Распределенная информационная гипертекстовая система World Wide Web является одним из самых популярных, если не самым популярным, ресурсом Internet. Простота поддержки баз данных Web и проста использования программ доступа к ресурсам Web привели к тому, что скорость установки Web-серверов такова, что их количество удваивается каждые 62 дня. Интегрированные мультипротокольные интерфейсы World Wide Web объединяют в себе не только средство просмотра Web, но и доступ к FTP-архивам и средство работы с электронной почтой.
Практически, мультипротокольные программы типа Netscape Navigator, Internet Explorer, Arena и т.п. стали стандартным интерфейсом доступа в Сеть. Кроме этого, для разработки самих страниц Web не требуется какого-то изощренного программного обеспечения. Достаточно иметь обычный текстовый редактор и уже можно разрабатывать не только информационные страницы, но и стандартные формы ввода информации. Все это подвигло разработчиков программного обеспечения заговорить о технологии World Wide Web, как о технологии, способной удовлетворить множеству требований разнообразных задач, которые встречаются в организации информационной системы корпорации. После того, как Sun объявила о возможности использования в World Wide Web мобильных кодов Java, то последние сомнения о возможности организации корпоративного информационного сервиса на основе технологии World Wide Web отпали, и вся концепция получила название Intranet.
Разберем историю проекта, архитектуру программного обеспечения и протоколы World Wide Web более подробно.
3.5.1. История развития, отцы-основатели, современное состояние
Что же предлагал Тим Бернерс-Ли в 1989 году и что из этого получилось? В "World Wide Web: Proposal for HyperText Project", направленных руководству CERN, он считал, что информационная система, построенная на принципах гипертекста, должна объединить все множество информационных ресурсов CERN, которое состояло из базы данных отчетов, компьютерной документации, списков почтовых адресов, информационной реферативной системы, наборов данных результатов экспериментов и т.п. Гипертекстовая технология должна была позволить легко "перепрыгивать" из одного документа в другой.
Проект делился на две фазы, или, как у нас принято говорить, очереди. Первая очередь (продолжительностью в три месяца) должна была показать жизнеспособность идеи проекта. В течении этого этапа работ предполагалось разработать программы-интерфейсы для работы в алфавитно-цифровом режиме и программу-интерфейс для Macintosh и NeXT, работающую в графическом режиме, сервер для доступа к ресурсам Usenet, сервер для доступа к информационно-поисковой системе CERN, гипертекстовый сервер и программу-шлюз между Internet и DECnet.
В последующие три месяца (вторая очередь) предполагалось разработать средства подготовки гипертекстовых документов, полноэкранную программу просмотра для VM/XA, X-Window-интерфейс и систему автоматической нотификации просматриваемых материалов.
Кроме программного обеспечения предполагалось разработать общий протокол обмена информацией в сети, метод отображения текста на экране компьютера, создать набор базовых документов, иллюстрирующих работу системы, который мог бы пополняться за счет документов пользователей, обеспечить поиск по ключевым словам в этом наборе документов.
Любопытно, что из проекта в обязательном порядке исключались всякие исследования, связанные с конвертированием информации из форматов каких-либо редакторов в форматы данных системы, возможностью работы с видео- и аудио-информацией, все работы, связанные с защитой информации от несанкционированного доступа.
На всю эту полугодовую работу автор просил 4-х разработчиков (software designers) и одного программиста, и для каждого из них отдельное рабочее место (компьютер того типа, для которого разработчик будет писать программное обеспечение). Кроме этого требовалось приобрести коммерческое программное обеспечение, которое было бы полезно при разработке системы (Guide, KMS, FrameMaker).
Как видно, запросы были невелики, и в октябре 1990 года проект стартовал. Уже в ноябре был реализован прототип системы для NeXT, к рождеству "задышал" line mode browser, разработке которого придавалось особое значение, т.к. он открывал доступ к системе через telnet, а в марте его можно было уже демонстрировать. Через год в Internet был установлен анонимный telnet для доступа в систему. Первое сообщение об WWW было послано в телеконференции: alt.hypertext, com.sys.next, comp.text.sgml и comp.mail. multimedia, в августе 1991 года.
По современным меркам результаты, которых достигли разработчики к 1991 году выглядят довольно скромно, если не вдаваться в суть работы и ограничиться только внешним ее проявлением. Сообщество Internet получило еще одну программу, работающую в режиме командной строки. Прошло еще целых полтора года до того момента, когда программа Mosaic, разработанная Марком Андресеном (Mark Andressen) из Национального Центра Суперкомпьютерных Приложений (NCSA), и построенная на принципах WWW, обеспечили бурный рост популярности "паутины" в Internet.
NCSA начала проект по разработке интерфейса в World Wide Web месяц спустя после объявления CERN. Одна из задач NCSA - это разработка доступных некоммерческих программ, с другой стороны NCSA изучает новые технологии на предмет их коммерческого применения в будущем. World Wide Web безусловно подходила под эти два параметра. Кроме того, спецификации WWW производили впечатление добротно выполненной академической работы с обзором литературы по данному вопросу, обилием ссылок и обоснованностью принятых решений. Мультипротокольный переносимый интерфейс в WWW, создание которого начала Группа Разработки Программного Обеспечения NCSA, был назван Mosaic. Пробная версия программы была закончена в первой половине 1993 года, а в августе 1993 была анонсирована альфа-версия для Internet.
Следует отметить, что сам проект Mosaic внес огромный вклад в развитие спецификаций World Wide Web, существенно обогатив различные компоненты системы. Разработчики Mosaic ввели в стандарты WWW большое количество новшеств. Агрессивная политика команды NCSA привела к тому, что многие программы-интерфейсы, разработанные в рамках ранних стандартов, постепенно стали отмирать, не выдержав конкуренции. Для самого NCSA это закончилось тем, что лидер команды, Марк Андресен, покинул в марте 1994 года NCSA и организовал коммерческую корпорацию Netscape. C этого момента начался новый этап борьбы, но теперь между старыми коллегами. Netscape активно навязывает свои стандарты, что приводит к тому, что документы, подготовленные с расширениями Netscape неправильно отображаются Mosaic, а документы с расширенными возможностями NCSA могут вообще не отображаться Netscape.
Следует отметить, что проект NCSA преследовал большие цели, нежели просто программу-интерфейс в WWW. С самого начала Mosaic разрабатывалась как программа с возможностями доступа к ресурсам Internet посредством различных протоколов, в число которых входили FTP, telnet, NNTP, SMTP. Однако вначале предполагалось, что делаться это будет за счет вызова внешних, относительно Mosaic, программ. В настоящее время Netscape сам поддерживает, кроме перечисленных, протоколы доступа в Gopher и Wais. Последнее позволяет использовать Netscape, впрочем как и Mosaic, для работы вне рамок World Wide Web.
Mosaic на некоторое время затмила разработки CERN. Однако эта группа имела хорошо продуманную стратегию развития системы, которая включала в себя следующие основные моменты: разработка и поддержка стандартов спецификаций системы, разработка библиотеки свободно распространяемых мобильных кодов системы, полного комплекта средств, обеспечивающих разработку и реализацию компонентов системы на любом типе компьютера в сети, подготовка набора справочных и демонстрационных документов о состоянии сети и направлениях ее развития. Данная стратегия позволила распространять программное обеспечение, разработанное в рамках проекта в Internet, а наличие line mode broser'а позволила открыть возможности WWW для огромной аудитории пользователей алфавитно-цифровых устройств, подключенных в сеть. Некоторое время NCSA лидировала и по числу установок серверов, однако в настоящее время CERN обеспечил себе паритет и в этой области. Правда, и здесь не обошлось без "накладок". Так, форматы файлов конфигурации программы imagemap, обеспечивающей работу с графическими гипертекстовыми ссылками, у этих двух серверов различны.
Другим показателем успешного развития работ является образование W3-консорциума. Консорциум образован после подписания соглашения между Масачусетским Технологическим Институтом (MIT, USA) и Национальным Институтом Информатики и Автоматики (INRA, France) c согласия CERN. Если не вдаваться в подробности, то смысл этого соглашения заключается в том, что все программное обеспечение аккумулируется в MIT, участники имеют право copyright на все разработанное программное обеспечение и спецификации. Программное обеспечение распространяется свободно. За представителем MIT закрепляется должность директора, а за представителем INRA - должность зам. директора. Взносы полноправных участников W3C составляют $50.000 в год, а ассоциированных членов - $5.000 в год, соглашение заключено на три года начиная с 1 октября 1994 года. Любопытно, что организации с годовым оборотом, превышающим $50 миллионов, обязаны регистрироваться как полноправные члены, и что консорциум надеется получать прибыль, превышающую $1,5 миллиона, т.к. предусмотрен порядок использования средств сверх этой суммы. Средства до этого предела используются на развитие системы и исследования.
Образование Netscape Corporation и W3C легко объяснимы с точки зрения роста популярности WWW. В марте 1993 года трафик World Wide Web составлял 0,1% от общего трафика сети NSF, сентябре 1993 года он уже составил 1,0% от общего трафика сети NSF. В октябре 1993 года количество зарегистрированных серверов WWW равнялось 500, а к июню 1994 года оно достигло 1500 и продолжает стремительно расти.
Следует отметить, что появление технологии WWW и ее бурный прогресс не одинок. Приблизительно в это же время появились и другие распределенные информационные технологии в Internet. Это, в первую очередь, Gopher и Wais. Столь бурный рост этого сектора компьютерных технологий привел к появлению на свет очень интересного документа, подготовленного по заказу Комиссии Европейского Союза к ежегодной встрече руководителей Союза 24-25 июня 1994 года на Корфу. Документ прямо обращает внимание руководителей стран Союза на тот факт, что происходит бурный рост рынка информационных технологий, и если Союз не хочет в очередной раз оказаться на вторых ролях, то должен предпринять энергичные усилия по поддержке работ в этой области. Авторы доклада утверждают, что происходит очередная техническая революция, вызванная возможностями современных телекоммуникационных систем и компьютерных сетей. Авторы выделяют десять основных сфер применения новых технологий:
В каком-то смысле учреждение W3C является ответом профессионалов на медлительность бюрократов из Комиссии ЕвроСоюза. Среди учредителей W3C один из авторов документа - Мартин Банжеманн (Martin Bangemann).
Следующим важным этапом развития технологии World Wide Web стало появление весной 1995 года языка программирования Java, анонсированного компанией Sun Microsystems. Если быть более точным, то прямое отношение к World Wide Web имеет не сам язык, а мобильные коды и возможность их интерпретации программами просмотра Web. Создав свой броузер (программу просмотра) HotJava, Sun смогла продемонстрировать, что идеология интерпретации языка разметки документов может быть расширена. В страницы теперь можно стало встраивать фрагменты программ, которые после передачи по сети активировались на компьютере пользователя, расширяя тем самым концепцию распределенных вычислений.
К этому времени кроме Java появились еще и языки управления сценариями просмотра документов, самым известным из которых стал JavaScript. Тем самым, к середине 1996 года технология World Wide Web превратилась в полноценную гипертекстовую технологию, которая стала позволять решать большинство из тех задач, до которых доросли локальные гипертекстовые системы.
Учитывая все сказанное выше, попытаемся подробно остановиться на особенностях World Wide Web и отдельных ее компонентах, спецификациях и способах наращивания системы за счет внешнего программного обеспечения, существующем программном обеспечении и особенностях его функционирования на различных компьютерных платформах. Этим вопросам и будут посвящены следующие несколько разделов.
3.5.2. Понятие гипертекста
В предыдущем разделе речь шла об истории и основных вехах развития World Wide Web. В последнее время часто приходится слышать, что WWW - это очень просто. Однако, за этой кажущейся простотой скрывается хорошо продуманная сложная система. При этом следует заметить, что система бурно развивается. Для того, чтобы более точно описать это развитие, наши англоязычные коллеги используют эпитет "dramatic". Познакомимся более подробно с WWW.
В 1989 году, когда Т.Бернерс-Ли предложил свою систему, в мире информационных технологий наблюдался повышенный интерес к новому и модному в то время направлению - гипертекстовым системам. Сама идея, но не термин, была введена В.Бушем (Vannevar Bush) в 1945 году в предложениях по созданию электромеханической информационной системы Memex. Несмотря на то, что Буш был советником по науке президента Рузвельта, идея не была реализована. В 1965 году Т.Нельсон (Ted Nelson) ввел в обращение сам термин "гипертекст", развил и даже реализовал некоторые идеи, связанные с работой с "нелинейными" текстами. В 1968 году изобретатель манипулятора "мышь" Д.Енжильбард (Doug Engelbart) продемонстрировал работу с системой, имеющей типичный гипертекстовый интерфейс, и, что интересно, проведена эта демонстрация была с использованием системы телекоммуникаций. Однако внятно описать свою систему он не смог. В 1975 году идея гипертекста нашла воплощение в информационной системе внутреннего распорядка атомного авианосца "Карл Винстон", которая получила название ZOG. В коммерческом варианте система известна как KMS. Работы в этом направлении продолжались и, время от времени, появлялись реализации типа HyperCard фирмы Apple или HyperNode фирмы Xerox. В 1987 была проведена первая специализированная конференция Hypertext'87, материалам которой был посвящен специальный выпуск журнала "Communication ACM".
Идея гипертекстовой информационной системы состоит в том, что пользователь имеет возможность просматривать документы (страницы текста) в том порядке, в котором ему это больше нравится, а не последовательно, как это принято при чтении книг. Поэтому Т.Нельсон и определил гипертекст как нелинейный текст. Достигается это путем создания специального механизма связи различных страниц текста при помощи гипертекстовых ссылок, т.е. у обычного текста есть ссылки типа "следующий-предыдущий", а у гипертекста можно построить еще сколь угодно много других ссылок. Любимыми примерами специалистов по гипертексту являются энциклопедии, Библия, системы типа "Help".
Простой, на первый взгляд, механизм построения ссылок оказывается довольно сложной задачей, т.к. можно построить статические ссылки, динамические ссылки, ассоциированные с документом в целом или только с отдельными его частями, т.е. контекстные ссылки. Дальнейшее развитие этого подхода приводит к расширению понятия гипертекста за счет других информационных ресурсов, включая графику, аудио- и видео-информацию, до понятия гипермедиа. Тем, кто интересуется более подробно различными схемами и способами разработки гипертекстовых систем, стоит обратиться к специальной литературе.
3.5.3. Основные компоненты технологии World Wide Web
К 1989 году гипертекст представлял новую, многообещающую технологию, которая имела относительно большое число реализаций с одной стороны, а с другой стороны делались попытки построить формальные модели гипертекстовых систем, которые носили скорее описательный характер и были навеяны успехом реляционного подхода описания данных. Идея Т.Бернерс-Ли заключалась в том, чтобы применить гипертекстовую модель к информационным ресурсам, распределенным в сети, и сделать это максимально простым способом. Он заложил три краеугольных камня системы из четырех существующих ныне, разработав:
Позже команда NCSA добавила к этим трем компонентам четвертый:
Java не включается в этот список намеренно, т.к. область применения этого языка гораздо шире чем простое "оживление" World Wide Web.
Идея HTML - пример чрезвычайно удачного решения проблемы построения гипертекстовой системы при помощи специального средства управления отображением. На разработку языка гипертекстовой разметки существенное влияние оказали два фактора: исследования в области интерфейсов гипертекстовых систем и желание обеспечить простой и быстрый способ создания гипертекстовой базы данных, распределенной на сети.
В 1989 году активно обсуждалась проблема интерфейса гипертекстовых систем, т.е. способов отображения гипертекстовой информации и навигации в гипертекстовой сети. Значение гипертекстовой технологии сравнивали со значением книгопечатания. Утверждалось, что лист бумаги и компьютерные средства отображния/воспроизведения серьезно отличаются друг от друга, и поэтому форма представления информации тоже должна отличаться. Наиболее эффективной формой организации гипертекста были признаны контекстные гипертекстовые ссылки, а кроме того, было признано деление на ссылки, ассоциированные со всем документом в целом и отдельными его частями.
Самым простым способом создания любого документа является его набивка в текстовом редакторе. Опыт создания хорошо размеченных для последующего отображения документов в CERN'е был - трудно найти физика, который не пользовался бы системой TeX или LaTeX. Кроме того к тому времени существовал стандарт языка разметки - Standard Generalised Markup Language (SGML).
Следует также принять во внимание, что согласно своим предложениям Т.Бернерс-Ли предполагал объединить в единую систему имеющиеся информационные ресурсы CERN, и первыми демонстрационными системами должны были стать системы для NeXT и VAX/VMS.
Обычно гипертекстовые системы имеют специальные программные средства построения гипертекстовых связей. Сами гипертекстовые ссылки хранятся в специальных форматах или даже составляют специальные файлы. Такой подход хорош для локальной системы, но не для распределенной на множестве различных компьютерных платформ. В HTML гипертекстовые ссылки встроены в тело документа и хранятся как его часть. Часто в системах применяют специальные форматы хранения данных для повышения эффективности доступа. В WWW документы - это обычные ASCII- файлы, которые можно подготовить в любом текстовом редакторе. Таким образом, проблема создания гипертекстовой базы данных была решена чрезвычайно просто.
В качестве базы для разработки языка гипертекстовой разметки был выбран SGML (Standard Generalised Markup Language). Следуя академическим традициям, Бернерс-Ли описал HTML в терминах SGML (как описывают язык программирования в терминах формы Бекуса-Наура). Естественно, что в HTML были реализованы все разметки, связанные с выделением параграфов, шрифтов, стилей и т.п., т.к. реализация для NeXT подразумевала графический интерфейс. Важным компонентом языка стало описание встроенных и ассоциированных гипертекстовых ссылок, встроенной графики и обеспечение возможности поиска по ключевым словам.
С момента разработки первой версии языка (HTML 1.0) прошло уже пять лет. За это время произошло довольно серьезное развитие языка. Почти вдвое увеличилось число элементов разметки, оформление документов все больше приближается оформлению качественных печатных изданий, развиваются средства описания нетекстовых информационных ресурсов и способы взаимодействия с прикладным программным обеспечением. Совершенствуется механизм разработки типовых стилей. Фактически, в настоящее время HTML развивается в сторону создания стандартного языка разработки интерфейсов как локальных, так и распределенных систем.
Вторым краеугольным камнем WWW стала универсальная форма адресации информационных ресурсов. Universal Resource Identification (URI) представляет собой довольно стройную систему, учитывающую опыт адресации и идентификации e-mail, Gopher, WAIS, telnet, ftp и т.п. Но реально из всего, что описано в URI, для организации баз данных в WWW требуется только Universal Resource Locator (URL). Без наличия этой спецификации вся мощь HTML оказалась бы бесполезной. URL используется в гипертекстовых ссылках и обеспечивает доступ к распределенным ресурсам сети. В URL можно адресовать как другие гипертекстовые документы формата HTML, так и ресурсы e-mail, telnet, ftp, Gopher, WAIS, например. Различные интерфейсные программы по-разному осуществляют доступ к этим ресурсам. Одни, как например Netscape, сами способны поддерживать взаимодействие по протоколам, отличным от протокола HTTP, базового для WWW, другие, как например Chimera, вызывают для этой цели внешние программы. Однако, даже в первом случае, базовой формой представления отображаемой информации является HTML, а ссылки на другие ресурсы имеют форму URL. Следует отметить, что программы обработки электронной почты в формате MIME также имеют возможность отображать документы, представленные в формате HTML. Для этой цели в MIME зарезервирован тип "text/html".
Третьим в нашем списке стоит протокол обмена данными в World Wide Web - HTTP (Hyper-Text Transfer Protocol). Данный протокол предназначен для обмена гипертекстовыми документами и учитывает специфику такого обмена. Так в процессе взаимодействия, клиент может получить новый адрес ресурса на сети (relocation), запросить встроенную графику, принять и передать параметры и т. п. Управление в HTTP реализовано в виде ASCII-команд. Реально, разработчик гипертекстовой базы данных сталкивается с элементами протокола только при использовании внешних расчетных программ или при доступе к внешним, относительно WWW, информационным ресурсам, например базам данных.
Последняя составляющая технологии WWW - это уже плод работы группы NCSA - спецификация CGI (Common Gateway Interface). CGI была специально разработана для расширения возможностей WWW за счет подключения всевозможного внешнего программного обеспечения. Такой подход логично продолжал принцип публичности и простоты разработки и наращивания возможностей WWW. Если команда CERN предложила простой и быстрый способ разработки баз данных, то NCSA развила этот принцип на разработку программных средств. Надо заметить, что в общедоступной библиотеке CERN были модули, позволяющие программистам подключать свои программы к серверу HTTP, но это требовало использования этой библиотеки. Предложенный и описанный в CGI способ подключения не требовал дополнительных библиотек и буквально ошеломлял своей простотой. Сервер взаимодействовал с программами через стандартные потоки ввода/вывода, что упрощает программирование до предела. При реализации CGI чрезвычайно важное место заняли методы доступа, описанные в HTTP. И хотя реально используются только два из них (GET и POST), опыт развития HTML показывает, что сообщество WWW ждет развития и CGI по мере усложнения задач, в которых будет использоваться WWW-технология.
3.5.4. Архитектура построения системы
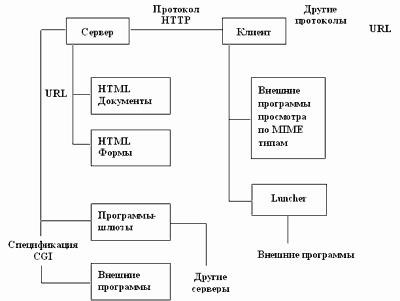
От описания основных компонентов перейдем к архитектуре взаимодействия программного обеспечения в системе World Wide Web. WWW построена по хорошо известной схеме "клиент-сервер". На рисунке 3.25 показано, как разделены функции в этой схеме.
Программа-клиент выполняет функции интерфейса пользователя и обеспечивает доступ практически ко всем информационным ресурсам Internet. В этом смысле она выходит за обычные рамки работы клиента только с сервером определенного протокола, как это происходит в telnet, например. Отчасти, довольно широко распространенное мнение, что Mosaic или Netscape, которые безусловно являются WWW-клиентами, это просто графический интерфейс в Internet, является верным. Однако, как уже было отмечено, базовые компоненты WWW-технологии (HTML и URL) играют при доступе к другим ресурсам Mosaic не последнюю роль, и поэтому мультипротокольные клиенты должны быть отнесены именно к World Wide Web, а не к другим информационным технологиям Internet. Фактически, клиент - это интерпретатор HTML. И как типичный интерпретатор, клиент в зависимости от команд (разметки) выполняет различные функции. В круг этих функций входит не только размещение текста на экране, но и обмен информацией с сервером по мере анализа полученного HTML-текста, что наиболее наглядно происходит при отображении встроенных в текст графических образов. При анализе URL-спецификации или по командам сервера клиент запускает дополнительные внешние программы для работы с документами в форматах, отличных от HTML, например GIF, JPEG, MPEG, Postscript и т.п. Вообще говоря, для запуска клиентом программ независимо от типа документа была разработана программа Luncher, но в последнее время гораздо большее распространение получил механизм согласования запускаемых программ через MIME-типы.
Другую часть программного комплекса WWW составляет сервер протокола HTTP, базы данных документов в формате HTML, управляемые сервером, и программное обеспечение, разработанное в стандарте спецификации CGI. До самого последнего времени (до образования Netscape) реально использовалось два HTTP-сервера: сервер CERN и сервер NCSA. Но в настоящее время число базовых серверов расширилось. Появился очень неплохой сервер для MS-Windows и Apachie-сервер для Unix- платформ. Существуют и другие, но два последних можно выделить из соображений доступности использования. Сервер для Windows - это shareware, но без встроенного самоликвидатора, как в Netscape. Учитывая распространенность персоналок в нашей стране, такое программное обеспечение дает возможность попробовать, что такое WWW. Второй сервер - это ответ на угрозу коммерциализации. Netscape уже не распространяет свой сервер Netsite свободно и прошел слух, что NCSA-сервер также будет распространяться на коммерческой основе. В результате был разработан Apachie, который по словам его авторов будет freeware, и реализует новые дополнения к протоколу HTTP, связанные с защитой от несанкционированного доступа, которые предложены группой по разработке этого протокола и реализуются практически во всех коммерческих серверах.
Рис. 3.25. Архитектура WWW-технологии
База данных HTML-документов - это часть файловой системы, которая содержит текстовые файлы в формате HTML и связанные с ними графику и другие ресурсы. Особое внимание хотелось бы обратить на документы, содержащие элементы экранных форм. Эти документы реально обеспечивают доступ к внешнему программному обеспечению.
Прикладное программное обеспечение, работающее с сервером, можно разделить на программы-шлюзы и прочие. Шлюзы - это программы, обеспечивающие взаимодействие сервера с серверами других протоколов, например ftp, или с распределенными на сети серверами Oracle. Прочие программы - это программы, принимающие данные от сервера и выполняющие какие-либо действия: получение текущей даты, реализацию графических ссылок, доступ к локальным базам данных или просто расчеты.
Все, что было сказано до этого момента, можно отнести к классической схеме World Wide Web. В настоящее время следует говорить об изменении общей архитектуры.
Как видно из рисунка 3.26, к середине 1996 года произошли некоторые изменения в архитектуре сервиса World Wide Web.
Произошел возврат к модульной структуре сервера World Wide Web. Этот возврат был реализован в виде спецификации API. API - это спецификация разработки прикладных модулей, которые встраиваются в сервер, точнее редактируются совместно с модулями сервера. Применение во всех серверах многопотоковой технологии выполнения подзадач делает такой способ расширения возможностей сервера более экономичным с точки зрения ресурсов вычислительной установки, чем разработка CGI-скриптов.
В дополнение к HTML активно стал применяться еще один язык разметки - VRML (Virtual Reality Modeling Language). В данном случае речь идет об описании трехмерных сен и возможности "бродить" по этим мирам. При этом в VRML также, как и в HTML предусмотрены гипертекстовые ссылки, что позволяет создавать смешанные базы данных, где информационный архив, например, можно представить в виде книг в библиотеке, среди которых может путешествовать автор, выбирая нужную ему тематику и источник, которые затем представляются в формате документа HTML.
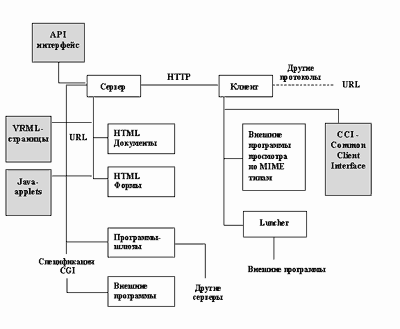
Рис. 3.26. Архитектура World Wide Web к середине 1996 года
Java-applet'ы - это мобильные коды Java, ссылки на которые вмонтированы в тело документа. При доступе к такому документу программа просмотра пользователя предварительно анализирует документ на предмет наличия в нем такого типа ссылок, и, если они существуют, то подкачивает мобильные коды в свою память. Коды могут сразу выполняться по мере размещения их на компьютере пользователя, но могут активироваться и при помощи специальных команд.
Как видно из рисунка, изменения коснулись и клиентской части технологии. В настоящее время происходит постепенный переход от простой классической архитектуры клиент-сервер к архитектуре с сервером приложений, в роли которого выступает программа-клиент. В частности, NCSA опубликовала спецификацию CCI (Common Client Interface) для разработки приложений для работы с сервисами World Wide Web через программу Mosaic.
Завершая обсуждение архитектуры World Wide Web хотелось бы еще раз подчеркнуть, что ее компоненты существуют практически для всех типов компьютерных платформ и свободно доступны в сети. Любой, кто имеет доступ в Internet, может создать свой WWW-сервер, или, по крайней мере, посмотреть информацию с других серверов.
3.5.4.1. Язык гипертекстовой разметки HTML
Язык гипертекстовой разметки HTML (HyperText Markup Language) был предложен Тимом Бернерсом-Ли в 1989 году в качестве одного из компонентов технологии разработки распределенной гипертекстовой системы World Wide Web.
Разработчики HTML пытались решить две задачи:
Первая задача была решена за счет выбора таговой модели описания документа. Такая модель широко применяется в системах подготовки документов для печати. Примером такой системы является хорошо известный язык разметки научных документов TeX, предложенный Американским Математическим Обществом, и программы его интерпретации.
К моменту создания HTML существовал стандарт языка разметки печатных документов - SGML (Standard Generalized Markup Language), который и был взят в качестве основы HTML. Предполагалось, что такое решение поможет использовать существующее программное обеспечение для интерпретации нового языка. Однако, будучи доступным широкому кругу пользователей Internet, HTML зажил своей собственной жизнью. Вероятно, многие администраторы баз данных WWW и разработчики программного обеспечения для этой системы имеют довольно смутное представление о стандартном языке разметки SGML.
Вторым важным моментом, повлиявшим на судьбу HTML, стал выбор в качестве элемента гипертекстовой базы данных обычного текстового файла, который хранится средствами файловой системы операционной среды компьютера. Такой выбор был сделан под влиянием следующих факторов:
Таким образом, гипертекстовая база данных в концепции WWW - это набор текстовых файлов, написанных на языке HTML, который определяет форму представления информации (разметка) и структуру связей этих файлов (гипертекстовые ссылки).
Такой подход предполагает наличие еще одной компоненты технологии - интерпретатора языка. В World Wide Web функции интерпретатора разделены между сервером гипертекстовой базы данных и интерфейсом пользователя.
Сервер, кроме доступа к документам и обработки гипертекстовых ссылок, осуществляет также препроцессорную обработку документов, в то время как интерфейс пользователя осуществляет интерпретацию конструкций языка, связанных с представлением информации.
К настоящему времени известна уже третья версия языка - HTML 3.0, которая находится в стадии развития. Если первая версия языка (HTML 1.0) была направлена на представление языка как такового, где описание его возможностей носило скорее рекомендательный характер, вторая версия языка ( HTML 2.0) фиксировала практику использования конструкций языка, версия ++ ( HTML++) представляла новые возможности, расширяя набор элементов HTML в сторону отображения научной информации и таблиц, а также улучшения стиля компоновки изображений и текста, то версия 3.0 призвана упорядочить все нововведения и согласовать их с существующей практикой. Кроме этого, в версии 3.0 снова делается попытка формализации интерфейса пользователя гипертекстовой распределенной системы.
3.5.4.2. Принципы построения и интерпретации HTML
Таговая модель описывает документ как совокупность элементов, каждый из которых окружен тагами. По своему значению таги близки к понятию скобок "begin/end" в универсальных языках программирования, которые задают области действия имен локальных переменных и т. п. Таги определяют область действия правил интерпретации текстовых элементов документа. Типичным примером такого рода является таг стиля Italic, который определяет область отображения курсива.
Текст на языке HTML:
Текст следующий за словом "Italic" <I>отображается как курсив</I>.
Текст отображаемый программой интерпретации:
Текст следующий за словом "Italic" отображается как курсив.
В приведенном выше примере элемент текста, который должен быть выделен курсивом, заключен между тагом начала стиля "Italic" - <I> и тагом конца стиля - </I>. Общая схема построения элемента текста в формате HTML может быть записана в следующем виде:
"элемент" := <"имя элемента" "список атрибутов"> содержание элемента </"имя элемента">
Конструкция перед содержанием элемента называется тагом начала элемента, а конструкция, расположенная после содержания элемента, - тагом конца элемента.
Структура гипертекстовой сети задается гипертекстовыми ссылками. Гипертекстовая ссылка - это адрес другого HTML документа, который тематически, логически или каким-либо другим способом связан с документом, в котором ссылка определена.
Для записи гипертекстовых ссылок в системе WWW была разработана специальная форма, которая называется Universe Resource Locator. Типичным примером использования этой записи можно считать следующий пример:
Этот текст содержит <A HREF="http://polyn.net.kiae.su/altai/index.html"> гипертекстовую ссылку</A>.
В приведенном выше примере элемент "A", который в HTML называют якорем (anchor), использует атрибут "HREF", который обозначает гипертекстовую ссылку (HyperText REFerence), для записи этой ссылки в форме URL. Данная ссылка указывает на документ с именем "index.html" в директории "altai" на сервере "polyn.net.kiae.su", доступ к которому осуществляется по протоколу "http".
Гипертекстовые ссылки в HTML делятся на два класса: контекстные гипертекстовые ссылки и общие. Контекстные ссылки вмонтированы в тело документа, как это было продемонстрировано в предыдущем примере, в то время как общие ссылки связаны со всем документом в целом и могут быть использованы при просмотре любого фрагмента документа. Оба класса ссылок присутствуют в стандарте языка с самого его рождения, однако, первоначально наибольшей популярностью пользовались контекстные ссылки. Эта популярность привела к тому, что механизм использования общих ссылок практически полностью "атрофировался". Однако по мере стандартизации интерфейса пользователя и стилей представления информации разработчики языка снова вернулись к общим ссылкам и стремятся приспособить их к задачам управления этим интерфейсом.
Структура HTML-документа позволяет использовать вложенные друг в друга элементы. Собственно, сам документ - это один большой элемент с именем "HTML":
<HTML> Содержание документа </HTML>
Сам элемент HTML или гипертекстовый документ состоит из двух частей: заголовка документа (HEAD) и тела документа (BODY):
<HTML> <HEAD> Содержание заголовка </HEAD> <BODY> Содержание тела документа </BODY> </HTML>
Приведенная выше форма записи определяет классический HTML-документ. Введение в язык HTML фреймов определило еще один шаблон документа:
<HTML> <!-- Author: HTMLed User Date: January 21, 1996 --> <HEAD> </HEAD> <FRAMESET COLS="40%,*"> <NOFRAMES> <BODY> Sorry there are not a frame support in your browser. </BODY> </NOFRAMES> <FRAMESET ROWS="120,*,60"> <FRAME SRC=banner.htm NAME=banner> <FRAME SRC="www.htm" NAME=content> <FRAME SRC="bottom.htm" NAME=bottom> </FRAMESET> <FRAMESET ROWS="100%"> <FRAME SRC="www_hist.htm" NAME=info> </FRAMESET> </FRAMESET> </HTML>
В данном примере представлен документ, который состоит из трех окон внутри рабочего окна программы просмотра, в каждое из которых загружается обычный документ.
Рассмотрим пример классического документа:
<HTML> <!-- Author: Pavel Khramtsov Date: January 21, 1996 --> <HEAD> <TITLE>This is a Baner</TITLE> </HEAD> <BODY BACKGROUND=www_wall.jpg VLINK=0000FF LINK=FF0000> <CENTER> <TABLE> <TR><TD><IMG SRC="interne0.jpg"></TD> <TD CENTER> <H3>Администрирование Internet</H3> <I>Центр Информационных Технологий, 1996.</I> </TD></TR> </TABLE> </CENTER> </BODY> </HTML>
Все, что расположено между <HTML> и </HTML> - это документ. Содержание элемента HEAD определяет заголовок документа, который состоит из двух элементов: TITLE и BASE. Вслед за заголовком начинается тело документа, которое содержит в своих первых строках некоторую вводную информацию и содержание документа, оформленное в виде списка.
Каждый документ в системе World Wide Web имеет свое имя, которое указывается в элементе TITLE заголовка документа. Его мы видим в первой строке интерфейса.
Контейнер BODY открывает тело документа. В качестве фона в этом элементе определена картинка back.gif. Эта картинка - "back.gif" - задана частичной формой спецификации URL, которая не задает полного адреса ресурса в сети.
Затем мы определили таблицу, состоящую из двух ячеек. В одной ячейке картинка, в то время как в другой - текстовый фрагмент. Текст определен как заголовок третьего уровня, который должен отображаться стилем Italic.
Кроме текстовых фрагментов и описаний фреймов на странице могут встретиться программы на JavaScript:
<HTML>
<HEAD>
<TITLE>JavaScript</TITLE>
<SCRIPT LANGUAGE="JavaScript">
<!-- Hide script from user
// * * *
// * * Form runing string
// * * *
adv_string = "Internet\""
status_string = adv_string+adv_string+adv_string+adv_string+adv_string+adv_string
// * * *
// * * Background function definition
// * * *
i=0
function background()
{
// Select 50 symbols from status string target.
window.status = status_string.substring(i,i+180)
// After last character move to first position
if(++i == 180) i=0
// The Clock is here
current_date = new Date()
window.document.form1.clock.value =
current_date.getHours()+":"+current_date.getMinutes()
+":"+current_date.getSeconds()
// Set timeout between function execution
id = setTimeout("background()",500)
window.document.form1.kuku.value = "number" + i
}
// This is the end of code definition -->
</SCRIPT>
</HEAD>
<BODY onLoad="background()" BACKGROUND=www_wal0.jpg>
<H1>JavaScript</H1>
<HR>
JavaScript - текст о JavaScript.:
<UL>
<LI><A HREF="#m_clock">Часы</A>
<LI><A HREF="#wind">Бегущая строка</A>
</UL>
<HR>
<A NAME=m_clock>
<FORM NAME=form1 ACTION="new_window()">
<INPUT NAME=clock TYPE=text SIZE=8 MAXLENGTH=8>
<HR>
<A NAME=wind>
<INPUT TYPE=button NAME=help Value="HELP"
onClick="window.open('clock.htm','Clock_Window','
scrollbars=yes,width=450,height=350')">.
<HR>
<INPUT NAME=kuku type=text>
<HR>
</FORM
<P>
</BODY>
</HTML>
В данном случае описаны две программы: программа идущих часов и программа бегущей строки. Данный язык поддерживают не все программы просмотра.
Назад | Содержание | Вперед