УЗБЕКСКОЕ АГЕНТСТВО СВЯЗИ И ИНФОРМАТИЗАЦИИ
ТАШКЕНТСКИЙ УНИВЕРСИТЕТ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Кафедра «Автоматизации почтовой cлужбы»
Методическое
пособие по дисциплине
«Автоматизация технологических
процессов почтовой службы»
(специальность 5840200-«Почтовая служба»)
Ташкент 2006 г
Данное методическое пособие содержит информацию об истории изобретения
и основных характеристиках штрихового кодирования, а также методику расчета
опережающего информационного потока.
Рецензенты: доцент Ибрагимов Г.И.;
начальник отдела ОАО «Ўзбекистон почтаси» Абдулазизова Г.С.
Содержание
|
|
Введение…………………………………………………………………. |
4 |
|
1. |
История изобретения и
последующее развитие штрих кода………… |
7 |
|
2. |
Техническое оборудование
для чтения и печати штрих кода……….. |
9 |
|
3. |
Сравнительная оценка существующих методов кодирования информации на
почтовых отправлениях и перспективы их применения |
19 |
|
4. |
Основные проблемы механизации и
автоматизации производственного процесса по обработке посылочной почты……………. |
25 |
|
5. |
Концентрация обработки посылок в
механизированных центрах и задачи, решаемые при этом…………………………………………….. |
27 |
|
6. |
Концентрация обработки посылок в
механизированных центрах и задачи, решаемые при этом…………………………………………….. |
28 |
|
7. |
Формирование, оценка и возможности
использования опережающего информационного потока…………………………….. |
29 |
|
8. |
Расчет величины ОИП………………………………………………….. |
31 |
|
9. |
Расчет затрат на передачу ОИП
средствами связи электросвязи……. |
32 |
|
|
Список
используемой литературы…………………………………….. |
34 |
Введение
Век телекоммуникации робототизации уже начался и вряд
ли можно найти сейчас предприятие, которое не использовало бы компьютерные
технологии. Развитие информационных технологий в совокупности с растущей
локальной и глобальной сетью позволило создать одну большую централизованную
базу данных. В сфере транспортировки прозрачность и мобильность информации о
грузе (место нахождение, время доставки и т. п.) дает возможность планировать
скорость обработки грузов и качество транспортировки. На помощь бланкам и
длинным реестрам с описанием груза пришли маленькие ярлыки с вертикальными
полосами, которые называются штрих кодом.
Штриховой код - это
символ, состоящий из четкого рисунка полос и пространства между ними,
иллюстрирующий машинный код букв и чисел в двоичной системе. По мнению
специалистов, системы штрихового кодирования имеют значительную перспективу,
поскольку являются естественным материалом для ЭВМ и дают возможность решить
одну из самых сложных компьютерных проблем - ввод данных. Это связано с тем,
что ЭВМ легче считывает широкие и узкие штрихи и промежутки между ними, чем
буквы и цифры. Такая система почти
полностью исключает
ошибки. Самый простой
способ ввода информации в
ЭВМ осуществляется с помощью
клавиатуры. Однако этот способ несовременен, так как при самой высокой
квалификации оператор не может достаточно быстро ввести информацию. Кроме того,
очень много времени требуется на поиск и исправление ошибок (оператор допускает в среднем одну ошибку на
каждые 300 печатных знаков).
Все это привело к необходимости поиска способов автоматизированного
считывания информации, к числу которых относится штриховое кодирование.
Информация считывается машинным способом с большой скоростью и достоверностью -
на два порядка выше, чем при клавиатурном вводе информации.
Системы штрихового кодирования могут быть полезны и предприятиям-
изготовителям, и распределяющим организациям (оптовым торговым фирмам и предприятиям),
и потребителям. Торговая фирма может использовать штриховые коды на получаемой
ею продукции для регистрации, сортировки, контроля за хранением, поиска и
проверки изделий перед отгрузкой. Наличие штрихового кода на товаре или его
упаковке поднимает престиж фирмы, играет роль рекламы товара и самого
предприятия.
В зарубежной практике
штриховое кодирование информации широко применяется в коммерческой
деятельности, транспортных и складских системах, сфере учета материальных
запасов, технологическом процессе и т.д.
Использование штриховых кодов а системе торговли упрощает труд кассира,
приблизительно на 30% сокращает время получения покупателем чека за купленный
товар и ввода данных в ЭВМ. При этом объем проданных товаров увеличивается.
Автоматизированный учет проданных товаров может быть проведен в любое время,
что позволяет по мере надобности подавать со склада необходимые товары. Дает
возможность прогнозировать их поступление в розничную торговлю (это особенно
важно для скоропортящихся продуктов), а также упрощает инвентаризацию товаров
на складах и в магазинах, предоставляет персоналу информацию о наиболее ходовых
товарах. С помощью кодов контролируется качество продукции, ее соответствие
первоначально заданному образцу.
В настоящее время в США около 90% всех основных выпускаемых товаров
имеют штриховые коды, в Германии - около 80%, во Франции - более 70%, в Швеции
- около 45%.
Штриховой код
выполняет примерно ту же роль, что и почтовый индекс, который мы пишем
стилизованными цифрами в углу конверта. Информация, содержащаяся на наклейке, с
легкостью прочитывается и расшифровывается специальными оптическими
устройствами, связанными с ЭВМ. Такими устройствами оборудованы кассы крупных
зарубежных магазинов.
Каждый товар имеет свой индивидуальный цифровой код, который
присутствует во всех документах, фиксирующих товарные операции, что позволяет,
в частности, в сфере розничной торговли обеспечить сокращение затрат времени на
суммирование цен, уменьшить возможность допущения ошибок на контрольно-кассовом
пункте, сократить время обслуживания покупателя.
Кассир проводит специальным электронно-оптическим датчиком над
наклейкой, и на табло тотчас высвечивается цена товара. Одновременно информация
о том, что товар продан, поступает в центральный компьютер. Он подсчитывает
количество оставшегося товара и при необходимости требует со склада новую
партию. Складом заведует робот-кладовщик. Поиск нужного товара на полках
осуществляется также с помощью штрихового кода.
Чёрно-белые штрихи на
упаковке - принятая в мировой практике система маркировки товаров и продукции.
В ней закодированы необходимые сведенья о стране - производителе,
предприятии-изготовителе и самом изделии. Понимать язык штриховых кодов и уметь
им пользоваться - это значит освоить ещё одну ступеньку на пути к
цивилизованному рынку и взаимовыгодному международному сотрудничеству.
Автоматизация
технологического процесса невозможна без надежного ввода в техническую систему
необходимых атрибутов почтового отправления (адрес получателя, адрес
отправителя, характеристика отправления и др.), которые являются управляющей
информацией. Естественно, что эти сообщения должны бьпъ переведены на некоторый
машинный язык.
Анализ существующих методов кодирования штучных грузов
показывает, что они предназначены в основном для кодирования (маркировки)
отдельных признаков (идентификаторов), по которым осуществляется
автоматическая сортировка грузов, для широкой комплексной автоматизации
процессов обработки посылочной почты необходима более обширная информация, а
именно, информация о предприятиях связи приёма и назначения посылки, ее номере
и виде. Кодирование этой информации может осуществляться с помощью
стилизованных цифр, для которых применимы оптические методы считывания.
Для
решения проблем комплексной автоматизации процессов обработки посылочной почты
существует необходимость применения таких методов кодирования информации и
машиночитаемых кодов, считывание и обработку которых можно было бы
осуществлять с помощью более простых и удобных в эксплуатации, надежных и недорогих
устройств. При этом станет возможной автоматизация процессов обработки
посылочной почты на предприятиях почтовой связи всех уровней (магистральных,
узлов и отделений связи).
В результате анализа существующих методов кодирования
информации на посылках установлено, что наиболее перспективными являются
методы, основанные на применении так называемых штриховых кодов.
Система штрихового кодирования весьма эффективна при
обработке различных штучных грузов, например, в автоматизированных складах,
где требуется опознать груз и адресовать его в требуемом направлении. Система
штрихового кодирования обладает более высокой надежностью по сравнению с
буквенно-цифровой системой. Особенно большая эффективность достигается при
сочетании штрихового кодирования с лазерными сканирующими устройствами,
обеспечивающими быстрое и точное считывание информации.
1.История
изобретения и последующее развитие штрих кода.
Штриховое кодирование было изобретено молодым инженером Давидом
Коллинзом. После окончания в 50-х годах инженерного факультета Массачусетского
технологического института, он поступил работать на Пенсильванскую железную
дорогу, где ему пришлось столкнуться с кропотливой, приносящей мало радости
работой - сортировкой вагонов. Их надо было пересчитать, оперативно выяснить
номера, справиться по ним в документации, определить, куда каждый должен
следовать... Процедура довольно длительная, не гарантирующая безошибочности ее
выполнения. Тогда пришла идея освещать номера вагонов прожекторами и считывать
их с помощью фотоэлементов. Чтобы упростить распознавание, инженер-изобретатель
предложил записывать номера не только обычными цифрами, но и специальным кодом,
состоящим из красных и синих полос, расположенных на стенке вагона в
прямоугольнике длиной до полуметра.
Испытания подтвердили:
сканирующее устройство способно правильно считывать коды даже при скорости
движения вагона около 100 км/час. Но Коллинз не успокоился на этом. Достигнутый
успех лишь подтолкнул его к дальнейшему совершенствованию системы. В 1968 году
он перешел от прожекторов, требовавших изрядного расхода энергии, к жестко
сфокусированному лазерному лучу. Размеры сканирующей установки резко
сократились. Меньше стала и сама кодовая маркировка.
Это, в свою очередь, натолкнуло Коллинза на мысль, что придуманный
штриховой код можно использовать не только на железной дороге. Он вспомнил, как
14-летним мальчиком подрабатывал по выходным на складе одного супермаркета.
Сколько времени уходило на поиск нужного товара! Здесь именно и получил новое
применение штриховой код в виде кода товара.
Сегодня удается считывать код с помощью светового пятна диаметром всего
в четверть миллиметра. Штриховой код позволяет считывать в ПЭВМ информацию о
номере товара практически мгновенно и абсолютно точно ( не более одной ошибки
на 10 млн. считываний ).
Таким образом, в 60-е годы штриховое кодирование стало впервые
применяться в США для идентификации железнодорожных вагонов, а в 1973 году
появился "Универсальный товарный код" (UPC - Universal Product Code)
для использования а промышленности и торговле.
В Западной Европе для
идентификации потребительских товаров с 1977 года стала применяться аналогичная
система под названием "Европейский артикул" (EAN - European Article
Numbering).
Европейская система кодирования является разновидностью UPC. Код EAN
представляет собой набор цифр от 0 до 9. Все кодовое обозначение может
выражаться восемью (EAN-8) или тринадцатью (EAN-13) цифрами. Сокращенный символ
(EAN-8) используется для маркировки товаров малых размеров. Американский и
западноевропейский коды совместимы. Единственная разница между ними заключается
в том, что код UPC содержит 12 знаков, а код EAN-13.
Широко известна также западногерманская система кодирования: BAN
(Bunaeseinheitliche Artikelnummer).
Существует более 50 систем штрихового кодирования. Активно применяются
четыре из них:
UPC;
код 39 (Code 39) высокой, средней и низкой плотности;
код "2 из
5"(Interleaved 2-of-5);
код Codabar.
В международной практике наибольшее распространение получили коды EAN.
В зависимости от применения существует три группы товарных кодов EAN:
международные;
национальные;
локальные.
Международные коды используются как внутри страны, так и за ее
пределами. При этом коды, нанесенные на упаковку товара одной страной, понятны
и могут быть расшифрованы и в другой.
Национальные коды могут использоваться только в пределах одной страны,
например, для развесного товара, хотя при необходимости могут быть прочитаны и
в другой стране.
Локальные коды могут быть использованы торговым предприятием только в
системе управления данного предприятия и преследуют вполне определенные цели.
Существуют различные способы кодирования информации, называемые (штрих
кодовыми кодировками или символиками). Различают линейные (одномерные) и
двухмерные символики штрих кодов.
Линейными (одномерными) в отличие от двухмерных называются штрих коды,
читаемые в одном направлении (по горизонтали). Наиболее распространенные
линейные символики: EAN, UPC, Code39, Code128, Codabar, Interleaved 2 of 5.
Линейные символики позволяют кодировать небольшой объем информации (до 20-30
символов - обычно цифр) с помощью несложных штрих кодов, читаемых недорогими
сканерами.
Двухмерными называются
символики, разработанные для кодирования большого объема информации (до
нескольких страниц текста). Двухмерный код считывается при помощи специального
сканера двухмерных кодов и позволяет быстро и безошибочно вводить большой объем
информации. Расшифровка такого кода проводится в двух измерениях (по
горизонтали и по вертикали).
Носителем основной информации в штриховом коде является соотношение
ширины темных полос (штрихов) и ширины светлых полос (пробелов) между штрихами.
Причем каждая цифра кодируется определенным количеством штрихов и пробелов,
которые имеют соответствующую ширину и определенное расположение в отведенном
для цифры месте.
Отведенное для каждой цифры кода место называется цифровой знак и
является основной единицей информации штрихового кода. Все цифровые знаки, как
правило, имеют одинаковую ширину и состоят из модулей, поэтому ширина штрихов и
пробелов всегда кратна модулю. Модуль - самый узкий элемент, что видно из
рисунка:
Для того чтобы удобно
записывать штриховой код каждой цифры, а не рисовать сами штрихи, применяют
двоичную систему записи цифр, хорошо знакомую программистам, которая очень
удачно сочетается с штриховым изображением. Для этого штрихи обозначают цифрой
"1", а пробелы - "0". К примеру штриховой код цифры 5 в
системе EAN записывается в этой системе так: 0110001.

2. Характеристика штриховых кодов
Код ITF является непрерывным двунаправленным контролепригодным кодом
переменной длины и позволяет кодировать цифровую информацию (цифры от 0 до 9).

Рис.1. Пример штрихового
кода ITF
Код ITF используется во многих областях для кодирования цифровых данных
и является международным стандартным кодом для маркирования тары и упаковки
единиц поставки.
Код ITF может быть применен в автоматизированных системах для:
идентификации предметов складирования, багажа в аэропортах;
нумерации авиационных билетов;
идентификации почтовых отправлений и др.
Структура штрихового
кода
Штриховой Код ITF
принадлежит к семейству кодов "2 из 5" и имеет пять элементов в
знаке, два из которых являются широкими.
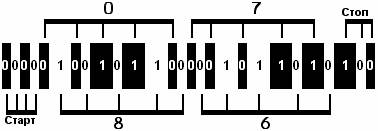
Рис.2. Структура штрихового
кода ITF
Особенностью Кода ITF является представление пар цифр в знаках
штрихового кода при помощи пяти штрихов и пяти промежутков. На нечетных
позициях (считая слева направо) цифры изображаются штрихами, а на четных -
промежутками (чередование). При кодировании данных с нечетным количеством
знаков впереди записывается "0"
В двоичном изображении широкий штрих или широкий промежуток идентичен
"1", узкий штрих или узкий промежуток - "0". Соотношение
ширины широкого и узкого элементов составляет не менее. чем 2,5:1. Знак
"Старт" состоит из двух узких штрихов и двух узких промежутков. Знак
"Стоп" состоит из одного широкого штриха, одного узкого штриха и
одного узкого промежутка.
Перевод цифр в двоичную
систему записи
Знак Комбинация широких (1) и узких (0) элементов
0 00110
1 10001
2 01001
3 11000
4 00101
5 10100
6 01100
7 00011
8 10010
9 01010
"Старт" 0000
"Стоп" 100
Контрольный разряд
В штрих кодовом символе ITF для повышения надежности считывания
рекомендуется использовать контрольный знак.
Контрольный знак располагается непосредственно после информационных
знаков перед знаком "Стоп". Если добавление контрольного знака делает
количество знаков в кодируемых данных нечетным, впереди кодовой строки
непосредственно после знака "Старт" добавляется "0".
Последовательность
расчета контрольной цифры для кода ITF определяют сумму числовых значений
знаков, расположенных на нечетных позициях в кодовой строке, начиная с первого
информационного знака после знака "Старт" и умножают эту сумму на 3;
определяют сумму числовых значений знаков расположенных на четных
позициях в кодовой строке, начиная со второго информационного знака после знака
"Старт";
суммируют значения, полученные в п.1 и п.2;
числовое значение
контрольного знака определяют как число, дополняющее результат до ближайшего
числа, кратного 10.
Контрольная цифра
вводится исключительно для ручного или программного контроля. Считывающие
устройства никаким образом не проверяют ее, как, например, в Code-128, поэтому
приведенный алгоритм не является догмой.
Штриховой Код 128
является непрерывным
двунаправленным контролепригодным кодом переменной длины и позволяет отобразить
128 знаков ASCII.
Код 128 - код высокой плотности, отличительной особенностью которого
является возможность кодирования ста пар чисел, позволяющей вдвое увеличить
плотность записи при представлении штриховым кодом цифровых данных.
Знаки штрихового Кода
128 состоят из трех штрихов и трех промежутков. Штрихи и промежутки имеют
модульное построение и их ширина составляет от одного до четырех модулей.
Ширина знака равна одиннадцати модулям. Исключением является знак
"Стоп", который состоит из тринадцати модулей и имеет четыре штриха и
три промежутка.

Рис.3. Пример структуры штрихового кода 128
Каждый знак Кода 128 может иметь три значения в зависимости от
управляющего знака впереди. Выбор одного из трех знаков "Старт"
означает обращение при кодировании к одной из трех подсистем (A,B,C). Переход
от одной подсистемы к другой в кодовом ряду может осуществляться при помощи
соответствующего знака "Shift".
Штрих кодовый символ
Кода 128 состоит из зоны стабилизации (1), предшествующей знаку
"Старт", соответствующего знака "Старт" (2) подсистемы A, B
или C, информационных знаков (3), в том числе и контрольного знака (4), знака
"Стоп" (5) и зоны стабилизации (6), следующей за знаком
"Стоп".
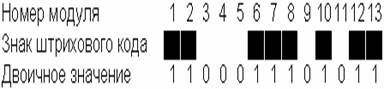

Рис.3. Структура штрихового кода 128
Контрольное число - это остаток, полученный от деления на число 103
значения выражения:
 где:
где:
![]() - числовое
значение знака "Старт";
- числовое
значение знака "Старт";
![]() - количество знаков в кодовой строке;
- количество знаков в кодовой строке;
![]() - номер позиции знака в кодовой строке,счита с первого
знака, следующим за знаком "Старт";
- номер позиции знака в кодовой строке,счита с первого
знака, следующим за знаком "Старт";
![]() - числовое значение знака в i-й позиции.
- числовое значение знака в i-й позиции.
Пример расчета
контрольного числа.
Числовые значения
знаков смотрим по таблице.
Код данных c o d e 1
2 8
Номер позиции ![]() 1 2
3 4 5
6 7 8
1 2
3 4 5
6 7 8
Числовое значение
знака (![]() )
35 79 68
69 0 17
18 24
)
35 79 68
69 0 17
18 24
Значение ![]() 35 158 204 176 0 102
126 192
35 158 204 176 0 102
126 192
1093
Числовое значение
знака "Старт" подсистемы B равно 104 (по таблице).

1197/103=11 и 64 в
остатке. Числовому значению 64 соответствует знак [`] (по таблице). Таким
образом, полное представление данных с учетом контрольного знака будет: [Code
128`].
0 SP SP 00 2
1 2 2 2 2
1 ! ! 01 2
2 2 1 2 2
2 " " 02 2
2 2 2 2 1
3 # # 03 1
2 1 2 2 3
4 $ $ 04 1
2 1 3 2 2
5 % % 05 1
3 1 2 2 2
6 & & 06 1
2 2 2 1 3
7 ' ' 07 1
2 2 3 1 2
8 ( ( 08 1
3 2 2 1 2
9 ) ) 09 2
2 1 2 1 3
10 * * 10 2
2 1 3 1 2
11 + + 11 2
3 1 2 1 2
12 , , 12 1
1 2 2 3 2
13 - - 13 1
2 2 1 3 2
14 . . 14 1
2 2 2 3 1
15 / / 15 1
1 3 2 2 2
16 0 0 16 1
2 3 1 2 2
17 1 1 17 1
2 3 2 2 1
18 2 2 18 2
2 3 2 1 1
19 3 3 19 2
2 1 1 3 2
20 4 4 20 2
2 1 2 3 1
21 5 5 21 2
1 3 2 1 2
22 6 6 22 2
2 3 1 1 2
23 7 7 23 3
1 2 1 3 1
24 8 8 24 3
1 1 2 2 2
25 9 9 25 3
2 1 1 2 2
26 : : 26 3
2 1 2 2 1
27 ; ; 27 3
1 2 2 1 2
28 < < 28 3
2 2 1 1 2
29 = = 29 3
2 2 2 1 1
30 > > 30 2
1 2 1 2 3
31 ? ? 31 2
1 2 3 2 1
32 @ @ 32 2
3 2 1 2 1
33 A A 33 1
1 1 3 2 3
34 B B 34 1
3 1 1 2 3
35 C C 35 1
3 1 3 2 1
36 D D 36 1
1 2 3 1 3
37 E E 37 1
3 2 1 1 3
38 F F 38 1
3 2 3 1 1
39 G G 39 2
1 1 3 1 3
40 H H 40 2
3 1 1 1 3
41 I I 41 2
3 1 3 1 1
42 J J 42 1
1 2 1 3 3
43 K K 43 1
1 2 3 3 1
44 L L 44 1
3 2 1 3 1
45 M M 45 1
1 3 1 2 3
46 N N 46 1
1 3 3 2 1
47 O O 47 1
3 3 1 2 1
48 P P 48 3
1 3 1 2 1
49 Q Q 49 2
1 1 3 3 1
50 R R 50 2
3 1 1 3 1
51 S S 51 2
1 3 1 1 3
52 T T 52 2
1 3 3 1 1
53 U U 53 2
1 3 1 3 1
54 V V 54 3
1 1 1 2 3
55 W W 55 3
1 1 3 2 1
56 X X 56 3
3 1 1 2 1
57 Y Y 57 3
1 2 1 1 3
58 Z Z 58 3
1 2 3 1 1
59 [ [ 59 3
3 2 1 1 1
60 \ \ 60 3
1 4 1 1 1
61 ] ] 61 2
2 1 4 1 1
62 ^ ^ 62 4
3 1 1 1 1
63 _ _ 63 1
1 1 2 2 4
64 NUL ` 64 1
1 1 4 2 2
65 SOH a 65 1
2 1 1 2 4
66 STX b 66 1
2 1 4 2 1
67 ETX c 67 1
4 1 1 2 2
68 EOT d 68 1
4 1 2 2 1
69 ENQ e 69 1
1 2 2 1 4
70 ACK f 70 1
1 2 4 1 2
71 BEL g 71 1
2 2 1 1 4
72 BS h 72 1
2 2 4 1 1
73 HT i 73 1
4 2 1 1 2
74 LF j 74 1
4 2 2 1 1
75 VT k 75 2
4 1 2 1 1
76 FF I 76 2
2 1 1 1 4
77 CR m 77 4
1 3 1 1 1
78 SO n 78 2
4 1 1 1 2
79 SI o 79 1
3 4 1 1 1
80 DLE p 80 1
1 1 2 4 2
81 DC1 q 81 1
2 1 1 4 2
82 DC2 r 82 1
2 1 2 4 1
83 DC3 s 83 1
1 4 2 1 2
84 DC4 t 84 1
2 4 1 1 2
85 NAK u 85 1
2 4 2 1 1
86 SYN v 86 4
1 1 2 1 2
87 ETB w 87 4
2 1 1 1 2
88 CAN x 88 4
2 1 2 1 1
89 EM y 89 2
1 2 1 4 1
90 SUB z 90 2
1 4 1 2 1
91 ESC { 91 4
1 2 1 2 1
92 FS | 92 1
1 1 1 4 3
93 GS } 93 1
1 1 3 4 1
94 RS ~ 94 1
3 1 1 4 1
95
96 FNC 3 FNC
3 96 1 1 4 3 1 1
97 FNC 2 FNC
2 97 4 1 1 1 1 3
98 SHIFT SHIFT 98 4
1 1 3 1 1
99 CODE C CODE
C 99 1
1 3 1 4 1
100 CODE B FNC
4 CODE
B 1 1 4 1 3 1
101 FNC 4 CODE
A CODE A 3 1 1 1 4 1
102 FNC 1 FNC
1 FNC 1 4 1 1 1 3 1
103 Start A Start
A Start A
2 1 1 4 1 2
104 Start B Start
B Start B
2 1 1 2 1 4
105 Start C Start
C Start C
2 1 1 2 3 2
106 Stop Stop Stop 2 3 3 1 1 1 2
Штриховой Код 39
Рассмотрим код 39. Код 39 (Code 39) или код «3 из 9» — алфавитно-цифровой штриховой код изменяемой длины (рис. ).
Рис.2.

Своим
названием он обязан тому, что является кодовой комбинацией трех из девяти.
Каждый отображаемый символ в этом коде представляется с помощью девяти
элементов (пяти штрихов и четырех пробелов между ними). Три элемента из девяти
— широкие, шесть элементов — узкие. Два из пяти штрихов и один пробел широкие,
а остальные штрихи и пробелы — узкие. Это позволяет считывать 40 комбинаций
для штрихового представления 10 цифровых знаков (от 0 до 9), 26 букв
латинского алфавита, тире, точки, пробела (разрядки) и звездочки, являющейся
признаком начала и конца кодового слова. Четыре дополнительных знака {$, /, +,
%) представлены пятью узкими штрихами, тремя широкими про белами и одним узким
пробелом.
Штрихи
и пробелы имеют два уровня по ширине. Минимальное отношение ширины широкого
элемента к ширине узкого составляет 2:1. Максимальное отношение может
составлять 3:1. Постоянство относительных размеров широких и узких элементов
должно выдерживаться в пределах считываемых символов, но одном носителе
штрихового кода.
Код 39 является дискретным, т. е. пробелы между
штриховыми символами знаков алфавита кода не несут в себе информации, а служат
только разделителями. Ширина пробела-разделителя, как правило, равна ширине
узкого элемента.
Штриховые символы всех знаков алфавита кода 39 — самоконтролирующиеся.
Это значит, что дефекты печати автоматически обнаруживаются при оптическом
считывании кода, благодаря чему обеспечивается высокий уровень точности
вводимых в ЭВМ данных. При этом сводится к минимуму число ошибок ввода типа
«подстановка», когда один закодированный знак может быть принят декодирующим
устройством (дешифратором) за другой. При применении высокоточного
декодирующего оборудования и наивысшем качестве печати можно ожидать всего
лишь одну подстановку, но 70 миллионов считанных символов.
Для тех случаев, когда требуется чрезвычайно высокая
точность данных, предусмотрено применение дополнительного контрольного знака.
Для вычисления контрольного знака кодового слова, а коде 39 каждому знаку
алфавита кода присвоено определенное числовое значение, которое можно назвать
слагаемым контрольного Знака. В табл1 приведен алфавит кода 39 а натуральном,
штриховом И двоичном представлении, а также слагаемые контрольного знака (SPACE — пробел между словами при печатании, разрядка).
Контрольный знак вычисляется путем суммирования слагаемых
контрольного знака всех злаков кодового слова и деления полученной суммы на 43.
Полученный при этом остаток. И будет контрольным знаком. Если сумма слагаемых
контрольного долится на 43 без остатка, то контрольным знаком будет 0. Контрольным знаком кодового
слова в коде 39 может быть цифра,
буква либо символ алфавита коде.
В противоположность большинству существующих
штриховых кодов,
характеризующихся фиксированной длиной кодового слова, у кода 39 кодовое слово
может быть любой длины, которую только допускает применяемое считывающее устройство.
Важнейшими характеристиками штриховых кодов,
от которых зависит их считываемость и правильная интерпретируемость дешифратором
представленных данных, являются: плотность кода, выражаемая числом знаков его алфавита
на единице длины штрихового
изображения кодового слова и находящаяся в прямой зависимости от ширины элементов кода; допуски на размерные отклонения
элементов штрихового символа кодового слова при его печати; соотношение ширины элементов;
светоотражательная способность
элементов и их контрастность.
Преимущество любого штрихового кода перед
другими видами машиночитаемых кодов является то, что он может правильно считываться даже при
наличии локальных дефектов печати. Это могут быть локальные непропечатки штрихов, а
также выступы на боковых краях штрихов, образующиеся вследствие локального расплывания либо
разбрызгивания чернил или краски в процессе печатания штриховых символов. Такого
рода дефекты изменяют номинальную ширину штрихов и пробелов. При этом локальная частичная
непропечатка штриха может превратить широкий штрих в узкий, а месте
дефекта и, наоборот, слишком большой выступ может превратить узкий штрих в широкий.
Если при оптическом считывании
сканирующий луч света пройдет через один из таких дефектов, то
произойдет отказ считывания, поскольку получится недопустимое для данного кода число узких и широких штрихов
в штриховом символе кодового слова. А если
луч пересечет два дефекта
противоположного качества в пределах штрихового символа одного знака кодового
слова, то может случиться подстановка, т. е. один закодированный знак может
быть принят дешифратором за другой. В первом случае считывание можно
повторить, направив луч по бездефектному
участку штрихового символа, а во втором
случае при отсутствии в конце кодового слова контрольного знака произойдет необнаруженное искажение
информации.
К дефектам печати относится также неровность
боковых краев или образующих штрихов во всей их высоте. Если эта неровность находится
в пределах допусков на отклонение ширины штрихов и пробелов от номинальной, то
она не влияет отрицательно на правильность
считываемого кода.
Светоотражательная способность штрихов и
пробелов выражается процентом отражаемого ими количества света в двух полосах спектра (В633 и
В900) по отношению к фотометрическому эталону из оксида магния либо сульфата бария. Максимальная светоотражательная способность штрихов
устанавливается исходя из
светоотражательной способности пробелов. При этом должно соблюдаться требование, чтобы минимально
допустимое отношение светоотражательных способностей пробелов и штрихов составляло 4:1. Это отношение является минимально
допустимой контрастностью штрихового
символа.
Штриховые символы данных, напечатанные таким образом, что допустимое минимальное значение их
контрастности находится в спектральной
полосе B6S3
(длина волны я центре полосы 633 нм ± 5 %), предназначены для оптического считывания с помощью сканирующих устройств с
источником света с гелионеоновым
лазером либо с другим источником, излучающим кроеный свет в пределах спектральной полосы В633.
Штриховые символы, допустимое минимальное
значение контрастности которых находится в спектральной полосе В900 (длина волны в центре
полосы 900 нм +\ - 10 %), считываются с помощью устройств с источником света,
построенным на основе арсенида гелия, испускающим свет, близкий к инфракрасному.
Код 39 может быть рекомендован к
использованию в сфере почтовой связи.
Таблица 1
![]()
|
Знак алфавита |
Штриховой символ |
Двоичное представление |
Слагаемое контроль- ного знака |
|
|
штрихи |
пробелы |
|||
|
1 |
|
10001 |
0100 |
1 |
|
2 |
|
01001 |
0100 |
2 |
|
3 |
|
11000 |
0100 |
3 |
|
4 |
|
00101 |
0100 |
4 |
|
5 |
|
10100 |
0100 |
5 |
|
6 |
|
01100 |
0100 |
6 |
|
7 |
|
00011 |
0100 |
7 |
|
8 |
|
10010 |
0100 |
8 |
|
9 |
|
01010 |
0100 |
9 |
|
0 |
|
00110 |
0100 |
0 |
|
A |
|
10001 |
0010 |
10 |
|
B |
|
01001 |
0010 |
11 |
|
C |
|
11000 |
0010 |
12 |
|
D |
|
00101 |
0010 |
13 |
|
E |
|
10100 |
0010 |
14 |
|
F |
|
01100 |
0010 |
15 |
|
G |
|
00011 |
0010 |
16 |
|
H |
|
10010 |
0010 |
17 |
|
I |
|
01010 |
0010 |
18 |
|
J |
|
00110 |
0010 |
19 |
|
K |
|
10001 |
0001 |
20 |
|
L |
|
01001 |
0001 |
21 |
|
M |
|
11000 |
0001 |
22 |
|
N |
|
00101 |
0001 |
23 |
|
O |
|
10100 |
0001 |
24 |
|
P |
|
01100 |
0001 |
25 |
|
Q |
|
00011 |
0001 |
26 |
|
R |
|
10010 |
0001 |
27 |
|
S |
|
01010 |
0001 |
28 |
|
T |
|
00110 |
0001 |
29 |
|
U |
|
10001 |
1000 |
30 |
|
V |
|
01001 |
1000 |
31 |
|
W |
|
11000 |
1000 |
32 |
|
X |
|
00101 |
1000 |
33 |
|
Y |
|
10100 |
1000 |
34 |
|
Z |
|
01100 |
1000 |
35 |
|
- |
|
00011 |
1000 |
36 |
|
. |
|
10010 |
1000 |
37 |
|
Space |
|
01010 |
1000 |
38 |
|
* |
|
00110 |
1000 |
- |
|
$ |
|
00000 |
1110 |
39 |
|
‘ |
|
00000 |
1101 |
40 |
|
+ |
|
00000 |
1011 |
41 |
|
% |
|
00000 |
0111 |
42 |
3.Техническое
оборудование для чтения и печати штрих кода.
Считывание кода производится различными оптическими системами, задача
которых основывается на измерении интенсивности отраженного света от черных и
белых полос кода.
Для считывания штрихового кода используется самая разнообразная по
сложности и техническим возможностям аппаратура в ручном (переносном) и
стационарном исполнении.
По принципу работы ручные сканирующие устройства делятся на контактные
и дистанционные. Рабочий элемент контактного устройства представляет собой
световое перо, передвигающееся непосредственно по поверхности штрихового кода.
Этот способ считается более дешевым. Хотя техника достаточно сложная оператора
можно обучить за несколько минут.
В дистанционных устройствах используется лазерный или другой оптический
луч, и код считывается с расстояния до одного метра, а также и через прозрачную
упаковку.
Отдельные устройства обладают очень высокой разрешающей способностью и
могут считывать миниатюрный штриховой код с боль-шой плотностью.
Стационарные устройства предполагают движение изделия со штриховым
кодом относительно луча, сканирующего вдоль последовательности символов.
Использование международных кодов сокращает время обработки
грузопотоков за счет машинной обработки информации, считанной с использованием
ручных или стационарных устройств.
Контактный CCD-сканер
Контактный сканер -
наиболее популярная (благодаря соотношению цена/ производительность) модель
считывателя штрих-кода. Простейшее и наиболее часто употребляемое устройство.
Для считывания информации достаточно поднести его к изображению штрихового кода
и нажать на кнопку. Сканер легкий, удобно располагается в руке, не очень дорог.
Существует ограничение на длину считываемого штрих кода (60 - 80 мм). Если
необходимость каждый раз подносить сканер к метке не существенна, а длина штрих
кода невелика, то такой сканер - очень хороший выбор.

"Световое перо"
Сканер в виде толстого карандаша. Считывающий конец сканера необходимо
поднести к краю метки и провести им по всей длине штрих кода. Эти устройства
очень дешевы, компактны и легки, потребляют мало энергии, не имеют ограничений
по длине считываемых кодов. Возможно сканирование с неровных поверхностей.
Сканер идеален для применения в системах, где объемы сканирования невелики, а
качество штрих кодовых меток высокое.
Световое перо может использоваться в различных условиях, но требует от
оператора некоторых навыков - движение должно быть плавным и равномерным.
Поэтому световое перо не всегда обеспечивает уверенное считывание штрих-кода на
мягких или гибких поверхностях.

Лазерный сканер
Бесконтактный сканер,
считывает штриховой код с расстояния от 5 см до 6,5 м, а некоторые модели и до
10 метров. Отличается низкими требованиями к качеству считываемого штрихового
кода - возможно считывание даже плохо напечатанных и частично поврежденных
меток. Дороже описанных выше моделей, хорош при считывании кодов на неровных
поверхностях и в труднодоступных местах. Классические примеры применения -
снятие информации с движущихся грузов, с высоко стоящих коробок на складе,
через стеклянные перегородки.

Многоплоскостной сканер
Отличается от всех упомянутых выше тем, что не он подносится к предмету
с меткой, а наоборот. Имеет систему вращающихся зеркал, заставляющих лазерный
луч все время менять плоскость сканирования. При этом предмет с меткой
достаточно быстро пронести рядом с окном сканера
на расстоянии 5-25 см
не особенно заботясь об ориентации штрих кодового изображения. "Мертвая
зона" у подобных устройств минимальна, а у некоторых вообще отсутствует.
Обычно встраивается в рабочее место и обеспечивают очень высокую
производительность труда, т.к. не тратится время на взаимную ориентацию сканера
и штрих кодовой метки. Подобные устройства применяются на рабочих местах кассиров
в супермаркетах, на складах химических реактивов - везде, где требуется быстро
обработать большой поток разнородных небольших предметов.

Необслуживаемый (автоматический) сканер
Применяется в
автоматизированных процессах и на конвейере. Сильно различаются по
производительности (скорости сканирования), требуемой ориентации штрих кода
(одно направление, несколько направлений сканирования или многоплоскостные) и
по цене. Цены варьируются от нескольких сотен за однонаправленные малопроизводительные
модели до многих тысяч долларов за высокопроизводительные системы.
Сканеры двумерных (2-D) штрих кодов
Помимо обычных стандартов одномерных (1D) штрих кодов (таких как Code
39, EAN/UPC) эти устройства могут считывать и коды в 2-D стандартах. Несколько
ныне существующих 2-D стандартов штрихового кодирования предназначены для
повышения информационной емкости или плотности (или и того, и другого вместе)
штрих кодовых меток. Некоторые из них лучше приспособлены для чтения лазерными
сканерами, другие - для чтения CCD - сканерами.
Терминалы сбора данных
Портативный терминал это компактное автономное устройство включающее в
себя микрокомпьютер, дисплей, клавиатуру, память, коммуникационный порт RS-232,
аккумуляторные батареи. Для сбора данных к терминалам подключаются
дополнительно или встраиваются различные типы сканеров: лазерные, ПЗС, световые
перья.
Терминал позволяет
вводить данные с клавиатуры, или с помощью сканера и сохранять их в собственной
памяти до передачи (и после передачи) в компьютер или другое внешнее
устройство. Программное обеспечение, как правило совместимо с FoxPro, Access,
Excel, и другими аналогичными приложениями. Для удобства использования
портативных терминалов, выпускаются Генераторы Прикладных Программ, позволяющие
даже неподготовленным пользователям очень быстро настраивать устройства на свои
задачи.

Общие сведения
Для того, чтобы нанести штриховой код на ту или иную упаковку, есть два
принципиально разных пути. Первый заключается в том, что штриховой код
наносится в типографии, где сама упаковка или наклейка на нее печатаются. Для
тиражей в миллионы экземпляров альтернативы пожалуй и не найти, а как быть,
если нужны десятки или сотни тысяч, или даже просто - десятки, сотни, единицы
различных этикеток с кодом?
Для этих нужд значительно удобнее самостоятельная печать штрихового
кода.
Во-первых, этикетки могут быть напечатаны в любых количествах и нести
самую разнообразную информацию.
Во-вторых, их можно печатать непосредственно в том месте где они
наклеиваются: склад, магазин, конвейер и т.п.
Однако, требуются инвестиции в оборудование и программное обеспечение
для печати этикеток, а стоимость этикетки чуть выше, чем стоимость напечатанной
в типографии.
Допустим, Вы предпочли печатать этикетки собственными силами. Для этого
существует несколько принципиально разных возможностей. Если Вы не планируете
часто и относительно помногу печатать этикетки, то задачу вполне может решить
обыкновенный принтер (матричный, лазерный или струйный), нужно только заранее
побеспокоиться о специальных расходных материалах - листах формата А4,
рассеченных на этикетки нужного Вам размера.
С помощью обычных
принтеров Вы легко напечатаете штриховой код практически из любого Windows
приложения (Word, Excel, CorelDRAW и т.д.). Причем некоторые из них, например
CorelDRAW, имеют встроенные механизмы для работы со штриховым кодом. Другие
программы, лишенные встроенных механизмов работы со штрих кодом нужно
использовать осторожно.
Во-первых, для генерации в них штрих кода Вам понадобятся True Type
шрифты штрихового кода, о которых также нужно позаботиться заранее.
Во-вторых, генерация штрихового кода с помощью True Type шрифта требует
от пользователя определенной подготовки, а в самой печати его на обычном
принтере есть определенные тонкости. Расстояния между черными штрихами и их
толщина - параметры не терпящие произвольного представления. К сожалению,
красящая лента матричного принтера, картриджи лазерных и струйных устройств
весьма переменчивы. Нужно быть очень внимательным к степени их износа, чтобы
штрихи не получились излишне жирными - они просто сольются, или слишком бледными
- тогда код не сможет быть считан сканером.
В-третьих, Вам
потребуются листы формата А4, рассеченные на этикетки. Минус этого носителя
заключается в неудобстве их отклеивания от подложки. Самым простым и самым
медленным приспособлением для отклеивания таких этикеток являются человеческие
руки. Альтернативой им являются так называемые "диспенсеры" -
автоматические устройства, которые отклеивают этикетки рядами и удерживают их
на выходе клеящим слоем вверх или вниз. Скорость работы с использованием
автоматического диспенсера возрастает примерно в 3-4 раза.
Специализированные термо- и термотрансферные принтеры штрихового кода.
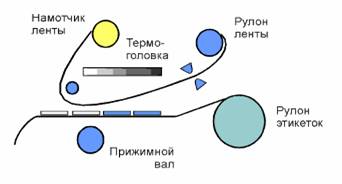
Совершенно другие возможности для печати этикеток Вам предоставят
специализированные принтеры, разделяемые на два больших класса - термо и
термотрансферные. Первые создают изображение подобно печатающему устройству
факсового аппарата, когда головка принтера воздействует термонагревом на
термочувствительную же бумагу (этикетки).
Термотрансферные
принтеры печатают за счет переноса краски с красящей ленты, установленной в
принтере, на этикетку с помощью горячей термоголовки. Краска вжигается в
этикетку в тот момент, когда она протягивается между термоголовкой и прижимным
валом внутри принтера.. Изображение полученное на термотрансферном принтере
более долговечно, оно менее подвержено воздействиям окружающей среды (солнечный
свет, высокая температура и т.д.) чем термочувствительная бумага. Однако
себестоимость отпечатанной термотрансферным способом этикетки немного выше
отпечатанной термоспособом. [1]
Почему печать этикеток на специализированных принтерах более выгодна по
сравнению с использованием обычного принтера?
Во-первых, все они адаптированы для печати штрихового кода, т.е. имеют
встроенные механизмы для создания штрих-кода самых различных символик.
Во-вторых, в качестве расходных материалов они используют рулоны
этикеток. И на выходе также создают рулоны отпечатанных этикеток (при наличии
так называемых внешних или внутренних смотчиков или "ревайндеров" от
англ Rewinder).
И в-третьих, большинство специализированных принтеров имеют огромное
число дополнительных опций или приспособлений, что позволяет один и тот же
принтер использовать в самых различных условиях. Рассмотрим немного более
подробно основные режимы их работы.
Режим сматывания
отпечатанных этикеток (Rewind). Готовые этикетки сматываются в рулон с помощью
внешнего или внутреннего смотчика. Обеспечивает большую скорость печати - рулон
из 2000 этикеток печатается около 10 минут, а есть и более быстрые модели
принтеров. Отпечатанный рулон этикеток вставляется в ручной аппликатор -
недорогое механическое приспособление в виде этикет-пистолета, которое по
нажатию на курок отклеивает этикетку от подложки. Вам достаточно провести таким
пистолетом по упаковке или коробке и очередная этикетка будет наклеена на нее.
О наличии такого аппликатора Вам нужно побеспокоиться и в том случае, если
этикетки Вы заказываете в типографии и не желаете наклеивать их руками.
Tear off - при этом режиме этикетка после печати дополнительно
выдвигается для того, чтобы край ее установился непосредственно над гребенкой,
так что этикетка вместе с подложкой может быть просто оторвана от рулона.
Peel off режим. Интересен тем, что напечатанная этикетка отклеивается
от подложки и таким образом ее можно просто взять руками и тут же наклеить на
коробку, упаковку и т.д. Очень удобно использовать Peel off для печати
непосредственно в месте наклеивания, например, на складе.
Нож. Опционально принтеры могут комплектовать ножом для отрезания
этикеток.
Реализация этих
основных режимов в самых разных комбинациях и моделях принтеров позволяет
удовлетворить практически любые потребности пользователей: от переносных
принтеров, печатающих этикетки "на ходу" в единичных экземплярах без
подключения к компьютеру, до настольных "мини-типографий" по
оперативной печати относительно больших тиражей наклеек, несущих любую
необходимую для Вас информацию.
4.Сравнительная
оценка существующих методов кодирования информации на почтовых отправлениях и
перспективы их применения
Рациональность применения того или иного метола кодирования
зависит от вида почтового отправления, объема информации, подлежащей
кодированию, и технологического процесса обработки почтовых отправлений.
Особенно остро стоит проблема выбора рационального метода кодирования
информации для тяжелой почты. Наиболее перспективными в настоящее время для
применения в автоматизированных системах обработки почты являются методы
оптического кодирования и считывания информации при помощи стилизованных знаков
и штриховых кодов.
Если сравнивать
кодирование стилизованными знаками и штрих-кодами, то по таким важным критериям
как способ нанесения информации, надежность достоверного считывания, необходимость
ориентации объекта по отношению к считывающему объекту, возможность применения
в существующих технологических процессах обработки почты большим преимуществом
обладает использование штрих-кодов.
Для кодирования информации штриховыми кодами необходимо
применение специальных печатающих устройств, что приводит к дополнительным
затратам. Однако высокая надежность, простота конструкции, низкая стоимость
считывающих устройств, достоверность считывания информации, снижение
трудозатрат на оформление посылок, универсальность применения в технологических
процессах обработки посылочной почты являются неоспоримыми преимуществами
использования штриховых кодов по сравнению со стилизованными знаками. Особенно
большим преимуществом является универсальность применения устройств считывания
штриховых кодов. Благодаря большому количеству модификаций эти устройства
могут использоваться в различных точках технологического процесса обработки
почты на предприятиях почтовой связи всех уровней.
Применение
штриховых кодов для кодирования информации на посылках и сопроводительных
документах, создание и внедрение устройств нанесения (печати) и считывания
штриховых кодов значительно повышает уровень автоматизации процессов обработки
посылочной почтя (и другой тяжелой почты), повысит пропускную способность
сортировочных установок и предприятий в целом. В конечном счете на основе
кодирования информации на почтовых отправлениях и их автоматизированной
идентификации станет возможной комплексная автоматизация процессов обработки
почты со значительным сокращением затрат ручного труда.
В настоящее время в нашей стране и за рубежом разработаны и
применяются методы цифровой индексации почтовых отправлений, но не существует
единого метода кодирования почтовых отправлений машиночитаемыми кодами.
Для обработки письменной корреспонденции успешно
применяется метод кодирования почтовых отправлений десятичными цифрами шестизначного
почтового индекса, которые пишутся так называемым стилизованным шрифтом по трафаретам
на лицевой части конверта. За рубежом для этой цели используется не только
считывание стилизованных цифр, но и машинописных цифр почтового индекса, а
также перекодировка писем бинарными штриховыми кодами.
Важной
проблемой является применение рациональных методов кодирования информации на
посылочной почте. Отсутствие рациональных методов кодирования информации на посылках
и надежных устройств считывания этой информации сдерживает комплексную
автоматизацию трудоемких процессов обработки посылочной почты.
Зарубежный опыт показывает, что наиболее приемлемым методом
кодирования информации на посылочной почте является применение штриховых
кодов. Система штрихового кодирования обладает более высокой надежностью по
сравнению с буквенно-цифровой системой кодирования. Считывание штриховых кодов
осуществляется с помощью простых по конструкции и недорогих устройств.
Кодирование штриховыми кодами необходимых реквизитов
(почтовых индексов места приема и места назначения почтового отправления,
номера, массы, вида почтового отправления и т.д.), и их нанесение (печать
ярлыков) целесообразно осуществлять в местах приема посылок с помощью
специальных устройств. В основу создания простых по конструкции, недорогих и
надежных устройств могут быть положены устройства печати барабанного типа.
За основу
создания устройств считывания штриховых кодов должны быть приняты
оптоэлектронные методы. При этом устройства считывания должны быть выполнены в
виде переносных контактных и стационарных дистанционных устройств. Переносные
считывающие устройства могут применяться при ручном способе считывания
информации с посылок с помощью светового карандаша, стационарные устройства —
на сортировочных установках в крупных сортировочных узлах.
На основе применения машиночитаемых кодов и
микропроцессорных устройств предоставляется возможность создания
высокоэффективных роботизированных линий разгрузки и транспортирования
почтовых отправлений, автоматизированных складов для их обработки и
накапливания, комплексной автоматизации процессов обработки почты, в результате
чего будет получен значительный экономический и социальный эффект.
5.Основные
проблемы механизации и автоматизации производственного процесса по обработке
посылочной почты
Прием,
обработка, продвижение и доставка (выдача) посылок - один из наиболее
трудоемких производственных процессов почтовой связи. Если учесть, что каждая
посылка в процессе ее продвижения сортируется в среднем три-четыре раза, то
наиболее трудоемкими операциями являются сортировка и перевозка посылок. Как
подчеркивается, большая часть операций производственного процесса выполняется
с высоким удельным весом ручного труда.
Тенденция к росту почтового обмена в целом, включая и
посылочный обмен, в промышленно развитых странах поставила на повестку дня
вопрос о необходимости глубокой механизации и автоматизации производственного
процесса почтовой связи.
Решение перечисленных задач связано, прежде всего, с
необходимостью выделения для этих целей значительных капитальных вложений. В
большинстве развитых стран эти средства направлены на решение таких задач, как
концентрация обработки посылок в механизированных центрах, изменение функций
предприятий, изменение почтовых правил, стандартизация посылок (масса,
габаритные размеры, написание адреса), организация контейнерных перевозок.
Концентрация обработки посылок в крупных сортировочных центрах, являющихся
главными опорными пунктами всей системы почтовых сообщений, дает возможность
эффективно использовать разнообразные средства комплексной механизации и
автоматизации производственного процесса. Опыт ряда зарубежных стран
показывает, что в таких узлах обрабатывается более 70-75% всего почтового
обмена.
Следующая задача, решение которой позитивно сказалось бы на
совершенстве технологии обработки посылочной почты в условиях широкого
внедрения средств механизации и автоматизации — стандартизация посылок.
Большинство стран, принявших участие в изучении КСПИ, признают важность и
достаточную сложность этого вопроса. Практически во всех странах считается, что
стандартизация должна распространяться не только на габаритные размеры и массу
посылок, но также на их материал и написание адреса на них.
Одно из важнейших технологических изменений связано с
использованием жестких контейнеров для перевозки посылок. Предпосылкой для все
более широкого применения контейнеров послужили рост посылочного обмена и его
концентрация в крупных уздах с достаточно мощными потоками посылочной почты
между ними. Внедряются контейнерные перевозки на всех видах транспорта.
Контейнеризация, в свои очередь, вызвала необходимость решения многих
организационно-технических вопросов, таких как:
- разработка и внедрение средств
механизированной и автоматизированной загрузки и выгрузки посылок в контейнеры
и из контейнеров;
- строительство специальных площадок
(терминалов);
- использование специализированного
транспорта и др.
6.
Концентрация
обработки посылок в механизированных центрах и задачи, решаемые при этом
Тенденция к концентрации производственного процесса по
обработке и продвижению посылок вытекает из тех преимуществ, которые она
создает. Главное здесь заключается в возможности организации поточного процесса
сортировки посылок. При поточном производстве экономически выгодно
использовать новое дорогостоящее высокопроизводительное оборудование, так как
увеличивается степень его загрузки, а значит и эффективность использования.
Современные
сортировочные комплексы имеют высокую производительность (до 100 посылок/
мин.), они имеют, как правило, от двух до четырех узлов ввода, что создает
возможность оптимальной загрузки. Количество накопителей в установках различно:
от 34 до 570. В большинстве центров их число составляет от 40 до 120. Как
правило, используются гравитационные накопители. Применяются установки с
механизированными накопителями. Чаще всего выгрузка из накопителей
производится вручную, однако, в ряде сортировочных центров посылки из накопителей
подаются непосредственно на внешний транспорт: в почтовые вагоны (Канада, Новая
Зеландия, Норвегия), в автомобили (Бразилия, Канада, Норвегия).
Непосредственная подача посылок из накопителей установок в контейнеры применяется
в ряде сортировочных центров США, Канады, Бразилии, Франции и ряда других
стран.
В большинстве промышленно развитых стран управление
процессом сортировки посылок в крупных центрах частично автоматизировано, и
достаточно широко применяются ЭВМ. Сортировка посылок с применением ЭВМ
выполняется по следующей схеме: если соответствующий контроллер ЭВМ не вводит
индекс автоматически, то сам оператор на стартовом столе считывает с посылки
индекс и на устройстве клавишного типа набирает его. ЭВМ, приняв индекс,
преобразует его в номер направления, после чего следует команда соответствующим
исполнительным органам сортировочной машины.
Для большинства применяемых комплексов типичны следующие
задачи:
- управление транспортирующим и сортирующим
оборудованием;
- оперативный обмен информацией о
производственном процессе между центральными пунктами и рабочими местами;
- сбор, обработка, анализ и документирование
различного рода статистической информации,
- надзор за работой подсистем и важных
участков производственного процесса;
- реакция на различного рода отклонения и
изменения в производственном процессе; изменение программ сортировки;
- защита персонала и оборудования путем
введения в действие блокировок, аварийных отключений, резервного оборудования.
7. Формирование, оценка и возможности использования
опережающего информационного потока
Широкое
применение средств вычислительной техники и концентрация обработки почты в
механизированных центрах создает возможность комплексного и более полного
использования той закодированной информации, которая сопровождает почтовое
отправление, одним из вышеописанных способов. В центрах обработки посылок ее
главное назначение — это управление процессом сортировки, но помимо этого
формирование оперативной статистики и возможность передачи этих данных между
центрами позволит существенно усилить системные свойства сети перевозки почты.
Обеспечить более четкую взаимозависимость территориально
рассредоточенных технологических процессов и более жесткий
пространственно-временной контроль за продвижением почты возможно, если
служебная информация об отправлениях, прошедших сортировку, будет передаваться
в транзитные или оконечные центры сортировки, опережая материальный поток.
Естественно, статистические характеристики пропущенной нагрузки, формирующие
этот опережающий информационный поток (ОИП), должны быть научно обоснованными.
Очевидно, что эти оперативные данные будут передаваться средствами
электросвязи, а не перевозкой дискеты иди другого носителя информации в
смежный центр механизированной обработки почты.
ОИП должны формироваться на основании
индивидуальных атрибутов каждого отправления, которые в не сокращенном виде
могут выражаться вектором V = {V![]() , V
, V![]() ,...,V^}, созданных и хранящихся в базе данных системы
центра.
,...,V^}, созданных и хранящихся в базе данных системы
центра.
V![]() – адрес отправителя
(индекс) 6 цифр, 3 байта;
– адрес отправителя
(индекс) 6 цифр, 3 байта;
V![]() – адрес получателя
(индекс) 6 цифр, 3 байта;
– адрес получателя
(индекс) 6 цифр, 3 байта;
V![]() – номер посылки 4
цифры, 2 байта;
– номер посылки 4
цифры, 2 байта;
V![]() – вид посылки,
согласно принятой системы стандартизации 1 буква, 1 байт;
– вид посылки,
согласно принятой системы стандартизации 1 буква, 1 байт;
V![]() – объявленная
стоимость 4 цифр, 2 байта ;
– объявленная
стоимость 4 цифр, 2 байта ;
V![]() – габаритные размеры и
вес отправления 12 цифр, 6 байта;
– габаритные размеры и
вес отправления 12 цифр, 6 байта;
V![]() –
пространственно-временные характеристики уже пройденного пути от отправителя к
получателю (формируется автоматически в системе управления) 40 цифр, 20 байта;
–
пространственно-временные характеристики уже пройденного пути от отправителя к
получателю (формируется автоматически в системе управления) 40 цифр, 20 байта;
V![]() – иные параметры
отправления.
– иные параметры
отправления.
Всего 37 байта
Оценим верхнюю границу необходимого
объема памяти. Для хранения этого вектора в базе данных созданы в процессе
сортировки в центре механизированной обработки почты.
|
V1 |
V2 |
V3 |
V4 |
V5 |
V6 |
V7 |
V8 |
![]() В крупнейших мировых центрах по
сортировке почтовых отправлений обрабатывается не более 500 тыс. посылок в
сутки, поэтому суточное накопление базы данных не будет превышать 18 Мбайт, что
вполне приемлемо для современных средств вычислительной техники.
В крупнейших мировых центрах по
сортировке почтовых отправлений обрабатывается не более 500 тыс. посылок в
сутки, поэтому суточное накопление базы данных не будет превышать 18 Мбайт, что
вполне приемлемо для современных средств вычислительной техники.
По мере прохождения в некотором центре С
сортировки появляются отправления принадлежащие соответствующему направлению.
По каждому из направлений формируется сообщение ![]() , которое образует ОИП.
, которое образует ОИП.
Sº- адресные реквизиты отправлений (часть цифр
индекса получателя), необходимое для сортировки на следующем технологическом
этапе (центре)-3 цифры, 2р байта;
S¹ - число посылок каждого типа которое будет
отправлено ближайшем транспортом в направление V- 2m байта;
S² - примерные весовые и габаритные
характеристики- 10 цифр, 5 байта;
S³ - время прибытия транспорта в центр обработки-
8 цифр, 4 байта.
![]()
Эти сообщения посылаются по мере отправки транспорта в
назначенный центр обработки почты. Заблаговременная передача этой информации
позволит оптимизировать технологический процесс, резервировать транспортные
средства для перевозки почты и повысить коэффициент их использования,
резервировать трудовые ресурсы для обработки отправлений; создаст возможность
для прогнозирования ближайшей нагрузки и, следовательно, оперативного
маневрирования всеми производственными ресурсами центра. Помимо этого
полученная информация обеспечит более жесткий контроль за сохранностью и
временными интервалами движения отправления к получателю путем выявления узких
мест в технологической цепочке.
Определение размера сообщения осуществляется по формуле:
![]() =Sº+S¹+S²+S³=2p+2m+5+4=2(p
=Sº+S¹+S²+S³=2p+2m+5+4=2(p![]() *(Δt+m))+9
*(Δt+m))+9
где p![]() (t)- количество посылок, оказавшееся в i-м
накопителе за интервал времени между отходом ближайшего и предыдущего
транспорта в i-м направлении;
(t)- количество посылок, оказавшееся в i-м
накопителе за интервал времени между отходом ближайшего и предыдущего
транспорта в i-м направлении;
т —
общее число типов отправлений, обрабатываемых в центре. Не претендуя на точность,
примем т=5 .
8.
Расчет величины ОИП
Для определения величины суточного ОИП, исходящего из некоторого
центра С
механизированной
обработки почты, надо определить суточный поток в каждом направлении. Зная
среднюю величину суточного потока почтовых отправлений через центр Тс,
общее число направлений п, модель распределения ![]() по этим направлениям (
по этим направлениям (![]() — часть нагрузки, остающаяся внутри района С) и
расписание движения транспорта в каждом направлении, можно определить размеры
каждого сообщения |
— часть нагрузки, остающаяся внутри района С) и
расписание движения транспорта в каждом направлении, можно определить размеры
каждого сообщения |![]() |. Суммируя
размеры этих сообщений (например, в байтах) за сутки, получим суточный ОИП,
исходящий из центра С в i-м направлении:
|. Суммируя
размеры этих сообщений (например, в байтах) за сутки, получим суточный ОИП,
исходящий из центра С в i-м направлении:
![]()
![]()
![]()
где k=1, 2, 3,...; ![]() — это порядковой номер
транспорта (номер маршрута), отправленного за текущие сутки в i-м направлении (всего их
— это порядковой номер
транспорта (номер маршрута), отправленного за текущие сутки в i-м направлении (всего их ![]() ); а
); а ![]() — интервал
времени между отправкой k-го и k-1 маршрутов, в течение которого
формировалось сообщение
— интервал
времени между отправкой k-го и k-1 маршрутов, в течение которого
формировалось сообщение ![]() .
.
Для
теоретического расчета ![]() i=1,2,..
n сделаем ряд предположений.
i=1,2,..
n сделаем ряд предположений.
1.
Распределение
Тс в направлении других центров механизированной обработки
почты осуществляется пропорционально населению тех
2.
регионов,
которые обслуживаются этими центрами, т.е.
T![]() =T
=T![]() *
*![]()
где ![]() — население
региона, который обслуживается i-м центром.
— население
региона, который обслуживается i-м центром.
Практически
закон распределения нагрузки Тс более сложен и для каждого
центра может быть установлен экспериментально, но для учебных целей вполне
корректной может быть формула ().
3.
Транспорты,
уходящие из С, отходят через равные интервалы времени Δt![]() = Δt
= Δt![]() .= Δt
.= Δt![]() =….= Δt
=….= Δt![]() и
имеют одинаковые параметры грузоподъемности, т.е. не бывают переполнены и
вывозят равные части суточной нагрузки Тс. Следовательно,
число отправлений в каждом из них примерно одинаково, а поэтому количество
посылок в каждом определяется:
и
имеют одинаковые параметры грузоподъемности, т.е. не бывают переполнены и
вывозят равные части суточной нагрузки Тс. Следовательно,
число отправлений в каждом из них примерно одинаково, а поэтому количество
посылок в каждом определяется:
p![]() (Δt
(Δt![]() ) = p
) = p![]() (Δt
(Δt![]() )= ….= p
)= ….= p![]() (Δt
(Δt![]() )=
)= ![]()
где ![]() — число маршрутов из центра С в центр i за сутки.
— число маршрутов из центра С в центр i за сутки.
9. Расчет затрат на передачу ОИП средствами
электросвязи
Информация, содержащаяся в ОИП, принятая в центрах и
обработанная в их системах управления, позволяет дать точную оценку
отправленной к ним на сортировку нагрузки. Это позволит прогнозировать ее
состояние на ближайшее время. При этом ближайший прогноз очень точен, так как
все сообщения, описывающие нагрузки прибывающих маршрутов, уже должны поступить
и быть обработаны в ЭВМ. Более дальние прогнозы не учитывают информацию о
коротких маршрутах, так как те еще не отправлены из исходящих центров и
сообщений от них не поступило в систему управления.
Информация о поступающей нагрузке может быть предварительно
отсортирована (частичный индекс получателя имеется), и определена
перспективная загруженность каждого направления в собственном центре
обработки. А это та самая оперативная информация для руководителя, что позволит
ему оптимизировать управление центром.
Естественно,
что за доставку этой информации необходимо нести некоторые расходы. Попытаемся
оценить их, учитывая, что сообщения о маршрутах, находящихся в пути длительное
время (несколько суток), могут передаваться по каналам связи во время спада
нагрузки (в ночное время), когда действуют минимальные тарифные платежи. Это
связано с тем, что нет жесткого лимита времени на доставку этих сообщений. Для
коротких маршрутов этот лимит должен существовать и даже ужесточаться. I
Исходя из этого, будем оценивать
верхнюю границу П платы за доставку ОИП, по которой можно будет оценить
его целесообразность с экономический точки зрения.
К техническим средствам доставки ОИП можно отнести
телеграфную сеть АТ-50 со скоростью передачи информации 50 Бод (h=6 байт/сек), сеть передачи данных ПД-200
(h=25 байт/сек) и
междугородную телеграфную сеть, которая вполне надежно позволяет передавать
через нее данные между ЭВМ, используя модемы со скоростью 1600, 2400 бит/сок (h= 200 и 300 байт/сек).
Для оценки
платы ![]() за передачу
суточного ОИП из центра С (она взимается в пункте исходящей нагрузки) надо
определить плату по каждому направлению за сутки, которую затем просуммировать:
за передачу
суточного ОИП из центра С (она взимается в пункте исходящей нагрузки) надо
определить плату по каждому направлению за сутки, которую затем просуммировать:
П![]() =
=![]() =
=![]()
![]() (k)
(k)
n - число
направлений (исходных),исходящих из С;
П![]() (k)- плата за передачу сообщения
(k)- плата за передачу сообщения ![]() ;
;
k- порядковый
номер маршрута, почтовое содержимое которого описывается сообщением ![]() .
.![]()
Плата П![]() (k)за
передачу сообщения
(k)за
передачу сообщения ![]() очевидно будет пропорциональна времени занятия канала, а,
следовательно, размерам сообщения и зависеть от принятой системы тарифов.
Естественно, что чем дальше друг от друга располагаются центры, там больше тариф
на предоставление канала для передачи между ними информации. Для упрощения
сложной системы тарифных платежей за предоставление услуг связи, существующей
в нашей стране, воспользуемся упрощенной формулой, аппроксимирующей линейной
зависимостью стоимость x использования канала связи в течение
единицы времени от протяженности:
очевидно будет пропорциональна времени занятия канала, а,
следовательно, размерам сообщения и зависеть от принятой системы тарифов.
Естественно, что чем дальше друг от друга располагаются центры, там больше тариф
на предоставление канала для передачи между ними информации. Для упрощения
сложной системы тарифных платежей за предоставление услуг связи, существующей
в нашей стране, воспользуемся упрощенной формулой, аппроксимирующей линейной
зависимостью стоимость x использования канала связи в течение
единицы времени от протяженности:
x=![]() R
R
R- протяженность канала в сотнях км, округленная до
целого числа с избытком;
![]() - коэффициент , физический смысл- цена использования канала в
течении одной сек. для передачи сообщений на 100 км.
- коэффициент , физический смысл- цена использования канала в
течении одной сек. для передачи сообщений на 100 км.
Для АТ выберем: ![]()
![]() =0,1; для ПД-200
=0,1; для ПД-200 ![]()
![]() =0,5; а для передачи сообщений по каналам МТС
=0,5; а для передачи сообщений по каналам МТС ![]()
![]()
![]() =1. Конкретные величины этих
коэффициентов не имеют большого практического значения, так как в настоящее
время наблюдается рост тарифов и эта тенденция, скорее всего, сохранится.
=1. Конкретные величины этих
коэффициентов не имеют большого практического значения, так как в настоящее
время наблюдается рост тарифов и эта тенденция, скорее всего, сохранится.
Воспользуемся
формулой () для определения платы ![]() за предоставление каналов сети ПД-200 для пропускания
суточного ОИП из Центра С в А. Пусть расстояние между С и А равно 635 км (
за предоставление каналов сети ПД-200 для пропускания
суточного ОИП из Центра С в А. Пусть расстояние между С и А равно 635 км (![]() ), тогда
), тогда ![]() ,где t — время занятия
канала.
,где t — время занятия
канала.
Учитывая, что это время прямо
пропорционально размерам ОИП (R![]() ) и обратно
пропорционально скорости передачи по каналу:
) и обратно
пропорционально скорости передачи по каналу:
П![]() =
=![]() R
R![]()
![]() χ ,
χ ,
где
χ – коэффициент, учитывающий превышение платы к сверх
реального времени при передачи коротких сообщений: χ=1,2
- 2,4.
Список используемой литературы
1. Барсук И.В., Гиль Г.К., Воскресенская
А.Л. и др. Организация автоматизированной обработки почтовых отправлений в
крупных узлах связи.
— М.:
Радио и связь, 1985.
2. Бутенко Б.П., Коршунов В.В., Мамзелев И.А., Мицкевич В.А. Технологические
процессы в. почтовой связи. Кн. 2. Основы функционирования.
— М.:
Радио и связь, 1998.
3. Бутенко Б.П., Мамзелев И.А., Мицкевич
В.А. Технологические процессы в почтовой связи. Кн. 1, Основные характеристики
и техническое обеспечение. — М.: Радио и связь, 1998.
4. Инструкция и формат статистической
отчетности предприятий связи. — М.: Радио и связь, 1985.
5. Королев В.И., Карпова М.В. Применение
средств вычислительной техники в почтовой связи/МИС. -М. ,1988,
6. Красносельский Н.И.,
Воронцов Ю.А., Аппак
М.А. Автоматизированные
системы управления в связи. — М.: Радио и связь, 1986.
7. Мамзелев И.А. Вычислительные системы в
технике связи. — М.: Радио и связь, 1987.
8. Мамзелев И.А., Мицкевич В.А.
Технологические процессы в почтовой связи
и Роспечати. Учебное
пособие, части 1-3.
- М.:
"Информ-связьиздат", 1993.
9. Общеотраслевые руководящие методические
материалы но созданию автоматизированных систем управления технологическими
процессами (АСУТП). —М.: Финансы и статистика, 1982.
10. Почтовые правила. Общая и техническая
части. — М.: Радио и связь, 1992.
11. Применение штриховых кодов при переработке
грузов / Кандуазки Н. Нияку то кикай, 1984..
12. Романов Б.А.,.Кушниренко А.С. БВА8Е-1У:
назначение, функции, применение. - М.: Радио и связь, 1991.
13. Связь
почтовая. Термины и представления ГОСТ 16408.400. Издание официальное. — М.:
Радио и связь, 1984.
14. Справочник начальника отделения связи. —
М.: Радио и связь, 1981.
15. Фигурнов В.Э. 1ВМ РС для пользователя.
—М.: Финансы и статистика, 1990.
Методическое
пособие:
«Автоматизация технологических процессов почтовой службы»
Рассмотрено
на заседании кафедры
«Автоматизация
почтовой службы» протокол №______________
Рекомендовано
к печати
Составитель:
Ишдавлетова Э.Т.
Ответственный
редактор: профессор Муминов Н.А.
Корректор:
Ходжелепесова Ю.Н.
Формат 60x84 1/16 Заказ № 356 Тираж 50
Отпечатано в Издательско –
полиграфическом центре «ALOQACHI» при ТУИТ
Ташкент ул. Амир Темура, 108