Рис. 1. Отделы и сотрудники: реляционный и сетевой проекты
Уважаемые читатели!
С некоторой задержкой предлагаю Вашему вниманию пересказ очередной публикации Дейта из серии, посвященной тридцатилетию реляционного подхода. В принципе, в этой заметке не содержатся какие-либо откровения, но она посвящена одной из интересных статей Кодда и Дейта, которая до сих пор остается важным источником. По крайней мере, те из Вас, кто не помнит или не знает эту статью, тепень получат о ней представление.
Успехов всем Вам, Сергей Кузнецов
Intelligent Enterprise, May 11, 1999, Volume 2, Number 7
An Analysis of Codd's Contribution to the Great Debate C.J. Date
(www.intelligententerprise.com/991105/online2.html)
Великий Спор являлся спором между сторонниками реляционного и сетевого подходов. Он происходил во время ACM SIGMOD Workshop on Data Description, Access, and Control в 1974 г.; основными докладчиками были Эдгар Ф. Кодд в пользу реляционного подхода (поразительно!) и Чарльз В. Бахман в пользу сетевого подхода, или подхода CODASYL. В процессе подготовки обсуждения Кодд написал статью под названием "Интерактивная поддержка непрограммистов: реляционный и сетевой подходы" [1], и именно эта статья обсуждается в данной заметке.
Замечание: официально авторами статьи числятся Кодд и Дейт, однако на самом деле статья целиком написана Коддом. (И наоборот, статья с соображениями о прикладном программировании [2], авторами которой числятся те же два автора, была написана Дейтом.)
Конечно, сейчас битва между реляционным и сетевым подходами кажется древней историей. (Победили хорошие парни.) Несмотря на это, статья Кодда -- написанная более 25 лет тому назад -- по-прежнему представляет собой великолепный пример ясных рассуждений. Действительно, замечательным фактом является то, что в то время, когда нормой являлось беспорядочное мышление, Кодд оказался в состоянии разорвать замкнутый круг и сосредоточиться на действительно важных предметах. Позвольте уточнить:
Исходя из этого, Кодд приступает к определению абстракции такой модели. (И, конечно, после этого он переходит к сравнению этой абстракции с реляционной моделью.)
Таким образом, Кодд представляет собой первого человека, который попытался дать формальное определение не только реляционной модели (конечно, он сделал это), но также и сетевой модели! Конечно же, ни в одном из документов CODASYL такая попытка не предпринималась. (На самом деле, статья вышла в свет вовремя, хотя к этому времени основные сражения закончились. Теперь мы опять видим старые добрые проблемы в связи с объектными СУБД. Как отмечают некоторые авторы, объектные СУБД в некоторых аспектах напоминают CODASYL. Это тот случай, когда незнание истории усугубляет ситуацию.)
В любом случае, наиболее значительное достижение статьи "Interactive Support for Nonprogrammers: The Relational and Network Approaches", вероятно, состоит в введении понятия существенности, понятия, которое является критическим для правильного понимания моделей данных в целом и различия между отношениями и сетями, в частности. (В действительности, именно главным образом по этой причине мне захотелось поговорить об этой статье в данной серии.)
Помимо введения понятия существенности, в статье Кодда также поднимается ряд вопросов относительно уместности использовния сетевых структур в качестве компонента того, что он называет "принципиальной схемой" - вопросов, на которые, насколько мне известно, до сих пор нет ответов в доступной литературе. Цитирую: "В прошлом многих разработчиков проограммного обеспечения ... смущало различие между двумя совершенно различными понятиями: с одной стороны, расширениями возможностей и, с другой стороны, общностью приложения." Как верно! "Критическим аспектом систем управления базами данных является то, что это богатство возможностей (т.е. их изменчивость) структур данных ... должно поддерживаться принципиальной схемой. Если возможности этих структур данных ... выходят за пределы некоторого минимума, нужно задать следующие вопросы ... "Мне не хочется здесь подробно обсуждать эти вопросы, однако я уже говорил об этом в одной из предыдущих публикаций [3]).
Между прочим, эта цитата напоминает мне другую, которая взята из вводной статьи Кодда о нормализации [4]. "В нескольких существующих системах допускается разнообразие физических представлений заданной логической структуры... Сложность физических представлений, поддерживаемых этими системами, видимо, невозможно понять, поскольку эти представления выбираются в расчете на повышение эффективности... Еще менее понимаема тенденция к все более и более усложняемым структурам данных, с которыми ... непосредственно имеют дело пользователи. Конечно же, при выборе логических структур данных должно присутствовать только одно соображение - удобство большинства пользователей." Опять, как это верно!
Вернемся к "Interactive Support". В статье содержится приложение, в котором сравниваются версии CODASYL/COBOL и relational/Alpha простого приложения управления магазином. Это сравнение убедительно демонстрирует простоту реляционного подхода (конечно, с точки зрения пользователя). Полные подробности сравнения содержатся в реальном программном коде обоих решений. Я отсылаю вас к исходному тексту статьи; при этом мне хочется повторить некоторые замечания из одной из моих предыдущих статей [5], в которой обсуждался тот же самый пример. Вот некоторая статистика:
| CODASYL | relational | |
| GO TO | 15 | 0 |
| PERFORM UNTIL | 1 | 0 |
| currency indicators | 10 | 0 |
| IF | 12 | 0 |
| FIND | 9 | 0 |
| GET | 4 | 1 |
| STORE / PUT | 2 | 1 |
| MODIFY | 1 | 0 |
| MOVE CURRENCY | 4 | 0 |
| other MOVEs | 9 | 1 |
| SUPPRESS CURRENCY | 4 | 0 |
| total statements | > 60 | 3 |
Относительная простота реляционного решения просто поражает. Замечание: реляционное решение может быть сведено к одному оператору PUT; GET и MOVE не являются строго обязательными. Более того (хотя Кодд не упоминает этот факт), решение CODASYL - которое заимствовано из другого источника, а не создано самим Коддом - содержит по меньшей мере две ошибки!
Этот пример проясняет и еще один вопрос. Цитируя Кодда, "Предостерегаем читателя от попытки сравнения [разных] подходов исключительно на основе основных различий в [структурах данных]. Достаточное внимание должно уделяться ... и операторам." И далее он добавляет: "В обсуждениях реляционного подхода часто преобладают аспекты компонента [структур данных] в ущерб [другим компонентам]. Для обоснования этого подхода все ... компоненты должны рассматриваться в одном пакете."
Несмотря на важность этого понятия, исходя из собственного опыта, я считаю, что с этим понятием реально знакомы лишь немногие профессионалы в области баз данных. Поэтому эта заметка представляет собой в основном введение в этот предмет. Замечание: Следующий далее материал частично основан на одной из моих предыдущих статей [6].
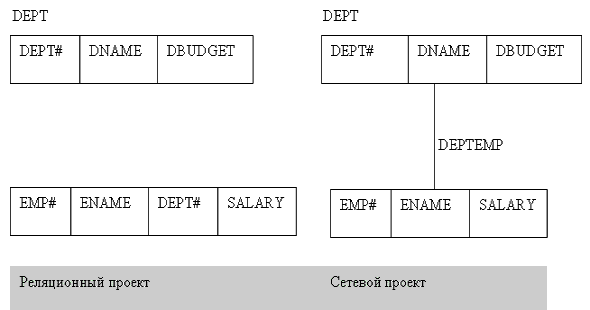
Прежде всего, "всем известно", что единственной структурой данных, используемой в реляционной модели, является отношение. Однако, чтобы понять значимость этого факта, требуется знать по крайней мере одну другую структуру данных, например, структуру связей, поддерживаемую в иерархических и сетевых системах. Рассмотрим пример. На Рис. 1 показаны (a) реляционный проект простой базы данных "отделы-сотрудники" и (b) сетевой эквивалент этого проекта. (На самом деле, пример прост по той причине, что в сетевом исполнении проект представляет собой скорее иерархию, но это не важно для нашей цели. Иерархии и сети в большей степени похожи друг на друга, чем на отношения.)
Рис. 1. Отделы и сотрудники: реляционный и сетевой проекты
В сетевом проекте использован "набор (set) в смысле CODASYL" (не нужно путать это понятие с понятием математического множества!). Каждый экземпляр этого набора включает строку DEPT, множество соответствующих строк EMP и экземпляр связи ("DEPTEMP"), соединяющей эти строки DEPT и EMP. (Я использую здесь термин "строка" вместо более принятого слова "запись", чтобы обойти несущественные вопросы, связанные с различием в терминологии этих двух подходов.) Можно представлять ссылку в данном наборе CODASYL как цепочку указателей - указатель от строки DEPT на первую строку EMP для этого отдела, указатель от этой строки EMP на следующую строку для того же отдела и т.д., и, наконец, указатель от последней строки EMP на исходную строку DEPT. Замечание: Эти указатели не обязательно представляются на физическом уровне хранения как реальные указатели, но пользователи обязаны отоситься к ним как к реальным указателям. (Такова сетевая модель!)
Заметим теперь, что строки EMP в сетевом проекте не включают столбец DEPT#. Поэтому для того, чтобы найти, в каком отделе числится данный служащий, нам требуется пройти по экземпляру связи DEPTEMP от требуемой строки EMP к соответствующей строке DEPT; аналогично, чтобы найти служащих данного отдела, нам нужно пройти по экземпляру связи EMPDEPT от требуемой строки DEPT к соответствующим строкам EMP. Другими словами, информация, которая была бы представлена внешним ключом в реляционном проекте, представляется ссылкой в сетевом проекте; ссылки являются сетевым аналогом внешних ключей (вольно выражаясь).
Рассмотрим теперь пару запросов по отношению к этой базе данных. Для каждого запроса я покажу реляционную формулировку (SQL) и ее сетевой эквивалент с использованием гипотетической расширенной версии SQL, в которой поддерживаются связи.
Q1: Получить номера и имена служащих с заработной платой, большей 20K.
| Реляционная формулировка: | Сетевая формулировка: |
| SELECT EMP#, ENAME | SELECT EMP#, ENAME |
| FROM EMP | FROM EMP |
| WHERE SALARY > 20K ; | WHERE SALARY > 20K ; |
Q2: Получить номера и имена служащих из отдела получающих заработную плату больше 20K.
| Реляционная формулировка: | Сетевая формулировка: |
| SELECT EMP#, ENAME | SELECT EMP#, ENAME |
| FROM EMP | FROM EMP |
| WHERE SALARY > 20K | WHERE SALARY > 20K |
| AND DEPT# = 'D3' ; | AND ( SELECT DEPT# FROM DEPT OVER EMP ) = 'D3' ; |
Для запроса Q1 обе формулировки, очевидно, идентичны; однако для запроса Q2 это не так. Реляционная формулировка для Q2 имеет ту же основную форму, что и для Q1 (SELECT-FROM-WHERE с простым условием в разделе WHERE); в отличие от этого, в сетевой формулировке вынужденно используется новая языковая конструкция - раздел OVER (который в моем гипотетическом варианте дает возможность в SQL прохода по ссылкам). Конечно, в этой формулировке условие WHERE не является простым условием ограничения.
Таким образом, Q2 иллюстрирует тот важный момент, что для сетей определенно требуются дополнительные операции доступа к данным. Отметим также, что эти операции являются дополнительными; реляционные операции, как показывает Q1, по-прежнему необходимы. Более того, заметим, что это замечание относится не только ко всем операциям манипулирования данными (включая операции обновления), но также и к операциям определения, операциям обеспечения безопасности, операциям обеспечения целостности и т.д. Следовательно, связи в сетевых структурах данных определенно добавляют сложность. Однако они не дают дополнительной мощности - нет ничего, что можно было бы представить с помощью сетей и нельзя было бы представить с помощью отношений; нет такого запроса, который можно было бы представить сетевой системе и нельзя бы представить системе реляционной.
Иногда говорят, что можно уменьшить сложность путем добавления к EMP компонента DEPT# (внешнего ключа), как это показано на Рис. 2. В этом доработанном варианте запрос Q2 (сетевая версия) может формулироваться без конструкции OVER; на самом деле, формулировка эквивалента реляционной. Причина этого состоит в том, что DEPT и EMP в этом пересмотренном проекте означают то же самое, что и в реляционном варианте; база данных такая же, что и реляционная, если не принимать во внимание связь DEPTEMP. Но эта связь является полностью избыточной - она не представляет какую-либо информацию, которая не представлена также и внешним ключом. Поэтому мы можем игнорировать эту связь без потери какой-либо функциональности.
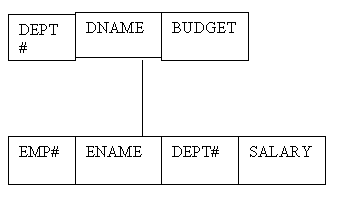
Сеть: связь DEPTEMP не является существенной
Рис. 2. Отделы и сотрудники: сетевой проект с внешним ключом EMP.DEPT#
Теперь (наконец!) я поясню смысл понятия существенности. Конструкция, связанная с данными, существенна, если ее утрата вызывает потерю информации - вполне точно, я понимаю это так, что перестанет достигаться некоторое отношение. Например, в реляционном варианте базы данных отделов и сотрудников все конструкции данных в этом смысле существенны. Аналогично, в начальной сетевой версии (Рис. 1) все конструкции (все строки, все столбцы и все связи) тоже существенны. Но в пересмотренном сетевом варианте (Рис. 2) строки и столбцы продолжают быть существенными, а связь - нет. Нет такой информации, которую можно было бы получить из сети и нельзя было бы получить только из строк и столбцов; вообще отсутствует логическая потребность в связи.
Замечание: Некоторые люди думают, что имеет место обратная ситуация - существенна именно связь, а не внешний ключ. Но это противоречит тому, что поскольку некоторые строки и столбцы должны быть существенными и ничего больше не требуется, то зачем нам нужно что-то еще?
Теперь (наконец) я могу пояснить, в чем состоит принципиальное различие между реляционной базой данных и базой данных другого рода, скажем, сетевой. В реляционной базе данных единственной существенной конструкцией данных является отношение. В других базах данных должна присутствовать по меньшей мере одна дополнительная существенная конструкция данных (такая, как существенная связь). Если бы это было не так, то база данных была бы по существу реляционной с явной демонстрацией некоторых путей доступа. (Не требуется, чтобы пользователи явно применяли эти пути доступа; единственный вопрос состоит в том, почему мы показываем эти пути доступа, а другие не делают этого.) И именно эти дополнительные существенные конструкции данных в основном (но не полностью) приводят к сложности нереляционных баз данных.
Замечание: Конкретно, в случае CODASYL имеется, по меньшей мере, четыре дополнительных конструкции, которые могут использоваться для существенного сохранения информации. Однако рассмотрение подробностей этих конструкций могло бы завести нас слишком далеко.
Понятие существенности позволяет мне объяснить, почему важно то, что строки отношений не упорядочены. В упорядоченном файле порядок сам по себе может быть существенным в упомянутом выше смысле. Например, файл регистрации температуры мог бы поддерживаться в том порядке, в котором производились наблюдения. Этот порядок уже несет информацию, которая может быть потеряна при другом устройстве файла -- точно так же, как если уронить колоду карт, то мы потеряем информацию о предыдущем порядке карт в колоде. (Если вы чересчур молоды, чтобы что-нибудь знать о колодах карт и их порядке, вы можете проигнорировать этот пример.) И для существенного порядка, равно как и для существенных связей требуются дополнительные операции -- "найти n-тую запись", "вставить запись между n-той и (n+1)-ой и т.д. По этой причине упорядоченность не допускается в реляционной модели.
В отличие от сказанного выше, иногда люди считают, что несущественное упорядочение является приемлемым. Файл является несущественно упорядоченным, если он упорядочен на основе значения (значений) некоторого (некоторых) поля (полей) -- например, файл с информацией о служащих может быть упорядочен по значениям номеров служащих, но никакая информация не должна быть потеряна при перемещении записей. В действительности, некоторые "реляционные" системы поддерживают упорядочивание в этом смысле. Однако заметим, что отношения не упорядочены по определению; было бы правильнее относиться к "упорядоченному отношению" как к совсем другому предмету -- возможно, как к последовательному файлу. В этом смысле, операцию ORDER BY языка SQL лучше считать операцией преобразования отношения в такой файл, а не "упорядочиванием отношения".
В любом случае, все несущественные конструкции данных могут вызывать проблемы, поскольку они несут информацию, даже если они не существенны. Например, они могут нарушать требования безопасности. Предположим, что файл служащих упорядочен (несущественно) в порядке возрастания заработной платы. Тогда тот факт, что запись о вашем менеджере появляется после вашей личной записи, что-то вам говорит, даже если вам не дано право видеть реальные размеры заработной платы.
В заключение позвольте мне вернуться к стаптье Кодда про "великое сражение". Кодд отмечает, что "недостаточно принимать во внимание подходы, используемые сегодня -- нам нужно ясно осознавать будущее развитие событий". Он говорит, что существенно возрастет роль "случайных" пользователей систем баз данных (в действительности, скоро они будут представлять большинство), и мы должны уделять внимание другим подходам, требуемым для поддержки таких пользователей. Вот некоторые цитаты:
И сегодня эти наблюдения нуждаются лишь в незначительных корректировках.