Такие имена информационных служб как Lycos, AltaVista, Yahoo, OpenText, InfoSeek и ряд других, хорошо известны пользователям Internet. Без пользования услугами этих систем практически нельзя найти что-либо полезное в море информационных ресурсов Сети. Но что они из себя представляют, как устроены, почему результат поиска в терабайтах информации выдается так быстро, как устроено ранжирование документов при выдаче, что из себя представляют информационные массивы этих систем - этим вопросам посвящен этот раздел.
Предварительные замечания
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено довольно большое количество статей, основная масса которых приходится на конец 70-х - начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник "Научно-техническая информация. Серия 2. Информационные процессы и системы", который выходит до сих пор. На русском языке издана так же и "библия" по разработке этого рода систем - "Динамические библиотечно-информационные системы" Жерарда Солтона (Gerard Salton)[1] (список литературы приводится в конце учебного пособия), в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения, появилось нечто принципиально новое, чего не было раньше. Если быть точным, то информационно-поисковые системы в Internet - это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам.
При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти, и в сети не будет каталога отражающего конкретную предметную область. именно по этой причине для множества серверов Gopher, которое называется GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий мы видим и в World Wide Web. Собственно еще в 1988 году на в специальном выпуске "Communication of the acm"[2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал проблему организации поиска информации в больших гипертекстовых сетях в качестве первоочередной задачи для следующего поколения систем этого типа. До сих пор многие идеи, высказанные в этом разделе, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли[3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена не хорошим программам талантливых одиночек, а средствам, которые являются результатом долгосрочного планирования последовательного движения к поставленной цели научных и производственных коллективов. Рано или поздно этап исследований заканчивается и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако, многие проблемы, которые ставит перед разработчиками ИПС Internet не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital[4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
3.6.1. Архитектура современных информационно-поисковых систем World Wide Web
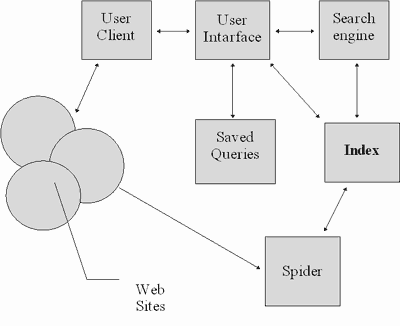
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения, рассмотрим типовую схему такой системы (рисунок 3.41). В различных публикациях, посвященных конкретным системам[5,6], приводятся схемы, которые отличаются друг от друга только применением конкретных программных решений, но не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере представленном в [6]:
Рис. 3.41. Структура ИПС для Internet (Budi Yuwono, Dik L.Lee. Search and Ranking Algorims for Locating Resources on the World Wide Web)
На этой схеме обозначены:
client - это программа просмотра конкретного информационного ресурса. В настоящее время наиболее популярны мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов World Wide Web, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
user interface - интерфейс пользователя - это не просто программа просмотра. В случае информационно-поисковой системы под этим словосочетанием понимают и способ общения пользователя с поисковым аппаратом системы, т.е. с системой формирования запросов и просмотров результатов поиска. Просмотр результатов поиска и информационных ресурсов сети - это совершенно разные вещи, на которых остановимся чуть позже.
search engine - поисковая машина служит для трансляции запроса пользователя, который подготавливается на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
index database - индекс - это основной массив данных информационно-поисковой системы. Он служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
queries - запросы пользователя сохраняются в его личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно хранить запросы, на которые система дает хорошие ответы.
index robot - робот-индексировщик служит для сканирования Internet и поддержки базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
www sites - это весь Internet. А если говорить более точно, то это те информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принцип построения каждой из этих компонент более подробно и определим в чем отличие данной системы от традиционной информационно-поисковой системы локального типа.
3.6.2. Информационные ресурсы и их представление в информационно-поисковой системе
Как видно из схемы (рисунок 3.41) документальным массивом ИПС Internet является все множество документов шести основных типов: WWW-страницы, Gopher-файлы, документы Wais, записи архивов FTP, новости Usenet, статьи почтовых списков рассылки. Все это довольно разнородная информация, которая представлена в виде различных, никак несогласованных друг с другом форматов данных. Здесь есть и текстовая информация, и графическая информация, и аудио информация и вообще все, что есть в указанных выше хранилищах. Естественно встает вопрос, как информационно-поисковая система должна со всем этим работать. В традиционных системах есть понятие поискового образа документа - ПОД'а. ПОД (Поисковый Образ Документа) - это нечто, что заменяет собой документ и используется при поиске вместо реального документа. Поисковый образ является результатом применения некоторой модели информационного массива документов к реальному массиву. Наиболее популярной моделью является векторная модель[7], в которой каждому документу приписывается список терминов, наиболее адекватно отражающих его смысл. Если быть более точным, то документу приписывается вектор, размерность которого равна числу терминов, которыми можно воспользоваться при поиске. При булевой векторной модели элемент вектора равен 1 или 0, в зависимости от наличия термина в ПОД'е документа или его отсутствия. В более сложных моделях термины взвешиваются, т.е. элемент вектора равен не 1 или 0, а некоторому числу, которое отражает соответствие данного термина документу. Именно последняя модель наиболее популярна в информационно-поисковых системах Internet[4,6,7]. Вообще говоря, существуют и другие модели описания документов: вероятностная модель информационных потоков и поиска, и модель поиска в нечетких множествах[7]. Анализ преимуществ и недостатков применения этих моделей при реализации информационно-поисковых систем в Internet - это тема специального исследования. Здесь имеет смысл обратить внимание читателя только на то, что пока именно линейная модель применяется в системах Lycos, WebCrawler, AltaVista, OpenText, AliWeb и ряде других. Исследования по применению других моделей также ведутся, например, в рамках проекта AltaVista[4] или научными группами[6]. Таким образом, первая задача, которою должна решить информационно-поисковая система - это приписывание списка ключевых слов документу или информационному ресурсу. Именно эта процедура и называется индексированием. Часто, однако, индексированием называют составление файла инвертированного списка, в котором каждому термину индексирования ставится в соответствие список документов, в которых он встречается. Такая процедура является только частным случаем, а точнее техническим аспектом создания поискового аппарата информационно-поисковой системы.
Проблема, связанная с индексированием, заключается в том, что приписывание поискового образа документу или информационному ресурсу опирается на представление о словаре, из которого эти термины выбираются, как о фиксированной совокупности терминов. В традиционных системах существовало разбиение на системы с контролируемым словарем и системы со свободным словарем. Контролируемый словарь предполагал ведение некоторой лексической базы данных, добавление терминов в которую производилось администратором системы. Таким образом, все новые документы могли быть заиндексированы только теми терминами, которые были в этой базе данных. Свободный словарь пополнялся автоматически по мере появления новых документов. Однако, на момент актуализации словарь также фиксировался. Актуализация предполагала полную перезагрузку базы данных. В момент этого обновления перегружались сами документы и обновлялся словарь, а после его обновления производилась переиндексация документов. Процедура актуализации занимала достаточно много времени и доступ к системе в момент ее актуализации закрывался.
Теперь представим себе возможность такой процедуры в анархичном Internet, где ресурсы появляются и исчезают ежедневно. При создании программы Veronica для GopherSpace предполагалось, что все серверы должны быть зарегистрированы и таким образом велся учет наличия или отсутствия ресурса. Veronica раз в месяц проверяла наличие документов Gopher и обновляла свою базу данных ПОД'ов документов Gopher. В World Wide Web ничего подобного нет. Для решения этой задачи используются программы сканирования сети или роботы-индексировщики. Разработка роботов - это довольно нетривиальная задача, т.к. существует опасность зацикливания робота или попадания на виртуальные страницы. Все системы имеют своего робота. Робот просматривает сеть, находит новые ресурсы, приписывает им термины и помещает в базу данных индекса. Главный вопрос заключается в том, какие термины приписывать документам, откуда их брать, ведь ряд ресурсов вообще не является текстом. В настоящее время различные роботы используют для индексирования следующие источники для пополнения своих виртуальных словарей: гипертекстовые ссылки, заголовки (title), заглавия (H1, H2 и т.п.), аннотации, списки ключевых слов и полные тексты документов, сообщения администраторов о своих Web-страницах[9]. Для индексирования telnet, gopher, ftp, нетекстовой информации используются главным образом URL, для новостей Usenet и почтовых списков - поля Subject и Keywords. Наибольший простор для построения ПОД'ов дают HTML-документы. Однако не следует думать, что все термины из перечисленных выше элементов документов попадают в их поисковые образы. Очень активно используются списки запрещенных слов (stop-words), которые не могут быть использованы для индексирования, общих слов (предлоги, союзы и т.п.), а также часто производится нормализация лексики. Таким образом, даже то, что в OpenText, например, называется полнотекстовым индексированием реально является выбором слов из текста документа и сравнением с целым набором различных словарей, после которого термин попадает в поисковый образ документа, а потом и в индекс системы. Для того, чтобы не раздувать словарей и индексов, а индекс Lycos, например, равен 4TB, применяется такое понятие как "вес" термина[10]. Документ обычно индексируется 40[6] - 100[8] наиболее "тяжелых" терминами.
После того, как ресурсы заиндексированы, т.е. система составила массив поисковых образов документов, начинается построение поискового аппарата системы. Совершенно очевидно, что лобовой просмотр файла или файлов ПОД'ов займет много времени, что абсолютно не приемлемо для интерактивной системы, которой является Web. Для того, чтобы можно было быстро находить информацию в базе данных ПОД'ов строится индекс. Индекс в большинстве систем - система связанных между собой файлов, которая нацелена на быстрый поиск данных по запросу пользователя. Структура и состав индексов различных систем могут отличаться друг от друга и зависят от многих факторов. К этим факторам можно отнести и размер массива поисковых образов, и информационно-поисковый язык системы, и размещения различных компонентов системы и т.п. Рассмотрим структуру индекса на примере системы[6]. Этот проект выбран потому, что он позволяет реализовывать не только примитивный булевый поиск, но и контекстный поиск, взвешенный поиск и ряд других возможностей, которые отсутствуют во многих поисковых системах, например Internet, Yahoo.
Индекс рассматриваемой системы состоит из таблицы идентификаторов страниц (page-ID), таблицы ключевых слов (Keyword-ID), таблицы модификации страниц, таблицы заголовков, таблицы гипертекстовых связей, инвертированного списка (IL) и прямого списка (FL).
Page-ID отображает идентификаторы станиц в URL этих страниц, Keyword-ID отображает каждое ключевое слов в уникальный идентификатор этого слова, таблица заголовков отображает идентификатор страницы в заголовок страницы, таблица гипертекстовых ссылок отображает идентификатор страниц в гипертекстовую ссылку на эту страницу. Инвертированный список ставит в соответствие каждому ключевому слову список пар (номер документа, идентификатор страницы, позиция слова в странице), а прямой список - это массив поисковых образов страниц. Все эти файлы так или иначе используются при поиске, но главным среди них, безусловно, является файл инвертированного списка. Результат поиска в этом файле - это объединение и/или пересечение списков идентификаторов страниц. Результирующий список, который преобразовывается в список заголовков, снабженных гипертекстовыми ссылками, возвращается пользователю в его программу просмотра Web. Для того, чтобы быстро искать записи инвертированного списка, над ним надстраивается еще несколько файлов, например, файл буквенных пар с указанием записей инвертированного списка, с этих пар начинающихся, а также применяется механизм прямого доступа к данным - хеширование.
Для обновления индекса применяется комбинация двух подходов. Первый можно назвать коррекцией индекса "на ходу". Для этого служит таблица модификации страниц. Суть такого решения довольно проста: старая запись индекса ссылается на новую, которая и используется при поиске. Когда число таких ссылок становится достаточным для того, чтобы ощутить это при поиске, то происходит полное обновление индекса, т.е. его перезагрузка.
Успех информационно-поисковой системы с точки зрения скорости поиска, определяется исключительно архитектурой индекса. Как правило, способ организации этих массивов является "секретом фирмы" и гордостью компании. Для того, чтобы убедиться в этом, достаточно почитать материалы OpenText[11].
3.6.3. Информационно-поисковый язык системы
Однако, индекс - это только часть поискового аппарата, причем не видная глазу пользователя. Второй частью этого аппарата является информационно-поисковый язык. ИПЯ позволяет сформулировать запрос к системе в довольно простой и доходчивой форме. Уже давно осталась позади романтика создания ИПЯ, как естественного языка. Именно этот подход использовался в системе Wais на первых стадиях ее реализации. Если даже пользователю предлагается вводить запросы на естественном языке, то это не значит, что система будет осуществлять семантический разбор запроса пользователя. Проза жизни заключается в том, что обычно фраза разбивается на слова, из этого списка удаляются запрещенные и общие слова, иногда производится нормализация лексики, а затем все слова связываются либо логическим AND, либо OR. Таким образом запрос типа:
>Software that is used on Unix Platform
будет преобразован в:
>Unix AND Platform AND Software
что будет означать примерно следующее: "Найди все документы, в которых слова Unix, Platform и Software встречаются одновременно".
Возможны и варианты. Так в большинстве систем фраза "Unix Platform" будет опознана как ключевая фраза, и не будет разделяться на отдельные слова. Вообще говоря, и все три слова могут быть опознаны как одна ключевая фраза. Другой подход заключается в вычислении близости между запросом и документом. Именно этот подход используется в Lycos, например. В этом случае, в соответствии с векторной моделью представления документов и запросов вычисляется мера близости. К настоящему времени известно около дюжины различных мер близости. Наиболее часто применяется cos угла между поисковым образом документа и запросом пользователя. Именно эти проценты соответствия документа запросу и выдаются в качестве справочной информации при списке найденных документов.
Наиболее продвинутым языком запросов из современных информационно-поисковых систем Internet обладает AltaVista[4]. Кроме обычного набора AND, OR, NOT, эта система позволяет использовать еще и NEAR. Последний оператор позволяет организовать контекстный поиск. Все документы в системе разбиты на поля, поэтому в запросе можно указать в какой части документа пользователь хочет увидеть ключевое слово (в ссылке, заголовке и т.п.). Можно также задать поле ранжирования выдачи и критерий близости документов запросу.
3.6.4. Типы информационно-поисковых языков
Главная задача информационно-поисковой системы - это поиск информации релевантной информационным потребностям пользователя. Слово релевантность означает соответствие между желаемой и действительно получаемой информацией. Релевантность можно еще представить как меру близости между реально полученными документами и тем, что следовало бы получить из системы. Естественно, что здесь возникает две задачи, которые следует решить: представление информации в системе и формулирование информационных потребностей пользователя. Эти две проблемы тесно связаны друг с другом. Руководства по многим информационно-поисковым системам Internet (Yahoo, OpenText и др.), что система реализует запрос типа "найди похожее". Но что значит эта фраза в реальности? Как вычислить эту самую похожесть?
Наиболее распространенными моделями представления документов в информационно-поисковой системе являются различные вариации на тему векторной модели, когда документ представляется как набор терминов. Как уже упоминалось ранее, это не весь текст документа, а только небольшой набор терминов, который отражает его содержание. Базируясь на таком представлении о документе и рассмотрим различные информационно-поисковые языки.
3.6.5. Традиционные информационно-поисковые языки и их модификации
Наиболее распространенным ИПЯ является язык, позволяющий составить логические выражения из набора терминов. При этом используются булевые операторы AND, OR, NOT. Запрос при этом может выглядеть следующим образом:
((информационная and система ) or ИПС) not СУБД
В данном случае эта фраза означает: "Найди все документы, которые содержат одновременно слова "информационная" и "система", либо слово "ИПС", но не содержат слова "СУБД"".
Запрос можно рассматривать как и реальный документ из базы данных. В нашем случае, фактически, мы имеем дело с двумя запросами:
информационная and система not СУБД
и
ИПС not СУБД
каждый из которых подразумевает как бы два действия: сначала найти все документы, содержащие необходимые пользователю термины, а потом отсеять те, которые содержат термин "СУБД".
Такая схема достаточно проста, и поэтому наиболее широко применяется в современных информационно-поисковых системах. Но еще 20 лет тому назад были хорошо известны и ее недостатки.
Булевый поиск плохо масштабирует выдачу. Оператор AND может очень сильно сократить число документов, которые выдаются на запрос. При этом все будет очень сильно зависеть от того, насколько типичными для базы данных являются поисковые термины. Оператор OR напротив может привести к неоправданно широкому запросу, в котором полезная информация затеряется за информационным шумом. Для успешного применения этого ИПЯ следует хорошо знать лексику системы и ее тематическую направленность. Как правило, для системы с таким ИПЯ создаются специальные документально лексические базы данных со сложными словарями, которые называются тезаурусами и содержат информацию о связи терминов словаря друг с другом.
Модификацией булевого поиска является взвешенный булевый поиск. Идея такого поиска достаточно проста. Считается, что термин описывает содержание документа с какой-то точностью, и эту точность выражают в виде веса термина. При этом взвешивать можно как термины документа, так и термины запроса. Запрос может формулироваться на ИПЯ, описанном выше, но выдача документов при этом будет ранжироваться в зависимости от степени близости запроса и документа. При этом измерение близости строится таким образом, чтобы обычный булевый поиск был бы частным случаем взвешенного булевого поиска.
Языки типа "Like this"
При внимательном рассмотрении взвешенного поиска закрадывается естественное желание вообще обойтись без логических коннекторов и измерять близость документа и запроса какими-либо другими критериями. Наиболее простой моделью этого типа является линейная модель индексирования и поиска, когда близость документа и запроса рассматривается как угол между ними. В этом случае высчитывается sin угла, который получают как скалярное произведение двух векторов. В соответствии со значением меры близости происходит ранжирование документов при выдаче ссылок на них пользователю. Вообще говоря, скалярное произведение не очень хорошо подходит для информационно-поисковых систем Internet, так как длина запроса обычно невелика. Это в традиционных системах существовали специальные службы, которые отлаживали длинные запросы, а в Internet такие службы только нарождаются. Поэтому реально применяются другие меры близости, но принцип остается тот же: сначала вычисляется мера, а потом происходит ранжирование.
Рассмотренный подход дает возможность более мягкого расширения и уточнения запросов, но он также не гарантирует высоких показателей релевантности, в случае выбора неудачной лексики.
Поиск в нечетких множествах
При этом типе поиска весь массив документов описывается как набор нечетких множеств терминов. Каждый термин определяет некую монотонную функцию принадлежности документам документального массива. Когда запрашивается AND, то это интерпретируется как минимум из двух функций, соответствующих терминам запросов, OR - как максимум, NOT - как 1-<значение функции>. В соответствии с полученными значениями результат поиска также ранжируется, как и в случае с поиском по мерам близости.
Следует сразу сказать, что этот метод поиска используется только в исследовательских системах и распространен крайне ограничено.
Пороговые модели
Как было видно из предыдущего изложения, на конечном этапе поиска выборка найденных документов ранжируется. Но, совершенно очевидно, что меры близости или поиск в нечетких множествах приводит к ранжированию всего массива документов в базе данных. Современные информационно-поисковые системы Internet имеют базы данных только индексов, занимающие террабайты. Ранжировать целиком такие массивы - это просто безумная затея. Поэтому применяются пороговые модели, которые задают пороговые значения для документов, выдаваемых пользователю.
Кластерная модель и Вероятностная модель информационного поиска
В кластерной модели может использоваться два подхода. Первый заключается в том, что массив заранее разбивается на подмножества документов и при поиске высчитывается близость запроса некоторому подмножеству. В другом подходе кластер "накручивается" вокруг запроса и ближайших к нему терминов. Наиболее часто эта модель применяется в системах, уточняющих запрос по релевантности найденных документов.
При вероятностной модели вычисляется вероятность принадлежности документа классу релевантных запросу документов. При этом используется вероятность принадлежности терминов запроса каждому из документов базы данных.
Коррекция запроса по релевантности
Многие системы применяют механизм коррекции запроса по релевантности. Это означает, что процедура поиска носит интерактивный и итеративный характер. После проведения первичного поиска пользователь отмечает из всего списка найденных документов релевантные. На следующие итерации система расширяет/уточняет запрос пользователя терминами из этих документов и снова выполняет поиск. Так продолжается до тех пор пока пользователь не сочтет, что лучшего результата, чем он уже имеет добиться не удастся. Коррекция запроса по релевантности - это достаточно широко внедренный способ уточнения запросов. В некоторых системах пользователь может и не знать, о том, что эта процедура применяется, например, OpenText. В этом случае несколько итераций выполняется без его вмешательства.
Весь этот краткий обзор современного состояния ИПЯ ставил перед собой одну простую задачу: определить степень развития и современный уровень информационно-поисковых средств Internet.
3.6.6. Информационно-поисковые языки Internet
При описании и классификации информационно-поисковых систем ставилась задача проанализировать наиболее популярные и наиболее типичные системы, которыми пользуются в Сети.
Lycos
Как и большинство систем, Lycos дает возможность использовать простой запрос и более изощренный метод поиска. В простом запросе в качестве поискового критерия вводится предложение на естественном языке. Lycos производит нормализацию запроса, удаляя из него так называемые stop-слова, и только после этого приступает к его выполнению. Почти сразу выдается информация о числе документов на каждое слово, а уже позже и список ссылок на формально релевантные документы. В списке напротив каждого документа указывается его мера близости запросу, число слов из запроса, которые попали в документ и оценочная мера близости, которая может быть больше или меньше формально вычисленной. На апрель 1996 года в Lycos не был реализован булевый поиск, такие планы были анонсированы. Последнее предложение подразумевает только то, что нельзя вводить эти операторы в строке вместе с терминами, но использовать логику через систему меню Lycos позволяет. Последнее относится к расширенной форме запроса, который предназначен для использования искушенными пользователями системы, которые уже научились пользоваться этим механизмом.
Таким образом мы видим, что Lycos относится к системе с языком запросов типа "Like this", но предполагается его расширения и на другие способы организации поисковых предписаний.
AltaVista
Наиболее интересным с точки зрения информационно-поискового языка в AltaVista является возможность расширенного поиска. Здесь стоит сразу выделить, что в отличии от многих систем AltaVista поддерживает одноместный оператор NOT. Кроме этого есть еще и оператор NEAR, который реализует возможность контекстного поиска, когда термины должны располагаться рядом в тексте документа. AltaVista разрешает поиск по ключевым фразам, при этом она имеет довольно большой словарь этих фраз. Кроме всего прочего, при поиске в АltaVista можно задать имя поля где должно встретиться слово. Это может быть гипертекстовая ссылка, applet, название образа, заголовок и ряд других полей. К сожалению, подробно процедура ранжирования в документации по системе не описана, но сказано, что ранжирование применяется как при простом поиске, так и при расширенном запросе.
Реально эту систему можно отнести к системе с расширенным булевым поиском.
Yahoo
Данная система появилась в сети одной из первых, и поэтому говорить будем о сегодняшнем состоянии Yahoo, а не о состоянии годовой давности. В настоящее время Yahoo сотрудничает со многими производителями средств информационного поиска и на различных ее серверах используется различное программное обеспечение. На мой взгляд, это самая незатейливая информационная служба, которая сосредоточилась на информации о Web как таковой. ИПЯ Yahoo достаточно прост: все слова следует вводить через пробел и они соединяются либо AND, либо OR. При выдаче не выдается степени соответствия документа запросу, а только подчеркиваются слова из запроса, которые встретились в документе. При этом не производится нормализация лексики и не проводится анализ на "общие" слова. Хорошие результаты поиска получаются только тогда, когда пользователь знает, что информация в базе данных Yahoo точно есть. Ранжирование производится по числу терминов запроса в документе.
Yahoo относится к классу простых традиционных систем с ограниченными возможностями поиска.
OpenText
Информационная система OpenText представляет из себя самый коммерциализированный информационный продукт в сети. Все описания больше напоминают рекламу, чем реальное руководство по работе. Система позволяет провести поиск с использованием логических коннекторов, размер запроса ограничен тремя терминами или фразами. В данном случае речь идет о расширенном поиске. При выдаче результатов поиска сообщается степень соответствия документа запросу и размер документа. Система позволяет также улучшить результаты поиска в стиле традиционного булевого поиска.
OpenText можно было бы отнести без сомнения к разряду традиционных информационно-поисковых систем, если бы не механизм ранжирования.
InfoSeek
Система InfoSeek обладает довольно развитым информационно-поисковым языком, который позволяет не просто указывать какие термины должны встречаться в документах, но и своеобразно взвешивать их. Достигается это при помощи специальных знаков "+" - термин обязан быть в документе, "-" - термин обязан отсутствовать в документе. Кроме этого InfoSeek позволяет проводит то, что называется контекстным поиском. Это значит, что используя специальную форму запроса можно потребовать последовательной совместной встречаемости слов. Кроме этого можно указать, что некоторые слова должны совместно встречаться не только в одном документе, а даже в отдельном параграфе или заголовке. Есть возможность и указания ключевых фраз. Ключевая фраза от последовательной встречаемости отличается тем, что фраза всегда ищется как единое целое, а при последовательной встречаемости слова могут стоять рядом, но в произвольном порядке. Ранжирование при выдаче осуществляется по числу терминов запроса в документе, по числу фраз запроса в документе, за вычетом общих слов. Все эти факторы используются как вложенные процедуры.
Подводя краткое резюме можно сказать, что InfoSeek относится к традиционным системам с элементом взвешивания терминов при поиске.
WAIS
WAIS является одной из наиболее изощренных поисковых систем Internet. В отличии от многих поисковых машин, ИПЯ системы позволяет строить не только вложенные булевые запросы, считать формальную релевантность по различным мерам близости, взвешивать термины запроса и документа, но и осуществлять коррекцию запроса по релевантности. Система также позволяет использовать усечение терминов, разбиение документов на поля и ведение распределенных индексов. Не случайно именно эта система была выбрана в качестве основной поисковой машины для реализации энциклопедии "Британика" на Internet.
Применение языков на практике
Рассмотрим теперь небольшой сравнительный пример использования описанных выше поисковых машин. В качестве запроса использовалась фраза:
"Best on the Web"
Подразумевалось, что следует найти документ, связанный с конкурсами "Лучший на Сети". Понятно, что уже в самом запросе есть определенная некорректность, но тем интереснее посмотреть, как с ней справились различные системы. Эта фраза задавалась в качестве набора слов и при этом получались следующие результаты.
AltaVista - после нормализации лексики от запроса осталось только Best. Естественно, что при этом качество поиска было отвратительным. Однако, использование поиска по фразе как по единому целому, поставило требуемый документ на первое место в списке найденных.
Lycos - здесь отсеялись "on the" и документ был указан только в конце списка. Поиск по фразе улучшения результатов не дал.
InfoSeek - при расширенном поиске нужный документ был найден третьим в списке из десяти документов. Уточнение поиска привело только к миграции документа вглубь списка.
OpenText - документ занимает пятую строчку в списке из десяти документов. Как и в случае с InfoSeek уточнение запроса результатов не дало.
Yahoo - документ попал в список найденных и занял третье место (ошибка в запросе: вместо "on the" следовало указывать "of the"). Но здесь следует заметить, что основное место хранения этого документа база данных Yahoo, т.е. запрос точно совпадает с тематикой базы данных.
Следует заметить, что приведенный пример не стоит рассматривать как реальную оценку возможностей описанных выше систем. Это просто иллюстрация, которая поможет провести свой собственный выбор наиболее подходящего средства поиска.
В завершении хотелось бы обратить внимание читателей еще на один аспект выбора информационно-поисковой системы. Это профиль ее баз данных. Можно возразить, что все системы индексируют одно и тоже - массив документов Internet. Однако делают они это по-разному. Очень важен профиль системы, который задается разбиением документов по темам и словарем индексирования, а также способом его поддержания. Определенным ориентиром здесь могут служить виртуальные библиотеки. Но об этом в следующий раз.
3.6.7. Интерфейс системы
Важным фактором является вид представления информации в программе-интерфейсе. При этом различают два типа интерфейсных страниц: страницы запросов и страницы результатов поиска.
При составлении запроса к системе используют либо меню-ориентированный подход, либо командную строку. Меню-ориентированный подход позволяет ввести список терминов, обычно через пробел, и выбрать тип логической связи между ними. Логическая связь распространяется на все термины. На нашей схеме (рисунок 3.41) есть так называемые сохраненные запросы пользователя. В большинстве систем это просто фраза на ИПЯ, которую можно расширить за счет добавления новых терминов и логических операторов. Но это только один тип использования сохраненных запросов. В традиционных системах это называется расширением или уточнением запроса, в зависимости от того, что получаем в результате преобразования запроса: увеличение размера выборки или ее сокращение. При этом традиционная система хранит не запрос как таковой, а результат поиска, т.е. список идентификаторов документов, который объединяется/пересекается со списком полученным при поиске документов по новым терминам. К сожалению, сохранение списка идентификаторов найденных документов в World Wide Web не практикуется. Вызвано это особенностью протоколов взаимодействия программы-клиента и сервера системы, которые не поддерживают сеансовый режим работы.
Как стало уже понятно из выше изложенного, результат поиска в базе данных ИПС - это список указателей на удовлетворяющие запросу документы. Различные системы представляют этот список по-разному. В некоторых системах выдается только список ссылок, а в таких системах как Lycos, AltaVista, Yahoo кроме ссылок дается еще и краткое описание, которое заимствуется либо из заголовков, либо из тела самого документа. Кроме этого система сообщает на сколько найденный документ соответствует запросу. В Yahoo, например, сообщается сколько терминов запроса содержится в поисковом образе документа и в соответствии с этим ранжируется результат поиска. В Lycos выдается мера соответствия документа запросу и ранжирование производится по этому параметру. Обычно пользователь имеет возможность уточнить запрос.
При обзоре интерфейсов и средств поиска нельзя пройти мимо процедуры коррекции запросов по релевантности[7]. Релевантность - это мера соответствия найденного системой документа потребности пользователя. Различают формальную релевантность и реальную. Формальная - это та, что вычисляет система и на основании чего ранжируется выборка найденных документов. Реальная - это та, как сам пользователь оценивает найденные документы. Некоторые системы имеют для этого специальное поле[6], где пользователь может отметить документ как релевантный. При следующей поисковой итерации запрос расширяется терминами этого документа. И выдача снова ранжируется. Так происходит до тех пор, пока результат не стабилизируется. Это означает, что ничего лучше, чем полученная выборка, от данной системы не добьешься.
Кроме ссылок на документы в списке, полученном пользователем, могут оказаться ссылки на части документов или на их поля. Это происходит при наличии ссылок типа http://host/path#mark или ссылок по схеме WAIS. Возможны ссылки и на скрипты, но обычно такие ссылки роботы пропускают и система не индексирует. Если с http-ссылками все более или менее понятно, то ссылки WAIS - это гораздо более сложные объекты. Дело в том, что WAIS реализует архитектуру распределенной информационно-поисковой системы. Это значит, что одна ИПС, например, Lycos строит поисковый аппарат над поисковым аппаратом другой системы - WAIS. При этом серверы WAIS имеют свои собственные локальные базы данных. При загрузке документов в WAIS администратор может описать структуру документов, т.е. разбить их на поля, и хранить документы как один файл. индекс WAIS будет ссылаться на отдельные документы и их поля как на самостоятельные единицы хранения. В этом случае программа просмотра ресурсов Internet должна уметь работать с протоколом WAIS, чтобы получить доступ к этим документам.
Назад | Содержание | Вперед