Система программирования тройного
стандарта (3С++)
В.Сухомлин, Научно-исследовательский Вычислительный центр
МГУ им.
М.В.Ломоносова.
1. Введение
В настоящее время одним из перспективных и экономически оправданных подходов к развитию
информационной индустрии является создание информационных технологий (ИТ) и реализующих
их систем (ИТ-систем) на принципах открытости. Основными свойствам открытых систем
являются переносимость (программ, данных, пользовательских окружений), интероперабельность
(сетевая взаимосвязь и совместное использование ресурсов и данных компонентами
распределенных систем), масштабируемость (эффективность функционирования в широких
диапазонах характеристик производительности и ресурсов). Достижимость этих качеств возможна
лишь на основе высокого уровня стандартизованности интерфейсов ИТ-систем и поддерживающих
их платформ.
В настоящее время в обеспечение этого подхода создан мощный методический базис, включающий
в качестве концептуальной основы (метауровень) эталонные модели важнейших разделов области
ИТ (в первую очередь модели: OSI - для сетевого взаимодействия, ODP - для открытой
распределенной обработки, POSIX - для окружений открытых систем, DM - для управления
данными, CG - для компьютерной графики), а также обширный набор стандартов или базовых
спецификаций, регламентирующих процесс создания ИТ-систем или их компонент на принципах
открытости. Также в последние годы создан эффективный и гибкий инструмент комплексирования
ИТ - (функциональное) профилирование ИТ, значительно продвинуто решение проблемы
аттестации реализаций ИТ (ИТ-систем) на соответствие исходным спецификациям. Огромное
значение для технологии создания открытых ИТ-систем приобрела разработка единой таксономии
ИТ.
При всем кажущемся благополучии в области построения открытых ИТ-систем узким местом
остается, казалось бы давно решенная проблема, - стандартизация языков программирования и их
библиотечных окружений, составляющих основную часть прикладного интерфейса (в
терминологии международных стандартов - интерфейса на границе прикладной платформы и
прикладной программы или API).
В эру объектно-ориентированных технологий основным инструментальным языком построения
открытых ИТ-систем становится язык Си++. С целью обеспечения высокого уровня переносимости
программ, поддержки объектно-ориентированной технологии проектирования ИТ-систем,
бесшовной интеграции языков программирования с языками баз данных следующего поколения, в
настоящее время в рамках ИСО (подкомитет 22) осуществляется интенсивная работа по развитию
и стандартизации базового языка объектно-ориентированного программирования Си++, а также
набора объектно-ориентированных шаблонных библиотек. Данную работу планируется
завершить в 1998 г. (срок окончания работ неоднократно переносился). В настоящее время
опорными точками процесса формирования стандарта данного языка являются соответствующие
проекты стандарта, издаваемые указанным выше комитетом с периодичностью две-три версии в
год.
Следует отметить, что создание ведущими фирмами-разработчиками компиляторов,
соответствующих текущим проектам стандарта, значительно отстает от темпов развития языка и
его библиотечного окружения. Аттестация компиляторов ведущих фирм-поставщиков (таких как
Borland, Symantec, Microsoft) показывает наличие в них большого количества ошибок и
отклонений от стандарта. По существу, каждая из фирм, реализуя собственные диалекты языка,
включает нестандартные конструкции и возможности, не поддерживаемые другими фирмами-
разработчиками компиляторов.
Помимо некачественности зарубежных компиляторов, несоответствия их стандартным
спецификациям, в последнее время наблюдается тенденция значительного повышения цен на
компиляторы, особенно заметное для пользователей, работающих на более мощных, чем обычные
персональные компьютеры, системах - рабочих станциях. Помимо материальных потерь, которые
несет Россия ежегодно на массовых покупках этого вида продукта, большая опасность
монополизации данного рынка малым числом зарубежных фирм представляется, в частности, для
организаций, ответственных за решение задач, имеющих стратегическое значение. Зависимость от
зарубежных поставщиков, невозможность переноса их компиляторов на оригинальные
отечественные образцы вычислительной техники, делает неконкурентными отечественные
разработки, отрицательно сказывается на уровне технологий, в частности, кросс-технологий,
применяемых при создании многих технических систем. Таким образом, отсутствие качественных
отечественных компиляторов, соответствующих стандартному определению языка Си++,
оснащенных стандартным набором шаблонных библиотек, и предусматривающих переносимость
их и/или адаптацию на широкий спектр машинных архитектур в значительной степени сдерживает
развитие отечественной вычислительной техники и прикладных технологий, делает их
неконкурентноспособными на международном рынке.
В то же время отечественная школа разработчиков компиляторов богата своими традициями.
Сильными школами специалистов в этой области славились: ИПМ, ИТМиВТ, ВЦАН, НФ
ИТМиВТ, ЛГУ, РГУ, МГУ и др. Поэтому возрождение этих традиций, создание
высококачественных отечественных компиляторов, представляется важной стратегической задачей
в области ИТ.
Представляемый проект нацелен на разработку перспективной методологии систем
программирования тройного стандарта, оригинальных методов и алгоритмов построения
переносимой и адаптируемой к машинным архитектурам системы программирования тройного
стандарта (ТСС++) для объектно-ориентированного языка Си++, реализующей стандарт языка
Си++, полный набор стандартных шаблонных библиотек, технологический аттестационный
комплекс для проверки на соответствие стандарту компилятора системы и его версий. Таким
образом, система ТСС++ обеспечит высокий уровень переносимости (на уровне исходного текста)
создаваемого программного обеспечения открытых систем.
Основные задачи проекта можно сформулировать следующим образом:
- Разработать концепцию создания и сопровождения систем
программирования тройного стандарта, обеспечивающих реализацию
стандарта входного языка и стандарта его библиотечного окружения, а также
содержащих аппарат аттестации систем программирования на соответствие их
языковому стандарту. Данный аппарат обеспечивает устойчивость систем
тройного стандарта в условиях развития стандарта языка.
- Исследовать и разработать высокоэффективные алгоритмы и структуры
данных для реализации на их основе переносимого компилятора объектно-
ориентированного языка Си++ (с адаптируемой кодогенерацией),
соответствующего полному стандарту языка. Создать базовый компилятор
объектно-ориентированного языка Си++, соответствующего стандарту языка,
удовлетворяющий требованию параметризации кодогенерации для настройки
его на широкий спектр машинных архитектур, а также требованию
переносимости компилятора (на уровне исходного текста) на различные
платформы;
- Исследовать и разработать высокоэффективные алгоритмы и структуры
данных для реализации на их основе объектно-ориентированных шаблонных
библиотек, входящих в стандартное описание языка Си++. Создать полный
набор объектно-ориентированных шаблонных библиотек, входящих в
стандартное описание языка Си++.
- Исследовать и разработать методы, высокоэффективные алгоритмы и
структуры данных, вспомогательные инструментальные средства для
реализации на их основе пакета программ для аттестации компиляторов языка
Си++ на их соответствие стандарту. Создать пакет программ для аттестации
компиляторов языка Си++ на их соответствие стандарту.
В настоящее время в НИВЦ МГУ завершается реализация действующего прототипа компилятора
языка Си++ для операционных сред SunOS и Solaris. Входной язык компилятора соответствует
последней к настоящему времени версии проекта стандарта от 28 мая 1996 г. Благодаря
оригинальным структурным решениям и алгоритмам созданный компилятор обладает
производственными характеристиками, сравнимыми с имеющимися на этой платформе
зарубежными компиляторами.
Кроме этого, разворачивается работа по реализации некоторых компонент Стандартной
Библиотеки Си++. Предполагается переносимость реализации
Наконец, проведена разработка первой версии пакета программ для аттестации компилятора на
соответствие исходному описанию. Реализация пакета основывалась на оригинальном подходе и
методах, разработанных сотрудниками НИВЦ МГУ, и подтвердила практичность предложенных
методов аттестации компиляторов. Созданная тестовая система обеспечила достаточно полное
покрытие языкового многообразия и позволила как протестировать разрабатываемый
компилятор, так и выявить многочисленные ошибки в существующих компиляторах.
2. Компилятор Си++
Важнейшей задачей при разработке компилятора с языка программирования Си++, предпринятой
в рамках проекта системы программирования тройного стандарта, являлось обеспечение
максимально полного соответствия его входного языка стандартному определению Си++.
Понятно, что эта задача является весьма и весьма тяжелой. Невозможно обеспечить полную
синхронизацию процесса разработки с независимо идущим процессом стандартизации, который
протекает весьма интенсивно (новые версии проекта стандарта появляются примерно один раз в
квартал) и сопровождается постоянными модификациями как синтаксиса, так и семантики
языка.
К сожалению, появление очередной версии стандарта не сопровождается указателем изменений по
отношению к предыдущей версии, поэтому контроль соответствия компилятора последней версии
превращается в отдельную весьма трудоемкую задачу, которая в весьма незначительной степени
может быть автоматизирована (например, путем использования процессоров сравнения
текстов).
В качестве примера радикального изменения языка можно привести главу 14 проекта стандарта
(Шаблоны). Первые версии определяли сравнительно простые средства параметризации периода
компиляции (правда, описание содержало большое количество неясных мест), которые допускали
простую модель реализации, основанную на "отложенной компиляции". Однако, в 1995 году
указанная глава подверглась кардинальной ревизии (ее объем увеличился в несколько раз) с
существенным расширением возможностей и усложнением синтаксиса и семантики. В основном это
было обусловлено стремлением поддержать возможности, заложенные в Стандартной Библиотеке
Шаблонов (Standard Template Library) Александра Степанова [2], которая в качестве составной
части вошла в проект стандарта. "Новые шаблоны" не допускали отложенную компиляцию, явно
требуя полного синтаксического и семантического контроля непосредственно в месте описания
шаблонов. Это привело не только к перепроектированию соответствующих компонент
компилятора, но затронуло очень многие, формально не связанные с шаблонами, его модули.
Можно сказать, что многие алгоритмы трансляции пришлось параметризовать, научив их
"понимать" те или иные случаи вхождения шаблонных конструкций. Подчеркнем, что это
относится к давно разработанным и протестированным фрагментам компилятора.
Компилятор в целом можно рассматривать как композицию следующих процессоров, каждый из
которых реализован в виде независимой программы:
- Препроцессор Си++;
- Компилятор переднего плана Си++ (front-end compiler);
- Генератор объектного кода.
Построение компилятора в виде отдельных подсистем достаточно традиционно (в частности, в
среде UNIX). Помимо очевидного выигрыша по времени при одновременной разработке трех
компонент, а также упрощения тестирования и отладки, указанная структура обеспечивает более
легкую перенастраиваемость системы в целом, позволяя, например путем добавления новых
генераторов кода переносить компилятор на различные платформы.
Препроцессор. Данная компонента выполняет препроцессорную обработку исходного текста
согласно правилам соответствующей глава проекта стандарта Си++. Несмотря на значительную
семантическую независимость конструкций, обрабатываемых препроцессором, от самого языка
Си++, формально они являются частью определения языка. Именно по этой причине мы называем
данную компоненту "препроцессор Си++", хотя, очевидно, ее можно использовать для обработки
текстов любой природы.
Заметим, что в "минимальной" версии системы программирования могло бы и не быть реализации
препроцессора; в принципе, можно использовать аналогичный инструмент из любой Си-
ориентированной системы программирования. Наиболее существенным доводом в пользу
разработки собственной версии препроцессора было требование обеспечения полного
соответствия стандарту языка Си++, чего не обеспечивают многие препроцессоры известных
фирм-разработчиков.
Компилятор переднего плана. Эта компонента является центральной частью всего компилятора
Си++. Она воспринимает на входе текст программы на Си++ (в терминах стандарта - translation
unit), формируя на выходе файл с семантически эквивалентным представлением этой программы
на некотором промежуточном языке, который можно трактовать как "обобщенный
ассемблер".
Компилятор переднего плана построен по традиционной двухпроходной схеме. На первом проходе
осуществляется лексический и синтаксический анализ исходного текста, выполняется большой
массив семантических проверок, а также генерируется таблично-древовидное представление
программы.
Первичный лексический анализ (распознавание и кодирование лексем) выполняется по
традиционной схеме конечного автомата и для обеспечения большей эффективности реализован
без использования метасредств типа lex. Существенным моментом в схеме лексического разбора
компилятора является наличие дополнительной фазы - так называемого расширенного
лексического анализатора, функции которого заключаются, во-первых, в агрегации некоторых
"стандартных" последовательностей лексем в одну "суперлексему", и, во-вторых, в идентификации
имен везде, где это возможно; для этого используется ряд контекстных условий разбора, а также
привлекается информация из уже построенных семантических таблиц. Результатом этой функции
является подмена (уже на этапе лексического анализа) общего синтаксического понятия
"идентификатор" и соответствующей лексемы на более точное понятие, например, "объявляемое
имя", "имя типа", "имя-не-типа", "непосредственный базовый класс" и т.п. Для обозначения
подобных понятий используются соответствующие суперлексемы.
Синтаксический анализ реализован с использованием расширенного и оптимизирующего варианта
известного генератора YACC. Формальное описание языка Си++ основано на множестве лексем и
суперлексем (см. выше) и включает семантические действия, которые, как правило, сводятся к
вызовам функций обработки объявлений, генерации поддеревьев и вычислению контекстных
признаков. Свертка лексических последовательностей и ранняя идентификация имен, описанная
выше, привела к существенному (около 2-х раз) сокращению объема синтаксиса по сравнению с
аналогичным синтаксисом, используемым в свободно распространяемом компиляторе GNU
C++.
Совокупность семантических таблиц, организованная в соответствии со структурой областей
видимости исходной программы, содержит атрибуты всех программных сущностей, а дерево
программы отражает структуру исполняемых конструкций. Элементы семантических таблиц
("семантические слова") и узлы дерева связаны взаимными ссылками. Ссылки из дерева в таблицы
представляют, как правило, использующие вхождения объявленных сущностей. Обратные ссылки
обычно имеют характер атрибутов (например, ссылка из семантического слова переменной на
дерево выражения для инициализатора этой переменной).
Кроме того, на первом проходе практически полностью обрабатываются объявления шаблонов
функций и классов, а также настройки шаблонов классов (полная обработка вызовов функций-по-шаблону и некоторых других шаблонных конструкций откладывается до второго прохода).
Второй проход компилятора заключается в серии рекурсивных обходов дерева программы. При
этом выполняется довычисление атрибутов сущностей, необходимых для генерации
промежуточного кода (в частности, вычисляются размеры и смещения для стековых объектов),
производится частичное перестроение поддеревьев (например, формируются функциональные
эквиваленты операций преобразования типов, вставляются неявные вызовы деструкторов и т.п.),
специальным образом (в терминах стандарта - по алгоритму "best-matching" - поиска наилучшего
соответствия) обрабатываются вызовы функций, включая вызовы функций-по-шаблону. На
завершающей фазе второго прохода производится непосредственная генерация промежуточного
представления,
Генератор кода. В настоящее время в компиляторе используется фирменный генератор объектного
кода для платформ Sun и Sparc, полученный от компании-разработчика формата внутреннего
представления. Напомним, что генератор, как и другие компоненты компилятора, представляет
собой независимую программу, которая легко может быть заменена на эквивалентный по
интерфейсу генератор для некоторой другой платформы.
В настоящее время ведется разработка семейства оригинальных генераторов объектного кода для
нескольких аппаратных платформ, включая процессоры специального назначения.
Текущее состояние компилятора. В настоящее время разработка перешла в завершающую стадию.
Полностью реализован, отлажен и протестирован препроцессор. Компилятор переднего плана
практически полностью реализован; спроектированы все алгоритмы обработки "новых"
шаблонов, идет их реализация.
При тестировании компилятора переднего плана использовались средства аттестации,
создаваемые в рамках всего проекта (см. разд. 4). К началу октября 1996 г. компилятор успешно
обрабатывал около 97% тестов (используемый тестовый набор включает более 6000 тестов без
учета тестов на шаблонные конструкции). Проводились попытки сравнить степень соответствия
стандарту разрабатываемого компилятора с компиляторами известных фирм-производителей
инструментальных средств. Так, компилятор Watcom C++ версии 10.0 показал результат около
93%.
Специальные измерения производительности компилятора не проводились, однако эмпирически
можно утверждать, что его быстродействие сравнимо с быстродействием известных компиляторов
Си++, в частности, с GNU C++.
3. Стандартная библиотека Си++: принципы построения
Стандартная Библиотека языка Си++ (The Standard C++ Library) представляет собой весьма
значительную (как по объему, так и по "идеологической" насыщенности) часть готовящегося
стандарта языка Си++. Описание Библиотеки (главы 17-27) в совокупности составляет более
половины общего объема Предварительного Стандарта [1]. Помимо внушительного размера,
предлагаемый стандартный комплекс библиотечных ресурсов языка Си++ воплощает большое
количество важных принципов и подходов, отражающих современное состояние программистской
теории и практики.
Как и язык в целом, Библиотека находится в состоянии разработки, причем интенсивность ее
модификаций от версии к версии в целом выше, нежели интенсивность модификаций описания
собственно языка. Тем не менее, базовый состав Библиотеки и многие ее существенные
особенности можно считать уже устоявшимися. Это позволяет кратко рассмотреть ее основные
черты.
Прежде всего необходимо отметить несколько существенных черт, свойственных проекту
Стандартной Библиотеки. Важным (и в то же время очевидным) моментом представляется
адекватная поддержка воплощенной в языке парадигмы объектно-ориентированного
программирования. Практически все библиотечные ресурсы спроектированы в виде иерархий
классов; используется понятие абстрактных классов и механизм виртуальных функций.
Другая особенность - активное использование шаблонов (templates) для повышения уровня
абстракции базовых алгоритмов. Следует специально отметить, что в последних версиях проекта
Си++ средства типовой (с ударением на "и") параметризации времени компиляции,
обеспечиваемые в языке понятием шаблона, весьма существенно усилились новыми
возможностями, и произошло это прежде всего под влиянием требований, возникавших в процессе
проектирования Стандартной Библиотеки.
Между прочим, техника применения шаблонов в библиотечных модулях может служить
прекрасным пособием для изучения этого средства языка по причине тщательной продуманности
структуры и иерархии библиотечных шаблонов. Это тем более существенно, что сам по себе
данный языковой механизм спроектирован в Си++ явно не лучшим образом и теоретически может
приводить к невообразимо запутанным конструкциям.
Наконец, третья важная черта Библиотеки - использование механизма исключительных ситуаций
(exceptions). Практически все возможные "нештатные" эффекты в процессе выполнения
библиотечных функций специфицированы в виде исключительных ситуаций; в библиотеке
предусмотрена иерархия стандартных классов, предназначенных именно передачи значений при
возбуждении исключительных ситуаций.
Однако наиболее существенной идеологической концепцией, на основе которой строится
Стандартная Библиотека, является технология "generic programming" (обобщенного
программирования), впервые примененная для Си++ А.Степановым при разработке его Standard
Template Library [2, 4] (и вошедшей в качестве составной части в Стандартную Библиотеку). Как
результат, важнейшей особенностью Стандартной Библиотеки Си++ становится тенденция к
максимальному обобщению структур и алгоритмов при одновременном сохранении их
эффективности. Практически явное выделение понятийного ядра библиотеки позволило упростить
общую схему ее построения. Кроме того, произошел отказ от попыток создания замкнутой
системы классов и функций, предоставляющей пользователю фиксированный сервис. Наоборот,
основное внимание в библиотеке уделяется универсальным шаблонным средствам порождения
требуемого пользователю контекстно-ориентированного кода. С точки зрения классического
понимания слова "библиотека" С++ Standard Library скорее является средством быстрой
разработки контекстно-ориентированных библиотек, предоставляя программисту совокупность
понятий, в терминах которых он может проектировать собственные системы, и набор типовых
решений с использованием этих понятий.
Таким образом, общую структуру Стандартной Библиотеки Си++ можно представить как
объединение нескольких крупных компонент, каждая из которых предоставляет набор примитивов
и типовых решений, позволяющих достаточно легко построить набор конкретных классов и
функций для некоторой прикладной области.
Практически каждая компонента Библиотеки существенно использует возможности,
предоставляемые другими компонентами, за счет чего достигается максимальная гибкость,
общность и эффективность. В качестве примера можно привести следующую схему, отражающую
взаимодействие компонент библиотеки, используемых при реализации ввода/вывода. Здесь связь
вида Компонента1-->Компонента2 отражает тот факт, что для построения второй компоненты
привлекаются понятия из первой компоненты.
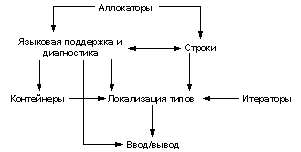
Классическое объектно-ориентированное программирование использует единственный базовый
механизм - механизм наследования с последовательным увеличением детализации при переходе от
класса родителя к классу потомку. В случае Стандартной библиотеки Си++ активное
использование шаблонных структур - шаблонных алгоритмов и шаблонных иерархий классов
позволяет библиотеке, с одной стороны, сохранять высокий уровень абстрактизации, а с другой -
предоставлять разработчику реально действующий код. Кроме того, исходное построение
библиотеки в виде совокупности четко выделенных блоков не только позволяет достичь простоты
и единообразности интерфейсов, но дает пользователю большую широту в выборе способов их
взаимодействия.
Заметим, что идея создания библиотек повторно используемых программных компонент реально
не столь нова, как кажется на первый взгляд. Еще в 1976 году МакИлрой в своей статье [5] (McIlroy
"Mass-Produced Software Components") аргументировал необходимость повторного использования
программного обеспечения, в том числе стандартизации и абстрактизации наиболее часто
используемых алгоритмов и структур данных, и, по всей видимости, единственным ограничением к
созданию подобного рода библиотек являлось отсутствие развитых средств абстрактизации у
большинства распространенных к тому времени языков программирования.
Подходя к проблеме эффективности библиотеки заметим, что абстрактизация компонент
библиотеки была достигнута без утраты эффективности по скорости. Как пример, можно привести
использование обобщенной функции sort, упорядочивающей натуральные числа по возрастанию,
для упорядочивания их по убыванию с привлечением понятия функционального объекта.
#include
#include
class IntGreater {
public:
bool operator()( int x, int y) const { return x>y; }
};
int main()
{
int x[1024];
............ // Инициализация
sort(&x[0],&x[1024]); // Обычное упорядочивание
sort(&x[0],&x[1024],IntGreater); // Упорядочивание по убыванию
}
При этом эффективность по скорости выполнения будет такой же, как и при написании
сортировки целых вручную, а реально может оказаться и выше за счет удачного выбора алгоритма
сортировки. Примеры использования средств STL можно найти в [3].
Стандартная Библиотека Си++ предоставляет:
- Расширяемый набор классов и определений, необходимых для
поддержки понятий самого языка Си++ (Language Support Library).
- Классы поддержки диагностики пользовательских приложений (Diagnostics
Library);
- Утилиты общего назначения (General Utilities);
- Контейнеры (Containers) и итераторы (Iterators);
- Обобщенные алгоритмы (Algorithms);
- Средства локализации программ (Locales);
- Классы и функции для математических вычислений (Numeric Library);
- Средства работы со строками (Strings Library);
- Ввод/вывод (Input/Output Library).
4. Тестовый пакет
4.1. Основные принципы аттестации
Исходя из общих критериев качества и требований к пакетам тестов были выбраны следующие
принципы разработки пакета аттестационных тестов для проверки компиляторов Си++ на
соответствие стандарту:
- Набор аттестационных тестов должен покрывать весь стандарт языка
C++.
- Программы, входящие в пакет, должны быть независимыми в том смысле,
что результаты компиляции или запуска любой из них не должны влиять на
условия или результаты компиляции или запуска любой другой тестовой
программы.
- Каждая тестовая программа необходима для проверки соответствия между
реализацией некоторой языковой конструкции и ее описанием в стандарте
языка C++.
4.2. Пакет тестов
Общая структура
Проблема реализации методов конформности языковых процессоров представляет собой
комплексную наукоемкую и весьма сложную в реализационном плане задачу. Аттестационный
пакет, разрабатываемый в рамках данного проекта, создавался с учетом научных результатов и
практического опыта, накопленных в МГУ [8].
Тестовый пакет построен иерархически в соответствии со структурой текста стандарта языка C++.
Тесты, содержащиеся в определенном каталоге (включая подкаталоги), должны тестировать
языковые ситуации, описанные в соответствующей части стандарта C++.
При этом подразумевался принцип независимости частей спецификации тестов (состоящих из
набора тестовых атрибутов, их значений, соответствующей таблицы решений и списка
ограничений), хотя он является лишь рекомендацией, а не требованием. Например, если
совместный список атрибутов и соответствующая таблица решений для более чем одной части
стандарта описывают сходную языковую конструкцию, то правильнее и удобнее будет создать
единый набор тестов для этих частей и расположить их в одном месте, а не разделять их или писать
несколько раз одинаковые тесты.
Группы тестов, соответствующие частям стандарта языка С++
Все тесты, содержащиеся в определенном каталоге, соответствующем части стандарта языка С++,
образуют группу тестов для этой части. Основная цель каждой группы состоит в проверке
реализации некоторого требования, содержащегося или выводимого из текста соответствующей
части стандарта языка.
Каждая группа тестов разделяется на две подгруппы, состоящие из А-тестов и Б-тестов
соответственно. А-тесты это самопpовеpяющиеся правильные программы, проверяющие
правильность реализации некой языковой конструкции, а Б-тесты - программы, содержащие
ошибки, необходимые для проверки правильности реакции компилятора на данные ошибки.
Кроме этого, группы тестов разделяются на подгруппы в соответствии с целями тестирования и
тестовыми спецификациями. Каждая такая спецификация определяет некоторую конструкцию,
описанную в стандарте языка С++, которая должна быть запрограммирована, и эффект, который
должен быть получен при обработке этой конструкции проверяемой реализацией компилятора.
Каждой отдельной спецификации должен соответствовать ровно один тест.
Спецификации тестов: создание и реализация
Стандарт языка С++ является неформализованным (частично формализованной является лишь
синтаксическая часть языка). Это ведет к тому, что процесс создания тестов тоже является
частично формализованным. В этом случае одним из возможных путей создания тестов является
глубокое изучение стандарта языка С++, в ходе которого выявляются и фиксируются ограничения,
накладываемые на реализацию компилятора и языковые конструкции, появляющиеся в
программах и программных элементах языка С++.
Таким образом, при разработке тестовых спецификаций используется частично формализованная
запись и специальные методы создания и уточнения тестовых атрибутов.
Следующие три раздела описывают методы разработки спецификаций для А-тестов и Б-тестов, а
также методы выбора гипотез для ограничения и уточнения тестовых спецификаций.
Создание спецификаций А-тестов: атрибуты тестов и таблицы решений
Спецификации для А-тестов выражены в виде таблиц решений для наборов тестовых
атрибутов.
Метод создания таблиц решений основан на методе функциональных диаграмм, описанном в
книгах Майеpса [6, 7]. Однако, несмотря на кажущуюся простоту, явное использование методов
Майеpса оказалось непрактичным.
При применении метода функциональных диаграмм к спецификациям языков программирования,
как к внешним спецификациям тестируемой системы, набор ситуаций, эффектов и отношений
между ними в полной функциональной диаграмме становится безгранично большим. Поэтому
возникла необходимость применять специальные приемы для разграничения рассматриваемых
вариантов связей. Одна из таких технологий заключается в использовании неполных
функциональных диаграмм: ситуации и эффекты, используемые в полной диаграмме, разделяются
и образуют несколько диаграмм, которые в дальнейшем преобразуются в таблицу решений.
Но даже создание неполных диаграмм чаще всего является довольно сложной задачей, поэтому
члены команды тестирования собственными методами анализировали неполные диаграммы и
преобразовывали их в таблицы решений.
Несмотря на эти замечания, разработка спецификаций для А-тестов включает в себя следующие
четыре шага:
- Определяется набор тестовых атрибутов. Атрибут теста - это любой атрибут или свойство
языковой конструкции или выражения, встречающиеся в рассматриваемой части стандарта, или
любое свойство контекста данной конструкции, которое может рассматриваться как предмет
отдельного тестирования.
- Для каждого тестового атрибута определяется набор возможных значений. Каждое значение
должно удовлетворять следующим двум требованиям:
- значение присутствует в стандарте,
- значение определяет отдельную тестируемую сущность.
- Определяется набор эффектов, получаемых при компиляции. Каждый эффект должен
удовлетворять следующим двум требованиям:
- существует возможность определения наличия или отсутствие данного
эффекта,
- данный эффект должен быть как можно проще.
- Создаются таблица решений. Каждая строка или столбец, в зависимости от выбранного
представления таблицы, должны содержать спецификацию для определенного теста, которая
состоит из двух частей. Первая часть отвечает за набор значений атрибутов, которые должны
реализовываться программой, а вторая описывает набор эффектов, которые получаются при
выполнении данной программы и могут быть определены при помощи среды пакета
тестирования.
Создание спецификаций для Б-тестов: "Б-значения" и "Ограничения"
Спецификации для Б-тестов и методы их создания отличаются от соответствующих методов для А-
тестов. Каждая такая спецификация состоит из двух частей.
Первая часть, называемая "Б-значения", состоит из набора ошибочных значений тестовых
атрибутов, определенных в соответствующей спецификации А-тестов. Каждое из ошибочных
значений должно удовлетворять следующим свойствам:
- значение присутствует в стандарте языка С++,
- значение определять отдельную тестируемую сущность.
Вторая часть называется "Ограничения" и состоит из формулировок ограничений, накладываемых
на программы языка С++ и явно выделенных в соответствующей части стандарта или логически
следующих из ее текста. Для некоторых ограничений явно указывается пути их нарушения.
Каждое ограничение, накладываемое на программы языка С++, может быть отражено, как в части
"Б-значения", так и в части "Ограничения", но не в обеих сразу.
Спецификация Б-тестов не предполагала создания таблиц решений, и единственным их эффектом
являлась диагностика в процессе компиляции. Это означает, что Б-тесты являются тестами этапа
компиляции. По крайней мере один тест был создан для каждого неправильного значения
тестовых атрибутов. Аналогично, для каждого ограничения был создан по крайней мере один
тест.
Если для некоторого ограничения добавлен набор возможностей его нарушения, то
подразумевалось написание набора тестов, проверяющих каждое из этих нарушений.
Гипотезы
Так как стандарт языка C++ является неформализованным, оценка значимости тестовых
атрибутов, их значений и комбинаций этих значений также была неформализованной. Главной
целью этой оценки является систематическое уменьшение количества тестов.
С другой стороны, принципы и результаты оценки важности атрибутов должны быть хорошо
документированы, поскольку они напрямую связаны с полнотой пакета тестов.
Для того, чтобы объяснить способ, которым оценивалась величина важности значений атрибутов,
необходимо явно сформулировать гипотезы о тестируемых свойствах реализации языка С++. Одна
из таких гипотез, называемая "Гипотеза об относительной корректности реализации", относится
ко всему пакету тестов. Эта гипотеза, называемая в дальнейшем ГОКР, формулируется так: "Когда
проверяется взаимодействие между различными языковыми конструкциями, предполагается, что
каждая из этих конструкций реализована правильно. Отсюда вытекает, что конкретное
представление данных конструкций не важно".
Предполагалось, что ГОКР будет использоваться только для ограничения количества тестов в
потенциально-бесконечном наборе тестов, а не для ограничения их сложности. Другими словами,
конкретный выбор языковых конструкций производился в соответствии с ГОКР, но был
тривиальным.
Поддержка версий
Пакет тестов строится и изменяется методом "от версии к версии". Любая конечная версия пакета
тестов является результатом точного последовательного выполнения следующих шагов:
- Строится и документиpуется список различий между стандартами C и C ++. Каждое
различие снабжается соответствующей ссылкой на стандарт языка C++.
- Для каждого различия выполняется следующая последовательность шагов:
- Каждое различие анализируется, чтобы определить может ли оно быть
основой для аттестационных тестов. Возможно, что некоторые различия
являются следствиями других различий или имеют информационное и
технологическое, а не нормативное значение.
- Для каждого различия, отбираемого, как основа для аттестационного
тестирования, определяется набор разделов стандарта C++ соответствующий
рассматриваемой языковой ситуации.
- Для каждого раздела стандарта C++ определяются атрибуты тестов и
соответствующие значения, а затем создается таблица решений. Эти действия
для различных разделов могут быть выполнены независимо.
- Если в течение выполнения шага 2. найдены новые различия между C и C++, они
объединяются в отдельный список различий. Этот список может быть добавлен к первоначальному
списку различий и тогда процесс создания набора тестов должен быть повторно начат с шага 2.,
или он может сохраняться как отдельный список, который нужно использовать при создании
следующей версии набора тестов. Выбор между этими альтернативами зависит от большого
количества неформальных причин, включая доступные ресурсы и значимости данных различий.
- На основе спецификаций, полученных в течение шага 3, создаются тесты. Для
дополнительного сокращения числа тестов могут использоваться формальные и неформальные
методы. (То есть тесты создаются только для выбранных, а не для всех спецификаций) Этот шаг
может быть повторен несколько раз для той же самой версии набора тестов (и, поэтому, для того
же самого набора спецификации); каждый раз невыбранные спецификации выбираются, чтобы
получить более полную версию пакета тестов.
4.3. Свойства тестов
Опишем подробнее свойства различных групп тестов и требования, предъявляемые к ним.
Классы тестов
Как уже неоднократно отмечалось, все тесты в пакете подразделены на два класса, в соответствии с
задачей тестирования и природой критериев успешного завершения или отказа:
А-тесты:
Тест относится к классу А-тестов, если он является правильной выполнимой (в соответствии со
стандартом языка C++) программой. А-тесты проверяют способность реализации обрабатывать
правильные с точки зрения стандарта программы правильным образом. А-тест считается успешно
завершенным, если его компиляция прошла успешно и вызов получившегося кода прошел без
ошибок. причем ошибками в последнем случае являются не только ошибки, выданные
соответствующей реализацией, но и сообщения самой программы о том, что данная реализация
обработала ее не соответствующем стандарту способом.
Б-тесты:
Тест относится к классу Б-тестов если он является неправильной (нарушающей требования
стандарта языка C++) программой. Б-тест проверяет способность реализации обнаруживать
нарушения стандарта в компилируемой программе. Б-тест считается успешно завершенным, если
во время компиляции определены все ошибки, содержащиеся в нем.
Полученные тесты являются компиляционными тестами, содержащими нарушения стандарта,
проверяемые на этапе компиляции. Это ограничение основано на следующих допущениях:
- Для любого ограничения, налагаемого стандартом языка C++, которое может быть
проверенно на этапе компиляции, и для любой реализации компилятора с языка C++, есть только
два случая: либо реализация способна обнаружить нарушения этого ограничения во время
компиляции, либо получается потенциально исполнимый код, содержащий это нарушение.
Последний случай считается несоответствием стандарту C++, даже если в процессе выполнения
программы появились сообщения об ошибках (ошибках исполнения кода программы). Ситуация,
при которой реализация проверяет данные ограничения в процессе выполнения программы,
кажется практически невероятной.
- Даже если реализация сама способна исправить ошибки программы, она должна выдать
сообщения о них, и конечный код должен отличаться от кода, полученного в ситуации, когда
ошибок нет.
- Все исключительные ситуации (как вызываемые так и обрабатываемые) могут быть проверены
с помощью А-тестов. Соответствующие тесты должны содержать соответствующую функцию
обработки исключительной ситуации, и во всем другом быть обычными А-тестами.
- Для других ошибок этапа выполнения (которые не сводятся к обработке исключительных
ситуаций) стандарт языка C++ не содержит ограничений (касающихся поведения реализации),
которые позволяют написать аттестационные тесты.
Общие требования к тестам
Основные требования, предъявляемые к тестам, следующие:
- Необходим отдельный тест для каждой спецификации. Однако, выяснено, что это
требование не может быть выполнено и, следовательно, должно стать целью. Основными
причинами этого стали:
- На этапе проектирования пакета тестов трудно оценить человеческие и
компьютерные ресурсы, необходимые для следующего этапа, на котором
происходит написание тестов. Поэтому, на этапе написания тестов полезно и
даже необходимо исправление спецификаций.
- Во время разработки спецификаций тестов, трудно проверить возможность
написания теста для каждой конкретной спецификации. Поэтому была
проведена лишь приблизительная оценка достижимости спецификаций. Все
явно недостижимые спецификации были удалены, но спорные были оставлены
в окончательном варианте набора тестовых спецификаций. При последующем
написании тестов появились спецификации, реализация которых
представляется сложной или технически невозможной. Эти спецификации тоже
удаляются из полного набора спецификаций. Данная практика является
общепринятой и будет продолжаться в процессе отладки пакета тестов.
- Стандарты написания тестов должны ограничивать использование некоторых языковых
конструкций, во всех случаях кроме случая, когда данная конструкция является тестируемой.
Каждый тест должен быть написан как можно проще и короче.
- Тесты должны быть просмотрены и отлажены для того, чтобы устранить ошибки и установить
соответствие между тестами и целями тестирования.
Специальные Требования к А-тестам
А-тесты могут быть разделены на две подгруппы. Первая состоит из тестов, которые производят
некоторые нетривиальные действия во время выполнения. Как правило, в течение этих действий
вычисляется некоторое значение, и затем оно сравнивается с эталонным значением. Спецификации
для этой подгруппы тестов могут содержать некоторые комбинация нетривиальных эффектов.
Другая подгруппа состоит из тестов которые проверяют правильность компиляции некоторой
комбинации языковых ситуаций. Спецификации для этой подгруппы обычно содержит только
один эффект типа "ситуация, содержащаяся в тесте, обрабатывается реализацией".
Различия между этими двумя подгруппами тестов существенны для проектировщиков и
разработчиков тестов, но они могут быть скрыты от конечного пользователя пакета тестов.
Поэтому, все А-тесты должны быть самопроверяющимися и сходно обрабатываться средой
тестирования.
Как было сказано выше, тесты, проверяющие обработку исключительных ситуаций, тоже могут
быть организованы как обычное А-тесты посредством выбора соответствующей структуры
обработки исключительной ситуации для каждого конкретного теста.
Специальные Требования к Б-тестам
- Каждый Б-тест должен содержать ровно одну ошибку, соответствующую спецификации
теста.
- Все Б-тесты в пакете тестов являются тестами процесса компиляции. (То есть, тест прошел если
его компиляция не удалась, и наоборот) Это предположение не полностью правильно, но оно
основано на общепринятой модели компилятора для языка фон Неймана и позволяет
организовывать естественную и удобную среду тестирования для B-tests.
Литература
- Working Paper for Draft Proposed International Standard for Information
Systems - Programming Language C++. WG21/N0836, Doc No: X3J16/96-0018, 26
January 1996.
- Alexander Stepanov, Meng Lee. The Standard Template Library. Doc No:
X3J16/94-0030R1.
- Musser D.R, Saini A. "C++ Programming with the Standard Template Library.
STL Tututorial and Reference Guide" New York: Addis-Westley Publ. 1996.
- D.R. Musser, A.A.Stepanov. "Algorithm-oriented Generic Libraries" Software
Practice and Experience, Vol. 24(7), July 1994
- D.McIlroy. "Mass-Produced Software Components", Petrocelli/Charter, 1976
- Майерс. "Надежность программного обеспечения", Москва, 1980
- Майерс. "Искусство тестирования программ", Москва, 1982
- С.И.Рыбин, В.Ш.Кауфман. Методы и средства контроля языковых
стандартов.- в сб. "Системная информатика", вып.3.- ВО "Наука", Новосибирск,
1993 г.
Владимир Сухомлин < such@such.srcc.msu.su >
Евгений Зуев < zueff@such.srcc.msu.su >
Александр Кротов < krotoff@such.srcc.msu.su >
Денис Давыдов < deen@such.srcc.msu.su >
Николай Недиков < nedikov@such.srcc.msu.su >
[Назад]
[Содержание]
[Вперед]