2.2.3. Протокол IP
Протокол IP является самым главным во всей иерархии протоколов семейства TCP/IP. Именно он используется для управления рассылкой TCP/IP пакетов по сети Internet. Среди различных функций, возложенных на IP обычно выделяют следующие:
Главными особенностями протокола IP является отсутствие ориентации на физическое или виртуальное соединение. Это значит, что прежде чем послать пакет в сеть, модуль операционной системы, реализующий IP, не проверяет возможность установки соединения, т.е. никакой управляющей информации кроме той, что содержится в самом IP-пакете, по сети не передается. Кроме этого, IP не заботится о проверке целостности информации в поле данных пакета, что заставляет отнести его к протоколам ненадежной доставки. Целостность данных проверяется протоколами транспортного уровня (TCP) или протоколами приложений.
Таким образом, вся информация о пути, по которому должен пройти пакет берется из самой сети в момент прохождения пакета. Именно эта процедура и называется маршрутизацией в отличии от коммутации, которая используется для предварительного установления маршрута следования данных, по которому потом эти данные отправляют.
Принцип маршрутизации является одним из тех факторов, который обеспечил гибкость сети Internet и ее победу в соревновании с другими сетевыми технологиями. Надо сказать, что маршрутизация является довольно ресурсоемкой процедурой, так как требует анализа каждого пакета, который проходит через шлюз или маршрутизатор, в то время как при коммутации анализируется только управляющая информация, устанавливается канал, физический или виртуальный, и все пакеты пересылаются по этому каналу без анализа маршрутной информации. Однако, эта слабость IP одновременно является и его силой. При неустойчивой работе сети пакеты могут пересылаться по различным маршрутам и затем собираться в единое сообщение. При коммутации путь придется каждый раз вычислять заново для каждого пакета, а в этом случае коммутация потребует больше накладных затрат, чем маршрутизация.
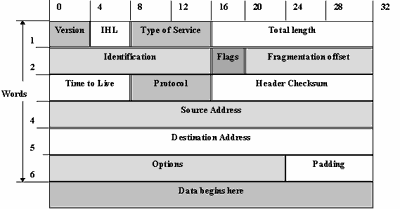
Вообще говоря, версий протокола IP существует несколько. В настоящее время используется версия Ipv4 (RFC791). Формат пакета протокола представлена на рисунке 2.8.
2.8. Формат пакета Ipv4
Фактически, в этом заголовке определены все основные данные, необходимые для перечисленных выше функций протокола IP: адрес отправителя (4-ое слово заголовка), адрес получателя (5-ое слово заголовка), общая длина пакета (поле Total Lenght) и тип пересылаемой датаграммы (поле Protocol).
Используя данные заголовка, машина может определить на какой сетевой интерфейс отправлять пакет. Если IP-адрес получателя принадлежит одной из ее сетей, то на интерфейс этой сети пакет и будет отправлен, в противном случае пакет отправят на другой шлюз (см. раздел 2.6).
Если пакет слишком долго "бродит" по сети, то очередной шлюз может отправить ICMP-пакет на машину-отправитель для того, чтобы уведомить о том, что надо использовать другой шлюз. При этом, сам IP-пакет будет уничтожен. На этом принципе работает программа ping, которая используется для деления маршрутов прохождения пакетов по сети.
Зная протокол транспортного уровня, IP-модуль производит раскапсулирование информации из своего пакета и ее направление на модуль обслуживания соответствующего транспорта.
При обсуждении формата заголовка пакета IP вернемся еще раз к инкапсулированию. Как уже отмечалось, при обычной процедуре инкапсулирования пакет просто помещается в поле данных фрейма, а в случае, когда это не может быть осуществлено, то разбивается на более мелкие фрагменты. Размер максимально возможного фрейма, который передается по сети, определяется величиной MTU (Maximum Transsion Unit), определенной для протокола канального уровня. Для того, чтобы потом восстановить пакет IP должен держать информацию о своем разбиении. Для этой цели используется поля "flags" и "fragmentation offset". В этих полях определяется, какая часть пакета получена в данном фрейме, если этот пакет был фрагментирован на более мелкие части.
Обсуждая протокол IP и вообще все семейство протоколов TCP/IP нельзя не упомянуть, что в настоящее время перед Internet возникло множество по-настоящему сложных проблем, которые требуют изменения базового протокола сети.
2.2.4. IPing - новое поколение протоколов IP
До сих пор, при обсуждении IP-технологии, основное внимание уделялось проблемам межсетевого обмена и путям их решения в рамках существующей технологии. Однако, все эти задачи, вызванные необходимостью приспособления IP к новым физическим средам передачи данных меркнут перед действительно серьезной проблемой - ростом числа пользователей Сети. Казалось бы, что тут страшного? Число пользователей увеличивается, следовательно растет популярность сети. Такое положение дел должно только радовать. Но проблема заключается в том, что Internet стал слишком большой, он перерос заложенные в него возможности. К 1994 году ISOC опубликовало данные, из которых стало ясно, что номера сетей класса B практически все уже выбраны, а остались только сети класса A и класса C. Класс A - это слишком большие сети. Реальные пользователи сети, такие как университеты или предприятия, не используют сети этого класса. Класс С хорош для очень небольших организаций. При современной насыщенности вычислительной техникой только мелкие конторы будут удовлетворены возможностями этого класса. Но если дело пойдет и дальше такими темпами, то класс C тоже быстро иссякнет. Самое парадоксальное заключается в том, что реально не все адреса, из выделенных пользователям сетей, реально используются. Большое число адресов пропадает из-за различного рода просчетов при организации подсетей, например, слишком широкая маска, или наоборот слишком "дальновидного планирования, когда в сеть закладывают большой запас "на вырост". Не следует думать, что эти адреса так и останутся невостребованными. Современное "железо" позволяет их утилизировать достаточно эффективно, но это стоит значительно дороже, чем простые способы, описанные выше. Одним словом, Internet, став действительно глобальной сетью, оказался зажатым в тисках своих собственных стандартов. Нужно было что-то срочно предпринимать, чтобы во время пика своей популярности не потерпеть сокрушительное фиаско.
В начале 1995 года IETF, после 3-x лет консультаций и дискуссий, выпустило предложения по новому стандарту протокола IP - IPv6, который еще называют IPing. К слову, следует заметить, что сейчас Internet-сообщество живет по стандарту IPv4. IPv6 призван не только решить адресную проблему, но и попутно помочь решению других задач, стоящих в настоящее время перед Internet.
Нельзя сказать, что до появления IPv6 не делались попытки обойти адресные ограничения IPv4. Например, в протоколах BOOTP (BOOTstrap Protocol) и DHCP (Dynamic Host Configuration Protocol) предлагается достаточно простой и естественный способ решения проблемы для ситуации, когда число физических подключений ограничено, или реально все пользователи не работают в сети одновременно. Типичной ситуацией такого сорта является доступ к Internet по коммутируемом каналу, например телефону. Ясно, что одновременно несколько пользователей физически не могут разговаривать по одному телефону, поэтому каждый из них при установке соединения запрашивает свою конфигурацию, в том числе и IP-адрес. Адреса выдаются из ограниченного набора адресов, который закреплен за телефонным пулом. IP-адрес пользователя может варьироваться от сессии. Фактически, DHCP - это расширение BOOTP в сторону увеличения числа протоколов, для которых возможна динамическая настройка удаленных машин. Следует заметить, что DHCP используют и для облегчения администрирования больших сетей, т.к. достаточно иметь только базу данных машин на одном компьютере локальной сети, и из нее загружать настройки удаленных компьютеров при их включении (под включением понимается, в данном случае не подключение к локальной компьютерной сети, а включение питания у компьютера, подсоединенного к сети).
Совершенно очевидно, что приведенный выше пример - это достаточно специфическое решение, ориентированное на специальный вид подключения к сети. Однако, не только адресная проблема определила появление нового протокола. Разработчики позаботились и о масштабируемой адресации IP-пакетов, ввели новые типы адресов, упростили заголовок пакета, ввели идентификацию типа информационных потоков для увеличения эффективности обмена данными, ввели поля идентификации и конфиденциальности информации.
Новый заголовок IP-пакета показан на рисунке 2.9.
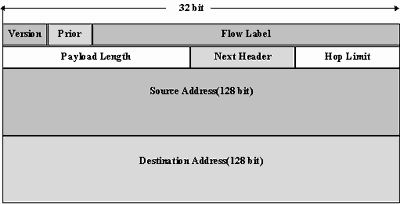
Рис. 2.9. Заголовок IPv6
В этом заголовке поле "версия" - номер версии IP, равное 6. Поле "приоритет" может принимать значения от 0 до 15. Первые 8 значений закреплены за пакетами, требующими контроля переполнения, например, 0 - несимвольная информация; 1 - информация заполнения (news), 2 - не критичная ко времени передача данных (e-mail); 4 - передача данных режима on-line (FTP, HTTP, NFS и т.п.); 6 - интерактивный обмен данными (telnet, X); 7 - системные данные или данные управления сетью (SNMP, RIP и т.п.). Поле "метка потока" предполагается использовать для оптимизации маршрутизации пакетов. В IPv6 вводится понятие потока, который состоит из пакетов. Пакеты потока имеют одинаковый адрес отправителя и одинаковый адрес получателя и ряд других одинаковых опций. Подразумевается, что маршрутизаторы будут способны обрабатывать это поле и оптимизировать процедуру пересылки пакетов, принадлежащих одному потоку. В настоящее время алгоритмы и способы использования поля "метка потока" находятся на стадии обсуждения. Поле длины пакета определяет длину следующей за заголовком части пакета в байтах. Поле "следующий заголовок" определяет тип следующего за заголовком IP-заголовка. Заголовок IPv6 имеет меньшее количество полей, чем заголовок IPv4. Многие необязательные поля могут быть указаны в дополнительных заголовках, если это необходимо. Поле "ограничение переходов" определяет число промежуточных шлюзов, которые ретранслируют пакет в сети. При прохождении шлюза это число уменьшается на единицу. При достижении значения "0" пакет уничтожается. После первых 8 байтов в заголовке указываются адрес отправителя пакета и адрес получателя пакета. Каждый из этих адресов имеет длину 16 байт. Таким образом, длина заголовка IPv6 составляет 48 байтов.
После 4 байтов IP-адреса стандарта IPv4, шестнадцать байт IP-адреса для IPv6 выглядят достаточными для удовлетворения любых потребностей Internet. Не все 2128 адресов можно использовать в качестве адреса сетевого интерфейса в сети. Предполагается выделение отдельных групп адресов, согласно специальным префиксам внутри IP-адреса, подобно тому, как это делалось при определении типов сетей в IPv4. Так, двоичный префикс "0000 010" предполагается закрепить за отображением IPX-адресов в IP-адреса. В новом стандарте выделяются несколько типов адресов: unicast addresses - адреса сетевых интерфейсов, anycast addresses - адреса не связанные с конкретным сетевым интерфейсом, но и не связанные с группой интерфейсов и multicast addresses - групповые адреса. Разница между последними двумя группами адресов в том, что anycast address это адрес конкретного получателя, но определяется адрес сетевого интерфейса только в локальной сети, где этот интерфейс подключен, а multicast-сообщение предназначено группе интерфейсов, которые имеют один multicast-адрес. Пока IPv6 не стал злобой дня, нет смысла углубляться в форматы новых IP-адресов. Отметим только, что существующие узлы Internet будут функционировать в сети без каких-либо изменений в их настройках и программном обеспечении. IPv6 предполагает две схемы включения "старых" адресов в новые. Предполагается расширять 4-х байтовый адрес за счет лидирующих байтов до 16-и байтового. При этом, для систем, которые не поддерживают IPv6, первые 10 байтов заполняются нулями, следующие два байта состоят из двоичных единиц, а за ними следует "старый" IP-адрес. Если система в состоянии поддерживать новый стандарт, то единицы в 11 и 12 байтах заменяются нулями.
Маршрутизировать IPv6-пакеты предполагается также, как и IPv4-пакеты. Однако, в стандарт были добавлены три новых возможности маршрутизации: маршрутизация поставщика IP-услуг, маршрутизация мобильных узлов и автоматическая переадресация. Эти функции реализуются путем прямого указания промежуточных адресов шлюзов при маршрутизации пакета. Эти списки помещаются в дополнительных заголовках, которые можно вставлять вслед за заголовком IP-пакета.
Кроме перечисленных возможностей, новый протокол позволяет улучшить защиту IP-трафика. Для этой цели в протоколе предусмотрены специальные опции. Первая опция предназначена для защиты от подмены IP-адресов машин. При ее использовании нужно кроме адреса подменять и содержимое поля идентификации, что усложняет задачу злоумышленника, который маскируется под другую машину. Вторая опция связана с шифрацией трафика. Пока IPv6 не стал реально действующим стандартом, говорить о конкретных механизмах шифрации трудно.
Завершая описание нового стандарта, следует отметить, что он скорее отражает современные проблемы IP-технологии и является достаточно проработанной попыткой их решения. Будет принят новый стандарт или нет покажет ближайшее будущее. Во всяком случае первые образцы программного обеспечения и "железа" уже существуют.
2.2.5. ICMP (Internet Control Message Protocol)
Данный протокол на ряду с IP и ARP относят к межсетевому уровню. Протокол используется для рассылки информационных и управляющих сообщений. При этом используются следующие виды сообщений:
Flow control - если принимающая машина (шлюз или реальный получатель информации) не успевает перерабатывать информацию, то данное сообщение приостанавливает отправку пакетов по сети.
Detecting unreachаble destination - если пакет не может достичь места назначения, то шлюз, который не может доставить пакет, сообщает об этом отправителю пакета. Информировать о невозможности доставки сообщения может и машина, чей IP-адрес указан в пакете. Только в этом случае речь будет идти о портах TCP и UDP, о чем будет сказано чуть позже.
Redirect routing - это сообщение посылается в том случае, если шлюз не может доставить пакет, но у него есть на этот счет некоторые соображения, а именно адрес другого шлюза.
Checking remote host - в этом случае используется так называемое ICMP Echo Message. Если необходимо проверить наличие стека TCP/IP на удаленной машине, то на нее посылается сообщение этого типа. Как только система получит это сообщение, она немедленно подтвердит его получение.
Последняя возможность широко используется в Internet. На ее основе работает команда ping.
Ix: {2} ping apollo.polyn.kiae.su
PING apollo.polyn.kiae.su (144.206.160.40): 56 data bytes
64 bytes from 144.206.160.40: icmp_seq=0 ttl=255 time=1.401 ms
64 bytes from 144.206.160.40: icmp_seq=1 ttl=255 time=0.844 ms
64 bytes from 144.206.160.40: icmp_seq=2 ttl=255 time=0.807 ms
64 bytes from 144.206.160.40: icmp_seq=3 ttl=255 time=0.912 ms
64 bytes from 144.206.160.40: icmp_seq=4 ttl=255 time=0.797 ms
64 bytes from 144.206.160.40: icmp_seq=5 ttl=255 ti^C
--- apollo.polyn.kiae.su ping statistics ---
6 packets transmitted, 6 packets received, 0% packet loss
round-trip min/avg/max = 0.797/0.930/1.401 ms
Ix: {3}
В приведенном выше примере сообщения посылаются на машину apollo.polyn.kiae.su, которая подтверждает их получение.
Другое использование ICMP - это получение сообщения о "кончине" пакета на шлюзе. При этом используется время жизни пакета, которое определяет число шлюзов, через которые пакет может пройти. Программа, которая использует этот прием, называется traceroute. К более подробному обсуждению ее возможностей мы вернемся в разделе 2.5. Здесь же только укажем, что она использует сообщение TIME EXECEED протокола ICMP.
quest:/usr/paul:\[1\]%traceroute www.netscape.com traceroute to www3.netscape.com (205.218.156.44), 30 hops max, 40 byte packets 1 Moscow-KIAE-4.Relcom.EU.net (144.206.136.12) 7 ms 4 ms 4 ms 2 Moscow-KIAE-3.Relcom.EU.net (193.125.152.14) 5 ms 4 ms 4 ms 3 Moscow-M9-2.Relcom.EU.net (193.124.254.37) 10 ms 8 ms 10 ms 4 StPetersburg-LE-1.Relcom.EU.net (193.124.254.33) 53 ms 24 ms 29 ms 5 Helsinki2.FI.EU.net (134.222.4.1) 33 ms 31 ms 39 ms 6 Pennsauken1.NJ.US.EU.net (134.222.228.30) 159 ms 292 ms 125 ms 7 mcinet-2.sprintnap.net (192.157.69.48) 528 ms 419 ms 400 ms 8 core2-hssi2-0.WestOrange.mci.net (204.70.1.49) 411 ms 495 ms 397 ms 9 borderx1-fddi-1.SanFrancisco.mci.net (204.70.158.52) 387 ms 342 ms 231 ms 10 borderx1-fddi-1.SanFrancisco.mci.net (204.70.158.52) 264 ms 265 ms 261 ms 11 netscape.SanFrancisco.mci.net (204.70.158.110) 250 ms 262 ms 252 ms 12 205.218.156.44 (205.218.156.44) 279 ms 295 ms 299 ms quest:/usr/paul:\[2\]%
При посылке пакета через Internet traceroute устанавливает значение TTL (Time To Live) последовательно от 1 до 30 (значение по умолчанию). TTL определяет число шлюзов, через которые может пройти IP-пакет. Если это число превышено, то шлюз, на котором происходит обнуление TTL, высылает ICMP-пакет. Traceroute сначала устанавливает значение TTL равное единице - отвечает ближайший шлюз, затем значение TTL равно 2 - отвечает следующий шлюз и т. д. Если пакет достиг получателя, то в этом случае возвращается сообщение другого типа - Detecting unreachаble destination, т.к. IP-пакет передается на транспортный уровень, а на нем нет обслуживания запросов traceroute (см. раздел 2.5).
После протоколов межсетевого уровня перейдем к протоколам транспортного уровня и первым из них рассмотрим протокол UDP.
2.2.6. User Datagram Protocol - UDP
Протокол UDP - это один из двух протоколов транспортного уровня, которые используются в стеке протоколов TCP/IP. UDP позволяет прикладной программе передавать свои сообщения по сети с минимальными издержками, связанными с преобразованием протоколов уровня приложения в протокол IP. Однако при этом, прикладная программа сама должна заботиться о подтверждении того, что сообщение доставлено по месту назначения. Заголовок UDP-датаграммы (сообщения) имеет вид, показанный на рисунке 2.10.

Рис. 2.10. Структура заголовка UDP-сообщения
Порты в заголовке определяют протокол UDP как мультиплексор, который позволяет собирать сообщения от приложений и отправлять их на уровень протоколов. При этом приложение использует определенный порт. Взаимодействующие через сеть приложения могут использовать разные порты, что и отражает заголовок пакета. Всего можно определить 216 разных портов. Первые 256 портов закреплены за, так называемыми "well known services", к которым относятся, например, 53 порт UDP, который закреплен за сервисом DNS.
Поле Length определяет общую длину сообщения. Поле Checksum служит для контроля целостности данных. Приложение, которое использует протокол UDP должно само заботится о целостности данных, анализируя поля Checksum и Length. Кроме этого, при обмене данными по UDP прикладная программа сама должна заботится о контроле доставки данных адресату. Обычно это достигается за счет обмена подтверждениями о доставке между прикладными программами.
Наиболее известными сервисами, основанными на UDP, является служба доменных имен BIND и распределенная файловая система NFS. Если возвратиться к примеру traceroute, то в этой программе также используется транспорт UDP. Собственно, именно сообщение UDP и засылается в сеть, но при этом используется такой порт, который не имеет обслуживания, поэтому и порождается ICMP-пакет, который и детектирует отсутствие сервиса на принимающей машине, когда пакет наконец достигает машину-адресата.
2.2.7. Transfer Control Protocol - TCP
Если для приложения контроль качества передачи данных по сети имеет значение, то в этом случае используется протокол TCP. Этот протокол еще называют надежным, ориентированным на соединение и потокоориентированным протоколом. Прежде чем обсудить эти свойства протокола, рассмотрим формат передаваемой по сети датаграммы (рисунок 2.11). Согласно этой структуре, в TCP, как и в UDP, имеются порты. Первые 256 портов закреплены за WKS, порты от 256 до 1024 закреплены за Unix-сервисами, а остальные можно использовать по своему усмотрению. В поле Sequence Number определен номер пакета в последовательности пакетов, которая составляет все сообщение, за тем идет поле подтверждения Asknowledgment Number и другая управляющая информация.
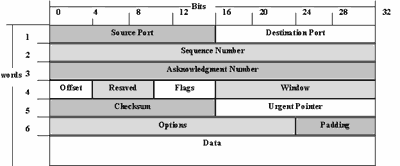
Рис. 2.11. Структура пакета TCP
Надежность TCP заключается в том, что источник данных повторяет их посылку, если только не получит в определенный промежуток времени от адресата подтверждение об их успешном получении. Этот механизм называется Positive Asknowledgement with Retransmission (PAR). Как мы ранее определили, единица пересылки (пакет данных, сообщение и т.п.) в терминах TCP носит название сегмента. В заголовке TCP существует поле контррольной суммы. Если при пересылке данные повреждены, то по контрольной сумме модуль, вычленяющий TCP-сегменты из пакетов IP, может определить это. Поврежденный пакет уничтожается, а источнику ничего не посылается. Если данные не были повреждены, то они пропускаются на сборку сообщения приложения, а источнику отправляется подтверждение.
Ориентация на соединение определяется тем, что прежде чем отправить сегмент с данными, модули TCP источника и получателя обмениваются управляющей информацией. Такой обмен называется handshake (буквально "рукопожатие"). В TCP используется трехфазный hand-shake:
Графически этот процесс представлен на рисунке 2.12.
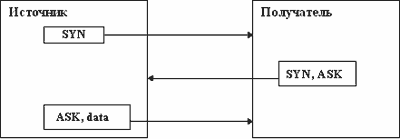
Рис. 2.12. Установка соединения TCP
После установки соединения источник посылает данные получателю и ждет от него подтверждений о их получении, затем снова посылает данные и т.д., пока сообщение не закончится. Заканчивается сообщение, когда в поле флагов выставляется бит FIN, что означает "нет больше данных".
Потоковый характер протокола определяется тем, что SYN определяет стартовый номер для отсчета переданных байтов, а не пакетов. Это значит, что если SYN был установлен в 0, и было передано 200 байтов, то номер, установленный в следующем пакете будет равен 201, а не 2.
Понятно, что потоковый характер протокола и требование подтверждения получения данных порождают проблему скорости передачи данных. Для ее решения используется "окно" - поле - window. Идея применения window достаточно проста: передавать данные не дожидаясь подтверждения об их получения. Это значит, что источник предает некоторое количество данных равное window без ожидания подтверждения об их приеме, и после этого останавливает передачу и ждет подтверждения. Если он получит подтверждение только на часть переданных данных, то он начнет передачу новой порции с номера, следующего за подтвержденным. Графически это изображено на рисунке 2.13.
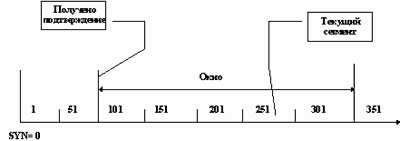
Рис. 2.13. Механизм передачи данных по TCP
В данном примере окно установлено в 250 байтов шириной. Это означает, что текущий сегмент - сегмент со смещением относительно SYN, равном 250 байтам. Однако, после передачи всего окна модуль TCP источника получил подтверждение на получение только первых 100 байтов. Следовательно, передача будет начата со 101 байта, а не с 251.
Таким образом, мы рассмотрели все основные свойства протокола TCP. Осталось только назвать наиболее известные приложения, которые использует TCP для обмена данными. Это в первую очередь TELNET и FTP, а также протокол HTTP, который является сердцем World Wide Web.
Прервем немного разговор о протоколах и обратим свое внимание на такую важнейшую компоненту всей системы TCP/IP как IP-адреса.
IP-адреса определены в том же самом RFC, что и протокол IP. Именно адреса являются той базой, на которой строится доставка сообщений через сеть TCP/IP.
IP-адрес - это 4-байтовая последовательность. Принято каждый байт этой последовательности записывать в виде десятичного числа. Например, приведенный ниже адрес является адресом одной из машин РНЦ "Курчатовский Институт":
144.206.160.32
Каждая точка доступа к сетевому интерфейсу имеет свой IP-адрес.
IP-адрес состоит из двух частей: адреса сети и номера хоста. Вообще говоря, под хостом понимают один компьютер, подключенный к Сети. В последнее время, понятие "хост" можно толковать более расширено. Это может быть и принтер с сетевой картой, и Х-терминал, и вообще любое устройство, которое имеет свой сетевой интерфейс.
Существует 5 классов IP-адресов. Эти классы отличаются друг от друга количеством битов, отведенных на адрес сети и адрес хоста в сети. На рисунке 2.14 показаны эти пять классов.
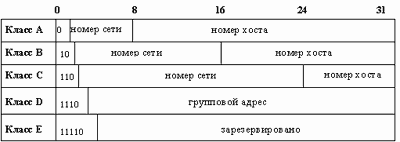
Рис. 2.14. Классы IP-адресов
Опираясь на эту структуру, можно подсчитать характеристики каждого класса в терминах числа сетей и числа машин в каждой сети.
| Класс | Диапазон значений первого октета | Возможное количество сетей | Возможное количество узлов |
| А | 1 - 126 | 126 | 16777214 |
| B | 128 - 191 | 16382 | 65534 |
| C | 192 - 223 | 2097150 | 254 |
| D | 224 - 239 | - | 228 |
| E | 240 - 247 | - | 227 |
Рис. 2.15. Характеристики классов IP-адресов
При разработке структуры IP-адресов предполагалось, что они будут использоваться по разному назначению.
Адреса класса A предназначены для использования в больших сетях общего пользования. Адреса класса B предназначены для использования в сетях среднего размера (сети больших компаний, научно-исследовательских институтов, университетов). Адреса класса C предназначены для использования в сетях с небольшим числом компьютеров (сети небольших компаний и фирм). Адреса класса D используют для обращения к группам компьютеров, а адреса класса E - зарезервированы.
Среди всех IP-адресов имеется несколько зарезервированных под специальные нужды. Ниже приведена таблица зарезервированных адресов.
| IP-адрес | Значение |
| все нули | данный узел сети |
| номер сети | все нули | данная IP-сеть |
| все нули | номер узла | узел в данной (локальной) сети |
| все единицы | все узлы в данной локальной IP-сети |
| номер сети | все единицы | все узлы указанной IP-сети |
| 127.0.0.1 | "петля" |
Рис. 2.16. Выделенные IP-адреса
Особое внимание в таблице (рисунок 2.16) уделяется последней строке. Адрес 127.0.0.1 предназначен для тестирования программ и взаимодействия процессов в рамках одного компьютера. В большинстве случаев в файлах настройки этот адрес обязательно должен быть указан, иначе система при запуске может зависнуть (как это случается в SCO Unix). Наличие "петли" чрезвычайно удобно с точки зрения использования сетевых приложений в локальном режиме для их тестирования и при разработке интегрированных систем.
Вообще, зарезервирована вся сеть 127.0.0.0. Эта сеть класса A реально не описывает ни одной настоящей сети.
Некоторые зарезервированные адреса используются для широковещательных сообщений. Например, номер сети (строка 2) используется для посылки сообщений этой сети (т.е. сообщений всем компьютерам этой сети). Адреса, содержащие все единицы, используются для широковещательных посылок (для запроса адресов, например).
Реальные адреса выделяются организациями, предоставляющими IP-услуги, из выделенных для них пулов IP-адресов. Согласно документации NIC (Network Information Centre) IP-адреса предоставляются бесплатно, но в прейскурантах наших организаций (как коммерческих, так и некоммерческих), занимающихся Internet-сервисом предоставление IP-адреса стоит отдельной строкой.
Важным элементом разбиения адресного пространства Internet являются подсети. Подсеть - это подмножество сети, не пересекающееся с другими подсетями. Это означает, что сеть организации (скажем, сеть класса С) может быть разбита на фрагменты, каждый из которых будет составлять подсеть. Реально, каждая подсеть соответствует физической локальной сети (например, сегменту Ethernet). Вообще говоря, подсети придуманы для того, чтобы обойти ограничения физических сетей на число узлов в них и максимальную длину кабеля в сегменте сети. Например, сегмент тонкого Ethernet имеет максимальную длину 185 м и может включать до 32 узлов. Как видно из рисунка 2.15, самая маленькая сеть - класса С - может состоять из 254 узлов. Для того, чтобы достичь этой цифры, надо объединить несколько физических сегментов сети. Сделать это можно либо с помощью физических устройств (например, репитеров), либо при помощи машин-шлюзов. В первом случае разбиения на подсети не требуется, т.к. логически сеть выглядит как одно целое. При использовании шлюза сеть разбивается на подсети (рисунок 2.17).
На рисунке 2.17 изображен фрагмент сети класса B - 144.206.0.0, состоящий из двух подсетей - 144.206.130.0 и 144.206.160.0. В центре схемы изображена машина шлюз, которая связывает подсети. Эта машина имеет два сетевых интерфейса и, соответственно, два IP-адреса.
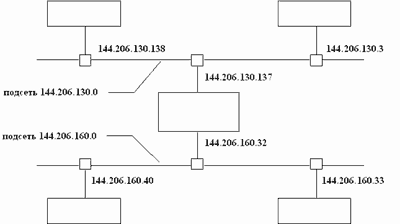
Рис. 2.17. Схема разбиения адресного пространства сети на подсети
В принципе, разбивать сеть на подсети необязательно. Можно использовать адреса сетей другого класса (с меньшим максимальным количеством узлов). Но при этом возникает, как минимум, два неудобства:
Разбиение сети на подсети использует ту часть IP-адреса, которая закреплена за номерами хостов. Администратор сети может замаскировать часть IP-адреса и использовать ее для назначения номеров подсетей. Фактически, способ разбиения адреса на две части, теперь будет применятся к адресу хоста из IP-адреса сети, в которой организуется разбиение на подсети.
Маска подсети - это четыре байта, которые накладываются на IP-адрес для получения номера подсети. Например, маска 255.255.255.0 позволяет разбить сеть класса В на 254 подсети по 254 узла в каждой. На рисунке 2.18 приведено маскирование подсети 144.206.160.0 из предыдущего примера.
На приведенной схеме (рисунок 2.18) сеть класса B (номер начинается с 10) разбивается на подсети маской 255.255.224.0. При этом первые два байта задают адрес сети и не участвуют в разбиении на подсети. Номер подсети задается тремя старшими битами третьего байта маски. Такая маска позволяет получить 6 подсетей. Для нумерации подсети нельзя использовать номер 000 и номер 111. Номер 160 задает 5-ю подсеть в сети 144.206.0.0. Для нумерования машин в подсети можно использовать оставшиеся после маскирования 13 битов, что позволяет создать подсеть из 8190 узлов. Честно говоря, в настоящее время такой сети в природе не существует и РНЦ "Курчатовский Институт", которому принадлежит сеть 144.206.0.0, рассматривает возможность пересмотра маски подсетей. Перестроить сеть, состоящую из более чем 400 машин, не такая простая задача, так как ей управляет 4 администратора, которые должны изменить маски на всех машинах сети. Ряд компьютеров работает в круглосуточном режиме и все изменения надо произвести в тот момент, когда это минимально скажется на работе пользователей сети. Данный пример показывает насколько внимательно следует подходить к вопросам планирования архитектуры сети и ее разбиения на подсети. Многие проблемы можно решить за счет аппаратных средств построения сети.

Рис. 2.18. Схема маскирования и вычисления номера подсети
К сожалению, подсети не только решают, но также и создают ряд проблем. Например, происходит потеря адресов, но уже не по причине физических ограничений, а по причине принципа построения адресов подсети. Как было видно из примера, выделение трех битов на адрес подсети не приводит к образованию 8-ми подсетей. Подсетей образуется только 6, так как номера сетей 0 и 7 использовать в силу специального значения IP-адресов, состоящих из 0 и единиц, нельзя. Таким образом, все комбинации адресов хоста внутри подсети, которые можно было бы связать с этими номерами, придется забыть. Чем шире маска подсети (чем больше места отводится на адрес хоста), тем больше потерь. В ряде случаев приходится выбирать между приобретением еще одной сети или изменением маски. При этом физические ограничения могут быть превышены за счет репитеров, хабов и т. п.
Назад | Содержание | Вперед