Николай Игнатович, IBM
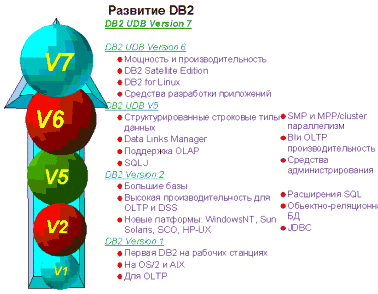
DB2 Universal Database (UDB) - это объектно-реляционная база данных IBM для операционных сред UNIX, OS/2 и Windows NT. Новая 7-я версия выходит в 2000 году и является продолжением успешного ряда предыдущих продуктов, DB2 Common Server V2.1 и DB2 Parallel Edition V1.2, DB2 Universal Database V5 и V6. Этот продукт, таким образом, создавался на солидной основе и объединил в себе проверенную заказчиками СУБД клиент/сервер и ведущие технологии IBM в сфере реляционных баз данных, функционирующих в критичных средах. Результатом явилась база данных с высочайшими показателями масштабируемости, расширяемости, простоты в использовании и управлении, которой можно доверить даже самые критичные приложения для баз данных.
DB2 Universal Database лучше всего можно описать с точки зрения ее ключевых характеристик:
Масштабируемость: Возможность работы на самом широком спектре аппаратного обеспечения от портативных компьютеров до серверов с массовым параллелизмом (MPP) - что позволяет наращивать систему по мере роста потребностей.
Расширяемость: Возможность поддержки мультимедийных и комплексных типов данных, а также простота настройки с соответствии с требованиями конкретных приложений.
Поддержка Web: Возможность обращаться к данным с помощью браузеров Web и использовать сетевые технологии, такие как Java, для работы в составе систем электронной коммерции и корпоративных сетей intranet.
Решения деловых партнеров: Широкий выбор инструментальных средств и приложений, позволяющих быстрее реализовать необходимые решения.
Деловые интеллектуальные системы: Возможность поддержки таких высокодоходных приложений, как хранилища данных, добыча данных, системы поддержки принятия решений и он-лайновой аналитической обработки OLAP.
Простота использования и управления: Простота использования и управления базой данных позволяет сократить затраты на поддержку и сроки обучения.
Доступ к данным и репликация: Возможность эффективного доступа к данным, которые могут быть расположены в любом месте сети, включая средства интеграции с данными, хранящимся на мейнфреймах и/или системах среднего уровня.
Открытость и поддержка множества платформ: Возможность простой интеграции базы данных с операционной средой за счет поддержки программных стандартов и различных аппаратных платформ.
Надежность, готовность и удобство обслуживания: Обеспечение работоспособности базы данных и доступности данных для поддержки наиболее критичных приложений по схеме 24x7 (24 часа в сутки, 7 дней в неделю).
Одним из главных преимуществ DB2 Universal Database является ее масштабируемость. Она может работать как на портативном компьютере, поддерживая мобильного пользователя, так и на машине с массовым параллелизмом, поддерживающей несколько терабайт данных и тысячи пользователей; кроме того, база данных, естественно, способна поддерживать различные конфигурации симметричных мультипроцессорных систем (SMP) и кластеров SMP. Важно отметить, что данная масштабируемость включает в себя одни и те объектно-реляционные функции как в старших, так и в младших версиях. Благодаря этому DB2 UDB идеально подходит для растущих малых и средних организаций; для крупных предприятий, которым необходимо развернуть двух- или трехуровневые приложения, охватывающие масштабы настольных систем, масштабы отделов и масштабы всего предприятия; а также для провайдеров услуг Internet и деловых партнеров, обслуживающих этих заказчиков. Вам вряд ли удастся перерасти DB2 UDB по мере расширения Ваших приложений и организации. Можно увеличивать количество данных, не жертвуя при этом производительностью обработки запросов, или просто добавить аппаратное обеспечение для ускорения обработки запросов.
Характеристики масштабируемости UDB можно разделить на следующие три основные группы функциональных возможностей:
В DB2 Universal Database параллельная обработка данных используется как для ускорения обработки транзакций (OLTP), так и для ускорения обработки запросов (OLAP, хранилища данных, добыча данных) - или для смешанных задач, включающих оба типа обработки. База данных поддерживает и параллельную обработку транзакций, и параллельную обработку запросов на всех основных архитектурах аппаратных средств, включая симметричные мультипроцессорные системы (SMP), кластеры и процессоры с массовым параллелизмом (MPP).
Параллельная обработка на SMP - на машине с SMP UDB будет автоматически выполнять несколько транзакций (операторов SQL) параллельно, распределяя их между несколькими процессорами. Кроме того, UDB может автоматически выполнить параллельную обработку одного запроса (оператора SQL), разбивая его на подзадачи и направляя каждую подзадачу на отдельный процессор. Более того, если данные для оператора SQL распределены на нескольких дисковых подсистемах, то для параллельного извлечения данных в UDB будут использоваться функции параллельного ввода/вывода.
Поддержка кластеров и систем с массовым параллелизмом MPP - База данных UDB может быть распределена на нескольких серверах в кластере или на нескольких узлах в системе с массовым параллелизмом. Несколько транзакций (операторов SQL) автоматически будут выполняться параллельно за счет распределения между несколькими узлами. Кроме того, UDB может автоматически выполнить параллельную обработку одного запроса (оператора SQL), разбивая его на подзадачи и направляя каждую подзадачу на отдельный узел. Основой эффективных средств параллельной обработки с использованием нескольких узлов является интеллектуальное разделение и параллельная оптимизация. UDB автоматически разделяет (распределяет) данные между несколькими узлами, причем оптимизатору известно местонахождение каждой строки и он может передавать обработку тому узлу, на котором находятся нужные данные - сокращая до минимума пересылку данных между узлами. Данная схема известна также как архитектура без коллективного использования и представляет собой самый лучший подход, гарантирующий масштабируемость с участием нескольких узлов, особенно когда работа ведется с очень крупными базами данных объемом сотни гигабайт или несколько терабайт.
Помимо расширенной параллельной обработки UDB поддерживает ряд других важных функций высокопроизводительной обработки данных, которые также значительно повышают производительность как обработки запросов, так и обработки транзакций. Благодаря этим и прочим функциональным возможностям DB2 UDB особенно хорошо подходит для работы со смешанными задачами. В числе этих высокопроизводительных характеристик следует отметить:
Поддержка 64-разрядной памяти: В настоящее время в системе дополнительно реализована поддержка очень больших объемов физической памяти (поддержка 64-разрядной памяти). В DB2 применяются 64-разрядные и 32-разрядные системы, позволяющие работать более чем с 4 Гбайт физической памяти. С помощью буферного пула в этой дополнительной памяти можно хранить используемые в настоящее время данные, благодаря чему значительно сокращается количество операций ввода/вывода и повышается производительность.
Несколько буферных пулов: Вы можете создать несколько буферных пулов различных размеров (по количеству страниц) и связать с ними табличные области, воспользовавшись оператором SQL CREATE BUFFERPOOL. Это предоставляет администратору более широкие возможности для управления доступностью данных в памяти. Например, рабочим таблицам транзакций можно выделить свой собственный буферный пул, благодаря чему можно будет избежать разовых запросов на выделение памяти. Этот механизм позволяет сохранить высокую производительность он-лайновой обработки транзакций (OLTP) при хорошем времени отклика системы на запросы конечных пользователей.
Асинхронная очистка страниц: Возможность переложить операции записи буферизованных страниц с задачи выполнения запроса SQL на другую задачу позволяет значительно улучшить время отклика системы на запросы. Задачи асинхронной очистки страниц обеспечивают наличие достаточного свободного пространства в буферах базы данных для обработки данных запроса. Эта функция позволяет избежать при обработке запроса ожидания синхронной записи модифицированных страниц из буфера на диск для освобождения места под данные запроса.
Последовательная упреждающая выборка: Производительность выполнения запросов, требующих большого количества последовательных операций ввода/вывода с диском, может быть значительно повышена в случае перекрытия во времени операций ввода/вывода и обработки в центральном процессоре. Данная возможность особенно полезна для обработки запросов.
Упреждающая выборка списка: Поддержка упреждающей выборки списка позволяет повысить производительность обработки запросов, обращающихся к данным случайным образом или не последовательно.
Расположение табличных областей на нескольких носителях: В UDB администраторы базы данных могут разделить базу данных на части, называемые табличными областями (tablespaces). При создании таблицы можно определить имена базовой (base), индексной (index) и длинной (long) табличной области. Использование индексных и длинных табличных областей позволяет хранить индексы и большие объекты LOB отдельно от остальных табличных данных. Благодаря такой гибкости повышается производительность и готовность базы данных. Табличные области могут охватывать одно или несколько физических запоминающих устройств, то есть располагаться на нескольких носителях.
Непосредственный доступ к носителям (работа с устройствами напрямую): UDB позволяет непосредственно работать с данными на устройстве, не тратя ресурсы на использование файловой системы, что повышает производительность базы данных и целостность данных. Администратор имеет возможность определить для табличной области режим непосредственной работы с устройством или использовать обычную файловую систему полностью совместимым с предыдущими версиями методом.
Чтение больших блоков: Данная функция позволяет считывать несколько дисковых страниц за одну операцию ввода/вывода, что сокращает нагрузку на центральный процессор и, соответственно, улучшает время отклика на запросы.
Утилита REORG: UDB включает в себя утилиту REORG, которая осуществляет переупорядочение строк по кластерам и устраняет фрагментацию, возникающую в результате обновлений и удалений. При этом значительно повышается производительность работы с таблицами, подвергающимися частым обновлениям. Кроме того, в комплект поставки входит утилита REORGCHK, позволяющая выявить те таблицы, которые следует реорганизовать.
Масштабируемость включает в себя гораздо больше, нежели чем просто ускорение обработки транзакций и запросов за счет параллельной обработки или других средств повышения производительности. Масштабируемыми должны быть также и обслуживающие операции, такие как загрузка данных, резервное копирование и восстановление, генерация индексов, чтобы эффективно осуществлять управление большими объемами данных.
Утилита высокоскоростной загрузки - DB2 UDB включает в себя высокоскоростную утилиту загрузки LOAD, с помощью которой можно значительно повысить скорость загрузки данных, обеспечив при этом их восстанавливаемость. Эта утилита может принимать данные в различных файловых форматах и непосредственно создавать страницы табличных областей, не затрачивая ресурсы на работу с контрольным журналом и обработку операторов SQL INSERT. Кроме того, с ее помощью можно создавать индексы и собирать статистические данные в процессе загрузки. Утилита LOAD может значительно сократить время, необходимое для обновления или добавления данных в хранилище данных.
Поддержка симметричных мультипроцессорных систем (SMP) утилитами - В DB2 UDB архитектура симметричных мультипроцессорных систем SMP задействуется не только при обработке транзакций и запросов, но и при работе с утилитами. Сюда входит:
Параллельная загрузка данных: Загрузка данных требует большое количество вычислительных ресурсов центрального процессора. При выполнении таких задач, как, например, синтаксический разбор и форматирование данных, утилита LOAD позволяет задействовать несколько процессоров. Кроме того, для параллельной записи данных в контейнеры утилита LOAD может использовать параллельные серверы ввода/вывода. При увеличении количества процессоров утилита LOAD демонстрирует линейную масштабируемость.
Параллельное создание индексов: При создании индексов в DB2 используются возможности параллельного ввода/вывода и параллельной работы центральных процессоров. Это помогает ускорить создание индексов при выполнении команды CREATE INDEX после перезапуска (когда индекс оказывается отмечен как недействительный) или при работе с утилитой REORG.
Параллельное резервное копирование и восстановление: Резервное копирование и восстановление данных требуют значительного объема операций ввода/вывода. При выполнении этих задач в DB2 используются возможности параллельного ввода/вывода и параллельной работы центральных процессоров. Преимущества нескольких процессоров реализуются в DB2 за счет распределения между процессорами операций манипулирования с буферами. Кроме того, возможно параллельное выполнение операций резервного копирования или восстановления с нескольких устройств (например, с накопителях на магнитной ленте).
Поддержка утилитами кластеров/систем с массовым параллелизмом (MPP) - При работе с утилитами в DB2 Universal Database также могут использоваться преимущества кластерных архитектур и архитектур с массовым параллелизмом. Сюда входит:
Параллельное разделение: Как отмечалось выше, основой для работы систем с массовым параллелизмом является интеллектуальное разделение. С помощью входящей в комплект поставки утилиты db2split данные можно разбить на разделы перед их загрузкой. После этого их можно загружать параллельно на нескольких узлах, что значительно сокращает общее время процесса загрузки.
Параллельная загрузка данных: После разделения данных утилиту LOAD можно запустить параллельно на всех узлах. Если каждый из узлов представляет собой симметричную мультипроцессорную систему SMP, то при выполнении задач синтаксического разбора и форматирования данных будут задействоваться возможности нескольких процессоров, а для параллельной записи данных в контейнеры будут использованы возможности параллельных серверов ввода/вывода.
Автозагрузчик: Новая структура управления упрощает процесс разделения и загрузки нескольких разделов таблицы.
Параллельное создание индексов: Команда создания индекса CREATE INDEX выполняется параллельно на всех узлах системы.
Параллельное резервное копирование и восстановление: Операции резервного копирования и восстановления могут выполняться параллельно на нескольких узлах. При выполнении этих задач в DB2 используются возможности параллельного ввода/вывода и параллельной работы центральных процессоров. Преимущества нескольких процессоров реализуются в DB2 за счет распределения между процессорами операций манипулирования с буферами.
Благодаря всем этим расширенным функциям параллельной обработки, средствам высокопроизводительной обработки и возможностям эффективной работы с крупными базами данных DB2 Universal Database является наиболее масштабируемой объектно-реляционной базой данных с поддержкой Web во всей отрасли. Если Вы начнете с небольшого сервера на основе NT, то позднее, когда потребуется большая емкость, Вы сможете легко обновить свое аппаратное обеспечение или переместить данные на более крупный сервер UNIX. Если создается крупное хранилище данных, то можно начать с одного узла и затем легко добавлять новые узлы для поддержки больших объемов данных, большего количества пользователей или для улучшения времени отклика. Независимо от того, насколько велики или малы сегодняшние потребности, Вы можете пребывать в твердой убежденности, что расширение Вашей организации не составит для Вас больших проблем.
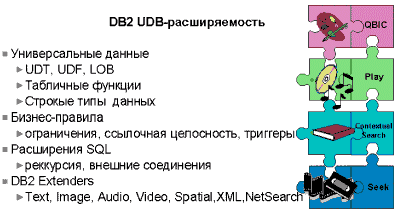
Одним из основных преимуществ базы данных DB2 Universal Database является ее расширяемость. Под расширяемостью мы подразумеваем возможность хранить и управлять не только традиционными реляционными таблицами с символами и числами, но и мультимедийными данными, комплексными объектами, такими как документы, изображения, аудио, видео, пространственные данные, временные ряды и т.д. Кроме того, сюда могут входить специализированные для конкретной отрасли объекты, такие как рентгеновские снимки, отпечатки пальцев, конструкторские чертежи, формы страховых исков и т.д. Основой для всего этого является так называемая объектно-реляционная технология. Объектно-реляционные возможности UDB позволяют добавлять к базе данных собственные типы данных и деловые функции - эффективно настраивая базу данных в соответствии с конкретными деловыми или прикладными требованиями. IBM первой реализовала такую возможность еще в 1995 году, в продукте DB2 Common Server версии 2. Реализация данной технологии в UDB является более продвинутой и более мощной по сравнению со всеми прочими "Универсальными серверами" на рынке И была подвергнута комплексным испытаниям в реальных условиях, которые подтвердили ее высокую надежность.
Характеристики расширяемости DB2 Universal Database можно разделить на следующие группы:
Универсальные данные
Деловые правила
Расширенный SQL
Расширения DB2 Extenders.
Все эти расширенные объектно-реляционные возможности открывают целый мир новых приложений - а также весьма продуктивный и эффективный способ создания этих приложений.
В базе данных DB2 Universal Database поддерживаются следующие ключевые объектно-реляционные возможности (все они реализованы в соответствии со стандартами SQL3 и поэтому представляют собой открытый, а не какой-нибудь внутрикорпоративный подход):
Определяемые пользователем типы данных (UDT) - с их помощью пользователи могут создавать новые типы данных, которые будут представлены в базе данных с использованием встроенных типов. Например, пользователь может определить два типа данных для валют: CDOLLAR для канадских долларов и USDOLLAR для долларов США. Оба этих типа будут различаться в том смысле, что их невозможно будет непосредственно сравнивать друг с другом или с десятичным (decimal) типом, хотя именно десятичный тип может быть выбран для внутреннего представления этих двух типов данных в DB2. Определяемые пользователем типы данных, как и встроенные типы, могут использоваться в качестве столбцов таблиц или параметров функций, включая определяемые пользователем функции User-Defined Functions (UDF). Например, пользователь может определить тип данных ANGLE (угол - значения которого могут находиться в пределах от 1 до 360) и создать собственные функции для работы с этим типом, такие как SINE (вычисление синуса), COSINE (вычисление косинуса) и TANGENT (вычисление тангенса).
Определяемые пользователем функции (UDF) - с их помощью в запросы можно включать мощные вычислительные предикаты и предикаты поиска для фильтрации ненужных данных непосредственно у их источника. Благодаря UDF пользователи могут создать наборы функций для работы с пользовательскими типами UDT, определив таким образом семантику этих типов. Поддержка UDF позволяет создавать библиотеки функций, причем их разработкой может заниматься IBM, сторонние поставщики или сами заказчики, и затем встраивать их непосредственно в базу данных. Оптимизатор SQL учитывает семантику и стоимость исполнения пользовательских функций UDF, что позволяет ему работать с этими функциями абсолютно аналогично встроенным функциям, таким как SUBSTR и LENGTH. Разработку приложений можно вести в различных средах, таких как C, C++, COBOL и FORTRAN, обеспечивая при этом коллективное использование набора пользовательских типов UDT и пользовательских функций UDF с помощью SQL.
Большие объекты (LOB) - с помощью больших объектов LOB пользователи могут хранить в базе данных очень крупные двоичные или текстовые объекты (размером в несколько гигабайт). Двоичные большие объекты можно использовать для хранения мультимедийных данных, таких как документы, видео, изображения и речь. Кроме того, большие объекты можно использовать для хранения небольших структур, семантика которых задана с помощью пользовательских типов UDT и пользовательских функций UDF. Для больших объектов LOB имеется мощный набор встроенных функций для выполнения поиска, выделения подстроки и конкатенации. С помощью UDF в любое время можно определить дополнительные функции. Таблица может содержать несколько столбцов с большими объектами LOB.
Определяемые пользователем табличные функции (Table UDF) - пользователи SQL могут теперь обращаться к данным, хранящимся не в реляционном формате, и при этом в полной мере использовать все возможности построения запросов реляционной базы данных. Часто бывает очень трудно, если не невозможно, включить данные из нереляционных источников в реляционную обработку. Определяемые пользователем табличные функции представляют собой расширение SQL, позволяющее разрешить эту проблему. Табличная функция представляет собой внешнюю определяемую пользователем функцию, которая создает производную таблицу. Программа этой функции может включать в себя обращение к данным из различных источников и преобразование их в табличную форму, возвращаемую этой табличной функцией. После создания табличной функции ее можно использовать в операторах FROM запросов. Табличные функции могут применяться не только для включения внешних данных в обработку с помощью мощных средств SQL, но и для постоянного ввода внешних данных в реляционные таблицы.
Определяемые пользователем функции OLE (OLE UDF) - технология OLE (Object Linking and Embedding - связывание и внедрение объектов) входит в архитектуру Microsoft для платформ Windows. DB2 предоставляет поддержку контроллера OLE для доступа к данным сервера OLE с помощью определяемых пользователем функций UDF. С помощью этих внешних функций UDF данные из серверов OLE могут передаваться через DB2 в запросы SQL.
С помощью деловых правил можно определить комплексные правила для целостности данных, обеспечивающие корректность данных в базе данных. Эти правила дополнительно расширяют прочие объектно-ориентированные функции. С их помощью можно расширить существующие только в виде кода объектные библиотеки (методы которых изменить невозможно) для поддержки дополнительных атрибутов объектов и проверки ограничений. Ключевые возможности деловых правил включают в себя:
Значения по умолчанию - позволяют устанавливать значения по умолчанию для тех строк, которым в операторах INSERT непосредственных значений не присваивается.
Проверка ограничений - проверка ограничений обычно используется для реализации деловых правил, которые невозможно реализовать с помощью ограничений на уникальность ключей или ссылочной целостности. Например, пользователь может определить ограничение на таблицу данных о служащих EMPLOYEE, чтобы должность работника могла принимать только одно из значений 'Sales', 'Mgr' или 'Clerk' и чтобы заработная плата работника, проработавшего в компании более 8 лет, составляла бы более 40 000 долларов.
Ссылочная целостность - ссылочная целостность позволяет устанавливать необходимые взаимосвязи между таблицами и внутри таблиц. Ссылочные ограничения объявляются при создании таблицы и обеспечивают согласованность значений данных между связанными столбцами различных таблиц. DB2 автоматически будет поддерживать эти взаимосвязи, так что разработчикам не придется программировать эти функции в приложении.
Триггеры - триггеры можно использовать для реализации комплексных межтабличных деловых правил, автоматической генерации значений для новой добавленной строки, считывания данных из других таблиц в целях ссылочной целостности, записи в другие таблицы в целях генерации контрольного журнала и/или реализации функции уведомления за счет создания триггера, запускающего определяемую пользователем функцию (например, отправки сообщения электронной почты). Например, пользователь может создать триггер, который будет увеличивать на единицу количество пользователей при каждом добавлении строки в таблицу служащих EMPLOYEE.
Расширенные запросы SQL позволяют включать в один непроцедурный оператор большой объем операций по обработке данных. В качестве примеров можно привести:
Рекурсивные запросы SQL: Изменения в оптимизаторе SQL позволяют поддерживать в базах данных сервера DB2 не только запросы по ведомости материалов, но и более мощные формы рекурсивных запросов, связанных с расчетами по формулам маршрута. Благодаря поддержке рекурсии становятся возможны, например, следующие запросы:
Запросы по ведомости материалов, когда пользователь желает узнать все составные компоненты какой-либо детали, все составные компоненты этих компонентов и т.д.
Запросы с расчетами по формулам маршрута, когда пользователь желает определить самый выгодный с точки зрения тарифов маршрут перелета с несколькими пересадками. С помощью рекурсивного SQL может быть, к примеру, сформулирован следующий запрос: определить все возможные варианты перелета из Торонто в Перт без пересадок в Лондоне или Чикаго и не более чем с тремя пересадками.
Оптимизатор позволяет произвести с рекурсивными и нерекурсивными запросами достаточно сложные преобразования и упрощения, обеспечивая выбор самых оптимальных способов доступа к данным в целях повышения производительности.
Поддержка внешних операций соединения: На основе стандартного синтаксиса SQL92 теперь поддерживаются операции соединения слева, справа и полностью внешние соединения - то есть такие операции соединения, результаты которых включают в себя не только соответствующие критериям строки, но и не соответствующие критериям строки. Операции внешнего соединения, которые ранее были реализованы только в DB2 Parallel Edition, теперь расширены и реализованы во всех версиях баз данных DB2 Universal Database. В новой реализации устранено ограничение на полностью внешние операции соединения и ограничение на максимум 31 таблицу, которые присутствовали в DB2 Parallel Edition.
Расширения DB2 Extenders строятся на основе объектно-реляционной инфраструктуры DB2. Каждое расширение представляет собой набор предопределенных пользовательских типов UDT, пользовательских функций UDF, триггеров, ограничений и хранимых процедур, решающих задачи определенной прикладной области. С помощью расширений пользователи могут хранить в таблицах DB2 текстовые документы, изображения, видео и аудио ролики путем добавления столбцов с новыми типами данных, определенными в расширении. Собственно данные могут храниться как внутри таблицы, так и вне ее во внешних файлах. Кроме того, эти новые типы данных имеют атрибуты, описывающие различные аспекты их внутренней структуры, такие как, например, "язык" и "формат" для текстовых данных. Каждое расширение включает в себя необходимые функции для создания, обновления, удаления и поиска данных с новыми типами, определенными в расширении. Пользователи могут включать эти новые типы данных и функции в операторы SQL, обеспечивая интегрированный поиск по содержимому для всех типов данных.
В состав версий для разработчиков входят несколько расширений DB2, к которым добавляются новые.
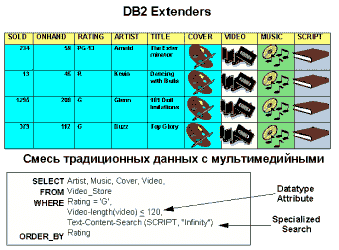
Текстовое расширение DB2 Text Extender: Текстовое расширение Text Extender позволяет использовать в запросах SQL мощные средства полнотекстового поиска, доступные благодаря поддержке в DB2 возможности хранить в базах данных неструктурированные текстовые документы объемом до 2 Гбайт. Расширение Text Extender предоставляет пользователям DB2 и разработчикам приложений быстрый, гибкий и интеллектуальный метод поиска в таких документах. Преимущество текстового расширения заключается в высокой скорости поиска среди многих тысяч больших текстовых документов, причем поиск производится не только непосредственно по критериям запроса, но и по различным формам слова и его синонимам. Расширение позволяет производить поиск не только в документах, сохраненных в базах данных DB2, но и в документах, записанных в обычных файлах.
Текстовое расширение Text Extender может работать с различными типами текстовых документов, включая документы текстовых процессоров в их родных форматах, и предлагает широкий спектр различных критериев поиска, таких как по слову, по фразе, с помощью символов шаблона и по близко расположенным словам, позволяя объединять различные критерии операциями булевой логики ("и/или").
В основе текстового расширения Text Extender положено высокопроизводительное, самое современное ядро поиска IBM. С его помощью приложения могут получать доступ к текстовым документами и извлекать их многими различными способами. В приложениях можно:
Осуществлять поиск документов, содержащих определенный текст, синонимы слова или фразы или несколько искомых слов поблизости друг от друга (например, в одном предложении или абзаце).
Осуществлять поиск по символам шаблона, используя маски для начала, середины или конца слова, а также маски для отдельных символов.
Производить поиск документов на различных языках и в различных форматах.
Осуществлять поиск по методу нечеткой логики тех слов, которые имеют сходные с заданным термином написание. Данная функция особенно полезна при поиске тех слов, в написании которых пользователь не уверен.
Производить поиск, формулируя критерии поиска на естественном языке.
Осуществлять поиск по именам людей, названиям мест или наименованиям организаций.
Производить поиск слов, произношение которых сходно с критерием поиска.
Функции текстового поиска можно интегрировать в запросы к деловым данным. Например, в приложении можно сформулировать запрос SQL, который будет осуществлять поиск текстовых документов, созданных определенным автором в течение указанного интервала дат и содержащих определенное слово или фразу. Благодаря программному интерфейсу текстового расширения Text Extender Вы можете также предоставить пользователям своих приложений возможность просматривать документы. При интеграции функций полнотекстового поиска в запросы выбора SELECT Вы получите мощное средство извлечения нужных документов, сочетающее в себе поиск по атрибутам и полнотекстовый поиск.
Расширение для работы с изображениями DB2 Image Extender: В расширении для работы с изображениями DB2 Image Extender для изображений определяются новые типы данных и функции, что возможно благодаря встроенной в DB2 UDB поддержке определяемых пользователем типов и определяемых пользователем функций. Кроме того, в этом расширении используется реализованная в DB2 UDB поддержка больших объектов объемом до 2 Гбайт и триггеры, позволяющие автоматически сохранять и работать с атрибутами изображений.
С помощью расширения для работы с изображениями DB2 Image Extender пользователи могут:
Импортировать и экспортировать изображения и атрибуты изображений в/из базы данных. При импортировании изображения расширение DB2 Image Extender сохраняет и позволяет работать с такими атрибутами изображения, как объем в байтах, формат, высота, ширина и количество цветов.
Управлять доступом к изображениям с тем же уровнем защиты, что и для традиционных деловых данных.
Преобразовывать форматы изображений. При импортировании или экспортировании можно либо сохранять исходный формат изображения, либо преобразовывать его в любой другой. Пользователю доступны и другие способы преобразования изображений, такие как вращение или масштабирование.
Защищать и восстанавливать изображения. Для изображений и их атрибутов, хранящихся в базе данных DB2, предоставляются те же функции защиты и восстановления, что и для традиционных деловых данных.
Осуществлять запросы к изображениям на основе связанных с ними деловых данных или на основе атрибутов изображений. Поиск изображений может осуществляться либо по указываемым пользователем данным, таким как название изображения, его номер или описание, либо по данным, сохраняемым расширением DB2 Image Extender, таким как формат изображения или распределение цветов.
Генерировать и отображать уменьшенные копии и сами изображения целиком. Уменьшенная копия (thumbnail) представляет собой миниатюрный вариант изображения. При импортировании изображения в базу данных расширение DB2 Image Extender создает и сохраняет в базе и его уменьшенную версию. С помощью DB2 Image Extender пользователь может извлечь как уменьшенную копию, так и полноразмерное изображение. После этого DB2 Image Extender может быть использован для запуска любимой программы просмотра для отображения уменьшенного или полноразмерного изображения.
Расширение для работы с изображениями DB2 Image Extender поддерживает широкий спектр различных форматов изображений, включая GIF (в том числе GIF с анимацией), JPEG, BMP и TIFF.
Расширение для работы с аудио DB2 Audio Extender: В расширении для работы с аудио DB2 Audio Extender для аудиофрагментов определяются новый тип данных и функции, что возможно благодаря встроенной в DB2 UDB поддержке определяемых пользователем типов и определяемых пользователем функций. Кроме того, в этом расширении используется реализованная в DB2 UDB поддержка больших объектов объемом до 2 Гбайт и триггеры, позволяющие автоматически сохранять и работать с атрибутами аудиозаписей.
С помощью расширения для работы с аудио DB2 Audio Extender пользователи могут:
Импортировать и экспортировать аудиоклипы и их атрибуты в/из базы данных. При импортировании аудиоклипа расширение DB2 Audio Extender сохраняет и позволяет работать с такими атрибутами аудиозаписи, как количество аудиоканалов, время звучания и скорость выборки.
Защищать и восстанавливать аудиоданные. Для аудиоклипов и их атрибутов, хранящихся в базе данных DB2, предоставляются те же функции защиты и восстановления, что и для традиционных деловых данных.
Осуществлять запросы к аудиоклипам на основе связанных с ними деловых данных или на основе атрибутов аудиозаписей. Поиск аудиоклипов может осуществляться либо по указываемым пользователем данным, таким как название аудиофрагмента, его номер или описание, либо по данным, сохраняемым расширением DB2 Audio Extender, таким как формат аудиозаписи или дата и время последнего обновления.
Проигрывать аудиоклипы. Расширение DB2 Audio Extender может быть использовано для извлечения аудиоклипа. После этого с помощью того же расширения DB2 Audio Extender пользователь может запустить свою любимую программу проигрывания для прослушивания аудиозаписи.
Расширение для работы с аудио DB2 Audio Extender поддерживает широкий спектр различных форматов аудио, такие как WAVE, MIDI, MPEG1 и AU, а также может работать с различными аудиосерверами, в которых аудиоклипы хранятся в виде файлов.
Расширение для работы с видео DB2 Video Extender: В расширении для работы с видео DB2 Video Extender для видеофрагментов определяются новый тип данных и функции, что возможно благодаря встроенной в DB2 UDB поддержке определяемых пользователем типов и определяемых пользователем функций. Кроме того, в этом расширении используется реализованная в DB2 UDB поддержка больших объектов объемом до 2 Гбайт и триггеры, позволяющие автоматически сохранять и работать с атрибутами видеозаписей.
С помощью расширения для работы с видео DB2 Video Extender пользователи могут:
Импортировать и экспортировать видеоклипы и их атрибуты в/из базы данных. При импортировании видеоклипа расширение DB2 Video Extender сохраняет и позволяет работать с такими атрибутами видеозаписи, как частота кадров, формат сжатия и количество видеодорожек.
Защищать и восстанавливать видеоданные. Для видеоклипов и их атрибутов, хранящихся в базе данных DB2, предоставляются те же функции защиты и восстановления, что и для традиционных деловых данных.
Осуществлять запросы к видеоклипам на основе связанных с ними деловых данных или на основе атрибутов видеозаписей. Поиск видеоклипов может осуществляться либо по указываемым пользователем данным, таким как название видеофрагмента, его номер или описание, либо по данным, сохраняемым расширением DB2 Video Extender, таким как формат видеозаписи или дата и время последнего обновления.
Создавать архивные записи. С помощью расширения DB2 Video Extender пользователь может автоматически разбить видеоклип на участки на основе изменения места действия. Изменение места действия определяется как точка в видеоклипе, где имеется существенное различие между соседними кадрами. При обнаружении изменения места действия DB2 Video Extender записывает данные для соответствующего фрагмента, включая репрезентативные кадры. Это позволяет легко создавать краткие изложения видеозаписей, которые называются архивными записями (storyboard).
Проигрывать видеоклипы. Расширение DB2 Video Extender может быть использовано для извлечения видеоклипа. После этого с помощью того же расширения DB2 Video Extender пользователь может запустить свою любимую программу просмотра видео для проигрывания видеозаписи.
Расширение для работы с видео DB2 Video Extender поддерживает широкий спектр различных форматов видеофайлов, такие как MPEG1, MPEG2, AVI и QuickTime, а также может работать с различными видеосерверами, в которых видеоклипы хранятся в виде файлов.
Благодаря поддержке в DB2 Universal Database универсальных данных, деловых правил, расширенного SQL, а также мультимедийных объектов и методов эту базу данных можно назвать одной из самых расширяемых объектно-реляционных баз данных в отрасли. Основными отличительными особенностями применяемой в DB2 технологии расширения является ее полное соответствие стандартам SQL и встроенная поддержка со стороны модуля оптимизатора. Благодаря этому реализация расширений оказывается более открытой и обеспечивает более высокую производительность по сравнению с другими реализациями.
Заказчикам необходима возможность предоставить доступ к данным, хранящимся в системах DB2, собственным служащим и выборочно своим поставщикам и клиентам через приложения для частных (intranet) и общедоступных (Internet) сетей. DB2 Universal Database полностью интегрирована с Web-технологиями, что позволяет легко предоставить доступ к данным через Internet или intranet, обеспечив при этом полную их защиту. Поддержка Web в приложениях для баз данных может быть реализована с помощью следующих входящих в комплект поставки компонентов UDB:
Net.Data - шлюз к базам данных для сервера Web
Поддержка Java в DB2
Web-сервер IBM HTTP Server.
Сервер Java-приложений WebSphere
В комплект поставки серверов входит копия продукта Net.Data, инструментального средства поддержки Web для реализации интерактивных приложений для связи баз данных с Web. Net.Data представляет собой стратегический продукт IBM, предназначенный для реализации доступа к реляционным базам данных через Internet/intranet на различных платформах. Он обеспечивает открытый доступ к данным DB2 и других источников данных, включая Oracle, Sybase и прочие ODBC-серверы. С помощью Net.Data приложения могут использовать DB2 для построения динамических страниц Web, необходимых для поддержки приложений электронной коммерции. Net.Data работает под OS/2, Linux, AIX, HP-UX, Windows NT, Solaris и SCO-UNIX.
Net.Data предоставляет надежные, высокопроизводительные функции разработки приложений и средства использования существующей деловой логики с помощью открытых прикладных интерфейсов. В Net.Data тесно интегрированы интерфейсы прикладного программирования серверов Web, включая серверы IBM, Lotus, Netscape и Microsoft, что обеспечивает более высокую производительность по сравнению с приложениями, в которых используется интерфейс CGI (common gateway interface).
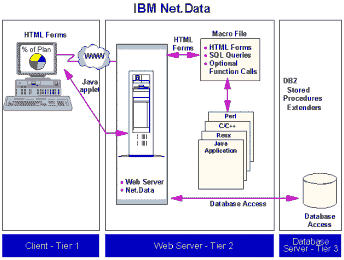
В целях достижения оптимальной производительности Net.Data предоставляет средства управления соединениями для основных реляционных баз данных. Net.Data позволяет устанавливать постоянные соединения с определенными базами данных. Данные соединения поддерживаются Net.Data для всех приложений Web и для всех вызовов приложений Web. Благодаря постоянному соединению с базой данных в приложениях не требуется терять время на повторяющиеся подключения к ней. Результатом этого является максимальная производительность интерактивного приложения для Web.
Приложения Net.Data представляют собой макросы на мощном макроязыке, включающем в себя конструкции замены переменных, условной логики и вызовов дополнительных функций. Net.Data поддерживает обработку на стороне клиента с помощью апплетов Java и Javascript. Для обработки на стороне сервера могут использоваться приложения Java и REXX, приложения Perl и C/C++.
Приложения на Java очень привлекательны для тех заказчиков, которым требуется разработать единое приложение, работающее на любой операционной системе, при минимальных затратах на разработку и поддержку этого приложения.
В DB2 поддерживается интерфейсы для доступа к базам данных из приложений на Java - Java Database Connectivity (JDBC) и SQLJ. В DB2 предоставляется поддержка родного Java на клиентских рабочих станциях и серверах DB2. Поддержка Java на клиентских рабочих станциях осуществляется двумя способами:
Для связи с сервером DB2 приложение Java использует продукт DB2 Client Application Enabler, который должен быть установлен на клиентской рабочей станции. С его помощью заказчики со сложившейся инфраструктурой клиент/сервер DB2 могут использовать Java в качестве средства разработки приложений для баз данных.
С помощью апплетов Java разрабатываемые приложения могут обращаться к серверам DB2, не требуя установки кода DB2 Client Application Enabler на клиентские рабочие станции. Апплеты Java могут автоматически загружаться на клиентские рабочие станции в момент вызова приложения.
Поддержка Java на серверах DB2 позволяет создавать на основе Java определяемые пользователем функции и хранимые процедуры.
Доступ к DB2 UDB через Web невозможно реализовать без сервера Web (иначе называемого сервером HTTP). Именно поэтому в комплект поставки серверов DB2 UDB входит Web-сервер IBM HTTP Server. IBM HTTP Server представляет собой масштабируемый высокопроизводительный сервер Web, созданный на основе известного Apache и работающий на широком спектре различных платформ. В нем реализованы самые современные средства защиты данных, функции индексирования сайтов и расширенные средства составления отчетов по серверной статистике.
Net.Data, поддержка Java и включение в комплект поставки Web-сервера IBM HTTP Server превращают DB2 Universal Database в наиболее полное решение среди всех баз данных с поддержкой Web, имеющихся сегодня на рынке. UDB включает в себя все необходимое для реализации системы электронной коммерции или корпоративной intranet.
Чтобы реализовать решение по управлению данными, отвечающее меняющимся потребностям бизнеса, потребуется мощная реляционная база данных и тщательно подобранные приложения, работающие с ней.
В тесном партнерстве с IBM разработкой решений в области планирования производственных ресурсов (enterprise resource planning, ERP) занимаются такие ведущие поставщики программного обеспечения, как Baan, Dassault, SAP, MEDSTAT, J.D. Edwards и PeopleSoft. Их решения предоставляют все функциональные возможности, которые могут потребоваться. Все эти первоклассные разработчики программного обеспечения уже осознали, что DB2 Universal Database обладает всеми показателями производительности, надежности и гибкости, необходимыми для удовлетворения требований современных операционных и деловых приложений.
Под деловыми интеллектуальными системами (Business Intelligence, BI) IBM понимает такие приложения, как хранилища данных, системы добычи данных, системы он-лайновой аналитической обработки (on-line analytical process, OLAP) и системы поддержки принятия решений. Многие заказчики ищут способы добычи данных и анализа своей операционной информации в целях получения преимуществ перед конкурентами. В настоящее время данное направление является одним из наиболее приоритетных в сфере технологий управления данными, так как подобные системы характеризуются очень высокой доходностью инвестиций.
Основная роль DB2 UDB в деловых интеллектуальных системах заключается в хранении данных. Однако, в таких приложениях чаще всего требуется нечто большее, нежели чем обычная база данных. С точки зрения внутренней обработки для таких приложений требуются инструментальные средства для доступа и извлечения данных из операционных источников, преобразования их в удобный формат с последующим распределением и загрузкой в хранилище данных. С точки зрения интерфейсной обработки необходимы инструментальные средства для поиска нужных данных и моделирования их в удобном для анализе виде, а также для обработки запросов и анализа данных. В случае добычи данных на основе отыскивания взаимосвязей для поиска закономерностей и взаимосвязей между данными требуются расширенные алгоритмы. IBM поставляет множество вспомогательных продуктов и услуг в классе деловых интеллектуальных систем, которые удовлетворяют всем этим требованиям и используют преимущества баз данных DB2. В IBM Intelligent Miner применяются самые современные алгоритмы добычи данных, позволяющие обнаружить важные закономерности и взаимосвязи в данных, так что пользователям не придется отыскивать их самим.
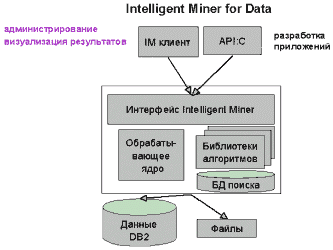
IBM и Hiperion Software выпускают сервер он-лайновой аналитической обработки DB2 OLAP Server, в котором объединенысредства многомерного анализа Essbase и реляционное ядро DB2.
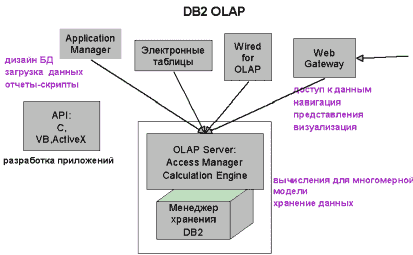
Несколько факторов превращают DB2 UDB в превосходное хранилище данных для приложений в классе деловых интеллектуальных систем:
Во-первых, эти приложения обычно оперируют большими объемами данных (от 50 до 300 Гбайт), которые иногда называют очень большими базами данных (very large databases, VLDB). UDB отвечает всем этим требованиям благодаря превосходной масштабируемости, включая расширенные средства параллельной обработки запросов и операций с очень большими базами данных.
Во-вторых, запросы к базам данных в этих приложениях бывают очень сложными. В UDB реализован наиболее мощный оптимизатор запросов в отрасли, обеспечивающий высочайшую производительность обработки запросов при минимальных затратах времени администратора для его настройки.
Наконец, в DB2 UDB реализован ряд новых функциональных возможностей, специально разработанных для поддержки он-лайновой аналитической обработки (OLAP).
Значительные усовершенствования в оптимизаторе SQL укрепили лидирующее положение DB2 с точки зрения оптимизации запросов для традиционных приложений, а также позволили распространить эти мощные функции на новые прикладные области, поддерживаемые описанными выше объектно-ориентированными расширениями. Новая технология оптимизации обеспечивает все функциональные возможности и производительность, необходимые заказчикам для анализа и использования огромных объемов ценной информации, хранящейся в базах данных.
Постоянно растущая роль приложений для поддержки принятия решений свидетельствует о важной тенденции, для которой характерно усложнение запросов к базам данных. Эти запросы могут формулироваться конечными пользователями, генерироваться автоматическими инструментальными средствами и получаться как результат различных прикладных интерфейсов по типу "укажи и щелкни мышью", широко распространенных сегодня в операционных средах DOS, Windows, OS/2 и UNIX.
Оптимизатор включает в себя очень сложный алгоритм переписывания запроса, с помощью которого сложный запрос автоматически преобразуется в более простой, который легче оптимизировать. В результате для конечного пользователя обеспечивается самая высокая возможная производительность вне зависимости от того, каким образом структурирован запрос.
Кроме того, при поиске наилучшего варианта исполнения запроса оптимизатор рассматривает большее количество альтернативных путей, а также использует более сложные методики моделирования стоимости выборки нужных данных с диска. Все эти методики приводят в результате к повышению на порядок производительности обработки сложных запросов по сравнению с существующей технологией оптимизации запросов SQL.
Для хранилищ данных и приложений он-лайновой аналитической обработки (OLAP) характерно использование специальной методики моделирования реляционных данных для нужд многомерного анализа (multidimensional analysis, MDA), называемой звездообразной схемой. В этой схеме очень часто требуется соединение крупной таблицы "фактов" с несколькими "размерными" таблицами с помощью очень сложного запроса SQL на соединение (JOIN). Любые методы оптимизации, которые пригодны для повышения производительности этих операций соединения, позволяют значительно повысить производительность всего приложения. В DB2 Universal Database для решения этой задачи вводятся два новых метода оптимизации:
Выполнение операции "И" над индексами с использованием динамических битовых отображений: Для эффективного объединения нескольких индексов в UDB используется технология динамических битовых отображений. При этом повышается производительность обработки запросов, в которых используются столбцы, являющиеся ключевыми для различных индексов одной и той же таблицы. Сюда входит использование индексов для выполнения многопозиционных операций соединения.
Звездообразные соединения: Для соединения большой таблицы фактов с несколькими относительно небольшими размерными таблицами в DB2 применяется новый алгоритм звездообразных соединений, использующий динамические битовые отображения в целях сокращения до минимума операций ввода/вывода данных.
Для приложений он-лайновой аналитической обработки (OLAP) и многомерного анализа (MDA) также характерны запросы, включающие в себя сложные группировки и агрегации данных. В DB2 UDB оператор GROUP BY расширен для поддержки "супергрупп". Одним из типов подобных супергрупп является группа ROLLUP, представляющая собой результирующее множество, которое включает в себя помимо обычных сгруппированных строк еще и строки "промежуточной суммы" и "общей суммы". Еще одним из типов супергрупп является группа CUBE, представляющая собой результирующее множество, которое включает в себя помимо всех строк, которые вошли бы в группу ROLLUP для тех же столбцов еще и "межтабличные" строки. Агрегация данных с помощью групп ROLLUP и CUBE особенно полезна в приложениях поддержки принятия решений (он-лайновой аналитической обработки), в которых производится многомерная агрегация базовых данных и агрегация в различных сворачивающихся/разворачивающихся иерархических структурах. Наиболее распространенным примером использования этого является трехмерный анализ данных, например, анализ продаж по продуктам, по магазинам и по месяцам.
Благодаря масштабируемости и высокой производительности параллельной обработки запросов DB2 Universal Database, расширенным средствам оптимизации запросов и уникальной поддержке функций он-лайновой аналитической обработки эта база данных является лучшим вариантом для любых приложений в классе деловых интеллектуальных систем.
DB2 Universal Database является одной из самых простых в использовании и управлении в данной отрасли. Она включает в себя полный набор графических инструментальных средств, удовлетворяющих всем потребностям:
Администраторов баз данных (Database Administrators, DBA) и прикладных программистов;
кроме того, в нее входят инструментальные средства, помогающие выполнять настройку клиентов, выполнять разовые запросы и составлять отчеты для конечных пользователей.
Центр управления Control Center - Центр управления Control Center был значительно усовершенствован в целях еще большего упрощения. Администратору базы данных DB2 UDB предоставляются все инструментальные средства, необходимые для установки, управления, мониторинга и настройки базы данных. Из единой точки управления Вы можете управлять как отдельной базой данных DB2 UDB (включая многоузловые базы данных DB2 Universal Database Enterprise - Extended Edition for AIX, версия 7.0), так и несколькими удаленными базами данных DB2 UDB. Помимо управления экземплярами баз данных, базами данных и табличными областями в Control Center предусмотрены также функции для схем, таблиц, видов, индексов, пользователей, групп пользователей, определяемых пользователем типов, определяемых пользователем функций, триггеров, дисков, для групп узлов DB2 Universal Database Enterprise - Extended Edition, для информации о разделах и хранимых процедур. Кроме того встроенный планировщик (Scheduler), позволяющий автоматически выполнять нужные задания в указанное время или с указанной периодичностью.
В центре управления Control Center реализована поддержка для настройки и работы системы репликации данных, которая позволяет регистрировать источники репликации и определять системы, на которые производится репликация. Репликация данных между базами данных входит в базовый набор функций DB2.
Функции отслеживания производительности позволяют на ранних этапах получать предупреждения о потенциальных проблемах или автоматически предпринимать меры для устранения этих проблем без вмешательства человека.
Наконец, в Control Center были добавлены "мастера" SmartGuides, обеспечивающие пошаговое выполнение различных задач. В комплект поставки входят "мастера" для настройки производительности базы данных, для конфигурирования базы данных, для создания/восстановления/резервного копирования базы данных, для создания табличной области и для создания таблицы.
Центр управления Control Center реализован на языке Java и может работать на различных платформах.
Корпоративный центр управления DB2 Enterprise Control Center for TME 10 (TM) (DB2 ECC) представляет собой отдельный программный продукт, который расширяет возможности центра управления DB2 UDB Control Center функциями управления крупномасштабными системами в инфраструктуре управления Tivoli. DB2 ECC может работать совместно с DB2 Control Center, обеспечивая широкий спектр функций управления: от согласованного управления большими группами баз данных DB2 UDB до управления на низком уровне отдельной базой данных DB2 UDB.
Командный центр Command Center - Командный центр Command Center, предоставляет интерактивное окно, позволяющее выполнять для баз данных DB2 различные задачи, такие как выполнение операторов SQL, команд DB2 и команд операционной системы и просмотр результатов выполнения одного или нескольких операторов SQL и команд DB2 в окне результата.
Версии DB2 для разработчиков - В DB2 Personal Developer's Edition и DB2 Universal Developer's Edition программистам предоставляется среда разработки, позволяющая создавать приложения для баз данных, обращающиеся к данным и управляющие данными в реляционных СУБД IBM. В версии DB2 для разработчиков входят инструментальные средства, документация и примеры исходного кода для разработки приложений на платформах рабочих станций, поддерживаемых серверами DB2 Universal Database. DB2 Personal Developer's Edition включает в себя все необходимое для разработки приложений на платформах Linux,OS/2 и Windows, включая наборы инструментальных средств разработчика (Software Developer's Kit, SDK). DB2 Universal Developer's Edition включает в себя все необходимое для разработки приложений на всех платформах, а также поддержку сетевого взаимодействия, Net.Data, WebSphere, HTTP Server и дополнительные SDK для всех поддерживаемых платформ.
VisualAge for Java Professional Edition: В комплект поставки версий для разработчиков входит также лицензионная копия VisualAge for Java Professional Edition. С помощью программной среды VisualAge for Java Вы можете создавать 100% Java-приложения, апплеты и компоненты JavaBean, способные работать на любой совместимой с Java виртуальной машине, под Java Development Kit или на базе любого браузера с поддержкой JDK .
Client Configuration Assistant и Auto-Discovery - С помощью этих средств значительно упрощена задача соединения клиента с базами данных на серверах. Многие из действий, которые необходимо было выполнить на клиенте и сервере, теперь автоматизированы. На стороне сервера DB2 автоматически обнаруживает протоколы, запущенные на рабочей станции. Вы выбираете подходящий протокол и даете DB2 команду на конфигурирование сервера и клиента. На стороне клиента стало гораздо проще устанавливать соединения с новой базой данных. Вы можете дать команду DB2 на автоматическое обнаружение доступных баз данных DB2 Universal Database, после чего остается только выбрать нужную базу данных из списка и дать команду на конфигурирование соединения. При этом будут полезны следующие интерфейсы:
Server Communications Configuration: С помощью опции Setup Communications центра управления Control Center Вы можете сконфигурировать серверный экземпляр DB2 и обновить настройки коммуникационных протоколов для поддержки соединений с серверными базами данных со стороны удаленных клиентов. Используя центр управления Control Center, с помощью интерфейса Server Communications Configuration Вы можете конфигурировать серверы DB2.
Client Configuration Assistant: Данный вспомогательный инструмент позволяет по шагам выполнить все действия, необходимые для конфигурирования и управления клиентом DB2, причем одновременно многие необходимые операции выполняются автоматически, скрытно от пользователя. После конфигурирования соединения с базой данных либо автоматически (путем поиска в сети или выбора профиля доступа), либо вручную с этой базой данных можно выполнять и другие действия.
Инструментальные средства администрирования баз данных, инструментальные средства разработки приложений и пользовательские инструментальные средства, входящие в DB2 Universal Database, позволяют очень легко произвести настройку системы и приступить к работе, а также легко осуществлять управление в процессе работы.
DB2 Universal Database представляет собой распределенную, полностью сетевую реляционную СУБД. Она обеспечивает гибкость размещения данных в любом месте сети, что необходимо для достижения оптимальных показателей обслуживания и продуктивности, а также предоставляет эффективные средства клиентского доступа к данным по сети. Более того, DB2 обеспечивает наиболее эффективную и безупречную интеграцию с данными на мейнфреймах и серверах данных среднего уровня во всей отрасли, что позволяет сократить затраты и повысить оборачиваемость средств, вложенных в данные, в аппаратное и программное обеспечение, а также в квалифицированные кадры.
Средства поддержки распределенных данных в DB2 UDB можно разделить на следующие 3 категории:
DB2 UDB предоставляет целый ряд функций, обеспечивающих эффективный доступ через сеть к серверам баз данных UDB с клиентских рабочих станций:
Хранимые процедуры: Клиенты DB2 могут вызывать хранимые процедуры, которые исполняются на сервере DB2. Благодаря хранимым процедурам обработка может быть переложена с клиента на сервер - что обеспечивает поддержку "тонких" клиентов. Кроме того, благодаря им значительно сокращается сетевой трафик и, соответственно, улучшается время отклика. Хранимые процедуры UDB в некотором роде уникальны, так как для их написания не требуется использовать какой-либо внутренний специальный язык - их можно писать на Basic, Java, C, C++ и т.д. В целях повышения эффективности эти процедуры могут возвращать несколько строк или несколько результирующих множеств.
Составной SQL: В клиентских приложениях DB2 несколько операторов SQL могут быть объединены в один составной оператор, который передается по сети и исполняется на сервере как один оператор. Это позволяет снизить объем сетевого трафика и получить значительный выигрыш в случае многочисленных вставок, обновлений или удалений, выполняемых по сети.
Блокировка строк: DB2 UDB позволяет снизить объем передаваемых по сети данных за счет буферизации строк как на стороне клиента, так и на стороне сервера. Размеры буферов являются настраиваемыми параметрами.
2-фазный протокол исполнения: Клиенты DB2 могут обращаться и производить обновление на нескольких серверах UDB за одну транзакцию (единицу работы). В серверах UDB имеются встроенные мониторы транзакций, которые фиксируют в контрольном журнале фазы транзакции и обеспечивают откат к предыдущему состоянию в случае сбоев. Процесс 2-фазного исполнения координируется клиентом.
Компонента DataPropagator Relational входит в состав DB2 Universal Database. Его функциональные возможности основаны на современной технологии фиксирования изменений. Этот продукт обеспечивает очень эффективный способ автоматической поддержки согласованных копий реляционных данных в семействе баз данных DB2, не требуя запуска отдельных окон пакетной обработки и явных знаний деловых приложений или внесения изменений в них.
Встроенная в DB2 Universal Database поддержка репликации обладает рядом существенных преимуществ по сравнению с предшествующим продуктом IBM DataPropagator Relational версии 1.2.1.
Более простое и интуитивно понятное администрирование: Средства администрирования системы репликации встроены в центр управления Control Center и поддерживают множество простых в использовании функций, обеспечивая управление из единой точки всей инфраструктурой репликации DB2. Эти функции поддерживаются на платформах OS/2, Windows NT или Windows 95 и не требуют локальной установки базы данных DB2.
Обслуживаемые множества для поддержки последовательности транзакций: С помощью обслуживаемых множеств обновления во всех связанных таблицах производятся за одну единицу работы, обеспечивая выполнение требований по ссылочной целостности.
Репликация с повсеместным обновлением: Мощные средства репликации с повсеместным обновлением поддерживаются строгими функциями обнаружения конфликтов и автоматической компенсационной правкой для нового поколения распределенных приложений.
Репликация по требованию для подключающихся время от времени и мобильных систем: Благодаря поддержке репликации по требованию, автоматическому подключению и отключению, а также сокращению до минимума времени соединения мобильные или подключающиеся время от времени системы с DB2 Universal Database Personal Edition на платформах OS/2, Windows NT или Windows 95 могут в полной мере и с высокой эффективностью участвовать в процедурах репликации по сценариям "только для чтения" и "с повсеместным обновлением".
Распространение данных на основе событий: Данный простой механизм позволяет управлять временем, когда будет выполняться распространение данных (например, в конце рабочего дня или после выполнения определенного пакетного задания), или ограничивать объем данных, участвующих в распространении (например, только данные, обновление которых произошло до 18:00).
Многим заказчикам требуется распределение данных между реляционными базами данных от различных поставщиков или на различных аппаратных платформах. Для решения этой задачи IBM разработала архитектуру распределенных реляционных баз данных Distributed Relational Database Architecture (DRDA). Эта архитектура стала стандартом де-факто для интеграции баз данных клиент/сервер и клиентских инструментальных средств с базами данных на мейнфреймах и системах среднего уровня в операционных средах OS/390, MVS, VSE, VM и OS/400. С помощью архитектуры DRDA в DB2 UDB обеспечивается наиболее полная и эффективная во всей отрасли интеграция данных с этими платформами.
Функциональные возможности DRDA можно разделить на 2 основных подмножества - функции клиента или реквестера и функции сервера:
Реквестер DRDA Application Requester (DRDA-AR): С его помощью клиентские рабочие станции DB2 могут прозрачно обращаться к данным в базах данных DB2 for OS/390, DB2 for MVS, DB2 for OS/400 и/или DB2 for VSE & VM. Реквестер DRDA-AR поставляется вместе с DB2 Connect или встраивается в DB2 UDB EE и EEE.
Сервер DRDA Application Server (DRDA-AS): Данный компонент обеспечивает возможность доступа к данным, хранящимся в DB2 Universal Database, для других реквестеров DRDA-AR. В частности, с его помощью приложения DB2 for MVS, DB2 for VSE & VM (SQL/DS) и DB2/400 (а также любые другие приложения, реализующие функциональные возможности реквестера DRDA) могут обращаться к данным, хранящимся в базах данных сервера UDB. Таким образом, с данными в базах данных DB2 UDB могут работать тысячи существующих приложений для баз данных на платформах MVS, VM и OS/400. Сервер DRDA-AS входит в состав DB2 UDB WE, EE и EEE.
Благодаря поддержке в DB2 Universal Database доступа к данным по схеме клиент/сервер, функциям репликации данных и интеграции с данными на хостах с помощью DRDA обеспечивается возможность гибкого размещения данных в любом месте сети, что необходимо для достижения оптимальных показателей обслуживания и продуктивности. Кроме того, DB2 Universal Database предоставляет эффективные средства доступа к данным по сети и интеграции с данными на мейнфреймах и системах среднего уровня, что позволяет сократить затраты и уменьшить время цикла.
К базам данных DB2 Universal Database можно получить доступ практически с любого клиента с помощью всех основных сетей. Кроме того, DB2 Universal Database поддерживает большинство отраслевых стандартов, что позволяет работать с системой, используя тысячи существующих инструментальных средств и приложений.
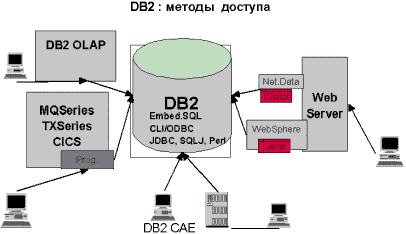
Серверы DB2 Universal Database и шлюзы DB2 Connect могут работать на следующих платформах:
AIX, Linux, HP-UX, OS/2, Solaris, Windows NT, Windows 2000.
Вместе с версиями для разработчиков DB2 поставляются наборы инструментальных средств Software Developer's Kits, обеспечивающие возможность разработки приложений с использованием внедренного SQL (SQL92E и SQL3) и интерфейса DB2 Call Level Interface (X/Open CLI), а также интерфейсы API для администрирования DB2 и документация, необходимые для разработки приложений DB2 ODBC и JDBC. Вместе с DB2 Personal Developer's Edition и DB2 Universal Developer's Edition поставляются предварительные компиляторы, предназначенные для разработки приложений с внедренным SQL на языках программирования C, C++, COBOL и FORTRAN. Кроме того, DB2 поддерживает через динамический интерпретатор язык REXX и язык Java.
Спецификации ODBC 3.0 - Интерфейс уровня вызовов DB2 Call Level Interface (DB2 CLI) был обновлен и включает в себя драйвер уровня 1, отвечающий последним спецификациям Microsoft (R) ODBC 3.0
Программирование на Java - DB2 позволяет разрабатывать приложения и апплеты, получающие доступ и манипулирующие данными в базах данных DB2. . Данная поддержка обеспечивается в DB2 с помощью драйверов DB2 JDBC, поставляемых вместе с DB2. Интерфейс прикладного программирования JDBC представляет собой стандартный способ доступа к базам данных из кода на Java. В коде Java операторы SQL передаются драйверу DB2 JDBC как аргументы функции.
Кроме того, Вы можете использовать язык программирования Java для разработки определяемых пользователем функций и хранимых процедур для исполнения на сервере.
Дополнительные открытые стандарты, поддерживаемые DB2, включают в себя:
Благодаря широкому выбору серверных и клиентских платформ DB2 UDB, а также поддержке открытых интерфейсов прикладного программирования и стандартов сетевой обработки данных Вы можете легко интегрировать DB2 в существующую среду обработки данных.
База данных с самым широким в мире спектром функциональных возможностей будет практически бесполезной для критичных приложений, если она не будет обеспечивать надежную защиту целостности данных и их постоянную доступность. Более того, так как ошибки и сбои неизбежны, большое значение имеют функции обнаружения, диагностики и быстрого устранения проблем. IBM занимается разработкой программного обеспечения для работы в критичных областях уже несколько десятилетий. IBM известно, как создавать и поставлять надежный" код и как быстро устранять проблемы в случае их проявления. DB2 Universal Database продолжает традиции своих продуктов-предшественников и обеспечивает в среде клиент/сервер показатели надежности, готовности и удобства обслуживания на уровне мейнфреймов.
Целостность данных является основополагающей задачей любой системы управления базами данных. При любом коллективном использовании данных существует необходимость в управлении и контролировании операций с ними, чтобы обеспечить точность значений в различных таблицах базы данных. В DB2 целостность данных обеспечивается с помощью:
Деловых правил и управления транзакциями
Управления конкурентным доступом к данным
Резервного копирования и восстановления с повторением обработки.
DB2 поддерживает как блокировку на уровне таблиц, так и блокировку на уровне строк. Блокировка на уровне строк обеспечивает большую избирательность и улучшенную поддержку параллельной обработки. Если в базу данных необходимо внести большой объем изменений, то Вы можете избежать конфликтов, заблокировав всю таблицу оператором LOCK TABLE до момента, пока вся транзакция не будет совершена или отменена с откатом к предыдущему состоянию. Блокировка на уровне таблиц и блокировка на уровне строк представляют собой два поддерживаемых метода блокировки.
Если две или более транзакции ожидают освобождения данных, заблокированных друг другом, то такая тупиковая ситуация называется взаимоблокировкой. Для обнаружения ситуаций взаимоблокировок в фоновом режиме периодически запускается детектор взаимоблокировок, проверяющий состояние всех блокировок в системе. В случае обнаружения такой ситуации детектор выбирает одну из транзакций, послуживших причиной взаимоблокировки, и приостанавливает ее. Для данной транзакции производится откат к предыдущему состоянию, а остальные транзакции могут продолжить работу. Периодичность активизации детектора взаимоблокировок определяется параметром в файле конфигурации базы данных.
Кроме того, можно воспользоваться функцией тайм-аута блокировок. Если блокировка не освобождается по истечении указанного в конфигурационном параметре интервала, то для ожидающего приложения объявляется тайм-аут, и пользователю или приложению возвращается код ошибки.
Резервное копирование и восстановление с повторением обработки - В случае потери он-лайновых данных из-за неисправности носителя (например, сбоя жесткого диска) средства резервного копирования и восстановления с повторением обработки позволят восстановить их, применив информацию об операциях из контрольного журнала к восстановленной с резервной копии базе данных. Контрольные журналы содержат информацию о всех изменениях, внесенных в базу данных с момента последнего резервного копирования. После применения информации из этих журналов база данных возвращается к тому же состоянию, которое было до сбоя. В целях повышения показателей готовности резервное копирование и восстановление может производиться на уровне табличных областей, или, в случае расположения базы данных на нескольких узлах, на уровне узла.
Для защиты от ошибок, вызванных приложениями, UDB поддерживает восстановление до определенного момента времени. Такое восстановление может производиться как на уровне базы данных, так и на уровне табличной области.
Все чаще и чаще, главным образом благодаря глобальному характеру нашей экономики, критичные приложения требуют готовности по схеме 24х7 (24 часа в сутки 7 дней в неделю). DB2 Universal Database обладает рядом характеристик, позволяющих удовлетворить требования данного стандарта:
Отказоустойчивость: Возможность перевода рабочей нагрузки с отказавшего сервера на другой связана с выполнением ряда операций, которые не могут контролироваться базой данных (например, сетевые соединения); в связи с этим в целях обеспечения отказоустойчивости в UDB поддерживаются различные средства на уровне операционной системы, такие как HACMP для AIX, кластеры Sun Solaris и Wolfpack для NT.
Резервное копирование и восстановление разделов базы данных: Администраторы могут выполнять резервное копирование и восстановление на уровне отдельных табличных областей, а не на уровне всей базы данных. Если табличная область содержит единственную таблицу, то резервное копирование и восстановление этой табличной области эквивалентно резервному копированию и восстановлению на уровне таблицы. В базах данных DB2 UDB ЕЕЕ, распределенных на нескольких узлах, резервное копирование и восстановление может осуществляться также на уровне узла.
Резервное копирование и восстановление в режиме он-лайн: В процессе резервного копирования табличные области могут находиться как в активном (он-лайн) режиме, так и в пассивном (отключенном) режиме. Во время восстановления все табличные области, за исключением восстанавливаемой, остаются в режиме он-лайн. В случае ошибки ввода/вывода (отказа диска, например) отключенными оказываются только затронутые табличные области (в ожидании восстановления). Вся оставшаяся часть базы данных остается в работоспособном состоянии.
Динамическое выделение памяти: Администраторы могут расширять размеры табличных областей, добавляя новые запоминающие устройства или блоки памяти без остановки работы базы данных. Данные в табличных областях автоматически перегруппируются в целях достижения оптимальной производительности. Кроме того, администраторы могут гибко управлять размещением данных. Например, данные, индексы и большие объекты LOB, принадлежащие одной и той же таблице, могут быть распределены по различным табличным областям в целях достижения максимальной производительности и в соответствии с другими операционными факторами.
Если проблема действительно проявляется, то очень важно быстро обнаружить источник проблемы, диагностировать ее причину и затем устранить ее. В DB2 UDB имеется ряд инструментальных средств и функций, помогающих справиться с этой задачей:

DB2 Universal Database распространяется в нескольких пакетах. Необходимо заметить, что в состав каждого пакета входят компакт-диски для различных платформ. Вы можете по своему усмотрению работать с базой данных на Linux, AIX, HP-UX, OS/2, Solaris или Windows NT; а также в любое время сменить платформу в рамках той же лицензии.
DB2 Universal Database Personal Edition (UDB PE): Эта однопользовательская полнофункциональная реляционная СУБД . Она предназначена для мобильных пользователей и приложений и поддерживает средства мобильной репликации.
DB2 Universal Database Workgroup Edition (UDB WE): Эта полнофункциональная реляционная СУБД клиент/сервер с поддержкой Web предназначена для серверов Intel, в том числе для симметричных мультипроцессорных систем с числом процессоров до четырех. Она представляет собой недорогое решение начального уровня, предназначенное главным образом для небольших организаций и отделов.
DB2 Universal Database Enterprise Edition (UDB EE): Данная полнофункциональная реляционная СУБД с поддержкой Web предназначена для самых различных платформ: от серверов Intel до крупных симметричных мультипроцессорных серверов UNIX. Данное исполнение подходит для средних и крупных организаций и отделов, особенно если для них важны средства взаимодействия с Internet и/или корпоративными системами.
DB2 Universal Database Enterprise - Extended Edition (UDB EEE): Данная полнофункциональная, полностью сетевая и полностью параллельная реляционная СУБД предназначена для кластерных серверов и/или серверов с массовым параллелизмом.
DB2 Connect Personal Edition (CPE): Данный продукт обеспечивает непосредственный доступ с настольных систем к данным, хранящимся в базах данных мейнфреймов и систем AS/400, используя протокол DRDA.
DB2 Connect Enterprise Edition (CEE): Данный многопользовательский шлюз обеспечивает прозрачный клиентский доступ к базам данных мейнфреймов и AS/400 с помощью протокола DRDA. Он предназначен для тех заказчиков, которые хотят объединить весь доступ к хосту с помощью сервера-шлюза. Физически шлюз может располагаться как вне сети, так и в центре обработки данных.
DB2 Universal Developer's Edition (UDE): Данный продукт включает в себя все инструментальные средства, необходимые программисту для разработки сетевых приложений DB2 (клиент/сервер или на основе Web). Он включает в себя все наборы инструментальных средств разработчика (SDK) для всех платформ. В комплект входит VisualAge Professional for Java.