Давайте отвлечемся от современных технических средств и программных продуктов, используемых при построении информационных систем, и вспомним, что происходило два десятилетия назад. В те времена при построении информационных систем самой популярной была модель "хост-компьютер + терминалы", реализованная на базе мэйнфреймов (например, IBM-360/370, или их отечественных аналогов - компьютеров серии ЕС ЭВМ), либо на базе так называемых мини-ЭВМ (например, PDP-11, также имевших отечественный аналог - СМ-4). Характерной особенностью такой системы была полная "неинтеллектуальность" терминалов, используемых в качестве рабочих мест - их работой управлял все тот же хост-компьютер (рис.1)
Рис.1. Этап 1: модель "хост-компьютер + терминалы"
Этот подход, весьма прогрессивный по тем временам, обладал некоторыми несомненными достоинствами. Во-первых, пользователи такой системы могли совместно использовать различные ресурсы хост-компьютера (оперативную память, процессор) и довольно дорогие для тех времен периферийные устройства (принтеры, графопостроители, устройства ввода с магнитных лент и гибких дисков, перфосчитыватели, дисковые накопители и иное оборудование, кажущееся по теперешним временам довольно экзотическим). Разумеется, используемые при этом операционные системы поддерживали многопользовательский многозадачный режим. Во-вторых, централизация ресурсов и оборудования облегчала и удешевляла эксплуатацию такой системы.
В чем были недостатки подобной архитектуры вычислений? Главным образом в полной зависимости пользователя от администратора хост-компьютера. Фактически пользователь (а нередко и программист) не имел возможности настроить рабочую среду под свои потребности - используемое программное обеспечение, в том числе и текстовые редакторы, компиляторы, СУБД, целиком и полностью было коллективным.
Не будет, наверное, большим преувеличением сказать, что в значительной степени именно этот недостаток подобных систем привел к бурному (и не прекратившемуся до сих пор) развитию индустрии персональных компьютеров. Наряду с дешевизной и простотой эксплуатации достаточно привлекательной особенностью настольных информационных систем стала так называемая персонализация рабочей среды, когда пользователь мог выбрать для себя инструменты для работы (текстовый редактор, СУБД, электронную таблицу и др.), наиболее соответствующие его потребностям. Естественно, и инструментов этих на рынке программных продуктов появилось довольно много. Именно в этот период появились электронные таблицы и настольные СУБД (dBase, FoxBase, Сlipper, Paradox и др.), нередко совмещающие в себе собственно СУБД и средства разработки приложений, использующих базы данных.

Рис.2. Этап 2: автономная персональная обработка данных
Следующим этапом развития архитектуры информационных систем было появление сетевых версий вышеупомянутых СУБД, позволяющих осуществлять многопользовательскую работу с общими данными в локальной сети. Этот подход сочетал в себе как удобства персонализации пользовательской среды и простоты эксплуатации, так и преимущества, связанные со вновь открывшимися возможностями совместного использования периферии (главным образом сетевых принтеров и сетевых дисков, в том числе хранящих коллективные данные). Отметим, что большинство информационных систем, реально эксплуатируемых сегодня в нашей стране, имеют именно такую архитектуру (в том числе некоторые информационные системы, реализованные на Delphi и C++Builder), и в случае не очень большого количества пользователей системы, не слишком большого объема данных и количества таблиц, невысоких требований к защите данных этот подход себя, безусловно, оправдывает.

Рис.3. Этап 3: коллективная обработка данных с использованием сетевых версий настольных СУБД и файлового сервера
Недостатки использования сетевых версий настольных СУБД обычно начинают проявляться в процессе длительной эксплуатации информационной системы, когда со временем увеличивается объем введенных пользователями данных, а иногда и число пользователей. Обычно в первую очередь замечается снижение производительности работы приложений, хотя нередко возникают и иные сбои в работе (например, разрушение индексов, нарушение ссылочной целостности данных). Причины этих явлений кроются в самой концепции хранения коллективных данных в файлах на сетевом диске и сосредоточении всей обработки данных внутри пользовательского приложения.
Возьмем простой пример. Допустим, пользователю нужно выбрать по какому-то признаку пять записей из таблицы, содержащей всего миллион подобных записей. Как происходит обработка данных при выполнении такого запроса с использованием коллективных файлов? Путем перебора записей и поиска нужных согласно какому-либо алгоритму, возможно, с использованием облегчающих поиск индексов. В любом случае этим занимается приложение, функционирующее на компьютере пользователя, и, следовательно, файлы или их части, нужные для поиска данных, фактически передаются по сети от файлового сервера к компьютеру пользователя. Поэтому при большом количестве данных и пользователей, а также при наличии многотабличных запросов пропускная способность сети может перестать удовлетворять предъявляемым к ней требованиям, связанным с эксплуатацией такой информационной системы.
Возросший сетевой трафик - не единственная неприятность, подстерегающая администратора и разработчика подобной информационной системы. Весьма частым явлением в этом случае является нарушение ссылочной целостности данных. Возьмем уже ставший классическим пример, приводимый во всех учебниках по базам данных. Имеются две таблицы формата dBase: список заказчиков какой-либо компании, и список их заказов, связанные по какому-либо полю, например, CUST_ID (рис.4). Вполне разумными требованиями, предъявляемыми к такой БД (иногда называемыми бизнес-правилами), являются уникальность значений этого поля в списке заказчиков (иначе как узнать, чьи заказы с этим CUST_ID находятся в таблице заказов?), и отсутствие в списке заказов записей со значениями CUST_ID, отсутствующими в таблице заказчиков (то есть "ничьих" заказов). В случае dBase выполнение таких требований реализуется на уровне логики приложения. При этом практически всегда имеется возможность произвольного редактирования таблиц иными средствами (от dBase III до обычных текстовых редакторов), что может привести к нарушению этих требований. Обычно для предотвращения подобных прецедентов используются различные организационно-технические меры, например, запрещение средствами сетевой ОС доступа к файлам с таблицами иначе как из конкретного приложения. При этом полной гарантии сохранения ссылочной целостности все равно нет, так как остается вероятность так называемых незавершенных транзакций (то есть попытки согласованного изменения данных в нескольких таблицах - например, удаления заказчика вместе со всеми его заказами, во время которого произошел сбой питания, в результате чего удалилась только часть данных). Отметим также, что если информационная система содержит несколько приложений, использующих общие данные, каждое из них должно содержать код, предотвращающий некорректное с точки зрения ссылочной целостности изменение данных.
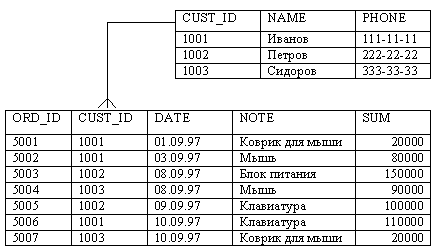
Рис.4.Пример связи "один-ко-многим"
Каким образом можно избежать подобных неприятностей? Ответ напрашивается сам собой: еще раз подумать об архитектуре информационной системы и сменить ее, если в обозримом будущем ожидаются подобные прецеденты. Использование серверных СУБД является в этом случае наиболее подходящим решением.
Назад | Содержание | Вперед