Гибкая архитектура хранилища
В отличие от большинства предлагаемых сегодня на рынке решений, приобретение которых заранее предполагает использование какой-то определенной архитектуры хранилища (главным образом, это ROLAP либо MOLAP) Microsoft OLAP Services не ограничивает выбор администратора, предлагая гибкую модель хранения. OLAP Services в равной степени поддерживают ROLAP, MOLAP, а также HOLAP (Hybrid OLAP, когда детали хранятся в реляционной базе, как в случае ROLAP, а агрегаты вычисляются и помещаются в собственное действительно многомерное хранилище, как в случае MOLAP). Если для нас являются критичными вопросы быстродействия, мы можем выбрать MOLAP, если мы не хотим забирать дополнительное место на диске за счет переноса детальных данных - можно выбрать ROLAP, если мы хотим взять лучшее из двух миров - то HOLAP. Более того, в Microsoft OLAP Services разные чаcти одного куба могут храниться в разных форматах, что позволяет более четко и аккуратно подстроиться под требования пользователя. Например, куб, содержащий данные о продажах, может быть разбит на несколько фрагментов (partitions), один из которых с данными за текущий год, запрашивается довольно часто, а остальные - не очень. Тогда, создавая фрагмент как сечение по текущему году, мы выбираем формат MOLAP, так как здесь наиболее критичным вопросом выступает производительность, для сечения по прошлому году - HOLAP, а для остальных исторических данных - ROLAP. Заметим, что фрагменты могут сливаться друг с другом. В случае выбора модели ROLAP OLAP Services определяют, инициализируют и поддерживают все необходимые дополнительные структуры в реляционной базе, избавляя администратора создавать эти объекты самому и строить сложные запросы по очень большому числу таблиц на разных серверах. Для конечного пользователя обращение к кубу происходит совершенно одинаково вне зависимости от его архитектуры.
Производительность и масштабируемость
Естественно, производительность и масштабируемость сильно зависят от размера базы данных, мощности аппаратной платформы и количества предвычисленных агрегатов. Тем не менее, такие возможности системы, как уже упоминавшиеся пользовательские разбиения, способны оказать на эти показатели сильное влияние. Подобно тому, как разбиения есть аналог применения условия фильтрации select ... where, виртуальные кубы можно уподобить результату операции view union над кубами. Если мы имеем кубы "Продажи" и "Маркетинг", построенные по системам учета торговых и маркетинговых операций (т.е. принципиально разные меры, но хотя бы одно общее измерение), и хотим проанализировать изменения объемов продаж в зависимости от проведения тех или иных маркетинговых мероприятий, мы можем создать виртуальный куб, являющийся объединением двух перечисленных, но не требующий, как и всякий нормальный view, в отличие от физического куба дополнительного места для своего хранения на диске. Виртуальные кубы связываются во время запроса через одно или несколько общих измерений.
Эти возможности позволяют распределить один логический куб по нескольким физическим, в том числе, находящимся на разных серверах. OLAP Services распределяет запрос по всем этим серверам, позволяя данным обрабатываться параллельно. Предположим, мы осуществляем продажи в 10 различных регионах, и за каждый регион отвечает свой выделенный сервер. Мы имеем один логический куб, разбитый по 10 серверам. Каждая из этих 10 частей в отдельности доступна аналитикам, занимающимся исследованиями данного отдельного региона. Тем не менее с точки зрения пользователя общий куб ничем не отличается от обычного куба. Он совершенно аналогично может адресовать ему запросы. Совершенно прозрачно для пользователя Microsoft OLAP Services разобьет этот запрос на несколько частей, пошлет каждому серверу свой запрос, соберет результаты, объединит их и вернет пользователю.
Говоря о производительности OLAP Services, нельзя не упомянуть о так называемом $1 Million Challenge со стороны Oracle. Напомним, что 23 ноября 1998 года на выставке COMDEX Fall Ларри Эллисон объявил о том, что корпорация Oracle выплатит 1 миллион долларов тому, кто продемонстрирует возможность SQL Server 7.0 достичь хотя бы сотой доли производительности по сравнению с Oracle8i на запросе №5 из серии тестов TPC-D версии 1.3.1. Напомним также, что тесты независмой организации Transaction Processing Council (TPC) включают серии TPC-C для замеров OLTP-производительности и TPC-D, относщиеся к области OLAP-запросов. Microsoft SQL Server давно и прочно занимает первые места в тестах ТРС-С по удельной (из расчета на один узел) производительности, достигая ее при существенно меньшей, чем другие производители серверов баз данных, стоимости системы. В то же время, SQL Server 7.0, вышедший в декабре 1998 г., не планировалось тестировать на текущей (1.3.1) версии TPC-D тестов, поскольку срок ее действия истекал в феврале 1999 г. Пересмотр текущей версии TPC-D тестов был связан с тем, что она допускала использование так называемых материализованных представлений (materialized views). В отличие от обычного представления, хранящего только определение запроса, материализованное представление позволяет сохранять его результаты. Таким образом, в случае использования материализованных представлений, тесты измеряют не реальную производительность обработки запроса, а, по сути дела, скорость чтения заранее подготовленных результатов. Однако формально материализованные представления не запрещены в TPC-D версии 1.3.1, чем не замедлили воспользоваться некоторые поставщики СУБД, отрапортовав о новых рекордах "производительности", превосходящих предыдущие на несколько порядков величины.
Тем не менее, учитывая тот факт, что Oracle постарался придать своему вызову максимально широкую огласку (хотя вышеупомянутые детали тестов были опущены и условия пари несколько раз в одностороннем порядке пересматривались) и вопрос переместился из сугубо технической области в маркетинговую, 16 марта Microsoft опубликовала (http://www.microsoft.com/ presspass/features/1999/03-16sql.htm) результаты тестирования SQL Server на терабайтной базе данных с использованием того же аналитического запроса (Query Five). Всего было произведен 21 замер производительности, показавший результаты от 0.062 с до 1.532 с, что дало средний результат в 1.075 с. Это значительно превосходит первоначальный результат Oracle и сопоставимо с его последним результатом в 0.7 с. В процессе проведения испытаний использовалось программное обеспечение Microsoft SQL Server 7.0 Enterprise Edition, Microsoft OLAP Services for SQL Server и аппаратная платформа HP NetServer LXr8000 с 4-мя процессорами Pentium II Xeon 450MHz и 4 GB DRAM, а также дисковый массив HP NetRAID-3Si с 560 дисками. Общая стоимость системы составила $512 899 (для сравнения: стоимость системы на которой демонстрировался Oracle, превысила 10 млн.долл.) Материализованные представления в ходе тестов не применялись.
Борьба со взрывным ростом данных и разреженностью
Одной из извечных проблем хранилищ данных является борьба со взрывным ростом данных. Суть ее состоит в следующем. Как мы знаем из п.2, чтобы OLAP-запросы отрабатывались максимально быстро, нужно, чтобы все агрегаты были заранее посчитаны. Однако добавление в хранилище агрегатов ведет к быстрому разбуханию занимаемого им места на диске. Это легко показать. Возьмем для начала 3-мерный куб. Пусть количество детальных членов (т.е. членов, не имеющих потомков) по одному измерению равно n1, по другому n2, по третьему - n3. Тогда в кубе придется вычислить n1n2 + n2n3 + n3n1 агрегатов-столбиков, n1 + n2 + n3 агрегатов-плоскостей и 1 агрегат - это общая сумма по всему кубу. Ради простоты положим n1 = n2 = n3 = n, тогда полное количество агрегатов 1 + 3n + 3n2 = (n3 - 1) / (n - 1). Для очень большого n это приблизительно n2. Выкладки легко проделать для куба с m измерениями (максимальная размерность куба в OLAP Services составляет 64), мы получаем, что количество агрегатов возрастает в степени m-1. Если вычислять все агрегаты, то, во-первых, это может занять продолжительное время, во-вторых, размер хранилища будет расти как степень числа измерений. Если агрегатов не вычислять, то мы не получаем никакого выигрыша в быстродействии, и все преимущество OLAP сводится только к тому, что нам не надо самим писать громадных SQL-запросов, подобных тому, что был показан в п.1.
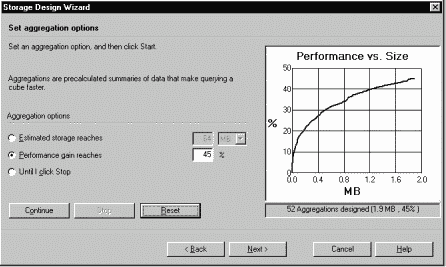
При определении структуры хранилища (Design Storage) Microsoft OLAP Services позволяют администратору произвести выбор между размером хранилища и количеством предвычисляемых агрегатов. Мы можем задать размер места на диске, которым готовы пожертвовать под объем хранилища и тогда Aggregation Wizard покажет нам количество агрегатов, которые будут вычислены, и какого повышения производительности при этом удастся достичь, либо, наоборот, от нас требуется ввести желаемый процент увеличения производительности (0% означает, что агрегаты отстутствуют, 100% - что будут вычисляться все возможные агрегаты) и тогда Aggregation Wizard произведет оценку дополнительного дискового пространства, которое для этого потребуется, и количества агрегатов. Сами агрегаты при этом не вычисляются (вычисление агрегатов происходит на этапе процессинга куба), так что оценка происходит очень быстро. Таким образом, для любого фрагмента нашего куба мы можем определить его структуру исходя из оптимального для нас критерия производительность / размер хранилища. Частичная предагрегация позволяет эффективно решить проблему взрывного роста данных. По известному правилу 20/80, характерному для степенных зависимостей, около 80% от максимально возможного числа агрегатов не оказывают существенного влияния на рост объема хранилища. Стадия взрывного роста, как правило, начинается на последних 20% агрегатов. Эвристический алгоритм в OLAP Services анализирует модель метаданных хранилища и определяет оптимальное множество агрегатов, вычисление которых даст максимальный выигрыш в производительности. Грубо говоря, это базовый набор агрегатов, от которых наиболее легко могут быть произведены остальные агрегаты, не вычисляемые на этапе наполнения хранилища. Когда в процессе обработки запроса требуется получить значение производного непредвычисленного агрегата, оно считается не путем сканирования детальных данных, а на основе базовых предвычисленных агрегатов.
Однако какой бы интеллектуальный алгоритм определения базового множества агрегатов ни использовался на стадии оценки структуры, он может опираться только на эвристику. Поэтому в дальнейшем для оптимизации хранилища под реальную работу с ним может применяться Usage-Based Optimization Wizard, который осуществляет тонкую настройку множества агрегатов с целью достижения максимальной производительности на типовых запросах, поступивших к выбранному кубу или его части в течение определенного периода времени. Usage-Based Optimization Wizard читает журнал транзакций за этот период времени и определяет агрегаты, вычисление которых могло бы ускорить выполнение данных запросов. В какой-то степени приницип его работы аналогичен Index Tuning Wizard в SQL Server 7.0. Администратор может ограничить список запросов в журнале, например, указав мастеру рассматривать только те из них, время ответы на которые заняло более n сек.
Как уже отмечалось выше, OLAP Services не хранит пустоты в кубах, решая таким образом проблему разреженности данных.
Процессинг куба
Одним из наиболее дорогостоящих по времени этапом является процессинг куба, во время которого происходит предвычисление тех агрегатов, которые были определены для этой цели на стадии проектирования структуры хранилища, а также (в случае MOLAP-формата) перенос детальных данных в куб из исходной реляционной базы. Этот процесс может быть оптимизирован следующими способами.
В качестве исходных реляционных данных, допускаются данные, хранящиеся на SQL Server, а также любые OLE DB-источники.
Запросы "что-если" и обратная запись
Поддержка запросов типа "что-если" и обратной записи (writeback) в куб связана с возможностью клиентских приложений обновлять данные в ячейках куба. Обе эти черты усиливают возможности OLAP Services как инструмента бизнес-анализа, позволяя аналитику получать ответы на условные запросы, например, "Что бы произошло с продажами в Центральном регионе за предыдущий месяц, если бы цены на продукт А были увеличены на 10%, а транспортные расходы снижены в 1.3 раза?" Запись значений в ячейки происходит через интерфейс OLE DB for OLAP (IMDRangeRowset) и должна быть защищена контекстом транзакции. До завершения транзакции все изменения кэшируются на клиенте и оказываются немедленно видны только в рамках текущей OLE DB-сессии. Случай отката транзакции (ITransaction::AbortTransaction) соответствует ситуации "что-если": изменили - посмотрели, что получается, - вернули все, как было. Фиксация транзакции соответствует обратной записи. При этом изменения могут быть внесены только в куб, помеченный как READ_WRITE, и только пользователем, обладающим правами на обновление куба. После фиксации (Commit) транзакции все остальные сессии получают возможность увидеть внесенные изменения. При этом поддерживается уровень изоляции read committed, т.е. остальные сессии не увидят изменения до тех пор, пока они все полностью не будут перенесены из клиентского кэша на сервер, что застраховывает от ситуации чтения частью новых, а частью старых (еще не успевших обновиться) данных. Перенос изменений из клиентского кэша на сервер происходит совершенно прозрачно для клиентского приложения. Не допускается обновление производных мер. Обновление членов измерения производится через интерфейсы DSO (Decision Support Objects).
Определяемые пользователем функции
OLAP Services поддерживает создание и использование определяемых пользователем функций (UDF). Функции принимают аргументы и возвращают значения в терминах синтаксиса MDX. Для их создания может привлекаться любое средство разработки, способное генерировать библиотеки ActiveX-объектов (Visual Basic, Visual C++ и т.п.)
PivotTable Service и клиентские приложения
Наряду с традиционным серверным кэшем Microsoft OLAP Services используют кэш на стороне клиента. Каждый клиент подключается к OLAP Services через PivotTable Service, который выступает в роли драйвера, осуществляющего диспетчеризацию соединения. PivotTable Service построен на определенной доле кода OLAP Services, работающих на сервере, и выполняет часть его функций (многомерные вычисления, управление запросами, интеллектуальный кэш) на стороне клиента. Предположим, пользователь последовательно запрашивает данные по продажам за январь, февраль и март этого года. Запросы выполняются, и данные оседают в кэше как на сервере, так и на клиенте. Предположим, далее, что пользователь запросил данные за 1-й квартал. Результат будет возвращен приложению немедленно без обращения к серверу, так как все необходимые данные уже имеются на клиенте. Если теперь пользователь захочет посмотреть, допустим, продажи за 1-й квартал этого года в сравнении с тем же периодом прошлого года, PivotTable Service пошлет на сервер запрос только о продажах за 1-й квартал прошлого года. Кроме того, этот механизм позволяет аналитику без труда сохранять части (where …) куба с сервера (например, продажи за прошлый год по Северо-Западному региону) как локальные кубы на клиенте, отсоединяться от сервера и продолжать работу на своем портативном компьютере, скажем, во время командировок. Простые OLAP-модели можно вообще создавать локально. Учитывая тот факт, что рабочее места аналитика на предприятии, как правило, представляет собой не самую слабую аппаратную конфигурацию в силу особенности решаемых им задач, подобный подход позволяет оптимизировать процесс вычислений, сняв часть нагрузки с OLAP-сервера, и понизить сетевой траффик. Сказанное не означает, грубо говоря, что кусок сервера переносится на клиента, который из-за этого тут же требует повышенной вычислительной мощности, иначе все "просядет". Я думаю, что 500 К памяти (не считая кэшированных данных) и 2 Мб места на диске, которые занимает PivotTable Service, на сегодня не являются чрезмерными требованиями к аппаратным ресурсам.
В качестве готового клиента к OLAP Services может использоваться MS Excel 2000, чей механизм сводных таблиц в новой версии прекрасно интегрирован для работы с хранилищами OLAP Services, включая операции погружения/свертки, фильтрации, построение отчетов и графиков, новые статистические функции, сохранение локальных кубов и т.д, что позволяет просматривать общую картину с любой степенью детализации в любом разрезе и служит удобным и мощным рабочим местом аналитика. Элементы управления Office Web Components, также входящие в новую версию MS Office, позволяют без особого труда реализовать сходную и расширенную функциональность в Web- и Win32-приложениях, разрабатываемых средствами Visual Basic, Visual C++, Visual J++ и других средств разработки в составе Visual Studio 6.0. Наконец, программные интерфейсы OLE DB for OLAP и ADO MD (ActiveX Data Objects MultiDimensional) предназначены для создания приложений для многомерного анализа под любые специфические потребности пользователей.