
|
=■ |
|
■> |
|
К |
|
|
|
|
<• |
|
<• |
< |
|
|
<■ |
|
<• |
|
Поясним построение таблицы на примере символа +.
Во-первых, в правилах грамматики R -» +Т | +TR символ + стоит слева от символа Т. Значит, в строке символа + в столбце, соответствующем символу Т, ставим знак =•. Кроме того, во множество ЦТ) входят символы Е, (, а, Ь. Тогда в строке символа + во всех столбцах, соответствующих этим четырем символам, ставим знак <•.
Во-вторых, символ + входит во множество L(R), а в грамматике имеются правила вида S -> TR и R -» +TR | -TR. Следовательно, надо рассмотреть также мно- жество R(T). Туда входят символы Е, F, ), а, Ь. Значит, в столбце символа + во всех строках, соответствующих этим пяти символам, ставим знак •>. Больше символ + ни в какие множества не входит и ни в каких правилах не встречается. Продолжая эти рассуждения для остальных терминальных и нетерминальных символов грамматики, заполняем все ячейки матрицы предшествования, приведенной выше. Если окажется, что согласно логике рассуждений в какую-либо клетку матрицы предшествования необходимо поместить более чем один-единственный знак =•, <• или •>, то это означает, что исходная грамматика не является грамматикой простого предшествования.
Отдельно можно рассмотреть заполнение строки для символа 1и (начало строки) и столбца для символа ±к (конец строки). Множество L(S), где S - целевой символ, содержит символы Т, Е, (, а, Ь. Помещаем знак <• в строку, соответствующую символу 1„ для всех пяти столбцов, соответствующих этим символам. Аналогично, множество R(S) содержит символы R, T, E, F, ), а, Ь. Помещаем знак •> в столбец, соответствующий символу 1к для всех семи строк, соответствующих этим символам.
Рассмотрим работу алгоритма распознавания на примерах. Последовательность разбора будем записывать в виде последовательности конфигураций МП-автомата из трех составляющих:
□
не просмотренная автоматом часть входной цепочки;
□
содержимое стека;
□
последовательность примененных правил грамматики.
Так как автомат имеет только одно состояние, то для определения его конфигурации достаточно двух составляющих - положения считывающей головки во входной цепочке и содержимого стека. Последовательность номеров правил несет дополнительную полезную информацию, по которой можно построить цепочку или дерево вывода (кроме того, последовательность примененных правил делает пример более наглядным). Правила в грамматике нумеруются в направлении слева направо и сверху вниз (всего в грамматике имеется 15 правил). Будем обозначать такт автомата символом *•. Введем также дополнительное обозначение *п, если на данном такте выполнялся перенос, и -нс, если выполнялась свертка.
Последовательности разбора цепочек входных символов будут, таким образом, иметь вид. Пример 1. Входная цепочка а+а*Ь.
1. {а+а*Ык; 1Н;
0} +п
2.
{+а*Ь±к; 1на; 0} +с
3.
{+a*blK; _LHE;
14} *с
4.
{+а*Ь±к; 1ИТ; 14,8}
5.
{а*ЬХк; 1„Т+; 14,8}
6.
{*ЫК; ±нТ+а; 14,8}
{*Ь±К;
±„Т+Е; 14,8,14}
8.
{Ь±к; 1Д+Е*; 14,8,14} *п
9.
{1к;
±НТ+Е*Ь; 14,8,14} +с
10.
{1к;
1НТ+Е*Е; 14,8,14,15} *с
11.
{±к; ±HT+EF; 14,8,14,15,9}+с
12.
{1к;
1НТ+Т; 14,8,14,15,9,7} +с
13.
{±к;
1HTR;
14,8,14,15,9,7,3} +с
14.
{1к; ±HS; 14,8,14,15,9,7,3,1}, алгоритм
завершен, цепочка принята.
Соответствующая цепочка вывода будет иметь вид (используется правосторонний вывод): S => TR => Т+Т => T+EF => Т+Е*Е => Т+Е*Ь => Т+а*Ь => Е+а*Ь => а+а*Ь.
Дерево вывода, соответствующее этой цепочке, приведено на рис. 12.6.
(?) £r\
© 0 )S)
© f/r
(a) Q (e)
Рис. 12.6. Первый пример дерева вывода для грамматики простого предшествования
Пример 2. Входная цепочка (а+а)*Ь.
1.
{(а+а)*Ь±к; 1„; 0} +п
2.
{a+a)*b±K;
iH(; 0} +„
3.
{+а)*Ык; 1и(а; 0} +с
4.
{+а)*Ык; 1Н(Е; 14} +с
5.
{+а)*Ь±к;
1Н(Т; 14,8} +п
6.
{а)*Ь±к;
1Н(Т+; 14,8} *п
7.
{)*ЫК;
±н(Т+а; 14,8} +с
8.
{)*ЫК;
±Н(Т+Е; 14,8,14} +с
9.
{)*ЫК; 1Н(Т+Т; 14,8,14,8} +с
10.
{)*ЫК;
1H(TR;
14,8,14,8,3} +с
11.
{)*Ь±К;
±H(S;
14,8,14,8,3,1}+п
12.
{*Ъ±к;
±H(S); 14,8,14,8,3,1}
+с
13.
{*ЫК;
±НЕ;
14,8,14,8,3,1,13} +п
14.
{Ь1к;
±НЕ*; 14,8,14,8,3,1,13} +п
15.
{1к;
1НЕ*Ь; 14,8,14,8,3,1,13} +с
16.
{±к;
1НЕ*Е; 14,8,14,8,3,1,13,15} +с
17.
{1к;
1HEF;
14,8,14,8,3,1,13,15,9} +с
18.
{1к;
1НТ; 14,8,14,8,3,1,13,15,9,7} tc
19.
{1к; _LHS; 14,8,14,8,3,1,13,15,9,7,2},
алгоритм завершен, цепочка принята.
Соответствующая цепочка вывода будет иметь вид (используется правосторонний вывод): S => Т => EF => Е*Е => E*b => (S)*b =^> (TR)*b => (T+T)*b => (T+E)*b => (T+a)*b => (E+a)*b => (a+a)*b. Дерево вывода, соответствующее этой цепочке, приведено на рис. 12.7.
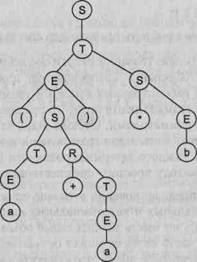
Рис. 12.7. Второй пример дерева вывода для грамматики простого предшествования
Пример 3. Входная цепочка а+а*.
1.
{а+а*±к;
1И; 0} +п
2.
{+а*±к; 1„а; 0} +с
3.
{+а*1к;
1ПЕ; 14} +с
4.
{+а*±к;
±НТ; 14,8} +п
5.
{а*±к; ХД+; 14,8} +п
6.
{*1к;
±нТ+а; 14,8} +е
7.
{*±к;
1„Т+Е; 14,8,14} +п
8.
{±к;
±ИТ+Е*; 14,8,14} +
9.
Ошибка! (Нет отношений предшествования между
символами * и _LK.)
Пример 4. Входная цепочка а+а)*Ь.
1.
{а+а)*Ык; 1и; 0} +п
2.
{+а)*Ык; 1на; 0} %
3.
{+а)*Ь±к; Х,Е; 14} +с
4.
{+а)*Ык; 1„Т; 14,8} *п
5.
{а)*Ь±к; ±НТ+; 14,8} +п
6.
{)*ЫК; 1кТ+а; 14,8} +с
7.
{)*ЫК; ±НТ+Е; 14,8,14} +с
8.
{)*ЫК; 1НТ+Т; 14,8,14,8} ^с
9.
{)*ЫК; 1HTR; 14,8,14,8,3} +с
10.
{)*blK; 1„S; 14,8,14,8,3,1} ^п
11.
{*ЫК; 1HS); 14,8,14,8,3,1} +с
12.
Ошибка! (Невозможно выбрать правило для свертки на этом шаге.)
Грамматики простого предшествования являются удобным механизмом для анализа входных цепочек КС-языков. Распознаватель для этого класса грамматик строить легче, чем для рассмотренных выше LR-грамматик. Однако при этом класс языков, заданных грамматиками простого предшествования уже, чем класс языков, заданных LR-грамматиками. Отсюда ясно, что не всякий детерминированный КС-язык может быть задан грамматикой простого предшествования, а следовательно, не для каждого детерминированного КС-языка можно построить распознаватель по методу простого предшествования.
У грамматик простого предшествования есть еще один недостаток — при большом количестве терминальных и нетерминальных символов в грамматике матрица предшествования будет иметь значительный объем (при этом следует заметить, что значительная часть ее ячеек может оставаться пустой). Поиск в такой матрице может занять некоторое время, что существенно при работе распознавателя — фактически время поиска линейно зависит от числа символов в грамматике, а объем матрицы — квадратично. Для того чтобы избежать хранения и обработки таких матриц, можно выполнить «линеаризацию матрицы предшествования». Тогда каждый раз, чтобы установить отношение предшествования между двумя символами, будет выполняться не поиск по матрице, а вычисление некой специально организованной функции. Вопросы линеаризации матрицы предшествования здесь не рассматриваются, с применяемыми при этом методами можно ознакомиться в [5, 6, т. 2, 23, 32].
Грамматики операторного предшествования
Операторной
грамматикой называется
КС-грамматика без Х-правил, в которой правые части всех правил не содержат смежных
нетерминальных символов. Для операторной грамматики отношения предшествования
можно задать на множестве терминальных
символов (включая символы J_„ и J_K).
Грамматикой операторного предшествования называется операторная КС-грамматика G(VN,VT,P,S), V = VTuVN, для которой выполняются следующие условия:
1. Для каждой упорядоченной пары терминальных
символов выполняется не
более чем одно из трех отношений предшествования:
О а =• Ь, если и только если существует правило A-»xaby еР или правило А-wcaCby, где a,beVT, A.CeVN, x.yeV;
О а <■ b, если и только если существует правило А->хаСу еР и вывод C=>*bz или вывод C=>*Dbz, где a,beVT, A,C,DeVN, x,y,zeV";
О а •> b, если и только если существует правило А-»хСЬу еР и вывод C=>*za или вывод C=>*zaD, где a,beVT, A,C,DeVN, x.y.zeV*1.
2. Различные порождающие правила имеют разные правые
части, ^.-правила от
сутствуют.
Отношения предшествования для грамматик операторного предшествования определены таким образом, что для них выполняется еще одна особенность — правила грамматики операторного предшествования не могут содержать двух смежных нетерминальных символов в правой части. То есть в грамматике операторного предшествования G(VN,VT,P,S), V = VTuVN не может быть ни одного правила вида: А-»хВСу, где A,B,CeVN, x,yeV* (здесь х и у — это произвольные цепочки символов, могут быть и пустыми).
Для грамматик операторного предшествования также известны следующие свойства:
□
всякая грамматика операторного предшествования задает детерминированный КС-язык (но не всякая
грамматика операторного предшествования при этом
является однозначной!);
□
легко проверить, является или нет произвольная КС-грамматика грамматикой операторного предшествования
(точно так же, как и для простого предшествования).
Как и для многих других классов грамматик, для грамматик операторного предшествования не существует алгоритма, который бы мог преобразовать произвольную КС-грамматику в грамматику операторного предшествования (или доказать, что преобразование невозможно).
Принцип работы распознавателя для грамматики операторного предшествования аналогичен грамматике простого предшествования, но отношения предшествования проверяются в процессе разбора только между терминальными символами.
В литературе отношения операторного
предшествования иногда обозначают другими символами, отличными от «<■», «•>» и
«=■», чтобы не путать их с отношениями простого предшествования. Например,
встречаются обозначения «<°», «°>» и «=°». В данном пособии путаница исключена,
поэтому будут использоваться одни и те же обозначения, хотя, по сути, отношения
предшествования несколько различны.
Для грамматики данного вида на основе
установленных отношений предшествования также строится матрица
предшествования, но она содержит только терминальные символы грамматики.
Для построения этой матрицы удобно ввести множества крайних левых и крайних правых терминальных символов относительно нетерминального символа А - Ll(A) или Rl(A):
□
L'(A) = {t | 3 A=>*tz
или Э A=>*Ctz }, где teVT,
A,CeVN, zeV;
□
R'(A) = {t | 3 A=>*zt
или 3 A=>*ztC }, где teVT,
A.CeVN, zeV*.
Тогда определения отношений операторного предшествования будут выглядеть так:
□ а =■ Ь, если 3 правило A—»xaby еР или правило U-»xaCby, где a,beVT, A,CeVN,
x,yeV;
□
а
<• b, если 3 правило
А-»хаСу еР и ЬеЬ'(С), где a,beVT,
A,CeVN, x,yEV*;
□
а
•> b, если 3 правило A-»xCby еР и aeR^C), где
a,beVT, A,CeVN, x.yeV*.
В данных определениях цепочки символов x,y,z могут
быть и пустыми цепочками.
Для нахождения множеств L'(A) и R'(A) предварительно необходимо выпол
нить построение множеств L(A) и R(A), как это было
рассмотрено ранее. Далее
для
построения Ll(A)
и R'(A) используется
следующий алгоритм:
Шаг 1. V AeVN:
Rl0(A)
= {t | A->ytB или A->yt,
teVT, BeVN, yeV},
V0(A)
= {t | A->Bty или A->ty,
teVT, BeVN, yeV}.
Для каждого нетерминального символа А ищем все правила, содержащие А в левой части. Во множество L(A) включаем самый левый терминальный символ из правой части правил, игнорируя нетерминальные символы, а во множество R(A) — самый крайний правый терминальный символ из правой части правил. Перехо-цим к шагу 2.
Шаг 2. V AeVN:
Rli(A) = RV,(A) u RV,(B), V В e (R(A) n VN),
Ц(А) = LVi(A) u LVi(B), V В e (L(A) n VN).
Цля каждого
нетерминального символа А: если множество L(A)
содержит нетер
минальные
символы грамматики А', А"... то его надо дополнить символами,
зходящими в соответствующие множества Ь'(А'), Ll(A"), ... и не входящими в Ll(A). Ту же операцию надо выполнить для множеств R(A) и Rl(A). Шаг 3. Если Э AeVN: R'^A) ± RVi(A) или Ц(А) * LVi(A), то i:=i+l и вернуться с шагу 2, иначе построение закончено: R(A) = R^A) и L(A) = 1Д(А). 1сли на предыдущем шаге хотя бы одно множество L'(A) или R'(A) для некоторого символа грамматики изменилось, то надо вернуться к шагу 2, иначе по-:троение закончено.
практического использования
матрицу предшествования дополняют симво-гами -L,,
и ±к (начало и конец цепочки). Для них определены следующие
отноше-1ия предшествования:
±н <• а, V aeVT, если 3 S=>*ax или 3 S=>*Cax, где S,CeVN, xeV* или если
aeLl(S);
1К ■> а, V aeVT, если 3 S=>*xa или 3 S=>*xaC, где S,CeVN, xeV* или если
aeR4(S).
Здесь S — целевой символ грамматики.
Матрица предшествования служит основой для работы распознавателя языка, заданного грамматикой операторного предшествования. Поскольку она содержит только терминальные символы, то, следовательно, будет иметь меньший размер, чем аналогичная матрица для грамматики простого предшествования. Следует отметить, что напрямую сравнивать матрицы двух грамматик нельзя — не всякая грамматика простого предшествования является грамматикой операторного предшествования, и наоборот. Например, рассмотренная далее в примере грамматика операторного предшествования не является грамматикой простого предшествования (читатели могут это проверить самостоятельно). Однако если две грамматики эквивалентны и задают один и тот же язык, то их множества терминальных символов должны совпадать. Тогда можно утверждать, что размер матрицы для грамматики операторного предшествования всегда будет меньше, чем размер матрицы эквивалентной ей грамматики простого предшествования. Все, что было сказано выше о способах хранения матриц для грамматик простого предшествования, в равной степени относится также и к грамматикам операторного предшествования, с той только разницей, что объем хранимой матрицы будет меньше.
Алгоритм «сдвиг-свертка» для грамматики операторного предшествования
Этот алгоритм в целом похож на алгоритм для грамматик простого предшествования, рассмотренный выше. Он также выполняется расширенным МП-автоматом и имеет те же условия завершения и обнаружения ошибок. Основное отличие состоит в том, что при определении отношения предшествования этот алгоритм не принимает во внимание находящиеся в стеке нетерминальные символы и при сравнении ищет ближайший к верхушке стека терминальный символ. Однако после выполнения сравнения и определения границ основы при поиске правила в грамматике нетерминальные символы следует, безусловно, принимать во внимание.
Алгоритм состоит из следующих шагов.
Шаг 1. Поместить в верхушку стека символ 1„, считывающую головку — в начало входной цепочки символов.
Шаг 2. Сравнить с помощью отношения предшествования терминальный символ, ближайший к вершине стека (левый символ отношения), с текущим символом входной цепочки, обозреваемым считывающей головкой (правый символ отношения). При этом из стека надо выбрать самый верхний терминальный символ, игнорируя все возможные нетерминальные символы. Шаг 3. Если имеет место отношение <■ или =•, то произвести сдвиг (перенос текущего символа из входной цепочки в стек и сдвиг считывающей головки на один шаг вправо) и вернуться к шагу 2. Иначе перейти к шагу 4.
Шаг 4. Если имеет место отношение •>, то произвести свертку. Для этого надо найти на вершине стека все терминальные символы, связанные отношением =■ («основу»), а также все соседствующие с ними нетерминальные символы (при определении отношения нетерминальные символы игнорируются). Если терминальных символов, связанных отношением =•, на верхушке стека нет, то в качестве основы используется один, самый верхний в стеке терминальный символ стека. Все (и терминальные, и нетерминальные) символы, составляющие основу, надо удалить из стека, а затем выбрать из грамматики правило, имеющее правую часть, совпадающую с основой, и поместить в стек левую часть выбранного правила. Если правило, совпадающее с основой, найти не удалось, то необходимо прервать выполнение алгоритма и сообщить об ошибке, иначе, если разбор не закончен, то вернуться к шагу 2.
Шаг 5. Если не установлено ни одно отношение предшествования между текущим символом входной цепочки и самым верхним терминальным символом в стеке, то надо прервать выполнение алгоритма и сообщить об ошибке.
Конечная конфигурация данного МП-автомата совпадает с конфигурацией при распознавании цепочек грамматик простого предшествования.
Пример построения распознавателя
для грамматики операторного предшествования
Рассмотрим в качестве примера грамматику для арифметических выражений над символами а и b G({+,-,/,*,a,b}, {S,T,E}, P, S):
Р:
S -*■ S+T I S-T i T
T -> T*E | T/E | E ■
E -> (S) | a | b
Эта грамматика уже много раз использовалась в качестве примера для построения распознавателей.
Видно, что эта грамматика является грамматикой операторного предшествования.
Построим множества крайних левых и крайних правых символов L(A), R(A) относительно всех нетерминальных символов грамматики. Рассмотрим работу алгоритма построения этих множеств по шагам.
1. Шаг 1.
|
Lq(S) - {S, T}, Lo(T) = {Т, Е}, Lo(E) - {(, а, Ь}, 2. Шаг 2. L,(S) - {S, Т, Е}; |
Ro(S) - {Т}, Ro(T) - {Е}, Ro(E) = {), a, b}, i - 1.
Rt(S)
= {T, E},
Lt(T) = {T, E, (, a, b}, R,(T) - {E, ), a, b},
L,(E)-{С *.*>}. Ri(E) = {), a, b}.
|з. Шаг 3. Так как L0(S) ф Lt(S), то i - 2 и возвращаемся к шагу 2.
И. Шаг 2.
L2(S) - {S,
Т, Е, (, a,
b}, R2(S) - {Т, Е, ), а, Ь},
L2(T) - {Т, Е, (, а, Ъ}, R2(T) - {Е, ), а, Ъ},
L2(E) = {(, a, b}, R2(E) = {), а, Ь}.
I 5. Шаг 3. Так как L^S) ф L2(S), to i - 3 и возвращаемся к шагу 2.
|6. Шаг 2.
L3(S) - {S, Т, Е, (, a, b}, R3(S) = {Т, Е,), а, Ь},
L3(T) - {Т, Е, (, a, b}, R3(T) - {Е,), а, Ь},
L3(E) = {(, a, b}, R3(E) - {), а, Ь}.
|
R(S) - {Т, Е, ), а, Ъ}, R(T) = {Е, ), а, Ь}, R(E) = {), а, Ь}. |
7. Построение закончено. Получили результат:
L(S) = {S, Т, Е, (, а, Ь},
ЦТ) = {Т, Е, (, а, Ь},
ЦЕ) - {(, а, Ь},
На основе полученных множеств построим множества крайних левых и крайни: правых терминальных символов 1ДА), R'(A) относительно всех нетерминаль ных символов грамматики. Рассмотрим работу алгоритма построения этих мне жеств по шагам.
|
Rco(S) = {+, -}, R'oCT) = {*, /}- |
1.
Шаг 1.
L'0(S) - {+, -},
L'o(T) - {*, /},
Ь'„(Е) - {(, a, b},
2.
Шаг 2.
LS(S) - {+, -,
*, /, (, a, b},RS(S) - {+, -, *, /},
L',(T) = {*,/,(, a,
b}, RS(T) = {*, /, ), a, b},
LS(E) - {(, a, b}, RS(E) -
{), a, b}.
3.
Шаг
3. Так как L^S) ф Ll,(S), то i - 2 и возвращаемся к шагу 2.
4.
Шаг 2.
L'2(S)
= {+, -, *, /, (, a, b},R'2(S) - {+, -, *, /,), a, b
},
L'2(T) - {*, /, (, a, b}, Rl2(T) = {*,
/, ), a, b},
L*2(E) = {(, a, b}, R'2(E) =
{), a, b}.
5.
Шаг
3. Так как RS(S) ф R'2(S), to i - 3 и возвращаемся к шагу 2.
6.
Шаг 2.
L'3(S) = {+, -, *, /,
(. a, bJ.R^S) = {+, -, *, /. )• a, b }, LS(T)
- {*, /, (, a, b}, Rl3(T)
= {*, /, ), a, b}
Ь*з(Е) = {(, a, b}, R'3(E)
= {), a, b}. 7. Построение закончено.
Получили результат:
Ll(S)
= {+, -, *, /, (, a, b}, R'(S) = {+, -, *, /, ), а, Ъ },
L'(T) -{•,/,(, a, b}, Rt(T) = {*,/,), а, Ь},
L'(E) - {(, a, b}, Rt(E)
= {), а, Ь}.
На основе этих множеств и правил грамматики G построим матрицу предшествования грамматики (табл. 12.5).
Таблица 12.5. Матрица предшествования грамматики
|
Символы |
+ |
- |
* |
|
( |
|
а |
b |
|
|
+ |
•> |
•> |
<• |
<■ |
<• |
•> |
<• |
<• |
.> |
|
- |
•> |
•> |
<• |
<■ |
<• |
•> |
<• |
<■ |
.> |
|
* |
■> |
•> ■ |
■> |
■> |
<• |
■> |
<■ |
<• |
.> |
|
/ |
•> |
•> |
■> |
■ > |
<• |
■ > |
<• |
<• |
.> |
|
( |
<. |
<. |
<■ |
|
<• |
=• |
<. |
<. |
|
|
) |
■> |
• > |
■> |
■ > |
|
• > |
|
|
.> |
|
а |
•> |
•> |
•> |
■ > |
|
• > |
|
|
.> |
|
b |
.> |
.> |
.> |
.> |
|
.> |
|
|
.> |
|
-L-и |
<• |
<■ |
<• |
<• |
<• |
|
<• |
<• |
|
Поясним, как заполняется матрица предшествования в таблице на примере символа +. В правиле грамматики S-»S+T (правило 1) этот символ стоит слева от нетерминального символа Т. Во множество L'(T) входят символы: *,/,(, а, Ь. Ставим знак <• в клетках матрицы, соответствующих этим символам, в строке для символа +. В то же время в этом же правиле символ + стоит справа от нетерминального символа S. Во множество R'(S) входят символы: +, -, *, /,), а, Ь. Ставим знак •> в клетках матрицы, соответствующим этим символам, в столбце для символа +. Больше символ + ни в каком правиле не встречается, значит, заполнение матрицы для него закончено, берем следующий символ и продолжаем заполнять матрицу таким же методом, пока не переберем все терминальные символы.
Отдельно рассмотрим символы 1И и ±к. В строке символа Хн ставим знак <• в клетках символов, входящих во множество L'(S). Это символы +, -, *, /, (, а, Ь. В столбце символа _1_к ставим знак •> в клетках символов, входящих во множество R'(S). Это символы +, -, *,/,), а, Ь.
Еще можно отметить, что в клетке соответствующей открывающей скобки (символ () слева и закрывающей скобке (символ )) справа помещается знак =• («составляют основу»). Так происходит, поскольку в грамматике присутствует правило E->(S), где эти символы стоят рядом (через нетерминальный символ) в его правой части. Следует отметить, что понятия «справа» и «слева» здесь имен важное значение: в клетке соответствующей закрывающей скобке (символ ) слева и открывающей скобке (символ () справа знак отсутствует — такое сочет; ние символов недопустимо (отношение (=•) верно, а отношение )=•( — неверно
Алгоритм разбора цепочек грамматики операторного предшествования игнор] рует нетерминальные символы. Поэтому имеет смысл преобразовать исходну грамматику таким образом, чтобы оставить в ней только один нетерминальнь: символ. Тогда получим следующий вид правил:
S -» S+S | S-S | S (правила 1, 2 и 3) S -> S*S | S/S | S (правила 4, 5 и 6) S -» (S) | а | b (правила 7, 8 и 9)
Если теперь исключить бессмысленные правила вида S-»S, то получим следу! щее множество правил (нумерацию правил сохраним в соответствии с исходш грамматикой):
Р:
S —> S-t-S ] S-S (правила 1, 2)
S -> S*S | S/S (правила 4. 5)
S —> CS) 1 a I b (правила 7. 8 и 9)
Такое преобразование не ведет к созданию эквивалентной грамматики и выпо няется только для упрощения работы алгоритма (который при выборе прав] все равно игнорирует нетерминальные символы) после построения матриг предшествования. Полученная в результате преобразования грамматика не я ляется однозначной, но в алгоритм распознавания уже были заложены все нес ходимые данные о порядке применения правил при создании матрицы предц ствования, поэтому распознаватель остается детерминированным. Построенн таким способом грамматика называется «остовной» грамматикой. Вывод, uoj ченный при разборе на основе остовной грамматики, называют результатом «( товного» разбора или «остовным» выводом [6, 23, 32].
По результатам остовного разбора можно построить соответствующий ему в вод на основе правил исходной грамматики. Однако эта задача не представлю практического интереса, поскольку остовный вывод отличается от вывода на ( нове исходной грамматики только тем, что в нем отсутствуют шаги, связанн с применением цепных правил, и не учитываются типы нетерминальных chmi лов. Для компиляторов же распознавание цепочек входного языка заключав! не в нахождении того или иного вывода, а в выявлении основных синтакси1 ских конструкций исходной программы с целью построения на их основе це1 чек языка результирующей программы. В этом смысле типы нетерминальн символов и цепные правила не несут никакой полезной информации, а нап] тив, только усложняют обработку цепочки вывода (или дерева вывода). Поэто для реального компилятора нахождение остовного вывода является даже 6oj полезным, чем нахождение вывода на основе исходной грамматики. Найденн остовный вывод в дальнейших преобразованиях уже не нуждается (более m робно см. главу «Основные принципы построения трансляторов»). Рассмотрим работу алгоритма распознавания на примерах. Последовательность разбора будем записывать в виде последовательности конфигураций расширенного МП-автомата из трех составляющих:
□
не
просмотренная автоматом часть входной цепочки;
□
содержимое
стека;
□
последовательность
примененных правил грамматики.
Так как автомат имеет только одно состояние, то для определения его конфигурации достаточно двух составляющих — положения считывающей головки во входной цепочке и содержимого стека. Последовательность номеров правил несет дополнительную полезную информацию, по которой можно построить цепочку или дерево вывода (кроме того, последовательность примененных правил делает пример более наглядным).
Будем обозначать такт автомата символом -г-. Введем также дополнительное обозначение -5-п, если на данном такте выполнялся перенос, и *С) если выполнялась свертка.
Последовательности разбора цепочек входных символов будут, таким образом, иметь вид, приведенный ниже.
Пример 1. Входная цепочка а+а*Ь.
1.
{а+а*Ык;
1Н; 0} ^п
2.
{+а*Ык;
1„а; 0} +с
3.
{+а*Ык;
1HS; 8}
+п
4.
{а*Ык;
1HS+; 8}
+п
5.
{*b±K; ±HS+a; 8} +с
6.
{*ЫК;
±HS+S; 8,8}
+п •
7.
{Ык;
1HS+S*; 8,8}
+п
8.
{1К;
1HS+S*b; 8,8}
+с
9.
{1К;
1HS+S*S; 8,8,9}
+с
10.
{1К;
1HS+S; 8,8,9,4}
+с
11.
{1К;
±HS; 8,8,9,4,1} — разбор завершен, цепочка принята.
Соответствующая цепочка вывода будет иметь вид (используется правосторонний вывод): S => S+S => S+S*S => S+S*b => S+a*b => a+a*b.
Дерево вывода, соответствующее этой цепочке, приведено на рис. 12.8.
Следует отметить, что распознаватель, работающий на основе грамматики операторного предшествования, имеет еще одно весьма полезное свойство — за счет того, что при построении цепочки вывода не учитываются типы нетерминальных символов, в результате игнорируются цепные правила, присутствующие в грамматике. Это сокращает длину цепочки вывода и размер дерева вывода1.
1 Из цепочки (и дерева) вывода удаляются цепные правила, которые, как
будет показано далее,
все равно не несут никакой полезной семантической (смысловой) нагрузки, а
потому для компилятора являются бесполезными. Это положительное свойство распознавателя.
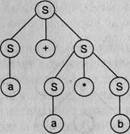
Рис. 12.8. Первый пример дерева вывода для грамматики операторного предшествования
Пример 2. Входная цепочка (а+а)*Ь.
1.
{(а+а)*Ь±к;
±н; 0}+п
2.
{а+а)*Ык;
1„(; 0} -п.
3.
{+а)*Ь±к;
±„(а; 0}+с
4.
{+а)*Ык; 1H(S; 8} ^п
5.
{a)*blK; 1,,(S+; 8} +п
6.
{)*ЫК; lH(S+a; 8} +с
7.
{)*ЫК;
1H(S+S; 8,8}
+с
8.
{)*blK; 1H(S; 8,8,1} ^п
9. {*ЫК; 1H(S); 8,8,1} +с
10. {*ЫК;
1HS; 8,8,1,7} +п
И. {Ык; 1,,S*; 8,8,1,7} +п
12.
{1К;
lHS*b; 8,8,1,7}.+с ч '
13.
{1К;
1HS*S; 8,8,1,7,9}
+с
14.
{±к;
_LHS; 8,8,1,7,9,4}
— разбор завершен, цепочка принята.
Соответствующая цепочка вывода будет иметь вид (используется правосторс ний вывод): S => S*S => S*b => (S)*b => (S+S)*b => (S+a)*b => (a+a)*b. Дерево вывода, соответствующее этой цепочке, приведено на рис. 12.9.
Пример 3- Входная цепочка а+а*.
1. {а+а*1к; 1Н; 0} +п
2.-{+а*-Ц;±на;0}+с
3.
{+а*±к;
1HS; 8}
^п
4.
{a*lK; 1HS+; 8} ^п
5.
{*±к;
±HS+a; 8}
+с
6.
{*1К;
1..S+S; 8,8} ^п
7.
{1К;
XHS+S*; 8,8}
н-с
8.
Ошибка!
(Нет правила для выполнения свертки на этом шаге.)
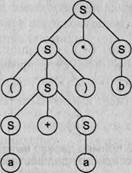
Рис. 12.9. Второй пример дерева вывода для грамматики
операторного предшествования '
Пример 4. Входная цепочка а+а)*Ь.
1.
{а+а)*Ь±к;
1Н; 0} +п
2.
{+а)*Ь±к; ±на;
0} +с
3.
{+a)*b±K; 1HS; 8} +п
4.
{a)*b; 1HS+; 7} +п
5.
{)*ЫК;
lHS+a; 8}
+с
6.
{)*Ь±К;
1HS+S; 8,8}
+с
7.
{)*Ь±К;
1HS; 8,8,1}
8.
Ошибка!
(Нет отношений предшествования между символами 1 . ч-н И ).)
Два первых примера наглядно демонстрируют, что приоритет onepai „
ленный в грамматике, влияет на последовательность разбора и следователь
ность применения правил, несмотря на то что нетерминальные сил распознователем не рассматриваются.
Как было сказано выше, матрица для грамматики операторного niu - „ редшествова-
ния всегда имеет меньший объем, чем матрица для эквивалентной е£
|
:о терминаль- |
|
спознаватель 'аьные симво-меньше |
простого предшествования (поскольку в первую из них входят тольк.г ные символы, а во вторую также и нетерминальные). Кроме того,
грамматики операторного предшествования игнорирует нетермина;
лы в процессе разбора, а значит, не учитывает цепные правила,
шагов и порождает более короткую цепочку вывода. Поэтому par
спознаватель для грамматик операторного предшествования всегда проще, чем, ^о„ ^„ u i распознаватель для эквивалентной ей грамматики простого предшествования.
Интересно, что поскольку распознаватель на основе грамматик с, „_,__„ „
операторного
предшествования не учитывает типы
нетерминальных символов, то _ у
л..__
^ он может ра~
оотать даже с некоторыми неоднозначными грамматиками, в котог
|
вила, различающиеся только типами нетерминальных символов. 1-г кой грамматики может служить грамматика G"({a,b}, {S,A,B}, P, S) „ _ „„_.,„. с правилами. |
|
Р: S - |
_jbiA ее 1 ь
А -» аАЬ | ab В -+ аВЬ | ab
Как и для любой другой грамматики операторного предшествования, расг ватель для этой грамматики будет детерминированным. Остовная грамм; построенная на ее основе, будет иметь только два правила вида: S—>aSb| ab. нозначность заключается в том, что каждому найденному остовному выво, дет соответствовать не один, а несколько выводов в исходной грамматике ( ном случае — всегда два вывода в зависимости от того, какое правило из ! будет применено на первом шаге вывода). Грамматики, содержащие пр; различающиеся только типами нетерминальных символов, практического: ния не имеют, а потому интереса для компиляторов не представляют.
К сожалению, хотя классы грамматик простого и операторного предшество несопоставимы1, но класс языков операторного предшествования уже, чем языков простого предшествования. Поэтому не всегда возможно для язы: данного грамматикой простого предшествования, построить грамматику < торного предшествования. Соответственно, поскольку класс языков, зад; грамматиками операторного предшествования, еще более узок, чем даже языков, заданных грамматиками простого предшествования, то с помощы грамматик можно определить далеко не каждый детерминированный КС Грамматики операторного предшествования — это очень удобный инстр для построения распознавателей, но они имеют ограниченную область npi ния.
Соотношение классов КС-языков и КС-грамматик
В этом подразделе рассматриваются вопросы, связанные с отношениями различными классами известных КС-языков и КС-грамматик. Эти соотно представляются весьма интересными с точки зрения теории формальны ков. Многие из них совсем неочевидны. Однако читатель, интересующийся ко практическими аспектами построения трансляторов и компиляторов, в принципе пропустить этот подраздел.
Особенности восходящих
и нисходящих распознавателей
Выше были рассмотрены варианты двух основных типов распознавател цепочек КС-языков — восходящих и нисходящих. Далее можно не расе вать распознаватели с возвратом и табличные распознаватели, поскол практическое применение сильно ограничено. Реальные компиляторы не с
![]() 1 В том, что эти два
класса грамматик несопоставимы, можно убедится, рассмот приведенных примера —
в них взяты различные по своей сути и классам грам хотя они и являются
эквивалентными — задают один и тот же язык. ся на основе универсальных распознавателей
из-за их высокой требовательности к необходимым вычислительным ресурсам. Как
правило, конкретную КС-грамматику и заданный ею КС-язык удается отнести к тому или
иному классу, для которого существует специального рода распознаватель с
линейной зависимостью требуемых вычислительных ресурсов от длины входной цепочки — линейный распознаватель.
1 В том, что эти два
класса грамматик несопоставимы, можно убедится, рассмот приведенных примера —
в них взяты различные по своей сути и классам грам хотя они и являются
эквивалентными — задают один и тот же язык. ся на основе универсальных распознавателей
из-за их высокой требовательности к необходимым вычислительным ресурсам. Как
правило, конкретную КС-грамматику и заданный ею КС-язык удается отнести к тому или
иному классу, для которого существует специального рода распознаватель с
линейной зависимостью требуемых вычислительных ресурсов от длины входной цепочки — линейный распознаватель.
Линейные распознаватели (распознаватели без возвратов) существуют и в виде восходящих, и в виде нисходящих распознавателей. И те и другие имеют линейную зависимость вычислительных ресурсов, необходимых для выполнения алгоритмов разбора, от длины входной цепочки символов. Существуют также другие варианты линейных распознавателей, сочетающие в себе некоторые черты восходящего и нисходящего разбора [6, т. 1].
Но возникает другой вопрос: очень часто одна и та же КС-грамматика может быть отнесена не к одному, а сразу к нескольким классам грамматик, допускающих построение линейных распознавателей. Иногда для этого надо выполнить некоторые преобразования правил грамматики1. В этом случае необходимо решить, какой из нескольких возможных распознавателей выбрать для практической реализации.
Если можно выбрать один из двух явно сопоставимых по сложности распознавателей (например, распознаватели Ь11(1)-грамматик и грамматик предшествования можно сопоставить по объему управляющих таблиц, так как они используют схожие алгоритмы работы), тогда ответ очевиден. Однако ответить на этот вопрос не всегда легко, поскольку могут быть построены два принципиально разных распознавателя, алгоритмы работы которых несопоставимы. В первую очередь речь идет именно о восходящих и нисходящих распознавателях: в основе первых лежит алгоритм подбора альтернатив, в основе вторых — алгоритм «сдвиг-свертка».
На вопрос о том, какой распознаватель — нисходящий или восходящий — выбрать для построения распознавателя, нет однозначного ответа. Эту проблему необходимо решать, опираясь на некую дополнительную информацию о том, как будут использованы или каким образом будут обработаны результаты работы распознавателя. Тут следует вспомнить, что распознаватель входных цепочек КС-языков — это всего лишь один из этапов компиляции, составная часть компилятора, лежащая в основе синтаксического анализатора входного языка программирования. И с этой точки зрения результаты работы распознавателя служат исходными данными для различных этапов компиляции: прежде всего синтаксического анализа, затем — генерации кода. Поэтому выбор того или иного распознавателя во многом зависит от реализации компилятора, от того, какие принципы положены в его основу.
Восходящий синтаксический анализ, как правило, привлекательнее нисходящего, так как для данного языка программирования часто легче построить право-Примером такой грамматики может служить грамматика арифметических выражений, которая была впервые упомянута в разделе «Проблемы однозначности и эквивалентности грамматик», глава 9, а потом многократно использовалась в качестве примера для иллюстрации работы различных распознавателей.
сторонний (восходящий) распознаватель на основе правоанализируемой гра матики. С этим вопросом мы уже сталкивались в данном пособии, когда говори о том, что класс языков, заданных LR-грамматиками, шире, чем класс язык< заданных LL-грамматиками (хотя следует сказать, что не все здесь столь од* значно).
С другой стороны, как будет показано далее, левосторонний (нисходящий) синт; сический анализ предпочтителен с точки зрения процесса трансляции, посколь на его основе легче организовать процесс порождения цепочек результируклщ языка. Ведь в задачу компилятора входит не только распознать (проанализи! вать) входную программу на входном языке, но и построить (синтезировать) ] зультирующую программу. Более подробную информацию об этом можно noj чить в разделе «Генерация кода. Методы генерации кода», глава 14 или в рабоп [6, т. 2, 42]. Левосторонний анализ, основанный на нисходящем распознавате оказывается предпочтительным также при учете вопросов, связанных с обна] жением и локализацией ошибок в тексте исходной программы [40, 82].
Желание использовать более простой класс грамматик для построения paci знавателя может потребовать каких-то манипуляций с заданной грамматик необходимых для ее преобразования к требуемому классу. При этом нере; грамматика становится неестественной и мало понятной, что в дальнейш затрудняет ее использование в схеме синтаксически управляемого перевод; трансляции на этапе генерации результирующего кода (см. главу «Генераци: оптимизация кода»). Поэтому часто бывает удобным использовать исходи грамматику такой, какая она есть, не стремясь преобразовать ее к более прос му классу.
В целом следует отметить, что с учетом всего сказанного выше, интерес пр ставляют как левосторонний, так и правосторонний анализ. Конкретный вы! зависит от реализации конкретного компилятора, а также от сложности грам тики входного языка программирования.
Отношения между классами КС-грамматик
В данном учебном пособии было рассмотрено несколько основных классов I грамматик, для которых существуют линейные распознаватели, — это LL-rp матики, LR-грамматики и грамматики предшествования. Не все они были { смотрены достаточно подробно, к тому же этими классами далеко не исчерпь ется список всех известных КС-грамматик такого рода. Можно еще, например, упомянуть класс грамматик ограниченного правого в текста (m,n) — ОПК(т,п). Это грамматики, допускающие построение распозн; теля, основанного на алгоритме «сдвиг-свертка», в котором однозначный вы между сдвигом и сверткой делается исходя из анализа m символов, находящи на верхушке стека, и п текущих символов входной цепочки, считая от поло ния считывающей головки расширенного МП-автомата [6, т. 1]. Все ОПК(т грамматики для всех значений тип составляют класс О ПК-грамматик. Г стейшим вариантом грамматик такого класса являются ОПК(1,1)-граммат1 Интересно, что с помощью этих грамматик, как и с помощью LR-грамма' можно определить любой детерминированный КС-язык. Далее в этом пункте будут рассмотрены различные классы КС-грамматик и существующие между ними нетривиальные соотношения.
В общем случае можно выделить правоанализируемые и левоанализируемые КС-грамматики. Об этих двух принципиально разных классах грамматик уже говорилось выше: первые предполагают построение левостороннего (восходящего) распознавателя, вторые — правостороннего (нисходящего). Это вовсе не значит, что для КС-языка, заданного, например, некоторой левоанализируемой грамматикой, невозможно построить расширенный МП-автомат, который порождает правосторонний вывод. Указанное разделение грамматик относится только к построению на их основе детерминированных МП-автоматов и детерминированных расширенных МП-автоматов. Только эти типы автоматов представляют интерес при создании компиляторов и анализе входных цепочек языков программирования. Недетерминированные автоматы, порождающие как левосторонние, так и правосторонние выводы, можно построить в любом случае для языка заданного любой КС-грамматикой, но для создания компилятора такие автоматы интереса не представляют (см. раздел «Распознаватели КС-языков. Автоматы с магазинной памятью», глава 11).
На рис. 12.10 изображена условная схема, дающая представление о
соотношении классов левоанализируемых и правоанализируемых КС-грамматик [5,6, т.
2,42,65].
|
лг |
|
|
||||
|
|
|
|
|
ПГ |
||
|
|
|
|
|
LR |
|
|
|
|
LL |
|
||||
|
|
|
|
||||
|
|
|
|
|
|||
|
|
|
|
||||
![]() Рис. 12.10. Соотношение классов левоанализируемых и правоанализируемых КС-грамматик
Рис. 12.10. Соотношение классов левоанализируемых и правоанализируемых КС-грамматик
Интересно, что классы левоанализируемых и правоанализируемых грамматик являются несопоставимыми. То есть существуют левоанализируемые КС-грамматики, на основе которых нельзя построить детерминированный расширенный МП-автомат, порождающий правосторонний вывод; и наоборот — существуют правоанализируемые КС-грамматики, не допускающие построение МП-автомата, порождающего левосторонний вывод. Конечно, существуют грамматики, подпадающие под оба класса и допускающие построение детерминированных автоматов как с правосторонним, так и с левосторонним выводом.
Следует помнить также, что все упомянутые классы КС-грамматик — это счетные, но бесконечные множества. Нельзя построить и рассмотреть все возможные левоанализируемые грамматики или даже все возможные LL(^-грамматики. Сопоставление классов КС-грамматик производится исключительно на основе анализа структуры их правил. Только на основании такого рода анализа произвольная КС-грамматика может быть отнесена в тот или иной класс (или несколько классов).
Все это тем более интересно, если вспомнить, что рассмотренный в данном пс бии класс левоанализируемых LL-грамматик является собственным подмно ством класса LR-грамматик: любая LL-грамматика является LR-грамматщ но не наоборот — существуют LR-грамматики, которые не являются LL-грам тиками. Этот факт также нашел свое отражение в схеме на рис. 12.10. Зна1 любая LL-грамматика является правоанализируемой, но существуют так» другие левоанализируемые грамматики, не попадающие в класс правоанал! руемых грамматик.
Для LL(k)-rpaMMaTHK, составляющих класс LL-грамматик, интересна еще с особенность: доказано, что всегда существует язык, который может быть з< LL(k)-rpaMMaTHKoft для некоторого к > 0, но не может быть задан LL(k-l)-r] матикой. Таким образом, все LL(k)-rpaMMaraKH для всех к представляют о: деленный интерес (другое дело, что распознаватели для них при больших зн ниях к будут слишком сложны). Интересно, что проблема эквивалентности двух LL(k)-rpaMMaraK разрешима.
С другой стороны, для LR(k)-rpaMMaTHK, составляющих класс LR-грамма доказано, что любой язык, заданный LR(k)-rpaMMaTHKoft с к > 1, может быт дан LR(l)-rpaMMaTHKoft. То есть LR(k)-rpaMMaTHKH с к > 1 интереса не преде ляют. Однако доказательство существования LR(l)-rpaMMaTHKH вовсе не озна что такая грамматика всегда может быть построена (проблема преобразов; КС-грамматик неразрешима).
На рис. 12.11 условно показана связь между некоторыми классами КС-гра тик, упомянутых в данном пособии. Из этой схемы видно, например, что Л1 ОПК-грамматика является LR-грамматикой, а также любая LL-грамматика s ется LR-грамматикой, но не всякая LL-грамматика является LR(l)-rpaMMaTH
![]() КС- грамматики
КС- грамматики
|
Однозначные |
|
|
|
ОПК |
|
LR(1) |
Операторного предшествования
(1,1)ОПК
Рис.
12.11. Схема взаимосвязи некоторых классов КС-грамматик
![]() Если вспомнить, что
любой детерминированный КС-язык может быть задан, например,
Ы1(1)-грамматикой (или ОПК(1,1)-грамматикой), но в то же время, классы
левоанализируемых и правоанализируемых грамматик несопоставимы, то напрашивается
вывод: один и тот же детерминированный КС-язык может быть задан двумя или
более несопоставимыми между собой грамматиками. Таким образом, можно
вернуться к мысли о том, что проблема преобразования КС-грамматик неразрешима
(на самом деле, конечно, наоборот: из неразрешимости проблемы преобразования
КС-грамматик следует возможность задать один и тот же КС-язык двумя
несопоставимыми грамматиками). Это, наверное, самый интересный вывод, который
можно сделать из сопоставления разных классов КС-грамматик.
Если вспомнить, что
любой детерминированный КС-язык может быть задан, например,
Ы1(1)-грамматикой (или ОПК(1,1)-грамматикой), но в то же время, классы
левоанализируемых и правоанализируемых грамматик несопоставимы, то напрашивается
вывод: один и тот же детерминированный КС-язык может быть задан двумя или
более несопоставимыми между собой грамматиками. Таким образом, можно
вернуться к мысли о том, что проблема преобразования КС-грамматик неразрешима
(на самом деле, конечно, наоборот: из неразрешимости проблемы преобразования
КС-грамматик следует возможность задать один и тот же КС-язык двумя
несопоставимыми грамматиками). Это, наверное, самый интересный вывод, который
можно сделать из сопоставления разных классов КС-грамматик.
Отношения между классами КС-языков
КС-язык называется языком некоторого класса КС-языков, если он может быть задан КС-грамматикой из данного класса КС-грамматик. Например, класс LL-языков составляют все языки, которые могут быть заданы с помощью LL-грам-матик.
Соотношение классов КС-языков представляет определенный интерес, оно не совпадает с соотношением классов КС-грамматик. Это связано с многократно уже упоминавшейся проблемой преобразования грамматик. Например, выше уже говорилось о том, что любой LL-язык является и Ы1(1)-языком — то есть язык, заданный LL-грамматикой, может быть задан также и Ъ11(1)-грамматикой. Однако не всякая LL-грамматика является при этом LR(l)-rpaMMaraKOU и не всегда можно найти способ, как построить LR(l)-rpaMMaTHKy, задающую тот же самый язык, что и исходная LL-грамматика.
На рис. 12.12 приведено соотношение
между некоторыми известными классами КС-языков [6, т. 2, 42, 47].
![]() КС-языки
КС-языки
![]() Детерминированные КС-языки LR(1 )-языки=1_К-языки (1,1)ОПК-языки=ОПК-языки
Детерминированные КС-языки LR(1 )-языки=1_К-языки (1,1)ОПК-языки=ОПК-языки
|
Языки простого предшествования |
|
|||
|
|
|
LL-языки |
||
|
|
Языки операторного предшествования |
|
|
|
![]()
![]() Рис. 12.12. Соотношение между различными классами КС-языков
Рис. 12.12. Соотношение между различными классами КС-языков
Следует обратить внимание прежде всего на то, что интересующий разработчиков компиляторов в первую очередь класс детерминированных КС-языков полностью совпадает с к«лассом LR-языков и, более того, совпадает с кл; LR(l)^3biKOB. To есть досказано, что для любого детерминированного КС-! существует задающая егоо LR(1) -грамматика. Этот факт уже упоминался i Проблема состоит в том,; что не всегда возможно найти такую грамматику формализованного алгоритма, как ее построить в общем случае. То же сам< носится к упоминавшимсся здесь ОПК-грамматикам и ОПК(1,1)-грамматю Также уже упоминалось,,, чт0 LL-языки являются собственным подмноже. LR-языков: всякий LL-яззык является одновременно LR-языком, но сущеа LR-языки, которые не являются LL-языками. Поэтому LL-языки образуют узкий класс, чем LR-язьцки.
Языки простого предшествования, в свою очередь, также являются собстве: подмножеством LR-языкссов, а языки операторного предшествования — собс ным подмножеством язы,1Ков простого предшествования. Интересно, что * операторного предшествования представляют собой более узкий класс, чем ки простого предшествовзания.
В то же время языки простого предшествования и LL-языки несопоставим жду собой: существуют я?3ыки простого предшествования, которые не явл5 LL-языками, и в то же вр<,емя существуют LL-языки, которые не являются я: ми простого предшествовзания. Однако существуют языки, которые одновр но являются и языками Простого предшествования, и LL-языками. Аналог] замечание относится такСЖе к соотношению между собой языков операто] предшествования и LL-H<3biKOB.
Можно еще отметить, чтсэ язык арифметических выражений над символами заданный грамматикой G(^{+,-,/,*,a,b},{S,T,E},P,S), P = {S->S+T|S-T|T, T->T*Ef E-»(S)|a|b}, который многократно использовался в примерах в данном уче пособии, подпадает под BjCe указанные выше классы языков. Из приведеннь нее по всей главе 3 призеров можно заключить, что этот язык является \ языком, и языком операторного предшествования, а следовательно, и яз простого предшествования и, конечно, LR(l)^3biKOM. В то же время этот по мере изложения материала пособия описывался различными граммати не все из которых могут (быть отнесены в указанные классы. Более того, в п он был задан с помощью, грамматики, которая не являлась даже однозначн
Таким образом, соотнощение классов КС-языков не совпадает с соотноше
задающих их классов К(3-грамматик. Это связано с неразрешимостью прс преобразования и
эквивгшентности грамматик, которые не имеют строго ф| . лизованного решения.
4. Основные принципы построения трансляторов.
Трансляторы, компиляторы и интерпретаторы – общая схема работы. Современные
компиляторы и интерпретаторы.
Основные принципы
построения трансляторов.
Трансляторы,
компиляторы, интерпретаторы – общая схема работы.
Определение транслятора, компилятора, интерпретатора
Для начала дадим несколько определений — что же все-таки такое есть уже многократно упоминавшиеся трансляторы и компиляторы.
Формальное определение транслятора
Транслятор — это программа, которая переводит входную программу на исходном (входном) языке в эквивалентную ей выходную программу на результирующем (выходном) языке. В этом определении слово «программа» встречается три раза, и это не ошибка и не тавтология. В работе транслятора, действительно, участвуют всегда три программы.
Во-первых, сам транслятор является программой1 — обычно он входит в состав системного программного обеспечения вычислительной системы. То есть транслятор — это часть программного обеспечения (ПО), он представляет собой набор машинных команд и данных и выполняется компьютером, как и все прочие программы в рамках операционной системы (ОС). Все составные части транслятора представляют собой фрагменты или модули программы со своими входными и выходными данными.
![]() Во-вторых, исходными данными для работы
транслятора служит текст входной программы — некоторая последовательность
предложений входного языка программирования. Обычно это символьный файл, но этот файл
должен содержать текст программы, удовлетворяющий синтаксическим и семантическим требованиям входного языка.
Кроме того, этот файл несет в себе некоторый смысл, определяемый семантикой
входного языка.
Во-вторых, исходными данными для работы
транслятора служит текст входной программы — некоторая последовательность
предложений входного языка программирования. Обычно это символьный файл, но этот файл
должен содержать текст программы, удовлетворяющий синтаксическим и семантическим требованиям входного языка.
Кроме того, этот файл несет в себе некоторый смысл, определяемый семантикой
входного языка.
В-третьих, выходными данными транслятора является текст результирующей программы. Результирующая программа строится по синтаксическим правилам, заданным в выходном языке транслятора, а ее смысл определяется семантикой выходного языка. Важным требованием в определении транслятора является эквивалентность входной и выходной программ. Эквивалентность двух программ означает совпадение их смысла с точки зрения семантики входного языка (для исходной программы) и семантики выходного языка (для результирующей программы). Без выполнения этого требования сам транслятор теряет всякий практический смысл.
Итак, чтобы создать транслятор, необходимо прежде всего выбрать входной и выходной языки. С точки зрения преобразования предложений входного языка в эквивалентные им предложения выходного языка транслятор выступает как переводчик. Например, трансляция программы с языка С в язык ассемблера по сути ничем не отличается от перевода, скажем, с русского языка на английский, с той только разницей, что сложность языков несколько иная (почему не существует трансляторов с естественных языков — см. раздел «Классификация языков и грамматик», глава 9). Поэтому и само слово «транслятор» (английское: translator) означает «переводчик».
Результатом работы транслятора будет результирующая программа, но только в том случае, если текст исходной программы является правильным — не содержит ошибок с точки зрения синтаксиса и семантики входного языка. Если исходная программа неправильная (содержит хотя бы одну ошибку), то результатом работы транслятора будет сообщение об ошибке (как правило, с дополнительными пояснениями и указанием места ошибки в исходной программе). В этом смысле транслятор сродни переводчику, например, с английского, которому подсунули неверный текст.
![]() Теоретически возможна реализация
транслятора с помощью аппаратных средств. Автору встречались такого рода разработки, однако широкое
практическое применение их не известно. В таком случае и все составные части транслятора могут быть
реализованы в виде аппаратных
средств и их фрагментов — вот тогда схема распознавателя может получить вполне практическое воплощение!
Теоретически возможна реализация
транслятора с помощью аппаратных средств. Автору встречались такого рода разработки, однако широкое
практическое применение их не известно. В таком случае и все составные части транслятора могут быть
реализованы в виде аппаратных
средств и их фрагментов — вот тогда схема распознавателя может получить вполне практическое воплощение!
![]() Определение компилятора.
Определение компилятора.
Отличие компилятора от транслятора
Кроме понятия «транслятор» широко употребляется также близкое ему по смыслу понятие «компилятор».
Компилятор — это транслятор, который осуществляет перевод исходной программы в эквивалентную ей объектную программу на языке машинных команд или на языке ассемблера.
Таким образом, компилятор отличается от транслятора лишь тем, что его результирующая программа всегда должна быть написана на языке машинных кодов.или на языке ассемблера. Результирующая программа транслятора, в общем случае, может быть написана на любом языке — возможен, например, транслятор программ с языка Pascal на язык С. Соответственно, всякий компилятор является транслятором, но не наоборот — не всякий транслятор будет компилятором. Например, упомянутый выше транслятор с языка Pascal на С компилятором являться не будет1.
Само слово «компилятор» происходит от английского термина «compiler» («составитель», «компоновщик»). Видимо, термин обязан своему происхождению способности компиляторов составлять объектные программы на основе исходных программ.
Результирующая программа компилятора называется «объектной программой» или «объектным кодом». Файл, в который она записана, обычно называется «объектным файлом». Даже в том случае, когда результирующая программа порождается на языке машинных команд, между объектной программой (объектным файлом) и исполняемой программой (исполняемым файлом) есть существенная разница. Порожденная компилятором программа не может непосредственно выполняться на компьютере, так как она не привязана к конкретной области памяти, где должны располагаться ее код и данные (более подробно — см. раздел «Принципы функционирования систем программирования», глава 15)2.
Компиляторы, безусловно, самый распространенный вид трансляторов (многие считают их вообще единственным видом трансляторов, хотя это не так). Они имеют самое широкое практическое применение, которым обязаны широкому распространению всевозможных языков программирования. Далее всегда будем говорить о компиляторах, подразумевая, что выходная программа написана на
Естественно, трансляторы и компиляторы, как и все прочие программы, разрабатывает человек (люди) — обычно это группа разработчиков. В принципе они могли бы создавать его непосредственно на языке машинных команд, однако объем кода и данных современных компиляторов таков, что их создание на языке машинных команд практически невозможно в разумные сроки при разумных трудозатратах. Поэтому практически все современные компиляторы также создаются с помощью компиляторов (обычно в этой роли выступают предыдущие версии компиляторов той же фирмы-производителя). И в этом качестве компилятор является уже выходной программой для другого компилятора, которая ничем не лучше и не хуже всех прочих порождаемых выходных программ2.
Определение интерпретатора. Разница между интерпретаторами и трансляторами
Кроме схожих между собой понятий «транслятор» и «компилятор» существует принципиально отличное от них понятие интерпретатора.
Интерпретатор — это программа, которая воспринимает входную программу на исходном языке и выполняет ее.
В отличие от трансляторов интерпретаторы не порождают результирующую программу (и вообще какого-либо результирующего кода) — и в этом принципиальная разница между ними. Интерпретатор, так же как и транслятор, анализирует текст исходной программы. Однако он не порождает результирующей программы, а сразу же выполняет исходную в соответствии с ее смыслом, заданным семантикой входного языка. Таким образом, результатом работы интерпретатора будет результат, заданный смыслом исходной программы, в том случае, если эта программа правильная, или сообщение об ошибке, если исходная программа неверна.
Конечно, чтобы исполнить исходную программу, интерпретатор так или иначе должен преобразовать ее в язык машинных кодов, поскольку иначе выполнение программ на компьютере невозможно. Он и делает это, однако полученные машинные коды не являются доступными — их не видит пользователь интерпретатора. Эти машинные коды порождаются интерпретатором, исполняются и унич-
![]() 1 Следует особо упомянуть, что сейчас в современных
системах программирования стали появляться компиляторы, в которых результирующая программа создается не
на языке машинных команд
и не на языке ассемблера, а на некотором промежуточном языке. Сам по себе этот
промежуточный язык не может непосредственно исполняться на компьютере, а требует специального
промежуточного интерпретатора для выполнения написанных на нем программ. Хотя в данном
случае термин «транслятор» был бы, наверное, более правильным, в литературе употребляется понятие
«компилятор», поскольку промежуточный язык является языком очень низкого
уровня, будучи родственным машинным командам и языкам ассемблера.
1 Следует особо упомянуть, что сейчас в современных
системах программирования стали появляться компиляторы, в которых результирующая программа создается не
на языке машинных команд
и не на языке ассемблера, а на некотором промежуточном языке. Сам по себе этот
промежуточный язык не может непосредственно исполняться на компьютере, а требует специального
промежуточного интерпретатора для выполнения написанных на нем программ. Хотя в данном
случае термин «транслятор» был бы, наверное, более правильным, в литературе употребляется понятие
«компилятор», поскольку промежуточный язык является языком очень низкого
уровня, будучи родственным машинным командам и языкам ассемблера.
Здесь возникает извечный вопрос «о курице и яйце». Конечно, в первом поколении самые первые компиляторы писались непосредственно на машинных командах, но потом, с появлением компиляторов, от этой практики отошли. Даже самые ответственные части компиляторов создаются, как минимум, с применением языка ассемблера — а он тоже обрабатывается компилятором. тожаются по мере надобности — так, как того требует конкретная реализа) интерпретатора. Пользователь же видит результат выполнения этих кодов -есть результат выполнения исходной программы (требование об эквивалент сти исходной программы и порожденных машинных кодов и в этом случае, ( условно, должно выполняться).
Более подробно вопросы, связанные с реализацией интерпретаторов и их от чием от компиляторов, рассмотрены далее в соответствующем разделе.
Назначение трансляторов, компиляторов и интерпретаторов. Примеры реализации
Первые программы, которые создавались еще для ЭВМ первого поколения, сались непосредственно на языке машинных кодов. Это была поистине аде работа. Сразу стало ясно, что человек не должен и не может говорить на яз машинных команд, даже если он специалист по вычислительной технике. О; ко и все попытки научить компьютер говорить на языках людей успехов увенчались и вряд ли когда-либо увенчаются (на что есть определенные o6i тивные причины, рассмотренные в первой главе этого пособия).
С тех пор все развитие программного обеспечения компьютеров неразрывно i зано с возникновением и развитием компиляторов.
Первыми компиляторами были компиляторы с языков ассемблера или, как назывались, мнемокодов. Мнемокоды превратили «филькину грамоту» яз машинных команд в более-менее доступный пониманию специалиста язык ^ монических (преимущественно англоязычных) обозначений этих команд. ( давать программы уже стало значительно проще, но исполнять сам мнемс (язык ассемблера) ни один компьютер неспособен, соответственно, возникла обходимость в создании компиляторов. Эти компиляторы элементарно про но они продолжают играть существенную роль в системах программировани сей день. Более подробно о языке ассемблера и компиляторах с него расска: далее в соответствующем разделе.
Следующим этапом стало создание языков высокого уровня. Языки высо] уровня (к ним относится большинство языков программирования) предста ют собой некоторое промежуточное звено между чисто формальными язык и языками естественного общения людей. От первых им досталась строгая с мализация синтаксических структуру предложений языка, от вторых — зн тельная часть словарного запаса, семантика основных конструкций и выражс (с элементами математических операций, пришедшими из алгебры).
Появление языков высокого уровня существенно
упростило процесс програи рования, хотя и не свело его до «уровня домохозяйки», как
самонадеянно п гали некоторые авторы на заре рождения языков программирования1.
Сна![]() таких языков были
единицы, затем десятки, сейчас, наверное, их насчитывается более сотни.
Процессу этому не видно конца. Тем не менее по-прежнему преобладают компьютеры
традиционной, «неймановской», архитектуры, которые умеют понимать только
машинные команды, поэтому вопрос о создании компиляторов продолжает быть
актуальным.
таких языков были
единицы, затем десятки, сейчас, наверное, их насчитывается более сотни.
Процессу этому не видно конца. Тем не менее по-прежнему преобладают компьютеры
традиционной, «неймановской», архитектуры, которые умеют понимать только
машинные команды, поэтому вопрос о создании компиляторов продолжает быть
актуальным.
Как только возникла массовая потребность в создании компиляторов, стала развиваться и специализированная теория. Со временем она нашла практическое приложение во множестве созданных компиляторов. Компиляторы создавались и продолжают создаваться не только для новых, но и для давно известных языков. Многие производители от известных, солидных фирм (таких, как Microsoft или Inprise) до мало кому знакомых коллективов авторов выпускают на рынок все новые и новые образцы компиляторов. Это обусловлено рядом причин, которые будут рассмотрены далее.
Наконец, с тех пор как большинство теоретических аспектов в области компиляторов получили свою практическую реализацию (а это, надо сказать, произошло довольно быстро, в конце 60-х годов), развитие компиляторов пошло по пути их дружественности человеку — пользователю, разработчику программ на языках высокого уровня. Логичным завершением этого процесса стало создание систем программирования — программных комплексов, объединяющих в себе кроме непосредственно компиляторов множество связанных с ними компонентов программного обеспечения. Появившись, системы программирования быстро завоевали рынок и ныне в массе своей преобладают на нем (фактически, обособленные компиляторы — это редкость среди современных программных средств). О том, что представляют собой и как организованы современные системы программирования, см. в главе «Современные системы программирования». Ныне компиляторы являются неотъемлемой частью любой вычислительной системы. Без их существования программирование любой прикладной задачи было бы затруднено, а то и просто невозможно. Да и программирование специализированных системных задач, как правило, ведется если не на языке высокого уровня (в этой роли в настоящее время чаще всего применяется язык С), то на языке ассемблера, следовательно, применяется соответствующий компилятор. Программирование непосредственно на языках машинных кодов происходит исключительно редко и только для решения очень узких вопросов. Несколько слов о примерах реализации компиляторов и интерпретаторов, а также о том, как они соотносятся с другими существующими программными средствами. Компиляторы, как будет показано далее, обычно несколько проще в реализации, чем интерпретаторы. По эффективности они также превосходят их — очевидно, что откомпилированный код будет исполняться всегда быстрее, чем происходит интерпретация аналогичной исходной программы. Кроме того, не каждый язык программирования допускает построение простого интерпретатора. Однако интерпретаторы имеют одно существенное преимущество — откомпилированный код всегда привязан к архитектуре вычислительной системы, на которую он ориентирован, а исходная программа — только к семантике языка программирования, которая гораздо легче поддается стандартизации. Этот аспект первоначально не принимали во внимание. Первыми компиляторами были компиляторы с мнемокодов. Их потомки — современные компиляторы с языков ассемблера — существую практически для всех известных вычислительных систем. Они предельно жестко ориентированы на архитектуру. Затем появились компиляторы с таких языков, как FORTRAN, ALGOL-68, PL/1. Они были ориентированы на большие ЭВМ с пакетной обработкой задач. Из вышеперечисленных только FORTRAN, пожалуй, продолжает использоваться по сей день, поскольку имеет огромное количество библиотек различного назначения [7]. Многие языки, родившись, так и не получили широкого распространения — ADA, Modula, Simula известны лишь узкому кругу специалистов. В то же время на рынке программных систем доминируют компиляторы языков, которым не прочили светлого будущего. В первую очередь, сейчас это С и C++. Первый из них родился вместе с операционными системами типа UNIX, вместе с нею завоевал свое «место под солнцем», а затем перешел под ОС других типов. Второй удачно воплотил в себе пример реализации идей объектно-ориентированного программирования на хорошо зарекомендовавшей себя практической базе1. Еще можно упомянуть довольно распространенный Pascal, который неожиданно для многих вышел за рамки чисто учебного языка для университетской среды.
История интерпретаторов не столь богата (пока!). Как уже было сказано, изначально им не предавали существенного значения, поскольку почти по всем параметрам они уступают компиляторам. Из известных языков, предполагавших интерпретацию, можно упомянуть разве что Basic, хотя большинству сейчас известна его компилируемая реализация Visual Basic, сделанная фирмой Microsoft [3, 63]. Тем не менее сейчас ситуация несколько изменилась, поскольку вопрос о переносимости программ и их аппаратно-платформенной независимости приобретает все большую актуальность с развитием сети Интернет. Самый известный сейчас пример — это язык Java (сам по себе он сочетает компиляцию и интерпретацию), а также связанный с ним JavaScript. В конце концов, язык HTML, на котором зиждется протокол HTTP, давший толчок столь бурному развитию Всемирной сети, — это тоже интерпретируемый язык. По мнению автора, в области появления новых интерпретаторов всех еще ждут сюрпризы, и появились уже первые из них — например, язык С# («си-диез», но название везде идет как «Си шарп»), анонсируемый фирмой Microsoft.
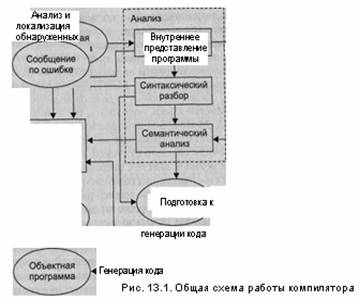 Об истории языков программирования и
современном состоянии рынка компиляторов можно говорить долго и много. Автор
считает возможным ограничиться уже сказанным, поскольку это не является целью данного
пособия. Желающие могут обратиться к литературе [7, 8, 14, 23, 30, 45, 66, 77, 81].
Об истории языков программирования и
современном состоянии рынка компиляторов можно говорить долго и много. Автор
считает возможным ограничиться уже сказанным, поскольку это не является целью данного
пособия. Желающие могут обратиться к литературе [7, 8, 14, 23, 30, 45, 66, 77, 81].
Этапы трансляции. Общая схема работы транслятора
На рис. 13.1 представлена общая схема
работы компилятора. Из нее видно, что ъ целом процесс компиляции состоит из
двух основных этапов — синтеза и анализа.
На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Результатом его работы служит некое внутреннее представление программы, понятное компилятору.
На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице (таблицах) идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код.
Кроме того, в составе компилятора присутствует часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки.
Эти этапы, в свою Очередь, состоят из
более мелких этапов, называемых фазами компиляции. Состав фаз компиляции приведен в
самом общем виде, их конкретная реализация и процесс взаимодействия
Во-первых, он является распознавателем для языка исходной программы. То ее он должен получить на вход цепочку символов входного языка, проверить принадлежность языку и, более того, выявить правила, по которым эта цепоч была построена (поскольку сам ответ на вопрос о принадлежности «да» и. «нет» представляет мало интереса). Интересно, что генератором цепочек входи го языка выступает пользователь — автор входной программы.
Во-вторых, компилятор является генератором для языка результирующей пр граммы. Он должен построить на выходе цепочку выходного языка по опре; ленным правилам, предполагаемым языком машинных команд или языком i семблера. Распознавателем этой цепочки будет выступать уже вычислительн система, под которую создается результирующая программа.
Далее дается перечень основных фаз (частей) компиляции и краткое описан их функций. Более подробная информация дана в подразделах, соответству щих этим фазам.
Лексический анализ (сканер) — это часть компилятора, которая читает лите] программы на исходном языке и строит из них слова (лексемы) исходного яз ка. На вход лексического анализатора поступает текст исходной программ а выходная информация передаётся для дальнейшей обработки компилятор на этапе синтаксического разбора. С теоретической точки зрения лексическ анализатор не является обязательной, необходимой частью компилятора. Од1 ко существует причины, которые определяют его присутствие практически всех компиляторах. Более подробно см. раздел «Лексические анализаторы (а неры). Принципы построения сканеров».
Синтаксический разбор — это основная часть компилятора на этапе анализа. О выполняет выделение синтаксических конструкций в тексте исходной прогре мы, обработанном лексическим анализатором. На этой же фазе компиляц проверяется синтаксическая правильность программы. Синтаксический раз£ играет главную роль — роль распознавателя текста входного языка програмл рования (см. раздел «Синтаксические анализаторы. Синтаксически управл; мый перевод» этой главы).
Семантический анализ — это часть компилятора, проверяющая правильно* текста исходной программы с точки зрения семантики входного языка. Крс непосредственно проверки, семантический анализ должен выполнять преоб; зования текста, требуемые семантикой входного языка (такие, как добавлен функций неявного преобразования типов). В различных реализациях компи. торов семантический анализ может частично входить в фазу синтаксическ* разбора, частично — в фазу подготовки к генерации кода.
Подготовка к генерации кода — это фаза, на которой компилятором выполнят ся предварительные действия, непосредственно связанные с синтезом текста зультирующей программы, но еще не ведущие к порождению текста на вых ном языке. Обычно в эту фазу входят действия, связанные с идентификащ элементов языка, распределением памяти и т. п. (см. раздел «Семантическ анализ и подготовка к генерации кода», глава 14).
Генерация кода — это фаза, непосредственно связанная с порождением кома составляющих предложения выходного языка и в целом текст результируюи
могут, конечно, различаться в зависимости от версии компилятора. Однако в том или ином виде все представленные фазы практически всегда присутствуют в каждом конкретном компиляторе [26, 40].
Компилятор в целом с точки зрения
теории формальных языков выступает в «двух ипостасях», выполняет две основные функции. ![]()
![]() программы. Это
основная фаза на этапе синтеза результирующей программы. Кроме
непосредственного порождения текста результирующей программы, генерация обычно
включает в себя также оптимизацию — процесс, связанный с обработкой уже порожденного
текста. Иногда оптимизацию выделяют в отдельную фазу компиляции, так как она оказывает
существенное влияние на качество и эффективность результирующей программы (см.
разделы «Генерация кода. Методы генерации кода» и « Оптимизация кода. Основные
методы оптимизации», глава 14).
программы. Это
основная фаза на этапе синтеза результирующей программы. Кроме
непосредственного порождения текста результирующей программы, генерация обычно
включает в себя также оптимизацию — процесс, связанный с обработкой уже порожденного
текста. Иногда оптимизацию выделяют в отдельную фазу компиляции, так как она оказывает
существенное влияние на качество и эффективность результирующей программы (см.
разделы «Генерация кода. Методы генерации кода» и « Оптимизация кода. Основные
методы оптимизации», глава 14).
Таблицы идентификаторов (иногда — «таблицы символов») — это специальным образом организованные наборы данных, служащие для хранения информации об элементах исходной программы, которые затем используются для порождения текста результирующей программы. Таблица идентификаторов в конкретной реализации компилятора может быть одна, или же таких таблиц может быть несколько. Элементами исходной программы, информацию о которых нужно хранить в процессе компиляции, являются переменные, константы, функции и т. п. — конкретный состав набора элементов зависит от используемого входного языка программирования. Понятие «таблицы» вовсе не предполагает, что это хранилище данных должно быть организовано именно в виде таблиц или других массивов информации — возможные методы их организации подробно рассмотрены далее, в разделе «Таблицы идентификаторов. Организация таблиц идентификаторов».
Представленное на рис. 13.1 деление процесса компиляции на фазы служит скорее методическим целям и на практике может не соблюдаться столь строго. Далее в подразделах этого пособия рассматриваются различные варианты технической организации представленных фаз компиляции. При этом указано, как они могут быть связаны между собой. Здесь рассмотрим только общие аспекты такого рода взаимосвязи.
Во-первых, на фазе лексического анализа лексемы выделяются из текста входной программы постольку, поскольку они необходимы для следующей фазы синтаксического разбора. Во-вторых, как будет показано ниже, синтаксический разбор и генерация кода могут выполняться одновременно. Таким образом, эти три фазы компиляции могут работать комбинированно, а вместе с ними может выполняться и подготовка к генерации кода. Далее рассмотрены технические вопросы реализации основных фаз компиляции, которые тесно связаны с понятием прохода.
Понятие прохода. Многопроходные и однопроходные компиляторы
Как уже было сказано, процесс компиляции программ состоит из нескольких фаз. В реальных компиляторах состав этих фаз может несколько отличаться от рассмотренного выше — некоторые из них могут быть разбиты на составляющие, другие, напротив, объединены в одну фазу. Порядок выполнения фаз компиляции также может меняться в разных вариантах компиляторов. В одном случае компилятор просматривает текст исходной программы, сразу выполняет все фазы компиляции и получает результат — объектный код. В другом варианте он выполняет над исходным текстом только некоторые из фаз компиляции и получает не конечный результат, а набор некоторых промежуточных данных. Эти данные затем снова подвергаются обработке, причем этот процесс может повторяться несколько раз.
Реальные компиляторы, как правило, выполняют трансляцию текста исходной программы за несколько проходов.
Проход — это процесс последовательного чтения компилятором данных из внешней памяти, их обработки и помещения результата работы во внешнюю память. Чаще всего один проход включает в себя выполнение одной или нескольких фаз компиляции. Результатом промежуточных проходов является внутреннее представление исходной программы, результатом последнего прохода — результирующая объектная программа.
В качестве внешней памяти могут выступать любые носители информации — оперативная память компьютера, накопители на магнитных дисках, магнитных лентах и т. п. Современные компиляторы, как правило, стремятся максимально использовать для хранения данных оперативную память компьютера, и только при недостатке объема доступной памяти используются накопители на жестких магнитных дисках. Другие носители информации в современных компиляторах не используются из-за невысокой скорости обмена данными.
При выполнении каждого прохода компилятору доступна информация, полученная в результате всех предыдущих проходов. Как правило, он стремится использовать в первую очередь только информацию, полученную на проходе, непосредственно предшествовавшем текущему, но в принципе может обращаться и к данным от более ранних проходов вплоть до исходного текста программы. Информация, получаемая компилятором при выполнении проходов, недоступна пользователю. Она либо хранится в оперативной памяти, которая освобождается компилятором после завершения процесса трансляции, либо оформляется в виде временных файлов на диске, которые также уничтожаются после завершения работы компилятора. Поэтому человек, работающий с компилятором, может даже не знать, сколько проходов выполняет компилятор — он всегда видит только текст исходной программы и результирующую объектную программу. Но количество выполняемых проходов — это важная техническая характеристика компилятора, солидные фирмы — разработчики компиляторов обычно указывают ее в описании своего продукта.
Понятно, что разработчики стремятся максимально сократить количество проходов, выполняемых компиляторами. При этом увеличивается скорость работы компилятора, сокращается объем необходимой ему памяти. Однопроходный компилятор, получающий на вход исходную программу и сразу же порождающий результирующую объектную программу, — это идеальный вариант.
Однако сократить число проходов не всегда
удается. Количество необходимых проходов определяется прежде всего грамматикой
и семантическими правилами исходного языка. Чем сложнее грамматика языка и чем
больше вариантов предполагают семантические правила — тем больше проходов
будет выполнять компилятор (конечно, играет свою роль и квалификация
разработчиков компилятора). Например, именно поэтому обычно компиляторы с
языка Pascal работают быстрее, чем компиляторы с языка С —
грамматика языка Pascal более проста, а семантические
правила более жесткие. ![]() Однопроходные
компиляторы — редкость, они возможны только для очень простых языков.
Реальные компиляторы выполняют, как правило, от двух до пяти проходов. Таким
образом, реальные компиляторы являются многопроходными. Наиболее распространены
двух- и трехпроходные компиляторы, например: первый проход — лексический анализ,
второй — синтаксический разбор и семантический анализ, третий — генерация и
оптимизация кода (варианты исполнения, конечно, зависят от разработчика). В
современных системах программирования нередко первый проход компилятора
(лексический анализ кода) выполняется параллельно с редактированием кода исходной
программы (такой вариант построения компиляторов рассмотрен далее в этой главе).
Однопроходные
компиляторы — редкость, они возможны только для очень простых языков.
Реальные компиляторы выполняют, как правило, от двух до пяти проходов. Таким
образом, реальные компиляторы являются многопроходными. Наиболее распространены
двух- и трехпроходные компиляторы, например: первый проход — лексический анализ,
второй — синтаксический разбор и семантический анализ, третий — генерация и
оптимизация кода (варианты исполнения, конечно, зависят от разработчика). В
современных системах программирования нередко первый проход компилятора
(лексический анализ кода) выполняется параллельно с редактированием кода исходной
программы (такой вариант построения компиляторов рассмотрен далее в этой главе).
Интерпретаторы. Особенности построения интерпретаторов
Интерпретатор — это программа, которая воспринимает входную программу на исходном языке и выполняет ее. Как уже было сказано выше, основное отличие интерпретаторов от трансляторов и компиляторов заключается в том, что интерпретатор не порождает результирующую программу, а просто выполняет исходную программу.
Термин «интерпретатор» (interpreter), как и «транслятор», означает «переводчик». С точки зрения терминологии эти понятия схожи, но с точки зрения теории формальных языков и компиляции между ними большая принципиальная разница. Если понятия «транслятор» и «компилятор» почти неразличимы, то с понятием «интерпретатор» их путать никак нельзя.
Простейшим способом реализации интерпретатора можно было бы считать вариант, когда исходная программа сначала полностью транслируется в машинные команды, а затем сразу же выполняется. В такой реализации интерпретатор, по сути, мало бы чем отличался от компилятора с той лишь разницей, что результирующая программа в нем была бы недоступна пользователю. Недостатком такого интерпретатора было бы то, что пользователь должен был бы ждать компиляции всей исходной программы прежде, чем начнется ее выполнение. По сути, в таком интерпретаторе не было бы никакого особого смысла — он не давал бы никаких преимуществ по сравнению с аналогичным компилятором1. Поэтому подавляющее большинство интерпретаторов действует так, что исполняет исходную программу последовательно, по мере ее поступления на вход интерпретатора. Тогда пользователю не надо ждать завершения компиляции всей исходной программы. Более того, он может последовательно вводить исходную программу и тут же наблюдать результат ее выполнения по мере ввода команд [82].
При таком порядке работы интерпретатора проявляется существенная особенность, которая отличает его от компилятора, — если интерпретатор исполняет команды по мере их поступления, то он не может выполнять оптимизацию исходной программы. Следовательно, фаза оптимизации в общей структуре интер- претатора будет отсутствовать. В остальном же она будет мало отличаться от структуры аналогичного компилятора. Следует только учесть, что на последнем этапе — генерации кода - машинные команды не записываются в объектный файл, а выполняются по мере их порождения.
Отсутствие шага оптимизации определяет еще одну особенность, характерную для многих интерпретаторов: в качестве внутреннего представления программы в них очень часто используется обратная польская запись (см. раздел «Генерация кода. Методы генерации кода», глава 14). Эта удобная форма представления операций обладает только одним существенным недостатком — она плохо поддается оптимизации. Но в интерпретаторах именно это как раз и не требуется.
Далеко не все языки программирования допускают построение интерпретаторов которые могли бы выполнять исходную программу по мере поступления команд Для этого язык должен допускать возможность существования компилятора выполняющего разбор исходной программы за один проход. Кроме того, язык не может интерпретироваться по мере поступления команд, если он допускает по явление обращений к функциям и структурам данных раньше их непосредствен ного описания. Поэтому данным методом не могут интерпретироваться такш языки, как С и Pascal.
Отсутствие шага оптимизации ведет к тому, что выполнение программы с помо щью интерпретатора является менее эффективным, чем с помощью аналогично го компилятора. Кроме того, при интерпретации исходная программа должна за ново разбираться всякий раз при ее выполнении, в то время как при компиляци] она разбирается только один раз, а после этого всегда используется объектны] файл. Таким образом, интерпретаторы всегда проигрывают компиляторам в про изводительности.
Преимуществом интерпретатора является независимость выполнения програм мы от архитектуры целевой вычислительной системы. В результате компиляци: получается объектный код, который всегда ориентирован на определенную архн тектуру. Для перехода на другую архитектуру целевой вычислительной систем] программу требуется откомпилировать заново. А для интерпретации программ] необходимо иметь только ее исходный текст и интерпретатор с соответствующе го языка.
Интерпретаторы долгое время значительно уступали в распространенности коь пиляторам. Как правило, интерпретаторы существовали для ограниченного крз га относительно простых языков программирования (таких, например, как Basic Высокопроизводительные профессиональные средства разработки программш го обеспечения строились на основе компиляторов.
Новый импульс развитию интерпретаторов придало распространение глобал] ных вычислительных сетей. Такие сети могут включать в свой состав ЭВМ ра: личной архитектуры, и тогда требование единообразного выполнения на каждс из них текста исходной программы становится определяющим. Поэтому с разв] тием глобальных сетей и распространением всемирной сети Интернет появило< много новых систем, интерпретирующий текст исходной программы. Мноп языки программирования, применяемые во Всемирной сети, предполагают име: но интерпретацию текста исходной программы без порождения объектного код
В современных системах программирования существуют реализации программного обеспечения, сочетающие в себе и функции компилятора, и функции интерпретатора — в зависимости от требований пользователя исходная программа либо компилируется, либо исполняется (интерпретируется). Кроме того, некоторые современные языки программирования предполагают две стадии разработки: сначала исходная программа компилируется в промежуточный код (некоторый язык низкого уровня), а затем этот результат компиляции выполняется с помощью интерпретатора данного промежуточного языка. Более подробно варианты таких систем рассмотрены в главе «Современные системы программирования».
Широко распространенным примером интерпретируемого языка может служить HTML (Hypertext Markup Language) — язык описания гипертекста. На его основе в настоящее время функционирует практически вся структура сети Интернет. Другой пример — языки Java и JavaScript — сочетают в себе функции компиляции и интерпретации. Текст исходной программы компилируется в некоторый промежуточный двоичный код, не зависящий от архитектуры целевой вычислительной системы, этот код распространяется по сети и выполняется на принимающей стороне — интерпретируется.
Трансляторы с языка ассемблера («ассемблеры»)
Язык ассемблера — это язык низкого уровня. Структура и взаимосвязь цепочек этого языка близки к машинным командам целевой вычислительной системы, где должна выполняться результирующая программа. Применение языка ассемблера позволяет разработчику управлять ресурсами (процессором, оперативной памятью, внешними устройствами и т. п.) целевой вычислительной системы на уровне машинных команд. Каждая команда исходной программы на языке ассемблера в результате компиляции преобразуется в одну машинную команду.
Транслятор с языка ассемблера всегда, безусловно, будет и компилятором, поскольку языком результирующей программы являются машинные коды. Транслятор с языка ассемблера зачастую просто называют «ассемблер» или «программа ассемблера».
Реализация компиляторов с языка ассемблера
Язык ассемблера, как правило, содержит мнемонические коды машинных команд. Чаще всего используется англоязычная мнемоника команд, но существуют и другие варианты языков ассемблера (в том числе существуют и русскоязычные варианты). Именно поэтому язык ассемблера раньше носил названия «язык мнемокодов» (сейчас это название уже практически не употребляется). Все возможные команды в каждом языке ассемблера можно разбить на две группы: в первую группу входят обычные команды языка, которые в процессе трансляции преобразуются в машинные команды; вторую группу составляют специальные команды языка, которые в машинные команды не преобразуются, но используются компилятором для выполнения задач компиляции (таких, например, как задача распределения памяти). Синтаксис языка чрезвычайно прост. Команды исходной программы записыв ются обычно таким образом, чтобы на одной строке программы располагала одна команда. Каждая команда языка ассемблера, как правило, может быть рг делена на три составляющих, следующих последовательно одна за другой: по метки, код операции и поле операндов. Компилятор с языка ассемблера обыч] предусматривает и возможность наличия во входной программе комментарш которые отделяются от команд заданным разделителем [93].
Поле метки содержит идентификатор, представляющий собой метку, либо явл ется пустым. Каждый идентификатор метки может встречаться в программе языке ассемблера только один раз. Метка считается описанной там, где она у посредственно встретилась в программе (предварительное описание меток требуется). Метка может быть использована для передачи управления на поь ченную ею команду. Нередко метка отделяется от остальной части команды сг циальным разделителем (чаще всего — двоеточием «:»).
Код операции всегда представляет собой строго определенную мнемонику одн из возможных команд процессора или также строго определенную команду ( мого компилятора. Код операции записывается алфавитными символами вхс ного языка. Чаще всего его длина составляет 3-4, реже — 5 или 6 символов.
Поле операндов либо является пустым, либо представляет собой список из одг го, двух, реже — трех операндов. Количество операндов строго определено и : висит от кода операции — каждая операция языка ассемблера предусматривг жестко заданное число своих операндов. Соответственно, каждому из этих вар антов соответствуют безадресные, одноадресные, двухадресные или трехадресн команды (большее число операндов практически не используется, в совреме ных ЭВМ даже трехадресные команды встречаются редко). В качестве опер; дов могут выступать идентификаторы или константы.
Особенностью языка ассемблера является то, что ряд идентификаторов в н выделяется специально для обозначения регистров процессора. Такие идет фикаторы, с одной стороны, не требуют предварительного описания, но, с Д1 гой, они не могут быть использованы пользователем для иных целей. Набор эт идентификаторов предопределен для каждого языка ассемблера.
Иногда язык ассемблера допускает использование в качестве операндов оп] деленных ограниченных сочетаний обозначений регистров, идентификатор и констант, которые объединены некоторыми знаками операций. Такие соче ния чаще всего используются для обозначения типов адресации, допустим в машинных командах целевой вычислительной системы.
Например, следующая последовательность команд
datas db 16 dup(O) loops: mov datas[bx+4].cx dec bx jnz loops
представляет собой пример последовательности команд языка ассемблера п; цессоров семейства Intel 80x86. Здесь присутствуют команда описания наб( данных (db), метка (loops), коды операций (mov, dec и jnz). Операндами яв. ются идентификатор набора данных (datas), обозначения регистров процессе
(Ьх и сх), метка (loops) и константа (4). Составной операнд datas[bx+4] отображает косвенную адресацию набора данных datas по базовому регистру Ьх со смещением 4.
Подобный синтаксис языка без труда может быть описан с помощью регулярной грамматики. Поэтому построение распознавателя для языка ассемблера не представляет труда. По этой же причине в компиляторах с языка ассемблера лексический и синтаксический разбор, как правило, совмещены в один распознаватель.
Семантика языка ассемблера целиком и полностью определяется целевой вычислительной системой, на которую ориентирован данный язык. Семантика языка ассемблера определяет, какая машинная команда соответствует каждой команде языка ассемблера, а также то, какие операнды и в каком количестве допустимы для того или иного кода операции.
Поэтому семантический анализ в компиляторе с языка ассемблера также прост, как и синтаксический. Основной его задачей является проверить допустимость операндов для каждого кода операции, а также проверить, что все идентификаторы и метки, встречающиеся во входной программе, описаны и обозначающие их идентификаторы не совпадают с предопределенными идентификаторами, используемыми для обозначения кодов операции и регистров процессора.
Схемы синтаксического и семантического анализа в компиляторе с языка ассемблера могут быть, таким образом, реализованы на основе обычного конечного автомата. Именно эта особенность определила тот факт, что компиляторы с языка ассемблера исторически явились первыми компиляторами, созданными для ЭВМ. Существует также ряд других особенностей, которые присущи именно языкам ассемблера и упрощают построение компиляторов для них.
Во-первых, в компиляторах с языка ассемблера не выполняется дополнительная идентификация переменных — все переменные языка сохраняют имена, присвоенные им пользователем. За уникальность имен в исходной программе отвечает ее разработчик, семантика языка никаких дополнительных требований на этот процесс не накладывает. Во-вторых, в компиляторах с языка ассемблера предельно упрощено распределение памяти. Компилятор с языка ассемблера работает только со статической памятью. Если используется динамическая память, то для работы с нею нужно использовать соответствующую библиотеку или функции ОС, а за ее распределение отвечает разработчик исходной программы. За передачу параметров и организацию дисплея памяти процедур и функций также отвечает разработчик исходной программы. Он же должен позаботиться и об отделении данных от кода программы — компилятор с языка ассемблера, в отличие от компиляторов с языков высокого уровня, автоматически такого разделения не выполняет. И в-третьих, на этапе генерации кода в компиляторе с языка ассемблера не производится оптимизация, поскольку разработчик исходной программы сам отвечает за организацию вычислений, последовательность машинных команд и распределение регистров процессора.
За исключением этих особенностей компилятор с языка ассемблера является обычным компилятором, но значительно упрощенным по сравнению с любым компилятором с языка высокого уровня. Компиляторы с языка ассемблера реализуются чаще всего по двухпроходной схеме. На первом проходе компилятор выполняет разбор исходной программы, ее преобразование в машинные коды и одновременно заполняет таблицу идентификаторов. Но на первом проходе в машинных командах остаются незаполненными адреса тех операндов, которые размещаются в оперативной памяти. На втором проходе компилятор заполняет эти адреса и одновременно обнаруживает неописанные идентификаторы. Это связано с тем, что операнд может быть описан в программе после того, как он первый раз был использован. Тогда его адрес еще не известен на момент построения машинной команды, а поэтому требуется второй проход. Типичным примером такого операнда является метка, предусматривающая переход вперед по ходу последовательности команд.
Макроопределения и макрокоманды
Разработка программ на языке ассемблера — достаточно трудоемкий процесс, требующий зачастую простого повторения одних и тех же многократно встречающихся операций. Примером может служить последовательность команд, выполняемых каждый раз для организации стекового дисплея памяти при входе в процедуру или функцию.
Для облегчения труда разработчика были созданы так называемые макрокоманды.
Макрокоманда представляет собой текстовую подстановку, в ходе выполнения которой каждый идентификатор определенного вида заменяется на цепочку символов из некоторого хранилища данных. Процесс выполнения макрокоманды называется макрогенерацией, а цепочка символов, получаемая в результате выполнения макрокоманды, — макрорасширением.
Процесс выполнения макрокоманд заключается в последовательном просмотре текста исходной программы, обнаружении в нем определенных идентификаторов и их замене на соответствующие строки символов. Причем выполняется именно текстовая замена одной цепочки символов (идентификатора) на другую цепочку символов (строку). Такая замена называется макроподстановкой [66, 83, 93].
Для того чтобы указать, какие идентификаторы на какие строки необходимо заменять, служат макроопределения. Макроопределения присутствуют непосредственно в тексте исходной программы. Они выделяются специальными ключевыми словами либо разделителями, которые не могут встречаться нигде больше в тексте программы. В процессе обработки все макроопределения полностью исключаются из текста входной программы, а содержащаяся в них информация запоминается для обработки при выполнении макрокоманд.
Макроопределение может содержать параметры. Тогда каждая соответствующая ему макрокоманда должна при вызове содержать строку символов вместо каждого параметра. Эта строка подставляется при выполнении макрокоманды в каждое место, где в макроопределении встречается соответствующий параметр. В качестве параметра макрокоманды может оказаться другая макрокоманда, тогда она будет рекурсивно вызвана всякий раз, когда необходимо выполнить подстановку параметра. В принципе макрокоманды могут образовывать последовательность
рекурсивных вызовов, аналогичную последовательности рекурсивных вызовов процедур и функций, но только вместо вычислений и передачи параметров они выполняют лишь текстовые подстановки1.
Макрокоманды и макроопределения обрабатываются специальным модулем, называемым макропроцессором или макрогенератором. Макрогенератор получает на вход текст исходной программы, содержащий макроопределения и макрокоманды, а на выходе его появляется текст макрорасширения исходной программы, не содержащий макроопределений и макрокоманд. Оба текста являются только текстами программы, никакая другая обработка не выполняется. Именно макрорасширение исходного текста поступает на вход компилятора.
Синтаксис макрокоманд и макроопределений не является строго заданным. Он может различаться в зависимости от реализации компилятора с языка ассемблера. Но сам принцип выполнения макроподстановок в тексте программы неизменен и не зависит от их синтаксиса.
Макрогенератор чаще всего не существует в виде отдельного программного модуля, а входит в состав компилятора с языка ассемблера. Макрорасширение исходной программы обычно недоступно ее разработчику. Более того, макроподстановки могут выполняться последовательно при разборе исходного текста на первом проходе компилятора вместе с разбором всего текста программы, и тогда макрорасширение исходной программы в целом может и вовсе не существовать как таковое.
Например, следующий текст определяет макрокоманду push_0 в языке ассемблера процессора типа Intel 8086:
push_O macro
хог ах,ах ■ push
ax endm
Семантика этой макрокоманды заключается в записи числа «0» в стек через регистр процессора ах. Тогда везде в тексте программы, где встретится макрокоманда
push_O
она будет заменена в результате макроподстановки на последовательность команд:
хог ах,ах ■ push ax
Это самый простой вариант макроопределения. Существует возможность создавать более сложные макроопределения с параметрами. Одно из таких макроопределений описано ниже:
Глубина такой рекурсии, как правило, сильно ограничена. На последовательность рекурсивных вызовов макрокоманд налагаются обычно существенно более жесткие ограничения, чем на последовательность рекурсивных вызовов процедур и функций, которая при стековой организации дисплея памяти ограничена только размером стека передачи параметров. add_abx macro xl,x2
add ax.xl
add bx.xl
add cx,x2
push ax
endm
Тогда в тексте программы макрокоманда также должна быть указана с соответствующим числом параметров. В данном примере макрокоманда
add_abx4,8 будет в результате макроподстановки заменена на последовательность команд:
add ах,4 add bx.4 add ex,8 push ax
Во многих компиляторах с языка ассемблера возможны еще более сложные конструкции, которые могут содержать локальные переменные и метки. Примером такой конструкции может служить макроопределение:
loop_ax macro xl,x2,yl
local loopax
mov ax.xl
хог bx.bx loopax: add bx.yl
sub ax,x2
jge loopax
endm
Здесь метка 1 oopax является локальной, определенной только внутри данного макроопределения. В этом случае уже не может быть выполнена простая текстовая подстановка макрокоманды в текст программы, поскольку если данную макрокоманду выполнить дважды, то это приведет к появлению в тексте программы двух одинаковых меток 1 оорах. В таком варианте макрогенератор должен использовать более сложные методы текстовых подстановок, аналогичные тем, что используются в компиляторах при идентификации лексических элементов входной программы, чтобы дать всем возможным локальным переменным и меткам макрокоманд уникальные имена в пределах всей программы. Макроопределения и макрокоманды нашли применение не только в языках ассемблера, но и во многих языках высокого уровня. Там их обрабатывает специальный модуль, называемый препроцессором языка (например, широко известен препроцессор языка С). Принцип обработки остается тем же самым, что и для программ на языке ассемблера — препроцессор выполняет текстовые подстановки непосредственно над строками самой исходной программы. В языках высокого уровня макроопределения должны быть отделены от текста самой исходной программы, чтобы препроцессор не мог спутать их с синтаксическими конструкциями входного языка. Для этого используются либо специальные символы и команды (команды препроцессора), которые никогда не могут встречаться в тексте исходной программы, либо макроопределения встречаются
внутри незначащей части исходной программы — входят в состав комментариев (такая реализация существует, например, в компиляторе с языка Pascal, созданном фирмой Borland). Макрокоманды, напротив, могут встречаться в произвольном месте исходного текста программы, и синтаксически их вызов может не отличаться от вызова функций во входном языке.
Следует помнить, что, несмотря на схожесть синтаксиса вызова, макрокоманды принципиально отличаются от процедур и функций, поскольку не порождают результирующего кода, а представляют собой текстовую подстановку, выполняемую прямо в тексте исходной программы. Результат вызова функции и макрокоманды может из-за этого серьезно отличаться.
Рассмотрим пример на языке С. Если описана функция
int fKint a) { return a + а: } и аналогичная ей макрокоманда
#define f2(a) ((a) + (а)) то результат их вызова не всегда будет одинаков.
Действительно, вызовы j=fl(i) и j=f2(i) (где i и j — некоторые целочисленные переменные) приведут к одному и тому же результату. Но вызовы j=fl(++i) и j=f2(++i) дадут разные значения переменной j. Дело в том, что поскольку f2 — это макроопределение, то во втором случае будет выполнена текстовая подстановка, которая приведет к последовательности операторов j=((++i) + (++i)). Видно, что в этой последовательности операция ++i будет выполнена дважды, в отличие от вызова функции fl(++i), где она выполняется только один раз.
5. Таблицы идентификаторов. Организация таблиц
идентификаторов. Назначение и особенности построения таблиц идентификаторов.
Простейшие методы построения таблиц идентификаторов. Хэш-функция и
хэш-адресация.
Таблицы идентификаторов. Организация таблиц идентификаторов
Назначение и особенности построения таблиц идентификаторов
Проверка правильности семантики и генерация кода требуют знания характеристик переменных, констант, функций и других элементов, встречающихся в программе на исходном языке. Все эти элементы в исходной программе, как правило, обозначаются идентификаторами. Выделение идентификаторов и других элементов исходной программы происходит на фазе лексического анализа. Их характеристики определяются на фазах синтаксического разбора, семантического анализа и подготовки к генерации кода. Состав возможных характеристик и методы их определения зависят от семантики входного языка. В любом случае компилятор должен иметь возможность хранить все найденные идентификаторы и связанные с ними характеристики в течение всего процесса компиляции, чтобы иметь возможность использовать их на различных фазах
компиляции. Для этой цели, как было сказано выше, в компиляторах используются специальные хранилища данных, называемые таблицами символов или таблицами идентификаторов.
Любая таблица идентификаторов состоит из набора полей, количество которых равно числу различных идентификаторов, найденных в исходной программе. Каждое поле содержит в себе полную информацию о данном элементе таблицы. Компилятор может работать с одной или несколькими таблицам идентификаторов — их количество зависит от реализации компилятора. Например, можно организовывать различные таблицы идентификаторов для различных модулей исходной программы или для различных типов элементов входного языка.
Состав информации, хранимой в таблице идентификаторов для каждого элемента исходной программы, зависит от семантики входного языка и типа элемента. Например, в таблицах идентификаторов может храниться следующая информация:
□ для переменных:
О имя переменной;
О тип данных переменной;
О область памяти, связанная с переменной;
□ для констант:
О название константы (если оно имеется);
О значение константы;
О тип данных константы (если требуется);
□ для функций:
О имя функции;
О количество и типы формальных аргументов функции;
О тип возвращаемого результата;
О адрес кода функции.
Приведенный выше состав хранимой информации, конечно же, является только примерным. Другие примеры такой информации указаны в [23, 42, 74]. Конкретное наполнение таблиц идентификаторов зависит от реализации компилятора. Кроме того, не вся информация, хранимая в таблице идентификаторов, заполняется компилятором сразу — он может несколько раз выполнять обращение к данным в таблице идентификаторов на различных фазах компиляции. Например, имена переменных могут быть выделены на фазе лексического анализа, типы данных для переменных — на фазе синтаксического разбора, а область памяти связывается с переменной только на фазе подготовки к генерации кода.
Вне зависимости от реализации компилятора принцип его работы с таблицей идентификаторов остается одним и тем же — на различных фазах компиляции компилятор вынужден многократно обращаться к таблице для поиска информации и записи новых данных. Как правило, каждый элемент в исходной программе однозначно идентифицируется своим именем (вопросы идентификации более подробно рассмотрены в разделе «Семантический анализ и подготовка к генерации кода», глава 14). Поэтому компилятору приходится часто выполнять поиск
![]() необходимого
элемента в таблице идентификаторов по его имени, в то время как процесс заполнения
таблицы выполняется нечасто — новые идентификаторы описываются в
программе гораздо реже, чем используются. Отсюда можно сделать вывод, что
таблицы идентификаторов должны быть организованы таким образом, чтобы
компилятор имел возможность максимально быстрого поиска нужного ему элемента
[33].
необходимого
элемента в таблице идентификаторов по его имени, в то время как процесс заполнения
таблицы выполняется нечасто — новые идентификаторы описываются в
программе гораздо реже, чем используются. Отсюда можно сделать вывод, что
таблицы идентификаторов должны быть организованы таким образом, чтобы
компилятор имел возможность максимально быстрого поиска нужного ему элемента
[33].
Простейшие методы построения таблиц идентификаторов
Простейший способ организации таблицы состоит в том, чтобы добавлять элементы в порядке их поступления. Тогда таблица идентификаторов будет представлять собой неупорядоченный массив информации, каждая ячейка которого будет содержать данные о соответствующем элементе таблицы.
Поиск нужного элемента в таблице будет в этом случае заключаться в последовательном сравнении искомого элемента с каждым элементом таблицы, пока не будет найден подходящий. Тогда, если за единицу принять время, затрачиваемое компилятором на сравнение двух элементов (как правило, это сравнение двух строк), то для таблицы, содержащей N элементов, в среднем будет выполнено N/2 сравнений [14].
Заполнение такой таблицы будет происходить элементарно просто — добавлением нового элемента в ее конец, и время, требуемое на добавление элемента (Т3), не будет зависеть от числа элементов в таблице N. Но если N велико, то поиск потребует значительных затрат времени. Время поиска (Т„) в такой таблице можно оценить как Тп = O(N). Поскольку поиск в таблице идентификаторов является чаще всего выполняемой компилятором операцией, а количество различных идентификаторов даже в реальной исходной программе достаточно велико (от нескольких сотен до нескольких тысяч элементов), то такой способ организации таблиц идентификаторов является неэффективным.
Поиск может быть выполнен более эффективно, если элементы таблицы упорядочены (отсортированы) согласно некоторому естественному порядку.
В нашем случае, когда поиск будет осуществляться по имени идентификатора, наиболее естественно расположить элементы таблицы в прямом или обратном алфавитном порядке. Эффективным методом поиска в упорядоченном списке из N элементов является бинарный или логарифмический поиск. Символ, который следует найти, сравнивается с элементом (N+l)/2 в середине таблицы. Если этот элемент не является искомым, то мы должны просмотреть только блок элементов, пронумерованных от 1 до (N+l)/2-l, или блок элементов от (N+l)/2+l до N в зависимости от того, меньше или больше искомый элемент того, с которым его сравнили. Затем процесс повторяется над нужным блоком в два раза меньшего размера. Так продолжается до тех пор, пока либо элемент не будет найден, либо алгоритм не дойдет до очередного блока, содержащего один или два элемента (с которыми уже можно выполнить прямое сравнение искомого элемента).
Так как на каждом шаге число элементов, которые могут содержать искомый элемент, сокращается наполовину, то максимальное число сравнений равно l+log2(N).
Тогда время поиска элемента в таблице идентификаторов можно оценить как Тп = O(log2 N). Для сравнения: при N=128 бинарный поиск требует самое большее 8 сравнений, а поиск в неупорядоченной таблице — в среднем 64 сравнения. Метод называют «бинарным поиском», поскольку на каждом шаге объем рассматриваемой информации сокращается в два раза, а «логарифмическим» — поскольку время, затрачиваемое на поиск нужного элемента в массиве, имеет логарифмическую зависимость от общего количества элементов в нем.
Недостатком метода является требование упорядочивания таблицы идентификаторов. Так как массив информации, в котором выполняется поиск, должен быть упорядочен, то время его заполнения уже будет зависеть от числа элементов в массиве. Таблица идентификаторов зачастую просматривается еще до того, как она заполнена полностью, поэтому требуется, чтобы условие упорядоченности выполнялось на всех этапах обращения к ней. Следовательно, для построения таблицы можно пользоваться только алгоритмом прямого упорядоченного включения элементов.
При добавлении каждого нового элемента в таблицу сначала надо определить место, куда поместить новый элемент, а потом выполнить перенос части информации в таблице, если элемент добавляется не в ее конец. Если пользоваться стандартными алгоритмами, применяемыми для организации упорядоченных массивов данных [14], а поиск места включения вести с помощью алгоритма бинарного поиска, то среднее время, необходимое на помещение всех элементов в таблицу, можно оценить следующим образом:
Т3 = O(N*log2 N) + k*O(№).
Здесь к — некоторый коэффициент, отражающий соотношение между временами, затрачиваемыми компьютером на выполнение операции сравнения и операции переноса данных.
В итоге при организации логарифмического поиска в таблице идентификаторов мы добиваемся существенного сокращения времени поиска нужного элемента за счет увеличения времени на помещение нового элемента в таблицу. Поскольку добавление новых элементов в таблицу идентификаторов происходит существенно реже1, чем обращение к ним, то этот метод следует признать более эффективным, чем метод организации неупорядоченной таблицы.
Построение таблиц идентификаторов по методу бинарного дерева
Можно сократить время поиска искомого элемента в таблице идентификаторов, не увеличивая значительно время, необходимое на ее заполнение. Для этого надо отказаться от организации таблицы в виде непрерывного массива данных.
![]() Как минимум при добавлении нового
идентификатора в таблицу компилятор должен проверить, существует или нет там такой идентификатор,
так как в большинстве языков программирования ни один идентификатор не может быть описан более
одного раза. Следовательно, каждая операция добавления нового элемента влечет,
как правило, не менее
одной операции поиска. Существует метод построения таблиц, при котором таблица
имеет форму бинарного дерева. Каждый узел дерева представляет собой элемент
таблицы, причем корневой узел является первым элементом, встреченным при
заполнении таблицы. Дерево называется бинарным, так как каждая вершина в нем
может иметь не более двух ветвей (и, следовательно, не более двух нижележащих вершин).
Для определенности
будем называть две ветви «правая» и «левая».
Как минимум при добавлении нового
идентификатора в таблицу компилятор должен проверить, существует или нет там такой идентификатор,
так как в большинстве языков программирования ни один идентификатор не может быть описан более
одного раза. Следовательно, каждая операция добавления нового элемента влечет,
как правило, не менее
одной операции поиска. Существует метод построения таблиц, при котором таблица
имеет форму бинарного дерева. Каждый узел дерева представляет собой элемент
таблицы, причем корневой узел является первым элементом, встреченным при
заполнении таблицы. Дерево называется бинарным, так как каждая вершина в нем
может иметь не более двух ветвей (и, следовательно, не более двух нижележащих вершин).
Для определенности
будем называть две ветви «правая» и «левая».
Рассмотрим алгоритм заполнения бинарного дерева. Будем считать, что алгоритм работает с потоком входных данных, содержащим идентификаторы (в компиляторе этот поток данных порождается в процессе разбора текста исходной программы). Первый идентификатор, как уже было сказано, помещается в вершину дерева. Все дальнейшие идентификаторы попадают в дерево по следующему алгоритму.
Шаг 1. Выбрать очередной идентификатор из входного потока данных. Если очередного идентификатора нет, то построение дерева закончено.
Шаг 2. Сделать текущим узлом дерева корневую вершину. Шаг 3. Сравнить очередной идентификатор с идентификатором, содержащемся в текущем узле дерева.
Шаг 4. Если очередной идентификатор меньше, то перейти к шагу 5, если равен — сообщить об ошибке и прекратить выполнение алгоритма (двух одинаковых идентификаторов быть не должно!), иначе — перейти к шагу 7. Шаг 5. Если у текущего узла существует левая вершина, то сделать ее текущим узлом и вернуться к шагу 3, иначе — перейти к шагу 6.
Шаг 6. Создать новую вершину, поместить в нее очередной идентификатор, сделать эту новую вершину левой вершиной текущего узла и вернуться к шагу 1.
Шаг 7. Если у текущего узла существует правая вершина, то сделать ее текущим узлом и вернуться к шагу 3, иначе — перейти к шагу 8.
Шаг 8. Создать новую вершину, поместить в нее очередной идентификатор, сделать эту новую вершину правой вершиной текущего узла и вернуться к шагу 1.
Рассмотрим в качестве примера последовательность идентификаторов GA, Dl, М22, Е, А12, ВС, F. На рис. 13.2 проиллюстрирован весь процесс построения бинарного дерева для этой последовательности идентификаторов.
Поиск нужного элемента в дереве выполняется по алгоритму, схожему с алгоритмом заполнения дерева.
Шаг 1. Сделать текущим узлом дерева корневую вершину. Шаг 2. Сравнить искомый идентификатор с идентификатором, содержащемся в текущем узле дерева.
Шаг 4. Если идентификаторы совпадают, то искомый идентификатор найден, алгоритм завершается, иначе — надо перейти к шагу 5.
Шаг 5. Если очередной идентификатор меньше, то перейти к шагу 6, иначе — перейти к шагу 7.

Шаг 6. Если у текущего узла существует левая вершина, то сделать ее текущим узлом и вернуться к шагу 2, иначе искомый идентификатор не найден, алгоритм завершается.
Шаг 7. Если у текущего узла существует правая вершина, то сделать ее текущим узлом и вернуться к шагу 2, иначе искомый идентификатор не найден, алгоритм завершается.
Например, произведем поиск в дереве, изображенном на рис. 13.2, идентификатора А12. Берем корневую вершину (она становится текущим узлом), сравниваем идентификаторы GA и А12. Искомый идентификатор меньше — текущим узлом становится левая вершина D1. Опять сравниваем идентификаторы. Искомый идентификатор меньше — текущим узлом становится левая вершина А12. При следующем сравнении искомый идентификатор найден.
Если искать отсутствующий
идентификатор — например, АН, — то поиск опять пойдет от корневой
Если искать отсутствующий идентификатор — например, АН, — то поиск опять пойдет от корневой вершины. Сравниваем идентификаторы GA и АН. Искомый идентификатор меньше — текущим узлом становится левая вершина D1. Опять сравниваем идентификаторы. Искомый идентификатор меньше — текущим узлом становится левая вершина А12. Искомый идентификатор меньше, но левая вершина у узла А12 отсутствует, поэтому в данном случае искомый идентификатор не найден.
Для данного метода число требуемых
сравнений и форма получившегося дерева во многом зависят от того порядка, в котором
поступают идентификаторы. Сравниваем идентификаторы GA и АН. Искомый идентификатор меньше — текущим узлом
становится левая вершина D1. Опять сравниваем
идентификаторы. Искомый идентификатор меньше —
текущим узлом становится левая
вершина А12. Искомый идентификатор меньше, но левая вершина у узла А12
отсутствует, поэтому в данном случае искомый идентификатор не найден.
Для данного метода число требуемых сравнений и форма получившегося дерева во многом зависят от того порядка, в котором поступают идентификаторы. Например, если в рассмотренном выше примере вместо последовательности идеи-тификаторов GA, Dl, M22, E, A12, ВС, F взять последовательность А12, GA, Dl, M22, E, ВС, F, то полученное дерево будет иметь иной вид. А если в качестве примера взять последовательность идентификаторов А, В, С, D, E, F, то дерево выродится в упорядоченный однонаправленный связный список. Эта особенность является недостатком данного метода организации таблиц идентификаторов. Другим недостатком является необходимость работы с динамическим выделением памяти при построении дерева.
Если предположить, что последовательность идентификаторов в исходной программе является статистически неупорядоченной (что в целом соответствует действительности), то можно считать, что построенное бинарное дерево будет невырожденным. Тогда среднее время на заполнение дерева (Т3) и на поиск элемента в нем (Т„) можно оценить следующим образом [6, т. 2]:
Т3 = N*O(log2 N). Tn
- O(log2 N).
В целом метод бинарного дерева является довольно удачным механизмом для организации таблиц идентификаторов. Он нашел свое применение в ряде компиляторов. Иногда компиляторы строят несколько различных деревьев для идентификаторов разных типов и разной длины [23, 74].
Хэш-функции и хэш-адресация
Принципы работы хэш-функций
Логарифмическая зависимость времени поиска и времени заполнения таблицы идентификаторов — это самый хороший результат, которого можно достичь за счет применения различных методов организации таблиц. Однако в реальных исходных программах количество идентификаторов столь велико, что даже логарифмическую зависимость времени поиска от их числа нельзя признать удовлетворительной. Необходимы более эффективные методы поиска информации в таблице идентификаторов.
Лучших результатов можно достичь, если применить методы, связанные с использованием хэш-функций и хэш-адресации.
Хэш-функцией F называется некоторое отображение множества входных элементов R на множество целых неотрицательных чисел Z: F(r) = n, reR, neZ. Сам термин «хэш-функция» происходит от английского термина «hash function» (hash — «мешать», «смешивать», «путать»). Вместо термина «хэширование» иногда используются термины «рандомизация», «переупорядочивание».
Множество допустимых входных элементов R называется областью определения хэш-функции. Множеством значений хэш-функции F называется подмножество М из множества целых неотрицательных чисел Z: McZ, содержащее все возможные значения, возвращаемые функцией F: VreR: F(r)eM. Процесс отображения области определения хэш-функции на множество значений называется «хэшированием».
При работе с таблицей идентификаторов
хэш-функция должна выполнять отображение имен идентификаторов на множество
целых неотрицательных чисел.
Областью определения хэш-функции будет множество всех возможных имен идентификаторов.
Хэш-адресация заключается в использовании значения, возвращаемого хэш-функцией, в качестве адреса ячейки из некоторого массива данных. Тогда размер массива данных должен соответствовать области значений используемой хэш-функции. Следовательно, в реальном компиляторе область значений хэш-функции никак не должна превышать размер доступного адресного пространства компьютера.
Метод организации таблиц идентификаторов, основанный на использовании хэш-адресации, заключается в размещении каждого элемента таблицы в ячейке, адрес которой возвращает хэш-функция, вычисленная для этого элемента. Тогда в идеальном случае для размещения любого элемента в таблице идентификаторов достаточно только вычислить его хэш-функцию и обратиться к нужной ячейке массива данных. Для поиска элемента в таблице необходимо вычислить хэш-функцию для искомого элемента и проверить, не является ли заданная ею ячейка массива пустой (если она не пуста — элемент найден, если пуста — не найден).
|
|
|
Поиск |
|
Идентификаторы |
|
Результат поиска |
На рис. 13.3 проиллюстрирован метод организации таблиц идентификаторов с использованием хэш-адресации. Трем различным идентификаторам Alf A2, А3 соответствуют на рисунке три значения хэш-функции nlf n2, п3. В ячейки, адресуемые щ, п2, п3, помещается информация об идентификаторах А,, А2, А3. При поиске идентификатора А3 вычисляется значение адреса п3 и выбираются данные из соответствующей ячейки таблицы.
Рис. 13.3. Организация таблицы идентификаторов с использованием хэш-адресации
Этот метод весьма эффективен — как
время размещения элемента в таблице, так и время его поиска определяются только
временем, затрачиваемым на вычисление хэш-функции, которое в общем случае
несопоставимо меньше времени, необходимого на многократные сравнения
элементов таблицы.
Метод имеет два очевидных недостатка. Первый из них — неэффективное использование объема памяти под таблицу идентификаторов: размер массива для ее хранения должен соответствовать области значений хэш-функции, в то время как реально хранимых в таблице идентификаторов может быть существенно меньше. Второй недостаток — необходимость соответствующего разумного выбора хэш-функции. Этому существенному вопросу посвящены следующие два подраздела.
Построение таблиц идентификаторов на основе хэш-функций
Существуют различные варианты хэш-функций. Получение результата хэш-функции — «хэширование» — обычно достигается за счет выполнения над цепочкой символов некоторых простых арифметических и логических операций. Самой простой хэш-функцией для символа является код внутреннего представления в ЭВМ литеры символа. Эту хэш-функцию можно использовать и для цепочки символов, выбирая первый символ в цепочке. Так, если двоичное ASCII представление символа А есть 00100001, то результатом хэширования идентификатора АТаЫе будет код 00100001.
|
Идентификаторы |
Хэш-функция, предложенная выше,
очевидно не удовлетворительна: при использовании такой хэш-функции возникнет новая
проблема — двум различным идентификаторам, начинающимся с одной и той же буквы,
будет соответствовать одно и то же значение хэш-функции. Тогда при хэш-адресации в одну
ячейку
таблицы идентификаторов по одному и тому же адресу должны быть помещены два различных
идентификатора, что явно невозможно. Такая ситуация, когда двум или более
идентификаторам соответствует одно и то же значение функции, называется коллизией.
Возникновение коллизии проиллюстрировано на рис. 13.4 — двум различным
идентификаторам At и А2
соответствуют два совпадающих значения хэш-функции, п, = п2.
Рис. 13.4. Возникновение коллизии при использовании хэш-адресации
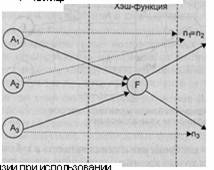
Естественно, что хэш-функция, допускающая коллизии, не может быть напрямую использована для хэш-адресации в таблице идентификаторов. Причем достаточно получить хотя бы один случай коллизии на всем множестве идентификаторов, чтобы такой хэш-функцией нельзя было пользоваться непосредственно. Но в примере взята самая элементарная хэш-функция. А возможно ли построить нетривиальную хэш-функцию, которая бы полностью исключала возникновение коллизий?
Очевидно, что для полного исключения коллизий хэш-функция должна быть взаимно однозначной: каждому элементу из области определения хэш-функции должно соответствовать одно значение из ее множества значений, но и каждому значению из множества значений этой функции должен соответствовать только один элемент из области ее определения. Тогда любым двум произвольным элементам из области определения хэш-функции будут всегда соответствовать два различных ее значения. Теоретически для идентификаторов такую хэш-функцию построить можно, так как и область определения хэш-функции (все возможные имена идентификаторов), и область ее значений (целые неотрицательные числа) являются бесконечными счетными множествами. Теоретически можно организовать взаимно однозначное отображение одного счетного множества на другое, но практически это сделать исключительно сложно1.
Практически существует ограничение, делающее
создание взаимно однозначной хэш-функции для идентификаторов невозможным. Дело в том,
что в реальности область значений любой хэш-функции ограничена размером
доступного адресного пространства в данной архитектуре компьютера. При
организации хэш-адресации значение, используемое в качестве адреса таблицы
идентификаторов, не может выходить за пределы, заданные адресной сеткой
компьютера2. Множество адресов любого компьютера с традиционной
архитектурой может быть велико, но всегда конечно, то есть ограничено.
Организовать взаимно однозначное отображение бесконечного множества на
конечное даже теоретически невозможно. Можно учесть, что длина принимаемой во внимание строки
идентификатора в реальных компиляторах также
практически ограничена — обычно она лежит в пределах от 32 до 128 символов (то есть и область определения
хэш-функции конечна). Но и тогда количество элементов в конечном множестве,
составляющем область определения
функции, будет превышать их количество в конечном множестве области значений функции (количество
всех возможных идентификаторов все
равно больше количества допустимых адресов в современных компьютерах). Таким
образом, создать взаимно однозначную хэш-функцию практи-![]() чески ни в каком
варианте невозможно. Следовательно, невозможно избежать возникновения
коллизий.
чески ни в каком
варианте невозможно. Следовательно, невозможно избежать возникновения
коллизий.
Пока для двух различных элементов результаты хэширования различны, время поиска совпадает со временем, затраченным на хэширование. Однако возникает затруднение, когда результаты хэширования двух разных элементов совпадают.
Для решения проблемы коллизии можно использовать много способов. Одним из них является метод «рехэширования» (или «расстановки»). Согласно этому методу, если для элемента А адрес h(A), вычисленный с помощью хэш-функции, указывает на уже занятую ячейку, то необходимо вычислить значение функции ni=ht(A) и проверить занятость ячейки по адресу щ. Если и она занята, то вычисляется значение Ь2(А), и так до тех пор, пока либо не будет найдена свободная ячейка, либо очередное значение h;(A) совпадет с h(A). В последнем случае считается, что таблица идентификаторов заполнена и места в ней больше нет — выдается информация об ошибке размещения идентификатора в таблице. Особенностью метода является то, что первоначально таблица идентификаторов должна быть заполнена информацией, которая позволила бы говорить о том, что все ее ячейки являются пустыми (не содержат данных). Например, если используются указатели для хранения имен идентификаторов, то таблицу надо предварительно заполнить пустыми указателями.
Такую таблицу идентификаторов можно организовать по следующему алгоритму размещения элемента.
Шаг 1. Вычислить значение хэш-функции n = h(A) для нового элемента А.
Шаг 2. Если ячейка по адресу п пустая, то поместить в нее элемент А и завершить алгоритм, иначе i:=l и перейти к шагу 3.
Шаг 3. Вычислить n; = hj(A). Если ячейка по адресу П| пустая, то поместить в нее элемент А и завершить алгоритм, иначе перейти к шагу 4.
Шаг 4. Если п = щ, то сообщить об ошибке и завершить алгоритм, иначе i:-i+l и вернуться к шагу 3.
Тогда поиск элемента А в таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму.
Шаг 1. Вычислить значение хэш-функции n = h(A) для нового элемента А.
Шаг 2. Если ячейка по адресу п пустая, то элемент не найден, алгоритм завершен, иначе сравнить имя элемента в ячейке п с именем искомого элемента А. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:= 1 и перейти к шагу 3.
Шаг 3. Вычислить П] = h;(A). Если ячейка по адресу п, пустая или п = щ, то элемент не найден и алгоритм завершен, иначе сравнить имя элемента в ячейке П; с именем искомого элемента А. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:=i+l и повторить к шаг 3.
Алгоритмы размещения и поиска элемента схожи по выполняемым операциям. Поэтому они будут совпадать и по оценкам времени, необходимого для их выполнения. При такой организации таблиц идентификаторов в случае возникновения коллизии алгоритм размещает элементы в пустых ячейках таблицы, выбирая их определенным образом. При этом элементы могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хэш-функции, что приведет к возникновению новых, дополнительных коллизий. Таким образом, количество операций, необходимых для поиска или размещения в таблице элемента, зависит от заполненности таблицы. Естественно, функции hj(A ) должны вычисляться единообразно на этапах размещения и поиска элемента. Вопрос только в том, как организовать вычисление функций h;(A).
Самым простым методом вычисления функции hj(A) является ее организация в виде hi(A) = (h(A) + pj) mod Nm, где pj — некоторое вычисляемое целое число, a Nm — максимальное число элементов в таблице идентификаторов. В свою очередь, самым простым подходом здесь будет положить pj = i. Тогда получаем формулу h;(A) = (h(A)+i) mod Nm. В этом случае при совпадении значений хэш-функции для каких-либо элементов поиск свободной ячейки в таблице начинается последовательно от текущей позиции, заданной хэш-функцией h(A).
Этот способ нельзя признать особенно удачным — при совпадении хэш-адресов элементы в таблице начинают группироваться вокруг них, что увеличивает число необходимых сравнений при поиске и размещении. Среднее время поиска элемента в такой таблице в зависимости от числа операций сравнения можно оценить следующим образом [23]:
Тп-O((l-Lf/2)/(l-LQ).
Здесь Lf — (load factor) степень заполненности таблицы идентификаторов — отношение числа занятых ячеек таблицы к максимально допустимому числу элементов в ней: Lf = N/Nm.
Рассмотрим в качестве примера ряд последовательных ячеек таблицы п(, п2, п3, п4, п5 и ряд идентификаторов, которые надо разместить в ней: А(, А2, А3, А4, А5 при условии, что h(Aj) = h(A2) = h(A5) = n^ h(A3) = n2; h(A4) = n4. Последовательность размещения идентификаторов в таблице при использовании простейшего метода рехэширования показана на рис. 13.5. В итоге после размещения в таблице для поиска идентификатора А) потребуется 1 сравнение, для А2 — 2 сравнения, для А3 — 2 сравнения, для А4 — 1 сравнение и для А5 — 5 сравнений.
Даже такой примитивный метод рехэширования является достаточно эффективным средством организации таблиц идентификаторов при неполном заполнении таблицы. Имея, например, даже заполненную на 90 % таблицу для 1024 идентификаторов, в среднем необходимо выполнить 5,5 сравнений для поиска одного идентификатора, в то время как даже логарифмический поиск дает в среднем от 9 до 10 сравнений. Сравнительная эффективность метода будет еще выше при росте числа идентификаторов и снижении заполненности таблицы.
Среднее время на помещение одного элемента в таблицу и на поиск элемента в таблице можно снизить, если применить более совершенный метод рехэширования. Одним из таких методов является использование в качестве р, для функции h,(A) - (h(A)+pi)modNm последовательности псевдослучайных целых чисел ри р2, ..., Рк- При хорошем выборе генератора псевдослучайных чисел длина по-
следовательности к будет k=Nm. Тогда среднее время поиска одного элемента в таблице можно оценить следующим образом [23]:
|
|
|
|
m |
Ai |
|
П2 |
A2 |
|
ПЗ |
Аз |
|
|
|
|
h(Ai> |
|
h(A2)------ ►г |
|
►П1 |
|
hi(A2) |
|
h(A3> |
|
П2 |
|
hi(A3) |
En
= O((l/Lf)*log2(l-Lf)).
|
|
|
|
Ai |
|
|
A? |
|
|
|
|
|
|
|
П1 |
Ai |
|
П2 |
A2 |
|
ПЗ |
A3 |
|
h(A4)------ ► щ |
A4 |
|
4 |
|
h(A5)------ ► ni
|
h2(As) |
|
h3(A5) |
|
П4(А5) |
|
A5 |
П2 ПЗ П4 П5
5
Рис. 13.5. Заполнение таблицы идентификаторов при использовании простейшего рехэширования
Существуют и другие методы организации функций рехэширования и,(А), основанные на квадратичных вычислениях или, например, на вычислении по формуле: hj(A) = (h(A)*i) mod Nm, если Nm — простое число [23]. В целом рехэширование позволяет добиться неплохих результатов для эффективного поиска элемента в таблице (лучших, чем бинарный поиск и бинарное дерево), но эффективность метода сильно зависит от заполненности таблицы идентификаторов и качества используемой хэш-функции — чем реже возникают коллизии, тем выше эффективность метода. Требование неполного заполнения таблицы ведет к неэффективному использованию объема доступной памяти.
Построение таблиц идентификаторов по методу цепочек
Неполное заполнение таблицы идентификаторов при применении хэш-функций ведет к неэффективному использованию всего объема памяти, доступного компилятору. Причем объем неиспользуемой памяти будет тем выше, чем больше информации хранится для каждого идентификатора. Этого недостатка можно избежать, если дополнить таблицу идентификаторов некоторой промежуточной хэщ-таблицей.
В ячейках хэш-таблицы может храниться либо пустое значение, либо значение указателя на некоторую область памяти из основной таблицы идентификаторов. Тогда хэш-функция вычисляет адрес, по которому происходит обращение сначала к хэш-таблице, а потом уже через нее по найденному адресу — к самой таблице идентификаторов. Если соответствующая ячейка таблицы идентификаторов пуста, то ячейка хэш-таблицы будет содержать пустое значение. Тогда вовсе не обязательно иметь в самой таблице идентификаторов ячейку для каждого возможного значения хэш-функции — таблицу можно сделать динамической так, чтобы ее объем рос по мере заполнения (первоначально таблица идентификаторов не содержит ни одной ячейки, а все ячейки хэш-таблицы имеют пустое значение).
Такой подход позволяет добиться двух положительных результатов: во-первых, нет необходимости заполнять пустыми значениями таблицу идентификаторов — это можно сделать только для хэш-таблицы; во-вторых, каждому идентификатору будет соответствовать строго одна ячейка в таблице идентификаторов (в ней не будет пустых неиспользуемых ячеек). Пустые ячейки в таком случае будут только в хэш-таблице, и объем неиспользуемой памяти не будет зависеть от объема информации, хранимой для каждого идентификатора — для каждого значения хэш-функции будет расходоваться только память, необходимая для хранения одного указателя на основную таблицу идентификаторов.
На основе этой схемы можно реализовать еще один способ организации таблиц идентификаторов с помощью хэш-функций, называемый «метод цепочек». Для метода цепочек в таблицу идентификаторов для каждого элемента добавляется еще одно поле, в котором может содержаться ссылка на любой элемент таблицы. Первоначально это поле всегда пустое (никуда не указывает). Также для этого метода необходимо иметь одну специальную переменную, которая всегда указывает на первую свободную ячейку основной таблицы идентификаторов (первоначально — указывает на начало таблицы).
Метод цепочек работает следующим образом по следующему алгоритму.
, Шаг 1. Во все ячейки хэш-таблицы поместить пустое значение, таблица идентификаторов не должна содержать ни одной ячейки, переменная FreePtr (указатель первой свободной ячейки) указывает на начало таблицы идентификаторов; i:=l.
Шаг 2. Вычислить значение хэш-функции щ для нового элемента Aj. Если ячейка хэш-таблицы по адресу П( пустая, то поместить в нее значение переменной FreePtr и перейти к шагу 5; иначе — перейти к шагу 3.
Шаг 3. Положить j:=l, выбрать из хэш-таблицы адрес ячейки таблицы идентификаторов nij и перейти к шагу 4.
Шаг 4. Для ячейки таблицы идентификаторов по адресу nij проверить значение поля ссылки. Если оно пустое, то записать в него адрес из переменной FreePtr и перейти к шагу 5; иначе j:=j+l, выбрать из поля ссылки адрес m.j и повторить шаг 4. Шаг 5. Добавить в таблицу идентификаторов новую ячейку, записать в нее информацию для элемента А, (поле ссылки должно быть пустым), в переменную FreePtr поместить адрес за концом добавленной ячейки. Если больше нет идентификаторов, которые надо разместить в таблице, то выполнение алгоритма закончено, иначе i:=i+l и перейти к шагу 2.
Поиск элемента в таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму.
Шаг 1. Вычислить значение хэш-функции п для искомого элемента А. Если ячейка хэш-таблицы по адресу п пустая, то элемент не найден и алгоритм завершен, иначе положить j:=l, выбрать из хэш-таблицы адрес ячейки таблицы идентификаторов nij=n.
дет не столь велико. Тогда и время поиска одного среди них будет незначительным (в принципе при высоком качестве хеш-функции подойдет даже перебор по неупорядоченному списку).
Такой подход имеет преимущество по сравнению с методом цепочек: для хранения идентификаторов с совпадающими значениями хэш-функции используются области памяти, не пересекающиеся с основной таблицей идентификаторов, а значит, их размещение не приведет к возникновению дополнительных коллизий. Недостатком метода является необходимость работы с динамически распределяемыми областями памяти. Эффективность такого метода, очевидно, в первую очередь зависит от качества применяемой хэш-функции, а во вторую — от метода организации дополнительных хранилищ данных. Хэш-адресация — это метод, который применяется не только для организации таблиц идентификаторов в компиляторах. Данный метод нашел свое применение и в операционных системах (см. часть 1 данного пособия), и в системах управления базами данных. Интересующиеся читатели могут обратиться к соответствующей литературе [23, 74].
6. Лексические анализаторы. Лексические
анализаторы (сканеры). Принципы построения сканеров. Регулярные языки и
грамматики. Построение лексических анализаторов. Оптимизации
Лексические анализаторы (сканеры). Принципы построения сканеров
Назначение лексического анализатора
Прежде чем перейти к рассмотрению лексических анализаторов, необходимо дать четкое определение того, что же такое лексема.
Лексема (лексическая единица языка) — это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка.
Лексемами языков естественного общения являются слова1. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т. п. Состав возможных лексем каждого конкретного языка программирования определяется синтаксисом этого языка. Лексический анализатор (или сканер) — это часть компилятора, которая читает исходную программу и выделяет в ее тексте лексемы входного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
С теоретической точки зрения лексический анализатор не является обязательной частью компилятора. Все его функции могут выполняться на этапе синтаксического разбора, поскольку полностью регламентированы синтаксисом
![]() В языках естественного общения лексикой
называется словарный запас языка. Лексический состав языка изучается лексикологией и фразеологией,
а значение лексем (слов языка)
— семасиологией. В языках программирования словарный запас, конечно, не столь
интересен и специальной наукой не изучается. входного языка. Однако существует
несколько причин, по которым в состав практически всех компиляторов включают
лексический анализ:
В языках естественного общения лексикой
называется словарный запас языка. Лексический состав языка изучается лексикологией и фразеологией,
а значение лексем (слов языка)
— семасиологией. В языках программирования словарный запас, конечно, не столь
интересен и специальной наукой не изучается. входного языка. Однако существует
несколько причин, по которым в состав практически всех компиляторов включают
лексический анализ:
□
применение лексического анализатора упрощает работу с
текстом исходной
программы на этапе синтаксического разбора и сокращает объем обрабаты
ваемой
информации, так как лексический анализатор структурирует посту-
пающий
на вход исходный текст программы и выкидывает всю незначащую
информацию;
□
для выделения в тексте и разбора лексем возможно
применять простую, эф
фективную
и теоретически хорошо проработанную технику анализа, в то вре
мя как
на этапе синтаксического анализа конструкций исходного языка ис
пользуются
достаточно сложные алгоритмы разбора;
□
сканер отделяет сложный по конструкции синтаксический
анализатор от ра
боты
непосредственно с текстом исходной программы, структура которого
может варьироваться в зависимости от версии входного языка — при такой
конструкции
компилятора для перехода от одной версии языка к другой дос
таточно
только перестроить относительно простой лексический анализатор.
Функции, выполняемые лексическим анализатором, и состав лексем, которые он выделяет в тексте исходной программы, могут меняться в зависимости от версии компилятора. То, какие функции должен выполнять лексический анализатор и какие типы лексем он должен выделять во входной программе, а какие оставлять для этапа синтаксического разбора, решают разработчики компилятора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев, незначащих пробелов, символов табуляции и перевода строки, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, ключевых (служебных) слов входного языка, знаков операций и разделителей.
В простейшем случае фазы лексического и синтаксического анализа могут выполняться компилятором последовательно. Но для многих языков программирования на этапе лексического анализа может быть недостаточно информации для однозначного определения типа и границ очередной лексемы. Иллюстрацией такого случая может служить пример оператора программы на языке FORTRAN, когда по части текста DO 10 1=1 невозможно определить тип оператора (а соответственно, и границы лексем). В случае DO 10 1=1.15 это присвоение вещественной переменной D010I значения константы 1.15 (пробелы в языке FORNTAN игнорируются), а в случае DO 10 1=1,15 — цикл с перечислением от 1 до 15 по целочисленной переменной I до метки 10.
Другим примером может служить оператор языка С, имеющий вид: k=i+++++j;. Существует только одна единственно верная трактовка этого оператора: k = i++ + ++j; (если явно пояснить ее с помощью скобок, то данная конструкция имеет вид: k = (i++) + (++j);). Однако найти ее лексический анализатор может, лишь просмотрев весь оператор до конца и перебрав все варианты, причем неверные варианты могут быть обнаружены только на этапе семантического анализа (например, вариант k = (i++)++ + j; является синтаксически правильным, но семантикой языка С не допускается). Конечно, чтобы эта конструкция была в принципе до-
![]() пустима, входящие в
нее операнды к, i и j должны
быть описаны и должны допускать выполнение операций языка ++ и +.
пустима, входящие в
нее операнды к, i и j должны
быть описаны и должны допускать выполнение операций языка ++ и +.
Поэтому в большинстве компиляторов лексический и синтаксический анализаторы — это взаимосвязанные части. Возможны два принципиально различных метода организации взаимосвязи лексического анализа и синтаксического разбора:
□
последовательный;
□
параллельный1.
При последовательном варианте лексический анализатор просматривает весь текст исходной программы от начала до конца и преобразует его в структурированный набор данных. Этот набор данных называют также таблицей лексем. В таблице лексем ключевые слова языка, идентификаторы и константы, как правило, заменяются на специально оговоренные коды, им соответствующие (конкретная кодировка определяется при реализации компилятора). Для идентификаторов и констант, кроме того, устанавливается связь между таблицей лексем и таблицей идентификаторов, которая заполняется параллельно.
В этом варианте лексический анализатор просматривает весь текст исходной программы один раз от начала до конца. Таблица лексем строится полностью вся сразу, и больше к ней компилятор не возвращается. Всю дальнейшую обработку выполняют следующие фазы компиляции.
При параллельном варианте лексический анализ исходного текста выполняется поэтапно так, что синтаксический анализатор, выполнив разбор очередной конструкции языка, обращается к сканеру за следующей лексемой. При этом он может сообщить информацию о том, какую лексему следует ожидать. В процессе разбора при возникновении ошибки может происходить «откат назад», чтобы попытаться выполнить анализ текста на другой основе. И только после того, как синтаксический анализатор успешно выполнит разбор очередной конструкции языка^(обычно такой конструкцией является оператор исходного языка), лексический анализатор помещает найденные лексемы в таблицу лексем и таблицу идентификаторов и продолжает разбор дальше в том же порядке.
Работа синтаксического и лексического анализаторов в варианте их
параллельного взаимодействия изображена в виде схемы на рис. 13.7. В качестве варианта
таблицы лексем можно рассмотреть некоторый фрагмент кода на языке Pascal и соответствующую ему таблицу лексем, представленную в табл. 13.1:
пустима, входящие в нее операнды к, i и j должны быть описаны и должны допускать выполнение операций языка ++ и +.
Поэтому в большинстве компиляторов лексический и синтаксический анализаторы — это взаимосвязанные части. Возможны два принципиально различных метода организации взаимосвязи лексического анализа и синтаксического разбора:
□
последовательный;
□
параллельный1.
При последовательном варианте лексический анализатор просматривает весь текст исходной программы от начала до конца и преобразует его в структурированный набор данных. Этот набор данных называют также таблицей лексем. В таблице лексем ключевые слова языка, идентификаторы и константы, как правило, заменяются на специально оговоренные коды, им соответствующие (конкретная кодировка определяется при реализации компилятора). Для идентификаторов и констант, кроме того, устанавливается связь между таблицей лексем и таблицей идентификаторов, которая заполняется параллельно.
В этом варианте лексический анализатор просматривает весь текст исходной программы один раз от начала до конца. Таблица лексем строится полностью вся сразу, и больше к ней компилятор не возвращается. Всю дальнейшую обработку выполняют следующие фазы компиляции.
При параллельном варианте лексический анализ исходного текста выполняется поэтапно так, что синтаксический анализатор, выполнив разбор очередной конструкции языка, обращается к сканеру за следующей лексемой. При этом он может сообщить информацию о том, какую лексему следует ожидать. В процессе разбора при возникновении ошибки может происходить «откат назад», чтобы попытаться выполнить анализ текста на другой основе. И только после того, как синтаксический анализатор успешно выполнит разбор очередной конструкции языка^(обычно такой конструкцией является оператор исходного языка), лексический анализатор помещает найденные лексемы в таблицу лексем и таблицу идентификаторов и продолжает разбор дальше в том же порядке.
Работа синтаксического и лексического анализаторов в варианте их
параллельного взаимодействия изображена в виде схемы на рис. 13.7. В качестве варианта
таблицы лексем можно рассмотреть некоторый фрагмент кода на языке Pascal и соответствующую ему таблицу лексем, представленную в табл. 13.1:
begin
for i:=1 to N do fg := fg * 0.5
|
f Лексический"^ Идентификаторы -J анализатор _______________ ( ^ (сканер) J |
|
Исходная программа |
Таблица
идентификаторов (таблица имен)
|
Очередная лексема |
Обращение за лексемой
![]() [ Синтаксический j I разбор (анализ) I
[ Синтаксический j I разбор (анализ) I
![]() Рис. 13.7. Параллельное взаимодействие лексического и синтаксического анализаторов
Рис. 13.7. Параллельное взаимодействие лексического и синтаксического анализаторов
|
Таблица 13.1. |
Лексемы программы |
|
|
|
Лексема |
|
Тип лексемы |
Значение |
|
begin |
|
Ключевое слово |
XI |
|
for |
|
Ключевое слово |
Х2 |
|
i |
|
Идентификатор |
i: 1 |
|
:= |
|
Знак присваивания |
:= |
|
1 |
|
Целочисленная константа |
1 |
|
to |
|
Ключевое слово |
ХЗ |
|
N |
|
Идентификатор |
N:2 |
|
do |
|
Ключевое слово |
Х4 |
|
fg |
|
Идентификатор |
fg:3 |
|
:= |
|
Знак присваивания |
:= |
|
fg |
|
Идентификатор |
fg:3 |
|
* |
|
Знак арифметической операции |
* |
|
0.5 |
|
Вещественная константа |
0.5 |
Поле «Значение» в табл. 13.1
подразумевает некое кодовое значение, которое б дет помещено в итоговую таблицу лексем
в результате работы лексического ан лизатора. Конечно, значения, которые записаны в примере, являются
уело ными. Конкретные коды определяются при
реализации компилятора. Важ1 отметить
также, что для идентификаторов устанавливается связка таблицы ле сем с таблицей идентификаторов (в примере это
отражено некоторым индексо следующим
после идентификатора за знаком :, а в реальном компиляторе в опять же
определяется его реализацией).
варианта данному лексическому анализатору на входе требуется задавать также и тип ожидаемой лексемы. Поэтому при непрямой работе лексического анализатора требуется его параллельное взаимодействие с синтаксическим распознавателем.
Выполнение действий, связанных с лексемами
Выполнение действий в процессе распознавания лексем представляет для сканера гораздо меньшую проблему. Фактически КА, который лежит в основе распознавателя лексем, должен иметь не только входной язык, но и выходной. Он должен не только уметь распознать правильную лексему на входе, но и породить связанную с ней последовательность символов на выходе. В такой конфигурации КА преобразуется в конечный преобразователь [5, 6, т. 1, 42].
Для сканера действия по обнаружению лексемы могут трактоваться несколько шире, чем только порождение цепочки символов выходного языка. Сканер должен уметь выполнять такие действия, как запись найденной лексемы в таблицу лексем, поиск ее в таблице символов и запись новой лексемы в таблицу символов. Набор действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же по обнаружению конца распознаваемой лексемы.
В КА сканера эти действия можно отобразить сравнительно просто — достаточно иметь возможность с каждым переходом на графе автомата (или в функции переходов автомата) связать выполнение некоторой произвольной функции f(q,a), где q — текущее состояние автомата, а — текущий входной символ. Функция может выполнять произвольные действия, доступные сканеру, в том числе работать с хранилищами данных, имеющимися в компиляторе (функция может быть и пустой — не выполнять никаких действий). Такую функцию, если она есть, обычно записывают на графе переходов КА под дугами, соединяющими состояния КА.
Построение лексических анализаторов
Теперь можно рассмотреть практическую реализацию сканеров. В принципе компилятор может иметь в своем составе не один, а несколько лексических анализаторов, каждый из которых предназначен для выборки и проверки определенного типа лексем.
Таким образом, обобщенный алгоритм работы простейшего лексического анализатора в компиляторе можно описать следующим образом:
□
из входного потока выбирается очередной символ, в
зависимости от которого
запускается
тот или иной сканер (символ может быть также проигнорирован
либо
признан ошибочным);
□
запущенный сканер просматривает входной поток символов
программы на
исходном
языке, выделяя символы, входящие в требуемую лексему, до обна
ружения
очередного символа, который может ограничивать лексему, либо до
обнаружения ошибочного символа;
□
при успешном распознавании информация о выделенной
лексеме заносится в
таблицу лексем и таблицу идентификаторов, алгоритм возвращается к перво-
му этапу и продолжает рассматривать входной поток символов с того местг на котором остановился сканер;
□ при неуспешном распознавании выдается сообщение об ошибке, а дальней шие действия зависят от реализации сканера — либо его выполнение прекра щается, либо делается попытка распознать следующую лексему (идет возвра к первому этапу алгоритма).
Рассмотрим пример анализа лексем,
представляющих собой целочисленны константы в формате языка С. В соответствии с требованиями языка,
таки константы могут быть десятичными,
восьмеричными или шестнадцатеричны ми.
Восьмеричной константой считается число, начинающееся с 0 и содержаще цифры от 0 до 7; шестнадцатеричная константа
должна начинаться с последовг тельности
символов Ох и может содержать цифры и буквы от а до f.
Остальны числа
считаются десятичными (правила их записи напоминать, наверное, не стс ит). Константа может
начинаться также с одного из знаков + или -, а в конц цифры, обозначающей
значение константы, в языке С может следовать буква ил две буквы, явно
обозначающие ее тип (u, U —
unsigned; h, H —
short;
При построении сканера будем учитывать, что константы входят в общий текс программы на языке С. Для избежания путаницы и сокращения объема инфор мации в примере будем считать, что все допустимые буквы являются строчным (читатели легко могут самостоятельно расширить пример для прописных бую которые язык С в константах не отличает от строчных).
Рассмотренные выше правила могут быть записаны в форме Бэкуса—Наура в грал матике целочисленных констант для языка С.
S)
|
G({S. |
w, u. |
L. \i |
. D. |
G. X, |
Q. 2 |
. N}. |
{0.. |
9. x. |
a. |
.f. u. 1. h. 1}. P |
|
P: |
|
|
|
|
|
|
|
|
|
|
|
S -> |
Gl |
zi |
1 D1 |
Ql |
Ul |
1 LI |
1 VI |
Wl |
|
|
|
W -> |
Lu |
Vu |
Ul | |
Uh |
|
|
|
|
|
|
|
и -> |
Gu | |
Zu |
Hu |
Qu |
|
|
|
|
|
|
|
L -> |
Gl |
zi |
HI | |
Ql |
|
|
|
|
|
|
|
V -> |
Gh |
Zh |
Hh | |
Qh |
|
|
|
|
|
|
|
D -> |
1 1 |
CNJ |
1 | 4 |
5 1 |
6 1 |
7 | 8 |
1 9 |
1 |
|
|
|
|
N1 |
N2 |
N3 | |
N4 | |
N5 |
N6 | |
N7 | |
N8 | |
N9 |
|
|
|
DO |
Dl |
D2 |
D3 | |
D4 |
D5 | |
D6 | |
D7 | |
D8 |
D9 | |
|
|
Z8 |
Z9 |
Q8 | |
Q9 |
|
|
|
|
|
|
|
G -» |
xo |
XI |
X2 |
X3 | |
X4 |
X5 | |
X6 | |
X7 | |
X8 |
X9 | |
|
|
Xa |
Xb |
Xc |
Xd | |
Xe |
Xf | |
|
|
|
|
|
|
GO |
Gl |
G2 | |
G3 | |
G4 |
G5 | |
G6 | |
G7 | |
G8 |
G9 | |
|
|
Ga |
Gb |
Gc |
Gd | |
Ge |
Gf |
|
|
|
|
|
X -> |
Zx |
|
|
|
|
|
|
|
|
|
|
Q -> |
ZO |
ZI |
Z2 |
Z3 | |
Z4 |
Z5 | |
Z6 | |
Z7 | |
|
|
|
i |
QO |
Ql |
Q2 |
Q3 | |
Q4 |
Q5 | |
Q6 | |
Q7 |
|
|
|
Z -> |
0 1 |
NO |
|
|
|
|
|
|
|
|
N -> + | -
Эта грамматика является леволинейной автоматной регулярной грамматико По ней можно построить КА, который будет распознавать цепочки входнс языка (см. раздел «Конечные автоматы», глава 10). Граф переходов этого автомата приведен на рис. 13.8. Видно, что построенный автомат является детерминированным КА, поэтому в дальнейших преобразованиях он не нуждается. Начальным состоянием автомата является состояние Н.

Рис. 13.8. Граф конечного автомата для распознавания целочисленных констант языка С
Приведем автомат к полностью определенному виду — дополним его новым состоянием Е, на которое замкнем все дуги неопределенных переходов. На графе автомата дуги, идущие в это состояние, не нагружены символами — они обозначают функцию перехода по любому символу, кроме тех символов, которыми уже помечены другие дуги, выходящие из той же вершины графа (такое соглашение принято, чтобы не загромождать обозначениями граф автомата). На рис. 13.8 это состояние и связанные с ним дуги переходов изображены пунктирными линиями.
При построении КА знаком «J.» были обозначены любые символы, которыми может завершаться целочисленная константа языка С. Однако в реальной программе этот символ не встречается. При моделировании КА следует принять во внимание, какими реальными символами входного языка может завершаться целочисленная константа языка С.
В языке С в качестве границы константы могут выступать:
□
знаки
пробелов, табуляции, перевода строки;
□
разделители
(, ), [, ], {, },,,:,;;
Q знаки операций +, -, *, /, &, |, ?, ~, <, >, Л, =, %.
Теперь можно написать программу, моделирующую работу указанного автомата. Ниже приводится текст функции на языке Pascal, реализующей данный распо-
знаватель. Результатом функции является текущее положение считывающей тс ловки анализатора в потоке входной информации после завершения разбор лексемы при успешном распознавании либо 0 при неуспешном распознавани (если лексема содержит ошибку).
В программе переменная iState отображает текущее состояние автомата, nepi менная i является счетчиком символов входной строки. В текст программы вш саны комментарии в те места функции, где возможно выполнить запись найде! ной лексемы в таблицу лексем и таблицу символов, а также выдать сообщеш об обнаруженной ошибке.
function RunAuto
(const slnput: string: iPos: integer): integer; type
TAutoState = (AUTOJ,
AUTOJ. AUTOJ, AUTOJ. AUTOJ, AUTOJ. AUTOJ. AUTOJ, AUTO_
AUTOJ, AUTOJ. AUTOJ, AUTOJ); const
AutoStop = [' '.
#10. #13. #7, '('. ')', '['. ']'. '{'• '}'■ '•'• ':'• ':'■ ' +
'■. '-
■*'. 7'. '&', 'I1. '?'■ '-'• '<'. '=■'■ '*'■ '"'■ '*']: var
iState : TAutoState; i.iL : integer;
sOut : string; begi n
i := iPos:
iL := Length(slnput):
sOut := ";
iState := AUTOJ:
repeat
case iState of AUTOJ;
case slnput[i] of
■ + ','-': iState := AUTOJ: '0': iState := AUTOJ: Т..'91:
iState := AUTOJ; else iState := AUTOJ; ' ■ end: AUTO J:
case slnput[i]
of , '01: iState := AUTOJ: 'I1..'9': iState :=
AUTOJ; else iState := AUTOJ; end; AUTOJ:
case slnput[i] of
'x1: iState := AUTOJ: ■0'..7':
iState := AUTO Q;
.'9': iState := AUTO D:
Else
|
|
if slnput[i] in AutoStop then |
|
|
|
iState := AUT0_ |
S |
|
|
else iState := |
AUTOJ: |
|
end |
|
|
|
AUTOJ: |
|
|
|
case slnput[i] of |
|
|
|
|
'О'./Э1, |
|
|
|
'a'., 'f: iState |
:= AUTOJ; |
|
|
else iState |
:= AUTOJ: |
|
end |
|
|
|
AUTOJ: |
|
|
|
case slnput[i] of |
|
|
|
|
'0'..7': iState |
:- AUTOJ; |
|
|
'8'.'9': iState |
:= AUTOJ: |
|
|
V: iState |
:= AUTOJ: |
|
1 |
'I1: iState |
:- AUTOJ; |
|
|
'h': iState |
:= AUTOJ; |
|
|
else |
|
|
|
if slnput[i] in AutoStop then |
|
|
|
iState :- AUTO. |
_S |
|
|
else iState := |
AUTOJ: |
|
end |
|
|
|
AUTOJ: |
|
|
|
case slnput[i] of |
|
|
|
|
■ 0'..'9': iState |
:= AUTOJ:. |
|
|
V: iState |
:= AUTOJ; |
|
|
'V: iState |
:= AUTOJ; |
|
|
'h': iState |
:- AUTOJ: |
|
|
else |
|
|
|
if slnput[i] in AutoStop then |
|
|
|
iState :- AUTO. |
_S |
|
|
else iState :- |
AUTOJ; |
|
end |
|
|
|
AUTOJ: |
|
|
|
case slnput[i] of |
|
|
|
|
'a'..'f': iState |
:= AUTOJ; |
|
|
V: iState |
:= AUTOJ; |
|
|
'1'; iState |
:= AUTOJ; |
|
|
'h': iState |
:= AUTOJ; |
|
|
else |
|
|
|
if slnput[i] in AutoStop then |
|
|
|
iState :- AUTO. |
J |
|
|
else iState :- |
AUTOJ; |
|
end |
|
|
|
AUTOJ |
|
|
|
case slnputfi] of |
|
|
'V ,'h1: iState := AUTOJ;
, else ' ■■
if slnput[i] in
AutoStop then iState := AUTOJ else iState := AUTOJ: end; AUTOJ:
case slnput[i] of
'u': iState := AUTOJ; else
if slnput[i] in
AutoStop then iState :- AUTOJ else iState := AUTOJ: end: AUTOJ:
case slnput[i] of
'u': iState := AUTOJ; else
if sInput[i] in AutoStop then iState :=
AUTOJ else iState := AUTOJ:
end; ■
AUTOJ:
if slnput[i] in
AutoStop then iState := AUTOJ else iState ;- AUTOJ; end {case};
if not (iState in [AUTOJ.AUTOJ]) then begin
sOut := sOut + slnput[i];
i :- i + 1: end; until ((iState = AUTOJ)
or (iState = AUTOJ)
or (i > iU):
if (iState - AUTOJ)
or (i > iL) then begin { Сюда надо вставить вызов функций записи лексемы sOut }
RunAuto := i; end else begin { Сюда надо вставить вызов функции формирования сообщения об ошибке }
RunAuto := 0; end; end: { RunAuto }
Конечно, рассмотренная программа — это всего лишь пример для моделиро вания такого рода автомата. Она построена так, чтобы можно было четко отеле дить соответствие между этой программой и построенным на рис. 13.8 автоматом. Конкретный распознаватель будет существенно зависеть от того, как организовано его взаимодействие с остальными частями компилятора. Это влияет на возвращаемое функцией значение, а также на то, как она должна действовать при обнаружении ошибки и при завершении распознавания лексемы. В данном примере предусмотрено, что основная часть лексического анализатора сначала считывает в память весь текст исходной программы, а потом начинает его последовательный просмотр. В зависимости от текущего символа вызывается тот или иной сканер. По результатам работы каждого сканера разбор либо продолжается с позиции, которую вернула функция сканера, либо прерывается, если функция возвращает 0.
Приведенный в примере сканер можно дополнить сканерами для констант с плавающей точкой языка С, а также идентификаторов и ключевых слов языка. В последнем случае распознающий КА будет явно недетерминированным, поскольку в языке С возможны, например, идентификатор i ffl и ключевое слово i f, имеющие принципиально разное значение. Такой КА потребует дополнительных преобразований.
В целом техника построения сканеров основывается на моделировании работы детерминированных и недетерминированных КА с дополнением функций распознавателя вызовами функций обработки ошибок, а также заполнения таблиц символов и таблиц идентификаторов. Такая техника не требует сложной математической обработки и принципиально важных преобразований входных грамматик. Для разработчиков сканера важно только решить, где кончаются функции сканера и начинаются функции синтаксического разбора. После этого процесс построения сканера легко поддается автоматизации.
Автоматизация построения лексических анализаторов (программа LEX)
Лексические распознаватели (сканеры) — это не только важная часть компиляторов. Лексический анализ применяется во многих других областях, связанных с обработкой текстовой информации на компьютере. Прежде всего, лексического анализа требуют все возможные командные процессоры и утилиты, требующие ввода командных строк и параметров пользователем. Кроме того, хотя бы самый примитивный лексический анализ вводимого текста применяют практически все современные текстовые редакторы и текстовые процессоры. Практически любой более-менее серьезный разработчик программного обеспечения рано или поздно сталкивается с необходимостью решать задачу лексического анализа (разбора)1. С одной стороны, задачи лексического анализа имеют широкое распространение, а с другой — допускают четко формализованное решение на основе техники моделирования работы КА. Все это вместе предопределило возможность автоматизации решения данной задачи. И программы, ориентированные на ее решение,
не замедлили появиться. Причем поскольку математический аппарат КА известен уже длительное время, да и с задачами лексического анализа программисты столкнулись довольно давно, то и программам, их решающим, насчитывается не один десяток лет.
Для решения задач построения лексических анализаторов существуют различные программы. Наиболее известной среди них является программа LEX. LEX — программа для генерации сканеров (лексических анализаторов). Входной язык содержит описания лексем в терминах регулярных выражений. Результатом работы LEX является программа на некотором языке программирования, которая читает входной файл (обычно это стандартный ввод) и выделяет из него последовательности символов (лексемы), соответствующие заданным регулярным выражениям.
История программы LEX тесно связана с историей операционных систем типа UNIX. Эта программа появилась в составе утилит ОС UNIX и в настоящее время входит в поставку практически каждой ОС этого типа. Однако сейчас существуют версии программы LEX практически для любой ОС, в том числе для широко распространенной MS-DOS.
Поскольку LEX появилась в среде ОС UNIX, то первоначально языком программирования, на котором строились порождаемые ею лексические анализаторы, был язык С. Но со временем появились версии LEX, порождающие сканеры и на основе других языков программирования (например, известны версии для языка Pascal).
Принцип работы LEX достаточно прост: на вход ей подается текстовый файл, содержащий описания нужных лексем в терминах регулярных выражений, а на выходе получается файл с текстом исходной программы сканера на заданном языке программирования (обычно — на С). Текст исходной программы сканера может быть дополнен вызовами любых функций из любых библиотек, поддерживаемых данным языком и системой программирования. Таким образом, LEX позволяет значительно упростить разработку лексических анализаторов, практически сводя эту работу к описанию требуемых лексем в терминах регулярных выражений.
Более подробную информацию о работе с программой LEX можно получить в [5, 11,31,39,67,68].
7. Синтаксические анализаторы. Основные принципы
работы синтаксических анализаторов. Дерево разбора. Преобразование дерева
разбора в дерево операций. Автоматизация построения синтаксических
анализаторов.
Синтаксические анализаторы. Синтаксически управляемый перевод
Основные принципы работы синтаксического анализатора
Синтаксический анализатор (синтаксический разбор) — это часть компилятора, которая отвечает за выявление основных синтаксических конструкций входного языка. В задачу синтаксического анализа входит: найти и выделить основные
синтаксические конструкции в тексте входной программы, установить тип и проверить правильность каждой синтаксической конструкции и, наконец, представить синтаксические конструкции в виде, удобном для дальнейшей генерации текста результирующей программы.
В основе синтаксического анализатора лежит распознаватель текста входной программы на основе грамматики входного языка. Как правило, синтаксические конструкции языков программирования могут быть описаны с помощью КС-грамматик (см. главу «Контекстно-свободные языки»), реже встречаются языки, которые могут быть описаны с помощью регулярных грамматик (см. главу «Регулярные языки»). Чаще всего регулярные грамматики применимы к языкам ассемблера, а языки высокого уровня построены на основе синтаксиса КС-языков. Распознаватель дает ответ на вопрос о том, принадлежит или нет цепочка входных символов заданному языку. Однако, как и в случае лексического анализа, задача синтаксического разбора не ограничивается только проверкой принадлежности цепочки заданному языку. Необходимо выполнить все перечисленные выше задачи, которые должен решить синтаксический анализатор. В таком варианте анализатор уже не является разновидностью МП-автомата — его функции можно трактовать шире. Синтаксический анализатор должен иметь некий вы-ходно'й язык, с помощью которого он передает следующим фазам компиляции всю информацию о найденных и разобранных синтаксических структурах. В таком случае он уже является преобразователем с магазинной памятью — МП-преобразователем1 [6, 23, 26, 40, 42].
Синтаксический разбор — это основная часть компилятора на этапе анализа. Без выполнения синтаксического разбора работа компилятора бессмысленна, в то время как лексический разбор в принципе является необязательной фазой. Все задачи по проверке синтаксиса входного языка могут быть решены на этапе синтаксического разбора. Сканер только позволяет избавить сложный по структуре синтаксический анализатор от решения примитивных задач по выявлению и запоминанию лексем входной программы.
Выходом лексического анализатора является таблица лексем (или цепочка лексем). Эта таблица образует вход синтаксического анализатора, который исследует только один компонент каждой лексемы — ее тип. Остальная информация о лексемах используется на более поздних фазах компиляции при семантическом анализе, подготовке к генерации и генерации кода результирующей программы. Синтаксический анализ (или разбор) — это процесс, в котором исследуется таблица лексем и устанавливается, удовлетворяет ли она структурным условиям, явно сформулированным в определении синтаксиса языка.
Синтаксический анализатор воспринимает выход лексического анализатора и бирает его в соответствии с грамматикой входного языка. Однако в грамма входного языка программирования обычно не уточняется, какие конструь следует считать лексемами. Примерами конструкций, которые обычно распс ются во время лексического анализа, служат ключевые слова, константы и и тификаторы. Но эти же конструкции могут распознаваться и синтаксичес анализатором. На практике не существует жесткого правила, определяющегс кие конструкции должны распознаваться на лексическом уровне, а какие ] оставлять синтаксическому анализатору. Обычно это определяет разрабо: компилятора исходя из технологических аспектов программирования, а тг синтаксиса и семантики входного языка. Принципы взаимодействия леке ского и синтаксического анализаторов были рассмотрены нами в разделе «. сические анализаторы (сканеры). Принципы построения сканеров» этой глг
Ниже рассмотрены технические аспекты, связанные с реализацией синтакс ских анализаторов для использования результатов их работы на этапе генерг кода. Тем не менее основу любого синтаксического анализатора всегда сое ляет распознаватель, построенный на основе какого-либо класса КС-грамма Поэтому главную роль в том, как функционирует синтаксический анализ; и какой алгоритм лежит в его основе, играют принципы построения распозн телей КС-языков, рассмотренные в главе «Контекстно-свободные языки», применения этих принципов невозможно выполнить эффективный синтакс ский разбор предложений входного языка.
Дерево разбора. Преобразование дерева разбора в дерево операций
Результатом работы распознавателя КС-грамматики входного языка явля> последовательность правил грамматики, примененных для построения вхо/ цепочки. По найденной последовательности, зная тип распознавателя, мо построить цепочку вывода или дерево вывода. В этом случае дерево вывода ступает в качестве дерева синтаксического разбора и представляет собой рез; тат работы синтаксического анализатора в компиляторе.
Однако ни цепочка вывода, ни дерево синтаксического разбора не являк целью работы компилятора. Дерево вывода содержит массу избыточной инс мации, которая для дальнейшей работы компилятора не требуется. Эта инс мация включает в себя все нетерминальные символы, содержащиеся в у: дерева, — после того как дерево построено, они не несут никакой смысле нагрузки и не представляют для дальнейшей работы интереса.
Для полного представления о типе и структуре найденной и разобранной < таксической конструкции входного языка в принципе достаточно знать по довательность номеров правил грамматики, примененных для ее построе] Однако форма представления этой достаточной информации может быть личной как в зависимости от реализации самого компилятора, так и от фазы i пиляции. Эта форма называется внутренним представлением программы (и» используется также термины «промежуточное представление» или «промежу ная программа»).
Различные формы внутреннего представления программы рассмотрены в разделе «Генерация кода. Методы генерации кода», глава 14. Здесь пойдет речь только о связных списочных структурах, представляющих деревья, так как именно эти структуры наиболее просто и эффективно строить на этапе синтаксического разбора, руководствуясь правилами и типом вывода, порожденного синтаксическим распознавателем.
В синтаксическом дереве внутренние узлы (вершины) соответствуют операциям, а листья представляют собой операнды. Как правило, листья синтаксического дерева связаны с записями в таблице идентификаторов. Структура синтаксического дерева отражает синтаксис языка программирования, на котором написана исходная программа.
Синтаксические деревья могут быть построены компилятором для любой части входной программы. Не всегда синтаксическому дереву должен соответствовать фрагмент кода результирующей программы — например, возможно построение синтаксических деревьев для декларативной части языка. В этом случае операции, имеющиеся в дереве, не требуют порождения объектного кода, но несут информацию о действиях, которые должен выполнить сам компилятор над соответствующими элементами. В том случае, когда синтаксическому дереву соответствует некоторая последовательность операций, влекущая порождение фрагмента объектного кода, говорят о дереве операций.
Дерево операций можно непосредственно построить из дерева вывода, порожденного синтаксическим анализатором. Для этого достаточно исключить из дерева вывода цепочки нетерминальных символов, а также узлы, не несущие семантической (смысловой) нагрузки при генерации кода. Примером таких узлов могут служить различные скобки, которые меняют порядок выполнения операций и операторов, но после построения дерева никакой смысловой нагрузки не несут, так как им не соответствует никакой объектный код. То, какой узел в дереве является операцией, а какой — операндом, никак невозможно определить из грамматики, описывающей синтаксис входного языка. Также ниоткуда не следует, каким операциям должен соответствовать объектный код в результирующей программе, а каким — нет. Все это определяется только исходя из семантики — «смысла» — языка входной программы. Поэтому только разработчик компилятора может четко определить, как при построении дерева операций должны различаться операнды и сами операции, а также то, какие операции являются семантически незначащими для порождения объектного кода. Алгоритм преобразования дерева семантического разбора в дерево операций можно представить следующим образом.
Шаг 1. Если в дереве больше не содержится узлов, помеченных нетерминальными символами, то выполнение алгоритма завершено; иначе — перейти к шагу 2. Шаг 2. Выбрать крайний левый узел дерева, помеченный нетерминальным символом грамматики и сделать его текущим. Перейти к шагу 3. Шаг 3. Если текущий узел имеет только один нижележащий узел, то текущий узел необходимо удалить из дерева, а связанный с ним узел присоединить к узлу вышележащего уровня (исключить из дерева цепочку) и вернуться к шагу 1; иначе — перейти к шагу 4.
Шаг 4. Если текущий узел имеет нижележащий узел (лист дерева), помечены терминальным символом, который не несет семантической нагрузки, тогда Э1 лист нужно удалить из дерева и вернуться к шагу 3; иначе — перейти к шагу Шаг 5. Если текущий узел имеет один нижележащий узел (лист дерева), пол ченный терминальным символом, обозначающим знак операции, а остальн узлы помечены как операнды, то лист, помеченный знаком операции, надо у; лить из дерева, текущий узел пометить этим знаком операции и перейти к шагу иначе — перейти к шагу 6.
Шаг 6. Если среди нижележащих узлов для текущего узла есть узлы, помече ные нетерминальными символами грамматики, то необходимо выбрать крайн левый среди этих узлов, сделать его текущим узлом и перейти к шагу 3; иначе выполнение алгоритма завершено.
Этот алгоритм всегда работает с узлом дерева, который считает текущим, и ctj мится исключить из дерева все узлы, помеченные нетерминальными символал То, какие из символов считать семантически незначащими, а какие считать зг ками операций, решает разработчик компилятора1. Если семантика языка зада корректно, то в результате работы алгоритма из дерева будут исключены в нетерминальные символы.
Возьмем в качестве примеров синтаксические деревья, построенные для цепоч: (а+а)*Ь из языка, заданного различными вариантами грамматики арифметик ских выражений. Эти деревья приведены выше в качестве примеров на рис. 12 12.7 и 12.9. Семантически незначащими символами в этой грамматике являют скобки (они задают порядок операций и влияют на синтаксический разбор, : результирующего кода не порождают) и пустые строки. Знаки операций зада* символами +, -, / и *, остальные символы (а и Ь) являются операндами.
В результате применения алгоритма преобразования деревьев синтаксическо разбора в дерево операций к деревьям, представленным на рис. 12.3, 12.7 и 12 получим дерево операций, представленное на рис. 13.9. Причем, несмотря на что исходные синтаксические деревья имели различную структуру, зависящ} от используемой грамматики, результирующее дерево операций в результате всег, имеет одну и ту же структуру, зависящую только от семантики входного язык
|
|
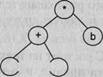
а ) (а Рис. 13.9. Пример дерева операций для языка арифметических выражений
Дерево операций является формой внутреннего представления программы, к торой удобно пользоваться на этапах синтаксического разбора, семантическо: анализа и подготовки к генерации кода, когда еще нет необходимости работа'
непосредственно с кодами команд результирующей программы. Дерево операций четко отражает связь всех операций между собой, поэтому его удобно использовать также для преобразований, связанных с перестановкой и переупорядочиванием операций без изменения конечного результата (таких, как арифметические преобразования). Более подробно эти вопросы рассмотрены в [5, 6, т. 2, 82].
Автоматизация построения синтаксических анализаторов (программа YACC)
При разработке различных прикладных программ часто возникает задача синтаксического разбора некоторого входного текста. Конечно, ее можно всегда решить, полностью самостоятельно построив соответствующий анализатор. И хотя задача выполнения синтаксического разбора встречается не столь часто, как задача выполнения лексического разбора, но все-таки и для ее решения были предложены соответствующие программные средства.
Автоматизированное построение синтаксических анализаторов может быть выполнено с помощью программы YACC.
Программа YACC (Yet Another Compiler Compiler) предназначена для построения синтаксического анализатора контекстно-свободного языка. Анализируемый язык описывается с помощью грамматики в виде, близком форме Бэкуса—Наура (нормальная форма Бэкуса—Наура — НФБН). Результатом работы YACC является исходный текст программы синтаксического анализатора. Анализатор, который порождается YACC, реализует восходящий LALR(l) распознаватель [5, 6, т. 1, 15, 65].
Как и программа LEX, служащая для автоматизации построения лексических анализаторов, программа YACC тесно связана с историей операционных систем типа UNIX. Эта программа входит в поставку многих версий ОС UNIX или Linux. Поэтому чаще всего результатом работы YACC является исходный текст синтаксического распознавателя на языке С. Однако существуют версии YACC, выполняющиеся под управлением ОС, отличных от UNIX, и порождающие исходный код на других языках программирования (например, Pascal). Принцип работы YACC похож на принцип работы LEX: на вход поступает файл, содержащий описание грамматики заданного КС-языка, а на выходе получаем текст программы синтаксического распознавателя, который, естественно, можно дополнять и редактировать, как и любую другую программу на заданном языке программирования.
Исходная грамматика для YACC состоит из трех секций, разделенных символом %%, — секции описаний, секции правил, в которой описывается грамматика, и секции программ, содержимое которой просто копируется в выходной файл. Например, ниже приведено описание простейшей грамматики для YACC, которая соответствует грамматике арифметических выражений, многократно использовавшейся в качестве примера в данном пособии:
£token a *start e
|
е : |
e |
+ ' m |
e |
- |
m |
|
|
m : |
m |
*' t |
m |
' Г |
t |
|
|
t : |
a |
■(' ( |
; ') |
|
|
|
Секция описаний содержит информацию о том, что идентификатор а являет лексемой (терминальным символом) грамматики, а символ е — ее начальным г терминальным символом.
Грамматика записана обычным образом — идентификаторы обозначают терм нальные и нетерминальные символы; символьные константы типа '+' и '-' сч таются терминальными символами. Символы :, |, ; принадлежат к метаязы YACC и читаются согласно НФБН «есть по определению», «или» и «конец щ вила» соответственно.
В отличие от LEX, который всегда способен построить лексический распозна! тель, если входной файл содержит правильное регулярное выражение, YAC не всегда может построить распознаватель, даже если входной язык задан щ вильной КС-грамматикой. Ведь заданная грамматика может и не принадлежа к классу LALR(l). В этом случае YACC выдаст сообщение об ошибке (налич: неразрешимого LALR(l) конфликта в грамматике) при построении синтакси* ского анализатора. Тогда пользователь должен либо преобразовать грамматш либо задать YACC некоторые дополнительные правила, которые могут обл( чить построение анализатора. Например, YACC позволяет указать правила, яв задающие приоритет операций и порядок их выполнения (слева направо и. справа налево).
С каждым правилом грамматики может быть связано действие, которое буг выполнено при свертке по данному правилу. Оно записывается в виде заключи ной в фигурные скобки последовательности операторов языка, на котором not ждается исходный текст программы распознавателя (обычно это язык С). Г следовательность должна располагаться после правой части соответствующе правила. Также YACC позволяет управлять действиями, которые будут выпс няться распознавателем в том случае, если входная цепочка не принадлежит : данному языку. Распознаватель имеет возможность выдать сообщение об oim ке, остановиться либо же продолжить разбор, предприняв некоторые действ] связанные с попыткой локализовать либо устранить ошибку во входной i почке.
Более подробные сведения о программе автоматизированного построения а таксических распознавателей YACC можно получить в [5, 11, 39, 68].
Генерация
и оптимизация кода
8. Семантический анализ и подготовка к
генерации кода. Назначение семантического анализа. Этапы семантического
анализа. Идентификация лексических единиц языков программирования. Распределение
памяти. Методы генерации
кода. Оптимизация кода. Основные методы оптимизации.
Семантический анализ
и подготовка к генерации кода
Назначение семантического анализа
Мы уже неоднократно упоминали, что практически вся языки программирования, строго говоря, не являются КС-языками. Поэтому полный разбор цепочек символов входного языка компилятор не может выполнить в рамках КС-языков с помощью КС-грамматик и МП-автоматов. Полный распознаватель для большинства языков программирования может быть построен в рамках КЗ-языков, поскольку все реальные языки программирования контекстно-зависимы1.
Итак, полный распознаватель для языка программирования можно построить на основе распознавателя КЗ-языка. Однако известно, что такой распознаватель имеет экспоненциальную зависимость требуемых для выполнения разбора цепочки вычислительных ресурсов от длины входной цепочки [6, т. 1]. Компилятор, построенный на основе такого распознавателя, будет неэффективным с точки зрения либо скорости работы, либо объема необходимой памяти. Поэтому такие компиляторы практически не используются, а все реально существующие компиляторы на этапе разбора входных цепочек проверяют только синтаксические конструкции входного языка, не учитывая его семантику.
С целью повысить эффективность компиляторов разбор цепочек входного языка выполняется в два этапа: первый — синтаксический разбор на основе распознавателя одного из известных классов КС-языков; второй — семантический анализ входной цепочки. Для проверки семантической правильности входной программы необходимо v всю информацию о найденных лексических единицах языка. Эта информ помещается в таблицу лексем на основе конструкций, найденных синтакс ским распознавателем. Примерами таких конструкциями являются блоки oi ния констант и идентификаторов (если они предусмотрены семантикой яз или операторы, где тот или иной идентификатор встречается впервые (если сание происходит по факту первого использования). Поэтому полный семг ческий анализ входной программы может быть произведен только после noi завершения ее синтаксического разбора.
Таким образом, входными данными для семантического анализа служат:
□
таблица идентификаторов;
□
результаты разбора синтаксических конструкций входного
языка.
Результаты выполнения синтаксического разбора могут быть представлены в с из форм внутреннего представления программы в компиляторе. Как правш этапе семантического анализа используются различные варианты деревьев таксического разбора, поскольку семантический анализатор интересует пр всего структура входной программы.
Семантический анализ обычно выполняется на двух этапах компиляции: на синтаксического разбора и в начале этапа подготовки к генерации кода. В вом случае всякий раз по завершении распознавания определенной синтак ской конструкции входного языка выполняется ее семантическая провер] основе имеющихся в таблице идентификаторов данных (такими конструкщ как правило, являются процедуры, функции и блоки операторов входного яз Во втором случае, после завершения всей фазы синтаксического разбора, bi няется полный семантический анализ программы на основании данных ъ лице идентификаторов (сюда попадает, например, поиск неописанных ид фикаторов). Иногда семантический анализ выделяют в отдельный этап (< компиляции.
В каждом компиляторе обычно присутствуют оба варианта семантическогс лизатора. Конкретная их реализация зависит от версии компилятора и сем ки входного языка [6, т. 2, 40, 74, 82].
Этапы семантического анализа
Семантический анализатор выполняет следующие основные действия:
□
проверка соблюдения во входной программе семантических
соглашений
ного
языка;
□
дополнение внутреннего представления программы в
компиляторе one
рами и
действиями, неявно предусмотренными семантикой входного яз
□
проверка элементарных семантических (смысловых) норм
языков про
мирования,
напрямую не связанных с входным языком.
Проверка соблюдения во входной программе семантических соглашений ного языка заключается в сопоставлении входных цепочек программы с тре ниями семантики входного языка программирования. Каждый язык прогр;
рования имеет четко заданные и специфицированные семантические соглашения, которые не могут быть проверены на этапе синтаксического разбора. Именно их в первую очередь проверяет семантический анализатор.
Примерами таких соглашений являются следующие требования:
□
каждая метка, на которую есть ссылка, должна один раз
присутствовать в про
грамме;
□
каждый идентификатор должен быть описан один раз, и ни
один идентифи
катор
не может быть описан более одного раза (с учетом блочной структуры
описаний);
□
все операнды в выражениях и операциях должны иметь типы,
допустимые
для
данного выражения или операции;
□
типы переменных в выражениях должны быть согласованы
между собой;
□
при вызове процедур и функций число и типы фактических
параметров долж
ны быть
согласованы с числом и типами формальных параметров.
Это только примерный перечень такого рода требований. Конкретный состав требований, которые должен проверять семантический анализатор, жестко связан с семантикой входного языка (например, некоторые языки допускают не описывать идентификаторы определенных типов). Варианты реализаций такого рода семантических анализаторов детально рассмотрены в [6, т. 2, 74].
Например, если мы возьмем оператор языка Pascal, имеющий вид:
а := b + с;
то с точки зрения синтаксического разбора это будет абсолютно правильный оператор. Однако мы не можем сказать, является ли этот оператор правильным с точки зрения входного языка (Pascal), пока не проверим семантические требования для всех входящих в него лексических элементов. Такими элементами здесь являются идентификаторы a, b и с. Не зная, что они собой представляют, мы не можем не только окончательно утверждать правильность приведенного выше оператора, но и понять его смысл. Фактически необходимо знать описание этих идентификаторов.
В том случае, если хотя бы один из них не описан, имеет место явная ошибка. Если это числовые переменные и константы, то мы имеем дело с оператором сложения, если же это строковые переменные и константы — с оператором конкатенации строк. Кроме того, идентификатор а, например, ни в коем случае не может быть константой — иначе нарушена семантика оператора присваивания. Также невозможно, чтобы одни из идентификаторов были числами, а другие — строками, или, скажем, идентификаторами массивов или структур — такое сочетание аргументов для операции сложения недопустимо. И это только некоторая часть соглашений, которые должен проверить компилятор с точки зрения семантики входного языка (в данном примере — Pascal).
Следует еще отметить, что от семантических соглашений зависит не только правильность оператора, но и его смысл. Действительно, операции алгебраического сложения и конкатенации строк имеют различный смысл, хотя и обозначаются в рассмотренном примере одним знаком операции — «+». Следовательно, от семантического анализатора зависит также и код результирующей программы. Если какое-либо из семантических требований входного языка не выполняет то компилятор выдает сообщение об ошибке и процесс компиляции на этом, ] правило, прекращается.
Дополнение внутреннего представления программы операторами и действия] неявно предусмотренными семантикой входного языка, связано с преобразо нием типов операндов в выражениях и при передаче параметров в процедур! функции.
Если вернуться к рассмотренному выше элементарному оператору языка Pasc а := b + с;
то можно отметить, что здесь выполняются две операции: одна операция ело; ния (или конкатенации, в зависимости от типов операндов) и одна операг. присвоения результата. Соответствующим образом должен быть порожден и i результирующей программы.
Однако не все так очевидно просто. Допустим, что где-то перед рассмотренн оператором мы имеем описание его операндов в виде:
var
а : real:
b : integer;
с : double:
из этого описания следует, что а — вещественная переменная языка Pascal, 1 целочисленная переменная, с — вещественная переменная с двойной точност Тогда смысл рассмотренного оператора с точки зрения входной програм существенным образом меняется, поскольку в языке Pascal нельзя напрям выполнять операции над операндами различных типов. Существуют прав] преобразования типов, принятые для данного языка. Кто выполняет эти пре разования?
Это может сделать разработчик программы — но тогда преобразования ти] в явном виде будут присутствовать в тексте входной программы (в рассмотр ном примере это не так). В другом случае это делает код, порождаемый компи тором, когда преобразования типов в явном виде в тексте программы не прис ствуют, но неявно предусмотрены семантическими соглашениями языка. / этого в составе библиотек функций, доступных компилятору, должны быть фу ции преобразования типов (более подробно о библиотеках функций см. в [ деле «Принципы функционирования систем программирования», глава 15). Вь вы этих функций как раз и будут встроены в текст результирующей прогр мы для удовлетворения семантических соглашений о преобразованиях типо! входном языке, хотя в тексте программы в явном виде они не присутствуют. Чт< это произошло, эти функции должны быть встроены и во внутреннее предст ление программы в компиляторе. За это также отвечает семантический анализат С учетом предложенных типов данных, в рассмотренном примере будут не , а четыре операции: преобразование целочисленной переменной b в формат ве ственных чисел с двойной точностью; сложение двух вещественных чисел с де ной точностью; преобразование результата в вещественное число с одинар точностью; присвоение результата переменной с. Количество операций возро вдвое, причем добавились два вызова весьма нетривиальных функций прео£
зования типов. Разработчик программы должен помнить об этом, если хочет добиваться высокой эффективности результирующего кода.
Преобразование типов — это только один вариант операций, неявно добавляемых компилятором в код программы на основе семантических соглашений. Другим примером такого рода операций могут служить операции вычисления адреса, когда происходит обращение к элементам сложных структур данных. Существуют и другие варианты такого рода операций (преобразование типов — только самый распространенный пример).
Таким образом, и здесь действия, выполняемые семантическим анализатором, существенным образом влияют на порождаемый компилятором код результирующей программы.
Проверка элементарных смысловых норм языков программирования, напрямую не связанных с входным языком, — это сервисная функция, которую предоставляют большинство современных компиляторов. Эта функция обеспечивает проверку компилятором некоторых соглашений, применимых к большинству современных языков программирования, выполнение которых связано со смыслом как всей входной программы в целом, так и отдельных ее фрагментов.
Примерами таких соглашений являются следующие требования:
□
каждая переменная или константа должна хотя бы один раз
использоваться
в
программе;
□
каждая
переменная должна быть определена до ее первого использования
при любом ходе выполнения программы
(первому использованию перемен
ной должно всегда предшествовать присвоение ей какого-либо значения);
□
результат функции должен быть определен при любом ходе
ее выполнения;
□
каждый оператор в исходной программе должен иметь
возможность хотя бы
один
раз выполниться;
□
операторы условия и выбора должны предусматривать
возможность хода вы
полнения
программы по каждой из своих ветвей;
□
операторы цикла должны предусматривать возможность
завершения цикла.
Конечно, это только примерный перечень основных соглашений. Конкретный состав проверяемых соглашений зависит от семантики языка. Однако, в отличие от семантических требований языка, строго проверяемых семантическим анализатором, выполнение данных соглашений не является обязательным. Поэтому то, какие конкретно соглашения будут проверяться и как они будут обрабатываться, зависит от качества компилятора, от функций, заложенных в него разработчиками. Простейший компилятор вообще может не выполнять этот этап семантического анализа и не проверять ни одного такого соглашения, даже если это и возможно с точки зрения семантики входного языка1.
Необязательность соглашений такого типа накладывает еще одну особенно на их обработку в семантическом анализаторе: их несоблюдение не может тр товаться как ошибка. Даже если компилятор полностью уверен в своей «пра те», тот факт, что какое-то из указанных соглашений не соблюдается, не дол> приводить к прекращению компиляции входной программы. Обычно факт об ружения несоблюдения такого рода соглашений трактуется компилятором «предупреждение» (warning). Компилятор выдает пользователю сообщение обнаружении несоблюдения одного из требований, не прерывая сам процесс к пиляции, — то есть он просто обращает внимание пользователя на то или и место в исходной программе. То, как реагировать на «предупреждение» (внос изменения в исходный код или проигнорировать этот факт), — это уже заб и ответственность разработчика программы.
Необязательность указанных соглашений объясняется тем, о чем уже говорил выше (см. раздел «Языки и цепочки символов. Способы задания языков», i ва 9), — ни один компилятор не способен полностью понять и оценить cmi исходной программы. А поскольку смысл программы доступен только челов (для плохо написанной программы — только ее разработчику, а в другом с чае — некоторому кругу лиц), то он и должен нести ответственность за семак ческие соглашения1.
Задача проверки семантических соглашений входного языка во многом свяэ с проблемой верификации программ. Эта проблема детально рассмотрен [1,25,46,51].
Рассмотрим в качестве примера функцию, представляющую собой фрагмент вз ной программы на языке С:
int f_test(int
a) { int b.c;
b = 0;
с = 0;
if (b=l) { return
a: }
с = a + b;
Практически любой современный
компилятор с этого языка обнаружит в дан месте входной программы массу «неточностей».
Например, переменная с оп: на, ей присваивается значение, но она нигде не
используется; значение переп ной Ь, присвоенное в операторе Ь=0, тоже никак не
используется; наконец, ус![]() ный оператор лишен
смысла, так как всегда предусматривает ход выполнения только по одной своей
ветке (и значит, оператор с=а+Ь; никогда выполнен не будет). Скорее всего,
компилятор выдаст еще одно предупреждение, характерное именно для языка С, —
в операторе if(b=l)
присвоение стоит в условии (это не запрещено ни синтаксисом, ни семантикой
языка, но является очень распространенной
смысловой ошибкой в С). В принципе смысл (а точнее, бессмысленность) этого фрагмента будет правильно воспринят и обработан компилятором.
ный оператор лишен
смысла, так как всегда предусматривает ход выполнения только по одной своей
ветке (и значит, оператор с=а+Ь; никогда выполнен не будет). Скорее всего,
компилятор выдаст еще одно предупреждение, характерное именно для языка С, —
в операторе if(b=l)
присвоение стоит в условии (это не запрещено ни синтаксисом, ни семантикой
языка, но является очень распространенной
смысловой ошибкой в С). В принципе смысл (а точнее, бессмысленность) этого фрагмента будет правильно воспринят и обработан компилятором.
Однако если взять аналогичный по смыслу, но синтаксически более сложный фрагмент программы, то картина будет несколько иная:
|
return a; |
int f test adcKint* a, int* b)
|
*а = 1; |
|
|
*b = 0: |
|
|
return |
*a: |
|
int f_test(int |
a) |
|
{ int b.c; |
|
|
b = 0; |
|
|
if (f_test_add(&b,&c) != 0) |
|
|
с = a + |
b; |
Здесь уже компилятор вряд ли сможет выяснить порядок изменения значения переменных и выполнение условий в данном фрагменте из двух функций (обе они сами по себе независимо вполне осмысленны!). Единственное предупреждение, которое, скорее всего, получит в данном случае разработчик, — это то, что функция f_test не всегда корректно возвращает результат (отсутствует оператор return перед концом функции). И то это предупреждение на самом деле не будет соответствовать истинному положению вещей.
В целом проверка дополнительных семантических соглашений является весьма полезной функцией компиляторов, но ответственность за смысл исходной программы всегда по-прежнему остается на ее разработчике.
Идентификация лексических единиц языков программирования
Идентификация переменных, типов, процедур, функций и других лексических
единиц
языков программирования — это установление однозначного соответствия между
данными объектами и их именами в тексте исходной программы. Идентификация
лексических единиц языка чаще всего выполняется на этапе семантического
анализа.
Как правило, большинство языков программирования требуют, чтобы в исходной программе имена лексических единиц не совпадали как между собой, так и с ключевыми словами синтаксических конструкций языка1. Однако чаще всего этого бывает недостаточно, чтобы установить однозначное соответствие между лексическими единицами и их именами, поскольку существуют дополнительные смысловые (семантические) ограничения, накладываемые языком на употребление этих имен.
Например, локальные переменные в большинстве языков программирования имеют так называемую «область видимости», которая ограничивает употребление имени переменной рамками того блока исходной программы, где эта переменная описана. Это значит, что с одной стороны, такая переменная не может быть использована вне пределов своей области видимости. С другой стороны, имя переменной может быть не уникальным, поскольку в двух различных областях видимости допускается существование двух различных переменных с одинаковым именем (причем в большинстве языков программирования, допускающих блочные структуры, области видимости переменных в них могут перекрываться). Другой пример такого рода ограничений на уникальность имен — это тот факт, что в языке программирования С две разные функции или процедуры с различными аргументами могут иметь одно и то же имя.
Безусловно, полный перечень таких ограничений зависит от семантики конкретного языка программирования. Все они четко заданы в описании языка и не могут допускать неоднозначности в толковании, но не могут быть полностью определены на этапе лексического разбора, а потому требуют от компилятора дополнительных действий на этапах синтаксического разбора и семантического анализа. Общая направленность этих действий такова, чтобы дать каждой лексической единице языка уникальное имя в пределах всей исходной программы и потом использовать это имя при синтезе результирующей программы. Можно дать примерный перечень действий компиляторов для идентификации переменных, констант, функций, процедур и других лексических единиц языка:
□
имена локальных переменных дополняются именами тех блоков
(функций,
процедур),
в которых эти переменные описаны;
□
имена внутренних переменных и функций модулей исходной
программы до
полняются
именем самих модулей, причем это касается только внутренних
имен и
не должно происходить, если переменная или функция доступны из
вне модуля;
□
имена процедур и функций, принадлежащих объектам
(классам), в объектно-
ориентированных
языках программирования дополняются наименованием
типа
объекта (класса), которому они принадлежат;
□ имена процедур и функций модифицируются в зависимости от типов их формальных аргументов.
Конечно, это далеко не полный перечень возможных действий компилятора, каждая реализация компилятора может предполагать свой набор действий. То, какие из них будут использоваться и как они будут реализованы на практике, зависит от языка исходной программы и разработчиков компилятора.
Как правило, уникальные имена, которые компилятор присваивает лексическим единицам языка, используются только во внутреннем представлении исходной программы компилятором, и человек, создавший исходную программу, не сталкивается с ними. Но они могут потребоваться пользователю в некоторых случаях — например, при отладке программы, при порождении текста результирующей программы на языке ассемблера или при использовании библиотеки, созданной версией компилятора для одного языка программирования в другом языке (или даже просто в другой версии компилятора). Тогда пользователь должен знать, по каким правилам компилятор порождает уникальные имена для лексических единиц исходной программы1.
Во многих современных компиляторах (и обрабатываемых ими входных языках) предусмотрены специальные настройки и ключевые слова, которые позволяют отключить процесс порождения компилятором уникальных имен для лексических единиц языка. Эти слова учтены в специальных синтаксических конструкциях языка (как правило, это конструкции, содержащие слова export или external). Если пользователь использует эти средства, то компилятор не применяет механизм порождения уникальных имен для указанных лексических единиц. В этом случае разработчик программы сам отвечает за уникальность имени данной лексической единицы в пределах всей исходной программы или даже в пределах всего проекта (если используются несколько различных исходных модулей — более подробно см. раздел «Принципы функционирования систем программирования», глава 15). Если требование уникальности не будет выполняться, могут возникнуть синтаксические или семантические ошибки на стадии компиляции либо же другие ошибки на более поздних этапах разработки программно- го обеспечения. Поскольку наиболее широко используемыми лексическими единицами в различных языках программирования являются, как правило, имена процедур или функций, то этот вопрос, прежде всего, касается именно их.
Распределение памяти. Принципы распределения памяти
Распределение памяти — это процесс, который ставит в соответствие лексическим единицам исходной программы адрес, размер и атрибуты области памяти, необходимой для этой лексической единицы. Область памяти — это блок ячеек памяти, выделяемый для данных, каким-то образом объединенных логически. Логика таких объединений задается семантикой исходного языка.
Распределение памяти работает с лексическими единицами языка — переменными, константами, функциями и т. п. — и с информацией об этих единицах, полученной на этапах лексического и синтаксического анализа. Как правило, исходными данными для процесса распределения памяти в компиляторе служат таблица идентификаторов, построенная лексическим анализатором, и декларативная часть программы (так называемая «область описаний»), полученная в результате синтаксического анализа. Не во всех языках программирования декларативная часть программы присутствует явно, некоторые языки предусматривают дополнительные семантические правила для описания констант и переменных; кроме того, перед распределением памяти надо выполнить идентификацию лексических единиц языка. Поэтому распределение памяти выполняется уже после семантического анализа текста исходной программы.
Процесс распределения памяти в современных компиляторах, как правило, работает с относительными, а не абсолютными адресами ячеек памяти (более подробно о разнице между абсолютными и относительными адресами см. в разделе «Принципы функционирования систем программирования», глава 15). Распределение памяти выполняется перед генерацией кода результирующей программы, потому что его результаты должны быть использованы в процессе генерации кода.
Во всех языках программирования существует понятие так называемых «базовых типов данных» (основных или «скалярных» типов). Размер области памяти, необходимый для лексической единицы базового типа, считается заранее известным. Он определяется семантикой языка и архитектурой вычислительной системы, на которой должна выполняться созданная компилятором результирующая программа. Размер памяти, выделяемой под лексические единицы базовых типов, не зависит от версии компилятора, что обеспечивает совместимость и переносимость исходных программ. Этого правила строго придерживаются ведущие разработчики компиляторов.
Идеальным вариантом для разработчиков программ был бы такой компилятор, ■у которого размер памяти для базовых типов зависел бы только от семантики языка. Но чаще всего зависимость результирующей программы от архитектуры вычислительной системы полностью исключить не удается. Тогда создатели компиляторов и языков программирования разрабатывают механизмы, позволяющие свести эту зависимость к минимуму.
Например, в языке программирования С базовыми типами данных являются типы char, int, long int и т. п. (реально этих типов, конечно, больше, чем три), а в языке программирования Pascal — типы byte, char, word, integer и т. п. Размер базового типа int в языке С для архитектуры компьютера на базе 16-разрядных процессоров составляет 2 байта, а для 32-разрядных процессоров — 4 байта. Разработчики исходной программы на этом языке, конечно, могут узнать данную информацию (она, как правило, известна для каждой версии компилятора), но если ее использовать в программе напрямую, то такая программа будет жестко привязана к конкретной архитектуре компьютера. Чтобы исключить подобную зависимость, лучше использовать механизм определения размера памяти для типа данных, предоставляемый языком программирования, — в языке С, например, это функция sizeof.
Для более сложных структур данных используются правила распределения памяти, определяемые семантикой (смыслом) этих структур. Эти правила достаточно просты и в принципе одинаковы во всех языках программирования.
Вот правила распределения памяти под основные виды структур данных:
□
для массивов — произведение числа элементов в массиве на
размер памяти
для одного элемента (то же
правило применимо и для строк, но во многих
языках строки содержат еще и дополнительную
служебную информацию фик
сированного объема);
□
для структур (записей с именованными полями) — сумма
размеров памяти
по всем
полям структуры;
□
для объединений (союзов, общих областей, записей с
вариантами) — размер
максимального поля в объединении;
□
для реализации объектов (классов) — размер памяти для
структуры с такими
же
именованными полями плюс память под служебную информацию объект
но-ориентированного
языка (как правило, фиксированного объема).
Формулы для вычисления объема памяти можно записать следующим образом:
□ для массивов: Умас =Y\(mi)-V3A,
i=i,n
где п — размерность массива, т{ — количество элементов г'-й размерности, Уэл — объем памяти для одного элемента;
□ для структур: Vcmp = ]ГУ„ШЯ.,
где п — общее количество полей в структуре, Vnom. — объем памяти для г-го поля структуры;
□ для объединений: V = max У„„„ ,
где п — общее количество полей в объединении, Vn0M. — объем памяти для г-го поля объединения.
Для более сложных структур данных входного языка объем памяти, отводимой под эти структуры данных, вычисляется рекурсивно. Например, если имеется массив структур, то при вычислении объема отводимой под этот массив памяти для вычисления объема памяти, необходимой для одного элемента массива, будет вызвана процедура вычисления памяти структуры. Такой подход определения объема занимаемой памяти очень удобен, если декларативная часть языка представлена в виде дерева типов. Тогда для вычисления объема памяти, занимаемой типом из каждой вершины дерева, нужно вычислить объем памяти для всех потомков этой вершины, а потом применить формулу, связанную непосредственно с самой вершиной (этот механизм подобен механизму СУ-перевода, применяемому при генерации кода). Как раз такого типа древовидные конструкции строит синтаксический разбор для декларативной части языка.
Далеко не все лексические единицы языка требуют для себя выделения памяти. То, под какие элементы языка нужно выделять ячейки памяти, а под какие нет, определяется исключительно реализацией компилятора и архитектурой используемой вычислительной системы. Так, целочисленные константы можно разместить в статической памяти, а можно и непосредственно в тексте результирующей программы (это позволяют практически все современные вычислительные системы), то же самое относится и к константам с плавающей точкой, но их размещение в тексте программы допустимо не всегда. Кроме того, в целях экономии памяти, занимаемой результирующей программой, под различные элементы языка компилятор может выделить одни и те же ячейки памяти. Например, в одной и той же области памяти могут быть размещены одинаковые строковые константы или две различные локальные переменные, которые никогда не используются одновременно.
Говоря об объеме памяти, занимаемой различными лексическими единицами и структурами данных языка, следует упомянуть еще один момент, связанный с выравниванием отводимых для различных лексических единиц границ областей памяти. Архитектура многих современных вычислительных систем предусматривает, что обработка данных выполняется более эффективно, если адрес, по которому выбираются данные, кратен определенному числу байт (как правило, это 2, 4, 8 или 16 байт)1. Современные компиляторы учитывают особенности вычислительных систем, на которые ориентирована результирующая программа. При распределении данных они могут размещать области памяти под лексические единицы наиболее оптимальным образом. Поскольку не всегда размер памяти, отводимой под лексическую единицу, кратен указанному числу байт, то в общем объеме памяти, отводимой под результирующую программу, могут появляться неиспользуемые области.
Например, если мы имеем описание переменных на языке С:
static char cl, с2, сЗ;
то, зная, что под одну переменную типа char отводится 1 байт памяти, можем ожидать, что для описанных выше переменных потребуется всего 3 байта памяти. Однако если кратность адресов для доступа к памяти установлена 4 байта, то под эти переменные будет отведено в целом 12 байт памяти, из которых 9 не будут использоваться.
Как правило, разработчику исходной программы не нужно знать, каким образом компилятор распределяет адреса под отводимые области памяти. Чаще всего компилятор сам выбирает оптимальный метод, и, изменяя границы выделенных областей, он всегда корректно осуществляет доступ к ним. Вопрос об этом может встать, если с данными программы, написанной на одном языке, работают программы, написанные на другом языке программирования (чаще всего, на языке ассемблера), реже такие проблемы возникают при использовании двух различных компиляторов с одного и того же входного языка. Большинство компиляторов позволяют пользователю в этом случае самому указать, использовать или нет кратные адреса и какую границу кратности установить (если это вообще возможно с точки зрения архитектуры целевой вычислительной системы).
Память можно разделить на локальную и глобальную память, динамическую и статическую память.
Глобальная и локальная память
Глобальная область памяти — это область памяти, которая выделяется один раз при инициализации результирующей программы и действует все время выполнения программы. Как правило, глобальная область памяти может быть доступна из любой части исходной программы, но многие языки программирования позволяют налагать синтаксические и семантические ограничения на доступность даже для глобальных областей памяти. При этом сами области памяти и связанные с ними лексические единицы остаются глобальными, ограничения налагаются только на возможность использования их в тексте программы на входном языке (и эти ограничения в принципе возможно обойти).
Локальная область памяти — это область памяти, которая выделяется в начале выполнения некоторого фрагмента результирующей программы (блока, функции, процедуры или оператора) и может быть освобождена по завершении выполнения данного фрагмента. Доступ к локальной оласти памяти всегда запрещен за пределами того фрагмента программы, в котором она выделяется. Это определяется как синтаксическими и семантическими правилами языка, так и кодом результирующей программы. Даже если удастся обойти ограничения, налагаемые входным языком, использование таких областей памяти вне их области видимости приведет к катастрофическим последствиям для результирующей программы.
Распределение памяти на локальные и глобальные области целиком определяется семантикой языка исходной программы. Только зная смысл синтаксических конструкций исходного языка, можно четко сказать, какая из них будет отнесена в глобальную область памяти, а какая — в локальную. Иногда в исходном языке для некоторых конструкций нет четкого разграничения, тогда решение об их отнесении в ту или иную область памяти принимается разработчиками компилятора и может зависеть от используемой версии компилятора. При этом разработчики исходной программы не должны полагаться на тот факт, что один раз принятое решение будет неизменным во всех версиях компилятора. Рассмотрим для примера фрагмент текста модуля программы на языке Pascal:
const
Global_l = 1; Global_2 : integer - 2;
|
var |
Global_I :
integer:
function Test
(Param: integer): pointer:
const • ' '
LocalJ. = 1;
Local_2 : integer = 2:
var ■ ■
Local_I : integer: begin
end;
Согласно семантике языка Pascal, переменная Global I является глобальной переменной языка и размещается в глобальной области памяти, константа Global 1 также является глобальной, но язык не требует, чтобы компилятор обязательно размещал ее в памяти — значение константы может быть непосредственно подставлено в код результирующей программы там, где она используется. Типизированная константа Global_2 является глобальной, но в отличие от константы Global 1 семантика языка предполагает, что эта константа обязательно будет размещена в памяти, а не в коде программы. Доступность идентификаторов Global_I, Global_2 и Globall из других модулей зависит от того, где и как они описаны. Например, для компилятора Borland Pascal переменные и константы, описанные в заголовке модулей, доступны из других модулей программы, а переменные и константы, описанные в теле модулей, недоступны, хотя и те и другие являются глобальными.
Параметр Param функции Test, переменная Locall и константа Local_l являются локальными элементами этой функции. Они не доступны вне пределов данной функции и располагаются в локальной области памяти. Типизированная константа Local_2 представляет собой очень интересный элемент программы. С одной стороны, она не доступна вне пределов функции Test и потому является ее локальным элементом. С другой стороны, как типизированная константа она будет располагаться в глобальной области памяти, хотя ниоткуда извне не может быть доступна (аналогичными конструкциями языка С, например, являются локальные переменные функций, описанные как static).
Семантические особенности языка должны учитывать создатели компилятора, когда разрабатывают модуль распределения памяти. Безусловно, это должен знать и разработчик исходной программы, чтобы не допускать семантических (смысловых) ошибок — этот тип ошибок сложнее всего поддается обнаружению. Так, в приведенном выше примере в качестве результата функции Test может выступать адрес переменной Globall или типизированной константы Global_2. Результатом функции не может быть адрес констант Globall или Local_l — это запрещено се-
мантикой языка. Гораздо сложнее вопрос с переменной Local _1 или параметром функции Рагаш. Будучи элементами локальной области памяти функции Test, они никак не могут выступать в качестве результата функции, потому что он будет использован вне самой функции, когда область ее локальной памяти может уже не существовать. Но ни синтаксис, ни семантика языка не запрещают использовать адрес этих элементов в качестве результата функции (и далеко не всегда компилятор способен хотя бы обнаружить факт такого использования адреса локальной переменной). Эти особенности языка должен учитывать разработчик программы. А вот адрес типизированной константы Local _2 в принципе может быть результатом функции Test. Ведь хотя она и является локальной константой, но размещается в глобальной области памяти (другое дело, что этим пользоваться не рекомендуется, поскольку нет гарантии, что принцип размещения локальных типизированных констант не изменится с переходом к другой версии компилятора)1.
Статическая и динамическая память
Статическая область памяти — это область памяти, размер которой известен на этапе компиляции. Поскольку для статической области памяти известен ее размер, компилятор всегда может выделить эту область памяти и связать ее с соответствующим элементом программы. Поэтому для статической области памяти компилятор порождает некоторый адрес (как правило, это относительный адрес в программе — см. раздел «Принципы функционирования систем программирования», глава 15). В статическую область памяти попадает большинство переменных и констант исходного языка.
Статические области памяти обрабатываются компилятором самым простейшим образом, поскольку напрямую связаны со своим адресом.
Динамическая область памяти — это область памяти, размер которой на этапе компиляции программы не известен. Размер динамической области памяти будет известен только в процессе выполнения результирующей программы. Поэтому для динамической области памяти компилятор не может непосредственно выделить адрес — для нее он порождает фрагмент кода, который отвечает за распределение памяти (ее выделение и освобождение). Как правило, с динамическими областями памяти связаны многие операции с указателями и с экземплярами объектов (классов) в объектно-ориентированных языках программирования.
Динамические области памяти, в свою очередь, можно разделить на динамические области памяти, выделяемые пользователем, и динамические области памяти, выделяемые непосредственно компилятором.
Динамические области памяти, выделяемые пользователем, появляются в тех случаях, когда разработчик исходной программы явно использует в тексте про-
граммы функции, связанные с распределением памяти (примером таких фу ций являются New и Dispose в языке Pascal, mall ос и free в языке С, new и del в языке C++ и др.). Функции распределения памяти могут использовать л напрямую средства ОС, либо средства исходного языка (которые, в конце в цов, все равно основаны на средствах ОС). В этом случае за своевременное вь ление и освобождение памяти отвечает сам разработчик, а не компилятор (пр ципы динамического распределения памяти в ОС более подробно описан части 1 этого пособия). Компилятор должен только построить код вызова а ветствующих функций и сохранения результата — в принципе, для него раб с динамической памятью пользователя ничем не отличается от работы с люб! другими функциями и дополнительных сложностей не вызывает.
Другое дело — динамические области памяти, выделяемые компилятором. ( появляются тогда, когда пользователь использует типы данных, операции которыми предполагают перераспределение памяти, не присутствующее в яв виде в тексте исходной программы1. Примерами таких типов данных могут < жить строки в некоторых языках программирования, динамические массив] конечно, многие операции над экземплярами объектов (классов) в объею ориентированных языках (наиболее характерный пример — тип данных st в версиях Borland Delphi языка Object Pascal). В этом случае сам компил* отвечает за порождение кода, который будет всегда обеспечивать своевремег выделение памяти под элементы программы, и за освобождение ее по мере пользования. Многие компиляторы объектно-ориентированных языков прог] мирования используют для этих целей специальный менеджер памяти, к котор обращаются во всех случаях при явном или неявном использовании динам ской памяти. Код менеджера памяти включается в текст результирующей ] граммы или поставляется в виде отдельной библиотеки.
Как статические, так и динамические области памяти сами по себе могут t глобальными или локальными.
Дисплей памяти процедуры (функции). Стековая организация дисплея памяти
Дисплей памяти процедуры (функции) — это область данных, доступных обработки в этой процедуре (функции).
Как правило, дисплей памяти процедуры включает следующие составляют
□
глобальные данные (переменные и константы) всей
программы;
□
формальные аргументы процедуры;
□
локальные данные (переменные и константы) данной
процедуры.
С глобальными данными никаких проблем не возникает — их адреса известны, они все устанавливаются на этапе распределения памяти. Даже если память под эти данные распределяется динамически, компилятору однозначно известно, как к этой памяти обратиться, и способ обращения одинаков для всей программы. Поэтому он всегда может создать код для обращения к этим данным вне зависимости от того, откуда это обращение происходит.
Сложнее с локальными параметрами и переменными процедуры. Они относятся к локальной памяти процедуры и потому должны быть как-то связаны с нею. Существует несколько вариантов связывания локальных переменных и параметров с кодом соответствующей процедуры или функции. Им соответствуют варианты организации дисплея памяти процедуры, перечисленные ниже:
□
статическая организация дисплея памяти процедуры;
□
динамическая организация дисплея памяти процедуры;
□
стековая организация дисплея памяти процедуры.
Статическая организация дисплея памяти процедуры (функции) предусматривает, что с каждой процедурой (функцией) исходной программы при распределении памяти компилятор связывает фиксированную область памяти, предназначенную для размещения ее локальных данных (переменных и параметров). Адрес этой области памяти фиксируется на этапе распределения памяти. Каждому формальному параметру процедуры (функции) и каждой локальной переменной соответствует своя группа ячеек в этой области памяти. Отдельная группа ячеек отводится для хранения адреса возврата — адреса, по которому должно быть передано управление по завершению выполнения процедуры (функции).
Тогда в каждой точке вызова процедуры компилятор порождает код, который размещает фактические параметры вызова процедуры (функции) в ячейках области памяти процедуры, соответствующих ее формальным параметрам. Перед вызовом процедуры запоминается адрес возврата, который должен указывать на фрагмент кода непосредственно за местом вызова, после чего управление передается самой процедуре. В коде процедуры обращение к локальным данным (параметрам и переменным) происходит по фиксированным адресам, которые для каждой процедуры известны после этапа распределения памяти. После завершения выполнения процедуры (функции) из фиксированной ячейки памяти извлекается код возврата и происходит передача управления по нему.
Схема статической организации памяти проиллюстрирована на рис. 14.1.
Данная схема мало чем отличается от обычного распределения памяти под статические глобальные данные, за исключением того, что области памяти процедур, которые никогда в тексте программы не вызывают друг друга, могут частично или полностью перекрываться. Эта схема проста и удобна, она не требует сложной адресации. За счет использования одной и той же области памяти для хранения локальных данных процедур и функций, которые в исходной програм ме никогда не вызывают друг друга, компилятор может добиться достаточш эффективного распределения памяти в результирующей программе. У этой схе мы есть один серьезный недостаток — она не допускает рекурсивных вызова процедур и функций.
Код программы
|
Заполнение параметров процедуры А |
Данные
![]() Область
Область
|
|
данных
|
Вызов (1) процедуры А |
процедуры А
![]() Параметры процедуры А
Параметры процедуры А
|
Заполнение параметров процедуры А |
![]() Адрес возврата
Адрес возврата
Вызов (2) процедуры А
![]()
![]() Код поцедуры А
Код поцедуры А
![]() Рис. 14.1. Схема статической организации дисплея памяти процедуры (функции)
Рис. 14.1. Схема статической организации дисплея памяти процедуры (функции)
Действительно, если в схеме, приведенной на рис. 14.1, в момент выполнен* кода процедуры А вновь выполнить рекурсивный вызов той же самой процед; ры, то все ее локальные данные будут записаны заново (в том числе и код во врата!). После возврата из вызванной процедуры данные вызвавшей процедур будут безвозвратно потеряны. Процедура, рекурсивно вызвавшая сама себя, в т кой схеме просто не сможет корректно завершиться. То же самое произойди если рекурсивный вызов будет происходить не непосредственно, а через цепоч] вызовов других процедур.
Этот серьезный недостаток ограничивает
применение данной схемы организ ции дисплея памяти процедур и функций в
современных компиляторах1.
![]() Динамическая
организация дисплея памяти процедуры (функции) основана на тех же принципах,
что и статическая, но память для локальных данных процедуры выделяется в ней
динамически всякий раз в момент вызова, а по завершении процедуры —
освобождается. Адрес области памяти, связанной с каждой процедурой, в данном
случае уже не может быть фиксированным — его надо каким-либо образом
передать в процедуру (функцию). Для этой цели используется один из регистров
процессора, называемый регистром адресации.
Динамическая
организация дисплея памяти процедуры (функции) основана на тех же принципах,
что и статическая, но память для локальных данных процедуры выделяется в ней
динамически всякий раз в момент вызова, а по завершении процедуры —
освобождается. Адрес области памяти, связанной с каждой процедурой, в данном
случае уже не может быть фиксированным — его надо каким-либо образом
передать в процедуру (функцию). Для этой цели используется один из регистров
процессора, называемый регистром адресации.
Тогда при вызове процедуры необходимо выполнить следующие действия:
□
выделить область памяти, необходимую для хранения
локальных данных про
цедуры,
и запомнить ее адрес;
□
заполнить значения параметров процедуры и адрес
возврата;
□
запомнить состояние регистра адресации в точке вызова;
□
поместить в регистр адресации адрес области памяти
процедуры и передать
управление
процедуре.
После выполнения этих действий может выполняться код вызванной процедуры. Доступ ко всем локальным данным и параметрам в нем осуществляется только через регистр адресации.
При возврате из процедуры необходимо выполнить следующие действия:
□
выбрать из области памяти процедуры адрес возврата (сразу
за точкой вызо
ва) и передать туда управление;
□
освободить область памяти, на которую указывает регистр
адресации;
□
по смещению относительно точки возврата выбрать
сохраненное значение
и
поместить его в регистр адресации.
После этого можно продолжить выполнение кода результирующей программы, следующего за вызовом процедуры.
Данная схема, хотя и допускает рекурсивные вызовы, не получила широкого распространения. Это вызвано целым рядом причин. Во-первых, она требует постоянного динамического перераспределения памяти — это достаточно сложная операция, которая замедляет выполнение вызовов. Во-вторых, такая схема предполагает достаточно сложную схему адресации локальных данных. Наконец, она требует хранения промежуточных данных непосредственно в исполняемом коде программы, что представляет определенную сложность.
В настоящее время эта схема не используется, поскольку уступает почти по всем показателям схеме стековой организации дисплея памяти.
Стековая организация дисплея памяти процедуры (функции) основана на том, что в момент вызова все параметры процедуры и адрес возврата помещаются в единый для всей результирующей программы стек параметров, а при завершении выполнения программы они извлекаются («выталкиваются») из стека. Код процедуры адресуется к локальным данным по смещениям относительно верхушки стека.
Эта схема получила наибольшее распространение в современных компиляторах, поэтому далее она рассмотрена наиболее подробно.
Стековая организация дисплея памяти процедуры (функции)
В этой схеме компилятор организует единый для всей программы стек параметров. Верхушка стека адресуется одним из регистров процессора — регистром стека. Для доступа к данным удобно использовать еще один регистр процессора, называемый базовым регистром. В начале выполнения результирующей программы стек пуст.
Тогда при вызове процедуры необходимо выполнить следующие действия:
□
поместить в стек все параметры процедуры;
□
запомнить в стеке адрес возврата и передать управление
вызываемой проце
дуре;
□
запомнить в стеке значение базового регистра;
□
запомнить состояние регистра стека в базовом регистре;
□
в начале выполнения вызываемой процедуры разместить в
стеке все необхо
димые
ей локальные данные.
После выполнения этих действий может выполняться код вызванной процедуры. Доступ ко всем локальным данным и параметрам в нем может выполняться через базовый регистр (параметры лежат в стеке ниже места, указанного базовым регистром, а локальные переменные и константы — выше места, указанного базовым регистром, но ниже места, указанного регистром стека).
При возврате из процедуры необходимо выполнить следующие действия:
□
выбрать из стека все локальные данные процедуры;
□
выбрать из стека значение базового регистра;
□
выбрать из стека адрес возврата;
□
передать управление по адресу возврата и выбрать из
стека все параметры
процедуры.
После этого можно продолжить выполнение кода результирующей программы; следующего за вызовом процедуры.
На рис. 14.2 показано, как изменяется содержание стека параметров при выполнении трех последовательных вызовов процедур: сначала процедуры А, затем процедуры В и снова процедуры А. При вызовах стек заполняется, а при возврате из кода процедур — освобождается в обратном порядке.
Из рис. 14.2 видно, что при рекурсивном вызове все локальные данные последовательно размещаются в стеке и при этом каждая процедура работает только ее своими данными. Более того, такая схема легко обеспечивает поддержку вызовов вложенных процедур, которые допустимы, например, в языке Pascal.
Стековая организация памяти получила широкое распространение в современных компиляторах. Практически все существующие ныне языки высокого уровня предполагают именно такую схему организации памяти, ее также использукл и в программах на языках ассемблера. Широкое распространение стековой организации дисплея памяти процедур и функций тесно связано также с тем, чте большинство операций, выполняемых при вызове процедуры в этой схеме, pea-
лизованы в виде соответствующих машинных команд во многих современных вычислительных системах. Это, как правило, все операции со стеком параметров, а также команды вызова процедуры (с автоматическим сохранением адреса возврата в стеке) и возврата из вызванной процедуры (с выборкой адреса возврата из стека). Такой подход значительно упрощает и ускоряет выполнение вызовов при стековой организации дисплея памяти процедуры (функции).
Вызов 1 процедуры А Содержимое стека:
Регистр стека
Локальные данные процедуры А
|
-| Базовый регистр | |
![]() Значение базового регистра 1
Значение базового регистра 1
![]() Адрес возврата вызова 1
Адрес возврата вызова 1
![]() Фактические параметры процедуры А
Фактические параметры процедуры А
|
Регистр стека |
![]() Вызов 2 процедуры В Содержимое стека:
Вызов 2 процедуры В Содержимое стека:
![]() Локальные данные процедуры В
Локальные данные процедуры В
|
4—| Базовый регистр | |
![]() Значение базового регистра 2
Значение базового регистра 2
![]() Адрес возврата вызова 2
Адрес возврата вызова 2
![]() Фактические параметры процедуры В
Фактические параметры процедуры В
![]() Локальные данные процедуры А
Локальные данные процедуры А
![]() Значение базового регистра 1
Значение базового регистра 1
![]() Адрес возврата вызова 1
Адрес возврата вызова 1
|
Вызов 3 процедуры А Содержимое стека: |
![]() Фактические параметры процедуры А
Фактические параметры процедуры А
|
Локальные данные процедуры А |
|
Значение базового регистра 3 |
4— Регистр стека
|
Адрес возврата вызова 3 |
[Базовый регистр
Фактические параметры процедуры А
![]() Локальные данные процедуры В
Локальные данные процедуры В
![]() Значение базового регистра 2
Значение базового регистра 2
![]() Адрес возврата вызова 2
Адрес возврата вызова 2
![]() Фактические параметры процедуры В
Фактические параметры процедуры В
![]() Локальные данные процедуры А
Локальные данные процедуры А
![]() Значение базового регистра 1
Значение базового регистра 1
![]() Адрес возврата вызова 1
Адрес возврата вызова 1
![]() Фактические параметры процедуры А
Фактические параметры процедуры А
![]() Рис. 14.2. Содержание стека параметров при выполнении трех последовательных вызовов процедур
Рис. 14.2. Содержание стека параметров при выполнении трех последовательных вызовов процедур
Стековая организация дисплея памяти процедуры позволяет организовать рекурсию вызовов (в отличие от статической схемы) и имеет все преимущества перед динамической схемой. Однако у этой схемы есть один существенный недостаток — память, отводимая под стек параметров, используется неэффективно. Очевидно, что стек параметров должен иметь размер, достаточный для хранения все* параметров, локальных данных и адресов при самом глубоком вложенном вызове процедуры в результирующей программе. Как правило, ни компилятор, ш разработчик программы не могут знать точно, какая максимальная глубина вложенных вызовов процедур возможна в программе. Следовательно, не известие заранее, какая глубина стека потребуется результирующей программе во врем* ее выполнения. Размер стека обычно выбирается разработчиком программы «с за пасом»1, так, чтобы гарантированно обеспечить любую возможную глубину вло женных вызовов процедур и функций. С другой стороны, большую часть време ни своей работы результирующая программа не использует значительную част] стека, значит, и часть оперативной памяти компьютера не используется, так Kai стек параметров сам по себе не может быть использован для других целей.
Стековая организация дисплея памяти процедур и функций присутствует прак тически во всех современных компиляторах. Тем не менее процедуры и функ ции, построенные с помощью одного входного языка высокого уровня, не всегд; могут быть использованы в программах, написанных на другом языке. Дело ] том, что стековая организация определяет основные принципы организации дис плея памяти процедуры, но не определяет механизм реализации данной схемь: В разных входных языках детали реализации этой схемы могут отличаться по рядком помещения параметров процедуры в стек и извлечения из него. Эти во просы определяются в соглашениях о вызове и передаче параметров, принятых различных входных языках программирования.
Параметры могут помещаться в стек в прямом порядке (в порядке их следовг ния в описании процедуры) или в обратном порядке. Извлекаться из стека он могут либо в момент возврата из процедуры (функции), либо непосредственн после возврата2. Кроме того, для повышения эффективности программ и увечения скорости вызова процедур и функций компиляторы могут предусматривать передачу части их параметров не через стек, а через свободные регистры процессора.
Обычно разработчику нет необходимости знать о том, какое соглашение о передаче параметров принято во входном языке программирования. При обработке вызовов внутри текста исходной программы компилятор сам корректно формирует код для выполнения вызовов процедур и функций. Наиболее развитые компиляторы могут варьировать код вызова в зависимости от типа и количества параметров процедуры (функции). Однако если разработчику необходимо использовать процедуры и функции, созданные на основе одного входного языка, в программе на другом входном языке, то компилятор не может знать заранее соглашение о передаче параметров, принятое для этих процедур и функций. В этом случае разработчик должен сам позаботиться о том, чтобы соглашения о передаче параметров в двух языках были согласованы, поскольку несогласованность в передаче параметров может привести к полной неработоспособности результирующей программы. Для этого во многих языках программирования существуют специальные ключевые слова, которые позволяют разработчику явно указать, какое соглашение о передаче параметров будет использовано для той или иной процедуры (функции).
Память для типов данных (RTTI-информация)
Современные компиляторы с объектно-ориентированных языков программирования предусматривают, что результирующая программа может обрабатывать не только переменные, константы и другие структуры данных, но и информацию о типах данных, описанных в исходной программе. Эта информация получила название RTTI — Run Time Type Information — «информация о типах во время выполнения».
Состав RTTI-информации определяется семантикой входного языка и реализацией компилятора. Как правило, для каждого типа данных в объектно-ориентированном языке программирования создается уникальный идентификатор типа данных, который используется для сопоставления типов. Для него может храниться наименование типа, а также другая служебная информация, которая используется компилятором в коде результирующей программы. Вся эта информация может быть в той или иной мере доступна пользователю. Еще одна цель хранения RTTI-информации — обеспечить корректный механизм вызова виртуальных процедур и функций (так называемое «позднее связывание»), предусмотренный во всех объектно-ориентированных языках программирования [8, 34, 35, 76, 71].
RTTI-информация хранится в результирующей программе в виде RTTI-табли-цы. RTTI-таблица представляет собой глобальную статическую структуру данных, которая создается и заполняется в момент начала выполнения результирующей программы. Компилятор с объектно-ориентированного входного языка отвечает за порождение в результирующей программе кода, ответственного за заполнение RTTI-таблицы.
Каждому типу данных в RTTI-таблице соответствует своя область данных, в торой хранится вся необходимая информация об этом типе данных, его взаи связи с другими типами данных в общей иерархии типов данных програм а также все указатели на код виртуальных процедур и функций, связаннь этим типом. Всю эту информацию и указатели размещает для каждого типа; ных в RTTI-таблице код, автоматически порождаемый компилятором.
В принципе всю эту информацию можно было бы разместить непосредстве в памяти, статически или динамически отводимой для каждого экземпляра с екта (класса) того или иного типа. Но поскольку данная информация для i объектов одного и того же типа совпадает, то это привело бы к нерациональн использованию оперативной памяти. Поэтому компилятор размещает всю hhij мацию по типу данных в одном месте, а каждому экземпляру объекта (кла> при выделении памяти для него добавляет только небольшой объем служеб информации, связывающей этот объект с соответствующим ему типом дан (как правило, эта служебная информация является указателем на нужную обл; данных в RTTI-таблице). При статическом распределении памяти под экземг ры объектов (классов) компилятор сам помещает в нее необходимую служеб] информацию, при динамическом распределении — порождает код, который полнит эту информацию во время выполнения программы (поскольку R1 таблица является статической областью данных, адрес ее известен и фика ван).
На рис. 14.3 приведена схема, иллюстрирующая построение RTTI-таблиць! связь с экземплярами объектов в результирующей программе.
Экземпляр объекта типа «Т1»
|
Информация о типе «Т1» |
![]()
![]()
![]() Данные объекта типа'ТГ
Данные объекта типа'ТГ
![]() Экземпляр объекта типа «Т1»
Экземпляр объекта типа «Т1»
|
Данные объекта типа «Т1» |
Информация о типе «Т2»
Экземпляр объекта типа «Т2»
![]()
![]()
![]() Данные объекта типа «Т2»
Данные объекта типа «Т2»
![]() Рис. 14.3. Взаимосвязь RTTI-таблицы с экземплярами объектов в результирующей программе
Рис. 14.3. Взаимосвязь RTTI-таблицы с экземплярами объектов в результирующей программе
Компилятор всегда сам автоматически строит код, ответственный в резул рующей программе за создание и заполнение RTTI-таблицы и за ее взаимос: с экземплярами объектов (классов) различных типов. Разработчику не надс
![]()
![]() ботиться об этом, тем
более что он, как правило, не может воздействовать на служебную информацию,
помещаемую компилятором в RTTI-таблицу.
ботиться об этом, тем
более что он, как правило, не может воздействовать на служебную информацию,
помещаемую компилятором в RTTI-таблицу.
Проблемы могут появиться в том случае, когда некоторая программа взаимодействует с динамически загружаемой библиотекой. При этом могут возникнуть ситуации, вызванные несоответствием типов данных в программе и библиотеке, хотя и та и другая могут быть построены на одном и том же входном языке с помощью одного и того же компилятора. Дело в том, что код инициализации программы, порождаемый компилятором, ответственен за создание и заполнение своей RTTI-таблицы, а код инициализации библиотеки, порождаемый тем же компилятором, — своей RTTI-таблицы. Если программа и динамически загружаемая библиотека работают с одними и теми же типами данных, то эти RTTI-таблицы будут полностью совпадать, но при этом они не будут одной и той же таблицей. Это уже должен учитывать разработчик программы при проверке соответствия типов данных.
Еще большие сложности могут возникнуть, если программа, построенная на основе входного объектно-ориентированного языка программирования, будет взаимодействовать с библиотекой или программой, построенной на основе другого объектно-ориентированного языка (или даже построенной на том же языке, но с помощью другого компилятора). Поскольку формат RTTI-таблиц и состав хранимой в них служебной информации не специфицированы для всех языков программирования, то они полностью зависят от используемой версии компилятора. Соответствующим образом различается и порождаемый компилятором код результирующей программы. В общем случае организовать такого рода взаимодействие между двумя фрагментами кода, порожденного двумя различными компиляторами, напрямую практически невозможно (о других возможностях такого рода взаимодействия см. в разделе «Примеры современных систем программирования», глава 15).
9. Генерация кода. Методы генерации кода. Общие
принципы генерации кода. Оптимизация линейных участков программы.
Машинно-зависимые методы оптимизации.
Генерация кода. Методы генерации кода
Общие принципы генерации кода. Синтаксически управляемый перевод
Генерация объектного кода — это перевод компилятором внутреннего представления исходной программы в цепочку символов выходного языка. Генерация объектного кода порождает результирующую объектную программу на языке ассемблера или непосредственно на машинном языке (в машинных кодах). Внутреннее представление программы может иметь любую структуру в зависимости от реализации компилятора, в то время как результирующая программа всегда представляет собой линейную последовательность команд. Поэтому генерация объектного кода (объектной программы) в любом случае должна выполнять действия, связанные с преобразованием сложных синтаксических структур в линейные цепочки.
Генерацию кода можно считать функцией, определенной на синтаксическом реве и на информации, содержащейся в таблице идентификаторов. Поэтому нерация объектного кода выполняется после того, как выполнен синтаксичесь анализ программы и все необходимые действия по подготовке к генерации кс распределено адресное пространство под функции и переменные, провере соответствие имен и типов переменных, констант и функций в синтаксичеа конструкциях исходной программы и т. д. Характер отображения входной п граммы в последовательность команд, выполняемого генерацией, зависит от вх ного языка, архитектуры вычислительной системы, на которую ориентиров; результирующая программа, а также от качества желаемого объектного кода.
В идеале компилятор должен выполнить синтаксический разбор всей вход! программы, затем провести ее семантический анализ, после чего приступит подготовке генерации и непосредственно генерации кода. Однако такая схема боты компилятора практически почти никогда не применяется. Дело в том, в общем случае ни один семантический анализатор и ни один компилятор способны проанализировать и оценить смысл всей входной программы в цел Формальные методы анализа семантики применимы только к очень незна тельной части возможных входных программ. Поэтому у компилятора нет пр тической возможности порождать эквивалентную выходную программу на ос ве всей входной программы.
Как правило, компилятор выполняет генерацию результирующего кода поэтаг на основе законченных синтаксических конструкций входной программы. К пилятор выделяет законченную синтаксическую конструкцию из текста вход] программы, порождает для нее фрагмент результирующего кода и помещает в текст выходной программы. Затем он переходит к следующей синтаксичес: конструкции. Так продолжается до тех пор, пока не будет разобрана вся вход программа. В качестве анализируемых законченных синтаксических констр ций выступают операторы, блоки операторов, описания процедур и функций, конкретный состав зависит от входного языка и реализации компилятора.
Смысл (семантику) каждой такой синтаксической конструкции входного яз: можно определить, исходя из ее типа, а тип определяется синтаксическим ана затором на основании грамматики входного языка. Примерами типов сит сических конструкций могут служить операторы цикла, условные оператс операторы выбора и т. д. Одни и те же типы синтаксических конструкций ха{ терны для различных языков программирования, при этом они различаю синтаксисом (который задается грамматикой языка), но имеют схожий см (который определяется семантикой). В зависимости от типа синтаксичес конструкции выполняется генерация кода результирующей программы, соот! ствующего данной синтаксической конструкции. Для семантически схожих i струкций различных входных языков программирования может порождаться повой результирующий код.
Чтобы компилятор мог построить код результирующей программы для синг сической конструкции входного языка, часто используется метод, называем синтаксически управляемым переводом — СУ-переводом. СУ-перевод — это новной метод порождения кода результирующей программы на основании зультатов синтаксического разбора. Для удобства понимания сути метода можно считать, что результат синтаксического разбора представлен в виде дерева синтаксического разбора (либо же дерева операций), хотя в реальных компиляторах это не всегда так.
Суть принципа СУ-перевода заключается в следующем: с каждой вершиной дерева синтаксического разбора N связывается цепочка некоторого промежуточного кода C(N). Код для вершины N строится путем сцепления (конкатенации) в фиксированном порядке последовательности кода C(N) и последовательностей кодов, связанных со всеми вершинами, являющимися прямыми потомками N. В свою очередь, для построения последовательностей кода прямых потомков вершины N потребуется найти последовательности кода для их потомков — потомков второго уровня вершины N — и т. д. Процесс перевода идет, таким образом, снизу вверх в строго установленном порядке, определяемом структурой дерева.
Для того чтобы построить СУ-перевод по заданному дереву синтаксического разбора, необходимо найти последовательность кода для корня дерева. Поэтому для каждой вершины дерева порождаемую цепочку кода надо выбирать таким образом, чтобы код, приписываемый корню дерева, оказался искомым кодом для всего оператора, представленного этим деревом. В общем случае необходимо иметь единообразную интерпретацию кода C(N), которая бы встречалась во всех ситуациях, где присутствует вершина N. В принципе эта задача может оказаться нетривиальной, так как требует оценки смысла (семантики) каждой вершины дерева. При применении СУ-перевода задача интерпретации кода для каждой вершины дерева решается только разработчиком компилятора.
Возможна модель компилятора, в которой синтаксический анализ входной программы и генерация кода результирующей программы объединены в одну фазу. Такую модель можно представить в виде компилятора, у которого операции генерации кода совмещены с операциями выполнения синтаксического разбора. Для описания компиляторов такого типа часто используется термин «СУ-ком-пиляция» (синтаксически управляемая компиляция).
Схему СУ-компиляции можно реализовать не для всякого входного языка программирования. Если принцип СУ-перевода применим ко всем входным КС-языкам, то применить СУ-компиляцию оказывается не всегда возможным. Однако известно, что схемы перевода на основе СУ-компиляции можно построить для многих из широко распространенных классов КС-языков, в частности для LR- и LL-языков [6, 15].
В процессе СУ-перевода и СУ-компиляции не только вырабатываются цепочки текста выходного языка, но и совершаются некоторые дополнительные действия, выполняемые самим компилятором. В общем случае схемы СУ-перевода могут предусматривать выполнение следующих действий:
□
помещение в выходной поток данных машинных кодов или
команд ассембле
ра,
представляющих собой результат работы (выход) компилятора;
□
выдача пользователю сообщений об обнаруженных ошибках и
предупрежде
ниях
(которые должны помещаться в выходной поток, отличный от потока,
используемого
для команд результирующей программы);
□ порождение и выполнение команд, указывающих, что
некоторые дейст
должны быть произведены самим компилятором (например, операции,
полняемые над данными, размещенными
в таблице идентификаторов).
Ниже рассмотрены основные технические вопросы, позволяющие реализо! схемы СУ-перевода и СУ-компиляции. Но прежде чем рассматривать их, ш ходимо разобраться со способами внутреннего представления программы в к пиляторе. От того, как исходная программа представляется внутри компилят во многом зависят методы, используемые для обработки команд этой програми
Способы внутреннего представления программ
Возможны различные формы внутреннего представления синтаксических ко рукций исходной программы в компиляторе. На этапе синтаксического раз( часто используется форма, именуемая деревом вывода (методы его построе рассматривались выше). Но формы представления, используемые на этапах i таксического анализа, оказываются неудобными в работе при генерации и о; мизации объектного кода. Поэтому перед оптимизацией и непосредственно ред генерацией объектного кода внутреннее представление программы мс преобразовываться в одну из соответствующих форм записи.
Все внутренние представления программы обычно содержат в себе две при] пиально различные вещи — операторы и операнды. Различия между фор?* внутреннего представления заключаются лишь в том, как операторы и one ды соединяются между собой. Также операторы и операнды должны отлича друг от друга, если они встречаются в любом порядке. За различение onepai и операторов, как уже было сказано выше, отвечает разработчик компиляч который руководствуется семантикой входного языка.
Известны следующие формы внутреннего представления программ1:
□
связочные списочные структуры, представляющие
синтаксические дерев
□
многоадресный код с явно именуемым результатом
(тетрады);
□
многоадресный код с неявно именуемым результатом
(триады);
□
обратная (постфиксная) польская запись операций;
□
ассемблерный код или машинные команды.
В каждом конкретном компиляторе может использоваться одна из этих <J выбранная разработчиками. Но чаще всего компилятор не ограничиваете;
пользованием только одной формы для внутреннего представления программы. На различных фазах компиляции могут использоваться различные формы, которые по мере выполнения проходов компилятора преобразуются одна в другую. Не все из перечисленных форм широко используются в современных компиляторах, и об этом будет сказано по мере их рассмотрения.
Некоторые компиляторы, незначительно оптимизирующие результирующий код, генерируют объектный код по мере разбора исходной программы. В этом случае применяется схема СУ-компиляции, когда фазы синтаксического разбора, семантического анализа, подготовки и генерации объектного кода совмещены в одном проходе компилятора. Тогда внутреннее представление программы существует только условно в виде последовательности шагов алгоритма разбора. В любом случае компилятор всегда будет работать с представлением программы в форме машинных команд — иначе он не сможет построить результирующую программу.
Далее все перечисленные формы представления рассматриваются более подробно.
Синтаксические деревья
Синтаксические деревья уже были рассмотрены выше. Это структура, представляющая собой результат работы синтаксического анализатора. Она отражает синтаксис конструкций входного языка и явно содержит в себе полную взаимосвязь операций. Очевидно также, что синтаксические деревья — это машинно-независимая форма внутреннего представления программы.
Недостаток синтаксических деревьев заключается в том, что они представляют собой сложные связные структуры, а потому не могут быть тривиальным образом преобразованы в линейную последовательность команд результирующей программы. Тем не менее они удобны при работе с внутренним представлением программы на тех этапах, когда нет необходимости непосредственно обращаться к командам результирующей программы.
Синтаксические деревья могут быть преобразованы в другие формы внутреннего представления программы, представляющие собой линейные списки, с учетом семантики входного языка. Алгоритмы такого рода преобразований рассмотрены далее. Эти преобразования выполняются на основе принципов СУ-компиляции.
Многоадресный код с явно именуемым результатом (тетрады)
Тетрады представляют собой запись операций в форме из четырех составляющих: операция, два операнда и результат операции. Например, тетрады могут выглядеть так: <операция>(<операнд1>,<операнд2>,<результат>).
Тетрады представляют собой линейную последовательность команд. При вычислении выражения, записанного в форме тетрад, они вычисляются одна за другой последовательно. Каждая тетрада в последовательности вычисляется так: операция, заданная тетрадой, выполняется над операндами и результат ее выполнения помещается в переменную, заданную результатом тетрады. Если какой-то из операндов (или оба операнда) в тетраде отсутствует (например, если тетрада представляет собой унарную операцию), то он может быть опущен или заменен пустым операндом (в зависимости от принятой формы записи и ее реализации).
Результат вычисления тетрады никогда опущен быть не может, иначе тетрад полностью теряет смысл. Порядок вычисления тетрад может быть изменен, н только если допустить наличие тетрад, целенаправленно изменяющих этот пор; док (например, тетрады, вызывающие переход на несколько шагов вперед ил назад при каком-то условии).
Тетрады представляют собой линейную последовательность, а потому для ни несложно написать тривиальный алгоритм, который будет преобразовыват последовательность тетрад в последовательность команд результирующей пр< граммы (либо последовательность команд ассемблера). В этом их преимущестг перед синтаксическими деревьями. А в отличие от команд ассемблера тетрад не зависят от архитектуры вычислительной системы, на которую ориентирован результирующая программа. Поэтому они представляют собой машинно-незав! симую форму внутреннего представления программы.
Тетрады требуют больше памяти для своего представления, чем триады, они та] же не отражают явно взаимосвязь операций между собой. Кроме того, есть ело? ности с преобразованием тетрад в машинный код, так как они плохо отображ ются в команды ассемблера и машинные коды, поскольку в наборах кома? большинства современных компьютеров редко встречаются операции с трек операндами.
Например, выражение A:=B*C+D-B*10, записанное в виде тетрад, будет иметь ви,
1. * ( В, С, Т1 )
2.
+ ( Tl.D, Т2 )
3.
* ( В. 10,ТЗ )
4.
- ( Т2.ТЗ.Т4 )
5.
:= ( Т4,0, А )
Здесь все операции обозначены соответствующими знаками (при этом приевс
ние также является операцией). Идентификаторы Т1.. Т4 обозначают време
ные переменные, используемые для хранения результатов вычисления тетрг Следует обратить внимание, что в последней тетраде (присвоение), которая тр бует только одного операнда, в качестве второго операнда выступает незначащ] операнд «0».
Многоадресный код с неявно именуемым результатом (триады)
Триады представляют собой запись операций в форме из трех составляющ! операция и два операнда. Например, триады могут иметь вид: <операция>(<операнд! <операнд2>). Особенностью триад является то, что один или оба операнда мог быть ссылками на другую триаду в том случае, если в качестве операнда данн триады выступает результат выполнения другой триады. Поэтому триады п записи последовательно нумеруют для удобства указания ссылок одних триад другие (в реализации компилятора в качестве ссылок можно использовать не i мера триад, а непосредственно ссылки в виде указателей — тогда при изменен нумерации и порядка следования триад менять ссылки не требуется).
Триады представляют собой линейную последовательность команд. При вычислении выражения, записанного в форме триад, они вычисляются одна за другой последовательно. Каждая триада в последовательности вычисляется так: операция, заданная триадой, выполняется над операндами, а если в качестве одного из операндов (или обоих операндов) выступает ссылка на другую триаду, то берется результат вычисления той триады. Результат вычисления триады нужно сохранять во временной памяти, так как он может быть затребован последующими триадами. Если какой-то из операндов в триаде отсутствует (например, если триада представляет собой унарную операцию), то он может быть опущен или заменен пустым операндом (в зависимости от принятой формы записи и ее реализации). Порядок вычисления триад, как и для тетрад, может быть изменен, но только если допустить наличие триад, целенаправленно изменяющих этот порядок (например, триады, вызывающие переход на несколько шагов вперед или назад при каком-то условии).
Триады представляют собой линейную последовательность, а потому для них несложно написать тривиальный алгоритм, который будет преобразовывать последовательность триад в последовательность команд результирующей программы (либо последовательность команд ассемблера). В этом их преимущество перед синтаксическими деревьями. Однако здесь требуется также и алгоритм, отвечающий за распределение памяти, необходимой для хранения промежуточных результатов вычисления, так как временные переменные для этой цели не используются. В этом отличие триад от тетрад.
Так же как и тетрады, триады не зависят от архитектуры вычислительной системы, на которую ориентирована результирующая программа. Поэтому они представляют собой машинно-независимую форму внутреннего представления программы.
Триады требуют меньше памяти для своего представления, чем тетрады, они также явно отражают взаимосвязь операций между собой, что делает их применение удобным. Необходимость иметь алгоритм, отвечающий за распределение памяти для хранения промежуточных результатов, не является недостатком, так как удобно распределять результаты не только по доступным ячейкам временной памяти, но и по имеющимся регистрам процессора. Это дает определенные преимущества. Триады ближе к двухадресным машинным командам, чем тетрады, а именно эти команды более всего распространены в наборах команд большинства современных компьютеров.
Например, выражение A:=B*C+D-B*10, записанное в виде триад, будет иметь вид:
1. * ( В, С
)
2.
+
П, D )
3.
*
( В, 10
)
4.
-
Г2, Л3 )
5.
:= ( А, А4 )
Здесь операции обозначены соответствующим знаком (при этом присвоение также является операцией), а знак Л означает ссылку операнда одной триады на результат другой.
Обратная польская запись операций
Обратная (постфиксная) польская запись — очень удобная для вычисления выражений форма записи операций и операндов. Эта форма предусматривает, что знаки операций записываются после операндов. Более подробно обратная польская запись рассмотрена далее.
Ассемблерный код и машинные команды
Машинные команды удобны тем, что при их использовании внутреннее представление программы полностью соответствует объектному коду и сложные преобразования не требуются. Команды ассемблера представляют собой лишь форм} записи машинных команд (см. раздел «Трансляторы, компиляторы и интерпре таторы — общая схема работы», глава 13), а потому в качестве формы внутренне го представления программы практически ничем не отличаются от них. Однако использование команд ассемблера или машинных команд для внутрен него представления программы требует дополнительных структур для отображе ния взаимосвязи операций. Очевидно, что в этом случае внутреннее представле ние программы получается зависимым от архитектуры вычислительной системы на которую ориентирован результирующий код. Значит, при ориентации ком пилятора на другой результирующий код потребуется перестраивать как сам! внутреннее представление программы, так и методы его обработки (при исполь зовании триад или тетрад этого не требуется).
Тем не менее машинные команды — это язык, на котором должна быть записан результирующая программа. Поэтому компилятор так или иначе должен рабе тать с ними. Кроме того, только обрабатывая машинные команды (или их npe/i ставление в форме команд ассемблера), можно добиться наиболее эффективно результирующей программы (см. далее в разделе «Оптимизация кода. Основны методы оптимизации»). Отсюда следует, что любой компилятор работает с npez ставлением результирующей программы в форме машинных команд, однак их обработка происходит, как правило, на завершающих этапах фазы генераци кода.
Обратная польская запись операций
Обратная польская запись — это постфиксная запись операций. Она была пре; ложена польским математиком Я. Лукашевичем, откуда и происходит ее назв; ние [6, т. 2, 23, 82]1.
В этой записи знаки операций записываются непосредственно за операндами. Г сравнению с обычной (инфиксной) записью операций в польской записи оп ранды следуют в том же порядке, а знаки операций — строго в порядке их bi
полнения. Тот факт, что в этой форме записи все операции выполняются в том порядке, в котором они записаны, делает ее чрезвычайно удобной для вычисления выражений на компьютере. Польская запись не требует учитывать приоритет операций, в ней не употребляются скобки, и в этом ее основное преимущество.
Она чрезвычайно эффективна в тех случаях, когда для вычислений используется стек. Ниже будет рассмотрен алгоритм вычисления выражений в форме обратной польской записи с использованием стека.
Главный недостаток обратной польской записи также проистекает из метода вычисления выражений в ней: поскольку используется стек, то для работы с ним всегда доступна только верхушка стека, а это.делает крайне затруднительной оптимизацию выражений в форме обратной польской записи. Практически выражения в форме обратной польской записи почти не поддаются оптимизации.
Но там, где оптимизация вычисления выражений не требуется или не имеет большого значения, обратная польская запись оказывается очень удобным методом внутреннего представления программы.
Обратная польская запись была предложена первоначально для записи арифметических выражений. Однако этим ее применение не ограничивается. В компиляторе можно порождать код в форме обратной польской записи для вычисления практически любых выражений1. Для этого достаточно ввести знаки, предусматривающие вычисление соответствующих операций. В том числе, возможно ввести операции условного и безусловного перехода, предполагающие изменение последовательности хода вычислений и перемещение вперед или назад на некоторое количество шагов в зависимости от результата на верхушке стека [6, т. 2, 74, 82]. Такой подход позволяет очень широко применять форму обратной польской записи.
Преимущества и недостатки обратной польской записи определяют и сферу ее применения. Так, она очень широко используется для вычисления выражений в интерпретаторах и командных процессорах, где оптимизация вычислений либо отсутствует вовсе, либо не имеет существенного значения.
Вычисление выражений с помощью обратной польской записи
Вычисление выражений в обратной польской записи идет элементарно просто с помощью стека. Для этого выражение просматривается в порядке слева направо, и встречающиеся в нем элементы обрабатываются по следующим правилам:
1.
Если встречается операнд, то он помещается в стек
(попадает на верхушку
стека).
2.
Если встречается знак унарной операции (операции,
требующей одного опе
ранда),
то операнд выбирается с верхушки стека, операция выполняется
и
результат помещается в стек (попадает на верхушку стека).
3. Если встречается знак бинарной операции (операции, требующей двух one рандов), то два операнда выбираются с верхушки стека, операция выполняв! ся и результат помещается в стек (попадает на верхушку стека).
Вычисление выражения заканчивается, когда достигается конец записи выраже
ния. Результат вычисления при этом всегда находится на верхушке стека.
Очевидно, что данный алгоритм можно легко расширить и для более сложны
операций, требующих три и более операндов.
На рис. 14.4 рассмотрены примеры вычисления выражений в обратной польско
записи.
|
6 |
|
7 |
|
10 |
|
4 |
|
+ |
|
* |
|
+ |
|
4 |
||||||||||||
|
10 |
10 |
14 |
||||||||||
|
7 |
7 |
7 |
7 |
98 |
||||||||
|
6 |
6 |
6 |
6 |
6 |
6 |
104 |
Вычисление выражения 6+7* (10+4) = 104
6 7 10 + 4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
4 |
|||||||||||
|
7 |
7 |
17 |
17 |
68 |
||||||||
|
6 |
6 |
6 |
6 |
6 |
6 |
74 |
![]() Вычисление выражения 6+(7+10) * 4=74
Вычисление выражения 6+(7+10) * 4=74
6 7 + 10 4
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
||||||||||||
|
7 |
10 |
10 |
40 |
|||||||||
|
6 |
6 |
13 |
13 |
13 |
13 |
53 |
![]() Вычисление выражения 6+7+10 * 4 = 53
Вычисление выражения 6+7+10 * 4 = 53
Рис. 14.4. Вычисление выражений в обратной польской записи с использованием стека
Схема СУ-компиляции для перевода выражений в обратную польскую запись
Существует множество алгоритмов, которые позволяют преобразовывать вьц жения из обычной (инфиксной) формы записи в обратную польскую запись. Далее рассмотрен алгоритм, построенный на основе схемы СУ-компиляции д языка арифметических выражений с операциями +, -, * и /. В качестве осно алгоритма выбрана грамматика арифметических выражений, которая уже мно: кратно рассматривалась ранее в качестве примера. Эта грамматика приведена далее.
![]()
![]() G({+.-./.*,a.b}. {S.T.E}. P. S): ' :
G({+.-./.*,a.b}. {S.T.E}. P. S): ' :
Р:
s -» s+т | s-т |
т • ■ ■ '
Т -» Т*Е | Т/Е | Е Е -> (S) | а | b
Схему СУ-компиляции будем строить с таким расчетом, что имеется выходная цепочка символов R и известно текущее положение указателя в этой цепочке р. Распознаватель, выполняя свертку или подбор альтернативы по правилу грамматики, может записывать символы в выходную цепочку и менять текущее положение указателя в ней.
Построенная таким образом схема СУ-компиляции для преобразования арифметических выражений в форму обратной польской записи оказывается исключительно простой [6, т. 2]. Она приведена ниже. В ней с каждым правилом грамматики связаны некоторые действия, которые записаны через ; (точку с запятой) сразу за правой частью каждого правила. Если никаких действий выполнять не нужно, в записи следует пустая цепочка (X).
S ->■ S+T; R(p) - "+". р=р+1
S -> S-T: R(p) = "-". р=р+1 ■ . .
S -> Т; X
Т -> Т*Е: R(p) = "*". р=р+1
Т -> Т/Е: R(p) = V". р=р+1
Т -> Е: к
Е -> (S); X
Е -> a; R(p) - "а". р=р+1
Е -> b: R(p) - "b". p=p+l
Эту схему СУ-компиляции можно использовать для любого распознавателя без возвратов, допускающего разбор входных цепочек на основе правил данной грамматики (например, для распознавателя на основе грамматики операторного предшествования, рассмотренного в разделе «Восходящие распознаватели КС-языков без возвратов», глава 12). Тогда, в соответствии с принципом СУ-перево-да, каждый раз выполняя свертку на основе некоторого правила, распознаватель будет выполнять также и действия, связанные с этим правилом. В результате его работы будет построена цепочка R, содержащая представление исходного выражения в форме обратной польской записи (строго говоря, в данном случае автомат будет представлять собой уже не только распознаватель, но и преобразователь цепочек [6, 42]).
Представленная схема СУ-компиляции, с одной стороны, иллюстрирует, насколько просто выполнить преобразование выражения в форму обратной польской записи, а с другой стороны, демонстрирует, как на практике работает сам принцип СУ-компиляции.
Схемы СУ-перевода
Выше был описан принцип СУ-перевода, позволяющий получить линейную последовательность команд результирующей программы или внутреннего пред-
ставления программы в компиляторе на основе результатов синтаксическо] разбора. Теперь построим вариант алгоритма генерации кода, который получа! на входе дерево операций и создает по нему фрагмент объектного кода для л: нейного участка результирующей программы. Рассмотрим примеры схем СУ-п ревода для арифметических операций. Эти схемы достаточно просты, и на i основе можно проиллюстрировать, как выполняется СУ-перевод в компилято при генерации кода.
В качестве формы представления результатов синтаксического разбора возьм< дерево операций (метод построения дерева операций рассмотрен выше). Для п строения внутреннего представления объектного кода (в дальнейшем — прос кода) по дереву операций может использоваться простейшая рекурсивная пр цедура обхода дерева. Можно использовать и другие методы обхода дерева важно, чтобы соблюдался принцип, что нижележащие операции в дереве всег выполняются перед вышележащими операциями (порядок выполнения опе{ ций одного уровня не важен, он не влияет на результат и зависит от порядка с хода вершин дерева).
Процедура генерации кода по дереву операций прежде всего должна опрс лить тип узла дерева. Он соответствует типу операции, символом которой noi чен узел дерева. После определения типа узла процедура строит код для узла, рева в соответствии с типом операции. Если все узлы следующего уровня р текущего узла есть листья дерева, то в код включаются операнды, соответств> щие этим листьям, и получившийся код становится результатом выполнен процедуры. Иначе процедура должна рекурсивно вызвать сама себя для гене ции кода нижележащих узлов дерева и результат выполнения включить в ci порожденный код. Фактически процедура генераций кода должна для кажд узла дерева выполнить конкатенацию цепочек команд, связанных с текущим лом и с нижележащими узлами. Конкатенация цепочек выполняется таким об зом, чтобы операции, связанные с нижележащими узлами, выполнялись до i полнения операции, связанной с текущим узлом.
Поэтому для построения внутреннего представления объектного кода по дер вывода в первую очередь необходимо разработать формы представления объе ного кода для четырех случаев, соответствующих видам текущего узла дер
■ вывода:
□
оба нижележащих узла дерева — листья, помеченные
операндами;
□
только левый нижележащий узел является листом дерева;
□
только правый нижележащий узел является листом дерева;
□
оба нижележащих узла не являются листьями дерева.
Рассмотрим построение двух видов внутреннего представления по дереву вода:
□
построение списка триад по дереву вывода;
□
построение ассемблерного кода по дереву вывода. •> ?
Далее рассматриваются две функции, реализующие схемы СУ-перевода для i дого их этих случаев.
![]()
![]() Пример схемы СУ-перевода дерева операций на язык ассемблера
Пример схемы СУ-перевода дерева операций на язык ассемблера
В качестве языка ассемблера возьмем язык ассемблера процессоров типа Intel 80x86. При этом будем считать, что операнды могут быть помещены в 16-разрядные регистры процессора и в коде результирующей объектной программы могут использоваться регистры АХ (аккумулятор) и DX (регистр данных), а также стек для хранения промежуточных результатов.
Функцию, реализующую перевод узла дерева в последовательность команд ассемблера, назовем Code. Входными данными функции должна быть информация об узле дерева операций. В ее реализации на каком-либо языке программирования эти данные можно представить в виде указателя на соответствующий узел дерева операций. Выходными данными является последовательность команд языка ассемблера. Будем считать, что она передается в виде строки, возвращаемой в качестве результата функции.
Тогда четырем формам текущего узла дерева для каждой арифметической операции будут соответствовать фрагменты кода на языке ассемблера, приведенные в табл. 14.1.
Каждой допустимой арифметической операции будет соответствовать своя команда на языке ассемблера. Если взять в качестве примера операции сложения (+), вычитания (-), умножения (*) и деления (/), то им будут соответствовать команды add, sub, mul и div. Причем в ассемблере Intel 80x86 от типа операции зависит не только тип, но и синтаксис команды (операции mul и di v в качестве первого операнда всегда предполагают регистр процессора АХ, который не нужно указывать в команде). Соответствующая команда должна записываться вместо act при порождении кода в зависимости от типа узла дерева.
Таблица 14.1. Преобразование узлов дерева вывода в код
на языке ассемблера для арифметических операций
|
Вид узла дерева |
Результирующий код |
Примечание |
|||||
|
|
|
|
|
mov ax, operl act ax, oper2 |
act — команда соответствующей операции |
||
|
|
act |
|
|||||
|
/ |
|
Ч |
|||||
|
орег 1 |
|
|
|
орег 2 |
|
operl, oper2 — операнды (листья дерева) |
|
|
|
|
|
|
|
|||
|
|
|
|
|
Code (Узел 2) mov dx, ax mov ax, operl |
Узел 2 -нижележащий узел (не лист!) дерева |
||
|
|
act |
|
|||||
|
/ |
|
\ |
|||||
|
орег 1 |
|
|
|
Узел 2 |
|
act ax, dx |
Code (Узел 2) -код, порождаемый процедурой для нижележащего узла |
Теперь последовательность порождаемого кода определена для всех возможных типов узлов дерева.
|
|

|
U5 |
Рассмотрим в качестве примера выражение A:=B*C+D-B*10. Соответствующее ему дерево вывода приведено на рис. 14.5.
Рис. 14.5. Дерево операций для арифметического выражения «A:=B*C+D-B*10»
|
Шаг1. Шаг 2. |
Построим последовательность команд языка ассемблера, соответствующую дереву операций на рис. 14.5. Согласно принципу СУ-перевода, построение начинается от корня дерева. Для удобства иллюстрации рекурсивного построения последовательности команд все узлы дерева помечены от U1 до U5. Рассмотрим последовательность построения цепочки команд языка ассемблера по шагам рекурсии. Эта последовательность приведена ниже.
Code(U2) mov A, ax
Code(U3) push ax Code(U5) mov dx, ax pop ax sub ax, dx mov A, ax
|
ШагЗ. |
Code(U4) add ax. D push ax Code(U5) mov dx. ax pop ax sub ax, dx mov A,ax
|
Шаг 4. |
mov ax, В mul С add ax. D
|
push |
ax |
|
Code(U5) |
|
|
mo dx, ax |
|
|
pop |
ax |
|
sub |
ax. dx |
|
mov |
A, ax |
|
mov |
ax, В |
|
mul |
С |
|
add |
ax, D |
|
push |
ax |
|
mov |
ax, В |
|
mul |
10 |
|
mov |
dx, ax |
|
pop |
ax |
|
sub |
ax, dx |
|
mov |
A, ax |
Полученный объектный код на языке ассемблера, очевидно, может быть оптим зирован. Вопросы оптимизации результирующего кода рассмотрены далее в ра деле «Оптимизация кода. Основные методы оптимизации».
В рассмотренном примере при порождении кода преднамеренно не были прин ты во внимание многие вопросы, возникающие при построении реальных ко; пиляторов. Это было сделано для упрощения примера. Например, фрагмеш кода, соответствующие различным узлам дерева, принимают во внимание ti операции, но никак не учитывают тип операндов. А в языке ассемблера опера дам различных типов соответствуют существенно различающиеся команды, м гут использоваться различные регистры (например, если сравнить операции целыми числами и числами с плавающей точкой). Некоторые типы операнд! (например, строки) не могут быть обработаны одной командой языка, а требу* целой последовательности команд. Такую последовательность разумнее оформи в виде функции библиотеки языка, тогда выполнение операции будет предста лять собой вызов этой функции.
Кроме того, ориентация на определенный язык ассемблера, очевидно, сводит i нет универсальность метода. Каждый тип операций жестко связывается с поел довательностью определенных команд, ориентированных на некоторую архите туру вычислительной системы.
Все эти требования ведут к тому, что в реальном компиляторе при генерации к да надо принимать во внимание очень многие особенности, зависящие как от с мантики входного языка, так и от архитектуры целевой вычислительной систем на которой будет выполняться результирующая программа. В результате увел: чится число различных типов узлов дерева, каждому из которых будет соотве ствовать своя последовательность команд. Это может осложнить алгоритм ген рации кода, что особенно нежелательно в том случае, если порождаемый код ] является окончательным и требует дальнейшей обработки.
Указанных проблем можно избежать, если порождать код не в виде цепочки команд ассемблера, а в виде последовательности команд машинно-независимого метода внутреннего представления программы — например, тетрад или триад.
Пример схемы СУ-перевода дерева операций в последовательность триад
Как и в случае с порождением команд ассемблера, функцию, реализующую перевод узла дерева в последовательность триад, назовем Code. Входные и выходные данные у этой функции будут те же, что и при работе с командами ассемблера. Триады являются машинно-независимой формой внутреннего представления в компиляторе результирующей объектной программы, а потому не требуют оговорки дополнительных условий при генерации кода. Триады взаимосвязаны между собой, поэтому для установки корректной взаимосвязи функция генерации кода должна учитывать также текущий номер очередной триады (i). Будем рассматривать те же варианты узлов дерева, что и для команд ассемблера. Тогда четырем формам текущего узла дерева будут соответствовать последовательности триад объектного кода, приведенные в табл. 14.3.
Таблица 14.3. Преобразование типовых узлов дерева вывода в последовательность триад
|
Вид узла дерева |
Результирующий код |
Примечание |
|||||||||||
|
|
act |
ч |
i) act (operl, oper2) |
act — тип триады operl, oper2 — операнды (листья дерева вывода) |
|||||||||
|
/ |
|
||||||||||||
|
operl |
|
1 |
орег 2 |
||||||||||
|
|
act |
|
i) Code (Узел 2, i) |
Узел 2 — нижележащий узел дерева вывода |
|||||||||
|
/ |
ч |
i+j) act |
Code (Узел 2, i) - |
||||||||||
|
орег 1 |
|
|
Узел 2 |
(operl, Ai+j-l) |
последовательность триад, порождаемая |
||||||||
|
|
|
для Узла 2, начиная с триады с номером i, j — количество триад, порождаемых для Узла 2 |
|||||||||||
|
|
act |
|
i) Code (Узел 2, i) |
Узел 2 — нижележащий узел дерева вывода |
|||||||||
|
|
i+j) act |
Code (Узел 2, i) - |
|||||||||||
|
Узел 2 |
[ |
|
орег 2 |
(Ai+j-l, oper2) |
триад, порождаемая |
||||||||
|
|
|
для Узла 2, начиная с триады с номером i, j — количество триад, порождаемых для Узла 2 |
|||||||||||
|
Вид узла дерева |
Результирую- |
Примечание |
|||||||||||
|
|
щий код |
|
|||||||||||
|
|
act |
|
i) Code |
Узел 2, Узел 3 - |
|
||||||||
|
|
|
|
|
(Узел 2, i) |
нижележащие узлы |
|
|||||||
|
/ |
|
\ |
|
||||||||||
|
/ \ |
i+j) Code |
дерева вывода |
|
||||||||||
|
Узел 2 |
|
УзелЗ |
(Узел 3, i+j) |
Code (Узел 2, i) - T"f f\f* П О TT/^TU *"1 ф£^ ТТ TL Г 1 /~Ч^**Т"Т |
|
||||||||
|
|
i+j+k) act |
1ЮСЛеДиВа1сЛЬНОС1 Ь |
|
||||||||||
|
|
П+j-l, |
триад, порождаемая |
|
||||||||||
|
|
Ai+j+k-l) |
для Узла 2, начиная |
|
||||||||||
|
|
|
с триады с номером i, |
|
||||||||||
|
|
|
j — количество триад, |
|
||||||||||
|
|
|
порождаемых для Узла 2 |
|
||||||||||
|
|
|
Code (Узел 3, i+j) - |
|
||||||||||
|
|
|
последовательность |
|
||||||||||
|
|
|
триад, порождаемая для |
|
||||||||||
|
|
|
Узла 3, начиная с |
|
||||||||||
|
|
|
триады с номером i+j, |
|
||||||||||
|
|
|
к — количество триад, |
|
||||||||||
|
|
|
порождаемых для Узла 3 |
|
||||||||||
Для триад не требуется учитывать операцию присваивания как отдельный тип узла дерева. Она преобразуется в триаду обычного вида.
Рассмотрим в качестве примера то же самое выражение A:=B*C+D-B*10. Соответствующее ему дерево вывода уже было приведено на рис. 14.5.
Построим последовательность триад, соответствующую дереву операций на рис. 14.5. Согласно принципу СУ-перевода, построение начинается от корня дерева.


Следует обратить внимание, что в данном алгоритме последовательные номера триад (а следовательно, и ссылки на них) устанавливаются не сразу. Это не имеет значения при рекурсивной организации процедуры, но если используется другой способ обхода дерева операций, при реализации генерации кода лучше увязывать триады между собой именно по ссылке (указателю), а не по порядковому номеру.
Использование триад позволяет сократить количество рассматриваемых вариантов узлов дерева операций. В этом случае не требуется принимать во внимание типы операндов и ориентироваться на архитектуру целевой вычислительной системы. Все эти аспекты необходимо будет принимать во внимание уже на этапе преобразования триад в последовательность команд ассемблера или непосредственно в последовательность машинных команд результирующей программы.
Как и последовательность команд ассемблера, последовательность триад можно оптимизировать. Для триад разработаны универсальные (машинно-независимые) алгоритмы оптимизации кода. Уже после их выполнения (оптимизации внутреннего представления) триады могут быть преобразованы в команды на языке ассемблера.
Оптимизация кода.
Основные методы оптимизации
Общие принципы оптимизации кода
Как уже говорилось выше, в подавляющем большинстве случаев генерация кода выполняется компилятором не для всей входной программы в целом, а последовательно для отдельных ее конструкций. Полученные для каждой синтаксической конструкции входной программы фрагменты результирующего кода также последовательно объединяются в общий текст результирующей программы. При этом связи между различными фрагментами результирующего кода в полной мере не учитываются.
В свою очередь, для построения результирующего кода различных синтаксических конструкций входного языка используется метод СУ-перевода. Он также объединяет цепочки построенного кода по структуре дерева без учета их взаимосвязей (что видно из примеров, приведенных выше).
Построенный таким образом код результирующей программы может содержать лишние команды и данные. Это снижает эффективность выполнения результирующей программы. В принципе компилятор может завершить на этом гене-рацию кода, поскольку результирующая программа построена и она является эквивалентной по смыслу (семантике) программе на входном языке. Однако эффективность результирующей программы важна для ее разработчика, поэтому большинство современных компиляторов выполняют еще один этап компиляции — оптимизацию результирующей программы (или просто «оптимизацию»), чтобы повысить ее эффективность насколько это возможно. Важно отметить два момента: во-первых, выделение оптимизации в отдельный этап генерации кода — это вынужденный шаг. Компилятор вынужден производить оптимизацию построенного кода, поскольку он не может выполнить семантический анализ всей входной программы в целом, оценить ее смысл и, исходя из него, построить результирующую программу. Оптимизация нужна, поскольку результирующая программа строится не вся сразу, а поэтапно. Во-вторых, оптимизация — это необязательный этап компиляции. Компилятор может вообще не выполнять оптимизацию, и при этом результирующая программа будет правильной, а сам компилятор будет полностью выполнять свои функции. Однако практически все компиляторы так или иначе выполняют оптимизацию, поскольку их разработчики стремятся завоевать хорошие позиции на рынке средств разработки программного обеспечения. Оптимизация, которая существенно влияет на эффективность результирующей программы, является здесь немаловажным фактором.
Теперь дадим определение понятию «оптимизация».
Оптимизация программы — это обработка, связанная с переупорядочиванием и изменением операций в компилируемой программе с целью получения более эффективной результирующей объектной программы. Оптимизация выполняется на этапах подготовки к генерации и непосредственно при генерации объектного кода.
В качестве показателей эффективности результирующей программы можно использовать два критерия: объем памяти, необходимый для выполнения результирующей программы (для хранения всех ее данных и кода), и скорость выполнения (быстродействие) программы. Далеко не всегда удается выполнить оптимизацию так, чтобы удовлетворить обоим этим критериям. Зачастую сокращение необходимого программе объема данных ведет к уменьшению ее быстродействия, и наоборот. Поэтому для оптимизации обычно выбирается либо один из упомянутых критериев, либо некий комплексный критерий, основанный на них. Выбор критерия оптимизации обычно выполняет непосредственно пользователь в настройках компилятора.
Но, даже выбрав критерий оптимизации, в общем случае практически невозможно построить код результирующей программы, который бы являлся самым коротким или самым быстрым кодом, соответствующим входной программе. Дело в том, что нет алгоритмического способа нахождения самой короткой или самой быстрой результирующей программы, эквивалентной заданной исходной программе. Эта задача в принципе неразрешима. Существуют алгоритмы, которые можно ускорять сколь угодно много раз для большого числа возможных входных данных, и при этом для других наборов входных данных они окажутся неоптимальными [6, т. 2]. К тому же компилятор обладает весьма ограниченными средствами анализа семантики всей входной программы в целом. Все, что можносделать на этапе оптимизации, — это выполнить над заданной программой последовательность преобразований в надежде сделать ее более эффективной.
Чтобы оценить эффективность результирующей программы, полученной с помощью того или иного компилятора, часто прибегают к сравнению ее с эквивалентной программой (программой, реализующей тот же алгоритм), полученной из исходной программы, написанной на языке ассемблера. Лучшие оптимизирующие компиляторы могут получать результирующие объектные программы из сложных исходных программ, написанных на языках высокого уровня, почти не уступающие по качеству программам на языке ассемблера. Обычно соотношение эффективности программ, построенных с помощью компиляторов с языков высокого уровня, к эффективности программ, построенных с помощью ассемблера, составляет 1,1-1,3. То есть объектная программа, построенная с помощью компилятора с языка высокого уровня, обычно содержит на 10-30 % больше команд, чем эквивалентная ей объектная программа, построенная с помощью ассемблера, а также выполняется на 10-30 % медленнее1.
Это очень неплохие результаты, достигнутые компиляторами с языков высокого уровня, если сравнить трудозатраты на разработку программ на языке ассемблера и языке высокого уровня. Далеко не каждую программу можно реализовать на языке ассемблера в приемлемые сроки (а значит, и выполнить напрямую приведенное выше сравнение можно только для узкого круга программ).
Оптимизацию можно выполнять на любой стадии генерации кода, начиная от завершения синтаксического разбора и вплоть до последнего этапа, когда порождается код результирующей программы. Если компилятор использует несколько различных форм внутреннего представления программы, то каждая из них может быть подвергнута оптимизации, причем различные формы внутреннего представления ориентированы на различные методы оптимизации [6, т. 2, 74, 82]. Таким образом, оптимизация в компиляторе может выполняться несколько раз на этапе генерации кода.
Принципиально различаются два основных вида оптимизирующих преобразований:
□
преобразования исходной программы (в форме ее
внутреннего представления
в
компиляторе), не зависящие от результирующего объектного языка;
□
преобразования результирующей объектной программы.
Первый вид преобразований не зависит от архитектуры целевой вычислительной системы, на которой будет выполняться результирующая программа. Обычно он основан на выполнении хорошо известных и обоснованных математических и логических преобразований, производимых над внутренним представлением программы (некоторые из них будут рассмотрены ниже).
Второй вид преобразований может зависеть не только от свойств объектного языка (что очевидно), но и от архитектуры вычислительной системы, на которой будет выполняться результирующая программа. Так, например, при оптимизации может учитываться объем кэш-памяти и методы организации конвейерных операций центрального процессора. В большинстве случаев эти преобразования сильно зависят от реализации компилятора и являются «ноу-хау» производителей компилятора. Именно этот тип оптимизирующих преобразований позволяет существенно повысить эффективность результирующего кода. Используемые методы оптимизации ни при каких условиях не должны приводить к изменению «смысла» исходной программы (то есть к таким ситуациям, когда результат выполнения программы изменяется после ее оптимизации). Для преобразований первого вида проблем обычно не возникает. Преобразования второго вида могут вызывать сложности, поскольку не все методы оптимизации, используемые создателями компиляторов, могут быть теоретически обоснованы и доказаны для всех возможных видов исходных программ. Именно эти преобразования могут повлиять на «смысл» исходной программы. Поэтому большинство компиляторов предусматривает возможность отключать те или иные из возможных методов оптимизации.
Нередко оптимизация ведет к тому, что смысл программы оказывается не совсем таким, каким его ожидал увидеть разработчик программы, но не по причине наличия ошибки в оптимизирующей части компилятора, а потому, что пользователь не принимал во внимание некоторые аспекты программы, связанные с оптимизацией. Например, компилятор может исключить из программы вызов некоторой функции с заранее известным результатом, но если эта функция имела «побочный эффект» — изменяла некоторые значения в глобальной памяти, — смысл программы может измениться. Чаще всего это говорит о плохом стиле программирования исходной программы. Такие ошибки трудноуловимы, для их нахождения следует обратить внимание на предупреждения разработчику программы, выдаваемые семантическим анализом, или отключить оптимизацию. Применение оптимизации также нецелесообразно в процессе отладки исходной программы.
У современных компиляторов существуют возможности выбора не только общего критерия оптимизации, но и отдельных методов, которые будут использоваться при выполнении оптимизации.
Методы преобразования программы зависят от типов синтаксических конструкций исходного языка. Теоретически разработаны методы оптимизации для многих типовых конструкций языков программирования.
Оптимизация может выполняться для следующих типовых синтаксических конструкций:
□
линейных участков программы;
□
логических выражений;
□
циклов;
□
вызовов процедур и функций;
□
других конструкций входного языка.
Во всех случаях могут использоваться как машинно-зависимые, так и машинно-независимые методы оптимизации.
Далее будут рассмотрены только некоторые машинно-независимые методы оптимизации, касающиеся в первую очередь линейных участков программы. Перечень их здесь далеко не полный. С остальными машинно-независимыми методами можно более подробно ознакомиться в [6, т. 2]. Что касается машинно-зависимых методов, то они, как правило, редко упоминаются в литературе. Некоторые из них рассматриваются в технических описаниях компиляторов. Здесь эти методы будут рассмотрены только в самом общем виде.
Оптимизация линейных участков программы Принципы оптимизации линейных участков
Линейный участок программы — это выполняемая по порядку последовательность операций, имеющая один вход и один выход. Чаще всего линейный участок содержит последовательность вычислений, состоящих из арифметических операций и операторов присвоения значений переменным.
Любая программа предусматривает выполнение вычислений и присваивания значений, поэтому линейные участки встречаются в любой программе. В реальных программах они составляют существенную часть программного кода. Поэтому для линейных участков разработан широкий спектр методов оптимизации кода.
Кроме того, характерной особенностью любого линейного участка является последовательный порядок выполнения операций, входящих в его состав. Ни одна операция в составе линейного участка программы не может быть пропущена, ни одна операция не может быть выполнена большее число раз, чем соседние с нею операции (иначе этот фрагмент программы просто не будет линейным участком). Это существенно упрощает задачу оптимизации линейных участков программ. Поскольку все операции линейного участка выполняются последовательно, их можно пронумеровать в порядке их выполнения.
Для операций, составляющих линейный участок программы, могут применяться следующие виды оптимизирующих преобразований:
□
удаление бесполезных присваиваний;
□
исключение избыточных вычислений (лишних операций);
□
свертка операций объектного кода;
□
перестановка операций;
□
арифметические преобразования.
Удаление бесполезных присваиваний заключается в том, что если в составе линейного участка программы имеется операция присвоения значения некоторой произвольной переменной А с номером i, а также операция присвоения значения той же переменной А с номером j, i<j и ни в одной операции между i и j не используется значение переменной А, то операция присвоения значения с номером i является бесполезной. Фактически бесполезная операция присваивания значения дает переменной значение, которое нигде не используется. Такая операция может быть исключена без ущерба для смысла программы. В общем случае, бесполезными могут оказаться не только операции присваивания, но и любые другие операции линейного участка, результат выполнения которых нигде не используется.
Например, во фрагменте программы i
А :- В * С: D :- В + С; А := D * С;
операция присвоения А: =В*С; является бесполезной и может быть удалена. Вместе с удалением операции присвоения здесь может быть удалена и операция умножения, которая в результате также окажется бесполезной.
Обнаружение бесполезных операций присваивания далеко не всегда столь очевидно, как было показано в примере выше. Проблемы могут возникнуть, если между двумя операциями присваивания в линейном участке выполняются действия над указателями (адресами памяти) или вызовы функций, имеющих так называемый «побочный эффект».
Например, в следующем фрагменте программы
Р :- @А;
А :- В * С;
D :- РА + С;
А :- D * С;
операция присвоения А:=В*С; уже не является бесполезной, хотя это и не столь очевидно. В этом случае неверно следовать простому принципу о том, что если переменная, которой присвоено значение в операции с номером 1, не встречается ни в одной операции между i и j, то операция присвоения с номером i является бесполезной.
Не всегда удается установить, используется или нет присвоенное переменной значение, только на основании факта упоминания переменной в операциях. Тогда устранение лишних присваиваний становится достаточно сложной задачей, требующей учета операций с адресами памяти и ссылками.
Исключение избыточных вычислений (лишних операций) заключается в нахождении и удалении из объектного кода операций, которые повторно обрабатывают одни и те же операнды. Операция линейного участка с порядковым номером i считается лишней, если существует идентичная ей операция с порядковым номером j, j<i и никакой операнд, обрабатываемый этой операцией, не изменялся никакой операцией, имеющей порядковый номер между 1 и j.
Свертка объектного кода — это выполнение во время компиляции тех операций исходной программы, для которых значения операндов уже известны. Тривиальным примером свертки является вычисление выражений, все операнды которых являются константами. Более сложные варианты алгоритма свертки принимают во внимание также и переменные, и функции, значения для которых уже известны.
Не всегда компилятору удается выполнить свертку, даже если выражение допускает ее выполнение. Например, выражение А:=2*В*С*3; может быть преобразовано к виду А:=6*В*С;, но при порядке вычислений А:=2*(В*(С*3)); это не столь оче-видно. Для более эффективного выполнения свертки объектного кода возможно совместить ее выполнение с другим методом — перестановкой операций.
Хорошим стилем программирования является объединение вместе операций, производимых над константами, чтобы облегчить компилятору выполнение свертки. Например, если имеется константа Р1=3.14, представляющая соответствующую математическую постоянную, то операцию b=sin(2rca); лучше записать в виде B:=sin(2*PI*A); или даже B:=sin((2*PI)*A);, чем в виде B:=sin(2*A*PI);.
Перестановка операций заключается в изменении порядка следования операций, которое может повысить эффективность программы, но не будет влиять на конечный результат вычислений.
Например, операции умножения в выражении А:=2*В*3*С; можно переставить без изменения конечного результата и выполнить в порядке А:=(2*3)*(В*С);. Тогда представляется возможным выполнить свертку и сократить количество операций.
Другое выражение A:=(B+C)+(D+E); может потребовать как минимум одной ячейки памяти (или регистра процессора) для хранения промежуточного результата. Но при вычислении его в порядке A:=B+(C+(D+E)); можно обойтись одним регистром, в то время как результат будет тем же.
Особое значение перестановка операций приобретает в тех случаях, когда порядок их выполнения влияет на эффективность программы в зависимости от архитектурных особенностей целевой вычислительной системы (таких, как использование регистров процессора, конвейеров обработки данных и т. п.). Эти особенности рассмотрены далее в подразделе, посвященном машинно-зависимым методам оптимизации.
Арифметические преобразования представляют собой выполнение изменения характера и порядка следования операций на основании известных алгебраических и логических тождеств.
Например, выражение A:=B*C+B*D; может быть заменено на A:=B*(C+D);. Конечный результат при этом не изменится, но объектный код будет содержать на одну операцию умножения меньше.
К арифметическим преобразованиям можно отнести и такие действия, как замена возведения в степень на умножение; а целочисленного умножения на константы, кратные 2, — на выполнение операций сдвига. В обоих случаях удается повысить быстродействие программы заменой сложных операций на более простые.
Далее подробно рассмотрены два метода: свертка объектного кода и исключение лишних операций.
Свертка объектного кода
Свертка объектного кода — это выполнение во время компиляции тех операций исходной программы, для которых значения операндов уже известны. Нет необходимости многократно выполнять эти операции в результирующей программе — вполне достаточно один раз выполнить их при компиляции программы.
Простейший вариант свертки — выполнение в компиляторе операций, операндами которых являются константы. Несколько более сложен процесс определения тех операций, значения которых могут быть известны в результате выполнения других операций. Для этой цели при оптимизации линейных участков программы используется специальный алгоритм свертки объектного кода. Алгоритм свертки для линейного участка программы работает со специальной таблицей Т, которая содержит пары (<переменная>,<константа>) для всех переменных, значения которых уже известны. Кроме того, алгоритм свертки помечает те операции во внутреннем представлении программы, для которых в результате свертки уже не требуется генерация кода. Так как при выполнении алгоритма свертки учитывается взаимосвязь операций, то удобной формой представления для него являются триады, так как в других формах представления операций (таких, как тетрады или команды ассемблера) требуются дополнительные структуры, чтобы отразить связь результатов одних операций с операндами других. Рассмотрим выполнение алгоритма свертки объектного кода для триад. Для пометки операций, не требующих порождения объектного кода, будем использовать триады специального вида С(К,О).
Алгоритм свертки триад последовательно просматривает триады линейного участка и для каждой триады делает следующее:
1.
Если операнд есть переменная, которая содержится в таблице
Т, то операнд
заменяется
на соответствующее значение константы.
2.
Если операнд есть ссылка на особую триаду типа С(К,0), то
операнд заменяет
ся на
значение константы К.
3.
Если все операнды триады являются константами, то триада
может быть
свернута.
Тогда данная триада выполняется и вместо нее помещается особая
триада
вида С(К,0), где К — константа, являющаяся результатом выполнения
свернутой триады. (При генерации кода для особой триады объектный код не
порождается,
а потому она в дальнейшем может быть просто исключена.)
4.
Если триада является присваиванием типа А:=В, тогда:
О если В — константа, то А со значением константы заносится в таблицу Т (если там уже было старое значение для А, то это старое значение исключается);
0 если В — не константа, то А вообще исключается из
таблицы Т, если оно
там есть.
Рассмотрим пример выполнения алгоритма.
Пусть фрагмент исходной программы (записанной на языке типа Pascal) имеет вид:
1 := 1 + 1;
I := 3:
J := 6*1 + I;
Ее внутреннее представление в форме триад будет иметь вид:
1.
+
(1.1)
:= (I. "D
3.
![]() := (I. 3)
:= (I. 3)
4.
*
(6, I)
5.
+
Г4, I)
6.
:=
(J. Л5)
Процесс выполнения алгоритма свертки показан в табл. 14.4.
Таблица 14.4. Пример работы алгоритма свертки
|
Триада |
Шаг 1 |
Шаг 2 |
ШагЗ |
Шаг 4 |
Шаг 5 |
Шаг 6 |
|
1 |
С (2, 0) |
С (2, 0) |
С (2, 0) |
С (2, 0) |
С (2, 0) |
С (2, 0) |
|
2 |
:-(1,Л1) |
:- (I- 2) |
:- (I, 2) |
:- (I. 2) |
:- (I. 2) |
:- (I- 2) |
|
3 |
:- (I. 3) |
:- О. 3) |
:- (I. 3) |
:- (I, 3) |
:- (I, 3) |
:- (I. 3) |
|
4 |
* (6,1) |
* (6,1) |
* (6,1) |
С (18, 0) |
С (18, 0) |
С (18, 0) |
|
5 |
+ (Ч I) |
+ (Л4,I) |
+ (Ч I) |
+ (Ч I) |
С (21, 0) 1 |
С (21, 0) |
|
6 |
:= G, Л5) |
:= 0. Л5) |
:- G, Л5) |
:=G,A5) |
:= G, Л5) |
:= G, 21) |
|
т |
(.) |
(1,2) |
(1,3) |
(1.3) |
(1,3) |
(1,3) G-21) |
Если исключить особые триады типа С(К,О) (которые не порождают объектного кода), то в результате выполнения свертки получим следующую последовательность триад:
1.
:=
(I. 2)
2. := (I. 3)
3.
:=
(J, 21)
Алгоритм свертки объектного кода позволяет исключить из линейного участка программы операции, для которых на этапе компиляции уже известен результат. За счет этого сокращается время выполнения1, а также объем кода результирующей программы.
Свертка объектного кода в принципе может выполняться не только для линейных участков программы. Когда операндами являются константы, логика выполнения программы значения не имеет — свертка может быть выполнена в любом случае. Если же необходимо учитывать известные значения переменных, то нужно принимать во внимание и логику выполнения результирующей программы.
Поэтому для нелинейных участков программы (ветвлений и циклов) алгоритм будет более сложным, чем последовательный просмотр линейного списка триад.
Исключение лишних операций
Алгоритм исключения лишних операций просматривает операции в порядке их следования. Так же как и алгоритму свертки, алгоритму исключения лишних операций проще всего работать с триадами, потому что они полностью отражают взаимосвязь операций. Рассмотрим алгоритм исключения лишних операций для триад.
Чтобы следить за внутренней зависимостью переменных и триад, алгоритм присваивает им некоторые значения, называемые числами зависимости, по следующим правилам:
□
изначально
для каждой переменной ее число зависимости равно 0, так как в на
чале работы программы
значение переменной не зависит ни от какой триады;
□
после
обработки i -й
триады, в которой переменной А присваивается некото
рое значение, число зависимости A (dep(A))
получает значение i, так как зна
чение А теперь зависит от
данной i -й
триады;
□
при
обработке i-й триады ее число зависимости (dep(i)) принимается равным
значению 1+(максимальное
из чисел зависимости операндов).
Таким образом, при использовании чисел зависимости триад и переменных можно утверждать, что если i-я триада идентична j-й триаде (j<i), то i-я триада считается лишней в том и только в том случае, когда dep(i)=dep(j).
Алгоритм исключения лишних операций использует в своей работе триады особого вида SAME С j, 0). Если такая триада встречается в позиции с номером i, то это означает, что в исходной последовательности триад некоторая триада i идентична триаде j.
Алгоритм исключения лишних операций последовательно просматривает триады линейного участка. Он состоит из следующих шагов, выполняемых для каждой триады:
1.
Если
какой-то операнд триады ссылается на особую триаду вида SAME (j, 0), то
он заменяется на ссылку на
триаду с номером j (Aj).
2.
Вычисляется
число зависимости текущей триады с номером i, исходя из чи
сел зависимости ее
операндов.
3.
Если
в просмотренной части списка триад существует идентичная j-я триада,
причем j<i и dep(i)=dep( j), то текущая триада i заменяется на триаду особого
видаБАМЕи.О).
4.
Если
текущая триада есть присвоение, то вычисляется число зависимости со
ответствующей переменной.
Рассмотрим работу алгоритма на примере:
D := D + С*В: А := D + С*В; С := D + С*В;
Этому фрагменту программы будет соответствовать следующая последовательность триад:
1.
* (С В)
2.
+ (D, Л1)
3.
:= (D. А2) ' .
4.
* (С, В) , . ,
■
5.
+ (D, Л4)
6.
:= (А, Л5)
7.
* (С, В) ■■.'■■
8. + (D, А7)
9. := (С, Л8)
Видно, что в данном примере некоторые операции вычисляются дважды над одними и теми же операндами, а значит, они являются лишними и могут быть исключены. Работа алгоритма исключения лишних операций отражена в табл. 14.5.
|
Таблица 14.5. Пример |
работы алгоритма исключения лишних операций |
|||||
|
Обрабатываемая триада i |
Числа зависимости переменных |
Числа зависимости триад dep(i) |
Триады, полученные после выполнения алгоритма |
|||
|
А |
В |
с |
D |
|||
|
1) * (С, В) |
0 |
0 |
0 |
0 |
1 |
1) * (С, В) |
|
2) + (D, Л1) |
0 |
0 |
0 |
0 |
2 |
2) + (D, Л1) |
|
3) := (D, Л2) |
0 |
0 |
0 |
3 |
3 |
3) :- (D, Л2) |
|
4) * (С, В) |
0 |
0 |
0 |
3 |
1 |
4) SAME (1, 0) |
|
5) + (D, Л4) |
0 |
0 |
0 |
3 |
4 |
5) + (D, Л1) |
|
6) := (А, Л5) |
6 |
0 |
0 |
3 |
5 |
6) :- (А, Л5) |
|
7) * (С, В) |
6 |
0 |
0 |
3 |
1 |
7) SAME (1, 0) |
|
8) + (D, Л7) |
6 |
0 |
0 |
3 |
4 |
8) SAME (5, 0) |
|
9) := (С, Л8) |
6 |
0 |
9 |
3 |
5 |
9) := (С, Л5) |
Теперь, если исключить триады особого вида SAME (з, 0), то в результате выполнения алгоритма получим следующую последовательность триад:
1.
* (С, В)
2. + (D, 1)
3.
:= (D, Л2)
4.
+ (D, А1)
5.
:= (А, Л4)
6.
:= (С. Л4)
Обратите внимание, что.в итоговой последовательности изменилась нумерация триад и номера в ссылках одних триад на другие. Если в компиляторе в качестве ссылок использовать не номера триад, а непосредственно указатели на них, то изменения ссылок в таком варианте не потребуется.
Алгоритм исключения лишних операций позволяет избежать повторного выполнения одних и тех же операций над одними и теми же операндами. В результате оптимизации по этому алгоритму сокращается и время выполнения, и объем кода результирующей программы.
Другие методы оптимизации программ Оптимизация вычисления логических выражений
Особенность оптимизации логических выражений заключается в том, что не всегда необходимо полностью выполнять вычисление всего выражения для того, чтобы знать его результат. Иногда по результату первой операции или даже по значению одного операнда можно заранее определить результат вычисления всего выражения.
Операция называется предопределенной для некоторого значения операнда, если ее результат зависит только от этого операнда и остается неизменным (инвариантным) относительно значений других операндов.
Операция логического сложения (ог) является предопределенной для логического значения «истина» (true), а операция логического умножения — предопределена для логического значения «ложь» (false).
Эти факты могут быть использованы для оптимизации логических выражений. Действительно, получив значение «истина» в последовательности логических сложений или значение «ложь» в последовательности логических умножений, нет никакой необходимости далее производить вычисления — результат уже определен и известен.
Например, выражение А ог В ог С or D не имеет смысла вычислять, если известно, что значение переменной А есть True («истина»).
Компиляторы строят объектный код вычисления логических выражений таким образом, что вычисление выражения прекращается сразу же, как только его значение становится предопределенным. Это позволяет ускорить вычисления при выполнении результирующей программы. В сочетании с преобразованиями логических выражений на основе тождеств булевой алгебры и перестановкой операций эффективность данного метода может быть несколько увеличена.
Не всегда такие преобразования инвариантны к смыслу программы. Например, при вычислении выражения A or F(B) or G(C) функции F и G не будут вызваны и выполнены, если значением переменной А является true. Это не важно, если результатом этих функций является только возвращаемое ими значение, но если они обладают «побочным эффектом» (о котором было сказано выше в замечаниях), то семантика программы может измениться.
В большинстве случаев современные компиляторы позволяют исключить такого рода оптимизацию, и тогда все логические выражения будут вычисляться до конца, без учета предопределенности результата. Однако лучше избегать такого
Хорошим стилем считается также принимать во внимание эту особенность вычисления логических выражений. Тогда операнды в логических выражениях следует стремиться располагать таким образом, чтобы в первую очередь вычислялись те из них, которые чаще определяют все значение выражения. Кроме того, значения функций лучше вычислять в конце, а не в начале логического выражения, чтобы избежать лишних обращений к ним. Так, рассмотренное выше выражение лучше записывать и вычислять в порядке A or F(B) or G(C), чем в порядке F(6) or G(C) or A.
He только логические операции могут иметь предопределенный
результат. Некоторые математические операции и функции также обладают этим
свойством. Например, умножение на 0 не имеет смысла выполнять.
Другой пример такого рода преобразований — это исключение вычислений для инвариантных операндов.
Операция называется инвариантной относительно некоторого значения операнда, если ее результат не зависит от этого значения операнда и определяется другими операндами.
Например, логическое сложение (or) инвариантно относительно значения «ложь» (False), логическое умножение (and).— относительно значения «истина»; алгебраическое сложение инвариантно относительно 0, а алгебраическое умножение — относительно 1.
Выполнение такого рода операций можно исключить из текста программы, если известен инвариантный для них операнд. Этот метод оптимизации имеет смысл в сочетании с методом свертки операций.
Оптимизация передачи параметров в процедуры и функции
Выше рассмотрен метод передачи параметров в процедуры и функции через стек. Этот метод применим к большинству языков программирования и используется практически во всех современных компиляторах для различных архитектур целевых вычислительных систем (на которых выполняется результирующая программа).
Данный метод прост в реализации и имеет хорошую аппаратную поддержку во многих архитектурах. Однако он является неэффективным в том случае, если процедура или функция выполняет несложные вычисления над небольшим количеством параметров. Тогда всякий раз при вызове процедуры или функции компилятор будет создавать объектный код для размещения ее фактических параметров в стеке, а при выходе из нее — код для освобождения ячеек, занятых параметрами. При выполнении результирующей программы этот код будет задействован. Если процедура или функция выполняет небольшие по объему вычисления, код для размещения параметров в стеке и доступа к ним может составлять существенную часть ко всему коду, созданному для этой процедуры или функции. А если эта функция вызывается многократно, то этот код будет заметно снижать эффективность ее выполнения.
Существуют методы, позволяющие снизить затраты кода и времени выполнения на передачу параметров в процедуры и функции и повысить в результате эффективность результирующей программы:
□
передача параметров через регистры процессора;
□
подстановка кода функции в вызывающий объектный код.
Метод передачи параметров через регистры процессора позволяет разместить все или часть параметров, передаваемых в процедуру или функцию, непосредственно в регистрах процессора, а не в стеке. Это позволяет ускорить обработку параметров функции, поскольку работа с регистрами процессора всегда выполняется быстрее, чем с ячейками оперативной памяти, где располагается стек. Если все параметры удается разместить в регистрах, то сокращается также и объем кода, поскольку исключаются все операции со стеком при размещении в нем параметров.
Понятно, что регистры процессора, используемые для передачи параметров в процедуру или функцию, не могут быть задействованы напрямую для вычислений внутри этой процедуры или функции. Поскольку программно доступных регистров процессора всегда ограниченное количество, то при выполнении сложных вычислений могут возникнуть проблемы с их распределением. Тогда компилятор должен выбрать: либо использовать регистры для передачи параметров и снизить эффективность вычислений (часть промежуточных результатов, возможно, потребуется размещать в оперативной памяти или в том же стеке), либо использовать свободные регистры для вычислений и снизить эффективность передачи параметров. Поэтому реализация данного метода зависит от количества программно доступных регистров процессора в целевой вычислительной системе и от используемого в компиляторе алгоритма распределения регистров. В современных процессорах число программно доступных регистров постоянно увеличивается с разработкой все новых и новых их вариантов, поэтому и значение этого метода постоянно возрастает.
Этот метод имеет ряд недостатков. Во-первых, очевидно, он зависит от архитектуры целевой вычислительной системы. Во-вторых, процедуры и функции, оптимизированные таким методом, не могут быть использованы в качестве процедур или функций библиотек подпрограмм ни в каком виде. Это вызвано тем, что методы передачи параметров через регистры процессора не стандартизованы (в отличие от методов передачи параметров через стек) и зависят от реализации компилятора. Наконец, этот метод не может быть использован, если где бы то ни было в процедуре или функции требуется выполнить операции с адресами (указателями) на параметры.
В большинстве современных компиляторов метод передачи параметров в процедуры и функции выбирается самим компилятором автоматически в процессе генерации кода для каждой процедуры и функции. Однако разработчик имеет, как правило, возможность запретить передачу параметров через регистры процессора либо для определенных функций (для этого используются специальные ключевые слова входного языка), либо для всех функций в программе (для этого используются настройки компилятора).
Некоторые языки программирования (такие, например, как С и C++) позволяют разработчику исходной программы явно указать, какие параметры или локаль-
ные переменные процедуры он желал бы разместить в регистрах процессора. Тогда компилятор стремится распределить свободные регистры в первую очередь именно для этих параметров и переменных.
Метод подстановки кода функции в вызывающий объектный код (так называемая inline-подстановка) основан на том, что объектный код функции непосредственно включается в вызывающий объектный код всякий раз в месте вызова функции.
Для разработчика исходной программы такая функция (называемая inline-функ-цией) ничем не отличается от любой другой функции, но для вызова ее в результирующей программе используется принципиально другой механизм. По сути, вызов функции в результирующем объектном коде вовсе не выполняется — просто все вычисления, производимые функцией, выполняются непосредственно в самом вызывающем коде в месте ее вызова.
Очевидно, что в общем случае такой метод оптимизации ведет не только к увеличению скорости выполнения программы, но и к увеличению объема объектного кода. Скорость увеличивается за счет отказа от всех операций, связанных с вызовом функции, — это не только сама команда вызова, но и все действия, связанные с передачей параметров. Вычисления при этом идут непосредственно с фактическими параметрами функции. Объем кода растет, так как приходится всякий раз включать код функции в место ее вызова. Тем не менее если функция очень проста и включает в себя лишь несколько машинных команд, то можно даже добиться сокращения кода результирующей программы, так как при включении кода самой функции в место ее вызова оттуда исключаются операции, связанные с передачей ей параметров.
Как правило, этот метод применим к очень простым функциям или процедурам, иначе объем результирующего кода может существенно возрасти. Кроме того, он применим только к функциям, вызываемым непосредственно по адресу, без применения косвенной адресации через таблицы RTTI (см. раздел «Семантический анализ и подготовка к генерации кода» этой главы). Некоторые компиляторы допускают применять его только к функциям, предполагающим последовательные вычисления и не содержащим циклов.
Ряд языков программирования (например, C++) позволяют разработчику явно указать, для каких функций он желает использовать inline-подстановку. В C++, например, для этой цели служит ключевое слово входного языка inline.
Оптимизация циклов
Циклом в программе называется любая последовательность участков программы, которая может выполняться повторно.
Циклы присущи подавляющему большинству программ. Во многих программах есть циклы, выполняемые многократно. Большинство языков программирования имеют синтаксические конструкции, специально ориентированные на организацию циклов. Очевидно, такие циклы легко обнаруживаются на этапе синтаксического разбора.
Однако понятие цикла с точки зрения объектной программы, определенной выше, является более общим. Оно включает в себя не только циклы, явно описанные в синтаксисе языка. Циклы могут быть организованы в исходной программе с помощью любых конструкций, допускающих передачу управления (прежде всего, с помощью условных операторов и операторов безусловного перехода). Дл5 результирующей объектной программы не имеет значения, с помощью какю конструкций организован цикл в исходной программе.
Чтобы обнаружить все циклы в исходной программе, используются методы, ос нованные на построении графа управления программы [6, т. 2]. Циклы обычно содержат в себе один или несколько линейных участков, где про изводятся вычисления. Поэтому методы оптимизации линейных участков позво ляют повысить также и эффективность выполнения циклов, причем они оказы ваются тем более эффективными, чем больше кратность выполнения цикла. Н есть методы оптимизации программ, специально ориентированные на оптимиза цию циклов. Для оптимизации циклов используются следующие методы:
□
вынесение инвариантных вычислений из циклов;
□
замена операций с индуктивными переменными;
□
слияние и развертывание циклов.
Вынесение инвариантных вычислений из циклов
заключается в вынесении г пределы циклов тех операций, операнды
которых не изменяются в процессе вь полнения цикла. Очевидно, что такие
операции могут быть выполнены один р; до начала цикла, а полученные результаты
потом могут использоваться в то цикла. Например, цикл1
for i:=l
to 10 do
begin
A[i] := В
* С * A[i];
end: может быть заменен на последовательность операций
D := В * С;
■ for i:=1 to 10 do
begin
A[i] :- D * A[i]; '
end:
если значения В и С не изменяются нигде в теле цикла. При этом операция ум! жения В*С будет выполнена только один раз, в то время как в первом варианте она выполнялась 10 раз над одними и теми же результатами.
Неизменность операндов в теле цикла может оказаться не столь очевидной. Отсутствие присвоения значений переменным не может служить достоверным признаком их неизменности. В общем случае компилятору придется принимать во внимание все операции, которые так или иначе могут повлиять на инвариантность переменных. Такими операциями являются операции над указателями, вызовы функций (даже если сами переменные не передаются в функцию в качестве параметров, она может изменять их значения через «побочные эффекты»). Поскольку невозможно отследить все изменения указателей (адресов) и все «побочные эффекты» на этапе компиляции, компилятор вынужден отказаться от вынесения из цикла инвариантных переменных всякий раз, когда в теле цикла появляются «подозрительные» операции, которые могут поставить под сомнение инвариантность той или иной переменной.
Замена операций с индуктивными переменными заключается в изменении сложных операций с индуктивными переменными в теле цикла на более простые операции. Как правило, выполняется замена умножения на сложение. Переменная называется индуктивной в цикле, если ее значения в процессе выполнения цикла образуют арифметическую прогрессию. Таких переменных в цикле может быть несколько, тогда в теле цикла их иногда можно заменить на одну единственную переменную, а реальные значения для каждой переменной будут вычисляться с помощью соответствующих коэффициентов соотношения (за пределами цикла значения всем переменным должны быть присвоены, если, конечно, они используются).
Простейшей индуктивной переменной является переменная-счетчик цикла с перечислением значений (цикл типа for, который встречается в синтаксисе многих современных языков программирования). Более сложные случаи присутствия индуктивных переменных в цикле требуют специального анализа тела цикла. Не всегда выявление таких переменных является тривиальной задачей. После того как индуктивные переменные выявлены, необходимо проанализировать те операции в теле цикла, где они используются. Часть таких операций может быть упрощена. Как правило, речь идет о замене умножения на сложение [6, т. 2, 82].
Например, цикл
S := 10:
for i:=l to N do A[i] := i*S;
может быть заменен на последовательность операций
S :- 10:
Т :- S:
i := 1:
while i <=
10 do
begin
A[i] := T; T :=
T + 10; i :- i + 1: end:
Здесь использован синтаксис языка Pascal, a T — это некоторая новая временная переменная (использовать для той же цели уже существующую переменную S не вполне корректно, так как ее значение может быть использовано и после завершения этого цикла). В итоге удалось отказаться от выполнения N операций ум-
ножения, заменив их на N операций сложения (которые обычно выполняю' быстрее). Индуктивной переменной в первом варианте цикла являлась i, a втором варианте — i и Т. В другом примере
S
:= 10: -■
'
for i:=l to N do R := R + F(S); S :-
S + 10;
две индуктивных переменных — i и S. Если заменить их на одну, то выясни' что переменная i вовсе не имеет смысла, тогда этот цикл можно заменить на следовательность операций
S := 10: М :- 10 + N*10;
while S <- М do
begin R := R + F(S): S :- S + 10; end;
Здесь удалось исключить N операций сложения для переменной i за счет до( ления новой временной переменной М (как и в предыдущем примере, испол: ван синтаксис языка Pascal).
В современных реальных компиляторах такие преобразования используются, таточно редко, поскольку они требуют достаточно сложного анализа програм в то время как достигаемый выигрыш невелик — разница в скорости выпо. ния сложения и умножения, равно как и многих других операций, в совре! ных вычислительных системах не столь существенна. Кроме того, существ варианты циклов, для которых эффективность указанных методов преобраз ния является спорной [6, т. 2].
Слияние и развертывание циклов предусматривает два различных варианта образований: слияния двух вложенных циклов в один и замена цикла на ли ную последовательность операций. Слияние двух циклов можно проиллюстрировать на примере циклов
for i:=1 to N do
for j:=l to M do A[i.j] := 0: ,
Здесь происходит инициализация двумерного массива. Но в объектном двумерный массив —
это всего лишь область памяти размером N*M,
поэ' (с
точки зрения объектного кода, но. не входного языка!) эту операцию mi представить так:
К := N*M;
for i:-l to K do A[i]
:= 0;
Развертывание циклов можно выполнить для циклов, кратность выполнени торых известна уже на этапе компиляции. Тогда цикл, кратностью N, можь менить на линейную последовательность N операций, содержащих тело ци
Например, цикл
for i:=l to 3 do A[i] := i; можно заменить операциями
A[l] :- 1; ,
A[2] i- 2:
A[3] := 3; .
Незначительный выигрыш в скорости достигается за счет исключения всех операций с индуктивной переменной, однако объем программы может существенно возрасти.
Машинно-зависимые методы оптимизации
Машинно-зависимые методы оптимизации ориентированы на конкретную архитектуру целевой вычислительной системы, на которой будет выполняться результирующая программа. Как правило, каждый компилятор ориентирован на одну определенную архитектуру целевой вычислительной системы. Иногда возможно в настройках компилятора явно указать одну из допустимых целевых архитектур. В любом случае результирующая программа всегда порождается для четко заданной целевой архитектуры.
Архитектура вычислительной системы есть представление аппаратной и программной составляющих частей системы и взаимосвязи между ними с точки зрения системы как единого целого. Понятие «архитектура» включает в себя особенности и аппаратных, и программных средств целевой вычислительной системы. При выполнении машинно-зависимой оптимизации компилятор может принимать во внимание те или иные ее составляющие. То, какие конкретно особенности архитектуры будут приняты во внимание, зависит от реализации компилятора и определяется его разработчиками.
Количество существующих архитектур вычислительных систем к настоящему времени очень велико. Поэтому не представляется возможным рассмотреть все ориентированные на них методы оптимизации даже в форме краткого обзора. Интересующиеся этим вопросом могут обратиться к специализированной литературе [6, т. 2, 40, 74, 82]. Далее будут рассмотрены только основные два аспекта машинно-зависимой оптимизации: распределение регистров процессора и порождение кода для параллельных вычислений.
Распределение регистров процессора
Процессоры, на базе которых строятся современные вычислительные системы, имеют, как правило, несколько программно-доступных регистров. Часть из них может быть предназначена для выполнения каких-либо определенных целей (например, регистр — указатель стека или регистр — счетчик команд), другие могут быть использованы практически произвольным образом при выполнении различных операций (так называемые «регистры общего назначения»). Использование регистров общего назначения для хранения значений операндов и результатов вычислений позволяет добиться увеличения быстродействия программы, так как действия над регистрами процессора всегда выполняются быстрее, чем над ячейками памяти. Кроме того, в ряде процессоров не все операции могут быть выполнены над ячейками памяти, а потому часто требуется предварительная загрузка операнда в регистр. Результат выполнения операции чаще всего тоже оказывается в регистре, и если необходимо, его надо выгрузить (записать) в ячейку памяти.
Программно доступных регистров процессора всегда ограниченное количество. Поэтому встает вопрос об их распределении при выполнении вычислений. Этим занимается алгоритм распределения регистров, который присутствует практич ски в каждом современном компиляторе в части генерации кода результиру] щей программы.
При распределении регистров под хранение промежуточных и окончательных г зультатов вычислений может возникнуть ситуация, когда значение той или hhi переменной (связанной с нею ячейки памяти) необходимо загрузить в регис для дальнейших вычислений, а все имеющиеся доступные регистры уже занят Тогда компилятору перед созданием кода по загрузке переменной в регистр t обходимо сгенерировать код для выгрузки одного из значений из регистра ячейку памяти (чтобы освободить регистр). Причем выгружаемое значение ; тем, возможно, придется снова загружать в регистр. Встает вопрос о выборе тс регистра, значение которого нужно выгрузить в память. При этом возникает необходимость выработки стратегии замещения регистр процессора. Она чем-то сродни стратегиям замещения процессов и страниц в i мяти компьютера, которые были рассмотрены в части 1 данного пособия. Од] ко отличие заключается в том, что, в отличие от диспетчера памяти в ОС, комг лятор может проанализировать код и выяснить, какое из выгружаемых значен ему понадобится для дальнейших вычислений и когда (следует помнить, v компилятор сам вычислений не производит — он только порождает код для н иное дело — интерпретатор). Как правило, стратегии замещения регистров п] цессора предусматривают, что выгружается тот регистр, значение которого бу; использовано в последующих операциях позже всех (хотя не всегда эта стра гия является оптимальной).
Кроме общего распределения регистров могут использоваться алгоритмы р пределения регистров специального характера. Например, во многих процес pax есть регистр-аккумулятор, который ориентирован на выполнение различи арифметических операций (операции с ним выполняются либо быстрее, Л1 имеют более короткую запись). Поэтому в него стремятся всякий раз загруз: чаще всего используемые операнды; он же используется, как правило, при пе даче результатов функций и отдельных операторов. Могут быть также регист ориентированные на хранение счетчиков циклов, базовых указателей и т. п. Тс компилятор должен стремиться распределить их именно для тех целей, на : полнение которых они ориентированы.
Оптимизация кода для процессоров, допускающих распараллеливание вычислений
Многие современные процессоры допускают возможность параллельного полнения нескольких операций. Как правило, речь идет об арифметических с рациях.
Тогда компилятор может порождать объектный код таким образом, чтобы в содержалось максимально возможное количество соседних операций, все с ранды которых не зависят друг от друга. Решение такой задачи в глобаль объеме для всей программы в целом не представляется возможным, но для i кретного оператора оно, как правило, заключается в порядке выполнения ore ций. В этом случае нахождение оптимального варианта сводится к выполне] перестановки операций (если она возможна, конечно). Причем оптимальный
![]() риант зависит как от
характера операции, так и от количества имеющихся в процессоре конвейеров
для выполнения параллельных вычислений. Например, операцию A+B+C+D+E+F на
процессоре с одним потоком обработки данных лучше выполнять в порядке ((((A+B)+C)+D)+E)+F. Тогда потребуется
меньше ячеек
для хранения промежуточных результатов, а скорость выполнения от порядка операций в
данном случае не зависит.
риант зависит как от
характера операции, так и от количества имеющихся в процессоре конвейеров
для выполнения параллельных вычислений. Например, операцию A+B+C+D+E+F на
процессоре с одним потоком обработки данных лучше выполнять в порядке ((((A+B)+C)+D)+E)+F. Тогда потребуется
меньше ячеек
для хранения промежуточных результатов, а скорость выполнения от порядка операций в
данном случае не зависит.
Та же операция на процессоре с двумя потоками обработки данных в целях увеличения скорости выполнения может быть обработана в порядке ((А+В)+С)+ +((D+E)+F). Тогда по крайней мере операции А+В и D+E, а также сложение с их результатами могут быть обработаны в параллельном режиме. Конкретный порядок команд, а также распределение регистров для хранения промежуточных результатов будут зависеть от типа процессора.
На процессоре с тремя потоками
обработки данных ту же операцию можно уже разбить на части в виде (A+B)+(C+D)+(E+F). Теперь уже три
операции А+В, C+D и
E+F могут быть выполнены
параллельно. Правда, их результаты уже должны быть обработаны
последовательно, но тут уже следует принять во внимание соседние операции для
нахождения наиболее оптимального варианта.
10.Понятие и
структура системы программирования. История возникновения систем
программирования.
Структура современной системы
программирования.Современные системы
программирован!
Понятие и структура системы программирования
История возникновения систем программирования
Всякий компилятор является составной частью системного программного печения. Основное назначение компиляторов — служить для разработки прикладных и системных программ с помощью языков высокого уровня. Любая программа, как системная, так и прикладная, проходит этапы жизш цикла, начиная от проектирования и вплоть до внедрения и сопровожден] 25,43]. А компиляторы — это средства, служащие для создания програм обеспечения на этапах кодирования, тестирования и отладки. Однако сам по себе компилятор не решает полностью всех задач, связ с разработкой новой программы. Средств только лишь компилятора недос но для того, чтобы обеспечить прохождение программой указанных этапо ненного цикла. Поэтому компиляторы — это программное обеспечение, к< функционирует в тесном взаимодействии с другими техническими среде применяемыми на данных этапах.
Основные технические средства, используемые в комплексе с компилят включают в себя следующие программные модули:
□
текстовые редакторы, служащие для создания текстов
исходных прогр
□
компоновщики, позволяющие объединять несколько объектных
модул
рождаемых
компилятором, в единое целое;
□
библиотеки прикладных программ, содержащие в себе наиболее
ча<
пользуемые
функции и подпрограммы в виде готовых объектных мод^
□ загрузчики, обеспечивающие подготовку готовой программы к выполнению;
О отладчики, выполняющие программу в заданном режиме с целью поиска, обнаружения и локализации ошибок.
Первоначально компиляторы представляли собой обособленные программные модули, решающие исключительно задачу перевода исходного текста программы на входном языке в язык машинных кодов. Компиляторы разрабатывались вне связи с другими техническими средствами, с которыми им приходилось взаимодействовать. В задачу разработчика программы входило обеспечить взаимосвязь всех используемых технических средств:
□
подать входные данные в виде текста исходной программы на
вход компиля
тора;
□
получить
от компилятора результаты его работы в виде набора объектных
файлов;
□
подать весь набор полученных объектных файлов вместе с
необходимыми
библиотеками
подпрограмм на вход компоновщику;
□
получить
от компоновщика единый файл программы (исполняемый файл)
и подготовить его к выполнению с помощью
загрузчика;
□
поставить программу на выполнение, при необходимости
использовать от
ладчик
для проверки правильности выполнения программы.
Все эти действия выполнялись с помощью последовательности команд, инициировавших запуск соответствующих программных модулей с передачей им всех необходимых параметров. Параметры передавались каждому модулю в командной строке и представляли собой набор имен файлов и настроек, реализованных в виде специальных «ключей». Пользователи могли выполнять эти команды последовательно вручную, а с развитием средств командных процессоров ОС они стали объединять их в командные файлы.
Со временем разработчики компиляторов постарались облегчить труд пользователей, предоставив им все необходимое множество программных модулей в составе одной поставки компилятора. Теперь компиляторы поставлялись уже вкупе со всеми необходимыми сопровождающими техническими средствами. Кроме того, были унифицированы форматы объектных файлов и файлов библиотек подпрограмм. Теперь разработчики, имея компилятор от одного производителя, могли в принципе пользоваться библиотеками и объектными файлами, полученными от другого производителя компиляторов.
Для написания командных файлов компиляции был предложен специальный командный язык — язык Makefile [31, 39, 67, 68, 90]. Он позволял в достаточно гибкой и удобной форме описать весь процесс создания программы от порождения исходных текстов до подготовки ее к выполнению. Это было удобное, но достаточно сложное техническое средство, требующее от разработчика высокой степени подготовки и профессиональных знаний, поскольку сам командный язык Makefile был по сложности сравним с простым языком программирования. Язык Makefile стал стандартным средством, единым для компиляторов всех разработчиков. Такая структура средств разработки существовала достаточно долгое время, а в некоторых случаях она используется и по сей день (особенно при создании системных программ). Ее широкое распространение было связано с тем, что сама по себе вся эта структура средств разработки была очень удобной при пакетном выполнении программ на компьютере, что способствовало ее повсеместному применению в эпоху «mainframe».
Следующим шагом в развитии средств разработки стало появление так называемой «интегрированной среды разработки». Интегрированная среда объединила в себе возможности текстовых редакторов исходных текстов программ и командный язык компиляции. Пользователь (разработчик исходной программы) теперь не должен был выполнять всю последовательность действий от порождения исходного кода до его выполнения, от него также не требовалось описывать этот процесс с помощью системы команд в Makefile. Теперь ему было достаточно только указать в удобной интерфейсной форме состав необходимых для создания программы исходных модулей и библиотек. Ключи, необходимые компилятору и другим техническим средствам, также задавались в виде интерфейсных форм настройки.
После этого интегрированная среда разработки сама автоматически готовила всю необходимую последовательность команд Makefile, выполняла их, получала результат и сообщала о возникших ошибках при их наличии. Причем сам текст исходных модулей пользователь мог изменить здесь же, не прерывая работу с интегрированной средой, чтобы потом при необходимости просто повторить весь процесс компиляции.
Создание интегрированных сред разработки стало возможным благодаря бурному развитию персональных компьютеров и появлению развитых средств интерфейса пользователя (сначала текстовых, а потом и графических). Их появление на рынке определило дальнейшие развитие такого рода технических средств. Пожалуй, первой удачной средой такого рода можно признать интегрированную среду программирования Turbo Pascal на основе языка Pascal производства фирмы Borland [34, 71, 72, 98]. Ее широкая популярность определила тот факт, что со временем все разработчики компиляторов обратились к созданию интегрированных средств разработки для своих продуктов.
Развитие интегрированных сред несколько снизило требования к профессиональным навыкам разработчиков исходных программ. Теперь в простейшем случае от разработчика требовалось только знание исходного языка (его синтаксиса и семантики). При создании прикладной программы ее разработчик мог в простейшем случае даже не разбираться в архитектуре целевой вычислительной системы.
Дальнейшее развитие средств разработки также тесно связано с повсеместным распространением развитых средств графического интерфейса пользователя. Такой интерфейс стал неотъемлемой составной частью многих современных ОС и так называемых графических оболочек [35, 71]. Со временем он стал стандартом «де-факто» практически во всех современных прикладных программах.
Это не могло не сказаться на требованиях, предъявляемым к средствам разработки программного обеспечения. В их состав были сначала включены соответ-
ствующие библиотеки, обеспечивающие поддержку развитого графического интерфейса пользователя и взаимодействие с функциями API (application program interface, прикладной программный интерфейс) операционных систем. А затем для работы с ними потребовались дополнительные средства, обеспечивающие разработку внешнего вида интерфейсных модулей. Такая работа была уже более характерна для дизайнера, чем для программиста.
Для описания графических элементов программ потребовались соответствующие языки. На их основе сложилось понятие «ресурсов» (resources)1 прикладных программ.
Ресурсами прикладной программы будем называть множество данных, обеспечивающих внешний вид интерфейса пользователя этой программы и не связанных напрямую с логикой выполнения программы. Характерными примерами ресурсов являются: тексты сообщений, выдаваемых программой; цветовая гамма элементов интерфейса; надписи на таких элементах, как кнопки и заголовки окон и т. п.
Для формирования структуры ресурсов, в свою очередь, потребовались редакторы ресурсов, а затем и компиляторы ресурсов, обрабатывающие результат их работы2. Ресурсы, полученные с выхода компиляторов ресурсов, стали обрабатываться компоновщиками и загрузчиками.
Весь этот комплекс программно-технических средств в настоящие время составляет новое понятие, которое здесь названо «системой программирования».
Структура современной системы программирования
Системой программирования будем называть весь комплекс программных средств, предназначенных для кодирования, тестирования и отладки программного обеспечения. Нередко системы программирования взаимосвязаны и с другими техническими средствами, служащими целям создания программного обеспечения на более ранних этапах жизненного цикла (от формулировки требований и анализа до проектирования). Однако рассмотрение таких систем выходит за рамки данного учебного пособия.
Системы программирования в современном мире
доминируют на рынке средств разработки. Практически все фирмы-разработчики
компиляторов поставляют свои продукты в составе соответствующей системы
программирования в комплексе всех прочих технических средств. Отдельные компиляторы
являются редкостью и, как правило, служат только узко специализированным целям.  На рис. 15.1
приведена общая структура современной системы программирования. На ней
выделены все основные составляющие современной системы программирования и их
взаимосвязь. Отдельные составляющие разбиты по группам в соответствии с
этапами развития средств разработки. Эти группы отражают все этапы развития от
отдельных программных компонентов до цельной системы программирования.
На рис. 15.1
приведена общая структура современной системы программирования. На ней
выделены все основные составляющие современной системы программирования и их
взаимосвязь. Отдельные составляющие разбиты по группам в соответствии с
этапами развития средств разработки. Эти группы отражают все этапы развития от
отдельных программных компонентов до цельной системы программирования.
Зэтап
|
/'Исходный^. !„ ! /' PecvDcy N* ' ' кпп V ^Компилятору гесУРсы l;> К0Л ■ ресурсов | '.интерфейса,'-^ |
|
Загрузчик |
|
код ^ресурсов,' |
Редактор; ресурсов | (интерфейсных! форм) |
Выполнение Рис. 15.1. Общая структура и этапы развития систем программирования
Из рис. 15.1 видно, что современная система программирования — это достаточно сложный комплекс различных программно-технических средств. Все они служат цели создания прикладного и системного программного обеспечения.
Тенденция такова, что все развитие систем программирования идет в направлении неуклонного повышения их дружественности и сервисных возможностей. Это связано с тем, что на рынке в первую очередь лидируют те системы программирования, которые позволяют существенно снизить трудозатраты, потребные для создания программного обеспечения на этапах жизненного цикла, связанных с кодированием, тестированием и отладкой программ. Показатель снижения трудозатрат в настоящее время считается более существенным, чем показатели, определяющие эффективность результирующей программы, построенной с помощью системы программирования.
В качестве основных тенденций в развитии современных систем программирования следует указать внедрение в них средств разработки на основе так называемых «языков четвертого поколения» — 4GL (four generation languages), — а также поддержка систем «быстрой разработки программного обеспечения» — RAD (rapid application development).
Языки четвертого поколения — 4GL — представляют собой широкий набор средств, ориентированных на проектирование и разработку программного обеспечения. Они строятся на основе оперирования не синтаксическими структурами языка и описаниями элементов интерфейса, а представляющими их графическими образами. На таком уровне проектировать и разрабатывать прикладное программное обеспечение может пользователь, не являющийся квалифицированным программистом, зато имеющий представление о предметной области, на работу в
которой ориентирована прикладная программа. Языки четвертого поколения являются следующим (четвертым по счету) этапом в развитии систем программирования.
Описание программы, построенное на основе языков 4GL, транслируется затем в исходный текст и файл описания ресурсов интерфейса, представляющие собой обычный текст на соответствующем входном языке высокого уровня. С этим текстом уже может работать профессиональный программист-разработчик — он может корректировать и дополнять его необходимыми функциями. Дальнейший ход создания программного обеспечения идет уже традиционным путем, как это показано на рис. 15.1.
Такой подход позволяет разделить работу проектировщика, ответственного за общую концепцию всего проекта создаваемой системы, дизайнера, отвечающего за внешний вид интерфейса пользователя, и профессионального программиста, отвечающего непосредственно за создание исходного кода создаваемого программного обеспечения.
В целом языки четвертого поколения решают уже более широкий класс задач, чем традиционные системы программирования. Они составляют часть средств автоматизированного проектирования и разработки программного обеспечения, поддерживающих все этапы жизненного цикла — CASE-систем. Их рассмотрение выходит за рамки данного учебного пособия.
Более подробную информацию о языках 4GL, технологии RAD и CASE-систе-мах в целом можно получить в [35, 43].
11. Принципы функционирования систем
программирования. Функции текстовых редакторов в системах программирования.
Компилятор как составная часть системы программирования.
Принципы функционирования систем программирования
Функции текстовых редакторов в системах программирования
Текстовый редактор в системе программирования — это программа, позволяющая создавать, изменять и обрабатывать исходные тексты программ на языках высокого уровня.
В принципе текстовые редакторы появились вне какой-либо связи со средствами разработки. Они решали задачи создания, редактирования, обработки и хранения на внешнем носителе любых текстов, которые не обязательно должны были быть исходными текстами программ на языках высокого уровня. Эти функции многие текстовые редакторы выполняют и по сей день.
Возникновение интегрированных сред разработки на определенном этапе развития средств разработки программного обеспечения позволило непосредственно включить текстовые редакторы в состав этих средств. Первоначально такой подход привел к тому, что пользователь (разработчик исходной программы) работал только в среде текстового редактора, не отрываясь от нее для выполнения компиляции, компоновки, загрузки и запуска программы на выполнение. Для этого
потребовалось создать средства, позволяющие отображать ход всего процесса разработки программы в среде текстового редактора, — такие, например, как метод отображения ошибок в исходной программе, обнаруженных на этапе компиляции, с позиционированием на место в тексте исходной программы, содержащее ошибку.
Можно сказать, что с появлением интегрированных сред разработки ушло в прошлое то время, когда разработчики исходных текстов вынуждены были первоначально готовить тексты программ на бумаге с последующим вводом их в компьютер. Процессы написания текстов и собственно создание программного обеспечения стали единым целым.
Интегрированные среды разработки оказались очень удобным средством. Они стали завоевывать рынок средств разработки программного обеспечения. А с их развитием расширялись и возможности, предоставляемые разработчику в среде текстового редактора. Со временем появились средства пошаговой отладки программ непосредственно по их исходному тексту, объединившие в себе возможности отладчика и редактора исходного текста. Другим примером может служить очень удобное средство, позволяющее графически выделить в исходном тексте программы все лексемы исходного языка по их типам — оно сочетает в себе возможности редактора исходных текстов и лексического анализатора компилятора.
В итоге в современных системах программирования текстовый редактор стал важной составной частью, которая не только позволяет пользователю подготавливать исходные тексты программ, но и выполняет все интерфейсные и сервисные функции, предоставляемые пользователю системой программирования. И хотя современные разработчики по-прежнему могут использовать произвольные средства для подготовки исходных текстов программ, как правило, они все же предпочитают пользоваться именно тем текстовым редактором, который включен в состав данной системы программирования.
Компилятор как составная часть системы программирования
Компиляторы являются, безусловно, основными модулями в составе любой системы программирования. Поэтому не случайно, что они стали одним из главных предметов рассмотрения в данном учебном пособии. Без компилятора никакая система программирования не имеет смысла, а все остальные ее составляющие на самом деле служат лишь целям обеспечения работы компилятора и выполнения им своих функций.
От первых этапов развития систем программирования вплоть до появления интегрированных сред разработки пользователи (разработчики исходных программ) всегда так или иначе имели дело с компилятором. Они непосредственно взаимодействовали с ним как с отдельным программным модулем.
Сейчас, работая с системой программирования, пользователь, как правило, имеет дело только с ее интерфейсной частью, которую обычно представляет текстовый редактор с расширенными функциями. Запуск модуля компилятора и вся его работа происходят автоматически и скрытно от пользователя — разработчик видит только конечные результаты выполнения компилятора. Хотя многие современные системы программирования сохранили прежнюю возможность непосредственного взаимодействия разработчика с компилятором (это и Makefile, и так называемый «интерфейс командной строки»), но пользуется этими средствами только узкий круг профессионалов. Большинство пользователей систем программирования сейчас редко непосредственно сталкиваются с компиляторами.
На самом деле, кроме самого основного компилятора, выполняющего перевод исходного текста на входном языке в язык машинных команд, большинство систем программирования могут содержать в своем составе целый ряд других компиляторов и трансляторов. Так, большинство систем программирования содержат в своем составе и компилятор с языка ассемблера, и компилятор (транслятор) с входного языка описания ресурсов. Все они редко непосредственно взаимодействуют с пользователем.
Тем не менее, работая с любой системой программирования, следует помнить, что основным модулем ее всегда является компилятор. Именно технические характеристики компилятора, прежде всего, влияют на эффективность результирующих программ, порождаемых системой программирования.
Компоновщик. Назначение и функции компоновщика.
12. Компоновщик. Назначение и функции компоновщика
Компоновщик (или редактор связей) предназначен для связывания между собой объектных файлов, порождаемых компилятором, а также файлов библиотек, входящих в состав системы программирования1.
Объектный файл (или набор объектных файлов) не может быть исполнен до тех пор, пока все модули и секции не будут в нем увязаны между собой. Это и делает редактор связей (компоновщик). Результатом его работы является единый файл (часто называемый «исполняемым файлом»), который содержит весь текст результирующей программы на языке машинных кодов. Компоновщик может порождать сообщение об ошибке, если при попытке собрать объектные файлы в единое целое он не смог обнаружить какой-либо необходимой составляющей.
Функция компоновщика достаточно проста. Он начинает свою работу с того, что выбирает из первого объектного модуля программную секцию и присваивает ей начальный адрес. Программные секции остальных объектных модулей получают адреса относительно начального адреса в порядке следования. При этом может выполняться также функция выравнивания начальных адресов программных секций. Одновременно с объединением текстов программных секций объединяются секции данных, таблицы идентификаторов и внешних имен. Разрешаются межсекционные ссылки.
Процедура разрешения ссылок сводится к вычислению значений адресных констант процедур, функций и переменных с учетом перемещений секций относительно начала собираемого программного модуля. Если при этом обнаруживаются ссылки к внешним переменным, отсутствующим в списке объектных модулей, редактор связей организует их поиск в библиотеках, доступных в системе программирования. Если же и в библиотеке необходимую составляющую найти не удается, формируется сообщение об ошибке.
Обычно компоновщик формирует простейший программный модуль, создаваемый как единое целое. Однако в более сложных случаях компоновщик может создавать и другие модули: программные модули с оверлейной структурой, объектные модули библиотек и модули динамически подключаемых библиотек (работа с оверлейными и динамически подключаемыми модулями в ОС описана в первой части данного пособия).
13. Загрузчики и отладчики. Функции загрузчика
Большинство объектных модулей в современных системах программирования строятся на основе так называемых относительных адресов. Компилятор, порождающий объектные файлы, а затем и компоновщик, объединяющий их в единое целое, не могут знать точно, в какой реальной области памяти компьютера будет располагаться программа в момент ее выполнения. Поэтому они работают не с реальными адресами ячеек ОЗУ, а с некоторыми относительными адресами. Такие адреса отсчитываются от некоторой условной точки, принятой за начало области памяти, занимаемой результирующей программой (обычно это точка начала первого модуля программы).
Конечно, ни одна программа не может быть исполнена в этих относительных адресах. Поэтому требуется модуль, который бы выполнял преобразование относительных адресов в реальные (абсолютные) адреса непосредственно в момент запуска программы на выполнение. Этот процесс называется трансляцией адресов и выполняет его специальный модуль, называемый загрузчиком.
Однако загрузчик не всегда является составной частью системы программирования, поскольку выполняемые им функции очень зависят от архитектуры целевой вычислительной системы, в которой выполняется результирующая программа, созданная системой программирования. На первых этапах развития ОС загрузчики существовали в виде отдельных модулей, которые выполняли трансляцию адресов и готовили программу к выполнению — создавали так называемый «образ задачи». Такая схема была характерна для многих ОС (например, для ОСРВ на ЭВМ типа СМ-1, ОС RSX/11 или RAFOS на ЭВМ типа СМ-4 и т. п. [20, 57]). Образ задачи можно было сохранить на внешнем носителе или же создавать его вновь всякий раз при подготовке программы к выполнению.
С развитием архитектуры вычислительных средств компьютера появилась возможность выполнять трансляцию адресов непосредственно в момент запуска программы на выполнение. Для этого потребовалось в состав исполняемого файла включить соответствующую таблицу, содержащую перечень ссылок на адреса, которые необходимо подвергнуть трансляции. В момент запуска исполняемого файла ОС обрабатывала эту таблицу и преобразовывала относительные адреса в абсолютные. Такая схема, например, характерна для ОС типа MS-DOS, которые широко распространены в среде персональных компьютеров. В этой схеме модуль загрузчика как таковой отсутствует (фактически он входит в состав ОС), а система программирования ответственна только за подготовку таблицы трансляции адресов — эту функцию выполняет компоновщик.
В современных ОС существуют сложные методы преобразования адресов, которые работают непосредственно уже во время выполнения программы. Эти методы основаны на возможностях, аппаратно заложенных в архитектуру вычислительных комплексов. Методы трансляции адресов могут быть основаны на сегментной, страничной и сегментно-страничной организации памяти (все эти методы рассмотрены в первой части данного пособия). Тогда для выполнения трансляции адресов в момент запуска программы должны быть подготовлены соответствующие системные таблицы. Эти функции целиком ложатся на модули ОС, поэтому они не выполняются в системах программирования.
Еще одним модулем системы программирования, функции которого тесно связаны с выполнением программы, является отладчик.
Отладчик — это программный модуль, который позволяет выполнить основные задачи, связанные с мониторингом процесса выполнения результирующей прикладной программы. Этот процесс называется отладкой и включает в себя следующие основные возможности:
□
последовательное пошаговое выполнение результирующей
программы на ос
нове шагов
по машинным командам или по операторам входного языка;
□
выполнение результирующей программы до достижения ею
одной из задан
ных точек останова (адресов останова);
□
выполнение результирующей программы до наступления
некоторых заданных
условий,
связанных с данными и адресами, обрабатываемыми этой програм
мой;
□
просмотр содержимого областей памяти, занятых командами
или данными
результирующей
программы.
Первоначально отладчики представляли собой отдельные программные модули, которые могли обрабатывать результирующую программу в терминах языка машинных команд. Их возможности в основном сводились к моделированию выполнения результирующих программ в архитектуре соответствующей вычислительной системы. Выполнение могло идти непрерывно либо по шагам. Дальнейшее развитие отладчиков связано со следующими принципиальными моментами:
□
появлением интегрированных сред разработки;
□
появление возможностей аппаратной поддержки средств
отладки во многих
вычислительных
системах.
Первый из этих шагов дал возможность разработчикам программ работать не в терминах машинных команд, а в терминах исходного языка программирования, что значительно сократило трудозатраты на отладку программного обес- печения. При этом отладчики перестали быть отдельными модулями и стал] интегрированной частью систем программирования, поскольку они должны был] теперь поддерживать работу с таблицами идентификаторов (см. раздел «Табли цы идентификаторов. Организация таблиц идентификаторов», глава 15) и вы поднять задачу, обратную идентификации лексических единиц языка (см. разде. «Семантический анализ и подготовка к генерации кода», глава 14). Это связано тем, что в такой среде отладка программы идет в терминах имен, данных поль зователем, а не в терминах внутренних имен, присвоенных компилятором. Сс ответствующие изменения потребовались также в функциях компиляторов компоновщиков, поскольку они должны были включать таблицу имен в соста объектных и исполняемых файлов для ее обработки отладчиком.
Второй шаг позволил значительно расширить возможности средств отладю Теперь для них не требовалось моделировать работу и архитектуру соответа вующей вычислительной системы. Выполнение результирующей программы режиме отладки стало возможным в той же среде, что и в обычном режиме. В зг дачу отладчика входили только функции перевода вычислительной системы соответствующий режим перед запуском результирующей программы на отла/ ку. Во многом эти функции являются приоритетными, поскольку зачастую тр( буют установки системных таблиц и флагов процессора вычислительной сист< мы (мы рассмотрели большую часть этих вопросов в первой части данног учебного пособия).
Отладчики в современных системах программирования представляют собо модули с развитым интерфейсом пользователя, работающие непосредственн с текстом и модулями исходной программы. Многие их функции интегрирован: с функциями текстовых редакторов исходных текстов, входящих в состав систе программирования.
14. Библиотеки подпрограмм как составная часть систем программирования
Библиотеки подпрограмм составляют существенную часть систем программир< вания. Наряду с дружественностью пользовательского интерфейса состав до* тупных библиотек подпрограмм во многом определяет возможности систем программирования и ее позиции на рынке средств разработки программно! обеспечения.
Библиотеки подпрограмм входили в состав средств разработки, начиная с самь ранних этапов их развития. Даже когда компиляторы еще представляли собс отдельные программные модули, они уже были связаны с соответствующими би( лиотеками, поскольку компиляция так или иначе предусматривает связь програм со стандартными функциями исходного языка. Эти функции обязательно дол> ны входить в состав библиотек.
С точки зрения системы
программирования, библиотеки подпрограмм состою из двух основных компонентов.
Это собственно файл (или множество файло] библиотеки, содержащий объектный код, и
набор файлов описаний функций, по, программ, констант и переменных, составляющих
библиотеку.
15. Лексический анализ «на лету». Система подсказок и
справок.
Дополнительные возможности систем программирования
Лексический анализ «на лету». Система подсказок и справок
Лексический анализ «на лету» — это функция текстового редактора в составе системы программирования. Она заключается в поиске и выделении лексем входного языка в тексте программы непосредственно в процессе ее создания разработчиком.
Реализуется это следующим образом: разработчик создает исходный текст программы (набирает его или получает из некоторого другого источника), и в то же время система программирования параллельно выполняет поиск лексем в этом тексте.
В простейшем случае обнаруженные лексемы просто выделяются в тексте с помощью графических средств интерфейса текстового редактора — цветом, шрифтом и т. п. Это облегчает труд разработчика программы, делает исходный текст более наглядным и способствует обнаружению ошибок на самом раннем этапе — на этапе подготовки исходного кода.
В более развитых системах программирования найденные лексемы не просто выделяются по ходу подготовки исходного текста, но и помещаются в таблицу идентификаторов компилятора, входящего в состав системы программирования. Такой подход позволяет экономить время на этапе компиляции, поскольку первая ее фаза — лексический анализ — уже выполнена на этапе подготовки исходного текста программы.
Следующей сервисной возможностью, предоставляемой разработчику системой программирования за счет лексического анализа «на лету», является возможность обращения разработчика к таблице идентификаторов в ходе подготовки исходного текста программы. Разработчик может дать компилятору команду найти нужную ему лексему в таблице. Поиск может выполняться по типу или по какой-то части информации лексемы (например, по нескольким первым буквам). Причем поиск может быть контекстно-зависимым — система программирования предоставит разработчику возможность найти лексему именно того типа, который может быть использован в данном месте исходного текста. Кроме самой , лексемы разработчику может быть предоставлена некоторая информация о ней — например, типы и состав формальных параметров для функции, перечень доступных методов для типа или экземпляра класса. Это опять же облегчает труд разработчика, поскольку избавляет его от необходимости помнить состав функций и типов многих модулей (прежде всего, библиотечных) или обращаться лишний раз к документации и справочной информации.
Лексический анализ «на лету» — мощная
функция, значительно облегчающая труд, связанный с подготовкой исходного
текста. Она входит не только в состав многих систем программирования, но также
и в состав многих текстовых редакторов, поставляемых отдельно от систем
программирования (в последнем случае она позволяет настроиться на лексику того или
иного языка).
Другой удобной сервисной функцией в современных системах программирования является система подсказок и справок. Как правило, она содержит три основные части:
□
справку по семантике и синтаксису используемого входного
языка;
□
подсказку по работе с самой системой программирования;
□
справку о функциях библиотек, входящих в состав системы
программирова
ния.
Система подсказок и справок в
настоящее время является составной частью многих прикладных и системных программ.
Как правило, она поддерживается соответствующими утилитами ОС. Поэтому, кроме
всего прочего, многие системы программирования включают в свой состав сервисные
функции, позволяющие создавать и дополнять систему подсказок и справок. Это
делается таким образом, чтобы разработчик мог создавать и распространять
вместе со своими прикладными программами соответствующие им подсказки и
справки.
16.Разработка программ в архитектуре «клиент—сервер»
Структура приложения, построенного в архитектуре
«клиент - сервер».
Распространение динамически подключаемых библиотек и ресурсов прикладных программ привело к ситуации, когда большинство прикладных программ стало представлять собой не единый программный модуль, а набор сложным образом взаимосвязанных между собой компонентов. Многие из этих компонентов либо входили в состав ОС, либо же требовалась их поставка и установка от других разработчиков, которые очень часто могли быть никак не связаны с разработчиками самой прикладной программы.
При этом среди всего множества компонентов прикладной программы можно было выделить две логически цельные составляющие: первая — обеспечивающая «нижний уровень» работы приложения, отвечающая за методы хранения, доступа и разделения данных; вторая — организующая «верхний уровень» работы приложения, включающий в себя логику обработки данных и интерфейс пользователя.
Первая составляющая, как правило, представляла собой набор компонентов сторонних разработчиков. Часто она так или иначе была связана с доступом к базам данных, которые могли предусматривать достаточно сложную организацию. Для работы ее компонентов требовалось наличие высокопроизводительной вычислительной системы.
Вторая составляющая включала в себя собственно алгоритмы, логику и весь интерфейс, созданные разработчиками программы. Она требовала наличие связи с методами доступа к данным, содержащимся в первой составляющей. Требования к вычислительным системам, необходимым для выполнения ее компонентов, были обычно существенно ниже, чем для первой составляющей.
Тогда сложилось понятие приложения, построенного на основе архитектуры «клиент—сервер». В первую (серверную) составляющую такого приложения относят все методы, связанные с доступом к данным. Чаще всего их реализует сер-
вер БД (сервер данных) из соответствующей СУБД (системы управления базами данных) в комплекте с драйверами доступа к нему. Во вторую (клиентскую) часть приложения относят все методы обработки данных и представления их пользователю. Клиентская часть взаимодействует, с одной стороны, с сервером, получая от него данные, а с другой стороны — с пользователем, ресурсами приложения и ОС, осуществляя обработку данных и отображение результатов. Результаты обработки клиент опять-таки может сохранить в БД, воспользовавшись функциями серверной части.
Кроме того, со временем на рынке СУБД стали доминировать несколько наиболее известных компаний-производителей. Они предлагали стандартизованные интерфейсы для доступа к создаваемым ими СУБД. На них, в свою очередь, стали ориентироваться и разработчики прикладных программ. Такая ситуация оказала влияние и на структуру систем программирования. Многие из них стали предлагать средства, ориентированные на создание приложений в архитектуре «клиент—сервер». Как правило, эти средства поставляются в составе системы программирования и поддерживают возможность работы с широким диапазоном известных серверов данных через один или несколько доступных интерфейсов обмена данными. Разработчик прикладной программы выбирает одно из доступных средств плюс возможный тип сервера (или несколько воз- : можных типов), и тогда его задача сводится только к созданию клиентской части ,; приложения, построенной на основе выбранного интерфейса. Создав клиентскую часть, разработчик может далее использовать и распространять ее только в комплексе с соответствующими средствами из состава системы программирования. Интерфейс обмена данными обычно входит в состав системы программирования. Большинство систем программирования предоставляют возможность распространения средств доступа к серверной части без каких-либо дополнительных ограничений.
Что касается серверной части, то возможны два пути: простейшие серверы БД требуют от разработчиков приобретения лицензий на средства создания и отладки БД, но часто позволяют распространять результаты работы без дополнительных ограничений; мощные серверы БД, ориентированные на работу десятков и сотен пользователей, требуют приобретения лицензий как на создание, так и на распространение серверной части приложения. В этом случае конечный пользователь приложения получает целый комплекс программных продуктов от множества разработчиков.
Более подробно об организации приложений на основе архитектуры «клиент-сервер» можно узнать в [9, 35, 63].
Разработка программ в трехуровневой архитектуре. Серверы приложений
Трехуровневая архитектура разработки приложений явилась логическим продолжением идей, заложенных в архитектуре «клиент—сервер». Недостатком архитектуры приложений типа «клиент—сервер» стал тот факт, что в клиентской части приложения совмещались как довольно сложные функции,
связанные с обработкой получаемых от сервера данных, так и более про функции организации интерфейса пользователя. Для выполнения этих фун к вычислительной системе должны предъявляться различные требования, и ] случае когда выполняется сложная обработка данных, эти требования со a ны «клиентской» части приложения могут быть непомерно велики. Кроме обработка данных («бизнес-логика» приложения), как правило, изменяете: значительно по мере прохождения жизненного цикла, развития приложен выхода его новых версий. В то же время интерфейсная часть может серьез» доизменяться и в предельном случае подстраиваться под требования конкр< го заказчика.
Еще одним фактором, повлиявшим на дальнейшее развитие архитектуры « ент—сервер», стало распространение глобальных сетей и всемирной сети Инте Многие приложения стали нуждаться в предоставлении пользователю воз] ности доступа к данным посредством сети. Возможностей архитектуры « ент—сервер» для этой цели стало во многих случаях недостаточно, поско клиент зачастую мог не иметь никаких вычислительных ресурсов, кроме граммы навигации по сети (браузера, browser).
Поэтому дальнейшим развитием архитектуры «клиент—сервер» стало раз; ние клиентской части в свою очередь еще на две составляющих: сервер прил ний (английские термины «application server» или «middleware»), реализую обработку данных («бизнес-логику» приложения), и «тонкий клиент» («thin clie обеспечивающий интерфейс и доступ к результатам обработки (далее «toi клиент» будем называть просто «клиентом»). Серверная часть осталась бе: менений, но теперь она получила название «сервер баз данных» («database ver»), чтобы не путаться с сервером приложений.
Разделение клиентской части на две составляющих потребовало организг взаимодействия между этими составляющими. Причем это взаимодействие д( но, с одной стороны, быть достаточно тесным, так как клиент должен выпол отображение получаемых от сервера данных за время с разумной задержкой лательно минимальной); а с другой стороны, он должен допускать обмен да! ми по протоколам, поддерживаемым глобальными сетями. Поэтому появи некоторое число стандартов, ориентированных на организацию такого рода е модействия. Стали появляться новые интерфейсы обмена данными. Среди можно выделить семейство стандартов COM/DCOM, предложенных фир Microsoft для ОС семейства Microsoft Windows [103], а также семейство с дартов CORBA (Common Object Request Broker Architecture), поддержива< широким кругом производителей и разработчиков программного обеспече для большого спектра различных ОС [99]. Детальное рассмотрение такого стандартов и принципов их организации не входит в рамки данного учебногс собия.
Системы программирования в настоящее время ориентируются на поддер средств разработки приложений в трехуровневой (трехзвенной) архитект Средства поддержки тех или иных стандартов сейчас появляются в составе i гих систем программирования [3, 35, 63, 98, 104, 105]. Принципы их использования и распространения аналогичны принципам, применяемым для средств : держки архитектуры типа «клиент—сервер». Следует заметить, что существ
системы программирования, ориентированные на разработку либо клиентской части, либо сервера приложений; и в то же время многие системы программирования стремятся предоставить разработчикам средства для создания обеих частей в трехуровневой архитектуре. Серверная часть (сервер баз данных) в трехуровневой архитектуре по-прежнему чаще всего является продуктом другого разработчика1.
Более подробно об организации приложений на основе трехуровневой технологии можно узнать в [2, 35, 63].
Примеры современных систем программирования
В этом разделе пособия ни в коем случае не ставится задача полного описания тех или иных систем программирования, доступных в настоящее время на рынке современных средств разработки программного обеспечения. Полное описание многих из них по объему будет значительно превышать весь материал данного пособия. Автор только дает краткий обзор наиболее известных и распространенных в настоящее время систем программирования с точки зрения их компонентов, ложащихся на общую структуру типовой системы программирования.
Для краткого описания автором были выбраны только самые известные из всего широкого спектра систем программирования, распространенные именно на рынке Российской Федерации. Информация о данных системах программирования дается как на основании соответствующей литературы, так и на основании личного опыта работы автора.
Системы программирования компании Borland/Inprise
Системы программирования компании Borland достаточно широко известны разработчикам в России. Известность и распространенность этих систем программирования определила, прежде всего, простота их использования, поскольку именно в системах программирования этой компании были впервые реализованы на практике идеи интегрированной среды программирования.
Turbo Pascal
Система программирования Turbo Pascal была создана компанией Borland на основе расширения языка Pascal, получившего название Borland Pascal. Отсюда происходит и само название системы программирования.
Сам язык Pascal был предложен Н. Виртом в конце 70-х годов как хорошо структурированный учебный язык. Расширения, привнесенные в язык компанией Borland, преследовали две основные цели:
□
упрощение обработки в языке структур, представляющих
наиболее распро
страненные
типы данных — строки и файлы (например, в язык был внесен
новый тип данных string);
□
реализация в языке основных возможностей
объектно-ориентированных язы
ков
программирования.
Последнее нововведение потребовало серьезной доработки синтаксиса языка. В него были внесены новые ключевые слова, синтаксические конструкции и типы данных. Однако предложенный вариант языка нельзя признать удачным, хотя бы потому, что в нем не полностью реализованы все механизмы объектно-ориентированного программирования. Например, отсутствуют такие мощные средства, как исключения и шаблоны. Есть и другие сложности в использовании языка.
Компания Borland построила и реализовала эффективный однопроходный компилятор с языка Borland Pascal. За счет этого в данной системе программирования удалось добиться относительно высокой скорости компиляции исходных программ. Для ускорения работы компоновщика компанией Borland был предложен собственный уникальный формат объектных файлов — модулей исходной программы — TPU (Turbo Pascal Unit)1. По этой причине модули, созданные в системе программирования Turbo Pascal, не могли быть использованы в других системах программирования. Также из них невозможно было создавать библиотеки, ориентированные на другие языки и системы программирования. Обратная задача — использование стандартных объектных файлов и библиотек в системе программирования Turbo Pascal — была решаема, но имела серьезные ограничения. В состав системы программирования Turbo Pascal, кроме компилятора с языка Borland Pascal, входил также компилятор с языка ассемблера (а с появлением возможности разработки результирующих программ для среды Microsoft Windows — компилятор ресурсов). Среда программирования позволяла компоновать как единые исполняемые файлы, так и оверлейные программы для ОС типа MS-DOS.
Первоначально система программирования Turbo Pascal строилась на основе библиотеки RTL (run time library) языка Borland Pascal. Эта библиотека не предоставляла пользователю широкого набора функций — в основном она только реализовывала базовые математические функции и функции языка. Однако можно сказать об одной характерной черте данной библиотеки — она включала в свой состав объектный код менеджера памяти для управления распределением динамической памяти («кучей» — heap — в терминах языка Pascal), который автоматически подключался к каждой результирующей программе, созданной с помощью данной системы программирования. Этот модуль получился доволь-
![]() но удачным и нашел свое
дальнейшее применение в других системах программирования данной
компании-разработчика.
но удачным и нашел свое
дальнейшее применение в других системах программирования данной
компании-разработчика.
Несмотря на недостатки, система программирования Turbo Pascal получила широкое распространение и завоевала свое место на рынке. Основной причиной явилось то, что система впервые была построена в виде интегрированной среды. Данный факт предопределил ее широкое распространение, и, прежде всего, в университетской среде, где требовались простые и понятные в использовании средства разработки.
Первые версии системы программирования были ориентированы только на работу в ОС MS-DOS персональных компьютеров на базе процессоров типа Intel 80x86. На исполнение в среде этой ОС были ориентированы и результирующие программы, разрабатываемые с помощью данной среды программирования.
Система программирования Turbo Pascal получила широкое распространение и дальнейшее развитие. Компания Borland выпустила несколько ее реализаций (наиболее распространенные из них — версии 5.5 и 7.0). Последние реализации данной системы программирования могли создавать результирующие программы, ориентированные на работу как в ОС типа MS-DOS, так и в среде типа Microsoft Windows. В них были реализованы все основные преимущества, предоставляемые интегрированной средой программирования, такие как лексический анализ программ «на лету» и встроенная контекстная подсказка.
По мере распространения системы программирования Turbo Pascal шла разработка библиотек подпрограмм и функций для нее. Были созданы такие библиотеки, как Turbo Professional (TP), Turbo Vision, Object Window Library (OWL) для среды MS-DOS и ObjectWindows для среды Microsoft Windows. Широкому распространению данных библиотек по-прежнему мешал тот факт, что в системе программирования Turbo Pascal используется уникальный, нестандартный формат объектных файлов. Отсутствие стандарта языка Borland Pascal во многом сдерживало развитие этой системы программирования и не способствовало ее применению как профессионального средства разработки.
Системе программирования Turbo Pascal здесь уделено много внимания по той причине, что это одна из самых распространенных в настоящее время систем программирования учебного назначения. Кроме того, это первая появившаяся на рынке система программирования, которая полностью реализовала в себе идеи интегрированной среды программирования. Эти идеи, заложенные в системе программирования Turbo Pascal, нашли применение во многих современных системах программирования. По системе программирования Turbo Pascal выпущена огромная масса литературы — можно обратиться, например, к книгам [34, 71, 72].
Borland Delphi
Система программирования Borland Delphi явилась логическим продолжением и дальнейшим развитием идей, заложенных компанией-разработчиком еще в системе программирования Turbo Pascal.
В качестве основных в новой системе программирования можно указать следующие принципиальные изменения:
□ новый язык программирования — Object Pascal, явившийся серьезной переработкой прежней версии языка Borland Pascal;
Q компонентная модель среды разработки, в первую очередь ориентированная на технологию разработки RAD (rapid application development).
Язык программирования Object Pascal создавался в то время, когда на рынке средств разработки уже существовало значительное количество объектно-ориентированных языков, включая такие известные, как C++ и Java. Компания Borland попыталась учесть все недостатки существующих языков объектно-ориентированного программирования, а также свой опыт создания языка Borland Pascal. По мнению автора, во многом ей это удалось. Новый язык вышел довольно удачным как с точки зрения синтаксиса, так и с точки зрения предоставляемых возможностей. Этот язык поддерживает практически все основные механизмы объектно-ориентированного программирования.
Компонентная модель среды разработки предусматривает создание основной части программы в виде набора взаимосвязанных компонентов — классов объектно-ориентированного языка. Во время разработки исходной программы (design time) компоненты предстают в виде графических образов и обозначений, связанных между собой. Каждый компонент обладает определенным набором свойств (properties), событий (events) и методов. Каждому из них соответствует свой фрагмент исходного кода программы, отвечающий за обработку метода или реакции на какое-то событие. Разработчик может располагать на экране и связывать между собой компоненты, а также редактировать связанный с ними исходный код программы. Причем поведение компонентов во время выполнения программы (run time) полностью определяется их взаимосвязью, исходным кодом программы и объектным кодом самого компонента.
Система программирования Borland Delphi предназначена для создания результирующих программ, выполняющихся в среде ОС Windows различных типов. Основу системы программирования Borland Delphi и ее компонентной моделр составляет библиотека VCL (visual component library). В этой библиотеке реализованы в виде компонентов все основные органы управления и интерфейса ОС Также в ее состав входят классы, обеспечивающие разработку приложений дл$ архитектуры «клиент—сервер» и трехуровневой архитектуры (в современных pea лизациях Borland Delphi). Разработчик имеет возможность не только использо вать любые компоненты, входящие в состав библиотеки VCL, но также и раз рабатывать свои собственные компоненты, основанные на любом из классо] данной библиотеки. Эти новые компоненты становятся частью системы про граммирования и затем могут быть использованы другими разработчиками. Для поддержки разработки результирующих программ для архитектуры «кли ент—сервер» в состав Borland Delphi входит средство BDE (Borland database engine Оно обеспечивает результирующим программам возможность доступа к шире кому диапазону серверов БД посредством классов библиотеки VCL. Посредст вом BDE результирующая программа может взаимодействовать с серверами Б; типа Microsoft SQL Server, Interbase, Sybase, Oracle и т. п. Система програм мирования Borland Delphi поддерживает также создание результирующих прс грамм, выполняющихся в архитектуре «клиент—сервер», на базе других техне логий, например ADO (ActiveX Data Objects).
Система программирования Borland Delphi выдержала несколько реализаций. Последние реализации данной системы программирования (прежде всего, версии 4 и 5) включают широкий набор средств для поддержки разработки результирующих программ в трехуровневой архитектуре приложений. Система программирования Borland Delphi позволяет разрабатывать как серверную, так и клиентскую часть приложения в данной архитектуре. Возможно использование как технологий COM/DCOM (наиболее распространенных в среде ОС типа Microsoft Windows), так и технологии CORBA (но только при разработке клиентской части приложения).
В качестве недостатков данной системы программирования можно указать использование нестандартного формата объектных файлов (сохранился еще от системы Turbo Pascal, но в последней версии Borland Delphi 5 можно использовать стандартный формат), а также нестандартного формата для хранения ресурсов пользовательского интерфейса. Кроме того, сам язык Object Pascal не является признанным стандартом. Этот факт несколько затрудняет использование Borland Delphi в масштабных проектах в качестве основного средства разработки.
Тем не менее система программирования Borland Delphi получила широкое распространение среди разработчиков в Российской Федерации. Более подробную информацию по данной системе программирования можно найти в технической литературе (например, [35]), либо на сайте компании-производителя [98].
Borland C++ Builder
Система программирования Borland C++ Builder объединила в себе идеи интегрированной среды разработки, реализованные компанией в системах программирования Turbo Pascal и Borland Delphi с возможностями языка программирования C++. История этой системы программирования начинается с интегрированной среды разработки Borland Turbo С.
Среда Turbo С представляла собой реализацию идей, заложенных компанией-разработчиком в системе программирования Turbo Pascal для языка программирования С. Компания Borland стремилась перенести удачную реализацию идей интегрированной среды разработки на новую основу. Компилятор Turbo С не был однопроходным, и потому время компиляции исходной программы превышало время компиляции аналогичной программы в Turbo Pascal. Кроме того, в системе программирования использовался стандартный компоновщик исполняемых файлов MS-DOS.
Преимущество Turbo С заключалось в том, что эта система программирования строилась на базе стандартного языка программирования С. Данный язык получил широкое распространение среди разработчиков в качестве языка системного программирования, для него существовали компиляторы под многие типы целевых архитектур. В этом было главное отличие системы программирования Turbo С от схожей по организации системы программирования Turbo Pascal, которая строилась на основе поддержки нестандартного расширения языка Pascal.
С развитием системы программирования на базе Turbo Pascal развивались и системы программирования на основе Turbo С.
Современная реализация Borland C++ Builder ориентирована на разработку результирующих программ, выполняющихся под управлением ОС Microsoft Windows всех типов. Сама система программирования Borland C++ Builder, как и Borland Delphi, также функционирует под управлением ОС типа Microsoft Windows. Он полностью поддерживает стандарт языка С, что делает возможным создание с помощью данной системы программирования модулей и библиотек, используемых в других средствах разработки (чего очень сложно достигнуть с помощью Borland Delphi).
По возможностям, внешнему виду и технологиям система программирования Borland C++ Builder схожа с системой программирования Borland Delphi. В ее основу положены те же основные идеи и технологии. Структура классов языка C++ в системе программирования Borland C++ Builder построена в той же библиотеке VCL (visual control library), в которой строится структура классов Object Pascal в системе программирования Borland Delphi. Правда, разработчик, создающий программы на C++, может не пользоваться классами VCL и взять за основу любую другую библиотеку, чего нельзя сказать о разработчике, использующем Object Pascal — набор доступных библиотек для последнего языка сильно ограничен.
Успешное распространение систем программирования Turbo Pascal и Borland Delphi способствовало и внедрению на рынок системы программирования Borland C++ Builder от той же компании-разработчика. Эта система программирования занимает прочную позицию на рынке средств разработки для языка C++, где существует довольно жесткая конкуренция. Более подробную информацию по данной системе программирования можно найти в технической литературе ([80]), либо на сайте компании-производителя [98].
Системы программирования фирмы Microsoft
Компания Microsoft в настоящее время как производитель операционных систем и программного обеспечения доминирует на рынке персональных компьютеров, построенных на базе процессоров типа Intel 8.0x86. Прежде всего, это относится ко всем вариантам ОС типа Microsoft Windows.
Этот факт явился одним из главных факторов, которые обусловили прочную позицию данной компании на рынке средств разработки программных продуктов для ОС типа Microsoft Windows. Все виды ОС типа Microsoft Windows создавались как закрытые системы. Поэтому безусловное знание компанией-разработчиком структуры и внутреннего устройства «своей» ОС зачастую являлось определяющим в ситуации, когда надо было создать средство разработки приложений для данной ОС. Хорошие финансовые ресурсы и положение компании на рынке позволили ей создать довольно удачные системы программирования, несмотря на то, что она начала их разработку довольно поздно и не являлась «законодателем мод» в данной области.
Microsoft Visual Basic
Это средство разработки прошло долгую историю под руководством компании Microsoft. История языка Basic на персональных компьютерах началась с прими-
тивных интерпретаторов данного языка. Сам по себе язык Basic позволял легко организовать интерпретацию исходного кода программ, а его синтаксис и семантика достаточно просты для понимания даже непрофессиональными разработчиками.
Система программирования Microsoft Visual Basic также первоначально была ориентирована на интерпретацию исходного кода. Однако требования и условия на рынке средств разработки толкнули компанию-производителя на создание компилятора, вошедшего в состав данной системы программирования. При этом основные функции библиотеки языка были вынесены в отдельную, динамически подключаемую библиотеку VBRun, которая должна присутствовать в ОС для выполнения результирующих программ, созданных с помощью данной системы программирования. Различные версии системы программирования Microsoft Visual Basic ориентированы на различные версии данной библиотеки. Интерпретатор языка был сохранен и внедрен компанией-разработчиком в состав модулей другого программного продукта — Microsoft Office.
Развитие системы программирования Visual Basic потребовало существенного изменения синтаксиса и семантики самого языка. С точки зрения автора, это решение нельзя признать технически удачным, так как изначально простой и достаточно примитивный язык исходного текста (не ориентированный на создание объектно-ориентированных программ) был изменен так, чтобы иметь возможность решать несвойственные ему задачи. Однако этот ход компании был продиктован скорее маркетинговой политикой, чем техническими требованиями. При всем множестве привнесенных в язык новшеств компании удалось сохранить присущую ему простоту и наглядность всей системы программирования в целом.
Последняя версия данной системы программирования — Microsoft Visual Basic 6.0 — является одним из эффективных средств для создания результирующих программ, ориентированных на выполнение под управлением ОС типа Microsoft Windows. Эта система программирования ориентирована на технологию разработки RAD. Microsoft Visual Basic 6.0 содержит интегрированные средства визуальной работы с базами данных, поддерживающие проектирование и доступ к базам данных SQL Server, Oracle и т. п. К этим средствам относятся Visual Database Tools, ADO/OLE DB, Data Environment Designer, Report Designer и ряд других.
В данной системе программирования поддерживается также создание серверных Web-приложений, работающих с любым средством просмотра на базе новых Web-классов. В новой версии обеспечивается и отладка приложений для сервера IIS (Internet information server) производства компании Microsoft. В Microsoft Visual Basic 6.0 возможно создание интерактивных Web-страниц.
Microsoft Visual Basic 6.0 обеспечивает простое создание приложений, ориентированных на данные. Visual Basic 6.0 позволяет создавать результирующие программы, выполняемые в архитектуре «клиент—сервер», которые могут работать с любыми базами данных. Система программирования Microsoft Visual Basic ориентирована, прежде всего, на создание клиентской части приложений.
Теперь Visual Basic 6.0 поддерживает универсальный интерфейс доступа к данным Microsoft при помощи технологии ADO. Visual Basic 6.0 обеспечивает про
смотр таблиц, изменение данных, создание запросов SQL из среды разработки для любой совместимой с ODBC или OLE DB базы данных. Так же как и в редакторе Visual Basic, синтаксис SQL выделяется цветом и незамедлительно проверяется на наличие ошибок. Это делает код SQL легче читаемым и менее подверженным случайным ошибкам.
Новая версия продукта поддерживает коллективную разработку, масштабируемость, создание компонентов промежуточного слоя, пригодных к многократному использованию в любом СОМ-совместимом продукте. Поддержка широкого спектра интерфейсов доступа к данным дает возможность применять эту систему программирования для разработки клиентской части приложений, выполняющихся в трехуровневой архитектуре.
Среда разработки обладает множеством новых возможностей, таких как выделение синтаксиса и автоматическое завершение ключевых слов. Система программирования Microsoft Visual Basic интегрируется с семейством программных продуктов Microsoft BackOffice, которое обеспечивает среду для выполнения и создания сложных приложений масштаба предприятия для работы в локальных сетях или в Интернете. Использование новых интегрированных визуальных средств работы с данными облегчает выполнение рутинных задач по обеспечению доступа к ним; эти средства доступны прямо из среды разработки Visual Basic.
Система программирования Visual Basic неплохо сочетает в себе простоту и эффективность разработки. Все недостатки, присущие данной системе, в большинстве своем проистекают из недостатков используемого исходного языка программирования. Средства языка Basic даже после значительной модификации ограничивают возможности его применения в современных архитектурах взаимодействия приложений, которые в значительной мере основаны на объектно-ориентированном подходе. Кроме того, язык программирования в системе Visual Basic не является признанным стандартом, а потому возникают трудности по использованию созданных на его основе модулей и компонентов в других средствах разработки.
Информацию о системе программирования Visual Basic можно найти в многочисленной технической литературе (например, [3, 63]), либо же на сайте представительства компании [105].
Microsoft Visual C++
Система программирования Microsoft Visual C++ представляет собой реализацию среды разработки для распространенного языка системного программирования C++, выполненную компанией Microsoft. Эта система программирования в настоящее время построена в виде интегрированной среды разработки, включающей в себя все необходимые средства для разработки результирующих программ, ориентированных на выполнение под управлением ОС типа Microsoft Windows различных версий.
Основу системы программирования Microsoft Visual C++ составляет библиотека классов MFC (Microsoft foundation classes). В этой библиотеке реализованы в виде классов C++ все основные органы управления и интерфейса ОС. Также
в ее состав входят классы, обеспечивающие разработку приложений для архитектуры «клиент—сервер» и трехуровневой архитектуры (в современных версиях библиотеки). Система программирования Microsoft Visual C++ позволяет разрабатывать любые приложения, выполняющиеся в среде ОС типа Microsoft Windows, в том числе серверные или клиентские результирующие программы, осуществляющие взаимодействие между собой по одной из указанных выше архитектур.
Классы библиотеки MFC ориентированы на использование технологий СОМ/ DCOM, а также построенной на их основе технологии ActiveX для организации взаимодействия между клиентской и серверной частью разрабатываемых приложений. На основе классов библиотеки пользователь может создавать свои собственные классы в языке C++, организовывать свои структуры данных.
В отличие от систем программирования компании Borland, система программирования Microsoft Visual C++ ориентирована на использование стандартных средств хранения и обработки ресурсов интерфейса пользователя в ОС Windows. Это не удивительно, поскольку все версии ОС типа Windows разрабатываются самой компанией Microsoft. Microsoft Visual C++ обеспечивает все необходимые средства для создания профессиональных Windows-приложений. От версии к версии продукт становится проще в использовании, расширяются возможности применения, повышается производительность.
Система программирования Microsoft Visual C++ выдержала несколько реализаций. В процессе выхода новых версий системы программирования было выпущено и несколько версий библиотеки MFC, на которой основана данная система.
Сама по себе библиотека MFC является, по мнению автора, довольно удачной реализацией широкого набора классов языка C++, ориентированного на разработку результирующих программ, выполняющихся под управлением ОС типа Microsoft Windows. Это во многом обусловлено тем, что создатель библиотеки — компания Microsoft — одновременно является и создателем ОС типа Microsoft Windows, на которые ориентирован объектный код библиотеки. Библиотека может быть подключена к результирующей программе с помощью обычного компоновщика либо использоваться как динамическая библиотека, подключаемая к программе во время ее выполнения. Библиотека MFC достаточно широко распространена. Ее возможно использовать не только в составе систем программирования производства компании Microsoft, но и в системах программирования других производителей.
В комплект поставки данной системы программирования входят также новый мастер для поэтапного создания приложений, интегрированный отладчик создаваемых приложений, профилировщик исходного кода, галерея классов и объектов, а также средство для создания дистрибутивов — InstallShield.
Visual C++ 6.0 полностью интегрируется с Visual Studio 6.0 и другими средствами разработки, входящими в состав данного пакета. Эта интеграция, в частности, обеспечивает мгновенный доступ к MSDN (Microsoft developer network) library, содержащей документацию, примеры кода, статьи и другую информацию для разработчиков. Система программирования Visual C++ 6.0 широко известна. Информацию о ней можно найти в многочисленной технической литературе, а также на сайте представительства компании [104].
Концепция .NET
Концепция .NET (произносится как «dot net» — «дот нет») — это не система программирования, а новейшая технология, предложенная фирмой Microsoft с целью унификации процесса разработки программного обеспечения с помощью различных систем программирования. Концепция .NET разработана компанией совсем недавно, и в настоящее время (2000-2001 годы) происходит ее постепенное внедрение на рынок средств разработки.
Концепция Microsoft .NET — это целостный взгляд компании Microsoft на новую эпоху в развитии Интернета. В рамках этой концепции самые разнообразные программные приложения предоставляются пользователям и разработчикам как сервисы, которые взаимодействуют между собой в соответствии с конкретными потребностями бизнеса, доступны на самых разных устройствах, имеют понятный и полностью адаптирующийся к потребностям каждого пользователя интерфейс.
Концепция Microsoft .NET — закономерный этап в развитии информационных технологий, приложений и сервисов, позволяющий разработчикам воспользоваться преимуществами сочетания открытых стандартов и архитектуры новой ОС производства компании Microsoft — Microsoft Windows 2000.
Большинство операционных систем, существовавших до настоящего времени, были неспособны предоставить необходимую корпоративным приложениям среду исполнения. Для них приходилось создавать специальные серверы приложений. Новая ОС производства компании Microsoft — Microsoft Windows 2000 — непосредственно предоставляет многие функций сервера приложений на уровне системных сервисов. Поэтому в концепции .NET управление приложениями концентрируется на более специфических для корпоративной среды и Интернет-служб задачах — управлении множеством объектов, приложений и серверов. Их решает сервер масштабирования приложений.
Концепция .NET содержит много новых идей и предложений, выдвинутых и реализуемых компанией Microsoft. С точки зрения систем программирования основные идеи архитектуры .NET заключаются в том, что в ОС типа Windows 2000 организуется специальная виртуальная машина, исполняющая (интерпретирующая) команды некоторого промежуточного низкоуровневого языка. Любая программа, исполняемая в .NET, представляет собой набор команд данного промежуточного языка. При этом сами команды этого языка интерпретируются независимо от архитектуры вычислительной системы и версии ОС, где они исполняются.
Таким образом, любая система программирования, ориентированная на данную концепцию, сможет создавать код результирующей программы не в виде последовательности машинных команд, специфичных для архитектуры той или иной ОС, а в виде промежуточного низкоуровневого кода. Этот код будет интерпретироваться единообразно и независимо от архитектуры целевой вычислительной
системы. Кроме того, любая результирующая программа, исполняемая в .NET, сможет воспользоваться сервисными функциями другой программы, доступной в .NET, вне зависимости от того, с помощью какой системы программирования были разработаны обе эти программы. Это значительно расширяет возможности программ, исполняемых в рамках .NET, особенно с учетом возможности удаленного (сетевого) доступа ко многим предоставляемым сервисам.
В первую очередь на поддержку концепции .NET будут, безусловно, ориентированы системы программирования производства компании Microsoft. Это коснется рассмотренных выше систем программирования Microsoft Visual C++ и Microsoft Visual Basic. Кроме того, компания предлагает новую систему программирования, построенную на базе нового языка С# (произносится «Си-шарп»), которая специально ориентирована на поддержку концепции .NET. При успешном развитии концепции и ее внедрении на рынок ОС и средств разработки на нее будут ориентироваться и системы программирования других разработчиков.
Поддержка концепции .NET в системах программирования не отменяет в них поддержку традиционного пути создания программного обеспечения. Возможность создания результирующих программ, исполняющихся под управлением .NET, идет в дополнение к возможности создания «традиционных» результирующих программ, построенных из машинных команд, ориентированных на определенную архитектуру целевой вычислительной системы. Однако далеко не все модули существующих в настоящий момент библиотек могут быть использованы в рамках данной концепции. Это в равной степени касается и распространенных библиотек MFC и VBRun, используемых в системах программирования от Microsoft.
Концепция .NET ориентирована исключительно на новые ОС типа Windows 2000 производства компании Microsoft (а также на все последующие версии данного типа ОС). Она не переносима на ОС других типов, а также на архитектуру, не совместимую с традиционной архитектурой персональных компьютеров, построенных на базе процессоров Intel 80x86. Этот факт ограничивает ее широкое распространение, поскольку она поддерживается пока только одной компанией-производителем, хотя и доминирующей на рынке ОС для персональных компьютеров.
Концепция .NET еще достаточно нова и не нашла пока широкого отражения в технической литературе. Со временем эта ситуация, конечно, изменится, а пока для более подробной информации рекомендуется обратиться на сайт представительства компании Microsoft [106].
Системы программирования под ОС Linux и UNIX
Системы программирования в составе ОС типа UNIX
Вся история ОС UNIX тесно связана с историей языка программирования С. Фактически эти два программных продукта не смогли бы существовать друг без друга.
Язык программирования С появился как базовый язык программирования в ОС типа UNIX. Более того, сама операционная система представляла (и представляет) собой набор файлов, написанных на исходном языке программирования С. То есть практически любая ОС типа UNIX поставляется в виде исходного текста на языке С (кроме незначительной части ядра ОС, ориентированной на особенности архитектуры вычислительной системы, где она выполняется). Всякий раз при изменении основных параметров ОС происходит компиляция и компоновка ядра ОС заново, а при перезапуске ОС вновь созданное ядро активируется. Этот принцип характерен для всех ОС типа UNIX.
Таким образом, ни одна ОС типа UNIX фактически не может существовать без наличия в ее составе компилятора и компоновщика для языка программирования С (поскольку речь идет о ядре ОС, то роль загрузчика несколько отличается от его роли в обычной системе программирования). Соответственно, все производители ОС типа UNIX включают в ее состав и системы программирования языка С. По указанным причинам этот язык программирования стал основным для этого типа ОС (хотя под ОС типа UNIX существуют системы программирования с других языков — например, Lisp, FORTRAN, Pascal, — они используются не так часто, как С).
В ОС типа UNIX сложились основные особенности и характеристики второго этапа в развитии систем программирования. Именно здесь системы программирования стали представлять собой комплекс из библиотек языка, компилятора и компоновщика, выполняемых под управлением специальных командных файлов. Функции загрузчика в данном случае большей частью выполняются самой ОС. В ОС типа UNIX сложился, стал применяться и был стандартизован командный язык компиляции Makefile. Кроме того,, именно в ОС этого типа были разработаны упомянутые в данном учебном пособии методы автоматизации разработки компиляторов, основанные на использовании программ LEX и YACC [11, 31, 39, 67, 68, 90]. К тому же практически все ОС типа UNIX обладают мощными командными процессорами, выполняющими команды пользователя в ОС. Возможности этих командных процессоров, по сути, соответствуют возможностям интерпретаторов языков программирования.
Принцип, по которому распространяется и устанавливается любая ОС типа UNIX, стал применяться и к прикладным программам, разрабатываемым для исполнения под управлением данного типа ОС. Обычно прикладная программа, ориентированная на выполнение под ОС типа UNIX, поставляется в виде набора исходных кодов (чаще всего на языке программирования С). При установке прикладной программы на конкретную ОС такого типа она автоматически компилируется и компонуется, после чего готова к выполнению. Такой метод распространения прикладных программ в виде исходных кодов значительно снижает их зависимость от архитектуры конкретной вычислительной системы1. Однако
![]() он требует
обязательного наличия соответствующей системы программирования в составе ОС (вот
почему в качестве языка разработки прикладных программ под ОС типа UNIX чаще всего выступает именно С).
он требует
обязательного наличия соответствующей системы программирования в составе ОС (вот
почему в качестве языка разработки прикладных программ под ОС типа UNIX чаще всего выступает именно С).
Системы программирования в ОС типа UNIX долгое время не выходили за рамки второго этапа развития систем программирования. Они продолжают оставаться такими и по сей день в той части, которая отвечает за распространение исходного кода самой ОС и прикладных программ, разработанных для нее. Так происходит, поскольку в этом случае система программирования не требует наличия интегрированной среды и вполне может быть ограничена командными файлами. Однако развитие графического интерфейса пользователя оказало свое влияние и на системы программирования под ОС данного типа.
Системы программирования, построенные на базе интегрированных сред разработки, стали появляться и под ОС типа UNIX. Характерная черта их заключалась в том, что практически все они строились именно в графической среде на основе стандартного графического интерфейса. Так произошло, потому что в ОС типа UNIX (в отличие от ОС, ориентированных на персональные компьютеры) практически сразу в качестве стандарта «де-факто» установился стандарт графического интерфейса пользователя на основе среды X Window [31, 67, 68]. Это позволило унифицировать библиотеки систем программирования (все они строятся на базе библиотеки Xlib), компиляторы и компоновщики ресурсов пользовательского интерфейса. Широкие возможности командных процессоров в ОС типа UNIX облегчают построение интегрированной среды в системах программирования. Поэтому сейчас существует широкий выбор таких сред от многих производителей (при наличии хотя бы небольшого опыта работы в ОС разработчик имеет возможность сам построить интегрированную среду программирования под управлением ОС).
Описания базовых систем программирования под ОС типа UNIX можно найти в любой технической литературе по этим ОС, которая имеется в настоящее время в достаточном количестве [11, 31, 34, 67, 68].
Системы программирования проекта GNU
Проект GNU был начат в 1984 году. Само название «GNU» является рекурсивной аббревиатурой «GNU's Not UNIX» - «GNU не UNIX». Манифест проекта GNU [102] был написан Ричардом Столлменом (Richard Stallman) в начале работы над проектом GNU и адресован желающим помочь или принять участие в проекте. В течение нескольких первых лет работы над проектом он был незначительно обновлен, чтобы отразить ход работ.
Идея проекта GNU заключается в свободном распространении всех программ, созданных в рамках этого проекта. Программы распространяются в виде исходного кода, причем пользователь не только получает этот код в пользование, но и имеет право вносить в него изменения, а также распространять исходный или модифицированный код всем желающим участникам проекта. Во многом своему существованию и развитию проект обязан наличию по всему миру большого количества профессионалов-энтузиастов, не возражающих против свободного распространения и использования созданных ими программ. Более точные форму-
лировки сути проекта и условий участия в нем можно найти на сайте [100] или [102] (в русском переводе).
GNU — это название полной UNIX-совместимой программной системы, которая разрабатывается и безвозмездно предоставляется всем желающим ее использовать в рамках проекта. Система GNU способна исполнять UNIX-программы, но не идентична ОС типа UNIX. Улучшения основаны на имеющемся опыте работы с другими операционными системами. В качестве языка системного программирования в системе доступны как С, так и Lisp. Кроме этого, поддерживаются коммуникационные протоколы UUCP, MIT Chaosnet и сети Интернет.
Безусловно, по самой своей сути проект предполагает наличие в своем составе систем программирования. В противном случае распространение исходных кодов программ в рамках проекта будет просто бессмысленным. Очевидно, базовой системой программирования в проекте GNU стала система программирования на языке С. Хотя GNU и не UNIX, но проект перенял многие положительные черты ОС этого типа, в том числе — создание и распространение ядра ОС на основе языка С. Другим фактором, обусловившим создание системы программирования языка С в рамках проекта GNU, стало то, что большинство профессионалов-энтузиастов, основавших проект, использовали именно этот язык программирования.
Со временем система программирования GNU С преобразовалась в более развитую систему программирования GNU C++, поскольку именно язык C++ получил широкое распространение в среде профессионалов. Затем в рамках проекта стали доступны и системы программирования на основе многих других языков программирования, в частности известного языка Pascal.
По внешнему виду, интерфейсу и функциональным возможностям системы программирования, созданные в рамках проекта GNU, мало чем отличаются от систем программирования, ориентированных на ОС типа UNIX. Главным отличием являются условия, определяющие правила распространения и использования данных систем программирования. Особенности проекта обусловили и тот факт, что большинство созданных в нем систем программирования не ориентировано на интегрированные среды разработки, а функционируют в рамках командных процессоров. И хотя возможности ОС, созданной в проекте GNU, позволяют разработчику, использующему одну из систем программирования, самому создать интегрированную среду разработки (при наличии у него соответствующих профессиональных навыков), эта особенность не является положительной чертой проекта.
Поэтому в последнее время и в рамках проекта GNU стали появляться системы программирования, построенные на основе интегрированной среды разработки. Кроме того, известные компании-производители средств разработки стали обращать внимание на данный проект по причине его широкого распространения. Они стали предлагать свои системы программирования, ориентированные на выполнение в ОС, созданной в рамках проекта GNU. Об одной из такой систем программирования (Borland Kylix) несколько слов сказано ниже.
Операционная система, созданная и поддерживаемая сообществом разработчиков в рамках проекта GNU, получила название Linux. В ходе работы над проек-
том было создано большое количество программного обеспечения, в том числе и систем программирования (кроме указанной уже системы GNU C++). Даже краткий обзор их возможностей здесь не представляется возможным. Информацию о них можно найти в любой технической литературе, посвященной ОС Linux и проекту GNU, либо в сети Интернет [67, 68, 100].
Положительной чертой проекта можно считать так же тот факт, что многие системы программирования, созданные в рамках проекта, оказались совместимыми и с ОС типа UNIX, которые формально не входят в проект GNU. Та же система программирования GNU C++, созданная в рамках проекта GNU, может с успехом использоваться (и используется) под многими версиями ОС типа UNIX.
Проект Borland Kylix
Проект Borland Kylix представляет собой попытку компании Borland перенести на ОС типа Linux опыт создания систем программирования, который компания накопила за долгое время работы в этой сфере для ОС типа Microsoft Windows. В рамках проекта Borland Kylix компания Borland создала и распространяет на рынке программного обеспечения одноименную систему программирования, основанную на языке программирования Object Pascal. Данный язык известен в среде разработчиков для системы программирования Borland Delphi, ориентированной на ОС типа Windows. Компания Borland реализовывает проект Borland Kylix таким образом, чтобы перенести в созданную систему программирования под ОС Linux все черты, присущие системе программирования Borland Delphi, уже существующей под ОС типа Microsoft Windows (эта система программирования была рассмотрена выше в данной главе).
Основой проекта Borland Kylix стала библиотека компонентов CLX (произносится «клик»), в которой компания Borland реализовала все основные органы управления пользовательского интерфейса и средства обработки данных, ориентированные на ОС Linux. Библиотека построена в виде компонентов на основе иерархии классов языка Object Pascal. Надо сказать, что данная библиотека отлична от библиотеки VCL, которая в настоящее время используется в системе программирования Borland Delphi и построена на основе того же языка. Перенести классы библиотеки VCL в новый проект системы программирования под ОС Linux оказалось для компании Borland принципиально невозможным. Следующим шагом в проекте Borland Kylix компания предполагает создание в его рамках системы программирования на основе языка C++. Эта система программирования должна быть построена на основе той же библиотеки CLX, что и система программирования на основе Object Pascal (примерно так же, как Borland Delphi и Borland C++ Builder построены на основе одной и той же библиотеки VCL).
Дальнейшим развитием проекта Borland Kylix компания Borland видит внедрение библиотеки CLX в существующие системы программирования Borland Delphi и Borland C++ Builder, ориентированные на ОС типа Windows. В случае успешного развития проекта использование одной из указанных систем программирования компании Borland существенно облегчит перенос приложений между двумя принципиально различными типами ОС. В рамках этого проекта разра-
ботчик, пользуясь только средствами библиотеки CLX, сможет создавать исходный код на языке Object Pascal или C++ таким образом, что результирующие программы, построенные на основе этого кода с помощью Borland Kylix, будут выполняться в ОС типа Linux, а построенные с помощью Borland Delphi или Borland C++ Builder — в ОС типа Microsoft Windows. В случае успеха проект Borland Kylix может быть распространен и на различные ОС типа UNIX.
Этот проект был выбран в качестве примера потому, что системы программирования производства компании Borland достаточно широко распространены на рынке России. Внимание, уделяемое компанией Borland ОС типа Linux, говорит о широком распространении проекта GNU в среде разработчиков.
Проект Borland Kylix только начал развиваться. Он еще не нашел широкого отражения в технической литературе, поэтому подробности лучше получить на сайте компании [98].
Разработка программного обеспечения для сети Интернет
Интернет — это всемирная «сеть сетей». Он объединяет в себя вычислительные системы и локальные сети, построенные на базе различных аппаратно-программных архитектур. При осуществлении взаимодействия по сети двух компьютеров один из них выступает в качестве источника данных (Интернет-сервера), а другой — приемника данных (Интернет-клиента). Сервер подготавливает данные, а клиент принимает их и каким-то образом обрабатывает. Нередко в качестве данных выступают тексты программ, которые подготавливает сервер, а исполнять должен клиент.
В таких условиях определяющим становится требование унифицированного исполнения кода программы вне зависимости от архитектуры вычислительной системы. Компиляция и создание объектного кода в условиях всемирной сети становятся бессмысленными, потому что заранее не известно, на какой вычислительной системе потребуется исполнять полученный в результате компиляции код. По этой причине сервер не может передавать по сети объектный код или команды ассемблера — вполне может так случиться, что клиент просто не способен их исполнить. Можно попытаться создать сервер таким образом, чтобы он мог подготавливать программы для всех известных типов клиентов. Однако это, во-первых, значительно увеличит нагрузку на сервер, а во-вторых, не гарантирует от ситуации, когда связь с сервером установит клиент нового, еще не известного серверу типа (поскольку количество возможных архитектур компьютеров непостоянно и ничем в принципе не ограничено).
Поэтому основной особенностью программирования в сети Интернет является использование в качестве основного средства программирования интерпретируемых языков. При интерпретации исполняется не объектный код, а сам исходный код программы, и уже непосредственно интерпретатор на стороне клиента отвечает за то, чтобы этот исходный код был исполнен всегда одним и тем же образом вне зависимости от архитектуры вычислительной системы. Тогда сервер готовит код программы всегда одним и тем же образом вне зависимости от типа клиента.
![]() В такой ситуации
нагрузка на Интернет-клиента может возрасти. Но задачу можно несколько
упростить: Интернет-сервер может готовить не высокоуровневый код исходной
программы, а некий унифицированный промежуточный код низкого уровня,
предназначенный для исполнения на стороне клиента. Тогда в обмене данными участвуют
еще две дополнительные программы: компилятор (точнее — транслятор) на
стороне сервера, транслирующий исходный код программы на некотором языке
высокого уровня в промежуточный низкоуровневый код; и интерпретатор на
стороне клиента, отвечающий за исполнение промежуточного кода вне зависимости от
архитектуры вычислительной системы клиента.
В такой ситуации
нагрузка на Интернет-клиента может возрасти. Но задачу можно несколько
упростить: Интернет-сервер может готовить не высокоуровневый код исходной
программы, а некий унифицированный промежуточный код низкого уровня,
предназначенный для исполнения на стороне клиента. Тогда в обмене данными участвуют
еще две дополнительные программы: компилятор (точнее — транслятор) на
стороне сервера, транслирующий исходный код программы на некотором языке
высокого уровня в промежуточный низкоуровневый код; и интерпретатор на
стороне клиента, отвечающий за исполнение промежуточного кода вне зависимости от
архитектуры вычислительной системы клиента.
Во многих случаях при использовании исполнения программ в глобальной сети применяется именно такая схема.
Для реализации такого рода схем существует много технических и языковых средств. Существует также значительное количество языков программирования, ориентированных на использование в глобальной сети [10, 16, 91]. Интернет-программирование — это отдельная и довольно интересная область разработки программ, но в целом вопросы, затрагиваемые в ней, лежат за пределами данного учебного пособия. Далее дается только очень краткий обзор принципов, положенных в основу тех или иных языков программирования с глобальной сети.
Язык HTML. Программирование статических Web-страниц
Язык HTML (hypertext markup language, язык разметки гипертекста) во многом определил развитие и широкое распространение сети Интернет по всему миру. Сам по себе язык достаточно прост, а для овладения им нужны только самые примитивные знания в области программирования.
Язык позволяет описывать структурированный текст (гипертекст), содержащий ссылки и взаимосвязи фрагментов; графические элементы (изображения), которые могут быть связаны как с текстовой информацией, так и между собой; а также простейшие элементы графического интерфейса пользователя (кнопки, списки, поля редактирования). На основе описания, построенного в текстовом виде на HTML, эти элементы могут располагаться на экране, им могут присваиваться различные атрибуты, определяющие используемые ресурсы интерфейса пользователя (такие, как цвет, шрифты, размер и т. п.). В результате получается графический образ — Web-страница (от «web» — «паутина» — слова, входящего в состав аббревиатуры WWW — World Wide Web — Всемирная паутина). Она в принципе может содержать различные мультимедийные элементы, включая графику, видео и анимацию.
Широкому распространению HTML послужил принцип, на основе которого этот язык стал
использоваться в глобальной сети. Суть его достаточно проста: Интернет-сервер
создает текст на языке HTML и передает его в
виде текстового файла на клиентскую сторону сети по специальному протоколу
обмена данными HTTP (hypertext transfer protocol, протокол передачи
гипертекста). Клиент, получая исходный текст на языке HTML, интерпретирует его и в соответствии с результатом интерпретации
строит соответствующие интерфейсные формы и изображения на экране
клиентского компьютера.
Грамматика HTML проста (она относится к регулярным грамматикам), а потому не составляет сложности построить соответствующий интерпретатор. Такими интерпретаторами явились программы-навигаторы в сети Интернет (браузеры, browser), которые, по сути, минимально должны были содержать две составляющих: клиентскую часть для обмена данными по протоколу HTTP и интерпретатор языка HTML. Некоторое время на рынке существовало огромное количество такого рода программ, в настоящее время преобладают две — Internet Explorer (производства компании Microsoft) и Netscape Navigator (производства компании Netscape). Первый из них доминирует на архитектуре персональных компьютеров на базе процессоров типа Intel 80x86 под управлением ОС типа Microsoft Windows.
Гораздо разнообразнее программное обеспечение серверной части. Это вызвано тем, что в протоколе HTTP нигде строго не специфицирован источник HTML-текста. Им может быть обычный текстовый файл, и тогда клиент будет видеть у себя статическую картинку всякий раз, когда устанавливает соединение с данным сервером. Но может быть и так, что сервер будет порождать новый HTML-текст всякий раз, когда клиент устанавливает с ним соединение, или даже менять текст по мере работы клиента с сервером. Тогда и изображение на стороне клиента, зависящее от интерпретируемого текста HTML, будет динамически изменяться по мере изменения текста. Последний вариант представляет гораздо больший интерес с точки зрения предоставляемых возможностей. Вопрос только в том, как организовать динамическое изменение HTML-текста. Вот в этом направлении и шло развитие основных средств Интернет-программирования.
Описание языка HTML можно найти на многих сайтах в глобальной сети, а также в многочисленной литературе по Интернет-программированию (например, в [16, 91]).
Язык HTML прост и тем удобен. Однако отсюда проистекают и основные его недостатки. Во-первых, он не предоставляет средств динамического изменения содержимого интерфейсных форм и изображений, поэтому основной метод — динамическое изменение самого текста HTML. Во-вторых, данный язык не предоставляет никаких методов поддержки современных архитектур типа «клиент-сервер» или трехуровневой архитектуры. Он не позволяет обмениваться данными ни с серверами БД, ни с серверами приложений как на стороне сервера, где готовятся тексты HTML, так и на стороне клиента, где эти тексты интерпретируются. Наконец, этот язык имеет очень ограниченные средства для реакции на действия пользователя в интерфейсных формах, созданных с его помощью.
Для устранения этих недостатков были предложены различные средства. Некоторые из них рассмотрены ниже.
Программирование динамических Web-страниц
Основная идея динамической генерации Web-страниц заключается в том, что большая часть HTML-страницы не хранится в файле на сервере, а порождается непосредственно каждый раз при обращении клиента к серверу. Тогда сервер формирует страницу и сразу же по готовности передает ее клиенту. Таким образом, всякий раз при новом обращении клиент получает новый текст HTML, и не ис- ключено, что тексты могут значительно различаться между собой даже при обращении к одному и тому же серверу.
Вопрос только в том, как обеспечить динамическую генерацию HTML-кода на стороне сервера.
Самое очевидное решение заключается в том, чтобы разработать некоторый исполняемый файл (приложение), который будет динамически строить новый HTML-код. Тогда на вход такого исполняемого файла поступают некоторые параметры (например, данные, которые пользователь ввел в форме или командной строке), а на выходе он должен порождать HTML-код в виде текста. Для этой цели служат специальные приложения, называемые CGI-приложениями.
CGI (common gateway interface, общедоступный шлюзовой интерфейс) — это интерфейс для запуска внешних программ на сервере в ответ на действия клиента, установившего соединение с ним через глобальную сеть. Пользуясь этим интерфейсом, приложения могут получать информацию от удаленного пользователя, анализировать ее, формировать HTML-код и отсылать его клиенту. CGI-прило-жения могут получать данные из заполненной формы, построенной с помощью HTML, либо из командной строки описания URL (universal resource locator, универсальный указатель ресурса). Строка URL вводится в программе-навигаторе, осуществляющей доступ к серверу со стороны клиента через глобальную сеть по протоколу HTTP. To, какие CGI-приложения по каким действиям пользователя должны выполняться на сервере, указывается непосредственно в коде HTML-страницы, которую сервер передает клиенту.
Кроме интерфейса CGI существуют и другие варианты интерфейсов, позволяющие динамически создавать HTML-код путем запуска на сервере приложений в ответ на действия клиента. Например, можно выделить интерфейс ISAPI (Internet server application programming interface, интерфейс прикладных программ Интернет-сервера). Отличие ISAPI от CGI заключается в том, что для поддержки CGI создаются отдельные приложения, выполняющиеся в виде самостоятельных программ, a ISAPI поддерживается с помощью библиотек, динамически подключаемых к серверу. ISAPI-библиотеки исполняются непосредственно в адресном пространстве сервера, имеют большие возможности и обеспечивают более высокую производительность сервера, в то время как CGI-приложения исполняются в ОС сервера как отдельные процессы и вынуждены определенным образом организовывать обмен данными с самим сервером (что снижает производительность). Но, с другой стороны, ошибка в библиотеке ISAPI может привести к выходу всего сервера из строя и его длительной неработоспособности. В то же время ошибка в коде CGI-приложения может, в худшем случае, привести только к аварийному завершению выполнения этого приложения, а сам сервер при этом сохранит работоспособность. Тогда в результате ошибки будет неверно отображена только какая-то одна HTML-страница либо часть страницы, а все остальные части сервера будут продолжать исправно работать.
Современные системы программирования, в том числе и те из них, что были рассмотрены в качестве примеров в данном пособии, позволяют создавать приложения и библиотеки, рассчитанные на работу в глобальной сети в соответствии со стандартами CGI или ISAPI. При этом создание исходного кода приложения практически ничем не отличается от создания обычной исполняемой програм-
мы, компилятор по-прежнему порождает объектные файлы, но компоновщик собирает исполняемый файл или библиотеку с учетом того, что они будут исполняться в архитектуре сервера глобальной сети. Функции загрузчика выполняет ОС по команде сервера либо сам Интернет-сервер.
Этот метод удобен, но имеет один серьезный недостаток: при изменении содержимого динамической HTML-страницы или же при изменении логики ее реакции на действия Интернет-клиента требуется создать новые код CGI или ISAPI-приложения. А для этого нужно выполнить полностью весь цикл построения результирующей программы, начиная от изменения исходного кода, включая компиляцию и компоновку. Поскольку содержимое Web-страниц меняется довольно часто (в отличие от обычных программ), то такой подход нельзя признать очень эффективным. Кроме того, может потребоваться перенос Интернет-сервера с одной архитектуры вычислительной системы на другую, а это также потребует перестройки всех используемых CGI-приложений и ISAPI-библиотек. Лучших результатов можно добиться, если не выполнять на сервере уже скомпилированный и готовый объектный код, а интерпретировать код программы, написанной на некотором языке. При интерпретации исходного кода сервер, конечно, будет иметь производительность ниже, чем при исполнении готового объектного кода, но чаще всего этим можно пренебречь, поскольку производительность серверов Интернета ограничивает чаще всего не мощность вычислительной системы, а пропускная способность канала обмена данными. Тогда зависимость кода сервера от архитектуры вычислительной системы будет минимальной, а изменить содержимое порождаемой HTML-страницы можно будет сразу же, как только будет изменен порождающий ее исходный код (без дополнительной перекомпиляции).
Существует несколько языков и соответствующих им интерпретаторов, которые нашли применение в этой области и успешно служат цели порождения HTML-страниц. Среди них можно назвать язык Perl, лежащий в основе различных версий Web-технологии PHP (Personal home pages), и язык сценариев, на котором основана Web-технология ASP (Active server pages), — последний предложен и поддерживается известным производителем программного обеспечения — фирмой Microsoft. Компонент, интерпретирующий ASP, появился в составе версии IIS (Internet information server) 3.0. В результате разработчики получили более простые в применении и вместе с тем более мощные средства создания Web-приложений.
Текст на интерпретируемых языках, которые поддерживаются такими Web-технологиями, как ASP или РНР, представляет собой часть текста обычных HTML-страниц со встроенными в них сценариями (script). Эти сценарии можно писать на любом языке, поддерживаемом сервером; Интернет-сервер обрабатывает их при поступлении запроса о URL-адресе соответствующего файла. Он разбирает текст HTML-страницы, находит в нем тексты сценариев, вырезает их и интерпретирует в соответствии с синтаксисом и семантикой данного языка. В результате интерпретации получается выходной текст на языке HTML, который сервер вставляет непосредственно в то место исходной страницы, где встретился сценарий. Так обрабатывается динамическая Web-страница на любом интерпретируемом языке, ориентированном на работу в глобальной сети. Естественно, для
работы со страницей сервер должен иметь в своем составе интерпретатор соответствующего языка.
Все эти языки сценариев обладают присущими им
характерными особенно
стями.
Во-первых, они имеют мощные встроенные функции и средства для рабо
ты со
строками, поскольку основной задачей программ, написанных с помощью
таких
языков, является обработка входных параметров (строковых) и порожде
ние HTML-кода (который также является текстом). Во-вторых, все они имеют
средства
для работы в архитектуре «клиент—сервер» для обмена информацией с
серверами БД, а многие современные версии таких языков (например, язык, под
держиваемый Web-технологией ASP) — средства для функционирования в трех
уровневой
архитектуре для обмена данными с серверами приложений.
Технологии
интерпретируемых языков сценариев, отделившие процесс написа
ния
кода HTML от процесса создания прикладных компонентов,
способствовали
более
эффективному сотрудничеству между дизайнерами Web-страниц
и разра
ботчиками
программ. Благодаря тому, что динамические данные и приложения
генерируются
с помощью интерпретируемых языков непосредственно иа Интер
нет-сервере,
информация остается там, где ею легче всего управлять.
Недостаток
всех перечисленных методов заключается в том, что сначала сервер
вынужден
строить HTML-описание, собирая его некоторым образом из
каких-то
своих данных, а затем Интернет-клиент на своей стороне разбирает (интерпрети
рует)
полученное описание HTML-страницы. Таким
образом, выполняется как
бы двойная работа по генерации, а затем интерпретации текстов языка HTML.
Кроме
того, между клиентом и сервером по сети передаются довольно громозд
кие описания HTML-страниц, что может
значительно увеличивать трафик сети.
Тем не
менее, несмотря на недостатки, данные методы довольно распространены
в
глобальной сети, поскольку они очень просты, а кроме того, не требуют от кли
ентского
компьютера ничего, кроме способности интерпретировать тексты HTML.
Эта
особенность довольно существенна. '
Есть и другие варианты генерации динамических HTML-страниц. Рассмотренные далее методы, хотя и снижают нагрузку на сеть, но предъявляют определенные требования к клиентской части, что не всегда приемлемо. Информацию по перечисленным выше языкам, поддерживающим такие методы, можно найти в соответствующей технической литературе (она частично имеется в [10, 91]), но лучше обратиться на соответствующие сайты во Всемирной сети [103, 107, 108].
Языки программирования Java и Java Script
Язык Java был разработан компанией Sun в качестве средства Web-программирования. Этот язык, в отличие от языка описания гипертекста HTML, является полноценным языком программирования. Он содержит в себе все основные операторы, конструкции и структуры данных, присущие языкам программирования. Синтаксические конструкции и семантика языка Java большей частью были заимствованы из языков программирования С и C++.
Основная идея, отличающая язык Java от многих других языков программирования, не ориентированных на применение в глобальной сети, заключается в том, что Java не является полностью компилируемым языком. Исходная программа, созданная на языке Java, не преобразуется в машинные коды. Компилятор языка порождает некую промежуточную результирующую программу на специальном низкоуровневом двоичном коде (эта результирующая программа называется Java-апплетом, а код, на котором она строится, — Java байт-кодом). Именно этот код интерпретируется при исполнении результирующей Java-программы. Такой метод исполнения кода, основанный на интерпретации, делает его практически независимым от архитектуры целевой вычислительной системы.
Таким образом, для исполнения Java-программы необходимы две составляющие: компилятор промежуточного двоичного кода, порождающий его из исходного текста Java-программы, и интерпретатор, исполняющий этот промежуточный двоичный код. Такой интерпретатор получил название виртуальной Java-машины. Описание основных особенностей реализации виртуальной Java-машины (интерпретатора промежуточного низкоуровневого кода) с точки зрения системы программирования описаны в [74, 91].
Одной из отличительных особенностей данного языка является использование специального механизма распределения памяти (менеджера памяти). В языке Java не могут быть использованы функции динамического распределения памяти и связанные с ними операции над адресами и указателями, поскольку они зависят от архитектуры вычислительной системы. Динамическая память в языке может выделяться только под классы и объекты самого языка. Для этого менеджер памяти должен сам организовывать своевременное выделение областей памяти при создании новых классов и объектов, а затем освобождать области памяти, которые уже больше не используются. В последнем случае должна решаться непростая задача сборки мусора — поиска неиспользуемых фрагментов в памяти и их освобождение. Причем, поскольку в языке Java за распределение памяти отвечает не пользователь, а интерпретатор кода, эти задачи должны решаться независимо от хода выполнения самой Java-программы.
Менеджер памяти входит в состав виртуальной Java-машины и, безусловно, зависит от архитектуры вычислительной системы, где функционирует эта машина, но интерпретируемые ею программы при этом остаются независимыми от архитектуры. Хороший менеджер памяти — важная составляющая виртуальной Java-машины наряду с быстродействующим интерпретатором промежуточного низкоуровневого кода.
При выполнении Java-программы в глобальной сети компилятор, порождающий промежуточный низкоуровневый код, находится на стороне Интернет-сервера, а интерпретатор, выполняющий этот код, — на стороне клиента. По сети от сервера к клиенту передается только уже скомпилированный код. С этой точки зрения использование языка Java для исполнения программ в сети и организации динамических Web-страниц дает преимущества по сравнению с использованием других языков, выполняемых на стороне сервера, как описано выше. Преимущество заключается в том, что по сети не надо передавать громоздкие HTML-описания страниц, что значительно снижает трафик в сети.
Однако отсюда проистекают и основные недостатки, присущие языку Java. Главный из них заключается в том, что на клиентской стороне должна присутство-
вать виртуальная Java-машина для интерпретации поступающего из сети кода. Это значит, что так или иначе интерпретатор языка Java должен входить в состав архитектуры целевой вычислительной системы, а без его наличия функционирование такой схемы становится невозможным. Кроме того, промежуточный код языка исполняется на стороне клиента, а значит, скорость его выполнения и возможности Java-программы во многом зависят от производительности клиентского компьютера, которая может оказаться недостаточно высокой у машины, ориентированной только на подключение к глобальной сети. Речь идет не только о скорости интерпретации команд, но и о том, что клиентская система должна быть способна работать со всеми базовыми классами, присущими языку Java. Таким образом, требования к производительности клиентского компьютера для выполнения на ней Java-программ могут оказаться непомерно высокими.
Еще одна особенность связана с необходимостью обеспечения безопасности при исполнении Java-программ. Поскольку код исполняемой программы поступает из глобальной сети, то нет никакой гарантии, что этот код не содержит фатальную ошибку. Кроме того, такой код может быть преднамеренно создан со злым умыслом. Имея все возможности языка программирования (в отличие от текста HTML) и исполняясь в среде вычислительной системы клиента, он может привести к выходу из строя этой системы или к повреждению хранящихся, в ней данных. Потому при построении интерпретатора виртуальной Java-машины нужно целенаправленно выделять и отслеживать потенциально опасные команды (такие, как выполнение программ или обращение к файлам на клиентской машине). Несмотря на то что большинство производителей виртуальных Java-машин считаются с этим правилом, проблема безопасности остается актуальной при использовании языка Java.
Язык Java быстро завоевал популярность и занял значительное место на рынке языков программирования и связанных с ними средств разработки. По сути, этот язык явился первой удачной реализацией двухэтапной модели выполнения программ, построенной на использовании компилятора промежуточного кода с последующей интерпретацией полученного кода. Независимость выполнения Java-программ от архитектуры целевой вычислительной системы способствовала росту популярности языка, который стал применяться не только как удобное средство Web-программирования, но и как средство разработки прикладных программ, ориентированных на различные вычислительные архитектуры.
Росту популярности языка программирования Java и построенных на его основе систем программирования способствовал также тот факт, что в его состав входят встроенные средства поддержки интерфейса с серверами БД, ориентированные на разработку приложений, выполняющихся в архитектуре «клиент—сервер». Системы программирования языка Java совместимы также с известной группой стандартов, ориентированной на разработку результирующих программ, выполняющихся в трехуровневой архитектуре — CORBA.
Первоначально язык поддерживался только одним разработчиком — компанией Sun. Но со временем и с ростом популярности языка в его поддержку стали включаться и другие известные компании-производители программных продуктов. Среди них можно выделить уже упоминавшуюся в данном пособии компанию Borland, создавшую на базе языка Java систему программирования Borland
JBuilder. В настоящее время компании, поддерживающие системы программирования на основе языка Java, образуют специальное сообщество для поддержки и распространения средств разработки на основе данного языка. Всю необходимую информацию можно получить на сайте [101] и во многих других местах всемирной сети Интернет, которая во многом способствовала развитию этого языка1.
Основной проблемой языка Java остается его производительность. При прочих равных условиях интерпретируемая программа, построенная на основе системы программирования для Java, будет уступать в скорости откомпилированной программе, созданной в любой другой современной системе программирования. Поэтому язык Java практически не применяется в программах, требующих сложных расчетов и математических функций. Но во многих прикладных программах, где производительность не играет столь принципиального значения, он вполне может быть использован, так как дает преимущества в независимости результирующей программы от архитектуры целевой вычислительной системы. Большинство современных ОС допускают наличие в своем составе виртуальных Java-машин для интерпретации результирующего кода Java-программ.
Необходимость иметь в составе архитектуры вычислительной системы клиентского компьютера виртуальную Java-машину, а также довольно высокие требования к производительности компьютеров на клиентской стороне в ряде случаев ограничивают возможности применения языка Java. С другой стороны, зачастую для организации динамической Web-страницы достаточно лишь выполнить ряд простых действий, не укладывающихся в рамки статического HTML. Для этого нет необходимости создавать, компилировать и передавать по сети полноценную Java-программу.
Чтобы решить эти проблемы, был предложен командный язык Java Script, который можно назвать упрощенным вариантом языка Java.
Фрагменты кода, написанные на Java Script, передаются непосредственно внутри текста HTML-страниц. Синтаксис и семантика Java Script в целом соответствуют языку Java, но возможности его выполнения сильно ограничены — они не выходят за рамки той программы, которая интерпретирует HTML-страницу. В таком случае эта программа выступает и в роли виртуальной Java-машины для выполнения операторов Java Script. Чаще всего это программа навигации по сети — браузер. Он находит в тексте HTML-страницы операторы языка Java Script, выделяет их и исполняет по всем правилам языка Java. Однако выполнение Java Script происходит только в рамках адресного пространства программы-навигатора. Это, с одной стороны, ограничивает его возможности, но, с другой стороны, увеличивает безопасность выполнения операторов, так как в худшем
случае при наличии некорректных операторов языка неработоспособной окажется только запущенная программа-навигатор, но не вся клиентская система в целом. Операторы Java Script сейчас широко используются для организации динамических Web-страниц. Их выполнение (интерпретация) обеспечивается всеми современными программами-навигаторами в глобальной сети. Более подробную информацию о языке Java Script и его возможностях можно найти в [10] или на многих сайтах, посвященных языку Java [101].