Журнал "Открытые Системы", #09-10/1999
Михаил Кузьминский
Знание архитектуры процессора, или в более узком смысле, его системы команд, необходимо не только для программирующих на языке ассемблера данного процессора. В учебные курсы в области информатики традиционно входят дисциплины, в которых рассматривается программирование на ассемблере. В период доминирования больших универсальных ЭВМ большинство специалистов знали ассемблер мэйнфреймов IBM S/360-370 (соответственно ЕС ЭВМ). Затем доминирующим стал, вероятно, ассемблер x86. Современные специалисты по компьютерным архитектурам хорошо знают и системы команд RISC-процессоров.
Системы команд современных RISC-процессоров во многом похожи друг на друга. Например, говорят, что в этом смысле MIPS и Alpha близки друг к другу. Однако появление архитектуры IA-64, которая претендует на монополию на рынке микропроцессоров, разработчики из HP и Intel характеризуют как наступление эры "пост-RISC". Доступная информация свидетельствует, что IA-64 революционным образом отличается от предшественников, даже от своих прямых предков таких, как HP PA-RISC. Процессоры с архитектурой IA-64 (Merced, McKinley и т.д.) могут обойти RISC-процессоры по производительности.
Со временем архитектура IA-64 способна вытеснить в будущем x86 (IA-32) не только на рынке, но и в качестве багажа "базовых знаний" специалистов по информатике. Однако необходимость разработки для IA-64 весьма сложных компиляторов и трудности с созданием оптимизированных машинных кодов может вызвать дефицит специалистов, пишущих на ассемблере IA-64, особенно на начальных этапах. Это делает актуальным анализ IA-64.
На момент подготовки статьи детали микроархитектуры процессора Merced, получившего официальное название Itanium, все еще не раскрыты. Официальная информация [1,2] позволяет сделать определенные предположения о характеристиках Itanium. Укажем также на публикацию по микроархитектуре E2K [3] отечественной разработки, имеющей близкие к IA-64 архитектурные особенности.
Основным источником данных для данной статьи послужили, естественно, публикации [1,2]. Мы остановимся в первую очередь на концептуально новых особенностях IA-64 и общем описании. Более традиционные части системы команд IA-64 напоминают обычный набор команд RISC, в первую очередь архитектуры PA-RISC. Cовместимость с PA-RISC в IA-64 обеспечивается за счет динамической трансляции команд (т.е. подобно Compaq/DEC FX!32). Применительно к прикладным программам такой подход оказывается вполне эффективным благодаря близости части команд PA-RISC к соответствующим командам IA-64.
Что касается аппаратно поддерживаемой совместимости с архитектурой IA-32, то, с точки зрения автора, это тема для отдельного разговора; основной интерес представляет собой в первую очередь принципиально новые черты IA-64. По мнению автора, аппаратная совместимость с IA-32 препятствует эффективному развитию IA-64 и росту производительности. Косвенным подтверждением этому служат неофициальные "приватные" данные о том, что McKinley, производительность которого должна быть гораздо выше Merced, якобы не имеет столь развитых средств аппаратной поддержки IA-32, как у Merced.
Наиболее кардинальным нововведением IA-64 по сравнению с RISC является "явный параллелизм команд (EPIC - Explicitly Parallel Instruction Computing), привносящий в IA-64 некоторые элементы, напоминающие архитектуру "сверхбольшого командного слова" (VLIW - Very Large Instruction Word). В обеих архитектурах явный параллелизм представлен уже на уровне команд, управляющих одновременной работой функциональных исполнительных устройств (ФИУ). Соответствующие "широкие команды" HP/Intel назвали связками (bundle).
![]()
Рис. 1. Формат связки команд IA-64
Связка имеет длину 128 разрядов (рис. 1). Она включает 3 поля - "слота" для команд длиной 41 разрядов каждая, и 5-разрядное поле шаблона. Предполагается, что команды связки могут выполняться параллельно разными ФИУ. Возможные взаимозависимости, препятствующие параллельному выполнению команд связки, отражаются в поле шаблона. Не утверждается, впрочем, что параллельно не могут выполняться и команды разных связок.
Шаблон указывает, какого типа команды находятся в слотах связки. В общем случае команды одного типа могут выполняться в более чем одном типе ФИУ (табл.1). Шаблоном задаются так называемые остановки, определяющие слот, после начала выполнения команд которого команды последующих слотов должны ждать завершения. Порядок слотов в связке (возрастание справа налево) отвечает и порядку байт - little endian. Однако данные в памяти могут располагаться и в режиме big endian. Режим устанавливается специальным разрядом в регистре маски пользователя.
| Тип команд | Тип исполнительного устройства | Описание команд |
|---|---|---|
| A | I или M | Целочисленные, АЛУ |
| I | I | Целочисленные неарифметические |
| M | M | Обращение в память |
| F | F | C плавающей запятой |
| B | B | Переходы |
| L+X | I | Расширенные |
При использовании ассемблера остановки отмечаются двумя подряд знаками "точка с запятой" - ";;". Места, в которых необходимо указывать остановку выглядят интуитивно понятными, по крайней мере, в приведенных в [1,2] примерах.
Последовательность команд от остановки до остановки (или выполняемого перехода) называется группой команд. Она начинается с заданного адреса команды (адрес связки плюс номер слота) и включает все последующие команды - с увеличением номера слота в связке, а затем и адресов связок, пока не встретится остановка.
Рассмотрим теперь файлы регистров IA-64. В их число входят: 128 регистров общего назначения GR; 128 регистров с плавающей запятой FR; 64 регистра предикатов PR; 8 регистров перехода BR; 128 прикладных регистра AR; не менее 4 регистров идентификатора процессора CPUID; cчетчик команд IP, указывающий на адрес связки, содержащей исполняемую команду; регистр маркера текущего окна CFM, описывающий окно стека регистров и др.
Регистры CPUID являются 64-разрядными. В CPUID-регистрах 0 и 1 лежит информация о производителе, в регистре 2 находится серийный номер процессора, а в регистре 3 задается тип процессора (cемейство, модель, версия архитектуры и т.п.) и число CPUID-регистров. Разряды регистра 4 указывают на поддержку конкретных особенностей IA-64, т.е. тех, которые реализованы в данном процессоре.
Прикладные регистры AR0-AR127 - специализированные (в основном 64-разрядные) регистры, применяемые в IA-64 и IA-32. AR0-7 называются регистрами ядра; запись в них привилегирована, но они доступны на чтение в любом приложении и используются для передачи приложению сообщений от операционной системы.
Среди других прикладных регистров укажем на AR16 (RSC) - регистр конфигурации стека регистров, используемый для управления работой "машиной" стека регистров IA-64 (RSE); AR17 (BSP), в котором находится адрес в памяти, где сохраняется положение GR32 в текущем окне стека; AR40 (FPSR) - регистр состояния для команд с плавающей запятой IA-64; AR44 (ITC) - интервальный таймер; AR64 (PFS) - регистр предыдущего состояния функции, куда автоматически копируются некоторые другие регистры при вызове подпрограмм; AR65 (LC), используемый для организации циклов со счетчиком, и, наконец, 6-разрядный регистр эпилога AR66 (EC). Ряд AR-регистров является фактически регистрами IA-32 (дескриптор сегмента кодов, дескриптор сегмента стека и др.).
64-разрядные регистры GR0-127 применяются не только для целочисленных операций IA-64; GR8-31 в режиме IA-32 используются также под целочисленные регистры и регистры селекторов и дескрипторов сегментов IA-32. GR0-31 называются статическими регистрами (GR0 всегда содержит 0), а GR32-127 - стекируемыми регистрами. Статические регистры "видны" всем программам. Стекируемые регистры становятся доступными в программной единице через окно стека регистров, включающее локальные и выходные регистры, число которых задается командой alloc.
82-разрядные регистры с плавающей запятой FR0-127 также подразделяются на статические (FR0-31, причем всегда FR0=0.0, FR1=1.0) и вращаемые (FR32-127). FR8-31 в режиме IA-32 содержат числа с плавающей запятой и мультимедийные регистры.
Вращение регистров является в некотором роде частным случаем переименования регистров, применяемого во многих современных суперскалярных процессоров с внеочередным спекулятивным выполнением команд. В отличие от них, вращение регистров в IA-64 управляется программно. К обсуждению вращения регистров мы вернемся ниже, а содержимое FR будет рассмотрено в разделе, посвященном операциям с плавающей запятой.
64-разрядные регистры переходов BR0-7 применяются для указания адреса перехода в соответствующих командах перехода (если адрес перехода не кодируется в команде явно). Регистры предикатов PR0-63 являются одноразрядными; в них помещаются результаты команд сравнения. Обычно эти команды устанавливают сразу два геистра PR в зависимости от условия - соответственно истинность условия и его отрицания. Такая избыточность обеспечивает дополнительную гибкость.
В отечественном микропроцессоре E2K [3] предикатных регистров в два раза меньше. Хотя это позволяет хранить столько же условий, сколько в IA-64, в последней предикатные регистры применяются еще и для организации программно конвейеризованных циклов (Software Pipelining - SWP). Использование предикатных регистров - важнейшая особенность, кардинально отличающая IA-64 от всех других микропроцессоров, кроме E2K.
PR0-15 являются статическими (PR0 всегда равен 1), а PR16-63 - вращаемыми. Статические предикатные регистры используются в командах условного перехода. Кроме того, почти все команды IA-64 могут быть выполнены "под предикатом".
Работа стека регистров
Файл регистров GR отличается от FR и PR тем, что последние содержат фиксированные подмножества статических и вращаемых регистров, в то время как в файле GR вне подмножества статических регистров применяется стек регистров, и программной единице доступна лишь его часть - окно стека регистров. В отличие от статических регистров, стекируемое подмножество локально для любой программной единицы и может иметь размер от 0 до 96 регистров, начиная с GR32.
Использование этого механизма в IA-64 позволяет, как мы увидим, избежать накладных расходов, связанных с сохранением/восстановлением большого числа регистров при вызовах подпрограмм и возвратах из них (однако статические регистры при необходимости все-таки приходится сохранять и восстанавливать, явно кодируя соответствующие команды). Автоматическое сохранение/восстановление стекируемого подмножества регистров осуществляет RSE, и в программе об этом заботиться не надо. В режиме IA-32 работа с этим стеком регистров, естественно, отключается.
Мы до сих пор не рассматривали один из важнейших регистров IA-64 - 38-разрядный регистр CFM, в котором как раз сохраняется состояние "текущего" окна стека регистров. Как и другие маркеры окна, CFM содержит общий размер окна стека, число локальных регистров и (кратное 8) число вращаемых регистров в окне, а также 3 значения базы для переименования регистров - соответственно rrb.gr, rrb.fr и rrb.pr.
Итак, окно стека имеет две области переменного размера - локальную и выходную. Рассмотрим вызов процедур подробнее. При переходе типа "вызов процедуры" CFM вызывающей подпрограммы сохраняется в поле PFM (Previous Frame Marker) регистра PFS, и создается CFM вызываемой подпрограммы. Сразу после вызова размер локальной области вызываемой подпрограммы равен размеру выходной области вызывающей и перекрывается с ней. При этом стекируемые регистры автоматически переименовываются таким образом, что первый регистр выходной области вызывающей подпрограммы становится регистром GR32 вызываемой (рис.2, где procA - это вызывающая, а procB - вызываемая подпрограмма). Перекрытие их выходных областей позволяет эффективно передавать параметры через регистры.
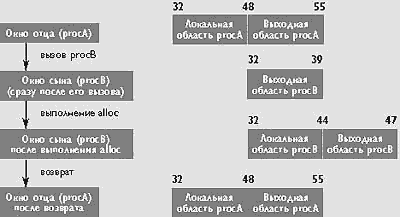
Рис. 2. Стек регистров при вызове procB из procA
Как мы уже указывали, вызываемая подпрограмма может изменить размеры своих локальной и выходной областей командой alloc; cоответствующим образом будут изменены и поля в CFM. Команда alloc обычно используется вызываемой подпрограммой для того, чтобы распределить себе определенное число локальных регистров и заиметь выходную область для передачи параметров уже собственному "потомку". Если запрошенное в команде alloc количество регистров оказывается недоступным (переполнение стека), alloc приостанавливает процессор и RSE будет сохранять регистры вызывающей подпрограммы, пока запрошенное alloc число регистров не будет доступным.
При переходе типа "возврат из процедуры" CFM восстанавливается из PFM, а обратное переименование регистров восстанавливает состояние вызывающей подпрограммы. Если некоторые ее регистры были ранее "сброшены" RSE, то при возврате RSE приостановит процессор до тех пор, пока не будут восстановлены эти регистры.
В этом разделе статьи мы дадим краткий обзор системы команд IA-64, а точнее, ее "непривилегированной части". Именно это подмножество команд определяет наиболее принципиальные особенности IA-64. Cреди этих принципиальных особенностей следует особо отметить спекулятивное выполнение команд и применение предикатов.
Все рассматриваемые команды можно подразделить на: команды работы со стеком регистров (например, alloc); целочисленные команды; команды сравнения и работы с предикатами; команды доступа в память; команды перехода; мультимедийные команды; команды пересылок между регистрами; "разные" (операции над строками и подсчет числа единиц в слове); команды работы с плавающей запятой.
Целочисленные команды IA-64 включают арифметические операции (add, sub и др.), логические операции (and, or, xor и др.), операции над битами и сдвиги, а также 32-разрядные операции. Большинство этих команд трехадресные, а их аргументы лежат в регистрах; однако встречается и литеральное представление аргументов. Имеются также модификации команд add и sub, которые являются четырехадресными: в них к сумме/разности регистров прибавляется/вычитается 1.
Отметим, что команда умножения целых чисел в регистрах GR отсутствует; для перемножения необходима пересылка целых в регистры FR и применение операции умножения, выполняемой в ФИУ вещественного типа. Некоторые специалисты считают это "наименее удачной" чертой системы команд IA-64.
Команды сравнения и работа с предикатами - это одна из принципиально новых особенностей IA-64 по сравнению с RISC-архитектурой. Приведем сначала несколько типичных примеров команд этой группы. Команда cmp сравнивает два регистра GR (или регистр GR и литерал) на одно из 10 возможных условий (больше, меньше или равно и т.п.). Команда tbit тестирует заданный бит GR. Команда fcmp сравнивает два числа с плавающей запятой. Однако результатом сравнения является не единственный код условия, что типично для обычных процессоров. Логический результат сравнения (1 - истина, 0 - ложь) записывается обычно в пару предикатных регистров (во второй пишется отрицание первого).
Эти значения предикатных регистров используются затем не только в командах условного перехода, как в обычных микропроцессорах. Почти все команды IA-64 выполнимы "под предикатом", т.е. могут выполняться или нет в зависимости от значения указанного в команде PR-регистра. Это позволяет во многих случаях избежать применения условных переходов, которые, как известно, отрицательно сказываются на производительности микропроцессоров. Вместо этого процессор c архитектурой IA-64, имеющий большое число ресурсов (в частности, регистров и ФИУ), может исполнить обе ветви программы. Рассмотрим простейший Пример 1.
Пример 1.
Фрагмент программы в фортрановском представлении:
IF(I.EQ.J) THEN K=K+1 ELSE L=L+1 ENDIF
в ассемблерном:
cmp.eq p3,p4=r4,r5;; (p3) add r6=r6,r0,1 (p4) add r7=r7,r0,1
(мы используем, вслед за [1], "фортрановский" синтаксис). Предположим, что значения I, J, K, L уже лежат в r4, r5, r6, r7 cоответственно (так обозначаются регистры GR в ассемблере IA-64). Тогда мы получим следующий фрагмент программы...
Здесь команды сложения add использованы в четырехадресной форме; они помещают в регистр-результат (r6 и r7 соответственно) старое значение этого регистра плюс 1 (формально еще плюс значение в r0, которое равно нулю). Команды add используются с так называемыми квалифицирующими предикатами p3, p4. Если значения I и J совпадают, то получаем значения предикатных регистров (p3) = 1, а (р4) = 0. Тогда первая команда add выполняется, а вторая - нет.
Преимуществом такого подхода состоит в линейности выполняемого участка программы вместо ветвления. Обе команды add могут, кстати, выполниться параллельно. Возможности команд типа условной пересылки cmove в ряде RISC-процессоров, в общем случае значительно меньше, чем предикатный подход. Это преимущество IA-64 становится еще более существенным, если учесть расширенные возможности спекулятивного выполнения команд в IA-64.
Спекулятивное выполнение
Рассмотрим теперь команды доступа в память. Прежде всего, это команды загрузки регистров и записи из них в оперативную память. Команда ld загружает в GR 1-, 2-, 4- и 8-байтные целочисленные величины; аналогично ldf загружает в FR числа с плавающей запятой размером 4, 8, 10 байт, а также пары 4-байтных чисел. В этих командах можно указать также на тонкие особенности работы с оперативной памятью и кэшем. Имеются и специальные команды работы с кэшем.
Принципиальной является возможность кодирования указанных команд загрузки в специальных спекулятивных формах. Различают загрузку спекулятивную по управлению и спекулятивную по данным.
Спекулятивное по управлению выполнение означает возможность заранее выполнить команды, расположенные за командой условного перехода, до того, как будет известно, будет ли осуществляться этот условный переход на соответствующую ветвь программы. При наличии большого числа ресурсов процессора это позволяет заранее запускать на выполнение команды, которые начнут выполняться одновременно с уже начавшими выполняться другими командами (в других ФИУ). Однако позднее может выясниться, что эти спекулятивно выполненные команды оказались выполненными напрасно, так как переход на эту ветвь не произошел, и нужно произвести "откат".
Поскольку эти спекулятивно выполненные команды могут привести к прерыванию, в IA-64 предусмотрен механизм, позволяющий зафиксировать, что возникло прерывание, но само прерывание "отложить" до тех пор, пока не будет затребован опрос его наличия. Признак отложенного прерывания записывается в регистр результата (затем его можно опросить специальной командой chk.s). В дальнейшем признак отложенного прерывания последовательно "распространяется" на регистры результатов спекулятивных команд, в регистрах исходных данных которых взведен признак отложенного прерывания.
Все команды можно разделить на спекулятивно выполнимые и спекулятивно невыполнимые. Последние могут вызывать прерывания, которые не могут быть отложены. Обычные вычислительные команды, имеющие GR или FR в качестве регистров результата, - спекулятивные. Если же команда изменяет другие типы регистров, она неспекулятивная.
Кроме обычных неспекулятивных команд (ld, ldf...) в IA-64 имеются их спекулятивные модификации (ld.s, ldf.s...). Вычислительные команды в общем случае не вызывают прерываний (операции с плавающей запятой обрабатывают прерывания специальным образом), поэтому единственным способом сгенерировать признак отложенного прерывания являются команды спекулятивной загрузки. Другие команды его могут только "распространять".
В точке программы, где надо использовать результат спекулятивного выполнения, следует применять спекулятивную команду chk.s, проверяющую признак отложенного прерывания. Если оно имелось, chk.s передаст управление по указанному в ней адресу, по которому программист должен расположить коды обработки ситуации. Поскольку стало ясно, что спекулятивное выполнение команды действительно понадобилось, можно закодировать копию спекулятивно выполненного фрагмента программы, но уже с неспекулятивными командами загрузки.
Другой тип спекулятивного выполнения может иметь место, когда вслед за записью в память идет команда загрузки регистра, и невозможно заранее определить, не будут ли перекрываться в памяти используемые этими командами данные. В IA-64 имеются спекулятивные команды загрузки (ld.a, ldf.a...), которые называются "усовершенствованными" (advanced) командами загрузки. Аналогично взаимозависимости между командами по управлению, "расшиваемой" применением спекулятивных команд с "постфиксом" .s, продвинутые команды загрузки вместе с соответствующей командой проверки chk.a (аналог chk.s) позволяют исключить задержки выполнения при наличии взаимозависимости по данным.
Обратимся теперь к командам перехода. Адрес перехода выравнивается всегда на границу связки, т.е. управление передается на ее слот 0. Имеется команда перехода относительно счетчика команд, в которой явно кодируется 21-разрядное смещение. Эти переходы осуществимы в пределах +/-16 Мбайт относительно счетчика. В непрямых командах перехода адрес перехода задается в регистре BR.
Обычный условный переход br.cond, или просто br, использует значение кодируемого в команде предикатного регистра PR для определения истинности условия. Указав в команде PR0, в котором всегда лежит 1, можно получить безусловный переход. PR0 кодируется также в командах вызова процедур/возврата (br.call/br.ret). Имеется 5 типов команд перехода, применяемых для организации циклов. Команда br.cloop используется для организации циклов со счетчиком, в которых адрес перехода кодируется относительно IP. В команде используется регистр LC: если он не равен 0, его содержимое уменьшается на 1, и выполняется переход; если LC = 0, перехода не будет. Применение команд работы с циклами мы рассмотрим позже при обсуждении программно конвейеризованных циклов.
В расширении кода операции команды перехода можно закодировать подсказку для процессора о стратегии динамического или статического предсказания этого перехода. Подобные схемы используются в PA-8x00.
Операции с плавающей запятой
Программная модель вычислений с плавающей запятой в IA-64, в отличие от IA-32, ориентирована на работу с регистрами FR, а не со стеком, что уже само по себе облегчает создание более высокопроизводительных программ. В IA-64 непосредственно поддерживается 6 типов данных, в том числе три стандарта IEEE754 (одинарная точность SP, двойная точность DP и двойная расширенная точность DE),
82-разрядный формат FR и 64-разрядные целые - со знаком и без знака. Формат DE, также как и формат с размещением двух чисел (SP) с плавающей запятой, используемый в векторных мультимедийных командах, унаследован архитектурой IA-64 от IA-32. Формат регистров FR включает 64-разрядную мантиссу, 17-разрядный порядок и 1 бит под знак числа. Кроме того, на уровне подпрограмм предлагается поддержка четверной точности.
В 64-разрядном регистре FPSR указываются признаки деления на ноль, переполнения порядка, исчезновения порядка, потери значимости, формат данных и другая информация о состоянии.
FP-команды загрузки имеют модификации, соответствующие всем аппаратно поддерживаемым типам данных, которые в ассемблере задаются последним символом мнемокода (lfds - для SP, ldfd - для DP и т.д.). Арифметические команды включают операции типа "умножить-и-сложить" и "умножить-и-вычесть", команды вычисления максимума/минимума, а также команды расчета обратной величины и обратного квадратного корня. Применение двух последних вместо команд деления и квадратного корня соответственно упрощает работу с конвейерами. Реализация команды обращения вместо деления была применена, как известно, еще в легендарном Cray-1.
Приведем Пример 2, иллюстрирующий как работу с плавающей запятой, так и организацию циклов со счетчиком - сложение двух массивов чисел с плавающей запятой (DP).
Пример 2.
Фрагмент программы в фортрановском представлении:
DO I=1,N C(I)=A(I)+B(I) ENDDO
в ассемблерном:
Lbl: ldfd f6=[r6],8 //Загрузка в f6 A(I) ldfd f7=[r7],8;; //Загрузка в f7 B(I) fadd f8=f6, f7;; //Сложение f6 и f7 stfd [r8]=f8,8 //Запись C(I) br.cloop Lbl;; //Переход на метку
В его ассемблерном представлении приведено только собственно тело цикла.
В этом примере предполагается, что в регистре r6 лежит адрес начала массива A, в r7 - начала массива B, а в r8 - начала массива С. После выполнения каждой команды ldfd и команды stfd содержимое регистров r6-8 соответственно увеличивается на 8 (размер элемента массива в байтах), что указывается в последнем аргументе этих команд. Команда fadd складывает регистры f6 и f7, помещая результат в f8. Наконец, br.cloop обеспечивает переход на начало тела цикла. Не правда ли, очень похоже на старый добрый RISC? То ли еще будет...
Cовременные оптимизирующие компиляторы суперскалярных RISC-процессоров активно используют технику SWP ([4]). Аппаратная поддержка SWP в IA-64 имеет принципиальное значение для увеличения производительности и эффективности использования оперативной памяти.
SWP-циклы аналогичны обычным аппаратным конвейерам. В таком цикле также имеется три фазы. В фазе заполнения конвейера (пролог) новая итерация цикла запускается на выполнение на каждой стадии. В фазе ядра на каждой стадии запускается одна итерация, и одна итерация завершается (конвейер заполнен). В фазе эпилога новых итераций не запускается, а завершается выполнение ранее запущенных итераций (см. Пример 3).
Пример 3.
Фрагмент программы в фортрановском представлении:
DO I=1,N IND(I)=JND(I)+K ENDDO
в ассемблерном:
Lbl:ld8 r8=[r5],8;; //Загрузка JND(I) add r9=r8,r7;; //r9=r8+r7 st8 [r6]=r9,8 //Запись IND(I) br.cloop Lbl;; //Переход по счетчику SWP-аналог: mov lc=99 //Установка LC mov ec=4 //Установка EC mov pr.rot=1<<16 //Установка PR Lbl: (p16) ld8 r32=[r5],8;; //Загрузка JND(I) (p18) add r35=r34,r7;; //r35=r34+r7 (p19) st8 [r6]=r36,8 //Запись IND(I) br.ctop Lbl;;
Число тактов T между запуском последовательных итераций цикла называется интервалом инициации. Мы рассмотрим только случай постоянного числа тактов. В простейшем случае T равно 1, очередная итерация цикла может запускаться на каждом такте.
Каждой стадии цикла должен быть выделен PR-регистр из области вращения, определяющий, следует ли выполнять команды данной стадии. В простейшем случае стадия цикла включает одну команду. При использовании раскрутки (unrolling) циклов, которую часто необходимо применять для эффективного использования ресурсов процессора, каждая стадия включает несколько однотипных команд (скажем, для четных и нечетных итераций - при двухкратной раскрутке). В этом случае для каждой команды стадии кодируется один и тот же PR-регистр.
Пример 4.
Фрагмент программы в фортрановском представлении:
DO I=1,N S=S+A(I)*B(I) ENDDO
SWP-аналог:
Lbl: (p16) ldfd f50=[r5],8 //Загрузка A(I) (p16) ldfd f60=[r6],8 //Загрузка B(I) (p25) fma f41=f59,f69,f46 //f41=f59*f69+f46 br.ctop.sptk Lbl;; fadd f7=f42,f43 //Частичная сумма 1 fadd f8=f44,f45;; //Частичная сумма 2 fadd f9=f7,f8;; //Их сумма fadd f10=f9,f46 //Окончательная сумма
SWP поддерживается как для исходных циклов со счетчиком, использующих команду br.cloop, так и для циклов while. Для циклов со счетчиком на первой стадии цикла должен применяться PR16, а для циклов while - любой PR-регистр из области вращения. Предикаты последующих стадий должны иметь более высокие номера PR. Инициализация предикативных стадий возложена на программиста.
Как мы увидим, применение PR-регистров, вращаемых регистров GR и FR и специальных SWP-команд перехода позволяет не увеличивать размер кода SWP-цикла, что характерно для оптимизации циклов в RISC-процессорах. Вращение на одну регистрную позицию вышеупомянутых регистров осуществляется аппаратно при выполнении SWP-команды перехода (br.ctop - для циклов со счетчиком при расположении команды перехода в конце тела цикла).
| Номер такта | Команды и порты | Значения регистров перед br.ctop | ||||||||
| M | I | M | B | p16 | p17 | p18 | p19 | LC | EC | |
| 1 | ld8 | br.ctop | 1 | 0 | 0 | 0 | 99 | 4 | ||
| 2 | ld8 | br.ctop | 1 | 1 | 0 | 0 | 98 | 4 | ||
| 3 | ld8 | add | br.ctop | 1 | 1 | 1 | 0 | 97 | 4 | |
| 4 | ld8 | add | st8 | br.ctop | 1 | 1 | 1 | 1 | 96 | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 99 | ld8 | add | st8 | br.ctop | 1 | 1 | 1 | 1 | 0 | 4 |
| 100 | add | st8 | br.ctop | 0 | 1 | 1 | 1 | 0 | 3 | |
| 101 | add | st8 | br.ctop | 0 | 0 | 1 | 1 | 0 | 2 | |
| 102 | st8 | br.ctop | 0 | 0 | 0 | 1 | 0 | 1 | ||
| ... | 0 | 0 | 0 | 0 | 0 | 0 | ||||
При выполнении такой команды вращение регистров осуществляется путем их переименования благодаря уменьшению на 1 базовых значений в CFM - соответственно полей CFM.rrb.gr, CFM.rrb.fr и CFM.rrb.pr. Вообще изменение полей rrb, приводящее к переименованию регистров, происходит при выполнении команд очистки rrb (clrrrb, clrrrb.pr) и переходов типа вызова процедур/возврата (br.call/br.ret) и SWP-переходов, в том числе br.ctop. Файлы вращаемых регистров с точки зрения их переименования зациклены: регистр с максимальным номером после вращения переходит в регистр с минимальным номером из области вращения. Так, PR63 после вращения становится PR16.
Рассмотрим теперь, как организовывается работа SWP-цикла со счетчиком. При этом используется регистр LC, в который помещается значение N-1 (N - число итераций цикла), и регистр ЕС, куда надо поместить число стадий в теле цикла. Пока LC больше 0, br.ctop продолжает выполнение цикла, уменьшая LC на 1 и вращая регистры на 1 путем уменьшения rrb. Команда br.ctop, принявшая решение о продолжении цикла, устанавливает в 1 регистр PR63, который после вращения становится PR16.
Когда LC становится равным 0, начинается фаза эпилога. В ней br.ctop будет продолжать цикл, уменьшая EC на 1 - до тех пор, пока EC не обнулится. Тогда br.ctop завершит цикл, передав управление на следующую команду.
Проиллюстрируем сказанное выше на конкретном примере SWP-цикла (в примере 3 мы незначительно модернизировали соответствующий пример из [1]).
Предположим, что все целые величины - 64-разрядные.
Предполагается, что в регистре GR5 лежит адрес начала массива IND, а в GR6 - адрес начала JND; K загружена в GR7. Первая команда ld8 загружает 8 байт из адреса, указанного в GR5, в GR8. В конце ее выполнения к GR5 прибавляется 8. Команда add складывает GR8 и GR7, помещая результат в GR9. Команда st8 записывает содержимое этого регистра в память, адрес которой находится в GR6, и в конце выполнения увеличивает его на 8.
В [1] соответствующий пример относится к 32-разрядным целым и предполагается, что команда ld4 занимает два такта. Это типично для микропроцессоров, и мы предполагаем, что ld8 также занимает два такта. Можно предположить, что в теле цикла (без br.cloop) остальные команды занимают один такт, тогда это тело состоит из четырех стадий, вторая из которых - пустая (ожидание завершения ld8 на втором такте).
Вследствие наличия большого числа ФИУ и соответствующих портов, команды цикла, представленные в примере 3, могли бы в принципе выполняться одновременно, если бы они работали с разными регистрами (т.е. не было бы взаимозависимости). Это хорошо видно из табл. 2, в которой нетрудно разглядеть аналогии с заполнением аппаратных конвейеров.
На тактах 1-3 происходит заполнение конвейера (пролог), такты 4-5 относятся к фазе ядра, такты 6-8 отвечают эпилогу. Если бы не было взаимозависимости, команды ld8, add и st8 могли бы работать параллельно в фазе ядра (предполагается, что имеется два порта памяти). Скажем, когда add начинает работу, ld8 могла бы начать новую загрузку, но уже в другой GR-регистр. В суперскалярных RISC-процессорах для достижения подобных целей приходится создавать отдельные коды для пролога и эпилога, раскручивать циклы, что приводит к увеличению длины кода.
В IA-64 эти проблемы решены элегантно и эффективно. Нет необходимости вручную заниматься переименованием регистров, чтобы избавиться от взаимозависимости - для этого есть вращение регистров. Не нужно писать пролог и эпилог - все автоматизировано за счет применения PR-регистров и SWP-команд.
SWP-аналог примера 3 использует команду br.ctop. Соответственно первой стадии (команда ld8) выделяется PR16, второй (add) - PR18, четвертой (st8) - PR19. Вместо статических GR7-9 мы будем использовать вращаемые регистры, начиная с GR32. Перед началом выполнения цикла в LC загружается значение N-1 (99), а в EC - 4 (на 1 больше числа стадий эпилога). Кроме того, нужно установить вращаемые PR-регистры, что делается сразу для всех предикативных регистров командой mov pr.rot.
Вследствие вращения регистров величина JND(I), загружаемая в GR32, двумя тактами позднее (по завершению ld8) уже оказывается в GR34. Аналогично, IND(I)+K, помещаемая в GR35, по завершению команды add (один такт) окажется в GR36. Эти "измененные" номера регистров должны кодироваться в программе.
Приведем, наконец, завершающий пример - цикл, рассчитывающий скалярное произведение векторов [1]. В примере 4 адреса начал A и B лежат в GR5 и GR6; предполагается, что ldfd используют два порта памяти, а времена выполнения ldfd и fma составляют 9 и 5 тактов соответственно (в [1] предполагается 9 тактов на ldfs). В команде br.ctop.sptk последняя компонента мнемокода - статическая "подсказка": статическое предсказание, что переход будет осуществлен.
В цикле вычисляются пять частичных сумм: A(1)*B(1)+A(6)*B(6)+..., A(2)*B(2)+ A(7)*B(7)+..., ..., A(5)*B(5)+A(10)*B(10)+... , и все эти суммирования идут с шагом 5. В этом можно убедиться, если прокрутить вручную первые итерации цикла и учесть, что каждый раз при br.ctop происходит переименование регистров FR (как и PR). Поэтому A(I) попадает в f50 при ldfd, и девять итераций (девять тактов) спустя будет в f59, а B(I) из f60 окажется в f69, и т.д.
В примере 4 опущено обнуление регистров частичных сумм и другие подобные "мелочи" (до начала цикла). По завершению цикла пять частичных сумм складываются, и результирующая сумма S оказывается в f10. Если проанализировать этот исходно простой пример, отследив, почему используются те или иные номера регистров, то станет ясно, что SWP-оптимизация требует от программиста большой тщательности и знания времен выполнения команд. Более того, такая привязка означает, что если в процессорах IA-64 нового поколения изменятся времена выполнения команд (например, при переходе от Merced к McKinley), то оптимизированную программу для достижения высокой производительности необходимо переделать. Однако компактность и эффективность оптимизированных кодов несомненны.
IA-64 в первом приближении
Некоторые приведенные в статье данные о времени выполнения команд (ldfd/ldfs, fma), основанные на примерах в [1], могут оказаться иными в конкретной реализации Itanium. Однако если предположить, что оценки эти окажутся близкими к реальности, становится понятным высказывавшееся мнение о том, что Itanium будет эффективно работать с векторизуемыми кодами. Действительно, в этом случае большие задержки команд типа ldfs или fma будут исключены благодаря использованию SWP.
В рамках одной журнальной статьи трудно дать полное введение в такую сложную архитектуру, как IA-64. Автор же постарался представить наиболее важные отличительные особенности IA-64.
Михаил Кузьминский - старший научный сотрудник Центра компьютерного обеспечения химических исследований РАН. С ним можно связаться по телефону:
(095) 135-6388.