Королёв А.Н.
Мы живем в век тотальной информатизации и всех нас, вне зависимости от рода нашей деятельности, ежедневно бомбардируют потоки информации. Увы, в особенности это относится к людям, принимающим решения. Статистика показывает, что в современной компании руководитель получает в день порядка сотни сообщений по электронной почте. Из элементарного подсчета следует, что сто почтовых сообщений в день, умноженные на полторы минуты (среднее время, необходимое для того, чтобы прочесть сообщение и ответить на него) дадут нам 2 часа 30 минут. Итак, каждый день два с половиной часа времени лица, принимающего решения, уходят на работу с электронной почтой.
Выражения "экспоненциальный рост", "информационный взрыв" и т.п. создают ощущение неизбежности наступления того момента, когда практически все время человека, принимающего решения, уходит на ознакомление с информацией, на собственно же принятие решения времени не остается.
Разумеется, реальная ситуация не столь трагична. На своем пути поток "сырой" информации проходит ряд этапов, на каждом из которых из всего множества поступающей информации выделяются только наиболее важные данные, непосредственно необходимые для принятия решения.
Таким образом, с ростом количества "сырой" информации все большее значение приобретает аналитическая обработка информации. Можно указать ряд требований к этому процессу.
Во-первых, информация должна анализироваться динамически, в реальном масштабе времени. Действительно, если мы хотим анализировать, например, ежедневно поступающие сводки новостей, то результаты анализа мы явно хотим получать хотя бы на следующий день (а еще лучше - в тот же самый). Обзор, самый что ни на есть подробный и совершенный, но пришедший с недельным опозданием, будет представлять в наше время постоянных перемен чисто исторический интерес.
Во-вторых, при анализе должна учитываться вся поступившая ранее информация - ведь один и тот же факт может трактоваться по-разному в различном контексте. Предположим, мы имеем сообщение типа "На 17 марта 1999 года курс доллара США на ММВБ составил 23 рубля 41,18 копейки". Казалось бы, простейшее сообщение, но его смысл кардинально меняется, если мы узнаем, что 16 марта за один доллар США давали не 23 рубля 34,73 копейки, а, к примеру, 6 рублей 25 копеек. Узнаваемая ситуация, не правда ли?
В-третьих, требование полноты - в процессе анализа информация, принципиальная для принятия решения, не должна исключаться из итогового обзора.
С требованием полноты связано требование точности - зашумленность результата информацией, не относящейся к делу должна быть минимальной, а в идеале отсутствовать вовсе.
Большинству существующих в настоящее время информационно-поисковых систем присущи при работе с текстовой информацией такие ограничения, как незначительное использование смысла текста, высокие требования к качеству подготовки документов для добавления в архив и к уровню подготовки самих пользователей системы. В основе работы этих систем лежит организация поиска по ключевым словам с построением на их основе сложных выражений, содержащих логические операторы. Разумеется, такие системы позволяют построить достаточно полный и избирательный запрос, но за такую возможность пользователю, работающему с системой, необходимо не только в совершенстве владеть языком построения запросов системы, но и хорошо представлять особенности текстов из своей предметной области. В частности, пользователь таких систем должен хорошо представлять, какими словами необходимая ему информация может быть выражена в тексте. Ч. Мидоу, один из видных специалистов США в области информационного поиска пишет по этому поводу:
"Важно понять, что умение точно сформулировать вопросы к карточному каталогу не обязательно связано со способностями в некоторой области знаний. Блестящий физик наделен даром установления подобной связи не более чем способностью общаться со своими коллегами по профессии в Исландии на их родном языке. Библиотечный язык отличается от обычного языка и искусством его использования нельзя овладеть сразу".
Итак, использование традиционной информационно-поисковой системы требует освоения некоего языка запросов, иногда достаточно специфичного для отдельной системы. Представляет ли это проблему для пользователя? Чтобы убедиться в этом, достаточно попытаться найти необходимую информацию в Internet при помощи какой-нибудь поисковой системы, например, Rambler или Alta Vista.
Кроме того, подобные системы не используют семантику обрабатываемых текстов. Этот недостаток не позволяет найти предложение, содержащее личное местоимение, являющееся перифразом для запроса и т.п. Ряд информационно-поисковых систем не учитывает даже синонимию. Все это снижает полноту результатов поиска.
На точность поиска, в свою очередь влияют ошибки в исходном тексте. Основной источник таких ошибок - операция распознавания символов в отсканированном тексте.
Одной из информационно-поисковых систем, практически лишенных вышеописанных недостатков, является электронная архивная система Excalibur RetrievalWare производства компании Excalibur Technologies Corp (США) - мирового лидера в области корпоративных информационно-поисковых систем. По результатам тестирования Национального института стандартов и технологий при правительстве США программные продукты этой компании в течение последних пяти лет занимают первое место по резхультатам независимого тестирования. В результате они используются Госдепартаментом и Национальной Библиотекой Конгресса США, ЦРУ, компаниями Ford Motors, Lockheed, Reynold Electrical & Engineering, Maine Yankee Atomic Power Corp., в России же - ФАПСИ РФ, Конституционным судом РФ, Федеральным институтом промышленной собственности РФ, рядом ведущих российских банков и др. Такой широкий спектр разнообразных внедрений во многом определяется как уникальным механизмом нечеткого поиска, так и широкими возможностями создания собственных приложений, основанных на базовой технологии.
Основу подхода составляет уникальная технология APRP - технология адаптивного распознавания образов, разработанная около 30 лет назад доктором Джеймсом Дау III (James Dow III). Ядро технологии выросло из его работ посвященных изучению и разработке сетевых моделей, способных идентифицировать, или, точнее, распознавать присутствие тех или иных образов в составе данных специфического вида. В своей работе, связанной с изучением физиологии центральной нервной системы земноводных, Дау пытался понять, как лягушки с их ограниченными зрительными способностями распознают объекты окружающего их мира. Модель зрительного аппарата земноводных и была положена доктором Дау в основу его технологии индексирования и нечеткого поиска. В результате был создан комплекс методов, способных адаптироваться к особенностям обрабатываемой информации и поисковые системы обогатились интеллектом лягушки.
Основу поискового механизма составляет нейронная сеть, позволяющая выделять в зашумленной битовой последовательности "похожие фрагменты", не требуя точного контекстного совпадения запроса и фрагмента в документе. В результате оказывается, что системе, в принципе, безразлично, к информации какого вида относится битовая последовательность и что ищется: текст, звук, изображение и т.п. Ее стихия - поиск любой неструктурированной информации.
Одно из важных преимуществ системы - полная автоматизация обработки поступающих в систему документов. Используется полнотекстовый поиск, а не механизмы приписывания документам экспертами ключевых слов, категорий и т.п. Минимальное участие человека в процессе ввода документов повышает эффективность работы системы.
Технология APRP позволяет строить архивы, в которых объем индексной информации не превышает тридцати процентов от общего объема хранимых документов. Столь компактный индекс существенно повышает скорость работы системы - в особенности, на больших архивах. Например, при объеме архива до 5 гигабайт время поиска меньше 3 сек, при объеме до 20 Гб - не превышает 5 сек, при объеме до 100 Гб время меньше 9 сек, а при объеме архива порядка двух терабайт время поиска меньше 20 сек (экспериментальные данные).
Масштабируемость программного обеспечения Excalibur RetrievalWare объясняется не только способностью системы работать на широком спектре вычислительных машин - от рядовой "писишки" до мощного многопроцессорного сервера, но и с возможностью построения распределенных многопроцессорных конфигураций, в которых система работает в параллельном режиме и каждый сервер отвечает за свою часть базы данных.
Компания "Весть-МетаТехнология", являющаяся эксклюзивным представителем Excalibur Technologies в России, разработала русский семантический сервер RetrievalWare, позволяющий использовать при поиске информации базу лингвистических знаний о русском языке. Таким образом, пользователь системы должен только ввести запрос на естественном языке - все остальное система сделает сама. Как она это сделает - об этом несколько слов ниже.
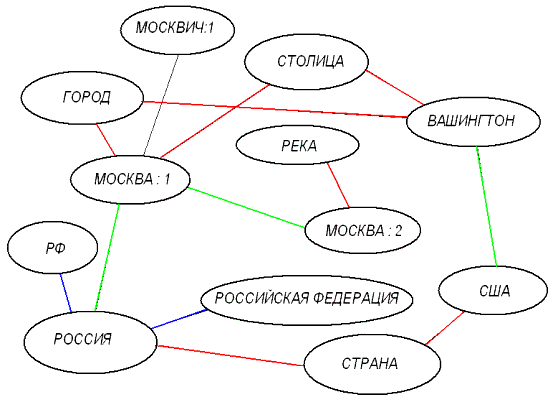
Семантическая сеть (см. рис. 1) является ориентированным графом, связывающим между собой слова и понятия и приписывающим связям между ними определенные весовые коэффициенты. Основное преимущество, которое дает применение семантических сетей в RetrievalWare состоит в возможности искать необходимую информацию, пользуясь смыслом слов.
Рис 1. Фрагмент семантической сети.
Итак, семантическая сеть описывает взаимосвязи между словами и понятиями.
Теперь, введя в поисковом запросе слово "РОССИЯ", мы можем быть уверены, что в тексте будут найдены и "РФ", и "РОССИЙСКАЯ ФЕДЕРАЦИЯ".
Разумеется, работа семантического сервера не заключается исключительно в расширении слов запроса всеми другими словами, которые хоть как-то с ними связаны. Хотя то же слово "РОССИЯ" может быть расширено несколькими словами - "РФ", "СТРАНА", "МОСКВА", "РОССИЯНИН", "СНГ" и т.п. Реально, при поиске одни расширения являются более значимыми, чем другие. В примере с запросом "РОССИЯ" в первую очередь будут искаться документы, содержащие слово "РОССИЯ" (точное совпадение с запросом), потом - близкие синонимы "РФ" и "РОССИЙСКАЯ ФЕДЕРАЦИЯ" и так далее.
"Семантичность" Excalibur RetrievalWare не ограничивается добавлением в запрос слов, расширяющих смысл запроса - на это способны и традиционные информационно-поисковые системы, использующие логические операторы в запросе. Она проявляется и в оригинальной системе выставления оценок найденным документам, учитывающей не только такие параметры, как полнота результатов поиска или физическое расстояние между словами в тексте, но и смысловой контекст документа.
Действительно, разве нельзя по словарю документа и сравнительной частоте встречаемости определить, что мы имеем перед глазами - газетную статью, юридический документ или, к примеру, описание технологии производства какого-нибудь механизма? Можно. Для того чтобы сделать это, нам достаточно одного взгляда на документ. Но способен ли сделать это компьютер? Опыт использования системы Excalibur RetrievalWare показывает - да, способен.
Наложение семантической сети на множество слов запроса определяет смысловой контекст, в рамках которого осуществляется поиск. Рассмотрим, к примеру, следующую пару запросов - "ВЫБОРЫ МЭРА МОСКВЫ" и "ОТКРЫТИЕ НАВИГАЦИИ НА МОСКВЕ". И в одном и в другом запросе есть слово "МОСКВА". Разумеется, мы с Вами понимаем, что в первом случае имеется в виду город Москва, а во втором - Москва-река. Мы-то это понимаем, а понимает ли компьютер?.. Оказывается, да. Значения слова "МОСКВА" в каждом из контекстов поясняются словами "МЭР" и "ВЫБОРЫ" в первом случае и словом "НАВИГАЦИЯ" во втором. Произведя же поиск, система поставит в начале списка результатов в первом случае документы, содержащие помимо выражения "ВЫБОРЫ МЭРА МОСКВЫ" и слова "ГОРОД", "МОСКВИЧ", "БЮЛЛЮТЕНЬ" и т. п., во втором же - "СУДОХОДСТВО", "РЕКА"…
Тому, кто сомневается в необходимости подобных семантических изысков, предлагаю ответить на вопрос - какова будет эффективность Вашей работы с системой, если в ответ на запрос "ВЫСТУПЛЕНИЕ ЛЕБЕДЯ" Вы будете получать репертуар московских театров и Красную книгу?
В настоящее время семантическая сеть для английского языка представляет собой базу знаний, состоящую из 400,000 значений слов и более 1,600,000 связей между ними. К сожалению, как это ни странно, до последнего времени разработок такого масштаба для русского языка не велось, поэтому используемая семантическая сеть значительно меньше и включает в себя общеупотребительную и общеполитическую лексику. Тем не менее, в рамках семантического сервера RetrievalWare все технические проблемы уже решены, и пополнение базы знаний представляет собой вопрос времени и усилий квалифицированных лингвистов и экспертов в конкретных предметных областях.
Система RetrievalWare позволяет одновременно использовать несколько семантических сетей. Иерархическая организация представляемых ими словарей системы позволяет создавать "пирамиды" словарей (см. рис. 2) для тех или иных областей деятельности, организаций, проектов или даже отдельных пользователей.
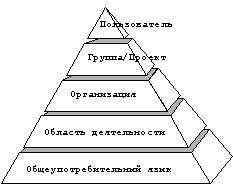
Рис. 2. Организация многоуровневых словарей.
Разработка предметного тезауруса - основная проблема представления языковых знаний, от качества решения которой зависит точность семантического поиска. Именно поэтому тезаурусы разрабатываются специалистами - лингвистами с учетом специфики языка, на котором будут формулироваться запросы при поиске информации и привлечением знаний специалистов в конкретной предметной области.
Типы связей, которые использует тезаурус системы можно воспринимать как меру смыслового сходства между значениями слов (семантическое расстояние).
Отметим, что уже сегодня система может применять все русскоязычные лингвистические ресурсы параллельно с оригинальными англоязычными на всех этапах ее применения: от индексирования до обработки запроса. Это делает возможной нормальную обработку как текстов на английском и/или русском языках, так и двуязычных текстов. Нет проблем и с различными русскими кодировками (Win1251, KOI-8R, ISO8859-5, DOS866 и т.п.).
Вернемся же теперь к работе с системой в реальном времени и приведем небольшой пример.
Представим себе, что некое аналитическое агентство использует систему для анализа информации электронных агентств новостей. Предположим также, что нас интересует активность какого-нибудь политического деятеля. Мы можем ежедневно (ежечасно, ежеминутно) вводить в систему один и тот же запрос, сортировать результаты по степени новизны и изучать их. Да, мы можем делать это так, но проще поручить черновую работу компьютеру (а точнее - системе Excalibur RetrievalWare) - пусть он сам просматривает поступающие документы и помещает ссылки на те из них, которые представляют интерес, в отдельную папку - рубрику.
При этом для создания запроса для рубрицирования (то есть выполнения описанной выше операции), вовсе необязательно писать сложные конструкции на особом языке - достаточно выбрать один или несколько эталонных документов, чтобы система отслеживала все похожие.
При этом поддерживается более 200 форматов данных, обеспечивается работа как со структурированной (в рамках СУБД), так и неструктурированной информацией.
Для просмотра документов используются стандартные операционные среды. Если документы хранятся в формате некоторого приложения, то оно автоматически запускается для их просмотра. Кроме того, внешние приложения могут обращаться к документам, хранимым в электронном архиве.
Если ко всему выше сказанному добавить многоплатформенность системы и масштабируемость построенных на ее основе решений, а также полный набор возможностей для работы в корпоративных сетях intranet и в глобальной сети Интернет, то станут окончательно понятны причины признанного лидерства архивных систем, созданных компанией Excalibur Technologies Corp.