Даниэла Флореску, Алон Леви, Альберто Мендельсон
Журнал СУБД, #04-05/98
Популярность World-Wide Web (WWW) превратила его в главное средство распространения информации. Релевантность концепций баз данных проблемам управления этой информацией и обработки запросов привела в последнее время к значительной активизации исследований, связанных с этими проблемами. Хотя основной возникающий здесь вопрос - как управлять большими объемами данных - относится к традиционной сфере интересов сообщества специалистов в области баз данных, новый контекст WWW вынуждает нас значительно расширить ранее используемые технологии. Основная цель этого обзора состоит в том, чтобы классифицировать различные задачи, к решению которых применялись концепции баз данных, уделяя особое внимание тем техническим нововведениям, которые при этом потребовались.
Мы не утверждаем, что технология баз данных - это волшебная палочка, которая позволит решить все проблемы управления информацией в среде WWW. Вероятно, настолько же важны и другие технологии, такие как информационный поиск, искусственный интеллект, а также гипертекст и гипермедиа. Однако обсуждение всей проводимой в этих областях работы и взаимодействия между нею и идеями баз данных вывело бы нас далеко за рамки этого обзора.
Мы сосредоточимся здесь на трех классах задач, связанных с управлением информацией в среде WWW.
Моделирование и запросы в WWW: Предположим, что мы рассматриваем Web как ориентированный граф, узлы которого являются страницами Web, а дуги - связями между страницами. Первая задача, которую мы рассмотрим, это задача формулировки запросов для поиска определенных страниц Web. При этом запросы могут быть основаны на содержании нужных страниц и на структуре связей, соединяющих эти страницы. Простейшим примером такой задачи, который решается с помощью "поисковых машин" Web, является поиск страницы на основе содержащихся в ней слов. Простое обобщение такого запроса состоит в применении более сложных предикатов к содержанию страницы (например, найти страницы, которые содержат слово "Клинтон" после связи, указывающей на изображение). Наконец, в качестве примера запроса, который вовлекает структуру страниц, рассмотрим запрос, в котором требуется найти все изображения, достижимые из корня Web-сайта CNN, используя пути, включающие не более пяти связей. Последний тип запросов особенно полезен для обнаружения нарушений ограничений целостности на Web-сайте или в совокупности Web-сайтов.
Выборка и интеграция информации: Некоторые Web-сайты могут рассматриваться на более тонком уровне гранулярности, чем страницы, как контейнеры структурированных данных (множеств кортежей, множеств объектов и т.д.). Например, сайт Internet Movie Database (http://www.imdb.com) может рассматриваться как внешний интерфейс базы данных о кинофильмах. В связи с ростом числа таких сайтов становятся актуальными две следующие задачи. Первая задача состоит в том, чтобы фактически осуществлять выборку данных, представленных в структурированном виде (например, множество кортежей) из HTML-страниц, их содержащих. Эта задача решается с помощью набора программ-оболочек (wrapper), создание и поддержка которых порождает ряд проблем. Если мы рассматриваем сайты такого рода как автономные неоднородные базы данных, возникает вторая задача - формулировка запросов, которые требуют интеграции данных. Вторая задача решается с помощью систем медиаторов (или систем интеграции данных).
Разработка и реструктуризация Web-сайтов: Другой аспект применения концепций и технологий баз данных - разработка и реструктуризация Web-сайтов, а также управление ими. В отличие от предыдущих двух классов задач, которые имеют дело с уже существующими Web-сайтами, здесь рассматривается процесс создания новых сайтов. Конструирование Web-сайтов может начинаться либо с некоторых исходных данных (хранимых в базах данных или в структурированных файлах), либо путем реструктуризации уже существующих Web-сайтов. Выполнение этой задачи требует использования каких-либо методов моделирования структуры Web-сайта и языков для реструктуризации данных таким образом, чтобы они соответствовали желаемой структуре.
Прежде, чем начать наш обзор, следует отметить, что мы не будем рассматривать в нем ряд вопросов, связанных с применением концепций баз данных к WWW, в частности, кэширование и тиражирование данных (см. о недавних разработках в этой области в работах [WWW98, GRC97]), обработка транзакций и безопасность в Web-средах (см., например, [Bil98]), вопросы эффективности, доступности и масштабируемости для Web-серверов (см., например, [CS98]), или, наконец, методы индексирования и технология "роботов" (crawler) (см., например, [CGMP98]). Кроме того, данную статью не следует рассматривать как обзор существующих программных продуктов, даже в тех областях, на которых мы концентрируем здесь наше внимание. Заметим, наконец, что имеется также несколько не затронутых здесь областей, которые не имеют прямого отношения к рассматриваемым системам, но в которых получены результаты, применимые к ним. К числу таких областей относятся системы управления коллекциями документов и классификации (ranking) документов (например, Harvest [BDH+95], Gloss [GGMT99]), а также гибкие системы ответов на запросы [BT98]. В заключение, нужно подчеркнуть, что сфера использования технологий баз данных в среде Web (Web/DB) очень динамична. Поэтому в нашей работе, без сомнения, есть какие-либо упущения, за которые мы заранее приносим свои извинения.
Обзор организован следующим образом. Раздел 2 мы начинаем с обсуждения основных проблем, которые возникают при разработке моделей данных для приложений Web/DB. Каждый из трех следующих разделов посвящен одному из упомянутых выше классов задач. Заключительный раздел 6 представляет перспективы и направления будущих исследований.
Создание систем для решения любой из указанных выше задач требует, чтобы мы выбрали какой-либо метод для моделирования ее предметной области. В частности, нам необходимо в этих задачах моделировать сам Web, структуру Web-сайтов, внутреннюю структуру страниц Web, и, наконец, содержание сайтов с более тонкой степенью гранулярности. В этом разделе мы обсудим главные факторы, характеризующие модели данных, используемые в приложениях Web.
Графовые модели данных: Как отмечалось выше, для некоторых из обсуждаемых здесь приложений необходимо моделировать множество страниц Web, а также связи между ними. Эти страницы могут полностью находится на нескольких сайтах либо на единственном сайте. Следовательно, естественный способ моделирования этих данных основан на модели данных помеченных графов. В этой модели узлы представляют страницы Web (или внутренние компоненты страниц), а дуги - связи между страницами. Метки на дугах могут рассматриваться как имена атрибутов. Наряду с моделью помеченных графов было разработано несколько языков запросов. Одной из центральных возможностей, общей для этих языков является способность формулировать над заданным графом запросы, основанные на правильных выражениях путей (regular path expression). Правильные выражения путей дают возможность формулировать навигационные запросы над структурой этого графа.
Модели слабоструктурированных данных: Второй аспект моделирования данных для приложений Web заключается в том, что во многих случаях структура этих данных не является постоянной. При моделировании структуры Web-сайта мы не имеем какой-либо фиксированной схемы, которая была бы задана заранее. В случае моделирования данных, поступающих из множества источников, представления некоторых атрибутов (например, адресов) могут различаться для разных источников. Поэтому в некоторых проектах исследовались модели слабоструктурированных данных. Первоначальными стимулирующими причинами этой работы послужили существование и относительный успех в научном сообществе "разрешающих" (permissive) моделей данных, подобных [TMD92], необходимость обмена объектами между неоднородными источниками [PGMW95], а также задачи управления коллекциями документов [MP96].
Вообще говоря, слабоструктурированными называются данные, обладающие какими-либо из следующих характеристик:
Модели слабоструктурированных данных были основаны на помеченных ориентированных графах [Abi97, Bun97]2. В модели слабоструктурированных данных не налагается какого-либо ограничения на множество дуг, которые исходят от данного узла в графе, или на типы значений атрибутов. В связи с упомянутыми выше характеристиками слабоструктурированных данных становится важной в этом контексте дополнительная возможность - запрашивать схему (т.е., метки дуг в графе). Эта возможность обеспечивается в языках запросов для слабоструктурированных данных благодаря переменным-дугам, которые связаны с метками дуг, но не с узлами графа.
Помимо разработки моделей и языков запросов для слабоструктурированных данных, нужно упомянуть также и недавно опубликованные довольно важные работы, посвященные некоторым вопросам управления слабоструктурированными данными, в частности, реконструкции структуры слабоструктурированных данных [NAM98], поддержке представлений [ZGM98, AMR+98], агрегированию (summarization) слабоструктурированных данных ([BDFS97, GW97]), а также рассуждениям относительно слабоструктурированных данных [CGL98, FFLS98]. Независимо от релевантности этих работ задачам, которые рассматриваются в этом обзоре, системы, основанные на предложенных в них методах, будут иметь особенно важное значение для управления большими объемами XML-данных [XML98].
Другие характеристики моделей данных Web: Другая отличительная черта моделей, используемых в приложениях Web/DB - присутствие специфических для Web конструкций в представлении данных. Например, в некоторых моделях различаются унарное отношение, идентифицирующее страницы, и бинарное отношение для связей между страницами. Кроме того, мы можем различать связи внутри Web-сайта и внешние связи. Важная причина отличать отношение связей состоит в том, что они, вообще говоря, могут обходиться только в прямом направлении. К свойствам второго порядка, которыми различаются обсуждаемые здесь модели данных, можно отнести: (1) способность моделирования некоторого порядка на множестве элементов в базе данных, (2) моделирование вложенных структур данных и (3) поддержка типов коллекций (множества, мультимножества, массивы). Примером модели данных, которая включает явным образом специфические для Web конструкции (страницы и схемы страниц), вложенность и типы коллекций, является ADM - модель данных в проекте ARANEUS [AMM97b]. Следует отметить, что все модели, которые мы упоминаем в этой статье, позволяют представлять только статические структуры. Так, например, в работах по моделированию структуры Web-сайта не рассматриваются динамические страницы Web, созданные в результате ввода данных пользователем.
Важный аспект языков запросов данных в приложениях Web - необходимость генерировать сложные структуры в результате обработки запроса. Например, результат некоторого запроса в системе управления Web-сайтом может представлять собой граф, моделирующий этот Web-сайт. Следовательно, фундаментальная характеристика многих из языков, которые мы обсуждаем в этой статье, состоит в том, что их выражения запросов содержат компонент структурирования наряду с традиционным компонентом фильтрации данных.
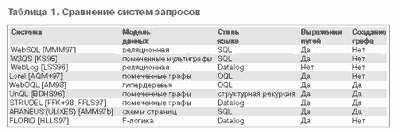
В Таблице 1 представлена сводка некоторых систем запросов для Web, рассматриваемых в этой работе. Более подробную версию этой таблицы, содержащую URL сайтов с доступными описаниями этих систем, можно найти в: http://www.cs.washington.edu/homes/alon/wedb.html. В последующих разделах нашего обзора мы подробно проиллюстрируем возможности языков запросов для Web, основанных на этих моделях.
Если Web рассматривается как большая, графового типа база данных, естественно формулировать запросы, которые выходят за рамки основной парадигмы информационного поиска, поддерживаемой современными механизмами поиска, и принимают во внимание структуру. Имеется в виду не только внутренняя структура страниц Web, но и внешняя структура связей, которые их соединяют. В часто цитируемой статье об ограничениях гипертекстовых систем [Hal88] Халаш говорит:
"Поиск по содержанию игнорирует структуру гипермедийной сети. Напротив, при структурном поиске в гипермедийной структуре осуществляется поиск таких подсетей, которые соответствуют заданному шаблону" и приводит примеры, где такие запросы оказываются полезными.
3.1. Структурный информационный поиск
Первыми инструментальными средствами для обработки запросов в Web, были известные поисковые машины, которые теперь широко развернуты и активно используются. Они основаны на поисковых индексах слов и фраз, встречающихся в документах, обнаруженных "роботами" (crawler) Web. Совсем недавно были предприняты усилия, направленные на преодоление ограничений этой парадигмы за счет использования в запросах структуры связей. Например, в [Kle98], [BH98] и [CDRR98] предлагается использовать структуру Web для анализа многочисленных сайтов, выдаваемых поисковой машиной в качестве релевантных запросу, с тем, чтобы выделить из них те, которые, вероятно, являются авторитетными источниками по интересующему вопросу. Для того, чтобы поддержать анализ связности (connectivity) для этого и других приложений (например, для эффективных реализаций языков запросов, описанных ниже), быстрый доступ к структурной информации обеспечивается сервером связности [BBH+98]. Прототип поисковой машины Web следующего поколения Google [BP98] интенсивно использует структуру Web для повышения производительности функционирования "робота" и индексирования. Другие методы, опирающиеся на использование структуры связей, предлагаются в [PPR96, CK98]. В этих работах структурная информация обычно используется "за сценой" для повышения качества ответов на запросы, которые в чистом виде ориентированы на содержание. Спертус [Spe97] указывает много полезных приложений, связанных с обработкой запросов, которые в явном виде принимают во внимание структуру связей.
3.2. Родственные парадигмы запросов
В этом подразделе мы кратко опишем несколько семейств языков запросов, которые не разрабатывались специально для использования в среде Web. Однако поскольку концепции, на которых они основаны, по своему духу подобны концепциям языков запросов Web, которые мы здесь обсуждаем, эти языки могут быть также полезными для приложений Web.
Гипертекстовые/документальные языки запросов: Ряд моделей и языков запросов для структурированных документов и гипертекстов был предложен еще в период, предшествующий появлению Web. Так, Абитебул и др. [ACM93] и Кристофидес и др. [CACS94] отображают документы в объекты объектно-ориентированной базы данных посредством семантических действий, присоединенных к грамматике. Далее можно делать запросы относительно такого представления базы данных с использованием языка запросов базы данных. Новый аспект этого подхода заключается в возможности производить запросы относительно структуры с помощью переменных-путей. Гутинг и др. [GZC89] моделируют документы, использующие вложенные упорядоченные отношения и используют некоторое обобщение алгебры вложенных отношений как язык запросов. Бири и Корнацкий [BK90] предлагают логику, формулы которой специфицируют шаблоны на графе гипертекста.
Графовые языки запросов: Исследования, связанные с использованием графов для моделирования баз данных, которые были стимулированы такими приложениями, как разработка программного обеспечения и управление компьютерными сетями, привели к созданию языков целого ряда языков, например, G, G+ и GraphLog [CMW87, CMW88, CM90], основанных на графах. В частности, G и G+ основаны на помеченных графах. Они поддерживают использование в запросах правильных выражений путей и графовых конструкций. Язык GraphLog, семантика которого основана на Datalog, был применен в [CM89] для гипертекстовых запросов. Переденс и др. [PdBA+92] разработали графовый язык запросов для объектно-ориентированных баз данных.
Языки запросов для слабоструктурированных данных: Такие языки запросов для слабоструктурированных данных, как Lorel [AQM+97], UnQL [BDHS96] и STRUDQL [FFLS97], также используют помеченные графы как гибкую модель данных. В отличие от графовых языков запросов, они делают акцент на возможности запрашивать схему и приспосабливаться к нерегулярностям в данных, таких, например, как опущенные или повторяющиеся поля, неоднородные записи. В аналогичной работе из области объектно-ориентированных систем [Har94] предложены модели и запросы с "недостаточной схемой" (schema-shy) для управления информацией относительно артефактов разработки программного обеспечения.
Как уже говорилось, эти языки не были разработаны специально для Web, и в них не делается различия, например, между дугами графа, которые представляют соединения между документом и одной из его частей, и дугами, представляющими гиперссылки из одного документа Web на другой. Их модели данных, хотя они и элегантны, не слишком богаты, поскольку в них испытывается недостаток таких важных средств, как записи и упорядоченные коллекции.
3.3. Языки запросов первого поколения для Web
Авторы языков запросов первого поколения для Web стремились сочетать в них возможности запросов, основанных на содержании, присущие поисковым машинам Web, с возможностями запросов, основанных на структуре, подобными тем, которые характерны для систем баз данных. Такие языки, к числу которых относятся W3QL [KS95], WebSQL [MMM97, AMM97a] и WebLog [LSS96], сочетают в себе условия, налагаемые на образцы текста, появляющиеся в документах, с графовыми шаблонами, описывающими структуру связей. Далее мы будем использовать WebSQL для демонстрации примеров запросов, возможных в языках такого рода.
Язык WebSQL: В языке WebSQL предлагается моделировать Web как реляционную базу данных, состоящую из двух (виртуальных) отношений: Документ и Якорь. Отношение Документ содержит по одному кортежу для каждого документа из Web, а отношение Якорь - по одному кортежу для каждого якоря в каждом документе из Web. Такая реляционная абстракция Web позволяет нам использовать для формулировки запросов язык, подобный SQL.
Если бы Документ и Якорь были фактическими отношениями, мы могли бы просто использовать SQL, чтобы записывать на нем запросы. Но поскольку эти отношения являются полностью виртуальными и не имеется какого-либо способа производить над ними вычисления, мы не можем оперировать ими непосредственно. Семантика WebSQL зависит от материализации частей этих отношений путем спецификации представляющих интерес документов во фразе FROM запроса. Основным способом материализации части Web является навигация из известных URL. Для описания такой навигации используются правильные выражения путей. Атом такого правильного выражения может иметь форму d1 = > d2, означающую, что документ d1 указывает на d2, и d2 хранится на ином сервере, чем d1. Он может иметь также форму d1 - > d2, которая, в свою очередь, означает, что d1 указывает на d2, и d2 хранится на том же самом сервере, что и d1.
Предположим, например, что мы хотим найти список триплетов вида (d1, d2, метка), где d1 - документ, хранимый на нашем локальном сайте, d2 - документ, хранимый где-либо еще, и d1 указывает на d2 с помощью связи, помеченной меткой. Допустим также, что все наши локальные документы достижимы из www.mysite.start. Тогда указанную задачу можно решить с помощью запроса:
SELECT d.url, e.url, a.label
FROM Document d SUCH THAT
<www.mysite.start> -> d,
Document e SUCH THAT d => e,
Anchor a SUCH THAT a.base = d.url
WHERE a.href = e.url
Предложение FROM порождает экземпляры двух переменных, определенных на отношении Документ, - d и e, и одной переменной a - на отношении Якорь. Области определения переменной d принадлежит каждый локальный документ, достижимый из начального документа, а e принимает значения на множестве всех не локальных документов, достижимых непосредственно из d. В свою очередь, значением переменной a может являться каждая связь, которая исходит из документа d. Дополнительное условие, предписывающее, чтобы целевым документом связи a был документ e, задается предложением WHERE. Другим способом материализации части отношений Документ и Якорь является использование условий, налагаемых на содержание (content condition). Например, если для нас представляли интерес только документы, которые содержат строку "база данных", мы могли бы добавить в предложение FROM условие: d MENTIONS "база данных". В этом случае в реализации использовались бы поисковые машины для генерации возможных документов, удовлетворяющих условию NENTION.
Другие языки: Язык W3QL [KS95] подобен, по существу, WebSQL, с некоторыми значительными различиями: он использует внешние программы (аналогично определяемым пользователем функциям в объектно-реляционных языках) для спецификации условий, налагаемых на содержание файлов, а не формирование условий в синтаксисе языка, и это обеспечивает механизмы для обработки форм, встречающихся в процессе навигации. В работе [KS98] Конопницкий и Шмуэли описывают планируемые расширения, позволяющие превратить W3QL в то, что мы называем теперь языками второго поколения. Эти расширения предусматривают моделирование внутренней структуры документов, иерархическое моделирование Web, в котором явно фигурирует понятие Web-сайта, а также отказ от использования метода внешних программ для спецификации в пользу обобщенного расширяемого метода, основанного на стандарте MIME.
WebLog [LSS96] отличается от рассмотренных выше языков использованием дедуктивных правил вместо SQL-подобного синтаксиса (см. описание FLORID ниже).
WQL, язык запросов проекта WebDB [LSCH98], подобен WebSQL, но он в большей мере поддерживает функциональные возможности SQL, допуская, например, агрегацию и группирование, и, кроме того, обеспечивает ограниченную поддержку запросов внутридокументной структуры. Это обстоятельство позволяет отнести его к классу языков, обсуждаемых в следующем подразделе.
3.4. Второе поколение: Языки манипулирования данными Web
Рассмотренные выше языки интерпретируют страницы Web как атомарные объекты с двумя свойствами: они могут содержать или не содержать некоторые текстовые образцы и они могут указывать на другие объекты. Опыт использования таких языков показывает, что имеется две основные области приложений, для которых они могут быть полезны. Одна из них, рассматриваемая в разделе 4, - создание оболочек (wrapping) для данных, трансформация и реструктуризация данных. Вторая из этих областей - создание и реструктуризация Web-сайтов - обсуждается в разделе 5. В обеих этих областях приложений часто оказывается существенной возможность иметь доступ к внутренней структуре страниц Web из языка запросов, если мы хотим, чтобы декларативные запросы могли оперировать большой частью задачи. Например, задача извлечения множества кортежей из HTML-страниц сайта Internet Movie Database требует синтаксического анализа HTML-страниц и избирательного доступа к некоторым поддеревьям в дереве синтаксического анализа.
В этом подразделе мы опишем языки запросов второго поколения для Web, которые мы называем "языками манипулирования данными Web". Эти языки превосходят языки первого поколения в двух важных аспектах. Прежде всего, они обеспечивают доступ к структуре объектов Web, которыми они манипулируют. В отличие от языков первого поколения, они моделируют внутреннюю структуру документов Web, а также внешние связи, которые их соединяют. Они поддерживают связи для моделирования гиперссылок, а некоторые из них поддерживают также упорядоченные совокупности записей для более естественного представления данных. Во-вторых, эти языки обеспечивают возможности создания новых сложных структур в результате запроса. Поскольку данные в Web обычно являются слабоструктурированными, в этих языках придается особое значение поддержке возможностей для работы со слабоструктурированными данными. Далее кратко описываются три языка этого класса: WebOQL [AM98], STRUQL [FFLS97] и FLORID [HLLS97].
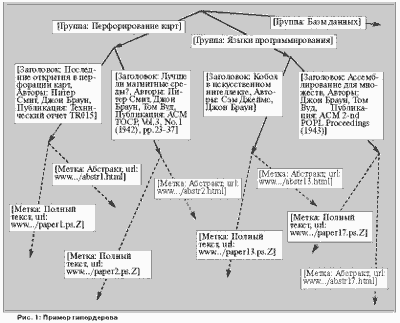
Основная структура данных в WebOQL - гипердерево. Гипердеревья - это упорядоченные деревья с помеченными дугами, причем имеется два типа дуг - внутренние и внешние. Внутренние дуги используются для представления структурированных объектов, а внешние - для представления связей (обычно гиперссылок) между объектами. Дуги снабжаются метками, в качестве которых используются записи. На рис. 1, заимствованном из [Aro97], показано гипердерево, содержащее описания публикаций нескольких исследовательских групп. Такое дерево можно было бы легко построить, например, из HTML-файла, используя обобщенную HTML-оболочку (wrapper).
Web представляет собой множество взаимосвязанных гипердеревьев. Язык WebOQL позволяет манипулировать как отдельными гипердеревьями, так и Web в целом, и они (гипердеревья и Web) могут создаваться в результате обработки запроса.
WebOQL - функциональный язык, но запросы формулируются в знакомой форме select-from-where. Предположим, например, что база данных документов на рис. 1 имеет имя СтатьиПоИнформатике и что мы хотим осуществить из нее выборку названия и URL полных текстов статей Смита. Тогда нужно использовать следующий запрос:
select [y.Название, y'.Url]
from x in СтатьиПоИнформатике, y in x'
where y.Авторы ~ "Смит"
В этом запросе переменная x определена на множестве простых деревьев базы данных СтатьиПоИнформатике (соответствующих исследовательским группам), а при заданном значении x переменная y, в свою очередь, принимает значения на множестве простых деревьев x'. Переменная x' обозначает результат применения к дереву x прим-оператора ('), который возвращает первое поддерево его параметра. Тот же самый оператор используется для извлечения из дерева y его первого поддерева в y'.Url. Квадратные скобки обозначают оператор Hang. Этот оператор строит дугу, которая помечена записью, образуемой аргументом (в приведенном примере предполагается, что запись включает поля с указанными именами). Наконец, тильда (~) представляет собой предикат сопоставления со строковым образцом: его левый аргумент - строка, а правый - образец.
Создание Web: Рассмотренные выше запросы отображают гипердерево в другое гипердерево, или, если говорить в более общих терминах, запрос - это функция, которая отображает один Web в другой. Например, следующий запрос создает новую страницу для каждой исследовательской группы (использующей имя группы как URL). Каждая страница содержит публикации соответствующей группы.
select x' as x.Группа from x in СтатьиПоИнформатике
В общем случае фраза select имеет вид: 'select q1 as s1, q2 as s2, ..., qm as sm', где каждое qi - это запрос, а каждое из si - или запрос строки или схема. Фразы "as" создают URL s1, s2,... , sm, которые присваиваются новым страницам, полученным в результате выполнения каждого из запросов qi.
Шаблоны навигации: Шаблоны навигации - это правильные выражения в алфавите предикатов, определенных над записями. Они позволяют специфицировать структуру путей, по которым необходимо следовать для того, чтобы найти значения переменных.
Шаблоны навигации полезны, главным образом, для двух целей. Первая из них - извлечение поддеревьев из деревьев, структура которых достаточно детально нам неизвестна или содержит неправильности (irregularities). Вторая цель - выполнение повторяющихся операций над деревьями, соединенными внешними дугами. Фактически, возможность различать внутренние и внешние дуги в гипердеревьях становится действительно полезной, когда мы используем шаблоны навигации, которые позволяют обходить внешние дуги. Предположим, что мы имеем некоторый программный продукт, документация к которому представлена в формате HTML, и мы хотим сформировать полнотекстовый индекс для нее. Такие документы образуют сложный гипертекст, но можно просматривать их и последовательно, следуя по связям, помеченным меткой "Следующий". Для формирования полнотекстового индекса нам необходимо снабдить индексатор текстом каждого документа и его URL. Мы можем получить эту информацию, используя следующий запрос:
select [ x.Url, x.Текст ]
from x in browse(<root.html>)
via (^*[Текст ~ <Следующий>]>)*
STRUQL - это язык запросов системы управления Web-сайтами STRUDEL, описываемой ниже в разделе 5. Хотя STRUQL был разработан в контексте специфического приложения Web, он является универсальным языком запросов для слабоструктурированных данных, основанным на модели данных помеченных ориентированных графов. Кроме того, модель данных STRUDEL включает именованные коллекции и поддерживает несколько атомарных типов, которые обычно появляются на страницах Web, таких как URL и Postscript, текст, изображение и HTML-файлы. Результат запроса в STRUQL представляет собой граф в той же самой модели данных, что и входные графы. В системе STRUDEL язык STRUQL использовался для решения двух задач: для запросов к неоднородным источникам с тем, чтобы интегрировать их в граф данных сайта, и для запросов к этому графу данных с целью продуцирования графа сайта.
Запрос в STRUQL представляет собой набор, возможно, вложенных блоков следующего вида:
[where C1,...,Ck] [create N1,...,Nn] [link L1,...,Lp] [collect G1,...,Gq].
Фраза where может включать либо условия принадлежности множеству, либо условия, налагаемые на пары узлов, выражающие используемые правильные выражения путей. Фраза where продуцирует все связывания bindings) переменных-узлов и переменных-дуг со значениями из исходного графа. Оставшиеся фразы используют функции Сколема для построения нового графа из этих связываний.
Для иллюстрации возможностей STRUQL приведем запрос, определяющий некоторый Web-сайт, начиная с библиографического файла Bibtex, моделируемого как помеченный граф. Рассматриваемый Web-сайт будет состоять из страниц трех видов: страницы PaperPresentation для каждого источника в библиографии, страницы Year для каждого года, указывающей все статьи, опубликованные в этом году, и, наконец, страницы Root, указывающей на все страницы Year. После того, как будет приведен запрос в STRUQL, мы покажем, как он представляется в WebOQL. Это позволит почувствовать различия между данными языками.
Запись указанного запроса в STRUQL имеет следующий вид:
// Создать страницу Root create RootPage()
// Создать представление для каждой
// публикации x
where Publications(x), x -> 1 -> v
create PaperPresentation(x)
link PaperPresentation(x) -> 1 -> v
{ // Создать страницу для каждого года
where 1 = <year>
create YearPage(v)
link YearPage(v) -> <Year> -> u
YearPage(v) -> <Paper> ->PaperPresentation(x),
// Связать корневую страницу с каждой
// страницей года
RootPage() -> <YearPage> -> YearPage(v) }
Здесь выражение Publications(x) во фразе where обозначает, что x принадлежит совокупности публикаций Publications. В свою очередь, атом x -> 1 -> v обозначает, что существует связь в графе от x к v, и метка соответствующей дуги - 1. Такая же нотация используется во фразе link для того, чтобы специфицировать вновь созданные ребра в результирующем графе. После создания корневой страницы Root первый оператор create генерирует страницу для каждой публикации, обозначенную функцией Сколема PaperPresentation. Второй оператор create, вложенный во внешний запрос, генерирует страницу Year для каждого года и связывает ее со страницей Root, а также со страницами PaperPresentation тех публикаций, которые относятся к этому году. Отметим, что функция Сколема YearPage обеспечивает, чтобы страница Year для конкретного года создавалась только один раз, независимо от того, сколько статей было опубликовано в этом году.
Теперь приведем запись того же самого запроса в WebOQL:
select unique [Url: x.year, Label:>YearPage>] as <RootPage>, [label: <Paper> / x] as x.year from x in browse(<bibtex: myfile.bib>) | select [year: y.url] + y as y.url from y in <browse(RootPage)>
Запрос в WebOQL состоит из двух подзапросов. Полученная в результате первого из них подструктура Web поступает в качестве исходных данных во второй запрос, что достигается с помощью использования оператора <|>. Первый подзапрос строит страницы Root, Paper и Year, а второй переопределяет каждую страницу Year, добавляя к ней поле <year>.
Система FLORID [HLLS97, LHL+98] - реализация прототипа дедуктивного и объектно-ориентированного формализма F-логики [KLW95]. Чтобы использовать FLORID как механизм обработки запросов для Web, документ Web моделируется следующими двумя классами:
url::string[get => webdoc]. webdoc::string[url => url; author => string; modif => string; type => string; hrefs@(string) => url; error =>> string].
Первая из этих деклараций вводит класс url, подкласс string с единственным методом get. Нотация get => webdoc означает, что get - метод, вырабатывающий единственное значение (single-valued), который возвращает объект типа webdoc. Метод get является определяемым системой. Результатом вызова u.get для url u в заголовке дедуктивного правила является выборка из Web документа с данным URL и кэширование его в локальной базе данных FLORID как объекта webdoc с идентификатором объекта u.get.
Класс webdoc с методами self, author, modif, type, hrefs и error моделирует основную информацию, общую для всех документов Web. Нотация hrefs@(string) = >> url означает, что многозначный метод hrefs получает string как аргумент и возвращает множество объектов типа url. Идея состоит в том, что, если d есть webdoc, то d.hrefs@(aLabel) возвращает URL всех документов, на которые указывают связи, помеченные как aLabel внутри документа d.
По необходимости могут декларироваться подклассы документов с использованием наследования F-логики, например:
htmldoc::webdoc[title => string; text => string].
Вычисление во FLORID выражается наборами дедуктивных правил. Например, приведенная ниже программа осуществляет выборку из Web множества всех документов, достижимых непосредственно или косвенным образом из URL www.cs.toronto.edu по связям, метки которых содержат строку "база данных".
(<www.cs.toronto.edu>:url).get.(Y:url).get
<-(X:url).get[hrefs@(L)=>>{Y}],
substr(<база данных>,L).
FLORID обеспечивает мощный формализм для управления слабоструктурированными данными в контексте Web. Однако, он не обеспечивает в настоящее время конструирования в результате вычисления новых сайтов. Результат всегда представляет собой некоторое множество объектов F-логики в локальной памяти.
Языки ULIXES и PENELOPE
В проекте ARANEUS [AMM97b] процесс обработки запросов и реструктуризации разбивается на две фазы. На первой фазе для построения реляционных представлений над Web используется язык ULIXES. Эти представления могут далее анализироваться и интегрироваться с использованием стандартных технологий баз данных. По запросам, сформулированным на языке ULIXES, производится выборка реляционных данных из экземпляров схем страниц, которые определены средствами модели ADM, с интенсивным использованием выражений путей без символа <*> (star-free). Вторая фаза заключается в генерации гипертекстовых представлений данных с использованием языка PENELOPE. Проблемы оптимизации запросов для реляционных представлений, поддерживаемых над множествами страниц Web, например, построенных средствами ULIXES, обсуждаются в [MMM98].
Интерактивные интерфейсы запросов
Все языки, рассмотренные в предыдущих двух подразделах, слишком сложны для непосредственного применения интерактивными пользователями, точно так же, как и SQL. Предполагается, что они, подобно SQL, должны использоваться, главным образом, как инструментальные средства программирования. Однако проводились работы по созданию интерактивных интерфейсов запросов, пригодных для случайных пользователей. Одним из них является Dataguides [GW97] - интерактивное средство запросов для слабоструктурированных данных, основанное на иерархических "выжимках" (summaries) графа данных. Расширения для поддержки запросов в отдельных сложных Web-сайтах рассмотрены в [GW98]. Система, описанная в [HML+98], поддерживает запросы, которые сочетают мультимедийные возможности, например, схожесть с данным эскизом или изображением, возможности работы с текстами, такие как поиск по ключевым словам, а также семантику предметной области.
Теория запросов в Web
Определяя семантику языков запросов первого поколения для Web, можно немедленно обнаружить, что легко формулируемые запросы вида "перечислить все документы Web, которые не указывают ни на какие другие документы", могут быть довольно трудными для исполнения. В связи с этим обстоятельством возникают, естественно, вопросы о вычислимости запросов в таком контексте. Абитебул и Виану [AV97a], а также Мендельсон и Мило [MM97] предложили формальные способы категоризации запросов в Web, в соответствии с тем, могут ли они в принципе быть вычисленными или нет. Ключевая идея заключается, по существу, в том, что единственный возможный способ доступа в Web - это навигация по связям из известных стартовых точек. (Заметим, что специальным частным случаем является навигация по связям, исходя из больших совокупностей стартовых точек, называемых индексными серверами или поисковыми машинами). Абитебул и Виану [AV97b] обсуждают также фундаментальные проблемы, возникающие при оптимизации запросов, связанных с обходом путей. Михайла, Мило и Мендельсон [MMM97] показывают, как анализировать запросы в WebSQL на основе максимального числа Web-сайтов. Флореску, Леви и Сучу [FLS98] описывают алгоритм для запросов по содержанию, для запросов с правильными выражениями путей, который затем используется для проверки ограничений целостности на структуре Web-сайтов [FFLS98].
Как утверждалось ранее, WWW содержит все возрастающее число информационных источников, которые могут просматриваться как контейнеры множеств кортежей. Эти "кортежи" могут быть либо встроенными в HTML-страницы, либо быть скрытыми за интерфейсами форм. Благодаря написанию специальных программ, называемых оболочками (wrapper), можно создать иллюзию, что данный Web-сайт обслуживает множества кортежей. Будем называть комбинацию такого Web-сайта и ассоциированной с ним оболочки Web-источником.
Задача системы интеграции информации, поддерживаемой средствами Web, состоит в том, чтобы отвечать на запросы, которые могут потребовать извлечения и комбинирования данных из множества Web-источников. Например, рассмотрим такую предметную область, как кино. Сайт Internet Movie Database содержит исчерпывающие данные о кинофильмах, составе исполнителей ролей, жанрах и руководителях съемки. Во множестве других Web-источников (например, на Web-сайтах большинства газет) могут быть найдены также рецензии на кинофильмы, а некоторые Web-источники предоставляют расписания показа кинофильмов. Комбинируя данные из этих источников мы можем отвечать на запросы типа: выдать мне какой-либо фильм с Фрэнком Синатрой в главной роли, который можно посмотреть сегодня вечером в Париже, время сеанса и рецензии на него.
Для ответов на запросы с использованием множества Web-источников был создан целый ряд систем [GMPQ+97, EW94, WBJ+95, LRO96, FW97, DG97b, AKS96, Coh98, AAB+98, BEM+98]. Многие из проблем, с которыми пришлось столкнуться при их разработке, аналогичны проблемам, связанным с созданием неоднородных систем базы данных [ACPS96, WAC+93, HZ96, TRV98, FRV96, Bla96, HKWY97]. Наряду с этим, системы интеграции данных Web должны иметь дело с: (1) с большим и развивающимся количеством Web-источников, (2) немногими метаданными, характеризующими источники, и (3) большой степенью автономности источников.
Важные различия при построении систем интеграции данных, а, следовательно, и систем интеграции данных Web, возникают в связи с тем, принимается ли подход, основанный на хранилищах данных, или виртуальный подход (см. для сравнения [HZ96, Hul97]). В случае использования первого подхода данные из множества Web-источников загружаются в хранилище данных, и далее все запросы будут обращены к этому хранилищу данных. В таком случае необходимо, чтобы при изменении данных в источниках обновлялось и хранилище данных. Однако преимущество состоит в том, что может быть гарантирована адекватная эффективность на стадии обработки запроса. При виртуальном подходе данные остаются в Web-источниках, и запросы к системе интеграции данных декомпозируются на стадии исполнения на запросы к отдельным источникам. При таком подходе данные не тиражируются, и тем самым гарантируется их актуальность на стадии обработки запросов. С другой стороны, поскольку Web-источники автономны, для обеспечения адекватной эффективности необходимы более изощренные техника оптимизации запросов и исполнения. Виртуальный подход более уместен при построении таких систем, где число источников велико, данные изменяются часто, и имеется слабый контроль над Web-источниками. По этим причинам большинство исследований недавнего времени было сосредоточено на виртуальном подходе, и поэтому им прежде всего будет посвящено наше дальнейшее обсуждение. Нужно, однако, подчеркнуть, что многие проблемы, которые возникают при виртуальном подходе, возникают также и при использовании хранилищ данных (хотя зачастую и в несколько иной форме). Следовательно, наше обсуждение имеет отношение к обоим указанным случаям. Прежде чем перейти непосредственно к обсуждению, нам хотелось бы обратить внимание читателей на два коммерческих приложения систем интеграции данных Web, в одном из которых был принят подход с хранилищем данных [Jun98], а в другом - виртуальный подход [Jan98].
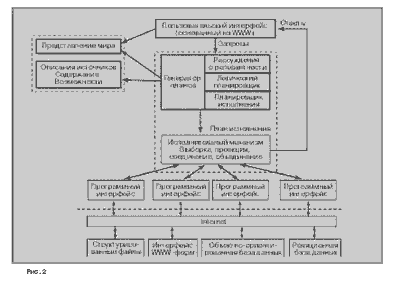
Архитектура прототипа системы виртуальной интеграции данных показана на рис. 2. Имеется две главных особенности, отличающие такую систему от традиционной системы базы данных:
Рассмотрим теперь основные проблемы, которые исследуются в работах, связанных с созданием систем интеграции данных Web.
Спецификация промежуточной схемы и переформулирование запросов: Промежуточная схема в системе интеграции данных представляет собой совокупность наборов имен атрибутов, которые используются для формулировки запросов. Для обработки запроса система интеграции данных должна транслировать его формулировку в терминах промежуточной схемы в запросы к источникам данных, которые имеют их собственные локальные схемы. Чтобы сделать это, системе необходимо множество описаний источников. Несколько недавних исследований было посвящено проблемам определения принципов спецификации описаний источников и их использования для переформулирования запросов. Вообще говоря, было предложено два общих подхода: Глобальная схема как представление (Global as View, GAV) [GMPQ+97, PAGM96, ACPS96, HKWY97, FRV96, TRV98] и Локальная схема как представление (Local as View, LAV) [LRO96, KW96, DG97a, DG97b, FW97]. Детальное сопоставление этих подходов можно найти в [Ull97].
При подходе GAV для каждого отношения R в промежуточной схеме, мы записываем запрос над отношениями источников, которые определяют, каким образом можно получить кортежи R из источников. Подход LAV является противоположным. Для каждого источника информации S мы записываем запрос над отношениями в промежуточной схеме, который описывает, какие кортежи находятся в S. Главное преимущество подхода GAV состоит в том, что переформулирование запросов является очень простым, поскольку оно сводится к развертыванию представлений. Напротив, при подходе LAV можно более просто добавлять или удалять источники, так как описания источников не должны принимать во внимание возможные взаимодействия с другими источниками, как в случае подхода GAV. В случае LAV, кроме того, более просто описываются ограничения на содержание источников. Проблема переформулирования запросов становится некоторым вариантом проблемы ответа на запросы с использованием представлений [YL87, TSI96, LMSS95, CKPS95, RSU95, DG97b].
Полнота данных в Web-источниках: Вообще говоря, источники, которые мы находим на WWW, не обязательно являются достаточно полными в той предметной области, к которой они относятся. Например, маловероятно, что некоторый источник библиографии в полной мере представляет область информатики. Однако, в некоторых случаях, мы можем высказывать определенные утверждения о степени полноты источников. Например, база данных DB&LP *3) содержит полную подборку работ, опубликованных в трудах наиболее важных конференций по базам данных. Знания о полноте Web-источника могут помочь системе интеграции данных несколькими способами. Наиболее важно, что отрицательный ответ от полного источника является значимым, поскольку он позволяет исключить бессмысленные обращения системы интеграции данных к другим источникам. Проблема описания полноты Web-источников и использования этой информации для обработки запросов исследуется в работах [Mot89, EGW94, Lev96, Dus97, AD98, FW97]. В работе [FKL97] предлагается вероятностный формализм для описания содержания и перекрытий источников информации, а также приводятся алгоритмы оптимального выбора источников.
Различие возможностей обработки запросов: В аспекте систем интеграции данных Web, Web-источники имеют, как представляется, в значительной степени различные потенциальные возможности обработки запросов. Главные причины таких различий заключаются в том, что: (1) внутренние данные источников могут фактически храниться в структурированных файлах или в унаследованной системе, и в таких случаях интерфейс к этим данным, естественно, ограничен, и (2) даже если данные хранятся в традиционной системе базы данных, Web-сайт может обеспечить лишь ограниченные возможности доступа по причинам безопасности или эффективности.
Для создания эффективной системы интеграции данных эти возможности должны явным образом описываться для системы, строго учитываться и в максимально возможной степени использоваться для повышения эффективности. Будем различать два типа возможностей: отрицательные возможности, которые ограничивают способы доступа к данным, и положительные возможности, когда источник способен выполнять некоторые алгебраические действия в дополнение к простым выборкам данных.
Основная форма отрицательных возможностей - ограничения на способы связывания (binding patterns), которые могут использоваться в запросах, адресованных источнику. Например, обращаясь к сайту Internet Movie Database, невозможно запросить выборку всех фильмов с их актерскими составами. Вместо этого имеется возможность запросить сведения об актерах данного фильма или о множестве фильмов, в которых играет данный конкретный актер. Проблема ответа на запросы при наличии ограничений на способы связывания рассматривается в работах [RSU95, KW96, LRO96, FW97].
Положительные возможности порождают дополнительное требование к системе интеграции данных. Если источник данных обладает способностью выполнять такие операции, как селекция и соединение, мы хотели бы в максимально возможной степени перенести обработку на источник, сокращая тем самым объем локальной обработки и количество данных, передаваемых по сети. Проблема описания вычислительных возможностей источников данных и их использования для создания планов исполнения запросов рассматривается в [PGGMU95, TRV98, LRU96, HKWY97, VP97a].
Оптимизация запросов: Во многих работах по системам интеграции данных Web исследовались проблемы выбора минимального набора Web-источников, к которым необходимо осуществить доступ для обработки заданного запроса, и определения минимального запроса, который должен быть адресован каждому из них. Однако проблема выбора оптимального плана исполнения запроса для доступа к Web-источникам до сих пор не привлекала достаточного внимания. Поэтому она мало отражена в литературе по интеграции данных [HKWY97] и остается активной областью исследований. Дополнительные трудности, связанные с оптимизацией запросов для источников в среде WWW, состоят в том, что мы имеем незначительную статистику по данным в источниках, и, следовательно, мало информации для оценки стоимости планов исполнения запросов. В работе [NGT98] рассматривается проблема калибровки модели стоимости для планов исполнения запросов в этом контексте. В [YPAGM98] обсуждается проблема оптимизации запросов слияния (fusion query), которые являются специальным классом запросов на интеграцию данных, предусматривающих выборку различных атрибутов данного объекта из множественных источников. Мы полагаем, что обработка запросов в системах интеграции данных - это область, где можно было бы извлечь пользу из таких идей, как перемежающиеся планирование и исполнение, а также вычисление условных планов [GC94, KD98].
Механизмы исполнения запросов: Еще меньше внимания было уделено проблеме разработки механизмов исполнения запросов, предназначенных для интеграции данных Web. Необходимость создания таких механизмов вызвана автономностью источников данных и непредсказуемостью пропускной способности сети. В частности, при доступе к Web-источникам могут иметь место начальные задержки, прежде чем данные начинают передаваться, и даже если это случается, поступление данных может быть очень интенсивным. В работах [AFT98, UFA98] рассматривается проблема адаптации планов исполнения запросов к начальным задержкам в поступлении данных.
Создание оболочек: Напомним, что роль оболочки (wrapper) заключается в обеспечении выборки данных из Web-сайта в форме, которая дает возможность манипулировать ими системе интеграции данных. Например, задача оболочки может состоять в формулировании запроса к Web-источнику c использованием интерфейса в виде формы и выборке множества кортежей ответа из результирующей HTML-страницы. Трудность создания оболочек заключается в том, что HTML-страница обычно разрабатывается для просмотра человеком, а не для выборки данных программами. По этой причине данные часто оказываются встроенными в тексты на естественном языке или скрытыми в примитивах графического представления. Кроме того, форма HTML-страниц часто изменяется, что создает трудности для поддержки оболочек. Несколько работ было посвящено проблеме конструирования инструментальных средств для быстрого создания оболочек. Один из классов таких инструментальных средств (см., например, [HGMN+98, GRVB98]) основан на специализированных грамматиках, позволяющих специфицировать, каким образом данные размещаются на HTML-странице, и, тем самым, как извлекать требуемые данные. Второй класс средств основан на применении методов индуктивного обучения для автоматического обучения оболочки. Используя алгоритмы, базирующиеся на таких методах, мы сначала задаем системе набор HTML-страниц таких, что содержащиеся в них данные помечены. На основе этих обучающих примеров автоматически строится грамматика, с помощью которой может осуществляться выборка данных из последующих страниц. Конечно, чем большее число примеров мы задаем системе, тем более точной будет порождаемая в результате грамматика, и задача состоит в том, чтобы найти такие языки для оболочек, которые можно обучить с помощью малого числа примеров. Впервые идея конструирования оболочки на основе индуктивного обучения и набор алгоритмов для обучения простых классов оболочек были преложены в [KDW97]. Алгоритм, описанный в [AK97], использует специфические эвристические подходы для общепринятых применений HTML с тем, чтобы добиться быстрого обучения. Следует также отметить, что методы машинного обучения также использовались для изучения отображения между схемами источников и промежуточными схемами [PE95, DEW97]. Работа [CDF+98) представляет собой первый шаг в попытке ликвидировать существующий разрыв между подходами к проблеме создания оболочек, основанными на машинном обучении и на обработке естественного языка. В заключение, нужно отметить, что появление языка XML может обеспечить разработчикам Web-сайтов возможности для экспортирования данных, содержащихся на их сайтах, в машиночитаемой форме, тем самым значительно упрощая создание оболочек.
Соответствие объектов на множестве источников: Одна из наиболее трудных проблем, связанных с получением ответов на запросы над множеством источников, заключается в выявлении ситуации, когда два объекта, упомянутые в двух различных источниках, представляют один и тот же объект в реальном мире. Эта проблема возникает потому, что каждый источник использует свои собственные соглашения об именовании и обозначениях. В большинстве систем эта проблема решается благодаря использованию специфических для предметной области эвристических подходов (как, например, в [FHM94]). В системе WHIRL [Coh98] соответствие объектов на множестве источников поддерживается с помощью методов из области информационного поиска. Кроме того, соответствующие объекты изящно интегрируются в новом алгоритме исполнения запросов.
В двух предыдущих разделах обсуждались задачи, которые касались запросов, адресованных к существующим Web-сайтам и их содержанию. Однако, принимая во внимание тот факт, Web-сайты, по существу, обеспечивают доступ к сложным структурам информации, естественно применить методы систем баз данных для создания и поддержки Web-сайтов. Можно выделить два общих класса задач создания Web-сайтов: создание Web-сайтов из некоторой совокупности внутренних (underlying) источников данных и создание их путем реструктуризации существующих Web-сайтов. Как оказалось, для обоих этих классов задач необходимы одни и те же методы. Более того, заметим, что обеспечение Web-интерфейса для данных, которые содержатся в единственной системе базы данных [NS96], является простым частным случаем задачи создания Web-сайтов.4
Для того, чтобы стали понятными проблема создания Web-сайтов и возможность импорта для этой цели технологий баз данных, перечислим те задачи, которые должен решать создатель Web-сайта: (1) выбор тех данных, которые будут представлены на сайте и обеспечение доступа к ним, (2) проектирование структуры сайта, то есть, определение данных, содержащихся на каждой странице, и связей между страницами, и (3) проектирование графического представления страниц. В существующих инструментальных средствах управления Web-сайтами эти задачи, по большей части, взаимозависимы. При отсутствии каких-либо инструментальных средств создания сайта, разработчик вручную пишет содержимое HTML-файлов или пишет программы для их продуцирования. Одновременно он должен сосредоточить свое внимание на содержании страницы, ее связях с другими страницами, а также на ее графическом представлении. В результате, весьма утомительным становится решение нескольких других важных задач, таких как автоматическое обновление сайта, реструктуризация сайта или спецификация ограничений целостности, налагаемых на структуру сайта.
Web-сайты как декларативно определенные структуры: С целью применения технологий баз данных для создания Web-сайтов было разработано несколько систем [FFK+98, AMM98, AM98, CDSS98, PF98, JB97, LSB+98, TN98]. Общая характерное свойство этих систем состоит в том, что они обеспечивают явное декларативное представление структуры Web-сайта. Структура Web-сайта рассматривается как представление, определенное над существующими данными. Однако, следует подчеркнуть, что языки, используемые для создания этих представлений, дают в результате графы Web-страниц с гипертекстовыми связями, а не простые таблицы. Указанные выше системы различаются моделями данных, которую они используют, языками запросов, а также использованием или отказом от использования промежуточного логического представления Web-сайта наряду с наличием конечного представления в формате HTML.
Создание Web-сайта, использующего декларативное представление его структуры, обеспечивает несколько важных преимуществ. Так как структура и содержание Web-сайта определяются декларативно по запросу, а не процедурным образом с помощью программы, достаточно просто могут создаваться множественные версии такого сайта. Например, возможно легко построить внутренние и внешние представления сайта организации или создать сайты, предназначенные для различных классов пользователей. В настоящее время создание множественных версий требует написания многочисленных наборов программ или создания вручную различных наборов HTML-файлов. Создание множественных версий сайта может быть осуществлено либо написанием различных запросов, специфицирующих определения версий сайта, либо путем изменения графического представления независимо от внутренней структуры. Кроме того, декларативное представление структуры Web-сайта также позволяет легко поддерживать эволюцию этой структуры. Например, чтобы реорганизовать страницы, основанные на часто используемых шаблонах [PE97], или расширить содержание сайта, просто переписывают запрос, специфицирующий определение сайта, а не перерабатывают набор программ или HTML-файлов. Декларативная спецификация Web-сайтов обладает и другими достоинствами. Например, появляется возможность формулировать и налагать на сайт ограничения целостности [FFLS98], осуществлять обновление сайта фрагментарно, когда происходят изменения внутренних данных. Помимо этого, декларативная спецификация обеспечивает платформу для разработки алгоритмов оптимизации управления Web-сайтом с интенсивной обработкой данных на стадии исполнения. Актуальной проблемой управления Web-сайтом на стадии исполнения является автоматический поиск оптимального компромисса между предварительной обработкой частей Web-сайта и обработкой непосредственно при обращении. Отметим, наконец, что создание Web-сайтов, использующих эту парадигму, также облегчит решение задач обработки запросов к Web-сайтам и интеграции данных из множественных Web-источников.
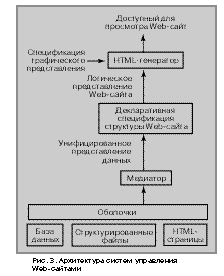
Архитектура прототипа системы с декларативно определенной структурой показана на рис. 3. На нижнем уровне системы осуществляется доступ к множеству источников данных, содержащих те данные, которые будут обслуживаться на Web-сайте. Эти данные могут храниться в базах данных, в структурированных файлах, или на уже существующих Web-сайтах. Данные представляются в системе средствами некоторой модели данных, и система обеспечивает унифицированный интерфейс к этим источникам данных, используя технологии, подобные описанным в предыдущем разделе. Главным шагом в создании Web-сайта является спецификация выражения, которое в декларативной форме представляет структуру Web-сайта. Это выражение записывается на специальном языке запросов, предоставляемом системой. В результате применения этого запроса к внутренним данным формируется логическое представление Web-сайта в терминах модели данных системы (например, как помеченный ориентированный граф). Наконец, для фактического создания доступного для просмотра Web-сайта система содержит метод (например, HTML-шаблоны) для трансляции специфицированной логической структуры в набор HTML-файлов.
Рассмотрим теперь кратко наиболее важные характеристики различных систем. Система STRUDEL [FFK+98] использует в качестве модели слабоструктурированных данных помеченные ориентированные графы для моделирования как внутренних данных, так и Web-сайта. В этой системе используется единственный язык запросов STRUQL, служащий и для интеграции исходных данных и для определения структуры Web-сайта. Система ARANEUS [AMM97b] использует более структурированную модель данных ADM и предоставляет язык для преобразования данных в ADM, а также язык для создания Web-сайта из данных, моделируемых средствами ADM. Кроме того, ARANEUS использует в этой модели данных специфические для Web конструкции. Система Autoweb [PF98] основана на модели проектирования гипермедийной среды (Hypermedia Design Model, HDM) - инструментальном средстве для разработки гипермедийных приложений. Модель данных этой системы базируется на модели "сущность-связь". "Схема доступа" определяет, как осуществлять навигацию и доступ к гипербазе на просматриваемом сайте. "Схема представления" определяет, каким образом представляются объекты и пути в гипербазе и схемах доступа. Во всех трех упомянутых выше системах обеспечивается строгое разделение между стадиями создания логической структуры Web-сайта и спецификации графического представления сайта. Система YAT [CDSS98] демонстрирует применение языка конвертирования данных к решению проблемы создания Web-сайта. При использовании YAT, проектировщик Web-сайта записывает множество правил преобразования исходных данных в дерево абстрактного синтаксиса, представляющее результирующие данные в формате HTML, опуская фазу промежуточного логического представления. Фактически, другие языки для конвертирования данных (например, [MZ98, MPP+93, PMSL94]) могут подобным же образом использоваться для создания Web-сайта. Система WIRM [JB97] аналогична указанным выше системам в том смысле, что она дает пользователям возможность строить Web-сайты, в которых страницы могут рассматриваться как чувствительные к контексту представления внутренних данных. Главное назначение WIRM состоит в интеграции данных медицинских исследований в рамках национального проекта по изучению мозга человека.
В связи с темой данного обзора важным становится вопрос, порождает ли World-Wide Web какие-либо новые проблемы для сообщества специалистов в области баз данных. Во многих отношениях WWW не похож на базу данных. Например, не имеется никакой унифицированной структуры, никаких ограничений целостности, никаких транзакций, никакого стандартного языка запросов или модели данных. Но, тем не менее, как показывает данный обзор, мощные абстракции, разработанные в области баз данных, могут играть ключевую роль в преодолении сложности Web и в обеспечении ценных услуг.
Особенно важно рассматривать большой Web-сайт не просто как базу данных, а как информационную систему, построенную на основе одной или более баз данных со сложной навигационной структурой. При такой точке зрения Web-сайт имеет много сходных характеристик с информационными системами других типов. Разработка такого Web-сайта требует расширения методологий проектирования информационных систем [AMM98, PF98]. Использование этих принципов при построении Web-сайтов будет также оказывать влияние на способы осуществления запросов к Web-сайтам и интеграции данные из множественных Web-источников.
Значительное влияние на использование технологий баз данных для приложений Web будет оказывать несколько тенденций. Первая из них - это, конечно, появление и развитие языка XML. Существенно новые возможности, предоставляемые XML, и связанные с ним инициативы, касающиеся метаданных, несомненно, могут способствовать применимости концепций баз данных для Web, обеспечивая множество необходимых структур в широко принятом формате. Хотя доступность данных в формате XML уменьшит необходимость сосредоточения внимания на оболочках, конвертирующих воспринимаемые человеком данные в машиночитаемые данные, все еще остается нерешенной проблема семантической интеграции данных из Web-источников. Опираясь на наш опыт разработки методов манипулирования слабоструктурированными данными, мы полагаем, что в настоящее время имеется уникальная возможность для разработки инструментальных средств манипулирования данными в формате XML. Фактически, некоторые разработанные концепции такого рода уже адаптируются к контексту XML [DFF+98, GMW98]. Другие проекты, которые осуществляются в настоящее время в сообществе баз данных в области архитектур и языков метаданных (например, [MRT98, KMSS98]), также должны, вероятно, воспользоваться преимуществами XML и обеспечить интеграцию со средой XML.
Вторая тенденция, которая будет воздействовать на возможность применения технологий баз данных для запросов в Web - это рост так называемого скрытого Web. Скрытым Web называется совокупность страниц Web, которые генерируются программами, определяемыми введенными пользователем данными, и, следовательно, не доступны для индексирования поисковыми роботами Web. В недавней статье [LG98] утверждается, что скрытый Web уже содержит примерно 80% Web. Если наши инструментальные средства должны быть способными извлекать пользу из данных в скрытом Web, то мы должны разработать методы для идентификации сайтов, которые генерируют страницы Web, классифицировать их и автоматически создавать для них интерфейсы запросов.
В рассматриваемой области нет недостатка в возможных направлениях будущих исследований. В прошлом большая часть работ была сосредоточена на логическом уровне и была посвящена разработке соответствующих моделей данных, языков запросов и методов описания различных аспектов Web-источников. Напротив, проблемам оптимизации запросов и исполнения запросов уделялось относительно небольшое внимание в сообществе специалистов по базам данных, и их исследование становится одной из наиболее важных задач для дальнейшей работы. Некоторые из важных направлений предусматривают обогащение моделей данных и языков запросов благодаря использованию различных форм метаданных об источниках (например, вероятностной информации) и основанных на строгих принципах комбинаций возможностей для запросов структурированных и неструктурированных источников данных в WWW.
Мы попытались привести в этой статье представительный список публикаций по вопросу о Web и базах данных. Помимо включенных в него работ читатели могут обратиться к материалам недавно проведенных симпозиумов, связанных с темой данного обзора [SSD97, Web98, AII98].
Авторы благодарны следующим коллегам за их предложения и комментарии по ранней версии этой статьи: Сержу Абитебулу (Serge Abiteboul), Густаво Аросена (Gustavo Arocena), Паоло Атцени (Paolo Atzeni), Хосе Блекли (Jose Blakeley), Нику Кушмерику (Nick Kushmerick), Бертраму Лудешеру (Bertram Ludascher), Ч. Мохану (C. Mohan), Янису Папаконстантиноусу (Yannis Papakonstantinou), Одеду Шмуэли (Oded Shmueli), Антони Томазису (Anthony Tomasic) и Дэну Велду (Dan Weld).
[AAB+98] Jos Luis Ambite, Naveen Ashish, Greg Barish, Craig A. Knoblock, Steven Minton, Pragnesh J. Modi, Ion Muslea, Andrew Philpot, and Sheila Tejada. ARIADNE: A system for constructing mediators for internet sources (system demonstration). In Proc. of ACM SIGMOD Conf. on Management of Data, Seattle, WA, 1998.
[Abi97] Serge Abiteboul. Querying semi-structured data. In Proc. of the Int. Conf. on Database Theory (ICDT), Delphi, Greece, 1997.
[ACM93] Serge Abiteboul, Sophie Cluet, and Tova Milo. Querying and updating the file. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), Dublin, Ireland, 1993.
[ACPS96] S. Adali, K. Candan, Y. Papakonstantinou, and V.S. Subrahmanian. Query caching and optimization in distributed mediator systems. In Proc. of ACM SIGMOD Conf. on Management of Data, Montreal, Canada, 1996.
[AD98] S. Abiteboul and O. Duschka. Complexity of answering queries using materialized views. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), Seattle, WA, 1998.
[AFT98] Laurent Amsaleg, Michael Franklin, and Anthony Tomasic. Dynamic query operator scheduling for wide-area remote access. Distributed and Parallel Databases, 6(3):217-246, July 1998.
[AII98] Proceedings of the AAAI Workshop on Intelligent Data Integration, Madison, Wisconsin, July 1998.
[AK97] Naveen Ashish and Craig A. Knoblock. Wrapper generation for semi-structured internet sources. SIGMOD Record, 26(4):8-15, 1997.
[AKS96] Yigal Arens, Craig A. Knoblock, and Wei-Min Shen. Query reformulation for dynamic information integration. International Journal on Intelligent and Cooperative Information Systems, (6) 2/3:99-130, June 1996.
[AM98] Gustavo Arocena and Alberto Mendelzon. WebOQL: Restructuring documents, databases and webs. In Proc. of Int. Conf. on Data Engineering (ICDE), Orlando, Florida, 1998.
[AMM97a] Gustavo O. Arocena, Alberto O. Mendelzon, and George A. Mihaila. Applications of a web query language. In Proc. of the Int. WWW Conf., April 1997.
[AMM97b] Paolo Atzeni, Giansalvatore Mecca, and Paolo Merialdo. To weave the web. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), 1997.
[AMM98] Paolo Atzeni, Giansalvatore Mecca, and Paolo Merialdo. Design and maintenance of dataintensive web sites. In Proc. of the Conf. on Extending Database Technology (EDBT), Valencia, Spain, 1998.
[AMR+98] Serge Abiteboul, Jason McHugh, Michael Rys, Vasilis Vassalos, and Janet Weiner. Incremental maintenance for materialized views over semistructured data. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), New York City, USA, 1998.
[AQM+97] Serge Abiteboul, Dallan Quass, Jason McHugh, Jennifer Widom, and Janet Wiener. The Lorel query language for semistructured data. International Journal on Digital Libraries, 1(1):68-88, April 1997.
[Aro97] Gustavo Arocena. WebOQL: Exploiting document structure in web queries. Master's thesis, University of Toronto, 1997.
[AV97a] S. Abiteboul and V. Vianu. Queries and computation on the Web. In Proc. of the Int. Conf. on Database Theory (ICDT), Delphi, Greece, 1997.
[AV97b] Serge Abiteboul and Victor Vianu. Regular path queries with constraints. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), Tucson, Arizona, May 1997.
[BBH+98] Krisha Bharat, Andrei Broder, Monika Henzinger, Puneet Kumar, and Suresh Venkatasubramanian. The connectivity server: fast access to linkage information on the web. In Proc. of the Int. WWW Conf., April 1998.
[BBMR89] Alex Borgida, Ronald Brachman, Deborah McGuinness, and Lori Resnick. CLASSIC: A structural data model for objects. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 59-67, Portland, Oregon, 1989.
[BDFS97] Peter Buneman, Susan Davidson, Mary Fernandez, and Dan Suciu. Adding structure to unstructured data. In Proc. of the Int. Conf. on Database Theory (ICDT), Delphi, Greece, 1997.
[BDH+95] C. M. Bowman, Peter B. Danzig, Darren R. Hardy, Udi Manber, and Michael F. Schwartz. The harvest information discovery and access system. Computer Networks and ISDN Systems, 28(1-2):119-125, December 1995.
[BDHS96] P. Buneman, S. Davidson, G. Hillebrand, and D. Suciu. A query language and optimization techniques for unstructured data. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 505-516, Montreal, Canada, 1996.
[BEM+98] C. Beeri, G. Elber, T. Milo, Y. Sagiv, O. Shmueli, N. Tishby, Y. Kogan, D. Konopnicki, P. Mogilevski, and N. Slonim. Websuite - a tool suite for harnessing web data. In Proceedings of the International Workshop on the Web and Databases, Valencia, Spain, 1998.
[BH98] Krishna Bharat and Monika Henzinger. Improved algorithms for topic distillation in hyperlinked environments. In Proc. 21st Int'l ACM SIGIR Conference, 1998.
[Bil98] David Billard. Transactional services for the web. In Proceedings of the International Workshop on the Web and Databases, pages 11-17, Valencia, Spain, 1998.
[BK90] C. Beeri and Y. Kornatzky. A logical query language for hypertext systems. In Proc. of the European Conference on Hypertest, pages 67-80. Cambridge University Press, 1990.
[Bla96] Jose A. Blakeley. Data access for the masses through OLE DB. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 161-172, Montreal, Canada, 1996.
[BP98] Sergey Brin and Lawrence Page. The anatomy of a large-scale hypertextual web search engine. In Proc. of the Int. WWW Conf., April 1998.
[BT98] Philippe Bonnet and Anthony Tomasic. Partial answers for unavailable data sources. In Proceedings of the 1998 Workshop on Flexible Query-Answering Systems (FQAS'98), pages 43-54. Department of Computer Science, Roskilde University, 1998.
[Bun97] Peter Buneman. Semistructured data. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), pages 117-121, Tucson, Arizona, 1997.
[CACS94] V. Christophides, S. Abiteboul, S. Cluet, and M. Scholl. From structured documents to novel query facilities. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 313-324, Minneapolis, Minnesota, 1994.
[CDF+98] Mark Craven, Dan DiPasquo, Dayne Freitag, Andrew McCallum, Tom Mitchell, Kamal Nigam, and Sean Slattery. Learning to extract symbolic knowledge from the world-wide web. In Proceedings of the AAAI Fifteenth National Conference on Artificial Intelligence, 1998.
[CDRR98] Soumen Chakrabarti, Byron Dom, Prabhakar Raghavan, and Sridhar Rajagopalan. Automatic resource compilation by analyzing hyperlink structure and associated text. In Proc. of the Int. WWW Goof., April 1998.
[CDSS98] Sophie Cluet, Claude Delobel, Jerome Simeon, and Katarzyna Smaga. Your mediators need data conversion. In Proc. of ACM SIGMOD Conf. on Management of Data, Seattle, WA, 1998.
[CGL98] Diego Calvanese, Giuseppe De Giacomo, and Maurizio Lenzerini. What can knowledge representation do for semi-structured data? In Proceedings of the AAAI Fifteenth National Conference on Artificial Intelligence, 1998.
[CGMP98] Junghoo Cho, Hector Garcia-Molina, and Lawrence Page. Efficient crawling through url ordering. In Proc. of the Int. WWW Conf., April 1998.
[CK98] J. Carriere and R. Kazman. Webquery: Searching and visualizing the web through connectivity. In Proc. of the Int. WWW Conf., April 1998.
[CKPS95] Surajit Chaudhuri, Ravi Krishnamurthy, Spyros Potamianos, and Kyuseok Shim. Optimizing queries with materialized views. In Proc. of Int. Conf. on Data Engineering (ICDE), Taipei, Taiwan, 1995.
[CM89] Mariano P. Consens and Alberto O. Mendelzon. Expressing structural hypertext queries in graphlog. In Proc. 2nd. ACM Conference on Hypertext, pages 269-292, Pittsburgh, November 1989.
[CM90] Mariano Consens and Alberto Mendelzon. GraphLog: a visual formalism for real life recursion. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), pages 404-416, Atlantic City, NJ, 1990.
[CMW87] Isabel F. Cruz, Alberto O. Mendelzon, and Peter T. Wood. A graphical query language supporting recursion. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 323-330, San Francisco, CA, 1987.
[CMW88] I.F. Cruz, A.0. Mendelzon, and P.T. Wood. G+: Recursive queries without recursion. In Proceedings of the Second International Conference on Expert Database Systems, pages 355-368, 1988.
[Coh98] William Cohen. Integration of heterogeneous databases without common domains using queries based on textual similarity. In Proc. of ACM SIGMOD Conf. on Management of Data, Seattle, WA, 1998.
[CS98] Pei Cao and Sekhar Sarukkai, editors. Proceedings of Workshop on Internet Server Performance, Madison, Wisconsin, 1998. http://www.cs.wisc.edu/cao/WISP98-program.html.
[DEW97] B. Doorenbos, O. Etzioni, and D. Weld. Scalable comparison-shopping agent for the world-wide web. In Proceedings of the International Conference on Autonomous Agents, February 1997.
[DFF+98] Alin Deutsch, Mary Fernandez, Daniela Florescu, Alon Levy, and Dan Suciu. A query language for XML. http://www.research.att.com/mff/xml/w3cnote.html, 1998.
[DG97a] Oliver M. Duschka and Michael R. Genesereth. Answering recursive queries using views. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), Tucson, Arizona, 1997.
[DG97b] Oliver M. Duschka and Michael R. Genesereth. Query planning in infomaster. In Proceedings of the ACM Symposium on Applied Computing, San Jose, CA, 1997.
[Dus97] Oliver Duschka. Query optimization using local completeness. In Proceedings of the AAAI Fourteenth National Conference on Artificial Intelligence, 1997.
[EGW94] Oren Etzioni, Keith Golden, and Daniel Weld. Tractable closed world reasoning with updates. In Proceedings of the Conference on Principles of Knowledge Representation and Reasoning, KR-94, 1994. Extended version to appear in Artificial Intelligence.
[EW94] Oren Etzioni and Dan Weld. A softbot-based interface to the internet. CACM, 37(7):72-76, 1994.
[FFK+98] Mary Fernandez, Daniela Florescu, Jaewoo Kang, Alon Levy, and Dan Suciu. Catching the boat with Strudel: Experiences with a web-site management system. In Proc. of ACM SICMOD Conf. on Management of Data, Seattle, WA, 1998.
[FFLS97] Mary Fernandez, Daniela Florescu, Alon Levy, and Dan Suciu. A query language for a web-site management system. SIGMOD Record, 26(3):4-11, September 1997.
[FFLS98] Mary Fernandez, Daniela Florescu, Alon Levy, and Dan Suciu. Reasoning about web-sites. In Working notes of the AAAI-98 Workshop on Artificial Intelligence and Data Integration. American Association of Artificial Intelligence, 1998.
[FHM94] Douglas Fang, Joachim Hammer, and Dennis McLeod. The identification and resolution of semantic heterogeneity in multidatabase systems. In Multidatabase Systems: An Advanced Solution for Global Information Sharing, pages 52-60. IEEE Computer Society Press, Los Alamitos, California, 1994.
[FKL97] Daniela Florescu, Daphne Koller, and Alon Levy. Using probabilistic information in data integration. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), pages 216-225, Athens, Greece, 1997.
[FLS98] Daniela Florescu, Alon Levy, and Dan Suciu. Query containment for conjunctive queries with regular expressions. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), Seattle, WA, 1998.
[FRV96] Daniela Florescu, Louiqa Raschid, and Patrick Valduriez. A methodology for query reformulation in cis using semantic knowledge. Int. Journal of Intelligent & Cooperative Information Systems, special issue on Formal Methods in Cooperative Information Systems, 5(4), 1996.
[FW97] M. Friedman and D. Weld. Efficient execution of information gathering plans. In Proceedings of the International Joint Conference on Artificial Intelligence, Nagoya, Japan, 1997.
[GC94] G. Graefe and R. Cole. Optimization of dynamic query evaluation plans. In Proc. of ACM SIGMOD Conf. on Management of Data, Minneapolis, Minnesota, 1994.
[GGMT99] Luis Gravano, Hector Garcia-Molina, and Anthony Tomasic. GlOSS: Text-source discovery over the internet. ACM Transactions on Database Systems (to appear), 1999.
[GMPQ+97] H. Garcia-Molina, Y. Papakonstantinou, D. Quass, A. Rajaraman, Y. Sagiv, J. Ullman, and J. Widom. The TSIMMIS project: Integration of heterogenous information sources, March 1997.
[GMW98] R. Goldman, J. McHugh, and J. Widom. Lore: A database management system for XML. Presentation, Stanford University Database Group, 1998.
[GRC97] S. Gadde, M. Rabinovich, and J. Chase. Reduce, reuse, recycle: An approach to building large internet caches. In Proceedings of the Workshop on Hot Topics in Operating Systems (HotOS), May 1997.
[GRVB98] Jean-Robert Gruser, Louiqa Raschid, Maria Esther Vidal, and Laura Bright. Wrapper generation for web accessible data sources. In Proceedings of the CoopIS, 1998.
[GW97] Roy Goldman and Jennifer Widom. Dataguides: Enabling query formulation and optimization in semistructured databases. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), Athens, Greece, 1997.
[GW98] Roy Goldman and Jennifer Widom. Interactive query and search in semistructured databases. In Proceedings of the International Workshop on the Web and Databases, pages 42-48, Valencia, Spain, 1998.
[GZC89] Ralf Hartmut Guting, Roberto Zicari, and David M. Choy. An algebra for structured office documents. ACM TOIS, 7(2):123-157, 1989.
[Hal88] Frank G. Halasz. Reflections on Notecards: Seven issues for the next generation of hypermedia systems. Comm. of the ACM, 31(7):836-852, 1988.
[Har94] Coleman Harrison. Aql: An adaptive query language. Technical Report NU-CCS-94-19, Northeastern University, October 1994. Master's Thesis.
[HGMN+98] Joachim Hammer, Hector Garcia-Molina, Svetlozar Nestorov, Ramana Yerneni, Markus M. Breunig, and Vasilis Vassalos. Template-based wrappers in the TSIMMIS system (system demonstration). In Proc. of ACM SIGMOD Conf. on Management of Data, Tucson, Arizona, 1997.
[HKWY97] Laura Haas, Donald Kossmann, Edward Wimmers, and Jun Yang. Optimizing queries across diverse data sources. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), Athens, Greece, 1997.
[HLLS97] Rainer Himmeroder, Georg Lausen, Bertram Ludascher, and Christian Schlepphorst. On a declarative semantics for web queries. In Proc. of the Int. Conf. on Deductive and Object-Oriented Databases (DOOD), pages 386-398, Singapore, December 1997. Springer.
[HML+98] Kyoji Hirata, Sougata Mukherjea, Wen-Syan Li, Yusaku Okamura, and Yoshinori Hara. Facilitating object-based navigation through multimedia web databases. TAPOS, 4{4), 1998. In press.
[Hul97] Richard Hull. Managing semantic heterogeneity in databases: A theoretical perspective. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), pages 51-61, Tucson, Arizona, 1997.
[HZ96] Richard Hull and Gang Zhou. A framework for supporting data integration using the materialized and virtual approaches. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 481-492, Montreal, Canada, 1996.
[Jan98] http://www.jango.excite.com, 1998.
[JB97] R. Jakobovits and J. F. Brinkley. Managing medical research data with a web-interfacing repository manager. In American Medical Informatics Association Fall Symposium, pages 454-458, Nashville, Oct. 1997.
[Jun98] http://www.junglee.com, 1998.
[KD98] Navin Kabra and David J. DeWitt. Efficient mid-query re-optimization of sub-optimal query execution plans. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 106-117, Seattle, WA, 1998.
[KDW97] N. Kushmerick, R. Doorenbos, and D. Weld. Wrapper induction for information extraction. In Proceedings of the 15th International Joint Conference on Artificial Intelligence, 1997.
[Kle98] Jon Kleinberg. Authoritative sources in a hyperlinked environment. In Proceedings of 9th ACM-SIAM Symposium on Discrete Algorithms, 1998.
[KLW95] M. Kifer, G. Lausen, and J. Wu. Logical foundations of object-oriented and frame-based languages. J. ACM, 42{4):741-843, 1995.
[KMSS98] Y. Kogan, D. Michaeli, Y. Sagiv, and O. Shmueli. Utilizing the multiple facets of www contents. Data and Knowledge Engineering, 1998. In press.
[KS95] D. Konopnicki and O. Shmueli. W3QS: A query system for the World Wide Web. In Proc. of the Int. Conf, on Very Large Data Bases (VLDB), pages 54-65, Zurich, Switzerland, 1995.
[KS98] David Konopnicki and Oded Shmueli. Bringing database functionality to the WWW. In Proceedings of the International Workshop on the Web and Databases, Valencia, Spain, pages 49-55, 1998.
[KW96] Chung T. Kwok and Daniel S. Weld. Planning to gather information. In Proceedings of the AAAI Thirteenth National Conference on Artificial Intelligence, 1996.
[Lev96] Alon Y. Levy. Obtaining complete answers from incomplete databases. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), Bombay, India, 1996.
[LG98] S. Lawrence and C.L. Giles. Searching the world wide web. Science, 280(4):98-100, 1998.
[LHL+98] Bertram Ludascher, Rainer Himmeroder, Georg Lausen, Wolfgang May, and Christian Schlepphorst. Managing semistructured data with FLORID: A deductive object-oriented perspective. Information Systems, 23(8), 1998. to appear.
[LMSS95] Alon Y. Levy, Alberto O. Mendelzon, Yehoshua Sagiv, and Divesh Srivastava. Answering queries using views. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), San Jose, CA, 1995.
[LRO96] Alon Y. Levy, Anand Rajaraman, and Joann J. Ordille. Querying heterogeneous information sources using source descriptions. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), Bombay, India, 1996.
[LRU96] Alon Y. Levy, Anand Rajaraman, and Jeffrey D. Ullman. Answering queries using limited external processors. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), Montreal, Canada, 1996.
[LSB+98] T. Lee, L. Sheng, T. Bozkaya, N.H. Balkir, Z.M. Ozsoyoglu, and G. Ozsoyoglu. Querying multimedia presentations based on content. to appear in IEEE Trans. on Know. and Data Engineering, 1998.
[LSCH98] Wen-Syan Li, Junho Shim, K. Selcuk Canadan, and Yoshinori Hara. WebDB: A web query system and its modeling, language, and implementation. In Proc. IEEE Advances in Digital Libraries'98, 1998.
[LSS96] Laks V. S. Lakshmanan, Fereidoon Sadri, and Iyer N. Subramanian. A declarative language for querying and restructuring the Web. In Proc. of 6th. International Workshop on Research Issues in Data Engineering, RIDE'96, New Orleans, February 1996.
[MM97] Alberto O. Mendelzon and Tova Milo. Formal models of web queries. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), pages 134-143, Tucson, Arizona, May 1997.
[MMM97] A. Mendelzon, G. Mihaila, and T. Milo. Querying the world wide web. International Journal on Digital Libraries, 1(1):54-67, April 1997.
[MMM98] Giansalvatore Mecca, Alberto O. Mendelzon, and Paolo Merialdo. Efficient queries over web views. In Proc. of the Conf. on Extending Database Technology (EDBT), Valencia, Spain, 1998.
[Mot89] Amihai Motro. Integrity = validity + completeness. ACM Transactions on Database Systems, 14(4):480-502, December 1989.
[MP96] Kenneth Moore and Michelle Peterson. A groupware benchmark based on Lotus Notes. In Proc. of Int. Conf. on Data Engineering (ICDE), 1996.
[MPP+93] Bernhard Mitschang, Hamid Pirahesh, Peter Pistor, Bruce G. Lindsay, and Norbert Sdkamp. Sql/xnf - processing composite objects as abstractions over relational data. In Proc. of Int. Conf. on Data Engineering (ICDE), pages 272-282, Vienna, Austria, 1993.
[MRT98] George A. Mihaila, Louiqa Raschid, and Anthony Tomasic. Equal time for data on the internet with websemantics. In Proc. of the Conf. on Extending Database Technology (EDBT), Valencia, Spain, 1998.
[MZ98] Tova Milo and Sagit Zohar. Using schema matching to simplify heterogeneous data translation. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), New York City, USA, 1998.
[NAM98] Svetlozar Nestorov, Serge Abiteboul, and Rajeev Motwani. Extracting schema from semistructured data. In Proc. of ACM SIGMOD Conf. on Management of Data, Seattle, WA, 1998.
[NGT98] Hubert Naacke, Georges Gardarin, and Anthony Tomasic. Leveraging mediator cost models with heterogeneous data sources. In Proc. of Int. Conf. on Data Engineering (ICDE), Orlando, Florida, 1998.
[NS96] Tam Nguyen and V. Srinivasan. Accessing relational databases from the world wide web. In Proc. of ACM SIGMOD Conf. on Management of Data, Montreal, Canada, 1996.
[PAGM96] Y. Papakonstantinou, S. Abiteboul, and H. Garcia-Molina. Object fusion in mediator systems. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), Bombay, India, 1996.
[PdBA+92] Jan Paredaens, Jan Van den Bussche, Mare Andries, Marc Gemis and Marc Gyssens, Inge Thyssens, Dirk Van Gucht, Vijay Sarathy, and Lawre nce V. Saxton. An overview of GOOD. SIGMOD Record, 21(1):25-31, 1992.
[PE95] Mike Perkowitz and Oren Etzioni. Category translation: Learning to understand information on the internet. In Working Notes of the AAAI Spring Symposium on Information Gathering from Heterogeneous Distributed Environments. American Association for Artificial Intelligence, 1995.
[PE97] Mike Perkowitz and Oren Etzioni. Adaptive web sites: an AI challenge. In Proceedings of the 15th International Joint Conference on Artificial Intelligence, 1997.
[PF98] P. Paolini and P. Fraternali. A conceptual model and a tool environment for developing more scalable, dynamic, and customizable web applications. In Proc. of the Conf. on Extending Database Technology (EDBT), Valencia, Spain, 1998.
[PGGMU95] Yannis Papakonstantinou, Ashish Gupta, Hector Garcia-Molina, and Jeffrey Ullman. A query translation scheme for rapid implementation of wrappers. In Proc. of the Int. Conf. on Deductive and Object-Oriented Databases (DOOD), 1995.
[PGMW95] Yannis Papakonstantinou, Hector Garcia-Molina, and Jennifer Widom. Object exchange across heterogeneous information sources. In Proc. of Int. Conf. on Data Engineering (ICDE), pages 251-260, Taipei, Taiwan, 1995.
[PMSL94] Hamid Pirahesh, Bernhard Mitschang, Norbert Sdkamp, and Bruce G. Lindsay. Composite-object views in relational dbms: an implementation perspective. Information Systems, IS 19(1):69-88, 1994.
[PPR96] P. Pirolli, J. Pitkow, and R. Rao. Silk from a sow's ear: Extracting usable structures from the web. In Proc. ACM SIGCHI Conference, 1996.
[RSU95] Anand Rajaraman, Yehoshua Sagiv, and Jeffrey D. Ullman. Answering queries using templates with binding patterns. In Proc. of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems (PODS), San Jose, CA, 1995.
[Spe97] Ellen Spertus. ParaSite: Mining structural information on the web. In Proc. of the Int. WWW Conf., April 1997.
[SSD97] Proceedings of Workshop on Management of Semistructured Data, Tucson, Arizona, May 1997.
[TMD92] J. Thierry-Mieg and R. Durbin. A C.elegans database: syntactic definitions for the ACEDB data base manager, 1992.
[TN98] Motomichi Toyama and T. Nagafuji. Dynamic and structured presentation of database contents on the web. In Proc. of the Gonf. on Extending Database Technology (EDBT), Valencia, Spain, 1998.
[TRV98] A. Tomasic, L. Raschid, and P. Valduriez. Scaling access to distributed heterogeneous data sources with Disco. IEEE Transactions On Knowledge and Data Engineering (to appear), 1998.
[TSI96] Odysseas G. Tsatalos, Marvin H. Solomon, and Yannis E. Ioannidis. The GMAP: A versatile tool for physical data independence. VLDB Journal, 5(2):101-118, 1996.
[UFA98] Tolga Urhan, Michael J. Franklin, and Laurent Amsaleg. Cost based query scrambling for initial delays. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 130-141, Seattle, WA, 1998.
[Ull97] Jeffrey D. Ullman. Information integration using logical views. In Proc. of the Int. Conf. on Database Theory (ICDT), Delphi, Greece, 1997.
[VP97a] Vasilis Vassalos and Yannis Papakonstantinou. Describing and using the query capabilities of heterogeneous sources. In Proc. of the Int. Conf, on Very Large Data Bases (VLDB), Athens, Greece, 1997.
[VP97b] Anne-Marie Vercoustre and Francois Paradis. A descriptive language for information object reuse through virtual documents. In Proceedings of the 4th International Conference on Object-Oriented Information Systems (OOIS'97), Brisbane, Australia, November 1997.
[WAC+93] Darrel Woelk, Paul Attie, Phil Cannata, Greg Meredith, Amit Seth, Munindar Sing, and Christine Tomlinson. Task scheduling using intertask dependencies in Carnot. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 491-494, 1993.
[WBJ+95] Darrell Woelk, Bill Bohrer, Nigel Jacobs, K. Ong, Christine Tomlinson, and C. Unnikrishnan. Carnot and infosleuth: Database technology and the world wide web. In Proc. of ACM SIGMOD Conf. on Management of Data, pages 443-444, San Jose, CA, 1995.
[Web98] Proceedings of the International Workshop on the Web and Databases, Valencia, Spain, March 1998. http://poincare.dia.uniroma3.it:8080/webdb98/papers.html
[WWW98] Proceedings of 3d WWW Caching Workshop (Manchester, England), June 1998.
[XML98] http://w3c.org/XML/, 1998.
[YL87] H. Z. Yang and P. A. Larson. Query transformation for PSJ-queries. In Proc. of the Int. Conf. on Very Large Data Bases (VLDB), pages 245-254, Brighton, England, 1987.
[YPAGM98] Ramana Yerneni, Yannis Papakonstantinou, Serge Abiteboul, and Hector Garcia-Molina. Fusion queries over internet databases. In Proc. of the Conf. on Extending Database Technology (EDBT), pages 57-71, Valencia, Spain, 1998.
[ZGM98] Yue Zhuge and Hector Garcia-Molina. Graph structured views and their incremental maintenance. In Proc. of Int. Conf. on Data Engineering (ICDE), Orlando, Florida, February 1998.