
Журнал "Открытые Системы", #09-10/1999
Павел Храмцов
Прикладное программирование для Web начиналось с обработки запросов пользователя и динамической генерации страниц на стороне сервера. Эта же тенденция получила развитие и в языках программирования вставок в HTML-документы. Затем появились языки программирования элементов HTML-документов на стороне клиента. И те, и другие привязаны к модели данных HTML. Сегодня, когда Web мигрирует к стеку спецификаций XML, разработчики средств программирования должны это учесть и правильно отреагировать, позволив, например, манипулировать элементами XML-разметки. Стандарт, призванный обозначить и решить эту задачу, получил название Document Object Model - DOM.
Как известно, все начиналось с SGML [1], породившего HTML [2], а когда возможности последнего были исчерпаны, произошел частичный откат к SGML. В результате появился новый язык - XML (eXtensible Markup Language) или, более точно, стек спецификаций языков разметки различного назначения, которые базируются на общих синтаксических правилах [4]. Возникновение XML было обусловлено, в частности, стремлением разработчиков унифицировать форму хранения документов для различных носителей информации. Не последнюю роль сыграла и необходимость развития и унификации формата хранения метаданных, а также преобразования документов в процессе их отображения и просмотра.
Параллельно с процессом развития формального статического описания содержания документа развивались и способы его изменения. Первоначально они были обозначены в JavaScript, затем язык программирования Java позволил размещать внутри документа и видоизменять информацию любого типа. Появление VBScript и JScript означало, что Microsoft движется в том же направлении. Постепенно технология Java опустилась до уровня средств разработки приложений Web, а сценарное направление оформилось в концепцию DHTML (Dynamic HTML).
И XML, и DHTML, и Java в конечном итоге замкнулись на модель данных Web, множество страниц Web, которые, с точки зрения разработчиков поисковых языков XML, представляют собой сплошной поток разнотипных данных [5]. Один документ (страница) - это подмножество всех документов (страниц) Web. Модель данных Web определяют в виде графа - "лес" из деревьев.
Рис.1. Графическое представление структуры HTML-документа
Чтобы представить предмет нашего обсуждения в более простом виде, возьмем HTML-документ и "препарируем" его с точки зрения такой графовой модели данных (рис. 1). Весь документ - это один большой элемент разметки HTML. При этом документ является блочным элементом, который не может пересекаться с другими документами, однако может содержать блоки, например, HEAD и BODY. В свою очередь HEAD и BODY тоже могут включать другие блоки. При этом элемент BODY в своих атрибутах способен определить свойства всего отображаемого тела документа, например, цвет текста, цвет фона или, скажем, цвет гипертекстовых ссылок. Если двигаться еще дальше внутрь BODY, то с очень большой вероятностью в типичном HTML-документе можно встретить элемент разметки IMG, у которого есть свои свойства.
Теперь назовем узлы графа объектами, а программам разрешим изменять свойства этих объектов. Скажем, значение атрибута SRC у объекта, который соответствует элементу разметки IMG. При этом выполнять такие изменения можно, используя метод из набора стандартных методов, общих как для сценариев языков, так и для Java. Все это образует концепцию DOM - Document Object Model. Собственно DOM - это интерфейс прикладного программирования в рамках модели данных Web или, другими словами, набор стандартных методов объектов Web. Если нужно вывести текст в тело документа, это можно сделать на любом языке программирования, который поддерживает DOM:
document.write(<kuku>);
Здесь задействован стандартный метод write объекта document. Имя метода, значение, которое он возвращает, аргументы метода и их типы - все стандартизовано в DOM.
Таким образом, путь развития Web-технологии пролегает от статической HTML-разметки через скриптовые языки, Java и DHTML к спецификациям XML и DOM. Остановимся на этапах этого пути подробнее.
HTML предполагает, что документ состоит из стандартных элементов разметки, которые отображаются совершенно определенным образом. Набор элементов HTML - это типизация компонентов обычного печатного документа: заглавия, списки различных типов, параграфы, таблицы, цитирование и т.п. При этом все элементы разделены на два типа: строковые и блочные. К первым можно отнести параграф, список, таблицу. К строковым элементам - выделение курсивом или насыщенностью, текст гипертекстовых ссылок. Все это определено в Document Type Definition спецификации HTML, которая формально записана на SGML.
Жесткие правила отображения элементов на ранних стадиях становления Web-технологий позволяли обеспечить четкие и ясные требования к браузерам, а также возможность быстрого наполнения Web информацией. По мере увеличения количества информации и усложнения структуры набора документов Web-узлов простота технологии стала превращаться в недостаток. Приходилось копировать фрагменты кода, вводить новые элементы разметки для варьирования форматов изображения в зависимости от контекста, поддерживать все более сложные форматы графических файлов.
Следует также учитывать, что создание Web-узлов превратилось сегодня в отдельный вид профессиональной деятельности. При этом узел стал самостоятельным товаром, стоимость которого не должна превышать разумных пределов, определяемых его функциональным назначением (виртуальный магазин, информационная служба, ядро корпоративной системы и т.п.). Исходя из этого, сформировалось определенное понимание состава функций ПО Web-узла, типизации страниц Web-узла по их функциональному назначению, составу компонентов и методам обработки информации на страницах.
Первое, с чем столкнулись авторы и разработчики Web-узлов, - это необходимость повторения фрагментов кода на каждой странице, например логотипа компании или главного меню Web-узла. Для решения этой проблемы используется метод подстановок, заимствованный из программирования макроопределений. Так появились Server Site Includes (SSI). Вставка внешнего файла в HTML-страницу - это самый простой способ применения SSI:
<html> <head> ... </head> <body> ... <!-#include virtual= <file.htm> -> ... <!-#include file= <file.htm> -> ... </body> </html>
Строчки HTML-комментариев содержат директивы SSI. В первом случае указывается виртуальный путь в рамках дерева документов сервера. Во втором случае - путь относительно каталога, в котором размещен документ, куда осуществляется вставка.
Вставка в документ результатов исполнения программ открывает гораздо больше возможностей. Такие вставки тоже могут быть двух типов:
<html> <head> ... </head> <body> ... <!-#exec cmd= <date> -> ... <!-#exec cgi = <my_prog.cgi> -> ... </body> </html>
Конструкция <exec cmd=> дает возможность вставить в документ результат выполнения внешней программы, например, date (вставка текущей даты). Вариант <exec cgi=> позволяет вставить в документ результат выполнения cgi-сценария. Это очень мощное средство проектирования страниц узла, которое позволяет через механизм CGI принимать запросы от браузеров и генерировать страницы с учетом результатов выполнения этих запросов. Именно таким способом первоначально реализовывались системы поиска в базах данных, а позднее и системы поиска информации по ключевым словам.
Порядок обработки запроса от браузера на получение документа со вставками (Server Parsed Document) следующий:
Таким образом, сервер является интерпретатором языка SSI, т.е. в составе модулей сервера должен быть и модуль интерпретации SSI.
Вполне естественно, что идея SSI получила дальнейшее развитие, например, появилась возможность условной генерации вставки по условию. Кроме того, были разработаны расширенные языки SSI. Наиболее известными продолжениями данного подхода с определенными оговорками можно считать пакет PHP, чрезвычайно популярный среди разработчиков узлов под управлением сервера Apache, а также механизм ASP, который был реализован в IISt. Но главную роль в развитии технологии программирования составных документов сыграл механизм LiveWare, впервые реализованный в 1995 году в серверах компании Netscape Communications. Благодаря SSI документ стал составным на стороне сервера. Но Web-технология имеет архитектуру клиент-сервер, поэтому необходимо было реализовать такие же возможности формирования документа и на стороне клиента.
Для большинства разработчиков Web программирование в рамках спецификации LiveWare связано с JavaScript. Этот простой объектно-ориентированный язык программирования на стороне браузера позволил "оживить" Web-страницы. Примечательно, что практически все учебники по JavaScript начинаются с описания элемента разметки SCRIPT. В этом легко усматривается традиция SSI. Дело в том, что JavaScript предполагает четыре способа размещения программного кода на HTML-странице и передачи управления интерпретатору для выполнения этого кода. Элемент разметки SCRIPT - только один из них. При этом методологически правильнее начать изучение языка с URL-схемы javascript, позволяющей программировать гипертекстовые переходы, или с обработчиков событий, программирование которых позволяет заменять правила реакции браузера на действия пользователя по умолчанию.
Интерпретация кода в элементе SCRIPT происходит только в момент начальной загрузки страницы. Управление переходит к интерпретатору в момент, когда HTML-программа синтаксического разбора "натыкается" на элемент разметки SCRIPT. Код выполняется, и результат его работы подставляется в документ (если это можно сделать). Налицо типичная вставка, реализованная на стороне клиента.
Остановимся теперь на технологии, которая стала, с одной стороны, развитием HTML-разметки, а с другой - следующим шагом по направлению к XML. Речь идет о каскадных таблицах стилей, Cascading Style Sheets (CSS), патентом на спецификацию которых владеет Microsoft. Но спецификация относится к категории открытых стандартов и может использоваться всеми разработчиками ПО для Web. Основная идея CSS состоит в том, чтобы отделить логическую структуру документа от формы его представления (способа форматирования изображения на носителе).
С появлением CSS в HTML стало возможным использование двух обобщенных элементов разметки: DIV (обобщенный блок) и SPAN (обобщенный строчный элемент разметки). Теперь можно составлять логическую структуру документов, а затем определять формат ее отображения.
Этот подход изменил всю технологию проектирования страниц Web-узла. Теперь сначала определяются типы страниц, потом логическая структура страницы для каждого типа и в последнюю очередь для каждого логического элемента определяется его состав и внешний вид.
Возможность указания стиля во внешнем файле позволяет применять одно определение стилей для всего узла и изменять вид страниц, редактируя только данный файл. Следующий шаг на этом пути - динамическое переопределение стиля на стороне клиента в зависимости от условий отображения документа и действий пользователя. Для программирования таких изменений применяется язык типа JavaScript.
До сих пор речь шла о развитии технологий, опирающихся на HTML - элементы разметки и способы их размещения на страницах. Но есть еще один аспект Web-технологии - язык программирования Java.
Первоначально в Java не предполагалось осуществлять манипулирование объектами HTML-страницы и, хотя Duke бегал по границе экрана браузера Sun, реально Java внедрился в документ только в виде элемента разметки applet. Как универсальный язык программирования интерфейсов, главным образом графических, Java поддерживал более абстрактные типы данных и объекты, чем это требовалось для программирования HTML-страниц.
Сейчас ситуация изменилась. На Java написаны браузеры и серверы. При этом Java-код являетя изначально интерпретируемым. Следовательно, на Java можно писать SSI и изменять содержание документа на стороне браузера. Но возможности Java сегодня используются прежде всего для преодоления негативных особенностей HTTP-обмена (поддержка постоянных TCP-соединений) и вывода динамически изменяемой графики. Следует отметить, что протокол HTTP версии 1.1 [6] позволяет компоновать документ из различных частей, которые могут располагаться на разных серверах. Это не установка нового соединения для подкачки картинки при разборе HTML-документа, а список заголовков HTTP-отклика, в которых указывается URL. Таким образом, HTTP модифицирован для поддержки составных документов.
DTD HTML определяет правила построения HTML-документа, синтаксис элементов разметки и их возможное взаимное расположение. Если взглянуть на документ как на множество объектов, которые ассоциируются с элементами разметки, то DTD будет задавать иерархию классов этих объектов.
Логическая структура документа определяет отношения объектов между собой. Существует, по крайней мере, две модели объектов документа: модель JavaScript и DOM. Первая поддерживается, с некоторыми оговорками, практически всеми наиболее популярными браузерами. Вторая только претендует на роль стандарта и должна в будущем поддерживаться всеми браузерами.
Отношения отдельных объектов между собой сводятся, главным образом, к отношениям типа "часть-целое", а структура документа представляет собой дерево. В роли остова выступает дерево блочных элементов разметки документа. Затем на этот остов накладываются строчные элементы и стили. Кроме того, у документа существует поддерево классов объектов документа, определяемое в DTD. Изменение свойств класса приводит к изменению свойств всех объектов данного класса (рис. 2).
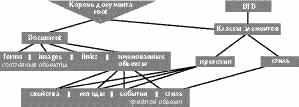
Рис. 2. Логическая структура документа.
Следует отметить, что логическая структура на рис. 2 гораздо ближе к модели данных Internet Explore, чем к JavaScript. Тем не менее, IE поддерживает модель JavaScript за исключением слоев, а в новой версии Netscape Navigator обещана поддержка DOM, которая совпадает с моделью IE.
В модели JavaScript самым старшим объектом является объект window - считается, что все происходящее с документом вложено в окно. У окна имеется несколько объектов-свойств: location, history, document, navigator. Это не полный перечень объектов окна, но для иллюстрации модели данных JavaScript он достаточен.
Объект location ассоциируется с полем location браузера, где отображается URL загруженного в окно документа. У location есть свойства и методы. При изменении значения свойства location или при вызове метода происходит перезагрузка документа. При перезагрузке может пополняться защищенный массив объекта history - множество URL, которые посещал пользователь. Основным способом использование history являются методы window.history.back(), window.history.forward() и window.history.go(-1).
Объект navigator позволяет отображать документ в соответствии с требованиями браузера и его настройками. Подчинение этого объекта window выглядит несколько нелогично: несмотря на множество обслуживаемых окон программа браузера одна. Наиболее полезны свойства объекта navigator, например, фрагмент кода позволяет загрузить страницы по типу навигатора.
<html> <head> <script> if(window.navigator.appName== <Microsoft Internet Explorer>) window.location.replace (<explorer.htm>); </script> </head> <body> ... </body> </html>
Если необходимо проверить исполняемость Java-кода на стороне браузера, например, для загрузки страницы с апплетом или без него, то это можно сделать, применив соответствующий метод объекта navigator.
Объект document ассоциирован с телом документа и включает в себя другие объекты, которые могут быть поименованы, как, например, объекты IMG или FORM, а также могут входить во встроенный массив, как, например, гипертекстовые ссылки (links[] ).
Первоначально в JavaScript особое внимание уделялось формам. По этой причине к формам относится наибольшее число классов объектов документа. Это и сама форма объект FORM, и элементы формы: поля ввода (input) различных типов, меню (select) и его составляющие (options), поля ввода больших блоков текста (textarea). У каждого из этих объектов достаточно большое количество свойств и методов.
Наибольших визуальных эффектов достигают за счет изменения свойства src объекта IMG, который может быть поименованным объектом документа. Он также входит во встроенный массив document.images[].
В JavaScript можно изменять значения гипертекстовых ссылок, а также указывать JavaScript-код вместо гипертекстовой ссылки, используя схему URL javascript. Это позволяет, в частности, отказаться от кнопок в формах и отправлять данные формы, нажимая на гипертекстовую ссылку.
Таким образом, видно, что модель данных JavaScript - это дерево. К его объектам принято обращаться по составным именам, например: window.document.cookie - строка ассоциативный массив "волшебных ключиков", window.document.forms.length - число форм в документе, window.document.images[0].src - URL первой картинки документа, window.location.href - URL загруженного в данный момент документа, window.frames.length - число фреймов в документе.
Сам объект при этом рассматривается как тройка: свойства, методы, события. Свойства - это скалярные характеристики объекта, методы - это функции, которые могут изменять свойства. События это внешние воздействия на объект, для которых можно написать функцию-обработчик события. Именно с программированием событий связаны различные эффекты типа расцвечивания черно-белых картинок или изменения картинки при прохождении курсора мыши через гипертекстовую ссылку.
Особенность модели событий в JavaScript заключается в том, что события жестко привязаны к объекту. Например, у гипертекстовой ссылки у элемента ... может быть событие onMouseover, а у элемента IMG такого события, а, следовательно, и обработчика этого события, быть не может. Логика в этом есть: IMG - это пассивный объект. В него никто не будет тыкать курсором мыши и по умолчанию при проходе курсора над IMG информация на экране не меняется. У пассивного объекта нет функций обработчиков событий, которые можно было бы заменить JavaScript-кодом. Другое дело гипертекстовая ссылка. При проходе курсора мыши над ней в строке статуса отображается URL, при выборе мышью ссылки происходит переход на другую страницу - по крайней мере, три стандартных обработчика событий у гипертекстовой ссылки имеется.
Кстати сказать, для свойств объектов в модели JavaScript определены свои правила инициализации. Например, размер картинки, если он только не указан явно в элементе разметки IMG, будет определяться первой картинкой. Все остальные картинки будут масштабироваться в этот размер независимо от их реальных линейных размеров. Аналогичное "поведение" характерно и для кнопок. Их размер определяется первой надписью, значение атрибута value элемента разметки INPUT. Это сделано для того, чтобы не переформатировать загруженный документ.
С точки зрения традиционного программирования наличие стандартных обработчиков событий и возможность изменения свойств - это вопрос инициализации данных и резервирования места под код и значения переменных. В JavaScript он решается в момент загрузки документа, когда создаются все встроенные объекты документа. После того, как произошло событие Load (обработчик onLoad элемента разметки BODY), встроенные объекты больше не создаются. По этой же причине при использовании метода document.write() после события Load приходится переписывать содержание загруженной страницы. Структура встроенных объектов страницы после ее загрузки не может быть изменена. Фактически модель данных JavaScript опирается на неизменный шаблон, который задается HTML-разметкой. Программист может только манипулировать свойствами объектов в рамках этого шаблона. Сами объекты при этом разделены на активные и пассивные, в зависимости от наличия у них обработчиков событий.
Концепция динамического HTML (DHTML) интерпретируется разработчиками основных браузеров по-разному. Для Netscape это тройка: JavaScript, загружаемые шрифты и стили. При этом предполагается расширение набора элементов разметки за счет элементов разметки стилей и элемента LAYER. Для Microsoft DHTML - это JScript, расширяющий возможности JavaScript. Он позволяет программировать стили, изменять содержимое документа без его перезагрузки и использовать другую схему обработки событий, которые, в свою очередь, жестко не привязываются к документу.
Стили создают отдельную иерархию объектов, причем очень многое зависит от типа селектора, который описывается стилем. Если это селектор класса элементов разметки, то это одна ветка дерева объектов документа, если это селектор произвольного класса, то это другая ветка дерева объектов документа, если это селектор идентификатор объекта, то это третья ветка объектов документа.
<style>
p {font-size:10pt}
kuku {color:red}
#blue {color:blue};
</style>
...
<script>
document.styleSheets[0].rules[0]
.style.fontSize=>10pt>;
document.styleSheets[0].rules[1]
.style.color=>red>;
document.styleSheets[0].rules[2]
.style.color=>blue>;
</script>
...
<a id=ref href=...>...</a>
<script>
document.all.ref.style.color=
<blue>;
document.all.ref.style.fontStyle=
<italic>;
document.all.tags(<a>).item(0)
.style.fontSize=>10pt>;
document.links[0].style
.backgroundColor=>black>;
</script>
Стоит отметить, что для использования идентификатора у элемента разметки в JScript совсем необязательно создавать связанный с ним селектор идентификатора в описаниях стилей - управлять через него стилями все равно нельзя.
Программирование стилей естественным образом приводит к переформатированию документа, что нарушает принципы неизменности загруженного документа JavaScript. В предыдущем примере это используется для изменения кегля гипертекстовой ссылки, к которой мы обращаемся как к элементу коллекции (встроенному массиву) гипертекстовых ссылок. Выбираем же этот элемент последовательно, применяя методы tags() и items(), либо обращаясь к массиву links[].
JScript позволяет поименовать любой элемент разметки документа, однако делается это не через атрибут name, а через атрибут id. При этом у поименованного таким образом объекта есть два свойства innerText и innerHTML. Свойства эти можно изменять. Первое из них позволяет изменить текст внутри элемента разметки, а второе - содержание HTML-разметки внутри элемента разметки, что дает возможность создавать новые объекты внутри документа.
<p id=kuku onMouseover= <document.all.ref.style .color='red';document.all.ref .innerText='красная гипертекстовая ссылка';> onMouseout= <document.all.ref .style.color='blue'; document.all.ref.innerText= 'гипертекстовая ссылка';>> Здесь размещена <a href=... id=ref onClick= <document.all.kuku.innerHTML= 'Здесь нет гипертекстовой ссылки'; return false;> style= <color:blue;>> гипертекстовая ссылка </a> </p>
В последнем примере обработчики событий onMouseover и onMouseout применялись для обработки движения мыши над блоком текста, т.е. событий, связанных с пассивным элементом разметки. Здесь мы наблюдаем принципиальное отличие от первоначальной модели событий JavaScript.
Любое событие может быть связано с элементом разметки - это достигается указанием у этого элемента атрибута обработчика данного события. Другими словами, у всех элементов разметки определен весь перечень возможных событий и обработчики этих событий для каждого класса элементов. Программист через атрибут обработчика может переопределить действие, выполняемое по умолчанию.
В JScript применяется "пузырьковый" метод обработки событий. Это означает, что если для какого-то объекта происходит некоторое событие, то сначала вызывается обработчик события, связанный с этим объектом, а потом событие передается обработчику данного события для старшего объекта в иерархии объектов документа. Программист имеет возможность запретить передачу обработки события наверх.
Для поддержки совместимости со статическим HTML и JavaScript большинство обработчиков не выполняют никаких операций, хотя по умолчанию события всегда транслируются на верхний уровень.
И последний штрих к "портрету" JScript. Этот язык и его модель данных можно использовать для программирования Active Server Pages (ASP). Главное здесь не запутаться между директивами JScript, предназначенными для интерпретации на стороне сервера и JScript-кодом, который следует исполнять на стороне браузера.
Объектные модели данных JavaScript, JScript и Java предшествовали появленю Document Object Model [7] - спецификации интерфейса прикладного программирования для HTML и XML. DOM наследует многие свойства этих моделей и творчески развивает их. DOM определяет логическую структуру документа, способы доступа к его элементам и манипулирования ими. При этом термин "документ" понимается широко - это единица информационного описания, которую можно закодировать на XML. Другими словами, XML-описание рассматривается в качестве документа, а DOM определяет способы манипулирования этим описанием.
В рамках DOM программист может создавать документы, получать доступ к их составным частям (элементам), добавлять, удалять элементы и изменять их содержание. Главным в DOM был универсальный, независимый от языка программирования, интерфейс прикладного программирования документов Web.
В спецификации DOM специально оговаривается вопрос о том, что применение DOM не подразумевает модель данных типа "дерево" или "лес деревьев". Авторы подчеркивают, что они оперируют структурной моделью данных (structured model), избегая формулировки "модель данных типа дерево или леса". XML, для которого разработана DOM, опирается на представление данных в виде леса деревьев, но для манипулирования структурами такого типа не обязательно использовать именно эту модель данных. Можно обойтись списками или другими моделями, которые однозначно отображаются на деревья. Авторы специально подчеркивают, что если две разных реализации DOM создают один и тот же документ, то они создают одну и ту же модель данных с одинаковыми объектами и отношениями между ними. О таких реализациях DOM говорят, что они изоморфны. Таким образом, DOM определяет:
Основное отличие модели данных DOM от абстрактной модели данных SGML состоит в том, что модель SGML строится вокруг собственно данных. В объектно-ориентированных языках программирования, для которых разработана концепция DOM, данные инкапсулированы в объекты, которые их скрывают и защищают от изменений. Изменять данные можно только с помощью методов, указанных в спецификациях объектов. DOM определяет данные и методы манипуляции данными применительно к XML и HTML.
Спецификация DOM состоит из двух частей: ядра DOM и применения DOM к HTML. Ядро обеспечивает функциональную полноту для обработки XML-документов, а также базис для DOM HTML.
Следует отметить, что, определяя объекты и методы манипулирования ими, спецификация DOM уровня 1 ничего не говорит о событиях и принципах их обработки. Это существенно ограничивает возможность быстрого применения DOM в современных средствах программирования Web, где обработка событий является одним из ключевых элементов технологии программирования. Строго говоря, DOM позволяет реализовать с точностью до обработки событий модель объектов JavaScript, но явно недостаточна для реализации модели объектов DHTML, хотя именно последняя концепция бралась авторами DOM за основу.
Ядро DOM позволяет определить документ как множество узлов, связанных между собой отношением "родитель-потомок", а ключевым объектом является Document. Отношение "родитель-потомок" определено в DOM следующим образом:
Document =: Element, ProcessingInstruction, Comment, DocumentType DocumentFragment =: Element, ProcessingInstruction, Comment,Text, CDATASection, EntityReference DocumentType =: нет потомков EntityReference =: Element, ProcessingInstruction, Comment, Text, CDATASection,EntityReference Element =: Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference Attr =: Text, EntityReference ProcessingInstruction =: нет потомков Comment =: нет потомков Text =: нет потомков CDATASection =: нет потомков Entity := Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference
С другой стороны в DOM определен объект Node (узел), у которого определен интерфейс NodeList, устанавливающий порядок узлов потомков объекта Node.
Если вы ждете, что сейчас речь пойдет о дереве интерфейсов DOM, то вас придется огорчить - такого дерева в DOM нет. Каждый интерфейс описывает атрибут и методы, которые, в свою очередь, могут иметь тип другого интерфейса. Можно, конечно, попытаться построить такое дерево, но хочу сразу предупредить, что в графе появятся кольца.
Описание интерфейсов дано в обычном алфавитном порядке и разбито на описание ядра DOM и DOM HTML, а в ядре выделены фундаментальные интерфейсы. Следует отметить, что описание интерфейса - это фактически описание класса объектов. Только для методов класса отсутствуют реализации методов, которые перечислены в интерфейсах. В описании интерфейсов есть переменные, но, в отличие от Java, где тоже имеется механизм интерфейсов, они могут определять как неизменяемые, так и изменяемые свойства объектов класса. Реализация интерфейсов в конкретных языках программирования -задача разработчиков этих языков в рамках описания соответствующих классов.
В DOM рассматриваются два уровня интерфейсов: базовый, оперирующий узлами, ориентирован на применение в рамках Java или других языков разработки приложений; прикладной уровень, который оперирует объектами типа Document или Element, а в рамках DOM HTML конкретными классами объектов HTML. Последний тип интерфейсов ориентирован на скриптовые языки и может применяться более широким кругом программистов.
Авторы, подчеркивая языковую независимость DOM, для спецификации интерфейсов используют OMG IDL в том виде, в каком она определена в спецификации CORBA_2.2. Например, определение интерфейса Document в этой нотации будет выглядеть следующим образом:
interface Document : Node {
readonly attribute DocumentType doctype;
readonly attribute
DOMImplementation implementation;
readonly attribute Element documentElement;
Element createElement(in DOMString tagName)
raises(DOMException);
DocumentFragment createDocumentFragment();
Text createTextNode(in DOMString data);
Comment createComment(in DOMString data);
CDATASection createCDATASection
(in DOMString data)
raises(DOMException);
ProcessingInstruction
createProcessingInstruction
(in DOMString target in DOMString data);
raises(DOMException);
Attr createAttribute(in DOMString name)
raises(DOMException);
EntityReference createEntityReference
(in DOMString name) raises(DOMException);
NodeList getElementsByTagName
(in DOMString tagname);
};
Интерфейсы более высокого уровня, например, интерфейс HTMLFromElement раздела DOM HTML будет в данной нотации определяться следующим образом:
interface HTMLFormElement :
HTMLElement {
readonly attribute
HTMLCollection elements
readonly attribute long
length;
attribute DOMString
name;
attribute DOMString
acceptCharset;
attribute DOMString
acton;
attribute DOMString
enctype;
attribute DOMString
method
attribute DOMString
target
void
submit();
void
reset();
};
Обсуждать декларацию интерфейса Document не имеет смысла - при программировании на JavaScript с ним просто нельзя столкнуться, т.к. там нет таких возможностей. Типовое программирование на JScript также обходится без программирования свойств документа. Декларацию HTMLFormElement, напротив, стоит рассмотреть - это типовая задача при программировании передачи данных из формы при контроле ввода на стороне клиента.
Что мы видим в декларации HTMLFormElement? Атрибут elements - это коллекция в терминах DOM или встроенный массив в терминах JavaScript, причем массив неизменяемый. Добавить в него новые элементы нельзя. Атрибут length определен как неизменяемый. В комментариях к этому описанию в спецификации указано, что его значение равно числу элементов в форме. Name - это имя формы, и его можно менять. Атрибут acceptCharset определяет типы кодировки, которые поддерживает сервер. Остальные атрибуты имеют те же значения, что и в HTML. Методы submit и reset не возвращают значений и имеют тот же смысл, что и в JavaScript. Замечание по поводу типа кодировки сервера позволяет говорить о том, что DOM определяет интерфейс прикладного программирования, как на стороне клиента, так и на стороне сервера.
Важно отметить еще один момент. Когда программист работает с одним языком, например, с JavaScript или Java, вопрос о единстве описания переменных и методов объектов сводится к удобству и скорости адаптации при переходе от одного языка программирования к другому. Но современные браузеры в рамках технологий JavaScript, JScript, VBScript и Java позволяют организовать обмен данными между фрагментами кода, написанными на разных языках. Например, в JavaScript существует механизм LiveConnect, который определяет правила передачи данных и использование методов Java в JavaScript и наоборот. При таком положении дел стандартизация интерфейсов не только полезна, но и просто необходима.
Объектная модель документа должна послужить соединительным звеном между программированием и логической структурой документа, формой его представления на носителях. Логическая структура и форма представления описывается в рамках XML. Программирование Web - это языки Java, JavaScript, JScript. Стандарт DOM позволяет формально описать правила манипулирования структурой XML-документов и их содержанием в рамках объектно-ориентированного программирования, которое реализуют перечисленные языки.
Во многом усилия по разработчиков DOM напоминают попытки создания различных версий спецификаций HTML (версий 2.0 и 3.2). Первая версия языка и последняя четвертая версия скорее похожи на декларации о намерениях, чем на готовые к использованию спецификации. То же происходит и со спецификациями прикладного программирования. Первая версия DOM во многом уже отстает от языков программирования, реализованных в современных браузерах JScript в IE 5.0 или JavaScript браузера Gecko - новой версии Netscape Navigator. Первая версия спецификации DOM еще не реализована, а на подходе уже вторая, в которой планируется писать механизм обработки прерываний. Кроме того, ведутся работы над скриптовым языком ECMAScript, где будут обобщены возможности JavaScript и JScript, а также приняты во внимание особенности структуры данных XML-документов.
Павел Храмцов - сотрудник Российского Научного Центра "Курчатовский Институт". С ним можно связаться по электронной почте по адресу: paul@kiae.su