Оптимизация запросов в DB2 является одной из наиболее совершенной технологий в индустрии. Оптимизатор функционирует на базе модели оценки стоимости исполнения запроса. В оптимизаторе DB2 помимо размеров таблиц и доступных маршрутов исполнения учитываются еще и скорость процессора и скорость дисковых операций ввода/вывода, причем запросы, для которых возможна более эффективная обработка, полностью переписываются.
В состав DB2 UDB входит целый ряд средств, предназначенных для оптимизации использования памяти базой данных и гибкого управления буфер-пулами. Одно из таких средств, Global SQL Cache (глобальный кэш SQL), сохраняет в памяти как статический, так и динамический SQL, что дает возможность его повторного использования множеством пользователей. Это минимизирует доступы к каталогам для совместно используемых SQL запросов.
Множество расширений превращают DB2 Universal Database в решение с высокими показателями готовности, обеспечивающее круглосуточную работу приложений. Сюда входит поддержка кластеризации на широком спектре различных операционных систем для разделения и дублирования рабочей нагрузки, табличное пространство с фиксацией во времени (point-in-time tablespace), восстановление на уровне таблиц и быстрый перезапуск.
Использование параллелизма
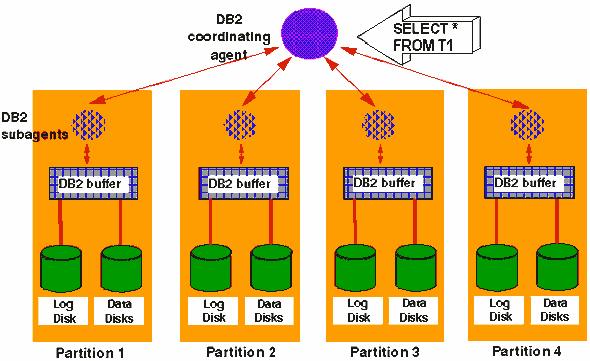
DB2 UDB хорошо поддерживает параллелизм SMP (симметричной многопроцессорности). Индивидуальные запросы прозрачно делятся и параллельно исполняются на множестве процессоров (так называемый "внутризапросный параллелизм"). Этот подход позволяет в полной мере использовать возможности систем SMP. Внутризапросный параллелизм ускоряет исполнение запросов на системах SMP, а также на кластерах узлов SMP. Утилита загрузки LOAD и операции резервного копирования и восстановления множества табличных пространств также могут исполняться параллельно.
Пользователи могут сами задавать необходимый уровень параллелизма или использовать параметры, которые установлены в DB2 по умолчанию и зависят от количества доступных процессоров. При создании индексов также можно пользоваться ресурсами множества процессоров, что значительно ускоряет работу и, в частности, процесс реорганизации, который требует переназначения индексов
Тесты уже показали DB2 UDB V5.2 как наиболее производительную и масштабируемую в компьютерной индустрии база данных для анализа данных и систем принятия решений.
Например, в стандартных тестах TPC-D, она занимает лидирующие позиции в категориях для баз объемом 1 терабайт, 300 гигабайт(GB), 100 GB на Windows NT и на 100GB баз данных для 4xSMP серверов.
Поддержка архитектуры Virtual Interconnect Architecture (VIA) позволил DB2 UDB EEE for NT продемонстрировать исполнение операций сложного анализа данных (data mining) на 200GB базе данных на 16-узловом кластере для NT. Никакая другая база данных не может поддерживать такую масштабируемость кластеров для Intel.
Внутризапросный параллелизм между узлами кластеров позволяет автоматически распараллелить исполнение запроса между процессорами каждого узла симметрично-многопроцессорного(SMP) кластера, значительно уменьшая время исполнения сложных запросов.
Назад | Содержание | Вперед