В традиционных ОС понятие нити тождественно понятию процесса. В действительности желательно иметь несколько нитей управления, разделяющих единое адресное пространство, но выполняющихся квазипараллельно.
Предположим, например, что файл-сервер блокируется, ожидания выполнения операции с диском. Если сервер имеет несколько нитей управления, вторая нить может выполняться, пока первая нить находится в состоянии ожидания. Это повышает пропускную способность и производительность. Эта цель не достигается путем создания двух независимых серверных процессов, потому что они должны разделять общий буфер кэша, который требуется им, чтобы быть в одном адресном пространстве.
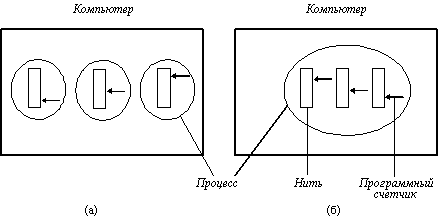
На рисунке 3.9,а показана машина с тремя процессами. Каждый процесс имеет собственный программный счетчик, собственный стек, собственный набор регистров и собственное адресное пространство. Каждый процесс не должен ничего делать с остальными, за исключением того, что они могут взаимодействовать посредством системных примитивов связи, таких как семафоры, мониторы, сообщения. На рисунке 3.9,б показана другая машина с одним процессом. Этот процесс состоит из нескольких нитей управления, обычно называемых просто нитями или иногда облегченными процессами. Во многих отношениях нити подобны мини-процессам. Каждая нить выполняется строго последовательно и имеет свой собственный программный счетчик и стек. Нити разделяют процессор так, как это делают процессы (разделение времени). Только на многопроцессорной системе они действительно выполняются параллельно. Нити могут, например, порождать нити-потомки, могут переходить в состояние ожидания до завершения системного вызова, как обычные процессы, пока одна нить заблокирована, другая нить того же процесса может выполняться.
Рис. 3.9. а) Три процесса с одной нитью каждый
б) Один процесс с тремя нитями
Нити делают возможным сохранение идеи последовательных процессов, которые выполняют блокирующие системные вызовы (например, RPC для обращения к диску), и в то же время позволяют достичь параллелизма вычислений. Блокирующие системные вызовы делают проще программирование, а параллелизм повышает производительность.
Один из возможных способов организации вычислительного процесса показан на рисунке 3.10,а. Здесь нить-диспетчер читает приходящие запросы на работу из почтового ящика системы. После проверки запроса диспетчер выбирает простаивающую (то есть блокированную) рабочую нить, передает ей запрос и активизирует ее, устанавливая, например, семафор, который она ожидает.
Когда рабочая нить активизируется, она проверяет, может ли быть выполнен запрос с данными разделяемого блока кэша, к которому имеют отношение все нити. Если нет, она посылает сообщение к диску, чтобы получить нужный блок (предположим, это READ), и переходит в состояние блокировки, ожидая завершения дисковой операции. В этот момент происходит обращение к планировщику, в результате работы которого активизируется другая нить, возможно, нить-диспетчер или некоторая рабочая нить, готовая к выполнению.
Структура с диспетчером не единственный путь организации многонитевой обработки. В модели "команда" все нити эквивалентны, каждая получает и обрабатывает свои собственные запросы. Иногда работы приходят, а нужная нить занята, особенно, если каждая нить специализируется на выполнении особого вида работ. В этом случае может создаваться очередь незавершенных работ. При такой организации нити должны вначале просматривать очередь работ, а затем почтовый ящик.
Нити могут быть также организованы в виде конвейера. В этом случае первая нить порождает некоторые данные и передает их для обработки следующей нити и т.д. Хотя эта организация и не подходит для файл-сервера, для других задач, например, задач типа "производитель-потребитель", это хорошее решение.
Нити часто полезны и для клиентов. Например, если клиент хочет растиражировать файл на много серверов, он может создать по одной нити для копирования на каждом сервере. Другое использование нитей клиентами - это управление сигналами, такими как прерывание с клавиатуры (del или break). Вместо обработки сигнала прерывания одна нить назначается для постоянного ожидания поступления сигналов. Таким образом, использование нитей может сократить необходимое количество прерываний пользовательского уровня.
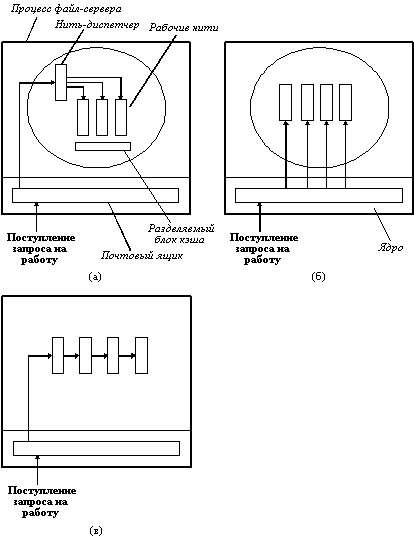
Рис. 3.10. Три способа организации нитей в процессе:
а - модель диспетчер/рабочие нити; б - модель "команда"; в - модель конвейера
Другой аргумент в пользу нитей не имеет отношения ни к удаленным вызовам, ни к коммуникациям. Некоторые прикладные задачи легче программировать, используя параллелизм, например задачи типа "производитель-потребитель". Не столь важно параллельное выполнение, сколь важна ясность программы. А поскольку они разделяют общий буфер, не стоит их делать отдельными процессами.
Наконец, в многопроцессорных системах нити из одного адресного пространства могут выполняться параллельно на разных процессорах. С другой стороны, правильно сконструированные программы, которые используют нити, должны работать одинаково хорошо на однопроцессорной машине в режиме разделения времени между нитями и на настоящем мультипроцессоре.
Существует два подхода к управлению нитями: статический и динамический. При статическом подходе вопрос, сколько будет нитей, решается уже на стадии написания программы или на стадии компиляции. Каждой нити назначается фиксированный стек. Этот подход простой, но негибкий. Более общим является динамический подход, который позволяет создавать и удалять нити оперативно по ходу выполнения. Системный вызов для создания нити обычно содержится в нити главной программы в виде указателя на процедуру с указанием размера стека, а также других параметров, например, диспетчерского приоритета. Вызов обычно возвращает идентификатор нити, который можно использовать в последующих вызовах, связанных с этой нитью. В этой модели процесс начинается с одной нити, но может создавать их еще, когда необходимо.
Завершаться нити могут одним из двух способов: по своей инициативе, когда завершается работа, и извне. Во многих случаях, например, при конвейерной модели, нити создаются сразу же после старта процесса и никогда не уничтожаются.
Поскольку нити разделяют общую память, они могут (и, как правило, делают это) использовать ее для сохранения данных, которые совместно используются множеством нитей, таких, например, как буфер в системе "производитель-потребитель". Доступ к разделяемым данным обычно программируется с использованием критических секций, предотвращающих попытки сразу нескольких нитей обратиться к одним и тем же данным в одно и то же время. Критическая секция наиболее легко реализуется с использованием семафоров, мониторов и аналогичных конструкций.
Нити могут быть реализованы как в пользовательском пространстве, так и в пространстве ядра. В первом случае нити работают на базе прикладной системы, управляющей всеми операциями с нитями. Первым преимуществом такого способа является то, что можно реализовать нити в операционной системе, которая их не поддерживает. ОС прикладная среда, управляющая нитями, кажется одним процессом. Все вызовы (ПРИОСТАНОВИТЬ, ПРОВЕРИТЬ СЕМАФОР и т. д.) обрабатываются как вызовы функций этой прикладной среды. Она сохраняет регистры и переключает указатели счетчика команд и стека. В этом случае переключение происходит быстрее, чем с помощью ядра. Такая реализация имеет еще одно преимущество - для каждого процесса можно организовать свою схему планирования. Однако этот подход связан с некоторыми проблемами, одна из которых состоит в следующем. При выполнении блокирующих системных вызовов приостанавливается весь набор нитей, принадлежащих этому процессу. Чтобы избежать этого, можно сделать все системные вызовы неблокирующими, но это требует изменений в ОС, что нежелательно, так как одной из целей реализации нитей в пользовательском пространстве является их работа в существующих операционных системах.
Такой проблемы не существует при реализации нитей в пространстве ядра. Преимущество заключается также и в том, что ядро может при диспетчеризации выбирать нить из другого процесса. Однако хотя механизм управления нитями аналогичен первому случаю, временные затраты на переключение нитей выше, так как тратится время на переключение из режима пользователя в режим ядра.
Обычно в распределенных системах используются как RPC, так и нити. Так как нити были введены как дешевая альтернатива стандартным процессам, то естественно, что исследователи обратили особое внимание в этом контексте на RPC: нельзя ли их также сделать облегченными. Было замечено, что в распределенных системах значительное количество RPC обрабатывается на той же машине, на которой они были вызваны (локально), например, вызовы к менеджеру окон. Поэтому была предложена новая схема, которая делает возможным для нити одного процесса вызвать нить другого процесса на этой же машине более эффективно, чем обычным способом.
Идея заключается в следующем. Когда стартует серверная нить S, то она экспортирует свой интерфейс, сообщая о нем ядру. Интерфейс определяет, какие процедуры могут быть вызваны, каковы их параметры и т.п. Когда стартует клиентская нить C, то она импортирует интерфейс из ядра в том случае, если собирается вызвать S, и ей дается специальный идентификатор для выполнения определенного вызова. Ядро теперь знает, что C собирается позже вызвать S и создает специальные структуры данных для подготовки к вызову.
Одна из этих структур данных является стеком аргументов, который разделяется нитями C и S и отображается в оба адресных пространства для чтения и записи. Для вызова сервера нить C помещает аргументы в разделяемый стек, используя обычную процедуру передачи параметров, а затем прерывает ядро, помещая данный ей идентификатор в регистр. По этому идентификатору ядро видит, что вызов является локальным. (Если бы он был удаленным, то ядро обработало бы его обычным способом для удаленных вызовов.) Затем ядро выполняет переключение из адресного пространства клиента в адресное пространство нити-сервера и запускает в рамках клиентской нити требуемую процедуру сервера. При таком способе вызова аргументы уже загружены в нужное место, так что копирование или перегруппировка аргументов не требуется. Главный результат - локальный вызов RPC - будет выполнен этим способом гораздо быстрее.
Другой прием широко используется для ускорения удаленных RPC. Идея основана на следующем наблюдении: когда нить-сервер блокируется, ожидая нового запроса, ее контекст почти всегда не содержит важной информации. Следовательно, когда нить завершает обработку запроса, то ее просто удаляют. При поступлении на сервер нового сообщения ядро создает новую нить для обслуживания этого запроса. Кроме того ядро помещает сообщение в адресное пространство сервера и устанавливает новый стек нити для доступа к сообщению. Эту схему иногда называют неявным вызовом.
Этот метод имеет несколько преимуществ по сравнению с обычным RPC. Во-первых, нити не должны блокироваться, ожидая новую работу, следовательно контекст не нужно сохранять, во-вторых, создание новой нити проще, чем активизация существующей приостановленной, так как не нужно восстанавливать контекст.