Михаил Талантов, опубликована в КомпьютерПресс (www.cpress.ru), N 9 (1999)
Этой публикацией мы продолжаем разговор о проблемах поиска в сети Интернет, с которыми неизбежно приходится сталкиваться пользователям - и рядовым, и поисковикам-профессионалам. Те из этих проблем, которые не лежат на поверхности, нередко дают о себе знать лишь "задним числом", после того как определенный этап поисковых работ завершен, и, возможно, исходя из его результатов уже принято какое-либо решение. Что же мешает сделать ситуацию прозрачной с самого начала эксплуатации той или иной информационно-поисковой системы (ИПС)? Ответ довольно прост: отсутствие исчерпывающей информации о ней со стороны разработчика. Прямым следствием этого становятся недостоверность получаемых данных и их неконтролируемая потеря. Редко удается встретить в Сети поисковую систему, которая не обладала бы некоторыми "недокументированными" особенностями. Казалось бы, что пользователю необходимо не так уж много сведений, а именно: 1) как происходит наполнение базы данных ИПС и каков ее объем; 2) полный спектр возможностей поискового языка системы; 3) основные особенности представления результатов поиска, прежде всего, алгоритма ранжирования записей из списка отклика на поисковый запрос. Увы, источником этой информации обычно является не документ, доступный с головной страницы поискового сервера, а разбросанные по Сети, книгам и компьютерным журналам публикации отдельных авторов. Причинами такого положения дел, по-видимому, оказывается не только небрежность разработчика, но и фактор, именуемый маркетинговой политикой. Проще говоря, предоставление поисковой системой наиболее полной информации о себе не всегда положительно сказывается на ее рейтинге. Тем не менее взять ситуацию под контроль в ряде случаях оказывается под силу пользователю. Выяснить особенности работы избранного поискового сервиса часто удается с помощью тестирования. Построение специальных тестовых запросов, быстро проясняющих именно тот аспект работы системы, который наиболее важен для текущей задачи, во многих случаях оказывается нетривиальным. Тому, как избежать некоторых неприятностей при работе с ИПС, мы и посвятим наше обсуждение. В качестве примеров, иллюстрирующих изложение, будут рассмотрены широко известные поисковые системы Интернета.
Любая поисковая машина или каталог регламентируют свою работу по сбору данных из Сети. Очевидно, что формирование поискового образа информационного объекта, или, другими словами, его "отражения" в "зеркале" поисковой системы неизбежно связано с некоторыми искажениями. По сути главным при этом становится вопрос о том алгоритме, на основе которого создается поисковый образ. Объектом-оригиналом при этом может стать как Web-страница, так и файл "закрытого" формата, который не доступен для проникновения сканирующих программ ИПС, например, видео или аудио-запись. Определенный шаблон обычно используется и при построении поискового образа для физического лица или компании в момент их регистрации в поисковой службе. Отсечение, фильтрация информации от оригинала свойственны всем без исключения ИПС, в том числе и полнотекстовым системам глобального охвата и самого общего назначения.
Фильтрация может регламентироваться как на техническом, так и на лингвистическом уровне, однако задача у нее одна -при минимальных материальных затратах добиться реальной эффективности поиска.
В связи с этим на практике часто возникает вопрос - что становится причиной неудачного поиска: отсутствие ли в Сети с высокой вероятностью на данный момент времени информации, релевантной запросу, или то, что эта информация потенциально не доступна для рассматриваемой поисковой системы. "Подводным камнем" этот аспект становится тогда, когда получен ненулевой отклик на поисковый запрос, а доля недополученных данных оказывается неконтролируемой. Некоторый свет на особенности работы глобальных ИПС проливает сравнительный анализ их возможностей, который был приведен в прошлом выпуске. Однако, если детали алгоритма фильтрации не известны, наиболее чувствительные потери данных возникают именно при использовании специализированных поисковых служб.
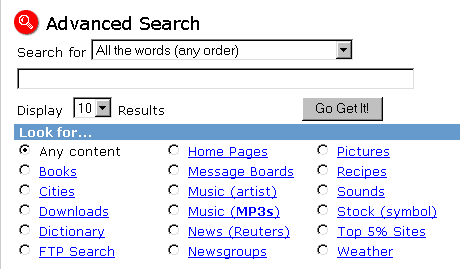
Рассмотрим несколько примеров. Немало специализированных систем имеют собственный интерфейс для ввода поисковых запросов. Тем не менее можно считать веянием времени, когда многие подобные сервисы интегрируются в шаблоны глобальных ИПС в виде фильтров. Такими возможностями всегда был известен HotBot, недавно соответствующие элементы были внедрены на AltaVista, есть они и на Еxcite. Постоянно расширяется набор фильтров поисковой системы Lycos (см. рис.1), на которой мы остановимся подробнее.
Рис.1. Шаблон расширенного поиска на Lycos с поддержкой многочисленных фильтров (http://lycospro.lycos.com/).
Представьте себя на месте пользователя, впервые пришедшего на такую известную глобальную поисковую систему, как Lycos, с желанием найти в Сети сведения о некотором книжном издании. Введя соответствующие ключевые слова и выбрав фильтр "Books", мы получаем отклик, который при отсутствии дополнительной информации нельзя расценить иначе, как получение данных о книгах, собранных по всему Интернету. Интересно задать вопрос, а может ли в масштабе Сети автоматически вестись отбор таких сведений? Если говорить только о пространстве WWW, то в большинстве случаев программы-пауки, сканирующие Сеть, используют для распознавания типа данных специальные элементы языка HTML, с помощью которых в Web-страницу внедряются определенные информационные блоки. Название элемента может нести смысловую нагрузку и отождествляться с типом информации. Так, если бы гипотетически существовал элемент HTML book, заключающий в себе сведения о книге и ее авторе, он мог бы размещаться на странице и в простейшем случае иметь вид:
<book> Название книги и автор</book>
(сами элементы <book> в окне браузера не должны отображаться). При этом вся информация о книгах, публикуемая таким образом в WWW, могла бы благополучно и без участия человека накапливаться в базе данных ИПС. Но элемента book в стандарте HTML пока не существует. Следовательно, приходится прибегать либо к "ручному" отбору, либо к автоматическому просмотру некоторых наперед заданных каталогов отдельных узлов, и, возможно, имеющих отношение к продаже книжной продукции или библиотекам.
В случае Lycos все гораздо проще. Поиск происходит всего навсего по одному единственному узлу компании (www.barnesandnoble.com), заинтересованной в реализации своего товара. К чести разработчика следует сказать, что после нескольких лет молчания по поводу фильтра "books" в глубине предлагаемой документации сегодня можно найти скромное упоминание об арендаторе фильтра. Ранее его владельца просто было нельзя идентифицировать, и только спустя некоторое время, становилось понятно, что система работает с довольно незначительной по объему и специфически пополняемой базой данных.
Не менее серьезно выглядят опасения, когда поиск связан с информацией, привязанной к определенному формату ее хранения, например, звуковым файлам. В течение нескольких месяцев поиск "звуков в Интернете" на Lycos оставался чем-то таинственным, напоминающим работу с небольшой, но со вкусом собранной коллекцией. Тестирование системы с помощью простых запросов показывало, что в основном в ней представлены форматы wav и au. Недавно стало известно, что теперь поддерживаются также и mp3, mid, ra , ram и aif. При этом объем накопленных записей, доступных через большинство фильтров, продолжает сохраняться в тайне.
Ясно, что если интересующий вас формат не входит в поддерживаемый на данный момент системой перечень, вы получите нулевой отклик, причину которого следовало бы четко представлять с самого начала.
Происхождение сопроводительных записей к звуковым файлам на Lycos, которые отображаются в результатах поиска, по-прежнему не регламентировано разработчиком.
Аналогичные проблемы существуют и на других ИПС. Хотелось бы отметить типичный в этом отношении прием: использование шаблона глобальной ИПС как для поиска информации, относящейся ко всему Интернет-простанству, так и для поиска по некоторым избранным базам данных или коллекциям. К сожалению, реальное поле поиска оговаривается далеко не всегда, и часто его приходится выяснять самостоятельно во избежание неверных выводов в дальнейшем.
Ситуация может осложниться тем, что на поисковом сервере вы не найдете исчерпывающего описания того, как работают операторы языка запросов.
Даже на уже зрелых, не первый год работающих ИПС, с этим можно столкнуться. Рассмотрим на примере AltaVista, как это может стать источником определенных проблем.
Несмотря на недавнее появление графического фильтра (см. рис.2), многие пользователи системы продолжают эксплуатировать прозрачный по своей природе оператор image, позволяющий находить в индексе графические файлы. На этот счет справка AltaVista исчерпывает себя тем, что рекомендует ввести в шаблон запрос, в котором вслед за указанным оператором должно следовать имя или часть имени искомого файла. Таким образом, для поиска файла с изображением акрополя следует задать запрос в виде image: acropolis.
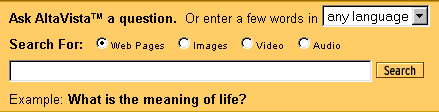
Рис.2 Шаблон простого поиска AltaVista (www.altavista.com) с фильтрами и меню выбора языка поиска.
Увеличит ли наши шансы на успех, знание того, как реально отрабатывает оператор image? Если посмотреть на откликнувшиеся документы, а затем на их HTML-источник, то легко убедиться, что в каждом из них в месте вставки графического образа присутствует элемент <IMG>. Внутри него в качестве обязательного атрибута стоит URL, с которого собственно и извлекается сам файл:
<IMG SRC="http://www.citforum.ru/buildings/acropolis.gif">
Фактически же Web-страница дает отклик, если ключевое слово входит не только в имя файла, но и в название любого каталога и в доменное имя сервера, содержащихся в URL элемента <IMG>. То есть документ, включающий в себя приведенную выше строку, откликнулся бы и на запрос image:buildings. Следовательно, поиск по имени каталога, которое так же как и имя файла несет смысловую нагрузку, позволяет получить графические данные, которые нельзя извлечь в первом случае. Предположим, что Web-мастер неосторожно назвал искомый файл acr1.gif, но разумно положил его в каталог buildings.Тогда по запросу image:buildings могут откликнуться релевантные документы с изображением акрополя, вставленным в Web-страницу с помощью строки:
<IMG SRC="http://www.citforum.ru/buildings/acr1.gif">
В расширенном поиске AltaVista используются логические операторы и скобки. Однако на сервере ничего не говорится о том, допустимо ли их применять внутри специальных полей поиска, таких как поле image. Уже заведомо зарегистрированный в индексе графический файл, найденный ранее, можно использовать для проверки работоспособности отдельных поисковых запросов. Так, если предположить, что файл с URL из последнего примера существует, то
тестовый запрос в виде image:( buildings AND acr1) должен дать корректный ненулевой отклик, и, таким образом, подтвердить, что комбинирование операторов допустимо. На практике это действительно возможно.
Хотелось бы еще раз подчеркнуть, что речь здесь идет не о порочности отдельных поисковых систем, а о конструктивном подходе к разрешению возникающих вопросов. При этом нередки и ситуации, которые предугадать крайне сложно.
Если, скажем, на той же AltaVista организовать поиск по ключевому слову "президент" (оно специально выбрано в качестве тестового как довольно распространенное), легко убедиться, что отклик зависит от двух факторов: какой язык выбран в меню шаблона (см. рис.2 справа вверху) - русский (Russian) или любой (any language), а также какая русская кодировка установлена в меню браузера. Результаты поиска приведены в таблице 1.
| Кодировка/Язык | Русский (Russian) | Любой (Any) |
| Windows-1251 | 47 | 583 |
| Koi8-r | 3 | 52 |
Таблица 1. Количество документов, откликнувшихся на запрос "президент*" ( маска * использована для увеличения отклика ) на AltaVista в зависимости от кодировки и типа языка, установленного в шаблоне.
Анализ списка отклика показывает, что, во-первых, при вводе запроса только в одной кодировке неминуемо теряются данные. Во-вторых, становится ясно, как система идентифицирует тот или иной язык документа. Оказывается, если некоторая начальная часть документа написана на языке, отличном от русского, то этот документ уже не описывается ИПС как русскоязычный. Как результат этой недокументированной особенности, максимальный отклик индекса при поиске по русскоязычному термину достигается при установке пункта меню "any language", а не "Russian".
В шаблоне расширенного поиска популярной бизнес-ориентированной системы Open Text Livelink Pinstripe (OTLP) (рис.3) также скрыты некоторые проблемы, никак не освещенные в справочном материале ИПС .
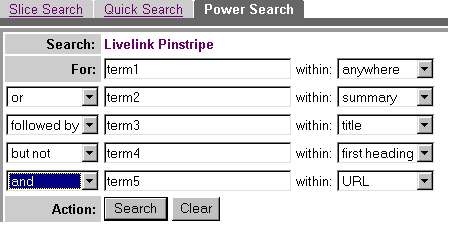
Рис. 3. Шаблон расширенного поиска OTLP (http://pinstripe.opentext.com/search/power.html) с модельным запросом.
Как видно из рисунка, шаблон позволяет задать свое поле поиска для каждого термина, а затем связать термины с помощью логических операторов. Однако, как только терминов становится больше двух - возникает вопрос, в какой последовательности будут отрабатывать операторы, и соответственно, что из себя будет представлять результат. Даже для такого простого запроса как term1 AND term2 OR term3 разумно предположить двоякую интерпретацию, которую можно проиллюстрировать с помощью выделения в скобки логических единиц (в самом шаблоне скобки не применяются). И вариант (term1 AND term2) OR term3, и вариант term1 AND (term2 OR term3) кажутся приемлемыми, давая при этом совершенно разный отклик. Тестовый запрос и последующий анализ откликнувшихся документов показывает справедливость первого варианта, т.е. что операторы выполняются по мере своего появления в шаблоне, и в документе будут присутствовать либо term1 и term2 одновременно, либо term3. Как в таком шаблоне вводить запросы с участием фраз (а это возможно), автор предлагает выяснить читателям самостоятельно. В данном случае приходится констатировать очевидную небрежность разработчика по отношению к пользователям системы.
Подавляющее большинство ИПС Интернета сегодня активно работает с так называемыми стоп-словами (stop-words). К последним относят служебные части речи, которые не несут смысловую нагрузку, а также некоторые наиболее общеупотребительные в Сети слова, такие как information, Internet, Web, business и другие. Известно, что AltaVista, Excite, HotBot и Lycos применяют в работе технику стоп-слов, а Infoseek и NorthernLight ее не практикуют.
При появлении стоп-слов в поисковом запросе без специальных ухищрений ИПС может не учитывать их при поиске и ранжировании результатов, иногда информируя об этом пользователя, иногда - нет. В целом неучет стоп-слов при обработке запроса сокращает время поиска и повышает релевантность отклика. Однако, стоит вам захотеть отыскать что-нибудь вроде классической фразы Шекспира "to be or not to be", состоящей только из стоп-слов, и вы уже не владеете ситуацией.
Хотя стоп-слова и могут игнорироваться в простых запросах, в индексе полнотекстовой ИПС они присутствуют наряду с остальными. Такой системой является, например, AltaVista (индексируются все слова документа). HotBot в свою очередь, напротив, индексирует все, кроме стоп-слов.
Тем не менее и HotBot выполняет полнотекстовое индексирование отдельных значимых полей документа, так что запросы со стоп-словами, оформленные в виде фразы, дают и на этой ИПС результативный отклик.
Перечень стоп-слов не стандартизован, так что он может быть оригинальным для каждого сервиса. Разработчики редко приводят сведения об этом аспекте работы ИПС, однако при необходимости поиск по ключевым словам stop, words плюс название интересующей вас поисковой машины позволяет обнаружить в Сети версии соответствующих перечней.
Наиболее общие принципы выхода из проблемной ситуации следующие: по возможности избегать употребления стоп-слов в запросах, исключить применение логических операторов типа and, or, not и других в тех шаблонах, в которых они не поддерживаются и будут восприняты как стоп-слова.
Если же без стоп-слов в запросе нельзя обойтись, то следует включить их во фразу, что во многих системах означает заключение в кавычки. В отдельных случаях полезно протестировать работу шаблонов простого и расширенного поиска ИПС, в которых техника поддержки стоп-слов может быть различной.
Самая захватывающая интрига Сети, которую порождают ИПС, связана с особенностями работы алгоритма, ранжирующего результаты в списке отклика. Эти сведения обычно не предаются широкой огласке, но они крайне необходимы Web-мастерам, продвигающим в суровой кокурентной борьбе свои узлы через поисковые системы Интернета. Попасть в первые несколько десятков записей из списка отклика на ИПС по часто повторяющимся в Сети запросам - значит обеспечить свою доступность для потенциальных клиентов. (см. КомпьютерПресс N 5, с. 114).
Тем не менее и при решении поисковых задач во время работы со списком отклика из-за недостатка информации также могут возникать некоторые проблемы.
В предыдущем выпуске мы говорили о том, что простые тестовые запросы, позволяют с самого начала работы с ИПС понять, насколько широко в индексе представлена искомая информация. Однако не всякая ИПС дает полное число документов, содержащихся в отклике на запрос (например, Lycos, не дает). В какой-то мере это позволяет системе сохранить свое лицо, избежав сравнения с гигантами - Northern Light, AltaVista или HotBot. При решении профессиональных поисковых задач к таким сервисам следует обращаться в последнюю очередь.
Обычно в списке отклика появляется информация, которая включает в себя заголовок страницы, адрес и аннотацию. Аннотация берется либо из специального META-элемента, задаваемого автором документа, либо в ее качестве выступают несколько первых нередактируемых строк текста, взятых со страницы. В некоторых случаях указывается язык документа. Выше мы уже обратили внимание на проколы алгоритма AltaVista, связанные с идентификацией языка, и подобные случаи не редкость и на других ИПС.
Другая обескураживающая неприятность - это возможное отсутствие в найденных документах тех самых ключевых слов, по которым проводился поиск. Причиной подобного явления, если не считать незарегистрированное обновление страницы без изменения адреса, оказывается тот факт, что ключевые слова были заданы автором в специальном поле - элементе META. Оно доступно для сканирования роботом ИПС, но не отображается на странице. В этом случае путем просмотра META-элементов HTML-источника у вас есть возможность убедиться в недобросовестности автора: несоответствие ключевых слов содержанию документа - это прямая дезинформация.
Еще одна проблема вообще неочевидна для единичного пользователя. Речь идет о том, как поисковый сервер обрабатывает запросы в случае, когда их поступает слишком много, т. е. в режиме переполнения. Так, автору статьи не раз приходилось сталкиваться с тем, что, например на AltaVista, при одинаковом и практически одновременном тестовом запросе с 10-15 компьютеров, количество результатов, появляющихся в отклике для каждого пользователя системы иногда может отличаться на десятки тысяч. В действительности, попадая в режим перегрузки, поисковый сервер не имеет большого выбора, а именно: либо он отклоняет запрос, либо обслуживает его по "сокращенному" варианту. Последний вполне может предполагать предоставление лишь части удовлетворяющих запросу данных. Выход очевиден: проверять достоверность отклика ИПС многократно и в разное время суток.
Здесь нам хотелось бы остановиться на некоторых более чем реальных опасностях, которые подстерегают пользователя, доверившегося мало известному поисковому серверу. Написать об этом автора заставляет случай. Человеку была срочно необходима информация о наличии прямых электропоездов между двумя городами СНГ. Воспользовавшись Рамблером, ему быстро удалось локализовать сервер, предлагающий необходимые сведения (рис.4).
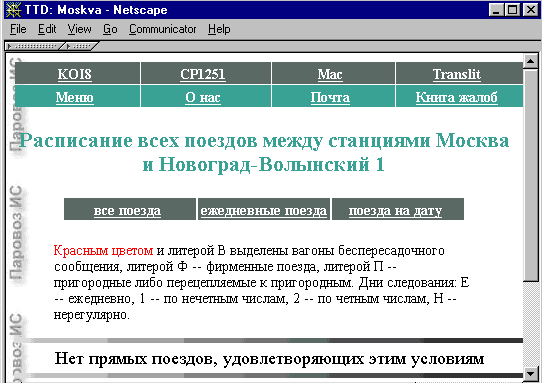
Рис.4 Результат обработки поискового запроса на сервере
"полных железнодорожных расписаний" по России и СНГ
http://pavel.physics.sunysb.edu:8080/
После введения станций отправления и назначения система ответила отрицательно (см. рис.4, строка внизу). Такой категоричный ответ сервера заставил человека прекратить дальнейшие поиски и принять решение, о котором скоро пришлось пожалеть. Предъявить претензии к разработчику системы также оказалось невозможным. Дело в том, что чуть ниже под результатом поиска пользователем не была замечена одна важная деталь, а именно надпись "Расписание рекламное, возможны изменения, за которые не несут ответственности ни распространитель, ни МПС". При этом если бы фраза об отказе была сформулирована чуть мягче, пользователь, вероятно, смог бы продолжить поиск в Сети и получить положительный результат.
В некоторых случаях маркетинговая агрессивность разработчика начинает носить вызывающий характер. Вот уже не один месяц, на серверах HotBot и AltaVista расположено рекламное объявление крупнейшей книготорговой компании Amazon (www. amazon.com) и ряда других. При этом на любой запрос в ИПС рядом с результатами поиска появляется баннер, намекающий на то, что как раз по тематике выполненного поиска и можно найти информацию на Amazon, даже если в запросе фигурировал мистический "господин Иванов". (см. рис.5)

Рис.5. "Умный" баннер на сервере www.altavista.com
Подстановка терминов из поискового шаблона в баннер производится путем их механического переноса и без всякого контроля на предмет действительного наличия книг данной тематики на сервере компании. К тому же найти "Иванова" на Amazon нельзя в принципе, поскольку вплоть до последнего момента русскоязычная литература там не продавалась. В данном случае плата за доверчивость - это несколько минут напрасно потраченного времени.
Таким образом, от привычного уважения к печатному слову, в Сети лучше отказаться, особенно если сервер генерирует реплики автоматически.
Практика показывает, что сделать качественную поисковую систему, во всех отношениях прозрачную для пользователя, не всегда оказывается в интересах и силах разработчика. В конечном итоге разрешить львиную долю проблем можно лишь совместными усилиями пользователей и создателей ИПС при активном обмене мнениями. На западе для этой цели уже издается журнал "Searchers" (http://www.infotoday.com/searcher) для людей, занимающихся поиском профессионально. В таблице 2 представлен перечень серверов, публикующих информацию о проблемах поиска, а также их краткая характеристика.
| http://www.searchenginewatch.com/ | Один из самых известных сайтов. Материалы для поисковиков и Web-мастеров по всем аспектам работы поисковых систем под редакцией Danny Sullivan. Действует бесплатный список рассылки - более 60 тыс. подписчиков Англ. |
| http://www.monash.com/spidap.html | Обширные и систематически обновляемые материалы по поиску, новости. Англ. |
| http://www.promotion.aha.ru/ | Promo.ru., свежие материалы по поисковым машинам и каталогам, освещены русскоязычные поисковые системы. Рус. |
| http://www.notess.com/search/ | Редактор сайта Greg R. Notess - автор нескольких бестселлеров об Интернете и стратегиях поиска. Обзоры поисковых систем. Англ. |
| http://www.askscott.com/ | AskScott, материалы по глубинным аспектам поисковых технологий. Англ. |
| http://www.researchbuzz.com/ | Новые статьи по поиску, советы пользователям. Англ |
| http://www.zdnet.com/products/internetuser/search.html | Новые статьи по поиску. Англ. |
| http://www.howandwhy.com/Computer/Searching.html | Обзор и сравнительная характеристика поисковых языков наиболее известных поисковых машин. Англ. |
| http://www.citforum.ru/pp/ | Подборка оригинальных статей по поиску, обновляется систематически. Рус. |
| http://www.zhurnal.ru/search/articles.html | Ссылки на русскоязычные статьи о системах и секретах поиска, не обновляется, интересен с скорее с "исторической" точки зрения. Рус. |
Таблица 2. Некоторые сервера с материалами по поиску информации в Интернете.
В заключение хотелось бы отметить, что основная цель этой статьи, поставленная автором, была далека от того, чтобы перечислить некоторый набор, возможно, полезных сведений об отдельных поисковых сервисах Сети. Она была совсем в другом - привлечь внимание читателя к более важному моменту: инструмент, с помощью которого нам приходится решать реально значимые для себя задачи, требует осторожности, изучения и "обкатки". В особенности, если этот инструмент всегда наполовину чужой, каким является для пользователя поисковая система Интернета. В противном случае последствия его применения будут плохо предсказуемы.
Координаты автора:
Центр Информационных Технологий
e-mail: tala@citmgu.ru