
Михаил Талантов, опубликовано в КомпьютерПресс N 7 (1999)
Этой статьей мы продолжаем начатый в прошлом выпуске журнала разговор о поиске информации в сети Интернет, поставленном на профессиональную основу.
Как ранее было отмечено, чертами, присущими профессиональному поиску, являются его полнота, достоверность и высокая скорость. Наиболее серьезным и нетривиальным фактором, определяющим, насколько быстро поисковик приходит к цели, оказывается грамотное планирование поисковой процедуры. Говоря более предметно, речь здесь идет с одной стороны о выборе типа ресурсов, которые потенциально способны нести информацию, релевантную поисковой задаче (см. КомпьютерПресс N 6'99). С другой стороны - о выборе инструментов поиска, обслуживающих соответствующее информационное поле, в зависимости от их предполагаемой результативности. Если говорить о наиболее емком на сегодняшний день c точки зрения информационного наполнения пространстве WWW, то относительное изобилие поисковых средств Всемирной Паутины делает решение большинства практических задач многовариантным. Построение оптимальной последовательности применения тех или иных инструментов на каждом шаге поиска и предопределяет его эффективность. Помочь решить проблему выбора может четкое представление о видах, назначении и особенностях работы информационно-поисковых систем (ИПС) Интернета.
Рис.1 Организация поисковых сервисов Интернета.
Согласно схеме на рис.1 реальными носителями информации о ресурсах, которыми располагает Сеть, являются поисковые машины (автоматические индексы) и каталоги. В силу того, что они, хотя и различными средствами, самостоятельно обеспечивают все этапы обработки информации от ее получения с узлов-первоисточников до предоставления пользователю возможности поиска, их часто называют автономными системами.
Автономные поисковые системы могут различаться по принципу отбора информации, который в той или иной степени присутствует и в алгоритме сканирующей программы автоматического индекса, и в регламенте поведения сотрудников каталога, отвечающих за регистрацию. Как правило, сравниваются два основных показателя: пространственный масштаб, в котором работает ИПС, и ее специализация.
Сначала о масштабе. При формировании информационного массива поисковая система может следить за обновлением наперед заданного набора документов, каталогов или конечного числа узлов, отобранных по какому-либо принципу. Такие системы, реализованные в Интернете, несколько условно можно назвать локальными. Глобальные поисковые системы в отличие от локальных решают более трудоемкую задачу - по возможности наиболее полный охват ресурсов всего информационного поля Сети (WWW, FTP или другого), которое они обслуживают. Следствием этого становится возрастание роли механизма, который используется глобальной системой для постоянного увеличения числа подконтрольных узлов.
Построение региональных и специализированных поисковых сервисов предполагает активную фильтрацию информации.
Специализация поисковой системы на базе какого-либо профиля или тематики, будь то поиск людей и организаций, компьютерного "железа" или файлов мультимедиа в формате MP3, теоретически может происходить как на глобальной, так и на локальной основе. Разумеется, систему проще построить и сопровождать на ограниченном пространстве обновляемых узлов, что обычно и реализуется на практике.
Региональными поисковыми службами информация фильтруется в основном на основе распознавания домена верхнего уровня сервера, например, ru и su для России. Серьезным недостатком таких систем является неучет ими большого количества ресурсов, размещаемых региональными разработчиками в традиционно популярном домене com.
Региональные мотивы нередко привносятся и в сервис глобальных ИПС. Система Lycos, например, ранжирует результаты из списка отклика в зависимости от того, из какого региона поступил запрос.
Еще одно важное направление в деле регионализации поисковых сервисов связано с разработкой узлов-зеркал (mirrors) для наиболее популярных поисковых систем. Зеркала должны содержать точную копию индекса первичной ИПС и гарантировать быстрое обслуживание обращений, поступающих из определенной географической зоны. На практике обновление индекса зеркальной системы всегда происходит с запаздыванием. Так, для австралийского зеркала поисковой машины AltaVista, лидера по количеству зеркал, оно обычно составляет 1-2 дня при безаварийной работе, и это лучшее время. Альтернатива между скоростью работы и полнотой данных становится значимой для пользователя, если он имеет возможность обратиться и к зеркалу, и к первоисточнику.
В прошлый раз мы отдельно отметили, что именно становление автоматических индексов, охватывающих ресурсы определенного типа, имеет знаковый характер. Это событие всегда было связано с фазой бурного развития соответствующего информационного поля, а на текущий момент - с пространством WWW. Реально лишь высокая скорость автоматического индексирования документов с помощью программ-роботов способна обуздать информационный хаос в Сети. Применение же при поиске каталогов ресурсов в "чистом виде", без возможности поиска по ключевым словам, скорее напоминает серфинг, а не серьезную работу с информацией. Тем не менее роль каталогов, заметно упавшая на глобальном уровне накопления данных, остается важной для регионального поиска.
Каталоги WWW, содержащие большое количество записей, например, Yahoo! (более 750 тыс.) или русскоязычный АУ (более 20 тыс.), нередко размещают на своих страницах локальные поисковые машины, реализуемые в виде традиционных шаблонов. Поскольку визуально и в работе последние мало чем отличаются от шаблонов на автоматических индексах, сами каталоги такого типа часто неверно называют поисковыми машинами. Дело здесь не в чистоте терминологии, которая неинтересна рядовому пользователю. Проблема в том, что непонимание того, как внутренне функционирует поисковая система, влечет за собой неконтролируемую потерю информации. Так, следуя ошибочному определению, можно легко поставить на одну ступеньку глобальный автоматический индекс Northern Light и "поисковую машину"-каталог Yahoo. Это означает пытаться сравнивать в едином ключе сервисы, нацеленные на решение совершенно разных, по крайней мере, с точки зрения профессионального поиска, задач. Локальная поисковая машина каталога предполагает поиск по ключевым словам, входящим в названия разделов, узлов и другим немногочисленным данным, которые вводятся при регистрации. В то время как в автоматическом индексе информация об отдельном узле намного шире - в идеале вплоть до единичного слова каждого документа, причем с учетом специальных полей Web-страницы и режима обновления данных.
Простота организации локальной по Web-узлу поисковой машины делает ее частым атрибутом не только каталогов, но и самых рядовых сайтов. Если сравнить содержимое индекса локальной системы с информацией о том же самом узле из индекса глобальной поисковой машины, то локальная система имеет все шансы превзойти глобальную и по полноте данных, и по частоте их обновления.
Благодаря этому довольно часто наиболее эффективный путь от запроса на глобальной ИПС к конечному блоку информации лежит через промежуточное звено -локальный поисковый сервис узла (см. схему на рис.2). Под внутренним на схеме понимается поиск внутри конечного объекта, если это возможно, например, поиск по тексту Web-страницы, поддерживаемый большинством браузеров.

Рис.2. Уровни поисковой процедуры.
Чрезвычайно важной проблемой Сети является интеграция различных поисковых сервисов в единую систему. Для Паутины 1999 год уже стал знаменателен одним неординарным событием - при участии 15 крупнейших поисковых систем Интернета в феврале стартовал проект SESP (Search Engine Standards Project), призванный стандартизировать работу поисковых служб. Материалы о нем можно найти по адресу http://www.searchenginewatch.com/standards/990204.html.
Уже первые документы проекта дают понять, что задачей стандарта является максимально сблизить синтаксис и возможности поисковых языков различных ИПС. В частности, одним из обязательных требований становится поддержка любой поисковой системой единых команд запросов, локализующих узел по его доменному имени, а документ - по URL.
Понятно, что даже это простое соглашение поставило бы учет и контроль информации в масштабе Сети на принципиально новый уровень.
Теоретически привлекает перспектива создания сверхмощной глобальной поисковой системы, которая бы была способна сопровождать Сеть в ее полном информационном объеме. Однако на практике это пока невозможно, и решение проблемы интеграции смещается в сторону разработки метапоисковых систем (см. рис.1).
Метапоисковая система может быть реализована как в самой Сети, например, на Telnet- или Web-доступном узле (см. ссылки в следующем разделе статьи), так и в виде локальной клиентской программы (www.listsoft.ru, раздел "Программы-Поиск". Не обладая собственной индексной базой данных, метапоисковая система выступает в качестве шлюза, который передает через свой интерфейс запросы на автономные ИПС и возвращает результаты поиска.
Одно из назначений метапоискового сервиса при поиске - тестирование Сети на предмет информации, релевантной запросу. Метасистемы позволяют также оценить результативность применения отдельных ИПС для решения конкретной поисковой задачи. К сожалению, для предметного и тонкого поиска метасистемы пока еще плохо применимы. Проблема заключается в том, что язык запросов мета-шлюза располагает лишь самыми общими для большинства ИПС, и поэтому крайне скромными возможностями. Появление проекта стандарта поисковых систем SESP в этом отношении открывает новые перспективы в развитии метасистем, поскольку стандартизация ИПС существенно расширит возможности шлюзования.
Отметим, что метасистема допускает передачу запросов не только на автоматические индексы, но и в те каталоги, которые сопровождаются локальной поисковой машиной
Среди довольно легковесных продуктов целого семейства локальных клиентов метапоиска, выделяется программа, известная под именем Inforia Quest 98 (рис.3).
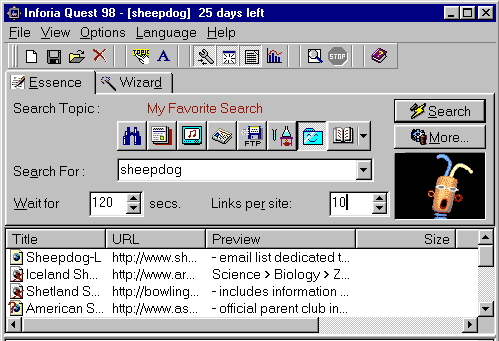
Рис.3 Локальный метапоисковый клиент Inforia Quest 98.
Пробный вариант ее последней версии можно найти на узле http://www.inforia.com/quest.
По итогам прошлого года она была признана одной из лучших в своем классе и претендует на роль профессионального поискового инструмента.
Беглый взгляд на возможности этой программы позволяет обозначить черты метапоисковых клиентов самого последнего поколения.
Прежде всего, программа интегрирует в себе не только поисковые сервисы Web-пространства, но и другие поля информационного сектора Сети, а именно: файловые архивы FTP и систему телеконференций.
При обработке поискового запроса допускается соединение более чем со 100 поисковыми системами, включая и специализированные.
Отчетная информация о найденных ресурсах отображается в рабочей области программы. Ссылки, дублирующие уже найденные, системой исключаются. Полученные адреса немедленно проверяются на доступность. Есть возможность выбрать набор необходимых поисковых систем из полного списка, установить время проведения поиска и ограничение на число ссылок, полученных от каждого поискового сервера. Сам перечень ИПС, с которыми взаимодействует программа обновляется автоматически с сервера разработчика при работе в Сети.
Большим завоеванием программы является то, что она поддерживает некоторое подобие поискового языка: работают два логических оператора и поиск по фразам.
Однако всякий раз, когда язык метасистемы не в состоянии обеспечить точное построение поискового запроса, приходится прибегать к автономным сервисам Сети, в первую очередь к поисковым машинам WWW.
После знакомства с несколькими глобальными поисковыми машинами Сети, пользователь, как правило, останавливается на одной-двух, с которыми и предпочитает работать в дальнейшем. На основе каких же мотивов делается такой выбор? Рейтинги популярности поисковых систем по опросам читателей, публикуемые такими известными изданиями как PC Magazine, Internet World и другими, оставляют нелучшее впечатление. Эмоции торжествуют над осознанием реальных возможностей, маркетинговые решения над техническими. Так, каталог Yahoo с легкостью одерживает победу над индексами HotBot и Lycos, Excite и WebCrawler - над AltaVista, а одна из крупнейших поисковых машин Northern Light какое-то время безоговорочно проигрывает почти всем.
Чтобы грамотно распорядиться таким важным поисковым инструментом как автоматический индекс, необходимо учитывать два определяющих аспекта его работы. Первый- это индексирование программой-роботом содержимого Web-страниц. Адрес очередного документа робот узнает либо от автора ресурса, который представил его в систему, либо из гиперссылки, найденной им на уже пройденной странице. Подробнее о проблемах индексирования можно прочитать в КомпьютерПресс, N5'99, c.114. Второй аспект - обработка запросов пользователей по ключевым словам на основе синтаксиса поискового языка системы. Обе эти фазы работы поисковой машины тесно связаны - чем больше информации о ресурсе извлечено при сканировании, тем потенциально шире возможности поиска. Тот факт, что каждая система в обоих случаях имеет свою специфику, может быть использован для тонкой настройки на решение поисковой задачи.
Поскольку индексы сканируют единое информационное поле - WWW, то в них может находиться информация об одних и тех же ресурсах. Однако время, затраченное на получение результата при поиске, может существенно зависеть от выбранной поисковой машины. Кроме того, как будет показано ниже, использование всего одной поисковой системы не дает никаких гарантий по полноте охваченных ресурсов.
Приведем несколько ссылок, которые указывают на страницы, содержащие крупнейшие в Сети перечни поисковых систем
http://dir.yahoo.com/Computers_and_Internet/Internet/World_Wide_Web/Searching_the_Web/Search_Engines/
http://dmoz.org/Computers/Internet/WWW/Search_Engines/
http://www.webtaxi.com/
Некоторые важные для обсуждения характеристики лидирующих поисковых машин, связанные как с фазой индексирования, так и с фазой обработки запросов, представлены в таблице 1.
| Поисковая машина | AltaVista | Excite | HotBot | InfoSeek | Lycos | Northern Light | Web Crawler |
|---|---|---|---|---|---|---|---|
| Показатели индексирования | |||||||
| Размер индекса в млн. документов | 150 | 55 | 110 | 45 | 50 | 140 | 2 |
| Скорость индексирования, документов в день | 10 млн | 3 млн | до 10 млн | Нет данных | от 6 до 10 млн | более 3 млн | Нет данных |
| Время регистрации | 1-2 дня | 2 недели | 2 недели | 2 дня | 2-3 недели | 2-4 недели | 2 недели |
| Полная глубина индексирования | Да | Нет | Да | Нет | Нет | Да | Нет |
| Полная поддержка фреймов | Да | Нет | Нет | Нет | Нет | Да | Нет |
| Закрытые паролем узлы | Да | Нет | Да | Нет | Нет | Нет | Нет |
| Учет частоты обновления | Да | Нет | Нет | Да | Нет | Нет | Нет |
| Особенности поисковых языков | |||||||
| Поиск по домену | Да | Нет | Да | Да | Да | Нет | Нет |
| Поиск по URL | Да | Нет | Нет | Да | Да | Да | Нет |
| Учет регистра | Да | Нет | Частично | Да | Нет | Частично | Нет |
| Поиск по заголовку | Да | Нет | Да | Да | Да | Да | Нет |
| Использование маски "*" | Да | Нет | Да | Нет | Нет | Да | Нет |
| Поддержка NEAR и его ширина | 10 слов | Нет | Нет | Нет | 25 слов | Нет | 2 слова |
| Поддержка кириллицы | Да | Нет | Нет | Да | Да | Да | Нет |
Таблица 1. Сравнительные показатели глобальных поисковых машин общего назначения. Сетевые адреса поисковых машин строятся на базе их имен по шаблону www.имя.com (двусложные имена пишутся слитно)
Начнем с особенностей индексирования. Большой объем индекса, безусловно, выглядит как разумный аргумент при выборе поисковой системы. Однако он далеко не единственный. Любые начальные сведения о характере информации, служащей предметом поиска, делают задачу выбора более тонкой. Например, если нас интересуют сведения, которые могли поступить в Сеть только за последнюю неделю, то следует предпочесть поисковые машины с высокой скоростью индексирования и минимальным временем регистрации, через которое документ по представлению автора появляется в индексе.
Для ускорения сканирования узла робот поисковой машины может ограничивать глубину его индексирования. WebCrawler, например, вообще сканирует только домашнюю страницу сайта. В результате даже такой крупный индекс как Excite может оказаться непригодным для поиска данных, которые в типичных случаях принято размещать в глубине узла.
Из трех крупнейших конкурирующих индексов AltaVista, Northern Light и HotBot у последнего есть серьезные проблемы со сканированием узлов, содержащих фреймы. Отсюда следует, что при масштабном сборе информации из Сети HotBot во избежание потерь можно использовать только как систему, дополнительную к двум первым.
Нередко разработчики коммерческих узлов закрывают под пароль доступ к материалам сайта. Заинтересованные тем не менее в рекламе, они часто прибегают к возможности открыть доступ к их ресурсам роботам поисковых систем. Из таблицы видно, что только два индекса корректно работают с закрытами узлами.
Таким образом, при поиске информации, которая потенциально является продаваемой, их применение обязательно.
Роботы поисковых систем, сканирующие Сеть, могут увязывать частоту своих повторных посещений уже зарегистрированного узла со скоростью обновления его материалов (AltaVista, InfoSeek). Эта черта полезна при поиске сведений, которым присуще частое обновление, например, новостей.
В нижнем блоке таблицы выделены возможности поисковых языков отдельных систем, которые также допускают специфичное применение.
Так, ключевые слова, входящие в доменное имя узла, сегодня широко используются при поиске всевозможных компаний. Если есть начальные сведения о терминах, которые могут быть включены в названия каталогов или файлов - носителей релевантной информации, то следует использовать поисковые машины, поддерживающие поиск по URL. Даже такая казалось бы незначительная деталь как учет регистра при построении запроса в определенных ситуациях становится крайне полезной. Например, при сборе сведений о Турции (Turkey) системы, которые фиксируют при индексировании регистр каждой буквы слова, позволяют легко избавиться от документов с термином turkey (индюк).
Поиск по заголовку страницы (элемент title) достаточно эффективно применяется, когда разыскиваются организации, особенно с двусложным длинным названием. Односложное название обычно входит в имя домена или в URL как есть, а многосложное формирует аббревиатуру. По домену или URL их легче всего и оказывается локализовать. Название же компании из двух слов, например, American Cybernetics, не позволяет точно угадать имя сервера (ни www.americancybernetics.com, ни www.ac.com не являются верными). Поэтому в синтаксисе AltaVista запрос
title:"American Cybernetics" является наиболее эффективным. Ясно, что лидеры некоторых опросов - поисковые службы Excite или WebCrawler выглядят здесь несостоятельными.
Следует помнить, что одноименные операторы в разных поисковых системах могут иметь неодинаковые свойства. Оператор близости NEAR иллюстрирует этот факт. На запрос типа "термин_1 NEAR термин_2" откликнутся документы, заиндексированные роботами AltaVista, Lycos или WebCrawler, если заданные термины присутствуют в документах в пределах определенной близости друг к другу, неодинаковой для разных систем (см. таблицу). Разницу в интерпретации оператора NEAR можно тонко использовать при поиске.
Еще одно замечание необходимо сделать о возможности "теневой" профилизации глобальных поисковых машин. Чисто технические особенности работы сервиса могут спровоцировать увеличение доли одной тематики информации перед другой. В результате равные по объему индексы могут давать неодинаковый отклик по отдельным запросам, что следует учитывать при планировании поиска. Существует ли такой крен в каждом конкретном случае выясняется с помощью тестовых запросов.
Разумеется, исчерпывающий сравнительный анализ даже всего семи поисковых систем выходит за рамки одной статьи. Более важная задача автору виделась в том, чтобы обозначить общий подход к проблеме выбора поискового инструмента на основе детального анализа его возможностей. Полезно отметить, что обычно поисковые сервера разделяют интерфейс для ввода запросов на "простой" и "расширенный" (advanced, power). Все необходимые для профессиональной работы с системой возможности скрыты в "расширенном" интерфейсе, и именно с него стоит начинать знакомство с любой новой для себя поисковой машиной.
В целом нетрудно видеть, что борьба за глобальное лидерство разворачивается между тремя наиболее крупными поисковыми системами AltaVista, HotBot и Northern Light .
Еще два года назад трудно было себе представить, что первенство AltaVista кто-то сможет оспорить. Казалось бы, что с течением времени соперничать с гигантом становится все труднее.Однако в 1998 году к лидеру заметно приблизился HotBot, а нынешний год отмечен скандальными заявлениями разработчиков Northern Light о том, что индекс этой системы является самым крупным в Сети. Действительно, невероятный скачок индекса Northern Light от 67 млн. документов по данным прошлого года до нынешних 140 млн. говорит о том, что вся борьба еще впереди. Разница в объеме индексов этой тройки при достаточно большом количестве нюансов его определения не настолько значительна, чтобы быть принципиальной. Более важно то, что соперничество систем способствует развитию индивидуальности каждой из них.
AltaVista отличается, пожалуй, самым изысканным и гибким языком запросов, требующим однако специального изучения. Но он того стоит. Посмотрите, например, как изящно выглядит запрос на получение электронных текстов Джека Лондона с какого-либо нерусского сервера.
(url:etext) and text:(Jack near London) and not (text:(city or capital) or domain:ru)
Запрос тут же отсекает нерелевантную информацию о столице Великобритании.
Другая черта AltaVista - это многоязыковая поддержка индекса и возможность перевода в режиме on-line текста Web-страницы c распространенных европейских языков на английский.
HotBot отличает от AltaVista шаблонный и поэтому более простой подход к построению запроса, а также богатый набор фильтров для поиска специфических объектов, таких как ActiveX,VRML, VB Script и других.
Northern Light в этом отношении имеет достаточно стандартный набор функций. Система пытается заработать очки на сопровождении уникальной коллекции ссылок (более 5 тысяч записей) в основном на статьи из периодических изданий. Поддержка индексом кириллицы делает его вместе с AltaVista неплохим дополнением к региональным российским поисковым системам Рамблер, Яндекс и Апорт при русскоязычном поиске.
Сегодня при решении поисковых задач возрастает роль чувствительности поисковых систем к закрытым форматам хранения данных. Речь идет о тех форматах, внутренняя структура которых в отличие, например, от Web-страниц, закрыта от проникновения сканирующих программ. Файлы мультимедиа, заархивированные данные и PDF -файлы могут оказаться ничуть не менее полезными, чем гипертекстовые данные.
Если цель поиска с самого начала связана с одним из таких форматов, то целесообразно использовать глобальные системы с поддержкой соответствующих фильтров (например, Lycos, HotBot) или специализированные системы.
Трудоемкие поисковые работы, связанные с масштабным сбором информации из Сети, нуждаются в планировании. Ошибочная логика построения запроса, неоптимизированная последовательность применения инструментов, попытка форсировать поиск - все это не просто затягивает получение результата на дни и даже недели, но может поставить под вопрос смысл всей поисковой кампании.

Рис. 4. Изменение числа заиндекированных на май 1999 года документов (правый столбец) в процентах от их общего количества в Паутине по отношению к апрелю 1998 года (левый столбец) для различных поисковых машин: 1-AltaVista, 2-Northern Light, 3 - HotBot , 4- Excite, 5- Lycos, 6- Infoseek, 7- WebCrawler (по материалам Science magazine и Forrester Research)
Несмотря на постоянный рост индексов поисковых систем, оценки показывают, что увеличение общего числа документов в WWW за последний год с 320 до 550 миллионов в целом ухудшило картину доступности информации. Из гистораммы на рис.4 следует, что доля документов, захваченная отдельным индексом значительно упала и не превышает 30 процентов. Отсюда ясно, что только применение совокупности поисковых машин, способно дать полноценную информационную картину для поисковых задач, при решении которых существенна полнота поиска.
Тем не менее независимо от характера задачи, непродуманное метание от одного поискового сервиса к другому существенно увеличивает время получения результата.
Остановимся на нескольких важных моментах, связанных с планированием и первыми шагами поисковой процедуры.
Начинать обычно приходится со всестороннего лексического анализа информации, подлежащей поиску. Необходимо получить из любого источника прецедент подробного и грамотного описания исследуемого вопроса. Таким источником вполне может стать как узко специальный справочник, так и электронная энциклопедия общего профиля. На основе изученного материала необходимо сформировать максимально широкий набор ключевых слов в виде отдельных терминов, словосочетаний, профессиональной лексики и клише, при необходимости - и на нескольких языках. Заранее стоит побеспокоиться о потенциальной возможности уточнения поискового запроса - редких словах, возможно, названий
и фамилий, тесно связанных c проблемой. Желательно также предвидеть,
какие из выбранных терминов, могут привнести в отклик поисковых систем нерелевантные документы. После накопления этого багажа можно перейти к получению предварительной информации из Сети.
Основная задача этой фазы работы - преломить проблему через призму Интернета, который является не только носителем технологий, но и традиций, и собственной этики. Сетевая лексика, сленг и написание общеупотребительных слов здесь могут отличаться от общепринятых.
Довольно трудно, например, догадаться, что появление огромного количества англоязычных электронных текстов литературных произведений в Сети связано с именем сетевого проекта "Gutenberg". Или что название операционной системы OS/2 допускает два вида написания - "OS/2" и "OS2". Одно неловкое движение - и десятки тысяч полезных документов выпадают из поля зрения.
Рейтинги потенциальных поставщиков нужной информации в обычной жизни и в электронном пространстве также могут существенно отличаться. В этой связи возможно, одно из главных положений, которое должно привлекать заказчика поисковых работ в Сети - это присутствие в ней совершенно уникальных источников,
не допускаемых или неконкурентных на традиционном рынке информации. При поиске в Сети заметную роль начинает играть видение психологического портрета поставщика информации, к чертам которого могут проявлять чувствительность поисковые инструменты.
Прецедент существования в Сети необходимых данных лучше всего найти в известном каталоге, поддерживающем поиск по ключевым словам. В целом при решении простых, "любительских" задач уровня "погода в Сочи" или "карта метро Рима" каталог может быть более быстрым источником получения информации, чем на автоматический индекс и при больших гарантиях достоверности.
После лексического анализа информации наступает технологический этап. Выбор информационного поля Сети и поисковых инструментов производится на основе подходов, изложенных нами ранее.
Используются тестовые запросы из 1-2 ключевых слов или фразы, затем анализируется количественный отклик. Содержательный анализ данных позволяет корректировать запросы по релевантности отклика. В этой работе могут применяться и метапоисковые, и крупные автономные системы. В результате тестирования выясняются наиболее представительные источники информации, после чего следует уточнить последовательность применения поисковых инструментов. На этом этап планирования завершается.
В заключение отметим, что в особенности для задачи сбора информации из Сети сегодня заметно возрастает роль региональных и специализированных поисковых сервисов. Использование глобальных индексов не для прямого поиска нужных сведений, а для локализации этих поисковых инструментов нередко позволяет в сжатые сроки форсировать поисковую кампанию.